WO2019176018A1 - Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム - Google Patents
Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム Download PDFInfo
- Publication number
- WO2019176018A1 WO2019176018A1 PCT/JP2018/010008 JP2018010008W WO2019176018A1 WO 2019176018 A1 WO2019176018 A1 WO 2019176018A1 JP 2018010008 W JP2018010008 W JP 2018010008W WO 2019176018 A1 WO2019176018 A1 WO 2019176018A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- user
- speaker
- voice
- user account
- meaning
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 13
- 238000012545 processing Methods 0.000 claims abstract description 53
- 230000008569 process Effects 0.000 claims description 7
- 230000004044 response Effects 0.000 claims description 4
- 238000013473 artificial intelligence Methods 0.000 description 55
- 238000004891 communication Methods 0.000 description 8
- 238000010586 diagram Methods 0.000 description 6
- 238000012546 transfer Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 4
- 235000013305 food Nutrition 0.000 description 3
- 230000010365 information processing Effects 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000004590 computer program Methods 0.000 description 1
- 230000035622 drinking Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
Images


Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
Definitions
- the present invention relates to a technique for controlling an AI speaker system.
- AI Artificial Intelligence speakers have been developed that accept user voice instructions and perform actions desired by the user.
- Patent Document 1 when performing a voice conversation with a user, it is more effective when the voice conversation is made into a natural content according to the user or when the conversation is used as a means for achieving a certain purpose.
- a technique for promoting dialogue is disclosed.
- the present invention provides analysis means for analyzing the meaning of an input user's voice, and specifying means for specifying a speaker user account for identifying a user who has emitted the voice in an AI speaker based on the voice print of the input voice.
- an AI speaker system comprising processing means for performing processing based on the analyzed meaning of the voice and a user attribute corresponding to the specified speaker user account.
- the specifying means stores a voice print of each user in association with the speaker user account of the user, specifies the speaker user account corresponding to the input voice print, and the processing means , Storing the speaker user account of each user in association with the user attribute of the user, and analyzing the meaning of the analyzed voice and the user attribute corresponding to the specified speaker user account You may make it perform the process based on a result.
- the processing means selects a service providing apparatus that performs a service corresponding to the analyzed meaning of the voice, and analyzes a result of analyzing the user attribute corresponding to the identified speaker user account. And a sound emission process corresponding to the data transmitted from the service providing apparatus may be performed in response to the notification.
- a service user for identifying the user in the service providing apparatus An account may be specified based on the specified speaker user account, and the specified service user account may be notified to the selected service providing apparatus.
- the present invention includes an analysis step for analyzing the meaning of an input user's voice, a specification step for specifying a speaker user account for identifying a user who has emitted the voice based on the voice print of the input voice, and an analysis There is provided a method of controlling an AI speaker system, comprising processing steps for performing processing based on the meaning of the voice and the user attribute corresponding to the specified speaker user account.
- the present invention provides an analysis step for analyzing the meaning of an input user's voice in a computer, and a specifying step for specifying a speaker user account for identifying a user who has emitted the voice based on the voice print of the input voice. And a processing step for performing processing based on the analyzed meaning of the voice and a user attribute corresponding to the specified speaker user account.
- an AI speaker system that can perform various services desired by a user.
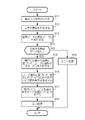
- FIG. 1 is a diagram showing a configuration of an AI speaker system 9 according to the present embodiment.
- the AI speaker system 9 includes an AI speaker 1, a service providing device 2, and a network 3 that connects these devices so that they can communicate with each other.
- the AI speaker system 9 may include a plurality of AI speakers 1, service providing apparatuses 2, and networks 3.
- the AI speaker 1 is a device that inputs a user's voice through a microphone or the like and outputs a voice through a dynamic speaker or an electrostatic speaker.
- an information processing device called a smart speaker or a home speaker It is.
- the service providing apparatus group 2 is one or more information processing apparatuses that provide a service requested from the AI speaker 1 via the network 3.
- the service providing apparatus group 2 provides services such as music distribution, store guidance, weather forecast, transfer guidance, news distribution, and a search engine.
- a user account is individually assigned to one user.
- a user account granted in a certain service can identify the user only in that service.
- the network 3 is a communication line that connects the AI speaker 1 and the service providing apparatus group 2 in a communicable manner, and is, for example, the Internet.
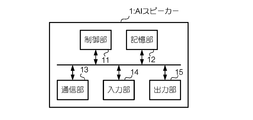
- FIG. 2 is a diagram illustrating an example of the configuration of the AI speaker 1.
- the AI speaker 1 includes a control unit 11, a storage unit 12, a communication unit 13, an input unit 14, and an output unit 15.
- the control unit 11 includes a CPU (Central Processing Unit), a ROM (Read Only Memory), and a RAM (Random Access Memory), and a computer program (hereinafter simply referred to as a program) in which the CPU is stored in the ROM and the storage unit 12. Are read out and executed to control each part of the AI speaker 1.
- a CPU Central Processing Unit
- ROM Read Only Memory
- RAM Random Access Memory
- the communication unit 13 is a communication circuit connected to the network 3 by wire or wireless.
- the AI speaker 1 exchanges information with the service providing apparatus 2 connected to the network 3 by the communication unit 13.
