EP3253028A1 - Method for managing instance node and management device - Google Patents
Method for managing instance node and management device Download PDFInfo
- Publication number
- EP3253028A1 EP3253028A1 EP15889000.4A EP15889000A EP3253028A1 EP 3253028 A1 EP3253028 A1 EP 3253028A1 EP 15889000 A EP15889000 A EP 15889000A EP 3253028 A1 EP3253028 A1 EP 3253028A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- instance node
- application
- resource configuration
- node
- configuration specification
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims description 60
- 238000007726 management method Methods 0.000 claims abstract description 131
- 238000012544 monitoring process Methods 0.000 claims description 29
- 238000001514 detection method Methods 0.000 claims description 18
- 230000008439 repair process Effects 0.000 claims description 4
- 230000006870 function Effects 0.000 description 21
- 238000010586 diagram Methods 0.000 description 18
- 238000012545 processing Methods 0.000 description 15
- 230000008569 process Effects 0.000 description 13
- 230000036541 health Effects 0.000 description 11
- 238000005516 engineering process Methods 0.000 description 4
- 230000008571 general function Effects 0.000 description 4
- 238000013024 troubleshooting Methods 0.000 description 4
- 230000007423 decrease Effects 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 238000011084 recovery Methods 0.000 description 3
- 239000013589 supplement Substances 0.000 description 3
- 239000002699 waste material Substances 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 230000003862 health status Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/084—Configuration by using pre-existing information, e.g. using templates or copying from other elements
- H04L41/0846—Configuration by using pre-existing information, e.g. using templates or copying from other elements based on copy from other elements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/40—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks using virtualisation of network functions or resources, e.g. SDN or NFV entities
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1446—Point-in-time backing up or restoration of persistent data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/203—Failover techniques using migration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2041—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant with more than one idle spare processing component
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3003—Monitoring arrangements specially adapted to the computing system or computing system component being monitored
- G06F11/3006—Monitoring arrangements specially adapted to the computing system or computing system component being monitored where the computing system is distributed, e.g. networked systems, clusters, multiprocessor systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0654—Management of faults, events, alarms or notifications using network fault recovery
- H04L41/0663—Performing the actions predefined by failover planning, e.g. switching to standby network elements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0654—Management of faults, events, alarms or notifications using network fault recovery
- H04L41/0668—Management of faults, events, alarms or notifications using network fault recovery by dynamic selection of recovery network elements, e.g. replacement by the most appropriate element after failure
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L65/00—Network arrangements, protocols or services for supporting real-time applications in data packet communication
- H04L65/40—Support for services or applications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1097—Protocols in which an application is distributed across nodes in the network for distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45562—Creating, deleting, cloning virtual machine instances
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/4557—Distribution of virtual machine instances; Migration and load balancing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45575—Starting, stopping, suspending or resuming virtual machine instances
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0876—Aspects of the degree of configuration automation
- H04L41/0886—Fully automatic configuration
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
Definitions
- the present invention relates to the field of cloud computing technologies, and specifically, to an instance node management method and a management device.
- a solution in which a primary instance node and a secondary instance node are used is a highly reliable solution that is most dominant in the industry.
- An application instance of a primary instance node is backed up on a secondary instance node.
- the primary instance node is normal, all external requests are used for accessing the primary instance node, and the external requests are switched to the secondary instance node only when the primary instance node is faulty and cannot run normally.
- the secondary instance node occupies a resource that is absolutely the same as a resource occupied by the primary instance node, but is in a standby state all the time, which causes a waste of physical resources.
- a resource utilization rate of the two primary instance nodes cannot reach 50%. Otherwise, when a single point is faulty, all pressure is concentrated on the other active primary instance node, and excessively high pressure causes that a service cannot run normally. As a result, more usage wastes of node resources are caused.
- Embodiments of the present invention provide an instance node management method, which, on a basis of ensuring high availability of an application that is hosted on a cloud platform, can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- the embodiments of the present invention further provide a corresponding management device.
- a first aspect of the present invention provides an instance node management method, where the method is applied to a management device of a cloud platform, and the method includes:
- the method further includes:
- the method further includes:
- the method further includes:
- the method further includes:
- the method further includes:
- the method further includes:
- a second aspect of the present invention provides a management device of a cloud platform, where the management device includes:
- the management device further includes:
- the second creating module is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification.
- the management device further includes a repairing module, where the repairing module is configured to repair the faulty primary instance node to obtain the repaired primary instance node; and the first adjustment module is further configured to adjust a resource configuration specification of the repaired primary instance node to the minimum resource configuration specification of the application, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application.
- the management device further includes an acquiring module, where the acquiring module is configured to acquire accesses of the application by user equipment; and the second creating module is specifically configured to: when the accesses acquired by the acquiring module, of the application exceed a preset threshold, create at least two secondary instance nodes for the application according to the minimum resource configuration specification determined by the determining module, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification.
- the management device further includes a monitoring module, where the monitoring module is configured to monitor the secondary instance node, created by the second creating module, of the application; and the second creating module is further configured to: when the monitoring module learns, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node.
- the management device further includes a detection module and a second adjustment module, where the detection module is configured to detect a resource quantity required for running the instance of the application; and the second adjustment module is configured to adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity detected by the detection module.
- a primary instance node is created for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; a minimum resource configuration specification required by a secondary instance node of the application is determined according to running start information of the primary instance node, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and the secondary instance node of the application is created according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- the instance node management method can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- the embodiments of the present invention provide an instance node management method, which, on a basis of ensuring high availability of an application that is hosted on a cloud platform, can reduce occupancy of a spare resource and increase an application hosting capacity and size on the cloud platform.
- the embodiments of the present invention further provide a corresponding management device. The following separately provides detailed descriptions.
- Massive applications can be hosted on a cloud platform.
- a primary instance node and a secondary instance node need to be created for each application in an operating environment of the cloud platform, where the primary instance node is configured to run an instance of an application, and the secondary instance node is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application.
- a management device on the cloud platform manages both the primary instance node and the secondary instance node.
- Each of the primary instance node and the secondary instance node is actually a virtual machine or function node allocated by the management device to the application, where a granularity of the function node is less than that of the virtual machine, and both the primary instance node and the secondary instance node can use resources on the cloud platform.
- the resources on the cloud platform refer to hardware resources provided by many physical hosts, and include but are not limited to a core quantity of a central processing unit (Central Processing Unit, CPU), a memory size, a hard disk size, network bandwidth, and the like.
- CPU central processing unit
- a primary instance node that runs an instance of the application is created for the application hosted by the user on the cloud platform; a minimum resource configuration specification of a secondary instance node of the application is determined according to running start information of the primary instance node; and the secondary instance node of the application is created according to the minimum resource configuration specification, so that a resource configuration specification of the secondary instance node is the same as the minimum resource configuration specification, and the resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application.
- a resource configuration specification of an instance node is used to indicate a resource quantity allocated to the instance node, such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth allocated to the instance node.
- the minimum resource configuration specification is used to indicate a minimum resource quantity that is required for starting or running the instance of the application.
- the instance of the application can be understood as a copy or mirror of an executable version of the application.
- the cloud platform can create one or more instances for one application, and each instance of the application may be specifically an independent process or thread.
- the user may be an application operator.
- the running start information of the primary instance node may indicate a basic resource required for running the instance of the application, such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth required when the primary instance node starts operating.
- the minimum resource configuration specification of the secondary instance node may refer to specification information such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth required when the secondary instance node is configured to run the application.
- the primary instance node when a primary instance node is normal, the primary instance node provides a service for access by user equipment; when the primary instance node is faulty, a management device switches the access by the user equipment to a secondary instance node, and sets the secondary instance node of the application as a working instance node that provides a service for the access by the user equipment; and adjusts a resource configuration specification of the working instance node to be the same as a resource configuration specification of the primary instance node of the application.
- the management device may adjust the resource configuration specification of the working instance node to be slightly greater or less than the resource configuration specification of the primary instance node of the application.
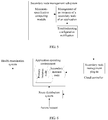
- the management device in an embodiment of the present invention may include a cloud controller, a secondary node management subsystem, and a health examination system in FIG. 2 , as shown in FIG. 2 :
- FIG. 3 shows a procedure of an example of processing performed when a primary instance node is faulty.
- a health examination system notifies a secondary node management subsystem of such case.
- the secondary node management subsystem instructs a cloud controller to start and expand a minimum secondary instance node, uses an expanded secondary instance node as a conventional instance node to replace the primary instance node of the application to run an instance of the application, and creates a secondary instance node according to a minimum resource configuration specification.
- the conventional instance herein may also be referred to as a working instance node and refers to an instance node that runs the instance of the application currently.
- a cloud platform includes the following several parts: a cloud controller, a health examination system, a secondary node management subsystem, a route distribution system, and an application operating environment.
- a cloud controller a health examination system
- a secondary node management subsystem a route distribution system
- an application operating environment a management device.
- the management device has functions of the cloud controller, the health examination system, the secondary node management subsystem, and the route distribution system.
- the secondary node management subsystem on the cloud platform, the secondary node management system is mainly responsible for computing a minimum resource configuration specification of a secondary instance node, instructing the cloud controller to start and expand the secondary instance node when a primary instance node is faulty, and then after the secondary instance node is started as a conventional working instance node, creating a secondary instance node again according to the minimum resource configuration specification.
- the expanding the secondary instance node to form a conventional working instance node refers to adjusting a resource configuration specification of the secondary instance node to be the same as a resource configuration specification of the primary instance node of the application. It should be noted that the "same" described in this embodiment of the present invention does not refer to being absolutely the same in numerical value. In an actual application, a specific error is allowed, for example, the resource configuration specification of the secondary instance node is slightly greater or less than or substantially the same as the resource configuration specification of the primary instance node.
- a secondary node management subsystem mainly includes the following three modules: a minimum-specification computing module, a module for managing an instance of a secondary node of an application, and a troubleshooting configuration notification module.
- the minimum-specification computing module mainly acquires, when an application is deployed on a cloud platform for the first time and after a primary instance node of the application has been started successfully, a minimum configuration specification of a required resource in a process of initializing the primary instance node.
- the specification includes but is not limited to a core quantity of a CPU, a memory size, a hard disk size, network bandwidth, and the like.
- a cloud controller is to be notified of the specification, and the specification is recorded on the cloud controller and used as a specification basis of subsequently starting a new secondary instance node.
- the module for managing an instance of a secondary node of an application is mainly configured to determine and check a case of a secondary instance node of the application. A quantity and an operating status of the secondary instance node are managed by the module. When sustained pressure of the application is relatively high, the system can determine a quantity of minimum secondary instance nodes to be increased, so that multiple secondary instances can be quickly started in a case of a sudden fault to ensure smooth operation.
- the troubleshooting configuration notification module is a processing mechanism that is used when a health examination system detects that an instance is faulty. Faults of two types of instances are included herein: one is a fault of a conventional instance node, and the other is a fault of a secondary instance node with a minimum specification.
- the troubleshooting configuration notification module instructs the cloud controller to start a secondary instance node, and quickly expands the secondary instance node to reach a specification of the conventional instance node; in this case, a quantity of minimum secondary instance nodes is correspondingly decreased by 1, that is, the cloud controller is instructed to create a minimum secondary instance node, and when the minimum secondary instance node is faulty, the same operation as what is performed when the conventional instance node is faulty is performed.
- the cloud controller manages an instance node and configures route distribution. Instance nodes of all cloud applications are distributed to specified application operating environments by the cloud controller. In an instance access manner, the cloud controller sends a policy to a route distribution system. As a general function system on the cloud platform, the cloud controller is not described in detail in the present invention.
- the route distribution system mainly controls an external access request to be distributed to an operating instance node of a corresponding application, receives a processing result of the instance node, and feeds back the result to user equipment that sends the access request.
- the route distribution system is not described in detail in the present invention.
- the health examination system is responsible for checking a health status of instance nodes of all applications and instructing the secondary node management system to perform fault recovery, create a minimum secondary instance node, and the like. As a general function system on the cloud platform, the health examination system is not described in detail in the present invention.
- the application operating environment is mainly a carrier such as a virtual machine or a container, and an operating system, a software stack, and a resource such as a computing/storage/network resource that are required for operating an application are provided for normal operation of an instance of an application.
- a general function system on the cloud platform the application operating environment is not described in detail in the present invention.
- the foregoing steps can ensure that a cloud application has a sufficient primary and secondary supporting capacity; in addition, a specification of a secondary instance node can be far less than that of a conventional instance node, which effectively reduces a resource waste caused by a requirement of high availability.
- FIG. 6 another embodiment of instance node management in embodiments of the present invention is basically the same as the embodiment corresponding to FIG. 4 except for partial simplification in structure.
- a secondary instance management node may be included in a cloud controller in implementation, and is deployed together with the cloud controller in a manner of a plug-in/component or the like of the cloud controller.
- the cloud controller is first instructed to perform inter-system communication, and then the cloud controller allows a secondary node management plug-in to perform related processing.
- a secondary node management node can directly notify a router/an application operating environment or the like to perform route distribution management configuration and to implement creation/expansion or the like of a secondary instance node.
- simplification may further be performed on the secondary node management system/plug-in.
- a basic demand of high availability can be met provided that there is one secondary instance node. Therefore, a module for managing an instance of a secondary node of an application can be removed, where only fault handling and minimum-specification computing functions are retained.
- a process of creating a cloud application for the first time is the same as that in the foregoing embodiment.
- a secondary node resource pool does not need to be determined or detected, a secondary instance node in the cloud application is directly converted into a conventional node, and a secondary instance node is created again.
- a process of creating a cloud application for the first time is the same as that in the foregoing embodiment, but a difference lies in that: when a fault occurs and after a secondary instance node is converted into a conventional node, the cloud controller recovers a faulty conventional instance instead of creating a secondary instance node again, and after recovery, a health examination system instructs the secondary node management system to recycle a started secondary instance node, for recovery to an initial state.
- a resource configuration specification of the repaired conventional instance node may be adjusted to a minimum resource configuration specification of the application, so that the repaired conventional instance node becomes a secondary instance node of the application.
- a dynamic adjustment method may be further added based on computing of a minimum specification of a secondary node and management of the secondary node.
- a minimum specification is dynamically computed according to an entire operating status, obtained by statistics collection, of the application, and specification refresh is performed in real time on a backup node instance with a minimum specification in a current environment.
- an instance with a complete specification is first created, and after starting is complete, the specification of the instance is decreased to a minimum specification that is obtained by means of computing, so as to reduce resource consumption.
- a conventional instance node When a fault is being recovered, a conventional instance node is first recovered, the recovered conventional instance node is used as an instance node with a minimum specification, and a specification of the recovered conventional instance node is decreased to a minimum specification.
- operating environments on the cloud platform may be different, such as a container or a virtual machine, and a difference exists in manners of implementing a secondary instance node with a minimum specification.
- a container such as a container or a virtual machine
- the methods in the foregoing embodiments can be quickly implemented; in a technology in which a virtual machine is used, because a technology of longitudinal scale out/in and expansion regarding a virtual machine is immature, a method of longitudinal scale out/in and transverse scale out/in is used herein, that is, in a cloud environment meeting longitudinal scale out/in, the method in the foregoing embodiments is directly used, while in a cloud environment that does not meet longitudinal scale out/in, a transverse scale out/in mechanism is used.
- Creation of a secondary instance node is the same as that in the foregoing embodiment, but in use, a demand of temporary reliability is met by establishing multiple secondary instance nodes, and after a conventional instance node is recovered, and then a temporarily generated secondary instance node is released, so as to ensure effective utilization of a resource.
- the instance node management method can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- an embodiment of an instance node management method provided by embodiments of the present invention includes:
- a primary instance node is created for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; a minimum resource configuration specification required by a secondary instance node of the application is determined according to running start information of the primary instance node, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and the secondary instance node of the application is created according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- the instance node management method can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- the method may further include:
- the above method step may specifically comprise:
- a resource occupancy rate of a secondary instance node is quite low; and when the primary instance node is faulty, the secondary instance node is quickly expanded to take over work of the primary instance node, so that an application access demand is met, and an application hosting capacity and size on a cloud platform are increased.
- the method may further include:
- the method may further include:
- the above method step may comprise:
- a faulty primary instance node may be further repaired in a timely manner; in this case, a resource utilization rate of a cloud platform is further increased.
- the method may further include:
- minimum secondary instance nodes of a corresponding quantity can be created according to accesses of an application; in this case, a sudden and unexpected fault caused when application pressure is excessively high can be avoided, thereby further improving high availability of a cloud platform.
- the method may further include:
- a faulty instance node in created secondary instance nodes may be further monitored in a timely manner, and a new available secondary instance node is created in a timely manner, so as to avoid that when a primary instance node is faulty, no available secondary instance node takes over work of the primary instance node, thereby further improving high availability of a cloud platform.
- the method may further include:
- dynamic adjustment may be further performed on a resource configuration specification of a created secondary instance node according to a resource quantity required for operating an application; and if a quantity of resources required by the application is low, a resource may be further saved, and if the quantity of resources required by the application is high, takeover efficiency may be further improved when a primary instance node is faulty.
- FIG. 7 The embodiment corresponding to FIG. 7 and the optional embodiments corresponding to the embodiment can be understood with reference to the related descriptions in FIG. 1 to FIG. 6 , and details are not described herein again.
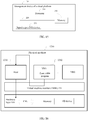
- a first creating module 201, a second creating module 203, a first adjustment module 204, a repairing module 205, an acquiring module 206, a detection module 208, and a second adjustment module 209 that are involved in a process of describing a management device 20 of a cloud platform in the following are the same as the functions of the cloud controller described in the embodiments of FIG. 1 to FIG. 4
- functions implemented by a determining module 202 and a monitoring module 207 are the same as the functions of the secondary node management subsystem described in the embodiments of FIG. 1 to FIG. 4
- the determining module 202 may be the minimum-specification computing module in FIG. 5
- the monitoring module 207 may be the module for managing an instance of a secondary node of an application and the troubleshooting configuration notification module.
- an embodiment of a management device 20 of a cloud platform provided by embodiments of the present invention includes:
- the instance node management device can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- the management device 20 further includes:
- a resource occupancy rate of a secondary instance node is quite low; and when the primary instance node is faulty, the secondary instance node is quickly expanded to take over work of the primary instance node, so that an application access demand is met, and an application hosting capacity and size on a cloud platform are increased.
- the second creating module 203 is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification.
- the management device 20 further includes a repairing module 205.
- the repairing module 205 is configured to repair the faulty primary instance node to obtain the repaired primary instance node.
- the first adjustment module 204 is further configured to adjust a resource configuration specification of the primary instance node repaired by the repairing module 205 to the minimum resource configuration specification of the application, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application.
- a faulty primary instance node may be further repaired in a timely manner; in this case, a resource utilization rate of a cloud platform is further increased.
- the management device 20 further includes an acquiring module 206.
- the acquiring module 206 is configured to acquire accesses of the application by user equipment.
- the second creating module 203 is specifically configured to: when the accesses acquired by the acquiring module 206, of the application exceed a preset threshold, create at least two secondary instance nodes for the application according to the minimum resource configuration specification determined by the determining module, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification.
- minimum secondary instance nodes of a corresponding quantity can be created according to accesses of an application; in this case, a sudden and unexpected fault caused when application pressure is excessively high can be avoided, thereby further improving high availability of a cloud platform.
- the management device 20 further includes a monitoring module 207.
- the monitoring module 207 is configured to monitor the secondary instance node, created by the second creating module 203, of the application.
- the second creating module 203 is further configured to: when the monitoring module 211 learns, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node.
- a faulty instance node in created secondary instance nodes may be further monitored in a timely manner, and a new available secondary instance node is created in a timely manner, so as to avoid that when a primary instance node is faulty, no available secondary instance node takes over work of the primary instance node, thereby further improving high availability of a cloud platform.
- the management device 20 further includes a detection module 212 and a second adjustment module 213.
- the detection module 208 is configured to detect a resource quantity required for running the instance of the application.
- the second adjustment module 209 is configured to adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity detected by the detection module 212.
- dynamic adjustment may be further performed on a resource configuration specification of a created secondary instance node according to an operating status of an application; and if a quantity of resources required by the application is low, a resource may be further saved, and if the quantity of resources required by the application is high, takeover efficiency may be further improved when a primary instance node is faulty.
- FIG. 8 to FIG. 13 can be understood with reference to the descriptions in FIG. 1 to FIG. 7 , and details are not described herein again.
- a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may be implemented by a processor executing a program or an instruction in a memory (that is, by cooperation of a processor and a special instruction in a memory coupled with the processor); in another implementation manner, a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may also be implemented by using a specific circuit; for the specific implementation manner, refer to the prior art, and details
- a hardware structure of a management device may include three parts:
- the transceiver component is a hardware circuit configured to complete packet receiving and sending.
- the hardware component may also be referred to as a "hardware processing module", or more simply, may be short for “hardware”.
- the hardware component mainly includes a hardware circuit that implements, based on a application-specific hardware circuit such as an FPGA and an ASIC (which may also coordinate with another matching component, for example, a memory), some specific functions; a processing speed of the hardware component is usually much higher than that of a general purpose processor, but it is difficult to change a function once the function is customized; therefore, the hardware component is inflexible in implementation and is usually configured to process some specific functions.
- the hardware component may also include a processor such as an MCU (a microprocessor, for example, a single-chip microcomputer) or a CPU; however, a primary function of these processors is not to complete big data processing, but is mainly to perform control; in such application scenario, a system including these components is a hardware component.
- a processor such as an MCU (a microprocessor, for example, a single-chip microcomputer) or a CPU; however, a primary function of these processors is not to complete big data processing, but is mainly to perform control; in such application scenario, a system including these components is a hardware component.
- the software component (or short for "software”) mainly includes a general purpose processor (for example, a CPU) and some matching devices of the general purpose processor (for example, a storage device such as a memory or a hard disk).
- the processor may be enabled, by means of programming, to have a corresponding processing function.
- the software component can be configured flexibly according to a service requirement, but a speed thereof is usually lower than that of the hardware component.
- the hardware component may send processed data by using the transceiver component, or may send processed data to the transceiver component over an interface connected to the transceiver component.
- the transceiver component is configured to receive a switch instruction in the foregoing embodiment, and the software component or hardware component is configured to perform APP registration, service quality control, or the like.
- a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may be implemented by a processor executing a program or an instruction in a memory.
- an input/output I/O device for example, a network adapter
- FIG. 15 is a schematic structural diagram of a management device 20 provided by an embodiment of the present invention.
- the management device 20 includes a processor 210, a memory 250, and an input/output I/O device 230, where the memory 250 may include a read-only memory and a random access memory and provide an operation instruction and data for the processor 210.
- a part of the memory 250 may further include a non-volatile random access memory (NVRAM).
- NVRAM non-volatile random access memory
- the memory 250 stores the following elements: an executable module or a data structure, or subsets thereof, or extension sets thereof.
- an operation instruction stored in the memory 250 (the operation instruction may be stored in an operating system) is invoked to:
- the management device can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- the processor 210 controls an operation of the management device 20, and the processor 210 may also be referred to as a CPU (Central Processing Unit, central processing unit).
- the memory 250 may include a read-only memory and a random access memory and provide an instruction and data for the processor 210. A part of the memory 250 may further include a non-volatile random access memory (NVRAM).
- NVRAM non-volatile random access memory
- all components of the management device 20 are coupled together by using a bus system 220, where in addition to including a data bus, the bus system 220 may further include a power bus, a control bus, a status signal bus, and the like. However, for clear description, all kinds of buses are marked as the bus system 220 in the figure.
- the methods disclosed in the foregoing embodiments of the present invention may be applied to the processor 210, or may be implemented by the processor 210.
- the processor 210 may be an integrated circuit chip and has a signal processing capability. In an implementation process, all steps of the foregoing methods may be completed by using an integrated logic circuit of hardware in the processor 210 or by using an instruction in a software form.
- the foregoing processor 210 may be a general purpose processor, a digital signal processor (DSP), an application-specific integrated circuit (ASIC), a field-programmable gate array (FPGA) or another programmable logic device, a discrete gate or transistor logic device, or a discrete hardware component, and can implement or execute the methods, steps, and logic block diagrams disclosed in this embodiment of the present invention.
- the general purpose processor may be a microprocessor, or the processor may be any conventional processor or the like.
- the steps of the methods disclosed with reference to the embodiments of the present invention may be executed and completed by a hardware encoding processor, or may be executed and completed by using a combination of hardware and software modules in an encoding processor.
- the software module may be located in a storage medium mature in the art such as a random access memory, a flash memory, a read-only memory, a programmable read-only memory, an electrically erasable programmable memory, or a register.
- the storage medium is located in the memory 250, the processor 210 reads information in the memory 250, and the steps of the foregoing methods are completed with reference to hardware of the processor 210.
- the processor 210 is further configured to: when the primary instance node is faulty, adjust the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node, and set the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application.
- a resource occupancy rate of a secondary instance node is quite low; and when the primary instance node is faulty, the secondary instance node is quickly expanded to take over work of the primary instance node, so that an application access demand is met, and an application hosting capacity and size on a cloud platform are increased.
- the processor 210 is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification.
- the processor 210 is further configured to: repair the faulty primary instance node to obtain the repaired primary instance node; and adjust a resource configuration specification of the repaired primary instance node to be the same as the minimum resource configuration specification, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application.
- a faulty primary instance node may be further repaired in a timely manner; in this case, a resource utilization rate of a cloud platform is further increased.
- the processor 210 is further configured to: acquire accesses of the application by user equipment; and create at least two secondary instance nodes for the application according to the minimum resource configuration specification when the accesses of the application exceed a preset threshold, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification.
- minimum secondary instance nodes of a corresponding quantity can be created according to accesses of an application; in this case, a sudden and unexpected fault caused when application pressure is excessively high can be avoided, thereby further improving high availability of a cloud platform.
- the processor 210 is further configured to: monitor the created secondary instance node of the application; and when it is learned, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node.
- a faulty instance node in created secondary instance nodes may be further monitored in a timely manner, and a new available secondary instance node is created in a timely manner, so as to avoid that when a primary instance node is faulty, no available secondary instance node takes over work of the primary instance node, thereby further improving high availability of a cloud platform.
- the processor 210 is further configured to: detect a resource quantity required for running the instance of the application; and adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity.
- dynamic adjustment may be further performed on a resource configuration specification of a created secondary instance node according to an operating status of an application; and if a quantity of resources required by the application is low, a resource may be further saved, and if the quantity of resources required by the application is high, takeover efficiency may be further improved when a primary instance node is faulty.
- a management device of a cloud platform may be specifically a cloud host in a cloud computing system, where the cloud host may be a virtual machine running on a physical machine.
- a physical machine 1200 includes a hardware layer 100, a VMM (Virtual Machine Monitor, virtual machine monitor) 110 running at the hardware layer 100, and several virtual machines (VM, Virtual Machine) and a host machine Host 1201 that run on the VMM 110, where the hardware layer includes but is not limited to an I/O device, a CPU, and a memory.
- the management device of a cloud platform provided by this embodiment of the present invention may be specifically a virtual machine in a physical machine 1200, for example, a VM 1202.
- One or more cloud applications run on the VM 1202, where each cloud application is used to implement a corresponding service function, such as a database application or a map application. These applications may be developed by a developer and then deployed in the cloud computing system.
- an executable program further runs on the VM 1202.
- the VM 1202 runs the executable program and invokes, in a program running process, a hardware resource of the hardware layer 100 by using the host machine Host 1201, so as to implement functions of a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module of the management device of the cloud platform.
- the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module may be included in the foregoing executable program in a form of a software module or a function.
- the executable program may include the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module.
- the VM 1202 invokes a resource such as a CPU or a Memory of the hardware layer 100 to run the executable program, so as to implement the functions of the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module.
- a resource such as a CPU or a Memory of the hardware layer 100 to run the executable program, so as to implement the functions of the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module.
- FIG. 15 The embodiment corresponding to FIG. 15 and the other optional embodiments can be understood with reference to the descriptions in FIG. 1 to FIG. 13 , and details are not described herein again.
- the program may be stored in a computer-readable storage medium.
- the storage medium may include: a ROM, a RAM, a magnetic disk, or an optical disc.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Quality & Reliability (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Multimedia (AREA)
- Hardware Redundancy (AREA)
- Stored Programmes (AREA)
Abstract
Description
- This application claims priority to Chinese Patent Application No.
201510180650.3 - The present invention relates to the field of cloud computing technologies, and specifically, to an instance node management method and a management device.
- In the era of cloud computing, massive applications and services all are hosted on a cloud platform. In addition to ensuring high availability of the cloud platform itself, the cloud platform still needs to provide assurance of high availability for the applications and services hosted on the cloud platform. In an existing solution, high availability of an application or a service is usually implemented by deploying two primary instance nodes or by deploying a primary instance node and a secondary instance node. For a solution implementing high availability by using two primary instance nodes, instances of multiple applications are parallel, and all instance nodes can normally receive external request information and process the external request information. If an instance node of the instance nodes is faulty, load born by the instance node is shared by another instance node. A solution in which a primary instance node and a secondary instance node are used is a highly reliable solution that is most dominant in the industry. An application instance of a primary instance node is backed up on a secondary instance node. When the primary instance node is normal, all external requests are used for accessing the primary instance node, and the external requests are switched to the secondary instance node only when the primary instance node is faulty and cannot run normally.
- It can be seen from the foregoing that, in the solution in which a primary instance node and a secondary instance node are used, the secondary instance node occupies a resource that is absolutely the same as a resource occupied by the primary instance node, but is in a standby state all the time, which causes a waste of physical resources. However, in the solution in which two primary instance nodes are used, a resource utilization rate of the two primary instance nodes cannot reach 50%. Otherwise, when a single point is faulty, all pressure is concentrated on the other active primary instance node, and excessively high pressure causes that a service cannot run normally. As a result, more usage wastes of node resources are caused.
- Embodiments of the present invention provide an instance node management method, which, on a basis of ensuring high availability of an application that is hosted on a cloud platform, can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform. The embodiments of the present invention further provide a corresponding management device.
- A first aspect of the present invention provides an instance node management method, where the method is applied to a management device of a cloud platform, and the method includes:
- creating a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application;
- determining, according to running start information of the primary instance node, a minimum resource configuration specification required by a secondary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and
- creating the secondary instance node of the application according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- With reference to the first aspect, in a first possible implementation manner, after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method further includes:
- when the primary instance node is faulty, adjusting the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node, and setting the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application.
- With reference to the first possible implementation manner of the first aspect, in a second possible implementation manner, after the adjusting the resource configuration specification of the working instance node to be the same as the resource configuration specification of the primary instance node of the application, the method further includes:
- creating a secondary instance node for the application again according to the minimum resource configuration specification.
- With reference to the first possible implementation manner of the first aspect, in a third possible implementation manner, after the adjusting the resource configuration specification of the working instance node to be the same as the resource configuration specification of the primary instance node of the application, the method further includes:
- repairing the faulty primary instance node to obtain the repaired primary instance node; and
- adjusting a resource configuration specification of the repaired primary instance node to be the same as the minimum resource configuration specification, and setting the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application.
- With reference to the first aspect or any one of the first to third possible implementation manners of the first aspect, in a fourth possible implementation manner, after the determining a minimum resource configuration specification of a secondary instance node of the application, the method further includes:
- acquiring accesses of the application by user equipment; and
- the creating the secondary instance node of the application according to the minimum resource configuration specification includes:
- creating at least two secondary instance nodes for the application according to the minimum resource configuration specification when the accesses of the application exceed a preset threshold, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification.
- With reference to the first aspect or any one of the first to third possible implementation manners of the first aspect, in a fifth possible implementation manner, after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method further includes:
- monitoring the created secondary instance node of the application; and
- when it is learned, by monitoring, that the secondary instance node of the application is faulty, creating a secondary instance node having a same quantity as the faulty secondary instance node.
- With reference to the first aspect or any one of the first to third possible implementation manners of the first aspect, in a sixth possible implementation manner, after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method further includes:
- detecting a resource quantity required for running the instance of the application; and
- adjusting the resource configuration specification of the created secondary instance node of the application according to the required resource quantity.
- A second aspect of the present invention provides a management device of a cloud platform, where the management device includes:
- a first creating module, configured to create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application;
- a determining module, configured to determine, according to running start information of the primary instance node created by the first creating module, a minimum resource configuration specification required by a secondary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and
- a second creating module, configured to create the secondary instance node of the application according to the minimum resource configuration specification determined by the determining module, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- With reference to the second aspect, in a first possible implementation manner, the management device further includes:
- a first adjustment module, configured to: when the primary instance node is faulty, adjust the resource configuration specification of the secondary instance node created by the second creating module to be the same as the resource configuration specification of the primary instance node, and set the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application.
- With reference to the first possible implementation manner of the second aspect, in a second possible implementation manner,
the second creating module is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification. - With reference to the first possible implementation manner of the second aspect, in a third possible implementation manner,
the management device further includes a repairing module, where
the repairing module is configured to repair the faulty primary instance node to obtain the repaired primary instance node; and
the first adjustment module is further configured to adjust a resource configuration specification of the repaired primary instance node to the minimum resource configuration specification of the application, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application. - With reference to the second aspect or any one of the first to third possible implementation manners of the second aspect, in a fourth possible implementation manner, the management device further includes an acquiring module, where
the acquiring module is configured to acquire accesses of the application by user equipment; and
the second creating module is specifically configured to: when the accesses acquired by the acquiring module, of the application exceed a preset threshold, create at least two secondary instance nodes for the application according to the minimum resource configuration specification determined by the determining module, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification. - With reference to the second aspect or any one of the first to third possible implementation manners of the second aspect, in a fifth possible implementation manner, the management device further includes a monitoring module, where
the monitoring module is configured to monitor the secondary instance node, created by the second creating module, of the application; and
the second creating module is further configured to: when the monitoring module learns, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node. - With reference to the second aspect or any one of the first to third possible implementation manners of the second aspect, in a sixth possible implementation manner, the management device further includes a detection module and a second adjustment module, where
the detection module is configured to detect a resource quantity required for running the instance of the application; and
the second adjustment module is configured to adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity detected by the detection module. - According to the embodiments of the present invention, a primary instance node is created for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; a minimum resource configuration specification required by a secondary instance node of the application is determined according to running start information of the primary instance node, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and the secondary instance node of the application is created according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application. Compared with the prior art in which a secondary instance node needs to occupy a same resource as a primary instance node to ensure high availability of an application on a cloud platform, on a basis of ensuring high availability of an application that is hosted on a cloud platform, the instance node management method provided by the embodiments of the present invention can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- To describe the technical solutions in the embodiments of the present invention or in the prior art more clearly, the following briefly describes the accompanying drawings required for describing the embodiments or the prior art. Apparently, the accompanying drawings in the following description show merely some embodiments of the present invention, and a person of ordinary skill in the art may still derive other drawings from these accompanying drawings without creative efforts.
-
FIG. 1 is a schematic diagram of an embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 2 is a schematic diagram of another embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 3 is a schematic diagram of another embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 4 is a schematic diagram of another embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 5 is a schematic diagram of another embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 6 is a schematic diagram of another embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 7 is a schematic diagram of another embodiment of an instance node management method according to the embodiments of the present invention; -
FIG. 8 is a schematic diagram of an embodiment of a management device according to the embodiments of the present invention; -
FIG. 9 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; -
FIG. 10 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; -
FIG. 11 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; -
FIG. 12 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; -
FIG. 13 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; -
FIG. 14 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; -
FIG. 15 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention; and -
FIG. 16 is a schematic diagram of another embodiment of a management device according to the embodiments of the present invention. - The embodiments of the present invention provide an instance node management method, which, on a basis of ensuring high availability of an application that is hosted on a cloud platform, can reduce occupancy of a spare resource and increase an application hosting capacity and size on the cloud platform. The embodiments of the present invention further provide a corresponding management device. The following separately provides detailed descriptions.
- To make a person skilled in the art understand the solutions in the present invention better, the following clearly and completely describes the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Apparently, the described embodiments are merely a part rather than all of the embodiments of the present invention. All other embodiments obtained by a person of ordinary skill in the art based on the embodiments of the present invention without creative efforts shall fall within the protection scope of the present invention.
- Massive applications can be hosted on a cloud platform. To ensure high-availability performance of each application, a primary instance node and a secondary instance node need to be created for each application in an operating environment of the cloud platform, where the primary instance node is configured to run an instance of an application, and the secondary instance node is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application. A management device on the cloud platform manages both the primary instance node and the secondary instance node. Each of the primary instance node and the secondary instance node is actually a virtual machine or function node allocated by the management device to the application, where a granularity of the function node is less than that of the virtual machine, and both the primary instance node and the secondary instance node can use resources on the cloud platform. The resources on the cloud platform refer to hardware resources provided by many physical hosts, and include but are not limited to a core quantity of a central processing unit (Central Processing Unit, CPU), a memory size, a hard disk size, network bandwidth, and the like.
- In the embodiments of the present invention, after a user hosts an application on a cloud platform, a primary instance node that runs an instance of the application is created for the application hosted by the user on the cloud platform; a minimum resource configuration specification of a secondary instance node of the application is determined according to running start information of the primary instance node; and the secondary instance node of the application is created according to the minimum resource configuration specification, so that a resource configuration specification of the secondary instance node is the same as the minimum resource configuration specification, and the resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application. A resource configuration specification of an instance node is used to indicate a resource quantity allocated to the instance node, such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth allocated to the instance node. The minimum resource configuration specification is used to indicate a minimum resource quantity that is required for starting or running the instance of the application. The instance of the application can be understood as a copy or mirror of an executable version of the application. The cloud platform can create one or more instances for one application, and each instance of the application may be specifically an independent process or thread.
- The user may be an application operator. The running start information of the primary instance node may indicate a basic resource required for running the instance of the application, such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth required when the primary instance node starts operating. The minimum resource configuration specification of the secondary instance node may refer to specification information such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth required when the secondary instance node is configured to run the application.
- As shown in
FIG. 1 , when a primary instance node is normal, the primary instance node provides a service for access by user equipment; when the primary instance node is faulty, a management device switches the access by the user equipment to a secondary instance node, and sets the secondary instance node of the application as a working instance node that provides a service for the access by the user equipment; and adjusts a resource configuration specification of the working instance node to be the same as a resource configuration specification of the primary instance node of the application. Certainly, instead of adjusting the resource configuration specification of the working instance node to be the same as the resource configuration specification of the primary instance node of the application, the management device may adjust the resource configuration specification of the working instance node to be slightly greater or less than the resource configuration specification of the primary instance node of the application. - The management device in an embodiment of the present invention may include a cloud controller, a secondary node management subsystem, and a health examination system in
FIG. 2 , as shown inFIG. 2 : - Step 1: An application deployer deploys a cloud application on a cloud platform by using the cloud controller.
- Step 2: The cloud controller creates, according to a specification of the application, a primary instance node that runs the application, where the primary instance node has an initial resource configuration specification, the initial resource configuration specification is usually a system default or is usually set by a developer/maintainer according to experience, and the initial resource configuration specification can ensure that sufficient resources can be used by the primary instance node to carry an instance of the application.
- Step 3: After establishment of the primary instance node is complete, the health examination system identifies the primary instance node of the newly added cloud application.
- Step 4: The health examination system instructs the secondary node management subsystem to compute a minimum resource configuration specification.
- Step 5: The secondary node management subsystem computes a minimum resource configuration specification of a secondary instance node according to running information of the primary instance node that has been started and that runs normally, where the running information may indicate a resource that is actually occupied for running the instance of the application normally, the minimum resource configuration specification indicates a minimum resource quantity that is required for starting or running the instance of the application, and the minimum resource configuration specification is usually far less than the initial resource configuration specification of the primary instance node.
- Step 6: The cloud controller creates a secondary instance node according to the obtained minimum resource configuration specification, where a resource configuration specification of the created secondary instance node is the same as the minimum resource configuration specification.
-
FIG. 3 shows a procedure of an example of processing performed when a primary instance node is faulty. When detecting that a primary instance node is faulty, a health examination system notifies a secondary node management subsystem of such case. The secondary node management subsystem instructs a cloud controller to start and expand a minimum secondary instance node, uses an expanded secondary instance node as a conventional instance node to replace the primary instance node of the application to run an instance of the application, and creates a secondary instance node according to a minimum resource configuration specification. The conventional instance herein may also be referred to as a working instance node and refers to an instance node that runs the instance of the application currently. - As shown in
FIG. 4 , in another embodiment of an instance node management method provided by embodiments of the present invention, a cloud platform includes the following several parts: a cloud controller, a health examination system, a secondary node management subsystem, a route distribution system, and an application operating environment. Each of the cloud controller, the health examination system, the secondary node management subsystem, and the route distribution system may be understood as a constituent part of a management device. The management device has functions of the cloud controller, the health examination system, the secondary node management subsystem, and the route distribution system. - Functions of all the parts include the following:
- The secondary node management subsystem: on the cloud platform, the secondary node management system is mainly responsible for computing a minimum resource configuration specification of a secondary instance node, instructing the cloud controller to start and expand the secondary instance node when a primary instance node is faulty, and then after the secondary instance node is started as a conventional working instance node, creating a secondary instance node again according to the minimum resource configuration specification.
- The expanding the secondary instance node to form a conventional working instance node refers to adjusting a resource configuration specification of the secondary instance node to be the same as a resource configuration specification of the primary instance node of the application. It should be noted that the "same" described in this embodiment of the present invention does not refer to being absolutely the same in numerical value. In an actual application, a specific error is allowed, for example, the resource configuration specification of the secondary instance node is slightly greater or less than or substantially the same as the resource configuration specification of the primary instance node.
- As shown in
FIG. 5 , a secondary node management subsystem mainly includes the following three modules: a minimum-specification computing module, a module for managing an instance of a secondary node of an application, and a troubleshooting configuration notification module. - The minimum-specification computing module mainly acquires, when an application is deployed on a cloud platform for the first time and after a primary instance node of the application has been started successfully, a minimum configuration specification of a required resource in a process of initializing the primary instance node. The specification includes but is not limited to a core quantity of a CPU, a memory size, a hard disk size, network bandwidth, and the like. A cloud controller is to be notified of the specification, and the specification is recorded on the cloud controller and used as a specification basis of subsequently starting a new secondary instance node.
- The module for managing an instance of a secondary node of an application is mainly configured to determine and check a case of a secondary instance node of the application. A quantity and an operating status of the secondary instance node are managed by the module. When sustained pressure of the application is relatively high, the system can determine a quantity of minimum secondary instance nodes to be increased, so that multiple secondary instances can be quickly started in a case of a sudden fault to ensure smooth operation.
- The troubleshooting configuration notification module is a processing mechanism that is used when a health examination system detects that an instance is faulty. Faults of two types of instances are included herein: one is a fault of a conventional instance node, and the other is a fault of a secondary instance node with a minimum specification. When the conventional instance is faulty, the troubleshooting configuration notification module instructs the cloud controller to start a secondary instance node, and quickly expands the secondary instance node to reach a specification of the conventional instance node; in this case, a quantity of minimum secondary instance nodes is correspondingly decreased by 1, that is, the cloud controller is instructed to create a minimum secondary instance node, and when the minimum secondary instance node is faulty, the same operation as what is performed when the conventional instance node is faulty is performed.
- The cloud controller: manages an instance node and configures route distribution. Instance nodes of all cloud applications are distributed to specified application operating environments by the cloud controller. In an instance access manner, the cloud controller sends a policy to a route distribution system. As a general function system on the cloud platform, the cloud controller is not described in detail in the present invention.
- The route distribution system: mainly controls an external access request to be distributed to an operating instance node of a corresponding application, receives a processing result of the instance node, and feeds back the result to user equipment that sends the access request. As a general function system on the cloud platform, the route distribution system is not described in detail in the present invention.
- The health examination system: is responsible for checking a health status of instance nodes of all applications and instructing the secondary node management system to perform fault recovery, create a minimum secondary instance node, and the like. As a general function system on the cloud platform, the health examination system is not described in detail in the present invention.
- The application operating environment: the application operating environment on the cloud platform is mainly a carrier such as a virtual machine or a container, and an operating system, a software stack, and a resource such as a computing/storage/network resource that are required for operating an application are provided for normal operation of an instance of an application. As a general function system on the cloud platform, the application operating environment is not described in detail in the present invention.
- In an embodiment of the present invention, for a procedure in which instance node management is implemented, there are two cases: initial deployment and fault occurrence, which can be understood with reference to the corresponding descriptions in
FIG. 1 to FIG. 5 and is not excessively described herein. - It can be seen that in this embodiment of the present invention, the foregoing steps can ensure that a cloud application has a sufficient primary and secondary supporting capacity; in addition, a specification of a secondary instance node can be far less than that of a conventional instance node, which effectively reduces a resource waste caused by a requirement of high availability.
- As shown in
FIG. 6 , another embodiment of instance node management in embodiments of the present invention is basically the same as the embodiment corresponding toFIG. 4 except for partial simplification in structure. A secondary instance management node may be included in a cloud controller in implementation, and is deployed together with the cloud controller in a manner of a plug-in/component or the like of the cloud controller. - In this embodiment, the cloud controller is first instructed to perform inter-system communication, and then the cloud controller allows a secondary node management plug-in to perform related processing. After computing/configuration is complete, a secondary node management node can directly notify a router/an application operating environment or the like to perform route distribution management configuration and to implement creation/expansion or the like of a secondary instance node.
- In a processing procedure, all processes of interaction between the cloud controller and a secondary node management system are implemented within the cloud controller, which is similar to another procedure.
- Further, simplification may further be performed on the secondary node management system/plug-in. In most cases of implementation of a cloud application, a basic demand of high availability can be met provided that there is one secondary instance node. Therefore, a module for managing an instance of a secondary node of an application can be removed, where only fault handling and minimum-specification computing functions are retained.
- A process of creating a cloud application for the first time is the same as that in the foregoing embodiment. When a fault occurs, a secondary node resource pool does not need to be determined or detected, a secondary instance node in the cloud application is directly converted into a conventional node, and a secondary instance node is created again.
- Optionally, in another embodiment of an instance node management method provided by the embodiment of the present invention, a process of creating a cloud application for the first time is the same as that in the foregoing embodiment, but a difference lies in that: when a fault occurs and after a secondary instance node is converted into a conventional node, the cloud controller recovers a faulty conventional instance instead of creating a secondary instance node again, and after recovery, a health examination system instructs the secondary node management system to recycle a started secondary instance node, for recovery to an initial state. Alternatively, after the fault is repaired, a resource configuration specification of the repaired conventional instance node may be adjusted to a minimum resource configuration specification of the application, so that the repaired conventional instance node becomes a secondary instance node of the application.
- Optionally, in another embodiment of the instance node management method provided by the embodiment of the present invention, a dynamic adjustment method may be further added based on computing of a minimum specification of a secondary node and management of the secondary node. In a process of operating a conventional instance, a minimum specification is dynamically computed according to an entire operating status, obtained by statistics collection, of the application, and specification refresh is performed in real time on a backup node instance with a minimum specification in a current environment.
- Optionally, in the method for creating an instance with a minimum specification, considering that some applications may use massive temporary resources in initialization and starting processes while a quantity of occupied and consumed resources is lower after the initialization is complete, for a process of creating a minimum secondary instance node, an instance with a complete specification is first created, and after starting is complete, the specification of the instance is decreased to a minimum specification that is obtained by means of computing, so as to reduce resource consumption.
- When a fault is being recovered, a conventional instance node is first recovered, the recovered conventional instance node is used as an instance node with a minimum specification, and a specification of the recovered conventional instance node is decreased to a minimum specification.
- In addition, in this embodiment of the present invention, operating environments on the cloud platform may be different, such as a container or a virtual machine, and a difference exists in manners of implementing a secondary instance node with a minimum specification. In a technology in which a container is applied, the methods in the foregoing embodiments can be quickly implemented; in a technology in which a virtual machine is used, because a technology of longitudinal scale out/in and expansion regarding a virtual machine is immature, a method of longitudinal scale out/in and transverse scale out/in is used herein, that is, in a cloud environment meeting longitudinal scale out/in, the method in the foregoing embodiments is directly used, while in a cloud environment that does not meet longitudinal scale out/in, a transverse scale out/in mechanism is used. Creation of a secondary instance node is the same as that in the foregoing embodiment, but in use, a demand of temporary reliability is met by establishing multiple secondary instance nodes, and after a conventional instance node is recovered, and then a temporarily generated secondary instance node is released, so as to ensure effective utilization of a resource.
- Compared with the prior art in which a secondary instance node needs to occupy a same resource as a primary instance node to ensure high availability of an application on a cloud platform, on a basis of ensuring high availability of an application that is hosted on a cloud platform, the instance node management method provided by this embodiment of the present invention can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- It should be noted that the solution in this embodiment of the present invention can not only be applied to a cloud platform, but also be applied to multiple scenarios in which application reliability needs to be improved other than the cloud platform.
- Referring to
FIG. 7 , an embodiment of an instance node management method provided by embodiments of the present invention includes: - 101: Create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application.
The instance node management method provided by this embodiment of the present invention is applied to a management device of the cloud platform. - 102: Determine, according to running start information of the primary instance node, a minimum resource configuration specification required by a secondary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application.
The running start information of the primary instance node may be a basic resource required for running the application, such as a core quantity of a CPU, a memory size, a hard disk size, or network bandwidth required when the primary instance node starts operating. The minimum resource configuration specification of the secondary instance node may refer to specification information such as a core quantity of a CPU, a memory size, a hard disk size, and network bandwidth of the secondary instance node. - 103: Create the secondary instance node of the application according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- According to this embodiment of the present invention, a primary instance node is created for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; a minimum resource configuration specification required by a secondary instance node of the application is determined according to running start information of the primary instance node, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and the secondary instance node of the application is created according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application. Compared with the prior art in which a secondary instance node needs to occupy a same resource as a primary instance node to ensure high availability of an application on a cloud platform, on a basis of ensuring high availability of an application that is hosted on a cloud platform, the instance node management method provided by this embodiment of the present invention can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- Optionally, on a basis of the embodiment corresponding to
FIG. 7 , in a first optional embodiment of an instance node management method provided by the embodiment of the present invention, after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method may further include: - when the primary instance node is faulty, adjusting the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node, and setting the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application.
- The above method step may specifically comprise:
- receiving a switch instruction that is generated when the primary instance node of the application is faulty;
- setting, according to the switch instruction, the secondary instance node of the application as a working instance node that provides a service for access by user equipment; and
- adjusting a resource configuration specification of the working instance node to be the same as the resource configuration specification of the primary instance node of the application.
- In this embodiment of the present invention, when a primary instance node is normal, a resource occupancy rate of a secondary instance node is quite low; and when the primary instance node is faulty, the secondary instance node is quickly expanded to take over work of the primary instance node, so that an application access demand is met, and an application hosting capacity and size on a cloud platform are increased.
- Optionally, on a basis of the first optional embodiment of the foregoing instance node management method, in a second optional embodiment of the instance node management method provided by the embodiment of the present invention, after the adjusting a resource configuration specification of the working instance node to be the same as the resource configuration specification of the primary instance node of the application, the method may further include:
- creating a secondary instance node for the application again according to the minimum resource configuration specification.
- In this embodiment of the present invention, when a quantity of minimum secondary instance nodes decreases, dynamic supplement is performed in a timely manner, which avoids that an application access request cannot be responded to when a working instance node is faulty next time, thereby improving reliability and user experience.
- Optionally, on a basis of the first optional embodiment of the foregoing instance node management method, in a third optional embodiment of the instance node management method provided by the embodiment of the present invention, after the adjusting a resource configuration specification of the working instance node to be the same as the resource configuration specification of the primary instance node of the application, the method may further include:
- repairing the faulty primary instance node to obtain the repaired primary instance node; and
- adjusting a resource configuration specification of the repaired primary instance node to be the same as the minimum resource configuration specification, and setting the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application.
- Optionally, the above method step may comprise:
- repairing the faulty primary instance node;
- switching, to the primary instance node, the working instance node that provides the service for the access by the user equipment; and
- adjusting the resource configuration specification of the working instance node to be the same as a minimum resource configuration specification of the application.
- In this embodiment of the present invention, a faulty primary instance node may be further repaired in a timely manner; in this case, a resource utilization rate of a cloud platform is further increased.
- Optionally, on a basis of any embodiment of the foregoing instance node management method, in a fourth optional embodiment of the instance node management method provided by the embodiment of the present invention, after the determining a minimum resource configuration specification of a secondary instance node of the application, the method may further include:
- acquiring accesses of the application by the user equipment; and
- the creating the secondary instance node of the application according to the minimum resource configuration specification includes:
- creating at least two secondary instance nodes for the application according to the minimum resource configuration specification when the accesses of the application exceed a preset threshold, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification.
- In this embodiment of the present invention, minimum secondary instance nodes of a corresponding quantity can be created according to accesses of an application; in this case, a sudden and unexpected fault caused when application pressure is excessively high can be avoided, thereby further improving high availability of a cloud platform.
- Optionally, on a basis of any embodiment of the foregoing instance node management method, in a fifth optional embodiment of the instance node management method provided by the embodiment of the present invention, after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method may further include:
- monitoring the created secondary instance node of the application; and
- when it is learned, by monitoring, that the secondary instance node of the application is faulty, creating a secondary instance node having a same quantity as the faulty secondary instance node.
- In this embodiment of the present invention, a faulty instance node in created secondary instance nodes may be further monitored in a timely manner, and a new available secondary instance node is created in a timely manner, so as to avoid that when a primary instance node is faulty, no available secondary instance node takes over work of the primary instance node, thereby further improving high availability of a cloud platform.
- Optionally, on a basis of any embodiment of the foregoing instance node management method, in a sixth optional embodiment of the instance node management method provided by the embodiment of the present invention, after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method may further include:
- detecting a resource quantity required for running the instance of the application; and
- adjusting the resource configuration specification of the created secondary instance node of the application according to the required resource quantity.
- In this embodiment of the present invention, dynamic adjustment may be further performed on a resource configuration specification of a created secondary instance node according to a resource quantity required for operating an application; and if a quantity of resources required by the application is low, a resource may be further saved, and if the quantity of resources required by the application is high, takeover efficiency may be further improved when a primary instance node is faulty.
- The embodiment corresponding to
FIG. 7 and the optional embodiments corresponding to the embodiment can be understood with reference to the related descriptions inFIG. 1 to FIG. 6 , and details are not described herein again. - It should be noted that functions of a first creating
module 201, a second creatingmodule 203, afirst adjustment module 204, a repairingmodule 205, an acquiringmodule 206, adetection module 208, and asecond adjustment module 209 that are involved in a process of describing amanagement device 20 of a cloud platform in the following are the same as the functions of the cloud controller described in the embodiments ofFIG. 1 to FIG. 4 , and functions implemented by a determiningmodule 202 and amonitoring module 207 are the same as the functions of the secondary node management subsystem described in the embodiments ofFIG. 1 to FIG. 4 , where the determiningmodule 202 may be the minimum-specification computing module inFIG. 5 , and themonitoring module 207 may be the module for managing an instance of a secondary node of an application and the troubleshooting configuration notification module. - Referring to
FIG. 8 , an embodiment of amanagement device 20 of a cloud platform provided by embodiments of the present invention includes: - a first creating
module 201, configured to create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application; - a determining
module 202, configured to determine, according to running start information of the primary instance node created by the first creatingmodule 201, a minimum resource configuration specification required by a secondary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and - a second creating
module 203, configured to create the secondary instance node of the application according to the minimum resource configuration specification determined by the determiningmodule 202, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application. - Compared with the prior art in which a secondary instance node needs to occupy a same resource as a primary instance node to ensure high availability of an application on a cloud platform, on a basis of ensuring high availability of an application that is hosted on a cloud platform, the instance node management device provided by this embodiment of the present invention can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- Optionally, refer to
FIG. 9 on a basis of the embodiment corresponding toFIG. 8 . In a first optional embodiment of themanagement device 20 of the cloud platform provided by the embodiment of the present invention, themanagement device 20 further includes: - a
first adjustment module 204, configured to: when the primary instance node is faulty, adjust the resource configuration specification of the secondary instance node, created by the second creatingmodule 203, of the application to be the same as the resource configuration specification of the primary instance node of the application, and set the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application. - In this embodiment of the present invention, when a primary instance node is normal, a resource occupancy rate of a secondary instance node is quite low; and when the primary instance node is faulty, the secondary instance node is quickly expanded to take over work of the primary instance node, so that an application access demand is met, and an application hosting capacity and size on a cloud platform are increased.
- Optionally, on a basis of the embodiment corresponding to
FIG. 9 , in a second optional embodiment of themanagement device 20 of the cloud platform provided by the embodiment of the present invention,
the second creatingmodule 203 is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification. - In this embodiment of the present invention, when a quantity of minimum secondary instance nodes decreases, dynamic supplement is performed in a timely manner, which avoids that an application access request cannot be responded to when a working instance node is faulty next time, thereby improving reliability and user experience.
- Optionally, refer to
FIG. 10 on a basis of the embodiment corresponding toFIG. 9 . In a third optional embodiment of themanagement device 20 of the cloud platform provided by the embodiment of the present invention, themanagement device 20 further includes a repairingmodule 205. - The repairing
module 205 is configured to repair the faulty primary instance node to obtain the repaired primary instance node. - The
first adjustment module 204 is further configured to adjust a resource configuration specification of the primary instance node repaired by the repairingmodule 205 to the minimum resource configuration specification of the application, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application. - In this embodiment of the present invention, a faulty primary instance node may be further repaired in a timely manner; in this case, a resource utilization rate of a cloud platform is further increased.
- Optionally, refer to
FIG. 11 on a basis of any embodiment of the foregoing management device. In a fourth optional embodiment of themanagement device 20 of the cloud platform provided by the embodiment of the present invention, themanagement device 20 further includes an acquiringmodule 206. - The acquiring
module 206 is configured to acquire accesses of the application by user equipment. - The second creating
module 203 is specifically configured to: when the accesses acquired by the acquiringmodule 206, of the application exceed a preset threshold, create at least two secondary instance nodes for the application according to the minimum resource configuration specification determined by the determining module, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification. - In this embodiment of the present invention, minimum secondary instance nodes of a corresponding quantity can be created according to accesses of an application; in this case, a sudden and unexpected fault caused when application pressure is excessively high can be avoided, thereby further improving high availability of a cloud platform.
- Optionally, refer to
FIG. 12 on a basis of any embodiment of the foregoing management device. In a fifth optional embodiment of themanagement device 20 of the cloud platform provided by the embodiment of the present invention, themanagement device 20 further includes amonitoring module 207. - The
monitoring module 207 is configured to monitor the secondary instance node, created by the second creatingmodule 203, of the application. - The second creating
module 203 is further configured to: when the monitoring module 211 learns, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node. - In this embodiment of the present invention, a faulty instance node in created secondary instance nodes may be further monitored in a timely manner, and a new available secondary instance node is created in a timely manner, so as to avoid that when a primary instance node is faulty, no available secondary instance node takes over work of the primary instance node, thereby further improving high availability of a cloud platform.
- Optionally, refer to
FIG. 13 on a basis of any embodiment of the foregoing management device. In a sixth optional embodiment of themanagement device 20 of the cloud platform provided by the embodiment of the present invention, themanagement device 20 further includes a detection module 212 and a second adjustment module 213. - The
detection module 208 is configured to detect a resource quantity required for running the instance of the application. - The
second adjustment module 209 is configured to adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity detected by the detection module 212. - In this embodiment of the present invention, dynamic adjustment may be further performed on a resource configuration specification of a created secondary instance node according to an operating status of an application; and if a quantity of resources required by the application is low, a resource may be further saved, and if the quantity of resources required by the application is high, takeover efficiency may be further improved when a primary instance node is faulty.
- The management device described in
FIG. 8 to FIG. 13 can be understood with reference to the descriptions inFIG. 1 to FIG. 7 , and details are not described herein again. - In the multiple embodiments of the foregoing management device, it should be understood that: in an implementation manner, a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may be implemented by a processor executing a program or an instruction in a memory (that is, by cooperation of a processor and a special instruction in a memory coupled with the processor); in another implementation manner, a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may also be implemented by using a specific circuit; for the specific implementation manner, refer to the prior art, and details are not described herein again; and in still another implementation manner, a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may also be implemented by using a field-programmable gate array (FPGA, Field-Programmable Gate Array; for the specific implementation manner, refer to the prior art, and details are not described herein again. The present invention includes but is not limited to the foregoing implementation manners. It should be understood that solutions implemented according to the idea of the present invention all fall within the protection scope of the embodiments of the present invention.
- This embodiment provides a hardware structure of a management device. Referring to
FIG. 14 , a hardware structure of a management device may include three parts: - a transceiver component, a software component, and a hardware component.
- The transceiver component is a hardware circuit configured to complete packet receiving and sending.
- The hardware component may also be referred to as a "hardware processing module", or more simply, may be short for "hardware". The hardware component mainly includes a hardware circuit that implements, based on a application-specific hardware circuit such as an FPGA and an ASIC (which may also coordinate with another matching component, for example, a memory), some specific functions; a processing speed of the hardware component is usually much higher than that of a general purpose processor, but it is difficult to change a function once the function is customized; therefore, the hardware component is inflexible in implementation and is usually configured to process some specific functions. It should be noted that in an actual application, the hardware component may also include a processor such as an MCU (a microprocessor, for example, a single-chip microcomputer) or a CPU; however, a primary function of these processors is not to complete big data processing, but is mainly to perform control; in such application scenario, a system including these components is a hardware component.
- The software component (or short for "software") mainly includes a general purpose processor (for example, a CPU) and some matching devices of the general purpose processor (for example, a storage device such as a memory or a hard disk). The processor may be enabled, by means of programming, to have a corresponding processing function. When the function is implemented by using software, the software component can be configured flexibly according to a service requirement, but a speed thereof is usually lower than that of the hardware component. After processing of the software is complete, the hardware component may send processed data by using the transceiver component, or may send processed data to the transceiver component over an interface connected to the transceiver component.
- In this embodiment, the transceiver component is configured to receive a switch instruction in the foregoing embodiment, and the software component or hardware component is configured to perform APP registration, service quality control, or the like.
- Other functions of the hardware component and the software component have been described in detail in the foregoing embodiments, and details are not described herein again.
- The following describes in detail, with reference to the accompanying drawings, a technical solution in which a receiving module may be implemented by an input/output I/O device (for example, a network adapter), and a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module may be implemented by a processor executing a program or an instruction in a memory.
-
FIG. 15 is a schematic structural diagram of amanagement device 20 provided by an embodiment of the present invention. Themanagement device 20 includes aprocessor 210, amemory 250, and an input/output I/O device 230, where thememory 250 may include a read-only memory and a random access memory and provide an operation instruction and data for theprocessor 210. A part of thememory 250 may further include a non-volatile random access memory (NVRAM). - In some implementation manners, the
memory 250 stores the following elements: an executable module or a data structure, or subsets thereof, or extension sets thereof. - In this embodiment of the present invention, an operation instruction stored in the memory 250 (the operation instruction may be stored in an operating system) is invoked to:
- create a primary instance node for an application hosted on the cloud platform, where the primary instance node is configured to run an instance of the application;
- determine, according to running start information of the primary instance node, a minimum resource configuration specification required by a secondary instance node of the application, where the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; and
- create the secondary instance node of the application according to the minimum resource configuration specification, where a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- It can be seen that compared with the prior art in which a secondary instance node needs to occupy a same resource as a primary instance node to ensure high availability of an application on a cloud platform, on a basis of ensuring high availability of an application that is hosted on a cloud platform, the management device provided by this embodiment of the present invention can reduce occupancy of a spare resource and increase an application hosting capability and scale on the cloud platform.
- The
processor 210 controls an operation of themanagement device 20, and theprocessor 210 may also be referred to as a CPU (Central Processing Unit, central processing unit). Thememory 250 may include a read-only memory and a random access memory and provide an instruction and data for theprocessor 210. A part of thememory 250 may further include a non-volatile random access memory (NVRAM). In a specific application, all components of themanagement device 20 are coupled together by using abus system 220, where in addition to including a data bus, thebus system 220 may further include a power bus, a control bus, a status signal bus, and the like. However, for clear description, all kinds of buses are marked as thebus system 220 in the figure. - The methods disclosed in the foregoing embodiments of the present invention may be applied to the
processor 210, or may be implemented by theprocessor 210. Theprocessor 210 may be an integrated circuit chip and has a signal processing capability. In an implementation process, all steps of the foregoing methods may be completed by using an integrated logic circuit of hardware in theprocessor 210 or by using an instruction in a software form. The foregoingprocessor 210 may be a general purpose processor, a digital signal processor (DSP), an application-specific integrated circuit (ASIC), a field-programmable gate array (FPGA) or another programmable logic device, a discrete gate or transistor logic device, or a discrete hardware component, and can implement or execute the methods, steps, and logic block diagrams disclosed in this embodiment of the present invention. The general purpose processor may be a microprocessor, or the processor may be any conventional processor or the like. The steps of the methods disclosed with reference to the embodiments of the present invention may be executed and completed by a hardware encoding processor, or may be executed and completed by using a combination of hardware and software modules in an encoding processor. The software module may be located in a storage medium mature in the art such as a random access memory, a flash memory, a read-only memory, a programmable read-only memory, an electrically erasable programmable memory, or a register. The storage medium is located in thememory 250, theprocessor 210 reads information in thememory 250, and the steps of the foregoing methods are completed with reference to hardware of theprocessor 210. - Optionally, the
processor 210 is further configured to: when the primary instance node is faulty, adjust the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node, and set the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application. - In this embodiment of the present invention, when a primary instance node is normal, a resource occupancy rate of a secondary instance node is quite low; and when the primary instance node is faulty, the secondary instance node is quickly expanded to take over work of the primary instance node, so that an application access demand is met, and an application hosting capacity and size on a cloud platform are increased.
- Optionally, the
processor 210 is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification. - In this embodiment of the present invention, when a quantity of minimum secondary instance nodes decreases, dynamic supplement is performed in a timely manner, which avoids that an application access request cannot be responded to when a working instance node is faulty next time, thereby improving reliability and user experience.
- Optionally, the
processor 210 is further configured to: repair the faulty primary instance node to obtain the repaired primary instance node; and adjust a resource configuration specification of the repaired primary instance node to be the same as the minimum resource configuration specification, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application. - In this embodiment of the present invention, a faulty primary instance node may be further repaired in a timely manner; in this case, a resource utilization rate of a cloud platform is further increased.
- Optionally, the
processor 210 is further configured to: acquire accesses of the application by user equipment; and create at least two secondary instance nodes for the application according to the minimum resource configuration specification when the accesses of the application exceed a preset threshold, where a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification. - In this embodiment of the present invention, minimum secondary instance nodes of a corresponding quantity can be created according to accesses of an application; in this case, a sudden and unexpected fault caused when application pressure is excessively high can be avoided, thereby further improving high availability of a cloud platform.
- Optionally, the
processor 210 is further configured to: monitor the created secondary instance node of the application; and when it is learned, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node. - In this embodiment of the present invention, a faulty instance node in created secondary instance nodes may be further monitored in a timely manner, and a new available secondary instance node is created in a timely manner, so as to avoid that when a primary instance node is faulty, no available secondary instance node takes over work of the primary instance node, thereby further improving high availability of a cloud platform.
- Optionally, the
processor 210 is further configured to: detect a resource quantity required for running the instance of the application; and adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity. - In this embodiment of the present invention, dynamic adjustment may be further performed on a resource configuration specification of a created secondary instance node according to an operating status of an application; and if a quantity of resources required by the application is low, a resource may be further saved, and if the quantity of resources required by the application is high, takeover efficiency may be further improved when a primary instance node is faulty.
- It should be noted that a management device of a cloud platform according to an embodiment of the present invention may be specifically a cloud host in a cloud computing system, where the cloud host may be a virtual machine running on a physical machine. As shown in
FIG. 16 , aphysical machine 1200 includes ahardware layer 100, a VMM (Virtual Machine Monitor, virtual machine monitor) 110 running at thehardware layer 100, and several virtual machines (VM, Virtual Machine) and ahost machine Host 1201 that run on theVMM 110, where the hardware layer includes but is not limited to an I/O device, a CPU, and a memory. The management device of a cloud platform provided by this embodiment of the present invention may be specifically a virtual machine in aphysical machine 1200, for example, aVM 1202. One or more cloud applications run on theVM 1202, where each cloud application is used to implement a corresponding service function, such as a database application or a map application. These applications may be developed by a developer and then deployed in the cloud computing system. In addition, an executable program further runs on theVM 1202. TheVM 1202 runs the executable program and invokes, in a program running process, a hardware resource of thehardware layer 100 by using thehost machine Host 1201, so as to implement functions of a determining module, a first creating module, a second creating module, a first adjustment module, a repairing module, an acquiring module, a monitoring module, a detection module, and a second adjustment module of the management device of the cloud platform. Specifically, the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module may be included in the foregoing executable program in a form of a software module or a function. For example, the executable program may include the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module. TheVM 1202 invokes a resource such as a CPU or a Memory of thehardware layer 100 to run the executable program, so as to implement the functions of the determining module, the first creating module, the second creating module, the first adjustment module, the repairing module, the acquiring module, the monitoring module, the detection module, and the second adjustment module. - The embodiment corresponding to
FIG. 15 and the other optional embodiments can be understood with reference to the descriptions inFIG. 1 to FIG. 13 , and details are not described herein again. - A person of ordinary skill in the art may understand that all or some of the steps of the methods in the embodiments may be implemented by a program instructing relevant hardware (such as a processor). The program may be stored in a computer-readable storage medium. The storage medium may include: a ROM, a RAM, a magnetic disk, or an optical disc.
- The foregoing describes in detail the instance node management method and the management device that are provided by the embodiments of the present invention. In this specification, specific examples are used to elaborate a principle and an implementation manner of the present invention. The description of the foregoing embodiments is only intended to help understand the method of the present invention and its core ideas. In addition, a person of ordinary skill in the art may, based on the idea of the present invention, make modifications with respect to the specific implementation manners and the application scope. Therefore, the content of this specification shall not be construed as a limitation to the present invention.
Claims (14)
- An instance node management method, wherein the method is applied to a management device of a cloud platform, and the method comprises:creating a primary instance node for an application hosted on the cloud platform, wherein the primary instance node is configured to run an instance of the application;determining, according to running start information of the primary instance node, a minimum resource configuration specification required by a secondary instance node of the application, wherein the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; andcreating the secondary instance node of the application according to the minimum resource configuration specification, wherein a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- The method according to claim 1, wherein after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method further comprises:when the primary instance node is faulty, adjusting the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node, and setting the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application.
- The method according to claim 2, wherein after the adjusting the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node of the application, the method further comprises:creating a secondary instance node for the application again according to the minimum resource configuration specification.
- The method according to claim 2, wherein after the adjusting the resource configuration specification of the secondary instance node to be the same as the resource configuration specification of the primary instance node of the application, the method further comprises:repairing the faulty primary instance node to obtain the repaired primary instance node; andadjusting a resource configuration specification of the repaired primary instance node to be the same as the minimum resource configuration specification, and setting the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application.
- The method according to any one of claims 1 to 4, wherein after the determining a minimum resource configuration specification of a secondary instance node of the application, the method further comprises:acquiring accesses of the application by user equipment; andthe creating the secondary instance node of the application according to the minimum resource configuration specification comprises:creating at least two secondary instance nodes for the application according to the minimum resource configuration specification when the accesses of the application exceed a preset threshold, wherein a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification.
- The method according to any one of claims 1 to 4, wherein after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method further comprises:monitoring the created secondary instance node of the application; andwhen it is learned, by monitoring, that the secondary instance node of the application is faulty, creating a secondary instance node having a same quantity as the faulty secondary instance node.
- The method according to any one of claims 1 to 4, wherein after the creating the secondary instance node of the application according to the minimum resource configuration specification, the method further comprises:detecting a resource quantity required for running the instance of the application; andadjusting the resource configuration specification of the created secondary instance node of the application according to the required resource quantity.
- A management device of a cloud platform, wherein the management device comprises:a first creating module, configured to create a primary instance node for an application hosted on the cloud platform, wherein the primary instance node is configured to run an instance of the application;a determining module, configured to determine, according to running start information of the primary instance node created by the first creating module, a minimum resource configuration specification required by a secondary instance node of the application, wherein the secondary instance node of the application is configured to replace, when the primary instance node of the application is faulty, the primary instance node of the application to run the instance of the application; anda second creating module, configured to create the secondary instance node of the application according to the minimum resource configuration specification determined by the determining module, wherein a resource configuration specification of the secondary instance node of the application is less than a resource configuration specification of the primary instance node of the application.
- The management device according to claim 8, wherein the management device further comprises:a first adjustment module, configured to: when the primary instance node is faulty, adjust the resource configuration specification of the secondary instance node created by the second creating module to be the same as the resource configuration specification of the primary instance node, and set the secondary instance node as a working instance node to replace the primary instance node of the application to run the instance of the application.
- The management device according to claim 9, wherein:the second creating module is further configured to create a secondary instance node for the application again according to the minimum resource configuration specification.
- The management device according to claim 9, wherein the management device further comprises a repairing module, wherein
the repairing module is configured to repair the faulty primary instance node to obtain the repaired primary instance node; and
the first adjustment module is further configured to adjust a resource configuration specification of the repaired primary instance node to the minimum resource configuration specification of the application, and set the repaired primary instance node as the secondary instance node of the application to replace, when the working instance node is faulty, the working instance node to run the instance of the application. - The management device according to any one of claims 8 to 11, wherein the management device further comprises an acquiring module, wherein
the acquiring module is configured to acquire accesses of the application by user equipment; and
the second creating module is specifically configured to: when the accesses acquired by the acquiring module, of the application exceed a preset threshold, create at least two secondary instance nodes for the application according to the minimum resource configuration specification determined by the determining module, wherein a resource configuration specification of each created secondary instance node is the same as the minimum resource configuration specification. - The management device according to any one of claims 8 to 11, wherein the management device further comprises a monitoring module, wherein
the monitoring module is configured to monitor the secondary instance node, created by the second creating module, of the application; and
the second creating module is further configured to: when the monitoring module learns, by monitoring, that the secondary instance node of the application is faulty, create a secondary instance node having a same quantity as the faulty secondary instance node. - The management device according to any one of claims 8 to 11, wherein the management device further comprises a detection module and a second adjustment module, wherein
the detection module is configured to detect a resource quantity required for running the instance of the application; and
the second adjustment module is configured to adjust the resource configuration specification of the created secondary instance node of the application according to the required resource quantity detected by the detection module.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201510180650.3A CN104836850A (en) | 2015-04-16 | 2015-04-16 | Instance node management method and management equipment |
| PCT/CN2015/092667 WO2016165304A1 (en) | 2015-04-16 | 2015-10-23 | Method for managing instance node and management device |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP3253028A1 true EP3253028A1 (en) | 2017-12-06 |
| EP3253028A4 EP3253028A4 (en) | 2018-02-28 |
| EP3253028B1 EP3253028B1 (en) | 2020-09-02 |
Family
ID=53814479
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP15889000.4A Active EP3253028B1 (en) | 2015-04-16 | 2015-10-23 | Method for managing instance node and management device |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10601657B2 (en) |
| EP (1) | EP3253028B1 (en) |
| CN (1) | CN104836850A (en) |
| WO (1) | WO2016165304A1 (en) |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104836850A (en) | 2015-04-16 | 2015-08-12 | 华为技术有限公司 | Instance node management method and management equipment |
| CN106874142B (en) * | 2015-12-11 | 2020-08-07 | 华为技术有限公司 | Real-time data fault-tolerant processing method and system |
| CN106959894B (en) * | 2016-01-11 | 2020-11-24 | 北京京东尚科信息技术有限公司 | Resource allocation method and device |
| EP3340518A1 (en) * | 2016-12-21 | 2018-06-27 | Gemalto M2M GmbH | Method for operating a user equipment communicating in parallel in a cellular network |
| CN108259418B (en) * | 2016-12-28 | 2021-08-24 | 中移(苏州)软件技术有限公司 | System and method for function hosting service |
| CN106775953A (en) * | 2016-12-30 | 2017-05-31 | 北京中电普华信息技术有限公司 | Realize the method and system of OpenStack High Availabitities |
| US10200411B1 (en) * | 2017-01-24 | 2019-02-05 | Intuit Inc. | Method and system for providing instance re-stacking and security ratings data to identify and evaluate re-stacking policies in a cloud computing environment |
| US10230598B1 (en) * | 2017-01-24 | 2019-03-12 | Intuit Inc. | Method and system for providing visualization of instance data to identify and evaluate re-stacking policies in a cloud computing environment |
| CN107656728B (en) * | 2017-09-15 | 2020-08-04 | 网宿科技股份有限公司 | Application program instance creating method and cloud server |
| US11012824B2 (en) * | 2018-04-12 | 2021-05-18 | Qualcomm Incorporated | Communicating multiple instances of a message in a random medium access control system |
| CN111435320B (en) * | 2019-01-14 | 2023-04-11 | 阿里巴巴集团控股有限公司 | Data processing method and device |
| CN110457114B (en) * | 2019-07-24 | 2020-11-27 | 杭州数梦工场科技有限公司 | Application cluster deployment method and device |
| CN110781002A (en) * | 2019-10-24 | 2020-02-11 | 浪潮云信息技术有限公司 | Elastic expansion method, management system, terminal and storage medium |
| CN113127380A (en) * | 2019-12-31 | 2021-07-16 | 华为技术有限公司 | Method for deploying instances, instance management node, computing node and computing equipment |
| CN113190343A (en) * | 2020-01-14 | 2021-07-30 | 阿里巴巴集团控股有限公司 | Application instance control method, device, equipment and system |
| US11226845B2 (en) | 2020-02-13 | 2022-01-18 | International Business Machines Corporation | Enhanced healing and scalability of cloud environment app instances through continuous instance regeneration |
| CN114168307A (en) * | 2020-09-10 | 2022-03-11 | 华为云计算技术有限公司 | Method, device and system for creating instances |
| CN114442477B (en) * | 2022-04-11 | 2022-06-07 | 北京信云筑科技有限责任公司 | Equipment health management system based on Internet of things |
| DE112023000003T5 (en) * | 2022-06-29 | 2024-03-07 | Hewlett Packard Enterprise Development Lp | HIGH AVAILABILITY SYSTEMS WITH THIN-PROVISIONED SECONDARY SERVERS |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7287179B2 (en) * | 2003-05-15 | 2007-10-23 | International Business Machines Corporation | Autonomic failover of grid-based services |
| US20080189700A1 (en) * | 2007-02-02 | 2008-08-07 | Vmware, Inc. | Admission Control for Virtual Machine Cluster |
| US8762339B2 (en) * | 2010-11-29 | 2014-06-24 | International Business Machines Corporation | Disaster recovery utilizing collapsible virtualized capacity |
| US8595192B1 (en) | 2010-12-01 | 2013-11-26 | Symantec Corporation | Systems and methods for providing high availability to instance-bound databases |
| US20130097296A1 (en) * | 2011-10-18 | 2013-04-18 | Telefonaktiebolaget L M Ericsson (Publ) | Secure cloud-based virtual machine migration |
| CN102497288A (en) * | 2011-12-13 | 2012-06-13 | 华为技术有限公司 | Dual-server backup method and dual system implementation device |
| US20140020156A1 (en) * | 2012-06-22 | 2014-01-23 | Gayle Manning | Versatile and convertible legwear |
| US20140007097A1 (en) * | 2012-06-29 | 2014-01-02 | Brocade Communications Systems, Inc. | Dynamic resource allocation for virtual machines |
| US9110717B2 (en) * | 2012-07-05 | 2015-08-18 | International Business Machines Corporation | Managing use of lease resources allocated on fallover in a high availability computing environment |
| CN103810015A (en) * | 2012-11-09 | 2014-05-21 | 华为技术有限公司 | Virtual machine establishing method and equipment |
| WO2014080438A1 (en) * | 2012-11-20 | 2014-05-30 | Hitachi, Ltd. | Storage system and data management method |
| CN103077079B (en) * | 2012-12-28 | 2016-06-08 | 华为技术有限公司 | Virtual machine (vm) migration control method and device |
| US9141487B2 (en) * | 2013-01-15 | 2015-09-22 | Microsoft Technology Licensing, Llc | Healing cloud services during upgrades |
| EP2849064B1 (en) * | 2013-09-13 | 2016-12-14 | NTT DOCOMO, Inc. | Method and apparatus for network virtualization |
| CN104836850A (en) * | 2015-04-16 | 2015-08-12 | 华为技术有限公司 | Instance node management method and management equipment |
| US9569277B1 (en) * | 2016-01-29 | 2017-02-14 | International Business Machines Corporation | Rebalancing virtual resources for virtual machines based on multiple resource capacities |
| US10152268B1 (en) * | 2016-03-30 | 2018-12-11 | EMC IP Holding Company LLC | System and methods for replication resource management in asymmetric secure multi-tenancy deployments in protection storage |
-
2015
- 2015-04-16 CN CN201510180650.3A patent/CN104836850A/en active Pending
- 2015-10-23 EP EP15889000.4A patent/EP3253028B1/en active Active
- 2015-10-23 WO PCT/CN2015/092667 patent/WO2016165304A1/en active Application Filing
-
2017
- 2017-10-13 US US15/783,500 patent/US10601657B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20180048522A1 (en) | 2018-02-15 |
| EP3253028A4 (en) | 2018-02-28 |
| EP3253028B1 (en) | 2020-09-02 |
| WO2016165304A1 (en) | 2016-10-20 |
| US10601657B2 (en) | 2020-03-24 |
| CN104836850A (en) | 2015-08-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10601657B2 (en) | Instance node management method and management device | |
| CN108234158B (en) | VNF establishment method, NFVO and network system | |
| CN107526659B (en) | Method and apparatus for failover | |
| US9405563B2 (en) | Resource management method and apparatus for virtual machine system, and virtual machine system | |
| CN103152419B (en) | A kind of high availability cluster management method of cloud computing platform | |
| CN109669762B (en) | Cloud computing resource management method, device, equipment and computer readable storage medium | |
| US9513690B2 (en) | Apparatus and method for adjusting operating frequencies of processors based on result of comparison of power level with a first threshold and a second threshold | |
| WO2015169199A1 (en) | Anomaly recovery method for virtual machine in distributed environment | |
| CN105159798A (en) | Dual-machine hot-standby method for virtual machines, dual-machine hot-standby management server and system | |
| CN111290834A (en) | Method, device and equipment for realizing high availability of service based on cloud management platform | |
| US9210059B2 (en) | Cluster system | |
| JP2008305070A (en) | Information processor and information processor system | |
| CN102025776A (en) | Disaster tolerant control method, device and system | |
| CN105812169A (en) | Host and standby machine switching method and device | |
| CN109254876A (en) | The management method and device of database in cloud computing system | |
| CN104572241A (en) | Method and device for switching over application programs and system | |
| CN104123183A (en) | Cluster assignment dispatching method and device | |
| KR20150124642A (en) | Communication failure recover method of parallel-connecte server system | |
| CN105515838A (en) | Service configuration method and HA (High Available) cluster system | |
| CN101557307B (en) | Dispatch automation system application state management method | |
| CN108234215B (en) | Gateway creating method and device, computer equipment and storage medium | |
| WO2012119388A1 (en) | Method and device for handling faults of services configured on node device in communication system | |
| CN106326042B (en) | Method and device for determining running state | |
| CN107423113B (en) | Method for managing virtual equipment, out-of-band management equipment and standby virtual equipment | |
| CN107783855B (en) | Fault self-healing control device and method for virtual network element |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE INTERNATIONAL PUBLICATION HAS BEEN MADE |
|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20170831 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| A4 | Supplementary search report drawn up and despatched |
Effective date: 20180125 |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: H04L 29/08 20060101AFI20180119BHEP Ipc: H04L 12/24 20060101ALI20180119BHEP Ipc: G06F 9/455 20180101ALI20180119BHEP |
|
| DAV | Request for validation of the european patent (deleted) | ||
| DAX | Request for extension of the european patent (deleted) | ||
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| 17Q | First examination report despatched |
Effective date: 20190516 |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTG | Intention to grant announced |
Effective date: 20200317 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 1310137 Country of ref document: AT Kind code of ref document: T Effective date: 20200915 Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602015058625 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: FP |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG4D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20201203 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20201202 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20201202 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1310137 Country of ref document: AT Kind code of ref document: T Effective date: 20200902 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20210104 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: AL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20210102 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602015058625 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20201023 Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20201031 |
|
| 26N | No opposition filed |
Effective date: 20210603 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20201031 Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20201031 Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20201031 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R079 Ref document number: 602015058625 Country of ref document: DE Free format text: PREVIOUS MAIN CLASS: H04L0029080000 Ipc: H04L0065000000 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: TR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: MT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200902 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: NL Payment date: 20230915 Year of fee payment: 9 Ref country code: IE Payment date: 20230912 Year of fee payment: 9 Ref country code: GB Payment date: 20230831 Year of fee payment: 9 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20230911 Year of fee payment: 9 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20230830 Year of fee payment: 9 |