WO2016165304A1 - 一种实例节点管理的方法及管理设备 - Google Patents
一种实例节点管理的方法及管理设备 Download PDFInfo
- Publication number
- WO2016165304A1 WO2016165304A1 PCT/CN2015/092667 CN2015092667W WO2016165304A1 WO 2016165304 A1 WO2016165304 A1 WO 2016165304A1 CN 2015092667 W CN2015092667 W CN 2015092667W WO 2016165304 A1 WO2016165304 A1 WO 2016165304A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- application
- instance node
- node
- resource configuration
- standby
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 85
- 238000007726 management method Methods 0.000 claims description 106
- 238000012544 monitoring process Methods 0.000 claims description 22
- 230000008439 repair process Effects 0.000 claims description 16
- 238000001514 detection method Methods 0.000 claims description 12
- 238000010586 diagram Methods 0.000 description 18
- 230000006870 function Effects 0.000 description 16
- 230000008569 process Effects 0.000 description 13
- 238000012545 processing Methods 0.000 description 12
- 230000036541 health Effects 0.000 description 10
- 238000004364 calculation method Methods 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 4
- 230000008571 general function Effects 0.000 description 4
- 230000009469 supplementation Effects 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 239000002699 waste material Substances 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 230000003862 health status Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 238000013468 resource allocation Methods 0.000 description 1
Images















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/084—Configuration by using pre-existing information, e.g. using templates or copying from other elements
- H04L41/0846—Configuration by using pre-existing information, e.g. using templates or copying from other elements based on copy from other elements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/40—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks using virtualisation of network functions or resources, e.g. SDN or NFV entities
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1446—Point-in-time backing up or restoration of persistent data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/203—Failover techniques using migration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2041—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant with more than one idle spare processing component
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3003—Monitoring arrangements specially adapted to the computing system or computing system component being monitored
- G06F11/3006—Monitoring arrangements specially adapted to the computing system or computing system component being monitored where the computing system is distributed, e.g. networked systems, clusters, multiprocessor systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0654—Management of faults, events, alarms or notifications using network fault recovery
- H04L41/0663—Performing the actions predefined by failover planning, e.g. switching to standby network elements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0654—Management of faults, events, alarms or notifications using network fault recovery
- H04L41/0668—Management of faults, events, alarms or notifications using network fault recovery by dynamic selection of recovery network elements, e.g. replacement by the most appropriate element after failure
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L65/00—Network arrangements, protocols or services for supporting real-time applications in data packet communication
- H04L65/40—Support for services or applications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1097—Protocols in which an application is distributed across nodes in the network for distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45562—Creating, deleting, cloning virtual machine instances
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/4557—Distribution of virtual machine instances; Migration and load balancing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45575—Starting, stopping, suspending or resuming virtual machine instances
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0876—Aspects of the degree of configuration automation
- H04L41/0886—Fully automatic configuration
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
Definitions
- the present invention relates to the field of cloud computing technologies, and in particular, to a method and a management device for instance node management.
- the cloud platform In the era of cloud computing, a large number of applications and services are hosted on the cloud platform. In addition to ensuring high availability, the cloud platform also provides high availability guarantees for applications and services hosted on it.
- Existing solutions usually implement high availability of applications and services by deploying primary and secondary instance nodes.
- For the high availability scheme of the primary primary instance node multiple application instances are in a side-by-side relationship, and all instance nodes can receive external request information and process them normally. In the event that one of the instance nodes fails, the load it is responsible for will be shared with other instance nodes.
- the active/standby instance node solution is the most popular high-reliability solution in the industry.
- the application instance of the primary instance node is backed up at the standby instance point. When the primary instance node is normal, all external requests access the primary instance node, and only the primary instance node fails. When it is not working properly, the external request is switched to the standby instance node.
- the standby instance node occupies the same resources as the primary instance node, but is always in a standby state, resulting in waste of physical resources.
- the primary primary instance node scheme two primary instances The resource utilization of the node cannot reach 50%. Otherwise, when a single point of failure occurs, all the pressure is concentrated on the other active primary instance node. If the pressure is too large, the service will not be normal, which will result in more node resources. The waste of use.
- An example node management method provided by the embodiment of the present invention can reduce the occupation of the standby resource and improve the hosting capability and scale of the application on the cloud platform on the basis of ensuring high availability of the application to the cloud platform.
- the embodiment of the invention also provides a corresponding management device.
- a first aspect of the present invention provides a method for managing an instance node, where the method is applied to a management device of a cloud platform, and the method includes:
- the standby instance node of the application is used to replace the application when the primary instance node of the application fails
- the primary instance node runs an instance of the application
- the method further includes:
- the resource configuration specification of the standby instance node is adjusted to be the same as the resource configuration specification of the primary instance node, and the standby instance node is set as a working instance node to replace the The primary instance node of the application runs an instance of the application.
- the method further includes:
- a standby instance node is created for the application again according to the minimum resource configuration specification.
- the method further includes:
- any one of the foregoing first to third possible implementation manners after determining the minimum resource configuration specification of the standby instance node of the application, the method further includes:
- the creating a standby instance node of the application according to the minimum resource configuration specification includes:
- At least two standby instance nodes are created for the application according to the minimum resource configuration specification, where a resource configuration specification of each of the created standby instance nodes is the minimum
- the resource configuration specifications are the same.
- the method further includes:
- the method further includes:
- the resource configuration specification of the standby instance node of the created application is adjusted according to the required resource amount.
- a second aspect of the present invention provides a management device for a cloud platform, where the management device includes:
- a first creating module configured to create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application;
- a determining module configured to determine, according to the running startup information of the primary instance node that is created by the first creating module, a minimum resource configuration specification required by the standby instance node of the application; When the primary instance node of the application fails, the instance of the application is taken over by the primary instance node of the application;
- a second creation module configured to create a standby instance node of the application according to the minimum resource configuration specification determined by the determining module, where a resource configuration specification of the standby instance node of the application is smaller than a primary instance of the application The resource configuration specification of the node.
- the management device further includes:
- a first adjustment module configured to adjust, when the primary instance node is faulty, a resource configuration specification of the standby instance node created by the second creation module to be the same as a resource configuration specification of the primary instance node, and
- the standby instance node is configured as a working instance node to take over the instance of the application by the primary instance node of the application.
- the second creating module is further configured to create a standby instance node for the application again according to the minimum resource configuration specification.
- the management device further includes: a repair module,
- the repair module is configured to repair the faulty primary instance node to obtain a repaired primary instance node
- the first adjustment module is further configured to adjust a resource configuration specification of the repaired primary instance node to a minimum resource configuration specification of the application, and set the repaired primary instance node to the application
- An instance node is provided to facilitate execution of an instance of the application when the working instance node fails.
- the management device further includes an acquiring module
- the obtaining module is configured to acquire a visit amount of the user equipment to the application
- the second creating module is configured to: when the access quantity of the application acquired by the acquiring module exceeds a preset threshold, create at least two for the application according to the minimum resource configuration specification determined by the determining module.
- Each of the standby instance nodes has the same resource configuration specification as the minimum resource configuration specification.
- the management device further includes a monitoring module
- the monitoring module is configured to monitor a standby instance node of the application that has been created by the second creation module;
- the second creation module is further configured to: when the monitoring module detects that the standby instance node of the application is faulty, create a standby instance node that has the same number of failed standby instance nodes.
- the management device further includes a detection module and a second adjustment module
- the detecting module is configured to detect an amount of resources required to run an instance of the application
- the second adjustment module is configured to adjust a resource configuration specification of the standby instance node of the application that is created according to the required resource quantity detected by the detection module.
- the embodiment of the present invention is to create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; and determine the application according to the running startup information of the primary instance node.
- the minimum resource configuration specification required by the instance node; the standby instance node of the application is configured to succeed the instance instance of the application to run the instance of the application when the primary instance node of the application fails; according to the minimum resource
- the configuration specification is used to create a standby instance node of the application, where the resource configuration specification of the standby instance node of the application is smaller than the resource configuration specification of the primary instance node of the application.
- the method for managing the instance node needs to occupy the same resource as the primary instance node, and the method for managing the instance node provided by the embodiment of the present invention can ensure the application is hosted to the cloud platform.
- the occupation of backup resources can be reduced, and the hosting capacity and scale of applications on the cloud platform can be improved.
- FIG. 1 is a schematic diagram of an embodiment of a method for managing an instance node in an embodiment of the present invention
- FIG. 2 is a schematic diagram of another embodiment of a method for managing an instance node in an embodiment of the present invention.
- FIG. 3 is a schematic diagram of another embodiment of a method for managing an instance node in an embodiment of the present invention.
- FIG. 4 is a schematic diagram of another embodiment of a method for managing an instance node in an embodiment of the present invention.
- FIG. 5 is a schematic diagram of another embodiment of a method for managing an instance node in an embodiment of the present invention.
- FIG. 6 is a schematic diagram of another embodiment of a method for managing an instance node in an embodiment of the present invention.
- FIG. 7 is a schematic diagram of another embodiment of a method for managing an instance node in an embodiment of the present invention.
- FIG. 8 is a schematic diagram of an embodiment of a management device according to an embodiment of the present invention.
- FIG. 9 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 10 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 11 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 12 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 13 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 14 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 15 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- FIG. 16 is a schematic diagram of another embodiment of a management device according to an embodiment of the present invention.
- the embodiment of the invention provides a method for managing an instance node. On the basis of ensuring that the application is hosted on the cloud platform, the occupancy of the standby resource can be reduced, and the hosting capability and scale of the application on the cloud platform can be improved.
- the embodiment of the invention also provides a corresponding management device. The details are described below separately.
- the cloud platform can host a large number of applications.
- a primary instance node and a standby instance node are created for each application, and the main instance node is used to run the application instance.
- the standby instance node is configured to take over the instance of the application by the primary instance node of the application when the primary instance node of the application fails.
- the management device on the cloud platform manages the primary instance node and the standby instance node in a unified manner.
- the primary instance node and the standby instance node are actually virtual machines allocated by the management device for the application or functional nodes having a smaller granularity than the virtual machine.
- Both the primary instance node and the standby instance node can utilize resources on the cloud platform.
- the resources on the cloud platform refer to the hardware resources provided by many physical hosts, including but not limited to the number of cores of the Central Processing Unit (CPU), memory, hard disk size, and network bandwidth.
- CPU Central Processing Unit
- the primary instance node that runs the instance of the application is created for the application hosted by the user to the cloud platform, and the startup information is started according to the running of the primary instance node. Determining a minimum resource configuration specification of the standby instance node of the application; The small resource configuration specification is used to create a standby instance node of the application, so that the resource configuration specification of the standby instance node is the same as the minimum resource configuration specification, and the resource configuration specification of the standby instance node of the application is smaller than the application.