- the input unit 14 is a microphone or the like for inputting sound, and sends a sound signal indicating the input sound to the control unit 11.
- the output unit 15 is, for example, a dynamic speaker or an electrostatic speaker, and emits sound according to a signal instructed by the control unit 11.
- the storage unit 12 is a large-capacity storage unit such as a solid state drive or a hard disk drive, and stores various programs and data read by the CPU of the control unit 11.
- the storage unit 12 stores, for example, a voiceprint database (hereinafter referred to as DB), a user account DB, and a user attribute DB.
- DB voiceprint database
- user account DB user account database
- user attribute DB user attribute database
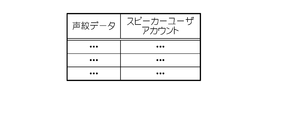
- FIG. 3 is a diagram showing the voiceprint DB stored in the storage unit 12.
- the voiceprint DB stores each user's voiceprint data in association with a speaker user account that is identification information for identifying the user in the AI speaker 1.
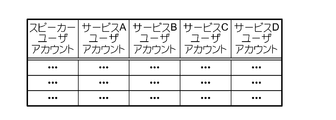
- FIG. 4 is a diagram showing the account DB stored in the storage unit 12.
- the account DB is identification information for identifying the speaker user account that is identification information for identifying the user in the AI speaker 1 and the user for the service (services A, B, C, and D) of the respective service providing apparatuses 2.
- Service user accounts (service A user account, service B user account, service C user account, service A user account) are stored in association with each other. That is, in the account DB, a speaker user account of a certain user and one or more service user accounts of the user are associated with each other.
- FIG. 5 is a diagram showing the user attribute DB stored in the storage unit 12.
- the user attribute DB stores a speaker user account, which is identification information for identifying the user in the AI speaker 1, and a user attribute of the user in association with each other.
- User attributes include, for example, age, sex, hobbies and preferences, area information of the user's home or office, history of the user's location information, search history on the network 3, browsing history on the network 3, communication via the network 3 Includes purchase history of goods or services in sales.
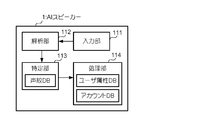
- FIG. 6 is a diagram showing a functional configuration of the AI speaker 1.
- the control unit 11 of the AI speaker 1 reads and executes the program stored in the storage unit 12, the AI speaker 1 realizes functions such as the input unit 111, the analysis unit 112, the specifying unit 113, and the processing unit 114.
- the input unit 111 inputs a user's voice.
- the analysis unit 112 analyzes the meaning of the user's voice input to the input unit 111 using, for example, a hidden Markov model.
- the specifying unit 113 specifies a speaker user account for identifying the user who has emitted the voice based on the voice print of the voice input to the input unit 111. More specifically, the specifying unit 113 stores each user's voiceprint and the user's speaker user account in association with each other (voiceprint DB), and selects a speaker user account corresponding to the input voiceprint. Identify.
- the processing unit 114 performs processing based on the meaning of the voice analyzed by the analysis unit 112 and the user attribute corresponding to the speaker user account specified by the specifying unit 113. Specifically, the processing unit 114 stores the speaker user account of each user and the user attribute of the user in association with each other (user attribute DB), and the meaning of the analyzed voice and the specified speaker Processing based on the result of analyzing the user attribute corresponding to the user account is performed.
- the processing unit 114 selects the service providing apparatus 2 that provides a service corresponding to the meaning of the voice analyzed by the analysis unit 112, and the user corresponding to the speaker user account specified by the specifying unit 113
- the result of analyzing the attribute is notified to the selected service providing apparatus 2, and sound emission processing is performed according to the data transmitted from the service providing apparatus 2 in response to the notification.
- the processing unit 114 stores the speaker user account of each user and the service user account of the user in association with each other (account DB), and analyzes the user attribute corresponding to the speaker user account specified by the specifying unit 113.
- the selected service providing apparatus 2 is notified of the result, a service user account for identifying the user in the service providing apparatus 2 is identified based on the speaker user account, and the identified service user account is selected.
- the service providing apparatus 2 is notified.
- FIG. 7 is a flowchart showing an operation flow of the AI speaker 1.
- the input unit 111 receives a user's voice input (step S11).
- This voice includes, for example, “Make music”, “Is there a restaurant to eat dinner?”, “Tell me today's weather”, “What is the train time?”.
- the analysis unit 112 analyzes the meaning of the input user's voice (step S12).
- speech semantic analysis various known semantic analysis algorithms may be used.
- the specifying unit 113 analyzes the input voice, generates voice print data, and collates it with the voice print data included in the voice print DB (step S13). In this voiceprint generation, various known voiceprint generation algorithms may be used. If there is a voice print DB that matches the voice print data input by the user (step S14; YES), the specifying unit 113 refers to the speaker user account corresponding to the voice print data in the voice print DB. The speaker user account of the user who made the sound is specified. If there is no voice print DB that matches the voice print data input by the user (step S14; NO), the specifying unit 113 performs a predetermined error process (step S19), and the process shown in FIG. Ends.
