WO2016157467A1 - データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 - Google Patents
データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 Download PDFInfo
- Publication number
- WO2016157467A1 WO2016157467A1 PCT/JP2015/060299 JP2015060299W WO2016157467A1 WO 2016157467 A1 WO2016157467 A1 WO 2016157467A1 JP 2015060299 W JP2015060299 W JP 2015060299W WO 2016157467 A1 WO2016157467 A1 WO 2016157467A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- target data
- index
- analysis system
- data analysis
- Prior art date
Links
- 238000007405 data analysis Methods 0.000 title claims abstract description 198
- 238000000034 method Methods 0.000 title claims description 25
- 238000011156 evaluation Methods 0.000 claims abstract description 139
- 239000000284 extract Substances 0.000 claims abstract description 22
- 239000000470 constituent Substances 0.000 claims description 47
- 230000008451 emotion Effects 0.000 claims description 37
- 230000014509 gene expression Effects 0.000 claims description 26
- 238000004458 analytical method Methods 0.000 claims description 18
- 230000009471 action Effects 0.000 claims description 12
- 230000008859 change Effects 0.000 claims description 10
- 238000009826 distribution Methods 0.000 claims description 6
- 238000004364 calculation method Methods 0.000 description 42
- 238000007726 management method Methods 0.000 description 29
- 230000006870 function Effects 0.000 description 25
- 238000012545 processing Methods 0.000 description 24
- 238000000605 extraction Methods 0.000 description 17
- 239000013598 vector Substances 0.000 description 17
- 239000003550 marker Substances 0.000 description 14
- 238000003860 storage Methods 0.000 description 11
- 238000010586 diagram Methods 0.000 description 10
- 238000012544 monitoring process Methods 0.000 description 9
- 238000000611 regression analysis Methods 0.000 description 9
- 238000004891 communication Methods 0.000 description 8
- 239000000463 material Substances 0.000 description 7
- 239000011159 matrix material Substances 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- 230000008569 process Effects 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 230000006399 behavior Effects 0.000 description 5
- 238000013459 approach Methods 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 230000008520 organization Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 238000012795 verification Methods 0.000 description 3
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 2
- 239000002131 composite material Substances 0.000 description 2
- 238000011840 criminal investigation Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 230000002996 emotional effect Effects 0.000 description 2
- 238000011835 investigation Methods 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 238000004393 prognosis Methods 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 238000012706 support-vector machine Methods 0.000 description 2
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000002730 additional effect Effects 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 238000012550 audit Methods 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000003012 network analysis Methods 0.000 description 1
- 230000000474 nursing effect Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 238000011867 re-evaluation Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 238000012353 t test Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 230000017105 transposition Effects 0.000 description 1
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
- G06F16/285—Clustering or classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
- G06F16/2264—Multidimensional index structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24578—Query processing with adaptation to user needs using ranking
Definitions
- the present invention relates to a data analysis system and the like for analyzing data.
- Patent Document 1 provides a mechanism that allows flexible extraction of closely related extracted keywords based on the relationship between extracted keywords in a document set in order to extract information from big data. For this purpose, the degree of contribution for discriminating from other documents with respect to the keywords included in the classified documents is calculated, and based on the calculated degree of contribution, a self-organizing map is used to calculate the document. There has been proposed an apparatus for displaying information in accordance with a unit by calculating the arrangement information of the keyword from the appearance frequency of the keyword included in the document in the unit after classifying and displaying the unit.
- an object of the present invention is to provide a data analysis technique capable of efficiently finding information necessary for a user.
- the present invention relates to data analysis for evaluating target data, and evaluates a plurality of target data, and the evaluation may correspond to, for example, the relationship between each target data and a predetermined case. .
- an index that enables ranking of the plurality of target data is generated by the evaluation, and the index changes based on an input given by a user.
- the order of the plurality of target data changes, for example, according to the index that changes based on the input.
- the input classifies reference data different from the plurality of target data based on the relevance between the reference data and the predetermined case.
- the classification is, for example, divided into a plurality of classification information according to the content of the reference data, and at least one of the plurality of classification information is given to the reference data by the input.
- the present invention for example, by evaluating the degree of each component included in the reference data that contributes to the combination provided from the input control device, according to the classification information given by the input A pattern that characterizes the reference data is extracted from the reference data.
- the present invention for example, based on the extracted pattern, evaluates the relevance between the target data and the predetermined case to determine the index, sets the determined index to the target data, the index In response, the plurality of target data is ranked, and the plurality of the ranked target data is notified to the user.
- the user can know, for example, the magnitude of the relevance with the predetermined case among the plurality of target data by using the plurality of target data ordered. If the user cannot agree on the level of relevance between multiple target data, the index will change due to this change if the classification information given to the reference data is changed.
- the order of the target data changes. For example, after the user understands the content of the entire reference data, the user determines classification information to be given to the reference data according to the content. Depending on the content of the reference data, the user may be concerned about which classification information is optimum among a plurality of pieces of classification information in the reference data. For example, the user can determine which classification information should be given to the reference data based on the plurality of target data arranged in order.
- the present invention has an effect that information necessary for the user can be efficiently found.
- (A) is a conceptual drawing conceptual drawing of target data
- (B) is a schematic diagram showing an example of a display format of classification results. It is a conceptual diagram with which it uses for description of a target concept.
- FIG. 1 is a block diagram illustrating an example of a hardware configuration of a data analysis system.
- the data analysis system includes, for example, a business server 14 that can execute a main process of data analysis, and one or a plurality of client devices 10 that can execute a related process of the data analysis.
- the storage system 18, the client device 10, and the business server 14 including the database 22 that records the target data to be subjected to data analysis and the results of evaluation / classification of the target data.
- a management computer 12 that provides the management function.
- “data” may be any data expressed in a format that can be processed by the data analysis system.
- the data may be, for example, unstructured data whose structure definition is incomplete at least in part, and document data (for example, e-mail (attached) including at least part of a sentence described in a natural language.
- File header information e.g, technical papers, patent publications, product specifications, blueprints, and other documents explaining technical matters
- presentation materials eg. academic papers, patent publications, product specifications, blueprints, and other documents explaining technical matters
- presentation materials eg. academic papers, patent publications, product specifications, blueprints, and other documents explaining technical matters
- presentation materials eg., academic papers, patent publications, product specifications, blueprints, and other documents explaining technical matters
- presentation materials eg., academic papers, patent publications, product specifications, blueprints, and other documents explaining technical matters
- presentation materials eg., academic papers, patent publications, product specifications, blueprints, and other documents explaining technical matters
- presentation materials eg., financial reports, Meeting materials,
- the “component” of the data may be partial data constituting at least a part of the data, for example, a morpheme, a keyword, a sentence, and / or a paragraph constituting a document, or constituting a voice.
- Partial sound, volume (gain) information, and / or timbre information, partial image, partial pixel, and / or luminance information constituting an image, frame image constituting a video, motion information, and / or Or it may be three-dimensional information.
- the client device 10 provides reference data to a user who has the authority to evaluate and classify data (evaluation authority user).
- the evaluation authority user can make an input for evaluating / classifying the reference data via the client device 10.
- the “reference data” may be, for example, data (classified data) associated with classification information by the user.
- “target data” may be data that is not associated with the classification information (unclassified data that is not presented to the user as reference data and is not classified for the user).
- the “classification information” may be an identification label used for classifying the reference data.
- the classification information includes, for example, a “Related” label indicating that the reference data is related to a predetermined case as a whole, a “High” label indicating that the both are particularly related, and “Non- Information that categorizes the reference data into three as in the “Related” label, or the reference, such as “good”, “slightly good”, “normal”, “slightly bad”, and “bad” It may be information that classifies data into a plurality of types such as five.
- predetermined case includes a wide range of objects for which the data analysis system evaluates relevance with data, and the scope thereof is not limited.
- a predetermined case may be a case where a discovery procedure is required when the data analysis system is realized as a discovery support system, or a case where the data analysis system is realized as a criminal investigation support (forensic) system.
- forensic criminal investigation support
- an e-mail monitoring system it may be a fraud (for example, information leakage, collusion, etc.), or a medical application system (for example, pharmacovigilance support system, clinical trial efficiency) System, medical risk hedging system, fall prediction (fall prevention) system, prognosis prediction system, diagnosis support system, etc.), it may be a case / case related to medicine or an Internet application system (for example, smart mail system) , Information aggregation (curation )
- a system, user monitoring system, social media management system, etc. it may be a case / case related to the Internet, or when implemented as a project evaluation system, it may be a project that has been performed in the past
- a marketing support system it may be a product / service targeted for marketing, or when implemented as an intellectual property evaluation system, it may be an intellectual property targeted for evaluation, or as an unauthorized transaction monitoring system If realized, it may be an unauthorized financial transaction, if realized as a call center escalation system,
- the client device 10 includes known computer hardware resources, and includes, for example, a memory (for example, a hard disk, a flash memory, etc.), a controller (CPU; Central Processing Unit), a bus, and an input / output interface (for example, a keyboard). , A display, etc.) and a communication interface.
- the client device 10 is communicably connected to the business server 14 and the management computer 12 via the communication interface by communication means 20 such as a LAN.
- the memory stores an application program for causing the client device 10 to function, and the controller executes the application program to input / output necessary for classification / evaluation processing to the evaluation authority user. Make it possible.
- the business server 14 broadly refers to patterns (abstract rules, meanings, concepts, styles, distributions, samples, etc. included in the data based on the classification result for the reference data, so-called “specific patterns”. And the target data is evaluated based on the pattern. That is, the business server 14 presents reference data to the user, allows the user to input classification information for the reference data, learns a pattern based on the input result of the user, and applies to the target data based on the learning result. By enabling the evaluation, the data desired by the user can be separated from a large number of target data. Similar to the client device 10, the business server 14 may include, for example, a memory, a controller, a bus, an input / output interface, and a communication interface as hardware resources. The memory stores an application program that causes the business server 14 to function, and the controller executes processing for data analysis based on the application program.
- the management computer 12 executes predetermined management processing on the client device 10, the storage system 18, and the business server 14. Similarly to the client device 10, the management computer 12 may include, for example, a memory, a controller, a bus, an input / output interface, and a communication interface as hardware resources.
- the memory of the management computer 12 stores an application program for the controller to execute management processing, for example.
- the storage system 18 may be composed of, for example, a disk array system, and may include a database 22 that records target data and evaluation / classification results for the target data.
- the business server 14 and the storage system 18 are connected (16) by a DAS (Direct Attached Storage) method or a SAN (Storage Area Network).
- DAS Direct Attached Storage
- SAN Storage Area Network
- the hardware configuration shown in FIG. 1 is merely an example, and the data analysis system can be realized by other hardware configurations.
- a configuration in which part or all of the processing executed in the business server 14 is executed in the client device 10 may be performed, or the storage system 18 may be built in the business server 14.
- the hardware configuration is not limited to any one (for example, the configuration illustrated in FIG. 1).
- FIG. 2 is a functional block diagram illustrating an example of a functional configuration of the business server 14. As illustrated in FIG. 2, for example, the business server 14 samples a plurality of part of target data from target data stored in the database 22 according to a predetermined standard (for example, random), and uses this as reference data.
- a predetermined standard for example, random
- a classification information receiving unit 104 that accepts setting (labeling) of classification information from a user having an evaluator authority, and a plurality of reference data is classified for each classification information based on the classification information.
- a learning unit 105 that learns a pattern included in the reference data.
- the business server 14 performs, for example, a storage execution unit 201 that stores data components and evaluation values of the components in the database 22 and a search process on the database 22 to search for patterns from target data other than reference data.
- a search unit 106 an index indicating the level of relevance between the target data and the predetermined case is calculated for each target data, a calculation unit 107 that ranks the plurality of target data based on the index, and the target data
- a classification unit 108 that assigns classification information to the target data based on the converted result.
- FIG. 3 is a flowchart illustrating an operation example of the data analysis system.
- An administrative user having administrator authority gives the management computer 12 a request (extraction request 300) for extracting (sampling) reference data.
- the extraction request 300 is, for example, a request for randomly sampling a predetermined number of pieces of data recorded in the database 22 as reference data, or a predetermined range of data (for example, a data update date of 3 days Or a request for sampling a predetermined number of data as reference data.
- the management user can appropriately set the ratio or number of data extracted as reference data.
- the management computer 12 generates an extraction command 302 based on the extraction request 300 and transmits the extraction command 302 to the business server 14.
- the reference data providing unit 102 provided in the business server 14 extracts a predetermined number of reference data from the database 22 based on the extraction command 302 from the management computer 12 (304).
- the reference data providing unit 102 of the business server 14 sends the extracted reference data to the specific client device 10 (the client device specified by the extraction command 302) (312).
- the specific client device 10 activates the evaluation classification input interface and presents the evaluation classification input screen to the evaluation authority user.
- FIG. 4 is an example of the evaluation classification input screen.
- the evaluation classification input screen may include, for example, a reference data list 500 and a check box 502 indicating classification information for each target data.
- the reference data details 506 may include, for example, a data ID 510, a data name 512, and the content of target data (text of document data, etc.) 506.
- the evaluation authority user can classify the reference data by checking the check box indicating the label for each reference data after grasping the contents of the reference data by referring to the reference data details 506. For example, if the evaluation authority user thinks that the data is related to a predetermined case, check the checkbox indicating “Related”, and if it is particularly related, check the check box indicating “High” and do not relate When thinking, check the checkbox indicating “Non-Related”. When the check box is checked, the information is sent to the business server (314), and the business server 14 records the combination of the classification information and the reference data in the database 22.
- the learning unit 105 provided in the business server 14 refers to the combination recorded in the database 22 and extracts components from a set of reference data for each classification information (316).
- the learning unit 105 can extract, for example, morphemes (keywords) that appear at a predetermined frequency or more in a plurality of reference data with the same classification information as constituent elements.
- the learning unit 105 can evaluate the extracted components based on a predetermined evaluation standard (for example, the amount of transmitted information) (318). For example, when the learning unit 105 extracts a keyword as a constituent element from document data (text data), the keyword is evaluated by calculating an evaluation value of the keyword based on the predetermined evaluation criterion.
- the “evaluation value” indicates, for example, the degree to which the keyword contributes to the combination of the reference data and the classification information (the distribution / frequency of the constituent elements appearing in each data depending on the classification information). It may be a feature amount.
- the learning part 105 can acquire a pattern from the said reference data as a learning result based on the user's input with respect to reference data.
- the storage execution unit 201 provided in the business server 14 stores the component extracted by the learning unit 105, the evaluation value of the component, and the threshold value in the database 22.
- the business server 14 compares the constituent elements with the target data, evaluates the level of relevance between the target data and the predetermined case, and ranks the target data.
- the search unit 106 sequentially fetches a plurality of target data from the database 22, reads a plurality of constituent elements included in the target data in order, and whether or not each constituent element appears in the target data. (320).
- the calculation unit 107 ranks the plurality of target data based on the magnitude of the index by calculating the index of the target data based on the evaluation value of the constituent element.
- the ordering may be, for example, associating target data with an index calculated for the target data.
- the calculation unit 107 generates a vector (so-called “Bag-of-words”) that represents the presence or absence of a component included in the target data. For example, when the keyword “price” is included in the target data, the arithmetic unit 107 sets “1” to the dimension of the vector corresponding to “price”. The computing unit 107 calculates the index by calculating the inner product of the vector and the evaluation value (evaluation value) of each component (following equation).
- s represents the vector
- w represents the evaluation value vector
- T represents transposition
- the calculation unit 107 can also calculate one index for each target data, and the target data is divided into predetermined segments (for example, sentences, paragraphs, and predetermined lengths).
- one index can be calculated for each unit divided by a partial moving image including a predetermined number of frames (details will be described later).
- the calculation unit 107 preliminarily extracts target data that does not include keywords, related terms, or components selected in the learning unit 105 from the target of index calculation. Can be eliminated.
- the classification unit 108 sets the classification information for the target data based on an index indicating the relationship between the target data and the predetermined case (an index that enables ranking of a plurality of target data based on the relationship). To do.
- the classification unit 108 can set classification information for the target data when the index of the target data is equal to or greater than a predetermined threshold.
- the classification unit 108 presents a plurality of ordered target data to the user, and allows the user to input classification information for each of the plurality of target data, or automatically classifies the user. You may check the information so that you can change it. The higher the index, the higher the degree of expectation that the target data is related to a given case, and the higher the likelihood that the target data will be labeled “Related” or “High” (classification information). This is because if there is information (for example, a specific word) that hinders the content of the target data, the “Related” label may not be set for the target data.
- the business server 14 registers the management table of the target data in the database 22.
- FIG. 6 is an example of a management table that stores target data. For each target data (data 1, 2, 3,...), For example, a target data ID, a name of the target data, an index, classification information, and the like are recorded.
- the evaluation of the target data in the business server 14 is, for example, calculating an index of the target data, setting a label for each of the plurality of target data based on the index, or determining the plurality of target data based on the size of the index. It includes predetermined calculation processing related to the level of relevance between a plurality of target data and a predetermined case, such as enabling identification.
- the business server 14 transmits the management table stored in the database 22 to the client device 10.
- the client device 10 sorts and displays the target data in descending order of the index. For example, the client device 10 can present an input field for automatically or manually adding the classification information to the target data.
- the evaluation authority user can input a label of “Related”, “High”, or “Non-Related” for each target data.
- the administrator can set a label for classification with respect to the upper predetermined number of all the target data arranged in order, or a predetermined percentage of the target data.
- [Learning execution pattern] The administrator can set a learning execution pattern in the learning unit 105 in advance.
- the execution pattern for example, (1) after the classification information is input to all of the reference data extracted by the reference data providing unit 102, the business server 14 learns the pattern of the reference data, and based on the pattern First mode for calculating indexes for all target data, (2) The business server 14 performs learning each time classification information is input to each of a plurality of reference data, and the target data every time the learning is performed (3) The client device 10 provides the reference data. (2) The index is calculated for the target data while the pattern is sequentially updated based on the classification of each reference data.
- the combination of the data other than the reference data extracted by the unit 102 and the classification information is supplied to the learning unit 105, and the business server 14 does not sequentially update the pattern.
- the evaluation authority user sets classification information in the target data
- the combination of the target data and the classification information is fed back to the learning unit 105 to update the pattern.
- the second aspect since the order of the target data is changed every time the classification information is given to each reference data, the user having the classification authority can change the change of the order of the target data. Can be confirmed.
- the result of classifying the target data is sequentially reflected in the pattern obtained by the learning unit 105, there is an additional effect that the accuracy of evaluating the data can be sequentially improved.
- the learning unit 105 includes a plurality of constituent elements constituting at least a part of reference data in a reference data set (a data set including a plurality of combinations of reference data and classification information for classifying the reference data).
- the degree of contribution to the combination is evaluated as the evaluation value based on a predetermined standard (for example, the amount of transmitted information).
- the learning unit 105 selects the constituent elements until the index of the data with the “Related” or “High” label set is larger than the index of the data with no label set, and the configuration It is possible to repeatedly evaluate the evaluation value of the element and correct the evaluation value of the constituent element.
- the data analysis system can find a component that appears in a plurality of data to which classification information of “Related” or “High” is attached and has an influence on the combination of the data and the label.
- the amount of transmitted information is calculated from a predetermined definition formula using, for example, the appearance probability of a predetermined word and the appearance probability of predetermined classification information.
- the learning unit 105 calculates the component evaluation value wgt using, for example, the following expression.
- wgt indicates the initial value of the evaluation value of the i-th selected keyword before learning.
- Wgt indicates the evaluation value of the i-th selected keyword after the L-th learning.
- ⁇ means a learning parameter in the L-th learning, and ⁇ means a learning effect threshold.
- the learning unit 105 can evaluate, for example, that the component represents the characteristic of the predetermined classification information as the value of the calculated transmission information amount increases.
- the learning unit 105 also calculates an intermediate value between the lowest value of the index of the reference data set with “Related” and the highest value of the index of the reference data set with “Non-Related” with respect to the target data. It can be set as a threshold (predetermined reference value) when automatically determining whether or not “Related” is set.
- the learning unit 105 may continue to re-evaluate the evaluation value until the recall rate reaches a predetermined target value, for example.
- the recall is an index indicating the ratio (coverage) of the data to be discovered to a predetermined number of data. For example, when the recall is 80% with respect to 30% of all data. , 80% of data to be found (for example, lawsuit-related material) is included in the data of the top 30% of the index.
- the amount of data to be discovered is proportional to the amount reviewed by the person, so the greater the deviation from this proportionality, the greater the data analysis performance of the system. Will be good.
- the calculation unit 107 has a recall ratio calculation function for calculating a recall ratio regarding determination of the relevance between data and a predetermined case based on an index of data, and a reselection function for reselecting components from reference data. be able to.
- the learning unit 105 reselects the constituent elements from the reference data until the recall exceeds the target value, and the arithmetic unit 107 is reselected. Repeating the ordering of the target data again based on the constituent elements.
- a component other than the component selected last time may be selected, or a part of the component selected last time may be replaced with a new component.
- the calculation unit 107 calculates the index of the target data with the reselected component, the evaluation value of one or a plurality of components may be changed. Further, the calculation unit 107 calculates an index (second index) of each data using the reselected component and its evaluation value, and the first index and the second index obtained before reselecting the component. The recall rate may be recalculated from the index.
- the reference data providing unit 102 randomly samples reference data to be presented to the reviewer (evaluation authority user) from the target data in the database 22.
- the display processing unit 103 outputs the extracted reference data to the screen display unit of the client device 10.
- the reviewer reviews the reference data displayed on the screen display unit and assigns classification information to the reference data.
- the learning unit 105 analyzes the reference data and selects components. Specifically, the learning unit 105 extracts N component elements that appear in common in the reference data to which common classification information is assigned, and calculates an evaluation value for each of the extracted component elements.
- the evaluation value of the first extracted component is Wgt1, the second is Wgt2, and the Nth is Wgtn.
- the learning unit 105 selects morphemes using the evaluation values from Wgt1 to Wgtn.
- the components are rearranged in descending order of evaluation values, satisfy the following formula, and m morphemes (configurations) in order from the top of the evaluation value until the sum reaches a target value (K is an arbitrary constant) Element).
- the calculation unit 107 extracts data including the selected m constituent elements from the target data, and calculates an index of each target data based on the evaluation value of the constituent elements included in the target data.
- the calculation unit 107 ranks the data in descending order of the index, and determines data of the index upper A% (A is an arbitrary constant) of all data.
- the calculation unit 107 specifies data having an index equal to or higher than a predetermined reference value among the data included in A% and having the same “Related” or “High” label (classification information) as the reference data.
- the reproduction rate X1 (Xn: the reproduction rate calculated for the nth time) is calculated from the ratio between the number of data included in A% and the number of data set with labels.
- the calculation unit 107 determines whether or not the recall rate X1 has been calculated to be equal to or greater than the target value K. If it is determined that it has been calculated, the process ends. Otherwise, the learning unit 105 reselects the constituent elements. Specifically, from the N components selected previously, from the components excluding the m components, the following formula is satisfied, and the evaluation value is ordered from the top until the sum reaches the target value. I components are selected.
- the composite index S2 of each document is calculated from the following equation.
- the calculation unit 107 calculates the recall rate again, and repeats the recalculation of the recall rate until the target value K is exceeded. Thereby, it is possible to improve the accuracy in ordering data up to the target recall rate.
- recall rate may be a precision rate.
- Precision Rate is an index indicating the ratio (accuracy) of data to be truly discovered to the data discovered by the data analysis system.
- the expression “the matching rate is 80% when 30% of all data is processed” indicates that the ratio of data to be discovered is 80% of the data of the top 30% of the index.
- the data analysis system for example, based on the relationship between the recall calculated for the target data and the rank of the index (for example, a normalized rank obtained by dividing the rank by the number of data) The number of data required when the user confirms the target data can be calculated.
- the computing unit 107 calculates the evaluation value of the first component included in the target data (evaluation value of the first component) and the evaluation value of the second component included in the target data (the evaluation value of the second component).
- the index of the target data may be determined in consideration of the correlation (co-occurrence) with. For example, when the connection between the first component and the second component is strong, when the first component appears in the target data, the calculation unit 107 determines the frequency at which the second component appears in the target data.
- the indicator can be calculated in consideration.
- the data analysis system can calculate the index in consideration of the correlation between a plurality of components, and therefore can extract target data related to a predetermined case with higher accuracy.
