WO2018225594A1 - 符号化装置、復号装置、符号化方法及び復号方法 - Google Patents
符号化装置、復号装置、符号化方法及び復号方法 Download PDFInfo
- Publication number
- WO2018225594A1 WO2018225594A1 PCT/JP2018/020659 JP2018020659W WO2018225594A1 WO 2018225594 A1 WO2018225594 A1 WO 2018225594A1 JP 2018020659 W JP2018020659 W JP 2018020659W WO 2018225594 A1 WO2018225594 A1 WO 2018225594A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- inter
- motion vector
- prediction
- image
- units
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 624
- 230000033001 locomotion Effects 0.000 claims abstract description 680
- 239000013598 vector Substances 0.000 claims abstract description 426
- 230000008569 process Effects 0.000 claims abstract description 251
- 230000015654 memory Effects 0.000 claims abstract description 98
- 238000012545 processing Methods 0.000 claims description 273
- 238000013139 quantization Methods 0.000 description 52
- 238000010586 diagram Methods 0.000 description 50
- 230000002146 bilateral effect Effects 0.000 description 47
- 238000006243 chemical reaction Methods 0.000 description 47
- 238000010364 biochemical engineering Methods 0.000 description 39
- 238000012937 correction Methods 0.000 description 39
- 238000009795 derivation Methods 0.000 description 37
- 238000011156 evaluation Methods 0.000 description 29
- 239000000470 constituent Substances 0.000 description 21
- 230000000694 effects Effects 0.000 description 16
- 230000002457 bidirectional effect Effects 0.000 description 13
- 238000004891 communication Methods 0.000 description 12
- 230000000052 comparative effect Effects 0.000 description 12
- 230000006870 function Effects 0.000 description 11
- 230000009467 reduction Effects 0.000 description 11
- 230000005236 sound signal Effects 0.000 description 9
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 6
- 230000006978 adaptation Effects 0.000 description 6
- 230000003044 adaptive effect Effects 0.000 description 6
- 230000003287 optical effect Effects 0.000 description 6
- 230000009466 transformation Effects 0.000 description 6
- 230000005540 biological transmission Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 230000002093 peripheral effect Effects 0.000 description 5
- 230000002123 temporal effect Effects 0.000 description 5
- 230000001131 transforming effect Effects 0.000 description 5
- 238000004590 computer program Methods 0.000 description 4
- 238000003702 image correction Methods 0.000 description 4
- 101100537098 Mus musculus Alyref gene Proteins 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 101150095908 apex1 gene Proteins 0.000 description 3
- 229910003460 diamond Inorganic materials 0.000 description 3
- 239000010432 diamond Substances 0.000 description 3
- 238000007906 compression Methods 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 230000001360 synchronised effect Effects 0.000 description 2
- 125000002066 L-histidyl group Chemical group [H]N1C([H])=NC(C([H])([H])[C@](C(=O)[*])([H])N([H])[H])=C1[H] 0.000 description 1
- 241000023320 Luma <angiosperm> Species 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 230000003190 augmentative effect Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 239000000446 fuel Substances 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- OSWPMRLSEDHDFF-UHFFFAOYSA-N methyl salicylate Chemical group COC(=O)C1=CC=CC=C1O OSWPMRLSEDHDFF-UHFFFAOYSA-N 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000010295 mobile communication Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
Images





























Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/109—Selection of coding mode or of prediction mode among a plurality of temporal predictive coding modes
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/577—Motion compensation with bidirectional frame interpolation, i.e. using B-pictures
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/513—Processing of motion vectors
- H04N19/517—Processing of motion vectors by encoding
- H04N19/52—Processing of motion vectors by encoding by predictive encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/137—Motion inside a coding unit, e.g. average field, frame or block difference
- H04N19/139—Analysis of motion vectors, e.g. their magnitude, direction, variance or reliability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/14—Coding unit complexity, e.g. amount of activity or edge presence estimation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
- H04N19/159—Prediction type, e.g. intra-frame, inter-frame or bidirectional frame prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/186—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a colour or a chrominance component
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/573—Motion compensation with multiple frame prediction using two or more reference frames in a given prediction direction
Definitions
- the present disclosure relates to an encoding device, a decoding device, an encoding method, and a decoding method.
- H.264 has been used as a standard for encoding moving images.
- 265 exists.
- H. H.265 is also called HEVC (High Efficiency Video Coding).
- This disclosure is intended to provide a decoding device, an encoding device, a decoding method, or an encoding method that can reduce the processing amount.
- An encoding apparatus includes a circuit and a memory, and the circuit uses the memory in the first operation mode in units of prediction blocks obtained by dividing an image included in a moving image.
- a first motion that derives one motion vector and generates a prediction image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector in units of the prediction block Compensation processing is performed, and in the second operation mode, a second motion vector is derived in units of sub-blocks obtained by dividing the prediction block, and an image generated by motion compensation using the second motion vector in units of sub-blocks
- the second motion compensation process for generating the predicted image without referring to the spatial gradient of the luminance is performed.
- a decoding apparatus includes a circuit and a memory, and the circuit uses the memory in the first operation mode to generate a first prediction block unit obtained by dividing an image included in a moving image.
- First motion compensation for deriving a motion vector and generating a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector for each prediction block
- a second motion vector is derived in units of sub-blocks obtained by dividing the prediction block, and in the image generated by motion compensation using the second motion vector in units of sub-blocks.
- a second motion compensation process for generating a predicted image without referring to the spatial gradient of luminance is performed.
- the present disclosure can provide a decoding device, an encoding device, a decoding method, or an encoding method that can reduce the processing amount.
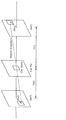
- FIG. 1 is a block diagram showing a functional configuration of the encoding apparatus according to Embodiment 1.
- FIG. 2 is a diagram illustrating an example of block division in the first embodiment.
- FIG. 3 is a table showing conversion basis functions corresponding to each conversion type.
- FIG. 4A is a diagram illustrating an example of the shape of a filter used in ALF.
- FIG. 4B is a diagram illustrating another example of the shape of a filter used in ALF.
- FIG. 4C is a diagram illustrating another example of the shape of a filter used in ALF.
- FIG. 5A is a diagram illustrating 67 intra prediction modes in intra prediction.
- FIG. 5B is a flowchart for explaining the outline of the predicted image correction process by the OBMC process.
- FIG. 5A is a diagram illustrating 67 intra prediction modes in intra prediction.
- FIG. 5B is a flowchart for explaining the outline of the predicted image correction process by the OBMC process.
- FIG. 5A is a
- FIG. 5C is a conceptual diagram for explaining the outline of the predicted image correction process by the OBMC process.
- FIG. 5D is a diagram illustrating an example of FRUC.
- FIG. 6 is a diagram for explaining pattern matching (bilateral matching) between two blocks along the motion trajectory.
- FIG. 7 is a diagram for explaining pattern matching (template matching) between a template in the current picture and a block in the reference picture.
- FIG. 8 is a diagram for explaining a model assuming constant velocity linear motion.
- FIG. 9A is a diagram for explaining derivation of a motion vector in units of sub-blocks based on motion vectors of a plurality of adjacent blocks.
- FIG. 9B is a diagram for explaining the outline of the motion vector deriving process in the merge mode.
- FIG. 9A is a diagram for explaining derivation of a motion vector in units of sub-blocks based on motion vectors of a plurality of adjacent blocks.
- FIG. 9B is a diagram for explaining the outline of
- FIG. 9C is a conceptual diagram for explaining an outline of DMVR processing.
- FIG. 9D is a diagram for describing an overview of a predicted image generation method using luminance correction processing by LIC processing.
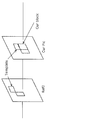
- FIG. 10 is a block diagram showing a functional configuration of the decoding apparatus according to the first embodiment.
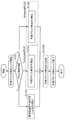
- FIG. 11 is a flowchart of inter-screen prediction processing according to Comparative Example 1.
- FIG. 12 is a flowchart of inter-screen prediction processing according to Comparative Example 2.
- FIG. 13 is a flowchart of the inter-screen prediction process according to the first embodiment.
- FIG. 14 is a flowchart of inter-screen prediction processing according to a modification of the first embodiment.
- FIG. 15 is a flowchart of an encoding process and a decoding process according to a modification of the first embodiment.
- FIG. 16 is a conceptual diagram showing the template FRUC method according to the first embodiment.
- FIG. 17 is a conceptual diagram showing the bilateral FRUC method according to the first embodiment.
- FIG. 18 is a flowchart showing an operation for deriving a motion vector by the FRUC method according to the first embodiment.
- FIG. 19 is a conceptual diagram showing BIO processing according to the first embodiment.
- FIG. 20 is a flowchart showing the BIO processing according to the first embodiment.
- FIG. 21 is a block diagram illustrating an implementation example of the coding apparatus according to Embodiment 1.
- FIG. 22 is a block diagram illustrating an implementation example of the decoding apparatus according to the first embodiment.
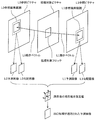
- FIG. 23 is an overall configuration diagram of a content supply system that implements a content distribution service.
- FIG. 23 is an overall configuration diagram of a content supply system that implements a content distribution service.
- FIG. 24 is a diagram illustrating an example of a coding structure at the time of scalable coding.
- FIG. 25 is a diagram illustrating an example of an encoding structure at the time of scalable encoding.
- FIG. 26 is a diagram illustrating a display screen example of a web page.
- FIG. 27 shows an example of a web page display screen.
- FIG. 28 is a diagram illustrating an example of a smartphone.
- FIG. 29 is a block diagram illustrating a configuration example of a smartphone.
- An encoding apparatus includes a circuit and a memory, and the circuit uses two memories in two different pictures in units of prediction blocks obtained by dividing an image included in a moving image.
- the first motion vector is derived by the first inter-screen prediction method using the degree of matching of the two reconstructed images in the two regions, and motion compensation using the derived first motion vector is performed in the prediction block unit.
- a first motion compensation process for generating a predicted image with reference to a spatial gradient of luminance in the generated image is performed.
- the encoding apparatus performs the motion vector derivation processing and the first motion compensation processing by the first inter-frame prediction method in units of prediction blocks, for example, when performing these processing in units of sub-blocks.
- the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed. Therefore, the encoding apparatus can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the circuit uses the memory and further performs second prediction by a second inter-screen prediction method that uses the degree of matching between the target prediction block and the reconstructed image of the region included in the reference picture in the prediction block unit.
- a second motion compensation process for deriving a motion vector and generating a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using the second motion vector is performed for each predicted block.
- An encoded bitstream including information for specifying the second motion vector may be generated.
- the processing unit of the motion compensation process can be made the same when the first inter-screen prediction method is used and when the second inter-screen prediction method is used. This can facilitate the implementation of the motion compensation process.
- the two regions in the first inter-picture prediction method are (1) a region in the target picture adjacent to the target prediction block and a region in the reference picture, or (2) in two different reference pictures. These two regions may be used.
- a decoding device includes a circuit and a memory, and the circuit uses prediction data obtained by dividing a picture included in a moving picture by using the memory in two different pictures.
- a first motion vector is derived by a first inter-screen prediction method that uses the degree of adaptation of two reconstructed images in two regions, and is generated by motion compensation using the derived first motion vector for each prediction block.
- a first motion compensation process for generating a predicted image with reference to a spatial gradient of luminance in the obtained image is performed.
- the decoding apparatus performs the motion vector derivation process and the first motion compensation process by the first inter-frame prediction method in units of prediction blocks, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed. Therefore, the decoding apparatus can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the circuit acquires information for specifying the second motion vector in units of the prediction blocks from the encoded bitstream using the memory, and uses the information in units of the prediction blocks.
- the second motion vector is derived by a second inter-screen prediction method, and a spatial gradient of luminance in an image generated by motion compensation using the derived second motion vector is referenced for each prediction block. Then, the second motion compensation process for generating a predicted image may be performed.
- the processing unit of the motion compensation process can be made the same when the first inter-screen prediction method is used and when the second inter-screen prediction method is used. This can facilitate the implementation of the motion compensation process.
- the two regions in the first inter-picture prediction method are (1) a region in the target picture adjacent to the target prediction block and a region in the reference picture, or (2) in two different reference pictures. These two regions may be used.
- the encoding method includes a first screen that uses a degree of matching between two reconstructed images in two regions in two different pictures in units of prediction blocks obtained by dividing an image included in a moving image.
- a first motion vector is derived by an inter prediction method, and a predicted image is obtained by referring to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector in the prediction block unit. Generate motion compensation processing.
- the encoding method when the motion vector derivation process and the first motion compensation process by the first inter-frame prediction method are performed in units of prediction blocks, for example, these processes are performed in units of sub-blocks. Compared to the above, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed. Therefore, the encoding method can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the decoding method is based on a prediction block unit obtained by dividing an image included in a moving image, and uses a degree of matching between two reconstructed images in two regions in two different pictures.
- a first motion vector is derived by a prediction method, and a prediction image is generated by referring to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector in the prediction block unit. Perform motion compensation processing.
- the decoding method performs the motion vector derivation process and the first motion compensation process by the first inter-frame prediction method in units of prediction blocks, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed. Therefore, the decoding method can reduce the processing amount while suppressing a decrease in encoding efficiency.
- An encoding apparatus includes a circuit and a memory, and the circuit uses the memory in the first operation mode in units of prediction blocks obtained by dividing an image included in a moving image.
- a first motion that derives one motion vector and generates a prediction image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector in units of the prediction block Compensation processing is performed, and in the second operation mode, a second motion vector is derived in units of sub-blocks obtained by dividing the prediction block, and an image generated by motion compensation using the second motion vector in units of sub-blocks
- the second motion compensation process for generating the predicted image without referring to the spatial gradient of the luminance is performed.
- the encoding apparatus performs the motion vector derivation process and the first motion compensation process in units of prediction blocks in the first operation mode, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the encoding apparatus performs motion vector derivation processing and second motion compensation processing in units of sub-blocks.
- the second motion compensation process does not refer to the spatial gradient of luminance, the amount of processing is smaller than that of the first motion compensation process.
- the encoding apparatus can improve the encoding efficiency by having such two operation modes. Thus, the encoding apparatus can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the circuit derives the first motion vector in units of the prediction block by a first inter-screen prediction method, and in the second operation mode, the first inter-screen prediction method
- the first inter-screen prediction method may be derived for each sub-block by using a different second inter-screen prediction method.
- the second inter-screen prediction method may be an inter-screen prediction method that uses the degree of matching between two reconstructed images in two regions in two different pictures.
- the first inter-screen prediction method includes (1) an inter-third screen that uses a degree of matching between a reconstructed image of a region in a target picture adjacent to a target prediction block and a reconstructed image of a region in a reference picture.
- One of a prediction method and (2) a fourth inter-screen prediction method that uses the degree of adaptation of two reconstructed images of two regions in two different reference pictures, and the second inter-screen prediction method May be the other of the third inter-screen prediction method and the fourth inter-screen prediction method.
- the first inter-screen prediction method may be the third inter-screen prediction method
- the second inter-screen prediction method may be the fourth inter-screen prediction method
- the first inter-screen prediction method is an inter-screen prediction method that uses a degree of matching between a target prediction block and a reconstructed image of an area included in a reference picture, and specifies the derived first motion vector.
- An encoded bitstream including information for the above may be generated.
- a decoding apparatus includes a circuit and a memory, and the circuit uses the memory in the first operation mode to generate a first prediction block unit obtained by dividing an image included in a moving image.
- First motion compensation for deriving a motion vector and generating a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector for each prediction block
- a second motion vector is derived in units of sub-blocks obtained by dividing the prediction block, and in the image generated by motion compensation using the second motion vector in units of sub-blocks.
- a second motion compensation process for generating a predicted image without referring to the spatial gradient of luminance is performed.
- the decoding apparatus performs the motion vector derivation process and the first motion compensation process in units of prediction blocks in the first operation mode, for example, compared with a case where these processes are performed in units of sub-blocks.
- the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the decoding apparatus performs motion vector derivation processing and second motion compensation processing in units of subblocks.
- the second motion compensation process does not refer to the spatial gradient of luminance, the amount of processing is smaller than that of the first motion compensation process.
- the decoding apparatus can improve encoding efficiency by having such two operation modes.
- the encoding apparatus can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the circuit derives the first motion vector in units of the prediction block by a first inter-screen prediction method, and in the second operation mode, the first inter-screen prediction method
- the first inter-screen prediction method may be derived for each sub-block by using a different second inter-screen prediction method.
- the second inter-screen prediction method may be an inter-screen prediction method that uses the degree of matching between two reconstructed images in two regions in two different pictures.
- the first inter-screen prediction method includes (1) an inter-third screen that uses a degree of matching between a reconstructed image of a region in a target picture adjacent to a target prediction block and a reconstructed image of a region in a reference picture.
- One of a prediction method and (2) a fourth inter-screen prediction method that uses the degree of adaptation of two reconstructed images of two regions in two different reference pictures, and the second inter-screen prediction method May be the other of the third inter-screen prediction method and the fourth inter-screen prediction method.
- the first inter-screen prediction method may be the third inter-screen prediction method
- the second inter-screen prediction method may be the fourth inter-screen prediction method
- information for specifying the first motion vector in units of the prediction block is acquired from an encoded bit stream, and the first motion vector is derived using the information. May be.
- the encoding method derives a first motion vector in units of prediction blocks obtained by dividing an image included in a moving image, and the first motion vector derived in units of the prediction blocks.
- a first motion compensation process for generating a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using one motion vector is performed, and in the second operation mode, the predicted block is subdivided.
- a second motion vector is derived for each block, and a predicted image is generated for each sub-block without referring to a spatial gradient of luminance in an image generated by motion compensation using the second motion vector. 2. Perform motion compensation processing.
- the encoding method performs the motion vector derivation process and the first motion compensation process in units of prediction blocks, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the encoding method performs motion vector derivation processing and second motion compensation processing in units of sub-blocks.
- the second motion compensation process does not refer to the spatial gradient of luminance, the amount of processing is smaller than that of the first motion compensation process.
- the encoding method can improve the encoding efficiency by having such two operation modes. Thus, the encoding method can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the first motion vector in the first operation mode, is derived in units of prediction blocks obtained by dividing an image included in a moving image, and the first motion vector derived in units of the prediction block is derived.
- a first motion compensation process for generating a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using a motion vector and in the second operation mode, a sub-block obtained by dividing the predicted block
- a second motion vector is derived in units, and a predicted image is generated in each sub-block unit without referring to a spatial gradient of luminance in an image generated by motion compensation using the second motion vector. Perform motion compensation processing.
- the decoding method performs the motion vector derivation process and the first motion compensation process in units of prediction blocks, for example, compared with the case where these processes are performed in units of sub-blocks.
- the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the motion vector derivation process and the second motion compensation process are performed in units of sub-blocks.
- the second motion compensation process does not refer to the spatial gradient of luminance
- the amount of processing is smaller than that of the first motion compensation process.
- the decoding method can improve the coding efficiency by having such two operation modes.
- the encoding method can reduce the processing amount while suppressing a decrease in encoding efficiency.
- these comprehensive or specific aspects may be realized by a system, an apparatus, a method, an integrated circuit, a computer program, or a non-transitory recording medium such as a computer-readable CD-ROM.
- the present invention may be realized by any combination of an apparatus, a method, an integrated circuit, a computer program, and a recording medium.
- an outline of the first embodiment will be described as an example of an encoding device and a decoding device to which the processing and / or configuration described in each aspect of the present disclosure to be described later can be applied.
- the first embodiment is merely an example of an encoding device and a decoding device to which the processing and / or configuration described in each aspect of the present disclosure can be applied, and the processing and / or processing described in each aspect of the present disclosure.
- the configuration can also be implemented in an encoding device and a decoding device different from those in the first embodiment.