- the resource configuration specification of the primary instance node where the standby instance node of the application is configured to take over the instance of the application when the primary instance node of the application fails, wherein the resource configuration of the instance node
- the specification is used to indicate the amount of resources allocated for the instance node, such as the number of CPU cores allocated for the instance node, memory, hard disk size, network bandwidth, etc.; the minimum resource configuration specification is used to indicate the need to start or run an instance of the application. The smallest amount of resources.
- An instance of an application can be understood as a copy or image of an executable version of an application.
- the cloud platform can create one or more instances for an application, and each instance of the application can be a separate process or thread.
- the user may be an application operator, and the running startup information of the primary instance node may indicate basic resources required for running the instance of the application, for example, the number of cores of the CPU when the primary instance node starts running, the size of the memory, the size of the hard disk, and the network. bandwidth.
- the minimum resource configuration specification of the standby instance node may be the specification information of the number of cores, memory, hard disk size, and network bandwidth required by the instance node for running the application.
- the primary instance node when the primary instance node is normal, the primary instance node provides a service for accessing the user equipment, and when the primary instance node fails, the management device switches the access of the user equipment to the standby instance node, and the The standby instance node of the application is set as a working instance node that provides access to the user equipment; the resource configuration specification of the working instance node is adjusted to be the same as the resource configuration specification of the primary instance node of the application.
- the adjustment may be slightly larger or slightly smaller than the resource configuration specification of the primary instance node of the application.
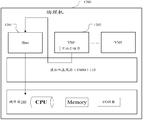
- the management device in the embodiment of the present invention may include the cloud controller, the standby node management subsystem, and the health check system in FIG. 2 . as shown in picture 2:
- Step 1 The deployer of the application deploys the cloud application to the cloud platform through the cloud controller.
- Step 2 The cloud controller creates a primary instance node that runs the application according to the specification of the application, where the primary instance node has an initial resource configuration specification, where the initial resource configuration specification is usually a system default value or a developer/mainerator is set according to experience. And the initial resource configuration specification can ensure that the primary instance node has sufficient resources to use to carry an instance of the application.
- the initial resource configuration specification is usually a system default value or a developer/mainerator is set according to experience.
- the initial resource configuration specification can ensure that the primary instance node has sufficient resources to use to carry an instance of the application.
- Step 3 After the main instance node is built, the health check system identifies the primary instance node of the newly added cloud application.
- Step 4 The health check system notifies the standby node management subsystem to perform calculation of the minimum resource configuration specification.
- Step 5 The standby node management subsystem calculates a minimum resource configuration specification of the standby instance node according to the running information of the primary instance node that has been started and runs normally.
- the running information may indicate a resource actually occupied by an instance of the application running normally, and the minimum resource configuration specification indicates a minimum amount of resources required to start or run an instance of the application, the minimum resource configuration specification is usually much smaller than that of the primary instance node.
- Step 6 The cloud controller creates a standby instance node according to the obtained minimum resource configuration specification, where the resource configuration specification of the created standby instance node and the minimum resource configuration specification.
- Figure 3 shows an example of the processing when the primary instance node is faulty.
- the health check system detects that the primary instance node is faulty, it notifies the standby node management subsystem that the standby node management subsystem notifies the cloud controller to enable and expand the minimized standby.
- the instance node is used as a regular instance node to take over the instance of the application, and then create a standby instance node according to the minimum resource configuration specification.
- a conventional example herein may also be referred to as a work instance node, and refers to an instance node that is currently running an instance of the application.
- the cloud platform includes the following parts: a cloud controller, a health check system, a standby node management subsystem, and a route distribution system. And the application runtime environment.
- the cloud controller, the health check system, the standby node management subsystem, and the route distribution system can all be understood as being part of the management device, and the management device has a cloud controller, a health check system, a standby node management subsystem, and a route distribution system. The function.
- the standby node management subsystem On the cloud platform, the standby node management system is mainly responsible for calculating the minimum resource configuration specification of the standby instance node, and notifying the cloud controller to start and expand the standby instance node when the primary instance node is faulty, and After the standby instance node is enabled as a regular working instance node, the standby instance node is created again according to the minimum resource configuration specification.
- the expansion of the standby instance node into a regular working instance node means that the resource of the standby instance node is configured.
- the specification is adjusted to be the same as the resource configuration specification of the primary instance node of the application. It should be noted that the “same” in the embodiment of the present invention is not absolutely the same in the index value. In practical applications, a certain error is allowed, for example, the standby instance node is larger than the primary instance node.
- the resource allocation specifications are slightly larger or slightly smaller, or substantially the same.
- the standby node management subsystem mainly includes the following three modules: a minimum specification calculation module, an application standby node instance management module, and a fault processing configuration notification module.
- the minimization specification calculation module is mainly configured to obtain the minimum configuration specification of the required resources from the initialization process of the main instance node after the primary instance node has been successfully started. Specifications include, but are not limited to, CPU cores, memory, hard drive size, network bandwidth, and more. This specification will be notified to the cloud controller and recorded on the cloud controller as a basis for subsequent startup of the new standby instance node.
- the application standby node instance management module is used to determine and check the standby instance nodes of the application.
- the number of running instance nodes and the running status are managed by this module.
- the system can determine the number of backup instance nodes that are minimized to support the sudden failure. You can quickly enable multiple standby instances to ensure unobstructed operation.
- the fault handling configuration notification module is a processing mechanism when the health check system detects an instance fault. This includes two instances of failures, one is the failure of the regular instance node, and the other is the failure of the standby instance node that minimizes the specification.
- the fault handling configuration notification module notifies the cloud controller to enable a standby instance node and rapidly expands it to the regular instance node specification; at this time, the number of minimized standby instance nodes is correspondingly reduced by one, that is, the notification
- the cloud controller creates a new standby instance node. When the minimized standby instance node fails, it also performs the same operation as the normal instance node failure.
- Cloud Controller Configuration of instance node management and route distribution.
- the instance nodes of all cloud applications are distributed by the cloud controller to the specified application running environment, and the instance access mode is sent by the cloud controller to the route distribution system as a general function system on the cloud platform.
- the invention is not described in detail.
- the routing distribution system mainly controls the external access request to be distributed to the running instance node of the corresponding application, receives the processing result of the instance node, and feeds back to the user equipment that sends the access request, as a general function system on the cloud platform, and the present invention No detailed description.
- the health check system is responsible for checking the health status of the instance nodes of all applications, and notifying the standby node management system for fault recovery, and minimizing the creation of the standby instance nodes, etc., as a general function system on the cloud platform, which is not described in detail in the present invention. .
- Application running environment The application running environment on the cloud platform, mainly the virtual machine, container and other carriers, and provides the operating system, software stack, computing/storage/network and other resources required for the application to run, so that the application instance can run normally.
- the present invention will not be described in detail.
- the management implementation process of the example node in the embodiment of the present invention is divided into two situations: initial deployment and fault occurrence.
- initial deployment refers to the corresponding description in the parts of FIG. 1 to FIG. 5, and the details are not described herein.
- the foregoing steps can ensure that the cloud application has sufficient active/standby support capability, and the specification of the standby instance node can be much smaller than that of the conventional instance node, thereby effectively reducing resources caused by high availability requirements. Wasted the situation.
- FIG. 6 another embodiment of the management of the instance node in the embodiment of the present invention is substantially the same as the embodiment corresponding to FIG. 4, except that the structure is partially simplified.
- the instance management node can be included in the cloud controller and deployed with the cloud controller in a plug-in/component of the cloud controller.
- the inter-system communication first notifies the cloud controller, and then the cloud controller transfers the related processing to the standby node management plug-in.
- the standby node management node can directly notify the routing/application running environment, such as route distribution management configuration and instance node creation/expansion.
- the process of creating a cloud application for the first time is the same as the above embodiment.
- it is not necessary to determine the resource pool of the standby node, and directly convert the standby instance node in the cloud application into a regular node, and then create a standby instance node.
- the process of creating the cloud application for the first time is the same, and the difference is that when the fault occurs, the standby instance node is converted into a regular node, not again.
- a standby instance node is created.
- the cloud controller replaces the failed normal instance.
- the health check system notifies the standby node management system to recover the enabled standby instance node and restore the initial state.
- the resource configuration specification of the repaired regular instance node is adjusted to the minimum resource configuration specification of the application, and becomes a standby instance node of the application.
- a method for dynamically adjusting is added to the calculation and management of the minimum specification of the standby node.
- the minimum running specification is dynamically calculated according to the statistics of the overall running state of the application, and the specification refresh of the minimum-specified backup node instance in the current environment is performed in real time.
- it may also be a method of creating a minimum specification instance, considering that some applications may use a large amount of temporary resources during the initialization startup process, and after the initialization is completed, the amount of resources consumed is relatively low. Therefore, the process of creating a minimized standby instance node begins with creating a complete specification instance, and then shrinking its specifications to the calculated minimum specification after the startup is complete. To reduce resource consumption.
- the first instance node is restored first, and then used as the minimum specification instance node, which is reduced to the minimum specification.
- the running environment for the cloud platform may be different, such as a container, a virtual machine, etc., and the implementation manner of the minimum specification standby instance node is different.
- the container technology the above various embodiments of the method can be quickly implemented; when using the virtual machine technology, due to the immature vertical expansion and expansion technology for the virtual machine, the vertical + horizontal expansion method is adopted here.
- the method of the foregoing embodiment is directly used, and in the cloud environment that does not satisfy the vertical scaling, the horizontal scaling mechanism is adopted, and the creation of the standby instance node is the same as the above, but in use, Establish multiple standby instance nodes to meet the short-term reliability requirements, and restore the regular instance nodes, and then release the temporarily generated standby instance nodes to ensure the effective use of resources.
- the instance node needs to occupy the same resource as the main instance node, and the method for managing the instance node provided by the embodiment of the present invention may On the basis of ensuring high availability of application hosting to the cloud platform, the occupation of standby resources can be reduced, and the hosting capacity and scale of applications on the cloud platform can be improved.
- an embodiment of a method for managing an instance node includes:
- the management method of the instance node provided by the embodiment of the present invention is applied to a management device of the cloud platform.
- the standby instance node of the application is used to replace the primary instance node of the application when the application fails
- the primary instance node of the application runs an instance of the application.
- the running startup information of the primary instance node may be a basic resource required for running the application, for example, the number of cores of the CPU when the primary instance node starts running, the size of the memory, the size of the hard disk, and the network bandwidth.
- the minimum resource configuration specification of the standby node can be the number of cores, memory, hard disk size, and network bandwidth of the instance node.
- the embodiment of the present invention is to create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; and determine the application according to the running startup information of the primary instance node.
- the minimum resource configuration specification required by the instance node; the standby instance node of the application is configured to succeed the instance instance of the application to run the instance of the application when the primary instance node of the application fails; according to the minimum resource
- the configuration specification is used to create a standby instance node of the application, where the resource configuration specification of the standby instance node of the application is smaller than the resource configuration specification of the primary instance node of the application.
- the method for managing the instance node needs to occupy the same resource as the primary instance node, and the method for managing the instance node provided by the embodiment of the present invention can ensure the application is hosted to the cloud platform.
