WO2018199338A1 - Nucleic acid molecule for treatment of hepatitis b - Google Patents
Nucleic acid molecule for treatment of hepatitis b Download PDFInfo
- Publication number
- WO2018199338A1 WO2018199338A1 PCT/JP2018/017347 JP2018017347W WO2018199338A1 WO 2018199338 A1 WO2018199338 A1 WO 2018199338A1 JP 2018017347 W JP2018017347 W JP 2018017347W WO 2018199338 A1 WO2018199338 A1 WO 2018199338A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- region
- bases
- nucleic acid
- acid molecule
- nucleotide sequence
- Prior art date
Links
Images






Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7105—Natural ribonucleic acids, i.e. containing only riboses attached to adenine, guanine, cytosine or uracil and having 3'-5' phosphodiester links
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/66—Microorganisms or materials therefrom
- A61K35/76—Viruses; Subviral particles; Bacteriophages
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/06—Organic compounds, e.g. natural or synthetic hydrocarbons, polyolefins, mineral oil, petrolatum or ozokerite
- A61K47/22—Heterocyclic compounds, e.g. ascorbic acid, tocopherol or pyrrolidones
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/02—Suppositories; Bougies; Bases therefor; Ovules
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/06—Ointments; Bases therefor; Other semi-solid forms, e.g. creams, sticks, gels
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/08—Solutions
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/10—Dispersions; Emulsions
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/14—Particulate form, e.g. powders, Processes for size reducing of pure drugs or the resulting products, Pure drug nanoparticles
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/20—Pills, tablets, discs, rods
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/48—Preparations in capsules, e.g. of gelatin, of chocolate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/70—Web, sheet or filament bases ; Films; Fibres of the matrix type containing drug
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/20—Antivirals for DNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
Definitions
- the present invention relates to a nucleic acid molecule that effectively suppresses expression of a hepatitis B virus (HBV) gene, and for the suppression of hepatitis B virus proliferation, the treatment of hepatitis B, cirrhosis, and liver cancer, including the nucleic acid molecule.
- HBV hepatitis B virus
- hepatitis B virus is infected between 1.3 million and 1.5 million people in Japan, and about 350 million people worldwide. Main causes of chronic hepatitis along with hepatitis C virus It has become.
- Chronic hepatitis C can be expected to eliminate the HCV virus at a considerably high rate by the current therapy, but the current therapy for chronic hepatitis B cannot completely eliminate the HBV virus.
- Current therapies for chronic hepatitis B include interferon (IFN) therapy and nucleic acid analog preparation therapy.
- IFN interferon
- nucleic acid analog preparation sedates hepatitis and improves liver function, but is forced to take for a long time, and hepatitis relapses in most cases due to discontinuation of medication.
- Non-patent Documents 1 and 2 transcription from cccDNA (covalently closed circular DNA, closed circular DNA, or completely closed double-stranded DNA) present in a minute amount in the hepatocyte nucleus after the treatment occurs after the treatment is completed. Therefore, development of a new innovative therapeutic agent having a different mechanism of action from the above-described therapeutic methods is demanded (Non-patent Documents 1 and 2).
- Non-patent document 3 summarizes the mechanism of action of chronic hepatitis B drug candidates.
- translational suppression of all viral proteins by siRNA can be expected to completely block the function of HBV as a virus.
- Nucleic acid drugs can target molecules such as mRNA and miRNA that cannot be targeted by conventional low-molecular-weight drugs and antibody drugs, and are highly expected as next-generation drugs. As a result, the creation of pharmaceuticals for diseases that have been difficult to treat is expected, and the current situation is that research is actively conducted all over the world.
- RNA interference As a technique for suppressing gene expression in nucleic acid medicine, for example, RNA interference (RNAi) is known. Inhibition of gene expression by RNA interference is generally performed, for example, by administering a short double-stranded RNA molecule to a cell or the like.
- the double-stranded RNA molecule is usually referred to as siRNA (small interfering RNA).
- siRNA small interfering RNA
- the present invention relates to a nucleic acid molecule that effectively suppresses the expression of hepatitis B virus gene, and a medicament for inhibiting the growth of hepatitis B virus containing the nucleic acid molecule, the treatment of hepatitis B, cirrhosis, and liver cancer.
- An object is to provide a composition.
- the present inventors designed and synthesized two types of novel siRNA sequences for HBV genotype C. They were introduced into cultured human cells Huh7 expressing HBV virus, and their ability to suppress virus production was evaluated using the secreted amounts of S antigen and e antigen of HBV virus as indicators. As a result, it was found that the two sequences (us1, us2) have high inhibitory activity. Furthermore, the present inventors have found that a single-stranded nucleic acid molecule carrying these two sequences has an activity equivalent to that of siRNA, thereby completing the present invention.
- a nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as a hepatitis B virus gene expression suppression sequence (i) a nucleotide sequence represented by SEQ ID NO: 2; A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1; A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having [2] The nucleic acid molecule according to [1], wherein the total number of bases is 100 bases or less.
- a double-stranded nucleic acid molecule One strand contains the nucleotide sequence of (i) and the other strand contains the nucleotide sequence of (iii) annealed to the nucleotide sequence of (i); or one strand contains the nucleotide sequence of (ii), the other
- nucleotide sequences of (i), (ii), (iii), and (iv) are the nucleotide sequences represented by SEQ ID NOs: 2, 1, 4, 3, respectively [3] to [6]
- the linker region (Lx) has a non-nucleotide structure containing at least one of a pyrrolidine skeleton and a piperidine skeleton; And at least one of the region (X) and the region (Xc) includes the expression suppressing sequence; (B) comprising region (Xc), linker region (Lx), region (X), region (Y), linker region (Ly) and region (Yc) in this order from 5 ′ side to 3
- X 1 and X 2 are each independently H 2 , O, S or NH; Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S; R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A; L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom, However, when Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other; L 2 is an alkylene chain consisting of
- the ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond
- the region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
- the region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
- R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I).
- nucleic acid molecule according to any one of [10] to [19], wherein in (B), the number of bases (Yc) in the region (Yc) is 1 to 11 bases. [21] The nucleic acid molecule according to [20], wherein the number of bases (Yc) in the region (Yc) is 1 to 7 bases. [22] The nucleic acid molecule according to [20], wherein the number of bases (Yc) in the region (Yc) is 1 to 3 bases. [23] The nucleic acid molecule according to any one of [10] to [13], wherein in (A), the number of bases (Xc) in the region (Xc) is 19 to 30 bases.
- nucleic acid molecule according to any one of [10] to [23], wherein the total number of bases is 80 or less.
- nucleic acid molecule according to [10] wherein in (B), the linker regions (Lx) and (Ly) are composed of nucleotide residues of 1 to 20 bases.
- nucleotide sequence of (i) and the nucleotide sequence of (iii), or the nucleotide sequence of (ii) and the nucleotide sequence of (iv) are linked by a group represented by the following formula: [1] The nucleic acid molecule according to any one of to [4].
- nucleic acid molecule according to any one of [1] to [4], [10] to [13] or [23], which is represented by any of the following. 5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13) 5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14) (In the sequence, -Lx- represents a group represented by the following formula.)
- nucleic acid molecule according to any one of [1] to [4] or [10] to [22], which is represented by any of the following. 5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17) 5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18) (In the sequence, -Lx- and -Ly- represent a group represented by the following formula.)
- nucleic acid molecule according to any one of [1] to [4], [10], [12] to [22] or [26] represented by any of the following. 5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15) 5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16) [32] An expression vector for expressing the nucleic acid molecule according to [5] to [9], [26] or [31].
- a pharmaceutical composition comprising the nucleic acid molecule according to any one of [1] to [31] or the expression vector according to [32].
- the pharmaceutical composition according to [33] which is used for inhibiting hepatitis B virus growth.
- the expression of the hepatitis B virus gene can be effectively suppressed by the nucleic acid molecule of the present invention.
- the pharmaceutical composition containing the nucleic acid molecule of the present invention effectively suppresses the expression of hepatitis B virus gene, particularly surface antigen gene, thereby suppressing hepatitis B virus growth, hepatitis B, cirrhosis, liver cancer. It is useful for the treatment of
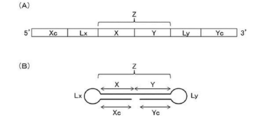
- FIG. 1 is a schematic diagram showing an example of the nucleic acid molecule of the present invention.
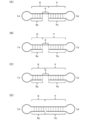
- FIG. 2 is a schematic diagram showing another example of the nucleic acid molecule of the present invention.
- FIG. 3 is a schematic diagram showing another example of the nucleic acid molecule of the present invention.
- FIG. 4 is a schematic diagram showing another example of the nucleic acid molecule of the present invention.
- FIG. 5 is a graph showing the suppressive activity of hepatitis B virus surface antigen (HBs antigen) gene expression of each siRNA designed based on the hepatitis B virus genome sequence of the present invention.
- HBs antigen hepatitis B virus surface antigen
- FIG. 6 is a graph showing the concentration-dependent HBs antigen expression suppression activity and HBe antigen expression suppression activity of each siRNA designed based on the hepatitis B virus genome sequence of the present invention.
- FIG. 7 is a graph showing the HBs antigen expression-suppressing activity of the siRNA and single-stranded nucleic acid molecule of the present invention.
- FIG. 8 is a graph showing the concentration-dependent HBs antigen expression suppression activity of the siRNA and single-stranded nucleic acid molecule of the present invention.
- the present invention provides a nucleic acid molecule having activity of suppressing the expression of hepatitis B virus gene.
- Hepatitis B virus invades hepatocytes by infection and proliferates.
- the immune function works to eliminate it, but it is impossible to selectively attack only the virus in the hepatocyte, and the hepatocyte itself attacks. When received, it is destroyed, leading to the development of hepatitis.
- Hepatitis B virus has an incomplete double-stranded DNA in which genetic information is conserved, and a DNA polymerase is centrally located in the core (HBc antigen), outer shell (HBe antigen), and outer membrane (HBs antigen). ).
- cccDNA covalent circular DNA
- mRNA 3.5 kb, 2.4 kb, 2.1 kb, 0.7 kb
- HBs antigen, HBc antigen, HBe antigen and reverse transcriptase are structural proteins.
- An active polymerase, X protein is translated (Molecular Therapy 2013; 21 (5) 973-985, FIG. 3a).
- S ORF open reading frames
- core ORF X ORF
- polymerase ORF polymerase ORF
- S ORF consists of three types of proteins that make up the HBs antigen, large S protein (including pre-S1, pre-S2 and S region), Middle S protein (including pre-S2 and S region), and Small S protein ( (Consisting only of the S region).
- the core ORF encodes a core protein and a precore protein.
- the core protein forms a core particle, and the pre-core protein becomes HBe antigen after 19 hydrophobic signal peptides and 34 amino acid residues at the C-terminus are cleaved.
- the X ORF codes for an X protein that is thought to be involved in virus growth and the development of hepatocellular carcinoma.
- the polymerase ORF encodes a DNA polymerase protein having reverse transcriptase activity.
- a certain type of mRNA is incorporated into the core particle as pregenomic RNA, a minus-strand DNA is synthesized by the action of reverse transcriptase, and then a plus-strand DNA is synthesized into an incomplete circular double-stranded DNA. Furthermore, it is wrapped in an envelope formed from HBs antigens to become virus particles (Dane particles) and released into the blood.
- HBs antigen translated by mRNA, hollow particles containing HBc antigen and p22cr antigen (particles without DNA nucleus), HBe antigen passing through liver cell membrane, etc. are Dane particle blood A large amount is released into the blood and secreted as a route different from the medium release.
- Diagnosis of hepatitis B is performed by detecting the HBs antigen and / or HBe antigen in blood.
- a positive HBs antigen in the blood indicates that HBV is present in the liver, HBV components are synthesized, and hepatitis B is infected at the time of examination.
- the HBs antigen in the blood grasps the virus growth in the liver and provides an index for judging the completion of treatment.
- HBe antigen is a protein that is excessively produced when HBV proliferates, and indicates that infectivity is strong when HBV is actively proliferating in the liver.
- the nucleic acid molecule suppresses the expression of hepatitis B virus gene by introducing the nucleic acid molecule to be evaluated into a cell infected with hepatitis B virus or a cell into which hepatitis B virus genome has been introduced (preferably a human cell).
- a cell infected with hepatitis B virus or a cell into which hepatitis B virus genome has been introduced preferably a human cell.
- the amount of hepatitis B virus HBs antigen released (translocated) or the amount of hepatitis B virus HBe antigen has not been introduced or a negative control nucleic acid molecule has been introduced.
- the amount of hepatitis B virus HBs antigen released or transferred from a cell infected with hepatitis B virus or a cell (preferably a human cell) into which hepatitis B virus genome has been introduced, or hepatitis B virus HBe antigen It can be evaluated by comparing it with the amount of.
- the amount of hepatitis B virus HBs antigen or HBe antigen can be evaluated by detecting the antigen by a known immunological technique using an antibody that specifically recognizes hepatitis B virus HBs antigen or HBe antigen. it can. Examples of immunological methods include flow cytometry analysis, radioisotope immunoassay (RIA method), ELISA method (Methods in Enzymol. 70: 419-439 (1980)), Western blotting, immunohistochemical staining, etc. Can do.
- the present invention provides a nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as an expression suppressing sequence and having an activity of suppressing the expression of hepatitis B virus gene: (i) represented by SEQ ID NO: 2 Nucleotide sequence; A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1; A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having
- nucleotide sequences represented by SEQ ID NOs: 1 and 2 are the following sequences. 5'-UCCACCACGAGUCUAGACU-3 '(SEQ ID NO: 1) 5'-ACUCCCAUAGGAAUCUUGC-3 '(SEQ ID NO: 2)
- the nucleotide sequences represented by SEQ ID NOs: 1 and 2 are the hepatitis B virus genotype C complete genome (GenBank Accession No. AB0143481, No. AB113875, No. AB113876, No. AB113878, No. AB113879). No. AB246344), nucleotide numbers 245 to 263 (5′-AGUCUAGACUCGUGGUGGA-3 ′ (SEQ ID NO: 3)) and nucleotide numbers 629 to 647 (5′-GCAAGAUUCCUAUGGGAGU-3 ′ (SEQ ID NO: 4)) Each corresponds to a sequence that is completely complementary to the corresponding sequence.
- sequences represented by nucleotide numbers 245 to 263 and nucleotide numbers 629 to 647 are both sequences in the coding region of S protein and polymerase protein of hepatitis B virus. Due to the structure of the hepatitis B virus genome, the S protein and the coding region of the polymerase overlap, but they are translated into separate proteins due to the different reading frames. As described above, a plurality of ORFs may exist in mRNA transcribed from the hepatitis B virus genome.
- hepatitis B virus surface antigen gene protein when the function of mRNA encoding hepatitis B virus surface antigen gene protein is inhibited by the nucleic acid molecule having the activity of suppressing the expression of hepatitis B virus gene of the present invention, translation of other proteins encoded by the RNA May also be suppressed.
- the expression of the hepatitis B virus surface antigen gene protein is suppressed by the nucleic acid molecule having the activity of suppressing the expression of hepatitis B virus gene of the present invention, the proliferation of hepatitis B virus is suppressed, and as a result, other B types Hepatitis virus gene expression may be suppressed.
- the expression suppression activity means that gene expression is suppressed as a result of suppression of gene transcription, degradation of gene transcript, and / or inhibition of protein translation from gene transcript.
- the number of nucleotides to be deleted, substituted, inserted or added is as long as the resulting nucleic acid molecule has activity of suppressing the expression of hepatitis B virus gene. Although it is not particularly limited, it is usually 1 or 2, preferably 1.
- the position of the base to be substituted is usually within 8 bases from the 5 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base, Alternatively, it is within 8 bases from the 3 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base.
- the nucleotide sequence (i) may be a nucleotide sequence represented by SEQ ID NO: 5 or SEQ ID NO: 7.
- the nucleotide sequence represented by SEQ ID NO: 5 is the nucleotide sequence represented by SEQ ID NO: 2 (C type, Genotype C) of hepatitis B virus genotype A (Genotype A) and B type (Genotype B). Corresponding sequence.
- SEQ ID NO: 5 the 8th base and the 5th base from the 3 ′ end of the nucleotide represented by SEQ ID NO: 2 were substituted from A to U and from C to U, respectively. Is an array.
- a sequence completely complementary to the nucleotide sequence represented by SEQ ID NO: 5 is shown in SEQ ID NO: 6.
- the nucleotide sequence represented by SEQ ID NO: 7 is a sequence corresponding to the nucleotide sequence represented by SEQ ID NO: 2 (C type, Genotype C) of the hepatitis B virus genotype D (Genotype D).
- SEQ ID NO: 7 the 5th base and the 2nd base from the 3 ′ end of the nucleotide represented by SEQ ID NO: 2 were substituted from C to U and from G to C, respectively. Is an array.
- a sequence completely complementary to the nucleotide sequence represented by SEQ ID NO: 7 is shown in SEQ ID NO: 8.
- the position of the base to be deleted is usually within 5 bases from the 5 ′ end, preferably within 4, 3, 2 or 1 base, or from the 3 ′ end. Within 5 bases, preferably within 4, 3, 2 or 1 base.
- the position of the base to be inserted is usually between 5 and 4 bases from the 5 ′ end, preferably between 4 and 3 bases, 3 bases and 2 bases. Between bases, or between 2 bases and 1 base, or between 5 bases and 4 bases from the 3 ′ end, preferably between 4 bases and 3 bases, between 3 bases and 2 bases, or between 2 bases and 1 base Between.
- the position to which a base is added is 1 base from the 5 'end or 1 base from the 3' end.
- the degree of sequence identity is not particularly limited as long as the resulting nucleic acid molecule has the activity of suppressing the expression of hepatitis B virus gene, but usually 85% Above, preferably 90% or more.
- identity % is determined by any algorithm known in the art, such as Needleman et al. (1970) (J. Mol. Biol. 48: 444-453), Myers and Miller (CABIOS, 1988, 4: 11-17) or the like. The Needleman et al.
- Algorithm is incorporated in the GAP program of the GCG software package, and the identity (%) is, for example, BLOSUM 62 matrix or PAM250 matrix, and gap weight: 16, 14, 12, 10, 8, 6 or 4 and length weight: 1, 2, 3, 4, 5 or 6 can be used.
- the Myers and Miller algorithms are also incorporated into the ALIGN program which is part of the GCG sequence alignment software package.
- the ALIGN program for example, PAM120 weight restable table, gap length penalty 12, and gap penalty 4 can be used.
- a method showing the lowest value among the above methods may be adopted.
- the length of the nucleotide sequence is 17 to 21 bases, preferably 18 to 20 bases, more preferably 19 bases.
- the expression suppression sequence may be, for example, a sequence consisting of the nucleotide sequence or a sequence containing the nucleotide sequence.
- the length of the expression suppression sequence is not particularly limited, and is, for example, 18 to 32 bases long, preferably 19 to 30 bases long, and more preferably 19, 20, or 21 bases long.
- the numerical range of the number of bases discloses all positive integers belonging to the range.
- the description “1 to 4 bases” includes “1, 2, 3, 4 bases”. "Means all disclosures (the same applies hereinafter).
- the nucleic acid molecule of the present invention preferably further has, for example, a complementary sequence that can be annealed with the expression suppressing sequence.
- the complementary sequence is, for example, in the same strand as the expression suppressing sequence and forms a single-stranded nucleic acid molecule composed of one single strand.
- the complementary sequence only needs to be annealable with the expression suppression sequence, for example.
- the complementary sequence may be, for example, a sequence exhibiting 100% complementarity with the expression suppression sequence, or a sequence exhibiting complementarity of less than 100% within a range that can be annealed.
- the complementarity is not particularly limited, and examples thereof include 90% to 100%, 93% to 100%, 95% to 100%, 98% to 100%, and 99% to 100%.
- the nucleic acid molecule of the present invention is a nucleotide sequence of (i) and a complementary sequence capable of annealing to the nucleotide sequence of (i), wherein the complementary sequence is (iii) below; or ( a nucleotide sequence of ii) and a complementary sequence which can be annealed to the nucleotide sequence of (ii), wherein the complementary sequence is (iv) below.
- nucleotide sequence represented by SEQ ID NO: 4 A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 4; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 4
- a nucleotide sequence represented by SEQ ID NO: 3 A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 3; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 3
- the number of nucleotides to be deleted, substituted, inserted, or added is as long as the resulting nucleic acid molecule has the activity of suppressing the expression of hepatitis B virus gene. Although it is not particularly limited, it is usually 1 or 2, preferably 1.
- the position of the base to be substituted is usually within 8 bases from the 5 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base, Alternatively, it is within 8 bases from the 3 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base.
- the position of the base to be deleted is usually within 5 bases from the 5 ′ end, preferably within 4, 3, 2 or 1 base, or from the 3 ′ end. Within 5 bases, preferably within 4, 3, 2 or 1 base.
- the position of the base to be inserted is usually between 5 and 4 bases from the 5 ′ end, preferably between 4 and 3 bases, 3 bases and 2 bases. Between bases, or between 2 bases and 1 base, or between 5 bases and 4 bases from the 3 ′ end, preferably between 4 bases and 3 bases, between 3 bases and 2 bases, or between 2 bases and 1 base Between.
- the position to which a base is added is one base from the 5 'end or one base from the 3' end.
- the degree of sequence identity is not particularly limited as long as the resulting nucleic acid molecule has the activity of suppressing the expression of hepatitis B virus gene, but usually 85% Above, preferably about 90% or more.
- the nucleotide sequence of (iii) is preferably a sequence that is completely complementary to the nucleotide sequence of (i), and the nucleotide sequence of (iv) is preferably completely complementary to the nucleotide sequence of (ii) Is an array.
- the nucleic acid molecule of the present invention can be a DNA molecule, an RNA molecule, a chimeric nucleic acid molecule (hereinafter referred to as a chimeric nucleic acid molecule) or a hybrid nucleic acid molecule.
- a chimeric nucleic acid molecule refers to a single-stranded or double-stranded nucleic acid molecule containing RNA and DNA in a single nucleic acid molecule
- a hybrid nucleic acid molecule refers to one strand of a double-stranded nucleic acid molecule. Is a RNA molecule or a chimeric nucleic acid molecule and the other strand is a DNA molecule or a chimeric nucleic acid molecule.
- the nucleic acid molecule of the present invention is single-stranded or double-stranded.
- Double stranded embodiments include double stranded RNA molecules, double stranded DNA molecules, RNA / DNA hybrid nucleic acid molecules, RNA / chimeric nucleic acid hybrid nucleic acid molecules, chimeric nucleic acid / chimeric nucleic acid hybrid nucleic acid molecules and chimeric nucleic acid / DNA hybrid nucleic acids Includes molecules.
- nucleotide sequence is described as an RNA sequence unless otherwise specified.
- polynucleotide is DNA
- uracil (U) is appropriately read as thymine (T).
- nucleic acid molecule capable of specifically suppressing the expression of the hepatitis B virus gene of the present invention examples include, for example, siRNA molecules, dsRDC (double-strand RNA DNA Chimera) molecules, and the following single-stranded nucleic acids of the present invention.
- the length of the nucleic acid molecule of the present invention is not particularly limited as long as it has the activity of suppressing the expression of hepatitis B virus gene, but it is usually 17 bases or more, preferably 19 bases or more, more preferably 21 bases or more.
- the length of the nucleic acid molecule of the present invention is usually 200 bases or less, preferably 150 bases or less, more preferably 100 bases or less (eg, 90 bases or less, 80 bases or less, 70 or less) because of ease of synthesis or antigenicity problems. Bases or less, 60 bases or less, 50 bases or less).
- the length of the nucleic acid molecule of the present invention is generally 17 bases to 200 bases, preferably 19 bases to 150 bases, more preferably 21 bases to 100 bases (21 bases to 90 bases, 21 bases to 80 bases, about 21 bases to 70 bases, 21 bases to 60 bases, 21 bases to 50 bases).
- the total number of bases of the nucleic acid molecule is not particularly limited as long as it has activity to suppress the expression of hepatitis B virus gene, but is usually 17 bases or more, preferably 19 bases or more, more preferably 21 bases or more.
- the total number of bases of the nucleic acid molecule of the present invention is usually 400 bases or less, preferably 300 bases or less, more preferably 200 bases or less (eg, 180 bases or less, 160 bases or less) due to ease of synthesis or antigenicity problems. 140 bases or less, 120 bases or less, 100 bases or less, 90 bases or less, 80 bases or less, 70 bases or less, 60 bases or less, 50 bases or less).
- the length of the nucleic acid molecule of the present invention is generally 17 bases to 400 bases, preferably 19 bases to 300 bases, more preferably 21 bases to 200 bases (21 bases to 180 bases, 21 bases to 160 bases, 21 bases to 140 bases, 21 bases to 120 bases, 21 bases to 100 bases, 21 bases to 90 bases, 21 bases to 80 bases, 21 bases to 70 bases, 21 bases to 60 bases, 21 bases to 50 bases) .
- the nucleic acid molecules of the present invention are preferably isolated. “Isolated” means that an operation to remove factors other than the target component has been performed, and that the naturally occurring state has been removed.
- the purity of the “isolated nucleic acid” (percentage of the target nucleic acid weight in the total weight of the evaluation target) is usually 70% or more, preferably 80% or more, more preferably 90% or more, and still more preferably 99%. % Or more. 2. Double-stranded nucleic acid molecule
- the nucleic acid molecule of the present invention is a double-stranded nucleic acid molecule.
- the double-stranded nucleic acid molecule comprises a nucleotide sequence of (i) on one strand and a sequence annealed to the nucleotide sequence of (i) on the other strand, or a nucleotide sequence of (ii) on one strand In the other strand is annealed to the nucleotide sequence of (ii).
- the sequence annealed to the nucleotide sequence (i) is not particularly limited as long as it can be annealed, but is preferably the nucleotide sequence (iii).
- the sequence annealed to the nucleotide sequence of (ii) is not particularly limited as long as it can be annealed, but is preferably the nucleotide sequence of (iv).
- nucleotide sequences (i), (ii), (iii), and (iv) may be nucleotide sequences represented by SEQ ID NOs: 2, 1, 4, 3, respectively.
- the length of the double-stranded nucleic acid molecule of the present invention is not particularly limited as long as it has the activity of suppressing the expression of hepatitis B virus gene, but is usually 17 bases or more, preferably 19 bases or more, more preferably 21 bases or more. is there.
- the length of the double-stranded nucleic acid molecule of the present invention is usually 100 bases or less, preferably 75 bases or less, more preferably 50 bases or less (eg, 45 bases or less, 40 or less, for ease of synthesis or antigenicity problems). Bases, 35 bases, 30 bases, 25 bases, 24 bases, 23 bases, 22 bases).
- the length of the nucleic acid molecule of the present invention is usually 17 to 100 bases, preferably 19 to 75 bases, more preferably 21 to 50 bases (21 to 45 bases, 21 to 40 bases, 21 bases to 35 bases, 21 bases to 30 bases, 21 bases to 25 bases, 21 bases to 24 bases, 21 bases to 23 bases, 21 bases to 22 bases).
- the double-stranded nucleic acid molecule may have an additional base (overhang sequence) that does not form a base pair at the 5 'and / or 3' end.
- the length of the overhang sequence is not particularly limited as long as siRNA can specifically suppress the expression of the target gene, but is usually 5 bases or less, for example, 2 to 4 bases.
- the additional base may be DNA or RNA, but the use of DNA can improve the stability of the RNA molecule. Examples of such an additional base sequence include ug-3 ′, uu-3 ′, tg-3 ′, tt-3 ′, ggg-3 ′, guuu-3 ′, gttt-3 ′, and ttttt-3. Examples of the sequence include ', uuuu-3', but are not limited thereto.
- the total number of bases of the double-stranded nucleic acid molecule is not particularly limited as long as it has the activity of suppressing the expression of hepatitis B virus gene, but is usually 34 bases or more, preferably 38 bases or more, more preferably 42 bases or more. is there.
- the total number of bases of the double-stranded nucleic acid molecule of the present invention is usually 200 bases or less, preferably 150 bases or less, more preferably 100 bases or less (eg, 90 bases or less) from the viewpoint of ease of synthesis and antigenicity. 80 bases or less, 70 bases or less, 60 bases or less, 50 bases or less, 48 bases or less, 46 bases or less, 44 bases or less).
- the length of the nucleic acid molecule of the present invention is usually 34 to 200 bases, preferably 38 to 150 bases, more preferably 42 to 100 bases (42 to 90 bases, 42 to 80 bases, 42 bases to 70 bases, 42 bases to 60 bases, 42 bases to 50 bases, 42 bases to 48 bases, 42 bases to 46 bases, 42 bases to 44 bases).
- tt-3 ′ is added to the nucleotide sequence represented by SEQ ID NO: 1, 2, 3, 4 represented by SEQ ID NO: 9, 10, 11, 12.
- SEQ ID NO: 1, 2, 3, 4 represented by SEQ ID NO: 9, 10, 11, 12.
- the double-stranded nucleic acid molecule is preferably a nucleotide sequence represented by SEQ ID NO: 10 and a nucleotide sequence represented by SEQ ID NO: 12 annealed to the sequence shown below; or a nucleotide represented by SEQ ID NO: 9
- a double-stranded nucleic acid molecule comprising a sequence and a nucleotide sequence represented by SEQ ID NO: 11 annealed to the sequence.
- the double-stranded nucleic acid molecule is preferably an siRNA molecule shown below.
- siRNA refers to the double-stranded nucleic acid molecule in which the base sequence other than the overhang sequence is composed only of ribonucleotide residues.
- the nucleic acid molecule of the present invention is used for suppressing the expression of the hepatitis B virus gene, and as the expression suppressing sequence for the hepatitis B virus gene, the nucleic acid molecule of the above (i) or (ii) It is characterized by comprising a nucleotide sequence.
- the expression suppression sequence may be, for example, a sequence consisting of the nucleotide sequence or a sequence containing the nucleotide sequence.
- the length of the expression suppression sequence is not particularly limited, and is, for example, 18 to 32 bases long, preferably 19 to 30 bases long, and more preferably 19, 20, or 21 bases long.
- the numerical range of the number of bases discloses all positive integers belonging to the range.
- the description “1 to 4 bases” includes “1, 2, 3, 4 bases”. "Means all disclosures (the same applies hereinafter).
- the single-stranded nucleic acid molecule of the present invention further has, for example, a complementary sequence that can be annealed with the expression suppressing sequence.
- the complementary sequence is, for example, in the same strand as the expression suppressing sequence and forms a single-stranded nucleic acid molecule composed of one single strand.
- the complementary sequence only needs to be annealable with the expression suppression sequence, for example.
- the complementary sequence may be, for example, a sequence exhibiting 100% complementarity with the expression suppression sequence, or a sequence exhibiting complementarity of less than 100% within a range that can be annealed.
- the complementarity is not particularly limited, and examples thereof include 90% to 100%, 93% to 100%, 95% to 100%, 98% to 100%, and 99% to 100%.
- the complementary sequence includes, for example, the nucleotide sequence (iii) or (iv).
- nucleotide sequence (iii) or (iv) is referred to as an s nucleotide sequence.
- the complementary sequence may be, for example, a sequence composed of the s nucleotide sequence or a sequence containing the s nucleotide sequence.
- the length of the complementary sequence is not particularly limited, and is, for example, 18 to 32 bases long, preferably 19 to 30 bases long, and more preferably 19, 20, or 21 bases long.
- the expression suppression sequence and the complementary sequence may each be, for example, an RNA molecule consisting only of ribonucleotide residues, or an RNA molecule containing deoxyribonucleotide residues in addition to ribonucleotide residues.
- nucleic acid molecule examples include a form in which the expression suppressing sequence and the complementary sequence are directly linked and a form in which they are indirectly linked.
- Examples of the direct linking include linking by a phosphodiester bond.
- Examples of the indirect linkage include linkage via a linker region.
- the order in which the expression suppressing sequence and the complementary sequence are linked is not particularly limited, and for example, the 3 ′ end of the expression suppressing sequence and the 5 ′ end of the complementary sequence may be linked. The 5 ′ end may be linked to the 3 ′ end of the complementary sequence, preferably the latter.
- the linker region may be composed of, for example, nucleotide residues, may be composed of non-nucleotide residues, or may be composed of the nucleotide residues and non-nucleotide residues.
- nucleotide residues include a ribonucleotide residue and a deoxyribonucleotide residue.
- a molecule in which a 5′-side region and a 3′-side region are annealed with each other to form a double-stranded structure can be mentioned.
- This can also be said to be a form of shRNA (small hairpin RNA or short hairpin RNA).
- shRNA small hairpin RNA or short hairpin RNA.
- the shRNA has a hairpin structure and generally has one stem region and one loop region.
- the nucleic acid molecule of this embodiment includes, for example, a region (X), a linker region (Lx), and a region (Xc), and the linker region (Lx) is between the region (X) and the region (Xc). Takes a linked structure.
- the region (Xc) preferably has a structure complementary to the region (X). Specifically, one of the region (X) and the region (Xc) has the expression suppressing sequence.
- the other includes the complementary sequence. Since the region (X) and the region (Xc) each have one of the expression suppression sequence and the complementary sequence, for example, a stem structure can be formed by intramolecular annealing, and the linker region (Lx) It becomes a loop structure.
- the nucleic acid molecule may have, for example, the region (Xc), the linker region (Lx), and the region (X) in the order from 5 ′ side to 3 ′ side, or from the 3 ′ side. You may have the said area
- the expression suppression sequence may be arranged, for example, in either the region (X) or the region (Xc), and may be arranged downstream of the complementary sequence, that is, 3 ′ side of the complementary sequence. preferable.
- FIG. 1A is a schematic diagram showing an outline of the order of each region
- FIG. 1B is a schematic diagram showing a state in which the nucleic acid molecule forms a double strand in the molecule. is there.
- the nucleic acid molecule forms a double strand between the region (Xc) and the region (X), and the Lx region loops according to its length.
- FIG. 1 merely shows the linking order of the regions and the positional relationship of each region forming a duplex. For example, the length of each region, the shape of the linker region (Lx), etc. Not limited.
- the number of bases in the region (Xc) and the region (X) is not particularly limited. Although the length of each area
- the relationship between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc) satisfies, for example, the following (3) or (5) In this case, specifically, for example, the following condition (11) is satisfied.
- X ⁇ Xc 1 to 10, preferably 1, 2 or 3, More preferably 1 or 2 (11)
- X Xc (5)
- the region may be a region composed of only the expression suppression sequence or a region including the expression suppression sequence, for example.
- the number of bases of the expression suppression sequence is, for example, as described above.
- the region containing the expression suppression sequence may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence, for example.
- the number of bases of the additional sequence is, for example, 1 to 31 bases, preferably 1 to 21 bases, and more preferably 1 to 11 bases.
- the number of bases in the region (Xc) is not particularly limited.
- the lower limit of Xc is, for example, 19 bases.
- the upper limit is, for example, 50 bases, preferably 30 bases, and more preferably 25 bases.
- Specific examples of the number of bases in the region (Xc) are, for example, 19 to 50 bases, preferably 19 to 30 bases, more preferably 19 to 25 bases.
- the number of bases in the region (X) is not particularly limited.
- the lower limit is, for example, 19 bases, preferably 20 bases, and more preferably 21 bases.
- the upper limit is 50 bases, for example, More preferably, it is 40 bases, More preferably, it is 30 bases.
- the linker region (Lx) preferably has a structure that does not cause self-annealing within its own region.
- the linker region (Lx) includes a nucleotide residue as described above, the length is not particularly limited.
- the linker region (Lx) preferably has a length that allows the region (X) and the region (Xc) to form a double chain.
- the lower limit of the number of bases in the linker region (Lx) is, for example, 1 base, preferably 2 bases, more preferably 3 bases, and the upper limit thereof is, for example, 100 bases, preferably 80 bases, more preferably 50 bases.
- the total length of the nucleic acid molecule is not particularly limited.
- the lower limit of the total number of bases is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, still more preferably 44 bases.
- the base is particularly preferably 46 bases, and the upper limit thereof is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, and particularly preferably 80 bases.
- the lower limit of the total number of bases excluding the linker region (Lx) is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, still more preferably 44 bases. Yes, particularly preferably 46 bases, and the upper limit is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, particularly preferably 80 bases. .
- a second form of the single-stranded nucleic acid molecule is a molecule in which the 5 ′ region and the 3 ′ region are separately annealed in the molecule to form two double-stranded structures (stem structures).
- the nucleic acid molecule of the present embodiment includes, for example, a 5 ′ side region (Xc), an internal region (Z), and a 3 ′ side region (Yc) from the 5 ′ side to the 3 ′ side in the order described above.
- Z) is formed by connecting an inner 5 ′ side region (X) and an inner 3 ′ side region (Y), and the 5 ′ side region (Xc) is complementary to the inner 5 ′ side region (X).
- the 3 ′ side region (Yc) is preferably complementary to the inner 3 ′ side region (Y).
- the 5 ′ region (Xc) when the internal 5 ′ region (X) of the internal region (Z) has the expression suppressing sequence, the 5 ′ region (Xc) preferably has the complementary sequence, When the internal 3 ′ side region (Y) of the region (Z) has the expression suppressing sequence, the 3 ′ side region (Yc) preferably has the complementary sequence.
- the inner 5 ′ region (X) of the inner region (Z) when the 5 ′ region (Xc) has the expression suppressing sequence, the inner 5 ′ region (X) of the inner region (Z) preferably has the complementary sequence, and the 3 ′ region When (Yc) has the expression suppression sequence, the internal 3 ′ side region (Y) of the internal region (Z) preferably has the complementary sequence.
- the 5′-side region (Xc) is complementary to the inner 5′-side region (X), and the 3′-side region (Yc) is the inner 3′-side region (Y).
- the region (Xc) is folded toward the region (X), and the region (Xc) and the region (X) can form a double chain by self-annealing.
- the region (Yc) is folded toward the region (Y), and the region (Yc) and the region (Y) can form a double chain by self-annealing.
- the inner region (Z) is connected to the inner 5 'region (X) and the inner 3' region (Y).
- the region (X) and the region (Y) are directly connected, for example, and do not have an intervening sequence therebetween.
- the inner region (Z) is defined as “the inner 5 ′ side region (X) and the inner 3 ′ side in order to indicate the arrangement relationship between the 5 ′ side region (Xc) and the 3 ′ side region (Yc)”.
- the region (Y) is connected to each other ”, and in the inner region (Z), the 5 ′ side region (Xc) and the 3 ′ side region (Yc) are, for example,
- the use of nucleic acid molecules is not limited to being a separate and independent region. That is, for example, when the internal region (Z) has the expression suppression sequence, the expression suppression sequence is arranged across the region (X) and the region (Y) in the internal region (Z). Also good.
- the 5 'side region (Xc) and the inner 5' side region (X) may be directly connected or indirectly connected, for example.
- direct linkage includes, for example, linkage by a phosphodiester bond.
- a linker region (Lx) is provided between the region (Xc) and the region (X), and the region (Xc) and the region ( And X) are linked together.
- the 3'-side region (Yc) and the internal 3'-side region (Y) may be directly connected or indirectly connected, for example.
- direct linkage includes, for example, linkage by a phosphodiester bond.
- a linker region (Ly) is provided between the region (Yc) and the region (Y), and the region (Yc) and the region ( And Y) are linked.
- the nucleic acid molecule may have, for example, both the linker region (Lx) and the linker region (Ly), or one of them.
- the linker region (Lx) is provided between the 5 ′ side region (Xc) and the inner 5 ′ side region (X), and the 3 ′ side region (Yc) and the inner 3 'The linker region (Ly) is not present between the side region (Y), that is, the region (Yc) and the region (Y) are directly linked.
- the linker region (Ly) is provided between the 3 ′ side region (Yc) and the inner 3 ′ side region (Y), and the 5 ′ side region (Xc) and the The linker region (Lx) is not provided between the internal 5′-side region (X), that is, the region (Xc) and the region (X) are directly linked.
- the linker region (Lx) and the linker region (Ly) each preferably have a structure that does not cause self-annealing within its own region.
- FIG. 2 (A) is a schematic diagram showing an outline of the order of each region from the 5 ′ side to the 3 ′ side of the nucleic acid molecule
- FIG. 2 (B) shows that the nucleic acid molecule is the molecule. It is a schematic diagram which shows the state which forms the double chain
- FIG. 2 merely shows the connection order of the regions and the positional relationship of the regions forming the double chain.
- the length of each region is not limited to this.
- FIG. 3A is a schematic diagram showing, as an example, an outline of the order of each region from the 5 ′ side to the 3 ′ side of the nucleic acid molecule
- FIG. FIG. 2 is a schematic diagram showing a state in which a double chain is formed in the molecule.
- the nucleic acid molecule is divided between the 5′-side region (Xc) and the inner 5′-side region (X), and between the inner 3′-side region (Y) and the 3′-side.
- a double chain is formed with the side region (Yc), and the Lx region and the Ly region have a loop structure.
- FIG. 3 merely shows the order of connection of the regions and the positional relationship of the regions forming the double chain.
- the length of each region is not limited thereto.
- the number of bases in the 5 ′ region (Xc), the internal 5 ′ region (X), the internal 3 ′ region (Y) and the 3 ′ region (Yc) is particularly limited. For example, it is as follows.
- the 5′-side region (Xc) may be complementary to the entire region of the inner 5′-side region (X), for example.
- the region (Xc) has the same base length as the region (X), and is composed of a base sequence complementary to the entire region from the 5 ′ end to the 3 ′ end of the region (X).
- the region (Xc) has the same base length as the region (X), and all bases in the region (Xc) are complementary to all bases in the region (X). That is, for example, it is preferably completely complementary.
- the present invention is not limited to this.
- 1 to several (2, 3, 4 or 5) bases may be non-complementary.
- the 5′-side region (Xc) may be complementary to a partial region of the inner 5′-side region (X), for example.
- the region (Xc) has, for example, the same base length as the partial region of the region (X), that is, consists of a base sequence having a base length shorter by one base or more than the region (X). preferable. More preferably, the region (Xc) has the same base length as the partial region of the region (X), and all the bases of the region (Xc) are included in the partial region of the region (X). It is preferred that it is complementary to all bases, that is, for example, completely complementary.
- the partial region of the region (X) is preferably, for example, a region (segment) having a base sequence continuous from the 5 ′ terminal base (first base) in the region (X).
- the 3′-side region (Yc) may be complementary to the entire region of the inner 3′-side region (Y), for example.
- the region (Yc) has, for example, the same base length as the region (Y) and is composed of a base sequence complementary to the entire region from the 5 ′ end to the 3 ′ end of the region (Y).
- the region (Yc) has the same base length as the region (Y), and all bases in the region (Yc) are complementary to all bases in the region (Y). That is, for example, it is preferable to be completely complementary.
- the present invention is not limited to this.
- 1 to several (2, 3, 4 or 5) bases may be non-complementary.
- the 3′-side region (Yc) may be complementary to a partial region of the inner 3′-side region (Y), for example.
- the region (Yc) has, for example, the same base length as the partial region of the region (Y), that is, consists of a base sequence having a base length shorter by one base or more than the region (Y). preferable. More preferably, the region (Yc) has the same base length as the partial region of the region (Y), and all the bases of the region (Yc) are included in the partial region of the region (Y). It is preferred that it is complementary to all bases, that is, for example, completely complementary.
- the partial region of the region (Y) is preferably, for example, a region (segment) having a base sequence continuous from the base at the 3 'end (first base) in the region (Y).
- the number of bases (Z) in the internal region (Z), the number of bases (X) in the internal 5 ′ side region (X), and the number of bases (Y) in the internal 3 ′ side region (Y) Relationship between the number of bases (Z) in the internal region (Z), the number of bases (Xc) in the 5′-side region (Xc), and the number of bases (Yc) in the 3′-side region (Yc) Satisfies, for example, the conditions of the following formulas (1) and (2).
- Z X + Y (1)
- the relationship between the number of bases (X) in the inner 5 ′ region (X) and the number of bases (Y) in the inner 3 ′ region (Y) is not particularly limited, For example, any condition of the following formula may be satisfied.
- X Y (19) X ⁇ Y (20) X> Y (21)
- the number of bases (X) in the inner 5 ′ side region (X), the number of bases (Xc) in the 5 ′ side region (Xc), the number of bases in the inner 3 ′ side region (Y) (Y ) And the number of bases (Yc) in the 3′-side region (Yc) satisfy, for example, the following conditions (a) to (d).
- Y Yc (4)
- X Xc (5) Y> Yc (6) (C)
- the conditions of the following formulas (7) and (8) are satisfied.
- X> Xc (7) Y> Yc (8) (D)
- the conditions of the following formulas (9) and (10) are satisfied.
- X Xc (9)
- Y Yc (10)
- the difference between the number of bases (X) in the inner 5 ′ side region (X) and the number of bases (Xc) in the 5 ′ side region (Xc), the inner 3 ′ side region ( The difference between the number of bases (Y) of Y) and the number of bases (Yc) of the 3 ′ side region (Yc) preferably satisfies the following condition, for example.
- A The conditions of the following formulas (11) and (12) are satisfied.
- FIG. 4 is a nucleic acid molecule comprising the linker region (Lx) and the linker region (Ly), (A) is the nucleic acid molecule of (a), (B) is the nucleic acid molecule of (b), (C) is an example of the nucleic acid molecule of (c), and (D) is an example of the nucleic acid molecule of (d).
- a dotted line shows the state which has formed the double chain
- FIG. 4 has the number of bases (X) in the inner 5 ′ side region (X) and the number of bases (Y) in the inner 3 ′ side region (Y) as “X ⁇ Y” in the formula (20).
- FIG. 4 is merely a relationship between the inner 5 ′ side region (X) and the 5 ′ side region (Xc), and the relationship between the inner 3 ′ side region (Y) and the 3 ′ side region (Yc).
- the length and shape of each region are not limited thereto, and the presence or absence of the linker region (Lx) and the linker region (Ly) is not limited thereto.
- the nucleic acid molecules (a) to (c) include, for example, the 5 ′ side region (Xc) and the internal 5 ′ side region (X), and the 3 ′ side region (Yc) and the internal 3 ′ side.
- the region (Y) has a base that cannot be aligned with any of the 5 ′ side region (Xc) and the 3 ′ side region (Yc) in the internal region (Z) by forming a double chain, respectively. It can be said that the structure has a base that does not form a double chain.
- the base that cannot be aligned also referred to as a base that does not form a double chain
- free base In FIG.
- the free base region is indicated by “F”.
- the number of bases in the region (F) is not particularly limited.
- the number of bases (F) in the region (F) is, for example, the number of bases “X-Xc” in the case of the nucleic acid molecule (a), and “Y—Yc” in the case of the nucleic acid molecule (b). In the case of the nucleic acid molecule (c), it is the total number of bases “X—Xc” and “Y—Yc”.
- the nucleic acid molecule (d) has a structure in which, for example, the entire region of the internal region (Z) is aligned with the 5 ′ side region (Xc) and the 3 ′ side region (Yc), It can also be said that the entire region (Z) forms a double chain.
- the nucleic acid molecule (d) the 5 'end of the 5' side region (Xc) and the 3 'end of the 3' side region (Yc) are unlinked.
- each region is exemplified below for the nucleic acid molecule, but the present invention is not limited to this.
- the total number of bases of the free base (F) in the 5 ′ side region (Xc), the 3 ′ side region (Yc), and the internal region (Z) is the number of bases in the internal region (Z). .
- the lengths of the 5 ′ side region (Xc) and the 3 ′ side region (Yc) depend on, for example, the length of the internal region (Z), the number of free bases (F), and the position thereof. Can be determined as appropriate.
- the number of bases in the internal region (Z) is, for example, 19 bases or more.
- the lower limit of the number of bases is, for example, 19 bases, preferably 20 bases, and more preferably 21 bases.
- the upper limit of the number of bases is, for example, 50 bases, preferably 40 bases, and more preferably 30 bases.
- Specific examples of the number of bases in the internal region (Z) include, for example, 19 bases, 20 bases, 21 bases, 22 bases, 23 bases, 24 bases, 25 bases, 26 bases, 27 bases, 28 bases, 29 bases, or , 30 bases.
- the internal region (Z) may be, for example, a region composed only of the expression suppression sequence or a region including the expression suppression sequence.
- the number of bases of the expression suppression sequence is, for example, as described above.
- the internal region (Z) contains the expression suppression sequence it may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence.
- the number of bases of the additional sequence is, for example, 1 to 31 bases, preferably 1 to 21 bases, more preferably 1 to 11 bases, and further preferably 1 to 7 bases.
- the number of bases in the 5 ′ side region (Xc) is, for example, 1 to 29 bases, preferably 1 to 11 bases, more preferably 1 to 7 bases, and further preferably 1 to 4 bases. Particularly preferred are 1 base, 2 bases and 3 bases.
- the internal region (Z) or the 3 'side region (Yc) includes the expression suppression sequence, for example, such a base number is preferable.
- the number of bases in the internal region (Z) is 19 to 30 bases (for example, 19 bases)
- the number of bases in the 5 ′ side region (Xc) is, for example, 1 to 11 bases
- the number is preferably 1 to 7 bases, more preferably 1 to 4 bases, and still more preferably 1 base, 2 bases, and 3 bases.
- the 5′-side region (Xc) may be, for example, a region composed only of the expression suppression sequence, or a region including the expression suppression sequence But you can.
- the length of the expression suppression sequence is, for example, as described above.
- the 5 'region (Xc) contains the expression suppression sequence, it may further have an additional sequence on the 5' side and / or 3 'side of the expression suppression sequence.
- the number of bases of the additional sequence is, for example, 1 to 11 bases, and preferably 1 to 7 bases.
- the number of bases in the 3 ′ side region (Yc) is, for example, 1 to 29 bases, preferably 1 to 11 bases, more preferably 1 to 7 bases, and further preferably 1 to 4 bases. Particularly preferred are 1 base, 2 bases and 3 bases.
- the internal region (Z) or the 5 'side region (Xc) includes the expression suppression sequence, for example, such a base number is preferable.
- the number of bases in the internal region (Z) is 19 to 30 bases (for example, 19 bases)
- the number of bases in the 3 ′ side region (Yc) is, for example, 1 to 11 bases
- the number is preferably 1 to 7 bases, more preferably 1 to 4 bases, and still more preferably 1 base, 2 bases, and 3 bases.
- the 3 ′ side region (Yc) may be, for example, a region composed only of the expression suppression sequence, or a region including the expression suppression sequence But you can.
- the length of the expression suppression sequence is, for example, as described above.
- the 3 'side region (Yc) includes the expression suppression sequence, it may further have an additional sequence on the 5' side and / or 3 'side of the expression suppression sequence.
- the number of bases of the additional sequence is, for example, 1 to 11 bases, and preferably 1 to 7 bases.
- the number of bases in the internal region (Z), the 5′-side region (Xc), and the 3′-side region (Yc) is expressed by, for example, “Z ⁇ Xc + Yc” in the formula (2). Can do.
- the number of bases “Xc + Yc” is, for example, the same as or smaller than the inner region (Z).
- “Z ⁇ (Xc + Yc)” is, for example, 1 to 10, preferably 1 to 4, more preferably 1, 2 or 3.
- the “Z ⁇ (Xc + Yc)” corresponds to the number of bases (F) in the free base region (F) in the internal region (Z).
- the linker region (Lx) preferably has, for example, a length that allows the internal 5 ′ side region (X) and the 5 ′ side region (Xc) to form a double chain, and the linker region (Ly) ) Is, for example, preferably a length such that the inner 3 ′ side region (Y) and the 3 ′ side region (Yc) can form a double chain.
- the lengths of the linker region (Lx) and the linker region (Ly) may be the same or different, and the base sequences thereof may be the same or different.
- the lower limit of the number of bases in the linker region (Lx) and the linker region (Ly) is, for example, 1 base, preferably 2 bases, more preferably 3 bases, and the upper limit thereof is, for example, 100 bases, preferably 80 bases, more preferably 50 bases.
- Specific examples of the number of bases in each linker region include 1 to 50 bases, 1 to 30 bases, 1 to 20 bases, 1 to 10 bases, 1 to 7 bases, and 1 to 4 bases. This is not a limitation.
- the total length of the nucleic acid molecule is not particularly limited.
- the lower limit of the total number of bases is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, still more preferably 44 bases.
- the base is particularly preferably 46 bases, and the upper limit thereof is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, and particularly preferably 80 bases. .
- the lower limit of the total number of bases excluding the linker region (Lx) and the linker region (Ly) is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, More preferably, it is 44 bases, particularly preferably 46 bases, and the upper limit is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, Preferably, it is 80 bases.
- the 5 'end and the 3' end may be bound or unbound.
- the nucleic acid molecule of this form is a circular single-stranded nucleic acid molecule.
- the nucleic acid molecule of the present embodiment is preferably a non-phosphate group at the 5 'end, for example, since it can maintain unbonded at both ends.
- a third form of the single-stranded nucleic acid molecule is a molecule in which the linker region has a non-nucleotide structure.
- This embodiment can use the above description except that the linker region (Lx) and / or the linker region (Ly) has a non-nucleotide structure in the nucleic acid molecules of the first and second forms.
- the non-nucleotide structure is not particularly limited, and examples thereof include polyalkylene glycol, pyrrolidine skeleton and piperidine skeleton.
- examples of the polyalkylene glycol include polyethylene glycol.
- the pyrrolidine skeleton may be, for example, a skeleton of a pyrrolidine derivative in which one or more carbons constituting the 5-membered ring of pyrrolidine are substituted.
- the carbon at the 2-position of the 5-membered ring C— It is preferable that it is carbon atoms other than carbon of 2).
- the carbon may be substituted with, for example, nitrogen, oxygen or sulfur.
- the pyrrolidine skeleton may contain, for example, a carbon-carbon double bond or a carbon-nitrogen double bond in the 5-membered ring of pyrrolidine.
- the carbon and nitrogen constituting the 5-membered ring of pyrrolidine may be bonded, for example, to hydrogen or a substituent as described below.
- the linker region (Lx) is substituted with the region (X) and the region (Xc), and the linker region (Ly) is substituted with the region (Y) and the region (Yc), for example, the pyrrolidine skeleton.
- the preferred position at which the substituent is substituted is any one carbon and nitrogen of the 5-membered ring, preferably at the 2-position of the 5-membered ring.
- Carbon (C-2) and nitrogen are examples of the main non-nucleotide structure containing the pyrrolidine skeleton.
- the proline, prolinol, and the like are excellent in safety because they are, for example, in-vivo substances and their reduced forms.
- the piperidine skeleton may be, for example, a skeleton of a piperidine derivative in which one or more carbons constituting the six-membered ring of piperidine are substituted, and when substituted, for example, the carbon at the 2-position of piperidine (C-2) It is preferably a carbon atom other than carbon.
- the carbon may be substituted with, for example, nitrogen, oxygen or sulfur.
- the piperidine skeleton may contain, for example, a carbon-carbon double bond or a carbon-nitrogen double bond in the 6-membered ring of piperidine.
- the carbon and nitrogen constituting the piperidine 6-membered ring may be bonded to, for example, a hydrogen group or a substituent as described later.
- the linker region (Lx) includes the region (X) and the region (Xc), the linker region (Ly) includes the region (Y) and the region (Yc), and any one of the piperidine skeleton, for example. It may be bonded via a group, preferably any one carbon atom of the six-membered ring and nitrogen, more preferably carbon (C-2) at the 2-position of the six-membered ring and nitrogen. It is.
- the linker region may include, for example, only a non-nucleotide residue having the non-nucleotide structure, or may include a non-nucleotide residue having the non-nucleotide structure and a nucleotide residue.
- the linker region is represented by the following formula (I), for example.
- X 1 and X 2 are each independently H 2 , O, S or NH; Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S; R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A; L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