- the calculation unit 107 can calculate the index of the target data by reflecting the correlation (co-occurrence, etc.) between the component and other components in the appearance information of the component. For example, the calculation unit 107 multiplies the appearance management vector of the component by a correlation matrix indicating the correlation with other components. For example, when the keyword “price” appears in the target data, the correlation matrix indicates the likelihood (ie, correlation) that another keyword (for example, “adjustment”) appears in relation to “price”, and the correlation matrix information. Is a square matrix.
- the correlation matrix may be optimized based on the reference data. For example, when the keyword “price” appears in the target data, the value obtained by normalizing the number of occurrences of other keywords (“adjustment”) between 0 and 1 (ie, the maximum likelihood estimate) is displayed in the correlation matrix. Stored. Therefore, the data analysis system can obtain a correlation vector for reflecting the correlation of a plurality of components in the data index.
- the calculation unit 107 calculates a data index based on the sum of all correlation vectors, for example, as shown in the following equation. More specifically, the calculation unit 107 calculates the inner product of the sum value of the correlation vectors and the vector W of the evaluation value for the keyword as shown in the following formula instead of the above formula. An index of data can be calculated.
- C represents a correlation matrix
- s s represents an s-th keyword vector
- TFnorm total value
- TF i represents the appearance frequency (Term Frequency) of the i-th keyword
- s js represents the j-th element of the s-th keyword vector.
- the calculation unit 107 calculates an index for each target data by calculating the following equation.
- w i is the i-th element of the evaluation value vector W.
- the arithmetic unit 107 not only orders the data by calculating an index of the entire target data, but also divides the target data into a plurality of parts (for example, sentences or paragraphs (partial target data) included in the data), for example. Then, by evaluating each partial data based on the learned pattern (that is, calculating an index of the partial target data), the partial target data is ranked.
- the calculation unit 107 integrates the indexes of the plurality of partial target data (for example, extracts the maximum value from the indexes of the plurality of partial target data and uses it as the index of the entire data, The average is used as the index of the entire data, or a predetermined number of indexes of the multiple partial target data are selected in the descending order and added together to form the index of the overall data, and the integrated index is used as the evaluation result of the target data. You can also Thereby, the data analysis system can more accurately select useful data suitable for the purpose of use from the target data.
- the data analysis system can analyze phases indicating each stage where a predetermined case progresses. For example, if a given case is a collusion act, the collusion act can be done in the relationship building phase (the stage of building relationships with competitors), the preparation phase (the stage of exchanging information about competitors with competitors), the competition phase (customers The above three phases are usually set in the above order (providing feedback, getting feedback, and communicating with competitors). May be.
- the data analysis system learns a plurality of patterns corresponding to the plurality of phases from a plurality of types of reference data respectively prepared for a plurality of preset phases, and targets based on the plurality of phases, respectively. By analyzing the data, for example, it is possible to specify “in which phase the organization to be analyzed is currently in”.
- the data analysis system will explain in detail the flow of identifying phases.
- the data analysis system refers to a plurality of types of reference data respectively prepared for a plurality of preset phases, evaluates components included in the plurality of types of reference data, and The result of evaluating the constituent element (for example, an evaluation value) is associated with each other and stored in the database 22 for each phase (that is, a plurality of patterns corresponding to the plurality of phases are respectively learned). Therefore, for example, in the “relationship building phase” (phase 1), keyword evaluation values such as “schedule” and “adjustment” are larger than in the “execution phase” (phase 3), or in the “preparation phase” (phase 2). , Keyword evaluation values such as “competitive product” and “investigation” may be larger than those in the “relationship building phase” (phase 1). Also, different keywords may be set for each stage.
- the data analysis system calculates an index for each of a plurality of phases by analyzing the target data based on the pattern learned for each phase. Then, the data analysis system determines whether or not the index satisfies a predetermined determination criterion (for example, a threshold) set in advance for each phase (for example, whether or not the index exceeds the threshold). When it is determined that the condition is satisfied, the count value corresponding to the phase is increased. Finally, the data analysis system identifies the current phase based on the count value (for example, the phase having the maximum count value is set as the current phase). Alternatively, when it is determined that the index calculated for each phase satisfies a predetermined determination criterion set for the phase, the data analysis system can also specify the phase as the current phase.
- a predetermined determination criterion for example, a threshold
- the data analysis system can reset a predetermined criterion (for example, a threshold value) set in advance in a data adaptive manner.
- a predetermined criterion for example, a threshold value
- the calculation unit 107 uses a result obtained by ranking a plurality of target data. For example, the calculation unit 107 performs regression analysis on the relationship between the index of the target data and the ranking of the index (that is, the rank when the index is arranged in ascending order), and sets the threshold based on the result of the regression analysis. Can be determined.
- the computing unit 107 determines the values of ⁇ and ⁇ (for example, by the method of least squares) based on the index calculated for a plurality of target data and the ranking of the index.
- the applicant conducts verification using the coefficient of determination, F test, and t test for the model using the above function, and confirms the validity / optimality of the model.
- FIG. 7 is a graph showing a characteristic example of the exponential function model obtained by performing regression analysis based on the index and the ranking.
- FIG. 8 is a graph showing a characteristic example of the exponential function model obtained by re-evaluating the exponential function model. 7 and 8, the horizontal axis indicates the index, and the vertical axis indicates the ranking on a logarithmic scale. Therefore, the fitting curve (regression curve) using an exponential function is shown by a straight line in FIGS. 7 and 8, and the lower the vertical axis is, the higher the ranking is, and the higher the ranking is, the lower the ranking is.
- the computing unit 107 identifies an index indicated by an exponential function corresponding to the threshold value, and sets the index as a threshold value (predetermined criterion) in a phase, so that the calculation unit 107 has been set in advance for the phase.
- the threshold can be changed.
- the data analysis system re-evaluates the target data that has been ordered by regression analysis, thereby setting the threshold value (predetermined criterion) for the index calculated for each phase based on the pattern obtained by learning.
- the target data can be dynamically changed to match the result of the evaluation.
- the data analysis system can also continuously monitor the progress of the phase by continuously monitoring the data image of the target data.
- the data analysis system can adjust the learning process executed by the learning unit 105 based on the verification result. For example, when an evaluation authority user verifies target data to which a high index is given by the data analysis system and determines that the target data should not be given a high index, the evaluation authority user Is given the label “Non-Related”.
- the learning unit 105 feeds back the target data as reference data, for example, increases / decreases the evaluation value of the component included in the reference data, adds / deletes the component, and executes relearning, Update the pattern.
- the learning unit 105 calculates the index and ranking of the target data again based on the updated pattern, and performs regression analysis on the calculation result again (FIG. 8).
- the learning unit 105 sets the corrected threshold value for each phase by executing the same processing as described in FIG. 7 based on the result of the new regression analysis.
- phase progress based on prediction model
- the data analysis system is based on an index determined by evaluating multiple target data based on a model that can predict the progress of a predetermined action related to a predetermined case. Can be predicted and presented.
- the data analysis system for example, generates a regression model having variables calculated for the first phase (for example, the relationship building phase) and the index calculated for the second phase (for example, the preparation phase). Assuming and predicting the probability (e.g. probability) of going to the third phase (e.g. competition phase) based on pre-optimized regression coefficients.
- the data analysis system delimits at predetermined intervals.
- the respective patterns are learned from the obtained reference data (for example, the target data of the first section, the target data of the second section, ...) (that is, the component and the result of evaluating the component at each predetermined time) Acquisition), and the target data can be analyzed based on each of the patterns.
- the computing unit 107 can analyze the structure of the target data and reflect the analysis result in the evaluation of the target data. For example, when the target data includes at least part of the document data, the calculation unit 107 displays the sentence data expression form (for example, whether the sentence is an affirmative form, a negative form, or a negative form). Etc.) and the analysis result can be reflected in the index of the target data.
- the positive form is, for example, that the sentence predicate is “delicious”, the negative form is “taste” or “not delicious”, and the negative form is “delicious” or “It was not good”.
- the calculation unit 107 sets, for example, “+ ⁇ ” for the positive form, “ ⁇ ” for the negative form, and “+ ⁇ ” for the negative form ( ⁇ , ⁇ , ⁇ : the same or different numerical values).
- the index calculated for each of the target data can be adjusted using these parameters.
- the arithmetic unit 107 detects that the sentence included in the target data is negative, for example, by canceling the sentence, the component included in the sentence is not used as a basis for calculating the index ( The component is not considered).
- the data analysis system can reflect the structure analysis result of the data in the index, so that the data can be evaluated with higher accuracy.
- the calculation unit 107 can analyze the syntax of the sentence as the structure of the target data and reflect the analysis result on the index of the target data.
- the calculation unit 107 may provide superiority or inferiority in the evaluation value of the morpheme depending on, for example, where the morpheme (component) is located in the subject, object, or predicate of the sentence.
- the position in the syntax of the morpheme may be controlled by a vector, and the evaluation value of the morpheme is given superiority or inferiority depending on whether it is a subject, an object, or a predicate.
- the arithmetic unit 107 can obtain the target data index by combining the position control vectors in the syntax of the morpheme.
- the data analysis system can extract the user's emotion from the target data.
- online product sites, restaurant guides, and the like often describe the user's comments on the product / service along with the user's comments. Therefore, the data analysis system creates reference data based on the comment and the evaluation, and evaluates the target data based on the reference data to determine whether the user has a good impression on the product / service. Can be guessed.
- comments on products / services with high ratings often use good feeling words (for example, “Good”, “Happy”, etc.).
- comments often use words of bad emotion (for example, “bad”, “clogged”, etc.)
- data analysis systems learn patterns from reference data consisting of a combination of comments and ratings. And based on the said pattern, the emotion of the user who produced
- the classification unit 108 classifies the reference data based on the superiority or inferiority of emotion. For example, when the consumer's evaluation is performed in five stages, the classification unit 108 classifies the classification information (for example, “good impression” or “bad impression”) in the reference data according to the stage evaluation. Or 5 categories of labels indicating “good”, “somewhat good”, “normal”, “somewhat bad”, and “bad”.
- the learning unit 105 extracts components from the reference data in which the classification information is set. In particular, the learning unit 105 can extract a component indicating emotional expression (for example, a morpheme corresponding to an adjective, an adjective verb, an adverb, etc.).
- the learning unit 105 generates an emotion marker (emotion evaluation information, an index indicating whether the user has a positive impression or a bad impression) for a component indicating emotional expression as follows. That is, the learning unit 105 counts the number of times A F at which a constituent element (constituent element A) indicating emotion expression appears in one or more reference data classified as good impressions. Then, the learning unit 105 calculates a frequency RF P at which the component A appears in the reference data.
- N P is the total number of components included in the reference data classified into good impression.
- the learning unit 105 counts the number A N of occurrences of the component A in the reference data classified as bad impression, and calculates the frequency RF N of appearance of the component A in the reference data.
- N N is the total number of components included in the reference data classified as bad impression.
- the learning unit 105 calculates the emotion marker (the emotion determination index value P (A)) of the component A using the frequency calculated using the above two formulas as follows.
- the learning unit 105 sets “+1” as the emotion marker as a component that is often used for data that has a good impression of the component A.
- the component A is designated as “-1” as the emotion marker as a component that is often used for data having a bad impression.
- words such as “good”, “beautiful”, and “delicious” are easy to add “+1”, and words such as “bad”, “dirty”, and “bad” are set to “ ⁇ 1”. Tend to be.
- the computing unit 107 extracts the constituent elements for which the emotion marker is set from the target data, and acquires the emotion marker values of the extracted constituent elements.
- the calculation unit 107 adds the emotion marker value as many times as the number of times the component appears in the target data. For example, when the emotion marker set for the component “good” is “+1” and appears five times in the unclassified data, the emotion index based on the component “good” in the unclassified data is “ 5 ”. Further, for example, when the emotion marker set for the component “bad” is “ ⁇ 1” and appears three times in the unclassified data, the emotion based on the component “bad” in the unclassified data The indicator is “ ⁇ 3”.
- the calculation unit 107 calculates an emotion index while determining whether a negative expression or an exaggerated expression exists in the component.
- the negative expression is an expression that denies the component, for example, an expression such as “not good” or “not delicious”. If there are such expressions, they are treated as opposite expressions, for example, “bad” if they are “not good”, and “bad” if they are not “good”.
- the expression is treated as the opposite expression. For example, when an emotion marker of “+1” is set for the expression “good”, this is set to a negative value. It is good as well. Alternatively, the value set as the emotion marker may be decreased by a predetermined amount (for example, 1.5). Furthermore, it is also possible to deny the negation, that is, to detect whether there is a double negative expression, and when there is a double negative expression, the component may be positively determined.
- exaggerated expression is an expression that exaggerates (emphasizes) the constituent elements, and refers to expressions such as “very”, “very”, and “very”, for example.
- the emotion index is calculated by multiplying the emotion marker value by a predetermined value (for example, twice). For example, if there is an expression “very delicious” and the emotion marker value of “delicious” is “+1”, the emotion index for this expression is set to “+2” (increase).
- a predetermined value for example, twice. For example, if there is an expression “very delicious” and the emotion marker value of “delicious” is “+1”, the emotion index for this expression is set to “+2” (increase).
- the arithmetic unit 107 calculates the emotion index based on all the constituent elements as shown in the following formula, and adds them to calculate the index S of the target data.
- s i is an emotion marker of the i-th component.
- the calculation unit 107 ranks the target data based on the emotion index. When the index is larger than 0, it is determined that the target data is likely to have a good impression, and when the index is less than 0, it is determined that the target data is likely to have a bad impression.
- the plurality of target data that are ordered are presented to the user.
- the data analysis system has a predetermined management function.
- the management function is executed by the management program of the management computer 12.
- the management function when there are a plurality of evaluation authority users, there is a form in which the accuracy of classification of each person is displayed on the management screen.
- FIG. 9 is a schematic diagram showing an example of the management screen of the data analysis system.
- the management screen is created by the display processing unit 103 from the data index of the calculation unit 107.
- the display processing unit 103 outputs a display screen 260 to the monitor of the management computer 12.
- the display screen 260 includes, for example, a plurality of sections associated with each predetermined range of the index, and a display area 262 that displays the ratio.
- the ratio refers to the total number of target data included in the index range and the number of target data for which the “Related” label is set by the evaluation authority user as being related to a predetermined case out of the total number of target data. Is the ratio.
- the divisions are set separately by 1000, for example, the indices are 0 to 999 and 1000 to 1999, and each section is divided into, for example, 200 indices.
- the ratio is expressed by a change (gradation) in the form of additional information such as color tone.
- the colder the color tone the lower the ratio, that is, the lower the rate that the “Related” label was set by the reviewer in the target data (the higher the rate of non-related), and the warmer the color “ The "Related” label indicates that the rate set by the reviewer is high.
- the data analysis system uses the gradation corresponding to the ratio of the data to which the predetermined classification information (label) is associated with all the data to calculate the distribution of the ratio with respect to the result of evaluating each of the plurality of data. It can be displayed so as to be visible.
- the management authority user can easily grasp the suitability of the classification accuracy of each evaluation authority user by referring to the color of each subdivision displayed on the display screen 260. For example, a certain evaluation authority user has a high ratio of setting the “Related” flag regardless of the area where the index is small, while a certain evaluation authority user sets the “Non-Related” flag regardless of the area where the index is high. The setting ratio is high, and the classification by these evaluation authority users indicates that the accuracy is low.
- the data analysis system can visualize interrelationships (data transmission / reception, exchange, etc.) between a plurality of nodes (people, organizations, computers).
- the display processing unit 103 determines the relationship between a plurality of persons related to a predetermined case based on the result of data ranking by the calculation unit 107 so that the degree of the relationship can be understood. It can be displayed on the device 10.
- the display processing unit 103 displays each node in a circle, and when there is a relationship between one node and another node, an arrow between the node and the other node is displayed. Combine and display with.
- the size of each node indicates the magnitude of the relationship between the nodes. That is, the larger the node size is, the higher the relationship with the node 30 is.
- the nodes become smaller in the order of node 31, node 36, node 35, node 32, node 33, and node 34. Therefore, in the example of FIG. 10, it shows that the relationship with the node 30 is high in the order of the node 31, the node 36, the node 35, the node 32, the node 33, and the node 34. It is determined based on the magnitude of the relationship, the magnitude of the data index, or the superiority or inferiority of the label. Instead of or together with the size of the node, the thickness or color of an arrow or line segment connecting the nodes can be changed.
- the node may be specified by a URL or an email address.
- FIG. 10 shows the correlation display centered on the node 30, but the display processing unit 103 can also change the central node.
- the display processing unit can also set a plurality of nodes as a central node on one screen.
- time information such as data time stamp, transmission time, incoming time, and update time can be displayed so as to be understood by the correlation between nodes. As the occurrence of the correlation between the nodes is closer to the current time, the form (color tone) of the connection display between the nodes may be changed.
- the data analysis system determines whether or not the first component representing the predetermined operation is included in the data, and when determining that the first component is included, the second component representing the target of the predetermined operation is determined. Identify. For example, when a sentence “determine the specification” is included in the data, a component (word) “specification” and “determine” is extracted from the sentence, and a predetermined operation “determining” is expressed. A second component (object) called “specification” that is the target of one component (verb) is specified.
- the data analysis system includes meta information (attribute information) indicating attributes (properties / characteristics) of data including the first component and the second component, and the first component and the second component.
- the meta information is information indicating a predetermined attribute of the data. For example, when the data is an e-mail, the name of the person who transmitted the e-mail, the name of the received person, the e-mail address, It may be the date and time of transmission / reception. Then, the data analysis system associates the two components with the meta information and causes the client device 10 to display them.
- a sentence “exchange technology” is included in an e-mail (data, communication information), and the words “technology” (second component) and “exchange” (first component)
- the data analysis system displays the “technology” and “interact” in association with the names of the persons who have transmitted and received the electronic mail (for example, “person A” and “person B”).
- “person A” and “person B” intend to “exchange” with respect to a certain “technology”.
- a sentence “confirm specification” is included in the presentation material attached to the e-mail, and “specification” (second component) and “confirm” (first component) ) Is extracted, the data analysis system associates the “specification” and “determine” with the date and time when the presentation material was created (for example, 16:30 on March 30, 2015). To display. As a result, “person A” and “person B” intend to “exchange” with respect to a certain “technology”, and at “16:30 on March 30, 2015,“ It can be inferred that the “specification” is being “confirmed”.
- the data analysis system of the present invention can realize a support function for allowing the user to grasp the contents of the target data in a short time.
- the calculation unit 107 executes a topic (context) detection function. As shown in FIG. 11A, the arithmetic unit 107 extracts data including constituent elements of a concept lower than the preselected concept from the target data, and the contents of each extracted target data (e-mail, etc.) 11 are created at moderate abstraction levels, the target data are clustered so that the contents of the target data can be confirmed based on the created summaries, and the result of the clustering of the target data is shown in FIG. Present it to the user in such a form.
- Such a topic detection function is realized by two phases, a preparation phase and an application phase.
- the preparation phase is a phase for extracting only the keywords of the subordinate concepts of each target concept set in advance by the user and creating the above-described target concept extraction database in which the extracted keywords are respectively associated with the corresponding target concepts. is there.
- the application phase the target concept extraction database created in the preparation phase is used to create a summary that expresses the content of the target data in a higher level concept, and the target data is clustered based on the created summary. This is a phase in which the result is displayed in response to a request from the user.
- the user selects several target concepts corresponding to the topic to be detected from the target data, and registers the selected target concepts in the data analysis system in advance.
- the topics to be detected are “injustice” and “dissatisfaction”
- the concept categories are “behavior”, “emotion”, “nature and state”, “risk” and “money” as shown in FIG.
- risk and “dangerous” and “dangerous” and “money” “money paid for human labor” and so on. Set each.
- the arithmetic unit 107 searches the dictionary of the database 22 for a keyword representing the subordinate concept for each registered target concept, and selects each keyword detected by the search.
- the above-described target concept extraction database associated with the corresponding target concept is created.
- the calculation unit 107 uses the target concept extraction database created as described above, and includes the target data including keywords registered in the target concept extraction database from the target data. Extract data. Further, the calculation unit 107 creates a summary of the target data extracted in this way, using the superordinate concept of the keyword detected at that time for the content of the text.
- the display processing unit 103 clusters the target data based on the summary of the corresponding target data created in this way and presents the result to the user. .
- the combination of reference data and classification information is set by the classification information receiving unit 104 for each of a plurality of classification information. That is, a plurality of combinations of classification information and reference data are set. Further, the learning unit 105 evaluates, for example, a component that appears in common in a plurality of reference data with the same classification information in consideration of the degree of contribution to the combination of the reference data and the classification information, A component having an evaluation result (evaluation value) of a predetermined value or more is selected as one of patterns common to a plurality of reference data. Since the evaluation / classification policy / standard for the reference data may differ for each evaluator, the data analysis system may allow multiple evaluators to participate in the evaluation / classification for the reference data. .
- the data analysis system may set the classification information in the target data that is ordered based on the input by the user. Or, according to the evaluation result for the target data (for example, when the index of the target data satisfies the predetermined evaluation criterion (for example, whether the index exceeds a predetermined threshold)), Classification information may be given to the target data without requiring user input.
- the evaluation standard may be set by a user having management authority, or may be set by a data analysis system based on the result of regression analysis of the measurement result of reference data or target data.
- the data analysis system for example, extracts useful constituent elements from a plurality of target data classified according to predetermined classification information and attached with the same classification information, and converts the target data into reference data based on the constituent elements. It can be analyzed whether it can be classified in the same way. The extraction of the constituent elements may be performed for each target data grouped by each of the plurality of classification information, for example.
- the morpheme and other components selected by the learning unit 105 are recorded in the database 22. Further, the business server 14 determines in advance components that can be classified as “relevant” if they are highly relevant to the superiority or inferiority of a predetermined case from the result of past classification processing and are included in the target data. It can also be registered in the database 22.
- a constituent element that is highly relevant to the target data to which a code related to a predetermined case is assigned based on the result of past classification processing is registered in the database 22 .
- the morphemes once registered in the database 22 are increased or decreased according to the learning results performed by the data analysis system, and can be additionally registered and deleted manually.
- the data analysis system can learn a plurality of patterns (a combination of data components and results of evaluating the components) and store them in the database 22.
- the data analysis system can hold the above combination for each predetermined case type.
- the data analysis system is realized as a crime investigation support system and analyzes data that can be evidence of crime
- the data analysis system is realized as an Internet application system and analyzes a web page
- the data The analysis system holds a plurality of different patterns.
- the user inputs the type of the predetermined case, and the data analysis system can process the target data based on the pattern corresponding to the type.
- the data analysis system calculates the temporary evaluation values of all the components, and then the temporary evaluation of the target components for which the evaluation values are calculated.
- a final evaluation value can be calculated by adding a temporary evaluation value of a component other than the component to the value.
- the data analysis system calculates an evaluation value for each of the plurality of components (that is, evaluates each of the plurality of components), and the first configuration that is one of the plurality of components
- the first constituent element is configured to reflect the evaluation value calculated for the second constituent element, which is another one of the plurality of constituent elements, with respect to the evaluation value calculated for the constituent element.
- the calculated evaluation value is updated, and the updated evaluation value is associated with the first component and stored in the database 22 as the evaluation value of the first component.
- the data analysis system can calculate the evaluation value of the component for evaluating the data in consideration of the relevance with other components, so that the data can be analyzed with higher accuracy. Can do.
- the data analysis system evaluates each component included in the reference data based on a predetermined standard (for example, the amount of transmitted information), and based on the evaluated result, the target data is compared with a predetermined case. A positive index (main index) indicating the level of relevance is calculated.
- the data analysis system selects a predetermined number of data as partial data (for example, randomly) from the target data having a low positive index (for example, data in which the positive index is almost zero), and selects the selected data
- the constituent elements included in the obtained data are each evaluated based on the predetermined criteria.
- the data analysis system calculates a negative index (sub-index) indicating the weakness of relevance between the target data and the predetermined case for the target data based on the evaluated result.
- the data analysis system extracts target data according to the positive index and the negative index (for example, ranks the entire data in order so that the positive index is higher and the negative index is lower).
- the data analysis system not only derives an index (positive index) indicating that it is related to a predetermined case, but also does not relate to the predetermined case according to the positive index (the predetermined case and The index (negative index) indicating that the relevance is low) is also derived. Thereby, the data analysis system can analyze data with higher accuracy.
- the data analysis system can be realized, for example, as an information asset utilization system (project evaluation system).
- this data analysis system can be realized as a system that can utilize information assets (data) possessed by a company / skilled person according to the situation (dynamically) by extracting the information assets.
- information assets data
- a company / skilled person for example, (1) in order to improve the efficiency of development sites where shortening of the development period is desired, information relating to products developed in the past can be reused according to the requirements of the development, or (2) skilled technology It is possible to identify useful information assets based on the expertise possessed by a person. That is, the data analysis system can efficiently find information necessary for the user (past information assets).
- the data analysis system can be realized as, for example, an Internet application system (for example, a smart mail system, an information aggregation (curation) system, a user monitoring system, a social media management system, etc.).
- the data analysis system uses data (for example, a message posted by the user to the SNS, recommended information posted on the website, a profile of the user or organization, etc.) as a predetermined evaluation criterion (for example, the user's preference). For example, whether the user's preference is similar to the user's preference, whether the user's preference matches the restaurant attribute, etc. It is possible to display a list of other users, present restaurant information that suits the user's preferences, and warn organizations that may harm the user. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as a driving support system, for example.
- the data analysis system determines whether the data (for example, data acquired from an in-vehicle sensor, a camera, a microphone, or the like) is information that the skilled driver has focused on during a predetermined evaluation standard (for example, driving by the skilled driver). For example, useful information that can make driving safe and comfortable can be automatically extracted. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as, for example, a financial system (for example, a fraudulent transaction monitoring system, a stock price prediction system, etc.).
- the data analysis system uses the data (for example, a report document to the bank, the market price of the stock price, etc.) for a predetermined evaluation standard (for example, whether there is a risk of fraud or whether the stock price increases).
- a report having an unauthorized purpose can be detected, or a future stock price can be predicted. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as a medical application system (for example, a pharmacovigilance support system, a clinical trial efficiency system, a medical risk hedging system, a fall prediction (fall prevention) system, a prognosis prediction system, a diagnosis support system, etc.).
- the data analysis system uses data (eg, electronic medical records, nursing records, patient diaries, etc.) for a predetermined evaluation standard (eg, whether or not to take a specific risk action of a patient, For example, predicting that a patient will be in a dangerous state (for example, falling) or objectively evaluating the efficacy of a drug. can do. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as, for example, a mail control system (smart mail system).
- the data analysis system evaluates the data (for example, e-mail, attached file, etc.) based on a predetermined evaluation standard (for example, whether it is necessary to reply to the e-mail), For example, important mails (mails that require action) can be extracted from a large number of mails. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as a discovery support system, for example.
- the data analysis system uses data (for example, documents, e-mails, spreadsheet data, etc.) based on a predetermined evaluation standard (for example, whether or not the data should be submitted in the discovery procedure in this case).
- a predetermined evaluation standard for example, whether or not the data should be submitted in the discovery procedure in this case.
- the data analysis system can be realized as a forensic support system, for example.
- the data analysis system uses data (eg, documents, e-mails, spreadsheet data, etc.) based on predetermined evaluation criteria (eg, whether the data is evidence that can prove criminal activity). For example, evidence that proves the criminal act can be extracted. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as, for example, an email monitoring system (email audit support system).
- the data analysis system uses the data (for example, e-mail, attached file, etc.) based on a predetermined evaluation standard (for example, whether or not the user who sent / received the e-mail tried to cheat) By evaluating, for example, a sign of fraud such as information leakage or collusion can be found. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as an intellectual property evaluation system, for example.
- the data analysis system uses the data (eg, patent gazettes, documents summarizing the invention, academic papers, etc.) as the proof of rejecting / invalidating a given patent.
- invalid materials can be extracted from a large number of documents (for example, patent gazettes, academic papers, sentences posted on the Internet).
- the data analysis system for example, combines each claim of a patent to be invalidated with a “Related” label (classification information), and each claim of an unrelated patent different from the patent and “Non- A combination with a “Related” label (classification information) is acquired as reference data, a pattern is learned from the reference data, and an index is calculated for a large number of documents (target data) (for example, an index for each paragraph of a patent publication) And the target data can be evaluated by adding a predetermined number from the top of the index to obtain the index of the patent publication. That is, the data analysis system can efficiently find information necessary for the user.
- target data for example, an index for each paragraph of a patent publication
- the data analysis system can be realized as a call center escalation system, for example.
- the data analysis system evaluates the data (for example, telephone call history, recorded voice, etc.) based on a predetermined evaluation criterion (for example, whether or not it is similar to a past correspondence case).
- a predetermined evaluation criterion for example, whether or not it is similar to a past correspondence case.
- the data analysis system can be realized as a marketing support system, for example.
- the data analysis system uses the data (for example, company / individual profile, product information, etc.) based on a predetermined evaluation standard (for example, whether the individual is male or female, or the consumer has a good feeling for the product. For example, it is possible to extract a market evaluation for a certain product. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system can be realized as a credit check system, for example.
- the data analysis system uses data (for example, company profile, information about company performance, stock price information, press release, etc.) based on a predetermined evaluation standard (for example, whether the company goes bankrupt, For example, it is possible to predict the growth / bankruptcy of a company. That is, the data analysis system can efficiently find information necessary for the user.
- the data analysis system of the present invention includes a discovery support system, a criminal investigation support system, an e-mail monitoring system, a medical application system, an Internet application system, an information asset utilization system, a marketing support system, an intellectual property evaluation system, a call center escalation.
- a predetermined evaluation standard whether or not it is related to a predetermined case
- the data analysis system of the present invention regards a data group including a plurality of data as a “collection of data based on the results of human thought and action”, for example, analysis related to human action, human action. Extract patterns from data and evaluate the relevance between the pattern and a given case by performing prediction analysis, analysis to detect specific human behavior, analysis to suppress specific human behavior, etc.
- a predetermined evaluation standard whether or not it is related to a predetermined case
- the data analysis system of the present invention regards a data group including a plurality of data as a “collection of data based on the results of human thought and action”, for example, analysis related to human action, human action. Extract patterns from
- preprocessing for example, extracting an important part from the data and extracting only the important part from the data
- the analysis target may be applied), or the mode of displaying the data analysis result may be changed. It will be understood by those skilled in the art that a variety of such variations can exist, and all variations fall within the scope of the present invention.
- Example of data analysis system processing data other than document data In the above-described embodiment, the example in which the data analysis system analyzes the document data has been mainly described. However, the data analysis system uses data other than the document data (for example, audio data, image data, video data, etc.). It can also be analyzed.
- the data analysis system may analyze the speech data itself, convert the speech data into document data by speech recognition, and use the converted document data as an analysis target. Also good.
- the data analysis system for example, divides the voice data into partial voices of a predetermined length to form the constituent elements, and uses the partial voice analysis method (for example, a hidden Markov model, Kalman filter, etc.)
- the voice data can be analyzed by identifying.
- a speech is recognized using an arbitrary speech recognition algorithm (for example, a recognition method using a hidden Markov model), and the procedure similar to the procedure described in the embodiment is performed on the recognized data. Can be analyzed.
- the data analysis system When analyzing image data, the data analysis system, for example, divides the image data into partial images of a predetermined size to form components, and any image recognition method (for example, pattern matching, support vector machine, neural network) The image data can be analyzed by identifying the partial image using a network or the like.
- image recognition method for example, pattern matching, support vector machine, neural network
- the data analysis system when analyzing video data, divides a plurality of frame images included in the video data into partial images each having a predetermined size to form a component, and an arbitrary image recognition method (for example, The video data can be analyzed by identifying the partial image using pattern matching, support vector machine, neural network, or the like.
- the control block of the data analysis system may be realized by a logic circuit (hardware) formed in an integrated circuit (IC chip) or the like, or may be realized by software using a CPU (Central Processing Unit).
- the data analysis system includes a CPU that executes a program (control program for the data analysis system) that is software that implements each function, and a ROM in which the program and various data are recorded so as to be readable by the computer (or CPU) (Read Only Memory) or a storage device (these are referred to as “recording media”), a RAM (Random Access Memory) for developing the program, and the like.
- a computer reads the said program from the said recording medium and runs it.
- a “non-temporary tangible medium” such as a tape, a disk, a card, a semiconductor memory, a programmable logic circuit, or the like can be used.
- the program may be supplied to the computer via an arbitrary transmission medium (such as a communication network or a broadcast wave) that can transmit the program.
- the present invention can also be realized in the form of a data signal embedded in a carrier wave in which the program is embodied by electronic transmission.
- the above program can be implemented in any programming language, for example, a script language such as Python, ActionScript, JavaScript (registered trademark), an object-oriented programming language such as Objective-C, Java (registered trademark), HTML5, or the like Can be implemented using other markup languages.
- a script language such as Python, ActionScript, JavaScript (registered trademark), an object-oriented programming language such as Objective-C, Java (registered trademark), HTML5, or the like
- any recording medium computer-readable recording medium that records the above program falls within the scope of the present invention.
- a data analysis system is a data analysis system for evaluating target data, the system including a memory, an input control device, and a controller, and the controller includes a plurality of targets.
- the data is evaluated, the evaluation corresponds to the relationship between each target data and a predetermined case, and an index that enables the ordering of the plurality of target data is generated by the evaluation.
- the index can be changed based on an input given via the input control device, the memory at least temporarily stores the plurality of target data to be evaluated by the controller, and the input control device
- the controller allows the user to input an order for the plurality of target data, and the order of the plurality of target data is changed based on the input.
- the input is to classify reference data different from the plurality of target data based on the relationship between the reference data and the predetermined case
- Classification is divided into a plurality of classification information according to the content of the reference data, at least one of the plurality of classification information is provided to the reference data by the input, Presenting the reference data to the user, and providing the controller with a combination of the reference data and the at least one classification information given to the presented reference data by the user input,
- the controller evaluates the degree to which each of the plurality of components included in the reference data contributes to the combination provided from the input control device.
- a pattern characterized by the reference data is extracted from the reference data according to the classification information given by the input, and the relationship between the target data and the predetermined case is extracted based on the extracted pattern.
- the index is determined by evaluating sex, the determined index is set in the target data, the plurality of target data is ranked according to the index, and the plurality of the ranked target data is notified to the user .
- the data analysis system is the data analysis system according to the first aspect, wherein the controller compares the index with a predetermined threshold, and based on the comparison result, the plurality of objects. Classification information related to the predetermined case is set for each data.
- the controller determines whether the plurality of target data satisfy a predetermined determination criterion, and From a plurality of target data determined to satisfy a predetermined criterion, a predetermined number of target data is selected, the predetermined number of target data is re-evaluated based on the pattern, and the re-evaluated result Based on this, the predetermined criterion is changed.
- the controller uses a combination of new reference data and the classification information given to the new reference data. Further, the pattern is updated by obtaining and evaluating the degree that at least some of the constituent elements of the new reference data contribute to the combination of the new reference data and the classification information, and based on the updated pattern Then, the relevance between the target data and the predetermined case is evaluated, and the index is determined.
- the controller calculates a reproduction rate based on a result of evaluating the plurality of target data, and the reproduction rate The pattern is repeatedly extracted from the reference data so as to rise.
- the data analysis system is the data analysis system according to the first to fifth aspects, wherein the controller corresponds to the classification information every time the combination is provided from the input control device.
- the pattern is updated sequentially by evaluating the degree that at least some of the constituent elements of the reference data contribute to the combination.
- the data analysis system is the data analysis system according to any one of the first to sixth aspects, wherein the controller defines a concept corresponding to at least a part of the constituent elements of the target data and the constituent elements and the constituent elements. Extraction is performed by referring to a database in which concepts are associated with each other, and a summary of the plurality of target data is output based on the extracted concepts.
- the data analysis system is the data analysis system according to any of the first to seventh aspects, wherein the controller extracts the plurality of target data for each subject included in the plurality of target data in common. Clustering.
- the target data includes at least user evaluation information for the predetermined case
- the controller includes the target data.
- the emotion for the predetermined case generated based on the evaluation information is extracted from the target data.
- the controller responds to a ratio of the target data associated with the classification information to all target data.
- the distribution of the ratio with respect to the result of evaluating each of the plurality of target data is displayed in a visually recognizable manner using gradation.
- the plurality of target data is information transmitted / received between a plurality of computers, and the controller Based on the result of analyzing the information to be obtained, the tightness between the plurality of computers is visualized.
- the data analysis system is the data analysis system according to the first to eleventh aspects, wherein the pattern can change over time, and the controller stores the reference data.
- the pattern is extracted from each of a plurality of reference data acquired every predetermined time, and the plurality of reference data acquired every predetermined time is evaluated, and each of the plurality of target data is evaluated every predetermined time based on the pattern. decide.
- the controller divides the target data into partial target data constituting at least a part of the target data.
- a plurality of partial target data is evaluated based on the extracted pattern, the indexes obtained by evaluating the plurality of partial target data are integrated, and the integrated indexes are used.
- Each of the plurality of target data is evaluated.
- the data analysis system is the data analysis system according to any one of the first to thirteenth aspects, wherein the controller has a relationship between the component and the classification information for classifying reference data including the component.
- the evaluation value for the component is calculated as a result of evaluating the degree based on the strength of the target data, and the target data is calculated based on the evaluation value calculated for at least some of the components of the target data.
- the plurality of target data are evaluated by determining the index so as to indicate the level of relevance between the predetermined case and the predetermined case.
- the controller is configured such that the constituent element and another constituent element different from the constituent element have the same reference.
- the correlation between the component and the other component is evaluated based on the frequency of appearance in at least a part of the data, and the plurality of target data are evaluated based on the correlation.
- the data analysis system is the data analysis system according to any one of the first to fifteenth aspects, wherein the controller is based on a model capable of predicting progress of a predetermined action related to the predetermined case.
- the following actions are presented from the indicators determined by evaluating multiple target data.
- the data analysis system is the data analysis system according to the first to sixteenth aspects, wherein the controller has the plurality of objects for each phase which is an index indicating each stage in which a predetermined action progresses. Data is evaluated, and the current phase is identified from the index determined for each phase by evaluating the plurality of target data.
- the target data is document data including at least a part of one or more sentences
- the controller includes the controller
- the structure of the sentence is analyzed, and the index is determined for the target data based on the analysis result.
- the data analysis system is the data analysis system according to the eighteenth aspect, wherein the controller determines the expression form of the sentence based on the result of analyzing the structure of the sentence, The target data is evaluated based on the determined result.
- the data analysis method is a data analysis method for evaluating target data, wherein each of the target data is evaluated based on an evaluation criterion. And a first step corresponding to the relationship between the target data and the predetermined case, and the evaluation generates an index that allows the plurality of target data to be ordered, and the index is determined according to an input given by the user. A second step that can be varied, a third step that stores at least temporarily the plurality of target data evaluated in the first step, and an input for ordering the plurality of target data The order of the plurality of target data changes according to the index that changes according to the input, and the input is different from the plurality of target data.
- the reference data is classified based on the relationship between the reference data and the predetermined case, the classification is divided into a plurality of classification information according to the content of the reference data, At least one of the plurality of classification information includes a fourth step that is given to the reference data by the input, a fifth step that presents the reference data to the user, and the input by the user, A sixth step for providing a combination of the at least one classification information given to the presented reference data and the reference data; and a combination in which a plurality of components included in the reference data are provided.
- a pattern in which the reference data is characterized according to the classification information given by the input by evaluating the degree of contribution to each A seventh step of extracting from the reference data, and using the extracted pattern as the evaluation criterion, evaluating the relevance between the target data and the predetermined case based on the pattern, and determining the index 8, a ninth step of setting the determined index in the target data, a tenth step of performing ranking of the plurality of target data according to the index, and the ranking An eleventh step of notifying the user of a plurality of target data.
- the data analysis program according to the first aspect of the present invention causes a computer to execute each step of the data analysis method according to the first aspect.
- the recording medium according to the first aspect of the present invention records the data analysis program according to the first aspect.
- a data analysis system includes a memory and one or more controllers capable of executing one or more programs stored in the memory, and includes a plurality of data sets included in a data set stored in the memory.
- the data analysis system for evaluating each of the data, wherein the controller acquires a data set including a plurality of combinations of reference data and classification information for classifying the reference data as a reference data set, and at least the reference data
- a plurality of constituent elements constituting a part learn a pattern included in the reference data by evaluating a degree of contribution to a plurality of combinations included in the acquired reference data set, respectively.
- the multiple target data Based on the multiple target data, the multiple target data The data were evaluated respectively, depending on the evaluation of the plurality of target data, respectively, to present the plurality of target data to the user via a predetermined display interface.
- the present invention can be widely applied to arbitrary computers such as personal computers, servers, workstations, mainframes, and the like.
- Client device 12 Management computer 14
- Business server 18 Storage system 22 Database
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本発明は、複数の対象データを評価するデータ分析に関し、当該評価は、各対象データと所定の事案との関連性に対応する。複数の対象データの序列化を可能とする指標が評価により生成され、ユーザが与えた入力に基づいて指標が変化する。複数の対象データの序列は、入力に基づいて変化する指標に応じて変化する。入力は、複数の対象データとは異なる参照データを、当該参照データと所定の事案との関連性に基づいて分類する。当該分類は、参照データの内容に応じて複数の分類情報に分けられたものであり、複数の分類情報のうちの少なくとも1つは、入力によって参照データに付与される。本発明は、入力により付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出する。本発明は、抽出したパターンに基づいて、対象データと所定の事案との関連性を評価して指標を決定し、決定した指標を対象データに設定し、指標に応じて複数の対象データを序列化し、序列化された複数の対象データをユーザに報知する。
Description
本発明は、データを分析するためのデータ分析システム等に関するものである。
コンピュータの急速な発展により社会の情報化が進んだ結果、企業・個人の活動に、膨大な量の情報(ビッグデータ)が関係するようになっている。これにより、ビッグデータの中から、所望の情報を分別する必要性が重要視されている。
ビッグデータから所望の情報を抽出するためのアプローチとして、例えば、データをあらかじめ分類することによって所望のデータを抽出するアプローチ、単純なテキスト検索に基づいて所望のデータを抽出可能とするアプローチ、自然言語処理に基づいて所望のデータを抽出するアプローチ等がある。
例えば、下記の特許文献1には、ビッグデータから情報を抽出するために、文書集合における抽出キーワード間の関係に基づき、関連が深い抽出キーワードを、柔軟に、近くに配置可能な仕組みを提供することを目的として、分野分類された文書に含まれるキーワードに対して他文書との弁別するための寄与度を算出し、この算出した寄与度に基づいて自己組織化マップを用いて、前記文書をユニットに分類させて表示した後、当該ユニットにおける前記文書に含まれるキーワードの出現頻度から当該キーワードの配置情報を算出して、ユニットに合わせて表示する装置が提案されている。
ユーザにとって必要な情報をビッグデータの中から的確に見つけるためには、ユーザの意図や検索の目的、さらに、ユーザにとってのデータ全体の印象など、キーワードや符号だけでは把握し切れないファクタに対する配慮も必要であるものの、上述の従来手法では到底不十分であるため、結局のところ、ユーザが膨大な情報一つ一つを分別する必要があり、多大な労力や時間を費やすことを避けることができなかった。
そこで、本発明は、ユーザにとって必要な情報を効率的に発見可能なデータ分析技術を提供することを目的とする。
本発明は、対象データを評価するデータ分析に関する発明であって、複数の対象データを評価し、当該評価は、例えば、各対象データと所定の事案との関連性に対応するものであってよい。また、前記複数の対象データの序列化を可能とする指標が、前記評価により生成され、ユーザが与えた入力に基づいて前記指標が変化する。
前記複数の対象データの序列は、例えば、前記入力に基づいて変化する前記指標に応じて変化する。前記入力は、例えば、前記複数の対象データとは異なる参照データを、当該参照データと前記所定の事案との関連性に基づいて分類する。当該分類は、例えば、前記参照データの内容に応じて複数の分類情報に分けられたものであり、前記複数の分類情報のうちの少なくとも1つは、前記入力によって前記参照データに付与される。
本発明は、例えば、前記参照データに含まれる複数の構成要素について、前記入力制御装置から提供された組み合わせにそれぞれ寄与する度合いを評価することによって、前記入力により付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出する。
本発明は、例えば、前記抽出したパターンに基づいて、前記対象データと前記所定の事案との関連性を評価して前記指標を決定し、前記決定した指標を前記対象データに設定し、前記指標に応じて前記複数の対象データを序列化し、前記序列化された複数の対象データをユーザに報知する。
序列化された複数の対象データによって、ユーザは、例えば、複数の対象データの間で、前記所定の事案との関連性の大小を知ることができる。ユーザが、複数の対象データ間での関連性の大小に同意できない場合には、参照データに付与される分類情報を変更すれば、この変更によって指標が変化し、さらに、変化された指標によって複数の対象データの序列が変わる。ユーザは、例えば、参照データ全体の内容を理解した後その内容に応じて、参照データに付与される分類情報を決定する。ユーザは、参照データの内容次第によって、参照データに複数ある分類情報のうちどの分類情報が最適かを悩むことはあり得る。ユーザは、例えば、前記序列化した複数の対象データによって、参照データにどの分類情報を付与すべきかを決めることができる。
本発明は、ユーザにとって必要な情報を効率的に発見することができるという効果を奏する。
本発明の実施形態を図面に基づいて説明する。
〔データ分析システムの構成〕
図1は、データ分析システムのハードウェア構成の一例を示すブロック図である。図1に例示するように、データ分析システムは、例えば、データ分析の主要処理を実行可能な業務サーバ14と、当該データ分析の関連処理を実行可能な一つ、又は、複数のクライアント装置10と、データ分析の対象となる対象データ、及び、当該対象データに対する評価・分類の結果を記録するデータベース22を備えるストレージシステム18と、クライアント装置10、及び、業務サーバ14に対して、データ分析のための管理機能を提供する管理計算機12とを備えている。
図1は、データ分析システムのハードウェア構成の一例を示すブロック図である。図1に例示するように、データ分析システムは、例えば、データ分析の主要処理を実行可能な業務サーバ14と、当該データ分析の関連処理を実行可能な一つ、又は、複数のクライアント装置10と、データ分析の対象となる対象データ、及び、当該対象データに対する評価・分類の結果を記録するデータベース22を備えるストレージシステム18と、クライアント装置10、及び、業務サーバ14に対して、データ分析のための管理機能を提供する管理計算機12とを備えている。
なお、本実施の形態において、「データ」は、データ分析システムによって処理可能となる形式で表現された任意のデータであってよい。このとき、上記データは、例えば、少なくとも一部において構造定義が不完全な非構造化データであってよく、自然言語によって記述された文章を少なくとも一部に含む文書データ(例えば、電子メール(添付ファイル・ヘッダ情報を含む)、技術文書(例えば、学術論文、特許公報、製品仕様書、設計図など、技術的事項を説明する文書を広く含む)、プレゼンテーション資料、表計算資料、決算報告書、打ち合わせ資料、報告書、営業資料、契約書、組織図、事業計画書など)、音声データ(例えば、会話・音楽などを録音したデータ)、画像データ(例えば、複数の画素またはベクター情報から構成されるデータ)、映像データ(例えば、複数のフレーム画像から構成されるデータ)などを広く含む。このとき、データの「構成要素」は、上記データの少なくとも一部を構成する部分データであってよく、例えば、文書を構成する形態素、キーワード、センテンス、および/または段落であったり、音声を構成する部分音声、ボリューム(ゲイン)情報、および/または音色情報であったり、画像を構成する部分画像、部分画素、および/または輝度情報であったり、映像を構成するフレーム画像、モーション情報、および/または3次元情報であったりしてよい。
クライアント装置10は、データを評価・分類する権限があるユーザ(評価権限ユーザ)に参照データを提供する。上記評価権限ユーザは、クライアント装置10を介して当該参照データを評価・分類するための入力を行うことができる。なお、本実施の形態において、上記「参照データ」は、例えば、ユーザによって分類情報が対応付けられたデータ(分類済みのデータ)であってよい。一方、「対象データ」は、当該分類情報が対応付けられていないデータ(参照データとしてユーザに提示されておらず、ユーザにとっては分類がなされていない未分類のデータ)であってよい。ここで、上記「分類情報」は、参照データを分類するために用いる識別ラベルであってよい。分類情報は、例えば、参照データが全体として所定の事案に関係することを示す「Related」ラベル、両者が特に関係することを示す「High」ラベル、および、両者が関係しないことを示す「Non-Related」ラベルのように、当該参照データを3つに分類する情報であったり、「良い」、「やや良い」、「普通」、「やや悪い」、および、「悪い」のように、当該参照データを5つなど複数のタイプに分類する情報であったりしてよい。
また、上記「所定の事案」は、データ分析システムがデータとの関連性を評価する対象を広く含み、その範囲は制限されない。例えば、所定の事案は、データ分析システムがディスカバリ支援システムとして実現される場合、ディスカバリ手続きが要求される本件訴訟であってよいし、犯罪捜査支援(フォレンジック)システムとして実現される場合、捜査対象となる犯罪であってよいし、電子メール監視システムとして実現される場合、不正行為(例えば、情報漏えい、談合など)であってよいし、医療応用システム(例えば、ファーマコビジランス支援システム、治験効率化システム、医療リスクヘッジシステム、転倒予測(転倒防止)システム、予後予測システム、診断支援システムなど)として実現される場合、医薬に関する事例・事案であってよいし、インターネット応用システム(例えば、スマートメールシステム、情報アグリゲーション(キュレーション)システム、ユーザ監視システム、ソーシャルメディア運営システムなど)として実現される場合、インターネットに関する事例・事案であってよいし、プロジェクト評価システムとして実現される場合、過去に遂行したプロジェクトであってよいし、マーケティング支援システムとして実現される場合、マーケティング対象となる商品・サービスであってよいし、知財評価システムとして実現される場合、評価対象となる知的財産であってよいし、不正取引監視システムとして実現される場合、不正な金融取引であってよいし、コールセンターエスカレーションシステムとして実現される場合、過去の対応事例であってよいし、信用調査システムとして実現される場合、信用調査する対象であってよいし、ドライビング支援システムとして実現される場合、車両の運転に関することであってよいし、営業支援システムとして実現される場合、営業成績であってよい。
クライアント装置10は、公知のコンピュータハードウェア資源を備えており、例えば、メモリ(例えば、ハードディスク、フラッシュメモリ等)と、コントローラ(CPU;Central Processing Unit)と、バスと、入出力インターフェース(例えば、キーバード、ディスプレイ等)と、通信インターフェースとを備えてよい。クライアント装置10は、LAN等の通信手段20によって、業務サーバ14および管理計算機12と上記通信インターフェースを介して通信可能に接続されている。また、上記メモリには、クライアント装置10を機能させるアプリケーションプログラムなどが記憶されており、上記コントローラは、当該アプリケーションプログラムを実行することにより、分類・評価の処理に必要な入出力を評価権限ユーザに対して可能にする。
業務サーバ14は、参照データに対する分類の結果に基づいて、当該参照データからパターン(データに含まれる抽象的な規則、意味、概念、様式、分布、サンプルなどを広く指し、いわゆる「特定のパターン」に限定されない)を学習し、当該パターンに基づいて対象データを評価する。すなわち、業務サーバ14は、ユーザに参照データを提示し、当該ユーザに当該参照データに対する分類情報の入力を許容し、ユーザの入力結果に基づいてパターンを学習し、学習結果に基づいて対象データに対する評価を可能にすることによって、ユーザが所望するデータを、多数の対象データから分別し得るようにしたものである。業務サーバ14は、クライアント装置10と同様に、ハードウェア資源として、例えば、メモリと、コントローラと、バスと、入出力インターフェースと、通信インターフェースとを備えてよい。また、上記メモリには、業務サーバ14を機能させるアプリケーションプログラムが記憶されており、上記コントローラは、当該アプリケーションプログラムに基づいて、データ分析のための処理を実行する。
管理計算機12は、クライアント装置10、ストレージシステム18、及び、業務サーバ14に対して、所定の管理処理を実行する。管理計算機12は、クライアント装置10と同様に、ハードウェア資源として、例えば、メモリと、コントローラと、バスと、入出力インターフェースと、通信インターフェースとを備えてよい。また、管理計算機12のメモリには、例えば、上記コントローラが管理処理を実行するためのアプリケーションプログラムが記憶されている。
ストレージシステム18は、例えば、ディスクアレイシステムから構成され、対象データと当該対象データに対する評価・分類の結果とを記録するデータベース22を備えてよい。業務サーバ14とストレージシステム18とは、DAS(Direct Attached Storage)方式、又は、SAN(Storage Area Network)によって接続(16)されている。
なお、図1に示されるハードウェア構成は、あくまで例示に過ぎず、データ分析システムは、他のハードウェア構成によっても実現され得る。例えば、業務サーバ14において実行される処理の一部または全部がクライアント装置10において実行される構成であってもよいし、ストレージシステム18が業務サーバ14に内蔵される構成であってもよい。データ分析システムを実現可能なハードウェア構成が多様に存在し得ることは、当業者に理解されるところであり、いずれか(例えば、図1に例示されるような構成)に限定されない。
〔データ分析システムの機能〕
図2は、業務サーバ14の機能構成の一例を示す機能ブロック図である。図2に例示するように、業務サーバ14は、例えば、データベース22に保存された対象データから、所定の基準(例えば、ランダム)にしたがって、一部の対象データを複数サンプリングし、これを参照データとして提供する参照データ提供部102と、参照データに対する分類や、参照データ以外のデータに対する序列化や分類のための情報等をクライアント装置10の表示手段に出力させる表示処理部103と、参照データに対して、評価者権限を持ったユーザからの分類情報の設定(ラベル付け)を受け付ける分類情報受付部104と、分類情報に基づいて、複数の参照データを分類情報ごとに分類し、分類情報ごとの参照データに含まれるパターンを学習する学習部105とを備えてよい。
図2は、業務サーバ14の機能構成の一例を示す機能ブロック図である。図2に例示するように、業務サーバ14は、例えば、データベース22に保存された対象データから、所定の基準(例えば、ランダム)にしたがって、一部の対象データを複数サンプリングし、これを参照データとして提供する参照データ提供部102と、参照データに対する分類や、参照データ以外のデータに対する序列化や分類のための情報等をクライアント装置10の表示手段に出力させる表示処理部103と、参照データに対して、評価者権限を持ったユーザからの分類情報の設定(ラベル付け)を受け付ける分類情報受付部104と、分類情報に基づいて、複数の参照データを分類情報ごとに分類し、分類情報ごとの参照データに含まれるパターンを学習する学習部105とを備えてよい。
業務サーバ14は、例えば、データの構成要素および当該構成要素の評価値をデータベース22に記憶させる記憶実行部201と、データベース22に対する検索処理を行って、パターンを参照データ以外の対象データから探索する探索部106と、対象データと所定の事案との関連性の高低を示す指標を対象データごとに算出し、当該指標に基づいて複数の対象データを序列化する演算部107と、対象データを序列化した結果に基づいて、当該対象データに対して分類情報を付与する分類部108と、をさらに備えてよい。
なお、上記において、****部と表記した構成は、業務サーバ14が備えたコントローラが、プログラム(データ分析プログラム)を実行することによって実現する機能構成であるため、****部を、****処理または****機能と言い換えてもよい。また、****部をハードウェア資源によって代替することもできるため、これらの機能ブロックがハードウェアのみ、ソフトウェアのみ、またはそれらの組み合わせによって多様な形で実現できることは当業者には理解されるところであり、いずれかに限定されるものではない。
〔データ分析システムの動作〕
図3は、データ分析システムの動作例を示すフローチャートである。管理者権限を有する管理ユーザは、参照データを抽出(サンプリング)するリクエスト(抽出リクエスト300)を、管理計算機12に与える。抽出リクエスト300は、例えば、データベース22に記録されているデータの中から所定数のデータを、参照データとしてランダムにサンプリングするリクエストであったり、所定範囲のデータ(例えば、データの更新日時が3日以内のもの)から所定数のデータを、参照データとしてサンプリングするリクエストであったりしてよい。なお、参照データとして抽出されるデータの割合または数は、管理ユーザが適宜設定することができる。
図3は、データ分析システムの動作例を示すフローチャートである。管理者権限を有する管理ユーザは、参照データを抽出(サンプリング)するリクエスト(抽出リクエスト300)を、管理計算機12に与える。抽出リクエスト300は、例えば、データベース22に記録されているデータの中から所定数のデータを、参照データとしてランダムにサンプリングするリクエストであったり、所定範囲のデータ(例えば、データの更新日時が3日以内のもの)から所定数のデータを、参照データとしてサンプリングするリクエストであったりしてよい。なお、参照データとして抽出されるデータの割合または数は、管理ユーザが適宜設定することができる。
管理計算機12は、抽出リクエスト300に基づいて抽出コマンド302を生成し、当該抽出コマンド302を業務サーバ14に送信する。業務サーバ14が備えた参照データ提供部102は、管理計算機12からの抽出コマンド302に基づいて、データベース22から所定数の参照データを抽出する(304)。
業務サーバ14の参照データ提供部102は、抽出された参照データを特定のクライアント装置10(抽出コマンド302で特定されたクライアント装置)に送る(312)。当該特定のクライアント装置10は、評価分類入力インターフェースを起動させ、評価分類入力画面を評価権限ユーザに提示する。図4は、当該評価分類入力画面の一例である。評価分類入力画面は、例えば、参照データのリスト500と、対象データごとの分類情報を示すチェックボックス502とを含んでよい。
評価権限ユーザが、複数の参照データを一覧可能にするリストから1つの参照データを選択すると、図5に示されるように、例えば、当該選択された対象データの詳細506が表示されるようになっている。参照データの詳細506は、例えば、データのID510と、データの名称512と、対象データの内容(文書データのテキスト等)506とから構成されてよい。
評価権限ユーザは、参照データの詳細506を参照して参照データの内容を把握した後、参照データごとのラベルを示すチェックボックスにチェックを入れることにより、当該参照データを分類することができる。例えば、データが所定の事案に関係すると評価権限ユーザが考える場合、「Related」を示すチェックボックスにチェックを入れ、特に関係すると考える場合、「High」を示すチェックボックスにチェックを入れ、関係しないと考える場合、「Non-Related」を示すチェックボックスにチェックを入れる。チェックボックスにチェックを入れると、その情報が業務サーバに送られ(314)、業務サーバ14は、分類情報と参照データの組み合わせをデータベース22に記録する。
業務サーバ14が備えた学習部105は、データベース22に記録された上記組み合わせを参照し、分類情報ごとに参照データの集合から構成要素を抽出する(316)。学習部105は、例えば、同じ分類情報が付された複数の参照データに所定の頻度以上で出現する形態素(キーワード)を、構成要素として抽出することができる。
また、学習部105は、所定の評価基準(例えば、伝達情報量)に基づいて、抽出した構成要素を評価することができる(318)。例えば、学習部105が文書データ(テキストデータ)から構成要素としてキーワードを抽出した場合、上記所定の評価基準に基づいて、当該キーワードの評価値を算出することにより当該キーワードを評価する。ここで、上記「評価値」は、例えば、当該キーワードが参照データと分類情報との組み合わせに寄与する度合い(構成要素が各データに出現する分布・頻度の、分類情報に応じた偏り)を示す特徴量であってよい。これにより、学習部105は、参照データに対するユーザの入力に基づいて、パターンを学習の結果として当該参照データから取得することができる。
業務サーバ14が備えた記憶実行部201は、学習部105が抽出した構成要素と、当該構成要素の評価値と、閾値とをデータベース22に記憶させる。次に、業務サーバ14は、構成要素と対象データとを比較して、対象データと所定の事案との関連性の高低を評価し、対象データを序列化する。具体的には、探索部106が、データベース22から複数の対象データを順番に取り込み、当該対象データに含まれる複数の構成要素を順番に読み込み、当該対象データに各構成要素が出現しているか否かを探索する(320)。当該構成要素が対象データに出現している場合、演算部107が、当該構成要素の評価値に基づいて対象データの指標を算出することによって、複数の対象データを当該指標の大小に基づいて序列化する(322)。ここで、序列化とは、例えば、対象データと当該対象データに対して算出された指標とを対応付けることであってよい。
当該処理において、演算部107は、対象データに含まれる構成要素の有無を表現したベクトル(いわゆる「Bag-of-words」)を生成する。例えば、対象データに「価格」というキーワードが含まれている場合、演算部107は、「価格」に対応する当該ベクトルの次元に「1」をセットする。演算部107は、当該ベクトルと各構成要素の評価値(評価値)との内積を計算する(次式)ことにより、上記指標を算出する。
なお、演算部107は、上記のように、対象データごとに1つの指標を算出することもできるし、対象データを所定の区切り(例えば、センテンス、段落、所定の長さで分割された部分音声、所定数のフレームを含む部分動画など)で分けた単位ごとに1つの指標を算出することもできる(詳細については後述する)。また、演算部107は、例えば、対象データのうち、データベース22に事前に登録されたキーワード、関連用語、または学習部105において選定された構成要素を含まない対象データを、指標算出の対象から事前に排除することができる。
分類部108は、対象データと所定の事案との関連性を示す指標(当該関連性に基づいて複数の対象データを序列化可能とする指標)に基づいて、対象データに対して分類情報を設定する。例えば、分類部108は、対象データの指標が所定の閾値以上である場合、当該対象データに対して分類情報を設定することができる。
分類部108は、例えば、序列化された複数の対象データをユーザにそれぞれ提示し、当該ユーザが当該複数の対象データに分類情報をそれぞれ設定する入力を許容したり、ユーザが自動分類された分類情報を確認し、これを変更できるようにしたりしてもよい。指標が上位であるほど、対象データが所定の事案に関連する期待度は高く、対象データに「Related」、または「High」のラベル(分類情報)が設定される可能は高くなるが、例えば、対象データの内容にそれを妨げる情報(例えば、特定の単語)がある場合には、対象データに「Related」のラベルを設定すべきでない場合もあるからである。
業務サーバ14は、対象データの管理テーブルをデータベース22に登録する。図6は、対象データを格納する管理テーブルの一例である。対象データの夫々(データ1,2,3・・・・)について、例えば、対象データID、対象データの名称、指標、分類情報などが記録されている。業務サーバ14における対象データに対する評価とは、例えば、対象データの指標を計算したり、指標に基づいて複数の対象データの夫々にラベルを設定したり、複数の対象データを指標の大小に基づいて識別できるようにさせたり等、複数の対象データと所定の事案との関連性の高低に関する所定の演算処理を含むものである。
業務サーバ14は、データベース22に格納された管理テーブルをクライアント装置10に送信する。クライアント装置10は、指標が大きい順に、対象データをソートして表示する。クライアント装置10は、例えば、対象データに対する分類情報の付与を、自動で行うか、手動で行うかの入力欄を提示することができる。ユーザが手動付与を選択すると、評価権限ユーザは、各対象データについて、「Related」、「High」、又は、「Non-Related」のラベルが入力可能となる。管理者は、例えば、序列化された全対象データの上位所定数、あるいは、所定パーセントの対象データに対して分類のためのラベルを設定することもできる。
〔学習の実行パターン〕
管理者は、学習部105に、学習の実行パターンを予め設定することができる。当該実行パターンには、例えば、(1)参照データ提供部102によって抽出された参照データの全てに分類情報が入力された後、業務サーバ14が参照データのパターンを学習し、当該パターンに基づいて全ての対象データに対して指標を算出する第1の態様、(2)業務サーバ14が、複数の参照データの夫々に分類情報が入力されるたびに学習を行い、当該学習のたびに対象データの指標を算出する(すなわち、参照データ一つ一つの分類に基づいて上記パターンを逐次更新しながら、対象データの指標を算出する)第2の態様、(3)クライアント装置10が、参照データ提供部102によって抽出された参照データ以外のデータと分類情報との組み合わせを学習部105に供給し、業務サーバ14が、上記パターンを逐次更新しながら対象データの指標を算出する(例えば、評価権限ユーザが対象データに分類情報を設定した場合、当該対象データと分類情報との組み合わせを学習部105にフィードバックして上記パターンを更新する)第3の態様など、複数の態様がある。上記第2の態様においては、参照データ一つ一つへの分類情報の付与が行われる都度、対象データの序列が変更されるため、分類権限を有するユーザは、対象データの序列の変動推移を確認することができる。上記第3の態様においては、対象データを分類した結果が学習部105で得られるパターンに逐次反映されるため、データを評価する精度を逐次向上させることができるという付加的な効果をさらに奏する。
管理者は、学習部105に、学習の実行パターンを予め設定することができる。当該実行パターンには、例えば、(1)参照データ提供部102によって抽出された参照データの全てに分類情報が入力された後、業務サーバ14が参照データのパターンを学習し、当該パターンに基づいて全ての対象データに対して指標を算出する第1の態様、(2)業務サーバ14が、複数の参照データの夫々に分類情報が入力されるたびに学習を行い、当該学習のたびに対象データの指標を算出する(すなわち、参照データ一つ一つの分類に基づいて上記パターンを逐次更新しながら、対象データの指標を算出する)第2の態様、(3)クライアント装置10が、参照データ提供部102によって抽出された参照データ以外のデータと分類情報との組み合わせを学習部105に供給し、業務サーバ14が、上記パターンを逐次更新しながら対象データの指標を算出する(例えば、評価権限ユーザが対象データに分類情報を設定した場合、当該対象データと分類情報との組み合わせを学習部105にフィードバックして上記パターンを更新する)第3の態様など、複数の態様がある。上記第2の態様においては、参照データ一つ一つへの分類情報の付与が行われる都度、対象データの序列が変更されるため、分類権限を有するユーザは、対象データの序列の変動推移を確認することができる。上記第3の態様においては、対象データを分類した結果が学習部105で得られるパターンに逐次反映されるため、データを評価する精度を逐次向上させることができるという付加的な効果をさらに奏する。
〔構成要素の再評価〕
前述したように、学習部105は、参照データの少なくとも一部を構成する複数の構成要素が、参照データセット(参照データと当該参照データを分類する分類情報との組み合わせを複数含むデータセット)における当該組み合わせに寄与する度合いを、所定の基準(例えば、伝達情報量)に基づいて、上記評価値として評価する。
前述したように、学習部105は、参照データの少なくとも一部を構成する複数の構成要素が、参照データセット(参照データと当該参照データを分類する分類情報との組み合わせを複数含むデータセット)における当該組み合わせに寄与する度合いを、所定の基準(例えば、伝達情報量)に基づいて、上記評価値として評価する。
このとき、学習部105は、「Related」または「High」のラベルが設定されたデータの指標が、これらのラベルが設定されないデータの指標よりも大きくなるまで、構成要素を選定するとともに、当該構成要素の評価値を繰り返し評価し、当該構成要素の評価値を修正することができる。これによって、データ分析システムは、「Related」または「High」の分類情報が付された複数のデータに出現し、データとラベルとの組み合わせに影響がある構成要素を見つけ出すことができる。なお、伝達情報量は、例えば、所定の単語の出現確率と、所定の分類情報の出現確率とを用い、所定の定義式から算出される。具体的には、学習部105は、例えば、以下の式を用いて構成要素の評価値wgtを算出する。

また、学習部105は、「Related」が設定された参照データの指標の最低値と、「Non-Related」が設定された参照データの指標の最高値との中間値を、対象データに対して「Related」の設定の有無を自動判定する際の閾値(所定の基準値)とすることができる。
学習部105は、例えば、再現率が所定の目標値になるまで、評価値の再評価を継続するようにしてもよい。ここで、再現率とは、所定数のデータに対して発見すべきデータが占める割合(網羅性)を示す指標であり、例えば、全データの30%に対して再現率が80%である場合、発見すべきデータ(例えば、訴訟関連資料)の80%が、指標上位30%のデータの中に含まれていることを示す。データ分析システムを用いず、人がデータに総当たり(リニアレビュー)した場合、発見すべきデータの量は人がレビューした量に比例するため、この比例からの乖離が大きいほどシステムのデータ分析性能が良いことになる。演算部107は、データの指標に基づいて、データと所定の事案との関連性の判断に関する再現率を算出する再現率算出機能と、参照データから構成要素を再選定する再選定機能とを有することができる。
学習部105は、序列化された対象データの再現率が目標値を下回っていた場合、再現率が目標値を上回るまで、構成要素を参照データから再選定し、演算部107は、再選定された構成要素に基づいて対象データの序列化を再度実行することを繰り返す。構成要素を再選定する場合、前回選定した構成要素を除いた構成要素を選定するようにしてもよいし、前回選定した構成要素の一部を新たな構成要素に置き換えてもよい。また、演算部107が、再選定された構成要素で対象データの指標を計算する場合、一つ又は複数の構成要素の評価値を変更するようにしてもよい。また、演算部107は、再選定した構成要素とその評価値とを用いて各データの指標(第2指標)を算出し、構成要素の再選定前に得られた第1指標と第2の指標とから、再現率を計算し直してもよい。
次に、再現率を再計算する処理の具体例について説明する。まず、参照データ提供部102が、データベース22の対象データからレビュア(評価権限ユーザ)に提示するための参照データをランダムにサンプリングする。次に、表示処理部103が抽出された参照データをクライアント装置10の画面表示部に出力させる。レビュアは、画面表示部に表示された参照データをレビューし、参照データに対して分類情報を付与する。学習部105は、参照データを解析し、構成要素を選定する。具体的には、学習部105は、共通の分類情報が付与された参照データに共通して出現する構成要素をN個抽出し、抽出した構成要素のそれぞれについて評価値を算出する。例えば、1番目に抽出した構成要素の評価値をWgt1、2番目をWgt2、N番目をWgtnとする。学習部105は、このWgt1からWgtnの評価値を用いて、形態素を選定する。構成要素を評価値の降順に並び替え、以下の式を満たし、その総和が目標値(Kとする:Kは任意の定数)に到達するまで評価値の上位から順番にm個の形態素(構成要素)を選択する。

次に、演算部107が、選定されたm個の構成要素を含むデータを対象データから抽出し、当該対象データに含まれる構成要素の評価値に基づいて、各対象データの指標を算出する。演算部107は、指標の降順にデータを序列化し、全データの指標上位A%(Aは任意の定数)のデータを決定する。演算部107は、A%に含まれるデータのうち、所定の基準値以上の指標を有し、参照データと同じ「Related」または「High」のラベル(分類情報)が設定されたデータを特定し、A%に含まれるデータ数とラベルが設定されたデータ数との比から再現率X1(Xn:n回目に算出した再現率)を算出する。
次に、演算部107は、目標値K以上に再現率X1が計算されたか否かを判定する。計算されたと判定する場合、処理を終了する。そうでない場合、学習部105は構成要素を再選定する。具体的には、先に選定したN個の構成要素から、前記m個の構成要素を除いた構成要素から、以下の式を満たし、その総和が目標値に到達するまで評価値の上位から順番にi個の構成要素を選択する。
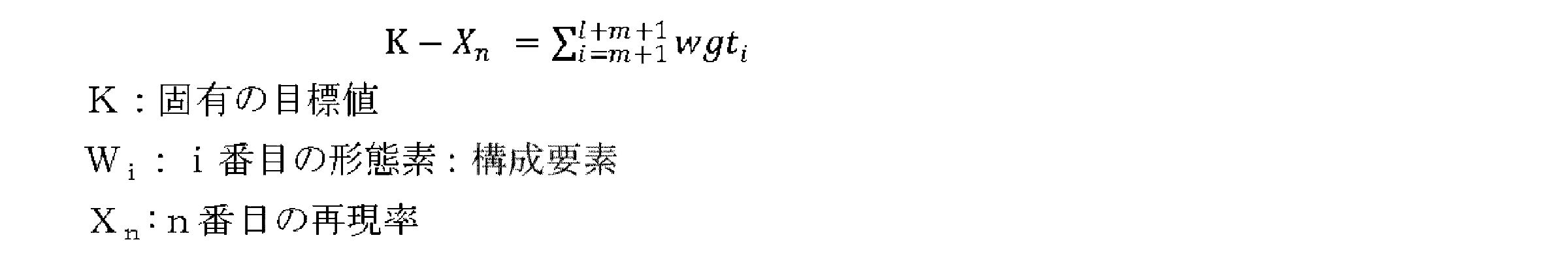
演算部107は、再選定された構成要素を含むデータを抽出し、各データの第2の指標S1rを計算し、初回に計算した指標S1と第2の指標S1rとの残差Δ1(Δ1=S1r-S1)を用いて、以下の式から各文書の合成指標S2を算出する。

合成指標S2を用いて、演算部107は再現率を再度算出し、目標値Kを上回るまで、再現率の再計算を繰り返す。これにより、目標再現率まで、データ序列化における精度を向上させることが可能となる。
なお、上記において「再現率」として説明した箇所は、適合率であってもよい。ここで、「適合率」(Precision Rate)は、データ分析システムによって発見されたデータに対して、真に発見すべきデータが占める割合(正確性)を示す指標である。例えば、「全データを30%処理した時点で、適合率が80%」と表現した場合、指標上位30%のデータに対して、発見すべきデータの占める割合が80%であることを示す。また、データ分析システムは、例えば、対象データに対して算出された再現率と指標の順位(例えば、データ数によって当該順位を除算した規格化順位であってもよい)との関係に基づいて、ユーザが当該対象データを確認する際に必要なデータ数を算出することができる。
〔構成要素間の相関を考慮した指標算出〕
演算部107は、対象データに含まれる第1構成要素の評価値(第1構成要素の評価値)と、当該対象データに含まれる第2構成要素の評価値(第2構成要素の評価値)との相関(共起)を考慮して、対象データの指標を決定してもよい。例えば、第1の構成要素と第2の構成要素との結び付きが強い場合、演算部107は、第1構成要素が対象データに出現した場合、当該対象データにおいて第2構成要素が出現する頻度を考慮して、指標を計算できる。このような相関関係として、例えば、談合・カルテル等の不正検証を所定の事案として想定した場合、入札、価格、調整という各キーワードが同じ通信記録データに出現し易い事が経験上分かっているため、各キーワード夫々の評価値を加算した値に、これらデータの組み合わせに基づく所定値を加算するなどして、対象データの指標を増加させればよい。これにより、データ分析システムは、複数の構成要素間の相関関係をも考慮して指標を算出できるため、より高い精度で所定の事案に関連する対象データを抽出することができる。
演算部107は、対象データに含まれる第1構成要素の評価値(第1構成要素の評価値)と、当該対象データに含まれる第2構成要素の評価値(第2構成要素の評価値)との相関(共起)を考慮して、対象データの指標を決定してもよい。例えば、第1の構成要素と第2の構成要素との結び付きが強い場合、演算部107は、第1構成要素が対象データに出現した場合、当該対象データにおいて第2構成要素が出現する頻度を考慮して、指標を計算できる。このような相関関係として、例えば、談合・カルテル等の不正検証を所定の事案として想定した場合、入札、価格、調整という各キーワードが同じ通信記録データに出現し易い事が経験上分かっているため、各キーワード夫々の評価値を加算した値に、これらデータの組み合わせに基づく所定値を加算するなどして、対象データの指標を増加させればよい。これにより、データ分析システムは、複数の構成要素間の相関関係をも考慮して指標を算出できるため、より高い精度で所定の事案に関連する対象データを抽出することができる。
演算部107は、構成要素の出現情報に、当該構成要素と他の構成要素との相関(共起等)を反映させることによって、対象データの指標を算出することができる。演算部107は、例えば、構成要素の出現管理ベクトルに他の構成要素との相関を示す相関マトリクスを乗じる。相関マトリクスは、例えば、「価格」というキーワードが対象データに出現した場合、「価格」に対して他のキーワード(例えば「調整」)の出現しやすさ(すなわち、相関)を、相関マトリクスの情報で表す正方行列である。
相関マトリクスは、参照データに基づいて最適化されてよい。例えば、対象データに「価格」というキーワードが出現する場合、他のキーワード(「調整」)の出現数を0~1の間に正規化した値(すなわち、最尤推定値)が、相関マトリクスに格納されている。したがって、データ分析システムは、複数の構成要素の相関をデータの指標に反映させるための相関ベクトルを得ることができる。
演算部107は、例えば、下記の式に示されるように、全ての相関ベクトルについて合算した値に基づいて、データの指標を算出する。より具体的には、演算部107は、前述の式に代えて、下記の式に示されるように、相関ベクトルの合算値とキーワードに対する評価値のベクトルWとの内積を算出することによって、対象データの指標を算出することができる。

ここで、Cは相関マトリクスを表し、ssはs番目のキーワードベクトルを表す。また、TFnorm(合算した値)は、下記の式に示されるように計算する。

ここで、TFiはi番目のキーワードの出現頻度(Term Frequency)を表し、sjsはs番目のキーワードベクトルのj番目の要素を表す。
上記式をまとめると、演算部107は、以下の式を計算することによって対象データごとに指標を算出する。

ここで、wiは評価値ベクトルWのi番目の要素である。
〔部分分割した各部分データに対する指標算出〕
演算部107は、対象データ全体の指標を算出することによってデータを序列化するだけでなく、例えば、対象データを複数のパーツ(例えば、データに含まれるセンテンスまたは段落(部分対象データ))に分割し、学習したパターンに基づいて各部分データを評価(すなわち、部分対象データの指標を算出)することによって、当該部分対象データを序列化する。そして、演算部107は、複数の部分対象データの指標を統合(例えば、複数の部分対象データの指標の中から最大値を抽出して全体データの指標としたり、複数の部分対象データの指標の平均を全体データの指標としたり、複数の部分対象データの指標を大きい順から所定数選択して合算して全体データの指標としたり等)し、当該統合された指標を対象データの評価結果とすることもできる。これにより、データ分析システムは、活用目的に適した有用データを対象データの中からより的確に選択することができる。
演算部107は、対象データ全体の指標を算出することによってデータを序列化するだけでなく、例えば、対象データを複数のパーツ(例えば、データに含まれるセンテンスまたは段落(部分対象データ))に分割し、学習したパターンに基づいて各部分データを評価(すなわち、部分対象データの指標を算出)することによって、当該部分対象データを序列化する。そして、演算部107は、複数の部分対象データの指標を統合(例えば、複数の部分対象データの指標の中から最大値を抽出して全体データの指標としたり、複数の部分対象データの指標の平均を全体データの指標としたり、複数の部分対象データの指標を大きい順から所定数選択して合算して全体データの指標としたり等)し、当該統合された指標を対象データの評価結果とすることもできる。これにより、データ分析システムは、活用目的に適した有用データを対象データの中からより的確に選択することができる。
〔フェーズ分析〕
データ分析システムは、所定の事案が進展する各段階を示すフェーズを分析することができる。例えば、所定の事案が談合行為である場合、当該談合行為は、関係構築フェーズ(競合他社と関係を構築する段階)、準備フェーズ(競合他社と競合に関する情報を交換する段階)、競合フェーズ(顧客へ価格を提示し、フィードバックを得て、競合他社とコミュニケーションを取る段階)の順に進むことが通常である(経験的・理論的に既知である)ため、上記フェーズには上記3つのフェーズが設定されてよい。データ分析システムは、予め設定された複数のフェーズに対してそれぞれ準備される複数種類の参照データから、当該複数のフェーズに対応する複数のパターンをそれぞれ学習し、当該複数のフェーズにそれぞれ基づいて対象データを分析することによって、例えば「分析対象である組織が、現在どのフェーズにあるか」を特定することができる。
データ分析システムは、所定の事案が進展する各段階を示すフェーズを分析することができる。例えば、所定の事案が談合行為である場合、当該談合行為は、関係構築フェーズ(競合他社と関係を構築する段階)、準備フェーズ(競合他社と競合に関する情報を交換する段階)、競合フェーズ(顧客へ価格を提示し、フィードバックを得て、競合他社とコミュニケーションを取る段階)の順に進むことが通常である(経験的・理論的に既知である)ため、上記フェーズには上記3つのフェーズが設定されてよい。データ分析システムは、予め設定された複数のフェーズに対してそれぞれ準備される複数種類の参照データから、当該複数のフェーズに対応する複数のパターンをそれぞれ学習し、当該複数のフェーズにそれぞれ基づいて対象データを分析することによって、例えば「分析対象である組織が、現在どのフェーズにあるか」を特定することができる。
データ分析システムが、フェーズを特定する流れを詳細に説明する。まず、データ分析システムは、予め設定された複数のフェーズに対してそれぞれ準備される複数種類の参照データを参照し、当該複数種類の参照データにそれぞれ含まれる構成要素を評価し、当該構成要素と当該構成要素を評価した結果(例えば、評価値)とを対応付けて、フェーズごとにデータベース22に格納する(すなわち、当該複数のフェーズに対応する複数のパターンをそれぞれ学習する)。したがって、例えば、「関係構築フェーズ」(フェーズ1)では、「日程」、「調整」などのキーワード評価値が「実行フェーズ」(フェーズ3)よりも大きかったり、「準備フェーズ」(フェーズ2)では、「競合製品」、「調査」などのキーワード評価値が「関係構築フェーズ」(フェーズ1)よりも大きかったりする。また、ステージごとに異なるキーワードが設定される場合もある。
次に、データ分析システムは、上記フェーズごとに学習されたパターンに基づいて対象データを分析することにより、複数のフェーズに対してそれぞれ指標を算出する。そして、データ分析システムは、当該指標が各フェーズに対して予め設定された所定の判定基準(例えば、閾値)を満たしているか否か(例えば、当該指標が当該閾値を超過しているか否か)を判定し、満たしていると判定する場合、当該フェーズに対応するカウント値を増加させる。最後に、データ分析システムは、当該カウント値に基づいて現在のフェーズを特定する(例えば、最大のカウント値を有するフェーズを、現在のフェーズとする)。または、フェーズごとに算出された指標が、当該フェーズに設定された所定の判定基準を満たしていると判定した場合、データ分析システムは、当該フェーズを現在のフェーズとして特定することもできる。
データ分析システムは、予め設定された所定の判定基準(例えば、閾値)を、データ適応的に再設定することができる。このとき、演算部107は、複数の対象データを序列化した結果を利用する。演算部107は、例えば、対象データの指標と当該指標のランキング(すなわち、指標を昇順で並べた場合における順位)との関係に対して回帰分析を行い、当該回帰分析の結果に基づいて閾値を決定することができる。
演算部107は、例えば、指数型分布族に属する関数(y=eαx+β(eは自然対数の底、α及びβは実数である))を用いて、上記回帰分析を行うことができる。演算部107は、複数の対象データに対して算出した指標と当該指標のランキングとに基づいて、(例えば、最小二乗法により)上記αおよびβの値を決定する。なお、出願人は、この上記関数を用いたモデルについて、決定係数、F検定、及びt検定を用いた検証を行い、当該モデルの妥当性・最適性を確認している。
図7は、指標とランキングとに基づいて回帰分析することにより得られた、指数関数モデルの特性例を示すグラフである。図8は、指数関数モデルを再評価して得られた、上記指数関数モデルの特性例を示すグラフである。図7および図8において、横軸は指標を示し、縦軸はランキングを対数スケールで示す。したがって、指数関数を用いたフィッティングカーブ(回帰曲線)は、図7および図8において直線で示されており、縦軸の下ほどランキングが高く、上ほどランキングが低い。
管理者は、ランキングに対して予め閾値を設定しておく。例えば、図7において、管理者は、演算部107に当該閾値として1.E-03(=0.001=0.1%)を設定しておく。演算部107は、この閾値に対応する、指数関数によって示される指標を特定し、当該指標をあるフェーズにおける閾値(所定の判定基準)として設定することにより、当該フェーズに対して予め設定されていた閾値を変更することができる。このように、データ分析システムは、序列化された対象データを回帰分析によって再評価することにより、フェーズごとに算出される指標に対する閾値(所定の判定基準)を、学習によって得られたパターンに基づいて対象データを評価した結果に適合するように、動的に変更することができる。また、データ分析システムは、対象データのデータイメージを継続的にモニタすることによって、フェーズの進行を継続的に監視することもできる。
さらに、データ分析システムは、対象データを評価した結果が評価権限ユーザによって検証された場合、当該検証結果に基づいて、学習部105が実行する学習処理を調整することできる。例えば、評価権限ユーザが、データ分析システムによって高い指標が与えられた対象データを検証したところ、当該対象データには高い指標が与えられるべきではない判断した場合、当該評価権限ユーザは、当該対象データに「Non-Related」のラベルを付与する。学習部105は、当該対象データを参照データとしてフィードバックし、例えば、当該参照データに含まれる構成要素の評価値を増減させたり、構成要素の追加・削除を行ったりして再学習を実行し、パターンを更新する。
そして、学習部105は、更新したパターンに基づいて対象データの指標とランキングを再度算出し、当該算出結果に対して再度回帰分析を行う(図8)。学習部105は、新たな回帰分析の結果に基づいて、図7における説明と同様の処理を実行することにより、フェーズごとに修正した閾値を設定する。
〔時系列情報を利用した分析〕
(1)予測モデルに基づくフェーズ進展予測
データ分析システムは、所定の事案に関係する所定の行為の進展を予測可能なモデルに基づいて、複数の対象データを評価することによって決定した指標から、次の行為を予測・提示することができる。データ分析システムは、例えば、第1フェーズ(例えば、関係構築フェーズ)に対して算出された指標と、第2フェーズ(例えば、準備フェーズ)に対して算出された指標とを変数とする回帰モデルを仮定し、予め最適化した回帰係数に基づいて、第3フェーズ(例えば、競合フェーズ)に進む可能性(例えば、確率)を予測することができる。
(1)予測モデルに基づくフェーズ進展予測
データ分析システムは、所定の事案に関係する所定の行為の進展を予測可能なモデルに基づいて、複数の対象データを評価することによって決定した指標から、次の行為を予測・提示することができる。データ分析システムは、例えば、第1フェーズ(例えば、関係構築フェーズ)に対して算出された指標と、第2フェーズ(例えば、準備フェーズ)に対して算出された指標とを変数とする回帰モデルを仮定し、予め最適化した回帰係数に基づいて、第3フェーズ(例えば、競合フェーズ)に進む可能性(例えば、確率)を予測することができる。
(2)所定時間ごとの学習
時間の経過とともにその性質が変化するデータ(例えば、時間の経過とともに進行する病状を記録した電子カルテなど)を分析する場合、データ分析システムは、所定時間ごとに区切られた参照データ(例えば、第1区間の対象データ、第2区間の対象データ・・・)からそれぞれパターンを学習し(すなわち、当該所定時間ごとに構成要素と当該構成要素を評価した結果とを取得し)、当該パターンにそれぞれ基づいて、対象データを分析することができる。
時間の経過とともにその性質が変化するデータ(例えば、時間の経過とともに進行する病状を記録した電子カルテなど)を分析する場合、データ分析システムは、所定時間ごとに区切られた参照データ(例えば、第1区間の対象データ、第2区間の対象データ・・・)からそれぞれパターンを学習し(すなわち、当該所定時間ごとに構成要素と当該構成要素を評価した結果とを取得し)、当該パターンにそれぞれ基づいて、対象データを分析することができる。
〔データ構造に基づく分析〕
演算部107は、対象データの構造を解析し、当該解析した結果を対象データの評価に反映させることができる。例えば、対象データが少なくとも一部に文書データを含む場合、演算部107は、文書データのセンテンスの表現形態(例えば、当該センテンスが肯定形であるか、否定形であるか、消極形であるかなど)を解析して解析結果を対象データの指標に反映させることができる。ここで、肯定形とは、例えば、センテンスの述語が「美味しい」であり、否定形とは、「不味い」または「美味しくない」であり、消極形とは、「美味しいとはいえなかった」または「不味いとはいえかった」などである。
演算部107は、対象データの構造を解析し、当該解析した結果を対象データの評価に反映させることができる。例えば、対象データが少なくとも一部に文書データを含む場合、演算部107は、文書データのセンテンスの表現形態(例えば、当該センテンスが肯定形であるか、否定形であるか、消極形であるかなど)を解析して解析結果を対象データの指標に反映させることができる。ここで、肯定形とは、例えば、センテンスの述語が「美味しい」であり、否定形とは、「不味い」または「美味しくない」であり、消極形とは、「美味しいとはいえなかった」または「不味いとはいえかった」などである。
演算部107は、例えば、肯定形に「+α」を設定し、否定形に「-β」を設定し、消極形に「+θ」を設定し(α、β、θ:同一又は異なる数値であってよい)、これらのパラメータを用いて、対象データに対してそれぞれ算出した指標を調整することができる。または、演算部107は、対象データに含まれるセンテンスが否定型であることを検知した場合、例えば、当該センテンスをキャンセルすることにより、当該センテンスに含まれる構成要素を指標算出の基礎にしない(当該構成要素を考慮しない)ことができる。これによって、データ分析システムは、データの構造解析結果を指標に反映させることができるため、より高い精度でデータを評価することができる。
演算部107は、対象データの構造として、センテンスの構文を解析して、その解析結果を対象データの指標に反映させることができる。演算部107は、例えば、形態素(構成要素)がセンテンスの主語、目的語、述語のどこに位置するかによって、当該形態素の評価値に優劣を設けてもよい。形態素の構文中の位置はベクトルによって制御されればよく、主語であるか、目的語であるか、述語であるかに応じて、形態素の評価値に優劣を付ける。演算部107は、形態素の出現ベクトルと評価値とから対象データの指標を算出する際、形態素の構文中の位置の制御ベクトルを合わせて、対象データの指標を求めることができる。
〔感情分析〕
データ分析システムは、対象データからユーザの感情を抽出することができる。一般に、オンライン商品サイトや、レストランガイドなどでは、ユーザのコメントとともに、商品・サービスに対する当該ユーザの評価が記載されていることが多い。そこで、データ分析システムは、コメントと評価とに基づいて参照データを作成し、当該参照データに基づいて対象データを評価することによって、商品・サービスに対してユーザが好印象を抱いたか否かを推測することができる。概念的には、当該評価が高い商品・サービスに対するコメントには、好感情の単語(例えば、「良かった」、「楽しかった」など)が用いられることが多く、当該評価が低い商品・サービスに対するコメントには、悪感情の単語(例えば、「悪かった」、「つまらなった」など)が用いられることが多いため、データ分析システムは、コメントと評価との組み合わせから成る参照データからパターンを学習し、当該パターンに基づいて、コメントのみから成る対象データから当該コメントを生成したユーザの感情を、感情指標として抽出することができる。
データ分析システムは、対象データからユーザの感情を抽出することができる。一般に、オンライン商品サイトや、レストランガイドなどでは、ユーザのコメントとともに、商品・サービスに対する当該ユーザの評価が記載されていることが多い。そこで、データ分析システムは、コメントと評価とに基づいて参照データを作成し、当該参照データに基づいて対象データを評価することによって、商品・サービスに対してユーザが好印象を抱いたか否かを推測することができる。概念的には、当該評価が高い商品・サービスに対するコメントには、好感情の単語(例えば、「良かった」、「楽しかった」など)が用いられることが多く、当該評価が低い商品・サービスに対するコメントには、悪感情の単語(例えば、「悪かった」、「つまらなった」など)が用いられることが多いため、データ分析システムは、コメントと評価との組み合わせから成る参照データからパターンを学習し、当該パターンに基づいて、コメントのみから成る対象データから当該コメントを生成したユーザの感情を、感情指標として抽出することができる。
まず、分類部108は、参照データを感情の優劣に基づいて分類する。例えば、分類部108は、消費者の評価が5段階に行われている場合、段階評価に応じて、参照データに分類情報(例えば、「好印象」または「悪印象」を示す2分類のラベルであったり、「良い」、「やや良い」、「普通」、「やや悪い」、「悪い」を示す5分類のラベルであったりしてよい)を設定する。次に、学習部105は、分類情報が設定された参照データから構成要素を抽出する。特に、学習部105は、感情表現を示す構成要素(例えば、形容詞、形容動詞、副詞などに対応する形態素)を抽出することができる。
そして、学習部105は、感情表現を示す構成要素についての感情マーカー(感情評価情報、ユーザが好印象を抱くか、悪印象を抱くかを示す指標)を下記のようにして生成する。すなわち、学習部105は、好印象と分類された1以上の参照データにおいて、感情表現を示す構成要素(構成要素A)が出現する回数AFをカウントする。そして、学習部105は、この参照データにおいて構成要素Aが出現する頻度RFPを算出する。

ここで、NPは、好印象に分類された参照データに含まれる全構成要素数である。
次に学習部105は、悪印象に分類された参照データにおいて、構成要素Aが出現する回数ANをカウントし、参照データにおいて構成要素Aが出現する頻度RFNを算出する。

ここで、NNは、悪印象に分類された参照データに含まれる全構成要素数である。
そして、学習部105は、上記二つの式を用いて算出された頻度を用いて構成要素Aの感情マーカー(感情判定指標値P(A))を次のように算出する。

さらに、学習部105は、感情判定指標値P(A)が1よりも大きい場合に、構成要素Aを好印象を抱くデータに用いられることが多い構成要素として、その感情マーカーとして「+1」を指定し、感情判定指標値P(A)が1よりも小さい場合に、構成要素Aを、悪印象を抱くデータに用いられることが多い構成要素として、その感情マーカーとして「-1」を指定してデータベース22に格納する。例えば、「良い」、「きれい」、「おいしい」というような語には「+1」がつきやすく、「悪い」、「汚い」、「まずい」というような語には「-1」が設定される傾向となる。
演算部107は、対象データから感情マーカーが設定されている構成要素を抽出し、抽出した構成要素それぞれの感情マーカー値を取得する。演算部107は、構成要素が対象データに出現する回数だけ、感情マーカー値を加算する。例えば、「良い」という構成要素に対して設定されている感情マーカーが「+1」で、未分類データに5回出現する場合に、未分類データの「良い」という構成要素に基づく感情指標を「5」とする。また、例えば、「悪い」という構成要素に対して設定されている感情マーカーが「-1」で、未分類データに3回出現する場合に、未分類データの「悪い」という構成要素に基づく感情指標を「-3」とする。
演算部107は、否定表現または誇張表現が構成要素に存在するか否かを判定しながら感情指標を算出する。否定表現とは、構成要素を否定する表現であり、例えば、「良くない」、「おいしくない」というような表現である。このような表現がある場合には、これらは逆の表現として扱い、例えば、「良くない」であれば「悪い」とし、「おいしくない」であれば「まずい」として扱う。なお、ここでは、逆の表現として扱うこととしたが、これは、例えば、「良い」という表現に対して、「+1」の感情マーカーが設定されている場合に、これを負の値にすることとしてもよい。あるいは、感情マーカーとして設定されている値を所定量(例えば、1.5)だけ減少させることとしてもよい。また、更には、否定を否定する、すなわち、二重否定表現があるか否かを検出し、二重否定表現がある場合には、構成要素を肯定的に判定することとしてもよい。
また、誇張表現とは、構成要素をより誇張(強調)する表現であり、例えば、「とても」、「すごく」、「大変」というような表現のことを指す。このような誇張表現が構成要素にかかっている場合には、その感情マーカー値を所定倍(例えば、2倍)にして感情指標を算出する。例えば、「とてもおいしい」という表現がある場合であって、「おいしい」の感情マーカー値が「+1」であるときには、この表現に対する感情指標を「+2」とする(増大させる)。なお、所定倍にする構成要素は、誇張表現がかかっている構成要素のみである。
このようにして、演算部107は、下記式に示すように、全ての構成要素に基づく感情指標を算出し、合算して対象データの指標Sを算出する。

ここで、siは、i番目の構成要素の感情マーカーである。
演算部107は、感情指標に基づいて、対象データを序列化する。指標が、0よりも大きい場合には、対象データは好印象を抱かれやすい判定され、指標が0未満である場合に、対象データは悪印象が抱かれやすいと判定される。序列化された複数の対象データは、ユーザに提示される。
〔ヒートマップの表示〕
データ分析システムは、所定の管理機能を備えている。当該管理機能は、管理計算機12の管理プログラムによって実行される。管理機能の一例として、評価権限ユーザが複数いる場合、各人の分類の精度を管理画面によって表示する形態がある。
データ分析システムは、所定の管理機能を備えている。当該管理機能は、管理計算機12の管理プログラムによって実行される。管理機能の一例として、評価権限ユーザが複数いる場合、各人の分類の精度を管理画面によって表示する形態がある。
図9は、データ分析システムの管理画面の一例を示す模式図である。当該管理画面は、演算部107のデータの指標から表示処理部103によって作成される。表示処理部103は管理計算機12のモニタに表示画面260を出力する。表示画面260は、例えば、指標の予め定められた各範囲のそれぞれに対応づけられた複数の区画、及び、比率を表示する表示領域262を有する。比率とは、指標の範囲に含まれる対象データの総数と、対象データの総数のうち、所定の事案と関係するとして、「Related」のラベルが評価権限ユーザによって設定された対象データの数との比である。
区画は、例えば、指標が0~999、1000~1999のように、1000ずつ分かれて設定され、各区画は、例えば、指標は200ごとに細分化されている。各細分化された小区画ごとに、比率が色調等の付加情報の形態の変化(グラデーション)によって表現される。例えば、色調が寒色系であるほど、比率が低い、すなわち、対象データに「Related」のラベルがレビュアによって設定された率が低く(Non-Relatedである率が高く)、暖色系であるほど「Related」のラベルがレビュアによって設定された率が高いことを示している。例えば、表示領域262の縦方向に評価権限ユーザの識別欄266があり、関連性指標欄268は、評価権限ユーザごとに区別されている。データ分析システムは、所定の分類情報(ラベル)が対応付けられたデータが、すべてのデータに対して占める割合に応じたグラデーションを用いて、複数のデータをそれぞれ評価した結果に対する当該割合の分布を視認可能に表示することができる。
管理権限ユーザは、表示画面260に表示される各小区画の色を参照することで、各評価権限ユーザの分類精度の適否を把握し易くなる。例えば、ある評価権限ユーザは指標が小さい領域にも拘らず「Related」のフラグを設定する割合が高く、一方、ある評価権限ユーザは指標が高い領域にも拘らず「Non-Related」のフラグを設定する割合が高く、これら評価権限ユーザによる分類は精度が低いことを示している。
〔ネットワーク分析〕
データ分析システムは、複数のノード(人、組織、コンピュータ)間の相互関係(データの送受信や交換等)を可視化することができる。この場合、表示処理部103は、例えば、演算部107によるデータの序列化の結果に基づいて、所定の事案に関連する複数の人物の関係性を、当該関連性の程度が分かるように、クライアント装置10に表示させることができる。
データ分析システムは、複数のノード(人、組織、コンピュータ)間の相互関係(データの送受信や交換等)を可視化することができる。この場合、表示処理部103は、例えば、演算部107によるデータの序列化の結果に基づいて、所定の事案に関連する複数の人物の関係性を、当該関連性の程度が分かるように、クライアント装置10に表示させることができる。
図10に示すように、表示処理部103は、各ノードを円形に表示すると共に、一つノードと他のノードとの間に関係性がある場合、当該ノードと当該他ノードとの間を矢印で結合して表示する。各ノードの大きさは、ノード間の関係性の大小を示す。すなわち、ノードの大きさが大きいほど、ノード30との関係性が高いことを示す。図10の例においては、ノード31、ノード36、ノード35、ノード32、ノード33、ノード34の順にノードの小さくなっている。したがって、図10の例においては、ノード31、ノード36、ノード35、ノード32、ノード33、ノード34の順にノード30との関係性が高いことを示す。関係性の大小、データの指標の大小、又は、ラベルの優劣に基づいて決定される。ノードの大小に代えて、或いは、これと共に、ノード間を結合する矢印若しくは線分の太さや色等を変化させることもできる。
ノードはURLやEメールアドレスによって特定されてもよい。図10はノード30を中心にした相関関係表示であるが、表示処理部103は、中心ノードを変更することも出来る。また、表示処理部は一つの画面に複数のノードを中心ノードとして設定することもできる。また、データのタイムスタンプ、送信時刻、着信時刻、更新時刻などの時間情報をノード間の相関関係に分かるように表示することもできる。ノード間の相関関係の発生が現在時刻に近いほど、ノード間の連結表示の形態(色調)を変えればよい。
また、データ分析システムは、所定の動作を表す第1の構成要素がデータに含まれるか否かを判定し、含まれると判定する場合、当該所定の動作の対象を表す第2の構成要素を特定する。例えば、「仕様を確定する」という文章が上記データに含まれる場合、当該文章から「仕様」および「確定する」という構成要素(単語)を抽出し、「確定する」という所定の動作を表す第1の構成要素(動詞)の対象である「仕様」という第2の構成要素(目的語)を特定する。次に、上記データ分析システムは、上記第1の構成要素および第2の構成要素を含むデータの属性(性質・特徴)を示すメタ情報(属性情報)と、当該第1の構成要素および第2の構成要素とを関連付ける。ここで、上記メタ情報は、データが有する所定の属性を示す情報であり、例えば、上記データが電子メールである場合、当該電子メールを送信した人物の名前、受信した人物の名前、メールアドレス、送受信された日時などであってよい。そして、データ分析システムは、2つの構成要素とメタ情報とを対応付けて、クライアント装置10に表示させる。
例えば、「技術を交流する」という文章が電子メール(データ、通信情報)に含まれており、「技術」(第2の構成要素)および「交流する」(第1の構成要素)という単語が抽出された場合、データ分析システムは、上記「技術」および「交流する」と、上記電子メールを送受信した人物の名前(例えば、「人物A」および「人物B」)とを関連付けて表示する。これにより、「人物A」と「人物B」とが、ある「技術」についての「交流」を企図していることが推測できる。さらに、例えば、「仕様を確定する」という文章が、上記電子メールに添付されたプレゼンテーション資料に含まれており、「仕様」(第2の構成要素)および「確定する」(第1の構成要素)という単語が抽出された場合、データ分析システムは、上記「仕様」および「確定する」と、上記プレゼンテーション資料が作成された日時(例えば、2015年3月30日16時30分)とを関連付けて表示する。これにより、「人物A」と「人物B」とが、ある「技術」についての「交流」を企図する中で、2015年3月30日16時30分の時点において、当該「技術」の「仕様」を「確定」しようとしていることが推測できる。
本発明のデータ分析システムによって、複数の対象データが序列化されるものの、全ての対象データの内容に目を通すことは時間を要することになり、そもそも容易いことにはならない。そこで、データ分析システムは、ユーザに対象データの内容を短時間で把握できるようにするための支援機能を実現することができる。
〔概念の抽出〕
演算部107はトピック(コンテキスト)検出機能を実行する。演算部107は、図11(A)に示すように、対象データの中から予め選定された概念の下位概念の構成要素を含むデータを抽出し、抽出した各対象データ(電子メール等)の内容の要約を適度な抽象度でそれぞれ作成し、作成した要約に基づいて対象データの内容を確認できるようにするために対象データをクラスタリングし、対象データのクラスタリングの結果を例えば図11(B)のような形式でユーザに提示する。
演算部107はトピック(コンテキスト)検出機能を実行する。演算部107は、図11(A)に示すように、対象データの中から予め選定された概念の下位概念の構成要素を含むデータを抽出し、抽出した各対象データ(電子メール等)の内容の要約を適度な抽象度でそれぞれ作成し、作成した要約に基づいて対象データの内容を確認できるようにするために対象データをクラスタリングし、対象データのクラスタリングの結果を例えば図11(B)のような形式でユーザに提示する。
このようなトピック検出機能は、準備フェーズ及び適用フェーズの2段階のフェーズにより実現される。準備フェーズは、予めユーザにより設定された各対象概念の下位概念のキーワードだけを抽出し、抽出したキーワードをそれぞれ対応する対象概念に対応付けた上述の対象概念抽出用データベースを作成するためのフェーズである。また適用フェーズは、準備フェーズで作成した対象概念抽出用データベースを利用して該当する対象データの内容を上位概念で表現した要約を作成し、作成した要約に基づいて該当する対象データをクラスタリングして結果をユーザからの要求に応じて表示するフェーズである。
準備フェーズでは、まず、ユーザが、対象データから検出したい話題(トピック)に応じた幾つかの対象概念を選定し、選定した対象概念を予めデータ分析システムに登録する。例えば、検出したいトピックが「不正」及び「不満」である場合、図12に示すように、概念のカテゴリを「行動」、「感情」、「性質や状態」、「リスク」及び「金銭」の5つに分けて、例えば「行動」については「復讐する」及び「軽蔑する」など、「感情」については「苦しむこと」及び「腹を立てること」など、「性質や状態」については「鈍重だ」及び「心や態度が悪い」など、「リスク」については「脅す」及び「だます」など、「金銭」については「人の労働に対して支払われるお金」などの概念を対象概念としてそれぞれ設定する。
演算部107は、このようにして対象概念が設定されると、登録された対象概念ごとに、その下位概念を表すキーワードをデータベース22の辞書上で検索し、当該検索により検出した個々のキーワードをそれぞれ対応する対象概念に対応付けた上述の対象概念抽出用データベースを作成する。
一方、適用フェーズでは、演算部107は、上述のようにして作成した対象概念抽出用データベースを利用して、対象データの中から、対象概念抽出用データベースに登録されたキーワードをテキスト内に含む対象データを抽出する。また、演算部107は、このようにして抽出した対象データについて、そのテキストの内容をそのとき検出したキーワードの上位概念を用いて表した要約を作成する。
例えば図11の場合、(A)に示すように、「e-mail_1」については、「監視システム受注」という箇所から「システム」、「販売」及び「する」という対象概念が抽出され、「e-mail_2」については、「会計システム導入」という箇所から「システム」、「販売」及び「する」という上位概念が抽出されるため、これら「e-mail_1」及び「e-mail_2」については、いずれも「システム 販売 する」という要約が作成されることになる。
そして、表示処理部103は、この後、ユーザからの要求があった場合に、このようにして作成した該当する対象データの要約に基づいて、対象データをクラスタリングしてその結果をユーザに提示する。
例えば、図11の場合、上述のように「e-mail_1」及び「e-mail_2」について「システム 販売 する」という同じ要約が作成されるため、これら「e-mail_1」及び「e-mail_2」が同一のグループに分類される。そして、この分類結果が例えば(B)のように要約を「内容」とする形式で表示される。このようにして、ユーザは、対象データの内容を把握することができる。
〔その他の構成〕
分類情報受付部104によって、複数の分類情報の夫々について、参照データと分類情報との組み合わせが設定される。すなわち、分類情報と参照データとの組み合わせが複数設定される。また、学習部105は、例えば、同一の分類情報が付された複数の参照データに共通して出現する構成要素を、参照データと分類情報との組み合わせに寄与する度合いを考慮して評価し、評価結果(評価値)が所定以上の構成要素を、複数の参照データに共通するパターンの一つとして選定する。なお、参照データに対する評価・分類の方針・基準は、評価者ごとに異なる場合があるため、データ分析システムは、参照データに対する評価・分類に複数の評価者の参加を許容するようにしてもよい。
分類情報受付部104によって、複数の分類情報の夫々について、参照データと分類情報との組み合わせが設定される。すなわち、分類情報と参照データとの組み合わせが複数設定される。また、学習部105は、例えば、同一の分類情報が付された複数の参照データに共通して出現する構成要素を、参照データと分類情報との組み合わせに寄与する度合いを考慮して評価し、評価結果(評価値)が所定以上の構成要素を、複数の参照データに共通するパターンの一つとして選定する。なお、参照データに対する評価・分類の方針・基準は、評価者ごとに異なる場合があるため、データ分析システムは、参照データに対する評価・分類に複数の評価者の参加を許容するようにしてもよい。
データ分析システムは、ユーザによる入力に基づいて、序列化された対象データに分類情報を設定してよい。または、データ分析システムは、対象データに対する評価結果に応じて(例えば、対象データの指標が当該所定の評価基準(例えば、指標が所定の閾値を超過しているか否か)を満足する場合)、ユーザの入力を要することなく、当該対象データに分類情報を与えてもよい。上記評価基準は、管理権限を有するユーザによって設定されてもよいし、参照データ又は対象データの測定結果を回帰分析して結果に基づいて、データ分析システムによって設定されてもよい。また、データ分析システムは、例えば、所定の分類情報にしたがって分類され、同じ分類情報が付された複数の対象データから有用な構成要素を抽出し、当該構成要素に基づいて対象データを参照データと同じように分類できるか否かを解析することができる。構成要素の抽出は、例えば、複数の分類情報の夫々でグルーピングされた対象データごとに行われてよい。
既述のとおり、学習部105で選定された、形態素を始めとする構成要素は、データベース22に記録される。また、業務サーバ14は、過去の分類処理の結果から、所定の事案の優劣との関連性が高く、対象データに含まれていれば、「関係あり」と分類され得る構成要素を、事前に、データベース22に登録することもできる。
また、過去の分類処理の結果から、所定の事案との関連性に係る符号が付与された対象データと関連性が高い構成要素をデータベース22に登録しておくことも可能である。一度データベース22に登録された形態素は、データ分析システムが行う学習の結果によって増減される他、手動によっても追加登録及び削除が可能である。
データ分析システムは、複数のパターン(データの構成要素と当該構成要素を評価した結果との組み合わせ)を学習し、データベース22に保持することができる。例えば、データ分析システムは、所定の事案の種類ごとに上記組み合わせを保持することができる。これにより、例えば、データ分析システムが犯罪捜査支援システムとして実現され、犯罪の証拠となり得るデータを分析する場合と、データ分析システムがインターネット応用システムとして実現され、ウェブページを分析する場合とでは、データ分析システムは、互いに異なる複数のパターンを保持することになる。このとき、ユーザが当該所定の事案の種類を入力し、データ分析システムが当該種類に応じたパターンに基づいて対象データを処理することができる。
データ分析システムは、参照データに含まれる構成要素の評価値を算出する際に、全ての構成要素の仮の評価値を算出し、その後に、評価値を算出する対象の構成要素の仮の評価値に、当該構成要素以外の構成要素の仮の評価値を加味して、最終的な評価値を算出することができる。具体的には、データ分析システムは、複数の構成要素各々に評価値を算出し(すなわち、当該複数の構成要素をそれぞれ評価し)、当該複数の構成要素のうちの一つである第1構成要素に対して算出された評価値に対して、当該複数の構成要素のうちの他の一つである第2構成要素に対して算出された評価値を反映させるように、当該第1構成要素に対して算出された評価値を更新し、当該更新された評価値を当該第1構成要素に対応付けて、当該第1構成要素の評価値としてデータベース22に格納する。これにより、データ分析システムは、データを評価するための構成要素の評価値を、他の構成要素との関連性も考慮した上で算出することができるため、より高い精度でデータを分析することができる。
データ分析システムは、参照データに含まれる構成要素を所定の基準(例えば、伝達情報量)に基づいてそれぞれ評価し、当該評価された結果に基づいて、対象データに対して、所定の事案との関連性の高低を示すポジティブ指標(主指標)をそれぞれ算出する。次に、データ分析システムは、上記ポジティブ指標が低い対象データ(例えば、当該ポジティブ指標がほとんどゼロとなるデータ)の中から所定数のデータを(例えば、ランダムに)部分データとして選出し、当該選出されたデータに含まれる構成要素を上記所定の基準に基づいてそれぞれ評価する。そして、データ分析システムは、当該評価された結果に基づいて、対象データと上記所定の事案との関連性の弱さを示すネガティブ指標(副指標)を、当該対象データに対して算出する。最後に、データ分析システムは、上記ポジティブ指標およびネガティブ指標にしたがって、対象データを抽出する(例えば、ポジティブ指標が高く、ネガティブ指標が低いデータから順に並ぶように、データ全体を序列化する)。
以上のように、データ分析システムは、所定の事案と関連することを示す指標(ポジティブ指標)を導出するだけでなく、当該ポジティブ指標にしたがって、当該所定の事案と関連しない(当該所定の事案との関連性が低い)ことを示す指標(ネガティブ指標)も導出する。これにより、データ分析システムは、より高い精度でデータを分析することができる。
〔データ分析システムのアプリケーション例〕
データ分析システムは、例えば、情報資産活用システム(プロジェクト評価システム)として実現され得る。すなわち、このデータ分析システムは、企業・熟練者が有する情報資産(データ)を、状況に応じて(動的に)抽出することによって、当該情報資産を活用可能なシステムとして実現され得る。これにより、例えば、(1)開発期間の短縮化が望まれる開発現場を効率化するために、過去に開発した製品に関する情報を当該開発の要件に応じて再利用したり、(2)熟練技術者が有する専門知識に基づいて、有用な情報資産を特定したりすることができる。すなわち、データ分析システムは、ユーザにとって必要な情報(過去の情報資産)を効率的に発見することができる。
データ分析システムは、例えば、情報資産活用システム(プロジェクト評価システム)として実現され得る。すなわち、このデータ分析システムは、企業・熟練者が有する情報資産(データ)を、状況に応じて(動的に)抽出することによって、当該情報資産を活用可能なシステムとして実現され得る。これにより、例えば、(1)開発期間の短縮化が望まれる開発現場を効率化するために、過去に開発した製品に関する情報を当該開発の要件に応じて再利用したり、(2)熟練技術者が有する専門知識に基づいて、有用な情報資産を特定したりすることができる。すなわち、データ分析システムは、ユーザにとって必要な情報(過去の情報資産)を効率的に発見することができる。
データ分析システムは、例えば、インターネット応用システム(例えば、スマートメールシステム、情報アグリゲーション(キュレーション)システム、ユーザ監視システム、ソーシャルメディア運営システムなど)として実現され得る。この場合、当該データ分析システムは、データ(例えば、ユーザがSNSに投稿したメッセージ、ウェブサイトに掲載されたお勧め情報、ユーザまたは団体のプロフィールなど)を所定の評価基準(例えば、当該ユーザの嗜好と他のユーザの嗜好とが類似しているか否か、当該ユーザの嗜好とレストランの属性とが一致しているか否かなど)に基づいて評価することによって、例えば、当該ユーザと気の合いそうな他のユーザを一覧表示させたり、当該ユーザの嗜好に合ったレストランの情報を提示したり、当該ユーザに危害を与えかねない団体を警告したりすることができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、ドライビング支援システムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、車載センサ・カメラ・マイクなどから取得されるデータ)を所定の評価基準(例えば、熟練ドライバによる運転中に、当該熟練ドライバが着目した情報か否かなど)に基づいて評価することによって、例えば、運転を安全・快適にし得る有用な情報を自動的に抽出することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、金融システム(例えば、不正取引監視システム、株価予測システムなど)として実現され得る。この場合、当該データ分析システムは、データ(例えば、銀行に対する届け出書類、株価の時価など)を所定の評価基準(例えば、不正目的のおそれがあるか否か、株価が上昇するか否かなど)に基づいて評価することによって、例えば、不正目的を有する届け出を摘発したり、将来の株価を予測したりすることができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、医療応用システム(例えば、ファーマコビジランス支援システム、治験効率化システム、医療リスクヘッジシステム、転倒予測(転倒防止)システム、予後予測システム、診断支援システムなど)として実現され得る。この場合、当該データ分析システムは、データ(例えば、電子カルテ、看護記録、患者の日記など)を所定の評価基準(例えば、患者の特定の危険行動を取るか否か、ある薬剤が病気に対して効能を発揮したか否かなど)に基づいて評価することによって、例えば、患者が危険な状態(例えば、転倒するなど)に陥ることを予測したり、薬剤の効能を客観的に評価したりすることができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、メール制御システム(スマートメールシステム)として実現され得る。この場合、当該データ分析システムは、データ(例えば、電子メール、添付ファイルなど)を所定の評価基準(例えば、当該電子メールに返信する必要があるか否かなど)に基づいて評価することによって、例えば、大量のメールの中から重要なメール(アクションを要するメール)を抽出することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、ディスカバリ支援システムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、ドキュメント、電子メール、表計算データなど)を所定の評価基準(例えば、本件訴訟におけるディスカバリ手続きにおいて当該データを提出すべきか否かなど)に基づいて評価することによって、例えば、本件訴訟に関連する文書のみを法廷に提出することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、フォレンジック支援システムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、ドキュメント、電子メール、表計算データなど)を所定の評価基準(例えば、当該データが犯罪行為を立証可能な証拠であるか否かなど)に基づいて評価することによって、例えば、当該犯罪行為を立証する証拠を抽出することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、メール監視システム(メール監査支援システム)として実現され得る。この場合、当該データ分析システムは、データ(例えば、電子メール、添付ファイルなど)を所定の評価基準(例えば、当該電子メールを送受信したユーザが不正行為を行おうとしているか否かなど)に基づいて評価することによって、例えば、情報漏洩・談合などの不正行為の予兆を発見することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、知財評価システムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、特許公報、発明を要約した文書、学術論文など)を所定の評価基準(例えば、当該特許公報は所与の特許を拒絶・無効にする証拠となり得るか否かなど)に基づいて評価することによって、例えば、多数の文献(例えば、特許公報、学術論文、インターネットに掲載された文章)の中から無効資料を抽出することができる。このとき、データ分析システムは、例えば、無効対象となる特許の各請求項と「Related」ラベル(分類情報)との組み合わせ、および、当該特許とは異なる無関係な特許の各請求項と「Non-Related」ラベル(分類情報)との組み合わせを参照データとして取得し、当該参照データからパターンを学習し、多数の文献(対象データ)に対して指標を算出する(例えば、特許公報の段落ごとに指標を算出し、当該指標の上位から所定数分を合算することによって、当該特許公報の指標とする)ことによって、当該対象データを評価することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、コールセンターエスカレーションシステムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、電話の通話履歴、録音された音声など)を所定の評価基準(例えば、過去の対応事例と類似するか否かなど)に基づいて評価することによって、例えば、過去の対応事例の中から現在の状況に最適な対応方法を抽出することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、マーケティング支援システムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、企業・個人のプロフィール、製品情報など)を所定の評価基準(例えば、当該個人は男性か女性か、消費者は製品に対して好感を抱いているか否かなど)に基づいて評価することによって、例えば、ある製品に対する市場の評価を抽出することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
また、データ分析システムは、例えば、信用調査システムとして実現され得る。この場合、当該データ分析システムは、データ(例えば、企業のプロフィール、企業の業績に関する情報、株価に関する情報、プレスリリースなど)を所定の評価基準(例えば、当該企業が倒産するか否か、当該企業が成長するか否かなど)に基づいて評価することによって、例えば、企業の成長・倒産を予測することができる。すなわち、データ分析システムは、ユーザにとって必要な情報を効率的に発見することができる。
このように、本発明のデータ分析システムは、ディスカバリ支援システム、犯罪捜査支援システム、電子メール監視システム、医療応用システム、インターネット応用システム、情報資産活用システム、マーケティング支援システム、知財評価システム、コールセンターエスカレーションシステム、信用調査システム、営業支援システム、ドライビング支援システムなど、データを所定の評価基準(所定の事案に関連するか否か)に基づいて評価することによって、ユーザにとって必要な情報を効率的に発見する任意のシステムとして実現され得る。特に、本発明のデータ分析システムは、複数のデータを含むデータ群を、「人間の思考および行動の結果によるデータの集合体」として捉え、例えば、人間の行動に関連する分析、人間の行動を予測する分析、人間の特定の行動を検知する分析、人間の特定の行動を抑制する分析などを行うことによって、データからパターンを抽出し、当該パターンと所定の事案との関連性を評価することによって、ユーザにとって必要な情報を効率的に発見することができる。
なお、本発明のデータ分析システムが応用される分野によっては、当該分野に特有の事情を考慮して、例えば、データに前処理(例えば、当該データから重要箇所を抜き出し、当該重要箇所のみをデータ分析の対象とするなど)を施したり、データ分析の結果を表示する態様を変化させたりしてよい。こうした変形例が多様に存在し得ることは、当業者に理解されるところであり、すべての変形例が本発明の範疇に入る。
〔データ分析システムが文書データ以外のデータを処理する例〕
上記した実施の形態においては、データ分析システムが文書データを分析する例を主に説明したが、当該データ分析システムは、文書データ以外のデータ(例えば、音声データ、画像データ、映像データなど)を分析することもできる。
上記した実施の形態においては、データ分析システムが文書データを分析する例を主に説明したが、当該データ分析システムは、文書データ以外のデータ(例えば、音声データ、画像データ、映像データなど)を分析することもできる。
例えば、音声データを分析する場合、データ分析システムは、当該音声データ自体を分析の対象としてもよいし、音声認識により当該音声データを文書データに変換し、変換後の文書データを分析の対象としてもよい。前者の場合、データ分析システムは、例えば、音声データを所定の長さの部分音声に分割して構成要素とし、任意の音声分析手法(例えば、隠れマルコフモデル、カルマンフィルタなど)を用いて当該部分音声を識別することによって、当該音声データを分析できる。後者の場合、任意の音声認識アルゴリズム(例えば、隠れマルコフモデルを用いた認識方法など)を用いて音声を認識し、認識後のデータに対して、実施の形態において説明した手順と同様の手順で分析できる。
また、画像データを分析する場合、データ分析システムは、例えば、画像データを所定の大きさの部分画像に分割して構成要素とし、任意の画像認識手法(例えば、パターンマッチング、サポートベクターマシン、ニューラルネットワークなど)を用いて当該部分画像を識別することによって、当該画像データを分析できる。
さらに、映像データを分析する場合、データ分析システムは、例えば、映像データに含まれる複数のフレーム画像を所定の大きさの部分画像にそれぞれ分割して構成要素とし、任意の画像認識手法(例えば、パターンマッチング、サポートベクターマシン、ニューラルネットワークなど)を用いて当該部分画像を識別することによって、当該映像データを分析できる。
〔ソフトウェア・ハードウェアによる実現例〕
データ分析システムの制御ブロックは、集積回路(ICチップ)等に形成された論理回路(ハードウェア)によって実現してもよいし、CPU(Central Processing Unit)を用いてソフトウェアによって実現してもよい。後者の場合、データ分析システムは、各機能を実現するソフトウェアであるプログラム(データ分析システムの制御プログラム)を実行するCPU、当該プログラムおよび各種データがコンピュータ(またはCPU)で読み取り可能に記録されたROM(Read Only Memory)または記憶装置(これらを「記録媒体」と称する)、当該プログラムを展開するRAM(Random Access Memory)などを備えている。そして、コンピュータ(またはCPU)が上記プログラムを上記記録媒体から読み取って実行することにより、本発明の目的が達成される。上記記録媒体としては、「一時的でない有形の媒体」、例えば、テープ、ディスク、カード、半導体メモリ、プログラマブルな論理回路などを用いることができる。また、上記プログラムは、当該プログラムを伝送可能な任意の伝送媒体(通信ネットワークや放送波等)を介して上記コンピュータに供給されてもよい。本発明は、上記プログラムが電子的な伝送によって具現化された、搬送波に埋め込まれたデータ信号の形態でも実現され得る。なお、上記プログラムは、任意のプログラミング言語によって実装可能であり、例えば、Python、ActionScript、JavaScript(登録商標)などのスクリプト言語、Objective-C、Java(登録商標)などのオブジェクト指向プログラミング言語、HTML5などのマークアップ言語などを用いて実装され得る。また、上記プログラムを記録した任意の記録媒体(コンピュータ読み取り可能な記録媒体)も、本発明の範疇に入る。
データ分析システムの制御ブロックは、集積回路(ICチップ)等に形成された論理回路(ハードウェア)によって実現してもよいし、CPU(Central Processing Unit)を用いてソフトウェアによって実現してもよい。後者の場合、データ分析システムは、各機能を実現するソフトウェアであるプログラム(データ分析システムの制御プログラム)を実行するCPU、当該プログラムおよび各種データがコンピュータ(またはCPU)で読み取り可能に記録されたROM(Read Only Memory)または記憶装置(これらを「記録媒体」と称する)、当該プログラムを展開するRAM(Random Access Memory)などを備えている。そして、コンピュータ(またはCPU)が上記プログラムを上記記録媒体から読み取って実行することにより、本発明の目的が達成される。上記記録媒体としては、「一時的でない有形の媒体」、例えば、テープ、ディスク、カード、半導体メモリ、プログラマブルな論理回路などを用いることができる。また、上記プログラムは、当該プログラムを伝送可能な任意の伝送媒体(通信ネットワークや放送波等)を介して上記コンピュータに供給されてもよい。本発明は、上記プログラムが電子的な伝送によって具現化された、搬送波に埋め込まれたデータ信号の形態でも実現され得る。なお、上記プログラムは、任意のプログラミング言語によって実装可能であり、例えば、Python、ActionScript、JavaScript(登録商標)などのスクリプト言語、Objective-C、Java(登録商標)などのオブジェクト指向プログラミング言語、HTML5などのマークアップ言語などを用いて実装され得る。また、上記プログラムを記録した任意の記録媒体(コンピュータ読み取り可能な記録媒体)も、本発明の範疇に入る。
〔まとめ〕
本発明の第1の態様に係るデータ分析システムは、対象データを評価するデータ分析システムであって、前記システムは、メモリと、入力制御装置と、コントローラとを備え、前記コントローラは、複数の対象データを評価し、当該評価は、各対象データと所定の事案との関連性に対応するものであり、前記複数の対象データの序列化を可能とする指標を、前記評価により生成し、ユーザが前記入力制御装置を介して与えた入力に基づいて前記指標を変化させることができ、前記メモリは、前記コントローラが評価する前記複数の対象データを少なくとも一時的に記憶し、前記入力制御装置は、前記コントローラが前記複数の対象データを序列化するための入力を前記ユーザに許容し、当該複数の対象データの序列は、前記入力に基づいて変化する前記指標に応じて変化するものであり、前記入力は、前記複数の対象データとは異なる参照データを、当該参照データと前記所定の事案との関連性に基づいて分類するものであり、当該分類は、前記参照データの内容に応じて複数の分類情報に分けられたものであり、前記複数の分類情報のうちの少なくとも1つは、前記入力によって前記参照データに付与されるものであり、前記参照データを前記ユーザに提示し、前記ユーザの入力により、前記提示された参照データに対して与えられた前記少なくとも1つの分類情報と当該参照データとの組み合わせを、前記コントローラに提供し、前記コントローラは、前記参照データに含まれる複数の構成要素が、前記入力制御装置から提供された組み合わせにそれぞれ寄与する度合いを評価することによって、前記入力により付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出し、前記抽出したパターンに基づいて、前記対象データと前記所定の事案との関連性を評価して前記指標を決定し、前記決定した指標を前記対象データに設定し、前記指標に応じて前記複数の対象データを序列化し、前記序列化した複数の対象データをユーザに報知する。
本発明の第1の態様に係るデータ分析システムは、対象データを評価するデータ分析システムであって、前記システムは、メモリと、入力制御装置と、コントローラとを備え、前記コントローラは、複数の対象データを評価し、当該評価は、各対象データと所定の事案との関連性に対応するものであり、前記複数の対象データの序列化を可能とする指標を、前記評価により生成し、ユーザが前記入力制御装置を介して与えた入力に基づいて前記指標を変化させることができ、前記メモリは、前記コントローラが評価する前記複数の対象データを少なくとも一時的に記憶し、前記入力制御装置は、前記コントローラが前記複数の対象データを序列化するための入力を前記ユーザに許容し、当該複数の対象データの序列は、前記入力に基づいて変化する前記指標に応じて変化するものであり、前記入力は、前記複数の対象データとは異なる参照データを、当該参照データと前記所定の事案との関連性に基づいて分類するものであり、当該分類は、前記参照データの内容に応じて複数の分類情報に分けられたものであり、前記複数の分類情報のうちの少なくとも1つは、前記入力によって前記参照データに付与されるものであり、前記参照データを前記ユーザに提示し、前記ユーザの入力により、前記提示された参照データに対して与えられた前記少なくとも1つの分類情報と当該参照データとの組み合わせを、前記コントローラに提供し、前記コントローラは、前記参照データに含まれる複数の構成要素が、前記入力制御装置から提供された組み合わせにそれぞれ寄与する度合いを評価することによって、前記入力により付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出し、前記抽出したパターンに基づいて、前記対象データと前記所定の事案との関連性を評価して前記指標を決定し、前記決定した指標を前記対象データに設定し、前記指標に応じて前記複数の対象データを序列化し、前記序列化した複数の対象データをユーザに報知する。
また、本発明の第2の態様に係るデータ分析システムは、上記第1の態様において、前記コントローラは、前記指標と所定の閾値とを比較し、当該比較した結果に基づいて、前記複数の対象データ夫々に前記所定の事案に関連する分類情報を設定する。
また、本発明の第3の態様に係るデータ分析システムは、上記第1~2の態様において、前記コントローラは、前記複数の対象データが所定の判定基準を満たしているか否かを判定し、前記所定の判定基準を満たしていると判定された複数の対象データから、所定数の対象データを選出し、前記パターンに基づいて前記所定数の対象データをそれぞれ再評価し、前記再評価した結果に基づいて、前記所定の判定基準を変更する。
また、本発明の第4の態様に係るデータ分析システムは、上記第1~3の態様において、前記コントローラは、新たな参照データと当該新たな参照データに付与される前記分類情報との組み合わせをさらに取得し、前記新たな参照データの少なくとも一部の構成要素が、当該新たな参照データと分類情報との組み合わせに寄与する度合い評価することによって、前記パターンを更新し、前記更新したパターンに基づいて前記対象データと前記所定の事案との関連性を評価し、前記指標を決定する。
また、本発明の第5の態様に係るデータ分析システムは、上記第1~4の態様において、前記コントローラは、前記複数の対象データを評価した結果に基づいて再現率を算出し、前記再現率が上昇するように、前記参照データから繰り返し前記パターンを抽出する。
また、本発明の第6の態様に係るデータ分析システムは、上記第1~5の態様において、前記コントローラは、前記入力制御装置から前記組み合わせが提供されるたびに、前記分類情報に対応する前記参照データの少なくとも一部の構成要素が、当該組み合わせに寄与する度合いを評価することによって、前記パターンを逐次更新する。
また、本発明の第7の態様に係るデータ分析システムは、上記第1~6の態様において、前記コントローラは、前記対象データの少なくとも一部の構成要素に対応する概念を、当該構成要素と当該概念とを対応付けたデータベースを参照することによって抽出し、前記抽出した概念に基づいて前記複数の対象データの要約を出力する。
また、本発明の第8の態様に係るデータ分析システムは、上記第1~7の態様において、前記コントローラは、前記複数の対象データに共通して含まれる主題ごとに、当該複数の対象データをクラスタリングする。
また、本発明の第9の態様に係るデータ分析システムは、上記第1~8の態様において、前記対象データは、前記所定の事案に対するユーザの評価情報を少なくとも含み、前記コントローラは、前記対象データを生成したユーザの感情であって、前記評価情報に基づいて生じた前記所定の事案に対する感情を、当該対象データから抽出する。
また、本発明の第10の態様に係るデータ分析システムは、上記第1~9の態様において、前記コントローラは、前記分類情報が対応付けられた対象データの、全ての対象データに対する割合に応じたグラデーションを用いて、前記複数の対象データを夫々評価した結果に対する前記割合の分布を視認可能に表示する。
また、本発明の第11の態様に係るデータ分析システムは、上記第1~10の態様において、前記複数の対象データは、複数の計算機間で送受信される情報であり、前記コントローラは、前記送受信される情報を分析した結果に基づいて、前記複数の計算機間の緊密度を可視化する。
また、本発明の第12の態様に係るデータ分析システムは、上記第1~11の態様において、前記パターンは、時間の経過に応じて変化し得るものであり、前記コントローラは、前記参照データを所定時間ごとに取得し、前記所定時間ごとに取得した複数の参照データ夫々から前記パターンを抽出し、前記パターンに基づいて、前記所定時間ごとに前記複数の対象データ夫々を評価して前記指標を決定する。
また、本発明の第13の態様に係るデータ分析システムは、上記第1~12の態様において、前記コントローラは、前記対象データの少なくとも一部を構成する部分対象データを、当該対象データを分割することによって複数生成し、前記抽出したパターンに基づいて前記複数の部分対象データを夫々評価し、前記複数の部分対象データを評価して得られた前記指標を統合し、前記統合した指標を用いて前記複数の対象データを夫々評価する。
また、本発明の第14の態様に係るデータ分析システムは、上記第1~13の態様において、前記コントローラは、前記構成要素と、当該構成要素を含む参照データを分類する前記分類情報との関係の強さに基づいて、当該構成要素に対する評価値を、前記度合いを評価した結果として算出し、前記対象データの少なくとも一部の構成要素に対して算出された評価値に基づいて、当該対象データと前記所定の事案との関連性の高低を示すように前記指標を決定することによって、前記複数の対象データを評価する。
また、本発明の第15の態様に係るデータ分析システムは、上記第1~14の態様において、前記コントローラは、前記構成要素と、当該構成要素とは異なる他の構成要素とが、同一の参照データの少なくとも一部に出現する頻度に基づいて、当該構成要素と当該他の構成要素との相関を評価し、前記相関にさらに基づいて前記複数の対象データを夫々評価する。
また、本発明の第16の態様に係るデータ分析システムは、上記第1~15の態様において、前記コントローラは、前記所定の事案に関係する所定行為の進展を予測可能なモデルに基づいて、前記複数の対象データを評価することによって決定した指標から、次の行為を提示する。
また、本発明の第17の態様に係るデータ分析システムは、上記第1~16の態様において、前記コントローラは、所定の行為が進展する各段階を示す指標であるフェーズごとに、前記複数の対象データを評価し、前記複数の対象データを評価することによって前記フェーズごとに決定された指標から、現在のフェーズを特定する。
また、本発明の第18の態様に係るデータ分析システムは、上記第1~17の態様において、前記対象データは、1以上のセンテンスを少なくとも一部に含む文書データであり、前記コントローラは、前記センテンスが有する構造を解析し、当該解析した結果に基づいて前記対象データに前記指標を決定する。
また、本発明の第19の態様に係るデータ分析システムは、上記第18の態様において、前記コントローラは、前記センテンスが有する構造を解析した結果に基づいて、当該センテンスの表現形態を判定し、当該判定した結果に基づいて前記対象データを評価する。
また、本発明の第1の態様に係るデータ分析方法は、対象データを評価するデータ分析方法であって、複数の対象データを評価基準に基づいてそれぞれ評価し、前記評価基準は、各対象データと所定の事案との関連性に対応する第1のステップと、前記評価によって、前記複数の対象データの序列化を可能とする指標を生成し、当該指標を、ユーザが与えた入力に応じて変化させることができる第2のステップと、前記第1のステップで評価される前記複数の対象データを少なくとも一時的に記憶する第3のステップと、前記複数の対象データを序列化するための入力を前記ユーザに許容し、当該複数の対象データの序列は、前記入力に応じて変化する前記指標に応じて変化するものであり、前記入力は、前記複数の対象データとは異なる参照データを、当該参照データと前記所定の事案との関連性に基づいて分類するものであり、当該分類は、前記参照データの内容に応じて複数の分類情報に分けられたものであり、前記複数の分類情報のうちの少なくとも1つは、前記入力によって前記参照データに付与される第4のステップと、前記参照データを前記ユーザに提示する第5のステップと、前記ユーザの入力により、前記提示された参照データに対して与えられた前記少なくとも1つの分類情報と当該参照データとの組み合わせを提供するス第6のステップと、当該参照データに含まれる複数の構成要素が前記提供された組み合わせにそれぞれ寄与する度合いを評価することによって、前記入力によって付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出する第7のステップと、当該抽出したパターンを前記評価基準とし、当該パターンに基づいて、前記対象データと前記所定の事案との関連性を評価して前記指標を決定する第8のステップと、当該決定された指標を当該対象データに設定する第9のステップと、前記指標に応じた、前記複数の対象データの序列化を実行する第10のステップと、前記序列化した複数の対象データをユーザに報知する第11のステップとを含む。
また、本発明の第1の態様に係るデータ分析プログラムは、コンピュータに上記第1の態様に係るデータ分析方法の各ステップを実行させる。
また、本発明の第1の態様に係る記録媒体は、上記第1の態様に係るデータ分析プログラムを記録する。
また、本発明の別態様に係るデータ分析システムは、メモリと当該メモリに格納された1以上のプログラムを実行可能な1以上のコントローラとを備え、当該メモリに記憶されたデータセットに含まれる複数のデータをそれぞれ評価するデータ分析システムであって、前記コントローラは、参照データと当該参照データを分類する分類情報との組み合わせを複数含むデータセットを、参照データセットとして取得し、前記参照データの少なくとも一部を構成する複数の構成要素が、前記取得した参照データセットに含まれる複数の組み合わせに寄与する度合いをそれぞれ評価することによって、当該参照データに含まれるパターンを学習し、前記学習したパターンに基づいて複数の対象データを序列化することによって、当該複数の対象データをそれぞれ評価し、前記複数の対象データをそれぞれ評価した結果に基づいて、当該複数の対象データを所定の表示インターフェースを介してユーザに提示する。
本発明は、パーソナルコンピュータ、サーバ、ワークステーション、メインフレームなど、任意のコンピュータに広く適用することができる。
10 クライアント装置
12 管理計算機
14 業務サーバ
18 ストレージシステム
22 データベース
12 管理計算機
14 業務サーバ
18 ストレージシステム
22 データベース
Claims (22)
- 対象データを評価するデータ分析システムであって、
前記システムは、メモリと、入力制御装置と、コントローラとを備え、
前記コントローラは、
複数の対象データを評価し、当該評価は、各対象データと所定の事案との関連性に対応するものであり、
前記複数の対象データの序列化を可能とする指標を、前記評価により生成し、
ユーザが前記入力制御装置を介して与えた入力に基づいて前記指標を変化させることができ、
前記メモリは、
前記コントローラが評価する前記複数の対象データを少なくとも一時的に記憶し、
前記入力制御装置は、
前記コントローラが前記複数の対象データを序列化するための入力を前記ユーザに許容し、当該複数の対象データの序列は、前記入力に基づいて変化する前記指標に応じて変化するものであり、前記入力は、前記複数の対象データとは異なる参照データを、当該参照データと前記所定の事案との関連性に基づいて分類するものであり、当該分類は、前記参照データの内容に応じて複数の分類情報に分けられたものであり、前記複数の分類情報のうちの少なくとも1つは、前記入力によって前記参照データに付与されるものであり、
前記参照データを前記ユーザに提示し、
前記ユーザの入力により、前記提示された参照データに対して与えられた前記少なくとも1つの分類情報と当該参照データとの組み合わせを、前記コントローラに提供し、
前記コントローラは、
前記参照データに含まれる複数の構成要素が、前記入力制御装置から提供された組み合わせにそれぞれ寄与する度合いを評価することによって、前記入力により付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出し、
前記抽出したパターンに基づいて、前記対象データと前記所定の事案との関連性を評価して前記指標を決定し、
前記決定した指標を前記対象データに設定し、
前記指標に応じて前記複数の対象データを序列化し、
前記序列化した複数の対象データをユーザに報知する、
データ分析システム。 - 前記コントローラは、前記指標と所定の閾値とを比較し、当該比較した結果に基づいて、前記複数の対象データ夫々に前記所定の事案に関連する分類情報を設定する、請求項1記載のデータ分析システム。
- 前記コントローラは、
前記複数の対象データが所定の判定基準を満たしているか否かを判定し、
前記所定の判定基準を満たしていると判定された複数の対象データから、所定数の対象データを選出し、
前記パターンに基づいて前記所定数の対象データをそれぞれ再評価し、
前記再評価した結果に基づいて、前記所定の判定基準を変更する、
請求項1又は2記載のデータ分析システム。 - 前記コントローラは、
新たな参照データと当該新たな参照データに付与される前記分類情報との組み合わせをさらに取得し、
前記新たな参照データの少なくとも一部の構成要素が、当該新たな参照データと分類情報との組み合わせに寄与する度合い評価することによって、前記パターンを更新し、
前記更新したパターンに基づいて前記対象データと前記所定の事案との関連性を評価し、前記指標を決定する、請求項1乃至3の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記複数の対象データを評価した結果に基づいて再現率を算出し、
前記再現率が上昇するように、前記参照データから繰り返し前記パターンを抽出する、
請求項1乃至4の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記入力制御装置から前記組み合わせが提供されるたびに、前記分類情報に対応する前記参照データの少なくとも一部の構成要素が、当該組み合わせに寄与する度合いを評価することによって、前記パターンを逐次更新する、
請求項1乃至5の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記対象データの少なくとも一部の構成要素に対応する概念を、当該構成要素と当該概念とを対応付けたデータベースを参照することによって抽出し、
前記抽出した概念に基づいて前記複数の対象データの要約を出力する、
請求項1乃至6の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記複数の対象データに共通して含まれる主題ごとに、当該複数の対象データをクラスタリングする、
請求項1乃至7の何れか一項記載のデータ分析システム。 - 前記対象データは、前記所定の事案に対するユーザの評価情報を少なくとも含み、
前記コントローラは、
前記対象データを生成したユーザの感情であって、前記評価情報に基づいて生じた前記所定の事案に対する感情を、当該対象データから抽出する
請求項1乃至8の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記分類情報が対応付けられた対象データの、全ての対象データに対する割合に応じたグラデーションを用いて、前記複数の対象データを夫々評価した結果に対する前記割合の分布を視認可能に表示する、
請求項1乃至9の何れか一記載のデータ分析システム。 - 前記複数の対象データは、複数の計算機間で送受信される情報であり、
前記コントローラは、
前記送受信される情報を分析した結果に基づいて、前記複数の計算機間の緊密度を可視化する、
請求項1乃至10の何れか一項記載のデータ分析システム。 - 前記パターンは、時間の経過に応じて変化し得るものであり、
前記コントローラは、
前記参照データを所定時間ごとに取得し、
前記所定時間ごとに取得した複数の参照データ夫々から前記パターンを抽出し、
前記パターンに基づいて、前記所定時間ごとに前記複数の対象データ夫々を評価して前記指標を決定する、
請求項1乃至11の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記対象データの少なくとも一部を構成する部分対象データを、当該対象データを分割することによって複数生成し、
前記抽出したパターンに基づいて前記複数の部分対象データを夫々評価し、
前記複数の部分対象データを評価して得られた前記指標を統合し、
前記統合した指標を用いて前記複数の対象データを夫々評価する、
請求項1乃至12の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記構成要素と、当該構成要素を含む参照データを分類する前記分類情報との関係の強さに基づいて、当該構成要素に対する評価値を、前記度合いを評価した結果として算出し、
前記対象データの少なくとも一部の構成要素に対して算出された評価値に基づいて、当該対象データと前記所定の事案との関連性の高低を示すように前記指標を決定することによって、前記複数の対象データを評価する、
請求項1乃至13の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記構成要素と、当該構成要素とは異なる他の構成要素とが、同一の参照データの少なくとも一部に出現する頻度に基づいて、当該構成要素と当該他の構成要素との相関を評価し、
前記相関にさらに基づいて前記複数の対象データを夫々評価する、
請求項1乃至14の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記所定の事案に関係する所定行為の進展を予測可能なモデルに基づいて、前記複数の対象データを評価することによって決定した指標から、次の行為を提示する、
請求項1乃至15の何れか一項記載のデータ分析システム。 - 前記コントローラは、
所定の行為が進展する各段階を示す指標であるフェーズごとに、前記複数の対象データを評価し、
前記複数の対象データを評価することによって前記フェーズごとに決定された指標から、現在のフェーズを特定する、
請求項16記載のデータ分析システム。 - 前記対象データは、1以上のセンテンスを少なくとも一部に含む文書データであり、
前記コントローラは、
前記センテンスが有する構造を解析し、当該解析した結果に基づいて前記対象データに前記指標を決定する、請求項1乃至17の何れか一項記載のデータ分析システム。 - 前記コントローラは、
前記センテンスが有する構造を解析した結果に基づいて、当該センテンスの表現形態を判定し、当該判定した結果に基づいて前記対象データを評価する、
請求項18記載のデータ分析システム。 - 対象データを評価するデータ分析方法であって、
複数の対象データを評価基準に基づいてそれぞれ評価し、前記評価基準は、各対象データと所定の事案との関連性に対応する第1のステップと、
前記評価によって、前記複数の対象データの序列化を可能とする指標を生成し、当該指標を、ユーザが与えた入力に応じて変化させることができる第2のステップと、
前記第1のステップで評価される前記複数の対象データを少なくとも一時的に記憶する第3のステップと、
前記複数の対象データを序列化するための入力を前記ユーザに許容し、当該複数の対象データの序列は、前記入力に応じて変化する前記指標に応じて変化するものであり、前記入力は、前記複数の対象データとは異なる参照データを、当該参照データと前記所定の事案との関連性に基づいて分類するものであり、当該分類は、前記参照データの内容に応じて複数の分類情報に分けられたものであり、前記複数の分類情報のうちの少なくとも1つは、前記入力によって前記参照データに付与される第4のステップと、
前記参照データを前記ユーザに提示する第5のステップと、
前記ユーザの入力により、前記提示された参照データに対して与えられた前記少なくとも1つの分類情報と当該参照データとの組み合わせを提供するス第6のステップと、
当該参照データに含まれる複数の構成要素が前記提供された組み合わせにそれぞれ寄与する度合いを評価することによって、前記入力によって付与された分類情報に応じて当該参照データが特徴付けられるパターンを当該参照データから抽出する第7のステップと、
当該抽出したパターンを前記評価基準とし、当該パターンに基づいて、前記対象データと前記所定の事案との関連性を評価して前記指標を決定する第8のステップと、
当該決定された指標を当該対象データに設定する第9のステップと、
前記指標に応じた、前記複数の対象データの序列化を実行する第10のステップと、
前記序列化した複数の対象データをユーザに報知する第11のステップと、
を含む、データ分析方法。 - 請求項20記載のデータ分析方法に含まれる各ステップを、コンピュータに実行させるデータ分析プログラム。
- 請求項21に記載のデータ分析プログラムを記録したコンピュータ読み取り可能な記録媒体。
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201580078606.XA CN107851097B (zh) | 2015-03-31 | 2015-03-31 | 数据分析系统、数据分析方法、数据分析程序及存储介质 |
| JP2016564340A JP6182279B2 (ja) | 2015-03-31 | 2015-03-31 | データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 |
| EP15887615.1A EP3279804A4 (en) | 2015-03-31 | 2015-03-31 | Data analysis system, data analysis method, data analysis program, and recording medium |
| PCT/JP2015/060299 WO2016157467A1 (ja) | 2015-03-31 | 2015-03-31 | データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 |
| KR1020177031349A KR101981075B1 (ko) | 2015-03-31 | 2015-03-31 | 데이터 분석 시스템, 데이터 분석 방법, 데이터 분석 프로그램, 및 기록매체 |
| US14/921,444 US9563652B2 (en) | 2015-03-31 | 2015-10-23 | Data analysis system, data analysis method, data analysis program, and storage medium |
| TW105109780A TWI598755B (zh) | 2015-03-31 | 2016-03-29 | 資料分析系統、資料分析方法、內儲資料分析程式的電腦程式產品及內儲資料分析程式的記錄媒體 |
| US15/382,337 US10204153B2 (en) | 2015-03-31 | 2016-12-16 | Data analysis system, data analysis method, data analysis program, and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2015/060299 WO2016157467A1 (ja) | 2015-03-31 | 2015-03-31 | データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/921,444 Continuation US9563652B2 (en) | 2015-03-31 | 2015-10-23 | Data analysis system, data analysis method, data analysis program, and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016157467A1 true WO2016157467A1 (ja) | 2016-10-06 |
Family
ID=57004108
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2015/060299 WO2016157467A1 (ja) | 2015-03-31 | 2015-03-31 | データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 |
Country Status (7)
| Country | Link |
|---|---|
| US (2) | US9563652B2 (ja) |
| EP (1) | EP3279804A4 (ja) |
| JP (1) | JP6182279B2 (ja) |
| KR (1) | KR101981075B1 (ja) |
| CN (1) | CN107851097B (ja) |
| TW (1) | TWI598755B (ja) |
| WO (1) | WO2016157467A1 (ja) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018156325A (ja) * | 2017-03-16 | 2018-10-04 | 富士通株式会社 | 生成プログラム、生成方法および生成装置 |
| CN111797686A (zh) * | 2020-05-29 | 2020-10-20 | 中南大学 | 基于时间序列相似性分析的泡沫浮选生产过程运行状态稳定度评估方法 |
| WO2020240714A1 (ja) * | 2019-05-28 | 2020-12-03 | リンカーズ株式会社 | 検索システム、検索方法及び検索アプリケーションソフトウェア |
| JP2021043818A (ja) * | 2019-09-12 | 2021-03-18 | 花王株式会社 | 包装袋の資源活用の選択を支援する選択支援システム |
| WO2021131206A1 (ja) | 2019-12-24 | 2021-07-01 | 株式会社日立製作所 | 評価装置、評価方法および評価プログラム |
| WO2021199101A1 (ja) * | 2020-03-30 | 2021-10-07 | 日本電気株式会社 | 犯罪捜査支援システム、犯罪捜査支援装置、犯罪捜査支援方法、及び、犯罪捜査支援プログラムが格納された記録媒体 |
| WO2024143374A1 (ja) | 2022-12-27 | 2024-07-04 | 武田薬品工業株式会社 | 業務支援システム、業務支援方法、データ管理プログラム及び検索プログラム |
| JP7568592B2 (ja) | 2021-07-29 | 2024-10-16 | 株式会社日立ソリューションズ | モデルの評価方法及び計算機システム |
Families Citing this family (47)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104335523B (zh) * | 2014-04-15 | 2018-08-21 | 华为技术有限公司 | 一种权限控制方法、客户端及服务器 |
| WO2017073373A1 (ja) * | 2015-10-30 | 2017-05-04 | 株式会社モルフォ | 学習システム、学習装置、学習方法、学習プログラム、教師データ作成装置、教師データ作成方法、教師データ作成プログラム、端末装置及び閾値変更装置 |
| US20170154314A1 (en) * | 2015-11-30 | 2017-06-01 | FAMA Technologies, Inc. | System for searching and correlating online activity with individual classification factors |
| US10915563B2 (en) * | 2016-03-28 | 2021-02-09 | Hitachi, Ltd. | Analysis server device, data analysis system, and data analysis method |
| JP6638537B2 (ja) | 2016-04-21 | 2020-01-29 | 株式会社島津製作所 | 試料解析システム |
| US11144576B2 (en) * | 2016-10-28 | 2021-10-12 | Hewlett-Packard Development Company, L.P. | Target class feature model |
| US10768910B2 (en) * | 2016-10-31 | 2020-09-08 | Teletracking Technologies, Inc. | Systems and methods for generating interactive hypermedia graphical user interfaces on a mobile device |
| JP6683111B2 (ja) | 2016-11-28 | 2020-04-15 | 株式会社島津製作所 | 試料解析システム |
| JP6784612B2 (ja) * | 2017-03-02 | 2020-11-11 | 株式会社日立製作所 | 分析ソフトウェア管理システム及び分析ソフトウェア管理方法 |
| TWI649660B (zh) * | 2017-05-05 | 2019-02-01 | 張漢威 | 資料分析系統及其分析方法 |
| US10459450B2 (en) | 2017-05-12 | 2019-10-29 | Autonomy Squared Llc | Robot delivery system |
| CN108363709A (zh) * | 2017-06-08 | 2018-08-03 | 国云科技股份有限公司 | 一种基于用户使用主成分的图表推荐系统及方法 |
| JP6842405B2 (ja) * | 2017-12-18 | 2021-03-17 | 株式会社日立製作所 | 分析支援方法、分析支援サーバ及び記憶媒体 |
| US11042786B2 (en) * | 2018-03-30 | 2021-06-22 | Mitsubishi Electric Corporation | Learning processing device, data analysis device, analytical procedure selection method, and recording medium |
| US11599083B2 (en) * | 2018-05-31 | 2023-03-07 | Mitsubishi Electric Corporation | Work analysis apparatus for analyzing work including series of actions performed by working subject |
| CN109166069B (zh) * | 2018-07-17 | 2020-09-08 | 华中科技大学 | 基于马尔科夫逻辑网络的数据关联方法、系统及设备 |
| CN109036553B (zh) * | 2018-08-01 | 2022-03-29 | 北京理工大学 | 一种基于自动抽取医疗专家知识的疾病预测方法 |
| JP7020345B2 (ja) * | 2018-08-27 | 2022-02-16 | 日本電信電話株式会社 | 評価装置、方法、及びプログラム |
| JP7063292B2 (ja) | 2019-03-15 | 2022-05-09 | オムロン株式会社 | 制御システム、設定装置、および設定プログラム |
| JP6607589B1 (ja) * | 2019-03-29 | 2019-11-20 | 株式会社 情報システムエンジニアリング | 情報提供システム及び情報提供方法 |
| CN110008255A (zh) * | 2019-04-03 | 2019-07-12 | 平安信托有限责任公司 | 业务数据分析方法、装置、计算机设备和存储介质 |
| CN113015971B (zh) * | 2019-05-17 | 2022-06-07 | 爱酷赛股份有限公司 | 聚类分析方法、聚类分析系统及可读存储介质 |
| JP7353851B2 (ja) * | 2019-08-02 | 2023-10-02 | キヤノン株式会社 | システム、方法、及びプログラム |
| US10657018B1 (en) * | 2019-08-26 | 2020-05-19 | Coupang Corp. | Systems and methods for dynamic aggregation of data and minimization of data loss |
| TWI723602B (zh) * | 2019-10-30 | 2021-04-01 | 國立中央大學 | 社群式學習創建系統與電腦程式產品 |
| KR102120232B1 (ko) * | 2019-11-04 | 2020-06-16 | (주)유엠로직스 | 칼만필터 알고리즘을 이용한 사이버 표적공격 탐지 시스템 및 그 탐지 방법 |
| KR102091986B1 (ko) * | 2019-12-26 | 2020-03-20 | 한국생산성본부 | 고객의 여정 분석 정보에 기반하는 인공지능 마케팅 시스템 |
| TWI767192B (zh) * | 2020-02-26 | 2022-06-11 | 傑睿資訊服務股份有限公司 | 智慧分析系統之應用方法 |
| JP7480536B2 (ja) * | 2020-03-12 | 2024-05-10 | 富士フイルムビジネスイノベーション株式会社 | 文書処理装置及びプログラム |
| JP7298522B2 (ja) * | 2020-03-17 | 2023-06-27 | 横河電機株式会社 | 評価システム及び評価方法 |
| US11983930B2 (en) * | 2020-03-27 | 2024-05-14 | Nec Corporation | Person flow prediction system, person flow prediction method, and programrecording medium |
| JP7419955B2 (ja) * | 2020-04-27 | 2024-01-23 | 横河電機株式会社 | データ解析システム、データ解析方法、およびプログラム |
| KR20210143464A (ko) * | 2020-05-20 | 2021-11-29 | 삼성에스디에스 주식회사 | 데이터 분석 장치 및 그것의 데이터 분석 방법 |
| KR102244699B1 (ko) * | 2020-06-15 | 2021-04-27 | 주식회사 크라우드웍스 | 인공지능 학습데이터 생성을 위한 크라우드소싱 기반 프로젝트의 문장 유사도를 이용한 감정 라벨링 방법 |
| CN112015912B (zh) * | 2020-08-25 | 2023-07-04 | 杭州指令集智能科技有限公司 | 一种基于知识图谱的指标智能可视化方法及装置 |
| JP7502963B2 (ja) * | 2020-10-27 | 2024-06-19 | 株式会社日立製作所 | 情報処理システムおよび情報処理方法 |
| CN112699249B (zh) * | 2020-12-31 | 2022-11-15 | 上海浦东发展银行股份有限公司 | 基于知识图谱的信息处理方法、装置、设备及存储介质 |
| JP7049010B1 (ja) | 2021-03-02 | 2022-04-06 | 株式会社インタラクティブソリューションズ | プレゼンテーション評価システム |
| CN113420053A (zh) * | 2021-05-07 | 2021-09-21 | 北京沃东天骏信息技术有限公司 | 一种数据处理方法、装置、电子设备及存储介质 |
| KR102410415B1 (ko) * | 2021-06-23 | 2022-06-22 | 주식회사 셀타스퀘어 | 지능형 약물감시 플랫폼을 제공하기 위한 방법 및 장치 |
| CN113673958B (zh) * | 2021-08-23 | 2025-01-17 | 广东电网有限责任公司 | 一种适用于供电所的信息提取分配方法及设备 |
| US12254111B2 (en) | 2022-01-03 | 2025-03-18 | Bank Of America Corporation | Information security systems and methods for early change detection and data protection |
| JP2023118523A (ja) * | 2022-02-15 | 2023-08-25 | 富士通株式会社 | 均衡解探索プログラム、均衡解探索方法および情報処理装置 |
| JP2023160216A (ja) * | 2022-04-21 | 2023-11-02 | 株式会社日立製作所 | 作業支援装置、作業支援システム |
| JP7553676B1 (ja) | 2023-09-28 | 2024-09-18 | 株式会社小野測器 | 評価者が複数の評価対象にそれぞれ主観的な評価を与えることを支援する方法、プログラム、情報処理装置及びシステム |
| CN117610990B (zh) * | 2023-11-13 | 2024-06-28 | 中国通信建设集团有限公司数智科创分公司 | 一种基于大数据的司法案例质量智能评价系统及方法 |
| KR102729313B1 (ko) * | 2023-12-13 | 2024-11-14 | 에이치엠컴퍼니 주식회사 | 디지털 포렌식 분석 결과에 대한 자연어 처리 및 추론을 수행하는 전자 장치의 동작 방법 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202983A (ja) * | 2000-12-28 | 2002-07-19 | Matsushita Electric Ind Co Ltd | 分類への帰属度計算基準作成方法及び装置 |
| JP2004514220A (ja) * | 2000-11-15 | 2004-05-13 | 株式会社ジャストシステム | テキスト内の感情と情緒を分析するための方法および装置 |
| JP2004157981A (ja) * | 2002-07-09 | 2004-06-03 | Canon Inc | 要約表現装置 |
| JP2007172249A (ja) * | 2005-12-21 | 2007-07-05 | Fujitsu Ltd | 文書分類プログラム、文書分類装置、および文書分類方法 |
| JP2009251825A (ja) * | 2008-04-03 | 2009-10-29 | Nec Corp | 文書クラスタリングシステム、その方法及びプログラム |
| WO2014057964A1 (ja) * | 2012-10-09 | 2014-04-17 | 株式会社Ubic | フォレンジックシステムおよびフォレンジック方法並びにフォレンジックプログラム |
| WO2014057962A1 (ja) * | 2012-10-09 | 2014-04-17 | 株式会社Ubic | フォレンジックシステム及びフォレンジック方法並びにフォレンジックプログラム |
| JP5572255B1 (ja) * | 2013-10-11 | 2014-08-13 | 株式会社Ubic | デジタル情報分析システム、デジタル情報分析方法、及びデジタル情報分析プログラム |
| WO2015025551A1 (ja) * | 2013-08-23 | 2015-02-26 | 株式会社Ubic | 相関関係表示システム、相関関係表示方法、及び相関関係表示プログラム |
| WO2015030112A1 (ja) * | 2013-08-29 | 2015-03-05 | 株式会社Ubic | 文書分別システム及び文書分別方法並びに文書分別プログラム |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6606659B1 (en) * | 2000-01-28 | 2003-08-12 | Websense, Inc. | System and method for controlling access to internet sites |
| US20140122110A1 (en) * | 2000-08-01 | 2014-05-01 | Logical Images, Inc. | System and method for problem-oriented patient-contextualized medical search and clinical decision support to improve diagnostic, management, and therapeutic decisions |
| CN1291337C (zh) | 2001-05-22 | 2006-12-20 | 鸿富锦精密工业(深圳)有限公司 | 线上资料撷取分析的代理服务系统及方法 |
| US20030130993A1 (en) * | 2001-08-08 | 2003-07-10 | Quiver, Inc. | Document categorization engine |
| US20040205482A1 (en) * | 2002-01-24 | 2004-10-14 | International Business Machines Corporation | Method and apparatus for active annotation of multimedia content |
| US7203707B2 (en) | 2004-02-13 | 2007-04-10 | Taiwan Semiconductor Manufacturing Co., Ltd. | System and method for knowledge asset acquisition and management |
| US7756845B2 (en) * | 2006-12-28 | 2010-07-13 | Yahoo! Inc. | System and method for learning a weighted index to categorize objects |
| US7711747B2 (en) * | 2007-04-06 | 2010-05-04 | Xerox Corporation | Interactive cleaning for automatic document clustering and categorization |
| CN101377776B (zh) * | 2007-08-29 | 2010-06-30 | 中国科学院自动化研究所 | 一种交互式图像检索方法 |
| US8311960B1 (en) * | 2009-03-31 | 2012-11-13 | Emc Corporation | Interactive semi-supervised machine learning for classification |
| US9245243B2 (en) * | 2009-04-14 | 2016-01-26 | Ureveal, Inc. | Concept-based analysis of structured and unstructured data using concept inheritance |
| CN101833565B (zh) * | 2010-03-31 | 2011-10-19 | 南京大学 | 一种主动选择代表性图像的相关反馈方法 |
| CN102508909B (zh) * | 2011-11-11 | 2014-08-20 | 苏州大学 | 一种基于多智能算法及图像融合技术的图像检索方法 |
| US8543576B1 (en) * | 2012-05-23 | 2013-09-24 | Google Inc. | Classification of clustered documents based on similarity scores |
| US20140006338A1 (en) | 2012-06-29 | 2014-01-02 | Applied Materials, Inc. | Big data analytics system |
| JP5700007B2 (ja) | 2012-09-13 | 2015-04-15 | キヤノンマーケティングジャパン株式会社 | 情報処理装置、方法、およびプログラム |
| US9348899B2 (en) * | 2012-10-31 | 2016-05-24 | Open Text Corporation | Auto-classification system and method with dynamic user feedback |
| CN103150369A (zh) * | 2013-03-07 | 2013-06-12 | 人民搜索网络股份公司 | 作弊网页识别方法及装置 |
| US9122681B2 (en) * | 2013-03-15 | 2015-09-01 | Gordon Villy Cormack | Systems and methods for classifying electronic information using advanced active learning techniques |
| CN103514369B (zh) * | 2013-09-18 | 2016-07-06 | 上海交通大学 | 一种基于主动学习的回归分析系统及方法 |
-
2015
- 2015-03-31 CN CN201580078606.XA patent/CN107851097B/zh active Active
- 2015-03-31 WO PCT/JP2015/060299 patent/WO2016157467A1/ja unknown
- 2015-03-31 KR KR1020177031349A patent/KR101981075B1/ko active Active
- 2015-03-31 EP EP15887615.1A patent/EP3279804A4/en not_active Ceased
- 2015-03-31 JP JP2016564340A patent/JP6182279B2/ja active Active
- 2015-10-23 US US14/921,444 patent/US9563652B2/en active Active
-
2016
- 2016-03-29 TW TW105109780A patent/TWI598755B/zh active
- 2016-12-16 US US15/382,337 patent/US10204153B2/en active Active
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004514220A (ja) * | 2000-11-15 | 2004-05-13 | 株式会社ジャストシステム | テキスト内の感情と情緒を分析するための方法および装置 |
| JP2002202983A (ja) * | 2000-12-28 | 2002-07-19 | Matsushita Electric Ind Co Ltd | 分類への帰属度計算基準作成方法及び装置 |
| JP2004157981A (ja) * | 2002-07-09 | 2004-06-03 | Canon Inc | 要約表現装置 |
| JP2007172249A (ja) * | 2005-12-21 | 2007-07-05 | Fujitsu Ltd | 文書分類プログラム、文書分類装置、および文書分類方法 |
| JP2009251825A (ja) * | 2008-04-03 | 2009-10-29 | Nec Corp | 文書クラスタリングシステム、その方法及びプログラム |
| WO2014057964A1 (ja) * | 2012-10-09 | 2014-04-17 | 株式会社Ubic | フォレンジックシステムおよびフォレンジック方法並びにフォレンジックプログラム |
| WO2014057962A1 (ja) * | 2012-10-09 | 2014-04-17 | 株式会社Ubic | フォレンジックシステム及びフォレンジック方法並びにフォレンジックプログラム |
| WO2015025551A1 (ja) * | 2013-08-23 | 2015-02-26 | 株式会社Ubic | 相関関係表示システム、相関関係表示方法、及び相関関係表示プログラム |
| WO2015030112A1 (ja) * | 2013-08-29 | 2015-03-05 | 株式会社Ubic | 文書分別システム及び文書分別方法並びに文書分別プログラム |
| JP5572255B1 (ja) * | 2013-10-11 | 2014-08-13 | 株式会社Ubic | デジタル情報分析システム、デジタル情報分析方法、及びデジタル情報分析プログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3279804A4 * |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018156325A (ja) * | 2017-03-16 | 2018-10-04 | 富士通株式会社 | 生成プログラム、生成方法および生成装置 |
| WO2020240714A1 (ja) * | 2019-05-28 | 2020-12-03 | リンカーズ株式会社 | 検索システム、検索方法及び検索アプリケーションソフトウェア |
| JPWO2020240714A1 (ja) * | 2019-05-28 | 2021-09-13 | リンカーズ株式会社 | 検索システム、検索方法及び検索アプリケーションソフトウェア |
| JP2021043818A (ja) * | 2019-09-12 | 2021-03-18 | 花王株式会社 | 包装袋の資源活用の選択を支援する選択支援システム |
| WO2021131206A1 (ja) | 2019-12-24 | 2021-07-01 | 株式会社日立製作所 | 評価装置、評価方法および評価プログラム |
| WO2021199101A1 (ja) * | 2020-03-30 | 2021-10-07 | 日本電気株式会社 | 犯罪捜査支援システム、犯罪捜査支援装置、犯罪捜査支援方法、及び、犯罪捜査支援プログラムが格納された記録媒体 |
| JPWO2021199101A1 (ja) * | 2020-03-30 | 2021-10-07 | ||
| JP7567904B2 (ja) | 2020-03-30 | 2024-10-16 | 日本電気株式会社 | 犯罪捜査支援システム、犯罪捜査支援方法、及び、犯罪捜査支援プログラム |
| CN111797686A (zh) * | 2020-05-29 | 2020-10-20 | 中南大学 | 基于时间序列相似性分析的泡沫浮选生产过程运行状态稳定度评估方法 |
| CN111797686B (zh) * | 2020-05-29 | 2024-04-02 | 中南大学 | 基于时间序列相似性分析的泡沫浮选生产过程运行状态稳定度评估方法 |
| JP7568592B2 (ja) | 2021-07-29 | 2024-10-16 | 株式会社日立ソリューションズ | モデルの評価方法及び計算機システム |
| WO2024143374A1 (ja) | 2022-12-27 | 2024-07-04 | 武田薬品工業株式会社 | 業務支援システム、業務支援方法、データ管理プログラム及び検索プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| CN107851097B (zh) | 2021-10-01 |
| KR101981075B1 (ko) | 2019-05-22 |
| CN107851097A (zh) | 2018-03-27 |
| US10204153B2 (en) | 2019-02-12 |
| TW201706884A (zh) | 2017-02-16 |
| JPWO2016157467A1 (ja) | 2017-04-27 |
| US20160292197A1 (en) | 2016-10-06 |
| TWI598755B (zh) | 2017-09-11 |
| EP3279804A4 (en) | 2018-10-31 |
| US20170097983A1 (en) | 2017-04-06 |
| US9563652B2 (en) | 2017-02-07 |
| KR20170130604A (ko) | 2017-11-28 |
| JP6182279B2 (ja) | 2017-08-16 |
| EP3279804A1 (en) | 2018-02-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6182279B2 (ja) | データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 | |
| Aldunate et al. | Understanding customer satisfaction via deep learning and natural language processing | |
| Shen et al. | Sentiment based matrix factorization with reliability for recommendation | |
| Guo et al. | Big social data analytics in journalism and mass communication: Comparing dictionary-based text analysis and unsupervised topic modeling | |
| JP5885875B1 (ja) | データ分析システム、データ分析方法、プログラム、および、記録媒体 | |
| JP6144427B2 (ja) | データ分析システムおよびデータ分析方法並びにデータ分析プログラム | |
| Gómez-Benito et al. | Effectiveness of combining statistical tests and effect sizes when using logistic discriminant function regression to detect differential item functioning for polytomous items | |
| CN106611375A (zh) | 一种基于文本分析的信用风险评估方法及装置 | |
| WO2016189605A1 (ja) | データ分析に係るシステム、制御方法、制御プログラム、および、その記録媒体 | |
| Lee et al. | Using Mahalanobis–Taguchi system, logistic regression, and neural network method to evaluate purchasing audit quality | |
| JP2017201543A (ja) | データ分析システム、データ分析方法、データ分析プログラム、および、記録媒体 | |
| JP5933863B1 (ja) | データ分析システム、制御方法、制御プログラム、および記録媒体 | |
| WO2016203652A1 (ja) | データ分析に係るシステム、制御方法、制御プログラム、および、その記録媒体 | |
| JP6178480B1 (ja) | データ分析システム、その制御方法、プログラム、及び、記録媒体 | |
| Li et al. | Empirical study of factors that influence the perceived usefulness of online mental health community members | |
| Lee et al. | Deriving topic-related and interaction features to predict top attractive reviews for a specific business entity | |
| Ng et al. | Sentiment analysis on consumers’ opinions–evaluating online retailers through analyzing sentiment for face masks during COVID-19 pandemic | |
| JP6026036B1 (ja) | データ分析システム、その制御方法、プログラム、及び、記録媒体 | |
| Alessandro et al. | Fairness and bias in algorithmic hiring: a multidisciplinary survey | |
| WO2016111007A1 (ja) | データ分析システム、データ分析システムの制御方法、及びデータ分析システムの制御プログラム | |
| Jishag et al. | Automated review analyzing system using sentiment analysis | |
| Patidar et al. | Analysis of people’s opinions based on the vaccination procedure and e-commerce product reviews using XLnet framework | |
| Afrinanda et al. | Comparison Of Machine Learning Algorithm Models In Bitcoin Price Sentiment Analysis | |
| Probierz et al. | Emotion detection from text in social networks | |
| Shanmugarajah et al. | WoKnack–A Professional Social Media Platform for Women Using Machine Learning Approach |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2016564340 Country of ref document: JP Kind code of ref document: A |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 15887615 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 20177031349 Country of ref document: KR Kind code of ref document: A |