WO2011052181A1 - ビット列キー分類・分配装置、分類・分配方法及びプログラム - Google Patents
ビット列キー分類・分配装置、分類・分配方法及びプログラム Download PDFInfo
- Publication number
- WO2011052181A1 WO2011052181A1 PCT/JP2010/006305 JP2010006305W WO2011052181A1 WO 2011052181 A1 WO2011052181 A1 WO 2011052181A1 JP 2010006305 W JP2010006305 W JP 2010006305W WO 2011052181 A1 WO2011052181 A1 WO 2011052181A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- key
- classification
- node
- link
- tree
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
- G06F16/316—Indexing structures
- G06F16/322—Trees
Definitions
- the present invention relates to a technique for classifying bit string keys to be classified and a technique for distributing the classified keys to output destinations.
- the basic merge sort method is to divide data into two pairs, rearrange them, and combine the rearranged ones.
- the processing is divided into a first-stage process for obtaining a plurality of sorted data by sorting while repeating the division of the data to be sorted, and a second-stage process for sorting the entire data to be sorted by repeatedly merging the sorted data.
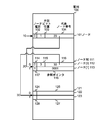
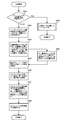
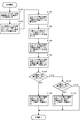
- Patent Document 2 discloses a process shown in FIG. 1 as a process subsequent to the merge sort.
- sorted data are stored in block 1 to block N, the minimum value of block 1 is 13, the minimum value of block 2 is 8, and the next largest data is 22. Is illustrated. Similarly, it is exemplified that the minimum value of the block 3 is 53, the minimum value of the block 4 is 24, and the minimum value of the block N is 9.
- merge sort is realized by taking out the minimum value from each block and generating a data string based on the minimum value of each block.
- merge sort is realized by taking out the minimum value from each block and generating a data string based on the minimum value of each block.
- Patent Document 3 an example stored in an array of a coupled node tree is disclosed in Patent Document 3 below.
- the reason why the coupled node tree is stored in the array is that the position of the node can be expressed by the array number, and the amount of position information indicating the position of the representative node can be reduced.
- Patent Document 4 there are a method for searching for the minimum and maximum values of an arbitrary subtree of a coupled node tree, and a method for extracting index keys from an arbitrary subtree of a coupled node tree in ascending or descending order. It is disclosed.
- a coupled node tree will be described with reference to FIGS. 2A and 2B as one of the background arts of the present invention.
- FIG. 2A is a diagram illustrating a configuration example of a coupled node tree stored in an array described in Patent Document 3.
- the node 101 is arranged in the array element with the array element number 10 in the array 100.
- the node 101 includes a node type 102, a discrimination bit position 103, and a representative node number 104.
- the value of the node type 102 is 0, indicating that the node 101 is a branch node. 1 is stored in the discrimination bit position 103.
- the representative node number 104 stores the array element number 20 of the representative node of the link destination node pair.
- the array element number stored in the representative node number may be referred to as a representative node number.
- the array element number stored in the representative node number may be represented by a code attached to the node or a code attached to the node pair.
- the node [0] 112 that is the representative node of the node pair 111 is stored in the array element of the array element number 20. Then, node [1] 113 paired with the representative node is stored in the next adjacent array element (array number 20 + 1).
- the node [0] 112 is a branch node like the node 101. 0 is stored in the node type 114 of the node [0] 112, 3 is stored in the discrimination bit position 115, and 30 is stored in the representative node number 116.
- the node [1] 113 includes a node type 117 and a reference pointer 118a.
- the node type 117 stores 1 and indicates that the node [1] 113 is a leaf node.
- the reference pointer 118a stores a pointer for referring to the index key storage area. In the following, for simplicity of description, data stored in the reference pointer is also referred to as a reference pointer.
- a representative node may be represented by a node [0] and a node paired therewith may be represented by a node [1].
- a node stored in an array element having a certain array number may be referred to as a node having the array number, and an array number of the array element in which the node is stored may be referred to as a node array number.
- index key corresponding to the leaf node in order to show the relationship between a certain leaf node and the index key stored in the storage area indicated by the reference pointer of the leaf node, it may be referred to as an index key corresponding to the leaf node, and the leaf node corresponding to the index key Sometimes it is.
- the 0 or 1 added to the array elements stored in the node [0] 112, the node [1] 113, the node 122, and the node 123 are linked to either node of the node pair when searching with the search key. It shows what to do.
- the search key bit value 0 or 1 at the discrimination bit position of the preceding branch node is linked to the node of the array element number obtained by adding the representative node number. Therefore, by adding the bit value of the discrimination bit position of the search key to the representative node number of the preceding branch node, the array element number of the array element storing the link destination node can be obtained.
- FIG. 2B is a diagram conceptually showing a tree structure of a coupled node tree and an example of an index key storage area.
- Reference numeral 410a indicates the root node of the coupled node tree 400 illustrated in FIG. 2B.
- the root node 410a is a representative node of the node pair 401a arranged in the array element number 420.
- a node pair 401b is arranged below the root node 410a
- a node pair 401c and a node pair 401f are arranged below it
- a node pair 401h and a node pair 401g are arranged below the node pair 401f.
- a node pair 401d is arranged below the node pair 401c, and a node pair 401e is arranged therebelow.
- the code 0 or 1 added before each node is the same as the code assigned before the array element described in FIG. 2A.
- the tree is traced according to the bit value of the discrimination bit position of the search key, and the leaf node corresponding to the index key to be searched is found.
- the node type 460a of the root node 410a is 0, indicating that it is a branch node, and the discrimination bit position 430a indicates 0.
- the representative node number is 420a, which is the array element number of the array element stored in the representative node 410b of the node pair 401b.
- the node pair 401b is composed of nodes 410b and 411b, and their node types 460b and 461b are both 0, indicating that they are branch nodes. 1 is stored in the discrimination bit position 430b of the node 410b, and the array element number 420b of the array element stored in the representative node 410c of the node pair 401c is stored in the representative node number of the link destination.
- this node is a leaf node, and therefore includes the reference pointer 450c.
- the reference pointer 450c stores a pointer that refers to the storage area in which the index key 270c is stored. Data stored in the reference pointer 450c is also referred to as a reference pointer and is represented by reference numeral 480c. Similarly in other leaf nodes, the reference pointer and the data stored in the reference pointer are represented by the same reference pointer. In the area pointed to by the reference pointer 480c of the index key storage area 311 illustrated in FIG. 2B, “000111” is stored as the index key 270c.
- the node type 461c of the other node 411c of the node pair 401c is 0, the discrimination bit position 431c is 2, and the array element number 421c of the array element stored in the representative node 410d of the node pair 401d is stored in the representative node number. ing.
- the node type 460d of the node 410d is 0, the discrimination bit position 430d is 5, and the array element number 420d of the array element in which the representative node 410e of the node pair 401e is stored is stored in the representative node number.
- the node type 461d of the node 411d paired with the node 410d is 1, and the reference pointer 451d stores a reference pointer 481d indicating the storage area in which the index key 271d of “011010” is stored.
- the node types 460e and 461e of the nodes 410e and 411e of the node pair 401e are both 1, indicating that both are leaf nodes.
- Reference pointers 450e and 451e of the nodes 410e and 411e respectively store reference pointers 480e and 481e to the storage areas storing the index key 270e having the value "010010" and the index key 271e having the value "010011". Yes.
- the node types 460f and 461f of the nodes 410f and 411f of the node pair 401f are both 0, and both are branch nodes.
- 5 and 3 are stored in the discrimination bit positions 430f and 431f, respectively.
- the array node number 420f of the array element in which the representative node 410g of the node pair 401g is stored is stored in the representative node number of the node 410f, and the node [0] 410h that is the representative node of the node pair 401h is stored in the representative node number of the node 411f.
- the array element number 421f of the stored array element is stored.
- the node types 460g and 461g of the nodes 410g and 411g of the node pair 401g are both 1, indicating that both are leaf nodes.
- Reference pointers 480g and 481g to storage areas storing index keys 270g and 271g having values "100010" and "1000011” are stored in the reference pointers 450g and 451g of the nodes 410g and 411g, respectively.
- the node types 460h and 461h of the node [0] 410h which is the representative node of the node pair 401h, and the node [1] 411h paired with the node [0] 410h are both 1, indicating that both are leaf nodes.
- the discrimination bit positions are 0, 1, 2,... From the left.
- processing is started from the root node 410a using the bit string “100010” as a search key. Since the discrimination bit position 430a of the root node 410a is 0, the bit value of 0 when the discrimination bit position of the search key “100010” is 0 is 1. Therefore, the node is linked to the node 411b stored in the array element having the array element number obtained by adding 1 to the array element number 420a storing the representative node number.
- the discrimination bit position of the search key “100010” is 0 when the bit value of 2 is viewed. Therefore, the array number 421b in which the representative node number is stored Link to the node 410f stored in the array element.
- the discrimination bit position of the search key “100010” is 0 when the bit value of 5 is viewed, so that the array number 420f in which the representative node number is stored is Link to the node 410g stored in the array element.
- the storage area indicated by the reference pointer 480g is referred to, and the index key 270g stored therein is read and compared with the search key. Then, the values of both the index key 270g and the search key are “100010” and match. In this way, a search using a coupled node tree is performed.
- Patent Document 3 discloses an index key classification method in which one index key is included in a block.
- a method for classifying an index key having a plurality of index keys in a block which is a premise of the subsequent processing of the merge sort.
- the problem to be solved by the present invention is that when classifying data consisting of bit strings (hereinafter, sometimes referred to as a bit string key or simply as a key, and sometimes referred to as an index key) into a plurality of blocks. And a technique for distributing a bit string key classified to an output destination by applying a coupled node tree technique.
- bit strings hereinafter, sometimes referred to as a bit string key or simply as a key, and sometimes referred to as an index key
- a key is sequentially selected as a classification key from a key storage means for storing a classification target key, and a classification tree using a coupled node tree is generated by the classification key.
- the leaf nodes are associated with keys classified into N blocks.
- the number of stages of the classification tree is limited according to the number N of blocks.
- the leaf node of the classification tree includes key access information used to acquire position information of the classification key stored in the key storage means.
- a key position search table for acquiring key position information is generated using the key access information.
- leaf nodes are sequentially extracted from the classification tree generated by all the keys to be classified, and correspond to the leaf nodes from the key position search table using the key access information read from the leaf nodes.
- the position information of the keys classified into blocks is obtained, and the keys are read from the key storage means and output to the output destination.
- the upper bit value up to the discrimination bit position of the nearest upper branch node of a leaf node matches in any key classified in the same block, and the branch node immediately higher than the leaf node Keys having different bit values up to the discrimination bit position are classified into other blocks. Therefore, according to the present invention, by generating a classification tree having a coupled node tree structure, keys can be efficiently classified so that there is no overlap in the range of key values to be classified.
- FIG. 3 is a diagram conceptually showing a tree structure of a classification tree according to an embodiment of the present invention and explaining an index key management area. It is a figure explaining the state before inserting classification key "010011”. It is a figure explaining the state after inserting classification key "010011" and before inserting classification key "010010".
- FIG. 1 It is a figure which shows the example of a processing flow which connects the classification key in one embodiment of this invention with the key link table of a leaf node. It is a figure explaining the example of a processing flow which searches the classification tree in one embodiment of this invention, and connects a classification key to the key link table of a leaf node. It is a figure explaining the example of a processing flow which searches the node containing the minimum value of the index key in one embodiment of this invention. It is a figure explaining the example of a processing flow which connects the classification reference pointer of the node pair of the leaf node in one embodiment of this invention.
- FIG. 3 is a diagram for explaining the concept of classification processing according to an embodiment of the present invention.
- the example illustrated in FIG. 3 classifies keys into four blocks. Therefore, the classification tree has two levels.
- FIG. 3 shows a key string 110 including keys to be classified.
- the key “1111” exists in the storage area where the key position, which is the key position where the key included in the key string 110 exists, is 110a (hereinafter referred to as the key position 110a).
- the key positions 110b, 110c, 110d, and 110e have keys “0011”, “1010”, and “0001”, respectively. , “1110” exists.
- the classification is performed according to the classification by the discrimination bit position (classification of 2 stages) 140. Is done. Even if it is classified into three blocks, it is classified into four blocks after being classified into four blocks by classification by classification bit position (classification of 2 stages) 140, and is classified into one block Therefore, even if the number of blocks is 2 to the power of n, generality is not lost.
- the discrimination bit position 142a used for classification in the classification 141a by the discrimination bit position of the first stage of the classification by the discrimination bit position (classification of 2 stages) 140 is 0.
- those with a bit value 143a of 0 at bit position 0 are further classified by the classification 141b according to the discrimination bit position in the second stage, as indicated by the dotted arrow set 150a.
- the one with the bit value 143a of the bit position 0 being 1 is further classified by the classification 141c based on the discrimination bit position of the second stage as indicated by the dotted arrow set 151a.
- the discrimination bit position 142b used for classification in the classification 141b based on the discrimination bit position in the second stage is 2.
- the index key “0001” having the bit value 143b of the bit position 2 of 0 is classified as indicated by the dotted arrow 150b.
- the classified key 131a is stored in the key column 130a.
- the index key “0011” having the bit value 143b of the bit position 2 of 1 is indicated by the dotted arrow 151b.
- the classified key column 130b stores the classified key 131b.
- the discrimination bit position 142c used for classification in the classification 141c based on the discrimination bit position in the second stage is 1.
- the index key “1010” in which the bit value 143c at the bit position 1 is 0 is classified as indicated by the dotted arrow 150c.
- the classified key 131c is stored in the key column 130c.
- the classification keys “1111” and “1110” having the bit value 143c of 1 in the bit position 1 are a group of dotted arrows.
- the classified key column 130d stores the classified keys 131d and 131e, respectively.
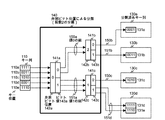
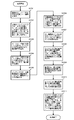
- FIG. 4 is a diagram illustrating a hardware configuration example for the present embodiment.
- FIG. 4 shows an example of a system in which a bit string key classification / distribution device 300 is connected to bit string key sorting devices 340a, 340b,..., 340m via a network 347.
- the distribution destination of the bit string keys classified by the bit string key classification / distribution device 300 is a bit string key sort device, which is one example, and can be applied to other applications such as tabulation processing. Further, the distribution destination device is not limited to one connected via a network, and may be a central processing unit of a multiprocessor system, for example.
- the key classification according to the present embodiment is performed by the data processing device 301 including at least the central processing unit 302 and the cache memory 303 using the data storage device 308.
- the distribution of the classified keys to the exemplified bit string sorting devices 340a, 340b,..., 340m is also performed by the data processing device 301 using the data storage device 308.
- the data storage device 308 having the index key management area 320 for storing the data for searching the position information of the keys classified into each block can be realized by the main storage device 305 or the external storage device 306.
- the bit string sorting devices 340a, 340b,..., 340m sort the distributed classified keys in parallel.
- a configuration example of the bit string sorting device 340a is shown.
- the bit string sorting is performed by a data processing device 301 a including at least a central processing unit 302 and a cache memory 303 using a data storage device 308 a.
- the data storage device 308a having the array 309a and the index key storage area 310a can be realized by the main storage device 305a or the external storage device 306a.
- the main storage device 305, the external storage device 306, and the communication device 307 of the bit string classification / distribution device 300 are connected to the data processing device 301 by one bus 304, but the connection method is limited to this. It is not a thing.
- the main storage device 305 can be in the data processing device 301, and the search path stack 310 can be realized as hardware in the central processing unit 302.
- the index key storage area 311 has the external storage device 306, the search path stack 310 and the index key management area 320 in the main storage device 305, etc., depending on the usable hardware environment, the size of the index key set, etc. It will be apparent that the hardware configuration can be selected accordingly.
- a temporary storage area of the main storage device 305 corresponding to each process is used in order to use various values, initial setting values, and the like obtained during the process in later processes. It is natural. The same applies to the connection method of each device and the configuration of the data storage device in the bit string sorting devices 340a, 340b,.
- FIG. 5 is a diagram conceptually showing a tree structure of a classification tree according to an embodiment of the present invention and explaining an index key management area.
- the classification tree 200 illustrated in FIG. 5 is for classifying the index key stored in the index key storage area 311 illustrated in FIG. 2B into four blocks.
- a key classification table 321 and a key link table 322 are stored in the index key management area 320 shown in FIG.
- the key classification table 321 and the key link table constitute an example of the key position search table described above, and the classification reference pointer pointing to the entry of the key classification table 321 is an example of the key access information described above.
- Reference numerals such as 270h described in the index key management area 320 in FIG. 5 indicate index keys “101011” indicated by reference numerals such as 270h described in the index key storage area 311 in FIG. 2B.
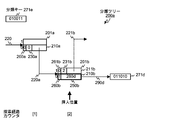
- Reference numeral 210a indicates the root node of the classification tree 200 illustrated in FIG.
- the root node 210a is a representative node of the node pair 201a arranged at the array element number 220.
- a node pair 201b is arranged below the root node 210a, and a node pair 201c and a node pair 201f are arranged below it.
- the node type 260a of the root node 210a is 0, indicating that it is a branch node, and the discrimination bit position 230a indicates 0.
- the representative node number is 220a, which is the array element number of the array element stored in the representative node 210b of the node pair 201b.
- the node pair 201b is composed of nodes 210b and 211b, and the node types 260b and 261b are both 0, indicating that they are branch nodes. 1 is stored in the discrimination bit position 230b of the node 210b, and the array element number 220b of the array element stored in the representative node 210c of the node pair 201c is stored in the link representative node number.
- this node is a leaf node.
- the leaf node of the classification tree includes a classification reference pointer 250c.
- the classification reference pointer 250c stores a pointer that points to an entry in the key classification table included in the index key management area 320.
- Data stored in the classification reference pointer 250c is also referred to as a classification reference pointer and is represented by reference numeral 280c.
- the data stored in the classification reference pointer and the classification reference pointer are represented by the same classification reference pointer.
- a classification reference pointer 280e is stored in the classification reference pointer 251c of the node 211c.
- the element array number 221b is stored.
- the node types 260f and 261f of the node [0] 210f, which is the representative node of the node pair 201f, and the node [1] 211f paired therewith are both 1, and both are leaf nodes.
- Classification reference pointers 280g and 280h are stored in the classification reference pointers 250f and 251f of the nodes 210f and 211f, respectively.
- a classification tree 200 for classifying a classification key into four blocks includes a root node 210a that is a first-stage branch node, a node 210b and a node 211b that are second-stage branch nodes, and As the third-stage nodes, four leaf nodes 210c, 211c, 210f, and 211f corresponding to the respective blocks are included.
- an index key classified into a block corresponding to a leaf node may be referred to as an index key included in the leaf node.
- the index key management area 320 includes a key classification table 321 and a key link table 322.
- the storage status of each data in the index key management area 320 shown in FIG. 5 is obtained when all index keys stored in the index key storage area 311 shown in FIG. 2B are classified into four blocks.
- the key classification table 321 has four entries corresponding to the number of blocks for classifying index keys.
- the head address of each entry is indicated by the classification reference pointers 280c, 280e, 280g, and 280h of the four leaf nodes 210c, 211c, 210f, and 211f of the classification tree 200, respectively.
- the key classification table 321 includes a minimum value key 312a, a maximum value key 312b, a key output destination 312e, a head link 312c, and a tail link 312d in each entry.
- a key management pointer 370c indicating an entry in the key link table 322 is stored in both the head link 312c and the end link 312d of the entry indicated by the classification reference pointer 280c.
- a key management pointer 370e and a key management pointer 371d are stored in the first link 312c and the last link 312d of the entry indicated by the classification reference pointer 280e, respectively.
- a key management pointer 370g and a key management pointer 371g are stored in the first link 312c and the last link 312d of the entry indicated by the classification reference pointer 280g, respectively.
- a key management pointer 370h and a key management pointer 371h are stored in the first link 312c and the last link 312d of the entry indicated by the classification reference pointer 280h, respectively.
- Description of values stored in the minimum value key 312a, the maximum value key 312b, and the key output destination 312e is omitted. The values of the minimum value key 312a and the maximum value key 312b are written and updated while the classification tree 200 is generated, but the key output destination 312e is written after the generation of the classification tree is completed. Note that the output destination of the key can be set to correspond to the block for classifying the classification target key separately from the key classification table.
- the key link table 322 is used to write a link relationship between index keys for sequentially tracing index keys associated with the same leaf node, and entries corresponding to the number of index keys to be classified are stored. Have. For example, if the index key storage area is shown in FIG. 2B, it has eight entries. The head address of each entry is indicated by key management pointers 370c, 370e, 371e, 371d, 370g, 371g, 370h, 371h, and index keys 270c, 270e, 271e, 271d, 270g, 271g, 270h, 271h, respectively. It is associated.
- the key link table 322 includes a key reference pointer 313a and a link 313b in each entry.
- the key reference pointer 313a indicates an index key storage area associated with a key management pointer indicating the entry. Therefore, if the storage area of the index is as shown in FIG. 2B, the key reference pointer 313a of the key link table 322 pointed to by the key management pointer 370c, 370e, 371e, 371d, 370g, 371g, 370h, 371h has a reference pointer.
- 480c, 480e, 481e, 481d, 480g, 481g, 480h, and 481h are stored, but the key reference pointer 313a is not shown in FIG.
- the link 313b of the key link table 322 pointed to by the key management pointer stores a key management pointer associated with an index key classified into the same block as the index key associated with the key management pointer.
- the index key 270h associated with the key management pointer 370h and the index key 271h associated with the key management pointer 371h are classified into blocks corresponding to the classification reference pointer 280h.
- a key management pointer 371h is stored in the link 313b of the key link table 322 pointed to by the key management pointer 370h which is the first link 312c of the block.
- the key management pointer 371h associated with the index key 271h is stored in the end link of the key classification table 321. Since the index key 271h is the index key at the end of the block, the link of the key link table 322 pointed to by the key management pointer 371h. Nothing is stored in 313b.
- the index key 270g associated with the key management pointer 370g and the index key 271g associated with the key management pointer 371g are classified into blocks corresponding to the classification reference pointer 280g.
- a key management pointer 371g is stored in the link 313b of the key link table 322 pointed to by the key management pointer 370g associated with the index key 270g which is the top link 312c of the block. Since the key management pointer 371g associated with the index key 271g is stored in the end link of the key classification table 321, and the index key 271g is the index key at the end of the block, there is nothing in the link 313b pointed to by the key management pointer 371g. Also not stored.
- the index key 270e associated with the key management pointer 370e, the index key 271e associated with the key management pointer 371e, and the index key 271d associated with the key management pointer 371d are in the block corresponding to the classification reference pointer 280e. It is classified.
- a key management pointer 371e is stored in the link 313b of the key link table 322 pointed to by the key management pointer 370e associated with the index key 270e which is the top link 312c of the block.
- a key management pointer 371d is stored in the link 313b of the key link table 322 pointed to by the key management pointer 371e.
- the key management pointer 371d associated with the index key 271d is stored in the tail link of the key classification table 321. Since the index key 271d is the index key at the end of the block, the key link table 322 pointed to by the key management pointer 371d. Nothing is stored in the link 313b.
- the index key 270c associated with the key management pointer 370c is classified into blocks corresponding to the classification reference pointer 280c. Since the key management pointer 370c associated with the index key 270c is stored in both the start link 312c and the end link 312d of the key classification table 321 pointed to by the classification reference pointer 280c, the blocks are classified into blocks corresponding to the classification reference pointer 280c. The only index key that is being used is the index key 270c. Therefore, nothing is stored in the link 313b of the key link table 322 pointed to by the key management pointer 370c.
- associating an index key with a leaf node is sometimes referred to as linking the index key to the key link table of the leaf node. Also, a leaf node associated with an index key may be referred to as a leaf node that is linked to the index key.
- All the index keys of the block corresponding to the classification reference pointer of the key classification table 321 can be extracted as follows. First, the key reference pointer 313a is read using the head link 312c pointed to by the classification reference pointer as the key management pointer of the key link table 322, and the index key pointed to by the key reference pointer 313a is taken out from the index key storage area. Next, the key reference pointer 313a is read using the link 313b as the key management pointer of the key link table 322, and the index key pointed to by the key reference pointer 313a is taken out from the index key storage area. The link 313b is the last link 312d of the key classification table 321. Repeat until
- the description of the portion of the hierarchy below the node 211b in the classification tree 200 is omitted. Further, it is assumed that the index key 271d “011010” has already been classified into blocks corresponding to the leaf node 210b, that is, linked to the key link table of the leaf node 210b.
- an index key read from an index key storage area and subject to classification processing may be referred to as a classification key. Also, classifying a classification key into blocks corresponding to leaf nodes by a classification tree, that is, connecting to a key link table of a leaf node may insert a classification key into the classification tree.
- the classification key is set to an existing leaf node.
- a parent node that is the nearest higher node of a node pair composed of existing leaf nodes is used as a leaf node, and a classification key is linked to the key link table of the leaf node.
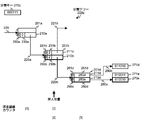
- FIG. 6A is a diagram illustrating the classification tree 200a that is in a state before the classification key 270e “010011” is inserted.
- the classification tree 200a shown in FIG. 6A is obtained by replacing the node 210b of the classification tree 200 shown in FIG. 5 with a leaf node, and the classification reference pointer 280d is stored in the classification reference pointer 250b.
- description of nodes lower than the node 211b is omitted.
- the omission of the description of the lower nodes is the same in FIGS. 6B to 6E.
- the index key 271d “011010” stored in the index key storage area 311 is associated with the leaf node 210b via the index key management area 320 by the classification reference pointer 280d. ing. In other words, the index key 271d is linked to the key link table of the leaf node 210b.
- FIG. 6A shows a classification key 271e “010011” as a classification key to be inserted and its insertion position.
- the count value of the searched route counter is described.
- the count value of the search path counter can insert a node pair including a leaf node connected to the classification key into the classification tree while satisfying the limitation on the number of stages of the classification tree when the classification key is inserted into the classification tree. It is used for the judgment.
- the count value of the searched route counter is counted up, for example, with an initial value of 0, and assumes a value of 1 at the root node as shown in FIG. 6A.
- the node pair including the leaf node connected to the classification key is also satisfied while satisfying the restriction on the number of stages in the classification tree. Obviously, it can be determined whether it can be inserted into the classification tree.
- the search by the inserted classification key 271e is performed.
- the leaf node 210b is obtained.
- the value of the searched route counter is 2 at the leaf node 210b.
- a difference bit position that is a bit position that first becomes a different bit value when viewed from the upper bit position of the index key 271d “011010” linked to the key link table of the classification key 271e “010011” and the leaf node 210b, and a branch node
- the classification key 271e is inserted below the leaf node 210b according to the relative positional relationship of the discrimination bit position of 210a. Therefore, the insertion position of the classification key 271e is the node 210b as shown in the figure. Since the maximum number of stages of the classification tree is 3 and the count value of the search path counter is 2, the number of stages is satisfied. Therefore, the node pair including the leaf node connected to the inserted classification key 271e is assigned to the lower level of the node 210b. Can be inserted.
- FIG. 6B is a diagram for explaining the classification tree 200b in a state after the classification key 271e “010011” is inserted and before the classification key 270e “010010” is inserted.
- the node pair 201d including the leaf node connected to the classification key 271e “010011” is inserted below the node 210b.
- the node 210b which is a leaf node is a branch node, and the difference bit position 2 between the index key 271d and the classification key 271e is stored in the discrimination bit position.
- the representative node number 220b of the node 210b is the array element number of the array element in which the representative node 210d of the inserted node pair 201d is arranged.
- the leaf node connected to the classification key 271d is the node 211d which is the node [1] of the node pair 201d.
- the contents of the node 210b shown in FIG. 6A are copied to the node 211d in FIG. 6B.
- the node 210d which is the node [0] of the node pair 201d, becomes a leaf node connected to the classification key 271e.
- the classification reference pointer 280e is stored in the classification reference pointer 250d.
- the classification key 271e “010011” stored in the index key storage area 311 is associated with the leaf node 210d via the index key management area 320 by the classification reference pointer 280e. Yes. That is, the classification key 271e “010011” is classified into the leaf node 210d.
- the classification key 270e “010010” is described as the classification key to be inserted next, and the node 210d is shown as the insertion position of the classification key 270e.
- the count value of the searched route counter is displayed as 3 which is the maximum number of stages in the leaf node 210d. Therefore, a node pair including a leaf node connected to the classification key 270e cannot be inserted below the node 210d due to the stage number limitation.
- FIG. 6C is a diagram for explaining the classification tree 200c in a state after the classification key 270e “010010” is inserted and before the classification key 270c “000111” is inserted.
- the classification key 270e “010010” is set as indicated by a dotted arrow 290e in FIG. 6C.
- the index key 271e “010011” it is linked to the key link table of the leaf node 210d at the insertion position shown in FIG. 6B. This process will be described in detail later, but is performed by writing the key classification table 321 and the key link table 322 in the index key management area 320.
- the classification key 270c “000111” is described as the classification key to be inserted next, and the node 210b is shown as the insertion position of the classification key 270c.
- the count value of the searched route counter is displayed in two stages. The count value displayed in the upper stage is counted when the insertion position is obtained, and corresponds to the node 210b that is the second insertion position from the count value 1 corresponding to the root node 210a in the first stage. The count value is counted up to 2.
- the count value displayed in the lower row is counted when the node 210b that is the insertion position is used as a search start node, and leaf nodes in a hierarchy lower than the node 210b are sequentially searched to obtain the number of leaf nodes.
- the count value 2 corresponding to the search start node 210b is counted up to the count value 3 corresponding to the third leaf node 210d.
- the number of stages of the leaf node 210d becomes 4. Therefore, since the limit on the number of stages is exceeded, a node pair including a leaf node connected to the classification key 270c cannot be inserted below the node 210b.
- FIG. 6D is a diagram for explaining the classification tree 200d in a state where the index key linked to the key link table of the leaf node at the lower position of the insertion position for inserting the node pair is linked to the key link table of the leaf node at the insertion position. is there.
- a node pair cannot be inserted below the node 210b that is the insertion position of the classification tree 200c shown in FIG. 6C. Therefore, according to the present invention, a parent node of two leaf nodes (child nodes) constituting a node pair is a leaf node, and the key link table of the leaf node that is the parent node is added to the key link table of the two child nodes.
- index keys to be connected hereinafter, sometimes referred to as integrating the leaf nodes at the lower position of the insertion position or integrating the leaf nodes
- the number of classification tree stages is reduced and inserted. Allows insertion of a node pair containing leaf nodes concatenated with a classification key.
- the node 210b of the classification tree 200d is a node that is the upper branch node of the node pair 201d composed of the leaf node 210d and the leaf node 211d, with the contents of the leaf node 210d of the classification tree 200c shown in FIG. 6C. It is written in 210b. Then, as indicated by the dotted arrow 290e in FIG. 6D, the index key 270e “010010”, the index key 271e “010011”, and the index key 271d “011010” are connected to the key link table of the leaf node 210b shown in FIG. 6D. .
- the classification key 270c “000111” is described as the classification key to be inserted next, and the node 210b is shown as the insertion position of the classification key 270c. Further, the lower count value of the search path counter in the leaf node 210b is decreased by 1 and displayed as 2. Therefore, the number of stages of the classification tree 200d is reduced by 1, and a node pair including a leaf node connected to the classification key 270c can be inserted below the node 210b of the classification tree 200d.
- FIG. 6E is a diagram for explaining the state of the classification tree 200e in which the classification key 270c “000111” is inserted into the classification tree 200d after the lower leaf nodes at the insertion position are integrated.
- the node pair 201c including the leaf node connected to the classification key 270c “000111” is inserted below the node 210b.
- the node 210b which is a leaf node is a branch node, and the difference bit position 1 between the classification key 270c and the index key 270e is stored in the discrimination bit position.
- the representative node number 220b of the node 210b is the array element number of the array element in which the representative node 210c of the inserted node pair 201c is arranged.
- the leaf node connected to the classification key 270c is the node 210c that is the node [0] of the node pair 201c.
- the classification reference pointer 280c is stored in the classification reference pointer 250c.
- the classification key 270c “000111” stored in the index key storage area 311 is associated with the leaf node 210c via the index key management area 320 by the classification reference pointer 280c. Yes. That is, the classification key 270c “000111” is classified into the leaf node 210c.
- FIG. 6E the contents of the node 210b shown in FIG. 6D are copied to the node 211c in FIG. 6E. According to the flow described above, the classification tree 200 shown in FIG. 5 is generated.
- FIG. 7A and FIG. 7B an overview of the overall processing of index key classification processing and distribution processing for outputting classified classified keys to an output destination according to an embodiment of the present invention will be described. To do.
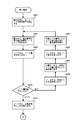
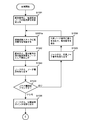
- FIG. 7A is a diagram showing a processing flow example of classification processing in one embodiment of the present invention.
- a classification tree is generated based on the classification key, and data is written into the index key management area to classify the index key to be classified in association with the leaf node of the classification tree.
- a classification tree is generated using a classification key, and writing data to the index key management area is sometimes simply referred to as generating a classification tree.
- step S701 the maximum number of stages of the classification tree is acquired.
- the acquisition of the maximum number of stages may be to directly acquire the maximum number of stages, or may be determined from the number of blocks for classifying the classification target keys. As described above, for example, when the number of blocks is 8, the maximum number of stages is 4, and a value obtained by adding 1 to the power of the minimum power of 2 that is not smaller than the number of blocks is set as the maximum number of stages. it can.
- step S701a the storage position of the first key in the index key storage area is set in the key reference pointer of the index key storage area.
- the key reference pointer in the index key storage area is not particularly shown in the figure, but various values are set in the middle of processing, and the set values are used in later processing. This is one of the temporary storage areas.
- step S702 it is determined whether all the keys to be classified have been processed. If processed, the process proceeds to step S711 and subsequent steps shown in FIG. 7B via step S706. The process proceeds to S703.
- step S703 the key pointed to by the key reference pointer is read from the index key storage area and set as a classification key.
- step S704 a classification tree is generated using the classification key. Details of the classification tree generation processing in step S704 will be described later with reference to FIGS. 8 and 9A to 9C.
- step S705 the storage position of the next key stored in the index key storage area is set in the key reference pointer of the index key storage area, and the flow returns to step S702.
- the loop process from step S702 to step S705 is repeated until it is determined in step S702 that all keys have been processed, and the classification process in which all keys are determined to have been processed in step S702 is terminated.
- the key output destination is set as the key output destination in the key classification table, and the flow proceeds to the distribution processing in step S711 and subsequent steps shown in FIG. 7B.
- FIG. 7B is a diagram showing an example of a processing flow of distribution processing in one embodiment of the present invention.
- the classification key classified for each block is read out based on the data in the index key management area written in the classification process, and is output to the output destination.
- step S711 the array element number of the root node of the classification tree is set as the array element number of the search start node.
- step S712 the end number is stored as the first array number stored in the search path stack that stores the array element number of the array element where the node traced in the search process is stored. This end number only needs to be distinguishable from the array number of the array element storing the node to be traced in the search process.
- step S714 an array is searched from the search start node, a leaf node including the minimum value of the index key is obtained, and index keys linked to the key link table of the leaf node are sequentially extracted. Details of the processing in step S714 will be described later with reference to FIGS. 15A and 15B.
- step S718 the array element number is extracted from the search path stack, the stack pointer of the search path stack is decremented by 1, and the process proceeds to step S719.
- step S719 it is determined whether the array element number extracted in step S718 is a terminal number. If it is determined that the terminal number is the terminal number, the process is terminated. If the terminal number is not the terminal number, the process proceeds to step S721.
- step S721 the node position of which array element of the node pair is stored in the array number is obtained from the array element number extracted in step S718.
- the node position can be obtained from the array number by storing the node [0] in the array element of the even-numbered array.
- step S722 it is determined whether or not the node position obtained in step S721 is on the node [1] side. If it is determined in step S722 that the node is [1], the process returns to step S718.
- step S722 If it is determined in step S722 that the node is [0] side, the process proceeds to step S723, and 1 is added to the array element number to obtain the array element number of the node [1] paired with that node.
- step S724 the array element number of node [1] obtained in step S723 is set in the array element number of the search start node, and the process returns to step S714.
- step S714 to step S724 described above is repeated while the stack pointer of the search path stack is decremented by 1 in step S718 until it is determined in step S719 that the array element number extracted from the search path stack is the end number. If the array element number extracted from the search path stack is the terminal number, the processing is completed because the processing has been completed for all leaf nodes of the classification tree.
- the process of extracting the classification key stored in the classification tree shown in FIG. 7B is the process of extracting index keys in ascending order from the coupled node tree disclosed in FIG. , Sometimes referred to as the processing of the prior invention).
- leaf nodes are obtained in ascending order.
- the keys classified into the respective blocks can be extracted by obtaining them in descending order.
- there is one index key linked to the leaf node whereas in the present invention, there can be a plurality of index keys linked to the key link table of the leaf node. This is essentially different in that the index keys linked to the link table are sequentially extracted.
- FIG. 8 is a diagram for explaining an example of the entire processing flow for generating a classification tree using a classification key according to an embodiment of the present invention.
- the classification key is set in the temporary storage area in step S703 shown in FIG. 7A.
- step S801 it is determined whether or not the root node array number has been registered. If the array number of the root node has not been registered, the process proceeds to step S802 and subsequent steps, and a new classification tree is generated with the leaf node connected to the classification key set in the temporary storage area as the root node.
- step S802 the index reference management area classification reference pointer and key management pointer are acquired.
- the classification reference pointer and key management pointer acquired here set the index key management area 320 on the data storage device 308, and determine the addresses of the key classification table entry and the key link table entry to be used first. Is obtained.
- step S803 the key management pointer is written in the first link and the end link of the key classification table pointed to by the classification reference pointer, and the classification key is written in the minimum value key and the maximum value key.
- step S804 the key indicated by the key management pointer is written.
- the key reference pointer used for reading the key in step S703 of FIG. 7A is written into the key reference pointer of the link table.
- the classification key to be processed first is the classification key 271d illustrated in FIG. 2B, the classification pointer pointing to the entry used first in the key classification table 321 shown in FIG.
- the entry used first in the key link table 322 If the key management pointer pointing to 371d is 371d, the classification key 271d is assigned to the minimum value key 312a and the maximum value key 312b of the key classification table 321 pointed to by the classification pointer 280d, and the key management pointer 371d is assigned to the start link 312c and the end link 312d.
- the reference pointer 481d shown in FIG. 2B is written to the key reference pointer 313a of the key link table 322 pointed to by the key management pointer 371d.
- step S805 an empty node pair is obtained from the array, and the array element number of the array element to be the representative node is acquired from the node pair.
- step S806 0 is added to the array number obtained in step S805. Determine the sequence number. (In actuality, it is equal to the array element number acquired in step S805).
- step S807 1 (leaf node) is written in the node type of the root node to be inserted and the classification reference pointer obtained in step S802 is written in the classification reference pointer in the array element having the array number obtained in step S806.
- step S808 The array element number of the root node acquired in step S805 is registered, and the process ends. If the above-described classification key to be processed first is the key 271d, the leaf node 210b shown in FIG. 6A is the classification key generated first. Although the entry pointed to by the classification reference pointer 280d is not described in the key classification table shown in FIG. 5, in the process of sequentially inserting the classification key, the entry of the key classification table that was originally used is another entry. May not be used in combination.
- step S801 determines whether the array element number of the root node has been registered. If it is determined in step S801 that the array element number of the root node has been registered, the process proceeds to step S809, and a new classification tree is created by inserting a classification key into the classification tree in which the root node has been registered. Generate and finish the process. Details of the processing in step S809 will be described next with reference to FIGS. 9A to 9C.
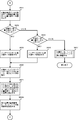
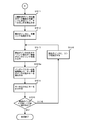
- FIG. 9A is a diagram showing an example of a processing flow at the first stage of processing for inserting a classification key into a classification tree according to an embodiment of the present invention.
- This first-stage process is a search process for obtaining a leaf node using the root node of the classification tree as a search start node and the classification key as a search key.
- the count value of the search path counter is counted up in correspondence with the hierarchy of nodes on the search path reaching the leaf node.
- step S901 the array element number of the root node is set in the array element number, and the process proceeds to step S903.
- step S903 the array element indicated by the array element number is read from the array as a node.
- step S904 the node type is extracted from the node.
- step S905 it is determined whether the node type is a branch node.
- step S905 If it is determined in step S905 that the read node is a branch node, the process proceeds to step S906, where the discrimination bit position is extracted from the node, and in step S907, the bit value corresponding to the extracted discrimination bit position is classified. Take out from the key.
- step S908 the representative node number is extracted from the node.
- step S909 the bit value extracted from the classification key is added to the representative node number to obtain a new array number, and the process returns to step S902.
- step S909 the classification reference pointer is extracted from the leaf node, and the process proceeds to step S911 shown in FIG. 9B.
- FIG. 9B is a diagram showing an example of a processing flow in the middle stage of processing for inserting the classification key into the classification tree according to the embodiment of the present invention.
- the key linked to the key link table of the leaf node obtained in the first processing is compared with the value of the classification key to determine whether the classification key is linked to the key link table of the leaf node. If they are connected, they are connected, and if they are not connected, preparation is made for the processing for obtaining the insertion position of the node pair including the leaf node to be connected to the classification key.
- step S911 the minimum value key and the maximum value key of the key classification table pointed to by the classification reference pointer extracted in step S910 of FIG. 9A are read.
- step S915 it is determined whether the classification key is smaller than the minimum value key.
- step S916 it is further determined in step S916 whether the classification key is larger than the maximum value key. If it is determined in step S916 that the classification key is not larger than the maximum value key, that is, it is determined that the value of the classification key is between the minimum value key and the maximum value key, the classification key is determined in step S917. Are connected to the key link table of the leaf node, and the insertion process is terminated. Details of the processing in step S917 will be described later with reference to FIG.
- step S916 determines whether the classification key is larger than the maximum value key. If it is determined in step S916 that the classification key is larger than the maximum value key, the process proceeds to step S918, the index key is set to the maximum value, and the process proceeds to step S920. If it is determined in step S915 described above that the classification key is smaller than the minimum value key, the minimum value is set in the index key in step S919, and the flow advances to step S920.
- step S920 the bit string comparison between the classification key and the index key set in step S918 or step S919 is performed by, for example, exclusive OR to obtain a difference bit string.
- step S921 the bit position (difference bit position) of the first non-matching bit viewed from the upper 0th bit is obtained from the difference bit string obtained in step S920.
- a CPU having a priority encoder can input a difference bit string to obtain a mismatched bit position. It is also possible to obtain the bit position of the first non-matching bit by performing processing equivalent to that of the priority encoder in software.
- step S922a the array element number of the root node is set as the array element number of the insertion position, and the process proceeds to step S922b shown in FIG. 9C.
- FIG. 9C is a diagram showing an example of a process flow at the latter stage of the process of inserting the classification key into the classification tree according to the embodiment of the present invention.
- the classification key is linked to the key link table of the leaf node based on the preparation made in the intermediate processing shown in FIG. 9B.
- step S922b the search path counter is set to 0 as an initial value, and the process proceeds to step S923.
- step S923 the count value of the searched route counter is incremented by one.
- step S924a the array element indicated by the array element number at the insertion position is read from the array as a node.
- step S924b the node type is extracted from the node, and the process proceeds to step S925.
- step S925 it is determined whether the node type extracted in step S924b indicates a branch node. If the node type does not indicate a branch node, that is, indicates a leaf node, the process proceeds to step S932.
- step S926 the discrimination bit position is extracted from the node.
- step S927 it is determined whether the discrimination bit position is higher than the difference bit position obtained in step S921. . If the discrimination bit position is not higher than the difference bit position, the process proceeds to step S935.
- step S928a the bit value indicated by the discrimination bit position is extracted from the classification key, and the representative node number is extracted from the node in step S928b.
- step S929 the value obtained by adding the value obtained in step S928a to the representative node number is set as the array number of the insertion position, and the process returns to step S923.
- step S929 The loop processing from step S923 to step S929 is repeated until it is determined in step S925 that the node type is a leaf node, or in step S927, it is determined that the discrimination bit position of the branch node is not higher than the difference bit position. Repeat the search from the root node.
- the array element number at the insertion position set at step S929 immediately before exiting from the loop processing at step S925 or step S927, or the array element number at the insertion position set at step S922a when the root node is a leaf node is linked to the classification key.
- the insertion position of a node pair including a leaf node is shown.
- step S923 to step S929 The loop processing from step S923 to step S929 described above is performed in order to determine the relative positional relationship between the discrimination bit position and the difference bit position between the classification key and the index key by tracing the branch node on the search path. Similar to the search processing shown in 9A, the search path is traced again from the root node, which is the search start node, toward the leaf node.
- step S925 If it is determined in step S925 that the node type extracted in step S924 indicates a leaf node, the process proceeds to step S932, where the search path counter indicates the maximum value that is the value of the maximum number of stages in the classification tree. judge.
- step S933 the classification key is inserted at the insertion position, and the insertion process is terminated.
- An example of the state where the node at the insertion position is a leaf node and the count value of the search path counter is not the maximum value is the state described above with reference to FIG. 6A.
- An example of a state in which the classification key is inserted at the insertion position is shown in FIG. 6B. Details of the processing in step S933 will be described later with reference to FIG.
- step S932 determines whether the count value of the search path counter is the maximum value. If it is determined in step S932 that the count value of the search path counter is the maximum value, the process proceeds to step S934, and the classification key is connected to the key link table of the leaf node to end the insertion process.
- An example of a state where the count value of the search route counter is the maximum value is the state described above with reference to FIG. 6B.
- An example of the state in which the classification key is linked to the key link table of the leaf node is shown in FIG. 6C. Note that the upper bit value up to the discrimination bit position of the branch node immediately above the leaf node is the same for any key classified in the same block, and is different up to the discrimination bit position of the branch node immediately above the leaf node.
- step S934 Since a key having a bit value is classified into another block, even if the classification key is connected to a leaf node in step S934, there is no duplication in the value range of the classification key classified into each block. . Details of the processing in step S934 will be described later with reference to FIG.
- step S927 if it is determined that the discrimination bit position is not in a positional relationship higher than the difference bit position obtained in step S921, the process proceeds to step S935.
- step S935 a process for guaranteeing that the number of stages in the classification tree does not exceed the limit when the classification key is inserted at the insertion position is performed. That is, when the classification key is inserted at the insertion position, it is checked whether the number of leaf nodes below the insertion position does not exceed the maximum value. If there is a leaf node that exceeds the limit, the node pair including that leaf node is included. If the parent node of the leaf node is a leaf node and the key linked to the key link table of the leaf node that constitutes the node pair is linked to the key link table of the parent node that is the leaf node, Do everything. With the processing in step S935, even if a classification key is inserted at the insertion position, the number of stages in the classification tree does not exceed the maximum value.
- An example of a state where the number of leaf nodes below the insertion position exceeds the maximum value when the classification key is inserted at the insertion position is the state described above with reference to FIG. 6C.
- the value of the search path counter in the leaf node 210d at the lower position of the insertion position is 3, which is the maximum value.
- step S935 the process proceeds to step S936, and as in step S933 described above, the classification key is inserted at the insertion position, and the insertion process is terminated.
- a search path counter is obtained by using a parent node of a node pair including a leaf node as a leaf node and connecting the key linked to the key link table of the leaf node constituting the node pair to the key link table of the parent node as a leaf node.
- An example of the state in which the value of is reduced by one from the maximum value and the classification key is inserted at the insertion position is the state described above with reference to FIG. 6E. Details of the processing in step S936 will be described next with reference to FIG. 10 as described in step S933.
- FIG. 10 is a diagram showing an example of a processing flow for inserting the classification key into the insertion position according to the embodiment of the present invention, and describes the detailed processing of steps S933 and S936 shown in FIG. 9C.
- step S1001 an empty node pair is obtained from the array, and the array element number of the array element to be the representative node of the node pair is acquired.
- step S1002 the classification key is compared with the size of the index key set in the process shown in FIG. 9B. If the classification key is large, a value 1 is obtained, and a Boolean value 0 is obtained.
- step S1003 the array element number obtained by adding the Boolean value obtained in step S1002 to the array element number of the representative node obtained in step S1001 is obtained.
- step S1004 an array element number obtained by adding the logical negation value of the Boolean value obtained in step S1002 to the array element number of the representative node obtained in step S1001 is obtained.
- step S1005 the index key management area classification reference pointer and key management pointer are acquired.
- the classification reference pointer and the key management pointer in the index key management area are acquired in order to secure entries in the key classification table and the key link table corresponding to the leaf node including the classification key to be inserted.
- the key management pointer can be acquired by passing the start address of the key management pointer as a key management pointer.
- the number of entries in the key classification table is the number of blocks that finally classify the key, in other words, the number of leaf nodes in the classification tree.
- the key link table there are as many free entries as the number of keys to be classified.
- This area is secured in the index key management area in advance, and each time an acquisition request is made, the leading address of the empty entry is sequentially passed as a classification reference pointer, whereby the classification reference pointer can be acquired.
- a parent node of a node pair including a leaf node is a leaf node
- a key linked to the key link table of the leaf node constituting the node pair is a leaf node. Entries that are no longer required by the process of linking to the key link table of the parent node are deleted.
- step S1006 the key management pointer acquired in step S1005 is written in the first link and the end link of the key classification table pointed to by the classification reference pointer acquired in step S1005, and the classification key is written in the minimum value key and the maximum value key.
- step S1007 the key reference pointer in the index key storage area is written into the key reference pointer in the key link table pointed to by the key management pointer.
- the key reference pointer in the index key storage area is set in step S701 or step S705 shown in FIG. 7A.
- step S1008 1 (leaf node) is written in the node type of the array element pointed to by the array element number obtained in step S1003, and the classification reference pointer obtained in step S1005 is written in the classification reference pointer.
- step S1009 the contents of the array element with the array element number at the insertion position are read from the array, and in step S1010, the contents read in step S1009 are written into the array element pointed to by the array element number obtained in step S1004.
- the array number of the insertion position is set in step S929 shown in FIG. 9C.
- step S1011 0 (branch node) is set as the node type of the array element indicated by the array element number at the insertion position, the differential bit position obtained in step S921 shown in FIG. 9C is set as the discrimination bit position, and the representative node number is set in step S1001. The representative node number obtained in the above is written, and the process ends.
- the representative node number obtained in step S1001 is the representative node number 220b of the node 210b illustrated in FIG. 6B and step S1002.
- the Boolean value obtained in step S1008 is 0, the leaf node generated in step S1008 is the node 210d shown in FIG. 6B, the array element read in step S1009 is the node 210b shown in FIG. 6A, and the node generated in step S1010 is the node shown in FIG.
- the node 211d shown and the branch node generated in step S1011 are the node 210b shown in FIG. 6B.
- FIG. 11 is a diagram showing an example of a processing flow for linking the classification key to the key link table of the leaf node according to the embodiment of the present invention, and details of step S917 shown in FIG. 9B and step S934 shown in FIG. 9C. The process will be described.
- the process of connecting the classification key to the key link table of the leaf node is performed by rewriting the key classification table and the key link table in the index key management area without changing the classification tree.
- step S1101 the key management pointer of the index key management area is acquired.
- step S1102 the key reference pointer in the index key storage area is written in the key reference pointer in the key link table pointed to by the key management pointer.
- step S1103 the tail link of the key classification table pointed to by the classification reference pointer extracted in step S910 shown in FIG. 9A is read.
- step S1104 the link of the key link table pointed to by the tail link is acquired in step S1101. Write key management pointer.
- step S1105 the key management pointer is written in the end link of the key classification table pointed to by the classification reference pointer extracted in step S910 shown in FIG. 9A.
- step S1106 the minimum value key and the maximum value key in the key classification table pointed to by the classification reference pointer extracted in step S910 shown in FIG. 9A are read.
- step S1107 it is determined whether the classification key is smaller than the minimum value key.
- step S1108 the classification key is written in the minimum value key of the key classification table pointed to by the classification reference pointer extracted in step S910 shown in FIG. 9A, and the process is terminated.
- step S1109 If the classification key is not smaller than the minimum value key, it is determined in step S1109 whether the classification key is larger than the maximum value key. If the classification key is not larger than the maximum value key, the process is terminated. If the classification key is larger than the maximum value key, in step S1110, the maximum value key of the key classification table pointed to by the classification reference pointer extracted in step S910 shown in FIG. 9A. The classification key is written in and the process is terminated.
- the process flow illustrated in FIG. 11 is the same as that in step S917 shown in FIG. 9B and step S934 shown in FIG. 9C. However, the process in step S917 shown in FIG. Since it is assumed that the value is within the range between the value of the minimum value key and the value of the maximum value key, the process of step S917 shown in FIG. 9B can be the process of steps S1101 to S1105.
- FIG. 12 is a diagram for explaining an example of a processing flow for preparing for the number of stages of the classification tree not exceeding the limit when the classification key is inserted at the insertion position according to the embodiment of the present invention. Detailed processing of step S935 shown will be described. As described above with reference to FIG. 9C, the processing shown in FIG. 12 is performed by performing the discrimination bit position of the branch node arranged in the array element indicated by the array element number of the insertion position set in step S929 on the search path. Is executed when it is determined that the positional relationship is not higher than the difference bit position obtained in step S921.
- the classification key When the classification key is inserted at the insertion position, it is checked whether the number of leaf nodes below the insertion position does not exceed the maximum value. If there is a leaf node that exceeds the limit, the node pair including the leaf node is checked. All of the leaf nodes below the insertion position are connected to the key link table of the parent node and the key linked to the key link table of the leaf node constituting the node pair. Do about.
- step S1201 the array element number of the insertion position is set as the array element number of the search start node, and the process proceeds to step S1204.
- step S1204 the array is searched from the search start node to obtain a leaf node including the minimum value of the index key.
- the array number of the insertion position is set in step S929 shown in FIG. 9C. Details of the processing in step S1204 will be described later with reference to FIG.
- step S1205 it is determined whether the count value of the searched route counter is the maximum value.
- the count value of the search path counter is counted when the leaf node is obtained in step S1204, and indicates the level of the classification tree in which the obtained leaf node is obtained.
- step S1205 If it is determined in step S1205 that the count value of the search path counter is not the maximum value, the process proceeds to step S1206, the array element number is extracted from the search path stack, the stack pointer of the search path stack is decremented by 1, and the process proceeds to step S1209. .
- the array element number extracted from the search path stack in step S1206 is the array element number of the array element in which the leaf node including the minimum value of the index key is obtained in step S1204, or one time of the loop processing from step S1206 to step S1212a. This is the array element number pointed to by the stack pointer decremented by 1 in step S1206 in the previous loop.
- step S1205 if it is determined in step S1205 that the count value of the searched route counter is the maximum value, the process branches to step S1207.
- step S1207 the array element number is extracted from the search path stack by decrementing the stack pointer value of the search path stack by one, and the extracted array number is set as the array number of the parent node.
- the parent node is a node immediately above the leaf node obtained in step S1204 and including the minimum value of the index key.
- a node immediately above a certain node is called a parent node of the node, and a node immediately below is called a child node.
- step S1208 the leaf node linked to the key linked to the key link table of the leaf node obtained in step S1204 and the key linked to the key link table of the leaf node that forms a pair with the leaf node is determined in step S1206.
- the array number set in step 1 that is, the array element of the parent node.
- the branch node (parent node) immediately above the leaf node obtained in step S1204 is set as a leaf node, and the key link table of the parent node as a leaf node is connected to the key link table of the leaf node obtained in step S1204.
- the key linked to the key link table of the leaf node paired with the leaf node Details of the processing in step S1208 will be described later with reference to FIG.
- step S1208a the count value of the search route counter is decremented by 1, and the process proceeds to step S1209.
- the reason why the count value of the search route counter is decreased by 1 is that the number of leaf nodes has been decreased by 1 by setting the parent node as a leaf node in the process of step S1207.
- the count value of the search route counter when the minimum value search is performed again in step S1204 can be matched with the number of steps of the search route.
- step S1209 it is determined whether the array element number extracted in step S1206 or the array element number of step S1207 is the insertion position array element. As a result of the determination, if the array number is at the insertion position, the processing for all the leaf nodes lower than the node at the insertion position has been completed, so the concatenation process is terminated. If the result of determination is not an array number at the insertion position, processing proceeds to step S1211.
- step S1211 from the array element number extracted in step S1206 or step S1207, the node position indicating which array element of the node pair stores the node of the array element number is obtained.
- the node position can be obtained from the array number by storing the node [0] in the array element of the even-numbered array.
- step S1212 it is determined whether or not the node position obtained in step S1211 is on the node [1] side. If it is determined in step S1212 that the node is on the node [1] side, the count value of the search path counter is decremented by 1 in step S1212a, and the process returns to step S1206.
- step S1212 If it is determined in step S1212 that the node is the node [0] side, the process proceeds to step S1213, and 1 is added to the array element number to obtain the array element number of the node [1] paired with the node.
- step S1214 the array element number of node [1] obtained in step S1213 is set in the array element number of the search start node, and the process returns to step S1204.
- the number of leaf nodes is increased by reducing the stack pointer of the search path stack by 1 in step S1206 or by making the parent node a leaf node in the processing in steps S1207 to S1208a. While decreasing, it is repeated until it is determined in step S1209 that the array element number extracted from the search path stack is the array element number of the insertion position.
- step S1204 when the node immediately below the insertion position node is a leaf node and the number of stages is the maximum value, in step S1204, the node 210d is obtained as a node including the minimum value, and is added to the search path stack.
- the array element number 220b which is the array element number of the node at the insertion position and the array element number 220b of the array element in which the node 210d is arranged. Since the count value of the search path counter is the maximum value, the array element number 220a is extracted in step S1207.
- the array element number is the array element number of the insertion position. It is determined that there is, and the process ends.
- step S1206 the process proceeds to step S1206 by the determination in step S1205, the array element number 220b is extracted from the search path stack, and the determination in step S1209 is negative.
- step S1214 is reached via step S1211, step S1212, and step S1213.
- step S1214 the array element number 220b + 1 is set as the array element number of the search start node, the minimum value search in step S1204 is performed using the node 211d as the search start node, and the node 211d is obtained as a leaf node including the minimum value of the index key. .
- the loop processing from step S1206 to step S1212a is executed, and when the array element number 220a at the insertion position is extracted in step S1206, the processing is terminated by the determination in step S1209.
- a leaf node including the minimum value of the subtree having the node at the insertion position as a root node is searched, so that the node position of the leaf node is on the node [0] side.
- the next minimum value search is performed using the node [1] constituting the same node pair as a search start node.
- a leaf node including the maximum value of the subtree having the insertion position node as a root node is searched.
- the node position of the leaf node is on the node [1] side, and the loop process of steps S1206 to S1212a is repeated until the array element number of the insertion position is extracted from the search path stack in step S1206, and the array element number is determined in step S1209. It is determined that the sequence number is the insertion position, and the process is terminated.
- FIG. 13 is a diagram illustrating an example of a processing flow for searching for a node including the minimum value of the index key according to an embodiment of the present invention, and illustrates detailed processing in step S1204 illustrated in FIG.
- step S1301 the array element number of the search start node is set as the array element number.
- the array element number of the search start node is set in step S1201 or step S1214 shown in FIG.
- step S1302 the array element number is stored in the search path stack.
- step S1303 the array element indicated by the array element number is read from the array as a node.
- step S1304 the node type is extracted from the read node, and the process advances to step S1305.
- step S1305 it is determined whether the node type is that of a branch node. If it is determined that the node type is that of a branch node, the process proceeds to step S1305a, and the value of the search path counter is incremented by one.
- step S1306 the representative node number of the array is extracted from the node.
- step S1307 the value 0 is added to the extracted representative node number, and the result is set as a new array number, and the process returns to step S1302.
- step S1305 the processes from step S1302 to step S1307 are repeated until the node extracted in step S1304 is determined to be a leaf node.
- step S1305 the node extracted in step S1304 is determined to be a leaf node. And the process ends.
- the coupled node tree is stored in the array.
- the coupled node tree is stored in the array. It is not essential to store the index key by linking only the representative node of the two nodes constituting the node pair or only the node arranged in the storage area adjacent to the representative node to reach the leaf node. Obviously, it is possible to search for leaf nodes that contain the minimum value.
- FIG. 14 illustrates an example of a processing flow in which a parent node of a node pair including a leaf node in the embodiment of the present invention is used as a leaf node, and the key link table of the node pair is linked to the key link table of the parent node. It is a figure and demonstrates the detail of the process of step S1208 shown in FIG. In the process of connecting the key link table of the node pair including the leaf node to the key link table of the parent node, the classification reference pointer corresponding to each node forming the node pair is integrated with the classification reference pointer of the parent node.
- step S1401 the array element pointed to by the array element number of the parent node is read from the array as a node, and in step S1402, the representative node number is extracted from the read node.
- the representative node number 220b of the parent node 210b is extracted.
- step S1403 the value 1 is added to the representative node number to obtain a one-side array number.
- step S1404 the array element pointed to by the array element number on the one side is read from the array as a node.
- step S1405 the classification reference pointer is extracted from the node and set as the classification reference pointer on the one side.
- the node 211d pointed to by the array element number 220b + 1 is read, and the classification reference pointer 280d is set to the one-side classification reference pointer that is a temporary storage area.
- step S1406 the value 0 is added to the representative node number to obtain the array element number at node position 0.
- step S1407 the array element pointed to by the array element on the 0 side is read from the array as a node.
- step S1408 the classification reference pointer is extracted from the node and set as the classification reference pointer on the 0 side.
- the node 210d pointed to by the array element number 220b is read, and the classification reference pointer 280e is set to the zero-side classification reference pointer that is a temporary storage area.
- step S1409 the head link, tail link, and maximum value key of the key classification table pointed to by the one-side classification reference pointer are read out, set to the one-side head link and one-side end link, and the maximum value key. Is set to the maximum value key on the 1 side.
- step S1410 the tail link of the key classification table pointed to by the 0-side classification reference pointer is read.
- step S1411 the head of the one side set in step S1409 is set to the link of the key link table pointed to by the read tail link.
- step S1412 the 1-side end link is written in the end link of the key classification table pointed to by the 0-side classification reference pointer, and the 1-side maximum value key is written in the maximum value key.
- the classification reference pointer of the parent node as the leaf node is used as the classification reference pointer of the child node on the 0 side, and the key link table and the key classification table are rewritten accordingly.
- the processing of writing the first link on the 1 side to the link of the key link table pointed to by the end link of the key classification table pointed to by the 0 side classification reference pointer in step S1411 is linked to the key link table of the 0 side leaf node.
- a link to the key linked to the key link table of the leaf node on the one side is set.
- step S1413 the contents read in step S1407 are written in the array element indicated by the array number of the parent node.
- the contents of the node 210d illustrated in FIG. 6C are written to the node 210b illustrated in FIG. 6D.
- step S1414 the node pair pointed to by the representative node number obtained in step S1401 is deleted, and in step S1415, the entry in the key classification table pointed to by the one-side classification reference pointer obtained in step S1405 is deleted, and the process ends. To do.
- FIG. 15A and FIG. 15B processing for retrieving an array from the search start node, obtaining a leaf node including the minimum value of the index key, and sequentially retrieving the index key linked to the key link table of the leaf node explain.
- the processing flow illustrated in FIGS. 15A and 15B explains details of the processing in step S714 shown in FIG. 7B.
- FIG. 15A is a process of retrieving an array from a search start node, obtaining a leaf node including the minimum value of an index key, and sequentially retrieving index keys linked to the key link table of the leaf node in an embodiment of the present invention. It is a figure explaining the example of a process flow of a front
- the first-stage process illustrated in FIG. 15A searches the array from the search start node, obtains the leaf node including the minimum value of the index key, and extracts the classification reference pointer from the leaf node.
- the array element number of the search start node is set as the array element number.
- the array element number of the search start node is the array element number of the root node of the classification tree set in step S711 shown in FIG. 7B or the array element number of node [1] set in step S724.
- step S1501a the array element number is stored in the search path stack.
- step S1502 the array element indicated by the array element number is read from the array as a node.
- step S1503 the node type is extracted from the read node, and the process proceeds to step S1504.
- step S1504 it is determined whether the node type extracted in step S1503 indicates a branch node. If the node type indicates a branch node, the process proceeds to step S1505, the representative node number is extracted from the node read in step S1502, and in step S1506, the value 0 is added to the extracted representative node number, and the array number And returns to step S1501a.
- step S1504 if it is determined in step S1504 that the node type extracted in step S1503 is a leaf node, the process advances to step S1508, the classification reference pointer is extracted from the node read in step S1502, and the process advances to step S1511 shown in FIG. 15B. .
- FIG. 15B is a process of retrieving an array from the search start node, obtaining a leaf node including the minimum value of the index key, and sequentially retrieving the index key linked to the key link table of the leaf node in one embodiment of the present invention. It is a figure explaining the process flow example of a back
- the index keys connected to the key link table of the leaf node including the minimum value of the index key obtained in the previous process are sequentially extracted and output to the output destination.
- step S1511 the head link and tail link of the key classification table pointed to by the classification reference pointer extracted in step S1508 shown in FIG. 15A and the output destination of the key are read.
- the read pointer is The read head link is set.
- step S1513 the key reference pointer and link in the key link table pointed to by the read pointer are read out.
- the read pointer is set in step S1512 or step S1516 described later.
- step S1513a the key indicated by the key reference pointer read in step S1513 is read from the index key storage area, and in step S1514, the read key is output to the output destination of the key read in step S1511. The process proceeds to S1515.
- step S1515 it is determined whether the read pointer and the tail link match. If they do not match, the link read in step S1513 is set in the read pointer in step S1516, and the process returns to step S1513.
- step S1515 If it is determined in step S1515 that the read pointer matches the end link, all index keys linked to the key link table of the leaf node including the minimum value of the index key obtained in the preceding process shown in FIG. Since it has been output, the process is terminated.
- bit string key classification device and the bit string key distribution device according to the present invention can be constructed on a computer by a program that causes a computer such as the data processing device 301 illustrated in FIG. 4 to execute these processing flows. Therefore, functional configuration examples of the bit string key classification device and the bit string key distribution device according to the present invention will be described below.
- FIG. 16 is a diagram for explaining a functional block configuration example of the bit string key classification / distribution device according to the embodiment of the present invention.
- the bit string key classification device 500 includes a classification tree maximum level acquisition unit 510, a classification tree generation unit 520, and a key storage unit 550, and the maximum number of levels acquired by the classification tree maximum level acquisition unit 510.
- the bit string keys to be classified stored in the key storage unit 550 are read out as the classification keys, and the classification target bit string keys are classified by generating the classification tree 530 and the key position search table 540.
- the key position search table 540 can be a key classification table 321 and a key link table 322.
- the bit string key distribution device 600 includes a leaf node extraction unit 610 and a classification key output unit 620.
- the leaf node extraction unit 610 sequentially extracts leaf nodes from the classification tree 530, and the classification key output unit 620 extracts a leaf node.
- the key access information is read from the leaf node extracted by the means 610, the key position information is extracted from the key position search table using the key access information, the key is read from the key storage means based on the key position information, and output destination Output to.
- the key output destination can also be set in the key classification table at the end of the classification process, but it is set corresponding to the block that classifies the key to be classified, and every time a leaf node is extracted from the classification tree Can also be determined.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/456,955 US20120209855A1 (en) | 2009-10-27 | 2012-04-26 | Bit-string key classification/distribution apparatus, classification/distribution method, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009-246868 | 2009-10-27 | ||
| JP2009246868A JP5165662B2 (ja) | 2009-10-27 | 2009-10-27 | ビット列キー分類・分配装置、分類・分配方法及びプログラム |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/456,955 Continuation US20120209855A1 (en) | 2009-10-27 | 2012-04-26 | Bit-string key classification/distribution apparatus, classification/distribution method, and program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011052181A1 true WO2011052181A1 (ja) | 2011-05-05 |
Family
ID=43921616
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2010/006305 Ceased WO2011052181A1 (ja) | 2009-10-27 | 2010-10-25 | ビット列キー分類・分配装置、分類・分配方法及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20120209855A1 (enExample) |
| JP (1) | JP5165662B2 (enExample) |
| WO (1) | WO2011052181A1 (enExample) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110233946A (zh) * | 2019-06-17 | 2019-09-13 | 三角兽(北京)科技有限公司 | 执行外呼业务方法、电子设备及计算机可读存储介质 |
| CN117997537A (zh) * | 2024-04-03 | 2024-05-07 | 四川杰通瑞联科技有限公司 | 具有通用性的数据加密和解密的方法及存储装置 |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104021261A (zh) * | 2013-02-28 | 2014-09-03 | 国际商业机器公司 | 医疗领域数据处理方法和装置 |
| JP6016215B2 (ja) * | 2013-12-20 | 2016-10-26 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | トライ木構造を有するレコード群を高い効率でマージソートする方法、装置及びコンピュータプログラム |
| JP6253514B2 (ja) * | 2014-05-27 | 2017-12-27 | ルネサスエレクトロニクス株式会社 | プロセッサ |
| US10114559B2 (en) | 2016-08-12 | 2018-10-30 | International Business Machines Corporation | Generating node access information for a transaction accessing nodes of a data set index |
| US9990281B1 (en) * | 2016-11-29 | 2018-06-05 | Sap Se | Multi-level memory mapping |
| CN107451486B (zh) * | 2017-06-30 | 2021-05-18 | 华为技术有限公司 | 一种文件系统的权限设置方法及装置 |
| US11238046B2 (en) * | 2018-02-19 | 2022-02-01 | Nippon Telegraph And Telephone Corporation | Information management device, information management method, and information management program |
| JP7237782B2 (ja) * | 2019-09-13 | 2023-03-13 | キオクシア株式会社 | ストレージシステム及びその制御方法 |
| KR102315397B1 (ko) * | 2021-06-22 | 2021-10-20 | 주식회사 크라우드웍스 | 데이터 필터링을 활용한 프로젝트 관리 방법 및 장치 |
| CN113903410B (zh) * | 2021-12-08 | 2022-03-11 | 成都健数科技有限公司 | 一种化合物检索方法及系统 |
| US12277090B2 (en) | 2022-10-11 | 2025-04-15 | Netapp, Inc. | Mechanism to maintain data compliance within a distributed file system |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005208709A (ja) * | 2004-01-20 | 2005-08-04 | Fuji Xerox Co Ltd | データ分類処理装置、およびデータ分類処理方法、並びにコンピュータ・プログラム |
| JP2007011548A (ja) * | 2005-06-29 | 2007-01-18 | Fujitsu Ltd | データ集合分割プログラム、データ集合分割装置、およびデータ集合分割方法 |
| JP2008015872A (ja) * | 2006-07-07 | 2008-01-24 | S Grants Co Ltd | ビット列検索装置、検索方法及びプログラム |
| JP2008269503A (ja) * | 2007-04-25 | 2008-11-06 | S Grants Co Ltd | ビット列検索方法及び検索プログラム |
-
2009
- 2009-10-27 JP JP2009246868A patent/JP5165662B2/ja not_active Expired - Fee Related
-
2010
- 2010-10-25 WO PCT/JP2010/006305 patent/WO2011052181A1/ja not_active Ceased
-
2012
- 2012-04-26 US US13/456,955 patent/US20120209855A1/en not_active Abandoned
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005208709A (ja) * | 2004-01-20 | 2005-08-04 | Fuji Xerox Co Ltd | データ分類処理装置、およびデータ分類処理方法、並びにコンピュータ・プログラム |
| JP2007011548A (ja) * | 2005-06-29 | 2007-01-18 | Fujitsu Ltd | データ集合分割プログラム、データ集合分割装置、およびデータ集合分割方法 |
| JP2008015872A (ja) * | 2006-07-07 | 2008-01-24 | S Grants Co Ltd | ビット列検索装置、検索方法及びプログラム |
| JP2008269503A (ja) * | 2007-04-25 | 2008-11-06 | S Grants Co Ltd | ビット列検索方法及び検索プログラム |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110233946A (zh) * | 2019-06-17 | 2019-09-13 | 三角兽(北京)科技有限公司 | 执行外呼业务方法、电子设备及计算机可读存储介质 |
| CN117997537A (zh) * | 2024-04-03 | 2024-05-07 | 四川杰通瑞联科技有限公司 | 具有通用性的数据加密和解密的方法及存储装置 |
| CN117997537B (zh) * | 2024-04-03 | 2024-06-11 | 四川杰通瑞联科技有限公司 | 具有通用性的数据加密和解密的方法及存储装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20120209855A1 (en) | 2012-08-16 |
| JP5165662B2 (ja) | 2013-03-21 |
| JP2011095849A (ja) | 2011-05-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5165662B2 (ja) | ビット列キー分類・分配装置、分類・分配方法及びプログラム | |
| JP4379894B2 (ja) | カップルドノードツリーの分割/結合方法及びプログラム | |
| JP4402120B2 (ja) | ビット列検索装置、検索方法及びプログラム | |
| JP4527753B2 (ja) | ビット列検索装置、検索方法及びプログラム | |
| JP5473893B2 (ja) | コード列検索装置、検索方法及びプログラム | |
| CN101535993B (zh) | 比特序列检索装置及检索方法 | |
| JP4514768B2 (ja) | カップルドノードツリーの退避/復元装置、退避/復元方法及びプログラム | |
| JP5241738B2 (ja) | 表からツリー構造データを構築する方法及び装置 | |
| JP2009140161A (ja) | ビット列のマージソート方法及びプログラム | |
| JP2008015872A (ja) | ビット列検索装置、検索方法及びプログラム | |
| JP4545231B2 (ja) | カップルドノードツリーの分割/結合方法及びプログラム | |
| US8166043B2 (en) | Bit strings search apparatus, search method, and program | |
| JP4417431B2 (ja) | カップルドノードツリーの分割/結合方法及びプログラム | |
| JP4567754B2 (ja) | ビット列検索装置、検索方法及びプログラム | |
| JP5220057B2 (ja) | ビット列検索装置、検索方法及びプログラム | |
| JP4813575B2 (ja) | ビット列検索装置 | |
| JP2017004128A (ja) | 情報処理装置、システム、及びプログラム | |
| SUBLOGARITHMIC | Univ. of PJ Šafárik Jesenná 5, 04154 Košice | |
| JPS6041129A (ja) | 索引システム | |
| JPH01144120A (ja) | 階層化ネットワークルート探索装置 | |
| JP2009199577A (ja) | ビット列検索装置、検索方法及びプログラム | |
| JPH06149572A (ja) | RETEネットワークのβメモリ管理方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 10826317 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 10826317 Country of ref document: EP Kind code of ref document: A1 |