- L 2 is an alkylene
- the ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond
- the region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
- the region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
- R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I).
- X 1 and X 2 are each independently, for example, H 2 , O, S or NH.
- X 1 being H 2 means that X 1 together with the carbon atom to which X 1 is bonded forms CH 2 (methylene group). The same is true for X 2.
- Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S.
- l 1 or 2.
- ring A is a 5-membered ring, for example, the pyrrolidine skeleton.
- main non-nucleotide structure containing the pyrrolidine skeleton include proline and prolinol.
- ring A is a 6-membered ring, for example, the piperidine skeleton.
- one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen or sulfur.
- Ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond in ring A.
- any optical isomer may be used.
- R 3 is a hydrogen atom or a substituent bonded to C-3, C-4, C-5 or C-6 on the ring A.
- R 3 is the above-described substituent, the substituent R 3 may be one, plural, or absent, and when plural, it may be the same or different.
- the substituent R 3 is, for example, halogen, OH, OR 4 , NH 2 , NHR 4 , NR 4 R 5 , SH, SR 4 or an oxo group ( ⁇ O).
- R 4 and R 5 are, for example, each independently a substituent or a protecting group, and may be the same or different.
- substituents include halogen, alkyl, alkenyl, alkynyl, haloalkyl, aryl, heteroaryl, arylalkyl, cycloalkyl, cycloalkenyl, cycloalkylalkyl, cyclylalkyl, hydroxyalkyl, alkoxyalkyl, aminoalkyl, heterocyclylalkenyl. , Heterocyclylalkyl, heteroarylalkyl, silyl, silyloxyalkyl and the like. The same applies hereinafter.
- the substituent R 3 may be any of these listed substituents.
- the protecting group is, for example, a functional group that converts a highly reactive functional group to inert, and examples thereof include known protecting groups.
- the protecting group for example, the description in the literature (J.F.W. McOmie, “Protecting Groups in Organic Chemistry” Prenum Press, London and New York, 1973) can be cited.
- the protective group is not particularly limited, and examples thereof include tert-butyldimethylsilyl group (TBDMS), bis (2-acetoxyethyloxy) methyl group (ACE), triisopropylsilyloxymethyl group (TOM), 1- (2 -Cyanoethoxy) ethyl group (CEE), 2-cyanoethoxymethyl group (CEM), tolylsulfonylethoxymethyl group (TEM), dimethoxytrityl group (DMTr) and the like.
- R 3 is OR 4
- the protecting group is not particularly limited, and examples thereof include a TBDMS group, an ACE group, a TOM group, a CEE group, a CEM group, and a TEM group.
- the silyl-containing group of [Chemical Formula 5] of Japanese Patent No. 5555346 is also exemplified. The same applies hereinafter.
- L 1 is an alkylene chain consisting of n carbon atoms.
- the hydrogen atom on the alkylene carbon atom may be substituted with, for example, OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a .
- L 1 may be a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom.
- the polyether chain is, for example, polyethylene glycol.
- L 2 is an alkylene chain composed of m carbon atoms.
- the hydrogen atom on the alkylene carbon atom may be substituted with, for example, OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c , or may not be substituted.
- L 2 may be a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom.
- Y 2 is NH, O or S
- the L 2 atom bonded to Y 2 is carbon
- the L 2 atom bonded to OR 2 is carbon
- oxygen atoms are not adjacent to each other. That is, for example, when Y 2 is O, the oxygen atom and the oxygen atom of L 2 are not adjacent, and the oxygen atom of OR 2 and the oxygen atom of L 2 are not adjacent.
- N in L 1 and m in L 2 are not particularly limited, and the lower limit is, for example, 0, and the upper limit is not particularly limited.
- n and m can be appropriately set according to the desired length of the linker region (Lx) or (Ly), for example.
- n and m are each preferably 0 to 30, more preferably 0 to 20, and still more preferably 0 to 15 from the viewpoint of production cost and yield.
- n + m is, for example, 0 to 30, preferably 0 to 20, and more preferably 0 to 15.
- R a , R b , R c and R d are, for example, each independently a substituent or a protecting group.
- the substituent and the protecting group are the same as described above, for example.
- hydrogen atoms may be independently substituted with halogens such as Cl, Br, F and I, for example.
- the region (Xc) and the region (X) are in the linker region (Lx), the region (Yc) and the region (Y) are in the linker region (Ly), for example, —OR 1 — Alternatively, the bonds are made through —OR 2 —.
- R 1 and R 2 may or may not exist.
- R 1 and R 2 are each independently a nucleotide residue or the structure of formula (I) above.
- the linker region (Lx) and the linker region (Ly) are, for example, of the formula (I) except for the nucleotide residue R 1 and / or R 2 It is formed from the non-nucleotide residue consisting of a structure and the nucleotide residue.
- the linker region (Lx) and the linker region (Ly) are, for example, the non-nucleotide residue having the structure of the formula (I) Two or more structures are connected.
- the structure of the formula (I) may include 1, 2, 3, or 4, for example.
- the structure of (I) may be directly linked or may be bonded via the nucleotide residue, for example.
- R 1 and R 2 are not present, the linker region (Lx) and the linker region (Ly) are formed only from the non-nucleotide residue having the structure of the formula (I), for example.
- the linker region (Lx) and the linker region (Ly) are formed from the non-nucleotide residue and the nucleotide residue, the non-nucleotide in the linker region (Lx) and the linker region (Ly)
- the lower limit of the total number of nucleotide residues and the nucleotide residues is, for example, 2, 3, or 4, and the upper limit is, for example, 100, 80, or 50.
- Specific examples of the number of ring A in each linker region include, for example, 2 to 50, 2 to 30, 2 to 20, 2 to 10, 2 to 7, 2 to 4, 2 to Although 3 etc. can be illustrated, it is not restrict
- the number of the non-nucleotide residues in the linker region (Lx) and the linker region (Ly) is The lower limit is, for example, 1, 2, or 3.
- the upper limit is, for example, 100, 80, or 50.
- Specific examples of the number of ring A in each linker region include 1 to 50, 1 to 30, 1 to 20, 1 to 10, 1 to 7, 1 to 4, 1 to Although 2 etc. can be illustrated, it is not restrict
- the combination of the region (Xc) and the region (X), the region (Yc) and the region (Y), and the —OR 1 — and —OR 2 — is not particularly limited.
- One of the following conditions can be given.
- Condition (1) The region (Xc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (X) is bonded through —OR 1 —.
- the region (Yc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (Y) is bonded through —OR 2 —.
- Condition (2) The region (Xc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (X) is bonded through —OR 1 —.
- the region (Yc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (Y) is bonded through —OR 1 —.
- Condition (3) The region (Xc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (X) is bonded through —OR 2 —.
- the region (Yc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (Y) is bonded through —OR 2 —.
- Condition (4) The region (Xc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (X) is bonded through —OR 2 —.
- the region (Yc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (Y) is bonded through —OR 1 —.
- Examples of the structure of the formula (I) include the following formulas (I-1) to (I-9), in which n and m are the same as those in the formula (I).
- q is an integer of 0 to 10.
- n, m and q are not particularly limited and are as described above.
- a preferred embodiment of the nucleic acid molecule of the present invention in which the linker region Lx has the structure represented by the above formula (I-6a) is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 13 or 14.
- a preferred embodiment of the nucleic acid molecule of the present invention when the linker regions Lx and Ly include nucleotide residues is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 15 or 16.
- a preferred embodiment of the nucleic acid molecule of the present invention in which the linker regions Lx and Ly have the structure shown in the above formula (I-6a) is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 17 or 18. it can.
- the linker regions Lx and Ly are more preferably a group represented by the following formula.
- the structural unit of the nucleic acid molecule of the present invention is not particularly limited, and examples thereof include nucleotide residues.
- the nucleotide residue include a ribonucleotide residue and a deoxyribonucleotide residue.
- the nucleotide residue include an unmodified unmodified nucleotide residue and a modified modified nucleotide residue.
- the nucleic acid molecule of the present invention can improve nuclease resistance and stability, for example, by including the modified nucleotide residue.
- the nucleic acid molecule of the present invention may further contain a non-nucleotide residue in addition to the nucleotide residue, for example.
- each of the constituent units in the region other than the linker is preferably the nucleotide residue.
- Each region is composed of the following residues (1) to (3), for example. (1) Unmodified nucleotide residue (2) Modified nucleotide residue (3) Unmodified nucleotide residue and modified nucleotide residue
- the structural unit of the linker region is not particularly limited, and examples thereof include the nucleotide residue and the non-nucleotide residue.
- the linker region may be composed of, for example, only the nucleotide residue, may be composed of only the non-nucleotide residue, or may be composed of the nucleotide residue and the non-nucleotide residue.
- the linker region is composed of the following residues (1) to (7), for example.
- both structural units may be the same or different.
- Specific examples include, for example, a form in which the constituent units of both linker regions are the nucleotide residues, a form in which the constituent units of both linker regions are the non-nucleotide residues, and the constituent units of one region are the nucleotide residues.
- the other linker region is a non-nucleotide residue.
- nucleic acid molecule of the present invention examples include a molecule composed only of the nucleotide residue, a molecule containing the non-nucleotide residue in addition to the nucleotide residue, and the like.
- the nucleotide residue may be, for example, only the unmodified nucleotide residue, only the modified nucleotide residue, or the unmodified nucleotide residue and the modification. Both nucleotide residues may be used.
- the number of the modified nucleotide residue is not particularly limited, and is, for example, “one or several”, specifically For example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the number of the non-nucleotide residue is not particularly limited, and is, for example, “one or several”, specifically, for example, 1 to Eight, one to six, one to four, one, two or three.
- the number of the modified ribonucleotide residue is not particularly limited, and is, for example, “one or several”. Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the modified ribonucleotide residue relative to the unmodified ribonucleotide residue may be, for example, the deoxyribonucleotide residue in which a ribose residue is replaced with a deoxyribose residue.
- the number of the deoxyribonucleotide residue is not particularly limited, and is, for example, “one or several” Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the number of the modified deoxyribonucleotide residue is not particularly limited, and is, for example, “one or several”. Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the modified deoxyribonucleotide residue relative to the unmodified deoxyribonucleotide residue may be, for example, the ribonucleotide residue in which a deoxyribose residue is replaced with a ribose residue.
- the number of the ribonucleotide residue is not particularly limited, and is, for example, “one or several”. Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
- the nucleic acid molecule of the present invention may contain, for example, a labeling substance and be labeled with the labeling substance.
- the labeling substance is not particularly limited, and examples thereof include fluorescent substances, dyes, isotopes and the like.
- the labeling substance include fluorophores such as pyrene, TAMRA, fluorescein, Cy3 dye, and Cy5 dye, and examples of the dye include Alexa dye such as Alexa488.
- the isotope include a stable isotope and a radioactive isotope, and preferably a stable isotope.
- the stable isotope has a low risk of exposure and does not require a dedicated facility, so that it is easy to handle and the cost can be reduced.
- the stable isotope does not change the physical properties of the labeled compound, for example, and is excellent in properties as a tracer.
- the stable isotope is not particularly limited, and examples thereof include 2 H, 13 C, 15 N, 17 O, 18 O, 33 S, 34 S, and 36 S.
- the nucleic acid molecule of the present invention can suppress the expression of the hepatitis B virus gene. For this reason, the nucleic acid molecule of the present invention can be used, for example, as a therapeutic agent for diseases caused by hepatitis B virus.
- “treatment” includes, for example, the meanings of preventing the disease, improving the disease, and improving the prognosis. Examples of the disease include hepatitis B, cirrhosis, and liver cancer.
- the method of using the nucleic acid molecule of the present invention is not particularly limited, and for example, the nucleic acid molecule may be administered to an administration subject having the hepatitis B virus.
- the administration target examples include non-human animals such as humans and non-human mammals other than humans. Moreover, for example, it may be administered to cells, tissues or organs such as human or non-human animals, and the nucleic acid molecule of the present invention is preferably administered to hepatocytes, liver tissues or liver. The administration may be, for example, in vivo or in vitro.
- the cells are not particularly limited.
- various cultured cells such as Huh7, A549, HeLa, 293, and COS7
- pluripotent stem cells such as ES cells and iPS cells
- somatic stem cells such as hematopoietic stem cells
- pluripotent Examples include various cultured cells derived from stem cells or somatic stem cells, cells isolated from living bodies such as primary cultured cells, and the like.
- the nucleic acid molecule of the present invention When the nucleic acid molecule of the present invention is administered to an administration subject in vivo, the nucleic acid molecule binds to a cell surface receptor in order to efficiently deliver the organ to a specific organ, tissue or cell in the living body. It may be conjugated with a ligand.
- the nucleic acid molecule of the present invention can be conjugated with a surface receptor ligand or the like characteristic of liver cells in order to improve delivery efficiency to the liver.
- ligands include cholesterol and N-acetylgalactosamine (GalNAc) clusters. Examples of the N-acetylgalactosamine (GalNAc) cluster include compounds having the following structural formula.
- nucleic acid molecule of the present invention refers to the description of the composition of the present invention, expression suppression method, treatment method and the like described later.
- nucleic acid molecule of the present invention can suppress the expression of the hepatitis B virus gene as described above, it is useful, for example, as a research tool for pharmaceuticals, diagnostic agents, agricultural chemicals, agricultural chemicals, medicine, life sciences, etc. It is.
- nucleotide residues include, for example, sugars, bases and phosphates as constituent elements.
- examples of the nucleotide residue include a ribonucleotide residue and a deoxyribonucleotide residue as described above.
- the ribonucleotide residue has, for example, a ribose residue as a sugar, and has adenine (A), guanine (G), cytosine (C), and uracil (U) as bases
- the deoxyribose residue is For example, it has a deoxyribose residue as a sugar and has adenine (A), guanine (G), cytosine (C) and thymine (T) as bases.
- the nucleotide residue includes an unmodified nucleotide residue and a modified nucleotide residue.
- each of the constituent elements is, for example, the same or substantially the same as that existing in nature, and preferably the same or substantially the same as that naturally occurring in the human body. .
- the modified nucleotide residue is, for example, a nucleotide residue obtained by modifying the unmodified nucleotide residue.
- the modified nucleotide residue for example, any of the constituent elements of the unmodified nucleotide residue may be modified.
- “modification” refers to, for example, substitution, addition and / or deletion of the component, substitution, addition and / or deletion of atoms and / or functional groups in the component, and is referred to as “modification”. be able to.
- modified nucleotide residue include naturally occurring nucleotide residues, artificially modified nucleotide residues, and the like. For example, Limbac et al.
- modified nucleosides of RNA Nucleic Acids Res. 22: 2183-2196
- the modified nucleotide residue may be, for example, a residue of the nucleotide substitute.
- ribophosphate skeleton examples include modification of a ribose-phosphate skeleton (hereinafter referred to as ribophosphate skeleton).
- a ribose residue can be modified.
- the ribose residue can be modified, for example, at the 2′-position carbon.
- a hydroxyl group bonded to the 2′-position carbon can be replaced with hydrogen or a halogen such as fluoro.
- the ribose residue can be replaced with deoxyribose.
- the ribose residue can be substituted with, for example, a stereoisomer, and can be substituted with, for example, an arabinose residue.
- the ribophosphate skeleton may be substituted with a non-ribophosphate skeleton having a non-ribose residue and / or non-phosphate, for example.
- the non-ribophosphate skeleton include uncharged ribophosphate skeletons.
- the substitute for the nucleotide substituted with the non-ribophosphate skeleton include morpholino, cyclobutyl, pyrrolidine and the like.
- Other examples of the substitute include artificial nucleic acid monomer residues. Specific examples include PNA (peptide nucleic acid), LNA (Locked Nucleic Acid), ENA (2'-O, 4'-C-Ethylene-bridged Nucleic Acid), and PNA is preferable.
- a phosphate group can be modified.
- the phosphate group closest to the sugar residue is called an ⁇ -phosphate group.
- the ⁇ -phosphate group is negatively charged, and the charge is evenly distributed over two oxygen atoms that are not bound to a sugar residue.
- the four oxygen atoms in the ⁇ -phosphate group in the phosphodiester bond between nucleotide residues, the two oxygen atoms that are non-bonded to the sugar residue are hereinafter referred to as “non-linking oxygen”.
- the two oxygen atoms bonded to the sugar residue are hereinafter referred to as “linking oxygen”.
- the ⁇ -phosphate group is preferably subjected to, for example, a modification that makes it uncharged or a modification that makes the charge distribution in the unbound oxygen asymmetric.
- the phosphate group may replace the non-bonded oxygen, for example.
- the oxygen is, for example, one of S (sulfur), Se (selenium), B (boron), C (carbon), H (hydrogen), N (nitrogen), and OR (R is an alkyl group or an aryl group).
- R is an alkyl group or an aryl group.
- the non-bonded oxygen for example, both are preferably substituted, and more preferably, both are substituted with S.
- the modified phosphate group include phosphorothioate, phosphorodithioate, phosphoroselenate, boranophosphate, boranophosphate ester, phosphonate hydrogen, phosphoramidate, alkyl or arylphosphonate, and phosphotriester. Among them, phosphorodithioate in which the two non-bonded oxygens are both substituted with S is preferable.
- the phosphate group may substitute, for example, the bonded oxygen.
- the oxygen can be substituted, for example, with any atom of S (sulfur), C (carbon) and N (nitrogen), and the modified phosphate group is, for example, a bridged phosphoramidate, S substituted with N Substituted bridged phosphorothioates, bridged methylene phosphonates substituted with C, and the like.
- the binding oxygen substitution is preferably performed, for example, on at least one of the 5 ′ terminal nucleotide residue and the 3 ′ terminal nucleotide residue of the nucleic acid molecule of the present invention. For the 'side, substitution with N is preferred.
- the phosphate group may be substituted with, for example, the phosphorus-free linker.
- the linker include siloxane, carbonate, carboxymethyl, carbamate, amide, thioether, ethylene oxide linker, sulfonate, sulfonamide, thioform acetal, form acetal, oxime, methyleneimino, methylenemethylimino, methylenehydrazo, methylenedimethyl. Hydrazo, methyleneoxymethylimino and the like, preferably methylenecarbonylamino group and methylenemethylimino group.
- nucleic acid molecule of the present invention for example, at least one nucleotide residue at the 3 'end and the 5' end may be modified.
- the modification may be, for example, either the 3 'end or the 5' end, or both.
- the modification is, for example, as described above, and is preferably performed on the terminal phosphate group.
- the phosphate group may be modified entirely, or one or more atoms in the phosphate group may be modified. In the former case, for example, the entire phosphate group may be substituted or deleted.
- Examples of the modification of the terminal nucleotide residue include addition of other molecules.
- Examples of the other molecule include functional molecules such as a labeling substance and a protecting group as described above.
- Examples of the protecting group include S (sulfur), Si (silicon), B (boron), ester-containing groups, and the like.
- the functional molecule such as the labeling substance can be used for detecting the nucleic acid molecule of the present invention, for example.
- the other molecule may be added to the phosphate group of the nucleotide residue, for example, or may be added to the phosphate group or the sugar residue via a spacer.
- the terminal atom of the spacer can be added or substituted, for example, to the binding oxygen of the phosphate group or O, N, S or C of the sugar residue.
- the binding site of the sugar residue is preferably, for example, C at the 3 'position or C at the 5' position, or an atom bonded thereto.
- the spacer can be added or substituted at a terminal atom of a nucleotide substitute such as PNA.
- the spacer is not particularly limited.
- n is a positive integer
- n 3 or 6 is preferable.
- the molecule to be added to the terminal includes, for example, a dye, an intercalating agent (for example, acridine), a crosslinking agent (for example, psoralen, mitomycin C), a porphyrin (TPPC4, texaphyrin, suffirin), a polycyclic Aromatic hydrocarbons (eg phenazine, dihydrophenazine), artificial endonucleases (eg EDTA), lipophilic carriers (eg cholesterol, cholic acid, adamantaneacetic acid, 1-pyrenebutyric acid, dihydrotestosterone, 1,3-bis- O (hexadecyl) glycerol, geranyloxyhexyl group, hexadecylglycerol, borneol, menthol, 1,3-propanediol, heptadecyl group, palmitic acid, myristic acid, O3- (oleoy
- the 5 ′ end may be modified with, for example, a phosphate group or a phosphate group analog.
- the phosphate group include 5 ′ monophosphate ((HO) 2 (O) P—O-5 ′), 5 ′ diphosphate ((HO) 2 (O) P—O—P (HO)) (O) -O-5 ′), 5 ′ triphosphate ((HO) 2 (O) PO— (HO) (O) PO—P (HO) (O) —O-5 ′) 5'-guanosine cap (7-methylated or unmethylated, 7m-GO-5 '-(HO) (O) PO- (HO) (O) PO-OP (HO) ( O) —O-5 ′), 5′-adenosine cap (Appp), any modified or unmodified nucleotide cap structure (N—O-5 ′-(HO) (O) PO— (HO) (O ) P—O—P (HO) (O) (O) (O) (O) (O
- the base is not particularly limited.
- the base may be, for example, a natural base or a non-natural base.
- the base may be, for example, naturally derived or a synthetic product.
- As the base for example, a general base or a modified analog thereof can be used.
- Examples of the base include purine bases such as adenine and guanine, and pyrimidine bases such as cytosine, uracil and thymine.
- Other examples of the base include inosine, thymine, xanthine, hypoxanthine, nubalarine, isoguanisine, and tubercidine.
- the base examples include alkyl derivatives such as 2-aminoadenine and 6-methylated purine; alkyl derivatives such as 2-propylated purine; 5-halouracil and 5-halocytosine; 5-propynyluracil and 5-propynylcytosine; -Azouracil, 6-azocytosine and 6-azothymine; 5-uracil (pseudouracil), 4-thiouracil, 5-halouracil, 5- (2-aminopropyl) uracil, 5-aminoallyluracil; 8-halogenated, aminated, Thiolated, thioalkylated, hydroxylated and other 8-substituted purines; 5-trifluoromethylated and other 5-substituted pyrimidines; 7-methylguanine; 5-substituted pyrimidines; 6-azapyrimidines; N-2, N -6 and O-6 substituted purines (2-aminopropyladenyl 5-
- the modified nucleotide residue may include, for example, a residue lacking a base, that is, an abasic ribophosphate skeleton.
- the modified nucleotide residues are, for example, US Provisional Application No. 60 / 465,665 (filing date: April 25, 2003) and International Application No. PCT / US04 / 07070 (filing date: 2004/3). The residues described on the 8th of May) can be used, and the present invention can incorporate these documents.
- Method for synthesizing nucleic acid molecule of the present invention is not particularly limited, and conventionally known methods can be adopted.
- Examples of the synthesis method include a synthesis method using a genetic engineering technique, a chemical synthesis method, and the like.
- Examples of genetic engineering techniques include in vitro transcription synthesis, a method using a vector, and a method using a PCR cassette.
- the vector is not particularly limited, and examples thereof include non-viral vectors such as plasmids and viral vectors.
- the chemical synthesis method is not particularly limited, and examples thereof include a phosphoramidite method and an H-phosphonate method.
- a commercially available automatic nucleic acid synthesizer can be used.
- amidite is generally used.
- the amidite is not particularly limited, and commercially available amidites include, for example, RNA Phosphoramidates (2′-O-TBDMSi, trade name, Michisato Pharmaceutical), ACE amidite, TOM amidite, CEE amidite, CEM amidite, TEM amidite, etc. Is given.
- the expression vector of the present invention comprises a nucleic acid encoding the nucleic acid molecule of the present invention, and is characterized by expressing the nucleic acid molecule of the present invention. “Expression” of the nucleic acid molecule of the present invention includes not only the case where the nucleic acid molecule of the present invention is formed by transcription but also the case where the nucleic acid molecule of the present invention is formed by processing after transcription.
- the expression vector of the present invention is characterized by containing the nucleic acid, and other configurations are not limited at all.
- the nucleic acid is inserted so that the vector can be expressed.
- the vector into which the nucleic acid is inserted is not particularly limited, and for example, a general vector can be used, and examples thereof include viral vectors and non-viral vectors. Examples of the non-viral vector include a plasmid vector.
- the above-described nucleic acid molecule of the present invention or the nucleic acid encoding the same is functionally used as a promoter capable of exhibiting promoter activity in cells to be administered (for example, human hepatocytes). It is connected.
- the promoter used is not particularly limited as long as it can function in human hepatocytes to be administered.
- a pol I promoter, pol II promoter, pol III promoter, or the like can be used as the promoter.
- SV40-derived early promoter, viral promoter such as cytomegalovirus LTR, mammalian constituent protein gene promoter such as ⁇ -actin gene promoter, and RNA promoter such as tRNA promoter are used.
- RNA expression it is preferable to use a pol III promoter as a promoter.
- a pol III promoter include U6 promoter, H1 promoter, tRNA promoter and the like.
- the expression vector preferably contains a transcription termination signal, that is, a terminator region, downstream of the nucleic acid molecule of the present invention or the nucleic acid encoding it.
- a selection marker gene for selecting transformed cells a gene that imparts resistance to drugs such as tetracycline, ampicillin, and kanamycin, a gene that complements an auxotrophic mutation, and the like.
- examples of vectors suitable for human administration include retroviruses, adenoviruses, virus vectors such as adeno-associated viruses, plasmid vectors, and the like.
- adenovirus has advantages such as extremely high gene transfer efficiency and can be introduced into non-dividing cells.
- gene expression is transient and usually lasts only about 4 weeks.
- use of an adeno-associated virus that has relatively high gene transfer efficiency can be introduced into non-dividing cells, and can be integrated into the chromosome via an inverted terminal repeat (ITR) Also preferred.
- ITR inverted terminal repeat
- composition of the present invention is a composition for suppressing the expression of hepatitis B virus gene, and is characterized by comprising the nucleic acid molecule or expression vector of the present invention.
- the composition of the present invention is characterized by containing the nucleic acid molecule or expression vector of the present invention, and other configurations are not limited at all.
- the composition of the present invention can also be referred to as, for example, an expression suppression reagent.
- the expression of the hepatitis B virus gene can be suppressed by administration to a subject in which the hepatitis B virus is present.
- composition of the present invention is characterized by including the nucleic acid molecule or expression vector of the present invention.
- the composition of the present invention is characterized by containing the nucleic acid molecule or expression vector of the present invention, and other configurations are not limited at all.
- the composition of the present invention can also be referred to as, for example, a pharmaceutical product or a pharmaceutical composition.
- the expression of the gene can be suppressed and the disease can be treated.
- the disease are as described above, and include hepatitis B, cirrhosis, liver cancer and the like.
- treatment includes, for example, the meanings of prevention of the above-mentioned diseases, improvement of the diseases, and improvement of the prognosis.
- the method of using the pharmaceutical composition of the present invention is not particularly limited.
- the nucleic acid molecule or the expression vector may be administered to an administration subject having the hepatitis B virus.
- Examples of the administration target include cells, tissues or organs.
- Examples of the administration subject include non-human animals such as humans and non-human mammals other than humans.
- the administration may be, for example, in vivo or in vitro.
- the cells are not particularly limited, and examples thereof include the cells described above.
- the administration method is not particularly limited, and can be appropriately determined according to the administration subject, for example.
- the administration subject is a cultured cell
- examples thereof include a method using a transfection reagent and an electroporation method.
- the pharmaceutical composition of the present invention may contain, for example, only the nucleic acid molecule or expression vector of the present invention, or may contain other additives.
- the additive is not particularly limited, and for example, a pharmaceutically acceptable additive is preferable.
- the type of the additive is not particularly limited, and can be appropriately selected depending on, for example, the type of administration target.
- the nucleic acid molecule or the expression vector may form a complex with the additive, for example.
- the additive can also be referred to as a complexing agent, for example.
- the complex formation for example, the nucleic acid molecule can be efficiently delivered.
- the binding between the nucleic acid molecule and the complexing agent is not particularly limited, and examples thereof include non-covalent binding. Examples of the complex include an inclusion complex.
- the complexing agent is not particularly limited, and examples thereof include a polymer, cyclodextrin, adamantine and the like.
- examples of the cyclodextrin include a linear cyclodextrin copolymer and a linear oxidized cyclodextrin copolymer.
- Examples of the additive include a carrier, a binding substance to a target cell, a condensing agent, a fusing agent, an excipient, and the like.
- Carriers include, for example, excipients such as sucrose, starch, mannitol, sorbit, lactose, glucose, cellulose, talc, calcium phosphate, calcium carbonate, cellulose, methylcellulose, hydroxypropylcellulose, polypropylpyrrolidone, gelatin, gum arabic , Binders such as polyethylene glycol, sucrose, starch, disintegrants such as starch, carboxymethylcellulose, hydroxypropyl starch, sodium-glycol starch, sodium bicarbonate, calcium phosphate, calcium citrate, magnesium stearate, aerosil, talc, Lubricants such as sodium lauryl sulfate, fragrances such as citric acid, menthol, glycyrrhizin / ammonium salt, glycine, orange powder, sodium benzoate, sulfite Preservatives such as sodium, methylparaben and propylparaben, stabilizers such as citric acid, sodium citrate and
- the pharmaceutical composition of the present invention may further contain a reagent for nucleic acid introduction.
- the nucleic acid introduction reagent include cationic lipids such as lipofectin, lipofectamine, DOGS (transfectam), DOPE, DOTAP, DDAB, DHDAB, HDEAB, polybrene, or poly (ethyleneimine) (PEI); Polysaccharides such as schizophyllan (SPG) can be used.
- retronectin, fibronectin, polybrene, or the like can be used as an introduction reagent.
- Examples of the dosage unit form of the pharmaceutical composition of the present invention include liquids, tablets, pills, drinking liquids, powders, suspensions, emulsions, granules, extracts, fine granules, syrups, soaking agents, decoctions, and eye drops. , Lozenges, poultices, liniments, lotions, ointments, plasters, capsules, suppositories, enemas, injections (solutions, suspensions, etc.), patches, ointments, jelly, pasta Examples include agents, inhalants, creams, sprays, nasal drops, aerosols and the like.
- the content of the nucleic acid molecule or expression vector of the present invention in the pharmaceutical composition is not particularly limited and is appropriately selected within a wide range, and is, for example, about 0.01 to 100% by weight of the whole pharmaceutical composition.
- the concentration of the nucleic acid molecule or expression vector of the present invention in the pharmaceutical composition is not particularly limited and is appropriately selected within a wide range.
- the concentration is about 0.01 nM to 1 M of the entire pharmaceutical composition, preferably about 0. 1 nM to 10 mM, more preferably 1 nM to 100 nM.
- the pharmaceutical composition of the present invention is administered by a method according to various forms when used. For example, it is administered orally in the case of tablets, pills, drinking liquids, suspensions, emulsions, granules and capsules, and in the case of injections intravenous, intramuscular, intradermal, subcutaneous, intraarticular cavity, It is administered intraperitoneally or in tumor tissue. In the case of a suppository, it is administered intrarectally.
- the dosage of the pharmaceutical composition of the present invention includes the activity and type of the active ingredient, the mode of administration (eg, oral and parenteral), the severity of the disease, the animal species to be administered, the drug acceptability of the administration target, the body weight
- the amount of active ingredient per day for an adult is usually about 0.001 mg to about 2.0 g, although it varies depending on the age and the like.
- the pharmaceutical composition of the present invention is usually safely administered to humans so that the nucleic acid molecule or expression vector of the present invention is delivered to a target cell (eg, hepatocyte, liver cancer cell).
- a target cell eg, hepatocyte, liver cancer cell.
- the pharmaceutical composition of the present invention is useful as a pharmaceutical composition for inhibiting the growth of hepatitis B virus.
- the nucleic acid molecule or expression vector of the present invention By administering an effective amount of the nucleic acid molecule or expression vector of the present invention to a target human infected with hepatitis B virus, the growth of hepatitis B virus in the human can be suppressed. If the growth of hepatitis B virus can be suppressed, the onset of hepatitis B can be prevented, and if hepatitis B has already developed, it can be recovered.
- Hepatitis B can be treated by using the pharmaceutical composition for inhibiting the growth of hepatitis B virus of the present invention. Therefore, the pharmaceutical composition of the present invention is useful for the treatment of hepatitis B.
- hepatitis B in the human can be treated.
- hepatitis B When hepatitis B becomes severe, it causes cirrhosis and liver cancer.
- the pharmaceutical composition for treating hepatitis B of the present invention cirrhosis and liver cancer can be treated. Therefore, the pharmaceutical composition of the present invention is useful for the treatment of cirrhosis and liver cancer.
- cirrhosis or liver cancer in the human By administering an effective amount of the nucleic acid molecule or expression vector of the present invention to a target human, cirrhosis or liver cancer in the human can be treated.
- the expression suppression method of the present invention is a method of suppressing the expression of hepatitis B virus gene or a method of suppressing hepatitis B virus growth, wherein the present invention Using a nucleic acid molecule, an expression vector and / or a pharmaceutical composition.
- the expression suppression method or hepatitis B virus growth suppression method of the present invention is characterized by using the nucleic acid molecule, expression vector and / or pharmaceutical composition of the present invention, and other steps and conditions are not limited. Not.
- the expression suppression method or hepatitis B virus growth suppression method of the present invention includes, for example, a step of administering the nucleic acid molecule to a subject in which hepatitis B virus is present.
- the administration step for example, the nucleic acid molecule is brought into contact with the administration subject.
- the administration subject include cells, tissues, and organs.
- the administration subject include non-human animals such as humans and non-human mammals other than humans.
- the administration may be, for example, in vivo or in vitro.
- the nucleic acid molecule may be administered alone, or the composition of the present invention containing the nucleic acid molecule may be administered.
- the administration method is not particularly limited, and can be appropriately selected depending on, for example, the type of administration target.
- the therapeutic method of the disease of this invention is characterized by including the process of administering the nucleic acid molecule of the said this invention, an expression vector, and / or pharmaceutical composition to a patient as mentioned above.
- the therapeutic method of the present invention is characterized by using the nucleic acid molecule of the present invention, and other steps and conditions are not limited at all.
- the diseases targeted by the present invention are, for example, as described above, and include hepatitis B, cirrhosis, liver cancer and the like.
- the expression suppression method of the present invention can be used.
- the administration method is not particularly limited, and may be, for example, oral administration or parenteral administration.
- the dosage of the nucleic acid molecule of the present invention in the treatment method of the present invention is not particularly limited as long as it is a therapeutically effective amount for the above-mentioned disease, and the type, severity, species of animal to be administered, age, weight, drug Usually, it is about 0.0001 to about 100 mg / kg per adult, for example about 0.001 to about 10 mg / kg, preferably about 0.005 to about 5 mg / kg, although it varies depending on the acceptability, administration route, etc. obtain.
- the amount can be administered, for example, at intervals of 3 times a day to once every 2 weeks, preferably once a day to once a week.
- nucleic acid molecule is the use of the nucleic acid molecule, expression vector and / or pharmaceutical composition of the present invention for the suppression of hepatitis B virus gene expression.
- the present invention also provides the nucleic acid molecule, expression vector and / or the present invention for use in inhibiting the expression of hepatitis B virus gene, inhibiting the growth of hepatitis B virus, or treating hepatitis B, cirrhosis, liver cancer.
- a pharmaceutical composition is provided.
- the present invention also provides the nucleic acid molecule, expression vector and / or the present invention for the suppression of hepatitis B virus gene expression, hepatitis B virus growth suppression, or the manufacture of a therapeutic agent for hepatitis B, cirrhosis or liver cancer. Or use of a pharmaceutical composition is provided.
- Example 1 SiRNA evaluation method for HBV-derived mRNA For evaluation, established human hepatoma cell Huh7 cells were used. Huh7 cells were cultured using penicillin / streptomycin, 10% FBS-containing DMEM (high glucose) medium. In experiments after the introduction of the plasmid, a medium not containing penicillin / streptomycin was used.
- Huh7 cells are seeded in a 24-well plate at 3 ⁇ 10 4 cells / 500 ⁇ L / well and 24 hours later, a plasmid that expresses a 1.4-fold long HBV genome by lipofection and expression of GaussiaLuc as a secreted luciferase for correction of introduction efficiency Plasmid was co-introduced.
- Lipofectamine 3000 was used as the lipofection reagent.
- RNAiMAX was used as the lipofection reagent.
- RNAiMAX 1.5 ⁇ L of RNAiMAX was added to a 50 nM siRNA solution diluted with OPTI-MEM in a serum-free medium so that the total volume became 50 ⁇ L, and after 5 minutes, to 24 well Huh7 cells (with a final siRNA concentration of 5 nM) ) Added.
- siRNA_upstream1_P S (us1) 5'-AGUCUAGACUCGUGGUGGAtt-3 '(SEQ ID NO: 11) 3'-ttUCAGAUCUGAGCACCACCU -5 '(SEQ ID NO: 9)
- siRNA_upstream2_P S (us2) 5'- GCAAGAUUCCUAUGGGAGUtt-3 '(SEQ ID NO: 12) 3'-ttCGUUCUAAGGAUACCCUCA -5 '(SEQ ID NO: 10)
- Negative Control siRNA Negative) 5′-UACUAUUCGACACGCGAAGtt-3 ′ (SEQ ID NO: 19) 3'-ttAUGAUAAGCUGUGCGCUUC -5 '(SEQ ID NO: 20)
- GaussiaLuc assay was performed to correct the plasmid introduction efficiency using a part of the culture solution. Specifically, 15 ⁇ L of a substrate solution (NEB, BioLux Gaussia Luciferase Assay Kit) was added to 5 ⁇ L of the culture supernatant, and luminescence was measured with a plate reader after 1 minute.
- a substrate solution NEB, BioLux Gaussia Luciferase Assay Kit
- RNAiMAX 1.5 ⁇ L of RNAiMAX was added to 50 ⁇ L each of 1 nM, 10 nM, and 100 nM solutions of us1 siRNA and us2 siRNA to be introduced in serum-free medium OPTI-MEM, and these were added to Huh7 cells in the medium.
- a final concentration of 0.1 nM (us1_0.1, us2_0.1), 1 nM (us1_1, us2_1), or 10 nM (us1_10, us2_10) was added and tested in the same manner as described above after 96 hours of plasmid introduction. Antigen and HBe antigen production inhibitory effects were observed (FIG. 6, n 3).
- the present invention provides a nucleic acid molecule that is less toxic to cells and that can effectively suppress the expression of a hepatitis B virus gene, and a pharmaceutical composition containing the nucleic acid molecule.
- the pharmaceutical composition of the present invention is useful for suppressing the growth of hepatitis B virus with reduced side effects, and hence for treating hepatitis B, cirrhosis, and liver cancer. It is.
Abstract
The present invention provides: a nucleic acid molecule that effectively inhibits hepatitis B virus gene expression; and a pharmaceutical composition that comprises said nucleic acid molecule and is used for inhibiting hepatitis B virus growth and for treating hepatitis B, hepatic cirrhosis, or hepatic cancer. More specifically, provided is a nucleic acid molecule that includes the nucleotide sequence defined in (i) or (ii) as a sequence for inhibiting the expression of hepatitis B virus gene. (i) Nucleotide sequence represented by SEQ ID NO:2; a nucleotide sequence represented by SEQ ID NO:2, wherein one or two bases are deleted, substituted, inserted, or added; or a nucleotide sequence that has 90% or more identity to the nucleotide sequence represented by SEQ ID NO:2. (ii) Nucleotide sequence represented by SEQ ID NO:1; a nucleotide sequence represented by SEQ ID NO:1, wherein one or two bases are deleted, substituted, inserted, or added; or a nucleotide sequence that has 90% or more identity to the nucleotide sequence represented by SEQ ID NO:1.
Description
本発明は、B型肝炎ウイルス(HBV)遺伝子の発現を効果的に抑制する核酸分子、および当該核酸分子を含む、B型肝炎ウイルス増殖抑制用、B型肝炎、肝硬変および肝臓がんの治療用の医薬組成物に関する。
The present invention relates to a nucleic acid molecule that effectively suppresses expression of a hepatitis B virus (HBV) gene, and for the suppression of hepatitis B virus proliferation, the treatment of hepatitis B, cirrhosis, and liver cancer, including the nucleic acid molecule. To a pharmaceutical composition.
B型肝炎ウイルスには、日本国内で130万~150万人、世界中ではおよそ3億5,000万人が感染していると言われており、C型肝炎ウイルスと共に慢性肝炎の主な原因となっている。
It is said that hepatitis B virus is infected between 1.3 million and 1.5 million people in Japan, and about 350 million people worldwide. Main causes of chronic hepatitis along with hepatitis C virus It has become.
慢性C型肝炎では、現状の治療法によって、かなりの高率でHCVウイルスの完全排除が期待できるが、慢性B型肝炎の現在の治療法では、HBVウイルスの完全排除は出来ない。現状の慢性B型肝炎に対する治療法にはインターフェロン(IFN)療法と核酸アナログ製剤療法がある。IFN療法の奏効率は30~40%に留まり、強い副作用も伴う。一方の、核酸アナログ製剤は服用により肝炎が鎮静化し肝機能が改善するが、長期の服用を余儀なくされ、投薬中止によりほとんどの症例で肝炎が再燃する。これは、肝細胞核内に治療後も微量に存在するcccDNA(covalenty closed circular DNA、閉環状DNAまたは完全閉鎖二重鎖DNA)からの転写が治療終了後に起こるためである。したがって、前記の治療法と作用機序の異なる新たな革新的治療薬の開発が求められている(非特許文献1、2)。
Chronic hepatitis C can be expected to eliminate the HCV virus at a considerably high rate by the current therapy, but the current therapy for chronic hepatitis B cannot completely eliminate the HBV virus. Current therapies for chronic hepatitis B include interferon (IFN) therapy and nucleic acid analog preparation therapy. The response rate of IFN therapy is only 30-40%, with strong side effects. On the other hand, the nucleic acid analog preparation sedates hepatitis and improves liver function, but is forced to take for a long time, and hepatitis relapses in most cases due to discontinuation of medication. This is because transcription from cccDNA (covalently closed circular DNA, closed circular DNA, or completely closed double-stranded DNA) present in a minute amount in the hepatocyte nucleus after the treatment occurs after the treatment is completed. Therefore, development of a new innovative therapeutic agent having a different mechanism of action from the above-described therapeutic methods is demanded (Non-patent Documents 1 and 2).
慢性B型肝炎治療薬候補の作用機序が、非特許文献3にまとめられている。中でも、siRNAによる全ウイルスタンパク質の翻訳抑制は、HBVのウイルスとしての機能を完全に遮断することが期待できる。
Non-patent document 3 summarizes the mechanism of action of chronic hepatitis B drug candidates. In particular, translational suppression of all viral proteins by siRNA can be expected to completely block the function of HBV as a virus.
核酸医薬品は従来の低分子医薬品や抗体医薬品では狙えないmRNAやmiRNA等の分子を創薬ターゲットとすることが可能であり、次世代の医薬品として高い期待が寄せられている。それにより、これまで治療が困難であった疾病に対する医薬品の創出が期待されており、全世界で研究が盛んに行われているのが現状である。
Nucleic acid drugs can target molecules such as mRNA and miRNA that cannot be targeted by conventional low-molecular-weight drugs and antibody drugs, and are highly expected as next-generation drugs. As a result, the creation of pharmaceuticals for diseases that have been difficult to treat is expected, and the current situation is that research is actively conducted all over the world.
その一方で、核酸医薬品の開発においては、「(1)核酸分子の生体内での不安定性」「(2)副作用の懸念」「(3)薬物送達技術(DDS)の困難性」等の克服すべき課題があることが指摘されている。それにより、開発品の多さに比較して上市品は、未だ数少ないのが現状である。
On the other hand, in the development of nucleic acid pharmaceuticals, “(1) in vivo instability of nucleic acid molecules”, “(2) concerns about side effects”, “(3) difficulties in drug delivery technology (DDS)”, etc. It is pointed out that there are issues to be addressed. As a result, the number of products on the market is still few compared to the number of developed products.
核酸医薬における、遺伝子の発現を抑制する技術として、例えば、RNA干渉(RNAi)が知られている。RNA干渉による遺伝子の発現抑制は、例えば、短い二本鎖のRNA分子を、細胞等に投与することによって、実施されるのが一般的である。前記二本鎖のRNA分子は、通常、siRNA(small interfering RNA)と呼ばれる。近年、本出願人らはsiRNAに代わるより効果的な一本鎖核酸分子を新たに見出している(特許文献1、2)。
As a technique for suppressing gene expression in nucleic acid medicine, for example, RNA interference (RNAi) is known. Inhibition of gene expression by RNA interference is generally performed, for example, by administering a short double-stranded RNA molecule to a cell or the like. The double-stranded RNA molecule is usually referred to as siRNA (small interfering RNA). In recent years, the present applicants have newly found a more effective single-stranded nucleic acid molecule to replace siRNA (Patent Documents 1 and 2).
B型肝炎の治療のために、B型肝炎ウイルスの増殖を強力に抑制することのできる核酸の探索が望まれている。そこで、本発明は、B型肝炎ウイルス遺伝子の発現を効果的に抑制する核酸分子、および当該核酸分子を含むB型肝炎ウイルス増殖抑制用、B型肝炎、肝硬変、肝臓がんの治療用の医薬組成物を提供することを目的とする。
For the treatment of hepatitis B, it is desired to search for a nucleic acid that can strongly suppress the growth of hepatitis B virus. Therefore, the present invention relates to a nucleic acid molecule that effectively suppresses the expression of hepatitis B virus gene, and a medicament for inhibiting the growth of hepatitis B virus containing the nucleic acid molecule, the treatment of hepatitis B, cirrhosis, and liver cancer. An object is to provide a composition.
本発明者らは、HBV genotype Cに対する新規なsiRNA配列を2種類設計し合成した。それらをHBVウイルスを発現させた肝培養細胞Huh7に導入し、HBVウイルスのS抗原、e抗原の分泌量を指標にウイルス産生抑制能を評価した。その結果、2配列(us1、us2)が高い抑制活性を有することを見出した。さらにこれらの2配列を搭載した一本鎖核酸分子もsiRNAと同等の活性を有していることを見出し、本発明を完成した。
The present inventors designed and synthesized two types of novel siRNA sequences for HBV genotype C. They were introduced into cultured human cells Huh7 expressing HBV virus, and their ability to suppress virus production was evaluated using the secreted amounts of S antigen and e antigen of HBV virus as indicators. As a result, it was found that the two sequences (us1, us2) have high inhibitory activity. Furthermore, the present inventors have found that a single-stranded nucleic acid molecule carrying these two sequences has an activity equivalent to that of siRNA, thereby completing the present invention.
即ち、本発明は以下のとおりである。
[1] 以下の(i)または(ii)のヌクレオチド配列をB型肝炎ウイルス遺伝子発現抑制配列として含む核酸分子
(i)配列番号2で表されるヌクレオチド配列;
配列番号2で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号2で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(ii)配列番号1で表されるヌクレオチド配列;
配列番号1で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号1で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。
[2] 塩基数の合計が100塩基以下である、[1]に記載の核酸分子。
[3] (i)のヌクレオチド配列および(i)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iii)である相補配列;または
(ii)のヌクレオチド配列および(ii)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iv)である相補配列
を含む、[1]または[2]に記載の核酸分子
(iii)配列番号4で表されるヌクレオチド配列;
配列番号4で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号4で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(iv)配列番号3で表されるヌクレオチド配列;
配列番号3で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号3で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。
[4] (iii)のヌクレオチド配列が(i)のヌクレオチド配列に完全に相補的な配列であり、
(iv)のヌクレオチド配列が(ii)のヌクレオチド配列に完全に相補的な配列である、[3]に記載の核酸分子。
[5] 二本鎖核酸分子であって、
一方の鎖に(i)のヌクレオチド配列、他方の鎖に該(i)のヌクレオチド配列にアニーリングした(iii)のヌクレオチド配列を含むか、;または
一方の鎖に(ii)のヌクレオチド配列、他方の鎖に該(ii)のヌクレオチド配列にアニーリングした(iv)のヌクレオチド配列を含むRNA分子である、[3]または[4]に記載の核酸分子。
[6] 塩基数の合計が60塩基以下である、[3]~[5]のいずれかに記載の核酸分子。
[7] (i)、(ii)、(iii)および(iv)のヌクレオチド配列が、それぞれ配列番号2、1、4、3で表されるヌクレオチド配列である、[3]~[6]のいずれかに記載の核酸分子。
[8] 二本鎖のうちの少なくとも1方の鎖の3’末端にオーバーハング配列を更に有する、[5]~[7]のいずれかに記載の核酸分子。
[9] 配列番号10で表されるヌクレオチド配列および該配列にアニーリングした配列番号12で表されるヌクレオチド配列;または
配列番号9で表されるヌクレオチド配列および該配列にアニーリングした配列番号11で表されるヌクレオチド配列
から成る、[8]に記載の核酸分子。
[10] B型肝炎ウイルス遺伝子発現抑制配列として(i)または(ii)で表されるヌクレオチド配列を含む、以下の(A)または(B)の一本鎖核酸分子である、[1]~[4]のいずれかに記載の核酸分子:
(A)領域(X)、リンカー領域(Lx)および領域(Xc)のみからなり、
5’側から3’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)の順で配置され、
前記リンカー領域(Lx)が、ピロリジン骨格およびピペリジン骨格の少なくとも一方を含む非ヌクレオチド構造を有し、
かつ前記領域(X)および前記領域(Xc)の少なくとも一方が、前記発現抑制配列を含む;
(B)領域(Xc)、リンカー領域(Lx)、領域(X)、領域(Y)、リンカー領域(Ly)および領域(Yc)を、5’側から3’側にかけてこの順序で含み、
前記領域(X)と前記領域(Y)とが連結して、内部領域(Z)を形成し、
前記領域(Xc)が、前記領域(X)と相補的であり、
前記領域(Yc)が、前記領域(Y)と相補的であり、
かつ前記リンカー領域(Lx)およびリンカー領域(Ly)が、各々独立して存在しないか、ヌクレオチド残基から成るか、またはピロリジン骨格およびピペリジン骨格の少なくとも一方を含む非ヌクレオチド構造を有し、
前記内部領域(Z)が、前記発現抑制配列を含む。
[11] 前記リンカー領域(Lx)および(Ly)が、下記式(I)で表わされる、[10]に記載の鎖核酸分子。 That is, the present invention is as follows.
[1] A nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as a hepatitis B virus gene expression suppression sequence (i) a nucleotide sequence represented by SEQ ID NO: 2;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having
[2] The nucleic acid molecule according to [1], wherein the total number of bases is 100 bases or less.
[3] A nucleotide sequence of (i) and a complementary sequence capable of annealing to the nucleotide sequence of (i), wherein the complementary sequence is (iii) below; or (ii) the nucleotide sequence and (ii) The nucleic acid molecule (iii) according to [1] or [2], which comprises a complementary sequence that can be annealed to the nucleotide sequence of (1), wherein the complementary sequence is the following (iv): Nucleotide sequence to be;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 4; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 4 A nucleotide sequence represented by SEQ ID NO: 3;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 3; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 3 Nucleotide sequence having
[4] The nucleotide sequence of (iii) is a sequence completely complementary to the nucleotide sequence of (i),
The nucleic acid molecule according to [3], wherein the nucleotide sequence of (iv) is a sequence completely complementary to the nucleotide sequence of (ii).
[5] A double-stranded nucleic acid molecule,
One strand contains the nucleotide sequence of (i) and the other strand contains the nucleotide sequence of (iii) annealed to the nucleotide sequence of (i); or one strand contains the nucleotide sequence of (ii), the other The nucleic acid molecule according to [3] or [4], which is an RNA molecule comprising the nucleotide sequence of (iv) annealed to the nucleotide sequence of (ii) in a strand.
[6] The nucleic acid molecule according to any one of [3] to [5], wherein the total number of bases is 60 bases or less.
[7] The nucleotide sequences of (i), (ii), (iii), and (iv) are the nucleotide sequences represented by SEQ ID NOs: 2, 1, 4, 3, respectively [3] to [6] The nucleic acid molecule according to any one of the above.
[8] The nucleic acid molecule according to any one of [5] to [7], further having an overhang sequence at the 3 ′ end of at least one of the double strands.
[9] The nucleotide sequence represented by SEQ ID NO: 10 and the nucleotide sequence represented by SEQ ID NO: 12 annealed to the sequence; or the nucleotide sequence represented by SEQ ID NO: 9 and SEQ ID NO: 11 annealed to the sequence The nucleic acid molecule according to [8], consisting of a nucleotide sequence.
[10] The following single-stranded nucleic acid molecule (A) or (B) comprising the nucleotide sequence represented by (i) or (ii) as a hepatitis B virus gene expression suppression sequence: The nucleic acid molecule according to any one of [4]:
(A) It consists only of region (X), linker region (Lx) and region (Xc),
From the 5 ′ side to the 3 ′ side, the region (Xc), the linker region (Lx) and the region (X) are arranged in this order,
The linker region (Lx) has a non-nucleotide structure containing at least one of a pyrrolidine skeleton and a piperidine skeleton;
And at least one of the region (X) and the region (Xc) includes the expression suppressing sequence;
(B) comprising region (Xc), linker region (Lx), region (X), region (Y), linker region (Ly) and region (Yc) in this order from 5 ′ side to 3 ′ side,
The region (X) and the region (Y) are connected to form an internal region (Z),
The region (Xc) is complementary to the region (X);
The region (Yc) is complementary to the region (Y);
And each of the linker region (Lx) and the linker region (Ly) does not exist independently, consists of a nucleotide residue, or has a non-nucleotide structure including at least one of a pyrrolidine skeleton and a piperidine skeleton,
The internal region (Z) includes the expression suppression sequence.
[11] The strand nucleic acid molecule according to [10], wherein the linker regions (Lx) and (Ly) are represented by the following formula (I).
[1] 以下の(i)または(ii)のヌクレオチド配列をB型肝炎ウイルス遺伝子発現抑制配列として含む核酸分子
(i)配列番号2で表されるヌクレオチド配列;
配列番号2で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号2で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(ii)配列番号1で表されるヌクレオチド配列;
配列番号1で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号1で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。
[2] 塩基数の合計が100塩基以下である、[1]に記載の核酸分子。
[3] (i)のヌクレオチド配列および(i)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iii)である相補配列;または
(ii)のヌクレオチド配列および(ii)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iv)である相補配列
を含む、[1]または[2]に記載の核酸分子
(iii)配列番号4で表されるヌクレオチド配列;
配列番号4で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号4で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(iv)配列番号3で表されるヌクレオチド配列;
配列番号3で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号3で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。
[4] (iii)のヌクレオチド配列が(i)のヌクレオチド配列に完全に相補的な配列であり、
(iv)のヌクレオチド配列が(ii)のヌクレオチド配列に完全に相補的な配列である、[3]に記載の核酸分子。
[5] 二本鎖核酸分子であって、
一方の鎖に(i)のヌクレオチド配列、他方の鎖に該(i)のヌクレオチド配列にアニーリングした(iii)のヌクレオチド配列を含むか、;または
一方の鎖に(ii)のヌクレオチド配列、他方の鎖に該(ii)のヌクレオチド配列にアニーリングした(iv)のヌクレオチド配列を含むRNA分子である、[3]または[4]に記載の核酸分子。
[6] 塩基数の合計が60塩基以下である、[3]~[5]のいずれかに記載の核酸分子。
[7] (i)、(ii)、(iii)および(iv)のヌクレオチド配列が、それぞれ配列番号2、1、4、3で表されるヌクレオチド配列である、[3]~[6]のいずれかに記載の核酸分子。
[8] 二本鎖のうちの少なくとも1方の鎖の3’末端にオーバーハング配列を更に有する、[5]~[7]のいずれかに記載の核酸分子。
[9] 配列番号10で表されるヌクレオチド配列および該配列にアニーリングした配列番号12で表されるヌクレオチド配列;または
配列番号9で表されるヌクレオチド配列および該配列にアニーリングした配列番号11で表されるヌクレオチド配列
から成る、[8]に記載の核酸分子。
[10] B型肝炎ウイルス遺伝子発現抑制配列として(i)または(ii)で表されるヌクレオチド配列を含む、以下の(A)または(B)の一本鎖核酸分子である、[1]~[4]のいずれかに記載の核酸分子:
(A)領域(X)、リンカー領域(Lx)および領域(Xc)のみからなり、
5’側から3’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)の順で配置され、
前記リンカー領域(Lx)が、ピロリジン骨格およびピペリジン骨格の少なくとも一方を含む非ヌクレオチド構造を有し、
かつ前記領域(X)および前記領域(Xc)の少なくとも一方が、前記発現抑制配列を含む;
(B)領域(Xc)、リンカー領域(Lx)、領域(X)、領域(Y)、リンカー領域(Ly)および領域(Yc)を、5’側から3’側にかけてこの順序で含み、
前記領域(X)と前記領域(Y)とが連結して、内部領域(Z)を形成し、
前記領域(Xc)が、前記領域(X)と相補的であり、
前記領域(Yc)が、前記領域(Y)と相補的であり、
かつ前記リンカー領域(Lx)およびリンカー領域(Ly)が、各々独立して存在しないか、ヌクレオチド残基から成るか、またはピロリジン骨格およびピペリジン骨格の少なくとも一方を含む非ヌクレオチド構造を有し、
前記内部領域(Z)が、前記発現抑制配列を含む。
[11] 前記リンカー領域(Lx)および(Ly)が、下記式(I)で表わされる、[10]に記載の鎖核酸分子。 That is, the present invention is as follows.
[1] A nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as a hepatitis B virus gene expression suppression sequence (i) a nucleotide sequence represented by SEQ ID NO: 2;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having
[2] The nucleic acid molecule according to [1], wherein the total number of bases is 100 bases or less.
[3] A nucleotide sequence of (i) and a complementary sequence capable of annealing to the nucleotide sequence of (i), wherein the complementary sequence is (iii) below; or (ii) the nucleotide sequence and (ii) The nucleic acid molecule (iii) according to [1] or [2], which comprises a complementary sequence that can be annealed to the nucleotide sequence of (1), wherein the complementary sequence is the following (iv): Nucleotide sequence to be;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 4; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 4 A nucleotide sequence represented by SEQ ID NO: 3;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 3; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 3 Nucleotide sequence having
[4] The nucleotide sequence of (iii) is a sequence completely complementary to the nucleotide sequence of (i),
The nucleic acid molecule according to [3], wherein the nucleotide sequence of (iv) is a sequence completely complementary to the nucleotide sequence of (ii).
[5] A double-stranded nucleic acid molecule,
One strand contains the nucleotide sequence of (i) and the other strand contains the nucleotide sequence of (iii) annealed to the nucleotide sequence of (i); or one strand contains the nucleotide sequence of (ii), the other The nucleic acid molecule according to [3] or [4], which is an RNA molecule comprising the nucleotide sequence of (iv) annealed to the nucleotide sequence of (ii) in a strand.
[6] The nucleic acid molecule according to any one of [3] to [5], wherein the total number of bases is 60 bases or less.
[7] The nucleotide sequences of (i), (ii), (iii), and (iv) are the nucleotide sequences represented by SEQ ID NOs: 2, 1, 4, 3, respectively [3] to [6] The nucleic acid molecule according to any one of the above.
[8] The nucleic acid molecule according to any one of [5] to [7], further having an overhang sequence at the 3 ′ end of at least one of the double strands.
[9] The nucleotide sequence represented by SEQ ID NO: 10 and the nucleotide sequence represented by SEQ ID NO: 12 annealed to the sequence; or the nucleotide sequence represented by SEQ ID NO: 9 and SEQ ID NO: 11 annealed to the sequence The nucleic acid molecule according to [8], consisting of a nucleotide sequence.
[10] The following single-stranded nucleic acid molecule (A) or (B) comprising the nucleotide sequence represented by (i) or (ii) as a hepatitis B virus gene expression suppression sequence: The nucleic acid molecule according to any one of [4]:
(A) It consists only of region (X), linker region (Lx) and region (Xc),
From the 5 ′ side to the 3 ′ side, the region (Xc), the linker region (Lx) and the region (X) are arranged in this order,
The linker region (Lx) has a non-nucleotide structure containing at least one of a pyrrolidine skeleton and a piperidine skeleton;
And at least one of the region (X) and the region (Xc) includes the expression suppressing sequence;
(B) comprising region (Xc), linker region (Lx), region (X), region (Y), linker region (Ly) and region (Yc) in this order from 5 ′ side to 3 ′ side,
The region (X) and the region (Y) are connected to form an internal region (Z),
The region (Xc) is complementary to the region (X);
The region (Yc) is complementary to the region (Y);
And each of the linker region (Lx) and the linker region (Ly) does not exist independently, consists of a nucleotide residue, or has a non-nucleotide structure including at least one of a pyrrolidine skeleton and a piperidine skeleton,
The internal region (Z) includes the expression suppression sequence.
[11] The strand nucleic acid molecule according to [10], wherein the linker regions (Lx) and (Ly) are represented by the following formula (I).