- the processing unit 114 selects the service providing apparatus 2 that performs a service corresponding to the meaning of the analyzed voice (step S15). For example, if the user's voice is “over music”, the processing unit 114 determines that the user desires to provide music, and selects the service providing apparatus 2 that performs music distribution. In addition, for example, if the user's voice is “Is there a restaurant that eats dinner?”, The processing unit 114 determines that the user wants to provide information about a restaurant store, and stores information The service providing apparatus 2 that performs is selected. For example, if the user's voice is “tell me today's weather”, the processing unit 114 determines that the user wants to provide the weather forecast, and the service providing apparatus 2 that performs the weather forecast. Select. Also, for example, if the user's voice is “What is the train time?”, The processing unit 114 determines that the user wants to provide information related to a train transfer, and provides a transfer guidance service 2 is selected.
- the processing unit 114 analyzes a user attribute corresponding to the specified speaker user account, and provides a service according to the personality, hobbies, or preferences of the user in the selected service providing apparatus 2.
- a service provision condition is generated (step S16). For example, if the selected service is music distribution, the user is a male in his 50s, and the music preference determined from the user attributes is classical music, the processing unit 114 prefers the male in his 50s as a service provision condition. Generate information called classical music. In addition, for example, if the selected service is store guidance, the user is a woman in her 20s, and the taste of eating and drinking determined from the user attributes is Korean food, the processing unit 114 sets the service provision condition as a woman in her 20s Information that Korean food is preferred by.
- the processing unit 114 sets today's XX prefecture as the service provision condition. Generates information called city weather forecast. Further, for example, if the selected service is a transfer guide and the commuting route determined from the user attribute is a route of home ⁇ a station ⁇ b station ⁇ c company, the processing unit 114 sets the service provision condition as the above Information of route transfer guidance is generated.
- This request includes a service count for identifying the user in the service providing apparatus 2 and the service providing conditions.
- the service providing device 2 performs processing according to this request.
- the service providing apparatus 2 that distributes music confirms that the service user account included in the request is included in the account database in the apparatus, and then, for example, meets the service provision condition of classical music preferred by men in their 50s.
- the matching music data is searched from the music database in the device itself or in the external device and transmitted to the AI speaker 1.
- the service providing apparatus 2 that provides store guidance confirms that the service user account included in the request is included in the account database in the apparatus, and provides, for example, a service called Korean food preferred by women in their 20s.
- Store data matching the conditions is retrieved from the store database in the own device or in the external device and transmitted to the AI speaker 1.
- the service providing apparatus 2 that performs the weather forecast confirms that the service user account included in the request is included in the account database in the own apparatus, and for example, the weather in today's XX city Weather forecast data that matches the service provision condition of forecast is retrieved from the weather forecast database in the own device or in an external device and transmitted to the AI speaker 1.
- the service providing apparatus 2 that performs route guidance confirms that the service user account included in the request is included in the account database in the own apparatus, and then, for example, home ⁇ a station ⁇ b station ⁇ c company The route guidance data that matches the service provision condition of route guidance is retrieved from the route guidance database in the device itself or in the external device and transmitted to the AI speaker 1.
- the processing unit 114 performs sound emission processing according to the data transmitted from the service providing device 2 in response to the request (step S18). For example, if the selected service is music distribution, the processing unit 114 outputs a sound corresponding to the music data transmitted from the service providing apparatus 2. Further, for example, if the selected service is store guidance, the processing unit 114 generates and outputs a voice for reading the store data transmitted from the service providing apparatus 2. For example, if the selected service is a weather forecast, the processing unit 114 generates and outputs a voice for reading out the weather forecast data transmitted from the service providing apparatus 2. For example, if the selected service is route guidance, the processing unit 114 generates and outputs a voice for reading out the route guidance data transmitted from the service providing apparatus 2.
- the processing executed by the control unit 11 of the AI speaker 1 can be considered as a method for controlling the AI speaker 1. That is, the present invention includes an analysis step of analyzing the meaning of the input user's voice, and a specifying step of specifying a speaker user account that identifies the user who has emitted the voice based on the voice print of the input voice.
- the AI speaker system may include a processing step of performing processing based on the meaning of the analyzed voice and a user attribute corresponding to the identified speaker user account. Note that the steps of processing performed in the AI speaker system 9 are not limited to the example described in the above-described embodiment. The steps of this process may be interchanged as long as there is no contradiction.
- the program executed by the control unit 11 of the AI speaker 1 is a recording medium readable by a computer device, such as a magnetic recording medium such as a magnetic tape and a magnetic disk, an optical recording medium such as an optical disk, a magneto-optical recording medium, or a semiconductor memory. Can be provided in a stored state.
- the program may be downloaded via a communication line such as the Internet.
- various devices other than the CPU may be applied as the control means exemplified by the control unit 11 described above. For example, a dedicated processor or the like is used.
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
特定部113は、入力された音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する。処理部114は、解析された音声の意味と、特定されたスピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う。具体的には、処理部114は、それぞれのユーザのスピーカーユーザアカウントと当該ユーザのユーザ属性とを対応付けて記憶しており、解析された音声の意味と、特定されたスピーカーユーザアカウントに対応するユーザ属性を解析した結果とに基づいた処理を行う。
Description
本発明は、AIスピーカーシステムを制御する技術に関する。
ユーザの音声による指示を受け付けてユーザが望む動作を行うAI(Artificial Intelligence)スピーカーが開発されている。特許文献1には、ユーザと音声対話を行うに際して、その音声対話をそのユーザに応じた自然な内容にすることや、ある目的を達成するための手段として対話を使う場合に、より効果的に対話を進める技術が開示されている。
AIスピーカーの普及に伴い、ユーザが望むあらゆるサービスがAIスピーカーシステム経由で実現されることが期待されている。しかしながら、ユーザが望むサービスはサードパーティのものも含めて様々なものがあり、また、各サービスにおいてユーザのアカウントが個別に設定されているという事情もあって、AIスピーカーシステム経由で多様なサービスを提供することは現実的には難しいという問題があった。
本発明は、ユーザが望む様々なサービスを行い得るAIスピーカーシステムを提供することを目的とする。
本発明は、入力されたユーザの音声の意味を解析する解析手段と、入力された前記音声の声紋に基づいて、AIスピーカーにおいて当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定手段と、解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理手段とを備えるAIスピーカーシステムを提供する。
前記特定手段は、それぞれのユーザの声紋と当該ユーザの前記スピーカーユーザアカウントとを対応付けて記憶しており、入力された前記音声の声紋に対応する前記スピーカーユーザアカウントを特定し、前記処理手段は、それぞれのユーザの前記スピーカーユーザアカウントと当該ユーザのユーザ属性とを対応付けて記憶しており、解析された前記音声の意味と、特定された前記スピーカーユーザアカウントに対応する前記ユーザ属性を解析した結果とに基づいた処理を行うようにしてもよい。
前記処理手段は、解析された前記音声の意味に対応するサービスを行うサービス提供装置を選択し、特定された前記スピーカーユーザアカウントに対応する前記ユーザ属性を解析した結果を、選択されたサービス提供装置に通知し、当該通知に応じて前記サービス提供装置から送信されてくるデータに応じた放音処理を行うようにしてもよい。
前記処理手段は、特定された前記スピーカーユーザアカウントに対応する前記ユーザ属性を解析した結果を、選択されたサービス提供装置に通知する場合に、当該サービス提供装置において前記ユーザを識別するためのサービスユーザアカウントを、特定された前記スピーカーユーザアカウントに基づいて特定し、特定した前記サービスユーザアカウントを選択されたサービス提供装置に通知するようにしてもよい。
本発明は、入力されたユーザの音声の意味を解析する解析ステップと、入力された前記音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定ステップと、 解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理ステップとを備えるAIスピーカーシステムの制御方法を提供する。
本発明は、コンピュータに、入力されたユーザの音声の意味を解析する解析ステップと、入力された前記音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定ステップと、解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理ステップとを実行させるためのプログラムを提供する。
本発明によれば、ユーザが望む様々なサービスを行い得るAIスピーカーシステムを提供するができる。
1…AIスピーカー、11…制御部、12…記憶部、12…通信部、14…入力部、15…出力部、111…入力部、112…解析部、113…特定部、114…処理部、2…サービス提供装置、3…ネットワーク、9…AIスピーカーシステム。
<実施形態>
<AIスピーカーシステムの全体構成>
図1は、本実施形態に係るAIスピーカーシステム9の構成を示す図である。AIスピーカーシステム9は、AIスピーカー1と、サービス提供装置2と、これらを通信可能に接続するネットワーク3と、を有する。なお、AIスピーカーシステム9は、AIスピーカー1、サービス提供装置2、ネットワーク3のそれぞれを複数有してもよい。
<AIスピーカーシステムの全体構成>
図1は、本実施形態に係るAIスピーカーシステム9の構成を示す図である。AIスピーカーシステム9は、AIスピーカー1と、サービス提供装置2と、これらを通信可能に接続するネットワーク3と、を有する。なお、AIスピーカーシステム9は、AIスピーカー1、サービス提供装置2、ネットワーク3のそれぞれを複数有してもよい。
AIスピーカー1は、マイクロフォン等によってユーザの音声を入力し、ダイナミックスピーカーや静電スピーカー等によって音声を出力する装置であり、AIスピーカーという呼称以外にも、例えばスマートスピーカーとかホームスピーカーと呼ばれる情報処理装置である。サービス提供装置群2は、ネットワーク3を介してAIスピーカー1から要求されたサービスを提供する1以上の情報処理装置である。例えば、サービス提供装置群2は、音楽配信、店舗案内、天気予報、乗換案内、ニュース配信、検索エンジン等のサービスをそれぞれ提供する。これらのサービス提供装置2が提供するサービスにおいて、1のユーザに対して個別にユーザアカウントが付与されている。或るサービスにおいて付与されたユーザアカウントは、そのサービスにおいてのみそのユーザを識別することが可能となっている。ネットワーク3は、AIスピーカー1及びサービス提供装置群2を通信可能に接続する通信回線であり、例えばインターネット等である。
<AIスピーカーの構成>
図2は、AIスピーカー1の構成の一例を示す図である。AIスピーカー1は、制御部11、記憶部12、通信部13、入力部14、及び出力部15を有する。
図2は、AIスピーカー1の構成の一例を示す図である。AIスピーカー1は、制御部11、記憶部12、通信部13、入力部14、及び出力部15を有する。
制御部11は、CPU(Central Processing Unit)、ROM(Read Only Memory)、RAM(Random Access Memory)を有し、CPUがROM及び記憶部12に記憶されているコンピュータプログラム(以下、単にプログラムという)を読み出して実行することによりAIスピーカー1の各部を制御する。
通信部13は、有線又は無線によりネットワーク3に接続する通信回路である。AIスピーカー1は、通信部13によりネットワーク3に接続されたサービス提供装置2と情報をやり取りする。
入力部14は、音声を入力するマイクロフォン等であり、入力した音声を示す音声信号を制御部11に送る。
出力部15は、例えばダイナミックスピーカーや静電スピーカー等であり、制御部11により指示された信号に応じて放音する。
記憶部12は、例えばソリッドステートドライブ、ハードディスクドライブ等の大容量の記憶手段であり、制御部11のCPUに読み込まれる各種のプログラム、データ等を記憶する。この、記憶部12は、例えば声紋データベース(以下、DBという)と、ユーザアカウントDBと、ユーザ属性DBとを記憶する。
図3は、記憶部12に記憶されている声紋DBを示す図である。声紋DBは、それぞれのユーザの声紋データと、AIスピーカー1において当該ユーザを識別する識別情報であるスピーカーユーザアカウントとを対応付けて記憶している。
図4は、記憶部12に記憶されているアカウントDBを示す図である。アカウントDBは、AIスピーカー1において当該ユーザを識別する識別情報であるスピーカーユーザアカウントと、それぞれのサービス提供装置2のサービス(サービスA,B,C,D)において当該ユーザを識別する識別情報であるサービスユーザアカウント(サービスAユーザアカウント、サービスBユーザアカウント、サービスCユーザアカウント、サービスAユーザアカウント)とを対応付けて記憶している。つまり、アカウントDBにおいては、或るユーザのスピーカーユーザアカウントと、そのユーザの1以上のサービスユーザアカウントとが対応付けられている。
図5は、記憶部12に記憶されているユーザ属性DBを示す図である。ユーザ属性DBは、AIスピーカー1において当該ユーザを識別する識別情報であるスピーカーユーザアカウントと、当該ユーザのユーザ属性とを対応付けて記憶している。ユーザ属性は、例えば年齢、性別、趣味嗜好のほか、ユーザの自宅や勤務先のエリア情報、そのユーザの位置情報の履歴、ネットワーク3における検索履歴、ネットワーク3における閲覧履歴、ネットワーク3を介した通信販売における商品またはサービスの購入履歴等を含む。
<AIスピーカーの機能的構成>
図6は、AIスピーカー1の機能的構成を示す図である。AIスピーカー1の制御部11が記憶部12に記憶されているプログラムを読み出して実行することにより、AIスピーカー1は入力部111、解析部112、特定部113及び処理部114といった機能を実現する。
図6は、AIスピーカー1の機能的構成を示す図である。AIスピーカー1の制御部11が記憶部12に記憶されているプログラムを読み出して実行することにより、AIスピーカー1は入力部111、解析部112、特定部113及び処理部114といった機能を実現する。
入力部111は、ユーザの音声を入力する。
解析部112は、例えば隠れマルコフモデル等を用いて、入力部111に入力されたユーザの音声の意味を解析する。
特定部113は、入力部111に入力された音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する。より具体的には、特定部113は、それぞれのユーザの声紋と当該ユーザのスピーカーユーザアカウントとを対応付けて記憶しており(声紋DB)、入力された音声の声紋に対応するスピーカーユーザアカウントを特定する。
処理部114は、解析部112により解析された音声の意味と、特定部113により特定されたスピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う。具体的には、処理部114は、それぞれのユーザのスピーカーユーザアカウントと当該ユーザのユーザ属性とを対応付けて記憶しており(ユーザ属性DB)、解析された音声の意味と、特定されたスピーカーユーザアカウントに対応するユーザ属性を解析した結果とに基づいた処理を行う。さらに具体的に説明すると、処理部114は、解析部112により解析された音声の意味に対応するサービスを行うサービス提供装置2を選択し、特定部113により特定されたスピーカーユーザアカウントに対応するユーザ属性を解析した結果を、選択されたサービス提供装置2に通知し、当該通知に応じてサービス提供装置2から送信されてくるデータに応じて放音処理を行う。処理部114は、それぞれのユーザのスピーカーユーザアカウントと当該ユーザのサービスユーザアカウントとを対応付けて記憶しており(アカウントDB)、特定部113により特定されたスピーカーユーザアカウントに対応するユーザ属性を解析した結果を選択されたサービス提供装置2に通知する場合に、当該サービス提供装置2においてユーザを識別するためのサービスユーザアカウントを、上記スピーカーユーザアカウントに基づいて特定し、特定したサービスユーザアカウントを選択されたサービス提供装置2に通知する。
<AIスピーカーの動作>
図7は、AIスピーカー1の動作の流れを示すフローチャートである。まず、入力部111はユーザの音声の入力を受付ける(ステップS11)。この音声は、例えば「音楽をかけて」とか、「晩御飯を食べる店はあるかな?」とか、「今日の天気を教えて」とか、「電車の時間は?」といった内容である。
図7は、AIスピーカー1の動作の流れを示すフローチャートである。まず、入力部111はユーザの音声の入力を受付ける(ステップS11)。この音声は、例えば「音楽をかけて」とか、「晩御飯を食べる店はあるかな?」とか、「今日の天気を教えて」とか、「電車の時間は?」といった内容である。
次に、解析部112は、入力されたユーザの音声の意味を解析する(ステップS12)。この音声の意味解析においては、周知の様々な意味解析アルゴリズムを用いればよい。
次に、特定部113は、入力された音声を解析してその声紋データを生成し、声紋DBに含まれる声紋データと照合する(ステップS13)。この声紋生成においては、周知の様々な声紋生成アルゴリズムを用いればよい。声紋DBにおいて、ユーザにより入力された音声の声紋データと合致するものがあれば(ステップS14;YES)、特定部113は、声紋DBにおいてその声紋データと対応するスピーカーユーザアカウントを参照することで、その音声を発したユーザのスピーカーユーザアカウントを特定する。なお、声紋DBにおいて、ユーザにより入力された音声の声紋データと合致するものがなければ(ステップS14;NO)、特定部113は所定のエラー処理を行って(ステップS19)、図7の示す処理は終了する。
次に、処理部114は、解析された音声の意味に対応するサービスを行うサービス提供装置2を選択する(ステップS15)。例えば、ユーザの音声が「音楽をかけて」であれば、処理部114は、ユーザが音楽の提供を希望しているという意味に判断し、音楽配信を行うサービス提供装置2を選択する。また、例えば、ユーザの音声が「晩御飯を食べる店はあるかな?」であれば、処理部114は、ユーザが飲食店の店舗に関する情報提供を希望しているという意味に判断し、店舗案内を行うサービス提供装置2を選択する。また、例えば、ユーザの音声が「今日の天気を教えて」であれば、処理部114は、ユーザが天気予報の提供を希望しているという意味に判断し、天気予報を行うサービス提供装置2を選択する。また、例えば、ユーザの音声が「電車の時間は?」であれば、処理部114は、ユーザが電車の乗り換えに関する情報提供を希望しているという意味に判断し、乗換案内を行うサービス提供装置2を選択する。
次に、処理部114は、特定されたスピーカーユーザアカウントに対応するユーザ属性を解析して、選択されたサービス提供装置2においてそのユーザの個性や趣味嗜好或いは嗜好に応じたサービスを提供するためのサービス提供条件を生成する(ステップS16)。例えば、選択されたサービスが音楽配信であり、ユーザが50代男性で、ユーザ属性から判断される音楽の嗜好がクラシック音楽であれば、処理部114は、サービス提供条件として、50代男性が好むクラシック音楽、という情報を生成する。また、例えば、選択されたサービスが店舗案内であり、ユーザが20代女性で、ユーザ属性から判断される飲食の嗜好が韓国料理であれば、処理部114は、サービス提供条件として、20代女性が好む韓国料理、という情報を生成する。また、例えば、選択されたサービスが天気予報であり、ユーザ属性から判断される自宅住所が○○県○○市であれば、処理部114は、サービス提供条件として、今日の○○県○○市の天気予報、という情報を生成する。また、例えば、選択されたサービスが乗換案内であり、ユーザ属性から判断される通勤ルートが自宅→a駅→b駅→c会社という経路であれば、処理部114は、サービス提供条件として、上記経路の乗換案内、という情報を生成する。
そして、処理部114は、選択されたサービス提供装置2に対するリクエストを行う(ステップS17)。このリクエストには、そのサービス提供装置2においてユーザを識別するサービスカウントと、上記サービス提供条件とが含まれている。
サービス提供装置2は、このリクエストに応じた処理を行う。例えば音楽配信を行うサービス提供装置2は、リクエストに含まれるサービスユーザアカウントが自装置内のアカウントデータベースに含まれていることを確認したうえで、例えば50代男性が好むクラシック音楽というサービス提供条件に合致する音楽データを自装置内又は外部装置内の音楽データベースから検索してAIスピーカー1に送信する。また、例えば店舗案内を行うサービス提供装置2は、リクエストに含まれるサービスユーザアカウントが自装置内のアカウントデータベースに含まれていることを確認したうえで、例えば20代女性が好む韓国料理というサービス提供条件に合致する店舗データを自装置内又は外部装置内の店舗データベースから検索してAIスピーカー1に送信する。また、例えば天気予報を行うサービス提供装置2は、リクエストに含まれるサービスユーザアカウントが自装置内のアカウントデータベースに含まれていることを確認したうえで、例えば今日の○○県○○市の天気予報というサービス提供条件に合致する天気予報データを自装置内又は外部装置内の天気予報データベースから検索してAIスピーカー1に送信する。また、例えば経路案内を行うサービス提供装置2は、リクエストに含まれるサービスユーザアカウントが自装置内のアカウントデータベースに含まれていることを確認したうえで、例えば自宅→a駅→b駅→c会社という経路の案内というサービス提供条件に合致する経路案内データを自装置内又は外部装置内の経路案内データベースから検索してAIスピーカー1に送信する。
処理部114は、上記リクエストに応じてサービス提供装置2から送信されてくるデータに応じた放音処理を行う(ステップS18)。例えば、選択されたサービスが音楽配信であれば、処理部114は、サービス提供装置2から送信されてくる音楽データに応じた音を出力する。また、例えば、選択されたサービスが店舗案内であれば、処理部114は、サービス提供装置2から送信されてくる店舗データを読み上げる音声を生成して出力する。例えば、選択されたサービスが天気予報であれば、処理部114は、サービス提供装置2から送信されてくる天気予報データを読み上げる音声を生成して出力する。また、例えば、選択されたサービスが経路案内であれば、処理部114は、サービス提供装置2から送信されてくる経路案内データを読み上げる音声を生成して出力する。
以上の実施形態によれば、各サービスにおいてユーザのサービスユーザアカウントが個別に設定されている場合であっても、そのサービスユーザアカウントをユーザが都度入力することなく、AIスピーカーシステム経由でユーザが望むサービスを提供することが可能となる。
<変形例>
以上が実施形態の説明であるが、この実施形態の内容は以下のように変形し得る。また、以下の変形例を組合せてもよい。例えば図6で例示したAIスピーカー1の機能構成の一部は省略されてもよいし、さらに別の機能が追加されてもよい。図6に示したAIスピーカー1が備える機能は、AIスピーカーシステム9に属するいずれかの装置又は端末が実装していればよい。また、物理的に複数の装置からなるコンピュータ装置群が連携して、図6に示したAIスピーカー1と同等の機能を実装してもよい。
以上が実施形態の説明であるが、この実施形態の内容は以下のように変形し得る。また、以下の変形例を組合せてもよい。例えば図6で例示したAIスピーカー1の機能構成の一部は省略されてもよいし、さらに別の機能が追加されてもよい。図6に示したAIスピーカー1が備える機能は、AIスピーカーシステム9に属するいずれかの装置又は端末が実装していればよい。また、物理的に複数の装置からなるコンピュータ装置群が連携して、図6に示したAIスピーカー1と同等の機能を実装してもよい。
