WO2013073316A1 - 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム - Google Patents
立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム Download PDFInfo
- Publication number
- WO2013073316A1 WO2013073316A1 PCT/JP2012/076045 JP2012076045W WO2013073316A1 WO 2013073316 A1 WO2013073316 A1 WO 2013073316A1 JP 2012076045 W JP2012076045 W JP 2012076045W WO 2013073316 A1 WO2013073316 A1 WO 2013073316A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- video
- viewpoint
- depth map
- residual
- pixel
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 166
- 239000002131 composite material Substances 0.000 claims abstract description 112
- 239000000284 extract Substances 0.000 claims abstract description 7
- 238000012545 processing Methods 0.000 claims description 198
- 238000001514 detection method Methods 0.000 claims description 182
- 238000000926 separation method Methods 0.000 claims description 141
- 230000015572 biosynthetic process Effects 0.000 claims description 102
- 238000003786 synthesis reaction Methods 0.000 claims description 100
- 230000002194 synthesizing effect Effects 0.000 claims description 74
- 238000009432 framing Methods 0.000 claims description 45
- 239000000203 mixture Substances 0.000 claims description 45
- 238000005520 cutting process Methods 0.000 claims description 24
- 230000006870 function Effects 0.000 claims description 9
- 238000000605 extraction Methods 0.000 claims description 2
- 230000010339 dilation Effects 0.000 claims 1
- 230000008569 process Effects 0.000 description 48
- 230000009467 reduction Effects 0.000 description 44
- 230000004048 modification Effects 0.000 description 32
- 238000012986 modification Methods 0.000 description 32
- 230000005540 biological transmission Effects 0.000 description 31
- 238000010586 diagram Methods 0.000 description 18
- 230000008859 change Effects 0.000 description 10
- 230000033001 locomotion Effects 0.000 description 9
- 230000006835 compression Effects 0.000 description 8
- 238000007906 compression Methods 0.000 description 8
- 238000004364 calculation method Methods 0.000 description 7
- 238000001914 filtration Methods 0.000 description 5
- 230000007257 malfunction Effects 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 230000000916 dilatatory effect Effects 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 238000009499 grossing Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 208000003464 asthenopia Diseases 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000002427 irreversible effect Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000011946 reduction process Methods 0.000 description 1
- 238000005549 size reduction Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images



























Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/10—Processing, recording or transmission of stereoscopic or multi-view image signals
- H04N13/106—Processing image signals
- H04N13/161—Encoding, multiplexing or demultiplexing different image signal components
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/10—Processing, recording or transmission of stereoscopic or multi-view image signals
- H04N13/194—Transmission of image signals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/10—Processing, recording or transmission of stereoscopic or multi-view image signals
- H04N13/106—Processing image signals
- H04N13/111—Transformation of image signals corresponding to virtual viewpoints, e.g. spatial image interpolation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N2213/00—Details of stereoscopic systems
- H04N2213/005—Aspects relating to the "3D+depth" image format
Definitions
- the present invention relates to a stereoscopic video encoding apparatus that encodes stereoscopic video, a stereoscopic video encoding method, a stereoscopic video encoding program, a stereoscopic video decoding apparatus that decodes encoded stereoscopic video, and stereoscopic video decoding.
- the present invention relates to a method and a stereoscopic video decoding program.
- Patent Document 1 discloses a method for restoring a multi-viewpoint video using a small number of viewpoint videos and a depth map.
- Patent Document 1 describes a method of encoding / decoding a multi-view video (image signal) and its depth map (depth signal).
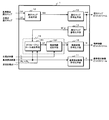
- FIG. 35 the image coding apparatus described in Patent Document 1 will be described.
- the image encoding device described in Patent Document 1 includes a code management unit 101, an image signal encoding unit 107, a depth signal encoding unit 108, a unitization unit 109, and a parameter information encoding unit 110. It is configured with.
- each viewpoint video (image signal) is subjected to predictive encoding between viewpoint videos by the image signal encoding unit 107, and the depth map (depth signal) of one or more viewpoints is a depth signal.
- the encoding unit 108 performs inter-view prediction encoding.
- Patent Document 1 describes a method of synthesizing a thinned viewpoint video using a depth map attached to a transmitted viewpoint video. However, the same number of depth maps as the number of viewpoints are encoded and encoded. There is a problem that encoding efficiency is low because transmission is required.
- the multi-view video and the depth map are individually subjected to inter-view prediction encoding.
- the conventional inter-view prediction encoding method searches for a corresponding pixel position between viewpoint videos, extracts a shift amount of the pixel position as a disparity vector, and uses the extracted disparity vector to perform an inter-view prediction code. To decrypt / decrypt. For this reason, there are problems that it takes time to search for a disparity vector, the prediction accuracy is poor, and the encoding / decoding speed is low.
- the present invention has been made in view of such problems, and a stereoscopic video encoding apparatus, a stereoscopic video encoding method, a stereoscopic video encoding program, and a coding thereof that efficiently encode and transmit a stereoscopic video. It is an object of the present invention to provide a stereoscopic video decoding apparatus, a stereoscopic video decoding method, and a stereoscopic video decoding program for decoding a stereoscopic video.
- the stereoscopic video encoding device is a depth map that is a map of information for each pixel of a multi-view video and a depth value that is a parallax between viewpoints in the multi-view video.
- a stereoscopic video encoding device that encodes a map, a reference viewpoint video encoding unit, an intermediate viewpoint depth map synthesis unit, a depth map encoding unit, a depth map decoding unit, and a projected video prediction unit And a residual video encoding unit, and the projected video prediction unit includes an occlusion hole detection unit and a residual video extraction unit.
- the stereoscopic video encoding apparatus encodes the reference viewpoint video that is the video at the reference viewpoint of the multi-view video by the reference viewpoint video encoding means, and outputs the encoded video as a reference viewpoint video bitstream.
- the stereoscopic video encoding device includes a reference viewpoint depth map that is a depth map at the reference viewpoint and a depth map at a sub-viewpoint that is a viewpoint other than the reference viewpoint of the multi-view video, by an intermediate viewpoint depth map synthesis unit.
- An intermediate viewpoint depth map which is a depth map at an intermediate viewpoint between the reference viewpoint and the sub viewpoint, is synthesized using a certain sub viewpoint depth map.
- the stereoscopic video encoding apparatus encodes the intermediate viewpoint depth map by the depth map encoding means, and outputs the encoded depth map bitstream.
- the data amount for the depth map to be encoded is reduced by half in the case of two original depth maps.
- the stereoscopic video encoding apparatus decodes the encoded intermediate viewpoint depth map by the depth map decoding means, and generates a decoded intermediate viewpoint depth map.
- the stereoscopic video encoding apparatus includes an occlusion hole that is a pixel region that cannot be projected when the reference viewpoint video is projected onto another viewpoint using the decoded intermediate viewpoint depth map by the projected video prediction unit. Are extracted from the sub-viewpoint video to generate a residual video.
- the stereoscopic video encoding apparatus uses the decoding intermediate viewpoint depth map by the occlusion hole detection means to generate a residual video, and the occlusion is performed when the reference viewpoint video is projected onto the sub-viewpoint.
- the stereoscopic video encoding apparatus uses not the intermediate viewpoint depth map before encoding but the intermediate viewpoint depth map that has undergone encoding / decoding.
- the decoded depth map includes many errors with respect to the original depth map. Therefore, by using the same depth map as the depth map at the intermediate viewpoint used when the multi-view video is generated by decoding the bitstream described above with the stereoscopic video decoding device, the pixel that becomes the occlusion hole is accurately detected. Can do.
- the stereoscopic video encoding apparatus encodes the residual video by the residual video encoding means, and outputs the residual video bit stream.
- the residual video encoding means encodes the residual video by the residual video encoding means, and outputs the residual video bit stream.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 1, wherein the occlusion hole detection means includes a sub-viewpoint projection means and a hole pixel detection means.
- the stereoscopic video encoding device projects the decoded intermediate viewpoint depth map onto the sub-viewpoint by the sub-viewpoint projection unit, and generates a subviewpoint projection depth map that is a depth map at the subviewpoint. To do.
- the stereoscopic video encoding device for the pixel of interest that is a pixel of interest as a determination target of whether to be a pixel to be the occlusion hole for each pixel in the sub-viewpoint projection depth map by the hole pixel detection means,
- the target pixel is detected as a pixel that becomes the occlusion hole To do. That is, the stereoscopic video encoding device detects a pixel that becomes an occlusion hole using a depth map at a sub-viewpoint far away from the reference viewpoint. Accordingly, the stereoscopic video encoding device detects a pixel region that is predicted to be an occlusion hole with little leakage.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 2, wherein the occlusion hole detecting means includes hole mask expansion means for expanding a hole mask indicating a pixel position of an occlusion hole. It was set as the structure which has.
- the occlusion hole detection means expands the hole mask made of the detected pixels, which is the detection result of the hole pixel detection means, by a predetermined number of pixels by the hole mask expansion means. Then, the stereoscopic video encoding apparatus cuts out pixels included in the hole mask (first hole mask) expanded by the hole mask expansion unit from the sub-viewpoint video by the residual video cutting unit and extracts the residual. Generate video. As a result, the stereoscopic video encoding apparatus can detect the occlusion hole due to an error in the decoded depth map with respect to the original depth map that is often included when the depth map is encoded using an encoding method with a high compression rate. It is possible to absorb the detection omission of the pixel.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 2 or claim 3, wherein the occlusion hole detection means detects the detected hole position with the second hole pixel detection means.
- the second sub-viewpoint projection means for projecting to the sub-viewpoint and the hole mask composition means for integrating the plurality of generated hole masks are further provided.
- the stereoscopic video encoding device pays attention to the second hole pixel detection unit as a determination target for determining whether or not each pixel is the occlusion hole for each pixel in the decoding intermediate viewpoint depth map.
- the target pixel For a target pixel that is a pixel, when a depth value in a pixel that is a predetermined number of pixels away from the target pixel toward the reference viewpoint side is greater than a depth value in the target pixel by a predetermined value or more, the target pixel is A hole mask is generated by detecting the pixel as an occlusion hole.
- the stereoscopic video encoding device generates a hole mask (second hole mask) obtained by projecting the hole mask generated by the second hole pixel detection unit onto the sub-viewpoint by the second sub-viewpoint projection unit.
- the 3D image encoding apparatus includes a first hole mask obtained by projecting a detection result of the first hole mask and the second hole pixel detection unit, which is a detection result of the hole pixel detection unit, to a sub-viewpoint by a hole mask synthesis unit. Is the detection result of the occlusion hole detection means.
- the stereoscopic video encoding apparatus detects an occlusion hole using an intermediate viewpoint depth map that is a depth map at an intermediate viewpoint, and more appropriately occlusions. A pixel that becomes a hole is detected.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 4, wherein the occlusion hole detection means includes a designated viewpoint projection means, a third hole pixel detection means, and a third sub-viewpoint projection. And means.
- the stereoscopic video encoding device projects the decoded intermediate viewpoint depth map to an arbitrary specified viewpoint position by the specified viewpoint projection means, and generates a specified viewpoint depth map that is a depth map at the specified viewpoint. Generate.
- the stereoscopic video encoding device uses the third hole pixel detection unit to identify a pixel of interest that is a pixel of interest as a determination target for determining whether the pixel is the occlusion hole for each pixel in the designated viewpoint depth map.
- the target pixel is the pixel that becomes the occlusion hole.
- the stereoscopic video encoding device generates a hole mask (third hole mask) obtained by projecting the hole mask generated by the third hole pixel detection unit onto the sub viewpoint by the third sub-viewpoint projection unit.
- the 3D video encoding device uses the hole mask composing unit to project the first hole mask, which is the detection result by the hole pixel detection unit, and the second hole obtained by projecting the detection result by the second hole pixel detection unit to the sub-viewpoint.
- the logical sum of the mask and the third hole mask obtained by projecting the detection result of the third hole pixel detection means onto the sub-viewpoint is taken as the detection result of the occlusion hole detection means.
- the stereoscopic video encoding device uses the depth map at the specified viewpoint when decoding the encoded data on the decoding side to generate a multi-viewpoint video. The detected occlusion hole is detected, and the occlusion hole is detected more appropriately.
- the stereoscopic video encoding apparatus is the stereoscopic video encoding apparatus according to any one of claims 1 to 5, wherein the depth map frame forming means, the depth map separating means, and the residual video frame are used. And further comprising an adjusting means.
- the stereoscopic video encoding apparatus reduces and combines the plurality of intermediate viewpoint depth maps for the reference viewpoint and the plurality of sub-viewpoints in the multi-view video by the depth map frame forming unit. Then, a framed depth map that is framed into one frame image is generated.
- the stereoscopic video encoding apparatus separates the plurality of reduced intermediate viewpoint depth maps that are framed from the framed depth map by the depth map separation unit, and has the same size as the reference viewpoint video. A plurality of the combined depth maps are generated.
- the stereoscopic video encoding apparatus reduces and combines the plurality of residual videos for the reference viewpoint and the plurality of sub-viewpoints in the multi-view video by the residual video framing means. A framed residual video that is framed into two frame images is generated.
- the stereoscopic video encoding apparatus generates a plurality of intermediate viewpoint depth maps at an intermediate viewpoint between the reference viewpoint and each of the plurality of sub-viewpoints by the intermediate viewpoint depth map synthesis unit.
- the stereoscopic video encoding device generates the framed depth map by reducing and combining the plurality of intermediate viewpoint depth maps generated by the depth map combining unit by the depth map frame forming unit.
- the stereoscopic video encoding apparatus encodes the framed depth map by the depth map encoding means and outputs the encoded depth map bit stream.
- the stereoscopic video encoding apparatus performs encoding while reducing the data amount of a plurality of intermediate viewpoint depth maps generated between a plurality of sets of viewpoints.
- the depth map decoding unit decodes the framed depth map encoded by the depth map encoding unit to generate a decoded framed depth map.
- the stereoscopic video encoding apparatus separates the plurality of intermediate viewpoint depth maps reduced from the decoded framed depth map by the depth map separating unit, and decodes the decoding intermediate having the same size as the reference viewpoint video. Generate viewpoint depth map.
- the stereoscopic video encoding device uses the decoded intermediate viewpoint depth map separated by the depth map separation means by the projected video prediction means, and uses the decoded intermediate viewpoint depth map corresponding to each of the decoded intermediate viewpoint depth maps.
- the residual video is generated from the sub-view video at the viewpoint.
- the stereoscopic video encoding apparatus generates the framed residual video by reducing and combining the plurality of residual videos generated by the projected video prediction unit by the residual video framing unit. .
- the stereoscopic video encoding apparatus encodes the framed residual video by the residual video encoding means and outputs the encoded residual video bitstream.
- the stereoscopic video encoding apparatus performs encoding while reducing the data amount of a plurality of residual videos generated between a plurality of sets of viewpoints.
- the stereoscopic video decoding device wherein the multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video are encoded bits.
- a stereoscopic video encoding apparatus that decodes a stream to generate a multi-view video, wherein a reference viewpoint video decoding unit, a depth map decoding unit, a residual video decoding unit, a depth map projection unit, and a projection Video projection means, and the projected video synthesis means includes reference viewpoint video projection means and residual video projection means.
- the stereoscopic video decoding apparatus decodes and decodes the reference viewpoint video bitstream in which the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded by the reference viewpoint video decoding means.
- a standardized reference viewpoint video is generated.
- the depth map decoding means encodes an intermediate viewpoint depth map that is a depth map in an intermediate viewpoint between the reference viewpoint and a sub-viewpoint that is another viewpoint away from the reference viewpoint.
- the decoded depth map bitstream is decoded to generate a decoded combined depth map.
- the stereoscopic video decoding apparatus extracts, from the sub-viewpoint video, a pixel that becomes an occlusion hole, which is a pixel region that cannot be projected, when the reference viewpoint video is projected onto another viewpoint by the residual video decoding unit.
- a residual video bitstream obtained by encoding a residual video that is a video is decoded to generate a decoded residual video.
- the stereoscopic video decoding apparatus projects the decoded intermediate viewpoint depth map to a designated viewpoint, which is a viewpoint designated from the outside as a viewpoint of the multi-view video, by the depth map projecting unit, and the designated viewpoint A specified viewpoint depth map that is a depth map at is generated.
- the stereoscopic video decoding device combines the video obtained by projecting the decoded reference viewpoint video and the decoded residual video on the designated viewpoint using the designated viewpoint depth map by the projected video synthesis means, A designated viewpoint video that is a video at the designated viewpoint is generated.
- the stereoscopic video decoding apparatus uses an occlusion hole that is a pixel area that cannot be projected when the decoded reference viewpoint video is projected onto the specified viewpoint using the specified viewpoint depth map by the reference viewpoint video projection unit. For the pixel that does not become the occlusion hole, the decoded reference viewpoint video is projected onto the specified viewpoint using the specified viewpoint depth map to be a pixel of the specified viewpoint video.
- the stereoscopic video decoding apparatus projects the decoded residual video onto the designated viewpoint by using the designated viewpoint depth map for the pixel serving as the occlusion hole by the residual video projecting unit. Let it be a picture pixel.
- the stereoscopic video decoding apparatus uses the reference viewpoint video, the depth map at the intermediate viewpoint between the reference viewpoint and the sub viewpoint, and the residual video extracted from the sub viewpoint video to the video at an arbitrary viewpoint. Is generated.
- the stereoscopic video decoding device is the stereoscopic video decoding device according to claim 7, wherein the reference viewpoint video projection means includes hole pixel detection means.
- the stereoscopic video decoding device uses the hole pixel detection unit to focus the pixel of interest as a determination target for determining whether or not each pixel is a pixel that becomes an occlusion hole in the designated viewpoint depth map.
- the target pixel is defined as a pixel that becomes an occlusion hole.
- the stereoscopic video decoding device generates a designated viewpoint video by selecting pixels from the video obtained by projecting the reference viewpoint video onto the designated viewpoint and the video obtained by projecting the residual video onto the designated viewpoint according to the detection result. Then, an appropriate pixel is selected to generate a designated viewpoint video. That is, the stereoscopic video decoding device uses a result of detecting pixels that become an occlusion hole using a depth map at a specified viewpoint, which is a viewpoint that actually generates an image, and a video obtained by projecting a reference viewpoint video onto the specified viewpoint and The designated viewpoint video is generated by selecting an appropriate pixel from the video obtained by projecting the residual video onto the designated viewpoint.
- the stereoscopic video decoding device is the stereoscopic video decoding device according to claim 8, wherein the reference viewpoint video projection unit expands a hole mask indicating a pixel position of an occlusion hole. It was set as the structure which has.
- the stereoscopic video decoding device expands the hole mask indicating the pixel position detected by the hole pixel detection unit by the predetermined number of pixels by the hole mask expansion unit. Then, the stereoscopic video decoding apparatus projects the decoded residual video onto the designated viewpoint with respect to the pixels in the hole mask expanded by the hole mask dilating means by the residual video projecting means. Pixels. Then, the stereoscopic video decoding apparatus, according to the result of expanding the hole mask detected using the depth map at the designated viewpoint, the video obtained by projecting the reference viewpoint video onto the designated viewpoint and the video obtained by projecting the residual video onto the designated viewpoint. A designated viewpoint video is generated by selecting a pixel from. Thereby, especially when the decoded intermediate viewpoint depth map is encoded at a high compression rate, the stereoscopic video decoding apparatus absorbs occlusion hole detection omission due to an error included in the decoded intermediate viewpoint depth map. .
- the stereoscopic video decoding device is the stereoscopic video decoding device according to claim 9, wherein the residual video projection means includes a hole filling processing means.
- the stereoscopic video decoding device detects pixels that are not included in the residual video in the designated viewpoint video by the hole-filling processing unit, and uses pixel values around the pixels that are not included. The pixel values of the pixels not included are interpolated. Accordingly, the stereoscopic video decoding device generates a designated viewpoint video without a hole.
- the stereoscopic video decoding device is the stereoscopic video decoding device according to any one of claims 7 to 10, further comprising a depth map separation unit and a residual video separation unit. It was.
- the stereoscopic video decoding apparatus reduces and combines the plurality of intermediate viewpoint depth maps in the intermediate viewpoint between the reference viewpoint and each of the plurality of sub-viewpoints by the depth map separation unit.
- a framed depth map which is one frame image is separated for each of the plurality of intermediate viewpoints, and an intermediate viewpoint depth map having the same size as the reference viewpoint video is generated.
- the stereoscopic video decoding apparatus separates a framed residual video that is one frame image obtained by reducing and combining the plurality of residual videos for the plurality of sub-viewpoints by using a residual video separation unit. The decoded residual image having the same size as the reference viewpoint image is generated.
- the stereoscopic video decoding apparatus generates a decoded framed depth map by decoding the depth map bitstream in which the framed depth map is encoded by the depth map decoding unit. Further, the stereoscopic video decoding device generates a decoded framed residual video by decoding the residual video bitstream in which the framed residual video is encoded by the residual video decoding unit. . Further, the stereoscopic video decoding apparatus separates the plurality of reduced intermediate viewpoint depth maps from the decoded framed depth map by the depth map separating unit, and a plurality of the same size as the reference viewpoint video. The decoding intermediate viewpoint depth map is generated.
- the stereoscopic video decoding apparatus separates the plurality of reduced residual videos from the decoded framed residual video by the residual video separation unit, and has the same size as the reference viewpoint video. A plurality of the decoded residual images are generated. Further, the stereoscopic video decoding apparatus projects the corresponding decoded intermediate viewpoint depth map to the designated viewpoint for each of the plurality of designated viewpoints by the depth map projecting unit, and uses the depth map at the designated viewpoint. A certain viewpoint depth map is generated. In addition, the stereoscopic video decoding device uses the projected viewpoint synthesizing unit to use the designated viewpoint depth map corresponding to each of the plurality of designated viewpoints to respectively correspond to the corresponding decoding reference viewpoint video and the decoding residual.
- a video obtained by projecting the difference video onto the designated viewpoint is synthesized to generate a designated viewpoint video that is a video at the designated viewpoint.
- the stereoscopic video decoding apparatus uses a reference viewpoint video, a depth map in which a plurality of intermediate viewpoint depth maps are framed, and a residual video in which a plurality of residual videos are framed. Generate video at the viewpoint.
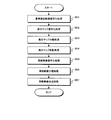
- the stereoscopic video encoding method encodes a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video.
- the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded and output as a reference viewpoint video bitstream.
- a reference viewpoint depth map that is a depth map at the reference viewpoint, and a sub viewpoint depth map that is a depth map at a sub viewpoint that is a viewpoint other than the reference viewpoint of the multi-view video Is used to generate an intermediate viewpoint depth map that is a depth map at an intermediate viewpoint between the reference viewpoint and the sub viewpoint.
- the intermediate viewpoint depth map is encoded and output as a depth map bitstream.
- the data amount for the depth map to be encoded is reduced by half in the case of two original depth maps.
- the encoded intermediate viewpoint depth map is decoded to generate a decoded intermediate viewpoint depth map.
- the projected video prediction processing step when the reference viewpoint video is projected onto another viewpoint using the decoded intermediate viewpoint depth map, a pixel that is an occlusion hole that is a pixel area that cannot be projected is selected as the sub-viewpoint. Cut out from video to generate residual video.
- the occlusion hole detection processing step a pixel that becomes an occlusion hole when the reference viewpoint video is projected onto the sub-viewpoint is detected using the decoded intermediate viewpoint depth map.
- the residual video cut-out processing step the residual video is generated by cutting out the pixel that becomes the occlusion hole from the sub-viewpoint video.
- an intermediate viewpoint depth map that has undergone encoding / decoding is used instead of the intermediate viewpoint depth map before encoding.
- the decoded depth map includes many errors with respect to the original depth map. Therefore, by using the same depth map as the depth map at the intermediate viewpoint used when the above-described bitstream is decoded to generate a multi-viewpoint video, a pixel that becomes an occlusion hole can be accurately detected.
- the residual video encoding processing step the residual video is encoded and output as a residual video bitstream. As a result, of the data about the sub-viewpoint video, only the portion extracted as the residual video is to be encoded, and the amount of data to be encoded is reduced.
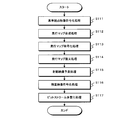
- the stereoscopic video decoding method wherein a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video are encoded bits.
- a projected video composition processing step wherein the projected video composition processing step includes a reference viewpoint video projection processing step and a residual video projection processing step.
- the reference viewpoint video bitstream in which the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded is decoded and decoded.
- a standardized reference viewpoint video is generated.
- a depth map bitstream in which an intermediate viewpoint depth map that is a depth map in an intermediate viewpoint between the reference viewpoint and another viewpoint that is distant from the reference viewpoint is encoded Is decoded, and a decoding synthesis depth map is generated.
- the residual video decoding processing step when the reference viewpoint video is projected onto another viewpoint, the residual video is a video obtained by cutting out a pixel that becomes an occlusion hole that is a pixel area that cannot be projected from the sub-viewpoint video. Is decoded to generate a decoded residual video.
- the decoding intermediate viewpoint depth map is projected to a designated viewpoint which is a viewpoint designated from the outside as the viewpoint of the multi-view video, and is designated as a depth map at the designated viewpoint Generate viewpoint depth map.
- the projected video composition processing step using the designated viewpoint depth map, a video obtained by projecting the decoded reference viewpoint video and the decoded residual video onto the designated viewpoint is synthesized, and the video at the designated viewpoint is used. A certain viewpoint video is generated.
- the reference viewpoint video projection processing step using the specified viewpoint depth map, when the decoded reference viewpoint video is projected onto the specified viewpoint, pixels that are occlusion holes that are pixel areas that cannot be projected are detected. For the pixels that do not become the occlusion hole, the decoded reference viewpoint video is projected onto the designated viewpoint using the designated viewpoint depth map to be the pixels of the designated viewpoint video.
- the decoded residual video is projected onto the designated viewpoint using the designated viewpoint depth map with respect to the pixel serving as the occlusion hole, and is used as the pixel of the designated viewpoint video.
- a video at an arbitrary viewpoint is generated using the reference viewpoint video, the depth map at the intermediate viewpoint between the reference viewpoint and the sub viewpoint, and the residual video cut out from the sub viewpoint video.
- the stereoscopic video encoding program according to claim 14 is for encoding a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video.
- Computer reference viewpoint video encoding means, intermediate viewpoint depth map synthesis means, depth map encoding means, depth map decoding means, projection video prediction means, residual video encoding means, occlusion hole detection means, residual video
- This is a program for functioning as a cutting means.
- the stereoscopic video encoding program encodes the reference viewpoint video that is the video at the reference viewpoint of the multi-view video by the reference viewpoint video encoding means, and outputs the encoded video as a reference viewpoint video bitstream.
- the stereoscopic video encoding program includes a reference viewpoint depth map that is a depth map at the reference viewpoint and a depth map at a sub-viewpoint that is a viewpoint other than the reference viewpoint of the multi-view video.
- An intermediate viewpoint depth map which is a depth map at an intermediate viewpoint between the reference viewpoint and the sub viewpoint, is synthesized using a certain sub viewpoint depth map.
- the stereoscopic video encoding program encodes the intermediate viewpoint depth map by the depth map encoding means, and outputs the encoded depth map bitstream.
- the data amount for the depth map to be encoded is reduced by half in the case of two original depth maps.
- the stereoscopic video encoding program decodes the encoded intermediate viewpoint depth map by the depth map decoding means, and generates a decoded intermediate viewpoint depth map.
- the stereoscopic video encoding program uses an occlusion hole that is a pixel area that cannot be projected when the reference viewpoint video is projected onto another viewpoint using the decoded intermediate viewpoint depth map by the projected video prediction unit. Are extracted from the sub-viewpoint video to generate a residual video.
- the stereoscopic video encoding program uses the decoding intermediate viewpoint depth map by the occlusion hole detecting means to project the reference viewpoint video onto the sub-viewpoint.
- the stereoscopic video encoding program uses not the intermediate viewpoint depth map before encoding but the intermediate viewpoint depth map that has undergone encoding / decoding.
- the decoded depth map includes many errors with respect to the original depth map. Therefore, by using the same depth map as the depth map at the intermediate viewpoint used when the above-described bitstream is decoded to generate a multi-viewpoint video, a pixel that becomes an occlusion hole can be accurately detected.
- the stereoscopic video encoding program encodes the residual video by the residual video encoding means and outputs it as a residual video bitstream.
- the residual video encoding means encodes the residual video by the residual video encoding means and outputs it as a residual video bitstream.
- the stereoscopic video decoding program encodes a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video.
- a computer is connected to a reference viewpoint video decoding means, a depth map decoding means, a residual video decoding means, a depth map projection means, a projection video synthesis means, a reference viewpoint video.
- This is a program for functioning as projection means and residual video projection means.
- the stereoscopic video decoding program decodes and decodes the reference viewpoint video bitstream in which the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded by the reference viewpoint video decoding means.
- a standardized reference viewpoint video is generated.
- the stereoscopic video decoding program encodes an intermediate viewpoint depth map that is a depth map in an intermediate viewpoint between the reference viewpoint and a sub-viewpoint that is another viewpoint away from the reference viewpoint by the depth map decoding means.
- the decoded depth map bitstream is decoded to generate a decoded combined depth map.
- the stereoscopic video decoding program extracts, from the sub-viewpoint video, a pixel that becomes an occlusion hole, which is a pixel region that cannot be projected, when the reference video is projected onto another viewpoint by the residual video decoding means.
- a residual video bitstream obtained by encoding a residual video that is a video is decoded to generate a decoded residual video.
- the stereoscopic video decoding program projects the decoded intermediate viewpoint depth map to a designated viewpoint, which is a viewpoint designated from the outside as a viewpoint of the multi-view video, by the depth map projecting unit, and the designated viewpoint A specified viewpoint depth map that is a depth map at is generated.
- the stereoscopic video decoding program synthesizes a video obtained by projecting the decoded reference viewpoint video and the decoded residual video on the designated viewpoint by using the designated viewpoint depth map by the projected video synthesis means, A designated viewpoint video that is a video at the designated viewpoint is generated.
- the stereoscopic video decoding program uses an occlusion hole that is a pixel area that cannot be projected when the decoded reference viewpoint video is projected onto the specified viewpoint using the specified viewpoint depth map by the reference viewpoint video projecting unit. For the pixel that does not become the occlusion hole, the decoded reference viewpoint video is projected onto the specified viewpoint using the specified viewpoint depth map to be a pixel of the specified viewpoint video.
- the stereoscopic video decoding program projects the decoded residual video to the designated viewpoint by using the designated viewpoint depth map for the pixel to be the occlusion hole by the residual video projection means. Let it be a picture pixel.
- the stereoscopic video decoding program uses the reference viewpoint video, the depth map at the intermediate viewpoint between the reference viewpoint and the sub-viewpoint, and the residual video extracted from the sub-viewpoint video to the video at an arbitrary viewpoint. Is generated.
- the stereoscopic video encoding apparatus encodes a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video.
- An encoding device comprising: a reference viewpoint video encoding unit, a depth map synthesis unit, a depth map encoding unit, a depth map decoding unit, a projected video prediction unit, and a residual video encoding unit. It was set as the structure provided.
- the stereoscopic video encoding apparatus encodes the reference viewpoint video that is the video at the reference viewpoint of the multi-view video by the reference viewpoint video encoding means, and outputs the encoded video as a reference viewpoint video bitstream.
- the stereoscopic video encoding device may include a reference viewpoint depth map that is a depth map at the reference viewpoint and a depth map at a sub-viewpoint that is another viewpoint away from the reference viewpoint of the multi-viewpoint video by a depth map synthesis unit.
- the sub-viewpoint depth map is projected onto a predetermined viewpoint and combined to generate a combined depth map that is a depth map at the predetermined viewpoint. This reduces the amount of data for the depth map to be encoded.
- the stereoscopic video encoding apparatus encodes the composite depth map by the depth map encoding means and outputs the encoded depth map as a depth map bitstream.
- the stereoscopic video encoding apparatus decodes the encoded combined depth map by the depth map decoding unit, and generates a decoded combined depth map.
- the stereoscopic video encoding device uses a decoded video depth map to project a residual video that is a prediction residual when a video at another viewpoint is predicted from the reference viewpoint video using the decoded synthesized depth map. Generate.
- the stereoscopic video encoding apparatus encodes the residual video by the residual video encoding means, and outputs the residual video bit stream. This reduces the amount of video data for other viewpoints.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 16, wherein the depth map synthesis means uses the reference viewpoint depth map and the plurality of sub-viewpoint depth maps as a common viewpoint.
- a composite depth map at the common viewpoint is generated by projecting onto the common viewpoint, and a residual video framing means is further provided.
- the stereoscopic video encoding device combines three or more depth maps including the reference viewpoint depth map into one combined depth map at the common viewpoint by the depth map combining unit. Thereby, the data amount about the depth map is reduced to 1/3 or less.
- the stereoscopic video encoding apparatus reduces and combines the plurality of residual videos for the reference viewpoint and the plurality of sub-viewpoints by using a residual video framing unit, and forms a single frame image. Generate framed residual video.
- the stereoscopic video encoding apparatus encodes the framed residual video by the residual video encoding means and outputs the encoded residual video bitstream. As a result, the data amount for the residual video is reduced to 1 ⁇ 2 or less.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 16 or claim 17, wherein the projected video prediction means uses the decoded synthesized depth map to calculate the reference viewpoint.
- the projected video prediction means uses the decoded synthesized depth map to calculate the reference viewpoint.
- the stereoscopic video encoding apparatus generates a residual video by performing a logical operation of cutting out only pixel data serving as an occlusion hole by the projected video prediction unit. This greatly reduces the amount of data for the residual video.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 16 or claim 17, wherein the projected video prediction means uses the decoded synthesized depth map to generate the reference viewpoint.
- a residual image is generated by calculating a pixel-by-pixel difference between an image obtained by projecting an image on the sub-viewpoint and the sub-viewpoint image.
- the stereoscopic video encoding apparatus generates a residual video by performing subtraction between two videos for the entire video by the projected video prediction unit. Accordingly, the stereoscopic video decoding device can synthesize a high-quality stereoscopic video using the residual video.
- the stereoscopic video encoding device is the stereoscopic video encoding device according to claim 16, wherein the reference viewpoint video bitstream, the depth map bitstream, and the residual video bitstream are:
- Each of the auxiliary information includes a header including a predetermined start code and first identification information for identifying that it is a one-viewpoint video in this order, and includes information indicating each position of the reference viewpoint and the sub-viewpoint
- a bit stream multiplexing unit that multiplexes the reference viewpoint video bit stream, the depth map bit stream, and the residual video bit stream and outputs the multiplexed bit stream.
- the stereoscopic video encoding device outputs the reference viewpoint video bitstream as it is by the bitstream multiplexing means, and the start map, the first identification information, and the depth map bitstream. Between the second identification information for identifying the data relating to the stereoscopic video and the third identification information for identifying the depth map bit stream in this order, and outputting the residual video. For the bitstream, the second identification information and the fourth identification information for identifying the residual video bitstream are inserted in this order between the start code and the first identification information. And for the auxiliary information, the start code, the second identification information, and the fifth identification information for identifying the auxiliary information And outputs a header containing in this order in addition to the auxiliary information.
- the bit stream for the stereoscopic video is multiplexed and transmitted to the stereoscopic video decoding apparatus.
- the reference viewpoint video is transmitted as a bit stream of one viewpoint video, and other information is transmitted as a bit stream related to a stereoscopic video different from the one viewpoint video.
- the stereoscopic video decoding device wherein the multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video are encoded bits.
- a stereoscopic video decoding apparatus that decodes a stream to generate a multi-view video, wherein a reference viewpoint video decoding means, a depth map decoding means, a residual video decoding means, a depth map projection means, and a projection And a video composition means.
- the stereoscopic video decoding apparatus decodes and decodes the reference viewpoint video bitstream in which the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded by the reference viewpoint video decoding means.
- a standardized reference viewpoint video is generated.
- the stereoscopic video decoding apparatus may include a reference viewpoint depth map that is a depth map at the reference viewpoint and a depth at a sub-viewpoint that is another viewpoint away from the reference viewpoint of the multi-view video by a depth map decoding unit.
- a depth map bitstream encoded with a combined depth map that is a depth map at a predetermined viewpoint generated by combining the sub-viewpoint depth map that is a map is decoded to generate a decoded combined depth map.
- the stereoscopic video decoding apparatus uses the residual video decoding unit to predict a prediction residual when a video at another viewpoint away from the reference viewpoint is predicted from the reference viewpoint video using the decoding composite depth map.
- the residual video bitstream obtained by encoding the residual video is decoded to generate a decoded residual video.
- the stereoscopic video decoding device projects the decoded composite depth map to a designated viewpoint that is a viewpoint designated from the outside as a viewpoint of the multi-view video by a depth map projecting unit, and A designated viewpoint depth map that is a depth map is generated.
- the stereoscopic video decoding device combines the video obtained by projecting the decoded reference viewpoint video and the decoded residual video on the designated viewpoint using the designated viewpoint depth map by the projected video synthesis means, A designated viewpoint video that is a video at the designated viewpoint is generated. As a result, a multi-view video composed of videos at the reference viewpoint and the designated viewpoint is generated.
- the stereoscopic video decoding device is the stereoscopic video decoding device according to claim 21, wherein the composite depth map uses the reference viewpoint depth map and the plurality of sub-viewpoint depth maps as a common viewpoint.
- a depth map at the common viewpoint synthesized by projection is separated, and a framed residual image that is one frame image obtained by reducing and combining the plurality of residual images for the plurality of sub-viewpoints is separated.
- the apparatus further includes residual video separation means for generating the decoded residual video having the same size as the reference viewpoint video.
- the stereoscopic video decoding apparatus decodes the residual video bitstream in which the framed residual video is encoded by the residual video decoding means, and generates a decoded framed residual. Generating a video, separating the plurality of reduced residual videos from the decoded framed residual video by the residual video separation means, and a plurality of the decoding having the same size as the reference viewpoint video Generate a residual image. Then, the stereoscopic video decoding device uses the projected video synthesis means to convert the decoded reference viewpoint video and any one of the plurality of decoded residual videos to the specified viewpoint using the specified viewpoint depth map. Is combined with the projected image to generate a specified viewpoint image that is an image at the specified viewpoint. As a result, a multi-view video is generated using the residual video whose data amount is reduced by framing.
- the stereoscopic video decoding device is the stereoscopic video decoding device according to claim 21 or claim 22, wherein the residual video bitstream is obtained by separating the reference viewpoint video from the reference viewpoint.
- a residual video generated by cutting out a pixel that becomes an occlusion hole, which is a pixel region that cannot be projected, from the sub-viewpoint video, and the projected video synthesis means The image projection unit and the residual image projection unit are included.
- the stereoscopic video decoding device uses the specified viewpoint depth map to generate a pixel area that cannot be projected when the decoded reference viewpoint video is projected onto the specified viewpoint by the reference viewpoint video projection unit.
- a pixel that becomes a certain occlusion hole is detected, and for the pixel that does not become the occlusion hole, the decoded reference viewpoint video is projected onto the specified viewpoint using the specified viewpoint depth map to be a pixel of the specified viewpoint video.
- the stereoscopic video decoding apparatus projects the decoded residual video to the designated viewpoint by using the designated viewpoint depth map for the pixel to be the occlusion hole by the residual video projection unit, and the designated viewpoint. Let it be a picture pixel.
- a designated viewpoint video in which a video for the reference viewpoint and a residual video that is a video for the sub-viewpoint are combined is generated.
- the stereoscopic video decoding device wherein the residual video bitstream is obtained by using the decoded synthesized depth map as the reference viewpoint in the stereoscopic video decoding device according to claim 21 or claim 22.
- a residual video generated by calculating a pixel-by-pixel difference between a video obtained by projecting a video on the sub-viewpoint and the sub-viewpoint video is encoded, and the projected video synthesizing unit includes a residual adding unit. It was set as the structure which has.
- the stereoscopic video decoding device uses the specified viewpoint depth map to a video obtained by projecting the decoding reference viewpoint video onto the specified viewpoint using the specified viewpoint depth map by the residual addition unit. Then, a video obtained by projecting the decoded residual video onto the designated viewpoint is added for each pixel to generate the designated viewpoint video. As a result, a designated viewpoint video in which a video for the reference viewpoint and a residual video that is a video for the sub-viewpoint are combined is generated.
- the stereoscopic video decoding device is the stereoscopic video decoding device according to claim 21, wherein the reference viewpoint video bitstream is a first video that identifies a predetermined start code and one viewpoint video.
- a header including identification information in this order, and the depth map bitstream includes, between the start code and the first identification information, second identification information for identifying that the data is related to stereoscopic video,
- a header including fourth identification information for identifying the residual video bit stream in this order, and the auxiliary information bit stream includes the start code.
- the stereoscopic video decoding device uses the bitstream separation unit to separate the reference viewpoint video bitstream, the depth map bitstream, the residual video bitstream, the reference viewpoint, and the sub-viewpoint.
- the stereoscopic video decoding apparatus separates the bit stream having the first identification information immediately after the start code from the multiplexed bit stream as the reference viewpoint video bit stream by using the reference viewpoint video bit stream separation unit.
- the separated reference viewpoint video bitstream is output to the reference viewpoint video decoding means.
- the stereoscopic video decoding device uses the depth map bitstream separation means to generate the bitstream having the second identification information and the third identification information in this order immediately after the start code from the multiplexed bitstream.
- the bit stream is separated as a depth map bit stream, and the bit stream obtained by removing the second identification information and the third identification information from the bit stream is output to the depth map decoding means.
- the stereoscopic video decoding device uses the residual video bitstream separating means to generate a bitstream having the second identification information and the fourth identification information in this order immediately after the start code from the multiplexed bitstream.
- the bit stream separated as the residual video bit stream and the second identification information and the fourth identification information removed from the bit stream is output to the residual video decoding means.
- the stereoscopic video decoding apparatus uses the auxiliary information separation unit to generate a bitstream having the second identification information and the fifth identification information in this order immediately after the start code from the multiplexed bitstream.
- the bit stream is separated as a bit stream, and the bit stream obtained by removing the second identification information and the fifth identification information from the bit stream is output as auxiliary information to the projected video composition means. Accordingly, the stereoscopic video decoding device receives the multiplexed bit stream and generates a multi-view video.
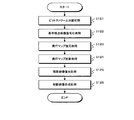
- the stereoscopic video encoding method encodes a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video.
- the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded and output as a reference viewpoint video bitstream.
- a reference viewpoint depth map that is a depth map at the reference viewpoint and a sub viewpoint depth map that is a depth map at a sub viewpoint that is another viewpoint away from the reference viewpoint of the multi-view video are projected onto a predetermined viewpoint and combined to generate a combined depth map that is a depth map at the predetermined viewpoint. This reduces the amount of data for the depth map to be encoded.
- the composite depth map is encoded and output as a depth map bitstream.
- the encoded combined depth map is decoded to generate a decoded combined depth map.
- a residual video that is a prediction residual when a video at another viewpoint is predicted from the reference viewpoint video is generated using the decoded synthesized depth map. Then, in the residual video encoding processing step, the residual video is encoded and output as a residual video bitstream. This reduces the amount of video data for other viewpoints.
- the stereoscopic video encoding method according to claim 27 is the stereoscopic video encoding method according to claim 26, wherein the reference viewpoint video bitstream, the depth map bitstream, and the residual video bitstream are:
- Each of the auxiliary information includes a header including a predetermined start code and first identification information for identifying that it is a one-viewpoint video in this order, and includes information indicating each position of the reference viewpoint and the sub-viewpoint And a bit stream multiplexing process step of multiplexing the reference viewpoint video bit stream, the depth map bit stream, and the residual video bit stream, and outputting the multiplexed bit stream.
- the reference viewpoint video bitstream is output as it is, and the start map and the first identification information are output for the depth map bitstream.
- the second identification information for identifying that the data is related to stereoscopic video and the third identification information for identifying the depth map bitstream in this order, and outputting the residual
- the second identification information and the fourth identification information for identifying the residual video bitstream are inserted in this order between the start code and the first identification information.
- auxiliary information a fifth code for identifying the start code, the second identification information, and the auxiliary information is provided. And another information to output a header including in this order in addition to the auxiliary information.
- the bit stream for the stereoscopic video is multiplexed and transmitted to the stereoscopic video decoding apparatus.
- the reference viewpoint video is transmitted as a bit stream of one viewpoint video, and other information is transmitted as a bit stream related to a stereoscopic video different from the one viewpoint video.
- the stereoscopic video decoding method wherein a multi-view video and a depth map that is a map of information for each pixel of a depth value that is a parallax between viewpoints in the multi-view video are encoded bits.
- a stereoscopic video decoding method for decoding a stream to generate a multi-view video wherein a reference viewpoint video decoding processing step, a depth map decoding processing step, a residual video decoding processing step, and a depth map projection processing
- the procedure includes a step and a projected video composition processing step.
- the reference viewpoint video bitstream in which the reference viewpoint video that is the video at the reference viewpoint of the multi-view video is encoded is decoded and decoded.
- a standardized reference viewpoint video is generated.
- a reference viewpoint depth map that is a depth map at the reference viewpoint and a sub viewpoint depth that is a depth map at a sub viewpoint that is another viewpoint away from the reference viewpoint of the multi-view video is decoded to generate a decoded combined depth map.
- a residual video that is a prediction residual when a video at another viewpoint away from the reference viewpoint from the reference viewpoint video is predicted using the decoded combined depth map is obtained.
- the encoded residual video bitstream is decoded to generate a decoded residual video.
- the decoded combined depth map is projected onto a designated viewpoint that is a viewpoint designated externally as a viewpoint of the multi-view video, and a designated viewpoint depth that is a depth map at the designated viewpoint. Generate a map.
- a video obtained by projecting the decoded reference viewpoint video and the decoded residual video onto the designated viewpoint is synthesized, and the video at the designated viewpoint is used.
- a certain viewpoint video is generated.
- a multi-view video composed of videos at the reference viewpoint and the designated viewpoint is generated.
- the stereoscopic video decoding method is the stereoscopic video decoding method according to claim 28, wherein the reference viewpoint video bitstream is a first video that identifies a predetermined start code and one viewpoint video.
- a header including identification information in this order, and the depth map bitstream includes, between the start code and the first identification information, second identification information for identifying that the data is related to stereoscopic video,
- a header including fourth identification information for identifying the residual video bit stream in this order, and the auxiliary information bit stream includes the start code.
- de, and the second identification information has a header containing fifth and identification information in this order to identify said an auxiliary information bit stream, and further comprising steps a bit stream separating process step.
- the reference viewpoint video bitstream, the depth map bitstream, the residual video bitstream, the reference viewpoint, and the subviewpoint A multiplexed bitstream obtained by multiplexing a bitstream including auxiliary information including information indicating each position, the reference viewpoint video bitstream, the depth map bitstream, the residual video bitstream, and the Separated into auxiliary information.
- bit stream having the first identification information is separated from the multiplexed bit stream immediately after the start code as the reference viewpoint video bit stream, and the separated reference viewpoint video bit stream is subjected to the reference viewpoint video decoding process.
- bit stream having the second identification information and the third identification information in this order immediately after the start code is separated from the multiplexed bit stream as the depth map bit stream, and the bit stream is The bit stream from which the second identification information and the third identification information are removed is used in the depth map decoding processing step, and the second identification information, the fourth identification information, and the like are immediately after the start code from the multiplexed bit stream.
- a bit stream having the residual video bit stream And the bit stream obtained by removing the second identification information and the fourth identification information from the bit stream is used in the residual video decoding processing step, and immediately after the start code from the multiplexed bit stream.
- a bit stream having the second identification information and the fifth identification information in this order is separated as the auxiliary information bit stream, and the bit stream obtained by removing the second identification information and the fifth identification information from the bit stream As auxiliary information, it is used in the projected video composition step.
- a stereoscopic video is generated using the multiplexed bit stream.
- the stereoscopic video encoding device is a hardware (eg, CPU (central processing unit)) and memory provided in a general computer, and includes hardware resources such as a reference viewpoint video encoding unit, a depth map synthesis unit, and a depth map. It can also be realized by a stereoscopic video encoding program according to claim 30 for functioning as an encoding means, a depth map decoding means, a projected video prediction means, and a residual video encoding means.
- the stereoscopic video encoding apparatus can also be realized by the stereoscopic video encoding program according to claim 31 for causing a general computer to further function as bit stream multiplexing means.
- the stereoscopic video decoding apparatus is configured such that a standard computer video decoding unit, a depth map decoding unit, a residual video decoding unit, and a hardware resource such as a CPU and a memory included in a general computer are used. Further, the present invention can be realized by a stereoscopic video decoding program according to claim 32 for functioning as a depth map projecting unit and a projected video synthesizing unit.
- the stereoscopic video decoding apparatus is a stereoscopic video decoding apparatus according to claim 33, which further causes hardware resources such as a CPU and a memory included in a general computer to function as bitstream separation means. It can also be realized by a computer program.
- the data is a depth map at the intermediate viewpoint between the reference viewpoint and the sub-viewpoint
- the data for the sub-viewpoint video is a residual video in which only the pixels that become occlusion holes are extracted without being projected from the reference viewpoint video Therefore, encoding can be performed with high efficiency with respect to the original data amount.
- a stereoscopic video decoding is performed when a residual video is generated by cutting out a pixel of a sub-viewpoint video using this detection result. It is possible to appropriately cut out pixels necessary for generating an image at an arbitrary viewpoint in the apparatus.
- the pixel of the sub-viewpoint image is selected using this detection result.
- the occlusion hole in addition to the detection of the occlusion hole using the depth map at the sub-viewpoint, the occlusion hole is detected using the intermediate viewpoint depth map that is the depth map at the intermediate viewpoint, and more appropriate. Therefore, a more appropriate residual image can be generated using the detection result.
- the depth map at the specified viewpoint when the encoded data is decoded and the multi-view video is generated on the decoding side. Since the occlusion hole is detected using, a more appropriate residual image can be generated using the detection result.
- the stereoscopic video encoding apparatus since the amount of data is reduced by framing the intermediate viewpoint depth map and the residual video between a plurality of viewpoints, the stereoscopic video encoding apparatus increases these data. It can be encoded with efficiency.
- the amount of data for the depth map and the sub-viewpoint video is reduced, and the multi-viewpoint video is decoded by decoding the encoded data with high efficiency. Can be generated.
- a composite depth map that is a depth map at an intermediate viewpoint between the reference viewpoint and the sub viewpoint can be used, and only the depth map at the reference viewpoint or the sub viewpoint is used as the position of the viewpoint of the generated video. Therefore, it is possible to generate a specified viewpoint video with good image quality.
- the reference viewpoint video is projected onto the designated viewpoint using the result of detecting the pixel that becomes the occlusion hole using the depth map at the designated viewpoint that is the viewpoint that actually generates the video. Since the designated viewpoint video is generated by appropriately selecting the pixels from the video obtained by projecting the video and the residual video to the designated viewpoint, it is possible to generate the designated viewpoint video with good image quality.
- the tenth aspect of the present invention since a video without a hole is generated, it is possible to generate a specified viewpoint video with good image quality.
- the framed depth map and residual video can be separated to generate the original size depth map and residual video.
- the depth map and residual video in multiple systems are reduced and framed into respective frame images to reduce the amount of data, and the encoded data is decoded with high efficiency. Can be generated.
- the reference viewpoint depth map and the sub viewpoint depth map are combined to reduce the amount of data, and the sub viewpoint video Since the difference video is generated to reduce the data amount, the multi-view video can be encoded with high efficiency.
- the data amount is further reduced by combining three or more depth maps into one, and the data amount is further reduced by reducing two or more residual images into frames. Therefore, the encoding efficiency can be further improved.
- the eighteenth aspect of the present invention since only the pixels that are occlusion holes in the sub-viewpoint video are cut out and the data is reduced, the encoding efficiency can be improved.
- the residual video is generated by calculating the difference of the entire video from the video obtained by projecting the reference viewpoint video onto the sub-viewpoint for the sub-viewpoint video, on the stereoscopic video decoding device side, Using this residual video, a high-quality multi-view video can be synthesized.
- the video for the reference viewpoint is transmitted as a bit stream of a single viewpoint video, Since information is transmitted as a bit stream related to stereoscopic video, an existing stereoscopic video decoding device that decodes one-view video can decode a multiplexed bit stream as one-view video without malfunction.
- the data amount of the depth map and the sub-viewpoint video is reduced, and the multi-viewpoint video is decoded by decoding the encoded data with high efficiency. Can be generated.
- the data amount of the depth map and the sub-viewpoint video is further reduced, and the multi-viewpoint video can be generated by decoding the encoded data with higher efficiency.
- the data amount of the sub-viewpoint video is further reduced, and the multi-viewpoint video can be generated by decoding the encoded data with higher efficiency.
- multi-view video can be generated with high quality by decoding data obtained by encoding high-quality residual video for the sub-view video.
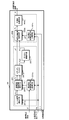
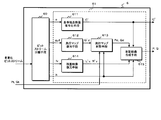
- FIG. 1 is a block diagram illustrating a configuration of a stereoscopic video transmission system including a stereoscopic video encoding device and a stereoscopic video decoding device according to the first and second embodiments of the present invention.
- FIG. It is a block diagram which shows the structure of the stereo image coding apparatus which concerns on 1st Embodiment of this invention. It is a block diagram which shows the detailed structure of the stereo image coding apparatus which concerns on 1st Embodiment of this invention, (a) shows depth map synthetic
- (A) is a block diagram which shows the detailed structure of the projection image prediction means in the stereo image coding apparatus which concerns on 3rd Embodiment of this invention
- (b) shows the structure of the projection image prediction means in the modification. It is a block diagram. It is a block diagram which shows the structure of the stereo image decoding apparatus which concerns on 3rd Embodiment of this invention. It is explanatory drawing for demonstrating the outline
- (A) is a block diagram which shows the detailed structure of the projection image prediction means in the stereo image decoding apparatus concerning 3rd Embodiment of this invention
- (b) shows the structure of the projection image prediction means in the modification.
- FIG. 4th Embodiment of this invention It is a figure which shows the data structure in 4th Embodiment of this invention, (a) is a conventional bit stream, (b) is a reference
- the stereoscopic video transmission system S encodes and transmits a stereoscopic video captured by a camera or the like together with a depth map, and generates a multi-view video at the transmission destination.
- the stereoscopic video transmission system S includes a stereoscopic video encoding device 1, a stereoscopic video decoding device 2, a stereoscopic video creation device 3, and a stereoscopic video display device 4.
- the stereoscopic video encoding device 1 encodes the stereoscopic video created by the stereoscopic video creation device 3, outputs it as a bit stream to the transmission path, and transmits it to the stereoscopic video decoding device 2.
- the stereoscopic video decoding device 2 decodes the bitstream transmitted from the stereoscopic video encoding device 1, generates a multi-view video, outputs it to the stereoscopic video display device 4, and displays the stereoscopic video. is there.
- bitstream transmitted from the stereoscopic video encoding device 1 to the stereoscopic video decoding device 2 may be a plurality of bitstreams corresponding to each of a plurality of types of signals, for example. Further, as in a fourth embodiment to be described later, these signals may be multiplexed and transmitted as one bit stream. The same applies to other embodiments described later.
- the stereoscopic video creation device 3 is a camera that can capture a stereoscopic video, a CG (computer graphics) creation device, or the like.
- the stereoscopic video creation device 3 generates a stereoscopic video (multi-view video) and an associated depth map, and generates a stereoscopic video code. Is output to the converter 1.
- the stereoscopic video display device 4 receives the multi-view video generated by the stereoscopic video decoding device 2 and displays the stereoscopic video.
- the stereoscopic video encoding device 1 (hereinafter referred to as “encoding device” as appropriate) according to the first embodiment includes a reference viewpoint video encoding unit 11, a depth map synthesis unit 12, Depth map encoding means 13, depth map decoding means 14, projected video prediction means 15, and residual video encoding means 16 are provided.
- the projected video prediction unit 15 includes an occlusion hole detection unit 151 and a residual video cutout unit 152.
- the encoding device 1 has a reference viewpoint image C that is an image viewed from a reference viewpoint, and a left image that is viewed from a left viewpoint (sub-viewpoint) that is a viewpoint horizontally separated from the reference viewpoint in the left direction.
- the left designated viewpoints 1 to n (designated viewpoints), which are viewpoints designated to generate a video, are input.
- the right viewpoint toward the subject is used as the reference viewpoint
- the left viewpoint is used as the left viewpoint (sub-viewpoint).
- the present invention is not limited to this.
- the left viewpoint may be the reference viewpoint and the right viewpoint may be the sub viewpoint.
- the reference viewpoint and the sub-viewpoint are not limited to being separated in the horizontal direction, and may be separated in any direction such as a vertical direction or an oblique direction that changes the angle at which the subject is observed from the viewpoint.
- the encoding apparatus 1 outputs an encoded reference viewpoint video c obtained by encoding the reference viewpoint video C as a reference viewpoint video bitstream based on these input data, and is intermediate between the reference viewpoint and the left viewpoint.
- An encoded residual video lv obtained by encoding a left residual video (residual video) Lv that is a difference from the left viewpoint video L is output as a residual video bitstream.
- each bit stream output from the encoding device 1 is transmitted to the stereoscopic video decoding device 2 (see FIG. 1) via a transmission path.
- each video is composed of a subject in a circular foreground and another subject as a background. It shall be.
- pixels (circular regions) corresponding to the subject in the foreground have a large depth value. It is shown brightly in the drawing.
- the pixel corresponding to the subject in the background has a small depth value, and is dark in the drawing.
- the depth map attached to each viewpoint video has a depth value for each pixel, which is a value corresponding to the shift amount of the pixel position corresponding to the same subject point shown in the reference viewpoint video C and the left viewpoint video L. It is assumed that the map defined in the above is given in advance for each pixel of the video of each viewpoint.
- the reference viewpoint video encoding means 11 receives the reference viewpoint video C from the outside, encodes it according to a predetermined encoding method, generates an encoded reference viewpoint video c, and outputs it as a reference viewpoint video bitstream to the transmission path It is.
- the encoding method used here it is preferable to use an encoding method that is prevalent as a 2D (two-dimensional) video encoding method.
- the MPEG-2 Moving Picture Experts Group-2
- H.264 MPEG-4 AVC (Moving Picture Experts Group-4 Advanced Video Coding) standard encoding system.
- MPEG-4 AVC Moving Picture Experts Group-4 Advanced Video Coding
- the depth map synthesis means (intermediate viewpoint depth map synthesis means) 12 inputs the reference viewpoint depth map Cd and the left viewpoint depth map Ld from the outside, and sets the intermediate viewpoint as an intermediate viewpoint between the reference viewpoint and the left viewpoint, respectively. Project a depth map at the intermediate viewpoint. Then, the depth map synthesis means 12 synthesizes the two depth maps at the generated intermediate viewpoint to generate a left composite depth map (intermediate viewpoint depth map) Md and outputs it to the depth map encoding means 13.
- any depth map used in the present embodiment is handled as image data in the same format as a video such as the reference viewpoint video C.
- a depth value is set as the luminance component (Y), and a predetermined value (for example, “128” in the case of an 8-bit signal per component) is set as the color difference components (Pb, Pr).
- a predetermined value for example, “128” in the case of an 8-bit signal per component
- the depth map synthesizing unit 12 includes intermediate viewpoint projecting units 121 and 122 and a map synthesizing unit 123 as shown in FIG.
- the intermediate viewpoint projecting means 121 is on the opposite side of the reference viewpoint depth map Cd from the reference viewpoint in terms of the number of pixels corresponding to 1 ⁇ 2 of the depth value that is the pixel value of each pixel. by shifting to the right, to generate a depth map M C d at the middle point of view.
- the depth map M C d the pixel depth value generated by shifting without the pixels (pixel values) produced, referred to as occlusion hole.
- the depth value of an effective pixel in the vicinity of a predetermined range of the pixel position is set as the depth value of the pixel.
- the minimum depth value among the depth values of the pixels in the vicinity of the predetermined range is the depth value of the pixel. Accordingly, the depth value of the pixel corresponding to the background (background) subject hidden behind the foreground subject due to occlusion can be interpolated substantially correctly.
- the intermediate viewpoint projection unit 121 outputs the generated depth map M C d to the map synthesis unit 123.
- the distance from the reference viewpoint to the left viewpoint is b
- the distance from the reference viewpoint to the left designated viewpoint as an arbitrary viewpoint is c
- the distance from the left intermediate viewpoint to the left designated viewpoint is a.
- the distance from the left designated viewpoint to the left viewpoint is d.
- the distance from the reference viewpoint to the left intermediate viewpoint and the distance from the left intermediate viewpoint to the left viewpoint are both b / 2.
- the depth value means that when a depth map or video is projected to a viewpoint separated by a distance b which is a distance between the reference viewpoint and the left viewpoint, the pixel is shifted in the right direction opposite to the viewpoint shift direction.
- the shift amount of the number of pixels is proportional to the shift amount of the viewpoint. Therefore, when projecting the depth map at the reference viewpoint to the designated viewpoint separated by c from the reference viewpoint, each pixel is shifted to the right by the number of pixels corresponding to (c / b) times the depth value. It becomes. If the viewpoint shift direction is rightward, the pixel is shifted rightward, which is the opposite side.
- the intermediate viewpoint projection unit 122 sets each pixel on the side opposite to the direction of the intermediate viewpoint when viewed from the left viewpoint by the number of pixels corresponding to 1/2 of the depth value that is the pixel value.
- a depth map M L d at the intermediate viewpoint is generated by shifting to a certain left direction.
- an occlusion hole is generated in the depth map M L d, and this is filled with pixel values of effective pixels around the pixel in the same manner as the intermediate viewpoint projection unit 121 described above.
- the intermediate viewpoint projection unit 122 outputs the generated depth map M L d to the map synthesis unit 123.
- the original depth map (reference viewpoint) is determined from the difference in the depth value of each pixel in each depth map. Pixels at different positions in the depth map Cd and the left viewpoint depth map Ld) may be at the same position after the shift. When a plurality of pixels overlap at the same position after shifting the pixel position, the pixel having the largest depth value among them is set as the depth value in that pixel. Accordingly, the depth value of the foreground subject remains in the depth map after projection (the depth maps M C d and M L d at the intermediate viewpoint), and the occlusion relationship that is the overlapping relationship of the subjects can be correctly maintained.
- the map synthesizing unit 123 synthesizes the depth maps M C d and M L d at the two intermediate viewpoints input from the intermediate viewpoint projecting units 121 and 122 into one to generate a left synthesized depth map Md, and the depth map code Output to the conversion means 13.
- the map synthesis unit 123 synthesizes the two depth maps M C d and M L d into one to generate the left synthesized depth map Md, the same applies to both the depth maps M C d and M L d.
- the average value of the depth values at the pixel position is set as the depth value at the pixel.
- the map composition unit 123 adds the 3 ⁇ 3, 5 ⁇ 5, 7 ⁇ 7, 9 ⁇ 9, 11 ⁇ 11, 13 ⁇ 13, 15 ⁇ 15, and 17 ⁇ 17 pixels to the left composite depth map Md.
- the quality of the depth map before filtering is poor, and even a non-smooth depth map containing many erroneous depth values can be replaced with the median depth value of each pixel in the surrounding pixel area, A smoother depth map is obtained, and the quality of the designated viewpoint video synthesized by the stereoscopic video decoding device 2 is improved. Even if the median filter processing is performed, the portion where the depth value greatly changes is saved, so that the depth values of the foreground and the background are not mixed.
- the depth map encoding unit 13 encodes the left composite depth map Md input from the depth map synthesis unit 12 using a predetermined encoding method to generate an encoded depth map md, and outputs the encoded depth map md to the transmission path. .
- the encoding method used here may be the same as the encoding method in which the reference viewpoint video is encoded as described above.
- a higher encoding efficiency encoding method such as HEVC (High Efficiency Video Coding) is used. May be.
- the depth map decoding unit 14 decodes the depth map bitstream that is the encoded depth map md generated by the depth map encoding unit 13 based on the encoding method, and decodes the depth map bitstream at the intermediate viewpoint.
- a left composite depth map (decoded intermediate viewpoint depth map) M′d is generated.
- the depth map decoding unit 14 outputs the generated decoded left composite depth map M′d to the occlusion hole detection unit 151.
- the projected video prediction means 15 inputs the reference viewpoint video C, the left viewpoint video L, and the left designated viewpoints Pt 1 to Pt n from the outside, and the decoded left composite depth from the depth map decoding means 14.
- the map M′d is input, a left residual video Lv is generated, and is output to the residual video encoding means 16.
- the projected video prediction unit 15 includes an occlusion hole detection unit 151 and a residual video cutout unit 152.
- the occlusion hole detection means 151 inputs the reference viewpoint video C and the left designated viewpoints Pt 1 to Pt n from the outside, and inputs the decoded left composite depth map M′d from the depth map decoding means 14, and the reference viewpoint video C Is detected as a pixel region that becomes an occlusion hole that is predicted to occur when projected onto the left viewpoint, intermediate viewpoint, and left designated viewpoints Pt 1 to Pt n .
- the occlusion hole detection unit 151 generates a hole mask Lh indicating a pixel region that becomes an occlusion hole as a detection result, and outputs the detection result to the residual image cutout unit 152.
- the hole mask Lh in the present embodiment is binary data (0, 1) having the same size as the image such as the reference viewpoint image C, and can project the reference viewpoint image C to the left viewpoint without becoming an occlusion hole.
- the value “0” is set for the remaining pixels, and the value “1” is set for the pixels that are occlusion holes.
- the occlusion hall OH will be described.
- the case where the reference viewpoint video C is projected to the left viewpoint using the left viewpoint projection depth map L′ d that is the depth map at the left viewpoint will be described as an example.
- the pixel of the subject that is the foreground close to the viewpoint position is projected to a position greatly displaced by the shift of the viewpoint position.
- the pixel of the subject that is a background far away from the viewpoint position is projected to a position that hardly shifts due to the shift of the viewpoint position. Therefore, as shown as a left viewpoint projection image L C of FIG. 4, after the round the subject to be the foreground is shifted in the right direction, there was no corresponding pixels in the reference viewpoint image C by hiding the foreground
- the black crescent-shaped region remains as a region where pixels are not projected.
- An area where this pixel is not projected is an occlusion hole OH.
- an occlusion hole is generally generated when an image is projected to an arbitrary viewpoint using a depth map related to the image (the viewpoint does not have to be the same as the image).
- the residual video clipping unit 152 described later extracts the pixels in the pixel region in the occlusion hole OH from the left viewpoint video L to generate the left residual video Lv.
- the left composite depth map Md can also be used.
- the depth map decoding means 14 is unnecessary.
- an encoding method that can obtain a high compression rate is generally non-inverse transform, it is preferable to use a decoded left composite depth map M′d as in this embodiment. Accordingly, it is possible to accurately predict an occlusion hole that occurs when the stereoscopic video decoding device 2 (see FIG. 1) generates a multi-view video using the decoded left composite depth map M′d.
- the residual image cutout unit 152 inputs the left viewpoint video L from the outside, inputs the hole mask Lh from the occlusion hole detection unit 151, and displays the pixel in the pixel region that becomes the occlusion hole indicated by the hole mask Lh as the left viewpoint.
- the left residual video Lv is generated by extracting from the video L.
- the residual video cutout unit 152 outputs the generated left residual video Lv to the residual video encoding unit 16.
- the left residual video Lv is image data in the same format as the reference viewpoint video C and the left viewpoint video L.
- pixels in a pixel region that does not become an occlusion hole have a predetermined pixel value.
- the predetermined value is preferably set to 128 which is an intermediate pixel value for both the luminance component (Y) and the color difference components (Pb, Pr).
- the residual video encoding unit 16 receives the left residual video Lv from the residual video cutout unit 152, encodes the left residual video Lv by a predetermined encoding method, and generates an encoded residual video lv.
- the residual video bit stream is output to the transmission path.
- the encoding method used here may be the same as the encoding method in which the reference viewpoint video C is encoded, or may be an encoding method with higher encoding efficiency such as HEVC.
- the occlusion hole detection means 151 will be described in more detail with reference to FIG. 3B (refer to FIGS. 2 and 4 as appropriate).
- the occlusion hole detection unit 151 includes a first hole mask generation unit 1511, a second hole mask generation unit 1512, and a third hole mask generation unit 1513 (1513 1 to 1513 n ). , And a hole mask synthesizing unit 1514 and a hole mask expanding unit 1515.
- the first hole mask generation means 1511 predicts a pixel area that becomes an occlusion hole OH when the reference viewpoint video C is projected to the left viewpoint, generates a hole mask Lh 1 indicating the pixel area, and generates a hole mask synthesis means. 1514 is output.
- the first hole mask generating unit 1511 includes a left viewpoint projecting unit 1511a and a first hole pixel detecting unit 1511b.
- the left viewpoint projection means (sub-viewpoint projection means) 1511a receives the decoded left composite depth map M′d from the depth map decoding means 14, and projects this decoded left composite depth map M′d onto the left viewpoint.
- the left viewpoint projection depth map L′ d which is the depth map at the left viewpoint, is generated and output to the first hole pixel detection means 1511b.
- the left-view projection depth map L′ d is the number of pixels corresponding to half the depth value of each pixel of the decoded left composite depth map M′d, which is the depth map of the intermediate viewpoint. It can be generated by shifting to the right. When a plurality of pixels overlap the same pixel after shifting all the pixels, a plurality of depth maps at the intermediate viewpoint are generated by the intermediate viewpoint projection means 121 and 122 (see FIG. 3A). The maximum depth value among the depth values of the pixel is set as the depth value of the pixel position.
- the depth value of the effective pixel in the vicinity of the predetermined range of the pixel position is calculated as the depth value of the pixel, as in the case of generating the depth map at the intermediate viewpoint by the map synthesis unit 123 described above.
- Depth value In this case, the minimum depth value among the depth values of the pixels in the vicinity of the predetermined range may be set as the depth value of the pixel.
- the first hole pixel detection means (hole pixel detection means) 1511b inputs the reference viewpoint video C from the outside, inputs the left viewpoint projection depth map L′ d from the left viewpoint projection means 1511a, and outputs the left viewpoint projection depth.
- the map viewpoint L′ d is used to project the reference viewpoint video C to the left viewpoint, a pixel area to be an occlusion hole OH is predicted, and a hole mask Lh 1 indicating the pixel area is generated, and hole mask synthesis means It outputs to 1514.
- the first hole pixel detection unit 1511b sequentially performs median filter processing of 3 ⁇ 3 and 5 ⁇ 5 pixels on the left viewpoint projection depth map L′ d input from the left viewpoint projection unit 1511a to perform encoding and decoding. The error of depth value caused by conversion and projection is reduced. Then, the pixel area that becomes the occlusion hole OH is detected using the left viewpoint projection depth map L′ d after the median filter processing.
- a method for detecting a pixel serving as an occlusion hole will be described in more detail.
- the depth value at the pixel of interest is x
- the depth value at a pixel away from the pixel of interest by a predetermined number of pixels Pmax to the right is y.
- the predetermined number of pixels Pmax separated in the right direction is, for example, the number of pixels corresponding to the maximum amount of parallax in the corresponding video, that is, the amount of parallax corresponding to the maximum depth value.
- the depth value in the right neighboring pixel is z.
- it is determined that the pixel of interest is a pixel that becomes an occlusion hole.
- Equation (1) k is a predetermined coefficient, and can be a value of about “0.8” to “0.6”, for example.
- the “predetermined value” can be set to “4”, for example.
- the second hole mask generating means 1512 predicts a pixel area that becomes an occlusion hole OH when the reference viewpoint video C is projected onto the intermediate viewpoint, and a hole mask indicating the pixel area. Lh 2 is generated and output to the hole mask combining means 1514.
- the second hole mask generation unit 1512 includes a second hole pixel detection unit 1512a and a left viewpoint projection unit 1512b.
- the second hall pixel detection unit 1512a receives the reference viewpoint video C from the outside, receives the decoded left composite depth map M′d from the depth map decoding unit 14, and projects the reference viewpoint video C to the intermediate viewpoint In addition, a pixel area serving as an occlusion hole is detected, a hole mask at an intermediate viewpoint indicating the pixel area is generated, and output to the left viewpoint projection unit 1512b.
- the second hole pixel detection means 1512a applies the median filter processing of 3 ⁇ 3 and 5 ⁇ 5 pixels to the decoded left composite depth map M′d in order, and the depth value generated by encoding and decoding The pixel region that becomes an occlusion hole is detected after reducing the error.
- the generation of holes mask in the second hole pixel detection unit 1512a is only the depth map used is different, can be performed in the same manner as formation of holes mask Lh 1 in the first hole pixel detection unit 1511b described above.
- Left viewpoint projection means (second sub perspective projection means) 1512b receives a hole mask in the intermediate viewpoint from the second hole pixel detection means 1512a, the hole mask, to produce a hole mask Lh 2 obtained by projecting the left viewpoint.
- Left viewpoint projection means 1512b outputs the generated hole mask Lh 2 into the hole mask synthesis unit 1514.
- the projection of the hole mask at the intermediate viewpoint to the left viewpoint is a pixel corresponding to 1 ⁇ 2 times the depth value of the corresponding pixel in the decoded left composite depth map M′d for each pixel of the hole mask at the intermediate viewpoint. It can be generated by shifting to the right by a number.
- each third hole mask generation unit 1513 includes a designated viewpoint projection unit 1513a, a third hole pixel detection unit 1513b, and a left viewpoint projection unit 1513c. ing.
- the designated viewpoint projection means (designated viewpoint projection means) 1513a receives the decoded left composite depth map M′d from the depth map decoding means 14, and uses this decoded left composite depth map M′d as the left designated viewpoint Pt (Pt 1 to Pt n ), a left designated viewpoint depth map that is a depth map at the left designated viewpoint Pt (Pt 1 to Pt n ) is generated, and is output to the third hole pixel detection means 1513b.
- the depth map at the left designated viewpoints Pt 1 to Pt n has a distance from the intermediate viewpoint to the left designated viewpoint, and b is a distance from the reference viewpoint to the left viewpoint.
- the decoded left composite depth map M′d which is a depth map at the intermediate viewpoint
- the number of pixels corresponding to a value obtained by multiplying the depth value at that pixel by (a / b) is specified as viewed from the intermediate viewpoint. It can be generated by shifting in the direction opposite to the viewpoint (right direction in the example of FIG. 5A).
- the third hole pixel detection means 1513b receives the reference viewpoint video C from the outside, inputs the left designated viewpoint depth map from the designated viewpoint projection means 1513a, and converts the reference viewpoint video C to the corresponding left designated viewpoints Pt 1 to Pt n .
- a pixel area that becomes an occlusion hole is detected, hole masks at the left designated viewpoints Pt 1 to Pt n indicating the pixel area are generated, and output to the left viewpoint projection unit 1513c.
- the third hole pixel detection unit 1513b interpolates the occlusion hole generated in the left designated viewpoint projection depth map input from the designated viewpoint projection unit 1513a with the surrounding effective pixels, and then further 3 ⁇ 3 and 5 ⁇ 5 pixels.
- the median filter process is sequentially performed to reduce the depth value error caused by the encoding, decoding, and projection. Thereafter, the third hole pixel detection means 1513b detects a pixel region that becomes an occlusion hole using the left designated viewpoint projection depth map.
- the generation of holes mask in the third hole pixel detection unit 1513b is only the depth map used is different, can be performed in the same manner as formation of holes mask Lh 1 in the first hole pixel detection unit 1511b described above.
- the left viewpoint projection means (third sub-viewpoint projection means) 1513c inputs the hole masks at the corresponding left designated viewpoints Pt 1 to Pt n from the third hole pixel detection means 1513b, and projects the hole masks to the left viewpoint. Hole masks Lh 31 to Lh 3n are generated. The left viewpoint projection unit 1513c outputs the generated hole masks Lh 31 to Lh 3n to the hole mask synthesis unit 1514.
- the hole masks Lh 31 to Lh 3n at the left viewpoint have a distance from the left designated viewpoint to the left viewpoint as d and a distance from the reference viewpoint to the left viewpoint as b.
- the left designated viewpoints Pt 1 to Pt n use the same viewpoint as that input to the stereoscopic video decoding apparatus 2 as viewpoints in the multi-view video generated by the stereoscopic video decoding apparatus 2 (see FIG. 1). However, if it is unknown, a viewpoint obtained by dividing the reference viewpoint position and the sub-viewpoint (left or right viewpoint) position at equal intervals may be used.
- the left designated viewpoints Pt 1 to Pt n may be one or two or more.
- third hole mask generation means 1513 (1513 1 to 1513 n ) is provided, and left designated viewpoints Pt 1 to Pt n that are actually designated by the stereoscopic video decoding device 2 (see FIG. 1) are provided. It is preferable to add the hole masks Lh 31 to Lh 3n in the pixel region that becomes an occlusion hole predicted when projected, so that a more appropriate left residual image Lv can be generated.
- the hole mask synthesizing unit 1514 receives the hole mask Lh 1 from the first hole mask generating unit 1511, the hole mask Lh 2 from the second hole mask generating unit 1512, and the hole mask Lh from the third hole mask generating units 1513 1 to 1513 n. 31 to Lh 3n are respectively input as detection results of pixel regions to be occlusion holes, and the input hole masks (detection results) are combined to generate one hole mask Lh 0 , and hole mask expansion means 1515 Output to.
- the hole mask compositing means 1514 calculates the logical sum of the pixel areas to be occlusion holes for the plurality of input hole masks Lh 1 , Lh 2 , Lh 31 to Lh 3n , and at least one hole mask uses the occlusion hole.
- the pixel which becomes is a pixel which becomes an occlusion hole.
- the hole mask dilating means 1515 receives the hole mask Lh 0 from the hole mask synthesizing means 1514, and dilates the pixel area to be an occlusion hole in the hole mask Lh 0 in all directions by a predetermined number of pixels. .
- the hole mask expansion means 1515 outputs the expanded hole mask Lh to the residual image cutout means 152 (see FIG. 2).
- the predetermined number of pixels to be expanded can be, for example, 16 pixels.
- the stereoscopic video decoding device 2 (see FIG. 1) generates a multi-viewpoint video.
- the occlusion hole difference due to the difference in viewpoint (designated viewpoint) is covered, and appropriate pixels can be copied from the left residual video Lv and used.
- the hole mask expansion means 1515 may be provided before the hole mask synthesis means 1514. That is, the same effect can be obtained by performing an OR operation after expanding each hole mask.
- the stereoscopic video decoding device 2 generates a multi-view video by decoding the bitstream transmitted from the stereoscopic video encoding device 1 shown in FIG. 2 via a transmission path.
- the stereoscopic video decoding device 2 (hereinafter referred to as “decoding device” as appropriate) according to the first embodiment includes a reference viewpoint video decoding unit 21, a depth map decoding unit 22, and Depth map projection means 23, residual video decoding means 24, and projected video synthesis means 25.
- the projected video synthesizing unit 25 includes a reference viewpoint video projecting unit 251 and a residual video projecting unit 252.
- the decoding apparatus 2 includes an encoded reference viewpoint video c output as a reference viewpoint video bit stream from the encoding apparatus 1, an encoded depth map md output as a depth bitmap stream, and a residual video bitmap stream.
- the encoded residual video lv output as, and the input data are processed, and the reference viewpoint video (decoded reference viewpoint video) C ′ that is the video at the reference viewpoint and the left designated viewpoint (designated viewpoint) )
- a left designated viewpoint video (designated viewpoint video) P which is a video at Pt, is generated and output to the stereoscopic video display device 4 to display the stereoscopic video.
- the left designated viewpoint video P generated by the decoding device 2 may be one or two or more.
- the reference viewpoint video decoding means 21 receives an encoded reference viewpoint video c output as a reference viewpoint video bitstream from the encoding device 1, decodes the encoded reference viewpoint video c with the encoding method, and generates a reference A viewpoint video (decoding reference viewpoint video) C ′ is generated.