前記式中、
X1およびX2は、それぞれ独立して、H2、O、SまたはNHであり;
Y1およびY2は、それぞれ独立して、単結合、CH2、NH、OまたはSであり;
R3は、環A上のC-3、C-4、C-5またはC-6に結合する水素原子または置換基であり;
L1は、n個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORa、NH2、NHRa、NRaRb、SH、もしくはSRaで置換されていてもよく、および/または、
L1は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y1が、NH、OまたはSの場合、Y1に結合するL1の原子は炭素であり、OR1に結合するL1の原子は炭素であり、酸素原子同士は隣接せず;
L2は、m個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORc、NH2、NHRc、NRcRd、SHもしくはSRcで置換されていてもよく、および/または、
L2は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y2が、NH、OまたはSの場合、Y2に結合するL2の原子は炭素であり、OR2に結合するL2の原子は炭素であり、酸素原子同士は隣接せず;
Ra、Rb、RcおよびRdは、それぞれ独立して、置換基または保護基であり;
lは、1または2であり;
mは、0~30の範囲の整数であり;
nは、0~30の範囲の整数であり;
環Aは、前記環A上のC-2以外の1個の炭素原子が、窒素、酸素または硫黄で置換されていてもよく、
前記環A内に、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよく、
前記領域(Xc)および前記領域(X)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Lx)に結合し、
前記領域(Yc)および前記領域(Y)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Ly)に結合し、
ここで、R1およびR2は、存在しても存在しなくてもよく、存在する場合、R1およびR2は、それぞれ独立して、ヌクレオチド残基または前記構造(I)である。
[12] 前記領域(X)の塩基数(X)および前記5’側領域(Xc)の塩基数(Xc)が、下記式(3)または式(5)の条件を満たす、[10]または[11]に記載の核酸分子。
X>Xc ・・・(3)
X=Xc ・・・(5)
[13] 前記領域(X)の塩基数(X)および前記5’側領域(Xc)の塩基数(Xc)が、下記式(11)の条件を満たす、[12]に記載の核酸分子。
X-Xc=1、2または3 ・・・(11)
[14] 前記(B)において、前記領域(Z)の塩基数(Z)、前記領域(Xc)の塩基数(Xc)および前記領域(Yc)の塩基数(Yc)が、下記式(2)の条件を満たす、[10]~[13]のいずれかに記載の核酸分子。
Z≧Xc+Yc ・・・(2)
[15] 前記(B)において、前記領域(X)の塩基数(X)、前記(Xc)の塩基数(Xc)、前記領域(Y)の塩基数(Y)および前記領域(Yc)の塩基数(Yc)が、下記(a)~(d)のいずれかの条件を満たす、[10]~[14]のいずれかに記載の核酸分子:
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10)
[16] 前記(a)~(d)において、前記領域(X)の塩基数(X)と前記領域(Xc)の塩基数(Xc)の差、前記領域(Y)の塩基数(Y)と前記領域(Yc)の塩基数(Yc)の差が、下記条件を満たす、[15]に記載の核酸分子。
(a)下記式(11)および(12)の条件を満たす。
X-Xc=1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1、2または3 ・・・(15)
Y-Yc=1、2または3 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18)
[17] 前記(B)において、前記領域(Xc)の塩基数(Xc)が、1~11塩基である、[10]~[16]のいずれかに記載の核酸分子。
[18] 前記領域(Xc)の塩基数(Xc)が、1~7塩基である、[17]に記載の核酸分子。
[19] 前記領域(Xc)の塩基数(Xc)が、1~3塩基である、[17]に記載の核酸分子。
[20] 前記(B)において、前記領域(Yc)の塩基数(Yc)が、1~11塩基である、[10]~[19]のいずれかに記載の核酸分子。
[21] 前記領域(Yc)の塩基数(Yc)が、1~7塩基である、[20]に記載の核酸分子。
[22] 前記領域(Yc)の塩基数(Yc)が、1~3塩基である、[20]に記載の核酸分子。
[23] 前記(A)において、前記領域(Xc)の塩基数(Xc)が、19~30塩基である、[10]~[13]のいずれかに記載の核酸分子。
[24] 塩基数の合計が80塩基以下である、[10]~[23]のいずれかに記載の核酸分子。
[25] RNA分子である、[10]~[24]のいずれかに記載の核酸分子。
[26] 前記(B)において、前記リンカー領域(Lx)および(Ly)が、1~20塩基のヌクレオチド残基から成る、[10]に記載の核酸分子。
[27] (i)のヌクレオチド配列と(iii)のヌクレオチド配列、または(ii)のヌクレオチド配列と(iv)のヌクレオチド配列とが、下記式で表される基で連結されている、[1]~[4]のいずれかに記載の核酸分子。 In the above formula,
X 1 and X 2 are each independently H 2 , O, S or NH;
Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S;
R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A;
L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or
L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other;
L 2 is an alkylene chain consisting of m carbon atoms, where the hydrogen atom on the alkylene carbon atom is replaced by OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c And / or
L 2 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 2 is NH, O or S, the atom of L 2 bonded to Y 2 is carbon, the atom of L 2 bonded to OR 2 is carbon, and oxygen atoms are not adjacent to each other;
R a , R b , R c and R d are each independently a substituent or a protecting group;
l is 1 or 2;
m is an integer ranging from 0 to 30;
n is an integer ranging from 0 to 30;
In ring A, one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen or sulfur.
The ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond,
The region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
The region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
Here, R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I).
[12] The number of bases (X) in the region (X) and the number of bases (Xc) in the 5′-side region (Xc) satisfy the condition of the following formula (3) or formula (5): [11] The nucleic acid molecule according to [11].
X> Xc (3)
X = Xc (5)
[13] The nucleic acid molecule according to [12], wherein the number of bases (X) in the region (X) and the number of bases (Xc) in the 5 ′ side region (Xc) satisfy the condition of the following formula (11).
X−Xc = 1, 2 or 3 (11)
[14] In (B), the number of bases (Z) in the region (Z), the number of bases (Xc) in the region (Xc), and the number of bases (Yc) in the region (Yc) are represented by the following formula (2): ), The nucleic acid molecule according to any one of [10] to [13].
Z ≧ Xc + Yc (2)
[15] In (B), the number of bases (X) in the region (X), the number of bases (Xc) in the (Xc), the number of bases (Y) in the region (Y), and the number of bases in the region (Yc) The nucleic acid molecule according to any one of [10] to [14], wherein the number of bases (Yc) satisfies any of the following conditions (a) to (d):
(A) Satisfy the conditions of the following formulas (3) and (4).
X> Xc (3)
Y = Yc (4)
(B) The conditions of the following formulas (5) and (6) are satisfied.
X = Xc (5)
Y> Yc (6)
(C) The conditions of the following formulas (7) and (8) are satisfied.
X> Xc (7)
Y> Yc (8)
(D) The conditions of the following formulas (9) and (10) are satisfied.
X = Xc (9)
Y = Yc (10)
[16] In (a) to (d), the difference between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc), the number of bases (Y) in the region (Y) The nucleic acid molecule according to [15], wherein the difference in the number of bases (Yc) in the region (Yc) satisfies the following condition.
(A) The conditions of the following formulas (11) and (12) are satisfied.
X−Xc = 1, 2 or 3 (11)
Y−Yc = 0 (12)
(B) The conditions of the following formulas (13) and (14) are satisfied.
X−Xc = 0 (13)
Y−Yc = 1, 2 or 3 (14)
(C) The conditions of the following formulas (15) and (16) are satisfied.
X−Xc = 1, 2 or 3 (15)
Y−Yc = 1, 2 or 3 (16)
(D) The conditions of the following formulas (17) and (18) are satisfied.
X−Xc = 0 (17)
Y−Yc = 0 (18)
[17] The nucleic acid molecule according to any one of [10] to [16], wherein in (B), the number of bases (Xc) in the region (Xc) is 1 to 11 bases.
[18] The nucleic acid molecule according to [17], wherein the number of bases (Xc) in the region (Xc) is 1 to 7 bases.
[19] The nucleic acid molecule according to [17], wherein the number of bases (Xc) in the region (Xc) is 1 to 3 bases.
[20] The nucleic acid molecule according to any one of [10] to [19], wherein in (B), the number of bases (Yc) in the region (Yc) is 1 to 11 bases.
[21] The nucleic acid molecule according to [20], wherein the number of bases (Yc) in the region (Yc) is 1 to 7 bases.
[22] The nucleic acid molecule according to [20], wherein the number of bases (Yc) in the region (Yc) is 1 to 3 bases.
[23] The nucleic acid molecule according to any one of [10] to [13], wherein in (A), the number of bases (Xc) in the region (Xc) is 19 to 30 bases.
[24] The nucleic acid molecule according to any one of [10] to [23], wherein the total number of bases is 80 or less.
[25] The nucleic acid molecule according to any one of [10] to [24], which is an RNA molecule.
[26] The nucleic acid molecule according to [10], wherein in (B), the linker regions (Lx) and (Ly) are composed of nucleotide residues of 1 to 20 bases.
[27] The nucleotide sequence of (i) and the nucleotide sequence of (iii), or the nucleotide sequence of (ii) and the nucleotide sequence of (iv) are linked by a group represented by the following formula: [1] The nucleic acid molecule according to any one of to [4].
X1およびX2は、それぞれ独立して、H2、O、SまたはNHであり;
Y1およびY2は、それぞれ独立して、単結合、CH2、NH、OまたはSであり;
R3は、環A上のC-3、C-4、C-5またはC-6に結合する水素原子または置換基であり;
L1は、n個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORa、NH2、NHRa、NRaRb、SH、もしくはSRaで置換されていてもよく、および/または、
L1は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y1が、NH、OまたはSの場合、Y1に結合するL1の原子は炭素であり、OR1に結合するL1の原子は炭素であり、酸素原子同士は隣接せず;
L2は、m個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORc、NH2、NHRc、NRcRd、SHもしくはSRcで置換されていてもよく、および/または、
L2は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y2が、NH、OまたはSの場合、Y2に結合するL2の原子は炭素であり、OR2に結合するL2の原子は炭素であり、酸素原子同士は隣接せず;
Ra、Rb、RcおよびRdは、それぞれ独立して、置換基または保護基であり;
lは、1または2であり;
mは、0~30の範囲の整数であり;
nは、0~30の範囲の整数であり;
環Aは、前記環A上のC-2以外の1個の炭素原子が、窒素、酸素または硫黄で置換されていてもよく、
前記環A内に、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよく、
前記領域(Xc)および前記領域(X)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Lx)に結合し、
前記領域(Yc)および前記領域(Y)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Ly)に結合し、
ここで、R1およびR2は、存在しても存在しなくてもよく、存在する場合、R1およびR2は、それぞれ独立して、ヌクレオチド残基または前記構造(I)である。
[12] 前記領域(X)の塩基数(X)および前記5’側領域(Xc)の塩基数(Xc)が、下記式(3)または式(5)の条件を満たす、[10]または[11]に記載の核酸分子。
X>Xc ・・・(3)
X=Xc ・・・(5)
[13] 前記領域(X)の塩基数(X)および前記5’側領域(Xc)の塩基数(Xc)が、下記式(11)の条件を満たす、[12]に記載の核酸分子。
X-Xc=1、2または3 ・・・(11)
[14] 前記(B)において、前記領域(Z)の塩基数(Z)、前記領域(Xc)の塩基数(Xc)および前記領域(Yc)の塩基数(Yc)が、下記式(2)の条件を満たす、[10]~[13]のいずれかに記載の核酸分子。
Z≧Xc+Yc ・・・(2)
[15] 前記(B)において、前記領域(X)の塩基数(X)、前記(Xc)の塩基数(Xc)、前記領域(Y)の塩基数(Y)および前記領域(Yc)の塩基数(Yc)が、下記(a)~(d)のいずれかの条件を満たす、[10]~[14]のいずれかに記載の核酸分子:
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10)
[16] 前記(a)~(d)において、前記領域(X)の塩基数(X)と前記領域(Xc)の塩基数(Xc)の差、前記領域(Y)の塩基数(Y)と前記領域(Yc)の塩基数(Yc)の差が、下記条件を満たす、[15]に記載の核酸分子。
(a)下記式(11)および(12)の条件を満たす。
X-Xc=1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1、2または3 ・・・(15)
Y-Yc=1、2または3 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18)
[17] 前記(B)において、前記領域(Xc)の塩基数(Xc)が、1~11塩基である、[10]~[16]のいずれかに記載の核酸分子。
[18] 前記領域(Xc)の塩基数(Xc)が、1~7塩基である、[17]に記載の核酸分子。
[19] 前記領域(Xc)の塩基数(Xc)が、1~3塩基である、[17]に記載の核酸分子。
[20] 前記(B)において、前記領域(Yc)の塩基数(Yc)が、1~11塩基である、[10]~[19]のいずれかに記載の核酸分子。
[21] 前記領域(Yc)の塩基数(Yc)が、1~7塩基である、[20]に記載の核酸分子。
[22] 前記領域(Yc)の塩基数(Yc)が、1~3塩基である、[20]に記載の核酸分子。
[23] 前記(A)において、前記領域(Xc)の塩基数(Xc)が、19~30塩基である、[10]~[13]のいずれかに記載の核酸分子。
[24] 塩基数の合計が80塩基以下である、[10]~[23]のいずれかに記載の核酸分子。
[25] RNA分子である、[10]~[24]のいずれかに記載の核酸分子。
[26] 前記(B)において、前記リンカー領域(Lx)および(Ly)が、1~20塩基のヌクレオチド残基から成る、[10]に記載の核酸分子。
[27] (i)のヌクレオチド配列と(iii)のヌクレオチド配列、または(ii)のヌクレオチド配列と(iv)のヌクレオチド配列とが、下記式で表される基で連結されている、[1]~[4]のいずれかに記載の核酸分子。 In the above formula,
X 1 and X 2 are each independently H 2 , O, S or NH;
Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S;
R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A;
L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or
L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other;
L 2 is an alkylene chain consisting of m carbon atoms, where the hydrogen atom on the alkylene carbon atom is replaced by OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c And / or
L 2 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 2 is NH, O or S, the atom of L 2 bonded to Y 2 is carbon, the atom of L 2 bonded to OR 2 is carbon, and oxygen atoms are not adjacent to each other;
R a , R b , R c and R d are each independently a substituent or a protecting group;
l is 1 or 2;
m is an integer ranging from 0 to 30;
n is an integer ranging from 0 to 30;
In ring A, one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen or sulfur.
The ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond,
The region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
The region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
Here, R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I).
[12] The number of bases (X) in the region (X) and the number of bases (Xc) in the 5′-side region (Xc) satisfy the condition of the following formula (3) or formula (5): [11] The nucleic acid molecule according to [11].
X> Xc (3)
X = Xc (5)
[13] The nucleic acid molecule according to [12], wherein the number of bases (X) in the region (X) and the number of bases (Xc) in the 5 ′ side region (Xc) satisfy the condition of the following formula (11).
X−Xc = 1, 2 or 3 (11)
[14] In (B), the number of bases (Z) in the region (Z), the number of bases (Xc) in the region (Xc), and the number of bases (Yc) in the region (Yc) are represented by the following formula (2): ), The nucleic acid molecule according to any one of [10] to [13].
Z ≧ Xc + Yc (2)
[15] In (B), the number of bases (X) in the region (X), the number of bases (Xc) in the (Xc), the number of bases (Y) in the region (Y), and the number of bases in the region (Yc) The nucleic acid molecule according to any one of [10] to [14], wherein the number of bases (Yc) satisfies any of the following conditions (a) to (d):
(A) Satisfy the conditions of the following formulas (3) and (4).
X> Xc (3)
Y = Yc (4)
(B) The conditions of the following formulas (5) and (6) are satisfied.
X = Xc (5)
Y> Yc (6)
(C) The conditions of the following formulas (7) and (8) are satisfied.
X> Xc (7)
Y> Yc (8)
(D) The conditions of the following formulas (9) and (10) are satisfied.
X = Xc (9)
Y = Yc (10)
[16] In (a) to (d), the difference between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc), the number of bases (Y) in the region (Y) The nucleic acid molecule according to [15], wherein the difference in the number of bases (Yc) in the region (Yc) satisfies the following condition.
(A) The conditions of the following formulas (11) and (12) are satisfied.
X−Xc = 1, 2 or 3 (11)
Y−Yc = 0 (12)
(B) The conditions of the following formulas (13) and (14) are satisfied.
X−Xc = 0 (13)
Y−Yc = 1, 2 or 3 (14)
(C) The conditions of the following formulas (15) and (16) are satisfied.
X−Xc = 1, 2 or 3 (15)
Y−Yc = 1, 2 or 3 (16)
(D) The conditions of the following formulas (17) and (18) are satisfied.
X−Xc = 0 (17)
Y−Yc = 0 (18)
[17] The nucleic acid molecule according to any one of [10] to [16], wherein in (B), the number of bases (Xc) in the region (Xc) is 1 to 11 bases.
[18] The nucleic acid molecule according to [17], wherein the number of bases (Xc) in the region (Xc) is 1 to 7 bases.
[19] The nucleic acid molecule according to [17], wherein the number of bases (Xc) in the region (Xc) is 1 to 3 bases.
[20] The nucleic acid molecule according to any one of [10] to [19], wherein in (B), the number of bases (Yc) in the region (Yc) is 1 to 11 bases.
[21] The nucleic acid molecule according to [20], wherein the number of bases (Yc) in the region (Yc) is 1 to 7 bases.
[22] The nucleic acid molecule according to [20], wherein the number of bases (Yc) in the region (Yc) is 1 to 3 bases.
[23] The nucleic acid molecule according to any one of [10] to [13], wherein in (A), the number of bases (Xc) in the region (Xc) is 19 to 30 bases.
[24] The nucleic acid molecule according to any one of [10] to [23], wherein the total number of bases is 80 or less.
[25] The nucleic acid molecule according to any one of [10] to [24], which is an RNA molecule.
[26] The nucleic acid molecule according to [10], wherein in (B), the linker regions (Lx) and (Ly) are composed of nucleotide residues of 1 to 20 bases.
[27] The nucleotide sequence of (i) and the nucleotide sequence of (iii), or the nucleotide sequence of (ii) and the nucleotide sequence of (iv) are linked by a group represented by the following formula: [1] The nucleic acid molecule according to any one of to [4].

[28] リンカー領域(Lx)および/またはリンカー領域(Ly)が下記式で表される基である、[10]~[25]のいずれかに記載の核酸分子。
[28] The nucleic acid molecule according to any one of [10] to [25], wherein the linker region (Lx) and / or the linker region (Ly) is a group represented by the following formula.

[29] 以下のいずれかで表される、[1]~[4]、[10]~[13]または[23]のいずれかに記載の核酸分子。
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
(該配列中、-Lx-は、下記式で表される基を示す。) [29] The nucleic acid molecule according to any one of [1] to [4], [10] to [13] or [23], which is represented by any of the following.
5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
(In the sequence, -Lx- represents a group represented by the following formula.)
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
(該配列中、-Lx-は、下記式で表される基を示す。) [29] The nucleic acid molecule according to any one of [1] to [4], [10] to [13] or [23], which is represented by any of the following.
5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
(In the sequence, -Lx- represents a group represented by the following formula.)

[30] 以下のいずれかで表される、[1]~[4]または[10]~[22]のいずれかに記載の核酸分子。
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18)
(該配列中、-Lx-および-Ly-は、下記式で表される基を示す。) [30] The nucleic acid molecule according to any one of [1] to [4] or [10] to [22], which is represented by any of the following.
5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
(In the sequence, -Lx- and -Ly- represent a group represented by the following formula.)
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18)
(該配列中、-Lx-および-Ly-は、下記式で表される基を示す。) [30] The nucleic acid molecule according to any one of [1] to [4] or [10] to [22], which is represented by any of the following.
5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
(In the sequence, -Lx- and -Ly- represent a group represented by the following formula.)

[31] 以下のいずれかで表される、[1]~[4]、[10]、[12]~[22]または[26]のいずれかに記載の核酸分子。
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16)
[32] [5]~[9]、[26]または[31]記載の核酸分子を発現する発現ベクター。
[33] [1]~[31]のいずれか記載の核酸分子又は[32]記載の発現ベクターを含む、医薬組成物。
[34] B型肝炎ウイルス増殖抑制用である、[33]記載の医薬組成物。
[35] B型肝炎の治療用である、[33]記載の医薬組成物。
[36] 肝硬変の治療用である、[33]記載の医薬組成物。
[37] 肝臓がんの治療用である、[33]記載の医薬組成物。 [31] The nucleic acid molecule according to any one of [1] to [4], [10], [12] to [22] or [26] represented by any of the following.
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16)
[32] An expression vector for expressing the nucleic acid molecule according to [5] to [9], [26] or [31].
[33] A pharmaceutical composition comprising the nucleic acid molecule according to any one of [1] to [31] or the expression vector according to [32].
[34] The pharmaceutical composition according to [33], which is used for inhibiting hepatitis B virus growth.
[35] The pharmaceutical composition according to [33], which is used for treatment of hepatitis B.
[36] The pharmaceutical composition according to [33], which is used for treating cirrhosis.
[37] The pharmaceutical composition according to [33], which is used for treatment of liver cancer.
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16)
[32] [5]~[9]、[26]または[31]記載の核酸分子を発現する発現ベクター。
[33] [1]~[31]のいずれか記載の核酸分子又は[32]記載の発現ベクターを含む、医薬組成物。
[34] B型肝炎ウイルス増殖抑制用である、[33]記載の医薬組成物。
[35] B型肝炎の治療用である、[33]記載の医薬組成物。
[36] 肝硬変の治療用である、[33]記載の医薬組成物。
[37] 肝臓がんの治療用である、[33]記載の医薬組成物。 [31] The nucleic acid molecule according to any one of [1] to [4], [10], [12] to [22] or [26] represented by any of the following.
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16)
[32] An expression vector for expressing the nucleic acid molecule according to [5] to [9], [26] or [31].
[33] A pharmaceutical composition comprising the nucleic acid molecule according to any one of [1] to [31] or the expression vector according to [32].
[34] The pharmaceutical composition according to [33], which is used for inhibiting hepatitis B virus growth.
[35] The pharmaceutical composition according to [33], which is used for treatment of hepatitis B.
[36] The pharmaceutical composition according to [33], which is used for treating cirrhosis.
[37] The pharmaceutical composition according to [33], which is used for treatment of liver cancer.
本発明の核酸分子によって、B型肝炎ウイルス遺伝子の発現を効果的に抑制することができる。本発明の核酸分子を含む医薬組成物は、B型肝炎ウイルス遺伝子、特に表面抗原遺伝子の発現を効果的に抑制することにより、B型肝炎ウイルス増殖抑制用、B型肝炎、肝硬変、肝臓がんの治療用として有用である。
The expression of the hepatitis B virus gene can be effectively suppressed by the nucleic acid molecule of the present invention. The pharmaceutical composition containing the nucleic acid molecule of the present invention effectively suppresses the expression of hepatitis B virus gene, particularly surface antigen gene, thereby suppressing hepatitis B virus growth, hepatitis B, cirrhosis, liver cancer. It is useful for the treatment of
1.核酸分子1. Nucleic acid molecule
本発明は、B型肝炎ウイルス遺伝子の発現抑制活性を有する核酸分子を提供する。
The present invention provides a nucleic acid molecule having activity of suppressing the expression of hepatitis B virus gene.
B型肝炎ウイルスは、感染により肝細胞に侵入して増殖する。B型肝炎ウイルスが異物と認識された場合、それを排除するために免疫機能が働くが、肝細胞の中のウイルスのみを選択的に攻撃することは不可能であり、肝細胞自体が攻撃を受けて破壊され、肝炎の発症をもたらす。B型肝炎が重症化した場合には、肝硬変や肝臓がんが引き起こされる。
¡Hepatitis B virus invades hepatocytes by infection and proliferates. When hepatitis B virus is recognized as a foreign body, the immune function works to eliminate it, but it is impossible to selectively attack only the virus in the hepatocyte, and the hepatocyte itself attacks. When received, it is destroyed, leading to the development of hepatitis. When hepatitis B becomes severe, cirrhosis and liver cancer are caused.
B型肝炎ウイルスは、遺伝情報を保存している不完全二重鎖DNA、DNAポリメラーゼが中心部に位置し、それがコア(HBc抗原)、外殻(HBe抗原)、および外膜(HBs抗原)に取り囲まれている構造を有する。
Hepatitis B virus has an incomplete double-stranded DNA in which genetic information is conserved, and a DNA polymerase is centrally located in the core (HBc antigen), outer shell (HBe antigen), and outer membrane (HBs antigen). ).
B型肝炎ウイルスが肝細胞に侵入すると、ウイルス遺伝子が肝細胞の核内に移動し、不完全環状二重鎖DNAが完全閉鎖二重鎖DNA、covalenty closed circular DNA(cccDNA)に転換される。肝細胞核内のcccDNAからは4種のmRNA(3.5kb、2.4kb、2.1kb、0.7kb)が転写され、それらより構造タンパク質であるHBs抗原、HBc抗原、HBe抗原および逆転写酵素活性を有するポリメラーゼ、Xタンパク質が翻訳される(Molecular Therapy 2013;21(5)973-985、Figure 3a)。
When hepatitis B virus invades hepatocytes, the viral gene moves into the nucleus of the hepatocytes, and the incomplete circular double-stranded DNA is converted into a completely closed double-stranded DNA, covalent circular DNA (cccDNA). Four kinds of mRNA (3.5 kb, 2.4 kb, 2.1 kb, 0.7 kb) are transcribed from cccDNA in hepatocyte nucleus, and HBs antigen, HBc antigen, HBe antigen and reverse transcriptase are structural proteins. An active polymerase, X protein, is translated (Molecular Therapy 2013; 21 (5) 973-985, FIG. 3a).
ウイルスゲノムおよび前記4種類のmRNAには、タンパク質として翻訳可能な4つのORF(open reading frame)(S ORF、コアORF、X ORF、ポリメラーゼORF)の一部または全部が存在する(Molecular Therapy 2013;21(5)973-985、Figure 3a)。S ORFはHBs抗原を構成する3種類のタンパク質、large Sタンパク質(pre-S1、pre-S2およびS領域を含む)、Middle Sタンパク質(pre-S2およびS領域を含む)、そしてSmall Sタンパク質(S領域のみから成る)をコードする。コアORFは、コアタンパク質およびプレコアタンパク質をコードする。コアタンパク質はコア粒子を形成し、プレコアタンパク質は19個の疎水性シグナルペプチドとC末端の34アミノ酸残基が切断された後にHBe抗原となる。X ORFは、ウイルスの増殖や肝細胞癌の発症に関与すると考えられているXタンパク質をコードする。また、ポリメラーゼORFは、逆転写酵素活性を有するDNAポリメラーゼタンパク質をコードする。
In the viral genome and the four types of mRNAs, there are some or all of four ORFs (open reading frames) (S ORF, core ORF, X ORF, polymerase ORF) that can be translated as proteins (Molecular Therapy 2013; 21 (5) 973-985, FIG. 3a). S ORF consists of three types of proteins that make up the HBs antigen, large S protein (including pre-S1, pre-S2 and S region), Middle S protein (including pre-S2 and S region), and Small S protein ( (Consisting only of the S region). The core ORF encodes a core protein and a precore protein. The core protein forms a core particle, and the pre-core protein becomes HBe antigen after 19 hydrophobic signal peptides and 34 amino acid residues at the C-terminus are cleaved. The X ORF codes for an X protein that is thought to be involved in virus growth and the development of hepatocellular carcinoma. The polymerase ORF encodes a DNA polymerase protein having reverse transcriptase activity.
あるタイプのmRNAはpregenomic RNAとしてコア粒子に取り込まれ、逆転写酵素の働きによりマイナス鎖DNAが合成され、次にプラス鎖DNAが合成され不完全環状二本鎖DNAとなる。さらに、HBs抗原より形成されるエンベロープに包まれてウイルス粒子(Dane粒子)となり血中に放出される。Dane粒子の血中放出以外の増殖ルートとして、mRNAにより翻訳されたHBs抗原、HBc抗原とp22cr抗原を含む中空粒子(DNAの核が無い粒子)や肝細胞膜を通過するHBe抗原などはDane粒子血中放出とは別ルートとして多量に血中に放出、分泌される。
A certain type of mRNA is incorporated into the core particle as pregenomic RNA, a minus-strand DNA is synthesized by the action of reverse transcriptase, and then a plus-strand DNA is synthesized into an incomplete circular double-stranded DNA. Furthermore, it is wrapped in an envelope formed from HBs antigens to become virus particles (Dane particles) and released into the blood. As a growth route other than the release of Dane particles in blood, HBs antigen translated by mRNA, hollow particles containing HBc antigen and p22cr antigen (particles without DNA nucleus), HBe antigen passing through liver cell membrane, etc. are Dane particle blood A large amount is released into the blood and secreted as a route different from the medium release.
B型肝炎の診断は、血液中の前記HBs抗原および/またはHBe抗原を検出することにより行われる。
血液中のHBs抗原が陽性であることは肝臓にHBVが存在し、HBVの成分が合成されていること、検査時にB型肝炎に感染していることを示す。血中のHBs抗原は肝臓内のウイルス増殖を把握し、治療完遂を判断する上での指標を提供する。
HBe抗原はHBVが増殖する際に過剰に産生されるタンパク質であり、肝臓でHBVが活発に増殖している状態で、感染力が強いことを示す。 Diagnosis of hepatitis B is performed by detecting the HBs antigen and / or HBe antigen in blood.
A positive HBs antigen in the blood indicates that HBV is present in the liver, HBV components are synthesized, and hepatitis B is infected at the time of examination. The HBs antigen in the blood grasps the virus growth in the liver and provides an index for judging the completion of treatment.
HBe antigen is a protein that is excessively produced when HBV proliferates, and indicates that infectivity is strong when HBV is actively proliferating in the liver.
血液中のHBs抗原が陽性であることは肝臓にHBVが存在し、HBVの成分が合成されていること、検査時にB型肝炎に感染していることを示す。血中のHBs抗原は肝臓内のウイルス増殖を把握し、治療完遂を判断する上での指標を提供する。
HBe抗原はHBVが増殖する際に過剰に産生されるタンパク質であり、肝臓でHBVが活発に増殖している状態で、感染力が強いことを示す。 Diagnosis of hepatitis B is performed by detecting the HBs antigen and / or HBe antigen in blood.
A positive HBs antigen in the blood indicates that HBV is present in the liver, HBV components are synthesized, and hepatitis B is infected at the time of examination. The HBs antigen in the blood grasps the virus growth in the liver and provides an index for judging the completion of treatment.
HBe antigen is a protein that is excessively produced when HBV proliferates, and indicates that infectivity is strong when HBV is actively proliferating in the liver.
核酸分子の、B型肝炎ウイルス遺伝子の発現抑制活性は、評価対象の核酸分子をB型肝炎ウイルスに感染した細胞またはB型肝炎ウイルスゲノムを導入した細胞(好ましくは、ヒト細胞)等に導入し、当該細胞外に放出された(移行した)B型肝炎ウイルスHBs抗原の量あるいはB型肝炎ウイルスHBe抗原の量を、評価対象の核酸分子を導入していないか、ネガティブコントロールの核酸分子を導入した、B型肝炎ウイルスに感染した細胞またはB型肝炎ウイルスゲノムを導入した細胞(好ましくは、ヒト細胞)から放出された(移行した)B型肝炎ウイルスHBs抗原の量あるいはB型肝炎ウイルスHBe抗原の量と比較すること等により評価することが出来る。B型肝炎ウイルスHBs抗原あるいはHBe抗原の量は、B型肝炎ウイルスHBs抗原あるいはHBe抗原を特異的に認識する抗体を用いて、公知の免疫学的手法により抗原を検出することにより評価することができる。免疫学的手法としては、フローサイトメトリー解析、放射性同位元素免疫測定法(RIA法)、ELISA法(Methods in Enzymol.70:419-439(1980))、ウェスタンブロッティング、免疫組織染色等を挙げることができる。
The nucleic acid molecule suppresses the expression of hepatitis B virus gene by introducing the nucleic acid molecule to be evaluated into a cell infected with hepatitis B virus or a cell into which hepatitis B virus genome has been introduced (preferably a human cell). The amount of hepatitis B virus HBs antigen released (translocated) or the amount of hepatitis B virus HBe antigen has not been introduced or a negative control nucleic acid molecule has been introduced. The amount of hepatitis B virus HBs antigen released or transferred from a cell infected with hepatitis B virus or a cell (preferably a human cell) into which hepatitis B virus genome has been introduced, or hepatitis B virus HBe antigen It can be evaluated by comparing it with the amount of. The amount of hepatitis B virus HBs antigen or HBe antigen can be evaluated by detecting the antigen by a known immunological technique using an antibody that specifically recognizes hepatitis B virus HBs antigen or HBe antigen. it can. Examples of immunological methods include flow cytometry analysis, radioisotope immunoassay (RIA method), ELISA method (Methods in Enzymol. 70: 419-439 (1980)), Western blotting, immunohistochemical staining, etc. Can do.
本発明は、以下の(i)または(ii)のヌクレオチド配列を発現抑制配列として含み、B型肝炎ウイルス遺伝子の発現抑制活性を有する、核酸分子を提供する
(i)配列番号2で表されるヌクレオチド配列;
配列番号2で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号2で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(ii)配列番号1で表されるヌクレオチド配列;
配列番号1で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号1で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。 The present invention provides a nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as an expression suppressing sequence and having an activity of suppressing the expression of hepatitis B virus gene: (i) represented by SEQ ID NO: 2 Nucleotide sequence;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having
(i)配列番号2で表されるヌクレオチド配列;
配列番号2で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号2で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(ii)配列番号1で表されるヌクレオチド配列;
配列番号1で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号1で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。 The present invention provides a nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as an expression suppressing sequence and having an activity of suppressing the expression of hepatitis B virus gene: (i) represented by SEQ ID NO: 2 Nucleotide sequence;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having
前記の配列番号1および2で表されるヌクレオチド配列は、以下の配列である。
5’-UCCACCACGAGUCUAGACU-3’(配列番号1)
5’-ACUCCCAUAGGAAUCUUGC-3’(配列番号2) The nucleotide sequences represented by SEQ ID NOs: 1 and 2 are the following sequences.
5'-UCCACCACGAGUCUAGACU-3 '(SEQ ID NO: 1)
5'-ACUCCCAUAGGAAUCUUGC-3 '(SEQ ID NO: 2)
5’-UCCACCACGAGUCUAGACU-3’(配列番号1)
5’-ACUCCCAUAGGAAUCUUGC-3’(配列番号2) The nucleotide sequences represented by SEQ ID NOs: 1 and 2 are the following sequences.
5'-UCCACCACGAGUCUAGACU-3 '(SEQ ID NO: 1)
5'-ACUCCCAUAGGAAUCUUGC-3 '(SEQ ID NO: 2)
配列番号1および2で表されるヌクレオチド配列は、B型肝炎ウイルスの遺伝子型C型(Genotype C)完全ゲノム(GenBank Accession No.AB014381、No.AB113875、No.AB113876、No.AB113878、No.AB113879、No.AB246344)のヌクレオチド配列中、ヌクレオチド番号245~263(5’-AGUCUAGACUCGUGGUGGA-3’(配列番号3))およびヌクレオチド番号629~647(5’-GCAAGAUUCCUAUGGGAGU-3’(配列番号4))に対応する配列に完全に相補的な配列にそれぞれ相当する。
The nucleotide sequences represented by SEQ ID NOs: 1 and 2 are the hepatitis B virus genotype C complete genome (GenBank Accession No. AB0143481, No. AB113875, No. AB113876, No. AB113878, No. AB113879). No. AB246344), nucleotide numbers 245 to 263 (5′-AGUCUAGACUCGUGGUGGA-3 ′ (SEQ ID NO: 3)) and nucleotide numbers 629 to 647 (5′-GCAAGAUUCCUAUGGGAGU-3 ′ (SEQ ID NO: 4)) Each corresponds to a sequence that is completely complementary to the corresponding sequence.
前記ヌクレオチド番号245~263およびヌクレオチド番号629~647で表される配列は、両方とも、B型肝炎ウイルスのSタンパク質およびポリメラーゼタンパク質のコーディング領域中の配列である。B型肝炎ウイルスゲノムの構造上、Sタンパク質およびポリメラーゼのコーディング領域は重複しているが、読み枠が異なっているため、別個のタンパク質に翻訳される。上記の通り、B型肝炎ウイルスゲノムから転写されるmRNAには、複数のORFが存在し得る。従って、本発明のB型肝炎ウイルス遺伝子の発現抑制活性を有する核酸分子によりB型肝炎ウイルス表面抗原遺伝子タンパク質をコードするmRNAの機能が阻害された場合、該RNAにコードされる他のタンパク質の翻訳も抑制されることがあり得る。本発明のB型肝炎ウイルス遺伝子の発現抑制活性を有する核酸分子によりB型肝炎ウイルス表面抗原遺伝子タンパク質の発現が抑制された場合、B型肝炎ウイルスの増殖が抑制され、結果的に他のB型肝炎ウイルス遺伝子の発現が抑制されることがあり得る。
The sequences represented by nucleotide numbers 245 to 263 and nucleotide numbers 629 to 647 are both sequences in the coding region of S protein and polymerase protein of hepatitis B virus. Due to the structure of the hepatitis B virus genome, the S protein and the coding region of the polymerase overlap, but they are translated into separate proteins due to the different reading frames. As described above, a plurality of ORFs may exist in mRNA transcribed from the hepatitis B virus genome. Therefore, when the function of mRNA encoding hepatitis B virus surface antigen gene protein is inhibited by the nucleic acid molecule having the activity of suppressing the expression of hepatitis B virus gene of the present invention, translation of other proteins encoded by the RNA May also be suppressed. When the expression of the hepatitis B virus surface antigen gene protein is suppressed by the nucleic acid molecule having the activity of suppressing the expression of hepatitis B virus gene of the present invention, the proliferation of hepatitis B virus is suppressed, and as a result, other B types Hepatitis virus gene expression may be suppressed.
発現抑制活性は、遺伝子転写の抑制、遺伝子転写産物分解、および/または遺伝子転写産物からのタンパク質の翻訳の阻害等により、結果的に遺伝子の発現が抑制されていることを意味する。
The expression suppression activity means that gene expression is suppressed as a result of suppression of gene transcription, degradation of gene transcript, and / or inhibition of protein translation from gene transcript.
前記配列番号2又は1で表されるヌクレオチド配列において、欠失、置換、挿入、もしくは付加されるヌクレオチドの数は、結果として得られる核酸分子が、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常1個または2個、好ましくは1個である。
In the nucleotide sequence represented by SEQ ID NO: 2 or 1, the number of nucleotides to be deleted, substituted, inserted or added is as long as the resulting nucleic acid molecule has activity of suppressing the expression of hepatitis B virus gene. Although it is not particularly limited, it is usually 1 or 2, preferably 1.
前記配列番号2又は1で表されるヌクレオチド配列において、置換される塩基の位置は、通常、5’末端から8塩基以内、好ましくは7、6、5、4、3、2もしくは1塩基以内、または3’末端から8塩基以内、好ましくは7、6、5、4、3、2もしくは1塩基以内である。
In the nucleotide sequence represented by SEQ ID NO: 2 or 1, the position of the base to be substituted is usually within 8 bases from the 5 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base, Alternatively, it is within 8 bases from the 3 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base.
一態様において、前記(i)のヌクレオチド配列は、配列番号5または配列番号7で表されるヌクレオチド配列であり得る。
In one embodiment, the nucleotide sequence (i) may be a nucleotide sequence represented by SEQ ID NO: 5 or SEQ ID NO: 7.
配列番号5で表されるヌクレオチド配列は、B型肝炎ウイルスの遺伝子型A型(Genotype A)、B型(Genotype B)の、配列番号2で表されるヌクレオチド配列(C型、Genotype C)に対応する配列である。配列番号5で表されるヌクレオチド配列は、配列番号2で表されるヌクレオチドの、3’末端から8番目の塩基及び5番目の塩基が、それぞれ、AからUへ、CからUへ置換された配列である。配列番号5で表されるヌクレオチド配列に完全に相補的な配列を、配列番号6に示す。
The nucleotide sequence represented by SEQ ID NO: 5 is the nucleotide sequence represented by SEQ ID NO: 2 (C type, Genotype C) of hepatitis B virus genotype A (Genotype A) and B type (Genotype B). Corresponding sequence. In the nucleotide sequence represented by SEQ ID NO: 5, the 8th base and the 5th base from the 3 ′ end of the nucleotide represented by SEQ ID NO: 2 were substituted from A to U and from C to U, respectively. Is an array. A sequence completely complementary to the nucleotide sequence represented by SEQ ID NO: 5 is shown in SEQ ID NO: 6.
配列番号7で表されるヌクレオチド配列は、B型肝炎ウイルスの遺伝子型D型(Genotype D)の、配列番号2で表されるヌクレオチド配列(C型、Genotype C)に対応する配列である。配列番号7で表されるヌクレオチド配列は、配列番号2で表されるヌクレオチドの、3’末端から5番目の塩基及び2番目の塩基が、それぞれ、CからUへ、GからCへ置換された配列である。配列番号7で表されるヌクレオチド配列に完全に相補的な配列を、配列番号8に示す。
The nucleotide sequence represented by SEQ ID NO: 7 is a sequence corresponding to the nucleotide sequence represented by SEQ ID NO: 2 (C type, Genotype C) of the hepatitis B virus genotype D (Genotype D). In the nucleotide sequence represented by SEQ ID NO: 7, the 5th base and the 2nd base from the 3 ′ end of the nucleotide represented by SEQ ID NO: 2 were substituted from C to U and from G to C, respectively. Is an array. A sequence completely complementary to the nucleotide sequence represented by SEQ ID NO: 7 is shown in SEQ ID NO: 8.
前記配列番号2又は1で表されるヌクレオチド配列において、欠失される塩基の位置は、通常、5’末端から5塩基以内、好ましくは4、3、2もしくは1塩基以内、または3’末端から5塩基以内、好ましくは4、3、2もしくは1塩基以内である。
In the nucleotide sequence represented by SEQ ID NO: 2 or 1, the position of the base to be deleted is usually within 5 bases from the 5 ′ end, preferably within 4, 3, 2 or 1 base, or from the 3 ′ end. Within 5 bases, preferably within 4, 3, 2 or 1 base.
前記配列番号2又は1で表されるヌクレオチド配列において、挿入される塩基の位置は、通常、5’末端から5塩基と4塩基の間、好ましくは4塩基と3塩基の間、3塩基と2塩基の間、もしくは2塩基と1塩基の間、または3’末端から5塩基と4塩基の間、好ましくは4塩基と3塩基の間、3塩基と2塩基の間、もしくは2塩基と1塩基の間である。
In the nucleotide sequence represented by SEQ ID NO: 2 or 1, the position of the base to be inserted is usually between 5 and 4 bases from the 5 ′ end, preferably between 4 and 3 bases, 3 bases and 2 bases. Between bases, or between 2 bases and 1 base, or between 5 bases and 4 bases from the 3 ′ end, preferably between 4 bases and 3 bases, between 3 bases and 2 bases, or between 2 bases and 1 base Between.
前記配列番号2又は1で表されるヌクレオチド配列において、塩基が付加される位置は、5’末端から1塩基、または3’末端から1塩基である。
In the nucleotide sequence represented by SEQ ID NO: 2 or 1, the position to which a base is added is 1 base from the 5 'end or 1 base from the 3' end.
前記配列番号2又は1で表されるヌクレオチド配列において、配列同一性の程度は、結果として得られる核酸分子が、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常85%以上、好ましくは90%以上である。
In the nucleotide sequence represented by SEQ ID NO: 2 or 1, the degree of sequence identity is not particularly limited as long as the resulting nucleic acid molecule has the activity of suppressing the expression of hepatitis B virus gene, but usually 85% Above, preferably 90% or more.
ヌクレオチド配列同一性は自体公知の方法により決定できる。例えば、当該分野で慣用のプログラム(例えば、BLAST、FASTA等)を初期設定で用いて決定することができる。例えば、NCBI BLAST(National Center for Biotechnology Information Basic Local Alignment Search Tool)を用い、以下の条件(期待値=10;ギャップコスト=Linear;フィルタリング=ON;マッチスコア=1;ミスマッチスコア=-2)にて計算することができる。別の局面では、同一性(%)は、当該分野で公知の任意のアルゴリズム、例えば、Needlemanら(1970)(J.Mol.Biol.48:444-453)、MyersおよびMiller(CABIOS,1988,4:11-17)のアルゴリズム等を使用して決定することができる。Needlemanらのアルゴリズムは、GCGソフトウェアパッケージのGAPプログラムに組み込まれており、同一性(%)は、例えば、BLOSUM 62 matrixまたはPAM250 matrix、ならびにgap weight:16、14、12、10、8、6もしくは4、およびlength weight:1、2、3、4、5もしくは6のいずれかを使用することによって決定することができる。また、MyersおよびMillerのアルゴリズムは、GCG配列アラインメントソフトウェアパッケージの一部であるALIGNプログラムに組み込まれている。ヌクレオチド配列を比較するためにALIGNプログラムを利用する場合、例えば、PAM120 weight residue table、gap length penalty 12、gap penalty 4を用いることができる。ヌクレオチド配列同一性の算出については、前記の方法のなかで最も低い値を示す方法を採用してもよい。
Nucleotide sequence identity can be determined by a method known per se. For example, a program commonly used in the field (for example, BLAST, FASTA, etc.) can be determined using the initial setting. For example, NCBI BLAST (National Center for Biotechnology Information Basic Alignment Search Search Tool) is used and the following conditions (expected value = 10; gap cost = Linear; filtering = ON; match score = 1) Can be calculated. In another aspect, identity (%) is determined by any algorithm known in the art, such as Needleman et al. (1970) (J. Mol. Biol. 48: 444-453), Myers and Miller (CABIOS, 1988, 4: 11-17) or the like. The Needleman et al. Algorithm is incorporated in the GAP program of the GCG software package, and the identity (%) is, for example, BLOSUM 62 matrix or PAM250 matrix, and gap weight: 16, 14, 12, 10, 8, 6 or 4 and length weight: 1, 2, 3, 4, 5 or 6 can be used. The Myers and Miller algorithms are also incorporated into the ALIGN program which is part of the GCG sequence alignment software package. When using the ALIGN program for comparing nucleotide sequences, for example, PAM120 weight restable table, gap length penalty 12, and gap penalty 4 can be used. For calculation of nucleotide sequence identity, a method showing the lowest value among the above methods may be adopted.
前記ヌクレオチド配列の長さは、17~21塩基長であり、好ましくは18~20塩基長、より好ましくは19塩基長である。
The length of the nucleotide sequence is 17 to 21 bases, preferably 18 to 20 bases, more preferably 19 bases.
前記発現抑制配列は、例えば、前記ヌクレオチド配列からなる配列でもよいし、前記ヌクレオチド配列を含む配列でもよい。
The expression suppression sequence may be, for example, a sequence consisting of the nucleotide sequence or a sequence containing the nucleotide sequence.
前記発現抑制配列の長さは、特に制限されず、例えば、18~32塩基長であり、好ましくは19~30塩基長であり、より好ましくは19、20、21塩基長である。本発明において、例えば、塩基数の数値範囲は、その範囲に属する正の整数を全て開示するものであり、例えば、「1~4塩基」との記載は、「1、2、3、4塩基」の全ての開示を意味する(以下、同様)。
The length of the expression suppression sequence is not particularly limited, and is, for example, 18 to 32 bases long, preferably 19 to 30 bases long, and more preferably 19, 20, or 21 bases long. In the present invention, for example, the numerical range of the number of bases discloses all positive integers belonging to the range. For example, the description “1 to 4 bases” includes “1, 2, 3, 4 bases”. "Means all disclosures (the same applies hereinafter).
本発明の核酸分子は、例えば、さらに、前記発現抑制配列とアニーリング可能な相補配列を有することが好ましい。前記相補配列は、例えば、前記発現抑制配列と同じ鎖にあり、1つの一本鎖から構成される一本鎖核酸分子を形成する。
The nucleic acid molecule of the present invention preferably further has, for example, a complementary sequence that can be annealed with the expression suppressing sequence. The complementary sequence is, for example, in the same strand as the expression suppressing sequence and forms a single-stranded nucleic acid molecule composed of one single strand.
前記相補配列は、例えば、前記発現抑制配列とアニーリング可能であればよい。前記相補配列は、例えば、前記発現抑制配列と、100%の相補性を示す配列でもよいし、アニーリング可能な範囲で100%未満の相補性を示す配列でもよい。前記相補性は、特に制限されず、例えば、90%~100%、93%~100%、95%~100%、98%~100%、99%~100%等が例示できる。
The complementary sequence only needs to be annealable with the expression suppression sequence, for example. The complementary sequence may be, for example, a sequence exhibiting 100% complementarity with the expression suppression sequence, or a sequence exhibiting complementarity of less than 100% within a range that can be annealed. The complementarity is not particularly limited, and examples thereof include 90% to 100%, 93% to 100%, 95% to 100%, 98% to 100%, and 99% to 100%.
一態様において、本発明の核酸分子は、(i)のヌクレオチド配列および(i)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iii)である相補配列;または
(ii)のヌクレオチド配列および(ii)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iv)である相補配列を含む。
(iii)配列番号4で表されるヌクレオチド配列;
配列番号4で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号4で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(iv)配列番号3で表されるヌクレオチド配列;
配列番号3で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号3で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。 In one embodiment, the nucleic acid molecule of the present invention is a nucleotide sequence of (i) and a complementary sequence capable of annealing to the nucleotide sequence of (i), wherein the complementary sequence is (iii) below; or ( a nucleotide sequence of ii) and a complementary sequence which can be annealed to the nucleotide sequence of (ii), wherein the complementary sequence is (iv) below.
(Iii) the nucleotide sequence represented by SEQ ID NO: 4;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 4; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 4 A nucleotide sequence represented by SEQ ID NO: 3;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 3; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 3 Nucleotide sequence having
(ii)のヌクレオチド配列および(ii)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iv)である相補配列を含む。
(iii)配列番号4で表されるヌクレオチド配列;
配列番号4で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号4で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(iv)配列番号3で表されるヌクレオチド配列;
配列番号3で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号3で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。 In one embodiment, the nucleic acid molecule of the present invention is a nucleotide sequence of (i) and a complementary sequence capable of annealing to the nucleotide sequence of (i), wherein the complementary sequence is (iii) below; or ( a nucleotide sequence of ii) and a complementary sequence which can be annealed to the nucleotide sequence of (ii), wherein the complementary sequence is (iv) below.
(Iii) the nucleotide sequence represented by SEQ ID NO: 4;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 4; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 4 A nucleotide sequence represented by SEQ ID NO: 3;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 3; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 3 Nucleotide sequence having
前記配列番号4又は3で表されるヌクレオチド配列において、欠失、置換、挿入、もしくは付加されるヌクレオチドの数は、結果として得られる核酸分子が、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常1個または2個、好ましくは1個である。
In the nucleotide sequence represented by SEQ ID NO: 4 or 3, the number of nucleotides to be deleted, substituted, inserted, or added is as long as the resulting nucleic acid molecule has the activity of suppressing the expression of hepatitis B virus gene. Although it is not particularly limited, it is usually 1 or 2, preferably 1.
前記配列番号4又は3で表されるヌクレオチド配列において、置換される塩基の位置は、通常、5’末端から8塩基以内、好ましくは7、6、5、4、3、2もしくは1塩基以内、または3’末端から8塩基以内、好ましくは7、6、5、4、3、2もしくは1塩基以内である。
In the nucleotide sequence represented by SEQ ID NO: 4 or 3, the position of the base to be substituted is usually within 8 bases from the 5 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base, Alternatively, it is within 8 bases from the 3 ′ end, preferably within 7, 6, 5, 4, 3, 2 or 1 base.
前記配列番号4又は3で表されるヌクレオチド配列において、欠失される塩基の位置は、通常、5’末端から5塩基以内、好ましくは4、3、2もしくは1塩基以内、または3’末端から5塩基以内、好ましくは4、3、2もしくは1塩基以内である。
In the nucleotide sequence represented by SEQ ID NO: 4 or 3, the position of the base to be deleted is usually within 5 bases from the 5 ′ end, preferably within 4, 3, 2 or 1 base, or from the 3 ′ end. Within 5 bases, preferably within 4, 3, 2 or 1 base.
前記配列番号4又は3で表されるヌクレオチド配列において、挿入される塩基の位置は、通常、5’末端から5塩基と4塩基の間、好ましくは4塩基と3塩基の間、3塩基と2塩基の間、もしくは2塩基と1塩基の間、または3’末端から5塩基と4塩基の間、好ましくは4塩基と3塩基の間、3塩基と2塩基の間、もしくは2塩基と1塩基の間である。
In the nucleotide sequence represented by SEQ ID NO: 4 or 3, the position of the base to be inserted is usually between 5 and 4 bases from the 5 ′ end, preferably between 4 and 3 bases, 3 bases and 2 bases. Between bases, or between 2 bases and 1 base, or between 5 bases and 4 bases from the 3 ′ end, preferably between 4 bases and 3 bases, between 3 bases and 2 bases, or between 2 bases and 1 base Between.
前記配列番号4又は3で表されるヌクレオチド配列において、塩基が付加される位置は、5’末端から1塩基、または3’末端から1塩基である。
In the nucleotide sequence represented by SEQ ID NO: 4 or 3, the position to which a base is added is one base from the 5 'end or one base from the 3' end.
前記配列番号4又は3で表されるヌクレオチド配列において、配列同一性の程度は、結果として得られる核酸分子が、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常85%以上、好ましくは約90%以上である。
In the nucleotide sequence represented by SEQ ID NO: 4 or 3, the degree of sequence identity is not particularly limited as long as the resulting nucleic acid molecule has the activity of suppressing the expression of hepatitis B virus gene, but usually 85% Above, preferably about 90% or more.
(iii)のヌクレオチド配列は、好ましくは、(i)のヌクレオチド配列に完全に相補的な配列であり、(iv)のヌクレオチド配列は、好ましくは、(ii)のヌクレオチド配列に完全に相補的な配列である。
The nucleotide sequence of (iii) is preferably a sequence that is completely complementary to the nucleotide sequence of (i), and the nucleotide sequence of (iv) is preferably completely complementary to the nucleotide sequence of (ii) Is an array.
本発明の核酸分子は、DNA分子、RNA分子、RNAとDNAのキメラ核酸(以下、キメラ核酸分子と称する)分子またはハイブリッド核酸分子であり得る。ここでキメラ核酸分子とは、一本鎖または二本鎖の核酸分子において一本の核酸分子の中にRNAとDNAを含むことをいい、ハイブリッド核酸分子とは、二本鎖において、一方の鎖がRNA分子またはキメラ核酸分子でもう一方の鎖がDNA分子またはキメラ核酸分子である核酸分子をいう。
The nucleic acid molecule of the present invention can be a DNA molecule, an RNA molecule, a chimeric nucleic acid molecule (hereinafter referred to as a chimeric nucleic acid molecule) or a hybrid nucleic acid molecule. The term “chimeric nucleic acid molecule” as used herein refers to a single-stranded or double-stranded nucleic acid molecule containing RNA and DNA in a single nucleic acid molecule, and a hybrid nucleic acid molecule refers to one strand of a double-stranded nucleic acid molecule. Is a RNA molecule or a chimeric nucleic acid molecule and the other strand is a DNA molecule or a chimeric nucleic acid molecule.
本発明の核酸分子は、一本鎖または二本鎖である。二本鎖の態様には、二本鎖RNA分子、二本鎖DNA分子、RNA/DNAハイブリッド核酸分子、RNA/キメラ核酸ハイブリッド核酸分子、キメラ核酸/キメラ核酸ハイブリッド核酸分子およびキメラ核酸/DNAハイブリッド核酸分子が含まれる。
The nucleic acid molecule of the present invention is single-stranded or double-stranded. Double stranded embodiments include double stranded RNA molecules, double stranded DNA molecules, RNA / DNA hybrid nucleic acid molecules, RNA / chimeric nucleic acid hybrid nucleic acid molecules, chimeric nucleic acid / chimeric nucleic acid hybrid nucleic acid molecules and chimeric nucleic acid / DNA hybrid nucleic acids Includes molecules.
なお、本明細書においてヌクレオチド配列は、別段にことわりのない限りRNAの配列として記載するが、ポリヌクレオチドがDNAである場合は、ウラシル(U)をチミン(T)に適宜読み替えるものとする。
In the present specification, the nucleotide sequence is described as an RNA sequence unless otherwise specified. However, when the polynucleotide is DNA, uracil (U) is appropriately read as thymine (T).
本発明の、B型肝炎ウイルス遺伝子の発現を特異的に抑制し得る核酸分子の形態としては、例えば、siRNA分子、dsRDC(double-strand RNA DNA Chimera)分子、下記の本発明の一本鎖核酸分子、アンチセンス核酸分子、アンチジーン分子、リボザイム分子、アプタマー分子等が挙げられる。
Examples of the form of the nucleic acid molecule capable of specifically suppressing the expression of the hepatitis B virus gene of the present invention include, for example, siRNA molecules, dsRDC (double-strand RNA DNA Chimera) molecules, and the following single-stranded nucleic acids of the present invention. Molecule, antisense nucleic acid molecule, antigene molecule, ribozyme molecule, aptamer molecule and the like.
本発明の核酸分子の長さは、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常17塩基以上、好ましくは19塩基以上、より好ましくは21塩基以上である。本発明の核酸分子の長さは、合成の容易さや抗原性の問題等から、通常200塩基以下、好ましくは150塩基以下、より好ましくは100塩基以下(例、90塩基以下、80塩基以下、70塩基以下、60塩基以下、50塩基以下)である。即ち、本発明の核酸分子の長さは、通常、17塩基~200塩基、好ましくは19塩基~150塩基、より好ましくは21塩基~100塩基(21塩基~90塩基、21塩基~80塩基、約21塩基~70塩基、21塩基~60塩基、21塩基~50塩基)である。
The length of the nucleic acid molecule of the present invention is not particularly limited as long as it has the activity of suppressing the expression of hepatitis B virus gene, but it is usually 17 bases or more, preferably 19 bases or more, more preferably 21 bases or more. The length of the nucleic acid molecule of the present invention is usually 200 bases or less, preferably 150 bases or less, more preferably 100 bases or less (eg, 90 bases or less, 80 bases or less, 70 or less) because of ease of synthesis or antigenicity problems. Bases or less, 60 bases or less, 50 bases or less). That is, the length of the nucleic acid molecule of the present invention is generally 17 bases to 200 bases, preferably 19 bases to 150 bases, more preferably 21 bases to 100 bases (21 bases to 90 bases, 21 bases to 80 bases, about 21 bases to 70 bases, 21 bases to 60 bases, 21 bases to 50 bases).
前記核酸分子の塩基数の合計は、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常17塩基以上、好ましくは19塩基以上、より好ましくは21塩基以上である。本発明の核酸分子の塩基数の合計は、合成の容易さや抗原性の問題等から、通常400塩基以下、好ましくは300塩基以下、より好ましくは200塩基以下(例、180塩基以下、160塩基以下、140塩基以下、120塩基以下、100塩基以下、90塩基以下、80塩基以下、70塩基以下、60塩基以下、50塩基以下)である。即ち、本発明の核酸分子の長さは、通常、17塩基~400塩基、好ましくは19塩基~300塩基、より好ましくは21塩基~200塩基(21塩基~180塩基、21塩基~160塩基、約21塩基~140塩基、21塩基~120塩基、21塩基~100塩基、21塩基~90塩基、21塩基~80塩基、21塩基~70塩基、21塩基~60塩基、21塩基~50塩基)である。
The total number of bases of the nucleic acid molecule is not particularly limited as long as it has activity to suppress the expression of hepatitis B virus gene, but is usually 17 bases or more, preferably 19 bases or more, more preferably 21 bases or more. The total number of bases of the nucleic acid molecule of the present invention is usually 400 bases or less, preferably 300 bases or less, more preferably 200 bases or less (eg, 180 bases or less, 160 bases or less) due to ease of synthesis or antigenicity problems. 140 bases or less, 120 bases or less, 100 bases or less, 90 bases or less, 80 bases or less, 70 bases or less, 60 bases or less, 50 bases or less). That is, the length of the nucleic acid molecule of the present invention is generally 17 bases to 400 bases, preferably 19 bases to 300 bases, more preferably 21 bases to 200 bases (21 bases to 180 bases, 21 bases to 160 bases, 21 bases to 140 bases, 21 bases to 120 bases, 21 bases to 100 bases, 21 bases to 90 bases, 21 bases to 80 bases, 21 bases to 70 bases, 21 bases to 60 bases, 21 bases to 50 bases) .
本発明の核酸分子は、好ましくは単離されている。「単離」とは、目的とする成分以外の因子を除去する操作がなされ、天然に存在する状態を脱していることを意味する。「単離された核酸」の純度(評価対象物の総重量に占める目的とする核酸重量の百分率)は、通常70%以上、好ましくは80%以上、より好ましくは90%以上、更に好ましくは99%以上である。
2.二本鎖核酸分子 The nucleic acid molecules of the present invention are preferably isolated. “Isolated” means that an operation to remove factors other than the target component has been performed, and that the naturally occurring state has been removed. The purity of the “isolated nucleic acid” (percentage of the target nucleic acid weight in the total weight of the evaluation target) is usually 70% or more, preferably 80% or more, more preferably 90% or more, and still more preferably 99%. % Or more.
2. Double-stranded nucleic acid molecule
2.二本鎖核酸分子 The nucleic acid molecules of the present invention are preferably isolated. “Isolated” means that an operation to remove factors other than the target component has been performed, and that the naturally occurring state has been removed. The purity of the “isolated nucleic acid” (percentage of the target nucleic acid weight in the total weight of the evaluation target) is usually 70% or more, preferably 80% or more, more preferably 90% or more, and still more preferably 99%. % Or more.
2. Double-stranded nucleic acid molecule
一態様において、上記本発明の核酸分子は二本鎖核酸分子である。該二本鎖核酸分子は、一方の鎖に(i)のヌクレオチド配列を、他方の鎖に該(i)のヌクレオチド配列にアニーリングした配列を含むか、または一方の鎖に(ii)のヌクレオチド配列を、他方の鎖に該(ii)のヌクレオチド配列にアニーリングした配列を含む。(i)のヌクレオチド配列にアニーリングした配列は、アニーリング可能な配列であれば特に限定されないが、好ましくは(iii)のヌクレオチド配列である。(ii)のヌクレオチド配列にアニーリングした配列は、アニーリング可能な配列であれば特に限定されないが、好ましくは(iv)のヌクレオチド配列である。
In one embodiment, the nucleic acid molecule of the present invention is a double-stranded nucleic acid molecule. The double-stranded nucleic acid molecule comprises a nucleotide sequence of (i) on one strand and a sequence annealed to the nucleotide sequence of (i) on the other strand, or a nucleotide sequence of (ii) on one strand In the other strand is annealed to the nucleotide sequence of (ii). The sequence annealed to the nucleotide sequence (i) is not particularly limited as long as it can be annealed, but is preferably the nucleotide sequence (iii). The sequence annealed to the nucleotide sequence of (ii) is not particularly limited as long as it can be annealed, but is preferably the nucleotide sequence of (iv).
前記二本鎖核酸分子においては、前記(i)、(ii)、(iii)および(iv)のヌクレオチド配列は、それぞれ配列番号2、1、4、3で表されるヌクレオチド配列であり得る。
In the double-stranded nucleic acid molecule, the nucleotide sequences (i), (ii), (iii), and (iv) may be nucleotide sequences represented by SEQ ID NOs: 2, 1, 4, 3, respectively.
二本鎖の本発明の核酸分子の長さは、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常17塩基以上、好ましくは19塩基以上、より好ましくは21塩基以上である。二本鎖の本発明の核酸分子の長さは、合成の容易さや抗原性の問題等から、通常100塩基以下、好ましくは75塩基以下、より好ましくは50塩基以下(例、45塩基以下、40塩基以下、35塩基以下、30塩基以下、25塩基以下、24塩基以下、23塩基以下、22塩基以下)である。即ち、本発明の核酸分子の長さは、通常、17塩基~100塩基、好ましくは19塩基~75塩基、より好ましくは21塩基~50塩基(21塩基~45塩基、21塩基~40塩基、約21塩基~35塩基、21塩基~30塩基、21塩基~25塩基、21塩基~24塩基、21塩基~23塩基、21塩基~22塩基)である。
The length of the double-stranded nucleic acid molecule of the present invention is not particularly limited as long as it has the activity of suppressing the expression of hepatitis B virus gene, but is usually 17 bases or more, preferably 19 bases or more, more preferably 21 bases or more. is there. The length of the double-stranded nucleic acid molecule of the present invention is usually 100 bases or less, preferably 75 bases or less, more preferably 50 bases or less (eg, 45 bases or less, 40 or less, for ease of synthesis or antigenicity problems). Bases, 35 bases, 30 bases, 25 bases, 24 bases, 23 bases, 22 bases). That is, the length of the nucleic acid molecule of the present invention is usually 17 to 100 bases, preferably 19 to 75 bases, more preferably 21 to 50 bases (21 to 45 bases, 21 to 40 bases, 21 bases to 35 bases, 21 bases to 30 bases, 21 bases to 25 bases, 21 bases to 24 bases, 21 bases to 23 bases, 21 bases to 22 bases).
前記二本鎖核酸分子は、5’および/または3’末端に塩基対を形成しない、付加的な塩基(オーバーハング配列)を有していてもよい。該オーバーハング配列の長さは、siRNAが標的遺伝子の発現を特異的に抑制可能である限り特に限定されないが、通常5塩基以下、例えば2~4塩基である。該付加的塩基は、DNAでもRNAでもよいが、DNAを用いるとRNA分子の安定性を向上させることができる。このような付加的塩基の配列としては、例えばug-3’、uu-3’、tg-3’、tt-3’、ggg-3’、guuu-3’、gttt-3’、ttttt-3’、uuuuu-3’などの配列が挙げられるが、これに限定されるものではない。
The double-stranded nucleic acid molecule may have an additional base (overhang sequence) that does not form a base pair at the 5 'and / or 3' end. The length of the overhang sequence is not particularly limited as long as siRNA can specifically suppress the expression of the target gene, but is usually 5 bases or less, for example, 2 to 4 bases. The additional base may be DNA or RNA, but the use of DNA can improve the stability of the RNA molecule. Examples of such an additional base sequence include ug-3 ′, uu-3 ′, tg-3 ′, tt-3 ′, ggg-3 ′, guuu-3 ′, gttt-3 ′, and tttttt-3. Examples of the sequence include ', uuuu-3', but are not limited thereto.
二本鎖の前記核酸分子の塩基数の合計は、B型肝炎ウイルス遺伝子の発現抑制活性を有する限り、特に限定されないが、通常34塩基以上、好ましくは38塩基以上、より好ましくは42塩基以上である。二本鎖の本発明の核酸分子の塩基数の合計は、合成の容易さや抗原性の問題等から、通常200塩基以下、好ましくは150塩基以下、より好ましくは100塩基以下(例、90塩基以下、80塩基以下、70塩基以下、60塩基以下、50塩基以下、48塩基以下、46塩基以下、44塩基以下)である。即ち、本発明の核酸分子の長さは、通常、34塩基~200塩基、好ましくは38塩基~150塩基、より好ましくは42塩基~100塩基(42塩基~90塩基、42塩基~80塩基、約42塩基~70塩基、42塩基~60塩基、42塩基~50塩基、42塩基~48塩基、42塩基~46塩基、42塩基~44塩基)である。
The total number of bases of the double-stranded nucleic acid molecule is not particularly limited as long as it has the activity of suppressing the expression of hepatitis B virus gene, but is usually 34 bases or more, preferably 38 bases or more, more preferably 42 bases or more. is there. The total number of bases of the double-stranded nucleic acid molecule of the present invention is usually 200 bases or less, preferably 150 bases or less, more preferably 100 bases or less (eg, 90 bases or less) from the viewpoint of ease of synthesis and antigenicity. 80 bases or less, 70 bases or less, 60 bases or less, 50 bases or less, 48 bases or less, 46 bases or less, 44 bases or less). That is, the length of the nucleic acid molecule of the present invention is usually 34 to 200 bases, preferably 38 to 150 bases, more preferably 42 to 100 bases (42 to 90 bases, 42 to 80 bases, 42 bases to 70 bases, 42 bases to 60 bases, 42 bases to 50 bases, 42 bases to 48 bases, 42 bases to 46 bases, 42 bases to 44 bases).
前記オーバーハング配列が付加された好ましい配列としては、例えば、配列番号9、10、11、12で表される、配列番号1、2、3、4で表されるヌクレオチド配列にtt-3’がそれぞれ付加された配列が挙げられる。
As a preferable sequence to which the overhang sequence is added, for example, tt-3 ′ is added to the nucleotide sequence represented by SEQ ID NO: 1, 2, 3, 4 represented by SEQ ID NO: 9, 10, 11, 12. Each added sequence can be mentioned.
前記二本鎖核酸分子は、好ましくは、以下に示される、配列番号10で表されるヌクレオチド配列および該配列にアニーリングした配列番号12で表されるヌクレオチド配列;または
配列番号9で表されるヌクレオチド配列および該配列にアニーリングした配列番号11で表されるヌクレオチド配列
から成る二本鎖核酸分子である。 The double-stranded nucleic acid molecule is preferably a nucleotide sequence represented by SEQ ID NO: 10 and a nucleotide sequence represented by SEQ ID NO: 12 annealed to the sequence shown below; or a nucleotide represented by SEQ ID NO: 9 A double-stranded nucleic acid molecule comprising a sequence and a nucleotide sequence represented by SEQ ID NO: 11 annealed to the sequence.
配列番号9で表されるヌクレオチド配列および該配列にアニーリングした配列番号11で表されるヌクレオチド配列
から成る二本鎖核酸分子である。 The double-stranded nucleic acid molecule is preferably a nucleotide sequence represented by SEQ ID NO: 10 and a nucleotide sequence represented by SEQ ID NO: 12 annealed to the sequence shown below; or a nucleotide represented by SEQ ID NO: 9 A double-stranded nucleic acid molecule comprising a sequence and a nucleotide sequence represented by SEQ ID NO: 11 annealed to the sequence.
前記二本鎖核酸分子は、好ましくは、下記に示されるsiRNA分子である。本明細書中、siRNAは、前記二本鎖核酸分子のうち、オーバーハング配列以外の塩基配列がリボヌクレオチド残基のみで構成されているものを指す。
The double-stranded nucleic acid molecule is preferably an siRNA molecule shown below. In the present specification, siRNA refers to the double-stranded nucleic acid molecule in which the base sequence other than the overhang sequence is composed only of ribonucleotide residues.

3.一本鎖核酸分子
本発明の核酸分子は、前述のように、B型肝炎ウイルス遺伝子の発現抑制用であって、B型肝炎ウイルス遺伝子の発現抑制配列として、前記(i)または(ii)のヌクレオチド配列を含むことを特徴とする。 3. Single-stranded nucleic acid molecule As described above, the nucleic acid molecule of the present invention is used for suppressing the expression of the hepatitis B virus gene, and as the expression suppressing sequence for the hepatitis B virus gene, the nucleic acid molecule of the above (i) or (ii) It is characterized by comprising a nucleotide sequence.
本発明の核酸分子は、前述のように、B型肝炎ウイルス遺伝子の発現抑制用であって、B型肝炎ウイルス遺伝子の発現抑制配列として、前記(i)または(ii)のヌクレオチド配列を含むことを特徴とする。 3. Single-stranded nucleic acid molecule As described above, the nucleic acid molecule of the present invention is used for suppressing the expression of the hepatitis B virus gene, and as the expression suppressing sequence for the hepatitis B virus gene, the nucleic acid molecule of the above (i) or (ii) It is characterized by comprising a nucleotide sequence.
前記発現抑制配列は、例えば、前記ヌクレオチド配列からなる配列でもよいし、前記ヌクレオチド配列を含む配列でもよい。
The expression suppression sequence may be, for example, a sequence consisting of the nucleotide sequence or a sequence containing the nucleotide sequence.
前記発現抑制配列の長さは、特に制限されず、例えば、18~32塩基長であり、好ましくは19~30塩基長であり、より好ましくは19、20、21塩基長である。本発明において、例えば、塩基数の数値範囲は、その範囲に属する正の整数を全て開示するものであり、例えば、「1~4塩基」との記載は、「1、2、3、4塩基」の全ての開示を意味する(以下、同様)。
The length of the expression suppression sequence is not particularly limited, and is, for example, 18 to 32 bases long, preferably 19 to 30 bases long, and more preferably 19, 20, or 21 bases long. In the present invention, for example, the numerical range of the number of bases discloses all positive integers belonging to the range. For example, the description “1 to 4 bases” includes “1, 2, 3, 4 bases”. "Means all disclosures (the same applies hereinafter).
一本鎖の本発明の核酸分子は、例えば、さらに、前記発現抑制配列とアニーリング可能な相補配列を有することが好ましい。前記相補配列は、例えば、前記発現抑制配列と同じ鎖にあり、1つの一本鎖から構成される一本鎖核酸分子を形成する。
It is preferable that the single-stranded nucleic acid molecule of the present invention further has, for example, a complementary sequence that can be annealed with the expression suppressing sequence. The complementary sequence is, for example, in the same strand as the expression suppressing sequence and forms a single-stranded nucleic acid molecule composed of one single strand.
前記相補配列は、例えば、前記発現抑制配列とアニーリング可能であればよい。前記相補配列は、例えば、前記発現抑制配列と、100%の相補性を示す配列でもよいし、アニーリング可能な範囲で100%未満の相補性を示す配列でもよい。前記相補性は、特に制限されず、例えば、90%~100%、93%~100%、95%~100%、98%~100%、99%~100%等が例示できる。
The complementary sequence only needs to be annealable with the expression suppression sequence, for example. The complementary sequence may be, for example, a sequence exhibiting 100% complementarity with the expression suppression sequence, or a sequence exhibiting complementarity of less than 100% within a range that can be annealed. The complementarity is not particularly limited, and examples thereof include 90% to 100%, 93% to 100%, 95% to 100%, 98% to 100%, and 99% to 100%.
前記相補配列は、例えば、前記(iii)または(iv)のヌクレオチド配列を含む。
The complementary sequence includes, for example, the nucleotide sequence (iii) or (iv).
以下、前記(iii)または(iv)のヌクレオチド配列をsヌクレオチド配列という。
Hereinafter, the nucleotide sequence (iii) or (iv) is referred to as an s nucleotide sequence.
前記相補配列は、例えば、前記sヌクレオチド配列からなる配列でもよいし、前記sヌクレオチド配列を含む配列でもよい。
The complementary sequence may be, for example, a sequence composed of the s nucleotide sequence or a sequence containing the s nucleotide sequence.
前記相補配列の長さは、特に制限されず、例えば、18~32塩基長であり、好ましくは19~30塩基長であり、より好ましくは19、20、21塩基長である。
The length of the complementary sequence is not particularly limited, and is, for example, 18 to 32 bases long, preferably 19 to 30 bases long, and more preferably 19, 20, or 21 bases long.
前記発現抑制配列と前記相補配列はそれぞれ、例えば、リボヌクレオチド残基のみからなるRNA分子でもよいし、リボヌクレオチド残基の他に、デオキシリボヌクレオチド残基を含むRNA分子でもよい。
The expression suppression sequence and the complementary sequence may each be, for example, an RNA molecule consisting only of ribonucleotide residues, or an RNA molecule containing deoxyribonucleotide residues in addition to ribonucleotide residues.
前記核酸分子は、例えば、前記発現抑制配列と前記相補配列とが、直接的に連結している形態および間接的に連結している形態があげられる。前記直接的な連結は、例えば、ホスホジエステル結合による連結があげられる。前記間接的な連結は、例えば、リンカー領域を介した連結があげられる。前記発現抑制配列と前記相補配列との連結順序は、特に制限されず、例えば、前記発現抑制配列の3’末端と前記相補配列の5’末端とが連結してもよく、前記発現抑制配列の5’末端と前記相補配列の3’末端とが連結してもよく、好ましくは後者である。前記リンカー領域は、例えば、ヌクレオチド残基から構成されてもよいし、非ヌクレオチド残基から構成されてもよく、前記ヌクレオチド残基および非ヌクレオチド残基から構成されてもよい。前記ヌクレオチド残基は、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基があげられる。
Examples of the nucleic acid molecule include a form in which the expression suppressing sequence and the complementary sequence are directly linked and a form in which they are indirectly linked. Examples of the direct linking include linking by a phosphodiester bond. Examples of the indirect linkage include linkage via a linker region. The order in which the expression suppressing sequence and the complementary sequence are linked is not particularly limited, and for example, the 3 ′ end of the expression suppressing sequence and the 5 ′ end of the complementary sequence may be linked. The 5 ′ end may be linked to the 3 ′ end of the complementary sequence, preferably the latter. The linker region may be composed of, for example, nucleotide residues, may be composed of non-nucleotide residues, or may be composed of the nucleotide residues and non-nucleotide residues. Examples of the nucleotide residue include a ribonucleotide residue and a deoxyribonucleotide residue.
以下に、前記一本鎖核酸分子の具体例を例示するが、本発明は、これには制限されない。
Hereinafter, specific examples of the single-stranded nucleic acid molecule will be exemplified, but the present invention is not limited thereto.
(3-1)
前記一本鎖核酸分子の第1形態として、5’側領域および3’側領域が、互いにアニーリングして二重鎖構造(ステム構造)を形成する分子があげられる。これは、shRNA(small hairpin RNAまたはshort hairpin RNA)の形態とも言える。shRNAは、ヘアピン構造をとっており、一般的に、一つのステム領域と一つのループ領域とを有する。 (3-1)
As a first form of the single-stranded nucleic acid molecule, a molecule in which a 5′-side region and a 3′-side region are annealed with each other to form a double-stranded structure (stem structure) can be mentioned. This can also be said to be a form of shRNA (small hairpin RNA or short hairpin RNA). The shRNA has a hairpin structure and generally has one stem region and one loop region.
前記一本鎖核酸分子の第1形態として、5’側領域および3’側領域が、互いにアニーリングして二重鎖構造(ステム構造)を形成する分子があげられる。これは、shRNA(small hairpin RNAまたはshort hairpin RNA)の形態とも言える。shRNAは、ヘアピン構造をとっており、一般的に、一つのステム領域と一つのループ領域とを有する。 (3-1)
As a first form of the single-stranded nucleic acid molecule, a molecule in which a 5′-side region and a 3′-side region are annealed with each other to form a double-stranded structure (stem structure) can be mentioned. This can also be said to be a form of shRNA (small hairpin RNA or short hairpin RNA). The shRNA has a hairpin structure and generally has one stem region and one loop region.
本形態の核酸分子は、例えば、領域(X)、リンカー領域(Lx)および領域(Xc)を含み、前記領域(X)と前記領域(Xc)との間に、前記リンカー領域(Lx)が連結された構造をとる。そして、前記領域(Xc)が、前記領域(X)と相補的である構造が好ましく、具体的には、前記領域(X)および前記領域(Xc)のうち、一方が、前記発現抑制配列を含み、他方が、前記相補配列を含むことが好ましい。前記領域(X)と前記領域(Xc)は、それぞれ、前記発現抑制配列および前記相補配列のいずれかを有するため、例えば、分子内アニーリングにより、ステム構造を形成でき、前記リンカー領域(Lx)がループ構造となる。
The nucleic acid molecule of this embodiment includes, for example, a region (X), a linker region (Lx), and a region (Xc), and the linker region (Lx) is between the region (X) and the region (Xc). Takes a linked structure. The region (Xc) preferably has a structure complementary to the region (X). Specifically, one of the region (X) and the region (Xc) has the expression suppressing sequence. Preferably, the other includes the complementary sequence. Since the region (X) and the region (Xc) each have one of the expression suppression sequence and the complementary sequence, for example, a stem structure can be formed by intramolecular annealing, and the linker region (Lx) It becomes a loop structure.
前記核酸分子は、例えば、5’側から3’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)を、前記順序で有してもよいし、3’側から5’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)を、前記順序で有してもよい。前記発現抑制配列は、例えば、前記領域(X)と前記領域(Xc)のいずれに配置してもよく、前記相補配列の下流側、すなわち、前記相補配列よりも3’側に配置することが好ましい。
The nucleic acid molecule may have, for example, the region (Xc), the linker region (Lx), and the region (X) in the order from 5 ′ side to 3 ′ side, or from the 3 ′ side. You may have the said area | region (Xc), the said linker area | region (Lx), and the said area | region (X) in the said order toward 5 'side. The expression suppression sequence may be arranged, for example, in either the region (X) or the region (Xc), and may be arranged downstream of the complementary sequence, that is, 3 ′ side of the complementary sequence. preferable.
本形態の核酸分子の一例を、図1の模式図に示す。図1(A)は、各領域の順序の概略を示す模式図であり、図1(B)は、前記核酸分子が、前記分子内において二重鎖を形成している状態を示す模式図である。図1(B)に示すように、前記核酸分子は、前記領域(Xc)と前記領域(X)との間で、二重鎖が形成され、前記Lx領域が、その長さに応じてループ構造をとる。図1は、あくまでも、前記領域の連結順序および二重鎖を形成する各領域の位置関係を示すものであり、例えば、各領域の長さ、前記リンカー領域(Lx)の形状等は、これに制限されない。
An example of the nucleic acid molecule of this embodiment is shown in the schematic diagram of FIG. FIG. 1A is a schematic diagram showing an outline of the order of each region, and FIG. 1B is a schematic diagram showing a state in which the nucleic acid molecule forms a double strand in the molecule. is there. As shown in FIG. 1B, the nucleic acid molecule forms a double strand between the region (Xc) and the region (X), and the Lx region loops according to its length. Take the structure. FIG. 1 merely shows the linking order of the regions and the positional relationship of each region forming a duplex. For example, the length of each region, the shape of the linker region (Lx), etc. Not limited.
前記核酸分子において、前記領域(Xc)および前記領域(X)の塩基数は、特に制限されない。以下に各領域の長さを例示するが、本発明は、これには制限されない。
In the nucleic acid molecule, the number of bases in the region (Xc) and the region (X) is not particularly limited. Although the length of each area | region is illustrated below, this invention is not restrict | limited to this.
前記核酸分子において、前記領域(X)の塩基数(X)と前記領域(Xc)の塩基数(Xc)との関係は、例えば、下記(3)または(5)の条件を満たし、前者の場合、具体的には、例えば、下記(11)の条件を満たす。
X>Xc ・・・(3)
X-Xc=1~10、好ましくは1、2または3、
より好ましくは1または2 ・・・(11)
X=Xc ・・・(5) In the nucleic acid molecule, the relationship between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc) satisfies, for example, the following (3) or (5) In this case, specifically, for example, the following condition (11) is satisfied.
X> Xc (3)
X−Xc = 1 to 10, preferably 1, 2 or 3,
More preferably 1 or 2 (11)
X = Xc (5)
X>Xc ・・・(3)
X-Xc=1~10、好ましくは1、2または3、
より好ましくは1または2 ・・・(11)
X=Xc ・・・(5) In the nucleic acid molecule, the relationship between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc) satisfies, for example, the following (3) or (5) In this case, specifically, for example, the following condition (11) is satisfied.
X> Xc (3)
X−Xc = 1 to 10, preferably 1, 2 or 3,
More preferably 1 or 2 (11)
X = Xc (5)
前記領域(X)または前記領域(Xc)が前記発現抑制配列を含む場合、前記領域は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の塩基数は、例えば、前述の通りである。前記発現抑制配列を含む領域は、例えば、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~31塩基であり、好ましくは、1~21塩基であり、より好ましくは、1~11塩基である。
When the region (X) or the region (Xc) includes the expression suppression sequence, the region may be a region composed of only the expression suppression sequence or a region including the expression suppression sequence, for example. The number of bases of the expression suppression sequence is, for example, as described above. The region containing the expression suppression sequence may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence, for example. The number of bases of the additional sequence is, for example, 1 to 31 bases, preferably 1 to 21 bases, and more preferably 1 to 11 bases.
前記領域(Xc)の塩基数は、特に制限されない。前記領域(X)が、前記発現抑制配列を含む場合、Xcの下限は、例えば、19塩基である。その上限は、例えば、50塩基であり、好ましくは30塩基であり、より好ましくは25塩基である。前記領域(Xc)の塩基数の具体例は、例えば、19塩基~50塩基であり、好ましくは、19塩基~30塩基、より好ましくは19塩基~25塩基である。
The number of bases in the region (Xc) is not particularly limited. When the region (X) includes the expression suppression sequence, the lower limit of Xc is, for example, 19 bases. The upper limit is, for example, 50 bases, preferably 30 bases, and more preferably 25 bases. Specific examples of the number of bases in the region (Xc) are, for example, 19 to 50 bases, preferably 19 to 30 bases, more preferably 19 to 25 bases.
前記領域(X)の塩基数は、特に制限されない。その下限は、例えば、19塩基であり、好ましくは20塩基であり、より好ましくは21塩基である。その上限は、例えば、50塩基であり、より好ましくは40塩基であり、さらに好ましくは30塩基である。
The number of bases in the region (X) is not particularly limited. The lower limit is, for example, 19 bases, preferably 20 bases, and more preferably 21 bases. The upper limit is 50 bases, for example, More preferably, it is 40 bases, More preferably, it is 30 bases.
前記リンカー領域(Lx)は、それ自体の領域内部において、自己アニーリングを生じない構造であることが好ましい。
The linker region (Lx) preferably has a structure that does not cause self-annealing within its own region.
前記リンカー領域(Lx)が、前述のようにヌクレオチド残基を含む場合、その長さは、特に制限されない。前記リンカー領域(Lx)は、例えば、前記領域(X)と前記領域(Xc)とが二重鎖を形成可能な長さであることが好ましい。前記リンカー領域(Lx)の塩基数は、その下限が、例えば、1塩基であり、好ましくは2塩基であり、より好ましくは3塩基であり、その上限が、例えば、100塩基であり、好ましくは80塩基であり、より好ましくは50塩基である。
When the linker region (Lx) includes a nucleotide residue as described above, the length is not particularly limited. For example, the linker region (Lx) preferably has a length that allows the region (X) and the region (Xc) to form a double chain. The lower limit of the number of bases in the linker region (Lx) is, for example, 1 base, preferably 2 bases, more preferably 3 bases, and the upper limit thereof is, for example, 100 bases, preferably 80 bases, more preferably 50 bases.
前記核酸分子の全長は、特に制限されない。前記核酸分子において、前記塩基数の合計(全長の塩基数)は、下限が、例えば、38塩基であり、好ましくは40塩基であり、より好ましくは42塩基であり、さらに好ましくは44塩基であり、特に好ましくは46塩基であり、その上限は、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。前記核酸分子において、前記リンカー領域(Lx)を除く塩基数の合計は、下限が、例えば、38塩基であり、好ましくは40塩基であり、より好ましくは42塩基であり、さらに好ましくは44塩基であり、特に好ましくは46塩基であり、上限が、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。
The total length of the nucleic acid molecule is not particularly limited. In the nucleic acid molecule, the lower limit of the total number of bases (the total number of bases) is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, still more preferably 44 bases. The base is particularly preferably 46 bases, and the upper limit thereof is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, and particularly preferably 80 bases. . In the nucleic acid molecule, the lower limit of the total number of bases excluding the linker region (Lx) is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, still more preferably 44 bases. Yes, particularly preferably 46 bases, and the upper limit is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, particularly preferably 80 bases. .
(3-2)
前記一本鎖核酸分子の第2形態として、5’側領域および3’側領域が、それぞれ別個に分子内アニーリングして、2つの二重鎖構造(ステム構造)を形成する分子があげられる。 (3-2)
A second form of the single-stranded nucleic acid molecule is a molecule in which the 5 ′ region and the 3 ′ region are separately annealed in the molecule to form two double-stranded structures (stem structures).
前記一本鎖核酸分子の第2形態として、5’側領域および3’側領域が、それぞれ別個に分子内アニーリングして、2つの二重鎖構造(ステム構造)を形成する分子があげられる。 (3-2)
A second form of the single-stranded nucleic acid molecule is a molecule in which the 5 ′ region and the 3 ′ region are separately annealed in the molecule to form two double-stranded structures (stem structures).
本形態の核酸分子は、例えば、5’側から3’側にかけて、5’側領域(Xc)、内部領域(Z)および3’側領域(Yc)を、前記順序で含み、前記内部領域(Z)が、内部5’側領域(X)および内部3’側領域(Y)が連結して構成され、前記5’側領域(Xc)が、前記内部5’側領域(X)と相補的であり、前記3’側領域(Yc)が、前記内部3’側領域(Y)と相補的である構造が好ましい。そして、前記内部領域(Z)、前記5’側領域(Xc)および前記3’側領域(Yc)の少なくとも一つが、前記発現抑制配列を含むことが好ましい。具体的には、前記内部領域(Z)の前記内部5’側領域(X)が前記発現抑制配列を有する場合、前記5’側領域(Xc)が前記相補配列を有することが好ましく、前記内部領域(Z)の前記内部3’側領域(Y)が前記発現抑制配列を有する場合、前記3’側領域(Yc)が前記相補配列を有することが好ましい。また、前記5’側領域(Xc)が前記発現抑制配列を有する場合、前記内部領域(Z)の前記内部5’側領域(X)が前記相補配列を有することが好ましく、前記3’側領域(Yc)が前記発現抑制配列を有する場合、前記内部領域(Z)の前記内部3’側領域(Y)が前記相補配列を有することが好ましい。
The nucleic acid molecule of the present embodiment includes, for example, a 5 ′ side region (Xc), an internal region (Z), and a 3 ′ side region (Yc) from the 5 ′ side to the 3 ′ side in the order described above. Z) is formed by connecting an inner 5 ′ side region (X) and an inner 3 ′ side region (Y), and the 5 ′ side region (Xc) is complementary to the inner 5 ′ side region (X). And the 3 ′ side region (Yc) is preferably complementary to the inner 3 ′ side region (Y). And it is preferable that at least one of the internal region (Z), the 5 'side region (Xc) and the 3' side region (Yc) includes the expression suppressing sequence. Specifically, when the internal 5 ′ region (X) of the internal region (Z) has the expression suppressing sequence, the 5 ′ region (Xc) preferably has the complementary sequence, When the internal 3 ′ side region (Y) of the region (Z) has the expression suppressing sequence, the 3 ′ side region (Yc) preferably has the complementary sequence. In addition, when the 5 ′ region (Xc) has the expression suppressing sequence, the inner 5 ′ region (X) of the inner region (Z) preferably has the complementary sequence, and the 3 ′ region When (Yc) has the expression suppression sequence, the internal 3 ′ side region (Y) of the internal region (Z) preferably has the complementary sequence.
前記核酸分子において、前記5’側領域(Xc)は、前記内部5’側領域(X)と相補的であり、前記3’側領域(Yc)は、前記内部3’側領域(Y)と相補的である。このため、5’側において、前記領域(Xc)が前記領域(X)に向かって折り返し、前記領域(Xc)と前記領域(X)とが、自己アニーリングによって、二重鎖を形成可能であり、また、3’側において、前記領域(Yc)が前記領域(Y)に向かって折り返し、前記領域(Yc)と前記領域(Y)とが、自己アニーリングによって、二重鎖を形成可能である。
In the nucleic acid molecule, the 5′-side region (Xc) is complementary to the inner 5′-side region (X), and the 3′-side region (Yc) is the inner 3′-side region (Y). Complementary. Therefore, on the 5 ′ side, the region (Xc) is folded toward the region (X), and the region (Xc) and the region (X) can form a double chain by self-annealing. In addition, on the 3 ′ side, the region (Yc) is folded toward the region (Y), and the region (Yc) and the region (Y) can form a double chain by self-annealing. .
前記内部領域(Z)は、前述のように、前記内部5’領域(X)と前記内部3’領域(Y)が連結されている。前記領域(X)と前記領域(Y)は、例えば、直接的に連結され、その間に介在配列を有していない。前記内部領域(Z)は、前記5’側領域(Xc)および前記3’側領域(Yc)との配列関係を示すために、「前記内部5’側領域(X)と前記内部3’側領域(Y)が連結して構成される」と表わすものであって、前記内部領域(Z)において、前記5’側領域(Xc)と前記3’側領域(Yc)とが、例えば、前記核酸分子の使用において、別個の独立した領域であることを限定するものではない。すなわち、例えば、前記内部領域(Z)が、前記発現抑制配列を有する場合、前記内部領域(Z)において、前記領域(X)と前記領域(Y)とにわたって、前記発現抑制配列が配置されてもよい。
As described above, the inner region (Z) is connected to the inner 5 'region (X) and the inner 3' region (Y). The region (X) and the region (Y) are directly connected, for example, and do not have an intervening sequence therebetween. The inner region (Z) is defined as “the inner 5 ′ side region (X) and the inner 3 ′ side in order to indicate the arrangement relationship between the 5 ′ side region (Xc) and the 3 ′ side region (Yc)”. The region (Y) is connected to each other ”, and in the inner region (Z), the 5 ′ side region (Xc) and the 3 ′ side region (Yc) are, for example, The use of nucleic acid molecules is not limited to being a separate and independent region. That is, for example, when the internal region (Z) has the expression suppression sequence, the expression suppression sequence is arranged across the region (X) and the region (Y) in the internal region (Z). Also good.
前記核酸分子において、前記5’側領域(Xc)と前記内部5’側領域(X)とは、例えば、直接連結してもよいし、間接的に連結してもよい。前者の場合、直接的な連結は、例えば、ホスホジエステル結合による連結があげられる。後者の場合、例えば、前記領域(Xc)と前記領域(X)との間に、リンカー領域(Lx)を有し、前記リンカー領域(Lx)を介して、前記領域(Xc)と前記領域(X)とが連結している形態があげられる。
In the nucleic acid molecule, the 5 'side region (Xc) and the inner 5' side region (X) may be directly connected or indirectly connected, for example. In the former case, direct linkage includes, for example, linkage by a phosphodiester bond. In the latter case, for example, a linker region (Lx) is provided between the region (Xc) and the region (X), and the region (Xc) and the region ( And X) are linked together.
前記核酸分子において、前記3’側領域(Yc)と前記内部3’側領域(Y)とは、例えば、直接連結してもよいし、間接的に連結してもよい。前者の場合、直接的な連結は、例えば、ホスホジエステル結合による連結があげられる。後者の場合、例えば、前記領域(Yc)と前記領域(Y)との間に、リンカー領域(Ly)を有し、前記リンカー領域(Ly)を介して、前記領域(Yc)と前記領域(Y)とが連結している形態があげられる。
In the nucleic acid molecule, the 3'-side region (Yc) and the internal 3'-side region (Y) may be directly connected or indirectly connected, for example. In the former case, direct linkage includes, for example, linkage by a phosphodiester bond. In the latter case, for example, a linker region (Ly) is provided between the region (Yc) and the region (Y), and the region (Yc) and the region ( And Y) are linked.
前記核酸分子は、例えば、前記リンカー領域(Lx)および前記リンカー領域(Ly)の両方を有してもよいし、いずれか一方を有してもよい。後者の場合、例えば、前記5’側領域(Xc)と前記内部5’側領域(X)との間に前記リンカー領域(Lx)を有し、前記3’側領域(Yc)と前記内部3’側領域(Y)との間に前記リンカー領域(Ly)を有さない、つまり、前記領域(Yc)と前記領域(Y)とが直接連結された形態があげられる。また、後者の場合、例えば、前記3’側領域(Yc)と前記内部3’側領域(Y)との間に前記リンカー領域(Ly)を有し、前記5’側領域(Xc)と前記内部5’側領域(X)との間に前記リンカー領域(Lx)を有さない、つまり、前記領域(Xc)と前記領域(X)とが直接連結された形態があげられる。
The nucleic acid molecule may have, for example, both the linker region (Lx) and the linker region (Ly), or one of them. In the latter case, for example, the linker region (Lx) is provided between the 5 ′ side region (Xc) and the inner 5 ′ side region (X), and the 3 ′ side region (Yc) and the inner 3 'The linker region (Ly) is not present between the side region (Y), that is, the region (Yc) and the region (Y) are directly linked. In the latter case, for example, the linker region (Ly) is provided between the 3 ′ side region (Yc) and the inner 3 ′ side region (Y), and the 5 ′ side region (Xc) and the The linker region (Lx) is not provided between the internal 5′-side region (X), that is, the region (Xc) and the region (X) are directly linked.
前記リンカー領域(Lx)および前記リンカー領域(Ly)は、それぞれ、それ自体の領域内部において、自己アニーリングを生じない構造であることが好ましい。
The linker region (Lx) and the linker region (Ly) each preferably have a structure that does not cause self-annealing within its own region.
本形態の核酸分子について、前記リンカー領域を有さない一例を、図2の模式図に示す。図2(A)は、前記核酸分子について、5’側から3’側に向かって、各領域の順序の概略を示す模式図であり、図2(B)は、前記核酸分子が、前記分子内において二重鎖を形成している状態を示す模式図である。図2(B)に示すように、前記核酸分子は、前記5’側領域(Xc)が折り返し、前記5’側領域(Xc)と前記内部5’側領域(X)との間で二重鎖が形成され、前記3’側領域(Yc)が折り返し、前記3’側領域(Yc)と前記内部3’側領域(Y)との間で二重鎖が形成される。図2は、あくまでも、各領域の連結順番および二重鎖を形成する各領域の位置関係を示すものであり、例えば、各領域の長さ等は、これに制限されない。
An example of the nucleic acid molecule of this embodiment that does not have the linker region is shown in the schematic diagram of FIG. FIG. 2 (A) is a schematic diagram showing an outline of the order of each region from the 5 ′ side to the 3 ′ side of the nucleic acid molecule, and FIG. 2 (B) shows that the nucleic acid molecule is the molecule. It is a schematic diagram which shows the state which forms the double chain | strand in the inside. As shown in FIG. 2 (B), the nucleic acid molecule is folded between the 5′-side region (Xc) and doubled between the 5′-side region (Xc) and the internal 5′-side region (X). A chain is formed, the 3 ′ side region (Yc) is folded, and a double chain is formed between the 3 ′ side region (Yc) and the inner 3 ′ side region (Y). FIG. 2 merely shows the connection order of the regions and the positional relationship of the regions forming the double chain. For example, the length of each region is not limited to this.
前記核酸分子について、前記リンカー領域を有する一例を、図3の模式図に示す。図3(A)は、一例として、前記核酸分子について、5’側から3’側に向かって、各領域の順序の概略を示す模式図であり、図3(B)は、前記核酸分子が、前記分子内において二重鎖を形成している状態を示す模式図である。図3(B)に示すように、前記核酸分子は、前記5’側領域(Xc)と前記内部5’側領域(X)との間、前記内部3’側領域(Y)と前記3’側領域(Yc)との間で、二重鎖が形成され、前記Lx領域および前記Ly領域が、ループ構造をとる。図3は、あくまでも、各領域の連結順番および二重鎖を形成する各領域の位置関係を示すものであり、例えば、各領域の長さ等は、これに制限されない。
An example of the nucleic acid molecule having the linker region is shown in the schematic diagram of FIG. FIG. 3A is a schematic diagram showing, as an example, an outline of the order of each region from the 5 ′ side to the 3 ′ side of the nucleic acid molecule, and FIG. FIG. 2 is a schematic diagram showing a state in which a double chain is formed in the molecule. As shown in FIG. 3 (B), the nucleic acid molecule is divided between the 5′-side region (Xc) and the inner 5′-side region (X), and between the inner 3′-side region (Y) and the 3′-side. A double chain is formed with the side region (Yc), and the Lx region and the Ly region have a loop structure. FIG. 3 merely shows the order of connection of the regions and the positional relationship of the regions forming the double chain. For example, the length of each region is not limited thereto.
前記核酸分子において、前記5’側領域(Xc)、前記内部5’側領域(X)、前記内部3’側領域(Y)および前記3’側領域(Yc)の塩基数は、特に制限されず、例えば、以下の通りである。
In the nucleic acid molecule, the number of bases in the 5 ′ region (Xc), the internal 5 ′ region (X), the internal 3 ′ region (Y) and the 3 ′ region (Yc) is particularly limited. For example, it is as follows.
前記5’側領域(Xc)は、前述のように、例えば、前記内部5’側領域(X)の全領域に相補的でもよい。この場合、前記領域(Xc)は、例えば、前記領域(X)と同じ塩基長であり、前記領域(X)の5’末端から3’末端の全領域に相補的な塩基配列からなることが好ましい。前記領域(Xc)は、より好ましくは、前記領域(X)と同じ塩基長であり、且つ、前記領域(Xc)の全ての塩基が、前記領域(X)の全ての塩基と相補的である、つまり、例えば、完全に相補的であることが好ましい。なお、これには制限されず、例えば、前述のように、1ないし数(2、3、4もしくは5)塩基が非相補的でもよい。
As described above, the 5′-side region (Xc) may be complementary to the entire region of the inner 5′-side region (X), for example. In this case, for example, the region (Xc) has the same base length as the region (X), and is composed of a base sequence complementary to the entire region from the 5 ′ end to the 3 ′ end of the region (X). preferable. More preferably, the region (Xc) has the same base length as the region (X), and all bases in the region (Xc) are complementary to all bases in the region (X). That is, for example, it is preferably completely complementary. However, the present invention is not limited to this. For example, as described above, 1 to several (2, 3, 4 or 5) bases may be non-complementary.
また、前記5’側領域(Xc)は、前述のように、例えば、前記内部5’側領域(X)の部分領域に相補的でもよい。この場合、前記領域(Xc)は、例えば、前記領域(X)の部分領域と同じ塩基長であり、すなわち、前記領域(X)よりも、1塩基以上短い塩基長の塩基配列からなることが好ましい。前記領域(Xc)は、より好ましくは、前記領域(X)の前記部分領域と同じ塩基長であり、且つ、前記領域(Xc)の全ての塩基が、前記領域(X)の前記部分領域の全ての塩基と相補的である、つまり、例えば、完全に相補的であることが好ましい。前記領域(X)の前記部分領域は、例えば、前記領域(X)における、5’末端の塩基(1番目の塩基)から連続する塩基配列からなる領域(セグメント)であることが好ましい。
Further, as described above, the 5′-side region (Xc) may be complementary to a partial region of the inner 5′-side region (X), for example. In this case, the region (Xc) has, for example, the same base length as the partial region of the region (X), that is, consists of a base sequence having a base length shorter by one base or more than the region (X). preferable. More preferably, the region (Xc) has the same base length as the partial region of the region (X), and all the bases of the region (Xc) are included in the partial region of the region (X). It is preferred that it is complementary to all bases, that is, for example, completely complementary. The partial region of the region (X) is preferably, for example, a region (segment) having a base sequence continuous from the 5 ′ terminal base (first base) in the region (X).
前記3’側領域(Yc)は、前述のように、例えば、前記内部3’側領域(Y)の全領域に相補的でもよい。この場合、前記領域(Yc)は、例えば、前記領域(Y)と同じ塩基長であり、前記領域(Y)の5’末端から3’末端の全領域に相補的な塩基配列からなることが好ましい。前記領域(Yc)は、より好ましくは、前記領域(Y)と同じ塩基長であり、且つ、前記領域(Yc)の全ての塩基が、前記領域(Y)の全ての塩基と相補的である、つまり、例えば、完全に相補であることが好ましい。なお、これには制限されず、例えば、前述のように、1ないし数(2、3、4もしくは5)塩基が非相補的でもよい。
As described above, the 3′-side region (Yc) may be complementary to the entire region of the inner 3′-side region (Y), for example. In this case, the region (Yc) has, for example, the same base length as the region (Y) and is composed of a base sequence complementary to the entire region from the 5 ′ end to the 3 ′ end of the region (Y). preferable. More preferably, the region (Yc) has the same base length as the region (Y), and all bases in the region (Yc) are complementary to all bases in the region (Y). That is, for example, it is preferable to be completely complementary. However, the present invention is not limited to this. For example, as described above, 1 to several (2, 3, 4 or 5) bases may be non-complementary.
また、前記3’側領域(Yc)は、前述のように、例えば、前記内部3’側領域(Y)の部分領域に相補的でもよい。この場合、前記領域(Yc)は、例えば、前記領域(Y)の部分領域と同じ塩基長であり、すなわち、前記領域(Y)よりも、1塩基以上短い塩基長の塩基配列からなることが好ましい。前記領域(Yc)は、より好ましくは、前記領域(Y)の前記部分領域と同じ塩基長であり、且つ、前記領域(Yc)の全ての塩基が、前記領域(Y)の前記部分領域の全ての塩基と相補的である、つまり、例えば、完全に相補であることが好ましい。前記領域(Y)の前記部分領域は、例えば、前記領域(Y)における、3’末端の塩基(1番目の塩基)から連続する塩基配列からなる領域(セグメント)であることが好ましい。
Further, as described above, the 3′-side region (Yc) may be complementary to a partial region of the inner 3′-side region (Y), for example. In this case, the region (Yc) has, for example, the same base length as the partial region of the region (Y), that is, consists of a base sequence having a base length shorter by one base or more than the region (Y). preferable. More preferably, the region (Yc) has the same base length as the partial region of the region (Y), and all the bases of the region (Yc) are included in the partial region of the region (Y). It is preferred that it is complementary to all bases, that is, for example, completely complementary. The partial region of the region (Y) is preferably, for example, a region (segment) having a base sequence continuous from the base at the 3 'end (first base) in the region (Y).
前記核酸分子において、前記内部領域(Z)の塩基数(Z)と、前記内部5’側領域(X)の塩基数(X)および前記内部3’側領域(Y)の塩基数(Y)との関係、前記内部領域(Z)の塩基数(Z)と、前記5’側領域(Xc)の塩基数(Xc)および前記3’側領域(Yc)の塩基数(Yc)との関係は、例えば、下記式(1)および(2)の条件を満たす。
Z=X+Y ・・・(1)
Z≧Xc+Yc ・・・(2) In the nucleic acid molecule, the number of bases (Z) in the internal region (Z), the number of bases (X) in the internal 5 ′ side region (X), and the number of bases (Y) in the internal 3 ′ side region (Y) Relationship between the number of bases (Z) in the internal region (Z), the number of bases (Xc) in the 5′-side region (Xc), and the number of bases (Yc) in the 3′-side region (Yc) Satisfies, for example, the conditions of the following formulas (1) and (2).
Z = X + Y (1)
Z ≧ Xc + Yc (2)
Z=X+Y ・・・(1)
Z≧Xc+Yc ・・・(2) In the nucleic acid molecule, the number of bases (Z) in the internal region (Z), the number of bases (X) in the internal 5 ′ side region (X), and the number of bases (Y) in the internal 3 ′ side region (Y) Relationship between the number of bases (Z) in the internal region (Z), the number of bases (Xc) in the 5′-side region (Xc), and the number of bases (Yc) in the 3′-side region (Yc) Satisfies, for example, the conditions of the following formulas (1) and (2).
Z = X + Y (1)
Z ≧ Xc + Yc (2)
本発明の核酸分子において、前記内部5’側領域(X)の塩基数(X)と前記内部3’側領域(Y)の塩基数(Y)の長さの関係は、特に制限されず、例えば、下記式のいずれの条件を満たしてもよい。
X=Y ・・・(19)
X<Y ・・・(20)
X>Y ・・・(21) In the nucleic acid molecule of the present invention, the relationship between the number of bases (X) in the inner 5 ′ region (X) and the number of bases (Y) in the inner 3 ′ region (Y) is not particularly limited, For example, any condition of the following formula may be satisfied.
X = Y (19)
X <Y (20)
X> Y (21)
X=Y ・・・(19)
X<Y ・・・(20)
X>Y ・・・(21) In the nucleic acid molecule of the present invention, the relationship between the number of bases (X) in the inner 5 ′ region (X) and the number of bases (Y) in the inner 3 ′ region (Y) is not particularly limited, For example, any condition of the following formula may be satisfied.
X = Y (19)
X <Y (20)
X> Y (21)
前記核酸分子において、前記内部5’側領域(X)の塩基数(X)、前記5’側領域(Xc)の塩基数(Xc)、前記内部3’側領域(Y)の塩基数(Y)および前記3’側領域(Yc)の塩基数(Yc)の関係は、例えば、下記(a)~(d)のいずれかの条件を満たす。
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10) In the nucleic acid molecule, the number of bases (X) in the inner 5 ′ side region (X), the number of bases (Xc) in the 5 ′ side region (Xc), the number of bases in the inner 3 ′ side region (Y) (Y ) And the number of bases (Yc) in the 3′-side region (Yc) satisfy, for example, the following conditions (a) to (d).
(A) Satisfy the conditions of the following formulas (3) and (4).
X> Xc (3)
Y = Yc (4)
(B) The conditions of the following formulas (5) and (6) are satisfied.
X = Xc (5)
Y> Yc (6)
(C) The conditions of the following formulas (7) and (8) are satisfied.
X> Xc (7)
Y> Yc (8)
(D) The conditions of the following formulas (9) and (10) are satisfied.
X = Xc (9)
Y = Yc (10)
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10) In the nucleic acid molecule, the number of bases (X) in the inner 5 ′ side region (X), the number of bases (Xc) in the 5 ′ side region (Xc), the number of bases in the inner 3 ′ side region (Y) (Y ) And the number of bases (Yc) in the 3′-side region (Yc) satisfy, for example, the following conditions (a) to (d).
(A) Satisfy the conditions of the following formulas (3) and (4).
X> Xc (3)
Y = Yc (4)
(B) The conditions of the following formulas (5) and (6) are satisfied.
X = Xc (5)
Y> Yc (6)
(C) The conditions of the following formulas (7) and (8) are satisfied.
X> Xc (7)
Y> Yc (8)
(D) The conditions of the following formulas (9) and (10) are satisfied.
X = Xc (9)
Y = Yc (10)
前記(a)~(d)において、前記内部5’側領域(X)の塩基数(X)と前記5’側領域(Xc)の塩基数(Xc)の差、前記内部3’側領域(Y)の塩基数(Y)と前記3’側領域(Yc)の塩基数(Yc)の差は、例えば、下記条件を満たすことが好ましい。(a)下記式(11)および(12)の条件を満たす。
X-Xc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(15)
Y-Yc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18) In (a) to (d), the difference between the number of bases (X) in the inner 5 ′ side region (X) and the number of bases (Xc) in the 5 ′ side region (Xc), the inner 3 ′ side region ( The difference between the number of bases (Y) of Y) and the number of bases (Yc) of the 3 ′ side region (Yc) preferably satisfies the following condition, for example. (A) The conditions of the following formulas (11) and (12) are satisfied.
X−Xc = 1 to 10, preferably 1, 2, 3 or 4,
More preferably 1, 2 or 3 (11)
Y−Yc = 0 (12)
(B) The conditions of the following formulas (13) and (14) are satisfied.
X−Xc = 0 (13)
Y−Yc = 1 to 10, preferably 1, 2, 3 or 4,
More preferably 1, 2 or 3 (14)
(C) The conditions of the following formulas (15) and (16) are satisfied.
X−Xc = 1 to 10, preferably 1, 2 or 3,
More preferably 1 or 2 (15)
Y−Yc = 1 to 10, preferably 1, 2 or 3,
More preferably 1 or 2 (16)
(D) The conditions of the following formulas (17) and (18) are satisfied.
X−Xc = 0 (17)
Y−Yc = 0 (18)
X-Xc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1~10、好ましくは1、2、3または4、
より好ましくは1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(15)
Y-Yc=1~10、好ましくは、1、2または3、
より好ましくは1または2 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18) In (a) to (d), the difference between the number of bases (X) in the inner 5 ′ side region (X) and the number of bases (Xc) in the 5 ′ side region (Xc), the inner 3 ′ side region ( The difference between the number of bases (Y) of Y) and the number of bases (Yc) of the 3 ′ side region (Yc) preferably satisfies the following condition, for example. (A) The conditions of the following formulas (11) and (12) are satisfied.
X−Xc = 1 to 10, preferably 1, 2, 3 or 4,
More preferably 1, 2 or 3 (11)
Y−Yc = 0 (12)
(B) The conditions of the following formulas (13) and (14) are satisfied.
X−Xc = 0 (13)
Y−Yc = 1 to 10, preferably 1, 2, 3 or 4,
More preferably 1, 2 or 3 (14)
(C) The conditions of the following formulas (15) and (16) are satisfied.
X−Xc = 1 to 10, preferably 1, 2 or 3,
More preferably 1 or 2 (15)
Y−Yc = 1 to 10, preferably 1, 2 or 3,
More preferably 1 or 2 (16)
(D) The conditions of the following formulas (17) and (18) are satisfied.
X−Xc = 0 (17)
Y−Yc = 0 (18)
前記(a)~(d)の核酸分子について、それぞれの構造の一例を、図4の模式図に示す。図4は、前記リンカー領域(Lx)および前記リンカー領域(Ly)を含む核酸分子であり、(A)は、前記(a)の核酸分子、(B)は、前記(b)の核酸分子、(C)は、前記(c)の核酸分子、(D)は、前記(d)の核酸分子の例である。図4において、点線は、自己アニーリングにより二重鎖を形成している状態を示す。図4の核酸分子は、前記内部5’側領域(X)の塩基数(X)と前記内部3’側領域(Y)の塩基数(Y)を、前記式(20)の「X<Y」として表わすが、これには制限されず、前述のように、前記式(19)の「X=Y」でも、前記式(21)の「X>Y」でもよい。また、図4は、あくまでも、前記内部5’側領域(X)と前記5’側領域(Xc)との関係、前記内部3’側領域(Y)と前記3’側領域(Yc)との関係を示す模式図であり、例えば、各領域の長さ、形状等は、これには制限されず、また、リンカー領域(Lx)およびリンカー領域(Ly)の有無も、これには制限されない。
An example of the structure of each of the nucleic acid molecules (a) to (d) is shown in the schematic diagram of FIG. FIG. 4 is a nucleic acid molecule comprising the linker region (Lx) and the linker region (Ly), (A) is the nucleic acid molecule of (a), (B) is the nucleic acid molecule of (b), (C) is an example of the nucleic acid molecule of (c), and (D) is an example of the nucleic acid molecule of (d). In FIG. 4, a dotted line shows the state which has formed the double chain | strand by self-annealing. The nucleic acid molecule of FIG. 4 has the number of bases (X) in the inner 5 ′ side region (X) and the number of bases (Y) in the inner 3 ′ side region (Y) as “X <Y” in the formula (20). However, the present invention is not limited to this, and as described above, “X = Y” in the formula (19) or “X> Y” in the formula (21) may be used. Further, FIG. 4 is merely a relationship between the inner 5 ′ side region (X) and the 5 ′ side region (Xc), and the relationship between the inner 3 ′ side region (Y) and the 3 ′ side region (Yc). For example, the length and shape of each region are not limited thereto, and the presence or absence of the linker region (Lx) and the linker region (Ly) is not limited thereto.
前記(a)~(c)の核酸分子は、例えば、前記5’側領域(Xc)と前記内部5’側領域(X)、および、前記3’側領域(Yc)と前記内部3’側領域(Y)が、それぞれ二重鎖を形成することによって、前記内部領域(Z)において、前記5’側領域(Xc)および前記3’側領域(Yc)のいずれともアライメントできない塩基を有する構造であり、二重鎖を形成しない塩基を有する構造ともいえる。前記内部領域(Z)において、前記アライメントできない塩基(二重鎖を形成しない塩基ともいう)を、以下、「フリー塩基」という。図4において、前記フリー塩基の領域を、「F」で示す。前記領域(F)の塩基数は、特に制限されない。前記領域(F)の塩基数(F)は、例えば、前記(a)の核酸分子の場合、「X-Xc」の塩基数であり、前記(b)の核酸分子の場合、「Y-Yc」の塩基数であり、前記(c)の核酸分子の場合、「X-Xc」の塩基数と「Y-Yc」の塩基数との合計数である。
The nucleic acid molecules (a) to (c) include, for example, the 5 ′ side region (Xc) and the internal 5 ′ side region (X), and the 3 ′ side region (Yc) and the internal 3 ′ side. The region (Y) has a base that cannot be aligned with any of the 5 ′ side region (Xc) and the 3 ′ side region (Yc) in the internal region (Z) by forming a double chain, respectively. It can be said that the structure has a base that does not form a double chain. In the internal region (Z), the base that cannot be aligned (also referred to as a base that does not form a double chain) is hereinafter referred to as “free base”. In FIG. 4, the free base region is indicated by “F”. The number of bases in the region (F) is not particularly limited. The number of bases (F) in the region (F) is, for example, the number of bases “X-Xc” in the case of the nucleic acid molecule (a), and “Y—Yc” in the case of the nucleic acid molecule (b). In the case of the nucleic acid molecule (c), it is the total number of bases “X—Xc” and “Y—Yc”.
他方、前記(d)の核酸分子は、例えば、前記内部領域(Z)の全領域が、前記5’側領域(Xc)および前記3’側領域(Yc)とアライメントする構造であり、前記内部領域(Z)の全領域が二重鎖を形成する構造ともいえる。なお、前記(d)の核酸分子において、前記5’側領域(Xc)の5’末端と前記3’側領域(Yc)の3’末端は、未連結である。
On the other hand, the nucleic acid molecule (d) has a structure in which, for example, the entire region of the internal region (Z) is aligned with the 5 ′ side region (Xc) and the 3 ′ side region (Yc), It can also be said that the entire region (Z) forms a double chain. In the nucleic acid molecule (d), the 5 'end of the 5' side region (Xc) and the 3 'end of the 3' side region (Yc) are unlinked.
前記核酸分子について、各領域の長さを以下に例示するが、本発明は、これには制限されない。
The length of each region is exemplified below for the nucleic acid molecule, but the present invention is not limited to this.
前記5’側領域(Xc)、前記3’側領域(Yc)、および前記内部領域(Z)における前記フリー塩基(F)の塩基数の合計は、前記内部領域(Z)の塩基数となる。このため、前記5’側領域(Xc)および前記3’側領域(Yc)の長さは、例えば、前記内部領域(Z)の長さ、前記フリー塩基の数(F)およびその位置に応じて、適宜決定できる。
The total number of bases of the free base (F) in the 5 ′ side region (Xc), the 3 ′ side region (Yc), and the internal region (Z) is the number of bases in the internal region (Z). . For this reason, the lengths of the 5 ′ side region (Xc) and the 3 ′ side region (Yc) depend on, for example, the length of the internal region (Z), the number of free bases (F), and the position thereof. Can be determined as appropriate.
前記内部領域(Z)の塩基数は、例えば、19塩基以上である。前記塩基数の下限は、例えば、19塩基であり、好ましくは20塩基であり、より好ましくは21塩基である。前記塩基数の上限は、例えば、50塩基であり、好ましくは40塩基であり、より好ましくは30塩基である。前記内部領域(Z)の塩基数の具体例は、例えば、19塩基、20塩基、21塩基、22塩基、23塩基、24塩基、25塩基、26塩基、27塩基、28塩基、29塩基、または、30塩基である。
The number of bases in the internal region (Z) is, for example, 19 bases or more. The lower limit of the number of bases is, for example, 19 bases, preferably 20 bases, and more preferably 21 bases. The upper limit of the number of bases is, for example, 50 bases, preferably 40 bases, and more preferably 30 bases. Specific examples of the number of bases in the internal region (Z) include, for example, 19 bases, 20 bases, 21 bases, 22 bases, 23 bases, 24 bases, 25 bases, 26 bases, 27 bases, 28 bases, 29 bases, or , 30 bases.
前記内部領域(Z)が前記発現抑制配列を含む場合、前記内部領域(Z)は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の塩基数は、例えば、前述の通りである。前記内部領域(Z)が前記発現抑制配列を含む場合、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~31塩基であり、好ましくは、1~21塩基であり、より好ましくは、1~11塩基であり、さらに好ましくは、1~7塩基である。
When the internal region (Z) includes the expression suppression sequence, the internal region (Z) may be, for example, a region composed only of the expression suppression sequence or a region including the expression suppression sequence. The number of bases of the expression suppression sequence is, for example, as described above. When the internal region (Z) contains the expression suppression sequence, it may further have an additional sequence on the 5 'side and / or 3' side of the expression suppression sequence. The number of bases of the additional sequence is, for example, 1 to 31 bases, preferably 1 to 21 bases, more preferably 1 to 11 bases, and further preferably 1 to 7 bases.
前記5’側領域(Xc)の塩基数は、例えば、1~29塩基であり、好ましくは1~11塩基であり、より好ましくは1~7塩基であり、さらに好ましくは1~4塩基であり、特に好ましくは1塩基、2塩基、3塩基である。前記内部領域(Z)または前記3’側領域(Yc)が前記発現抑制配列を含む場合、例えば、このような塩基数が好ましい。具体例として、前記内部領域(Z)の塩基数が、19~30塩基(例えば、19塩基)の場合、前記5’側領域(Xc)の塩基数は、例えば、1~11塩基であり、好ましくは1~7塩基であり、より好ましくは1~4塩基であり、さらに好ましくは1塩基、2塩基、3塩基である。
The number of bases in the 5 ′ side region (Xc) is, for example, 1 to 29 bases, preferably 1 to 11 bases, more preferably 1 to 7 bases, and further preferably 1 to 4 bases. Particularly preferred are 1 base, 2 bases and 3 bases. When the internal region (Z) or the 3 'side region (Yc) includes the expression suppression sequence, for example, such a base number is preferable. As a specific example, when the number of bases in the internal region (Z) is 19 to 30 bases (for example, 19 bases), the number of bases in the 5 ′ side region (Xc) is, for example, 1 to 11 bases, The number is preferably 1 to 7 bases, more preferably 1 to 4 bases, and still more preferably 1 base, 2 bases, and 3 bases.
前記5’側領域(Xc)が前記発現抑制配列を含む場合、前記5’側領域(Xc)は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の長さは、例えば、前述の通りである。前記5’側領域(Xc)が前記発現抑制配列を含む場合、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~11塩基であり、好ましくは、1~7塩基である。
When the 5′-side region (Xc) includes the expression suppression sequence, the 5′-side region (Xc) may be, for example, a region composed only of the expression suppression sequence, or a region including the expression suppression sequence But you can. The length of the expression suppression sequence is, for example, as described above. When the 5 'region (Xc) contains the expression suppression sequence, it may further have an additional sequence on the 5' side and / or 3 'side of the expression suppression sequence. The number of bases of the additional sequence is, for example, 1 to 11 bases, and preferably 1 to 7 bases.
前記3’側領域(Yc)の塩基数は、例えば、1~29塩基であり、好ましくは1~11塩基であり、より好ましくは1~7塩基であり、さらに好ましくは1~4塩基であり、特に好ましくは1塩基、2塩基、3塩基である。前記内部領域(Z)または前記5’側領域(Xc)が前記発現抑制配列を含む場合、例えば、このような塩基数が好ましい。具体例として、前記内部領域(Z)の塩基数が、19~30塩基(例えば、19塩基)の場合、前記3’側領域(Yc)の塩基数は、例えば、1~11塩基であり、好ましくは1~7塩基であり、より好ましくは1~4塩基であり、さらに好ましくは1塩基、2塩基、3塩基である。
The number of bases in the 3 ′ side region (Yc) is, for example, 1 to 29 bases, preferably 1 to 11 bases, more preferably 1 to 7 bases, and further preferably 1 to 4 bases. Particularly preferred are 1 base, 2 bases and 3 bases. When the internal region (Z) or the 5 'side region (Xc) includes the expression suppression sequence, for example, such a base number is preferable. As a specific example, when the number of bases in the internal region (Z) is 19 to 30 bases (for example, 19 bases), the number of bases in the 3 ′ side region (Yc) is, for example, 1 to 11 bases, The number is preferably 1 to 7 bases, more preferably 1 to 4 bases, and still more preferably 1 base, 2 bases, and 3 bases.
前記3’側領域(Yc)が前記発現抑制配列を含む場合、前記3’側領域(Yc)は、例えば、前記発現抑制配列のみから構成される領域でもよいし、前記発現抑制配列を含む領域でもよい。前記発現抑制配列の長さは、例えば、前述の通りである。前記3’側領域(Yc)が前記発現抑制配列を含む場合、前記発現抑制配列の5’側および/または3’側に、さらに付加配列を有してもよい。前記付加配列の塩基数は、例えば、1~11塩基であり、好ましくは、1~7塩基である。
When the 3 ′ side region (Yc) includes the expression suppression sequence, the 3 ′ side region (Yc) may be, for example, a region composed only of the expression suppression sequence, or a region including the expression suppression sequence But you can. The length of the expression suppression sequence is, for example, as described above. When the 3 'side region (Yc) includes the expression suppression sequence, it may further have an additional sequence on the 5' side and / or 3 'side of the expression suppression sequence. The number of bases of the additional sequence is, for example, 1 to 11 bases, and preferably 1 to 7 bases.
前述のように、前記内部領域(Z)、前記5’側領域(Xc)および前記3’側領域(Yc)の塩基数は、例えば、前記式(2)の「Z≧Xc+Yc」で表わすことができる。具体例として、「Xc+Yc」の塩基数は、例えば、前記内部領域(Z)と同じ、または、前記内部領域(Z)より小さい。後者の場合、「Z-(Xc+Yc)」は、例えば、1~10、好ましくは1~4、より好ましくは1、2または3である。前記「Z-(Xc+Yc)」は、前記内部領域(Z)における前記フリー塩基の領域(F)の塩基数(F)に相当する。
As described above, the number of bases in the internal region (Z), the 5′-side region (Xc), and the 3′-side region (Yc) is expressed by, for example, “Z ≧ Xc + Yc” in the formula (2). Can do. As a specific example, the number of bases “Xc + Yc” is, for example, the same as or smaller than the inner region (Z). In the latter case, “Z− (Xc + Yc)” is, for example, 1 to 10, preferably 1 to 4, more preferably 1, 2 or 3. The “Z− (Xc + Yc)” corresponds to the number of bases (F) in the free base region (F) in the internal region (Z).
前記リンカー領域(Lx)および前記リンカー領域(Ly)が、前述のようにヌクレオチド残基を含む場合、その長さは、特に制限されない。前記リンカー領域(Lx)は、例えば、前記内部5’側領域(X)と前記5’側領域(Xc)とが二重鎖を形成可能な長さであることが好ましく、前記リンカー領域(Ly)は、例えば、前記内部3’側領域(Y)と前記3’側領域(Yc)とが二重鎖を形成可能な長さであることが好ましい。前記リンカー領域(Lx)および前記リンカー領域(Ly)の長さは、例えば、同じでも異なってもよく、また、その塩基配列も、同じでも異なってもよい。前記リンカー領域(Lx)および前記リンカー領域(Ly)の塩基数は、その下限が、例えば、1塩基であり、好ましくは2塩基であり、より好ましくは3塩基であり、その上限が、例えば、100塩基であり、好ましくは80塩基であり、より好ましくは50塩基である。前記各リンカー領域の塩基数は、具体例として、例えば、1~50塩基、1~30塩基、1~20塩基、1~10塩基、1~7塩基、1~4塩基等が例示できるが、これには制限されない。
When the linker region (Lx) and the linker region (Ly) contain nucleotide residues as described above, the length is not particularly limited. The linker region (Lx) preferably has, for example, a length that allows the internal 5 ′ side region (X) and the 5 ′ side region (Xc) to form a double chain, and the linker region (Ly) ) Is, for example, preferably a length such that the inner 3 ′ side region (Y) and the 3 ′ side region (Yc) can form a double chain. The lengths of the linker region (Lx) and the linker region (Ly) may be the same or different, and the base sequences thereof may be the same or different. The lower limit of the number of bases in the linker region (Lx) and the linker region (Ly) is, for example, 1 base, preferably 2 bases, more preferably 3 bases, and the upper limit thereof is, for example, 100 bases, preferably 80 bases, more preferably 50 bases. Specific examples of the number of bases in each linker region include 1 to 50 bases, 1 to 30 bases, 1 to 20 bases, 1 to 10 bases, 1 to 7 bases, and 1 to 4 bases. This is not a limitation.
前記核酸分子の全長は、特に制限されない。前記核酸分子において、前記塩基数の合計(全長の塩基数)は、下限が、例えば、38塩基であり、好ましくは40塩基であり、より好ましくは42塩基であり、さらに好ましくは44塩基であり、特に好ましくは46塩基であり、その上限は、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。前記核酸分子において、前記リンカー領域(Lx)およびリンカー領域(Ly)を除く塩基数の合計は、下限が、例えば、38塩基であり、好ましくは40塩基であり、より好ましくは42塩基であり、さらに好ましくは44塩基であり、特に好ましくは46塩基であり、上限が、例えば、300塩基であり、好ましくは200塩基であり、より好ましくは150塩基であり、さらに好ましくは100塩基であり、特に好ましくは80塩基である。
The total length of the nucleic acid molecule is not particularly limited. In the nucleic acid molecule, the lower limit of the total number of bases (the total number of bases) is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, still more preferably 44 bases. The base is particularly preferably 46 bases, and the upper limit thereof is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, and particularly preferably 80 bases. . In the nucleic acid molecule, the lower limit of the total number of bases excluding the linker region (Lx) and the linker region (Ly) is, for example, 38 bases, preferably 40 bases, more preferably 42 bases, More preferably, it is 44 bases, particularly preferably 46 bases, and the upper limit is, for example, 300 bases, preferably 200 bases, more preferably 150 bases, still more preferably 100 bases, Preferably, it is 80 bases.
本形態の核酸分子は、例えば、5’末端と3’末端とが、結合してもよいし、未結合でもよい。前者の場合、本形態の核酸分子は、環状の一本鎖核酸分子である。後者の場合、本形態の核酸分子は、例えば、両末端の未結合を維持できることから、5’末端が非リン酸基であることが好ましい。
In the nucleic acid molecule of this embodiment, for example, the 5 'end and the 3' end may be bound or unbound. In the former case, the nucleic acid molecule of this form is a circular single-stranded nucleic acid molecule. In the latter case, the nucleic acid molecule of the present embodiment is preferably a non-phosphate group at the 5 'end, for example, since it can maintain unbonded at both ends.
(3-3)
前記一本鎖核酸分子の第3形態として、前記リンカー領域が、非ヌクレオチド構造である分子があげられる。 (3-3)
A third form of the single-stranded nucleic acid molecule is a molecule in which the linker region has a non-nucleotide structure.
前記一本鎖核酸分子の第3形態として、前記リンカー領域が、非ヌクレオチド構造である分子があげられる。 (3-3)
A third form of the single-stranded nucleic acid molecule is a molecule in which the linker region has a non-nucleotide structure.
本形態は、前記第1形態および前記第2形態の核酸分子において、前記リンカー領域(Lx)および/または前記リンカー領域(Ly)が、非ヌクレオチド構造を有する以外は、前述の説明を援用できる。
This embodiment can use the above description except that the linker region (Lx) and / or the linker region (Ly) has a non-nucleotide structure in the nucleic acid molecules of the first and second forms.
前記非ヌクレオチド構造は、特に制限されず、例えば、ポリアルキレングリコール、ピロリジン骨格、ピペリジン骨格等があげられる。前記ポリアルキレングリコールは、例えば、ポリエチレングリコールがあげられる。
The non-nucleotide structure is not particularly limited, and examples thereof include polyalkylene glycol, pyrrolidine skeleton and piperidine skeleton. Examples of the polyalkylene glycol include polyethylene glycol.
前記ピロリジン骨格は、例えば、ピロリジンの5員環を構成する炭素が、1個以上、置換されたピロリジン誘導体の骨格でもよく、置換される場合、例えば、5員環の2位の炭素(C-2)の炭素以外の炭素原子であることが好ましい。前記炭素は、例えば、窒素、酸素または硫黄で置換されてもよい。前記ピロリジン骨格は、例えば、ピロリジンの5員環内に、例えば、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよい。前記ピロリジン骨格において、ピロリジンの5員環を構成する炭素および窒素は、例えば、水素が結合してもよいし、後述するような置換基が結合してもよい。前記リンカー領域(Lx)は、前記領域(X)および前記領域(Xc)と、前記リンカー領域(Ly)は、前記領域(Y)および前記領域(Yc)と、例えば、前記ピロリジン骨格に置換されたいずれの基を介して結合してもよく、置換基の置換される好ましい位置は、前記5員環のいずれか1個の炭素と窒素であり、好ましくは、前記5員環の2位の炭素(C-2)と窒素である。前記ピロリジン骨格を含む非ヌクレオチドの主要構造としては、例えば、プロリン、プロリノール等があげられる。前記プロリン、プロリノール等は、例えば、生体内物質およびその還元体であるため、安全性にも優れる。
The pyrrolidine skeleton may be, for example, a skeleton of a pyrrolidine derivative in which one or more carbons constituting the 5-membered ring of pyrrolidine are substituted. When substituted, for example, the carbon at the 2-position of the 5-membered ring (C— It is preferable that it is carbon atoms other than carbon of 2). The carbon may be substituted with, for example, nitrogen, oxygen or sulfur. The pyrrolidine skeleton may contain, for example, a carbon-carbon double bond or a carbon-nitrogen double bond in the 5-membered ring of pyrrolidine. In the pyrrolidine skeleton, the carbon and nitrogen constituting the 5-membered ring of pyrrolidine may be bonded, for example, to hydrogen or a substituent as described below. The linker region (Lx) is substituted with the region (X) and the region (Xc), and the linker region (Ly) is substituted with the region (Y) and the region (Yc), for example, the pyrrolidine skeleton. The preferred position at which the substituent is substituted is any one carbon and nitrogen of the 5-membered ring, preferably at the 2-position of the 5-membered ring. Carbon (C-2) and nitrogen. Examples of the main non-nucleotide structure containing the pyrrolidine skeleton include proline and prolinol. The proline, prolinol, and the like are excellent in safety because they are, for example, in-vivo substances and their reduced forms.
前記ピペリジン骨格は、例えば、ピペリジンの6員環を構成する炭素が、1個以上、置換されたピペリジン誘導体の骨格でもよく、置換される場合、例えば、ピペリジンの2位の炭素(C-2)の炭素以外の炭素原子であることが好ましい。前記炭素は、例えば、窒素、酸素または硫黄で置換されてもよい。前記ピペリジン骨格は、例えば、ピペリジンの6員環内に、例えば、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよい。前記ピペリジン骨格において、ピペリジンの6員環を構成する炭素および窒素は、例えば、水素基が結合してもよいし、後述するような置換基が結合してもよい。前記リンカー領域(Lx)は、前記領域(X)および前記領域(Xc)と、前記リンカー領域(Ly)は、前記領域(Y)および前記領域(Yc)と、例えば、前記ピペリジン骨格のいずれの基を介して結合してもよく、好ましくは、前記6員環のいずれか1個の炭素原子と窒素であり、より好ましくは、前記6員環の2位の炭素(C-2)と窒素である。
The piperidine skeleton may be, for example, a skeleton of a piperidine derivative in which one or more carbons constituting the six-membered ring of piperidine are substituted, and when substituted, for example, the carbon at the 2-position of piperidine (C-2) It is preferably a carbon atom other than carbon. The carbon may be substituted with, for example, nitrogen, oxygen or sulfur. The piperidine skeleton may contain, for example, a carbon-carbon double bond or a carbon-nitrogen double bond in the 6-membered ring of piperidine. In the piperidine skeleton, the carbon and nitrogen constituting the piperidine 6-membered ring may be bonded to, for example, a hydrogen group or a substituent as described later. The linker region (Lx) includes the region (X) and the region (Xc), the linker region (Ly) includes the region (Y) and the region (Yc), and any one of the piperidine skeleton, for example. It may be bonded via a group, preferably any one carbon atom of the six-membered ring and nitrogen, more preferably carbon (C-2) at the 2-position of the six-membered ring and nitrogen. It is.
前記リンカー領域は、例えば、前記非ヌクレオチド構造からなる非ヌクレオチド残基のみを含んでもよいし、前記非ヌクレオチド構造からなる非ヌクレオチド残基と、ヌクレオチド残基とを含んでもよい。
The linker region may include, for example, only a non-nucleotide residue having the non-nucleotide structure, or may include a non-nucleotide residue having the non-nucleotide structure and a nucleotide residue.
前記リンカー領域は、例えば、下記式(I)で表わされる。
The linker region is represented by the following formula (I), for example.