AIスピーカー1の制御部11が実行する処理は、AIスピーカー1の制御方法として観念され得る。すなわち、本発明は、入力されたユーザの音声の意味を解析する解析ステップと、入力された前記音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定ステップと、解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理ステップとを備えるAIスピーカーシステムの制御方法として提供されてもよい。なお、AIスピーカーシステム9において行われる処理のステップは、上述した実施形態で説明した例に限定されない。この処理のステップは、矛盾のない限り、入れ替えられてもよい。
AIスピーカー1の制御部11によって実行されるプログラムは、磁気テープ及び磁気ディスク等の磁気記録媒体、光ディスク等の光記録媒体、光磁気記録媒体、半導体メモリ等の、コンピュータ装置が読取り可能な記録媒体に記憶された状態で提供し得る。また、このプログラムを、インターネット等の通信回線経由でダウンロードさせてもよい。なお、上述した制御部11によって例示した制御手段としてはCPU以外にも種々の装置が適用される場合があり、例えば、専用のプロセッサ等が用いられる。
Claims (6)
- 入力されたユーザの音声の意味を解析する解析手段と、
入力された前記音声の声紋に基づいて、AIスピーカーにおいて当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定手段と、
解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理手段と
を備えるAIスピーカーシステム。 - 前記特定手段は、それぞれのユーザの声紋と当該ユーザの前記スピーカーユーザアカウントとを対応付けて記憶しており、入力された前記音声の声紋に対応する前記スピーカーユーザアカウントを特定し、
前記処理手段は、それぞれのユーザの前記スピーカーユーザアカウントと当該ユーザのユーザ属性とを対応付けて記憶しており、解析された前記音声の意味と、特定された前記スピーカーユーザアカウントに対応する前記ユーザ属性を解析した結果とに基づいた処理を行う
請求項1に記載のAIスピーカーシステム。 - 前記処理手段は、
解析された前記音声の意味に対応するサービスを行うサービス提供装置を選択し、
特定された前記スピーカーユーザアカウントに対応する前記ユーザ属性を解析した結果を、選択されたサービス提供装置に通知し、
当該通知に応じて前記サービス提供装置から送信されてくるデータに応じた放音処理を行う
請求項2に記載のAIスピーカーシステム。 - 前記処理手段は、
特定された前記スピーカーユーザアカウントに対応する前記ユーザ属性を解析した結果を、選択されたサービス提供装置に通知する場合に、
当該サービス提供装置において前記ユーザを識別するためのサービスユーザアカウントを、特定された前記スピーカーユーザアカウントに基づいて特定し、特定した前記サービスユーザアカウントを選択されたサービス提供装置に通知する
請求項3に記載のAIスピーカーシステム。 - 入力されたユーザの音声の意味を解析する解析ステップと、
入力された前記音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定ステップと、
解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理ステップと
を備えるAIスピーカーシステムの制御方法。 - コンピュータに、
入力されたユーザの音声の意味を解析する解析ステップと、
入力された前記音声の声紋に基づいて、当該音声を発したユーザを識別するスピーカーユーザアカウントを特定する特定ステップと、
解析された前記音声の意味と特定された前記スピーカーユーザアカウントに対応するユーザ属性とに基づいた処理を行う処理ステップと
を実行させるためのプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2018/010008 WO2019176018A1 (ja) | 2018-03-14 | 2018-03-14 | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム |
| PCT/JP2019/010552 WO2019177102A1 (ja) | 2018-03-14 | 2019-03-14 | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2018/010008 WO2019176018A1 (ja) | 2018-03-14 | 2018-03-14 | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019176018A1 true WO2019176018A1 (ja) | 2019-09-19 |
Family
ID=67906824
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2018/010008 WO2019176018A1 (ja) | 2018-03-14 | 2018-03-14 | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム |
| PCT/JP2019/010552 WO2019177102A1 (ja) | 2018-03-14 | 2019-03-14 | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/010552 WO2019177102A1 (ja) | 2018-03-14 | 2019-03-14 | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| WO (2) | WO2019176018A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111048064A (zh) * | 2020-03-13 | 2020-04-21 | 同盾控股有限公司 | 基于单说话人语音合成数据集的声音克隆方法及装置 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014164112A (ja) * | 2013-02-25 | 2014-09-08 | Sharp Corp | 電気機器 |
