WO2016155564A1 - 卷积神经网络模型的训练方法及装置 - Google Patents
卷积神经网络模型的训练方法及装置 Download PDFInfo
- Publication number
- WO2016155564A1 WO2016155564A1 PCT/CN2016/077280 CN2016077280W WO2016155564A1 WO 2016155564 A1 WO2016155564 A1 WO 2016155564A1 CN 2016077280 W CN2016077280 W CN 2016077280W WO 2016155564 A1 WO2016155564 A1 WO 2016155564A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- training
- convolution
- initial
- feature
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/32—Normalisation of the pattern dimensions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/46—Descriptors for shape, contour or point-related descriptors, e.g. scale invariant feature transform [SIFT] or bags of words [BoW]; Salient regional features
- G06V10/469—Contour-based spatial representations, e.g. vector-coding
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/192—Recognition using electronic means using simultaneous comparisons or correlations of the image signals with a plurality of references
- G06V30/194—References adjustable by an adaptive method, e.g. learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Definitions
- the present invention relates to the field of image recognition, and in particular to a training method and apparatus for a convolutional neural network model.
- a CNN Convolutional Neural Network
- a CNN model is often used to determine the category of an image to be identified. Before identifying the category of the image to be identified by the CNN model, it is necessary to train the CNN model first.
- the model parameters of the CNN model to be trained are initialized, and the model parameters include an initial convolution kernel of each convolution layer, an initial bias matrix of each convolution layer, and a fully connected layer.
- the initial weight matrix and the initial offset vector of the fully connected layer are obtained from each of the pre-selected training images, a fixed height and a fixed width of the to-be-processed area are obtained, and the fixed height and the fixed width match the type of the image to be recognized that can be processed preset by the CNN model to be trained.
- the to-be-processed area corresponding to each training image is input to the CNN model to be trained.
- each convolution layer the convolution operation and the maximum pooling operation are performed on each to-be-processed region using the initial convolution kernel and the initial bias matrix of each convolutional layer, and each convolution region is obtained in each convolution.
- a feature image on the layer each feature image is processed using the initial weight matrix of the fully connected layer and the initial bias vector to obtain the class probability of each to-be-processed region.
- Class error is calculated by category probability.
- the category error average is calculated based on the category error of all training images.
- the model parameters of the CNN to be trained are adjusted using the category error average.
- the model parameters obtained when the number of iterations reaches a specified number of times are used as model parameters of the trained CNN model.
- the trained CNN model can only recognize images with fixed height and fixed width, resulting in good training.
- the CNN model has certain limitations in identifying images, resulting in limited application.
- an embodiment of the present invention provides a training method and apparatus for a CNN model.
- the technical solution is as follows:
- a training method of a CNN model comprising:
- initial model parameters of the CNN model to be trained including an initial convolution kernel of each level of convolutional layers, an initial bias matrix of the convolutional layers of the levels, an initial weight matrix of the fully connected layer, and the The initial offset vector of the fully connected layer;
- the model parameters obtained when the number of iterations reaches the preset number are taken as the model parameters of the trained CNN model.
- a training apparatus for a CNN model comprising:
- a first acquiring module configured to acquire initial model parameters of the CNN model to be trained, where the initial model parameters include an initial convolution kernel of each convolution layer, an initial bias matrix of the convolutional layers of the levels, and a fully connected layer An initial weight matrix and an initial offset vector of the fully connected layer;
- a second acquiring module configured to acquire multiple training images
- a feature extraction module configured to perform a convolution operation and a maximum pooling on each training image on the convolution layer of each level by using an initial convolution kernel and an initial bias matrix on the convolution layers of each level Operating to obtain a first feature image of each training image on the convolutional layers of the levels;
- a horizontal pooling module configured to perform a horizontal pooling operation on the first feature image of each training image on at least one level of the convolution layer, to obtain a second feature image of each training image on each of the convolution layers;
- a first determining module configured to determine a feature vector of each training image according to a second feature image of each training image on each convolution layer
- a processing module configured to process each feature vector according to the initial weight matrix and an initial offset vector to obtain a class probability vector of each training image
- a calculation module configured to calculate a category error according to the category probability vector of each training image and an initial category of each training image
- An adjustment module configured to model parameters of the CNN model to be trained based on the category error Make adjustments
- An iterative module configured to continue the process of adjusting the model parameters based on the adjusted model parameters and the plurality of training images until the number of iterations reaches a preset number of times;
- the second determining module is configured to use the model parameter obtained when the number of iterations reaches a preset number of times as a model parameter of the trained CNN model.
- a server comprising:
- One or more processors are configured to perform calculations, calculations, and calculations, and calculations.
- a memory coupled to the one or more processors, the memory for storing instructions executable by the one or more processors;
- the one or more processors are configured to execute the memory stored instructions to perform the training method of the CNN model provided in the first aspect above.
- the feature image obtained after the maximum pooling operation is further subjected to a horizontal pooling operation. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- FIG. 1 is a flowchart of a training method of a CNN model according to an embodiment of the present invention
- FIG. 2 is a flowchart of a training method of a CNN model according to another embodiment of the present invention.
- FIG. 3 is a schematic diagram of a CNN model to be trained according to another embodiment of the present invention.
- FIG. 4 is a schematic diagram of a process of a horizontal pooling operation according to another embodiment of the present invention.
- FIG. 5 is a flowchart of a training method of a CNN model according to another embodiment of the present invention.
- FIG. 6 is a schematic structural diagram of a training apparatus for a CNN model according to another embodiment of the present invention.
- FIG. 7 is a schematic structural diagram of a terminal according to another embodiment of the present invention.
- FIG. 8 is a schematic structural diagram of a server according to another embodiment of the present invention.
- FIG. 1 is a flowchart of a training method of a CNN model according to an embodiment of the present invention. As shown in FIG. 1 , the method process provided by the embodiment of the present invention includes:
- initial model parameters of the CNN model to be trained wherein the initial model parameters include an initial convolution kernel of each convolution layer, an initial bias matrix of each convolution layer, an initial weight matrix of the fully connected layer, and a full connection.
- the initial offset vector of the layer is derived from the initial convolution kernel of each convolution layer.
- acquiring a plurality of training images includes:
- any initial training image maintaining the aspect ratio of the initial training image, processing the initial training image as a first image having a specified height;
- the first image is processed into a second image having a specified width, and an image having a specified height and a specified width is used as a training image corresponding to the initial training image.
- processing the first image as a second image having a specified width comprises:
- the width of the first image is smaller than the specified width, uniformly filling the pixels on the left and right sides of the first image with the specified gray value until the width of the first image reaches a specified width, and obtaining the second image;
- the pixels on the left and right sides of the first image are uniformly Cropping, until the width of the first image reaches a specified width, the second image is obtained.
- acquiring a plurality of training images includes:
- the aspect ratio of the initial training image is maintained, the initial training image is processed as an image having a specified height, and the width corresponding to the specified height is taken as the width of each initial training image.
- the training image is an image in a natural scene
- the image in the natural scene includes characters in different languages
- the CNN model to be trained is a language recognition classifier.
- each convolution layer using the initial convolution kernel and the initial bias matrix on each convolution layer, respectively perform convolution operation and maximum pooling operation on each training image, and obtain each training image in A first feature image on each of the convolutional layers.
- a convolution operation and a maximum pooling operation are performed separately for each training image using the initial convolution kernel and the initial bias matrix on each convolutional layer to obtain a volume of each training image at each level.
- the first feature image on the laminate includes:
- the first feature image on the upper convolutional layer is input to the current convolutional layer, and the first convolutional layer is used to the upper convolutional layer using the initial convolution kernel and the initial bias matrix on the current convolutional layer.
- the first feature image is subjected to a convolution operation to obtain a convolution image on the current convolution layer, wherein if the current convolution layer is the first-level convolution layer, the first feature image on the upper convolution layer For training images;
- the first feature image on each of the training images on at least one of the first convolutional layers Performing a horizontal pooling operation to obtain a second feature image of each training image on each convolution layer, including:
- the maximum values extracted from all the lines of each image are arranged into a one-dimensional vector
- a one-dimensional vector of all the images in the first feature image on the convolutional layer is combined to obtain a second feature image on the convolution layer.
- determining a feature vector for each training image based on the second feature image of each training image on each of the convolutional layers includes:
- the elements of all the rows in the second feature image of the training image on each convolution layer are connected end to end to obtain a feature vector of the training image.
- the class error is calculated based on the class probability vector of each training image and the initial category of each training image, including:
- the class error of each training image is calculated according to the class probability vector of each training image and the initial category of each training image by the following formula:
- Loss represents the category error of each training image
- label represents the initial category of each training image
- y i represents an element in the category probability vector of each training image
- y label represents the category probability corresponding to the initial category
- the average of the category errors of all training images is calculated, and the average of the category errors is taken as the category error.
- the model parameter obtained when the number of iterations reaches a preset number is used as a model parameter of the trained CNN model.
- the method provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image on each convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- the CNN model to be trained includes a four-level convolution layer and two fully-connected layers, and each of the convolution layers includes the same or different number of convolution kernels and offset matrices;
- Performing a horizontal pooling operation on the first feature image of each training image on at least one level of the convolution layer to obtain a second feature image of each training image on each of the convolution layers including:
- Determining a feature vector of each training image according to a second feature image of each training image on each convolutional layer including:
- any training image determined based on the second feature image of the training image on the second level convolution layer, the second feature image on the third level convolution layer, and the second feature image on the fourth level convolution layer The feature vector of the training image.
- FIG. 2 is a flowchart of a training method of a CNN model according to another embodiment of the present invention. As shown in FIG. 2, the method process provided by the embodiment of the present invention includes:
- the initial model parameters include an initial convolution kernel of each convolution layer, an initial bias matrix of each convolution layer, an initial weight matrix of the fully connected layer, and a full connection.
- the initial offset vector of the layer includes an initial convolution kernel of each convolution layer, an initial bias matrix of each convolution layer, an initial weight matrix of the fully connected layer, and a full connection.
- the process of training the CNN model is a process of determining model parameters of the CNN to be trained.
- an initial model parameter may be initialized for the CNN model to be trained, and the initial model parameters are continuously optimized in the subsequent training process, and the optimized optimal model parameters are used as the trained CNN model. Model parameters. Therefore, when training the CNN model to be trained, it is necessary to obtain the initial model parameters of the CNN model to be trained.
- the CNN model to be trained generally includes at least two levels of convolution layers and at least one level of fully connected layers, and each level of the convolution layer includes a plurality of convolution kernels and a plurality of offset matrices, each level of the full connection layer including a plurality of weights Matrix and multiple offset vectors. Therefore, the acquired model parameters include an initial convolution kernel of each convolutional layer, an initial bias matrix of each convolutional layer, an initial weight matrix of the fully connected layer, and an initial bias vector of the fully connected layer.
- the number of the convolutional layer and the number of the fully connected layers included in the CNN model to be trained are not specifically limited in the embodiment of the present invention. When it is implemented, it can be set as needed.
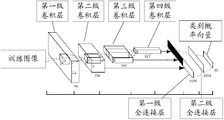
- FIG. 3 it shows a schematic diagram of a CNN model to be trained.
- the CNN model to be trained shown in FIG. 3 includes a four-level convolutional layer and a two-level fully connected layer.
- the number of the convolution kernel and the offset matrix included in each level of the convolutional layer, and the number of the weight matrix and the offset vector included in the per-connection layer of each stage are not specifically limited in the embodiment of the present invention.
- embodiments of the present invention also do not define the dimensions of each convolution kernel and offset matrix, as well as the dimensions of each weight matrix and each offset vector.
- the convolution kernel and the offset moment included in each level of the convolutional layer The number of arrays and their dimensions, as well as the number and dimensions of the weighted matrices and offset vectors for each level, can be empirical values.
- the first level convolutional layer may include 96 convolution kernels C 1 having a size of 5 ⁇ 5. And 96 offset matrices B 1 having a size of 5 ⁇ 5,
- a value may be randomly selected within the specified numerical range as the value of each element in the initial model parameter. For example, for each of the initial convolution kernel, the initial weight matrix, the initial bias matrix, and the initial offset vector, a random number can be taken in the [-r, r] interval.
- r is a threshold for initializing model parameters, which may be an empirical value. For example, r can take 0.001.
- the category of the training image is related to the recognition category of the CNN model to be trained.
- the training image may be an image including characters or character strings of different languages.
- the training images are images including different colors and the like.
- the training image may be an image in a natural scene, and the image in the natural scene includes characters in different languages.
- the CNN model to be trained can identify the classifier for the language.
- the embodiment of the present invention does not specifically limit the size of the training image.
- it may be combined with the category of the training image.
- the specific value of the height may be limited, and the width thereof is not limited.
- all training images may have the same height and width, that is, all training images have a specified height and a specified width.
- the heights of all training images can be the same, but their widths can be different.
- all training images have a specified height, but the widths are different.
- a pixel whose height is the first value is specified, and a pixel whose width is the second value is specified.
- the first value may be an empirical value, for example, the first value may be 32 or the like.
- the second value may be a random number selected within a preset range.
- the value of the second value may be related to the image category.
- the preset range can be between 48 and 256.
- the first way all training images in this mode have a specified height and a specified width.
- a plurality of initial training images may be acquired first, and for an initial training image of the plurality of initial training images, an aspect ratio of the initial training image may be maintained, and the initial training image is first processed to have a designation a first image of height; then, processing the first image into a second image having a specified width.
- a training image having a specified height and a specified width corresponding to the initial training image can be obtained. For all the initial training images, you can get multiple trainings. Practice the image.
- the initial training image may be processed into a training image of 32 pixels * 60 pixels.
- the width of the first image when the first image is processed into the second image having the specified width, the width of the first image may be larger than the specified width, and may be smaller than the specified width. Therefore, for both cases, in order to obtain an image of a specified width, there are two different processing situations as follows.
- the first case when the width of the first image is smaller than the specified width, the pixels of the specified gray value are uniformly filled on the left and right sides of the first image until the width of the first image reaches a specified width.
- the specific value of the specified gray value can be set as needed or empirically.
- the specified gray value can be zero.
- pixels of a specified gray value of 2 pixels may be filled to the left of the first image, and 2 pixels may be filled to the right of the first image.
- the pixel of the specified gray value may be filled to the left of the first image.
- the second case when the width of the first image is larger than the specified width, the pixels on the left and right sides of the first image may be uniformly cropped until the width of the first image reaches a specified width.
- the specified width is 120 pixels and the width of a certain first image is 124 pixels
- 2 pixels can be cropped on the left side of the first image
- 2 pixels can be cropped on the right side of the first image.
- a plurality of initial training images may be acquired first, and for any of the plurality of initial training images, an aspect ratio of the initial training image may be maintained, and the initial training image is processed to have a designation a height image and the width corresponding to the specified height as the initial training The width of the image.
- the specified height corresponds to a width of 120 pixels
- the height of the training image obtained by the method is a specified height and the width is 120 pixels.
- each training image has a specified height, but the widths are different. At this time, when training the CNN model to be trained, it can be ensured that the trained CNN model has higher recognition accuracy.
- the CNN model to be trained is specifically trained by using the acquired plurality of training images, only a plurality of training images obtained by the foregoing first manner may be used, thereby realizing quick acquisition of the trained CNN model; Only a plurality of training images obtained by the second method described above are used, thereby ensuring that the trained CNN model has a higher recognition accuracy.
- the CNN model can be trained by using the training images obtained in the first mode and the second mode simultaneously, so as to improve the speed of training the CNN model, and ensure that the trained CNN model has higher recognition accuracy.
- each convolution layer on each convolution layer, using the initial convolution kernel and the initial bias matrix on each convolution layer, respectively performing convolution operation and maximum pooling operation on each training image, and obtaining each training image in A first feature image on each of the convolutional layers.
- the training image may be subjected to a convolution operation and a maximum pooling operation on each convolution layer.
- each of the training images is subjected to a convolution operation and a maximum pooling operation using the initial convolution kernel and the initial bias matrix on each convolution layer to obtain a convolution layer of each training image at each level.
- the first feature image on the top is implemented by the following steps 2031 to 2033:
- the first feature image on the upper convolution layer is input into the current convolution layer, using the initial convolution kernel on the current convolution layer and the initial bias matrix, for the upper level volume
- the first feature image on the layer is subjected to a convolution operation to obtain a convolved image on the current convolution layer.
- the current convolutional layer is a first-level convolutional layer
- the first feature image on the upper-level convolutional layer is the training image itself.
- the training image may be first transmitted to the first-level convolutional layer, and the initial volume on the first-level convolutional layer is used.
- the accumulation and initial bias matrix convolute the training image to obtain a convolved image on the first level convolution layer.
- a maximum pooling operation is performed on the convolved image on the first-level convolution layer to obtain a first feature image on the first-level convolution layer.
- the first feature image on the first level convolutional layer is transferred to the second level convolutional layer, and the convolution operation and the maximum pooling operation are continued on the second level convolutional layer.
- each volume in the current convolution layer may be used.
- the first feature image is convolved on the first convolutional layer, and the sliding step size of the convolution kernel in the current convolutional layer on the first feature image on the upper convolutional layer is controlled to be 1.
- pixels at the edge of the image may not be convoluted during the convolution operation, thereby causing the size of the convolved image obtained after the convolution operation to occur. Variety.
- the convolved image may be pixel-filled before the convolution operation of each of the convolution layers, thereby ensuring that the size of the image to be convolved is unchanged after the convolution operation.
- a preset gray value may be used around the image to be convolved, such as with "0".
- the step size of the filling is related to the dimension of the convolution kernel.
- the dimension of the convolution kernel is n
- the step size of the padding is (n-1)/2.
- the convolution kernel is 3*3
- the step size of the padding is 1 pixel.
- the image to be convolved described in this step is an image input to each convolution layer.
- the image to be convolved is a training image; if the current convolutional layer is not a first-level convolutional layer, the image to be convolved is a higher-level convolutional layer.
- the first feature image on.
- a sliding frame of a specified size such as a 3 ⁇ 3 sliding frame, may be used in the convolution image on the current convolution layer.
- Each convolution image slides from left to right and from top to bottom, and the step size of the slide is a preset pixel, such as a preset pixel of 2 pixels.
- the sliding frame slides on each convolution image the elements of less than 0 of all the elements contained in the sliding frame are set to 0, and then the largest of all the elements are taken out and reconstructed in the order of sliding. New image. After the operation is completed, the first feature image on the current convolution layer will be obtained.
- the length and width of the first feature image on the current convolution layer can be expressed by the following formula:
- floor represents the rounding down function.
- floor(2.5) 2.
- w represents the length or width of the first feature image on the current convolutional layer
- m is the number of pixels included in the length or width of the sliding frame
- l is the sliding step size
- w 0 is the convolution image on the current convolution layer Height or width.
- the size of the convolutional image on the current convolutional layer is 32 ⁇ w 0
- the sliding frame is 3*3
- the sliding step is 2, for example, after the maximum pooling operation, the first on the current convolution layer is obtained.
- the size of the feature image is 15 ⁇ w 1 .
- the first feature image on all the convolution layers may be horizontally pooled, or the first feature image on the partial convolution layer may be horizontally pooled.
- the CNN model to be trained includes a four-level convolutional layer
- horizontal pooling operations may be performed on each level of the convolutional layer, or only in the second-level convolution, the third-level convolutional layer, and the fourth-level Horizontal pooling operations on the convolutional layer.
- a horizontal pooling operation is performed on the first feature image of each training image on at least one level of the convolution layer, and a second feature image of each training image on each of the convolution layers is obtained, including but not It is limited to be implemented by the following steps 2041 to 2043:
- the first feature image includes an image of a preset value that is the same as the number of convolution kernels and offset matrices of the level convolution layer.
- the maximum value of each row is arranged into a one-dimensional vector of length 7 according to the arrangement of pixels of each image from top to bottom.
- FIG. 4 shows a schematic diagram of a process of performing a horizontal pooling operation on one of the first feature images on the second convolutional layer.
- step 2041 in conjunction with the above example if R 2 in all 256 images, if all of the 2 image R 256 are the above-described operation is repeated to obtain a 256-dimensional vector of length 7.
- Each one-dimensional vector is treated as a column vector, which is sequentially spliced into an image H 1 having a height and a width of 7 and 256, respectively.
- H 1 is the second feature image on the second-level convolution layer obtained after the horizontal pooling operation of R 2 .
- the CNN model to be trained includes a four-level convolutional layer and a two-level fully connected layer, and each of the convolutional layers includes the same or different number of convolution kernels and offset matrices, respectively.
- the first feature image of each training image on at least one convolution layer is subjected to a horizontal pooling operation to obtain a second feature image of each training image on each convolution layer, Leveling the first feature image on the second-level convolution layer, the first feature image on the third-level convolution layer, and the first image feature on the fourth-level convolution layer for each training image And obtaining a second feature image of each training image on the second level convolution layer, a second feature image on the third level convolution layer, and a second feature image on the fourth level convolution layer.
- the feature vector is a cascade of the second feature image on the convolution layer of each training image, and all the rows in the second feature image on each convolution layer are of The elements are connected end to end.
- the second feature image on the second level convolution layer, the second feature image on the third level convolution layer, and the A second feature image on the fourth-level convolutional layer determines a feature vector of the training image.
- the second feature image on the second-level convolution layer, the second feature image on the third-level convolution layer, and the second feature image on the fourth-level convolution layer may be performed. Cascading, and the first feature image of the second feature image on the second-level convolutional layer, the second feature image on the third-level convolutional layer, and the elements of all the rows in the second feature image on the fourth-level convolutional layer Then, the feature vector of the training image is obtained.
- the second feature image of the training image on the second-level convolution layer is H 1
- the second feature image on the third-level convolution layer is H 2
- the second feature image on the fourth-level convolution layer is H 3
- the elements of all the rows are connected end to end to obtain a third one-dimensional vector.
- the first one-dimensional vector, the second one-dimensional vector and the third one-dimensional vector are connected end to end to obtain a feature vector of the training image.
- a feature vector of a training image it may be input into a fully connected layer, multiplied by the weight matrix of the fully connected layer, and the product result is added to the offset vector of the fully connected layer, thereby obtaining The class probability vector of the training image.
- the class probability vector is a one-dimensional vector, and the number of elements in the class probability vector is related to the number of image categories that the CNN model to be trained can recognize. For example, if the image to be trained is capable of distinguishing images of ten categories, the category probability vector includes ten elements. Each element represents the probability that the training image belongs to a certain category.
- the class error is calculated according to the class probability vector of each training image and the initial category of each training image, including but not limited to the following steps: 2071 to 2073:
- the initial category can be manually extracted and recorded. On this basis, when acquiring the initial category of each training image, it can be directly obtained from the recorded data.
- Loss represents the category error of each training image
- label represents the initial category of each training image
- y i represents an element in the category probability vector of each training image
- y label represents the category probability corresponding to the initial category. For example, when the initial training image is of the first class, y label is y 1 , which is the first element in the class probability vector.
- the class error is reversely transmitted back to the CNN model to be trained, thereby implementing the update of the to-be-trained All elements in the model parameters of the CNN model.
- SGD Spochastic gradient descent
- the class error is reversely transmitted back to the CNN model to be trained to update all the elements in the model parameters of the CNN model to be trained, which is not specifically limited in the embodiment of the present invention.
- steps 203 to 208 are repeated until the number of repetitions, that is, the number of iterations reaches a preset number of times.
- the specific numerical range of the preset number of times is not specifically limited in the embodiment of the present invention.
- the value of the preset number of times can be relatively large.
- the preset number of times may be an empirical value. For example, take 300,000.
- the model parameter obtained when the number of iterations reaches a preset number is used as a model parameter of the trained CNN model.
- the model parameters obtained when the number of iterations reaches 300,000 are the model parameters of the trained CNN model.
- the category probability vector includes 10 elements, each of which corresponds to one category, and if the second element of the category probability vector is closest to 1, the image to be identified belongs to the second category.
- the method provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image on each convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- the embodiment of the present invention provides a fourth-level convolution layer and a two-level fully-connected layer in the CNN model to be trained.
- the method is explained.
- the second level volume is The horizontal feature operation of the first feature image on the laminate, the first feature image on the third-level convolution layer, and the first feature image on the fourth-level convolution layer will be described as an example.
- the method process provided by the embodiment of the present invention includes:
- initial model parameters of the CNN model to be trained include an initial convolution kernel and an initial bias matrix of the first-level convolutional layer, an initial convolution kernel of the second-level convolutional layer, and an initial bias Matrix, initial convolution kernel and initial bias matrix of the third-order convolutional layer, initial convolution kernel and initial bias matrix of the fourth-order convolutional layer, initial weight matrix of the first-level fully connected layer, and initial bias Vector, initial weight matrix of the second-level fully connected layer, and initial offset vector.