- the encoding apparatus or decoding apparatus according to the first embodiment corresponds to the constituent elements described in each aspect of the present disclosure among a plurality of constituent elements constituting the encoding apparatus or decoding apparatus. Replacing the constituent elements with constituent elements described in each aspect of the present disclosure (2) A plurality of constituent elements constituting the encoding apparatus or decoding apparatus with respect to the encoding apparatus or decoding apparatus of the first embodiment The constituent elements corresponding to the constituent elements described in each aspect of the present disclosure are added to the present disclosure after arbitrary changes such as addition, replacement, and deletion of functions or processes to be performed on some constituent elements among the constituent elements.
- a component that performs a part of processing performed by a component is a component that is described in each aspect of the present disclosure, a component that includes a part of a function included in a component described in each aspect of the present disclosure, or a book (6)
- a method performed by the encoding device or the decoding device according to Embodiment 1 is performed in combination with a component that performs a part of processing performed by the component described in each aspect of the disclosure.
- the process corresponding to the process described in each aspect of the present disclosure is replaced with the process described in each aspect of the present disclosure.
- the encoding apparatus according to the first embodiment or A part of the plurality of processes included in the method performed by the decoding device is performed in combination with the processes described in each aspect of the present disclosure
- the processes and / or configurations described in each aspect of the present disclosure are not limited to the above examples.
- the present invention may be implemented in an apparatus used for a different purpose from the moving picture / picture encoding apparatus or moving picture / picture decoding apparatus disclosed in the first embodiment, and the processing and / or described in each aspect.
- the configuration may be implemented alone.
- you may implement combining the process and / or structure which were demonstrated in the different aspect.
- FIG. 1 is a block diagram showing a functional configuration of encoding apparatus 100 according to Embodiment 1.
- the encoding device 100 is a moving image / image encoding device that encodes moving images / images in units of blocks.
- an encoding apparatus 100 is an apparatus that encodes an image in units of blocks, and includes a dividing unit 102, a subtracting unit 104, a transforming unit 106, a quantizing unit 108, and entropy encoding.
- Unit 110 inverse quantization unit 112, inverse transform unit 114, addition unit 116, block memory 118, loop filter unit 120, frame memory 122, intra prediction unit 124, inter prediction unit 126, A prediction control unit 128.
- the encoding device 100 is realized by, for example, a general-purpose processor and a memory.
- the processor when the software program stored in the memory is executed by the processor, the processor performs the division unit 102, the subtraction unit 104, the conversion unit 106, the quantization unit 108, the entropy encoding unit 110, and the inverse quantization unit 112.
- the encoding apparatus 100 includes a dividing unit 102, a subtracting unit 104, a transforming unit 106, a quantizing unit 108, an entropy coding unit 110, an inverse quantizing unit 112, an inverse transforming unit 114, an adding unit 116, and a loop filter unit 120.
- the intra prediction unit 124, the inter prediction unit 126, and the prediction control unit 128 may be implemented as one or more dedicated electronic circuits.
- the dividing unit 102 divides each picture included in the input moving image into a plurality of blocks, and outputs each block to the subtracting unit 104.
- the dividing unit 102 first divides a picture into blocks of a fixed size (for example, 128 ⁇ 128).
- This fixed size block may be referred to as a coding tree unit (CTU).
- the dividing unit 102 divides each of the fixed size blocks into blocks of a variable size (for example, 64 ⁇ 64 or less) based on recursive quadtree and / or binary tree block division.
- This variable size block may be referred to as a coding unit (CU), a prediction unit (PU) or a transform unit (TU).
- CU, PU, and TU do not need to be distinguished, and some or all blocks in a picture may be processing units of CU, PU, and TU.
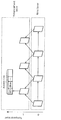
- FIG. 2 is a diagram showing an example of block division in the first embodiment.
- a solid line represents a block boundary by quadtree block division
- a broken line represents a block boundary by binary tree block division.
- the block 10 is a 128 ⁇ 128 pixel square block (128 ⁇ 128 block).
- the 128 ⁇ 128 block 10 is first divided into four square 64 ⁇ 64 blocks (quadtree block division).
- the upper left 64 ⁇ 64 block is further divided vertically into two rectangular 32 ⁇ 64 blocks, and the left 32 ⁇ 64 block is further divided vertically into two rectangular 16 ⁇ 64 blocks (binary tree block division). As a result, the upper left 64 ⁇ 64 block is divided into two 16 ⁇ 64 blocks 11 and 12 and a 32 ⁇ 64 block 13.
- the upper right 64 ⁇ 64 block is horizontally divided into two rectangular 64 ⁇ 32 blocks 14 and 15 (binary tree block division).
- the lower left 64x64 block is divided into four square 32x32 blocks (quadrant block division). Of the four 32 ⁇ 32 blocks, the upper left block and the lower right block are further divided.
- the upper left 32 ⁇ 32 block is vertically divided into two rectangular 16 ⁇ 32 blocks, and the right 16 ⁇ 32 block is further divided horizontally into two 16 ⁇ 16 blocks (binary tree block division).
- the lower right 32 ⁇ 32 block is horizontally divided into two 32 ⁇ 16 blocks (binary tree block division).
- the lower left 64 ⁇ 64 block is divided into a 16 ⁇ 32 block 16, two 16 ⁇ 16 blocks 17 and 18, two 32 ⁇ 32 blocks 19 and 20, and two 32 ⁇ 16 blocks 21 and 22.
- the lower right 64x64 block 23 is not divided.
- the block 10 is divided into 13 variable-size blocks 11 to 23 based on the recursive quadtree and binary tree block division.
- Such division may be called QTBT (quad-tree plus binary tree) division.
- one block is divided into four or two blocks (quadrature tree or binary tree block division), but the division is not limited to this.
- one block may be divided into three blocks (triple tree block division).
- Such a division including a tri-tree block division may be called an MBT (multi type tree) division.
- the subtraction unit 104 subtracts the prediction signal (prediction sample) from the original signal (original sample) in units of blocks divided by the division unit 102. That is, the subtraction unit 104 calculates a prediction error (also referred to as a residual) of a coding target block (hereinafter referred to as a current block). Then, the subtraction unit 104 outputs the calculated prediction error to the conversion unit 106.
- a prediction error also referred to as a residual of a coding target block (hereinafter referred to as a current block).
- the original signal is an input signal of the encoding device 100, and is a signal (for example, a luminance (luma) signal and two color difference (chroma) signals) representing an image of each picture constituting the moving image.
- a signal representing an image may be referred to as a sample.
- the transform unit 106 transforms the prediction error in the spatial domain into a transform factor in the frequency domain, and outputs the transform coefficient to the quantization unit 108. Specifically, the transform unit 106 performs, for example, a predetermined discrete cosine transform (DCT) or discrete sine transform (DST) on a prediction error in the spatial domain.
- DCT discrete cosine transform
- DST discrete sine transform
- the conversion unit 106 adaptively selects a conversion type from a plurality of conversion types, and converts a prediction error into a conversion coefficient using a conversion basis function corresponding to the selected conversion type. May be. Such a conversion may be referred to as EMT (explicit multiple core transform) or AMT (adaptive multiple transform).
- the plurality of conversion types include, for example, DCT-II, DCT-V, DCT-VIII, DST-I and DST-VII.
- FIG. 3 is a table showing conversion basis functions corresponding to each conversion type. In FIG. 3, N indicates the number of input pixels. Selection of a conversion type from among these multiple conversion types may depend on, for example, the type of prediction (intra prediction and inter prediction), or may depend on an intra prediction mode.
- Information indicating whether or not to apply such EMT or AMT (for example, called an AMT flag) and information indicating the selected conversion type are signaled at the CU level.
- AMT flag information indicating whether or not to apply such EMT or AMT
- the signalization of these pieces of information need not be limited to the CU level, but may be other levels (for example, a sequence level, a picture level, a slice level, a tile level, or a CTU level).
- the conversion unit 106 may reconvert the conversion coefficient (conversion result). Such reconversion is sometimes referred to as AST (adaptive secondary transform) or NSST (non-separable secondary transform). For example, the conversion unit 106 performs re-conversion for each sub-block (for example, 4 ⁇ 4 sub-block) included in the block of the conversion coefficient corresponding to the intra prediction error. Information indicating whether or not NSST is applied and information related to the transformation matrix used for NSST are signaled at the CU level. Note that the signalization of these pieces of information need not be limited to the CU level, but may be other levels (for example, a sequence level, a picture level, a slice level, a tile level, or a CTU level).
- the separable conversion is a method of performing the conversion a plurality of times by separating the number of dimensions of the input for each direction, and the non-separable conversion is two or more when the input is multidimensional.
- the dimensions are collectively regarded as one dimension, and conversion is performed collectively.
- non-separable conversion if an input is a 4 ⁇ 4 block, it is regarded as one array having 16 elements, and 16 ⁇ 16 conversion is performed on the array. The thing which performs the conversion process with a matrix is mentioned.
- a 4 ⁇ 4 input block is regarded as a single array having 16 elements, and then the Givens rotation is performed multiple times on the array (Hypercube Givens Transform) is also a non-separable. It is an example of conversion.
- the quantization unit 108 quantizes the transform coefficient output from the transform unit 106. Specifically, the quantization unit 108 scans the transform coefficients of the current block in a predetermined scanning order, and quantizes the transform coefficients based on the quantization parameter (QP) corresponding to the scanned transform coefficients. Then, the quantization unit 108 outputs the quantized transform coefficient (hereinafter referred to as a quantization coefficient) of the current block to the entropy encoding unit 110 and the inverse quantization unit 112.
- QP quantization parameter
- the predetermined order is an order for quantization / inverse quantization of transform coefficients.
- the predetermined scanning order is defined in ascending order of frequency (order from low frequency to high frequency) or descending order (order from high frequency to low frequency).
- the quantization parameter is a parameter that defines a quantization step (quantization width). For example, if the value of the quantization parameter increases, the quantization step also increases. That is, if the value of the quantization parameter increases, the quantization error increases.
- the entropy encoding unit 110 generates an encoded signal (encoded bit stream) by performing variable length encoding on the quantization coefficient that is input from the quantization unit 108. Specifically, the entropy encoding unit 110 binarizes the quantization coefficient, for example, and arithmetically encodes the binary signal.
- the inverse quantization unit 112 inversely quantizes the quantization coefficient that is an input from the quantization unit 108. Specifically, the inverse quantization unit 112 inversely quantizes the quantization coefficient of the current block in a predetermined scanning order. Then, the inverse quantization unit 112 outputs the inverse-quantized transform coefficient of the current block to the inverse transform unit 114.
- the inverse transform unit 114 restores the prediction error by inverse transforming the transform coefficient that is an input from the inverse quantization unit 112. Specifically, the inverse transform unit 114 restores the prediction error of the current block by performing an inverse transform corresponding to the transform by the transform unit 106 on the transform coefficient. Then, the inverse transformation unit 114 outputs the restored prediction error to the addition unit 116.
- the restored prediction error does not match the prediction error calculated by the subtraction unit 104 because information is lost due to quantization. That is, the restored prediction error includes a quantization error.
- the adder 116 reconstructs the current block by adding the prediction error input from the inverse transform unit 114 and the prediction sample input from the prediction control unit 128. Then, the adding unit 116 outputs the reconfigured block to the block memory 118 and the loop filter unit 120.
- the reconstructed block is sometimes referred to as a local decoding block.
- the block memory 118 is a storage unit for storing blocks in an encoding target picture (hereinafter referred to as current picture) that are referred to in intra prediction. Specifically, the block memory 118 stores the reconstructed block output from the adding unit 116.
- the loop filter unit 120 applies a loop filter to the block reconstructed by the adding unit 116 and outputs the filtered reconstructed block to the frame memory 122.
- the loop filter is a filter (in-loop filter) used in the encoding loop, and includes, for example, a deblocking filter (DF), a sample adaptive offset (SAO), an adaptive loop filter (ALF), and the like.
- a least square error filter is applied to remove coding distortion. For example, for each 2 ⁇ 2 sub-block in the current block, a plurality of multiples based on the direction of the local gradient and the activity are provided. One filter selected from the filters is applied.
- sub-blocks for example, 2 ⁇ 2 sub-blocks
- a plurality of classes for example, 15 or 25 classes.
- the direction value D of the gradient is derived, for example, by comparing gradients in a plurality of directions (for example, horizontal, vertical, and two diagonal directions).
- the gradient activation value A is derived, for example, by adding gradients in a plurality of directions and quantizing the addition result.
- a filter for a sub-block is determined from among a plurality of filters.
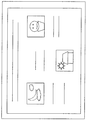
- FIG. 4A to 4C are diagrams showing a plurality of examples of filter shapes used in ALF.
- 4A shows a 5 ⁇ 5 diamond shape filter
- FIG. 4B shows a 7 ⁇ 7 diamond shape filter
- FIG. 4C shows a 9 ⁇ 9 diamond shape filter.
- Information indicating the shape of the filter is signalized at the picture level. It should be noted that the signalization of the information indicating the filter shape need not be limited to the picture level, but may be another level (for example, a sequence level, a slice level, a tile level, a CTU level, or a CU level).
- ON / OFF of ALF is determined at the picture level or the CU level, for example. For example, for luminance, it is determined whether to apply ALF at the CU level, and for color difference, it is determined whether to apply ALF at the picture level.
- Information indicating ALF on / off is signaled at the picture level or the CU level. Signaling of information indicating ALF on / off need not be limited to the picture level or the CU level, and may be performed at other levels (for example, a sequence level, a slice level, a tile level, or a CTU level). Good.
- a coefficient set of a plurality of selectable filters (for example, up to 15 or 25 filters) is signalized at the picture level.
- the signalization of the coefficient set need not be limited to the picture level, but may be another level (for example, sequence level, slice level, tile level, CTU level, CU level, or sub-block level).
- the frame memory 122 is a storage unit for storing a reference picture used for inter prediction, and is sometimes called a frame buffer. Specifically, the frame memory 122 stores the reconstructed block filtered by the loop filter unit 120.
- the intra prediction unit 124 generates a prediction signal (intra prediction signal) by referring to the block in the current picture stored in the block memory 118 and performing intra prediction (also referred to as intra-screen prediction) of the current block. Specifically, the intra prediction unit 124 generates an intra prediction signal by performing intra prediction with reference to a sample (for example, luminance value and color difference value) of a block adjacent to the current block, and performs prediction control on the intra prediction signal. To the unit 128.
- the intra prediction unit 124 performs intra prediction using one of a plurality of predefined intra prediction modes.
- the plurality of intra prediction modes include one or more non-directional prediction modes and a plurality of directional prediction modes.
- One or more non-directional prediction modes are for example H.264. It includes Planar prediction mode and DC prediction mode defined by H.265 / HEVC (High-Efficiency Video Coding) standard (Non-patent Document 1).
- the multiple directionality prediction modes are for example H.264. It includes 33-direction prediction modes defined in the H.265 / HEVC standard. In addition to the 33 directions, the plurality of directionality prediction modes may further include 32 direction prediction modes (a total of 65 directionality prediction modes).
- FIG. 5A is a diagram illustrating 67 intra prediction modes (two non-directional prediction modes and 65 directional prediction modes) in intra prediction. The solid line arrows The 33 directions defined in the H.265 / HEVC standard are represented, and the dashed arrow represents the added 32 directions.
- the luminance block may be referred to in the intra prediction of the color difference block. That is, the color difference component of the current block may be predicted based on the luminance component of the current block.
- Such intra prediction is sometimes called CCLM (cross-component linear model) prediction.
- the intra prediction mode (for example, called CCLM mode) of the color difference block which refers to such a luminance block may be added as one of the intra prediction modes of the color difference block.
- the intra prediction unit 124 may correct the pixel value after intra prediction based on the gradient of the reference pixel in the horizontal / vertical direction. Intra prediction with such correction may be called PDPC (position dependent intra prediction combination). Information indicating whether or not PDPC is applied (for example, referred to as a PDPC flag) is signaled, for example, at the CU level.
- the signalization of this information need not be limited to the CU level, but may be another level (for example, a sequence level, a picture level, a slice level, a tile level, or a CTU level).
- the inter prediction unit 126 refers to a reference picture stored in the frame memory 122 and is different from the current picture, and performs inter prediction (also referred to as inter-screen prediction) of the current block, thereby generating a prediction signal (inter prediction signal). Prediction signal). Inter prediction is performed in units of a current block or a sub-block (for example, 4 ⁇ 4 block) in the current block. For example, the inter prediction unit 126 performs motion estimation in the reference picture for the current block or sub-block. Then, the inter prediction unit 126 generates an inter prediction signal of the current block or sub-block by performing motion compensation using motion information (for example, a motion vector) obtained by motion search. Then, the inter prediction unit 126 outputs the generated inter prediction signal to the prediction control unit 128.
- inter prediction also referred to as inter-screen prediction
- a motion vector predictor may be used for signalizing the motion vector. That is, the difference between the motion vector and the predicted motion vector may be signaled.
- an inter prediction signal may be generated using not only the motion information of the current block obtained by motion search but also the motion information of adjacent blocks. Specifically, the inter prediction signal is generated in units of sub-blocks in the current block by weighted addition of the prediction signal based on the motion information obtained by motion search and the prediction signal based on the motion information of adjacent blocks. May be.
- Such inter prediction motion compensation
- OBMC overlapped block motion compensation
- OBMC block size information indicating the size of a sub-block for OBMC
- OBMC flag information indicating whether or not to apply the OBMC mode
- the level of signalization of these information does not need to be limited to the sequence level and the CU level, and may be other levels (for example, a picture level, a slice level, a tile level, a CTU level, or a sub-block level). Good.
- FIG. 5B and FIG. 5C are a flowchart and a conceptual diagram for explaining the outline of the predicted image correction process by the OBMC process.
- a prediction image (Pred) by normal motion compensation is acquired using a motion vector (MV) assigned to an encoding target block.
- MV motion vector
- a prediction image (Pred_L) is obtained by applying the motion vector (MV_L) of the encoded left adjacent block to the encoding target block, and prediction is performed by superimposing the prediction image and Pred_L with weights. Perform the first correction of the image.
- the motion vector (MV_U) of the encoded upper adjacent block is applied to the block to be encoded to obtain a prediction image (Pred_U), and the prediction image and Pred_U that have been subjected to the first correction are weighted. Then, the second correction of the predicted image is performed by superimposing and making it the final predicted image.
- the two-step correction method using the left adjacent block and the upper adjacent block has been described here, the correction may be performed more times than the two steps using the right adjacent block and the lower adjacent block. Is possible.
- the area to be overlapped may not be the pixel area of the entire block, but only a part of the area near the block boundary.
- the processing target block may be a prediction block unit or a sub-block unit obtained by further dividing the prediction block.
- obmc_flag is a signal indicating whether or not to apply the OBMC process.
- the encoding apparatus it is determined whether or not the encoding target block belongs to a complex motion region, and if it belongs to a complex motion region, a value 1 is set as obmc_flag. Encoding is performed by applying the OBMC process, and if it does not belong to a complex region of motion, the value 0 is set as obmc_flag and the encoding is performed without applying the OBMC process.
- the decoding apparatus by decoding the obmc_flag described in the stream, decoding is performed by switching whether to apply the OBMC process according to the value.
- the motion information may be derived on the decoding device side without being converted into a signal.
- H.M. A merge mode defined in the H.265 / HEVC standard may be used.
- the motion information may be derived by performing motion search on the decoding device side. In this case, motion search is performed without using the pixel value of the current block.
- the mode in which motion search is performed on the decoding device side is sometimes called a PMMVD (patterned motion vector derivation) mode or an FRUC (frame rate up-conversion) mode.
- PMMVD patterned motion vector derivation
- FRUC frame rate up-conversion
- FIG. 5D An example of FRUC processing is shown in FIG. 5D.
- a list of a plurality of candidates each having a predicted motion vector (may be common with the merge list) is generated Is done.
- the best candidate MV is selected from a plurality of candidate MVs registered in the candidate list. For example, the evaluation value of each candidate included in the candidate list is calculated, and one candidate is selected based on the evaluation value.
- a motion vector for the current block is derived based on the selected candidate motion vector.
- the selected candidate motion vector (best candidate MV) is directly derived as a motion vector for the current block.
- the motion vector for the current block may be derived by performing pattern matching in the peripheral region at the position in the reference picture corresponding to the selected candidate motion vector. That is, the same method is used to search the area around the best candidate MV, and if there is an MV with a good evaluation value, the best candidate MV is updated to the MV, and the current block is updated. The final MV may be used. It is also possible to adopt a configuration in which the processing is not performed.
- the same processing may be performed when processing is performed in units of sub-blocks.
- the evaluation value is calculated by obtaining a difference value of the reconstructed image by pattern matching between a region in the reference picture corresponding to the motion vector and a predetermined region. Note that the evaluation value may be calculated using information other than the difference value.
- the first pattern matching and the second pattern matching may be referred to as bilateral matching and template matching, respectively.
- pattern matching is performed between two blocks in two different reference pictures that follow the motion trajectory of the current block. Therefore, in the first pattern matching, a region in another reference picture along the motion trajectory of the current block is used as the predetermined region for calculating the candidate evaluation value described above.
- FIG. 6 is a diagram for explaining an example of pattern matching (bilateral matching) between two blocks along a motion trajectory.
- first pattern matching two blocks along the motion trajectory of the current block (Cur block) and two blocks in two different reference pictures (Ref0, Ref1) are used.
- two motion vectors MV0, MV1 are derived.
- MV0, MV1 a reconstructed image at a designated position in the first encoded reference picture (Ref0) designated by the candidate MV, and a symmetric MV obtained by scaling the candidate MV at a display time interval.
- the difference from the reconstructed image at the designated position in the second encoded reference picture (Ref1) designated in (2) is derived, and the evaluation value is calculated using the obtained difference value.
- the candidate MV having the best evaluation value among the plurality of candidate MVs may be selected as the final MV.
- the motion vectors (MV0, MV1) pointing to the two reference blocks are temporal distances between the current picture (Cur Pic) and the two reference pictures (Ref0, Ref1). It is proportional to (TD0, TD1).
- the first pattern matching uses a mirror-symmetric bi-directional motion vector Is derived.
- pattern matching is performed between a template in the current picture (a block adjacent to the current block in the current picture (for example, an upper and / or left adjacent block)) and a block in the reference picture. Therefore, in the second pattern matching, a block adjacent to the current block in the current picture is used as the predetermined region for calculating the candidate evaluation value described above.
- FIG. 7 is a diagram for explaining an example of pattern matching (template matching) between a template in the current picture and a block in the reference picture.
- the current block is searched by searching the reference picture (Ref0) for the block that most closely matches the block adjacent to the current block (Cur block) in the current picture (Cur Pic).
- Ref0 the reference picture
- the reconstructed image of the encoded region of the left adjacent area and / or the upper adjacent area, and the equivalent in the encoded reference picture (Ref0) designated by the candidate MV When a difference from the reconstructed image at the position is derived, an evaluation value is calculated using the obtained difference value, and a candidate MV having the best evaluation value among a plurality of candidate MVs is selected as the best candidate MV. Good.
- FRUC flag Information indicating whether or not to apply such FRUC mode
- FRUC flag information indicating whether or not to apply such FRUC mode
- the FRUC mode is applied (for example, when the FRUC flag is true)
- information indicating the pattern matching method (first pattern matching or second pattern matching) (for example, called the FRUC mode flag) is signaled at the CU level. It becomes. Note that the signalization of these pieces of information need not be limited to the CU level, but may be other levels (for example, sequence level, picture level, slice level, tile level, CTU level, or sub-block level). .
- BIO bi-directional optical flow
- FIG. 8 is a diagram for explaining a model assuming constant velocity linear motion.
- (v x , v y ) indicates a velocity vector
- ⁇ 0 and ⁇ 1 are the time between the current picture (Cur Pic) and two reference pictures (Ref 0 , Ref 1 ), respectively.
- the distance. (MVx 0 , MVy 0 ) indicates a motion vector corresponding to the reference picture Ref 0
- (MVx 1 , MVy 1 ) indicates a motion vector corresponding to the reference picture Ref 1 .
- This optical flow equation consists of (i) the product of the time derivative of the luminance value, (ii) the horizontal component of the horizontal velocity and the spatial gradient of the reference image, and (iii) the vertical velocity and the spatial gradient of the reference image. Indicates that the sum of the products of the vertical components of is equal to zero. Based on a combination of this optical flow equation and Hermite interpolation, a block-based motion vector obtained from a merge list or the like is corrected in pixel units.
- the motion vector may be derived on the decoding device side by a method different from the derivation of the motion vector based on the model assuming constant velocity linear motion.
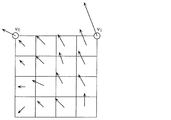
- a motion vector may be derived for each subblock based on the motion vectors of a plurality of adjacent blocks.
- This mode may be referred to as an affine motion compensation prediction mode.
- FIG. 9A is a diagram for explaining derivation of a motion vector in units of sub-blocks based on motion vectors of a plurality of adjacent blocks.
- the current block includes 16 4 ⁇ 4 sub-blocks.
- the motion vector v 0 of the upper left corner control point of the current block is derived based on the motion vector of the adjacent block
- the motion vector v 1 of the upper right corner control point of the current block is derived based on the motion vector of the adjacent sub block. Is done.
- the motion vector (v x , v y ) of each sub-block in the current block is derived by the following equation (2).
- x and y indicate the horizontal position and vertical position of the sub-block, respectively, and w indicates a predetermined weight coefficient.
- Such an affine motion compensation prediction mode may include several modes in which the motion vector derivation methods of the upper left and upper right corner control points are different.
- Information indicating such an affine motion compensation prediction mode (for example, called an affine flag) is signaled at the CU level. Note that the information indicating the affine motion compensation prediction mode need not be limited to the CU level, but other levels (for example, sequence level, picture level, slice level, tile level, CTU level, or sub-block level). ).
- the prediction control unit 128 selects either the intra prediction signal or the inter prediction signal, and outputs the selected signal to the subtraction unit 104 and the addition unit 116 as a prediction signal.
- FIG. 9B is a diagram for explaining the outline of the motion vector deriving process in the merge mode.
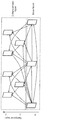
- a prediction MV list in which prediction MV candidates are registered is generated.
- prediction MV candidates spatial adjacent prediction MVs that are MVs of a plurality of encoded blocks located spatially around the encoding target block, and the position of the encoding target block in the encoded reference picture are projected.
- Temporal adjacent prediction MV that is MV of neighboring blocks combined prediction MV that is MV generated by combining MV values of spatial adjacent prediction MV and temporal adjacent prediction MV, zero prediction MV that is MV having a value of zero, and the like There is.
- variable length encoding unit describes and encodes merge_idx which is a signal indicating which prediction MV is selected in the stream.
- the prediction MV registered in the prediction MV list described with reference to FIG. 9B is an example, and the number of prediction MVs may be different from the number in the figure, or may not include some types of prediction MVs in the figure. It may be the composition which added prediction MV other than the kind of prediction MV in a figure.
- the final MV may be determined by performing DMVR processing, which will be described later, using the MV of the encoding target block derived by the merge mode.
- FIG. 9C is a conceptual diagram for explaining an outline of DMVR processing.
- the optimal MVP set in the processing target block is set as a candidate MV, and reference pixels from a first reference picture that is a processed picture in the L0 direction and a second reference picture that is a processed picture in the L1 direction are set according to the candidate MV. Are obtained, and a template is generated by taking the average of each reference pixel.
- the peripheral areas of the candidate MVs of the first reference picture and the second reference picture are searched, respectively, and the MV with the lowest cost is determined as the final MV.
- the cost value is calculated using a difference value between each pixel value of the template and each pixel value of the search area, an MV value, and the like.
- FIG. 9D is a diagram for explaining an outline of a predicted image generation method using luminance correction processing by LIC processing.
- an MV for obtaining a reference image corresponding to a block to be encoded is derived from a reference picture that is an encoded picture.
- the predicted image for the encoding target block is generated by performing the brightness correction process using the brightness correction parameter for the reference image in the reference picture specified by MV.
- the shape of the peripheral reference region in FIG. 9D is an example, and other shapes may be used.
- the process of generating a predicted image from one reference picture has been described, but the same applies to the case of generating a predicted image from a plurality of reference pictures, and the same applies to reference images acquired from each reference picture.
- the predicted image is generated after performing the luminance correction processing by the method.
- lic_flag is a signal indicating whether to apply LIC processing.
- the encoding device it is determined whether or not the encoding target block belongs to an area where the luminance change occurs, and if it belongs to the area where the luminance change occurs, lic_flag is set. Encode by applying LIC processing with a value of 1 set, and if not belonging to an area where a luminance change has occurred, set 0 as lic_flag and perform encoding without applying the LIC processing .
- the decoding device by decoding lic_flag described in the stream, decoding is performed by switching whether to apply the LIC processing according to the value.
- a method for determining whether or not to apply LIC processing for example, there is a method for determining whether or not LIC processing has been applied to peripheral blocks.
- the encoding target block is in the merge mode
- whether or not the surrounding encoded blocks selected in the derivation of the MV in the merge mode processing are encoded by applying the LIC processing. Judgment is performed, and encoding is performed by switching whether to apply the LIC processing according to the result.
- the decoding process is exactly the same.
- FIG. 10 is a block diagram showing a functional configuration of decoding apparatus 200 according to Embodiment 1.
- the decoding device 200 is a moving image / image decoding device that decodes moving images / images in units of blocks.
- the decoding device 200 includes an entropy decoding unit 202, an inverse quantization unit 204, an inverse transformation unit 206, an addition unit 208, a block memory 210, a loop filter unit 212, and a frame memory 214. And an intra prediction unit 216, an inter prediction unit 218, and a prediction control unit 220.
- the decoding device 200 is realized by, for example, a general-purpose processor and a memory.
- the processor executes the entropy decoding unit 202, the inverse quantization unit 204, the inverse transformation unit 206, the addition unit 208, the loop filter unit 212, and the intra prediction unit. 216, the inter prediction unit 218, and the prediction control unit 220.
- the decoding apparatus 200 is dedicated to the entropy decoding unit 202, the inverse quantization unit 204, the inverse transformation unit 206, the addition unit 208, the loop filter unit 212, the intra prediction unit 216, the inter prediction unit 218, and the prediction control unit 220. It may be realized as one or more electronic circuits.
- the entropy decoding unit 202 performs entropy decoding on the encoded bit stream. Specifically, the entropy decoding unit 202 performs arithmetic decoding from a coded bitstream to a binary signal, for example. Then, the entropy decoding unit 202 debinarizes the binary signal. As a result, the entropy decoding unit 202 outputs the quantized coefficient to the inverse quantization unit 204 in units of blocks.
- the inverse quantization unit 204 inversely quantizes the quantization coefficient of a decoding target block (hereinafter referred to as a current block) that is an input from the entropy decoding unit 202. Specifically, the inverse quantization unit 204 inversely quantizes each quantization coefficient of the current block based on the quantization parameter corresponding to the quantization coefficient. Then, the inverse quantization unit 204 outputs the quantization coefficient (that is, the transform coefficient) obtained by inverse quantization of the current block to the inverse transform unit 206.
- a decoding target block hereinafter referred to as a current block
- the inverse quantization unit 204 inversely quantizes each quantization coefficient of the current block based on the quantization parameter corresponding to the quantization coefficient. Then, the inverse quantization unit 204 outputs the quantization coefficient (that is, the transform coefficient) obtained by inverse quantization of the current block to the inverse transform unit 206.
- the inverse transform unit 206 restores the prediction error by inverse transforming the transform coefficient that is an input from the inverse quantization unit 204.
- the inverse conversion unit 206 determines the current block based on the information indicating the read conversion type. Inverts the conversion coefficient of.
- the inverse transform unit 206 applies inverse retransformation to the transform coefficient.
- the adder 208 reconstructs the current block by adding the prediction error input from the inverse converter 206 and the prediction sample input from the prediction controller 220. Then, the adding unit 208 outputs the reconfigured block to the block memory 210 and the loop filter unit 212.
- the block memory 210 is a storage unit for storing a block that is referred to in intra prediction and that is within a decoding target picture (hereinafter referred to as a current picture). Specifically, the block memory 210 stores the reconstructed block output from the adding unit 208.
- the loop filter unit 212 applies a loop filter to the block reconstructed by the adding unit 208, and outputs the filtered reconstructed block to the frame memory 214, the display device, and the like.
- one filter is selected from the plurality of filters based on the local gradient direction and activity, The selected filter is applied to the reconstruction block.
- the frame memory 214 is a storage unit for storing a reference picture used for inter prediction, and is sometimes called a frame buffer. Specifically, the frame memory 214 stores the reconstructed block filtered by the loop filter unit 212.
- the intra prediction unit 216 performs intra prediction with reference to the block in the current picture stored in the block memory 210 based on the intra prediction mode read from the encoded bitstream, so that a prediction signal (intra prediction Signal). Specifically, the intra prediction unit 216 generates an intra prediction signal by performing intra prediction with reference to a sample (for example, luminance value and color difference value) of a block adjacent to the current block, and performs prediction control on the intra prediction signal. Output to the unit 220.
- a prediction signal for example, luminance value and color difference value
- the intra prediction unit 216 may predict the color difference component of the current block based on the luminance component of the current block.
- the intra prediction unit 216 corrects the pixel value after intra prediction based on the gradient of the reference pixel in the horizontal / vertical direction.
- the inter prediction unit 218 refers to the reference picture stored in the frame memory 214 and predicts the current block. Prediction is performed in units of a current block or a sub-block (for example, 4 ⁇ 4 block) in the current block. For example, the inter prediction unit 218 generates an inter prediction signal of the current block or sub-block by performing motion compensation using motion information (for example, a motion vector) read from the encoded bitstream, and generates the inter prediction signal. The result is output to the prediction control unit 220.
- motion information for example, a motion vector
- the inter prediction unit 218 When the information read from the encoded bitstream indicates that the OBMC mode is to be applied, the inter prediction unit 218 includes not only the motion information of the current block obtained by motion search but also the motion information of adjacent blocks. To generate an inter prediction signal.
- the inter prediction unit 218 follows the pattern matching method (bilateral matching or template matching) read from the encoded stream. Motion information is derived by performing motion search. Then, the inter prediction unit 218 performs motion compensation using the derived motion information.
- the inter prediction unit 218 derives a motion vector based on a model assuming constant velocity linear motion. Also, when the information read from the encoded bitstream indicates that the affine motion compensated prediction mode is applied, the inter prediction unit 218 determines the motion vector in units of subblocks based on the motion vectors of a plurality of adjacent blocks. Is derived.
- the prediction control unit 220 selects either the intra prediction signal or the inter prediction signal, and outputs the selected signal to the adding unit 208 as a prediction signal.
- FIG. 11 is a flowchart of inter-screen prediction processing in units of prediction blocks in the video encoding method and video decoding method according to Comparative Example 1.
- the process illustrated in FIG. 11 is repeatedly performed in units of prediction blocks that are processing units of inter-screen prediction processing.
- the operation of the inter prediction unit 126 included in the encoding device 100 will be mainly described, but the operation of the inter prediction unit 218 included in the decoding device 200 is also the same.
- the inter prediction unit 126 derives a motion vector (MV) in units of prediction blocks according to the normal inter-screen prediction method (S102).
- the normal inter-screen prediction method is a conventional method that does not use the FRUC method.
- a motion vector is derived on the encoding side, and information indicating the derived motion vector is transferred from the encoding side to the decoding side. This is the transmission method.
- the inter prediction unit 126 obtains an inter-screen prediction image by performing motion compensation in units of prediction blocks using motion vectors in units of prediction blocks (S103).
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the template FRUC method (S104). Thereafter, the inter prediction unit 126 derives a motion vector in units of subblocks obtained by dividing the prediction block according to the template FRUC method (S105).
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the bilateral FRUC method (S106). Thereafter, the inter prediction unit 126 derives a motion vector according to the bilateral FRUC method in units of subblocks obtained by dividing the prediction block (S107).
- the inter prediction unit 126 derives a motion vector in units of subblocks according to the template FRUC method or the bilateral FRUC method, and then performs motion compensation in units of subblocks using the derived motion vector in units of subblocks. Then, an inter-screen prediction image is acquired (S108).
- the motion vector is corrected in units of sub-blocks, thereby making it possible to follow a fine motion. Thereby, the improvement of encoding efficiency is realizable. On the other hand, there is a possibility that a block in which deformation occurs in units of pixels cannot be sufficiently handled.
- FIG. 12 is a flowchart of inter-screen prediction processing in units of prediction blocks in the video encoding method and video decoding method according to Comparative Example 2.
- BIO processing is used as motion compensation processing. That is, in the process shown in FIG. 12, steps S103 and S108 are changed to steps S103A and S108A with respect to the process shown in FIG.
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the normal inter-screen prediction method (S102). Next, the inter prediction unit 126 obtains an inter-screen prediction image by performing motion compensation by BIO processing in units of prediction blocks using the motion vectors in units of prediction blocks (S103A).
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the template FRUC method (S104). Thereafter, the inter prediction unit 126 derives a motion vector according to the template FRUC method in units of subblocks obtained by dividing the prediction block (S105).
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the bilateral FRUC method (S106). Thereafter, the inter prediction unit 126 derives a motion vector according to the bilateral FRUC method in units of subblocks obtained by dividing the prediction block (S107).
- the inter prediction unit 126 derives a motion vector for each subblock in accordance with the template FRUC method or the bilateral FRUC method, and then performs motion compensation by BIO processing for each subblock using the derived motion vector for each subblock. By doing so, an inter-screen prediction image is acquired (S108A).
- the inter prediction unit 126 can correct the predicted image in units of pixels by performing the BIO process after the FRUC process. Thereby, there is a possibility that the coding efficiency can be improved even for a block in which deformation occurs.
- BIO processing is performed in units of prediction blocks, and in the FRUC method, BIO processing is performed in units of sub-blocks.
- BIO processing is performed in units of prediction blocks, and in the FRUC method, BIO processing is performed in units of sub-blocks.
- the inter prediction unit 126 can execute at least two types of motion vector derivation methods, the normal inter-screen prediction method and the FRUC method, in the inter-screen prediction process.
- the normal inter-screen prediction method information regarding the motion vector of the processing target block is encoded into a stream.
- the FRUC method information regarding the motion vector of the block to be processed is not encoded into a stream, and the motion is performed using the reconstructed image of the processed region and the processed reference picture in a common method on the encoding side and the decoding side.
- a vector is derived.
- the inter prediction unit 126 further performs motion compensation on the processed reference picture using a motion vector for each prediction block to obtain a predicted image, and derives a local motion estimation value by obtaining a luminance gradient value. Then, a BIO process for generating a predicted image corrected using the derived local motion estimation value is performed.
- the inter prediction unit 126 performs processing in units of prediction blocks in the FRUC method, and derives motion vectors in units of prediction blocks. Further, in the BIO process, the inter prediction unit 126 always receives a motion vector in units of prediction blocks regardless of which motion vector derivation method is used, and generates a prediction image using a common process in units of prediction blocks.
- FIG. 13 is a flowchart of inter-screen prediction processing in units of prediction blocks in the video encoding method and video decoding method according to the present embodiment.
- the processing illustrated in FIG. 13 is repeatedly performed in units of prediction blocks that are processing units of inter-screen prediction processing.
- the operation of the inter prediction unit 126 included in the encoding device 100 will be mainly described, but the operation of the inter prediction unit 218 included in the decoding device 200 is also the same.
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the normal inter-screen prediction method (S102), similarly to the process illustrated in FIG. Next, the inter prediction unit 126 obtains an inter-screen prediction image by performing motion compensation by BIO processing in units of prediction blocks using the motion vectors in units of prediction blocks (S103A).
- the inter prediction unit 126 when the FRUC control information indicates 1 (1 in S101), the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the template FRUC method (S104). When the FRUC control information indicates 2 (2 in S101), the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the bilateral FRUC method (S106). In the process illustrated in FIG. 13, unlike the process illustrated in FIG. 12, the inter prediction unit 126 does not derive a motion vector for each subblock when the FRUC method is used.
- the inter prediction unit 126 derives a motion vector for each prediction block according to the template FRUC method or the bilateral FRUC method, and then performs motion compensation by the BIO processing for each prediction block using the derived motion vector for each prediction block. By doing so, an inter-screen prediction image is acquired (S103A).
- the inter prediction unit 126 determines whether the FRUC control information indicates any of the normal inter-screen prediction method, the template FRUC method, and the bilateral FRUC method. A motion vector for each prediction block is derived. Then, the inter prediction unit 126 performs BIO processing in units of prediction blocks. That is, in any case, the processing unit is a prediction block unit, and the processing unit is the same.
- FRUC control information number shown above is an example, and other numbers may be used. Further, only one of the template FRUC method and the bilateral FRUC method may be used. Also, common processing can be used for encoding and decoding.
- both the FRUC processing for sub-blocks for correcting motion vectors in units of sub-blocks and the BIO processing for correcting prediction images in units of pixels are performed.
- the FRUC processing in units of sub-blocks and the BIO processing are both processing that performs correction in units smaller than the prediction block, have similar properties, and have similar effects.
- these processes are integrated into the BIO process.
- the processing amount can be reduced by not performing the FRUC processing in units of sub-blocks with a large processing amount.
- the BIO processing when the FRUC method is used is changed from the sub-block unit to the predicted block unit, and the processing amount can be reduced.
- the processing according to the present embodiment illustrated in FIG. 13 is less efficient in encoding even for a block in which deformation occurs while suppressing an increase in the processing amount as compared with Comparative Example 2 illustrated in FIG. There is a possibility that it can be improved.
- BIO processing that receives a motion vector in units of prediction blocks is performed regardless of the value of FRUC control information.
- BIO processing that uses a motion vector in units of sub-blocks as input becomes unnecessary. Thereby, the mounting can be simplified.
- BIO processing in step S103A does not have to be completely the same in a plurality of motion vector derivation methods. That is, the BIO processing used may be different in either or each of the case where the normal inter-screen prediction method is used, the case where the template FRUC method is used, and the case where the bilateral FRUC method is used. .
- the BIO process in step S103A is another process for generating a predicted image while correcting the predicted image in units of pixels or units smaller than the predicted block ( It may be replaced with a modified example of BIO processing. Even in that case, two processes having the same properties as described above can be integrated into one process, so that an increase in the processing amount is suppressed as compared with the comparative example 2, and the block in which the deformation occurs is also suppressed. There is a possibility that encoding efficiency can be improved.
- the BIO process in step S103A may be replaced with another process for generating a predicted image while correcting a predicted image using a motion vector in units of predicted blocks as an input. Good. Even in this case, the above-described processing using the motion vector in units of sub-blocks as input becomes unnecessary, and the implementation can be simplified.
- the inter prediction unit 126 may perform the process illustrated in FIG. 13 when performing the BIO process, and may perform the process illustrated in FIG. 11 when not performing the BIO process.
- the inter prediction unit 126 may not perform the sub-block unit motion vector derivation process as in FIG. That is, the inter prediction unit 126 may perform a process in which the process in step S108A illustrated in FIG. 13 is replaced with a motion compensation process in units of predicted blocks that does not include a BIO process.
- FIG. 14 is a flowchart of inter-screen prediction processing in the moving picture coding method and the moving picture decoding method according to the modification of the present embodiment.
- the processing illustrated in FIG. 14 is repeatedly performed in units of prediction blocks that are processing units of inter-screen prediction processing.
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the normal inter-screen prediction method (S102), similarly to the process illustrated in FIG. Next, the inter prediction unit 126 obtains an inter-screen prediction image by performing motion compensation by BIO processing in units of prediction blocks using the motion vectors in units of prediction blocks (S103A).
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the template FRUC method, similarly to the process illustrated in FIG. 13 (S104). Next, the inter prediction unit 126 obtains an inter-screen prediction image by performing motion compensation by BIO processing in units of prediction blocks using the motion vectors in units of prediction blocks (S103A).
- the inter prediction unit 126 derives a motion vector in units of prediction blocks according to the bilateral FRUC method (S106). Thereafter, the inter prediction unit 126 derives a motion vector according to the bilateral FRUC method in units of subblocks obtained by dividing the prediction block (S107).
- the inter prediction unit 126 acquires an inter-screen prediction image by performing motion compensation in units of subblocks using the derived motion vector in units of subblocks (S108). Note that the motion compensation here is normal motion compensation, not BIO processing.
- the inter prediction unit 126 performs the motion of the derived prediction block unit when the normal inter-screen prediction method is used (0 in S101) and when the template FRUC method is used (1 in S101).
- An inter-screen prediction image is acquired by performing motion compensation by BIO processing in units of prediction blocks using vectors.
- the inter prediction unit 126 performs inter-screen prediction by performing normal motion compensation that does not apply BIO processing using a motion vector in units of sub-blocks. Get an image.
- the FRUC control information number is an example, and other numbers may be used. Also, in the inter prediction unit 218 included in the decoding 200, the same processing as the inter prediction unit 126 included in the encoding device 100 is performed.
- the inter prediction unit 126 derives a motion vector for each prediction block when the template FRUC method is used, performs BIO processing for each prediction block, and performs a sub-block when the bilateral FRUC method is used.
- motion vectors are derived in units of blocks and normal motion compensation processing is performed in units of sub-blocks
- bilateral FRUC motion vectors are derived in units of prediction blocks and BIO processing in units of prediction blocks
- a motion vector may be derived in units of sub-blocks and normal motion compensation processing in units of sub-blocks may be performed.
- the effect of improving the coding efficiency by deriving the motion vector in units of sub-blocks is larger in the bilateral FRUC method. Therefore, as shown in FIG. 14, it is preferable to derive a motion vector in units of sub-blocks in the bilateral FRUC method.
- both the template FRUC method and the bilateral FRUC method are used, but only one of them may be used.
- the inter prediction unit 126 derives a motion vector in units of subblocks and performs normal motion compensation processing.
- the BIO processing in step S103A does not have to be completely the same in a plurality of motion vector derivation methods. That is, the BIO process used may be different between when the normal inter-screen prediction method is used and when the template FRUC method is used.
- the BIO process in step S103A is another process for generating a predicted image while correcting the predicted image in units of pixels or units smaller than the predicted block ( It may be replaced with a modified example of BIO processing.
- the BIO process in step S103A may be replaced with another process for generating a predicted image while correcting a predicted image using a motion vector in units of predicted blocks as an input. Good.
- the processing shown in FIG. 14 applies only one of the FRUC processing for sub-block units for correcting motion vectors in units of sub-blocks and the BIO processing for correcting prediction images in units of pixels in the FRUC method. To do. Accordingly, the processing shown in FIG. 14 can use a method having a large synergistic effect for each FRUC method, although the processing amount is almost equal to that of the processing shown in FIG. Thereby, encoding efficiency can be improved.
- the encoding apparatus 100 performs the processing shown in FIG.
- the process in the decoding device 200 is the same.
- the encoding apparatus 100 derives the first motion vector in units of prediction blocks obtained by dividing the image included in the moving image by the first inter-screen prediction method (In step S112, a first motion compensation process using the derived first motion vector is performed for each prediction block (S113).
- the first motion compensation processing is, for example, BIO processing, and motion that generates a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector. Compensation processing.
- the encoding apparatus 100 derives a second motion vector in units of sub-blocks obtained by dividing the prediction block by the second inter-screen prediction method (S114).
- a second motion compensation process using the second motion vector is performed in sub-block units (S115).
- the second motion compensation process is, for example, a motion compensation process that does not apply the BIO process, and the prediction is performed without referring to the spatial gradient of the luminance in the image generated by the motion compensation using the second motion vector. This is motion compensation processing for generating an image.
- the encoding apparatus 100 performs the motion vector derivation process and the first motion compensation process in units of prediction blocks in the first operation mode, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the encoding apparatus 100 performs the motion vector derivation process and the second motion compensation process on a sub-block basis.
- the encoding apparatus 100 can improve encoding efficiency by having such two operation modes. Thus, the encoding apparatus 100 can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the first inter-screen prediction method is different from the second inter-screen prediction method.
- the second inter-screen prediction method is an inter-screen prediction method that uses the degree of matching between two reconstructed images in two regions in two different pictures, and is, for example, the FRUC method.
- the first inter-picture prediction method is (1) third inter-picture prediction using the degree of matching between the reconstructed image of the region in the target picture adjacent to the target prediction block and the reconstructed image of the region in the reference picture.
- a scheme for example, a template FRUC scheme
- a fourth inter-picture prediction scheme for example, a bilateral FRUC scheme
- the second inter-screen prediction method is the other of the third inter-screen prediction method and the fourth inter-screen prediction method.
- the first inter-screen prediction method is a third inter-screen prediction method (for example, a template FRUC method), and the second inter-screen prediction method is a fourth inter-screen prediction method (for example, a bilateral FRUC method).
- a third inter-screen prediction method for example, a template FRUC method
- the second inter-screen prediction method is a fourth inter-screen prediction method (for example, a bilateral FRUC method).
- the first inter-screen prediction method is an inter-screen prediction method (normal inter-screen prediction method) that uses the degree of matching between the target prediction block and the reconstructed image of the region included in the reference picture. Then, an encoded bit stream including information for specifying the derived first motion vector is generated. Also, in the first inter-screen prediction method, the decoding apparatus 200 acquires information for specifying the first motion vector in units of prediction blocks from the encoded bitstream, and derives the first motion vector using the information. To do.
- an inter-screen prediction method normal inter-screen prediction method
- Temporal FRUC method and bilateral FRUC method a method for deriving a motion vector according to the template FRUC method or the bilateral FRUC method will be described.
- a method for deriving a motion vector in units of blocks and a method for deriving a motion vector in units of sub-blocks are basically the same.
- a method for deriving a motion vector of a block and a method for deriving a motion vector of a sub-block will be described as methods for deriving a motion vector of a processing target region.
- FIG. 16 is a conceptual diagram showing a template FRUC method used for derivation of a motion vector of a processing target area in the encoding device 100 and the decoding device 200.
- a motion vector is derived using a common method between the encoding device 100 and the decoding device 200 without encoding and decoding of motion vector information of the processing target region.
- a motion vector is derived using a reconstructed image of an adjacent region that is a region adjacent to the processing target region and a reconstructed image of a corresponding adjacent region that is a region in the reference picture.
- the adjacent region is one or both of the region adjacent to the left and the region adjacent above the processing target region.
- the corresponding adjacent region is a region specified using a candidate motion vector that is a candidate motion vector of the processing target region. Specifically, the corresponding adjacent region is a region indicated by the candidate motion vector from the adjacent region. In addition, the relative position of the corresponding adjacent area with respect to the corresponding area indicated by the candidate motion vector from the processing target area is equal to the relative position of the adjacent area with respect to the processing target area.
- FIG. 17 is a conceptual diagram showing a bilateral FRUC method used in the encoding device 100 and the decoding device 200 for deriving the motion vector of the processing target region.
- the bilateral FRUC method similarly to the template FRUC method, a method common to the encoding device 100 and the decoding device 200 is used without encoding and decoding of motion vector information of the processing target region. A motion vector is derived.
- a motion vector is derived using two reconstructed images of two regions in two reference pictures. For example, as shown in FIG. 17, a motion vector is derived using the reconstructed image of the corresponding region in the first reference picture and the reconstructed image of the symmetric region in the second reference picture.
- each of the corresponding region and the symmetric region is a region specified using a candidate motion vector that is a candidate motion vector of the processing target region.
- the corresponding region is a region indicated by the candidate motion vector from the processing target region.
- the symmetric region is a region indicated by a symmetric motion vector from the processing target region.
- a symmetric motion vector is a motion vector constituting a set of candidate motion vectors for bidirectional prediction.
- the symmetric motion vector may be a motion vector derived by scaling the candidate motion vector.
- FIG. 18 is a flowchart illustrating an operation in which the inter prediction unit 126 of the encoding device 100 derives a motion vector according to the template FRUC method or the bilateral FRUC method.
- the inter prediction unit 218 of the decoding device 200 operates in the same manner as the inter prediction unit 126 of the encoding device 100.
- the inter prediction unit 126 derives candidate motion vectors by referring to respective motion vectors of one or more processed regions that are temporally or spatially adjacent to the processing target region.
- the inter prediction unit 126 derives a candidate motion vector for bidirectional prediction. That is, the inter prediction unit 126 derives candidate motion vectors as a set of two motion vectors.
- the inter prediction unit 126 when the motion vector of the processed region is a motion vector for bidirectional prediction, the inter prediction unit 126 directly uses the motion vector for bidirectional prediction as a candidate motion vector for bidirectional prediction. Derived as When the motion vector of the processed region is a unidirectional prediction motion vector, the inter prediction unit 126 derives a bidirectional prediction motion vector from the unidirectional prediction motion vector by scaling or the like. Candidate motion vectors may be derived.
- the inter prediction unit 126 derives a motion vector that refers to the second reference picture by scaling the motion vector that refers to the first reference picture in accordance with the display time interval in the bilateral FRUC scheme. Thereby, the inter prediction unit 126 derives candidate motion vectors constituting a set of the motion vector for unidirectional prediction and the scaled motion vector as a candidate motion vector for bidirectional prediction.
- the inter prediction unit 126 may derive the motion vector of the processed region as a candidate motion vector when the motion vector of the processed region is a bidirectional motion vector. Then, when the motion vector of the processed region is a unidirectional motion vector, the inter prediction unit 126 may not derive the motion vector of the processed region as a candidate motion vector.
- the inter prediction unit 126 derives the motion vector of the processed region as a candidate motion vector regardless of whether the motion vector of the processed region is a motion vector of bidirectional prediction or a motion vector of unidirectional prediction. .
- the inter prediction unit 126 generates a candidate motion vector list composed of candidate motion vectors (S201).
- the inter prediction unit 126 may include the motion vector for each block as a candidate motion vector in the candidate motion vector list.
- the inter prediction unit 126 may include the motion vector in units of blocks in the candidate motion vector list as a candidate motion vector having the highest priority.
- the inter prediction unit 126 when the block-wise motion vector is a unidirectional prediction motion vector, the inter prediction unit 126 derives a bidirectional motion candidate motion vector from the unidirectional prediction motion vector by scaling or the like. May be.
- the inter prediction unit 126 may derive a candidate motion vector for bidirectional prediction by scaling or the like from the motion vector for unidirectional prediction, as in the case where the surrounding motion vector is a motion vector for unidirectional prediction.
- the inter prediction unit 126 may include a candidate motion vector derived as a candidate motion vector for bidirectional prediction from a motion vector for unidirectional prediction in the candidate motion vector list.
- the inter prediction unit 126 may include a motion vector in units of blocks as a candidate motion vector in the candidate motion vector list when the motion vector in units of blocks is a motion vector for bidirectional prediction. . Then, when the motion vector in units of blocks is a motion vector for unidirectional prediction, the inter prediction unit 126 may not include the motion vector in units of blocks as a candidate motion vector in the candidate motion vector list.
- the inter prediction unit 126 selects the best candidate motion vector from one or more candidate motion vectors included in the candidate motion vector list (S202). At that time, the inter prediction unit 126 calculates an evaluation value for each of the one or more candidate motion vectors according to the matching degrees of the two reconstructed images in the two evaluation target regions.
- the two evaluation target areas are an adjacent area and a corresponding adjacent area as shown in FIG. 16, and in the bilateral FRUC method, the two evaluation target areas are as shown in FIG. A region and a symmetric region.
- the corresponding adjacent region used in the template FRUC method, and the corresponding region and the symmetric region used in the bilateral FRUC method are determined according to the candidate motion vector.
- the inter prediction unit 126 calculates a better evaluation value as the degree of matching between the two reconstructed images of the two evaluation target regions is higher. Specifically, the inter prediction unit 126 derives a difference value between two reconstructed images of two evaluation target regions. Then, the inter prediction unit 126 calculates an evaluation value using the difference value. For example, the inter prediction unit 126 calculates a better evaluation value as the difference value is smaller.
- the inter prediction unit 126 may calculate the evaluation value using the difference value and other information. For example, the priority order of one or more candidate motion vectors, the code amount based on the priority order, and the like may affect the evaluation value.
- the inter prediction unit 126 selects a candidate motion vector having the best evaluation value from among one or more candidate motion vectors as the best candidate motion vector.
- the inter prediction unit 126 derives a motion vector of the processing target region by searching around the best candidate motion vector (S203).
- the inter prediction unit 126 similarly calculates an evaluation value for a motion vector indicating a region around the region indicated by the best candidate motion vector. Then, when there is a motion vector whose evaluation value is better than that of the best candidate motion vector, the inter prediction unit 126 updates the best candidate motion vector with a motion vector whose evaluation value is better than that of the best candidate motion vector. Then, the inter prediction unit 126 derives the updated best candidate motion vector as the final motion vector of the processing target region.
- the inter prediction unit 126 may derive the best candidate motion vector as the final motion vector of the processing target region without performing the process of searching around the best candidate motion vector (S203).
- the best candidate motion vector is not limited to the candidate motion vector having the best evaluation value.
- One of one or more candidate motion vectors having an evaluation value equal to or higher than a reference may be selected as the best candidate motion vector according to a predetermined priority.
- the process related to the processing target area and the processed area is, for example, an encoding or decoding process. More specifically, the process related to the processing target area and the processed area may be a process for deriving a motion vector. Alternatively, the process related to the processing target area and the processed area may be a reconstruction process.
- FIG. 19 is a conceptual diagram showing BIO processing in the encoding device 100 and the decoding device 200.
- BIO processing a predicted image of the processing target block is generated with reference to a spatial gradient of luminance in an image obtained by performing motion compensation of the processing target block using the motion vector of the processing target block.
- the L0 motion vector (MV_L0) is a motion vector for referring to the L0 reference picture that is the processed picture
- the L1 motion vector (MV_L1) is a motion vector for referring to the L1 reference picture that is the processed picture. is there.
- the L0 reference picture and the L1 reference picture are two reference pictures that are simultaneously referenced in the bi-prediction processing of the processing target block.
- a normal inter-screen prediction mode As a method for deriving the L0 motion vector (MV_L0) and the L1 motion vector (MV_L1), a normal inter-screen prediction mode, a merge mode, an FRUC mode, or the like may be used.
- a motion vector is derived by performing motion detection using an image of a processing target block in the encoding device 100, and motion vector information is encoded.
- the decoding apparatus 200 derives a motion vector by decoding motion vector information.
- the L0 reference picture is referred to, and the motion compensation of the processing target block is performed using the L0 motion vector (MV_L0), thereby obtaining the L0 predicted image.
- an L0 predicted image is obtained by applying a motion compensation filter to an image in the L0 reference pixel range including the block indicated in the L0 reference picture from the processing target block by the L0 motion vector (MV_L0) and its periphery. May be.
- an L0 gradient image indicating the spatial gradient of luminance at each pixel of the L0 predicted image is acquired.
- the L0 gradient image is acquired by referring to the luminance of each pixel in the L0 reference pixel range including the block indicated in the L0 reference picture from the processing target block by the L0 motion vector (MV_L0) and the periphery thereof.
- an L1 predicted image is obtained by referring to the L1 reference picture and performing motion compensation of the processing target block using the L1 motion vector (MV_L1).
- an L1 predicted image is obtained by applying a motion compensation filter to an image in the L1 reference pixel range including the block indicated in the L1 reference picture from the processing target block by the L1 motion vector (MV_L1) and its periphery. May be.
- an L1 gradient image indicating a spatial gradient of luminance at each pixel of the L1 predicted image is acquired.
- the L1 gradient image is acquired by referring to the luminance of each pixel in the L1 reference pixel range including the block indicated in the L1 reference picture from the processing target block by the L1 motion vector (MV_L1) and the periphery thereof.
- a local motion estimation value is derived for each pixel of the processing target block. Specifically, at that time, the pixel value of the corresponding pixel position in the L0 predicted image, the gradient value of the corresponding pixel position in the L0 gradient image, the pixel value of the corresponding pixel position in the L1 predicted image, and the L1 gradient image The gradient value of the corresponding pixel position is used.
- the local motion estimation value may also be referred to as a corrected motion vector (corrected MV).
- a pixel correction value is derived using the gradient value of the corresponding pixel position in the L0 gradient image, the gradient value of the corresponding pixel position in the L1 gradient image, and the local motion estimation value.
- a predicted pixel value is derived using the pixel value of the corresponding pixel position in the L0 predicted image, the pixel value of the corresponding pixel position in the L1 predicted image, and the pixel correction value. .
- a predicted image to which the BIO process is applied is derived.
- the pixel value at the corresponding pixel position in the L0 predicted image and the predicted pixel value obtained from the pixel value at the corresponding pixel position in the L1 predicted image are corrected by the pixel correction value.
- the prediction image obtained from the L0 prediction image and the L1 prediction image is corrected using the spatial gradient of the luminance in the L0 prediction image and the L1 prediction image.
- FIG. 20 is a flowchart illustrating an operation performed by the inter-screen prediction unit 126 of the encoding device 100 as a BIO process.
- the inter-screen prediction unit 218 of the decoding device 200 operates in the same manner as the inter-screen prediction unit 126 of the encoding device 100.
- the inter-screen prediction unit 126 refers to the L0 reference picture using the L0 motion vector (MV_L0) and acquires the L0 predicted image (S401). Then, the inter-screen prediction unit 126 refers to the L0 reference picture with the L0 motion vector and acquires the L0 gradient image (S402).
- the inter-screen prediction unit 126 refers to the L1 reference picture using the L1 motion vector (MV_L1), and acquires the L1 predicted image (S401). Then, the inter-screen prediction unit 126 refers to the L1 reference picture using the L1 motion vector, and acquires an L1 gradient image (S402).
- the inter-screen prediction unit 126 derives a local motion estimation value for each pixel of the processing target block (S411). At that time, the pixel value of the corresponding pixel position in the L0 predicted image, the gradient value of the corresponding pixel position in the L0 gradient image, the pixel value of the corresponding pixel position in the L1 predicted image, and the corresponding pixel position in the L1 gradient image A slope value is used.
- the inter-screen prediction unit 126 uses the gradient value of the corresponding pixel position in the L0 gradient image, the gradient value of the corresponding pixel position in the L1 gradient image, and the local motion estimation value.
- the pixel correction value is derived.
- the inter-screen prediction unit 126 uses the pixel value of the corresponding pixel position in the L0 predicted image, the pixel value of the corresponding pixel position in the L1 predicted image, and the pixel correction value for each pixel of the processing target block.
- a predicted pixel value is derived (S412).
- the inter-screen prediction unit 126 generates a predicted image to which the BIO process is applied.
- I x 0 [x, y] is a horizontal gradient value at the pixel position [x, y] of the L0 gradient image.
- I x 1 [x, y] is a horizontal gradient value at the pixel position [x, y] of the L1 gradient image.
- I y 0 [x, y] is a vertical gradient value at the pixel position [x, y] of the L0 gradient image.
- I y 1 [x, y] is a vertical gradient value at the pixel position [x, y] of the L1 gradient image.
- I 0 [x, y] is a pixel value at the pixel position [x, y] of the L0 predicted image.
- I 1 [x, y] is a pixel value at the pixel position [x, y] of the L1 predicted image.
- ⁇ I [x, y] is the difference between the pixel value at the pixel position [x, y] of the L0 predicted image and the pixel value at the pixel position [x, y] of the L1 predicted image.
- ⁇ is, for example, a set of pixel positions included in a region having the pixel position [x, y] as a center.
- w [i, j] is a weighting coefficient for the pixel position [i, j]. The same value may be used for w [i, j].
- G x [x, y], G y [x, y], G x G y [x, y], sG x G y [x, y], sG x 2 [x, y], sG y 2 [x , Y], sG x dI [x, y], sG y dI [x, y], etc. are auxiliary calculated values.
- u [x, y] is a value in the horizontal direction that constitutes the local motion estimation value at the pixel position [x, y].
- v [x, y] is a value in the vertical direction constituting the local motion estimation value at the pixel position [x, y].
- b [x, y] is a pixel correction value at the pixel position [x, y].
- p [x, y] is a predicted pixel value at the pixel position [x, y].
- the inter-screen prediction unit 126 derives a local motion estimation value for each pixel. However, the inter-screen prediction unit 126 performs local estimation for each sub-block that is an image data unit coarser than the pixel and smaller than the processing target block. A motion estimate may be derived.
- ⁇ may be a set of pixel positions included in the sub-block. Then, sG x G y [x, y], sG x 2 [x, y], sG y 2 [x, y], sG x dI [x, y], sG y dI [x, y], u [ x, y] and v [x, y] may be calculated for each sub-block instead of for each pixel.
- the encoding device 100 and the decoding device 200 can apply a common BIO process. That is, the encoding apparatus 100 and the decoding apparatus 200 can apply the BIO process by the same method.
- FIG. 21 is a block diagram illustrating an implementation example of the encoding device 100 according to Embodiment 1.
- the encoding device 100 includes a circuit 160 and a memory 162.
- a plurality of components of the encoding device 100 shown in FIGS. 1 and 11 are implemented by the circuit 160 and the memory 162 shown in FIG.
- the circuit 160 is a circuit that performs information processing and is a circuit that can access the memory 162.
- the circuit 160 is a dedicated or general-purpose electronic circuit that encodes a moving image.
- the circuit 160 may be a processor such as a CPU.
- the circuit 160 may be an aggregate of a plurality of electronic circuits. Further, for example, the circuit 160 may serve as a plurality of constituent elements excluding a constituent element for storing information among a plurality of constituent elements of the encoding device 100 illustrated in FIG. 1 and the like.
- the memory 162 is a dedicated or general-purpose memory in which information for the circuit 160 to encode a moving image is stored.
- the memory 162 may be an electronic circuit or may be connected to the circuit 160. In addition, the memory 162 may be included in the circuit 160.
- the memory 162 may be an aggregate of a plurality of electronic circuits. Further, the memory 162 may be a magnetic disk or an optical disk, or may be expressed as a storage or a recording medium.
- the memory 162 may be a non-volatile memory or a volatile memory.
- a moving image to be encoded may be stored, or a bit string corresponding to the encoded moving image may be stored.
- the memory 162 may store a program for the circuit 160 to encode a moving image.
- the memory 162 may serve as a component for storing information among a plurality of components of the encoding device 100 illustrated in FIG. Specifically, the memory 162 may serve as the block memory 118 and the frame memory 122 shown in FIG. More specifically, the memory 162 may store a reconstructed block, a reconstructed picture, and the like.
- not all of the plurality of components shown in FIG. 1 or the like may be mounted, or all of the plurality of processes described above may not be performed. Some of the plurality of components shown in FIG. 1 and the like may be included in another device, and some of the plurality of processes described above may be executed by another device. In the encoding device 100, some of the plurality of components shown in FIG. 1 and the like are mounted, and a part of the plurality of processes described above is performed, so that motion compensation is efficiently performed. Is called.
- the encoding apparatus 100 uses the degree of matching between two reconstructed images in two regions in two different pictures in units of prediction blocks obtained by dividing an image included in a moving image.
- a first motion vector is derived by the prediction method (S104 or S106 in FIG. 13).
- the first inter-screen prediction method is, for example, the FRUC method described above.
- the first inter-screen prediction method includes at least one of a template FRCU method and a bilateral FRUC method. That is, the two regions in the first inter-picture prediction method are (1) a region in the target picture adjacent to the target prediction block, a region in the reference picture, or (2) two different reference pictures. There are two areas.
- the first inter-screen prediction method is a method for deriving a motion vector by the same method on the encoding side and the decoding side. Also, in the first inter-picture prediction method, information indicating a motion vector is not signaled to the encoded stream and is not transmitted from the encoding side to the decoding side. In the first inter-screen prediction method, the encoding apparatus 100 uses the pixel value of the encoded prediction block and derives the motion vector without using the pixel value of the target prediction block.
- the encoding apparatus 100 refers to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector for each prediction block, and generates a prediction image. Compensation processing is performed (S103A in FIG. 13).
- the first motion compensation process is, for example, the above-described BIO process and includes correction using a luminance gradient.
- the prediction image is corrected in units smaller than the prediction block (for example, pixel units or block units).
- a predicted image is generated using a region in the reference picture indicated by the motion vector and pixels around the region.
- the encoding apparatus 100 performs the motion vector derivation process and the first motion compensation process by the first inter-frame prediction method in units of prediction blocks, for example, when performing these processes in units of sub-blocks. Compared to the above, the processing amount can be reduced.
- the first motion compensation process including the correction using the luminance gradient can realize the correction in units smaller than the prediction block unit, so that it is possible to suppress a decrease in encoding efficiency when the process is not performed in subblock units. Therefore, the encoding apparatus 100 can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the encoding device 100 derives the second motion vector by the second inter-frame prediction method using the degree of matching between the target prediction block and the reconstructed image of the region included in the reference picture in units of prediction blocks (see FIG. 13 S102). Then, the encoding device 100 generates an encoded bit stream including information for specifying the second motion vector.
- the second inter-screen prediction method is, for example, the above-described normal inter-screen prediction method.
- the second inter-frame prediction method is a method for deriving motion vectors by different methods on the encoding side and the decoding side.
- the encoding apparatus 100 derives a motion vector using the pixel value of the encoded prediction block and the pixel value of the target prediction block.
- the encoding apparatus 100 signals information indicating the derived motion vector to the encoded stream.
- information indicating the motion vector derived by the encoding device 100 is transmitted from the encoding device 100 to the decoding device 200.
- the decoding apparatus 200 derives a motion vector using the information included in the encoded stream.
- the encoding apparatus 100 refers to a spatial gradient of luminance in an image generated by motion compensation using the derived second motion vector for each prediction block, and generates a prediction image. Compensation processing is performed (S103A in FIG. 13).
- the second motion compensation process is, for example, the above-described BIO process and includes correction using a luminance gradient.
- the prediction image is corrected in units smaller than the prediction block (for example, pixel units or block units).
- a predicted image is generated using a region in the reference picture indicated by the motion vector and pixels around the region.
- the second motion compensation process may be the same process as the first motion compensation process, or may be a partly different process.
- the processing unit of the motion compensation process can be made the same when the first inter-screen prediction method is used and when the second inter-screen prediction method is used. This can facilitate the implementation of the motion compensation process.
- the encoding apparatus 100 derives the first motion vector in units of prediction blocks obtained by dividing the image included in the moving image by the first inter-screen prediction method. Then (S112), the first motion compensation process using the derived first motion vector is performed for each prediction block (S113).
- the first motion compensation processing is, for example, BIO processing, and motion that generates a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector. Compensation processing.
- the encoding apparatus 100 derives a second motion vector in units of sub-blocks obtained by dividing the prediction block by the second inter-screen prediction method (S114).
- a second motion compensation process using the second motion vector is performed in sub-block units (S115).
- the second motion compensation process is, for example, a motion compensation process that does not apply the BIO process, and the prediction is performed without referring to the spatial gradient of the luminance in the image generated by the motion compensation using the second motion vector. This is motion compensation processing for generating an image.
- the encoding apparatus 100 performs the motion vector derivation process and the first motion compensation process in units of prediction blocks in the first operation mode, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the encoding apparatus 100 performs the motion vector derivation process and the second motion compensation process on a sub-block basis.
- the encoding apparatus 100 can improve encoding efficiency by having such two operation modes. Thus, the encoding apparatus 100 can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the first inter-screen prediction method is different from the second inter-screen prediction method.
- the second inter-screen prediction method is an inter-screen prediction method that uses the degree of matching between two reconstructed images in two regions in two different pictures, and is, for example, the FRUC method.
- the first inter-picture prediction method is (1) third inter-picture prediction using the degree of matching between the reconstructed image of the region in the target picture adjacent to the target prediction block and the reconstructed image of the region in the reference picture.
- a scheme for example, a template FRUC scheme
- a fourth inter-picture prediction scheme for example, a bilateral FRUC scheme
- the second inter-screen prediction method is the other of the third inter-screen prediction method and the fourth inter-screen prediction method.
- the first inter-screen prediction method is a third inter-screen prediction method (for example, a template FRUC method), and the second inter-screen prediction method is a fourth inter-screen prediction method (for example, a bilateral FRUC method).
- a third inter-screen prediction method for example, a template FRUC method
- the second inter-screen prediction method is a fourth inter-screen prediction method (for example, a bilateral FRUC method).
- the first inter-screen prediction method is an inter-screen prediction method (normal inter-screen prediction method) that uses the degree of matching between the target prediction block and the reconstructed image of the region included in the reference picture. Then, an encoded bit stream including information for specifying the derived first motion vector is generated.
- inter-screen prediction method normal inter-screen prediction method
- FIG. 22 is a block diagram illustrating an implementation example of the decoding apparatus 200 according to Embodiment 1.
- the decoding device 200 includes a circuit 260 and a memory 262.
- a plurality of components of the decoding device 200 shown in FIGS. 10 and 12 are implemented by the circuit 260 and the memory 262 shown in FIG.
- the circuit 260 is a circuit that performs information processing and is a circuit that can access the memory 262.
- the circuit 260 is a dedicated or general-purpose electronic circuit that decodes a moving image.
- the circuit 260 may be a processor such as a CPU.
- the circuit 260 may be an aggregate of a plurality of electronic circuits. Further, for example, the circuit 260 may serve as a plurality of constituent elements excluding the constituent elements for storing information among the plurality of constituent elements of the decoding device 200 illustrated in FIG. 10 and the like.
- the memory 262 is a dedicated or general-purpose memory in which information for the circuit 260 to decode a moving image is stored.
- the memory 262 may be an electronic circuit or may be connected to the circuit 260. Further, the memory 262 may be included in the circuit 260.
- the memory 262 may be an aggregate of a plurality of electronic circuits.
- the memory 262 may be a magnetic disk or an optical disk, or may be expressed as a storage or a recording medium. Further, the memory 262 may be a nonvolatile memory or a volatile memory.
- the memory 262 may store a bit sequence corresponding to the encoded moving image, or may store a moving image corresponding to the decoded bit sequence.
- the memory 262 may store a program for the circuit 260 to decode a moving image.
- the memory 262 may serve as a component for storing information among a plurality of components of the decoding device 200 illustrated in FIG. 10 and the like. Specifically, the memory 262 may serve as the block memory 210 and the frame memory 214 shown in FIG. More specifically, the memory 262 may store a reconstructed block, a reconstructed picture, and the like.
- the decoding device 200 not all of the plurality of components shown in FIG. 10 and the like may be implemented, or all of the plurality of processes described above may not be performed. Some of the plurality of components shown in FIG. 10 and the like may be included in another device, and some of the plurality of processes described above may be executed by another device. Then, in the decoding device 200, some of the plurality of components shown in FIG. 10 and the like are mounted, and motion compensation is efficiently performed by performing some of the plurality of processes described above. .
- the decoding apparatus 200 performs first inter-frame prediction using the degree of matching between two reconstructed images in two regions in two different pictures in units of prediction blocks obtained by dividing an image included in a moving image.
- the first motion vector is derived by the method (S104 or S106 in FIG. 13).
- the first inter-screen prediction method is, for example, the FRUC method described above.
- the first inter-screen prediction method includes at least one of a template FRCU method and a bilateral FRUC method. That is, the two regions in the first inter-picture prediction method are (1) a region in the target picture adjacent to the target prediction block, a region in the reference picture, or (2) two different reference pictures. There are two areas.
- the first inter-screen prediction method is a method for deriving a motion vector by the same method on the encoding side and the decoding side. Also, in the first inter-picture prediction method, information indicating a motion vector is not signaled to the encoded stream and is not transmitted from the encoding side to the decoding side. In the first inter-screen prediction method, the decoding apparatus 200 derives a motion vector using the pixel value of the decoded prediction block and not using the pixel value of the target prediction block.
- the decoding apparatus 200 generates a prediction image by referring to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector in units of prediction blocks. Processing is performed (S103A in FIG. 13).
- the first motion compensation process is, for example, the above-described BIO process and includes correction using a luminance gradient.
- the prediction image is corrected in units smaller than the prediction block (for example, pixel units or block units).
- a predicted image is generated using a region in the reference picture indicated by the motion vector and pixels around the region.
- the decoding apparatus 200 performs the motion vector derivation process and the first motion compensation process by the first inter-frame prediction method in units of prediction blocks, for example, when performing these processes in units of sub-blocks. Compared with this, the processing amount can be reduced.
- the first motion compensation process including the correction using the luminance gradient can realize the correction in units smaller than the prediction block unit, so that it is possible to suppress a decrease in encoding efficiency when the process is not performed in subblock units. Therefore, the decoding device 200 can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the decoding device 200 acquires information for specifying the second motion vector in units of prediction blocks from the encoded bitstream.
- the decoding apparatus 200 derives the second motion vector by the second inter-screen prediction method using the above information in units of prediction blocks (S102 in FIG. 13).
- the second inter-screen prediction method is, for example, the above-described normal inter-screen prediction method.
- the second inter-frame prediction method is a method for deriving motion vectors by different methods on the encoding side and the decoding side.
- the encoding apparatus 100 derives a motion vector using the pixel value of the encoded prediction block and the pixel value of the target prediction block.
- the encoding apparatus 100 signals information indicating the derived motion vector to the encoded stream.
- information indicating the motion vector derived by the encoding device 100 is transmitted from the encoding device 100 to the decoding device 200.
- the decoding apparatus 200 derives a motion vector using the information included in the encoded stream.
- the decoding apparatus 200 generates a prediction image by referring to a spatial gradient of luminance in an image generated by motion compensation using the derived second motion vector in units of prediction blocks. Processing is performed (S103A in FIG. 13).
- the second motion compensation process is, for example, the above-described BIO process and includes correction using a luminance gradient.
- the prediction image is corrected in units smaller than the prediction block (for example, pixel units or block units).
- a predicted image is generated using a region in the reference picture indicated by the motion vector and pixels around the region.
- the second motion compensation process may be the same process as the first motion compensation process, or may be a partly different process.
- the processing unit of the motion compensation process can be made the same when the first inter-screen prediction method is used and when the second inter-screen prediction method is used. This can facilitate the implementation of the motion compensation process.
- the decoding apparatus 200 derives the first motion vector in units of prediction blocks obtained by dividing the image included in the moving image by the first inter-screen prediction method. (S112) A first motion compensation process using the derived first motion vector is performed for each prediction block (S113).
- the first motion compensation processing is, for example, BIO processing, and motion that generates a predicted image with reference to a spatial gradient of luminance in an image generated by motion compensation using the derived first motion vector. Compensation processing.
- the decoding apparatus 200 derives the second motion vector in units of subblocks obtained by dividing the prediction block by the second inter-screen prediction method (S114).
- a second motion compensation process using the second motion vector is performed in block units (S115).
- the second motion compensation process is, for example, a motion compensation process that does not apply the BIO process, and the prediction is performed without referring to the spatial gradient of the luminance in the image generated by the motion compensation using the second motion vector. This is motion compensation processing for generating an image.
- the decoding apparatus 200 performs the motion vector derivation process and the first motion compensation process in units of prediction blocks, for example, compared with the case where these processes are performed in units of sub-blocks.
- the processing amount can be reduced.
- the first motion compensation process that generates a prediction image with reference to the spatial gradient of luminance can realize correction in units smaller than the prediction block unit, so that encoding is performed when processing is not performed in subblock units. Reduction in efficiency can be suppressed.
- the decoding apparatus 200 performs motion vector derivation processing and second motion compensation processing in units of subblocks.
- the decoding apparatus 200 can improve encoding efficiency by having such two operation modes. In this way, the decoding device 200 can reduce the processing amount while suppressing a decrease in encoding efficiency.
- the first inter-screen prediction method is different from the second inter-screen prediction method.
- the second inter-screen prediction method is an inter-screen prediction method that uses the degree of matching between two reconstructed images in two regions in two different pictures, and is, for example, the FRUC method.
- the first inter-picture prediction method is (1) third inter-picture prediction using the degree of matching between the reconstructed image of the region in the target picture adjacent to the target prediction block and the reconstructed image of the region in the reference picture.
- a scheme for example, a template FRUC scheme
- a fourth inter-picture prediction scheme for example, a bilateral FRUC scheme
- the second inter-screen prediction method is the other of the third inter-screen prediction method and the fourth inter-screen prediction method.
- the first inter-screen prediction method is a third inter-screen prediction method (for example, a template FRUC method), and the second inter-screen prediction method is a fourth inter-screen prediction method (for example, a bilateral FRUC method).
- a third inter-screen prediction method for example, a template FRUC method
- the second inter-screen prediction method is a fourth inter-screen prediction method (for example, a bilateral FRUC method).
- the decoding apparatus 200 acquires information for specifying the second motion vector in units of sub-blocks from the encoded bit stream, and derives the second motion vector using the information. To do.
- the encoding device 100 and the decoding device 200 in the present embodiment may be used as an image encoding device and an image decoding device, respectively, or may be used as a moving image encoding device and a moving image decoding device, respectively. Good.
- the encoding device 100 and the decoding device 200 can each be used as an inter prediction device (inter-screen prediction device).
- the encoding device 100 and the decoding device 200 may correspond to only the inter prediction unit (inter-screen prediction unit) 126 and the inter prediction unit (inter-screen prediction unit) 218, respectively.
- Other components such as the conversion unit 106 and the inverse conversion unit 206 may be included in other devices.
- each component may be configured by dedicated hardware or may be realized by executing a software program suitable for each component.
- Each component may be realized by a program execution unit such as a CPU or a processor reading and executing a software program recorded on a recording medium such as a hard disk or a semiconductor memory.
- each of the encoding device 100 and the decoding device 200 includes a processing circuit (Processing Circuit) and a storage device (Storage) electrically connected to the processing circuit and accessible from the processing circuit. You may have.
- the processing circuit corresponds to the circuit 160 or 260
- the storage device corresponds to the memory 162 or 262.
- the processing circuit includes at least one of dedicated hardware and a program execution unit, and executes processing using a storage device. Further, when the processing circuit includes a program execution unit, the storage device stores a software program executed by the program execution unit.
- the software that realizes the encoding apparatus 100 or the decoding apparatus 200 of the present embodiment is the following program.
- Each component may be a circuit as described above. These circuits may constitute one circuit as a whole, or may be separate circuits. Each component may be realized by a general-purpose processor or a dedicated processor.
- the encoding / decoding device may include the encoding device 100 and the decoding device 200.
- the aspect of the encoding apparatus 100 and the decoding apparatus 200 was demonstrated based on embodiment, the aspect of the encoding apparatus 100 and decoding apparatus 200 is not limited to this embodiment. As long as it does not deviate from the gist of the present disclosure, the encoding device 100 and the decoding device 200 may be configured in which various modifications conceived by those skilled in the art have been made in the present embodiment, or in a form constructed by combining components in different embodiments. It may be included within the scope of the embodiment.
- This aspect may be implemented in combination with at least a part of other aspects in the present disclosure.
- a part of the processing, a part of the configuration of the apparatus, a part of the syntax, and the like described in the flowchart of this aspect may be combined with another aspect.
- each of the functional blocks can usually be realized by an MPU, a memory, and the like. Further, the processing by each functional block is usually realized by a program execution unit such as a processor reading and executing software (program) recorded on a recording medium such as a ROM. The software may be distributed by downloading or the like, or may be distributed by being recorded on a recording medium such as a semiconductor memory. Naturally, each functional block can be realized by hardware (dedicated circuit).
- each embodiment may be realized by centralized processing using a single device (system), or may be realized by distributed processing using a plurality of devices. Good.
- the number of processors that execute the program may be one or more. That is, centralized processing may be performed, or distributed processing may be performed.
- the system includes an image encoding device using an image encoding method, an image decoding device using an image decoding method, and an image encoding / decoding device including both.
- Other configurations in the system can be appropriately changed according to circumstances.
- FIG. 23 is a diagram showing an overall configuration of a content supply system ex100 that implements a content distribution service.
- the communication service providing area is divided into desired sizes, and base stations ex106, ex107, ex108, ex109, and ex110, which are fixed wireless stations, are installed in each cell.
- devices such as a computer ex111, a game machine ex112, a camera ex113, a home appliance ex114, and a smartphone ex115 via the Internet ex101, the Internet service provider ex102 or the communication network ex104, and the base stations ex106 to ex110.
- the content supply system ex100 may be connected by combining any of the above elements.
- Each device may be directly or indirectly connected to each other via a telephone network or a short-range wireless communication without using the base stations ex106 to ex110 which are fixed wireless stations.
- the streaming server ex103 is connected to each device such as a computer ex111, a game machine ex112, a camera ex113, a home appliance ex114, and a smartphone ex115 via the Internet ex101.
- the streaming server ex103 is connected to a terminal in a hot spot in the airplane ex117 via the satellite ex116.
- the streaming server ex103 may be directly connected to the communication network ex104 without going through the Internet ex101 or the Internet service provider ex102, or may be directly connected to the airplane ex117 without going through the satellite ex116.
- the camera ex113 is a device that can shoot still images and moving images such as a digital camera.
- the smartphone ex115 is a smartphone, a cellular phone, or a PHS (Personal Handyphone System) that is compatible with a mobile communication system generally called 2G, 3G, 3.9G, 4G, and 5G in the future.
- a mobile communication system generally called 2G, 3G, 3.9G, 4G, and 5G in the future.
- the home appliance ex118 is a device included in a refrigerator or a household fuel cell cogeneration system.
- a terminal having a photographing function is connected to the streaming server ex103 through the base station ex106 or the like, thereby enabling live distribution or the like.
- the terminal (computer ex111, game machine ex112, camera ex113, home appliance ex114, smartphone ex115, terminal in airplane ex117, etc.) is used for the still image or video content captured by the user using the terminal.
- the encoding process described in each embodiment is performed, and the video data obtained by the encoding and the sound data obtained by encoding the sound corresponding to the video are multiplexed, and the obtained data is transmitted to the streaming server ex103. That is, each terminal functions as an image encoding device according to an aspect of the present disclosure.
- the streaming server ex103 streams the content data transmitted to the requested client.
- the client is a computer or the like in the computer ex111, the game machine ex112, the camera ex113, the home appliance ex114, the smart phone ex115, or the airplane ex117 that can decode the encoded data.
- Each device that has received the distributed data decrypts and reproduces the received data. That is, each device functions as an image decoding device according to an aspect of the present disclosure.
- the streaming server ex103 may be a plurality of servers or a plurality of computers, and may process, record, and distribute data in a distributed manner.
- the streaming server ex103 may be realized by a CDN (Contents Delivery Network), and content distribution may be realized by a network connecting a large number of edge servers and edge servers distributed all over the world.
- CDN Contents Delivery Network
- edge servers that are physically close to each other are dynamically allocated according to clients. Then, the content can be cached and distributed to the edge server, thereby reducing the delay.
- the processing is distributed among multiple edge servers, the distribution subject is switched to another edge server, or the part of the network where the failure has occurred Since detouring can be continued, high-speed and stable distribution can be realized.
- the captured data may be encoded at each terminal, may be performed on the server side, or may be shared with each other.
- a processing loop is performed twice.
- the first loop the complexity of the image or the code amount in units of frames or scenes is detected.
- the second loop processing for maintaining the image quality and improving the coding efficiency is performed.
- the terminal performs the first encoding process
- the server receiving the content performs the second encoding process, thereby improving the quality and efficiency of the content while reducing the processing load on each terminal. it can.
- the encoded data of the first time performed by the terminal can be received and reproduced by another terminal, enabling more flexible real-time distribution.
- the camera ex113 or the like extracts a feature amount from an image, compresses data relating to the feature amount as metadata, and transmits the metadata to the server.
- the server performs compression according to the meaning of the image, for example, by determining the importance of the object from the feature amount and switching the quantization accuracy.
- the feature data is particularly effective for improving the accuracy and efficiency of motion vector prediction at the time of re-compression on the server.
- simple coding such as VLC (variable length coding) may be performed at the terminal, and coding with a large processing load such as CABAC (context adaptive binary arithmetic coding) may be performed at the server.
- a plurality of video data in which almost the same scene is captured by a plurality of terminals.
- a GOP Group of Picture
- a picture unit or a tile obtained by dividing a picture using a plurality of terminals that have performed shooting and other terminals and servers that have not performed shooting as necessary.
- Distributed processing is performed by assigning encoding processing in units or the like. Thereby, delay can be reduced and real-time property can be realized.
- the server may manage and / or instruct the video data captured by each terminal to refer to each other.
- the encoded data from each terminal may be received by the server and the reference relationship may be changed among a plurality of data, or the picture itself may be corrected or replaced to be encoded again. This makes it possible to generate a stream with improved quality and efficiency of each piece of data.
- the server may distribute the video data after performing transcoding to change the encoding method of the video data.
- the server may convert the MPEG encoding system to the VP encoding. 264. It may be converted into H.265.
- the encoding process can be performed by a terminal or one or more servers. Therefore, in the following, description such as “server” or “terminal” is used as the subject performing processing, but part or all of processing performed by the server may be performed by the terminal, or processing performed by the terminal may be performed. Some or all may be performed at the server. The same applies to the decoding process.
- the server not only encodes a two-dimensional moving image, but also encodes a still image automatically based on a scene analysis of the moving image or at a time specified by the user and transmits it to the receiving terminal. Also good.
- the server can acquire the relative positional relationship between the photographing terminals, the server obtains the three-dimensional shape of the scene based on not only the two-dimensional moving image but also the video obtained by photographing the same scene from different angles. Can be generated.
- the server may separately encode the three-dimensional data generated by the point cloud or the like, and the video to be transmitted to the receiving terminal based on the result of recognizing or tracking the person or the object using the three-dimensional data.
- the images may be selected or reconstructed from videos captured by a plurality of terminals.
- the user can arbitrarily select each video corresponding to each photographing terminal and enjoy a scene, or can display a video of an arbitrary viewpoint from three-dimensional data reconstructed using a plurality of images or videos. You can also enjoy the clipped content.
- sound is collected from a plurality of different angles, and the server may multiplex and transmit sound from a specific angle or space according to the video.
- the server may create viewpoint images for the right eye and the left eye, respectively, and perform encoding that allows reference between each viewpoint video by Multi-View Coding (MVC) or the like. You may encode as another stream, without referring. At the time of decoding another stream, it is preferable to reproduce in synchronization with each other so that a virtual three-dimensional space is reproduced according to the viewpoint of the user.
- MVC Multi-View Coding
- the server superimposes virtual object information in the virtual space on the camera information in the real space based on the three-dimensional position or the movement of the user's viewpoint.
- the decoding device may acquire or hold virtual object information and three-dimensional data, generate a two-dimensional image according to the movement of the user's viewpoint, and create superimposition data by connecting them smoothly.
- the decoding device transmits the movement of the user's viewpoint to the server in addition to the request for the virtual object information, and the server creates superimposition data according to the movement of the viewpoint received from the three-dimensional data held in the server,
- the superimposed data may be encoded and distributed to the decoding device.
- the superimposed data has an ⁇ value indicating transparency in addition to RGB
- the server sets the ⁇ value of a portion other than the object created from the three-dimensional data to 0 or the like, and the portion is transparent. May be encoded.
- the server may generate data in which a RGB value of a predetermined value is set as the background, such as a chroma key, and the portion other than the object is set to the background color.
- the decryption processing of the distributed data may be performed at each terminal as a client, may be performed on the server side, or may be performed in a shared manner.
- a terminal may once send a reception request to the server, receive content corresponding to the request at another terminal, perform a decoding process, and transmit a decoded signal to a device having a display.
- a part of a region such as a tile in which a picture is divided may be decoded and displayed on a viewer's personal terminal while receiving large-size image data on a TV or the like. Accordingly, it is possible to confirm at hand the area in which the person is responsible or the area to be confirmed in more detail while sharing the whole image.
- access to encoded data on the network such as when the encoded data is cached in a server that can be accessed from the receiving terminal in a short time, or copied to the edge server in the content delivery service. It is also possible to switch the bit rate of received data based on ease.
- the content switching will be described using a scalable stream that is compression-encoded by applying the moving image encoding method shown in each of the above embodiments shown in FIG.
- the server may have a plurality of streams of the same content and different quality as individual streams, but the temporal / spatial scalable implementation realized by dividing into layers as shown in the figure.
- the configuration may be such that the content is switched by utilizing the characteristics of the stream.
- the decoding side decides which layer to decode according to internal factors such as performance and external factors such as the state of communication bandwidth, so that the decoding side can combine low-resolution content and high-resolution content. You can switch freely and decrypt. For example, when the user wants to continue watching the video that was viewed on the smartphone ex115 while moving on a device such as an Internet TV after returning home, the device only has to decode the same stream to a different layer, so the load on the server side Can be reduced.
- the enhancement layer includes meta information based on image statistical information, etc., in addition to the configuration in which the picture is encoded for each layer and the enhancement layer exists above the base layer.
- the decoding side may generate content with high image quality by super-resolution of the base layer picture based on the meta information.
- Super-resolution may be either improvement of the SN ratio at the same resolution or enlargement of the resolution.
- the meta information includes information for specifying a linear or non-linear filter coefficient used for super-resolution processing, or information for specifying a parameter value in filter processing, machine learning, or least square calculation used for super-resolution processing. .
- the picture may be divided into tiles or the like according to the meaning of the object in the image, and the decoding side may select only a part of the region by selecting the tile to be decoded.
- the decoding side can determine the position of the desired object based on the meta information. Can be identified and the tile containing the object can be determined.
- the meta information is stored using a data storage structure different from the pixel data such as the SEI message in HEVC. This meta information indicates, for example, the position, size, or color of the main object.
- meta information may be stored in units composed of a plurality of pictures, such as streams, sequences, or random access units.
- the decoding side can acquire the time when the specific person appears in the video, etc., and can match the picture in which the object exists and the position of the object in the picture by combining with the information in units of pictures.
- FIG. 26 is a diagram showing an example of a web page display screen on the computer ex111 or the like.
- FIG. 27 is a diagram illustrating a display screen example of a web page on the smartphone ex115 or the like.
- the web page may include a plurality of link images that are links to the image content, and the appearance differs depending on the browsing device. When a plurality of link images are visible on the screen, the display device until the user explicitly selects the link image, or until the link image approaches the center of the screen or the entire link image enters the screen.
- the (decoding device) displays a still image or an I picture included in each content as a link image, displays a video like a gif animation with a plurality of still images or I pictures, or receives only a base layer to receive a video. Are decoded and displayed.
- the display device When the link image is selected by the user, the display device decodes the base layer with the highest priority. If there is information indicating that the HTML constituting the web page is scalable content, the display device may decode up to the enhancement layer. Also, in order to ensure real-time properties, the display device only decodes forward reference pictures (I picture, P picture, forward reference only B picture) before being selected or when the communication band is very strict. In addition, the delay between the decoding time of the first picture and the display time (delay from the start of content decoding to the start of display) can be reduced by displaying. Further, the display device may intentionally ignore the reference relationship of pictures and roughly decode all B pictures and P pictures with forward reference, and perform normal decoding as the number of received pictures increases over time.
- forward reference pictures I picture, P picture, forward reference only B picture
- the receiving terminal when transmitting and receiving still image or video data such as two-dimensional or three-dimensional map information for automatic driving or driving support of a car, the receiving terminal adds meta data to image data belonging to one or more layers. Weather or construction information may also be received and decoded in association with each other. The meta information may belong to a layer or may be simply multiplexed with image data.
- the receiving terminal since the car, drone, airplane, or the like including the receiving terminal moves, the receiving terminal transmits the position information of the receiving terminal at the time of the reception request, thereby seamless reception and decoding while switching the base stations ex106 to ex110. Can be realized.
- the receiving terminal can dynamically switch how much meta-information is received or how much map information is updated according to the user's selection, the user's situation, or the communication band state. become.
- the encoded information transmitted by the user can be received, decoded and reproduced in real time by the client.
- the content supply system ex100 can perform not only high-quality and long-time content by a video distributor but also unicast or multicast distribution of low-quality and short-time content by an individual. Moreover, such personal contents are expected to increase in the future.
- the server may perform the encoding process after performing the editing process. This can be realized, for example, with the following configuration.
- the server After shooting, the server performs recognition processing such as shooting error, scene search, semantic analysis, and object detection from the original image or encoded data. Then, the server manually or automatically corrects out-of-focus or camera shake based on the recognition result, or selects a less important scene such as a scene whose brightness is lower than that of other pictures or is out of focus. Edit such as deleting, emphasizing the edge of an object, and changing the hue.
- the server encodes the edited data based on the editing result. It is also known that if the shooting time is too long, the audience rating will decrease, and the server will move not only in the less important scenes as described above, but also in motion according to the shooting time. A scene with few images may be automatically clipped based on the image processing result. Alternatively, the server may generate and encode a digest based on the result of the semantic analysis of the scene.
- the server may change and encode the face of the person in the periphery of the screen or the inside of the house into an unfocused image.
- the server recognizes whether or not a face of a person different from the person registered in advance is shown in the encoding target image, and if so, performs processing such as applying a mosaic to the face part. May be.
- the user designates a person or background area that the user wants to process an image from the viewpoint of copyright, etc., and the server replaces the designated area with another video or blurs the focus. It is also possible to perform such processing. If it is a person, the face image can be replaced while tracking the person in the moving image.
- the decoding device first receives the base layer with the highest priority and performs decoding and reproduction, depending on the bandwidth.
- the decoding device may receive the enhancement layer during this time, and may play back high-quality video including the enhancement layer when played back twice or more, such as when playback is looped.
- a stream that is scalable in this way can provide an experience in which the stream becomes smarter and the image is improved gradually, although it is a rough moving picture when it is not selected or at the beginning of viewing.
- the same experience can be provided even if the coarse stream played back the first time and the second stream coded with reference to the first video are configured as one stream. .
- these encoding or decoding processes are generally processed in the LSI ex500 included in each terminal.
- the LSI ex500 may be configured as a single chip or a plurality of chips.
- moving image encoding or decoding software is incorporated into some recording medium (CD-ROM, flexible disk, hard disk, etc.) that can be read by the computer ex111 and the like, and encoding or decoding processing is performed using the software. Also good.
- moving image data acquired by the camera may be transmitted. The moving image data at this time is data encoded by the LSI ex500 included in the smartphone ex115.
- the LSI ex500 may be configured to download and activate application software.
- the terminal first determines whether the terminal is compatible with the content encoding method or has a specific service execution capability. If the terminal does not support the content encoding method or does not have the capability to execute a specific service, the terminal downloads a codec or application software, and then acquires and reproduces the content.
- the content supply system ex100 via the Internet ex101, but also a digital broadcasting system, at least the moving image encoding device (image encoding device) or the moving image decoding device (image decoding device) of the above embodiments. Any of these can be incorporated.
- the unicasting of the content supply system ex100 is suitable for multicasting because it uses a satellite or the like to transmit and receive multiplexed data in which video and sound are multiplexed on broadcasting radio waves.
- the same application is possible for the encoding process and the decoding process.
- FIG. 28 is a diagram illustrating the smartphone ex115.
- FIG. 29 is a diagram illustrating a configuration example of the smartphone ex115.
- the smartphone ex115 receives the antenna ex450 for transmitting / receiving radio waves to / from the base station ex110, the camera unit ex465 capable of taking video and still images, the video captured by the camera unit ex465, and the antenna ex450.
- a display unit ex458 for displaying data obtained by decoding the video or the like.
- the smartphone ex115 further includes an operation unit ex466 that is a touch panel or the like, a voice output unit ex457 that is a speaker or the like for outputting voice or sound, a voice input unit ex456 that is a microphone or the like for inputting voice, and photographing.
- Memory unit ex467 that can store encoded video or still image, recorded audio, received video or still image, encoded data such as mail, or decoded data, and a user, and network
- An external memory may be used instead of the memory unit ex467.
- a main control unit ex460 that comprehensively controls the display unit ex458, the operation unit ex466, and the like, a power supply circuit unit ex461, an operation input control unit ex462, a video signal processing unit ex455, a camera interface unit ex463, a display control unit ex459, a modulation / Demodulation unit ex452, multiplexing / demultiplexing unit ex453, audio signal processing unit ex454, slot unit ex464, and memory unit ex467 are connected via bus ex470.
- the power supply circuit unit ex461 starts up the smartphone ex115 in an operable state by supplying power from the battery pack to each unit.
- the smartphone ex115 performs processing such as calling and data communication based on the control of the main control unit ex460 having a CPU, a ROM, a RAM, and the like.
- the voice signal picked up by the voice input unit ex456 is converted into a digital voice signal by the voice signal processing unit ex454, spread spectrum processing is performed by the modulation / demodulation unit ex452, and digital / analog conversion is performed by the transmission / reception unit ex451.
- the data is transmitted via the antenna ex450.
- the received data is amplified and subjected to frequency conversion processing and analog-digital conversion processing, spectrum despreading processing is performed by the modulation / demodulation unit ex452, and converted to analog audio signal by the audio signal processing unit ex454, and then this is output to the audio output unit ex457.
- text, still image, or video data is sent to the main control unit ex460 via the operation input control unit ex462 by the operation of the operation unit ex466 of the main body unit, and transmission / reception processing is performed similarly.
- the video signal processing unit ex455 uses the video signal stored in the memory unit ex467 or the video signal input from the camera unit ex465 as described above.
- the video data is compressed and encoded by the moving image encoding method shown in the form, and the encoded video data is sent to the multiplexing / demultiplexing unit ex453.
- the audio signal processing unit ex454 encodes the audio signal picked up by the audio input unit ex456 while the camera unit ex465 captures a video or a still image, and sends the encoded audio data to the multiplexing / separating unit ex453. To do.
- the multiplexing / demultiplexing unit ex453 multiplexes the encoded video data and the encoded audio data by a predetermined method, and the modulation / demodulation unit (modulation / demodulation circuit unit) ex452 and the modulation / demodulation unit ex451 perform modulation processing and conversion.
- the data is processed and transmitted via the antenna ex450.
- the multiplexing / demultiplexing unit ex453 performs multiplexing By separating the data, the multiplexed data is divided into a bit stream of video data and a bit stream of audio data, and the encoded video data is supplied to the video signal processing unit ex455 via the synchronization bus ex470. The converted audio data is supplied to the audio signal processing unit ex454.
- the video signal processing unit ex455 decodes the video signal by the video decoding method corresponding to the video encoding method shown in each of the above embodiments, and is linked from the display unit ex458 via the display control unit ex459.
- a video or still image included in the moving image file is displayed.
- the audio signal processing unit ex454 decodes the audio signal, and the audio is output from the audio output unit ex457. Since real-time streaming is widespread, depending on the user's situation, there may be occasions where audio playback is not socially appropriate. Therefore, it is desirable that the initial value is a configuration in which only the video data is reproduced without reproducing the audio signal. Audio may be synchronized and played back only when the user performs an operation such as clicking on video data.
- the smartphone ex115 has been described here as an example, in addition to a transmission / reception terminal having both an encoder and a decoder as a terminal, a transmission terminal having only an encoder and a reception having only a decoder There are three possible mounting formats: terminals.
- terminals In the digital broadcasting system, it has been described as receiving or transmitting multiplexed data in which audio data or the like is multiplexed with video data.
- multiplexed data includes character data related to video in addition to audio data. Multiplexing may be performed, and video data itself may be received or transmitted instead of multiplexed data.
- the terminal often includes a GPU. Therefore, a configuration may be adopted in which a wide area is processed in a lump by utilizing the performance of the GPU by using a memory shared by the CPU and the GPU or a memory whose addresses are managed so as to be used in common. As a result, the encoding time can be shortened, real-time performance can be ensured, and low delay can be realized. In particular, it is efficient to perform motion search, deblocking filter, SAO (Sample Adaptive Offset), and transformation / quantization processing in batches in units of pictures or the like instead of the CPU.
- SAO Sample Adaptive Offset
- This aspect may be implemented in combination with at least a part of other aspects in the present disclosure.
- a part of the processing, a part of the configuration of the apparatus, a part of the syntax, and the like described in the flowchart of this aspect may be combined with another aspect.
- the present disclosure can be used for, for example, a television receiver, a digital video recorder, a car navigation, a mobile phone, a digital camera, a digital video camera, a video conference system, or an electronic mirror.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Error Detection And Correction (AREA)
- Reduction Or Emphasis Of Bandwidth Of Signals (AREA)
Abstract
Description
まず、後述する本開示の各態様で説明する処理および/または構成を適用可能な符号化装置および復号化装置の一例として、実施の形態1の概要を説明する。ただし、実施の形態1は、本開示の各態様で説明する処理および/または構成を適用可能な符号化装置および復号化装置の一例にすぎず、本開示の各態様で説明する処理および/または構成は、実施の形態1とは異なる符号化装置および復号化装置においても実施可能である。
(2)実施の形態1の符号化装置または復号化装置に対して、当該符号化装置または復号化装置を構成する複数の構成要素のうち一部の構成要素について機能または実施する処理の追加、置き換え、削除などの任意の変更を施した上で、本開示の各態様で説明する構成要素に対応する構成要素を、本開示の各態様で説明する構成要素に置き換えること
(3)実施の形態1の符号化装置または復号化装置が実施する方法に対して、処理の追加、および/または当該方法に含まれる複数の処理のうちの一部の処理について置き換え、削除などの任意の変更を施した上で、本開示の各態様で説明する処理に対応する処理を、本開示の各態様で説明する処理に置き換えること
(4)実施の形態1の符号化装置または復号化装置を構成する複数の構成要素のうちの一部の構成要素を、本開示の各態様で説明する構成要素、本開示の各態様で説明する構成要素が備える機能の一部を備える構成要素、または本開示の各態様で説明する構成要素が実施する処理の一部を実施する構成要素と組み合わせて実施すること
(5)実施の形態1の符号化装置または復号化装置を構成する複数の構成要素のうちの一部の構成要素が備える機能の一部を備える構成要素、または実施の形態1の符号化装置または復号化装置を構成する複数の構成要素のうちの一部の構成要素が実施する処理の一部を実施する構成要素を、本開示の各態様で説明する構成要素、本開示の各態様で説明する構成要素が備える機能の一部を備える構成要素、または本開示の各態様で説明する構成要素が実施する処理の一部を実施する構成要素と組み合わせて実施すること
(6)実施の形態1の符号化装置または復号化装置が実施する方法に対して、当該方法に含まれる複数の処理のうち、本開示の各態様で説明する処理に対応する処理を、本開示の各態様で説明する処理に置き換えること
(7)実施の形態1の符号化装置または復号化装置が実施する方法に含まれる複数の処理のうちの一部の処理を、本開示の各態様で説明する処理と組み合わせて実施すること
まず、実施の形態1に係る符号化装置の概要を説明する。図1は、実施の形態1に係る符号化装置100の機能構成を示すブロック図である。符号化装置100は、動画像/画像をブロック単位で符号化する動画像/画像符号化装置である。
分割部102は、入力動画像に含まれる各ピクチャを複数のブロックに分割し、各ブロックを減算部104に出力する。例えば、分割部102は、まず、ピクチャを固定サイズ(例えば128x128)のブロックに分割する。この固定サイズのブロックは、符号化ツリーユニット(CTU)と呼ばれることがある。そして、分割部102は、再帰的な四分木(quadtree)及び/又は二分木(binary tree)ブロック分割に基づいて、固定サイズのブロックの各々を可変サイズ(例えば64x64以下)のブロックに分割する。この可変サイズのブロックは、符号化ユニット(CU)、予測ユニット(PU)あるいは変換ユニット(TU)と呼ばれることがある。なお、本実施の形態では、CU、PU及びTUは区別される必要はなく、ピクチャ内の一部又はすべてのブロックがCU、PU、TUの処理単位となってもよい。
減算部104は、分割部102によって分割されたブロック単位で原信号(原サンプル)から予測信号(予測サンプル)を減算する。つまり、減算部104は、符号化対象ブロック(以下、カレントブロックという)の予測誤差(残差ともいう)を算出する。そして、減算部104は、算出された予測誤差を変換部106に出力する。
変換部106は、空間領域の予測誤差を周波数領域の変換係数に変換し、変換係数を量子化部108に出力する。具体的には、変換部106は、例えば空間領域の予測誤差に対して予め定められた離散コサイン変換(DCT)又は離散サイン変換(DST)を行う。
量子化部108は、変換部106から出力された変換係数を量子化する。具体的には、量子化部108は、カレントブロックの変換係数を所定の走査順序で走査し、走査された変換係数に対応する量子化パラメータ(QP)に基づいて当該変換係数を量子化する。そして、量子化部108は、カレントブロックの量子化された変換係数(以下、量子化係数という)をエントロピー符号化部110及び逆量子化部112に出力する。
エントロピー符号化部110は、量子化部108から入力である量子化係数を可変長符号化することにより符号化信号(符号化ビットストリーム)を生成する。具体的には、エントロピー符号化部110は、例えば、量子化係数を二値化し、二値信号を算術符号化する。
逆量子化部112は、量子化部108からの入力である量子化係数を逆量子化する。具体的には、逆量子化部112は、カレントブロックの量子化係数を所定の走査順序で逆量子化する。そして、逆量子化部112は、カレントブロックの逆量子化された変換係数を逆変換部114に出力する。
逆変換部114は、逆量子化部112からの入力である変換係数を逆変換することにより予測誤差を復元する。具体的には、逆変換部114は、変換係数に対して、変換部106による変換に対応する逆変換を行うことにより、カレントブロックの予測誤差を復元する。そして、逆変換部114は、復元された予測誤差を加算部116に出力する。
加算部116は、逆変換部114からの入力である予測誤差と予測制御部128からの入力である予測サンプルとを加算することによりカレントブロックを再構成する。そして、加算部116は、再構成されたブロックをブロックメモリ118及びループフィルタ部120に出力する。再構成ブロックは、ローカル復号ブロックと呼ばれることもある。
ブロックメモリ118は、イントラ予測で参照されるブロックであって符号化対象ピクチャ(以下、カレントピクチャという)内のブロックを格納するための記憶部である。具体的には、ブロックメモリ118は、加算部116から出力された再構成ブロックを格納する。
ループフィルタ部120は、加算部116によって再構成されたブロックにループフィルタを施し、フィルタされた再構成ブロックをフレームメモリ122に出力する。ループフィルタとは、符号化ループ内で用いられるフィルタ(インループフィルタ)であり、例えば、デブロッキング・フィルタ(DF)、サンプルアダプティブオフセット(SAO)及びアダプティブループフィルタ(ALF)などを含む。
フレームメモリ122は、インター予測に用いられる参照ピクチャを格納するための記憶部であり、フレームバッファと呼ばれることもある。具体的には、フレームメモリ122は、ループフィルタ部120によってフィルタされた再構成ブロックを格納する。
イントラ予測部124は、ブロックメモリ118に格納されたカレントピクチャ内のブロックを参照してカレントブロックのイントラ予測(画面内予測ともいう)を行うことで、予測信号(イントラ予測信号)を生成する。具体的には、イントラ予測部124は、カレントブロックに隣接するブロックのサンプル(例えば輝度値、色差値)を参照してイントラ予測を行うことでイントラ予測信号を生成し、イントラ予測信号を予測制御部128に出力する。
インター予測部126は、フレームメモリ122に格納された参照ピクチャであってカレントピクチャとは異なる参照ピクチャを参照してカレントブロックのインター予測(画面間予測ともいう)を行うことで、予測信号(インター予測信号)を生成する。インター予測は、カレントブロック又はカレントブロック内のサブブロック(例えば4x4ブロック)の単位で行われる。例えば、インター予測部126は、カレントブロック又はサブブロックについて参照ピクチャ内で動き探索(motion estimation)を行う。そして、インター予測部126は、動き探索により得られた動き情報(例えば動きベクトル)を用いて動き補償を行うことでカレントブロック又はサブブロックのインター予測信号を生成する。そして、インター予測部126は、生成されたインター予測信号を予測制御部128に出力する。

予測制御部128は、イントラ予測信号及びインター予測信号のいずれかを選択し、選択した信号を予測信号として減算部104及び加算部116に出力する。
次に、上記の符号化装置100から出力された符号化信号(符号化ビットストリーム)を復号可能な復号装置の概要について説明する。図10は、実施の形態1に係る復号装置200の機能構成を示すブロック図である。復号装置200は、動画像/画像をブロック単位で復号する動画像/画像復号装置である。
エントロピー復号部202は、符号化ビットストリームをエントロピー復号する。具体的には、エントロピー復号部202は、例えば、符号化ビットストリームから二値信号に算術復号する。そして、エントロピー復号部202は、二値信号を多値化(debinarize)する。これにより、エントロピー復号部202は、ブロック単位で量子化係数を逆量子化部204に出力する。
逆量子化部204は、エントロピー復号部202からの入力である復号対象ブロック(以下、カレントブロックという)の量子化係数を逆量子化する。具体的には、逆量子化部204は、カレントブロックの量子化係数の各々について、当該量子化係数に対応する量子化パラメータに基づいて当該量子化係数を逆量子化する。そして、逆量子化部204は、カレントブロックの逆量子化された量子化係数(つまり変換係数)を逆変換部206に出力する。
逆変換部206は、逆量子化部204からの入力である変換係数を逆変換することにより予測誤差を復元する。
加算部208は、逆変換部206からの入力である予測誤差と予測制御部220からの入力である予測サンプルとを加算することによりカレントブロックを再構成する。そして、加算部208は、再構成されたブロックをブロックメモリ210及びループフィルタ部212に出力する。
ブロックメモリ210は、イントラ予測で参照されるブロックであって復号対象ピクチャ(以下、カレントピクチャという)内のブロックを格納するための記憶部である。具体的には、ブロックメモリ210は、加算部208から出力された再構成ブロックを格納する。
ループフィルタ部212は、加算部208によって再構成されたブロックにループフィルタを施し、フィルタされた再構成ブロックをフレームメモリ214及び表示装置等に出力する。
フレームメモリ214は、インター予測に用いられる参照ピクチャを格納するための記憶部であり、フレームバッファと呼ばれることもある。具体的には、フレームメモリ214は、ループフィルタ部212によってフィルタされた再構成ブロックを格納する。
イントラ予測部216は、符号化ビットストリームから読み解かれたイントラ予測モードに基づいて、ブロックメモリ210に格納されたカレントピクチャ内のブロックを参照してイントラ予測を行うことで、予測信号(イントラ予測信号)を生成する。具体的には、イントラ予測部216は、カレントブロックに隣接するブロックのサンプル(例えば輝度値、色差値)を参照してイントラ予測を行うことでイントラ予測信号を生成し、イントラ予測信号を予測制御部220に出力する。
インター予測部218は、フレームメモリ214に格納された参照ピクチャを参照して、カレントブロックを予測する。予測は、カレントブロック又はカレントブロック内のサブブロック(例えば4x4ブロック)の単位で行われる。例えば、インター予測部218は、符号化ビットストリームから読み解かれた動き情報(例えば動きベクトル)を用いて動き補償を行うことでカレントブロック又はサブブロックのインター予測信号を生成し、インター予測信号を予測制御部220に出力する。
予測制御部220は、イントラ予測信号及びインター予測信号のいずれかを選択し、選択した信号を予測信号として加算部208に出力する。
本実施の形態に係る画面間予測処理について説明する前に、本実施の形態の手法を用いない場合の画面間予測処理の例について説明する。
本実施の形態に係るインター予測部126により画面間予測処理について説明する。インター予測部126は、画面間予測処理において、通常画面間予測方式と、FRUC方式との、少なくとも2種類の動きベクトル導出方式を実行可能である。通常画面間予測方式では、処理対象ブロックの動きベクトルに関する情報がストリームに符号化される。FRUC方式では、処理対象ブロックの動きベクトルに関する情報はストリームに符号化されず、符号化側と復号化側とで共通の方法で、処理済み領域の再構成画像及び処理済み参照ピクチャを用いて動きベクトルが導出される。
以下、本実施の形態に係る画面間予測処理の変形例について説明する。図14は、本実施の形態の変形例に係る動画像符号化方法及び動画像復号化方法における画面間予測処理のフローチャートである。図14に示す処理は、画面間予測処理の処理単位である予測ブロック単位で繰り返し行われる。
以下、テンプレートFRUC方式又はバイラテラルFRUC方式に従って動きベクトルを導出する方法を説明する。ブロック単位の動きベクトルを導出する方法と、サブブロック単位の動きベクトルを導出する方法とは、基本的に同じである。下記の説明では、ブロックの動きベクトルを導出する方法、及び、サブブロックの動きベクトルを導出する方法を処理対象領域の動きベクトルを導出する方法として説明する。
図19は、符号化装置100及び復号装置200におけるBIO処理を示す概念図である。BIO処理では、処理対象ブロックの動きベクトルを用いて処理対象ブロックの動き補償を行うことにより得られる画像における輝度の空間的な勾配を参照して、処理対象ブロックの予測画像が生成される。

図21は、実施の形態1に係る符号化装置100の実装例を示すブロック図である。符号化装置100は、回路160及びメモリ162を備える。例えば、図1及び図11に示された符号化装置100の複数の構成要素は、図21に示された回路160及びメモリ162によって実装される。
図22は、実施の形態1に係る復号装置200の実装例を示すブロック図である。復号装置200は、回路260及びメモリ262を備える。例えば、図10及び図12に示された復号装置200の複数の構成要素は、図22に示された回路260及びメモリ262によって実装される。
また、本実施の形態における符号化装置100及び復号装置200は、それぞれ、画像符号化装置及び画像復号装置として利用されてもよいし、動画像符号化装置及び動画像復号装置として利用されてもよい。あるいは、符号化装置100及び復号装置200は、それぞれ、インター予測装置(画面間予測装置)として利用され得る。
以上の各実施の形態において、機能ブロックの各々は、通常、MPU及びメモリ等によって実現可能である。また、機能ブロックの各々による処理は、通常、プロセッサなどのプログラム実行部が、ROM等の記録媒体に記録されたソフトウェア(プログラム)を読み出して実行することで実現される。当該ソフトウェアはダウンロード等により配布されてもよいし、半導体メモリなどの記録媒体に記録して配布されてもよい。なお、各機能ブロックをハードウェア(専用回路)によって実現することも、当然、可能である。
図23は、コンテンツ配信サービスを実現するコンテンツ供給システムex100の全体構成を示す図である。通信サービスの提供エリアを所望の大きさに分割し、各セル内にそれぞれ固定無線局である基地局ex106、ex107、ex108、ex109、ex110が設置されている。
また、ストリーミングサーバex103は複数のサーバ又は複数のコンピュータであって、データを分散して処理したり記録したり配信するものであってもよい。例えば、ストリーミングサーバex103は、CDN(Contents Delivery Network)により実現され、世界中に分散された多数のエッジサーバとエッジサーバ間をつなぐネットワークによりコンテンツ配信が実現されていてもよい。CDNでは、クライアントに応じて物理的に近いエッジサーバが動的に割り当てられる。そして、当該エッジサーバにコンテンツがキャッシュ及び配信されることで遅延を減らすことができる。また、何らかのエラーが発生した場合又はトラフィックの増加などにより通信状態が変わる場合に複数のエッジサーバで処理を分散したり、他のエッジサーバに配信主体を切り替えたり、障害が生じたネットワークの部分を迂回して配信を続けることができるので、高速かつ安定した配信が実現できる。
近年では、互いにほぼ同期した複数のカメラex113及び/又はスマートフォンex115などの端末により撮影された異なるシーン、又は、同一シーンを異なるアングルから撮影した画像或いは映像を統合して利用することも増えてきている。各端末で撮影した映像は、別途取得した端末間の相対的な位置関係、又は、映像に含まれる特徴点が一致する領域などに基づいて統合される。
コンテンツの切り替えに関して、図24に示す、上記各実施の形態で示した動画像符号化方法を応用して圧縮符号化されたスケーラブルなストリームを用いて説明する。サーバは、個別のストリームとして内容は同じで質の異なるストリームを複数有していても構わないが、図示するようにレイヤに分けて符号化を行うことで実現される時間的/空間的スケーラブルなストリームの特徴を活かして、コンテンツを切り替える構成であってもよい。つまり、復号側が性能という内的要因と通信帯域の状態などの外的要因とに応じてどのレイヤまで復号するかを決定することで、復号側は、低解像度のコンテンツと高解像度のコンテンツとを自由に切り替えて復号できる。例えば移動中にスマートフォンex115で視聴していた映像の続きを、帰宅後にインターネットTV等の機器で視聴したい場合には、当該機器は、同じストリームを異なるレイヤまで復号すればよいので、サーバ側の負担を軽減できる。
図26は、コンピュータex111等におけるwebページの表示画面例を示す図である。図27は、スマートフォンex115等におけるwebページの表示画面例を示す図である。図26及び図27に示すようにwebページが、画像コンテンツへのリンクであるリンク画像を複数含む場合があり、閲覧するデバイスによってその見え方は異なる。画面上に複数のリンク画像が見える場合には、ユーザが明示的にリンク画像を選択するまで、又は画面の中央付近にリンク画像が近付く或いはリンク画像の全体が画面内に入るまでは、表示装置(復号装置)は、リンク画像として各コンテンツが有する静止画又はIピクチャを表示したり、複数の静止画又はIピクチャ等でgifアニメのような映像を表示したり、ベースレイヤのみ受信して映像を復号及び表示したりする。
また、車の自動走行又は走行支援のため2次元又は3次元の地図情報などの静止画又は映像データを送受信する場合、受信端末は、1以上のレイヤに属する画像データに加えて、メタ情報として天候又は工事の情報なども受信し、これらを対応付けて復号してもよい。なお、メタ情報は、レイヤに属してもよいし、単に画像データと多重化されてもよい。
また、コンテンツ供給システムex100では、映像配信業者による高画質で長時間のコンテンツのみならず、個人による低画質で短時間のコンテンツのユニキャスト、又はマルチキャスト配信が可能である。また、このような個人のコンテンツは今後も増加していくと考えられる。個人コンテンツをより優れたコンテンツにするために、サーバは、編集処理を行ってから符号化処理を行ってもよい。これは例えば、以下のような構成で実現できる。
また、これらの符号化又は復号処理は、一般的に各端末が有するLSIex500において処理される。LSIex500は、ワンチップであっても複数チップからなる構成であってもよい。なお、動画像符号化又は復号用のソフトウェアをコンピュータex111等で読み取り可能な何らかの記録メディア(CD-ROM、フレキシブルディスク、又はハードディスクなど)に組み込み、そのソフトウェアを用いて符号化又は復号処理を行ってもよい。さらに、スマートフォンex115がカメラ付きである場合には、そのカメラで取得した動画データを送信してもよい。このときの動画データはスマートフォンex115が有するLSIex500で符号化処理されたデータである。
図28は、スマートフォンex115を示す図である。また、図29は、スマートフォンex115の構成例を示す図である。スマートフォンex115は、基地局ex110との間で電波を送受信するためのアンテナex450と、映像及び静止画を撮ることが可能なカメラ部ex465と、カメラ部ex465で撮像した映像、及びアンテナex450で受信した映像等が復号されたデータを表示する表示部ex458とを備える。スマートフォンex115は、さらに、タッチパネル等である操作部ex466と、音声又は音響を出力するためのスピーカ等である音声出力部ex457と、音声を入力するためのマイク等である音声入力部ex456と、撮影した映像或いは静止画、録音した音声、受信した映像或いは静止画、メール等の符号化されたデータ、又は、復号化されたデータを保存可能なメモリ部ex467と、ユーザを特定し、ネットワークをはじめ各種データへのアクセスの認証をするためのSIMex468とのインタフェース部であるスロット部ex464とを備える。なお、メモリ部ex467の代わりに外付けメモリが用いられてもよい。
102 分割部
104 減算部
106 変換部
108 量子化部
110 エントロピー符号化部
112、204 逆量子化部
114、206 逆変換部
116、208 加算部
118、210 ブロックメモリ
120、212 ループフィルタ部
122、214 フレームメモリ
124、216 イントラ予測部
126、218 インター予測部
128、220 予測制御部
160、260 回路
162、262 メモリ
200 復号装置
202 エントロピー復号部
Claims (14)
- 回路と、
メモリとを備え、
前記回路は、前記メモリを用いて、
第1動作モードでは、
動画像に含まれる画像を分割した予測ブロック単位で第1動きベクトルを導出し、
前記予測ブロック単位で、導出された前記第1動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照して予測画像を生成する第1動き補償処理を行い、
第2動作モードでは、
前記予測ブロックを分割したサブブロック単位で第2動きベクトルを導出し、
前記サブブロック単位で、前記第2動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照せずに予測画像を生成する第2動き補償処理を行う
符号化装置。 - 前記回路は、
前記第1動作モードでは、第1画面間予測方式により、前記予測ブロック単位で前記第1動きベクトルを導出し、
前記第2動作モードでは、前記第1画面間予測方式と異なる第2画面間予測方式により、前記サブブロック単位で前記第2動きベクトルを導出する
請求項1記載の符号化装置。 - 前記第2画面間予測方式は、互いに異なる2つのピクチャ内の2つの領域の2つの再構成画像の適合度合いを用いる画面間予測方式である
請求項2記載の符号化装置。 - 前記第1画面間予測方式は、(1)対象予測ブロックに隣接する対象ピクチャ内の領域の再構成画像と、参照ピクチャ内の領域の再構成画像との適合度合いを用いる第3画面間予測方式と、(2)互いに異なる2つの参照ピクチャ内の2つの領域の2つの再構成画像の適合度合いを用いる第4画面間予測方式とのうちの一方であり、
前記第2画面間予測方式は、前記第3画面間予測方式と前記第4画面間予測方式とのうちの他方である
請求項3記載の符号化装置。 - 前記第1画面間予測方式は前記第3画面間予測方式であり、
前記第2画面間予測方式は前記第4画面間予測方式である
請求項4記載の符号化装置。 - 前記第1画面間予測方式は、対象予測ブロックと、参照ピクチャに含まれる領域の再構成画像との適合度合いを用いる画面間予測方式であり、導出された前記第1動きベクトルを特定するための情報を含む符号化ビットストリームが生成される
請求項3記載の符号化装置。 - 回路と、
メモリとを備え、
前記回路は、前記メモリを用いて、
第1動作モードでは、
動画像に含まれる画像を分割した予測ブロック単位で第1動きベクトルを導出し、
前記予測ブロック単位で、導出された前記第1動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照して予測画像を生成する第1動き補償処理を行い、
第2動作モードでは、
前記予測ブロックを分割したサブブロック単位で第2動きベクトルを導出し、
前記サブブロック単位で、前記第2動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照せずに予測画像を生成する第2動き補償処理を行う
復号装置。 - 前記回路は、
前記第1動作モードでは、第1画面間予測方式により、前記予測ブロック単位で前記第1動きベクトルを導出し、
前記第2動作モードでは、前記第1画面間予測方式と異なる第2画面間予測方式により、前記サブブロック単位で前記第2動きベクトルを導出する
請求項7記載の復号装置。 - 前記第2画面間予測方式は、互いに異なる2つのピクチャ内の2つの領域の2つの再構成画像の適合度合いを用いる画面間予測方式である
請求項8記載の復号装置。 - 前記第1画面間予測方式は、(1)対象予測ブロックに隣接する対象ピクチャ内の領域の再構成画像と、参照ピクチャ内の領域の再構成画像との適合度合いを用いる第3画面間予測方式と、(2)互いに異なる2つの参照ピクチャ内の2つの領域の2つの再構成画像の適合度合いを用いる第4画面間予測方式とのうちの一方であり、
前記第2画面間予測方式は、前記第3画面間予測方式と前記第4画面間予測方式とのうちの他方である
請求項9記載の復号装置。 - 前記第1画面間予測方式は前記第3画面間予測方式であり、
前記第2画面間予測方式は前記第4画面間予測方式である
請求項10記載の復号装置。 - 前記第1画面間予測方式では、符号化ビットストリームから、前記第1動きベクトルを前記予測ブロック単位で特定するための情報を取得し、前記情報を用いて前記第1動きベクトルを導出する
請求項9記載の復号装置。 - 第1動作モードでは、
動画像に含まれる画像を分割した予測ブロック単位で第1動きベクトルを導出し、
前記予測ブロック単位で、導出された前記第1動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照して予測画像を生成する第1動き補償処理を行い、
第2動作モードでは、
前記予測ブロックを分割したサブブロック単位で第2動きベクトルを導出し、
前記サブブロック単位で、前記第2動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照せずに予測画像を生成する第2動き補償処理を行う
符号化方法。 - 第1動作モードでは、
動画像に含まれる画像を分割した予測ブロック単位で第1動きベクトルを導出し、
前記予測ブロック単位で、導出された前記第1動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照して予測画像を生成する第1動き補償処理を行い、
第2動作モードでは、
前記予測ブロックを分割したサブブロック単位で第2動きベクトルを導出し、
前記サブブロック単位で、前記第2動きベクトルを用いた動き補償により生成された画像における輝度の空間的な勾配を参照せずに予測画像を生成する第2動き補償処理を行う
復号方法。
Priority Applications (13)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202311200874.7A CN117097891A (zh) | 2017-06-05 | 2018-05-30 | 解码装置、编码装置、存储介质、解码方法和编码方法 |
| CN201880036730.3A CN110692242B (zh) | 2017-06-05 | 2018-05-30 | 编码装置、解码装置、编码方法和解码方法 |
| KR1020237029406A KR102679175B1 (ko) | 2017-06-05 | 2018-05-30 | 부호화 장치, 복호 장치, 부호화 방법 및 복호 방법 |
| CN202311208167.2A CN117041563A (zh) | 2017-06-05 | 2018-05-30 | 解码装置、编码装置、存储介质、解码方法和编码方法 |
| KR1020197035779A KR102574175B1 (ko) | 2017-06-05 | 2018-05-30 | 부호화 장치, 복호 장치, 부호화 방법 및 복호 방법 |
| CN202311204072.3A CN117041562A (zh) | 2017-06-05 | 2018-05-30 | 解码装置、编码装置、存储介质、解码方法和编码方法 |
| CN202311199423.6A CN117097890A (zh) | 2017-06-05 | 2018-05-30 | 解码装置、编码装置、存储介质、解码方法和编码方法 |
| JP2019523480A JPWO2018225594A1 (ja) | 2017-06-05 | 2018-05-30 | 符号化装置、復号装置、符号化方法及び復号方法 |
| KR1020247020976A KR20240101722A (ko) | 2017-06-05 | 2018-05-30 | 부호화 장치, 복호 장치, 부호화 방법 및 복호 방법 |
| US16/702,254 US10728543B2 (en) | 2017-06-05 | 2019-12-03 | Encoder, decoder, encoding method, and decoding method |
| US16/901,869 US11115654B2 (en) | 2017-06-05 | 2020-06-15 | Encoder, decoder, encoding method, and decoding method |
| US17/374,085 US11831864B2 (en) | 2017-06-05 | 2021-07-13 | Encoder, decoder, encoding method, and decoding method |
| US18/489,678 US20240048691A1 (en) | 2017-06-05 | 2023-10-18 | Encoder, decoder, encoding method, and decoding method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762515208P | 2017-06-05 | 2017-06-05 | |
| US62/515,208 | 2017-06-05 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US16/702,254 Continuation US10728543B2 (en) | 2017-06-05 | 2019-12-03 | Encoder, decoder, encoding method, and decoding method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018225594A1 true WO2018225594A1 (ja) | 2018-12-13 |
Family
ID=64567434
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2018/020659 WO2018225594A1 (ja) | 2017-06-05 | 2018-05-30 | 符号化装置、復号装置、符号化方法及び復号方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (4) | US10728543B2 (ja) |
| JP (4) | JPWO2018225594A1 (ja) |
| KR (3) | KR20240101722A (ja) |
| CN (5) | CN117041563A (ja) |
| TW (1) | TWI814726B (ja) |
| WO (1) | WO2018225594A1 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116437105A (zh) | 2017-05-19 | 2023-07-14 | 松下电器(美国)知识产权公司 | 解码装置和编码装置 |
| WO2018212111A1 (ja) * | 2017-05-19 | 2018-11-22 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 符号化装置、復号装置、符号化方法及び復号方法 |
| CN113784137A (zh) * | 2019-09-23 | 2021-12-10 | 杭州海康威视数字技术股份有限公司 | 编解码方法、装置及设备 |
| US11418792B2 (en) * | 2020-03-27 | 2022-08-16 | Tencent America LLC | Estimating attributes for the classification of adaptive loop filtering based on projection-slice theorem |
| CN116095322B (zh) * | 2023-04-10 | 2023-07-25 | 深圳传音控股股份有限公司 | 图像处理方法、处理设备及存储介质 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017058899A1 (en) * | 2015-09-28 | 2017-04-06 | Qualcomm Incorporated | Improved bi-directional optical flow for video coding |
| WO2017134957A1 (ja) * | 2016-02-03 | 2017-08-10 | シャープ株式会社 | 動画像復号装置、動画像符号化装置、および予測画像生成装置 |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR0171147B1 (ko) * | 1995-03-20 | 1999-03-20 | 배순훈 | 그레디언트 변화를 이용한 특징점 선정장치 |
| US8325822B2 (en) * | 2006-01-20 | 2012-12-04 | Qualcomm Incorporated | Method and apparatus for determining an encoding method based on a distortion value related to error concealment |
| US8503536B2 (en) * | 2006-04-07 | 2013-08-06 | Microsoft Corporation | Quantization adjustments for DC shift artifacts |
| RU2549512C2 (ru) * | 2010-09-30 | 2015-04-27 | Мицубиси Электрик Корпорейшн | Устройство кодирования движущихся изображений, устройство декодирования движущихся изображений, способ кодирования движущихся изображений и способ декодирования движущихся изображений |
| JP2014192702A (ja) * | 2013-03-27 | 2014-10-06 | National Institute Of Information & Communication Technology | 複数の入力画像をエンコーディングする方法、プログラムおよび装置 |
| US20160191945A1 (en) * | 2014-12-24 | 2016-06-30 | Sony Corporation | Method and system for processing video content |
| CN107925775A (zh) * | 2015-09-02 | 2018-04-17 | 联发科技股份有限公司 | 基于双向预测光流技术的视频编解码的运动补偿方法及装置 |
-
2018
- 2018-05-30 KR KR1020247020976A patent/KR20240101722A/ko unknown
- 2018-05-30 CN CN202311208167.2A patent/CN117041563A/zh active Pending
- 2018-05-30 CN CN201880036730.3A patent/CN110692242B/zh active Active
- 2018-05-30 CN CN202311200874.7A patent/CN117097891A/zh active Pending
- 2018-05-30 JP JP2019523480A patent/JPWO2018225594A1/ja active Pending
- 2018-05-30 KR KR1020197035779A patent/KR102574175B1/ko active IP Right Grant
- 2018-05-30 KR KR1020237029406A patent/KR102679175B1/ko active IP Right Grant
- 2018-05-30 WO PCT/JP2018/020659 patent/WO2018225594A1/ja active Application Filing
- 2018-05-30 CN CN202311199423.6A patent/CN117097890A/zh active Pending
- 2018-05-30 CN CN202311204072.3A patent/CN117041562A/zh active Pending
- 2018-05-31 TW TW107118740A patent/TWI814726B/zh active
-
2019
- 2019-12-03 US US16/702,254 patent/US10728543B2/en active Active
-
2020
- 2020-06-15 US US16/901,869 patent/US11115654B2/en active Active
- 2020-10-12 JP JP2020171656A patent/JP2021002891A/ja active Pending
-
2021
- 2021-07-13 US US17/374,085 patent/US11831864B2/en active Active
-
2022
- 2022-05-02 JP JP2022075714A patent/JP7432653B2/ja active Active
-
2023
- 2023-10-18 US US18/489,678 patent/US20240048691A1/en active Pending
- 2023-12-04 JP JP2023204315A patent/JP7553686B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017058899A1 (en) * | 2015-09-28 | 2017-04-06 | Qualcomm Incorporated | Improved bi-directional optical flow for video coding |
| WO2017134957A1 (ja) * | 2016-02-03 | 2017-08-10 | シャープ株式会社 | 動画像復号装置、動画像符号化装置、および予測画像生成装置 |
Non-Patent Citations (2)
| Title |
|---|
| "Harmonization and improvement for BIO", STUDY GROUP 16- CONTRIBUTION 1045, September 2015 (2015-09-01), pages 1 - 3 * |
| CHEN, JIANLE ET AL.: "Algorithm Description of Joint Exploration Test Model 5 (JEM 5)", JOINT VIDEO EXPLORATION TEAM (JVET) OF ITU-T SG 16 WP 3, vol. 1, February 2017 (2017-02-01), Geneva, CH, pages 1 - 3, XP030150647 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110692242A (zh) | 2020-01-14 |
| JP2021002891A (ja) | 2021-01-07 |
| KR20230131285A (ko) | 2023-09-12 |
| CN117097891A (zh) | 2023-11-21 |
| US10728543B2 (en) | 2020-07-28 |
| CN110692242B (zh) | 2023-10-03 |
| KR102574175B1 (ko) | 2023-09-04 |
| TW202402052A (zh) | 2024-01-01 |
| JP7553686B2 (ja) | 2024-09-18 |
| TWI814726B (zh) | 2023-09-11 |
| JPWO2018225594A1 (ja) | 2020-02-06 |
| US20240048691A1 (en) | 2024-02-08 |
| US20200314417A1 (en) | 2020-10-01 |
| JP7432653B2 (ja) | 2024-02-16 |
| CN117041562A (zh) | 2023-11-10 |
| JP2024015159A (ja) | 2024-02-01 |
| TW201909632A (zh) | 2019-03-01 |
| CN117041563A (zh) | 2023-11-10 |
| CN117097890A (zh) | 2023-11-21 |
| JP2022093625A (ja) | 2022-06-23 |
| KR20240101722A (ko) | 2024-07-02 |
| US11831864B2 (en) | 2023-11-28 |
| US20210344906A1 (en) | 2021-11-04 |
| KR20200015518A (ko) | 2020-02-12 |
| US20200107018A1 (en) | 2020-04-02 |
| KR102679175B1 (ko) | 2024-06-27 |
| US11115654B2 (en) | 2021-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2018199051A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| WO2018212110A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019208677A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| JP2018152852A (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018221631A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| JP2019017066A (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019151279A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018021374A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| JPWO2018190207A1 (ja) | 復号装置、復号方法及びプログラム | |
| WO2018101288A1 (ja) | 符号化装置、符号化方法、復号装置および復号方法 | |
| WO2018190207A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019155971A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019208372A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018105582A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018212111A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019189346A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018193968A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018199050A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018225594A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019221103A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018225593A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| WO2019151284A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018097115A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019189344A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2018221554A1 (ja) | 符号化装置、符号化方法、復号装置及び復号方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18814250 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2019523480 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 20197035779 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 18814250 Country of ref document: EP Kind code of ref document: A1 |