- the occupation of backup resources can be reduced, and the hosting capacity and scale of applications on the cloud platform can be improved.
- the creating the After the application instance node is applied may further include:
- the resource configuration specification of the standby instance node is adjusted to be the same as the resource configuration specification of the primary instance node, and the standby instance node is set as a working instance node to replace the The primary instance node of the application runs an instance of the application.
- the standby instance node of the application as a working instance node that provides access to the user equipment access.
- the resource configuration specification of the working instance node is adjusted to be the same as the resource configuration specification of the primary instance node of the application.
- the resource occupancy rate of the standby instance node is very low.
- the primary instance node fails, the primary instance node is rapidly expanded to take over the work of the primary instance node, thereby satisfying the application access requirement and improving the cloud platform.
- the hosting capabilities and scale of the application are very low.
- the method may further include:
- a standby instance node is created for the application again according to the minimum resource configuration specification.
- the dynamic supplementation in time avoids the access request of the application when the next working instance node fails, thereby improving the reliability and improving the user.
- the dynamic supplementation in time avoids the access request of the application when the next working instance node fails, thereby improving the reliability and improving the user.
- the method may further include:
- the faulty primary instance node can also be repaired in time, which further improves the utilization of resources in the cloud platform.
- the method may further include:
- the creating a standby instance node of the application according to the minimum resource configuration specification includes:
- At least two standby instance nodes are created for the application according to the minimum resource configuration specification, where a resource configuration specification of each of the created standby instance nodes is the minimum
- the resource configuration specifications are the same.
- a corresponding number of minimized standby instance nodes can be created according to the access amount of the application, so as to prevent unexpected failures when the application pressure is too large, thereby further improving the high availability of the cloud platform.
- the method may further include:
- the fault instance section in the created standby instance node may also be monitored in time. Point, create a new available standby instance node in time to avoid the failure of the primary instance node, and no available standby instance node to take over the work of the primary instance node, thereby further improving the high availability of the cloud platform.
- the method may further include:
- the resource configuration specification of the standby instance node of the created application is adjusted according to the required resource amount.
- the resource configuration specification may be dynamically adjusted according to the amount of resources required to run the application, and if the application requirement is low, the resource may be further saved, if the application is When the demand is high, the success rate of the failure of the primary instance node can also be improved.
- FIG. 7 The corresponding embodiment of FIG. 7 and its corresponding alternative embodiment can be understood by referring to the related description in the parts of FIG. 1 to FIG. 6 , and no further description is made herein.
- the first creation module 201, the second creation module 203, the first adjustment module 204, the repair module 205, the acquisition module 206, and the detection module 208 involved in the process of the management device 20 of the cloud platform are described below.
- the function of the second adjustment module 209 is the same as that of the cloud controller described in the embodiment of FIG. 1 to FIG. 4, and the functions performed by the determination module 202 and the monitoring module 207 are the same as those described in the embodiments of FIGS. 1-4.
- the standby node management subsystem has the same function.
- the determining module 202 can be the minimum specification calculation module in FIG. 5, and the monitoring module 207 can be an application standby node instance management module and a fault handling configuration notification module.
- an embodiment of the management device 20 of the cloud platform provided by the embodiment of the present invention includes:
- a first creating module 201 configured to create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application;
- the determining module 202 is configured to determine, according to the running startup information of the primary instance node that is created by the first creating module 201, a minimum resource configuration specification required by the standby instance node of the application; And executing an instance of the application by replacing a primary instance node of the application when the primary instance node of the application fails;
- a second creation module 203 configured to create a standby instance node of the application according to the minimum resource configuration specification determined by the determining module 202, where a resource configuration specification of the standby instance node of the application is smaller than the application The resource configuration specification of the primary instance node.
- the standby node needs to occupy the same resources as the primary instance node, and the management device of the instance node provided by the embodiment of the present invention can ensure the application is hosted to the cloud platform.
- the occupation of backup resources can be reduced, and the hosting capacity and scale of applications on the cloud platform can be improved.
- the management device 20 further includes:
- the first adjustment module 204 is configured to adjust, when the primary instance node is faulty, the resource configuration specification of the standby instance node of the application created by the second creation module 203 to the resource of the primary instance node of the application.
- the configuration specifications are the same, and the standby instance node is set as a working instance node to take over the instance of the application by the primary instance node of the application.
- the resource occupancy rate of the standby instance node is very low.
- the primary instance node fails, the primary instance node is rapidly expanded to take over the work of the primary instance node, thereby satisfying the application access requirement and improving the cloud platform.
- the hosting capabilities and scale of the application are very low.
- the second creating module 203 is further configured to create a standby instance node for the application again according to the minimum resource configuration specification.
- the dynamic supplementation in time avoids the access request of the application when the next working instance node fails, thereby improving the reliability and improving the user.
- the dynamic supplementation in time avoids the access request of the application when the next working instance node fails, thereby improving the reliability and improving the user.
- the management device 20 further includes: Repair module 205,
- the repair module 205 is configured to repair the faulty primary instance node to obtain the repaired primary instance node;
- the first adjustment module 204 is further configured to adjust a resource configuration specification of the primary instance node that is repaired by the repair module 205 to a minimum resource configuration specification of the application, and set the repaired primary instance node to The standby instance node of the application is configured to take over the instance of the application by the working instance node when the working instance node fails.
- the faulty primary instance node can also be repaired in time, which further improves the utilization of resources in the cloud platform.
- the management device 20 further includes the following. Module 206,
- the obtaining module 206 is configured to acquire a visit amount of the user equipment to the application
- the second creating module 203 is specifically configured to create, for the application, the minimum resource configuration specification determined by the determining module, when the access amount of the application acquired by the acquiring module 206 exceeds a preset threshold. At least two standby instance nodes, wherein the resource configuration specifications of each of the created standby instance nodes are the same as the minimum resource configuration specification.
- a corresponding number of minimized standby instance nodes can be created according to the access amount of the application, so as to prevent unexpected failures when the application pressure is too large, thereby further improving the high availability of the cloud platform.
- the management device 20 further includes monitoring.
- Module 207 the management device 20 of the cloud platform provided by the embodiment of the present invention.
- the monitoring module 207 is configured to monitor a standby instance node of the application that has been created by the second creating module 203.
- the second creating module 203 is further configured to: when the monitoring module 211 detects that the standby instance node of the application is faulty, create a standby instance node that has the same number of failed standby instance nodes.
- the faulty instance node in the created standby instance node may be monitored in time, and a new available standby instance node may be created in time to avoid that the primary instance node fails, and no available standby instance node takes over the primary instance node. Work to further improve the high availability of the cloud platform.
- the management device 20 further includes a detection module 212 and a second adjustment module 213.
- the detecting module 208 is configured to detect an amount of resources required to run an instance of the application
- the second adjustment module 209 is configured to adjust a resource configuration specification of the standby instance node of the application that has been created according to the required resource amount detected by the detection module 212.
- the resource configuration specification may be dynamically adjusted according to the running state of the application, and if the application requirement is low, the resource may be further saved, if the application demand is high. At the same time, the success rate of the failure of the primary instance node can also be improved.
- FIG. 8 to FIG. 13 can be understood by referring to the description in FIG. 1 to FIG. 7, and no further description is made herein.
- the receiving module may be implemented by an input/output I/O device (such as a network card), the determining module, the first creating module, The second creation module, the first adjustment module, the repair module, the acquisition module, the monitoring module, the detection module, and the second adjustment module may be implemented by the processor executing a program or an instruction in the memory (in other words, by the processor and the In another implementation manner, the receiving module may be implemented by an input/output I/O device (such as a network card), and the determining module and the first creating module are implemented by using a special instruction in the processor-coupled memory.
- an input/output I/O device such as a network card
- the second creation module, the first adjustment module, the repair module, the acquisition module, the monitoring module, the detection module, and the second adjustment module are also respectively implemented by using a dedicated circuit.
- the receiving module may be implemented by an input/output I/O device (such as a network card), the determining module, and the first creating module.
- the second creation module, the first adjustment module, the repair module, the acquisition module, the monitoring module, the detection module, and the second adjustment module can also be implemented by a Field-Programmable Gate Array (FPGA).
- FPGA Field-Programmable Gate Array
- the hardware structure of a management device may include:
- Transceiver device software device and hardware device
- the transceiver device is a hardware circuit for completing packet transmission and reception
- Hardware devices can also be called “hardware processing modules", or simpler, or simply “hardware”. Hardware devices mainly include dedicated hardware circuits based on FPGAs, ASICs (and other supporting devices, such as memory). The hardware circuits of certain functions are often processed much faster than general-purpose processors, but once the functions are customized, they are difficult to change. Therefore, they are not flexible to implement and are usually used to handle some fixed functions. It should be noted that the hardware device may also include an MCU (microprocessor, such as a single chip microcomputer) or a processor such as a CPU in practical applications, but the main function of these processors is not to complete the processing of big data, but mainly used for processing. Some control is performed. In this application scenario, the system that is paired with these devices is a hardware device.
- MCU microprocessor, such as a single chip microcomputer
- Software devices mainly include general-purpose processors (such as CPU) and some supporting devices (such as memory, hard disk and other storage devices), which can be programmed to let the processor have the corresponding processing functions.
- general-purpose processors such as CPU
- some supporting devices such as memory, hard disk and other storage devices
- the processed data can be sent through the transceiver device through the hardware device, or the processed data can be sent to the transceiver device through an interface connected to the transceiver device.
- the transceiver device is configured to perform the reception of the switching instruction in the foregoing embodiment, and the software device or the hardware device is used for APP registration, service quality control, and the like.
- the receiving module may be implemented by an input/output I/O device (such as a network card), the determining module, the first creating module, the second creating module, the first adjusting module, the repairing module, the acquiring module, and the monitoring module.
- the detection module and the second adjustment module may be described in detail by a technical solution that can be implemented by a processor executing a program or instruction in a memory:
- FIG. 15 is a schematic structural diagram of a management device 20 according to an embodiment of the present invention.
- the management device 20 includes a processor 210, a memory 250, and an input/output I/O device 230.
- the memory 250 can include read only memory and random access memory, and provides operational instructions and data to the processor 210.
- a portion of the memory 250 may also include non-volatile random access memory (NVRAM).
- NVRAM non-volatile random access memory
- the memory 250 stores the following elements, executable modules or data. Structures, or their subsets, or their extension set:
- the operation instruction can be stored in an operating system
- the standby instance node of the application is used to replace the application when the primary instance node of the application fails
- the primary instance node runs an instance of the application
- the backup instance node needs to occupy the same resources as the main instance node, and the management device provided by the embodiment of the present invention can ensure that the application is hosted on the cloud platform.
- the occupation of backup resources can be reduced, and the hosting capacity and scale of applications on the cloud platform can be improved.
- the processor 210 controls the operation of the management device 20, which may also be referred to as a CPU (Central Processing Unit).
- Memory 250 can include read only memory and random access memory and provides instructions and data to processor 210. A portion of the memory 250 may also include non-volatile random access memory (NVRAM).