前記式(I)中、例えば、
X1およびX2は、それぞれ独立して、H2、O、SまたはNHであり;
Y1およびY2は、それぞれ独立して、単結合、CH2、NH、OまたはSであり;
R3は、環A上のC-3、C-4、C-5またはC-6に結合する水素原子または置換基であり、
L1は、n個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORa、NH2、NHRa、NRaRb、SH、もしくはSRaで置換されていてもよく、および/または、
L1は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y1が、NH、OまたはSの場合、Y1に結合するL1の原子は炭素であり、OR1に結合するL1の原子は炭素であり、酸素原子同士は隣接せず;
L2は、m個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORc、NH2、NHRc、NRcRd、SHもしくはSRcで置換されていてもよく、および/または、
L2は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y2が、NH、OまたはSの場合、Y2に結合するL2の原子は炭素であり、OR2に結合するL2の原子は炭素であり、酸素原子同士は隣接せず;
Ra、Rb、RcおよびRdは、それぞれ独立して、置換基または保護基であり;
lは、1または2であり;
mは、0~30の範囲の整数であり;
nは、0~30の範囲の整数であり;
環Aは、前記環A上のC-2以外の1個の炭素原子が、窒素、酸素、硫黄で置換されていてもよく、
前記環A内に、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよく、
前記領域(Xc)および前記領域(X)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Lx)に結合し、
前記領域(Yc)および前記領域(Y)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Ly)に結合し、
ここで、R1およびR2は、存在しても存在しなくてもよく、存在する場合、R1およびR2は、それぞれ独立して、ヌクレオチド残基または前記構造(I)である。 In the formula (I), for example,
X 1 and X 2 are each independently H 2 , O, S or NH;
Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S;
R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A;
L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or
L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other;
L 2 is an alkylene chain consisting of m carbon atoms, where the hydrogen atom on the alkylene carbon atom is replaced by OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c And / or
L 2 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 2 is NH, O or S, the atom of L 2 bonded to Y 2 is carbon, the atom of L 2 bonded to OR 2 is carbon, and oxygen atoms are not adjacent to each other;
R a , R b , R c and R d are each independently a substituent or a protecting group;
l is 1 or 2;
m is an integer ranging from 0 to 30;
n is an integer ranging from 0 to 30;
In ring A, one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen, or sulfur.
The ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond,
The region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
The region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
Here, R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I).
X1およびX2は、それぞれ独立して、H2、O、SまたはNHであり;
Y1およびY2は、それぞれ独立して、単結合、CH2、NH、OまたはSであり;
R3は、環A上のC-3、C-4、C-5またはC-6に結合する水素原子または置換基であり、
L1は、n個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORa、NH2、NHRa、NRaRb、SH、もしくはSRaで置換されていてもよく、および/または、
L1は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y1が、NH、OまたはSの場合、Y1に結合するL1の原子は炭素であり、OR1に結合するL1の原子は炭素であり、酸素原子同士は隣接せず;
L2は、m個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORc、NH2、NHRc、NRcRd、SHもしくはSRcで置換されていてもよく、および/または、
L2は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y2が、NH、OまたはSの場合、Y2に結合するL2の原子は炭素であり、OR2に結合するL2の原子は炭素であり、酸素原子同士は隣接せず;
Ra、Rb、RcおよびRdは、それぞれ独立して、置換基または保護基であり;
lは、1または2であり;
mは、0~30の範囲の整数であり;
nは、0~30の範囲の整数であり;
環Aは、前記環A上のC-2以外の1個の炭素原子が、窒素、酸素、硫黄で置換されていてもよく、
前記環A内に、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよく、
前記領域(Xc)および前記領域(X)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Lx)に結合し、
前記領域(Yc)および前記領域(Y)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Ly)に結合し、
ここで、R1およびR2は、存在しても存在しなくてもよく、存在する場合、R1およびR2は、それぞれ独立して、ヌクレオチド残基または前記構造(I)である。 In the formula (I), for example,
X 1 and X 2 are each independently H 2 , O, S or NH;
Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S;
R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A;
L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or
L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other;
L 2 is an alkylene chain consisting of m carbon atoms, where the hydrogen atom on the alkylene carbon atom is replaced by OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c And / or
L 2 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 2 is NH, O or S, the atom of L 2 bonded to Y 2 is carbon, the atom of L 2 bonded to OR 2 is carbon, and oxygen atoms are not adjacent to each other;
R a , R b , R c and R d are each independently a substituent or a protecting group;
l is 1 or 2;
m is an integer ranging from 0 to 30;
n is an integer ranging from 0 to 30;
In ring A, one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen, or sulfur.
The ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond,
The region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
The region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
Here, R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I).
前記式(I)中、X1およびX2は、例えば、それぞれ独立して、H2、O、SまたはNHである。前記式(I)中において、X1がH2であるとは、X1が、X1の結合する炭素原子とともに、CH2(メチレン基)を形成することを意味する。X2についても同様である。
In the formula (I), X 1 and X 2 are each independently, for example, H 2 , O, S or NH. In the formula (I), X 1 being H 2 means that X 1 together with the carbon atom to which X 1 is bonded forms CH 2 (methylene group). The same is true for X 2.
前記式(I)中、Y1およびY2は、それぞれ独立して、単結合、CH2、NH、OまたはSである。
In the formula (I), Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S.
前記式(I)中、環Aにおいて、lは、1または2である。l=1の場合、環Aは、5員環であり、例えば、前記ピロリジン骨格である。前記ピロリジン骨格を含む非ヌクレオチドの主要構造は、例えば、プロリン、プロリノール等があげられる。l=2の場合、環Aは、6員環であり、例えば、前記ピペリジン骨格である。環Aは、環A上のC-2以外の1個の炭素原子が、窒素、酸素または硫黄で置換されてもよい。また、環Aは、環A内に、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよい。環Aに不斉炭素が存在するときは、いずれの光学異性体であってもよい。
In the formula (I), in ring A, l is 1 or 2. When l = 1, ring A is a 5-membered ring, for example, the pyrrolidine skeleton. Examples of the main non-nucleotide structure containing the pyrrolidine skeleton include proline and prolinol. When l = 2, ring A is a 6-membered ring, for example, the piperidine skeleton. In ring A, one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen or sulfur. Ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond in ring A. When asymmetric carbon is present in ring A, any optical isomer may be used.
前記式(I)中、R3は、環A上のC-3、C-4、C-5またはC-6に結合する水素原子または置換基である。R3が前記置換基の場合、置換基R3は、1でも複数でも、存在しなくてもよく、複数の場合、同一でも異なってもよい。
In the formula (I), R 3 is a hydrogen atom or a substituent bonded to C-3, C-4, C-5 or C-6 on the ring A. When R 3 is the above-described substituent, the substituent R 3 may be one, plural, or absent, and when plural, it may be the same or different.
置換基R3は、例えば、ハロゲン、OH、OR4、NH2、NHR4、NR4R5、SH、SR4またはオキソ基(=O)等である。
The substituent R 3 is, for example, halogen, OH, OR 4 , NH 2 , NHR 4 , NR 4 R 5 , SH, SR 4 or an oxo group (═O).
R4およびR5は、例えば、それぞれ独立して、置換基または保護基であり、同一でも異なってもよい。前記置換基は、例えば、ハロゲン、アルキル、アルケニル、アルキニル、ハロアルキル、アリール、ヘテロアリール、アリールアルキル、シクロアルキル、シクロアルケニル、シクロアルキルアルキル、シクリルアルキル、ヒドロキシアルキル、アルコキシアルキル、アミノアルキル、ヘテロシクリルアルケニル、ヘテロシクリルアルキル、ヘテロアリールアルキル、シリル、シリルオキシアルキル等があげられる。以下、同様である。置換基R3は、これらの列挙する置換基でもよい。
R 4 and R 5 are, for example, each independently a substituent or a protecting group, and may be the same or different. Examples of the substituent include halogen, alkyl, alkenyl, alkynyl, haloalkyl, aryl, heteroaryl, arylalkyl, cycloalkyl, cycloalkenyl, cycloalkylalkyl, cyclylalkyl, hydroxyalkyl, alkoxyalkyl, aminoalkyl, heterocyclylalkenyl. , Heterocyclylalkyl, heteroarylalkyl, silyl, silyloxyalkyl and the like. The same applies hereinafter. The substituent R 3 may be any of these listed substituents.
前記保護基は、例えば、反応性の高い官能基を不活性に変換する官能基であり、公知の保護基等があげられる。前記保護基は、例えば、文献(J.F.W.McOmie,「Protecting Groups in Organic Chemistry」Prenum Press,London and New York,1973)の記載を援用できる。前記保護基は、特に制限されず、例えば、tert-ブチルジメチルシリル基(TBDMS)、ビス(2-アセトキシエチルオキシ)メチル基(ACE)、トリイソプロピルシリルオキシメチル基(TOM)、1-(2-シアノエトキシ)エチル基(CEE)、2-シアノエトキシメチル基(CEM)およびトリルスルフォニルエトキシメチル基(TEM)、ジメトキシトリチル基(DMTr)等があげられる。R3がOR4の場合、前記保護基は、特に制限されず、例えば、TBDMS基、ACE基、TOM基、CEE基、CEM基およびTEM基等があげられる。この他にも、日本国特許第5555346号明細書の[化5]のシリル含有基もあげられる。以下、同様である。
The protecting group is, for example, a functional group that converts a highly reactive functional group to inert, and examples thereof include known protecting groups. As the protecting group, for example, the description in the literature (J.F.W. McOmie, “Protecting Groups in Organic Chemistry” Prenum Press, London and New York, 1973) can be cited. The protective group is not particularly limited, and examples thereof include tert-butyldimethylsilyl group (TBDMS), bis (2-acetoxyethyloxy) methyl group (ACE), triisopropylsilyloxymethyl group (TOM), 1- (2 -Cyanoethoxy) ethyl group (CEE), 2-cyanoethoxymethyl group (CEM), tolylsulfonylethoxymethyl group (TEM), dimethoxytrityl group (DMTr) and the like. When R 3 is OR 4 , the protecting group is not particularly limited, and examples thereof include a TBDMS group, an ACE group, a TOM group, a CEE group, a CEM group, and a TEM group. In addition to this, the silyl-containing group of [Chemical Formula 5] of Japanese Patent No. 5555346 is also exemplified. The same applies hereinafter.
前記式(I)中、L1は、n個の炭素原子からなるアルキレン鎖である。前記アルキレン炭素原子上の水素原子は、例えば、OH、ORa、NH2、NHRa、NRaRb、SH、もしくはSRaで置換されていてもよい。または、L1は、前記アルキレン鎖の1つ以上の炭素原子が酸素原子で置換されたポリエーテル鎖でもよい。前記ポリエーテル鎖は、例えば、ポリエチレングリコールである。なお、Y1が、NH、OまたはSの場合、Y1に結合するL1の原子は炭素であり、OR1に結合するL1の原子は炭素であり、酸素原子同士は隣接しない。つまり、例えば、Y1がOの場合、その酸素原子とL1の酸素原子は隣接せず、OR1の酸素原子とL1の酸素原子は隣接しない。
In the formula (I), L 1 is an alkylene chain consisting of n carbon atoms. The hydrogen atom on the alkylene carbon atom may be substituted with, for example, OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a . Alternatively, L 1 may be a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom. The polyether chain is, for example, polyethylene glycol. When Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other. That is, for example, when Y 1 is O, the oxygen atom and the oxygen atom of L 1 are not adjacent, and the oxygen atom of OR 1 and the oxygen atom of L 1 are not adjacent.
前記式(I)中、L2は、m個の炭素原子からなるアルキレン鎖である。前記アルキレン炭素原子上の水素原子は、例えば、OH、ORc、NH2、NHRc、NRcRd、SHもしくはSRcで置換されてもよいし、置換されていなくてもよい。または、L2は、前記アルキレン鎖の1つ以上の炭素原子が酸素原子で置換されたポリエーテル鎖でもよい。なお、Y2が、NH、OまたはSの場合、Y2に結合するL2の原子は炭素であり、OR2に結合するL2の原子は炭素であり、酸素原子同士は隣接しない。つまり、例えば、Y2がOの場合、その酸素原子とL2の酸素原子は隣接せず、OR2の酸素原子とL2の酸素原子は隣接しない。
In the formula (I), L 2 is an alkylene chain composed of m carbon atoms. The hydrogen atom on the alkylene carbon atom may be substituted with, for example, OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c , or may not be substituted. Alternatively, L 2 may be a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom. When Y 2 is NH, O or S, the L 2 atom bonded to Y 2 is carbon, the L 2 atom bonded to OR 2 is carbon, and oxygen atoms are not adjacent to each other. That is, for example, when Y 2 is O, the oxygen atom and the oxygen atom of L 2 are not adjacent, and the oxygen atom of OR 2 and the oxygen atom of L 2 are not adjacent.
L1のnおよびL2のmは、特に制限されず、それぞれ、下限は、例えば、0であり、上限も、特に制限されない。nおよびmは、例えば、前記リンカー領域(Lx)または(Ly)の所望の長さに応じて、適宜設定できる。nおよびmは、例えば、製造コストおよび収率等の点から、それぞれ、0~30が好ましく、より好ましくは0~20であり、さらに好ましくは0~15である。nとmは、同じでもよいし(n=m)、異なってもよい。n+mは、例えば、0~30であり、好ましくは0~20であり、より好ましくは0~15である。
N in L 1 and m in L 2 are not particularly limited, and the lower limit is, for example, 0, and the upper limit is not particularly limited. n and m can be appropriately set according to the desired length of the linker region (Lx) or (Ly), for example. For example, n and m are each preferably 0 to 30, more preferably 0 to 20, and still more preferably 0 to 15 from the viewpoint of production cost and yield. n and m may be the same (n = m) or different. n + m is, for example, 0 to 30, preferably 0 to 20, and more preferably 0 to 15.
Ra、Rb、RcおよびRdは、例えば、それぞれ独立して、置換基または保護基である。前記置換基および前記保護基は、例えば、前述と同様である。
R a , R b , R c and R d are, for example, each independently a substituent or a protecting group. The substituent and the protecting group are the same as described above, for example.
前記式(I)において、水素原子は、例えば、それぞれ独立して、Cl、Br、FおよびI等のハロゲンに置換されてもよい。
In the formula (I), hydrogen atoms may be independently substituted with halogens such as Cl, Br, F and I, for example.
前記領域(Xc)および前記領域(X)は、前記リンカー領域(Lx)に、前記領域(Yc)および前記領域(Y)は、前記リンカー領域(Ly)に、例えば、それぞれ、-OR1-または-OR2-を介して、結合する。ここで、R1およびR2は、存在しても存在しなくてもよい。R1およびR2が存在する場合、R1およびR2は、それぞれ独立して、ヌクレオチド残基または前記式(I)の構造である。R1および/またはR2が前記ヌクレオチド残基の場合、前記リンカー領域(Lx)および前記リンカー領域(Ly)は、例えば、ヌクレオチド残基R1および/またはR2を除く前記式(I)の構造からなる前記非ヌクレオチド残基と、前記ヌクレオチド残基とから形成される。R1および/またはR2が前記式(I)の構造の場合、前記リンカー領域(Lx)および前記リンカー領域(Ly)は、例えば、前記式(I)の構造からなる前記非ヌクレオチド残基が、2つ以上連結された構造となる。前記式(I)の構造は、例えば、1個、2個、3個または4個含んでもよい。このように、前記構造を複数含む場合、前記(I)の構造は、例えば、直接連結されてもよいし、前記ヌクレオチド残基を介して結合してもよい。他方、R1およびR2が存在しない場合、前記リンカー領域(Lx)および前記リンカー領域(Ly)は、例えば、前記式(I)の構造からなる前記非ヌクレオチド残基のみから形成される。
The region (Xc) and the region (X) are in the linker region (Lx), the region (Yc) and the region (Y) are in the linker region (Ly), for example, —OR 1 — Alternatively, the bonds are made through —OR 2 —. Here, R 1 and R 2 may or may not exist. When R 1 and R 2 are present, R 1 and R 2 are each independently a nucleotide residue or the structure of formula (I) above. When R 1 and / or R 2 is the nucleotide residue, the linker region (Lx) and the linker region (Ly) are, for example, of the formula (I) except for the nucleotide residue R 1 and / or R 2 It is formed from the non-nucleotide residue consisting of a structure and the nucleotide residue. When R 1 and / or R 2 has the structure of the formula (I), the linker region (Lx) and the linker region (Ly) are, for example, the non-nucleotide residue having the structure of the formula (I) Two or more structures are connected. The structure of the formula (I) may include 1, 2, 3, or 4, for example. As described above, when a plurality of the structures are included, the structure of (I) may be directly linked or may be bonded via the nucleotide residue, for example. On the other hand, when R 1 and R 2 are not present, the linker region (Lx) and the linker region (Ly) are formed only from the non-nucleotide residue having the structure of the formula (I), for example.
前記リンカー領域(Lx)および前記リンカー領域(Ly)が、前記非ヌクレオチド残基と、前記ヌクレオチド残基とから形成される場合、前記リンカー領域(Lx)および前記リンカー領域(Ly)における、前記非ヌクレオチド残基と、前記ヌクレオチド残基の合計数は、その下限が、例えば、2個、3個または4個であり、その上限が、例えば、100個、80個または50個である。前記各リンカー領域中の環Aの数は、具体例として、例えば、2~50個、2~30個、2~20個、2~10個、2~7個、2~4個、2~3個等が例示できるが、これには制限されない。
When the linker region (Lx) and the linker region (Ly) are formed from the non-nucleotide residue and the nucleotide residue, the non-nucleotide in the linker region (Lx) and the linker region (Ly) The lower limit of the total number of nucleotide residues and the nucleotide residues is, for example, 2, 3, or 4, and the upper limit is, for example, 100, 80, or 50. Specific examples of the number of ring A in each linker region include, for example, 2 to 50, 2 to 30, 2 to 20, 2 to 10, 2 to 7, 2 to 4, 2 to Although 3 etc. can be illustrated, it is not restrict | limited to this.
前記リンカー領域(Lx)および前記リンカー領域(Ly)が、前記非ヌクレオチド残基から形成される場合、前記リンカー領域(Lx)および前記リンカー領域(Ly)における、前記非ヌクレオチド残基の数は、その下限が、例えば、1個、2個または3個であり、その上限が、例えば、100個、80個または50個である。前記各リンカー領域中の環Aの数は、具体例として、例えば、1~50個、1~30個、1~20個、1~10個、1~7個、1~4個、1~2個等が例示できるが、これには制限されない。
When the linker region (Lx) and the linker region (Ly) are formed from the non-nucleotide residues, the number of the non-nucleotide residues in the linker region (Lx) and the linker region (Ly) is The lower limit is, for example, 1, 2, or 3. The upper limit is, for example, 100, 80, or 50. Specific examples of the number of ring A in each linker region include 1 to 50, 1 to 30, 1 to 20, 1 to 10, 1 to 7, 1 to 4, 1 to Although 2 etc. can be illustrated, it is not restrict | limited to this.
前記領域(Xc)および前記領域(X)、ならびに、前記領域(Yc)および前記領域(Y)と、前記-OR1-および-OR2-との結合の組合せは、特に制限されず、例えば、以下のいずれかの条件があげられる。
条件(1)
前記領域(Xc)は、-OR2-を介して、前記領域(X)は、-OR1-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR1-を介して、前記領域(Y)は、-OR2-を介して、前記式(I)の構造と結合する。
条件(2)
前記領域(Xc)は、-OR2-を介して、前記領域(X)は、-OR1-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR2-を介して、前記領域(Y)は、-OR1-を介して、前記式(I)の構造と結合する。
条件(3)
前記領域(Xc)は、-OR1-を介して、前記領域(X)は、-OR2-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR1-を介して、前記領域(Y)は、-OR2-を介して、前記式(I)の構造と結合する。
条件(4)
前記領域(Xc)は、-OR1-を介して、前記領域(X)は、-OR2-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR2-を介して、前記領域(Y)は、-OR1-を介して、前記式(I)の構造と結合する。 The combination of the region (Xc) and the region (X), the region (Yc) and the region (Y), and the —OR 1 — and —OR 2 — is not particularly limited. One of the following conditions can be given.
Condition (1)
The region (Xc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (X) is bonded through —OR 1 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (Y) is bonded through —OR 2 —.
Condition (2)
The region (Xc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (X) is bonded through —OR 1 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (Y) is bonded through —OR 1 —.
Condition (3)
The region (Xc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (X) is bonded through —OR 2 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (Y) is bonded through —OR 2 —.
Condition (4)
The region (Xc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (X) is bonded through —OR 2 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (Y) is bonded through —OR 1 —.
条件(1)
前記領域(Xc)は、-OR2-を介して、前記領域(X)は、-OR1-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR1-を介して、前記領域(Y)は、-OR2-を介して、前記式(I)の構造と結合する。
条件(2)
前記領域(Xc)は、-OR2-を介して、前記領域(X)は、-OR1-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR2-を介して、前記領域(Y)は、-OR1-を介して、前記式(I)の構造と結合する。
条件(3)
前記領域(Xc)は、-OR1-を介して、前記領域(X)は、-OR2-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR1-を介して、前記領域(Y)は、-OR2-を介して、前記式(I)の構造と結合する。
条件(4)
前記領域(Xc)は、-OR1-を介して、前記領域(X)は、-OR2-を介して、前記式(I)の構造と結合し、
前記領域(Yc)は、-OR2-を介して、前記領域(Y)は、-OR1-を介して、前記式(I)の構造と結合する。 The combination of the region (Xc) and the region (X), the region (Yc) and the region (Y), and the —OR 1 — and —OR 2 — is not particularly limited. One of the following conditions can be given.
Condition (1)
The region (Xc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (X) is bonded through —OR 1 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (Y) is bonded through —OR 2 —.
Condition (2)
The region (Xc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (X) is bonded through —OR 1 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (Y) is bonded through —OR 1 —.
Condition (3)
The region (Xc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (X) is bonded through —OR 2 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (Y) is bonded through —OR 2 —.
Condition (4)
The region (Xc) is bonded to the structure of the formula (I) through —OR 1 —, and the region (X) is bonded through —OR 2 —.
The region (Yc) is bonded to the structure of the formula (I) through —OR 2 —, and the region (Y) is bonded through —OR 1 —.
前記式(I)の構造は、例えば、下記式(I-1)~式(I-9)が例示でき、下記式において、nおよびmは、前記式(I)と同じである。下記式において、qは、0~10の整数である。
Examples of the structure of the formula (I) include the following formulas (I-1) to (I-9), in which n and m are the same as those in the formula (I). In the following formula, q is an integer of 0 to 10.

前記式(I-1)~(I-9)において、n、mおよびqは、特に制限されず、前述の通りである。具体例として、前記式(I-1)において、n=8、前記(I-2)において、n=3、前記式(I-3)において、n=4または8、前記(I-4)において、n=7または8、前記式(I-5)において、n=3およびm=4、前記(I-6)において、n=8およびm=4、前記式(I-7)において、n=8およびm=4、前記(I-8)において、n=5およびm=4、前記式(I-9)において、q=1およびm=4があげられる。前記式(I-4)の一例(n=8)を、下記式(I-4a)に、前記式(I-6)の一例(n=5、m=4)を、下記式(I-6a)に示す。
In the above formulas (I-1) to (I-9), n, m and q are not particularly limited and are as described above. As a specific example, in the formula (I-1), n = 8, in the (I-2), n = 3, in the formula (I-3), n = 4 or 8, and (I-4) N = 7 or 8, in the formula (I-5), n = 3 and m = 4, in the (I-6), n = 8 and m = 4, in the formula (I-7), In n = 8 and m = 4, in the above (I-8), n = 5 and m = 4, and in the formula (I-9), q = 1 and m = 4. An example (n = 8) of the formula (I-4) is represented by the following formula (I-4a), an example (n = 5, m = 4) of the formula (I-6) is represented by the following formula (I− This is shown in 6a).

リンカー領域Lxが上記式(I-6a)に示す構造である本発明の核酸分子の好ましい実施態様として、配列番号13または14で表される塩基配列からなる核酸分子を挙げることができる。また、リンカー領域LxおよびLyがヌクレオチド残基を含む場合の本発明の核酸分子の好ましい実施態様として、配列番号15または16で表される塩基配列からなる核酸分子を挙げることができる。更に、リンカー領域LxおよびLyが上記式(I-6a)に示す構造である本発明の核酸分子の好ましい実施態様として、配列番号17または18で表される塩基配列からなる核酸分子を挙げることができる。
Psh_upstream1_P, S (Psh_us1)
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)
Psh_upstream1_P, S (Psh_us2)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
nk_upstream1_P, S (nk_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
nk_upstream1_P, S (nk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16)
PnK_upstream1_P, S (PnK_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
PnK_upstream2_P, S (Pnk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18) A preferred embodiment of the nucleic acid molecule of the present invention in which the linker region Lx has the structure represented by the above formula (I-6a) is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 13 or 14. A preferred embodiment of the nucleic acid molecule of the present invention when the linker regions Lx and Ly include nucleotide residues is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 15 or 16. Furthermore, a preferred embodiment of the nucleic acid molecule of the present invention in which the linker regions Lx and Ly have the structure shown in the above formula (I-6a) is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 17 or 18. it can.
Psh_upstream1_P, S (Psh_us1)
5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13)
Psh_upstream1_P, S (Psh_us2)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
nk_upstream1_P, S (nk_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
nk_upstream1_P, S (nk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16)
PnK_upstream1_P, S (PnK_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
PnK_upstream2_P, S (Pnk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
Psh_upstream1_P, S (Psh_us1)
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)
Psh_upstream1_P, S (Psh_us2)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
nk_upstream1_P, S (nk_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
nk_upstream1_P, S (nk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16)
PnK_upstream1_P, S (PnK_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
PnK_upstream2_P, S (Pnk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18) A preferred embodiment of the nucleic acid molecule of the present invention in which the linker region Lx has the structure represented by the above formula (I-6a) is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 13 or 14. A preferred embodiment of the nucleic acid molecule of the present invention when the linker regions Lx and Ly include nucleotide residues is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 15 or 16. Furthermore, a preferred embodiment of the nucleic acid molecule of the present invention in which the linker regions Lx and Ly have the structure shown in the above formula (I-6a) is a nucleic acid molecule consisting of the base sequence represented by SEQ ID NO: 17 or 18. it can.
Psh_upstream1_P, S (Psh_us1)
5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13)
Psh_upstream1_P, S (Psh_us2)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
nk_upstream1_P, S (nk_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
nk_upstream1_P, S (nk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16)
PnK_upstream1_P, S (PnK_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
PnK_upstream2_P, S (Pnk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
上記本発明の核酸分子において、リンカー領域LxおよびLyは、さらに好ましくは、下記式で表される基である。
In the nucleic acid molecule of the present invention, the linker regions Lx and Ly are more preferably a group represented by the following formula.

本発明の核酸分子の構成単位は、特に制限されず、例えば、ヌクレオチド残基があげられる。前記ヌクレオチド残基は、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基があげられる。前記ヌクレオチド残基は、例えば、修飾されていない非修飾ヌクレオチド残基および修飾された修飾ヌクレオチド残基があげられる。本発明の核酸分子は、例えば、前記修飾ヌクレオチド残基を含むことによって、ヌクレアーゼ耐性を向上し、安定性を向上可能である。また、本発明の核酸分子は、例えば、前記ヌクレオチド残基の他に、さらに、非ヌクレオチド残基を含んでもよい。
The structural unit of the nucleic acid molecule of the present invention is not particularly limited, and examples thereof include nucleotide residues. Examples of the nucleotide residue include a ribonucleotide residue and a deoxyribonucleotide residue. Examples of the nucleotide residue include an unmodified unmodified nucleotide residue and a modified modified nucleotide residue. The nucleic acid molecule of the present invention can improve nuclease resistance and stability, for example, by including the modified nucleotide residue. Moreover, the nucleic acid molecule of the present invention may further contain a non-nucleotide residue in addition to the nucleotide residue, for example.
本発明の核酸分子において、前記リンカー以外の領域の構成単位は、それぞれ、前記ヌクレオチド残基が好ましい。前記各領域は、例えば、下記(1)~(3)の残基で構成される。
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基 In the nucleic acid molecule of the present invention, each of the constituent units in the region other than the linker is preferably the nucleotide residue. Each region is composed of the following residues (1) to (3), for example.
(1) Unmodified nucleotide residue (2) Modified nucleotide residue (3) Unmodified nucleotide residue and modified nucleotide residue
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基 In the nucleic acid molecule of the present invention, each of the constituent units in the region other than the linker is preferably the nucleotide residue. Each region is composed of the following residues (1) to (3), for example.
(1) Unmodified nucleotide residue (2) Modified nucleotide residue (3) Unmodified nucleotide residue and modified nucleotide residue
本発明の核酸分子において、前記リンカー領域の構成単位は、特に制限されず、例えば、前記ヌクレオチド残基および前記非ヌクレオチド残基があげられる。前記リンカー領域は、例えば、前記ヌクレオチド残基のみから構成されてもよいし、前記非ヌクレオチド残基のみから構成されてもよいし、前記ヌクレオチド残基と前記非ヌクレオチド残基から構成されてもよい。前記リンカー領域は、例えば、下記(1)~(7)の残基で構成される。
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基
(4)非ヌクレオチド残基
(5)非ヌクレオチド残基および非修飾ヌクレオチド残基
(6)非ヌクレオチド残基および修飾ヌクレオチド残基
(7)非ヌクレオチド残基、非修飾ヌクレオチド残基および修飾ヌクレオチド残基 In the nucleic acid molecule of the present invention, the structural unit of the linker region is not particularly limited, and examples thereof include the nucleotide residue and the non-nucleotide residue. The linker region may be composed of, for example, only the nucleotide residue, may be composed of only the non-nucleotide residue, or may be composed of the nucleotide residue and the non-nucleotide residue. . The linker region is composed of the following residues (1) to (7), for example.
(1) Unmodified nucleotide residues (2) Modified nucleotide residues (3) Unmodified nucleotide residues and modified nucleotide residues (4) Nonnucleotide residues (5) Nonnucleotide residues and unmodified nucleotide residues (6) ) Non-nucleotide residues and modified nucleotide residues (7) Non-nucleotide residues, unmodified nucleotide residues and modified nucleotide residues
(1)非修飾ヌクレオチド残基
(2)修飾ヌクレオチド残基
(3)非修飾ヌクレオチド残基および修飾ヌクレオチド残基
(4)非ヌクレオチド残基
(5)非ヌクレオチド残基および非修飾ヌクレオチド残基
(6)非ヌクレオチド残基および修飾ヌクレオチド残基
(7)非ヌクレオチド残基、非修飾ヌクレオチド残基および修飾ヌクレオチド残基 In the nucleic acid molecule of the present invention, the structural unit of the linker region is not particularly limited, and examples thereof include the nucleotide residue and the non-nucleotide residue. The linker region may be composed of, for example, only the nucleotide residue, may be composed of only the non-nucleotide residue, or may be composed of the nucleotide residue and the non-nucleotide residue. . The linker region is composed of the following residues (1) to (7), for example.
(1) Unmodified nucleotide residues (2) Modified nucleotide residues (3) Unmodified nucleotide residues and modified nucleotide residues (4) Nonnucleotide residues (5) Nonnucleotide residues and unmodified nucleotide residues (6) ) Non-nucleotide residues and modified nucleotide residues (7) Non-nucleotide residues, unmodified nucleotide residues and modified nucleotide residues
本発明の核酸分子が、前記リンカー領域(Lx)および前記リンカー領域(Ly)の両方を有する場合、例えば、両方の構成単位が同じでもよいし、異なってもよい。具体例として、例えば、両方のリンカー領域の構成単位が前記ヌクレオチド残基である形態、両方のリンカー領域の構成単位が前記非ヌクレオチド残基である形態、一方の領域の構成単位が前記ヌクレオチド残基であり、他方のリンカー領域の構成単位が非ヌクレオチド残基である形態等があげられる。
When the nucleic acid molecule of the present invention has both the linker region (Lx) and the linker region (Ly), for example, both structural units may be the same or different. Specific examples include, for example, a form in which the constituent units of both linker regions are the nucleotide residues, a form in which the constituent units of both linker regions are the non-nucleotide residues, and the constituent units of one region are the nucleotide residues. And the other linker region is a non-nucleotide residue.
本発明の核酸分子は、例えば、前記ヌクレオチド残基のみから構成される分子、前記ヌクレオチド残基の他に前記非ヌクレオチド残基を含む分子等があげられる。本発明の核酸分子において、前記ヌクレオチド残基は、前述のように、例えば、前記非修飾ヌクレオチド残基のみでもよいし、前記修飾ヌクレオチド残基のみでもよいし、前記非修飾ヌクレオチド残基および前記修飾ヌクレオチド残基の両方でもよい。前記核酸分子が、前記非修飾ヌクレオチド残基と前記修飾ヌクレオチド残基を含む場合、前記修飾ヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。本発明の核酸分子が、前記非ヌクレオチド残基を含む場合、前記非ヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~8個、1~6個、1~4個、1、2または3個である。
Examples of the nucleic acid molecule of the present invention include a molecule composed only of the nucleotide residue, a molecule containing the non-nucleotide residue in addition to the nucleotide residue, and the like. In the nucleic acid molecule of the present invention, as described above, the nucleotide residue may be, for example, only the unmodified nucleotide residue, only the modified nucleotide residue, or the unmodified nucleotide residue and the modification. Both nucleotide residues may be used. When the nucleic acid molecule includes the unmodified nucleotide residue and the modified nucleotide residue, the number of the modified nucleotide residue is not particularly limited, and is, for example, “one or several”, specifically For example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2. When the nucleic acid molecule of the present invention includes the non-nucleotide residue, the number of the non-nucleotide residue is not particularly limited, and is, for example, “one or several”, specifically, for example, 1 to Eight, one to six, one to four, one, two or three.
前記核酸分子が、例えば、非修飾リボヌクレオチド残基の他に修飾リボヌクレオチド残基を含む場合、前記修飾リボヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。前記非修飾リボヌクレオチド残基に対する前記修飾リボヌクレオチド残基は、例えば、リボース残基がデオキシリボース残基に置換された前記デオキシリボヌクレオチド残基でもよい。前記核酸分子が、例えば、前記非修飾リボヌクレオチド残基の他に前記デオキシリボヌクレオチド残基を含む場合、前記デオキシリボヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。
When the nucleic acid molecule includes, for example, a modified ribonucleotide residue in addition to an unmodified ribonucleotide residue, the number of the modified ribonucleotide residue is not particularly limited, and is, for example, “one or several”. Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2. The modified ribonucleotide residue relative to the unmodified ribonucleotide residue may be, for example, the deoxyribonucleotide residue in which a ribose residue is replaced with a deoxyribose residue. When the nucleic acid molecule includes, for example, the deoxyribonucleotide residue in addition to the unmodified ribonucleotide residue, the number of the deoxyribonucleotide residue is not particularly limited, and is, for example, “one or several” Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
前記核酸分子が、例えば、非修飾デオキシリボヌクレオチド残基の他に修飾デオキシリボヌクレオチド残基を含む場合、前記修飾デオキシリボヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。前記非修飾デオキシリボヌクレオチド残基に対する前記修飾デオキシリボヌクレオチド残基は、例えば、デオキシリボース残基がリボース残基に置換された前記リボヌクレオチド残基でもよい。前記核酸分子が、例えば、前記非修飾デオキシリボヌクレオチド残基の他に前記リボヌクレオチド残基を含む場合、前記リボヌクレオチド残基の個数は、特に制限されず、例えば、「1もしくは数個」であり、具体的には、例えば、1~5個、好ましくは1~4個、より好ましくは1~3個、最も好ましくは1または2個である。
When the nucleic acid molecule includes, for example, a modified deoxyribonucleotide residue in addition to an unmodified deoxyribonucleotide residue, the number of the modified deoxyribonucleotide residue is not particularly limited, and is, for example, “one or several”. Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2. The modified deoxyribonucleotide residue relative to the unmodified deoxyribonucleotide residue may be, for example, the ribonucleotide residue in which a deoxyribose residue is replaced with a ribose residue. When the nucleic acid molecule includes, for example, the ribonucleotide residue in addition to the unmodified deoxyribonucleotide residue, the number of the ribonucleotide residue is not particularly limited, and is, for example, “one or several”. Specifically, for example, 1 to 5, preferably 1 to 4, more preferably 1 to 3, and most preferably 1 or 2.
本発明の核酸分子は、例えば、標識物質を含み、前記標識物質で標識化されてもよい。前記標識物質は、特に制限されず、例えば、蛍光物質、色素、同位体等があげられる。前記標識物質は、例えば、ピレン、TAMRA、フルオレセイン、Cy3色素、Cy5色素等の蛍光団があげられ、前記色素は、例えば、Alexa488等のAlexa色素等があげられる。前記同位体は、例えば、安定同位体および放射性同位体があげられ、好ましくは安定同位体である。前記安定同位体は、例えば、被ばくの危険性が少なく、専用の施設も不要であることから取り扱い性に優れ、また、コストも低減できる。また、前記安定同位体は、例えば、標識した化合物の物性変化がなく、トレーサーとしての性質にも優れる。前記安定同位体は、特に制限されず、例えば、2H、13C、15N、17O、18O、33S、34Sおよび36Sがあげられる。
The nucleic acid molecule of the present invention may contain, for example, a labeling substance and be labeled with the labeling substance. The labeling substance is not particularly limited, and examples thereof include fluorescent substances, dyes, isotopes and the like. Examples of the labeling substance include fluorophores such as pyrene, TAMRA, fluorescein, Cy3 dye, and Cy5 dye, and examples of the dye include Alexa dye such as Alexa488. Examples of the isotope include a stable isotope and a radioactive isotope, and preferably a stable isotope. For example, the stable isotope has a low risk of exposure and does not require a dedicated facility, so that it is easy to handle and the cost can be reduced. In addition, the stable isotope does not change the physical properties of the labeled compound, for example, and is excellent in properties as a tracer. The stable isotope is not particularly limited, and examples thereof include 2 H, 13 C, 15 N, 17 O, 18 O, 33 S, 34 S, and 36 S.
本発明の核酸分子は、前述のように、B型肝炎ウイルス遺伝子の発現抑制ができる。このため、本発明の核酸分子は、例えば、B型肝炎ウイルスが原因となる疾患の治療剤として使用できる。本発明において、「治療」は、例えば、前記疾患の予防、疾患の改善、予後の改善の意味を含み、いずれでもよい。前記疾患は、B型肝炎、肝硬変、肝臓がん等があげられる。
As described above, the nucleic acid molecule of the present invention can suppress the expression of the hepatitis B virus gene. For this reason, the nucleic acid molecule of the present invention can be used, for example, as a therapeutic agent for diseases caused by hepatitis B virus. In the present invention, “treatment” includes, for example, the meanings of preventing the disease, improving the disease, and improving the prognosis. Examples of the disease include hepatitis B, cirrhosis, and liver cancer.
本発明の核酸分子の使用方法は、特に制限されず、例えば、前記B型肝炎ウイルスを有する投与対象に、前記核酸分子を投与すればよい。
The method of using the nucleic acid molecule of the present invention is not particularly limited, and for example, the nucleic acid molecule may be administered to an administration subject having the hepatitis B virus.
前記投与対象は、例えば、ヒト、ヒトを除く非ヒト哺乳類等の非ヒト動物があげられる。また、例えば、ヒトまたは非ヒト動物等の細胞、組織または器官に投与してもよく、本発明の核酸分子は、好ましくは、肝細胞、肝臓の組織、肝臓に投与される。前記投与は、例えば、in vivoでもin vitroでもよい。前記細胞は、特に制限されず、例えば、Huh7、A549、HeLa、293、COS7等の各種培養細胞、ES細胞、iPS細胞等の多能性幹細胞、造血幹細胞等の体性幹細胞、前記多能性幹細胞もしくは体性幹細胞から分化誘導された各種培養細胞、初代培養細胞等の生体から単離した細胞等があげられる。
Examples of the administration target include non-human animals such as humans and non-human mammals other than humans. Moreover, for example, it may be administered to cells, tissues or organs such as human or non-human animals, and the nucleic acid molecule of the present invention is preferably administered to hepatocytes, liver tissues or liver. The administration may be, for example, in vivo or in vitro. The cells are not particularly limited. For example, various cultured cells such as Huh7, A549, HeLa, 293, and COS7, pluripotent stem cells such as ES cells and iPS cells, somatic stem cells such as hematopoietic stem cells, and the pluripotent Examples include various cultured cells derived from stem cells or somatic stem cells, cells isolated from living bodies such as primary cultured cells, and the like.
本発明の核酸分子を投与対象にin vivoで投与する場合、該核酸分子は、生体内の特定の器官、組織または細胞に臓器への送達を効率よく行なうために、細胞表面受容体と結合するリガンドとコンジュゲートしていてもよい。本発明の核酸分子は、肝臓への送達効率を向上させるために、肝臓の細胞に特徴的な表面受容体のリガンド等とコンジュゲートすることができる。
かかるリガンドとしては、コレステロールおよびN-acetylgalactosamine(GalNAc)クラスター等が挙げられる。
N-acetylgalactosamine(GalNAc)クラスターとしては、例えば、以下の構造式の化合物が挙げられる。 When the nucleic acid molecule of the present invention is administered to an administration subject in vivo, the nucleic acid molecule binds to a cell surface receptor in order to efficiently deliver the organ to a specific organ, tissue or cell in the living body. It may be conjugated with a ligand. The nucleic acid molecule of the present invention can be conjugated with a surface receptor ligand or the like characteristic of liver cells in order to improve delivery efficiency to the liver.
Such ligands include cholesterol and N-acetylgalactosamine (GalNAc) clusters.
Examples of the N-acetylgalactosamine (GalNAc) cluster include compounds having the following structural formula.
かかるリガンドとしては、コレステロールおよびN-acetylgalactosamine(GalNAc)クラスター等が挙げられる。
N-acetylgalactosamine(GalNAc)クラスターとしては、例えば、以下の構造式の化合物が挙げられる。 When the nucleic acid molecule of the present invention is administered to an administration subject in vivo, the nucleic acid molecule binds to a cell surface receptor in order to efficiently deliver the organ to a specific organ, tissue or cell in the living body. It may be conjugated with a ligand. The nucleic acid molecule of the present invention can be conjugated with a surface receptor ligand or the like characteristic of liver cells in order to improve delivery efficiency to the liver.
Such ligands include cholesterol and N-acetylgalactosamine (GalNAc) clusters.
Examples of the N-acetylgalactosamine (GalNAc) cluster include compounds having the following structural formula.

本発明の核酸分子の使用に関しては、後述する本発明の組成物、発現抑制方法および治療方法等の記載を参照できる。
Referring to the use of the nucleic acid molecule of the present invention, reference can be made to the description of the composition of the present invention, expression suppression method, treatment method and the like described later.
本発明の核酸分子は、前述のように、B型肝炎ウイルス遺伝子の発現を抑制可能であることから、例えば、医薬品、診断薬および農薬、ならびに、農薬、医学、生命科学等の研究ツールとして有用である。
Since the nucleic acid molecule of the present invention can suppress the expression of the hepatitis B virus gene as described above, it is useful, for example, as a research tool for pharmaceuticals, diagnostic agents, agricultural chemicals, agricultural chemicals, medicine, life sciences, etc. It is.
4.ヌクレオチド残基
前記ヌクレオチド残基は、例えば、構成要素として、糖、塩基およびリン酸を含む。前記ヌクレオチド残基は、前述のように、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基があげられる。前記リボヌクレオチド残基は、例えば、糖としてリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびウラシル(U)を有し、前記デオキシリボース残基は、例えば、糖としてデオキシリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびチミン(T)を有する。 4). Nucleotide residues The nucleotide residues include, for example, sugars, bases and phosphates as constituent elements. Examples of the nucleotide residue include a ribonucleotide residue and a deoxyribonucleotide residue as described above. The ribonucleotide residue has, for example, a ribose residue as a sugar, and has adenine (A), guanine (G), cytosine (C), and uracil (U) as bases, and the deoxyribose residue is For example, it has a deoxyribose residue as a sugar and has adenine (A), guanine (G), cytosine (C) and thymine (T) as bases.
前記ヌクレオチド残基は、例えば、構成要素として、糖、塩基およびリン酸を含む。前記ヌクレオチド残基は、前述のように、例えば、リボヌクレオチド残基およびデオキシリボヌクレオチド残基があげられる。前記リボヌクレオチド残基は、例えば、糖としてリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびウラシル(U)を有し、前記デオキシリボース残基は、例えば、糖としてデオキシリボース残基を有し、塩基として、アデニン(A)、グアニン(G)、シトシン(C)およびチミン(T)を有する。 4). Nucleotide residues The nucleotide residues include, for example, sugars, bases and phosphates as constituent elements. Examples of the nucleotide residue include a ribonucleotide residue and a deoxyribonucleotide residue as described above. The ribonucleotide residue has, for example, a ribose residue as a sugar, and has adenine (A), guanine (G), cytosine (C), and uracil (U) as bases, and the deoxyribose residue is For example, it has a deoxyribose residue as a sugar and has adenine (A), guanine (G), cytosine (C) and thymine (T) as bases.
前記ヌクレオチド残基は、未修飾ヌクレオチド残基および修飾ヌクレオチド残基があげられる。前記未修飾ヌクレオチド残基は、前記各構成要素が、例えば、天然に存在するものと同一または実質的に同一であり、好ましくは、人体において天然に存在するものと同一または実質的に同一である。
The nucleotide residue includes an unmodified nucleotide residue and a modified nucleotide residue. In the unmodified nucleotide residue, each of the constituent elements is, for example, the same or substantially the same as that existing in nature, and preferably the same or substantially the same as that naturally occurring in the human body. .
前記修飾ヌクレオチド残基は、例えば、前記未修飾ヌクレオチド残基を修飾したヌクレオチド残基である。前記修飾ヌクレオチド残基は、例えば、前記未修飾ヌクレオチド残基の構成要素のいずれが修飾されてもよい。本発明において、「修飾」は、例えば、前記構成要素の置換、付加および/または欠失、前記構成要素における原子および/または官能基の置換、付加および/または欠失であり、「改変」ということができる。前記修飾ヌクレオチド残基は、例えば、天然に存在するヌクレオチド残基、人工的に修飾したヌクレオチド残基等があげられる。前記天然由来の修飾ヌクレオチド残基は、例えば、リンバックら(Limbach et al.、1994、Summary:the modified nucleosides of RNA、Nucleic Acids Res.22:2183~2196)を参照できる。また、前記修飾ヌクレオチド残基は、例えば、前記ヌクレオチドの代替物の残基でもよい。
The modified nucleotide residue is, for example, a nucleotide residue obtained by modifying the unmodified nucleotide residue. In the modified nucleotide residue, for example, any of the constituent elements of the unmodified nucleotide residue may be modified. In the present invention, “modification” refers to, for example, substitution, addition and / or deletion of the component, substitution, addition and / or deletion of atoms and / or functional groups in the component, and is referred to as “modification”. be able to. Examples of the modified nucleotide residue include naturally occurring nucleotide residues, artificially modified nucleotide residues, and the like. For example, Limbac et al. (Limbach et al., 1994, Summary: the modified nucleosides of RNA, Nucleic Acids Res. 22: 2183-2196) can be referred to as the naturally-occurring modified nucleotide residues. The modified nucleotide residue may be, for example, a residue of the nucleotide substitute.
前記ヌクレオチド残基の修飾は、例えば、リボース-リン酸骨格(以下、リボリン酸骨格)の修飾があげられる。
Examples of the modification of the nucleotide residue include modification of a ribose-phosphate skeleton (hereinafter referred to as ribophosphate skeleton).
前記リボリン酸骨格において、例えば、リボース残基を修飾できる。前記リボース残基は、例えば、2’位炭素を修飾でき、具体的には、例えば、2’位炭素に結合する水酸基を、水素またはフルオロ等のハロゲンに置換できる。前記2’位炭素の水酸基を水素に置換することで、リボース残基をデオキシリボースに置換できる。前記リボース残基は、例えば、立体異性体に置換でき、例えば、アラビノース残基に置換してもよい。
In the ribophosphate skeleton, for example, a ribose residue can be modified. The ribose residue can be modified, for example, at the 2′-position carbon. Specifically, for example, a hydroxyl group bonded to the 2′-position carbon can be replaced with hydrogen or a halogen such as fluoro. By substituting the hydroxyl group at the 2'-position with hydrogen, the ribose residue can be replaced with deoxyribose. The ribose residue can be substituted with, for example, a stereoisomer, and can be substituted with, for example, an arabinose residue.
前記リボリン酸骨格は、例えば、非リボース残基および/または非リン酸を有する非リボリン酸骨格に置換してもよい。前記非リボリン酸骨格は、例えば、前記リボリン酸骨格の非荷電体があげられる。前記非リボリン酸骨格に置換された、前記ヌクレオチドの代替物は、例えば、モルホリノ、シクロブチル、ピロリジン等があげられる。前記代替物は、この他に、例えば、人工核酸モノマー残基があげられる。具体例として、例えば、PNA(ペプチド核酸)、LNA(Locked Nucleic Acid)、ENA(2’-O,4’-C-Ethylene-bridged Nucleic Acid)等があげられ、好ましくはPNAである。
The ribophosphate skeleton may be substituted with a non-ribophosphate skeleton having a non-ribose residue and / or non-phosphate, for example. Examples of the non-ribophosphate skeleton include uncharged ribophosphate skeletons. Examples of the substitute for the nucleotide substituted with the non-ribophosphate skeleton include morpholino, cyclobutyl, pyrrolidine and the like. Other examples of the substitute include artificial nucleic acid monomer residues. Specific examples include PNA (peptide nucleic acid), LNA (Locked Nucleic Acid), ENA (2'-O, 4'-C-Ethylene-bridged Nucleic Acid), and PNA is preferable.
前記リボリン酸骨格において、例えば、リン酸基を修飾できる。前記リボリン酸骨格において、糖残基に最も隣接するリン酸基は、αリン酸基と呼ばれる。前記αリン酸基は、負に荷電し、その電荷は、糖残基に非結合の2つの酸素原子にわたって、均一に分布している。前記αリン酸基における4つの酸素原子のうち、ヌクレオチド残基間のホスホジエステル結合において、糖残基と非結合である2つの酸素原子は、以下、「非結合(non-linking)酸素」ともいう。他方、前記ヌクレオチド残基間のホスホジエステル結合において、糖残基と結合している2つの酸素原子は、以下、「結合(linking)酸素」という。前記αリン酸基は、例えば、非荷電となる修飾、または、前記非結合酸素における電荷分布が非対称型となる修飾を行うことが好ましい。
In the ribophosphate skeleton, for example, a phosphate group can be modified. In the ribophosphate skeleton, the phosphate group closest to the sugar residue is called an α-phosphate group. The α-phosphate group is negatively charged, and the charge is evenly distributed over two oxygen atoms that are not bound to a sugar residue. Of the four oxygen atoms in the α-phosphate group, in the phosphodiester bond between nucleotide residues, the two oxygen atoms that are non-bonded to the sugar residue are hereinafter referred to as “non-linking oxygen”. Say. On the other hand, in the phosphodiester bond between the nucleotide residues, the two oxygen atoms bonded to the sugar residue are hereinafter referred to as “linking oxygen”. The α-phosphate group is preferably subjected to, for example, a modification that makes it uncharged or a modification that makes the charge distribution in the unbound oxygen asymmetric.
前記リン酸基は、例えば、前記非結合酸素を置換してもよい。前記酸素は、例えば、S(硫黄)、Se(セレン)、B(ホウ素)、C(炭素)、H(水素)、N(窒素)およびOR(Rは、アルキル基またはアリール基)のいずれかの原子で置換でき、好ましくは、Sで置換される。前記非結合酸素は、例えば、両方が置換されていることが好ましく、より好ましくは、両方がSで置換される。前記修飾リン酸基は、例えば、ホスホロチオエート、ホスホロジチオエート、ホスホロセレネート、ボラノホスフェート、ボラノホスフェートエステル、ホスホネート水素、ホスホロアミデート、アルキルまたはアリールホスホネート、およびホスホトリエステル等があげられ、中でも、前記2つの非結合酸素が両方ともSで置換されているホスホロジチオエートが好ましい。
The phosphate group may replace the non-bonded oxygen, for example. The oxygen is, for example, one of S (sulfur), Se (selenium), B (boron), C (carbon), H (hydrogen), N (nitrogen), and OR (R is an alkyl group or an aryl group). And is preferably substituted with S. In the non-bonded oxygen, for example, both are preferably substituted, and more preferably, both are substituted with S. Examples of the modified phosphate group include phosphorothioate, phosphorodithioate, phosphoroselenate, boranophosphate, boranophosphate ester, phosphonate hydrogen, phosphoramidate, alkyl or arylphosphonate, and phosphotriester. Among them, phosphorodithioate in which the two non-bonded oxygens are both substituted with S is preferable.
前記リン酸基は、例えば、前記結合酸素を置換してもよい。前記酸素は、例えば、S(硫黄)、C(炭素)およびN(窒素)のいずれかの原子で置換でき、前記修飾リン酸基は、例えば、Nで置換した架橋ホスホロアミデート、Sで置換した架橋ホスホロチオエート、およびCで置換した架橋メチレンホスホネート等があげられる。前記結合酸素の置換は、例えば、本発明の核酸分子の5’末端ヌクレオチド残基および3’末端ヌクレオチド残基の少なくとも一方において行うことが好ましく、5’側の場合、Cによる置換が好ましく、3’側の場合、Nによる置換が好ましい。
The phosphate group may substitute, for example, the bonded oxygen. The oxygen can be substituted, for example, with any atom of S (sulfur), C (carbon) and N (nitrogen), and the modified phosphate group is, for example, a bridged phosphoramidate, S substituted with N Substituted bridged phosphorothioates, bridged methylene phosphonates substituted with C, and the like. The binding oxygen substitution is preferably performed, for example, on at least one of the 5 ′ terminal nucleotide residue and the 3 ′ terminal nucleotide residue of the nucleic acid molecule of the present invention. For the 'side, substitution with N is preferred.
前記リン酸基は、例えば、前記リン非含有のリンカーに置換してもよい。前記リンカーは、例えば、シロキサン、カーボネート、カルボキシメチル、カルバメート、アミド、チオエーテル、エチレンオキサイドリンカー、スルホネート、スルホンアミド、チオホルムアセタール、ホルムアセタール、オキシム、メチレンイミノ、メチレンメチルイミノ、メチレンヒドラゾ、メチレンジメチルヒドラゾ、およびメチレンオキシメチルイミノ等を含み、好ましくは、メチレンカルボニルアミノ基およびメチレンメチルイミノ基を含む。
The phosphate group may be substituted with, for example, the phosphorus-free linker. Examples of the linker include siloxane, carbonate, carboxymethyl, carbamate, amide, thioether, ethylene oxide linker, sulfonate, sulfonamide, thioform acetal, form acetal, oxime, methyleneimino, methylenemethylimino, methylenehydrazo, methylenedimethyl. Hydrazo, methyleneoxymethylimino and the like, preferably methylenecarbonylamino group and methylenemethylimino group.
本発明の核酸分子は、例えば、3’末端および5’末端の少なくとも一方のヌクレオチド残基が修飾されてもよい。前記修飾は、例えば、3’末端および5’末端のいずれか一方でもよいし、両方でもよい。前記修飾は、例えば、前述の通りであり、好ましくは、末端のリン酸基に行うことが好ましい。前記リン酸基は、例えば、全体を修飾してもよいし、前記リン酸基における1つ以上の原子を修飾してもよい。前者の場合、例えば、リン酸基全体の置換でもよいし、欠失でもよい。
In the nucleic acid molecule of the present invention, for example, at least one nucleotide residue at the 3 'end and the 5' end may be modified. The modification may be, for example, either the 3 'end or the 5' end, or both. The modification is, for example, as described above, and is preferably performed on the terminal phosphate group. For example, the phosphate group may be modified entirely, or one or more atoms in the phosphate group may be modified. In the former case, for example, the entire phosphate group may be substituted or deleted.
前記末端のヌクレオチド残基の修飾は、例えば、他の分子の付加があげられる。前記他の分子は、例えば、前述のような標識物質、保護基等の機能性分子があげられる。前記保護基は、例えば、S(硫黄)、Si(ケイ素)、B(ホウ素)、エステル含有基等があげられる。前記標識物質等の機能性分子は、例えば、本発明の核酸分子の検出等に利用できる。
Examples of the modification of the terminal nucleotide residue include addition of other molecules. Examples of the other molecule include functional molecules such as a labeling substance and a protecting group as described above. Examples of the protecting group include S (sulfur), Si (silicon), B (boron), ester-containing groups, and the like. The functional molecule such as the labeling substance can be used for detecting the nucleic acid molecule of the present invention, for example.
前記他の分子は、例えば、前記ヌクレオチド残基のリン酸基に付加してもよいし、スペーサーを介して、前記リン酸基または前記糖残基に付加してもよい。前記スペーサーの末端原子は、例えば、前記リン酸基の前記結合酸素、または、糖残基のO、N、SもしくはCに、付加または置換できる。前記糖残基の結合部位は、例えば、3’位のCもしくは5’位のC、またはこれらに結合する原子が好ましい。前記スペーサーは、例えば、前記PNA等のヌクレオチド代替物の末端原子に、付加または置換することもできる。
The other molecule may be added to the phosphate group of the nucleotide residue, for example, or may be added to the phosphate group or the sugar residue via a spacer. The terminal atom of the spacer can be added or substituted, for example, to the binding oxygen of the phosphate group or O, N, S or C of the sugar residue. The binding site of the sugar residue is preferably, for example, C at the 3 'position or C at the 5' position, or an atom bonded thereto. The spacer can be added or substituted at a terminal atom of a nucleotide substitute such as PNA.
前記スペーサーは、特に制限されず、例えば、-(CH2)n-、-(CH2)nN-、-(CH2)nO-、-(CH2)nS-、O(CH2CH2O)nCH2CH2OH、無塩基糖、アミド、カルボキシ、アミン、オキシアミン、オキシイミン、チオエーテル、ジスルフィド、チオ尿素、スルホンアミド、およびモルホリノ等、ならびに、ビオチン試薬およびフルオレセイン試薬等を含んでもよい。前記式において、nは、正の整数であり、n=3または6が好ましい。
The spacer is not particularly limited. For example, — (CH 2 ) n —, — (CH 2 ) n N—, — (CH 2 ) n O—, — (CH 2 ) n S—, O (CH 2 CH 2 O) n CH 2 CH 2 OH, abasic sugar, amide, carboxy, amine, oxyamine, oxyimine, thioether, disulfide, thiourea, sulfonamide, morpholino and the like, and biotin reagent and fluorescein reagent Good. In the above formula, n is a positive integer, and n = 3 or 6 is preferable.
前記末端に付加する分子は、これらの他に、例えば、色素、インターカレート剤(例えば、アクリジン)、架橋剤(例えば、ソラレン、マイトマイシンC)、ポルフィリン(TPPC4、テキサフィリン、サッフィリン)、多環式芳香族炭化水素(例えば、フェナジン、ジヒドロフェナジン)、人工エンドヌクレアーゼ(例えば、EDTA)、親油性担体(例えば、コレステロール、コール酸、アダマンタン酢酸、1-ピレン酪酸、ジヒドロテストステロン、1,3-ビス-O(ヘキサデシル)グリセロール、ゲラニルオキシヘキシル基、ヘキサデシルグリセロール、ボルネオール、メントール、1,3-プロパンジオール、ヘプタデシル基、パルミチン酸、ミリスチン酸、O3-(オレオイル)リトコール酸、O3-(オレオイル)コール酸、ジメトキシトリチル、またはフェノキサジン)およびペプチド複合体(例えば、アンテナペディアペプチド、Tatペプチド)、アルキル化剤、リン酸、アミノ、メルカプト、PEG(例えば、PEG-40K)、MPEG、[MPEG]2、ポリアミノ、アルキル、置換アルキル、放射線標識マーカー、酵素、ハプテン(例えば、ビオチン)、輸送/吸収促進剤(例えば、アスピリン、ビタミンE、葉酸)、合成リボヌクレアーゼ(例えば、イミダゾール、ビスイミダゾール、ヒスタミン、イミダゾールクラスター、アクリジン-イミダゾール複合体、テトラアザマクロ環のEu3+複合体)等があげられる。
In addition to these, the molecule to be added to the terminal includes, for example, a dye, an intercalating agent (for example, acridine), a crosslinking agent (for example, psoralen, mitomycin C), a porphyrin (TPPC4, texaphyrin, suffirin), a polycyclic Aromatic hydrocarbons (eg phenazine, dihydrophenazine), artificial endonucleases (eg EDTA), lipophilic carriers (eg cholesterol, cholic acid, adamantaneacetic acid, 1-pyrenebutyric acid, dihydrotestosterone, 1,3-bis- O (hexadecyl) glycerol, geranyloxyhexyl group, hexadecylglycerol, borneol, menthol, 1,3-propanediol, heptadecyl group, palmitic acid, myristic acid, O3- (oleoyl) lithocholic acid, O3- (oleoyl) call , Dimethoxytrityl, or phenoxazine) and peptide conjugates (e.g., antennapedia peptide, Tat peptide), alkylating agents, phosphate, amino, mercapto, PEG (e.g., PEG-40K), MPEG, [MPEG] 2, Polyamino, alkyl, substituted alkyl, radiolabeled marker, enzyme, hapten (eg, biotin), transport / absorption enhancer (eg, aspirin, vitamin E, folic acid), synthetic ribonuclease (eg, imidazole, bisimidazole, histamine, imidazole cluster) , Acridine-imidazole complex, tetraaza macrocycle Eu 3+ complex) and the like.
本発明の核酸分子は、前記5’末端が、例えば、リン酸基またはリン酸基アナログで修飾されてもよい。前記リン酸基は、例えば、5’一リン酸((HO)2(O)P-O-5’)、5’二リン酸((HO)2(O)P-O-P(HO)(O)-O-5’)、5’三リン酸((HO)2(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5’)、5’-グアノシンキャップ(7-メチル化または非メチル化、7m-G-O-5’-(HO)(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5’)、5’-アデノシンキャップ(Appp)、任意の修飾または非修飾ヌクレオチドキャップ構造(N-O-5’-(HO)(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5’)、5’一チオリン酸(ホスホロチオエート:(HO)2(S)P-O-5’)、5’一ジチオリン酸(ホスホロジチオエート:(HO)(HS)(S)P-O-5’)、5’-ホスホロチオール酸((HO)2(O)P-S-5’)、硫黄置換の一リン酸、二リン酸および三リン酸(例えば、5’-α-チオ三リン酸、5’-γ-チオ三リン酸等)、5’-ホスホルアミデート((HO)2(O)P-NH-5’、(HO)(NH2)(O)P-O-5’)、5’-アルキルホスホン酸(例えば、RP(OH)(O)-O-5’、(OH)2(O)P-5’-CH2、Rはアルキル(例えば、メチル、エチル、イソプロピル、プロピル等))、5’-アルキルエーテルホスホン酸(例えば、RP(OH)(O)-O-5’、Rはアルキルエーテル(例えば、メトキシメチル、エトキシメチル等))等があげられる。
In the nucleic acid molecule of the present invention, the 5 ′ end may be modified with, for example, a phosphate group or a phosphate group analog. Examples of the phosphate group include 5 ′ monophosphate ((HO) 2 (O) P—O-5 ′), 5 ′ diphosphate ((HO) 2 (O) P—O—P (HO)) (O) -O-5 ′), 5 ′ triphosphate ((HO) 2 (O) PO— (HO) (O) PO—P (HO) (O) —O-5 ′) 5'-guanosine cap (7-methylated or unmethylated, 7m-GO-5 '-(HO) (O) PO- (HO) (O) PO-OP (HO) ( O) —O-5 ′), 5′-adenosine cap (Appp), any modified or unmodified nucleotide cap structure (N—O-5 ′-(HO) (O) PO— (HO) (O ) P—O—P (HO) (O) —O-5 ′), 5 ′ monothiophosphoric acid (phosphorothioate: (HO) 2 (S) P—O-5 ′), 5 ′ monodithiophosphoric acid (phosphoro Dithioate: (HO) (HS) S) P-O-5 ' ), 5'- phosphorythiolation acid ((HO) 2 (O) P-S-5'), monophosphate sulfur substitutions, diphosphate and triphosphate (e.g., 5′-α-thiotriphosphate, 5′-γ-thiotriphosphate, etc.), 5′-phosphoramidate ((HO) 2 (O) P—NH-5 ′, (HO) (NH 2 ) (O) P—O-5 ′), 5′-alkylphosphonic acids (eg, RP (OH) (O) —O-5 ′, (OH) 2 (O) P-5′—CH 2 , R Is alkyl (eg, methyl, ethyl, isopropyl, propyl, etc.), 5′-alkyl ether phosphonic acid (eg, RP (OH) (O) —O-5 ′, R is alkyl ether (eg, methoxymethyl, ethoxy) Methyl and the like)) and the like.
前記ヌクレオチド残基において、前記塩基は、特に制限されない。前記塩基は、例えば、天然の塩基でもよいし、非天然の塩基でもよい。前記塩基は、例えば、天然由来でもよいし、合成品でもよい。前記塩基は、例えば、一般的な塩基、その修飾アナログ等が使用できる。
In the nucleotide residue, the base is not particularly limited. The base may be, for example, a natural base or a non-natural base. The base may be, for example, naturally derived or a synthetic product. As the base, for example, a general base or a modified analog thereof can be used.
前記塩基は、例えば、アデニンおよびグアニン等のプリン塩基、シトシン、ウラシルおよびチミン等のピリミジン塩基があげられる。前記塩基は、この他に、イノシン、チミン、キサンチン、ヒポキサンチン、ヌバラリン(nubularine)、イソグアニシン(isoguanisine)、ツベルシジン(tubercidine)等があげられる。前記塩基は、例えば、2-アミノアデニン、6-メチル化プリン等のアルキル誘導体;2-プロピル化プリン等のアルキル誘導体;5-ハロウラシルおよび5-ハロシトシン;5-プロピニルウラシルおよび5-プロピニルシトシン;6-アゾウラシル、6-アゾシトシンおよび6-アゾチミン;5-ウラシル(プソイドウラシル)、4-チオウラシル、5-ハロウラシル、5-(2-アミノプロピル)ウラシル、5-アミノアリルウラシル;8-ハロ化、アミノ化、チオール化、チオアルキル化、ヒドロキシル化および他の8-置換プリン;5-トリフルオロメチル化および他の5-置換ピリミジン;7-メチルグアニン;5-置換ピリミジン;6-アザピリミジン;N-2、N-6、およびO-6置換プリン(2-アミノプロピルアデニンを含む);5-プロピニルウラシルおよび5-プロピニルシトシン;ジヒドロウラシル;3-デアザ-5-アザシトシン;2-アミノプリン;5-アルキルウラシル;7-アルキルグアニン;5-アルキルシトシン;7-デアザアデニン;N6,N6-ジメチルアデニン;2,6-ジアミノプリン;5-アミノ-アリル-ウラシル;N3-メチルウラシル;置換1,2,4-トリアゾール;2-ピリジノン;5-ニトロインドール;3-ニトロピロール;5-メトキシウラシル;ウラシル-5-オキシ酢酸;5-メトキシカルボニルメチルウラシル;5-メチル-2-チオウラシル;5-メトキシカルボニルメチル-2-チオウラシル;5-メチルアミノメチル-2-チオウラシル;3-(3-アミノ-3-カルボキシプロピル)ウラシル;3-メチルシトシン;5-メチルシトシン;N4-アセチルシトシン;2-チオシトシン;N6-メチルアデニン;N6-イソペンチルアデニン;2-メチルチオ-N6-イソペンテニルアデニン;N-メチルグアニン;O-アルキル化塩基等があげられる。また、プリンおよびピリミジンは、例えば、米国特許第3,687,808号、「Concise Encyclopedia Of Polymer Science And Engineering」、858~859頁、クロシュビッツ ジェー アイ(Kroschwitz J.I.)編、John Wiley & Sons、1990、およびイングリッシュら(Englischら)、Angewandte Chemie、International Edition、1991、30巻、p.613に開示されるものが含まれる。
Examples of the base include purine bases such as adenine and guanine, and pyrimidine bases such as cytosine, uracil and thymine. Other examples of the base include inosine, thymine, xanthine, hypoxanthine, nubalarine, isoguanisine, and tubercidine. Examples of the base include alkyl derivatives such as 2-aminoadenine and 6-methylated purine; alkyl derivatives such as 2-propylated purine; 5-halouracil and 5-halocytosine; 5-propynyluracil and 5-propynylcytosine; -Azouracil, 6-azocytosine and 6-azothymine; 5-uracil (pseudouracil), 4-thiouracil, 5-halouracil, 5- (2-aminopropyl) uracil, 5-aminoallyluracil; 8-halogenated, aminated, Thiolated, thioalkylated, hydroxylated and other 8-substituted purines; 5-trifluoromethylated and other 5-substituted pyrimidines; 7-methylguanine; 5-substituted pyrimidines; 6-azapyrimidines; N-2, N -6 and O-6 substituted purines (2-aminopropyladenyl 5-propynyluracil and 5-propynylcytosine; dihydrouracil; 3-deaza-5-azacytosine; 2-aminopurine; 5-alkyluracil; 7-alkylguanine; 5-alkylcytosine; 7-deazaadenine; N6 2,6-diaminopurine; 5-amino-allyl-uracil; N3-methyluracil; substituted 1,2,4-triazole; 2-pyridinone; 5-nitroindole; 3-nitropyrrole; -Methoxyuracil; uracil-5-oxyacetic acid; 5-methoxycarbonylmethyluracil; 5-methyl-2-thiouracil; 5-methoxycarbonylmethyl-2-thiouracil; 5-methylaminomethyl-2-thiouracil; 3- (3 -Amino-3-carboxypropyl) uracil 3-methylcytosine; 5-methylcytosine; N4-acetylcytosine; 2-thiocytosine; N6-methyladenine; N6-isopentyladenine; 2-methylthio-N6-isopentenyladenine; N-methylguanine; O-alkylated base Etc. Purines and pyrimidines are disclosed in, for example, U.S. Pat. No. 3,687,808, “Concise Encyclopedia Of Polymer And Engineering”, pages 858-859, edited by Kroschwitz JI & W. JI. Sons, 1990, and English et al., Angewante Chemie, International Edition, 1991, 30, p. 613 is included.
前記修飾ヌクレオチド残基は、これらの他に、例えば、塩基を欠失する残基、すなわち、無塩基のリボリン酸骨格を含んでもよい。また、前記修飾ヌクレオチド残基は、例えば、米国仮出願第60/465,665号(出願日:2003年4月25日)、および国際出願第PCT/US04/07070号(出願日:2004年3月8日)に記載される残基が使用でき、本発明は、これらの文献を援用できる。
In addition to these, the modified nucleotide residue may include, for example, a residue lacking a base, that is, an abasic ribophosphate skeleton. The modified nucleotide residues are, for example, US Provisional Application No. 60 / 465,665 (filing date: April 25, 2003) and International Application No. PCT / US04 / 07070 (filing date: 2004/3). The residues described on the 8th of May) can be used, and the present invention can incorporate these documents.
5.本発明の核酸分子の合成方法
本発明の核酸分子の合成方法は、特に制限されず、従来公知の方法が採用できる。前記合成方法は、例えば、遺伝子工学的手法による合成法、化学合成法等があげられる。遺伝子工学的手法は、例えば、インビトロ転写合成法、ベクターを用いる方法、PCRカセットによる方法があげられる。前記ベクターは、特に制限されず、プラスミド等の非ウイルスベクター、ウイルスベクター等があげられる。前記化学合成法は、特に制限されず、例えば、ホスホロアミダイト法およびH-ホスホネート法等があげられる。前記化学合成法は、例えば、市販の自動核酸合成機を使用可能である。前記化学合成法は、一般に、アミダイトが使用される。前記アミダイトは、特に制限されず、市販のアミダイトとして、例えば、RNA Phosphoramidites(2’-O-TBDMSi、商品名、三千里製薬)、ACEアミダイトおよびTOMアミダイト、CEEアミダイト、CEMアミダイト、TEMアミダイト等があげられる。 5). Method for synthesizing nucleic acid molecule of the present invention The method for synthesizing a nucleic acid molecule of the present invention is not particularly limited, and conventionally known methods can be adopted. Examples of the synthesis method include a synthesis method using a genetic engineering technique, a chemical synthesis method, and the like. Examples of genetic engineering techniques include in vitro transcription synthesis, a method using a vector, and a method using a PCR cassette. The vector is not particularly limited, and examples thereof include non-viral vectors such as plasmids and viral vectors. The chemical synthesis method is not particularly limited, and examples thereof include a phosphoramidite method and an H-phosphonate method. In the chemical synthesis method, for example, a commercially available automatic nucleic acid synthesizer can be used. In the chemical synthesis method, amidite is generally used. The amidite is not particularly limited, and commercially available amidites include, for example, RNA Phosphoramidates (2′-O-TBDMSi, trade name, Michisato Pharmaceutical), ACE amidite, TOM amidite, CEE amidite, CEM amidite, TEM amidite, etc. Is given.
本発明の核酸分子の合成方法は、特に制限されず、従来公知の方法が採用できる。前記合成方法は、例えば、遺伝子工学的手法による合成法、化学合成法等があげられる。遺伝子工学的手法は、例えば、インビトロ転写合成法、ベクターを用いる方法、PCRカセットによる方法があげられる。前記ベクターは、特に制限されず、プラスミド等の非ウイルスベクター、ウイルスベクター等があげられる。前記化学合成法は、特に制限されず、例えば、ホスホロアミダイト法およびH-ホスホネート法等があげられる。前記化学合成法は、例えば、市販の自動核酸合成機を使用可能である。前記化学合成法は、一般に、アミダイトが使用される。前記アミダイトは、特に制限されず、市販のアミダイトとして、例えば、RNA Phosphoramidites(2’-O-TBDMSi、商品名、三千里製薬)、ACEアミダイトおよびTOMアミダイト、CEEアミダイト、CEMアミダイト、TEMアミダイト等があげられる。 5). Method for synthesizing nucleic acid molecule of the present invention The method for synthesizing a nucleic acid molecule of the present invention is not particularly limited, and conventionally known methods can be adopted. Examples of the synthesis method include a synthesis method using a genetic engineering technique, a chemical synthesis method, and the like. Examples of genetic engineering techniques include in vitro transcription synthesis, a method using a vector, and a method using a PCR cassette. The vector is not particularly limited, and examples thereof include non-viral vectors such as plasmids and viral vectors. The chemical synthesis method is not particularly limited, and examples thereof include a phosphoramidite method and an H-phosphonate method. In the chemical synthesis method, for example, a commercially available automatic nucleic acid synthesizer can be used. In the chemical synthesis method, amidite is generally used. The amidite is not particularly limited, and commercially available amidites include, for example, RNA Phosphoramidates (2′-O-TBDMSi, trade name, Michisato Pharmaceutical), ACE amidite, TOM amidite, CEE amidite, CEM amidite, TEM amidite, etc. Is given.
6.発現ベクター
本発明の発現ベクターは、前記本発明の核酸分子をコードする核酸を含み、本発明の核酸分子を発現させることを特徴とする。本発明の核酸分子の「発現」には、転写によって本発明の核酸分子が形成される場合に加え、転写後のプロセッシングによって本発明の核酸分子が形成される場合も含まれる。本発明の発現ベクターは、前記核酸を含むことが特徴であり、その他の構成は、何ら制限されない。本発明の発現ベクターは、例えば、ベクターに発現可能なように前記核酸が挿入されている。前記核酸を挿入するベクターは、特に制限されず、例えば、一般的なベクターが使用でき、ウイルスベクターおよび非ウイルスベクター等があげられる。前記非ウイルスベクターは、例えば、プラスミドベクターがあげられる。 6). Expression vector The expression vector of the present invention comprises a nucleic acid encoding the nucleic acid molecule of the present invention, and is characterized by expressing the nucleic acid molecule of the present invention. “Expression” of the nucleic acid molecule of the present invention includes not only the case where the nucleic acid molecule of the present invention is formed by transcription but also the case where the nucleic acid molecule of the present invention is formed by processing after transcription. The expression vector of the present invention is characterized by containing the nucleic acid, and other configurations are not limited at all. In the expression vector of the present invention, for example, the nucleic acid is inserted so that the vector can be expressed. The vector into which the nucleic acid is inserted is not particularly limited, and for example, a general vector can be used, and examples thereof include viral vectors and non-viral vectors. Examples of the non-viral vector include a plasmid vector.
本発明の発現ベクターは、前記本発明の核酸分子をコードする核酸を含み、本発明の核酸分子を発現させることを特徴とする。本発明の核酸分子の「発現」には、転写によって本発明の核酸分子が形成される場合に加え、転写後のプロセッシングによって本発明の核酸分子が形成される場合も含まれる。本発明の発現ベクターは、前記核酸を含むことが特徴であり、その他の構成は、何ら制限されない。本発明の発現ベクターは、例えば、ベクターに発現可能なように前記核酸が挿入されている。前記核酸を挿入するベクターは、特に制限されず、例えば、一般的なベクターが使用でき、ウイルスベクターおよび非ウイルスベクター等があげられる。前記非ウイルスベクターは、例えば、プラスミドベクターがあげられる。 6). Expression vector The expression vector of the present invention comprises a nucleic acid encoding the nucleic acid molecule of the present invention, and is characterized by expressing the nucleic acid molecule of the present invention. “Expression” of the nucleic acid molecule of the present invention includes not only the case where the nucleic acid molecule of the present invention is formed by transcription but also the case where the nucleic acid molecule of the present invention is formed by processing after transcription. The expression vector of the present invention is characterized by containing the nucleic acid, and other configurations are not limited at all. In the expression vector of the present invention, for example, the nucleic acid is inserted so that the vector can be expressed. The vector into which the nucleic acid is inserted is not particularly limited, and for example, a general vector can be used, and examples thereof include viral vectors and non-viral vectors. Examples of the non-viral vector include a plasmid vector.
当該発現ベクターにおいては、好ましくは、上述の本発明の核酸分子またはそれをコードする核酸が、投与対象である細胞(例えば、ヒト肝細胞等)内でプロモーター活性を発揮し得るプロモーターに機能的に連結されている。
In the expression vector, preferably, the above-described nucleic acid molecule of the present invention or the nucleic acid encoding the same is functionally used as a promoter capable of exhibiting promoter activity in cells to be administered (for example, human hepatocytes). It is connected.
使用されるプロモーターは、投与対象であるヒト肝細胞内で機能し得るものであれば特に制限はない。プロモーターとしては、polI系プロモーター、polII系プロモーター、polIII系プロモーター等を使用することができる。具体的には、SV40由来初期プロモーター、サイトメガロウイルスLTR等のウイルスプロモーター、β-アクチン遺伝子プロモーター等の哺乳動物の構成タンパク質遺伝子プロモーター、ならびにtRNAプロモーター等のRNAプロモーター等が用いられる。
The promoter used is not particularly limited as long as it can function in human hepatocytes to be administered. As the promoter, a pol I promoter, pol II promoter, pol III promoter, or the like can be used. Specifically, SV40-derived early promoter, viral promoter such as cytomegalovirus LTR, mammalian constituent protein gene promoter such as β-actin gene promoter, and RNA promoter such as tRNA promoter are used.
RNAの発現を意図する場合には、プロモーターとしてpolIII系プロモーターを使用することが好ましい。polIII系プロモーターとしては、例えば、U6プロモーター、H1プロモーター、tRNAプロモーター等を挙げることができる。
When RNA expression is intended, it is preferable to use a pol III promoter as a promoter. Examples of the polIII promoter include U6 promoter, H1 promoter, tRNA promoter and the like.
前記発現ベクターは、好ましくは本発明の核酸分子またはそれをコードする核酸の下流に転写終結シグナル、すなわちターミネーター領域を含有する。さらに、形質転換細胞選択のための選択マーカー遺伝子(テトラサイクリン、アンピシリン、カナマイシン等の薬剤に対する抵抗性を付与する遺伝子、栄養要求性変異を相補する遺伝子等)をさらに含有することもできる。
The expression vector preferably contains a transcription termination signal, that is, a terminator region, downstream of the nucleic acid molecule of the present invention or the nucleic acid encoding it. Furthermore, a selection marker gene for selecting transformed cells (a gene that imparts resistance to drugs such as tetracycline, ampicillin, and kanamycin, a gene that complements an auxotrophic mutation, and the like) can be further contained.
本発明において、ヒトへの投与に好適なベクターとしては、レトロウイルス、アデノウイルス、アデノ随伴ウイルス等のウイルスベクター、プラスミドベクター等が挙げられる。このうち、アデノウイルスは、遺伝子導入効率が極めて高く、非分裂細胞にも導入可能である等の利点を有する。但し、導入遺伝子の宿主染色体への組込みは極めて稀であるので、遺伝子発現は一過性で通常約4週間程度しか持続しない。治療効果の持続性を考慮すれば、比較的遺伝子導入効率が高く、非分裂細胞にも導入可能で、且つ逆位末端繰り返し配列(ITR)を介して染色体に組み込まれ得るアデノ随伴ウイルスの使用もまた好ましい。
In the present invention, examples of vectors suitable for human administration include retroviruses, adenoviruses, virus vectors such as adeno-associated viruses, plasmid vectors, and the like. Among these, adenovirus has advantages such as extremely high gene transfer efficiency and can be introduced into non-dividing cells. However, since integration of the transgene into the host chromosome is extremely rare, gene expression is transient and usually lasts only about 4 weeks. Considering the persistence of the therapeutic effect, use of an adeno-associated virus that has relatively high gene transfer efficiency, can be introduced into non-dividing cells, and can be integrated into the chromosome via an inverted terminal repeat (ITR) Also preferred.
7.組成物
本発明の組成物は、前述のように、B型肝炎ウイルス遺伝子の発現を抑制するための組成物であり、前記本発明の核酸分子または発現ベクターを含むことを特徴とする。本発明の組成物は、前記本発明の核酸分子または発現ベクターを含むことが特徴であり、その他の構成は、何ら制限されない。本発明の組成物は、例えば、発現抑制用試薬ということもできる。 7). Composition As described above, the composition of the present invention is a composition for suppressing the expression of hepatitis B virus gene, and is characterized by comprising the nucleic acid molecule or expression vector of the present invention. The composition of the present invention is characterized by containing the nucleic acid molecule or expression vector of the present invention, and other configurations are not limited at all. The composition of the present invention can also be referred to as, for example, an expression suppression reagent.
本発明の組成物は、前述のように、B型肝炎ウイルス遺伝子の発現を抑制するための組成物であり、前記本発明の核酸分子または発現ベクターを含むことを特徴とする。本発明の組成物は、前記本発明の核酸分子または発現ベクターを含むことが特徴であり、その他の構成は、何ら制限されない。本発明の組成物は、例えば、発現抑制用試薬ということもできる。 7). Composition As described above, the composition of the present invention is a composition for suppressing the expression of hepatitis B virus gene, and is characterized by comprising the nucleic acid molecule or expression vector of the present invention. The composition of the present invention is characterized by containing the nucleic acid molecule or expression vector of the present invention, and other configurations are not limited at all. The composition of the present invention can also be referred to as, for example, an expression suppression reagent.
本発明によれば、例えば、前記B型肝炎ウイルスが存在する対象に投与することで、前記B型肝炎ウイルス遺伝子の発現抑制を行うことができる。
According to the present invention, for example, the expression of the hepatitis B virus gene can be suppressed by administration to a subject in which the hepatitis B virus is present.
また、本発明の組成物は、前述のように、前記本発明の核酸分子または発現ベクターを含むことを特徴とする。本発明の組成物は、前記本発明の核酸分子または発現ベクターを含むことが特徴であり、その他の構成は何ら制限されない。本発明の組成物は、例えば、医薬品または医薬組成物ということもできる。
Further, as described above, the composition of the present invention is characterized by including the nucleic acid molecule or expression vector of the present invention. The composition of the present invention is characterized by containing the nucleic acid molecule or expression vector of the present invention, and other configurations are not limited at all. The composition of the present invention can also be referred to as, for example, a pharmaceutical product or a pharmaceutical composition.
本発明によれば、例えば、前記B型肝炎ウイルスが原因となる疾患の患者に投与することで、前記遺伝子の発現を抑制し、前記疾患を治療できる。前記疾患は、例えば、前述の通りであって、B型肝炎、肝硬変、肝臓がん等があげられる。本発明において、「治療」は、前述のように、例えば、前記疾患の予防、疾患の改善、予後の改善の意味を含み、いずれでもよい。
According to the present invention, for example, by administering to a patient with a disease caused by the hepatitis B virus, the expression of the gene can be suppressed and the disease can be treated. Examples of the disease are as described above, and include hepatitis B, cirrhosis, liver cancer and the like. In the present invention, as described above, “treatment” includes, for example, the meanings of prevention of the above-mentioned diseases, improvement of the diseases, and improvement of the prognosis.
本発明の医薬組成物は、その使用方法は、特に制限されず、例えば、前記B型肝炎ウイルスを有する投与対象に、前記核酸分子または発現ベクターを投与すればよい。
The method of using the pharmaceutical composition of the present invention is not particularly limited. For example, the nucleic acid molecule or the expression vector may be administered to an administration subject having the hepatitis B virus.
前記投与対象は、例えば、細胞、組織または器官があげられる。前記投与対象は、例えば、ヒト、ヒトを除く非ヒト哺乳類等の非ヒト動物があげられる。前記投与は、例えば、in vivoでもin vitroでもよい。前記細胞は、特に制限されず、例えば、前述のような細胞等があげられる。
Examples of the administration target include cells, tissues or organs. Examples of the administration subject include non-human animals such as humans and non-human mammals other than humans. The administration may be, for example, in vivo or in vitro. The cells are not particularly limited, and examples thereof include the cells described above.
前記投与方法は、特に制限されず、例えば、投与対象に応じて適宜決定できる。前記投与対象が培養細胞の場合、例えば、トランスフェクション試薬を使用する方法、エレクトロポレーション法等があげられる。
The administration method is not particularly limited, and can be appropriately determined according to the administration subject, for example. When the administration subject is a cultured cell, examples thereof include a method using a transfection reagent and an electroporation method.
本発明の医薬組成物は、例えば、本発明の核酸分子または発現ベクターのみを含んでもよいし、さらにその他の添加物を含んでもよい。前記添加物は、特に制限されず、例えば、医薬的に許容された添加物が好ましい。前記添加物の種類は、特に制限されず、例えば、投与対象の種類に応じて適宜選択できる。
The pharmaceutical composition of the present invention may contain, for example, only the nucleic acid molecule or expression vector of the present invention, or may contain other additives. The additive is not particularly limited, and for example, a pharmaceutically acceptable additive is preferable. The type of the additive is not particularly limited, and can be appropriately selected depending on, for example, the type of administration target.
本発明の医薬組成物において、前記核酸分子または発現ベクターは、例えば、前記添加物と複合体を形成してもよい。前記添加物は、例えば、複合化剤ということもできる。前記複合体形成により、例えば、前記核酸分子を効率よくデリバリーすることができる。前記核酸分子と前記複合化剤との結合は、特に制限されず、例えば、非共有結合があげられる。前記複合体は、例えば、包接複合体があげられる。
In the pharmaceutical composition of the present invention, the nucleic acid molecule or the expression vector may form a complex with the additive, for example. The additive can also be referred to as a complexing agent, for example. By the complex formation, for example, the nucleic acid molecule can be efficiently delivered. The binding between the nucleic acid molecule and the complexing agent is not particularly limited, and examples thereof include non-covalent binding. Examples of the complex include an inclusion complex.
前記複合化剤は、特に制限されず、ポリマー、シクロデキストリン、アダマンチン等があげられる。前記シクロデキストリンは、例えば、線状シクロデキストリンコポリマー、線状酸化シクロデキストリンコポリマー等があげられる。
The complexing agent is not particularly limited, and examples thereof include a polymer, cyclodextrin, adamantine and the like. Examples of the cyclodextrin include a linear cyclodextrin copolymer and a linear oxidized cyclodextrin copolymer.
前記添加剤は、この他に、例えば、担体、標的細胞への結合物質、縮合剤、融合剤、賦形剤等があげられる。
Examples of the additive include a carrier, a binding substance to a target cell, a condensing agent, a fusing agent, an excipient, and the like.
担体としては、例えば、ショ糖、デンプン、マンニット、ソルビット、乳糖、グルコース、セルロース、タルク、リン酸カルシウム、炭酸カルシウム等の賦形剤、セルロース、メチルセルロース、ヒドロキシプロピルセルロース、ポリプロピルピロリドン、ゼラチン、アラビアゴム、ポリエチレングリコール、ショ糖、デンプン等の結合剤、デンプン、カルボキシメチルセルロース、ヒドロキシプロピルスターチ、ナトリウム-グリコール-スターチ、炭酸水素ナトリウム、リン酸カルシウム、クエン酸カルシウム等の崩壊剤、ステアリン酸マグネシウム、エアロジル、タルク、ラウリル硫酸ナトリウム等の滑剤、クエン酸、メントール、グリチルリチン・アンモニウム塩、グリシン、オレンジ粉等の芳香剤、安息香酸ナトリウム、亜硫酸水素ナトリウム、メチルパラベン、プロピルパラベン等の保存剤、クエン酸、クエン酸ナトリウム、酢酸等の安定剤、メチルセルロース、ポリビニルピロリドン、ステアリン酸アルミニウム等の懸濁剤、界面活性剤等の分散剤、水、生理食塩水、オレンジジュース等の希釈剤、カカオ脂、ポリエチレングリコール、白灯油等のベースワックスなどが挙げられるが、それらに限定されるものではない。
Carriers include, for example, excipients such as sucrose, starch, mannitol, sorbit, lactose, glucose, cellulose, talc, calcium phosphate, calcium carbonate, cellulose, methylcellulose, hydroxypropylcellulose, polypropylpyrrolidone, gelatin, gum arabic , Binders such as polyethylene glycol, sucrose, starch, disintegrants such as starch, carboxymethylcellulose, hydroxypropyl starch, sodium-glycol starch, sodium bicarbonate, calcium phosphate, calcium citrate, magnesium stearate, aerosil, talc, Lubricants such as sodium lauryl sulfate, fragrances such as citric acid, menthol, glycyrrhizin / ammonium salt, glycine, orange powder, sodium benzoate, sulfite Preservatives such as sodium, methylparaben and propylparaben, stabilizers such as citric acid, sodium citrate and acetic acid, suspensions such as methylcellulose, polyvinylpyrrolidone and aluminum stearate, dispersants such as surfactants, water, physiological Examples include, but are not limited to, diluents such as saline and orange juice, base waxes such as cacao butter, polyethylene glycol, and white kerosene.
本発明の核酸分子または発現ベクターの細胞内への導入を促進するために、本発明の医薬組成物は更に核酸導入用試薬を含むことができる。また、核酸導入試薬としては、リポフェクチン、リポフェクタミン(lipofectamine)、DOGS(トランスフェクタム)、DOPE、DOTAP、DDAB、DHDEAB、HDEAB、ポリブレン、もしくはポリ(エチレンイミン)(PEI)等の陽イオン性脂質またはシゾフィラン(SPG)等の多糖類を用いることが出来る。また、発現ベクターとしてレトロウイルスを用いる場合には、導入試薬としてレトロネクチン、ファイブロネクチン、ポリブレン等を用いることができる。
In order to promote introduction of the nucleic acid molecule or expression vector of the present invention into cells, the pharmaceutical composition of the present invention may further contain a reagent for nucleic acid introduction. Examples of the nucleic acid introduction reagent include cationic lipids such as lipofectin, lipofectamine, DOGS (transfectam), DOPE, DOTAP, DDAB, DHDAB, HDEAB, polybrene, or poly (ethyleneimine) (PEI); Polysaccharides such as schizophyllan (SPG) can be used. When a retrovirus is used as an expression vector, retronectin, fibronectin, polybrene, or the like can be used as an introduction reagent.
本発明の医薬組成物の投与単位形態としては、液剤、錠剤、丸剤、飲用液剤、散剤、懸濁剤、乳剤、顆粒剤、エキス剤、細粒剤、シロップ剤、浸剤、煎剤、点眼剤、トローチ剤、パップ剤、リニメント剤、ローション剤、眼軟膏剤、硬膏剤、カプセル剤、坐剤、浣腸剤、注射剤(液剤、懸濁剤など)、貼付剤、軟膏剤、ゼリー剤、パスタ剤、吸入剤、クリーム剤、スプレー剤、点鼻剤、エアゾール剤などが例示される。
Examples of the dosage unit form of the pharmaceutical composition of the present invention include liquids, tablets, pills, drinking liquids, powders, suspensions, emulsions, granules, extracts, fine granules, syrups, soaking agents, decoctions, and eye drops. , Lozenges, poultices, liniments, lotions, ointments, plasters, capsules, suppositories, enemas, injections (solutions, suspensions, etc.), patches, ointments, jelly, pasta Examples include agents, inhalants, creams, sprays, nasal drops, aerosols and the like.
医薬組成物中の本発明の核酸分子または発現ベクターの含有量は、特に限定されず広範囲に適宜選択されるが、例えば、医薬組成物全体の約0.01ないし100重量%である。
The content of the nucleic acid molecule or expression vector of the present invention in the pharmaceutical composition is not particularly limited and is appropriately selected within a wide range, and is, for example, about 0.01 to 100% by weight of the whole pharmaceutical composition.
医薬組成物中の本発明の核酸分子または発現ベクターの含有濃度は、特に限定されず広範囲に適宜選択されるが、例えば、医薬組成物全体の約0.01nMないし1Mであり、好ましくは0.1nMないし10mMであり、より好ましくは1nMないし100nMである。
The concentration of the nucleic acid molecule or expression vector of the present invention in the pharmaceutical composition is not particularly limited and is appropriately selected within a wide range. For example, the concentration is about 0.01 nM to 1 M of the entire pharmaceutical composition, preferably about 0. 1 nM to 10 mM, more preferably 1 nM to 100 nM.
本発明の医薬組成物は、その使用に際し各種形態に応じた方法で投与される。例えば、錠剤、丸剤、飲用液剤、懸濁剤、乳剤、顆粒剤およびカプセル剤の場合には経口投与され、注射剤の場合には静脈内、筋肉内、皮内、皮下、関節腔内、腹腔内もしくは腫瘍組織内に投与され、坐剤の場合には直腸内投与される。
The pharmaceutical composition of the present invention is administered by a method according to various forms when used. For example, it is administered orally in the case of tablets, pills, drinking liquids, suspensions, emulsions, granules and capsules, and in the case of injections intravenous, intramuscular, intradermal, subcutaneous, intraarticular cavity, It is administered intraperitoneally or in tumor tissue. In the case of a suppository, it is administered intrarectally.
本発明の医薬組成物の投与量は、有効成分の活性や種類、投与様式(例、経口、非経口)、病気の重篤度、投与対象となる動物種、投与対象の薬物受容性、体重、年齢等によって異なり一概に云えないが、通常、成人1日あたり有効成分量として約0.001mg~約2.0gである。
The dosage of the pharmaceutical composition of the present invention includes the activity and type of the active ingredient, the mode of administration (eg, oral and parenteral), the severity of the disease, the animal species to be administered, the drug acceptability of the administration target, the body weight However, the amount of active ingredient per day for an adult is usually about 0.001 mg to about 2.0 g, although it varies depending on the age and the like.
本発明の医薬組成物は、通常、本発明の核酸分子または発現ベクターが、標的とする細胞(例、肝細胞、肝臓の癌細胞)に送達されるように、ヒトに対して安全に投与される。
The pharmaceutical composition of the present invention is usually safely administered to humans so that the nucleic acid molecule or expression vector of the present invention is delivered to a target cell (eg, hepatocyte, liver cancer cell). The
B型肝炎ウイルスの遺伝子発現を本発明の核酸分子により抑制すると、B型肝炎ウイルスの増殖が低下する。従って、本発明の医薬組成物は、B型肝炎ウイルス増殖抑制用医薬組成物として有用である。本発明の核酸分子または発現ベクターの有効量を対象のB型肝炎ウイルスに感染したヒトに投与することにより、当該ヒトにおけるB型肝炎ウイルスの増殖を抑制することができる。B型肝炎ウイルスの増殖を抑制できれば、B型肝炎の発症を阻止することができ、また、既にB型肝炎を発症している場合は、回復させることができる。本発明のB型肝炎ウイルス増殖抑制用医薬組成物を用いることにより、B型肝炎を治療することができる。従って、本発明の医薬組成物は、B型肝炎の治療に有用である。本発明の核酸分子または発現ベクターの有効量を対象ヒトに投与することにより、当該ヒトにおけるB型肝炎を治療することができる。
When the gene expression of hepatitis B virus is suppressed by the nucleic acid molecule of the present invention, the growth of hepatitis B virus decreases. Therefore, the pharmaceutical composition of the present invention is useful as a pharmaceutical composition for inhibiting the growth of hepatitis B virus. By administering an effective amount of the nucleic acid molecule or expression vector of the present invention to a target human infected with hepatitis B virus, the growth of hepatitis B virus in the human can be suppressed. If the growth of hepatitis B virus can be suppressed, the onset of hepatitis B can be prevented, and if hepatitis B has already developed, it can be recovered. Hepatitis B can be treated by using the pharmaceutical composition for inhibiting the growth of hepatitis B virus of the present invention. Therefore, the pharmaceutical composition of the present invention is useful for the treatment of hepatitis B. By administering an effective amount of the nucleic acid molecule or expression vector of the present invention to a subject human, hepatitis B in the human can be treated.
B型肝炎は重症化すると肝硬変や肝臓がんを引き起こす。本発明のB型肝炎治療用医薬組成物を用いることにより、肝硬変や肝臓がんを治療することができる。従って、本発明の医薬組成物は、肝硬変や肝臓がんの治療に有用である。本発明の核酸分子または発現ベクターの有効量を対象ヒトに投与することにより、当該ヒトにおける肝硬変や肝臓がんを治療することができる。
When hepatitis B becomes severe, it causes cirrhosis and liver cancer. By using the pharmaceutical composition for treating hepatitis B of the present invention, cirrhosis and liver cancer can be treated. Therefore, the pharmaceutical composition of the present invention is useful for the treatment of cirrhosis and liver cancer. By administering an effective amount of the nucleic acid molecule or expression vector of the present invention to a target human, cirrhosis or liver cancer in the human can be treated.
8.発現抑制方法、B型肝炎ウイルス増殖抑制方法
本発明の発現抑制方法は、前述のように、B型肝炎ウイルス遺伝子の発現を抑制する方法またはB型肝炎ウイルス増殖抑制方法であって、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物を使用することを特徴とする。本発明の発現抑制方法またはB型肝炎ウイルス増殖抑制方法は、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物を使用することが特徴であって、その他の工程および条件は、何ら制限されない。 8). Expression suppression method, hepatitis B virus growth suppression method As described above, the expression suppression method of the present invention is a method of suppressing the expression of hepatitis B virus gene or a method of suppressing hepatitis B virus growth, wherein the present invention Using a nucleic acid molecule, an expression vector and / or a pharmaceutical composition. The expression suppression method or hepatitis B virus growth suppression method of the present invention is characterized by using the nucleic acid molecule, expression vector and / or pharmaceutical composition of the present invention, and other steps and conditions are not limited. Not.
本発明の発現抑制方法は、前述のように、B型肝炎ウイルス遺伝子の発現を抑制する方法またはB型肝炎ウイルス増殖抑制方法であって、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物を使用することを特徴とする。本発明の発現抑制方法またはB型肝炎ウイルス増殖抑制方法は、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物を使用することが特徴であって、その他の工程および条件は、何ら制限されない。 8). Expression suppression method, hepatitis B virus growth suppression method As described above, the expression suppression method of the present invention is a method of suppressing the expression of hepatitis B virus gene or a method of suppressing hepatitis B virus growth, wherein the present invention Using a nucleic acid molecule, an expression vector and / or a pharmaceutical composition. The expression suppression method or hepatitis B virus growth suppression method of the present invention is characterized by using the nucleic acid molecule, expression vector and / or pharmaceutical composition of the present invention, and other steps and conditions are not limited. Not.
本発明の発現抑制方法またはB型肝炎ウイルス増殖抑制方法は、例えば、B型肝炎ウイルスが存在する対象に、前記核酸分子を投与する工程を含む。前記投与工程により、例えば、前記投与対象に前記核酸分子を接触させる。前記投与対象は、例えば、細胞、組織または器官があげられる。前記投与対象は、例えば、ヒト、ヒトを除く非ヒト哺乳類等の非ヒト動物があげられる。前記投与は、例えば、in vivoでもin vitroでもよい。
The expression suppression method or hepatitis B virus growth suppression method of the present invention includes, for example, a step of administering the nucleic acid molecule to a subject in which hepatitis B virus is present. By the administration step, for example, the nucleic acid molecule is brought into contact with the administration subject. Examples of the administration subject include cells, tissues, and organs. Examples of the administration subject include non-human animals such as humans and non-human mammals other than humans. The administration may be, for example, in vivo or in vitro.
本発明の発現抑制方法は、例えば、前記核酸分子を単独で投与してもよいし、前記核酸分子を含む前記本発明の組成物を投与してもよい。前記投与方法は、特に制限されず、例えば、投与対象の種類に応じて適宜選択できる。
In the expression suppression method of the present invention, for example, the nucleic acid molecule may be administered alone, or the composition of the present invention containing the nucleic acid molecule may be administered. The administration method is not particularly limited, and can be appropriately selected depending on, for example, the type of administration target.
9.治療方法
本発明の疾患の治療方法は、前述のように、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物を、患者に投与する工程を含むことを特徴とする。本発明の治療方法は、前記本発明の核酸分子を使用することが特徴であって、その他の工程および条件は、何ら制限されない。本発明が対象とする疾患は、例えば、前述の通りであって、B型肝炎、肝硬変、肝臓がん等があげられる。 9. Therapeutic method The therapeutic method of the disease of this invention is characterized by including the process of administering the nucleic acid molecule of the said this invention, an expression vector, and / or pharmaceutical composition to a patient as mentioned above. The therapeutic method of the present invention is characterized by using the nucleic acid molecule of the present invention, and other steps and conditions are not limited at all. The diseases targeted by the present invention are, for example, as described above, and include hepatitis B, cirrhosis, liver cancer and the like.
本発明の疾患の治療方法は、前述のように、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物を、患者に投与する工程を含むことを特徴とする。本発明の治療方法は、前記本発明の核酸分子を使用することが特徴であって、その他の工程および条件は、何ら制限されない。本発明が対象とする疾患は、例えば、前述の通りであって、B型肝炎、肝硬変、肝臓がん等があげられる。 9. Therapeutic method The therapeutic method of the disease of this invention is characterized by including the process of administering the nucleic acid molecule of the said this invention, an expression vector, and / or pharmaceutical composition to a patient as mentioned above. The therapeutic method of the present invention is characterized by using the nucleic acid molecule of the present invention, and other steps and conditions are not limited at all. The diseases targeted by the present invention are, for example, as described above, and include hepatitis B, cirrhosis, liver cancer and the like.
本発明の治療方法は、例えば、前記本発明の発現抑制方法等を援用できる。前記投与方法は、特に制限されず、例えば、経口投与および非経口投与のいずれでもよい。
本発明の治療方法における本発明の核酸分子の投与量は、前記疾患の治療上有効な量であれば特に制限されず、疾患の種類、重症度、投与対象の動物種、齢、体重、薬物受容性、投与経路等によって異なるが、通常、成人1回あたり約0.0001~約100mg/kg、例えば約0.001~約10mg/kg、好ましくは約0.005~約5mg/kgであり得る。当該量を、例えば、1日3回~2週間に1回、好ましくは1日~1週間に1回の間隔で投与することができる。 For the treatment method of the present invention, for example, the expression suppression method of the present invention can be used. The administration method is not particularly limited, and may be, for example, oral administration or parenteral administration.
The dosage of the nucleic acid molecule of the present invention in the treatment method of the present invention is not particularly limited as long as it is a therapeutically effective amount for the above-mentioned disease, and the type, severity, species of animal to be administered, age, weight, drug Usually, it is about 0.0001 to about 100 mg / kg per adult, for example about 0.001 to about 10 mg / kg, preferably about 0.005 to about 5 mg / kg, although it varies depending on the acceptability, administration route, etc. obtain. The amount can be administered, for example, at intervals of 3 times a day to once every 2 weeks, preferably once a day to once a week.
本発明の治療方法における本発明の核酸分子の投与量は、前記疾患の治療上有効な量であれば特に制限されず、疾患の種類、重症度、投与対象の動物種、齢、体重、薬物受容性、投与経路等によって異なるが、通常、成人1回あたり約0.0001~約100mg/kg、例えば約0.001~約10mg/kg、好ましくは約0.005~約5mg/kgであり得る。当該量を、例えば、1日3回~2週間に1回、好ましくは1日~1週間に1回の間隔で投与することができる。 For the treatment method of the present invention, for example, the expression suppression method of the present invention can be used. The administration method is not particularly limited, and may be, for example, oral administration or parenteral administration.
The dosage of the nucleic acid molecule of the present invention in the treatment method of the present invention is not particularly limited as long as it is a therapeutically effective amount for the above-mentioned disease, and the type, severity, species of animal to be administered, age, weight, drug Usually, it is about 0.0001 to about 100 mg / kg per adult, for example about 0.001 to about 10 mg / kg, preferably about 0.005 to about 5 mg / kg, although it varies depending on the acceptability, administration route, etc. obtain. The amount can be administered, for example, at intervals of 3 times a day to once every 2 weeks, preferably once a day to once a week.
10.核酸分子の使用
本発明の使用は、B型肝炎ウイルス遺伝子の発現抑制のための、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物の使用である。
本発明はまた、B型肝炎ウイルス遺伝子の発現抑制、B型肝炎ウイルス増殖抑制、あるいはB型肝炎、肝硬変、肝臓がんの治療における使用のための、本発明の核酸分子、発現ベクターおよび/または医薬組成物を提供する。
本発明はまた、B型肝炎ウイルス遺伝子の発現抑制、B型肝炎ウイルス増殖抑制、あるいはB型肝炎、肝硬変、肝臓がんの治療剤の製造のための、本発明の核酸分子、発現ベクターおよび/または医薬組成物の使用を提供する。 10. Use of nucleic acid molecule The use of the present invention is the use of the nucleic acid molecule, expression vector and / or pharmaceutical composition of the present invention for the suppression of hepatitis B virus gene expression.
The present invention also provides the nucleic acid molecule, expression vector and / or the present invention for use in inhibiting the expression of hepatitis B virus gene, inhibiting the growth of hepatitis B virus, or treating hepatitis B, cirrhosis, liver cancer. A pharmaceutical composition is provided.
The present invention also provides the nucleic acid molecule, expression vector and / or the present invention for the suppression of hepatitis B virus gene expression, hepatitis B virus growth suppression, or the manufacture of a therapeutic agent for hepatitis B, cirrhosis or liver cancer. Or use of a pharmaceutical composition is provided.
本発明の使用は、B型肝炎ウイルス遺伝子の発現抑制のための、前記本発明の核酸分子、発現ベクターおよび/または医薬組成物の使用である。
本発明はまた、B型肝炎ウイルス遺伝子の発現抑制、B型肝炎ウイルス増殖抑制、あるいはB型肝炎、肝硬変、肝臓がんの治療における使用のための、本発明の核酸分子、発現ベクターおよび/または医薬組成物を提供する。
本発明はまた、B型肝炎ウイルス遺伝子の発現抑制、B型肝炎ウイルス増殖抑制、あるいはB型肝炎、肝硬変、肝臓がんの治療剤の製造のための、本発明の核酸分子、発現ベクターおよび/または医薬組成物の使用を提供する。 10. Use of nucleic acid molecule The use of the present invention is the use of the nucleic acid molecule, expression vector and / or pharmaceutical composition of the present invention for the suppression of hepatitis B virus gene expression.
The present invention also provides the nucleic acid molecule, expression vector and / or the present invention for use in inhibiting the expression of hepatitis B virus gene, inhibiting the growth of hepatitis B virus, or treating hepatitis B, cirrhosis, liver cancer. A pharmaceutical composition is provided.
The present invention also provides the nucleic acid molecule, expression vector and / or the present invention for the suppression of hepatitis B virus gene expression, hepatitis B virus growth suppression, or the manufacture of a therapeutic agent for hepatitis B, cirrhosis or liver cancer. Or use of a pharmaceutical composition is provided.
以下、実施例を示して本発明をより具体的に説明するが、本発明は以下に示す実施例によって何ら限定されるものではない。
Hereinafter, the present invention will be described more specifically with reference to examples. However, the present invention is not limited to the examples shown below.
以下、実施例により本発明をより詳細に説明するが、本発明はこれらの実施例により何ら限定されるものではない。
Hereinafter, the present invention will be described in more detail with reference to examples, but the present invention is not limited to these examples.
[実施例1]
HBV由来mRNAに対するsiRNAの評価方法
評価には、株化ヒト肝がん細胞Huh7細胞を用いた。Huh7細胞の培養はペニシリン・ストレプトマイシン、10%FBS含有DMEM(high glucose)培地を使用した。プラスミドの導入以降の実験には、ペニシリン・ストレプトマイシンを含まない培地を用いた。 [Example 1]
SiRNA evaluation method for HBV-derived mRNA For evaluation, established human hepatoma cell Huh7 cells were used. Huh7 cells were cultured using penicillin / streptomycin, 10% FBS-containing DMEM (high glucose) medium. In experiments after the introduction of the plasmid, a medium not containing penicillin / streptomycin was used.
HBV由来mRNAに対するsiRNAの評価方法
評価には、株化ヒト肝がん細胞Huh7細胞を用いた。Huh7細胞の培養はペニシリン・ストレプトマイシン、10%FBS含有DMEM(high glucose)培地を使用した。プラスミドの導入以降の実験には、ペニシリン・ストレプトマイシンを含まない培地を用いた。 [Example 1]
SiRNA evaluation method for HBV-derived mRNA For evaluation, established human hepatoma cell Huh7 cells were used. Huh7 cells were cultured using penicillin / streptomycin, 10% FBS-containing DMEM (high glucose) medium. In experiments after the introduction of the plasmid, a medium not containing penicillin / streptomycin was used.
Huh7細胞を3x104cells/500μL/wellとなるよう24ウエルプレートに播種し、24時間後にリポフェクション法により1.4倍長のHBVゲノムを発現するプラスミドと導入効率補正用として分泌型ルシフェラーゼのGaussiaLuc発現プラスミドを共導入した。リポフェクション試薬にはLipofectamine3000を使用した。具体的には、50ngのpGaussiaLuc、225ngのpTRE2/1.4xHBV(genotype C)、225ngのcarrier plasmidを1μLのp3000試薬と混合後、全量が50μLとなるよう無血清培地のOPTI-MEMで希釈し、1.5μLのLipofectamine3000試薬と混合し、5分後に24ウエルで培養中のHuh7細胞へ添加した。
さらに24時間後に培地を新しい培地500μLに交換し、リポフェクション法によりsiRNAを導入した。リポフェクション試薬にはRNAiMAXを使用した。具体的には、全量が50μLとなるよう無血清培地のOPTI-MEMで希釈した50nMのsiRNA溶液に1.5μLのRNAiMAXを添加し、5分後に24ウエルのHuh7細胞へ(最終siRNA濃度5nMとして)添加した。 Huh7 cells are seeded in a 24-well plate at 3 × 10 4 cells / 500 μL / well and 24 hours later, a plasmid that expresses a 1.4-fold long HBV genome by lipofection and expression of GaussiaLuc as a secreted luciferase for correction of introduction efficiency Plasmid was co-introduced. Lipofectamine 3000 was used as the lipofection reagent. Specifically, 50 ng of pGaussiaLuc, 225 ng of pTRE2 / 1.4xHBV (genotype C), 225 ng of carrier plasmid was mixed with 1 μL of p3000 reagent, and diluted with OPTI-MEM in a serum-free medium to a total volume of 50 μL. The mixture was mixed with 1.5 μL of Lipofectamine 3000 reagent and added to Huh7 cells in culture in 24 wells after 5 minutes.
After 24 hours, the medium was replaced with 500 μL of fresh medium, and siRNA was introduced by the lipofection method. RNAiMAX was used as the lipofection reagent. Specifically, 1.5 μL of RNAiMAX was added to a 50 nM siRNA solution diluted with OPTI-MEM in a serum-free medium so that the total volume became 50 μL, and after 5 minutes, to 24 well Huh7 cells (with a final siRNA concentration of 5 nM) ) Added.
さらに24時間後に培地を新しい培地500μLに交換し、リポフェクション法によりsiRNAを導入した。リポフェクション試薬にはRNAiMAXを使用した。具体的には、全量が50μLとなるよう無血清培地のOPTI-MEMで希釈した50nMのsiRNA溶液に1.5μLのRNAiMAXを添加し、5分後に24ウエルのHuh7細胞へ(最終siRNA濃度5nMとして)添加した。 Huh7 cells are seeded in a 24-well plate at 3 × 10 4 cells / 500 μL / well and 24 hours later, a plasmid that expresses a 1.4-fold long HBV genome by lipofection and expression of GaussiaLuc as a secreted luciferase for correction of introduction efficiency Plasmid was co-introduced. Lipofectamine 3000 was used as the lipofection reagent. Specifically, 50 ng of pGaussiaLuc, 225 ng of pTRE2 / 1.4xHBV (genotype C), 225 ng of carrier plasmid was mixed with 1 μL of p3000 reagent, and diluted with OPTI-MEM in a serum-free medium to a total volume of 50 μL. The mixture was mixed with 1.5 μL of Lipofectamine 3000 reagent and added to Huh7 cells in culture in 24 wells after 5 minutes.
After 24 hours, the medium was replaced with 500 μL of fresh medium, and siRNA was introduced by the lipofection method. RNAiMAX was used as the lipofection reagent. Specifically, 1.5 μL of RNAiMAX was added to a 50 nM siRNA solution diluted with OPTI-MEM in a serum-free medium so that the total volume became 50 μL, and after 5 minutes, to 24 well Huh7 cells (with a final siRNA concentration of 5 nM) ) Added.
導入したsiRNAは、以下の通りである。
(a) siRNA_upstream1_P, S (us1)
5’- AGUCUAGACUCGUGGUGGAtt-3’(配列番号11)
3’-ttUCAGAUCUGAGCACCACCU -5’(配列番号9)
(b) siRNA_upstream2_P, S (us2)
5’- GCAAGAUUCCUAUGGGAGUtt-3’(配列番号12)
3’-ttCGUUCUAAGGAUACCCUCA -5’(配列番号10)
(c) Negative Control siRNA (Negative)
5’- UACUAUUCGACACGCGAAGtt-3’(配列番号19)
3’-ttAUGAUAAGCUGUGCGCUUC -5’(配列番号20) The introduced siRNA is as follows.
(a) siRNA_upstream1_P, S (us1)
5'-AGUCUAGACUCGUGGUGGAtt-3 '(SEQ ID NO: 11)
3'-ttUCAGAUCUGAGCACCACCU -5 '(SEQ ID NO: 9)
(b) siRNA_upstream2_P, S (us2)
5'- GCAAGAUUCCUAUGGGAGUtt-3 '(SEQ ID NO: 12)
3'-ttCGUUCUAAGGAUACCCUCA -5 '(SEQ ID NO: 10)
(c) Negative Control siRNA (Negative)
5′-UACUAUUCGACACGCGAAGtt-3 ′ (SEQ ID NO: 19)
3'-ttAUGAUAAGCUGUGCGCUUC -5 '(SEQ ID NO: 20)
(a) siRNA_upstream1_P, S (us1)
5’- AGUCUAGACUCGUGGUGGAtt-3’(配列番号11)
3’-ttUCAGAUCUGAGCACCACCU -5’(配列番号9)
(b) siRNA_upstream2_P, S (us2)
5’- GCAAGAUUCCUAUGGGAGUtt-3’(配列番号12)
3’-ttCGUUCUAAGGAUACCCUCA -5’(配列番号10)
(c) Negative Control siRNA (Negative)
5’- UACUAUUCGACACGCGAAGtt-3’(配列番号19)
3’-ttAUGAUAAGCUGUGCGCUUC -5’(配列番号20) The introduced siRNA is as follows.
(a) siRNA_upstream1_P, S (us1)
5'-AGUCUAGACUCGUGGUGGAtt-3 '(SEQ ID NO: 11)
3'-ttUCAGAUCUGAGCACCACCU -5 '(SEQ ID NO: 9)
(b) siRNA_upstream2_P, S (us2)
5'- GCAAGAUUCCUAUGGGAGUtt-3 '(SEQ ID NO: 12)
3'-ttCGUUCUAAGGAUACCCUCA -5 '(SEQ ID NO: 10)
(c) Negative Control siRNA (Negative)
5′-UACUAUUCGACACGCGAAGtt-3 ′ (SEQ ID NO: 19)
3'-ttAUGAUAAGCUGUGCGCUUC -5 '(SEQ ID NO: 20)
さらに24時間後に、培養液の一部を用いてプラスミド導入効率を補正するためGaussiaLucのアッセイを行った。具体的には、5μLの培養上清に15μLの基質溶液(NEB社、BioLux Gaussia Luciferase Assay Kit)を添加し、1分後にプレートリーダーにより発光測定を行った。
After another 24 hours, GaussiaLuc assay was performed to correct the plasmid introduction efficiency using a part of the culture solution. Specifically, 15 μL of a substrate solution (NEB, BioLux Gaussia Luciferase Assay Kit) was added to 5 μL of the culture supernatant, and luminescence was measured with a plate reader after 1 minute.
GaussiaLucのアッセイと同時に(プラスミド導入48時間後)、あるいはさらに培養を継続しプラスミド導入72時間後、96時間後に培養上清を回収し、遠心により細胞残渣を除去し、HBs抗原量あるいはHBe抗原量の定量を行った。あるいは、プラスミド導入48時間後より、24時間おきに培地交換を行い、回収したそれぞれの培養上清中のHBs抗原量あるいはHBe抗原量の定量を行った。
At the same time as the GaussiaLuc assay (48 hours after plasmid introduction) or further, culture is continued and 72 hours and 96 hours after plasmid introduction, the culture supernatant is recovered, and cell debris is removed by centrifugation, and the amount of HBs antigen or HBe antigen is recovered. Was quantified. Alternatively, the medium was changed every 24 hours from 48 hours after plasmid introduction, and the amount of HBs antigen or HBe antigen in each collected culture supernatant was quantified.
HBs抗原量あるいはHbe抗原量の定量は、それぞれsysmex社B型肝炎ウイルス表面抗原キットのHISCL HBsAg試薬、HISCL HBeAg試薬を用いて、添付書に従い実施した。
Quantification of the amount of HBs antigen or the amount of Hbe antigen was carried out according to the attached document using HISCL HBsAg reagent and HISCL HBeAg reagent of Sysmex hepatitis B surface antigen kit, respectively.
その結果、us1のsiRNAおよびus2のsiRNAを導入した場合に、siRNA導入なしの場合、ネガティブコントロールのsiRNAを導入した場合と比較して、検出されたHBs抗原量が顕著に少なかった(図5、n=1)。
As a result, when the siRNA of us1 and the siRNA of us2 were introduced, the amount of HBs antigen detected was significantly smaller when no siRNA was introduced than when the negative control siRNA was introduced (FIG. 5, n = 1).
[実施例2]
また、導入するus1のsiRNAおよびus2のsiRNAの、無血清培地OPTI-MEM中1nM、10nMおよび100nMの溶液各50μLに、1.5μLのRNAiMAXを添加して、それらを培地中のHuh7細胞に、最終濃度0.1nM(us1_0.1、us2_0.1)、1nM(us1_1、us2_1)、または10nM(us1_10、us2_10)として加え、プラスミド導入96時間後に上記と同様に試験したところ、濃度依存的なHBs抗原およびHBe抗原の産生抑制効果が観察された(図6、n=3)。 [Example 2]
In addition, 1.5 μL of RNAiMAX was added to 50 μL each of 1 nM, 10 nM, and 100 nM solutions of us1 siRNA and us2 siRNA to be introduced in serum-free medium OPTI-MEM, and these were added to Huh7 cells in the medium. A final concentration of 0.1 nM (us1_0.1, us2_0.1), 1 nM (us1_1, us2_1), or 10 nM (us1_10, us2_10) was added and tested in the same manner as described above after 96 hours of plasmid introduction. Antigen and HBe antigen production inhibitory effects were observed (FIG. 6, n = 3).
また、導入するus1のsiRNAおよびus2のsiRNAの、無血清培地OPTI-MEM中1nM、10nMおよび100nMの溶液各50μLに、1.5μLのRNAiMAXを添加して、それらを培地中のHuh7細胞に、最終濃度0.1nM(us1_0.1、us2_0.1)、1nM(us1_1、us2_1)、または10nM(us1_10、us2_10)として加え、プラスミド導入96時間後に上記と同様に試験したところ、濃度依存的なHBs抗原およびHBe抗原の産生抑制効果が観察された(図6、n=3)。 [Example 2]
In addition, 1.5 μL of RNAiMAX was added to 50 μL each of 1 nM, 10 nM, and 100 nM solutions of us1 siRNA and us2 siRNA to be introduced in serum-free medium OPTI-MEM, and these were added to Huh7 cells in the medium. A final concentration of 0.1 nM (us1_0.1, us2_0.1), 1 nM (us1_1, us2_1), or 10 nM (us1_10, us2_10) was added and tested in the same manner as described above after 96 hours of plasmid introduction. Antigen and HBe antigen production inhibitory effects were observed (FIG. 6, n = 3).
[実施例3]
更に、us1のsiRNAおよびus2のsiRNAの配列について、以下のRNA配列を作製し、プラスミド導入96時間後に上記と同様に試験した。PnK_upstream1_P, S (PnK_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
PnK_upstream2_P, S (Pnk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18)
nk_upstream1_P, S (nk_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
nk_upstream1_P, S (nk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16)
Psh_upstream1_P, S (Psh_us1)
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)Psh_upstream1_P, S (Psh_us2)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
ここで、LxおよびLyは下記式で表される基である。 [Example 3]
Furthermore, for the sequences of us1 siRNA and us2 siRNA, the following RNA sequences were prepared and tested in the same manner as described above 96 hours after introduction of the plasmid. PnK_upstream1_P, S (PnK_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
PnK_upstream2_P, S (Pnk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
nk_upstream1_P, S (nk_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
nk_upstream1_P, S (nk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16)
Psh_upstream1_P, S (Psh_us1)
5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13) Psh_upstream1_P, S (Psh_us2)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
Here, Lx and Ly are groups represented by the following formula.
更に、us1のsiRNAおよびus2のsiRNAの配列について、以下のRNA配列を作製し、プラスミド導入96時間後に上記と同様に試験した。PnK_upstream1_P, S (PnK_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
PnK_upstream2_P, S (Pnk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18)
nk_upstream1_P, S (nk_us1)
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
nk_upstream1_P, S (nk_us2)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16)
Psh_upstream1_P, S (Psh_us1)
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)Psh_upstream1_P, S (Psh_us2)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
ここで、LxおよびLyは下記式で表される基である。 [Example 3]
Furthermore, for the sequences of us1 siRNA and us2 siRNA, the following RNA sequences were prepared and tested in the same manner as described above 96 hours after introduction of the plasmid. PnK_upstream1_P, S (PnK_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
PnK_upstream2_P, S (Pnk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
nk_upstream1_P, S (nk_us1)
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
nk_upstream1_P, S (nk_us2)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16)
Psh_upstream1_P, S (Psh_us1)
5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13) Psh_upstream1_P, S (Psh_us2)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
Here, Lx and Ly are groups represented by the following formula.

その結果、いずれの核酸分子を導入した場合も、siRNA導入なしの場合、ネガティブコントロールのsiRNAを導入した場合と比較して、検出された抗原量が顕著に少なかった(図7、n=3)。これらのうち、最も高い効果を示したのはPsh_us2であった。
As a result, when any nucleic acid molecule was introduced, the amount of antigen detected was significantly smaller when no siRNA was introduced than when a negative control siRNA was introduced (FIG. 7, n = 3). . Of these, Psh_us2 showed the highest effect.
[実施例4]
また、各核酸分子の、無血清培地OPTI-MEM中1nM、10nMおよび100nMの溶液各50μLに、1.5μLのRNAiMAXを添加して、それらを培地中のHuh7細胞に、最終濃度0.1nM、1nM、または10nMとして加え、siRNA導入後24時間ごとに培地を交換し、HBV導入後24~48時間、48~72時間、72~96時間、96~120時間培養した培養液の上清により上記と同様に試験し培養上清中のHBs抗原量を定量したところ、経時的且つ濃度依存的なHBs抗原産生抑制効果が観察された(図8、n=1)。 [Example 4]
Also, 1.5 μL of RNAiMAX was added to 50 μL of each 1 nM, 10 nM and 100 nM solution of each nucleic acid molecule in serum-free medium OPTI-MEM, and these were added to Huh7 cells in the medium at a final concentration of 0.1 nM, Add 1 nM or 10 nM, change the medium every 24 hours after siRNA introduction, and use the culture supernatant after 24-48 hours, 48-72 hours, 72-96 hours, 96-120 hours after HBV introduction. When the amount of HBs antigen in the culture supernatant was quantified in the same manner as described above, a time-dependent and concentration-dependent HBs antigen production inhibitory effect was observed (FIG. 8, n = 1).
また、各核酸分子の、無血清培地OPTI-MEM中1nM、10nMおよび100nMの溶液各50μLに、1.5μLのRNAiMAXを添加して、それらを培地中のHuh7細胞に、最終濃度0.1nM、1nM、または10nMとして加え、siRNA導入後24時間ごとに培地を交換し、HBV導入後24~48時間、48~72時間、72~96時間、96~120時間培養した培養液の上清により上記と同様に試験し培養上清中のHBs抗原量を定量したところ、経時的且つ濃度依存的なHBs抗原産生抑制効果が観察された(図8、n=1)。 [Example 4]
Also, 1.5 μL of RNAiMAX was added to 50 μL of each 1 nM, 10 nM and 100 nM solution of each nucleic acid molecule in serum-free medium OPTI-MEM, and these were added to Huh7 cells in the medium at a final concentration of 0.1 nM, Add 1 nM or 10 nM, change the medium every 24 hours after siRNA introduction, and use the culture supernatant after 24-48 hours, 48-72 hours, 72-96 hours, 96-120 hours after HBV introduction. When the amount of HBs antigen in the culture supernatant was quantified in the same manner as described above, a time-dependent and concentration-dependent HBs antigen production inhibitory effect was observed (FIG. 8, n = 1).
本発明により、細胞への毒性が少なく、安定な、B型肝炎ウイルス遺伝子の発現を効果的に抑制できる核酸分子、および該核酸分子を含む医薬組成物が提供される。B型肝炎ウイルス由来の抗原を産生抑制することにより、本発明の医薬組成物は、副作用が軽減されたB型肝炎ウイルス増殖抑制用、ひいてはB型肝炎、肝硬変、肝臓がんの治療用として有用である。
The present invention provides a nucleic acid molecule that is less toxic to cells and that can effectively suppress the expression of a hepatitis B virus gene, and a pharmaceutical composition containing the nucleic acid molecule. By inhibiting the production of antigen derived from hepatitis B virus, the pharmaceutical composition of the present invention is useful for suppressing the growth of hepatitis B virus with reduced side effects, and hence for treating hepatitis B, cirrhosis, and liver cancer. It is.
本出願は日本で出願された特願2017-088960(出願日:2017年4月27日)を基礎としており、その内容は本明細書に全て包含されるものである。
This application is based on Japanese Patent Application No. 2017-088960 (filing date: April 27, 2017) filed in Japan, the contents of which are incorporated in full herein.
Claims (37)
- 以下の(i)または(ii)のヌクレオチド配列をB型肝炎ウイルス遺伝子発現抑制配列として含む核酸分子
(i)配列番号2で表されるヌクレオチド配列;
配列番号2で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号2で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(ii)配列番号1で表されるヌクレオチド配列;
配列番号1で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号1で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。 A nucleic acid molecule comprising the following nucleotide sequence (i) or (ii) as a hepatitis B virus gene expression suppression sequence (i) a nucleotide sequence represented by SEQ ID NO: 2;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 2; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 2 A nucleotide sequence represented by SEQ ID NO: 1;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted, or added in the nucleotide sequence represented by SEQ ID NO: 1; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 1 Nucleotide sequence having - 塩基数の合計が100塩基以下である、請求項1に記載の核酸分子。 The nucleic acid molecule according to claim 1, wherein the total number of bases is 100 bases or less.
- (i)のヌクレオチド配列および(i)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iii)である相補配列;または
(ii)のヌクレオチド配列および(ii)のヌクレオチド配列にアニーリング可能な相補配列であって、該相補配列が以下の(iv)である相補配列
を含む、請求項1または2に記載の核酸分子
(iii)配列番号4で表されるヌクレオチド配列;
配列番号4で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号4で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列
(iv)配列番号3で表されるヌクレオチド配列;
配列番号3で表されるヌクレオチド配列において、1個もしくは2個の塩基が欠失、置換、挿入、もしくは付加されたヌクレオチド配列;または
配列番号3で表されるヌクレオチド配列と90%以上の同一性を有するヌクレオチド配列。 A nucleotide sequence of (i) and a complementary sequence capable of annealing to the nucleotide sequence of (i), wherein the complementary sequence is (iii) below; or (ii) the nucleotide sequence and (ii) the nucleotide The nucleotide sequence represented by the nucleic acid molecule (iii) SEQ ID NO: 4 according to claim 1 or 2, wherein the nucleotide sequence comprises a complementary sequence that can be annealed to a sequence, and wherein the complementary sequence is (iv):
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 4; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 4 A nucleotide sequence represented by SEQ ID NO: 3;
A nucleotide sequence in which one or two bases have been deleted, substituted, inserted or added in the nucleotide sequence represented by SEQ ID NO: 3; or 90% or more identity with the nucleotide sequence represented by SEQ ID NO: 3 Nucleotide sequence having - (iii)のヌクレオチド配列が(i)のヌクレオチド配列に完全に相補的な配列であり、
(iv)のヌクレオチド配列が(ii)のヌクレオチド配列に完全に相補的な配列である、請求項3に記載の核酸分子。 The nucleotide sequence of (iii) is a sequence completely complementary to the nucleotide sequence of (i),
4. The nucleic acid molecule of claim 3, wherein the nucleotide sequence of (iv) is a sequence that is completely complementary to the nucleotide sequence of (ii). - 二本鎖核酸分子であって、
一方の鎖に(i)のヌクレオチド配列、他方の鎖に該(i)のヌクレオチド配列にアニーリングした(iii)のヌクレオチド配列を含むか、;または
一方の鎖に(ii)のヌクレオチド配列、他方の鎖に該(ii)のヌクレオチド配列にアニーリングした(iv)のヌクレオチド配列を含むRNA分子である、請求項3または4に記載の核酸分子。 A double-stranded nucleic acid molecule,
One strand contains the nucleotide sequence of (i) and the other strand contains the nucleotide sequence of (iii) annealed to the nucleotide sequence of (i); or one strand contains the nucleotide sequence of (ii), the other 5. The nucleic acid molecule of claim 3 or 4, wherein the nucleic acid molecule is an RNA molecule comprising in the strand (iv) a nucleotide sequence annealed to the (ii) nucleotide sequence. - 塩基数の合計が60塩基以下である、請求項3~5のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 3 to 5, wherein the total number of bases is 60 bases or less.
- (i)、(ii)、(iii)および(iv)のヌクレオチド配列が、それぞれ配列番号2、1、4、3で表されるヌクレオチド配列である、請求項3~6のいずれか1項に記載の核酸分子。 The nucleotide sequence of (i), (ii), (iii) and (iv) is the nucleotide sequence represented by SEQ ID NO: 2, 1, 4, 3 respectively. The described nucleic acid molecule.
- 二本鎖のうちの少なくとも1方の鎖の3’末端にオーバーハング配列を更に有する、請求項5~7のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 5 to 7, further comprising an overhang sequence at the 3 'end of at least one of the double strands.
- 配列番号10で表されるヌクレオチド配列および該配列にアニーリングした配列番号12で表されるヌクレオチド配列;または
配列番号9で表されるヌクレオチド配列および該配列にアニーリングした配列番号11で表されるヌクレオチド配列
から成る、請求項8に記載の核酸分子。 The nucleotide sequence represented by SEQ ID NO: 10 and the nucleotide sequence represented by SEQ ID NO: 12 annealed to the sequence; or the nucleotide sequence represented by SEQ ID NO: 9 and the nucleotide sequence represented by SEQ ID NO: 11 annealed to the sequence 9. The nucleic acid molecule of claim 8 consisting of: - B型肝炎ウイルス遺伝子発現抑制配列として(i)または(ii)で表されるヌクレオチド配列を含む、以下の(A)または(B)の一本鎖核酸分子である、請求項1~4のいずれか1項に記載の核酸分子:
(A)領域(X)、リンカー領域(Lx)および領域(Xc)のみからなり、
5’側から3’側にかけて、前記領域(Xc)、前記リンカー領域(Lx)および前記領域(X)の順で配置され、
前記リンカー領域(Lx)が、ピロリジン骨格およびピペリジン骨格の少なくとも一方を含む非ヌクレオチド構造を有し、
かつ前記領域(X)および前記領域(Xc)の少なくとも一方が、前記発現抑制配列を含む;
(B)領域(Xc)、リンカー領域(Lx)、領域(X)、領域(Y)、リンカー領域(Ly)および領域(Yc)を、5’側から3’側にかけてこの順序で含み、
前記領域(X)と前記領域(Y)とが連結して、内部領域(Z)を形成し、
前記領域(Xc)が、前記領域(X)と相補的であり、
前記領域(Yc)が、前記領域(Y)と相補的であり、
かつ前記リンカー領域(Lx)およびリンカー領域(Ly)が、各々独立して存在しないか、ヌクレオチド残基から成るか、またはピロリジン骨格およびピペリジン骨格の少なくとも一方を含む非ヌクレオチド構造を有し、
前記内部領域(Z)が、前記発現抑制配列を含む。 5. The single-stranded nucleic acid molecule according to (A) or (B) below, comprising the nucleotide sequence represented by (i) or (ii) as a hepatitis B virus gene expression suppression sequence: Or a nucleic acid molecule according to claim 1
(A) It consists only of region (X), linker region (Lx) and region (Xc),
From the 5 ′ side to the 3 ′ side, the region (Xc), the linker region (Lx) and the region (X) are arranged in this order,
The linker region (Lx) has a non-nucleotide structure containing at least one of a pyrrolidine skeleton and a piperidine skeleton;
And at least one of the region (X) and the region (Xc) includes the expression suppressing sequence;
(B) comprising region (Xc), linker region (Lx), region (X), region (Y), linker region (Ly) and region (Yc) in this order from 5 ′ side to 3 ′ side,
The region (X) and the region (Y) are connected to form an internal region (Z),
The region (Xc) is complementary to the region (X);
The region (Yc) is complementary to the region (Y);
And each of the linker region (Lx) and the linker region (Ly) does not exist independently, consists of a nucleotide residue, or has a non-nucleotide structure including at least one of a pyrrolidine skeleton and a piperidine skeleton,
The internal region (Z) includes the expression suppression sequence. - 前記リンカー領域(Lx)および(Ly)が、下記式(I)で表わされる、請求項10に記載の鎖核酸分子。

前記式中、
X1およびX2は、それぞれ独立して、H2、O、SまたはNHであり;
Y1およびY2は、それぞれ独立して、単結合、CH2、NH、OまたはSであり;
R3は、環A上のC-3、C-4、C-5またはC-6に結合する水素原子または置換基であり;
L1は、n個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORa、NH2、NHRa、NRaRb、SH、もしくはSRaで置換されていてもよく、および/または、
L1は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y1が、NH、OまたはSの場合、Y1に結合するL1の原子は炭素であり、OR1に結合するL1の原子は炭素であり、酸素原子同士は隣接せず;
L2は、m個の炭素原子からなるアルキレン鎖であり、ここで、アルキレン炭素原子上の水素原子は、OH、ORc、NH2、NHRc、NRcRd、SHもしくはSRcで置換されていてもよく、および/または、
L2は、前記アルキレン鎖の一つ以上の炭素原子が、酸素原子で置換されたポリエーテル鎖であり、
ただし、Y2が、NH、OまたはSの場合、Y2に結合するL2の原子は炭素であり、OR2に結合するL2の原子は炭素であり、酸素原子同士は隣接せず;
Ra、Rb、RcおよびRdは、それぞれ独立して、置換基または保護基であり;
lは、1または2であり;
mは、0~30の範囲の整数であり;
nは、0~30の範囲の整数であり;
環Aは、前記環A上のC-2以外の1個の炭素原子が、窒素、酸素または硫黄で置換されていてもよく、
前記環A内に、炭素-炭素二重結合または炭素-窒素二重結合を含んでもよく、
前記領域(Xc)および前記領域(X)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Lx)に結合し、
前記領域(Yc)および前記領域(Y)は、それぞれ、-OR1-または-OR2-を介して、前記リンカー領域(Ly)に結合し、
ここで、R1およびR2は、存在しても存在しなくてもよく、存在する場合、R1およびR2は、それぞれ独立して、ヌクレオチド残基または前記構造(I)である。 The strand nucleic acid molecule according to claim 10, wherein the linker regions (Lx) and (Ly) are represented by the following formula (I).
In the above formula,
X 1 and X 2 are each independently H 2 , O, S or NH;
Y 1 and Y 2 are each independently a single bond, CH 2 , NH, O or S;
R 3 is a hydrogen atom or substituent bonded to C-3, C-4, C-5 or C-6 on ring A;
L 1 is an alkylene chain consisting of n carbon atoms, where the hydrogen atom on the alkylene carbon atom is OH, OR a , NH 2 , NHR a , NR a R b , SH, or SR a May be substituted and / or
L 1 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 1 is NH, O or S, the atom of L 1 bonded to Y 1 is carbon, the atom of L 1 bonded to OR 1 is carbon, and oxygen atoms are not adjacent to each other;
L 2 is an alkylene chain consisting of m carbon atoms, where the hydrogen atom on the alkylene carbon atom is replaced by OH, OR c , NH 2 , NHR c , NR c R d , SH or SR c And / or
L 2 is a polyether chain in which one or more carbon atoms of the alkylene chain are substituted with an oxygen atom,
However, when Y 2 is NH, O or S, the atom of L 2 bonded to Y 2 is carbon, the atom of L 2 bonded to OR 2 is carbon, and oxygen atoms are not adjacent to each other;
R a , R b , R c and R d are each independently a substituent or a protecting group;
l is 1 or 2;
m is an integer ranging from 0 to 30;
n is an integer ranging from 0 to 30;
In ring A, one carbon atom other than C-2 on ring A may be substituted with nitrogen, oxygen or sulfur.
The ring A may contain a carbon-carbon double bond or a carbon-nitrogen double bond,
The region (Xc) and the region (X) are each bonded to the linker region (Lx) via —OR 1 — or —OR 2 —;
The region (Yc) and the region (Y) are each bonded to the linker region (Ly) via —OR 1 — or —OR 2 —,
Here, R 1 and R 2 may be present or absent, and when present, R 1 and R 2 are each independently a nucleotide residue or the structure (I). - 前記領域(X)の塩基数(X)および前記5’側領域(Xc)の塩基数(Xc)が、下記式(3)または式(5)の条件を満たす、請求項10または11に記載の核酸分子。
X>Xc ・・・(3)
X=Xc ・・・(5) The number of bases (X) of the region (X) and the number of bases (Xc) of the 5 'side region (Xc) satisfy the condition of the following formula (3) or formula (5). Nucleic acid molecules.
X> Xc (3)
X = Xc (5) - 前記領域(X)の塩基数(X)および前記5’側領域(Xc)の塩基数(Xc)が、下記式(11)の条件を満たす、請求項12に記載の核酸分子。
X-Xc=1、2または3 ・・・(11) The nucleic acid molecule according to claim 12, wherein the number of bases (X) in the region (X) and the number of bases (Xc) in the 5 'side region (Xc) satisfy the condition of the following formula (11).
X−Xc = 1, 2 or 3 (11) - 前記(B)において、前記領域(Z)の塩基数(Z)、前記領域(Xc)の塩基数(Xc)および前記領域(Yc)の塩基数(Yc)が、下記式(2)の条件を満たす、請求項10~13のいずれか1項に記載の核酸分子。
Z≧Xc+Yc ・・・(2) In (B), the number of bases (Z) in the region (Z), the number of bases (Xc) in the region (Xc), and the number of bases (Yc) in the region (Yc) are the conditions of the following formula (2) The nucleic acid molecule according to any one of claims 10 to 13, which satisfies the following conditions.
Z ≧ Xc + Yc (2) - 前記(B)において、前記領域(X)の塩基数(X)、前記(Xc)の塩基数(Xc)、前記領域(Y)の塩基数(Y)および前記領域(Yc)の塩基数(Yc)が、下記(a)~(d)のいずれかの条件を満たす、請求項10~14のいずれか1項に記載の核酸分子:
(a)下記式(3)および(4)の条件を満たす。
X>Xc ・・・(3)
Y=Yc ・・・(4)
(b)下記式(5)および(6)の条件を満たす。
X=Xc ・・・(5)
Y>Yc ・・・(6)
(c)下記式(7)および(8)の条件を満たす。
X>Xc ・・・(7)
Y>Yc ・・・(8)
(d)下記式(9)および(10)の条件を満たす。
X=Xc ・・・(9)
Y=Yc ・・・(10) In (B), the number of bases (X) in the region (X), the number of bases (Xc) in the (Xc), the number of bases (Y) in the region (Y), and the number of bases in the region (Yc) ( The nucleic acid molecule according to any one of claims 10 to 14, wherein Yc) satisfies any of the following conditions (a) to (d):
(A) Satisfy the conditions of the following formulas (3) and (4).
X> Xc (3)
Y = Yc (4)
(B) The conditions of the following formulas (5) and (6) are satisfied.
X = Xc (5)
Y> Yc (6)
(C) The conditions of the following formulas (7) and (8) are satisfied.
X> Xc (7)
Y> Yc (8)
(D) The conditions of the following formulas (9) and (10) are satisfied.
X = Xc (9)
Y = Yc (10) - 前記(a)~(d)において、前記領域(X)の塩基数(X)と前記領域(Xc)の塩基数(Xc)の差、前記領域(Y)の塩基数(Y)と前記領域(Yc)の塩基数(Yc)の差が、下記条件を満たす、請求項15に記載の核酸分子。
(a)下記式(11)および(12)の条件を満たす。
X-Xc=1、2または3 ・・・(11)
Y-Yc=0 ・・・(12)
(b)下記式(13)および(14)の条件を満たす。
X-Xc=0 ・・・(13)
Y-Yc=1、2または3 ・・・(14)
(c)下記式(15)および(16)の条件を満たす。
X-Xc=1、2または3 ・・・(15)
Y-Yc=1、2または3 ・・・(16)
(d)下記式(17)および(18)の条件を満たす。
X-Xc=0 ・・・(17)
Y-Yc=0 ・・・(18) In (a) to (d), the difference between the number of bases (X) in the region (X) and the number of bases (Xc) in the region (Xc), the number of bases (Y) in the region (Y) and the region The nucleic acid molecule according to claim 15, wherein the difference in the number of bases (Yc) of (Yc) satisfies the following condition.
(A) The conditions of the following formulas (11) and (12) are satisfied.
X−Xc = 1, 2 or 3 (11)
Y−Yc = 0 (12)
(B) The conditions of the following formulas (13) and (14) are satisfied.
X−Xc = 0 (13)
Y−Yc = 1, 2 or 3 (14)
(C) The conditions of the following formulas (15) and (16) are satisfied.
X−Xc = 1, 2 or 3 (15)
Y−Yc = 1, 2 or 3 (16)
(D) The conditions of the following formulas (17) and (18) are satisfied.
X−Xc = 0 (17)
Y−Yc = 0 (18) - 前記(B)において、前記領域(Xc)の塩基数(Xc)が、1~11塩基である、請求項10~16のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 10 to 16, wherein in (B), the number of bases (Xc) of the region (Xc) is 1 to 11 bases.
- 前記領域(Xc)の塩基数(Xc)が、1~7塩基である、請求項17に記載の核酸分子。 The nucleic acid molecule according to claim 17, wherein the number of bases (Xc) in the region (Xc) is 1 to 7 bases.
- 前記領域(Xc)の塩基数(Xc)が、1~3塩基である、請求項17に記載の核酸分子。 The nucleic acid molecule according to claim 17, wherein the number of bases (Xc) in the region (Xc) is 1 to 3 bases.
- 前記(B)において、前記領域(Yc)の塩基数(Yc)が、1~11塩基である、請求項10~19のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 10 to 19, wherein in (B), the number of bases (Yc) of the region (Yc) is 1 to 11 bases.
- 前記領域(Yc)の塩基数(Yc)が、1~7塩基である、請求項20に記載の核酸分子。 The nucleic acid molecule according to claim 20, wherein the number of bases (Yc) in the region (Yc) is 1 to 7 bases.
- 前記領域(Yc)の塩基数(Yc)が、1~3塩基である、請求項20に記載の核酸分子。 The nucleic acid molecule according to claim 20, wherein the number of bases (Yc) in the region (Yc) is 1 to 3 bases.
- 前記(A)において、前記領域(Xc)の塩基数(Xc)が、19~30塩基である、請求項10~13のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 10 to 13, wherein in (A), the number of bases (Xc) of the region (Xc) is 19 to 30 bases.
- 塩基数の合計が80塩基以下である、請求項10~23のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 10 to 23, wherein the total number of bases is 80 or less.
- RNA分子である、請求項10~24のいずれか1項に記載の核酸分子。 The nucleic acid molecule according to any one of claims 10 to 24, which is an RNA molecule.
- 前記(B)において、前記リンカー領域(Lx)および(Ly)が、1~20塩基のヌクレオチド残基から成る、請求項10に記載の核酸分子。 The nucleic acid molecule according to claim 10, wherein in (B), the linker regions (Lx) and (Ly) are composed of nucleotide residues of 1 to 20 bases.
- (i)のヌクレオチド配列と(iii)のヌクレオチド配列、または(ii)のヌクレオチド配列と(iv)のヌクレオチド配列とが、下記式で表される基で連結されている、請求項1~4のいずれか1項に記載の核酸分子。

- リンカー領域(Lx)および/またはリンカー領域(Ly)が下記式で表される基である、請求項10~25のいずれか1項に記載の核酸分子。

- 以下のいずれかで表される、請求項1~4、10~13または23のいずれか1項に記載の核酸分子。
5’-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3’(配列番号13)
5’-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3’(配列番号14)
(該配列中、-Lx-は、下記式で表される基を示す。)

5'-AGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUU-3 '(SEQ ID NO: 13)
5'-GCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUU-3 '(SEQ ID NO: 14)
(In the sequence, -Lx- represents a group represented by the following formula.)
- 以下のいずれかで表される、請求項1~4または10~22のいずれか1項に記載の核酸分子。
5’-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3’(配列番号17)
5’-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3’(配列番号18)
(該配列中、-Lx-および-Ly-は、下記式で表される基を示す。)

5'-AAGUCUAGACUCGUGGUGGAUUCC-Lx-GGAAUCCACCACGAGUCUAGACUUUC-Ly-G-3 '(SEQ ID NO: 17)
5'-AGCAAGAUUCCUAUGGGAGUUUCC-Lx-GGAAACUCCCAUAGGAAUCUUGCUUC-Ly-G-3 '(SEQ ID NO: 18)
(In the sequence, -Lx- and -Ly- represent a group represented by the following formula.)
- 以下のいずれかで表される、請求項1~4、10、12~22または26のいずれか1項に記載の核酸分子。
5’-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3’(配列番号15)
5’-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3’(配列番号16) The nucleic acid molecule according to any one of claims 1 to 4, 10, 12 to 22 or 26, which is represented by any of the following:
5'-AAGUCUAGACUCGUGGUGGAUUCCCCACACCGGAAUCCACCACGAGUCUAGACUUUCUUCGG-3 '(SEQ ID NO: 15)
5'-AGCAAGAUUCCUAUGGGAGUUUCCCCACACCGGAAACUCCCAUAGGAAUCUUGCUUCUUCGG-3 '(SEQ ID NO: 16) - 請求項5~9、26または31記載の核酸分子を発現する発現ベクター。 An expression vector for expressing the nucleic acid molecule according to claim 5-9, 26 or 31.
- 請求項1~31のいずれか1項記載の核酸分子又は請求項32記載の発現ベクターを含む、医薬組成物。 A pharmaceutical composition comprising the nucleic acid molecule according to any one of claims 1 to 31 or the expression vector according to claim 32.
- B型肝炎ウイルス増殖抑制用である、請求項33記載の医薬組成物。 34. The pharmaceutical composition according to claim 33, which is used for inhibiting hepatitis B virus growth.
- B型肝炎の治療用である、請求項33記載の医薬組成物。 34. The pharmaceutical composition according to claim 33, which is used for treatment of hepatitis B.
- 肝硬変の治療用である、請求項33記載の医薬組成物。 34. The pharmaceutical composition according to claim 33, which is used for treating cirrhosis.
- 肝臓がんの治療用である、請求項33記載の医薬組成物。 34. The pharmaceutical composition according to claim 33, which is used for treatment of liver cancer.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019514692A JPWO2018199338A1 (en) | 2017-04-27 | 2018-04-27 | Nucleic acid molecule for hepatitis B treatment |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017088960 | 2017-04-27 | ||
| JP2017-088960 | 2017-04-27 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018199338A1 true WO2018199338A1 (en) | 2018-11-01 |
Family
ID=63918465
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2018/017347 WO2018199338A1 (en) | 2017-04-27 | 2018-04-27 | Nucleic acid molecule for treatment of hepatitis b |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2018199338A1 (en) |
| WO (1) | WO2018199338A1 (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190064628A (en) * | 2016-10-14 | 2019-06-10 | 프리시젼 바이오사이언시스 인코포레이티드 | A manipulated meganuclease specific for the recognition sequence in the hepatitis B viral genome |
| WO2020255062A1 (en) * | 2019-06-20 | 2020-12-24 | Janssen Sciences Ireland Unlimited Company | Lipid nanoparticle or liposome delivery of hepatitis b virus (hbv) vaccines |
| WO2021107097A1 (en) * | 2019-11-28 | 2021-06-03 | 株式会社ボナック | Nucleic acid molecule for hepatitis b treatment use |
| WO2021117770A1 (en) * | 2019-12-10 | 2021-06-17 | 富士フイルム株式会社 | Pharmaceutical composition and treatment agent |
| US11725194B2 (en) | 2017-12-19 | 2023-08-15 | Janssen Sciences Ireland Unlimited Company | Hepatitis B virus (HBV) vaccines and uses thereof |
| US11788077B2 (en) | 2018-04-12 | 2023-10-17 | Precision Biosciences, Inc. | Polynucleotides encoding optimized engineered meganucleases having specificity for a recognition sequence in the Hepatitis B virus genome |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012005368A1 (en) * | 2010-07-08 | 2012-01-12 | 株式会社ボナック | Single-strand nucleic acid molecule for controlling gene expression |
| WO2012017919A1 (en) * | 2010-08-03 | 2012-02-09 | 株式会社ボナック | Single-stranded nucleic acid molecule having nitrogen-containing alicyclic skeleton |
| JP2013537423A (en) * | 2010-08-17 | 2013-10-03 | メルク・シャープ・エンド・ドーム・コーポレイション | RNA interference-mediated inhibition of hepatitis B virus (HBV) gene expression using small interfering nucleic acids (siNA) |
-
2018
- 2018-04-27 WO PCT/JP2018/017347 patent/WO2018199338A1/en active Application Filing
- 2018-04-27 JP JP2019514692A patent/JPWO2018199338A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012005368A1 (en) * | 2010-07-08 | 2012-01-12 | 株式会社ボナック | Single-strand nucleic acid molecule for controlling gene expression |
| WO2012017919A1 (en) * | 2010-08-03 | 2012-02-09 | 株式会社ボナック | Single-stranded nucleic acid molecule having nitrogen-containing alicyclic skeleton |
| JP2013537423A (en) * | 2010-08-17 | 2013-10-03 | メルク・シャープ・エンド・ドーム・コーポレイション | RNA interference-mediated inhibition of hepatitis B virus (HBV) gene expression using small interfering nucleic acids (siNA) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190064628A (en) * | 2016-10-14 | 2019-06-10 | 프리시젼 바이오사이언시스 인코포레이티드 | A manipulated meganuclease specific for the recognition sequence in the hepatitis B viral genome |
| KR102305215B1 (en) | 2016-10-14 | 2021-09-28 | 프리시젼 바이오사이언시스 인코포레이티드 | Engineered meganucleases specific for recognition sequences in the hepatitis B virus genome |
| US11725194B2 (en) | 2017-12-19 | 2023-08-15 | Janssen Sciences Ireland Unlimited Company | Hepatitis B virus (HBV) vaccines and uses thereof |
| US11788077B2 (en) | 2018-04-12 | 2023-10-17 | Precision Biosciences, Inc. | Polynucleotides encoding optimized engineered meganucleases having specificity for a recognition sequence in the Hepatitis B virus genome |
| WO2020255062A1 (en) * | 2019-06-20 | 2020-12-24 | Janssen Sciences Ireland Unlimited Company | Lipid nanoparticle or liposome delivery of hepatitis b virus (hbv) vaccines |
| WO2021107097A1 (en) * | 2019-11-28 | 2021-06-03 | 株式会社ボナック | Nucleic acid molecule for hepatitis b treatment use |
| WO2021117770A1 (en) * | 2019-12-10 | 2021-06-17 | 富士フイルム株式会社 | Pharmaceutical composition and treatment agent |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2018199338A1 (en) | 2020-03-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2018199338A1 (en) | Nucleic acid molecule for treatment of hepatitis b | |
| WO2015093495A1 (en) | Single-stranded nucleic acid molecule for controlling expression of tgf-β1 gene | |
| TWI527901B (en) | A single stranded nucleic acid molecule used to control gene expression | |
| TWI515294B (en) | A single stranded nucleic acid molecule having a nitrogen-containing lipid | |
| US8785121B2 (en) | Single-stranded nucleic acid molecule for controlling gene expression | |
| JP6882741B2 (en) | Single-stranded nucleic acid molecule that suppresses the expression of prorenin gene or prorenin receptor gene and its use | |
| WO2013133393A1 (en) | Single-stranded nucleic acid molecule for inhibiting vegf gene expression | |
| JP6283859B2 (en) | Periostin gene expression suppressing nucleic acid molecule, periostin gene expression suppressing method, and use thereof | |
| CN110996969B (en) | Therapeutic agent for fibrotic diseases | |
| WO2021241040A1 (en) | Nucleic acid molecule inhibiting sars-cov-2 gene expression and use thereof | |
| WO2021107097A1 (en) | Nucleic acid molecule for hepatitis b treatment use | |
| JP2017046596A (en) | SINGLE-STRANDED NUCLEIC ACID MOLECULE FOR REGULATION OF TGF-β1 GENE EXPRESSION | |
| US10337009B2 (en) | Single-stranded nucleic acid molecule for inhibiting TGF-β1 expression | |
| JP2020198784A (en) | Nucleic acid molecule for regulating immune function and use thereof | |
| JP2014140341A (en) | Nucleic acid molecule for inhibiting expression of rpn2 gene, method for repressing expression of rpn2 gene, and use thereof | |
| JP2015182988A (en) | EXPRESSION INHIBITOR OF NF-κB RELA GENE, PHARMACEUTICALS FOR ALLERGIC DERMATITIS AND APPLICATIONS THEREOF |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18789909 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2019514692 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 18789909 Country of ref document: EP Kind code of ref document: A1 |