WO2014021318A1 - 音声分析合成のためのスペクトル包絡及び群遅延の推定システム及び音声信号の合成システム - Google Patents
音声分析合成のためのスペクトル包絡及び群遅延の推定システム及び音声信号の合成システム Download PDFInfo
- Publication number
- WO2014021318A1 WO2014021318A1 PCT/JP2013/070609 JP2013070609W WO2014021318A1 WO 2014021318 A1 WO2014021318 A1 WO 2014021318A1 JP 2013070609 W JP2013070609 W JP 2013070609W WO 2014021318 A1 WO2014021318 A1 WO 2014021318A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- group delay
- synthesis
- envelope
- spectrum
- speech
- Prior art date
Links
Images

































Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
- G10L21/007—Changing voice quality, e.g. pitch or formants characterised by the process used
- G10L21/013—Adapting to target pitch
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/15—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being formant information
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/18—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being spectral information of each sub-band
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/45—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of analysis window
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/022—Blocking, i.e. grouping of samples in time; Choice of analysis windows; Overlap factoring
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
- G10L2025/906—Pitch tracking
Definitions
- the present invention relates to a spectral envelope and group delay estimation system and method for speech analysis and synthesis, and a speech signal synthesis system and method.
- Non-Patent Document 1 is one of important signal processing in handling speech (singing voice and speech) and instrument sound. If an appropriate spectral envelope can be obtained from an audio signal (observation signal), a wide range of applications such as high-performance analysis, high-quality synthesis, and sound deformation can be considered. If the phase information (group delay) can be appropriately estimated in addition to the spectral envelope, the naturalness of the synthesized sound can be improved.
- Non-Patent Document 2 it is known that perceptual naturalness monotonously decreases in accordance with the magnitude of deviation when the initial phase deviates more than ⁇ / 8 from natural speech.
- Non-Patent Document 3 it is known that the minimum phase response is more natural than the zero phase response when the impulse response is obtained from the spectral envelope to form a unit waveform (waveform for one period) (non-phase response) Patent Document 3).
- Non-patent Document 4 there is a research (Non-patent Document 4) for performing phase control of unit waveforms for the purpose of improving naturalness.
- Non-Patent Documents 5 and 6 Phase vocoder
- an input signal is handled by being developed into a power spectrogram on a time-frequency plane.
- Non-Patent Documents 7 and 8 LPC analysis
- cepstrum cepstrum
- various extensions and combinations have been made
- Non-Patent Documents 9 to 13 since the envelope outline is determined by the analysis order of LPC or cepstrum, there is a possibility that the envelope cannot be expressed appropriately depending on the order.
- Pitch Synchronized Overlap-Add (PSOLA) (Non-Patent Documents 1 and 14) that extracts a time-domain waveform as a unit waveform based on a pitch mark and superimposes and adds it as a basic period has long been an analysis adapted to F0.
- PSOLA Pitch Synchronized Overlap-Add
- problems related to difficulty in applying pitch marks, changes in F0, and quality deterioration in unsteady portions there are problems related to difficulty in applying pitch marks, changes in F0, and quality deterioration in unsteady portions.
- Non-Patent Documents 15 and 16 in speech / music signals also involves F0 estimation in order to model the harmonic structure.
- STRAIGHT (Non-patent Document 27), which incorporates the concept of F0 adaptive analysis into a system based on source filter analysis (VOCODER), is used by research communities around the world due to its high quality of analysis and synthesis. STRAIGHT obtains a spectral envelope from which periodicity is removed from the input speech signal by processing such as smoothing adapted to F0, but has high temporal resolution in addition to high quality. Further, there are extensions to TANDEM-STRAIGHT (Non-Patent Document 28) that removes fluctuations in the time direction by the TANDEM window, spectral peak enhancement (Non-Patent Document 29), high-speed calculation method (Non-Patent Document 30), and the like.
- phase is not estimated explicitly and a non-periodic component (defined as “a component that cannot be described by a sum of harmonic components or a response driven by a periodic pulse train”) is Gaussian noise.
- the combination quality by the mixed excitation convoluted with, and the method of spreading the high-frequency phase (group delay) using random numbers, etc., are aimed at improving the naturalness of the synthesis quality.
- the criteria for phase manipulation are not clear.
- there is a method of extracting and using the excitation signal by deconvolution of the original speech signal and the impulse response waveform of the estimated envelope (Non-patent Document 31), but the phase is expressed efficiently. No, it is difficult to apply to interpolation and conversion operations.
- there is a research to analyze and synthesize by estimating and smoothing the group delay (Non-Patent Documents 32 and 33), but a pitch mark is necessary.
- Non-Patent Document 35 In addition to the above studies, there is also a study to model the spectral envelope by a mixed Gaussian distribution (GMM), a study to model the STRAIGHT spectrum (Non-Patent Document 34), and an estimation by simultaneous optimization of F0 and the envelope were formulated. There is research (Non-Patent Document 35).
- Non-patent documents 36 to 38 There is a study not only for a single sound but also for a vocal in a music acoustic signal (Non-Patent Document 39), and based on the assumption that the same phoneme has a similar vocal tract shape.
- an accurate phoneme label is required, and when there is a large variation due to a difference in context such as a singing voice, it may lead to excessive smoothing.
- Patent Document 1 Japanese Patent Laid-Open No. 10-97287 (Patent Document 1) includes a step of convolving a phase adjustment component with a random number and a band limiting function on the frequency axis to obtain a band limited random number, a band limited random number, Multiplying the target value of the delay time variation to obtain the group delay characteristic, integrating the group delay characteristic by frequency, obtaining the phase characteristic, and multiplying the phase characteristic by the imaginary unit, An invention obtained by obtaining a phase adjustment component by using an exponent of an exponential function is disclosed.
- McAulay, R. and T.Quatieri Speech Analysis / Synthesis Based on A Sinusoidal Representation, IEEE Trans. ASSP, Vol. 34, No. 4, pp. 744-755 (1986).
- Serra, X. and Smith, J . Spectral Modeling Synthesis: A Sound Analysis / Synthesis Based on A Deterministic Plus Stochastic Decomposition, Computer Music Journal, Vol. 14, No. 4, pp. 12-24 (1990).
- Hideki Sakano, Riku Jinbayashi, Satoshi Nakamura, Kiyohiro Shikano, Hideki Kawahara Efficient representation method of short-time phase using time domain smoothing group delay, IEICE Transactions, Vol. J84-D-II, No . 4, pp. 621-628 (2001).
- Hideki Sakano, Riku Jinbayashi, Satoshi Nakamura, Kiyohiro Shikano, Hideki Kawahara Voice quality control method using phase control by time-domain smoothing group delay, IEICE Transactions, Vol. J83-D-II, No. 11 , Pp. 2276-2282 (2000).
- pitch mark time information indicating the driving point (and analysis time) of the waveform when performing analysis in synchronization with the fundamental frequency for estimation of the spectral envelope and group delay.
- Excitation time of glottal sound source or time with large amplitude in the basic period is used]
- presumed incidental information such as phoneme information (phoneme label)
- An object of the present invention is to analyze and synthesize speech (sing voice and speech) with high accuracy and time resolution by estimating its spectral envelope and group delay from speech signals for high performance analysis and high quality synthesis. It is an object to provide a system and method for estimating the spectral envelope and group delay.
- Another object of the present invention is to provide an audio signal synthesizing system and method having higher synthesizing performance than before.
- Still another object of the present invention is to provide a computer-readable recording medium in which a spectrum envelope and group delay estimation program for speech analysis and synthesis and a speech signal synthesis program are recorded.
- a spectral envelope and group delay estimation system for speech analysis and synthesis includes a fundamental frequency estimation unit, an amplitude spectrum acquisition unit, a group delay extraction unit, and a spectral envelope integration implemented using at least one processor. And a group delay integration unit.
- the fundamental frequency estimation unit estimates the fundamental frequency F0 at all times or all sampling points from the audio signal.
- the amplitude spectrum acquisition unit divides the acoustic signal into a plurality of frames around each time or each sampling point using a window whose window width is changed according to the fundamental frequency F0 at all times or all sampling points.
- An amplitude spectrum in each of a plurality of frames is acquired by performing DFT (Discrete Fourier Transform) analysis on the audio signal in the frame.
- DFT Discrete Fourier Transform
- the group delay extraction unit performs a group delay extraction algorithm with DFT (Discrete Fourier Transform) analysis on audio signals in a plurality of frames, and extracts a group delay as a frequency derivative of a phase in each of the plurality of frames.
- the spectrum envelope integration unit obtains a composite spectrum by superposing a plurality of amplitude spectra corresponding to a plurality of frames included in a predetermined period determined based on the basic period of the basic frequency F0 at a predetermined time interval, The polymerization spectrum is averaged to sequentially obtain a spectrum envelope for speech synthesis.
- DFT Discrete Fourier Transform
- the group delay integration unit selects a group delay corresponding to the maximum envelope for each frequency component of the spectrum envelope from a plurality of group delays at a predetermined time interval, and integrates the selected group delays for speech synthesis.
- the group delay is obtained sequentially.
- a spectrum envelope for speech synthesis is sequentially obtained from a superposition spectrum obtained from an amplitude spectrum obtained for each of a plurality of frames, and a maximum envelope for each frequency component of the spectrum envelope is obtained from a plurality of group delays.
- a group delay is selected, and a plurality of selected group delays are integrated to sequentially obtain a group delay for speech synthesis.
- the spectral envelope estimation performance for speech synthesis obtained in this way is high, and the estimated group delay for speech synthesis can be estimated with more detail than in the prior art.
- the fundamental frequency estimation unit determines the voiced and unvoiced intervals in conjunction with the estimation of the fundamental frequency F0, and interpolates the fundamental frequency F0 in the unvoiced interval with the value in the voiced interval or assigns a predetermined value to the unvoiced interval. . In this way, the spectral envelope and group delay can be estimated in the same framework as in the voiced section even in the unvoiced section.
- a method for obtaining a spectrum envelope for speech synthesis by averaging the polymerization spectrum is arbitrary.
- the spectral envelope for speech synthesis can be obtained as the average of the maximum envelope and the minimum envelope of the superposition spectrum.
- the spectral envelope for speech synthesis may be obtained by averaging the intermediate values of the maximum envelope and the minimum envelope of the superposition spectrum.
- the minimum envelope for obtaining the average it is preferable to use a modified minimum envelope obtained by modifying the maximum envelope so as to fill the valley of the minimum envelope.
- a modified minimum envelope obtained by modifying the maximum envelope so as to fill the valley of the minimum envelope.
- the spectrum envelope integration unit preferably obtains a spectrum envelope for speech synthesis by replacing the spectrum envelope value of the band below the frequency bin corresponding to F0 with the spectrum envelope value of the frequency bin corresponding to F0. .
- the replaced spectrum envelope may be filtered by a two-dimensional low-pass filter.
- noise can be removed from the replaced spectral envelope, so that the synthesized speech can have a more natural listening impression.
- the group delay integration unit stores the group delay in the frame corresponding to the maximum envelope for each frequency component of the superposition spectrum for each frequency, corrects the deviation of the stored group delay analysis time, and normalizes the stored group delay.
- the normalized group delay is preferably configured as a group delay for speech synthesis. This is because the group delay has a spread (interval) in the time axis direction according to the fundamental period corresponding to the fundamental frequency F0. In this way, by normalizing the group delay in the time axis direction, the influence of the fundamental frequency F0 can be removed, and a group delay that can be deformed according to F0 at the time of resynthesis can be obtained.
- a group delay for speech synthesis is obtained by replacing the group delay value in the band below the frequency bin corresponding to F0 with the group delay value of the frequency bin corresponding to F0. preferable. This is based on the fact that the group delay in the band below the frequency bin corresponding to F0 is unstable. Therefore, in this way, it is possible to stabilize the group delay in the band equal to or lower than the frequency bin corresponding to F0, and to make the synthesized voice listening more natural.
- the group delay integration unit it is preferable to use a smoothed group delay as a group delay for speech synthesis. This is because it is convenient for the analysis and synthesis system to have a continuously changing value.
- the replaced group delay is converted by a sin function and a cos function to remove discontinuities caused by the fundamental period.
- a group delay for speech synthesis is obtained by performing filtering using a two-dimensional low-pass filter and then returning the sin function and the cos function to the original state using a tan ⁇ 1 function.
- the conversion of the group delay into a sin function and a cos function is for the convenience of filter processing in a two-dimensional low-pass filter.
- the audio signal synthesis system of the present invention includes a reading unit, a conversion unit, a unit waveform generation unit, and a synthesis unit realized by at least one processor.
- the reading unit stores the spectrum envelope and the group delay for speech analysis and synthesis estimated by the spectral envelope and group delay estimation system for speech analysis and synthesis according to the present invention and stored for each predetermined time interval.
- a spectral envelope and group delay for synthesis are read out from the group delay data file with a fundamental period for synthesis consisting of the reciprocal of the fundamental frequency for synthesis.
- the conversion unit converts the read group delay into a phase spectrum.
- the unit waveform generation unit generates a unit waveform from the read spectrum envelope and phase spectrum.
- the synthesizing unit outputs a synthesized audio signal by superimposing and adding the generated unit waveforms at a basic period for synthesis. According to the synthesis system of the present invention, the group delay can be entirely reproduced and synthesized, and the synthesis quality can be naturally obtained.
- a discontinuous state suppressing unit that suppresses occurrence of a discontinuous state in the time direction in the low band delay of the read group delay may be further provided.
- the discontinuous state suppression unit When the discontinuous state suppression unit is provided, the synthesis quality becomes more natural.
- the discontinuous state suppressing unit is preferably configured to smooth the group delay in the low frequency region after adding the optimum offset to the group delay for each voiced interval and normalizing again. By smoothing in this way, instability in the low frequency region of group delay can be eliminated.
- the group delay of the read frame is converted by the sin function and the cos function, and then the sin function and the cos function are returned to the original state by the tan ⁇ 1 function after being filtered by the two-dimensional low-pass filter.
- a group delay for speech synthesis is preferable. In this way, filtering can be performed by the two-dimensional low-pass filter, and smoothing can be easily performed.
- a correction unit that performs correction by multiplying the group delay by a basic period for synthesis as a coefficient before conversion by the conversion unit or after the discontinuous state suppression unit.
- the group delay having a spread (interval) in the time axis direction according to the fundamental period corresponding to the fundamental frequency F0 can be normalized in the time axis direction, and a more accurate phase spectrum can be obtained.
- the synthesis unit is preferably configured to convert the analysis window into a synthesis window, and to superimpose and add a corrected unit waveform obtained by multiplying the synthesis window by the unit waveform at a basic period.
- a corrected unit waveform corrected by the synthesis window as described above, a more natural synthesized voice can be heard.
- the spectral envelope and group delay estimation method of the present invention includes a fundamental frequency estimation step, an amplitude spectrum acquisition step, a group delay extraction step, a spectral envelope integration step, and a group delay integration step, which are executed using at least one processor. And execute.
- the fundamental frequency estimation step the fundamental frequency F0 is estimated from the audio signal at all times or all sampling points.
- the amplitude spectrum acquisition step divides the audio signal into a plurality of frames around each time or each sampling point using a window whose window width is changed according to the fundamental frequency F0 at all times or all sampling points. An amplitude spectrum in each of a plurality of frames is acquired by performing DFT analysis on the audio signal in the frame.
- a group delay extraction algorithm with DFT analysis is performed on audio signals in a plurality of frames to extract a group delay as a phase frequency derivative in each of the plurality of frames.
- the spectrum envelope integration step obtains a composite spectrum by superposing a plurality of amplitude spectra corresponding to a plurality of frames included in a predetermined period determined based on the basic period of the basic frequency F0 at a predetermined time interval, The polymerization spectrum is averaged to sequentially obtain a spectrum envelope for speech synthesis.
- the group delay integration step selects a group delay corresponding to the maximum envelope for each frequency component of the spectrum envelope from a plurality of group delays at a predetermined time interval, and integrates the selected group delays for speech synthesis. The group delay is obtained sequentially.
- the program for estimating the spectral envelope and group delay for speech analysis and synthesis configured to enable the computer to execute the above method is recorded on a non-transitory computer-readable recording medium.
- the reading step, the conversion step, the unit waveform generation step, and the synthesis step are executed using at least one processor.
- the reading step from the spectral envelope and group delay data file created by storing the spectral envelope and group delay for speech analysis and synthesis estimated by the spectral envelope and group delay estimation method of the present invention for each predetermined time interval, A spectral envelope and group delay for synthesis are read out with a fundamental period for synthesis composed of the reciprocal of the fundamental frequency for synthesis.
- the conversion step converts the read group delay into a phase spectrum.
- the unit waveform generation step generates a unit waveform from the read spectrum envelope and phase spectrum.
- the synthesizing step outputs a synthesized audio signal by superimposing and adding the plurality of generated unit waveforms at a basic period for synthesis.
- the voice signal synthesis program configured to enable the computer to execute the voice signal synthesis method is recorded on a computer-readable recording medium.
- FIG. 1 It is a block diagram which shows the basic composition of an example of embodiment of the spectrum envelope and the group delay estimation system for speech analysis synthesis of this invention, and a speech synthesis system.
- A is a waveform of a singing voice signal
- B is a spectrum envelope thereof
- C is a diagram showing a relationship between (normalized) group delays.
- It is a flowchart which shows the basic algorithm of the computer program used when implementing this Embodiment using a computer. It is a figure used in order to explain the estimation process of the spectrum envelope for speech synthesis. It is a figure used in order to demonstrate the estimation process of the group delay for speech synthesis.
- or (C) is a figure used in order to demonstrate the spectrum envelope estimated as the average of the maximum envelope and the minimum envelope. It is a figure which shows the locus
- (A) shows a maximum envelope
- (B) is a diagram showing a group delay corresponding to the maximum envelope.
- (A) is a singing voice waveform
- (B) is a diagram showing a group delay corresponding to the F0 adaptive spectrum and the maximum envelope. It is a flowchart which shows an example of the algorithm of the program used when calculating
- FIG. 1 is a block diagram showing a basic configuration of an example of an embodiment of a spectrum envelope and group delay estimation system and a speech synthesis system for speech analysis and synthesis according to the present invention.
- the spectrum envelope and group delay estimation system 1 of the present embodiment includes a fundamental frequency estimation unit 3, an amplitude spectrum acquisition unit 5, and a group delay extraction unit that are realized by installing a program in a computer having at least one processor. 7, a spectrum envelope integration unit 9, a group delay integration unit 11, and a memory 13.
- the speech signal synthesis system 2 includes a reading unit 15, a conversion unit 17, a unit waveform generation unit 19, a synthesis unit 21, which are realized by installing a speech signal synthesis program in a computer having at least one processor.
- the discontinuous state suppressing unit 23 and the correcting unit 25 are included.
- the spectrum envelope and group delay estimation system 1 is shown in FIG. 2 (C) and a spectrum envelope for synthesis as shown in FIG. 2 (B) from a speech signal (singing voice waveform) as shown in FIG. 2 (A).
- a group delay for synthesis as such phase information is estimated.
- the horizontal axis is time and the vertical axis is frequency
- the magnitude of the spectrum envelope and the relative magnitude of the group delay at a frequency at a certain time are colors and grays. Displayed due to differences in scale.
- FIG. 3 is a flowchart showing a basic algorithm of a computer program used when the present embodiment is implemented using a computer.
- FIG. 4 is a diagram used for explaining a spectral envelope estimation process for speech synthesis.
- FIG. 5 is a diagram used for explaining a group delay estimation step for speech synthesis.
- FIG. 6 shows a plurality of frames of waveforms, a spectrum corresponding to the short-time Fourier transform (STFT), and a group delay.
- STFT short-time Fourier transform
- FIG. 6 since each spectrum has a valley and the valley is filled in another frame, there is a possibility that a steady spectrum envelope can be obtained by integrating these valleys.
- the peak of the group delay which means that it is far from the analysis time
- the valley of the spectrum are associated, it may not be possible to obtain a smooth envelope only by using a single window. I understand.
- the audio signal is divided into a plurality of frames around each time or each sampling point using a window whose window width is changed according to the fundamental frequency F0 at all times or all sampling points.
- the spectrum envelope for speech synthesis to be estimated is considered to be between the maximum envelope and the minimum envelope of the superposition spectrum described later, and first, the maximum value (maximum envelope) and the minimum value (minimum envelope). Calculate However, in the maximum / minimum operation, a smooth envelope cannot be obtained in the time direction, and a step-like trajectory corresponding to the fundamental frequency F0 is drawn. Finally, the spectral envelope for speech synthesis is obtained as the average of the maximum envelope and the minimum envelope. At the same time, the maximum to minimum range is stored as the spectrum envelope existence range (FIG. 7). Further, as the group delay to be estimated, a value corresponding to the maximum envelope is used in order to express the most resonant time.
- the fundamental frequency estimation unit 3 is configured to generate an audio signal (acoustics and singing voices that do not include large noise and speech voices). Signal) (step ST1 in FIG. 3), the pitch (fundamental frequency F0) is estimated from the audio signal at all times or at all sampling points. In the present embodiment, this estimation is performed in units of time of 1/444100 seconds. Simultaneously with the estimation, the voiced section and the unvoiced section are determined (step ST2 in FIG. 3).
- a voiced threshold is set, and a voiced section and a voiceless section are determined with a section having a pitch higher than the threshold as a voiced section.
- an appropriate pitch value is given or linear interpolation is performed so as to connect adjacent voiced sections so that the fundamental frequency does not become discontinuous.
- a method as described in [Non-Patent Document 27] or the like can be used to estimate the pitch.
- the estimation accuracy of the fundamental frequency F0 is preferably as high as possible.
- the amplitude spectrum acquisition unit 5 performs the F0 adaptive analysis shown in step ST3 in FIG. 3 and acquires the F0 adaptive spectrum (amplitude spectrum) in step ST4 in FIG.
- the amplitude spectrum acquisition unit 5 divides the audio signal into a plurality of frames around each time or each sampling point using a window whose window width is changed according to the fundamental frequency F0 at all times or all sampling points.
- windowing is performed using a Gaussian window ⁇ ( ⁇ ) represented by the following formula (1) in which the window width is changed according to the fundamental frequency F0.
- Frames X1 to Xn are generated by dividing the waveform of the audio signal for each time unit.
- ⁇ (t) is a standard deviation determined by the fundamental frequency F 0 (t) at the analysis time t
- the Gaussian window is normalized by the RMS value with N as the FFT length.
- This window length is also used in PSOLA analysis and the like, and is known to be an appropriate length for approximating a local spectral envelope (Non-Patent Document 1).
- the amplitude spectrum acquisition unit 5 performs DFT (Discrete Fourier Transform) including FFT (Fast Fourier Transform) analysis on the divided audio signals in the plurality of frames X1 to Xn, so that the amplitude spectrum Y1 in each of the plurality of frames. Get Yn.
- FIG. 8 shows an example of the result of F0 adaptive analysis.
- the amplitude spectrum thus obtained includes fluctuations in the time direction due to F0, and peaks appear with a slight shift in the time direction depending on the frequency band. In the present specification, this is called F0 adaptive spectrum. 8 is the singing voice waveform, the second figure is the F0 adaptive spectrum, the third to fifth figures are enlarged views of a part of the upper figure, and the frequency 645. It is a trajectory in the time direction at 9961 Hz.
- the fundamental frequency estimation unit 3 performs the F0 adaptive analysis shown in step ST3 in FIG. 3 and acquires the F0 adaptive spectrum (amplitude spectrum) in step ST4 in FIG.
- the amplitude spectrum acquisition unit 5 divides the audio signal into a plurality of frames around each time or each sampling point using a window whose window width is changed according to the fundamental frequency F0 at all times or all sampling points.
- a frame X1 is obtained by performing windowing using a Gaussian window whose window width is changed according to the fundamental frequency F0 and dividing the waveform of the audio signal for each time unit. Create Xn.
- the F0 adaptive analysis in the amplitude spectrum acquisition unit 5 and the group delay extraction unit 7 may be performed in common.
- the group delay extraction unit 7 performs a group delay extraction algorithm with DFT (Discrete Fourier Transform) analysis on the audio signals in the plurality of frames X1 to Xn to obtain the frequency differential of the phase in each of the plurality of frames X1 to Xn.
- Group delays Z1 to Zn are extracted.
- An example of the group delay extraction algorithm is described in detail in Non-Patent Documents 32 and 33.
- the spectrum envelope integration unit 9 has a predetermined time interval, that is, a discrete time of the spectrum envelope (1 ms interval in this embodiment), and within a predetermined period determined based on the basic period (1 / F0) of the fundamental frequency F0. A plurality of amplitude spectra corresponding to a plurality of contained frames are superposed to obtain a superposition spectrum. Then, the polymerization spectrum is averaged to sequentially obtain the spectrum envelope SE for speech synthesis.
- FIG. 9 shows steps ST50 to ST57 for obtaining the spectrum envelope SE in the multiple frame integration analysis step ST5 of FIG. Steps ST51 to ST56 included in step ST50 are performed every 1 ms. Note that step ST52 is a step performed to obtain a group delay GD for speech synthesis described later.
- the maximum envelope is obtained from a superposed spectrum obtained by superposing amplitude spectra (F0 adaptive spectrum) for a plurality of frames in the range of ⁇ 1 / (2 ⁇ F0) to 1 / (2 ⁇ F0) before and after the analysis time t. Is selected.
- FIG. 10 shows an analysis time around t in order to obtain a maximum envelope from a superposition spectrum obtained by superposing amplitude spectra for a plurality of frames in the range of ⁇ 1 / (2 ⁇ F0) to 1 / (2 ⁇ F0).
- the maximum amplitude portion is indicated by a dark color.
- the maximum envelope is obtained by connecting the maximum amplitude parts for each frequency.
- the group delay corresponding to the frame from which the amplitude spectrum selected as the maximum envelope acquired in step ST52 is obtained is stored for each frequency. That is, as shown in FIG. 10, the group delay value (time) corresponding to the frequency at which the maximum amplitude value was obtained from the group delay corresponding to the amplitude spectrum from which the maximum amplitude value was acquired corresponds to that frequency. Save as group delay.
- step ST53 from the superposition spectrum obtained by superposing the amplitude spectra (F0 adaptive spectrum) for a plurality of frames in the range of ⁇ 1 / (2 ⁇ F0) to 1 / (2 ⁇ F0) before and after the analysis time t. Select the minimum envelope.
- a composite spectrum obtained by superposing the amplitude spectra for a plurality of frames in the range of ⁇ 1 / (2 ⁇ F0) to 1 / (2 ⁇ F0) to obtain a minimum envelope means that around the analysis time t is ⁇
- the minimum envelope of the superposition spectrum is obtained by connecting the minimum amplitude portions.
- the method of averaging the polymerization spectra to obtain “spectrum envelope for speech synthesis” is arbitrary.
- a spectrum envelope for speech synthesis is obtained as an average of the maximum envelope and the minimum envelope of the superposition spectrum (step ST55).
- a spectrum envelope for speech synthesis may be obtained by averaging the intermediate values of the maximum envelope and the minimum envelope of the polymerization spectrum.
- a modified minimum envelope obtained by deforming the maximum envelope so as to fill the valley of the minimum envelope is used as the minimum envelope for obtaining the average in step ST54.
- the synthesized speech has a more natural listening impression.
- the spectrum envelope integration unit 9 replaces the spectrum envelope value of the band below the frequency bin corresponding to the fundamental frequency F0 with the spectrum envelope value of the frequency bin corresponding to the fundamental frequency F0.
- a spectrum envelope for. This is because the spectral envelope in the band below the frequency bin corresponding to the fundamental frequency F0 is unstable. Therefore, in this way, it is possible to make the synthesized speech more natural listening impression by stabilizing the spectral envelope in the band below the frequency bin corresponding to the fundamental frequency F0.
- step ST50 (steps ST51 to ST56) is performed for each predetermined time unit (1 ms), and the spectrum envelope for each time unit (1 ms) is estimated.
- step ST57 the replaced spectrum envelope is filtered by the two-dimensional low-pass filter. When filtering is performed, noise can be removed from the replaced spectral envelope, so that the synthesized speech can have a more natural listening impression.
- the spectrum envelope is defined as the average of the maximum value (maximum envelope) and the minimum value (minimum envelope) in the spectrum of the integrated range (step ST55).
- the reason why the maximum envelope is not simply used as the spectrum envelope is to consider the possibility of including the influence of side lobes of the analysis window.
- many valleys resulting from F0 remain in the minimum envelope, and it is difficult to treat as a spectrum envelope. Therefore, in the present embodiment, the valley is removed while maintaining the envelope outline by changing the maximum envelope over the minimum envelope (step ST54).
- FIG. 11 shows these examples and the flow of calculation. Specifically, in order to implement step ST54, as shown in FIG.
- the peak of the minimum envelope (marked by ⁇ ) is calculated, and the ratio of the amplitude of the minimum envelope and the maximum envelope at that frequency is calculated. ( ⁇ mark).
- the conversion ratio of the entire band is obtained by linearly interpolating the conversion ratio on the frequency axis ( ⁇ mark).
- the new minimum envelope is obtained by multiplying the maximum envelope by this conversion ratio and then deforming it so as to be equal to or greater than the old minimum envelope.
- FIG. 11C since components below the fundamental frequency F0 cannot be stably estimated in many cases, an envelope below the fundamental frequency F0 is used as a process equivalent to smoothing by a window having the fundamental frequency F0 width. Replace with the amplitude value at F0 (step ST56).
- the envelope obtained by the maximum / minimum operation has a stepwise discontinuity in the time direction, it is removed by a two-dimensional low-pass filter on the time-frequency axis (step ST57), and the envelope is obtained in the time direction.
- a smooth spectral envelope is obtained (FIG. 12).
- the group delay integration unit 11 illustrated in FIG. 1 selects a group delay corresponding to the maximum envelope for each frequency component of the spectrum envelope SE from a plurality of group delays at a predetermined time interval, and integrates the selected plurality of group delays. Then, the group delay GD for speech synthesis is obtained sequentially. That is, the spectrum envelope for speech synthesis is sequentially obtained from the overlap spectrum obtained from the amplitude spectrum obtained for each of a plurality of frames, and the group delay corresponding to the maximum envelope for each frequency component of the spectrum envelope is selected from the plurality of group delays. Then, the group delays for speech synthesis are sequentially obtained by integrating the selected group delays.
- the group delay for speech synthesis is defined as a group delay value corresponding to the maximum envelope [FIG.
- FIG. 9B is a diagram in which the group delay GD thus obtained is drawn on the F0 adaptive spectrum (amplitude spectrum) in association with the estimated time for the singing voice waveform shown in FIG. 9A. Show. As can be seen from FIG. 9B, the group delay corresponding to the maximum envelope substantially corresponds to the peak time of the F0 adaptive spectrum.
- the group delay obtained in this way has a spread (interval) in the time axis direction corresponding to the fundamental period corresponding to the fundamental frequency F0, it is normalized and handled in the time axis direction.
- the group delay corresponding to the maximum envelope at time t and frequency f is
- mod (x, y) means a remainder obtained by dividing x by y.
- Problem 2 is a problem similar to the estimation of the spectral envelope, and is caused by the fact that the waveform is driven every basic period.
- g x (f, t) and g y (f, t) are respectively smoothed. Keep it.
- FIG. 15 is a flowchart showing an example of an algorithm of a program used when a group delay GD for speech synthesis is obtained using a computer from a plurality of fundamental frequency adaptive group delays (group delays indicated by Z1 to Zn in FIG. 6). It is.
- step ST52 of FIG. 9 is included in step ST150 performed every 1 ms. That is, in step ST52, the group delay corresponding to the superposition spectrum selected as the maximum envelope is stored for each frequency.
- step ST521 the deviation in analysis time is corrected (see FIG. 5).
- the group delay integration unit 11 stores the group delay in the frame corresponding to the maximum envelope for each frequency component of the superposition spectrum for each frequency, and corrects the difference in the analysis time of the stored group delay. This is because the group delay has a spread (interval) in the time axis direction according to the fundamental period corresponding to the fundamental frequency F0.
- the group delay in which the deviation in analysis time is corrected is normalized to a range of 0 to 1. This normalization is performed in the steps shown in detail in FIG. FIG. 17 shows the group delay state in the normalization processing step. First, the value of the group delay of the frequency bin corresponding to n ⁇ F0 is stored [step ST522A and FIG. 17 (A)].
- step ST522B and FIG. 17 (B) the stored value is subtracted from the group delay [step ST522B and FIG. 17 (B)]. Then, a remainder in the basic period of the group delay is calculated from a value obtained by subtracting the stored value from the group delay [step ST522C and FIG. 17C].
- the above-described value (remainder calculation result) is normalized (divided) by the basic period to obtain a normalized group delay [step ST522D and FIG. 17 (D)]. In this way, by normalizing the group delay in the time axis direction, the influence of the fundamental frequency F0 can be removed, and a group delay that can be deformed according to F0 at the time of resynthesis can be obtained.
- the value obtained by replacing the group delay value in the band equal to or lower than the frequency bin corresponding to F0 with the group delay value of the frequency bin corresponding to F0 is used for speech synthesis.
- group delay As the basis of group delay. This is based on the fact that the group delay in the band below the frequency bin corresponding to F0 is unstable. Therefore, in this way, it is possible to stabilize the group delay in the band equal to or lower than the frequency bin corresponding to F0, and to make the synthesized voice listening more natural.
- the replaced group delay may be used as it is as the group delay for speech synthesis. However, in this embodiment, the replaced group delay obtained every 1 ms is smoothed in step ST524. This is because it is convenient for the group delay to be a continuously changing value in order to handle it as an analysis / synthesis system.
- step ST524A the group delay replaced for each frame is converted by the sin function and the cos function to remove discontinuities caused by the fundamental period.
- step ST524B the total frame, after filtering by the two-dimensional low-pass filter, those returning to the original state by tan -1 function sin function and cos function of the group delay at step ST524C speech synthesis For the group delay.
- the conversion of the group delay into a sin function and a cos function is for the convenience of filter processing in a two-dimensional low-pass filter.
- the formula used for this calculation is the same as the formula used in the synthesis described later.
- the spectrum envelope and group delay for speech synthesis estimated as described above are stored in the memory 13 of FIG.
- the speech signal synthesis system 2 shown in FIG. 1 includes a readout unit 15, a conversion unit 17, a unit waveform generation unit 19, and a synthesis unit 21 as basic components, and a discontinuous state suppression unit 23 and a correction unit 25.
- FIG. 19 is a flowchart illustrating an example of an algorithm of a program used when the synthesis system is realized using a computer.
- 20 and 21 are waveform diagrams used to explain the process of synthesizing the audio signal.
- the reading unit 15 stores the spectrum envelope and group delay for speech synthesis estimated by the spectrum envelope and group delay estimation system 1 for speech analysis and synthesis at predetermined time intervals. From the created spectrum envelope and group delay data file, the spectrum envelope and group delay for synthesis are read out from the memory 13 at the fundamental period 1 / F0 for synthesis composed of the reciprocal of the fundamental frequency F0 for synthesis. Then, the conversion unit 17 converts the read group delay into a phase spectrum as shown in FIG. The unit waveform generator 19 generates a unit waveform from the read spectrum envelope and phase spectrum as shown in FIG. Then, the synthesizer 21 superimposes and adds a plurality of unit waveforms generated as shown in FIG. 21 at the basic period for synthesis, and outputs a synthesized audio signal. According to this synthesizing system, it is possible to synthesize a group delay as a whole and to obtain a natural synthesis quality.
- amendment part 25 which suppress generation
- the discontinuous state suppressing unit 23 is realized by step ST102 of FIG.
- step 102 as shown in FIG. 22, the optimum offset is searched for each voiced section in step ST102A to update the group delay, and then the low-frequency group delay is smoothed in step ST102B.
- the group delay update in step ST102A is executed by the steps shown in FIG. 24 and 25 are diagrams used for explaining the update of the group delay.
- the discontinuous state suppressing unit 23 performs an update by adding an optimum offset to the group delay for each voiced section and normalizing again (step ST102A in FIG. 23), and then smoothes the group delay in the low frequency region. (Step ST102B in FIG. 23).
- the value of the frequency bin corresponding to the fundamental frequency F0 for synthesis is extracted [step ST102a and FIG. 23].
- the average of the central Gaussian function is changed from 0 to 1, and the fitting with each is calculated (step ST102b and FIG. 23).
- the Gaussian function is a Gaussian function having an average of 0.9 and a standard deviation of 0.1 / 3, and the fitting result is a distribution that takes into account the group delay of the frequency bin corresponding to the fundamental frequency F0 as shown in FIG.
- the offset of the group delay is determined so that the center (final value) of this distribution is 0.5 (step ST102c in Fig. 23), and the remainder is added by 1 by adding the offset to the group delay.
- Fig. 25 shows an example of the group delay when the offset is added to the group delay and the remainder is taken as 1.
- the group delay of the frequency bin corresponding to the fundamental frequency F0 reflecting the offset is as shown in FIG.
- step ST102B the group delay in the low frequency region is smoothed.
- FIG. 26 shows a flowchart of an example of an algorithm for smoothing in the low frequency region.
- FIGS. 27A to 27C and FIGS. 28D to 28F sequentially show an example of the state of smoothing in step ST102B.
- step ST102e of FIG. 26 the group delay of the frame in which the discontinuous state is suppressed after reading is converted by the sin function and the cos function [FIGS. 27B and 27C]. Thereafter, in step ST102f of FIG.
- filter processing is performed with a two-dimensional low-pass filter on the frequency band of 1 to 4300 Hz or less of all frames.
- a two-dimensional low-pass filter for example, a two-dimensional triangular window filter having a time direction of 0.6 ms and a frequency direction of 48.4497 Hz can be used.
- the sin function and the cos function are returned to the original state by the tan ⁇ 1 function in step ST102g [see FIGS. 28D to 28F and equation (9)].
- the smoothing is performed by the discontinuous state suppressing unit 23 as in the present embodiment, instability in the low frequency region of the group delay can be eliminated.
- the correction unit 25 that performs correction by multiplying the group delay by the basic period for synthesis as a coefficient before conversion by the conversion unit 17 shown in FIG. 1 or after the discontinuous state suppression unit 23 is further provided. I have.
- the group delay having a spread (interval) in the time axis direction corresponding to the fundamental period corresponding to the fundamental frequency F0 can be normalized in the time axis direction. A high phase spectrum can be obtained.
- the unit waveform generation unit 19 converts the analysis window into a synthesis window and generates a corrected unit waveform by multiplying the synthesis window by the unit waveform. Then, the synthesis unit 21 superimposes and adds the correction unit waveform at the basic period.
- FIG. 29 is a flowchart showing a detailed algorithm of step ST104 of FIG. First, in step 104A, the group delay and spectrum envelope subjected to the above smoothing are extracted at a fundamental period (fundamental frequency F0 for synthesis). Next, in step 104B, the group delay is multiplied by the fundamental period as a coefficient. The correction unit 25 is realized by this step 104B. Next, in step ST104C, the group delay is converted into a phase spectrum.
- the conversion unit 17 is configured by this step ST104C.
- step ST104D a unit waveform (impulse response) is generated from the spectrum envelope (amplitude spectrum) and the phase spectrum.
- step 104E a “window” for converting to a Hanning window (composite window), which is a window with an amplitude of 1 by adding a Gaussian window (analysis window), is applied to the unit waveform, and the composite window is applied to the unit waveform.
- a correction unit waveform is generated. Specifically, a gauss window (analysis window) used for analysis is divided from a Hanning window (synthesis window) having a basic period length to generate a “window” for conversion.
- step 104F a plurality of correction unit waveforms are superimposed and added at a basic period (reciprocal of the basic frequency F0) to create a synthesized audio signal.
- step ST104F in the case of an unvoiced sound, it is preferable to perform superposition after convolving Gaussian noise.
- a Hanning window is used as the analysis window, the original sound is not deformed due to the effect of windowing, but the improvement of time and frequency resolution and the influence of side lobes (the Hanning window has a lower side lobe attenuation).
- a Gaussian window is used for analysis.
- step ST102B By using the corrected unit waveform corrected by the synthesis window as described above, a more natural synthesized voice can be heard.
- the calculation in step ST102B described above will be described in detail.
- the group delays g x (f, t) and g y (f, t) developed by sin and cos are finally returned to the group delay g (f, t) by the following calculation.
- the shape of the estimated group delay changes suddenly at places where the formant frequency fluctuates, and the synthesis quality may be greatly affected especially when the power is high in the low frequency range. This is considered due to the fact that the fluctuation caused by F0 described above (FIG. 8) fluctuates at a speed higher than F0 in a certain frequency band. For example, in FIG. 14 (B), the fluctuation in the vicinity of 500 Hz is faster than the vicinity of 1500 Hz. As a result, the shape of the group delay changes before and after the center of FIG. 14B, and the shape of the unit waveform also changes.
- a new common offset is added so that discontinuity in the time direction does not occur as much as possible in the low range of the group delay g (f, t) in the same voiced interval. I took the remainder (because it was normalized) at 1. Then, a two-dimensional low-pass filter with a long time constant was applied to the low region of the group delay to eliminate such instantaneous fluctuations.
- the frequency bin number is 2049 bins (FFT length is 4096), which is a value often used in STRAIGHT, and the analysis time unit is 1 ms. In the above embodiment, it means a time unit for executing the integration process in the multiple frame integration analysis every 1 ms.
- the analysis result of natural speech is compared with the result of further analysis of the synthesis result reflecting the group delay.
- the frequency bin number was set to 4097 bins (FFT length is 8192).
- the STRAIGHT spectrogram and the proposed spectrogram are displayed side by side, and the spectral envelope at 0.4 seconds is superimposed and displayed.
- the listening impression of the synthesis of sound from the proposed spectrogram using STRAIGHT using the non-periodic component estimated by STRAIGHT was not inferior to the resynthesis from the STRAIGHT spectrogram.
- Table 1 lists the parameters given to the Klatt synthesizer.
- the values of the first and second formant frequencies are set as shown in Table 2 to generate spectrum envelopes, and sine waves are superimposed from these spectrum envelopes with F0 as 125 Hz, Six types of sounds were synthesized.
- the logarithmic spectral distance LSD shown below was used for evaluation of estimation accuracy.
- T is the number of voiced frames
- (F L , F H ) is the frequency range in the evaluation
- S g (t, f) and S e (t , F) are the spectral envelopes estimated as the correct spectral envelopes.
- the normalization factor alpha (t) in order to evaluate its shape S g (t, f) and ⁇ (t) S e (t , f) is the square error epsilon 2 of Calculations were made to minimize.
- Table 3 shows the evaluation results
- FIG. 31 shows an example of estimation.
- the logarithmic spectral distance of the spectral envelope estimated by the above embodiment was lower than either STRAIGHT or TANDEM-STRAIGHT in 13 out of 14 samples, and the lowest was higher in 8 samples. From this result, according to the present embodiment, it was confirmed that there is a possibility that it can be used for high-quality synthesis and high-accuracy analysis.
- FIG. 32 shows the result of estimating the spectral envelope and group delay according to the present embodiment using male unaccompanied singing as an input and recombining them.
- the group delay in the re-synthesized sound the result of the low-pass filter applied to the low band or the whole is seen, but the group delay is reproduced and synthesized as a whole, and the synthesis quality is natural.
- the spectrum envelope estimated in the above embodiment estimates the possible range at the same time and may be used in voice quality conversion, spectrum shape deformation, segment connection synthesis, and the like.
- the group delay can be stored and synthesized. Further, in the conventional technique using group delay (Non-Patent Documents 32 and 33), even if the group delay is smoothed (even if troughs are cut), the combined quality is not affected. On the other hand, according to the above-described embodiment, the valleys can be appropriately filled by integrating a plurality of frames. Further, according to the present embodiment, since the group delay resonates at different times for each frequency band (FIG. 14), it is possible to analyze in more detail beyond the analysis by a single pitch marking. Further, according to the above embodiment, the relationship between the F0 adaptive spectrum and the group delay corresponding to the maximum envelope peak as shown in FIG. 33 is obtained. As can be seen from a comparison between FIG. 33 and FIG. 14 described above, according to the above embodiment, by performing peak detection when calculating the maximum envelope, extra noise (error) caused by a variation in formant frequency, etc. ) Can be removed.
- the present invention is not limited to the above-described embodiments, and embodiments that are modified or changed without departing from the gist of the present invention are also included in the present invention.
- the pitch mark [time information indicating the waveform driving point (and analysis time) when performing analysis in synchronization with the fundamental frequency, excitation time of the glottal sound source, or time having a large amplitude in the fundamental period. Can be analyzed stably regardless of the type of sound, without the premise of accompanying information such as phoneme information.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Auxiliary Devices For Music (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
まず本実施の形態において、音声合成のためのスペクトル包絡と群遅延を求める方法を簡単に説明する。図6に複数フレームの波形とそれに対応する短時間フーリエ変換(STFT)によるスペクトルと群遅延を示す。図6に示すように、それぞれのスペクトルには谷があり、別のフレームではその谷が埋まっているため、これらを統合することで定常なスペクトル包絡が得られる可能性がある。ここで、群遅延のピーク(分析時刻から離れていることを意味する)とスペクトルの谷が対応付いていることから、単一の窓を使っただけでは、滑らかな包絡が得られないことが分かる。そこで本実施の形態では、全時刻または全サンプリング点における基本周波数F0に応じて窓幅を変えた窓を用いて、各時刻または各サンプリング点を中心として音声信号を複数のフレームに分割する。そして本実施の形態において、推定すべき音声合成のためのスペクトル包絡は、後述する重合スペクトルの最大包絡と最小包絡の間にあると考え、まず最大値(最大包絡)と最小値(最小包絡)を計算する。ただし、最大・最小の操作では、時間方向に滑らかな包絡を得られず、基本周波数F0に応じたステップ状の軌跡を描くため、それを平滑化して滑らかにする。最後に、最大包絡と最小包絡の平均として音声合成のためのスペクトル包絡を得る。同時に、最大から最小の範囲をスペクトル包絡の存在範囲として保存する(図7)。また、推定すべき群遅延としては、最も共振する時刻を表現するために、最大包絡に対応する値を用いる。





以上の操作によって、群遅延g(f,t)は(0,1)の範囲で正規化された値となる。しかし、基本周期による剰余処理と、基本周期を範囲として統合していることが原因で、次の問題が残る。

上述のようにして得られたスペクトル包絡と、正規化された群遅延を用いて合成するためには、従来の分析合成システムと同様、時間軸伸縮や振幅の制御を行い、合成のための基本周波数F0を指定する。そして指定した合成のための基本周波数F0とスペクトル包絡と、正規化された群遅延とに基づいて単位波形を順次生成し、生成した複数の単位波形を重畳加算することで音声を合成する。図1に示した音声信号の合成システム2は、読み出し部15と、変換部17と、単位波形生成部19と、合成部21とを基本構成要素とし、不連続状態抑制部23および補正部25を付随要素として構成される。図19は、合成システムをコンピュータを用いて実現する場合に用いるプログラムのアルゴリズムの一例を示すフローチャートである。また図20及び図21は、音声信号の合成の過程を説明するために用いる波形図である。
ここで上述のステップST102Bにおける演算について詳しく説明する。sinとcosで展開された群遅延gx(f,t)とgy(f,t)から、最終的に以下の計算によって群遅延g(f,t)に戻してから扱う。
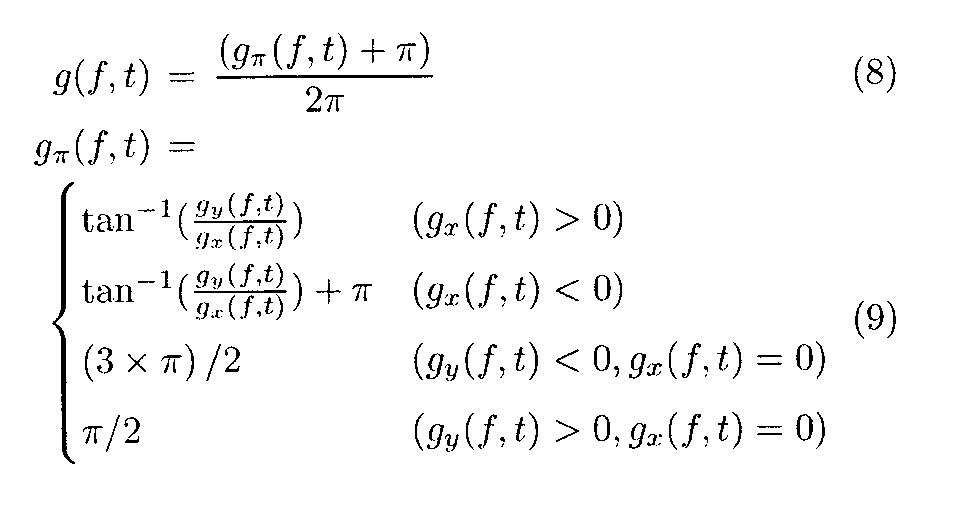
上記実施の形態によるスペクトル包絡の推定精度は、従来、特に性能が高いSTRAIGHT(非特許文献27)、TANDEM-STRAIGHT(非特許文献28)と比較する。実験には男性の無伴奏歌唱(ソロ)をRWC研究用音楽データベース(後藤真孝,橋口博樹,西村拓一,岡 隆一:RWC 研究用音楽データベース:研究目的で利用可能な著作権処理済み楽曲・楽器音データベース,情報処理学会論文誌,Vol. 45, No. 3, pp.728-738 (2004).)(音楽ジャンル:RWC-MDB-G-2001 No.91)から、女性の話声をAISTハミングデータベース(E008)(後藤真孝,西村拓一:AIST ハミングデータベース:歌声研究用音楽データベース,情報処理学会研究報告,2005-MUS-61,pp. 7-12 (2005).)から、楽器音としてピアノとバイオリンの音を前術のRWC研究用音楽データベース[楽器音:ピアノ(RWC-MDB-I-2001,No.01,011PFNOM)とバイオリン(RWC-MDB-I-2001,No.16,161VLGLM)]からそれぞれ用いた。スペクトル包絡の推定精度の比較では、周波数bin数を、STRAIGHTで良く用いられる値である2049bins(FFT長が4096)、分析の時間単位を1msとした。上記実施の形態においては、多重フレーム統合分析における統合処理を1msごとに実行する時間単位を意味する。
本試験では、自然音声を対象としてSTRAIGHTスペクトルと分析結果を比較する。
本試験では、スペクトル包絡とF0が既知である合成音を用いて、その推定精度を評価する。具体的には、前述した自然音声及び楽器音をSTRAIGHTで分析再合成した音と、cascade-type Klatt 合成器(Klatt, D. H.: Software for A Cascade/parallel Formant Synthesizer, J. Acoust. Soc. Am., Vol. 67, pp. 971-995 (1980).)によってスペクトル包絡をパラメータ制御した合成音を用いた。




男性の無伴奏歌唱を入力として、本実施の形態によってスペクトル包絡と群遅延を推定し、それを再合成した結果を図32に示す。再合成音における群遅延では、低域や全体にかけたローパスフィルタの結果が見られるが、全体的に群遅延を再現して合成できており、合成品質も自然であった。
上記実施の形態で推定したスペクトル包絡は存在可能範囲を同時に推定しており、声質変換やスペクトル形状の変形、素片接続合成等において活用できる可能性がある。
2 合成システム
3 基本周波数推定部
5 振幅スペクトル取得部
7 群遅延抽出部
9 スペクトル包絡統合部
11 群遅延統合部
13 メモリ
15 読み出し部
17 変換部
19 単位波形生成部
21 合成部
23 不連続状態抑制部
25 補正部
Claims (37)
- 音声信号から全時刻または全サンプリング点において基本周波数F0を推定する基本周波数推定部と、
前記全時刻または全サンプリング点における前記基本周波数F0に応じて窓幅を変えた窓を用いて、各時刻または各サンプリング点を中心として前記音声信号を複数のフレームに分割し、前記複数のフレーム中の音声信号についてDFT分析を行うことにより、前記複数のフレームそれぞれにおける振幅スペクトルを取得する振幅スペクトル取得部と、
前記複数のフレーム中の音声信号についてDFT分析を伴う群遅延抽出アルゴリズムを実施して前記複数のフレームのそれぞれにおける位相の周波数微分としての群遅延を抽出する群遅延抽出部と、
所定の時間間隔で、前記基本周波数F0の基本周期に基づいて定められた所定の期間内に含まれる前記複数のフレームに対応する前記複数の振幅スペクトルを重合して重合スペクトルを求め、該重合スペクトルを平均化して音声合成のためのスペクトル包絡を順次求めるスペクトル包絡統合部と、
所定の時間間隔で、前記複数の群遅延から前記スペクトル包絡の周波数成分ごとの最大包絡に対応する群遅延を選択し、選択した複数の群遅延を統合して音声合成のための群遅延を順次求める群遅延統合部とを少なくとも1つのプロセッサを用いて実現してなる音声分析合成のためのスペクトル包絡及び群遅延の推定システム。 - 前記基本周波数推定部では、基本周波数F0の推定と併せて有声区間及び無声区間の判定を行い、前記無声区間における基本周波数F0を前記有声区間における値で補間するかまたは前記無声区間に予め定めた値を付与する請求項1に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記スペクトル包絡統合部では、前記重合スペクトルの前記最大包絡と最小包絡の平均として前記音声合成のためのスペクトル包絡を求める請求項1に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記スペクトル包絡統合部では、前記重合スペクトルの前記最大包絡と最小包絡の中間値を平均として前記音声合成のためのスペクトル包絡を求める請求項3に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 平均を求める際の最小包絡として、前記最小包絡の谷を埋めるように前記最大包絡を変形して得た変形最小包絡を用いる請求項3または4に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記スペクトル包絡統合部では、F0に対応する周波数bin以下の帯域のスペクトル包絡の値をF0に対応する周波数binのスペクトル包絡の値で置換したものを前記音声合成のためのスペクトル包絡として求める請求項3に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 置換した前記スペクトル包絡をフィルタ処理する二次元ローパスフィルタを更に備えている請求項6に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記群遅延統合部では、前記重合スペクトルの周波数成分ごとの前記最大包絡に対応する前記フレームにおける前記群遅延を周波数ごとに保存し、保存した群遅延の分析時刻のずれを補正し、前記保存した群遅延を正規化し、正規化した群遅延を前記音声合成のための群遅延とする請求項1に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記群遅延統合部では、F0に対応する周波数bin以下の帯域の前記群遅延の値をF0に対応する周波数binの群遅延の値で置換したものを前記音声合成のための群遅延とする請求項8に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記群遅延統合部では、置換した前記群遅延を平滑化したものを前記音声合成のための群遅延とする請求項9に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 前記平滑化では、置換した前記群遅延をsin関数及びcos関数で変換して基本周期に起因する不連続を除去し、その後二次元ローパスフィルタによりフィルタ処理した後に前記sin関数及びcos関数をtan-1関数により元の状態に戻したものを前記音声合成のための群遅延とする請求項10に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 請求項1乃至11の各部をコンピュータを用いて実現することを特徴とする音声分析合成のためのスペクトル包絡及び群遅延の推定システム。
- 請求項1乃至11のいずれか1項に記載のシステムにより推定した前記音声分析合成のためのスペクトル包絡及び群遅延を前記所定の時間間隔ごとに保存して作成したスペクトル包絡及び群遅延データファイルから、合成のための基本周波数の逆数からなる合成のための基本周期で、前記合成のためのスペクトル包絡及び群遅延を読み出す読み出し部と、
読み出した前記群遅延を位相スペクトルに変換する変換部と、
読み出した前記スペクトル包絡と前記位相スペクトルとから単位波形を生成する単位波形生成部と、
生成した複数の前記単位波形を前記合成のための基本周期で重畳加算して合成された音声信号を出力する合成部とを少なくとも1つのプロセッサを用いて実現してなる音声信号の合成システム。 - 前記変換部による変換の前に、前記読み出した群遅延の低域における時間方向の不連続状態の発生を抑制する不連続状態抑制部を更に備えた請求項13に記載の音声信号の合成システム。
- 前記不連続状態抑制部では、有声区間ごとに最適なオフセットを加算した後、低周波数領域の群遅延を平滑化する請求項14に記載の音声信号の合成システム。
- 前記平滑化では、読み出したフレームの前記群遅延をsin関数及びcos関数で変換して前記合成のための基本周期に起因する不連続を除去し、その後二次元ローパスフィルタによりフィルタ処理した後に前記sin関数及びcos関数をtan-1関数により元の状態に戻したものを前記音声合成のための群遅延とする請求項15に記載の音声信号の合成システム。
- 前記変換部による変換の前または前記不連続状態抑制部の後に、前記群遅延に前記合成のための基本周期を係数として乗ずる補正を実施する補正部を更に備える請求項14または15に記載の音声信号の合成システム。
- 前記合成部は、分析窓を合成窓に変換し、前記合成窓を前記単位波形に掛けた補正単位波形を基本周期で重畳加算することを特徴とする請求項13に記載の音声信号の合成システム。
- 音声信号から全時刻または全サンプリング点において基本周波数F0を推定する基本周波数推定ステップと、
前記全時刻または全サンプリング点における前記基本周波数F0に応じて窓幅を変えた窓を用いて、各時刻または各サンプリング点を中心として前記音声信号を複数のフレームに分割し、前記複数のフレーム中の音声信号についてDFT分析を行うことにより、前記複数のフレームそれぞれにおける振幅スペクトルを取得する振幅スペクトル取得ステップと、
前記複数のフレーム中の音声信号についてDFT分析を伴う群遅延抽出アルゴリズムを実施して前記複数のフレームのそれぞれにおける位相の周波数微分としての群遅延を抽出する群遅延抽出ステップと、
所定の時間間隔で、前記基本周波数F0の基本周期に基づいて定められた所定の期間内に含まれる前記複数のフレームに対応する前記複数の振幅スペクトルを重合して重合スペクトルを求め、該重合スペクトルを平均化して音声合成のためのスペクトル包絡を順次求めるスペクトル包絡統合ステップと、
所定の時間間隔で、前記複数の群遅延から前記スペクトル包絡の周波数成分ごとの最大包絡に対応する群遅延を選択し、選択した複数の群遅延を統合して音声合成のための群遅延を順次求める群遅延統合ステップとを少なくとも1つのプロセッサを用いて実行する音声分析合成のためのスペクトル包絡及び群遅延の推定方法。 - 前記基本周波数推定ステップでは、基本周波数F0の推定と併せて有声区間及び無声区間の判定を行い、前記無声区間における基本周波数F0を前記有声区間における値で補間するかまたは前記無声区間に予め定めた値を付与する請求項19に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 前記スペクトル包絡統合ステップでは、前記重合スペクトルの前記最大包絡と最小包絡の平均として前記音声合成のためのスペクトル包絡を求める請求項19に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 前記スペクトル包絡統合ステップでは、前記重合スペクトルの前記最大包絡と最小包絡の中間値を平均として前記音声合成のためのスペクトル包絡を求める請求項21に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 平均を求める際の最小包絡として、前記最小包絡の谷を埋めるように前記最大包絡を変形して得た変形最小包絡を用いる請求項21または22に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- F0に対応する周波数bin以下の帯域のスペクトル包絡の値をF0に対応する周波数binのスペクトル包絡の値で置換したものを前記音声合成のためのスペクトル包絡を求める請求項21に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 置換した前記スペクトル包絡を二次元ローパスフィルタによりフィルタ処理する請求項24に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 前記群遅延統合ステップでは、前記重合スペクトルの周波数成分ごとの前記最大包絡に対応する前記フレームにおける前記群遅延を周波数ごとに保存し、保存した群遅延の分析時刻のずれを補正し、前記保存した群遅延を正規化し、正規化した群遅延を前記音声合成のための群遅延とする請求項19に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 前記群遅延統合ステップでは、F0に対応する周波数bin以下の帯域の前記群遅延の値をF0に対応する周波数binの群遅延の値で置換したものを前記音声合成のための群遅延とする請求項20に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 前記群遅延統合ステップでは、置換した前記群遅延を平滑化したものを前記音声合成のための群遅延とする請求項27に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 前記平滑化では、置換した前記群遅延をsin関数及びcos関数で変換して基本周期に起因する不連続を除去し、その後二次元ローパスフィルタによりフィルタ処理した後に前記sin関数及びcos関数をtan-1関数により元の状態に戻したものを前記音声合成のための群遅延とする請求項28に記載の音声分析合成のためのスペクトル包絡及び群遅延の推定方法。
- 請求項19乃至29のいずれか1項に記載の方法により推定した前記音声分析合成のためのスペクトル包絡及び群遅延を前記所定の時間間隔ごとに保存して作成したスペクトル包絡及び群遅延データファイルから、合成のための基本周波数の逆数からなる合成のための基本周期で、前記合成のためのスペクトル包絡及び群遅延を読み出す読み出しステップと、
読み出した前記群遅延を位相スペクトルに変換する変換ステップと、
読み出した前記スペクトル包絡と前記位相スペクトルとから単位波形を生成する単位波形生成ステップと、
生成した複数の前記単位波形を前記合成のための基本周期で重畳加算して合成された音声信号を出力する合成ステップとを少なくとも1つのプロセッサを用いて実行する音声信号の合成方法。 - 前記変換ステップの前に、前記読み出した群遅延の低域における時間方向の不連続状態の発生を抑制する不連続状態抑制ステップを実施する請求項30に記載の音声信号の合成方法。
- 前記不連続状態抑制ステップでは、有声区間ごとに最適なオフセットを加算した後、低周波数領域の群遅延を平滑化する請求項31に記載の音声信号の合成方法。
- 前記平滑化では、読み出したフレームの前記群遅延をsin関数及びcos関数で変換して前記合成のための基本周期に起因する不連続を除去し、その後二次元ローパスフィルタによりフィルタ処理した後に前記sin関数及びcos関数をtan-1関数により元の状態に戻したものを前記音声合成のための群遅延とする請求項32に記載の音声信号の合成方法。
- 前記変換ステップの前または前記平滑化の後に、前記群遅延に前記合成のための基本周期を係数として乗ずる補正ステップを実施する請求項30または32に記載の音声信号の合成方法。
- 前記合成ステップでは、分析窓を合成窓に変換し、前記合成窓を前記単位波形に掛けた補正単位波形を基本周期で重畳加算することを特徴とする請求項30に記載の音声信号の合成方法。
- 音声信号から全時刻または全サンプリング点において基本周波数F0を推定する基本周波数推定ステップと、
前記全時刻または全サンプリング点における前記基本周波数F0に応じて窓幅を変えた窓を用いて、各時刻または各サンプリング点を中心として前記音声信号を複数のフレームに分割し、前記複数のフレーム中の音声信号についてDFT分析を行うことにより、前記複数のフレームにそれぞれにおける振幅スペクトルを取得する振幅スペクトル取得ステップと、
前記複数のフレーム中の音声信号についてDFT分析を伴う群遅延抽出アルゴリズムを実施して前記複数のフレームのそれぞれにおける位相の周波数微分としての群遅延を抽出する群遅延抽出ステップと、
所定の時間間隔で、前記基本周波数F0の基本周期に基づいて定められた所定の期間内に含まれる前記複数のフレームに対応する前記複数のスペクトルを重合して重合スペクトルを求め、該重合スペクトルを平均化して音声合成のためのスペクトル包絡を順次求めるスペクトル包絡統合ステップと、
所定の時間間隔で、前記複数の群遅延から前記スペクトル包絡の周波数成分ごとの最大包絡に対応する群遅延を選択し、選択した複数の群遅延を統合して音声合成のための群遅延を順次求める群遅延統合ステップとをコンピュータで実施することを可能にするように構成された音声分析合成のためのスペクトル包絡及び群遅延の推定用プログラムを記録してなる非一時的なコンピュータ読み取り可能な記録媒体。 - 請求項19乃至29のいずれか1項に記載の方法により推定した前記音声分析合成のためのスペクトル包絡及び群遅延を前記所定の時間間隔ごとに保存して作成したスペクトル包絡及び群遅延データファイルから、合成のための基本周波数の逆数からなる合成のための基本周期で、前記合成のためのスペクトル包絡及び群遅延を読み出す読み出しステップと、
読み出した前記群遅延を位相スペクトルに変換する変換ステップと、
読み出した前記スペクトル包絡と前記位相スペクトルとから単位波形を生成する単位波形生成ステップと、
生成した複数の前記単位波形を前記合成のための基本周期で重畳加算して合成された音声信号を出力する合成ステップとをコンピュータで実施することを可能にするように構成された音声信号の合成用プログラムを記録してなる非一時的なコンピュータ読み取り可能な記録媒体。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/418,680 US9368103B2 (en) | 2012-08-01 | 2013-07-30 | Estimation system of spectral envelopes and group delays for sound analysis and synthesis, and audio signal synthesis system |
| JP2014528171A JP5958866B2 (ja) | 2012-08-01 | 2013-07-30 | 音声分析合成のためのスペクトル包絡及び群遅延の推定システム及び音声信号の合成システム |
| EP13826111.0A EP2881947B1 (en) | 2012-08-01 | 2013-07-30 | Spectral envelope and group delay inference system and voice signal synthesis system for voice analysis/synthesis |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012171513 | 2012-08-01 | ||
| JP2012-171513 | 2012-08-01 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014021318A1 true WO2014021318A1 (ja) | 2014-02-06 |
Family
ID=50027991
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/070609 WO2014021318A1 (ja) | 2012-08-01 | 2013-07-30 | 音声分析合成のためのスペクトル包絡及び群遅延の推定システム及び音声信号の合成システム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US9368103B2 (ja) |
| EP (1) | EP2881947B1 (ja) |
| JP (1) | JP5958866B2 (ja) |
| WO (1) | WO2014021318A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017046904A1 (ja) * | 2015-09-16 | 2017-03-23 | 株式会社東芝 | 音声処理装置、音声処理方法及び音声処理プログラム |
| US9865247B2 (en) | 2014-07-03 | 2018-01-09 | Google Inc. | Devices and methods for use of phase information in speech synthesis systems |
| CN107924677A (zh) * | 2015-06-11 | 2018-04-17 | 交互智能集团有限公司 | 用于异常值识别以移除语音合成中的不良对准的系统和方法 |
Families Citing this family (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6083764B2 (ja) * | 2012-12-04 | 2017-02-22 | 国立研究開発法人産業技術総合研究所 | 歌声合成システム及び歌声合成方法 |
| JP6216553B2 (ja) * | 2013-06-27 | 2017-10-18 | クラリオン株式会社 | 伝搬遅延補正装置及び伝搬遅延補正方法 |
| RU2679254C1 (ru) * | 2015-02-26 | 2019-02-06 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Устройство и способ для обработки аудиосигнала для получения обработанного аудиосигнала с использованием целевой огибающей во временной области |
| US9564140B2 (en) * | 2015-04-07 | 2017-02-07 | Nuance Communications, Inc. | Systems and methods for encoding audio signals |
| US10325609B2 (en) * | 2015-04-13 | 2019-06-18 | Nippon Telegraph And Telephone Corporation | Coding and decoding a sound signal by adapting coefficients transformable to linear predictive coefficients and/or adapting a code book |
| CN107924683B (zh) * | 2015-10-15 | 2021-03-30 | 华为技术有限公司 | 正弦编码和解码的方法和装置 |
| US10345339B2 (en) | 2015-12-09 | 2019-07-09 | Tektronix, Inc. | Group delay based averaging |
| WO2017116961A1 (en) * | 2015-12-30 | 2017-07-06 | Baxter Corporation Englewood | Measurement of syringe graduation marks using a vision system |
| JP6724932B2 (ja) * | 2018-01-11 | 2020-07-15 | ヤマハ株式会社 | 音声合成方法、音声合成システムおよびプログラム |
| WO2020044362A2 (en) * | 2018-09-01 | 2020-03-05 | Indian Institute Of Technology Bombay | Real-time pitch tracking by detection of glottal excitation epochs in speech signal using hilbert envelope |
| US11694708B2 (en) * | 2018-09-23 | 2023-07-04 | Plantronics, Inc. | Audio device and method of audio processing with improved talker discrimination |
| US11264014B1 (en) * | 2018-09-23 | 2022-03-01 | Plantronics, Inc. | Audio device and method of audio processing with improved talker discrimination |
| US11031909B2 (en) * | 2018-12-04 | 2021-06-08 | Qorvo Us, Inc. | Group delay optimization circuit and related apparatus |
| KR20250044808A (ko) * | 2019-03-10 | 2025-04-01 | 카르돔 테크놀로지 엘티디. | 큐의 클러스터링을 사용한 음성 증강 |
| CN114402380A (zh) * | 2019-09-27 | 2022-04-26 | 雅马哈株式会社 | 音响信号解析方法、音响信号解析系统及程序 |
| DE102019220091A1 (de) * | 2019-12-18 | 2021-06-24 | GiaX GmbH | Vorrichtung und verfahren zum erfassen von gruppenlaufzeitinformationen und vorrichtung und verfahren zum senden eines messsignals über ein übertragungsmedium |
| CN111179973B (zh) * | 2020-01-06 | 2022-04-05 | 思必驰科技股份有限公司 | 语音合成质量评价方法及系统 |
| CN111341294B (zh) * | 2020-02-28 | 2023-04-18 | 电子科技大学 | 将文本转换为指定风格语音的方法 |
| CN111863028B (zh) * | 2020-07-20 | 2023-05-09 | 江门职业技术学院 | 一种发动机声音合成方法及系统 |
| CN112652315B (zh) * | 2020-08-03 | 2024-08-16 | 昆山杜克大学 | 基于深度学习的汽车引擎声实时合成系统及方法 |
| CN112309425B (zh) * | 2020-10-14 | 2024-08-30 | 浙江大华技术股份有限公司 | 一种声音变调方法、电子设备及计算机可读存储介质 |
| WO2022119626A1 (en) | 2020-12-04 | 2022-06-09 | Qorvo Us, Inc. | Power management integrated circuit |
| WO2022139936A1 (en) | 2020-12-22 | 2022-06-30 | Qorvo Us, Inc. | Power management apparatus operable with multiple configurations |
| US12267046B2 (en) | 2021-02-15 | 2025-04-01 | Qorvo Us, Inc. | Power amplifier system |
| US12212286B2 (en) | 2021-03-05 | 2025-01-28 | Qorvo Us, Inc. | Complementary envelope detector |
| US11545172B1 (en) * | 2021-03-09 | 2023-01-03 | Amazon Technologies, Inc. | Sound source localization using reflection classification |
| US12126305B2 (en) | 2021-05-27 | 2024-10-22 | Qorvo Us, Inc. | Radio frequency (RF) equalizer in an envelope tracking (ET) circuit |
| CN113938749B (zh) * | 2021-11-30 | 2023-05-05 | 北京百度网讯科技有限公司 | 音频数据处理方法、装置、电子设备和存储介质 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09179586A (ja) * | 1995-12-22 | 1997-07-11 | Oki Electric Ind Co Ltd | 音声ピッチマーク設定方法 |
| JPH1097287A (ja) | 1996-07-30 | 1998-04-14 | Atr Ningen Joho Tsushin Kenkyusho:Kk | 周期信号変換方法、音変換方法および信号分析方法 |
| JPH11219200A (ja) * | 1998-01-30 | 1999-08-10 | Sony Corp | 遅延検出装置及び方法、並びに音声符号化装置及び方法 |
| JP2001249674A (ja) * | 2000-03-06 | 2001-09-14 | Japan Science & Technology Corp | 駆動信号分析装置 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5602959A (en) * | 1994-12-05 | 1997-02-11 | Motorola, Inc. | Method and apparatus for characterization and reconstruction of speech excitation waveforms |
| WO2011026247A1 (en) * | 2009-09-04 | 2011-03-10 | Svox Ag | Speech enhancement techniques on the power spectrum |
| US9142220B2 (en) * | 2011-03-25 | 2015-09-22 | The Intellisis Corporation | Systems and methods for reconstructing an audio signal from transformed audio information |
-
2013
- 2013-07-30 EP EP13826111.0A patent/EP2881947B1/en not_active Not-in-force
- 2013-07-30 US US14/418,680 patent/US9368103B2/en not_active Expired - Fee Related
- 2013-07-30 WO PCT/JP2013/070609 patent/WO2014021318A1/ja active Application Filing
- 2013-07-30 JP JP2014528171A patent/JP5958866B2/ja active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09179586A (ja) * | 1995-12-22 | 1997-07-11 | Oki Electric Ind Co Ltd | 音声ピッチマーク設定方法 |
| JPH1097287A (ja) | 1996-07-30 | 1998-04-14 | Atr Ningen Joho Tsushin Kenkyusho:Kk | 周期信号変換方法、音変換方法および信号分析方法 |
| JPH11219200A (ja) * | 1998-01-30 | 1999-08-10 | Sony Corp | 遅延検出装置及び方法、並びに音声符号化装置及び方法 |
| JP2001249674A (ja) * | 2000-03-06 | 2001-09-14 | Japan Science & Technology Corp | 駆動信号分析装置 |
Non-Patent Citations (46)
| Title |
|---|
| ABE, M.; SMITH III, J. O.: "Design Criteria for Simple Sinusoidal Parameter Estimation based on Quadratic Interpolation of FFT Magnitude Peaks", PROC. AES 117TH CONVENTION, 2004 |
| AKAGIRI, H.; MORISE M.; IRINO, T.; KAWAHARA, H.: "Evaluation and Optimization of FO-Adaptive Spectral Envelope Extraction Based on Spectral Smoothing with Peak Emphasis", IEICE, JOURNAL, vol. J94-A, no. 8, 2011, pages 557 - 567 |
| AKAMINE, M.; KAGOSHIMA, T.: "Analytic Generation of Synthesis Units by Closed Loop Training for Totally Speaker Driven Text to Tpeech System (TOS Drive TTS", PROC. ICSLP1998, 1998, pages 1927 - 1930 |
| ATAL, B. S.; HANAUER, S.: "Speech Analysis and Synthesis by Linear Prediction of the Speech Wave", J. ACOUST. SOC. AM., vol. 50, no. 4, 1971, pages 637 - 655, XP002019898, DOI: doi:10.1121/1.1912679 |
| BANNNO, H.; JINLIN, L.; NAKAMURA, S.; SHIKANO, K.; KAWAHARA, H.: "Efficient Representation of Short-Time Phase Based on Time-Domain Smoothed Group Delay", IEICE, JOURNAL, vol. J84-D-II, no. 4, 2001, pages 621 - 628 |
| BANNNO, H.; JINLIN, L.; NAKAMURA, S.; SHIKANO, K.; KAWAHARA, H.: "Speech Manipulation Method Using Phase Manipulation Based on Time-Domain Smoothed Group Delay", IEICE, JOURNAL, vol. J83-D-II, no. 11, 2000, pages 2276 - 2282 |
| BONADA, J.: "Wide-Band Harmonic Sinusoidal Modeling", PROC. DAFX-08, 2008, pages 265 - 272, XP002503758 |
| DEPALLE, P.; H'ELIE, T.: "Extraction of Spectral Peak Parameters Using a Short-time Fourier Transform Modeling and No Sidelobe Windows", PROC. WASPAA1997, 1997 |
| FLANAGAN, J.; GOLDEN, R., PHASE VOCODER, BELL SYSTEM TECHNICAL JOURNAL, vol. 45, 1966, pages 1493 - 1509 |
| FUJIHARA, H.; GOTO, M.; OKUNO, H. G.: "A Novel Framework for Recognizing Phonemes of Singing Voice in Polyphonic Music", PROC. WASPAA2009, 2009, pages 17 - 20, XP031575122 |
| GEORGE, E.; SMITH, M.: "Analysis-by-Synthesis/Overlap-Add Sinusoidal Modeling Applied to The Analysis and Synthesis of Musical Tones", JOURNAL OF THE AUDIO ENGINEERING SOCIETY, vol. 40, no. 6, 1992, pages 497 - 515, XP001161167 |
| GOTO, M.; HASHIGUCHI, H.; NISHIMURA, T.; OKA, R.: "RWC Music Database for Experiments: Music and Instrument Sound Database", INFORMATION PROCESSING SOCIETY OF JAPAN (IPS) JOURNAL, vol. 45, no. 3, 2014, pages 728 - 738 |
| GOTO, M.; NISHIMURA, T.: "AIST Hamming Database, Music Database for Singing Research", IPS REPORT, 2005-MUS-61, 2005, pages 7 - 12 |
| GRIFFIN, D. W.: "Multi-Band Excitation Vocoder, Technical report (Massachusetts Institute of Technology", RESEARCH LABORATORY OF ELECTRONICS, 1987 |
| HAMAGAMI, T.: "Speech Synthesis Using Source Wave Shape Modification Technique by Harmonic Phase Control", ACOUSTICAL SOCIETY OF JAPAN, JOURNAL, vol. 54, no. 9, 1998, pages 623 - 631 |
| HIDEKI BANNO ET AL.: "Efficient Representation of Short-Time Phase Based on Time-Domain Smoothed Group Delay", THE TRANSACTIONS OF THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS, vol. J84-D-II, no. 4, 1 April 2001 (2001-04-01), pages 621 - 628, XP055192710 * |
| HIDEKI KAWAHARA ET AL.: "Source Information Representations for Synthetic Speech : Group Delay, Event and Harmonic Structures", IEICE TECHNICAL REPORT, vol. 101, no. 87, 18 May 2001 (2001-05-18), pages 9 - 16, XP008176526 * |
| HIDEKI KAWAHARA ET AL.: "Vocal fold closure and speech event detection using group delay", IEICE TECHNICAL REPORT, vol. 99, no. 679, 10 March 2000 (2000-03-10), pages 33 - 40, XP055192707 * |
| IMAI, S.; ABE, Y.: "Spectral Envelope Extraction by Improved Cepstral Method", IEICE, JOURNAL, vol. J62-A, no. 4, 1979, pages 217 - 223 |
| ITAKURA, F.; SAITO, S.: "Analysis Synthesis Telephony based on the Maximum Likelihood Method", REPORTS OF THE 6TH INT. CONG. ON ACOUST., vol. 2, no. C-5-5, 1968, pages C17 - 20, XP000646433 |
| ITO, M.; YANO, M.: "Perceptual Naturalness of Time-Scale Modified Speech", IEICE (THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEER) TECHNICAL REPORT EA, 2008, pages 13 - 18 |
| ITO, M.; YANO, M.: "Sinusoidal Modeling for Nonstationary Voiced Speech based on a Local Vector Transform", J. ACOUST. SOC. AM., vol. 121, no. 3, 2007, pages 1717 - 1727, XP012096491, DOI: doi:10.1121/1.2431581 |
| KAMEOKA, H.; ONO, N.; SAGAYAMA, S., SPEECH SPECTRUM MODELING FOR JOINT ESTIMATION OF SPECTRAL ENVELOPE AND FUNDAMENTAL FREQUENCY, vol. 18, no. 6, 2006, pages 2502 - 2505 |
| KAMEOKA, H.; ONO, N.; SAGAYAMA, S.: "Auxiliary Function Approach to Parameter Estimation of Constrained Sinusoidal Model for Monaural Speech Separation", PROC. ICASSP 2008, 2008, pages 29 - 32, XP031250480 |
| KAWAHARA, H.; MASUDA-KATSUSE, I.; DE CHEVEIGNE, A.: "Restructuring Speech Representations Using a Pitch Adaptive Time-frequency Smoothing and an Instantaneous Frequency Based on F0 Extraction: Possible Role of a Repetitive Structure in Sounds", SPEECH COMMUNICATION, vol. 27, 1999, pages 187 - 207, XP004163250, DOI: doi:10.1016/S0167-6393(98)00085-5 |
| KAWAHARA, H.; MORISE, M.; TAKAHASHI, T.; NISHIMURA, R.; IRINO, T.; BANNO, H.: "Tandem-STRAIGHT: A Temporally Stable Power Spectral Representation for Periodic Signals and Applications to Interference-free Spectrum, FO, and Aperiodicity Estimation", PROC. OF ICASSP 2008, 2008, pages 3933 - 3936, XP031251456 |
| KLATT, D.H.: "Software for A Cascade/parallel Formant Synthesizer", J. ACOUST. SOC. AM., vol. 67, 1980, pages 971 - 995 |
| MATSUBARA, T.; MORISE, M.; NISHIURA, T: "Perceptual Effect of Phase Characteristics of the Voiced Sound in High-Quality Speech Synthesis", ACOUSTICAL SOCIETY OF JAPAN, TECHNICAL COMMITTEE OF PSYCHOLOGICAL AND PHYSIOLOGICAL ACOUSTICS PAPERS, vol. 40, no. 8, 2010, pages 653 - 658 |
| MCAULAY, R.; T. QUATIERI: "Speech Analysis/Synthesis Based on A Sinusoidal Representation", IEEE TRANS. ASSP, vol. 34, no. 4, 1986, pages 744 - 755 |
| MORISE, M.: PLATINUM: "A Method to Extract Excitation Signals for Voice Synthesis System", ACOUST. SCI. & TECH., vol. 33, no. 2, 2012, pages 123 - 125 |
| MORISE, M.; MATSUBARA, T.; NAKANO, K.; NISHIURA N.: "A Rapid Spectrum Envelope Estimation Technique of Vowel for High-Quality Speech Synthesis", IEICE, JOURNAL, vol. J94-D, no. 7, 2011, pages 1079 - 1087 |
| MOULINES, E.; CHARPENTIER, F.: "Pitch-synchronous Waveform Processing Techniques for Text-to-speech Synthesis Using Diphones", SPEECH COMMUNICATION, vol. 9, no. 5-6, 1990, pages 453 - 467, XP024228778, DOI: doi:10.1016/0167-6393(90)90021-Z |
| PANTAZIS, Y.; ROSEC, O.; STYLIANOU, Y.: "Iterative Estimation of Sinusoidal Signal Parameters", IEEE SIGNAL PROCESSING LETTERS, vol. 17, no. 5, 2010, pages 461 - 464, XP011302693 |
| PAVLOVETS, A.; PETROVSKY, A.: "Robust HNR-based Closed-loop Pitch and Harmonic Parameters Estimation", PROC. INTERSPEECH2011, 2011, pages 1981 - 1984 |
| ROBEL, A.; RODET, X.: "Efficient Spectral Envelope Estimation and Its Application to Pitch Shifting and Envelope Preservation", PROC. DAFX2005, 2005, pages 30 - 35 |
| SERRA, X.; SMITH, J.: "Spectral Modeling Synthesis: A Sound Analysis/Synthesis Based on A Deterministic Plus Stochastic Decomposition", COMPUTER MUSIC JOURNAL, vol. 14, no. 4, 1990, pages 12 - 24, XP009122116, DOI: doi:10.2307/3680788 |
| SHIGA, Y.; KING, S.: "Estimating the Spectral Envelope of Voiced Speech Using Multi-frame Analysis", PROC. EUROSPEECH2003, 2003, pages 1737 - 1740 |
| SMITH, J.; SERRA, X.: "PARSHL: An Analysis/Synthesis Program for Non-harmonic Sounds Based on A Sinusoidal Representation", PROC. ICMC 1987, 1987, pages 290 - 297, XP009130237 |
| STYLIANOU, Y., HARMONIC PLUS NOISE MODELS FOR SPEECH, COMBINED WITH STATISTICAL METHODS, FOR SPEECH AND SPEAKER MODIFICATION |
| TODA, T.; TOKUDA, K.: "Statistical Approach to Vocal Tract Transfer Function Estimation Based on Factor Analyzed Trajectory HMM", PROC. ICASSP2008, 2008, pages 3925 - 3928, XP031251454 |
| TOKUDA, K.; KOBAYASHI, T.; MASUKO, T.; IMAI, S.: "Melgeneralized Cepstral Analysis - A Unified Approach to Speech Spectral Estimation", PROC. ICSLP1994, 1994, pages 1043 - 1045 |
| TOMOYASU NAKANO ET AL.: "Kasei Onsei Bunseki Gosei no Tameno FO Tekio Taju Frame Togo Bunseki ni Motozuku Spectrum Horaku to Gunchien no Suiteiho", IPSJ SIG NOTES, vol. 2012-MUS, no. 7, 9 August 2012 (2012-08-09), pages 1 - 9, XP055193196 * |
| VILLAVICENCIO, F.; ROBEL, A.; RODET, X.: "Extending Efficient Spectral Envelope Modeling to Mel-frequency Based Representation", PROC. ICASSP2008, 2008, pages 1625 - 1628, XP031250879 |
| VILLAVICENCIO, F.; ROBEL, A.; RODET, X.: "Improving LPC Spectral Envelope Extraction of Voiced Speech by True-Envelope Estimation", PROC. ICASSP2006, 2006, pages 869 - 872 |
| ZOLFAGHARI, P.; WATANABE, S.; NAKAMURA, A.; KATAGIRI, S.: "Modelling of the Speech Spectrum Using Mixture of Gaussians", PROC. ICASSP 2004, 2004, pages 553 - 556, XP010717688, DOI: doi:10.1109/ICASSP.2004.1326045 |
| ZOLZER, U.; AMATRIAIN, X.: "DAFX - Digital Audio Effect", 2002, WILEY |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9865247B2 (en) | 2014-07-03 | 2018-01-09 | Google Inc. | Devices and methods for use of phase information in speech synthesis systems |
| CN107924677A (zh) * | 2015-06-11 | 2018-04-17 | 交互智能集团有限公司 | 用于异常值识别以移除语音合成中的不良对准的系统和方法 |
| WO2017046904A1 (ja) * | 2015-09-16 | 2017-03-23 | 株式会社東芝 | 音声処理装置、音声処理方法及び音声処理プログラム |
| JPWO2017046904A1 (ja) * | 2015-09-16 | 2018-03-22 | 株式会社東芝 | 音声処理装置、音声処理方法及び音声処理プログラム |
| CN107924686A (zh) * | 2015-09-16 | 2018-04-17 | 株式会社东芝 | 语音处理装置、语音处理方法以及语音处理程序 |
| US10650800B2 (en) | 2015-09-16 | 2020-05-12 | Kabushiki Kaisha Toshiba | Speech processing device, speech processing method, and computer program product |
| US11170756B2 (en) | 2015-09-16 | 2021-11-09 | Kabushiki Kaisha Toshiba | Speech processing device, speech processing method, and computer program product |
| US11348569B2 (en) | 2015-09-16 | 2022-05-31 | Kabushiki Kaisha Toshiba | Speech processing device, speech processing method, and computer program product using compensation parameters |
| CN107924686B (zh) * | 2015-09-16 | 2022-07-26 | 株式会社东芝 | 语音处理装置、语音处理方法以及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2881947A4 (en) | 2016-03-16 |
| EP2881947B1 (en) | 2018-06-27 |
| US9368103B2 (en) | 2016-06-14 |
| JPWO2014021318A1 (ja) | 2016-07-21 |
| EP2881947A1 (en) | 2015-06-10 |
| JP5958866B2 (ja) | 2016-08-02 |
| US20150302845A1 (en) | 2015-10-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5958866B2 (ja) | 音声分析合成のためのスペクトル包絡及び群遅延の推定システム及び音声信号の合成システム | |
| Yegnanarayana et al. | An iterative algorithm for decomposition of speech signals into periodic and aperiodic components | |
| US10650800B2 (en) | Speech processing device, speech processing method, and computer program product | |
| JP5159325B2 (ja) | 音声処理装置及びそのプログラム | |
| US8255222B2 (en) | Speech separating apparatus, speech synthesizing apparatus, and voice quality conversion apparatus | |
| JP5961950B2 (ja) | 音声処理装置 | |
| Degottex et al. | A log domain pulse model for parametric speech synthesis | |
| Abe et al. | Sinusoidal model based on instantaneous frequency attractors | |
| Al-Radhi et al. | Time-Domain Envelope Modulating the Noise Component of Excitation in a Continuous Residual-Based Vocoder for Statistical Parametric Speech Synthesis. | |
| CN101983402A (zh) | 声音分析装置、声音分析合成装置、校正规则信息生成装置、声音分析系统、声音分析方法、校正规则信息生成方法、以及程序 | |
| Al-Radhi et al. | A continuous vocoder for statistical parametric speech synthesis and its evaluation using an audio-visual phonetically annotated Arabic corpus | |
| Kafentzis et al. | Time-scale modifications based on a full-band adaptive harmonic model | |
| JP4469986B2 (ja) | 音響信号分析方法および音響信号合成方法 | |
| JP2018077283A (ja) | 音声合成方法 | |
| Nakano et al. | A spectral envelope estimation method based on F0-adaptive multi-frame integration analysis. | |
| Violaro et al. | A hybrid model for text-to-speech synthesis | |
| Babacan et al. | Parametric representation for singing voice synthesis: A comparative evaluation | |
| Al-Radhi et al. | A continuous vocoder using sinusoidal model for statistical parametric speech synthesis | |
| Drugman et al. | Fast inter-harmonic reconstruction for spectral envelope estimation in high-pitched voices | |
| Rao | Unconstrained pitch contour modification using instants of significant excitation | |
| US20050131679A1 (en) | Method for synthesizing speech | |
| Hasan et al. | An approach to voice conversion using feature statistical mapping | |
| JP6834370B2 (ja) | 音声合成方法 | |
| Lehana et al. | Harmonic plus noise model based speech synthesis in Hindi and pitch modification | |
| Arakawa et al. | High quality voice manipulation method based on the vocal tract area function obtained from sub-band LSP of STRAIGHT spectrum |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13826111 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2014528171 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14418680 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2013826111 Country of ref document: EP |