| JP2016071050A (ja) * | 2014-09-29 | 2016-05-09 | シャープ株式会社 | 音声対話装置、音声対話システム、端末、音声対話方法およびコンピュータを音声対話装置として機能させるためのプログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106570443A (zh) * | 2015-10-09 | 2017-04-19 | 芋头科技(杭州)有限公司 | 一种快速识别方法及家庭智能机器人 |
| CN106128467A (zh) * | 2016-06-06 | 2016-11-16 | 北京云知声信息技术有限公司 | 语音处理方法及装置 |
-
2018
- 2018-03-14 WO PCT/JP2018/010008 patent/WO2019176018A1/ja active Application Filing
-
2019
- 2019-03-14 WO PCT/JP2019/010552 patent/WO2019177102A1/ja active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014164112A (ja) * | 2013-02-25 | 2014-09-08 | Sharp Corp | 電気機器 |
| JP2016071050A (ja) * | 2014-09-29 | 2016-05-09 | シャープ株式会社 | 音声対話装置、音声対話システム、端末、音声対話方法およびコンピュータを音声対話装置として機能させるためのプログラム |
Non-Patent Citations (1)
| Title |
|---|
| "The Favorites are on Amazon and Rakuten! Home Electronics 2017 the Best Hit 100. Kaden Hihyo", KADEN 2017 THE BEST HIT 100, vol. 9, no. 12, 2 November 2017 (2017-11-02), pages 34 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111048064A (zh) * | 2020-03-13 | 2020-04-21 | 同盾控股有限公司 | 基于单说话人语音合成数据集的声音克隆方法及装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2019177102A1 (ja) | 2019-09-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10853582B2 (en) | Conversational agent | |
| US11682393B2 (en) | Method and system for context association and personalization using a wake-word in virtual personal assistants | |
| EP3474558A2 (en) | Encapsulating and synchronizing state interactions between devices | |
| JP6224857B1 (ja) | 分類装置、分類方法および分類プログラム | |
| JP6310796B2 (ja) | 制御装置、制御方法および制御プログラム | |
| JP6370962B1 (ja) | 生成装置、生成方法および生成プログラム | |
| JP6408080B1 (ja) | 生成装置、生成方法及び生成プログラム | |
| JP7250946B2 (ja) | インテント駆動型コンタクトセンター | |
| JP6199517B1 (ja) | 決定装置、決定方法および決定プログラム | |
| JP2016045583A (ja) | 応答生成装置、応答生成方法及び応答生成プログラム | |
| US12105483B2 (en) | Intelligent device and method for controlling the same | |
| US11120812B1 (en) | Application of machine learning techniques to select voice transformations | |
| JP2019040166A (ja) | 音声合成辞書配信装置、音声合成配信システムおよびプログラム | |
| KR20190064313A (ko) | 개인화된 챗봇 서비스 제공 방법 및 그 장치 | |
| WO2019176018A1 (ja) | Aiスピーカーシステム、aiスピーカーシステムの制御方法、及びプログラム | |
| JP6555838B1 (ja) | 音声問合せシステム、音声問合せ処理方法、スマートスピーカー運用サーバー装置、チャットボットポータルサーバー装置、およびプログラム。 | |
| KR102284912B1 (ko) | 상담 서비스 제공 방법 및 장치 | |
| KR102485339B1 (ko) | 차량의 음성 명령 처리 장치 및 방법 | |
| JP2014109998A (ja) | 対話装置及びコンピュータ対話方法 | |
| US11907676B1 (en) | Processing orchestration for systems including distributed components | |
| US11755652B2 (en) | Information-processing device and information-processing method | |
| JP6482703B1 (ja) | 推定装置、推定方法および推定プログラム | |
| US11893996B1 (en) | Supplemental content output | |
| JP6898064B2 (ja) | 対話決定システム、対話決定方法、対話決定プログラム、及び端末装置 | |
| US11790898B1 (en) | Resource selection for processing user inputs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18909415 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 18909415 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |