WO2014126213A1 - Dispositif de sélection d'informations de séquence candidate pour détermination de similarité, procédé de sélection, et utilisation d'un tel dispositif et d'un tel procédé - Google Patents
Dispositif de sélection d'informations de séquence candidate pour détermination de similarité, procédé de sélection, et utilisation d'un tel dispositif et d'un tel procédé Download PDFInfo
- Publication number
- WO2014126213A1 WO2014126213A1 PCT/JP2014/053516 JP2014053516W WO2014126213A1 WO 2014126213 A1 WO2014126213 A1 WO 2014126213A1 JP 2014053516 W JP2014053516 W JP 2014053516W WO 2014126213 A1 WO2014126213 A1 WO 2014126213A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sequence information
- candidate
- similar
- group
- sequence
- Prior art date
Links
Images

Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/10—Applications; Uses in screening processes
- C12N2320/13—Applications; Uses in screening processes in a process of directed evolution, e.g. SELEX, acquiring a new function
Definitions
- the present invention relates to determination of similarity between sequence information in a sequence information group, specifically, a candidate selection method for selecting candidate sequence information for similarity determination from sequence information, and a similar sequence information group from candidate sequence information.
- the present invention relates to a similar selection method to be selected, a determination method for determining concentration of a target similar sequence information group, and apparatuses, programs, and recording media for executing these methods.
- nucleic acid molecules called aptamers have been developed as binding molecules to targets instead of antibodies.
- the aptamer is generally prepared by a SELEX (Systematic Evolution of Ligands by Exponential enrichment) method (Patent Document 1, Non-Patent Document 1).
- SELEX Systematic Evolution of Ligands by Exponential enrichment
- the contact between the nucleic acid library and the target and the amplification of the nucleic acid bound to the target are set as a single selection process, and a plurality of rounds are repeated. This enriches nucleic acid sequences that bind to the target in the round-by-round library from the initial library.
- aptamer candidate groups for example, a plurality of nucleic acid sequences having a relatively high degree of enrichment in the library are selected as aptamer candidate groups, and further, by binding strength with the target, etc., finally binding to the target
- the aptamer to be determined can be determined.
- aptamer candidate groups can be selected according to the degree of enrichment in the library, and therefore the degree of enrichment needs to be evaluated in the SELEX method.
- the evaluation of the degree of concentration is usually performed as follows. First, the nucleic acid sequence contained in each round library is decoded with a sequence. Then, the number of appearances of the same nucleic acid sequence in the library (hereinafter also referred to as the degree of duplication) is counted. The degree of concentration of each nucleic acid sequence is evaluated by increasing or decreasing the count number. For example, a multiplicity m n of the nucleic acid sequence X in the n-th round (R n), compared next round, i.e.
- the library also includes completely the same nucleotide sequence for a certain nucleic acid sequence (hereinafter also referred to as an original sequence), but a similar nucleic acid sequence having a mismatch of about several bases with respect to the original sequence (Hereinafter also referred to as similar sequences).
- the inventors of the present invention may have different binding strengths with the target, for example, but the characteristics of the target are the same as the original sequence. And has gained knowledge. For this reason, the evaluation of aptamers can be made more efficient by making the nucleic acid sequences that are similar to each other within an allowable range, instead of the classification of whether or not the nucleic acid sequences are completely identical, as the same sequence group.
- an object of the present invention is to provide an apparatus, a method, a program, and a recording medium for easily determining similarity between sequence information.
- the candidate selection device of the present invention comprises the following means (a), (b), (c) and (d):
- This is a candidate selection device that selects a candidate sequence information group as a similar determination candidate.
- (A) means for executing a step of counting the frequency of each virtual array information in the virtual array information group for each array information in the array information group;
- (d) the similarity of the comparison target sequence information with respect to the comparison source sequence information is the similarity set in the virtual sequence information group Means for executing a step of selecting the comparison source sequence information and the comparison destination sequence information as a candidate sequence information group for determining similarity between the
- the similarity selection apparatus of the present invention includes the following means (A) and (B), and the means (A) is a candidate selection apparatus of the present invention, and is similar to each other from the sequence information group: A similar selection device that selects similar sequence information groups.
- means for executing a step of selecting similar sequence information as a similar sequence information group G3
- the determination apparatus of the present invention comprises the following means (X) and (Y), wherein the means (X) is the similarity selection apparatus of the present invention, It is a determination device.
- (X) Means for executing a step of selecting target sequence information and similar sequence information from the sequence information group as a target similar sequence information group
- (Y) Similar to the target sequence information in the similar sequence information group Means for executing a step of determining the concentration of the similar sequence information group from the sum of the degree of overlap with the sequence information
- the candidate selection method of the present invention includes the following steps (a), (b), (c), and (d), a candidate sequence that is a candidate for determining similarity between sequence information from a sequence information group This is a candidate selection method for selecting an information group.
- A For each sequence information of the sequence information group, a step of counting the frequency of each virtual sequence information of the virtual sequence information group (b) From the sequence information group, the sequence information to be compared and the sequence information to be compared (C) The difference between the frequency of each virtual sequence information of the comparison source sequence information and the frequency of each virtual sequence information of the comparison target sequence information is determined as the comparison target sequence with respect to the comparison source sequence information.
- a step of calculating as the similarity of information (d) When the similarity of the comparison target sequence information with respect to the comparison source sequence information satisfies the allowable condition of the similarity set in the virtual sequence information group, the comparison source sequence information and Selecting the comparison target sequence information as a candidate sequence information group for judging similarity between sequence information
- the similar selection method of the present invention includes the following steps (A) and (B):
- the step (A) includes the candidate selection method of the present invention, and is a similar selection method for selecting similar sequence information groups similar to each other from the sequence information group.
- (A) a step of selecting a candidate sequence information group that is a candidate for determining similarity between sequence information from the sequence information group
- (B) comparing each candidate sequence information of the candidate sequence information group with each other, the same and similar sequences Selecting information as a similar sequence information group (G3)
- the determination method of the present invention includes the following steps (X) and (Y), wherein the step (X) includes the similar selection method of the present invention, This is a determination method.
- (X) a step of selecting target sequence information and similar sequence information from the sequence information group as a target similar sequence information group (Y) between the target sequence information and the similar sequence information in the similar sequence information group
- the program of the present invention is capable of executing on a computer at least one selected from the group consisting of the candidate selection method of the present invention, the similarity selection method of the present invention, and the determination method of the present invention. It is a program to do.
- the recording medium of the present invention records the program of the present invention.
- a candidate sequence group for determining similarity is selected. For this reason, for example, unlike the conventional method of confirming the similarity between all the sequence information, the similarity determination can be performed easily and efficiently. For this reason, for example, it is possible to reduce labor, time, and cost for determination of aptamer concentration.
- FIG. 1 is a block diagram showing an embodiment of a candidate selection apparatus of the present invention.
- FIG. 2 is a flowchart showing an embodiment of the candidate selection method and candidate selection program of the present invention.
- FIG. 3 is a flowchart showing an embodiment of the candidate selection method and candidate selection program of the present invention.
- FIG. 4 is a block diagram showing an embodiment of the similarity selection apparatus of the present invention.
- FIG. 5 is a flowchart for explaining an embodiment of the similarity selection method and the similarity selection program of the present invention.
- FIG. 6 is a flowchart for explaining an embodiment of the similarity selection method and the similarity selection program of the present invention.
- FIG. 7 is a block diagram showing another embodiment of the similar selection device of the present invention.
- FIG. 8 is a flowchart for explaining another embodiment of the similarity selection method and the similarity selection program of the present invention.
- FIG. 9 is a flowchart for explaining another embodiment of the similarity selection method and the similarity selection program of the present invention.
- sequence information group means a group composed of a plurality of pieces of sequence information, and the plurality of pieces of sequence information may be, for example, all different pieces of sequence information or different pieces of sequence information from the same sequence information. May be included.
- An object of the present invention is to select candidate sequence information that is a candidate for similarity determination when determining similarity between different sequence information. For this reason, the plurality of pieces of sequence information are preferably different pieces of sequence information, for example.
- the number of the sequence information included in the sequence information group is not particularly limited.
- array information is not particularly limited, and is information related to the arrangement of elements.
- the element include at least one of letters and symbols, and specific examples include letters or symbols indicating the type of nucleic acid, letters or symbols indicating the type of amino acid, and the like.
- characters or symbols indicating the type of nucleic acid include characters or symbols indicating the type of base such as A, G, C, T and U.
- the character or symbol indicating the type of amino acid include a three-letter code such as Met and a one-character code or symbol such as M.
- Specific examples of the sequence information include sequence information of nucleic acid sequences and sequence information of amino acid sequences.
- the length of the array information can also be referred to as the number of elements constituting the array information.
- the length of the sequence information is not particularly limited, and the number of elements is, for example, 5 to 200, preferably 10 to 150, and more preferably 20 to 120.
- the “virtual array information group” means a group composed of a plurality of virtual array information.
- the virtual array information is virtual array information constructed from elements (also referred to as structural units) constituting the array information.
- the element can be determined according to the type of array information of the array information group, and specifically, is the same element as the array information in the array information group.
- the virtual array information can be referred to as information in which the elements are arbitrarily arranged, for example, and the virtual array information group can be referred to as a group composed of a plurality of information in arbitrary different arrays.
- the length of the virtual array information can also be referred to as the number of elements constituting the virtual array information.
- the length of the virtual array information is not particularly limited, and the number of elements is, for example, 1 to 10, preferably 1 to 7, and more preferably 1 to 4. It is preferable that each virtual array information of the virtual array information group has the same length, for example.
- comparison or comparison sequence information selected from the sequence information group is referred to as comparison source sequence information and comparison destination sequence information, respectively.
- the former sequence information is also referred to as “comparison source” and the other sequence information is also referred to as “comparison destination”.
- frequency of virtual array information means the frequency at which the virtual array information appears in the target array information, and may be, for example, an element of the frequency vector and the number of appearances.
- frequency difference means a frequency difference between two or more pieces of sequence information, for example, a difference between the frequency of the sequence information of the comparison destination and the frequency of the sequence information of the comparison source.
- “similarity” indicates the degree of similarity of comparison target sequence information with respect to comparison source sequence information.
- the “similarity allowance condition” is a similarity condition indicating that the comparison target sequence information can be a candidate for similarity determination with respect to the comparison source sequence information.
- the similarity allowance condition can be set arbitrarily, and can be set, for example, based on the number of element mismatches allowed when two pieces of sequence information are compared.
- the comparison between the two pieces of sequence information is, for example, a comparison between the arrangements of the elements of the two pieces of sequence information.
- As the allowable condition for the similarity for example, a value obtained by multiplying the number of mismatches (M) allowed when two pieces of array information are compared with the length (number N of elements) of the virtual array information can be set.
- the “redundancy” means the number of pieces of sequence information that are completely the same in a group of sequence information composed of a plurality of pieces of sequence information.
- “similarity duplication” refers to the degree of duplication of sequence information that is completely the same in a sequence information group composed of a plurality of sequence information and other sequence information similar to the sequence information. It means the total with the degree of overlap.
- the sum of the degrees of overlap between the sequence information and each of the other similar sequence information is obtained by calculating the respective similar overlap information.
- the candidate selection device of the present invention includes the following means (a), (b), (c) and (d), and determines similarity between sequence information from the sequence information group: This is a candidate selection device that selects a candidate sequence information group as a candidate.
- the virtual sequence information group is a group of virtual sequence information constructed from elements constituting the sequence information.
- the means (c) is preferably means for executing the following steps (c1) and (c2).
- (C1) A step of obtaining a difference between the frequency in the comparison source sequence information and the frequency in the comparison destination sequence information for each virtual sequence information
- (c2) A positive difference among the frequency differences of the virtual sequence information Calculating the absolute value of only the sum of the absolute values or the absolute value of the sum of only the negative difference, and calculating the absolute value as the similarity of the comparison target sequence information with respect to the comparison source sequence information
- the allowable condition of the similarity is a condition set based on the number of mismatches allowable when two pieces of sequence information are compared.
- the comparison of two pieces of sequence information can also be called an alignment of two pieces of sequence information.
- the sequence information is preferably a base sequence, and the elements constituting the sequence information are preferably A, G, C, T, and U bases.
- the base length of the virtual sequence information is, for example, 1 to 10 bases.
- each virtual sequence information of the virtual sequence information group has the same base length.
- the allowable condition for the similarity is a condition set based on the number of mismatched bases allowed when two pieces of sequence information are compared.
- the allowable condition of the similarity is a value obtained by multiplying the number of mismatched bases (M) allowed when two pieces of sequence information are compared with the base length (N) of the virtual sequence information.
- M mismatched bases
- N base length
- the candidate selection device of the present invention preferably further includes the following means (e).
- the means (b) is obtained from the sequence information group every time the step is executed. It is preferable to select different sequence information as the comparison source sequence information.
- the candidate selection method of the present invention includes the following steps (a), (b), (c), and (d), and determines similarity between sequence information from the sequence information group:
- This is a candidate selection method for selecting a candidate sequence information group as a candidate.
- the description in the candidate selection device of the present invention can be used unless otherwise indicated.
- a step of counting the frequency of each virtual sequence information of the virtual sequence information group (b) From the sequence information group, the sequence information to be compared and the sequence information to be compared (C) The difference between the frequency of each virtual sequence information of the comparison source sequence information and the frequency of each virtual sequence information of the comparison target sequence information is determined as the comparison target sequence with respect to the comparison source sequence information.
- a step of calculating as the similarity of information (d) When the similarity of the comparison target sequence information with respect to the comparison source sequence information satisfies the allowable condition of the similarity set in the virtual sequence information group, the comparison source sequence information and Selecting the comparison target sequence information as a candidate sequence information group for judging similarity between sequence information
- the virtual sequence information group is a group of virtual sequence information constructed from elements constituting the sequence information.
- the step (c) preferably includes the following steps (c1) and (c2).
- (C1) A step of obtaining a difference between the frequency in the comparison source sequence information and the frequency in the comparison destination sequence information for each virtual sequence information
- (c2) A positive difference among the frequency differences of the virtual sequence information Calculating the absolute value of only the sum of the absolute values or the absolute value of the sum of only the negative difference, and calculating the absolute value as the similarity of the comparison target sequence information with respect to the comparison source sequence information
- the allowable condition for the similarity is a condition set based on the number of mismatches allowed when two pieces of sequence information are compared.
- the sequence information is preferably a base sequence, and the elements constituting the sequence information are preferably A, G, C, T, and U bases.
- the virtual sequence information preferably has a base length of 1 to 10 bases.
- each virtual sequence information of the virtual sequence information group has the same base length.
- the allowable condition for the similarity is a condition set based on the number of mismatched bases allowed when two pieces of sequence information are compared.
- the similarity allowance condition is a value obtained by multiplying the number of mismatched bases (M) allowed when two pieces of sequence information are compared with the base length (N) of the virtual sequence information. Preferably there is.
- the candidate selection method of the present invention preferably further includes the following step (e).
- step (e) it is preferable to select different sequence information as the comparison source sequence information from the sequence information group for each execution of the step.
- step (E) repeating the steps (b), (c) and (d)
- the candidate selection method of the present invention it is preferable that all the steps are executed on a computer. In the candidate selection method of the present invention, for example, all the steps may be executed by the candidate selection device of the present invention.
- sequence information is referred to as a sequence
- sequence information group is referred to as a sequence group.
- Embodiment 1 is related with the candidate selection apparatus and candidate selection method of this invention.
- the present embodiment is an example in which a nucleic acid base sequence is used as the sequence.
- a candidate sequence group that is a candidate for determining similarity between base sequences can be selected from a base sequence group consisting of a plurality of base sequences.
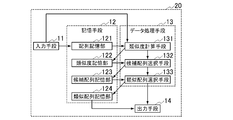
- FIG. 1 shows an example of the configuration of the candidate selection device of this embodiment.
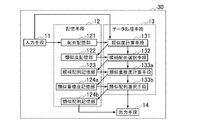
- the candidate selection device 10 includes an input unit 11, a sequence storage unit 121, a similarity storage unit 122 and a candidate sequence storage unit 123, a similarity calculation unit 131 and a candidate sequence selection unit 132, and an output unit 14.
- the similarity calculation means 131 and the candidate sequence selection means 132 may be incorporated into data processing means (data processing apparatus) 13 which is hardware, and software or the software is incorporated therein. It may be hardware.
- Each of the storage units 121, 122, and 123 may be incorporated in the storage unit 12 that is hardware, for example, as shown in FIG.
- the data processing unit 13 may include a CPU or the like.
- the sequence storage unit 121 includes an input unit 11 and a similarity calculation unit 131
- the similarity storage unit 122 includes a similarity calculation unit 131 and a candidate sequence selection unit 132
- the candidate sequence storage unit 123 includes a candidate sequence selection unit 132 and
- the output means 14 is electrically connected to each other.
- the input means 11 may be electrically connected to the similarity calculation means 131
- the similarity calculation means 131 may be electrically connected to the candidate sequence selection means 132
- the candidate sequence selection means 132 may be electrically connected to the output means 14, respectively.
- the candidate selection device 10 may store information in the storage unit 12, output the stored information to the data processing unit 13, and perform data processing, or input the information to the data processing unit 13. Data processing may be performed.
- the input means 11 is means (input device) for inputting information on the array group and the virtual array group.
- the input unit 11 is not particularly limited, and for example, a normal input unit, an input file, another computer, or the like provided in a computer such as a keyboard and a mouse can be used.
- the input unit 11 may be a unit that reads information on the array group and the virtual array group stored in a database. In this case, for example, the array information stored in advance in the server is called to the input means 11 through the network.
- the input unit 11 may include a communication interface, for example.
- the number of sequences to be input in the sequence group is not particularly limited, and the lower limit is, for example, 5, preferably 10, and the upper limit is, for example, 10 million, preferably 1 million.
- the information item of the sequence to be input is, for example, the order of elements constituting the sequence, that is, the base sequence.
- the length of the sequence is not particularly limited, and is, for example, 5 to 200 bases long, preferably 10 to 150 bases long, and more preferably 20 to 120 bases long.
- the number of virtual sequences in the virtual sequence group is not particularly limited and can be appropriately determined according to the base length of the virtual sequence.
- the lower limit of the base length is, for example, 1 base length, preferably 2 base lengths, more preferably 3 base lengths, and the upper limit thereof is, for example, 10 base lengths, preferably 9 bases. It is long, more preferably 8 bases long, and even more preferably 7 bases long.
- the lengths of the virtual arrays are preferably the same.
- the virtual sequence of the virtual sequence group the number is, for example, a fourth n-th power (4 n pieces).
- the number of virtual sequences of one base length is the first power of 4, that is, four of A, C, G, and T
- the number of virtual sequences having a length of 2 bases is the square of 4, that is, AA, AC, AG, AT, CC, CA, CG, CT, GG, GA, GC, GT, TT, TA, TC, TG It is 16 pieces.
- the similarity calculation unit 131 counts the frequency of each virtual sequence group for each sequence of the sequence group as the step (a), and compares the comparison source sequence and the comparison target sequence from the sequence group as the step (b). In step (c), the degree of similarity of the comparison target sequence with respect to the comparison source sequence is calculated.
- the order of the steps (a), (b), and (c) is not particularly limited, and the order is not limited.
- the frequency (S n ) in the comparison source sequence and the frequency (T n ) in the comparison target sequence are calculated for each virtual sequence as (c1).
- the difference (S n ⁇ T n ) with respect to () is obtained, and in the step (c2), only the absolute value of the sum of only the positive differences or the negative difference is included in the frequency difference (S n ⁇ T n ). This can be done by obtaining the absolute value of the sum of. That is, the absolute value of the sum is used as the similarity.
- Candidate sequence selection means 132 selects candidate sequences for determining similarity between sequence information based on the similarity of the comparison target sequence with respect to the comparison source sequence and the allowable condition of the similarity set in the virtual sequence group I do.
- the plurality of candidate sequences selected here becomes a candidate sequence group.
- the degree of similarity is 2 or less, the allowable sequence satisfies the allowable condition, and therefore the comparison source sequence and the comparison target sequence are selected as candidate sequences for determining similarity between the sequence information.
- the similarity exceeds 2
- the numerical value of the allowable condition is exceeded and the allowable condition is not satisfied, and therefore the comparison target sequence is not selected as a candidate sequence for determining similarity to the comparison source sequence.
- Target original sequence Seq1 aac cgg tt
- Target sequence Seq2 aac cAg tt
- the output means (output device) 14 may be any means that outputs the result of the candidate sequence selection means 132.
- the output unit 14 may be a unit that outputs information stored in the candidate sequence storage unit 123.
- the output means 14 is not particularly limited, and for example, a normal output device provided in a computer such as a display device or a printing device, an output file, another computer, or the like can be used.
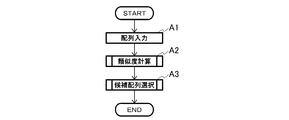
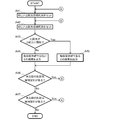
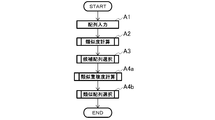
- the candidate selection method of this embodiment includes an A1 step (sequence input), an A2 step (similarity calculation), and an A3 step (candidate sequence selection).
- Each array in the array group and each virtual array in the virtual array group are input and stored in the array storage unit 121.
- the information items of the sequence group and the virtual sequence group include, for example, the order of bases in the sequence.
- a new comparison source sequence set (A21) and a new comparison target sequence set (A22) are performed from the sequence group, and each of the set comparison source sequence and the comparison target sequence Count the frequency of virtual arrays. Then, for each virtual array, the difference between the frequency of the comparison source sequence and the frequency of the comparison target sequence is obtained, and the sum of only positive differences or the sum of negative differences is calculated. Specifically, when n (n is a positive number) virtual arrays exist, n frequencies (S 1 ,..., S n ) as the frequencies of the virtual arrays for the comparison source array, For the comparison target sequence, n frequencies (T 1 ,..., T n ) are obtained.
- (A3) Candidate Sequence Selection Then, it is determined whether or not the similarity satisfies the allowable value of similarity, that is, whether or not it is higher than the allowable value (A31). In the case of NO, that is, when the similarity is smaller than an allowable value, it is determined that the comparison target sequence has an allowable number of mismatches with respect to the comparison source sequence, and the comparison source sequence and the comparison target A result indicating that the sequence is a candidate sequence for similarity determination is output (A32).
- an uncompared comparison target sequence is confirmed (A34). If YES, that is, if there is an uncompared comparison target sequence, the same processing is performed from step A22. If NO, that is, if there is no uncompared comparison target sequence, the presence or absence of an uncompared comparison source sequence is further confirmed (A35). If YES, that is, if there is an uncompared comparison source sequence, the same processing is performed from step A21. If NO, that is, if there is no uncompared comparison source sequence, the processing ends. In addition, when one sequence is compared as a comparison source sequence and another sequence is compared as a comparison target sequence, the comparison using the former as the comparison target sequence and the latter as the comparison source sequence is omitted and the comparison result is used. Also good.
- the A2 step and the A3 step will be described as an example of a case where the virtual sequence has a base length of 1.
- the comparison source sequence is Seq3
- the comparison target sequence is Seq4.
- M the number of mismatched bases that can be accepted as similar judgment candidates
- This absolute value 3 is the degree of similarity of the comparison target sequence Seq4 with respect to the comparison source sequence Seq3, and indicates that the comparison target sequence Seq4 has at least three mismatches when aligned with the comparison source sequence Seq3.
- the comparison target sequence Seq4 is excluded from the candidate sequences for similarity determination of the comparison source sequence Seq3.
- the similarity 3 the allowable value 3. Therefore, the comparison target sequence Seq4 is selected as a candidate sequence for similarity determination of the comparison source sequence Seq3.
- the comparison target sequence when the comparison target sequence satisfies the permissible condition, the comparison target sequence is selected as a candidate sequence for similarity determination together with the comparison source sequence. That is, it selects as a candidate sequence group.
- the comparison target sequence when the comparison target sequence does not satisfy the allowable condition, the comparison target sequence is not selected as a candidate sequence for similarity determination.
- the comparison source sequence when there is no comparison target sequence that satisfies the permissible condition for the comparison source sequence, the comparison source sequence is not selected as a candidate sequence for similarity determination.
- the input unit 11 and the similarity calculation unit 131, and the similarity calculation unit 131 and the candidate sequence selection unit 132 may be electrically connected to each other. Further, the candidate selection device 10 may or may not include various storage units, for example. In this case, for example, the similarity calculation unit 131 may calculate the similarity for each sequence input by the input unit 11, and the candidate sequence may be selected by the candidate sequence selection unit 132 for the calculated similarity. .
- the similarity selection apparatus of the present invention includes the following means (A) and (B) as described above,
- the (A) means is a similar selection device for selecting similar sequence information groups similar to each other from the sequence information group, characterized in that it is the candidate selection device of the present invention.
- (A) Means for executing a step of selecting a candidate sequence information group that is a candidate for similarity determination between sequence information from the sequence information group (B) Each candidate sequence information of the candidate sequence information group is compared with each other and identical And means for executing a step of selecting similar sequence information as a similar sequence information group (G3)
- the means (A) may be the candidate selection device of the present invention, and the description of the candidate selection device of the present invention can be used.
- the sequence information group is a group of the different sequence information selected from the sequence information group (G) including the same sequence information and different sequence information.
- the means (B) is preferably means for executing the following steps (B1), (B2), (B3), (B4) and (B5).
- (B1) A step of selecting candidate sequence information as a comparison source and candidate sequence information as a comparison destination from the candidate sequence information group (B2) Presence / absence of similarity of the comparison destination candidate sequence information with respect to the comparison source candidate sequence information (B3) The duplication degree of the comparison source candidate sequence information and the duplication degree of the comparison destination candidate sequence information similar to the comparison source candidate sequence information are summed, and the total value obtained is compared with the comparison (B4) selecting different candidate sequence information from the candidate sequence information group as candidate sequence information to be a new comparison source, and (B1), (B2) and (B4) B3) Step of repeating the step (B5) Among the candidate sequence information, the candidate sequence information showing the largest similarity redundancy and candidate sequence information similar to the candidate sequence information are selected as the similar sequence information group (G3) That process
- the presence or absence of similarity between the comparison source candidate sequence and the comparison destination candidate sequence is not particularly limited, and can be determined by a known method.
- sequences can be aligned with each other, and similarities and dissimilarities can be determined based on the number of allowable mismatches (different elements).
- the number of allowable mismatches is dissimilar when the number exceeds the allowable number of mismatches, and the number of mismatches is similar when the number is less than or equal to the allowable number of mismatches.
- the number of allowable mismatches is not particularly limited and can be arbitrarily determined.
- ⁇ Redundancy is reset to 0 while the subsequent process is repeated. Therefore, since the degree of duplication in the step (B3) is initial information of each array, it is also referred to as “initial degree of duplication”. In addition, the degree of overlap 0 reset in the subsequent process is also referred to as “redundancy 0” or “reset overlap”.
- the means (B) is a means for further executing the following steps (B6), (B7) and (B8).
- the recalculation of the similar overlap degree means, for example, resetting the already obtained similar overlap degree and newly calculating the similar overlap degree.
- (B6) Of the candidate sequence information, a step of resetting the redundancy of candidate sequence information showing the largest similarity redundancy and the redundancy of candidate sequence information similar to the candidate sequence information to 0 (B7)
- a step of recalculating the degree of similarity duplication for other candidate sequence information having a value other than 0 (B8) Among the other candidate sequence information, the candidate sequence information showing the largest degree of similarity duplication and similar to the candidate sequence information Reselecting candidate sequence information to be selected as a group of similar sequence information
- the means (B) is a means for further executing the following step (B9).
- (B9) Among the other candidate sequence information, reset the candidate sequence information showing the largest similar redundancy and the redundancy of candidate sequence information similar to the candidate sequence information to 0, and (B7) and (B B8) Repeating the process
- a plurality of similar sequence information groups can be selected by repeating the selection of a similar candidate group based on the largest similar redundancy and the recalculation of the similarity redundancy.
- the re-selection of the similar sequence information group is preferably performed until, for example, the redundancy is reset to 0 for all candidate sequences.
- the means (B) may execute the exclusion of combinations that have already been executed as a combination of the comparison source complementary sequence information and the comparison destination candidate sequence information in the step (B1). preferable.
- the information item of the array information may include, for example, the overlapping degree of each array in addition to the order of the elements constituting the array. In this case, it is preferable that all the sequences included in the sequence group are different sequences.
- sequence information the following (B ') means which performs the process which counts the said duplication degree may be included, for example.
- the array included in the array group may include, for example, an array in which the order of elements is completely the same in addition to a different array.
- B ′ Means for performing the step of counting the number of completely identical sequence information as the degree of duplication for the sequence information group
- the similarity selection method of the present invention includes the following steps (A) and (B) as described above,
- the step (A) includes the candidate selection method of the present invention, and is a similar selection method for selecting similar sequence information groups similar to each other from the sequence information group.
- (A) a step of selecting a candidate sequence information group that is a candidate for determining similarity between sequence information from the sequence information group
- (B) comparing each candidate sequence information of the candidate sequence information group with each other, the same and similar sequences Selecting information as a similar sequence information group (G3)
- the step (B) preferably includes the following steps (B1), (B2), (B3), (B4), and (B5).
- (B1) A step of selecting candidate sequence information as a comparison source and candidate sequence information as a comparison destination from the candidate sequence information group (B2) Presence / absence of similarity of the comparison destination candidate sequence information with respect to the comparison source candidate sequence information (B3) The duplication degree of the comparison source candidate sequence information and the duplication degree of the comparison destination candidate sequence information similar to the comparison source candidate sequence information are summed, and the total value obtained is compared with the comparison (B4) selecting different candidate sequence information from the candidate sequence information group as candidate sequence information to be a new comparison source, and (B1), (B2) and (B4) B3) Step of repeating the step (B5) Among the candidate sequence information, the candidate sequence information showing the largest similarity redundancy and candidate sequence information similar to the candidate sequence information are selected as the similar sequence information group (G3) That process
- the step (B) preferably further includes the following steps (B6), (B7), and (B8).
- B6 Of the candidate sequence information, a step of resetting the redundancy of candidate sequence information showing the largest similarity redundancy and the redundancy of candidate sequence information similar to the candidate sequence information to 0 (B7)
- the candidate sequence information showing the largest degree of similarity duplication and similar to the candidate sequence information Reselecting candidate sequence information to be selected as a group of similar sequence information
- the step (B) preferably further includes the following step (B9).
- (B9) Among the other candidate sequence information, reset the candidate sequence information showing the largest similar redundancy and the redundancy of candidate sequence information similar to the candidate sequence information to 0, and (B7) and (B B8) Repeating the process
- step (B) it is preferable to exclude combinations already executed as combinations of the comparison source complementary sequence information and the comparison destination candidate sequence information in the step (B1).
- the similarity selection method of the present invention it is preferable that all the steps are executed on a computer. In the similarity selection method of the present invention, for example, all the steps may be executed by the similarity selection device of the present invention.
- the present invention is not limited to the following embodiments.
- the description of the said Embodiment 1 can be used for selection of the said candidate sequence group.
- the sequence information is referred to as a sequence
- the sequence information group is referred to as a sequence group.
- the second embodiment relates to a similarity selection device and a similarity selection method of the present invention.
- the present embodiment is an example in which a nucleic acid base sequence is used as the sequence.
- the description of Embodiment 1 can be used unless otherwise indicated.
- a candidate sequence that is a candidate for determining similarity between base sequences is selected from a base sequence group that includes a plurality of base sequences, and is similar to each other from a candidate sequence group that includes a plurality of the candidate sequences. Similar sequences can be selected as groups of similar sequences.
- FIG. 4 shows an example of the similarity selection device of the present embodiment.
- the similarity selection device 20 includes an input unit 11, a sequence storage unit 121, a similarity storage unit 122, a candidate sequence storage unit 123 and a similar sequence storage unit 124, a similarity calculation unit 131, and a candidate sequence selection unit. 132 and similar sequence selection means 133, and output means 14.
- the similarity calculation unit 131, the candidate sequence selection unit 132, and the similar sequence selection unit 133 may be incorporated in the data processing unit 13 that is hardware, and the software or the software is incorporated. Hardware may be used.
- Each of the storage units 121, 122, 123, and 124 may be incorporated in the storage unit 12 that is hardware, for example, as shown in FIG.
- the data processing unit 13 may include a CPU or the like.
- the candidate sequence storage unit 123 is further electrically connected to the similar sequence selection unit 133, and the similar sequence storage unit 124 is electrically connected to the similar sequence selection unit 133 and the output unit 14, respectively.
- the candidate sequence selection unit 132 may be electrically connected to the similar sequence selection unit 133, and the similar sequence selection unit 133 may be electrically connected to the output unit 14, respectively.
- the similarity selection device 20 may store information in the storage unit 12, output the stored information to the data processing unit 13, and perform data processing, or input the information to the data processing unit 13. Data processing may be performed.
- the information item of the array to be input includes the overlapping degree of each array in addition to the order of the elements constituting the array as described above.
- the information item includes the degree of duplication, it is preferable that all of the arrays constituting the array group are different arrays.
- the (B ′) means may be included.
- the means (B ′) the number of completely identical sequence information can be counted as the degree of duplication for the sequence group.
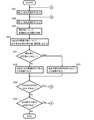
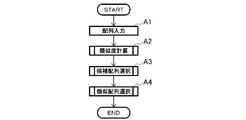
- the similarity selection method of this embodiment includes an A1 step (sequence input), an A2 step (similarity calculation), an A3 step (candidate sequence selection), and an A4 step (similar sequence selection).
- A1 step sequence input
- A2 step similarity calculation
- A3 step candidate sequence selection
- A4 step similar sequence selection
- the A1 step, the A2 step, and the A3 step can be performed in the same manner as in the first embodiment, and specifically, can be performed according to the above-described flowchart of FIG.
- the information item of the sequence group includes, for example, the order of bases in the sequence and the degree of sequence overlap
- the information item of the virtual sequence group includes, for example, the order of bases in the sequence.
- a new comparison source candidate sequence set (A41) and a new comparison target candidate sequence set (A42) are performed from the candidate sequence group selected in the A3 step, and the set comparison target candidate sequences are Then, it is determined whether or not it is similar to the comparison source candidate sequence (A43). In the case of NO, that is, when the comparison target candidate sequence is not similar to the comparison source candidate sequence, a result that the comparison target candidate sequence is not a similar sequence group with the comparison source candidate sequence is obtained. Output (A44). On the other hand, in the case of YES, that is, when the comparison target candidate sequence is similar to the comparison source candidate sequence, the result that the comparison target candidate sequence is a similar sequence group with the comparison source candidate sequence is obtained. Output (A45).
- step A46 the presence or absence of an uncompared comparison target candidate sequence is confirmed with respect to the comparison source candidate sequence. If YES, that is, if there is an uncompared comparison target sequence, the same processing is performed from step A42. If NO, that is, if there is no uncompared comparison target candidate sequence, the presence / absence of an uncompared comparison source candidate sequence is further confirmed (A47). If YES, that is, if there is an uncompared comparison source candidate sequence, the same processing is performed from step A41. If NO, that is, if there is no uncompared comparison source candidate sequence, the processing ends.
- comparison result May be used.
- the comparison source candidate sequence and the comparison destination candidate sequence from each candidate sequence in the candidate sequence group, and judging similarity between sequences, the comparison source candidate sequence and A similar sequence group consisting of similar candidate sequences for comparison can be selected.
- the input unit 11 and the similarity calculation unit 131, the similarity calculation unit 131 and the candidate sequence selection unit 132, and the candidate sequence selection unit 132 and the similar sequence selection unit 133 are electrically connected, respectively. It may be connected.
- the similarity selection apparatus 20 may be provided with various memory
- the similarity calculation unit 131 calculates the similarity for each sequence input by the input unit 11, the candidate sequence selection unit 132 selects a candidate sequence group for the calculated similarity, and The similar sequence group may be selected by the similar sequence selection means 133 for the selected candidate sequence group.
- the third embodiment relates to the similar selection device and the similar selection method of the present invention, as in the second embodiment.
- the present embodiment is an example in which the degree of overlap is used in the selection of the similar sequence group in the second embodiment.
- the description of Embodiments 1 and 2 can be incorporated unless otherwise specified.
- a similar sequence group can be easily selected by using the similarity between sequences.
- FIG. 7 shows an example of the similarity selection device of this embodiment.
- the similarity selection device 30 includes a similar redundancy degree storage unit 124 a and a similar sequence storage part 124 b, a similar redundancy degree calculation unit 133 a, and a similar sequence selection unit 133 b.
- the similarity duplication degree calculation unit 133a and the similar sequence selection unit 133b may be incorporated in the data processing unit 13 which is hardware, or may be software or hardware in which the software is incorporated.
- the similar redundancy storage unit 124 a and the similar sequence storage unit 124 b may be incorporated in the storage unit 12 that is hardware.
- the candidate sequence storage unit 123 is electrically connected to the similar redundancy calculation unit 133a, and the similar redundancy storage unit 124a is electrically connected to the similar redundancy calculation unit 133a and the similar sequence selection unit 133b.
- the similar sequence storage unit 124b is electrically connected to the similar sequence selection unit 133b and the output unit 14, respectively.
- the candidate sequence selection unit 132 is electrically connected to the similarity duplication degree calculation unit 133a
- the similarity duplication degree calculation unit 133a is electrically connected to the similar sequence selection unit 133b
- the similar sequence selection unit 133b is electrically connected to the output unit 14, respectively. May be.
- the similarity selection method of this embodiment includes an A1 step (sequence input), an A2 step (similarity calculation), an A3 step (candidate sequence selection), and an A4 step (similar sequence selection).
- the A4 step includes an A4a step (similar redundancy calculation) and an A4b step (similar sequence selection based on the calculation result of similar redundancy). 8 and 9, the same steps as those in FIGS. 5 and 6 are denoted by the same reference numerals.
- the A1 step, the A2 step, and the A3 step can be performed in the same manner as in the second embodiment.
- the information item of the array to be input includes, for example, the overlapping degree of each array in addition to the order of the elements constituting the array.
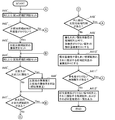
- a new comparison source candidate sequence is set (A41 ′) from the candidate sequence group selected in the A3 step, and it is determined whether or not the degree of overlap is 0 (A42 ′). In the case of NO, that is, when the multiplicity is 0 (initial multiplicity is 0 or reset multiplicity is 0), a new comparison source candidate sequence is set again (A41 ′). On the other hand, if YES, that is, if the degree of overlap is not 0 (initial degree of overlap ⁇ 1), the degree of overlap of the comparison source candidate sequence is set (A43 ′).
- a new comparison destination candidate sequence is set (A44 ′), and it is determined whether or not the comparison destination candidate sequence is similar to the comparison source candidate sequence (A45 ′).
- the similarity of the comparison source candidate sequence and the similarity of the comparison destination candidate sequence are summed, and the total value is similar overlap Degree (A46 ').
- This similarity overlap is called the similarity overlap of the comparison source candidate sequence.
- NO that is, when the comparison destination candidate sequence is not similar to the comparison source candidate sequence, the presence or absence of an uncompared comparison destination candidate sequence is confirmed (A47 ′).
- step A44 ′ If YES, that is, if there is an uncompared comparison target candidate sequence, the same processing is performed from step A44 ′. If NO, that is, if there is no uncompared comparison target candidate sequence, the presence or absence of an uncompared comparison source candidate sequence is further confirmed (A48 ′). If YES, that is, if there is an uncompared comparison source candidate sequence, the same processing is performed from step A41 ′. In the case of NO, that is, when there is no uncompared comparison source candidate sequence, the similarity redundancy is reset, that is, reset to 0 for candidate sequences other than the candidate sequence with the highest similarity redundancy and the similarity redundancy is not 0. Set (A49 ').
- the redundancy is reset to 0 for the candidate sequence having the largest similar redundancy and a candidate sequence similar to the candidate sequence (A410 ′).
- the presence / absence of a candidate sequence whose degree of overlap is not 0 is confirmed (A411 ′). If YES, that is, if there is a candidate sequence whose degree of polymerization is not 0 (initial duplication degree ⁇ 1), this is set as a new comparison source candidate sequence, and the same processing is performed from step A41 ′.
- a candidate sequence with a non-zero degree of overlap and a candidate sequence similar thereto are taken as similar sequence groups, and a list of similar sequence groups is output (A412 ′) ).
- the information items to be output include, for example, each sequence included in the similar sequence group and the similar overlap degree.
- the candidate sequence group there are five different sequences (Seq1, Seq2, Seq3, Seq4, Seq5) included in the candidate sequence group, and the respective overlapping degrees (that is, the number of occurrences) are ⁇ 5, The case of 4, 3, 2, 1 ⁇ will be described as an example.
- Table 1 shows the types of candidate sequences and their redundancy.
- the initial duplication degree of the comparison source candidate sequence and the initial duplication degree of the comparison destination candidate sequence similar thereto are summed, and this total value is calculated as the similar duplication degree of the comparison source candidate sequence.
- Table 3 below shows the similarity overlap.
- a comparison source candidate sequence showing the largest similarity duplication is selected from the comparison source candidate sequences, and the comparison source candidate sequence and a comparison destination candidate sequence similar thereto are used as a similar sequence group.
- Seq4 showing the largest degree of similar duplication 11 and Seq1 and Seq2 similar thereto are the same similar sequence group.
- the similarity redundancy is reset for the candidate sequences whose similarity redundancy is not 0, and the initial of the comparison source candidate sequence showing the largest similarity redundancy
- the duplication degree and the initial duplication degree of a similar comparison target candidate sequence are reset to 0 (reset duplication degree 0).
- the similar duplication degree is reset, and the initial duplication degree of Seq4 and Seq1 and Seq2 similar to it is reset to 0 (re-set) Setting overlap 0).
- the similar candidate group is calculated and the similar candidate group is selected based on the largest similar degree of overlap.
- the selection of similar candidate groups is preferably repeated until the initial redundancy of all candidate sequences is reset to zero.
- Seq3 showing the largest similar redundancy 3 among candidate sequences whose non-redundancy is not 0 is set as a similar sequence group.
- one sequence is a comparison source candidate sequence
- the other sequence is a comparison destination candidate sequence
- the one sequence is a comparison destination candidate sequence
- the other sequence is a comparison source candidate
- the candidate sequence group can be classified into a similar sequence group.
- the concentration determination apparatus of the present invention includes the following (X) and (Y) means, and the (X) means is the similar selection apparatus of the present invention. It is a determination apparatus of concentration of similar sequence information group.
- (Y) Similar to the target sequence information in the similar sequence information group Means for executing a step of determining the concentration of the similar sequence information group from the sum of the degree of overlap with the sequence information
- the (X) means may be the similarity selection apparatus of the present invention, and the description of the similarity selection apparatus of the present invention can be used.
- the (X) means executes a step of selecting a similar sequence information group as a comparison source and a similar sequence information group as a comparison destination, respectively.
- the (Y) means is preferably means for executing the following steps (Y1) and (Y2). (Y1) the sum of the degrees of overlap between the target sequence information in the similar sequence information group of the comparison source and the similar sequence information, the target sequence information in the similar sequence information group of the comparison destination, and the sequence information similar thereto (Y2) when the sum of the duplication degrees in the similar sequence information group of the comparison source is larger than the sum of the duplication degrees in the similar sequence information group of the comparison destination, Determining that the comparison source similar sequence information group is more concentrated than the comparison target sequence information group
- the determination of concentration may be performed, for example, by comparing differences in the degree of concentration between the sequence information for different sequence information included in the same sequence information group.
- the similar sequence information group of the comparison source and the similar sequence information group of the comparison destination are similar sequence information groups selected from the same sequence group, and the purpose of the similar sequence information group of the comparison source And the target sequence information of the similar sequence information group to be compared are different sequence information. Thereby, for example, it is possible to select sequence information having a relatively high degree of enrichment and similar sequence information from the same sequence information group.
- a similar sequence information group having a relatively high concentration is selected from a plurality of similar sequence information groups included in a specific round library, that is, an aptamer having a high concentration is selected. Selection of sequence groups can be performed.
- the determination of the enrichment may be performed, for example, by comparing the difference in enrichment level between the sequence information groups for the same sequence information included in different sequence information groups.
- the similar sequence information group of the comparison source and the similar sequence information group of the comparison destination are similar sequence information groups selected from different sequence groups, and the purpose of the similar sequence information group of the comparison source And the target sequence information of the comparison target similar sequence information group are the same sequence information.
- a sequence information group having a relatively high degree of enrichment can be selected for a similar sequence information group of specific sequence information.
- a library with a relatively high concentration of a specific aptamer-like sequence group can be selected from among the libraries in each round.
- the enrichment determination method of the present invention includes the following steps (X) and (Y), wherein the step (X) includes the similarity selection method of the present invention, This is a determination method. Unless otherwise indicated, the description in the concentration determination apparatus of the present invention can be used for the concentration determination method of the present invention.
- (X) a step of selecting target sequence information and similar sequence information from the sequence information group as a similar sequence information group to be determined
- (Y) the target sequence information and the similar sequence in the similar sequence information group
- the step (X) is a step of selecting a similar sequence information group as a comparison source and a similar sequence information group as a comparison destination, respectively.
- the step (Y) preferably includes the following steps (Y1) and (Y2). (Y1) the sum of the degrees of overlap between the target sequence information in the similar sequence information group of the comparison source and the similar sequence information, the target sequence information in the similar sequence information group of the comparison destination, and the sequence information similar thereto (Y2) when the sum of the duplication degrees in the similar sequence information group of the comparison source is larger than the sum of the duplication degrees in the similar sequence information group of the comparison destination, Determining that the comparison source similar sequence information group is more concentrated than the comparison target sequence information group
- the enrichment determination method of the present invention is a similar sequence information group in which the similar sequence information group of the comparison source and the similar sequence information group of the comparison destination are selected from the same sequence group,
- the target sequence information of the comparison source similar sequence information group and the target sequence information of the comparison target similar sequence information group may be different sequence information.
- the concentration determination method of the present invention is a similar sequence information group in which the similar sequence information group of the comparison source and the similar sequence information group of the comparison destination are selected from different sequence groups,
- the target sequence information of the comparison source similar sequence information group and the target sequence information of the comparison target similar sequence information group may be the same sequence information.
- the use of the present invention is not particularly limited, but is preferably applied to, for example, determination of concentration in aptamer preparation. According to the present invention, as described above, for example, it is possible to compare the enrichment degree of different aptamer-like sequence information groups in the same library, or to compare the enrichment degree of the same aptamer-like sequence information group in different libraries. It is.
- Example 1 In this example, similar sequence groups were classified by a similar selection method of the present invention for a library targeting low molecular weight compounds.
- sequence group 85,800 nucleic acid sequence groups having a length of 40 bases were used.
- Table 7 shows the conditions of the virtual sequence group, the allowable number of mismatched bases, and the allowable conditions.
- a candidate sequence group for determining similarity is selected. For this reason, for example, unlike the conventional method of confirming the similarity between all the sequence information, the similarity determination can be performed easily and efficiently. For this reason, for example, it is possible to reduce labor, time, and cost for determination of aptamer concentration.
Landscapes
- Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Genetics & Genomics (AREA)
- Theoretical Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Wood Science & Technology (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Evolutionary Biology (AREA)
- Zoology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Databases & Information Systems (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- General Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Data Mining & Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015500317A JP6072890B2 (ja) | 2013-02-15 | 2014-02-14 | 類似判断の候補配列情報の選択装置、選択方法、およびそれらの用途 |
| EP14752140.5A EP2958038A1 (fr) | 2013-02-15 | 2014-02-14 | Dispositif de sélection d'informations de séquence candidate pour détermination de similarité, procédé de sélection, et utilisation d'un tel dispositif et d'un tel procédé |
| US14/768,030 US20150379197A1 (en) | 2013-02-15 | 2014-02-14 | Selection device for candidate sequence information for similarity determination, selection method, and use for such device and method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013027851 | 2013-02-15 | ||
| JP2013-027851 | 2013-02-15 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014126213A1 true WO2014126213A1 (fr) | 2014-08-21 |
Family
ID=51354211
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/053516 WO2014126213A1 (fr) | 2013-02-15 | 2014-02-14 | Dispositif de sélection d'informations de séquence candidate pour détermination de similarité, procédé de sélection, et utilisation d'un tel dispositif et d'un tel procédé |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20150379197A1 (fr) |
| EP (1) | EP2958038A1 (fr) |
| JP (1) | JP6072890B2 (fr) |
| WO (1) | WO2014126213A1 (fr) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8990234B1 (en) * | 2014-02-28 | 2015-03-24 | Lucas J. Myslinski | Efficient fact checking method and system |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2763958B2 (ja) | 1990-06-11 | 1998-06-11 | ネクスター ファーマスーティカルズ,インコーポレイテッド | 核酸リガンド |
| JP2005102695A (ja) * | 2003-09-12 | 2005-04-21 | National Institute Of Advanced Industrial & Technology | 物質特異的に結合するタンパク質及びその遺伝子の探索、解析方法 |
| JP2012146066A (ja) * | 2011-01-11 | 2012-08-02 | Nippon Software Management Kk | 核酸情報処理装置およびその処理方法 |
| JP2012146067A (ja) * | 2011-01-11 | 2012-08-02 | Nippon Software Management Kk | 核酸情報処理装置およびその処理方法 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6466685B1 (en) * | 1998-07-14 | 2002-10-15 | Kabushiki Kaisha Toshiba | Pattern recognition apparatus and method |
| US6867814B2 (en) * | 2000-04-18 | 2005-03-15 | Silicon Image, Inc. | Method, system and article of manufacture for identifying the source type and quality level of a video sequence |
| JP2002008189A (ja) * | 2000-06-22 | 2002-01-11 | Matsushita Electric Ind Co Ltd | 車両検出装置および車両検出方法 |
| US7707148B1 (en) * | 2003-10-07 | 2010-04-27 | Natural Selection, Inc. | Method and device for clustering categorical data and identifying anomalies, outliers, and exemplars |
| US8023577B2 (en) * | 2007-02-02 | 2011-09-20 | Texas Instruments Incorporated | Systems and methods for efficient channel classification |
| CA2697872A1 (fr) * | 2008-07-01 | 2010-01-07 | Panasonic Corporation | Procede pour evaluer un signal reproduit, dispositif d'evaluation de signal reproduit et dispositif de disque optique equipe de celui-ci |
| JP5445584B2 (ja) * | 2009-06-17 | 2014-03-19 | 富士通株式会社 | 生体認証装置、生体認証方法及び生体認証用コンピュータプログラム |
| WO2011148860A1 (fr) * | 2010-05-24 | 2011-12-01 | 日本電気株式会社 | Procédé de traitement de signaux, dispositif de traitement d'informations et programme de traitement de signaux |
| CN102592136B (zh) * | 2011-12-21 | 2013-10-16 | 东南大学 | 基于几何图像中中频信息的三维人脸识别方法 |
-
2014
- 2014-02-14 EP EP14752140.5A patent/EP2958038A1/fr not_active Withdrawn
- 2014-02-14 JP JP2015500317A patent/JP6072890B2/ja active Active
- 2014-02-14 US US14/768,030 patent/US20150379197A1/en not_active Abandoned
- 2014-02-14 WO PCT/JP2014/053516 patent/WO2014126213A1/fr active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2763958B2 (ja) | 1990-06-11 | 1998-06-11 | ネクスター ファーマスーティカルズ,インコーポレイテッド | 核酸リガンド |
| JP2005102695A (ja) * | 2003-09-12 | 2005-04-21 | National Institute Of Advanced Industrial & Technology | 物質特異的に結合するタンパク質及びその遺伝子の探索、解析方法 |
| JP2012146066A (ja) * | 2011-01-11 | 2012-08-02 | Nippon Software Management Kk | 核酸情報処理装置およびその処理方法 |
| JP2012146067A (ja) * | 2011-01-11 | 2012-08-02 | Nippon Software Management Kk | 核酸情報処理装置およびその処理方法 |
Non-Patent Citations (1)
| Title |
|---|
| SCIENCE, vol. 249, 1990, pages 505 - 510 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6072890B2 (ja) | 2017-02-01 |
| EP2958038A1 (fr) | 2015-12-23 |
| JPWO2014126213A1 (ja) | 2017-02-02 |
| US20150379197A1 (en) | 2015-12-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Zhou et al. | Evaluating fast maximum likelihood-based phylogenetic programs using empirical phylogenomic data sets | |
| Evans et al. | Protein complex prediction with AlphaFold-Multimer | |
| Sato et al. | IPknot: fast and accurate prediction of RNA secondary structures with pseudoknots using integer programming | |
| Reeder et al. | Consensus shapes: an alternative to the Sankoff algorithm for RNA consensus structure prediction | |
| Katoh et al. | Recent developments in the MAFFT multiple sequence alignment program | |
| Bao et al. | SEED: efficient clustering of next-generation sequences | |
| DK2511843T3 (en) | METHOD AND SYSTEM FOR DETERMINING VARIATIONS IN A SAMPLE POLYNUCLEOTIDE SEQUENCE IN TERMS OF A REFERENCE POLYNUCLEOTIDE SEQUENCE | |
| NL2011817C2 (en) | A method of generating a reference index data structure and method for finding a position of a data pattern in a reference data structure. | |
| Lai et al. | A de novo metagenomic assembly program for shotgun DNA reads | |
| Mattei et al. | A novel approach to represent and compare RNA secondary structures | |
| Liu et al. | Index suffix–prefix overlaps by (w, k)-minimizer to generate long contigs for reads compression | |
| Liu et al. | High-speed and high-ratio referential genome compression | |
| Patro et al. | Predicting protein interactions via parsimonious network history inference | |
| Chou et al. | Tailor: a computational framework for detecting non-templated tailing of small silencing RNAs | |
| Seetin et al. | TurboKnot: rapid prediction of conserved RNA secondary structures including pseudoknots | |
| Tambe et al. | Barcode identification for single cell genomics | |
| Ferdous et al. | Solving the minimum common string partition problem with the help of ants | |
| Storato et al. | K2mem: discovering discriminative k-mers from sequencing data for metagenomic reads classification | |
| JP6072890B2 (ja) | 類似判断の候補配列情報の選択装置、選択方法、およびそれらの用途 | |
| Huang et al. | Accurate classification of RNA structures using topological fingerprints | |
| Huang et al. | Fast and accurate search for non-coding RNA pseudoknot structures in genomes | |
| Chiu et al. | Pairwise RNA secondary structure alignment with conserved stem pattern | |
| KR101218795B1 (ko) | 그래프 분류를 위한 유사한 그래프 구조를 이용한 특징 선택 방법 및 장치 | |
| Zurkowski et al. | High-quality, customizable heuristics for RNA 3D structure alignment | |
| Sacomoto et al. | Navigating in a sea of repeats in rna-seq without drowning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14752140 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2015500317 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14768030 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REEP | Request for entry into the european phase |
Ref document number: 2014752140 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2014752140 Country of ref document: EP |