- the convolutional layers of each level may comprise the same or different number of convolution kernels and offset matrices, and the full connection layers of each level comprise the same or different number of weight matrices and offset vectors.
- the number of the convolution kernel and the offset matrix included in each level of the convolutional layer, and the number of the weight matrix and the offset vector included in the per-connection layer of each stage are not specifically limited in the embodiment of the present invention.
- embodiments of the present invention also do not define the dimensions of each convolution kernel and offset matrix, as well as the dimensions of each weight matrix and each offset vector.
- the number of convolution kernels and offset matrices included in each level of the convolutional layer and its dimensions, as well as the number and dimensions of the weighted matrix and offset vector of each level may take empirical values.
- the convolution kernel, the offset matrix, the weight matrix, and the offset vector in each convolutional layer in the initial model parameter are referred to as an initial convolution kernel, an initial bias matrix, and an initial weight matrix. And the initial offset vector. Therefore, when training the CNN model to be trained, it is necessary to obtain the initial convolution kernel of each convolutional layer, the initial bias matrix of each convolutional layer, the initial weight matrix of the fully connected layer, and the initial bias vector of the fully connected layer. .
- the first-level convolution layer includes 96 convolution kernels C 1 having a size of 5 ⁇ 5. And 96 offset matrices B 1 having a size of 5 ⁇ 5,
- the second-level convolutional layer contains 256 convolution kernels C 2 of size 5 ⁇ 5.
- 256 offset matrices B 2 having a size of 5 ⁇ 5
- the third-level convolutional layer contains 384 convolution kernels C 3 of size 3 ⁇ 3 .
- the fourth-level convolutional layer contains 512 convolution kernels C 4 of size 3 ⁇ 3.
- the first level fully connected layer includes a weight matrix W 1 having a size of 3456 ⁇ 1024 and an offset vector B 5 having a length of 1024; the second level fully connected layer includes a weight matrix W 2 having a size of 1024 ⁇ 10.
- the method provided by the embodiment of the present invention is explained by taking an offset vector B 6 of length 10 as an example.
- a value may be randomly selected within the specified numerical range as the value of each element in the initial model parameter. For example, for each of the initial convolution kernel, the initial weight matrix, the initial bias matrix, and the initial offset vector, a random number can be taken in the [-r, r] interval.
- r is the threshold of the initial model parameters, which may be empirical values. For example, r can take 0.001.
- the training image I is one of a plurality of training images.
- the process of training the CNN model to be trained is explained by taking the training image I as an example.
- the training image I has a specified height and a specified width.
- the specified height may be a pixel of a first value
- the specified width may be a pixel of a second value.
- the first value may be an empirical value, for example, the first value may be 32 or the like.
- the second value may be a random number selected within a preset range.
- the preset range may be between 48 and 256.
- the size of the training image is 32*w o as an example. Where 32 is the first value and w o is the second value.
- the training image I will be convoluted and maximized on the first level convolution layer using the initial convolution kernel and the initial bias matrix on the first level convolution layer in conjunction with each of the initial model parameter pairs in step 502.
- the steps of the operation are specifically described.
- the process of obtaining the first feature image R 1 of the training image I on the first-level convolution layer is as follows:
- 5031 Fill the training image I to obtain the filled training image I tr .
- This step is an optional step. By this step, it is possible to ensure that the convolution image on the first-order convolution layer obtained after the convolution operation on the first-order convolution layer has the same size as the training image I.
- the content of the padding has been described in step 203. For details, refer to the content in step 203, and details are not described herein again.
- the training image I is 32 ⁇ w o as an example, it is possible to uniformly fill the training image I with a “0” element.
- the length of the padding is 2, thereby obtaining a padded training image I tr of height and width of 36 pixels and w o +4 pixels, respectively.
- the padded training image I tr can be convolved with each convolution kernel of C 1 , and the sliding step of the convolution kernel on the padded training image I tr is 1 ,which is:
- step 203 The specific content of the maximum pooling operation has been described in step 203. For details, refer to the content in step 203, and details are not described herein again.
- a 3 x 3 sliding frame can be used to slide from left to right and top to bottom in each convolution image in the convolved image D 1 on the first level convolutional layer.
- the step size of the slide is 2.
- the element with less than 0 of the 9 elements contained in the box is set to 0, then the largest of the 9 elements is taken out, and a new image is reconstructed in the order of the sliding. .
- the first-level feature image R 1 on the first-level convolution layer is obtained.
- floor(2.5) 2.
- "3" in the numerator in the formula indicates the size of one dimension of the sliding frame
- "2" in the denominator indicates the step size of the sliding.
- 3 ⁇ 3 here is only used as an example, and in the specific implementation, the size of the sliding frame may also be other values.
- the embodiment of the present invention does not limit the size of the sliding frame.
- the first-level feature image R 1 on the first-level convolution layer is performed on the second-level convolution layer using the convolution kernel and the offset matrix of the second-level convolution layer in combination with each of the initial model parameter pairs described above.
- the steps of the convolution operation and the maximum pooling operation are specifically described.
- the process of obtaining the first feature image R 2 on the second-level convolution layer is as follows:
- This step is the same as the principle in step 5031. For details, refer to the content in step 5031 above.
- This step is an optional step. By this step, it is possible to ensure that the image after the convolution operation has the same size as the first feature image R 1 on the first-order convolution layer.
- the length of the padding includes, but is not limited to, 2, the padded image Rp 1 , And The height and width are 19 and w 1 +4, respectively.
- the filled image is obtained using the convolution kernel and the offset matrix pair on the second level convolutional layer
- a convolution operation is performed to obtain a convolution image D 2 on the second-level convolution layer.
- the principle of the step is the same as the principle of the step 5032.
- each convolution kernel convolution can be separately used in C 2
- the convolution kernel has a sliding step size of 1 in the image, and the convolved results are added to obtain each convolution image on the second secondary convolution layer.
- the ith convolution kernel Convolutional image obtained after convolving Rp 1 and The size is 15 ⁇ w 1 .
- the principle of this step is the same as the principle of 5033.
- the size is 7 ⁇ w 2 .
- 5044 Perform a horizontal pooling operation on the first feature image R 2 on the second-level convolution layer to obtain a second feature image H 1 on the second-level convolution layer.
- the i-th feature image in R 2 Is an image with height and width of 7 and w 2 respectively, extracted
- the maximum value of all the elements in each row is sequentially connected into a one-dimensional vector of length 7.
- Each one-dimensional vector is treated as a column vector, and is sequentially spliced into an image H 1 having a height and a width of 7 and 256, respectively.
- H 1 is the second feature image on the second convolution layer obtained after the horizontal pooling operation of R 2 .
- the first-level feature image on the second-level convolution layer on the third-level convolutional layer using the convolution kernel and the offset matrix on the third-level convolutional layer will be combined with the respective model parameter pairs in step 502.
- the steps of R 2 for the convolution operation and the maximum pool operation are specifically described.
- the process of obtaining the first feature image R 3 on the third-level convolution layer is as follows:
- 5051 Fill the first feature image R 2 on the second-level convolution layer to obtain the padded image Rp 2 .
- This step is the same as the principle in step 5031. For details, refer to the content in step 5031 above.
- This step is an optional step. By this step, it is possible to ensure that the image after the convolution operation has the same size as the first feature image R 2 on the second-order convolution layer.
- the length of the padding includes, but is not limited to, 1 and a new image Rp 2 is obtained after padding. among them, And The height and width are 9 and w 2 +2, respectively.
- the convolution operation is performed on the padded image Rp 2 using the convolution kernel and the offset matrix on the third-level convolution layer to obtain a convolution on the third-level convolution layer.
- Image D 3 On the third-level convolution layer, the convolution operation is performed on the padded image Rp 2 using the convolution kernel and the offset matrix on the third-level convolution layer to obtain a convolution on the third-level convolution layer.
- the principle of the step is the same as the principle of the above step 5032.
- the convolution kernel has a sliding step length of 1, in the image Rp 2 after the filling, that is:
- the convolution kernel Convolutional image obtained after convolving Rp 2 and The size is 7 ⁇ w 2 .
- the principle of this step is the same as the principle of 5033.
- the size is 3 ⁇ w 3 . among them,
- 5054 the first feature image R on the third level stage pool convolution operation layer 3, the second feature image obtained on the second stage H 2 convolutional layer.
- step 5044 The principle of this step is the same as the principle of the above step 5044. For details, refer to the content in step 5044 above.
- an image H 2 having a height and a width of 3 and 384, respectively, can be obtained.
- H 2 is the output after the horizontal pooling operation of R 3 .
- the convolution operation and the maximum pooling operation are performed on the first-level feature image R 3 on the third-level convolution layer by using the convolution kernel and the matrix of the fourth-level convolution layer.
- the first feature image R 4 on the fourth-level convolution layer is obtained.
- the first level feature image on the third level convolution layer will be used on the fourth level convolution layer in conjunction with the respective model parameter pairs in step 502, using the convolution kernel and the offset matrix on the fourth level convolution layer.
- the steps of R 3 performing the convolution operation and the maximum pooling operation are specifically described. Specifically, the process of obtaining the first feature image R 4 on the fourth-level convolution layer is as follows:
- the convolution kernel has a sliding step size of 1 on R 3 , namely:
- 5062 Perform a horizontal pooling operation on the first feature image R 4 on the fourth-level convolution layer to obtain a second feature image H 3 on the fourth-level convolution layer.
- step 5044 The principle of this step is the same as the principle of the above step 5044. For details, refer to the content in step 5044 above.
- the i-th feature image in R 4 Is a vector of length w 3 -2, extracted The maximum of all the elements in .
- 512 numbers are obtained, which are sequentially connected into a vector H 3 having a length of 512.
- H 3 is the output after the horizontal pooling operation of R 4 .
- the feature vector Fc 1 of the training image I is determined.
- the column vectors of H 1 and H 2 may be connected end to end and then concatenated, and then the vector H 3 may be cascaded to obtain a one-dimensional vector Fc 1 , and Fc 1 is used as the feature vector of the training image I.
- the length of the Fc 1 is 3456.
- the weight matrix of the first-level fully connected layer may be W 1 and the offset vector is B 5 , and the first-level fully connected layer output Fc 2 is calculated by the following formula:
- Fc 2 Fc 1 *W 1 +B 5 .
- the length of Fc 2 is 1024.
- the results obtained in the above various steps can be referred to the specific values in FIG.
- the numerical values in FIG. 3 are for example only and do not constitute a limitation on the embodiments of the present invention.
- step 206 and the step 207 The principle of the step is specifically described in the step 206 and the step 207. For details, refer to the content in the step 206 and the step 207, and details are not described herein again.
- the first level fully connected layer output Fc 2 can be used as an input to the second level fully connected layer. It can be obtained from the content in step 502 that the weight matrix of the second-level fully connected layer is W 2 and the offset vector is B 6 , and the class probability vector Y of the training image I is calculated.
- Y i represents the probability that the input image I belongs to the i-th class
- n represents the number of image categories that the CNN model to be trained can recognize.
- FIG. 3 is only described by taking the example that the CNN model to be trained can recognize 10 image categories.
- Loss -Lny label .
- step 208 The principle of this step has been specifically described in step 208. For details, refer to the content in step 208, and details are not described herein again.
- the learning rate in the SGD algorithm can be taken as 0.01, and the class error calculated in step 510 can be made.
- Reverse conduction back to the training CNN model to update the convolution kernels C 1 , C 2 , C 3 , C 4 , the bias matrices B 1 , B 2 , B 3 , B 4 , the weight matrices W 1 , W 2 and the bias Set all the elements in vectors B 5 and B 6 .
- Step 503 to step 511 are iteratively operated for a preset number of times N, and the model parameters obtained when the number of iterations reaches the preset number of times N are used as model parameters of the trained CNN model.
- N is not specifically limited in the embodiment of the present invention.
- the value of N can be relatively large.
- N may be an empirical value. For example, N takes 300000.
- the model parameters obtained when the number of iterations reaches 300,000 are the model parameters of the trained CNN model.
- the CNN model to be trained includes a four-level convolutional layer, and in the second-level convolutional layer,
- the CNN model trained by the above steps 501 to 512 has a relatively high accuracy, thereby improving the accuracy of training the CNN model.
- the method provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image on each convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
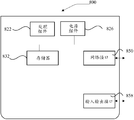
- FIG. 6 is a schematic structural diagram of a training apparatus of a CNN model according to another embodiment of the present invention, where the training apparatus of the CNN can be used to execute the CNN model provided by the embodiment corresponding to any of the foregoing FIG. 1, FIG. 2 or FIG. Training method.
- the device includes:
- the first obtaining module 601 is configured to obtain initial model parameters of the CNN model to be trained, where the initial model parameters include an initial convolution kernel of each convolution layer, an initial bias matrix of each convolution layer, and a fully connected layer. Initial weight matrix and initial offset vector of the fully connected layer;
- a second obtaining module 602 configured to acquire a plurality of training images
- the feature extraction module 603 is configured to perform a convolution operation and a maximum pooling operation on each training image by using an initial convolution kernel and an initial offset matrix on each convolution layer on each convolution layer. a first feature image of each training image on each of the convolution layers;
- the horizontal pooling module 604 is configured to perform a horizontal pooling operation on the first feature image of each training image on at least one level of the convolution layer to obtain a second feature image of each training image on each convolution layer;
- a first determining module 605 configured to determine a feature vector of each training image according to a second feature image of each training image on each convolution layer;
- the processing module 606 is configured to process each feature vector according to the initial weight matrix and the initial offset vector to obtain a class probability vector of each training image;
- a calculation module 607 configured to calculate a category error according to a class probability vector of each training image and an initial category of each training image
- An adjustment module 608, configured to adjust a model parameter of the CNN model to be trained based on the category error
- the iterative module 609 is configured to continue the process of adjusting the model parameters based on the adjusted model parameters and the plurality of training images until the number of iterations reaches a preset number of times;
- the second determining module 610 is configured to use the model parameter obtained when the number of iterations reaches a preset number of times as a model parameter of the trained CNN model.
- the apparatus provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image on each convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- the first obtaining module 601 includes:
- a first acquiring unit configured to acquire a plurality of initial training images
- a first processing unit configured to maintain an aspect ratio of the initial training image for any initial training image, and process each initial training image into a first image having a specified height
- a second processing unit configured to process the first image into an image having a specified width
- the first determining unit is configured to use an image having a specified height and a specified width as a training image corresponding to the initial training image.
- the first obtaining module 601 includes:
- a second acquiring unit configured to acquire a plurality of initial training images
- a third processing unit configured to maintain an aspect ratio of the initial training image for any initial training image, process the initial training image into an image having a specified height, and use a width corresponding to the specified height as a width of each initial training image.
- the first processing unit comprises:
- the crop subunit is configured to uniformly crop the left and right pixels of the processed initial training image when the initial width is greater than the specified width until the specified width is reached.
- the feature extraction module 603 includes:
- a convolution unit for inputting a first feature image on the upper convolution layer into the current convolution layer for any training image, using an initial convolution kernel and an initial bias matrix on the current convolution layer, The convolution operation is performed on the first feature image on the upper convolution layer to obtain a convolution image on the current convolution layer, wherein if the current convolution layer is the first convolution layer, the upper convolution layer The first feature image on the image is a training image;
- a maximum pooling unit configured to perform a maximum pooling operation on the convolution image on the current convolution layer to obtain a first feature image of the training image on the current convolution layer
- a transfer unit for continuing to transfer the first feature image on the current convolutional layer to the next-level convolution layer, and performing convolution operations and maximum pooling operations on the next-level convolution layer until convolution at the final level
- the layer performs a convolution operation and a maximum pooling operation to obtain a first feature image on the last layer of the convolutional layer.
- the horizontal pooling module 604 includes:
- An extracting unit configured to extract, from a first feature image of any training image on a convolution layer of any level, a maximum value in each row of each image in the first feature image on the convolution layer, wherein the first The feature image includes an image of a preset value, and the preset value is the same as the number of convolution kernels and offset matrices of the convolution layer;
- Arranging unit for arranging the maximum values extracted by all the lines of each image into a one-dimensional vector according to the pixel arrangement of each image
- a combining unit for combining one-dimensional vectors of all images in the first feature image on the convolution layer, A second feature image on the convolutional layer is obtained.
- the first determining module 605 is configured to, for any training image, end the elements of all the rows in the second feature image of the training image on each convolution layer to obtain the characteristics of the training image. vector.
- the calculation module 607 includes:
- An obtaining unit configured to acquire an initial category of each training image
- a first calculating unit configured to calculate a class error of each training image according to a class probability vector of each training image and an initial category of each training image by using the following formula:
- Loss represents the category error of each training image
- label represents the initial category of each training image
- y i represents an element in the category probability vector of each training image
- y label represents the category probability corresponding to the initial category
- a second calculating unit is configured to calculate a category error average of all the training images, and the category error average is used as a category error.
- the training image is an image in a natural scene
- the image in the natural scene includes characters in different languages
- the CNN model to be trained is a language recognition classifier.
- the CNN model to be trained includes a four-level convolution layer and two fully-connected layers, and each of the convolution layers includes the same or different number of convolution kernels and offset matrices;
- a horizontal pooling operation for the first feature image on the second level convolution layer of each training image, the first feature image on the third level convolution layer, and the first feature on the fourth level convolution layer The images are respectively subjected to a horizontal pooling operation to obtain a second feature image of each training image on the second-level convolution layer, a second feature image on the third-level convolution layer, and a second feature on the fourth-level convolution layer Feature image
- a first determining module configured to, for any training image, a second feature image on the second level convolution layer, a second feature image on the third level convolution layer, and a fourth level convolution layer according to the training image
- the second feature image determines a feature vector of the training image.
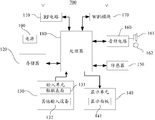
- FIG. 7 is a schematic structural diagram of a terminal according to an embodiment of the present invention.
- the terminal may be used to implement the training method of the CNN model provided by the embodiment corresponding to FIG. 1 , FIG. 2 , or FIG. 4 .
- FIG. 7 is a schematic structural diagram of a terminal according to an embodiment of the present invention.
- the terminal may be used to implement the training method of the CNN model provided by the embodiment corresponding to FIG. 1 , FIG. 2 , or FIG. 4 .
- the terminal may be used to implement the training method of the CNN model provided by the embodiment corresponding to FIG. 1 , FIG. 2 , or FIG. 4 .
- FIG. 7 is a schematic structural diagram of a terminal according to an embodiment of the present invention.
- the terminal may be used to implement the training method of the CNN model provided by the embodiment corresponding to FIG. 1 , FIG. 2 , or FIG. 4 . Specifically:
- the terminal 700 may include an RF (Radio Frequency) circuit 110, a memory 120 including one or more computer readable storage media, an input unit 130, a display unit 140, a sensor 150, an audio circuit 160, and a WiFi (Wireless Fidelity, wireless).
- the fidelity module 170 includes a processor 180 having one or more processing cores, and a power supply 190 and the like. It will be understood by those skilled in the art that the terminal structure shown in FIG. 7 does not constitute a limitation to the terminal, and may include more or less components than those illustrated, or a combination of certain components, or different component arrangements. among them:
- the RF circuit 110 can be used for transmitting and receiving information or during a call, and receiving and transmitting signals. Specifically, after receiving downlink information of the base station, the downlink information is processed by one or more processors 180. In addition, the data related to the uplink is sent to the base station. .
- the RF circuit 110 includes, but is not limited to, an antenna, at least one amplifier, a tuner, one or more oscillators, a Subscriber Identity Module (SIM) card, a transceiver, a coupler, an LNA (Low Noise Amplifier). , duplexer, etc.
- RF circuitry 110 can also communicate with the network and other devices via wireless communication.
- the wireless communication may use any communication standard or protocol, including but not limited to GSM (Global System of Mobile communication), GPRS (General Packet Radio Service), CDMA (Code Division Multiple Access). , Code Division Multiple Access), WCDMA (Wideband Code Division Multiple Access), LTE (Long Term Evolution), e-mail, SMS (Short Messaging Service), and the like.
- GSM Global System of Mobile communication
- GPRS General Packet Radio Service
- CDMA Code Division Multiple Access
- WCDMA Wideband Code Division Multiple Access
- LTE Long Term Evolution
- e-mail Short Messaging Service
- the memory 120 can be used to store software programs and modules, and the processor 180 executes various functional applications and data processing by running software programs and modules stored in the memory 120.
- the memory 120 can mainly include a storage program area and a storage data area, wherein the storage program area can store an operating system, At least one function required application (such as a sound playing function, an image playing function, etc.), etc.; the storage data area can store data (such as audio data, phone book, etc.) created according to the use of the terminal 700.
- memory 120 can include high speed random access memory, and can also include non-volatile memory, such as at least one magnetic disk storage device, flash memory device, or other volatile solid state storage device. Accordingly, memory 120 may also include a memory controller to provide access to memory 120 by processor 180 and input unit 130.
- the input unit 130 can be configured to receive input numeric or character information and to generate keyboard, mouse, joystick, optical or trackball signal inputs related to user settings and function controls.
- input unit 130 can include touch-sensitive surface 131 as well as other input devices 132.
- Touch-sensitive surface 131 also referred to as a touch display or trackpad, can collect touch operations on or near the user (such as a user using a finger, stylus, etc., on any suitable object or accessory on touch-sensitive surface 131 or The operation near the touch-sensitive surface 131) and driving the corresponding connecting device according to a preset program.
- the touch-sensitive surface 131 can include two portions of a touch detection device and a touch controller.
- the touch detection device detects the touch orientation of the user, and detects a signal brought by the touch operation, and transmits the signal to the touch controller; the touch controller receives the touch information from the touch detection device, converts the touch information into contact coordinates, and sends the touch information.
- the processor 180 is provided and can receive commands from the processor 180 and execute them.
- the touch-sensitive surface 131 can be implemented in various types such as resistive, capacitive, infrared, and surface acoustic waves.
- the input unit 130 can also include other input devices 132.
- other input devices 132 may include, but are not limited to, one or more of a physical keyboard, function keys (such as volume control buttons, switch buttons, etc.), trackballs, mice, joysticks, and the like.
- Display unit 140 can be used to display information entered by the user or information provided to the user and various graphical user interfaces of terminal 700, which can be constructed from graphics, text, icons, video, and any combination thereof.
- the display unit 140 may include a display panel 141.
- the display panel 141 may be configured in the form of an LCD (Liquid Crystal Display), an OLED (Organic Light-Emitting Diode), or the like.
- the touch-sensitive surface 131 may cover the display panel 141, and when the touch-sensitive surface 131 detects a touch operation on or near it, it is transmitted to the location
- the processor 180 determines the type of touch event, and then the processor 180 provides a corresponding visual output on the display panel 141 depending on the type of touch event.
- touch-sensitive surface 131 and display panel 141 are implemented as two separate components to implement input and input functions, in some embodiments, touch-sensitive surface 131 can be integrated with display panel 141 for input. And output function.
- Terminal 700 can also include at least one type of sensor 150, such as a light sensor, motion sensor, and other sensors.
- the light sensor may include an ambient light sensor and a proximity sensor, wherein the ambient light sensor may adjust the brightness of the display panel 141 according to the brightness of the ambient light, and the proximity sensor may close the display panel 141 when the terminal 700 moves to the ear. / or backlight.
- the gravity acceleration sensor can detect the magnitude of acceleration in each direction (usually three axes). When it is stationary, it can detect the magnitude and direction of gravity.
- attitude of the terminal such as horizontal and vertical screen switching, related Game, magnetometer attitude calibration), vibration recognition related functions (such as pedometer, tapping), etc.; as for the terminal 700 can also be configured with gyroscopes, barometers, hygrometers, thermometers, infrared sensors and other sensors, here Let me repeat.
- the audio circuit 160, the speaker 161, and the microphone 162 can provide an audio interface between the user and the terminal 700.
- the audio circuit 160 can transmit the converted electrical data of the received audio data to the speaker 161 for conversion to the sound signal output by the speaker 161; on the other hand, the microphone 162 converts the collected sound signal into an electrical signal by the audio circuit 160. After receiving, it is converted into audio data, and then processed by the audio data output processor 180, transmitted to the terminal, for example, via the RF circuit 110, or outputted to the memory 120 for further processing.
- the audio circuit 160 may also include an earbud jack to provide communication of the peripheral earphones with the terminal 700.
- WiFi is a short-range wireless transmission technology
- the terminal 700 can help users to send and receive emails, browse web pages, and access streaming media through the WiFi module 170, which provides wireless broadband Internet access for users.
- FIG. 7 shows the WiFi module 170, it can be understood that it does not belong to the essential configuration of the terminal 700, and may be omitted as needed within the scope of not changing the essence of the invention.
- the processor 180 is the control center of the terminal 700, which connects various parts of the entire terminal using various interfaces and lines, by running or executing software programs and/or modules stored in the memory 120, and adjusting The various functions and processing data of the terminal 700 are executed by the data stored in the memory 120, thereby performing overall monitoring of the terminal.
- the processor 180 may include one or more processing cores; preferably, the processor 180 may integrate an application processor and a modem processor, where the application processor mainly processes an operating system, a user interface, an application, and the like.
- the modem processor primarily handles wireless communications. It can be understood that the above modem processor may not be integrated into the processor 180.
- the terminal 700 also includes a power source 190 (such as a battery) for powering various components.
- a power source 190 such as a battery
- the power source can be logically coupled to the processor 180 through a power management system to manage functions such as charging, discharging, and power management through the power management system.
- Power supply 190 may also include any one or more of a DC or AC power source, a recharging system, a power failure detection circuit, a power converter or inverter, a power status indicator, and the like.
- the terminal 700 may further include a camera, a Bluetooth module, and the like, and details are not described herein again.
- the display unit of the terminal is a touch screen display
- the terminal further includes a memory, and one or more programs, wherein one or more programs are stored in the memory and configured to be processed by one or more Execution.
- the one or more programs include instructions for performing the following operations:
- initial model parameters of the CNN model to be trained wherein the initial model parameters include an initial convolution kernel of each convolutional layer, an initial bias matrix of each convolutional layer, an initial weight matrix of the fully connected layer, and a fully connected layer Initial offset vector;
- each training image is subjected to a convolution operation and a maximum pooling operation, respectively, to obtain each training image at each level. a first feature image on the convolution layer;
- Each feature vector is processed according to an initial weight matrix and an initial bias vector to obtain a class probability vector of each training image
- the model parameters of the CNN model to be trained are adjusted based on the category error
- the model parameters obtained when the number of iterations reaches the preset number are taken as the model parameters of the trained CNN model.
- the memory of the terminal further includes an instruction for performing the following operations: acquiring more Training images, including:
- any initial training image maintaining the aspect ratio of the initial training image, processing the initial training image as a first image having a specified height;
- the first image is processed into a second image having a specified width, and an image having the specified height and the specified width is used as a training image corresponding to the initial training image.
- the memory of the terminal further includes an instruction for: acquiring a plurality of training images, including:
- the aspect ratio of the initial training image is maintained, the initial training image is processed into an image having a specified height, and the width corresponding to the specified height is taken as the width of the initial training image.
- the memory of the terminal further comprises an instruction for: processing the first image into a second image having a specified width, include:
- the specified gray value is used on the left and right sides of the first image
- the pixels are uniformly filled until the width of the first image reaches a specified width, and the second image is obtained;
- the pixels on the left and right sides of the first image are uniformly cropped until the width of the first image reaches a specified width, and the second image is obtained.
- the memory of the terminal further comprises instructions for performing the following operations: using an initial convolution kernel and initial on each convolutional layer
- the offset matrix performs a convolution operation and a maximum pooling operation on each training image to obtain a first feature image of each training image on each convolution layer, including:
- the first feature image on the upper convolutional layer is input to the current convolutional layer, and the first convolutional layer is used to the upper convolutional layer using the initial convolution kernel and the initial bias matrix on the current convolutional layer.
- the first feature image is subjected to a convolution operation to obtain a convolution image on the current convolution layer, wherein if the current convolution layer is the first-level convolution layer, the first feature image on the upper convolution layer For training images;
- the memory of the terminal further comprises instructions for performing: at least one level of the convolution layer for each training image
- the first feature image is subjected to a horizontal pooling operation to obtain a second feature image of each training image on each of the convolution layers, including:
- the maximum values extracted from all the lines of each image are arranged into a one-dimensional vector
- the memory of the terminal further includes an instruction for performing the following operations: according to each training image on each convolution layer
- the second feature image determines the feature vector of each training image, including:
- the elements of all the rows in the second feature image of the training image on each convolution layer are connected end to end to obtain a feature vector of the training image.
- the memory of the terminal further includes an instruction for performing a following operation: a class probability vector according to each training image and each training image The initial category, calculating the category error, including:
- the class error of each training image is calculated according to the class probability vector of each training image and the initial category of each training image by the following formula:
- Loss represents the category error of each training image
- label represents the initial category of each training image
- y i represents an element in the category probability vector of each training image
- y label represents the category probability corresponding to the initial category
- the average of the category errors of all training images is calculated, and the average of the category errors is taken as the category error.
- the memory of the terminal further includes an instruction for performing the following operations: training the image as a natural scene
- the image of the natural scene includes characters of different languages
- the CNN model to be trained is a language recognition classifier.
- the memory of the terminal further includes an instruction for performing the following operations: the CNN model to be trained includes four a level convolutional layer and two fully connected layers, each of which includes the same or a different number of convolution kernels and offset matrices;
- Determining a feature vector of each training image according to a second feature image of each training image on each convolutional layer including:
- any training image determined based on the second feature image of the training image on the second level convolution layer, the second feature image on the third level convolution layer, and the second feature image on the fourth level convolution layer The feature vector of the training image.
- the terminal provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image at each level of the convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- the embodiment of the present invention provides a computer readable storage medium, which may be a computer readable storage medium included in the memory in the above embodiment, or may exist separately and not assembled into the terminal.
- Computer readable storage medium stores one or more programs that are used by one or more processors to perform a training method for a CNN model, the method comprising:
- initial model parameters of the CNN model to be trained wherein the initial model parameters include an initial convolution kernel of each convolutional layer, an initial bias matrix of each convolutional layer, an initial weight matrix of the fully connected layer, and a fully connected layer Initial offset vector;
- each training image is subjected to a convolution operation and a maximum pooling operation, respectively, to obtain each training image at each level. a first feature image on the convolution layer;
- Each feature vector is processed according to an initial weight matrix and an initial bias vector to obtain a class probability vector of each training image
- the model parameters of the CNN model to be trained are adjusted based on the category error
- the model parameters obtained when the number of iterations reaches the preset number are taken as the model parameters of the trained CNN model.
- the memory of the terminal further includes an instruction for performing the following operations: acquiring more Training images, including:
- any initial training image maintaining the aspect ratio of the initial training image, processing the initial training image as a first image having a specified height;
- the first image is processed into a second image having a specified width, and an image having a specified height and a specified width is used as a training image corresponding to the initial training image.
- the memory of the terminal further includes an instruction for: acquiring a plurality of training images, including:
- the aspect ratio of the initial training image is maintained, the initial training image is processed into an image having a specified height, and the width corresponding to the specified height is taken as the width of the initial training image.
- the memory of the terminal further comprises an instruction for: processing the first image into a second image having a specified width, include:
- the width of the first image is smaller than the specified width, uniformly filling the pixels on the left and right sides of the first image with the specified gray value until the width of the first image reaches a specified width, and obtaining the second image;
- the pixels on the left and right sides of the first image are uniformly cropped until the width of the first image reaches a specified width, and the second image is obtained.
- the memory of the terminal further comprises instructions for performing the following operations: using an initial convolution kernel and initial on each convolutional layer
- the offset matrix performs a convolution operation and a maximum pooling operation on each training image to obtain a first feature image of each training image on each convolution layer, including:
- the first feature image on the upper convolutional layer is input to the current convolutional layer, and the first convolutional layer is used to the upper convolutional layer using the initial convolution kernel and the initial bias matrix on the current convolutional layer.
- the first feature image is subjected to a convolution operation to obtain a convolution image on the current convolution layer, wherein if the current convolution layer is the first-level convolution layer, the first feature image on the upper convolution layer For training images;
- the memory of the terminal further comprises instructions for performing: at least one level of the convolution layer for each training image
- the first feature image is subjected to a horizontal pooling operation to obtain each training image on each of the convolution layers
- the second feature image includes:
- the maximum values extracted from all the lines of each image are arranged into a one-dimensional vector
- a one-dimensional vector of all the images in the first feature image on the convolutional layer is combined to obtain a second feature image on the convolution layer.
- the memory of the terminal further includes an instruction for performing the following operations: according to each training image on each convolution layer
- the second feature image determines the feature vector of each training image, including:
- the elements of all the rows in the second feature image of the training image on each convolution layer are connected end to end to obtain a feature vector of the training image.
- the memory of the terminal further includes an instruction for performing a following operation: a class probability vector according to each training image and each training image The initial category, calculating the category error, including:
- the class error of each training image is calculated according to the class probability vector of each training image and the initial category of each training image by the following formula:
- Loss represents the category error of each training image
- label represents the initial category of each training image
- y i represents an element in the category probability vector of each training image
- y label represents the category probability corresponding to the initial category
- the average of the category errors of all training images is calculated, and the average of the category errors is taken as the category error.
- the memory of the terminal further includes an instruction for performing the following operations: training the image For the image in the natural scene, the image in the natural scene includes characters in different languages, and the CNN model to be trained is a language recognition classifier.
- the memory of the terminal further includes an instruction for performing the following operations: the CNN model to be trained includes four a level convolutional layer and two fully connected layers, each of which includes the same or a different number of convolution kernels and offset matrices;
- Performing a horizontal pooling operation on the first feature image of each training image on at least one level of the convolution layer to obtain a second feature image of each training image on each of the convolution layers including:
- Determining a feature vector of each training image according to a second feature image of each training image on each convolutional layer including:
- any training image determined based on the second feature image of the training image on the second level convolution layer, the second feature image on the third level convolution layer, and the second feature image on the fourth level convolution layer The feature vector of the training image.
- the computer readable storage medium provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image on each convolution layer. . Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- a graphical user interface is provided in the embodiment of the present invention, and the graphical user interface is used on the terminal.
- the terminal includes a touch screen display, a memory, and one or more processors for executing one or more programs; the graphical user interface includes:
- initial model parameters of the CNN model to be trained wherein the initial model parameters include an initial convolution kernel of each convolutional layer, an initial bias matrix of each convolutional layer, an initial weight matrix of the fully connected layer, and a fully connected layer Initial offset vector;
- each training image is subjected to a convolution operation and a maximum pooling operation, respectively, to obtain each training image at each level. a first feature image on the convolution layer;
- Each feature vector is processed according to an initial weight matrix and an initial bias vector to obtain a class probability vector of each training image
- the model parameters of the CNN model to be trained are adjusted based on the category error
- the model parameters obtained when the number of iterations reaches the preset number are taken as the model parameters of the trained CNN model.
- the memory of the terminal further includes an instruction for performing the following operations: acquiring more Training images, including:
- each initial training image is maintained, and each initial training image is processed into an image having a specified height and a specified width to obtain a plurality of training images.
- the memory of the terminal further includes an instruction for: acquiring a plurality of training images, including:
- each initial training image is processed into an image having a specified height, and the width corresponding to the specified height is taken as the width of each initial training image to obtain a plurality of training images.
- the graphic user interface provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image at each level of the convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- FIG. 8 is a schematic structural diagram of a server, which may be used to perform the training method of the CNN model provided by the embodiment corresponding to any of the above FIG. 1, FIG. 2 or FIG. 5, according to an exemplary embodiment.
- server 800 includes a processing component 822 that further includes one or more processors, and memory resources represented by memory 832 for storing instructions executable by processing component 822, such as an application.
- An application stored in memory 832 may include one or more modules each corresponding to a set of instructions.
- the processing component 822 is configured to execute instructions to perform the training method of the CNN model provided by the embodiment corresponding to any of the above-described FIG. 1, FIG. 2, or FIG.
- Server 800 can also include a power component 828 configured to perform power to server 800 Management, a wired or wireless network interface 850 is configured to connect server 800 to the network, and an input/output (I/O) interface 858.
- Server 800 can operate based on an operating system stored in memory 832, such as Windows ServerTM, Mac OS XTM, UnixTM, LinuxTM, FreeBSDTM or the like.
- one or more programs are stored in the memory and configured to be executed by one or more processors, the one or more programs comprising instructions for:
- initial model parameters of the CNN model to be trained wherein the initial model parameters include an initial convolution kernel of each convolutional layer, an initial bias matrix of each convolutional layer, an initial weight matrix of the fully connected layer, and a fully connected layer Initial offset vector;
- each training image is subjected to a convolution operation and a maximum pooling operation, respectively, to obtain each training image at each level. a first feature image on the convolution layer;
- Each feature vector is processed according to an initial weight matrix and an initial bias vector to obtain a class probability vector of each training image
- the model parameters of the CNN model to be trained are adjusted based on the category error
- model parameters obtained when the number of iterations reaches the preset number of times is used as the trained CNN model. Model parameters.
- the memory of the server further includes an instruction for performing the following operations: acquiring more Training images, including:
- any initial training image maintaining the aspect ratio of the initial training image, processing the initial training image as a first image having a specified height;
- the first image is processed into a second image having a specified width, and an image having the specified height and the specified width is used as a training image corresponding to the initial training image.
- the memory of the server further includes an instruction for: acquiring a plurality of training images, including:
- the aspect ratio of the initial training image is maintained, the initial training image is processed into an image having a specified height, and the width corresponding to the specified height is taken as the width of the initial training image.
- the memory of the server further comprises instructions for: processing the first image into a second image having a specified width, include:
- the width of the first image is smaller than the specified width, uniformly filling the pixels on the left and right sides of the first image with the specified gray value until the width of the first image reaches a specified width, and obtaining the second image;
- the pixels on the left and right sides of the first image are uniformly cropped until the width of the first image reaches a specified width, and the second image is obtained.
- the memory of the server further comprises instructions for performing the following operations: using an initial convolution kernel and initial on each convolutional layer
- the offset matrix performs a convolution operation and a maximum pooling operation on each training image to obtain a first feature image of each training image on each convolution layer, including:
- the first feature image on the upper convolution layer For any training image, input the first feature image on the upper convolution layer into the current convolution a layer, using an initial convolution kernel and an initial bias matrix on the current convolutional layer, performing a convolution operation on the first feature image on the upper convolution layer to obtain a convolution image on the current convolution layer, where If the current convolutional layer is a first-level convolutional layer, the first feature image on the upper-level convolutional layer is a training image;
- the memory of the server further comprises instructions for performing: at least one level of the convolution layer for each training image
- the first feature image is subjected to a horizontal pooling operation to obtain a second feature image of each training image on each of the convolution layers, including:
- the maximum values extracted from all the lines of each image are arranged into a one-dimensional vector
- a one-dimensional vector of all the images in the first feature image on the convolutional layer is combined to obtain a second feature image on the convolution layer.
- the memory of the server further includes an instruction for performing the following operations: according to each training image on each convolution layer The second feature image determines the feature vector of each training image, including:
- the elements of all the rows in the second feature image of the training image on each convolution layer are connected end to end to obtain a feature vector of the training image.
- the memory of the server further comprises instructions for performing the following operations: according to the category of each training image The rate vector and the initial category of each training image, calculating the category error, including:
- the class error of each training image is calculated according to the class probability vector of each training image and the initial category of each training image by the following formula:
- Loss represents the category error of each training image
- label represents the initial category of each training image
- y i represents an element in the category probability vector of each training image
- y label represents the category probability corresponding to the initial category
- the average of the category errors of all training images is calculated, and the average of the category errors is taken as the category error.
- the memory of the server further includes an instruction for performing the following operations: training the image as a natural scene
- the image of the natural scene includes characters of different languages
- the CNN model to be trained is a language recognition classifier.
- the memory of the server further includes an instruction for performing the following operations: the CNN model to be trained includes four a level convolutional layer and two fully connected layers, each of which includes the same or a different number of convolution kernels and offset matrices;
- Performing a horizontal pooling operation on the first feature image of each training image on at least one level of the convolution layer to obtain a second feature image of each training image on each of the convolution layers including:
- Determining a feature vector of each training image according to a second feature image of each training image on each convolutional layer including:
- the second feature image on the second level convolution layer according to the training image determines a feature vector of the training image.
- the server provided by the embodiment of the present invention further performs a horizontal pooling operation on the feature image obtained after the maximum pooling operation by performing a convolution operation and a maximum pooling operation on the training image at each level of the convolution layer. Since the feature image identifying the horizontal direction feature of the feature image can be further extracted from the feature image when the horizontal pooling operation is performed, it is ensured that the trained CNN model is not displayed in the horizontal dimension of the image to be recognized when identifying the image category. Thereby, the image to be recognized of any size can be identified, so that the trained CNN model in this way has a wide application range in recognizing the image.
- the training device of the CNN model provided by the foregoing embodiment is only illustrated by the division of the above functional modules when training the CNN model. In actual applications, the functions may be allocated by different functional modules according to requirements. Upon completion, the internal structure of the device is divided into different functional modules to perform all or part of the functions described above.
- the training device, the terminal, and the server of the CNN model provided by the foregoing embodiments are in the same concept as the training method embodiment of the CNN model, and the specific implementation process is described in the method embodiment, and details are not described herein again.
- a person skilled in the art may understand that all or part of the steps of implementing the above embodiments may be completed by hardware, or may be instructed by a program to execute related hardware, and the program may be stored in a computer readable storage medium.
- the storage medium mentioned may be a read only memory, a magnetic disk or an optical disk or the like.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Multimedia (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Image Analysis (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020177018163A KR101887558B1 (ko) | 2015-04-02 | 2016-03-25 | 컨볼루션 신경망 모델의 트레이닝 방법 및 장치 |
| JP2017519841A JP6257848B1 (ja) | 2015-04-02 | 2016-03-25 | コンボリューションニューラルネットワークモデルの訓練方法及び装置 |
| US15/486,102 US9977997B2 (en) | 2015-04-02 | 2017-04-12 | Training method and apparatus for convolutional neural network model |
| US15/942,254 US10607120B2 (en) | 2015-04-02 | 2018-03-30 | Training method and apparatus for convolutional neural network model |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201510154027.0 | 2015-04-02 | ||
| CN201510154027.0A CN106156807B (zh) | 2015-04-02 | 2015-04-02 | 卷积神经网络模型的训练方法及装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/486,102 Continuation US9977997B2 (en) | 2015-04-02 | 2017-04-12 | Training method and apparatus for convolutional neural network model |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016155564A1 true WO2016155564A1 (zh) | 2016-10-06 |
Family
ID=57004224
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2016/077280 WO2016155564A1 (zh) | 2015-04-02 | 2016-03-25 | 卷积神经网络模型的训练方法及装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (2) | US9977997B2 (ko) |
| JP (1) | JP6257848B1 (ko) |
| KR (1) | KR101887558B1 (ko) |
| CN (1) | CN106156807B (ko) |
| WO (1) | WO2016155564A1 (ko) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018084473A1 (ko) * | 2016-11-07 | 2018-05-11 | 삼성전자 주식회사 | 신경망 학습에 기반한 입력 처리 방법 및 이를 위한 장치 |
| JP2019075122A (ja) * | 2017-10-18 | 2019-05-16 | 株式会社ストラドビジョン | プーリングタイプに対する情報を含むテーブルを作成するための方法、装置及びこれを利用したテスティング方法、テスティング装置 |
| JP2019153277A (ja) * | 2017-12-07 | 2019-09-12 | イムラ ウーロプ ソシエテ・パ・アクシオンス・シンプリフィエ | エンドツーエンド深層ニューラルネットワークを使用する危険ランク付け |
| US10599978B2 (en) | 2017-11-03 | 2020-03-24 | International Business Machines Corporation | Weighted cascading convolutional neural networks |
| US10692000B2 (en) | 2017-03-20 | 2020-06-23 | Sap Se | Training machine learning models |
| CN111353430A (zh) * | 2020-02-28 | 2020-06-30 | 深圳壹账通智能科技有限公司 | 人脸识别方法和系统 |
| CN111429334A (zh) * | 2020-03-26 | 2020-07-17 | 光子算数(北京)科技有限责任公司 | 一种数据处理方法、装置、存储介质及电子设备 |
| CN111860184A (zh) * | 2020-06-23 | 2020-10-30 | 广东省特种设备检测研究院珠海检测院 | 一种自动扶梯机械故障诊断方法和系统 |
| US10963738B2 (en) | 2016-11-07 | 2021-03-30 | Samsung Electronics Co., Ltd. | Method for processing input on basis of neural network learning and apparatus therefor |
| US11537857B2 (en) * | 2017-11-01 | 2022-12-27 | Tencent Technology (Shenzhen) Company Limited | Pooling processing method and system applied to convolutional neural network |
Families Citing this family (92)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20180027887A (ko) * | 2016-09-07 | 2018-03-15 | 삼성전자주식회사 | 뉴럴 네트워크에 기초한 인식 장치 및 뉴럴 네트워크의 트레이닝 방법 |
| US10366302B2 (en) * | 2016-10-10 | 2019-07-30 | Gyrfalcon Technology Inc. | Hierarchical category classification scheme using multiple sets of fully-connected networks with a CNN based integrated circuit as feature extractor |
| CN110348571B (zh) * | 2016-11-29 | 2024-03-29 | 华为技术有限公司 | 一种神经网络模型训练方法、装置、芯片和系统 |
| WO2018099473A1 (zh) | 2016-12-02 | 2018-06-07 | 北京市商汤科技开发有限公司 | 场景分析方法和系统、电子设备 |
| CN108154222B (zh) * | 2016-12-02 | 2020-08-11 | 北京市商汤科技开发有限公司 | 深度神经网络训练方法和系统、电子设备 |
| CN106790019B (zh) * | 2016-12-14 | 2019-10-11 | 北京天融信网络安全技术有限公司 | 基于特征自学习的加密流量识别方法及装置 |
| CN106815835A (zh) * | 2017-01-10 | 2017-06-09 | 北京邮电大学 | 损伤识别方法及装置 |
| CN106682736A (zh) * | 2017-01-18 | 2017-05-17 | 北京小米移动软件有限公司 | 图像识别方法及装置 |
| CN106709532B (zh) * | 2017-01-25 | 2020-03-10 | 京东方科技集团股份有限公司 | 图像处理方法和装置 |
| CN106909901B (zh) * | 2017-02-28 | 2020-06-05 | 北京京东尚科信息技术有限公司 | 从图像中检测物体的方法及装置 |
| US10395141B2 (en) | 2017-03-20 | 2019-08-27 | Sap Se | Weight initialization for machine learning models |
| WO2018171899A1 (en) * | 2017-03-24 | 2018-09-27 | Huawei Technologies Co., Ltd. | Neural network data processing apparatus and method |
| CN106951872B (zh) * | 2017-03-24 | 2020-11-06 | 江苏大学 | 一种基于无监督深度模型与层次属性的行人再识别方法 |
| US11037330B2 (en) * | 2017-04-08 | 2021-06-15 | Intel Corporation | Low rank matrix compression |
| WO2018191287A1 (en) * | 2017-04-13 | 2018-10-18 | Siemens Healthcare Diagnostics Inc. | Methods and apparatus for hiln characterization using convolutional neural network |
| CN107194464B (zh) * | 2017-04-25 | 2021-06-01 | 北京小米移动软件有限公司 | 卷积神经网络模型的训练方法及装置 |
| CN107229968B (zh) * | 2017-05-24 | 2021-06-29 | 北京小米移动软件有限公司 | 梯度参数确定方法、装置及计算机可读存储介质 |
| CN108304936B (zh) * | 2017-07-12 | 2021-11-16 | 腾讯科技(深圳)有限公司 | 机器学习模型训练方法和装置、表情图像分类方法和装置 |
| CN107464216A (zh) * | 2017-08-03 | 2017-12-12 | 济南大学 | 一种基于多层卷积神经网络的医学图像超分辨率重构方法 |
| KR101880901B1 (ko) | 2017-08-09 | 2018-07-23 | 펜타시큐리티시스템 주식회사 | 기계 학습 방법 및 장치 |
| US10262240B2 (en) * | 2017-08-14 | 2019-04-16 | Microsoft Technology Licensing, Llc | Fast deep neural network training |
| CN113762252B (zh) * | 2017-08-18 | 2023-10-24 | 深圳市道通智能航空技术股份有限公司 | 无人机智能跟随目标确定方法、无人机和遥控器 |
| US10740607B2 (en) | 2017-08-18 | 2020-08-11 | Autel Robotics Co., Ltd. | Method for determining target through intelligent following of unmanned aerial vehicle, unmanned aerial vehicle and remote control |
| KR101984274B1 (ko) * | 2017-08-30 | 2019-05-30 | 주식회사 한화 | 감시 정찰용 표적 탐지 및 형상 식별 장치와 그 방법 |
| KR102055359B1 (ko) * | 2017-10-24 | 2019-12-12 | 에스케이텔레콤 주식회사 | 연산 가속화가 적용된 신경망 모델의 생성 및 활용을 위한 장치 및 방법 |
| WO2019107881A1 (ko) * | 2017-11-28 | 2019-06-06 | 한국전자통신연구원 | 영상 변환 신경망 및 영상 역변환 신경망을 이용한 영상 처리 방법 및 장치 |
| CN108062547B (zh) * | 2017-12-13 | 2021-03-09 | 北京小米移动软件有限公司 | 文字检测方法及装置 |
| EP3499415A1 (en) * | 2017-12-14 | 2019-06-19 | Axis AB | Method and image processing entity for applying a convolutional neural network to an image |
| CN109934836B (zh) * | 2017-12-15 | 2023-04-18 | 中国科学院深圳先进技术研究院 | 一种图像锐化的检测方法 |
| KR102030132B1 (ko) * | 2017-12-15 | 2019-10-08 | 서강대학교산학협력단 | 악성 코드 검출 방법 및 시스템 |
| CN108124487B (zh) * | 2017-12-22 | 2023-04-04 | 达闼机器人股份有限公司 | 云端抄表方法及装置 |
| KR102129161B1 (ko) * | 2017-12-29 | 2020-07-01 | 중앙대학교 산학협력단 | 컨볼루션 신경망의 하이퍼파라미터를 설정하는 방법 및 이를 수행하는 단말 장치 |
| US11107229B2 (en) | 2018-01-10 | 2021-08-31 | Samsung Electronics Co., Ltd. | Image processing method and apparatus |
| KR102026280B1 (ko) * | 2018-01-10 | 2019-11-26 | 네이버 주식회사 | 딥 러닝을 이용한 씬 텍스트 검출 방법 및 시스템 |
| JP6854248B2 (ja) * | 2018-01-18 | 2021-04-07 | 株式会社日立製作所 | 境界探索テスト支援装置および境界探索テスト支援方法 |
| CN110119505A (zh) * | 2018-02-05 | 2019-08-13 | 阿里巴巴集团控股有限公司 | 词向量生成方法、装置以及设备 |
| KR102161690B1 (ko) * | 2018-02-05 | 2020-10-05 | 삼성전자주식회사 | 전자 장치 및 그 제어 방법 |
| CN108333959A (zh) * | 2018-03-09 | 2018-07-27 | 清华大学 | 一种基于卷积神经网络模型的机车节能操纵方法 |
| KR102154834B1 (ko) | 2018-03-29 | 2020-09-10 | 국민대학교산학협력단 | 저전력 및 고속 연산을 위한 dram용 비트와이즈 컨볼루션 회로 |
| CN108830139A (zh) * | 2018-04-27 | 2018-11-16 | 北京市商汤科技开发有限公司 | 人体关键点的深度前后关系预测方法、装置、介质及设备 |
| US11948088B2 (en) | 2018-05-14 | 2024-04-02 | Nokia Technologies Oy | Method and apparatus for image recognition |
| KR102183672B1 (ko) * | 2018-05-25 | 2020-11-27 | 광운대학교 산학협력단 | 합성곱 신경망에 대한 도메인 불변 사람 분류기를 위한 연관성 학습 시스템 및 방법 |
| JP7020312B2 (ja) * | 2018-06-15 | 2022-02-16 | 日本電信電話株式会社 | 画像特徴学習装置、画像特徴学習方法、画像特徴抽出装置、画像特徴抽出方法、及びプログラム |
| KR102176695B1 (ko) * | 2018-06-29 | 2020-11-09 | 포항공과대학교 산학협력단 | 뉴럴 네트워크 하드웨어 |
| US20200004815A1 (en) * | 2018-06-29 | 2020-01-02 | Microsoft Technology Licensing, Llc | Text entity detection and recognition from images |
| CN109165666A (zh) * | 2018-07-05 | 2019-01-08 | 南京旷云科技有限公司 | 多标签图像分类方法、装置、设备及存储介质 |
| CN110795976B (zh) * | 2018-08-03 | 2023-05-05 | 华为云计算技术有限公司 | 一种训练物体检测模型的方法、装置以及设备 |
| CN109086878B (zh) * | 2018-10-19 | 2019-12-17 | 电子科技大学 | 保持旋转不变性的卷积神经网络模型及其训练方法 |
| KR20200052440A (ko) * | 2018-10-29 | 2020-05-15 | 삼성전자주식회사 | 전자 장치 및 전자 장치의 제어 방법 |
| CN111222624B (zh) * | 2018-11-26 | 2022-04-29 | 深圳云天励飞技术股份有限公司 | 一种并行计算方法及装置 |
| KR102190304B1 (ko) * | 2018-11-30 | 2020-12-14 | 서울대학교 산학협력단 | Gpu 연산 기반의 딥러닝을 이용한 선호 콘텐츠 추천 장치 및 그 방법 |
| US11494645B2 (en) * | 2018-12-06 | 2022-11-08 | Egis Technology Inc. | Convolutional neural network processor and data processing method thereof |
| CN109740534B (zh) * | 2018-12-29 | 2021-06-25 | 北京旷视科技有限公司 | 图像处理方法、装置及处理设备 |
| US11557107B2 (en) | 2019-01-02 | 2023-01-17 | Bank Of America Corporation | Intelligent recognition and extraction of numerical data from non-numerical graphical representations |
| US10430691B1 (en) * | 2019-01-22 | 2019-10-01 | StradVision, Inc. | Learning method and learning device for object detector based on CNN, adaptable to customers' requirements such as key performance index, using target object merging network and target region estimating network, and testing method and testing device using the same to be used for multi-camera or surround view monitoring |
| US10387752B1 (en) * | 2019-01-22 | 2019-08-20 | StradVision, Inc. | Learning method and learning device for object detector with hardware optimization based on CNN for detection at distance or military purpose using image concatenation, and testing method and testing device using the same |
| US10423860B1 (en) * | 2019-01-22 | 2019-09-24 | StradVision, Inc. | Learning method and learning device for object detector based on CNN to be used for multi-camera or surround view monitoring using image concatenation and target object merging network, and testing method and testing device using the same |
| US10387753B1 (en) * | 2019-01-23 | 2019-08-20 | StradVision, Inc. | Learning method and learning device for convolutional neural network using 1×1 convolution for image recognition to be used for hardware optimization, and testing method and testing device using the same |
| US10387754B1 (en) * | 2019-01-23 | 2019-08-20 | StradVision, Inc. | Learning method and learning device for object detector based on CNN using 1×H convolution to be used for hardware optimization, and testing method and testing device using the same |
| US10402695B1 (en) * | 2019-01-23 | 2019-09-03 | StradVision, Inc. | Learning method and learning device for convolutional neural network using 1×H convolution for image recognition to be used for hardware optimization, and testing method and testing device using the same |
| CN109886279B (zh) * | 2019-01-24 | 2023-09-29 | 平安科技(深圳)有限公司 | 图像处理方法、装置、计算机设备及存储介质 |
| TWI761671B (zh) * | 2019-04-02 | 2022-04-21 | 緯創資通股份有限公司 | 活體偵測方法與活體偵測系統 |
| CN110516087B (zh) * | 2019-04-23 | 2021-12-07 | 广州麦仑信息科技有限公司 | 一种大规模分布式全掌脉络数据的闪速搜索比对方法 |
| EP3745153A1 (en) * | 2019-05-28 | 2020-12-02 | Koninklijke Philips N.V. | A method for motion artifact detection |
| CN110245695A (zh) * | 2019-05-30 | 2019-09-17 | 华中科技大学 | 一种基于卷积神经网络的tbm岩渣大小等级识别方法 |
| KR102036785B1 (ko) * | 2019-06-24 | 2019-11-26 | 김길곤 | 엘리베이터의 유지 및 보수의 공정을 제어하기 위한 방법 및 장치 |
| CN110334705B (zh) * | 2019-06-25 | 2021-08-03 | 华中科技大学 | 一种结合全局和局部信息的场景文本图像的语种识别方法 |
| CN110276411B (zh) * | 2019-06-28 | 2022-11-18 | 腾讯科技(深圳)有限公司 | 图像分类方法、装置、设备、存储介质和医疗电子设备 |
| CN110349237B (zh) * | 2019-07-18 | 2021-06-18 | 华中科技大学 | 基于卷积神经网络的快速体成像方法 |
| CN112241740B (zh) * | 2019-07-19 | 2024-03-26 | 新华三技术有限公司 | 一种特征提取方法及装置 |
| CN110569781B (zh) * | 2019-09-05 | 2022-09-09 | 河海大学常州校区 | 一种基于改进胶囊网络的时间序列分类方法 |
| US10943353B1 (en) | 2019-09-11 | 2021-03-09 | International Business Machines Corporation | Handling untrainable conditions in a network architecture search |
| US11023783B2 (en) * | 2019-09-11 | 2021-06-01 | International Business Machines Corporation | Network architecture search with global optimization |
| CN110955590A (zh) * | 2019-10-15 | 2020-04-03 | 北京海益同展信息科技有限公司 | 界面检测方法、图像处理方法、装置、电子设备及存储介质 |
| CN110704197B (zh) | 2019-10-17 | 2022-12-09 | 北京小米移动软件有限公司 | 处理内存访问开销的方法、装置及介质 |
| EP3997625A4 (en) * | 2019-10-29 | 2022-11-09 | Samsung Electronics Co., Ltd. | ELECTRONIC DEVICE AND ASSOCIATED CONTROL METHOD |
| CN111178446B (zh) | 2019-12-31 | 2023-08-04 | 歌尔股份有限公司 | 一种基于神经网络的目标分类模型的优化方法、装置 |
| CN111353542B (zh) * | 2020-03-03 | 2023-09-19 | 腾讯科技(深圳)有限公司 | 图像分类模型的训练方法、装置、计算机设备和存储介质 |
| US11436450B2 (en) | 2020-03-31 | 2022-09-06 | The Boeing Company | Systems and methods for model-based image analysis |
| KR102333545B1 (ko) * | 2020-04-28 | 2021-12-01 | 영남대학교 산학협력단 | 합성곱 신경망 기반의 영상 학습 방법 및 이를 수행하기 위한 장치 |
| CN113688840A (zh) * | 2020-05-19 | 2021-11-23 | 武汉Tcl集团工业研究院有限公司 | 图像处理模型的生成方法、处理方法、存储介质及终端 |
| CN112016599B (zh) * | 2020-08-13 | 2023-09-15 | 驭势科技(浙江)有限公司 | 用于图像检索的神经网络训练方法、装置及电子设备 |
| CN112085128B (zh) * | 2020-10-27 | 2022-06-07 | 苏州浪潮智能科技有限公司 | 一种基于脉动阵列的图像识别方法、装置和介质 |
| US20220138535A1 (en) * | 2020-11-04 | 2022-05-05 | Intrinsic Innovation Llc | Source-agnostic image processing |
| US11170581B1 (en) * | 2020-11-12 | 2021-11-09 | Intrinsic Innovation Llc | Supervised domain adaptation |
| CN112580662A (zh) * | 2020-12-09 | 2021-03-30 | 中国水产科学研究院渔业机械仪器研究所 | 一种基于图像特征识别鱼体方向的方法及系统 |
| AU2021204756A1 (en) * | 2021-05-21 | 2022-12-08 | Soul Machines | Transfer learning in image recognition systems |
| KR102617391B1 (ko) | 2021-07-30 | 2023-12-27 | 주식회사 딥엑스 | 이미지 신호 프로세서의 제어 방법 및 이를 수행하는 제어 장치 |
| CN114035120A (zh) * | 2021-11-04 | 2022-02-11 | 合肥工业大学 | 基于改进cnn的三电平逆变器开路故障诊断方法及系统 |
| WO2023219277A1 (ko) * | 2022-05-09 | 2023-11-16 | 삼성전자 주식회사 | 영상 처리 장치 및 그 동작 방법 |
| CN115082837B (zh) * | 2022-07-27 | 2023-07-04 | 新沂市新南环保产业技术研究院有限公司 | 对pet瓶进行灌装纯净水的流速控制系统及其控制方法 |
| CN117556208B (zh) * | 2023-11-20 | 2024-05-14 | 中国地质大学(武汉) | 多模态数据的智能卷积通用网络预测方法、设备及介质 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103996056A (zh) * | 2014-04-08 | 2014-08-20 | 浙江工业大学 | 一种基于深度学习的纹身图像分类方法 |
| US20150032449A1 (en) * | 2013-07-26 | 2015-01-29 | Nuance Communications, Inc. | Method and Apparatus for Using Convolutional Neural Networks in Speech Recognition |
| CN104463241A (zh) * | 2014-10-31 | 2015-03-25 | 北京理工大学 | 一种智能交通监控系统中的车辆类型识别方法 |
| CN104463194A (zh) * | 2014-11-04 | 2015-03-25 | 深圳市华尊科技有限公司 | 一种人车分类方法及装置 |
| CN104463172A (zh) * | 2014-12-09 | 2015-03-25 | 中国科学院重庆绿色智能技术研究院 | 基于人脸特征点形状驱动深度模型的人脸特征提取方法 |
Family Cites Families (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4607633B2 (ja) * | 2005-03-17 | 2011-01-05 | 株式会社リコー | 文字方向識別装置、画像形成装置、プログラム、記憶媒体および文字方向識別方法 |
| WO2009073895A1 (en) * | 2007-12-07 | 2009-06-11 | Verimatrix, Inc. | Systems and methods for performing semantic analysis of media objects |
| US20120213426A1 (en) * | 2011-02-22 | 2012-08-23 | The Board Of Trustees Of The Leland Stanford Junior University | Method for Implementing a High-Level Image Representation for Image Analysis |
| US8867828B2 (en) * | 2011-03-04 | 2014-10-21 | Qualcomm Incorporated | Text region detection system and method |
| JP5777367B2 (ja) * | 2011-03-29 | 2015-09-09 | キヤノン株式会社 | パターン識別装置、パターン識別方法及びプログラム |
| KR102219346B1 (ko) * | 2013-05-30 | 2021-02-23 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | 베이지안 최적화를 수행하기 위한 시스템 및 방법 |
| US9495620B2 (en) * | 2013-06-09 | 2016-11-15 | Apple Inc. | Multi-script handwriting recognition using a universal recognizer |
| US9898187B2 (en) * | 2013-06-09 | 2018-02-20 | Apple Inc. | Managing real-time handwriting recognition |
| CN105493141B (zh) * | 2013-08-23 | 2018-09-14 | 哈曼国际工业有限公司 | 非结构化道路边界检测 |
| WO2015112932A1 (en) * | 2014-01-25 | 2015-07-30 | Handzel Amir Aharon | Automated histological diagnosis of bacterial infection using image analysis |
| US20150347860A1 (en) * | 2014-05-30 | 2015-12-03 | Apple Inc. | Systems And Methods For Character Sequence Recognition With No Explicit Segmentation |
| US9251431B2 (en) * | 2014-05-30 | 2016-02-02 | Apple Inc. | Object-of-interest detection and recognition with split, full-resolution image processing pipeline |
| CN104102919B (zh) * | 2014-07-14 | 2017-05-24 | 同济大学 | 一种有效防止卷积神经网络过拟合的图像分类方法 |
| JP6282193B2 (ja) * | 2014-07-28 | 2018-02-21 | クラリオン株式会社 | 物体検出装置 |
| US9846977B1 (en) * | 2014-09-02 | 2017-12-19 | Metromile, Inc. | Systems and methods for determining vehicle trip information |
| US9665802B2 (en) | 2014-11-13 | 2017-05-30 | Nec Corporation | Object-centric fine-grained image classification |
| JP6360802B2 (ja) * | 2015-02-20 | 2018-07-18 | 株式会社デンソーアイティーラボラトリ | ニューラルネットワーク処理装置、ニューラルネットワーク処理方法、検出装置、検出方法、および、車両 |
| US9524450B2 (en) * | 2015-03-04 | 2016-12-20 | Accenture Global Services Limited | Digital image processing using convolutional neural networks |
| JP6380209B2 (ja) * | 2015-03-31 | 2018-08-29 | ブラザー工業株式会社 | 画像処理プログラム、画像処理装置、及び、画像処理方法 |
| US10115055B2 (en) * | 2015-05-26 | 2018-10-30 | Booking.Com B.V. | Systems methods circuits and associated computer executable code for deep learning based natural language understanding |
| US9767381B2 (en) * | 2015-09-22 | 2017-09-19 | Xerox Corporation | Similarity-based detection of prominent objects using deep CNN pooling layers as features |
| US10068171B2 (en) * | 2015-11-12 | 2018-09-04 | Conduent Business Services, Llc | Multi-layer fusion in a convolutional neural network for image classification |
| US10871548B2 (en) * | 2015-12-04 | 2020-12-22 | Fazecast, Inc. | Systems and methods for transient acoustic event detection, classification, and localization |
| US20170249339A1 (en) * | 2016-02-25 | 2017-08-31 | Shutterstock, Inc. | Selected image subset based search |
| US10354168B2 (en) * | 2016-04-11 | 2019-07-16 | A2Ia S.A.S. | Systems and methods for recognizing characters in digitized documents |
| US9904871B2 (en) * | 2016-04-14 | 2018-02-27 | Microsoft Technologies Licensing, LLC | Deep convolutional neural network prediction of image professionalism |
-
2015
- 2015-04-02 CN CN201510154027.0A patent/CN106156807B/zh active Active
-
2016
- 2016-03-25 KR KR1020177018163A patent/KR101887558B1/ko active IP Right Grant
- 2016-03-25 WO PCT/CN2016/077280 patent/WO2016155564A1/zh active Application Filing
- 2016-03-25 JP JP2017519841A patent/JP6257848B1/ja active Active
-
2017
- 2017-04-12 US US15/486,102 patent/US9977997B2/en active Active
-
2018
- 2018-03-30 US US15/942,254 patent/US10607120B2/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150032449A1 (en) * | 2013-07-26 | 2015-01-29 | Nuance Communications, Inc. | Method and Apparatus for Using Convolutional Neural Networks in Speech Recognition |
| CN103996056A (zh) * | 2014-04-08 | 2014-08-20 | 浙江工业大学 | 一种基于深度学习的纹身图像分类方法 |
| CN104463241A (zh) * | 2014-10-31 | 2015-03-25 | 北京理工大学 | 一种智能交通监控系统中的车辆类型识别方法 |
| CN104463194A (zh) * | 2014-11-04 | 2015-03-25 | 深圳市华尊科技有限公司 | 一种人车分类方法及装置 |
| CN104463172A (zh) * | 2014-12-09 | 2015-03-25 | 中国科学院重庆绿色智能技术研究院 | 基于人脸特征点形状驱动深度模型的人脸特征提取方法 |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10963738B2 (en) | 2016-11-07 | 2021-03-30 | Samsung Electronics Co., Ltd. | Method for processing input on basis of neural network learning and apparatus therefor |
| WO2018084473A1 (ko) * | 2016-11-07 | 2018-05-11 | 삼성전자 주식회사 | 신경망 학습에 기반한 입력 처리 방법 및 이를 위한 장치 |
| US10692000B2 (en) | 2017-03-20 | 2020-06-23 | Sap Se | Training machine learning models |
| JP2019075122A (ja) * | 2017-10-18 | 2019-05-16 | 株式会社ストラドビジョン | プーリングタイプに対する情報を含むテーブルを作成するための方法、装置及びこれを利用したテスティング方法、テスティング装置 |
| US11734554B2 (en) | 2017-11-01 | 2023-08-22 | Tencent Technology (Shenzhen) Company Limited | Pooling processing method and system applied to convolutional neural network |
| US11537857B2 (en) * | 2017-11-01 | 2022-12-27 | Tencent Technology (Shenzhen) Company Limited | Pooling processing method and system applied to convolutional neural network |
| US10599978B2 (en) | 2017-11-03 | 2020-03-24 | International Business Machines Corporation | Weighted cascading convolutional neural networks |
| US10915810B2 (en) | 2017-11-03 | 2021-02-09 | International Business Machines Corporation | Weighted cascading convolutional neural networks |
| JP7217138B2 (ja) | 2017-12-07 | 2023-02-02 | イムラ ウーロプ ソシエテ・パ・アクシオンス・シンプリフィエ | エンドツーエンド深層ニューラルネットワークを使用する危険ランク付け |
| JP2019153277A (ja) * | 2017-12-07 | 2019-09-12 | イムラ ウーロプ ソシエテ・パ・アクシオンス・シンプリフィエ | エンドツーエンド深層ニューラルネットワークを使用する危険ランク付け |
| CN111353430A (zh) * | 2020-02-28 | 2020-06-30 | 深圳壹账通智能科技有限公司 | 人脸识别方法和系统 |
| CN111429334A (zh) * | 2020-03-26 | 2020-07-17 | 光子算数(北京)科技有限责任公司 | 一种数据处理方法、装置、存储介质及电子设备 |
| CN111860184A (zh) * | 2020-06-23 | 2020-10-30 | 广东省特种设备检测研究院珠海检测院 | 一种自动扶梯机械故障诊断方法和系统 |
| CN111860184B (zh) * | 2020-06-23 | 2024-04-16 | 广东省特种设备检测研究院珠海检测院 | 一种自动扶梯机械故障诊断方法和系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6257848B1 (ja) | 2018-01-10 |
| US9977997B2 (en) | 2018-05-22 |
| JP2018503152A (ja) | 2018-02-01 |
| CN106156807A (zh) | 2016-11-23 |
| KR101887558B1 (ko) | 2018-08-10 |
| KR20170091140A (ko) | 2017-08-08 |
| US20170220904A1 (en) | 2017-08-03 |
| US10607120B2 (en) | 2020-03-31 |
| CN106156807B (zh) | 2020-06-02 |
| US20180225552A1 (en) | 2018-08-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2016155564A1 (zh) | 卷积神经网络模型的训练方法及装置 | |
| US10956771B2 (en) | Image recognition method, terminal, and storage medium | |
| EP3992845A1 (en) | Action identification method based on artificial intelligence and related apparatus | |
| EP3940638B1 (en) | Image region positioning method, model training method, and related apparatus | |
| WO2020233333A1 (zh) | 图像处理方法和装置 | |
| WO2018107921A1 (zh) | 回答语句确定方法及服务器 | |
| WO2020108483A1 (zh) | 模型训练方法、机器翻译方法、计算机设备和存储介质 | |
| WO2020103721A1 (zh) | 信息处理的方法、装置及存储介质 | |
| CN108846274B (zh) | 一种安全验证方法、装置及终端 | |
| WO2018113512A1 (zh) | 图像处理方法以及相关装置 | |
| CN110110045B (zh) | 一种检索相似文本的方法、装置以及存储介质 | |
| CN110555337B (zh) | 一种指示对象的检测方法、装置以及相关设备 | |
| WO2019233216A1 (zh) | 一种手势动作的识别方法、装置以及设备 | |
| CN110517339B (zh) | 一种基于人工智能的动画形象驱动方法和装置 | |
| WO2017088434A1 (zh) | 人脸模型矩阵训练方法、装置及存储介质 | |
| CN107704514A (zh) | 一种照片管理方法、装置及计算机可读存储介质 | |
| CN110083742B (zh) | 一种视频查询方法和装置 | |
| CN107817898B (zh) | 操作模式识别方法、终端及存储介质 | |
| CN110097570B (zh) | 一种图像处理方法和装置 | |
| WO2021016932A1 (zh) | 数据处理方法、装置及计算机可读存储介质 | |
| CN107329584A (zh) | 一种文字输入处理方法、移动终端以及计算机可读存储介质 | |
| CN110443852A (zh) | 一种图像定位的方法及相关装置 | |
| CN113536876A (zh) | 一种图像识别方法和相关装置 | |
| CN110503189A (zh) | 一种数据处理方法以及装置 | |
| CN109460158A (zh) | 字符输入方法、字符校正模型训练方法和移动终端 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16771319 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2017519841 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 20177018163 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 32PN | Ep: public notification in the ep bulletin as address of the adressee cannot be established |
Free format text: NOTING OF LOSS OF RIGHTS PURSUANT TO RULE 112(1) EPC (EPO FORM 1205A DATED 19/03/2018) |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 16771319 Country of ref document: EP Kind code of ref document: A1 |