- the reference viewpoint video decoding unit 21 outputs the generated reference viewpoint video C ′ to the reference viewpoint video projection unit 251 of the projected video synthesis unit 25 and also outputs one video (reference) to the stereoscopic video display device 4. (Viewpoint video).
- the depth map decoding means 22 receives the encoded depth map md output from the encoding device 1 as a depth bitmap stream, decodes the encoded depth map md by the encoding method, and performs the depth at the intermediate viewpoint.
- a decoded left composite depth map (decoded intermediate viewpoint depth map) M′d which is a map, is generated. This decoded left composite depth map M′d is the same as the decoded left composite depth map M′d generated by the depth map decoding means 14 (see FIG. 2) of the encoding device 1.
- the depth map decoding unit 22 outputs the generated decoded left composite depth map M′d to the depth map projection unit 23.
- the depth map projection means 23 inputs the decoded left composite depth map M′d, which is the depth map at the intermediate viewpoint, from the depth map decoding means 22, and uses the input decoded left composite depth map M′d as the left designated viewpoint Pt.
- the left designated viewpoint depth map Pd which is the depth map at the left designated viewpoint Pt, is generated.
- the depth map projection means 23 interpolates the occlusion hole of the projected left designated viewpoint depth map Pd with surrounding pixel values, and further performs median filter processing of 3 ⁇ 3 and 5 ⁇ 5 pixels in order, After reducing the error caused by the decoding and projection, the generated left designated viewpoint depth map Pd is output to the reference viewpoint video projection unit 251 and the residual video projection unit 252 of the projection video synthesis unit 25.
- the left designated viewpoint Pt is the left designated viewpoint Pt in the multi-view video generated by the decoding device 2, and may be input from setting means (not shown) determined in advance in the decoding device 2, or from the outside. You may make it input by a user's operation via input means, such as a keyboard. Further, the left designated viewpoint Pt may be one or two or more. When the left designated viewpoint Pt is 2 or more, the left designated viewpoint depth map Pd at each left designated viewpoint Pt is generated in sequence for each left designated viewpoint Pt, and sequentially output to the projected video composition means 25. And
- the residual video decoding means 24 receives the encoded residual video lv output as a residual video bit stream from the encoding device 1, decodes the encoded residual video lv with the encoding method, and outputs the left Residual video (decoded residual video) L′ v is generated and output to the residual video projection means 252 of the projected video synthesis means 25.
- the projected video synthesizing unit 25 receives the reference viewpoint video C ′ from the reference viewpoint video decoding unit 21, the left residual video L′ v from the residual video decoding unit 24, and the left designated viewpoint depth map from the depth map projection unit 23. Each of the Pd is input, and using these input data, a left designated viewpoint video P that is a video at the left designated viewpoint Pt is generated and output to the stereoscopic video display device 4 as one of the multi-viewpoint videos. .
- the projected video synthesizing unit 25 includes a reference viewpoint video projecting unit 251 and a residual video projecting unit 252.
- the reference viewpoint video projection means 251 constituting the projected video composition means 25 inputs the reference viewpoint video C ′ from the reference viewpoint video decoding means 21 and the left designated viewpoint depth map Pd from the depth map projection means 23, respectively. as image at specified viewpoint Pt, the reference viewpoint image C 'to generate the left specified viewpoint video P C for a pixel that can be projected to the left specified viewpoint Pt.
- Reference viewpoint image projection means 251 outputs the generated left specified viewpoint image P C to the residual image projection means 252. The detailed configuration of the reference viewpoint video projection unit 251 will be described later.
- the residual video projection means 252 constituting the projected video composition means 25 inputs the left residual video L′ v from the residual video decoding means 24 and the left designated viewpoint depth map Pd from the depth map projection means 23, respectively. , as an image in the left specified viewpoint Pt, pixels can not be projected reference viewpoint image C ', i.e., the pixels to be occlusion hole, to generate the left specified viewpoint video P to complement the left specified viewpoint video P C.
- the residual video projection means 252 outputs the generated left designated viewpoint video P to the stereoscopic video display device 4 (see FIG. 1). The detailed configuration of the residual video projection means 252 will be described later.
- the reference viewpoint video projection unit 251 includes a hole pixel detection unit 251a, a designated viewpoint video projection unit 251b, a reference viewpoint video pixel copying unit 251c, a median filter 251d, and a hole mask expansion unit 251e. , And is configured.
- the hall pixel detecting unit 251a receives the left designated viewpoint depth map Pd from the depth map projecting unit 23, and uses the left designated viewpoint depth map Pd for the reference viewpoint video C ′ input from the reference viewpoint video decoding unit 21. Then, a pixel that becomes an occlusion hole when projected onto the left designated viewpoint Pt is detected, a hole mask P 1 h indicating the detected pixel area is generated as a detection result, and is output to the reference viewpoint video pixel copying means 251c.
- the detection method of the pixel which becomes an occlusion hole in the hole pixel detection means 251a is replaced with the left viewpoint projection depth map L′ d in the first hole pixel detection means 1511b (see FIG. 3A) of the encoding device 1 described above.
- the right neighboring pixel of the target pixel that is the target of determination as to whether or not the pixel is an occlusion hole using the left designated viewpoint depth map Pd has a depth value larger than the depth value of the target pixel
- the target pixel is detected as a pixel that becomes an occlusion hole.
- the viewpoint position of each depth map and the viewpoint position of a projection destination differ, the adjustment is needed.
- the distance from the reference viewpoint to the left viewpoint is b, and the distance from the reference viewpoint to the left designated viewpoint is c.
- the depth value in the target pixel that is a target for determining whether or not the pixel is an occlusion hole is x
- the depth value in a pixel that is a predetermined number of pixels Pmax in the right direction from the target pixel is y.
- Equation (2) k is a predetermined coefficient, and can be a value of about “0.8” to “0.6”, for example.
- the “predetermined value” can be set to “4”, for example.
- the reference viewpoint image pixel copying unit 251c can copy appropriate pixels from the left designated viewpoint projection image P 1 C, which is an image obtained by projecting the reference viewpoint image C ′.
- the predetermined number of pixels separated in the right direction is set to four stages, the same determination is performed for each stage, and it is determined that the pixel is an occlusion hole in at least one stage.
- the target pixel is determined to be a pixel that becomes an occlusion hole.
- the predetermined number of pixels Pmax separated in the right direction set in four steps for example, as the first step, the number of pixels corresponding to the maximum amount of parallax in the corresponding video, that is, the maximum depth value is supported.
- the number of pixels to be used As the second stage, 1 ⁇ 2 of the number of pixels set in the first stage is set.
- the third stage is set to 1/4 of the number of pixels set in the first stage.
- the fourth stage is set to 1/8 of the number of pixels set in the first stage.
- the occlusion hole is overlooked when a large amount of parallax is set by detecting the pixel that becomes an occlusion hole by referring to the difference in depth value from the pixel at positions separated by the number of pixels in a plurality of stages. It is preferable that the occlusion hole by the subject as a narrow foreground can be appropriately detected.
- the number of steps for setting the predetermined number of pixels Pmax separated in the right direction is not limited to four steps, and may be two to three steps or five or more steps.
- the hole pixel detecting means 251a detects an occlusion hole in a predetermined range from the right end of the screen, which is an area not included in the left residual video (residual video) L′ v. As a detection region, occlusion hole detection is not performed, and an occlusion hole generated in this portion is filled by the hole filling processing means 252c. This prevents an occlusion hole that is not included in the residual video from being enlarged by the hole mask expansion means 251e, and prevents the quality of the composite video from being degraded.
- the predetermined range as the occlusion hole non-detection area is, for example, a pixel range corresponding to the maximum parallax amount from the right end of the video as shown in FIG.
- the designated viewpoint video projection means 251b inputs the reference viewpoint video C ′ from the reference viewpoint video decoding means 21 and the left designated viewpoint depth map Pd from the depth map projection means 23, respectively, and sets the reference viewpoint video C ′ as the left designated viewpoint.
- a left designated viewpoint projected image P 1 C which is an image projected onto Pt, is generated and output to the reference viewpoint image pixel copying unit 251c.
- the designated viewpoint video projecting means 251b shifts the left designated viewpoint depth map Pd to the left by the number of pixels corresponding to the value obtained by multiplying the depth value at that pixel position by (c / b).
- a pixel is extracted from the base viewpoint video C ′, and the extracted pixel value is set as the pixel value at the pixel position of the referenced depth value, thereby generating the left designated viewpoint projected video P 1 C.
- the reference viewpoint video pixel copying means 251c receives the left designated viewpoint projected video P 1 C from the designated viewpoint video projection means 251b and the hole mask P 1 h from the hole pixel detection means 251a, respectively, and from these input data, occlusion
- the left designated viewpoint video P 2 C is generated by copying pixels that can project the reference viewpoint video C ′ to the left designated viewpoint Pt without forming a hole. Further, the reference viewpoint video pixel copying unit 251c outputs the generated left designated viewpoint video P 2 C and the input hole mask P 1 h to the median filter 251d.
- the reference viewpoint image pixel copy unit 251c when generating the left specified viewpoint video P 2 C, performs the initialization processing for setting a predetermined value for all of the pixel values of the left specified viewpoint video P 2 C.
- This predetermined value is the same as the pixel value set for the pixels having no residual video in the residual video cutting means 152 (see FIG. 2) of the encoding device 1 (for example, 8 per component).
- the luminance component (Y) and the color difference components (Pb, Pr) are both “128”).
- the left designated viewpoint video P 2 C in which this predetermined value is set is generated as a pixel that becomes an occlusion hole.
- the median filter 251d receives the left designated viewpoint video P 2 C and the hole mask P 1 h from the reference viewpoint video pixel copying means 251c, and performs median filter processing on the respective input data to thereby respectively specify the left designated viewpoint video P C and generating a hole mask P 2 h, the resulting left specified viewpoint image P C to the residual video pixel copying unit 252b of the residual image projection means 252, and outputs the hole mask P 2 h in the hole mask expansion unit 251e.
- a filter having a pixel size of 3 ⁇ 3 can be used for the median filter processing applied to the left designated viewpoint video P 2 C .
- a pixel that becomes an isolated occlusion hole that has not been detected by the hole pixel detection means 251a is 3 ⁇ Interpolated with the median value of each pixel value in the three pixel regions.
- the hole mask expansion means 251e receives the hole mask P 2 h from the median filter 251d, and generates and generates a hole mask Ph in which a pixel area that becomes an occlusion hole in the hole mask P 2 h is expanded by a predetermined number of pixels.
- the hole mask Ph is output to the residual video pixel copying unit 252b of the residual video projection unit 252.
- the predetermined number of pixels to be expanded can be, for example, 8 pixels.
- pixels copied from the left designated viewpoint projected image P 1 C by the reference viewpoint video pixel copying means 251c by mistake due to the generation error of the left designated viewpoint depth map Pd are substantially defined as occlusion holes. It is possible to return to the “no pixel” state. For this pixel, an appropriate pixel value is copied by residual video projection means 252 described later.
- the residual video projection unit 252 includes a designated viewpoint video projection unit 252a, a residual video pixel copying unit 252b, and a hole filling processing unit 252c.
- the designated viewpoint video projection unit 252a inputs the left residual video L′ v from the residual video decoding unit 24 and the left designated viewpoint depth map Pd from the depth map projection unit 23, respectively, and the left residual video L′ v. Is generated on the left designated viewpoint Pt, and a left designated viewpoint projected residual video PLv is generated and output to the residual video pixel copying means 252b.
- the distance from the reference viewpoint to the left viewpoint is b, and the distance from the left viewpoint to the left designated viewpoint is d.
- the designated viewpoint video projection means 252a at the position shifted to the right by the number of pixels corresponding to a value obtained by multiplying the depth value at that pixel position by (d / b) for each pixel of the left designated viewpoint depth map Pd.
- a pixel is extracted from the left residual video L′ v, and the extracted pixel value is used as the pixel value at the pixel position of the referenced depth value, thereby generating the left designated viewpoint projected residual video PLv .
- Residual picture pixel copy unit 252b is a left specified viewpoint video P C from the median filter 251d of the reference viewpoint image projecting means 251, a hole mask Ph from the hole mask expansion unit 251e, the left viewpoint specified projection from the specified viewpoint video projection unit 252a
- Residual images P Lv are respectively input, and pixel values are extracted from the left designated viewpoint projected residual images P Lv for the pixels that have become occlusion holes from these input data, and copied to the left designated viewpoint video P C and it is intended to generate the left specified viewpoint image P 1 is a video in the left specified viewpoint Pt.
- Residual picture pixel copy unit 252b outputs the generated left specified viewpoint image P 1 in the filling processing means 252c.
- Filling processing means 252c inputs the left specified viewpoint image P 1 from the residual image pixel copying unit 252b, in the left specified viewpoint image P 1, the reference viewpoint image pixel copy unit 251c and the residual image pixel copy unit 252b,
- a left designated viewpoint video P is generated by setting an appropriate pixel value for a pixel for which a valid pixel has not been copied, and is output to the stereoscopic video display device 4 (see FIG. 1) as one video in the multi-view video.
- Filling processing means 252c checks the pixel values of the pixels of the left specified viewpoint image P 1, the initial pixel and the pixel values that match the pixel value set as an initial value by the reference viewpoint image pixel copy means 251c is within a predetermined range Pixels that match the value are detected, and a hole mask is generated that indicates such a pixel region.
- the pixel value agrees with the initial value within a predetermined range. For example, when the initial value of each component is “128”, the value of each component is a value between 127 and 129. That is. As a result, even when the pixel value slightly changes from the initial value due to encoding processing or the like, it can be appropriately detected.
- the hole filling processing means 252c expands the pixel area indicated by the generated hole mask by a predetermined number of pixels.
- the predetermined number of pixels may be, for example, one pixel.
- the pixel values are set so that the pixels not included in the left residual video L′ v do not feel strange with the surrounding pixels. can do.
- the median filter processing by the median filter 251d it is possible to appropriately fill the pixel that becomes the pixel region of the hole mask.
- the number of pixels to be expanded may be increased as the compression rate is higher in accordance with the size of the compression rate in encoding.
- the encoding device 1 generates an encoded reference viewpoint image c by encoding the reference viewpoint image C input from the outside with a predetermined encoding method by the reference viewpoint image encoding means 11, and generates a reference viewpoint image bit. Output as a stream (step S11).
- the encoding apparatus 1 uses the reference viewpoint depth map Cd and the left viewpoint depth map Ld input from the outside by the depth map synthesis unit 12 to use an intermediate viewpoint that is an intermediate viewpoint between the reference viewpoint and the left viewpoint.
- a left composite depth map Md which is a depth map, is synthesized (step S12).
- the encoding apparatus 1 generates the encoded depth map md by encoding the left composite depth map Md synthesized in step S12 by the depth map encoding means 13 using a predetermined encoding method, and generates the depth map bit. Output as a stream (step S13).
- the encoding apparatus 1 uses the depth map decoding unit 14 to decode the encoded depth map md generated in step S13 to generate a decoded left composite depth map M′d (step S14).
- the encoding device 1 uses the decoded left composite depth map M′d generated in step S14 by the projected video prediction unit 15 and the left viewpoint video L input from the outside, and uses the left residual video Lv. Is generated (step S15).
- the encoding apparatus 1 uses the occlusion hole detection means 151 to detect a pixel that becomes an occlusion hole by using the decoded left composite depth map M'd (occlusion hole detection processing). Then, the encoding device 1 extracts (cuts out) pixels in the pixel area detected by the occlusion hole detection unit 151 from the left viewpoint video L by the residual video cutout unit 152 and generates the left residual video Lv. (Residual image cutout processing).
- the encoding device 1 uses the residual video encoding unit 16 to encode the left residual video Lv generated in step S15 by a predetermined encoding method to generate an encoded residual video lv, and to generate a residual video lv.
- the difference video bit stream is output (step S16).
- the decoding device 2 decodes the reference viewpoint video bitstream by the reference viewpoint video decoding means 21, generates the reference viewpoint video C ′, and outputs it as one video of the multi-view video (step S21). .
- the decoding apparatus 2 decodes the depth map bitstream by the depth map decoding means 22 to generate a decoded left composite depth map M′d (step S22).
- the decoding apparatus 2 projects the decoded left composite depth map M′d generated in step S22 onto the left designated viewpoint Pt by the depth map projecting means 23, and the left map which is the depth map at the left designated viewpoint Pt.
- the designated viewpoint depth map Pd is generated (step S23).
- the decoding device 2 decodes the residual video bitstream by the residual video decoding means 24 to generate the left residual video L′ v (step S24).
- the decoding device 2 uses the left designated viewpoint depth map Pd generated in step S23 by the projected video synthesis unit 25, and the reference viewpoint video C ′ generated in step S21 and the left residual generated in step S24.
- the difference video L′ v and the video projected on the left designated viewpoint Pt are combined to generate the left designated viewpoint video P that is the video at the left designated viewpoint Pt (step S25).
- step S25 the decoding apparatus 2 cannot project when the reference viewpoint video projection unit 251 first projects the reference viewpoint video C ′ to the left specified viewpoint Pt using the left specified viewpoint depth map Pd.
- a pixel that is an occlusion hole that is a pixel area is detected, and in a pixel area that is not an occlusion hole, a pixel of a video obtained by projecting the reference viewpoint video C ′ onto the left designated viewpoint Pt is copied as a pixel of the left designated viewpoint video.
- the decoding device 2 uses the residual video projection means 252 to project the left residual video L′ v onto the left designated viewpoint Pt using the left designated viewpoint depth map Pd for the pixel region that becomes the occlusion hole. Are copied as the pixels of the left designated viewpoint video. As a result, the left designated viewpoint video P is completed.
- the encoding apparatus 1 includes the reference composite video C and the left composite depth map Md that is a depth map at an intermediate viewpoint that is an intermediate viewpoint between the reference viewpoint and the left viewpoint. Since the left residual video Lv consisting of the pixel region that becomes an occlusion hole when projected from the reference viewpoint video C to another viewpoint is encoded and transmitted as a bit stream, it is encoded with high encoding efficiency. Can do. Also, the decoding device 2 according to the first embodiment can decode these encoded data transmitted from the encoding device 1 to generate a multi-view video.
- the stereoscopic video transmission system including the stereoscopic video encoding device and the stereoscopic video decoding device according to the second embodiment is the same as the stereoscopic video transmission system S shown in FIG. 1 in the stereoscopic video encoding device 1 and the stereoscopic video decoding device. Since it is the same except that each of them includes a stereoscopic video encoding device 1A (see FIG. 12) and a stereoscopic video decoding device 2A (see FIG. 14) in place of 2, detailed description will be omitted.
- a stereoscopic video encoding apparatus 1A (hereinafter referred to as “encoding apparatus” as appropriate) according to the second embodiment includes a reference viewpoint video encoding unit 11, a depth map synthesis unit 12A, Depth map encoding means 13A, depth map decoding means 14A, projected video prediction means 15A, residual video encoding means 16A, depth map framing means 17, depth map separation means 18, and residual video Framing means 19.
- the encoding device 1A according to the second embodiment includes a reference viewpoint image C that is an image at the reference viewpoint, a left viewpoint image (sub-viewpoint image) L that is an image at the left viewpoint, and an accompanying depth map.
- the right viewpoint video (sub-viewpoint video) R that is the video at the right viewpoint and the right viewpoint depth (sub-level) that is the accompanying depth map.
- Inputting a viewpoint depth map) map Rd is different from the encoding apparatus 1 (see FIG. 2) according to the first embodiment. That is, the encoding apparatus 1A according to the second embodiment encodes a plurality of systems (two systems) of stereoscopic video.
- the encoding device 1A according to the second embodiment is similar to the encoding device 1 according to the first embodiment (see FIG. 2).
- the reference viewpoint video C, the left viewpoint video L, the reference viewpoint depth map Cd, and the left viewpoint depth Using the map Ld, a left composite depth map (intermediate viewpoint depth map) Md, which is a depth map at the left intermediate viewpoint, which is an intermediate viewpoint between the reference viewpoint and the left viewpoint, and a left residual video (residual video) Lv Generate.
- the encoding apparatus 1A further uses the reference viewpoint video C, the right viewpoint video R, the reference viewpoint depth map Cd, and the right viewpoint depth map (sub-viewpoint depth map) Rd to intermediate the reference viewpoint and the right viewpoint.
- a right composite depth map (intermediate viewpoint depth map) Nd, which is a depth map at the right intermediate viewpoint, which is the viewpoint, and a right residual video Rv are generated.
- the encoding device 1A converts the left composite depth map Md and the right composite depth map Nd, the left residual video Lv, and the right residual video Rv into a single image by reducing and combining them, respectively. It is encoded by a predetermined encoding method and output as a depth map bit stream and a residual video bit stream.
- the reference viewpoint video C is encoded by a predetermined encoding method and output as a reference viewpoint video bitstream, similarly to the encoding device 1 (see FIG. 2) according to the first embodiment.
- the method of generating the right composite depth map Nd and the right residual video Rv from the video at the reference viewpoint and the right viewpoint and the depth map is based on the left composite depth map Md and the left from the video and the depth map at the reference viewpoint and the left viewpoint.
- the left and right positional relationships are interchanged, and thus detailed description will be omitted as appropriate. Further, description of the same components as those in the first embodiment will be omitted as appropriate.
- the three viewpoints are set at positions spaced apart at equal intervals on a straight line extending in the horizontal direction toward the subject.
- the central viewpoint is the reference viewpoint
- the right viewpoint, which is the right viewpoint are sub-viewpoints.
- the present invention is not limited to this, and the three viewpoints may be arranged at different intervals, and the reference viewpoint and the sub-viewpoint are not limited to the case where they are separated in the horizontal direction. , May be separated in any direction.
- each video is circular as shown in the reference viewpoint video C, the left viewpoint video L, the right viewpoint video R and the like, as in the example shown in FIG. 4. It is assumed that it is composed of a subject in the foreground and other background subjects.
- the reference viewpoint video encoding means 11 shown in FIG. 12 is the same as the reference viewpoint video encoding means 11 shown in FIG.
- Depth map combination unit (intermediate viewpoint depth map combination unit) 12A is provided with a left depth map combination unit 12 L and the right depth map combination unit 12 R, the depth of the left intermediate viewpoint an intermediate viewpoint between the reference viewpoint and left viewpoints
- a left composite depth map Md that is a map and a right composite depth map Nd that is a depth map at a right intermediate viewpoint that is an intermediate viewpoint between the reference viewpoint and the right viewpoint are combined.
- the depth map combining unit 12A outputs the combined left combined depth map Md and right combined depth map Nd to the reducing unit 17a and the reducing unit 17b of the depth map framing unit 17, respectively.
- the left depth map combination unit 12 L have the same configuration as the depth map combination unit 12 shown in FIG.
- the right depth map combination unit 12 R in place of the left viewpoint depth map Ld, enter the right viewpoint depth map Rd, as shown in FIG. 5 (b), the left and right between the reference viewpoint depth map Cd Except that the positional relationship is reversed, it is the same as the left depth map composing means 12L, and thus detailed description thereof is omitted.
- Depth map framing unit 17 and frame the left synthesis depth map Md and right synthetic depth map Nd inputted from the left depth map combination unit 12 L and the right depth map combination unit 12 R into one image, the frame of the depth map Fd is generated, and the generated framed depth map Fd is output to the depth map encoding means 13A.
- the depth map framing means 17 includes reduction means 17a and 17b and a coupling means 17c.
- the reduction unit 17a and the reduction unit 17b when halving the height of the corresponding depth map, perform a filtering process using a low-pass filter and then thin out data every other line. Is preferable. As a result, occurrence of aliasing distortion of the high frequency component due to thinning can be prevented.
- the combining unit 17c inputs the left reduced composite depth map M 2 d and the right reduced composite depth map N 2 d from the reduction unit 17a and the reduction unit 17b, respectively, and combines the two depth maps in the vertical direction before the reduction.
- a framed depth map Fd that is a depth map having the same height as the depth map is generated.
- the combining unit 17c outputs the generated framed depth map Fd to the depth map encoding unit 13A.
- the depth map encoding unit 13A receives the framed depth map Fd from the combining unit 17c of the depth map frame forming unit 17, encodes the framed depth map Fd by a predetermined encoding method, and generates the encoded depth map fd. It is generated and output to the transmission path as a depth map bit stream.
- the depth map encoding unit 13A is the same as the depth map encoding unit 13 shown in FIG. 2 except that the depth map to be encoded is a framed depth map instead of a single depth map. Therefore, detailed description is omitted.
- the depth map decoding unit 14A is a depth map that is decoded and framed based on the encoding method of the depth map bitstream that is the encoded depth map fd generated by the depth map encoding unit 13A.
- a framed depth map (decoded framed depth map) F′d is generated.
- the depth map decoding unit 14 ⁇ / b> A outputs the generated framed depth map F′d to the separation unit 18 a of the depth map separation unit 18.
- the depth map decoding unit 14A is the same as the depth map decoding unit 14 shown in FIG. 2 except that the depth map to be decoded is a framed depth map instead of a single depth map. Therefore, detailed description is omitted.
- the depth map separation unit 18 receives the framed depth map F′d decoded from the depth map decoding unit 14A, and decodes the left reduced combined composite depth map M 2 that is two reduced depth maps. 'd and the decoded right-reduction composite depth map N 2 ' d are separated and enlarged to the original height to obtain a decoded left composite depth map (decoding intermediate viewpoint depth map) M'd and a decoded right composite depth map (Decoding intermediate viewpoint depth map) N′d is generated and output to the left projection video prediction unit 15 L and the right projection video prediction unit 15 R of the projection video prediction unit 15 A, respectively.
- the depth map separating unit 18 includes a separating unit 18a and enlarging units 18b and 18c.
- the separating unit 18a receives the framed depth map F′d from the depth map decoding unit 14A, and outputs the decoded left reduced composite depth map M 2 ′ d and the decoded right reduced composite depth map N 2. 'd is separated and output to the enlargement means 18b and the enlargement means 18c, respectively.
- the enlarging means 18b and the enlarging means 18c receive the decoded left reduced synthesized depth map M 2 'd and the decoded right reduced synthesized depth map N 2 ' d, respectively, from the separating means 18a, and the heights are each doubled. Then, a decoded left composite depth map M′d and a decoded right composite depth map N′d, which are depth maps of the original height, are generated. Expansion means 18b and enlarging means 18c is outputs the generated decoded left synthesized depth map was M'd and decoded right synthesized depth map N'd, the left projection image prediction means 15 L and the right projection image prediction unit 15 R, respectively To do.
- the reduced depth map may be simply enlarged by duplicating and inserting the same line data for each line, but the value of the pixel inserted for each line is changed to the value of the surrounding pixels by bicubic. It is preferable to perform interpolation so as to be connected smoothly by applying a filter because the pixel thinning effect at the time of reduction is corrected.
- the projected video prediction unit 15A uses the decoded left composite depth map M′d and the decoded right composite depth map N′d input from the expansion unit 18b and the expansion unit 18c of the depth map separation unit 18 to use the reference viewpoint video C Are extracted from the left viewpoint video L and the right viewpoint video R, and the left residual video (residual video) Lv and right are extracted from the left viewpoint video L and the right viewpoint video R, respectively.
- a residual video (residual video) Rv is generated.
- the projected video prediction unit 15A outputs the generated left residual video Lv and right residual video Rv to the reduction unit 19a and the reduction unit 19b of the residual video framing unit 19, respectively.
- the left projected video prediction means 15 L inputs the reference viewpoint video C, the left viewpoint video L, and the left designated viewpoint Pt from the outside, and also inputs the decoded left composite depth map M′d decoded from the enlargement means 18 b.
- the left residual video Lv is generated, and the generated left residual video Lv is output to the reduction means 19a of the residual video framing means 19.
- the left projection video prediction unit 15L has the same configuration as the projection video prediction unit 15 shown in FIG. 2 except that the data input / output destination is different, and thus detailed description thereof is omitted.
- one left designated viewpoint Pt is input from the outside, but a plurality of left designated viewpoints Pt may be inputted as in the example shown in FIG.
- the right projection video prediction unit 15 R replaces the left viewpoint video L, the decoded left composite depth map M′d, and the left designated viewpoint Pt in the left projection video prediction unit 15 L , respectively.
- the right composite video depth map N′d and the right designated viewpoint Qt are input, the right residual video Rv is output instead of the left residual video Lv, and the left and right positions of the reference viewpoint video C and the depth map Since the configuration is the same except that the relationship is reversed, detailed description is omitted.
- Residual picture framing means 19 to frame the left residual video Lv and Migizansa video Rv is input from the left projection image prediction means 15 L and the right projection image prediction unit 15 R into one image, framing remaining A difference video Fv is generated, and the generated framed residual video Fv is output to the residual video encoding means 16A.
- the residual video framing means 19 includes reduction means 19a and 19b and a combining means 19c.
- the left reduced residual image L 2 v and the right reduced residual image R 2 v, which are reduced by thinning out the pixels in the vertical direction and the height (the number of pixels in the vertical direction) are halved, are generated and combined.
- the reduction unit 19a and the reduction unit 19b have the same configuration as the reduction unit 17a and the reduction unit 17b, and thus detailed description thereof is omitted.
- the combining unit 19c inputs the left reduced residual image L 2 v and the right reduced residual image R 2 v from the reducing unit 19a and the reducing unit 19b, respectively, and combines the two residual images in the vertical direction to reduce A framed residual video Fv that is a residual video having the same height as the previous one residual video is generated.
- the combining unit 19c outputs the generated framed residual video Fv to the residual video encoding unit 16A.
- the residual video encoding means 16A receives the framed residual video Fv from the combining means 19c of the residual video framing means 19 and encodes the framed residual video Fv by a predetermined encoding method. Residual video fv is generated and output to the transmission path as a residual video bit stream.
- the residual video encoding means 16A is a residual video that is framed instead of a single residual video in the residual video to be encoded in the residual video encoding means 16 shown in FIG. Since other than that is the same, detailed description is abbreviate
- the stereoscopic video decoding device 2A decodes the bitstream transmitted from the stereoscopic video encoding device 1A shown in FIG. 12 via the transmission path to generate a multi-view video.
- a stereoscopic video decoding device 2A includes a reference viewpoint video decoding unit 21, a depth map decoding unit 22A, Depth map projection means 23A, residual video decoding means 24A, projected video synthesis means 25A, depth map separation means 26, and residual video separation means 27.
- the decoding device 2A encodes a depth map bit stream and a residual video bit stream into a depth map bit stream and a residual video bit stream. And the encoded residual video fv are input, and the framed depth map and residual video are separated to generate a left designated viewpoint video P and a right designated viewpoint video Q as a plurality of systems of designated viewpoint videos. This is different from the decoding device 2 (see FIG. 7) according to the first embodiment.
- the reference viewpoint video decoding means 21 is the same as the reference viewpoint video decoding means 21 shown in FIG.
- the depth map decoding unit 22A decodes the depth bitstream to generate a framed depth map (decoded framed depth map) F′d, and outputs it to the separation unit 26a of the depth map separation unit 26.
- the depth map decoding unit 22A has the same configuration as the depth map decoding unit 14A (see FIG. 12) in the encoding device 1A, and thus detailed description thereof is omitted.
- the depth map separation unit 26 receives the framed depth map F′d decoded from the depth map decoding unit 22A, and decodes the left reduced combined composite depth map M 2 that is two reduced depth maps. 'd and the decoded right reduced composite depth map N 2 ' d are separated and enlarged to the original height to generate a decoded left composite depth map M'd and a decoded right composite depth map N'd.
- the depth map separating unit 26 includes a separating unit 26a and enlargement units 26b and 26c.
- the depth map separating means 26 has the same configuration as the depth map separating means 18 in the encoding apparatus 1A shown in FIG.
- the separating unit 26a, the enlarging unit 26b, and the enlarging unit 26c correspond to the separating unit 18a, the enlarging unit 18b, and the enlarging unit 18c shown in FIG. 12, respectively.
- Depth map projection means 23A is configured to have a left depth map projection means 23 L and the right depth map projection means 23 R, the depth map at an intermediate point of view of left and right two channels, the left specifies a specified viewpoint of each strain Projecting the viewpoint Pt and the right designated viewpoint Qt, a left designated viewpoint depth map Pd and a right designated viewpoint depth map Qd, which are depth maps at the respective designated viewpoints, are generated.
- Depth map projection means 23A outputs the generated left viewpoint specified depth map Pd and the right specified viewpoint depth map Qd, the left projection image synthesizing means 25 L and the right projection image synthesizing means 25 R of each projection image synthesizing unit 25A.
- the left designated viewpoint (designated viewpoint) Pt and the right designated viewpoint (designated viewpoint) Qt are the left designated viewpoint and the right designated viewpoint in the multi-view video generated by the decoding apparatus 2A, and are predetermined by the decoding apparatus 2A. It may be input from a setting means (not shown) or may be input from the outside by a user operation via an input means such as a keyboard. Further, the left designated viewpoint Pt and the right designated viewpoint Qt may each be one or two or more. When the left designated viewpoint Pt and the right designated viewpoint Qt are 2 or more, the left designated viewpoint depth map Pd and the right designated viewpoint depth map Qd in the respective designated viewpoints sequentially for each of the left designated viewpoint Pt and the right designated viewpoint Qt, respectively. to generate, and outputs sequentially the left projection image synthesizing means 25 L and the right projection image synthesizing means 25 R projection video synthesis unit 25A.
- Left depth map projection means 23 L type a decoded depth map from the enlarged section 26b decodes the left synthesis depth map M'D, the decoding left synthesized depth map M'D left specified viewpoint Pt By projecting, a left designated viewpoint depth map (designated viewpoint depth map) Pd at the left designated viewpoint Pt is generated.
- Left depth map projection means 23 L outputs the generated left viewpoint specified depth map Pd left projection image synthesizing means 25 L.
- the right depth map projection means 23 R inputs the a decoded depth map from the enlargement section 26c decoded right synthesized depth map N'd, right viewpoint specified this decryption right synthesis depth maps N'd
- a right designated viewpoint depth map (designated viewpoint depth map) Qd at the right designated viewpoint Qt is generated by projection onto Qt.
- Right depth map projection means 23 R outputs generated right viewpoint specified depth map Qd right projection video synthesis unit 25 R.
- left depth map projection means 23 L since the same configuration as the depth map projection means 23 shown in FIG. 7, a detailed description thereof will be omitted.
- the right depth map projection means 23 R, the left depth map projection means 23 L, because except positional relationship of the left and right with reference viewpoint is reversed have the same structure, detailed description thereof is omitted.
- the residual video decoding unit 24A decodes the residual video bitstream to generate a framed residual video (decoded framed residual video) F′v, and the separation unit 27a of the residual video separation unit 27 Output to.
- the residual video decoding unit 24A is different from the residual video decoding unit 24 (see FIG. 7) in the decoding device 2 in whether a decoding target is a single residual video or a framed residual video. However, since it is the same structure, detailed description is abbreviate
- the residual video separation means 27 receives the framed residual video F′v decoded from the residual video decoding means 24A, and the left reduced residual video that is two reduced residual videos that are framed. L 2 'v and the right reduced residual video R 2 ' v are separated and enlarged to the original height, and left residual video (decoded residual video) L'v and right residual video (decoded residual) Video) R′v is generated. Residual picture separating means 27, the generated left residual video L'v and Migizansa video R'v, the left projection image synthesizing means 25 L and the right projection image synthesizing means 25 R of each projection image synthesizing unit 25A Output.
- the residual video separation means 27 is configured to include a separation means 27a and enlargement means 27b and 27c.
- the residual video separation means 27 has the same configuration as the depth map separation means 26 except that the target to be separated is a residual video or a depth map, and thus detailed description thereof is omitted.
- the separating unit 27a, the enlarging unit 27b, and the enlarging unit 27c correspond to the separating unit 26a, the enlarging unit 26b, and the enlarging unit 26c, respectively.
- the projected video synthesizing unit 25A includes a reference viewpoint video C ′ input from the reference viewpoint video decoding unit 21, a left residual video L′ v which is a residual video of two left and right systems input from the residual video separation unit 27, and From the left residual video R′v and the left designated viewpoint depth map Pd and the right designated viewpoint depth map Qd, which are the two left and right depth maps input from the depth map projection means 23A, the left which is the designated viewpoint of the two left and right systems
- the left designated viewpoint video P and the right designated viewpoint video Q which are designated viewpoint videos at the designated viewpoint Pt and the right designated viewpoint Qt, are generated.
- the projection image synthesizing unit 25A is configured to have a left projection image synthesizing means 25 L and the right projection image synthesizing means 25 R.
- the left projection video synthesizing means 25 L receives the reference viewpoint video C ′ from the reference viewpoint video decoding means 21, the left residual video L′ v from the enlargement means 27 b of the residual video separation means 27, and the depth map projection means 23 A.
- the left depth map projection means 23 L left specified from the viewpoint depth map Pd, respectively inputted, it generates the left specified viewpoint video P.
- the right projection video synthesizing unit 25 R receives the reference viewpoint video C ′ from the reference viewpoint video decoding unit 21, the right residual video R′v from the enlargement unit 27 c of the residual video separation unit 27, and the depth map projection unit.
- the right depth map projection means 23 R from the right viewpoint specified depth map Qd of 23A, and input respectively, to generate the right designation viewpoint image Q.
- the left projected video composition means 25L has the same configuration as the projected video composition means 25 in the decoding apparatus 2 shown in FIG.
- the right projection image synthesizing means 25 R, the left projection image synthesizing means 25 L, because except positional relationship of the left and right with reference viewpoint is reversed have the same structure, detailed description thereof is omitted.
- the encoding device 1A since the encoding device 1A according to the second embodiment encodes the depth map and the residual video by framing each of a plurality of systems of stereoscopic video, and outputs the result as a bitstream. A stereoscopic image can be encoded with encoding efficiency. Also, the decoding device 2A can generate a multi-view video by decoding the stereoscopic video encoded by the encoding device 1A.
- the encoding device 1A generates an encoded reference viewpoint image c by encoding the reference viewpoint image C input from the outside with a predetermined encoding method by the reference viewpoint image encoding means 11, and generates a reference viewpoint image bit. Output as a stream (step S31).
- the encoding device 1A uses the reference map depth map Cd and the left view depth map Ld input from the outside by the depth map combining unit 12A to use the left intermediate view point that is an intermediate view point between the reference view point and the left view point.
- the left composite depth map Md which is the depth map at, is synthesized, and the reference viewpoint depth map Cd and the right viewpoint depth map Rd input from the outside are used to create a right intermediate viewpoint that is an intermediate viewpoint between the reference viewpoint and the right viewpoint.
- a right composite depth map Nd which is a depth map, is synthesized (step S32).
- the encoding device 1A uses the depth map framing means 17 to reduce and combine the two composite depth maps Md and right composite depth map Nd, which are the two depth maps combined in step S32.
- the image is framed to generate a framed depth map Fd (step S33).
- the encoding apparatus 1A uses the depth map encoding unit 13A to encode the framed depth map Fd generated in step S33 using a predetermined encoding method to generate an encoded depth map fd, and to generate the depth map bit. Output as a stream (step S34).
- the encoding apparatus 1A uses the depth map decoding unit 14A to decode the encoded depth map fd generated in step S34 to generate a framed depth map F′d (step S35).
- the encoding apparatus 1A separates the two depth maps combined with the decoded framed depth map F′d generated in step S35 by the depth map separation unit 18, and sets the original size to each. It expands and produces
- the encoding device 1A uses the decoded left composite depth map M′d generated in step S36 by the projected video prediction unit 15A and the left viewpoint video L input from the outside to generate the left residual video Lv. And the right residual video Rv is generated using the decoded right composite depth map N′d generated in step S36 and the right viewpoint video R input from the outside (step S37).
- the encoding device 1A uses the residual video framing unit 19 to reduce and combine the left residual video Lv and the right residual video Rv, which are the two residual videos generated in step S37.
- a framed residual video Fv is generated by framing into one image (step S38).
- the encoding apparatus 1A then encodes the framed residual video Fv generated in step S38 by the residual video encoding unit 16A using a predetermined encoding method to generate the encoded residual video fv,
- the difference video bit stream is output (step S39).
- the decoding device 2A decodes the reference viewpoint video bitstream by the reference viewpoint video decoding means 21, generates the reference viewpoint video C ′, and outputs it as one video of the multi-view video (step S51). .
- the decoding apparatus 2A decodes the depth map bitstream by the depth map decoding unit 22A to generate a framed depth map F′d (step S52).
- the decoding device 2A separates the two depth maps combined with the decoded framed depth map F′d generated in step S52 by the depth map separation unit 26, and sets the original sizes to the original sizes. It expands and produces
- the decoding device 2A projects the decoded left composite depth map M′d generated in step S53 onto the left designated viewpoint Pt by the depth map projection means 23A, and is a depth map at the left designated viewpoint Pt.
- the left designated viewpoint depth map Pd is generated, and the decoded right composite depth map N′d generated in step S53 is projected onto the right designated viewpoint Qt, and the right designated viewpoint depth map which is the depth map at the right designated viewpoint Qt.
- Qd is generated (step S54).
- the decoding device 2A decodes the residual video bitstream by the residual video decoding unit 24A to generate a framed residual video F′v (step S55).
- the decoding device 2A separates the two residual videos combined with the decoded framed residual video F′v generated in step S55 by the residual video separation unit 27, and each of the originals The left residual video L′ v and the right residual video R′v are generated (step S56).
- the decoding device 2A, the left projection image synthesizing means 25 L by using the left specified viewpoint depth map Pd generated in step S54, the reference viewpoint image C 'generated in step S51, the left generated in step S55 a residual picture L'v, each synthesized image is projected to the left specified viewpoint Pt, to generate the left-specified viewpoint image P is an image of the left specified viewpoint Pt, the right projection image synthesizing unit 25 R, Using the right designated viewpoint depth map Qd generated in step S54, the reference viewpoint video C ′ generated in step S51 and the right residual video R′v generated in step S55 are respectively projected onto the right specified viewpoint Qt. The video is synthesized to generate a right designated viewpoint video Q that is a video at the right designated viewpoint Qt (step S57).
- the stereoscopic video encoding apparatus is the same as the depth map and residual video in the depth map framing means 17 and the residual video framing means 19 of the encoding apparatus 1A according to the second embodiment shown in FIG. 18 (a) and 18 (b), the pixels are thinned out in the horizontal direction to reduce the width to 1/2, and are arranged side by side in the horizontal direction to combine them into one image. It is to be framed.
- the stereoscopic video encoding apparatus is configured to separate the framed depth map F'd combined by being reduced in the horizontal direction in the depth map separating means 18 of the encoding apparatus 1A.
- the stereoscopic video decoding apparatus according to this modification is reduced in the horizontal direction in the depth map separation means 26 and the residual video separation means 27 of the decoding apparatus 2A according to the second embodiment shown in FIG.
- the combined framed depth map F′d and framed residual video F′v are separated.
- the configuration and operation of the stereoscopic video encoding apparatus and stereoscopic video decoding apparatus according to this modification are the same as those of the second embodiment except that the depth map and the residual video are reduced and combined in the horizontal direction and separated and enlarged. Since it is the same as the encoding apparatus 1A and the decoding apparatus 2A, detailed description is omitted.
- the depth maps used in the first and second embodiments set the depth value as the luminance component (Y) in the image data in the same format as the video such as the reference viewpoint video C, and the color difference components (Pb, Although a predetermined value is set for Pr), it may be handled as monochrome image data having only a luminance component (Y). As a result, the reduction in encoding efficiency due to the color difference components (Pb, Pr) can be made completely zero.
- the stereoscopic video transmission system including the stereoscopic video encoding device and the stereoscopic video decoding device according to the third embodiment is the same as the stereoscopic video transmission system S shown in FIG. 1 in the stereoscopic video encoding device 1 and the stereoscopic video decoding device. Since it is the same except that each of them includes a stereoscopic video encoding device 1B (see FIG. 19) and a stereoscopic video decoding device 2B (see FIG. 22) instead of 2, detailed description is omitted.
- the stereoscopic video encoding device 1B includes a reference viewpoint video encoding unit 11 and a depth map synthesis unit 12B.
- Depth map encoding means 13B, projected video prediction means 15B, residual video encoding means 16B, residual video framing means 19B, and depth map restoration means 30 are provided.
- the encoding device 1B according to the third embodiment is the reference viewpoint video C that is the video at the reference viewpoint, and the video at the left viewpoint, similarly to the encoding device 1A according to the second embodiment shown in FIG.
- Left viewpoint video (sub-viewpoint video) L, right viewpoint video (sub-viewpoint video) R that is a video at the right viewpoint, a reference viewpoint depth map Cd that is a depth map attached to these videos, and a left viewpoint depth map (sub-viewpoint) Depth map) Ld and right viewpoint depth map (sub-viewpoint depth map) Rd are input, and encoded reference viewpoint video c and encoded residual video fv encoded by a predetermined encoding method are respectively used as reference viewpoint video bits.
- the encoding device 1B synthesizes and encodes the input depth maps Cd, Ld, and Rd at the three viewpoints into a combined depth map Gd that is a depth map at a predetermined one common viewpoint, and forms a depth map bitstream.
- the output is different from the encoding device 1A according to the second embodiment (see FIG. 12).
- symbol is attached
- the three viewpoints are set at equal intervals on a straight line extending in the horizontal direction toward the subject.
- the central viewpoint is the reference viewpoint
- the right viewpoint, which is the right viewpoint are sub-viewpoints.
- the present invention is not limited to this, and the three viewpoints may be arranged at different intervals, and the reference viewpoint and the sub-viewpoint are not limited to the case where they are separated in the horizontal direction. , May be separated in any direction.
- each video has a circular shape, as in the example shown in FIG. 13. It is assumed that it is composed of a subject in the foreground and other background subjects.
- the reference viewpoint video encoding unit 11 shown in FIG. 19 is the same as the reference viewpoint video encoding unit 11 shown in FIG.
- the depth map composition unit 12B includes a left depth map projection unit 121B, a right depth map projection unit 122B, a map composition unit 123B, and a reduction unit 124.
- the left depth map projection unit 121B and the right depth map projection unit 122B receive the left viewpoint depth map Ld and the right viewpoint depth map Rd, respectively, and each of them is a common viewpoint depth map C that is a depth map projected onto a predetermined common viewpoint.
- L d and the common viewpoint depth map C R d are generated and output to the map composition unit 123B.
- the left depth map projecting unit 121B projects, for each pixel, the number of pixels that matches the depth value of each pixel in order to project the left viewpoint depth map Ld onto the reference viewpoint.
- a common viewpoint depth map C L d is generated.
- the maximum value among the projected pixel values is set as the depth value of the pixel.
- the portion fills the smaller depth value as the depth value of the pixel among the projected pixels adjacent to the left and right of the pixel. This correctly interpolates the depth value of the background that was hidden behind the foreground at the original viewpoint position.
- the right depth map projecting unit 122B shifts the right viewpoint depth map Rd to the reference viewpoint by shifting each pixel to the right by the number of pixels that matches the depth value of each pixel, thereby allowing the common viewpoint depth to be projected.
- a map C R d is generated.
- the right depth map projecting unit 122B also includes a pixel in which a plurality of pixel values are projected in the projection of the right viewpoint depth map Rd. The maximum value is set as the depth value of the pixel. Further, when there is a pixel that has not been projected, the portion fills the smaller depth value as the depth value of the pixel among the projected pixels adjacent to the left and right of the pixel.
- the common viewpoint is the reference viewpoint that is the center of gravity of the three viewpoints input from the outside. For this reason, it is not necessary to project the reference viewpoint depth map Cd.
- the present invention is not limited to this, and an arbitrary viewpoint can be set as a common viewpoint.
- the depth map obtained by projecting the reference viewpoint depth map Cd onto the common viewpoint instead of the reference viewpoint depth map Cd may be input to the map synthesis unit 123B.
- the left depth map projecting unit 121B and the right depth map projecting unit 122B may adjust the pixel shift amount during projection appropriately according to the distance from the reference viewpoint to the common viewpoint.
- the map composition unit 123B receives the common viewpoint depth map C L d and the common viewpoint depth map C R d from the left depth map projection unit 121B and the right depth map projection unit 122B, respectively, and externally (for example, a stereoscopic video creation device) 3 (see FIG. 1)), the reference viewpoint depth map Cd is input, and these three depth maps are combined into one to generate one combined depth map Gd at the reference viewpoint which is a common viewpoint.
- the map combining unit 123B outputs the generated combined depth map Gd to the reducing unit 124.
- the map synthesizing unit 123B generates a synthesized depth map Gd by smoothing the pixel values of the three depth maps for each pixel to obtain the pixel values of the synthesized depth map Gd.
- the smoothing of the pixel value an arithmetic average of three pixel values or a median calculation using a median filter can be mentioned.
- the errors in the depths included in the individual depth maps are smoothed, and a video of multiple viewpoints for composing a stereoscopic video on the decoding device side is synthesized. In this case, the quality of the synthesized viewpoint video can be improved.
- the reduction unit 124 receives the combined depth map Gd from the map combining unit 123B, and generates a reduced combined depth map G 2 d obtained by reducing the input combined depth map Gd. Then, the reduction unit 124 outputs the generated reduced composite depth map G 2 d to the depth map encoding unit 13B.
- the reduction unit 124 generates a reduced combined depth map G 2 d that is reduced to 1 ⁇ 2 in both the vertical and horizontal directions by thinning out the pixels of the combined depth map Gd every other pixel in the vertical and horizontal directions.
- the reduction unit 124 preferably does not perform the filtering process using the low-pass filter and directly thins the data. As a result, it is possible to prevent generation of a depth value at a level that was not in the original depth map due to the filter processing, and the quality of the composite video is maintained.
- the reduction ratio is not limited to 1 ⁇ 2, and may be reduced at a reduction ratio of 1 ⁇ 4, ⁇ ⁇ , etc. by repeating the 1 ⁇ 2 thinning process a plurality of times. A reduction ratio of 1/5 or the like may be used. Further, the reduction ratio may be different between the vertical direction and the horizontal direction. Furthermore, the reduction unit 124 may be omitted, and the combined depth map Gd with the same magnification data may be output from the map combining unit 123B to the depth map encoding unit 13B.
- the depth map encoding unit 13B receives the reduced combined depth map G 2 d from the reducing unit 124 of the depth map combining unit 12B, encodes the reduced combined depth map G 2 d by a predetermined encoding method, and encodes the encoded depth.
- a map g 2 d is generated and output to the transmission path as a depth map bit stream.
- the depth map transmitted as the depth map bitstream combines the depth maps at the three viewpoints into one, and is further reduced, so that the data amount of the depth map is reduced and the coding efficiency is reduced. Improved.
- the depth map encoding means 13B is the depth map encoding means 13 shown in FIG. 2, except that the depth map to be encoded is a reduced depth map instead of a single depth map of the same size. Are the same, and detailed description thereof is omitted.
- the depth map restoration unit 30 decodes the depth map bitstream, which is the encoded depth map g 2 d generated by the depth map encoding unit 13B, based on the encoding method and expands the original size.
- the decoding composition depth map G′d is restored.
- the depth map restoration means 30 includes a depth map decoding means 30a and an enlargement means 30b. Further, the depth map restoration unit 30 outputs the decoded synthesized depth map G'd restored to the left projection image prediction means 15B L and the right projection image prediction unit 15B R projection image prediction means 15B.
- the depth map decoding unit 30a receives the encoded depth map g 2 d from the depth map encoding unit 13B and decodes it based on the encoding method to generate a decoded reduced combined depth map G ′ 2 d.
- the depth map decoding unit 30a outputs the generated decoded reduced combined depth map G ′ 2 d to the expansion unit 30b. Since the depth map decoding unit 30a can be the same as the depth map decoding unit 14 shown in FIG. 2, detailed description thereof is omitted.
- the enlarging unit 30b receives the decoded reduced combined depth map G ′ 2 d from the depth map decoding unit 30a, and generates a decoded combined depth map G′d having the same size as the combined depth map Gd. Expansion means 30b outputs the generated decoded synthesized depth map G'd left projection image prediction means 15B L and the right projection image prediction unit 15B R.
- a difference between pixel values (depth values) of a plurality of pixels existing in the vicinity of the pixel is determined.
- the average value of the pixel values of the neighboring pixels is set as the pixel value of the pixel.
- the largest pixel value of the neighboring pixel is set as the pixel value of the pixel.
- a 2D median filter is applied to the depth map after the enlargement process.
- the contour portion of the depth value of the foreground subject can be smoothly connected, and the quality of the synthesized video generated using this synthesized depth map can be improved.
- the projected video prediction unit 15B projects the reference viewpoint video C to the left viewpoint and the right viewpoint, respectively, using the decoded composite depth map G′d input from the expansion unit 30b of the depth map restoration unit 30. Pixels in a pixel region that becomes an occlusion hole are extracted from the left viewpoint video L and the right viewpoint video R to generate a left residual video (residual video) Lv and a right residual video (residual video) Rv. .
- the projected video prediction unit 15B outputs the generated left residual video Lv and right residual video Rv to the reduction unit 19Ba and the reduction unit 19Bb of the residual video framing unit 19B, respectively.
- the left projected video prediction unit 15B L receives the left viewpoint video L and the left designated viewpoint Pt from the outside, and also inputs the decoded composite depth map G′d decoded from the enlargement unit 30b, and outputs the left residual video Lv. And the generated left residual video Lv is output to the reduction means 19Ba of the residual video framing means 19B.
- the left projection image prediction means 15B L in this embodiment is configured to include the occlusion hole detection unit 151B, and a residual video clipping unit 152.
- the projection image predicting means 15 of the first embodiment shown in FIG. 2 instead of the occlusion hole detection unit 151, may comprise an occlusion hole detection unit 151B different .
- the occlusion hole detection means 151B in this embodiment includes a first hole mask generation means 1511B, a second hole mask generation means 1512B, a third hole mask generation means 1513B (1513B 1 to 1513B n ), and a hole mask composition. Means 1514 and hole mask expansion means 1515 are provided.
- the occlusion hole detection means 151B in this embodiment is different from the occlusion hole detection means 151 in the first embodiment shown in FIG. 3B in the first hole mask generation means 1511, the second hole mask generation means 1512, and the third.
- a first hole mask generating means 1511B, a second hole mask generating means 1512B, and a third hole mask generating means 1513B (1513B 1 to 1513B n ) are provided. Is different.
- symbol is attached
- the first hole mask generation unit 1511B, the second hole mask generation unit 1512B, and the third hole mask generation unit 1513B in the present embodiment use the decoding synthesis depth at the reference viewpoint that is a common viewpoint as a depth map for occlusion hole detection.
- the map G′d is used. Therefore, the first hole mask generating unit 1511, the second hole mask generating unit 1512 and the first hole mask generating unit 1512 in the first embodiment using the decoded left composite depth map M′d which is a depth map at an intermediate viewpoint between the reference viewpoint and the left viewpoint.
- the three-hole mask generation means 1513 is a projection by depth map projection means (1511Ba, 1512Ba, 1513Ba) input to the first hole pixel detection means 1511b, the second hole pixel detection means 1512Bb, and the third hole pixel detection means 1513b, respectively.
- the amount of shift is different. Except for this shift amount, the first hole mask generating means 1511B, the second hole mask generating means 1512B, and the third hole mask generating means 1513B are the same as the first hole mask generating means 1511 and the second hole mask in the first embodiment. It has the same function as the generation unit 1512 and the third hole mask generation unit 1513.
- the reference viewpoint video C is unnecessary.
- the input of the reference viewpoint video C can be omitted.
- the first hole mask generation means 1511B predicts a pixel area that becomes an occlusion hole OH when the reference viewpoint video C is projected to the left viewpoint, and generates a hole mask Lh 1 indicating the pixel area to generate a hole mask synthesis means. 1514 is output.
- the first hole mask generation unit 1511B includes a left viewpoint projection unit 1511Ba and a first hole pixel detection unit 1511b.
- the left viewpoint projecting means 1511Ba receives the decoded combined depth map G′d from the depth map restoring means 30, projects this decoded combined depth map G′d to the left viewpoint, and is the depth map at the left viewpoint.
- a viewpoint projection depth map L′ d is generated and output to the first hole pixel detection means 1511b.
- the left viewpoint projecting means 1511Ba differs from the left viewpoint projecting means 1511a shown in FIG. 3B only in the shift amount when projecting the depth map, and can be used in the same manner. Omitted.
- the second hole mask generation means 1512B predicts a pixel area that becomes an occlusion hole OH when the reference viewpoint video C is projected onto a left intermediate viewpoint that is an intermediate viewpoint between the reference viewpoint and the left viewpoint, and the pixel area is The hole mask Lh 2 shown is generated and output to the hole mask synthesis means 1514.
- the second hole mask generation unit 1512B includes a left intermediate viewpoint projection unit 1512Ba, a second hole pixel detection unit 1512Bb, and a left viewpoint projection unit 1512Bc.
- the left intermediate viewpoint projection unit 1512Ba receives the decoded combined depth map G′d from the depth map restoration unit 30, projects the decoded combined depth map G′d onto the left intermediate viewpoint, and the depth map at the left intermediate viewpoint.
- the decoded left composite depth map M′d is generated and output to the second hole pixel detection means 1512Bb.
- the left intermediate viewpoint projection means 1512Ba differs from the left viewpoint projection means 1511a shown in FIG. 3B only in the shift amount when projecting the depth map, and can be used in the same manner. Is omitted.
- the second hole pixel detection means 1512Bb and the left viewpoint projection means 1512Bc are the same as the second hole pixel detection means 1512a and the left viewpoint projection means 1512b shown in FIG.
- the second hole mask generation unit 1512B may be omitted.
- the third hole mask generating means 1513B 1 to 1513B n (1513B) predict pixel regions that become occlusion holes OH when the reference viewpoint video C is projected to the left designated viewpoints Pt 1 to Pt n , respectively.
- Hole masks Lh 31 to Lh 3n indicating the pixel region are generated and output to the hole mask synthesis unit 1514.
- each third hole mask generating unit 1513B (1513B 1 to 1513B n ) includes a left designated viewpoint projecting unit 1513Ba, a third hole pixel detecting unit 1513b, and a left viewpoint projecting unit 1513c. Has been.
- the left designated viewpoint projection means 1513Ba receives the decoded composite depth map G′d from the depth map restoration means 30, and projects this decoded composite depth map G′d onto the left designated viewpoint Pt (Pt 1 to Pt n ).
- a left designated viewpoint depth map P′d which is a depth map at the left designated viewpoint Pt (Pt 1 to Pt n ) is generated and output to the third hole pixel detection means 1513b.
- the left designated viewpoint projecting unit 1513Ba differs from the left viewpoint projecting unit 1511a shown in FIG. 3B only in the shift amount when projecting the depth map, and the same can be used. Is omitted. Further, as shown in FIG.
- the third hole mask generating means 1513B detects a region that becomes an occlusion hole OH when projected onto one or a plurality of left designated viewpoints Pt (Pt 1 to Pt n ). You may make it like, and you may abbreviate
- the same ones as in the first embodiment can be used.
- the pixel value other than the region that becomes the occlusion hole OH indicated by the hole mask Lh from the left viewpoint image is set to a fixed value such as 128, and all of the left viewpoint image L is set. You may make it use the average value of a pixel value. By doing in this way, the amount of change between the portion with the effective pixel value of the residual video (that is, the region that becomes the occlusion hole OH) and the portion without the other (other region) is reduced, and the residual video Distortion in the encoding process can be reduced.
- the average value of all the pixel locations of the residual video may be used as the pixel value of the region where there is no effective pixel value.
- the right projection image prediction unit 15B R in the left projection image prediction unit 15B L, instead of the left viewpoint image L and the left specified viewpoint Pt, respectively enter the right viewpoint image R and the right viewpoint specified Qt, Hidarizansa Since the configuration is the same except that the right residual video Rv is output instead of the video Lv and the left-right positional relationship between the reference viewpoint and the viewpoint position of the depth map is reversed, the description is omitted.
- Residual picture framing means 19B is to frame the left residual video Lv and Migizansa video Rv is input from the left projection image prediction means 15B L and the right projection image prediction unit 15B R into one image, framing remaining The difference video Fv is generated, and the generated framed residual video Fv is output to the residual video encoding means 16B.
- the residual video framing means 19B is configured to include reducing means 19Ba, 19Bb and combining means 19Bc.
- Reduction means 19Ba and reduction unit 19Bb is left projection image prediction means 15B L and the right projection image prediction unit 15B R, respectively, the Hidarizansa video Lv and Migizansa video Rv, respectively enter, the residual picture input
- the left reduced residual image L 2 v which is reduced by thinning out pixels in the vertical direction and the horizontal direction, and has a height (number of pixels in the vertical direction) and width (number of pixels in the horizontal direction) of 1 ⁇ 2, respectively.
- a right reduced residual image R 2 v is generated and output to the combining unit 19Bc.
- the region in which the residual video is used is a small part of the multi-view video synthesized on the decoding device 2B (see FIG. 22) side. It does not drop greatly. Therefore, by performing thinning out (reduction processing) of the residual video, it is possible to improve the encoding efficiency without greatly degrading the image quality.
- the reduction unit 19Ba and the reduction unit 19Bb use a low-pass filter that uses, for example, a coefficient (1, 2, 1) 3-tap filter when reducing the left residual video Lv and the right residual video Rv. It is preferable to perform a thinning process after the filtering process. As a result, occurrence of aliasing distortion of the high frequency component due to thinning can be prevented.
- the low-pass filter processing is preferably performed using the above-described one-dimensional filter of coefficients before thinning out in the vertical direction and the horizontal direction in the respective directions because the processing amount can be reduced.
- the present invention is not limited to this, and the thinning process in the vertical direction and the horizontal direction may be performed after performing the two-dimensional low-pass filter process.
- a low-pass filter process is performed at the boundary between the region that becomes the occlusion hole OH (the region where there is an effective pixel) and the other region of the left reduced residual image L 2 v and the right reduced residual image R 2 v. It is preferable to apply. As a result, the change in the pixel value at the boundary between the area where there is an effective pixel and the area where there is no effective pixel is smoothed, and the efficiency of the encoding process can be improved.
- the reduction means 19Ba and the reduction means 19Bb are not limited to 1/2 in the vertical and horizontal reduction ratios, and may be other reduction ratios such as 1/4 and 1/3, and the reduction ratios are different in the vertical and horizontal directions. You may do it. Further, the size reduction unit 19Ba and 19Bb may be omitted while keeping the original size.
- the combining unit 19Bc inputs the left reduced residual image L 2 v and the right reduced residual image R 2 v from the reducing unit 19Ba and the reducing unit 19Bb, respectively, and combines the two residual images in the vertical direction to reduce the image.
- a framed residual video Fv which is one video frame that is the same size in the vertical direction and 1 ⁇ 2 in the horizontal direction with respect to the previous original size, is generated.
- the combining unit 19Bc outputs the generated framed residual video Fv to the residual video encoding unit 16B. Note that the combining unit 19Bc may combine the two residual images in the horizontal direction.
- the residual video encoding means 16B receives the framed residual video Fv from the combining means 19Bc of the residual video framing means 19B and encodes the framed residual video Fv by a predetermined encoding method. Residual video fv is generated and output to the transmission path as a residual video bit stream.
- the residual video encoding means 16B is a residual video that is framed instead of a single residual video in the residual video to be encoded in the residual video encoding means 16 shown in FIG. Since other than that is the same, detailed description is abbreviate
- the stereoscopic video decoding device 2B decodes the bit stream transmitted via the transmission path from the stereoscopic video encoding device 1B shown in FIG. 19 to generate a multi-view video.
- the stereoscopic video decoding device 2B includes a reference viewpoint video decoding unit 21, a depth map restoration unit 28, Depth map projection means 23B, residual video decoding means 24B, projected video synthesis means 25B, and residual video separation means 27B.
- the decoding device 2B includes an encoded depth map g 2 d in which one depth map is encoded as a depth map bit stream, and a plurality of systems (two systems) as residual video bit streams.
- the encoded residual video fv into which the residual video is framed is input, the framed residual video is separated, and the left designated viewpoint video P and the right designated viewpoint video are used as the designated viewpoint videos of a plurality of systems. Q is generated.
- the decoding device 2B according to the present embodiment further combines a depth map Cd, Ld, Rd at three viewpoints with a combined depth map Gd that is a depth map at a predetermined one common viewpoint, It is different from the decoding apparatus 2A according to the second embodiment (see FIG. 14) that the encoded reduced combined depth map g 2 d that has been reduced and encoded is used.
- the reference viewpoint video decoding means 21 is the same as the reference viewpoint video decoding means 21 shown in FIG.
- the depth map restoration means 28 decodes the depth bit stream, generates a decoded reduced combined depth map G 2 ′ d, generates a decoded combined depth map G′d of the original size, and performs depth map projection. and it outputs the left depth map projection means 23B L and the right depth map projection means 23B R means 23B.
- the depth map restoration means 28 includes a depth map decoding means 28a and an enlargement means 28b. Since the depth map restoration unit 28 has the same configuration as the depth map restoration unit 30 (see FIG. 19) in the encoding device 1B, detailed description thereof is omitted.
- the depth map decoding unit 28a and the enlarging unit 28b correspond to the depth map decoding unit 30a and the enlarging unit 30b shown in FIG. 19, respectively.
- Depth map projection means 23B is configured to have a left depth map projection means 23B L and the right depth map projection unit 23B R, the depth map at the reference viewpoint is a common viewpoint, the left specifies a specified viewpoint of each strain Projecting the viewpoint Pt and the right designated viewpoint Qt, a left designated viewpoint depth map Pd and a right designated viewpoint depth map Qd, which are depth maps at the respective designated viewpoints, are generated.
- Depth map projection means 23B outputs the generated left viewpoint specified depth map Pd and the right specified viewpoint depth map Qd, the left projection image synthesizing unit 25B L and the right projection image synthesizing unit 25B R of each projection video synthesis unit 25B.
- the depth map projection means 23B in this embodiment uses one or more left designated viewpoints (designated viewpoints) Pt and right designated viewpoints (designated viewpoints) Qt in the same manner as the depth map projection means 23A shown in FIG. type each generate a left viewpoint specified depth map Pd and the right specified viewpoint depth map Qd corresponding to the designated view point, the left projection image synthesizing unit 25B L and the right projection image synthesizing unit 25B R projection video synthesis unit 25B Output.
- the left depth map projection means 23B L inputs a decoded composite depth map G′d, which is a decoded depth map at the reference viewpoint, and projects this decoded composite depth map G′d onto the left designated viewpoint Pt.
- the left designated viewpoint depth map (designated viewpoint depth map) Pd at the left designated viewpoint Pt is generated.
- the left depth map projection means 23B L outputs the generated left designated viewpoint depth map Pd to the left projection video composition means 25B L.
- the right depth map projection means 23B R inputs the decoded synthesized depth map G'd a depth map in the decoded reference viewpoint, projection the decoded synthesized depth map G'd right specified viewpoint Qt Then, the right designated viewpoint depth map (designated viewpoint depth map) Qd at the right designated viewpoint Qt is generated.
- Right depth map projection means 23B R outputs the generated right viewpoint specified depth map Qd right projection video synthesis unit 25B R.
- the right depth map projection means 23B R, the left depth map projection unit 23B L, because except that the position relationship between the left and right with respect to the reference viewpoint is reversed have the same structure, detailed description thereof is omitted.
- the residual video decoding unit 24B decodes the residual video bitstream to generate a framed residual video (decoded framed residual video) F′v, and a separation unit 27Ba of the residual video separation unit 27B. Output to.
- the residual video decoding unit 24B has the same configuration as the residual video decoding unit 24A in the second embodiment shown in FIG. 14 except that the size of the framed residual video to be decoded is different. Therefore, detailed description is omitted.
- the residual video separating unit 27B receives the framed residual video F′v decoded from the residual video decoding unit 24B, and the left reduced residual video which is two reduced residual videos that are framed. L 2 'v and right reduced residual video R 2 ' v are separated and enlarged to the original size, left residual video (decoded residual video) L'v and right residual video (decoded residual video) ) R′v is generated. Residual image separation means 27B the generated left residual video L'v and Migizansa video R'v, the left projection image synthesizing unit 25B L and the right projection image synthesizing unit 25B R of each projection video synthesis unit 25B Output.
- the residual video separation means 27B has the same configuration as the residual video separation means 27 in the second embodiment shown in FIG. 14 except that the size of the framed residual video to be separated is different. Detailed description will be omitted.
- the separation means 27Ba, the enlargement means 27Bb, and the enlargement means 27Bc in the residual image separation means 27B correspond to the separation means 27a, the enlargement means 27b, and the enlargement means 27c in the residual image separation means 27, respectively.
- the projected video synthesizing unit 25B includes a reference viewpoint video C ′ input from the reference viewpoint video decoding unit 21, a left residual video L′ v that is a residual video of two left and right systems input from the residual video separation unit 27B, and From the left residual video R′v and the left designated viewpoint depth map Pd and the right designated viewpoint depth map Qd, which are the two left and right depth maps input from the depth map projection means 23B, the left which is the designated viewpoint of the two left and right systems.
- the left designated viewpoint video P and the right designated viewpoint video Q which are designated viewpoint videos at the designated viewpoint Pt and the right designated viewpoint Qt, are generated.
- the projection image synthesizing unit 25B is configured to have a left projection image synthesizing unit 25B L and the right projection image synthesizing unit 25B R.
- the left projection video synthesizing unit 25B L receives the reference viewpoint video C ′ from the reference viewpoint video decoding unit 21, the left residual video L′ v from the enlargement unit 27Bb of the residual video separation unit 27B, and the depth map projection unit 23B.
- the left designated viewpoint depth map Pd is respectively input from the left depth map projection means 23B L , and the left designated viewpoint video P is generated.
- the right projection video synthesis unit 25B R is the reference viewpoint image C 'from the reference viewpoint image decoding unit 21, the right residual picture R'v from expansion unit 27Bc residual image separation means 27B, the depth map projection means the right depth map projection means 23B R from the right viewpoint specified depth map Qd of 23B, respectively input, for generating a right specified viewpoint image Q.
- the left projection image synthesizing unit 25B L in the present embodiment, the reference viewpoint image projection means 251B, is configured to have a residual picture projection means 252B.
- the reference viewpoint video projecting means 251B inputs the reference viewpoint video C ′ from the reference viewpoint video decoding means 21 and the left designated viewpoint depth map Pd from the depth map projecting means 23B, respectively.
- the view image C 'to generate the left specified viewpoint video P C for a pixel that can be projected to the left specified viewpoint Pt.
- Reference viewpoint image projection means 251B outputs the generated left viewpoint specified image P C to the residual image projection means 252B.
- the reference viewpoint video projection unit 251B includes a hall pixel detection unit 251Ba, a designated viewpoint video projection unit 251Bb, a reference viewpoint video pixel copying unit 251Bc, and a hole mask expansion unit 251Bd. .
- Hall pixel detection unit 251Ba receives the left specified viewpoint depth map Pd from the left depth map projection means 23B L of the depth map projection means 23B, by using the left specified viewpoint depth map Pd, left specify standard viewpoint image C ' A pixel that becomes an occlusion hole when projected onto the viewpoint Pt is detected, and a hole mask P 1 h indicating the detected pixel region is generated as a detection result and output to the hole mask expansion means 251Bd. Since the detection method of the pixel which becomes the occlusion hole by the hole pixel detection means 251Ba is the same as that of the hole pixel detection means 251a in the first embodiment shown in FIG.
- Specifying viewpoint image projection means 251Bb has a standard viewpoint image C 'from the reference viewpoint image decoding unit 21, the left depth map projection means 23B L left specified from the viewpoint depth map Pd depth map projection means 23B, respectively input, the reference A left designated viewpoint projected image P 1 C , which is an image obtained by projecting the viewpoint image C ′ onto the left designated viewpoint Pt, is generated and output to the reference viewpoint image pixel copying unit 251Bc.
- the designated viewpoint video projection means 251Bb is the same as the designated viewpoint video projection means 251b in the first embodiment shown in FIG.
- the reference viewpoint image pixel copying unit 251Bc inputs the left specified viewpoint projection image P 1 C from the specified viewpoint image projection unit 251Bb, and the hole mask P 2 h from the hole mask expansion unit 251Bd, respectively, and from these input data, occlusion and copying the pixel capable of projecting the reference viewpoint image C 'in the left specified viewpoint Pt without becoming a hole, and generates a left specified viewpoint video P C.
- the reference viewpoint image pixel copy means 251Bc the generated left viewpoint specified image P C, outputs a residual picture pixel copy means 252Bb of residual picture projection means 252B.
- the reference viewpoint video pixel copying unit 251Bc is the same as the reference viewpoint video pixel copying unit 251c in the first embodiment shown in FIG.
- Hole mask expansion means 251Bd inputs the hole mask P 1 h from hole pixel detection unit 251Ba, a pixel region to be occlusion holes in the hole mask P 1 h, the hole mask P 2 h inflated by a predetermined number of pixels
- the generated hole mask P 2 h is output to the reference viewpoint image pixel copying unit 251Bc and the common hole detecting unit 252Be of the residual image projecting unit 252B.
- the predetermined number of pixels to be expanded can be, for example, two pixels.
- the residual video projection means 252B inputs the left residual video L′ v from the residual video decoding means 24B, and the left designated viewpoint depth map Pd from the left depth map projection means 23B L of the depth map projection means 23B. , as an image in the left specified viewpoint Pt, pixels can not be projected reference viewpoint image C ', i.e., the pixels to be occlusion hole, to produce a left specified viewpoint video P to complement the left specified viewpoint video P C.
- the residual video projection means 252B outputs the generated left designated viewpoint video P to the stereoscopic video display device 4 (see FIG. 1).
- the residual video projection unit 252B includes a designated viewpoint video projection unit 252Ba, a residual video pixel copying unit 252Bb, a hole filling processing unit 252Bc, a hole pixel detection unit 252Bd, and a common hole detection unit 252Be. It is configured.
- the designated viewpoint video projection means 252Ba includes the left residual video L′ v from the enlargement means 27Bb of the residual video separation means 27B, and the left designated viewpoint depth map Pd from the left depth map projection means 23B L of the depth map projection means 23B.
- each type generates a left specified viewpoint projection residual picture P Lv is a video obtained by projecting the Hidarizansa video L'v left specified viewpoint Pt, and outputs to the residual video pixel copying unit 252Bb.
- Residual picture pixel copy means 252Bb has a standard viewpoint image projection means left specified viewpoint video P C from the reference viewpoint image pixel copy means 251Bc of 251B, a hole mask P 2 h from the hole mask expansion means 251Bd, designated viewpoint image projection means The left designated viewpoint projection residual image P Lv is input from 252Ba, and the hole mask P 3 h is input from the hole pixel detection means 252Bd.
- the residual picture pixel copy means 252Bb refers hole mask P 2 h, the pixel that is the occlusion hole in the left specified viewpoint video P C, the pixel value from the left specified viewpoint projection residual picture P Lv extracted and copied to the left specified viewpoint video P C, to produce a left specified viewpoint image P 1 is a video in the left specified viewpoint Pt.
- the residual video pixel copying unit 252Bb uses the left designated viewpoint depth map Pd using the left designated viewpoint depth map Pd to indicate a pixel area (occlusion hole) that cannot be projected as a picture at the left designated viewpoint Pt.
- Residual picture pixel copy means 252Bb outputs the generated left specified viewpoint image P 1 in the filling processing means 252Bc.
- Filling processing means 252Bc is left specified viewpoint image P 1 from the residual image pixel copy means 252Bb, a hole mask P 4 h from the common hole detection means 252Be, respectively inputted.
- the hole-filling processing unit 252Bc uses the hole mask P 4 h to indicate pixels in which effective pixels are not copied by either the reference viewpoint video pixel copying unit 251Bc or the residual video pixel copying unit 252Bb in the left designated viewpoint video P 1 .
- the left designated viewpoint video P is generated by filling the holes with the effective pixel values around the pixels with reference to.
- the hole filling processing means 252Bc outputs the generated left designated viewpoint video P to the stereoscopic video display device 4 (see FIG. 1) as one video in the multi-view video.
- the hole pixel detection means 252Bd receives the left designated viewpoint depth map Pd from the left depth map projection means 23B L of the depth map projection means 23B, and uses the left designated viewpoint depth map Pd to make a left residual image that is an image at the left viewpoint.
- a pixel that becomes an occlusion hole when the difference image L′ v is projected onto the left designated viewpoint Pt is detected, and a hole mask P 3 h indicating the detected pixel region is generated as a detection result, and the residual image pixel copying unit 252Bb Output.
- the hole pixel detection means 252Bd detects a pixel that becomes an occlusion hole on the assumption that the left designated viewpoint is located on the right side of the left viewpoint. For this reason, the hole pixel detection means 252Bd uses the hole pixel detection means 251a in the first embodiment shown in FIG. 8 to detect the pixel value (depth) of the pixel located near the left of the pixel of interest. Value) is larger than the pixel value of the target pixel, and it is determined that the pixel is an occlusion hole when a predetermined condition is satisfied.
- the predetermined condition is the same as the determination condition by the hole pixel detection unit 251a except that the left and right relationship is switched.
- the common hole detection unit 252Be inputs the hole mask P 2 h from the hole mask expansion unit 251Bd and the hole mask P 3 h from the hole pixel detection unit 252Bd. Then, the common hole detecting unit 252Be calculates a logical product of the hole mask P 2 h and the hole mask P 3 h for each pixel, generates a hole mask P 4 h, and outputs the hole mask P 4 h to the hole filling processing unit 252Bc.
- the hole mask P 4 h is effective in that the effective pixels are not copied by the reference viewpoint image pixel copying unit 251 Bc or the residual image pixel copying unit 252 Bb in the left designated viewpoint image P 1 . This indicates a pixel that is a hole having no pixel value.
- right projection video synthesis unit 25B R right projection video synthesis unit 25B R
- the left projection image synthesizing unit 25B L because except that the position relationship between the left and right with respect to the reference viewpoint is reversed have the same structure, detailed description Omitted.
- the encoding device 1B synthesizes and encodes the depth map into a single depth map at the reference viewpoint, which is a common viewpoint, for a plurality of systems of stereoscopic images. Since the difference video is framed and encoded and output as a bit stream, a stereoscopic video can be encoded with high encoding efficiency.
- the decoding device 2B can generate a multi-view video by decoding the stereoscopic video encoded by the encoding device 1B.
- the encoding device 1B generates an encoded reference viewpoint video c by encoding the reference viewpoint video C input from the outside by a predetermined encoding method by the reference viewpoint video encoding means 11, and generates a reference viewpoint video bit. Output as a stream (step S71).
- step S72 includes the following three substeps.
- the encoding device 1B uses the left depth map projection unit 121B and the right depth map projection unit 122B to project the left viewpoint depth map Ld and the right viewpoint depth map Rd, respectively, to a reference viewpoint that is a common viewpoint, and thereby a common viewpoint.
- a depth map C L d and a common viewpoint depth map C R d are generated.
- the encoding device 1B uses the map synthesis unit 123B to generate a reference viewpoint depth map Cd, a common viewpoint depth map C L d, and a common viewpoint depth map C R d which are three depth maps at the common viewpoint (reference viewpoint). Combined into one, a combined depth map Gd is generated.
- the encoding apparatus 1B reduces the combined depth map Gd by the reducing unit 124 to generate a reduced combined depth map G 2 d.
- the depth map encoding unit 13B encodes the reduced combined depth map G 2 d generated in step S72 by a predetermined encoding method to generate an encoded depth map g 2 d. And output as a depth map bit stream (step S73).
- step S74 (Depth map restoration process)
- the encoding apparatus 1B causes the depth map restoration unit 30 to restore the encoded depth map g 2 d generated in step S73 and generate a decoded combined depth map G′d (step S74).
- this step S74 is composed of the following two sub-steps.
- the encoding device 1B the depth map decoding unit 30a, and generates an encoded depth map g 2 d decodes and decrypts reduced composite depth map G 2 'd. Then, the encoding device 1B generates the decoded combined depth map G′d by expanding the decoded reduced combined depth map G 2 ′ d to the original size by the expanding means 30b.
- the encoding device 1B uses the decoding synthesized depth map G′d generated in step S74 by the left projection video prediction unit 15B L of the projection video prediction unit 15B and the left viewpoint video L input from the outside. Te, generates the Hidarizansa video Lv, using the right projection image prediction unit 15B R projection image prediction unit 15B, and the decoding synthesis depth map G'd, a right viewpoint image R input from the outside, A right residual video Rv is generated (step S75).
- the encoding device 1B reduces and combines the left residual video Lv and the right residual video Rv, which are the two residual videos generated in step S75, by the residual video framing unit 19B.
- a framed residual video Fv is generated by framing into one image (step S76).
- the encoding apparatus 1B then encodes the framed residual video Fv generated in step S76 by the residual video encoding unit 16B using a predetermined encoding method to generate an encoded residual video fv.
- the difference video bit stream is output (step S77).
- the decoding device 2B decodes the reference viewpoint video bitstream by the reference viewpoint video decoding means 21, generates the reference viewpoint video C ′, and outputs it as one video of the multi-view video (step S91). .
- step S92 the decoding device 2B decodes the depth map bitstream by the depth map restoration means 28, and generates a decoded combined depth map G′d (step S92).
- S92 includes the following two substeps.
- the decoding device 2B uses the depth map decoding unit 28a to decode the encoded depth map g 2 d transmitted as the depth map bitstream to generate a decoded reduced combined depth map G 2 ′ d. Then, the decoding device 2B generates the decoded combined depth map G′d by expanding the decoded reduced combined depth map G 2 ′ d to the original size by the expanding means 28b.
- the decoding device 2B projects the decoded composite depth map G′d generated in step S92 onto the left specified viewpoint Pt by the left depth map projection means 23B L of the depth map projection means 23B, and specifies the left to generate the left-viewpoint specified depth map Pd is the depth map at the viewpoint Pt, the right depth map projection unit 23B R, decoding synthesized depth map G'd, it is projected to the right viewpoint specified Qt, right specified viewpoint Qt
- the right designated viewpoint depth map Qd which is the depth map at, is generated (step S93).
- the decoding device 2B decodes the residual video bitstream by the residual video decoding unit 24B to generate a framed residual video F′v (step S94).
- the decoding device 2B separates the two residual videos combined with the decoded framed residual video F′v generated in step S94 by the separation unit 27Ba of the residual video separation unit 27B. Further, the enlargement means 27Bb and the enlargement means 27Bc respectively enlarge the original size to generate the left residual video L′ v and the right residual video R′v (step S95).
- the decoding device 2B uses the left designated viewpoint depth map Pd generated in step S93 by the left projection image synthesis means 25B L and the reference viewpoint video C ′ generated in step S91 and the left generated in step S95.
- a residual picture L'v each synthesized image is projected to the left specified viewpoint Pt, to generate the left-specified viewpoint image P is an image of the left specified viewpoint Pt, the right projection video synthesis unit 25B R,
- the reference viewpoint video C ′ generated in step S91 and the right residual video R′v generated in step S95 are respectively projected onto the right specified viewpoint Qt.
- the video is synthesized to generate a right designated viewpoint video Q that is a video at the right designated viewpoint Qt (step S96).
- the reference viewpoint video C ′ generated in step S91 by the decoding device 2B and the left designated viewpoint video P and right designated viewpoint video Q generated in step 96 are shown as multi-view videos, for example, as shown in FIG. Is output to the stereoscopic video display device 4 to display a multi-view stereoscopic video.
- encoding apparatus 1C is the projection of the encoding apparatus 1B according to the third embodiment shown in FIG.
- the left viewpoint video L and the encoding reference viewpoint A left residual image Lv is generated by calculating a difference of pixel values for each image from the image obtained by projecting the decoded reference viewpoint image C ′ obtained by decoding the image c to the left viewpoint (subtraction type). It is.
- the right residual video Rv a difference in pixel value between the right viewpoint video R and a video obtained by projecting the decoded reference viewpoint video C ′ onto the right viewpoint is calculated for the entire video for each pixel.
- a right residual image Rv is generated.
- the right residual video Rv is generated by using the right viewpoint video R instead of the left viewpoint video L in the generation of the left residual video Lv and a video obtained by projecting the decoding reference viewpoint video C ′ to the left viewpoint.
- the description is omitted as appropriate because it is the same except that a video obtained by projecting the decoded reference viewpoint video C ′ onto the right viewpoint is used.
- FIG. 21 (b ) comprises a left projection image prediction unit 15C L illustrated.
- the encoding device 1C further uses the reference viewpoint video decoding for decoding the encoded reference viewpoint video c generated by the reference viewpoint video encoding means 11 in the encoding device 1B according to the third embodiment shown in FIG. It is assumed that it is provided with a converting means (not shown).
- This reference viewpoint video decoding means is the same as the reference viewpoint video decoding means 21 shown in FIG.
- the left projection image prediction means 15C L in this modification is configured by a residual calculation section 154.
- Left projection image prediction unit 15C L is decoded reference viewpoint image C 'from the reference viewpoint image decoding means (not shown), the decoding synthesis depth map G'd from the enlarged section 30b of the depth map recovery unit 30, respectively input.
- the left residual video Lv is output to the reduction means 19Ba of the residual video framing means 19B.
- the left viewpoint projection unit 153 receives the decoded reference viewpoint video C ′ from a reference viewpoint video decoding unit (not shown), and projects the decoded reference viewpoint video C ′ to the left viewpoint to generate a left viewpoint video L ′ C. To do.
- the left viewpoint projection unit 153 outputs the generated left viewpoint video L ′ C to the residual calculation unit 154.
- a predetermined value is set as the pixel value of the pixel.
- this predetermined value is preferably set to “128”, which is the median value of the range that can be taken by the pixel values for each component.
- the difference from the pixel value of the left viewpoint video L becomes data of 8 bits or less including the sign for each component, so that the coding efficiency can be improved.
- the residual calculation means 154 inputs the left viewpoint video L ′ C from the left viewpoint projection means 153 and also inputs the left viewpoint video L from the outside, and the difference between the left viewpoint video L and the left viewpoint video L ′ C A left residual video Lv is generated. Specifically, the residual calculation unit 154 determines, for each component of each pixel, a difference that is a value obtained by subtracting the pixel value of the left viewpoint image L′ C from the pixel value of the left viewpoint image L for the entire image as the pixel value. Left residual video Lv is generated. The residual calculation means 154 outputs the generated left residual video Lv to the reduction means 19Ba of the residual video framing means 19B.
- the decoding reference viewpoint video C ′ is used when generating the residual video
- the decoding device adds the residual video to restore the designated viewpoint video
- the video is subject to the same conditions, and a higher quality multi-view video can be obtained.
- the reference viewpoint video C may be used instead of the decoded reference viewpoint video C ′.
- the reference viewpoint video decoding means (not shown) can be omitted.
- the stereoscopic video decoding apparatus decodes a bitstream transmitted from the encoding apparatus 1C according to the above-described modification via a transmission path to generate a multi-view video.
- the stereoscopic video decoding apparatus is the decoding apparatus 2B according to the third embodiment shown in FIG.
- the left residual video Lv generated by the subtraction type is used instead of generating the left designated viewpoint video P using the left residual video Lv generated by the logical operation type. This is used to generate the left designated viewpoint video P.
- the right designated viewpoint video Q is generated by calculating the pixel value difference for each pixel between the right viewpoint video R and the video obtained by projecting the decoded reference viewpoint video C ′ onto the right viewpoint. Generated using residual video Rv. Note that the right designated viewpoint video Q is generated by using the right residual video Rv instead of the left residual video Lv in the generation of the left designated viewpoint video P, and the direction of projection is reversed left and right with respect to the reference viewpoint. Since the rest is the same, the description will be omitted as appropriate.
- FIG. 24 (b ) Decoding apparatus 2C according to the present modification, in order to generate the left specified viewpoint image P, in place of the left projection image synthesizing unit 25B L in the third embodiment shown in FIG. 24 (a), FIG. 24 (b ) to comprise a left projection image synthesizing unit 25C L illustrated.
- the left projection image synthesizing unit 25C L in this modification similarly to the left projection image synthesizing unit 25B L shown in FIG. 24 (a), the reference viewpoint image decoding means 21
- the left projection video synthesis means 25C L includes a reference viewpoint image projection means 251C, is configured to have a residual picture projection means 252C.
- the reference viewpoint video projecting means 251C does not have the hole mask dilating means 251Bd, and the reference viewpoint video pixel copying means 251Bc is different from the reference viewpoint video projecting means 251B shown in FIG. 24A.
- the difference is that the pixel copy unit 251Cc is provided and the hole mask P 1 h generated by the hole pixel detection unit 251Ba is output to the reference viewpoint video pixel copy unit 251Cc and the common hole detection unit 252Be.
- symbol is attached
- the residual video when generating a residual video with the subtraction type, unlike when generating a residual video with the logical operation type, the residual video is effective like the logical operation type because all pixels have valid pixel values. There is no fear that the part without pixels is used for the synthesis of the designated viewpoint video, and there is no need to expand the hole mask P 1 h.
- the reference viewpoint image pixel copying unit 251Cc receives the left specified viewpoint projection image P 1 C from the specified viewpoint image projection unit 251Bb and the hole mask P 1 h from the hole pixel detection unit 251Ba.
- the reference viewpoint image pixel copy means 251Cc refers hole mask P 1 h, the pixels in the region that do not occlusion hole in the left specified viewpoint projection video P 1 C, copied from the left viewpoint specified projection images P 1 C to generate the left specified viewpoint video P C Te.
- the reference viewpoint video pixel copying unit 251Cc with respect to the pixels in the region serving as the occlusion hole, is a predetermined set by the left viewpoint projection unit 153 (see FIG. 21B) for the pixels serving as the occlusion hole.
- the value is set as the pixel value of that pixel.
- the residual addition unit 252f to be described later, that the pixels of the left specified viewpoint projection residual picture P Lv to the pixel is summed, Appropriate pixel values are restored.
- the reference viewpoint image pixel copy means 251Cc outputs the generated left specified viewpoint image P C to the residual adding means 252f of residual picture projection means 252C.
- the residual video projection unit 252C is different from the residual video projection unit 252B shown in FIG. 24A in place of the designated viewpoint video projection unit 252Ba and the residual video pixel copying unit 252Bb, respectively.
- the difference adding means 252f is different from inputting the hole mask P 1 h to the common hole detecting means 252Be instead of the hole mask P 2 h.
- symbol is attached
- the designated viewpoint video projection means 252Ca in this modification is different from the designated viewpoint video projection means 252Ba in the third embodiment in that the left residual video L′ v that is the object to be projected is generated by a logical operation type, The difference is that it was generated by the subtraction type.
- the designated viewpoint video projection unit 252Ca generates the left designated viewpoint projected residual video P Lv by projecting the left residual video L′ v onto the left designated viewpoint using the left designated viewpoint depth map Pd, and generates the generated left and it outputs the specified viewpoint projection residual picture P Lv to the residual adding means 252f.
- the designated viewpoint video projection unit 252Ca sets a predetermined value for a pixel that becomes an occlusion hole when the left residual video L′ v is projected onto the left designated viewpoint.
- “0” is set as the predetermined value for all components of the pixel.
- Residual adding means 252f is the reference viewpoint image pixel copy means left specified from 251Cc view image P C, the left viewpoint specified projection residual picture P Lv from the specified viewpoint video projection unit 252Ca, inputs respectively. Then, the residual addition unit 252f includes a left viewpoint specified projection residual picture P Lv, adds the corresponding pixels to each other between the left specified viewpoint video P C, left specifies a video in the left specified viewpoint Pt view image P 1 is generated. Residual adding means 252f outputs the generated left specified viewpoint image P 1 in the filling processing means 252Bc.
- the common hole detection means 252Be obtains the hole mask P 1 h for the left designated viewpoint video Pc from the hole pixel detection means 251Ba, and the hole mask P 3 h for the left designated viewpoint projected residual video P Lv from the hole pixel detection means 252Bd. , Enter each. Then, the common hole detection unit 252Be calculates a logical product of the hole mask P 1 h and the hole mask P 3 h for each pixel to generate a hole mask P 4 h that is a common hole mask, and supplies the hole filling processing unit 252Bc to the hole filling processing unit 252Bc. Output.
- the left designated viewpoint image P is generated by filling in the holes that are the holes using the effective pixel values around the pixels.
- the hole filling processing means 252Bc outputs the generated left designated viewpoint video P to the stereoscopic video display device 4 (see FIG. 1) as one video in the multi-view video.
- the common hole detection means 252Be in this modification receives the hole mask P 1 h from the hole pixel detection means 251Ba and the hole mask P 3 h from the hole pixel detection means 252Bd. Then, the common hole detecting unit 252Be calculates a logical product of the hole mask P 1 h and the hole mask P 3 h for each pixel, generates a hole mask P 4 h, and outputs the hole mask P 4 h to the hole filling processing unit 252Bc. As described above, in the hole mask P 4 h, effective pixels are not copied by the reference viewpoint image pixel copying unit 251Cc in the left designated viewpoint image P 1 , and an effective residual is generated by the residual addition unit 252f. This indicates a pixel that is a hole without having a valid pixel value because it was not added.
- the operation of the encoding device 1C according to the present modification is the same as the operation of the encoding device 1B according to the third embodiment shown in FIG. 25 between the reference viewpoint video encoding processing step S71 and the projected video prediction processing step S75.
- the operation of the decoding apparatus 2C according to the present modification is the same as the left projection video shown in FIG. 24B in the projection video composition processing step S96 of the decoding apparatus 2B according to the third embodiment shown in FIG.
- the subtracted left residual video Lv and right residual video Rv are used by the projection video synthesizing means (not shown) including the synthesizing means 25C L and the right projection video synthesizing means (not shown) having the same configuration as this.
- the left designated viewpoint video P and the right designated viewpoint video Q are generated differently. Since other processes are the same as those of the decoding device 2B according to the third embodiment, description thereof will be omitted.
- the configuration of this modified example of the projection video prediction unit that generates the residual video in the subtraction type may be applied to the projection video prediction unit 15 in the first embodiment and the projection video prediction unit 15A in the second embodiment. it can.
- the configuration of this modified example of the projection video synthesizing means for generating the designated viewpoint video using the subtraction type residual video is the projection video synthesis means 25 in the first embodiment and the projection video synthesis in the second embodiment. It can also be applied to the means 25A.
- a stereoscopic video transmission system including a stereoscopic video encoding device and a stereoscopic video decoding device according to a fourth embodiment of the present invention will be described.
- the stereoscopic video transmission system including the stereoscopic video encoding device and the stereoscopic video decoding device according to the fourth embodiment is the same as the stereoscopic video transmission system S shown in FIG. 1 in the stereoscopic video encoding device 1 and the stereoscopic video decoding device. Instead of 2, each of them includes a stereoscopic video encoding device 5 (see FIG. 27) and a stereoscopic video decoding device 6 (see FIG. 31).
- the bit stream transmitted from the stereoscopic video encoding device 5 to the stereoscopic video decoding device 6 is necessary when combining the reference viewpoint video bit stream, the depth map bit stream, the residual video bit stream, and the designated viewpoint video. It is a multiplexed bit stream in which auxiliary information is multiplexed.
- auxiliary information is multiplexed.
- the stereoscopic video encoding device 5 (hereinafter referred to as “encoding device 5” as appropriate) according to the fourth embodiment includes a bitstream multiplexing means 50 and an encoding processing unit 51. Configured.
- the encoding processing unit 51 includes encoding apparatuses 1, 1A, 1B, and 1C (hereinafter referred to as “encoding apparatus 1 etc.” as appropriate) according to the first embodiment, the second embodiment, the third embodiment, and modifications thereof described above. And a plurality of viewpoint videos C, L, R and their associated depth maps Cd, Ld, Rd from the outside (for example, the stereoscopic video creation device 3 shown in FIG. 1), and a reference The viewpoint video bit stream, the depth map bit stream, and the residual video bit stream are output to the bit stream multiplexing means 50.
- bit stream multiplexing means 50 generates a multiplexed bit stream in which each bit stream output from the encoding processing unit 51 and auxiliary information h input from the outside are multiplexed, and the decoding apparatus 6 (see FIG. 31). ).
- the encoding processing unit 51 corresponds to the encoding device 1 or the like, and includes a reference viewpoint video encoding unit 511, a depth map synthesis unit 512, a depth map encoding unit 513, and a depth map restoration. Means 514, projected video prediction means 515, and residual video encoding means 516 are provided.
- each component of the encoding processing unit 51 will be described with reference to FIG. 27 (refer to FIGS. 2, 12 and 19 as appropriate).
- each component of the encoding processing unit 51 can be configured by one or more components in the encoding device 1 or the like, the correspondence between the components is shown, and detailed description is omitted as appropriate. To do.
- the reference viewpoint video encoding unit 511 receives the reference viewpoint video C from the outside, generates an encoded reference viewpoint video c obtained by encoding the reference viewpoint video C by a predetermined encoding method, and the bitstream multiplexing unit 50. Output to.
- the reference viewpoint video encoding unit 511 corresponds to the reference viewpoint video encoding unit 11 in the encoding device 1 or the like.
- the depth map combining means 512 inputs a reference viewpoint depth map Cd, a left viewpoint depth map Ld, and a right viewpoint depth map Rd from the outside, and appropriately combines these depth maps to generate a combined depth map G 2 d. It outputs to the depth map encoding means 513.
- the depth map input from the outside is not limited to three, and may be two or four or more.
- the combined depth map may be reduced, or two or more combined depth maps may be framed and further reduced.
- the encoding of data input / output between each component uses the encoding device 1 ⁇ / b> B according to the third embodiment shown in FIG. 19 as the configuration of the encoding processing unit 51.
- code when had shows (G 2 d, g 2 d , G 2 'd, Fv, fv, c) as an example.
- a code shall be read suitably. The same applies to FIG. 28 described later.
- the depth map combining means 512 includes a depth map combining means 12 of the encoding device 1, a depth map combining means 12A and a depth map frame forming means 17 of the encoding device 1A, or a depth map combining means 12B of the encoding devices 1B and 1C. It is equivalent to.
- the depth map encoding unit 513 receives the combined depth map G 2 d from the depth map combining unit 512, encodes it with a predetermined encoding method, generates an encoded depth map g 2 d, and generates a depth map restoration unit 514. And output to the bitstream multiplexing means 50.
- the depth map encoding unit 513 corresponds to the depth map encoding unit 13 of the encoding device 1, the depth map encoding unit 13A of the encoding device 1A, or the depth map encoding unit 13B of the encoding devices 1B and 1C. Is.
- the depth map restoration unit 514 receives the encoded depth map g 2 d from the depth map encoding unit 513, decodes the encoded depth map g 2 d, and generates a decoded combined depth map G′d.
- the depth map restoration unit 514 outputs the generated decoded composite depth map G′d to the projected video prediction unit 515.
- the encoded depth map input to the depth map restoration means 514 is not limited to a single composite depth map, and a plurality of depth maps may be framed and further reduced.
- Depth map restoration means 514 separates into individual composite depth maps after decoding if the input encoded depth map is framed, or after decoding or separates if it is reduced. After that, it will be enlarged to the original size and output.
- the depth map restoring means 514 is the depth map decoding means 14 of the encoding device 1, the depth map decoding means 14A and the depth map separating means 18 of the encoding device 1A, or the depth map restoring means 30 of the encoding devices 1B and 1C. It is equivalent to.
- the projected video prediction unit 515 inputs the decoded composite depth map G′d from the depth map restoration unit 514, and information on the left viewpoint video L, the right viewpoint video R, and the designated viewpoints Pt and Qt as necessary, from the outside. Then, the residual video Fv is generated.
- the projected video prediction unit 515 outputs the generated residual video Fv to the residual video encoding unit 516.
- the generated residual video may be one residual video, or may be one in which residual video between the reference viewpoint and a plurality of other viewpoints is framed, and further reduced. It may be done. In any case, the generated residual video is output to the residual video encoding means 516 as one viewpoint video.
- the projected video prediction unit 515 includes a projected video prediction unit 15 of the encoding device 1, a projected video prediction unit 15A and a residual video framing unit 19 of the encoding device 1A, and a projected video prediction unit 15B and a residual of the encoding device 1B. This corresponds to the video framing means 19B or the projected video prediction means 15C (not shown) of the encoding device 1C.
- the encoding processing unit 51 further includes reference viewpoint video decoding means (not shown). .
- the reference viewpoint video decoding means decodes the encoded reference viewpoint video c output from the reference viewpoint video encoding means 511 to generate a decoded reference viewpoint video C ′, and generates the generated decoding reference.
- the viewpoint video C ′ is output to the projected video prediction means 515.
- this reference viewpoint video decoding means the same reference viewpoint video decoding means 21 as shown in FIG. 7 can be used. Note that the projection video prediction unit 515 may not be provided with the reference viewpoint video decoding unit, and the reference viewpoint video C may be input and used.
- the residual video encoding unit 516 receives the residual video Fv from the projected video prediction unit 515 and encodes it using a predetermined encoding method to generate an encoded residual video fv.
- the residual video encoding unit 516 outputs the generated encoded residual video fv to the bit stream multiplexing unit 50.
- the residual video encoding unit 516 is a residual video encoding unit 16 of the encoding device 1, a residual video encoding unit 16A of the encoding device 1A, or a residual video encoding unit 16B of the encoding devices 1B and 1C. It is equivalent to.
- the bitstream multiplexing means 50 includes a switch (switching means) 501, auxiliary information header addition means 502, depth header addition means 503, and residual header addition means 504.
- switch switching means
- auxiliary information header addition means 502 auxiliary information header addition means 502
- depth header addition means 503 depth header addition means 503
- FIG. 28 for convenience of explanation, each bit stream will be described assuming that the encoding device 1B is used as the encoding processing unit 51, but the present invention is not limited to this.
- a signal name such as the residual video Fv is appropriately replaced.
- the bit stream multiplexing means 50 receives the reference viewpoint video bit stream, the depth map bit stream, and the residual video bit stream from the encoding processing unit 51, and auxiliary information indicating attributes of video included in these bit streams.
- h is input from the outside (for example, the stereoscopic image creation apparatus 3 shown in FIG. 1), and identification information is added so that these bit streams and auxiliary information h can be identified, respectively, and a multiplexed bit stream is generated. It is.
- the switch (switching means) 501 switches the connection between the four input terminals A1 to A4 and one output terminal B, selects one of the signals input to the input terminals A1 to A4, and outputs from the output terminal B As a result, the bit streams input to the four input terminals A1 to A4 are multiplexed and output.
- a bit stream of auxiliary information to which a predetermined header is added from the auxiliary information header adding means 502 is input to the input terminal A1.
- the encoded reference viewpoint video c is input as a reference viewpoint video bitstream from the reference viewpoint video encoding means 511 of the encoding processing unit 51 to the input terminal A2.
- a depth map bitstream to which a predetermined header is added from the depth header adding means 503 is input to the input terminal A3.
- a residual video bitstream to which a predetermined header is added is input to the input terminal A4 from the residual header adding means 504.
- bit streams generated by the reference viewpoint video encoding unit 511, the depth map encoding unit 513, and the residual video encoding unit 516 are all encoded as one viewpoint video. It is assumed that a header indicating that the data has been converted is included.
- the bitstreams 70 output by these encoding means all have the same header in accordance with the “one-view video” bitstream structure defined in the specification of the encoding method. Yes.
- bitstream body 703 of the one-view video.
- start code 701 for example, data “001” having a length of 3 bytes
- first identification indicating a bit stream of one-view video.
- Information 702 for example, 1-byte data and the lower 5 bits are “00001”
- bit stream body 703 of the one-view video.
- the end of the bitstream can be recognized, for example, by detecting an end code in which “0” of 3 bytes or more continues. It is assumed that the bitstream body 703 is encoded so as not to include a bit string that matches the start code and the end code.
- “000” having a length of 3 bytes may be added as a footer to the end of the bitstream, but “0” having 1 byte may be added.
- “000” of 3 bytes appears together with “00” of the first 2 bytes of the start code of the header in the bit stream following this bit stream. The end of the bitstream can be recognized.
- the bit stream that follows without adding “0” to the end of the bit stream can be recognized by “000” in the first 3 bytes of the start code of the header.
- the three systems of bit streams input from the encoding processing unit 51 to the bit stream multiplexing means 50 all have the structure of the bit stream 70 shown in FIG. Therefore, the bit stream multiplexing unit 50 determines whether the three streams of bit streams input from the encoding processing unit 51 are those of the reference viewpoint video or the depth map in the existing header given by the encoding unit. And a header and a flag are added as identification information for identifying whether the video is a residual video.
- the bitstream multiplexing means 50 uses the decoding device 6 (see FIG. 31) according to the present embodiment to generate stereoscopic video for auxiliary information necessary for synthesizing multiview video. A header and a flag are added and output as identification information for identifying the auxiliary information.
- the bit stream multiplexing unit 50 does not change the structure of the bit stream 71 with respect to the bit stream output from the reference viewpoint video encoding unit 511 without changing the structure of the bit stream 71, as shown in FIG.
- the viewpoint video bit stream is output via the switch 501.
- the depth header adding unit 503 inputs the encoded depth map g 2 d as the depth bit stream from the depth map encoding unit 513 of the encoding processing unit 51, and inserts predetermined identification information into the existing header.
- a bit stream having the structure of the bit stream 72 shown in 29 (c) is generated and output to the switch 501.
- the depth header adding unit 503 detects the start code 701 of the one-view video bitstream included in the depth map bitstream input from the depth map encoding unit 513, and immediately after this, the depth map bitstream Inserts a 1-byte “stereoscopic image header (second identification information) 704” indicating that the data is related to the stereoscopic image.
- the value of the stereoscopic video header 704 the value of the lower 5 bits is, for example, “11000”, which is a header value not defined so far in the MPEG-4 AVC standard, for example. This indicates that the bit stream after the stereoscopic video header 704 is a bit stream related to the stereoscopic video according to the present invention.
- the depth header adding means 503 further indicates a 1-byte depth flag (third identification information) after the stereoscopic video header 704 to indicate that the bit stream after the stereoscopic video header 704 is a depth map bit stream. 705 is inserted and multiplexed with another bit stream via the switch 501 and output. As the depth flag 705, for example, an 8-bit value of “100000000” can be assigned. Thereby, the decoding device 6 (see FIG. 31) of the present invention can identify that this bit stream is a depth map bit stream.
- the residual header adding unit 504 inputs the encoded residual video fv as a residual video bit stream from the residual video encoding unit 516 of the encoding processing unit 51, and inserts predetermined identification information into an existing header.
- a bit stream having the structure of the bit stream 73 shown in FIG. 29D is generated and output to the switch 501.
- the residual header adding unit 504 sets the start code 701 of the one-view video bitstream included in the residual video bitstream input from the residual video encoding unit 516 in the same manner as the depth header adding unit 503. Immediately thereafter, a 1-byte stereoscopic video header 704 (for example, the value of the lower 5 bits is “11000”) indicating that the residual video bit stream is data relating to stereoscopic video, and a residual video 1-byte residual flag (fourth identification information) 706 is inserted, and is multiplexed with another bit stream via the switch 501 and output. As the residual flag 706, a value different from the depth flag 705, for example, a value of “10100000” of 8 bits can be assigned.
- the decoding device 6 As in the case of the depth map bit stream described above, by inserting the stereoscopic video header 704, it is possible to prevent malfunction of an existing decoding device that decodes one viewpoint video. Also, by inserting the residual flag 706, the decoding device 6 (see FIG. 31) of the present invention can identify that this bit stream is a residual video map bit stream.
- the auxiliary information header adding means 502 inputs auxiliary information h necessary for the decoding device 6 to synthesize a multi-view video from the outside (for example, the stereoscopic video creation device 3 shown in FIG. 1), and inputs a predetermined header.
- a bit stream having the structure of the bit stream 74 shown in FIG. 29 (e) is generated and output to the switch 501.
- the auxiliary information header adding unit 502 adds the start code 701 (for example, 3-byte data “001”) to the head of the auxiliary information h input from the outside, and immediately thereafter, the subsequent bit string relates to the stereoscopic video.
- a stereoscopic video header 704 indicating that the data is data (for example, the value of the lower 5 bits is “11000”) is added.
- the auxiliary information header adding unit 502 adds a 1-byte auxiliary information flag (fifth identification information) 707 indicating that the subsequent data is auxiliary information after the stereoscopic video header 704.
- auxiliary information flag 707 a value that is neither the depth flag 705 nor the residual flag 706, for example, a value of “11000000” of 8 bits can be assigned.
- the auxiliary information header adding unit 502 adds the start code 701, the stereoscopic video header 704, and the auxiliary information flag 707 to the main body of the auxiliary information, and then multiplexes and outputs with the other bitstream via the switch 501. To do.
- the auxiliary information flag 707 the decoding device 6 (see FIG. 31) of the present invention identifies that this bit stream is an auxiliary information bit stream necessary for the synthesis of multi-view video. Can do.
- the switch 501 switches the auxiliary information bit stream, the reference viewpoint video bit stream, the depth map bit stream, and the residual video bit stream to be selected in this order, and outputs these bit streams as a multiplexed bit stream. To do.
- the auxiliary information is information indicating attributes of the multi-view video that is encoded and output by the encoding device 5.
- the auxiliary information includes, for example, information indicating the mode, the closest distance, the farthest distance, the focal distance, and the positions of the reference viewpoint and the sub-viewpoint. 6 is output.
- the decoding device 6 uses the depth map, the reference viewpoint video, and the residual video obtained by decoding the bitstream input from the encoding device 5 to project these videos onto the designated viewpoint and project at the designated viewpoint. When compositing the video, auxiliary information is referenced as necessary.
- auxiliary information is appropriately referred to when the depth map or the video is projected to another viewpoint in the decoding device 2 or the like according to the other embodiment described above.
- information indicating the position of each viewpoint as shown in FIG. 5 is included in the auxiliary information, and is used when calculating a shift amount when projecting a depth map or video.
- the auxiliary information necessary for the decoding device 6 (see FIG. 31) of the present invention to synthesize a multi-view video is the auxiliary information body 708 shown in FIG. 29 (e), for example, the parameter name shown in FIG. Separate the values with a space and arrange them side by side.
- the order of the parameters may be fixed, and only the values may be sequentially separated by a space and arranged.
- the parameter data length and the arrangement order may be determined in advance, the parameter values may be arranged in that order, and the parameter type may be identified by the number of bytes from the beginning.
- the parameters shown in FIG. 30 will be described.
- the “mode” is, for example, whether the encoded residual video and the combined depth map are “2 views and 1 depth” generated by the encoding device 1 according to the first embodiment, or according to the second embodiment.
- Stereo image data generation mode such as “3 view 2 depth” generated by the encoding device 1A or “3 view 1 depth” generated by the encoding device 1B according to the third embodiment. Is shown. For example, values “0”, “1”, “2”, and the like can be assigned and distinguished in correspondence with the respective embodiments described above.
- the “view” indicates the total number of viewpoints of videos included in the reference viewpoint video bit stream and the residual video bit stream.
- “Depth” indicates the number of viewpoints of the combined depth map included in the depth map bitstream.
- “Recent distance” indicates the distance to the subject closest to the camera among the subjects shown in the multi-view video input from the outside.
- the “farthest distance” indicates the distance from the camera to the farthest object among the subjects displayed in the multi-view video input from the outside, and both are designated viewpoint videos in the decoding device 6 (see FIG. 31). Is used when converting the value of the depth map into the amount of parallax, and used to determine the amount of pixel shift.
- “Focal distance” indicates the focal length of the camera that has captured the input multi-view video, and is used to determine the position of the designated viewpoint video to be synthesized by the decoding device 6 (see FIG. 31). Note that the focal length can be determined in units of the pixel size of an image sensor of a camera that captures a multi-viewpoint video or a stereoscopic video display device. However, it is not limited to this.
- the “left viewpoint coordinate value”, “reference viewpoint coordinate value”, and “right viewpoint coordinate value” represent the X coordinate of the camera that captured the left viewpoint video, the central reference viewpoint video, and the right viewpoint video, respectively, and are decoded. This is used to determine the position of the designated viewpoint video to be synthesized by the device 6 (see FIG. 31).
- the auxiliary information is not limited to the parameters described above, but may include other parameters.
- the center position of the image sensor in the camera when it is deviated from the optical axis of the camera, it may further include a value indicating the amount of deviation. This value can be used to correct the position of the composite video.
- auxiliary information when the auxiliary information includes a parameter that changes for each frame of the bitstream, a parameter that changes and a parameter that does not change may be inserted into the multiplexed bitstream as separate auxiliary information.
- auxiliary information including parameters that do not change in the entire bit stream of a series of stereoscopic images, such as a mode and a focal length, is inserted only once at the beginning of the series of bit streams. Parameters such as the nearest distance, the farthest distance, the left viewpoint coordinate, and the right viewpoint coordinate that may change from frame to frame may be inserted into the bitstream for each frame as separate auxiliary information.
- the start code 701 (see FIG. 29) in the bit stream is attached to each frame, and in order to distinguish the types of auxiliary information, for example, 8 bits are used as a plurality of types of auxiliary information flags 707.
- a value of “11000000” and a value of “11000001” are defined, and auxiliary information including parameters that change midway is inserted for each frame in the same procedure as described above.
- auxiliary information that changes midway is inserted into a series of bitstreams for each frame
- the reference visual video bitstream, depth map bitstream, residual video bitstream, and auxiliary information belonging to each frame are included.
- the auxiliary information is preferably output to the multiplexed bitstream first.
- the configuration of the stereoscopic video decoding device 6 according to the fourth embodiment will be described with reference to FIG.
- the stereoscopic video decoding device 6 decodes the bit stream transmitted via the transmission path from the stereoscopic video encoding device 5 shown in FIG. 27 to generate a multi-view video.
- the stereoscopic video decoding device 6 (hereinafter referred to as “decoding device 6” as appropriate) according to the fourth embodiment includes a bitstream separation means 60 and a decoding processing unit 61. It is configured.
- the bit stream separation means 60 receives the multiplexed bit stream from the encoding device 5 (see FIG. 27), and inputs the multiplexed bit stream into the reference viewpoint video bit stream, the depth map bit stream, and the residual video bit. Separated into a stream and auxiliary information.
- the bitstream separation means 60 separates the reference viewpoint video bitstream into the reference viewpoint video decoding means 611, the depth map bitstream into the depth map restoration means 612, and the residual video bitstream into the residual video restoration means 614.
- the auxiliary information is output to the depth map projecting unit 613 and the projected image synthesizing unit 615, respectively.
- the decoding processing unit 61 synthesizes the reference viewpoint video bit stream, the depth map bit stream, and the residual video bit stream from the bit stream separation unit 60 from the outside (for example, the stereoscopic video display device 4 shown in FIG. 1).
- the designated viewpoints Pt and Qt for the multi-viewpoints to be input are respectively input, the reference viewpoint video C ′ is decoded, and the left-designated viewpoint video P and the right-designated viewpoint video Q are synthesized to produce a multi-viewpoint video (C ′ , P, Q).
- the decoding processing unit 61 outputs the generated multi-viewpoint video to, for example, the stereoscopic video display device 4 illustrated in FIG. Then, the stereoscopic video display device 4 displays the multi-view video so as to be visible.
- the input reference viewpoint video bitstream, depth map bitstream, and residual video bitstream are MPEG-4 AVC code corresponding to the encoding device 5 described above.
- the data is encoded by the encoding method and has the bit stream structure shown in FIG.
- the decoding processing unit 61 includes decoding devices 2, 2A, 2B, and 2C (hereinafter referred to as “decoding device 2 etc.” as appropriate) according to the first embodiment, the second embodiment, the third embodiment, and modifications thereof. And a reference viewpoint video decoding unit 611, a depth map restoring unit 612, a depth map projecting unit 613, a residual video restoring unit 614, and a projected video synthesizing unit 615. ing.
- each component of the decryption processing unit 61 will be described with reference to FIG. 31 (refer to FIG. 7, FIG. 14 and FIG. 22 as appropriate).
- each component of the decoding processing unit 61 can be configured by one or more components in the decoding device 2 or the like, the correspondence between the components is shown, and detailed description is omitted as appropriate. To do.
- the reference viewpoint video decoding unit 611 receives the encoded reference viewpoint video c as the reference viewpoint video bitstream from the bitstream separation unit 60 and decodes the encoded reference viewpoint video c according to the encoding method to generate a decoded reference viewpoint video C ′.
- the generated decoded reference viewpoint video C ′ is output to the outside (for example, the stereoscopic video display device 4 shown in FIG. 1) as the reference viewpoint video of the multi-view video.
- the reference viewpoint video decoding unit 611 corresponds to the reference viewpoint video decoding unit 21 in the decoding device 2 or the like.
- the depth map restoration unit 612 receives the encoded depth map g 2 d as the depth map bit stream from the bit stream separation unit 60, decodes the encoded depth map g 2 d using the encoding method, and generates a decoded combined depth map G′d.
- the generated decoding combined depth map G′d is output to the depth map projection means 613.
- the depth map restoration means 612 separates the depth map that has been framed after decoding when the input coded synthesis depth map is framed, and the coding synthesized depth map has been reduced. In this case, after decoding or separation, the image is enlarged to the original size and output to the depth map projection means 613.
- the depth map restoring means 612 is the depth map decoding means 22 in the decoding device 2, the depth map decoding means 22A and the depth map separating means 26 in the decoding device 2A, or the depth map restoring means 28 in the decoding devices 2B and 2C. It is equivalent to.
- the depth map projecting means 613 receives the decoded combined depth map G′d from the depth map restoring means 612, the auxiliary information h from the bitstream separating means 60, and the outside (for example, the stereoscopic video display device 4 shown in FIG. 1).
- the left designated viewpoint Pt and the right designated viewpoint Qt are respectively input to generate a left designated viewpoint depth map Pd and a right designated viewpoint depth map Qd, which are depth maps at the left designated viewpoint Pt and the right designated viewpoint Qt, and the generated left
- the designated viewpoint depth map Pd and the right designated viewpoint depth map Qd are output to the projected video composition means 615.
- the depth map projection means 613 is not limited to two designated viewpoints input from the outside, but may be one or three or more. Further, the depth map projecting unit 613 is not limited to one decoding composite depth map input from the depth map restoring unit 612, and may be two or more. The depth map projection unit 613 generates a designated viewpoint depth map corresponding to each input designated viewpoint, and outputs it to the projected video composition unit 615.
- the depth map projecting means 613 corresponds to the depth map projecting means 23 in the decoding apparatus 2, the depth map projecting means 23A in the decoding apparatus 2A, and the depth map projecting means 23B in the decoding apparatuses 2B and 2C.
- the residual video restoration unit 614 receives the encoded residual video fv as the residual video bitstream from the bitstream separation unit 60, and decodes the residual video Lv by using the encoding method.
- the video R′v is generated, and the generated left residual video L′ v and right residual video R′v are output to the projected video synthesis means 615.
- the residual video restoration unit 614 separates the framed residual video after decoding, and the encoded residual video is reduced. In this case, after decoding or separation, the image is enlarged to the original size and output to the projected image synthesizing unit 615.
- the residual video restoration means 614 is a residual video decoding means 24 in the decoding device 2, a residual video decoding means 24A and a residual video separation means 27 in the decoding device 2A, or residuals in the decoding devices 2B and 2C. This corresponds to the difference video decoding means 24B and the residual video separation means 27B.
- the projected video synthesizing means 615 receives the decoded reference viewpoint video C ′ from the reference viewpoint video decoding means 611, the left and right designated viewpoint depth maps Pd and Qd from the depth map projection means 613, and the left residual from the residual video restoration means 614.
- the difference video L′ v and the right residual video R′v are input to the auxiliary information h from the bitstream separation unit, respectively, and the designated viewpoint videos P and Q at the left and right designated viewpoints Pt and Qt are generated.
- the projected video composition means 615 outputs the generated designated viewpoint videos P and Q to the outside (for example, the stereoscopic video display device 4 shown in FIG. 1) as designated viewpoint videos of the multi-viewpoint video.
- the projected video synthesis means 615 corresponds to the projected video synthesis means 25 in the decoding device 2, the projected video synthesis means 25A in the decoding device 2A, and the projected video synthesis means 25B in the decoding devices 2B and 2C.
- the bit stream separation means 60 separates the multiplexed bit stream input from the encoding device 5 (see FIG. 27) into a designated viewpoint video bit stream, a depth map bit stream, a residual video bit stream, and auxiliary information. Then, it outputs to each part of the decoding process part 61.
- FIG. 32 the bitstream separation means 60 includes a reference viewpoint video bitstream separation means 601, depth map bitstream separation means 602, residual video bitstream separation means 603, and auxiliary information separation. And means 604.
- the reference viewpoint video bitstream separation means 601 receives the multiplexed bitstream from the encoding device 5 (see FIG. 27), separates the reference viewpoint video bitstream from the multiplexed bitstream, and separates it as a reference viewpoint video bitstream.
- the encoded reference viewpoint video c is output to the reference viewpoint video decoding means 611. Further, when the input multiplexed bit stream is a bit stream other than the reference viewpoint video bit stream, the reference viewpoint video bit stream separation unit 601 transfers the multiplexed bit stream to the depth map bit stream separation unit 602.
- the reference viewpoint video bitstream separation means 601 checks the value from the beginning of the input multiplexed bitstream, and is a start code 701 defined by the MPEG-4 AVC encoding system, which is a 3-byte code. Search for the value “001”.
- the reference viewpoint video bitstream separation unit 601 detects the start code 701
- the reference viewpoint video bitstream separation unit 601 examines the value of a 1-byte header immediately after the start code 701, and a value indicating that it is the stereoscopic video header 704 (eg, the lower 5 bits are “11000 )).
- the reference viewpoint video bitstream separating means 601 uses the bit string from the start code 701 to the detection of 3 bytes “000” as the end code as the reference viewpoint video bitstream. Is output to the reference viewpoint video decoding means 611.
- the reference viewpoint video bit stream separating unit 601 converts the subsequent bit stream including the start code 701 into an end code (for example, a 3-byte “ 000 ”) is detected, it is transferred to the depth map bitstream separation means 602.
- the depth map bitstream separation unit 602 receives the multiplexed bitstream from the reference viewpoint video bitstream separation unit 601, separates the depth bitmap stream from the input multiplexed bitstream, and separates it as a depth map bitstream.
- the depth map g 2 d is output to the depth map restoring means 612.
- the depth map bitstream separation unit 602 transfers the multiplexed bitstream to the residual video bitstream separation unit 603 when the input multiplexed bitstream is a bitstream other than the depth map bitstream.
- the depth map bitstream separation unit 602 detects the start code 701 in the multiplexed bitstream, and the 1-byte header immediately after that detects the start code 701 in the multiplexed bitstream, similar to the reference viewpoint video bitstream separation unit 601 described above. In the case of the stereoscopic video header 704, it is further confirmed whether or not the 1-byte flag immediately after that is the depth flag 705.
- this flag is a value indicating the depth flag 705 (for example, 8-bit “10000000”)
- the depth map bitstream separation unit 602 keeps the start code 701 as it is, and the 1-byte stereoscopic image headers 704 and 1
- the bit stream from which the byte depth flag 705 has been deleted is output to the depth map restoring means 612 as a depth map bit stream until an end code (eg, “000” of 3 bytes) is detected.
- the depth map bitstream separating unit 602 includes the stereoscopic video header 704 and the depth inserted from the depth map bitstream separated from the multiplexed bitstream by the bitstream multiplexing unit 50 of the encoding device 5 (see FIG. 27).
- the flag 705 is deleted, and the bit stream having the structure of the one-viewpoint video bit stream shown in FIG. 29A is returned to the depth map restoring unit 612.
- the depth map restoration unit 612 can decode the depth map bit stream input from the depth map bit stream separation unit 602 as one viewpoint video.
- the depth map bitstream separation unit 602 includes the bitstream from the start code 701 until the end code is detected, including the end code, and remains. Transfer to the difference video bitstream separation means 603.
- the residual video bit stream separating unit 603 receives the multiplexed bit stream from the depth map bit stream separating unit 602, separates the residual video bitmap stream from the input multiplexed bit stream, and separates it as a residual video bit stream
- the encoded residual video fv is output to the residual video restoration means 614.
- the residual video bit stream separating unit 603 transfers the multiplexed bit stream to the auxiliary information separating unit 604 when the input multiplexed bit stream is a bit stream other than the residual video bit stream.
- the residual video bitstream separation unit 603 detects the start code 701 in the multiplexed bitstream, just like the reference viewpoint video bitstream separation unit 601, and the 1-byte header immediately after that. However, if it is a stereoscopic video header 704, it is further confirmed whether the 1-byte flag immediately after that is the residual flag 706 or not.
- this flag is a value indicating the residual flag 706 (for example, 8-bit “10100000”)
- the residual video bitstream separating means 603 leaves the start code 701 as it is and the 1-byte stereoscopic video header 704. And a 1-byte residual flag 706 deleted bit stream is output to the residual video restoring means 614 as a residual video bit stream until an end code (eg, 3 bytes “000”) is detected. .
- the residual video bitstream separating unit 603 is a stereoscopic video header 704 inserted by the bitstream multiplexing unit 50 of the encoding device 5 (see FIG. 27) from the residual video bitstream separated from the multiplexed bitstream.
- the residual flag 706 are deleted, and the bit stream having the structure of the single-view video bit stream shown in FIG. 29A is returned to the residual video restoration means 614. Accordingly, the residual video restoration unit 614 can decode the residual video bitstream input from the residual video bitstream separation unit 603 as one viewpoint video.
- the residual video bitstream separation unit 603 includes the bitstream from the start code 701 to the end code being detected up to the end code. Then, the information is transferred to the auxiliary information separation unit 604.
- the auxiliary information separating unit 604 receives the multiplexed bit stream from the residual video bit stream separating unit 603, separates the auxiliary information h from the input multiplexed bit stream, and converts the separated auxiliary information h into the depth map projecting unit 613 and It outputs to the projection image composition means 615. Further, when the input multiplexed bit stream is a bit stream other than the auxiliary information, the auxiliary information separating unit 604 ignores it as unknown data.
- the auxiliary information separation unit 604 detects the start code 701 in the multiplexed bit stream in the same manner as the reference viewpoint video bit stream separation unit 601 described above, and the 1-byte header immediately after that detects the 3D header. In the case of the video header 704, it is further confirmed whether or not the 1-byte flag immediately after that is the auxiliary information flag 707.
- the auxiliary information separating unit 604 When this flag is a value indicating the auxiliary information flag 707 (for example, “11000000” of 8 bits), the auxiliary information separating unit 604 is a bit string from the next bit of the auxiliary information flag 707 until the end code is detected. As auxiliary information h. The auxiliary information separating unit 604 outputs the separated auxiliary information h to the depth map projecting unit 613 and the projected image synthesizing unit 615. Further, when the input multiplexed bit stream is a bit stream other than the auxiliary information, the auxiliary information separating unit 604 ignores it as unknown data.
- bitstream separation means 60 the order in which the bitstreams are separated by the reference viewpoint video bitstream separation means 601, the depth map bitstream separation means 602, the residual video bitstream separation means 603, and the auxiliary information separation means 604 is as follows. It is not limited to the example shown in FIG. 32, It can change arbitrarily. These separation processes may be performed in parallel.
- the encoding device 5 inputs a reference viewpoint video C from the outside by the reference viewpoint video encoding means 511 and encodes the reference viewpoint video C by a predetermined encoding method.
- the standardized reference viewpoint video c is generated, and the generated encoded reference viewpoint video c is output to the bitstream multiplexing means 50 as a standard viewpoint video bitstream (step S111).
- the encoding device 5 inputs the reference viewpoint depth map Cd, the left viewpoint depth map Ld, and the right viewpoint depth map Rd from the outside by the depth map synthesis means 512, and synthesizes these depth maps as appropriate.
- a depth map G 2 d is generated and output to the depth map encoding means 513 (step S112).
- the encoding device 5 receives the combined depth map G 2 d from the depth map combining unit 512 by the depth map encoding unit 513, encodes it by a predetermined encoding method, and encodes the encoded depth map g 2 d. And the generated encoded depth map g 2 d is output as the depth map bit stream to the depth map restoring means 514 and the bit stream multiplexing means 50 (step S113).
- the encoding device 5 receives the encoded depth map g 2 d from the depth map encoding unit 513 by the depth map restoring unit 514, decodes the encoded depth map g 2 d, and decodes and combines the depth map. G′d is generated.
- the depth map restoration means 514 outputs the generated decoded composite depth map G′d to the projected video prediction means 515 (step S114).
- the encoding device 5 uses the projected video prediction unit 515 to generate the decoded synthesized depth map G′d from the depth map restoration unit 514 from the outside, the left viewpoint video L, the right viewpoint video R, and the designated viewpoint as required. Information on Pt and Qt is input to generate a residual video Fv.
- the projected video prediction unit 515 outputs the generated residual video Fv to the residual video encoding unit 516 (step S115).
- the encoding device 5 receives the residual video Fv from the projected video prediction unit 515 by the residual video encoding unit 516 and encodes it using a predetermined encoding method to generate the encoded residual video fv. .
- the residual video encoding unit 516 outputs the generated encoded residual video fv to the bit stream multiplexing unit 50 as a residual video bit stream (step S116).
- the encoding device 5 uses the bit stream multiplexing unit 50 to generate the reference viewpoint video bit stream that is the encoded reference viewpoint video c generated in step S111 and the encoded depth map g 2 d generated in step S113.
- a certain depth map bit stream, a residual video bit stream that is the encoded residual video fv generated in step S116, and auxiliary information h that is externally input together with the reference viewpoint video C and the like are multiplexed to obtain multiplexed bits. It outputs to the decoding apparatus 6 (refer FIG. 31) as a stream (step S117).
- bitstream multiplexing means 50 multiplexes the reference viewpoint video bitstream as it is without modifying the existing header. Also, the bit stream multiplexing means 50 multiplexes the depth map bit stream by inserting the stereoscopic video header 704 and the depth flag 705 immediately after the existing header start code 701 by the depth header adding means 503. Also, the bit stream multiplexing means 50 multiplexes the residual video bit stream by inserting a stereoscopic video header 704 and a residual flag 706 immediately after the existing header start code 701 by the residual header adding means 504. Turn into. Further, the bit stream multiplexing means 50 multiplexes the auxiliary information h by adding the start code 701, the stereoscopic video header 704, and the auxiliary information flag 707 as the header by the auxiliary information header adding means 502.
- the encoding device 5 multiplexes the reference viewpoint video bitstream, the depth map bitstream, the residual video bitstream, and the auxiliary information bitstream associated therewith.
- the bit stream is output to the decoding device 6 (see FIG. 31).
- the decoding device 6 inputs the multiplexed bit stream from the encoding device 5 (see FIG. 27) by the bit stream separation means 60, and converts the input multiplexed bit stream into the reference viewpoint.
- the video bit stream, the depth map bit stream, the residual video bit stream, and the auxiliary information h are separated.
- the bitstream separation means 60 separates the reference viewpoint video bitstream into the reference viewpoint video decoding means 611, the depth map bitstream into the depth map restoration means 612, and the residual video bitstream into the residual video restoration means 614.
- the auxiliary information h is output to the depth map projection means 613 and the projected video composition means 615, respectively (step S121).
- the bit stream separation means 60 separates the bit stream whose header immediately after the start code 701 is not the stereoscopic video header 704 as the reference viewpoint video bit stream by the reference viewpoint video bit stream separation means 601.
- the bitstream separation means 60 uses the depth map bitstream separation means 602 to obtain a depth of the bitstream in which the header immediately after the start code 701 is the stereoscopic video header 704 and the flag immediately after that is the depth flag 705.
- a bit stream that is separated as a map bit stream and from which the stereoscopic video header 704 and the depth flag 705 are removed is output.
- the bitstream separation means 60 uses the residual video bitstream separation means 603 to generate a bitstream in which the header immediately after the start code 701 is the stereoscopic video header 704 and the flag immediately after that is the residual flag 706. Are separated as a residual video bit stream, and a bit stream from which the stereoscopic video header 704 and the residual flag 706 are removed is output.
- bit stream separation means 60 uses the auxiliary information separation means 604 to convert the bit stream whose header immediately after the start code 701 is the stereoscopic video header 704 and whose flag immediately after that is the auxiliary information flag 707 to the auxiliary information. Separated as a stream, the auxiliary information body 708 is output as auxiliary information h.
- the decoding device 6 inputs the encoded reference viewpoint video c as the reference viewpoint video bit stream from the bit stream separation means 60 by the reference viewpoint video decoding means 611, decodes it by the encoding method, and decodes it.
- the standardized reference viewpoint video C ′ is generated, and the generated decoded reference viewpoint video C ′ is output to the outside as the standard viewpoint video of the multiview video (step S122).
- the decoding device 6 inputs the encoded depth map g 2 d as the depth map bitstream from the bitstream separation means 60 by the depth map restoration means 612, decodes it by the encoding method, and decodes and synthesizes it.
- the depth map G′d is generated, and the generated decoded combined depth map G′d is output to the depth map projection means 613 (step S123).
- the decoding device 6 uses the depth map projecting means 613 to obtain the decoded combined depth map G′d from the depth map restoring means 612, the auxiliary information h from the bitstream separating means 60, and the left designated viewpoint Pt and the outside from the outside.
- the right designated viewpoint Qt is input to generate a left designated viewpoint depth map Pd and a right designated viewpoint depth map Qd, which are depth maps at the left designated viewpoint Pt and the right designated viewpoint Qt, and the generated left designated viewpoint depth map Pd.
- the right designated viewpoint depth map Qd is output to the projected video composition means 615 (step S124).
- the decoding device 6 inputs the encoded residual video fv as a residual video bitstream from the bitstream separation unit 60 by the residual video restoration unit 614, decodes it with the encoding method, and decodes the left residual.
- the difference video L′ v and the right residual video R′v are generated, and the generated left residual video L′ v and right residual video R′v are output to the projected video synthesis means 615 (step S125).
- the decoding device 6 uses the projected video synthesizing unit 615 to decode the decoded reference viewpoint video C ′ from the reference viewpoint video decoding unit 611 and the left and right designated viewpoint depth maps Pd and Qd from the depth map projecting unit 613.
- the left residual video L′ v and the right residual video R′v are input from the residual video restoration means 614 and the auxiliary information h is input from the bitstream separation means, respectively, and the designated viewpoint videos at the left and right designated viewpoints Pt and Qt are input. P and Q are generated.
- the projected video synthesizing unit 615 outputs the generated designated viewpoint videos P and Q to the outside as designated viewpoint videos of the multi-viewpoint video (step S126).
- the decoding device 6 uses the reference viewpoint video bitstream, the depth map bitstream, the residual video bitstream, and the like from the multiplexed bitstream input from the encoding device 5 (see FIG. 27).
- the auxiliary information h is separated, and a stereoscopic image is generated using the separated data.
- these devices can be configured by using dedicated hardware for each configuration means, but are not limited thereto.
- these devices can be realized by causing a general computer to execute a program and operating an arithmetic device or a storage device in the computer.
- This program (stereoscopic video encoding program and stereoscopic video decoding program) can be distributed via a communication line, or can be written and distributed on a recording medium such as a CD-ROM.
- an autostereoscopic video requiring a large number of viewpoint videos can be efficiently compressed and transmitted as a small number of viewpoint videos and a depth map thereof, and a highly efficient and high quality stereoscopic video can be transmitted. It can be provided at low cost. Therefore, the stereoscopic image storing / transmitting apparatus and service using the present invention can easily store and transmit data even if it is a naked-eye stereoscopic image that requires a large number of viewpoint images, and a high-quality stereoscopic image. Can be provided.
- the present invention can be widely used for 3D television broadcasting, 3D video recorders, 3D movies, 3D video educational equipment, exhibition equipment, Internet services, and the like. Furthermore, the present invention can exert its effect even when used in a free viewpoint television or a free viewpoint movie in which the viewer can freely change the viewpoint position.
- the multi-view video generated by the stereoscopic video encoding device of the present invention can be used as a single-view video even if it is an existing decoding device that cannot decode the multi-view video.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Image Processing (AREA)
Abstract
Description
これによって、符号化する奥行マップについてのデータ量は元の奥行マップが2つの場合で、半分に削減されることとなる。
これによって、副視点映像についてのデータの内で、残差映像として切出された分だけが符号化対象となり、符号化されるデータ量が削減される。
これによって、立体映像符号化装置は、オクルージョンホールとなることが予測される画素領域を漏れが少なく検出する。
これによって、立体映像符号化装置は、特に圧縮率の高い符号化方式を用いて奥行マップを符号化した場合に多く含まれる元の奥行マップに対する復号化された奥行マップの誤差による、オクルージョンホールとなる画素の検出漏れを吸収することができる。
すなわち、立体映像符号化装置は、副視点における奥行マップを用いたオクルージョンホールの検出に加えて、中間視点における奥行マップである中間視点奥行マップを用いたオクルージョンホールの検出を行い、より適切にオクルージョンホールとなる画素を検出する。
すなわち、立体映像符号化装置は、副視点における奥行マップを用いたオクルージョンホールの検出に加えて、復号側で符号化データを復号して多視点映像を生成する際の指定視点における奥行マップを用いたオクルージョンホールの検出を行い、より適切にオクルージョンホールを検出する。
これによって、立体映像符号化装置は、複数組の視点間において生成された複数の中間視点奥行マップについてのデータ量を低減して符号化を行うこととなる。
これによって、立体映像符号化装置は、複数組の視点間において生成された複数の残差映像についてのデータ量を低減して符号化を行うこととなる。
これによって、立体映像復号化装置は、基準視点映像と、基準視点と副視点との中間視点における奥行マップと、副視点映像から切出された残差映像と、を用いて任意の視点における映像を生成する。
すなわち、立体映像復号化装置は、実際に映像を生成する視点である指定視点における奥行マップを用いてオクルージョンホールとなる画素を検出した結果を用いて、基準視点映像を指定視点に射影した映像及び残差映像を指定視点に射影した映像から適切な画素を選択して指定視点映像を生成する。
これによって、特に復号化中間視点奥行マップが高い圧縮率で符号化されていた場合に、立体映像復号化装置は、復号化した中間視点奥行マップに含まれる誤差によるオクルージョンホールの検出漏れを吸収する。
これによって、立体映像復号化装置は、穴のない指定視点映像を生成する。
これによって、立体映像復号化装置は、基準視点映像と、複数の中間視点奥行マップがフレーム化された奥行マップと、複数の残差映像がフレーム化された残差映像と、を用いて任意の視点における映像を生成する。
これによって、符号化する奥行マップについてのデータ量は元の奥行マップが2つの場合で、半分に削減されることとなる。
これによって、副視点映像についてのデータの内で、残差映像として切出された分だけが符号化対象となり、符号化されるデータ量が削減される。
これによって、基準視点映像と、基準視点と副視点との中間視点における奥行マップと、副視点映像から切出された残差映像と、を用いて任意の視点における映像を生成する。
これによって、符号化する奥行マップについてのデータ量は元の奥行マップが2つの場合で、半分に削減されることとなる。
これによって、副視点映像についてのデータの内で、残差映像として切出された分だけが符号化対象となり、符号化されるデータ量が削減される。
これによって、立体映像復号化プログラムは、基準視点映像と、基準視点と副視点との中間視点における奥行マップと、副視点映像から切出された残差映像と、を用いて任意の視点における映像を生成する。
これによって、符号化する奥行マップについてのデータ量が低減される。
これによって、他の視点についての映像のデータ量が低減される。
これによって、奥行マップについてのデータ量が1/3以下に低減される。
これによって、残差映像についてのデータ量が、1/2以下に低減される。
これによって、残差映像についてのデータ量が大きく低減される。
これによって、立体映像復号装置側では、この残差映像を用いて、高品質な立体映像を合成することができる。
これによって、立体映像についてのビットストリームが多重化されて立体映像復号化装置に伝送される。このときに、基準視点映像は1視点映像のビットストリームとして伝送され、他の情報は1視点映像とは異なる立体映像に関するビットストリームとして伝送される。
これによって、基準視点と指定視点とにおける映像からなる多視点映像が生成される。
これによって、フレーム化によってデータ量が低減された残差映像を用いて、多視点映像が生成される。
これによって、基準視点についての映像と、副視点についての映像である残差映像とが合成された指定視点映像が生成される。
これによって、基準視点についての映像と、副視点についての映像である残差映像とが合成された指定視点映像が生成される。
これによって、立体映像復号化装置は、多重化ビットストリームを受信して、多視点映像を生成する。
これによって、符号化する奥行マップについてのデータ量が低減される。
これによって、他の視点についての映像のデータ量が低減される。
これによって、立体映像についてのビットストリームが多重化されて立体映像復号化装置に伝送される。このときに、基準視点映像は1視点映像のビットストリームとして伝送され、他の情報は、1視点映像とは異なる立体映像に関するビットストリームとして伝送される。
これによって、基準視点と指定視点とにおける映像からなる多視点映像が生成される。
これによって、多重化ビットストリームを用いて、立体映像が生成される。
請求項17に記載の発明によれば、3以上の奥行マップを1つに合成してデータ量を更に低減するとともに、2以上の残差映像を縮小してフレーム化してデータ量を更に低減するため、符号化効率を更に向上することができる。
請求項18に記載の発明によれば、副視点映像についてオクルージョンホールとなる画素のみを切り出してデータ低減するため、符号化効率を向上することができる。
請求項19に記載の発明によれば、副視点映像について基準視点映像を副視点に射影した映像との映像全体の差を算出することにより残差映像を生成したため、立体映像復号装置側では、この残差映像を用いて、高品質な多視点映像を合成することができる。
請求項20、請求項27又は請求項31に記載の発明によれば、立体映像を多重化ビットストリームとして出力する際に、基準視点についての映像は1視点映像のビットストリームとして伝送され、他の情報は立体映像に関するビットストリームとして伝送されるため、1視点映像を復号化する既存の立体映像復号化装置では、誤動作することなく多重化ビットストリームを1視点映像として復号化することができる。
請求項22に記載の発明によれば、奥行マップと副視点映像とについてのデータ量が更に低減され、更に高い効率で符号化されたデータを復号化して多視点映像を生成することができる。
請求項23に記載の発明によれば、副視点映像についてのデータ量が更に低減され、更に高い効率で符号化されたデータを復号化して多視点映像を生成することができる。
請求項24に記載の発明によれば、副視点映像について、高品質な残差映像が符号化されたデータを復号化して多視点映像を高品質に生成することができる。
請求項25、請求項29又は請求項33に記載の発明によれば、多重化ビットストリームを分離したビットストリームを復号化して、多視点映像を生成することができる。
<第1実施形態>
[立体映像伝送システム]
まず、図1を参照して、本発明の第1実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムSについて説明する。
次に、図2から図4を参照(適宜図1参照)して、第1実施形態に係る立体映像符号化装置1の構成について説明する。
図2に示すように、第1実施形態に係る立体映像符号化装置1(以下、適宜に「符号化装置」と呼ぶ)は、基準視点映像符号化手段11と、奥行マップ合成手段12と、奥行マップ符号化手段13と、奥行マップ復号化手段14と、射影映像予測手段15と、残差映像符号化手段16と、を備えている。また、射影映像予測手段15は、オクルージョンホール検出手段151と、残差映像切出手段152とを有して構成されている。
中間視点射影手段121は、生成した奥行マップMCdをマップ合成手段123に出力する。
図5(a)に示すように、基準視点から左視点までの距離をb、基準視点から任意の視点である左指定視点までの距離をc、左中間視点から左指定視点までの距離をa、左指定視点から左視点までの距離をdとする。また、基準視点から左中間視点までの距離及び左中間視点から左視点までの距離は、何れもb/2である。
中間視点射影手段122は、左視点奥行マップLdについて、その各画素を、その画素値である奥行値の1/2に対応する画素数だけ、左視点から見て中間視点の方向と反対側である左方向にシフトさせることにより、中間視点における奥行マップMLdを生成する。その結果、奥行マップMLd内に、オクルージョンホールが生じるので、前記した中間視点射影手段121と同様に、これをその画素の周囲の有効な画素の画素値で埋める。
中間視点射影手段122は、生成した奥行マップMLdをマップ合成手段123に出力する。
オクルージョンホール検出手段151は、図3(b)に示すように、第1穴マスク生成手段1511と、第2穴マスク生成手段1512と、第3穴マスク生成手段1513(15131~1513n)と、穴マスク合成手段1514と、穴マスク膨張手段1515と、を有して構成されている。
図6に示すように、奥行マップ(左視点射影奥行マップL’d)において、オクルージョンホールとなる画素かどうかの判定対象となっている着目画素(図において×印で示した画素)の右近傍画素(図において●で示した画素)が、着目画素における奥行値よりも大きな奥行値を有している場合は、その着目画素はオクルージョンホールとなる画素であると判定し、オクルージョンホールとなる画素であることを示す穴マスクLhを生成する。なお、図6に示した穴マスクLhにおいて、オクルージョンホールとなる画素は白で示し、他の画素は黒で示している。
(z-x)≧k×g>(所定値) ・・・式(1)
となる場合に、着目画素をオクルージョンホールとなる画素であると判定する。
各画素について、復号化左合成奥行マップM’dの対応する画素における奥行値の1/2倍に対応する画素数だけ右方向にシフトすることで生成することができる。
なお、穴マスク膨張手段1515は、穴マスク合成手段1514の前においてもよい。すなわち、個々の穴マスクを膨張させた後に、論理和演算をしても同じ効果が得られる。
次に、図7から図9を参照(適宜図1参照)して、第1実施形態に係る立体映像復号化装置2の構成について説明する。立体映像復号化装置2は、図2に示した立体映像符号化装置1から伝送路を介して伝送されるビットストリームを復号化して、多視点映像を生成するものである。
基準視点映像射影手段251は、図8に示すように、ホール画素検出手段251aと、指定視点映像射影手段251bと、基準視点映像画素複写手段251cと、メディアンフィルタ251dと、穴マスク膨張手段251eと、を備えて構成されている。
また、オクルージョンホールとなる画素かどうかの判定対象となっている着目画素における奥行値をx、着目画素から右方向に所定の画素数Pmaxだけ離れた画素における奥行値をyとする。
(z-x)≧k×g>(所定値) ・・・式(2)
となる場合に、着目画素をオクルージョンホールとなる画素であると判定する。
また、基準視点映像画素複写手段251cは、生成した左指定視点映像P2 Cと、入力した穴マスクP1hとを、メディアンフィルタ251dに出力する。
残差映像射影手段252は、図8に示すように、指定視点映像射影手段252aと、残差映像画素複写手段252bと、穴埋め処理手段252cと、を有して構成されている。
次に、図10を参照(適宜図1及び図2参照)して、第1実施形態に係る立体映像符号化装置1の動作について説明する。
符号化装置1は、まず、基準視点映像符号化手段11によって、外部から入力した基準視点映像Cを、所定の符号化方式で符号化して符号化基準視点映像cを生成し、基準視点映像ビットストリームとして出力する(ステップS11)。
次に、符号化装置1は、奥行マップ合成手段12によって、外部から入力した基準視点奥行マップCd及び左視点奥行マップLdを用いて、基準視点と左視点との中間の視点である中間視点における奥行マップである左合成奥行マップMdを合成する(ステップS12)。
次に、符号化装置1は、奥行マップ符号化手段13によって、ステップS12で合成した左合成奥行マップMdを、所定の符号化方式で符号化して符号化奥行マップmdを生成し、奥行マップビットストリームとして出力する(ステップS13)。
次に、符号化装置1は、奥行マップ復号化手段14によって、ステップS13で生成した符号化奥行マップmdを復号化して復号化左合成奥行マップM’dを生成する(ステップS14)。
次に、符号化装置1は、射影映像予測手段15によって、ステップS14で生成した復号化左合成奥行マップM’dと、外部から入力した左視点映像Lとを用いて、左残差映像Lvを生成する(ステップS15)。
次に、符号化装置1は、残差映像符号化手段16によって、ステップS15で生成した左残差映像Lvを、所定の符号化方式で符号化して符号化残差映像lvを生成し、残差映像ビットストリームとして出力する(ステップS16)。
次に、図11を参照(適宜図1及び図7参照)して、第1実施形態に係る立体映像復号化装置2の動作について説明する。
復号化装置2は、まず、基準視点映像復号化手段21によって、基準視点映像ビットストリームを復号化して、基準視点映像C’を生成し、多視点映像の1つの映像として出力する(ステップS21)。
次に、復号化装置2は、奥行マップ復号化手段22によって、奥行マップビットストリームを復号化して、復号化左合成奥行マップM’dを生成する(ステップS22)。
次に、復号化装置2は、奥行マップ射影手段23によって、ステップS22で生成した復号化左合成奥行マップM’dを左指定視点Ptに射影して、左指定視点Ptにおける奥行マップである左指定視点奥行マップPdを生成する(ステップS23)。
次に、復号化装置2は、残差映像復号化手段24によって、残差映像ビットストリームを復号化して、左残差映像L’vを生成する(ステップS24)。
次に、復号化装置2は、射影映像合成手段25によって、ステップS23で生成した左指定視点奥行マップPdを用いて、ステップS21で生成した基準視点映像C’と、ステップS24で生成した左残差映像L’vとを、それぞれ左指定視点Ptに射影した映像を合成して、左指定視点Ptにおける映像である左指定視点映像Pを生成する(ステップS25)。
次に、本発明の第2実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムの構成について説明する。
第2実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムは、図1に示した立体映像伝送システムSにおいて、立体映像符号化装置1及び立体映像復号化装置2に代えて、それぞれ立体映像符号化装置1A(図12参照)及び立体映像復号化装置2A(図14参照)を含むこと以外は同様であるから、詳細な説明は省略する。
次に、図12及び図13を参照して、第2実施形態に係る立体映像符号化装置1Aの構成について説明する。
図12に示すように、第2実施形態に係る立体映像符号化装置1A(以下、適宜に「符号化装置」と呼ぶ)は、基準視点映像符号化手段11と、奥行マップ合成手段12Aと、奥行マップ符号化手段13Aと、奥行マップ復号化手段14Aと、射影映像予測手段15Aと、残差映像符号化手段16Aと、奥行マップフレーム化手段17と、奥行マップ分離手段18と、残差映像フレーム化手段19と、を備えている。
なお、縮小手段19a及び縮小手段19bは、縮小手段17a及び縮小手段17bと同様の構成であるから、詳細な説明は省略する。
次に、図14及び図15を参照して、第2実施形態に係る立体映像復号化装置2Aの構成について説明する。立体映像復号化装置2Aは、図12に示した立体映像符号化装置1Aから伝送路を介して伝送されるビットストリームを復号化して、多視点映像を生成するものである。
奥行マップ復号化手段22Aは、符号化装置1Aにおける奥行マップ復号化手段14A(図12参照)と同様の構成であるので、詳細な説明は省略する。
残差映像復号化手段24Aは、復号化装置2における残差映像復号化手段24(図7参照)と、復号化する対象が単一の残差映像かフレーム化された残差映像かが異なるだけで、同様の構成であるので、詳細な説明は省略する。
また、右射影映像合成手段25Rは、左射影映像合成手段25Lとは、基準視点との左右の位置関係が逆であること以外は同様の構成であるから、詳細な説明は省略する。
また、復号化装置2Aは、その符号化装置1Aで符号化した立体映像を復号化して、多視点映像を生成することができる。
次に、図16を参照(適宜図12及び図13参照)して、第2実施形態に係る立体映像符号化装置1Aの動作について説明する。
符号化装置1Aは、まず、基準視点映像符号化手段11によって、外部から入力した基準視点映像Cを、所定の符号化方式で符号化して符号化基準視点映像cを生成し、基準視点映像ビットストリームとして出力する(ステップS31)。
次に、符号化装置1Aは、奥行マップ合成手段12Aによって、外部から入力した基準視点奥行マップCd及び左視点奥行マップLdを用いて、基準視点と左視点との中間の視点である左中間視点における奥行マップである左合成奥行マップMdを合成するとともに、外部から入力した基準視点奥行マップCd及び右視点奥行マップRdを用いて、基準視点と右視点との中間の視点である右中間視点における奥行マップである右合成奥行マップNdを合成する(ステップS32)。
次に、符号化装置1Aは、奥行マップフレーム化手段17によって、ステップS32で合成した2つの奥行マップである左合成奥行マップMd及び右合成奥行マップNdを縮小して結合することで、1つの画像にフレーム化してフレーム化奥行マップFdを生成する(ステップS33)。
次に、符号化装置1Aは、奥行マップ符号化手段13Aによって、ステップS33で生成したフレーム化奥行マップFdを、所定の符号化方式で符号化して符号化奥行マップfdを生成し、奥行マップビットストリームとして出力する(ステップS34)。
次に、符号化装置1Aは、奥行マップ復号化手段14Aによって、ステップS34で生成した符号化奥行マップfdを復号化してフレーム化奥行マップF’dを生成する(ステップS35)。
次に、符号化装置1Aは、奥行マップ分離手段18によって、ステップS35で生成した復号化されたフレーム化奥行マップF’dに結合されている2つの奥行マップを分離し、それぞれ元のサイズに拡大して、復号化左合成奥行マップM’d及び復号化右合成奥行マップN’dを生成する(ステップS36)。
次に、符号化装置1Aは、射影映像予測手段15Aによって、ステップS36で生成した復号化左合成奥行マップM’dと、外部から入力した左視点映像Lとを用いて、左残差映像Lvを生成するとともに、ステップS36で生成した復号化右合成奥行マップN’dと、外部から入力した右視点映像Rとを用いて、右残差映像Rvを生成する(ステップS37)。
次に、符号化装置1Aは、残差映像フレーム化手段19によって、ステップS37で生成した2つの残差映像である左残差映像Lv及び右残差映像Rvを縮小して結合することで、1つの画像にフレーム化してフレーム化残差映像Fvを生成する(ステップS38)。
そして、符号化装置1Aは、残差映像符号化手段16Aによって、ステップS38で生成したフレーム化残差映像Fvを、所定の符号化方式で符号化して符号化残差映像fvを生成し、残差映像ビットストリームとして出力する(ステップS39)。
次に、図17を参照(適宜図14及び図15参照)して、第2実施形態に係る立体映像復号化装置2Aの動作について説明する。
復号化装置2Aは、まず、基準視点映像復号化手段21によって、基準視点映像ビットストリームを復号化して、基準視点映像C’を生成し、多視点映像の1つの映像として出力する(ステップS51)。
次に、復号化装置2Aは、奥行マップ復号化手段22Aによって、奥行マップビットストリームを復号化して、フレーム化奥行マップF’dを生成する(ステップS52)。
次に、復号化装置2Aは、奥行マップ分離手段26によって、ステップS52で生成した復号化されたフレーム化奥行マップF’dに結合されている2つの奥行マップを分離し、それぞれ元のサイズに拡大して、復号化左合成奥行マップM’d及び復号化右合成奥行マップN’dを生成する(ステップS53)。
次に、復号化装置2Aは、奥行マップ射影手段23Aによって、ステップS53で生成した復号化左合成奥行マップM’dを、左指定視点Ptに射影して、左指定視点Ptにおける奥行マップである左指定視点奥行マップPdを生成するとともに、ステップS53で生成した復号化右合成奥行マップN’dを、右指定視点Qtに射影して、右指定視点Qtにおける奥行マップである右指定視点奥行マップQdを生成する(ステップS54)。
また、復号化装置2Aは、残差映像復号化手段24Aによって、残差映像ビットストリームを復号化して、フレーム化残差映像F’vを生成する(ステップS55)。
次に、復号化装置2Aは、残差映像分離手段27によって、ステップS55で生成した復号化されたフレーム化残差映像F’vに結合されている2つの残差映像を分離し、それぞれ元のサイズに拡大して、左残差映像L’v及び右残差映像R’vを生成する(ステップS56)。
そして、復号化装置2Aは、左射影映像合成手段25Lによって、ステップS54で生成した左指定視点奥行マップPdを用いて、ステップS51で生成した基準視点映像C’と、ステップS55で生成した左残差映像L’vとを、それぞれ左指定視点Ptに射影した映像を合成して、左指定視点Ptにおける映像である左指定視点映像Pを生成するとともに、右射影映像合成手段25Rによって、ステップS54で生成した右指定視点奥行マップQdを用いて、ステップS51で生成した基準視点映像C’と、ステップS55で生成した右残差映像R’vとを、それぞれ右指定視点Qtに射影した映像を合成して、右指定視点Qtにおける映像である右指定視点映像Qを生成する(ステップS57)。
次に、本発明の第2実施形態の変形例に係る立体映像符号化装置及び立体映像復号化装置について説明する。
次に、本発明の第3実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムの構成について説明する。
第3実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムは、図1に示した立体映像伝送システムSにおいて、立体映像符号化装置1及び立体映像復号化装置2に代えて、それぞれ立体映像符号化装置1B(図19参照)及び立体映像復号化装置2B(図22参照)を含むこと以外は同様であるから、詳細な説明は省略する。
次に、図19及び図20を参照して、第3実施形態に係る立体映像符号化装置1Bの構成について説明する。
なお、第1実施形態又は第2実施形態と同様の構成要素については、同じ符号を付して説明を適宜省略する。
左奥行マップ射影手段121B及び右奥行マップ射影手段122Bは、それぞれ左視点奥行マップLd及び右視点奥行マップRdを入力し、それぞれ所定の1つの共通視点に射影した奥行マップである共通視点奥行マップCLd及び共通視点奥行マップCRdを生成し、マップ合成手段123Bに出力する。
左視点奥行マップLdの射影において、複数の画素値が射影された画素がある場合は、射影された画素値の内の最大値を、その画素の奥行値とする。最大値を共通視点奥行マップCLdの奥行値とすることにより、前景の被写体の奥行値が保存されるため、オクルージョン関係を正しく保って射影することができる。
また、射影されなかった画素がある場合は、その部分は、その画素の左右に近接する射影された画素の内で、小さい方の奥行値を当該画素の奥行値として穴埋めする。これによって、元の視点位置では前景に隠れて見えなかった背景の奥行値が正しく補間される。
但し、これに限定されるものではなく、任意の視点を共通視点とすることができる。基準視点以外を共通視点とする場合は、基準視点奥行マップCdに代えて、基準視点奥行マップCdを、その共通視点に射影した奥行マップをマップ合成手段123Bに入力するように構成すればよい。また、左奥行マップ射影手段121B及び右奥行マップ射影手段122Bについても、基準視点から共通視点までの距離に応じて、適宜に射影時の画素のシフト量を調整するようにすればよい。
マップ合成手段123Bは、生成した合成奥行マップGdを、縮小手段124に出力する。
このように、3つの奥行マップを合成することにより、個々の奥行マップ中に含まれる奥行の誤差が平滑化されて、復号化装置側で立体映像を構成するための多数の視点の映像を合成する際に、合成される視点映像の品質を改善することができる。
ここで、縮小手段124は、合成奥行マップGdの画素を、縦方向及び横方向にそれぞれ1画素置きに間引くことで、縦横それぞれ1/2に縮小した縮小合成奥行マップG2dを生成する。
本実施形態では、奥行マップビットストリームとして伝送される奥行マップは、3つの視点における奥行マップを1つに合成し、更に縮小されているため、奥行マップのデータ量が低減され、符号化効率が改善される。
また、奥行マップ復元手段30は、復元した復号化合成奥行マップG’dを射影映像予測手段15Bの左射影映像予測手段15BL及び右射影映像予測手段15BRに出力する。
図21(a)に示すように、本実施形態における左射影映像予測手段15BLは、オクルージョンホール検出手段151Bと、残差映像切出手段152とを備えて構成されている。本実施形態における左射影映像予測手段15BLは、図2に示した第1実施形態における射影映像予測手段15とは、オクルージョンホール検出手段151に代えて、オクルージョンホール検出手段151Bを備えることが異なる。
なお、第1実施形態における射影映像予測手段15及びオクルージョンホール検出手段151と同じ構成要素については、同じ符号を付して、説明は適宜省略する。
左視点射影手段1511Baは、図3(b)に示した左視点射影手段1511aとは、奥行マップを射影する際のシフト量が異なるだけで、同様のものを用いることができるため詳細な説明は省略する。
左中間視点射影手段1512Baは、図3(b)に示した左視点射影手段1511aとは、奥行マップを射影する際のシフト量が異なるだけで、同様のものを用いることができるため詳細な説明は省略する。
なお、第2穴マスク生成手段1512Bは、省略してもよい。
左指定視点射影手段1513Baは、図3(b)に示した左視点射影手段1511aとは、奥行マップを射影する際のシフト量が異なるだけで、同様のものを用いることができるため詳細な説明は省略する。
また、第3穴マスク生成手段1513Bは、図21(a)に示すように、1又は複数の左指定視点Pt(Pt1~Ptn)に射影する際にオクルージョンホールOHとなる領域を検出するようにしてもよいし、省略してもよい。
なお、残差映像切出手段152において、左視点映像から穴マスクLhで示されたオクルージョンホールOHとなる領域以外の画素値として、128などの固定値とする他に、左視点映像Lの全画素値の平均値を用いるようにしてもよい。このようにすることで、残差映像の有効な画素値がある部分(すなわち、オクルージョンホールOHとなる領域)と、ない部分(他の領域)との変化量をより少なくし、残差映像の符号化処理における歪を低減することができる。
また、第1実施形態の残差映像切出手段152においても、有効な画素値がない領域の画素値として、残差映像の全画素地の平均値を用いるようにしてもよい。
残差映像フレーム化手段19Bは、左射影映像予測手段15BL及び右射影映像予測手段15BRから入力した左残差映像Lv及び右残差映像Rvを1つの画像にフレーム化して、フレーム化残差映像Fvを生成し、生成したフレーム化残差映像Fvを残差映像符号化手段16Bに出力する。このために、残差映像フレーム化手段19Bは、縮小手段19Ba,19Bbと結合手段19Bcとを有して構成されている。
なお、低域通過フィルタ処理は、縦方向及び横方向について、それぞれの方向に間引く前に前記した係数の1次元フィルタを用いて行うようにすることが、処理量を低減できるため好ましい。但し、これに限定されず、2次元の低域通過フィルタ処理を行った後に、縦方向及び横方向の間引き処理を行うようにしてもよい。
なお、結合手段19Bcは、2つの残差映像を横方向に結合するようにしてもよい。
残差映像符号化手段16Bは、図2に示した残差映像符号化手段16において、符号化する残差映像が、単一の残差映像に代えて、フレーム化された残差映像であること以外は同様であるから、詳細な説明は省略する。
次に、図22及び図23を参照して、第3実施形態に係る立体映像復号化装置2Bの構成について説明する。立体映像復号化装置2Bは、図19に示した立体映像符号化装置1Bから伝送路を介して伝送されるビットストリームを復号化して、多視点映像を生成するものである。
本実施形態に係る復号化装置2Bは、3視点における奥行マップCd,Ld,Rdを、所定の1つの共通視点における奥行マップである合成奥行マップGdに合成された1系統の奥行マップを、更に縮小し符号化した符号化縮小合成奥行マップg2dを入力して用いることが、第2実施形態に係る復号化装置2A(図14参照)と異なる。
奥行マップ復元手段28は、符号化装置1Bにおける奥行マップ復元手段30(図19参照)と同様の構成であるので、詳細な説明は省略する。なお、奥行マップ復号化手段28a及び拡大手段28bは、それぞれ図19に示した奥行マップ復号化手段30a及び拡大手段30bに対応する。
なお、本実施形態における左奥行マップ射影手段23BLは、図14に示した第2実施形態における左奥行マップ射影手段23BLとは、入力する奥行マップの視点位置の違いにより、射影時のシフト量が異なること以外は同様であるから、詳細な説明は省略する。
なお、右奥行マップ射影手段23BRは、左奥行マップ射影手段23BLとは、基準視点に対する左右の位置関係が逆であること以外は同様の構成であるから、詳細な説明は省略する。
残差映像復号化手段24Bは、図14に示した第2実施形態における残差映像復号化手段24Aと、復号化する対象のフレーム化残差映像のサイズが異なること以外は同様の構成であるので、詳細な説明は省略する。
図24(a)に示すように、本実施形態における左射影映像合成手段25BLは、基準視点映像射影手段251Bと、残差映像射影手段252Bとを有して構成されている。
このために、基準視点映像射影手段251Bは、ホール画素検出手段251Baと、指定視点映像射影手段251Bbと、基準視点映像画素複写手段251Bcと、穴マスク膨張手段251Bdと、を備えて構成されている。
ホール画素検出手段251Baによるオクルージョンホールとなる画素の検出方法は、図8に示した第1実施形態におけるホール画素検出手段251aと同様であるから、詳細な説明は省略する。
なお、指定視点映像射影手段251Bbは、図8に示した第1実施形態における指定視点映像射影手段251bと同様であるから、詳細な説明は省略する。
また、基準視点映像画素複写手段251Bcは、生成した左指定視点映像PCを、残差映像射影手段252Bの残差映像画素複写手段252Bbに出力する。
なお、基準視点映像画素複写手段251Bcは、図8に示した第1実施形態における基準視点映像画素複写手段251cと同様であるから、詳細な説明は省略する。
このために、残差映像射影手段252Bは、指定視点映像射影手段252Baと、残差映像画素複写手段252Bbと、穴埋め処理手段252Bcと、ホール画素検出手段252Bdと、共通穴検出手段252Beと、を有して構成されている。
残差映像画素複写手段252Bbは、生成した左指定視点映像P1を穴埋め処理手段252Bcに出力する。
なお所定の条件とは、左右の関係が入れ替わること以外は、ホール画素検出手段251aによる判定条件と同様である。
なお、穴マスクP4hは、前記したように、左指定視点映像P1において基準視点映像画素複写手段251Bc又は残差映像画素複写手段252Bbの何れによっても有効な画素が複写されずに、有効な画素値を有さない穴となっている画素を示すものである。
また、復号化装置2Bは、その符号化装置1Bで符号化した立体映像を復号化して、多視点映像を生成することができる。
次に、図25を参照(適宜図19参照)して、第3実施形態に係る立体映像符号化装置1Bの動作について説明する。
符号化装置1Bは、まず、基準視点映像符号化手段11によって、外部から入力した基準視点映像Cを、所定の符号化方式で符号化して符号化基準視点映像cを生成し、基準視点映像ビットストリームとして出力する(ステップS71)。
次に、符号化装置1Bは、奥行マップ合成手段12Bによって、外部から入力した基準視点奥行マップCd、左視点奥行マップLd及び右視点奥行マップRdを合成し、基準視点を共通視点として、共通視点における1つの奥行マップを生成する(ステップS72)。本実施形態においては、このステップS72は、次に示す3つのサブステップから構成される。
次に、符号化装置1Bは、マップ合成手段123Bによって、共通視点(基準視点)における3つの奥行きマップである基準視点奥行マップCd、共通視点奥行マップCLd及び共通視点奥行マップCRdを1つに合成して、合成奥行マップGdを生成する。
最後に、符号化装置1Bは、縮小手段124によって、合成奥行マップGdを縮小して縮小合成奥行マップG2dを生成する。
次に、符号化装置1Bは、奥行マップ符号化手段13Bによって、ステップS72で生成した縮小合成奥行マップG2dを、所定の符号化方式で符号化して符号化奥行マップg2dを生成し、奥行マップビットストリームとして出力する(ステップS73)。
次に、符号化装置1Bは、奥行マップ復元手段30によって、ステップS73で生成した符号化奥行マップg2dを復元して復号化合成奥行マップG’dを生成する(ステップS74)。本実施形態においては、このステップS74は、次に示す2つのサブステップから構成される。
そして、符号化装置1Bは、拡大手段30bによって、復号化縮小合成奥行マップG2’dを元のサイズに拡大して復号化合成奥行マップG’dを生成する。
次に、符号化装置1Bは、射影映像予測手段15Bの左射影映像予測手段15BLによって、ステップS74で生成した復号化合成奥行マップG’dと、外部から入力した左視点映像Lとを用いて、左残差映像Lvを生成するとともに、射影映像予測手段15Bの右射影映像予測手段15BRによって、復号化合成奥行マップG’dと、外部から入力した右視点映像Rとを用いて、右残差映像Rvを生成する(ステップS75)。
次に、符号化装置1Bは、残差映像フレーム化手段19Bによって、ステップS75で生成した2つの残差映像である左残差映像Lv及び右残差映像Rvを縮小して結合することで、1つの画像にフレーム化してフレーム化残差映像Fvを生成する(ステップS76)。
そして、符号化装置1Bは、残差映像符号化手段16Bによって、ステップS76で生成したフレーム化残差映像Fvを、所定の符号化方式で符号化して符号化残差映像fvを生成し、残差映像ビットストリームとして出力する(ステップS77)。
次に、図26を参照(適宜図22参照)して、第3実施形態に係る立体映像復号化装置2Bの動作について説明する。
復号化装置2Bは、まず、基準視点映像復号化手段21によって、基準視点映像ビットストリームを復号化して、基準視点映像C’を生成し、多視点映像の1つの映像として出力する(ステップS91)。
次に、復号化装置2Bは、奥行マップ復元手段28によって、奥行マップビットストリームを復号化して、復号化合成奥行マップG’dを生成する(ステップS92)。本実施形態においては、このS92は、次に示す2つのサブステップから構成される。
そして、復号化装置2Bは、拡大手段28bによって、復号化縮小合成奥行マップG2’dを元のサイズに拡大して復号化合成奥行マップG’dを生成する。
次に、復号化装置2Bは、奥行マップ射影手段23Bの左奥行マップ射影手段23BLによって、ステップS92で生成した復号化合成奥行マップG’dを、左指定視点Ptに射影して、左指定視点Ptにおける奥行マップである左指定視点奥行マップPdを生成するとともに、右奥行マップ射影手段23BRによって、復号化合成奥行マップG’dを、右指定視点Qtに射影して、右指定視点Qtにおける奥行マップである右指定視点奥行マップQdを生成する(ステップS93)。
また、復号化装置2Bは、残差映像復号化手段24Bによって、残差映像ビットストリームを復号化して、フレーム化残差映像F’vを生成する(ステップS94)。
次に、復号化装置2Bは、残差映像分離手段27Bの分離手段27Baによって、ステップS94で生成した復号化されたフレーム化残差映像F’vに結合されている2つの残差映像を分離し、更に拡大手段27Bb及び拡大手段27Bcによって、それぞれ元のサイズに拡大して、左残差映像L’v及び右残差映像R’vを生成する(ステップS95)。
そして、復号化装置2Bは、左射影映像合成手段25BLによって、ステップS93で生成した左指定視点奥行マップPdを用いて、ステップS91で生成した基準視点映像C’と、ステップS95で生成した左残差映像L’vとを、それぞれ左指定視点Ptに射影した映像を合成して、左指定視点Ptにおける映像である左指定視点映像Pを生成するとともに、右射影映像合成手段25BRによって、ステップS93で生成した右指定視点奥行マップQdを用いて、ステップS91で生成した基準視点映像C’と、ステップS95で生成した右残差映像R’vとを、それぞれ右指定視点Qtに射影した映像を合成して、右指定視点Qtにおける映像である右指定視点映像Qを生成する(ステップS96)。
次に、本発明の第3実施形態の変形例に係る立体映像符号化装置及び立体映像復号化装置について説明する。
まず、図19及び図21(b)を参照して、本変形例に係る立体映像符号化装置の構成について説明する。
本変形例に係る立体映像符号化装置(全体構成は図示しないが、以下、適宜に「符号化装置1C」と呼ぶ)は、図19に示した第3実施形態に係る符号化装置1Bの射影映像予測手段15Bにおいて、左視点映像Lからオクルージョンホールとなる領域の画素を切出すこと(論理演算型)により左残差映像Lvを生成することに代えて、左視点映像Lと符号化基準視点映像cを復号化した復号化基準視点映像C’を左視点に射影した映像との画素値の差を画素毎に映像全体について算出すること(減算型)により左残差映像Lvを生成するものである。また、右残差映像Rvの生成についても同様に、右視点映像Rと復号化基準視点映像C’を右視点に射影した映像との画素値の差を画素毎に映像全体について算出することにより右残差映像Rvを生成する。
また、符号化装置1Cは、図19に示した第3実施形態に係る符号化装置1Bにおいて、更に基準視点映像符号化手段11が生成した符号化基準視点映像cを復号化する基準視点映像復号化手段(不図示)を備えるものとする。なお、この基準視点映像復号化手段は、図22に示した基準視点映像復号化手段21と同じものである。
左射影映像予測手段15CLは、不図示の基準視点映像復号化手段から復号化基準視点映像C’を、奥行マップ復元手段30の拡大手段30bから復号化合成奥行マップG’dを、それぞれ入力し、左残差映像Lvを残差映像フレーム化手段19Bの縮小手段19Baに出力する。
残差算出手段154は、生成した左残差映像Lvを残差映像フレーム化手段19Bの縮小手段19Baに出力する。
なお、残差映像を生成する際に、復号化基準視点映像C’に代えて基準視点映像Cを用いるようにしてもよい。これによって、基準視点映像復号化手段(不図示)を省略することができる。
次に、図22及び図24(b)を参照して、本変形例に係る立体映像復号化装置の構成について説明する。本変形例に係る立体映像復号化装置は、前記した変形例に係る符号化装置1Cから伝送路を介して伝送されるビットストリームを復号化して、多視点映像を生成するものである。
なお、右指定視点映像Qの生成は、左指定視点映像Pの生成において、左残差映像Lvに代えて右残差映像Rvを用い、射影する方向が、基準視点に対して左右逆となること以外は同様であるから、説明は適宜省略する。
このために、左射影映像合成手段25CLは、基準視点映像射影手段251Cと、残差映像射影手段252Cとを有して構成されている。
なお、第3実施形態と同様の構成については、同じ符号を付して適宜説明を省略する。
また、基準視点映像画素複写手段251Ccは、生成した左指定視点映像PCを残差映像射影手段252Cの残差加算手段252fに出力する。
なお、第3実施形態と同様の構成については、同じ符号を付して適宜説明を省略する。
指定視点映像射影手段252Caは、左指定視点奥行マップPdを用いて、左残差映像L’vを左指定視点に射影することで左指定視点射影残差映像PLvを生成し、生成した左指定視点射影残差映像PLvを残差加算手段252fに出力する。
なお、指定視点映像射影手段252Caのその他の構成は、第3実施形態における指定視点映像射影手段252Baと同様であるから、詳細な説明は省略する。
残差加算手段252fは、生成した左指定視点映像P1を穴埋め処理手段252Bcに出力する。
なお、穴マスクP4hは、前記したように、左指定視点映像P1において基準視点映像画素複写手段251Ccによって有効な画素が複写されず、かつ、残差加算手段252fによって有効な残差が加算されなかったため、有効な画素値を有さずに穴となっている画素を示すものである。
また、減算型で残差映像を生成する射影映像予測手段についての本変形例の構成は、第1実施形態における射影映像予測手段15及び第2実施形態における射影映像予測手段15Aに適用することもできる。同様に、減算型の残差映像を用いて指定視点映像を生成する射影映像合成手段についての本変形例の構成は、第1実施形態における射影映像合成手段25及び第2実施形態における射影映像合成手段25Aに適用することもできる。
次に、本発明の第4実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムの構成について説明する。
第4実施形態に係る立体映像符号化装置及び立体映像復号化装置を含んだ立体映像伝送システムは、図1に示した立体映像伝送システムSにおいて、立体映像符号化装置1及び立体映像復号化装置2に代えて、それぞれ立体映像符号化装置5(図27参照)及び立体映像復号化装置6(図31参照)を含むものである。また、立体映像符号化装置5から立体映像復号化装置6へ伝送されるビットストリームは、基準視点映像ビットストリーム、奥行マップビットストリーム、残差映像ビットストリーム及び指定視点映像を合成する際に必要な補助情報が多重化された多重化ビットストリームである。
なお、ビットストリームが多重化されること以外は、前記した各実施形態における立体映像伝送システムと同様であるから、共通する構成についての詳細な説明は適宜省略する。
次に、図27を参照して、第4実施形態に係る立体映像符号化装置5の構成について説明する。
図27に示すように、第4実施形態に係る立体映像符号化装置5(以下、適宜に「符号化装置5」と呼ぶ)は、ビットストリーム多重化手段50と符号化処理部51とを備えて構成されている。
また、ビットストリーム多重化手段50は、符号化処理部51から出力される各ビットストリーム及び外部から入力した補助情報hを多重化した多重化ビットストリームを生成し、復号化装置6(図31参照)に出力するものである。
以下、符号化処理部51の各構成要素について図27を参照(適宜図2、図12及び図19参照)して説明する。なお、符号化処理部51の各構成要素は、符号化装置1等における1又は2以上の構成要素によって構成することができるため、両者の構成要素の対応関係を示し、詳細な説明は適宜省略する。
基準視点映像符号化手段511は、符号化装置1等における基準視点映像符号化手段11に相当するものである。
奥行マップ符号化手段513は、符号化装置1の奥行マップ符号化手段13、符号化装置1Aの奥行マップ符号化手段13A、又は符号化装置1B,1Cの奥行マップ符号化手段13B、に相当するものである。
ここで、生成する残差映像は、1つの残差映像であってもよく、基準視点と複数の他の視点との間における残差映像が1つにフレーム化されたものでもよく、更に縮小されたものでもよい。何れの場合も、生成された残差映像は、1視点映像として残差映像符号化手段516に出力される。
この基準視点映像復号化手段(不図示)は、図7に示した基準視点映像復号化手段21と同様のものを用いることができる。
なお、基準視点映像復号化手段を備えず、射影映像予測手段515は、基準視点映像Cを入力して用いるようにしてもよい。
残差映像符号化手段516は、符号化装置1の残差映像符号化手段16、符号化装置1Aの残差映像符号化手段16A、又は符号化装置1B,1Cの残差映像符号化手段16B、に相当するものである。
図28に示すように、ビットストリーム多重化手段50は、スイッチ(切替手段)501と、補助情報ヘッダ付加手段502と、奥行ヘッダ付加手段503と、残差ヘッダ付加手段504と、を備えて構成されている。
なお、図28においては、説明の便宜上、符号化処理部51として、符号化装置1Bを用いた場合を想定して、各ビットストリームについて説明するが、これに限定されるものではない。他の実施形態における符号化装置1等を用いる場合は、残差映像Fvなどの信号名を、適宜読み替えるものとする。
まず、本実施形態に係る符号化装置5において、基準視点映像符号化手段511、奥行マップ符号化手段513及び残差映像符号化手段516が生成するビットストリームは、何れも、1視点映像として符号化されたことを示すヘッダを有するものとする。
なお、ビットストリーム本体703には、開始コード及び終了コードと一致するビット列は含まれないように符号化されているものとする。
これによって、本発明の復号化装置6(図31参照)は、このビットストリームが、奥行マップビットストリームであることを識別することができる。
なお、残差フラグ706としては、奥行フラグ705とは異なる値、例えば8ビットの「10100000」の値を割当てることができる。
なお、補助情報フラグ707としては、奥行フラグ705でも残差フラグ706でもない値、例えば8ビットの「11000000」の値を割当てることができる。
前記した奥行マップビットストリーム及び残差映像ビットストリームの場合と同様に、立体映像ヘッダ704を挿入することによって、1視点映像を復号化する既存の復号化装置の誤動作を防止することができる。また、補助情報フラグ707を挿入することにより、本発明の復号化装置6(図31参照)は、このビットストリームが、多視点映像の合成に必要な補助情報ビットストリームであることを識別することができる。
補助情報は、符号化装置5で符号化されて出力される多視点映像についての属性を示す情報である。補助情報には、例えば、モード、最近距離、最遠距離、焦点距離、並びに基準視点及び副視点の各位置を示す情報が含まれ、多視点映像に付随して符号化装置5から復号化装置6に出力される。
復号化装置6は、符号化装置5から入力したビットストリームを復号化して得られた奥行マップ、基準視点映像及び残差映像を用いて、これらの映像を指定視点に射影して指定視点における射影映像を合成する際に、必要に応じて補助情報を参照する。
例えば、図5に示したような、各視点の位置を示す情報が補助情報に含まれ、奥行マップや映像を射影する際のシフト量を算出するときに用いられる。
以下、図30に示したパラメータについて説明する。
なお、ここで「ビュー」とは、基準視点映像ビットストリームと残差映像ビットストリームに含まれる映像の視点数の合計を示すものである。また「デプス」とは、奥行マップビットストリームに含まれる合成奥行マップの視点数を示すものである。
次に、図31を参照して、第4実施形態に係る立体映像復号化装置6の構成について説明する。立体映像復号化装置6は、図27に示した立体映像符号化装置5から伝送路を介して伝送されるビットストリームを復号化して、多視点映像を生成するものである。
図31に示すように、第4実施形態に係る立体映像復号化装置6(以下、適宜に「復号化装置6」と呼ぶ)は、ビットストリーム分離手段60と復号化処理部61とを備えて構成されている。
また、復号化処理部61は、生成した多視点映像を、例えば、図1に示した立体映像表示装置4に出力する。そして、立体映像表示装置4は、この多視点映像を視認可能に表示する。
復号化処理部61は、前記した第1実施形態、第2実施形態、第3実施形態及びその変形例に係る復号化装置2,2A,2B,2C(以下、適宜「復号化装置2等」と呼ぶ)に相当するものであり、基準視点映像復号化手段611と、奥行マップ復元手段612と、奥行マップ射影手段613と、残差映像復元手段614と、射影映像合成手段615と、を備えている。
基準視点映像復号化手段611は、復号化装置2等における基準視点映像復号化手段21に相当するものである。
なお、奥行マップ復元手段612は、入力した符号化合成奥行きマップがフレーム化されている場合は、復号化した後にフレーム化されている奥行マップを分離し、符号化合成奥行きマップが縮小されている場合は、復号化した後に又は分離した後に元のサイズに拡大して、奥行マップ射影手段613に出力するものとする。
なお、残差映像復元手段614は、符号化残差映像がフレーム化されている場合は、復号化した後にフレーム化されている残差映像を分離し、符号化残差映像が縮小されている場合は、復号化した後に又は分離した後に元のサイズに拡大して、射影映像合成手段615に出力するものとする。
ビットストリーム分離手段60は、符号化装置5(図27参照)から入力した多重化ビットストリームを、指定視点映像ビットストリームと、奥行マップビットストリームと、残差映像ビットストリームと、補助情報とに分離して、復号化処理部61の各部に出力するものである。このために、ビットストリーム分離手段60は、図32に示すように、基準視点映像ビットストリーム分離手段601と、奥行マップビットストリーム分離手段602と、残差映像ビットストリーム分離手段603と、補助情報分離手段604と、を備えて構成されている。
また、基準視点映像ビットストリーム分離手段601は、入力した多重化ビットストリームが基準視点映像ビットストリーム以外のビットストリームの場合は、多重化ビットストリームを奥行マップビットストリーム分離手段602に転送する。
また、奥行マップビットストリーム分離手段602は、入力した多重化ビットストリームが奥行マップビットストリーム以外のビットストリームの場合は、多重化ビットストリームを残差映像ビットストリーム分離手段603に転送する。
これによって、奥行マップ復元手段612は、奥行マップビットストリーム分離手段602から入力される奥行マップビットストリームを1視点映像として復号化することができる。
また、残差映像ビットストリーム分離手段603は、入力した多重化ビットストリームが残差映像ビットストリーム以外のビットストリームの場合は、多重化ビットストリームを補助情報分離手段604に転送する。
これによって、残差映像復元手段614は、残差映像ビットストリーム分離手段603から入力される残差映像ビットストリームを1視点映像として復号化することができる。
また、補助情報分離手段604は、入力した多重化ビットストリームが補助情報以外のビットストリームの場合は、不明なデータとして無視する。
補助情報分離手段604は、分離した補助情報hを、奥行マップ射影手段613及び射影映像合成手段615に出力する。
また、補助情報分離手段604は、入力した多重化ビットストリームが補助情報以外のビットストリームの場合は、不明なデータとして無視する。
次に、図33を参照(適宜図27~図29参照)して、符号化装置5の動作について説明する。
図33に示すように、まず、符号化装置5は、基準視点映像符号化手段511によって、外部から基準視点映像Cを入力して、基準視点映像Cを所定の符号化方式で符号化した符号化基準視点映像cを生成し、生成した符号化基準視点映像cを基準視点映像ビットストリームとしてビットストリーム多重化手段50に出力する(ステップS111)。
次に、符号化装置5は、奥行マップ合成手段512によって、外部から基準視点奥行マップCd、左視点奥行マップLd及び右視点奥行マップRdを入力して、これらの奥行マップを適宜合成して合成奥行マップG2dを生成し、奥行マップ符号化手段513に出力する(ステップS112)。
次に、符号化装置5は、奥行マップ符号化手段513によって、奥行マップ合成手段512から合成奥行マップG2dを入力して、所定の符号化方式で符号化して符号化奥行マップg2dを生成し、生成した符号化奥行マップg2dを奥行マップビットストリームとして奥行マップ復元手段514及びビットストリーム多重化手段50に出力する(ステップS113)。
次に、符号化装置5は、奥行マップ復元手段514によって、奥行マップ符号化手段513から符号化奥行マップg2dを入力し、符号化奥行マップg2dを復号化し、復号化合成奥行マップG’dを生成する。奥行マップ復元手段514は、生成した復号化合成奥行マップG’dを射影映像予測手段515に出力する(ステップS114)。
次に、符号化装置5は、射影映像予測手段515によって、奥行マップ復元手段514から復号化合成奥行マップG’dを、外部から左視点映像L、右視点映像R及び必要に応じて指定視点Pt,Qtの情報を、それぞれ入力して、残差映像Fvを生成する。射影映像予測手段515は、生成した残差映像Fvを残差映像符号化手段516に出力する(ステップS115)。
次に、符号化装置5は、残差映像符号化手段516によって、射影映像予測手段515から残差映像Fvを入力し、所定の符号化方式により符号化して符号化残差映像fvを生成する。残差映像符号化手段516は、生成した符号化残差映像fvを残差映像ビットストリームとしてビットストリーム多重化手段50に出力する(ステップS116)。
次に、符号化装置5は、ビットストリーム多重化手段50によって、ステップS111で生成した符号化基準視点映像cである基準視点映像ビットストリームと、ステップS113で生成した符号化奥行マップg2dである奥行マップビットストリームと、ステップS116で生成した符号化残差映像fvである残差映像ビットストリームと、外部から基準視点映像Cなどとともに入力した補助情報hと、を多重化して、多重化ビットストリームとして復号化装置6(図31参照)に出力する(ステップS117)。
また、ビットストリーム多重化手段50は、奥行ヘッダ付加手段503によって、奥行マップビットストリームについて、既存のヘッダの開始コード701の直後に立体映像ヘッダ704と奥行フラグ705とを挿入して多重化する。
また、ビットストリーム多重化手段50は、残差ヘッダ付加手段504によって、残差映像ビットストリームについて、既存のヘッダの開始コード701の直後に立体映像ヘッダ704と残差フラグ706とを挿入して多重化する。
また、ビットストリーム多重化手段50は、補助情報ヘッダ付加手段502によって、補助情報hについて、ヘッダとして開始コード701と立体映像ヘッダ704と補助情報フラグ707とを付加して多重化する。
次に、図34を参照(適宜図29、図31及び図32参照)して、復号化装置6の動作について説明する。
図34に示すように、まず、復号化装置6は、ビットストリーム分離手段60によって、符号化装置5(図27参照)から多重化ビットストリームを入力し、入力した多重化ビットストリームを、基準視点映像ビットストリームと、奥行マップビットストリームと、残差映像ビットストリームと、補助情報hとに分離する。ビットストリーム分離手段60は、分離した、基準視点映像ビットストリームを基準視点映像復号化手段611に、奥行マップビットストリームを奥行マップ復元手段612に、残差映像ビットストリームを残差映像復元手段614に、補助情報hを奥行マップ射影手段613及び射影映像合成手段615に、それぞれ出力する(ステップS121)。
次に、復号化装置6は、基準視点映像復号化手段611によって、ビットストリーム分離手段60から基準視点映像ビットストリームとして符号化基準視点映像cを入力して、その符号化方式で復号化して復号化基準視点映像C’を生成し、生成した復号化基準視点映像C’を多視点映像の基準視点映像として外部に出力する(ステップS122)。
次に、復号化装置6は、奥行マップ復元手段612によって、ビットストリーム分離手段60から奥行マップビットストリームとして符号化奥行マップg2dを入力して、その符号化方式で復号化して復号化合成奥行マップG’dを生成し、生成した復号化合成奥行マップG’dを奥行マップ射影手段613に出力する(ステップS123)。
次に、復号化装置6は、奥行マップ射影手段613によって、奥行マップ復元手段612から復号化合成奥行マップG’dを、ビットストリーム分離手段60から補助情報hを、外部から左指定視点Pt及び右指定視点Qtを、それぞれ入力して、左指定視点Pt及び右指定視点Qtにおける奥行マップである左指定視点奥行マップPd及び右指定視点奥行マップQdを生成し、生成した左指定視点奥行マップPd及び右指定視点奥行マップQdを射影映像合成手段615に出力する(ステップS124)。
次に、復号化装置6は、残差映像復元手段614によって、ビットストリーム分離手段60から残差映像ビットストリームとして符号化残差映像fvを入力して、その符号化方式で復号化して左残差映像L’v及び右残差映像R’vを生成し、生成した左残差映像L’v及び右残差映像R’vを射影映像合成手段615に出力する(ステップS125)。
次に、復号化装置6は、射影映像合成手段615によって、基準視点映像復号化手段611から復号化基準視点映像C’を、奥行マップ射影手段613から左右の指定視点奥行マップPd,Qdを、残差映像復元手段614から左残差映像L’v及び右残差映像R’vを、ビットストリーム分離手段から補助情報hを、それぞれ入力して、左右の指定視点Pt,Qtにおける指定視点映像P,Qを生成する。射影映像合成手段615は、生成した指定視点映像P,Qを多視点映像の指定視点映像として外部に出力する(ステップS126)。
11 基準視点映像符号化手段
12、12A、12B 奥行マップ合成手段
121、122 中間視点射影手段
123 マップ合成手段
13、13A、13B 奥行マップ符号化手段
14、14A、30a 奥行マップ復号化手段
15、15A、15B、15C 射影映像予測手段
151、151B オクルージョンホール検出手段
1511 第1穴マスク生成手段
1511a 左視点射影手段(副視点射影手段)
1511b 第1ホール画素検出手段(ホール画素検出手段)
1512 第2穴マスク生成手段
1512a 第2ホール画素検出手段
1512b 左視点射影手段(第2副視点射影手段)
1513 第3穴マスク生成手段
1513a 指定視点射影手段
1513b 第3ホール画素検出手段
1513c 左視点射影手段(第3副視点射影手段)
1514 穴マスク合成手段
1515 穴マスク膨張手段
152 残差映像切出手段
153 左視点射影手段(副視点射影手段)
154 残差算出手段
16、16A、16B 残差映像符号化手段
17 奥行マップフレーム化手段
18 奥行マップ分離手段
19、19B 残差映像フレーム化手段
2、2A、2B 立体映像復号化装置
21 基準視点映像復号化手段
22、22A、28a 奥行マップ復号化手段
23、23A、23B 奥行マップ射影手段
24、24A、24B 残差映像復号化手段
25、25A、25B、25C 射影映像合成手段
251、251B、251C 基準視点映像射影手段
251a ホール画素検出手段
251b 指定視点映像射影手段
251c 基準視点映像画素複写手段
251d メディアンフィルタ
251e 穴マスク膨張手段
252、252B、252C 残差映像射影手段
252a 指定視点映像射影手段
252b 残差映像画素複写手段
252c 穴埋め処理手段
252f 残差加算手段
26 奥行マップ分離手段
27、27B 残差映像分離手段
28 奥行マップ復元手段
30 奥行マップ復元手段
5 立体映像符号化装置
50 ビットストリーム多重化手段
501 スイッチ(切替手段)
502 補助情報ヘッダ付加手段
503 奥行ヘッダ付加手段
504 残差ヘッダ付加手段
51 符号化処理部
511 基準視点映像符号化手段
512 奥行マップ合成手段
513 奥行マップ符号化手段
514 奥行マップ復元手段
515 射影映像予測手段
516 残差映像符号化手段
6 立体映像復号化装置
60 ビットストリーム分離手段
601 基準視点映像ビットストリーム分離手段
602 奥行マップビットストリーム分離手段
603 残差映像ビットストリーム分離手段
604 補助情報分離手段
61 復号化処理部
611 基準視点映像復号化手段
612 奥行マップ復元手段
613 奥行マップ射影手段
614 残差映像復元手段
615 射影映像合成手段
701 開始コード
702 1視点映像ヘッダ(第1識別情報)
703 ビットストリーム本体
704 立体映像ヘッダ(第2識別情報)
705 奥行フラグ(第3識別情報)
706 残差フラグ(第4識別情報)
707 補助情報フラグ(第5識別情報)
708 補助情報本体
Claims (33)
- 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、を符号化する立体映像符号化装置であって、
前記多視点映像の基準視点における映像である基準視点映像を符号化して、基準視点映像ビットストリームとして出力する基準視点映像符号化手段と、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点以外の視点である副視点における奥行マップである副視点奥行マップとを用いて、前記基準視点と前記副視点との中間視点における奥行マップである中間視点奥行マップを生成する中間視点奥行マップ合成手段と、
前記中間視点奥行マップを符号化して、奥行マップビットストリームとして出力する奥行マップ符号化手段と、
前記符号化された中間視点奥行マップを復号化して、復号化中間視点奥行マップを生成する奥行マップ復号化手段と、
前記復号化中間視点奥行マップを用いて、前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出して残差映像を生成する射影映像予測手段と、
前記残差映像を符号化して、残差映像ビットストリームとして出力する残差映像符号化手段と、を備え、
前記射影映像予測手段は、
前記復号化中間視点奥行マップを用いて、前記基準視点映像を前記副視点に射影したときにオクルージョンホールとなる画素を検出するオクルージョンホール検出手段と、
前記オクルージョンホール検出手段が検出したオクルージョンホールとなる画素を前記副視点映像から切出して前記残差映像を生成する残差映像切出手段と、を有することを特徴とする立体映像符号化装置。 - 前記オクルージョンホール検出手段は、
前記復号化中間視点奥行マップを前記副視点に射影して、前記副視点における奥行マップである副視点射影奥行マップを生成する副視点射影手段と、
前記副視点射影奥行マップにおいて、画素ごとに、前記オクルージョンホールとなる画素かどうかの判定対象として着目している画素である着目画素について、当該着目画素から前記基準視点側寄りに所定の画素数離れた画素における奥行値が、前記着目画素における奥行値よりも所定の値以上大きい場合に、前記着目画素を前記オクルージョンホールとなる画素として検出するホール画素検出手段と、を有することを特徴とする請求項1に記載の立体映像符号化装置。 - 前記オクルージョンホール検出手段は、前記ホール画素検出手段によって検出された画素位置を示す穴マスクを、所定の画素数だけ膨張させる穴マスク膨張手段を有し、前記残差映像切出手段は、前記穴マスク膨張手段によって膨張させた穴マスクに含まれる画素を前記副視点映像から切出して前記残差映像を生成することを特徴とする請求項2に記載の立体映像符号化装置。
- 前記オクルージョンホール検出手段は、
前記復号化中間視点奥行マップにおいて、画素ごとに、前記オクルージョンホールとなる画素かどうかの判定対象として着目している画素である着目画素について、当該着目画素から前記基準視点側寄りに所定の画素数離れた画素における奥行値が、前記着目画素における奥行値よりも所定の値以上大きい場合に、前記着目画素を前記オクルージョンホールとなる画素として検出する第2ホール画素検出手段と、
前記第2ホール画素検出手段による検出結果を、前記副視点に射影する第2副視点射影手段と、
前記ホール画素検出手段による検出結果及び前記第2副視点射影手段により射影された前記第2ホール画素検出手段による検出結果の論理和を前記オクルージョンホール検出手段の検出結果とする穴マスク合成手段と、を更に有することを特徴とする請求項2又は請求項3に記載の立体映像符号化装置。 - 前記オクルージョンホール検出手段は、
前記復号化中間視点奥行マップを任意の指定視点位置に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する指定視点射影手段と、
前記指定視点奥行マップにおいて、画素ごとに、前記オクルージョンホールとなる画素かどうかの判定対象として着目している画素である着目画素について、当該着目画素から前記基準視点側寄りに所定の画素数離れた画素における奥行値が、前記着目画素における奥行値よりも所定の値以上大きい場合に、前記着目画素を前記オクルージョンホールとなる画素として検出する第3ホール画素検出手段と、
前記第3ホール画素検出手段による検出結果を、前記副視点に射影する第3副視点射影手段と、を更に有し、
前記穴マスク合成手段は、前記ホール画素検出手段による検出結果、前記第2副視点射影手段により射影された前記第2ホール画素検出手段による検出結果及び前記第3副視点射影手段により射影された前記第3ホール画素検出手段による検出結果の論理和を前記オクルージョンホール検出手段の検出結果とすることを特徴とする請求項4に記載の立体映像符号化装置。 - 前記多視点映像において、前記基準視点と複数の前記副視点とについての複数の前記中間視点奥行マップを縮小して結合し、1つのフレーム画像にフレーム化したフレーム化奥行マップを生成する奥行マップフレーム化手段と、
前記フレーム化奥行マップから、フレーム化された複数の縮小された前記中間視点奥行マップを分離して、前記基準視点映像と同じ大きさの複数の前記中間視点奥行マップを生成する奥行マップ分離手段と、
前記多視点映像において、前記基準視点と複数の前記副視点とについての複数の前記残差映像を縮小して結合し、1つのフレーム画像にフレーム化したフレーム化残差映像を生成する残差映像フレーム化手段と、を更に備え、
前記中間視点奥行マップ合成手段は、前記基準視点と、複数の前記副視点のそれぞれとの間の中間視点における複数の前記中間視点奥行マップを生成し、
前記奥行マップフレーム化手段は、前記中間視点奥行マップ合成手段によって生成された複数の中間視点奥行マップを縮小して結合することで前記フレーム化奥行マップを生成し、
前記奥行マップ符号化手段は、前記フレーム化奥行マップを符号化して、前記奥行マップビットストリームとして出力し、
前記奥行マップ復号化手段は、前記奥行マップ符号化手段によって符号化されたフレーム化奥行マップを復号化して復号化フレーム化奥行マップを生成し、
前記奥行マップ分離手段は、前記復号化フレーム化奥行マップから縮小された複数の前記中間視点奥行マップを分離して、前記基準視点映像と同じ大きさの前記復号化中間視点奥行マップを生成し、
前記射影映像予測手段は、前記奥行マップ分離手段によって生成された復号化中間視点奥行マップを用いて、それぞれの前記復号化中間視点奥行マップに対応する前記副視点における前記副視点映像から前記残差映像を生成し、
前記残差映像フレーム化手段は、前記射影映像予測手段によって生成した複数の前記残差映像を縮小して結合することで前記フレーム化残差映像を生成し、
前記残差映像符号化手段は、前記フレーム化残差映像を符号化して、前記残差映像ビットストリームとして出力することを特徴とする請求項1乃至請求項5の何れか一項に記載の立体映像符号化装置。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、が符号化されたビットストリームを復号化して多視点映像を生成する立体映像復号化装置であって、
前記多視点映像の基準視点における映像である基準視点映像が符号化された基準視点映像ビットストリームを復号化し、復号化基準視点映像を生成する基準視点映像復号化手段と、
前記基準視点と前記基準視点から離れた他の視点である副視点との中間の視点における奥行マップである中間視点奥行マップが符号化された奥行マップビットストリームを復号化し、復号化中間視点奥行マップを生成する奥行マップ復号化手段と、
前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出した映像である残差映像が符号化された残差映像ビットストリームを復号化し、復号化残差映像を生成する残差映像復号化手段と、
前記復号化中間視点奥行マップを、前記多視点映像の視点として外部から指定された視点である指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する奥行マップ射影手段と、
前記指定視点奥行マップを用いて、前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成する射影映像合成手段と、を備え、
前記射影映像合成手段は、
前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を検出し、前記オクルージョンホールとならない画素について、前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影して前記指定視点映像の画素とする基準視点映像射影手段と、
前記オクルージョンホールとなる画素について、前記指定視点奥行マップを用いて、前記復号化残差映像を前記指定視点に射影して前記指定視点映像の画素とする残差映像射影手段と、を有することを特徴とする立体映像復号化装置。 - 前記基準視点映像射影手段は、前記指定視点奥行マップにおいて、画素ごとに、オクルージョンホールとなる画素かどうかの判定対象として着目している画素である着目画素について、当該着目画素から前記基準視点側寄りに所定の画素数離れた画素における奥行値が、前記着目画素における奥行値よりも所定の値以上大きい場合に、前記着目画素をオクルージョンホールとなる画素として検出するホール画素検出手段を有することを特徴とする請求項7に記載の立体映像復号化装置。
- 前記基準視点映像射影手段は、前記ホール画素検出手段で検出した画素からなるオクルージョンホールを、所定の画素数だけ膨張させる穴マスク膨張手段を有し、
前記残差映像射影手段は、前記穴マスク膨張手段によって膨張させたオクルージョンホールにおける画素について、前記復号化残差映像を前記指定視点に射影して前記指定視点映像の画素とすることを特徴とする請求項8に記載の立体映像復号化装置。 - 前記残差映像射影手段は、前記指定視点映像において、前記残差映像に含まれなかった画素を検出し、当該含まれなかった画素の周囲の画素値で当該含まれなかった画素の画素値を補間する穴埋め処理手段を備えることを特徴とする請求項9に記載の立体映像復号化装置。
- 前記基準視点と複数の前記副視点のそれぞれとの間の中間視点における複数の前記中間視点奥行マップを縮小して結合した1つのフレーム画像であるフレーム化奥行マップを、複数の前記中間視点ごとに分離して、前記基準視点映像と同じ大きさの中間視点奥行マップを生成する奥行マップ分離手段と、
前記複数の副視点についての複数の前記残差映像を縮小して結合した1つのフレーム画像であるフレーム化残差映像を分離して、前記基準視点映像と同じ大きさの前記復号化残差映像を生成する残差映像分離手段と、を更に備え、
前記奥行マップ復号化手段は、前記フレーム化奥行マップが符号化された前記奥行マップビットストリームを復号化して、復号化フレーム化奥行マップを生成し、
前記残差映像復号化手段は、前記フレーム化残差映像が符号化された前記残差映像ビットストリームを復号化して、復号化フレーム化残差映像を生成し、
前記奥行マップ分離手段は、前記復号化フレーム化奥行マップから、複数の縮小された前記中間視点奥行マップを分離して、前記基準視点映像と同じ大きさの複数の前記復号化中間視点奥行マップを生成し、
前記残差映像分離手段は、前記復号化フレーム化残差映像から、複数の縮小された前記残差映像を分離して、前記基準視点映像と同じ大きさの複数の前記復号化残差映像を生成し、
前記奥行マップ射影手段は、複数の前記指定視点ごとに、それぞれ対応する前記復号化中間視点奥行マップを前記指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成し、
前記射影映像合成手段は、複数の前記指定視点ごとに、それぞれ対応する前記指定視点奥行マップを用いて、それぞれ対応する前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成することを特徴とする請求項7乃至請求項10の何れか一項に記載の立体映像復号化装置。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、を符号化する立体映像符号化方法であって、
前記多視点映像の基準視点における映像である基準視点映像を符号化して、基準視点映像ビットストリームとして出力する基準視点映像符号化処理ステップと、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点以外の視点である副視点における奥行マップである副視点奥行マップとを用いて、前記基準視点と前記副視点との中間視点における奥行マップである中間視点奥行マップを生成する中間視点奥行マップ合成処理ステップと、
前記中間視点奥行マップを符号化して、奥行マップビットストリームとして出力する奥行マップ符号化処理ステップと、
前記符号化された中間視点奥行マップを復号化して、復号化中間視点奥行マップを生成する奥行マップ復号化処理ステップと、
前記復号化中間視点奥行マップを用いて、前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出して残差映像を生成する射影映像予測処理ステップと、
前記残差映像を符号化して、残差映像ビットストリームとして出力する残差映像符号化処理ステップと、を含み、
前記射影映像予測処理ステップは、
前記復号化中間視点奥行マップを用いて、前記基準視点映像を前記副視点に射影したときにオクルージョンホールとなる画素を検出するオクルージョンホール検出処理ステップと、
前記オクルージョンホール検出処理ステップで検出したオクルージョンホールとなる画素を前記副視点映像から切出して前記残差映像を生成する残差映像切出処理ステップと、を含むことを特徴とする立体映像符号化方法。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、が符号化されたビットストリームを復号化して多視点映像を生成する立体映像復号化方法であって、
前記多視点映像の基準視点における映像である基準視点映像が符号化された基準視点映像ビットストリームを復号化し、復号化基準視点映像を生成する基準視点映像復号化処理ステップと、
前記基準視点と前記基準視点から離れた他の視点である副視点との中間の視点における奥行マップである中間視点奥行マップが符号化された奥行マップビットストリームを復号化し、復号化中間視点奥行マップを生成する奥行マップ復号化処理ステップと、
前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出した映像である残差映像が符号化された残差映像ビットストリームを復号化し、復号化残差映像を生成する残差映像復号化処理ステップと、
前記復号化中間視点奥行マップを、前記多視点映像の視点として外部から指定された視点である指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する奥行マップ射影処理ステップと、
前記指定視点奥行マップを用いて、前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成する射影映像合成処理ステップと、を含み、
前記射影映像合成処理ステップは、
前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を検出し、前記オクルージョンホールとならない画素について、前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影して前記指定視点映像の画素とする基準視点映像射影処理ステップと、
前記オクルージョンホールとなる画素について、前記指定視点奥行マップを用いて、前記復号化残差映像を前記指定視点に射影して前記指定視点映像の画素とする残差映像射影処理ステップと、を含むことを特徴とする立体映像復号化方法。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、を符号化するために、コンピュータを、
前記多視点映像の基準視点における映像である基準視点映像を符号化して、基準視点映像ビットストリームとして出力する基準視点映像符号化手段、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点以外の視点である副視点における奥行マップである副視点奥行マップと用いて、前記基準視点と前記副視点との中間視点における奥行マップである中間視点奥行マップを生成する中間視点奥行マップ合成手段、
前記中間視点奥行マップを符号化して、奥行マップビットストリームとして出力する奥行マップ符号化手段、
前記符号化された中間視点奥行マップを復号化して、復号化中間視点奥行マップを生成する奥行マップ復号化手段、
前記復号化中間視点奥行マップを用いて、前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出して残差映像を生成する射影映像予測手段、
前記残差映像を符号化して、残差映像ビットストリームとして出力する残差映像符号化手段、
前記復号化中間視点奥行マップを用いて、前記基準視点映像を前記副視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を検出するオクルージョンホール検出手段、
前記オクルージョンホール検出手段が検出したオクルージョンホールとなる画素を前記副視点映像から切出して前記残差映像を生成する残差映像切出手段、
として機能させることを特徴とする立体映像符号化プログラム。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、が符号化されたビットストリームを復号化して多視点映像を生成するために、コンピュータを、
前記多視点映像の基準視点における映像である基準視点映像が符号化された基準視点映像ビットストリームを復号化し、復号化基準視点映像を生成する基準視点映像復号化手段、
前記基準視点と前記基準視点から離れた他の視点である副視点との中間の視点における奥行マップである中間視点奥行マップが符号化された奥行マップビットストリームを復号化し、復号化中間視点奥行マップを生成する奥行マップ復号化手段、
前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出した映像である残差映像が符号化された残差映像ビットストリームを復号化し、復号化残差映像を生成する残差映像復号化手段、
前記復号化中間視点奥行マップを、前記多視点映像の視点として外部から指定された視点である指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する奥行マップ射影手段、
前記指定視点奥行マップを用いて、前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成する射影映像合成手段、
前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を検出し、前記オクルージョンホールとならない画素について、前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影して前記指定視点映像の画素とする基準視点映像射影手段、
前記オクルージョンホールとなる画素について、前記指定視点奥行マップを用いて、前記復号化残差映像を前記指定視点に射影して前記指定視点映像の画素とする残差映像射影手段、
として機能させることを特徴とする立体映像復号化プログラム。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、を符号化する立体映像符号化装置であって、
前記多視点映像の基準視点における映像である基準視点映像を符号化して、基準視点映像ビットストリームとして出力する基準視点映像符号化手段と、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点から離れた他の視点である副視点における奥行マップである副視点奥行マップとを所定の視点に射影して合成し、前記所定の視点における奥行マップである合成奥行マップを生成する奥行マップ合成手段と、
前記合成奥行マップを符号化して、奥行マップビットストリームとして出力する奥行マップ符号化手段と、
前記符号化された合成奥行マップを復号化して、復号化合成奥行マップを生成する奥行マップ復号化手段と、
前記復号化合成奥行マップを用いて、前記基準視点映像から他の視点における映像を予測したときの予測残差である残差映像を生成する射影映像予測手段と、
前記残差映像を符号化して、残差映像ビットストリームとして出力する残差映像符号化手段と、
を備えることを特徴とする立体映像符号化装置。 - 前記奥行マップ合成手段は、前記基準視点奥行マップと複数の前記副視点奥行マップとを共通視点に射影して合成することで前記共通視点における1つの合成奥行マップを生成し、
前記基準視点と複数の前記副視点とについての複数の前記残差映像を縮小して結合し、1つのフレーム画像にフレーム化したフレーム化残差映像を生成する残差映像フレーム化手段を更に備え、
前記残差映像符号化手段は、前記フレーム化残差映像を符号化して、前記残差映像ビットストリームとして出力することを特徴とする請求項16に記載の立体映像符号化装置。 - 前記射影映像予測手段は、前記復号化合成奥行マップを用いて、前記基準視点映像を他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出して残差映像を生成することを特徴とする請求項16又は請求項17に記載の立体映像符号化装置。
- 前記射影映像予測手段は、前記復号化合成奥行マップを用いて、前記基準視点映像を前記副視点に射影した映像と、前記副視点映像との画素ごとの差を算出して残差映像を生成することを特徴とする請求項16又は請求項17に記載の立体映像符号化装置。
- 前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームとは、それぞれ、所定の開始コードと1視点映像であることを識別する第1識別情報とをこの順で含むヘッダを有しており、
前記基準視点及び前記副視点の各位置を示す情報を含む補助情報と、前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、を多重化して、多重化ビットストリームとして出力するビットストリーム多重化手段を更に備え、
前記ビットストリーム多重化手段は、
前記基準視点映像ビットストリームについてはそのまま出力し、
前記奥行マップビットストリームについては、前記開始コードと前記第1識別情報との間に、立体映像に関するデータであることを識別する第2識別情報と、前記奥行マップビットストリームであることを識別する第3識別情報とをこの順で挿入して出力し、
前記残差映像ビットストリームについては、前記開始コードと前記第1識別情報との間に、前記第2識別情報と、前記残差映像ビットストリームであることを識別する第4識別情報とをこの順で挿入して出力し、
前記補助情報については、前記開始コードと、前記第2識別情報と、前記補助情報であることを識別する第5識別情報とをこの順で含むヘッダを前記補助情報に付加して出力することを特徴とする請求項16に記載の立体映像符号化装置。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、が符号化されたビットストリームを復号化して多視点映像を生成する立体映像復号化装置であって、
前記多視点映像の基準視点における映像である基準視点映像が符号化された基準視点映像ビットストリームを復号化し、復号化基準視点映像を生成する基準視点映像復号化手段と、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点から離れた他の視点である副視点における奥行マップである副視点奥行マップとを合成して生成された所定の視点における奥行マップである合成奥行マップが符号化された奥行マップビットストリームを復号化し、復号化合成奥行マップを生成する奥行マップ復号化手段と、
前記基準視点映像から前記基準視点から離れた他の視点における映像を前記復号化合成奥行マップを用いて予測したときの予測残差である残差映像が符号化された残差映像ビットストリームを復号化し、復号化残差映像を生成する残差映像復号化手段と、
前記復号化合成奥行マップを、前記多視点映像の視点として外部から指定された視点である指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する奥行マップ射影手段と、
前記指定視点奥行マップを用いて、前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成する射影映像合成手段と、
を備えることを特徴とする立体映像復号化装置。 - 前記合成奥行マップは、前記基準視点奥行マップと複数の前記副視点奥行マップとを共通視点に射影して合成された前記共通視点における1つの奥行マップであり、
前記複数の副視点についての複数の前記残差映像を縮小して結合した1つのフレーム画像であるフレーム化残差映像を分離して、前記基準視点映像と同じ大きさの前記復号化残差映像を生成する残差映像分離手段を更に備え、
前記残差映像復号化手段は、前記フレーム化残差映像が符号化された前記残差映像ビットストリームを復号化して、復号化フレーム化残差映像を生成し、
前記残差映像分離手段は、前記復号化フレーム化残差映像から、複数の縮小された前記残差映像を分離して、前記基準視点映像と同じ大きさの複数の前記復号化残差映像を生成し、
前記射影映像合成手段は、前記指定視点奥行マップを用いて、前記復号化基準視点映像と、複数の前記復号化残差映像の何れか1つとを前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成することを特徴とする請求項21に記載の立体映像復号化装置。 - 前記残差映像ビットストリームは、前記基準視点映像を前記基準視点から離れた他の視点に射影したときに、射影できない画素領域であるオクルージョンホールとなる画素を前記副視点映像から切出すことで生成した残差映像が符号化されており、
前記射影映像合成手段は、
前記復号化基準視点映像を前記指定視点に射影したときに、前記指定視点奥行マップを用いて、射影できない画素領域であるオクルージョンホールとなる画素を検出し、前記オクルージョンホールとならない画素について、前記指定視点奥行マップを用いて、前記復号化基準視点映像を前記指定視点に射影して前記指定視点映像の画素とする基準視点映像射影手段と、
前記オクルージョンホールとなる画素について、前記指定視点奥行マップを用いて、前記復号化残差映像を前記指定視点に射影して前記指定視点映像の画素とする残差映像射影手段と、を有することを特徴とする請求項21又は請求項22に記載の立体映像復号化装置。 - 前記残差映像ビットストリームは、前記復号化合成奥行マップを用いて前記基準視点映像を前記副視点に射影した映像と、前記副視点映像との画素ごとの差を算出することで生成した残差映像が符号化されており、
前記射影映像合成手段は、
前記指定視点奥行マップを用いて前記復号化基準視点映像を前記指定視点に射影した映像に、前記指定視点奥行マップを用いて前記復号化残差映像を前記指定視点に射影した映像を、画素ごとに加算して前記指定視点映像を生成する残差加算手段を有することを特徴とする請求項21又は請求項22に記載の立体映像復号化装置。 - 前記基準視点映像ビットストリームは、所定の開始コードと1視点映像であることを識別する第1識別情報とをこの順で含むヘッダを有し、
前記奥行マップビットストリームは、前記開始コードと前記第1識別情報との間に、立体映像に関するデータであることを識別する第2識別情報と、前記奥行マップビットストリームであることを識別する第3識別情報とをこの順で含むヘッダを有し、
前記残差映像ビットストリームは、前記開始コードと前記第1識別情報との間に、前記第2識別情報と、前記残差映像ビットストリームであることを識別する第4識別情報とをこの順で含むヘッダを有し、
前記補助情報ビットストリームは、前記開始コードと、前記第2識別情報と、前記補助情報ビットストリームであることを識別する第5識別情報とをこの順で含むヘッダを有し、
前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、前記基準視点及び前記副視点の各位置を示す情報を含む補助情報を含むビットストリームと、が多重化された多重化ビットストリームを、前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、前記補助情報と、に分離するビットストリーム分離手段を更に備え、
前記ビットストリーム分離手段は、
前記多重化ビットストリームから前記開始コードの直後に前記第1識別情報を有するビットストリームを前記基準視点映像ビットストリームとして分離し、分離した基準視点映像ビットストリームを前記基準視点映像復号化手段に出力する基準視点映像ビットストリーム分離手段と、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第3識別情報とをこの順で有するビットストリームを前記奥行マップビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第3識別情報を除去したビットストリームを前記奥行マップ復号化手段に出力する奥行マップビットストリーム分離手段と、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第4識別情報とをこの順で有するビットストリームを前記残差映像ビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第4識別情報を除去したビットストリームを前記残差映像復号化手段に出力する残差映像ビットストリーム分離手段と、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第5識別情報とをこの順で有するビットストリームを前記補助情報ビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第5識別情報を除去したビットストリームを補助情報として前記射影映像合成手段に出力する補助情報分離手段と、
を有することを特徴とする請求項21に記載の立体映像復号化装置。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、を符号化する立体映像符号化方法であって、
前記多視点映像の基準視点における映像である基準視点映像を符号化して、基準視点映像ビットストリームとして出力する基準視点映像符号化処理ステップと、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点から離れた他の視点である副視点における奥行マップである副視点奥行マップとを所定の視点に射影して合成し、前記所定の視点における奥行マップである合成奥行マップを生成する奥行マップ合成処理ステップと、
前記合成奥行マップを符号化して、奥行マップビットストリームとして出力する奥行マップ符号化処理ステップと、
前記符号化された合成奥行マップを復号化して、復号化合成奥行マップを生成する奥行マップ復号化処理ステップと、
前記復号化合成奥行マップを用いて、前記基準視点映像から他の視点における映像を予測したときの予測残差である残差映像を生成する射影映像予測処理ステップと、
前記残差映像を符号化して、残差映像ビットストリームとして出力する残差映像符号化処理ステップと、
を含むことを特徴とする立体映像符号化方法。 - 前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームとは、それぞれ、所定の開始コードと1視点映像であることを識別する第1識別情報とをこの順で含むヘッダを有しており、
前記基準視点及び前記副視点の各位置を示す情報を含む補助情報と、前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、を多重化して、多重化ビットストリームとして出力するビットストリーム多重化処理ステップを更に含み、
前記ビットストリーム多重化処理ステップは、
前記基準視点映像ビットストリームについてはそのまま出力し、
前記奥行マップビットストリームについては、前記開始コードと前記第1識別情報との間に、立体映像に関するデータであることを識別する第2識別情報と、前記奥行マップビットストリームであることを識別する第3識別情報とをこの順で挿入して出力し、
前記残差映像ビットストリームについては、前記開始コードと前記第1識別情報との間に、前記第2識別情報と、前記残差映像ビットストリームであることを識別する第4識別情報とをこの順で挿入して出力し、
前記補助情報については、前記開始コードと、前記第2識別情報と、前記補助情報であることを識別する第5識別情報とをこの順で含むヘッダを前記補助情報に付加して出力することを特徴とする請求項26に記載の立体映像符号化方法。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、が符号化されたビットストリームを復号化して多視点映像を生成する立体映像復号化方法であって、
前記多視点映像の基準視点における映像である基準視点映像が符号化された基準視点映像ビットストリームを復号化し、復号化基準視点映像を生成する基準視点映像復号化処理ステップと、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点から離れた他の視点である副視点における奥行マップである副視点奥行マップとを合成して生成された所定の視点における奥行マップである合成奥行マップが符号化された奥行マップビットストリームを復号化し、復号化合成奥行マップを生成する奥行マップ復号化処理ステップと、
前記基準視点映像から前記基準視点から離れた他の視点における映像を前記復号化合成奥行マップを用いて予測したときの予測残差である残差映像が符号化された残差映像ビットストリームを復号化し、復号化残差映像を生成する残差映像復号化処理ステップと、
前記復号化合成奥行マップを、前記多視点映像の視点として外部から指定された視点である指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する奥行マップ射影処理ステップと、
前記指定視点奥行マップを用いて、前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成する射影映像合成処理ステップと、
を含むことを特徴とする立体映像復号化方法。 - 前記基準視点映像ビットストリームは、所定の開始コードと1視点映像であることを識別する第1識別情報とをこの順で含むヘッダを有し、
前記奥行マップビットストリームは、前記開始コードと前記第1識別情報との間に、立体映像に関するデータであることを識別する第2識別情報と、前記奥行マップビットストリームであることを識別する第3識別情報とをこの順で含むヘッダを有し、
前記残差映像ビットストリームは、前記開始コードと前記第1識別情報との間に、前記第2識別情報と、前記残差映像ビットストリームであることを識別する第4識別情報とをこの順で含むヘッダを有し、
前記補助情報ビットストリームは、前記開始コードと、前記第2識別情報と、前記補助情報ビットストリームであることを識別する第5識別情報とをこの順で含むヘッダを有し、
前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、前記基準視点及び前記副視点の各位置を示す情報を含む補助情報を含むビットストリームと、が多重化された多重化ビットストリームを、前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、前記補助情報と、に分離するビットストリーム分離処理ステップを更に含み、
前記ビットストリーム分離ステップは、
前記多重化ビットストリームから前記開始コードの直後に前記第1識別情報を有するビットストリームを前記基準視点映像ビットストリームとして分離し、分離した基準視点映像ビットストリームを前記基準視点映像復号化処理ステップで用い、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第3識別情報とをこの順で有するビットストリームを前記奥行マップビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第3識別情報を除去したビットストリームを前記奥行マップ復号化処理ステップで用い、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第4識別情報とをこの順で有するビットストリームを前記残差映像ビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第4識別情報を除去したビットストリームを前記残差映像復号化処理ステップで用い、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第5識別情報とをこの順で有するビットストリームを前記補助情報ビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第5識別情報を除去したビットストリームを補助情報として前記射影映像合成処理ステップで用いることを特徴とする請求項28に記載の立体映像復号化方法。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、を符号化するために、コンピュータを、
前記多視点映像の基準視点における映像である基準視点映像を符号化して、基準視点映像ビットストリームとして出力する基準視点映像符号化手段、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点から離れた他の視点である副視点における奥行マップである副視点奥行マップとを所定の視点に射影して合成し、前記所定の視点における奥行マップである合成奥行マップを生成する奥行マップ合成手段、
前記合成奥行マップを符号化して、奥行マップビットストリームとして出力する奥行マップ符号化手段、
前記符号化された合成奥行マップを復号化して、復号化合成奥行マップを生成する奥行マップ復号化手段、
前記復号化合成奥行マップを用いて、前記基準視点映像から他の視点における映像を予測したときの予測残差である残差映像を生成する射影映像予測手段、
前記残差映像を符号化して、残差映像ビットストリームとして出力する残差映像符号化手段、
として機能させる立体映像符号化プログラム。 - 前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームとは、それぞれ、所定の開始コードと1視点映像であることを識別する第1識別情報とをこの順で含むヘッダを有しており、
前記基準視点及び前記副視点の各位置を示す情報を含む補助情報と、前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、を多重化して、多重化ビットストリームとして出力するビットストリーム多重化手段として更に機能させ、
前記ビットストリーム多重化手段は、
前記基準視点映像ビットストリームについてはそのまま出力し、
前記奥行マップビットストリームについては、前記開始コードと前記第1識別情報との間に、立体映像に関するデータであることを識別する第2識別情報と、前記奥行マップビットストリームであることを識別する第3識別情報とをこの順で挿入して出力し、
前記残差映像ビットストリームについては、前記開始コードと前記第1識別情報との間に、前記第2識別情報と、前記残差映像ビットストリームであることを識別する第4識別情報とをこの順で挿入して出力し、
前記補助情報については、前記開始コードと、前記第2識別情報と、前記補助情報であることを識別する第5識別情報とをこの順で含むヘッダを前記補助情報に付加して出力することを特徴とする請求項30に記載の立体映像符号化プログラム。 - 多視点映像と、前記多視点映像における視点間の視差である奥行値の画素ごとの情報のマップである奥行マップと、が符号化されたビットストリームを復号化して多視点映像を生成するために、コンピュータを、
前記多視点映像の基準視点における映像である基準視点映像が符号化された基準視点映像ビットストリームを復号化し、復号化基準視点映像を生成する基準視点映像復号化手段、
前記基準視点における奥行マップである基準視点奥行マップと、前記多視点映像の前記基準視点から離れた他の視点である副視点における奥行マップである副視点奥行マップとを合成して生成された所定の視点における奥行マップである合成奥行マップが符号化された奥行マップビットストリームを復号化し、復号化合成奥行マップを生成する奥行マップ復号化手段、
前記基準視点映像から前記基準視点から離れた他の視点における映像を前記復号化合成奥行マップを用いて予測したときの予測残差である残差映像が符号化された残差映像ビットストリームを復号化し、復号化残差映像を生成する残差映像復号化手段、
前記復号化合成奥行マップを、前記多視点映像の視点として外部から指定された視点である指定視点に射影して、前記指定視点における奥行マップである指定視点奥行マップを生成する奥行マップ射影手段、
前記指定視点奥行マップを用いて、前記復号化基準視点映像及び前記復号化残差映像を前記指定視点に射影した映像を合成して、前記指定視点における映像である指定視点映像を生成する射影映像合成手段、
として機能させる立体映像復号化プログラム。 - 前記基準視点映像ビットストリームは、所定の開始コードと1視点映像であることを識別する第1識別情報とをこの順で含むヘッダを有し、
前記奥行マップビットストリームは、前記開始コードと前記第1識別情報との間に、立体映像に関するデータであることを識別する第2識別情報と、前記奥行マップビットストリームであることを識別する第3識別情報とをこの順で含むヘッダを有し、
前記残差映像ビットストリームは、前記開始コードと前記第1識別情報との間に、前記第2識別情報と、前記残差映像ビットストリームであることを識別する第4識別情報とをこの順で含むヘッダを有し、
前記補助情報ビットストリームは、前記開始コードと、前記第2識別情報と、前記補助情報ビットストリームであることを識別する第5識別情報とをこの順で含むヘッダを有し、
前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、前記基準視点及び前記副視点の各位置を示す情報を含む補助情報を含むビットストリームと、が多重化された多重化ビットストリームを、前記基準視点映像ビットストリームと、前記奥行マップビットストリームと、前記残差映像ビットストリームと、前記補助情報と、に分離するビットストリーム分離手段として更に機能させ、
前記ビットストリーム分離手段は、
前記多重化ビットストリームから前記開始コードの直後に前記第1識別情報を有するビットストリームを前記基準視点映像ビットストリームとして分離し、分離した基準視点映像ビットストリームを前記基準視点映像復号化手段に出力し、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第3識別情報とをこの順で有するビットストリームを前記奥行マップビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第3識別情報を除去したビットストリームを前記奥行マップ復号化手段に出力し、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第4識別情報とをこの順で有するビットストリームを前記残差映像ビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第4識別情報を除去したビットストリームを前記残差映像復号化手段に出力し、
前記多重化ビットストリームから前記開始コードの直後に前記第2識別情報と前記第5識別情報とをこの順で有するビットストリームを前記補助情報ビットストリームとして分離し、当該ビットストリームから前記第2識別情報及び前記第5識別情報を除去したビットストリームを補助情報として前記射影映像合成手段に出力することを特徴とする請求項32に記載の立体映像復号化プログラム。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP12849923.3A EP2797327A4 (en) | 2011-11-14 | 2012-10-05 | STEREOSCOPIC VIDEO ENCODING DEVICE, STEREOSCOPIC VIDEO DECODING DEVICE, STEREOSCOPIC VIDEO ENCODING METHOD, STEREOSCOPIC VIDEO DECODING METHOD, STEREOSCOPIC VIDEO ENCODING PROGRAM, AND STEREOSCOPIC VIDEO DECODING PROGRAM |
| US14/358,194 US20140376635A1 (en) | 2011-11-14 | 2012-10-05 | Stereo scopic video coding device, steroscopic video decoding device, stereoscopic video coding method, stereoscopic video decoding method, stereoscopic video coding program, and stereoscopic video decoding program |
| KR1020147016038A KR20140092910A (ko) | 2011-11-14 | 2012-10-05 | 입체 영상 부호화 장치, 입체 영상 복호화 장치, 입체 영상 부호화 방법, 입체 영상 복호화 방법, 입체 영상 부호화 프로그램 및 입체 영상 복호화 프로그램 |
| JP2013544185A JP6095067B2 (ja) | 2011-11-14 | 2012-10-05 | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム |
| CN201280067042.6A CN104041024B (zh) | 2011-11-14 | 2012-10-05 | 立体影像编码装置、立体影像解码装置、立体影像编码方法、立体影像解码方法、立体影像编码程序以及立体影像解码程序 |
| TW101138183A TWI549475B (zh) | 2011-11-14 | 2012-10-17 | Dimensional image coding apparatus, stereoscopic image decoding apparatus, stereo image coding method, stereo image decoding method, stereo image coding program, and stereo image decoding program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011-248176 | 2011-11-14 | ||
| JP2011248176 | 2011-11-14 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013073316A1 true WO2013073316A1 (ja) | 2013-05-23 |
Family
ID=48429386
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2012/076045 WO2013073316A1 (ja) | 2011-11-14 | 2012-10-05 | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20140376635A1 (ja) |
| EP (1) | EP2797327A4 (ja) |
| JP (1) | JP6095067B2 (ja) |
| KR (1) | KR20140092910A (ja) |
| CN (1) | CN104041024B (ja) |
| TW (1) | TWI549475B (ja) |
| WO (1) | WO2013073316A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014106915A1 (ja) * | 2013-01-07 | 2014-07-10 | 独立行政法人情報通信研究機構 | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム |
| JP2014235615A (ja) * | 2013-06-03 | 2014-12-15 | 富士通株式会社 | 画像処理装置、画像処理回路、画像処理プログラム、及び画像処理方法 |
| JP2015091136A (ja) * | 2013-11-05 | 2015-05-11 | 三星電子株式会社Samsung Electronics Co.,Ltd. | 映像処理方法及び装置 |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9865083B2 (en) * | 2010-11-03 | 2018-01-09 | Industrial Technology Research Institute | Apparatus and method for inpainting three-dimensional stereoscopic image |
| JP2014082541A (ja) * | 2012-10-12 | 2014-05-08 | National Institute Of Information & Communication Technology | 互いに類似した情報を含む複数画像のデータサイズを低減する方法、プログラムおよび装置 |
| EP2959683A1 (en) * | 2013-05-14 | 2015-12-30 | Huawei Technologies Co., Ltd. | Method and apparatus for computing a synthesized picture |
| CN105556972B (zh) * | 2013-07-18 | 2019-04-05 | 三星电子株式会社 | 用于层间视频解码和编码设备和方法的对深度图像的场景内预测方法 |
| WO2015013851A1 (zh) * | 2013-07-29 | 2015-02-05 | 北京大学深圳研究生院 | 一种虚拟视点合成方法及系统 |
| KR102350235B1 (ko) * | 2014-11-25 | 2022-01-13 | 삼성전자주식회사 | 영상 처리 방법 및 장치 |
| EP3232677A4 (en) * | 2014-12-10 | 2018-05-02 | Nec Corporation | Video generating device, video output device, video output system, video generating method, video output method, video output system control method, and recording medium |
| EP3035688B1 (en) * | 2014-12-18 | 2019-07-31 | Dolby Laboratories Licensing Corporation | Encoding and decoding of 3d hdr images using a tapestry representation |
| US10567739B2 (en) * | 2016-04-22 | 2020-02-18 | Intel Corporation | Synthesis of transformed image views |
| EP4432669A2 (en) | 2016-10-04 | 2024-09-18 | B1 Institute of Image Technology, Inc. | Image data encoding/decoding method and apparatus |
| US12022199B2 (en) | 2016-10-06 | 2024-06-25 | B1 Institute Of Image Technology, Inc. | Image data encoding/decoding method and apparatus |
| EP3432581A1 (en) * | 2017-07-21 | 2019-01-23 | Thomson Licensing | Methods, devices and stream for encoding and decoding volumetric video |
| JP6980496B2 (ja) * | 2017-11-21 | 2021-12-15 | キヤノン株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| EP3499896A1 (en) * | 2017-12-18 | 2019-06-19 | Thomson Licensing | Method and apparatus for generating an image, and corresponding computer program product and non-transitory computer-readable carrier medium |
| EP3691277A1 (en) * | 2019-01-30 | 2020-08-05 | Ubimax GmbH | Computer-implemented method and system of augmenting a video stream of an environment |
| US12081719B2 (en) * | 2019-12-20 | 2024-09-03 | Interdigital Ce Patent Holdings, Sas | Method and apparatus for coding and decoding volumetric video with view-driven specularity |
| CN116710962A (zh) * | 2020-12-14 | 2023-09-05 | 浙江大学 | 图像填充方法及装置、解码方法及装置、电子设备及介质 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH10191396A (ja) * | 1996-12-26 | 1998-07-21 | Matsushita Electric Ind Co Ltd | 中間視点画像生成方法および視差推定方法および画像伝送方法 |
| JP2008263528A (ja) * | 2007-04-13 | 2008-10-30 | Univ Nagoya | 画像情報処理方法及び画像情報処理システム |
| JP2009212664A (ja) * | 2008-03-03 | 2009-09-17 | Nippon Telegr & Teleph Corp <Ntt> | 距離情報符号化方法,復号方法,符号化装置,復号装置,符号化プログラム,復号プログラムおよびコンピュータ読み取り可能な記録媒体 |
| JP2010157821A (ja) | 2008-12-26 | 2010-07-15 | Victor Co Of Japan Ltd | 画像符号化装置、画像符号化方法およびそのプログラム |
| JP2010534878A (ja) * | 2007-07-26 | 2010-11-11 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 深さ関連情報伝達のための方法及び装置 |
| US20110122230A1 (en) * | 2008-07-21 | 2011-05-26 | Thomson Licensing | Coding device for 3d video signals |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6163337A (en) * | 1996-04-05 | 2000-12-19 | Matsushita Electric Industrial Co., Ltd. | Multi-view point image transmission method and multi-view point image display method |
| KR100751422B1 (ko) * | 2002-12-27 | 2007-08-23 | 한국전자통신연구원 | 스테레오스코픽 비디오 부호화 및 복호화 방법, 부호화 및복호화 장치 |
| US7324594B2 (en) * | 2003-11-26 | 2008-01-29 | Mitsubishi Electric Research Laboratories, Inc. | Method for encoding and decoding free viewpoint videos |
| CN101453662B (zh) * | 2007-12-03 | 2012-04-04 | 华为技术有限公司 | 立体视频通信终端、系统及方法 |
| KR101468267B1 (ko) * | 2008-10-02 | 2014-12-15 | 프라운호퍼-게젤샤프트 추르 푀르데룽 데어 안제반텐 포르슝 에 파우 | 중간 뷰 합성 및 멀티-뷰 데이터 신호 추출 |
| US9648346B2 (en) * | 2009-06-25 | 2017-05-09 | Microsoft Technology Licensing, Llc | Multi-view video compression and streaming based on viewpoints of remote viewer |
| EP2499829B1 (en) * | 2009-10-14 | 2019-04-17 | Dolby International AB | Methods and devices for depth map processing |
| US8537200B2 (en) * | 2009-10-23 | 2013-09-17 | Qualcomm Incorporated | Depth map generation techniques for conversion of 2D video data to 3D video data |
| CN103828359B (zh) * | 2011-09-29 | 2016-06-22 | 杜比实验室特许公司 | 用于产生场景的视图的方法、编码系统以及解码系统 |
-
2012
- 2012-10-05 KR KR1020147016038A patent/KR20140092910A/ko not_active Application Discontinuation
- 2012-10-05 WO PCT/JP2012/076045 patent/WO2013073316A1/ja active Application Filing
- 2012-10-05 CN CN201280067042.6A patent/CN104041024B/zh not_active Expired - Fee Related
- 2012-10-05 US US14/358,194 patent/US20140376635A1/en not_active Abandoned
- 2012-10-05 EP EP12849923.3A patent/EP2797327A4/en not_active Withdrawn
- 2012-10-05 JP JP2013544185A patent/JP6095067B2/ja not_active Expired - Fee Related
- 2012-10-17 TW TW101138183A patent/TWI549475B/zh not_active IP Right Cessation
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH10191396A (ja) * | 1996-12-26 | 1998-07-21 | Matsushita Electric Ind Co Ltd | 中間視点画像生成方法および視差推定方法および画像伝送方法 |
| JP2008263528A (ja) * | 2007-04-13 | 2008-10-30 | Univ Nagoya | 画像情報処理方法及び画像情報処理システム |
| JP2010534878A (ja) * | 2007-07-26 | 2010-11-11 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 深さ関連情報伝達のための方法及び装置 |
| JP2009212664A (ja) * | 2008-03-03 | 2009-09-17 | Nippon Telegr & Teleph Corp <Ntt> | 距離情報符号化方法,復号方法,符号化装置,復号装置,符号化プログラム,復号プログラムおよびコンピュータ読み取り可能な記録媒体 |
| US20110122230A1 (en) * | 2008-07-21 | 2011-05-26 | Thomson Licensing | Coding device for 3d video signals |
| JP2010157821A (ja) | 2008-12-26 | 2010-07-15 | Victor Co Of Japan Ltd | 画像符号化装置、画像符号化方法およびそのプログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP2797327A4 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014106915A1 (ja) * | 2013-01-07 | 2014-07-10 | 独立行政法人情報通信研究機構 | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム |
| JP2014235615A (ja) * | 2013-06-03 | 2014-12-15 | 富士通株式会社 | 画像処理装置、画像処理回路、画像処理プログラム、及び画像処理方法 |
| JP2015091136A (ja) * | 2013-11-05 | 2015-05-11 | 三星電子株式会社Samsung Electronics Co.,Ltd. | 映像処理方法及び装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2013073316A1 (ja) | 2015-04-02 |
| EP2797327A4 (en) | 2015-11-18 |
| TWI549475B (zh) | 2016-09-11 |
| JP6095067B2 (ja) | 2017-03-15 |
| US20140376635A1 (en) | 2014-12-25 |
| EP2797327A1 (en) | 2014-10-29 |
| CN104041024A (zh) | 2014-09-10 |
| TW201322736A (zh) | 2013-06-01 |
| KR20140092910A (ko) | 2014-07-24 |
| CN104041024B (zh) | 2016-03-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6095067B2 (ja) | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム | |
| JP6150277B2 (ja) | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム | |
| US8422801B2 (en) | Image encoding method for stereoscopic rendering | |
| KR101468267B1 (ko) | 중간 뷰 합성 및 멀티-뷰 데이터 신호 추출 | |
| EP2235685B1 (en) | Image processor for overlaying a graphics object | |
| US10158838B2 (en) | Methods and arrangements for supporting view synthesis | |
| EP1501316A1 (en) | Multimedia information generation method and multimedia information reproduction device | |
| JP2012186781A (ja) | 画像処理装置および画像処理方法 | |
| US20140085435A1 (en) | Automatic conversion of a stereoscopic image in order to allow a simultaneous stereoscopic and monoscopic display of said image | |
| US8941718B2 (en) | 3D video processing apparatus and 3D video processing method | |
| TW201415864A (zh) | 用於產生、傳送及接收立體影像之方法,以及其相關裝置 | |
| JP2007312407A (ja) | 立体画像表示装置およびその方法 | |
| US20120050465A1 (en) | Image processing apparatus and method using 3D image format | |
| CN102447863A (zh) | 一种多视点立体视频字幕处理方法 | |
| JP2014132722A (ja) | 立体映像符号化装置、立体映像復号化装置、立体映像符号化方法、立体映像復号化方法、立体映像符号化プログラム及び立体映像復号化プログラム | |
| EP2547109A1 (en) | Automatic conversion in a 2D/3D compatible mode |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201280067042.6 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 12849923 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2013544185 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 20147016038 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14358194 Country of ref document: US |