- NVRAM non-volatile random access memory
- the various components of the management device 20 are coupled together by a bus system 220.
- the bus system 220 may include a power bus, a control bus, a status signal bus, and the like in addition to the data bus. However, for clarity of description, various buses are labeled as bus system 220 in the figure.
- Processor 210 may be an integrated circuit chip with signal processing capabilities. In the implementation process, each step of the foregoing method may be completed by an integrated logic circuit of hardware in the processor 210 or an instruction in a form of software.
- the processor 210 described above may be a general purpose processor, a digital signal processor (DSP), an application specific integrated circuit (ASIC), an off-the-shelf programmable gate array (FPGA) or other programmable logic device, a discrete gate or transistor logic device, or discrete hardware. Component.
- DSP digital signal processor
- ASIC application specific integrated circuit
- FPGA off-the-shelf programmable gate array
- the methods, steps, and logical block diagrams disclosed in the embodiments of the present invention may be implemented or carried out.
- General purpose processor can be micro The processor or the processor can also be any conventional processor or the like.
- the steps of the method disclosed in the embodiments of the present invention may be directly implemented by the hardware decoding processor, or may be performed by a combination of hardware and software modules in the decoding processor.
- the software module can be located in a conventional storage medium such as random access memory, flash memory, read only memory, programmable read only memory or electrically erasable programmable memory, registers, and the like.
- the storage medium is located in the memory 250, and the processor 210 reads the information in the memory 250 and performs the steps of the above method in combination with its hardware.
- the processor 210 is further configured to: when the primary instance node is faulty, adjust a resource configuration specification of the standby instance node to be the same as a resource configuration specification of the primary instance node, and configure the standby instance node Set as a working instance node to take over the instance of the application by the primary instance node of the application.
- the resource occupancy rate of the standby instance node is very low.
- the primary instance node fails, the primary instance node is rapidly expanded to take over the work of the primary instance node, thereby satisfying the application access requirement and improving the cloud platform.
- the hosting capabilities and scale of the application are very low.
- the processor 210 is further configured to create a standby instance node for the application according to the minimum resource configuration specification.
- the dynamic supplementation in time avoids the access request of the application when the next working instance node fails, thereby improving the reliability and improving the user.
- the dynamic supplementation in time avoids the access request of the application when the next working instance node fails, thereby improving the reliability and improving the user.
- the processor 210 is further configured to repair the failed primary instance node to obtain the repaired primary instance node, and adjust the resource configuration specification of the repaired primary instance node to the minimum resource configuration.
- the specifications are the same, and the repaired primary instance node is set as the standby instance node of the application, so as to succeed the working instance node to run the instance of the application when the working instance node fails.
- the faulty primary instance node can also be repaired in time, which further improves the utilization of resources in the cloud platform.
- the processor 210 is further configured to acquire, by the user equipment, the amount of access to the application; when the amount of access of the application exceeds a preset threshold, create at least two for the application according to the minimum resource configuration specification.
- the resource configuration specifications are the same.
- a corresponding number of minimized standby instance nodes can be created according to the access amount of the application, so as to prevent unexpected failures when the application pressure is too large, thereby further improving the high availability of the cloud platform.
- the processor 210 is further configured to: monitor the standby instance node of the application that has been created; and when detecting that the standby instance node of the application is faulty, create a standby instance node that has the same number of failed standby instance nodes. .
- the faulty instance node in the created standby instance node may be monitored in time, and a new available standby instance node may be created in time to avoid that the primary instance node fails, and no available standby instance node takes over the primary instance node. Work to further improve the high availability of the cloud platform.
- the processor 210 is further configured to detect an amount of resources required to run an instance of the application, and adjust a resource configuration specification of the standby instance node of the created application according to the required amount of resources.
- the resource configuration specification may be dynamically adjusted according to the running state of the application, and if the application requirement is low, the resource may be further saved, if the application demand is high. At the same time, the success rate of the failure of the primary instance node can also be improved.
- the management device of the cloud platform provided by the embodiment of the present invention may be a cloud host in a cloud computing system, and the cloud host may be a virtual machine running on a physical machine.
- the physical machine 1200 includes a hardware layer 100, a VMM (Virtual Machine Monitor) 110 running on the hardware layer 100, and a host Host 1201 and a plurality of virtual machines running on the VMM 110.
- VM Virtual Machine
- the hardware layer includes but is not limited to: I/O device, CPU, and memory.
- the management device of the cloud platform provided by the embodiment of the present invention may be a virtual machine in the physical machine 1200, such as VM 1202.
- One or more cloud applications are running on the VM 1202, where each cloud application is used to implement Corresponding business functions, such as database applications, map applications, etc., can be developed by developers and then deployed to cloud computing systems.
- the VM 1202 is also configured to execute a program, and the VM 1202 executes the executable program, and calls the hardware resource of the hardware layer 100 through the host Host 1201 during the running of the program, so as to implement a determining module of the management device of the cloud platform.
- the functions of the first creation module, the second creation module, the first adjustment module, the repair module, the acquisition module, the monitoring module, the detection module, and the second adjustment module specifically, The determining module, the first creating module, the second creating module, the first adjusting module, the repairing module, the obtaining module, the monitoring module, the detecting module and the second adjusting module may be included in the executable program in the form of a software module or a function.
- the executable program may include: a determining module, a first creating module, a second creating module, a first adjusting module, a repairing module, an obtaining module, a monitoring module, a detecting module, and a second adjusting module, and the VM 1202 calls the hardware layer 100.
- the CPU, Memory, and the like to run the executable program, thereby implementing the determining module, the first creating module, the second creating module, the first adjusting module, the repairing module, the acquiring module, the monitoring module, the detecting module, and the second adjustment The function of the module.
- FIG. 15 and other optional embodiments can be understood by referring to the description of FIG. 1 to FIG. 13 , and no further description is made herein.
- the storage medium may include: a ROM, a RAM, a magnetic disk, or an optical disk.
Abstract
本发明公开了一种实例节点管理的方法,包括:为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。本发明实施例提供的实例节点管理的方法,可以在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。
Description
本申请要求于2015年4月16日提交中国专利局、申请号为201510180650.3、发明名称为“一种实例节点管理的方法及管理设备”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本发明涉及云计算技术领域,具体涉及一种实例节点管理的方法及管理设备。
在云计算时代,大量的应用和服务都被托管在云平台上。云平台除了要保证自身的高可用,还要对托管在其上的应用和服务提供高可用的保证。现有的方案通常是通过部署主主实例节点和主备实例节点来实现应用和服务的高可用的。针对主主实例节点的高可用方案,多个应用实例之间是并列的关系,所有的实例节点都能正常接收到外部的请求信息并进行处理。在其中某个实例节点出现故障的情况下,其所承担的负载,将被分担到其他的实例节点上去。主备实例节点方案是业界最主流的高可靠方案,在备节实例点上备份主实例节点的应用实例,在主实例节点正常时,外部请求全部访问主实例节点,只有在主实例节点出现故障不能正常运行时,外部请求才切换到备实例节点上去。
由此可见,主备实例节点方案,备实例节点占用了与主实例节点完全相同的资源,却一直处于待命的状态,造成了物理资源的浪费,而主主实例节点方案下,两个主实例节点的资源利用率都无法达到50%,否则出现单点故障时,全部的压力集中到另一个存活的主实例节点上,压力过大将导致业务无法正常,这样也就造成了更多的节点资源的使用浪费。
发明内容
本发明实施例提供的一种实例节点管理的方法,在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。本发明实施例还提供了相应的管理设备。
本发明第一方面提供一种实例节点管理的方法,所述方法应用于云平台的管理设备,所述方法包括:
为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;
根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;
根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
结合第一方面,在第一种可能的实现方式中,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还包括:
当所述主实例节点故障时,将所述备实例节点的资源配置规格调整到与所述主实例节点的资源配置规格相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
结合第一方面第一种可能的实现方式,在第二种可能的实现方式中,所述将所述工作实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同之后,所述方法还包括:
根据所述最小资源配置规格,再次为所述应用创建备实例节点。
结合第一方面第一种可能的实现方式,在第三种可能的实现方式中,所述将所述工作实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同之后,所述方法还包括:
修复发生故障的所述主实例节点,以得到修复后的主实例节点;
将所述修复后的主实例节点的资源配置规格调整到与所述最小资源配置规格相同,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
结合第一方面、第一方面第一种至第三种中任意一种可能的实现方式,在第四种可能的实现方式中,所述确定所述应用的备实例节点的最小资源配置规格之后,所述方法还包括:
获取用户设备对所述应用的访问量;
所述根据所述最小资源配置规格,创建所述应用的备实例节点,包括:
当所述应用的访问量超过预置阈值时,根据所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小资源配置规格相同。
结合第一方面、第一方面第一种至第三种中任意一种可能的实现方式,在第五种可能的实现方式中,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还包括:
监测已创建的所述应用的备实例节点;
当监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
结合第一方面、第一方面第一种至第三种中任意一种可能的实现方式,在第六种可能的实现方式中,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还包括:
检测运行所述应用的实例所需的资源量;
根据所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
本发明第二方面提供一种云平台的管理设备,所述管理设备包括:
第一创建模块,用于为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;
确定模块,用于根据所述第一创建模块创建的所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;
第二创建模块,用于根据所述确定模块确定的所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
结合第二方面,在第一种可能的实现方式中,所述管理设备还包括:
第一调整模块,用于当所述主实例节点故障时,将所述第二创建模块创建的所述备实例节点的资源配置规格调整到与所述主实例节点的资源配置规格相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
结合第二方面第一种可能的实现方式,在第二种可能的实现方式中,
所述第二创建模块,还用于根据所述最小资源配置规格,再次为所述应用创建备实例节点。
结合第二方面第一种可能的实现方式,在第三种可能的实现方式中,
所述管理设备还包括:修复模块,
所述修复模块,用于修复发生故障的所述主实例节点,以得到修复后的主实例节点;
所述第一调整模块,还用于将所述修复后的主实例节点的资源配置规格调整到所述应用的最小资源配置规格,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
结合第二方面、第二方面第一种至第三种中任意一种可能的实现方式,在第四种可能的实现方式中,所述管理设备还包括获取模块,
所述获取模块,用于获取用户设备对所述应用的访问量;
所述第二创建模块,具体用于当所述获取模块获取的所述应用的访问量超过预置阈值时,根据所述确定模块确定的所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小资源配置规格相同。
结合第二方面、第二方面第一种至第三种中任意一种可能的实现方式,在第五种可能的实现方式中,所述管理设备还包括监测模块,
所述监测模块,用于监测所述第二创建模块已创建的所述应用的备实例节点;
所述第二创建模块,还用于当所述监测模块监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
结合第二方面、第二方面第一种至第三种中任意一种可能的实现方式,在第六种可能的实现方式中,所述管理设备还包括检测模块和第二调整模块,
所述检测模块,用于检测运行所述应用的实例所需的资源量;
所述第二调整模块,用于根据所述检测模块检测到的所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
本发明实施例采用为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。与现有技术中为了保证云平台上应用的高可用性,备实例节点需要占用与主实例节点相同的资源相比,本发明实施例提供的实例节点管理的方法,可以在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例中实例节点管理的方法的一实施例示意图;
图2是本发明实施例中实例节点管理的方法的另一实施例示意图;
图3是本发明实施例中实例节点管理的方法的另一实施例示意图;
图4是本发明实施例中实例节点管理的方法的另一实施例示意图;
图5是本发明实施例中实例节点管理的方法的另一实施例示意图;
图6是本发明实施例中实例节点管理的方法的另一实施例示意图;
图7是本发明实施例中实例节点管理的方法的另一实施例示意图;
图8是本发明实施例中管理设备的一实施例示意图;
图9是本发明实施例中管理设备的另一实施例示意图;
图10是本发明实施例中管理设备的另一实施例示意图;
图11是本发明实施例中管理设备的另一实施例示意图;
图12是本发明实施例中管理设备的另一实施例示意图;
图13是本发明实施例中管理设备的另一实施例示意图;
图14是本发明实施例中管理设备的另一实施例示意图;
图15是本发明实施例中管理设备的另一实施例示意图;
图16是本发明实施例中管理设备的另一实施例示意图。
本发明实施例提供一种实例节点管理的方法,在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。本发明实施例还提供了相应的管理设备。以下分别进行详细说明。
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
云平台可以托管大量的应用,为了保证每个应用高可用的性能,在云平台的运行环境中,需要为每个应用创建主实例节点和备实例节点,主实例节点用于运行应用的实例,备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例。云平台上的管理设备会对主实例节点和备实例节点进行统一的管理。主实例节点和备实例节点实际上都是由管理设备为应用所分配的的虚拟机或者比虚拟机粒度更小的功能节点,主实例节点和备实例节点均可以利用云平台上的资源。云平台上的资源是指由众多物理主机所提供的硬件资源,包括但不限于中央处理器(Central Processing Unit,CPU)的核数,内存,硬盘大小,网络带宽等。
本发明实施例中,在用户将应用托管到云平台上后,为用户托管到所述云平台上的应用创建运行所述应用的实例的主实例节点,根据所述主实例节点的运行启动信息,确定所述应用的备实例节点的最小资源配置规格;根据所述最
小资源配置规格,创建所述应用的备实例节点,以使所述备实例节点的资源配置规格与所述最小资源配置规格相同,且所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格,所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例,其中,实例节点的资源配置规格用于指示为该实例节点分配的资源量,比如为实例节点分配的CPU核数,内存,硬盘大小,网络带宽等等;最小资源配置规格用于指示启动或运行该应用的实例所需要的最小的资源量。应用的实例可以理解为应用的可执行版本的拷贝或镜像,云平台可以为一个应用创建一个或多个实例,应用的每一个实例具体可以是一个独立的进程或线程。
其中,用户可以是应用运营商,主实例节点的运行启动信息可以指示运行所述应用的实例所需要的基本资源,例如:主实例节点开始运行时的CPU的核数,内存,硬盘大小,网络带宽。备实例节点的最小资源配置规格可以是指备实例节点用于运行所述应用所需的CPU的核数,内存,硬盘大小,网络带宽等规格信息。
如图1所示,在主实例节点正常时,由主实例节点为用户设备的访问提供服务,在主实例节点出现故障时,管理设备将用户设备的访问切换到备实例节点,并将所述应用的备实例节点设置为对用户设备的访问提供服务的工作实例节点;将所述工作实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同。当然,除了调整到与所述应用的主实例节点的资源配置规格相同外,也可以是调整到比所述应用的主实例节点的资源配置规格略大或略小。
本发明实施例中的管理设备可以包括图2中的云控制器、备节点管理子系统和健康检查系统。如图2所示:
步骤1、应用的部署者将云应用通过云控制器部署到云平台上。
步骤2、云控制器根据该应用的规格创建运行该应用的的主实例节点,该主实例节点具有初始资源配置规格,该初始资源配置规格通常为系统默认值或者开发者/维护者根据经验设置的,且该初始资源配置规格能够保证主实例节点有充足的资源可以使用,以承载应用的实例。
步骤3、在主实例节点构建完成后,健康检查系统识别到新增云应用的主实例节点。
步骤4、健康检查系统通知备节点管理子系统进行最小资源配置规格的计算。
步骤5、备节点管理子系统根据已经启动并正常运行的主实例节点的运行信息计算备实例节点的最小资源配置规格。运行信息可以指示正常运行所述应用的实例实际占用的资源,最小资源配置规格指示了启动或运行该应用的实例所需的最小的资源量,该最小资源配置规格通常远远小于主实例节点的初始资源配置规格。
步骤6、云控制器根据得到的最小资源配置规格,再创建一个备实例节点,其中,创建的备实例节点的资源配置规格与该最小资源配置规格。
图3为主实例节点故障时的处理示例流程,健康检查系统检测到主实例节点故障时,通知到备节点管理子系统,由备节点管理子系统去通知云控制器启用和扩容最小化的备实例节点作为常规实例节点,以接替所述应用的主实例节点运行所述应用的实例,并再根据最小资源配置规格创建出一个备实例节点。这里的常规实例也可以称为工作实例节点,是指当前运行所述应用的实例的实例节点。
如图4所示,本发明实施例提供的实例节点管理的方法的另一实施例中,云平台包括了以下几个部分:云控制器、健康检查系统、备节点管理子系统,路由分发系统和应用运行环境。其中,云控制器、健康检查系统、备节点管理子系统和路由分发系统都可以理解为是管理设备的组成部分,管理设备具有云控制器、健康检查系统、备节点管理子系统和路由分发系统的功能。
各部分的功能包括:
备节点管理子系统:在云平台上,备节点管理系统主要负责的是计算备实例节点的最小资源配置规格,以及在主实例节点故障时,通知云控制器启动并扩容备实例节点,以及在备实例节点启用成常规工作实例节点后,后续再次根据最小资源配置规格创建备实例节点。
备实例节点扩容成常规工作实例节点是指将所述备实例节点的资源配置
规格调整到与所述应用的主实例节点的资源配置规格相同。需要说明的是,本发明实施例所说的“相同”,并不是是指数值上绝对的相同,在实际应用中,允许存在一定的误差,比如,所述备实例节点比所述主实例节点的资源配置规格略大或略小,或者实质相同。
如图5所示,备节点管理子系统主要包括以下三个模块:最小化规格计算模块、应用备节点实例管理模块和故障处理配置通知模块。
其中,最小化规格计算模块,主要是在应用初次部署在云平台上,其主实例节点已经启动成功后,从主实例节点初始化过程中获取所需要资源的最小的配置规格。规格包括且不限于,CPU核数,内存,硬盘大小,网络带宽等。这个规格将通知给云控制器,并在云控制器上记录下来,作为后续启动新的备实例节点的规格依据。
应用备节点实例管理模块,主要用于判断和检查应用的备实例节点的情况。备实例节点的个数和运行状态,由该模块负责管理。当应用持续压力较大时,系统可以判断增加最小化的备实例节点的个数,以支撑突发故障的情况下,可以快速启用多个备实例,保证运行无障碍。
故障处理配置通知模块,是在健康检查系统检测到有实例故障时的处理机制。这里包括两种实例的故障,一是常规实例节点故障,二是最小化规格的备实例节点故障。常规实例故障时,该故障处理配置通知模块通知云控制器启用一个备实例节点,并将之快速扩容到常规实例节点规格;此时最小化的备实例节点个数相应的减少了一个,即通知云控制器,新建一个最小化的备实例节点,最小化的备实例节点出现故障时也是与常规实例节点故障进行相同的操作。
云控制器:实例节点的管理和路由分发的配置。所有云应用的实例节点,都是由云控制器分发到指定的应用运行环境中,实例的访问方式,由云控制器将策略发送到路由分发系统中去,作为云平台上的通用功能系统,本发明不作详细描述。
路由分发系统:主要控制将外部的访问请求分发到对应的应用的运行实例节点中去,接收实例节点的处理结果并反馈给发送访问请求的用户设备,作为云平台上的通用功能系统,本发明不作详细描述。
健康检查系统:负责检查所有应用的实例节点的健康状态,并通知备节点管理系统进行故障恢复,以及最小化的备实例节点的创建等,作为云平台上的通用功能系统,本发明不作详细描述。
应用运行环境:在云平台上的应用运行环境,主要是虚拟机、容器等载体,并提供了应用运行所需要的操作系统、软件栈、计算/存储/网络等资源,以供给应用实例正常运行,作为云平台上的通用功能系统,本发明不作详细描述。
本发明实施例中对实例节点的管理实现流程,分为初次部署和故障出现两种情况,可以参阅图1至图5部分的相应描述进行理解,本处不做过多赘述。
可见,本发明实施例中,通过上述步骤,可以保证云应用拥有足够的主备保障能力,而且备实例节点的规格能远小于常规的实例节点,有效的减少了因为高可用需要而造成的资源浪费情况。
如图6所示,本发明实施例中对实例节点的管理的另一实施例与图4对应的实施例基本相同,只是在结构上做了一部分的简化。备实例管理节点,在实现上,可以包含在云控制器上,以云控制器的一个插件/组件等方式,与云控制器部署在一起。
在本实施例上,系统间通信先通知到云控制器,再由云控制器将相关的处理交由备节点管理插件。备节点管理节点在计算/配置完成后,可以直接通知路由/应用运行环境等,进行路由分发管理配置,以及备实例节点创建/扩容等实现。
在处理流程上,所有云控制器与备节点管理系统之间的交互过程,全部在云控制器内部实现。其他流程一样。
进一步的,还可以在备节点管理系统/插件上进行进一步的简化。大部分云应用的实现上,只要存在1个备实例节点,就能够满足基本的高可用需求。因此,可以去除应用备节点实例管理模块,只留一部分故障处理和最小化规格计算的功能即可,
初次创建云应用的过程,与上述实施例相同,在故障出现时,不需要判断检测备节点资源池,直接将云应用中的备实例节点转化成常规节点,并再创建一个备实例节点。
可选地,本发明实施例提供的实例节点管的方法的另一实施例中,还可以是初次创建云应用的过程相同,区别在故障出现时,备实例节点转化成常规节点后,并非再次创建一个备实例节点,而是由云控制器将出故障的常规实例进行恢复,并在恢复后,由健康检查系统通知备节点管理系统,将被启用的备实例节点回收,恢复初始状态。也可以是在故障修复后,将修复后的常规实例节点的资源配置规格调整到所述应用的最小资源配置规格,成为所述应用的备实例节点。
可选地,本发明实施例提供的实例节点管的方法的另一实施例中,还可以是在备节点最小规格的计算和管理上,增加了动态调整的方法。在常规实例运行过程中,根据统计得到的应用整体运行状态,动态计算最小规格,并实时对当前环境下的最小规格备份节点实例进行规格刷新。
可选地,还可以是在创建最小规格实例的方法上,考虑到有些应用可能会在初始化启动过程中使用大量的临时性资源,而在初始化完成后,所占用消耗的资源量反而较低,因此创建最小化的备实例节点的过程,首先是创建一个完整规格的实例,待启动完成后,再将其规格缩小到计算所得的最小化规格。以降低资源消耗。
在故障发生恢复时,也是首先恢复一个常规实例节点,再将其作为最小规格实例节点使用,缩小到最小规格。
另外,本发明实施例中,面向云平台上运行环境可以不同,如容器,虚拟机等时,最小规格备实例节点的实现方式上有所区别。在应用容器技术时,上述的各种实施例方法都能快速实现;在使用的是虚拟机技术时,由于针对虚拟机的纵向伸缩扩容技术的不成熟,这里采用的是纵向+横向伸缩的方法,即满足纵向伸缩的云环境上,直接使用上述实施例的方法,而在不满足纵向伸缩的云环境上,采用横向伸缩的机制,备实例节点的创建与上述相同,但是在使用上,通过建立多个备实例节点来满足短暂的可靠性要求,并在常规实例节点恢复了,再将临时生成的备实例节点释放,以保证资源的有效利用。
与现有技术中为了保证云平台上应用的高可用性,备实例节点需要占用与主实例节点相同的资源相比,本发明实施例提供的实例节点管理的方法,可以
在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。
需要说明的是,本发明实施例的方案不仅可以适用于云平台,还可以适用于除云平台以外的需要提高应用可靠性的多种场景。
参阅图7,本发明实施例提供的实例节点管理的方法的一实施例包括:
101、为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例。
本发明实施例提供的实例节点的管理方法应用于云平台的管理设备。
102、根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例。
其中,主实例节点的运行启动信息可以是运行起所述应用所需要的基本资源,例如:主实例节点开始运行时的CPU的核数,内存,硬盘大小,网络带宽。备实例节点的最小资源配置规格可以是指备实例节点的CPU的核数,内存,硬盘大小,网络带宽等规格信息。
103、根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
本发明实施例采用为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。与现有技术中为了保证云平台上应用的高可用性,备实例节点需要占用与主实例节点相同的资源相比,本发明实施例提供的实例节点管理的方法,可以在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。
可选地,在上述图7对应的实施例的基础上,本发明实施例提供的实例节点管理的方法的第一个可选实施例中,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还可以包括:
当所述主实例节点故障时,将所述备实例节点的资源配置规格调整到与所述主实例节点的资源配置规格相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
具体可以是:
接收所述应用的主实例节点故障的切换指令;
根据所述切换指令,将所述应用的备实例节点设置为对用户设备访问提供服务的工作实例节点。
将所述工作实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同。
本发明实施例中,在主实例节点正常时,备实例节点的资源占用率很低,在主实例节点故障时,迅速扩容来接替主实例节点的工作,从而满足应用的访问需求,提高云平台上应用的托管能力和规模。
可选地,在上述实例节点管理的方法的第一个可选实施例的基础上,本发明实施例提供的实例节点管理的方法的第二个可选实施例中,所述将所述工作实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同之后,所述方法还可以包括:
根据所述最小资源配置规格,再次为所述应用创建备实例节点。
本发明实施例中,当最小化的备实例节点数量减少时,及时的动态补充,避免了下次工作实例节点出现故障时,导致无法响应应用的访问请求,从而提高了可靠性,提高了用户体验。
可选地,在上述实例节点管理的方法的第一个可选实施例的基础上,本发明实施例提供的实例节点管理的方法的第三个可选实施例中,所述将所述工作实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同之后,所述方法还可以包括:
修复发生故障的所述主实例节点,以得到修复后的主实例节点;
将所述修复后的主实例节点的资源配置规格调整到与所述最小资源配置规格相同,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
可选地,也可以是:
修复发生故障的所述主实例节点;
将对所述用户设备访问提供服务的工作实例节点切换到所述主实例节点;
将所述工作实例节点的资源配置规格调整到所述应用的最小资源配置规格。
本发明实施例中,还可以及时修复发生故障的主实例节点,这样进一步提高了云平台中资源的利用率。
可选地,在上述实例节点管理的方法的任一实施例的基础上,本发明实施例提供的实例节点管理的方法的第四个可选实施例中,所述确定所述应用的备实例节点的最小资源配置规格之后,所述方法还可以包括:
获取用户设备对所述应用的访问量;
所述根据所述最小资源配置规格,创建所述应用的备实例节点,包括:
当所述应用的访问量超过预置阈值时,根据所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小资源配置规格相同。
本发明实施例中,可以根据应用的访问量创建相应数量的最小化的备实例节点,这样,可以预防应用压力过大时,导致突发的意外故障,从而进一步提高了云平台的高可用性。
可选地,在上述实例节点管理的方法的任一实施例的基础上,本发明实施例提供的实例节点管理的方法的第五个可选实施例中,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还可以包括:
监测已创建的所述应用的备实例节点;
当监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
本发明实施例中,还可以及时监测已创建的备实例节点中的故障实例节
点,及时创建新的可用备实例节点,以避免主实例节点出现故障时,没有可用的备实例节点接替主实例节点的工作,从而进一步提高了云平台的高可用性。
可选地,在上述实例节点管理的方法的任一实施例的基础上,本发明实施例提供的实例节点管理的方法的第六个可选实施例中,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还可以包括:
检测运行所述应用的实例所需的资源量;
根据所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
本发明实施例中,针对已创建的备实例节点,还可以根据运行应用所需要的资源量,对齐资源配置规格进行动态调整,如果应用的需求量低时,还可以进一步节省资源,如果应用的需求量高时,还可以提高主实例节点故障时的接替效率。
图7对应的实施例以及其相应的可选实施例,可以参阅图1至图6部分的相关描述进行理解,本处不做过多赘述。
需要说明的是下述在描述云平台的管理设备20的过程中所涉及的第一创建模块201、第二创建模块203、第一调整模块204、修复模块205、获取模块206、检测模块208、第二调整模块209的功能与图1-图4实施例中的所描述的云控制器的功能相同,确定模块202、监测模块207所执行的功能与图1-图4实施例中的所描述的备节点管理子系统的功能相同。其中,确定模块202可以为图5中的最小化规格计算模块,监测模块207可以为应用备节点实例管理模块和故障处理配置通知模块。
参阅图8,本发明实施例提供的云平台的管理设备20的一实施例包括:
第一创建模块201,用于为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;
确定模块202,用于根据所述第一创建模块201创建的所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;
第二创建模块203,用于根据所述确定模块202确定的所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
与现有技术中为了保证云平台上应用的高可用性,备实例节点需要占用与主实例节点相同的资源相比,本发明实施例提供的实例节点的管理设备,可以在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。
可选地,在上述图8对应的实施例的基础上,参阅图9,本发明实施例提供的云平台的管理设备20的第一个可选实施例中,所述管理设备20还包括:
第一调整模块204,用于当所述主实例节点故障时,将所述第二创建模块203创建的所述应用的备实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
本发明实施例中,在主实例节点正常时,备实例节点的资源占用率很低,在主实例节点故障时,迅速扩容来接替主实例节点的工作,从而满足应用的访问需求,提高云平台上应用的托管能力和规模。
可选地,在上述图9对应的实施例的基础上,本发明实施例提供的云平台的管理设备20的第二个可选实施例中,
所述第二创建模块203,还用于根据所述最小资源配置规格,再次为所述应用创建备实例节点。
本发明实施例中,当最小化的备实例节点数量减少时,及时的动态补充,避免了下次工作实例节点出现故障时,导致无法响应应用的访问请求,从而提高了可靠性,提高了用户体验。
可选地,在上述图9对应的实施例的基础上,参阅图10,本发明实施例提供的云平台的管理设备20的第三个可选实施例中,所述管理设备20还包括:修复模块205,
所述修复模块205,用于修复发生故障的所述主实例节点,以得到修复后的主实例节点;
所述第一调整模块204,还用于将所述修复模块205修复后的主实例节点的资源配置规格调整到所述应用的最小资源配置规格,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
本发明实施例中,还可以及时修复发生故障的主实例节点,这样进一步提高了云平台中资源的利用率。
可选地,在上述管理设备任一实施例的基础上,参阅图11,本发明实施例提供的云平台的管理设备20的第四个可选实施例中,所述管理设备20还包括获取模块206,
所述获取模块206,用于获取用户设备对所述应用的访问量;
所述第二创建模块203,具体用于当所述获取模块206获取的所述应用的访问量超过预置阈值时,根据所述确定模块确定的所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小资源配置规格相同。
本发明实施例中,可以根据应用的访问量创建相应数量的最小化的备实例节点,这样,可以预防应用压力过大时,导致突发的意外故障,从而进一步提高了云平台的高可用性。
可选地,在上述管理设备任一实施例的基础上,参阅图12,本发明实施例提供的云平台的管理设备20的第五个可选实施例中,所述管理设备20还包括监测模块207,
所述监测模块207,用于监测所述第二创建模块203已创建的所述应用的备实例节点;
所述第二创建模块203,还用于当所述监测模块211监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
本发明实施例中,还可以及时监测已创建的备实例节点中的故障实例节点,及时创建新的可用备实例节点,以避免主实例节点出现故障时,没有可用的备实例节点接替主实例节点的工作,从而进一步提高了云平台的高可用性。
可选地,在上述管理设备任一实施例的基础上,参阅图13,本发明实施例
提供的云平台的管理设备20的第六个可选实施例中,所述管理设备20还包括检测模块212和第二调整模块213,
所述检测模块208,用于检测运行所述应用的实例所需的资源量;
所述第二调整模块209,用于根据所述检测模块212检测到的所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
本发明实施例中,针对已创建的备实例节点,还可以根据应用的运行状态,对齐资源配置规格进行动态调整,如果应用的需求量低时,还可以进一步节省资源,如果应用的需求量高时,还可以提高主实例节点故障时的接替效率。
图8至图13所描述的管理设备可以参阅图1至图7中的描述进行理解,本处不做过多赘述。
在上述管理设备的多个实施例中,应当理解的是,在一种实现方式下,接收模块可以是由输入/输出I/O设备(比如网卡)来实现,确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块可以由处理器执行存储器中的程序或指令来实现的(换言之,即由处理器以及与所述处理器耦合的存储器中的特殊指令相互配合来实现);在另一种实现方式下,接收模块可以是由输入/输出I/O设备(比如网卡)来实现,确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块也可以分别通过专有电路来实现,具体实现方式参见现有技术,这里不再赘述;在再一种实现方式下,接收模块可以是由输入/输出I/O设备(比如网卡)来实现,确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块也可以通过现场可编程门阵列(FPGA,Field-Programmable Gate Array)来实现,具体实现方式参见现有技术,这里不再赘述,本发明包括但不限于前述实现方式,应当理解的是,只要按照本发明的思想实现的方案,都落入本发明实施例所保护的范围。
本实施例提供了一种管理设备的硬件结构,参见图14所示,一种管理设备的硬件结构可以包括:
收发器件、软件器件以及硬件器件三部分;
收发器件为用于完成包收发的硬件电路;
硬件器件也可称“硬件处理模块”,或者更简单的,也可简称为“硬件”,硬件器件主要包括基于FPGA、ASIC之类专用硬件电路(也会配合其他配套器件,如存储器)来实现某些特定功能的硬件电路,其处理速度相比通用处理器往往要快很多,但功能一经定制,便很难更改,因此,实现起来并不灵活,通常用来处理一些固定的功能。需要说明的是,硬件器件在实际应用中,也可以包括MCU(微处理器,如单片机)、或者CPU等处理器,但这些处理器的主要功能并不是完成大数据的处理,而主要用于进行一些控制,在这种应用场景下,由这些器件搭配的系统为硬件器件。
软件器件(或者也简单“软件”)主要包括通用的处理器(例如CPU)及其一些配套的器件(如内存、硬盘等存储设备),可以通过编程来让处理器具备相应的处理功能,用软件来实现时,可以根据业务需求灵活配置,但往往速度相比硬件器件来说要慢。软件处理完后,可以通过硬件器件将处理完的数据通过收发器件进行发送,也可以通过一个与收发器件相连的接口向收发器件发送处理完的数据。
本实施例中,收发器件用于进行上述实施例中切换指令的接收,软件器件或硬件器件用于APP注册、服务质量控制等。
硬件器件及软件器件的其他功能在前述实施例中已经详细论述,这里不再赘述。
下面结合附图就接收模块可以是由输入/输出I/O设备(比如网卡)来实现,确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块可以是可以由处理器执行存储器中的程序或指令来实现的技术方案来做详细的介绍:
图15是本发明实施例提供的管理设备20的结构示意图。所述管理设备20包括处理器210、存储器250和输入/输出I/O设备230,存储器250可以包括只读存储器和随机存取存储器,并向处理器210提供操作指令和数据。存储器250的一部分还可以包括非易失性随机存取存储器(NVRAM)。
在一些实施方式中,存储器250存储了如下的元素,可执行模块或者数据
结构,或者他们的子集,或者他们的扩展集:
在本发明实施例中,通过调用存储器250存储的操作指令(该操作指令可存储在操作系统中),
为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;
根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;
根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
可见,与现有技术中为了保证云平台上应用的高可用性,备实例节点需要占用与主实例节点相同的资源相比,本发明实施例提供的管理设备,可以在保证应用托管到云平台上高可用的基础上,可以减少备用资源的占用,提高云平台上应用的托管能力和规模。
处理器210控制管理设备20的操作,处理器210还可以称为CPU(Central Processing Unit,中央处理单元)。存储器250可以包括只读存储器和随机存取存储器,并向处理器210提供指令和数据。存储器250的一部分还可以包括非易失性随机存取存储器(NVRAM)。具体的应用中管理设备20的各个组件通过总线系统220耦合在一起,其中总线系统220除包括数据总线之外,还可以包括电源总线、控制总线和状态信号总线等。但是为了清楚说明起见,在图中将各种总线都标为总线系统220。
上述本发明实施例揭示的方法可以应用于处理器210中,或者由处理器210实现。处理器210可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器210中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器210可以是通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现成可编程门阵列(FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理
器或者该处理器也可以是任何常规的处理器等。结合本发明实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器250,处理器210读取存储器250中的信息,结合其硬件完成上述方法的步骤。
可选地,处理器210还用于当所述主实例节点故障时,将所述备实例节点的资源配置规格调整到与所述主实例节点的资源配置规格相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
本发明实施例中,在主实例节点正常时,备实例节点的资源占用率很低,在主实例节点故障时,迅速扩容来接替主实例节点的工作,从而满足应用的访问需求,提高云平台上应用的托管能力和规模。
可选地,处理器210还用于根据所述最小资源配置规格,再次为所述应用创建备实例节点。
本发明实施例中,当最小化的备实例节点数量减少时,及时的动态补充,避免了下次工作实例节点出现故障时,导致无法响应应用的访问请求,从而提高了可靠性,提高了用户体验。
可选地,处理器210还用于修复发生故障的所述主实例节点,以得到修复后的主实例节点;将所述修复后的主实例节点的资源配置规格调整到与所述最小资源配置规格相同,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
本发明实施例中,还可以及时修复发生故障的主实例节点,这样进一步提高了云平台中资源的利用率。
可选地,处理器210还用于获取用户设备对所述应用的访问量;当所述应用的访问量超过预置阈值时,根据所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小
资源配置规格相同。
本发明实施例中,可以根据应用的访问量创建相应数量的最小化的备实例节点,这样,可以预防应用压力过大时,导致突发的意外故障,从而进一步提高了云平台的高可用性。
可选地,处理器210还用于监测已创建的所述应用的备实例节点;当监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
本发明实施例中,还可以及时监测已创建的备实例节点中的故障实例节点,及时创建新的可用备实例节点,以避免主实例节点出现故障时,没有可用的备实例节点接替主实例节点的工作,从而进一步提高了云平台的高可用性。
可选地,处理器210还用于检测运行所述应用的实例所需的资源量;根据所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
本发明实施例中,针对已创建的备实例节点,还可以根据应用的运行状态,对齐资源配置规格进行动态调整,如果应用的需求量低时,还可以进一步节省资源,如果应用的需求量高时,还可以提高主实例节点故障时的接替效率。
需要说明的是,本发明实施例提供的云平台的管理设备,具体可以为云计算系统中的一台云主机,该云主机可以为运行在物理机上的虚拟机。如图16所示,物理机1200包括硬件层100,运行在硬件层100之上的VMM(Virtual Machine Monitor,虚拟机监视器)110,以及运行在VMM 110之上的宿主机Host1201和若干虚拟机(VM,Virtual Machine),其中,硬件层包括但不限于:I/O设备、CPU和memory。本发明实施例提供的云平台的管理设备具体可以为物理机1200中的一台虚拟机,比如VM 1202,VM 1202上运行有一个或多个云应用,其中,每一个云应用都用于实现相应的业务功能,比如数据库应用、地图应用等等,这些云应用可以由开发者开发然后部署到云计算系统中。此外VM1202还运行有可以执行程序,VM 1202通过运行该可执行程序,并在程序运行的过程中通过宿主机Host 1201来调用硬件层100的硬件资源,以实现云平台的管理设备的确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块的功能,具体而言,
确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块可以以软件模块或函数的形式被包含在上述可执行程序中,比如该可执行程序可以包括:确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块,VM1202通过调用硬件层100中的CPU、Memory等资源,以运行该可执行程序,从而实现确定模块、第一创建模块、第二创建模块、第一调整模块、修复模块、获取模块、监测模块、检测模块和第二调整模块的功能。
图15对应的实施例以及其他可选实施例可以参阅图1-图13部分描述进行理解,本处不做过多赘述。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件(例如处理器)来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:ROM、RAM、磁盘或光盘等。
以上对本发明实施例所提供的实例节点管理的方法、管理设备进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
Claims (14)
- 一种实例节点管理的方法,其特征在于,所述方法应用于云平台的管理设备,所述方法包括:为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;根据所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;根据所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
- 根据权利要求1所述的方法,其特征在于,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还包括:当所述主实例节点故障时,将所述备实例节点的资源配置规格调整到与所述主实例节点的资源配置规格相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
- 根据权利要求2所述的方法,其特征在于,在将所述备实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同之后,所述方法还包括:根据所述最小资源配置规格,再次为所述应用创建备实例节点。
- 根据权利要求2所述的方法,其特征在于,所述将所述备实例节点的资源配置规格调整到与所述应用的主实例节点的资源配置规格相同之后,所述方法还包括:修复发生故障的所述主实例节点,以得到修复后的主实例节点;将所述修复后的主实例节点的资源配置规格调整到与所述最小资源配置规格相同,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
- 根据权利要求1-4任一所述的方法,其特征在于,所述确定所述应用的备实例节点的最小资源配置规格之后,所述方法还包括:获取用户设备对所述应用的访问量;所述根据所述最小资源配置规格,创建所述应用的备实例节点,包括:当所述应用的访问量超过预置阈值时,根据所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小资源配置规格相同。
- 根据权利要求1-4任一所述的方法,其特征在于,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还包括:监测已创建的所述应用的备实例节点;当监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
- 根据权利要求1-4任一所述的方法,其特征在于,所述根据所述最小资源配置规格,创建所述应用的备实例节点之后,所述方法还包括:检测运行所述应用的实例所需的资源量;根据所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
- 一种云平台的管理设备,其特征在于,所述管理设备包括:第一创建模块,用于为托管到所述云平台上的应用创建主实例节点,所述主实例节点用于运行所述应用的实例;确定模块,用于根据所述第一创建模块创建的所述主实例节点的运行启动信息,确定所述应用的备实例节点所需要的最小资源配置规格;所述应用的备实例节点用于在所述应用的主实例节点故障时接替所述应用的主实例节点运行所述应用的实例;第二创建模块,用于根据所述确定模块确定的所述最小资源配置规格,创建所述应用的备实例节点,其中,所述应用的备实例节点的资源配置规格小于所述应用的主实例节点的资源配置规格。
- 根据权利要求8所述的管理设备,其特征在于,所述管理设备还包括:第一调整模块,用于当所述主实例节点故障时,将所述第二创建模块创建的所述备实例节点的资源配置规格调整到与所述主实例节点的资源配置规格 相同,并将所述备实例节点设置为工作实例节点,以接替所述应用的主实例节点运行所述应用的实例。
- 根据权利要求9所述的管理设备,其特征在于,所述第二创建模块,还用于根据所述最小资源配置规格,再次为所述应用创建备实例节点。
- 根据权利要求9所述的管理设备,其特征在于,所述管理设备还包括:修复模块,所述修复模块,用于修复发生故障的所述主实例节点,以得到修复后的主实例节点;所述第一调整模块,还用于将所述修复后的主实例节点的资源配置规格调整到所述应用的最小资源配置规格,并将所述修复后的主实例节点设置为所述应用的备实例节点,以便于在所述工作实例节点故障时接替所述工作实例节点运行所述应用的实例。
- 根据权利要求8-11任一所述的管理设备,其特征在于,所述管理设备还包括获取模块,所述获取模块,用于获取用户设备对所述应用的访问量;所述第二创建模块,具体用于当所述获取模块获取的所述应用的访问量超过预置阈值时,根据所述确定模块确定的所述最小资源配置规格,为所述应用创建至少两个备实例节点,其中,创建的每个备实例节点的资源配置规格与所述最小资源配置规格相同。
- 根据权利要求8-11任一所述的管理设备,其特征在于,所述管理设备还包括监测模块,所述监测模块,用于监测所述第二创建模块已创建的所述应用的备实例节点;所述第二创建模块,还用于当所述监测模块监测到所述应用的备实例节点发生故障时,创建与发生故障的备实例节点数量相同的备实例节点。
- 根据权利要求8-11任一所述的管理设备,其特征在于,所述管理设备还包括检测模块和第二调整模块,所述检测模块,用于检测运行所述应用的实例所需的资源量;所述第二调整模块,用于根据所述检测模块检测到的所述所需的资源量,调整已创建的所述应用的备实例节点的资源配置规格。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP15889000.4A EP3253028B1 (en) | 2015-04-16 | 2015-10-23 | Method for managing instance node and management device |
| US15/783,500 US10601657B2 (en) | 2015-04-16 | 2017-10-13 | Instance node management method and management device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201510180650.3A CN104836850A (zh) | 2015-04-16 | 2015-04-16 | 一种实例节点管理的方法及管理设备 |
| CN201510180650.3 | 2015-04-16 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/783,500 Continuation US10601657B2 (en) | 2015-04-16 | 2017-10-13 | Instance node management method and management device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016165304A1 true WO2016165304A1 (zh) | 2016-10-20 |
Family
ID=53814479
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2015/092667 WO2016165304A1 (zh) | 2015-04-16 | 2015-10-23 | 一种实例节点管理的方法及管理设备 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10601657B2 (zh) |
| EP (1) | EP3253028B1 (zh) |
| CN (1) | CN104836850A (zh) |
| WO (1) | WO2016165304A1 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106775953A (zh) * | 2016-12-30 | 2017-05-31 | 北京中电普华信息技术有限公司 | 实现OpenStack高可用的方法与系统 |
| CN110178332A (zh) * | 2016-12-21 | 2019-08-27 | 金雅拓M2M有限责任公司 | 用于操作在蜂窝网络中并行通信的用户装备的方法、用户装备和蜂窝网络 |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104836850A (zh) | 2015-04-16 | 2015-08-12 | 华为技术有限公司 | 一种实例节点管理的方法及管理设备 |
| CN106874142B (zh) * | 2015-12-11 | 2020-08-07 | 华为技术有限公司 | 一种实时数据容错处理方法及系统 |
| CN106959894B (zh) * | 2016-01-11 | 2020-11-24 | 北京京东尚科信息技术有限公司 | 资源分配方法和装置 |
| CN108259418B (zh) * | 2016-12-28 | 2021-08-24 | 中移(苏州)软件技术有限公司 | 一种函数托管服务的系统和方法 |
| US10200411B1 (en) * | 2017-01-24 | 2019-02-05 | Intuit Inc. | Method and system for providing instance re-stacking and security ratings data to identify and evaluate re-stacking policies in a cloud computing environment |
| US10230598B1 (en) * | 2017-01-24 | 2019-03-12 | Intuit Inc. | Method and system for providing visualization of instance data to identify and evaluate re-stacking policies in a cloud computing environment |
| CN107656728B (zh) * | 2017-09-15 | 2020-08-04 | 网宿科技股份有限公司 | 一种应用程序实例的创建方法及云服务器 |
| US11012824B2 (en) * | 2018-04-12 | 2021-05-18 | Qualcomm Incorporated | Communicating multiple instances of a message in a random medium access control system |
| CN111435320B (zh) * | 2019-01-14 | 2023-04-11 | 阿里巴巴集团控股有限公司 | 一种数据处理方法及其装置 |
| CN110457114B (zh) * | 2019-07-24 | 2020-11-27 | 杭州数梦工场科技有限公司 | 应用集群部署方法及装置 |
| CN110781002A (zh) * | 2019-10-24 | 2020-02-11 | 浪潮云信息技术有限公司 | 一种弹性伸缩方法、管理系统、终端及存储介质 |
| CN113127380A (zh) * | 2019-12-31 | 2021-07-16 | 华为技术有限公司 | 部署实例的方法、实例管理节点、计算节点和计算设备 |
| US11226845B2 (en) | 2020-02-13 | 2022-01-18 | International Business Machines Corporation | Enhanced healing and scalability of cloud environment app instances through continuous instance regeneration |
| CN114168307A (zh) * | 2020-09-10 | 2022-03-11 | 华为云计算技术有限公司 | 创建实例的方法、设备以及系统 |
| CN114442477B (zh) * | 2022-04-11 | 2022-06-07 | 北京信云筑科技有限责任公司 | 基于物联网的设备健康管理系统 |
| DE112023000003T5 (de) * | 2022-06-29 | 2024-03-07 | Hewlett Packard Enterprise Development Lp | Hochverfügbarkeitssysteme mit thin-provisioned-sekundärserver |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102497288A (zh) * | 2011-12-13 | 2012-06-13 | 华为技术有限公司 | 一种双机备份方法和双机系统实现装置 |
| US20150082308A1 (en) * | 2013-09-13 | 2015-03-19 | Ntt Docomo, Inc. | Method and apparatus for network virtualization |
| CN104836850A (zh) * | 2015-04-16 | 2015-08-12 | 华为技术有限公司 | 一种实例节点管理的方法及管理设备 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7287179B2 (en) * | 2003-05-15 | 2007-10-23 | International Business Machines Corporation | Autonomic failover of grid-based services |
| US8554981B2 (en) * | 2007-02-02 | 2013-10-08 | Vmware, Inc. | High availability virtual machine cluster |
| US8762339B2 (en) | 2010-11-29 | 2014-06-24 | International Business Machines Corporation | Disaster recovery utilizing collapsible virtualized capacity |
| US8595192B1 (en) | 2010-12-01 | 2013-11-26 | Symantec Corporation | Systems and methods for providing high availability to instance-bound databases |
| US20130097296A1 (en) * | 2011-10-18 | 2013-04-18 | Telefonaktiebolaget L M Ericsson (Publ) | Secure cloud-based virtual machine migration |
| US20140020156A1 (en) * | 2012-06-22 | 2014-01-23 | Gayle Manning | Versatile and convertible legwear |
| US20140007097A1 (en) * | 2012-06-29 | 2014-01-02 | Brocade Communications Systems, Inc. | Dynamic resource allocation for virtual machines |
| US9110717B2 (en) * | 2012-07-05 | 2015-08-18 | International Business Machines Corporation | Managing use of lease resources allocated on fallover in a high availability computing environment |
| CN103810015A (zh) * | 2012-11-09 | 2014-05-21 | 华为技术有限公司 | 虚拟机创建方法和设备 |
| US9317381B2 (en) * | 2012-11-20 | 2016-04-19 | Hitachi, Ltd. | Storage system and data management method |
| CN103077079B (zh) * | 2012-12-28 | 2016-06-08 | 华为技术有限公司 | 虚拟机迁移控制方法和装置 |
| US9141487B2 (en) * | 2013-01-15 | 2015-09-22 | Microsoft Technology Licensing, Llc | Healing cloud services during upgrades |
| US9569277B1 (en) * | 2016-01-29 | 2017-02-14 | International Business Machines Corporation | Rebalancing virtual resources for virtual machines based on multiple resource capacities |
| US10152268B1 (en) * | 2016-03-30 | 2018-12-11 | EMC IP Holding Company LLC | System and methods for replication resource management in asymmetric secure multi-tenancy deployments in protection storage |
-
2015
- 2015-04-16 CN CN201510180650.3A patent/CN104836850A/zh active Pending
- 2015-10-23 EP EP15889000.4A patent/EP3253028B1/en active Active
- 2015-10-23 WO PCT/CN2015/092667 patent/WO2016165304A1/zh active Application Filing
-
2017
- 2017-10-13 US US15/783,500 patent/US10601657B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102497288A (zh) * | 2011-12-13 | 2012-06-13 | 华为技术有限公司 | 一种双机备份方法和双机系统实现装置 |
| US20150082308A1 (en) * | 2013-09-13 | 2015-03-19 | Ntt Docomo, Inc. | Method and apparatus for network virtualization |
| CN104836850A (zh) * | 2015-04-16 | 2015-08-12 | 华为技术有限公司 | 一种实例节点管理的方法及管理设备 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3253028A4 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110178332A (zh) * | 2016-12-21 | 2019-08-27 | 金雅拓M2M有限责任公司 | 用于操作在蜂窝网络中并行通信的用户装备的方法、用户装备和蜂窝网络 |
| CN106775953A (zh) * | 2016-12-30 | 2017-05-31 | 北京中电普华信息技术有限公司 | 实现OpenStack高可用的方法与系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3253028B1 (en) | 2020-09-02 |
| CN104836850A (zh) | 2015-08-12 |
| US20180048522A1 (en) | 2018-02-15 |
| EP3253028A4 (en) | 2018-02-28 |
| US10601657B2 (en) | 2020-03-24 |
| EP3253028A1 (en) | 2017-12-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2016165304A1 (zh) | 一种实例节点管理的方法及管理设备 | |
| CN107526659B (zh) | 用于失效备援的方法和设备 | |
| KR102059251B1 (ko) | 노드 시스템, 서버 장치, 스케일링 제어 방법 및 프로그램 | |
| US9367340B2 (en) | Resource management method and apparatus for virtual machine system, and virtual machine system | |
| US11640314B2 (en) | Service provision system, resource allocation method, and resource allocation program | |
| US9575785B2 (en) | Cluster system and method for providing service availability in cluster system | |
| US9176834B2 (en) | Tolerating failures using concurrency in a cluster | |
| EP4083786A1 (en) | Cloud operating system management method and apparatus, server, management system, and medium | |
| US9639486B2 (en) | Method of controlling virtualization software on a multicore processor | |
| KR20150005854A (ko) | 컴퓨터 시스템, pci 익스프레스 엔드포인트 디바이스에 액세스하는 방법 및 장치 | |
| US10846079B2 (en) | System and method for the dynamic expansion of a cluster with co nodes before upgrade | |
| JP6123626B2 (ja) | 処理再開方法、処理再開プログラムおよび情報処理システム | |
| EP3857370A1 (en) | Cost-efficient high-availability multi-single-tenant services | |
| US10353786B2 (en) | Virtualization substrate management device, virtualization substrate management system, virtualization substrate management method, and recording medium for recording virtualization substrate management program | |
| CN112148485A (zh) | 超融合平台故障恢复方法、装置、电子装置和存储介质 | |
| US20110154322A1 (en) | Preserving a Dedicated Temporary Allocation Virtualization Function in a Power Management Environment | |
| US9548906B2 (en) | High availability multi-partition networking device with reserve partition and method for operating | |
| CN109284169B (zh) | 基于进程虚拟化的大数据平台进程管理方法及计算机设备 | |
| US11055263B2 (en) | Information processing device and information processing system for synchronizing data between storage devices | |
| CN111158783B (zh) | 一种环境变量修改方法、装置、设备及可读存储介质 | |
| CN107783855B (zh) | 虚拟网元的故障自愈控制装置及方法 | |
| WO2024002190A1 (zh) | 基于监控器的容器调整方法、设备及存储介质 | |
| US11797287B1 (en) | Automatically terminating deployment of containerized applications | |
| CN114356214B (zh) | 一种针对kubernetes系统提供本地存储卷的方法及系统 | |
| TW201327139A (zh) | 節點置換處理方法與使用其之伺服器系統 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 15889000 Country of ref document: EP Kind code of ref document: A1 |
|
| REEP | Request for entry into the european phase |
Ref document number: 2015889000 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |