WO2010040571A2 - Method for a genome wide identification of expression regulatory sequences and use of genes and molecules derived thereof for the diagnosis and therapy of metabolic and/or tumorous diseases - Google Patents
Method for a genome wide identification of expression regulatory sequences and use of genes and molecules derived thereof for the diagnosis and therapy of metabolic and/or tumorous diseases Download PDFInfo
- Publication number
- WO2010040571A2 WO2010040571A2 PCT/EP2009/007431 EP2009007431W WO2010040571A2 WO 2010040571 A2 WO2010040571 A2 WO 2010040571A2 EP 2009007431 W EP2009007431 W EP 2009007431W WO 2010040571 A2 WO2010040571 A2 WO 2010040571A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- diseases
- genes
- hnf4α
- gene
- metabolic
- Prior art date
Links
- 108090000623 proteins and genes Proteins 0.000 title claims abstract description 135
- 201000010099 disease Diseases 0.000 title claims abstract description 70
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 title claims abstract description 70
- 238000000034 method Methods 0.000 title claims abstract description 45
- 230000002503 metabolic effect Effects 0.000 title claims abstract description 32
- 230000014509 gene expression Effects 0.000 title claims abstract description 22
- 230000001105 regulatory effect Effects 0.000 title claims abstract description 21
- 238000003745 diagnosis Methods 0.000 title claims abstract description 8
- 238000002560 therapeutic procedure Methods 0.000 title claims abstract description 7
- 101150068639 Hnf4a gene Proteins 0.000 claims abstract description 45
- 239000011159 matrix material Substances 0.000 claims abstract description 34
- 241000282414 Homo sapiens Species 0.000 claims abstract description 22
- 206010009944 Colon cancer Diseases 0.000 claims abstract description 17
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims abstract description 17
- 230000027455 binding Effects 0.000 claims abstract description 16
- 206010012601 diabetes mellitus Diseases 0.000 claims abstract description 16
- 238000009396 hybridization Methods 0.000 claims abstract description 10
- 108091028043 Nucleic acid sequence Proteins 0.000 claims abstract description 9
- 230000002759 chromosomal effect Effects 0.000 claims abstract description 9
- 239000002773 nucleotide Substances 0.000 claims abstract description 8
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 8
- 108700009124 Transcription Initiation Site Proteins 0.000 claims abstract description 7
- 238000011144 upstream manufacturing Methods 0.000 claims abstract description 7
- 238000002487 chromatin immunoprecipitation Methods 0.000 claims abstract 5
- -1 ME3 Proteins 0.000 claims description 72
- 239000003814 drug Substances 0.000 claims description 24
- 229940079593 drug Drugs 0.000 claims description 19
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 8
- 108091026890 Coding region Proteins 0.000 claims description 7
- 108020004414 DNA Proteins 0.000 claims description 7
- 102000004169 proteins and genes Human genes 0.000 claims description 7
- 102100034523 Histone H4 Human genes 0.000 claims description 6
- 101001067880 Homo sapiens Histone H4 Proteins 0.000 claims description 6
- 229920001184 polypeptide Polymers 0.000 claims description 6
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 6
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 6
- 102100035197 Cerebral cavernous malformations 2 protein Human genes 0.000 claims description 5
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 claims description 5
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 claims description 5
- 108090000174 Interleukin-10 Proteins 0.000 claims description 5
- 102000003814 Interleukin-10 Human genes 0.000 claims description 5
- 102100033496 Partitioning defective 3 homolog Human genes 0.000 claims description 5
- 210000000349 chromosome Anatomy 0.000 claims description 5
- 102100035682 Axin-1 Human genes 0.000 claims description 4
- 108700024832 B-Cell CLL-Lymphoma 10 Proteins 0.000 claims description 4
- 102100037598 B-cell lymphoma/leukemia 10 Human genes 0.000 claims description 4
- 101150074953 BCL10 gene Proteins 0.000 claims description 4
- 102100036329 Cyclin-dependent kinase 3 Human genes 0.000 claims description 4
- 102100026865 Cyclin-dependent kinase 5 activator 1 Human genes 0.000 claims description 4
- 102100024098 Deleted in lung and esophageal cancer protein 1 Human genes 0.000 claims description 4
- 102100035890 Delta(24)-sterol reductase Human genes 0.000 claims description 4
- 102100033992 Dual specificity protein phosphatase 22 Human genes 0.000 claims description 4
- 102100030013 Endoribonuclease Human genes 0.000 claims description 4
- 102100038595 Estrogen receptor Human genes 0.000 claims description 4
- 102100029055 Exostosin-1 Human genes 0.000 claims description 4
- 102100035290 Fibroblast growth factor 13 Human genes 0.000 claims description 4
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 claims description 4
- 102100036685 Growth arrest-specific protein 2 Human genes 0.000 claims description 4
- 102100034405 Headcase protein homolog Human genes 0.000 claims description 4
- 102100032827 Homeodomain-interacting protein kinase 2 Human genes 0.000 claims description 4
- 101000779615 Homo sapiens ALX homeobox protein 1 Proteins 0.000 claims description 4
- 101000874566 Homo sapiens Axin-1 Proteins 0.000 claims description 4
- 101001053992 Homo sapiens Deleted in lung and esophageal cancer protein 1 Proteins 0.000 claims description 4
- 101000929877 Homo sapiens Delta(24)-sterol reductase Proteins 0.000 claims description 4
- 101001017467 Homo sapiens Dual specificity protein phosphatase 22 Proteins 0.000 claims description 4
- 101000918311 Homo sapiens Exostosin-1 Proteins 0.000 claims description 4
- 101001072710 Homo sapiens Growth arrest-specific protein 2 Proteins 0.000 claims description 4
- 101001066401 Homo sapiens Homeodomain-interacting protein kinase 2 Proteins 0.000 claims description 4
- 101001050577 Homo sapiens Kinesin-like protein KIF2A Proteins 0.000 claims description 4
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 4
- 101000703463 Homo sapiens Rho GTPase-activating protein 35 Proteins 0.000 claims description 4
- 101000984753 Homo sapiens Serine/threonine-protein kinase B-raf Proteins 0.000 claims description 4
- 101000830933 Homo sapiens TNF receptor-associated factor 4 Proteins 0.000 claims description 4
- 101000823316 Homo sapiens Tyrosine-protein kinase ABL1 Proteins 0.000 claims description 4
- 108091006081 Inositol-requiring enzyme-1 Proteins 0.000 claims description 4
- 102000003810 Interleukin-18 Human genes 0.000 claims description 4
- 108090000171 Interleukin-18 Proteins 0.000 claims description 4
- 102100023426 Kinesin-like protein KIF2A Human genes 0.000 claims description 4
- 102100037136 Proteinase-activated receptor 1 Human genes 0.000 claims description 4
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 4
- 102100030676 Rho GTPase-activating protein 35 Human genes 0.000 claims description 4
- 102100027103 Serine/threonine-protein kinase B-raf Human genes 0.000 claims description 4
- 102100024809 TNF receptor-associated factor 4 Human genes 0.000 claims description 4
- 102100022596 Tyrosine-protein kinase ABL1 Human genes 0.000 claims description 4
- 230000033228 biological regulation Effects 0.000 claims description 4
- 210000004027 cell Anatomy 0.000 claims description 4
- 230000006870 function Effects 0.000 claims description 4
- 108020004999 messenger RNA Proteins 0.000 claims description 4
- 108010064131 neuronal Cdk5 activator (p25-p35) Proteins 0.000 claims description 4
- 101150060184 ACHE gene Proteins 0.000 claims description 3
- 102000034257 ADP-Ribosylation Factor 6 Human genes 0.000 claims description 3
- 108090000067 ADP-Ribosylation Factor 6 Proteins 0.000 claims description 3
- 102000017908 ADRA1B Human genes 0.000 claims description 3
- 102000017907 ADRA1D Human genes 0.000 claims description 3
- 101150037123 APOE gene Proteins 0.000 claims description 3
- 102100023388 ATP-dependent RNA helicase DHX15 Human genes 0.000 claims description 3
- 102100022936 ATPase inhibitor, mitochondrial Human genes 0.000 claims description 3
- 102100033639 Acetylcholinesterase Human genes 0.000 claims description 3
- 102100035990 Adenosine receptor A2a Human genes 0.000 claims description 3
- 102100032358 Adiponectin receptor protein 2 Human genes 0.000 claims description 3
- 102100026451 Aldo-keto reductase family 1 member B10 Human genes 0.000 claims description 3
- 102100026446 Aldo-keto reductase family 1 member C1 Human genes 0.000 claims description 3
- 102100032959 Alpha-actinin-4 Human genes 0.000 claims description 3
- 102100036439 Amyloid beta precursor protein binding family B member 1 Human genes 0.000 claims description 3
- 102100026683 Angiogenic factor with G patch and FHA domains 1 Human genes 0.000 claims description 3
- 102100025668 Angiopoietin-related protein 3 Human genes 0.000 claims description 3
- 102100029470 Apolipoprotein E Human genes 0.000 claims description 3
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 claims description 3
- 102100035769 Apoptotic chromatin condensation inducer in the nucleus Human genes 0.000 claims description 3
- 102100033648 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 3 Human genes 0.000 claims description 3
- 108091012583 BCL2 Proteins 0.000 claims description 3
- 108091007065 BIRCs Proteins 0.000 claims description 3
- 102100021677 Baculoviral IAP repeat-containing protein 2 Human genes 0.000 claims description 3
- 102100026340 Beta-1,4-galactosyltransferase 4 Human genes 0.000 claims description 3
- 102100026189 Beta-galactosidase Human genes 0.000 claims description 3
- 102100022549 Beta-hexosaminidase subunit beta Human genes 0.000 claims description 3
- 102100028253 Breast cancer anti-estrogen resistance protein 3 Human genes 0.000 claims description 3
- 108010077333 CAP1-6D Proteins 0.000 claims description 3
- 102100025752 CASP8 and FADD-like apoptosis regulator Human genes 0.000 claims description 3
- 102100037675 CCAAT/enhancer-binding protein gamma Human genes 0.000 claims description 3
- 102100031171 CCN family member 1 Human genes 0.000 claims description 3
- 102000017927 CHRM1 Human genes 0.000 claims description 3
- 102100029396 CLIP-associating protein 1 Human genes 0.000 claims description 3
- 102100038520 Calcitonin receptor Human genes 0.000 claims description 3
- 101000841393 Candida albicans Probable NADPH dehydrogenase Proteins 0.000 claims description 3
- 102100024966 Caspase recruitment domain-containing protein 10 Human genes 0.000 claims description 3
- 102100023344 Centromere protein F Human genes 0.000 claims description 3
- 102100036158 Ceramide kinase Human genes 0.000 claims description 3
- 102100031192 Chondroitin sulfate N-acetylgalactosaminyltransferase 1 Human genes 0.000 claims description 3
- 102100031162 Collagen alpha-1(XVIII) chain Human genes 0.000 claims description 3
- 102100039195 Cullin-1 Human genes 0.000 claims description 3
- 102100028908 Cullin-3 Human genes 0.000 claims description 3
- 102100028907 Cullin-4A Human genes 0.000 claims description 3
- 108010016788 Cyclin-Dependent Kinase Inhibitor p21 Proteins 0.000 claims description 3
- 102100026810 Cyclin-dependent kinase 7 Human genes 0.000 claims description 3
- 102100033270 Cyclin-dependent kinase inhibitor 1 Human genes 0.000 claims description 3
- 101710095827 Cyclopropane mycolic acid synthase 1 Proteins 0.000 claims description 3
- 101710095826 Cyclopropane mycolic acid synthase 2 Proteins 0.000 claims description 3
- 101710095828 Cyclopropane mycolic acid synthase 3 Proteins 0.000 claims description 3
- 101710110342 Cyclopropane mycolic acid synthase MmaA2 Proteins 0.000 claims description 3
- 108010019961 Cysteine-Rich Protein 61 Proteins 0.000 claims description 3
- 108010081668 Cytochrome P-450 CYP3A Proteins 0.000 claims description 3
- 102100028697 D-glucuronyl C5-epimerase Human genes 0.000 claims description 3
- 102100024829 DNA polymerase delta catalytic subunit Human genes 0.000 claims description 3
- 108010031042 Death-Associated Protein Kinases Proteins 0.000 claims description 3
- 102100038587 Death-associated protein kinase 1 Human genes 0.000 claims description 3
- 102100038605 Death-associated protein kinase 2 Human genes 0.000 claims description 3
- 102100036869 Diacylglycerol O-acyltransferase 1 Human genes 0.000 claims description 3
- 102100024099 Disks large homolog 1 Human genes 0.000 claims description 3
- 102100022258 Disks large homolog 5 Human genes 0.000 claims description 3
- 102100040341 E3 ubiquitin-protein ligase UBR5 Human genes 0.000 claims description 3
- 102100036093 Ectonucleotide pyrophosphatase/phosphodiesterase family member 7 Human genes 0.000 claims description 3
- 102100027118 Engulfment and cell motility protein 1 Human genes 0.000 claims description 3
- 102100033183 Epithelial membrane protein 1 Human genes 0.000 claims description 3
- 102100035177 Ergosterol biosynthetic protein 28 homolog Human genes 0.000 claims description 3
- 102100037577 FERM, ARHGEF and pleckstrin domain-containing protein 2 Human genes 0.000 claims description 3
- 102100023636 FYVE, RhoGEF and PH domain-containing protein 4 Human genes 0.000 claims description 3
- 102100023639 FYVE, RhoGEF and PH domain-containing protein 5 Human genes 0.000 claims description 3
- 102100026745 Fatty acid-binding protein, liver Human genes 0.000 claims description 3
- 102100035421 Forkhead box protein O3 Human genes 0.000 claims description 3
- 102100021337 Gap junction alpha-1 protein Human genes 0.000 claims description 3
- 102100030426 Gastrotropin Human genes 0.000 claims description 3
- 102100031150 Growth arrest and DNA damage-inducible protein GADD45 alpha Human genes 0.000 claims description 3
- 102100031487 Growth arrest-specific protein 6 Human genes 0.000 claims description 3
- 102100038885 Histone acetyltransferase p300 Human genes 0.000 claims description 3
- 102100038719 Histone deacetylase 7 Human genes 0.000 claims description 3
- 102100038720 Histone deacetylase 9 Human genes 0.000 claims description 3
- 101000866618 Homo sapiens 3-beta-hydroxysteroid-Delta(8),Delta(7)-isomerase Proteins 0.000 claims description 3
- 101000907886 Homo sapiens ATP-dependent RNA helicase DHX15 Proteins 0.000 claims description 3
- 101000902767 Homo sapiens ATPase inhibitor, mitochondrial Proteins 0.000 claims description 3
- 101000783751 Homo sapiens Adenosine receptor A2a Proteins 0.000 claims description 3
- 101000589401 Homo sapiens Adiponectin receptor protein 2 Proteins 0.000 claims description 3
- 101000718028 Homo sapiens Aldo-keto reductase family 1 member C1 Proteins 0.000 claims description 3
- 101000689698 Homo sapiens Alpha-1B adrenergic receptor Proteins 0.000 claims description 3
- 101000689696 Homo sapiens Alpha-1D adrenergic receptor Proteins 0.000 claims description 3
- 101000797282 Homo sapiens Alpha-actinin-4 Proteins 0.000 claims description 3
- 101000928670 Homo sapiens Amyloid beta precursor protein binding family B member 1 Proteins 0.000 claims description 3
- 101000690725 Homo sapiens Angiogenic factor with G patch and FHA domains 1 Proteins 0.000 claims description 3
- 101000693085 Homo sapiens Angiopoietin-related protein 3 Proteins 0.000 claims description 3
- 101000929927 Homo sapiens Apoptotic chromatin condensation inducer in the nucleus Proteins 0.000 claims description 3
- 101000733571 Homo sapiens Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 3 Proteins 0.000 claims description 3
- 101000766179 Homo sapiens Beta-1,4-galactosyltransferase 4 Proteins 0.000 claims description 3
- 101000765010 Homo sapiens Beta-galactosidase Proteins 0.000 claims description 3
- 101001045433 Homo sapiens Beta-hexosaminidase subunit beta Proteins 0.000 claims description 3
- 101000935648 Homo sapiens Breast cancer anti-estrogen resistance protein 3 Proteins 0.000 claims description 3
- 101000914211 Homo sapiens CASP8 and FADD-like apoptosis regulator Proteins 0.000 claims description 3
- 101000880590 Homo sapiens CCAAT/enhancer-binding protein gamma Proteins 0.000 claims description 3
- 101000990005 Homo sapiens CLIP-associating protein 1 Proteins 0.000 claims description 3
- 101000741435 Homo sapiens Calcitonin receptor Proteins 0.000 claims description 3
- 101000761182 Homo sapiens Caspase recruitment domain-containing protein 10 Proteins 0.000 claims description 3
- 101000907941 Homo sapiens Centromere protein F Proteins 0.000 claims description 3
- 101000715711 Homo sapiens Ceramide kinase Proteins 0.000 claims description 3
- 101000737028 Homo sapiens Cerebral cavernous malformations 2 protein Proteins 0.000 claims description 3
- 101000776615 Homo sapiens Chondroitin sulfate N-acetylgalactosaminyltransferase 1 Proteins 0.000 claims description 3
- 101000940068 Homo sapiens Collagen alpha-1(XVIII) chain Proteins 0.000 claims description 3
- 101000746063 Homo sapiens Cullin-1 Proteins 0.000 claims description 3
- 101000916238 Homo sapiens Cullin-3 Proteins 0.000 claims description 3
- 101000916245 Homo sapiens Cullin-4A Proteins 0.000 claims description 3
- 101000868333 Homo sapiens Cyclin-dependent kinase 1 Proteins 0.000 claims description 3
- 101000911952 Homo sapiens Cyclin-dependent kinase 7 Proteins 0.000 claims description 3
- 101001058422 Homo sapiens D-glucuronyl C5-epimerase Proteins 0.000 claims description 3
- 101000909198 Homo sapiens DNA polymerase delta catalytic subunit Proteins 0.000 claims description 3
- 101000956145 Homo sapiens Death-associated protein kinase 1 Proteins 0.000 claims description 3
- 101000927974 Homo sapiens Diacylglycerol O-acyltransferase 1 Proteins 0.000 claims description 3
- 101001053984 Homo sapiens Disks large homolog 1 Proteins 0.000 claims description 3
- 101000902114 Homo sapiens Disks large homolog 5 Proteins 0.000 claims description 3
- 101000951365 Homo sapiens Disks large-associated protein 5 Proteins 0.000 claims description 3
- 101000671838 Homo sapiens E3 ubiquitin-protein ligase UBR5 Proteins 0.000 claims description 3
- 101000876377 Homo sapiens Ectonucleotide pyrophosphatase/phosphodiesterase family member 7 Proteins 0.000 claims description 3
- 101001057862 Homo sapiens Engulfment and cell motility protein 1 Proteins 0.000 claims description 3
- 101000850989 Homo sapiens Epithelial membrane protein 1 Proteins 0.000 claims description 3
- 101000876557 Homo sapiens Ergosterol biosynthetic protein 28 homolog Proteins 0.000 claims description 3
- 101001028283 Homo sapiens FERM, ARHGEF and pleckstrin domain-containing protein 2 Proteins 0.000 claims description 3
- 101000827819 Homo sapiens FYVE, RhoGEF and PH domain-containing protein 4 Proteins 0.000 claims description 3
- 101000827825 Homo sapiens FYVE, RhoGEF and PH domain-containing protein 5 Proteins 0.000 claims description 3
- 101000911317 Homo sapiens Fatty acid-binding protein, liver Proteins 0.000 claims description 3
- 101000877681 Homo sapiens Forkhead box protein O3 Proteins 0.000 claims description 3
- 101000894966 Homo sapiens Gap junction alpha-1 protein Proteins 0.000 claims description 3
- 101001062849 Homo sapiens Gastrotropin Proteins 0.000 claims description 3
- 101001066158 Homo sapiens Growth arrest and DNA damage-inducible protein GADD45 alpha Proteins 0.000 claims description 3
- 101000923005 Homo sapiens Growth arrest-specific protein 6 Proteins 0.000 claims description 3
- 101001066896 Homo sapiens Headcase protein homolog Proteins 0.000 claims description 3
- 101000840551 Homo sapiens Hexokinase-2 Proteins 0.000 claims description 3
- 101000882390 Homo sapiens Histone acetyltransferase p300 Proteins 0.000 claims description 3
- 101001032113 Homo sapiens Histone deacetylase 7 Proteins 0.000 claims description 3
- 101001032092 Homo sapiens Histone deacetylase 9 Proteins 0.000 claims description 3
- 101001011989 Homo sapiens Inositol hexakisphosphate kinase 2 Proteins 0.000 claims description 3
- 101001001429 Homo sapiens Inositol monophosphatase 1 Proteins 0.000 claims description 3
- 101001077600 Homo sapiens Insulin receptor substrate 2 Proteins 0.000 claims description 3
- 101001034652 Homo sapiens Insulin-like growth factor 1 receptor Proteins 0.000 claims description 3
- 101000840572 Homo sapiens Insulin-like growth factor-binding protein 4 Proteins 0.000 claims description 3
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 claims description 3
- 101001008568 Homo sapiens Laminin subunit beta-1 Proteins 0.000 claims description 3
- 101000782981 Homo sapiens Muscarinic acetylcholine receptor M1 Proteins 0.000 claims description 3
- 101000979249 Homo sapiens Neuromodulin Proteins 0.000 claims description 3
- 101000975757 Homo sapiens Neutral ceramidase Proteins 0.000 claims description 3
- 101001026214 Homo sapiens Potassium voltage-gated channel subfamily A member 5 Proteins 0.000 claims description 3
- 101000690940 Homo sapiens Pro-adrenomedullin Proteins 0.000 claims description 3
- 101000876829 Homo sapiens Protein C-ets-1 Proteins 0.000 claims description 3
- 101000859935 Homo sapiens Protein CREG1 Proteins 0.000 claims description 3
- 101001021281 Homo sapiens Protein HEXIM1 Proteins 0.000 claims description 3
- 101001048456 Homo sapiens Protein Hook homolog 2 Proteins 0.000 claims description 3
- 101000994437 Homo sapiens Protein jagged-1 Proteins 0.000 claims description 3
- 101000736906 Homo sapiens Protein prune homolog 2 Proteins 0.000 claims description 3
- 101001098529 Homo sapiens Proteinase-activated receptor 1 Proteins 0.000 claims description 3
- 101001062222 Homo sapiens Receptor-binding cancer antigen expressed on SiSo cells Proteins 0.000 claims description 3
- 101000927776 Homo sapiens Rho guanine nucleotide exchange factor 11 Proteins 0.000 claims description 3
- 101000616556 Homo sapiens SH3 domain-containing protein 19 Proteins 0.000 claims description 3
- 101001133085 Homo sapiens Sialomucin core protein 24 Proteins 0.000 claims description 3
- 101000642613 Homo sapiens Sterol O-acyltransferase 2 Proteins 0.000 claims description 3
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 claims description 3
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 3
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 claims description 3
- 108090000191 Inhibitor of growth protein 1 Proteins 0.000 claims description 3
- 102000003781 Inhibitor of growth protein 1 Human genes 0.000 claims description 3
- 102100030212 Inositol hexakisphosphate kinase 2 Human genes 0.000 claims description 3
- 102100035679 Inositol monophosphatase 1 Human genes 0.000 claims description 3
- 102100025092 Insulin receptor substrate 2 Human genes 0.000 claims description 3
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 claims description 3
- 102100029224 Insulin-like growth factor-binding protein 4 Human genes 0.000 claims description 3
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 claims description 3
- 102100027448 Laminin subunit beta-1 Human genes 0.000 claims description 3
- 102100029107 Long chain 3-hydroxyacyl-CoA dehydrogenase Human genes 0.000 claims description 3
- 102100031349 N-acylneuraminate cytidylyltransferase Human genes 0.000 claims description 3
- 102100023206 Neuromodulin Human genes 0.000 claims description 3
- 102100023996 Neutral ceramidase Human genes 0.000 claims description 3
- 102100033616 Phospholipid-transporting ATPase ABCA1 Human genes 0.000 claims description 3
- 102100026651 Pro-adrenomedullin Human genes 0.000 claims description 3
- 102100035251 Protein C-ets-1 Human genes 0.000 claims description 3
- 102100027796 Protein CREG1 Human genes 0.000 claims description 3
- 102100036307 Protein HEXIM1 Human genes 0.000 claims description 3
- 102100032702 Protein jagged-1 Human genes 0.000 claims description 3
- 102100036040 Protein prune homolog 2 Human genes 0.000 claims description 3
- 102100029165 Receptor-binding cancer antigen expressed on SiSo cells Human genes 0.000 claims description 3
- 108010053823 Rho Guanine Nucleotide Exchange Factors Proteins 0.000 claims description 3
- 102100021708 Rho guanine nucleotide exchange factor 1 Human genes 0.000 claims description 3
- 102100033194 Rho guanine nucleotide exchange factor 11 Human genes 0.000 claims description 3
- 102100034258 Sialomucin core protein 24 Human genes 0.000 claims description 3
- 102100036673 Sterol O-acyltransferase 2 Human genes 0.000 claims description 3
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 claims description 3
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 3
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 claims description 3
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 claims description 3
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 claims description 3
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 claims description 3
- 108010031970 prostasin Proteins 0.000 claims description 3
- 102100035906 (Lyso)-N-acylphosphatidylethanolamine lipase Human genes 0.000 claims description 2
- 102100038369 1-acyl-sn-glycerol-3-phosphate acyltransferase beta Human genes 0.000 claims description 2
- 102100038368 1-acyl-sn-glycerol-3-phosphate acyltransferase gamma Human genes 0.000 claims description 2
- 102100038794 17-beta-hydroxysteroid dehydrogenase type 6 Human genes 0.000 claims description 2
- 102100038838 2-Hydroxyacid oxidase 2 Human genes 0.000 claims description 2
- OENIXTHWZWFYIV-UHFFFAOYSA-N 2-[4-[2-[5-(cyclopentylmethyl)-1h-imidazol-2-yl]ethyl]phenyl]benzoic acid Chemical compound OC(=O)C1=CC=CC=C1C(C=C1)=CC=C1CCC(N1)=NC=C1CC1CCCC1 OENIXTHWZWFYIV-UHFFFAOYSA-N 0.000 claims description 2
- 102100027324 2-hydroxyacyl-CoA lyase 1 Human genes 0.000 claims description 2
- 108010067083 3 beta-hydroxysteroid dehydrogenase type II Proteins 0.000 claims description 2
- 102100039082 3 beta-hydroxysteroid dehydrogenase/Delta 5->4-isomerase type 1 Human genes 0.000 claims description 2
- 108020003281 3-hydroxyisobutyrate dehydrogenase Proteins 0.000 claims description 2
- 102100021388 3-hydroxyisobutyrate dehydrogenase, mitochondrial Human genes 0.000 claims description 2
- 102100031908 A-kinase anchor protein 7 isoform gamma Human genes 0.000 claims description 2
- 101150092476 ABCA1 gene Proteins 0.000 claims description 2
- 108010016281 ADP-Ribosylation Factor 1 Proteins 0.000 claims description 2
- 102100034341 ADP-ribosylation factor 1 Human genes 0.000 claims description 2
- 102100039645 ADP-ribosylation factor-like protein 4A Human genes 0.000 claims description 2
- 102100022886 ADP-ribosylation factor-like protein 4C Human genes 0.000 claims description 2
- 102100022861 ADP-ribosylation factor-like protein 5A Human genes 0.000 claims description 2
- 102100022870 ADP-ribosylation factor-like protein 5B Human genes 0.000 claims description 2
- 102100028357 ADP-ribosylation factor-like protein 8B Human genes 0.000 claims description 2
- 102000017920 ADRB1 Human genes 0.000 claims description 2
- 108010079649 APOBEC-1 Deaminase Proteins 0.000 claims description 2
- 101150072844 APOM gene Proteins 0.000 claims description 2
- 102100034580 AT-rich interactive domain-containing protein 1A Human genes 0.000 claims description 2
- 108700005241 ATP Binding Cassette Transporter 1 Proteins 0.000 claims description 2
- 102100020970 ATP-binding cassette sub-family D member 2 Human genes 0.000 claims description 2
- 241000517645 Abra Species 0.000 claims description 2
- 102100039164 Acetyl-CoA carboxylase 1 Human genes 0.000 claims description 2
- 102100035709 Acetyl-coenzyme A synthetase, cytoplasmic Human genes 0.000 claims description 2
- 102100022715 Acetyl-coenzyme A thioesterase Human genes 0.000 claims description 2
- 102100024005 Acid ceramidase Human genes 0.000 claims description 2
- 102100022997 Acidic leucine-rich nuclear phosphoprotein 32 family member A Human genes 0.000 claims description 2
- 102100020963 Actin-binding LIM protein 1 Human genes 0.000 claims description 2
- 102100021516 Actin-binding Rho-activating protein Human genes 0.000 claims description 2
- 102100034064 Actin-like protein 6A Human genes 0.000 claims description 2
- 102100040430 Active breakpoint cluster region-related protein Human genes 0.000 claims description 2
- 102100034542 Acyl-CoA (8-3)-desaturase Human genes 0.000 claims description 2
- 102100025851 Acyl-coenzyme A thioesterase 2, mitochondrial Human genes 0.000 claims description 2
- 102100039140 Acyloxyacyl hydrolase Human genes 0.000 claims description 2
- 102100035984 Adenosine receptor A2b Human genes 0.000 claims description 2
- 102100032161 Adenylate cyclase type 5 Human genes 0.000 claims description 2
- 102100032158 Adenylate cyclase type 6 Human genes 0.000 claims description 2
- 102100032153 Adenylate cyclase type 8 Human genes 0.000 claims description 2
- 102100032156 Adenylate cyclase type 9 Human genes 0.000 claims description 2
- 108010072151 Agouti Signaling Protein Proteins 0.000 claims description 2
- 102100027211 Albumin Human genes 0.000 claims description 2
- 102100026608 Aldehyde dehydrogenase family 3 member A2 Human genes 0.000 claims description 2
- 108010019099 Aldo-Keto Reductase Family 1 member B10 Proteins 0.000 claims description 2
- 102100026448 Aldo-keto reductase family 1 member A1 Human genes 0.000 claims description 2
- 102100024086 Aldo-keto reductase family 1 member D1 Human genes 0.000 claims description 2
- 102100040121 Allograft inflammatory factor 1 Human genes 0.000 claims description 2
- 102100035248 Alpha-(1,3)-fucosyltransferase 4 Human genes 0.000 claims description 2
- 102100021266 Alpha-(1,6)-fucosyltransferase Human genes 0.000 claims description 2
- 102100039088 Amelogenin, X isoform Human genes 0.000 claims description 2
- 102100038778 Amphiregulin Human genes 0.000 claims description 2
- 102100032044 Amphoterin-induced protein 1 Human genes 0.000 claims description 2
- 102000052589 Anaphase-Promoting Complex-Cyclosome Apc4 Subunit Human genes 0.000 claims description 2
- 108700004605 Anaphase-Promoting Complex-Cyclosome Apc4 Subunit Proteins 0.000 claims description 2
- 102100040434 Ankyrin repeat and BTB/POZ domain-containing protein 2 Human genes 0.000 claims description 2
- 102100033897 Ankyrin repeat and SOCS box protein 1 Human genes 0.000 claims description 2
- 102100033900 Ankyrin repeat and SOCS box protein 13 Human genes 0.000 claims description 2
- 102100033899 Ankyrin repeat and SOCS box protein 14 Human genes 0.000 claims description 2
- 102100021626 Ankyrin repeat and SOCS box protein 2 Human genes 0.000 claims description 2
- 102100021617 Ankyrin repeat and SOCS box protein 4 Human genes 0.000 claims description 2
- 102100030718 Ankyrin repeat and SOCS box protein 9 Human genes 0.000 claims description 2
- 102100034613 Annexin A2 Human genes 0.000 claims description 2
- 102100034612 Annexin A4 Human genes 0.000 claims description 2
- 102100037324 Apolipoprotein M Human genes 0.000 claims description 2
- 102100021893 Apoptosis facilitator Bcl-2-like protein 14 Human genes 0.000 claims description 2
- 101100339431 Arabidopsis thaliana HMGB2 gene Proteins 0.000 claims description 2
- 102100022278 Arachidonate 5-lipoxygenase-activating protein Human genes 0.000 claims description 2
- 102100029361 Aromatase Human genes 0.000 claims description 2
- 102100031491 Arylsulfatase B Human genes 0.000 claims description 2
- 108010092776 Autophagy-Related Protein 5 Proteins 0.000 claims description 2
- 102000016614 Autophagy-Related Protein 5 Human genes 0.000 claims description 2
- 102100035634 B-cell linker protein Human genes 0.000 claims description 2
- 102000010595 BABAM2 Human genes 0.000 claims description 2
- 102100027961 BAG family molecular chaperone regulator 2 Human genes 0.000 claims description 2
- 102100027954 BAG family molecular chaperone regulator 3 Human genes 0.000 claims description 2
- 108010040168 Bcl-2-Like Protein 11 Proteins 0.000 claims description 2
- 102000001765 Bcl-2-Like Protein 11 Human genes 0.000 claims description 2
- 102100032423 Bcl-2-associated transcription factor 1 Human genes 0.000 claims description 2
- 102100021573 Bcl-2-binding component 3, isoforms 3/4 Human genes 0.000 claims description 2
- 102100021590 Bcl-2-like protein 10 Human genes 0.000 claims description 2
- 102100021670 Bcl-2-modifying factor Human genes 0.000 claims description 2
- 102100021334 Bcl-2-related protein A1 Human genes 0.000 claims description 2
- 102100039848 Beta-1,3-galactosyl-O-glycosyl-glycoprotein beta-1,6-N-acetylglucosaminyltransferase 3 Human genes 0.000 claims description 2
- 102100032438 Beta-1,3-galactosyltransferase 1 Human genes 0.000 claims description 2
- 102100031504 Beta-1,4 N-acetylgalactosaminyltransferase 2 Human genes 0.000 claims description 2
- 102100026349 Beta-1,4-galactosyltransferase 1 Human genes 0.000 claims description 2
- 102100027387 Beta-1,4-galactosyltransferase 5 Human genes 0.000 claims description 2
- 102100027386 Beta-1,4-galactosyltransferase 6 Human genes 0.000 claims description 2
- 102100031109 Beta-catenin-like protein 1 Human genes 0.000 claims description 2
- 101800001382 Betacellulin Proteins 0.000 claims description 2
- 102100035475 Blood vessel epicardial substance Human genes 0.000 claims description 2
- 101710174254 Blood vessel epicardial substance Proteins 0.000 claims description 2
- 102100024506 Bone morphogenetic protein 2 Human genes 0.000 claims description 2
- 102100024504 Bone morphogenetic protein 3 Human genes 0.000 claims description 2
- 102100024505 Bone morphogenetic protein 4 Human genes 0.000 claims description 2
- 102100022544 Bone morphogenetic protein 7 Human genes 0.000 claims description 2
- 102100022546 Bone morphogenetic protein 8A Human genes 0.000 claims description 2
- 102100022545 Bone morphogenetic protein 8B Human genes 0.000 claims description 2
- 102100028573 Brefeldin A-inhibited guanine nucleotide-exchange protein 2 Human genes 0.000 claims description 2
- 102100029896 Bromodomain-containing protein 8 Human genes 0.000 claims description 2
- 102100025430 Butyrophilin-like protein 3 Human genes 0.000 claims description 2
- 102100031172 C-C chemokine receptor type 1 Human genes 0.000 claims description 2
- 101710149814 C-C chemokine receptor type 1 Proteins 0.000 claims description 2
- 102100023705 C-C motif chemokine 14 Human genes 0.000 claims description 2
- 102100036150 C-X-C motif chemokine 5 Human genes 0.000 claims description 2
- 102100026199 C-type lectin domain family 3 member A Human genes 0.000 claims description 2
- 102100032957 C5a anaphylatoxin chemotactic receptor 1 Human genes 0.000 claims description 2
- 108010014064 CCCTC-Binding Factor Proteins 0.000 claims description 2
- 102100031168 CCN family member 2 Human genes 0.000 claims description 2
- 102100031023 CCR4-NOT transcription complex subunit 11 Human genes 0.000 claims description 2
- 102100024263 CD160 antigen Human genes 0.000 claims description 2
- 102000049320 CD36 Human genes 0.000 claims description 2
- 108010045374 CD36 Antigens Proteins 0.000 claims description 2
- 102100037904 CD9 antigen Human genes 0.000 claims description 2
- 102100025835 CDK2-associated and cullin domain-containing protein 1 Human genes 0.000 claims description 2
- 102100024119 CDK5 and ABL1 enzyme substrate 1 Human genes 0.000 claims description 2
- 102100038451 CDK5 regulatory subunit-associated protein 2 Human genes 0.000 claims description 2
- 108010083123 CDX2 Transcription Factor Proteins 0.000 claims description 2
- 102000017926 CHRM2 Human genes 0.000 claims description 2
- 102000017924 CHRM4 Human genes 0.000 claims description 2
- 108060001826 COP1 Proteins 0.000 claims description 2
- 102100024155 Cadherin-11 Human genes 0.000 claims description 2
- 102100027557 Calcipressin-1 Human genes 0.000 claims description 2
- 102100029171 Calcipressin-2 Human genes 0.000 claims description 2
- 102100024654 Calcitonin gene-related peptide type 1 receptor Human genes 0.000 claims description 2
- 102100029303 Calcium-regulated heat-stable protein 1 Human genes 0.000 claims description 2
- 102100021868 Calnexin Human genes 0.000 claims description 2
- 102100032539 Calpain-3 Human genes 0.000 claims description 2
- 102100035602 Calsequestrin-2 Human genes 0.000 claims description 2
- 102100032196 Carbohydrate sulfotransferase 12 Human genes 0.000 claims description 2
- 102100033378 Carbohydrate sulfotransferase 13 Human genes 0.000 claims description 2
- 102100038768 Carbohydrate sulfotransferase 3 Human genes 0.000 claims description 2
- 102100032144 Carbohydrate sulfotransferase 9 Human genes 0.000 claims description 2
- 102100021753 Cardiolipin synthase (CMP-forming) Human genes 0.000 claims description 2
- 108090000397 Caspase 3 Proteins 0.000 claims description 2
- 102100025634 Caspase recruitment domain-containing protein 16 Human genes 0.000 claims description 2
- 102100025632 Caspase recruitment domain-containing protein 18 Human genes 0.000 claims description 2
- 102100029855 Caspase-3 Human genes 0.000 claims description 2
- 102100028914 Catenin beta-1 Human genes 0.000 claims description 2
- 102100021633 Cathepsin B Human genes 0.000 claims description 2
- 102100024495 Cdc42 effector protein 4 Human genes 0.000 claims description 2
- 102100024491 Cdc42 effector protein 5 Human genes 0.000 claims description 2
- 102100036568 Cell cycle and apoptosis regulator protein 2 Human genes 0.000 claims description 2
- 102100031203 Centrosomal protein 43 Human genes 0.000 claims description 2
- 102100039219 Centrosome-associated protein CEP250 Human genes 0.000 claims description 2
- 101710110151 Centrosome-associated protein CEP250 Proteins 0.000 claims description 2
- 102100035401 Ceramide synthase 2 Human genes 0.000 claims description 2
- 102100034927 Cholecystokinin receptor type A Human genes 0.000 claims description 2
- 102100032766 Chordin-like protein 2 Human genes 0.000 claims description 2
- 102100038602 Chromatin assembly factor 1 subunit A Human genes 0.000 claims description 2
- 102100033361 Cilium assembly protein DZIP1 Human genes 0.000 claims description 2
- 102100031634 Cold shock domain-containing protein E1 Human genes 0.000 claims description 2
- 102100033601 Collagen alpha-1(I) chain Human genes 0.000 claims description 2
- 102100029136 Collagen alpha-1(II) chain Human genes 0.000 claims description 2
- 102100040512 Collagen alpha-1(IX) chain Human genes 0.000 claims description 2
- 102100027442 Collagen alpha-1(XII) chain Human genes 0.000 claims description 2
- 102100036213 Collagen alpha-2(I) chain Human genes 0.000 claims description 2
- 102100035432 Complement factor H Human genes 0.000 claims description 2
- 102100024340 Contactin-4 Human genes 0.000 claims description 2
- 102100032648 Copine-3 Human genes 0.000 claims description 2
- 102100029386 Copine-7 Human genes 0.000 claims description 2
- 102100041023 Coronin-2A Human genes 0.000 claims description 2
- 108010058546 Cyclin D1 Proteins 0.000 claims description 2
- 102100025191 Cyclin-A2 Human genes 0.000 claims description 2
- 108010025464 Cyclin-Dependent Kinase 4 Proteins 0.000 claims description 2
- 108010009356 Cyclin-Dependent Kinase Inhibitor p15 Proteins 0.000 claims description 2
- 102000009512 Cyclin-Dependent Kinase Inhibitor p15 Human genes 0.000 claims description 2
- 102100036874 Cyclin-I2 Human genes 0.000 claims description 2
- 102100036872 Cyclin-J-like protein Human genes 0.000 claims description 2
- 102100024112 Cyclin-T2 Human genes 0.000 claims description 2
- 102100024106 Cyclin-Y Human genes 0.000 claims description 2
- 102100036273 Cyclin-Y-like protein 1 Human genes 0.000 claims description 2
- 102100023263 Cyclin-dependent kinase 10 Human genes 0.000 claims description 2
- 102100034741 Cyclin-dependent kinase 20 Human genes 0.000 claims description 2
- 102100036252 Cyclin-dependent kinase 4 Human genes 0.000 claims description 2
- 102100031679 Cyclin-dependent kinase-like 1 Human genes 0.000 claims description 2
- 102100031620 Cysteine and glycine-rich protein 3 Human genes 0.000 claims description 2
- 102100032759 Cysteine-rich motor neuron 1 protein Human genes 0.000 claims description 2
- 102100039205 Cytochrome P450 3A4 Human genes 0.000 claims description 2
- 102100027567 Cytochrome P450 4A11 Human genes 0.000 claims description 2
- 102100038637 Cytochrome P450 7A1 Human genes 0.000 claims description 2
- 102100037068 Cytoplasmic dynein 1 light intermediate chain 1 Human genes 0.000 claims description 2
- 102100023044 Cytosolic acyl coenzyme A thioester hydrolase Human genes 0.000 claims description 2
- 102100027819 Cytosolic beta-glucosidase Human genes 0.000 claims description 2
- 102100020756 D(2) dopamine receptor Human genes 0.000 claims description 2
- 102100024398 DCC-interacting protein 13-beta Human genes 0.000 claims description 2
- 102100022690 DEP domain-containing protein 7 Human genes 0.000 claims description 2
- 102100025450 DNA replication factor Cdt1 Human genes 0.000 claims description 2
- 102100030960 DNA replication licensing factor MCM2 Human genes 0.000 claims description 2
- 102100033672 Deleted in azoospermia-like Human genes 0.000 claims description 2
- 102100031149 Deoxyribonuclease gamma Human genes 0.000 claims description 2
- 102100030438 Derlin-1 Human genes 0.000 claims description 2
- 102100038027 Diacylglycerol lipase-alpha Human genes 0.000 claims description 2
- 102100028572 Disabled homolog 2 Human genes 0.000 claims description 2
- 102100028571 Disabled homolog 2-interacting protein Human genes 0.000 claims description 2
- 102100034428 Dual specificity protein phosphatase 1 Human genes 0.000 claims description 2
- 102100037570 Dual specificity protein phosphatase 16 Human genes 0.000 claims description 2
- 102100021160 Dual specificity protein phosphatase 9 Human genes 0.000 claims description 2
- 102100021076 Dynactin subunit 2 Human genes 0.000 claims description 2
- 102100035834 Dynactin subunit 6 Human genes 0.000 claims description 2
- 102100024821 Dynamin-binding protein Human genes 0.000 claims description 2
- 102100032249 Dystonin Human genes 0.000 claims description 2
- 102100024108 Dystrophin Human genes 0.000 claims description 2
- 102100032917 E3 SUMO-protein ligase CBX4 Human genes 0.000 claims description 2
- 102100035273 E3 ubiquitin-protein ligase CBL-B Human genes 0.000 claims description 2
- 108091016436 EPS8 Proteins 0.000 claims description 2
- 102000020045 EPS8 Human genes 0.000 claims description 2
- 102100039247 ETS-related transcription factor Elf-4 Human genes 0.000 claims description 2
- 102100027100 Echinoderm microtubule-associated protein-like 4 Human genes 0.000 claims description 2
- 102100032222 Emopamil-binding protein-like Human genes 0.000 claims description 2
- 102100021598 Endoplasmic reticulum aminopeptidase 1 Human genes 0.000 claims description 2
- 101710168245 Endoplasmic reticulum aminopeptidase 1 Proteins 0.000 claims description 2
- 102100036448 Endothelial PAS domain-containing protein 1 Human genes 0.000 claims description 2
- 102100031785 Endothelial transcription factor GATA-2 Human genes 0.000 claims description 2
- 102100033902 Endothelin-1 Human genes 0.000 claims description 2
- 102100039369 Epidermal growth factor receptor substrate 15 Human genes 0.000 claims description 2
- 102100023400 Estradiol 17-beta-dehydrogenase 11 Human genes 0.000 claims description 2
- 102100033175 Ethanolamine kinase 1 Human genes 0.000 claims description 2
- 102100030862 Eyes absent homolog 2 Human genes 0.000 claims description 2
- 108091059597 FAIM3 Proteins 0.000 claims description 2
- 102100037789 FAST kinase domain-containing protein 1, mitochondrial Human genes 0.000 claims description 2
- 102100038665 FGGY carbohydrate kinase domain-containing protein Human genes 0.000 claims description 2
- 102100034553 Fanconi anemia group J protein Human genes 0.000 claims description 2
- 102100037819 Fas apoptotic inhibitory molecule 1 Human genes 0.000 claims description 2
- 102100037815 Fas apoptotic inhibitory molecule 3 Human genes 0.000 claims description 2
- 102100037679 Fasciculation and elongation protein zeta-2 Human genes 0.000 claims description 2
- 102100034334 Fatty acid CoA ligase Acsl3 Human genes 0.000 claims description 2
- 102100026748 Fatty acid-binding protein, intestinal Human genes 0.000 claims description 2
- 102100021056 Ferroptosis suppressor protein 1 Human genes 0.000 claims description 2
- 102100031509 Fibrillin-1 Human genes 0.000 claims description 2
- 102100028313 Fibrinogen beta chain Human genes 0.000 claims description 2
- 102100024783 Fibrinogen gamma chain Human genes 0.000 claims description 2
- 102100037680 Fibroblast growth factor 8 Human genes 0.000 claims description 2
- 102100037665 Fibroblast growth factor 9 Human genes 0.000 claims description 2
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 claims description 2
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 claims description 2
- 102100037564 Filamin-binding LIM protein 1 Human genes 0.000 claims description 2
- 102100027909 Folliculin Human genes 0.000 claims description 2
- 102100023371 Forkhead box protein N1 Human genes 0.000 claims description 2
- 102100023359 Forkhead box protein N3 Human genes 0.000 claims description 2
- 102100038644 Four and a half LIM domains protein 2 Human genes 0.000 claims description 2
- 102100035068 Fructosamine-3-kinase Human genes 0.000 claims description 2
- 102100037181 Fructose-1,6-bisphosphatase 1 Human genes 0.000 claims description 2
- 102100022272 Fructose-bisphosphate aldolase B Human genes 0.000 claims description 2
- 102100023685 G protein-coupled receptor kinase 5 Human genes 0.000 claims description 2
- 102100024165 G1/S-specific cyclin-D1 Human genes 0.000 claims description 2
- 102100024185 G1/S-specific cyclin-D2 Human genes 0.000 claims description 2
- 102100037854 G1/S-specific cyclin-E2 Human genes 0.000 claims description 2
- 108700031835 GRB10 Adaptor Proteins 0.000 claims description 2
- 108700031843 GRB7 Adaptor Proteins 0.000 claims description 2
- 101150052409 GRB7 gene Proteins 0.000 claims description 2
- 102100028617 GRIP and coiled-coil domain-containing protein 2 Human genes 0.000 claims description 2
- 102100023745 GTP-binding protein 4 Human genes 0.000 claims description 2
- 102100025626 GTP-binding protein GEM Human genes 0.000 claims description 2
- 102100027362 GTP-binding protein REM 2 Human genes 0.000 claims description 2
- 102100030708 GTPase KRas Human genes 0.000 claims description 2
- 102100031692 GTPase-activating protein and VPS9 domain-containing protein 1 Human genes 0.000 claims description 2
- 102100028496 Galactocerebrosidase Human genes 0.000 claims description 2
- 102100037777 Galactokinase Human genes 0.000 claims description 2
- 102100031687 Galactose mutarotase Human genes 0.000 claims description 2
- 102100039956 Geminin Human genes 0.000 claims description 2
- 102100031885 General transcription and DNA repair factor IIH helicase subunit XPB Human genes 0.000 claims description 2
- 102100039847 Globoside alpha-1,3-N-acetylgalactosaminyltransferase 1 Human genes 0.000 claims description 2
- 108010086246 Glucagon-Like Peptide-1 Receptor Proteins 0.000 claims description 2
- 102100032882 Glucagon-like peptide 1 receptor Human genes 0.000 claims description 2
- 102100025783 Glutamyl aminopeptidase Human genes 0.000 claims description 2
- 102100030943 Glutathione S-transferase P Human genes 0.000 claims description 2
- 102100024008 Glycerol-3-phosphate acyltransferase 1, mitochondrial Human genes 0.000 claims description 2
- 102100036669 Glycerol-3-phosphate dehydrogenase [NAD(+)], cytoplasmic Human genes 0.000 claims description 2
- 102100030395 Glycerol-3-phosphate dehydrogenase, mitochondrial Human genes 0.000 claims description 2
- 102100036076 Glycerophosphocholine cholinephosphodiesterase ENPP6 Human genes 0.000 claims description 2
- 102100033802 Golgi pH regulator A Human genes 0.000 claims description 2
- 102100033415 Golgi resident protein GCP60 Human genes 0.000 claims description 2
- 101150090959 Grb10 gene Proteins 0.000 claims description 2
- 102100023910 Growth factor receptor-bound protein 10 Human genes 0.000 claims description 2
- 102100023911 Growth factor receptor-bound protein 14 Human genes 0.000 claims description 2
- 102100033107 Growth factor receptor-bound protein 7 Human genes 0.000 claims description 2
- 102100020948 Growth hormone receptor Human genes 0.000 claims description 2
- 102100040895 Growth/differentiation factor 10 Human genes 0.000 claims description 2
- 102100025296 Guanine nucleotide-binding protein G(o) subunit alpha Human genes 0.000 claims description 2
- 102100025334 Guanine nucleotide-binding protein G(q) subunit alpha Human genes 0.000 claims description 2
- 102100022662 Guanylyl cyclase C Human genes 0.000 claims description 2
- 108700010013 HMGB1 Proteins 0.000 claims description 2
- 101150021904 HMGB1 gene Proteins 0.000 claims description 2
- 102100028006 Heme oxygenase 1 Human genes 0.000 claims description 2
- 101800000637 Hemokinin Proteins 0.000 claims description 2
- 102100023928 Heparan sulfate glucosamine 3-O-sulfotransferase 4 Human genes 0.000 claims description 2
- 102100023923 Heparan sulfate glucosamine 3-O-sulfotransferase 5 Human genes 0.000 claims description 2
- 102100022057 Hepatocyte nuclear factor 1-alpha Human genes 0.000 claims description 2
- 102100022054 Hepatocyte nuclear factor 4-alpha Human genes 0.000 claims description 2
- 102100031000 Hepatoma-derived growth factor Human genes 0.000 claims description 2
- 102100029274 Hexokinase HKDC1 Human genes 0.000 claims description 2
- 102100037907 High mobility group protein B1 Human genes 0.000 claims description 2
- 102100035009 Holocytochrome c-type synthase Human genes 0.000 claims description 2
- 102100031671 Homeobox protein CDX-2 Human genes 0.000 claims description 2
- 102100022374 Homeobox protein DLX-4 Human genes 0.000 claims description 2
- 102100030307 Homeobox protein Hox-A13 Human genes 0.000 claims description 2
- 102100029426 Homeobox protein Hox-C10 Human genes 0.000 claims description 2
- 101000929842 Homo sapiens (Lyso)-N-acylphosphatidylethanolamine lipase Proteins 0.000 claims description 2
- 101000605571 Homo sapiens 1-acyl-sn-glycerol-3-phosphate acyltransferase beta Proteins 0.000 claims description 2
- 101000605576 Homo sapiens 1-acyl-sn-glycerol-3-phosphate acyltransferase gamma Proteins 0.000 claims description 2
- 101001031333 Homo sapiens 17-beta-hydroxysteroid dehydrogenase type 6 Proteins 0.000 claims description 2
- 101001031584 Homo sapiens 2-Hydroxyacid oxidase 2 Proteins 0.000 claims description 2
- 101001009252 Homo sapiens 2-hydroxyacyl-CoA lyase 1 Proteins 0.000 claims description 2
- 101000744065 Homo sapiens 3 beta-hydroxysteroid dehydrogenase/Delta 5->4-isomerase type 1 Proteins 0.000 claims description 2
- 101000774725 Homo sapiens A-kinase anchor protein 7 isoform gamma Proteins 0.000 claims description 2
- 101000774727 Homo sapiens A-kinase anchor protein 7 isoforms alpha and beta Proteins 0.000 claims description 2
- 101000886015 Homo sapiens ADP-ribosylation factor-like protein 4A Proteins 0.000 claims description 2
- 101000974390 Homo sapiens ADP-ribosylation factor-like protein 4C Proteins 0.000 claims description 2
- 101000974441 Homo sapiens ADP-ribosylation factor-like protein 5A Proteins 0.000 claims description 2
- 101000974439 Homo sapiens ADP-ribosylation factor-like protein 5B Proteins 0.000 claims description 2
- 101000769042 Homo sapiens ADP-ribosylation factor-like protein 8B Proteins 0.000 claims description 2
- 101000924266 Homo sapiens AT-rich interactive domain-containing protein 1A Proteins 0.000 claims description 2
- 101000783774 Homo sapiens ATP-binding cassette sub-family D member 2 Proteins 0.000 claims description 2
- 101000837584 Homo sapiens Acetyl-CoA acetyltransferase, cytosolic Proteins 0.000 claims description 2
- 101000963424 Homo sapiens Acetyl-CoA carboxylase 1 Proteins 0.000 claims description 2
- 101000783232 Homo sapiens Acetyl-coenzyme A synthetase, cytoplasmic Proteins 0.000 claims description 2
- 101000678862 Homo sapiens Acetyl-coenzyme A thioesterase Proteins 0.000 claims description 2
- 101000975753 Homo sapiens Acid ceramidase Proteins 0.000 claims description 2
- 101000757200 Homo sapiens Acidic leucine-rich nuclear phosphoprotein 32 family member A Proteins 0.000 claims description 2
- 101000783802 Homo sapiens Actin-binding LIM protein 1 Proteins 0.000 claims description 2
- 101000677807 Homo sapiens Actin-binding Rho-activating protein Proteins 0.000 claims description 2
- 101000798882 Homo sapiens Actin-like protein 6A Proteins 0.000 claims description 2
- 101000964363 Homo sapiens Active breakpoint cluster region-related protein Proteins 0.000 claims description 2
- 101000848239 Homo sapiens Acyl-CoA (8-3)-desaturase Proteins 0.000 claims description 2
- 101000720371 Homo sapiens Acyl-coenzyme A thioesterase 2, mitochondrial Proteins 0.000 claims description 2
- 101000889541 Homo sapiens Acyloxyacyl hydrolase Proteins 0.000 claims description 2
- 101000783756 Homo sapiens Adenosine receptor A2b Proteins 0.000 claims description 2
- 101000775478 Homo sapiens Adenylate cyclase type 5 Proteins 0.000 claims description 2
- 101000775489 Homo sapiens Adenylate cyclase type 6 Proteins 0.000 claims description 2
- 101000775481 Homo sapiens Adenylate cyclase type 8 Proteins 0.000 claims description 2
- 101000775499 Homo sapiens Adenylate cyclase type 9 Proteins 0.000 claims description 2
- 101000693913 Homo sapiens Albumin Proteins 0.000 claims description 2
- 101000717967 Homo sapiens Aldehyde dehydrogenase family 3 member A2 Proteins 0.000 claims description 2
- 101000718007 Homo sapiens Aldo-keto reductase family 1 member A1 Proteins 0.000 claims description 2
- 101000690251 Homo sapiens Aldo-keto reductase family 1 member D1 Proteins 0.000 claims description 2
- 101000890626 Homo sapiens Allograft inflammatory factor 1 Proteins 0.000 claims description 2
- 101001022185 Homo sapiens Alpha-(1,3)-fucosyltransferase 4 Proteins 0.000 claims description 2
- 101000819490 Homo sapiens Alpha-(1,6)-fucosyltransferase Proteins 0.000 claims description 2
- 101000959114 Homo sapiens Amelogenin, X isoform Proteins 0.000 claims description 2
- 101000809450 Homo sapiens Amphiregulin Proteins 0.000 claims description 2
- 101000776170 Homo sapiens Amphoterin-induced protein 1 Proteins 0.000 claims description 2
- 101000964346 Homo sapiens Ankyrin repeat and BTB/POZ domain-containing protein 2 Proteins 0.000 claims description 2
- 101000925496 Homo sapiens Ankyrin repeat and SOCS box protein 1 Proteins 0.000 claims description 2
- 101000925512 Homo sapiens Ankyrin repeat and SOCS box protein 13 Proteins 0.000 claims description 2
- 101000925508 Homo sapiens Ankyrin repeat and SOCS box protein 14 Proteins 0.000 claims description 2
- 101000754299 Homo sapiens Ankyrin repeat and SOCS box protein 2 Proteins 0.000 claims description 2
- 101000754303 Homo sapiens Ankyrin repeat and SOCS box protein 4 Proteins 0.000 claims description 2
- 101000703112 Homo sapiens Ankyrin repeat and SOCS box protein 9 Proteins 0.000 claims description 2
- 101000924474 Homo sapiens Annexin A2 Proteins 0.000 claims description 2
- 101000924461 Homo sapiens Annexin A4 Proteins 0.000 claims description 2
- 101000971069 Homo sapiens Apoptosis facilitator Bcl-2-like protein 14 Proteins 0.000 claims description 2
- 101000755875 Homo sapiens Arachidonate 5-lipoxygenase-activating protein Proteins 0.000 claims description 2
- 101000919395 Homo sapiens Aromatase Proteins 0.000 claims description 2
- 101000923070 Homo sapiens Arylsulfatase B Proteins 0.000 claims description 2
- 101000803266 Homo sapiens B-cell linker protein Proteins 0.000 claims description 2
- 101100111156 Homo sapiens B4GALNT2 gene Proteins 0.000 claims description 2
- 101000697872 Homo sapiens BAG family molecular chaperone regulator 2 Proteins 0.000 claims description 2
- 101000697871 Homo sapiens BAG family molecular chaperone regulator 3 Proteins 0.000 claims description 2
- 101000933342 Homo sapiens BMP/retinoic acid-inducible neural-specific protein 1 Proteins 0.000 claims description 2
- 101000874539 Homo sapiens BRISC and BRCA1-A complex member 2 Proteins 0.000 claims description 2
- 101000798490 Homo sapiens Bcl-2-associated transcription factor 1 Proteins 0.000 claims description 2
- 101000971203 Homo sapiens Bcl-2-binding component 3, isoforms 1/2 Proteins 0.000 claims description 2
- 101000971209 Homo sapiens Bcl-2-binding component 3, isoforms 3/4 Proteins 0.000 claims description 2
- 101000971082 Homo sapiens Bcl-2-like protein 10 Proteins 0.000 claims description 2
- 101000896211 Homo sapiens Bcl-2-modifying factor Proteins 0.000 claims description 2
- 101000894929 Homo sapiens Bcl-2-related protein A1 Proteins 0.000 claims description 2
- 101000892264 Homo sapiens Beta-1 adrenergic receptor Proteins 0.000 claims description 2
- 101000887635 Homo sapiens Beta-1,3-galactosyl-O-glycosyl-glycoprotein beta-1,6-N-acetylglucosaminyltransferase 3 Proteins 0.000 claims description 2
- 101000798380 Homo sapiens Beta-1,3-galactosyltransferase 1 Proteins 0.000 claims description 2
- 101000766145 Homo sapiens Beta-1,4-galactosyltransferase 1 Proteins 0.000 claims description 2
- 101000937496 Homo sapiens Beta-1,4-galactosyltransferase 5 Proteins 0.000 claims description 2
- 101000937502 Homo sapiens Beta-1,4-galactosyltransferase 6 Proteins 0.000 claims description 2
- 101000922061 Homo sapiens Beta-catenin-like protein 1 Proteins 0.000 claims description 2
- 101000762366 Homo sapiens Bone morphogenetic protein 2 Proteins 0.000 claims description 2
- 101000762375 Homo sapiens Bone morphogenetic protein 3 Proteins 0.000 claims description 2
- 101000762379 Homo sapiens Bone morphogenetic protein 4 Proteins 0.000 claims description 2
- 101000899361 Homo sapiens Bone morphogenetic protein 7 Proteins 0.000 claims description 2
- 101000899364 Homo sapiens Bone morphogenetic protein 8A Proteins 0.000 claims description 2
- 101000899368 Homo sapiens Bone morphogenetic protein 8B Proteins 0.000 claims description 2
- 101000695920 Homo sapiens Brefeldin A-inhibited guanine nucleotide-exchange protein 2 Proteins 0.000 claims description 2
- 101000794020 Homo sapiens Bromodomain-containing protein 8 Proteins 0.000 claims description 2
- 101000934741 Homo sapiens Butyrophilin-like protein 3 Proteins 0.000 claims description 2
- 101000978381 Homo sapiens C-C motif chemokine 14 Proteins 0.000 claims description 2
- 101000947186 Homo sapiens C-X-C motif chemokine 5 Proteins 0.000 claims description 2
- 101000912587 Homo sapiens C-type lectin domain family 3 member A Proteins 0.000 claims description 2
- 101000867983 Homo sapiens C5a anaphylatoxin chemotactic receptor 1 Proteins 0.000 claims description 2
- 101000777550 Homo sapiens CCN family member 2 Proteins 0.000 claims description 2
- 101000919678 Homo sapiens CCR4-NOT transcription complex subunit 11 Proteins 0.000 claims description 2
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 claims description 2
- 101000738354 Homo sapiens CD9 antigen Proteins 0.000 claims description 2
- 101000983944 Homo sapiens CDK2-associated and cullin domain-containing protein 1 Proteins 0.000 claims description 2
- 101000910461 Homo sapiens CDK5 and ABL1 enzyme substrate 1 Proteins 0.000 claims description 2
- 101000882873 Homo sapiens CDK5 regulatory subunit-associated protein 2 Proteins 0.000 claims description 2
- 101000762236 Homo sapiens Cadherin-11 Proteins 0.000 claims description 2
- 101000580357 Homo sapiens Calcipressin-1 Proteins 0.000 claims description 2
- 101001062197 Homo sapiens Calcipressin-2 Proteins 0.000 claims description 2
- 101000760563 Homo sapiens Calcitonin gene-related peptide type 1 receptor Proteins 0.000 claims description 2
- 101000989513 Homo sapiens Calcium-regulated heat-stable protein 1 Proteins 0.000 claims description 2
- 101000898052 Homo sapiens Calnexin Proteins 0.000 claims description 2
- 101000867715 Homo sapiens Calpain-3 Proteins 0.000 claims description 2
- 101000947118 Homo sapiens Calsequestrin-2 Proteins 0.000 claims description 2
- 101000775621 Homo sapiens Carbohydrate sulfotransferase 12 Proteins 0.000 claims description 2
- 101000943855 Homo sapiens Carbohydrate sulfotransferase 13 Proteins 0.000 claims description 2
- 101000882992 Homo sapiens Carbohydrate sulfotransferase 3 Proteins 0.000 claims description 2
- 101000775602 Homo sapiens Carbohydrate sulfotransferase 9 Proteins 0.000 claims description 2
- 101000895518 Homo sapiens Cardiolipin synthase (CMP-forming) Proteins 0.000 claims description 2
- 101000933105 Homo sapiens Caspase recruitment domain-containing protein 18 Proteins 0.000 claims description 2
- 101000983518 Homo sapiens Caspase-10 Proteins 0.000 claims description 2
- 101000916173 Homo sapiens Catenin beta-1 Proteins 0.000 claims description 2
- 101000898449 Homo sapiens Cathepsin B Proteins 0.000 claims description 2
- 101000762421 Homo sapiens Cdc42 effector protein 4 Proteins 0.000 claims description 2
- 101000762416 Homo sapiens Cdc42 effector protein 5 Proteins 0.000 claims description 2
- 101000715194 Homo sapiens Cell cycle and apoptosis regulator protein 2 Proteins 0.000 claims description 2
- 101000776477 Homo sapiens Centrosomal protein 43 Proteins 0.000 claims description 2
- 101000737604 Homo sapiens Ceramide synthase 2 Proteins 0.000 claims description 2
- 101000946804 Homo sapiens Cholecystokinin receptor type A Proteins 0.000 claims description 2
- 101000941976 Homo sapiens Chordin-like protein 2 Proteins 0.000 claims description 2
- 101000741348 Homo sapiens Chromatin assembly factor 1 subunit A Proteins 0.000 claims description 2
- 101000926718 Homo sapiens Cilium assembly protein DZIP1 Proteins 0.000 claims description 2
- 101000940535 Homo sapiens Cold shock domain-containing protein E1 Proteins 0.000 claims description 2
- 101000771163 Homo sapiens Collagen alpha-1(II) chain Proteins 0.000 claims description 2
- 101000749901 Homo sapiens Collagen alpha-1(IX) chain Proteins 0.000 claims description 2
- 101000861874 Homo sapiens Collagen alpha-1(XII) chain Proteins 0.000 claims description 2
- 101000875067 Homo sapiens Collagen alpha-2(I) chain Proteins 0.000 claims description 2
- 101000737574 Homo sapiens Complement factor H Proteins 0.000 claims description 2
- 101000909504 Homo sapiens Contactin-4 Proteins 0.000 claims description 2
- 101000941769 Homo sapiens Copine-3 Proteins 0.000 claims description 2
- 101000919214 Homo sapiens Copine-7 Proteins 0.000 claims description 2
- 101000748858 Homo sapiens Coronin-2A Proteins 0.000 claims description 2
- 101000934320 Homo sapiens Cyclin-A2 Proteins 0.000 claims description 2
- 101000713125 Homo sapiens Cyclin-I2 Proteins 0.000 claims description 2
- 101000713133 Homo sapiens Cyclin-J-like protein Proteins 0.000 claims description 2
- 101000716088 Homo sapiens Cyclin-L1 Proteins 0.000 claims description 2
- 101000910484 Homo sapiens Cyclin-T2 Proteins 0.000 claims description 2
- 101000910602 Homo sapiens Cyclin-Y Proteins 0.000 claims description 2
- 101000716073 Homo sapiens Cyclin-Y-like protein 1 Proteins 0.000 claims description 2
- 101000908138 Homo sapiens Cyclin-dependent kinase 10 Proteins 0.000 claims description 2
- 101000945708 Homo sapiens Cyclin-dependent kinase 20 Proteins 0.000 claims description 2
- 101000715946 Homo sapiens Cyclin-dependent kinase 3 Proteins 0.000 claims description 2
- 101000945639 Homo sapiens Cyclin-dependent kinase inhibitor 3 Proteins 0.000 claims description 2
- 101000777728 Homo sapiens Cyclin-dependent kinase-like 1 Proteins 0.000 claims description 2
- 101000940764 Homo sapiens Cysteine and glycine-rich protein 3 Proteins 0.000 claims description 2
- 101000942095 Homo sapiens Cysteine-rich motor neuron 1 protein Proteins 0.000 claims description 2
- 101000725111 Homo sapiens Cytochrome P450 4A11 Proteins 0.000 claims description 2
- 101000957672 Homo sapiens Cytochrome P450 7A1 Proteins 0.000 claims description 2
- 101000954692 Homo sapiens Cytoplasmic dynein 1 light intermediate chain 1 Proteins 0.000 claims description 2
- 101000903587 Homo sapiens Cytosolic acyl coenzyme A thioester hydrolase Proteins 0.000 claims description 2
- 101000859692 Homo sapiens Cytosolic beta-glucosidase Proteins 0.000 claims description 2
- 101000931901 Homo sapiens D(2) dopamine receptor Proteins 0.000 claims description 2
- 101001053257 Homo sapiens DCC-interacting protein 13-beta Proteins 0.000 claims description 2
- 101001044727 Homo sapiens DEP domain-containing protein 7 Proteins 0.000 claims description 2
- 101000914265 Homo sapiens DNA replication factor Cdt1 Proteins 0.000 claims description 2
- 101000583807 Homo sapiens DNA replication licensing factor MCM2 Proteins 0.000 claims description 2
- 101000871280 Homo sapiens Deleted in azoospermia-like Proteins 0.000 claims description 2
- 101000845618 Homo sapiens Deoxyribonuclease gamma Proteins 0.000 claims description 2
- 101000842611 Homo sapiens Derlin-1 Proteins 0.000 claims description 2
- 101000950954 Homo sapiens Diacylglycerol lipase-alpha Proteins 0.000 claims description 2
- 101000915391 Homo sapiens Disabled homolog 2 Proteins 0.000 claims description 2
- 101000915396 Homo sapiens Disabled homolog 2-interacting protein Proteins 0.000 claims description 2
- 101000924017 Homo sapiens Dual specificity protein phosphatase 1 Proteins 0.000 claims description 2
- 101000881110 Homo sapiens Dual specificity protein phosphatase 12 Proteins 0.000 claims description 2
- 101000881117 Homo sapiens Dual specificity protein phosphatase 16 Proteins 0.000 claims description 2
- 101000968556 Homo sapiens Dual specificity protein phosphatase 9 Proteins 0.000 claims description 2
- 101001041190 Homo sapiens Dynactin subunit 2 Proteins 0.000 claims description 2
- 101000873769 Homo sapiens Dynactin subunit 6 Proteins 0.000 claims description 2
- 101000909230 Homo sapiens Dynamin-binding protein Proteins 0.000 claims description 2
- 101000966403 Homo sapiens Dynein light chain 1, cytoplasmic Proteins 0.000 claims description 2
- 101001053946 Homo sapiens Dystrophin Proteins 0.000 claims description 2
- 101000797579 Homo sapiens E3 SUMO-protein ligase CBX4 Proteins 0.000 claims description 2
- 101000737265 Homo sapiens E3 ubiquitin-protein ligase CBL-B Proteins 0.000 claims description 2
- 101000813135 Homo sapiens ETS-related transcription factor Elf-4 Proteins 0.000 claims description 2
- 101001057929 Homo sapiens Echinoderm microtubule-associated protein-like 4 Proteins 0.000 claims description 2
- 101001015930 Homo sapiens Emopamil-binding protein-like Proteins 0.000 claims description 2
- 101001066265 Homo sapiens Endothelial transcription factor GATA-2 Proteins 0.000 claims description 2
- 101000925493 Homo sapiens Endothelin-1 Proteins 0.000 claims description 2
- 101000812517 Homo sapiens Epidermal growth factor receptor substrate 15 Proteins 0.000 claims description 2
- 101000907855 Homo sapiens Estradiol 17-beta-dehydrogenase 11 Proteins 0.000 claims description 2
- 101000851032 Homo sapiens Ethanolamine kinase 1 Proteins 0.000 claims description 2
- 101000938438 Homo sapiens Eyes absent homolog 2 Proteins 0.000 claims description 2
- 101000878541 Homo sapiens FAST kinase domain-containing protein 1, mitochondrial Proteins 0.000 claims description 2
- 101001031630 Homo sapiens FGGY carbohydrate kinase domain-containing protein Proteins 0.000 claims description 2
- 101000848171 Homo sapiens Fanconi anemia group J protein Proteins 0.000 claims description 2
- 101000930766 Homo sapiens Far upstream element-binding protein 2 Proteins 0.000 claims description 2
- 101000878509 Homo sapiens Fas apoptotic inhibitory molecule 1 Proteins 0.000 claims description 2
- 101001065295 Homo sapiens Fas-binding factor 1 Proteins 0.000 claims description 2
- 101001027414 Homo sapiens Fasciculation and elongation protein zeta-2 Proteins 0.000 claims description 2
- 101000780194 Homo sapiens Fatty acid CoA ligase Acsl3 Proteins 0.000 claims description 2
- 101000911337 Homo sapiens Fatty acid-binding protein, intestinal Proteins 0.000 claims description 2
- 101000846893 Homo sapiens Fibrillin-1 Proteins 0.000 claims description 2
- 101000917163 Homo sapiens Fibrinogen beta chain Proteins 0.000 claims description 2
- 101001052043 Homo sapiens Fibrinogen gamma chain Proteins 0.000 claims description 2
- 101001027382 Homo sapiens Fibroblast growth factor 8 Proteins 0.000 claims description 2
- 101001027380 Homo sapiens Fibroblast growth factor 9 Proteins 0.000 claims description 2
- 101001028052 Homo sapiens Filamin-binding LIM protein 1 Proteins 0.000 claims description 2
- 101001060703 Homo sapiens Folliculin Proteins 0.000 claims description 2
- 101000907576 Homo sapiens Forkhead box protein N1 Proteins 0.000 claims description 2
- 101000907594 Homo sapiens Forkhead box protein N3 Proteins 0.000 claims description 2
- 101001031607 Homo sapiens Four and a half LIM domains protein 1 Proteins 0.000 claims description 2
- 101001031714 Homo sapiens Four and a half LIM domains protein 2 Proteins 0.000 claims description 2
- 101001022433 Homo sapiens Fructosamine-3-kinase Proteins 0.000 claims description 2
- 101001028852 Homo sapiens Fructose-1,6-bisphosphatase 1 Proteins 0.000 claims description 2
- 101001063910 Homo sapiens Fructose-1,6-bisphosphatase isozyme 2 Proteins 0.000 claims description 2
- 101000755933 Homo sapiens Fructose-bisphosphate aldolase B Proteins 0.000 claims description 2
- 101000829476 Homo sapiens G protein-coupled receptor kinase 5 Proteins 0.000 claims description 2
- 101000980741 Homo sapiens G1/S-specific cyclin-D2 Proteins 0.000 claims description 2
- 101000738575 Homo sapiens G1/S-specific cyclin-E2 Proteins 0.000 claims description 2
- 101001058870 Homo sapiens GRIP and coiled-coil domain-containing protein 2 Proteins 0.000 claims description 2
- 101000828886 Homo sapiens GTP-binding protein 4 Proteins 0.000 claims description 2
- 101000856606 Homo sapiens GTP-binding protein GEM Proteins 0.000 claims description 2
- 101000581787 Homo sapiens GTP-binding protein REM 2 Proteins 0.000 claims description 2
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 claims description 2
- 101001066325 Homo sapiens GTPase-activating protein and VPS9 domain-containing protein 1 Proteins 0.000 claims description 2
- 101000860395 Homo sapiens Galactocerebrosidase Proteins 0.000 claims description 2
- 101001024874 Homo sapiens Galactokinase Proteins 0.000 claims description 2
- 101001066315 Homo sapiens Galactose mutarotase Proteins 0.000 claims description 2
- 101000886596 Homo sapiens Geminin Proteins 0.000 claims description 2
- 101000920748 Homo sapiens General transcription and DNA repair factor IIH helicase subunit XPB Proteins 0.000 claims description 2
- 101000887519 Homo sapiens Globoside alpha-1,3-N-acetylgalactosaminyltransferase 1 Proteins 0.000 claims description 2
- 101000719019 Homo sapiens Glutamyl aminopeptidase Proteins 0.000 claims description 2
- 101001010139 Homo sapiens Glutathione S-transferase P Proteins 0.000 claims description 2
- 101000904268 Homo sapiens Glycerol-3-phosphate acyltransferase 1, mitochondrial Proteins 0.000 claims description 2
- 101001072574 Homo sapiens Glycerol-3-phosphate dehydrogenase [NAD(+)], cytoplasmic Proteins 0.000 claims description 2
- 101001009678 Homo sapiens Glycerol-3-phosphate dehydrogenase, mitochondrial Proteins 0.000 claims description 2
- 101000876254 Homo sapiens Glycerophosphocholine cholinephosphodiesterase ENPP6 Proteins 0.000 claims description 2
- 101001069247 Homo sapiens Golgi pH regulator A Proteins 0.000 claims description 2
- 101000926911 Homo sapiens Golgi resident protein GCP60 Proteins 0.000 claims description 2
- 101000904875 Homo sapiens Growth factor receptor-bound protein 14 Proteins 0.000 claims description 2
- 101001075287 Homo sapiens Growth hormone receptor Proteins 0.000 claims description 2
- 101000893563 Homo sapiens Growth/differentiation factor 10 Proteins 0.000 claims description 2
- 101000857837 Homo sapiens Guanine nucleotide-binding protein G(o) subunit alpha Proteins 0.000 claims description 2
- 101000857888 Homo sapiens Guanine nucleotide-binding protein G(q) subunit alpha Proteins 0.000 claims description 2
- 101000899808 Homo sapiens Guanylyl cyclase C Proteins 0.000 claims description 2
- 101001079623 Homo sapiens Heme oxygenase 1 Proteins 0.000 claims description 2
- 101001048120 Homo sapiens Heparan sulfate glucosamine 3-O-sulfotransferase 4 Proteins 0.000 claims description 2
- 101001048110 Homo sapiens Heparan sulfate glucosamine 3-O-sulfotransferase 5 Proteins 0.000 claims description 2
- 101001048116 Homo sapiens Heparan sulfate glucosamine 3-O-sulfotransferase 6 Proteins 0.000 claims description 2
- 101001045751 Homo sapiens Hepatocyte nuclear factor 1-alpha Proteins 0.000 claims description 2
- 101001045740 Homo sapiens Hepatocyte nuclear factor 4-alpha Proteins 0.000 claims description 2
- 101000988521 Homo sapiens Hexokinase HKDC1 Proteins 0.000 claims description 2
- 101001016827 Homo sapiens Histamine H2 receptor Proteins 0.000 claims description 2
- 101000946589 Homo sapiens Holocytochrome c-type synthase Proteins 0.000 claims description 2
- 101000901614 Homo sapiens Homeobox protein DLX-4 Proteins 0.000 claims description 2
- 101000989027 Homo sapiens Homeobox protein Hox-C10 Proteins 0.000 claims description 2
- 101000620022 Homo sapiens Hydroperoxide isomerase ALOXE3 Proteins 0.000 claims description 2
- 101001083553 Homo sapiens Hydroxyacyl-coenzyme A dehydrogenase, mitochondrial Proteins 0.000 claims description 2
- 101000839025 Homo sapiens Hydroxymethylglutaryl-CoA synthase, cytoplasmic Proteins 0.000 claims description 2
- 101001077644 Homo sapiens IQ motif and SEC7 domain-containing protein 1 Proteins 0.000 claims description 2
- 101001077638 Homo sapiens IQ motif and SEC7 domain-containing protein 3 Proteins 0.000 claims description 2
- 101000840540 Homo sapiens Iduronate 2-sulfatase Proteins 0.000 claims description 2
- 101001053708 Homo sapiens Inhibitor of growth protein 2 Proteins 0.000 claims description 2
- 101000852815 Homo sapiens Insulin receptor Proteins 0.000 claims description 2
- 101001076680 Homo sapiens Insulin-induced gene 1 protein Proteins 0.000 claims description 2
- 101001044940 Homo sapiens Insulin-like growth factor-binding protein 2 Proteins 0.000 claims description 2
- 101001078151 Homo sapiens Integrin alpha-11 Proteins 0.000 claims description 2
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 claims description 2
- 101000997650 Homo sapiens Integrin beta-1-binding protein 2 Proteins 0.000 claims description 2
- 101000976697 Homo sapiens Inter-alpha-trypsin inhibitor heavy chain H1 Proteins 0.000 claims description 2
- 101000609396 Homo sapiens Inter-alpha-trypsin inhibitor heavy chain H2 Proteins 0.000 claims description 2
- 101000609417 Homo sapiens Inter-alpha-trypsin inhibitor heavy chain H5 Proteins 0.000 claims description 2
- 101000852865 Homo sapiens Interferon alpha/beta receptor 2 Proteins 0.000 claims description 2
- 101000599613 Homo sapiens Interferon lambda receptor 1 Proteins 0.000 claims description 2
- 101001011393 Homo sapiens Interferon regulatory factor 2 Proteins 0.000 claims description 2
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 claims description 2
- 101001003142 Homo sapiens Interleukin-12 receptor subunit beta-1 Proteins 0.000 claims description 2
- 101001003138 Homo sapiens Interleukin-12 receptor subunit beta-2 Proteins 0.000 claims description 2
- 101001044887 Homo sapiens Interleukin-22 receptor subunit alpha-2 Proteins 0.000 claims description 2
- 101000599048 Homo sapiens Interleukin-6 receptor subunit alpha Proteins 0.000 claims description 2
- 101001055219 Homo sapiens Interleukin-9 receptor Proteins 0.000 claims description 2
- 101001056724 Homo sapiens Intersectin-1 Proteins 0.000 claims description 2
- 101001042036 Homo sapiens Isocitrate dehydrogenase [NAD] subunit alpha, mitochondrial Proteins 0.000 claims description 2
- 101001046985 Homo sapiens KN motif and ankyrin repeat domain-containing protein 1 Proteins 0.000 claims description 2
- 101001050038 Homo sapiens Kalirin Proteins 0.000 claims description 2
- 101001051563 Homo sapiens Katanin p80 WD40 repeat-containing subunit B1 Proteins 0.000 claims description 2
- 101000998011 Homo sapiens Keratin, type I cytoskeletal 19 Proteins 0.000 claims description 2
- 101001050606 Homo sapiens Ketohexokinase Proteins 0.000 claims description 2
- 101001137642 Homo sapiens Kinase suppressor of Ras 1 Proteins 0.000 claims description 2
- 101001091229 Homo sapiens Kinesin-like protein KIF16B Proteins 0.000 claims description 2
- 101000605748 Homo sapiens Kinesin-like protein KIF25 Proteins 0.000 claims description 2
- 101000971521 Homo sapiens Kinetochore scaffold 1 Proteins 0.000 claims description 2
- 101001091590 Homo sapiens Kininogen-1 Proteins 0.000 claims description 2
- 101001139134 Homo sapiens Krueppel-like factor 4 Proteins 0.000 claims description 2
- 101001139126 Homo sapiens Krueppel-like factor 6 Proteins 0.000 claims description 2
- 101000799318 Homo sapiens Long-chain-fatty-acid-CoA ligase 1 Proteins 0.000 claims description 2
- 101000780208 Homo sapiens Long-chain-fatty-acid-CoA ligase 4 Proteins 0.000 claims description 2
- 101000780205 Homo sapiens Long-chain-fatty-acid-CoA ligase 5 Proteins 0.000 claims description 2
- 101000780202 Homo sapiens Long-chain-fatty-acid-CoA ligase 6 Proteins 0.000 claims description 2
- 101001113704 Homo sapiens Lysophosphatidylcholine acyltransferase 1 Proteins 0.000 claims description 2
- 101000624643 Homo sapiens M-phase inducer phosphatase 3 Proteins 0.000 claims description 2
- 101000916644 Homo sapiens Macrophage colony-stimulating factor 1 receptor Proteins 0.000 claims description 2
- 101001019104 Homo sapiens Mediator of RNA polymerase II transcription subunit 14 Proteins 0.000 claims description 2
- 101000760730 Homo sapiens Medium-chain specific acyl-CoA dehydrogenase, mitochondrial Proteins 0.000 claims description 2
- 101001018149 Homo sapiens Mitogen-activated protein kinase kinase kinase 21 Proteins 0.000 claims description 2
- 101000896657 Homo sapiens Mitotic checkpoint serine/threonine-protein kinase BUB1 Proteins 0.000 claims description 2
- 101000928929 Homo sapiens Muscarinic acetylcholine receptor M2 Proteins 0.000 claims description 2
- 101000720512 Homo sapiens Muscarinic acetylcholine receptor M4 Proteins 0.000 claims description 2
- 101000970561 Homo sapiens Myc box-dependent-interacting protein 1 Proteins 0.000 claims description 2
- 101000873851 Homo sapiens N(G),N(G)-dimethylarginine dimethylaminohydrolase 1 Proteins 0.000 claims description 2
- 101000588448 Homo sapiens N-acetylglucosamine-6-phosphate deacetylase Proteins 0.000 claims description 2
- 101000829958 Homo sapiens N-acetyllactosaminide beta-1,6-N-acetylglucosaminyl-transferase Proteins 0.000 claims description 2
- 101001109465 Homo sapiens NACHT, LRR and PYD domains-containing protein 3 Proteins 0.000 claims description 2
- 101001072765 Homo sapiens Neutral alpha-glucosidase AB Proteins 0.000 claims description 2
- 101001025772 Homo sapiens Neutral alpha-glucosidase C Proteins 0.000 claims description 2
- 101000612089 Homo sapiens Pancreas/duodenum homeobox protein 1 Proteins 0.000 claims description 2
- 101001091194 Homo sapiens Peptidyl-prolyl cis-trans isomerase G Proteins 0.000 claims description 2
- 101000833899 Homo sapiens Peroxisomal acyl-coenzyme A oxidase 2 Proteins 0.000 claims description 2
- 101000829725 Homo sapiens Phospholipid hydroperoxide glutathione peroxidase Proteins 0.000 claims description 2
- 101000701363 Homo sapiens Phospholipid-transporting ATPase IC Proteins 0.000 claims description 2
- 101000905839 Homo sapiens Phospholipid-transporting ATPase VA Proteins 0.000 claims description 2
- 101000893745 Homo sapiens Plasma alpha-L-fucosidase Proteins 0.000 claims description 2
- 101000886179 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 3 Proteins 0.000 claims description 2
- 101000886222 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 5 Proteins 0.000 claims description 2
- 101000952113 Homo sapiens Probable ATP-dependent RNA helicase DDX5 Proteins 0.000 claims description 2
- 101000904181 Homo sapiens Probable gluconokinase Proteins 0.000 claims description 2
- 101000904173 Homo sapiens Progonadoliberin-1 Proteins 0.000 claims description 2
- 101000928339 Homo sapiens Progressive ankylosis protein homolog Proteins 0.000 claims description 2
- 101000881678 Homo sapiens Prolyl hydroxylase EGLN3 Proteins 0.000 claims description 2
- 101001001272 Homo sapiens Prostatic acid phosphatase Proteins 0.000 claims description 2
- 101000933604 Homo sapiens Protein BTG2 Proteins 0.000 claims description 2
- 101000898093 Homo sapiens Protein C-ets-2 Proteins 0.000 claims description 2
- 101000980965 Homo sapiens Protein CDV3 homolog Proteins 0.000 claims description 2
- 101000900767 Homo sapiens Protein cornichon homolog 1 Proteins 0.000 claims description 2
- 101000909882 Homo sapiens Protein cornichon homolog 4 Proteins 0.000 claims description 2
- 101000726148 Homo sapiens Protein crumbs homolog 1 Proteins 0.000 claims description 2
- 101001064096 Homo sapiens Protein disulfide-thiol oxidoreductase Proteins 0.000 claims description 2
- 101001040122 Homo sapiens Putative glycerol kinase 5 Proteins 0.000 claims description 2
- 101000897979 Homo sapiens Putative spermatid-specific linker histone H1-like protein Proteins 0.000 claims description 2
- 101000999079 Homo sapiens Radiation-inducible immediate-early gene IEX-1 Proteins 0.000 claims description 2
- 101000893689 Homo sapiens Ras GTPase-activating protein-binding protein 1 Proteins 0.000 claims description 2
- 101000994790 Homo sapiens Ras GTPase-activating-like protein IQGAP2 Proteins 0.000 claims description 2
- 101000994788 Homo sapiens Ras GTPase-activating-like protein IQGAP3 Proteins 0.000 claims description 2
- 101000683591 Homo sapiens Ras-responsive element-binding protein 1 Proteins 0.000 claims description 2
- 101000899806 Homo sapiens Retinal guanylyl cyclase 1 Proteins 0.000 claims description 2
- 101001075558 Homo sapiens Rho GTPase-activating protein 29 Proteins 0.000 claims description 2
- 101001106395 Homo sapiens Rho GTPase-activating protein 5 Proteins 0.000 claims description 2
- 101001106325 Homo sapiens Rho GTPase-activating protein 6 Proteins 0.000 claims description 2
- 101001106322 Homo sapiens Rho GTPase-activating protein 7 Proteins 0.000 claims description 2
- 101000885382 Homo sapiens Rho guanine nucleotide exchange factor 10-like protein Proteins 0.000 claims description 2
- 101000927774 Homo sapiens Rho guanine nucleotide exchange factor 12 Proteins 0.000 claims description 2
- 101000731730 Homo sapiens Rho guanine nucleotide exchange factor 18 Proteins 0.000 claims description 2
- 101000752249 Homo sapiens Rho guanine nucleotide exchange factor 3 Proteins 0.000 claims description 2
- 101000886112 Homo sapiens Rho guanine nucleotide exchange factor 37 Proteins 0.000 claims description 2
- 101000886114 Homo sapiens Rho guanine nucleotide exchange factor 38 Proteins 0.000 claims description 2
- 101000752245 Homo sapiens Rho guanine nucleotide exchange factor 5 Proteins 0.000 claims description 2
- 101000846336 Homo sapiens Ribitol-5-phosphate transferase FKTN Proteins 0.000 claims description 2
- 101000863845 Homo sapiens Sedoheptulokinase Proteins 0.000 claims description 2
- 101000576901 Homo sapiens Serine/threonine-protein kinase MRCK alpha Proteins 0.000 claims description 2
- 101000703089 Homo sapiens Set1/Ash2 histone methyltransferase complex subunit ASH2 Proteins 0.000 claims description 2
- 101000806155 Homo sapiens Short-chain dehydrogenase/reductase 3 Proteins 0.000 claims description 2
- 101000760716 Homo sapiens Short-chain specific acyl-CoA dehydrogenase, mitochondrial Proteins 0.000 claims description 2
- 101000824924 Homo sapiens Sorting nexin-32 Proteins 0.000 claims description 2
- 101000952234 Homo sapiens Sphingolipid delta(4)-desaturase DES1 Proteins 0.000 claims description 2
- 101000878981 Homo sapiens Squalene synthase Proteins 0.000 claims description 2
- 101000661522 Homo sapiens Starch-binding domain-containing protein 1 Proteins 0.000 claims description 2
- 101000904150 Homo sapiens Transcription factor E2F3 Proteins 0.000 claims description 2
- 101000866292 Homo sapiens Transcription factor E2F7 Proteins 0.000 claims description 2
- 101000819074 Homo sapiens Transcription factor GATA-4 Proteins 0.000 claims description 2
- 101000819088 Homo sapiens Transcription factor GATA-6 Proteins 0.000 claims description 2
- 101000894428 Homo sapiens Transcriptional repressor CTCFL Proteins 0.000 claims description 2
- 101000662969 Homo sapiens Transmembrane protein 8B Proteins 0.000 claims description 2
- 101000690425 Homo sapiens Type-1 angiotensin II receptor Proteins 0.000 claims description 2
- 101000823271 Homo sapiens Tyrosine-protein kinase ABL2 Proteins 0.000 claims description 2
- 101001022129 Homo sapiens Tyrosine-protein kinase Fyn Proteins 0.000 claims description 2
- 101000997835 Homo sapiens Tyrosine-protein kinase JAK1 Proteins 0.000 claims description 2
- 101000954157 Homo sapiens Vasopressin V1a receptor Proteins 0.000 claims description 2
- 101000983956 Homo sapiens Voltage-dependent L-type calcium channel subunit beta-2 Proteins 0.000 claims description 2
- 102100022363 Hydroperoxide isomerase ALOXE3 Human genes 0.000 claims description 2
- 102100028888 Hydroxymethylglutaryl-CoA synthase, cytoplasmic Human genes 0.000 claims description 2
- 102100025097 IQ motif and SEC7 domain-containing protein 1 Human genes 0.000 claims description 2
- 102100025098 IQ motif and SEC7 domain-containing protein 3 Human genes 0.000 claims description 2
- 102100029199 Iduronate 2-sulfatase Human genes 0.000 claims description 2
- 102100035692 Importin subunit alpha-1 Human genes 0.000 claims description 2
- 102100024067 Inhibitor of growth protein 2 Human genes 0.000 claims description 2
- 102100036721 Insulin receptor Human genes 0.000 claims description 2
- 102100025887 Insulin-induced gene 1 protein Human genes 0.000 claims description 2
- 102100022710 Insulin-like growth factor-binding protein 2 Human genes 0.000 claims description 2
- 102100025320 Integrin alpha-11 Human genes 0.000 claims description 2
- 102100025305 Integrin alpha-2 Human genes 0.000 claims description 2
- 102100033340 Integrin beta-1-binding protein 2 Human genes 0.000 claims description 2
- 102100023490 Inter-alpha-trypsin inhibitor heavy chain H1 Human genes 0.000 claims description 2
- 102100039440 Inter-alpha-trypsin inhibitor heavy chain H2 Human genes 0.000 claims description 2
- 102100039454 Inter-alpha-trypsin inhibitor heavy chain H5 Human genes 0.000 claims description 2
- 102100036718 Interferon alpha/beta receptor 2 Human genes 0.000 claims description 2
- 102100037971 Interferon lambda receptor 1 Human genes 0.000 claims description 2
- 102100029838 Interferon regulatory factor 2 Human genes 0.000 claims description 2
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 claims description 2
- 102100020790 Interleukin-12 receptor subunit beta-1 Human genes 0.000 claims description 2
- 102100020792 Interleukin-12 receptor subunit beta-2 Human genes 0.000 claims description 2
- 102100022703 Interleukin-22 receptor subunit alpha-2 Human genes 0.000 claims description 2
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 claims description 2
- 102100026244 Interleukin-9 receptor Human genes 0.000 claims description 2
- 102100025494 Intersectin-1 Human genes 0.000 claims description 2
- 102100021332 Isocitrate dehydrogenase [NAD] subunit alpha, mitochondrial Human genes 0.000 claims description 2
- 102100022891 KN motif and ankyrin repeat domain-containing protein 1 Human genes 0.000 claims description 2
- 102100023093 Kalirin Human genes 0.000 claims description 2
- 102100024953 Katanin p80 WD40 repeat-containing subunit B1 Human genes 0.000 claims description 2
- 102100033420 Keratin, type I cytoskeletal 19 Human genes 0.000 claims description 2
- 102100023418 Ketohexokinase Human genes 0.000 claims description 2
- 102100021001 Kinase suppressor of Ras 1 Human genes 0.000 claims description 2
- 102100034894 Kinesin-like protein KIF16B Human genes 0.000 claims description 2
- 102100038378 Kinesin-like protein KIF25 Human genes 0.000 claims description 2
- 102100021464 Kinetochore scaffold 1 Human genes 0.000 claims description 2
- 102100035792 Kininogen-1 Human genes 0.000 claims description 2
- 102100020677 Krueppel-like factor 4 Human genes 0.000 claims description 2
- 102100020679 Krueppel-like factor 6 Human genes 0.000 claims description 2
- 102100035838 Lactosylceramide 4-alpha-galactosyltransferase Human genes 0.000 claims description 2
- 102100034710 Laminin subunit gamma-1 Human genes 0.000 claims description 2
- 102100033995 Long-chain-fatty-acid-CoA ligase 1 Human genes 0.000 claims description 2
- 102100034319 Long-chain-fatty-acid-CoA ligase 4 Human genes 0.000 claims description 2
- 102100034318 Long-chain-fatty-acid-CoA ligase 5 Human genes 0.000 claims description 2
- 102100034337 Long-chain-fatty-acid-CoA ligase 6 Human genes 0.000 claims description 2
- 102100023740 Lysophosphatidylcholine acyltransferase 1 Human genes 0.000 claims description 2
- 102100023330 M-phase inducer phosphatase 3 Human genes 0.000 claims description 2
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 claims description 2
- 102100034820 Mediator of RNA polymerase II transcription subunit 14 Human genes 0.000 claims description 2
- 102100024590 Medium-chain specific acyl-CoA dehydrogenase, mitochondrial Human genes 0.000 claims description 2
- 102100033054 Mitogen-activated protein kinase kinase kinase 21 Human genes 0.000 claims description 2
- 102100021691 Mitotic checkpoint serine/threonine-protein kinase BUB1 Human genes 0.000 claims description 2
- 102100021970 Myc box-dependent-interacting protein 1 Human genes 0.000 claims description 2
- 102100035854 N(G),N(G)-dimethylarginine dimethylaminohydrolase 1 Human genes 0.000 claims description 2
- 102100031324 N-acetylglucosamine-6-phosphate deacetylase Human genes 0.000 claims description 2
- 102100023315 N-acetyllactosaminide beta-1,6-N-acetylglucosaminyl-transferase Human genes 0.000 claims description 2
- 102100022691 NACHT, LRR and PYD domains-containing protein 3 Human genes 0.000 claims description 2
- 102100036592 Neutral alpha-glucosidase AB Human genes 0.000 claims description 2
- 102100037413 Neutral alpha-glucosidase C Human genes 0.000 claims description 2
- 102100041030 Pancreas/duodenum homeobox protein 1 Human genes 0.000 claims description 2
- 102100026795 Peroxisomal acyl-coenzyme A oxidase 2 Human genes 0.000 claims description 2
- 101710178747 Phosphatidate cytidylyltransferase 1 Proteins 0.000 claims description 2
- 101710178746 Phosphatidate cytidylyltransferase 2 Proteins 0.000 claims description 2
- 102100033126 Phosphatidate cytidylyltransferase 2 Human genes 0.000 claims description 2
- 102100023410 Phospholipid hydroperoxide glutathione peroxidase Human genes 0.000 claims description 2
- 102100030448 Phospholipid-transporting ATPase IC Human genes 0.000 claims description 2
- 102100023496 Phospholipid-transporting ATPase VA Human genes 0.000 claims description 2
- 102100040523 Plasma alpha-L-fucosidase Human genes 0.000 claims description 2
- 102100039685 Polypeptide N-acetylgalactosaminyltransferase 3 Human genes 0.000 claims description 2
- 102100039697 Polypeptide N-acetylgalactosaminyltransferase 5 Human genes 0.000 claims description 2
- 102100037434 Probable ATP-dependent RNA helicase DDX5 Human genes 0.000 claims description 2
- 102100024009 Probable gluconokinase Human genes 0.000 claims description 2
- 102100029837 Probetacellulin Human genes 0.000 claims description 2
- 102100024028 Progonadoliberin-1 Human genes 0.000 claims description 2
- 102100036812 Progressive ankylosis protein homolog Human genes 0.000 claims description 2
- 102100037247 Prolyl hydroxylase EGLN3 Human genes 0.000 claims description 2
- 102100035703 Prostatic acid phosphatase Human genes 0.000 claims description 2
- 102100026034 Protein BTG2 Human genes 0.000 claims description 2
- 102100021890 Protein C-ets-2 Human genes 0.000 claims description 2
- 102100024449 Protein CDV3 homolog Human genes 0.000 claims description 2
- 102100022049 Protein cornichon homolog 1 Human genes 0.000 claims description 2
- 102100024517 Protein cornichon homolog 4 Human genes 0.000 claims description 2
- 102100027331 Protein crumbs homolog 1 Human genes 0.000 claims description 2
- 102100030728 Protein disulfide-thiol oxidoreductase Human genes 0.000 claims description 2
- 101001098058 Protobothrops flavoviridis Basic phospholipase A2 BP-I Proteins 0.000 claims description 2
- 208000003251 Pruritus Diseases 0.000 claims description 2
- 102100040908 Putative glycerol kinase 5 Human genes 0.000 claims description 2
- 102100021861 Putative spermatid-specific linker histone H1-like protein Human genes 0.000 claims description 2
- 102100036900 Radiation-inducible immediate-early gene IEX-1 Human genes 0.000 claims description 2
- 102100040854 Ras GTPase-activating protein-binding protein 1 Human genes 0.000 claims description 2
- 102100034418 Ras GTPase-activating-like protein IQGAP2 Human genes 0.000 claims description 2
- 102100034417 Ras GTPase-activating-like protein IQGAP3 Human genes 0.000 claims description 2
- 102100023544 Ras-responsive element-binding protein 1 Human genes 0.000 claims description 2
- 102100022663 Retinal guanylyl cyclase 1 Human genes 0.000 claims description 2
- 102100020899 Rho GTPase-activating protein 29 Human genes 0.000 claims description 2
- 102100021428 Rho GTPase-activating protein 5 Human genes 0.000 claims description 2
- 102100021426 Rho GTPase-activating protein 6 Human genes 0.000 claims description 2
- 102100039777 Rho guanine nucleotide exchange factor 10-like protein Human genes 0.000 claims description 2
- 102100033193 Rho guanine nucleotide exchange factor 12 Human genes 0.000 claims description 2
- 102100032432 Rho guanine nucleotide exchange factor 18 Human genes 0.000 claims description 2
- 102100021689 Rho guanine nucleotide exchange factor 3 Human genes 0.000 claims description 2
- 102100039706 Rho guanine nucleotide exchange factor 37 Human genes 0.000 claims description 2
- 102100039707 Rho guanine nucleotide exchange factor 38 Human genes 0.000 claims description 2
- 102100021688 Rho guanine nucleotide exchange factor 5 Human genes 0.000 claims description 2
- 102100031754 Ribitol-5-phosphate transferase FKTN Human genes 0.000 claims description 2
- 101001053942 Saccharolobus solfataricus (strain ATCC 35092 / DSM 1617 / JCM 11322 / P2) Diphosphomevalonate decarboxylase Proteins 0.000 claims description 2
- 102100030053 Secreted frizzled-related protein 3 Human genes 0.000 claims description 2
- 102100029990 Sedoheptulokinase Human genes 0.000 claims description 2
- 102100031075 Serine/threonine-protein kinase Chk2 Human genes 0.000 claims description 2
- 102100025352 Serine/threonine-protein kinase MRCK alpha Human genes 0.000 claims description 2
- 102100030733 Set1/Ash2 histone methyltransferase complex subunit ASH2 Human genes 0.000 claims description 2
- 102100037857 Short-chain dehydrogenase/reductase 3 Human genes 0.000 claims description 2
- 102100024639 Short-chain specific acyl-CoA dehydrogenase, mitochondrial Human genes 0.000 claims description 2
- 102100022831 Somatoliberin Human genes 0.000 claims description 2
- 101710142969 Somatoliberin Proteins 0.000 claims description 2
- 102100022381 Sorting nexin-32 Human genes 0.000 claims description 2
- 102100037416 Sphingolipid delta(4)-desaturase DES1 Human genes 0.000 claims description 2
- 102100037997 Squalene synthase Human genes 0.000 claims description 2
- 102100038035 Starch-binding domain-containing protein 1 Human genes 0.000 claims description 2
- 102100039081 Steroid Delta-isomerase Human genes 0.000 claims description 2
- 108091023040 Transcription factor Proteins 0.000 claims description 2
- 102000040945 Transcription factor Human genes 0.000 claims description 2
- 102100024027 Transcription factor E2F3 Human genes 0.000 claims description 2
- 102100031556 Transcription factor E2F7 Human genes 0.000 claims description 2
- 102100021380 Transcription factor GATA-4 Human genes 0.000 claims description 2
- 102100021382 Transcription factor GATA-6 Human genes 0.000 claims description 2
- 102100027671 Transcriptional repressor CTCF Human genes 0.000 claims description 2
- 102100021393 Transcriptional repressor CTCFL Human genes 0.000 claims description 2
- 102100037634 Transmembrane protein 8B Human genes 0.000 claims description 2
- 102100026803 Type-1 angiotensin II receptor Human genes 0.000 claims description 2
- 102100022651 Tyrosine-protein kinase ABL2 Human genes 0.000 claims description 2
- 102100035221 Tyrosine-protein kinase Fyn Human genes 0.000 claims description 2
- 102100033438 Tyrosine-protein kinase JAK1 Human genes 0.000 claims description 2
- 108010070808 UDP-galactose-lactosylceramide alpha 1-4-galactosyltransferase Proteins 0.000 claims description 2
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 claims description 2
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 claims description 2
- 102100037187 Vasopressin V1a receptor Human genes 0.000 claims description 2
- 102100025807 Voltage-dependent L-type calcium channel subunit beta-2 Human genes 0.000 claims description 2
- 108010020277 WD repeat containing planar cell polarity effector Proteins 0.000 claims description 2
- BOPGDPNILDQYTO-NDOGXIPWSA-N [[(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [(2r,3r,4r,5r)-5-(3-carbamoyl-4h-pyridin-1-yl)-3,4-dihydroxyoxolan-2-yl]methyl hydrogen phosphate Chemical compound C1=CCC(C(=O)N)=CN1[C@H]1[C@H](O)[C@@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]2[C@@H]([C@@H](O)[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)O1 BOPGDPNILDQYTO-NDOGXIPWSA-N 0.000 claims description 2
- 108010029483 alpha 1 Chain Collagen Type I Proteins 0.000 claims description 2
- 101150001938 anapc4 gene Proteins 0.000 claims description 2
- 238000003491 array Methods 0.000 claims description 2
- 102100039123 cAMP-regulated phosphoprotein 19 Human genes 0.000 claims description 2
- 238000012656 cationic ring opening polymerization Methods 0.000 claims description 2
- 208000035196 congenital hypomyelinating 2 neuropathy Diseases 0.000 claims description 2
- 108010049998 cyclic AMP-regulated phosphoprotein 19 Proteins 0.000 claims description 2
- 108010018033 endothelial PAS domain-containing protein 1 Proteins 0.000 claims description 2
- 108010052188 hepatoma-derived growth factor Proteins 0.000 claims description 2
- 108010021685 homeobox protein HOXA13 Proteins 0.000 claims description 2
- 108010011989 karyopherin alpha 2 Proteins 0.000 claims description 2
- 108010090909 laminin gamma 1 Proteins 0.000 claims description 2
- 239000000090 biomarker Substances 0.000 claims 21
- 230000000694 effects Effects 0.000 claims 19
- 230000004064 dysfunction Effects 0.000 claims 13
- 208000024172 Cardiovascular disease Diseases 0.000 claims 12
- 208000007342 Diabetic Nephropathies Diseases 0.000 claims 12
- 208000032131 Diabetic Neuropathies Diseases 0.000 claims 12
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 claims 12
- 208000033679 diabetic kidney disease Diseases 0.000 claims 12
- 210000001525 retina Anatomy 0.000 claims 12
- 208000001072 type 2 diabetes mellitus Diseases 0.000 claims 12
- 239000000203 mixture Substances 0.000 claims 10
- 230000008685 targeting Effects 0.000 claims 8
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 claims 6
- 102100032543 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Human genes 0.000 claims 6
- 238000012544 monitoring process Methods 0.000 claims 6
- 238000010606 normalization Methods 0.000 claims 6
- 102100024682 14-3-3 protein eta Human genes 0.000 claims 5
- 101000760084 Homo sapiens 14-3-3 protein eta Proteins 0.000 claims 5
- 101000803165 Homo sapiens Serine/threonine-protein phosphatase 2A 65 kDa regulatory subunit A beta isoform Proteins 0.000 claims 5
- 101001068027 Homo sapiens Serine/threonine-protein phosphatase 2A catalytic subunit alpha isoform Proteins 0.000 claims 5
- 102100035547 Serine/threonine-protein phosphatase 2A 65 kDa regulatory subunit A beta isoform Human genes 0.000 claims 5
- 102100034464 Serine/threonine-protein phosphatase 2A catalytic subunit alpha isoform Human genes 0.000 claims 5
- 102100022528 5'-AMP-activated protein kinase catalytic subunit alpha-1 Human genes 0.000 claims 4
- 101000677993 Homo sapiens 5'-AMP-activated protein kinase catalytic subunit alpha-1 Proteins 0.000 claims 4
- 102100025246 Neurogenic locus notch homolog protein 2 Human genes 0.000 claims 4
- 108010029751 Notch2 Receptor Proteins 0.000 claims 4
- 108010015181 PPAR delta Proteins 0.000 claims 4
- 102100038824 Peroxisome proliferator-activated receptor delta Human genes 0.000 claims 4
- 102100030529 Suppressor of cytokine signaling 7 Human genes 0.000 claims 4
- 230000000692 anti-sense effect Effects 0.000 claims 4
- 102100030390 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase beta-1 Human genes 0.000 claims 3
- 102100036438 Amyloid beta precursor protein binding family B member 2 Human genes 0.000 claims 3
- 102000036365 BRCA1 Human genes 0.000 claims 3
- 108700020463 BRCA1 Proteins 0.000 claims 3
- 101150072950 BRCA1 gene Proteins 0.000 claims 3
- 102100028237 Breast cancer anti-estrogen resistance protein 1 Human genes 0.000 claims 3
- 108010031504 Crk Associated Substrate Protein Proteins 0.000 claims 3
- 102100022731 Diacylglycerol kinase delta Human genes 0.000 claims 3
- 102100021838 E3 ubiquitin-protein ligase SIAH1 Human genes 0.000 claims 3
- 102100031748 E3 ubiquitin-protein ligase SIAH2 Human genes 0.000 claims 3
- 102100021223 Glucosidase 2 subunit beta Human genes 0.000 claims 3
- 101000583063 Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase beta-1 Proteins 0.000 claims 3
- 101000928680 Homo sapiens Amyloid beta precursor protein binding family B member 2 Proteins 0.000 claims 3
- 101001044810 Homo sapiens Diacylglycerol kinase delta Proteins 0.000 claims 3
- 101000616722 Homo sapiens E3 ubiquitin-protein ligase SIAH1 Proteins 0.000 claims 3
- 101000707245 Homo sapiens E3 ubiquitin-protein ligase SIAH2 Proteins 0.000 claims 3
- 101000967216 Homo sapiens Eosinophil cationic protein Proteins 0.000 claims 3
- 101000882584 Homo sapiens Estrogen receptor Proteins 0.000 claims 3
- 101001040875 Homo sapiens Glucosidase 2 subunit beta Proteins 0.000 claims 3
- 101001053662 Homo sapiens Inositol hexakisphosphate kinase 3 Proteins 0.000 claims 3
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 claims 3
- 101001018157 Homo sapiens Mitogen-activated protein kinase kinase kinase 20 Proteins 0.000 claims 3
- 101001135199 Homo sapiens Partitioning defective 3 homolog Proteins 0.000 claims 3
- 101000605432 Homo sapiens Phospholipid phosphatase 1 Proteins 0.000 claims 3
- 101001123448 Homo sapiens Prolactin receptor Proteins 0.000 claims 3
- 101000933601 Homo sapiens Protein BTG1 Proteins 0.000 claims 3
- 101000712530 Homo sapiens RAF proto-oncogene serine/threonine-protein kinase Proteins 0.000 claims 3
- 101001130509 Homo sapiens Ras GTPase-activating protein 1 Proteins 0.000 claims 3
- 101000588540 Homo sapiens Serine/threonine-protein kinase Nek6 Proteins 0.000 claims 3
- 101000800116 Homo sapiens Thy-1 membrane glycoprotein Proteins 0.000 claims 3
- 101000830596 Homo sapiens Tumor necrosis factor ligand superfamily member 15 Proteins 0.000 claims 3
- 101000801228 Homo sapiens Tumor necrosis factor receptor superfamily member 1A Proteins 0.000 claims 3
- 102100024076 Inositol hexakisphosphate kinase 3 Human genes 0.000 claims 3
- 102100037852 Insulin-like growth factor I Human genes 0.000 claims 3
- 102100033116 Mitogen-activated protein kinase kinase kinase 20 Human genes 0.000 claims 3
- 102100038121 Phospholipid phosphatase 1 Human genes 0.000 claims 3
- 102100029000 Prolactin receptor Human genes 0.000 claims 3
- 102100026036 Protein BTG1 Human genes 0.000 claims 3
- 102100033479 RAF proto-oncogene serine/threonine-protein kinase Human genes 0.000 claims 3
- 102100031426 Ras GTPase-activating protein 1 Human genes 0.000 claims 3
- 102100031401 Serine/threonine-protein kinase Nek6 Human genes 0.000 claims 3
- 108020004459 Small interfering RNA Proteins 0.000 claims 3
- 102100021796 Sonic hedgehog protein Human genes 0.000 claims 3
- 101710113849 Sonic hedgehog protein Proteins 0.000 claims 3
- 102100033523 Thy-1 membrane glycoprotein Human genes 0.000 claims 3
- 102100024587 Tumor necrosis factor ligand superfamily member 15 Human genes 0.000 claims 3
- 102100033732 Tumor necrosis factor receptor superfamily member 1A Human genes 0.000 claims 3
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims 3
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims 3
- 230000007423 decrease Effects 0.000 claims 3
- 239000000032 diagnostic agent Substances 0.000 claims 3
- 229940039227 diagnostic agent Drugs 0.000 claims 3
- 238000004519 manufacturing process Methods 0.000 claims 3
- 102100030492 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase epsilon-1 Human genes 0.000 claims 2
- 102100026201 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase eta-1 Human genes 0.000 claims 2
- 102100026205 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase gamma-1 Human genes 0.000 claims 2
- 102100031204 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase zeta-1 Human genes 0.000 claims 2
- 102100027832 14-3-3 protein gamma Human genes 0.000 claims 2
- 102100030489 15-hydroxyprostaglandin dehydrogenase [NAD(+)] Human genes 0.000 claims 2
- 102100022585 17-beta-hydroxysteroid dehydrogenase type 3 Human genes 0.000 claims 2
- 102100029077 3-hydroxy-3-methylglutaryl-coenzyme A reductase Human genes 0.000 claims 2
- 102100033875 3-oxo-5-alpha-steroid 4-dehydrogenase 2 Human genes 0.000 claims 2
- 102100038074 5'-AMP-activated protein kinase subunit beta-1 Human genes 0.000 claims 2
- 102100033757 Acyl-coenzyme A thioesterase 11 Human genes 0.000 claims 2
- 102100030942 Apolipoprotein A-II Human genes 0.000 claims 2
- 102100027321 Beta-1,4-galactosyltransferase 7 Human genes 0.000 claims 2
- 101150106705 Bhlhe41 gene Proteins 0.000 claims 2
- 102100038460 CDK5 regulatory subunit-associated protein 3 Human genes 0.000 claims 2
- 108091011896 CSF1 Proteins 0.000 claims 2
- 102100033471 Cbp/p300-interacting transactivator 2 Human genes 0.000 claims 2
- 108010077544 Chromatin Proteins 0.000 claims 2
- 102100026190 Class E basic helix-loop-helix protein 41 Human genes 0.000 claims 2
- 102000004360 Cofilin 1 Human genes 0.000 claims 2
- 108090000996 Cofilin 1 Proteins 0.000 claims 2
- 108010079362 Core Binding Factor Alpha 3 Subunit Proteins 0.000 claims 2
- 108010009392 Cyclin-Dependent Kinase Inhibitor p16 Proteins 0.000 claims 2
- 102100024458 Cyclin-dependent kinase inhibitor 2A Human genes 0.000 claims 2
- 102100036952 Cytoplasmic protein NCK2 Human genes 0.000 claims 2
- 102100027816 Cytotoxic and regulatory T-cell molecule Human genes 0.000 claims 2
- 101100107081 Danio rerio zbtb16a gene Proteins 0.000 claims 2
- 102100027274 Dual specificity protein phosphatase 6 Human genes 0.000 claims 2
- 102100036498 Dual specificity testis-specific protein kinase 2 Human genes 0.000 claims 2
- 102100021579 Enhancer of filamentation 1 Human genes 0.000 claims 2
- 102000009024 Epidermal Growth Factor Human genes 0.000 claims 2
- 102100029987 Erbin Human genes 0.000 claims 2
- 102100038636 FYVE, RhoGEF and PH domain-containing protein 2 Human genes 0.000 claims 2
- 102100037858 G1/S-specific cyclin-E1 Human genes 0.000 claims 2
- 102000054184 GADD45 Human genes 0.000 claims 2
- 102100037948 GTP-binding protein Di-Ras3 Human genes 0.000 claims 2
- 102100039788 GTPase NRas Human genes 0.000 claims 2
- 102100031153 Growth arrest and DNA damage-inducible protein GADD45 beta Human genes 0.000 claims 2
- 101001126442 Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase epsilon-1 Proteins 0.000 claims 2
- 101000691583 Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase eta-1 Proteins 0.000 claims 2
- 101000691599 Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase gamma-1 Proteins 0.000 claims 2
- 101001129086 Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase zeta-1 Proteins 0.000 claims 2
- 101000723517 Homo sapiens 14-3-3 protein gamma Proteins 0.000 claims 2
- 101001126430 Homo sapiens 15-hydroxyprostaglandin dehydrogenase [NAD(+)] Proteins 0.000 claims 2
- 101001045211 Homo sapiens 17-beta-hydroxysteroid dehydrogenase type 3 Proteins 0.000 claims 2
- 101000988577 Homo sapiens 3-hydroxy-3-methylglutaryl-coenzyme A reductase Proteins 0.000 claims 2
- 101000640851 Homo sapiens 3-oxo-5-alpha-steroid 4-dehydrogenase 2 Proteins 0.000 claims 2
- 101000600756 Homo sapiens 3-phosphoinositide-dependent protein kinase 1 Proteins 0.000 claims 2
- 101000742701 Homo sapiens 5'-AMP-activated protein kinase subunit beta-1 Proteins 0.000 claims 2
- 101000801224 Homo sapiens Acyl-coenzyme A thioesterase 11 Proteins 0.000 claims 2
- 101000793406 Homo sapiens Apolipoprotein A-II Proteins 0.000 claims 2
- 101000937508 Homo sapiens Beta-1,4-galactosyltransferase 7 Proteins 0.000 claims 2
- 101000882982 Homo sapiens CDK5 regulatory subunit-associated protein 3 Proteins 0.000 claims 2
- 101000944098 Homo sapiens Cbp/p300-interacting transactivator 2 Proteins 0.000 claims 2
- 101001024712 Homo sapiens Cytoplasmic protein NCK2 Proteins 0.000 claims 2
- 101001057587 Homo sapiens Dual specificity protein phosphatase 6 Proteins 0.000 claims 2
- 101000714156 Homo sapiens Dual specificity testis-specific protein kinase 2 Proteins 0.000 claims 2
- 101000851054 Homo sapiens Elastin Proteins 0.000 claims 2
- 101000898310 Homo sapiens Enhancer of filamentation 1 Proteins 0.000 claims 2
- 101001010810 Homo sapiens Erbin Proteins 0.000 claims 2
- 101001031749 Homo sapiens FYVE, RhoGEF and PH domain-containing protein 2 Proteins 0.000 claims 2
- 101000738568 Homo sapiens G1/S-specific cyclin-E1 Proteins 0.000 claims 2
- 101000951235 Homo sapiens GTP-binding protein Di-Ras3 Proteins 0.000 claims 2
- 101000744505 Homo sapiens GTPase NRas Proteins 0.000 claims 2
- 101001066164 Homo sapiens Growth arrest and DNA damage-inducible protein GADD45 beta Proteins 0.000 claims 2
- 101001066163 Homo sapiens Growth arrest and DNA damage-inducible protein GADD45 gamma Proteins 0.000 claims 2
- 101000716729 Homo sapiens Kit ligand Proteins 0.000 claims 2
- 101001064870 Homo sapiens Lon protease homolog, mitochondrial Proteins 0.000 claims 2
- 101001043594 Homo sapiens Low-density lipoprotein receptor-related protein 5 Proteins 0.000 claims 2
- 101001039035 Homo sapiens Lutropin-choriogonadotropic hormone receptor Proteins 0.000 claims 2
- 101000578936 Homo sapiens Membrane-associated guanylate kinase, WW and PDZ domain-containing protein 3 Proteins 0.000 claims 2
- 101000990982 Homo sapiens Mitochondrial Rho GTPase 1 Proteins 0.000 claims 2
- 101000628968 Homo sapiens Mitogen-activated protein kinase 13 Proteins 0.000 claims 2
- 101001005602 Homo sapiens Mitogen-activated protein kinase kinase kinase 11 Proteins 0.000 claims 2
- 101001122476 Homo sapiens Mu-type opioid receptor Proteins 0.000 claims 2
- 101000995138 Homo sapiens NFAT activation molecule 1 Proteins 0.000 claims 2
- 101001108356 Homo sapiens Nardilysin Proteins 0.000 claims 2
- 101000995200 Homo sapiens Neurabin-2 Proteins 0.000 claims 2
- 101000927793 Homo sapiens Neuroepithelial cell-transforming gene 1 protein Proteins 0.000 claims 2
- 101000896414 Homo sapiens Nuclear nucleic acid-binding protein C1D Proteins 0.000 claims 2
- 101000974343 Homo sapiens Nuclear receptor coactivator 4 Proteins 0.000 claims 2
- 101000979629 Homo sapiens Nucleoside diphosphate kinase A Proteins 0.000 claims 2
- 101001113465 Homo sapiens Partitioning defective 6 homolog beta Proteins 0.000 claims 2
- 101001124867 Homo sapiens Peroxiredoxin-1 Proteins 0.000 claims 2
- 101000579913 Homo sapiens Peroxisomal trans-2-enoyl-CoA reductase Proteins 0.000 claims 2
- 101001120056 Homo sapiens Phosphatidylinositol 3-kinase regulatory subunit alpha Proteins 0.000 claims 2
- 101000595741 Homo sapiens Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit beta isoform Proteins 0.000 claims 2
- 101000721642 Homo sapiens Phosphatidylinositol 4-phosphate 3-kinase C2 domain-containing subunit alpha Proteins 0.000 claims 2
- 101000604565 Homo sapiens Phosphatidylinositol glycan anchor biosynthesis class U protein Proteins 0.000 claims 2
- 101000730665 Homo sapiens Phospholipase D1 Proteins 0.000 claims 2
- 101000595923 Homo sapiens Placenta growth factor Proteins 0.000 claims 2
- 101000605403 Homo sapiens Plasminogen Proteins 0.000 claims 2
- 101000610107 Homo sapiens Pre-B-cell leukemia transcription factor 1 Proteins 0.000 claims 2
- 101001124937 Homo sapiens Pre-mRNA-splicing factor 38B Proteins 0.000 claims 2
- 101000617536 Homo sapiens Presenilin-1 Proteins 0.000 claims 2
- 101000611943 Homo sapiens Programmed cell death protein 4 Proteins 0.000 claims 2
- 101001043564 Homo sapiens Prolow-density lipoprotein receptor-related protein 1 Proteins 0.000 claims 2
- 101000986265 Homo sapiens Protein MTSS 1 Proteins 0.000 claims 2
- 101000849321 Homo sapiens Protein RRP5 homolog Proteins 0.000 claims 2
- 101001051777 Homo sapiens Protein kinase C alpha type Proteins 0.000 claims 2
- 101001026852 Homo sapiens Protein kinase C epsilon type Proteins 0.000 claims 2
- 101000971404 Homo sapiens Protein kinase C iota type Proteins 0.000 claims 2
- 101000971468 Homo sapiens Protein kinase C zeta type Proteins 0.000 claims 2
- 101000878540 Homo sapiens Protein-tyrosine kinase 2-beta Proteins 0.000 claims 2
- 101000665452 Homo sapiens RNA binding protein fox-1 homolog 2 Proteins 0.000 claims 2
- 101000708222 Homo sapiens Ras and Rab interactor 2 Proteins 0.000 claims 2
- 101000686231 Homo sapiens Ras-related GTP-binding protein C Proteins 0.000 claims 2
- 101001099888 Homo sapiens Ras-related protein Rab-3D Proteins 0.000 claims 2
- 101001109145 Homo sapiens Receptor-interacting serine/threonine-protein kinase 1 Proteins 0.000 claims 2
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 claims 2
- 101000727472 Homo sapiens Reticulon-4 Proteins 0.000 claims 2
- 101000669917 Homo sapiens Rho-associated protein kinase 1 Proteins 0.000 claims 2
- 101000867469 Homo sapiens Segment polarity protein dishevelled homolog DVL-3 Proteins 0.000 claims 2
- 101000654674 Homo sapiens Semaphorin-6A Proteins 0.000 claims 2
- 101000654734 Homo sapiens Septin-4 Proteins 0.000 claims 2
- 101000661821 Homo sapiens Serine/threonine-protein kinase 17A Proteins 0.000 claims 2
- 101000661819 Homo sapiens Serine/threonine-protein kinase 17B Proteins 0.000 claims 2
- 101000628647 Homo sapiens Serine/threonine-protein kinase 24 Proteins 0.000 claims 2
- 101000880439 Homo sapiens Serine/threonine-protein kinase 3 Proteins 0.000 claims 2
- 101000880431 Homo sapiens Serine/threonine-protein kinase 4 Proteins 0.000 claims 2
- 101001047637 Homo sapiens Serine/threonine-protein kinase LATS2 Proteins 0.000 claims 2
- 101001059454 Homo sapiens Serine/threonine-protein kinase MARK2 Proteins 0.000 claims 2
- 101001123812 Homo sapiens Serine/threonine-protein kinase Nek11 Proteins 0.000 claims 2
- 101000595531 Homo sapiens Serine/threonine-protein kinase pim-1 Proteins 0.000 claims 2
- 101001095320 Homo sapiens Serine/threonine-protein phosphatase PP1-beta catalytic subunit Proteins 0.000 claims 2
- 101000863858 Homo sapiens Sialic acid synthase Proteins 0.000 claims 2
- 101000687673 Homo sapiens Small integral membrane protein 6 Proteins 0.000 claims 2
- 101000631937 Homo sapiens Sodium- and chloride-dependent glycine transporter 2 Proteins 0.000 claims 2
- 101000639975 Homo sapiens Sodium-dependent noradrenaline transporter Proteins 0.000 claims 2
- 101000618133 Homo sapiens Sperm-associated antigen 5 Proteins 0.000 claims 2
- 101001108755 Homo sapiens Sphingomyelin phosphodiesterase 3 Proteins 0.000 claims 2
- 101000688561 Homo sapiens Sphingosine-1-phosphate lyase 1 Proteins 0.000 claims 2
- 101001131204 Homo sapiens Sulfhydryl oxidase 1 Proteins 0.000 claims 2
- 101000652220 Homo sapiens Suppressor of cytokine signaling 4 Proteins 0.000 claims 2
- 101000652224 Homo sapiens Suppressor of cytokine signaling 5 Proteins 0.000 claims 2
- 101000652226 Homo sapiens Suppressor of cytokine signaling 6 Proteins 0.000 claims 2
- 101000652229 Homo sapiens Suppressor of cytokine signaling 7 Proteins 0.000 claims 2
- 101000643632 Homo sapiens Synaptonemal complex protein 3 Proteins 0.000 claims 2
- 101000794197 Homo sapiens Testis-specific serine/threonine-protein kinase 3 Proteins 0.000 claims 2
- 101000798696 Homo sapiens Transmembrane protease serine 6 Proteins 0.000 claims 2
- 101000830565 Homo sapiens Tumor necrosis factor ligand superfamily member 10 Proteins 0.000 claims 2
- 101000610604 Homo sapiens Tumor necrosis factor receptor superfamily member 10B Proteins 0.000 claims 2
- 101000798130 Homo sapiens Tumor necrosis factor receptor superfamily member 11B Proteins 0.000 claims 2
- 101000801227 Homo sapiens Tumor necrosis factor receptor superfamily member 19 Proteins 0.000 claims 2
- 101000836755 Homo sapiens Type 2 lactosamine alpha-2,3-sialyltransferase Proteins 0.000 claims 2
- 101000922131 Homo sapiens Tyrosine-protein kinase CSK Proteins 0.000 claims 2
- 101001054878 Homo sapiens Tyrosine-protein kinase Lyn Proteins 0.000 claims 2
- 101000808753 Homo sapiens Ubiquitin-conjugating enzyme E2 variant 1 Proteins 0.000 claims 2
- 101100377226 Homo sapiens ZBTB16 gene Proteins 0.000 claims 2
- 101000730643 Homo sapiens Zinc finger protein PLAGL1 Proteins 0.000 claims 2
- 101001117146 Homo sapiens [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 1, mitochondrial Proteins 0.000 claims 2
- 102100027004 Inhibin beta A chain Human genes 0.000 claims 2
- 102100020880 Kit ligand Human genes 0.000 claims 2
- 229930186657 Lat Natural products 0.000 claims 2
- 102100021926 Low-density lipoprotein receptor-related protein 5 Human genes 0.000 claims 2
- 101000964266 Loxosceles laeta Dermonecrotic toxin Proteins 0.000 claims 2
- 102100040788 Lutropin-choriogonadotropic hormone receptor Human genes 0.000 claims 2
- 102000017274 MDM4 Human genes 0.000 claims 2
- 108050005300 MDM4 Proteins 0.000 claims 2
- 108010018650 MEF2 Transcription Factors Proteins 0.000 claims 2
- 108060004872 MIF Proteins 0.000 claims 2
- 102100028123 Macrophage colony-stimulating factor 1 Human genes 0.000 claims 2
- 102100028327 Membrane-associated guanylate kinase, WW and PDZ domain-containing protein 3 Human genes 0.000 claims 2
- 102100030331 Mitochondrial Rho GTPase 1 Human genes 0.000 claims 2
- 102100026930 Mitogen-activated protein kinase 13 Human genes 0.000 claims 2
- 102100025207 Mitogen-activated protein kinase kinase kinase 11 Human genes 0.000 claims 2
- 102100028647 Mu-type opioid receptor Human genes 0.000 claims 2
- 102100030173 Muellerian-inhibiting factor Human genes 0.000 claims 2
- 101000890749 Mycobacterium tuberculosis (strain ATCC 25618 / H37Rv) F420-dependent hydroxymycolic acid dehydrogenase Proteins 0.000 claims 2
- 102100031455 NAD-dependent protein deacetylase sirtuin-1 Human genes 0.000 claims 2
- 102100034394 NFAT activation molecule 1 Human genes 0.000 claims 2
- 102100021850 Nardilysin Human genes 0.000 claims 2
- 206010028980 Neoplasm Diseases 0.000 claims 2
- 102100034437 Neurabin-2 Human genes 0.000 claims 2
- 102100026379 Neurofibromin Human genes 0.000 claims 2
- 108010085793 Neurofibromin 1 Proteins 0.000 claims 2
- 108090000772 Neuropilin-1 Proteins 0.000 claims 2
- 108700002046 Nod1 Signaling Adaptor Proteins 0.000 claims 2
- 101150005821 Nod1 gene Proteins 0.000 claims 2
- 102100021713 Nuclear nucleic acid-binding protein C1D Human genes 0.000 claims 2
- 102100022927 Nuclear receptor coactivator 4 Human genes 0.000 claims 2
- 102100023252 Nucleoside diphosphate kinase A Human genes 0.000 claims 2
- 102100029424 Nucleotide-binding oligomerization domain-containing protein 1 Human genes 0.000 claims 2
- 108090000630 Oncostatin M Proteins 0.000 claims 2
- 101700056750 PAK1 Proteins 0.000 claims 2
- 108090000445 Parathyroid hormone Proteins 0.000 claims 2
- 102100023651 Partitioning defective 6 homolog beta Human genes 0.000 claims 2
- 102100029139 Peroxiredoxin-1 Human genes 0.000 claims 2
- 102100027506 Peroxisomal trans-2-enoyl-CoA reductase Human genes 0.000 claims 2
- 102100026169 Phosphatidylinositol 3-kinase regulatory subunit alpha Human genes 0.000 claims 2
- 102100036061 Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit beta isoform Human genes 0.000 claims 2
- 102100025058 Phosphatidylinositol 4-phosphate 3-kinase C2 domain-containing subunit alpha Human genes 0.000 claims 2
- 102100035194 Placenta growth factor Human genes 0.000 claims 2
- 102100038124 Plasminogen Human genes 0.000 claims 2
- 102100040171 Pre-B-cell leukemia transcription factor 1 Human genes 0.000 claims 2
- 102100022033 Presenilin-1 Human genes 0.000 claims 2
- 101710098940 Pro-epidermal growth factor Proteins 0.000 claims 2
- 102100036829 Probable peptidyl-tRNA hydrolase Human genes 0.000 claims 2
- 102100040992 Programmed cell death protein 4 Human genes 0.000 claims 2
- 108700003766 Promyelocytic Leukemia Zinc Finger Proteins 0.000 claims 2
- 102100028951 Protein MTSS 1 Human genes 0.000 claims 2
- 102100033976 Protein RRP5 homolog Human genes 0.000 claims 2
- 102100032421 Protein S100-A6 Human genes 0.000 claims 2
- 102100024924 Protein kinase C alpha type Human genes 0.000 claims 2
- 102100037339 Protein kinase C epsilon type Human genes 0.000 claims 2
- 102100021557 Protein kinase C iota type Human genes 0.000 claims 2
- 102100021538 Protein kinase C zeta type Human genes 0.000 claims 2
- 102100023068 Protein kinase C-binding protein NELL1 Human genes 0.000 claims 2
- 102100037787 Protein-tyrosine kinase 2-beta Human genes 0.000 claims 2
- 102100038187 RNA binding protein fox-1 homolog 2 Human genes 0.000 claims 2
- 102100031490 Ras and Rab interactor 2 Human genes 0.000 claims 2
- 102100025009 Ras-related GTP-binding protein C Human genes 0.000 claims 2
- 102100038474 Ras-related protein Rab-3D Human genes 0.000 claims 2
- 102100030706 Ras-related protein Rap-1A Human genes 0.000 claims 2
- 101100218716 Rattus norvegicus Bhlhb3 gene Proteins 0.000 claims 2
- 102100022501 Receptor-interacting serine/threonine-protein kinase 1 Human genes 0.000 claims 2
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 claims 2
- 102100029831 Reticulon-4 Human genes 0.000 claims 2
- 102100039313 Rho-associated protein kinase 1 Human genes 0.000 claims 2
- 102100039643 Rho-related GTP-binding protein Rho6 Human genes 0.000 claims 2
- 101710199571 Rho-related GTP-binding protein Rho6 Proteins 0.000 claims 2
- 102100025369 Runt-related transcription factor 3 Human genes 0.000 claims 2
- 108010005260 S100 Calcium Binding Protein A6 Proteins 0.000 claims 2
- 108091005487 SCARB1 Proteins 0.000 claims 2
- 102100031779 SH2 domain-containing protein 2A Human genes 0.000 claims 2
- 102100022340 SHC-transforming protein 1 Human genes 0.000 claims 2
- 102100037118 Scavenger receptor class B member 1 Human genes 0.000 claims 2
- 102100032754 Segment polarity protein dishevelled homolog DVL-3 Human genes 0.000 claims 2
- 102100032795 Semaphorin-6A Human genes 0.000 claims 2
- 102100032743 Septin-4 Human genes 0.000 claims 2
- 102100037955 Serine/threonine-protein kinase 17A Human genes 0.000 claims 2
- 102100037959 Serine/threonine-protein kinase 17B Human genes 0.000 claims 2
- 102100026764 Serine/threonine-protein kinase 24 Human genes 0.000 claims 2
- 102100037629 Serine/threonine-protein kinase 4 Human genes 0.000 claims 2
- 102100024043 Serine/threonine-protein kinase LATS2 Human genes 0.000 claims 2
- 102100028904 Serine/threonine-protein kinase MARK2 Human genes 0.000 claims 2
- 102100028775 Serine/threonine-protein kinase Nek11 Human genes 0.000 claims 2
- 102100027910 Serine/threonine-protein kinase PAK 1 Human genes 0.000 claims 2
- 102100036077 Serine/threonine-protein kinase pim-1 Human genes 0.000 claims 2
- 102100037764 Serine/threonine-protein phosphatase PP1-beta catalytic subunit Human genes 0.000 claims 2
- 102100029954 Sialic acid synthase Human genes 0.000 claims 2
- 108010041191 Sirtuin 1 Proteins 0.000 claims 2
- 102100024806 Small integral membrane protein 6 Human genes 0.000 claims 2
- 102100028886 Sodium- and chloride-dependent glycine transporter 2 Human genes 0.000 claims 2
- 102100029329 Somatostatin receptor type 1 Human genes 0.000 claims 2
- 102100021915 Sperm-associated antigen 5 Human genes 0.000 claims 2
- 102100021461 Sphingomyelin phosphodiesterase 3 Human genes 0.000 claims 2
- 102100024239 Sphingosine-1-phosphate lyase 1 Human genes 0.000 claims 2
- 108010048349 Steroidogenic Factor 1 Proteins 0.000 claims 2
- 102100029856 Steroidogenic factor 1 Human genes 0.000 claims 2
- 101710184555 Sterol regulatory element-binding protein cleavage-activating protein Proteins 0.000 claims 2
- 102100034371 Sulfhydryl oxidase 1 Human genes 0.000 claims 2
- 102100030523 Suppressor of cytokine signaling 5 Human genes 0.000 claims 2
- 102100036236 Synaptonemal complex protein 2 Human genes 0.000 claims 2
- 102100036235 Synaptonemal complex protein 3 Human genes 0.000 claims 2
- 101001045447 Synechocystis sp. (strain PCC 6803 / Kazusa) Sensor histidine kinase Hik2 Proteins 0.000 claims 2
- 102100033082 TNF receptor-associated factor 3 Human genes 0.000 claims 2
- 102000003718 TNF receptor-associated factor 5 Human genes 0.000 claims 2
- 108090000001 TNF receptor-associated factor 5 Proteins 0.000 claims 2
- 102000003714 TNF receptor-associated factor 6 Human genes 0.000 claims 2
- 108090000009 TNF receptor-associated factor 6 Proteins 0.000 claims 2
- 102100030168 Testis-specific serine/threonine-protein kinase 3 Human genes 0.000 claims 2
- 108010040625 Transforming Protein 1 Src Homology 2 Domain-Containing Proteins 0.000 claims 2
- 102000056172 Transforming growth factor beta-3 Human genes 0.000 claims 2
- 108090000097 Transforming growth factor beta-3 Proteins 0.000 claims 2
- 102100032452 Transmembrane protease serine 6 Human genes 0.000 claims 2
- 108010047933 Tumor Necrosis Factor alpha-Induced Protein 3 Proteins 0.000 claims 2
- 102100024596 Tumor necrosis factor alpha-induced protein 3 Human genes 0.000 claims 2
- 102100024598 Tumor necrosis factor ligand superfamily member 10 Human genes 0.000 claims 2
- 102100040112 Tumor necrosis factor receptor superfamily member 10B Human genes 0.000 claims 2
- 102100032236 Tumor necrosis factor receptor superfamily member 11B Human genes 0.000 claims 2
- 102100033760 Tumor necrosis factor receptor superfamily member 19 Human genes 0.000 claims 2
- 102100027107 Type 2 lactosamine alpha-2,3-sialyltransferase Human genes 0.000 claims 2
- 102100031167 Tyrosine-protein kinase CSK Human genes 0.000 claims 2
- 102100026857 Tyrosine-protein kinase Lyn Human genes 0.000 claims 2
- 102100038467 Ubiquitin-conjugating enzyme E2 variant 1 Human genes 0.000 claims 2
- 102100038388 Vasoactive intestinal polypeptide receptor 1 Human genes 0.000 claims 2
- 101710137655 Vasoactive intestinal polypeptide receptor 1 Proteins 0.000 claims 2
- 108010036639 WW Domain-Containing Oxidoreductase Proteins 0.000 claims 2
- 102100027534 WW domain-containing oxidoreductase Human genes 0.000 claims 2
- 102100040314 Zinc finger and BTB domain-containing protein 16 Human genes 0.000 claims 2
- 102100032570 Zinc finger protein PLAGL1 Human genes 0.000 claims 2
- 102100024148 [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 1, mitochondrial Human genes 0.000 claims 2
- 201000011510 cancer Diseases 0.000 claims 2
- 150000005829 chemical entities Chemical class 0.000 claims 2
- 239000003795 chemical substances by application Substances 0.000 claims 2
- 210000003483 chromatin Anatomy 0.000 claims 2
- 108010072917 class-I restricted T cell-associated molecule Proteins 0.000 claims 2
- 229940000406 drug candidate Drugs 0.000 claims 2
- 239000003623 enhancer Substances 0.000 claims 2
- 108010019691 inhibin beta A subunit Proteins 0.000 claims 2
- 230000002452 interceptive effect Effects 0.000 claims 2
- 238000002360 preparation method Methods 0.000 claims 2
- 108010036805 rap1 GTP-Binding Proteins Proteins 0.000 claims 2
- 108010082379 somatostatin receptor type 1 Proteins 0.000 claims 2
- 229940126836 transmembrane protease serine 6 synthesis reducer Drugs 0.000 claims 2
- VVSWDMJYIDBTMV-ORWNZLQRSA-N (2s,4ar,6s,7s,8s,8ar)-6-methoxy-2-phenyl-4,4a,6,7,8,8a-hexahydropyrano[3,2-d][1,3]dioxine-7,8-diol Chemical compound C1([C@H]2OC[C@H]3O[C@@H]([C@H]([C@H](O)[C@H]3O2)O)OC)=CC=CC=C1 VVSWDMJYIDBTMV-ORWNZLQRSA-N 0.000 claims 1
- 102100030408 1-acyl-sn-glycerol-3-phosphate acyltransferase alpha Human genes 0.000 claims 1
- 102100031251 1-acylglycerol-3-phosphate O-acyltransferase PNPLA3 Human genes 0.000 claims 1
- 102100038028 1-phosphatidylinositol 3-phosphate 5-kinase Human genes 0.000 claims 1
- 102100027831 14-3-3 protein theta Human genes 0.000 claims 1
- 102100022586 17-beta-hydroxysteroid dehydrogenase type 2 Human genes 0.000 claims 1
- 101710186714 2-acylglycerol O-acyltransferase 1 Proteins 0.000 claims 1
- 101710186725 2-acylglycerol O-acyltransferase 2 Proteins 0.000 claims 1
- 102100034689 2-hydroxyacylsphingosine 1-beta-galactosyltransferase Human genes 0.000 claims 1
- 102100040973 26S proteasome non-ATPase regulatory subunit 1 Human genes 0.000 claims 1
- 102100021834 3-hydroxyacyl-CoA dehydrogenase Human genes 0.000 claims 1
- 102100029103 3-ketoacyl-CoA thiolase Human genes 0.000 claims 1
- 102100026105 3-ketoacyl-CoA thiolase, mitochondrial Human genes 0.000 claims 1
- 101710082567 3-methylorcinaldehyde synthase Proteins 0.000 claims 1
- 102100024420 39S ribosomal protein S30, mitochondrial Human genes 0.000 claims 1
- MXCVHSXCXPHOLP-UHFFFAOYSA-N 4-oxo-6-propylchromene-2-carboxylic acid Chemical compound O1C(C(O)=O)=CC(=O)C2=CC(CCC)=CC=C21 MXCVHSXCXPHOLP-UHFFFAOYSA-N 0.000 claims 1
- 102100022681 40S ribosomal protein S27 Human genes 0.000 claims 1
- 102100036962 5'-3' exoribonuclease 1 Human genes 0.000 claims 1
- 102100039222 5'-3' exoribonuclease 2 Human genes 0.000 claims 1
- 102100036009 5'-AMP-activated protein kinase catalytic subunit alpha-2 Human genes 0.000 claims 1
- 102100038049 5'-AMP-activated protein kinase subunit beta-2 Human genes 0.000 claims 1
- 102100024626 5'-AMP-activated protein kinase subunit gamma-2 Human genes 0.000 claims 1
- 102100031126 6-phosphogluconolactonase Human genes 0.000 claims 1
- 102100026802 72 kDa type IV collagenase Human genes 0.000 claims 1
- 102100037991 85/88 kDa calcium-independent phospholipase A2 Human genes 0.000 claims 1
- 102100024049 A-kinase anchor protein 13 Human genes 0.000 claims 1
- 102100022884 ADP-ribosylation factor-like protein 4D Human genes 0.000 claims 1
- 102000012758 APOBEC-1 Deaminase Human genes 0.000 claims 1
- 102000000872 ATM Human genes 0.000 claims 1
- 102100022594 ATP-binding cassette sub-family G member 1 Human genes 0.000 claims 1
- 102100035623 ATP-citrate synthase Human genes 0.000 claims 1
- 102100032922 ATP-dependent 6-phosphofructokinase, muscle type Human genes 0.000 claims 1
- 102100040958 Aconitate hydratase, mitochondrial Human genes 0.000 claims 1
- 102100026041 Acrosin Human genes 0.000 claims 1
- 102100036409 Activated CDC42 kinase 1 Human genes 0.000 claims 1
- 102100021305 Acyl-CoA:lysophosphatidylglycerol acyltransferase 1 Human genes 0.000 claims 1
- 102100025854 Acyl-coenzyme A thioesterase 1 Human genes 0.000 claims 1
- 102100040277 Acyl-protein thioesterase 2 Human genes 0.000 claims 1
- 101150095323 Adcy10 gene Proteins 0.000 claims 1
- 102100035886 Adenine DNA glycosylase Human genes 0.000 claims 1
- 102100034540 Adenomatous polyposis coli protein Human genes 0.000 claims 1
- 102100032157 Adenylate cyclase type 10 Human genes 0.000 claims 1
- 102100040149 Adenylyl-sulfate kinase Human genes 0.000 claims 1
- 102100040152 Adenylyl-sulfate kinase Human genes 0.000 claims 1
- 102100024396 Adrenodoxin, mitochondrial Human genes 0.000 claims 1
- 102100033816 Aldehyde dehydrogenase, mitochondrial Human genes 0.000 claims 1
- 102100024090 Aldo-keto reductase family 1 member C3 Human genes 0.000 claims 1
- 102100024092 Aldo-keto reductase family 1 member C4 Human genes 0.000 claims 1
- 102100022299 All trans-polyprenyl-diphosphate synthase PDSS1 Human genes 0.000 claims 1
- 102100022622 Alpha-1,3-mannosyl-glycoprotein 2-beta-N-acetylglucosaminyltransferase Human genes 0.000 claims 1
- 102100024296 Alpha-1,6-mannosyl-glycoprotein 2-beta-N-acetylglucosaminyltransferase Human genes 0.000 claims 1
- 102100022524 Alpha-1-antichymotrypsin Human genes 0.000 claims 1
- 102100029231 Alpha-2,8-sialyltransferase 8B Human genes 0.000 claims 1
- 102100028042 Alpha-2-HS-glycoprotein Human genes 0.000 claims 1
- 102100034163 Alpha-actinin-1 Human genes 0.000 claims 1
- 102100021761 Alpha-mannosidase 2 Human genes 0.000 claims 1
- 102100023165 Alpha-mannosidase 2C1 Human genes 0.000 claims 1
- 102100024581 Alpha-taxilin Human genes 0.000 claims 1
- 102100040360 Angiomotin Human genes 0.000 claims 1
- 102100021623 Ankyrin repeat and SOCS box protein 7 Human genes 0.000 claims 1
- 102100034283 Annexin A5 Human genes 0.000 claims 1
- 102100036013 Antigen-presenting glycoprotein CD1d Human genes 0.000 claims 1
- 102100033715 Apolipoprotein A-I Human genes 0.000 claims 1
- 102100037320 Apolipoprotein A-IV Human genes 0.000 claims 1
- 102100030970 Apolipoprotein C-III Human genes 0.000 claims 1
- 101100288434 Arabidopsis thaliana LACS2 gene Proteins 0.000 claims 1
- 101100404726 Arabidopsis thaliana NHX7 gene Proteins 0.000 claims 1
- 108010004586 Ataxia Telangiectasia Mutated Proteins Proteins 0.000 claims 1
- 102100039341 Atrial natriuretic peptide receptor 2 Human genes 0.000 claims 1
- 108010028006 B-Cell Activating Factor Proteins 0.000 claims 1
- 102100021631 B-cell lymphoma 6 protein Human genes 0.000 claims 1
- 102100022976 B-cell lymphoma/leukemia 11A Human genes 0.000 claims 1
- 108700020462 BRCA2 Proteins 0.000 claims 1
- 102000052609 BRCA2 Human genes 0.000 claims 1
- 108700003785 Baculoviral IAP Repeat-Containing 3 Proteins 0.000 claims 1
- 102100021662 Baculoviral IAP repeat-containing protein 3 Human genes 0.000 claims 1
- 102100023973 Bax inhibitor 1 Human genes 0.000 claims 1
- 102100026596 Bcl-2-like protein 1 Human genes 0.000 claims 1
- 101150008012 Bcl2l1 gene Proteins 0.000 claims 1
- 102100029945 Beta-galactoside alpha-2,6-sialyltransferase 1 Human genes 0.000 claims 1
- 102100026031 Beta-glucuronidase Human genes 0.000 claims 1
- 102100032487 Beta-mannosidase Human genes 0.000 claims 1
- 102100030686 Beta-sarcoglycan Human genes 0.000 claims 1
- 102100038495 Bile acid receptor Human genes 0.000 claims 1
- 102100027950 Bile acid-CoA:amino acid N-acyltransferase Human genes 0.000 claims 1
- 101150104237 Birc3 gene Proteins 0.000 claims 1
- 102100037674 Bis(5'-adenosyl)-triphosphatase Human genes 0.000 claims 1
- 102100036461 Bis(5'-nucleosyl)-tetraphosphatase [asymmetrical] Human genes 0.000 claims 1
- 102100022525 Bone morphogenetic protein 6 Human genes 0.000 claims 1
- 101001042041 Bos taurus Isocitrate dehydrogenase [NAD] subunit beta, mitochondrial Proteins 0.000 claims 1
- 101150008921 Brca2 gene Proteins 0.000 claims 1
- 102100027157 Butyrophilin subfamily 2 member A1 Human genes 0.000 claims 1
- 102100028737 CAP-Gly domain-containing linker protein 1 Human genes 0.000 claims 1
- 102100034808 CCAAT/enhancer-binding protein alpha Human genes 0.000 claims 1
- 102100031173 CCN family member 4 Human genes 0.000 claims 1
- 108010056102 CD100 antigen Proteins 0.000 claims 1
- 108010062802 CD66 antigens Proteins 0.000 claims 1
- 102100030933 CDK-activating kinase assembly factor MAT1 Human genes 0.000 claims 1
- 102100031973 CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 2 Human genes 0.000 claims 1
- 108010033531 CMP-N-acetylneuraminate-poly-alpha-2,8-sialosyl sialyltransferase Proteins 0.000 claims 1
- 102100021786 CMP-N-acetylneuraminate-poly-alpha-2,8-sialyltransferase Human genes 0.000 claims 1
- 102100028226 COUP transcription factor 2 Human genes 0.000 claims 1
- 102100025659 Cadherin EGF LAG seven-pass G-type receptor 1 Human genes 0.000 claims 1
- 102100037885 Calcium-independent phospholipase A2-gamma Human genes 0.000 claims 1
- 102100029801 Calcium-transporting ATPase type 2C member 1 Human genes 0.000 claims 1
- 102100025228 Calcium/calmodulin-dependent protein kinase type II subunit delta Human genes 0.000 claims 1
- 101710134389 Carboxy-terminal domain RNA polymerase II polypeptide A small phosphatase 2 Proteins 0.000 claims 1
- 102100024533 Carcinoembryonic antigen-related cell adhesion molecule 1 Human genes 0.000 claims 1
- 102100024853 Carnitine O-palmitoyltransferase 2, mitochondrial Human genes 0.000 claims 1
- 102100033668 Cartilage matrix protein Human genes 0.000 claims 1
- 102100026549 Caspase-10 Human genes 0.000 claims 1
- 102100038918 Caspase-6 Human genes 0.000 claims 1
- 102000053642 Catalytic RNA Human genes 0.000 claims 1
- 108090000994 Catalytic RNA Proteins 0.000 claims 1
- 102100025045 Cell cycle checkpoint control protein RAD9B Human genes 0.000 claims 1
- 102100031441 Cell cycle checkpoint protein RAD17 Human genes 0.000 claims 1
- 102100027047 Cell division control protein 6 homolog Human genes 0.000 claims 1
- 102100025175 Cellular communication network factor 6 Human genes 0.000 claims 1
- 102100037631 Centrin-2 Human genes 0.000 claims 1
- 102100037633 Centrin-3 Human genes 0.000 claims 1
- 102100039118 Centromere/kinetochore protein zw10 homolog Human genes 0.000 claims 1
- 102100024502 Ceramide glucosyltransferase Human genes 0.000 claims 1
- 102100036165 Ceramide kinase-like protein Human genes 0.000 claims 1
- 102100035417 Ceramide synthase 5 Human genes 0.000 claims 1
- 102100029172 Choline-phosphate cytidylyltransferase A Human genes 0.000 claims 1
- 102100029173 Choline-phosphate cytidylyltransferase B Human genes 0.000 claims 1
- 102100033885 Collagen alpha-2(XI) chain Human genes 0.000 claims 1
- 102100030797 Conserved oligomeric Golgi complex subunit 2 Human genes 0.000 claims 1
- 108010024682 Core Binding Factor Alpha 1 Subunit Proteins 0.000 claims 1
- 102000015775 Core Binding Factor Alpha 1 Subunit Human genes 0.000 claims 1
- 108010043471 Core Binding Factor Alpha 2 Subunit Proteins 0.000 claims 1
- 102100029375 Crk-like protein Human genes 0.000 claims 1
- 102100031096 Cubilin Human genes 0.000 claims 1
- 108010016777 Cyclin-Dependent Kinase Inhibitor p27 Proteins 0.000 claims 1
- 102000000577 Cyclin-Dependent Kinase Inhibitor p27 Human genes 0.000 claims 1
- 102100036883 Cyclin-H Human genes 0.000 claims 1
- 102100021906 Cyclin-O Human genes 0.000 claims 1
- 102100024109 Cyclin-T1 Human genes 0.000 claims 1
- 102100031061 Cysteine/serine-rich nuclear protein 3 Human genes 0.000 claims 1
- 101710088629 Cysteine/serine-rich nuclear protein 3 Proteins 0.000 claims 1
- 102100031461 Cytochrome P450 2J2 Human genes 0.000 claims 1
- 102100039208 Cytochrome P450 3A5 Human genes 0.000 claims 1
- 102100024901 Cytochrome P450 4F3 Human genes 0.000 claims 1
- 102100025843 Cytohesin-4 Human genes 0.000 claims 1
- 102100034478 Cytokine-dependent hematopoietic cell linker Human genes 0.000 claims 1
- 102100040629 Cytosolic phospholipase A2 delta Human genes 0.000 claims 1
- 102100038281 Cytospin-A Human genes 0.000 claims 1
- 102100032620 Cytotoxic granule associated RNA binding protein TIA1 Human genes 0.000 claims 1
- 102100029813 D(1B) dopamine receptor Human genes 0.000 claims 1
- 102100037579 D-3-phosphoglycerate dehydrogenase Human genes 0.000 claims 1
- 102100038826 DNA helicase MCM8 Human genes 0.000 claims 1
- 102100033195 DNA ligase 4 Human genes 0.000 claims 1
- 102100035925 DNA methyltransferase 1-associated protein 1 Human genes 0.000 claims 1
- 102100028849 DNA mismatch repair protein Mlh3 Human genes 0.000 claims 1
- 102100022307 DNA polymerase alpha catalytic subunit Human genes 0.000 claims 1
- 102100039116 DNA repair protein RAD50 Human genes 0.000 claims 1
- 102100033934 DNA repair protein RAD51 homolog 2 Human genes 0.000 claims 1
- 102100039606 DNA replication licensing factor MCM3 Human genes 0.000 claims 1
- 101100174544 Danio rerio foxo1a gene Proteins 0.000 claims 1
- 101100457345 Danio rerio mapk14a gene Proteins 0.000 claims 1
- 101100457347 Danio rerio mapk14b gene Proteins 0.000 claims 1
- 102100038713 Death domain-containing protein CRADD Human genes 0.000 claims 1
- 102100032501 Death-inducer obliterator 1 Human genes 0.000 claims 1
- 102100036727 Deformed epidermal autoregulatory factor 1 homolog Human genes 0.000 claims 1
- 102100030012 Deoxyribonuclease-1 Human genes 0.000 claims 1
- 102100022735 Diacylglycerol kinase alpha Human genes 0.000 claims 1
- 102100022732 Diacylglycerol kinase beta Human genes 0.000 claims 1
- 102100030215 Diacylglycerol kinase eta Human genes 0.000 claims 1
- 102100030214 Diacylglycerol kinase iota Human genes 0.000 claims 1
- 101000947141 Dictyostelium discoideum Adenylate cyclase, terminal-differentiation specific Proteins 0.000 claims 1
- 102100031920 Dihydrolipoyllysine-residue succinyltransferase component of 2-oxoglutarate dehydrogenase complex, mitochondrial Human genes 0.000 claims 1
- 102100036039 Diphosphoinositol polyphosphate phosphohydrolase 2 Human genes 0.000 claims 1
- 102100022263 Disks large homolog 3 Human genes 0.000 claims 1
- 102100024105 DnaJ homolog subfamily C member 27 Human genes 0.000 claims 1
- 102100039104 Dolichyl-diphosphooligosaccharide-protein glycosyltransferase subunit DAD1 Human genes 0.000 claims 1
- 102100021331 Dual adapter for phosphotyrosine and 3-phosphotyrosine and 3-phosphoinositide Human genes 0.000 claims 1
- 102100023401 Dual specificity mitogen-activated protein kinase kinase 6 Human genes 0.000 claims 1
- 102100025734 Dual specificity protein phosphatase CDC14A Human genes 0.000 claims 1
- 102100026620 E3 ubiquitin ligase TRAF3IP2 Human genes 0.000 claims 1
- 102100035102 E3 ubiquitin-protein ligase MYCBP2 Human genes 0.000 claims 1
- 102000012199 E3 ubiquitin-protein ligase Mdm2 Human genes 0.000 claims 1
- 108050002772 E3 ubiquitin-protein ligase Mdm2 Proteins 0.000 claims 1
- 102100024739 E3 ubiquitin-protein ligase UHRF1 Human genes 0.000 claims 1
- 102100024748 E3 ubiquitin-protein ligase UHRF2 Human genes 0.000 claims 1
- 102100037024 E3 ubiquitin-protein ligase XIAP Human genes 0.000 claims 1
- 102100030796 E3 ubiquitin-protein ligase rififylin Human genes 0.000 claims 1
- 102000017930 EDNRB Human genes 0.000 claims 1
- 102100029060 EF-hand domain-containing protein 1 Human genes 0.000 claims 1
- 101150039033 Eci2 gene Proteins 0.000 claims 1
- 102100032053 Elongation of very long chain fatty acids protein 4 Human genes 0.000 claims 1
- 102100032670 Endophilin-B1 Human genes 0.000 claims 1
- 102100027117 Engulfment and cell motility protein 2 Human genes 0.000 claims 1
- 102100021823 Enoyl-CoA delta isomerase 2 Human genes 0.000 claims 1
- 102100032460 Ensconsin Human genes 0.000 claims 1
- 102100021793 Epsilon-sarcoglycan Human genes 0.000 claims 1
- 241000402754 Erythranthe moschata Species 0.000 claims 1
- 102100029174 Ethanolamine-phosphate cytidylyltransferase Human genes 0.000 claims 1
- 102100030341 Ethanolaminephosphotransferase 1 Human genes 0.000 claims 1
- 102100021654 Extracellular sulfatase Sulf-2 Human genes 0.000 claims 1
- 102100020903 Ezrin Human genes 0.000 claims 1
- 101150106966 FOXO1 gene Proteins 0.000 claims 1
- 102100030421 Fatty acid-binding protein 5 Human genes 0.000 claims 1
- 102100040684 Fermitin family homolog 2 Human genes 0.000 claims 1
- 108010010285 Forkhead Box Protein L2 Proteins 0.000 claims 1
- 102100035137 Forkhead box protein L2 Human genes 0.000 claims 1
- 102100035427 Forkhead box protein O1 Human genes 0.000 claims 1
- 102100030892 Fructose-1,6-bisphosphatase isozyme 2 Human genes 0.000 claims 1
- 102100022633 Fructose-2,6-bisphosphatase Human genes 0.000 claims 1
- 102100022629 Fructose-2,6-bisphosphatase Human genes 0.000 claims 1
- 102100022642 Fructose-2,6-bisphosphatase Human genes 0.000 claims 1
- 102100040861 G0/G1 switch protein 2 Human genes 0.000 claims 1
- 102100027149 GDP-fucose protein O-fucosyltransferase 1 Human genes 0.000 claims 1
- 108010062427 GDP-mannose 4,6-dehydratase Proteins 0.000 claims 1
- 102000002312 GDPmannose 4,6-dehydratase Human genes 0.000 claims 1
- 102100032950 GPI mannosyltransferase 1 Human genes 0.000 claims 1
- 102100036250 GPI mannosyltransferase 4 Human genes 0.000 claims 1
- 102100036858 GPI-anchor transamidase Human genes 0.000 claims 1
- 102100037740 GRB2-associated-binding protein 1 Human genes 0.000 claims 1
- 102100027541 GTP-binding protein Rheb Human genes 0.000 claims 1
- 102100032170 GTP-binding protein SAR1b Human genes 0.000 claims 1
- 102100036291 Galactose-1-phosphate uridylyltransferase Human genes 0.000 claims 1
- 102100021260 Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1 Human genes 0.000 claims 1
- 102100031351 Galectin-9 Human genes 0.000 claims 1
- 102100031416 Gastric triacylglycerol lipase Human genes 0.000 claims 1
- 102100041034 Glucosamine-6-phosphate isomerase 1 Human genes 0.000 claims 1
- 102100036636 Glucose 1,6-bisphosphate synthase Human genes 0.000 claims 1
- 102100036264 Glucose-6-phosphatase catalytic subunit 1 Human genes 0.000 claims 1
- 102100039684 Glucose-6-phosphate exchanger SLC37A4 Human genes 0.000 claims 1
- 108010051975 Glycogen Synthase Kinase 3 beta Proteins 0.000 claims 1
- 102100039264 Glycogen [starch] synthase, liver Human genes 0.000 claims 1
- 102100040094 Glycogen phosphorylase, brain form Human genes 0.000 claims 1
- 102100029481 Glycogen phosphorylase, liver form Human genes 0.000 claims 1
- 102100038104 Glycogen synthase kinase-3 beta Human genes 0.000 claims 1
- 102100033325 Golgi-specific brefeldin A-resistance guanine nucleotide exchange factor 1 Human genes 0.000 claims 1
- 102100026825 Group IIE secretory phospholipase A2 Human genes 0.000 claims 1
- 102100032939 Group XIIB secretory phospholipase A2-like protein Human genes 0.000 claims 1
- 102100033067 Growth factor receptor-bound protein 2 Human genes 0.000 claims 1
- 102100021383 Guanine nucleotide exchange factor DBS Human genes 0.000 claims 1
- 102100034192 Guanine nucleotide exchange factor MSS4 Human genes 0.000 claims 1
- 102100032134 Guanine nucleotide exchange factor VAV2 Human genes 0.000 claims 1
- 102100032191 Guanine nucleotide exchange factor VAV3 Human genes 0.000 claims 1
- 102100024979 Guanine nucleotide-binding protein subunit beta-like protein 1 Human genes 0.000 claims 1
- 102100033563 HCLS1-binding protein 3 Human genes 0.000 claims 1
- 102100039330 HMG box-containing protein 1 Human genes 0.000 claims 1
- 108010081348 HRT1 protein Hairy Proteins 0.000 claims 1
- 102100021881 Hairy/enhancer-of-split related with YRPW motif protein 1 Human genes 0.000 claims 1
- 102100037931 Harmonin Human genes 0.000 claims 1
- 102100023855 Heart- and neural crest derivatives-expressed protein 1 Human genes 0.000 claims 1
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 claims 1
- 102100031497 Heparan sulfate N-sulfotransferase 1 Human genes 0.000 claims 1
- 102100031415 Hepatic triacylglycerol lipase Human genes 0.000 claims 1
- 102100033071 Histone acetyltransferase KAT6A Human genes 0.000 claims 1
- 102100022537 Histone deacetylase 6 Human genes 0.000 claims 1
- 102100028707 Homeobox protein MSX-1 Human genes 0.000 claims 1
- 102100040615 Homeobox protein MSX-2 Human genes 0.000 claims 1
- 102100027886 Homeobox protein Nkx-2.2 Human genes 0.000 claims 1
- 102100029279 Homeobox protein SIX1 Human genes 0.000 claims 1
- 102100033798 Homeobox protein aristaless-like 4 Human genes 0.000 claims 1
- 101000583049 Homo sapiens 1-acyl-sn-glycerol-3-phosphate acyltransferase alpha Proteins 0.000 claims 1
- 101001129184 Homo sapiens 1-acylglycerol-3-phosphate O-acyltransferase PNPLA3 Proteins 0.000 claims 1
- 101001025044 Homo sapiens 1-phosphatidylinositol 3-phosphate 5-kinase Proteins 0.000 claims 1
- 101000723543 Homo sapiens 14-3-3 protein theta Proteins 0.000 claims 1
- 101001045223 Homo sapiens 17-beta-hydroxysteroid dehydrogenase type 2 Proteins 0.000 claims 1
- 101000946034 Homo sapiens 2-hydroxyacylsphingosine 1-beta-galactosyltransferase Proteins 0.000 claims 1
- 101000612655 Homo sapiens 26S proteasome non-ATPase regulatory subunit 1 Proteins 0.000 claims 1
- 101000896020 Homo sapiens 3-hydroxyacyl-CoA dehydrogenase Proteins 0.000 claims 1
- 101000841262 Homo sapiens 3-ketoacyl-CoA thiolase Proteins 0.000 claims 1
- 101000835276 Homo sapiens 3-ketoacyl-CoA thiolase, mitochondrial Proteins 0.000 claims 1
- 101000689854 Homo sapiens 39S ribosomal protein S30, mitochondrial Proteins 0.000 claims 1
- 101000678466 Homo sapiens 40S ribosomal protein S27 Proteins 0.000 claims 1
- 101000804879 Homo sapiens 5'-3' exoribonuclease 1 Proteins 0.000 claims 1
- 101000745788 Homo sapiens 5'-3' exoribonuclease 2 Proteins 0.000 claims 1
- 101000783681 Homo sapiens 5'-AMP-activated protein kinase catalytic subunit alpha-2 Proteins 0.000 claims 1
- 101000742799 Homo sapiens 5'-AMP-activated protein kinase subunit beta-2 Proteins 0.000 claims 1
- 101000760987 Homo sapiens 5'-AMP-activated protein kinase subunit gamma-2 Proteins 0.000 claims 1
- 101001066181 Homo sapiens 6-phosphogluconolactonase Proteins 0.000 claims 1
- 101000627872 Homo sapiens 72 kDa type IV collagenase Proteins 0.000 claims 1
- 101000833679 Homo sapiens A-kinase anchor protein 13 Proteins 0.000 claims 1
- 101000974500 Homo sapiens ADP-ribosylation factor-like protein 1 Proteins 0.000 claims 1
- 101000974385 Homo sapiens ADP-ribosylation factor-like protein 4D Proteins 0.000 claims 1
- 101000782969 Homo sapiens ATP-citrate synthase Proteins 0.000 claims 1
- 101000730838 Homo sapiens ATP-dependent 6-phosphofructokinase, muscle type Proteins 0.000 claims 1
- 101000965314 Homo sapiens Aconitate hydratase, mitochondrial Proteins 0.000 claims 1
- 101000720330 Homo sapiens Acrosin Proteins 0.000 claims 1
- 101000928956 Homo sapiens Activated CDC42 kinase 1 Proteins 0.000 claims 1
- 101001042227 Homo sapiens Acyl-CoA:lysophosphatidylglycerol acyltransferase 1 Proteins 0.000 claims 1
- 101000720368 Homo sapiens Acyl-coenzyme A thioesterase 1 Proteins 0.000 claims 1
- 101001038521 Homo sapiens Acyl-protein thioesterase 2 Proteins 0.000 claims 1
- 101001000351 Homo sapiens Adenine DNA glycosylase Proteins 0.000 claims 1
- 101000924577 Homo sapiens Adenomatous polyposis coli protein Proteins 0.000 claims 1
- 101000610212 Homo sapiens Adenylyl-sulfate kinase Proteins 0.000 claims 1
- 101000610215 Homo sapiens Adenylyl-sulfate kinase Proteins 0.000 claims 1
- 101000833098 Homo sapiens Adrenodoxin, mitochondrial Proteins 0.000 claims 1
- 101000718041 Homo sapiens Aldo-keto reductase family 1 member B10 Proteins 0.000 claims 1
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 claims 1
- 101000902409 Homo sapiens All trans-polyprenyl-diphosphate synthase PDSS1 Proteins 0.000 claims 1
- 101000678026 Homo sapiens Alpha-1-antichymotrypsin Proteins 0.000 claims 1
- 101000799406 Homo sapiens Alpha-actinin-1 Proteins 0.000 claims 1
- 101000615953 Homo sapiens Alpha-mannosidase 2 Proteins 0.000 claims 1
- 101000979029 Homo sapiens Alpha-mannosidase 2C1 Proteins 0.000 claims 1
- 101000760787 Homo sapiens Alpha-taxilin Proteins 0.000 claims 1
- 101000891154 Homo sapiens Angiomotin Proteins 0.000 claims 1
- 101000754271 Homo sapiens Ankyrin repeat and SOCS box protein 7 Proteins 0.000 claims 1
- 101000780122 Homo sapiens Annexin A5 Proteins 0.000 claims 1
- 101000716121 Homo sapiens Antigen-presenting glycoprotein CD1d Proteins 0.000 claims 1
- 101000733802 Homo sapiens Apolipoprotein A-I Proteins 0.000 claims 1
- 101000806793 Homo sapiens Apolipoprotein A-IV Proteins 0.000 claims 1
- 101000793223 Homo sapiens Apolipoprotein C-III Proteins 0.000 claims 1
- 101000961040 Homo sapiens Atrial natriuretic peptide receptor 2 Proteins 0.000 claims 1
- 101000971234 Homo sapiens B-cell lymphoma 6 protein Proteins 0.000 claims 1
- 101000903703 Homo sapiens B-cell lymphoma/leukemia 11A Proteins 0.000 claims 1
- 101000903937 Homo sapiens Bax inhibitor 1 Proteins 0.000 claims 1
- 101000863864 Homo sapiens Beta-galactoside alpha-2,6-sialyltransferase 1 Proteins 0.000 claims 1
- 101000933465 Homo sapiens Beta-glucuronidase Proteins 0.000 claims 1
- 101001016707 Homo sapiens Beta-mannosidase Proteins 0.000 claims 1
- 101000703495 Homo sapiens Beta-sarcoglycan Proteins 0.000 claims 1
- 101000603876 Homo sapiens Bile acid receptor Proteins 0.000 claims 1
- 101000697858 Homo sapiens Bile acid-CoA:amino acid N-acyltransferase Proteins 0.000 claims 1
- 101000928573 Homo sapiens Bis(5'-nucleosyl)-tetraphosphatase [asymmetrical] Proteins 0.000 claims 1
- 101000899390 Homo sapiens Bone morphogenetic protein 6 Proteins 0.000 claims 1
- 101000984926 Homo sapiens Butyrophilin subfamily 2 member A1 Proteins 0.000 claims 1
- 101000767052 Homo sapiens CAP-Gly domain-containing linker protein 1 Proteins 0.000 claims 1
- 101000945515 Homo sapiens CCAAT/enhancer-binding protein alpha Proteins 0.000 claims 1
- 101000777560 Homo sapiens CCN family member 4 Proteins 0.000 claims 1
- 101000583935 Homo sapiens CDK-activating kinase assembly factor MAT1 Proteins 0.000 claims 1
- 101000703758 Homo sapiens CMP-N-acetylneuraminate-beta-galactosamide-alpha-2,3-sialyltransferase 2 Proteins 0.000 claims 1
- 101000616698 Homo sapiens CMP-N-acetylneuraminate-poly-alpha-2,8-sialyltransferase Proteins 0.000 claims 1
- 101000860860 Homo sapiens COUP transcription factor 2 Proteins 0.000 claims 1
- 101000914155 Homo sapiens Cadherin EGF LAG seven-pass G-type receptor 1 Proteins 0.000 claims 1
- 101001095970 Homo sapiens Calcium-independent phospholipase A2-gamma Proteins 0.000 claims 1
- 101000728145 Homo sapiens Calcium-transporting ATPase type 2C member 1 Proteins 0.000 claims 1
- 101001077338 Homo sapiens Calcium/calmodulin-dependent protein kinase type II subunit delta Proteins 0.000 claims 1
- 101000909313 Homo sapiens Carnitine O-palmitoyltransferase 2, mitochondrial Proteins 0.000 claims 1
- 101000741087 Homo sapiens Caspase-6 Proteins 0.000 claims 1
- 101001077512 Homo sapiens Cell cycle checkpoint control protein RAD9B Proteins 0.000 claims 1
- 101001130422 Homo sapiens Cell cycle checkpoint protein RAD17 Proteins 0.000 claims 1
- 101000914465 Homo sapiens Cell division control protein 6 homolog Proteins 0.000 claims 1
- 101000934310 Homo sapiens Cellular communication network factor 6 Proteins 0.000 claims 1
- 101000880516 Homo sapiens Centrin-2 Proteins 0.000 claims 1
- 101000880522 Homo sapiens Centrin-3 Proteins 0.000 claims 1
- 101000743902 Homo sapiens Centromere/kinetochore protein zw10 homolog Proteins 0.000 claims 1
- 101000981050 Homo sapiens Ceramide glucosyltransferase Proteins 0.000 claims 1
- 101000715707 Homo sapiens Ceramide kinase-like protein Proteins 0.000 claims 1
- 101000737542 Homo sapiens Ceramide synthase 5 Proteins 0.000 claims 1
- 101000988444 Homo sapiens Choline-phosphate cytidylyltransferase A Proteins 0.000 claims 1
- 101000988443 Homo sapiens Choline-phosphate cytidylyltransferase B Proteins 0.000 claims 1
- 101000710619 Homo sapiens Collagen alpha-2(XI) chain Proteins 0.000 claims 1
- 101000749824 Homo sapiens Connector enhancer of kinase suppressor of ras 2 Proteins 0.000 claims 1
- 101000920113 Homo sapiens Conserved oligomeric Golgi complex subunit 2 Proteins 0.000 claims 1
- 101000919315 Homo sapiens Crk-like protein Proteins 0.000 claims 1
- 101000922080 Homo sapiens Cubilin Proteins 0.000 claims 1
- 101000713120 Homo sapiens Cyclin-H Proteins 0.000 claims 1
- 101000897441 Homo sapiens Cyclin-O Proteins 0.000 claims 1
- 101000910488 Homo sapiens Cyclin-T1 Proteins 0.000 claims 1
- 101000941723 Homo sapiens Cytochrome P450 2J2 Proteins 0.000 claims 1
- 101000909121 Homo sapiens Cytochrome P450 4F3 Proteins 0.000 claims 1
- 101000855828 Homo sapiens Cytohesin-4 Proteins 0.000 claims 1
- 101000710210 Homo sapiens Cytokine-dependent hematopoietic cell linker Proteins 0.000 claims 1
- 101000614104 Homo sapiens Cytosolic phospholipase A2 delta Proteins 0.000 claims 1
- 101000884816 Homo sapiens Cytospin-A Proteins 0.000 claims 1
- 101000654853 Homo sapiens Cytotoxic granule associated RNA binding protein TIA1 Proteins 0.000 claims 1
- 101000865210 Homo sapiens D(1B) dopamine receptor Proteins 0.000 claims 1
- 101000739890 Homo sapiens D-3-phosphoglycerate dehydrogenase Proteins 0.000 claims 1
- 101000957174 Homo sapiens DNA helicase MCM8 Proteins 0.000 claims 1
- 101000927810 Homo sapiens DNA ligase 4 Proteins 0.000 claims 1
- 101000930289 Homo sapiens DNA methyltransferase 1-associated protein 1 Proteins 0.000 claims 1
- 101000577867 Homo sapiens DNA mismatch repair protein Mlh3 Proteins 0.000 claims 1
- 101000902558 Homo sapiens DNA polymerase alpha catalytic subunit Proteins 0.000 claims 1
- 101000712511 Homo sapiens DNA repair and recombination protein RAD54-like Proteins 0.000 claims 1
- 101000743929 Homo sapiens DNA repair protein RAD50 Proteins 0.000 claims 1
- 101001132307 Homo sapiens DNA repair protein RAD51 homolog 2 Proteins 0.000 claims 1
- 101000963174 Homo sapiens DNA replication licensing factor MCM3 Proteins 0.000 claims 1
- 101000957914 Homo sapiens Death domain-containing protein CRADD Proteins 0.000 claims 1
- 101000869896 Homo sapiens Death-inducer obliterator 1 Proteins 0.000 claims 1
- 101000929421 Homo sapiens Deformed epidermal autoregulatory factor 1 homolog Proteins 0.000 claims 1
- 101000863721 Homo sapiens Deoxyribonuclease-1 Proteins 0.000 claims 1
- 101001044817 Homo sapiens Diacylglycerol kinase alpha Proteins 0.000 claims 1
- 101001044814 Homo sapiens Diacylglycerol kinase beta Proteins 0.000 claims 1
- 101000864599 Homo sapiens Diacylglycerol kinase eta Proteins 0.000 claims 1
- 101000864600 Homo sapiens Diacylglycerol kinase iota Proteins 0.000 claims 1
- 101000992065 Homo sapiens Dihydrolipoyllysine-residue succinyltransferase component of 2-oxoglutarate dehydrogenase complex, mitochondrial Proteins 0.000 claims 1
- 101000595333 Homo sapiens Diphosphoinositol polyphosphate phosphohydrolase 2 Proteins 0.000 claims 1
- 101000902100 Homo sapiens Disks large homolog 3 Proteins 0.000 claims 1
- 101001054007 Homo sapiens DnaJ homolog subfamily C member 27 Proteins 0.000 claims 1
- 101000884921 Homo sapiens Dolichyl-diphosphooligosaccharide-protein glycosyltransferase subunit DAD1 Proteins 0.000 claims 1
- 101001042034 Homo sapiens Dual adapter for phosphotyrosine and 3-phosphotyrosine and 3-phosphoinositide Proteins 0.000 claims 1
- 101000624426 Homo sapiens Dual specificity mitogen-activated protein kinase kinase 6 Proteins 0.000 claims 1
- 101000932600 Homo sapiens Dual specificity protein phosphatase CDC14A Proteins 0.000 claims 1
- 101000722054 Homo sapiens Dynamin-like 120 kDa protein, mitochondrial Proteins 0.000 claims 1
- 101001016186 Homo sapiens Dystonin Proteins 0.000 claims 1
- 101000913784 Homo sapiens E3 ubiquitin ligase TRAF3IP2 Proteins 0.000 claims 1
- 101000760417 Homo sapiens E3 ubiquitin-protein ligase UHRF1 Proteins 0.000 claims 1
- 101000760434 Homo sapiens E3 ubiquitin-protein ligase UHRF2 Proteins 0.000 claims 1
- 101000804865 Homo sapiens E3 ubiquitin-protein ligase XIAP Proteins 0.000 claims 1
- 101000703348 Homo sapiens E3 ubiquitin-protein ligase rififylin Proteins 0.000 claims 1
- 101000840938 Homo sapiens EF-hand domain-containing protein 1 Proteins 0.000 claims 1
- 101000921354 Homo sapiens Elongation of very long chain fatty acids protein 4 Proteins 0.000 claims 1
- 101000654648 Homo sapiens Endophilin-B1 Proteins 0.000 claims 1
- 101000967299 Homo sapiens Endothelin receptor type B Proteins 0.000 claims 1
- 101001057855 Homo sapiens Engulfment and cell motility protein 2 Proteins 0.000 claims 1
- 101001016782 Homo sapiens Ensconsin Proteins 0.000 claims 1
- 101000616437 Homo sapiens Epsilon-sarcoglycan Proteins 0.000 claims 1
- 101000988434 Homo sapiens Ethanolamine-phosphate cytidylyltransferase Proteins 0.000 claims 1
- 101000820626 Homo sapiens Extracellular sulfatase Sulf-2 Proteins 0.000 claims 1
- 101000854648 Homo sapiens Ezrin Proteins 0.000 claims 1
- 101001062855 Homo sapiens Fatty acid-binding protein 5 Proteins 0.000 claims 1
- 101000892677 Homo sapiens Fermitin family homolog 2 Proteins 0.000 claims 1
- 101000823467 Homo sapiens Fructose-2,6-bisphosphatase Proteins 0.000 claims 1
- 101000823463 Homo sapiens Fructose-2,6-bisphosphatase Proteins 0.000 claims 1
- 101000823442 Homo sapiens Fructose-2,6-bisphosphatase Proteins 0.000 claims 1
- 101000893656 Homo sapiens G0/G1 switch protein 2 Proteins 0.000 claims 1
- 101001122376 Homo sapiens GDP-fucose protein O-fucosyltransferase 1 Proteins 0.000 claims 1
- 101000730688 Homo sapiens GPI mannosyltransferase 1 Proteins 0.000 claims 1
- 101001074618 Homo sapiens GPI mannosyltransferase 4 Proteins 0.000 claims 1
- 101001071309 Homo sapiens GPI-anchor transamidase Proteins 0.000 claims 1
- 101001024897 Homo sapiens GRB2-associated-binding protein 1 Proteins 0.000 claims 1
- 101000637633 Homo sapiens GTP-binding protein SAR1b Proteins 0.000 claims 1
- 101001021379 Homo sapiens Galactose-1-phosphate uridylyltransferase Proteins 0.000 claims 1
- 101000894906 Homo sapiens Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1 Proteins 0.000 claims 1
- 101001130151 Homo sapiens Galectin-9 Proteins 0.000 claims 1
- 101000941284 Homo sapiens Gastric triacylglycerol lipase Proteins 0.000 claims 1
- 101001039324 Homo sapiens Glucosamine-6-phosphate isomerase 1 Proteins 0.000 claims 1
- 101001072892 Homo sapiens Glucose 1,6-bisphosphate synthase Proteins 0.000 claims 1
- 101000930910 Homo sapiens Glucose-6-phosphatase catalytic subunit 1 Proteins 0.000 claims 1
- 101001036117 Homo sapiens Glycogen [starch] synthase, liver Proteins 0.000 claims 1
- 101000748183 Homo sapiens Glycogen phosphorylase, brain form Proteins 0.000 claims 1
- 101000700616 Homo sapiens Glycogen phosphorylase, liver form Proteins 0.000 claims 1
- 101000926793 Homo sapiens Golgi-specific brefeldin A-resistance guanine nucleotide exchange factor 1 Proteins 0.000 claims 1
- 101000983148 Homo sapiens Group IIE secretory phospholipase A2 Proteins 0.000 claims 1
- 101000730862 Homo sapiens Group XIIB secretory phospholipase A2-like protein Proteins 0.000 claims 1
- 101000871017 Homo sapiens Growth factor receptor-bound protein 2 Proteins 0.000 claims 1
- 101000615232 Homo sapiens Guanine nucleotide exchange factor DBS Proteins 0.000 claims 1
- 101001134268 Homo sapiens Guanine nucleotide exchange factor MSS4 Proteins 0.000 claims 1
- 101000775776 Homo sapiens Guanine nucleotide exchange factor VAV2 Proteins 0.000 claims 1
- 101000775742 Homo sapiens Guanine nucleotide exchange factor VAV3 Proteins 0.000 claims 1
- 101000830152 Homo sapiens Guanine nucleotide-binding protein subunit beta-like protein 1 Proteins 0.000 claims 1
- 101000872208 Homo sapiens HCLS1-binding protein 3 Proteins 0.000 claims 1
- 101001035846 Homo sapiens HMG box-containing protein 1 Proteins 0.000 claims 1
- 101000805947 Homo sapiens Harmonin Proteins 0.000 claims 1
- 101000905239 Homo sapiens Heart- and neural crest derivatives-expressed protein 1 Proteins 0.000 claims 1
- 101000588589 Homo sapiens Heparan sulfate N-sulfotransferase 1 Proteins 0.000 claims 1
- 101000941289 Homo sapiens Hepatic triacylglycerol lipase Proteins 0.000 claims 1
- 101000944179 Homo sapiens Histone acetyltransferase KAT6A Proteins 0.000 claims 1
- 101000899330 Homo sapiens Histone deacetylase 6 Proteins 0.000 claims 1
- 101000985653 Homo sapiens Homeobox protein MSX-1 Proteins 0.000 claims 1
- 101000967222 Homo sapiens Homeobox protein MSX-2 Proteins 0.000 claims 1
- 101000632186 Homo sapiens Homeobox protein Nkx-2.2 Proteins 0.000 claims 1
- 101000634171 Homo sapiens Homeobox protein SIX1 Proteins 0.000 claims 1
- 101000779608 Homo sapiens Homeobox protein aristaless-like 4 Proteins 0.000 claims 1
- 101000777624 Homo sapiens Hsp90 co-chaperone Cdc37-like 1 Proteins 0.000 claims 1
- 101000635408 Homo sapiens Inactive N-acetylated-alpha-linked acidic dipeptidase-like protein 2 Proteins 0.000 claims 1
- 101001134447 Homo sapiens Inactive pancreatic lipase-related protein 1 Proteins 0.000 claims 1
- 101001056180 Homo sapiens Induced myeloid leukemia cell differentiation protein Mcl-1 Proteins 0.000 claims 1
- 101000609406 Homo sapiens Inter-alpha-trypsin inhibitor heavy chain H3 Proteins 0.000 claims 1
- 101000598002 Homo sapiens Interferon regulatory factor 1 Proteins 0.000 claims 1
- 101000999377 Homo sapiens Interferon-related developmental regulator 1 Proteins 0.000 claims 1
- 101000960234 Homo sapiens Isocitrate dehydrogenase [NADP] cytoplasmic Proteins 0.000 claims 1
- 101000992298 Homo sapiens Kappa-type opioid receptor Proteins 0.000 claims 1
- 101000944148 Homo sapiens Kazal-type serine protease inhibitor domain-containing protein 1 Proteins 0.000 claims 1
- 101000945500 Homo sapiens Kin of IRRE-like protein 3 Proteins 0.000 claims 1
- 101001137640 Homo sapiens Kinase suppressor of Ras 2 Proteins 0.000 claims 1
- 101001090713 Homo sapiens L-lactate dehydrogenase A chain Proteins 0.000 claims 1
- 101000972201 Homo sapiens L-lactate dehydrogenase A-like 6B Proteins 0.000 claims 1
- 101001134694 Homo sapiens LIM domain and actin-binding protein 1 Proteins 0.000 claims 1
- 101001020452 Homo sapiens LIM/homeobox protein Lhx3 Proteins 0.000 claims 1
- 101001004623 Homo sapiens Lactase-like protein Proteins 0.000 claims 1
- 101000896726 Homo sapiens Lanosterol 14-alpha demethylase Proteins 0.000 claims 1
- 101001054649 Homo sapiens Latent-transforming growth factor beta-binding protein 2 Proteins 0.000 claims 1
- 101001054646 Homo sapiens Latent-transforming growth factor beta-binding protein 3 Proteins 0.000 claims 1
- 101000978212 Homo sapiens Latent-transforming growth factor beta-binding protein 4 Proteins 0.000 claims 1
- 101000740227 Homo sapiens Lathosterol oxidase Proteins 0.000 claims 1
- 101001038427 Homo sapiens Leucine zipper putative tumor suppressor 2 Proteins 0.000 claims 1
- 101000703761 Homo sapiens Leucine-rich repeat protein SHOC-2 Proteins 0.000 claims 1
- 101000945751 Homo sapiens Leukocyte cell-derived chemotaxin-2 Proteins 0.000 claims 1
- 101000608935 Homo sapiens Leukosialin Proteins 0.000 claims 1
- 101001017969 Homo sapiens Leukotriene B4 receptor 2 Proteins 0.000 claims 1
- 101001047640 Homo sapiens Linker for activation of T-cells family member 1 Proteins 0.000 claims 1
- 101000841267 Homo sapiens Long chain 3-hydroxyacyl-CoA dehydrogenase Proteins 0.000 claims 1
- 101001043562 Homo sapiens Low-density lipoprotein receptor-related protein 2 Proteins 0.000 claims 1
- 101001047659 Homo sapiens Lymphocyte transmembrane adapter 1 Proteins 0.000 claims 1
- 101000762967 Homo sapiens Lymphokine-activated killer T-cell-originated protein kinase Proteins 0.000 claims 1
- 101001098256 Homo sapiens Lysophospholipase Proteins 0.000 claims 1
- 101001004953 Homo sapiens Lysosomal acid lipase/cholesteryl ester hydrolase Proteins 0.000 claims 1
- 101000624625 Homo sapiens M-phase inducer phosphatase 1 Proteins 0.000 claims 1
- 101000624631 Homo sapiens M-phase inducer phosphatase 2 Proteins 0.000 claims 1
- 101001115426 Homo sapiens MAGUK p55 subfamily member 3 Proteins 0.000 claims 1
- 101000978544 Homo sapiens MAP3K12-binding inhibitory protein 1 Proteins 0.000 claims 1
- 101001033820 Homo sapiens Malate dehydrogenase, mitochondrial Proteins 0.000 claims 1
- 101001034310 Homo sapiens Malignant fibrous histiocytoma-amplified sequence 1 Proteins 0.000 claims 1
- 101001052076 Homo sapiens Maltase-glucoamylase Proteins 0.000 claims 1
- 101001011884 Homo sapiens Matrix metalloproteinase-15 Proteins 0.000 claims 1
- 101001011886 Homo sapiens Matrix metalloproteinase-16 Proteins 0.000 claims 1
- 101001011887 Homo sapiens Matrix metalloproteinase-17 Proteins 0.000 claims 1
- 101001013139 Homo sapiens Matrix metalloproteinase-20 Proteins 0.000 claims 1
- 101000627852 Homo sapiens Matrix metalloproteinase-25 Proteins 0.000 claims 1
- 101000962483 Homo sapiens Max dimerization protein 1 Proteins 0.000 claims 1
- 101000576320 Homo sapiens Max-binding protein MNT Proteins 0.000 claims 1
- 101000573510 Homo sapiens McKusick-Kaufman/Bardet-Biedl syndromes putative chaperonin Proteins 0.000 claims 1
- 101000962131 Homo sapiens Mediator of RNA polymerase II transcription subunit 1 Proteins 0.000 claims 1
- 101000614988 Homo sapiens Mediator of RNA polymerase II transcription subunit 12 Proteins 0.000 claims 1
- 101001055427 Homo sapiens Mediator of RNA polymerase II transcription subunit 13 Proteins 0.000 claims 1
- 101000575066 Homo sapiens Mediator of RNA polymerase II transcription subunit 17 Proteins 0.000 claims 1
- 101000962119 Homo sapiens Mediator of RNA polymerase II transcription subunit 4 Proteins 0.000 claims 1
- 101000978431 Homo sapiens Melanocortin receptor 3 Proteins 0.000 claims 1
- 101001057135 Homo sapiens Melanoma-associated antigen H1 Proteins 0.000 claims 1
- 101000968916 Homo sapiens Methylsterol monooxygenase 1 Proteins 0.000 claims 1
- 101000628796 Homo sapiens Microsomal glutathione S-transferase 2 Proteins 0.000 claims 1
- 101000628785 Homo sapiens Microsomal glutathione S-transferase 3 Proteins 0.000 claims 1
- 101000588130 Homo sapiens Microsomal triglyceride transfer protein large subunit Proteins 0.000 claims 1
- 101000980562 Homo sapiens Microspherule protein 1 Proteins 0.000 claims 1
- 101000578920 Homo sapiens Microtubule-actin cross-linking factor 1, isoforms 1/2/3/5 Proteins 0.000 claims 1
- 101000962664 Homo sapiens Microtubule-associated protein RP/EB family member 1 Proteins 0.000 claims 1
- 101000957756 Homo sapiens Microtubule-associated protein RP/EB family member 2 Proteins 0.000 claims 1
- 101000957741 Homo sapiens Microtubule-associated protein RP/EB family member 3 Proteins 0.000 claims 1
- 101000573441 Homo sapiens Misshapen-like kinase 1 Proteins 0.000 claims 1
- 101000950710 Homo sapiens Mitogen-activated protein kinase 6 Proteins 0.000 claims 1
- 101000950695 Homo sapiens Mitogen-activated protein kinase 8 Proteins 0.000 claims 1
- 101001005609 Homo sapiens Mitogen-activated protein kinase kinase kinase 13 Proteins 0.000 claims 1
- 101001018147 Homo sapiens Mitogen-activated protein kinase kinase kinase 4 Proteins 0.000 claims 1
- 101001055085 Homo sapiens Mitogen-activated protein kinase kinase kinase 9 Proteins 0.000 claims 1
- 101001059989 Homo sapiens Mitogen-activated protein kinase kinase kinase kinase 3 Proteins 0.000 claims 1
- 101001059984 Homo sapiens Mitogen-activated protein kinase kinase kinase kinase 4 Proteins 0.000 claims 1
- 101001059982 Homo sapiens Mitogen-activated protein kinase kinase kinase kinase 5 Proteins 0.000 claims 1
- 101000957259 Homo sapiens Mitotic spindle assembly checkpoint protein MAD2A Proteins 0.000 claims 1
- 101000969594 Homo sapiens Modulator of apoptosis 1 Proteins 0.000 claims 1
- 101001012646 Homo sapiens Monoglyceride lipase Proteins 0.000 claims 1
- 101001039757 Homo sapiens Multiple C2 and transmembrane domain-containing protein 1 Proteins 0.000 claims 1
- 101001039762 Homo sapiens Multiple C2 and transmembrane domain-containing protein 2 Proteins 0.000 claims 1
- 101000583839 Homo sapiens Muscleblind-like protein 1 Proteins 0.000 claims 1
- 101000968663 Homo sapiens MutS protein homolog 5 Proteins 0.000 claims 1
- 101001030211 Homo sapiens Myc proto-oncogene protein Proteins 0.000 claims 1
- 101000635944 Homo sapiens Myelin protein P0 Proteins 0.000 claims 1
- 101001018552 Homo sapiens MyoD family inhibitor domain-containing protein Proteins 0.000 claims 1
- 101000591295 Homo sapiens Myocardin-related transcription factor B Proteins 0.000 claims 1
- 101000958866 Homo sapiens Myogenic factor 6 Proteins 0.000 claims 1
- 101001000109 Homo sapiens Myosin-10 Proteins 0.000 claims 1
- 101000588964 Homo sapiens Myosin-14 Proteins 0.000 claims 1
- 101000958744 Homo sapiens Myosin-7B Proteins 0.000 claims 1
- 101001116519 Homo sapiens Myotubularin-related protein 10 Proteins 0.000 claims 1
- 101001116520 Homo sapiens Myotubularin-related protein 11 Proteins 0.000 claims 1
- 101001116518 Homo sapiens Myotubularin-related protein 12 Proteins 0.000 claims 1
- 101000966872 Homo sapiens Myotubularin-related protein 2 Proteins 0.000 claims 1
- 101000966875 Homo sapiens Myotubularin-related protein 4 Proteins 0.000 claims 1
- 101001024511 Homo sapiens N-acetyl-D-glucosamine kinase Proteins 0.000 claims 1
- 101000829992 Homo sapiens N-acetylglucosamine-6-sulfatase Proteins 0.000 claims 1
- 101000730680 Homo sapiens N-acetylglucosaminyl-phosphatidylinositol de-N-acetylase Proteins 0.000 claims 1
- 101001126836 Homo sapiens N-acetylmuramoyl-L-alanine amidase Proteins 0.000 claims 1
- 101000938702 Homo sapiens N-acetyltransferase ESCO1 Proteins 0.000 claims 1
- 101000906927 Homo sapiens N-chimaerin Proteins 0.000 claims 1
- 101001016790 Homo sapiens NAD-dependent malic enzyme, mitochondrial Proteins 0.000 claims 1
- 101000978949 Homo sapiens NADP-dependent malic enzyme Proteins 0.000 claims 1
- 101000973157 Homo sapiens NEDD4 family-interacting protein 1 Proteins 0.000 claims 1
- 101000961071 Homo sapiens NF-kappa-B inhibitor alpha Proteins 0.000 claims 1
- 101000997257 Homo sapiens NF-kappa-B inhibitor-interacting Ras-like protein 1 Proteins 0.000 claims 1
- 101000997252 Homo sapiens NF-kappa-B inhibitor-interacting Ras-like protein 2 Proteins 0.000 claims 1
- 101001124388 Homo sapiens NPC intracellular cholesterol transporter 1 Proteins 0.000 claims 1
- 101001109579 Homo sapiens NPC intracellular cholesterol transporter 2 Proteins 0.000 claims 1
- 101000970025 Homo sapiens NUAK family SNF1-like kinase 2 Proteins 0.000 claims 1
- 101001024714 Homo sapiens Nck-associated protein 1 Proteins 0.000 claims 1
- 101000604463 Homo sapiens Netrin-G1 Proteins 0.000 claims 1
- 101000604469 Homo sapiens Netrin-G2 Proteins 0.000 claims 1
- 101000969961 Homo sapiens Neurexin-3 Proteins 0.000 claims 1
- 101000969963 Homo sapiens Neurexin-3-beta Proteins 0.000 claims 1
- 101000602237 Homo sapiens Neuroblastoma suppressor of tumorigenicity 1 Proteins 0.000 claims 1
- 101000604177 Homo sapiens Neuromedin-U receptor 2 Proteins 0.000 claims 1
- 101001108364 Homo sapiens Neuronal cell adhesion molecule Proteins 0.000 claims 1
- 101000654664 Homo sapiens Neuronal-specific septin-3 Proteins 0.000 claims 1
- 101000634196 Homo sapiens Neurotrophin-3 Proteins 0.000 claims 1
- 101000998855 Homo sapiens Nicotinamide phosphoribosyltransferase Proteins 0.000 claims 1
- 101001024120 Homo sapiens Nipped-B-like protein Proteins 0.000 claims 1
- 101000979342 Homo sapiens Nuclear factor NF-kappa-B p105 subunit Proteins 0.000 claims 1
- 101000598160 Homo sapiens Nuclear mitotic apparatus protein 1 Proteins 0.000 claims 1
- 101000602926 Homo sapiens Nuclear receptor coactivator 1 Proteins 0.000 claims 1
- 101000974356 Homo sapiens Nuclear receptor coactivator 3 Proteins 0.000 claims 1
- 101001109682 Homo sapiens Nuclear receptor subfamily 6 group A member 1 Proteins 0.000 claims 1
- 101000588345 Homo sapiens Nuclear transcription factor Y subunit gamma Proteins 0.000 claims 1
- 101000836620 Homo sapiens Nucleic acid dioxygenase ALKBH1 Proteins 0.000 claims 1
- 101000637342 Homo sapiens Nucleolysin TIAR Proteins 0.000 claims 1
- 101001128739 Homo sapiens Nucleoside diphosphate kinase 6 Proteins 0.000 claims 1
- 101000652382 Homo sapiens O-phosphoseryl-tRNA(Sec) selenium transferase Proteins 0.000 claims 1
- 101000613798 Homo sapiens OTU domain-containing protein 7B Proteins 0.000 claims 1
- 101001121324 Homo sapiens Oxidative stress-induced growth inhibitor 1 Proteins 0.000 claims 1
- 101000992383 Homo sapiens Oxysterol-binding protein 1 Proteins 0.000 claims 1
- 101000992378 Homo sapiens Oxysterol-binding protein 2 Proteins 0.000 claims 1
- 101000720693 Homo sapiens Oxysterol-binding protein-related protein 1 Proteins 0.000 claims 1
- 101001130823 Homo sapiens Oxysterol-binding protein-related protein 10 Proteins 0.000 claims 1
- 101000720655 Homo sapiens Oxysterol-binding protein-related protein 11 Proteins 0.000 claims 1
- 101000992396 Homo sapiens Oxysterol-binding protein-related protein 3 Proteins 0.000 claims 1
- 101000992394 Homo sapiens Oxysterol-binding protein-related protein 5 Proteins 0.000 claims 1
- 101000992392 Homo sapiens Oxysterol-binding protein-related protein 6 Proteins 0.000 claims 1
- 101000992388 Homo sapiens Oxysterol-binding protein-related protein 8 Proteins 0.000 claims 1
- 101000992387 Homo sapiens Oxysterol-binding protein-related protein 9 Proteins 0.000 claims 1
- 101001098232 Homo sapiens P2Y purinoceptor 1 Proteins 0.000 claims 1
- 101000986836 Homo sapiens P2Y purinoceptor 2 Proteins 0.000 claims 1
- 101000986821 Homo sapiens P2Y purinoceptor 4 Proteins 0.000 claims 1
- 101000986826 Homo sapiens P2Y purinoceptor 6 Proteins 0.000 claims 1
- 101000988394 Homo sapiens PDZ and LIM domain protein 5 Proteins 0.000 claims 1
- 101001099597 Homo sapiens PDZ domain-containing protein 8 Proteins 0.000 claims 1
- 101000736367 Homo sapiens PH and SEC7 domain-containing protein 3 Proteins 0.000 claims 1
- 101000736368 Homo sapiens PH and SEC7 domain-containing protein 4 Proteins 0.000 claims 1
- 101001129621 Homo sapiens PH domain leucine-rich repeat-containing protein phosphatase 1 Proteins 0.000 claims 1
- 101000572986 Homo sapiens POU domain, class 3, transcription factor 2 Proteins 0.000 claims 1
- 101000613575 Homo sapiens Paired box protein Pax-1 Proteins 0.000 claims 1
- 101000613577 Homo sapiens Paired box protein Pax-2 Proteins 0.000 claims 1
- 101000601661 Homo sapiens Paired box protein Pax-7 Proteins 0.000 claims 1
- 101000964469 Homo sapiens Palmitoyltransferase ZDHHC13 Proteins 0.000 claims 1
- 101001134442 Homo sapiens Pancreatic lipase-related protein 2 Proteins 0.000 claims 1
- 101000610209 Homo sapiens Pappalysin-2 Proteins 0.000 claims 1
- 101001135738 Homo sapiens Parathyroid hormone-related protein Proteins 0.000 claims 1
- 101001098564 Homo sapiens Partitioning defective 3 homolog B Proteins 0.000 claims 1
- 101001084254 Homo sapiens Peptidyl-tRNA hydrolase 2, mitochondrial Proteins 0.000 claims 1
- 101000987581 Homo sapiens Perforin-1 Proteins 0.000 claims 1
- 101001000631 Homo sapiens Peripheral myelin protein 22 Proteins 0.000 claims 1
- 101001064774 Homo sapiens Peroxidasin-like protein Proteins 0.000 claims 1
- 101001090047 Homo sapiens Peroxiredoxin-4 Proteins 0.000 claims 1
- 101000619805 Homo sapiens Peroxiredoxin-5, mitochondrial Proteins 0.000 claims 1
- 101000619708 Homo sapiens Peroxiredoxin-6 Proteins 0.000 claims 1
- 101000833892 Homo sapiens Peroxisomal acyl-coenzyme A oxidase 1 Proteins 0.000 claims 1
- 101000599612 Homo sapiens Peroxisomal carnitine O-octanoyltransferase Proteins 0.000 claims 1
- 101001082860 Homo sapiens Peroxisomal membrane protein 2 Proteins 0.000 claims 1
- 101001045218 Homo sapiens Peroxisomal multifunctional enzyme type 2 Proteins 0.000 claims 1
- 101000741790 Homo sapiens Peroxisome proliferator-activated receptor gamma Proteins 0.000 claims 1
- 101001123325 Homo sapiens Peroxisome proliferator-activated receptor gamma coactivator 1-beta Proteins 0.000 claims 1
- 101001038051 Homo sapiens Phlorizin hydrolase Proteins 0.000 claims 1
- 101000702718 Homo sapiens Phosphatidylcholine:ceramide cholinephosphotransferase 1 Proteins 0.000 claims 1
- 101000825940 Homo sapiens Phosphatidylcholine:ceramide cholinephosphotransferase 2 Proteins 0.000 claims 1
- 101000721646 Homo sapiens Phosphatidylinositol 3-kinase C2 domain-containing subunit gamma Proteins 0.000 claims 1
- 101000730433 Homo sapiens Phosphatidylinositol 4-kinase beta Proteins 0.000 claims 1
- 101001001531 Homo sapiens Phosphatidylinositol 5-phosphate 4-kinase type-2 alpha Proteins 0.000 claims 1
- 101001001505 Homo sapiens Phosphatidylinositol N-acetylglucosaminyltransferase subunit C Proteins 0.000 claims 1
- 101001001500 Homo sapiens Phosphatidylinositol N-acetylglucosaminyltransferase subunit H Proteins 0.000 claims 1
- 101001074631 Homo sapiens Phosphatidylinositol N-acetylglucosaminyltransferase subunit Y Proteins 0.000 claims 1
- 101000595859 Homo sapiens Phosphatidylinositol transfer protein alpha isoform Proteins 0.000 claims 1
- 101000595868 Homo sapiens Phosphatidylinositol transfer protein beta isoform Proteins 0.000 claims 1
- 101001096169 Homo sapiens Phosphatidylserine decarboxylase proenzyme, mitochondrial Proteins 0.000 claims 1
- 101001102158 Homo sapiens Phosphatidylserine synthase 1 Proteins 0.000 claims 1
- 101000833350 Homo sapiens Phosphoacetylglucosamine mutase Proteins 0.000 claims 1
- 101000734579 Homo sapiens Phosphoenolpyruvate carboxykinase [GTP], mitochondrial Proteins 0.000 claims 1
- 101000734572 Homo sapiens Phosphoenolpyruvate carboxykinase, cytosolic [GTP] Proteins 0.000 claims 1
- 101000583553 Homo sapiens Phosphoglucomutase-1 Proteins 0.000 claims 1
- 101001072903 Homo sapiens Phosphoglucomutase-2 Proteins 0.000 claims 1
- 101000983161 Homo sapiens Phospholipase A2, membrane associated Proteins 0.000 claims 1
- 101001096022 Homo sapiens Phospholipase B1, membrane-associated Proteins 0.000 claims 1
- 101001126234 Homo sapiens Phospholipid phosphatase 3 Proteins 0.000 claims 1
- 101001094827 Homo sapiens Phosphomannomutase 1 Proteins 0.000 claims 1
- 101000687955 Homo sapiens Phosphomevalonate kinase Proteins 0.000 claims 1
- 101001137939 Homo sapiens Phosphorylase b kinase regulatory subunit beta Proteins 0.000 claims 1
- 101000583156 Homo sapiens Pituitary homeobox 1 Proteins 0.000 claims 1
- 101000595669 Homo sapiens Pituitary homeobox 2 Proteins 0.000 claims 1
- 101000595674 Homo sapiens Pituitary homeobox 3 Proteins 0.000 claims 1
- 101000987238 Homo sapiens Platelet-activating factor acetylhydrolase 2, cytoplasmic Proteins 0.000 claims 1
- 101001126417 Homo sapiens Platelet-derived growth factor receptor alpha Proteins 0.000 claims 1
- 101000730607 Homo sapiens Pleckstrin homology domain-containing family G member 1 Proteins 0.000 claims 1
- 101000730606 Homo sapiens Pleckstrin homology domain-containing family G member 2 Proteins 0.000 claims 1
- 101000730610 Homo sapiens Pleckstrin homology domain-containing family G member 3 Proteins 0.000 claims 1
- 101000583178 Homo sapiens Pleckstrin homology domain-containing family M member 1 Proteins 0.000 claims 1
- 101000583692 Homo sapiens Pleckstrin homology-like domain family A member 1 Proteins 0.000 claims 1
- 101001126466 Homo sapiens Pleckstrin-2 Proteins 0.000 claims 1
- 101000886182 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 4 Proteins 0.000 claims 1
- 101000605345 Homo sapiens Prefoldin subunit 1 Proteins 0.000 claims 1
- 101001109792 Homo sapiens Pro-neuregulin-2, membrane-bound isoform Proteins 0.000 claims 1
- 101000702560 Homo sapiens Probable global transcription activator SNF2L1 Proteins 0.000 claims 1
- 101000600395 Homo sapiens Probable phosphoglycerate mutase 4 Proteins 0.000 claims 1
- 101000602149 Homo sapiens Programmed cell death protein 10 Proteins 0.000 claims 1
- 101000611939 Homo sapiens Programmed cell death protein 2 Proteins 0.000 claims 1
- 101000734646 Homo sapiens Programmed cell death protein 6 Proteins 0.000 claims 1
- 101000610537 Homo sapiens Prokineticin-1 Proteins 0.000 claims 1
- 101000611663 Homo sapiens Prolargin Proteins 0.000 claims 1
- 101000945496 Homo sapiens Proliferation marker protein Ki-67 Proteins 0.000 claims 1
- 101001098989 Homo sapiens Propionyl-CoA carboxylase alpha chain, mitochondrial Proteins 0.000 claims 1
- 101001098982 Homo sapiens Propionyl-CoA carboxylase beta chain, mitochondrial Proteins 0.000 claims 1
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 claims 1
- 101001135385 Homo sapiens Prostacyclin synthase Proteins 0.000 claims 1
- 101001135391 Homo sapiens Prostaglandin E synthase Proteins 0.000 claims 1
- 101000797623 Homo sapiens Protein AMBP Proteins 0.000 claims 1
- 101000668432 Homo sapiens Protein RCC2 Proteins 0.000 claims 1
- 101000685712 Homo sapiens Protein S100-A1 Proteins 0.000 claims 1
- 101000739146 Homo sapiens Protein SFI1 homolog Proteins 0.000 claims 1
- 101000800847 Homo sapiens Protein TFG Proteins 0.000 claims 1
- 101000620365 Homo sapiens Protein TMEPAI Proteins 0.000 claims 1
- 101000764357 Homo sapiens Protein Tob1 Proteins 0.000 claims 1
- 101000909879 Homo sapiens Protein cornichon homolog 3 Proteins 0.000 claims 1
- 101001026854 Homo sapiens Protein kinase C delta type Proteins 0.000 claims 1
- 101000620650 Homo sapiens Protein phosphatase 1A Proteins 0.000 claims 1
- 101000742054 Homo sapiens Protein phosphatase 1D Proteins 0.000 claims 1
- 101000599464 Homo sapiens Protein phosphatase inhibitor 2 Proteins 0.000 claims 1
- 101000702132 Homo sapiens Protein spinster homolog 1 Proteins 0.000 claims 1
- 101000702384 Homo sapiens Protein sprouty homolog 2 Proteins 0.000 claims 1
- 101000830696 Homo sapiens Protein tyrosine phosphatase type IVA 1 Proteins 0.000 claims 1
- 101000738322 Homo sapiens Prothymosin alpha Proteins 0.000 claims 1
- 101000610019 Homo sapiens Protocadherin beta-11 Proteins 0.000 claims 1
- 101000613391 Homo sapiens Protocadherin beta-16 Proteins 0.000 claims 1
- 101000738506 Homo sapiens Psychosine receptor Proteins 0.000 claims 1
- 101001091538 Homo sapiens Pyruvate kinase PKM Proteins 0.000 claims 1
- 101000576060 Homo sapiens RAD50-interacting protein 1 Proteins 0.000 claims 1
- 101001112424 Homo sapiens RB1-inducible coiled-coil protein 1 Proteins 0.000 claims 1
- 101000717450 Homo sapiens RCC1 and BTB domain-containing protein 1 Proteins 0.000 claims 1
- 101001111714 Homo sapiens RING-box protein 2 Proteins 0.000 claims 1
- 101000727821 Homo sapiens RING1 and YY1-binding protein Proteins 0.000 claims 1
- 101000743272 Homo sapiens RNA-binding protein 5 Proteins 0.000 claims 1
- 101001061776 Homo sapiens Rab-like protein 3 Proteins 0.000 claims 1
- 101001094496 Homo sapiens Radial spoke head 1 homolog Proteins 0.000 claims 1
- 101001017961 Homo sapiens Ragulator complex protein LAMTOR5 Proteins 0.000 claims 1
- 101000709121 Homo sapiens Ral guanine nucleotide dissociation stimulator-like 1 Proteins 0.000 claims 1
- 101000848700 Homo sapiens Rap guanine nucleotide exchange factor 1 Proteins 0.000 claims 1
- 101000848721 Homo sapiens Rap guanine nucleotide exchange factor 4 Proteins 0.000 claims 1
- 101001130505 Homo sapiens Ras GTPase-activating protein 2 Proteins 0.000 claims 1
- 101000620773 Homo sapiens Ras GTPase-activating protein 3 Proteins 0.000 claims 1
- 101001023826 Homo sapiens Ras GTPase-activating protein nGAP Proteins 0.000 claims 1
- 101000712972 Homo sapiens Ras association domain-containing protein 4 Proteins 0.000 claims 1
- 101001092170 Homo sapiens Ras-GEF domain-containing family member 1C Proteins 0.000 claims 1
- 101000743845 Homo sapiens Ras-related protein Rab-10 Proteins 0.000 claims 1
- 101000620798 Homo sapiens Ras-related protein Rab-11A Proteins 0.000 claims 1
- 101000620589 Homo sapiens Ras-related protein Rab-17 Proteins 0.000 claims 1
- 101001060862 Homo sapiens Ras-related protein Rab-31 Proteins 0.000 claims 1
- 101001060859 Homo sapiens Ras-related protein Rab-32 Proteins 0.000 claims 1
- 101000744542 Homo sapiens Ras-related protein Rab-33A Proteins 0.000 claims 1
- 101000620593 Homo sapiens Ras-related protein Rab-37 Proteins 0.000 claims 1
- 101000620554 Homo sapiens Ras-related protein Rab-38 Proteins 0.000 claims 1
- 101000620559 Homo sapiens Ras-related protein Rab-3B Proteins 0.000 claims 1
- 101001099877 Homo sapiens Ras-related protein Rab-43 Proteins 0.000 claims 1
- 101001077405 Homo sapiens Ras-related protein Rab-5C Proteins 0.000 claims 1
- 101000584767 Homo sapiens Ras-related protein Rab-6C Proteins 0.000 claims 1
- 101000712725 Homo sapiens Ras-related protein Rab-7L1 Proteins 0.000 claims 1
- 101000584785 Homo sapiens Ras-related protein Rab-7a Proteins 0.000 claims 1
- 101001132575 Homo sapiens Ras-related protein Rab-8B Proteins 0.000 claims 1
- 101001132549 Homo sapiens Ras-related protein Rab-9A Proteins 0.000 claims 1
- 101001130458 Homo sapiens Ras-related protein Ral-B Proteins 0.000 claims 1
- 101000584600 Homo sapiens Ras-related protein Rap-1b Proteins 0.000 claims 1
- 101001130441 Homo sapiens Ras-related protein Rap-2a Proteins 0.000 claims 1
- 101001130437 Homo sapiens Ras-related protein Rap-2b Proteins 0.000 claims 1
- 101000580043 Homo sapiens Ras-specific guanine nucleotide-releasing factor 2 Proteins 0.000 claims 1
- 101000580034 Homo sapiens Ras-specific guanine nucleotide-releasing factor RalGPS1 Proteins 0.000 claims 1
- 101000580036 Homo sapiens Ras-specific guanine nucleotide-releasing factor RalGPS2 Proteins 0.000 claims 1
- 101000641879 Homo sapiens Ras/Rap GTPase-activating protein SynGAP Proteins 0.000 claims 1
- 101001089266 Homo sapiens Receptor-interacting serine/threonine-protein kinase 3 Proteins 0.000 claims 1
- 101001130250 Homo sapiens Reticulon-4 receptor-like 1 Proteins 0.000 claims 1
- 101000854044 Homo sapiens Retinitis pigmentosa 1-like 1 protein Proteins 0.000 claims 1
- 101000742938 Homo sapiens Retinol dehydrogenase 12 Proteins 0.000 claims 1
- 101000665873 Homo sapiens Retinol-binding protein 3 Proteins 0.000 claims 1
- 101000733752 Homo sapiens Retroviral-like aspartic protease 1 Proteins 0.000 claims 1
- 101000731728 Homo sapiens Rho guanine nucleotide exchange factor 17 Proteins 0.000 claims 1
- 101000731737 Homo sapiens Rho guanine nucleotide exchange factor 26 Proteins 0.000 claims 1
- 101000927796 Homo sapiens Rho guanine nucleotide exchange factor 7 Proteins 0.000 claims 1
- 101000637411 Homo sapiens Rho guanine nucleotide exchange factor TIAM2 Proteins 0.000 claims 1
- 101000669921 Homo sapiens Rho-associated protein kinase 2 Proteins 0.000 claims 1
- 101000709025 Homo sapiens Rho-related BTB domain-containing protein 2 Proteins 0.000 claims 1
- 101000581118 Homo sapiens Rho-related GTP-binding protein RhoC Proteins 0.000 claims 1
- 101000581125 Homo sapiens Rho-related GTP-binding protein RhoF Proteins 0.000 claims 1
- 101000666634 Homo sapiens Rho-related GTP-binding protein RhoH Proteins 0.000 claims 1
- 101000687474 Homo sapiens Rhombotin-1 Proteins 0.000 claims 1
- 101000717377 Homo sapiens Ribokinase Proteins 0.000 claims 1
- 101000729289 Homo sapiens Ribose-5-phosphate isomerase Proteins 0.000 claims 1
- 101000945090 Homo sapiens Ribosomal protein S6 kinase alpha-3 Proteins 0.000 claims 1
- 101000945096 Homo sapiens Ribosomal protein S6 kinase alpha-5 Proteins 0.000 claims 1
- 101000650694 Homo sapiens Roundabout homolog 1 Proteins 0.000 claims 1
- 101000650697 Homo sapiens Roundabout homolog 2 Proteins 0.000 claims 1
- 101000693721 Homo sapiens SAM and SH3 domain-containing protein 1 Proteins 0.000 claims 1
- 101001093919 Homo sapiens SEC14-like protein 2 Proteins 0.000 claims 1
- 101100172525 Homo sapiens SELENOI gene Proteins 0.000 claims 1
- 101000707166 Homo sapiens SH2 domain-containing adapter protein F Proteins 0.000 claims 1
- 101000707230 Homo sapiens SH2 domain-containing protein 3A Proteins 0.000 claims 1
- 101000707228 Homo sapiens SH2 domain-containing protein 4A Proteins 0.000 claims 1
- 101000616538 Homo sapiens SH2 domain-containing protein 6 Proteins 0.000 claims 1
- 101000663831 Homo sapiens SH3 and PX domain-containing protein 2A Proteins 0.000 claims 1
- 101000632535 Homo sapiens SH3 domain-binding protein 4 Proteins 0.000 claims 1
- 101000963987 Homo sapiens SH3 domain-binding protein 5 Proteins 0.000 claims 1
- 101000617778 Homo sapiens SNF-related serine/threonine-protein kinase Proteins 0.000 claims 1
- 101000826081 Homo sapiens SRSF protein kinase 1 Proteins 0.000 claims 1
- 101000826077 Homo sapiens SRSF protein kinase 2 Proteins 0.000 claims 1
- 101100311211 Homo sapiens STARD13 gene Proteins 0.000 claims 1
- 101000706551 Homo sapiens SUN domain-containing protein 2 Proteins 0.000 claims 1
- 101000836983 Homo sapiens Secretoglobin family 1D member 1 Proteins 0.000 claims 1
- 101001087372 Homo sapiens Securin Proteins 0.000 claims 1
- 101000836557 Homo sapiens Septin-11 Proteins 0.000 claims 1
- 101000632319 Homo sapiens Septin-7 Proteins 0.000 claims 1
- 101000707474 Homo sapiens Serine incorporator 2 Proteins 0.000 claims 1
- 101000701401 Homo sapiens Serine/threonine-protein kinase 38 Proteins 0.000 claims 1
- 101000697608 Homo sapiens Serine/threonine-protein kinase 38-like Proteins 0.000 claims 1
- 101000913761 Homo sapiens Serine/threonine-protein kinase ICK Proteins 0.000 claims 1
- 101001047642 Homo sapiens Serine/threonine-protein kinase LATS1 Proteins 0.000 claims 1
- 101001059443 Homo sapiens Serine/threonine-protein kinase MARK1 Proteins 0.000 claims 1
- 101000601441 Homo sapiens Serine/threonine-protein kinase Nek2 Proteins 0.000 claims 1
- 101000729945 Homo sapiens Serine/threonine-protein kinase PLK2 Proteins 0.000 claims 1
- 101000709250 Homo sapiens Serine/threonine-protein kinase SIK2 Proteins 0.000 claims 1
- 101000864806 Homo sapiens Serine/threonine-protein kinase Sgk2 Proteins 0.000 claims 1
- 101000864831 Homo sapiens Serine/threonine-protein kinase Sgk3 Proteins 0.000 claims 1
- 101000838596 Homo sapiens Serine/threonine-protein kinase TAO3 Proteins 0.000 claims 1
- 101000665442 Homo sapiens Serine/threonine-protein kinase TBK1 Proteins 0.000 claims 1
- 101000770770 Homo sapiens Serine/threonine-protein kinase WNK1 Proteins 0.000 claims 1
- 101000770774 Homo sapiens Serine/threonine-protein kinase WNK2 Proteins 0.000 claims 1
- 101000742986 Homo sapiens Serine/threonine-protein kinase WNK4 Proteins 0.000 claims 1
- 101000611254 Homo sapiens Serine/threonine-protein phosphatase 2B catalytic subunit beta isoform Proteins 0.000 claims 1
- 101000620662 Homo sapiens Serine/threonine-protein phosphatase 6 catalytic subunit Proteins 0.000 claims 1
- 101000836075 Homo sapiens Serpin B9 Proteins 0.000 claims 1
- 101000836394 Homo sapiens Sestrin-1 Proteins 0.000 claims 1
- 101000739911 Homo sapiens Sestrin-3 Proteins 0.000 claims 1
- 101000632529 Homo sapiens Shugoshin 1 Proteins 0.000 claims 1
- 101000837008 Homo sapiens Sigma intracellular receptor 2 Proteins 0.000 claims 1
- 101000835995 Homo sapiens Slit homolog 1 protein Proteins 0.000 claims 1
- 101000651893 Homo sapiens Slit homolog 3 protein Proteins 0.000 claims 1
- 101000713288 Homo sapiens Solute carrier family 22 member 5 Proteins 0.000 claims 1
- 101000617964 Homo sapiens Sorcin Proteins 0.000 claims 1
- 101000702653 Homo sapiens Sorting nexin-1 Proteins 0.000 claims 1
- 101000633144 Homo sapiens Sorting nexin-10 Proteins 0.000 claims 1
- 101000633142 Homo sapiens Sorting nexin-11 Proteins 0.000 claims 1
- 101000633158 Homo sapiens Sorting nexin-12 Proteins 0.000 claims 1
- 101000633153 Homo sapiens Sorting nexin-13 Proteins 0.000 claims 1
- 101000633169 Homo sapiens Sorting nexin-14 Proteins 0.000 claims 1
- 101000702657 Homo sapiens Sorting nexin-19 Proteins 0.000 claims 1
- 101000687651 Homo sapiens Sorting nexin-24 Proteins 0.000 claims 1
- 101000687666 Homo sapiens Sorting nexin-27 Proteins 0.000 claims 1
- 101000708470 Homo sapiens Sorting nexin-3 Proteins 0.000 claims 1
- 101000824928 Homo sapiens Sorting nexin-31 Proteins 0.000 claims 1
- 101000664921 Homo sapiens Sorting nexin-4 Proteins 0.000 claims 1
- 101000665020 Homo sapiens Sorting nexin-5 Proteins 0.000 claims 1
- 101000665023 Homo sapiens Sorting nexin-7 Proteins 0.000 claims 1
- 101000868465 Homo sapiens Sorting nexin-9 Proteins 0.000 claims 1
- 101001038163 Homo sapiens Sperm protamine P1 Proteins 0.000 claims 1
- 101000618139 Homo sapiens Sperm-associated antigen 6 Proteins 0.000 claims 1
- 101000648184 Homo sapiens Spermatid nuclear transition protein 1 Proteins 0.000 claims 1
- 101000785978 Homo sapiens Sphingomyelin phosphodiesterase Proteins 0.000 claims 1
- 101000641017 Homo sapiens Sphingomyelin synthase-related protein 1 Proteins 0.000 claims 1
- 101000881230 Homo sapiens Sprouty-related, EVH1 domain-containing protein 1 Proteins 0.000 claims 1
- 101000651299 Homo sapiens Sprouty-related, EVH1 domain-containing protein 2 Proteins 0.000 claims 1
- 101001056878 Homo sapiens Squalene monooxygenase Proteins 0.000 claims 1
- 101000689199 Homo sapiens Src-like-adapter Proteins 0.000 claims 1
- 101000697529 Homo sapiens Stathmin-4 Proteins 0.000 claims 1
- 101000631826 Homo sapiens Stearoyl-CoA desaturase Proteins 0.000 claims 1
- 101000639987 Homo sapiens Stearoyl-CoA desaturase 5 Proteins 0.000 claims 1
- 101000617830 Homo sapiens Sterol O-acyltransferase 1 Proteins 0.000 claims 1
- 101000629597 Homo sapiens Sterol regulatory element-binding protein 1 Proteins 0.000 claims 1
- 101000585019 Homo sapiens Striatin-3 Proteins 0.000 claims 1
- 101000708766 Homo sapiens Structural maintenance of chromosomes protein 3 Proteins 0.000 claims 1
- 101000600903 Homo sapiens Substance-P receptor Proteins 0.000 claims 1
- 101000874160 Homo sapiens Succinate dehydrogenase [ubiquinone] iron-sulfur subunit, mitochondrial Proteins 0.000 claims 1
- 101000661446 Homo sapiens Succinate-CoA ligase [ADP-forming] subunit beta, mitochondrial Proteins 0.000 claims 1
- 101000832009 Homo sapiens Succinate-CoA ligase [ADP/GDP-forming] subunit alpha, mitochondrial Proteins 0.000 claims 1
- 101000661451 Homo sapiens Succinate-CoA ligase [GDP-forming] subunit beta, mitochondrial Proteins 0.000 claims 1
- 101000826399 Homo sapiens Sulfotransferase 1A1 Proteins 0.000 claims 1
- 101000826408 Homo sapiens Sulfotransferase 1B1 Proteins 0.000 claims 1
- 101000585344 Homo sapiens Sulfotransferase 1E1 Proteins 0.000 claims 1
- 101000585365 Homo sapiens Sulfotransferase 2A1 Proteins 0.000 claims 1
- 101000630720 Homo sapiens Supervillin Proteins 0.000 claims 1
- 101000642333 Homo sapiens Survival of motor neuron-related-splicing factor 30 Proteins 0.000 claims 1
- 101000643636 Homo sapiens Synaptonemal complex protein 2 Proteins 0.000 claims 1
- 101000740516 Homo sapiens Syntenin-2 Proteins 0.000 claims 1
- 101000666775 Homo sapiens T-box transcription factor TBX3 Proteins 0.000 claims 1
- 101000891113 Homo sapiens T-cell acute lymphocytic leukemia protein 1 Proteins 0.000 claims 1
- 101000652482 Homo sapiens TBC1 domain family member 8 Proteins 0.000 claims 1
- 101000674728 Homo sapiens TGF-beta-activated kinase 1 and MAP3K7-binding protein 2 Proteins 0.000 claims 1
- 101000662997 Homo sapiens TRAF2 and NCK-interacting protein kinase Proteins 0.000 claims 1
- 101000665590 Homo sapiens Tax1-binding protein 1 Proteins 0.000 claims 1
- 101000837136 Homo sapiens Tenascin-N Proteins 0.000 claims 1
- 101000837130 Homo sapiens Tenascin-R Proteins 0.000 claims 1
- 101000626142 Homo sapiens Tensin-1 Proteins 0.000 claims 1
- 101000626153 Homo sapiens Tensin-3 Proteins 0.000 claims 1
- 101000735431 Homo sapiens Terminal nucleotidyltransferase 4A Proteins 0.000 claims 1
- 101000735429 Homo sapiens Terminal nucleotidyltransferase 4B Proteins 0.000 claims 1
- 101000658739 Homo sapiens Tetraspanin-2 Proteins 0.000 claims 1
- 101000612990 Homo sapiens Tetraspanin-3 Proteins 0.000 claims 1
- 101000852559 Homo sapiens Thioredoxin Proteins 0.000 claims 1
- 101000773122 Homo sapiens Thioredoxin domain-containing protein 5 Proteins 0.000 claims 1
- 101000799466 Homo sapiens Thrombopoietin receptor Proteins 0.000 claims 1
- 101000653005 Homo sapiens Thromboxane-A synthase Proteins 0.000 claims 1
- 101000649020 Homo sapiens Thyroid receptor-interacting protein 6 Proteins 0.000 claims 1
- 101000831567 Homo sapiens Toll-like receptor 2 Proteins 0.000 claims 1
- 101000662809 Homo sapiens Trafficking protein particle complex subunit 4 Proteins 0.000 claims 1
- 101001041525 Homo sapiens Transcription factor 12 Proteins 0.000 claims 1
- 101000596771 Homo sapiens Transcription factor 7-like 2 Proteins 0.000 claims 1
- 101000666385 Homo sapiens Transcription factor Dp-2 Proteins 0.000 claims 1
- 101000904152 Homo sapiens Transcription factor E2F1 Proteins 0.000 claims 1
- 101000979190 Homo sapiens Transcription factor MafB Proteins 0.000 claims 1
- 101000642517 Homo sapiens Transcription factor SOX-6 Proteins 0.000 claims 1
- 101000711846 Homo sapiens Transcription factor SOX-9 Proteins 0.000 claims 1
- 101000653542 Homo sapiens Transcription factor-like 5 protein Proteins 0.000 claims 1
- 101000698001 Homo sapiens Transcription initiation protein SPT3 homolog Proteins 0.000 claims 1
- 101000636213 Homo sapiens Transcriptional activator Myb Proteins 0.000 claims 1
- 101000652684 Homo sapiens Transcriptional adapter 3 Proteins 0.000 claims 1
- 101000634900 Homo sapiens Transcriptional-regulating factor 1 Proteins 0.000 claims 1
- 101000669432 Homo sapiens Transducin-like enhancer protein 1 Proteins 0.000 claims 1
- 101000802109 Homo sapiens Transducin-like enhancer protein 3 Proteins 0.000 claims 1
- 101000836154 Homo sapiens Transforming acidic coiled-coil-containing protein 1 Proteins 0.000 claims 1
- 101000652720 Homo sapiens Transgelin-3 Proteins 0.000 claims 1
- 101000653679 Homo sapiens Translationally-controlled tumor protein Proteins 0.000 claims 1
- 101000629937 Homo sapiens Translocon-associated protein subunit alpha Proteins 0.000 claims 1
- 101000658581 Homo sapiens Transmembrane 4 L6 family member 4 Proteins 0.000 claims 1
- 101000638194 Homo sapiens Transmembrane emp24 domain-containing protein 4 Proteins 0.000 claims 1
- 101000891326 Homo sapiens Treacle protein Proteins 0.000 claims 1
- 101000766345 Homo sapiens Tribbles homolog 3 Proteins 0.000 claims 1
- 101000649014 Homo sapiens Triple functional domain protein Proteins 0.000 claims 1
- 101000772165 Homo sapiens Tubby-related protein 4 Proteins 0.000 claims 1
- 101000838301 Homo sapiens Tubulin gamma-1 chain Proteins 0.000 claims 1
- 101000633976 Homo sapiens Tuftelin Proteins 0.000 claims 1
- 101000830568 Homo sapiens Tumor necrosis factor alpha-induced protein 2 Proteins 0.000 claims 1
- 101000800807 Homo sapiens Tumor necrosis factor alpha-induced protein 8 Proteins 0.000 claims 1
- 101000597779 Homo sapiens Tumor necrosis factor ligand superfamily member 18 Proteins 0.000 claims 1
- 101000764263 Homo sapiens Tumor necrosis factor ligand superfamily member 4 Proteins 0.000 claims 1
- 101000679921 Homo sapiens Tumor necrosis factor receptor superfamily member 21 Proteins 0.000 claims 1
- 101000679903 Homo sapiens Tumor necrosis factor receptor superfamily member 25 Proteins 0.000 claims 1
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 claims 1
- 101000920026 Homo sapiens Tumor necrosis factor receptor superfamily member EDAR Proteins 0.000 claims 1
- 101000987003 Homo sapiens Tumor protein 63 Proteins 0.000 claims 1
- 101000610980 Homo sapiens Tumor protein D52 Proteins 0.000 claims 1
- 101000836174 Homo sapiens Tumor protein p53-inducible nuclear protein 1 Proteins 0.000 claims 1
- 101000892986 Homo sapiens Tyrosine-protein kinase FRK Proteins 0.000 claims 1
- 101000889732 Homo sapiens Tyrosine-protein kinase Tec Proteins 0.000 claims 1
- 101000820294 Homo sapiens Tyrosine-protein kinase Yes Proteins 0.000 claims 1
- 101001087416 Homo sapiens Tyrosine-protein phosphatase non-receptor type 11 Proteins 0.000 claims 1
- 101000671650 Homo sapiens U3 small nucleolar RNA-associated protein 14 homolog C Proteins 0.000 claims 1
- 101000662009 Homo sapiens UDP-N-acetylglucosamine pyrophosphorylase Proteins 0.000 claims 1
- 101000939534 Homo sapiens UDP-glucuronosyltransferase 2B11 Proteins 0.000 claims 1
- 101000939433 Homo sapiens UDP-glucuronosyltransferase 2B4 Proteins 0.000 claims 1
- 101000809490 Homo sapiens UTP-glucose-1-phosphate uridylyltransferase Proteins 0.000 claims 1
- 101000841466 Homo sapiens Ubiquitin carboxyl-terminal hydrolase 8 Proteins 0.000 claims 1
- 101000809046 Homo sapiens Ubiquitin conjugation factor E4 B Proteins 0.000 claims 1
- 101000772888 Homo sapiens Ubiquitin-protein ligase E3A Proteins 0.000 claims 1
- 101000807668 Homo sapiens Uracil-DNA glycosylase Proteins 0.000 claims 1
- 101000777301 Homo sapiens Uteroglobin Proteins 0.000 claims 1
- 101000807990 Homo sapiens Variable charge X-linked protein 3 Proteins 0.000 claims 1
- 101000666934 Homo sapiens Very low-density lipoprotein receptor Proteins 0.000 claims 1
- 101000843107 Homo sapiens Very-long-chain (3R)-3-hydroxyacyl-CoA dehydratase 3 Proteins 0.000 claims 1
- 101000621991 Homo sapiens Vinculin Proteins 0.000 claims 1
- 101001125402 Homo sapiens Vitamin K-dependent protein C Proteins 0.000 claims 1
- 101000804811 Homo sapiens WD repeat and SOCS box-containing protein 1 Proteins 0.000 claims 1
- 101000804821 Homo sapiens WD repeat and SOCS box-containing protein 2 Proteins 0.000 claims 1
- 101000621390 Homo sapiens Wee1-like protein kinase Proteins 0.000 claims 1
- 101000626697 Homo sapiens YEATS domain-containing protein 4 Proteins 0.000 claims 1
- 101000976377 Homo sapiens Zinc finger ZZ-type and EF-hand domain-containing protein 1 Proteins 0.000 claims 1
- 101000964584 Homo sapiens Zinc finger protein 160 Proteins 0.000 claims 1
- 101000744935 Homo sapiens Zinc finger protein 202 Proteins 0.000 claims 1
- 101000723746 Homo sapiens Zinc finger protein 22 Proteins 0.000 claims 1
- 101000734338 Homo sapiens [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 3, mitochondrial Proteins 0.000 claims 1
- 101000734339 Homo sapiens [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 4, mitochondrial Proteins 0.000 claims 1
- 101001026573 Homo sapiens cAMP-dependent protein kinase type I-alpha regulatory subunit Proteins 0.000 claims 1
- 101000614806 Homo sapiens cAMP-dependent protein kinase type II-beta regulatory subunit Proteins 0.000 claims 1
- 101001046427 Homo sapiens cGMP-dependent protein kinase 2 Proteins 0.000 claims 1
- 101001098818 Homo sapiens cGMP-inhibited 3',5'-cyclic phosphodiesterase A Proteins 0.000 claims 1
- 101000802101 Homo sapiens mRNA decay activator protein ZFP36L2 Proteins 0.000 claims 1
- 101001127470 Homo sapiens p53 apoptosis effector related to PMP-22 Proteins 0.000 claims 1
- 102100031587 Hsp90 co-chaperone Cdc37-like 1 Human genes 0.000 claims 1
- 102100021102 Hyaluronidase PH-20 Human genes 0.000 claims 1
- 102100031009 Inactive N-acetylated-alpha-linked acidic dipeptidase-like protein 2 Human genes 0.000 claims 1
- 102100033358 Inactive pancreatic lipase-related protein 1 Human genes 0.000 claims 1
- 102100026539 Induced myeloid leukemia cell differentiation protein Mcl-1 Human genes 0.000 claims 1
- 102100039460 Inter-alpha-trypsin inhibitor heavy chain H3 Human genes 0.000 claims 1
- 102100036981 Interferon regulatory factor 1 Human genes 0.000 claims 1
- 102100036527 Interferon-related developmental regulator 1 Human genes 0.000 claims 1
- 102000004901 Iron regulatory protein 1 Human genes 0.000 claims 1
- 108090001025 Iron regulatory protein 1 Proteins 0.000 claims 1
- 108010041872 Islet Amyloid Polypeptide Proteins 0.000 claims 1
- 102100027670 Islet amyloid polypeptide Human genes 0.000 claims 1
- 102100039905 Isocitrate dehydrogenase [NADP] cytoplasmic Human genes 0.000 claims 1
- 101710015718 KIAA0100 Proteins 0.000 claims 1
- 102100031819 Kappa-type opioid receptor Human genes 0.000 claims 1
- 102100033083 Kazal-type serine protease inhibitor domain-containing protein 1 Human genes 0.000 claims 1
- 102100034831 Kin of IRRE-like protein 3 Human genes 0.000 claims 1
- 102100021000 Kinase suppressor of Ras 2 Human genes 0.000 claims 1
- 102100034671 L-lactate dehydrogenase A chain Human genes 0.000 claims 1
- 102100022499 L-lactate dehydrogenase A-like 6B Human genes 0.000 claims 1
- 102100033339 LIM domain and actin-binding protein 1 Human genes 0.000 claims 1
- 102100036106 LIM/homeobox protein Lhx3 Human genes 0.000 claims 1
- 102100025640 Lactase-like protein Human genes 0.000 claims 1
- 102100021695 Lanosterol 14-alpha demethylase Human genes 0.000 claims 1
- 102100027017 Latent-transforming growth factor beta-binding protein 2 Human genes 0.000 claims 1
- 102100023757 Latent-transforming growth factor beta-binding protein 4 Human genes 0.000 claims 1
- 102100037199 Lathosterol oxidase Human genes 0.000 claims 1
- 102100040276 Leucine zipper putative tumor suppressor 2 Human genes 0.000 claims 1
- 102100031956 Leucine-rich repeat protein SHOC-2 Human genes 0.000 claims 1
- 102100032352 Leukemia inhibitory factor Human genes 0.000 claims 1
- 108090000581 Leukemia inhibitory factor Proteins 0.000 claims 1
- 102100034762 Leukocyte cell-derived chemotaxin-2 Human genes 0.000 claims 1
- 102100033375 Leukotriene B4 receptor 2 Human genes 0.000 claims 1
- 102100024032 Linker for activation of T-cells family member 1 Human genes 0.000 claims 1
- 102100021922 Low-density lipoprotein receptor-related protein 2 Human genes 0.000 claims 1
- 102100024034 Lymphocyte transmembrane adapter 1 Human genes 0.000 claims 1
- 102100026753 Lymphokine-activated killer T-cell-originated protein kinase Human genes 0.000 claims 1
- 102000004137 Lysophosphatidic Acid Receptors Human genes 0.000 claims 1
- 108090000642 Lysophosphatidic Acid Receptors Proteins 0.000 claims 1
- 102100037611 Lysophospholipase Human genes 0.000 claims 1
- 102100026001 Lysosomal acid lipase/cholesteryl ester hydrolase Human genes 0.000 claims 1
- 102100023326 M-phase inducer phosphatase 1 Human genes 0.000 claims 1
- 102100023325 M-phase inducer phosphatase 2 Human genes 0.000 claims 1
- 102100034069 MAP kinase-activated protein kinase 2 Human genes 0.000 claims 1
- 108010041955 MAP-kinase-activated kinase 2 Proteins 0.000 claims 1
- 102100023728 MAP3K12-binding inhibitory protein 1 Human genes 0.000 claims 1
- 108700012928 MAPK14 Proteins 0.000 claims 1
- 101150078127 MUSK gene Proteins 0.000 claims 1
- 102100039742 Malate dehydrogenase, mitochondrial Human genes 0.000 claims 1
- 102100039668 Malignant fibrous histiocytoma-amplified sequence 1 Human genes 0.000 claims 1
- 102100024295 Maltase-glucoamylase Human genes 0.000 claims 1
- 101150003941 Mapk14 gene Proteins 0.000 claims 1
- 108010072582 Matrilin Proteins Proteins 0.000 claims 1
- 102100030201 Matrix metalloproteinase-15 Human genes 0.000 claims 1
- 102100030200 Matrix metalloproteinase-16 Human genes 0.000 claims 1
- 102100030219 Matrix metalloproteinase-17 Human genes 0.000 claims 1
- 102100024131 Matrix metalloproteinase-25 Human genes 0.000 claims 1
- 102100039185 Max dimerization protein 1 Human genes 0.000 claims 1
- 102100025169 Max-binding protein MNT Human genes 0.000 claims 1
- 102100026300 McKusick-Kaufman/Bardet-Biedl syndromes putative chaperonin Human genes 0.000 claims 1
- 102100039204 Mediator of RNA polymerase II transcription subunit 1 Human genes 0.000 claims 1
- 102100021070 Mediator of RNA polymerase II transcription subunit 12 Human genes 0.000 claims 1
- 102100026161 Mediator of RNA polymerase II transcription subunit 13 Human genes 0.000 claims 1
- 102100025530 Mediator of RNA polymerase II transcription subunit 17 Human genes 0.000 claims 1
- 102100039206 Mediator of RNA polymerase II transcription subunit 4 Human genes 0.000 claims 1
- 102100023726 Melanocortin receptor 3 Human genes 0.000 claims 1
- 102100027256 Melanoma-associated antigen H1 Human genes 0.000 claims 1
- 101710151321 Melanostatin Proteins 0.000 claims 1
- 108010090314 Member 1 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 claims 1
- 102100026261 Metalloproteinase inhibitor 3 Human genes 0.000 claims 1
- 102100021091 Methylsterol monooxygenase 1 Human genes 0.000 claims 1
- 102100022259 Mevalonate kinase Human genes 0.000 claims 1
- 108700040132 Mevalonate kinases Proteins 0.000 claims 1
- 102100026723 Microsomal glutathione S-transferase 2 Human genes 0.000 claims 1
- 102100026722 Microsomal glutathione S-transferase 3 Human genes 0.000 claims 1
- 102100031545 Microsomal triglyceride transfer protein large subunit Human genes 0.000 claims 1
- 102100024160 Microspherule protein 1 Human genes 0.000 claims 1
- 102100028322 Microtubule-actin cross-linking factor 1, isoforms 1/2/3/5 Human genes 0.000 claims 1
- 102100039560 Microtubule-associated protein RP/EB family member 1 Human genes 0.000 claims 1
- 102100038615 Microtubule-associated protein RP/EB family member 2 Human genes 0.000 claims 1
- 102100038678 Microtubule-associated protein RP/EB family member 3 Human genes 0.000 claims 1
- 102100026287 Misshapen-like kinase 1 Human genes 0.000 claims 1
- 108010009513 Mitochondrial Aldehyde Dehydrogenase Proteins 0.000 claims 1
- 102100023200 Mitochondrial fission process protein 1 Human genes 0.000 claims 1
- 101710149340 Mitochondrial fission process protein 1 Proteins 0.000 claims 1
- 102100040216 Mitochondrial uncoupling protein 3 Human genes 0.000 claims 1
- 102000054819 Mitogen-activated protein kinase 14 Human genes 0.000 claims 1
- 102100037801 Mitogen-activated protein kinase 6 Human genes 0.000 claims 1
- 102100037808 Mitogen-activated protein kinase 8 Human genes 0.000 claims 1
- 102100025184 Mitogen-activated protein kinase kinase kinase 13 Human genes 0.000 claims 1
- 102100033060 Mitogen-activated protein kinase kinase kinase 4 Human genes 0.000 claims 1
- 102100026909 Mitogen-activated protein kinase kinase kinase 9 Human genes 0.000 claims 1
- 102100028193 Mitogen-activated protein kinase kinase kinase kinase 3 Human genes 0.000 claims 1
- 102100028194 Mitogen-activated protein kinase kinase kinase kinase 4 Human genes 0.000 claims 1
- 102100028195 Mitogen-activated protein kinase kinase kinase kinase 5 Human genes 0.000 claims 1
- 102100038792 Mitotic spindle assembly checkpoint protein MAD2A Human genes 0.000 claims 1
- 102100021440 Modulator of apoptosis 1 Human genes 0.000 claims 1
- 102100027983 Molybdenum cofactor sulfurase Human genes 0.000 claims 1
- 101710132461 Molybdenum cofactor sulfurase Proteins 0.000 claims 1
- 102100029814 Monoglyceride lipase Human genes 0.000 claims 1
- 102100025751 Mothers against decapentaplegic homolog 2 Human genes 0.000 claims 1
- 101710143123 Mothers against decapentaplegic homolog 2 Proteins 0.000 claims 1
- 102100034256 Mucin-1 Human genes 0.000 claims 1
- 102100040889 Multiple C2 and transmembrane domain-containing protein 1 Human genes 0.000 claims 1
- 102100040886 Multiple C2 and transmembrane domain-containing protein 2 Human genes 0.000 claims 1
- 241001529936 Murinae Species 0.000 claims 1
- 102100038168 Muscle, skeletal receptor tyrosine-protein kinase Human genes 0.000 claims 1
- 102100030965 Muscleblind-like protein 1 Human genes 0.000 claims 1
- 102100021156 MutS protein homolog 5 Human genes 0.000 claims 1
- 102100038895 Myc proto-oncogene protein Human genes 0.000 claims 1
- 102100030741 Myelin protein P0 Human genes 0.000 claims 1
- 102100033699 MyoD family inhibitor domain-containing protein Human genes 0.000 claims 1
- 102100034100 Myocardin-related transcription factor B Human genes 0.000 claims 1
- 102100021148 Myocyte-specific enhancer factor 2A Human genes 0.000 claims 1
- 102100039229 Myocyte-specific enhancer factor 2C Human genes 0.000 claims 1
- 102100038379 Myogenic factor 6 Human genes 0.000 claims 1
- 102100036640 Myosin-10 Human genes 0.000 claims 1
- 102100032972 Myosin-14 Human genes 0.000 claims 1
- 102100024958 Myotubularin-related protein 10 Human genes 0.000 claims 1
- 102100024963 Myotubularin-related protein 11 Human genes 0.000 claims 1
- 102100024957 Myotubularin-related protein 12 Human genes 0.000 claims 1
- 102100040602 Myotubularin-related protein 2 Human genes 0.000 claims 1
- 102100040599 Myotubularin-related protein 4 Human genes 0.000 claims 1
- WWGBHDIHIVGYLZ-UHFFFAOYSA-N N-[4-[3-[[[7-(hydroxyamino)-7-oxoheptyl]amino]-oxomethyl]-5-isoxazolyl]phenyl]carbamic acid tert-butyl ester Chemical compound C1=CC(NC(=O)OC(C)(C)C)=CC=C1C1=CC(C(=O)NCCCCCCC(=O)NO)=NO1 WWGBHDIHIVGYLZ-UHFFFAOYSA-N 0.000 claims 1
- 102100035286 N-acetyl-D-glucosamine kinase Human genes 0.000 claims 1
- 102100023282 N-acetylglucosamine-6-sulfatase Human genes 0.000 claims 1
- 102100032979 N-acetylglucosaminyl-phosphatidylinositol de-N-acetylase Human genes 0.000 claims 1
- 102100030397 N-acetylmuramoyl-L-alanine amidase Human genes 0.000 claims 1
- 102100030815 N-acetyltransferase ESCO1 Human genes 0.000 claims 1
- 102100023648 N-chimaerin Human genes 0.000 claims 1
- ZBZXYUYUUDZCNB-UHFFFAOYSA-N N-cyclohexa-1,3-dien-1-yl-N-phenyl-4-[4-(N-[4-[4-(N-[4-[4-(N-phenylanilino)phenyl]phenyl]anilino)phenyl]phenyl]anilino)phenyl]aniline Chemical compound C1=CCCC(N(C=2C=CC=CC=2)C=2C=CC(=CC=2)C=2C=CC(=CC=2)N(C=2C=CC=CC=2)C=2C=CC(=CC=2)C=2C=CC(=CC=2)N(C=2C=CC=CC=2)C=2C=CC(=CC=2)C=2C=CC(=CC=2)N(C=2C=CC=CC=2)C=2C=CC=CC=2)=C1 ZBZXYUYUUDZCNB-UHFFFAOYSA-N 0.000 claims 1
- 102100023175 NADP-dependent malic enzyme Human genes 0.000 claims 1
- 102100022547 NEDD4 family-interacting protein 1 Human genes 0.000 claims 1
- 102100039337 NF-kappa-B inhibitor alpha Human genes 0.000 claims 1
- 102100034306 NF-kappa-B inhibitor-interacting Ras-like protein 1 Human genes 0.000 claims 1
- 102100034325 NF-kappa-B inhibitor-interacting Ras-like protein 2 Human genes 0.000 claims 1
- 102100029565 NPC intracellular cholesterol transporter 1 Human genes 0.000 claims 1
- 102100022737 NPC intracellular cholesterol transporter 2 Human genes 0.000 claims 1
- 102100021733 NUAK family SNF1-like kinase 2 Human genes 0.000 claims 1
- 102100036954 Nck-associated protein 1 Human genes 0.000 claims 1
- 102100038699 Netrin-G2 Human genes 0.000 claims 1
- 102100021310 Neurexin-3 Human genes 0.000 claims 1
- 102100037142 Neuroblastoma suppressor of tumorigenicity 1 Human genes 0.000 claims 1
- 102100025254 Neurogenic locus notch homolog protein 4 Human genes 0.000 claims 1
- 102100038814 Neuromedin-U receptor 2 Human genes 0.000 claims 1
- 102100021852 Neuronal cell adhesion molecule Human genes 0.000 claims 1
- 102100032769 Neuronal-specific septin-3 Human genes 0.000 claims 1
- 108090000770 Neuropilin-2 Proteins 0.000 claims 1
- 102100029268 Neurotrophin-3 Human genes 0.000 claims 1
- 102100027341 Neutral and basic amino acid transport protein rBAT Human genes 0.000 claims 1
- 102100033223 Nicotinamide phosphoribosyltransferase Human genes 0.000 claims 1
- 102100035377 Nipped-B-like protein Human genes 0.000 claims 1
- 108010041253 Nogo Receptor 2 Proteins 0.000 claims 1
- 108010029741 Notch4 Receptor Proteins 0.000 claims 1
- 108010062309 Nuclear Receptor Interacting Protein 1 Proteins 0.000 claims 1
- 102100023050 Nuclear factor NF-kappa-B p105 subunit Human genes 0.000 claims 1
- 102100036961 Nuclear mitotic apparatus protein 1 Human genes 0.000 claims 1
- 102100037223 Nuclear receptor coactivator 1 Human genes 0.000 claims 1
- 102100022883 Nuclear receptor coactivator 3 Human genes 0.000 claims 1
- 102100038494 Nuclear receptor subfamily 1 group I member 2 Human genes 0.000 claims 1
- 102100022673 Nuclear receptor subfamily 4 group A member 3 Human genes 0.000 claims 1
- 102100022670 Nuclear receptor subfamily 6 group A member 1 Human genes 0.000 claims 1
- 102100029558 Nuclear receptor-interacting protein 1 Human genes 0.000 claims 1
- 102100031719 Nuclear transcription factor Y subunit gamma Human genes 0.000 claims 1
- 102100027051 Nucleic acid dioxygenase ALKBH1 Human genes 0.000 claims 1
- 102100032138 Nucleolysin TIAR Human genes 0.000 claims 1
- 102100032113 Nucleoside diphosphate kinase 6 Human genes 0.000 claims 1
- 102100040562 OTU domain-containing protein 7B Human genes 0.000 claims 1
- 102100026320 Oxidative stress-induced growth inhibitor 1 Human genes 0.000 claims 1
- 102100032163 Oxysterol-binding protein 1 Human genes 0.000 claims 1
- 102100032164 Oxysterol-binding protein 2 Human genes 0.000 claims 1
- 102100025924 Oxysterol-binding protein-related protein 1 Human genes 0.000 claims 1
- 102100031469 Oxysterol-binding protein-related protein 10 Human genes 0.000 claims 1
- 102100025875 Oxysterol-binding protein-related protein 11 Human genes 0.000 claims 1
- 102100032154 Oxysterol-binding protein-related protein 3 Human genes 0.000 claims 1
- 102100032148 Oxysterol-binding protein-related protein 5 Human genes 0.000 claims 1
- 102100032149 Oxysterol-binding protein-related protein 6 Human genes 0.000 claims 1
- 102100032151 Oxysterol-binding protein-related protein 8 Human genes 0.000 claims 1
- 102100032162 Oxysterol-binding protein-related protein 9 Human genes 0.000 claims 1
- 102100037600 P2Y purinoceptor 1 Human genes 0.000 claims 1
- 102100028045 P2Y purinoceptor 2 Human genes 0.000 claims 1
- 102100028070 P2Y purinoceptor 4 Human genes 0.000 claims 1
- 102100028074 P2Y purinoceptor 6 Human genes 0.000 claims 1
- 102100029181 PDZ and LIM domain protein 5 Human genes 0.000 claims 1
- 102100038533 PDZ domain-containing protein 8 Human genes 0.000 claims 1
- LGMXPVXJSFPPTQ-DJUJBXLVSA-N PGK2 Chemical compound CCCCC[C@H](O)\C=C\[C@@H]1[C@@H](C\C=C/CCCC(O)=O)C(=O)CC1=O LGMXPVXJSFPPTQ-DJUJBXLVSA-N 0.000 claims 1
- 102100036231 PH and SEC7 domain-containing protein 3 Human genes 0.000 claims 1
- 102100036232 PH and SEC7 domain-containing protein 4 Human genes 0.000 claims 1
- 102100031152 PH domain leucine-rich repeat-containing protein phosphatase 1 Human genes 0.000 claims 1
- 101150096217 PHYH gene Proteins 0.000 claims 1
- 101710125553 PLA2G6 Proteins 0.000 claims 1
- 102100026459 POU domain, class 3, transcription factor 2 Human genes 0.000 claims 1
- 102100040851 Paired box protein Pax-1 Human genes 0.000 claims 1
- 102100040852 Paired box protein Pax-2 Human genes 0.000 claims 1
- 102100037503 Paired box protein Pax-7 Human genes 0.000 claims 1
- 102100040764 Palmitoyltransferase ZDHHC13 Human genes 0.000 claims 1
- 102100033357 Pancreatic lipase-related protein 2 Human genes 0.000 claims 1
- 102100040154 Pappalysin-2 Human genes 0.000 claims 1
- 102100036899 Parathyroid hormone-related protein Human genes 0.000 claims 1
- 102100037499 Parkinson disease protein 7 Human genes 0.000 claims 1
- 102100037134 Partitioning defective 3 homolog B Human genes 0.000 claims 1
- 101710189920 Peptidyl-alpha-hydroxyglycine alpha-amidating lyase Proteins 0.000 claims 1
- 102100030867 Peptidyl-tRNA hydrolase 2, mitochondrial Human genes 0.000 claims 1
- 102100028467 Perforin-1 Human genes 0.000 claims 1
- 102000017795 Perilipin-1 Human genes 0.000 claims 1
- 108010067162 Perilipin-1 Proteins 0.000 claims 1
- 102100031894 Peroxidasin-like protein Human genes 0.000 claims 1
- 102100034768 Peroxiredoxin-4 Human genes 0.000 claims 1
- 102100022078 Peroxiredoxin-5, mitochondrial Human genes 0.000 claims 1
- 102100026798 Peroxisomal acyl-coenzyme A oxidase 1 Human genes 0.000 claims 1
- 102100037974 Peroxisomal carnitine O-octanoyltransferase Human genes 0.000 claims 1
- 102100030564 Peroxisomal membrane protein 2 Human genes 0.000 claims 1
- 102100022587 Peroxisomal multifunctional enzyme type 2 Human genes 0.000 claims 1
- 102100038825 Peroxisome proliferator-activated receptor gamma Human genes 0.000 claims 1
- 102100028961 Peroxisome proliferator-activated receptor gamma coactivator 1-beta Human genes 0.000 claims 1
- 102100040402 Phlorizin hydrolase Human genes 0.000 claims 1
- 102100030919 Phosphatidylcholine:ceramide cholinephosphotransferase 1 Human genes 0.000 claims 1
- 102100022771 Phosphatidylcholine:ceramide cholinephosphotransferase 2 Human genes 0.000 claims 1
- 108010030678 Phosphatidylethanolamine N-Methyltransferase Proteins 0.000 claims 1
- 102100025063 Phosphatidylinositol 3-kinase C2 domain-containing subunit gamma Human genes 0.000 claims 1
- 102100032619 Phosphatidylinositol 4-kinase beta Human genes 0.000 claims 1
- 102100036146 Phosphatidylinositol 5-phosphate 4-kinase type-2 alpha Human genes 0.000 claims 1
- 102100036163 Phosphatidylinositol N-acetylglucosaminyltransferase subunit C Human genes 0.000 claims 1
- 102100036162 Phosphatidylinositol N-acetylglucosaminyltransferase subunit H Human genes 0.000 claims 1
- 102100036331 Phosphatidylinositol N-acetylglucosaminyltransferase subunit Y Human genes 0.000 claims 1
- 102100038725 Phosphatidylinositol glycan anchor biosynthesis class U protein Human genes 0.000 claims 1
- 102100036062 Phosphatidylinositol transfer protein alpha isoform Human genes 0.000 claims 1
- 102100036063 Phosphatidylinositol transfer protein beta isoform Human genes 0.000 claims 1
- 102100039298 Phosphatidylserine synthase 1 Human genes 0.000 claims 1
- 102100024440 Phosphoacetylglucosamine mutase Human genes 0.000 claims 1
- 102100034792 Phosphoenolpyruvate carboxykinase [GTP], mitochondrial Human genes 0.000 claims 1
- 102100034796 Phosphoenolpyruvate carboxykinase, cytosolic [GTP] Human genes 0.000 claims 1
- 102100030999 Phosphoglucomutase-1 Human genes 0.000 claims 1
- 102100036629 Phosphoglucomutase-2 Human genes 0.000 claims 1
- 102100037392 Phosphoglycerate kinase 2 Human genes 0.000 claims 1
- 102100026831 Phospholipase A2, membrane associated Human genes 0.000 claims 1
- 102100037883 Phospholipase B1, membrane-associated Human genes 0.000 claims 1
- 102100030450 Phospholipid phosphatase 3 Human genes 0.000 claims 1
- 102100035367 Phosphomannomutase 1 Human genes 0.000 claims 1
- 102100024279 Phosphomevalonate kinase Human genes 0.000 claims 1
- 102100020854 Phosphorylase b kinase regulatory subunit beta Human genes 0.000 claims 1
- 102100039421 Phytanoyl-CoA dioxygenase, peroxisomal Human genes 0.000 claims 1
- 102100030345 Pituitary homeobox 1 Human genes 0.000 claims 1
- 102100036090 Pituitary homeobox 2 Human genes 0.000 claims 1
- 102100036088 Pituitary homeobox 3 Human genes 0.000 claims 1
- 102100027932 Platelet-activating factor acetylhydrolase 2, cytoplasmic Human genes 0.000 claims 1
- 102100030485 Platelet-derived growth factor receptor alpha Human genes 0.000 claims 1
- 102100040990 Platelet-derived growth factor subunit B Human genes 0.000 claims 1
- 102100032595 Pleckstrin homology domain-containing family G member 1 Human genes 0.000 claims 1
- 102100032594 Pleckstrin homology domain-containing family G member 2 Human genes 0.000 claims 1
- 102100032588 Pleckstrin homology domain-containing family G member 3 Human genes 0.000 claims 1
- 102100030349 Pleckstrin homology domain-containing family M member 1 Human genes 0.000 claims 1
- 102100030887 Pleckstrin homology-like domain family A member 1 Human genes 0.000 claims 1
- 102100030470 Pleckstrin-2 Human genes 0.000 claims 1
- 102100039682 Polypeptide N-acetylgalactosaminyltransferase 4 Human genes 0.000 claims 1
- 102100040169 Pre-B-cell leukemia transcription factor 3 Human genes 0.000 claims 1
- 102100038255 Prefoldin subunit 1 Human genes 0.000 claims 1
- 108010001511 Pregnane X Receptor Proteins 0.000 claims 1
- 102100022668 Pro-neuregulin-2, membrane-bound isoform Human genes 0.000 claims 1
- 102100028427 Pro-neuropeptide Y Human genes 0.000 claims 1
- 102100031031 Probable global transcription activator SNF2L1 Human genes 0.000 claims 1
- 102100037384 Probable phosphoglycerate mutase 4 Human genes 0.000 claims 1
- 102100037594 Programmed cell death protein 10 Human genes 0.000 claims 1
- 102100040676 Programmed cell death protein 2 Human genes 0.000 claims 1
- 102100034785 Programmed cell death protein 6 Human genes 0.000 claims 1
- 102100040126 Prokineticin-1 Human genes 0.000 claims 1
- 102100040659 Prolargin Human genes 0.000 claims 1
- 102100034836 Proliferation marker protein Ki-67 Human genes 0.000 claims 1
- 102100028772 Proline dehydrogenase 1, mitochondrial Human genes 0.000 claims 1
- 102100039022 Propionyl-CoA carboxylase alpha chain, mitochondrial Human genes 0.000 claims 1
- 102100039025 Propionyl-CoA carboxylase beta chain, mitochondrial Human genes 0.000 claims 1
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 claims 1
- 102100033075 Prostacyclin synthase Human genes 0.000 claims 1
- 102100033076 Prostaglandin E synthase Human genes 0.000 claims 1
- 108010065942 Prostaglandin-F synthase Proteins 0.000 claims 1
- 101710145576 Prostaglandin-H2 D-isomerase Proteins 0.000 claims 1
- 102100032859 Protein AMBP Human genes 0.000 claims 1
- 108010032428 Protein Deglycase DJ-1 Proteins 0.000 claims 1
- 102100023602 Protein Hook homolog 1 Human genes 0.000 claims 1
- 102100037163 Protein KIAA0100 Human genes 0.000 claims 1
- 102100039972 Protein RCC2 Human genes 0.000 claims 1
- 102100023097 Protein S100-A1 Human genes 0.000 claims 1
- 102100037271 Protein SFI1 homolog Human genes 0.000 claims 1
- 102100033661 Protein TFG Human genes 0.000 claims 1
- 102100022429 Protein TMEPAI Human genes 0.000 claims 1
- 102100024518 Protein cornichon homolog 3 Human genes 0.000 claims 1
- 102100037340 Protein kinase C delta type Human genes 0.000 claims 1
- 102100034433 Protein kinase C-binding protein NELL2 Human genes 0.000 claims 1
- 102100022343 Protein phosphatase 1A Human genes 0.000 claims 1
- 102100038675 Protein phosphatase 1D Human genes 0.000 claims 1
- 102100037976 Protein phosphatase inhibitor 2 Human genes 0.000 claims 1
- 102100030400 Protein sprouty homolog 2 Human genes 0.000 claims 1
- 102100024599 Protein tyrosine phosphatase type IVA 1 Human genes 0.000 claims 1
- 102100037925 Prothymosin alpha Human genes 0.000 claims 1
- 108010019674 Proto-Oncogene Proteins c-sis Proteins 0.000 claims 1
- 208000033550 Proximal spinal muscular atrophy type 4 Diseases 0.000 claims 1
- 102100037860 Psychosine receptor Human genes 0.000 claims 1
- 108010007100 Pulmonary Surfactant-Associated Protein A Proteins 0.000 claims 1
- 102100027773 Pulmonary surfactant-associated protein A2 Human genes 0.000 claims 1
- 102100034911 Pyruvate kinase PKM Human genes 0.000 claims 1
- 102100025895 RAD50-interacting protein 1 Human genes 0.000 claims 1
- 102000001195 RAD51 Human genes 0.000 claims 1
- 102100023588 RB1-inducible coiled-coil protein 1 Human genes 0.000 claims 1
- 102100020837 RCC1 and BTB domain-containing protein 1 Human genes 0.000 claims 1
- 101150020518 RHEB gene Proteins 0.000 claims 1
- 102100023874 RING-box protein 2 Human genes 0.000 claims 1
- 102100029760 RING1 and YY1-binding protein Human genes 0.000 claims 1
- 102100038152 RNA-binding protein 5 Human genes 0.000 claims 1
- 102100029564 Rab-like protein 3 Human genes 0.000 claims 1
- 102000020171 Rab20 Human genes 0.000 claims 1
- 108050007545 Rab20 Proteins 0.000 claims 1
- 102000028598 Rab30 Human genes 0.000 claims 1
- 108050007282 Rab30 Proteins 0.000 claims 1
- 102000028593 Rab35 Human genes 0.000 claims 1
- 108050007316 Rab35 Proteins 0.000 claims 1
- 108010068097 Rad51 Recombinase Proteins 0.000 claims 1
- 102100035089 Radial spoke head 1 homolog Human genes 0.000 claims 1
- 102100033373 Ragulator complex protein LAMTOR5 Human genes 0.000 claims 1
- 102100032665 Ral guanine nucleotide dissociation stimulator-like 1 Human genes 0.000 claims 1
- 102100033975 Ran-binding protein 3 Human genes 0.000 claims 1
- 101150020444 Ranbp3 gene Proteins 0.000 claims 1
- 102100034589 Rap guanine nucleotide exchange factor 1 Human genes 0.000 claims 1
- 102100034591 Rap guanine nucleotide exchange factor 4 Human genes 0.000 claims 1
- 102100031427 Ras GTPase-activating protein 2 Human genes 0.000 claims 1
- 102100022879 Ras GTPase-activating protein 3 Human genes 0.000 claims 1
- 102100035410 Ras GTPase-activating protein nGAP Human genes 0.000 claims 1
- 102100035770 Ras-GEF domain-containing family member 1C Human genes 0.000 claims 1
- 102100039103 Ras-related protein Rab-10 Human genes 0.000 claims 1
- 102100022873 Ras-related protein Rab-11A Human genes 0.000 claims 1
- 102100022292 Ras-related protein Rab-17 Human genes 0.000 claims 1
- 102100028191 Ras-related protein Rab-1A Human genes 0.000 claims 1
- 102100039767 Ras-related protein Rab-27A Human genes 0.000 claims 1
- 102100027838 Ras-related protein Rab-31 Human genes 0.000 claims 1
- 102100027915 Ras-related protein Rab-32 Human genes 0.000 claims 1
- 102100039761 Ras-related protein Rab-33A Human genes 0.000 claims 1
- 102100022294 Ras-related protein Rab-37 Human genes 0.000 claims 1
- 102100022305 Ras-related protein Rab-38 Human genes 0.000 claims 1
- 102100022306 Ras-related protein Rab-3B Human genes 0.000 claims 1
- 102100038479 Ras-related protein Rab-43 Human genes 0.000 claims 1
- 102100039099 Ras-related protein Rab-4A Human genes 0.000 claims 1
- 102100039100 Ras-related protein Rab-5A Human genes 0.000 claims 1
- 102100025138 Ras-related protein Rab-5C Human genes 0.000 claims 1
- 102100030021 Ras-related protein Rab-6C Human genes 0.000 claims 1
- 102100033100 Ras-related protein Rab-7L1 Human genes 0.000 claims 1
- 102100030019 Ras-related protein Rab-7a Human genes 0.000 claims 1
- 102100033959 Ras-related protein Rab-8B Human genes 0.000 claims 1
- 102100033966 Ras-related protein Rab-9A Human genes 0.000 claims 1
- 102100031425 Ras-related protein Ral-B Human genes 0.000 claims 1
- 102100030705 Ras-related protein Rap-1b Human genes 0.000 claims 1
- 102100031420 Ras-related protein Rap-2a Human genes 0.000 claims 1
- 102100031421 Ras-related protein Rap-2b Human genes 0.000 claims 1
- 102100027551 Ras-specific guanine nucleotide-releasing factor 1 Human genes 0.000 claims 1
- 102100027555 Ras-specific guanine nucleotide-releasing factor 2 Human genes 0.000 claims 1
- 102100027536 Ras-specific guanine nucleotide-releasing factor RalGPS1 Human genes 0.000 claims 1
- 102100027535 Ras-specific guanine nucleotide-releasing factor RalGPS2 Human genes 0.000 claims 1
- 102100033428 Ras/Rap GTPase-activating protein SynGAP Human genes 0.000 claims 1
- 101000832669 Rattus norvegicus Probable alcohol sulfotransferase Proteins 0.000 claims 1
- 108010038036 Receptor Activator of Nuclear Factor-kappa B Proteins 0.000 claims 1
- 102100033729 Receptor-interacting serine/threonine-protein kinase 3 Human genes 0.000 claims 1
- 102100021269 Regulator of G-protein signaling 1 Human genes 0.000 claims 1
- 101710140408 Regulator of G-protein signaling 1 Proteins 0.000 claims 1
- 102100021258 Regulator of G-protein signaling 2 Human genes 0.000 claims 1
- 101710140412 Regulator of G-protein signaling 2 Proteins 0.000 claims 1
- 102100037415 Regulator of G-protein signaling 3 Human genes 0.000 claims 1
- 101710140411 Regulator of G-protein signaling 3 Proteins 0.000 claims 1
- 102100030814 Regulator of G-protein signaling 9 Human genes 0.000 claims 1
- 102100031540 Reticulon-4 receptor-like 1 Human genes 0.000 claims 1
- 102100031541 Reticulon-4 receptor-like 2 Human genes 0.000 claims 1
- 102100035670 Retinitis pigmentosa 1-like 1 protein Human genes 0.000 claims 1
- 108010002342 Retinoblastoma-Like Protein p107 Proteins 0.000 claims 1
- 102000000582 Retinoblastoma-Like Protein p107 Human genes 0.000 claims 1
- 102100038054 Retinol dehydrogenase 12 Human genes 0.000 claims 1
- 102100033717 Retroviral-like aspartic protease 1 Human genes 0.000 claims 1
- 102100032437 Rho guanine nucleotide exchange factor 17 Human genes 0.000 claims 1
- 102100032447 Rho guanine nucleotide exchange factor 26 Human genes 0.000 claims 1
- 102100033200 Rho guanine nucleotide exchange factor 7 Human genes 0.000 claims 1
- 102100032206 Rho guanine nucleotide exchange factor TIAM2 Human genes 0.000 claims 1
- 102100039314 Rho-associated protein kinase 2 Human genes 0.000 claims 1
- 102100032658 Rho-related BTB domain-containing protein 2 Human genes 0.000 claims 1
- 102100027610 Rho-related GTP-binding protein RhoC Human genes 0.000 claims 1
- 102100039640 Rho-related GTP-binding protein RhoE Human genes 0.000 claims 1
- 108050007494 Rho-related GTP-binding protein RhoE Proteins 0.000 claims 1
- 102100027608 Rho-related GTP-binding protein RhoF Human genes 0.000 claims 1
- 102100038338 Rho-related GTP-binding protein RhoH Human genes 0.000 claims 1
- 102100024869 Rhombotin-1 Human genes 0.000 claims 1
- 102100020783 Ribokinase Human genes 0.000 claims 1
- 102100031139 Ribose-5-phosphate isomerase Human genes 0.000 claims 1
- 102100033643 Ribosomal protein S6 kinase alpha-3 Human genes 0.000 claims 1
- 102100033645 Ribosomal protein S6 kinase alpha-5 Human genes 0.000 claims 1
- 102100027702 Roundabout homolog 1 Human genes 0.000 claims 1
- 102100027739 Roundabout homolog 2 Human genes 0.000 claims 1
- 102100025373 Runt-related transcription factor 1 Human genes 0.000 claims 1
- 102100027160 RuvB-like 1 Human genes 0.000 claims 1
- 101710169742 RuvB-like protein 1 Proteins 0.000 claims 1
- 108010055623 S-Phase Kinase-Associated Proteins Proteins 0.000 claims 1
- 102100034374 S-phase kinase-associated protein 2 Human genes 0.000 claims 1
- 102100025543 SAM and SH3 domain-containing protein 1 Human genes 0.000 claims 1
- 102100035174 SEC14-like protein 2 Human genes 0.000 claims 1
- 102100031773 SH2 domain-containing adapter protein F Human genes 0.000 claims 1
- 102100031776 SH2 domain-containing protein 3A Human genes 0.000 claims 1
- 102100031777 SH2 domain-containing protein 4A Human genes 0.000 claims 1
- 102100021779 SH2 domain-containing protein 6 Human genes 0.000 claims 1
- 102100038875 SH3 and PX domain-containing protein 2A Human genes 0.000 claims 1
- 102100030680 SH3 and multiple ankyrin repeat domains protein 2 Human genes 0.000 claims 1
- 102100028409 SH3 domain-binding protein 4 Human genes 0.000 claims 1
- 102100040119 SH3 domain-binding protein 5 Human genes 0.000 claims 1
- 101710067890 SHANK2 Proteins 0.000 claims 1
- 108091006633 SLC12A6 Proteins 0.000 claims 1
- 108091006788 SLC20A1 Proteins 0.000 claims 1
- 108091006525 SLC27A2 Proteins 0.000 claims 1
- 108091006524 SLC27A3 Proteins 0.000 claims 1
- 108091006299 SLC2A2 Proteins 0.000 claims 1
- 108091006298 SLC2A3 Proteins 0.000 claims 1
- 108091006308 SLC2A8 Proteins 0.000 claims 1
- 108091006539 SLC35A2 Proteins 0.000 claims 1
- 108091006542 SLC35A3 Proteins 0.000 claims 1
- 108091006957 SLC35D1 Proteins 0.000 claims 1
- 108091006924 SLC37A4 Proteins 0.000 claims 1
- 108091006311 SLC3A1 Proteins 0.000 claims 1
- 108700028341 SMARCB1 Proteins 0.000 claims 1
- 101150008214 SMARCB1 gene Proteins 0.000 claims 1
- 102100022010 SNF-related serine/threonine-protein kinase Human genes 0.000 claims 1
- 108060009345 SORL1 Proteins 0.000 claims 1
- 108700022176 SOS1 Proteins 0.000 claims 1
- 102100023010 SRSF protein kinase 1 Human genes 0.000 claims 1
- 102100023015 SRSF protein kinase 2 Human genes 0.000 claims 1
- 101150024632 STARD5 gene Proteins 0.000 claims 1
- 101150063267 STAT5B gene Proteins 0.000 claims 1
- 108010011005 STAT6 Transcription Factor Proteins 0.000 claims 1
- 102100031131 SUN domain-containing protein 2 Human genes 0.000 claims 1
- 102100025746 SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily B member 1 Human genes 0.000 claims 1
- 101100379220 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) API2 gene Proteins 0.000 claims 1
- 101100197320 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) RPL35A gene Proteins 0.000 claims 1
- 101000702553 Schistosoma mansoni Antigen Sm21.7 Proteins 0.000 claims 1
- 101000714192 Schistosoma mansoni Tegument antigen Proteins 0.000 claims 1
- 101100294206 Schizosaccharomyces pombe (strain 972 / ATCC 24843) fta4 gene Proteins 0.000 claims 1
- 102100023152 Scinderin Human genes 0.000 claims 1
- 102100033004 Securin Human genes 0.000 claims 1
- 102100034940 Selenoprotein S Human genes 0.000 claims 1
- 101150105184 Selenos gene Proteins 0.000 claims 1
- 102100027744 Semaphorin-4D Human genes 0.000 claims 1
- 102100027068 Septin-11 Human genes 0.000 claims 1
- 102100027981 Septin-7 Human genes 0.000 claims 1
- 108010005020 Serine Peptidase Inhibitor Kazal-Type 5 Proteins 0.000 claims 1
- 102100031733 Serine incorporator 2 Human genes 0.000 claims 1
- 102100025420 Serine protease inhibitor Kazal-type 5 Human genes 0.000 claims 1
- 102100030514 Serine/threonine-protein kinase 38 Human genes 0.000 claims 1
- 102100027898 Serine/threonine-protein kinase 38-like Human genes 0.000 claims 1
- 102100026621 Serine/threonine-protein kinase ICK Human genes 0.000 claims 1
- 102100024031 Serine/threonine-protein kinase LATS1 Human genes 0.000 claims 1
- 102100028921 Serine/threonine-protein kinase MARK1 Human genes 0.000 claims 1
- 102100037703 Serine/threonine-protein kinase Nek2 Human genes 0.000 claims 1
- 102100031462 Serine/threonine-protein kinase PLK2 Human genes 0.000 claims 1
- 102100034377 Serine/threonine-protein kinase SIK2 Human genes 0.000 claims 1
- 102100030069 Serine/threonine-protein kinase Sgk2 Human genes 0.000 claims 1
- 102100028954 Serine/threonine-protein kinase TAO3 Human genes 0.000 claims 1
- 102100038192 Serine/threonine-protein kinase TBK1 Human genes 0.000 claims 1
- 102100029064 Serine/threonine-protein kinase WNK1 Human genes 0.000 claims 1
- 102100029063 Serine/threonine-protein kinase WNK2 Human genes 0.000 claims 1
- 102100038101 Serine/threonine-protein kinase WNK4 Human genes 0.000 claims 1
- 102100040321 Serine/threonine-protein phosphatase 2B catalytic subunit beta isoform Human genes 0.000 claims 1
- 102100022345 Serine/threonine-protein phosphatase 6 catalytic subunit Human genes 0.000 claims 1
- 102100025517 Serpin B9 Human genes 0.000 claims 1
- 102100027288 Sestrin-1 Human genes 0.000 claims 1
- 102100037575 Sestrin-3 Human genes 0.000 claims 1
- 102100028402 Shugoshin 1 Human genes 0.000 claims 1
- 102100028662 Sigma intracellular receptor 2 Human genes 0.000 claims 1
- 102100024474 Signal transducer and activator of transcription 5B Human genes 0.000 claims 1
- 102100023980 Signal transducer and activator of transcription 6 Human genes 0.000 claims 1
- 108010011033 Signaling Lymphocytic Activation Molecule Associated Protein Proteins 0.000 claims 1
- 102000013970 Signaling Lymphocytic Activation Molecule Associated Protein Human genes 0.000 claims 1
- 108010074687 Signaling Lymphocytic Activation Molecule Family Member 1 Proteins 0.000 claims 1
- 102100029215 Signaling lymphocytic activation molecule Human genes 0.000 claims 1
- 102100025490 Slit homolog 1 protein Human genes 0.000 claims 1
- 102100029797 Sodium-dependent phosphate transporter 1 Human genes 0.000 claims 1
- 102100034245 Solute carrier family 12 member 6 Human genes 0.000 claims 1
- 102100023537 Solute carrier family 2, facilitated glucose transporter member 2 Human genes 0.000 claims 1
- 102100022722 Solute carrier family 2, facilitated glucose transporter member 3 Human genes 0.000 claims 1
- 102100030936 Solute carrier family 2, facilitated glucose transporter member 8 Human genes 0.000 claims 1
- 102100036924 Solute carrier family 22 member 5 Human genes 0.000 claims 1
- 102100023047 Solute carrier family 27 member 3 Human genes 0.000 claims 1
- 102100032929 Son of sevenless homolog 1 Human genes 0.000 claims 1
- 102100026974 Sorbitol dehydrogenase Human genes 0.000 claims 1
- 101710184713 Sorbitol dehydrogenase Proteins 0.000 claims 1
- 102100021941 Sorcin Human genes 0.000 claims 1
- 102100025639 Sortilin-related receptor Human genes 0.000 claims 1
- 102100030992 Sorting nexin-1 Human genes 0.000 claims 1
- 102100029608 Sorting nexin-10 Human genes 0.000 claims 1
- 102100029609 Sorting nexin-11 Human genes 0.000 claims 1
- 102100029600 Sorting nexin-12 Human genes 0.000 claims 1
- 102100029606 Sorting nexin-13 Human genes 0.000 claims 1
- 102100029598 Sorting nexin-14 Human genes 0.000 claims 1
- 102100030998 Sorting nexin-19 Human genes 0.000 claims 1
- 102100024800 Sorting nexin-24 Human genes 0.000 claims 1
- 102100024807 Sorting nexin-27 Human genes 0.000 claims 1
- 102100032829 Sorting nexin-3 Human genes 0.000 claims 1
- 102100022384 Sorting nexin-31 Human genes 0.000 claims 1
- 102100038650 Sorting nexin-4 Human genes 0.000 claims 1
- 102100038624 Sorting nexin-5 Human genes 0.000 claims 1
- 102100038627 Sorting nexin-7 Human genes 0.000 claims 1
- 102100032854 Sorting nexin-9 Human genes 0.000 claims 1
- 101150100839 Sos1 gene Proteins 0.000 claims 1
- 102100021909 Sperm-associated antigen 6 Human genes 0.000 claims 1
- 102100028899 Spermatid nuclear transition protein 1 Human genes 0.000 claims 1
- 102100026263 Sphingomyelin phosphodiesterase Human genes 0.000 claims 1
- 102100034292 Sphingomyelin synthase-related protein 1 Human genes 0.000 claims 1
- 102100037614 Sprouty-related, EVH1 domain-containing protein 1 Human genes 0.000 claims 1
- 102100027650 Sprouty-related, EVH1 domain-containing protein 2 Human genes 0.000 claims 1
- 102100025560 Squalene monooxygenase Human genes 0.000 claims 1
- 102100024519 Src-like-adapter Human genes 0.000 claims 1
- 102100025252 StAR-related lipid transfer protein 13 Human genes 0.000 claims 1
- 102100026718 StAR-related lipid transfer protein 4 Human genes 0.000 claims 1
- 102100026709 StAR-related lipid transfer protein 5 Human genes 0.000 claims 1
- 101710190410 Staphylococcal complement inhibitor Proteins 0.000 claims 1
- 101150082484 Stard4 gene Proteins 0.000 claims 1
- 102100028049 Stathmin-4 Human genes 0.000 claims 1
- 102100033930 Stearoyl-CoA desaturase 5 Human genes 0.000 claims 1
- 102100021993 Sterol O-acyltransferase 1 Human genes 0.000 claims 1
- 102100026839 Sterol regulatory element-binding protein 1 Human genes 0.000 claims 1
- 102100029955 Striatin-3 Human genes 0.000 claims 1
- 102000004094 Stromal Interaction Molecule 1 Human genes 0.000 claims 1
- 108090000532 Stromal Interaction Molecule 1 Proteins 0.000 claims 1
- 108010030731 Stromal Interaction Molecule 2 Proteins 0.000 claims 1
- 102100035562 Stromal interaction molecule 2 Human genes 0.000 claims 1
- 102100032723 Structural maintenance of chromosomes protein 3 Human genes 0.000 claims 1
- 102100037346 Substance-P receptor Human genes 0.000 claims 1
- 102100035726 Succinate dehydrogenase [ubiquinone] iron-sulfur subunit, mitochondrial Human genes 0.000 claims 1
- 102100037811 Succinate-CoA ligase [ADP-forming] subunit beta, mitochondrial Human genes 0.000 claims 1
- 102100024241 Succinate-CoA ligase [ADP/GDP-forming] subunit alpha, mitochondrial Human genes 0.000 claims 1
- 102100037788 Succinate-CoA ligase [GDP-forming] subunit beta, mitochondrial Human genes 0.000 claims 1
- 102100023986 Sulfotransferase 1A1 Human genes 0.000 claims 1
- 102100023988 Sulfotransferase 1B1 Human genes 0.000 claims 1
- 102100029862 Sulfotransferase 1E1 Human genes 0.000 claims 1
- 102100029867 Sulfotransferase 2A1 Human genes 0.000 claims 1
- 102100026344 Supervillin Human genes 0.000 claims 1
- 102100036412 Survival of motor neuron-related-splicing factor 30 Human genes 0.000 claims 1
- 102100037225 Syntenin-2 Human genes 0.000 claims 1
- 108010001288 T-Lymphoma Invasion and Metastasis-inducing Protein 1 Proteins 0.000 claims 1
- 102000002154 T-Lymphoma Invasion and Metastasis-inducing Protein 1 Human genes 0.000 claims 1
- 102100038409 T-box transcription factor TBX3 Human genes 0.000 claims 1
- 102100040365 T-cell acute lymphocytic leukemia protein 1 Human genes 0.000 claims 1
- 102100030302 TBC1 domain family member 8 Human genes 0.000 claims 1
- 102100033455 TGF-beta receptor type-2 Human genes 0.000 claims 1
- 102100021227 TGF-beta-activated kinase 1 and MAP3K7-binding protein 2 Human genes 0.000 claims 1
- 102000004399 TNF receptor-associated factor 3 Human genes 0.000 claims 1
- 108090000922 TNF receptor-associated factor 3 Proteins 0.000 claims 1
- 102100037671 TRAF2 and NCK-interacting protein kinase Human genes 0.000 claims 1
- 102100038193 Tax1-binding protein 1 Human genes 0.000 claims 1
- 108010033710 Telomeric Repeat Binding Protein 2 Proteins 0.000 claims 1
- 102100030784 Telomeric repeat-binding factor 2 Human genes 0.000 claims 1
- 102100028651 Tenascin-N Human genes 0.000 claims 1
- 102100028644 Tenascin-R Human genes 0.000 claims 1
- 102100024547 Tensin-1 Human genes 0.000 claims 1
- 102100024548 Tensin-3 Human genes 0.000 claims 1
- 102100034939 Terminal nucleotidyltransferase 4A Human genes 0.000 claims 1
- 102100034938 Terminal nucleotidyltransferase 4B Human genes 0.000 claims 1
- 102100035873 Tetraspanin-2 Human genes 0.000 claims 1
- 102100040874 Tetraspanin-3 Human genes 0.000 claims 1
- 102100036407 Thioredoxin Human genes 0.000 claims 1
- 102100030269 Thioredoxin domain-containing protein 5 Human genes 0.000 claims 1
- 102100034196 Thrombopoietin receptor Human genes 0.000 claims 1
- 102100030973 Thromboxane-A synthase Human genes 0.000 claims 1
- 102100028099 Thyroid receptor-interacting protein 6 Human genes 0.000 claims 1
- 108010031429 Tissue Inhibitor of Metalloproteinase-3 Proteins 0.000 claims 1
- 102000019347 Tob1 Human genes 0.000 claims 1
- 102000019346 Tob2 Human genes 0.000 claims 1
- 108050006879 Tob2 Proteins 0.000 claims 1
- 102100024333 Toll-like receptor 2 Human genes 0.000 claims 1
- 102100037496 Trafficking protein particle complex subunit 4 Human genes 0.000 claims 1
- 102000004853 Transcription Factor DP1 Human genes 0.000 claims 1
- 108090001097 Transcription Factor DP1 Proteins 0.000 claims 1
- 102100021123 Transcription factor 12 Human genes 0.000 claims 1
- 102100035101 Transcription factor 7-like 2 Human genes 0.000 claims 1
- 102100038312 Transcription factor Dp-2 Human genes 0.000 claims 1
- 102100024026 Transcription factor E2F1 Human genes 0.000 claims 1
- 102100023234 Transcription factor MafB Human genes 0.000 claims 1
- 102100036694 Transcription factor SOX-6 Human genes 0.000 claims 1
- 102100034204 Transcription factor SOX-9 Human genes 0.000 claims 1
- 102100030647 Transcription factor-like 5 protein Human genes 0.000 claims 1
- 102100027912 Transcription initiation protein SPT3 homolog Human genes 0.000 claims 1
- 102100030780 Transcriptional activator Myb Human genes 0.000 claims 1
- 102100030836 Transcriptional adapter 3 Human genes 0.000 claims 1
- 102100023931 Transcriptional regulator ATRX Human genes 0.000 claims 1
- 102100029446 Transcriptional-regulating factor 1 Human genes 0.000 claims 1
- 102100039362 Transducin-like enhancer protein 1 Human genes 0.000 claims 1
- 102100034698 Transducin-like enhancer protein 3 Human genes 0.000 claims 1
- 108010082684 Transforming Growth Factor-beta Type II Receptor Proteins 0.000 claims 1
- 102100027049 Transforming acidic coiled-coil-containing protein 1 Human genes 0.000 claims 1
- 102100030986 Transgelin-3 Human genes 0.000 claims 1
- 102100029887 Translationally-controlled tumor protein Human genes 0.000 claims 1
- 102100026231 Translocon-associated protein subunit alpha Human genes 0.000 claims 1
- 102100034897 Transmembrane 4 L6 family member 4 Human genes 0.000 claims 1
- 102100031986 Transmembrane emp24 domain-containing protein 4 Human genes 0.000 claims 1
- 102100040421 Treacle protein Human genes 0.000 claims 1
- 108010088412 Trefoil Factor-1 Proteins 0.000 claims 1
- 102100039175 Trefoil factor 1 Human genes 0.000 claims 1
- 102100026390 Tribbles homolog 3 Human genes 0.000 claims 1
- OKKRPWIIYQTPQF-UHFFFAOYSA-N Trimethylolpropane trimethacrylate Chemical compound CC(=C)C(=O)OCC(CC)(COC(=O)C(C)=C)COC(=O)C(C)=C OKKRPWIIYQTPQF-UHFFFAOYSA-N 0.000 claims 1
- 108010039203 Tripeptidyl-Peptidase 1 Proteins 0.000 claims 1
- 102100034197 Tripeptidyl-peptidase 1 Human genes 0.000 claims 1
- 102100028101 Triple functional domain protein Human genes 0.000 claims 1
- 102100029299 Tubby-related protein 4 Human genes 0.000 claims 1
- 102100028979 Tubulin gamma-1 chain Human genes 0.000 claims 1
- 102100029243 Tuftelin Human genes 0.000 claims 1
- 102100024595 Tumor necrosis factor alpha-induced protein 2 Human genes 0.000 claims 1
- 102100033649 Tumor necrosis factor alpha-induced protein 8 Human genes 0.000 claims 1
- 102100036922 Tumor necrosis factor ligand superfamily member 13B Human genes 0.000 claims 1
- 102100035283 Tumor necrosis factor ligand superfamily member 18 Human genes 0.000 claims 1
- 102100026890 Tumor necrosis factor ligand superfamily member 4 Human genes 0.000 claims 1
- 102100028787 Tumor necrosis factor receptor superfamily member 11A Human genes 0.000 claims 1
- 102100022205 Tumor necrosis factor receptor superfamily member 21 Human genes 0.000 claims 1
- 102100022203 Tumor necrosis factor receptor superfamily member 25 Human genes 0.000 claims 1
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 claims 1
- 102100030810 Tumor necrosis factor receptor superfamily member EDAR Human genes 0.000 claims 1
- 102100027881 Tumor protein 63 Human genes 0.000 claims 1
- 102100040418 Tumor protein D52 Human genes 0.000 claims 1
- 102100027224 Tumor protein p53-inducible nuclear protein 1 Human genes 0.000 claims 1
- 102100040959 Tyrosine-protein kinase FRK Human genes 0.000 claims 1
- 102100021788 Tyrosine-protein kinase Yes Human genes 0.000 claims 1
- 102100033019 Tyrosine-protein phosphatase non-receptor type 11 Human genes 0.000 claims 1
- 102100040102 U3 small nucleolar RNA-associated protein 14 homolog C Human genes 0.000 claims 1
- 102100037921 UDP-N-acetylglucosamine pyrophosphorylase Human genes 0.000 claims 1
- 102100033778 UDP-N-acetylglucosamine transporter Human genes 0.000 claims 1
- 102100038413 UDP-N-acetylglucosamine-dolichyl-phosphate N-acetylglucosaminephosphotransferase Human genes 0.000 claims 1
- 102100033782 UDP-galactose translocator Human genes 0.000 claims 1
- 102100032284 UDP-glucuronic acid/UDP-N-acetylgalactosamine transporter Human genes 0.000 claims 1
- 102100029152 UDP-glucuronosyltransferase 1A1 Human genes 0.000 claims 1
- 101710205316 UDP-glucuronosyltransferase 1A1 Proteins 0.000 claims 1
- 102100029635 UDP-glucuronosyltransferase 2B11 Human genes 0.000 claims 1
- 102100029819 UDP-glucuronosyltransferase 2B7 Human genes 0.000 claims 1
- 101710200333 UDP-glucuronosyltransferase 2B7 Proteins 0.000 claims 1
- 102100038834 UTP-glucose-1-phosphate uridylyltransferase Human genes 0.000 claims 1
- 102100029088 Ubiquitin carboxyl-terminal hydrolase 8 Human genes 0.000 claims 1
- 102100038487 Ubiquitin conjugation factor E4 B Human genes 0.000 claims 1
- 102100030434 Ubiquitin-protein ligase E3A Human genes 0.000 claims 1
- 108010021098 Uncoupling Protein 3 Proteins 0.000 claims 1
- 102100031083 Uteroglobin Human genes 0.000 claims 1
- 108010075653 Utrophin Proteins 0.000 claims 1
- 102100029092 Utrophin Human genes 0.000 claims 1
- 102100038978 Variable charge X-linked protein 3 Human genes 0.000 claims 1
- 102100023048 Very long-chain acyl-CoA synthetase Human genes 0.000 claims 1
- 102100039066 Very low-density lipoprotein receptor Human genes 0.000 claims 1
- 102100031041 Very-long-chain (3R)-3-hydroxyacyl-CoA dehydratase 3 Human genes 0.000 claims 1
- 102100023486 Vinculin Human genes 0.000 claims 1
- 102100029477 Vitamin K-dependent protein C Human genes 0.000 claims 1
- 108010022133 Voltage-Dependent Anion Channel 1 Proteins 0.000 claims 1
- 102100037820 Voltage-dependent anion-selective channel protein 1 Human genes 0.000 claims 1
- 102100035334 WD repeat and SOCS box-containing protein 1 Human genes 0.000 claims 1
- 102100035329 WD repeat and SOCS box-containing protein 2 Human genes 0.000 claims 1
- 108700020467 WT1 Proteins 0.000 claims 1
- 101150084041 WT1 gene Proteins 0.000 claims 1
- 102100023037 Wee1-like protein kinase Human genes 0.000 claims 1
- 102100022748 Wilms tumor protein Human genes 0.000 claims 1
- 108010062653 Wiskott-Aldrich Syndrome Protein Family Proteins 0.000 claims 1
- 102100037103 Wiskott-Aldrich syndrome protein family member 2 Human genes 0.000 claims 1
- 102100024780 YEATS domain-containing protein 4 Human genes 0.000 claims 1
- 101001038499 Yarrowia lipolytica (strain CLIB 122 / E 150) Lysine acetyltransferase Proteins 0.000 claims 1
- 102100023894 Zinc finger ZZ-type and EF-hand domain-containing protein 1 Human genes 0.000 claims 1
- 102100040815 Zinc finger protein 160 Human genes 0.000 claims 1
- 102100039976 Zinc finger protein 202 Human genes 0.000 claims 1
- 102100028356 Zinc finger protein 22 Human genes 0.000 claims 1
- 102100034824 [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 3, mitochondrial Human genes 0.000 claims 1
- 102100034825 [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 4, mitochondrial Human genes 0.000 claims 1
- 201000006960 adult spinal muscular atrophy Diseases 0.000 claims 1
- 239000000556 agonist Substances 0.000 claims 1
- 108010075843 alpha-2-HS-Glycoprotein Proteins 0.000 claims 1
- 239000005557 antagonist Substances 0.000 claims 1
- 229940046836 anti-estrogen Drugs 0.000 claims 1
- 230000001833 anti-estrogenic effect Effects 0.000 claims 1
- 238000003782 apoptosis assay Methods 0.000 claims 1
- 108700000711 bcl-X Proteins 0.000 claims 1
- 108010005713 bis(5'-adenosyl)triphosphatase Proteins 0.000 claims 1
- 102100037490 cAMP-dependent protein kinase type I-alpha regulatory subunit Human genes 0.000 claims 1
- 102100021205 cAMP-dependent protein kinase type II-beta regulatory subunit Human genes 0.000 claims 1
- 102100022421 cGMP-dependent protein kinase 2 Human genes 0.000 claims 1
- 102100037093 cGMP-inhibited 3',5'-cyclic phosphodiesterase A Human genes 0.000 claims 1
- 230000023852 carbohydrate metabolic process Effects 0.000 claims 1
- 235000021256 carbohydrate metabolism Nutrition 0.000 claims 1
- 230000022131 cell cycle Effects 0.000 claims 1
- 230000011712 cell development Effects 0.000 claims 1
- 230000032341 cell morphogenesis Effects 0.000 claims 1
- 230000004663 cell proliferation Effects 0.000 claims 1
- 239000003153 chemical reaction reagent Substances 0.000 claims 1
- 230000000295 complement effect Effects 0.000 claims 1
- 150000001875 compounds Chemical class 0.000 claims 1
- 108010043113 dolichyl-phosphate alpha-N-acetylglucosaminyltransferase Proteins 0.000 claims 1
- 238000009509 drug development Methods 0.000 claims 1
- 239000003596 drug target Substances 0.000 claims 1
- 239000000328 estrogen antagonist Substances 0.000 claims 1
- 108010048296 hyaluronidase PH-20 Proteins 0.000 claims 1
- 238000001727 in vivo Methods 0.000 claims 1
- 230000004068 intracellular signaling Effects 0.000 claims 1
- 230000037356 lipid metabolism Effects 0.000 claims 1
- 239000003202 long acting thyroid stimulator Substances 0.000 claims 1
- 102100034703 mRNA decay activator protein ZFP36L2 Human genes 0.000 claims 1
- 238000013507 mapping Methods 0.000 claims 1
- 238000002483 medication Methods 0.000 claims 1
- 239000003595 mist Substances 0.000 claims 1
- 101150091791 mvk gene Proteins 0.000 claims 1
- 239000002547 new drug Substances 0.000 claims 1
- 210000000056 organ Anatomy 0.000 claims 1
- 230000005305 organ development Effects 0.000 claims 1
- 102100030898 p53 apoptosis effector related to PMP-22 Human genes 0.000 claims 1
- 229920005735 poly(methyl vinyl ketone) Polymers 0.000 claims 1
- 238000004393 prognosis Methods 0.000 claims 1
- 230000005522 programmed cell death Effects 0.000 claims 1
- 108020004930 proline dehydrogenase Proteins 0.000 claims 1
- 108010051009 proto-oncogene protein Pbx3 Proteins 0.000 claims 1
- 108010054067 rab1 GTP-Binding Proteins Proteins 0.000 claims 1
- 108010033990 rab27 GTP-Binding Proteins Proteins 0.000 claims 1
- 108010044923 rab4 GTP-Binding Proteins Proteins 0.000 claims 1
- 108010032037 rab5 GTP-Binding Proteins Proteins 0.000 claims 1
- 108010064950 regulator of g-protein signaling 9 Proteins 0.000 claims 1
- 238000003757 reverse transcription PCR Methods 0.000 claims 1
- 108091092562 ribozyme Proteins 0.000 claims 1
- 238000002317 scanning near-field acoustic microscopy Methods 0.000 claims 1
- 210000002966 serum Anatomy 0.000 claims 1
- 108010008054 testis specific phosphoglycerate kinase Proteins 0.000 claims 1
- 230000001225 therapeutic effect Effects 0.000 claims 1
- 210000001519 tissue Anatomy 0.000 claims 1
- 208000005606 type IV spinal muscular atrophy Diseases 0.000 claims 1
- 102000039446 nucleic acids Human genes 0.000 abstract description 3
- 108020004707 nucleic acids Proteins 0.000 abstract description 3
- 150000007523 nucleic acids Chemical class 0.000 abstract description 3
- 210000003917 human chromosome Anatomy 0.000 description 5
- 108091033380 Coding strand Proteins 0.000 description 3
- 208000009956 adenocarcinoma Diseases 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 210000001072 colon Anatomy 0.000 description 3
- 108010057167 dimethylaniline monooxygenase (N-oxide forming) Proteins 0.000 description 3
- 230000002440 hepatic effect Effects 0.000 description 3
- 102100038079 AP2-associated protein kinase 1 Human genes 0.000 description 2
- 102100036778 Arf-GAP with GTPase, ANK repeat and PH domain-containing protein 4 Human genes 0.000 description 2
- 102100034065 Atypical chemokine receptor 4 Human genes 0.000 description 2
- 102100023243 Calcium-activated potassium channel subunit beta-3 Human genes 0.000 description 2
- 102100033086 Calcium/calmodulin-dependent protein kinase type 1 Human genes 0.000 description 2
- 102100033462 DENN domain-containing protein 1B Human genes 0.000 description 2
- 102100024426 Dihydropyrimidinase-related protein 2 Human genes 0.000 description 2
- 102100035046 Dimethylaniline monooxygenase [N-oxide-forming] 4 Human genes 0.000 description 2
- 102100038024 Forkhead box protein D4-like 4 Human genes 0.000 description 2
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 2
- 101000742699 Homo sapiens AP2-associated protein kinase 1 Proteins 0.000 description 2
- 101000928220 Homo sapiens Arf-GAP with GTPase, ANK repeat and PH domain-containing protein 4 Proteins 0.000 description 2
- 101001049846 Homo sapiens Calcium-activated potassium channel subunit beta-3 Proteins 0.000 description 2
- 101000944250 Homo sapiens Calcium/calmodulin-dependent protein kinase type 1 Proteins 0.000 description 2
- 101000870914 Homo sapiens DENN domain-containing protein 1B Proteins 0.000 description 2
- 101001053503 Homo sapiens Dihydropyrimidinase-related protein 2 Proteins 0.000 description 2
- 101001025072 Homo sapiens Forkhead box protein D4-like 4 Proteins 0.000 description 2
- 101000599782 Homo sapiens Insulin-like growth factor 2 mRNA-binding protein 3 Proteins 0.000 description 2
- 101000728117 Homo sapiens Plasma membrane calcium-transporting ATPase 4 Proteins 0.000 description 2
- 101001092004 Homo sapiens Rho GTPase-activating protein 21 Proteins 0.000 description 2
- 102100022743 Laminin subunit alpha-4 Human genes 0.000 description 2
- 102100038815 Nocturnin Human genes 0.000 description 2
- 102100033323 Pecanex-like protein 4 Human genes 0.000 description 2
- 102100029743 Plasma membrane calcium-transporting ATPase 4 Human genes 0.000 description 2
- 102100037449 Potassium voltage-gated channel subfamily A member 4 Human genes 0.000 description 2
- 102100035753 Rho GTPase-activating protein 21 Human genes 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000003827 upregulation Effects 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 102100032386 1,5-anhydro-D-fructose reductase Human genes 0.000 description 1
- 102100035905 1-acylglycerol-3-phosphate O-acyltransferase ABHD5 Human genes 0.000 description 1
- 102100036933 12-(S)-hydroxy-5,8,10,14-eicosatetraenoic acid receptor Human genes 0.000 description 1
- 102100037429 17-beta-hydroxysteroid dehydrogenase 13 Human genes 0.000 description 1
- 108010041801 2',3'-Cyclic Nucleotide 3'-Phosphodiesterase Proteins 0.000 description 1
- PIGCSKVALLVWKU-UHFFFAOYSA-N 2-Aminoacridone Chemical compound C1=CC=C2C(=O)C3=CC(N)=CC=C3NC2=C1 PIGCSKVALLVWKU-UHFFFAOYSA-N 0.000 description 1
- XXQGYGJZNMSSFD-UHFFFAOYSA-N 2-[2-(dimethylcarbamoyl)phenoxy]acetic acid Chemical compound CN(C)C(=O)C1=CC=CC=C1OCC(O)=O XXQGYGJZNMSSFD-UHFFFAOYSA-N 0.000 description 1
- YMZPQKXPKZZSFV-CPWYAANMSA-N 2-[3-[(1r)-1-[(2s)-1-[(2s)-2-[(1r)-cyclohex-2-en-1-yl]-2-(3,4,5-trimethoxyphenyl)acetyl]piperidine-2-carbonyl]oxy-3-(3,4-dimethoxyphenyl)propyl]phenoxy]acetic acid Chemical compound C1=C(OC)C(OC)=CC=C1CC[C@H](C=1C=C(OCC(O)=O)C=CC=1)OC(=O)[C@H]1N(C(=O)[C@@H]([C@H]2C=CCCC2)C=2C=C(OC)C(OC)=C(OC)C=2)CCCC1 YMZPQKXPKZZSFV-CPWYAANMSA-N 0.000 description 1
- GXAFMKJFWWBYNW-OWHBQTKESA-N 2-[3-[(1r)-1-[(2s)-1-[(2s)-3-cyclopropyl-2-(3,4,5-trimethoxyphenyl)propanoyl]piperidine-2-carbonyl]oxy-3-(3,4-dimethoxyphenyl)propyl]phenoxy]acetic acid Chemical compound C1=C(OC)C(OC)=CC=C1CC[C@H](C=1C=C(OCC(O)=O)C=CC=1)OC(=O)[C@H]1N(C(=O)[C@@H](CC2CC2)C=2C=C(OC)C(OC)=C(OC)C=2)CCCC1 GXAFMKJFWWBYNW-OWHBQTKESA-N 0.000 description 1
- 102100026660 2-aminoethanethiol dioxygenase Human genes 0.000 description 1
- 102100037295 2-methoxy-6-polyprenyl-1,4-benzoquinol methylase, mitochondrial Human genes 0.000 description 1
- 102100035315 2-oxoisovalerate dehydrogenase subunit beta, mitochondrial Human genes 0.000 description 1
- 102100034510 2-phosphoxylose phosphatase 1 Human genes 0.000 description 1
- 102100027824 3'(2'),5'-bisphosphate nucleotidase 1 Human genes 0.000 description 1
- 102100022125 3-hydroxy-3-methylglutaryl-CoA lyase, cytoplasmic Human genes 0.000 description 1
- 102100023340 3-ketodihydrosphingosine reductase Human genes 0.000 description 1
- 102100035923 4-aminobutyrate aminotransferase, mitochondrial Human genes 0.000 description 1
- 102100027451 4-hydroxybenzoate polyprenyltransferase, mitochondrial Human genes 0.000 description 1
- 102100034406 5'-deoxynucleotidase HDDC2 Human genes 0.000 description 1
- 102100032296 A disintegrin and metalloproteinase with thrombospondin motifs 12 Human genes 0.000 description 1
- 102100032310 A disintegrin and metalloproteinase with thrombospondin motifs 14 Human genes 0.000 description 1
- 102100032309 A disintegrin and metalloproteinase with thrombospondin motifs 15 Human genes 0.000 description 1
- 102100032291 A disintegrin and metalloproteinase with thrombospondin motifs 16 Human genes 0.000 description 1
- 102100032308 A disintegrin and metalloproteinase with thrombospondin motifs 19 Human genes 0.000 description 1
- 102100032632 A disintegrin and metalloproteinase with thrombospondin motifs 6 Human genes 0.000 description 1
- 102100031912 A-kinase anchor protein 1, mitochondrial Human genes 0.000 description 1
- 102100031901 A-kinase anchor protein 2 Human genes 0.000 description 1
- 102100040079 A-kinase anchor protein 4 Human genes 0.000 description 1
- 102100040077 A-kinase anchor protein 6 Human genes 0.000 description 1
- 102100036614 ABC-type organic anion transporter ABCA8 Human genes 0.000 description 1
- 108091007504 ADAM10 Proteins 0.000 description 1
- 102100029377 ADAMTS-like protein 3 Human genes 0.000 description 1
- 102100022980 ADAMTS-like protein 4 Human genes 0.000 description 1
- 108091005671 ADAMTS12 Proteins 0.000 description 1
- 108091005673 ADAMTS14 Proteins 0.000 description 1
- 108091005672 ADAMTS15 Proteins 0.000 description 1
- 108091005675 ADAMTS16 Proteins 0.000 description 1
- 108091005570 ADAMTS19 Proteins 0.000 description 1
- 108091005665 ADAMTS6 Proteins 0.000 description 1
- 102100027783 ADP-ribose glycohydrolase OARD1 Human genes 0.000 description 1
- 102100033281 ADP-ribosylation factor GTPase-activating protein 3 Human genes 0.000 description 1
- 102100022909 ADP-ribosylation factor-like protein 14 Human genes 0.000 description 1
- 102100022910 ADP-ribosylation factor-like protein 15 Human genes 0.000 description 1
- 102100024379 AF4/FMR2 family member 1 Human genes 0.000 description 1
- 102100024387 AF4/FMR2 family member 3 Human genes 0.000 description 1
- 102100024381 AF4/FMR2 family member 4 Human genes 0.000 description 1
- 102100034212 AFG1-like ATPase Human genes 0.000 description 1
- 102100034215 AFG3-like protein 2 Human genes 0.000 description 1
- 102100026449 AKT-interacting protein Human genes 0.000 description 1
- 108050002283 AMMECR1 Proteins 0.000 description 1
- 102000011814 AMMECR1 Human genes 0.000 description 1
- 102100032897 AMP deaminase 2 Human genes 0.000 description 1
- 102100034482 AP-1 complex subunit beta-1 Human genes 0.000 description 1
- 102100028781 AP-1 complex subunit sigma-3 Human genes 0.000 description 1
- 102100034481 AP-1 complex-associated regulatory protein Human genes 0.000 description 1
- 102100022974 AP-2 complex subunit alpha-2 Human genes 0.000 description 1
- 102100040009 AP-3 complex subunit sigma-1 Human genes 0.000 description 1
- 102100028783 AP-3 complex subunit sigma-2 Human genes 0.000 description 1
- 102100040058 AP-4 complex subunit sigma-1 Human genes 0.000 description 1
- 102100040060 AP-5 complex subunit mu-1 Human genes 0.000 description 1
- 102100025679 APC membrane recruitment protein 3 Human genes 0.000 description 1
- 102100039602 ARF GTPase-activating protein GIT2 Human genes 0.000 description 1
- 102100034571 AT-rich interactive domain-containing protein 1B Human genes 0.000 description 1
- 102100038511 AT-rich interactive domain-containing protein 3A Human genes 0.000 description 1
- 102100038507 AT-rich interactive domain-containing protein 3B Human genes 0.000 description 1
- 102100030841 AT-rich interactive domain-containing protein 4A Human genes 0.000 description 1
- 102100030835 AT-rich interactive domain-containing protein 5B Human genes 0.000 description 1
- 102100023568 ATP synthase F(0) complex subunit C1, mitochondrial Human genes 0.000 description 1
- 102100028814 ATP synthase mitochondrial F1 complex assembly factor 1 Human genes 0.000 description 1
- 102100027757 ATP synthase subunit d, mitochondrial Human genes 0.000 description 1
- 102100027790 ATP synthase subunit e, mitochondrial Human genes 0.000 description 1
- 102100022961 ATP synthase subunit epsilon, mitochondrial Human genes 0.000 description 1
- 102100036622 ATP-binding cassette sub-family A member 10 Human genes 0.000 description 1
- 102100036613 ATP-binding cassette sub-family A member 9 Human genes 0.000 description 1
- 102100021503 ATP-binding cassette sub-family B member 6 Human genes 0.000 description 1
- 102100037128 ATP-binding cassette sub-family C member 10 Human genes 0.000 description 1
- 102100037129 ATP-binding cassette sub-family C member 11 Human genes 0.000 description 1
- 102100028163 ATP-binding cassette sub-family C member 4 Human genes 0.000 description 1
- 102100020973 ATP-binding cassette sub-family D member 3 Human genes 0.000 description 1
- 102100033106 ATP-binding cassette sub-family G member 5 Human genes 0.000 description 1
- 102100026141 ATP-dependent RNA helicase DDX25 Human genes 0.000 description 1
- 102100033391 ATP-dependent RNA helicase DDX3X Human genes 0.000 description 1
- 102100024768 ATP-dependent RNA helicase DDX50 Human genes 0.000 description 1
- 102100023439 ATP-dependent RNA helicase DHX29 Human genes 0.000 description 1
- 102100034149 ATPase PAAT Human genes 0.000 description 1
- 102100030381 Acetyl-coenzyme A synthetase 2-like, mitochondrial Human genes 0.000 description 1
- 102100040963 Acetylcholine receptor subunit epsilon Human genes 0.000 description 1
- 102100022142 Achaete-scute homolog 1 Human genes 0.000 description 1
- 102100022094 Acid-sensing ion channel 2 Human genes 0.000 description 1
- 102100036780 Actin filament-associated protein 1 Human genes 0.000 description 1
- 102100030374 Actin, cytoplasmic 2 Human genes 0.000 description 1
- 102100020961 Actin-binding LIM protein 3 Human genes 0.000 description 1
- 102100022498 Actin-like protein 8 Human genes 0.000 description 1
- 102100021581 Actin-related protein 10 Human genes 0.000 description 1
- 102000004373 Actin-related protein 2 Human genes 0.000 description 1
- 108090000963 Actin-related protein 2 Proteins 0.000 description 1
- 102100026401 Actin-related protein 2/3 complex subunit 5-like protein Human genes 0.000 description 1
- 102100029631 Actin-related protein 3B Human genes 0.000 description 1
- 102100031468 Actin-related protein 6 Human genes 0.000 description 1
- 102100022453 Actin-related protein T3 Human genes 0.000 description 1
- 102100027166 Activating molecule in BECN1-regulated autophagy protein 1 Human genes 0.000 description 1
- 102100021029 Activating signal cointegrator 1 complex subunit 3 Human genes 0.000 description 1
- 102100030963 Activating transcription factor 7-interacting protein 1 Human genes 0.000 description 1
- 102100032382 Activator of 90 kDa heat shock protein ATPase homolog 1 Human genes 0.000 description 1
- 102100034134 Activin receptor type-1B Human genes 0.000 description 1
- 102100021886 Activin receptor type-2A Human genes 0.000 description 1
- 102100022734 Acyl carrier protein, mitochondrial Human genes 0.000 description 1
- 102100035919 Acyl-CoA-binding domain-containing protein 5 Human genes 0.000 description 1
- 102100033568 Acyl-CoA-binding domain-containing protein 6 Human genes 0.000 description 1
- 102100030362 Acyl-coenzyme A synthetase ACSM2B, mitochondrial Human genes 0.000 description 1
- 102100025847 Acyl-coenzyme A thioesterase 6 Human genes 0.000 description 1
- 102100036661 Acylphosphatase-2 Human genes 0.000 description 1
- 102100029589 Acylpyruvase FAHD1, mitochondrial Human genes 0.000 description 1
- 102100030446 Adenosine 5'-monophosphoramidase HINT1 Human genes 0.000 description 1
- 102100036664 Adenosine deaminase Human genes 0.000 description 1
- 102100024439 Adhesion G protein-coupled receptor A2 Human genes 0.000 description 1
- 102100024438 Adhesion G protein-coupled receptor A3 Human genes 0.000 description 1
- 102100031933 Adhesion G protein-coupled receptor F5 Human genes 0.000 description 1
- 102100026441 Adhesion G-protein coupled receptor D1 Human genes 0.000 description 1
- 102100026443 Adhesion G-protein coupled receptor F1 Human genes 0.000 description 1
- 102100040023 Adhesion G-protein coupled receptor G6 Human genes 0.000 description 1
- 102100039732 Adhesion G-protein coupled receptor G7 Human genes 0.000 description 1
- 102100036774 Afamin Human genes 0.000 description 1
- NRCXNPKDOMYPPJ-HYORBCNSSA-N Aflatoxin P1 Chemical compound C=1([C@@H]2C=CO[C@@H]2OC=1C=C(C1=2)O)C=2OC(=O)C2=C1CCC2=O NRCXNPKDOMYPPJ-HYORBCNSSA-N 0.000 description 1
- 102100036457 Akirin-1 Human genes 0.000 description 1
- 102100036472 Akirin-2 Human genes 0.000 description 1
- 102100033814 Alanine aminotransferase 2 Human genes 0.000 description 1
- 102100037399 Alanine-tRNA ligase, cytoplasmic Human genes 0.000 description 1
- 102100034035 Alcohol dehydrogenase 1A Human genes 0.000 description 1
- 102100031226 Alkylglycerol monooxygenase Human genes 0.000 description 1
- 102100033657 All-trans retinoic acid-induced differentiation factor Human genes 0.000 description 1
- 102100031795 All-trans-retinol dehydrogenase [NAD(+)] ADH4 Human genes 0.000 description 1
- 102100026663 All-trans-retinol dehydrogenase [NAD(+)] ADH7 Human genes 0.000 description 1
- 102100034181 Alpha- and gamma-adaptin-binding protein p34 Human genes 0.000 description 1
- 102100027726 Alpha-(1,3)-fucosyltransferase 11 Human genes 0.000 description 1
- 102100026611 Alpha-1,2-mannosyltransferase ALG9 Human genes 0.000 description 1
- 102100034033 Alpha-adducin Human genes 0.000 description 1
- 102100032197 Alpha-crystallin A chain Human genes 0.000 description 1
- 102100040429 Alpha-ketoglutarate-dependent dioxygenase alkB homolog 7, mitochondrial Human genes 0.000 description 1
- 102100033804 Alpha-protein kinase 2 Human genes 0.000 description 1
- 102100031619 Alpha-tocopherol transfer protein-like Human genes 0.000 description 1
- 102100032360 Alstrom syndrome protein 1 Human genes 0.000 description 1
- 102100039160 Amiloride-sensitive amine oxidase [copper-containing] Human genes 0.000 description 1
- 102100040141 Aminopeptidase O Human genes 0.000 description 1
- 102100032040 Amphoterin-induced protein 2 Human genes 0.000 description 1
- 102100040038 Amyloid beta precursor like protein 2 Human genes 0.000 description 1
- 102100031818 Androgen-dependent TFPI-regulating protein Human genes 0.000 description 1
- 102100026468 Androgen-induced gene 1 protein Human genes 0.000 description 1
- 102100040357 Angiomotin-like protein 1 Human genes 0.000 description 1
- 102100025672 Angiopoietin-related protein 2 Human genes 0.000 description 1
- 102100035765 Angiotensin-converting enzyme 2 Human genes 0.000 description 1
- 108090000975 Angiotensin-converting enzyme 2 Proteins 0.000 description 1
- 102100022044 Ankyrin repeat and BTB/POZ domain-containing protein BTBD11 Human genes 0.000 description 1
- 102100027139 Ankyrin repeat and SAM domain-containing protein 1A Human genes 0.000 description 1
- 102100027150 Ankyrin repeat and SAM domain-containing protein 4B Human genes 0.000 description 1
- 102100033898 Ankyrin repeat and SOCS box protein 18 Human genes 0.000 description 1
- 102100036811 Ankyrin repeat and fibronectin type-III domain-containing protein 1 Human genes 0.000 description 1
- 102100033397 Ankyrin repeat and zinc finger domain-containing protein 1 Human genes 0.000 description 1
- 102100039181 Ankyrin repeat domain-containing protein 1 Human genes 0.000 description 1
- 102100034614 Ankyrin repeat domain-containing protein 11 Human genes 0.000 description 1
- 102100034270 Ankyrin repeat domain-containing protein 13A Human genes 0.000 description 1
- 102100023003 Ankyrin repeat domain-containing protein 30A Human genes 0.000 description 1
- 102100033368 Ankyrin repeat domain-containing protein 39 Human genes 0.000 description 1
- 102100039148 Ankyrin repeat domain-containing protein 49 Human genes 0.000 description 1
- 102100031326 Ankyrin repeat domain-containing protein 55 Human genes 0.000 description 1
- 102100039395 Ankyrin repeat domain-containing protein 9 Human genes 0.000 description 1
- 102100021716 Ankyrin repeat domain-containing protein SOWAHB Human genes 0.000 description 1
- 102100037289 Ankyrin repeat domain-containing protein SOWAHC Human genes 0.000 description 1
- 102100036818 Ankyrin-2 Human genes 0.000 description 1
- 102100036817 Ankyrin-3 Human genes 0.000 description 1
- 102100028118 Annexin A11 Human genes 0.000 description 1
- 102100034618 Annexin A3 Human genes 0.000 description 1
- 102100036824 Annexin A8 Human genes 0.000 description 1
- 102100031936 Anterior gradient protein 2 homolog Human genes 0.000 description 1
- 102100031930 Anterior gradient protein 3 Human genes 0.000 description 1
- 102100031325 Anthrax toxin receptor 2 Human genes 0.000 description 1
- 102100037435 Antiviral innate immune response receptor RIG-I Human genes 0.000 description 1
- 102100030760 Apolipoprotein F Human genes 0.000 description 1
- 102100036517 Apolipoprotein L domain-containing protein 1 Human genes 0.000 description 1
- 108010036280 Aquaporin 4 Proteins 0.000 description 1
- 102100023650 Aquaporin-11 Human genes 0.000 description 1
- 102100037276 Aquaporin-4 Human genes 0.000 description 1
- 102100029463 Aquaporin-8 Human genes 0.000 description 1
- 101100454193 Arabidopsis thaliana AAA1 gene Proteins 0.000 description 1
- 101000693933 Arabidopsis thaliana Fructose-bisphosphate aldolase 8, cytosolic Proteins 0.000 description 1
- 102100040158 Archaemetzincin-2 Human genes 0.000 description 1
- 102100024365 Arf-GAP domain and FG repeat-containing protein 1 Human genes 0.000 description 1
- 102100024371 Arf-GAP domain and FG repeat-containing protein 2 Human genes 0.000 description 1
- 102100036783 Arf-GAP with GTPase, ANK repeat and PH domain-containing protein 1 Human genes 0.000 description 1
- 102100033652 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 1 Human genes 0.000 description 1
- 102100033653 Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 2 Human genes 0.000 description 1
- 102100024003 Arf-GAP with SH3 domain, ANK repeat and PH domain-containing protein 1 Human genes 0.000 description 1
- 102100023221 Arginine and glutamate-rich protein 1 Human genes 0.000 description 1
- 102100029651 Arginine/serine-rich protein 1 Human genes 0.000 description 1
- 102100020999 Argininosuccinate synthase Human genes 0.000 description 1
- 102100023190 Armadillo repeat-containing protein 1 Human genes 0.000 description 1
- 102100028494 Armadillo repeat-containing protein 12 Human genes 0.000 description 1
- 102100023182 Armadillo repeat-containing protein 2 Human genes 0.000 description 1
- 102100038238 Aromatic-L-amino-acid decarboxylase Human genes 0.000 description 1
- 102100038105 Arpin Human genes 0.000 description 1
- 102100026442 Arrestin domain-containing protein 2 Human genes 0.000 description 1
- 102100021038 Arrestin domain-containing protein 4 Human genes 0.000 description 1
- 102100022143 Arsenite methyltransferase Human genes 0.000 description 1
- 102100037211 Aryl hydrocarbon receptor nuclear translocator-like protein 1 Human genes 0.000 description 1
- 102100024624 Arylacetamide deacetylase Human genes 0.000 description 1
- 102100033887 Arylsulfatase D Human genes 0.000 description 1
- 102100033896 Arylsulfatase H Human genes 0.000 description 1
- 102100033893 Arylsulfatase J Human genes 0.000 description 1
- 102100030732 Ashwin Human genes 0.000 description 1
- 102100034193 Aspartate aminotransferase, mitochondrial Human genes 0.000 description 1
- 102100022108 Aspartyl/asparaginyl beta-hydroxylase Human genes 0.000 description 1
- 102100027705 Astrotactin-2 Human genes 0.000 description 1
- 102000007372 Ataxin-1 Human genes 0.000 description 1
- 108010032963 Ataxin-1 Proteins 0.000 description 1
- 102000002785 Ataxin-10 Human genes 0.000 description 1
- 108010043914 Ataxin-10 Proteins 0.000 description 1
- 108010032953 Ataxin-7 Proteins 0.000 description 1
- 102000007368 Ataxin-7 Human genes 0.000 description 1
- 102100022999 Ataxin-7-like protein 1 Human genes 0.000 description 1
- 102000007370 Ataxin2 Human genes 0.000 description 1
- 108010032951 Ataxin2 Proteins 0.000 description 1
- 102100027765 Atlastin-2 Human genes 0.000 description 1
- 102100022716 Atypical chemokine receptor 3 Human genes 0.000 description 1
- 102100027393 Augurin Human genes 0.000 description 1
- 102100023610 Autophagy-related protein 2 homolog B Human genes 0.000 description 1
- 102100035683 Axin-2 Human genes 0.000 description 1
- 102100027470 Axonemal dynein light chain domain-containing protein 1 Human genes 0.000 description 1
- 102100032481 B-cell CLL/lymphoma 9 protein Human genes 0.000 description 1
- 102100032424 B-cell CLL/lymphoma 9-like protein Human genes 0.000 description 1
- 102100021568 B-cell scaffold protein with ankyrin repeats Human genes 0.000 description 1
- 102100027449 B9 domain-containing protein 1 Human genes 0.000 description 1
- 102100026434 BCAS3 microtubule associated cell migration factor Human genes 0.000 description 1
- 102100021247 BCL-6 corepressor Human genes 0.000 description 1
- 102100032427 BCLAF1 and THRAP3 family member 3 Human genes 0.000 description 1
- 102000017916 BDKRB1 Human genes 0.000 description 1
- 108060003359 BDKRB1 Proteins 0.000 description 1
- 102000017915 BDKRB2 Human genes 0.000 description 1
- 102100037541 BEN domain-containing protein 7 Human genes 0.000 description 1
- 102100035901 BICD family-like cargo adapter 1 Human genes 0.000 description 1
- 102100033724 BLOC-1-related complex subunit 6 Human genes 0.000 description 1
- 102100025140 BLOC-1-related complex subunit 7 Human genes 0.000 description 1
- 102100037150 BMP and activin membrane-bound inhibitor homolog Human genes 0.000 description 1
- 102100024507 BMP-2-inducible protein kinase Human genes 0.000 description 1
- 102100035755 BRD4-interacting chromatin-remodeling complex-associated protein Human genes 0.000 description 1
- 102100035745 BRD4-interacting chromatin-remodeling complex-associated protein-like Human genes 0.000 description 1
- 102100026032 BRI3-binding protein Human genes 0.000 description 1
- 102100032434 BTB/POZ domain-containing adapter for CUL3-mediated RhoA degradation protein 1 Human genes 0.000 description 1
- 102100032307 BTB/POZ domain-containing adapter for CUL3-mediated RhoA degradation protein 3 Human genes 0.000 description 1
- 102100024286 BTB/POZ domain-containing protein 1 Human genes 0.000 description 1
- 102100021692 BTB/POZ domain-containing protein 16 Human genes 0.000 description 1
- 102100024273 BTB/POZ domain-containing protein 3 Human genes 0.000 description 1
- 102100021746 BTB/POZ domain-containing protein 9 Human genes 0.000 description 1
- 102100022754 BTB/POZ domain-containing protein KCTD16 Human genes 0.000 description 1
- 102100040534 BTB/POZ domain-containing protein KCTD3 Human genes 0.000 description 1
- 102100040535 BTB/POZ domain-containing protein KCTD4 Human genes 0.000 description 1
- 102100028231 BTB/POZ domain-containing protein KCTD6 Human genes 0.000 description 1
- 102100028215 BTB/POZ domain-containing protein KCTD7 Human genes 0.000 description 1
- 102100027137 BUD13 homolog Human genes 0.000 description 1
- 102100024747 Band 4.1-like protein 1 Human genes 0.000 description 1
- 102100023045 Band 4.1-like protein 2 Human genes 0.000 description 1
- 102100023046 Band 4.1-like protein 3 Human genes 0.000 description 1
- 102100023051 Band 4.1-like protein 4B Human genes 0.000 description 1
- 102100021297 Bardet-Biedl syndrome 12 protein Human genes 0.000 description 1
- 102100031503 Barrier-to-autointegration factor-like protein Human genes 0.000 description 1
- 102100036597 Basement membrane-specific heparan sulfate proteoglycan core protein Human genes 0.000 description 1
- 102100037936 Basic helix-loop-helix domain-containing protein USF3 Human genes 0.000 description 1
- 102100022970 Basic leucine zipper transcriptional factor ATF-like Human genes 0.000 description 1
- 102100028164 Bestrophin-3 Human genes 0.000 description 1
- 102100027311 Beta,beta-carotene 15,15'-dioxygenase Human genes 0.000 description 1
- 102100039887 Beta-1,3-galactosyl-O-glycosyl-glycoprotein beta-1,6-N-acetylglucosaminyltransferase 4 Human genes 0.000 description 1
- 102100023993 Beta-1,3-galactosyltransferase 5 Human genes 0.000 description 1
- 102100027934 Beta-1,3-glucosyltransferase Human genes 0.000 description 1
- 102100026480 Beta-1,4-N-acetylgalactosaminyltransferase 3 Human genes 0.000 description 1
- 102100031006 Beta-Ala-His dipeptidase Human genes 0.000 description 1
- 102100030981 Beta-alanine-activating enzyme Human genes 0.000 description 1
- 102100029649 Beta-arrestin-1 Human genes 0.000 description 1
- 102100029648 Beta-arrestin-2 Human genes 0.000 description 1
- 102100039828 Beta-defensin 112 Human genes 0.000 description 1
- 102100020683 Beta-klotho Human genes 0.000 description 1
- 102100027991 Beta/gamma crystallin domain-containing protein 1 Human genes 0.000 description 1
- 102100027990 Beta/gamma crystallin domain-containing protein 2 Human genes 0.000 description 1
- 102100037468 Bifunctional peptidase and arginyl-hydroxylase JMJD5 Human genes 0.000 description 1
- 102100035752 Biliverdin reductase A Human genes 0.000 description 1
- 102100028845 Biogenesis of lysosome-related organelles complex 1 subunit 2 Human genes 0.000 description 1
- 102100024522 Bladder cancer-associated protein Human genes 0.000 description 1
- 102100035631 Bloom syndrome protein Human genes 0.000 description 1
- 108091009167 Bloom syndrome protein Proteins 0.000 description 1
- 102100028741 BolA-like protein 1 Human genes 0.000 description 1
- 102100025423 Bone morphogenetic protein receptor type-1A Human genes 0.000 description 1
- 102100027305 Box C/D snoRNA protein 1 Human genes 0.000 description 1
- 108090000715 Brain-derived neurotrophic factor Proteins 0.000 description 1
- 102000004219 Brain-derived neurotrophic factor Human genes 0.000 description 1
- 102100028265 Brain-specific angiogenesis inhibitor 1-associated protein 2-like protein 1 Human genes 0.000 description 1
- 102100028266 Brain-specific angiogenesis inhibitor 1-associated protein 2-like protein 2 Human genes 0.000 description 1
- 102100028243 Breast carcinoma-amplified sequence 1 Human genes 0.000 description 1
- 102100022595 Broad substrate specificity ATP-binding cassette transporter ABCG2 Human genes 0.000 description 1
- 102100027359 Bromo adjacent homology domain-containing 1 protein Human genes 0.000 description 1
- 102100021576 Bromodomain adjacent to zinc finger domain protein 2A Human genes 0.000 description 1
- 102100021743 Bromodomain and PHD finger-containing protein 3 Human genes 0.000 description 1
- 102100029892 Bromodomain and WD repeat-containing protein 1 Human genes 0.000 description 1
- 102100029833 Bromodomain and WD repeat-containing protein 3 Human genes 0.000 description 1
- 102100033641 Bromodomain-containing protein 2 Human genes 0.000 description 1
- 102100027140 Butyrophilin subfamily 1 member A1 Human genes 0.000 description 1
- 102100027155 Butyrophilin subfamily 3 member A2 Human genes 0.000 description 1
- 102100025429 Butyrophilin-like protein 2 Human genes 0.000 description 1
- 102100025371 Butyrophilin-like protein 8 Human genes 0.000 description 1
- 102100040397 C->U-editing enzyme APOBEC-1 Human genes 0.000 description 1
- 102100040399 C->U-editing enzyme APOBEC-2 Human genes 0.000 description 1
- 101710149863 C-C chemokine receptor type 4 Proteins 0.000 description 1
- 102100025074 C-C chemokine receptor-like 2 Human genes 0.000 description 1
- 102100023703 C-C motif chemokine 15 Human genes 0.000 description 1
- 102100023700 C-C motif chemokine 16 Human genes 0.000 description 1
- 102100036848 C-C motif chemokine 20 Human genes 0.000 description 1
- 102100031184 C-Maf-inducing protein Human genes 0.000 description 1
- 102100036166 C-X-C chemokine receptor type 1 Human genes 0.000 description 1
- 102100039398 C-X-C motif chemokine 2 Human genes 0.000 description 1
- 102100036189 C-X-C motif chemokine 3 Human genes 0.000 description 1
- 102100036170 C-X-C motif chemokine 9 Human genes 0.000 description 1
- 102100030630 C-myc promoter-binding protein Human genes 0.000 description 1
- 102100031478 C-type natriuretic peptide Human genes 0.000 description 1
- 108091058539 C10orf54 Proteins 0.000 description 1
- 102100032954 C2 domain-containing protein 2 Human genes 0.000 description 1
- 102100037080 C4b-binding protein beta chain Human genes 0.000 description 1
- 108700030955 C9orf72 Proteins 0.000 description 1
- 101150014718 C9orf72 gene Proteins 0.000 description 1
- 102100028743 CAP-Gly domain-containing linker protein 2 Human genes 0.000 description 1
- 102100039527 CBP80/20-dependent translation initiation factor Human genes 0.000 description 1
- 102100024935 CBY1-interacting BAR domain-containing protein 2 Human genes 0.000 description 1
- 102100034799 CCAAT/enhancer-binding protein delta Human genes 0.000 description 1
- 102100033849 CCHC-type zinc finger nucleic acid binding protein Human genes 0.000 description 1
- 101710116319 CCHC-type zinc finger nucleic acid binding protein Proteins 0.000 description 1
- 102100031024 CCR4-NOT transcription complex subunit 1 Human genes 0.000 description 1
- 101150033066 CD101 gene Proteins 0.000 description 1
- 108010017009 CD11b Antigen Proteins 0.000 description 1
- 102100024220 CD180 antigen Human genes 0.000 description 1
- 102100027209 CD2-associated protein Human genes 0.000 description 1
- 102100032912 CD44 antigen Human genes 0.000 description 1
- 108060001253 CD99 Proteins 0.000 description 1
- 102000024905 CD99 Human genes 0.000 description 1
- 102100027201 CDAN1-interacting nuclease 1 Human genes 0.000 description 1
- 102000014578 CDC26 Human genes 0.000 description 1
- 102100030155 CDC42 small effector protein 2 Human genes 0.000 description 1
- 101710036791 CEP192 Proteins 0.000 description 1
- 101700004197 CEP68 Proteins 0.000 description 1
- 101150108055 CHMP2B gene Proteins 0.000 description 1
- 101150028732 CHMP4B gene Proteins 0.000 description 1
- 102100040529 CKLF-like MARVEL transmembrane domain-containing protein 4 Human genes 0.000 description 1
- 102100040528 CKLF-like MARVEL transmembrane domain-containing protein 6 Human genes 0.000 description 1
- 102100040855 CKLF-like MARVEL transmembrane domain-containing protein 7 Human genes 0.000 description 1
- 102100039553 CKLF-like MARVEL transmembrane domain-containing protein 8 Human genes 0.000 description 1
- 102100028637 CLOCK-interacting pacemaker Human genes 0.000 description 1
- 102100025503 CMT1A duplicated region transcript 4 protein Human genes 0.000 description 1
- 102100032932 COBW domain-containing protein 1 Human genes 0.000 description 1
- 102100032933 COBW domain-containing protein 2 Human genes 0.000 description 1
- 102100032906 COBW domain-containing protein 3 Human genes 0.000 description 1
- 102100032934 COBW domain-containing protein 5 Human genes 0.000 description 1
- 102100036047 COMM domain-containing protein 10 Human genes 0.000 description 1
- 102100024311 COMM domain-containing protein 2 Human genes 0.000 description 1
- 102100022617 COMM domain-containing protein 7 Human genes 0.000 description 1
- 108091007903 COMMD10 Proteins 0.000 description 1
- 102100027997 COP9 signalosome complex subunit 4 Human genes 0.000 description 1
- 102100040758 CREB-regulated transcription coactivator 2 Human genes 0.000 description 1
- 102100040755 CREB-regulated transcription coactivator 3 Human genes 0.000 description 1
- 101710083734 CTP synthase Proteins 0.000 description 1
- 102100039866 CTP synthase 1 Human genes 0.000 description 1
- 102100035350 CUB domain-containing protein 1 Human genes 0.000 description 1
- 102100021288 CUE domain-containing protein 1 Human genes 0.000 description 1
- 102100021287 CUE domain-containing protein 2 Human genes 0.000 description 1
- 102100033210 CUGBP Elav-like family member 2 Human genes 0.000 description 1
- 102100032945 CWF19-like protein 2 Human genes 0.000 description 1
- 102100022443 CXADR-like membrane protein Human genes 0.000 description 1
- 102100038903 CXXC motif containing zinc binding protein Human genes 0.000 description 1
- 102100035685 CXXC-type zinc finger protein 4 Human genes 0.000 description 1
- 102100036167 CXXC-type zinc finger protein 5 Human genes 0.000 description 1
- 102100026860 CYFIP-related Rac1 interactor A Human genes 0.000 description 1
- 102100025805 Cadherin-1 Human genes 0.000 description 1
- 102100024156 Cadherin-12 Human genes 0.000 description 1
- 102100024154 Cadherin-13 Human genes 0.000 description 1
- 102100024152 Cadherin-17 Human genes 0.000 description 1
- 102100022480 Cadherin-20 Human genes 0.000 description 1
- 102100029756 Cadherin-6 Human genes 0.000 description 1
- 102100025332 Cadherin-9 Human genes 0.000 description 1
- 102100022511 Cadherin-like protein 26 Human genes 0.000 description 1
- 102100035355 Cadherin-related family member 3 Human genes 0.000 description 1
- 102100025523 Calcium uptake protein 2, mitochondrial Human genes 0.000 description 1
- 102100039534 Calcium-activated chloride channel regulator 4 Human genes 0.000 description 1
- 102100023073 Calcium-activated potassium channel subunit alpha-1 Human genes 0.000 description 1
- 102100036361 Calcium-binding and coiled-coil domain-containing protein 2 Human genes 0.000 description 1
- 102100022533 Calcium-binding protein 39 Human genes 0.000 description 1
- 102100032582 Calcium-dependent secretion activator 1 Human genes 0.000 description 1
- 102100020671 Calcium-transporting ATPase type 2C member 2 Human genes 0.000 description 1
- 102100026252 Calcium/calmodulin-dependent protein kinase II inhibitor 1 Human genes 0.000 description 1
- 102100025227 Calcium/calmodulin-dependent protein kinase type II subunit gamma Human genes 0.000 description 1
- 102100024436 Caldesmon Human genes 0.000 description 1
- 102100022442 Calmin Human genes 0.000 description 1
- 102100025580 Calmodulin-1 Human genes 0.000 description 1
- 102100025579 Calmodulin-2 Human genes 0.000 description 1
- 102100025926 Calmodulin-3 Human genes 0.000 description 1
- 102100033561 Calmodulin-binding transcription activator 1 Human genes 0.000 description 1
- 102100036339 Calmodulin-like protein 3 Human genes 0.000 description 1
- 102100036338 Calmodulin-like protein 4 Human genes 0.000 description 1
- 102100036419 Calmodulin-like protein 5 Human genes 0.000 description 1
- 102100025465 Calpain-10 Human genes 0.000 description 1
- 102100027238 Calpain-13 Human genes 0.000 description 1
- 102100032537 Calpain-2 catalytic subunit Human genes 0.000 description 1
- 102100030010 Calpain-7 Human genes 0.000 description 1
- 102100030003 Calpain-9 Human genes 0.000 description 1
- 102100033592 Calponin-3 Human genes 0.000 description 1
- 102100028801 Calsyntenin-1 Human genes 0.000 description 1
- 102100038716 Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase 2 Human genes 0.000 description 1
- 102100029949 Caprin-1 Human genes 0.000 description 1
- 102100033041 Carbonic anhydrase 13 Human genes 0.000 description 1
- 102100036368 Carbonic anhydrase 7 Human genes 0.000 description 1
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 1
- 102100036375 Carbonic anhydrase-related protein Human genes 0.000 description 1
- 102100021973 Carbonyl reductase [NADPH] 1 Human genes 0.000 description 1
- 102100027667 Carboxy-terminal domain RNA polymerase II polypeptide A small phosphatase 2 Human genes 0.000 description 1
- 102100035024 Carboxypeptidase B Human genes 0.000 description 1
- 102100026684 Carboxypeptidase O Human genes 0.000 description 1
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 1
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 description 1
- 102100025641 Carnosine N-methyltransferase Human genes 0.000 description 1
- 102100034357 Casein kinase I isoform alpha Human genes 0.000 description 1
- 102100034356 Casein kinase I isoform alpha-like Human genes 0.000 description 1
- 102100037402 Casein kinase I isoform delta Human genes 0.000 description 1
- 102100028906 Catenin delta-1 Human genes 0.000 description 1
- 102100024940 Cathepsin K Human genes 0.000 description 1
- 102100026540 Cathepsin L2 Human genes 0.000 description 1
- 102100028013 Cation channel sperm-associated auxiliary subunit beta Human genes 0.000 description 1
- 102100028062 Cation channel sperm-associated protein 2 Human genes 0.000 description 1
- 102100028061 Cation channel sperm-associated protein 3 Human genes 0.000 description 1
- 102100038909 Caveolin-2 Human genes 0.000 description 1
- 101150008735 Cdc26 gene Proteins 0.000 description 1
- 108091007854 Cdh1/Fizzy-related Proteins 0.000 description 1
- 108010072135 Cell Adhesion Molecule-1 Proteins 0.000 description 1
- 102100024649 Cell adhesion molecule 1 Human genes 0.000 description 1
- 102100031667 Cell adhesion molecule-related/down-regulated by oncogenes Human genes 0.000 description 1
- 102100027199 Cell death-inducing p53-target protein 1 Human genes 0.000 description 1
- 102100031584 Cell division cycle-associated 7-like protein Human genes 0.000 description 1
- 102100024478 Cell division cycle-associated protein 2 Human genes 0.000 description 1
- 102100024479 Cell division cycle-associated protein 3 Human genes 0.000 description 1
- 102100034231 Cell surface A33 antigen Human genes 0.000 description 1
- 102100021397 Cell surface glycoprotein CD200 receptor 2 Human genes 0.000 description 1
- 102100038503 Cellular retinoic acid-binding protein 1 Human genes 0.000 description 1
- 102100024175 Centriole, cilia and spindle-associated protein Human genes 0.000 description 1
- 102100035365 Centrosomal protein CEP57L1 Human genes 0.000 description 1
- 102100024782 Centrosomal protein POC5 Human genes 0.000 description 1
- 102100034888 Centrosomal protein kizuna Human genes 0.000 description 1
- 102100023304 Centrosomal protein of 120 kDa Human genes 0.000 description 1
- 102100023308 Centrosomal protein of 126 kDa Human genes 0.000 description 1
- 102100038741 Centrosomal protein of 135 kDa Human genes 0.000 description 1
- 101710117958 Centrosomal protein of 135 kDa Proteins 0.000 description 1
- 102100023309 Centrosomal protein of 152 kDa Human genes 0.000 description 1
- 101710181192 Centrosomal protein of 152 kDa Proteins 0.000 description 1
- 102100023255 Centrosomal protein of 162 kDa Human genes 0.000 description 1
- 102100035693 Centrosomal protein of 19 kDa Human genes 0.000 description 1
- 102100036178 Centrosomal protein of 192 kDa Human genes 0.000 description 1
- 102100033228 Centrosomal protein of 68 kDa Human genes 0.000 description 1
- 102100033229 Centrosomal protein of 70 kDa Human genes 0.000 description 1
- 101710121715 Centrosomal protein of 70 kDa Proteins 0.000 description 1
- 102100034754 Centrosomal protein of 83 kDa Human genes 0.000 description 1
- 102100035696 Centrosome-associated protein 350 Human genes 0.000 description 1
- 101710101089 Centrosome-associated protein 350 Proteins 0.000 description 1
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 description 1
- 102100032403 Charged multivesicular body protein 1b Human genes 0.000 description 1
- 102100038279 Charged multivesicular body protein 2b Human genes 0.000 description 1
- 102100038274 Charged multivesicular body protein 4b Human genes 0.000 description 1
- 108010082155 Chemokine CCL18 Proteins 0.000 description 1
- 102100025944 Chemokine-like protein TAFA-4 Human genes 0.000 description 1
- 102100034667 Chloride intracellular channel protein 1 Human genes 0.000 description 1
- 102100023511 Chloride intracellular channel protein 2 Human genes 0.000 description 1
- 102100023508 Chloride intracellular channel protein 4 Human genes 0.000 description 1
- 102100023503 Chloride intracellular channel protein 5 Human genes 0.000 description 1
- 102100032363 Choline dehydrogenase, mitochondrial Human genes 0.000 description 1
- 102100031065 Choline kinase alpha Human genes 0.000 description 1
- 102100029297 Cholinephosphotransferase 1 Human genes 0.000 description 1
- 102100029305 Chondroitin sulfate synthase 3 Human genes 0.000 description 1
- 102100030499 Chorion-specific transcription factor GCMa Human genes 0.000 description 1
- 102100032920 Chromobox protein homolog 2 Human genes 0.000 description 1
- 102100031668 Chromodomain Y-like protein Human genes 0.000 description 1
- 102100031665 Chromodomain Y-like protein 2 Human genes 0.000 description 1
- 102100031235 Chromodomain-helicase-DNA-binding protein 1 Human genes 0.000 description 1
- 102100031265 Chromodomain-helicase-DNA-binding protein 2 Human genes 0.000 description 1
- 102100038220 Chromodomain-helicase-DNA-binding protein 6 Human genes 0.000 description 1
- 102100020736 Chromosome-associated kinesin KIF4A Human genes 0.000 description 1
- 102100023331 Cilia- and flagella-associated protein 43 Human genes 0.000 description 1
- 102100025658 Cilia- and flagella-associated protein 46 Human genes 0.000 description 1
- 102100033687 Cilia- and flagella-associated protein 65 Human genes 0.000 description 1
- 102100033682 Cilia- and flagella-associated protein 69 Human genes 0.000 description 1
- 102100031191 Cilia- and flagella-associated protein 91 Human genes 0.000 description 1
- 108010005939 Ciliary Neurotrophic Factor Proteins 0.000 description 1
- 102100031614 Ciliary neurotrophic factor Human genes 0.000 description 1
- 102100026675 Ciliary-associated calcium-binding coiled-coil protein 1 Human genes 0.000 description 1
- 102100036444 Clathrin interactor 1 Human genes 0.000 description 1
- 102100040836 Claudin-1 Human genes 0.000 description 1
- 102100039518 Claudin-12 Human genes 0.000 description 1
- 102100039537 Claudin-14 Human genes 0.000 description 1
- 102100039585 Claudin-16 Human genes 0.000 description 1
- 102100040552 Claudin-23 Human genes 0.000 description 1
- 102100038447 Claudin-4 Human genes 0.000 description 1
- 102100026098 Claudin-7 Human genes 0.000 description 1
- 102100026097 Claudin-9 Human genes 0.000 description 1
- 102100023173 Clavesin-2 Human genes 0.000 description 1
- 102100026529 Cleavage and polyadenylation specificity factor subunit 6 Human genes 0.000 description 1
- 102100022256 Clustered mitochondria protein homolog Human genes 0.000 description 1
- 102100031552 Coactosin-like protein Human genes 0.000 description 1
- 102100029057 Coagulation factor XIII A chain Human genes 0.000 description 1
- 102100029058 Coagulation factor XIII B chain Human genes 0.000 description 1
- 102100028289 Coatomer subunit delta Human genes 0.000 description 1
- 102100024252 Coatomer subunit zeta-1 Human genes 0.000 description 1
- 102100023470 Cobalamin trafficking protein CblD Human genes 0.000 description 1
- 102100035932 Cocaine- and amphetamine-regulated transcript protein Human genes 0.000 description 1
- 102100040996 Cochlin Human genes 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 102100022043 Coenzyme Q-binding protein COQ10 homolog A, mitochondrial Human genes 0.000 description 1
- 102100025740 Coiled-coil domain-containing protein 103 Human genes 0.000 description 1
- 102100032377 Coiled-coil domain-containing protein 107 Human genes 0.000 description 1
- 102100032369 Coiled-coil domain-containing protein 112 Human genes 0.000 description 1
- 102100032370 Coiled-coil domain-containing protein 113 Human genes 0.000 description 1
- 102100031046 Coiled-coil domain-containing protein 12 Human genes 0.000 description 1
- 102100030444 Coiled-coil domain-containing protein 125 Human genes 0.000 description 1
- 102100031044 Coiled-coil domain-containing protein 13 Human genes 0.000 description 1
- 102100035236 Coiled-coil domain-containing protein 146 Human genes 0.000 description 1
- 102100036572 Coiled-coil domain-containing protein 170 Human genes 0.000 description 1
- 102100036577 Coiled-coil domain-containing protein 172 Human genes 0.000 description 1
- 102100036576 Coiled-coil domain-containing protein 174 Human genes 0.000 description 1
- 102100030507 Coiled-coil domain-containing protein 181 Human genes 0.000 description 1
- 102100032390 Coiled-coil domain-containing protein 25 Human genes 0.000 description 1
- 102100021981 Coiled-coil domain-containing protein 28A Human genes 0.000 description 1
- 102100031047 Coiled-coil domain-containing protein 3 Human genes 0.000 description 1
- 102100021966 Coiled-coil domain-containing protein 34 Human genes 0.000 description 1
- 102100024133 Coiled-coil domain-containing protein 50 Human genes 0.000 description 1
- 102100035167 Coiled-coil domain-containing protein 54 Human genes 0.000 description 1
- 102100031048 Coiled-coil domain-containing protein 6 Human genes 0.000 description 1
- 102100034953 Coiled-coil domain-containing protein 68 Human genes 0.000 description 1
- 102100023709 Coiled-coil domain-containing protein 71 Human genes 0.000 description 1
- 102100032371 Coiled-coil domain-containing protein 90B, mitochondrial Human genes 0.000 description 1
- 102100032351 Coiled-coil domain-containing protein 91 Human genes 0.000 description 1
- 102100032355 Coiled-coil domain-containing protein 92 Human genes 0.000 description 1
- 102100021964 Coiled-coil domain-containing protein 97 Human genes 0.000 description 1
- 102100038385 Coiled-coil domain-containing protein R3HCC1L Human genes 0.000 description 1
- 102100023691 Coiled-coil-helix-coiled-coil-helix domain-containing protein 5 Human genes 0.000 description 1
- 102100022145 Collagen alpha-1(IV) chain Human genes 0.000 description 1
- 102100031519 Collagen alpha-1(VI) chain Human genes 0.000 description 1
- 102100028256 Collagen alpha-1(XVII) chain Human genes 0.000 description 1
- 102100037296 Collagen alpha-1(XXII) chain Human genes 0.000 description 1
- 102100029078 Collagen alpha-1(XXVIII) chain Human genes 0.000 description 1
- 102100031502 Collagen alpha-2(V) chain Human genes 0.000 description 1
- 102100039551 Collagen triple helix repeat-containing protein 1 Human genes 0.000 description 1
- 102100024330 Collectin-12 Human genes 0.000 description 1
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 description 1
- 102100030790 Colorectal cancer-associated protein 1 Human genes 0.000 description 1
- 102100025407 Complement C1q and tumor necrosis factor-related protein 9A Human genes 0.000 description 1
- 102100025892 Complement C1q tumor necrosis factor-related protein 1 Human genes 0.000 description 1
- 102100025890 Complement C1q tumor necrosis factor-related protein 3 Human genes 0.000 description 1
- 102100025882 Complement C1q-like protein 3 Human genes 0.000 description 1
- 102100040494 Complement component C8 alpha chain Human genes 0.000 description 1
- 102100025680 Complement decay-accelerating factor Human genes 0.000 description 1
- 102100034622 Complement factor B Human genes 0.000 description 1
- 102100032768 Complement receptor type 2 Human genes 0.000 description 1
- 102100027823 Complexin-2 Human genes 0.000 description 1
- 102100040451 Connector enhancer of kinase suppressor of ras 3 Human genes 0.000 description 1
- 108010069176 Connexin 30 Proteins 0.000 description 1
- 102100030794 Conserved oligomeric Golgi complex subunit 1 Human genes 0.000 description 1
- 102100029265 Conserved oligomeric Golgi complex subunit 3 Human genes 0.000 description 1
- 102100036030 Conserved oligomeric Golgi complex subunit 5 Human genes 0.000 description 1
- 102100029158 Consortin Human genes 0.000 description 1
- 102100039201 Constitutive coactivator of peroxisome proliferator-activated receptor gamma Human genes 0.000 description 1
- 102100024342 Contactin-2 Human genes 0.000 description 1
- 102100040497 Contactin-associated protein-like 4 Human genes 0.000 description 1
- 102100040495 Contactin-associated protein-like 5 Human genes 0.000 description 1
- 102100041019 Coordinator of PRMT5 and differentiation stimulator Human genes 0.000 description 1
- 102100032636 Copine-1 Human genes 0.000 description 1
- 102100029384 Copine-8 Human genes 0.000 description 1
- 102100029385 Copine-9 Human genes 0.000 description 1
- 102100029767 Copper transport protein ATOX1 Human genes 0.000 description 1
- 102100034528 Core histone macro-H2A.1 Human genes 0.000 description 1
- 102100024445 Cornifelin Human genes 0.000 description 1
- 102100038810 Coronin-6 Human genes 0.000 description 1
- 102100031725 Cortactin-binding protein 2 Human genes 0.000 description 1
- 102100039445 Cortexin-3 Human genes 0.000 description 1
- 102100022615 Cotranscriptional regulator FAM172A Human genes 0.000 description 1
- 102100024300 Cryptic protein Human genes 0.000 description 1
- 102100038607 Cullin-associated NEDD8-dissociated protein 1 Human genes 0.000 description 1
- 102100025571 Cutaneous T-cell lymphoma-associated antigen 1 Human genes 0.000 description 1
- 102100026359 Cyclic AMP-responsive element-binding protein 1 Human genes 0.000 description 1
- 102100039297 Cyclic AMP-responsive element-binding protein 3-like protein 1 Human genes 0.000 description 1
- 102100039299 Cyclic AMP-responsive element-binding protein 3-like protein 2 Human genes 0.000 description 1
- 102100021306 Cyclic AMP-responsive element-binding protein 3-like protein 3 Human genes 0.000 description 1
- 102100027309 Cyclic AMP-responsive element-binding protein 5 Human genes 0.000 description 1
- 102100035373 Cyclin-D-binding Myb-like transcription factor 1 Human genes 0.000 description 1
- 102100036871 Cyclin-J Human genes 0.000 description 1
- 102100033250 Cyclin-dependent kinase 15 Human genes 0.000 description 1
- 102100033145 Cyclin-dependent kinase 19 Human genes 0.000 description 1
- 102100035353 Cyclin-dependent kinase 2-associated protein 1 Human genes 0.000 description 1
- 102100031685 Cyclin-dependent kinase-like 2 Human genes 0.000 description 1
- SXVPOSFURRDKBO-UHFFFAOYSA-N Cyclododecanone Chemical compound O=C1CCCCCCCCCCC1 SXVPOSFURRDKBO-UHFFFAOYSA-N 0.000 description 1
- 101150016994 Cysltr2 gene Proteins 0.000 description 1
- 102100026897 Cystatin-C Human genes 0.000 description 1
- 102100031051 Cysteine and glycine-rich protein 1 Human genes 0.000 description 1
- 102100033376 Cysteine and histidine-rich domain-containing protein 1 Human genes 0.000 description 1
- 102100025675 Cysteine and tyrosine-rich protein 1 Human genes 0.000 description 1
- 102100032777 Cysteine-rich C-terminal protein 1 Human genes 0.000 description 1
- 102100028180 Cysteine-rich and transmembrane domain-containing protein 1 Human genes 0.000 description 1
- 102100021784 Cysteine-rich protein 2-binding protein Human genes 0.000 description 1
- 102100027367 Cysteine-rich secretory protein 3 Human genes 0.000 description 1
- 102100038695 Cysteine-rich secretory protein LCCL domain-containing 1 Human genes 0.000 description 1
- 102100033539 Cysteinyl leukotriene receptor 2 Human genes 0.000 description 1
- 108010074918 Cytochrome P-450 CYP1A1 Proteins 0.000 description 1
- 108010026925 Cytochrome P-450 CYP2C19 Proteins 0.000 description 1
- 108010000543 Cytochrome P-450 CYP2C9 Proteins 0.000 description 1
- 102100031476 Cytochrome P450 1A1 Human genes 0.000 description 1
- 102100036324 Cytochrome P450 26C1 Human genes 0.000 description 1
- 102100036194 Cytochrome P450 2A6 Human genes 0.000 description 1
- 102100036212 Cytochrome P450 2A7 Human genes 0.000 description 1
- 102100029368 Cytochrome P450 2C18 Human genes 0.000 description 1
- 102100029363 Cytochrome P450 2C19 Human genes 0.000 description 1
- 102100029358 Cytochrome P450 2C9 Human genes 0.000 description 1
- 102100026515 Cytochrome P450 2S1 Human genes 0.000 description 1
- 102100026513 Cytochrome P450 2U1 Human genes 0.000 description 1
- 102100027419 Cytochrome P450 4B1 Human genes 0.000 description 1
- 102100031655 Cytochrome b5 Human genes 0.000 description 1
- 102100029878 Cytochrome b5 domain-containing protein 1 Human genes 0.000 description 1
- 102100033149 Cytochrome b5 reductase 4 Human genes 0.000 description 1
- 102100031596 Cytochrome c oxidase assembly factor 4 homolog, mitochondrial Human genes 0.000 description 1
- 102100029431 Cytochrome c oxidase assembly factor 7 Human genes 0.000 description 1
- 102100029080 Cytochrome c oxidase assembly protein COX14 Human genes 0.000 description 1
- 102100027475 Cytochrome c oxidase assembly protein COX18, mitochondrial Human genes 0.000 description 1
- 102100027476 Cytochrome c oxidase assembly protein COX19 Human genes 0.000 description 1
- 102100038800 Cytochrome c oxidase assembly protein COX20, mitochondrial Human genes 0.000 description 1
- 102100036035 Cytochrome c oxidase copper chaperone Human genes 0.000 description 1
- 102100026623 Cytochrome c oxidase subunit 4 isoform 2, mitochondrial Human genes 0.000 description 1
- 102100027563 Cytochrome c oxidase subunit 5A, mitochondrial Human genes 0.000 description 1
- 102100028997 Cytochrome c oxidase subunit 6A2, mitochondrial Human genes 0.000 description 1
- 102100025628 Cytochrome c oxidase subunit 7B2, mitochondrial Human genes 0.000 description 1
- 102100034126 Cytoglobin Human genes 0.000 description 1
- 102100038418 Cytoplasmic FMR1-interacting protein 2 Human genes 0.000 description 1
- 102100028523 Cytoplasmic dynein 1 intermediate chain 2 Human genes 0.000 description 1
- 102100039224 Cytoplasmic polyadenylation element-binding protein 2 Human genes 0.000 description 1
- 102100039315 Cytoplasmic polyadenylation element-binding protein 4 Human genes 0.000 description 1
- 102100034560 Cytosol aminopeptidase Human genes 0.000 description 1
- 102100039077 Cytosolic 10-formyltetrahydrofolate dehydrogenase Human genes 0.000 description 1
- 102100025721 Cytosolic carboxypeptidase 2 Human genes 0.000 description 1
- 102100025698 Cytosolic carboxypeptidase 4 Human genes 0.000 description 1
- 102100035149 Cytosolic endo-beta-N-acetylglucosaminidase Human genes 0.000 description 1
- 102100031007 Cytosolic non-specific dipeptidase Human genes 0.000 description 1
- 108010070357 D-Aspartate Oxidase Proteins 0.000 description 1
- 102100039693 D-amino acid oxidase activator Human genes 0.000 description 1
- 102100039462 D-aspartate oxidase Human genes 0.000 description 1
- 102100022768 D-beta-hydroxybutyrate dehydrogenase, mitochondrial Human genes 0.000 description 1
- 102100033937 D-glutamate cyclase, mitochondrial Human genes 0.000 description 1
- 102100026982 DCN1-like protein 1 Human genes 0.000 description 1
- 102100026981 DCN1-like protein 3 Human genes 0.000 description 1
- 102100037098 DCN1-like protein 4 Human genes 0.000 description 1
- 102100033466 DENN domain-containing protein 1A Human genes 0.000 description 1
- 102100025282 DENN domain-containing protein 2D Human genes 0.000 description 1
- 102100030418 DENN domain-containing protein 3 Human genes 0.000 description 1
- 102100029816 DEP domain-containing mTOR-interacting protein Human genes 0.000 description 1
- 102100024812 DNA (cytosine-5)-methyltransferase 3A Human genes 0.000 description 1
- 108010024491 DNA Methyltransferase 3A Proteins 0.000 description 1
- 102100040263 DNA dC->dU-editing enzyme APOBEC-3A Human genes 0.000 description 1
- 102100021122 DNA damage-binding protein 2 Human genes 0.000 description 1
- 102100026139 DNA damage-inducible transcript 4 protein Human genes 0.000 description 1
- 102100021603 DNA excision repair protein ERCC-6-like 2 Human genes 0.000 description 1
- 102100036218 DNA replication complex GINS protein PSF2 Human genes 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 102100027641 DNA-binding protein inhibitor ID-1 Human genes 0.000 description 1
- 102100027642 DNA-binding protein inhibitor ID-2 Human genes 0.000 description 1
- 102100039436 DNA-binding protein inhibitor ID-3 Human genes 0.000 description 1
- 102100039439 DNA-binding protein inhibitor ID-4 Human genes 0.000 description 1
- 102100040138 DNA-directed RNA polymerase II subunit GRINL1A, isoforms 4/5 Human genes 0.000 description 1
- 101700083528 DNAL1 Proteins 0.000 description 1
- OAUWKHSGCCPXOD-UHFFFAOYSA-N DOC1 Natural products C1=CC(O)=C2C(CC(=O)NCCCCCNCCCNCCCNCCCN)=CNC2=C1 OAUWKHSGCCPXOD-UHFFFAOYSA-N 0.000 description 1
- 102100027597 DOMON domain-containing protein FRRS1L Human genes 0.000 description 1
- 102100023108 DPY30 domain-containing protein 2 Human genes 0.000 description 1
- 102000015883 Dact2 Human genes 0.000 description 1
- 101000923091 Danio rerio Aristaless-related homeobox protein Proteins 0.000 description 1
- 101100327868 Danio rerio chmp4c gene Proteins 0.000 description 1
- 102100031602 Dedicator of cytokinesis protein 10 Human genes 0.000 description 1
- 102100031601 Dedicator of cytokinesis protein 11 Human genes 0.000 description 1
- 102100024352 Dedicator of cytokinesis protein 4 Human genes 0.000 description 1
- 102100024347 Dedicator of cytokinesis protein 5 Human genes 0.000 description 1
- 102100024351 Dedicator of cytokinesis protein 7 Human genes 0.000 description 1
- 102100021420 Defensin-5 Human genes 0.000 description 1
- 102100037101 Deoxycytidylate deaminase Human genes 0.000 description 1
- 102100024469 Dephospho-CoA kinase domain-containing protein Human genes 0.000 description 1
- 102100036411 Dermatopontin Human genes 0.000 description 1
- 102100037709 Desmocollin-3 Human genes 0.000 description 1
- 102100034579 Desmoglein-1 Human genes 0.000 description 1
- 102100034578 Desmoglein-2 Human genes 0.000 description 1
- 102100034573 Desmoglein-4 Human genes 0.000 description 1
- 102100036910 Deubiquitinase DESI2 Human genes 0.000 description 1
- 102100037127 Developmental pluripotency-associated protein 3 Human genes 0.000 description 1
- 102100037126 Developmental pluripotency-associated protein 4 Human genes 0.000 description 1
- 102100035762 Diacylglycerol O-acyltransferase 2 Human genes 0.000 description 1
- 102100030074 Dickkopf-related protein 1 Human genes 0.000 description 1
- 101000904064 Dictyostelium discoideum Glucosamine 6-phosphate N-acetyltransferase 1 Proteins 0.000 description 1
- 102100024758 Differentially expressed in FDCP 6 homolog Human genes 0.000 description 1
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 1
- 102100036238 Dihydropyrimidinase Human genes 0.000 description 1
- 102100024425 Dihydropyrimidinase-related protein 3 Human genes 0.000 description 1
- 102100024443 Dihydropyrimidinase-related protein 4 Human genes 0.000 description 1
- 102100022334 Dihydropyrimidine dehydrogenase [NADP(+)] Human genes 0.000 description 1
- 102100035041 Dimethylaniline monooxygenase [N-oxide-forming] 3 Human genes 0.000 description 1
- 102100025177 Dimethylglycine dehydrogenase, mitochondrial Human genes 0.000 description 1
- 102100029921 Dipeptidyl peptidase 1 Human genes 0.000 description 1
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 1
- 102100037923 Disco-interacting protein 2 homolog B Human genes 0.000 description 1
- 102100037928 Disco-interacting protein 2 homolog C Human genes 0.000 description 1
- 102100027023 Discoidin, CUB and LCCL domain-containing protein 1 Human genes 0.000 description 1
- 102100039673 Disintegrin and metalloproteinase domain-containing protein 10 Human genes 0.000 description 1
- 102100022825 Disintegrin and metalloproteinase domain-containing protein 22 Human genes 0.000 description 1
- 102100024362 Disintegrin and metalloproteinase domain-containing protein 7 Human genes 0.000 description 1
- 102100024117 Disks large homolog 2 Human genes 0.000 description 1
- 102100031250 Disks large-associated protein 1 Human genes 0.000 description 1
- 102100031245 Disks large-associated protein 2 Human genes 0.000 description 1
- 102100037983 Disks large-associated protein 4 Human genes 0.000 description 1
- 102100022273 Disrupted in schizophrenia 1 protein Human genes 0.000 description 1
- 102100035587 Distal membrane-arm assembly complex protein 1 Human genes 0.000 description 1
- 102100037957 Dixin Human genes 0.000 description 1
- 102100035372 DmX-like protein 1 Human genes 0.000 description 1
- 102100035347 DmX-like protein 2 Human genes 0.000 description 1
- 102100023318 DnaJ homolog subfamily B member 13 Human genes 0.000 description 1
- 102100023316 DnaJ homolog subfamily B member 14 Human genes 0.000 description 1
- 102100035426 DnaJ homolog subfamily B member 7 Human genes 0.000 description 1
- 102100023283 DnaJ homolog subfamily C member 11 Human genes 0.000 description 1
- 102100034108 DnaJ homolog subfamily C member 12 Human genes 0.000 description 1
- 102100034109 DnaJ homolog subfamily C member 13 Human genes 0.000 description 1
- 102100034115 DnaJ homolog subfamily C member 15 Human genes 0.000 description 1
- 102100022268 DnaJ homolog subfamily C member 18 Human genes 0.000 description 1
- 102100022266 DnaJ homolog subfamily C member 22 Human genes 0.000 description 1
- 102100031675 DnaJ homolog subfamily C member 5 Human genes 0.000 description 1
- 102100024961 DnaJ homolog subfamily C member 5B Human genes 0.000 description 1
- 102100022845 DnaJ homolog subfamily C member 9 Human genes 0.000 description 1
- 102100031606 Docking protein 4 Human genes 0.000 description 1
- 102100038191 Double-stranded RNA-specific editase 1 Human genes 0.000 description 1
- 101710167313 Drebrin-like protein Proteins 0.000 description 1
- 108010083068 Dual Oxidases Proteins 0.000 description 1
- 102100021217 Dual oxidase 2 Human genes 0.000 description 1
- 102100028981 Dual specificity phosphatase 29 Human genes 0.000 description 1
- 102100037568 Dual specificity protein phosphatase 15 Human genes 0.000 description 1
- 102100037574 Dual specificity protein phosphatase 18 Human genes 0.000 description 1
- 102100034427 Dual specificity protein phosphatase 21 Human genes 0.000 description 1
- 102100027088 Dual specificity protein phosphatase 5 Human genes 0.000 description 1
- 102100027275 Dual specificity protein phosphatase 7 Human genes 0.000 description 1
- 102100025699 Dual specificity protein phosphatase CDC14B Human genes 0.000 description 1
- 102100023115 Dual specificity tyrosine-phosphorylation-regulated kinase 2 Human genes 0.000 description 1
- 102100032244 Dynein axonemal heavy chain 1 Human genes 0.000 description 1
- 102100032299 Dynein axonemal heavy chain 10 Human genes 0.000 description 1
- 102100032300 Dynein axonemal heavy chain 11 Human genes 0.000 description 1
- 102100032294 Dynein axonemal heavy chain 12 Human genes 0.000 description 1
- 102100032297 Dynein axonemal heavy chain 17 Human genes 0.000 description 1
- 102100031646 Dynein axonemal heavy chain 6 Human genes 0.000 description 1
- 102100031647 Dynein axonemal heavy chain 7 Human genes 0.000 description 1
- 102100031636 Dynein axonemal heavy chain 9 Human genes 0.000 description 1
- 102100026664 Dynein heavy chain domain-containing protein 1 Human genes 0.000 description 1
- 102100024741 Dynein light chain 2, cytoplasmic Human genes 0.000 description 1
- 102100025032 Dynein regulatory complex protein 1 Human genes 0.000 description 1
- 102100037730 Dynein regulatory complex protein 8 Human genes 0.000 description 1
- 102100025018 Dynein regulatory complex subunit 2 Human genes 0.000 description 1
- 108010045061 Dysbindin Proteins 0.000 description 1
- 102000005611 Dysbindin Human genes 0.000 description 1
- 102100025709 Dyslexia-associated protein KIAA0319 Human genes 0.000 description 1
- 102100024074 Dystrobrevin alpha Human genes 0.000 description 1
- 102100032262 E2F-associated phosphoprotein Human genes 0.000 description 1
- 102100031290 E3 UFM1-protein ligase 1 Human genes 0.000 description 1
- 102100032045 E3 ubiquitin-protein ligase AMFR Human genes 0.000 description 1
- 102100027325 E3 ubiquitin-protein ligase HACE1 Human genes 0.000 description 1
- 102100034677 E3 ubiquitin-protein ligase HECTD1 Human genes 0.000 description 1
- 102100034674 E3 ubiquitin-protein ligase HECW1 Human genes 0.000 description 1
- 102100034675 E3 ubiquitin-protein ligase HECW2 Human genes 0.000 description 1
- 102100027414 E3 ubiquitin-protein ligase RNF19B Human genes 0.000 description 1
- 102100027418 E3 ubiquitin-protein ligase RNF213 Human genes 0.000 description 1
- 102100034816 E3 ubiquitin-protein ligase RNF220 Human genes 0.000 description 1
- 102100037660 EF-hand calcium-binding domain-containing protein 1 Human genes 0.000 description 1
- 102100040466 EF-hand calcium-binding domain-containing protein 12 Human genes 0.000 description 1
- 102100037359 EF-hand calcium-binding domain-containing protein 13 Human genes 0.000 description 1
- 102100033907 EF-hand calcium-binding domain-containing protein 3 Human genes 0.000 description 1
- 102100037661 EF-hand calcium-binding domain-containing protein 4B Human genes 0.000 description 1
- 102100029065 EF-hand domain-containing family member C2 Human genes 0.000 description 1
- 102100031418 EF-hand domain-containing protein D2 Human genes 0.000 description 1
- 102100031814 EGF-containing fibulin-like extracellular matrix protein 1 Human genes 0.000 description 1
- 102100029652 EH domain-binding protein 1 Human genes 0.000 description 1
- 102100032036 EH domain-containing protein 1 Human genes 0.000 description 1
- 102100032037 EH domain-containing protein 4 Human genes 0.000 description 1
- 108010008796 ELAV-Like Protein 3 Proteins 0.000 description 1
- 102100021664 ELAV-like protein 3 Human genes 0.000 description 1
- 102100032064 EMILIN-2 Human genes 0.000 description 1
- 102100038887 ENTH domain-containing protein 1 Human genes 0.000 description 1
- 102100037250 EP300-interacting inhibitor of differentiation 1 Human genes 0.000 description 1
- 102100021807 ER degradation-enhancing alpha-mannosidase-like protein 1 Human genes 0.000 description 1
- 102100032443 ER degradation-enhancing alpha-mannosidase-like protein 3 Human genes 0.000 description 1
- 102100031856 ERBB receptor feedback inhibitor 1 Human genes 0.000 description 1
- 102100030816 ESF1 homolog Human genes 0.000 description 1
- 102100023794 ETS domain-containing protein Elk-3 Human genes 0.000 description 1
- 102100023792 ETS domain-containing protein Elk-4 Human genes 0.000 description 1
- 102100032025 ETS homologous factor Human genes 0.000 description 1
- 102100039563 ETS translocation variant 1 Human genes 0.000 description 1
- 102100039562 ETS translocation variant 3 Human genes 0.000 description 1
- 102100039578 ETS translocation variant 4 Human genes 0.000 description 1
- 102100023078 Early endosome antigen 1 Human genes 0.000 description 1
- 102100023226 Early growth response protein 1 Human genes 0.000 description 1
- 102100027094 Echinoderm microtubule-associated protein-like 1 Human genes 0.000 description 1
- 102100030205 Echinoderm microtubule-associated protein-like 6 Human genes 0.000 description 1
- 102100036516 Ectonucleoside triphosphate diphosphohydrolase 7 Human genes 0.000 description 1
- 102100021977 Ectonucleotide pyrophosphatase/phosphodiesterase family member 2 Human genes 0.000 description 1
- 102100037249 Egl nine homolog 1 Human genes 0.000 description 1
- 102100030695 Electron transfer flavoprotein subunit alpha, mitochondrial Human genes 0.000 description 1
- 102100027262 Electron transfer flavoprotein subunit beta Human genes 0.000 description 1
- 102100031804 Electron transfer flavoprotein-ubiquinone oxidoreductase, mitochondrial Human genes 0.000 description 1
- 102100030801 Elongation factor 1-alpha 1 Human genes 0.000 description 1
- 102100023362 Elongation factor 1-gamma Human genes 0.000 description 1
- 102100031417 Elongation factor-like GTPase 1 Human genes 0.000 description 1
- 102100039248 Elongation of very long chain fatty acids protein 7 Human genes 0.000 description 1
- 102100035074 Elongator complex protein 3 Human genes 0.000 description 1
- 102100027259 Ena/VASP-like protein Human genes 0.000 description 1
- 102100030207 Endoplasmic reticulum membrane-associated RNA degradation protein Human genes 0.000 description 1
- 102100031862 Endoplasmic reticulum-Golgi intermediate compartment protein 1 Human genes 0.000 description 1
- 102100031863 Endoplasmic reticulum-Golgi intermediate compartment protein 2 Human genes 0.000 description 1
- 102100034237 Endosome/lysosome-associated apoptosis and autophagy regulator 1 Human genes 0.000 description 1
- 102100029109 Endothelin-3 Human genes 0.000 description 1
- 102100029112 Endothelin-converting enzyme 1 Human genes 0.000 description 1
- 102100037374 Enhancer of mRNA-decapping protein 3 Human genes 0.000 description 1
- 102100030881 Enoyl-CoA hydratase domain-containing protein 2, mitochondrial Human genes 0.000 description 1
- 102100021600 Ephrin type-A receptor 10 Human genes 0.000 description 1
- 102100031982 Ephrin type-B receptor 3 Human genes 0.000 description 1
- 108010043945 Ephrin-A1 Proteins 0.000 description 1
- 102000020086 Ephrin-A1 Human genes 0.000 description 1
- 108010044099 Ephrin-B1 Proteins 0.000 description 1
- 102100033946 Ephrin-B1 Human genes 0.000 description 1
- 102100023721 Ephrin-B2 Human genes 0.000 description 1
- 102100039354 Epoxide hydrolase 4 Human genes 0.000 description 1
- 102100025489 Equatorin Human genes 0.000 description 1
- 102100030376 Ermin Human genes 0.000 description 1
- 102100031690 Erythroid transcription factor Human genes 0.000 description 1
- 102100031855 Estrogen-related receptor gamma Human genes 0.000 description 1
- 102100033166 Ethanolamine kinase 2 Human genes 0.000 description 1
- 102100029106 Ethylmalonyl-CoA decarboxylase Human genes 0.000 description 1
- 101000914063 Eucalyptus globulus Leafy/floricaula homolog FL1 Proteins 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 102100021808 Eukaryotic elongation factor 2 kinase Human genes 0.000 description 1
- 102100022462 Eukaryotic initiation factor 4A-II Human genes 0.000 description 1
- 102100030667 Eukaryotic peptide chain release factor subunit 1 Human genes 0.000 description 1
- 102100039408 Eukaryotic translation initiation factor 1A, X-chromosomal Human genes 0.000 description 1
- 102100034174 Eukaryotic translation initiation factor 2-alpha kinase 3 Human genes 0.000 description 1
- 102100034295 Eukaryotic translation initiation factor 3 subunit A Human genes 0.000 description 1
- 102100029602 Eukaryotic translation initiation factor 4B Human genes 0.000 description 1
- 102100021002 Eukaryotic translation initiation factor 5A-2 Human genes 0.000 description 1
- 102100039466 Eukaryotic translation initiation factor 5B Human genes 0.000 description 1
- 102100040002 Eukaryotic translation initiation factor 6 Human genes 0.000 description 1
- 102100036935 Ewing's tumor-associated antigen 1 Human genes 0.000 description 1
- 102100026980 Exocyst complex component 5 Human genes 0.000 description 1
- 102100026976 Exocyst complex component 6 Human genes 0.000 description 1
- 102100026064 Exosome complex component RRP43 Human genes 0.000 description 1
- 102100026059 Exosome complex component RRP45 Human genes 0.000 description 1
- 102100035976 Exostosin-like 3 Human genes 0.000 description 1
- 102100036936 Extended synaptotagmin-3 Human genes 0.000 description 1
- 102100037122 Extracellular matrix organizing protein FRAS1 Human genes 0.000 description 1
- 102100023077 Extracellular matrix protein 2 Human genes 0.000 description 1
- 102100027300 Extracellular serine/threonine protein kinase FAM20C Human genes 0.000 description 1
- 102100030861 Eyes absent homolog 3 Human genes 0.000 description 1
- 102100040650 F-BAR and double SH3 domains protein 2 Human genes 0.000 description 1
- 102100038584 F-BAR domain only protein 2 Human genes 0.000 description 1
- 102100026541 F-actin-capping protein subunit alpha-3 Human genes 0.000 description 1
- 102100029956 F-actin-capping protein subunit beta Human genes 0.000 description 1
- 102100025496 F-box and WD repeat domain containing protein 10B Human genes 0.000 description 1
- 102100038003 F-box only protein 16 Human genes 0.000 description 1
- 102100038032 F-box only protein 17 Human genes 0.000 description 1
- 102100022114 F-box only protein 25 Human genes 0.000 description 1
- 102100022115 F-box only protein 27 Human genes 0.000 description 1
- 102100022113 F-box only protein 28 Human genes 0.000 description 1
- 102100040669 F-box only protein 32 Human genes 0.000 description 1
- 102100040667 F-box only protein 33 Human genes 0.000 description 1
- 102100040674 F-box only protein 38 Human genes 0.000 description 1
- 102100040671 F-box only protein 39 Human genes 0.000 description 1
- 102100024516 F-box only protein 5 Human genes 0.000 description 1
- 102100024513 F-box only protein 6 Human genes 0.000 description 1
- 102100039837 F-box/LRR-repeat protein 14 Human genes 0.000 description 1
- 102100027728 F-box/LRR-repeat protein 18 Human genes 0.000 description 1
- 102100037309 F-box/LRR-repeat protein 2 Human genes 0.000 description 1
- 102100027747 F-box/LRR-repeat protein 20 Human genes 0.000 description 1
- 102100038580 F-box/WD repeat-containing protein 10 Human genes 0.000 description 1
- 102100028147 F-box/WD repeat-containing protein 4 Human genes 0.000 description 1
- 101710105178 F-box/WD repeat-containing protein 7 Proteins 0.000 description 1
- 102100028138 F-box/WD repeat-containing protein 7 Human genes 0.000 description 1
- 102100026859 FAD-AMP lyase (cyclizing) Human genes 0.000 description 1
- 102000012040 FAM76A Human genes 0.000 description 1
- 108050002538 FAM76A Proteins 0.000 description 1
- 102100037585 FAST kinase domain-containing protein 3, mitochondrial Human genes 0.000 description 1
- 102000013339 FBXL17 Human genes 0.000 description 1
- 101150000662 FBXL17 gene Proteins 0.000 description 1
- 108091007098 FBXO33 Proteins 0.000 description 1
- 108091007026 FBXW10 Proteins 0.000 description 1
- 102100028406 FERM and PDZ domain-containing protein 2 Human genes 0.000 description 1
- 102100038515 FERM domain-containing protein 1 Human genes 0.000 description 1
- 102100038514 FERM domain-containing protein 3 Human genes 0.000 description 1
- 102100038519 FERM domain-containing protein 5 Human genes 0.000 description 1
- 102100038516 FERM domain-containing protein 6 Human genes 0.000 description 1
- 102100035076 FERM domain-containing protein 7 Human genes 0.000 description 1
- 102100036068 FERM domain-containing protein 8 Human genes 0.000 description 1
- 102100027867 FH2 domain-containing protein 1 Human genes 0.000 description 1
- 102100037683 FHF complex subunit HOOK interacting protein 1B Human genes 0.000 description 1
- 102100037673 FHF complex subunit HOOK interacting protein 2A Human genes 0.000 description 1
- 101150043847 FOXD1 gene Proteins 0.000 description 1
- 102100035441 FRAS1-related extracellular matrix protein 2 Human genes 0.000 description 1
- 102100038547 FSD1-like protein Human genes 0.000 description 1
- 102100035279 FYN-binding protein 2 Human genes 0.000 description 1
- 102000018825 Fanconi Anemia Complementation Group C protein Human genes 0.000 description 1
- 108010027673 Fanconi Anemia Complementation Group C protein Proteins 0.000 description 1
- 102100027280 Fanconi anemia group A protein Human genes 0.000 description 1
- 102100034554 Fanconi anemia group I protein Human genes 0.000 description 1
- 102100027297 Fatty acid 2-hydroxylase Human genes 0.000 description 1
- 102100031106 Fatty acid hydroxylase domain-containing protein 2 Human genes 0.000 description 1
- 102100040646 Fc receptor-like B Human genes 0.000 description 1
- 102100031512 Fc receptor-like protein 3 Human genes 0.000 description 1
- 102100039036 Feline leukemia virus subgroup C receptor-related protein 1 Human genes 0.000 description 1
- 101150111119 Fem1c gene Proteins 0.000 description 1
- 102100040965 Fer-1-like protein 6 Human genes 0.000 description 1
- 102100040683 Fermitin family homolog 1 Human genes 0.000 description 1
- 102100027626 Ferric-chelate reductase 1 Human genes 0.000 description 1
- 102100038652 Ferritin heavy polypeptide-like 17 Human genes 0.000 description 1
- 102100026167 Fez family zinc finger protein 2 Human genes 0.000 description 1
- 102100031752 Fibrinogen alpha chain Human genes 0.000 description 1
- 102100038664 Fibrinogen-like protein 1 Human genes 0.000 description 1
- 102100028417 Fibroblast growth factor 12 Human genes 0.000 description 1
- 102100035292 Fibroblast growth factor 14 Human genes 0.000 description 1
- 102100031734 Fibroblast growth factor 19 Human genes 0.000 description 1
- 102100024802 Fibroblast growth factor 23 Human genes 0.000 description 1
- 102100021066 Fibroblast growth factor receptor substrate 2 Human genes 0.000 description 1
- 102100038647 Fibroleukin Human genes 0.000 description 1
- 108010013996 Fibromodulin Proteins 0.000 description 1
- 102100039034 Fibromodulin Human genes 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 102100038545 Fibronectin type III and SPRY domain-containing protein 2 Human genes 0.000 description 1
- 102100026545 Fibronectin type III domain-containing protein 3B Human genes 0.000 description 1
- 102100026543 Fibronectin type III domain-containing protein 7 Human genes 0.000 description 1
- 102100036070 Fibrous sheath CABYR-binding protein Human genes 0.000 description 1
- 102100027628 Fibrous sheath-interacting protein 1 Human genes 0.000 description 1
- 102100027625 Fibrous sheath-interacting protein 2 Human genes 0.000 description 1
- 102100028065 Fibulin-5 Human genes 0.000 description 1
- 102100036950 Filamin-A-interacting protein 1 Human genes 0.000 description 1
- 102100026559 Filamin-B Human genes 0.000 description 1
- 102100026560 Filamin-C Human genes 0.000 description 1
- 102100035047 Flavin-containing monooxygenase 5 Human genes 0.000 description 1
- 102100028819 Folliculin-interacting protein 1 Human genes 0.000 description 1
- 108010008599 Forkhead Box Protein M1 Proteins 0.000 description 1
- 102100021109 Forkhead box protein B1 Human genes 0.000 description 1
- 102100021084 Forkhead box protein C1 Human genes 0.000 description 1
- 102100037057 Forkhead box protein D1 Human genes 0.000 description 1
- 102100037062 Forkhead box protein D2 Human genes 0.000 description 1
- 102100037060 Forkhead box protein D3 Human genes 0.000 description 1
- 102100037043 Forkhead box protein D4 Human genes 0.000 description 1
- 102100038038 Forkhead box protein D4-like 1 Human genes 0.000 description 1
- 102100020855 Forkhead box protein E3 Human genes 0.000 description 1
- 102100041006 Forkhead box protein J1 Human genes 0.000 description 1
- 102100035128 Forkhead box protein J3 Human genes 0.000 description 1
- 102100035120 Forkhead box protein L1 Human genes 0.000 description 1
- 102100023374 Forkhead box protein M1 Human genes 0.000 description 1
- 102100023360 Forkhead box protein N2 Human genes 0.000 description 1
- 102100028122 Forkhead box protein P1 Human genes 0.000 description 1
- 102100027579 Forkhead box protein P4 Human genes 0.000 description 1
- 102100027570 Forkhead box protein Q1 Human genes 0.000 description 1
- 102100029346 Forkhead box protein S1 Human genes 0.000 description 1
- 102100040680 Formin-binding protein 1 Human genes 0.000 description 1
- 102100028931 Formin-like protein 2 Human genes 0.000 description 1
- 102100040127 Four and a half LIM domains protein 5 Human genes 0.000 description 1
- 102100021261 Frizzled-10 Human genes 0.000 description 1
- 102100039820 Frizzled-4 Human genes 0.000 description 1
- 102100039818 Frizzled-5 Human genes 0.000 description 1
- 102100039676 Frizzled-7 Human genes 0.000 description 1
- 102100021303 Fucose mutarotase Human genes 0.000 description 1
- 102100022351 Fumarylacetoacetate hydrolase domain-containing protein 2A Human genes 0.000 description 1
- 102100039806 G patch domain-containing protein 1 Human genes 0.000 description 1
- 102100039805 G patch domain-containing protein 2 Human genes 0.000 description 1
- 102100033837 G-protein coupled receptor 135 Human genes 0.000 description 1
- 102100023416 G-protein coupled receptor 15 Human genes 0.000 description 1
- 102100041016 G-protein coupled receptor 157 Human genes 0.000 description 1
- 102100025361 G-protein coupled receptor 161 Human genes 0.000 description 1
- 102100021200 G-protein coupled receptor 176 Human genes 0.000 description 1
- 102100021245 G-protein coupled receptor 183 Human genes 0.000 description 1
- 101710101406 G-protein coupled receptor 183 Proteins 0.000 description 1
- 102100031183 G-protein coupled receptor 37-like 1 Human genes 0.000 description 1
- 102100033061 G-protein coupled receptor 55 Human genes 0.000 description 1
- 102100032524 G-protein coupled receptor family C group 5 member C Human genes 0.000 description 1
- 102100036001 G-protein coupled receptor-associated sorting protein 1 Human genes 0.000 description 1
- 102100023941 G-protein-signaling modulator 2 Human genes 0.000 description 1
- 102100035577 G2/M phase-specific E3 ubiquitin-protein ligase Human genes 0.000 description 1
- 102100033324 GATA zinc finger domain-containing protein 1 Human genes 0.000 description 1
- 108010021779 GATA5 Transcription Factor Proteins 0.000 description 1
- 102000008412 GATA5 Transcription Factor Human genes 0.000 description 1
- 102100033423 GDNF family receptor alpha-1 Human genes 0.000 description 1
- 102100040303 GDNF family receptor alpha-4 Human genes 0.000 description 1
- 102100040304 GDNF family receptor alpha-like Human genes 0.000 description 1
- 102100040014 GH3 domain-containing protein Human genes 0.000 description 1
- 108010013942 GMP Reductase Proteins 0.000 description 1
- 102100021188 GMP reductase 1 Human genes 0.000 description 1
- 102100021189 GMP reductase 2 Human genes 0.000 description 1
- 102100036772 GRAM domain-containing protein 2A Human genes 0.000 description 1
- 102100036838 GRAM domain-containing protein 2B Human genes 0.000 description 1
- 102100037759 GRB2-associated-binding protein 2 Human genes 0.000 description 1
- 102100023930 GREB1-like protein Human genes 0.000 description 1
- 102100033925 GS homeobox 1 Human genes 0.000 description 1
- 102100033924 GS homeobox 2 Human genes 0.000 description 1
- 102100027346 GTP cyclohydrolase 1 Human genes 0.000 description 1
- 102100033512 GTP:AMP phosphotransferase AK3, mitochondrial Human genes 0.000 description 1
- 102100021599 GTPase Era, mitochondrial Human genes 0.000 description 1
- 102100024422 GTPase IMAP family member 7 Human genes 0.000 description 1
- 102100040583 Galactosylceramide sulfotransferase Human genes 0.000 description 1
- 102100031689 Galanin-like peptide Human genes 0.000 description 1
- 102100025614 Galectin-related protein Human genes 0.000 description 1
- 101001077417 Gallus gallus Potassium voltage-gated channel subfamily H member 6 Proteins 0.000 description 1
- 102100034004 Gamma-adducin Human genes 0.000 description 1
- 102100025444 Gamma-butyrobetaine dioxygenase Human genes 0.000 description 1
- 102100034013 Gamma-glutamyl phosphate reductase Human genes 0.000 description 1
- 102100033713 Gamma-secretase subunit APH-1B Human genes 0.000 description 1
- 102100024582 Gamma-taxilin Human genes 0.000 description 1
- 102100030540 Gap junction alpha-5 protein Human genes 0.000 description 1
- 102100039401 Gap junction beta-6 protein Human genes 0.000 description 1
- 102100039290 Gap junction gamma-1 protein Human genes 0.000 description 1
- 102100037383 Gasdermin-B Human genes 0.000 description 1
- 102100037391 Gasdermin-E Human genes 0.000 description 1
- 102100028953 Gelsolin Human genes 0.000 description 1
- 102100022967 General transcription factor II-I repeat domain-containing protein 1 Human genes 0.000 description 1
- 102100032865 General transcription factor IIH subunit 5 Human genes 0.000 description 1
- 102100034626 Germ cell nuclear acidic protein Human genes 0.000 description 1
- 102100023303 Germ cell-less protein-like 1 Human genes 0.000 description 1
- 102100037410 Gigaxonin Human genes 0.000 description 1
- 102100041013 Glia maturation factor beta Human genes 0.000 description 1
- 102100023951 Glucosamine 6-phosphate N-acetyltransferase Human genes 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102100036255 Glucose-6-phosphatase 2 Human genes 0.000 description 1
- 102100033839 Glucose-dependent insulinotropic receptor Human genes 0.000 description 1
- 108090000369 Glutamate Carboxypeptidase II Proteins 0.000 description 1
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 1
- 102100034009 Glutamate dehydrogenase 1, mitochondrial Human genes 0.000 description 1
- 102100030652 Glutamate receptor 1 Human genes 0.000 description 1
- 102100029458 Glutamate receptor ionotropic, NMDA 2A Human genes 0.000 description 1
- 102100022630 Glutamate receptor ionotropic, NMDA 2B Human genes 0.000 description 1
- 102100038942 Glutamate receptor ionotropic, NMDA 3A Human genes 0.000 description 1
- 102100022193 Glutamate receptor ionotropic, delta-1 Human genes 0.000 description 1
- 102100022765 Glutamate receptor ionotropic, kainate 4 Human genes 0.000 description 1
- 102100039696 Glutamate-cysteine ligase catalytic subunit Human genes 0.000 description 1
- 102100025961 Glutaminase liver isoform, mitochondrial Human genes 0.000 description 1
- 102100039611 Glutamine synthetase Human genes 0.000 description 1
- 102100025945 Glutaredoxin-1 Human genes 0.000 description 1
- 102100023889 Glutaredoxin-related protein 5, mitochondrial Human genes 0.000 description 1
- 102100037473 Glutathione S-transferase A1 Human genes 0.000 description 1
- 102100037478 Glutathione S-transferase A2 Human genes 0.000 description 1
- 102100033370 Glutathione S-transferase A5 Human genes 0.000 description 1
- 102100022981 Glutathione S-transferase C-terminal domain-containing protein Human genes 0.000 description 1
- 102100039651 Glutathione S-transferase kappa 1 Human genes 0.000 description 1
- 102100023541 Glutathione S-transferase omega-1 Human genes 0.000 description 1
- 102100033053 Glutathione peroxidase 3 Human genes 0.000 description 1
- 102100036753 Glutathione peroxidase 6 Human genes 0.000 description 1
- 102100034176 Glutathione-specific gamma-glutamylcyclotransferase 1 Human genes 0.000 description 1
- 108010000445 Glycerate dehydrogenase Proteins 0.000 description 1
- 102100025591 Glycerate kinase Human genes 0.000 description 1
- 102100022556 Glycerol-3-phosphate dehydrogenase 1-like protein Human genes 0.000 description 1
- 102100040736 Glycerophosphodiester phosphodiesterase domain-containing protein 4 Human genes 0.000 description 1
- 102100040782 Glycerophosphodiester phosphodiesterase domain-containing protein 5 Human genes 0.000 description 1
- 102100039275 Glycine N-acyltransferase-like protein 2 Human genes 0.000 description 1
- 102100040870 Glycine amidinotransferase, mitochondrial Human genes 0.000 description 1
- 102100025506 Glycine cleavage system H protein, mitochondrial Human genes 0.000 description 1
- 102100033495 Glycine dehydrogenase (decarboxylating), mitochondrial Human genes 0.000 description 1
- 102100034551 Glycolipid transfer protein Human genes 0.000 description 1
- 101710094738 Glycolipid transfer protein Proteins 0.000 description 1
- 102100035716 Glycophorin-A Human genes 0.000 description 1
- 102100033807 Glycoprotein hormone beta-5 Human genes 0.000 description 1
- 102100034034 Glycoprotein integral membrane protein 1 Human genes 0.000 description 1
- 102100021700 Glycoprotein-N-acetylgalactosamine 3-beta-galactosyltransferase 1 Human genes 0.000 description 1
- 102100037825 Glycosaminoglycan xylosylkinase Human genes 0.000 description 1
- 102100025888 Glycosylated lysosomal membrane protein Human genes 0.000 description 1
- 102100040139 Glycosyltransferase 1 domain-containing protein 1 Human genes 0.000 description 1
- 102100037474 Glycosyltransferase-like domain-containing protein 1 Human genes 0.000 description 1
- 102100032530 Glypican-3 Human genes 0.000 description 1
- 102100021196 Glypican-5 Human genes 0.000 description 1
- 102100034223 Golgi apparatus protein 1 Human genes 0.000 description 1
- 102100021184 Golgi membrane protein 1 Human genes 0.000 description 1
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 1
- 102100035710 Golgi phosphoprotein 3-like Human genes 0.000 description 1
- 102100036700 Golgi reassembly-stacking protein 2 Human genes 0.000 description 1
- 102100040517 Golgi-associated kinase 1B Human genes 0.000 description 1
- 102100021613 Golgi-resident adenosine 3',5'-bisphosphate 3'-phosphatase Human genes 0.000 description 1
- 102100034158 Golgin subfamily A member 7B Human genes 0.000 description 1
- 102100034227 Grainyhead-like protein 2 homolog Human genes 0.000 description 1
- 102100033505 Granule associated Rac and RHOG effector protein 1 Human genes 0.000 description 1
- 102100039622 Granulocyte colony-stimulating factor receptor Human genes 0.000 description 1
- 102100033297 Graves disease carrier protein Human genes 0.000 description 1
- 102100038367 Gremlin-1 Human genes 0.000 description 1
- 102100023001 Growth hormone-regulated TBC protein 1 Human genes 0.000 description 1
- 102100035363 Growth/differentiation factor 7 Human genes 0.000 description 1
- 102100035970 Growth/differentiation factor 9 Human genes 0.000 description 1
- 102100023737 GrpE protein homolog 1, mitochondrial Human genes 0.000 description 1
- 102100023683 GrpE protein homolog 2, mitochondrial Human genes 0.000 description 1
- 102100029301 Guanine nucleotide exchange factor C9orf72 Human genes 0.000 description 1
- 102100033300 Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-12 Human genes 0.000 description 1
- 102100035909 Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-3 Human genes 0.000 description 1
- 102100035913 Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-4 Human genes 0.000 description 1
- 102100039844 Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-T2 Human genes 0.000 description 1
- 102100032610 Guanine nucleotide-binding protein G(s) subunit alpha isoforms XLas Human genes 0.000 description 1
- 102100039214 Guanine nucleotide-binding protein G(t) subunit alpha-2 Human genes 0.000 description 1
- 102100036738 Guanine nucleotide-binding protein subunit alpha-11 Human genes 0.000 description 1
- 102100036733 Guanine nucleotide-binding protein subunit alpha-12 Human genes 0.000 description 1
- 102100036703 Guanine nucleotide-binding protein subunit alpha-13 Human genes 0.000 description 1
- 102100022664 Guanylate cyclase activator 2B Human genes 0.000 description 1
- 102100035688 Guanylate-binding protein 1 Human genes 0.000 description 1
- 102100033968 Guanylyl cyclase-activating protein 2 Human genes 0.000 description 1
- 102100033971 Guanylyl cyclase-activating protein 3 Human genes 0.000 description 1
- 102100034471 H(+)/Cl(-) exchange transporter 5 Human genes 0.000 description 1
- 102100027490 H2.0-like homeobox protein Human genes 0.000 description 1
- 102100039336 HAUS augmin-like complex subunit 4 Human genes 0.000 description 1
- 108091005772 HDAC11 Proteins 0.000 description 1
- 102000016052 HEXIM2 Human genes 0.000 description 1
- 108050004369 HEXIM2 Proteins 0.000 description 1
- 102100032820 HIG1 domain family member 2A, mitochondrial Human genes 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 108700039143 HMGA2 Proteins 0.000 description 1
- 102100028670 HORMA domain-containing protein 2 Human genes 0.000 description 1
- 102100030373 HSPB1-associated protein 1 Human genes 0.000 description 1
- 101150017737 HSPB3 gene Proteins 0.000 description 1
- 102000017679 HTR3A Human genes 0.000 description 1
- 102000017678 HTR3B Human genes 0.000 description 1
- 102100034680 Haloacid dehalogenase-like hydrolase domain-containing 5 Human genes 0.000 description 1
- 102100034684 Haloacid dehalogenase-like hydrolase domain-containing protein 3 Human genes 0.000 description 1
- 102100027772 Haptoglobin-related protein Human genes 0.000 description 1
- 102100040352 Heat shock 70 kDa protein 1A Human genes 0.000 description 1
- 102100028765 Heat shock 70 kDa protein 4 Human genes 0.000 description 1
- 102100031624 Heat shock protein 105 kDa Human genes 0.000 description 1
- 102100032510 Heat shock protein HSP 90-beta Human genes 0.000 description 1
- 102100039168 Heat shock protein beta-3 Human genes 0.000 description 1
- 102100023043 Heat shock protein beta-8 Human genes 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 102100031963 Heme-binding protein 2 Human genes 0.000 description 1
- 102100022816 Hemojuvelin Human genes 0.000 description 1
- 102100029001 Heparan sulfate 2-O-sulfotransferase 1 Human genes 0.000 description 1
- 108010007712 Hepatitis A Virus Cellular Receptor 1 Proteins 0.000 description 1
- 102100034459 Hepatitis A virus cellular receptor 1 Human genes 0.000 description 1
- 102100034676 Hepatocyte cell adhesion molecule Human genes 0.000 description 1
- 102100029284 Hepatocyte nuclear factor 3-beta Human genes 0.000 description 1
- 102100022047 Hepatocyte nuclear factor 4-gamma Human genes 0.000 description 1
- 102100031017 Hepatoma-derived growth factor-like protein 1 Human genes 0.000 description 1
- 102100031188 Hephaestin Human genes 0.000 description 1
- 102100028716 Hermansky-Pudlak syndrome 3 protein Human genes 0.000 description 1
- 102100028715 Hermansky-Pudlak syndrome 4 protein Human genes 0.000 description 1
- 102100028721 Hermansky-Pudlak syndrome 5 protein Human genes 0.000 description 1
- 102100035669 Heterogeneous nuclear ribonucleoprotein A3 Human genes 0.000 description 1
- 102100034000 Heterogeneous nuclear ribonucleoprotein F Human genes 0.000 description 1
- 102100027703 Heterogeneous nuclear ribonucleoprotein H2 Human genes 0.000 description 1
- 102100033997 Heterogeneous nuclear ribonucleoprotein H3 Human genes 0.000 description 1
- 102100033993 Heterogeneous nuclear ribonucleoprotein L-like Human genes 0.000 description 1
- 102100024002 Heterogeneous nuclear ribonucleoprotein U Human genes 0.000 description 1
- 102100038030 High affinity immunoglobulin alpha and immunoglobulin mu Fc receptor Human genes 0.000 description 1
- 102100038006 High affinity immunoglobulin epsilon receptor subunit alpha Human genes 0.000 description 1
- 102100022132 High affinity immunoglobulin epsilon receptor subunit gamma Human genes 0.000 description 1
- 102100026119 High affinity immunoglobulin gamma Fc receptor IB Human genes 0.000 description 1
- 102100031336 High mobility group nucleosome-binding domain-containing protein 3 Human genes 0.000 description 1
- 102100028177 High mobility group nucleosome-binding domain-containing protein 4 Human genes 0.000 description 1
- 102100031483 High mobility group protein 20A Human genes 0.000 description 1
- 102100028999 High mobility group protein HMGI-C Human genes 0.000 description 1
- 102100028993 Hippocalcin-like protein 1 Human genes 0.000 description 1
- 102100032511 Histamine H4 receptor Human genes 0.000 description 1
- 108010014095 Histidine decarboxylase Proteins 0.000 description 1
- 102100030509 Histidine protein methyltransferase 1 homolog Human genes 0.000 description 1
- 102100037487 Histone H1.0 Human genes 0.000 description 1
- 102100033550 Histone H2A-Bbd type 1 Human genes 0.000 description 1
- 102100023919 Histone H2A.Z Human genes 0.000 description 1
- 102100030690 Histone H2B type 1-C/E/F/G/I Human genes 0.000 description 1
- 102100021640 Histone H2B type 1-L Human genes 0.000 description 1
- 102100033572 Histone H2B type 2-E Human genes 0.000 description 1
- 102100038806 Histone H2B type 3-B Human genes 0.000 description 1
- 102100034535 Histone H3.1 Human genes 0.000 description 1
- 102100021489 Histone H4-like protein type G Human genes 0.000 description 1
- 102100032838 Histone chaperone ASF1A Human genes 0.000 description 1
- 102100039385 Histone deacetylase 11 Human genes 0.000 description 1
- 102100026265 Histone-lysine N-methyltransferase ASH1L Human genes 0.000 description 1
- 101150073387 Hmga2 gene Proteins 0.000 description 1
- 102100031470 Homeobox protein ARX Human genes 0.000 description 1
- 102100026342 Homeobox protein BarH-like 2 Human genes 0.000 description 1
- 102100028528 Homeobox protein DBX2 Human genes 0.000 description 1
- 102100030087 Homeobox protein DLX-1 Human genes 0.000 description 1
- 102100031800 Homeobox protein ESX1 Human genes 0.000 description 1
- 102100039541 Homeobox protein Hox-A3 Human genes 0.000 description 1
- 102100034862 Homeobox protein Hox-B2 Human genes 0.000 description 1
- 102100028404 Homeobox protein Hox-B4 Human genes 0.000 description 1
- 102100020766 Homeobox protein Hox-C11 Human genes 0.000 description 1
- 102100020759 Homeobox protein Hox-C4 Human genes 0.000 description 1
- 102100022597 Homeobox protein Hox-C9 Human genes 0.000 description 1
- 102100040229 Homeobox protein Hox-D1 Human genes 0.000 description 1
- 102100034858 Homeobox protein Hox-D8 Human genes 0.000 description 1
- 102100030234 Homeobox protein cut-like 1 Human genes 0.000 description 1
- 102100038146 Homeobox protein goosecoid Human genes 0.000 description 1
- 102100028171 Homeobox-containing protein 1 Human genes 0.000 description 1
- 102100032822 Homeodomain-interacting protein kinase 1 Human genes 0.000 description 1
- 102100022603 Homeodomain-interacting protein kinase 4 Human genes 0.000 description 1
- 101000797917 Homo sapiens 1,5-anhydro-D-fructose reductase Proteins 0.000 description 1
- 101000929840 Homo sapiens 1-acylglycerol-3-phosphate O-acyltransferase ABHD5 Proteins 0.000 description 1
- 101001071349 Homo sapiens 12-(S)-hydroxy-5,8,10,14-eicosatetraenoic acid receptor Proteins 0.000 description 1
- 101000806241 Homo sapiens 17-beta-hydroxysteroid dehydrogenase 13 Proteins 0.000 description 1
- 101000690881 Homo sapiens 2-aminoethanethiol dioxygenase Proteins 0.000 description 1
- 101000952940 Homo sapiens 2-methoxy-6-polyprenyl-1,4-benzoquinol methylase, mitochondrial Proteins 0.000 description 1
- 101000597680 Homo sapiens 2-oxoisovalerate dehydrogenase subunit beta, mitochondrial Proteins 0.000 description 1
- 101001132150 Homo sapiens 2-phosphoxylose phosphatase 1 Proteins 0.000 description 1
- 101000684297 Homo sapiens 26S proteasome complex subunit SEM1 Proteins 0.000 description 1
- 101000935623 Homo sapiens 3'(2'),5'-bisphosphate nucleotidase 1 Proteins 0.000 description 1
- 101001045774 Homo sapiens 3-hydroxy-3-methylglutaryl-CoA lyase, cytoplasmic Proteins 0.000 description 1
- 101001050680 Homo sapiens 3-ketodihydrosphingosine reductase Proteins 0.000 description 1
- 101001000686 Homo sapiens 4-aminobutyrate aminotransferase, mitochondrial Proteins 0.000 description 1
- 101000725614 Homo sapiens 4-hydroxybenzoate polyprenyltransferase, mitochondrial Proteins 0.000 description 1
- 101001066900 Homo sapiens 5'-deoxynucleotidase HDDC2 Proteins 0.000 description 1
- 101000761343 Homo sapiens 5-hydroxytryptamine receptor 3A Proteins 0.000 description 1
- 101000964058 Homo sapiens 5-hydroxytryptamine receptor 3B Proteins 0.000 description 1
- 101000774717 Homo sapiens A-kinase anchor protein 1, mitochondrial Proteins 0.000 description 1
- 101000774738 Homo sapiens A-kinase anchor protein 2 Proteins 0.000 description 1
- 101000890604 Homo sapiens A-kinase anchor protein 4 Proteins 0.000 description 1
- 101000890611 Homo sapiens A-kinase anchor protein 6 Proteins 0.000 description 1
- 101000929669 Homo sapiens ABC-type organic anion transporter ABCA8 Proteins 0.000 description 1
- 101000701175 Homo sapiens ADAMTS-like protein 3 Proteins 0.000 description 1
- 101000975058 Homo sapiens ADAMTS-like protein 4 Proteins 0.000 description 1
- 101001008861 Homo sapiens ADP-ribose glycohydrolase OARD1 Proteins 0.000 description 1
- 101000927505 Homo sapiens ADP-ribosylation factor GTPase-activating protein 3 Proteins 0.000 description 1
- 101000974509 Homo sapiens ADP-ribosylation factor-like protein 14 Proteins 0.000 description 1
- 101000974504 Homo sapiens ADP-ribosylation factor-like protein 15 Proteins 0.000 description 1
- 101000833180 Homo sapiens AF4/FMR2 family member 1 Proteins 0.000 description 1
- 101000833166 Homo sapiens AF4/FMR2 family member 3 Proteins 0.000 description 1
- 101000833170 Homo sapiens AF4/FMR2 family member 4 Proteins 0.000 description 1
- 101000780581 Homo sapiens AFG1-like ATPase Proteins 0.000 description 1
- 101000780591 Homo sapiens AFG3-like protein 2 Proteins 0.000 description 1
- 101000718065 Homo sapiens AKT-interacting protein Proteins 0.000 description 1
- 101000797458 Homo sapiens AMP deaminase 2 Proteins 0.000 description 1
- 101000779222 Homo sapiens AP-1 complex subunit beta-1 Proteins 0.000 description 1
- 101000768014 Homo sapiens AP-1 complex subunit sigma-3 Proteins 0.000 description 1
- 101000779216 Homo sapiens AP-1 complex-associated regulatory protein Proteins 0.000 description 1
- 101000757394 Homo sapiens AP-2 complex subunit alpha-2 Proteins 0.000 description 1
- 101000959710 Homo sapiens AP-3 complex subunit sigma-1 Proteins 0.000 description 1
- 101000768007 Homo sapiens AP-3 complex subunit sigma-2 Proteins 0.000 description 1
- 101000890244 Homo sapiens AP-4 complex subunit sigma-1 Proteins 0.000 description 1
- 101000890223 Homo sapiens AP-5 complex subunit mu-1 Proteins 0.000 description 1
- 101000719170 Homo sapiens APC membrane recruitment protein 3 Proteins 0.000 description 1
- 101000888642 Homo sapiens ARF GTPase-activating protein GIT2 Proteins 0.000 description 1
- 101000924255 Homo sapiens AT-rich interactive domain-containing protein 1B Proteins 0.000 description 1
- 101000808887 Homo sapiens AT-rich interactive domain-containing protein 3A Proteins 0.000 description 1
- 101000808906 Homo sapiens AT-rich interactive domain-containing protein 3B Proteins 0.000 description 1
- 101000792933 Homo sapiens AT-rich interactive domain-containing protein 4A Proteins 0.000 description 1
- 101000792947 Homo sapiens AT-rich interactive domain-containing protein 5B Proteins 0.000 description 1
- 101000905799 Homo sapiens ATP synthase F(0) complex subunit C1, mitochondrial Proteins 0.000 description 1
- 101000789413 Homo sapiens ATP synthase mitochondrial F1 complex assembly factor 1 Proteins 0.000 description 1
- 101000936976 Homo sapiens ATP synthase subunit d, mitochondrial Proteins 0.000 description 1
- 101000936958 Homo sapiens ATP synthase subunit e, mitochondrial Proteins 0.000 description 1
- 101000975151 Homo sapiens ATP synthase subunit epsilon, mitochondrial Proteins 0.000 description 1
- 101000929654 Homo sapiens ATP-binding cassette sub-family A member 10 Proteins 0.000 description 1
- 101000929667 Homo sapiens ATP-binding cassette sub-family A member 9 Proteins 0.000 description 1
- 101000677883 Homo sapiens ATP-binding cassette sub-family B member 6 Proteins 0.000 description 1
- 101001029059 Homo sapiens ATP-binding cassette sub-family C member 10 Proteins 0.000 description 1
- 101001029057 Homo sapiens ATP-binding cassette sub-family C member 11 Proteins 0.000 description 1
- 101000986629 Homo sapiens ATP-binding cassette sub-family C member 4 Proteins 0.000 description 1
- 101000783770 Homo sapiens ATP-binding cassette sub-family D member 3 Proteins 0.000 description 1
- 101000912706 Homo sapiens ATP-dependent RNA helicase DDX25 Proteins 0.000 description 1
- 101000870662 Homo sapiens ATP-dependent RNA helicase DDX3X Proteins 0.000 description 1
- 101000830424 Homo sapiens ATP-dependent RNA helicase DDX50 Proteins 0.000 description 1
- 101000907919 Homo sapiens ATP-dependent RNA helicase DHX29 Proteins 0.000 description 1
- 101000614701 Homo sapiens ATP-sensitive inward rectifier potassium channel 11 Proteins 0.000 description 1
- 101001134010 Homo sapiens ATPase PAAT Proteins 0.000 description 1
- 101000773358 Homo sapiens Acetyl-coenzyme A synthetase 2-like, mitochondrial Proteins 0.000 description 1
- 101000965233 Homo sapiens Acetylcholine receptor subunit epsilon Proteins 0.000 description 1
- 101000901099 Homo sapiens Achaete-scute homolog 1 Proteins 0.000 description 1
- 101000901079 Homo sapiens Acid-sensing ion channel 2 Proteins 0.000 description 1
- 101000928226 Homo sapiens Actin filament-associated protein 1 Proteins 0.000 description 1
- 101000773237 Homo sapiens Actin, cytoplasmic 2 Proteins 0.000 description 1
- 101000783819 Homo sapiens Actin-binding LIM protein 3 Proteins 0.000 description 1
- 101000678435 Homo sapiens Actin-like protein 8 Proteins 0.000 description 1
- 101000754209 Homo sapiens Actin-related protein 10 Proteins 0.000 description 1
- 101000785745 Homo sapiens Actin-related protein 2/3 complex subunit 5-like protein Proteins 0.000 description 1
- 101000728742 Homo sapiens Actin-related protein 3B Proteins 0.000 description 1
- 101000923097 Homo sapiens Actin-related protein 6 Proteins 0.000 description 1
- 101000678410 Homo sapiens Actin-related protein T3 Proteins 0.000 description 1
- 101000836967 Homo sapiens Activating molecule in BECN1-regulated autophagy protein 1 Proteins 0.000 description 1
- 101000784211 Homo sapiens Activating signal cointegrator 1 complex subunit 3 Proteins 0.000 description 1
- 101000583854 Homo sapiens Activating transcription factor 7-interacting protein 1 Proteins 0.000 description 1
- 101000797989 Homo sapiens Activator of 90 kDa heat shock protein ATPase homolog 1 Proteins 0.000 description 1
- 101000799189 Homo sapiens Activin receptor type-1B Proteins 0.000 description 1
- 101000970954 Homo sapiens Activin receptor type-2A Proteins 0.000 description 1
- 101000678845 Homo sapiens Acyl carrier protein, mitochondrial Proteins 0.000 description 1
- 101000782705 Homo sapiens Acyl-CoA-binding domain-containing protein 5 Proteins 0.000 description 1
- 101000801610 Homo sapiens Acyl-CoA-binding domain-containing protein 6 Proteins 0.000 description 1
- 101000773359 Homo sapiens Acyl-coenzyme A synthetase ACSM2A, mitochondrial Proteins 0.000 description 1
- 101000773360 Homo sapiens Acyl-coenzyme A synthetase ACSM2B, mitochondrial Proteins 0.000 description 1
- 101000720379 Homo sapiens Acyl-coenzyme A thioesterase 6 Proteins 0.000 description 1
- 101000929554 Homo sapiens Acylphosphatase-2 Proteins 0.000 description 1
- 101000917337 Homo sapiens Acylpyruvase FAHD1, mitochondrial Proteins 0.000 description 1
- 101000842270 Homo sapiens Adenosine 5'-monophosphoramidase HINT1 Proteins 0.000 description 1
- 101000929495 Homo sapiens Adenosine deaminase Proteins 0.000 description 1
- 101000614487 Homo sapiens Adenylate kinase 4, mitochondrial Proteins 0.000 description 1
- 101000833358 Homo sapiens Adhesion G protein-coupled receptor A2 Proteins 0.000 description 1
- 101000833357 Homo sapiens Adhesion G protein-coupled receptor A3 Proteins 0.000 description 1
- 101000775045 Homo sapiens Adhesion G protein-coupled receptor F5 Proteins 0.000 description 1
- 101000718219 Homo sapiens Adhesion G-protein coupled receptor D1 Proteins 0.000 description 1
- 101000718228 Homo sapiens Adhesion G-protein coupled receptor F1 Proteins 0.000 description 1
- 101000959602 Homo sapiens Adhesion G-protein coupled receptor G6 Proteins 0.000 description 1
- 101000959592 Homo sapiens Adhesion G-protein coupled receptor G7 Proteins 0.000 description 1
- 101000928239 Homo sapiens Afamin Proteins 0.000 description 1
- 101000928511 Homo sapiens Akirin-1 Proteins 0.000 description 1
- 101000928488 Homo sapiens Akirin-2 Proteins 0.000 description 1
- 101000779415 Homo sapiens Alanine aminotransferase 2 Proteins 0.000 description 1
- 101000879354 Homo sapiens Alanine-tRNA ligase, cytoplasmic Proteins 0.000 description 1
- 101000780443 Homo sapiens Alcohol dehydrogenase 1A Proteins 0.000 description 1
- 101000776384 Homo sapiens Alkylglycerol monooxygenase Proteins 0.000 description 1
- 101000733623 Homo sapiens All-trans retinoic acid-induced differentiation factor Proteins 0.000 description 1
- 101000775437 Homo sapiens All-trans-retinol dehydrogenase [NAD(+)] ADH4 Proteins 0.000 description 1
- 101000690766 Homo sapiens All-trans-retinol dehydrogenase [NAD(+)] ADH7 Proteins 0.000 description 1
- 101000799569 Homo sapiens Alpha- and gamma-adaptin-binding protein p34 Proteins 0.000 description 1
- 101000862213 Homo sapiens Alpha-(1,3)-fucosyltransferase 11 Proteins 0.000 description 1
- 101000717828 Homo sapiens Alpha-1,2-mannosyltransferase ALG9 Proteins 0.000 description 1
- 101000799972 Homo sapiens Alpha-2-macroglobulin Proteins 0.000 description 1
- 101000799076 Homo sapiens Alpha-adducin Proteins 0.000 description 1
- 101000920937 Homo sapiens Alpha-crystallin A chain Proteins 0.000 description 1
- 101000891540 Homo sapiens Alpha-ketoglutarate-dependent dioxygenase alkB homolog 7, mitochondrial Proteins 0.000 description 1
- 101000779565 Homo sapiens Alpha-protein kinase 2 Proteins 0.000 description 1
- 101000795757 Homo sapiens Alpha-tocopherol transfer protein-like Proteins 0.000 description 1
- 101000797795 Homo sapiens Alstrom syndrome protein 1 Proteins 0.000 description 1
- 101000889627 Homo sapiens Aminopeptidase O Proteins 0.000 description 1
- 101000776165 Homo sapiens Amphoterin-induced protein 2 Proteins 0.000 description 1
- 101000890401 Homo sapiens Amyloid beta precursor like protein 2 Proteins 0.000 description 1
- 101000779315 Homo sapiens Anaphase-promoting complex subunit 10 Proteins 0.000 description 1
- 101000775248 Homo sapiens Androgen-dependent TFPI-regulating protein Proteins 0.000 description 1
- 101000718108 Homo sapiens Androgen-induced gene 1 protein Proteins 0.000 description 1
- 101000891169 Homo sapiens Angiomotin-like protein 1 Proteins 0.000 description 1
- 101000693081 Homo sapiens Angiopoietin-related protein 2 Proteins 0.000 description 1
- 101000896825 Homo sapiens Ankyrin repeat and BTB/POZ domain-containing protein BTBD11 Proteins 0.000 description 1
- 101000694621 Homo sapiens Ankyrin repeat and SAM domain-containing protein 1A Proteins 0.000 description 1
- 101000694601 Homo sapiens Ankyrin repeat and SAM domain-containing protein 4B Proteins 0.000 description 1
- 101000925502 Homo sapiens Ankyrin repeat and SOCS box protein 18 Proteins 0.000 description 1
- 101000928336 Homo sapiens Ankyrin repeat and fibronectin type-III domain-containing protein 1 Proteins 0.000 description 1
- 101000732626 Homo sapiens Ankyrin repeat and zinc finger domain-containing protein 1 Proteins 0.000 description 1
- 101000889396 Homo sapiens Ankyrin repeat domain-containing protein 1 Proteins 0.000 description 1
- 101000924476 Homo sapiens Ankyrin repeat domain-containing protein 11 Proteins 0.000 description 1
- 101000780149 Homo sapiens Ankyrin repeat domain-containing protein 13A Proteins 0.000 description 1
- 101000757191 Homo sapiens Ankyrin repeat domain-containing protein 30A Proteins 0.000 description 1
- 101000732378 Homo sapiens Ankyrin repeat domain-containing protein 39 Proteins 0.000 description 1
- 101000889457 Homo sapiens Ankyrin repeat domain-containing protein 49 Proteins 0.000 description 1
- 101000796113 Homo sapiens Ankyrin repeat domain-containing protein 55 Proteins 0.000 description 1
- 101000961318 Homo sapiens Ankyrin repeat domain-containing protein 9 Proteins 0.000 description 1
- 101000820669 Homo sapiens Ankyrin repeat domain-containing protein SOWAHB Proteins 0.000 description 1
- 101000879497 Homo sapiens Ankyrin repeat domain-containing protein SOWAHC Proteins 0.000 description 1
- 101000928344 Homo sapiens Ankyrin-2 Proteins 0.000 description 1
- 101000928342 Homo sapiens Ankyrin-3 Proteins 0.000 description 1
- 101000768066 Homo sapiens Annexin A11 Proteins 0.000 description 1
- 101000924454 Homo sapiens Annexin A3 Proteins 0.000 description 1
- 101000928300 Homo sapiens Annexin A8 Proteins 0.000 description 1
- 101000775021 Homo sapiens Anterior gradient protein 2 homolog Proteins 0.000 description 1
- 101000775037 Homo sapiens Anterior gradient protein 3 Proteins 0.000 description 1
- 101000796085 Homo sapiens Anthrax toxin receptor 2 Proteins 0.000 description 1
- 101000952099 Homo sapiens Antiviral innate immune response receptor RIG-I Proteins 0.000 description 1
- 101000793431 Homo sapiens Apolipoprotein F Proteins 0.000 description 1
- 101000928701 Homo sapiens Apolipoprotein L domain-containing protein 1 Proteins 0.000 description 1
- 101000684459 Homo sapiens Aquaporin-11 Proteins 0.000 description 1
- 101000771417 Homo sapiens Aquaporin-8 Proteins 0.000 description 1
- 101000889833 Homo sapiens Archaemetzincin-2 Proteins 0.000 description 1
- 101000833314 Homo sapiens Arf-GAP domain and FG repeat-containing protein 1 Proteins 0.000 description 1
- 101000833311 Homo sapiens Arf-GAP domain and FG repeat-containing protein 2 Proteins 0.000 description 1
- 101000928218 Homo sapiens Arf-GAP with GTPase, ANK repeat and PH domain-containing protein 1 Proteins 0.000 description 1
- 101000733555 Homo sapiens Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 1 Proteins 0.000 description 1
- 101000733557 Homo sapiens Arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 2 Proteins 0.000 description 1
- 101000975752 Homo sapiens Arf-GAP with SH3 domain, ANK repeat and PH domain-containing protein 1 Proteins 0.000 description 1
- 101000685364 Homo sapiens Arginine and glutamate-rich protein 1 Proteins 0.000 description 1
- 101000728589 Homo sapiens Arginine/serine-rich protein 1 Proteins 0.000 description 1
- 101000784014 Homo sapiens Argininosuccinate synthase Proteins 0.000 description 1
- 101000684952 Homo sapiens Armadillo repeat-containing protein 1 Proteins 0.000 description 1
- 101000769229 Homo sapiens Armadillo repeat-containing protein 12 Proteins 0.000 description 1
- 101000684967 Homo sapiens Armadillo repeat-containing protein 2 Proteins 0.000 description 1
- 101000884441 Homo sapiens Arpin Proteins 0.000 description 1
- 101000785765 Homo sapiens Arrestin domain-containing protein 2 Proteins 0.000 description 1
- 101000784133 Homo sapiens Arrestin domain-containing protein 4 Proteins 0.000 description 1
- 101000901111 Homo sapiens Arsenite methyltransferase Proteins 0.000 description 1
- 101000740484 Homo sapiens Aryl hydrocarbon receptor nuclear translocator-like protein 1 Proteins 0.000 description 1
- 101000760943 Homo sapiens Arylacetamide deacetylase Proteins 0.000 description 1
- 101000925559 Homo sapiens Arylsulfatase D Proteins 0.000 description 1
- 101000925530 Homo sapiens Arylsulfatase H Proteins 0.000 description 1
- 101000925514 Homo sapiens Arylsulfatase J Proteins 0.000 description 1
- 101000703100 Homo sapiens Ashwin Proteins 0.000 description 1
- 101000799549 Homo sapiens Aspartate aminotransferase, mitochondrial Proteins 0.000 description 1
- 101000901030 Homo sapiens Aspartyl/asparaginyl beta-hydroxylase Proteins 0.000 description 1
- 101000936743 Homo sapiens Astrotactin-2 Proteins 0.000 description 1
- 101000974896 Homo sapiens Ataxin-7-like protein 1 Proteins 0.000 description 1
- 101000936988 Homo sapiens Atlastin-2 Proteins 0.000 description 1
- 101000678892 Homo sapiens Atypical chemokine receptor 2 Proteins 0.000 description 1
- 101000678890 Homo sapiens Atypical chemokine receptor 3 Proteins 0.000 description 1
- 101000798902 Homo sapiens Atypical chemokine receptor 4 Proteins 0.000 description 1
- 101000936427 Homo sapiens Augurin Proteins 0.000 description 1
- 101000905703 Homo sapiens Autophagy-related protein 2 homolog B Proteins 0.000 description 1
- 101000874569 Homo sapiens Axin-2 Proteins 0.000 description 1
- 101000936503 Homo sapiens Axonemal dynein light chain domain-containing protein 1 Proteins 0.000 description 1
- 101000798495 Homo sapiens B-cell CLL/lymphoma 9 protein Proteins 0.000 description 1
- 101000798491 Homo sapiens B-cell CLL/lymphoma 9-like protein Proteins 0.000 description 1
- 101000971155 Homo sapiens B-cell scaffold protein with ankyrin repeats Proteins 0.000 description 1
- 101000695703 Homo sapiens B2 bradykinin receptor Proteins 0.000 description 1
- 101000936600 Homo sapiens B9 domain-containing protein 1 Proteins 0.000 description 1
- 101000766273 Homo sapiens BCAS3 microtubule associated cell migration factor Proteins 0.000 description 1
- 101000798486 Homo sapiens BCLAF1 and THRAP3 family member 3 Proteins 0.000 description 1
- 101100165236 Homo sapiens BCOR gene Proteins 0.000 description 1
- 101000739800 Homo sapiens BEN domain-containing protein 7 Proteins 0.000 description 1
- 101000873626 Homo sapiens BICD family-like cargo adapter 1 Proteins 0.000 description 1
- 101000871755 Homo sapiens BLOC-1-related complex subunit 6 Proteins 0.000 description 1
- 101000934599 Homo sapiens BLOC-1-related complex subunit 7 Proteins 0.000 description 1
- 101000740070 Homo sapiens BMP and activin membrane-bound inhibitor homolog Proteins 0.000 description 1
- 101000762370 Homo sapiens BMP-2-inducible protein kinase Proteins 0.000 description 1
- 101000802816 Homo sapiens BRD4-interacting chromatin-remodeling complex-associated protein Proteins 0.000 description 1
- 101000802808 Homo sapiens BRD4-interacting chromatin-remodeling complex-associated protein-like Proteins 0.000 description 1
- 101000933488 Homo sapiens BRI3-binding protein Proteins 0.000 description 1
- 101000798410 Homo sapiens BTB/POZ domain-containing adapter for CUL3-mediated RhoA degradation protein 1 Proteins 0.000 description 1
- 101000798319 Homo sapiens BTB/POZ domain-containing adapter for CUL3-mediated RhoA degradation protein 3 Proteins 0.000 description 1
- 101000761873 Homo sapiens BTB/POZ domain-containing protein 1 Proteins 0.000 description 1
- 101000896692 Homo sapiens BTB/POZ domain-containing protein 16 Proteins 0.000 description 1
- 101000761886 Homo sapiens BTB/POZ domain-containing protein 3 Proteins 0.000 description 1
- 101000896814 Homo sapiens BTB/POZ domain-containing protein 9 Proteins 0.000 description 1
- 101000974729 Homo sapiens BTB/POZ domain-containing protein KCTD16 Proteins 0.000 description 1
- 101000613894 Homo sapiens BTB/POZ domain-containing protein KCTD3 Proteins 0.000 description 1
- 101000613899 Homo sapiens BTB/POZ domain-containing protein KCTD4 Proteins 0.000 description 1
- 101001007228 Homo sapiens BTB/POZ domain-containing protein KCTD6 Proteins 0.000 description 1
- 101001007222 Homo sapiens BTB/POZ domain-containing protein KCTD7 Proteins 0.000 description 1
- 101000985003 Homo sapiens BUD13 homolog Proteins 0.000 description 1
- 101001049977 Homo sapiens Band 4.1-like protein 2 Proteins 0.000 description 1
- 101001049975 Homo sapiens Band 4.1-like protein 3 Proteins 0.000 description 1
- 101001049962 Homo sapiens Band 4.1-like protein 4B Proteins 0.000 description 1
- 101000894739 Homo sapiens Bardet-Biedl syndrome 12 protein Proteins 0.000 description 1
- 101000729827 Homo sapiens Barrier-to-autointegration factor-like protein Proteins 0.000 description 1
- 101001000001 Homo sapiens Basement membrane-specific heparan sulfate proteoglycan core protein Proteins 0.000 description 1
- 101000805924 Homo sapiens Basic helix-loop-helix domain-containing protein USF3 Proteins 0.000 description 1
- 101000903742 Homo sapiens Basic leucine zipper transcriptional factor ATF-like Proteins 0.000 description 1
- 101000697366 Homo sapiens Bestrophin-3 Proteins 0.000 description 1
- 101000937772 Homo sapiens Beta,beta-carotene 15,15'-dioxygenase Proteins 0.000 description 1
- 101000887642 Homo sapiens Beta-1,3-galactosyl-O-glycosyl-glycoprotein beta-1,6-N-acetylglucosaminyltransferase 4 Proteins 0.000 description 1
- 101000904597 Homo sapiens Beta-1,3-galactosyltransferase 5 Proteins 0.000 description 1
- 101000697896 Homo sapiens Beta-1,3-glucosyltransferase Proteins 0.000 description 1
- 101000766010 Homo sapiens Beta-1,4-N-acetylgalactosaminyltransferase 3 Proteins 0.000 description 1
- 101000919694 Homo sapiens Beta-Ala-His dipeptidase Proteins 0.000 description 1
- 101000773364 Homo sapiens Beta-alanine-activating enzyme Proteins 0.000 description 1
- 101000885652 Homo sapiens Beta-defensin 112 Proteins 0.000 description 1
- 101001139095 Homo sapiens Beta-klotho Proteins 0.000 description 1
- 101000859448 Homo sapiens Beta/gamma crystallin domain-containing protein 1 Proteins 0.000 description 1
- 101000859450 Homo sapiens Beta/gamma crystallin domain-containing protein 2 Proteins 0.000 description 1
- 101001025948 Homo sapiens Bifunctional peptidase and arginyl-hydroxylase JMJD5 Proteins 0.000 description 1
- 101000802825 Homo sapiens Biliverdin reductase A Proteins 0.000 description 1
- 101000935458 Homo sapiens Biogenesis of lysosome-related organelles complex 1 subunit 2 Proteins 0.000 description 1
- 101000762340 Homo sapiens Bladder cancer-associated protein Proteins 0.000 description 1
- 101000695294 Homo sapiens BolA-like protein 1 Proteins 0.000 description 1
- 101000934638 Homo sapiens Bone morphogenetic protein receptor type-1A Proteins 0.000 description 1
- 101000937756 Homo sapiens Box C/D snoRNA protein 1 Proteins 0.000 description 1
- 101000933364 Homo sapiens Brain protein I3 Proteins 0.000 description 1
- 101000935886 Homo sapiens Brain-specific angiogenesis inhibitor 1-associated protein 2-like protein 1 Proteins 0.000 description 1
- 101000935881 Homo sapiens Brain-specific angiogenesis inhibitor 1-associated protein 2-like protein 2 Proteins 0.000 description 1
- 101000935635 Homo sapiens Breast carcinoma-amplified sequence 1 Proteins 0.000 description 1
- 101000937839 Homo sapiens Bromo adjacent homology domain-containing 1 protein Proteins 0.000 description 1
- 101000971147 Homo sapiens Bromodomain adjacent to zinc finger domain protein 2A Proteins 0.000 description 1
- 101000896771 Homo sapiens Bromodomain and PHD finger-containing protein 3 Proteins 0.000 description 1
- 101000794040 Homo sapiens Bromodomain and WD repeat-containing protein 1 Proteins 0.000 description 1
- 101000794050 Homo sapiens Bromodomain and WD repeat-containing protein 3 Proteins 0.000 description 1
- 101000871850 Homo sapiens Bromodomain-containing protein 2 Proteins 0.000 description 1
- 101000984929 Homo sapiens Butyrophilin subfamily 1 member A1 Proteins 0.000 description 1
- 101000984917 Homo sapiens Butyrophilin subfamily 3 member A2 Proteins 0.000 description 1
- 101000934738 Homo sapiens Butyrophilin-like protein 2 Proteins 0.000 description 1
- 101000934742 Homo sapiens Butyrophilin-like protein 8 Proteins 0.000 description 1
- 101000964322 Homo sapiens C->U-editing enzyme APOBEC-2 Proteins 0.000 description 1
- 101000716068 Homo sapiens C-C chemokine receptor type 6 Proteins 0.000 description 1
- 101000978376 Homo sapiens C-C motif chemokine 15 Proteins 0.000 description 1
- 101000978375 Homo sapiens C-C motif chemokine 16 Proteins 0.000 description 1
- 101000713099 Homo sapiens C-C motif chemokine 20 Proteins 0.000 description 1
- 101000993081 Homo sapiens C-Maf-inducing protein Proteins 0.000 description 1
- 101000947174 Homo sapiens C-X-C chemokine receptor type 1 Proteins 0.000 description 1
- 101000889128 Homo sapiens C-X-C motif chemokine 2 Proteins 0.000 description 1
- 101000947193 Homo sapiens C-X-C motif chemokine 3 Proteins 0.000 description 1
- 101000947172 Homo sapiens C-X-C motif chemokine 9 Proteins 0.000 description 1
- 101000584310 Homo sapiens C-myc promoter-binding protein Proteins 0.000 description 1
- 101000867968 Homo sapiens C2 domain-containing protein 2 Proteins 0.000 description 1
- 101000740689 Homo sapiens C4b-binding protein beta chain Proteins 0.000 description 1
- 101000767059 Homo sapiens CAP-Gly domain-containing linker protein 2 Proteins 0.000 description 1
- 101100222250 Homo sapiens CATSPER3 gene Proteins 0.000 description 1
- 101000746131 Homo sapiens CBP80/20-dependent translation initiation factor Proteins 0.000 description 1
- 101000761495 Homo sapiens CBY1-interacting BAR domain-containing protein 2 Proteins 0.000 description 1
- 101000945965 Homo sapiens CCAAT/enhancer-binding protein delta Proteins 0.000 description 1
- 101000919672 Homo sapiens CCR4-NOT transcription complex subunit 1 Proteins 0.000 description 1
- 101000980829 Homo sapiens CD180 antigen Proteins 0.000 description 1
- 101000914499 Homo sapiens CD2-associated protein Proteins 0.000 description 1
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 1
- 101000914529 Homo sapiens CDAN1-interacting nuclease 1 Proteins 0.000 description 1
- 101000794294 Homo sapiens CDC42 small effector protein 2 Proteins 0.000 description 1
- 101000749431 Homo sapiens CKLF-like MARVEL transmembrane domain-containing protein 4 Proteins 0.000 description 1
- 101000749435 Homo sapiens CKLF-like MARVEL transmembrane domain-containing protein 6 Proteins 0.000 description 1
- 101000749308 Homo sapiens CKLF-like MARVEL transmembrane domain-containing protein 7 Proteins 0.000 description 1
- 101000888512 Homo sapiens CKLF-like MARVEL transmembrane domain-containing protein 8 Proteins 0.000 description 1
- 101000766839 Homo sapiens CLOCK-interacting pacemaker Proteins 0.000 description 1
- 101000914279 Homo sapiens CMT1A duplicated region transcript 4 protein Proteins 0.000 description 1
- 101000797557 Homo sapiens COBW domain-containing protein 1 Proteins 0.000 description 1
- 101000797558 Homo sapiens COBW domain-containing protein 2 Proteins 0.000 description 1
- 101000797562 Homo sapiens COBW domain-containing protein 3 Proteins 0.000 description 1
- 101000797561 Homo sapiens COBW domain-containing protein 5 Proteins 0.000 description 1
- 101000909581 Homo sapiens COMM domain-containing protein 2 Proteins 0.000 description 1
- 101000899983 Homo sapiens COMM domain-containing protein 7 Proteins 0.000 description 1
- 101000858667 Homo sapiens COP9 signalosome complex subunit 4 Proteins 0.000 description 1
- 101100275686 Homo sapiens CR2 gene Proteins 0.000 description 1
- 101000891901 Homo sapiens CREB-regulated transcription coactivator 2 Proteins 0.000 description 1
- 101000891906 Homo sapiens CREB-regulated transcription coactivator 3 Proteins 0.000 description 1
- 101000737742 Homo sapiens CUB domain-containing protein 1 Proteins 0.000 description 1
- 101000894809 Homo sapiens CUE domain-containing protein 1 Proteins 0.000 description 1
- 101000894806 Homo sapiens CUE domain-containing protein 2 Proteins 0.000 description 1
- 101000944442 Homo sapiens CUGBP Elav-like family member 2 Proteins 0.000 description 1
- 101000867952 Homo sapiens CWF19-like protein 2 Proteins 0.000 description 1
- 101000746022 Homo sapiens CX3C chemokine receptor 1 Proteins 0.000 description 1
- 101000955663 Homo sapiens CXXC motif containing zinc binding protein Proteins 0.000 description 1
- 101000947152 Homo sapiens CXXC-type zinc finger protein 4 Proteins 0.000 description 1
- 101000947154 Homo sapiens CXXC-type zinc finger protein 5 Proteins 0.000 description 1
- 101000912003 Homo sapiens CYFIP-related Rac1 interactor A Proteins 0.000 description 1
- 101000762238 Homo sapiens Cadherin-12 Proteins 0.000 description 1
- 101000762243 Homo sapiens Cadherin-13 Proteins 0.000 description 1
- 101000762247 Homo sapiens Cadherin-17 Proteins 0.000 description 1
- 101000899410 Homo sapiens Cadherin-19 Proteins 0.000 description 1
- 101000899459 Homo sapiens Cadherin-20 Proteins 0.000 description 1
- 101000794604 Homo sapiens Cadherin-6 Proteins 0.000 description 1
- 101000935111 Homo sapiens Cadherin-7 Proteins 0.000 description 1
- 101000935098 Homo sapiens Cadherin-9 Proteins 0.000 description 1
- 101000899450 Homo sapiens Cadherin-like protein 26 Proteins 0.000 description 1
- 101000737802 Homo sapiens Cadherin-related family member 3 Proteins 0.000 description 1
- 101000574820 Homo sapiens Calcium uptake protein 2, mitochondrial Proteins 0.000 description 1
- 101000888577 Homo sapiens Calcium-activated chloride channel regulator 4 Proteins 0.000 description 1
- 101001049859 Homo sapiens Calcium-activated potassium channel subunit alpha-1 Proteins 0.000 description 1
- 101001049845 Homo sapiens Calcium-activated potassium channel subunit beta-2 Proteins 0.000 description 1
- 101000714579 Homo sapiens Calcium-binding and coiled-coil domain-containing protein 2 Proteins 0.000 description 1
- 101000899411 Homo sapiens Calcium-binding protein 39 Proteins 0.000 description 1
- 101000867747 Homo sapiens Calcium-dependent secretion activator 1 Proteins 0.000 description 1
- 101000785236 Homo sapiens Calcium-transporting ATPase type 2C member 2 Proteins 0.000 description 1
- 101000913913 Homo sapiens Calcium/calmodulin-dependent protein kinase II inhibitor 1 Proteins 0.000 description 1
- 101001077334 Homo sapiens Calcium/calmodulin-dependent protein kinase type II subunit gamma Proteins 0.000 description 1
- 101000910297 Homo sapiens Caldesmon Proteins 0.000 description 1
- 101000901707 Homo sapiens Calmin Proteins 0.000 description 1
- 101000984164 Homo sapiens Calmodulin-1 Proteins 0.000 description 1
- 101000984150 Homo sapiens Calmodulin-2 Proteins 0.000 description 1
- 101000933777 Homo sapiens Calmodulin-3 Proteins 0.000 description 1
- 101000945309 Homo sapiens Calmodulin-binding transcription activator 1 Proteins 0.000 description 1
- 101000714692 Homo sapiens Calmodulin-like protein 3 Proteins 0.000 description 1
- 101000714684 Homo sapiens Calmodulin-like protein 4 Proteins 0.000 description 1
- 101000714353 Homo sapiens Calmodulin-like protein 5 Proteins 0.000 description 1
- 101000984149 Homo sapiens Calpain-10 Proteins 0.000 description 1
- 101000984469 Homo sapiens Calpain-13 Proteins 0.000 description 1
- 101000867692 Homo sapiens Calpain-2 catalytic subunit Proteins 0.000 description 1
- 101000793684 Homo sapiens Calpain-7 Proteins 0.000 description 1
- 101000793680 Homo sapiens Calpain-9 Proteins 0.000 description 1
- 101000945410 Homo sapiens Calponin-3 Proteins 0.000 description 1
- 101000916423 Homo sapiens Calsyntenin-1 Proteins 0.000 description 1
- 101000883291 Homo sapiens Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase 2 Proteins 0.000 description 1
- 101000793727 Homo sapiens Caprin-1 Proteins 0.000 description 1
- 101000855412 Homo sapiens Carbamoyl-phosphate synthase [ammonia], mitochondrial Proteins 0.000 description 1
- 101000867860 Homo sapiens Carbonic anhydrase 13 Proteins 0.000 description 1
- 101000714519 Homo sapiens Carbonic anhydrase 7 Proteins 0.000 description 1
- 101000910338 Homo sapiens Carbonic anhydrase 9 Proteins 0.000 description 1
- 101000714515 Homo sapiens Carbonic anhydrase-related protein Proteins 0.000 description 1
- 101000896985 Homo sapiens Carbonyl reductase [NADPH] 1 Proteins 0.000 description 1
- 101000725947 Homo sapiens Carboxy-terminal domain RNA polymerase II polypeptide A small phosphatase 2 Proteins 0.000 description 1
- 101000946524 Homo sapiens Carboxypeptidase B Proteins 0.000 description 1
- 101000910843 Homo sapiens Carboxypeptidase N catalytic chain Proteins 0.000 description 1
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 1
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 description 1
- 101000933083 Homo sapiens Carnosine N-methyltransferase Proteins 0.000 description 1
- 101000994700 Homo sapiens Casein kinase I isoform alpha Proteins 0.000 description 1
- 101000994694 Homo sapiens Casein kinase I isoform alpha-like Proteins 0.000 description 1
- 101001026336 Homo sapiens Casein kinase I isoform delta Proteins 0.000 description 1
- 101000916264 Homo sapiens Catenin delta-1 Proteins 0.000 description 1
- 101000761509 Homo sapiens Cathepsin K Proteins 0.000 description 1
- 101000983577 Homo sapiens Cathepsin L2 Proteins 0.000 description 1
- 101000859040 Homo sapiens Cation channel sperm-associated auxiliary subunit beta Proteins 0.000 description 1
- 101000740981 Homo sapiens Caveolin-2 Proteins 0.000 description 1
- 101000777781 Homo sapiens Cell adhesion molecule-related/down-regulated by oncogenes Proteins 0.000 description 1
- 101000914537 Homo sapiens Cell death-inducing p53-target protein 1 Proteins 0.000 description 1
- 101000777638 Homo sapiens Cell division cycle-associated 7-like protein Proteins 0.000 description 1
- 101000980905 Homo sapiens Cell division cycle-associated protein 2 Proteins 0.000 description 1
- 101000980907 Homo sapiens Cell division cycle-associated protein 3 Proteins 0.000 description 1
- 101000996823 Homo sapiens Cell surface A33 antigen Proteins 0.000 description 1
- 101000969553 Homo sapiens Cell surface glycoprotein CD200 receptor 1 Proteins 0.000 description 1
- 101000969556 Homo sapiens Cell surface glycoprotein CD200 receptor 2 Proteins 0.000 description 1
- 101001099865 Homo sapiens Cellular retinoic acid-binding protein 1 Proteins 0.000 description 1
- 101000980796 Homo sapiens Centriole, cilia and spindle-associated protein Proteins 0.000 description 1
- 101000737689 Homo sapiens Centrosomal protein CEP57L1 Proteins 0.000 description 1
- 101000687829 Homo sapiens Centrosomal protein POC5 Proteins 0.000 description 1
- 101001091251 Homo sapiens Centrosomal protein kizuna Proteins 0.000 description 1
- 101000908185 Homo sapiens Centrosomal protein of 120 kDa Proteins 0.000 description 1
- 101000908170 Homo sapiens Centrosomal protein of 126 kDa Proteins 0.000 description 1
- 101000908160 Homo sapiens Centrosomal protein of 162 kDa Proteins 0.000 description 1
- 101000715651 Homo sapiens Centrosomal protein of 19 kDa Proteins 0.000 description 1
- 101000945814 Homo sapiens Centrosomal protein of 83 kDa Proteins 0.000 description 1
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 description 1
- 101000788132 Homo sapiens Chemokine-like protein TAFA-4 Proteins 0.000 description 1
- 101000946430 Homo sapiens Chloride intracellular channel protein 1 Proteins 0.000 description 1
- 101000906639 Homo sapiens Chloride intracellular channel protein 2 Proteins 0.000 description 1
- 101000906636 Homo sapiens Chloride intracellular channel protein 4 Proteins 0.000 description 1
- 101000906624 Homo sapiens Chloride intracellular channel protein 5 Proteins 0.000 description 1
- 101000906631 Homo sapiens Chloride intracellular channel protein 6 Proteins 0.000 description 1
- 101000943088 Homo sapiens Choline dehydrogenase, mitochondrial Proteins 0.000 description 1
- 101000777314 Homo sapiens Choline kinase alpha Proteins 0.000 description 1
- 101000989606 Homo sapiens Cholinephosphotransferase 1 Proteins 0.000 description 1
- 101000989505 Homo sapiens Chondroitin sulfate synthase 3 Proteins 0.000 description 1
- 101000862639 Homo sapiens Chorion-specific transcription factor GCMa Proteins 0.000 description 1
- 101000797586 Homo sapiens Chromobox protein homolog 2 Proteins 0.000 description 1
- 101000777795 Homo sapiens Chromodomain Y-like protein Proteins 0.000 description 1
- 101000777787 Homo sapiens Chromodomain Y-like protein 2 Proteins 0.000 description 1
- 101000777047 Homo sapiens Chromodomain-helicase-DNA-binding protein 1 Proteins 0.000 description 1
- 101000777079 Homo sapiens Chromodomain-helicase-DNA-binding protein 2 Proteins 0.000 description 1
- 101000883736 Homo sapiens Chromodomain-helicase-DNA-binding protein 6 Proteins 0.000 description 1
- 101001139157 Homo sapiens Chromosome-associated kinesin KIF4A Proteins 0.000 description 1
- 101000907999 Homo sapiens Cilia- and flagella-associated protein 43 Proteins 0.000 description 1
- 101000914166 Homo sapiens Cilia- and flagella-associated protein 46 Proteins 0.000 description 1
- 101000944485 Homo sapiens Cilia- and flagella-associated protein 65 Proteins 0.000 description 1
- 101000944490 Homo sapiens Cilia- and flagella-associated protein 69 Proteins 0.000 description 1
- 101000776592 Homo sapiens Cilia- and flagella-associated protein 91 Proteins 0.000 description 1
- 101000910924 Homo sapiens Ciliary-associated calcium-binding coiled-coil protein 1 Proteins 0.000 description 1
- 101000851951 Homo sapiens Clathrin interactor 1 Proteins 0.000 description 1
- 101000749331 Homo sapiens Claudin-1 Proteins 0.000 description 1
- 101000888566 Homo sapiens Claudin-12 Proteins 0.000 description 1
- 101000888570 Homo sapiens Claudin-14 Proteins 0.000 description 1
- 101000888608 Homo sapiens Claudin-16 Proteins 0.000 description 1
- 101000749344 Homo sapiens Claudin-23 Proteins 0.000 description 1
- 101000882890 Homo sapiens Claudin-4 Proteins 0.000 description 1
- 101000912652 Homo sapiens Claudin-7 Proteins 0.000 description 1
- 101000912661 Homo sapiens Claudin-9 Proteins 0.000 description 1
- 101000907131 Homo sapiens Clavesin-2 Proteins 0.000 description 1
- 101000855366 Homo sapiens Cleavage and polyadenylation specificity factor subunit 6 Proteins 0.000 description 1
- 101000902167 Homo sapiens Clustered mitochondria protein homolog Proteins 0.000 description 1
- 101000940352 Homo sapiens Coactosin-like protein Proteins 0.000 description 1
- 101000918352 Homo sapiens Coagulation factor XIII A chain Proteins 0.000 description 1
- 101000918350 Homo sapiens Coagulation factor XIII B chain Proteins 0.000 description 1
- 101000860881 Homo sapiens Coatomer subunit delta Proteins 0.000 description 1
- 101000909614 Homo sapiens Coatomer subunit zeta-1 Proteins 0.000 description 1
- 101000977167 Homo sapiens Cobalamin trafficking protein CblD Proteins 0.000 description 1
- 101000715592 Homo sapiens Cocaine- and amphetamine-regulated transcript protein Proteins 0.000 description 1
- 101000748988 Homo sapiens Cochlin Proteins 0.000 description 1
- 101000896931 Homo sapiens Coenzyme Q-binding protein COQ10 homolog A, mitochondrial Proteins 0.000 description 1
- 101000932604 Homo sapiens Coiled-coil domain-containing protein 103 Proteins 0.000 description 1
- 101000868800 Homo sapiens Coiled-coil domain-containing protein 107 Proteins 0.000 description 1
- 101000868825 Homo sapiens Coiled-coil domain-containing protein 112 Proteins 0.000 description 1
- 101000868831 Homo sapiens Coiled-coil domain-containing protein 113 Proteins 0.000 description 1
- 101000777336 Homo sapiens Coiled-coil domain-containing protein 12 Proteins 0.000 description 1
- 101000772526 Homo sapiens Coiled-coil domain-containing protein 125 Proteins 0.000 description 1
- 101000777341 Homo sapiens Coiled-coil domain-containing protein 13 Proteins 0.000 description 1
- 101000737221 Homo sapiens Coiled-coil domain-containing protein 146 Proteins 0.000 description 1
- 101000715242 Homo sapiens Coiled-coil domain-containing protein 170 Proteins 0.000 description 1
- 101000715238 Homo sapiens Coiled-coil domain-containing protein 172 Proteins 0.000 description 1
- 101000715221 Homo sapiens Coiled-coil domain-containing protein 174 Proteins 0.000 description 1
- 101000772632 Homo sapiens Coiled-coil domain-containing protein 181 Proteins 0.000 description 1
- 101000868760 Homo sapiens Coiled-coil domain-containing protein 25 Proteins 0.000 description 1
- 101000896971 Homo sapiens Coiled-coil domain-containing protein 28A Proteins 0.000 description 1
- 101000777372 Homo sapiens Coiled-coil domain-containing protein 3 Proteins 0.000 description 1
- 101000897100 Homo sapiens Coiled-coil domain-containing protein 34 Proteins 0.000 description 1
- 101000910772 Homo sapiens Coiled-coil domain-containing protein 50 Proteins 0.000 description 1
- 101000737052 Homo sapiens Coiled-coil domain-containing protein 54 Proteins 0.000 description 1
- 101000777370 Homo sapiens Coiled-coil domain-containing protein 6 Proteins 0.000 description 1
- 101000946607 Homo sapiens Coiled-coil domain-containing protein 68 Proteins 0.000 description 1
- 101000978332 Homo sapiens Coiled-coil domain-containing protein 71 Proteins 0.000 description 1
- 101000868844 Homo sapiens Coiled-coil domain-containing protein 90B, mitochondrial Proteins 0.000 description 1
- 101000797737 Homo sapiens Coiled-coil domain-containing protein 91 Proteins 0.000 description 1
- 101000797732 Homo sapiens Coiled-coil domain-containing protein 92 Proteins 0.000 description 1
- 101000897079 Homo sapiens Coiled-coil domain-containing protein 97 Proteins 0.000 description 1
- 101000743767 Homo sapiens Coiled-coil domain-containing protein R3HCC1L Proteins 0.000 description 1
- 101000906987 Homo sapiens Coiled-coil-helix-coiled-coil-helix domain-containing protein 5 Proteins 0.000 description 1
- 101000901150 Homo sapiens Collagen alpha-1(IV) chain Proteins 0.000 description 1
- 101000941581 Homo sapiens Collagen alpha-1(VI) chain Proteins 0.000 description 1
- 101000860679 Homo sapiens Collagen alpha-1(XVII) chain Proteins 0.000 description 1
- 101000952998 Homo sapiens Collagen alpha-1(XXII) chain Proteins 0.000 description 1
- 101000770661 Homo sapiens Collagen alpha-1(XXVIII) chain Proteins 0.000 description 1
- 101000941594 Homo sapiens Collagen alpha-2(V) chain Proteins 0.000 description 1
- 101000746121 Homo sapiens Collagen triple helix repeat-containing protein 1 Proteins 0.000 description 1
- 101000909528 Homo sapiens Collectin-12 Proteins 0.000 description 1
- 101000920100 Homo sapiens Colorectal cancer-associated protein 1 Proteins 0.000 description 1
- 101000934939 Homo sapiens Complement C1q and tumor necrosis factor-related protein 9A Proteins 0.000 description 1
- 101000933670 Homo sapiens Complement C1q tumor necrosis factor-related protein 1 Proteins 0.000 description 1
- 101000933673 Homo sapiens Complement C1q tumor necrosis factor-related protein 3 Proteins 0.000 description 1
- 101000933641 Homo sapiens Complement C1q-like protein 3 Proteins 0.000 description 1
- 101000749892 Homo sapiens Complement component C8 alpha chain Proteins 0.000 description 1
- 101000856022 Homo sapiens Complement decay-accelerating factor Proteins 0.000 description 1
- 101000710032 Homo sapiens Complement factor B Proteins 0.000 description 1
- 101000859628 Homo sapiens Complexin-2 Proteins 0.000 description 1
- 101000749829 Homo sapiens Connector enhancer of kinase suppressor of ras 3 Proteins 0.000 description 1
- 101000920124 Homo sapiens Conserved oligomeric Golgi complex subunit 1 Proteins 0.000 description 1
- 101000770432 Homo sapiens Conserved oligomeric Golgi complex subunit 3 Proteins 0.000 description 1
- 101000876001 Homo sapiens Conserved oligomeric Golgi complex subunit 5 Proteins 0.000 description 1
- 101000771062 Homo sapiens Consortin Proteins 0.000 description 1
- 101000813317 Homo sapiens Constitutive coactivator of peroxisome proliferator-activated receptor gamma Proteins 0.000 description 1
- 101000909516 Homo sapiens Contactin-2 Proteins 0.000 description 1
- 101000749880 Homo sapiens Contactin-associated protein-like 4 Proteins 0.000 description 1
- 101000749883 Homo sapiens Contactin-associated protein-like 5 Proteins 0.000 description 1
- 101000748895 Homo sapiens Coordinator of PRMT5 and differentiation stimulator Proteins 0.000 description 1
- 101000941754 Homo sapiens Copine-1 Proteins 0.000 description 1
- 101000919220 Homo sapiens Copine-8 Proteins 0.000 description 1
- 101000919218 Homo sapiens Copine-9 Proteins 0.000 description 1
- 101000727865 Homo sapiens Copper transport protein ATOX1 Proteins 0.000 description 1
- 101001067929 Homo sapiens Core histone macro-H2A.1 Proteins 0.000 description 1
- 101000909804 Homo sapiens Cornifelin Proteins 0.000 description 1
- 101000957297 Homo sapiens Coronin-6 Proteins 0.000 description 1
- 101000941045 Homo sapiens Cortactin-binding protein 2 Proteins 0.000 description 1
- 101000889209 Homo sapiens Cortexin-3 Proteins 0.000 description 1
- 101000823488 Homo sapiens Cotranscriptional regulator FAM172A Proteins 0.000 description 1
- 101000980044 Homo sapiens Cryptic protein Proteins 0.000 description 1
- 101000741329 Homo sapiens Cullin-associated NEDD8-dissociated protein 1 Proteins 0.000 description 1
- 101000856239 Homo sapiens Cutaneous T-cell lymphoma-associated antigen 1 Proteins 0.000 description 1
- 101000855516 Homo sapiens Cyclic AMP-responsive element-binding protein 1 Proteins 0.000 description 1
- 101000745631 Homo sapiens Cyclic AMP-responsive element-binding protein 3-like protein 1 Proteins 0.000 description 1
- 101000745624 Homo sapiens Cyclic AMP-responsive element-binding protein 3-like protein 2 Proteins 0.000 description 1
- 101000895303 Homo sapiens Cyclic AMP-responsive element-binding protein 3-like protein 3 Proteins 0.000 description 1
- 101000726193 Homo sapiens Cyclic AMP-responsive element-binding protein 5 Proteins 0.000 description 1
- 101000804518 Homo sapiens Cyclin-D-binding Myb-like transcription factor 1 Proteins 0.000 description 1
- 101000713131 Homo sapiens Cyclin-J Proteins 0.000 description 1
- 101000944355 Homo sapiens Cyclin-dependent kinase 15 Proteins 0.000 description 1
- 101000944345 Homo sapiens Cyclin-dependent kinase 19 Proteins 0.000 description 1
- 101000737813 Homo sapiens Cyclin-dependent kinase 2-associated protein 1 Proteins 0.000 description 1
- 101000777764 Homo sapiens Cyclin-dependent kinase-like 2 Proteins 0.000 description 1
- 101000912205 Homo sapiens Cystatin-C Proteins 0.000 description 1
- 101000922020 Homo sapiens Cysteine and glycine-rich protein 1 Proteins 0.000 description 1
- 101000943802 Homo sapiens Cysteine and histidine-rich domain-containing protein 1 Proteins 0.000 description 1
- 101000856064 Homo sapiens Cysteine and tyrosine-rich protein 1 Proteins 0.000 description 1
- 101000942007 Homo sapiens Cysteine-rich C-terminal protein 1 Proteins 0.000 description 1
- 101000916674 Homo sapiens Cysteine-rich and transmembrane domain-containing protein 1 Proteins 0.000 description 1
- 101000895916 Homo sapiens Cysteine-rich protein 2-binding protein Proteins 0.000 description 1
- 101000726258 Homo sapiens Cysteine-rich secretory protein 3 Proteins 0.000 description 1
- 101000957711 Homo sapiens Cysteine-rich secretory protein LCCL domain-containing 1 Proteins 0.000 description 1
- 101000761960 Homo sapiens Cytochrome P450 11B1, mitochondrial Proteins 0.000 description 1
- 101000875398 Homo sapiens Cytochrome P450 26C1 Proteins 0.000 description 1
- 101000875170 Homo sapiens Cytochrome P450 2A6 Proteins 0.000 description 1
- 101000875173 Homo sapiens Cytochrome P450 2A7 Proteins 0.000 description 1
- 101000919360 Homo sapiens Cytochrome P450 2C18 Proteins 0.000 description 1
- 101000855328 Homo sapiens Cytochrome P450 2S1 Proteins 0.000 description 1
- 101000855331 Homo sapiens Cytochrome P450 2U1 Proteins 0.000 description 1
- 101000922386 Homo sapiens Cytochrome b5 Proteins 0.000 description 1
- 101000793979 Homo sapiens Cytochrome b5 domain-containing protein 1 Proteins 0.000 description 1
- 101000998613 Homo sapiens Cytochrome b5 reductase 4 Proteins 0.000 description 1
- 101000993410 Homo sapiens Cytochrome c oxidase assembly factor 4 homolog, mitochondrial Proteins 0.000 description 1
- 101000771297 Homo sapiens Cytochrome c oxidase assembly factor 7 Proteins 0.000 description 1
- 101000770621 Homo sapiens Cytochrome c oxidase assembly protein COX14 Proteins 0.000 description 1
- 101000725462 Homo sapiens Cytochrome c oxidase assembly protein COX18, mitochondrial Proteins 0.000 description 1
- 101000725442 Homo sapiens Cytochrome c oxidase assembly protein COX19 Proteins 0.000 description 1
- 101000957223 Homo sapiens Cytochrome c oxidase assembly protein COX20, mitochondrial Proteins 0.000 description 1
- 101000875933 Homo sapiens Cytochrome c oxidase copper chaperone Proteins 0.000 description 1
- 101000855214 Homo sapiens Cytochrome c oxidase subunit 4 isoform 2, mitochondrial Proteins 0.000 description 1
- 101000725076 Homo sapiens Cytochrome c oxidase subunit 5A, mitochondrial Proteins 0.000 description 1
- 101000915972 Homo sapiens Cytochrome c oxidase subunit 6A2, mitochondrial Proteins 0.000 description 1
- 101000856671 Homo sapiens Cytochrome c oxidase subunit 7B2, mitochondrial Proteins 0.000 description 1
- 101000870148 Homo sapiens Cytoglobin Proteins 0.000 description 1
- 101000956870 Homo sapiens Cytoplasmic FMR1-interacting protein 2 Proteins 0.000 description 1
- 101000915292 Homo sapiens Cytoplasmic dynein 1 intermediate chain 2 Proteins 0.000 description 1
- 101000745751 Homo sapiens Cytoplasmic polyadenylation element-binding protein 2 Proteins 0.000 description 1
- 101000745636 Homo sapiens Cytoplasmic polyadenylation element-binding protein 4 Proteins 0.000 description 1
- 101000924389 Homo sapiens Cytosol aminopeptidase Proteins 0.000 description 1
- 101000959030 Homo sapiens Cytosolic 10-formyltetrahydrofolate dehydrogenase Proteins 0.000 description 1
- 101000932634 Homo sapiens Cytosolic carboxypeptidase 2 Proteins 0.000 description 1
- 101000932590 Homo sapiens Cytosolic carboxypeptidase 4 Proteins 0.000 description 1
- 101000877468 Homo sapiens Cytosolic endo-beta-N-acetylglucosaminidase Proteins 0.000 description 1
- 101000919690 Homo sapiens Cytosolic non-specific dipeptidase Proteins 0.000 description 1
- 101000886242 Homo sapiens D-amino acid oxidase activator Proteins 0.000 description 1
- 101000903373 Homo sapiens D-beta-hydroxybutyrate dehydrogenase, mitochondrial Proteins 0.000 description 1
- 101000996136 Homo sapiens D-glutamate cyclase, mitochondrial Proteins 0.000 description 1
- 101000911746 Homo sapiens DCN1-like protein 1 Proteins 0.000 description 1
- 101000911716 Homo sapiens DCN1-like protein 3 Proteins 0.000 description 1
- 101000954846 Homo sapiens DCN1-like protein 4 Proteins 0.000 description 1
- 101000870904 Homo sapiens DENN domain-containing protein 1A Proteins 0.000 description 1
- 101000722280 Homo sapiens DENN domain-containing protein 2D Proteins 0.000 description 1
- 101000842747 Homo sapiens DENN domain-containing protein 3 Proteins 0.000 description 1
- 101000865183 Homo sapiens DEP domain-containing mTOR-interacting protein Proteins 0.000 description 1
- 101000964378 Homo sapiens DNA dC->dU-editing enzyme APOBEC-3A Proteins 0.000 description 1
- 101001041466 Homo sapiens DNA damage-binding protein 2 Proteins 0.000 description 1
- 101000912753 Homo sapiens DNA damage-inducible transcript 4 protein Proteins 0.000 description 1
- 101000898683 Homo sapiens DNA excision repair protein ERCC-6-like 2 Proteins 0.000 description 1
- 101000736065 Homo sapiens DNA replication complex GINS protein PSF2 Proteins 0.000 description 1
- 101001081590 Homo sapiens DNA-binding protein inhibitor ID-1 Proteins 0.000 description 1
- 101001081582 Homo sapiens DNA-binding protein inhibitor ID-2 Proteins 0.000 description 1
- 101001036287 Homo sapiens DNA-binding protein inhibitor ID-3 Proteins 0.000 description 1
- 101001036276 Homo sapiens DNA-binding protein inhibitor ID-4 Proteins 0.000 description 1
- 101000870895 Homo sapiens DNA-directed RNA polymerase II subunit GRINL1A Proteins 0.000 description 1
- 101001037037 Homo sapiens DNA-directed RNA polymerase II subunit GRINL1A, isoforms 4/5 Proteins 0.000 description 1
- 101000862412 Homo sapiens DOMON domain-containing protein FRRS1L Proteins 0.000 description 1
- 101001049997 Homo sapiens DPY30 domain-containing protein 2 Proteins 0.000 description 1
- 101000856025 Homo sapiens Dapper homolog 2 Proteins 0.000 description 1
- 101000866268 Homo sapiens Dedicator of cytokinesis protein 10 Proteins 0.000 description 1
- 101000866270 Homo sapiens Dedicator of cytokinesis protein 11 Proteins 0.000 description 1
- 101001052955 Homo sapiens Dedicator of cytokinesis protein 4 Proteins 0.000 description 1
- 101001052956 Homo sapiens Dedicator of cytokinesis protein 5 Proteins 0.000 description 1
- 101001052952 Homo sapiens Dedicator of cytokinesis protein 7 Proteins 0.000 description 1
- 101001041589 Homo sapiens Defensin-5 Proteins 0.000 description 1
- 101000865479 Homo sapiens Defensin-6 Proteins 0.000 description 1
- 101000955042 Homo sapiens Deoxycytidylate deaminase Proteins 0.000 description 1
- 101000832260 Homo sapiens Dephospho-CoA kinase domain-containing protein Proteins 0.000 description 1
- 101000929047 Homo sapiens Dermatopontin Proteins 0.000 description 1
- 101000968042 Homo sapiens Desmocollin-2 Proteins 0.000 description 1
- 101000880960 Homo sapiens Desmocollin-3 Proteins 0.000 description 1
- 101000924316 Homo sapiens Desmoglein-1 Proteins 0.000 description 1
- 101000924314 Homo sapiens Desmoglein-2 Proteins 0.000 description 1
- 101000924320 Homo sapiens Desmoglein-4 Proteins 0.000 description 1
- 101000928060 Homo sapiens Deubiquitinase DESI2 Proteins 0.000 description 1
- 101000881866 Homo sapiens Developmental pluripotency-associated protein 3 Proteins 0.000 description 1
- 101000881868 Homo sapiens Developmental pluripotency-associated protein 4 Proteins 0.000 description 1
- 101000930020 Homo sapiens Diacylglycerol O-acyltransferase 2 Proteins 0.000 description 1
- 101000864646 Homo sapiens Dickkopf-related protein 1 Proteins 0.000 description 1
- 101000830440 Homo sapiens Differentially expressed in FDCP 6 homolog Proteins 0.000 description 1
- 101000930818 Homo sapiens Dihydropyrimidinase Proteins 0.000 description 1
- 101001053501 Homo sapiens Dihydropyrimidinase-related protein 3 Proteins 0.000 description 1
- 101001053490 Homo sapiens Dihydropyrimidinase-related protein 4 Proteins 0.000 description 1
- 101000902632 Homo sapiens Dihydropyrimidine dehydrogenase [NADP(+)] Proteins 0.000 description 1
- 101001005618 Homo sapiens Dimethylglycine dehydrogenase, mitochondrial Proteins 0.000 description 1
- 101000793922 Homo sapiens Dipeptidyl peptidase 1 Proteins 0.000 description 1
- 101000908391 Homo sapiens Dipeptidyl peptidase 4 Proteins 0.000 description 1
- 101000805871 Homo sapiens Disco-interacting protein 2 homolog B Proteins 0.000 description 1
- 101000805870 Homo sapiens Disco-interacting protein 2 homolog C Proteins 0.000 description 1
- 101000911798 Homo sapiens Discoidin, CUB and LCCL domain-containing protein 1 Proteins 0.000 description 1
- 101000756722 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 22 Proteins 0.000 description 1
- 101000832771 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 7 Proteins 0.000 description 1
- 101001053980 Homo sapiens Disks large homolog 2 Proteins 0.000 description 1
- 101000844784 Homo sapiens Disks large-associated protein 1 Proteins 0.000 description 1
- 101000844782 Homo sapiens Disks large-associated protein 2 Proteins 0.000 description 1
- 101000951335 Homo sapiens Disks large-associated protein 4 Proteins 0.000 description 1
- 101000902072 Homo sapiens Disrupted in schizophrenia 1 protein Proteins 0.000 description 1
- 101000930299 Homo sapiens Distal membrane-arm assembly complex protein 1 Proteins 0.000 description 1
- 101000951250 Homo sapiens Dixin Proteins 0.000 description 1
- 101000804531 Homo sapiens DmX-like protein 1 Proteins 0.000 description 1
- 101000804534 Homo sapiens DmX-like protein 2 Proteins 0.000 description 1
- 101000908037 Homo sapiens DnaJ homolog subfamily B member 13 Proteins 0.000 description 1
- 101000908034 Homo sapiens DnaJ homolog subfamily B member 14 Proteins 0.000 description 1
- 101000804114 Homo sapiens DnaJ homolog subfamily B member 7 Proteins 0.000 description 1
- 101000908069 Homo sapiens DnaJ homolog subfamily C member 11 Proteins 0.000 description 1
- 101000870234 Homo sapiens DnaJ homolog subfamily C member 12 Proteins 0.000 description 1
- 101000870239 Homo sapiens DnaJ homolog subfamily C member 13 Proteins 0.000 description 1
- 101000870172 Homo sapiens DnaJ homolog subfamily C member 15 Proteins 0.000 description 1
- 101000902076 Homo sapiens DnaJ homolog subfamily C member 18 Proteins 0.000 description 1
- 101000902105 Homo sapiens DnaJ homolog subfamily C member 22 Proteins 0.000 description 1
- 101000845893 Homo sapiens DnaJ homolog subfamily C member 5 Proteins 0.000 description 1
- 101000909016 Homo sapiens DnaJ homolog subfamily C member 5B Proteins 0.000 description 1
- 101000903036 Homo sapiens DnaJ homolog subfamily C member 9 Proteins 0.000 description 1
- 101000845690 Homo sapiens Docking protein 4 Proteins 0.000 description 1
- 101000742223 Homo sapiens Double-stranded RNA-specific editase 1 Proteins 0.000 description 1
- 101000880945 Homo sapiens Down syndrome cell adhesion molecule Proteins 0.000 description 1
- 101000838329 Homo sapiens Dual specificity phosphatase 29 Proteins 0.000 description 1
- 101000881114 Homo sapiens Dual specificity protein phosphatase 15 Proteins 0.000 description 1
- 101000881099 Homo sapiens Dual specificity protein phosphatase 18 Proteins 0.000 description 1
- 101000924011 Homo sapiens Dual specificity protein phosphatase 21 Proteins 0.000 description 1
- 101001057612 Homo sapiens Dual specificity protein phosphatase 5 Proteins 0.000 description 1
- 101001057603 Homo sapiens Dual specificity protein phosphatase 7 Proteins 0.000 description 1
- 101000932592 Homo sapiens Dual specificity protein phosphatase CDC14B Proteins 0.000 description 1
- 101001049990 Homo sapiens Dual specificity tyrosine-phosphorylation-regulated kinase 2 Proteins 0.000 description 1
- 101001016198 Homo sapiens Dynein axonemal heavy chain 1 Proteins 0.000 description 1
- 101001016205 Homo sapiens Dynein axonemal heavy chain 10 Proteins 0.000 description 1
- 101001016208 Homo sapiens Dynein axonemal heavy chain 11 Proteins 0.000 description 1
- 101001016209 Homo sapiens Dynein axonemal heavy chain 12 Proteins 0.000 description 1
- 101001016203 Homo sapiens Dynein axonemal heavy chain 17 Proteins 0.000 description 1
- 101000866373 Homo sapiens Dynein axonemal heavy chain 6 Proteins 0.000 description 1
- 101000866372 Homo sapiens Dynein axonemal heavy chain 7 Proteins 0.000 description 1
- 101001054264 Homo sapiens Dynein heavy chain domain-containing protein 1 Proteins 0.000 description 1
- 101000908706 Homo sapiens Dynein light chain 2, cytoplasmic Proteins 0.000 description 1
- 101000908373 Homo sapiens Dynein regulatory complex protein 1 Proteins 0.000 description 1
- 101000880830 Homo sapiens Dynein regulatory complex protein 8 Proteins 0.000 description 1
- 101000908413 Homo sapiens Dynein regulatory complex subunit 2 Proteins 0.000 description 1
- 101001053689 Homo sapiens Dystrobrevin alpha Proteins 0.000 description 1
- 101000931797 Homo sapiens Dystrophin-related protein 2 Proteins 0.000 description 1
- 101001015949 Homo sapiens E2F-associated phosphoprotein Proteins 0.000 description 1
- 101000776154 Homo sapiens E3 ubiquitin-protein ligase AMFR Proteins 0.000 description 1
- 101001009246 Homo sapiens E3 ubiquitin-protein ligase HACE1 Proteins 0.000 description 1
- 101000872880 Homo sapiens E3 ubiquitin-protein ligase HECTD1 Proteins 0.000 description 1
- 101000872869 Homo sapiens E3 ubiquitin-protein ligase HECW1 Proteins 0.000 description 1
- 101000872871 Homo sapiens E3 ubiquitin-protein ligase HECW2 Proteins 0.000 description 1
- 101000994641 Homo sapiens E3 ubiquitin-protein ligase KCMF1 Proteins 0.000 description 1
- 101000650325 Homo sapiens E3 ubiquitin-protein ligase RNF19B Proteins 0.000 description 1
- 101000650316 Homo sapiens E3 ubiquitin-protein ligase RNF213 Proteins 0.000 description 1
- 101000734284 Homo sapiens E3 ubiquitin-protein ligase RNF220 Proteins 0.000 description 1
- 101000880372 Homo sapiens EF-hand calcium-binding domain-containing protein 1 Proteins 0.000 description 1
- 101000967379 Homo sapiens EF-hand calcium-binding domain-containing protein 12 Proteins 0.000 description 1
- 101000880228 Homo sapiens EF-hand calcium-binding domain-containing protein 13 Proteins 0.000 description 1
- 101000925434 Homo sapiens EF-hand calcium-binding domain-containing protein 3 Proteins 0.000 description 1
- 101000880368 Homo sapiens EF-hand calcium-binding domain-containing protein 4B Proteins 0.000 description 1
- 101000840931 Homo sapiens EF-hand domain-containing family member C2 Proteins 0.000 description 1
- 101000866913 Homo sapiens EF-hand domain-containing protein D2 Proteins 0.000 description 1
- 101001065272 Homo sapiens EGF-containing fibulin-like extracellular matrix protein 1 Proteins 0.000 description 1
- 101001012951 Homo sapiens EH domain-binding protein 1 Proteins 0.000 description 1
- 101000921221 Homo sapiens EH domain-containing protein 1 Proteins 0.000 description 1
- 101000921218 Homo sapiens EH domain-containing protein 4 Proteins 0.000 description 1
- 101000921278 Homo sapiens EMILIN-2 Proteins 0.000 description 1
- 101000882393 Homo sapiens ENTH domain-containing protein 1 Proteins 0.000 description 1
- 101000881670 Homo sapiens EP300-interacting inhibitor of differentiation 1 Proteins 0.000 description 1
- 101000895701 Homo sapiens ER degradation-enhancing alpha-mannosidase-like protein 1 Proteins 0.000 description 1
- 101001016391 Homo sapiens ER degradation-enhancing alpha-mannosidase-like protein 3 Proteins 0.000 description 1
- 101000920812 Homo sapiens ERBB receptor feedback inhibitor 1 Proteins 0.000 description 1
- 101000938692 Homo sapiens ESF1 homolog Proteins 0.000 description 1
- 101001048716 Homo sapiens ETS domain-containing protein Elk-4 Proteins 0.000 description 1
- 101000921245 Homo sapiens ETS homologous factor Proteins 0.000 description 1
- 101000813729 Homo sapiens ETS translocation variant 1 Proteins 0.000 description 1
- 101000813726 Homo sapiens ETS translocation variant 3 Proteins 0.000 description 1
- 101000813747 Homo sapiens ETS translocation variant 4 Proteins 0.000 description 1
- 101000877395 Homo sapiens ETS-related transcription factor Elf-1 Proteins 0.000 description 1
- 101001050162 Homo sapiens Early endosome antigen 1 Proteins 0.000 description 1
- 101001049697 Homo sapiens Early growth response protein 1 Proteins 0.000 description 1
- 101001057941 Homo sapiens Echinoderm microtubule-associated protein-like 1 Proteins 0.000 description 1
- 101001011835 Homo sapiens Echinoderm microtubule-associated protein-like 6 Proteins 0.000 description 1
- 101000852006 Homo sapiens Ectonucleoside triphosphate diphosphohydrolase 7 Proteins 0.000 description 1
- 101000897035 Homo sapiens Ectonucleotide pyrophosphatase/phosphodiesterase family member 2 Proteins 0.000 description 1
- 101000881648 Homo sapiens Egl nine homolog 1 Proteins 0.000 description 1
- 101001010541 Homo sapiens Electron transfer flavoprotein subunit alpha, mitochondrial Proteins 0.000 description 1
- 101001057122 Homo sapiens Electron transfer flavoprotein subunit beta Proteins 0.000 description 1
- 101000920874 Homo sapiens Electron transfer flavoprotein-ubiquinone oxidoreductase, mitochondrial Proteins 0.000 description 1
- 101000920078 Homo sapiens Elongation factor 1-alpha 1 Proteins 0.000 description 1
- 101001050451 Homo sapiens Elongation factor 1-gamma Proteins 0.000 description 1
- 101000866914 Homo sapiens Elongation factor-like GTPase 1 Proteins 0.000 description 1
- 101000813103 Homo sapiens Elongation of very long chain fatty acids protein 7 Proteins 0.000 description 1
- 101000877382 Homo sapiens Elongator complex protein 3 Proteins 0.000 description 1
- 101001057143 Homo sapiens Ena/VASP-like protein Proteins 0.000 description 1
- 101001011818 Homo sapiens Endoplasmic reticulum membrane-associated RNA degradation protein Proteins 0.000 description 1
- 101000920804 Homo sapiens Endoplasmic reticulum-Golgi intermediate compartment protein 1 Proteins 0.000 description 1
- 101000920800 Homo sapiens Endoplasmic reticulum-Golgi intermediate compartment protein 2 Proteins 0.000 description 1
- 101000925880 Homo sapiens Endosome/lysosome-associated apoptosis and autophagy regulator 1 Proteins 0.000 description 1
- 101000841213 Homo sapiens Endothelin-3 Proteins 0.000 description 1
- 101000841259 Homo sapiens Endothelin-converting enzyme 1 Proteins 0.000 description 1
- 101000880050 Homo sapiens Enhancer of mRNA-decapping protein 3 Proteins 0.000 description 1
- 101000919883 Homo sapiens Enoyl-CoA hydratase domain-containing protein 2, mitochondrial Proteins 0.000 description 1
- 101000898673 Homo sapiens Ephrin type-A receptor 10 Proteins 0.000 description 1
- 101001064458 Homo sapiens Ephrin type-B receptor 3 Proteins 0.000 description 1
- 101001049392 Homo sapiens Ephrin-B2 Proteins 0.000 description 1
- 101000812405 Homo sapiens Epoxide hydrolase 4 Proteins 0.000 description 1
- 101001056745 Homo sapiens Equatorin Proteins 0.000 description 1
- 101001063322 Homo sapiens Ermin Proteins 0.000 description 1
- 101001066268 Homo sapiens Erythroid transcription factor Proteins 0.000 description 1
- 101000920831 Homo sapiens Estrogen-related receptor gamma Proteins 0.000 description 1
- 101000851051 Homo sapiens Ethanolamine kinase 2 Proteins 0.000 description 1
- 101000841277 Homo sapiens Ethylmalonyl-CoA decarboxylase Proteins 0.000 description 1
- 101000895759 Homo sapiens Eukaryotic elongation factor 2 kinase Proteins 0.000 description 1
- 101001044475 Homo sapiens Eukaryotic initiation factor 4A-II Proteins 0.000 description 1
- 101000938790 Homo sapiens Eukaryotic peptide chain release factor subunit 1 Proteins 0.000 description 1
- 101001036349 Homo sapiens Eukaryotic translation initiation factor 1A, X-chromosomal Proteins 0.000 description 1
- 101000926508 Homo sapiens Eukaryotic translation initiation factor 2-alpha kinase 3 Proteins 0.000 description 1
- 101000925957 Homo sapiens Eukaryotic translation initiation factor 3 subunit A Proteins 0.000 description 1
- 101000896557 Homo sapiens Eukaryotic translation initiation factor 3 subunit B Proteins 0.000 description 1
- 101000840282 Homo sapiens Eukaryotic translation initiation factor 4B Proteins 0.000 description 1
- 101001002419 Homo sapiens Eukaryotic translation initiation factor 5A-2 Proteins 0.000 description 1
- 101001036496 Homo sapiens Eukaryotic translation initiation factor 5B Proteins 0.000 description 1
- 101000959746 Homo sapiens Eukaryotic translation initiation factor 6 Proteins 0.000 description 1
- 101000851494 Homo sapiens Ewing's tumor-associated antigen 1 Proteins 0.000 description 1
- 101000911703 Homo sapiens Exocyst complex component 5 Proteins 0.000 description 1
- 101000911670 Homo sapiens Exocyst complex component 6 Proteins 0.000 description 1
- 101001055989 Homo sapiens Exosome complex component RRP43 Proteins 0.000 description 1
- 101001055965 Homo sapiens Exosome complex component RRP45 Proteins 0.000 description 1
- 101000875556 Homo sapiens Exostosin-like 3 Proteins 0.000 description 1
- 101000851512 Homo sapiens Extended synaptotagmin-3 Proteins 0.000 description 1
- 101001029168 Homo sapiens Extracellular matrix organizing protein FRAS1 Proteins 0.000 description 1
- 101001050211 Homo sapiens Extracellular matrix protein 2 Proteins 0.000 description 1
- 101000937709 Homo sapiens Extracellular serine/threonine protein kinase FAM20C Proteins 0.000 description 1
- 101000938441 Homo sapiens Eyes absent homolog 3 Proteins 0.000 description 1
- 101000892420 Homo sapiens F-BAR and double SH3 domains protein 2 Proteins 0.000 description 1
- 101001030672 Homo sapiens F-BAR domain only protein 2 Proteins 0.000 description 1
- 101000983575 Homo sapiens F-actin-capping protein subunit alpha-3 Proteins 0.000 description 1
- 101000793778 Homo sapiens F-actin-capping protein subunit beta Proteins 0.000 description 1
- 101000914283 Homo sapiens F-box and WD repeat domain containing protein 10B Proteins 0.000 description 1
- 101000878641 Homo sapiens F-box only protein 16 Proteins 0.000 description 1
- 101000878584 Homo sapiens F-box only protein 17 Proteins 0.000 description 1
- 101000824144 Homo sapiens F-box only protein 25 Proteins 0.000 description 1
- 101000824171 Homo sapiens F-box only protein 27 Proteins 0.000 description 1
- 101000824152 Homo sapiens F-box only protein 28 Proteins 0.000 description 1
- 101000824114 Homo sapiens F-box only protein 31 Proteins 0.000 description 1
- 101000892323 Homo sapiens F-box only protein 32 Proteins 0.000 description 1
- 101000892310 Homo sapiens F-box only protein 38 Proteins 0.000 description 1
- 101000892313 Homo sapiens F-box only protein 39 Proteins 0.000 description 1
- 101001052797 Homo sapiens F-box only protein 5 Proteins 0.000 description 1
- 101001052796 Homo sapiens F-box only protein 6 Proteins 0.000 description 1
- 101000885595 Homo sapiens F-box/LRR-repeat protein 14 Proteins 0.000 description 1
- 101000862204 Homo sapiens F-box/LRR-repeat protein 18 Proteins 0.000 description 1
- 101001026881 Homo sapiens F-box/LRR-repeat protein 2 Proteins 0.000 description 1
- 101000862163 Homo sapiens F-box/LRR-repeat protein 20 Proteins 0.000 description 1
- 101001060244 Homo sapiens F-box/WD repeat-containing protein 4 Proteins 0.000 description 1
- 101001028247 Homo sapiens FAST kinase domain-containing protein 3, mitochondrial Proteins 0.000 description 1
- 101001060993 Homo sapiens FERM and PDZ domain-containing protein 2 Proteins 0.000 description 1
- 101001030544 Homo sapiens FERM domain-containing protein 1 Proteins 0.000 description 1
- 101001030545 Homo sapiens FERM domain-containing protein 3 Proteins 0.000 description 1
- 101001030539 Homo sapiens FERM domain-containing protein 5 Proteins 0.000 description 1
- 101001030537 Homo sapiens FERM domain-containing protein 6 Proteins 0.000 description 1
- 101001023114 Homo sapiens FERM domain-containing protein 7 Proteins 0.000 description 1
- 101001021984 Homo sapiens FERM domain-containing protein 8 Proteins 0.000 description 1
- 101001060553 Homo sapiens FH2 domain-containing protein 1 Proteins 0.000 description 1
- 101001027535 Homo sapiens FHF complex subunit HOOK interacting protein 1B Proteins 0.000 description 1
- 101001027519 Homo sapiens FHF complex subunit HOOK interacting protein 2A Proteins 0.000 description 1
- 101000877894 Homo sapiens FRAS1-related extracellular matrix protein 2 Proteins 0.000 description 1
- 101001030528 Homo sapiens FSD1-like protein Proteins 0.000 description 1
- 101001022170 Homo sapiens FYN-binding protein 2 Proteins 0.000 description 1
- 101000914673 Homo sapiens Fanconi anemia group A protein Proteins 0.000 description 1
- 101000848174 Homo sapiens Fanconi anemia group I protein Proteins 0.000 description 1
- 101000937693 Homo sapiens Fatty acid 2-hydroxylase Proteins 0.000 description 1
- 101001066086 Homo sapiens Fatty acid hydroxylase domain-containing protein 2 Proteins 0.000 description 1
- 101000892451 Homo sapiens Fc receptor-like B Proteins 0.000 description 1
- 101000846910 Homo sapiens Fc receptor-like protein 3 Proteins 0.000 description 1
- 101001029786 Homo sapiens Feline leukemia virus subgroup C receptor-related protein 1 Proteins 0.000 description 1
- 101000892916 Homo sapiens Fer-1-like protein 6 Proteins 0.000 description 1
- 101000892670 Homo sapiens Fermitin family homolog 1 Proteins 0.000 description 1
- 101000862406 Homo sapiens Ferric-chelate reductase 1 Proteins 0.000 description 1
- 101001031604 Homo sapiens Ferritin heavy polypeptide-like 17 Proteins 0.000 description 1
- 101000818014 Homo sapiens Ferroptosis suppressor protein 1 Proteins 0.000 description 1
- 101000912440 Homo sapiens Fez family zinc finger protein 2 Proteins 0.000 description 1
- 101000846244 Homo sapiens Fibrinogen alpha chain Proteins 0.000 description 1
- 101001031635 Homo sapiens Fibrinogen-like protein 1 Proteins 0.000 description 1
- 101000917234 Homo sapiens Fibroblast growth factor 12 Proteins 0.000 description 1
- 101000878181 Homo sapiens Fibroblast growth factor 14 Proteins 0.000 description 1
- 101000846394 Homo sapiens Fibroblast growth factor 19 Proteins 0.000 description 1
- 101001051973 Homo sapiens Fibroblast growth factor 23 Proteins 0.000 description 1
- 101000818410 Homo sapiens Fibroblast growth factor receptor substrate 2 Proteins 0.000 description 1
- 101001031613 Homo sapiens Fibroleukin Proteins 0.000 description 1
- 101001027128 Homo sapiens Fibronectin Proteins 0.000 description 1
- 101001030525 Homo sapiens Fibronectin type III and SPRY domain-containing protein 2 Proteins 0.000 description 1
- 101000913642 Homo sapiens Fibronectin type III domain-containing protein 3B Proteins 0.000 description 1
- 101000913695 Homo sapiens Fibronectin type III domain-containing protein 7 Proteins 0.000 description 1
- 101001021962 Homo sapiens Fibrous sheath CABYR-binding protein Proteins 0.000 description 1
- 101000862364 Homo sapiens Fibrous sheath-interacting protein 1 Proteins 0.000 description 1
- 101000862369 Homo sapiens Fibrous sheath-interacting protein 2 Proteins 0.000 description 1
- 101001060252 Homo sapiens Fibulin-5 Proteins 0.000 description 1
- 101000878304 Homo sapiens Filamin-A-interacting protein 1 Proteins 0.000 description 1
- 101000913551 Homo sapiens Filamin-B Proteins 0.000 description 1
- 101000913557 Homo sapiens Filamin-C Proteins 0.000 description 1
- 101001022794 Homo sapiens Flavin-containing monooxygenase 5 Proteins 0.000 description 1
- 101001059623 Homo sapiens Folliculin-interacting protein 1 Proteins 0.000 description 1
- 101000818727 Homo sapiens Forkhead box protein B1 Proteins 0.000 description 1
- 101000818310 Homo sapiens Forkhead box protein C1 Proteins 0.000 description 1
- 101001029314 Homo sapiens Forkhead box protein D2 Proteins 0.000 description 1
- 101001029308 Homo sapiens Forkhead box protein D3 Proteins 0.000 description 1
- 101001029302 Homo sapiens Forkhead box protein D4 Proteins 0.000 description 1
- 101001025074 Homo sapiens Forkhead box protein D4-like 1 Proteins 0.000 description 1
- 101000931489 Homo sapiens Forkhead box protein E3 Proteins 0.000 description 1
- 101000892910 Homo sapiens Forkhead box protein J1 Proteins 0.000 description 1
- 101001023387 Homo sapiens Forkhead box protein J3 Proteins 0.000 description 1
- 101001023352 Homo sapiens Forkhead box protein L1 Proteins 0.000 description 1
- 101000907593 Homo sapiens Forkhead box protein N2 Proteins 0.000 description 1
- 101001059893 Homo sapiens Forkhead box protein P1 Proteins 0.000 description 1
- 101000861403 Homo sapiens Forkhead box protein P4 Proteins 0.000 description 1
- 101000861406 Homo sapiens Forkhead box protein Q1 Proteins 0.000 description 1
- 101001062403 Homo sapiens Forkhead box protein S1 Proteins 0.000 description 1
- 101000892722 Homo sapiens Formin-binding protein 1 Proteins 0.000 description 1
- 101001059384 Homo sapiens Formin-like protein 2 Proteins 0.000 description 1
- 101000890783 Homo sapiens Four and a half LIM domains protein 5 Proteins 0.000 description 1
- 101000819451 Homo sapiens Frizzled-10 Proteins 0.000 description 1
- 101000885581 Homo sapiens Frizzled-4 Proteins 0.000 description 1
- 101000885585 Homo sapiens Frizzled-5 Proteins 0.000 description 1
- 101000885797 Homo sapiens Frizzled-7 Proteins 0.000 description 1
- 101000819791 Homo sapiens Fucose mutarotase Proteins 0.000 description 1
- 101000918487 Homo sapiens Fumarylacetoacetase Proteins 0.000 description 1
- 101000824573 Homo sapiens Fumarylacetoacetate hydrolase domain-containing protein 2A Proteins 0.000 description 1
- 101001034116 Homo sapiens G patch domain-containing protein 1 Proteins 0.000 description 1
- 101001034114 Homo sapiens G patch domain-containing protein 2 Proteins 0.000 description 1
- 101000996783 Homo sapiens G-protein coupled receptor 135 Proteins 0.000 description 1
- 101000829794 Homo sapiens G-protein coupled receptor 15 Proteins 0.000 description 1
- 101001039303 Homo sapiens G-protein coupled receptor 157 Proteins 0.000 description 1
- 101000857756 Homo sapiens G-protein coupled receptor 161 Proteins 0.000 description 1
- 101001040723 Homo sapiens G-protein coupled receptor 176 Proteins 0.000 description 1
- 101001066101 Homo sapiens G-protein coupled receptor 37-like 1 Proteins 0.000 description 1
- 101000871151 Homo sapiens G-protein coupled receptor 55 Proteins 0.000 description 1
- 101001014685 Homo sapiens G-protein coupled receptor family C group 5 member C Proteins 0.000 description 1
- 101001021410 Homo sapiens G-protein coupled receptor-associated sorting protein 1 Proteins 0.000 description 1
- 101000904754 Homo sapiens G-protein-signaling modulator 2 Proteins 0.000 description 1
- 101001000828 Homo sapiens G2/M phase-specific E3 ubiquitin-protein ligase Proteins 0.000 description 1
- 101000926786 Homo sapiens GATA zinc finger domain-containing protein 1 Proteins 0.000 description 1
- 101000997961 Homo sapiens GDNF family receptor alpha-1 Proteins 0.000 description 1
- 101001038365 Homo sapiens GDNF family receptor alpha-4 Proteins 0.000 description 1
- 101001038371 Homo sapiens GDNF family receptor alpha-like Proteins 0.000 description 1
- 101000886770 Homo sapiens GH3 domain-containing protein Proteins 0.000 description 1
- 101001040774 Homo sapiens GMP reductase 2 Proteins 0.000 description 1
- 101001071425 Homo sapiens GRAM domain-containing protein 2A Proteins 0.000 description 1
- 101001071433 Homo sapiens GRAM domain-containing protein 2B Proteins 0.000 description 1
- 101001024902 Homo sapiens GRB2-associated-binding protein 2 Proteins 0.000 description 1
- 101000904872 Homo sapiens GREB1-like protein Proteins 0.000 description 1
- 101001068303 Homo sapiens GS homeobox 1 Proteins 0.000 description 1
- 101001068302 Homo sapiens GS homeobox 2 Proteins 0.000 description 1
- 101000862581 Homo sapiens GTP cyclohydrolase 1 Proteins 0.000 description 1
- 101000998053 Homo sapiens GTP:AMP phosphotransferase AK3, mitochondrial Proteins 0.000 description 1
- 101000898754 Homo sapiens GTPase Era, mitochondrial Proteins 0.000 description 1
- 101000833390 Homo sapiens GTPase IMAP family member 7 Proteins 0.000 description 1
- 101000893879 Homo sapiens Galactosylceramide sulfotransferase Proteins 0.000 description 1
- 101001066300 Homo sapiens Galanin-like peptide Proteins 0.000 description 1
- 101001004750 Homo sapiens Galectin-related protein Proteins 0.000 description 1
- 101000799011 Homo sapiens Gamma-adducin Proteins 0.000 description 1
- 101000934612 Homo sapiens Gamma-butyrobetaine dioxygenase Proteins 0.000 description 1
- 101001133924 Homo sapiens Gamma-glutamyl phosphate reductase Proteins 0.000 description 1
- 101000733778 Homo sapiens Gamma-secretase subunit APH-1B Proteins 0.000 description 1
- 101000760789 Homo sapiens Gamma-taxilin Proteins 0.000 description 1
- 101000726548 Homo sapiens Gap junction alpha-5 protein Proteins 0.000 description 1
- 101000746078 Homo sapiens Gap junction gamma-1 protein Proteins 0.000 description 1
- 101001026281 Homo sapiens Gasdermin-B Proteins 0.000 description 1
- 101001026269 Homo sapiens Gasdermin-E Proteins 0.000 description 1
- 101001059150 Homo sapiens Gelsolin Proteins 0.000 description 1
- 101000903798 Homo sapiens General transcription factor II-I repeat domain-containing protein 1 Proteins 0.000 description 1
- 101000655402 Homo sapiens General transcription factor IIH subunit 5 Proteins 0.000 description 1
- 101000995459 Homo sapiens Germ cell nuclear acidic protein Proteins 0.000 description 1
- 101000830085 Homo sapiens Germ cell-less protein-like 1 Proteins 0.000 description 1
- 101001025761 Homo sapiens Gigaxonin Proteins 0.000 description 1
- 101001039387 Homo sapiens Glia maturation factor beta Proteins 0.000 description 1
- 101000904068 Homo sapiens Glucosamine 6-phosphate N-acetyltransferase Proteins 0.000 description 1
- 101000930907 Homo sapiens Glucose-6-phosphatase 2 Proteins 0.000 description 1
- 101000996752 Homo sapiens Glucose-dependent insulinotropic receptor Proteins 0.000 description 1
- 101000870042 Homo sapiens Glutamate dehydrogenase 1, mitochondrial Proteins 0.000 description 1
- 101001010445 Homo sapiens Glutamate receptor 1 Proteins 0.000 description 1
- 101001125242 Homo sapiens Glutamate receptor ionotropic, NMDA 2A Proteins 0.000 description 1
- 101000972850 Homo sapiens Glutamate receptor ionotropic, NMDA 2B Proteins 0.000 description 1
- 101000603180 Homo sapiens Glutamate receptor ionotropic, NMDA 3A Proteins 0.000 description 1
- 101000900493 Homo sapiens Glutamate receptor ionotropic, delta-1 Proteins 0.000 description 1
- 101000903333 Homo sapiens Glutamate receptor ionotropic, kainate 4 Proteins 0.000 description 1
- 101001034527 Homo sapiens Glutamate-cysteine ligase catalytic subunit Proteins 0.000 description 1
- 101000856993 Homo sapiens Glutaminase liver isoform, mitochondrial Proteins 0.000 description 1
- 101001002170 Homo sapiens Glutamine amidotransferase-like class 1 domain-containing protein 3, mitochondrial Proteins 0.000 description 1
- 101000888841 Homo sapiens Glutamine synthetase Proteins 0.000 description 1
- 101000856983 Homo sapiens Glutaredoxin-1 Proteins 0.000 description 1
- 101000905479 Homo sapiens Glutaredoxin-related protein 5, mitochondrial Proteins 0.000 description 1
- 101001026125 Homo sapiens Glutathione S-transferase A1 Proteins 0.000 description 1
- 101001026115 Homo sapiens Glutathione S-transferase A2 Proteins 0.000 description 1
- 101000870521 Homo sapiens Glutathione S-transferase A5 Proteins 0.000 description 1
- 101000903695 Homo sapiens Glutathione S-transferase C-terminal domain-containing protein Proteins 0.000 description 1
- 101001034434 Homo sapiens Glutathione S-transferase kappa 1 Proteins 0.000 description 1
- 101000906386 Homo sapiens Glutathione S-transferase omega-1 Proteins 0.000 description 1
- 101000871067 Homo sapiens Glutathione peroxidase 3 Proteins 0.000 description 1
- 101001071386 Homo sapiens Glutathione peroxidase 6 Proteins 0.000 description 1
- 101001071391 Homo sapiens Glutathione peroxidase 7 Proteins 0.000 description 1
- 101000943584 Homo sapiens Glutathione-specific gamma-glutamylcyclotransferase 1 Proteins 0.000 description 1
- 101000856267 Homo sapiens Glycerate kinase Proteins 0.000 description 1
- 101000900194 Homo sapiens Glycerol-3-phosphate dehydrogenase 1-like protein Proteins 0.000 description 1
- 101001038734 Homo sapiens Glycerophosphodiester phosphodiesterase domain-containing protein 4 Proteins 0.000 description 1
- 101001038855 Homo sapiens Glycerophosphodiester phosphodiesterase domain-containing protein 5 Proteins 0.000 description 1
- 101000888229 Homo sapiens Glycine N-acyltransferase-like protein 2 Proteins 0.000 description 1
- 101000893303 Homo sapiens Glycine amidinotransferase, mitochondrial Proteins 0.000 description 1
- 101000856845 Homo sapiens Glycine cleavage system H protein, mitochondrial Proteins 0.000 description 1
- 101000998096 Homo sapiens Glycine dehydrogenase (decarboxylating), mitochondrial Proteins 0.000 description 1
- 101001074244 Homo sapiens Glycophorin-A Proteins 0.000 description 1
- 101001069255 Homo sapiens Glycoprotein hormone beta-5 Proteins 0.000 description 1
- 101000926275 Homo sapiens Glycoprotein integral membrane protein 1 Proteins 0.000 description 1
- 101000805056 Homo sapiens Glycosaminoglycan xylosylkinase Proteins 0.000 description 1
- 101000857309 Homo sapiens Glycosylated lysosomal membrane protein Proteins 0.000 description 1
- 101001037042 Homo sapiens Glycosyltransferase 1 domain-containing protein 1 Proteins 0.000 description 1
- 101001026170 Homo sapiens Glycosyltransferase-like domain-containing protein 1 Proteins 0.000 description 1
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 1
- 101001040711 Homo sapiens Glypican-5 Proteins 0.000 description 1
- 101001069963 Homo sapiens Golgi apparatus protein 1 Proteins 0.000 description 1
- 101001040742 Homo sapiens Golgi membrane protein 1 Proteins 0.000 description 1
- 101001040734 Homo sapiens Golgi phosphoprotein 3 Proteins 0.000 description 1
- 101001074265 Homo sapiens Golgi phosphoprotein 3-like Proteins 0.000 description 1
- 101001072495 Homo sapiens Golgi reassembly-stacking protein 2 Proteins 0.000 description 1
- 101000893979 Homo sapiens Golgi-associated kinase 1B Proteins 0.000 description 1
- 101001044070 Homo sapiens Golgi-resident adenosine 3',5'-bisphosphate 3'-phosphatase Proteins 0.000 description 1
- 101001070504 Homo sapiens Golgin subfamily A member 7B Proteins 0.000 description 1
- 101001069929 Homo sapiens Grainyhead-like protein 2 homolog Proteins 0.000 description 1
- 101000870788 Homo sapiens Granule associated Rac and RHOG effector protein 1 Proteins 0.000 description 1
- 101000746364 Homo sapiens Granulocyte colony-stimulating factor receptor Proteins 0.000 description 1
- 101000997750 Homo sapiens Graves disease carrier protein Proteins 0.000 description 1
- 101001032872 Homo sapiens Gremlin-1 Proteins 0.000 description 1
- 101000903509 Homo sapiens Growth hormone-regulated TBC protein 1 Proteins 0.000 description 1
- 101001023968 Homo sapiens Growth/differentiation factor 7 Proteins 0.000 description 1
- 101001075110 Homo sapiens Growth/differentiation factor 9 Proteins 0.000 description 1
- 101000829489 Homo sapiens GrpE protein homolog 1, mitochondrial Proteins 0.000 description 1
- 101000829465 Homo sapiens GrpE protein homolog 2, mitochondrial Proteins 0.000 description 1
- 101001036092 Homo sapiens Guanine deaminase Proteins 0.000 description 1
- 101000926823 Homo sapiens Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-12 Proteins 0.000 description 1
- 101001073268 Homo sapiens Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-3 Proteins 0.000 description 1
- 101001073261 Homo sapiens Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-4 Proteins 0.000 description 1
- 101000887521 Homo sapiens Guanine nucleotide-binding protein G(I)/G(S)/G(O) subunit gamma-T2 Proteins 0.000 description 1
- 101001014590 Homo sapiens Guanine nucleotide-binding protein G(s) subunit alpha isoforms XLas Proteins 0.000 description 1
- 101001014594 Homo sapiens Guanine nucleotide-binding protein G(s) subunit alpha isoforms short Proteins 0.000 description 1
- 101000888142 Homo sapiens Guanine nucleotide-binding protein G(t) subunit alpha-2 Proteins 0.000 description 1
- 101001072407 Homo sapiens Guanine nucleotide-binding protein subunit alpha-11 Proteins 0.000 description 1
- 101001072398 Homo sapiens Guanine nucleotide-binding protein subunit alpha-12 Proteins 0.000 description 1
- 101001072481 Homo sapiens Guanine nucleotide-binding protein subunit alpha-13 Proteins 0.000 description 1
- 101000899814 Homo sapiens Guanylate cyclase activator 2B Proteins 0.000 description 1
- 101001001336 Homo sapiens Guanylate-binding protein 1 Proteins 0.000 description 1
- 101001068475 Homo sapiens Guanylyl cyclase-activating protein 2 Proteins 0.000 description 1
- 101001068472 Homo sapiens Guanylyl cyclase-activating protein 3 Proteins 0.000 description 1
- 101000710225 Homo sapiens H(+)/Cl(-) exchange transporter 5 Proteins 0.000 description 1
- 101001081101 Homo sapiens H2.0-like homeobox protein Proteins 0.000 description 1
- 101001035823 Homo sapiens HAUS augmin-like complex subunit 4 Proteins 0.000 description 1
- 101000990566 Homo sapiens HEAT repeat-containing protein 6 Proteins 0.000 description 1
- 101001066452 Homo sapiens HIG1 domain family member 2A, mitochondrial Proteins 0.000 description 1
- 101000985263 Homo sapiens HORMA domain-containing protein 2 Proteins 0.000 description 1
- 101000843045 Homo sapiens HSPB1-associated protein 1 Proteins 0.000 description 1
- 101000872857 Homo sapiens Haloacid dehalogenase-like hydrolase domain-containing 5 Proteins 0.000 description 1
- 101000872853 Homo sapiens Haloacid dehalogenase-like hydrolase domain-containing protein 3 Proteins 0.000 description 1
- 101001037759 Homo sapiens Heat shock 70 kDa protein 1A Proteins 0.000 description 1
- 101001078692 Homo sapiens Heat shock 70 kDa protein 4 Proteins 0.000 description 1
- 101000866478 Homo sapiens Heat shock protein 105 kDa Proteins 0.000 description 1
- 101001016856 Homo sapiens Heat shock protein HSP 90-beta Proteins 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101000843836 Homo sapiens Heme-binding protein 2 Proteins 0.000 description 1
- 101000756823 Homo sapiens Hemojuvelin Proteins 0.000 description 1
- 101000838692 Homo sapiens Heparan sulfate 2-O-sulfotransferase 1 Proteins 0.000 description 1
- 101000872875 Homo sapiens Hepatocyte cell adhesion molecule Proteins 0.000 description 1
- 101001062347 Homo sapiens Hepatocyte nuclear factor 3-beta Proteins 0.000 description 1
- 101001045749 Homo sapiens Hepatocyte nuclear factor 4-gamma Proteins 0.000 description 1
- 101001083786 Homo sapiens Hepatoma-derived growth factor-like protein 1 Proteins 0.000 description 1
- 101000993183 Homo sapiens Hephaestin Proteins 0.000 description 1
- 101000985492 Homo sapiens Hermansky-Pudlak syndrome 3 protein Proteins 0.000 description 1
- 101000985501 Homo sapiens Hermansky-Pudlak syndrome 4 protein Proteins 0.000 description 1
- 101000985516 Homo sapiens Hermansky-Pudlak syndrome 5 protein Proteins 0.000 description 1
- 101000854041 Homo sapiens Heterogeneous nuclear ribonucleoprotein A3 Proteins 0.000 description 1
- 101001017544 Homo sapiens Heterogeneous nuclear ribonucleoprotein F Proteins 0.000 description 1
- 101001081143 Homo sapiens Heterogeneous nuclear ribonucleoprotein H2 Proteins 0.000 description 1
- 101001017561 Homo sapiens Heterogeneous nuclear ribonucleoprotein H3 Proteins 0.000 description 1
- 101001017573 Homo sapiens Heterogeneous nuclear ribonucleoprotein L-like Proteins 0.000 description 1
- 101001047854 Homo sapiens Heterogeneous nuclear ribonucleoprotein U Proteins 0.000 description 1
- 101000878580 Homo sapiens High affinity immunoglobulin alpha and immunoglobulin mu Fc receptor Proteins 0.000 description 1
- 101000878611 Homo sapiens High affinity immunoglobulin epsilon receptor subunit alpha Proteins 0.000 description 1
- 101000824104 Homo sapiens High affinity immunoglobulin epsilon receptor subunit gamma Proteins 0.000 description 1
- 101000913077 Homo sapiens High affinity immunoglobulin gamma Fc receptor IB Proteins 0.000 description 1
- 101000866771 Homo sapiens High mobility group nucleosome-binding domain-containing protein 3 Proteins 0.000 description 1
- 101001006375 Homo sapiens High mobility group nucleosome-binding domain-containing protein 4 Proteins 0.000 description 1
- 101000867036 Homo sapiens High mobility group protein 20A Proteins 0.000 description 1
- 101000838883 Homo sapiens Hippocalcin-like protein 1 Proteins 0.000 description 1
- 101001016858 Homo sapiens Histamine H4 receptor Proteins 0.000 description 1
- 101000990524 Homo sapiens Histidine protein methyltransferase 1 homolog Proteins 0.000 description 1
- 101001026554 Homo sapiens Histone H1.0 Proteins 0.000 description 1
- 101000872104 Homo sapiens Histone H2A-Bbd type 1 Proteins 0.000 description 1
- 101000905054 Homo sapiens Histone H2A.Z Proteins 0.000 description 1
- 101001084682 Homo sapiens Histone H2B type 1-C/E/F/G/I Proteins 0.000 description 1
- 101000898901 Homo sapiens Histone H2B type 1-L Proteins 0.000 description 1
- 101000871966 Homo sapiens Histone H2B type 2-E Proteins 0.000 description 1
- 101001031390 Homo sapiens Histone H2B type 3-B Proteins 0.000 description 1
- 101001067844 Homo sapiens Histone H3.1 Proteins 0.000 description 1
- 101000898935 Homo sapiens Histone H4-like protein type G Proteins 0.000 description 1
- 101000923139 Homo sapiens Histone chaperone ASF1A Proteins 0.000 description 1
- 101000785963 Homo sapiens Histone-lysine N-methyltransferase ASH1L Proteins 0.000 description 1
- 101000923090 Homo sapiens Homeobox protein ARX Proteins 0.000 description 1
- 101000766187 Homo sapiens Homeobox protein BarH-like 2 Proteins 0.000 description 1
- 101000915301 Homo sapiens Homeobox protein DBX2 Proteins 0.000 description 1
- 101000864690 Homo sapiens Homeobox protein DLX-1 Proteins 0.000 description 1
- 101000920856 Homo sapiens Homeobox protein ESX1 Proteins 0.000 description 1
- 101000962622 Homo sapiens Homeobox protein Hox-A3 Proteins 0.000 description 1
- 101001019752 Homo sapiens Homeobox protein Hox-B2 Proteins 0.000 description 1
- 101000839788 Homo sapiens Homeobox protein Hox-B4 Proteins 0.000 description 1
- 101001003015 Homo sapiens Homeobox protein Hox-C11 Proteins 0.000 description 1
- 101001002994 Homo sapiens Homeobox protein Hox-C4 Proteins 0.000 description 1
- 101001045140 Homo sapiens Homeobox protein Hox-C9 Proteins 0.000 description 1
- 101001037162 Homo sapiens Homeobox protein Hox-D1 Proteins 0.000 description 1
- 101001019776 Homo sapiens Homeobox protein Hox-D8 Proteins 0.000 description 1
- 101000726740 Homo sapiens Homeobox protein cut-like 1 Proteins 0.000 description 1
- 101001032602 Homo sapiens Homeobox protein goosecoid Proteins 0.000 description 1
- 101001006354 Homo sapiens Homeobox-containing protein 1 Proteins 0.000 description 1
- 101001066404 Homo sapiens Homeodomain-interacting protein kinase 1 Proteins 0.000 description 1
- 101001045363 Homo sapiens Homeodomain-interacting protein kinase 4 Proteins 0.000 description 1
- 101001035137 Homo sapiens Homocysteine-responsive endoplasmic reticulum-resident ubiquitin-like domain member 1 protein Proteins 0.000 description 1
- 101001035135 Homo sapiens Homocysteine-responsive endoplasmic reticulum-resident ubiquitin-like domain member 2 protein Proteins 0.000 description 1
- 101001035951 Homo sapiens Hyaluronan-binding protein 2 Proteins 0.000 description 1
- 101001041120 Homo sapiens Hyaluronidase-4 Proteins 0.000 description 1
- 101001037204 Homo sapiens Hydrocephalus-inducing protein homolog Proteins 0.000 description 1
- 101001035752 Homo sapiens Hydroxycarboxylic acid receptor 3 Proteins 0.000 description 1
- 101000993380 Homo sapiens Hypermethylated in cancer 1 protein Proteins 0.000 description 1
- 101000993376 Homo sapiens Hypermethylated in cancer 2 protein Proteins 0.000 description 1
- 101000988834 Homo sapiens Hypoxanthine-guanine phosphoribosyltransferase Proteins 0.000 description 1
- 101100286226 Homo sapiens IBTK gene Proteins 0.000 description 1
- 101000998490 Homo sapiens INO80 complex subunit C Proteins 0.000 description 1
- 101001053590 Homo sapiens IQ domain-containing protein K Proteins 0.000 description 1
- 101001003233 Homo sapiens Immediate early response gene 2 protein Proteins 0.000 description 1
- 101001003229 Homo sapiens Immediate early response gene 5-like protein Proteins 0.000 description 1
- 101001076613 Homo sapiens Immortalization up-regulated protein Proteins 0.000 description 1
- 101001010610 Homo sapiens Immunoglobulin-like domain-containing receptor 1 Proteins 0.000 description 1
- 101001001478 Homo sapiens Importin subunit alpha-3 Proteins 0.000 description 1
- 101001001473 Homo sapiens Importin subunit alpha-4 Proteins 0.000 description 1
- 101000599445 Homo sapiens Importin-7 Proteins 0.000 description 1
- 101000731738 Homo sapiens Inactive ADP-ribosyltransferase ARH2 Proteins 0.000 description 1
- 101000919167 Homo sapiens Inactive carboxypeptidase-like protein X2 Proteins 0.000 description 1
- 101000967820 Homo sapiens Inactive dipeptidyl peptidase 10 Proteins 0.000 description 1
- 101000926208 Homo sapiens Inactive glutathione hydrolase 2 Proteins 0.000 description 1
- 101001047811 Homo sapiens Inactive heparanase-2 Proteins 0.000 description 1
- 101001067522 Homo sapiens Inactive polypeptide N-acetylgalactosaminyltransferase-like protein 5 Proteins 0.000 description 1
- 101000721401 Homo sapiens Inactive ubiquitin thioesterase OTULINL Proteins 0.000 description 1
- 101000633984 Homo sapiens Influenza virus NS1A-binding protein Proteins 0.000 description 1
- 101001054830 Homo sapiens Inhibin beta E chain Proteins 0.000 description 1
- 101000852379 Homo sapiens Inhibitory synaptic factor 2A Proteins 0.000 description 1
- 101000852852 Homo sapiens Innate immunity activator protein Proteins 0.000 description 1
- 101000975428 Homo sapiens Inositol 1,4,5-trisphosphate receptor type 1 Proteins 0.000 description 1
- 101000953492 Homo sapiens Inositol hexakisphosphate and diphosphoinositol-pentakisphosphate kinase 1 Proteins 0.000 description 1
- 101001011985 Homo sapiens Inositol hexakisphosphate kinase 1 Proteins 0.000 description 1
- 101001044094 Homo sapiens Inositol monophosphatase 2 Proteins 0.000 description 1
- 101001054823 Homo sapiens Inositol polyphosphate 1-phosphatase Proteins 0.000 description 1
- 101001053339 Homo sapiens Inositol polyphosphate 4-phosphatase type II Proteins 0.000 description 1
- 101001053362 Homo sapiens Inositol polyphosphate-4-phosphatase type I A Proteins 0.000 description 1
- 101000852596 Homo sapiens Inositol-trisphosphate 3-kinase A Proteins 0.000 description 1
- 101000852591 Homo sapiens Inositol-trisphosphate 3-kinase C Proteins 0.000 description 1
- 101001053270 Homo sapiens Insulin gene enhancer protein ISL-2 Proteins 0.000 description 1
- 101001076313 Homo sapiens Insulin growth factor-like family member 4 Proteins 0.000 description 1
- 101001077604 Homo sapiens Insulin receptor substrate 1 Proteins 0.000 description 1
- 101000599629 Homo sapiens Insulin-induced gene 2 protein Proteins 0.000 description 1
- 101000599778 Homo sapiens Insulin-like growth factor 2 mRNA-binding protein 1 Proteins 0.000 description 1
- 101001033715 Homo sapiens Insulinoma-associated protein 1 Proteins 0.000 description 1
- 101001033699 Homo sapiens Insulinoma-associated protein 2 Proteins 0.000 description 1
- 101001050468 Homo sapiens Integral membrane protein 2B Proteins 0.000 description 1
- 101001056814 Homo sapiens Integral membrane protein 2C Proteins 0.000 description 1
- 101001000801 Homo sapiens Integral membrane protein GPR137B Proteins 0.000 description 1
- 101000599647 Homo sapiens Integrator complex subunit 12 Proteins 0.000 description 1
- 101000998800 Homo sapiens Integrator complex subunit 3 Proteins 0.000 description 1
- 101001033770 Homo sapiens Integrator complex subunit 4 Proteins 0.000 description 1
- 101001033788 Homo sapiens Integrator complex subunit 6 Proteins 0.000 description 1
- 101001035237 Homo sapiens Integrin alpha-D Proteins 0.000 description 1
- 101001078143 Homo sapiens Integrin alpha-IIb Proteins 0.000 description 1
- 101001046677 Homo sapiens Integrin alpha-V Proteins 0.000 description 1
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 1
- 101001015004 Homo sapiens Integrin beta-3 Proteins 0.000 description 1
- 101001015059 Homo sapiens Integrin beta-5 Proteins 0.000 description 1
- 101000997670 Homo sapiens Integrin beta-8 Proteins 0.000 description 1
- 101001054329 Homo sapiens Interferon epsilon Proteins 0.000 description 1
- 101001077835 Homo sapiens Interferon regulatory factor 2-binding protein 2 Proteins 0.000 description 1
- 101001011442 Homo sapiens Interferon regulatory factor 5 Proteins 0.000 description 1
- 101001032345 Homo sapiens Interferon regulatory factor 8 Proteins 0.000 description 1
- 101000998500 Homo sapiens Interferon-induced 35 kDa protein Proteins 0.000 description 1
- 101001055245 Homo sapiens Interferon-induced protein with tetratricopeptide repeats 1B Proteins 0.000 description 1
- 101001082058 Homo sapiens Interferon-induced protein with tetratricopeptide repeats 2 Proteins 0.000 description 1
- 101001082060 Homo sapiens Interferon-induced protein with tetratricopeptide repeats 3 Proteins 0.000 description 1
- 101001082063 Homo sapiens Interferon-induced protein with tetratricopeptide repeats 5 Proteins 0.000 description 1
- 101000994815 Homo sapiens Interleukin-1 receptor accessory protein-like 1 Proteins 0.000 description 1
- 101001076418 Homo sapiens Interleukin-1 receptor type 1 Proteins 0.000 description 1
- 101000977768 Homo sapiens Interleukin-1 receptor-associated kinase 3 Proteins 0.000 description 1
- 101001003149 Homo sapiens Interleukin-10 receptor subunit beta Proteins 0.000 description 1
- 101001019590 Homo sapiens Interleukin-17 receptor E Proteins 0.000 description 1
- 101001019615 Homo sapiens Interleukin-18 receptor accessory protein Proteins 0.000 description 1
- 101001019591 Homo sapiens Interleukin-18-binding protein Proteins 0.000 description 1
- 101001044895 Homo sapiens Interleukin-20 receptor subunit beta Proteins 0.000 description 1
- 101001010626 Homo sapiens Interleukin-22 Proteins 0.000 description 1
- 101001044883 Homo sapiens Interleukin-22 receptor subunit alpha-1 Proteins 0.000 description 1
- 101000852980 Homo sapiens Interleukin-23 subunit alpha Proteins 0.000 description 1
- 101001037246 Homo sapiens Interleukin-27 receptor subunit alpha Proteins 0.000 description 1
- 101001043817 Homo sapiens Interleukin-31 receptor subunit alpha Proteins 0.000 description 1
- 101001033642 Homo sapiens Interphotoreceptor matrix proteoglycan 1 Proteins 0.000 description 1
- 101001044336 Homo sapiens Intraflagellar transport protein 122 homolog Proteins 0.000 description 1
- 101001055333 Homo sapiens Intraflagellar transport protein 20 homolog Proteins 0.000 description 1
- 101000961164 Homo sapiens Intraflagellar transport protein 43 homolog Proteins 0.000 description 1
- 101001044438 Homo sapiens Intraflagellar transport protein 52 homolog Proteins 0.000 description 1
- 101001010724 Homo sapiens Intraflagellar transport protein 88 homolog Proteins 0.000 description 1
- 101001047190 Homo sapiens Inward rectifier potassium channel 16 Proteins 0.000 description 1
- 101000944277 Homo sapiens Inward rectifier potassium channel 2 Proteins 0.000 description 1
- 101001056771 Homo sapiens Iodotyrosine deiodinase 1 Proteins 0.000 description 1
- 101000994149 Homo sapiens Iron-sulfur cluster assembly 2 homolog, mitochondrial Proteins 0.000 description 1
- 101000977762 Homo sapiens Iroquois-class homeodomain protein IRX-5 Proteins 0.000 description 1
- 101001081606 Homo sapiens Islet cell autoantigen 1 Proteins 0.000 description 1
- 101000994195 Homo sapiens Isochorismatase domain-containing protein 1 Proteins 0.000 description 1
- 101000875643 Homo sapiens Isoleucine-tRNA ligase, mitochondrial Proteins 0.000 description 1
- 101001056630 Homo sapiens JNK1/MAPK8-associated membrane protein Proteins 0.000 description 1
- 101000997838 Homo sapiens Janus kinase and microtubule-interacting protein 2 Proteins 0.000 description 1
- 101000994432 Homo sapiens Josephin-1 Proteins 0.000 description 1
- 101000975509 Homo sapiens Jun dimerization protein 2 Proteins 0.000 description 1
- 101000691574 Homo sapiens Junction plakoglobin Proteins 0.000 description 1
- 101001046633 Homo sapiens Junctional adhesion molecule A Proteins 0.000 description 1
- 101001050318 Homo sapiens Junctional adhesion molecule-like Proteins 0.000 description 1
- 101000614614 Homo sapiens Junctophilin-2 Proteins 0.000 description 1
- 101001056560 Homo sapiens Juxtaposed with another zinc finger protein 1 Proteins 0.000 description 1
- 101001046974 Homo sapiens KAT8 regulatory NSL complex subunit 1 Proteins 0.000 description 1
- 101000975000 Homo sapiens KAT8 regulatory NSL complex subunit 1-like protein Proteins 0.000 description 1
- 101001050622 Homo sapiens KH domain-containing, RNA-binding, signal transduction-associated protein 2 Proteins 0.000 description 1
- 101001008989 Homo sapiens KICSTOR subunit 2 Proteins 0.000 description 1
- 101001046971 Homo sapiens KN motif and ankyrin repeat domain-containing protein 4 Proteins 0.000 description 1
- 101000975108 Homo sapiens Katanin p60 ATPase-containing subunit A-like 2 Proteins 0.000 description 1
- 101000614666 Homo sapiens Kazrin Proteins 0.000 description 1
- 101001027146 Homo sapiens Kelch domain-containing protein 10 Proteins 0.000 description 1
- 101000945438 Homo sapiens Kelch domain-containing protein 2 Proteins 0.000 description 1
- 101000945443 Homo sapiens Kelch domain-containing protein 4 Proteins 0.000 description 1
- 101001047043 Homo sapiens Kelch repeat and BTB domain-containing protein 11 Proteins 0.000 description 1
- 101001047040 Homo sapiens Kelch repeat and BTB domain-containing protein 12 Proteins 0.000 description 1
- 101000997318 Homo sapiens Kelch repeat and BTB domain-containing protein 2 Proteins 0.000 description 1
- 101001047041 Homo sapiens Kelch repeat and BTB domain-containing protein 7 Proteins 0.000 description 1
- 101001047047 Homo sapiens Kelch repeat and BTB domain-containing protein 8 Proteins 0.000 description 1
- 101001091320 Homo sapiens Kelch-like protein 13 Proteins 0.000 description 1
- 101001049213 Homo sapiens Kelch-like protein 15 Proteins 0.000 description 1
- 101001045822 Homo sapiens Kelch-like protein 2 Proteins 0.000 description 1
- 101001049204 Homo sapiens Kelch-like protein 20 Proteins 0.000 description 1
- 101001006875 Homo sapiens Kelch-like protein 23 Proteins 0.000 description 1
- 101001006878 Homo sapiens Kelch-like protein 24 Proteins 0.000 description 1
- 101001006871 Homo sapiens Kelch-like protein 25 Proteins 0.000 description 1
- 101000945211 Homo sapiens Kelch-like protein 28 Proteins 0.000 description 1
- 101000945185 Homo sapiens Kelch-like protein 31 Proteins 0.000 description 1
- 101001027190 Homo sapiens Kelch-like protein 42 Proteins 0.000 description 1
- 101001008914 Homo sapiens Kelch-like protein 8 Proteins 0.000 description 1
- 101001050275 Homo sapiens Keratin, type I cuticular Ha1 Proteins 0.000 description 1
- 101000975472 Homo sapiens Keratin, type I cytoskeletal 12 Proteins 0.000 description 1
- 101000998020 Homo sapiens Keratin, type I cytoskeletal 18 Proteins 0.000 description 1
- 101000994460 Homo sapiens Keratin, type I cytoskeletal 20 Proteins 0.000 description 1
- 101001028394 Homo sapiens Keratin, type I cytoskeletal 39 Proteins 0.000 description 1
- 101000975496 Homo sapiens Keratin, type II cytoskeletal 8 Proteins 0.000 description 1
- 101000975505 Homo sapiens Keratin, type II cytoskeletal 80 Proteins 0.000 description 1
- 101001137908 Homo sapiens Keratin-associated protein 15-1 Proteins 0.000 description 1
- 101001051735 Homo sapiens Keratin-associated protein 26-1 Proteins 0.000 description 1
- 101001047413 Homo sapiens Keratin-associated protein 8-1 Proteins 0.000 description 1
- 101001091582 Homo sapiens Keratinocyte proline-rich protein Proteins 0.000 description 1
- 101000613882 Homo sapiens Keratinocyte-associated transmembrane protein 2 Proteins 0.000 description 1
- 101001139019 Homo sapiens Kin of IRRE-like protein 1 Proteins 0.000 description 1
- 101000975939 Homo sapiens Kinase D-interacting substrate of 220 kDa Proteins 0.000 description 1
- 101001090172 Homo sapiens Kinectin Proteins 0.000 description 1
- 101000605508 Homo sapiens Kinesin light chain 4 Proteins 0.000 description 1
- 101001050559 Homo sapiens Kinesin-1 heavy chain Proteins 0.000 description 1
- 101001006782 Homo sapiens Kinesin-associated protein 3 Proteins 0.000 description 1
- 101001091266 Homo sapiens Kinesin-like protein KIF13A Proteins 0.000 description 1
- 101001091256 Homo sapiens Kinesin-like protein KIF13B Proteins 0.000 description 1
- 101000971703 Homo sapiens Kinesin-like protein KIF1C Proteins 0.000 description 1
- 101001027628 Homo sapiens Kinesin-like protein KIF21A Proteins 0.000 description 1
- 101001006794 Homo sapiens Kinesin-like protein KIF6 Proteins 0.000 description 1
- 101001046532 Homo sapiens Kinesin-like protein KIFC3 Proteins 0.000 description 1
- 101000604876 Homo sapiens Kremen protein 1 Proteins 0.000 description 1
- 101001006886 Homo sapiens Krueppel-like factor 12 Proteins 0.000 description 1
- 101001046564 Homo sapiens Krueppel-like factor 13 Proteins 0.000 description 1
- 101001139146 Homo sapiens Krueppel-like factor 2 Proteins 0.000 description 1
- 101001139136 Homo sapiens Krueppel-like factor 3 Proteins 0.000 description 1
- 101001139130 Homo sapiens Krueppel-like factor 5 Proteins 0.000 description 1
- 101001139117 Homo sapiens Krueppel-like factor 7 Proteins 0.000 description 1
- 101000614690 Homo sapiens Kv channel-interacting protein 2 Proteins 0.000 description 1
- 101000614692 Homo sapiens Kv channel-interacting protein 4 Proteins 0.000 description 1
- 101001021858 Homo sapiens Kynureninase Proteins 0.000 description 1
- 101001027246 Homo sapiens Kynurenine 3-monooxygenase Proteins 0.000 description 1
- 101000614145 Homo sapiens Kynurenine formamidase Proteins 0.000 description 1
- 101001023330 Homo sapiens LIM and SH3 domain protein 1 Proteins 0.000 description 1
- 101000717987 Homo sapiens LIM domain-containing protein ajuba Proteins 0.000 description 1
- 101001138022 Homo sapiens La-related protein 1 Proteins 0.000 description 1
- 101001138020 Homo sapiens La-related protein 4 Proteins 0.000 description 1
- 101001010164 Homo sapiens La-related protein 4B Proteins 0.000 description 1
- 101000874532 Homo sapiens Lactosylceramide 1,3-N-acetyl-beta-D-glucosaminyltransferase Proteins 0.000 description 1
- 101001038306 Homo sapiens Lamin tail domain-containing protein 1 Proteins 0.000 description 1
- 101000972488 Homo sapiens Laminin subunit alpha-4 Proteins 0.000 description 1
- 101001051308 Homo sapiens Laminin subunit beta-4 Proteins 0.000 description 1
- 101001023271 Homo sapiens Laminin subunit gamma-2 Proteins 0.000 description 1
- 101000730000 Homo sapiens Late secretory pathway protein AVL9 homolog Proteins 0.000 description 1
- 101000981886 Homo sapiens Lengsin Proteins 0.000 description 1
- 101001064351 Homo sapiens Lethal(3)malignant brain tumor-like protein 1 Proteins 0.000 description 1
- 101000966275 Homo sapiens Lethal(3)malignant brain tumor-like protein 3 Proteins 0.000 description 1
- 101000966286 Homo sapiens Lethal(3)malignant brain tumor-like protein 4 Proteins 0.000 description 1
- 101000941869 Homo sapiens Leucine-rich repeat neuronal protein 4 Proteins 0.000 description 1
- 101000965732 Homo sapiens Leucine-rich repeat-containing protein 74A Proteins 0.000 description 1
- 101001065861 Homo sapiens Leucine-rich repeat-containing protein 75A Proteins 0.000 description 1
- 101000624524 Homo sapiens Leucine-tRNA ligase, cytoplasmic Proteins 0.000 description 1
- 101000624540 Homo sapiens Leucine-tRNA ligase, mitochondrial Proteins 0.000 description 1
- 101000605088 Homo sapiens Ligand-dependent corepressor Proteins 0.000 description 1
- 101000619643 Homo sapiens Ligand-dependent nuclear receptor-interacting factor 1 Proteins 0.000 description 1
- 101001130192 Homo sapiens Lipid droplet-associated hydrolase Proteins 0.000 description 1
- 101001077840 Homo sapiens Lipid-phosphate phosphatase Proteins 0.000 description 1
- 101000938676 Homo sapiens Liver carboxylesterase 1 Proteins 0.000 description 1
- 101000917826 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-a Proteins 0.000 description 1
- 101000611240 Homo sapiens Low molecular weight phosphotyrosine protein phosphatase Proteins 0.000 description 1
- 101001063392 Homo sapiens Lymphocyte function-associated antigen 3 Proteins 0.000 description 1
- 101000613958 Homo sapiens Lysine-specific demethylase 2A Proteins 0.000 description 1
- 101000614013 Homo sapiens Lysine-specific demethylase 2B Proteins 0.000 description 1
- 101000614017 Homo sapiens Lysine-specific demethylase 3A Proteins 0.000 description 1
- 101000613625 Homo sapiens Lysine-specific demethylase 4A Proteins 0.000 description 1
- 101001088893 Homo sapiens Lysine-specific demethylase 4C Proteins 0.000 description 1
- 101001088892 Homo sapiens Lysine-specific demethylase 5A Proteins 0.000 description 1
- 101001088883 Homo sapiens Lysine-specific demethylase 5B Proteins 0.000 description 1
- 101001025945 Homo sapiens Lysine-specific demethylase 7A Proteins 0.000 description 1
- 101001050886 Homo sapiens Lysine-specific histone demethylase 1A Proteins 0.000 description 1
- 101000742901 Homo sapiens Lysophosphatidylserine lipase ABHD12 Proteins 0.000 description 1
- 101000590691 Homo sapiens MAGUK p55 subfamily member 2 Proteins 0.000 description 1
- 101001055087 Homo sapiens MAP3K7 C-terminal-like protein Proteins 0.000 description 1
- 101001011499 Homo sapiens MAPK-interacting and spindle-stabilizing protein-like Proteins 0.000 description 1
- 101001018939 Homo sapiens MICOS complex subunit MIC10 Proteins 0.000 description 1
- 101001121072 Homo sapiens MICOS complex subunit MIC19 Proteins 0.000 description 1
- 101001121062 Homo sapiens MICOS complex subunit MIC25 Proteins 0.000 description 1
- 101001115711 Homo sapiens MORN repeat-containing protein 5 Proteins 0.000 description 1
- 101001045534 Homo sapiens MTRF1L release factor glutamine methyltransferase Proteins 0.000 description 1
- 101000760817 Homo sapiens Macrophage-capping protein Proteins 0.000 description 1
- 101000591256 Homo sapiens Maestro heat-like repeat-containing protein family member 2B Proteins 0.000 description 1
- 101000969822 Homo sapiens Maestro heat-like repeat-containing protein family member 7 Proteins 0.000 description 1
- 101000969821 Homo sapiens Maestro heat-like repeat-containing protein family member 9 Proteins 0.000 description 1
- 101000629860 Homo sapiens Major facilitator superfamily domain-containing protein 6-like Proteins 0.000 description 1
- 101000950648 Homo sapiens Malectin Proteins 0.000 description 1
- 101001012021 Homo sapiens Mammalian ependymin-related protein 1 Proteins 0.000 description 1
- 101001040781 Homo sapiens Mannose-1-phosphate guanyltransferase beta Proteins 0.000 description 1
- 101000955282 Homo sapiens Mediator of RNA polymerase II transcription subunit 27 Proteins 0.000 description 1
- 101001013272 Homo sapiens Mediator of RNA polymerase II transcription subunit 29 Proteins 0.000 description 1
- 101000834125 Homo sapiens Medium-chain acyl-CoA ligase ACSF2, mitochondrial Proteins 0.000 description 1
- 101001012669 Homo sapiens Melanoma inhibitory activity protein 2 Proteins 0.000 description 1
- 101000961414 Homo sapiens Membrane cofactor protein Proteins 0.000 description 1
- 101000993455 Homo sapiens Metal transporter CNNM2 Proteins 0.000 description 1
- 101000993450 Homo sapiens Metal transporter CNNM3 Proteins 0.000 description 1
- 101001055106 Homo sapiens Metastasis-associated in colon cancer protein 1 Proteins 0.000 description 1
- 101000653360 Homo sapiens Methylcytosine dioxygenase TET1 Proteins 0.000 description 1
- 101000653374 Homo sapiens Methylcytosine dioxygenase TET2 Proteins 0.000 description 1
- 101000936433 Homo sapiens Methylglutaconyl-CoA hydratase, mitochondrial Proteins 0.000 description 1
- 101001013097 Homo sapiens Methylmalonate-semialdehyde dehydrogenase [acylating], mitochondrial Proteins 0.000 description 1
- 101001000090 Homo sapiens Methyltransferase N6AMT1 Proteins 0.000 description 1
- 101001013999 Homo sapiens Microtubule cross-linking factor 1 Proteins 0.000 description 1
- 101000588157 Homo sapiens Microtubule-associated tumor suppressor candidate 2 Proteins 0.000 description 1
- 101001081183 Homo sapiens Minor histocompatibility protein HB-1 Proteins 0.000 description 1
- 101000962648 Homo sapiens Mitochondrial assembly of ribosomal large subunit protein 1 Proteins 0.000 description 1
- 101000961382 Homo sapiens Mitochondrial calcium uniporter regulator 1 Proteins 0.000 description 1
- 101000623681 Homo sapiens Mitochondrial fission regulator 2 Proteins 0.000 description 1
- 101000669640 Homo sapiens Mitochondrial import inner membrane translocase subunit TIM14 Proteins 0.000 description 1
- 101001034133 Homo sapiens Mitochondrial intermembrane space import and assembly protein 40 Proteins 0.000 description 1
- 101001051835 Homo sapiens Mitochondrial pyruvate carrier 1 Proteins 0.000 description 1
- 101001051048 Homo sapiens Mitochondrial pyruvate carrier 2 Proteins 0.000 description 1
- 101000980497 Homo sapiens Mitotic deacetylase-associated SANT domain protein Proteins 0.000 description 1
- 101001019013 Homo sapiens Mitotic interactor and substrate of PLK1 Proteins 0.000 description 1
- 101000929655 Homo sapiens Monoacylglycerol lipase ABHD2 Proteins 0.000 description 1
- 101000929834 Homo sapiens Monoacylglycerol lipase ABHD6 Proteins 0.000 description 1
- 101000655467 Homo sapiens Multidrug and toxin extrusion protein 1 Proteins 0.000 description 1
- 101000655429 Homo sapiens Multidrug and toxin extrusion protein 2 Proteins 0.000 description 1
- 101000957340 Homo sapiens Multivesicular body subunit 12B Proteins 0.000 description 1
- 101001011668 Homo sapiens Muscular LMNA-interacting protein Proteins 0.000 description 1
- 101000624898 Homo sapiens Myb/SANT-like DNA-binding domain-containing protein 3 Proteins 0.000 description 1
- 101001013759 Homo sapiens Myb/SANT-like DNA-binding domain-containing protein 4 Proteins 0.000 description 1
- 101001133804 Homo sapiens Myelin regulatory factor-like protein Proteins 0.000 description 1
- 101001023037 Homo sapiens Myoferlin Proteins 0.000 description 1
- 101001030182 Homo sapiens Myogenesis-regulating glycosidase Proteins 0.000 description 1
- 101001072470 Homo sapiens N-acetylglucosamine-1-phosphotransferase subunits alpha/beta Proteins 0.000 description 1
- 101000874526 Homo sapiens N-acetyllactosaminide beta-1,3-N-acetylglucosaminyltransferase 2 Proteins 0.000 description 1
- 101000874528 Homo sapiens N-acetyllactosaminide beta-1,3-N-acetylglucosaminyltransferase 3 Proteins 0.000 description 1
- 101000761218 Homo sapiens N-acetylneuraminate 9-O-acetyltransferase Proteins 0.000 description 1
- 101000797269 Homo sapiens N-acyl-aromatic-L-amino acid amidohydrolase (carboxylate-forming) Proteins 0.000 description 1
- 101000958771 Homo sapiens N-acylethanolamine-hydrolyzing acid amidase Proteins 0.000 description 1
- 101000958778 Homo sapiens N-alpha-acetyltransferase 60 Proteins 0.000 description 1
- 101000983292 Homo sapiens N-fatty-acyl-amino acid synthase/hydrolase PM20D1 Proteins 0.000 description 1
- 101000601416 Homo sapiens N-terminal EF-hand calcium-binding protein 1 Proteins 0.000 description 1
- 101000970374 Homo sapiens N-terminal Xaa-Pro-Lys N-methyltransferase 1 Proteins 0.000 description 1
- 101000589671 Homo sapiens NAD kinase 2, mitochondrial Proteins 0.000 description 1
- 101000588491 Homo sapiens NADH dehydrogenase (ubiquinone) complex I, assembly factor 6 Proteins 0.000 description 1
- 101000634783 Homo sapiens NOP protein chaperone 1 Proteins 0.000 description 1
- 101000884270 Homo sapiens Natural killer cell receptor 2B4 Proteins 0.000 description 1
- 101001014610 Homo sapiens Neuroendocrine secretory protein 55 Proteins 0.000 description 1
- 101000745167 Homo sapiens Neuronal acetylcholine receptor subunit alpha-4 Proteins 0.000 description 1
- 101000822093 Homo sapiens Neuronal acetylcholine receptor subunit alpha-9 Proteins 0.000 description 1
- 101000726905 Homo sapiens Neuronal acetylcholine receptor subunit beta-3 Proteins 0.000 description 1
- 101001009683 Homo sapiens Neuronal membrane glycoprotein M6-a Proteins 0.000 description 1
- 101000596892 Homo sapiens Neurotrimin Proteins 0.000 description 1
- 101000830386 Homo sapiens Neutrophil defensin 3 Proteins 0.000 description 1
- 101000979498 Homo sapiens Ninein-like protein Proteins 0.000 description 1
- 101000604223 Homo sapiens Nocturnin Proteins 0.000 description 1
- 101001010832 Homo sapiens Non-homologous end joining factor IFFO1 Proteins 0.000 description 1
- 101000972834 Homo sapiens Normal mucosa of esophagus-specific gene 1 protein Proteins 0.000 description 1
- 101000589497 Homo sapiens Nuclear cap-binding protein subunit 3 Proteins 0.000 description 1
- 101000995353 Homo sapiens Nuclear envelope phosphatase-regulatory subunit 1 Proteins 0.000 description 1
- 101001109633 Homo sapiens Nuclear exosome regulator NRDE2 Proteins 0.000 description 1
- 101001038567 Homo sapiens Nucleolar protein 4-like Proteins 0.000 description 1
- 101000851976 Homo sapiens Nucleoside diphosphate phosphatase ENTPD5 Proteins 0.000 description 1
- 101000897042 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 description 1
- 101000812677 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 description 1
- 101001018109 Homo sapiens Nucleotidyltransferase MB21D2 Proteins 0.000 description 1
- 101001137489 Homo sapiens ORC ubiquitin ligase 1 Proteins 0.000 description 1
- 101001098352 Homo sapiens OX-2 membrane glycoprotein Proteins 0.000 description 1
- 101001098357 Homo sapiens Orexin receptor type 2 Proteins 0.000 description 1
- 101001137510 Homo sapiens Outer dynein arm-docking complex subunit 2 Proteins 0.000 description 1
- 101001120710 Homo sapiens Ovarian cancer G-protein coupled receptor 1 Proteins 0.000 description 1
- 101000579857 Homo sapiens PC-esterase domain-containing protein 1B Proteins 0.000 description 1
- 101001126819 Homo sapiens PH-interacting protein Proteins 0.000 description 1
- 101001129712 Homo sapiens PHD and RING finger domain-containing protein 1 Proteins 0.000 description 1
- 101000738956 Homo sapiens POU domain, class 5, transcription factor 2 Proteins 0.000 description 1
- 101000730673 Homo sapiens PRELI domain containing protein 3A Proteins 0.000 description 1
- 101000871508 Homo sapiens PTB domain-containing engulfment adapter protein 1 Proteins 0.000 description 1
- 101000600748 Homo sapiens Pancreatic progenitor cell differentiation and proliferation factor-like protein Proteins 0.000 description 1
- 101001134725 Homo sapiens Pecanex-like protein 4 Proteins 0.000 description 1
- 101001096050 Homo sapiens Perilipin-2 Proteins 0.000 description 1
- 101000922137 Homo sapiens Peripheral plasma membrane protein CASK Proteins 0.000 description 1
- 101000608154 Homo sapiens Peroxiredoxin-like 2A Proteins 0.000 description 1
- 101000938567 Homo sapiens Persulfide dioxygenase ETHE1, mitochondrial Proteins 0.000 description 1
- 101000692247 Homo sapiens Phagosome assembly factor 1 Proteins 0.000 description 1
- 101000660828 Homo sapiens Phenylalanine-tRNA ligase beta subunit Proteins 0.000 description 1
- 101000842043 Homo sapiens Phenylalanine-tRNA ligase, mitochondrial Proteins 0.000 description 1
- 101000869523 Homo sapiens Phosphatidylinositide phosphatase SAC2 Proteins 0.000 description 1
- 101000595802 Homo sapiens Phospholipase A and acyltransferase 2 Proteins 0.000 description 1
- 101000929845 Homo sapiens Phospholipase ABHD3 Proteins 0.000 description 1
- 101000870428 Homo sapiens Phospholipase DDHD2 Proteins 0.000 description 1
- 101000801684 Homo sapiens Phospholipid-transporting ATPase ABCA1 Proteins 0.000 description 1
- 101000801640 Homo sapiens Phospholipid-transporting ATPase ABCA3 Proteins 0.000 description 1
- 101000701367 Homo sapiens Phospholipid-transporting ATPase IA Proteins 0.000 description 1
- 101000923322 Homo sapiens Phospholipid-transporting ATPase IH Proteins 0.000 description 1
- 101001129788 Homo sapiens Piezo-type mechanosensitive ion channel component 2 Proteins 0.000 description 1
- 101000851265 Homo sapiens Pikachurin Proteins 0.000 description 1
- 101000728095 Homo sapiens Plasma membrane calcium-transporting ATPase 1 Proteins 0.000 description 1
- 101000728125 Homo sapiens Plasma membrane calcium-transporting ATPase 2 Proteins 0.000 description 1
- 101001033026 Homo sapiens Platelet glycoprotein V Proteins 0.000 description 1
- 101001001797 Homo sapiens Pleckstrin homology domain-containing family S member 1 Proteins 0.000 description 1
- 101000887201 Homo sapiens Polyamine-transporting ATPase 13A2 Proteins 0.000 description 1
- 101000728236 Homo sapiens Polycomb group protein ASXL1 Proteins 0.000 description 1
- 101000829578 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 10 Proteins 0.000 description 1
- 101000829574 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 11 Proteins 0.000 description 1
- 101000829542 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 14 Proteins 0.000 description 1
- 101000888114 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 16 Proteins 0.000 description 1
- 101001002235 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 2 Proteins 0.000 description 1
- 101000886231 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 6 Proteins 0.000 description 1
- 101000994653 Homo sapiens Potassium channel regulatory protein Proteins 0.000 description 1
- 101001049841 Homo sapiens Potassium channel subfamily K member 1 Proteins 0.000 description 1
- 101000974745 Homo sapiens Potassium channel subfamily K member 10 Proteins 0.000 description 1
- 101001049829 Homo sapiens Potassium channel subfamily K member 5 Proteins 0.000 description 1
- 101000994626 Homo sapiens Potassium voltage-gated channel subfamily A member 1 Proteins 0.000 description 1
- 101000994632 Homo sapiens Potassium voltage-gated channel subfamily A member 2 Proteins 0.000 description 1
- 101001026209 Homo sapiens Potassium voltage-gated channel subfamily A member 4 Proteins 0.000 description 1
- 101001026192 Homo sapiens Potassium voltage-gated channel subfamily A member 6 Proteins 0.000 description 1
- 101000997292 Homo sapiens Potassium voltage-gated channel subfamily B member 1 Proteins 0.000 description 1
- 101001135493 Homo sapiens Potassium voltage-gated channel subfamily C member 4 Proteins 0.000 description 1
- 101001135471 Homo sapiens Potassium voltage-gated channel subfamily D member 3 Proteins 0.000 description 1
- 101000974715 Homo sapiens Potassium voltage-gated channel subfamily E member 3 Proteins 0.000 description 1
- 101001047102 Homo sapiens Potassium voltage-gated channel subfamily G member 1 Proteins 0.000 description 1
- 101001077448 Homo sapiens Potassium voltage-gated channel subfamily S member 2 Proteins 0.000 description 1
- 101001009082 Homo sapiens Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated channel 3 Proteins 0.000 description 1
- 101001032038 Homo sapiens Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated channel 4 Proteins 0.000 description 1
- 101001122801 Homo sapiens Pre-mRNA-processing factor 17 Proteins 0.000 description 1
- 101000894618 Homo sapiens Pre-mRNA-splicing factor CWC22 homolog Proteins 0.000 description 1
- 101000609379 Homo sapiens Pre-mRNA-splicing factor ISY1 homolog Proteins 0.000 description 1
- 101000933173 Homo sapiens Pro-cathepsin H Proteins 0.000 description 1
- 101000883801 Homo sapiens Probable ATP-dependent RNA helicase DDX52 Proteins 0.000 description 1
- 101000901928 Homo sapiens Probable ATP-dependent RNA helicase DHX35 Proteins 0.000 description 1
- 101000838314 Homo sapiens Probable E3 ubiquitin-protein ligase DTX2 Proteins 0.000 description 1
- 101000872514 Homo sapiens Probable E3 ubiquitin-protein ligase HERC1 Proteins 0.000 description 1
- 101000599816 Homo sapiens Probable E3 ubiquitin-protein ligase IRF2BPL Proteins 0.000 description 1
- 101000795318 Homo sapiens Probable E3 ubiquitin-protein ligase TRIML2 Proteins 0.000 description 1
- 101001070479 Homo sapiens Probable G-protein coupled receptor 101 Proteins 0.000 description 1
- 101000996785 Homo sapiens Probable G-protein coupled receptor 132 Proteins 0.000 description 1
- 101000887485 Homo sapiens Probable G-protein coupled receptor 148 Proteins 0.000 description 1
- 101000857740 Homo sapiens Probable G-protein coupled receptor 160 Proteins 0.000 description 1
- 101001071363 Homo sapiens Probable G-protein coupled receptor 21 Proteins 0.000 description 1
- 101001069617 Homo sapiens Probable G-protein coupled receptor 63 Proteins 0.000 description 1
- 101001069583 Homo sapiens Probable G-protein coupled receptor 85 Proteins 0.000 description 1
- 101001033058 Homo sapiens Probable G-protein coupled receptor 88 Proteins 0.000 description 1
- 101001028703 Homo sapiens Probable JmjC domain-containing histone demethylation protein 2C Proteins 0.000 description 1
- 101000887210 Homo sapiens Probable cation-transporting ATPase 13A5 Proteins 0.000 description 1
- 101000630121 Homo sapiens Probable cysteine-tRNA ligase, mitochondrial Proteins 0.000 description 1
- 101000717815 Homo sapiens Probable dolichyl pyrophosphate Glc1Man9GlcNAc2 alpha-1,3-glucosyltransferase Proteins 0.000 description 1
- 101001041337 Homo sapiens Probable imidazolonepropionase Proteins 0.000 description 1
- 101000729626 Homo sapiens Probable phospholipid-transporting ATPase IIA Proteins 0.000 description 1
- 101000729531 Homo sapiens Probable phospholipid-transporting ATPase IIB Proteins 0.000 description 1
- 101000701518 Homo sapiens Probable phospholipid-transporting ATPase IM Proteins 0.000 description 1
- 101000922698 Homo sapiens Probable polypeptide N-acetylgalactosaminyltransferase 8 Proteins 0.000 description 1
- 101000745667 Homo sapiens Probable serine carboxypeptidase CPVL Proteins 0.000 description 1
- 101000793153 Homo sapiens Probable splicing factor YJU2B Proteins 0.000 description 1
- 101000649043 Homo sapiens Probable tRNA methyltransferase 9B Proteins 0.000 description 1
- 101001052471 Homo sapiens Probable ubiquitin carboxyl-terminal hydrolase MINDY-4 Proteins 0.000 description 1
- 101000983583 Homo sapiens Procathepsin L Proteins 0.000 description 1
- 101000996764 Homo sapiens Progonadoliberin-2 Proteins 0.000 description 1
- 101001125520 Homo sapiens Proline and serine-rich protein 1 Proteins 0.000 description 1
- 101001125518 Homo sapiens Proline and serine-rich protein 2 Proteins 0.000 description 1
- 101001068552 Homo sapiens Proline-rich protein 15-like protein Proteins 0.000 description 1
- 101000742135 Homo sapiens Proline-rich protein 20A Proteins 0.000 description 1
- 101001123372 Homo sapiens Proline-rich protein 23C Proteins 0.000 description 1
- 101001080401 Homo sapiens Proteasome assembly chaperone 1 Proteins 0.000 description 1
- 101000920629 Homo sapiens Protein 4.1 Proteins 0.000 description 1
- 101000677768 Homo sapiens Protein ABHD12B Proteins 0.000 description 1
- 101000928477 Homo sapiens Protein AKNAD1 Proteins 0.000 description 1
- 101000797903 Homo sapiens Protein ALEX Proteins 0.000 description 1
- 101000684673 Homo sapiens Protein APCDD1 Proteins 0.000 description 1
- 101000684679 Homo sapiens Protein APCDD1-like Proteins 0.000 description 1
- 101000964086 Homo sapiens Protein Atg16l2 Proteins 0.000 description 1
- 101000803296 Homo sapiens Protein BNIP5 Proteins 0.000 description 1
- 101000803196 Homo sapiens Protein Bop Proteins 0.000 description 1
- 101000989787 Homo sapiens Protein C12orf4 Proteins 0.000 description 1
- 101000942217 Homo sapiens Protein C19orf12 Proteins 0.000 description 1
- 101000715341 Homo sapiens Protein C3orf33 Proteins 0.000 description 1
- 101000947115 Homo sapiens Protein CASC3 Proteins 0.000 description 1
- 101000761460 Homo sapiens Protein CASP Proteins 0.000 description 1
- 101000710074 Homo sapiens Protein CFAP20DC Proteins 0.000 description 1
- 101000771012 Homo sapiens Protein CMSS1 Proteins 0.000 description 1
- 101000919310 Homo sapiens Protein CREG2 Proteins 0.000 description 1
- 101000920985 Homo sapiens Protein CROC-4 Proteins 0.000 description 1
- 101000860338 Homo sapiens Protein CUSTOS Proteins 0.000 description 1
- 101000918642 Homo sapiens Protein DDI1 homolog 2 Proteins 0.000 description 1
- 101001128963 Homo sapiens Protein Dr1 Proteins 0.000 description 1
- 101000925095 Homo sapiens Protein EFR3 homolog A Proteins 0.000 description 1
- 101000881752 Homo sapiens Protein ELYS Proteins 0.000 description 1
- 101000881943 Homo sapiens Protein EURL homolog Proteins 0.000 description 1
- 101001063921 Homo sapiens Protein FAM104B Proteins 0.000 description 1
- 101000911753 Homo sapiens Protein FAM107B Proteins 0.000 description 1
- 101000875522 Homo sapiens Protein FAM110C Proteins 0.000 description 1
- 101000813310 Homo sapiens Protein FAM124A Proteins 0.000 description 1
- 101000813321 Homo sapiens Protein FAM124B Proteins 0.000 description 1
- 101000882133 Homo sapiens Protein FAM131B Proteins 0.000 description 1
- 101000882083 Homo sapiens Protein FAM135A Proteins 0.000 description 1
- 101000918287 Homo sapiens Protein FAM135B Proteins 0.000 description 1
- 101001062760 Homo sapiens Protein FAM13A Proteins 0.000 description 1
- 101001062754 Homo sapiens Protein FAM13C Proteins 0.000 description 1
- 101000854607 Homo sapiens Protein FAM167A Proteins 0.000 description 1
- 101001028905 Homo sapiens Protein FAM177B Proteins 0.000 description 1
- 101000877832 Homo sapiens Protein FAM184A Proteins 0.000 description 1
- 101000882257 Homo sapiens Protein FAM210A Proteins 0.000 description 1
- 101000911541 Homo sapiens Protein FAM214A Proteins 0.000 description 1
- 101000937717 Homo sapiens Protein FAM222A Proteins 0.000 description 1
- 101001062772 Homo sapiens Protein FAM234B Proteins 0.000 description 1
- 101000891842 Homo sapiens Protein FAM3B Proteins 0.000 description 1
- 101000891845 Homo sapiens Protein FAM3C Proteins 0.000 description 1
- 101000882233 Homo sapiens Protein FAM43A Proteins 0.000 description 1
- 101000882215 Homo sapiens Protein FAM47A Proteins 0.000 description 1
- 101000882220 Homo sapiens Protein FAM50B Proteins 0.000 description 1
- 101001048969 Homo sapiens Protein FAM78A Proteins 0.000 description 1
- 101001049023 Homo sapiens Protein FAM78B Proteins 0.000 description 1
- 101000877861 Homo sapiens Protein FAM83B Proteins 0.000 description 1
- 101000877847 Homo sapiens Protein FAM83C Proteins 0.000 description 1
- 101000877851 Homo sapiens Protein FAM83D Proteins 0.000 description 1
- 101000877854 Homo sapiens Protein FAM83F Proteins 0.000 description 1
- 101000911386 Homo sapiens Protein FAM8A1 Proteins 0.000 description 1
- 101000911553 Homo sapiens Protein FAM91A1 Proteins 0.000 description 1
- 101001065016 Homo sapiens Protein FAM9A Proteins 0.000 description 1
- 101001065010 Homo sapiens Protein FAM9B Proteins 0.000 description 1
- 101001065012 Homo sapiens Protein FAM9C Proteins 0.000 description 1
- 101000911776 Homo sapiens Protein FRA10AC1 Proteins 0.000 description 1
- 101001009852 Homo sapiens Protein GUCD1 Proteins 0.000 description 1
- 101000998434 Homo sapiens Protein ILRUN Proteins 0.000 description 1
- 101000994309 Homo sapiens Protein ITPRID1 Proteins 0.000 description 1
- 101001050347 Homo sapiens Protein IWS1 homolog Proteins 0.000 description 1
- 101001056567 Homo sapiens Protein Jumonji Proteins 0.000 description 1
- 101001004837 Homo sapiens Protein LEKR1 Proteins 0.000 description 1
- 101001017783 Homo sapiens Protein LRATD2 Proteins 0.000 description 1
- 101000577964 Homo sapiens Protein MIX23 Proteins 0.000 description 1
- 101000979760 Homo sapiens Protein NDNF Proteins 0.000 description 1
- 101000594765 Homo sapiens Protein NOXP20 Proteins 0.000 description 1
- 101000979460 Homo sapiens Protein Niban 1 Proteins 0.000 description 1
- 101001135375 Homo sapiens Protein PET117 homolog, mitochondrial Proteins 0.000 description 1
- 101000740224 Homo sapiens Protein SCAI Proteins 0.000 description 1
- 101000880790 Homo sapiens Protein SSUH2 homolog Proteins 0.000 description 1
- 101000618174 Homo sapiens Protein Spindly Proteins 0.000 description 1
- 101000623374 Homo sapiens Protein YAE1 homolog Proteins 0.000 description 1
- 101000757241 Homo sapiens Protein angel homolog 2 Proteins 0.000 description 1
- 101000983140 Homo sapiens Protein associated with UVRAG as autophagy enhancer Proteins 0.000 description 1
- 101000923332 Homo sapiens Protein asteroid homolog 1 Proteins 0.000 description 1
- 101000984782 Homo sapiens Protein broad-minded Proteins 0.000 description 1
- 101000928791 Homo sapiens Protein diaphanous homolog 1 Proteins 0.000 description 1
- 101000928408 Homo sapiens Protein diaphanous homolog 2 Proteins 0.000 description 1
- 101000928406 Homo sapiens Protein diaphanous homolog 3 Proteins 0.000 description 1
- 101000930354 Homo sapiens Protein dispatched homolog 1 Proteins 0.000 description 1
- 101000877404 Homo sapiens Protein enabled homolog Proteins 0.000 description 1
- 101000893100 Homo sapiens Protein fantom Proteins 0.000 description 1
- 101000931680 Homo sapiens Protein furry homolog Proteins 0.000 description 1
- 101000972637 Homo sapiens Protein kintoun Proteins 0.000 description 1
- 101001004288 Homo sapiens Protein lin-52 homolog Proteins 0.000 description 1
- 101001004334 Homo sapiens Protein lin-54 homolog Proteins 0.000 description 1
- 101000962977 Homo sapiens Protein mab-21-like 3 Proteins 0.000 description 1
- 101000685298 Homo sapiens Protein sel-1 homolog 3 Proteins 0.000 description 1
- 101000642195 Homo sapiens Protein turtle homolog A Proteins 0.000 description 1
- 101000666873 Homo sapiens Protein virilizer homolog Proteins 0.000 description 1
- 101000814373 Homo sapiens Protein wntless homolog Proteins 0.000 description 1
- 101001050438 Homo sapiens Protein-lysine N-methyltransferase EEF2KMT Proteins 0.000 description 1
- 101001098560 Homo sapiens Proteinase-activated receptor 2 Proteins 0.000 description 1
- 101001062751 Homo sapiens Pseudokinase FAM20A Proteins 0.000 description 1
- 101000800426 Homo sapiens Putative C->U-editing enzyme APOBEC-4 Proteins 0.000 description 1
- 101000919023 Homo sapiens Putative DENN domain-containing protein 10 B Proteins 0.000 description 1
- 101000805126 Homo sapiens Putative Dresden prostate carcinoma protein 2 Proteins 0.000 description 1
- 101000862167 Homo sapiens Putative F-box/LRR-repeat protein 21 Proteins 0.000 description 1
- 101000848490 Homo sapiens Putative RNA polymerase II subunit B1 CTD phosphatase RPAP2 Proteins 0.000 description 1
- 101000962553 Homo sapiens Putative hydroxypyruvate isomerase Proteins 0.000 description 1
- 101000945495 Homo sapiens Putative killer cell immunoglobulin-like receptor-like protein KIR3DX1 Proteins 0.000 description 1
- 101001035914 Homo sapiens Putative nuclease HARBI1 Proteins 0.000 description 1
- 101000910029 Homo sapiens Putative protein CASTOR 3 Proteins 0.000 description 1
- 101001048921 Homo sapiens Putative protein FAM86C1P Proteins 0.000 description 1
- 101001048929 Homo sapiens Putative protein N-methyltransferase FAM86B1 Proteins 0.000 description 1
- 101000873438 Homo sapiens Putative protein SEM1, isoform 2 Proteins 0.000 description 1
- 101000693429 Homo sapiens Putative sodium-coupled neutral amino acid transporter 11 Proteins 0.000 description 1
- 101000913904 Homo sapiens Putative transmembrane protein encoded by LINC00477 Proteins 0.000 description 1
- 101000894911 Homo sapiens Putative uncharacterized protein B3GALT5-AS1 Proteins 0.000 description 1
- 101000945056 Homo sapiens Putative uncharacterized protein CLLU1-AS1 Proteins 0.000 description 1
- 101000741723 Homo sapiens Putative uncharacterized protein DIP2C-AS1 Proteins 0.000 description 1
- 101000828058 Homo sapiens Putative uncharacterized protein FER1L6-AS1 Proteins 0.000 description 1
- 101000884745 Homo sapiens Putative uncharacterized protein PKD1L1-AS1 Proteins 0.000 description 1
- 101000639806 Homo sapiens Putative uncharacterized protein RUSC1-AS1 Proteins 0.000 description 1
- 101000651610 Homo sapiens Putative uncharacterized protein SSBP3-AS1 Proteins 0.000 description 1
- 101000650176 Homo sapiens Putative uncharacterized protein WWC2-AS2 Proteins 0.000 description 1
- 101000828060 Homo sapiens Putative uncharacterized protein encoded by FER1L6-AS2 Proteins 0.000 description 1
- 101000990534 Homo sapiens Putative uncharacterized protein encoded by HEXA-AS1 Proteins 0.000 description 1
- 101000922025 Homo sapiens Putative uncharacterized protein encoded by LINC00114 Proteins 0.000 description 1
- 101000888426 Homo sapiens Putative uncharacterized protein encoded by LINC00167 Proteins 0.000 description 1
- 101000793150 Homo sapiens Putative uncharacterized protein encoded by LINC00173 Proteins 0.000 description 1
- 101000914169 Homo sapiens Putative uncharacterized protein encoded by LINC00242 Proteins 0.000 description 1
- 101000793956 Homo sapiens Putative uncharacterized protein encoded by LINC00299 Proteins 0.000 description 1
- 101000941912 Homo sapiens Putative uncharacterized protein encoded by LINC00469 Proteins 0.000 description 1
- 101000746163 Homo sapiens Putative uncharacterized protein encoded by LINC00479 Proteins 0.000 description 1
- 101000884596 Homo sapiens Putative uncharacterized protein encoded by LINC00518 Proteins 0.000 description 1
- 101000777647 Homo sapiens Putative uncharacterized protein encoded by LINC00575 Proteins 0.000 description 1
- 101000900745 Homo sapiens Putative uncharacterized protein encoded by LINC00596 Proteins 0.000 description 1
- 101000906697 Homo sapiens Putative uncharacterized protein encoded by LINC00612 Proteins 0.000 description 1
- 101000794439 Homo sapiens Putative uncharacterized protein encoded by LINC01555 Proteins 0.000 description 1
- 101000725919 Homo sapiens Putative uncharacterized protein encoded by LINC02910 Proteins 0.000 description 1
- 101000710893 Homo sapiens Putative uncharacterized protein encoded by LINC02915 Proteins 0.000 description 1
- 101000734537 Homo sapiens Pyridoxal-dependent decarboxylase domain-containing protein 1 Proteins 0.000 description 1
- 101001131271 Homo sapiens Queuosine salvage protein Proteins 0.000 description 1
- 101000686485 Homo sapiens RELT-like protein 2 Proteins 0.000 description 1
- 101000692973 Homo sapiens RING finger protein 145 Proteins 0.000 description 1
- 101000704870 Homo sapiens RIPOR family member 3 Proteins 0.000 description 1
- 101000959153 Homo sapiens RNA demethylase ALKBH5 Proteins 0.000 description 1
- 101001048702 Homo sapiens RNA polymerase II elongation factor ELL2 Proteins 0.000 description 1
- 101001111916 Homo sapiens RNA-binding protein 43 Proteins 0.000 description 1
- 101001100309 Homo sapiens RNA-binding protein 47 Proteins 0.000 description 1
- 101000926083 Homo sapiens Rab GDP dissociation inhibitor beta Proteins 0.000 description 1
- 101000620788 Homo sapiens Rab proteins geranylgeranyltransferase component A 2 Proteins 0.000 description 1
- 101000889795 Homo sapiens Rabankyrin-5 Proteins 0.000 description 1
- 101000665456 Homo sapiens Ral GTPase-activating protein subunit alpha-2 Proteins 0.000 description 1
- 101001104105 Homo sapiens Rap1 GTPase-activating protein 2 Proteins 0.000 description 1
- 101001106420 Homo sapiens Reactive oxygen species modulator 1 Proteins 0.000 description 1
- 101001106795 Homo sapiens Refilin-A Proteins 0.000 description 1
- 101000686675 Homo sapiens Regulation of nuclear pre-mRNA domain-containing protein 2 Proteins 0.000 description 1
- 101000692894 Homo sapiens Regulator of microtubule dynamics protein 2 Proteins 0.000 description 1
- 101000692892 Homo sapiens Regulator of microtubule dynamics protein 3 Proteins 0.000 description 1
- 101000815628 Homo sapiens Regulatory-associated protein of mTOR Proteins 0.000 description 1
- 101000821435 Homo sapiens Replication stress response regulator SDE2 Proteins 0.000 description 1
- 101000667643 Homo sapiens Required for meiotic nuclear division protein 1 homolog Proteins 0.000 description 1
- 101000580351 Homo sapiens Respirasome Complex Assembly Factor 1 Proteins 0.000 description 1
- 101000686903 Homo sapiens Reticulophagy regulator 1 Proteins 0.000 description 1
- 101001100101 Homo sapiens Retinoic acid-induced protein 3 Proteins 0.000 description 1
- 101001090901 Homo sapiens Retroelement silencing factor 1 Proteins 0.000 description 1
- 101000581153 Homo sapiens Rho GTPase-activating protein 10 Proteins 0.000 description 1
- 101000581155 Homo sapiens Rho GTPase-activating protein 12 Proteins 0.000 description 1
- 101000581173 Homo sapiens Rho GTPase-activating protein 17 Proteins 0.000 description 1
- 101000581176 Homo sapiens Rho GTPase-activating protein 18 Proteins 0.000 description 1
- 101000581129 Homo sapiens Rho GTPase-activating protein 19 Proteins 0.000 description 1
- 101001091990 Homo sapiens Rho GTPase-activating protein 24 Proteins 0.000 description 1
- 101001091991 Homo sapiens Rho GTPase-activating protein 25 Proteins 0.000 description 1
- 101001075531 Homo sapiens Rho GTPase-activating protein 27 Proteins 0.000 description 1
- 101001075563 Homo sapiens Rho GTPase-activating protein 31 Proteins 0.000 description 1
- 101001106309 Homo sapiens Rho GTPase-activating protein 8 Proteins 0.000 description 1
- 101000871032 Homo sapiens Rhodopsin kinase GRK7 Proteins 0.000 description 1
- 101000849300 Homo sapiens Ribosomal RNA processing protein 36 homolog Proteins 0.000 description 1
- 101001023680 Homo sapiens Ribosomal RNA small subunit methyltransferase NEP1 Proteins 0.000 description 1
- 101000754924 Homo sapiens Ribosomal oxygenase 1 Proteins 0.000 description 1
- 101000984533 Homo sapiens Ribosome biogenesis protein BMS1 homolog Proteins 0.000 description 1
- 101000873502 Homo sapiens S-adenosylmethionine decarboxylase proenzyme Proteins 0.000 description 1
- 101001010890 Homo sapiens S-formylglutathione hydrolase Proteins 0.000 description 1
- 101000836389 Homo sapiens SET domain-containing protein 9 Proteins 0.000 description 1
- 101000616545 Homo sapiens SH3 domain-containing protein 21 Proteins 0.000 description 1
- 101000864837 Homo sapiens SIN3-HDAC complex-associated factor Proteins 0.000 description 1
- 101000651939 Homo sapiens SKI/DACH domain-containing protein 1 Proteins 0.000 description 1
- 101000709102 Homo sapiens SMC5-SMC6 complex localization factor protein 2 Proteins 0.000 description 1
- 101000711793 Homo sapiens SOSS complex subunit C Proteins 0.000 description 1
- 101000828739 Homo sapiens SPATS2-like protein Proteins 0.000 description 1
- 101000587811 Homo sapiens SPRY domain-containing protein 7 Proteins 0.000 description 1
- 101000835998 Homo sapiens SRA stem-loop-interacting RNA-binding protein, mitochondrial Proteins 0.000 description 1
- 101000588012 Homo sapiens SREBP regulating gene protein Proteins 0.000 description 1
- 101000820585 Homo sapiens SUN domain-containing ossification factor Proteins 0.000 description 1
- 101000834853 Homo sapiens SUZ domain-containing protein 1 Proteins 0.000 description 1
- 101000936922 Homo sapiens Sarcoplasmic/endoplasmic reticulum calcium ATPase 2 Proteins 0.000 description 1
- 101000716809 Homo sapiens Secretogranin-1 Proteins 0.000 description 1
- 101000822328 Homo sapiens Selenocysteine insertion sequence-binding protein 2-like Proteins 0.000 description 1
- 101000739577 Homo sapiens Selenocysteine-specific elongation factor Proteins 0.000 description 1
- 101000823935 Homo sapiens Serine palmitoyltransferase 3 Proteins 0.000 description 1
- 101000704221 Homo sapiens Serine palmitoyltransferase small subunit A Proteins 0.000 description 1
- 101000619121 Homo sapiens Serine protease 48 Proteins 0.000 description 1
- 101000868090 Homo sapiens Serine-rich coiled-coil domain-containing protein 2 Proteins 0.000 description 1
- 101000739901 Homo sapiens Sesquipedalian-1 Proteins 0.000 description 1
- 101000654630 Homo sapiens Shieldin complex subunit 1 Proteins 0.000 description 1
- 101000632626 Homo sapiens Shieldin complex subunit 2 Proteins 0.000 description 1
- 101000703745 Homo sapiens Shootin-1 Proteins 0.000 description 1
- 101000702394 Homo sapiens Signal peptide peptidase-like 2A Proteins 0.000 description 1
- 101000642630 Homo sapiens Sine oculis-binding protein homolog Proteins 0.000 description 1
- 101000864037 Homo sapiens Single-pass membrane and coiled-coil domain-containing protein 4 Proteins 0.000 description 1
- 101001026232 Homo sapiens Small conductance calcium-activated potassium channel protein 3 Proteins 0.000 description 1
- 101000703717 Homo sapiens Small integral membrane protein 14 Proteins 0.000 description 1
- 101000825929 Homo sapiens Small integral membrane protein 19 Proteins 0.000 description 1
- 101000821943 Homo sapiens Sodium-coupled neutral amino acid transporter 9 Proteins 0.000 description 1
- 101001012599 Homo sapiens Sodium-dependent glucose transporter 1 Proteins 0.000 description 1
- 101000701334 Homo sapiens Sodium/potassium-transporting ATPase subunit alpha-1 Proteins 0.000 description 1
- 101000753197 Homo sapiens Sodium/potassium-transporting ATPase subunit alpha-2 Proteins 0.000 description 1
- 101000789523 Homo sapiens Sodium/potassium-transporting ATPase subunit beta-1 Proteins 0.000 description 1
- 101000685671 Homo sapiens Solute carrier family 22 member 23 Proteins 0.000 description 1
- 101000637792 Homo sapiens Solute carrier family 35 member G5 Proteins 0.000 description 1
- 101000685990 Homo sapiens Specifically androgen-regulated gene protein Proteins 0.000 description 1
- 101000702734 Homo sapiens Spermatid-specific manchette-related protein 1 Proteins 0.000 description 1
- 101000629575 Homo sapiens Spermatogenesis-associated protein 32 Proteins 0.000 description 1
- 101000651408 Homo sapiens Spexin Proteins 0.000 description 1
- 101000693265 Homo sapiens Sphingosine 1-phosphate receptor 1 Proteins 0.000 description 1
- 101000633677 Homo sapiens Spindle and kinetochore-associated protein 3 Proteins 0.000 description 1
- 101000831940 Homo sapiens Stathmin Proteins 0.000 description 1
- 101000869535 Homo sapiens Sterile alpha motif domain-containing protein 15 Proteins 0.000 description 1
- 101000861263 Homo sapiens Steroid 21-hydroxylase Proteins 0.000 description 1
- 101000875401 Homo sapiens Sterol 26-hydroxylase, mitochondrial Proteins 0.000 description 1
- 101000616115 Homo sapiens Stress-associated endoplasmic reticulum protein 2 Proteins 0.000 description 1
- 101000648213 Homo sapiens Striatin-interacting protein 1 Proteins 0.000 description 1
- 101000648207 Homo sapiens Striatin-interacting protein 2 Proteins 0.000 description 1
- 101000874203 Homo sapiens Succinate dehydrogenase assembly factor 4, mitochondrial Proteins 0.000 description 1
- 101000648553 Homo sapiens Sushi domain-containing protein 6 Proteins 0.000 description 1
- 101000640303 Homo sapiens Synapse differentiation-inducing gene protein 1 Proteins 0.000 description 1
- 101000879389 Homo sapiens Syntabulin Proteins 0.000 description 1
- 101000852716 Homo sapiens T-cell immunomodulatory protein Proteins 0.000 description 1
- 101000738335 Homo sapiens T-cell surface glycoprotein CD3 zeta chain Proteins 0.000 description 1
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 description 1
- 101000595467 Homo sapiens T-complex protein 1 subunit gamma Proteins 0.000 description 1
- 101000596086 Homo sapiens TATA box-binding protein-associated factor RNA polymerase I subunit D Proteins 0.000 description 1
- 101000694973 Homo sapiens TATA-binding protein-associated factor 172 Proteins 0.000 description 1
- 101000633807 Homo sapiens TELO2-interacting protein 2 Proteins 0.000 description 1
- 101000669479 Homo sapiens TLD domain-containing protein 2 Proteins 0.000 description 1
- 101000596016 Homo sapiens TLR adapter interacting with SLC15A4 on the lysosome Proteins 0.000 description 1
- 101000795744 Homo sapiens TPA-induced transmembrane protein Proteins 0.000 description 1
- 101000835665 Homo sapiens TRPM8 channel-associated factor 1 Proteins 0.000 description 1
- 101000844252 Homo sapiens TYMS opposite strand protein Proteins 0.000 description 1
- 101000835541 Homo sapiens Target of Nesh-SH3 Proteins 0.000 description 1
- 101000653430 Homo sapiens Tectonic-1 Proteins 0.000 description 1
- 101000848647 Homo sapiens Telomerase RNA component interacting RNase Proteins 0.000 description 1
- 101000666416 Homo sapiens Terminal nucleotidyltransferase 5A Proteins 0.000 description 1
- 101000666429 Homo sapiens Terminal nucleotidyltransferase 5C Proteins 0.000 description 1
- 101001122914 Homo sapiens Testicular acid phosphatase Proteins 0.000 description 1
- 101000863840 Homo sapiens Testicular spindle-associated protein SHCBP1L Proteins 0.000 description 1
- 101000800679 Homo sapiens Testis development-related protein Proteins 0.000 description 1
- 101000759808 Homo sapiens Testis-expressed basic protein 1 Proteins 0.000 description 1
- 101000596739 Homo sapiens Testis-expressed protein 29 Proteins 0.000 description 1
- 101000837807 Homo sapiens Testis-expressed protein 43 Proteins 0.000 description 1
- 101000900750 Homo sapiens Testis-specific protein LINC02914 Proteins 0.000 description 1
- 101000658654 Homo sapiens Tetratricopeptide repeat protein 23-like Proteins 0.000 description 1
- 101000659166 Homo sapiens Tetratricopeptide repeat protein 30B Proteins 0.000 description 1
- 101000659173 Homo sapiens Tetratricopeptide repeat protein 39B Proteins 0.000 description 1
- 101000759409 Homo sapiens Tetratricopeptide repeat protein 39C Proteins 0.000 description 1
- 101000794211 Homo sapiens Thiosulfate sulfurtransferase/rhodanese-like domain-containing protein 2 Proteins 0.000 description 1
- 101000737828 Homo sapiens Threonylcarbamoyladenosine tRNA methylthiotransferase Proteins 0.000 description 1
- 101000819111 Homo sapiens Trans-acting T-cell-specific transcription factor GATA-3 Proteins 0.000 description 1
- 101000920618 Homo sapiens Transcription and mRNA export factor ENY2 Proteins 0.000 description 1
- 101000881764 Homo sapiens Transcription elongation factor 1 homolog Proteins 0.000 description 1
- 101000597047 Homo sapiens Transcription elongation factor A N-terminal and central domain-containing protein 2 Proteins 0.000 description 1
- 101000701142 Homo sapiens Transcription factor ATOH1 Proteins 0.000 description 1
- 101000984924 Homo sapiens Transcription factor BTF3 homolog 4 Proteins 0.000 description 1
- 101000866298 Homo sapiens Transcription factor E2F8 Proteins 0.000 description 1
- 101000813738 Homo sapiens Transcription factor ETV6 Proteins 0.000 description 1
- 101000843556 Homo sapiens Transcription factor HES-1 Proteins 0.000 description 1
- 101000843569 Homo sapiens Transcription factor HES-3 Proteins 0.000 description 1
- 101000723923 Homo sapiens Transcription factor HIVEP2 Proteins 0.000 description 1
- 101000723938 Homo sapiens Transcription factor HIVEP3 Proteins 0.000 description 1
- 101000635741 Homo sapiens Transcription initiation factor IIA subunit 1 Proteins 0.000 description 1
- 101000894871 Homo sapiens Transcription regulator protein BACH1 Proteins 0.000 description 1
- 101001010792 Homo sapiens Transcriptional regulator ERG Proteins 0.000 description 1
- 101001098095 Homo sapiens Transcriptional repressor p66-alpha Proteins 0.000 description 1
- 101001057681 Homo sapiens Translation initiation factor eIF-2B subunit beta Proteins 0.000 description 1
- 101000836189 Homo sapiens Translational activator of cytochrome c oxidase 1 Proteins 0.000 description 1
- 101000895030 Homo sapiens Transmembrane ascorbate-dependent reductase CYB561 Proteins 0.000 description 1
- 101000640723 Homo sapiens Transmembrane protein 131-like Proteins 0.000 description 1
- 101000831515 Homo sapiens Transmembrane protein 186 Proteins 0.000 description 1
- 101000674805 Homo sapiens Transmembrane protein 191A Proteins 0.000 description 1
- 101000787917 Homo sapiens Transmembrane protein 200A Proteins 0.000 description 1
- 101000680173 Homo sapiens Transmembrane protein 217 Proteins 0.000 description 1
- 101000798554 Homo sapiens Transmembrane protein 241 Proteins 0.000 description 1
- 101000763483 Homo sapiens Transmembrane protein 243 Proteins 0.000 description 1
- 101000597877 Homo sapiens Transmembrane protein 254 Proteins 0.000 description 1
- 101000787882 Homo sapiens Transmembrane protein 255B Proteins 0.000 description 1
- 101000597880 Homo sapiens Transmembrane protein 256 Proteins 0.000 description 1
- 101000851625 Homo sapiens Transmembrane protein 260 Proteins 0.000 description 1
- 101000851636 Homo sapiens Transmembrane protein 267 Proteins 0.000 description 1
- 101000637922 Homo sapiens Transmembrane protein 268 Proteins 0.000 description 1
- 101000648525 Homo sapiens Transmembrane protein 52B Proteins 0.000 description 1
- 101000597922 Homo sapiens Transmembrane protein 74B Proteins 0.000 description 1
- 101000662961 Homo sapiens Transmembrane protein 94 Proteins 0.000 description 1
- 101000788608 Homo sapiens Tubulin alpha-3D chain Proteins 0.000 description 1
- 101000788548 Homo sapiens Tubulin alpha-4A chain Proteins 0.000 description 1
- 101000638274 Homo sapiens Type 2 DNA topoisomerase 6 subunit B-like Proteins 0.000 description 1
- 101000714654 Homo sapiens Type III endosome membrane protein TEMP Proteins 0.000 description 1
- 101000765743 Homo sapiens Type-1 angiotensin II receptor-associated protein Proteins 0.000 description 1
- 101000617776 Homo sapiens U11/U12 small nuclear ribonucleoprotein 48 kDa protein Proteins 0.000 description 1
- 101000638903 Homo sapiens U3 small nucleolar RNA-associated protein 25 homolog Proteins 0.000 description 1
- 101000960621 Homo sapiens U3 small nucleolar ribonucleoprotein protein IMP3 Proteins 0.000 description 1
- 101000939251 Homo sapiens UBA-like domain-containing protein 2 Proteins 0.000 description 1
- 101000697875 Homo sapiens UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 1 Proteins 0.000 description 1
- 101000697888 Homo sapiens UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 2 Proteins 0.000 description 1
- 101000836466 Homo sapiens UDP-N-acetylglucosamine transferase subunit ALG14 homolog Proteins 0.000 description 1
- 101100155298 Homo sapiens UFL1 gene Proteins 0.000 description 1
- 101000807276 Homo sapiens UHRF1-binding protein 1 Proteins 0.000 description 1
- 101000768621 Homo sapiens UHRF1-binding protein 1-like Proteins 0.000 description 1
- 101000941915 Homo sapiens UPF0450 protein C17orf58 Proteins 0.000 description 1
- 101000884249 Homo sapiens UPF0462 protein C4orf33 Proteins 0.000 description 1
- 101001046918 Homo sapiens UPF0606 protein KIAA1549L Proteins 0.000 description 1
- 101000914187 Homo sapiens UPF0669 protein C6orf120 Proteins 0.000 description 1
- 101000794443 Homo sapiens UPF0688 protein C1orf174 Proteins 0.000 description 1
- 101000956262 Homo sapiens UPF0692 protein C19orf54 Proteins 0.000 description 1
- 101000888429 Homo sapiens UPF0705 protein C11orf49 Proteins 0.000 description 1
- 101000710297 Homo sapiens UPF0728 protein C10orf53 Proteins 0.000 description 1
- 101000952936 Homo sapiens Ubiquinone biosynthesis monooxygenase COQ6, mitochondrial Proteins 0.000 description 1
- 101001052436 Homo sapiens Ubiquitin carboxyl-terminal hydrolase MINDY-2 Proteins 0.000 description 1
- 101000721404 Homo sapiens Ubiquitin thioesterase otulin Proteins 0.000 description 1
- 101000644689 Homo sapiens Ubiquitin-conjugating enzyme E2 K Proteins 0.000 description 1
- 101000887051 Homo sapiens Ubiquitin-like-conjugating enzyme ATG3 Proteins 0.000 description 1
- 101000720061 Homo sapiens Uncharacterized aarF domain-containing protein kinase 5 Proteins 0.000 description 1
- 101000710301 Homo sapiens Uncharacterized protein C10orf67, mitochondrial Proteins 0.000 description 1
- 101000710299 Homo sapiens Uncharacterized protein C10orf82 Proteins 0.000 description 1
- 101000989695 Homo sapiens Uncharacterized protein C11orf52 Proteins 0.000 description 1
- 101000906693 Homo sapiens Uncharacterized protein C12orf42 Proteins 0.000 description 1
- 101000912683 Homo sapiens Uncharacterized protein C12orf76 Proteins 0.000 description 1
- 101000941707 Homo sapiens Uncharacterized protein C15orf39 Proteins 0.000 description 1
- 101000941911 Homo sapiens Uncharacterized protein C17orf50 Proteins 0.000 description 1
- 101000878912 Homo sapiens Uncharacterized protein C17orf78 Proteins 0.000 description 1
- 101000868048 Homo sapiens Uncharacterized protein C1orf100 Proteins 0.000 description 1
- 101000868050 Homo sapiens Uncharacterized protein C1orf105 Proteins 0.000 description 1
- 101000932776 Homo sapiens Uncharacterized protein C1orf115 Proteins 0.000 description 1
- 101000935151 Homo sapiens Uncharacterized protein C1orf131 Proteins 0.000 description 1
- 101000762224 Homo sapiens Uncharacterized protein C1orf141 Proteins 0.000 description 1
- 101000794432 Homo sapiens Uncharacterized protein C1orf50 Proteins 0.000 description 1
- 101000868045 Homo sapiens Uncharacterized protein C1orf87 Proteins 0.000 description 1
- 101000889070 Homo sapiens Uncharacterized protein C22orf31 Proteins 0.000 description 1
- 101000983603 Homo sapiens Uncharacterized protein C2orf27A Proteins 0.000 description 1
- 101000715347 Homo sapiens Uncharacterized protein C3orf20 Proteins 0.000 description 1
- 101000932572 Homo sapiens Uncharacterized protein C3orf62 Proteins 0.000 description 1
- 101000777664 Homo sapiens Uncharacterized protein C4orf19 Proteins 0.000 description 1
- 101000884255 Homo sapiens Uncharacterized protein C4orf36 Proteins 0.000 description 1
- 101000884236 Homo sapiens Uncharacterized protein C4orf45 Proteins 0.000 description 1
- 101000776454 Homo sapiens Uncharacterized protein C6orf141 Proteins 0.000 description 1
- 101000944542 Homo sapiens Uncharacterized protein C6orf15 Proteins 0.000 description 1
- 101000906814 Homo sapiens Uncharacterized protein C9orf152 Proteins 0.000 description 1
- 101000978303 Homo sapiens Uncharacterized protein CCDC198 Proteins 0.000 description 1
- 101000845637 Homo sapiens Uncharacterized protein DOCK8-AS1 Proteins 0.000 description 1
- 101000813311 Homo sapiens Uncharacterized protein FAM120AOS Proteins 0.000 description 1
- 101001027867 Homo sapiens Uncharacterized protein FAM241A Proteins 0.000 description 1
- 101001056490 Homo sapiens Uncharacterized protein KIAA0930 Proteins 0.000 description 1
- 101000782090 Homo sapiens Uncharacterized protein ZNF22-AS1 Proteins 0.000 description 1
- 101000710307 Homo sapiens Uncharacterized protein encoded by LINC01561 Proteins 0.000 description 1
- 101000715812 Homo sapiens Uncharacterized protein encoded by LINC01600 Proteins 0.000 description 1
- 101000854873 Homo sapiens V-type proton ATPase 116 kDa subunit a 4 Proteins 0.000 description 1
- 101000806601 Homo sapiens V-type proton ATPase catalytic subunit A Proteins 0.000 description 1
- 101000850434 Homo sapiens V-type proton ATPase subunit B, brain isoform Proteins 0.000 description 1
- 101000670960 Homo sapiens V-type proton ATPase subunit E 1 Proteins 0.000 description 1
- 101000670973 Homo sapiens V-type proton ATPase subunit E 2 Proteins 0.000 description 1
- 101000806424 Homo sapiens V-type proton ATPase subunit G 1 Proteins 0.000 description 1
- 101000805441 Homo sapiens V-type proton ATPase subunit G 3 Proteins 0.000 description 1
- 101000749351 Homo sapiens V-type proton ATPase subunit d 2 Proteins 0.000 description 1
- 101000910342 Homo sapiens VWFA and cache domain-containing protein 1 Proteins 0.000 description 1
- 101001070761 Homo sapiens Vasculin-like protein 1 Proteins 0.000 description 1
- 101000854827 Homo sapiens Vertnin Proteins 0.000 description 1
- 101000653426 Homo sapiens Very-long-chain enoyl-CoA reductase Proteins 0.000 description 1
- 101000904228 Homo sapiens Vesicle transport protein GOT1A Proteins 0.000 description 1
- 101000855326 Homo sapiens Vitamin D 25-hydroxylase Proteins 0.000 description 1
- 101000983936 Homo sapiens Voltage-dependent L-type calcium channel subunit beta-3 Proteins 0.000 description 1
- 101000910745 Homo sapiens Voltage-dependent calcium channel gamma-3 subunit Proteins 0.000 description 1
- 101000910748 Homo sapiens Voltage-dependent calcium channel gamma-4 subunit Proteins 0.000 description 1
- 101000740765 Homo sapiens Voltage-dependent calcium channel subunit alpha-2/delta-4 Proteins 0.000 description 1
- 101000743114 Homo sapiens WASH complex subunit 4 Proteins 0.000 description 1
- 101000854908 Homo sapiens WD repeat-containing protein 11 Proteins 0.000 description 1
- 101000650035 Homo sapiens WD repeat-containing protein 91 Proteins 0.000 description 1
- 101000976201 Homo sapiens Zinc finger C2HC domain-containing protein 1A Proteins 0.000 description 1
- 101000976205 Homo sapiens Zinc finger C2HC domain-containing protein 1C Proteins 0.000 description 1
- 101000723827 Homo sapiens Zinc finger CCHC domain-containing protein 24 Proteins 0.000 description 1
- 101000744900 Homo sapiens Zinc finger homeobox protein 3 Proteins 0.000 description 1
- 101000976594 Homo sapiens Zinc finger protein 117 Proteins 0.000 description 1
- 101000788754 Homo sapiens Zinc finger protein 362 Proteins 0.000 description 1
- 101000723920 Homo sapiens Zinc finger protein 40 Proteins 0.000 description 1
- 101000599046 Homo sapiens Zinc finger protein Eos Proteins 0.000 description 1
- 101000888783 Homo sapiens Zinc finger protein GLI4 Proteins 0.000 description 1
- 101000857276 Homo sapiens Zinc finger protein GLIS3 Proteins 0.000 description 1
- 101000599037 Homo sapiens Zinc finger protein Helios Proteins 0.000 description 1
- 101000911019 Homo sapiens Zinc finger protein castor homolog 1 Proteins 0.000 description 1
- 101000669028 Homo sapiens Zinc phosphodiesterase ELAC protein 2 Proteins 0.000 description 1
- 101000856240 Homo sapiens cTAGE family member 2 Proteins 0.000 description 1
- 101000744322 Homo sapiens eIF5-mimic protein 1 Proteins 0.000 description 1
- 101000802734 Homo sapiens eIF5-mimic protein 2 Proteins 0.000 description 1
- 101001059630 Homo sapiens m-AAA protease-interacting protein 1, mitochondrial Proteins 0.000 description 1
- 101000873780 Homo sapiens m7GpppN-mRNA hydrolase Proteins 0.000 description 1
- 101000932978 Homo sapiens mRNA (2'-O-methyladenosine-N(6)-)-methyltransferase Proteins 0.000 description 1
- 101000873785 Homo sapiens mRNA-decapping enzyme 1A Proteins 0.000 description 1
- 101000873789 Homo sapiens mRNA-decapping enzyme 1B Proteins 0.000 description 1
- 101000766249 Homo sapiens tRNA (guanine(10)-N2)-methyltransferase homolog Proteins 0.000 description 1
- 101000747206 Homo sapiens tRNA pseudouridine synthase Pus10 Proteins 0.000 description 1
- 101000940142 Homo sapiens tRNA wybutosine-synthesizing protein 5 Proteins 0.000 description 1
- 101000873442 Homo sapiens tRNA-splicing endonuclease subunit Sen15 Proteins 0.000 description 1
- 101000804631 Homo sapiens von Willebrand factor A domain-containing protein 5B1 Proteins 0.000 description 1
- 102100039923 Homocysteine-responsive endoplasmic reticulum-resident ubiquitin-like domain member 1 protein Human genes 0.000 description 1
- 102100039926 Homocysteine-responsive endoplasmic reticulum-resident ubiquitin-like domain member 2 protein Human genes 0.000 description 1
- 101150064744 Hspb8 gene Proteins 0.000 description 1
- 102100039238 Hyaluronan-binding protein 2 Human genes 0.000 description 1
- 102100021081 Hyaluronidase-4 Human genes 0.000 description 1
- 102100040204 Hydrocephalus-inducing protein homolog Human genes 0.000 description 1
- 102100039356 Hydroxycarboxylic acid receptor 3 Human genes 0.000 description 1
- 102100031612 Hypermethylated in cancer 1 protein Human genes 0.000 description 1
- 102100031613 Hypermethylated in cancer 2 protein Human genes 0.000 description 1
- 102100029098 Hypoxanthine-guanine phosphoribosyltransferase Human genes 0.000 description 1
- 101150009156 IGSF1 gene Proteins 0.000 description 1
- 101150091583 IGSF21 gene Proteins 0.000 description 1
- 108010007666 IMP cyclohydrolase Proteins 0.000 description 1
- 102100033277 INO80 complex subunit C Human genes 0.000 description 1
- 102100024415 IQ domain-containing protein K Human genes 0.000 description 1
- 101150018316 Igsf3 gene Proteins 0.000 description 1
- 102100020702 Immediate early response gene 2 protein Human genes 0.000 description 1
- 102100020701 Immediate early response gene 5-like protein Human genes 0.000 description 1
- 102100025886 Immortalization up-regulated protein Human genes 0.000 description 1
- 102100022514 Immunoglobulin superfamily member 1 Human genes 0.000 description 1
- 102100022516 Immunoglobulin superfamily member 2 Human genes 0.000 description 1
- 102100022487 Immunoglobulin superfamily member 21 Human genes 0.000 description 1
- 102100022519 Immunoglobulin superfamily member 3 Human genes 0.000 description 1
- 102100030713 Immunoglobulin-like domain-containing receptor 1 Human genes 0.000 description 1
- 102100036188 Importin subunit alpha-3 Human genes 0.000 description 1
- 102100036187 Importin subunit alpha-4 Human genes 0.000 description 1
- 101710125768 Importin-4 Proteins 0.000 description 1
- 102100037963 Importin-7 Human genes 0.000 description 1
- 102100032448 Inactive ADP-ribosyltransferase ARH2 Human genes 0.000 description 1
- 102100029326 Inactive carboxypeptidase-like protein X2 Human genes 0.000 description 1
- 102100040449 Inactive dipeptidyl peptidase 10 Human genes 0.000 description 1
- 102100034061 Inactive glutathione hydrolase 2 Human genes 0.000 description 1
- 102100024022 Inactive heparanase-2 Human genes 0.000 description 1
- 102100034548 Inactive polypeptide N-acetylgalactosaminyltransferase-like protein 5 Human genes 0.000 description 1
- 102100025186 Inactive ubiquitin thioesterase OTULINL Human genes 0.000 description 1
- 102100026214 Indian hedgehog protein Human genes 0.000 description 1
- 101710139099 Indian hedgehog protein Proteins 0.000 description 1
- 102100029241 Influenza virus NS1A-binding protein Human genes 0.000 description 1
- 102100026818 Inhibin beta E chain Human genes 0.000 description 1
- 102100027638 Inhibitor of Bruton tyrosine kinase Human genes 0.000 description 1
- 102100036359 Inhibitory synaptic factor 2A Human genes 0.000 description 1
- 102100036724 Innate immunity activator protein Human genes 0.000 description 1
- 102100020796 Inosine 5'-monophosphate cyclohydrolase Human genes 0.000 description 1
- 102100024039 Inositol 1,4,5-trisphosphate receptor type 1 Human genes 0.000 description 1
- 102100037739 Inositol hexakisphosphate and diphosphoinositol-pentakisphosphate kinase 1 Human genes 0.000 description 1
- 102100030213 Inositol hexakisphosphate kinase 1 Human genes 0.000 description 1
- 102100021608 Inositol monophosphatase 2 Human genes 0.000 description 1
- 102100026819 Inositol polyphosphate 1-phosphatase Human genes 0.000 description 1
- 102100024366 Inositol polyphosphate 4-phosphatase type II Human genes 0.000 description 1
- 102100025479 Inositol polyphosphate multikinase Human genes 0.000 description 1
- 102100024367 Inositol polyphosphate-4-phosphatase type I A Human genes 0.000 description 1
- 108010071021 Inositol-polyphosphate multikinase Proteins 0.000 description 1
- 102100036405 Inositol-trisphosphate 3-kinase A Human genes 0.000 description 1
- 102100036403 Inositol-trisphosphate 3-kinase C Human genes 0.000 description 1
- 102100024390 Insulin gene enhancer protein ISL-2 Human genes 0.000 description 1
- 102100025963 Insulin growth factor-like family member 4 Human genes 0.000 description 1
- 102100025087 Insulin receptor substrate 1 Human genes 0.000 description 1
- 102100037970 Insulin-induced gene 2 protein Human genes 0.000 description 1
- 102100037924 Insulin-like growth factor 2 mRNA-binding protein 1 Human genes 0.000 description 1
- 102100037920 Insulin-like growth factor 2 mRNA-binding protein 3 Human genes 0.000 description 1
- 102100039091 Insulinoma-associated protein 1 Human genes 0.000 description 1
- 102100039093 Insulinoma-associated protein 2 Human genes 0.000 description 1
- 102100023350 Integral membrane protein 2B Human genes 0.000 description 1
- 102100025464 Integral membrane protein 2C Human genes 0.000 description 1
- 102100035571 Integral membrane protein GPR137B Human genes 0.000 description 1
- 102100037944 Integrator complex subunit 12 Human genes 0.000 description 1
- 102100033263 Integrator complex subunit 3 Human genes 0.000 description 1
- 102100039134 Integrator complex subunit 4 Human genes 0.000 description 1
- 102100039133 Integrator complex subunit 6 Human genes 0.000 description 1
- 102100039904 Integrin alpha-D Human genes 0.000 description 1
- 102100025306 Integrin alpha-IIb Human genes 0.000 description 1
- 102100022338 Integrin alpha-M Human genes 0.000 description 1
- 102100022337 Integrin alpha-V Human genes 0.000 description 1
- 102100025304 Integrin beta-1 Human genes 0.000 description 1
- 102100032999 Integrin beta-3 Human genes 0.000 description 1
- 102100033010 Integrin beta-5 Human genes 0.000 description 1
- 102100033336 Integrin beta-8 Human genes 0.000 description 1
- 102100026688 Interferon epsilon Human genes 0.000 description 1
- 102100025356 Interferon regulatory factor 2-binding protein 2 Human genes 0.000 description 1
- 102100030131 Interferon regulatory factor 5 Human genes 0.000 description 1
- 102100038069 Interferon regulatory factor 8 Human genes 0.000 description 1
- 102100033273 Interferon-induced 35 kDa protein Human genes 0.000 description 1
- 102100026227 Interferon-induced protein with tetratricopeptide repeats 1B Human genes 0.000 description 1
- 102100027303 Interferon-induced protein with tetratricopeptide repeats 2 Human genes 0.000 description 1
- 102100027302 Interferon-induced protein with tetratricopeptide repeats 3 Human genes 0.000 description 1
- 102100027356 Interferon-induced protein with tetratricopeptide repeats 5 Human genes 0.000 description 1
- 102100034413 Interleukin-1 receptor accessory protein-like 1 Human genes 0.000 description 1
- 102100026016 Interleukin-1 receptor type 1 Human genes 0.000 description 1
- 102100023530 Interleukin-1 receptor-associated kinase 3 Human genes 0.000 description 1
- 102100020788 Interleukin-10 receptor subunit beta Human genes 0.000 description 1
- 102000003816 Interleukin-13 Human genes 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 101800003050 Interleukin-16 Proteins 0.000 description 1
- 102100035016 Interleukin-17 receptor E Human genes 0.000 description 1
- 102100035010 Interleukin-18 receptor accessory protein Human genes 0.000 description 1
- 102100035017 Interleukin-18-binding protein Human genes 0.000 description 1
- 102100022705 Interleukin-20 receptor subunit beta Human genes 0.000 description 1
- 102100030703 Interleukin-22 Human genes 0.000 description 1
- 102100022723 Interleukin-22 receptor subunit alpha-1 Human genes 0.000 description 1
- 102100036705 Interleukin-23 subunit alpha Human genes 0.000 description 1
- 102100040066 Interleukin-27 receptor subunit alpha Human genes 0.000 description 1
- 102100021594 Interleukin-31 receptor subunit alpha Human genes 0.000 description 1
- 102100039096 Interphotoreceptor matrix proteoglycan 1 Human genes 0.000 description 1
- 102100021502 Intraflagellar transport protein 122 homolog Human genes 0.000 description 1
- 102100026220 Intraflagellar transport protein 20 homolog Human genes 0.000 description 1
- 102100039342 Intraflagellar transport protein 43 homolog Human genes 0.000 description 1
- 102100022470 Intraflagellar transport protein 52 homolog Human genes 0.000 description 1
- 102100030007 Intraflagellar transport protein 88 homolog Human genes 0.000 description 1
- 102100022774 Inward rectifier potassium channel 16 Human genes 0.000 description 1
- 102100033114 Inward rectifier potassium channel 2 Human genes 0.000 description 1
- 102100025468 Iodotyrosine deiodinase 1 Human genes 0.000 description 1
- 108090001028 Iron regulatory protein 2 Proteins 0.000 description 1
- 102000004902 Iron regulatory protein 2 Human genes 0.000 description 1
- 102100031428 Iron-sulfur cluster assembly 2 homolog, mitochondrial Human genes 0.000 description 1
- 102100023529 Iroquois-class homeodomain protein IRX-5 Human genes 0.000 description 1
- 102100027640 Islet cell autoantigen 1 Human genes 0.000 description 1
- 102100031386 Isochorismatase domain-containing protein 1 Human genes 0.000 description 1
- 102100035997 Isoleucine-tRNA ligase, mitochondrial Human genes 0.000 description 1
- 102100025392 Isovaleryl-CoA dehydrogenase, mitochondrial Human genes 0.000 description 1
- 101710201965 Isovaleryl-CoA dehydrogenase, mitochondrial Proteins 0.000 description 1
- 102100025837 JNK1/MAPK8-associated membrane protein Human genes 0.000 description 1
- 102100033439 Janus kinase and microtubule-interacting protein 2 Human genes 0.000 description 1
- 102100032732 Josephin-1 Human genes 0.000 description 1
- 102100023976 Jun dimerization protein 2 Human genes 0.000 description 1
- 102100026153 Junction plakoglobin Human genes 0.000 description 1
- 102100022304 Junctional adhesion molecule A Human genes 0.000 description 1
- 102100023437 Junctional adhesion molecule-like Human genes 0.000 description 1
- 102100040503 Junctophilin-2 Human genes 0.000 description 1
- 102100025727 Juxtaposed with another zinc finger protein 1 Human genes 0.000 description 1
- 102100022903 KAT8 regulatory NSL complex subunit 1 Human genes 0.000 description 1
- 102100023009 KAT8 regulatory NSL complex subunit 1-like protein Human genes 0.000 description 1
- 102000017839 KCMF1 Human genes 0.000 description 1
- 102000017792 KCNJ11 Human genes 0.000 description 1
- 102000017714 KCNJ8 Human genes 0.000 description 1
- 108010011185 KCNQ1 Potassium Channel Proteins 0.000 description 1
- 108010038888 KCNQ3 Potassium Channel Proteins 0.000 description 1
- 102100023411 KH domain-containing, RNA-binding, signal transduction-associated protein 2 Human genes 0.000 description 1
- 101710014005 KIAA0040 Proteins 0.000 description 1
- 101710015514 KIAA0232 Proteins 0.000 description 1
- 101710038303 KIAA0319 Proteins 0.000 description 1
- 101710036322 KIAA0586 Proteins 0.000 description 1
- 101710059984 KIAA1191 Proteins 0.000 description 1
- 101710059804 KIAA1217 Proteins 0.000 description 1
- 101710059175 KIAA1958 Proteins 0.000 description 1
- 101710023482 KIAA2013 Proteins 0.000 description 1
- 102100027622 KICSTOR subunit 2 Human genes 0.000 description 1
- 102100022904 KN motif and ankyrin repeat domain-containing protein 4 Human genes 0.000 description 1
- 102100029874 Kappa-casein Human genes 0.000 description 1
- 102100022971 Katanin p60 ATPase-containing subunit A-like 2 Human genes 0.000 description 1
- 102100021190 Kazrin Human genes 0.000 description 1
- 102100037645 Kelch domain-containing protein 10 Human genes 0.000 description 1
- 102100033609 Kelch domain-containing protein 2 Human genes 0.000 description 1
- 102100033603 Kelch domain-containing protein 4 Human genes 0.000 description 1
- 102100022827 Kelch repeat and BTB domain-containing protein 11 Human genes 0.000 description 1
- 102100022834 Kelch repeat and BTB domain-containing protein 12 Human genes 0.000 description 1
- 102100034075 Kelch repeat and BTB domain-containing protein 2 Human genes 0.000 description 1
- 102100022835 Kelch repeat and BTB domain-containing protein 7 Human genes 0.000 description 1
- 102100022830 Kelch repeat and BTB domain-containing protein 8 Human genes 0.000 description 1
- 102100034861 Kelch-like protein 13 Human genes 0.000 description 1
- 102100023682 Kelch-like protein 15 Human genes 0.000 description 1
- 102100022120 Kelch-like protein 2 Human genes 0.000 description 1
- 102100023681 Kelch-like protein 20 Human genes 0.000 description 1
- 102100027795 Kelch-like protein 23 Human genes 0.000 description 1
- 102100027794 Kelch-like protein 24 Human genes 0.000 description 1
- 102100027800 Kelch-like protein 25 Human genes 0.000 description 1
- 102100033556 Kelch-like protein 28 Human genes 0.000 description 1
- 102100033584 Kelch-like protein 31 Human genes 0.000 description 1
- 102100037641 Kelch-like protein 42 Human genes 0.000 description 1
- 102100027615 Kelch-like protein 8 Human genes 0.000 description 1
- 102100023131 Keratin, type I cuticular Ha1 Human genes 0.000 description 1
- 102100023967 Keratin, type I cytoskeletal 12 Human genes 0.000 description 1
- 102100033421 Keratin, type I cytoskeletal 18 Human genes 0.000 description 1
- 102100032700 Keratin, type I cytoskeletal 20 Human genes 0.000 description 1
- 102100037158 Keratin, type I cytoskeletal 39 Human genes 0.000 description 1
- 102100023972 Keratin, type II cytoskeletal 8 Human genes 0.000 description 1
- 102100023977 Keratin, type II cytoskeletal 80 Human genes 0.000 description 1
- 102100020853 Keratin-associated protein 15-1 Human genes 0.000 description 1
- 102100024888 Keratin-associated protein 26-1 Human genes 0.000 description 1
- 102100023023 Keratin-associated protein 8-1 Human genes 0.000 description 1
- 102100035791 Keratinocyte proline-rich protein Human genes 0.000 description 1
- 102100040538 Keratinocyte-associated transmembrane protein 2 Human genes 0.000 description 1
- 102100020687 Kin of IRRE-like protein 1 Human genes 0.000 description 1
- 102100023924 Kinase D-interacting substrate of 220 kDa Human genes 0.000 description 1
- 102100034751 Kinectin Human genes 0.000 description 1
- 102100038316 Kinesin light chain 4 Human genes 0.000 description 1
- 102100023422 Kinesin-1 heavy chain Human genes 0.000 description 1
- 102100027930 Kinesin-associated protein 3 Human genes 0.000 description 1
- 102100034865 Kinesin-like protein KIF13A Human genes 0.000 description 1
- 102100034863 Kinesin-like protein KIF13B Human genes 0.000 description 1
- 102100021525 Kinesin-like protein KIF1C Human genes 0.000 description 1
- 102100037688 Kinesin-like protein KIF21A Human genes 0.000 description 1
- 102100027927 Kinesin-like protein KIF6 Human genes 0.000 description 1
- 102100022250 Kinesin-like protein KIFC3 Human genes 0.000 description 1
- 101000862382 Klebsiella pneumoniae (strain 342) NADH:fumarate oxidoreductase Proteins 0.000 description 1
- 102100038173 Kremen protein 1 Human genes 0.000 description 1
- 102100027792 Krueppel-like factor 12 Human genes 0.000 description 1
- 102100022254 Krueppel-like factor 13 Human genes 0.000 description 1
- 102100020675 Krueppel-like factor 2 Human genes 0.000 description 1
- 102100020678 Krueppel-like factor 3 Human genes 0.000 description 1
- 102100020680 Krueppel-like factor 5 Human genes 0.000 description 1
- 102100020692 Krueppel-like factor 7 Human genes 0.000 description 1
- 102100021173 Kv channel-interacting protein 2 Human genes 0.000 description 1
- 102100021175 Kv channel-interacting protein 4 Human genes 0.000 description 1
- 102100036091 Kynureninase Human genes 0.000 description 1
- 102100037652 Kynurenine 3-monooxygenase Human genes 0.000 description 1
- 102100040621 Kynurenine formamidase Human genes 0.000 description 1
- 102100035118 LIM and SH3 domain protein 1 Human genes 0.000 description 1
- 102100026447 LIM domain-containing protein ajuba Human genes 0.000 description 1
- 102100020859 La-related protein 1 Human genes 0.000 description 1
- 102100020861 La-related protein 4 Human genes 0.000 description 1
- 102100030946 La-related protein 4B Human genes 0.000 description 1
- 102100035655 Lactosylceramide 1,3-N-acetyl-beta-D-glucosaminyltransferase Human genes 0.000 description 1
- 102100040253 Lamin tail domain-containing protein 1 Human genes 0.000 description 1
- 102100024629 Laminin subunit beta-3 Human genes 0.000 description 1
- 102100024623 Laminin subunit beta-4 Human genes 0.000 description 1
- 102100035159 Laminin subunit gamma-2 Human genes 0.000 description 1
- 102100032642 Late secretory pathway protein AVL9 homolog Human genes 0.000 description 1
- 102100024144 Lengsin Human genes 0.000 description 1
- 102100030657 Lethal(3)malignant brain tumor-like protein 1 Human genes 0.000 description 1
- 102100040548 Lethal(3)malignant brain tumor-like protein 3 Human genes 0.000 description 1
- 102100040545 Lethal(3)malignant brain tumor-like protein 4 Human genes 0.000 description 1
- 102100032654 Leucine-rich repeat neuronal protein 4 Human genes 0.000 description 1
- 102100040978 Leucine-rich repeat-containing protein 74A Human genes 0.000 description 1
- 102100032098 Leucine-rich repeat-containing protein 75A Human genes 0.000 description 1
- 102100023339 Leucine-tRNA ligase, cytoplasmic Human genes 0.000 description 1
- 102100023342 Leucine-tRNA ligase, mitochondrial Human genes 0.000 description 1
- 102100038260 Ligand-dependent corepressor Human genes 0.000 description 1
- 102100022172 Ligand-dependent nuclear receptor-interacting factor 1 Human genes 0.000 description 1
- 102100031360 Lipid droplet-associated hydrolase Human genes 0.000 description 1
- 102100025357 Lipid-phosphate phosphatase Human genes 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 102100030984 Lymphocyte function-associated antigen 3 Human genes 0.000 description 1
- 102100040598 Lysine-specific demethylase 2A Human genes 0.000 description 1
- 102100040584 Lysine-specific demethylase 2B Human genes 0.000 description 1
- 102100040581 Lysine-specific demethylase 3A Human genes 0.000 description 1
- 102100040863 Lysine-specific demethylase 4A Human genes 0.000 description 1
- 102100033230 Lysine-specific demethylase 4C Human genes 0.000 description 1
- 102100033246 Lysine-specific demethylase 5A Human genes 0.000 description 1
- 102100033247 Lysine-specific demethylase 5B Human genes 0.000 description 1
- 102100037465 Lysine-specific demethylase 7A Human genes 0.000 description 1
- 102100024985 Lysine-specific histone demethylase 1A Human genes 0.000 description 1
- 102100038056 Lysophosphatidylserine lipase ABHD12 Human genes 0.000 description 1
- 102100026906 MAP3K7 C-terminal-like protein Human genes 0.000 description 1
- 102100030165 MAPK-interacting and spindle-stabilizing protein-like Human genes 0.000 description 1
- 102100033551 MICOS complex subunit MIC10 Human genes 0.000 description 1
- 102100026626 MICOS complex subunit MIC19 Human genes 0.000 description 1
- 102100026629 MICOS complex subunit MIC25 Human genes 0.000 description 1
- 102100023286 MORN repeat-containing protein 5 Human genes 0.000 description 1
- 102100022211 MTRF1L release factor glutamine methyltransferase Human genes 0.000 description 1
- 102100024573 Macrophage-capping protein Human genes 0.000 description 1
- 102100034104 Maestro heat-like repeat-containing protein family member 2B Human genes 0.000 description 1
- 102100021341 Maestro heat-like repeat-containing protein family member 7 Human genes 0.000 description 1
- 102100021340 Maestro heat-like repeat-containing protein family member 9 Human genes 0.000 description 1
- 101000783811 Magnaporthe oryzae (strain 70-15 / ATCC MYA-4617 / FGSC 8958) Jasmonate monooxygenase ABM Proteins 0.000 description 1
- 102100026237 Major facilitator superfamily domain-containing protein 6-like Human genes 0.000 description 1
- 102100037750 Malectin Human genes 0.000 description 1
- 102100030031 Mammalian ependymin-related protein 1 Human genes 0.000 description 1
- 102100021171 Mannose-1-phosphate guanyltransferase beta Human genes 0.000 description 1
- 102100039001 Mediator of RNA polymerase II transcription subunit 27 Human genes 0.000 description 1
- 102100029668 Mediator of RNA polymerase II transcription subunit 29 Human genes 0.000 description 1
- 102100026674 Medium-chain acyl-CoA ligase ACSF2, mitochondrial Human genes 0.000 description 1
- 102100029778 Melanoma inhibitory activity protein 2 Human genes 0.000 description 1
- 108010090306 Member 2 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 108010090837 Member 5 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 102100039373 Membrane cofactor protein Human genes 0.000 description 1
- 102100031677 Metal transporter CNNM2 Human genes 0.000 description 1
- 102100031678 Metal transporter CNNM3 Human genes 0.000 description 1
- 102100031347 Metallothionein-2 Human genes 0.000 description 1
- 102100030819 Methylcytosine dioxygenase TET1 Human genes 0.000 description 1
- 102100030803 Methylcytosine dioxygenase TET2 Human genes 0.000 description 1
- 102100027392 Methylglutaconyl-CoA hydratase, mitochondrial Human genes 0.000 description 1
- 102100029676 Methylmalonate-semialdehyde dehydrogenase [acylating], mitochondrial Human genes 0.000 description 1
- 102100036543 Methyltransferase N6AMT1 Human genes 0.000 description 1
- 102100031339 Microtubule cross-linking factor 1 Human genes 0.000 description 1
- 102100031549 Microtubule-associated tumor suppressor candidate 2 Human genes 0.000 description 1
- 102100027749 Minor histocompatibility protein HB-1 Human genes 0.000 description 1
- 102100039539 Mitochondrial assembly of ribosomal large subunit protein 1 Human genes 0.000 description 1
- 102100039374 Mitochondrial calcium uniporter regulator 1 Human genes 0.000 description 1
- 102100023199 Mitochondrial fission regulator 2 Human genes 0.000 description 1
- 102100039325 Mitochondrial import inner membrane translocase subunit TIM14 Human genes 0.000 description 1
- 102100039802 Mitochondrial intermembrane space import and assembly protein 40 Human genes 0.000 description 1
- 102100024828 Mitochondrial pyruvate carrier 1 Human genes 0.000 description 1
- 102100025031 Mitochondrial pyruvate carrier 2 Human genes 0.000 description 1
- 102100024249 Mitotic deacetylase-associated SANT domain protein Human genes 0.000 description 1
- 102100033607 Mitotic interactor and substrate of PLK1 Human genes 0.000 description 1
- 102100036617 Monoacylglycerol lipase ABHD2 Human genes 0.000 description 1
- 102100035912 Monoacylglycerol lipase ABHD6 Human genes 0.000 description 1
- 102100032877 Multidrug and toxin extrusion protein 1 Human genes 0.000 description 1
- 102100032858 Multidrug and toxin extrusion protein 2 Human genes 0.000 description 1
- 102100038748 Multivesicular body subunit 12B Human genes 0.000 description 1
- 101100274086 Mus musculus Chmp1b1 gene Proteins 0.000 description 1
- 101100275687 Mus musculus Cr2 gene Proteins 0.000 description 1
- 102100030176 Muscular LMNA-interacting protein Human genes 0.000 description 1
- 102100023254 Myb/SANT-like DNA-binding domain-containing protein 3 Human genes 0.000 description 1
- 102100031642 Myb/SANT-like DNA-binding domain-containing protein 4 Human genes 0.000 description 1
- 102100034041 Myelin regulatory factor-like protein Human genes 0.000 description 1
- 102100035083 Myoferlin Human genes 0.000 description 1
- 102100038899 Myogenesis-regulating glycosidase Human genes 0.000 description 1
- XUYPXLNMDZIRQH-LURJTMIESA-N N-acetyl-L-methionine Chemical compound CSCC[C@@H](C(O)=O)NC(C)=O XUYPXLNMDZIRQH-LURJTMIESA-N 0.000 description 1
- 102100036710 N-acetylglucosamine-1-phosphotransferase subunits alpha/beta Human genes 0.000 description 1
- 102100035628 N-acetyllactosaminide beta-1,3-N-acetylglucosaminyltransferase 2 Human genes 0.000 description 1
- 102100035629 N-acetyllactosaminide beta-1,3-N-acetylglucosaminyltransferase 3 Human genes 0.000 description 1
- 102100024973 N-acetylneuraminate 9-O-acetyltransferase Human genes 0.000 description 1
- 102100032946 N-acyl-aromatic-L-amino acid amidohydrolase (carboxylate-forming) Human genes 0.000 description 1
- 102100038360 N-acylethanolamine-hydrolyzing acid amidase Human genes 0.000 description 1
- 102100038334 N-alpha-acetyltransferase 60 Human genes 0.000 description 1
- 102100026873 N-fatty-acyl-amino acid synthase/hydrolase PM20D1 Human genes 0.000 description 1
- 102100037731 N-terminal EF-hand calcium-binding protein 1 Human genes 0.000 description 1
- 102100021721 N-terminal Xaa-Pro-Lys N-methyltransferase 1 Human genes 0.000 description 1
- 102100032217 NAD kinase 2, mitochondrial Human genes 0.000 description 1
- 102100031377 NADH dehydrogenase (ubiquinone) complex I, assembly factor 6 Human genes 0.000 description 1
- 102100029093 NOP protein chaperone 1 Human genes 0.000 description 1
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 description 1
- 102100039909 Neuronal acetylcholine receptor subunit alpha-4 Human genes 0.000 description 1
- 102100021520 Neuronal acetylcholine receptor subunit alpha-9 Human genes 0.000 description 1
- 102100030911 Neuronal acetylcholine receptor subunit beta-3 Human genes 0.000 description 1
- 102100030394 Neuronal membrane glycoprotein M6-a Human genes 0.000 description 1
- 102100035069 Neuronal vesicle trafficking-associated protein 2 Human genes 0.000 description 1
- 101710085178 Neuronal vesicle trafficking-associated protein 2 Proteins 0.000 description 1
- 102100024761 Neutrophil defensin 3 Human genes 0.000 description 1
- 102100023120 Ninein-like protein Human genes 0.000 description 1
- 102100029980 Non-homologous end joining factor IFFO1 Human genes 0.000 description 1
- 102100022646 Normal mucosa of esophagus-specific gene 1 protein Human genes 0.000 description 1
- 102100032343 Nuclear cap-binding protein subunit 3 Human genes 0.000 description 1
- 102100034422 Nuclear envelope phosphatase-regulatory subunit 1 Human genes 0.000 description 1
- 102100022727 Nuclear exosome regulator NRDE2 Human genes 0.000 description 1
- 102100040313 Nucleolar protein 4-like Human genes 0.000 description 1
- 102100036518 Nucleoside diphosphate phosphatase ENTPD5 Human genes 0.000 description 1
- 102100021969 Nucleotide pyrophosphatase Human genes 0.000 description 1
- 102100039306 Nucleotide pyrophosphatase Human genes 0.000 description 1
- 102100033052 Nucleotidyltransferase MB21D2 Human genes 0.000 description 1
- 102100035702 ORC ubiquitin ligase 1 Human genes 0.000 description 1
- 102100037589 OX-2 membrane glycoprotein Human genes 0.000 description 1
- 102100037588 Orexin receptor type 2 Human genes 0.000 description 1
- 102100035706 Outer dynein arm-docking complex subunit 2 Human genes 0.000 description 1
- 102100026070 Ovarian cancer G-protein coupled receptor 1 Human genes 0.000 description 1
- 101710195703 Oxygen-dependent coproporphyrinogen-III oxidase Proteins 0.000 description 1
- 101710146072 Oxygen-independent coproporphyrinogen III oxidase Proteins 0.000 description 1
- 102100027501 PC-esterase domain-containing protein 1B Human genes 0.000 description 1
- 102100031567 PHD and RING finger domain-containing protein 1 Human genes 0.000 description 1
- 102100037395 POU domain, class 5, transcription factor 2 Human genes 0.000 description 1
- 102100032984 PRELI domain containing protein 3A Human genes 0.000 description 1
- 102100033719 PTB domain-containing engulfment adapter protein 1 Human genes 0.000 description 1
- 102100037264 Pancreatic progenitor cell differentiation and proliferation factor-like protein Human genes 0.000 description 1
- 102100034850 Peptidyl-prolyl cis-trans isomerase G Human genes 0.000 description 1
- 102100037896 Perilipin-2 Human genes 0.000 description 1
- 102100039896 Peroxiredoxin-like 2A Human genes 0.000 description 1
- 102100030940 Persulfide dioxygenase ETHE1, mitochondrial Human genes 0.000 description 1
- 102100026062 Phagosome assembly factor 1 Human genes 0.000 description 1
- 102100035312 Phenylalanine-tRNA ligase beta subunit Human genes 0.000 description 1
- 102100029354 Phenylalanine-tRNA ligase, mitochondrial Human genes 0.000 description 1
- 102100032287 Phosphatidylinositide phosphatase SAC2 Human genes 0.000 description 1
- 102100036067 Phospholipase A and acyltransferase 2 Human genes 0.000 description 1
- 102100035907 Phospholipase ABHD3 Human genes 0.000 description 1
- 102100034179 Phospholipase DDHD2 Human genes 0.000 description 1
- 102100033623 Phospholipid-transporting ATPase ABCA3 Human genes 0.000 description 1
- 102100030622 Phospholipid-transporting ATPase IA Human genes 0.000 description 1
- 102100032688 Phospholipid-transporting ATPase IH Human genes 0.000 description 1
- 102100031694 Piezo-type mechanosensitive ion channel component 2 Human genes 0.000 description 1
- 102100033226 Pikachurin Human genes 0.000 description 1
- 102100029751 Plasma membrane calcium-transporting ATPase 1 Human genes 0.000 description 1
- 102100038411 Platelet glycoprotein V Human genes 0.000 description 1
- 102100036244 Pleckstrin homology domain-containing family S member 1 Human genes 0.000 description 1
- 102100039917 Polyamine-transporting ATPase 13A2 Human genes 0.000 description 1
- 102100029799 Polycomb group protein ASXL1 Human genes 0.000 description 1
- 102100023217 Polypeptide N-acetylgalactosaminyltransferase 10 Human genes 0.000 description 1
- 102100023218 Polypeptide N-acetylgalactosaminyltransferase 11 Human genes 0.000 description 1
- 102100023208 Polypeptide N-acetylgalactosaminyltransferase 14 Human genes 0.000 description 1
- 102100039228 Polypeptide N-acetylgalactosaminyltransferase 16 Human genes 0.000 description 1
- 102100020950 Polypeptide N-acetylgalactosaminyltransferase 2 Human genes 0.000 description 1
- 102100039695 Polypeptide N-acetylgalactosaminyltransferase 6 Human genes 0.000 description 1
- 102100034364 Potassium channel regulatory protein Human genes 0.000 description 1
- 102100023242 Potassium channel subfamily K member 1 Human genes 0.000 description 1
- 102100022798 Potassium channel subfamily K member 10 Human genes 0.000 description 1
- 102100023202 Potassium channel subfamily K member 5 Human genes 0.000 description 1
- 102100034368 Potassium voltage-gated channel subfamily A member 1 Human genes 0.000 description 1
- 102100034369 Potassium voltage-gated channel subfamily A member 2 Human genes 0.000 description 1
- 102100037448 Potassium voltage-gated channel subfamily A member 6 Human genes 0.000 description 1
- 102100034310 Potassium voltage-gated channel subfamily B member 1 Human genes 0.000 description 1
- 102100033165 Potassium voltage-gated channel subfamily C member 4 Human genes 0.000 description 1
- 102100033184 Potassium voltage-gated channel subfamily D member 3 Human genes 0.000 description 1
- 102100022753 Potassium voltage-gated channel subfamily E member 3 Human genes 0.000 description 1
- 102100022783 Potassium voltage-gated channel subfamily G member 1 Human genes 0.000 description 1
- 102100022807 Potassium voltage-gated channel subfamily H member 2 Human genes 0.000 description 1
- 101710163348 Potassium voltage-gated channel subfamily H member 8 Proteins 0.000 description 1
- 102100037444 Potassium voltage-gated channel subfamily KQT member 1 Human genes 0.000 description 1
- 102100034360 Potassium voltage-gated channel subfamily KQT member 3 Human genes 0.000 description 1
- 102100025065 Potassium voltage-gated channel subfamily S member 2 Human genes 0.000 description 1
- 102100027390 Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated channel 3 Human genes 0.000 description 1
- 102100038718 Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated channel 4 Human genes 0.000 description 1
- 102100028730 Pre-mRNA-processing factor 17 Human genes 0.000 description 1
- 102100021427 Pre-mRNA-splicing factor CWC22 homolog Human genes 0.000 description 1
- 102100039443 Pre-mRNA-splicing factor ISY1 homolog Human genes 0.000 description 1
- 102100025974 Pro-cathepsin H Human genes 0.000 description 1
- 102100026884 Pro-interleukin-16 Human genes 0.000 description 1
- 102100022661 Pro-neuregulin-1, membrane-bound isoform Human genes 0.000 description 1
- 102100038267 Probable ATP-dependent RNA helicase DDX52 Human genes 0.000 description 1
- 102100022424 Probable ATP-dependent RNA helicase DHX35 Human genes 0.000 description 1
- 102100028977 Probable E3 ubiquitin-protein ligase DTX2 Human genes 0.000 description 1
- 102100034747 Probable E3 ubiquitin-protein ligase HERC1 Human genes 0.000 description 1
- 102100037864 Probable E3 ubiquitin-protein ligase IRF2BPL Human genes 0.000 description 1
- 102100029704 Probable E3 ubiquitin-protein ligase TRIML2 Human genes 0.000 description 1
- 102100034137 Probable G-protein coupled receptor 101 Human genes 0.000 description 1
- 102100033838 Probable G-protein coupled receptor 132 Human genes 0.000 description 1
- 102100039878 Probable G-protein coupled receptor 148 Human genes 0.000 description 1
- 102100025346 Probable G-protein coupled receptor 160 Human genes 0.000 description 1
- 102100036934 Probable G-protein coupled receptor 21 Human genes 0.000 description 1
- 102100033862 Probable G-protein coupled receptor 63 Human genes 0.000 description 1
- 102100033863 Probable G-protein coupled receptor 85 Human genes 0.000 description 1
- 102100038404 Probable G-protein coupled receptor 88 Human genes 0.000 description 1
- 102100037169 Probable JmjC domain-containing histone demethylation protein 2C Human genes 0.000 description 1
- 102100039912 Probable cation-transporting ATPase 13A5 Human genes 0.000 description 1
- 102100026179 Probable cysteine-tRNA ligase, mitochondrial Human genes 0.000 description 1
- 102100026610 Probable dolichyl pyrophosphate Glc1Man9GlcNAc2 alpha-1,3-glucosyltransferase Human genes 0.000 description 1
- 101710127370 Probable head completion protein 1 Proteins 0.000 description 1
- 102100021059 Probable imidazolonepropionase Human genes 0.000 description 1
- 102100031600 Probable phospholipid-transporting ATPase IIA Human genes 0.000 description 1
- 102100031575 Probable phospholipid-transporting ATPase IIB Human genes 0.000 description 1
- 102100030468 Probable phospholipid-transporting ATPase IM Human genes 0.000 description 1
- 102100031440 Probable polypeptide N-acetylgalactosaminyltransferase 8 Human genes 0.000 description 1
- 102100039310 Probable serine carboxypeptidase CPVL Human genes 0.000 description 1
- 102100030966 Probable splicing factor YJU2B Human genes 0.000 description 1
- 102100028105 Probable tRNA methyltransferase 9B Human genes 0.000 description 1
- 102100024191 Probable ubiquitin carboxyl-terminal hydrolase MINDY-4 Human genes 0.000 description 1
- 102100026534 Procathepsin L Human genes 0.000 description 1
- 102100033841 Progonadoliberin-2 Human genes 0.000 description 1
- 102100029506 Proline and serine-rich protein 1 Human genes 0.000 description 1
- 102100029507 Proline and serine-rich protein 2 Human genes 0.000 description 1
- 102100033950 Proline-rich protein 15-like protein Human genes 0.000 description 1
- 102100038683 Proline-rich protein 20A Human genes 0.000 description 1
- 102100028962 Proline-rich protein 23C Human genes 0.000 description 1
- 102100029500 Prostasin Human genes 0.000 description 1
- 102100027583 Proteasome assembly chaperone 1 Human genes 0.000 description 1
- 102100031952 Protein 4.1 Human genes 0.000 description 1
- 102100021513 Protein ABHD12B Human genes 0.000 description 1
- 102100036477 Protein AKNAD1 Human genes 0.000 description 1
- 102100023735 Protein APCDD1 Human genes 0.000 description 1
- 102100023736 Protein APCDD1-like Human genes 0.000 description 1
- 102100040354 Protein Atg16l2 Human genes 0.000 description 1
- 102100035651 Protein BNIP5 Human genes 0.000 description 1
- 102100035548 Protein Bop Human genes 0.000 description 1
- 102100029336 Protein C12orf4 Human genes 0.000 description 1
- 102100032608 Protein C19orf12 Human genes 0.000 description 1
- 102100035828 Protein C3orf33 Human genes 0.000 description 1
- 102100035601 Protein CASC3 Human genes 0.000 description 1
- 102100034625 Protein CFAP20DC Human genes 0.000 description 1
- 102100029154 Protein CMSS1 Human genes 0.000 description 1
- 102100029369 Protein CREG2 Human genes 0.000 description 1
- 102100032188 Protein CROC-4 Human genes 0.000 description 1
- 102100028459 Protein CUSTOS Human genes 0.000 description 1
- 102100029130 Protein DDI1 homolog 2 Human genes 0.000 description 1
- 102100031227 Protein Dr1 Human genes 0.000 description 1
- 102100033963 Protein EFR3 homolog A Human genes 0.000 description 1
- 102100037113 Protein ELYS Human genes 0.000 description 1
- 102100037083 Protein EURL homolog Human genes 0.000 description 1
- 102100030896 Protein FAM104B Human genes 0.000 description 1
- 102100026983 Protein FAM107B Human genes 0.000 description 1
- 102100035979 Protein FAM110C Human genes 0.000 description 1
- 102100039184 Protein FAM124A Human genes 0.000 description 1
- 102100039198 Protein FAM124B Human genes 0.000 description 1
- 102100038972 Protein FAM131B Human genes 0.000 description 1
- 102100039003 Protein FAM135A Human genes 0.000 description 1
- 102100029056 Protein FAM135B Human genes 0.000 description 1
- 102100030557 Protein FAM13A Human genes 0.000 description 1
- 102100030559 Protein FAM13C Human genes 0.000 description 1
- 102100020937 Protein FAM167A Human genes 0.000 description 1
- 102100037218 Protein FAM177B Human genes 0.000 description 1
- 102100035471 Protein FAM184A Human genes 0.000 description 1
- 102100038863 Protein FAM210A Human genes 0.000 description 1
- 102100026957 Protein FAM214A Human genes 0.000 description 1
- 102100027298 Protein FAM222A Human genes 0.000 description 1
- 102100030561 Protein FAM234B Human genes 0.000 description 1
- 102100040307 Protein FAM3B Human genes 0.000 description 1
- 102100040823 Protein FAM3C Human genes 0.000 description 1
- 102100038924 Protein FAM43A Human genes 0.000 description 1
- 102100039011 Protein FAM47A Human genes 0.000 description 1
- 102100038927 Protein FAM50B Human genes 0.000 description 1
- 102100023831 Protein FAM78A Human genes 0.000 description 1
- 102100023807 Protein FAM78B Human genes 0.000 description 1
- 102100035443 Protein FAM83B Human genes 0.000 description 1
- 102100035463 Protein FAM83C Human genes 0.000 description 1
- 102100035447 Protein FAM83D Human genes 0.000 description 1
- 102100035448 Protein FAM83F Human genes 0.000 description 1
- 102100026751 Protein FAM8A1 Human genes 0.000 description 1
- 102100026955 Protein FAM91A1 Human genes 0.000 description 1
- 102100031840 Protein FAM9A Human genes 0.000 description 1
- 102100031842 Protein FAM9B Human genes 0.000 description 1
- 102100031841 Protein FAM9C Human genes 0.000 description 1
- 102100027038 Protein FRA10AC1 Human genes 0.000 description 1
- 102100021180 Protein GOLM2 Human genes 0.000 description 1
- 101710197448 Protein GOLM2 Proteins 0.000 description 1
- 102100030846 Protein GUCD1 Human genes 0.000 description 1
- 102100033275 Protein ILRUN Human genes 0.000 description 1
- 102100032824 Protein ITPRID1 Human genes 0.000 description 1
- 102100023375 Protein IWS1 homolog Human genes 0.000 description 1
- 102100025733 Protein Jumonji Human genes 0.000 description 1
- 102100025966 Protein LEKR1 Human genes 0.000 description 1
- 102100033355 Protein LRATD2 Human genes 0.000 description 1
- 102100028174 Protein MIX23 Human genes 0.000 description 1
- 102100024983 Protein NDNF Human genes 0.000 description 1
- 102100036207 Protein NOXP20 Human genes 0.000 description 1
- 102100023076 Protein Niban 1 Human genes 0.000 description 1
- 102100037197 Protein SCAI Human genes 0.000 description 1
- 102100037719 Protein SSUH2 homolog Human genes 0.000 description 1
- 102100021884 Protein Spindly Human genes 0.000 description 1
- 102100028545 Protein TALPID3 Human genes 0.000 description 1
- 102100023169 Protein YAE1 homolog Human genes 0.000 description 1
- 102100022990 Protein angel homolog 2 Human genes 0.000 description 1
- 102100022985 Protein arginine N-methyltransferase 1 Human genes 0.000 description 1
- 102100026827 Protein associated with UVRAG as autophagy enhancer Human genes 0.000 description 1
- 102100032661 Protein asteroid homolog 1 Human genes 0.000 description 1
- 102100027101 Protein broad-minded Human genes 0.000 description 1
- 102100036490 Protein diaphanous homolog 1 Human genes 0.000 description 1
- 102100036469 Protein diaphanous homolog 2 Human genes 0.000 description 1
- 102100036468 Protein diaphanous homolog 3 Human genes 0.000 description 1
- 102100035622 Protein dispatched homolog 1 Human genes 0.000 description 1
- 102100035093 Protein enabled homolog Human genes 0.000 description 1
- 102100040970 Protein fantom Human genes 0.000 description 1
- 102100037277 Protein fem-1 homolog C Human genes 0.000 description 1
- 102100020918 Protein furry homolog Human genes 0.000 description 1
- 102100022660 Protein kintoun Human genes 0.000 description 1
- 102100025689 Protein lin-52 homolog Human genes 0.000 description 1
- 102100025692 Protein lin-54 homolog Human genes 0.000 description 1
- 102100039625 Protein mab-21-like 3 Human genes 0.000 description 1
- 102100023163 Protein sel-1 homolog 3 Human genes 0.000 description 1
- 102100033219 Protein turtle homolog A Human genes 0.000 description 1
- 102100038288 Protein virilizer homolog Human genes 0.000 description 1
- 102100039471 Protein wntless homolog Human genes 0.000 description 1
- 102100023369 Protein-lysine N-methyltransferase EEF2KMT Human genes 0.000 description 1
- 102100037132 Proteinase-activated receptor 2 Human genes 0.000 description 1
- 102100030553 Pseudokinase FAM20A Human genes 0.000 description 1
- 102100033091 Putative C->U-editing enzyme APOBEC-4 Human genes 0.000 description 1
- 102100029479 Putative DENN domain-containing protein 10 B Human genes 0.000 description 1
- 102100037833 Putative Dresden prostate carcinoma protein 2 Human genes 0.000 description 1
- 102100027753 Putative F-box/LRR-repeat protein 21 Human genes 0.000 description 1
- 102100034621 Putative RNA polymerase II subunit B1 CTD phosphatase RPAP2 Human genes 0.000 description 1
- 102100020949 Putative glutamine amidotransferase-like class 1 domain-containing protein 3B, mitochondrial Human genes 0.000 description 1
- 102100039294 Putative hydroxypyruvate isomerase Human genes 0.000 description 1
- 102100034835 Putative killer cell immunoglobulin-like receptor-like protein KIR3DX1 Human genes 0.000 description 1
- 102100030016 Putative monooxygenase p33MONOX Human genes 0.000 description 1
- 102100039308 Putative nuclease HARBI1 Human genes 0.000 description 1
- 102100024356 Putative protein CASTOR 3 Human genes 0.000 description 1
- 102100023834 Putative protein FAM86C1P Human genes 0.000 description 1
- 102100023836 Putative protein N-methyltransferase FAM86B1 Human genes 0.000 description 1
- 102100034920 Putative protein SEM1, isoform 2 Human genes 0.000 description 1
- 102100025793 Putative sodium-coupled neutral amino acid transporter 11 Human genes 0.000 description 1
- 102100026483 Putative transmembrane protein encoded by LINC00477 Human genes 0.000 description 1
- 102100021263 Putative uncharacterized protein B3GALT5-AS1 Human genes 0.000 description 1
- 102100033537 Putative uncharacterized protein CLLU1-AS1 Human genes 0.000 description 1
- 102100038774 Putative uncharacterized protein DIP2C-AS1 Human genes 0.000 description 1
- 102100023564 Putative uncharacterized protein FER1L6-AS1 Human genes 0.000 description 1
- 102100038370 Putative uncharacterized protein PKD1L1-AS1 Human genes 0.000 description 1
- 102100034462 Putative uncharacterized protein RUSC1-AS1 Human genes 0.000 description 1
- 102100027312 Putative uncharacterized protein SSBP3-AS1 Human genes 0.000 description 1
- 102100027552 Putative uncharacterized protein WWC2-AS2 Human genes 0.000 description 1
- 102100023545 Putative uncharacterized protein encoded by FER1L6-AS2 Human genes 0.000 description 1
- 102100030487 Putative uncharacterized protein encoded by HEXA-AS1 Human genes 0.000 description 1
- 102100031095 Putative uncharacterized protein encoded by LINC00114 Human genes 0.000 description 1
- 102100039549 Putative uncharacterized protein encoded by LINC00167 Human genes 0.000 description 1
- 102100030974 Putative uncharacterized protein encoded by LINC00173 Human genes 0.000 description 1
- 102100025649 Putative uncharacterized protein encoded by LINC00242 Human genes 0.000 description 1
- 102100029914 Putative uncharacterized protein encoded by LINC00299 Human genes 0.000 description 1
- 102100032773 Putative uncharacterized protein encoded by LINC00469 Human genes 0.000 description 1
- 102100039530 Putative uncharacterized protein encoded by LINC00479 Human genes 0.000 description 1
- 102100038118 Putative uncharacterized protein encoded by LINC00518 Human genes 0.000 description 1
- 102100031589 Putative uncharacterized protein encoded by LINC00575 Human genes 0.000 description 1
- 102100022069 Putative uncharacterized protein encoded by LINC00596 Human genes 0.000 description 1
- 102100023445 Putative uncharacterized protein encoded by LINC00612 Human genes 0.000 description 1
- 102100030134 Putative uncharacterized protein encoded by LINC01555 Human genes 0.000 description 1
- 102100027606 Putative uncharacterized protein encoded by LINC02910 Human genes 0.000 description 1
- 102100033870 Putative uncharacterized protein encoded by LINC02915 Human genes 0.000 description 1
- 102100034759 Pyridoxal-dependent decarboxylase domain-containing protein 1 Human genes 0.000 description 1
- 102100034358 Queuosine salvage protein Human genes 0.000 description 1
- 102100024695 RELT-like protein 2 Human genes 0.000 description 1
- 102100026364 RING finger protein 145 Human genes 0.000 description 1
- 102100032024 RIPOR family member 3 Human genes 0.000 description 1
- 102100039083 RNA demethylase ALKBH5 Human genes 0.000 description 1
- 102100023750 RNA polymerase II elongation factor ELL2 Human genes 0.000 description 1
- 102100023860 RNA-binding protein 43 Human genes 0.000 description 1
- 102100038822 RNA-binding protein 47 Human genes 0.000 description 1
- 102100034328 Rab GDP dissociation inhibitor beta Human genes 0.000 description 1
- 102100022880 Rab proteins geranylgeranyltransferase component A 2 Human genes 0.000 description 1
- 102100040160 Rabankyrin-5 Human genes 0.000 description 1
- 102100038186 Ral GTPase-activating protein subunit alpha-2 Human genes 0.000 description 1
- 102100040091 Rap1 GTPase-activating protein 2 Human genes 0.000 description 1
- 101000629598 Rattus norvegicus Sterol regulatory element-binding protein 1 Proteins 0.000 description 1
- 102100021423 Reactive oxygen species modulator 1 Human genes 0.000 description 1
- 102100021329 Refilin-A Human genes 0.000 description 1
- 102100024756 Regulation of nuclear pre-mRNA domain-containing protein 2 Human genes 0.000 description 1
- 102100026410 Regulator of microtubule dynamics protein 2 Human genes 0.000 description 1
- 102100026409 Regulator of microtubule dynamics protein 3 Human genes 0.000 description 1
- 102100040969 Regulatory-associated protein of mTOR Human genes 0.000 description 1
- 102100021847 Replication stress response regulator SDE2 Human genes 0.000 description 1
- 102100039800 Required for meiotic nuclear division protein 1 homolog Human genes 0.000 description 1
- 102100027558 Respirasome Complex Assembly Factor 1 Human genes 0.000 description 1
- 102100024734 Reticulophagy regulator 1 Human genes 0.000 description 1
- 102100038453 Retinoic acid-induced protein 3 Human genes 0.000 description 1
- 102100034981 Retroelement silencing factor 1 Human genes 0.000 description 1
- 102100027663 Rho GTPase-activating protein 12 Human genes 0.000 description 1
- 102100027656 Rho GTPase-activating protein 17 Human genes 0.000 description 1
- 102100027655 Rho GTPase-activating protein 18 Human genes 0.000 description 1
- 102100027604 Rho GTPase-activating protein 19 Human genes 0.000 description 1
- 102100035741 Rho GTPase-activating protein 24 Human genes 0.000 description 1
- 102100035759 Rho GTPase-activating protein 25 Human genes 0.000 description 1
- 102100020894 Rho GTPase-activating protein 27 Human genes 0.000 description 1
- 102100020890 Rho GTPase-activating protein 31 Human genes 0.000 description 1
- 102100021443 Rho GTPase-activating protein 8 Human genes 0.000 description 1
- 102100033090 Rhodopsin kinase GRK7 Human genes 0.000 description 1
- 102100033981 Ribosomal RNA processing protein 36 homolog Human genes 0.000 description 1
- 102100035491 Ribosomal RNA small subunit methyltransferase NEP1 Human genes 0.000 description 1
- 102100022091 Ribosomal oxygenase 1 Human genes 0.000 description 1
- 102100027057 Ribosome biogenesis protein BMS1 homolog Human genes 0.000 description 1
- 102100035914 S-adenosylmethionine decarboxylase proenzyme Human genes 0.000 description 1
- 102100029991 S-formylglutathione hydrolase Human genes 0.000 description 1
- 102100027291 SET domain-containing protein 9 Human genes 0.000 description 1
- 102100021780 SH3 domain-containing protein 21 Human genes 0.000 description 1
- 102100030066 SIN3-HDAC complex-associated factor Human genes 0.000 description 1
- 102100027349 SKI/DACH domain-containing protein 1 Human genes 0.000 description 1
- 108091007628 SLC49A4 Proteins 0.000 description 1
- 102100032662 SMC5-SMC6 complex localization factor protein 2 Human genes 0.000 description 1
- 102000008935 SMN Complex Proteins Human genes 0.000 description 1
- 108010049037 SMN Complex Proteins Proteins 0.000 description 1
- 102100034200 SOSS complex subunit C Human genes 0.000 description 1
- 102100023521 SPATS2-like protein Human genes 0.000 description 1
- 102100031123 SPRY domain-containing protein 7 Human genes 0.000 description 1
- 102100025491 SRA stem-loop-interacting RNA-binding protein, mitochondrial Human genes 0.000 description 1
- 102100031580 SREBP regulating gene protein Human genes 0.000 description 1
- 102100021651 SUN domain-containing ossification factor Human genes 0.000 description 1
- 102100026877 SUZ domain-containing protein 1 Human genes 0.000 description 1
- 101100383104 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) GAB1 gene Proteins 0.000 description 1
- 101100186471 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) NAT1 gene Proteins 0.000 description 1
- 102100027732 Sarcoplasmic/endoplasmic reticulum calcium ATPase 2 Human genes 0.000 description 1
- 102100020867 Secretogranin-1 Human genes 0.000 description 1
- 102100022540 Selenocysteine insertion sequence-binding protein 2-like Human genes 0.000 description 1
- 102100037498 Selenocysteine-specific elongation factor Human genes 0.000 description 1
- 102100022070 Serine palmitoyltransferase 3 Human genes 0.000 description 1
- 102100031872 Serine palmitoyltransferase small subunit A Human genes 0.000 description 1
- 102100022638 Serine protease 48 Human genes 0.000 description 1
- 102100032895 Serine-rich coiled-coil domain-containing protein 2 Human genes 0.000 description 1
- 102100037580 Sesquipedalian-1 Human genes 0.000 description 1
- 102100032737 Shieldin complex subunit 1 Human genes 0.000 description 1
- 102100028378 Shieldin complex subunit 2 Human genes 0.000 description 1
- 102100031975 Shootin-1 Human genes 0.000 description 1
- 102100021400 Sickle tail protein homolog Human genes 0.000 description 1
- 102100030403 Signal peptide peptidase-like 2A Human genes 0.000 description 1
- 102100030404 Signal peptide peptidase-like 2B Human genes 0.000 description 1
- 102100036670 Sine oculis-binding protein homolog Human genes 0.000 description 1
- 102100029933 Single-pass membrane and coiled-coil domain-containing protein 4 Human genes 0.000 description 1
- 102100037442 Small conductance calcium-activated potassium channel protein 3 Human genes 0.000 description 1
- 102100031977 Small integral membrane protein 14 Human genes 0.000 description 1
- 102100022777 Small integral membrane protein 19 Human genes 0.000 description 1
- 102100021479 Sodium-coupled neutral amino acid transporter 9 Human genes 0.000 description 1
- 102100029795 Sodium-dependent glucose transporter 1 Human genes 0.000 description 1
- 102100030458 Sodium/potassium-transporting ATPase subunit alpha-1 Human genes 0.000 description 1
- 102100021955 Sodium/potassium-transporting ATPase subunit alpha-2 Human genes 0.000 description 1
- 102100028844 Sodium/potassium-transporting ATPase subunit beta-1 Human genes 0.000 description 1
- 102100023100 Solute carrier family 22 member 23 Human genes 0.000 description 1
- 102100032019 Solute carrier family 35 member G5 Human genes 0.000 description 1
- 102100037945 Solute carrier family 49 member 4 Human genes 0.000 description 1
- 102100023355 Specifically androgen-regulated gene protein Human genes 0.000 description 1
- 102100030920 Spermatid-specific manchette-related protein 1 Human genes 0.000 description 1
- 102100026838 Spermatogenesis-associated protein 32 Human genes 0.000 description 1
- 102100027690 Spexin Human genes 0.000 description 1
- 102100029220 Spindle and kinetochore-associated protein 3 Human genes 0.000 description 1
- 102100024237 Stathmin Human genes 0.000 description 1
- 102100032288 Sterile alpha motif domain-containing protein 15 Human genes 0.000 description 1
- 102100036325 Sterol 26-hydroxylase, mitochondrial Human genes 0.000 description 1
- 102100021814 Stress-associated endoplasmic reticulum protein 2 Human genes 0.000 description 1
- 102100028804 Striatin-interacting protein 1 Human genes 0.000 description 1
- 102100028805 Striatin-interacting protein 2 Human genes 0.000 description 1
- 102100035722 Succinate dehydrogenase assembly factor 4, mitochondrial Human genes 0.000 description 1
- 102100028858 Sushi domain-containing protein 6 Human genes 0.000 description 1
- 102100033922 Synapse differentiation-inducing gene protein 1 Human genes 0.000 description 1
- 102100037396 Syntabulin Human genes 0.000 description 1
- 102100036378 T-cell immunomodulatory protein Human genes 0.000 description 1
- 102100037906 T-cell surface glycoprotein CD3 zeta chain Human genes 0.000 description 1
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 1
- 102100036049 T-complex protein 1 subunit gamma Human genes 0.000 description 1
- 102100035207 TATA box-binding protein-associated factor RNA polymerase I subunit D Human genes 0.000 description 1
- 102100028639 TATA-binding protein-associated factor 172 Human genes 0.000 description 1
- 102100029259 TELO2-interacting protein 2 Human genes 0.000 description 1
- 102100039355 TLD domain-containing protein 2 Human genes 0.000 description 1
- 102100035166 TLR adapter interacting with SLC15A4 on the lysosome Human genes 0.000 description 1
- 102100031626 TPA-induced transmembrane protein Human genes 0.000 description 1
- 102100026351 TRPM8 channel-associated factor 1 Human genes 0.000 description 1
- 102100032009 TYMS opposite strand protein Human genes 0.000 description 1
- 102100026544 Target of Nesh-SH3 Human genes 0.000 description 1
- 102100030746 Tectonic-1 Human genes 0.000 description 1
- 102100034592 Telomerase RNA component interacting RNase Human genes 0.000 description 1
- 102100038311 Terminal nucleotidyltransferase 5A Human genes 0.000 description 1
- 102100038305 Terminal nucleotidyltransferase 5C Human genes 0.000 description 1
- 102100028526 Testicular acid phosphatase Human genes 0.000 description 1
- 102100029993 Testicular spindle-associated protein SHCBP1L Human genes 0.000 description 1
- 102100033675 Testis development-related protein Human genes 0.000 description 1
- 102100023292 Testis-expressed basic protein 1 Human genes 0.000 description 1
- 102100035103 Testis-expressed protein 29 Human genes 0.000 description 1
- 102100028513 Testis-expressed protein 43 Human genes 0.000 description 1
- 102100022062 Testis-specific protein LINC02914 Human genes 0.000 description 1
- 102100034910 Tetratricopeptide repeat protein 23-like Human genes 0.000 description 1
- 102100036174 Tetratricopeptide repeat protein 30B Human genes 0.000 description 1
- 102100036125 Tetratricopeptide repeat protein 39B Human genes 0.000 description 1
- 102100023273 Tetratricopeptide repeat protein 39C Human genes 0.000 description 1
- 102100030139 Thiosulfate sulfurtransferase/rhodanese-like domain-containing protein 2 Human genes 0.000 description 1
- 102100035310 Threonylcarbamoyladenosine tRNA methylthiotransferase Human genes 0.000 description 1
- 102100021386 Trans-acting T-cell-specific transcription factor GATA-3 Human genes 0.000 description 1
- 102100031954 Transcription and mRNA export factor ENY2 Human genes 0.000 description 1
- 102100037116 Transcription elongation factor 1 homolog Human genes 0.000 description 1
- 102100035145 Transcription elongation factor A N-terminal and central domain-containing protein 2 Human genes 0.000 description 1
- 102100029373 Transcription factor ATOH1 Human genes 0.000 description 1
- 102100027158 Transcription factor BTF3 homolog 4 Human genes 0.000 description 1
- 102100031555 Transcription factor E2F8 Human genes 0.000 description 1
- 102100039580 Transcription factor ETV6 Human genes 0.000 description 1
- 102100030773 Transcription factor HES-3 Human genes 0.000 description 1
- 102100028438 Transcription factor HIVEP2 Human genes 0.000 description 1
- 102100028336 Transcription factor HIVEP3 Human genes 0.000 description 1
- 102100030879 Transcription initiation factor IIA subunit 1 Human genes 0.000 description 1
- 102100037558 Transcriptional repressor p66-alpha Human genes 0.000 description 1
- 102100027065 Translation initiation factor eIF-2B subunit beta Human genes 0.000 description 1
- 102100027210 Translational activator of cytochrome c oxidase 1 Human genes 0.000 description 1
- 102100021338 Transmembrane ascorbate-dependent reductase CYB561 Human genes 0.000 description 1
- 102100033853 Transmembrane protein 131-like Human genes 0.000 description 1
- 102100024328 Transmembrane protein 186 Human genes 0.000 description 1
- 102100021220 Transmembrane protein 191A Human genes 0.000 description 1
- 102100025940 Transmembrane protein 200A Human genes 0.000 description 1
- 102100022215 Transmembrane protein 217 Human genes 0.000 description 1
- 102100032493 Transmembrane protein 241 Human genes 0.000 description 1
- 102100027021 Transmembrane protein 243 Human genes 0.000 description 1
- 102100035332 Transmembrane protein 254 Human genes 0.000 description 1
- 102100025927 Transmembrane protein 255B Human genes 0.000 description 1
- 102100035333 Transmembrane protein 256 Human genes 0.000 description 1
- 102100036809 Transmembrane protein 260 Human genes 0.000 description 1
- 102100036803 Transmembrane protein 267 Human genes 0.000 description 1
- 102100032080 Transmembrane protein 268 Human genes 0.000 description 1
- 102100028771 Transmembrane protein 52B Human genes 0.000 description 1
- 102100035338 Transmembrane protein 74B Human genes 0.000 description 1
- 102100037621 Transmembrane protein 94 Human genes 0.000 description 1
- 102100025236 Tubulin alpha-3D chain Human genes 0.000 description 1
- 102100032084 Type 2 DNA topoisomerase 6 subunit B-like Human genes 0.000 description 1
- 102100036349 Type III endosome membrane protein TEMP Human genes 0.000 description 1
- 102100026563 Type-1 angiotensin II receptor-associated protein Human genes 0.000 description 1
- 108010035075 Tyrosine decarboxylase Proteins 0.000 description 1
- 102100022009 U11/U12 small nuclear ribonucleoprotein 48 kDa protein Human genes 0.000 description 1
- 102100031542 U3 small nucleolar RNA-associated protein 25 homolog Human genes 0.000 description 1
- 102100029780 UBA-like domain-containing protein 2 Human genes 0.000 description 1
- 102100027960 UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 1 Human genes 0.000 description 1
- 102100027958 UDP-GalNAc:beta-1,3-N-acetylgalactosaminyltransferase 2 Human genes 0.000 description 1
- 102100027277 UDP-N-acetylglucosamine transferase subunit ALG14 homolog Human genes 0.000 description 1
- 102100037610 UHRF1-binding protein 1 Human genes 0.000 description 1
- 102100027977 UHRF1-binding protein 1-like Human genes 0.000 description 1
- 102100032775 UPF0450 protein C17orf58 Human genes 0.000 description 1
- 102100038065 UPF0462 protein C4orf33 Human genes 0.000 description 1
- 102100022864 UPF0606 protein KIAA1549L Human genes 0.000 description 1
- 102100025761 UPF0669 protein C6orf120 Human genes 0.000 description 1
- 102100030132 UPF0688 protein C1orf174 Human genes 0.000 description 1
- 102100038574 UPF0692 protein C19orf54 Human genes 0.000 description 1
- 102100039546 UPF0705 protein C11orf49 Human genes 0.000 description 1
- 102100034442 UPF0728 protein C10orf53 Human genes 0.000 description 1
- 102100037292 Ubiquinone biosynthesis monooxygenase COQ6, mitochondrial Human genes 0.000 description 1
- 102100024198 Ubiquitin carboxyl-terminal hydrolase MINDY-2 Human genes 0.000 description 1
- 102100025187 Ubiquitin thioesterase otulin Human genes 0.000 description 1
- 102100020696 Ubiquitin-conjugating enzyme E2 K Human genes 0.000 description 1
- 102100039930 Ubiquitin-like-conjugating enzyme ATG3 Human genes 0.000 description 1
- 102100025996 Uncharacterized aarF domain-containing protein kinase 5 Human genes 0.000 description 1
- 102100034444 Uncharacterized protein C10orf67, mitochondrial Human genes 0.000 description 1
- 102100034443 Uncharacterized protein C10orf82 Human genes 0.000 description 1
- 102100029351 Uncharacterized protein C11orf52 Human genes 0.000 description 1
- 102100023455 Uncharacterized protein C12orf42 Human genes 0.000 description 1
- 102100026138 Uncharacterized protein C12orf76 Human genes 0.000 description 1
- 102100031458 Uncharacterized protein C15orf39 Human genes 0.000 description 1
- 102100032772 Uncharacterized protein C17orf50 Human genes 0.000 description 1
- 102100037951 Uncharacterized protein C17orf78 Human genes 0.000 description 1
- 102100032988 Uncharacterized protein C1orf100 Human genes 0.000 description 1
- 102100032989 Uncharacterized protein C1orf105 Human genes 0.000 description 1
- 102100025480 Uncharacterized protein C1orf115 Human genes 0.000 description 1
- 102100025340 Uncharacterized protein C1orf131 Human genes 0.000 description 1
- 102100024164 Uncharacterized protein C1orf141 Human genes 0.000 description 1
- 102100030192 Uncharacterized protein C1orf50 Human genes 0.000 description 1
- 102100032994 Uncharacterized protein C1orf87 Human genes 0.000 description 1
- 102100039431 Uncharacterized protein C22orf31 Human genes 0.000 description 1
- 102100026633 Uncharacterized protein C2orf27A Human genes 0.000 description 1
- 102100035810 Uncharacterized protein C3orf20 Human genes 0.000 description 1
- 102100025713 Uncharacterized protein C3orf62 Human genes 0.000 description 1
- 102100031572 Uncharacterized protein C4orf19 Human genes 0.000 description 1
- 102100038064 Uncharacterized protein C4orf36 Human genes 0.000 description 1
- 102100038068 Uncharacterized protein C4orf45 Human genes 0.000 description 1
- 102100031216 Uncharacterized protein C6orf141 Human genes 0.000 description 1
- 102100033651 Uncharacterized protein C6orf15 Human genes 0.000 description 1
- 102100023763 Uncharacterized protein C9orf152 Human genes 0.000 description 1
- 102100023656 Uncharacterized protein CCDC198 Human genes 0.000 description 1
- 102100031157 Uncharacterized protein DOCK8-AS1 Human genes 0.000 description 1
- 102100039202 Uncharacterized protein FAM120AOS Human genes 0.000 description 1
- 102100037535 Uncharacterized protein FAM241A Human genes 0.000 description 1
- 102100037162 Uncharacterized protein KIAA0040 Human genes 0.000 description 1
- 102100037145 Uncharacterized protein KIAA0232 Human genes 0.000 description 1
- 102100025766 Uncharacterized protein KIAA0930 Human genes 0.000 description 1
- 102100022848 Uncharacterized protein KIAA1958 Human genes 0.000 description 1
- 102100022852 Uncharacterized protein KIAA2013 Human genes 0.000 description 1
- 102100036607 Uncharacterized protein ZNF22-AS1 Human genes 0.000 description 1
- 102100034494 Uncharacterized protein encoded by LINC01561 Human genes 0.000 description 1
- 102100036121 Uncharacterized protein encoded by LINC01600 Human genes 0.000 description 1
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 1
- 102100020737 V-type proton ATPase 116 kDa subunit a 4 Human genes 0.000 description 1
- 102100037466 V-type proton ATPase catalytic subunit A Human genes 0.000 description 1
- 102100033476 V-type proton ATPase subunit B, brain isoform Human genes 0.000 description 1
- 102100039465 V-type proton ATPase subunit E 1 Human genes 0.000 description 1
- 102100039464 V-type proton ATPase subunit E 2 Human genes 0.000 description 1
- 102100037433 V-type proton ATPase subunit G 1 Human genes 0.000 description 1
- 102100037818 V-type proton ATPase subunit G 3 Human genes 0.000 description 1
- 102100040566 V-type proton ATPase subunit d 2 Human genes 0.000 description 1
- 102100024424 VWFA and cache domain-containing protein 1 Human genes 0.000 description 1
- 102100034167 Vasculin-like protein 1 Human genes 0.000 description 1
- 102100020798 Vertnin Human genes 0.000 description 1
- 102100030747 Very-long-chain enoyl-CoA reductase Human genes 0.000 description 1
- 102100024010 Vesicle transport protein GOT1A Human genes 0.000 description 1
- 102100026523 Vitamin D 25-hydroxylase Human genes 0.000 description 1
- 102100025838 Voltage-dependent L-type calcium channel subunit beta-3 Human genes 0.000 description 1
- 102100024138 Voltage-dependent calcium channel gamma-3 subunit Human genes 0.000 description 1
- 102100024143 Voltage-dependent calcium channel gamma-4 subunit Human genes 0.000 description 1
- 102100037053 Voltage-dependent calcium channel subunit alpha-2/delta-4 Human genes 0.000 description 1
- 102100038143 WASH complex subunit 4 Human genes 0.000 description 1
- 102100020705 WD repeat-containing protein 11 Human genes 0.000 description 1
- 102100028273 WD repeat-containing protein 91 Human genes 0.000 description 1
- 210000002593 Y chromosome Anatomy 0.000 description 1
- 102100023878 Zinc finger C2HC domain-containing protein 1A Human genes 0.000 description 1
- 102100023880 Zinc finger C2HC domain-containing protein 1C Human genes 0.000 description 1
- 102100028460 Zinc finger CCHC domain-containing protein 24 Human genes 0.000 description 1
- 102100039966 Zinc finger homeobox protein 3 Human genes 0.000 description 1
- 102100023566 Zinc finger protein 117 Human genes 0.000 description 1
- 102100025432 Zinc finger protein 362 Human genes 0.000 description 1
- 102100028440 Zinc finger protein 40 Human genes 0.000 description 1
- 102100037793 Zinc finger protein Eos Human genes 0.000 description 1
- 102100039612 Zinc finger protein GLI4 Human genes 0.000 description 1
- 102100025879 Zinc finger protein GLIS3 Human genes 0.000 description 1
- 102100037796 Zinc finger protein Helios Human genes 0.000 description 1
- 102100026655 Zinc finger protein castor homolog 1 Human genes 0.000 description 1
- 102100039877 Zinc phosphodiesterase ELAC protein 2 Human genes 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 108010032969 beta-Arrestin 1 Proteins 0.000 description 1
- 108010032967 beta-Arrestin 2 Proteins 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 101150000895 c1galt1 gene Proteins 0.000 description 1
- 101150049218 chmp1b gene Proteins 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 239000013256 coordination polymer Substances 0.000 description 1
- 108010018719 cytochrome P-450 CYP4B1 Proteins 0.000 description 1
- 108010007340 deoxyadenosine kinase Proteins 0.000 description 1
- 230000003831 deregulation Effects 0.000 description 1
- 108020001096 dihydrofolate reductase Proteins 0.000 description 1
- BRFKTXCAUCYQBT-KIXJXINUSA-N dinophysistoxin 2 Chemical compound C([C@H](O1)[C@H](C)/C=C/[C@H]2CC[C@@]3(CC[C@H]4O[C@@H](C([C@@H](O)[C@@H]4O3)=C)[C@@H](O)C[C@H](C)[C@H]3O[C@@]4([C@@H](CCCO4)C)CCC3)O2)C(C)=C[C@]21O[C@H](C[C@@](C)(O)C(O)=O)CC[C@H]2O BRFKTXCAUCYQBT-KIXJXINUSA-N 0.000 description 1
- 229940090124 dipeptidyl peptidase 4 (dpp-4) inhibitors for blood glucose lowering Drugs 0.000 description 1
- 102100039119 eIF5-mimic protein 1 Human genes 0.000 description 1
- 102100035859 eIF5-mimic protein 2 Human genes 0.000 description 1
- 108010041998 erythrocyte membrane protein band 4.1-like 1 Proteins 0.000 description 1
- 108010038795 estrogen receptors Proteins 0.000 description 1
- 230000004129 fatty acid metabolism Effects 0.000 description 1
- FJEKYHHLGZLYAT-FKUIBCNASA-N galp Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(O)=O)[C@@H](C)CC)[C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)CNC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)N)[C@@H](C)O)C(C)C)C1=CNC=N1 FJEKYHHLGZLYAT-FKUIBCNASA-N 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 235000001727 glucose Nutrition 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 108010044853 histidine-rich proteins Proteins 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 210000004090 human X chromosome Anatomy 0.000 description 1
- 210000001182 human Y chromosome Anatomy 0.000 description 1
- 208000013403 hyperactivity Diseases 0.000 description 1
- 239000003999 initiator Substances 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 210000004153 islets of langerhan Anatomy 0.000 description 1
- 108010028309 kalinin Proteins 0.000 description 1
- 108010008094 laminin alpha 3 Proteins 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 102100028825 m-AAA protease-interacting protein 1, mitochondrial Human genes 0.000 description 1
- 102100035860 m7GpppN-mRNA hydrolase Human genes 0.000 description 1
- 102100025547 mRNA (2'-O-methyladenosine-N(6)-)-methyltransferase Human genes 0.000 description 1
- 102100035856 mRNA-decapping enzyme 1A Human genes 0.000 description 1
- 102100035858 mRNA-decapping enzyme 1B Human genes 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 102000006255 nuclear receptors Human genes 0.000 description 1
- 108020004017 nuclear receptors Proteins 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000011371 regulation of developmental process Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 102100026307 tRNA (guanine(10)-N2)-methyltransferase homolog Human genes 0.000 description 1
- 102100039155 tRNA pseudouridine synthase Pus10 Human genes 0.000 description 1
- 102100031143 tRNA wybutosine-synthesizing protein 5 Human genes 0.000 description 1
- 102100034921 tRNA-splicing endonuclease subunit Sen15 Human genes 0.000 description 1
- WWJZWCUNLNYYAU-UHFFFAOYSA-N temephos Chemical compound C1=CC(OP(=S)(OC)OC)=CC=C1SC1=CC=C(OP(=S)(OC)OC)C=C1 WWJZWCUNLNYYAU-UHFFFAOYSA-N 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 108010000982 uK-ATP-1 potassium channel Proteins 0.000 description 1
- SQQWBSBBCSFQGC-JLHYYAGUSA-N ubiquinone-2 Chemical compound COC1=C(OC)C(=O)C(C\C=C(/C)CCC=C(C)C)=C(C)C1=O SQQWBSBBCSFQGC-JLHYYAGUSA-N 0.000 description 1
- 102100035306 von Willebrand factor A domain-containing protein 5B1 Human genes 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/136—Screening for pharmacological compounds
Definitions
- the invention is directed to the use of particular human genes, nucleic acids hybridizing to said genes, and gene products encoded thereby in the context of the diagnosis and/or therapy of metabolic and/or cancerous diseases, preferably of diabetes mellitus and/or colorectal cancer.
- the invention further relates to a method for a genomewide identification of functional binding sites at specifically targeted DNA sequences with high resolution. Areas of application are the life sciences: biology, biochemistry, biotechnology, medicine and medical technology.
- Hepatic nuclear factor (HNF)-4 ⁇ is a member of the nuclear rece?ptor superfamily and known to be expressed in the liver, intestine, and pancreas (for review see Sladek et al. f 2001 ; Schrem, 2002). Many reports have highlighted the importance of HNF4 ⁇ in the regulation of developmental processes in determining the hepatic phenotype, as well as the regulation of diverse metabolic pathways (e.g., glucose, cholesterol, and fatty acid metabolism) (Sladek et al., 1990; Jiang et al., 1995; Yamagata et al., 1996; Hadzopoulou-Cladaras et al., 1997).
- HNF4 ⁇ is considered as a hepatic master regulatory protein, ln ⁇ contrast to other members of the nuclear receptor superfamily, HNF4 ⁇ binds to its cognate DNA binding site as a homodimer (Jiang 1997; Sladek 1990). HNF4 ⁇ is one of the best characterized transcription factors, and in the past some dozent direct binding sites were reported. The employment of ChlP-chip technologies demonstrated however that these are only the smallest fraction of the actual HNF4 ⁇ binding sites. Notably, Rada-lglesias et al. (2005) used custom made arrays with a low resolution encompasing the ENCODE regions, i. e.
- the aim of the invention is thus to provide a method allowing a genome-wide high resolution map of binding sites relevant for the transcription regulation induced by HNF4 ⁇ , and the identification of human chromosomal genes having at least one specific regulatory sequence in their natural environment, and the use of said genes or gene products encoded thereby or of RNA hybridizing to said genes for the diagnosis and therapy of diseases, preferably of adenocarcinomas of the colon, caused by an deregulation of HNF4 ⁇
- the invention is directed to the use of a human gene, in particular the coding region thereof, or of a gene product encoded thereby or of an antibody directed against said gene product, or of DNA or RNA sequences hybridizing to said gene and coding for a polypeptide having the function of said gene product for the therapy and/or diagnosis of metabolic and/or cancerous diseases and/or to screen for and to identify drugs against metabolic and/or cancerous diseases, such as diabetes mellitus and/or colorectal cancer may be, wherein the gene is selected from the group of the human chromosomal genes having at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4 ⁇ matrix) in the range of 100000 nucleotides upstream or downstream of their transcription start site in the human genome, and wherein the at least one expression regulatory sequence according to matrix 1 is located within the chromosomal position specified by the start and end sites according to Tables 9-32 (chromosomes 1-22, X-, Y-chromosome, wherein Table 9 refers
- the term "gene” according to the invention is directed to both the template strand, which refers to the sequence of the DNA that is copied during the synthesis of mRNA, and to the coding strand corresponding to the codons that are translated into a protein.
- the genes according to the invention and gene products encoded thereby can be easily derived from the common databases, as such are known to the person skilled in the art, wherein the UCSC Genome Database is particularly preferred: Karolchik D, Kuhn, RM, Baertsch R, Barber GP, Clawson H, Diekhans M, Giardine B, Harte RA, Hinrichs AS 1 Hsu F, Miller W, Pedersen JS, Pohl A, Raney BJ, Rhead B, Rosenbloom KR 1 Smith KE, Stanke M, Thakkapallayil A, Trumbower H, Wang T 1 Zweig AS, Haussler D, Kent WJ.
- coding region is directed to the portion of DNA or RNA that is transcribed into the mRNA, which then is translated into a protein. This does not include gene regions such as a recognition site, initiator sequence, or termination sequence.
- DNA sequences hybridizing to said gene or “DNA sequences, which hybridize to said gene”, respectively, according to the invention preferably relates to DNA molecules hybridizing with the coding strand of said gene, in particular with the coding region thereof.
- hybridizing refers to conventional hybridization conditions, preferably to hybridization conditions under which the Tm value is between 37°C to 70 0 C, preferably between 41 0 C to 66 0 C. [fl] An example for low stringency conditions is e.g.
- hybridisation under the conditions 42°C, 2*SSC, 0.1% SDS and an example for high stringency conditions is e.g. hybridization under the conditions: 65°C, 2*SSC, 0.1% SDS, wherein in the case that washing is necessary for equilibrium, the hybridization solution is used for the washings.
- hybridization refers to stringent hybridization conditions.
- transcription start site refers to the start codon or initiation codon in eukaryotes, in particular to the respective DNA sequence ATG of the coding strand coding for methionin.
- colonal cancer within the context of the invention is in particular directed to adenocarcinoma of the colon, in particular to colorectal adenocarcinoma associated with an upregulation or hyperactivity of HNF4 ⁇ .
- matrix or “matrices” according to the invention is directed to position weight matrix/matrices (PWM(s)), which are known to the person skilled in the art.
- PWM position weight matrix/matrices
- the first column specifies the position
- the second column provides the number of occurrences of A at that position
- the third column provides the number of occurrences of C at that position
- the fourth column provides the number of occurrences of G at that position
- the fifth column provides the number of occurrences of T at that position, such that the matrix contains log odds weights for computing a match score and provides a likelihood ratio to specify whether an input sequence matches the motif or not.
- the cut-offs for the matrices according to the invention are preferably set to minFN to maximize the sensitivity of the site prediction (false negative rate of 10%).
- the gene is selected from the group of genes, wherein genes having an expression regulatory sequence according to matrix 2 (CTCF matrix) between the transcription start site and the at least one expression regulatory sequence (matrix 1 ("de novo" HNF4 ⁇ matrix)) in the human genome are excluded from the group of genes.
- CTCF matrix matrix 2
- matrix 1 matrix 1
- the gene is selected from the group of genes further having at least one expression regulatory sequence selected from the group matrices 3- 6 (AP1 , GATA2, ER, HNF1 matrices), preferably according to matrix 3, in the range of 20-60 nucleotides upstream or downstream of the at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4 ⁇ matrix) in the human genome.
- group matrices 3- 6 AP1 , GATA2, ER, HNF1 matrices
- the gene is selected from the group of genes, wherein genes having an expression regulatory sequence according to matrix 7 (CART1 matrix) in the range of 20-60 nucleotides upstream or downstream of the at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4 ⁇ matrix)) in the human genome are excluded from the group of genes.
- CART1 matrix genes having an expression regulatory sequence according to matrix 7 (CART1 matrix) in the range of 20-60 nucleotides upstream or downstream of the at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4 ⁇ matrix)) in the human genome are excluded from the group of genes.
- the gene is selected from the group of genes located on the human chromosome 6 or the human chromosome 10, wherein genes located on chromosome 10 are particularly preferred.
- the gene is selected from the group of genes coded at least partially in the genomic regions according to table 33, which represent high density clusters of identified HNF4 ⁇ binding sites.
- the gene is selected from the group of the genes according to Table 34.
- Table 34 list of human chromosomal genes: 7A5, A2M, A4GALT, AAA1 , AADAC, AAK1 , AARS, AASDH, ABAT, ABC1, ABCA1, ABCA10, ABCA3, ABCA8, ABCA9, ABCB6, ABCC10, ABCC11, ABCC4, ABCD2, ABCD3, ABCG2, ABCG5, ABHD12, ABHD2, ABHD3, ABHD4, ABHD5, ABHD6, ABHD7, ABM, ABI3BP, ABL1, ABL2, ABLIM1, ABLIM3, ABP1, ABR, ABRA, ABTB2, ACACA, ACADM, ACADS, ACAT2, ACBD3, ACBD5, ACBD6, ACCN1, ACE2, ACHE, ACIN1, ACOI.ACOTI.ACOTH, ACOT12, ACOT2, ACOT6, ACOT7, ACOX2, ACP1, ACPL2, ACPP, ACPT, ACRC, ACSL1, ACSL3, ACSL4, ACSL5, ACSL6,
- GSTA2 GSTA5, GSTCD, GSTK1, GSTO1, GSTP1, GTDC1, GTF2A1, GTF2H5, GTF2IRD1, GTPBP4, GUCA1B, GUCA1C, GUCA2B, GUCY2C, GUCY2D, GULP1, GYPA, H1F0, H2AFB1, H2AFY, H2AFZ, H2-ALPHA, HABP2, HACE1, HACL1, HADH, HAK, HAO2, HAPLN 1, HAVCR1, HBLD1, HCCS, HCN3, HCN4, HCP1, HCRTR2, HDAC11, HDAC7A, HDAC9, HDC, HDDC2, HDGF, HDGFL1, HDHD3, HEBP2, HECA, HECTD1, HECW1, HECW2, HELZ 1 HEMK1, HEMK2, HEPH, HERC1, HERPUD1, HERPUD2, HERV- FRD, HES1, HES3, HEXB,
- PRTC7 PPTC7, PPYR1, PQLC1, PQLC2, PRDM1, PRDM10, PRDM8, PRDX1, PRDX4, PRDX6, PREP, PRF1, PRG1, PRG2, PRH1, PRICKLE1, PRICKLE2, PRKAA1, PRKAA2, PRKAG2, PRKAR1A, PRKAR2B, PRKCA, PRKCBP1, PRKCD, PRKCI, PRKG2, PRKRIR, PRL, PRLHR, PRM1, PRMT1, PROC, PR0CA1, PRODH, PR0M1, PR0S1, PR0X1, PRPF38B, PRPF39, PRPSAP1, PRPSAP2, PRR13, PRR15, PRR17, PRR3, PRR6, PRR8, PRRG4, PRRT1, PRSS12, PRSS16, PRSS23, PRSS3, PRSS35, PRSS8, PRTFDC1, PRTG, PRUNE, PSCD4, PSCDBP, PSD3, PSD4, PSEN1, PSKH2, PSMAL, PSMB3, PSMB4, PS
- the gene is selected from the group of genes regulated on the transcriptional level by the HNF4 ⁇ inducing agent Aroclor 1254, wherein the gene is preferably selected from the group of genes according to Table 35.
- Table 35 list of genes regulated on the transcriptional level by the HNF4 ⁇ inducing agent Aroclor 1254: ABCA1, ABCC3, ABP1, ACE2, ACOX1, ACSL5, ACY3, ACYP2, ADH4, AFF1, AFP, AGR2, AGT, AGXT2, AHSG, AIG1, AKAP7, ALB, ALDH6A1, ALDOB, AMICA1, AMMECR1, ANKRD9, ANKZF1, ANTXR2, ANXA4, AP1S3, APOA1, APOA4, APOB, APOBEC1, APOC3, APOM, AQP3, ARHGAP18, ARL4C, ASGR1, ATAD4, ATXN1, AXIN2, BCL2L14, BCMP11.
- the first aspect of the invention is, in one example, directed to the use, in particular the in vitro use, of
- (C) the template strand of a (A) or (B), wherein (C) is preferably a recombinant DNA molecule, or
- (D) the coding strand of (A) or (B), wherein (D) is preferably a recombinant DNA molecule, or
- the invention is thus also directed to the use of an antibody directed against a gene product encoded by a human gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma, or said antibody is used for the preparation of a diagnostic agent for for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma.
- antibodies are understood to include monoclonal antibodies and polyclonal antibodies and antibody fragments (e.g., Fab, and F(ab') 2 ) specific for one of said polypeptides.
- Polyclonal antibodies against selected antigens may be readily generated by one of ordinary skill in the art from a variety of warm-blooded animals such as horses, cows, goats, rabbits, mice, rats, chicken or preferably of eggs derived from immunized chicken.
- Monoclonal antibodies may be generated using conventional techniques (see Monoclonal Antibodies, Hybridomas: A New Dimension in Biological Analyses, Plenum Press, Kennett, McKearn, and Bechtol (eds.), 1980, and Antibodies: A Laboratory Manual, Harlow and Lane (eds.), Cold Spring Harbor Laboratory Press, 1988, which are incorporated herein by reference).
- the invention is thus further directed to the use of primer sequences, preferably primer pairs, directed against the mRNA of a human gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma, or said primer sequences are used for the preparation of a diagnostic agent for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma,
- a primer or of primers such as a primer pair may be, selected from Table M1 is particularly preferred.
- the first aspect of the invention is accordingly directed to the use of a human gene, in particular the coding region thereof, or of a gene product encoded thereby or of an antibody directed against said gene product or of RNA or DNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, as a biomarker in the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, wherein the gene is selected from one of the groups described herein, in particular to the group described in claim 1 , and the use is preferably performed for monitoring the therapeutic treatment of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuro
- a method for diagnosing, prognosing and/or staging metabolic and tumorous diseases in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer and/or monitoring the treatment of at least one of said diseases, is provided by
- biomarker is a gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 in a patient or in a sample of a patient suffering from or being susceptible to a metabolic and/or tumorous disease, and
- the first aspect of the invention may also be used in a method of qualifying the HNF4 ⁇ activity in a patient suffering or being susceptible to metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one said diseases, comprising determining in a sample of a subject suffering from or being susceptible to one of said diseases the level of at least one biomarker, wherein the biomarker is the gene product encoded by a gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , and/or the biomarker is the mRNA sequence encoding the gene product of said selected gene, and wherein the sample level of the at least one biomarker being significantly higher or lower than the level of said biomarker(s) in the sample of a subject without a disease associated
- Such method of qualifying the HNF4 ⁇ activity in a patient suffering from metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating such diseases preferably comprises administering a drug identified by the first aspect of the invention, or by the second aspect of the invention as described hereinafter, or administering a HNF4 ⁇ activity modulator, wherein the level of the at least one biomarker being significantly higher or lower than the level of said biomarker(s) in a subject without cancer associated with increased activity of HNF4 ⁇ is indicative that the subject will respond therapeutically to a method of treating cancer comprising administering said drug or administering a HNF4 ⁇ activity modulator.
- Such methods of qualifying the HNF4 ⁇ activity may be also used for monitoring the therapeutically response of a patient suffering from metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of said diseases comprising administering a drug identified by the first aspect of the invention, or by the second aspect of the invention as described hereinafter, or administering a HNF4 ⁇ activity modulator, wherein the level of the at least one biomarker before and after the treatment is determined, and a significant decrease or increase of said level(s), preferably a decrease or increase to the normal level(s), of the at least one biomarker after the treatment is indicative that the subject therapeutically responds to the administration said drug or to the administration of the HNF4 ⁇ activity modulator.
- metabolic and/or tumorous diseases in particular type 1 and/or type 2 diabetes mellit
- RT-PCR real time
- the invention is also directed to a composition for qualifying the HNF4 ⁇ activity in a patient suffering or being susceptible to a metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases, wherein the composition comprises an effective amount of at least one biomarker, and wherein the biomarker is a gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , and/or the biomarker is the gene product encoded by said gene, and/or wherein the composition comprises an effective amount of an antibody directed against said gene product.
- a metabolic and/or tumorous diseases in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases
- the gene according to the invention may be part of a recombinant DNA molecule for use in cloning a DNA sequence in bacteria, yeasts or animal cells.
- the gene according to the invention, or the DNA sequences hybridizing to said gene and encoding a polypeptide having the function of the gene product of said gene may be part by a vector.
- the invention is thus also directed to the use of a vector for the therapy and/or diagnosis of metabolic and/or cancerous diseases and/or to screen for and to identify drugs against metabolic and/or cancerous diseases, such as diabetes mellitus and/or colorectal cancer may be, wherein the vector comprises a gene selected from one of the goups of genes described herein, in particular the group according to claim 1 , or the vector comprises DNA sequences hybridizing to said gene and encoding a polypeptide having the function of the gene product of said gene.
- composition for qualifying the HNF4 ⁇ activity is used for the production of a diagnostic agent, in particular of a diagnostic standard.
- this composition is used for the production of a diagnostic agent for qualifying the HNF4 ⁇ activity in a patient suffering or being susceptible to a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases.
- a diagnostic agent for qualifying the HNF4 ⁇ activity in a patient suffering or being susceptible to a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases.
- this compositon is used for the production of a diagnostic agent for predicting or monitoring the response of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of said diseases with a drug, in particular a drug identified according to the first aspect of the invention , or according to the second aspect of the invention as described hereinafter, and/or with a HNF4 ⁇ activity modulator.
- a diagnostic agent for predicting or monitoring the response of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of
- the first aspect of the invention is, in another example, directed to the use, in particular the in vitro use, of
- (C) the template strand of a (A) or (B), wherein (C) is preferably a recombinant DNA molecule, or
- (D) the coding strand of (A) or (B), wherein (D) is preferably a recombinant DNA molecule, or
- the first aspect of the invention is, in a further example, directed to the use, in particular the in vitro use, of
- (C) the template strand of a (A) or (B) 1 wherein (C) is preferably a recombinant DNA molecule, or
- (D) the coding strand of (A) or (B), wherein (D) is preferably a recombinant DNA molecule, or
- the gene is preferably selected from the group of genes identified by the method according to the second aspect of the invention.
- an agent selected from the group consisting of: the agonists, antagonists, drugs, agents, antiestrogens, and compounds according to Tables 36-54, sulfonlyurea derivates, and Aroclor 1254, is used and/or tested and/or screened as the drug and/or as the HNF4 ⁇ activity modulator.
- Aroclor 1254 decreases the activity of pyruvate carboxylase (PC), phosphoenolpyrutvate carboxykinase (PEPCK) and glucose-6-phosphatase in diabetic liver.
- PC pyruvate carboxylase
- PEPCK phosphoenolpyrutvate carboxykinase
- glucose-6-phosphatase glucose-6-phosphatase
- Arocolor 1254 is thus a, at least putative, drug against diabetes mellitus.
- the administration of insulin to diabetic rats brings the increased amount of pyruvate carboxylase back to the normal level, as disclosed by Wallace & Jitrapakdee Biochemical Journal 340 1-16 (1999).
- Aroclor 1254 can inhibit tumor growth in rats, as described, for example, by the article "Inhibition of tumor growth in rats by feeding a polychlorinated biphenyl, Aroclor 1254" by Kervliet & Kimeldorf in Bull Environ Contam 1977 Aug , 18 (2) :243-6.
- Aroclor 1254 is thus a, at least putative, drug against cancerous diseases.
- Aroclor 1254 is thus a, at least putative, drug against metabolic diseases, in particular against diabetes mellitus, and/or against cancerous diseases.
- the second aspect of the invention provides a method for a genomewide identification of functional binding sites at targeted DNA sequences bound to DNA complexes in cells, healthy and diseased tissues and/or organs, wherein the method comprises, or preferably consists of, the steps of a. chromatin immunoprecipitation and b. DNA-DNA hybridisation for the c. de novo identification of gene targets.
- the method according to invention is used for the identification of the functional binding sites of a protein of interest, preferably of a transcription factor, and/or the method is characterized in that a. the chromatin immunoprecipitation comprises or consists of two rounds of sequential chromatin immunoprecipitation, b. a genome wide tiling array is used for the DNA-DNA hybridisation, and/or c. the de novo identification of gene targets comprises reducing the number of false enhancer-gene associations.
- the method according to invention is used for determining a region of ChIP enrichment in the immunoprecipitated sample (enrichment site), with respect to a control or to genomic DNA, preferably a HNF4 ⁇ binding site, and/or the method is characterized in that a. an anti HNF4 ⁇ antibody is used for the immunoprecipiation b. a human or murine array with a genome-wide 20-50 bp resolution is used, and/or c. all genes, which are separated from their associated enhancer by a CTCF-binding site, are removed from the group of the de novo identified genes (target list).
- the method according to invention is used for mapping the in vivo enrichment sites ' of a specific protein of interest, and/or the method is characterized in that a. Caco-2 cells are used, b. human tiling arrays with a genome-wide 35 bp resolution are used, and/or c. all genes, which are separated from their associated enhancer by the CTCF-binding site according to matrix 2, are removed from the target list.
- the method according to the invention further comprises the use of DNA-sequences and/or genes identified by the second aspect of the invention to screen for and to identify novel drug targets for the treatment of metabolic and cancerous diseases, preferably comprising the use according to the first aspect of the invention.
- novel identified sequences and genes encoding DNA are used.
- polypeptides encoded by novel identified sequences and genes are used.
- ES detection is further improved based on the frequency of motives of the protein of interest, in particular of HNF4 ⁇ -motives, within the enriched regions, which is determined by application of the MATCH algorithm,
- ChIP regions are analyzed for overrepresented motifs, in particular using motif analysis programs, such as from Biobase and Genomatix, as well as the tool CEAS -transcription factors cross-talking with the protein of interest, in particular with HNF4 ⁇ , are determinded
- the genomic position of the highest scoring motif of the protein of interest (highest likelihood ratio) , in particular of the HNF4 ⁇ motif (highest likelihood ratio), within the ChIP regions is retrieved and extended for 500 nucleotides to both flanks, and within these sequences, other enriched motifs are detected and preferably the distance to the DNA- binding motif of the protein of interest, in particular to the HNF4 ⁇ motif, is calculated
- AP1 an GATA motifs have their highest enrichment in a distance of 20 to 60 nucleotides to the DNA-binding motifs of the protein of interest, in particular to the HNF4 ⁇ motifs,
- RefSeq genes with a TSS separated by less than 100000 nucleotides from these binding sites are selected for associating the binding sites of the protein of interest, in particular the HNF4 ⁇ binding sites, identified by the ChlP-chip approach with target genes,
- the ChIP regions are scanned for transcription factor motifs using position-specific score matrices (PSSM) from TRANSFAC, in particular 533 well-defined PSSM,
- PSSM position-specific score matrices
- Ontology categorization is performed with GOFFA and DAVID, -de novo identified genes associated with the DNA binding sites of the protein of interest , in particular with the HNF4 ⁇ binding sites, are grouped by Ontology terms, in particular in genes in metabolic and cancerous disease,
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to develop new medications for the treatment of disease as a result of HNF4 ⁇ dysfunction.
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to develop new drug candidates for treatment of metabolic and tumorous diseases by interfering with the activity of polypeptides, as described herein, encoded by novel identified sequences and genes are used for the purpose of normalizing its activity and to restore a healthy condition.
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to optimize novel chemical entities for the purpose of drug development.
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting chromatin and its regulation by interfering with protein-DNA, protein-protein and multiprotein- DNA complexes for the purpose of normalizing gene activities in metabolic and cancerous diseases.
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting carbohydrate metabolism in metabolic and tumorous diseases for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting lipid metabolism in metabolic and tumorous disease for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of A4GALT, ABCA1 , ABCD2, ABCG1 , ABHD4, ACAA2, ACACA, ACADM, ACADS, ACAT2, ACBD3, ACLY, ACOT1 , ACOT11 , ACOT12, ACOT2, ACOT7, ACOX1 , ACOX2, ACSL1 , ACSL3, ACSL4, ACSL5, ACSL6, ACSS2, ADIPOR2, ADM, AGPAT1 , AGPAT2, AGPAT3, AKR1 B10, AKR1C1 , AKR1C3, AKR1C4, AKR1 D1 , ALDH3A2, ALOX5AP, ALOXE3, ANGPTL3, AOAH, APOA1 ,
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting intracellular signaling in metabolic and tumorous disease for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of ABL1, ABL2, ABR, ABRA 1 ACOT11, ACR, ADCY5, ADCY6, ADCY8, ADCY9, ADIPOR2, ADORA2A, ADORA2B, ADORA3, ADRA1B, ADRA1D, ADRB1, AGTR1, AKAP13, AKAP7, AMBP, ANP32A, APBB2, ARF1, ARF6, ARFGEF2, ARHGAP29, ARHGAP5, ARHGAP6, ARHGEF1, ARHGEF10L, ARHGEF11, ARHGEF12, ARHGEF17, ARHGEF18, ARHGEF3, ARHGEF5, ARHGEF7, ARID1A, ARL1, ARL4A, ARL4C, ARL4D, ARL5
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting cell cycle and cell proliferation in metabolic and tumorous disease for the purpose of its normalization , wherein a gene, in particular the coding region thereof, selected from the group consisting of
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting programmed cell death in metabolic and tumorous disease for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of ABL1, ACIN1, ACTN1, ACTN4, ADORA2A, AHR, ALB, AMID, AMIG02, ANXA4, ANXA5, APOE, APP 1 ASAH2, ATG5, AXIN1, BAD, BAG2, BAG3, BBC3, BCAR1, BCL10, BCL2, BCL2A1, BCL2L1, BCL2L10, BCL2L11, BCL2L14, BCLAF1, BID, BIRC2, BIRC3, BIRC4, BMF, BRAF, BRCA1, BRE, BTG1, CARD10, CARD4, CASP10, CASP3, CASP6, CBX4, CD28, CD3E, CD74, CDC2, CDK5R1,
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting cell morphogenesis and cell / organ development in metabolic and tumorous disease for the purpose of its normalization , wherein a gene, in particular the coding region thereof, selected from the group consisting of
- RNA sequences which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
- the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to select drug candidates of an antisense molecule, ribozyme, triple helix molecule or other new chemical entities targeting the chromatin.
- the invention further comprises a kit for qualifying the HNF4 ⁇ activity in a patient suffering or being susceptible to metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases, in particular for predicting or monitoring the response of a patient to suffering from at least one of said diseases by a method of treating metabolic and/or tumorous diseases comprising administering a HNF4 ⁇ activity modulator, comprising at least one standard indicative of the level of a biomarker selected from the groups of genes described herein, preferably the group according to claim 1 , or from the group of gene products encoded by said groups of genes in normal individuals or individuals having metabolic and/or tumorous disease associated with increased HNF4 ⁇ activity, and instructions for the use of the kit, and, preferably, wherein the
- the kit according to the invention further comprises at least one primer or primer pair specifically hybridizing with the mRNA of a biomarker selected from one of the groups of genes and/or at least one antibody specific for a biomarker selected from the group of gene products encoded by said genes, and reagents effective to detect said biomarker(s) in a serum sample.
- a medicament for the treatment of metabolic and tumorous diseases in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer
- the medicament comprises a composition that decreases the expression or activity of a HNF4 ⁇ modulated gene selected from one of the groups of genes described herein, preferably from the group specified in claim 1.
- siRNA composition wherein the siRNA composition reduces the expression of a de novo identified HNF4 ⁇ modulated gene selected from one of the groups of genes described herein, preferably from the group specified in claim
- the present invention thus employs SiRNA oligonucleotides directed to said genes specifically hybridizing with nucleic acids encoding the gene products of said genes and interfering with gene expression of said genes.
- the siRNA composition comprises siRNA (double stranded RNA) that corresponds to the nucleic acid ORF sequence of the gene product coded by one of said human genes or a subsequence thereof; wherein the subsequence is 19, 20, 21 , 22, 23, 24, or 25 contiguous RNA nucleotides in length and contains sequences that are complementary and non-complementary to at least a portion of the mRNA coding sequence.
- nucleotide sequences and siRNA according to the invention may be prepared by any standard method for producing a nucleotide sequence or siRNA, such as by recombinant methods, in particular synthetic nucleotide sequences and siRNA is preferred.
- an antisense composition comprising a nucleotide sequence complementary to a coding sequence of a HNF4 ⁇ modulated gene selected from one of the groups of genes described herein, preferably from the group specified in claim 1.
- coding sequence is directed to the portion of an mRNA which actually codes for a protein.
- nucleotide sequence complementary to a coding sequence in particular is directed to an oligonucleotide compound, preferably RNA or DNA, more preferably DNA, which is complementary to a portion of an mRNA, and which hybridizes to and prevents translation of the mRNA.
- the antisense DNA is complementary to the 5' regulatory sequence or the 5' portion of the coding sequence of said mRNA.
- the antisense composition comprises a nucleotide sequence containing between 10-40 nucleotides , preferably 12 to 25 nucleotides, and having a base sequence effective to hybridize to a region of processed or preprocessed human mRNA.
- the composition comprises a nucleotide sequence effective to form a base-paired heteroduplex structure composed of human RNA transcript and the oligonucleotide compound, whereby this structure is characterized by a Tm of dissociation of at least 45 0 C.
- the siRNA composition and/or the antisense composition is/are used for the preparation of a medicament, in particular for the preparation of a medicament for preventing, treating, or ameliorating metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer.
- metabolic and tumorous diseases in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer.
- siRNA composition and/or said antisense composition a composition is used.
- a nucleic acid, in particular DNA, hybridizing with the expression regulatory sequence of matrix 1 is used.
- This cell line differentiates into enterocytes upon confluence (Soutoglou et al., 2002). Furthermore, in differentiated Caco-2 cells HNF4 ⁇ protein expression is comparable to its expression in liver (Niehof and Borlak, 2008). Therefore, Caco-2 cells are an interesting system to study the HNF4 ⁇ gene regulatory network.
- the study according to the invention is the first genome-wide approach to identify nearby 6600 RefSeq genes targeted by HNF4 ⁇ .
- the importance of promoter-distal regions in HNF4 ⁇ mediated transcriptional control is highlighted, and a basis for elucidation of transcriptional networks formed by cooperating transcription factors acting in concert with HNF4 ⁇ is offered.
- good agreement between de novo identified genes and their expression in Caco-2 cells is demonstrated.
- HNF4 ⁇ binding sites described in literature and present in the Biobase database, including /WT (R00114), GCC (R08885), PCK (R12074), APOB (R01612), CYP2C9 (R15905), AKR1C4 (R13037), ACADM (R15923) or CYP27A1 (R15917).
- SHBG SHBG
- ALDH2 ALDH2
- HNF4 ⁇ binds predominantly to enhancer elements
- ES overall distribution of ES is very similar to that observed in genome-wide ChlP-chip for another member of the nuclear receptor family, i. e. the estrogen receptor (Carroll et al., 2006).
- a significant lack of preference for binding to 5' promoter-proximal regions has also been reported for other transcription factors, e.g. p53, cMyc or p63 (Table 7; Cawley et al., 2004; Wei et al., 2006; Yang et al., 2006).
- transcription factors like E2F1 show a clear preference for binding to 5' promoter- proximal regions (Bieda et al., 2006), but accumulating evidence is highly suggestive for promoter-proximal regions to constitute only a small fraction of mammalian gene regulatory sequences. Indeed, members of the nuclear receptor family clearly display higher activity at enhancer rather than promoter binding sites, as evidenced by the invention and other investigators (e.g. Bolton et al., 2007). Consequently, studies based on promoter sequence containing arrays can be misleading.
- the HNF4 ⁇ motif is highly enriched within the ChIP regions:
- HNF4 ⁇ binding motifs are highly abundant within the ChIP regions. Using stringent criteria to minimize false positives, an up to > 14-fold enrichment was detected for different HNF4 ⁇ matrices compared to the genomic background (Table 3). This enrichment allowed an easy 'de novo' identification of the HNF4 ⁇ motif: Among 5 motifs identified by a Gibbs motif sampler, 2 motifs represented HNF4 ⁇ binding sites (Fig. 4).
- regions with a low enrichment show a higher percentage of promoter- proximal binding sites, and a lower number of HNF4 ⁇ motifs, than regions with higher enrichment (Figure S3b). Therefore, it was demonstrated that often HNF4 ⁇ binding to promoter- proximal regions is indirect (due to interaction with other transcription factors), and therefore weaker. However, as HNF4 ⁇ motifs are still enriched in promoter-proximal regions it seems likely that HNF4 ⁇ can act as a promoter binding as well as an enhancer binding transcription factor.
- Enhancer elements defined by HNF4 ⁇ display high conservation
- the ChIP regions for overrepresented motifs were analyzed, using motif analysis programs from Biobase and Genomatix, as well as the tool CEAS.
- motifs with the highest fold enrichment are matrices similar to the HNF4 ⁇ binding motif, e. g. the binding motifs for COUP-TF, PPAR or LEF1 (Table 3; Fig. 6).
- These transcription factors are known to compete with HNF4 ⁇ for common binding sites (Galson et al., 1995; Hertz et al., 1995; Hertz et al., 1996; Dongol et al., 2007; For motif similarity see also Kielbasa et al., 2005).
- HNF4 ⁇ many motifs dissimilar to HNF4 ⁇ , e.g. the binding motifs for HNF1 , AP1 , GATA transcription factors or CREB, where also enriched within the ChIP regions (Table 3; Supplementary tables S1 , S2 and S3; Fig. 7). Significant overrepresentation of these motifs has been further confirmed with different sets of ChIP regions defined by high- and low stringency cut-off criteria (data not shown). The corresponding transcription factors can therefore be expected to form composite modules with HNF4 ⁇ . If these factors act combinatorial with HNF4 ⁇ , it could be further expected that the frequency of their motifs increases with decreasing distance to the HNF4 ⁇ binding sites. Therefore, the frequency of their motifs relative to the HNF4 ⁇ binding sites was analyzed identified in this study.
- HNF4 ⁇ and estrogen receptor (ER) binding motifs at flanking sequences were observed (Fig. 9). Enrichment of ER motifs, and possibly other motifs as well, could therefore be coincidental for enrichment of HNF4 ⁇ .
- the genomic position of the highest scoring HNF4 ⁇ motif (highest likelihood ratio) within the ChIP regions was retrieved and extended for 500 nucleotides to both flanks. Within these sequences, other enriched motifs were detected and the distance to the HNF4 ⁇ motif (i.e.
- Binding sites for ER and HNF4 ⁇ were compared, and a considerable overlap was found (Fig. 1 1). Using the low stringency set of HNF4 ⁇ binding sites binding, 15% of the ER binding sites were also targeted by HNF4 ⁇ , supporting the idea of cooperation between HNF4 ⁇ and the ER nuclear receptor.
- ChlP-chip experiments were employed by Rada-lglesias et al (2005) to identify HNF4 ⁇ binding sites within the ENCODE regions in HepG2 hepatoma cells.
- a ChlP-chip protocol was used by Odom et al. (2004) to identify binding sites within promoter regions in human hepatocytes and pancreatic islets.
- the genomewide approach according to the invention was compared with the aforementioned studies to identify regions which overlap amongst these platforms, and the data according to the invention was compared to the binding sites reported in these publications (Fig. 12; Table 7).
- enhancers appear to be promiscuous and can regulate multiple genes (West et al., 2005). Additionally, the genes with the TSS closest to the enhancer are not necessarily the ones regulated by this enhancer (Blackwood, 1998). Enhancer action can thus take place over hundreds of kilobases (Dekker et al.2008), and even cases of inter-chromosomal regulation by enhancers are known (Spilianakis et al., 2005). Nonetheless, most known enhancer elements are within 100000 nt of their respective TSS.
- Enhancer-blocking insulators Activity of an enhancer is defined by enhancer-blocking insulators. If an active insulator is placed between an enhancer and a promoter, no communication between them, and therefore no activation of transcription by the enhancer, is possible. In vertebrates, binding of the protein CTCF to an insulator element is required for insulator function. Recently, genome-wide data of insulator regions became available. Kim et al. (2007) identified 13.804 CTCF binding sites. Furthermore, they compared insulator activity between different cell types, and found that CTCF localization is largely invariant.
- HNF4 ⁇ is well known to have an important role in development (Sladek et al., 1990; Sladek et al, 1993), and is an essential driver for epithelial differentiation (Watt et al., 2003). Needless to say, HNF4 ⁇ ko mice die around E 8_5 due to deficient organ development.
- HNF4 ⁇ can be seen as a regulator of an epithelial phenotype, and several lines of evidence suggest HNF4 ⁇ to play an essential role in activation of the expression of genes encoding cell junction molecules (Spa ' th and Weiss, 1998; Chiba et al., 2003; Parviz et al., 2003; Satohisa et al., 2005; Battle et al., 2006).
- HNF4 ⁇ insulin receptor signaling.
- HNF4 ⁇ is well known to control the insulin secretory pathway (Miura et al., 2006), and was linked to rare monogenic disorder, maturity-onset diabetes of the young (MODY), confirming its role in insulin signaling (Yamagata et al., 1996).
- MODY maturity-onset diabetes of the young
- the overrepresentation of GO categories representing well known functions of HNF4 ⁇ supports the general biological significance of the association of binding sites according to the invention with target genes.
- HNF4 ⁇ gene targets Caco-2 cell cultures were treated with Aroclor 1254, a known HNF4 ⁇ inducer (Borlak et al., 2001). Indeed, after Aroclor 1254 treatment of Caco-2 cells, binding of the HNF4 ⁇ protein to the HNF1 promoter was increased (Niehof and Borlak, 2008). Caco-2 cells were treated with Aroclor 1254 for 48 and 72 hours. Strong induction of HNF4 ⁇ was confirmed by western blot analysis (Fig. 12) and increased binding activity by EMSA, and genome-wide expression profiling by microarray analyses was performed to search for regulated genes.
- HNF4 ⁇ targets based on its overexpression in mammalian cell lines were compared. Essentially, a high overlap, ranging from 65 to 94 %, of the genes identified by expression profiling experiments was found (Table 6). Interestingly, the highest overlap was found with the targets identified by Sumi et al. (2007).
- the approach used in this study differs from the others in the point that targets were not only identified by overexpression of HNF4 ⁇ , but also by knock down by si ' RNA, and only genes increased by overexpression and decreased by siRNA were reported as target genes. Therefore, targets reported here might be considered more reliable.
- ChlP-chip assays genome-wide scans for transcription factor binding sites becomes feasible.
- HNF4 ⁇ the transcription factor
- HNF4 ⁇ binding sites achieved by the use of high resolution tiling array.
- the regions surrounding the HNF4 ⁇ binding sites were analyzed for overrepresentation of transcription factor binding motifs from different databases with different algorithms, and it was shown for several motifs to be significantly overrepresented in these regions. Moreover, there are also motifs which are significantly underrepresented, such as CART. Based on a thorough and detailed analysis, it was possible to evidence a close relationship between HNF4 ⁇ and AP1 , GATA, ER or HNF1 binding sites. The close association of these motifs enabled to predict composite models formed by the corresponding transcription factors on bound enhancer elements.
- HNF4 ⁇ While single cases of synergistic action of HNF4 ⁇ with HNF1 (Fourel et al.,1996), ER (Harnish et al., 1996) or GATA transcription factors (Sumi et al., 2007; Alrefai et al., 2007) are already known, to the best of our knowledge the data according to the invention is the first report to suggest a collaborative action of HNF4 ⁇ and AP1. While over 95% of the identified binding sites are promoter distal sequences identified as enhancer elements, promoter proximal sites are highly enriched compared to random controls. This suggests that HNF4 ⁇ can also interact directly with the basal transcriptional machinery. The actual number of promoter-proximal binding sites will even be higher, as transcription start sites only of RefSeq annotated genes were included.
- enhancers could hardly be identified by available methods; their genome-wide mapping is only possible through the advent of ChlP-chip technology.
- One of the most promising aspects of future research will therefore be the integration of all the transcription factor binding sites into a genome-wide map of enhancer elements, like it is currently done within the ENCODE regions (See The ENCODE Project Consortium, 2007).
- Current methods for association of enhancers and their target genes are mostly restricted to CCC or related methods, which allow only the analysis of single enhancer elements, and are technically challenging (Dekker, 2006).
- association of promoter-distal transcription factor binding sites with their target genes is mostly based on the search for the closest transcription start site or the closest gene.
- insulator elements in determining enhancer activity has just been unravelled; Their position can be analyzed genome-wide (Dorman et al., 2007; Kim et al., 2007). Therefore, available data on insulator elements was used to narrow down the number of genes associated with the HNF4 ⁇ binding sites identified in the study according to the invention. Based on such analysis ⁇ 6000 RefSeq annotated gene targets were determined.
- HNF4 ⁇ targeted genes will help to identify novel drug targets for the treatment of cancerous and metabolic disease. This principle has been demonstrated by the invention and other investigators based on identification of novel HNF4 ⁇ gene targets in liver cancer and metabolic diseases (Niehof and Borlak, 2005; Niehof and Borlak, 2005; Niehof and Borlak, 2008)
- Caco-2 cells were obtained from and cultivated as recommended by Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH (Braunschweig, Germany), seeded with a density of 4 X 10 6 cells/75 cm 2 flask, and harvested after 11 days. Aroclor 1254 treatment was performed as described in Borlak et al. (2001).
- Chromatin immunoprecipitation (ChIP)
- Chromatin immunoprecipitation (ChIP) procedures were carried out as described by Weinmann et al. (2001) with some modifications. The samples were sonicated on ice until cross-linked chromatin was fragmented to approximately 0.2 to 1.6 kilobase pairs. Protein A Sepharose CLB4 (Amersham Biosciences, Freiburg, Germany) was blocked with 1 mg/ml bovine serum albumin and washed extensively before use. Chromatin preparations were precleared by incubation with "blocked" Protein A-Sepharose for 1 h at 4°C. Precleared chromatin from 2.5 X 10 7 cells was incubated with 1 ⁇ g of HNF4 ⁇ antibody and rotated at 4°C overnight.
- ChIP chromatin immunoprecipitation
- the GeneChlP WT Double-Stranded DNA Terminal Labeling Kit (P/N 900812) from Affymetrix was used. Fragmentation success was confirmed with the Agilent Bioanalyzer. The labeled samples were hybridized to Affymetrix Human tiling 2.0R arrays with a 35 base pair resolution.
- Raw data (CEL-files generated by GCOS after scanning) were analyzed for enriched regions by three independent algorithms, TAS (Affymetrix/Cawley et al., 2004), MAT (Johnson et al., 2006) and Tilemap (Ji et al., 2005).
- Initial cut off criteria were determined based on the detection of a weakly enriched positive control (OTC).
- OTC weakly enriched positive control
- ES Parameters for enrichment site (ES) detection were further improved based on the rate of HNF4 ⁇ -motives within the enriched regions, which was determined by application of the MATCH algorithm (KeI et al., 2003).
- ChIP was performed as previously described (Niehof et al., 2005). ChIP-DNA from three independent experiments (122, 124 and f3) was used for enrichment validation.
- Realtime PCR was performed on the Light Cycler (Roche Diagnostics, Mannheim, Germany) with the following conditions denaturation at 94°C for 120 s, extension at 72 0 C for different times, and fluorescence at different temperatures. Primer sequences, annealing times and temperatures, extension times and fluorescence temperatures are summarized in Table M1. The reaction was stopped after a total of 45 cycles, and at the end of each extension phase, fluorescence was observed and used for quantification within the linear range of amplification. ⁇ ct-values were calculated versus diluted total input, and normalization, i. e. calculation of ⁇ ct-values was performed using a ⁇ -actin negative control, HNF1 upstream. No enrichment of on negative control against the other was observed. Sequence conservation analysis
- Enrichment site centers left or Peak positions detected by MAT (right) were extend to 200 bp in both directions, and analyzed with CEAS (Ji et al., 2006) for conservation and motif content.
- CEAS extends the 200 bp genomic regions to 3000 bp, and calculates for each nucleotide the average conservation score, based on the high-quality phast- Cons (Siepel et al., 2005) information from the UCSC GoldenPath genome Resource. The average conservation scores were plotted against the nucleotides position.
- Total RNA was isolated using QIAGEN's RNeasy total RNA isolation kit according to the manufacturer's recommendations. 10 ⁇ g of total RNA were prepared for hybridization using the respective Affymetrix kits according to the manufacturer's recommendations. Samples were hybridized to Affymetrix U133Plus2.0 genechip arrays. GCOS 1.4 was used to calculate the level of differential expression at each time point relative to 0 h.
- HNF4 ⁇ gene targets Caco-2 cell cultures were treated with Aroclor 1254, a known HNF4 ⁇ inducer36. After Aroclor 1254 treatment of Caco-2 cells, binding of the HNF4 ⁇ protein to the HNF1 promoter was increased7. Caco-2 cells were treated with Aroclor 1254 for 48 and 72 hours, respectively. Strong induction of HNF4 ⁇ was confirmed by western blot analysis and increased binding activity was observed by EMSA (Fig. 7). A genome-wide expression profiling was performed by microarray analyses to search for regulated genes. Using stringent criteria, 536 RefSeq-annotated genes were identified to be regulated (Supplementary Table 4).
- HNF4 ⁇ ChIP was performed and enrichment of novel HNF4 ⁇ binding sites detected by ChlP-chip was confirmed by real time PCR.
- ChIP-DNA from three independent experiments was used. Normalization was performed using a ⁇ -actin negative control, and the values are shown as fold enrichment versus total input.
- HNF1 upstream is a second negative control, located upstream of the known HNF4 ⁇ binding site in the HNF1 promoter, and is used to confirm the ⁇ -actin negative control.
- Fig. 2 Distribution of ES relative to RefSeq loci. a) Location of HNF4 ⁇ binding sites relative to the closest transcription start sites (TSS) of RefSeq genes, compared to random distribution. The Y-axis gives the number of binding sites, and the X-axis the distance to closest TSS in nucleotides, b) Overrepresentation of HNF4 ⁇ ES in first, second an third introns of RefSeq annotated genes, relative to a random control regions.
- TSS transcription start sites
- Fig. 3 A) Each chromosome was divided into 150 'bins', and within each bin the number of ES was counted. In the grey line chart, the number of HNF4 ⁇ binding sites within each bin is represented as a single data point. Below each chromosome the minimum and maximum number of binding sites located in a single bin is given. B) The distribution of HNF4 ⁇ binding sites (grey line chart, upper half) is compared to the distribution of known genes on chromosome 10. Green arrows mark two gene-sparse regions, in which also hardly ES are found. The red arrows mark two region with a high number of HNF4 ⁇ binding sites and a low number of genes. Analyses where performed using the Ensembl tool Karyoview ( http://www.ensembl.org/Homo_sapiens/karyoview ).
- HNF4 ⁇ ChlP-chip enrichment sites allow easy 'de novo' prediction of the HNF4 ⁇ binding motif.
- the HNF4 ⁇ -motif as described by the TRANSFAC matrices M01031or M00134, was actually detected two times, with the second motif presenting only a half site.
- Fig. 5 a) Conservation of all HNF4 ⁇ binding sites (blue line). Enrichment site centers (blue) or Peak positions (red) were extend to 1000 bp in both directions, and for each nucleotide the average conservation score, based on the high-quality phast-Cons (Siepel et al., 2005) information from the UCSC GoldenPath genome Resource, was calculated. The average conservation scores were plotted against the nucleotides position. Analyses where performed with CEAS (Ji et al., 2006). b) HNF4 ⁇ motifs in the area of 1000 bp surrounding enrichment site peak or center positions were detected with MATCH, using cut offs to minimize false positives.
- the distance of the center of detected motifs to the peak or center position of the enrichment sites was calculated.
- a Histogram was created using bins of 50 nucleotides around the center or peak positions.
- the blue line shows the deviation of HNF4 ⁇ motifs relative to the enrichment site center, the red line shows the deviation relative to the peak position.
- Fig. 6 Computational screens were performed for motifs which are enriched within the detected HNF4 ⁇ ChlP-chip enriched regions. Binding sites were defined as the area of 300 surround the peak positions. Besides the expected overrepresentation of HNF4 ⁇ -motifs, an enrichment of HNF4 ⁇ -similiar motifs like COUP-TF, PPAR or LEF was found. Similarity of the motifs is visualized by using Weblogo depiction (http://weblogo.berkeley.edu/). A complete list of enriched motifs can be found in Table 3.
- Fig. 7 As described in Fig. 6, HNF4 ⁇ -dissimilar motifs are displayed. Dissimilarity is visiualized by using Weblogo.
- Fig. 8 Distribution of AP1 , CART, ER, GATA2, HNF1 and SREBP motifs within the regions enriched by HNF4 ⁇ -ChlP, relative to the peak position (represented as 0). Enrichment site centers were extend to 500 nt in both directions, and Motifs were detected by use of the MATCH algorithm using cutoff criteria to minimize the sum of false positives and false negatives. Regions were segmented into bins of 25 nt, and the number of occurrences of the different motifs within each bin was counted.
- Fig. 9 Display of the overlap between the binding motifs of HNF4 ⁇ and the estrogen receptor by use of Weblogo illustrations. Both motifs show an partial overlap.
- Fig. 10 Plot of the relative distance of HNF4 ⁇ motifs to other motifs enriched in the ChIP region. Within ChIP regions the most conserved HNF4 ⁇ motifs where identified. The sequences of the 500 nucleotides surrounding these most conserved HNF4 ⁇ motifs where retrieved and analyzed for those motifs of other TF that were also enriched in the ChIP regions. Then, the distance between these motifs and the HNF4 ⁇ motif was calculated using Cisgenome for motif detection, and plotted as histogram, using bins of 20 nt. The HNF4 ⁇ motif is found at the center, reaching from nt -6 to nt +6.
- Fig. 11 Overlap between estrogen receptor (ER) binding sites and HNF4 ⁇ binding sites.
- Fig. 12 For Rada Iglesias, the Random Control group (600nt) was used. For Odom et al, a number of promoter regions from the Huk13 array used in their study equal to the number of promoters they detected as binding sites was selected by random. This was necessary, because Odom et al. tested only promoter regions, and these regions are highly enriched within binding sites identified in this study. Therefore, comparison to the Random Control group (600nt) would have a high negative bias.
- Fig. S1 Venn diagram of overlap between ES identified by variable algorithms.
- ES were identified by use of three different algorithms. Although different parameter settings (e. g. band width of 200, 300 and 400 nucleotides) and different algorithms were used, the overlap was surprisingly high.
- the Venn diagram was calculated using the intersect function of Galaxy (Giardine et al., 2005).
- FIG. S2 HNF4 ⁇ induction in Caco-2 cells.
- Promoter-proximal ES might be indirect HNF4 ⁇ binding sites
- 100 promoter-proximal ES (-138 to -2 relative to the TSS) were compared to 100 promoter-distal ES (-24972 to -23489 relative to the TSS) by the bootstrapping analysis tool POBO (Kankainen and Holm, 2004).
- Promoter-proximal ES show a significantly lower number of HNF4 ⁇ motifs
- b) ES (300bp surround the peak position) were sorted by their Pvalue (as calculated by the MAT algorithm) and divided into bins of 1000 ES. For each bin the number of HNF4 ⁇ motif occurrences and the percentage of promoter-proximal ES was calculated. As can be clearly seen, ES with a high Pvalue (weak ES) are more likely to be located promoter-proximal, and to contain no HNF4 ⁇ binding motif.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Pathology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Immunology (AREA)
- Analytical Chemistry (AREA)
- Plant Pathology (AREA)
- Oncology (AREA)
- Hospice & Palliative Care (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
The invention is directed to the use of particular human genes, nucleic acids hybridizing to said genes, and gene products encoded thereby in the context of the diagnosis and/or therapy of metabolic and/or cancerous diseases, preferably of diabetes mellitus and/or colorectal cancer, wherein the gene is selected from the group of the human chromosomal genes having at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4α matrix) in the range of 100000 nucleotides upstream or downstream of their transcription start site in the human genome, and wherein the at least one expression regulatory sequence according to matrix 1 is located within the chromosomal position specified by particular start and end sites. The invention further relates to a method for a genomewide identification of functional binding sites at specifically targeted DNA sequences with high resolution, wherein the method comprises, or preferably consists of, the steps of: a) chromatin immunoprecipitation and b) DNA-DNA hybridisation for the c) de
novo identification of gene targets.
Description
Method for a genome wide identification of expression regulatory sequences and use of genes and molecules derived thereof for the diagnosis and therapy of metabolic and/or tumorous diseases
The invention is directed to the use of particular human genes, nucleic acids hybridizing to said genes, and gene products encoded thereby in the context of the diagnosis and/or therapy of metabolic and/or cancerous diseases, preferably of diabetes mellitus and/or colorectal cancer. The invention further relates to a method for a genomewide identification of functional binding sites at specifically targeted DNA sequences with high resolution. Areas of application are the life sciences: biology, biochemistry, biotechnology, medicine and medical technology.
Hepatic nuclear factor (HNF)-4α is a member of the nuclear rece?ptor superfamily and known to be expressed in the liver, intestine, and pancreas (for review see Sladek et al.f 2001 ; Schrem, 2002). Many reports have highlighted the importance of HNF4α in the regulation of developmental processes in determining the hepatic phenotype, as well as the regulation of diverse metabolic pathways (e.g., glucose, cholesterol, and fatty acid metabolism) (Sladek et al., 1990; Jiang et al., 1995; Yamagata et al., 1996; Hadzopoulou-Cladaras et al., 1997). Therefore, HNF4α is considered as a hepatic master regulatory protein, ln^contrast to other members of the nuclear receptor superfamily, HNF4α binds to its cognate DNA binding site as a homodimer (Jiang 1997; Sladek 1990). HNF4α is one of the best characterized transcription factors, and in the past some dozent direct binding sites were reported. The employment of ChlP-chip technologies demonstrated however that these are only the smallest fraction of the actual HNF4α binding sites. Notably, Rada-lglesias et al. (2005) used custom made arrays with a low resolution encompasing the ENCODE regions, i. e. 1 % of the genome, for ChlP-chip, and thus mapped 194 HNF4α binding sites in the human hepatoma cell line HepG2. In another study binding sites in hepatocytes and pancreatic islets were mapped, but the approach focused on promoter regions only (Odom et al, 2004; Odom et al, 2006). Based on the findings published by Rada-lglesias et al. (2005) only a small fraction of HNF4α binding sites are located in proximal promoter regions.
As of today, a genome-wide footprinting of binding sites targeted by HNF4α has not been reported.
However, such a system would allow to identify the common rationale underlying the genome wide regulation processes induced by protein-DNA binding within the context of diseases caused by HNF4α upregulation, such as adenocarcinomas of the colon may be, namely to identify specific regulatory sequences in the chromosomal genome which (a) bind to HNF4α and (b) bind to proteins other than HNF4α, wherein said proteins bind to HNF4α.
The aim of the invention is thus to provide a method allowing a genome-wide high resolution map of binding sites relevant for the transcription regulation induced by HNF4α, and the
identification of human chromosomal genes having at least one specific regulatory sequence in their natural environment, and the use of said genes or gene products encoded thereby or of RNA hybridizing to said genes for the diagnosis and therapy of diseases, preferably of adenocarcinomas of the colon, caused by an deregulation of HNF4α
To this end, the implementation of the actions and embodiments as described in the claims provides appropriate means to fulfill these demands in a satisfying manner.
Thus, the invention in its different aspects and embodiments is implemented according to the claims.
In the first aspect, the invention is directed to the use of a human gene, in particular the coding region thereof, or of a gene product encoded thereby or of an antibody directed against said gene product, or of DNA or RNA sequences hybridizing to said gene and coding for a polypeptide having the function of said gene product for the therapy and/or diagnosis of metabolic and/or cancerous diseases and/or to screen for and to identify drugs against metabolic and/or cancerous diseases, such as diabetes mellitus and/or colorectal cancer may be, wherein the gene is selected from the group of the human chromosomal genes having at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4α matrix) in the range of 100000 nucleotides upstream or downstream of their transcription start site in the human genome, and wherein the at least one expression regulatory sequence according to matrix 1 is located within the chromosomal position specified by the start and end sites according to Tables 9-32 (chromosomes 1-22, X-, Y-chromosome, wherein Table 9 refers to the human chromosome 1 , Table 10 refers to the human chromosome 2, etc., Table 30 refers to the human chromosome 22, Table 31 refers to the human X-chromosome, and Table 32 refers to the human Y-chromosome).
The term "gene" according to the invention is directed to both the template strand, which refers to the sequence of the DNA that is copied during the synthesis of mRNA, and to the coding strand corresponding to the codons that are translated into a protein. The genes according to the invention and gene products encoded thereby can be easily derived from the common databases, as such are known to the person skilled in the art, wherein the UCSC Genome Database is particularly preferred: Karolchik D, Kuhn, RM, Baertsch R, Barber GP, Clawson H, Diekhans M, Giardine B, Harte RA, Hinrichs AS1 Hsu F, Miller W, Pedersen JS, Pohl A, Raney BJ, Rhead B, Rosenbloom KR1 Smith KE, Stanke M, Thakkapallayil A, Trumbower H, Wang T1 Zweig AS, Haussler D, Kent WJ. The UCSC Genome Browser Database: 2008 update. Nucleic Acids Res. 2008 Jan;36:D773, which is incorporated herein by reference.
The term "coding region" according to the invention is directed to the portion of DNA or RNA that is transcribed into the mRNA, which then is translated into a protein. This does not include gene regions such as a recognition site, initiator sequence, or termination sequence.
The term "RNA sequences hybridizing to said gene" or "RNA sequences, which hybridize to said gene", respectively, according to the invention relates to RNA molecules hybridizing with the template strand of said gene, in particular with the coding region. The term "DNA sequences hybridizing to said gene" or "DNA sequences, which hybridize to said gene", respectively, according to the invention preferably relates to DNA molecules hybridizing with the coding strand of said gene, in particular with the coding region thereof. The term "hybridizing" as used herein refers to conventional hybridization conditions, preferably to hybridization conditions under which the Tm value is between 37°C to 700C, preferably between 410C to 660C. [fl] An example for low stringency conditions is e.g. hybridisation under the conditions 42°C, 2*SSC, 0.1% SDS and an example for high stringency conditions is e.g. hybridization under the conditions: 65°C, 2*SSC, 0.1% SDS, wherein in the case that washing is necessary for equilibrium, the hybridization solution is used for the washings. Most preferably, the term hybridization refers to stringent hybridization conditions.
The term "function of said gene product" is directed to biological activities of the polypeptide encoded by the selected gene, wherein the biological activities may easily be derived from common gene or protein databases, such as the ncbi or the SWISS-Prot databases may be and the biological activities can be determined according to the literature provided therein. Within the context of the invention the term "transcription start site" refers to the start codon or initiation codon in eukaryotes, in particular to the respective DNA sequence ATG of the coding strand coding for methionin.
The term "colorectal cancer" within the context of the invention is in particular directed to adenocarcinoma of the colon, in particular to colorectal adenocarcinoma associated with an upregulation or hyperactivity of HNF4α.
The term "matrix" or "matrices" according to the invention is directed to position weight matrix/matrices (PWM(s)), which are known to the person skilled in the art.
In the matrix/matrices according to the invention, the first column specifies the position, the second column provides the number of occurrences of A at that position, the third column provides the number of occurrences of C at that position, the fourth column provides the number of occurrences of G at that position, the fifth column provides the number of occurrences of T at that position, such that the matrix contains log odds weights for computing a match score and provides a likelihood ratio to specify whether an input sequence matches the motif or not.The cut-offs for the matrices according to the invention are preferably set to minFN to maximize the sensitivity of the site prediction (false negative rate of 10%).

In one embodiment of the invention the gene is selected from the group of genes, wherein genes having an expression regulatory sequence according to matrix 2 (CTCF matrix) between the transcription start site and the at least one expression regulatory sequence (matrix 1 ("de novo" HNF4α matrix)) in the human genome are excluded from the group of genes.


In another preferred embodiment of the invention the gene is selected from the group of genes further having at least one expression regulatory sequence selected from the group matrices 3- 6 (AP1 , GATA2, ER, HNF1 matrices), preferably according to matrix 3, in the range of 20-60 nucleotides upstream or downstream of the at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4α matrix) in the human genome.



In another preferred embodiment of the invention, the gene is selected from the group of genes located on the human chromosome 6 or the human chromosome 10, wherein genes located on chromosome 10 are particularly preferred.
In yet another preferred embodiment of the invention, the gene is selected from the group of genes coded at least partially in the genomic regions according to table 33, which represent high density clusters of identified HNF4α binding sites.


In a particular preferred embodiment of the invention the gene is selected from the group of the genes according to Table 34.
Table 34 - list of human chromosomal genes: 7A5, A2M, A4GALT, AAA1 , AADAC, AAK1 , AARS, AASDH, ABAT, ABC1, ABCA1, ABCA10, ABCA3, ABCA8, ABCA9, ABCB6, ABCC10, ABCC11, ABCC4, ABCD2, ABCD3, ABCG2, ABCG5, ABHD12, ABHD2, ABHD3, ABHD4, ABHD5, ABHD6, ABHD7, ABM, ABI3BP, ABL1, ABL2, ABLIM1, ABLIM3, ABP1, ABR, ABRA, ABTB2, ACACA, ACADM, ACADS, ACAT2, ACBD3, ACBD5, ACBD6, ACCN1, ACE2, ACHE, ACIN1, ACOI.ACOTI.ACOTH, ACOT12, ACOT2, ACOT6, ACOT7, ACOX2, ACP1, ACPL2, ACPP, ACPT, ACRC, ACSL1, ACSL3, ACSL4, ACSL5, ACSL6, ACSM2, ACSS1, ACSS2, ACTG1, ACTL6A, ACTL8, ACTN4, ACTR10, ACTR2, ACTR3B, ACTR6, ACVR1B, ACVR2A, ACY3, ACYP2, ADA, ADAM10, ADAM22, ADAM7, ADAMDECI.ADAMTSIO, ADAMTS12, ADAMTS14, ADAMTS15, ADAMTS16, ADAMTS19, ADAMTS6, ADAMTSL3, ADAMTSL4, ADAR1 ADARB1, ADCK5, ADCY5, ADCY6, ADCY8, ADCY9, ADD1, ADD3, ADFP, ADH1A, ADH4, ADH7, ADM, ADIPOQ1 ADIPOR2, ADK1 ADM, ADORA2A, ADORA2B, ADPRHL1, ADRA1B, ADRA1D, ADRB1, AFAP, AFF1, AFF3, AFF4, AFG3L2, AFM, AFMID, AFP1 AGBL2, AGGF1, AGPAT2, AGPAT3, AGR2, AGTR1, AGTRAP, AHCTF1, AHCY1 AHM1 AHNAK1 AHR, AHSA1, AIF1, AIFM2, AIG1, AIM1, AIM1L, AK3L1, AK3L2, AKAP1, AKAP2, AKAP4, AKAP6, AKAP7, AKR1A1, AKR1B10, AKR1C1, AKR1CL2, AKR1D1, ALB, ALDH18A1, ALDH1L1, ALDH3A2, ALDH6A1, ALDOB, ALG14, ALG8, ALG9, ALKBH5, ALKBH7, ALMS1, ALOX5AP, ALOXE3, ALS2CR7, AMAC 1, AMAC 1L2, AMD1, AMDHD1, AMDHD2, AMELX, AMFR, AMICA1, AMIGO1, AMIGO2, AMMECR1, AMOTL1, AMPD2, AMZ2, ANAPC4, ANGEL2, ANGPTL2, ANGPTL3, ANK2, ANK3, ANKFN1 , ANKFY1 , ANKH, ANKRD1 , ANKRD11 , ANKRD13A, ANKRD15, ANKRD30A, ANKRD38, ANKRD39, ANKRD49, ANKRD55, ANKRD56, ANKRD57, ANKRD9, ANKS1A, ANKS4B, ANKZF1, ANP32A, ANTXR2, ANXA11 , ANXA2, ANXA3, ANXA4, ANXA8, AOAH, AOF2, AP1B1, AP1S3, AP2A2, AP3S1, AP3S2, AP4S1, APBB1, APC1 APCDD1, APCDD1L, APEX2, APH1B, APLP2, APOBEC1, APOBEC2, APOBEC3A, APOBEC4, APOE, APOF, APOLD1, APOM, AQP11, AQP4, AQP8, AR, ARCN1, AREG, ARF1, ARF6, ARFGAP3, ARFGEF2, ARHGAP10, ARHGAP12, ARHGAP17, ARHGAP18, ARHGAP19. ARHGAP21, ARHGAP24, ARHGAP25, ARHGAP27, ARHGAP29, ARHGAP5, ARHGAP6, ARHGAP8, ARHGEF1, ARHGEF10L, ARHGEF11, ARHGEF12, ARHGEF18, ARHGEF3, ARHGEF5, ARID1A, ARID1B, ARID3A, ARID3B, ARID4A, ARID5B, ARL14, ARL15, ARL4A, ARL4C, ARL5A, ARL5B, ARL6IP2, ARL8B, ARMC1 , ARMC2, ARMC4, ARNTL, ARPC5L, ARPM1, ARPP-19, ARRB1, ARRB2, ARRDC2, ARRDC4, ARSB, ARSD, ARSH, ARSJ, ARTS-1, ARX, AS3MT, ASAH1, ASAH2, ASAHL, ASAM, ASB1, ASB13, ASB14, ASB18, ASB2, ASB4, ASB9, ASCC3, ASCL1, ASF1A, ASH1L, ASH2L, ASIP, ASL, ASPA, ASPH, ASS1, ASTE1, ASTN2, ASXL1, ATAD4, ATBF1, ATF3, ATF7IP, ATG16L2, ATG3, ATG5, ATIC, ATOH1, ATOX1, ATP10A, ATP11A, ATP13A2, ATP13A5, ATP1A1, ATP1A2, ATP1B1, ATP2A2, ATP2B1, ATP2B2, ATP2B4, ATP2C2, ATP5E, ATP5G1, ATP5H, ATP5I, ATP6V0A4, ATP6V0D2, ATP6V1A, ATP6V1B2, ATP6V1E1, ATP6V1E2, ATP6V1G1, ATP6V1G3, ATP8A1, ATP8B1, ATP8B4, ATP9A, ATP9B, ATPAF1, ATPIF1, ATRN1 ATXN1, ATXN10, ATXN2, ATXN7, ATXN7L4, AUH, AVPR1A, AXIN1, AXIN2, AYTL2, B3GALNT1, B3GALNT2, B3GALT1, B3GALT5, B3GALTL, B3GNT2, B3GNT3, B3GNT5, B4GALNT2, B4GALNT3, B4GALT1, B4GALT4, B4GALT5, B4GALT6, BAAT1 BACH1, BAG2, BAG3, BAHD1, BAIAP2L1, BAIAP2L2, BAMBI, BANK1, BARX2, BATF, BAZ2A, BBC3, BBOX1, BCAR3, BCAS1, BCAS3, BCKDHB, BCL10, BCL2, BCL2A1, BCL2L10, BCL2L11, BCL2L14, BCL9, BCL9L, BCLAF1, BCMO1, BCMP11, BCOR, BDH1, BDKRB1, BDKRB2, BDNF, BEST3,
BID, BIN1 , BIRC2, BLCAP, BLM, BLNK, BLOC1S2, BLVRA, BMF, BMP2, BMP2K, BMP3, BMP4, BMP7, BMP8A, BMP8B, BMPR1A, BMS1 L, BOLA1 , BPNT1 , BRAF, BRD2, BRD8, BRE BRI3, BRI3BP, BRP44, BRP44L, BRPF3, BRWD1 , BRWD2, BRWD3, BTAF1 , BTBD1 , BTBD11 , BTBD16, BTBD3, BTBD5, BTBD9, BTC, BTF3L4, BTG2, BTN 1A1 , BTN3A2, BTNL2, BTNL3, BTNL8, BUB1 , BUD13, BVES, BZW1 , BZW2, C10orf107, C10orf108, C10orf1 1 , C10orf1 14, C10orf1 18, C10orf12, C10orf125, C10orf132, C10orf22, C10orf25, C10orf28, C10orf30, C10orf32, C10orf4, C10orf46, C10orf47, C10orf53, C10orf54, C10orf56, C10orf57, C10orf58, C10orf6, C10orf67, C10orf79, C10orf81 , C10orf82, C10orf85, C10orf88, C10orf9, C10orf92, C10orf96, C11orf11 , C11orf37, C11orf44, C11orf47, C11orf49, C11orf52, C1 1orf54, C11orf56, C11orf69, C11orf75, C11orf77, C12orf28, C12orf33, C12orf34, C12orf35, C12orf39, C12orf4, C12orf42, C12orf43, C12orf45, C12orf49, C12orf59, C12orf62, C13orf1 , C13orf16, C13orf18, C13orf21 , C13orf23, C13orf3, C13orf7, C14orf100, C14orf101 , C14orf102, C14orf103, C14orf104, C14orf105, C14orf108, C14orf11 , C14orf1 12, C14orf115, C14orf1 18, C14orf135, C14orf140, C14orf147, C14orf155, C14orf156, C14orf159, C14orf161 , C14orf165, C14orf166B, C14orf169, C14orf174, C14orf177, C14orf179, C14orf29, C14orf32, C14orf4, C14orf43, C14orf46, C14orf94, C15orf21 , C15orf28, C15orf34, C15orf38, C15orf39, C15orf41 , C15orf48, C16orf5, C16orf51 , C16orf69, C16orf70, C17orf27, C17orf46, C17orf50, C17orf54, C17orf57, C17orf58, C17orf59, C17orf61 , C17orf76, C17orf78, C17orf79, C17orf85, C18orf17, C18orf19, C18orf37, C18orf43, C18orf45, C18orf56, C19orf12, C19orf21 , C19orf33, C19orf43, C19orf54, C1GALT1, C1orf100, C1orf103, C1orf104, C1orf105, C1orf106, C1orf107, C1orf108, C1 orf110, C1orf113, C1orf114, C1orf115, C1orf116, C1orf121 , C1orf123, C1orf125, C1orf129, C1 orf130, C1orf131 , C1orf137, C1orf14, C1orf141 , C1orf144, C1 orf146, C1orf151 , C1orf156, C1orf161, C1orf163, C1orf164, C1orf168, C1orf174, C1orf175, C1orf180, C1orf181 , C1orf19, C1orf191 , C1orf210, C1orf215, C1orf24, C1orf42, C1orf45, C1orf50, C1orf55, C1orf61 , C1orf62, C1orf63, C1orf71 , C1 orf74, C1orf82, C1orf83, C1orf85,i C1orf87, C1orf9, C1orf96, C1QL3, C1QTNF1 , C1QTNF3, C1QTNF9, C20orf112, C20orf118, C20orf121 , C20orf175, C20orf179, C20orf19, C20orf196, C20orf197, C20orf23, C20orf24, C20orf38, C20orf39, C20orf42, C20orf46, C20orf52, C20orf67, C20orf74, C20orf75, C21orf125, C21orf129, C21orf24, C21orf25, C21orf34, C21orf7, C21orf88, C21orf91 , C22orf13, C22orf29, C22orf31 , C22orf9, C2orf25, C2orf27, C2orf28, C2orf29, C2orf38, C2orf39, C2orf40, C2orf43, C2orf46, C2orf47, C2orf49, C3orf15, C3orf19, C3orf20, C3orf25, C3orf26, C3orf32, C3orf33, C3orf34, C3orf52, C3orf59, C3orf62, C4BPB, C4orf11 , C4orf16, C4orf18, C4orf19, C4orf24, C4orf31 , C4orf32, C4orf33, C4orf34, C4orf36, C5AR1 , C5orf15, C5orf16, C5orf21 , C5orf28, C5orf32, C5orf33, C5orf35, C5orf4, C6, C6orf10, C6orf105, C6orf106, C6orf107, C6orf120, C6orf122, C6orf128, C6orf130, C6orf141 , C6orf142, C6orf15, C6orf151 , C6orf153, C6orf166, C6orf170, C6orf182, C6orf195, C6orf213, C6orf218, C6orf48, C6orf57, C6orf60, C6orf70, C6orf72, C6orf75, C6orf81 , C6orf85, C6orf96, C6orf97, C7orf23, C7orf30, C7orf36, C8A, C8orf13, C8orf22, C8orf38, C8orf40, C8orf41 , C8orf42, C8orf54, C8orf70, C8orf78, C8ORFK23, C8ORFK32, C9orf102, C9orf103, C9orf11 , C9orf123, C9orf126, C9orf127, C9orf152, C9orf18, C9orf24, C9orf3, C9orf30, C9orf32, C9orf4, C9orf41 , C9orf52, C9orf64, C9orf66, C9orf72, C9orf80, C9orf91 , C9orf97, CA1 , CA13, CA2, CA4, CA7, CA8, CA9, CAB39, CABLES1 , CACHD1 , CACNA1 D, CACNA2D4, CACNB2, CACNB3, CACNG3, CACNG4, CADPS, CALCOCO2, CALCR, CALCRL, CALD1 , CALM1 , CALM2, CALM3, CALML3, CALML4, CALML5, CAMK1 , CAMK1 D, CAMK2G, CAMK2N1 , CAMTA1 , CAND1 , CANX, CAP1 , CAPG, CAPN10, CAPN13, CAPN2, CAPN3, CAPN7, CAPN9, CAPZA3, CAPZB, CARD10, CARHSP1 , CARKL, CART1 , CARTPT, CASC3, CASC4, CASC5, CASD1 , CASK, CASP10, CASP3, CASQ2, CAST, CASZ1 , CAT, CATSPER2, CATSPER3, CAV2, CBLB, CBR1 , CBWD1 , CBWD2, CBWD3, CBWD5, CBX2, CBX4, CCBP2, CCDC100, CCDC103, CCDC107, CCDC108, CCDC112, CCDC113, CCDC12, CCDC125, CCDC129, CCDC13, CCDC130, CCDC25, CCDC28A, CCDC3, CCDC34, CCDC41 , CCDC44, CCDC50, CCDC54, CCDC58, CCDC6, CCDC64, CCDC65, CCDC68, CCDC71 , CCDC90A, CCDC90B, CCDC91 , CCDC92, CCDC97, CCDC99, CCKAR, CCL14, CCL15, CCL16, CCL20, CCL4, CCM2, CCNA2, CCND1 , CCND2, CCNE2, CCNJ, CCNJL, CCNL1 , CCNT2, CCR1 , CCR4, CCR6, CCRK, CCRL1 , CCRN4L, CCT3, CD160, CD164, CD180, CD200, CD200R2, CD244, CD247, CD28, CD2AP, CD34, CD36, CD3E, CD44, CD46, CD55, CD58, CD74, CD86, CD8A, CD9, CD99, CDC14B, CDC2, CDC25C, CDC26, CDC2L6, CDC40, CDC42BPA, CDC42EP4, CDC42EP5, CDC42SE2, CDC91 L1 , CDCA2, CDCA3, CDCA7L, CDCP1 , CDGAP, CDH1 , CDH11 , CDH12,
CDH13, CDH17, CDH26, CDH6, CDH7, CDH9, CDK10, CDK3, CDK4, CDK5R1, CDK5RAP2, CDK7, CDKAL1, CDKL1, CDKL2, CDKN1A, CDKN2B, CDKN3, CDON, CDR2, CDRT1, CDRT4, CDS1, CDS2, CDT1, CDV3, CDX2, CDYL, CDYL2, CEACAM3, CEACAM6, CEBPD, CEBPG, CECR5, CEL1 CENPF, CENTD1, CENTD2, CENTD3, CENTG2, CEP135, CEP152, CEP192, CEP250, CEP350, CEP68, CEP70, CERK, CERKL1 CES1, CFB, CFC1, CFLAR, CFTR1 CG018, CGM 15, CHAC1, CHAF1A, CHCHD3, CHCHD4, CHCHD5, CHCHD6, CHCHD8, CHD1, CHD2, CHD6, CHDH, CHES1, CHGB, ChGn, CHKA, CHML, CHMP1B, CHMP2B, CHMP4B, CHN2, CHORDC1, CHPT1, CHRDL2, CHRM1, CHRM2, CHRM4, CHRNA4, CHRNA9, CHRNB3, CHRND1 CHRNE, CHST12, CHST13, CHST3, CHST9, CIAS1, CLASP1, CLCA4, CLCN5, CLDN1, CLDN12, CLDN14, CLDN16, CLDN23, CLDN4, CLDN7, CLDN9, CLEC3A, CLIC1, CLIC2, CLIC4, CLIC5, CLINT1, CLLU1OS, CLMN, CLSTN1, CMAS, CMIP, CMPK1 CMTM4, CMTM6, CMTM7, CMTM8, CNBP, CNDP1, CNDP2, CNFN, CNIH, CNIH4, CNKSR3, CNN3, CNNM2, CNNM3, CNOT1, CNP, CNTF, CNTN2, CNTN4, CNTNAP4, CNTNAP5, COBL1 COCH, COG1, COG3, COG5, COL12A1, COL17A1, COL18A1, COL1A1, COL1A2, COL22A1, COL28A1, COL2A1, COL4A1, COL5A2, COL6A1, COL9A1, COLEC12, COMMD10, COMMD2, COMMD7, COP1, COPA1 COPS4, COPZ1, COQ10A, COQ2, COQ5, COQ6, CORO2A, CORO6, COTL1, COVA1, COX17, COX18, COX19, COX4I2, COX5A, COX6A2, COX7B2, CP, CPB1, CPD, CPE, CPEB2, CPEB4, CPLX2, CPM1 CPN1, CPNE3, CPNE7, CPNE8, CPNE9, CPO, CPS1, CPSF6, CPVL, CPXM2, CR2, CRABP1, CRB1, CREB1, CREB3L1, CREB3L2, CREB3L3, CREB5, CREG1, CREG2, CREM1 CRIM1, CRISP3, CRISPLD1, CRLS1, CROP, CRSP2, CRSP8, CRTC2, CRTC3, CRYAA, CRYGC1 CRYGD1 CRYGS1 CSDE1, CSF1R, CSF3R, CSNK1A1, CSNK1A1L, CSNK1D, CSRP1, CSRP2BP, CSRP3, CSS3, CST3, CTAGE1, CTAGE5, CTCFL, CTDSP2, CTGF, CTGLF1, CTGLF5, CTHRC1, CTNNB1, CTNNBL1, CTNND1, CTPS, CTSB, CTSC, CTSH, CTSK, CTSL, CTSL2, CTSO1 CTTNBP2, CTXN3, CUBN1 CUEDC1, CUEDC2, CUGBP2, CUL1, CUL3, CUL4A, CUTL1, CWF19L2, CXADR1 CXCL2, CXCL3, CXCL5, CXCL9, CXCR7, CXorf15, CXorf21, CXorf23, CXorfθ, CXXC4, CXXC5, CXXC6, CYB561, CYB5A, CYB5D1, CYB5R4, CYCS1 CYFIP2, CYGB, CYLN2, CYP19A1, CYP1A1, CYP26C1, CYP27A1, CYP2A6, CYP2A7, CYP2C18, CYP2C19, CYP2C9, CYP2R1, CYP2S1, CYP2U1, CYP3A4, CYP4A11, CYP4B1, CYP7A1, CYR61, CYSLTR2, CYYR1, DAB2, DAB2IP, DACT2, DAK, DAOA, DAP1 DAPK1, DAPK2, DARS1 DAZL, DBC1, DBX2, DCAKD, DCBLD1, DCC1 DCP1A, DCP1B, DCP2, DCTD, DCTN2, DCTN6, DCUN1D1, DCUN1D3, DCUN1D4, DDAH1, DDB2, DDC, DDEF1, DDHD2, DDH, DDI2, DDIT4, DDO, DDR2, DDX25, DDX3X, DDX5, DDX50, DDX52, DDX58, DEF6, DEFA3, DEFA5, DEFB112, DEGS1, DENND1A, DENND1B, DENND2D, DENND3, DENND4A, DEPDC6, DEPDC7, DERA1 DERL1, DEXI1 DFNA5, DGAT1, DGAT2, DGKA1 DGKB1 DGKI1 DHCR24, DHFR, DHRS3, DHRS8, DHRSX1 DHX15, DHX29, DHX35, DIAPH1, DIAPH2, DIAPH3, DID01, DI01, DI03, DIP13B, DIP2B, DIP2C, DIRC2, DISC1, DISP1, DIXDC1, DKFZp434N035, DKFZp686l15217, DKFZp686K16132, DKFZp686L1814, DKFZp779B1540, DKK1, DLC1, DLD1 DLEC1, DLG1, DLG2, DLG5, DLGAP1, DLGAP2, DLGAP4, DLX1, DMD, DMGDH, DMTF1, DMXL1, DMXL2, DNAH1, DNAH10, DNAH11; DNAH7, DNAHL1, DNAJB13, DNAJB14, DNAJB7, DNAJC11, DNAJC12, DNAJC13, DNAJC15, DNAJC18, DNAJC19, DNAJC5, DNAJC5B, DNAJC9, DNAL1, DNAPTP6, DNASE1L3, DNMBP, DNMT3A, DOC1, DOCK10, DOCK11, DOCK4, DOCK5, DOCK7, D0CK9, DOK4, D0T1L, DPP10, DPP4, DPPA3, DPPA4, DPT, DPYD, DPYS, DPYSL2, DPYSL3, DPYSL4, DR1, DRD2, DRP2, DSC2, DSCR1, DSCR1L1, DSCR2, DSG1, DSG2, DSG4, DSP1 DST, DTL, DTNA, DTNB1 DTNBP1, DTX2, DUOX2, DUPD1, DUSP1, DUSP15, DUSP16, DUSP18, DUSP21, DUSP22, DUSP5, DUSP7, DUSP9, DUT1 DYDC2, DYNC1I2, DYNC1LI1, DYNLL2, DYRK2, DZIP1, E2F3, E2F7, E2F8, EBAG9, EBI2, EBP, EBPL, ECE1, ECHDC1, ECHDC2, ECM2, EDAR1 EDC3, EDD1, EDEM1, EDEM3, EDG1, EDN1, EDN3, EEA1, EEF1A1, EEF1G, EEF2K, EEFSEC, EFCAB1, EFCAB2, EFCAB3, EFCAB4B, EFCBP1, EFEMP1, EFHA1, EFHC2, EFHD2, EFNA1, EFNB1, EFNB2, EFTUD1, EGF1 EGFLAM, EGFR, EGLN1, EGLN3, EGR1, EHBP1, EHD1, EHD4, EHF, EID1, EIF1AX, EIF2AK3, EIF2B2, EIF3S10, EIF4A2, EIF4B, EIF5A2, EIF5B, ELAC2, ELAVL3, ELF1, ELF4, ELK3, ELK4, ELL2, ELMO1, ELM02, EL0VL2, EL0VL5, EL0VL6, ELOVL7, ELP3, EMG1, EMILIN2, EML1, EML4, EMP1, ENAH, EN0SF1, ENPEP, ENPP1, ENPP2, ENPP3, ENPP6, ENPP7, ENTHD1, ENTPD5, ENTPD7, ENY2, EP300, EPAS1, EPB41, EPB41L1, EPB41L2, EPB41L3, EPB41L4B, EPDR1, EPHA10, EPHB3, EPHX2, EPPB9, EPS15, EPS8, EPSTM, ERAL1, ERBB2, ERCC3, ERG, ERGIC1, ERGIC2, ERN1, ERRFI1,
ESD, ESF1, ESRRG, ESSPL, ESX1, ETAA1, ETF1, ETFA, ETFB, ETFDH, ETHE1, ETNK1, ETNK2, ETS1, ETS2, ETV1, ETV3, ETV4, ETV6, EVL, EXOC5, EXOC6, EXOSC8, EXOSC9, EXT1, EXTL3, EYA2, EYA3, F11R, F13A1, F13B, F2, F2R, F2RL1, F3, F5, FA2H, FABP1, FABP2, FABP6, FADS1, FAH, FAHD1, FAHD2A, FAIM, FAIM3, FAM100B, FAM101A, FAM104B, FAM105A, FAM105B, FAM107B, FAM109A, FAM110C, FAM113B, FAM114A1, FAM120AOS, FAM120B, FAM124A, FAM124B, FAM125B, FAM13A1, FAM13C1, FAM19A4, FAM20A, FAM20B, FAM20C, FAM35A, FAM36A, FAM38B, FAM3B, FAM3C, FAM40A, FAM40B, FAM43A, FAM45B, FAM46A, FAM46C, FAM47A, FAM49A, FAM50B, FAM54A, FAM60A, FAM62C, FAM63B, FAM70B, FAM76A, FAM78A, FAM78B, FAM7A2, FAM82A, FAM82C, FAM83B, FAM83C, FAM83D, FAM83F, FAM84B, FAM86A, FAM86B1, FAM86C, FAM8A1, FAM91A1, FAM92B, FAM9A, FAM9B, FAM9C, FANCC, FARP2, FARS2, FARSLB, FASTKD1, FASTKD3, FAT, FBLIM1, FBLN5, FBN1, FBP1, FBP2, FBXL10, FBXL11, FBXL14, FBXL17, FBXL18, FBXL2, FBXL20, FBXL21, FBXO16, FBXO17, FBXO25, FBXO27, FBXO28, FBXO31, FBXO32, FBXO33, FBXO38, FBXO39, FBXO6, FBXW10, FBXW4, FBXW7, FCAMR, FCER1A, FCER1G, FCGR1B, FCGR2A, FCHO2, FCHSD2, FCMD, FCRL3, FCRLB, FDFT1, FEM1C, FER1L3, FEZ2, FEZF2, FGA, FGB, FGD4, FGD5, FGF12, FGF14, FGF19, FGF2, FGF23, FGF8, FGF9, FGFR1OP, FGFR2, FGG, FGL1, FGL2, FHL1, FHL2, FHL5, FILIP1, F1P1L1, FKHL18, FKSG44, FLCN, FLJ10154, FLJ10159, FLJ10847, FLJ10986, FLJ11171, FLJ11506, FLJ12118, FLJ12331, FLJ13197, FLJ13236, FLJ14154, FLJ16124, FLJ16237, FLJ16641, FLJ16793, FLJ20054, FLJ20152, FLJ20184, FLJ20273, FLJ20294, FLJ20366, FLJ20674, FLJ20920, FLJ21062, FLJ21075, FLJ21127, FLJ21865, FLJ22374, FLJ22531, FLJ23834, FLJ23861, FLJ25371, FLJ25439, FLJ25476, FLJ25530, FLJ25680, FLJ25801, FLJ27505, FLJ30277, FLJ30934, FLJ30990, FLJ31196, FLJ31951, FLJ32310, FLJ32312, FLJ32549, FLJ32784, FLJ32894, FLJ34870, FLJ35773, FLJ35776, FLJ35779, FLJ36004, FLJ37357, FLJ37953, FLJ38377, FLJ38964, FLJ39198, FLJ39531, FLJ39653, FLJ39739, FLJ39779, FLJ39822, FLJ40142, FLJ40243, FLJ40296, FLJ40432, FLJ41603, FLJ42117, FLJ42133, FLJ42280, FLJ42562, FLJ42842, FLJ42953, FLJ42957, FLJ43505, FLJ44006, FLJ44048, FLJ44290, FLJ44796, FLJ45079, FLJ45139, FLJ45187, FLJ45244, FLJ45248, FLJ45337, FLJ45422, FLJ45557, FLJ45721, FLJ45803, FLJ45831, FLJ46210, FLJ46257, FLJ90709, FLNB, FLNC, FLT1, FLVCR, FMNL2, FMO2, FMO3, FMO4, FMO5, FMOD, FN1, FN3K, FNBP1, FNDC3B, FNDC6, FNDC7, FNIP1, FOLH1, FOS1 FOXA2, FOXB1, FOXC1, FOXD1, FOXD2, FOXD3, FOXD4, FOXD4L1, FOXD4L2, FOXD4L4, FOXE3, FOXJ1, FOXJ3, FOXL1, FOXM1, FOXN1, FOXN2, FOXO3A, FOXP1, FOXP4, FOXQ1, FRAS1, FREM2, FRMD1, FRMD3, FRMD5, FRMD6, FRMD7, FRMPD2, FRRS1, FRS2, FRY, FRZB, FSD1L, FSD2, FSIP1, FSIP2, FTHL17, FTS, FUCA2, FUT11, FUT4, FUT8, FVT1, FYN, FZD10, FZD4, FZD5, FZD7, G3BP1, G6PC2, GAB2, GADD45A, GAL3ST1, GALC, GALK1, GALM, GALNT10, GALNT11, GALNT14, GALNT2, GALNT3, GALNT5, GALNT6, GALNT8, GALNTL1, GALNTL5, GALP, GAN, GANAB, GANC, GAP43, GAPVD1, GARNL4, GAS2, GAS6, GATA1, GATA3, GATA4, GATA5, GATA6, GATAD1, GATAD2A, GATM, GATS, GBA3, GBGT1, GBP1, GCC2, GCH1, GCLC, GCM1, GCNT2, GCNT3, GCNT4, Gcomi, GCSH, GDA, GDF10, GDF7, GDF9, GDI2, GDPD4, GDPD5, GEM, GEMIN6, GENX-3414, GFRA1, GFRA4, GFRAL, GGH1 GGT2, GHDC, GHR, GHRH, GIMAP7, GINS2, GIT2, GJA1, GJA5, GJA7, GJB6, GK, GK5, GLCCM, GLCE, GLDC, GLG1, GLI4, GLIS3, GLP1R, GLRX, GLRX5, GLS, GLS2, GLT1D1, GLTP, GLTSCR1, GLUD1, GLUL, GLULD1, GLYATL2, GLYCTK, GMCL1, GMFB, GMNN, GMPPB, GMPR, GMPR2, GNA11, GNA12, GNA13, GNAO1, GNAQ, GNAS, GNAT2, GNG12, GNG3, GNG4, GNGT2, GNPNAT1, GNPTAB, GNRH1, GNRH2, GOLPH2, GOLPH3, GOLPH3L, GOLT1A, GORASP2, GOT2, GP5, GPA33, GPAM, GPATC1, GPATC2, GPBP1L1, GPC3, GPC5, GPD1, GPD1L, GPD2, GPHB5, GPIAP1, GPM6A, GPR101, GPR109B, GPR110, GPR116, GPR119, GPR124, GPR125, GPR126, GPR128, GPR132, GPR133, GPR135, GPR137B, GPR148, GPR15, GPR157, GPR160, GPR161, GPR176, GPR177, GPR21, GPR31, GPR37L1, GPR55, GPR63, GPR68, GPR85, GPR88, GPR89A, GPRASP1, GPRC5A, GPRC5C, GPSM2, GPSN2, GPT2, GPX3, GPX4, GPX6, GRAMD2, GRAMD3, GRB10, GRB14, GRB7, GREM1, GRHL2, GRIA1, GRID1, GRIK4, GRIN2A, GRIN2B, GRIN3A, GRINL1A, GRK5, GRK7, GRLF1, GRPEL1, GRPEL2, GRTP1, GSC, GSDML, GSH1, GSH2, GSN, GSR1 GSTA1. GSTA2, GSTA5, GSTCD, GSTK1, GSTO1, GSTP1, GTDC1, GTF2A1, GTF2H5, GTF2IRD1, GTPBP4, GUCA1B, GUCA1C, GUCA2B, GUCY2C, GUCY2D, GULP1, GYPA, H1F0, H2AFB1, H2AFY, H2AFZ, H2-ALPHA, HABP2, HACE1, HACL1, HADH, HAK,
HAO2, HAPLN 1, HAVCR1, HBLD1, HCCS, HCN3, HCN4, HCP1, HCRTR2, HDAC11, HDAC7A, HDAC9, HDC, HDDC2, HDGF, HDGFL1, HDHD3, HEBP2, HECA, HECTD1, HECW1, HECW2, HELZ1 HEMK1, HEMK2, HEPH, HERC1, HERPUD1, HERPUD2, HERV- FRD, HES1, HES3, HEXB, HEXIM1, HEXIM2, HFE2, HIBADH, HIC1, HIC2, HIGD2A, HILS1, HINT1, HIP2, HIPK1, HIPK2, HIPK4, HISPPD2A, HIST1H2BI, HIST1H2BL, HIST1H3G, HIST1H4B, HIST1H4C, HIST1H4G, HIST1H4H, HIST1H4K, HIST2H2BE, HIST3H2BB, HIST4H4, HIVEP1, HIVEP2, HIVEP3, HK1, HK2, HKDC1, HLA-A, HLX1, HMBOX1, HMG20A, HMGA2, HMGB1, HMGCLL1, HMGCS1, HMGN3, HMGN4, HMHB1, HMOX1, HMP19, HNF4A, HNF4G, HNRPA3, HNRPF, HNRPH2, HNRPH3, HNRPLL, HNRPU, HNT, HOM-TES-103, HORMAD2, HOXA13, HOXA3, HOXB2, HOXB4, HOXC10, HOXC11, HOXC4, HOXC9, HOXD1, HOXD8, HPCAL1, HPGD1 H-plk, HPR, HPRT1, HPS3, HPS4, HPS5, HPSE2, HRASLS2, HRB, HRBL, HRG, HRH2, HRH4, HS2ST1, HS3ST4, HS3ST5, HSD17B13, HSD17B6, HSD3B1, HSD3B2, HSP90AB1, HSPA1A, HSPA4, HSPB3, HSPB8, HSPBAP1, HSPC049, HSPC159, HSPG2, HSPH1, HTR3A, HTR3B, HYAL4, HYDIN, HYI, IARS2, IBRDC3, IBTK, ICA1, ICEBERG, ICMT1 ICOS, ID1, ID2, ID3, ID4, IDH3A, IDS, IER2, IER3, IER5L, IFI35, IFIT1L, IFIT2, IFIT3, IFIT5, IFNAR2, IFNE1, IFT122, IFT20, IFT52, IFT88, IGF1R, IGF2BP1, IGF2BP3, IGFBP2, IGFBP4, IGFL4, IGSF1, IGSF2, IGSF21, IGSF3, IGSF4, IGSF9, IHH, IHPK1, IHPK2, IK, IKZF2, IKZF4, IL10, IL10RB, IL12RB1, IL12RB2, IL13, IL16, IL17RE, IL18, IL18BP, IL18RAP, IL1R1, IL1RAPL1, IL22, IL22RA1, IL22RA2, IL23A, IL27RA, IL28RA, IL2RA, IL31RA, IL6R, IL8RA, IL9R, ILDR1, IMP3, IMP4, IMPA1, IMPA2, IMPAD1, IMPG1, ING1, ING2, INHBE, INPP1, INPP4A, INPP4B, INPP5F, INSIG1, INSIG2, INSM1, INSM2, INSR, INTS12, INTS3, INTS4, INTS6, IPF1, IPMK, IPO7, IQCK, IQGAP2, IQGAP3, IQSEC1, IQSEC3, IRAKI BP1, IRAK3, IREB2, IRF2, IRF2BP2, IRF5, IRF8, IRS1, IRS2, IRX5, ISG20, ISL2, ISOC1, ITCH, ITFG1, ITGA11, ITGA2, ITGA2B, ITGAD, ITGAM, ITGAV, ITGB1, ITGB1BP2, ITGB3, ITGB4BP, ITGB5, ITGB8, ITIH1, ITIH2, ITIH5, ITM2B, ITPKA, ITPKC, ITPR1, ITSN1, IVD, IVNS1ABP, IWS1, IXL, IYD, JAG1, JAK1, JAKMIP2, JARID1A, JARID1B, JARID2, JAZF1, JDP2, JMJD1A, JMJD1C, JMJD2A, JMJD2C, JMJD5, JOSD1, JOSD3, JPH2, JUB, JUP, KALRN, KATNAL2, KATNB1, KBTBD1, KBTBD11, KBTBD2, KBTBD7, KBTBD8, KCMF1, KCNA1, KCNA2, KCNA4, KCNA6, KCNB1, KCNC4, KCND3, KCNE3, KCNG1, KCNIP2, KCNIP4, KCNJ11, KCNJ16, KCNJ2, KCNJ8, KCNK1, KCNK10, KCNK5, KCNMA1, KCNMB2, KCNMB3, KCNN3, KCNQ1, KCNQ3, KCNRG, KCNS2, KCTD10, KCTD13, KCTD16, KCTD3, KCTD4, KCTD6, KCTD7, KDR, KHDRBS2, KHK, KIAA0040, KIAA0143, KIAA0152, KIAA0195, KIAA0232, KIAA0240, KIAA0241, KIAA0247, KIAA0251, KIAA0256, KIAA0265, KIAA0319, KIAA0355, KIAA0367, KIAA0427, KIAA0460, KIAA0586, KIAA0664, KIAA0701, KIAA0738, KIAA0746, KIAA0773, KIAA0774, KIAA0776, KIAA0802, KIAA0922, KIAA0980, KIAA1005, KIAA1009, KIAA1026, KIAA1033, KIAA1128, KIAA1160, KIAA1161, KIAA1189, KIAA1191, KIAA1217, KIAA1267, KIAA1303, KIAA1324, KIAA1333, KIAA1370, KIAA1377, KIAA1411, KIAA1429, KIAA1456, KIAA1467, KIAA1505, KIAA1542, KIAA1546, KIAA1598, KIAA1600, KIAA1604, KIAA1718, KIAA1727, KIAA1737, KIAA1772, KIAA1794, KIAA1804, KIAA1826, KIAA1913, KIAA1919, KIAA1958, KIAA2013, KIAA2018, KIDINS220, KIF13A, KIF13B, KIF1C, KIF21A, KIF25, KIF2A, KIF4A, KIF5B, KIF6, KIFAP3, KIFC3, KIR3DX1, KIRREL, KL, KLB, KLC4, KLF12, KLF13, KLF2, KLF3, KLF4, KLF5, KLF6, KLF7, KLHDC2, KLHDC4, KLHDC5, KLHDC6, KLHL13, KLHL15, KLHL2, KLHL20, KLHL23, KLHL24, KLHL25, KLHL8, KMO, KNG1, KPNA2, KPNA3, KPNA4, KRAS, KREMEN1, KRT12, KRT18, KRT19, KRT20, KRT31, KRT39, KRT8, KRT80, KRTAP15-1, KRTAP26-1, KRTAP8-1, KSR1, KTN1, Kua, KU-MEL-3, KYNU, L3MBTL, L3MBTL3, L3MBTL4, LACE1, LAMA3, LAMA4, LAMB1, LAMB3, LAMB4, LAMC1, LAMC2, LAP3, LARP1, LARP4, LARP5, LARS, LARS2, LASP1, LASS2, LASS5, LASS6, LAT1 LATS2, LAX1, LBH1 LBR, LBX2, LBXCOR1, LCE2D, LCMT1, LCOR, LCP1, LCT, LCTL, LDB2, LDHA, LDHAL6B, LEAP2, LECT2, LEMD3, LENG9, LEO1, LEPROT1 LEPROTL1, LFDH, LGALS14, LGALS3, LGALS4, LGALS8, LGR4, LGR5, LHCGR, LHFPL2, LHFPL5, LHPP1 LHX3, LHX9, LIAS, LIF, LIFR, LIG4, LIMA1, LIMS3, LIN9, LIPA, LIPC, LIPF, LIX1, LIX1L, LMBRD2, LMCD1, LMNB1, LMOD3, LMTK2, LNX1, LNX2, LOC112714, LOC123876, LOC124446, LOC130355, LOC145757, LOC148696, LOC149134, LOC149950, LOC150383, LOC151760, LOC152485, LOC153222, LOC158572, LOC196752, LOC196913, LOC200261, LOC202459, LOC220594, LOC220686, LOC222967, LOC255374, LOC283537, LOC283551 , LOC284009, LOC284402, LOC284751, LOC284757, LOC285016, LOC285074, LOC285382, LOC285498, LOC285908, LOC286334, LOC338809, LOC339745, LOC339977, LOC340156,
LOC340204, LOC340529, LOC347487, LOC348174, LOC375133, LOC375748, LOC387601, LOC387646, LOC387680, LOC387882, LOC387911, LOC388323, LOC388335, LOC388503, LOC388692, LOC388965, LOC389286, LOC389432, LOC399706, LOC399900, LOC400120, LOC400451, LOC400566, LOC400968, LOC401152, LOC401233, LOC401286, LOC401431, LOC401589, LOC401720, LOC401898, LOC440093, LOC440313, LOC440570, LOC440742, LOC440905, LOC441108, LOC441177, LOC441193, LOC441257, LOC441268, LOC441294, LOC442247, LOC51233, LOC54103, LOC552891, LOC642265, LOC642980, LOC643866, LOC643923, LOC644083, LOC645745, LOC646962, LOC650293, LOC653107, LOC90826, LOC91461, LOC92196, LOH12CR1, LONRF3, LOR, LOX, LPAAT-THETA, LPGAT1, LPHN3, LPIN1, LPIN2, LPIN3, LPP, LPXN, LRAP, LRAT, LRIG1, LRIG3, LRP1, LRP10, LRP2, LRP6, LRPPRC, LRRC1, LRRC16, LRRC17, LRRC18, LRRC2, LRRC28, LRRC31, LRRC4, LRRC40, LRRC48, LRRC52, LRRC61, LRRC8C, LRRC8D, LRRFIP1, LRRFIP2, LRRK1, LRRN3, LRRN5, LRRTM1, LRRTM2, LRTM2, LSM14A, LSM14B, LSM2, LSM6, LSP1, LTBP1, LTBP3, LTBP4, LTV1, LUM, LUZP1, LUZP2, LUZP4, LY6G5C, LY75, LYCAT, LYK5, LYN, LYNX1, LYPD1, LYPD6, LYPLAL1, LYRM2, LYRM5, LYSMD1, LYZL1, LYZL2, LYZL4, LZTR2, MACF1, MADD, MAFB, MAGEA4, MAGED1, MAGED2, MAGED4, MAGEF1, MAGEH 1, MAGM1 MAGI3, MALL, MAMDC1, MAML1, MAML3, MAN1A1, MAN1A2, MAN2C1, MANSC1, MAOB, MAP1LC3B, MAP2K2, MAP2K6, MAP3K13, MAP3K14, MAP3K15, MAP3K7IP2, MAP3K7IP3, MAP3K8, MAP3K9, MAP4K3, MAP4K4, MAP4K5, MAP6, MAPK14, MAPK6, MAPK8, MAPKAPK2, MAPRE1, MAPRE3, MARCH1, MARCH3, MARCH8, MARCKS, MARCKSL1, MARK1, MARK2, MARS2, MARVELD2, MARVELD3, MASP1, MAST2, MAT2B, MATN 1, MATN2, MATR3, MAX, MBD2, MBD5, MBIP, MBL2, MBNL1, MBNL2, MBNL3, MBOAT2, MBOAT5, MBP, MCART2, MCART6, MCC1 MCL1, MCM10, MCM8, MCMDC1, MCOLN3, MCTP1, MCTP2, MDFIC, MDM1, MDM2, MDM4, ME1, ME2, MED11, MED18, MED31, MED4, MED9, MEF2A, MEF2C, MEIS1, MEIS2, MEOX1, MEOX2, MEP1A, MEP1B, MERTK, MESDC1, MESP1, MESP2, METRNL, METHOD, METT5D1, METTL7A, METTL7B, METTL8, MFAP3L, MFGE8, MFHAS1, MFNG, MFSD1, MFSD2, MFSD4, MGAM, MGAT1, MGAT2, MGAT3, MGAT4A, MGAT5B, MGC11332, MGC13057, MGC21644, MGC21881, MGC23985, MGC24039, MGC26963, MGC29671, MGC33556, MGC33657, MGC33846, MGC34646, MGC35361, MGC39715, MGC4172, MGC42174, MGC4268, MGC44328, MGC45491, MGC50559, MGC51025, MGC52498, MGC61571, MGC87631, MGLL, MGMT, MIA2, MICAL2, MIF, MINK1, MINPP1, MIST, MITF, MKI67, MKI67IP, MKKS, MKL1, MKL2, MKS1, MLC1, MLH3, MLLT10, MLNR, MLSTD1, MLSTD2, MLXIPL, MMACHC, MMD, MME1 MMP15, MMP16, MMP17, MMP20, MMRN2, MND1, MNS1, MNT, M0AP1, MOBKL2C, MOCOS, M0CS1, MOGAT1, M0GAT2, M0RC1, MOS, M0SC2, M0SPD1, MPL, MPP5, MPP6, MPPED2, MPV17L, MPZ1 MPZL1, MRC1L1, MRGPRF, MRGPRX1, M-RIP, MRLC2, MRPL1, MRPL13, MRPL14, MRPL45, MRPL55, MRPS10, MRPS22, MRVM, MS4A10, MS4A8B, MSH5, MSI2, MSL2L1, MSRB2, MST4, MSX2, MT1F, MTA3, MTAP, MTDH, MTERFD3, MTF2, MTFMT, MTFR1, MTIF3, MTMR10, MTMR11, MTMR12, MTMR8, MTRF1L, MTRR, MTSS1, MTTP, MTUS1, MUC13, MUC20, MUSK, MUTED, MVP, MX2, MXD1, MYB, MYBPC1, MYBPHL, MYCBP2, MYCBPAP, MYCL1, MYCN, MYF6, MYH10, MYH14, MYH4, MYLIP, MYO10, MYO15A, MY018A, MY018B, MY01B, MY01D, MY01E, MYO1G, MY06, MYO7A, MYOC, MYOCD, MYOM1, MY0Z2, MYPN, MYST2, MYST3, MYST4, MYT1, N4BP1, N4BP2, NAALAD2, NAALADL2, NAB1, NACAL1 NAG6, NAG8, NANS, NAP1L4, NAP1L5, NAPE-PLD, NARG2, NARS2, NAT2, NAT5, NAT8B, NAT8L, NAV2, NAV3, NBEA, NBL1, NBPF1, NBPF11, NBPF15, NBPF3, NBPF4, NBR1, NCAM1, NCAPG2, NCF2, NCK2, NCKAP1, NC0A1, NCOA2, NC0R2, NDEL1, NDFIP1, NDFIP2, NDP1 NDST1, NDUFA8, NDUFA9, NDUFB4, NDUFV2, NEBL, NEDD1, NEDD4, NEDD9, NEIL3, NEK10, NEK11, NEK6, NELL2, NENF, NE01, NET1, NEU1, NEUROD1, NEUR0D4, NEUR0D6, NEXN, NF1, NFAM1, NFAT5, NFATC3, NFATC4, NFE2L2, NFIA1 NFKB1, NFKBIA, NFKBIZ1 NFRKB1 NFX1, NFXL1, NFYB, NFYC, NGB, NGFB, NGRN, NHLH2, NHLRC2, NHS, NID1, NID2, NIN, NINJ2, NIPBL, NIPSNAP1, NIT1, NIT2, NKAP, NKD1, NKIRAS1, NKIRAS2, NKPD1, NKX2-2, NKX3-1, NLF2, NLGN3, NLK, NMB, NME6, NMNAT3, NMT2, NMUR2, NNMT, NODAL, N0L5A, N0M01, NOMO2, N0M03, NOPE, N0S1AP, NOS2A, NOSTRIN, N0TCH2, NOTCH2NL, N0TCH4, NOVA1, N0X1, N0X3, NP, NPAL1, NPAL2, NPAS3, NPC2, NPEPPS, NPHP1, NPL1 NPNT, NPR2, NPS, NPSR1, NPTN1 NPTX2, NPY, NR1H4, NR1I3, NR2C1, NR2C2, NR2F1, NR2F6, NR4A2, NR5A1, NR6A1, NRBF2, NRG1, NRG2, NRIP1, NRIP2, NRP1, NRP2, NRSN1, NRXN3, NSFL1C, NSMCE1,
NSMCE2, NSUN5B, NSUN5C, NSUN6, NSUN7, NT5C2, NT5DC1, NT5DC3, NT5E, NTF3, NTNG1, NTSR2, NUAK2, NUB1, NUCKS1, NUDCD3, NUDT12, NUDT13, NUDT16, NUDT4 NUDT9, NUF2, NUFIP2, NUMA1, NUMB, NUP205, NUTF2, NXN, NXPH2, NXPH3, NYX, OAF, OAT, OBFC1, OBFC2A, OCA2, OCLN, ODC1, ODF1, OFCC1, OFD1, OGDH, OGDHL, 0GF0D2, OGG1, OIT3, 0LIG3, 0LR1, OMG, 0NECUT1, OPCML, OPN1SW, 0PN3, OPRK1, OPRM1, OPTN, OR10J1, OR10J5, OR10P1, OR13C5, 0R13F1, OR13H1, OR1D2, 0R1L1, 0R1L3, 0R1L4, 0R2B11, OR2B3, 0R2F1, OR2G3, OR2H2, OR2L2, OR2S2, OR4D2, OR4D9, OR4E2, OR4F17, OR4F29, OR4F4, OR4F5, OR52K2, OR5B12, OR5M11, OR5U1, OR6A2, 0R6B1, OR6S1, OR6V1, OR8D2, OR8G2, OR8G5, OR9Q2, 0RC2L, OSBP2, OSBPL10, 0SBPL1A, OSBPL3, 0SBPL5, 0SBPL6, 0SBPL8, 0SBPL9, OSM, 0SR2, OSTalpha, OSTbeta, OSTM1, OTOF, OTOP3, OTUD6B, 0TUD7B, OVOL1, OVOL2, 0XGR1, OXR1, P2RY1, P2RY12, P2RY4, P2RY5, P2RY6, P4HA1, P4HA3, PABPC4, PACRG, PACS 1, PACSIN2, PACSIN3, PADI2, PAG1, PAGE4, PAH, PAK1, PAK2, PAK6, PAK7, PALM2-AKAP2, PAM, PAMCI, PAN3, PANK1, PANK3, PANX1, PAOX, PAP2D, PAPD1, PAPD4, PAPD5, PAPLN, PAPOLA, PAPOLG, PAPPA2, PAPSS1, PAPSS2, PAQR3, PAQR8, PAQR9, PARD3, PARD3B, PARD6B, PARG, PARL1 PARN, PARP1, PARP11, PARP12, PARP15, PARP16, PARP2, PARP4, PARP8, PAX7, PBEF1, PBX1, PBX3, PC, PCBD1, PCBP1, PCCA, PCCB, PCDH1, PCDH7, PCDH8, PCDHGC5, PCGF2, PCGF5, PCM1, PCMTD2, PCNX, PCNXL2, PCSK1, PCSK2, PCSK5, PCSK6, PCSK9, PCTK3, PCYT1B, PCYT2, PDC, PDCD2, PDCD6, PDCL2, PDE1C, PDE3A, PDE4B, PDE6A, PDE6C, PDE6H, PDE7A, PDE8A, PDF, PDGFB, PDGFC, PDGFD, PDGFRL, PDHX, PDIA5, PDK1, PDK3, PDLIM2, PDLIM3, PDLIM5, PDPK1, PDPR1 PDSS1, PDXK, PDXP1 PDZD2, PDZD3, PDZD8, PDZK1IP1, PDZK5B, PDZRN3, PEBP1, PECAM1, PECR, PELH, PELI2, PER1, PERLD1, PERP1 PEX11G, PEX26, PEX5, PFAAP5, PFKFB1, PFKFB2, PFKM, PFKP, PFN2, PGAM4, PGBD5, PGCP, PGD1 PGDS, PGEA1, PGF1 PGK2, PGLYRP2, PGM2, PGM2L1, PGM3, PGPEP1, PGRMC2, PHACTR2, PHC2, PHC3, PHEX, PHF1, PHF10, PHF12, PHF15, PHF16, PHF17, PHF20, PHF20L1, PHF21A, PHF3, PHGDH, PHLDA3, PHLDB3, PHLPP, PHLPPL, PHOSPHO1, PHYH, PHYHIPL, PI3, PIB5PA, PICALM, PIG38, PIGC, PIGK, PIGL, PIGM, PIGR, PIGY, PIGZ, PIK3AP1, PIK3C2A, PIK3C2G, PIK3CA, PIK3CB, PIK3R1, PIK3R4, PIM1, PIN4, PIP3-E, PIP5K1B, PIP5K2A, PIP5K2B, PIP5K3, PISD, PITPNA, PITPNM2, PITX1, PITX2, PITX3, PIWIL2, PIWIL4, PJA2, PKD1L1, PKD1L2, PKD2L2, PKHD1L1, PKIB1 PKIG1 PKN2, PKP2, PKP4, PLA2G12B, PLA2G2A, PLA2G2E, PLA2G4A, PLA2G6, PLAC1, PLAC2, PLAGL1, PLAU1 PLB1, PLCB1, PLCE1, PLCG1, PLCH1, PLCXD2, PLCZ1, PLD1, PLEKHA1, PLEKHA5, PLEKHA6, PLEKHA7, PLEKHA8, PLEKHB1, PLEKHB2, PLEKHC1, PLEKHF2, PLEKHG1, PLEKHG3, PLEKHG6, PLEKHH1, PLEKHJ1, PLEKHM1, PLG1 PLGLB1, PLGLB2, PLIN, PL0D2, PLS1, PLXDC2, PLXNA2, PLXNA4B, PLXNC1, PMAIP1, PMFBP1, PMM1, PMP22CD, PMS2L5, PMVK1 PNLDC1, PNLIPRP2, PNMA2, PNMA3, PNOC, PNPLA1, PNPLA3, PNPLA8, PNPO, PNPT1, PNRC1, P0FUT1, POGZ1 P0LA1, P0LDIP3, P0LE4, POLI, POLN, POLQ, P0LR1D, P0LR1E, P0LR2C, POLR2E, POLR3B, P0LR3H, P0M121, POMP, P0N2, POP4, POPDC3, POR, P0T1, POU2AF1, P0U2F1, POU3F1, POU3F2, POU4F1, P0U6F1, POU6F2, PPA1, PPAP2A, PPAP2B, PPAPDC1B, PPARBP, PPARD, PPARG, PPARGC1B, PPCDC, PPCS, PPEF2, PPFIA1, PPIAL4, PPIB, PPID, PPIG, PPIL4, PPIL5, PPM1A, PPM1B, PPM1E, PPM1K, PPM1L, PPM2C, PPP1CB, PPP1R12A, PPP1R12C, PPP1R14A, PPP1R14C, PPP1R2, PPP1R9A, PPP1R9B, PPP2R1B, PPP2R2A, PPP2R2B, PPP2R3A, PPP2R5A, PPP2R5D, PPP3CB? PPTC7, PPYR1, PQLC1, PQLC2, PRDM1, PRDM10, PRDM8, PRDX1, PRDX4, PRDX6, PREP, PRF1, PRG1, PRG2, PRH1, PRICKLE1, PRICKLE2, PRKAA1, PRKAA2, PRKAG2, PRKAR1A, PRKAR2B, PRKCA, PRKCBP1, PRKCD, PRKCI, PRKG2, PRKRIR, PRL, PRLHR, PRM1, PRMT1, PROC, PR0CA1, PRODH, PR0M1, PR0S1, PR0X1, PRPF38B, PRPF39, PRPSAP1, PRPSAP2, PRR13, PRR15, PRR17, PRR3, PRR6, PRR8, PRRG4, PRRT1, PRSS12, PRSS16, PRSS23, PRSS3, PRSS35, PRSS8, PRTFDC1, PRTG, PRUNE, PSCD4, PSCDBP, PSD3, PSD4, PSEN1, PSKH2, PSMAL, PSMB3, PSMB4, PSMD14, PSPC1, PSTPIP2, PTBP2, PTCD2, PTCHD3, PTDSS1, PTEN, PTER, PTGES, PTGFRN, PTGIS, PTH, PTHLH, PTHR2, PTK2B, PTMS, PTP4A1, PTP4A2, PTPDC1, PTPLAD1, PTPN11, PTPN14, PTPN2, PTPN21, PTPN23, PTPN9, PTPRJ, PTPRM, PTPRN2, PTPRO, PTPRR, PTRH2, PTTG1IP, PTTG2, PUM1, PUNC, PVR, PVRL1, PVRL4, PXMP2, PXMP4, PYGB, PYG01, QDPR, QKI, QPCT, QRICH1, QSCN6, RAB11FIP1, RAB11FIP2, RAB11FIP4, RAB17, RAB1A, RAB20, RAB27A, RAB31, RAB32, RAB33A, RAB35, RAB37,
RAB38, RAB3B, RAB3D, RAB3GAP1, RAB3GAP2, RAB3IP, RAB43, RAB5A, RAB5C, RAB6C, RAB7L1, RAB8B, RAB9, RABGAP1L, RABGEF1, RABIF, RABL3, RAD18, RAD51L1, RAD54L, RAD9B, RAF1, RAM, RALB1 RALGPS1, RALGPS2, RALY, RAMP1, RAN, RANBP17, RANBP2, RANBP3, RANBP5, RANGNRF, RAP1A, RAP1B, RAP2A, RAP2B, RAPGEF1, RAPGEF4, RAPH1, RARA, RARB, RARSL, RASA3, RASAL2, RASGEF1C, RASGRF1, RASGRF2, RASL10B, RASL11B, RASL12, RASSF3, RASSF4, RASSF6, RAVER1, RAVER2, RB1CC1, RBBP8, RBCK1, RBJ, RBKS, RBM11, RBM12B, RBM24, RBM25, RBM26, RBM28, RBM34, RBM39, RBM41, RBM5, RBM9, RBMS1, RBMXL1, RBP2, RBP4, RBPMS, RBPSUH, RC74, RCBTB1, RCC2, RCHY1, RCL1, RCN3, RCOR1, RCSD1, RDH12, RDH14, RDHE2, RDM1, RDX, REEP1, REEP3, REEP6, REG4, REP15, REPS1, RERE, REST, REV3L, REXO1L1, REXO2, RFC1, RFFL, RFK, RFWD2, RFXDC1, RGL1, RGN, RGPD1, RGPD2, RGPD5, RGPD7, RGS1, RGS13, RGS18, RGS2, RGS21, RGS22, RGS3, RGS7BP, RGS8, RGS9, RHBDD3, RHBG, RHEB, RHO, RHOBTB2, RHOBTB3, RHOC, RHOF, RHOH, RHOT1, RHOU1 RHPN2, RIC8B, RICS, RICTOR1 RIMBP2, RIN2, RIOK1, RIOK2, RIOK3, RIPK3, RIPK4, RKHD2, RKHD3, RMM, RMND5A, RNASE1, RNASE9, RNASEH2B, RNASEL, RND1, RNF10, RNF11, RNF113B, RNF121, RNF128, RNF135, RNF138, RNF157, RNF168, RNF182, RNF183, RNF186, RNF19, RNF2, RNF32, RNF44, RNF6, RNF7, RNPEP, ROBO1, ROBO2, ROCK2, ROD1, ROR1, RORA, ROS1, RP11-311P8.3, RP13-360B22.2, RP1L1, RP3-473B4.1, RPA1, RPA3, RPAIN, RPIA, RPIB9, RPL10L, RPL17, RPL34, RPL4, RPL9, RPLPO, RPN2, RPS10, RPS12, RPS26, RPS27, RPS27L, RPS6KA6, RPUSD4, RRAGC, RRBP1, RREB1, RRM2, RRN3, RS1, RSBN1, RSBN1L, RSC1A1, RSF1, RSL1D1, RSN, RSPO3, RSPRY1, RTN1, RTN4, RTN4RL1, RTTN, RUNDC2B, RUNX1, RUNX2, RUSC2, RUVBL1, RWDD2, RWDD3, RXFP2, RXFP3, RXRA, RYBP, RYR1, S100A1, S100A10, S100G, S100P, S100Z, SAA4, SACM1L, SACS, SAE1, SALL1, SALL4, SAMD11, SAMD13, SAMD14, SAMD3, SAMD4A, SAMD8, SAP30, SAP30L, SAPS3, SAR1B, SASH1, SASP, SAT1, SAT2, SC5DL, SCAMP1, SCAMP2, SCAND2, SCAP, SCARA3, SCARB1, SCARB2, SCD5, SCGB1A1, SCGN, SCIN, SCMH1, SCML4, SCN3A, SCN8A, SCOC, SCP2, SCRT2, SCTR, SCUBE2, SCYL1, SCYL1BP1, SCYL3, SDC2, SDC4, SDCBP2, SDHB, SDK1, SDPR, SDR-O, SEC13L1, SEC14L1, SEC14L2, SEC24A, SEC24C, SEC61A1, SEC61A2, SEC61G, SECISBP2, SEH1L, SELE, SELI, SELL, SELPLG, SELS, SEMA3A, SEMA3G, SEMA4B, SEMA4D, SEMA4G, SEMA6A, SEMA6D, SENP2, SENP5, SENP6, SENP8, SEPHS1, SEPHS2, SEPP1, SERF1A, SERGEF1 SERINC2, SERINC3, SERINC5, SERPINA13, SERPINA3, SERPINA7, SERPINA9, SERPINB1, SERPINB9, SERPINE2, SERPINH1, SERTAD2, SERTAD3, SERTAD4, SESN1, SESN3, SESTD1, SETBP1, SETD2, SETD3, SETD4, SF3B3, SFMBT1, SFPQ, SFRP5, SFRS10, SFRS15, SFRS2IP, SFRS3, SFRS4, SFRS6, SFT2D1, SFT2D2, SFTPA2, SFXN1, SFXN3, SFXN5, SGCB, SGEF, SGOL1, SGPL1, SGPP1, SGPP2, SH2D1A, SH2D3A, SH2D4B, SH2D6, SH3BP4, SH3BP5, SH3BP5L, SH3D19, SH3GL1, SH3GLB1, SH3KBP1, SH3PX3, SH3PXD2A, SH3RF1, SH3RF2, SH3TC2, SHANK2, SHBG, SHC1, SHE, SHF, SHFM1, SH0C2, SHPRH, SHQ1, SHROOM3, SHR00M4, Sl, SIAE, SIAH1, SIAH2, SIDT1, SIGLEC12, SIL1, SIM1, SIN3A, SIPA1L1, SIPA1L2, SIPA1L3, SIRPA, SIRT1, SIX1, SKAP1, SKAP2, SKIL, SKP1A, SLA1 SLA/LP, SLAMF1, SLAMF6, SLAMF9, SLC10A2, SLC10A5, SLC11A2, SLC12A1, SLC12A3, SLC12A6, SLC12A7, SLC12A8, SLC13A2, SLC13A3, SLC13A5, SLC14A2, SLC15A1, SLC16A1, SLC16A10, SLC16A13, SLC16A4, SLC16A5, SLC16A7, SLC17A3, SLC17A4, SLC17A8, SLC19A2, SLC1A1, SLC1A3, SLC1A5, SLC1A7, SLC20A1, SLC20A2, SLC22A1, SLC22A16, SLC22A2, SLC22A9, SLC23A3, SLC24A1, SLC24A5, SLC25A14, SLC25A15, SLC25A16, SLC25A20, SLC25A24, SLC25A25, SLC25A3, SLC25A30, SLC25A33, SLC25A36, SLC25A37, SLC25A43, SLC25A44, SLC25A46, SLC26A2, SLC26A3, SLC26A8, SLC27A2, SLC28A1, SLC28A2, SLC2A1, SLC2A14, SLC2A2, SLC2A3, SLC2A7, SLC2A9, SLC30A1, SLC30A10, SLC30A4, SLC30A5, SLC33A1, SLC34A1, SLC35A5, SLC35B4, SLC35D1, SLC35D2, SLC35F2, SLC35F5, SLC36A2, SLC36A4, SLC37A1, SLC37A2, SLC37A4, SLC38A2, SLC39A10, SLC39A11, SLC39A14, SLC39A5, SLC3A1, SLC40A1, SLC41A1, SLC41A2, SLC41A3, SLC43A1, SLC43A2, SLC44A1, SLC44A3, SLC45A3, SLC4A4, SLC4A7, SLC4A8, SLC5A1, SLC5A10, SLC5A12, SLC5A4, SLC5A9, SLC6A11, SLC6A20, SLC6A4, SLC6A6, SLC6A7, SLC6A9, SLC7A11, SLC7A14, SLC7A5, SLC7A6, SLC7A7, SLC7A8, SLC9A2, SLC9A3R1, SLC9A4, SLC9A8, SLCO2A1, SLC02B1, SLC03A1, SLCO4A1, SLIT1, SLIT3, SLMAP, SMA4, SMAD2, SMAD3, SMAD5, SMAD6, SMAD7, SMAF1, SMAP1L, SMARCA1, SMARCA4, SMARCB1, SMARCD1, SMC3,
SMEK1, SMNDC1, SMOC1, SMOC2, SMOX, SMPD3, SMPDL3A, SMPX1 SMS, SMTNL2, SMUG1, SMURF1, SMURF2, SMYD2, SMYD4, SMYD5, SNAM, SNAPAP1 SNCAIP, SNF1LK2, SNFT1 SNIP, SNRK1 SNRPC, SNTB1, SNTG2, SNX10, SNX12, SNX13, SNX14, SNX24, SNX4, SNX7, SNX9, SOAT1, SOAT2, SOCS5, SOCS6, SOCS7, SOD2, SOLH, SORBS1, SORBS2, SORBS3, SORCS2, SORD, SORL1, SORT1, SOS1, SOSTDC1, SOX1, SOX13, SOX14, SOX30, SOX5, SOX6, SP1, SP3, SP5, SP6, SP8, SPAG17, SPAG5, SPAG6, SPAG9, SPAM1, SPANXN4, SPARC, SPATA1, SPATA12, SPATA13, SPATA20, SPATA8, SPATA9, SPATS2, SPECC1, SPECC1L, SPFH1, SPG21, SPG7, SPHAR, SPINK1, SPINK5, SPINK5L2, SPINT2, SPIRE1, SPN, SPOCD1, SPOCK2, SPOCK3, SPON1, SPOP, SPPL2A, SPPL2B, SPPL3, SPR, SPRED1, SPRED2, SPRY1, SPRY2, SPRY4, SPTAN1, SPTBN1, SPTBN2, SPTBN5, SPTLC2, SQLE, SRD5A2, SRD5A2L, SREBF1, SRFBP1, SRG, SRGAP1, SRGAP2, SRI, SRPK1, SRPK2, SRPX2, SSBP3, SSPN, SSR1, SSX2IP, ST14, ST18, ST3GAL2, ST3GAL3, ST3GAL6, ST5, ST6GAL1 , ST6GALNAC1 , ST6GALNAC3, ST8SIA4, STAMBPL1 , STARD13, STARD4, STARD5, STARD6, STAT5B, STAT6, STAU1, STC2, STEAP3, STEAP4, STIM2, STK10, STK11IP, STK17A, STK17B, STK3, STK31 , STK32A, STK35, STK38, STK38L, STK39, STK40, STOM, STON2, STOX2, STRA8, STRAP, STRBP, STRN, STRN3, STS-1, STT3B, STX1B2, STX3, STX6, STX7, STXBP4, STXBP5, STXBP6, STYX, SUB1, SUCLG2, SUCNR1, SUDS3, SUHW4, SULF2, SULT1A4, SULT1B1, SULT1E1, SUPT4H1, SUPT7L, SURF4, SUSD1, SUSD4, SUV39H1, SUV39H2, SV2B, SVIL, SVOP1 SYCP2, SYCP3, SYNCRIP, SYNE1, SYNGAP1, SYNJ2, SYNJ2BP, SYNPO2, SYNPR, SYPL1, SYT1, SYT11, SYT13, SYT15, SYT16, SYT3, SYT6, SYT7, SYT9, SYTL2, SYTL3, SYTL5, TAAR1, TAAR2, TAC1, TAC4, TACC2, TACR2, TACSTD 1, TAF 1 A, TAF4, TAGLN3, TAIP-2, TAL1, TAL2, TANC1, TANK, TAOK3, TARBP1, TASP1, TATDN2, TATDN3, TBC1D14, TBC1D16, TBC1D19, TBC1D2, TBC1D23, TBC1D2B, TBC1D4, TBC1D7, TBC1D8, TBC1D8B, TBC1D9, TBC1D9B, TBCC, TBCCD1, TBCE, TBK1, TBL1X, TBL1XR1, TBN, TBPL1, TBPL2, TBRG1, TBX15, TBX19, TBX4, TBXAS1, TCEA1, TCEAL8, TCF20, TCF23, TCF4, TCF7L1, TCFL5, TCHHL1, TCL6, TCN1, TCP10, TCP10L2, TCP11L1, TCP11L2, TEAD1, TEC, TECTA, TECTB, TEKT3, TEP1, TERF2, TES, TEX10, TEX101, TEX12, TEX14, TEX2, TFAP2A, TFAP2C, TFB1M, TFDP1, TFDP2, TFEB1 TFEC, TFF1, TFF2, TFF3, TFG, TFPI2, TG1 TGFBI1 TGFBR2, TGFBR3, TGFBRAP1, TGIF, TGIF2, TGM2, TGOLN2, THAP2, THAP9, THBS2, THEM2, THEM4, THEX1, THNSL1, THOC1, THOC3, TH0C7, THRAP1, THRAP2, THRB, THSD1, THUMPD3, THY1, TIAL1, TIAM1, TIAM2, TICAM2, TIE1, TIGD2, TIGD3, TIMM8A, TIMP4, TINAG1 TINP1, TIPRL, TJAP1, TJP1, TJP2, TLE1, TLN2, TLR2, TLR7, TLX1, TM2D1, TM2D2, TM4SF1, TM4SF11, TM4SF20, TM9SF3, TM9SF4, TMBIM1, TMC1, TMC7, TMCC1, TMCC3, TMCO1, TMCO2, TMED10, TMED4, TMED8, TMEM1, TMEM10, TMEM100, TMEM105, TMEM106A, TMEM106B, TMEM108, TMEM117, TMEM12, TMEM125, TMEM126A, TMEM128, TMEM132B, TMEM135, TMEM139, TMEM140, TMEM142A, TMEM144, TMEM150, TMEM154, TMEM156, TMEM158, TMEM161B, TMEM165, TMEM166, TMEM16F, TMEM16J, TMEM16K, TMEM17, TMEM171, TMEM173, TMEM174, TMEM177, TMEM180, TMEM19, TMEM2, TMEM20, TMEM23, TMEM24, TMEM26, TMEM30B, TMEM33, TMEM37, TMEM38B, TMEM40, TMEM41A, TMEM44, TMEM45A, TMEM45B, TMEM48, TMEM49, TMEM5, TMEM50B, TMEM51, TMEM56, TMEM60, TMEM62, TMEM63A, TMEM67, TMEM69, TMEM79, TMEM87B, TMEM9, TMEM92, TMEM93, TMEM97, TMEM98, TMEPAI, TMIGD1, TMOD3, TMPO, TMPRSS11B, TMPRSS12, TMPRSS13, TMPRSS2, TMPRSS3, TMPRSS4, TMPRSS5, TMPRSS6, TMTC3, TNFAIP2, TNFAIP3, TNFAIP8, TNFRSF10B, TNFRSF11A, TNFRSF19, TNFRSF1A, TNFRSF25, TNFRSF8, TNFSF10, TNFSF12-TNFSF13, TNFSF13B, TNFSF15, TNFSF18, TNFSF4, TNFSF5IP1, TNIK, TNIP1, TNIP2, TNIP3, TNK1, TNK2, TNKS2, TNMD1 TNN, TNNC2, TNNI3K, TNP1, TNPO1, TNPO3, TNR, TNRC4, TNRC6B, TNRC6C, TNS1, TNS3, TNXB, TOB1, TOB2, TOM1L2, TOMM34, TOMM40, TOMM7, TOP1, TOPBP1, TOR1B, TOR3A, TP53I13, TP53INP1, TP53INP2, TP73L, TPCN1, TPCN2, TPD52, TPM1, TPM3, TPMT, TPP1, TPPP1 TPT1, TRA2A, TRAF3, TRAF3IP2, TRAF3IP3, TRAK1, TRAM2, TRAPPC4, TRERF1, TREX1, TRIB1, TRIB3, TRIM14, TRIM16, TRIM16L, TRIM2, TRIM24, TRIM25, TRIM27, TRIM3, TRIM32, TRIM33, TRIM36, TRIM37, TRIM39, TRIM40, TRIM42, TRIM43, TRIM44, TRIM59, TRIM69, TRIM71, TRIM8, TRIM9, TRIO, TRIP6, TRIT1, TRPA1, TRPC4, TRPC4AP, TRPC6, TRPC7, TRPM3, TRPM6, TRPM7, TSC22D1 , TSC22D2, TSGA2, TSHZ1, TSKU, TSNARE1, TSPAN13, TSPAN15, TSPAN2, TSPAN3, TSPAN32, TSPAN33, TSPAN7, TSPAN8, TSPAN9, TSPYL4, TSR1, TSSK3, TTBK1, TTC1, TTC13,
TTC14, TTC17, TTC21B, TTC22, TTC26, TTC30A, TTC31, TTC6, TTC7A, TTC7B, TTL1 TTLL2, TTLL6, TTLL9, TTMB, TTR1 TTRAP1 TUBAL3, TUBG1, TUBG2, TULP4, TWF2, TXLNA TXLNB1 TXN, TXNDC11 , TXNDC13, TXNDC2, TXNDC5, TXNDC8, TXNL5, TYSND1 , TYW3 UACA, UAP1, UBAP1, UBAP2L, UBC, UBE2D4, UBE2H, UBE2I, UBE2L3, UBE2R2, UBE2W, UBE3A, UBE4A, UBE4B, UBL3, UBN1, UBR1, UBTD2, UCHL5, UCK1, UCK2, UCP3, UFM1, UGCG, UGCGL1, UGP2, UGT2A3, UGT2B7, UGT8, UHRF1, UHRF2, UIMC1, ULBP2, ULK1, ULK2, UMODL1, UNC45A, UNC5B, UNC84B, UNC93A, UNG, UNG2, UNQ473, UNQ5830, UNQ830, UNQ9433, UNQ9438, UPK1B, UPK3A, UPP2, URG4, USH1C, USH2A, USH3A, USP10, USP13, USP18, USP25, USP30, USP31, USP36, USP38, USP39, USP40, USP44, USP47, USP49, USP54, USP8, USP9X, USPL1, UTP14C, UTP15, UTRN, UTX, UVRAG1 UXS1, VAMP3, VANGL1, VAPA, VAPB, VARSL1 VAV2, VAV3, VAX1, VCL, VCPIP1, VCX, VCX3A, VDAC3, VEGFA1 VEZF1, VEZT, VGLL3, VIL1, VIL2, VILL, VIPR1, VIPR2, VKORC1L1, VLDLR, VPREB1, VPS13D, VPS37A, VPS37B, VPS37C, VPS39, VPS41, VPS4B, VPS52, VPS54, VPS8, VSIG4, VSIG8, VSNL1, VWCE, VWF, WASF2, WBSCR23, WDFY1, WDFY3, WDR20, WDR23, WDR26, WDR3, WDR36, WDR41 , WDR42A, WDR42B, WDR49, WDR52, WDR59, WDR60, WDR61, WDR63, WDR65, WDR66, WDR71, WDR72, WDR75, WDR78, WDR81, WDSUB1, WEE1, WFDC2, WHDC1L1, WHSC1, WIF1, WIPF1, WISP1, WNK1, WNK2, WNK4, WNT11 , WNT5A, WNT8B, WSB1 , WSB2, WT1 , WWC1 , WWC2, WWC3, WWOX, WWP2, WWTR1, XBP1, XCL2, XG1 XKR8, XKRX1 XPNPEP1, XPNPEP2, XPO4, XPO7, XRN1, XYLT1, YAF2, YAP1, YBX1, YEATS4, YIPF6, YPEL2, YPEL5, YTHDF3, YWHAE, YWHAG1 YWHAH, YWHAQ, YWHAZ1 YY1, ZADH1, ZAK1 ZBED1, ZBED2, ZBTB10, ZBTB16, ZBTB2, ZBTB20, ZBTB33, ZBTB40, ZBTB41, ZBTB46, ZBTB48, ZBTB7B, ZBTB8OS, ZC3H12B, ZC3H14, ZC3H15, ZC3H6, ZC3H7B, ZC3HAV1, ZCCHC10, ZCCHC11, ZCCHC12, ZCCHC13, ZCCHC14, ZCCHC6, ZCCHC7, ZCCHC8, ZCCHC9, ZCD1, ZCRB1, ZDHHC11, ZDHHC13, ZDHHC14, ZDHHC21, ZDHHC3, ZFAND2A, ZFAND2B, ZFAND3, ZFAT1, ZFHX1B, ZFP14, ZFP161, ZFP36, ZFP36L2, ZFP41, ZFP91, ZFPM1, ZFR1 ZFYVE20, ZFYVE27, ZHX2, ZHX3, ZKSCAN1, ZMAT3, ZMIZ1, ZMYND12, ZNF137, ZNF143, ZNF148, ZNF160, ZNF180, ZNF182, ZNF184, ZNF187, ZNF200, ZNF202, ZNF215, ZNF217, ZNF219, ZNF223, ZNF232, ZNF234, ZNF238, ZNF248, ZNF267, ZNF271, ZNF291, ZNF3, ZNF31, ZNF313, ZNF326, ZNF331, ZNF33B, ZNF34, ZNF341, ZNF346, ZNF354B, ZNF366, ZNF367, ZNF384, ZNF395, ZNF415, ZNF436, ZNF444, ZNF445, ZNF451, ZNF462, ZNF488, ZNF503, ZNF507, ZNF508, ZNF513, ZNF518, ZNF552, ZNF553, ZNF557, ZNF563, ZNF565, ZNF567, ZNF57, ZNF574, ZNF585B, ZNF587, ZNF592, ZNF599, ZNF608, ZNF609, ZNF622, ZNF641, ZNF644, ZNF650, ZNF652, ZNF664, ZNF692, ZNF704, ZNF706, ZNF710, ZNF740, ZNF746, ZNF750, ZNF775, ZNF783, ZNF786, ZNF79, ZNF92, ZNFX1, ZNRF2, ZP2, ZRANB1, ZSCAN2, ZSWIM2, ZSWIM3, ZUBR1, ZW10, ZZEF1 orZZZ3.
In yet a further preferred embodiment, the gene is selected from the group of genes regulated on the transcriptional level by the HNF4α inducing agent Aroclor 1254, wherein the gene is preferably selected from the group of genes according to Table 35.
Table 35 - list of genes regulated on the transcriptional level by the HNF4α inducing agent Aroclor 1254: ABCA1, ABCC3, ABP1, ACE2, ACOX1, ACSL5, ACY3, ACYP2, ADH4, AFF1, AFP, AGR2, AGT, AGXT2, AHSG, AIG1, AKAP7, ALB, ALDH6A1, ALDOB, AMICA1, AMMECR1, ANKRD9, ANKZF1, ANTXR2, ANXA4, AP1S3, APOA1, APOA4, APOB, APOBEC1, APOC3, APOM, AQP3, ARHGAP18, ARL4C, ASGR1, ATAD4, ATXN1, AXIN2, BCL2L14, BCMP11. BMP4, BPHL, BTNL3, C10orf114, C11orf54, C12orf28, C12orf59, C15orf48, C17orf61, C17orf76, C1orf115, C1orf163, C1orf19, C20orf75, C3orf26, C9orf52, CA9, CAPN3, CCND2, CD55, CDC25A, CDC6, CDKN1A, CEACAM1, CEACAM6, CEL, CES1, CFB, CG018, CGI-115, CHORDC1, CLDN2, CMTM8, COL6A1, COTL1, CPS1, CTSB, CYP1A1, CYP27A1, CYP2C9, CYR61, DDIT4, DEPDC7, DI01, DIP2C, DKK1, DPP4, DTL1 DUSP9, ECM2, EDN1, EEF1A1, EFNA1, ENPP7, EPHX2, ERBB3, ETHE1, EVA1, F11R, F2, F2R, FABP1, FAM110C, FAM13A1, FAM20C, FBP1, FGA, FGB, FGG, FGL1, FHIT, FLJ20273, FLJ20920, FLJ42562, FMO5, FOXD1, FOXQ1, FRMD3, FRY, GATM, GBA3, GJB1, GLRX, GLS, GLULD1, GNRH2, GOLT1A, GOSR2, GPA33, GPC3, GPR133, GPR157, GPR160, GRK5, GSN1 GSTA1, GUCY2C, HAL1 HAVCR1, HEPH, HHLA2, HIST2H2BE, HKDC1, HNF4A,
HNMT1 HSD17B2, HSPH1 , IGFBP2, IGSF4, IHH, IL6R, INSIG1 , INSIG2, JMJD1A, KCNJ8 KLB, KLC4, KLHL24, KNG1 , KRT20, LCT, LGALS14, LGR5, LHPP1 LIPA, LMCD1 , LOC283537, LOC388323, LOC401152, LOX, MAF, MALL1 MAOB, MAP4K4, MAP6, MBNL3, MCF2L, MCM10, MEP1A, METT10D, METTL7A, MGC24039, MGC33657, MGC4172, MGLL, MLN, MLXIPL, MUC13, MUC20, MYO1A, NAT2, NDRG1 , NR1 I3, NR5A2, NRP2, ODC1 , OIT3, OLR1 , OSTα, OSTβ, P4HA1 , PAG1 , PAPSS2, PCK1 , PCTK3, PCYT1 B, PDK1 , PDZK1 IP1 , PECAM1 , PGCP, PGPEP1 , PHLDA1 , PI3, PIGZ, PIPOX, PLA2G12B, PLD1 , PLOD2, PNRC1 , PODXL, P0LR3H, PPP1 R2, PRDM1 , PRLR, PRODH, PRSS23, PRSS35, RALGPS1 , RASL11 B, RDH5, REEP6, RHOF1 RNASE4, RNF183, RNF19, ROR1 , S100G, S100P, SAMD4A, SAT2, SC4M0L, SCD5, SDCBP2, SEMA6A, SEPP1 , SERPINA1 , SERPINA10, SERPINA6, SERPINC1 , Sl, SIAE, SLC11A2, SLC15A1 , SLC16A4, SLC17A4, SLC1A3, SLC23A3, SLC26A3, SLC39A5, SLC3A1 , SLC44A1 , SLC5A1 , SLC5A9, SLC6A4, SLC7A5, SLC7A6, SLC02B1 , SOAT2, SORL1 , ST6GAL1 , STOM, STS-1 , SULF2, SULT1C1 , SULT1 E1 , SULT2A1 , SYNCRIP, SYT7, TBC1 D4, TBC1 D8, TCF4, TEP1 , TFEC, TFF1 , TFF2, TFF3, TIMP3, TJP2, TM4SF20, TMCC1 , TMEM12, TMEM45A, TMEM92, TMPRSS4, TNFRSF19, TNFSF10, TNS1 , TOB1 , TSC22D2, TSR1 , TTC26, TTR, TTRAP, TUBAL3, UGT2A3, UNC93A, UPB1 , VAV3, WNK4, WNT11 , WWC1 , XPNPEP2, YPEL2, ZC3H6 and ZNF557
Within the context of diagnosis, the first aspect of the invention is, in one example, directed to the use, in particular the in vitro use, of
(A) a human gene, or
(B) the coding region of (A), or
(C) the template strand of a (A) or (B), wherein (C) is preferably a recombinant DNA molecule, or
(D) the coding strand of (A) or (B), wherein (D) is preferably a recombinant DNA molecule, or
(E) the gene product encoded by (A) - (D), or
(F) DNA or RNA sequences hybridizing with (C), and encoding a polypeptide having the biological activity of (E)1) for the diagnosis of colorectal cancer, wherein (A) is selected from one of the groups of genes described herein and, in particular, wherein the level of expression of (A) in a biological sample of a subject suffering from colon cancer is detected by measuring the level of (E) or (F) in the sample, preferably by the use of antibodies directed against (E) or by the use of primers directed against (F), and wherein a level of (E) or (F), being significantly higher or lower than the level of (E) or (F) in a control sample, is indicative of an overexpresssion of (A) in the biological sample, and wherein the subject, is then diagnosed as suffering from adenocarcinoma of the colon.
The invention is thus also directed to the use of an antibody directed against a gene product encoded by a human gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma, or said antibody is used for the preparation of a
diagnostic agent for for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma.
Within the inventive context, antibodies are understood to include monoclonal antibodies and polyclonal antibodies and antibody fragments (e.g., Fab, and F(ab')2) specific for one of said polypeptides. Polyclonal antibodies against selected antigens may be readily generated by one of ordinary skill in the art from a variety of warm-blooded animals such as horses, cows, goats, rabbits, mice, rats, chicken or preferably of eggs derived from immunized chicken. Monoclonal antibodies may be generated using conventional techniques (see Monoclonal Antibodies, Hybridomas: A New Dimension in Biological Analyses, Plenum Press, Kennett, McKearn, and Bechtol (eds.), 1980, and Antibodies: A Laboratory Manual, Harlow and Lane (eds.), Cold Spring Harbor Laboratory Press, 1988, which are incorporated herein by reference).
The invention is thus further directed to the use of primer sequences, preferably primer pairs, directed against the mRNA of a human gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma, or said primer sequences are used for the preparation of a diagnostic agent for the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, preferably colorectal adenocarcinoma, wherein the production of adequate primer sequences and the use thereof, e.g. in a quantitative RT-PCR, is known to the person skilled in the art.
Within the context of the invention the use of a primer or of primers, such as a primer pair may be, selected from Table M1 is particularly preferred.
The first aspect of the invention is accordingly directed to the use of a human gene, in particular the coding region thereof, or of a gene product encoded thereby or of an antibody directed against said gene product or of RNA or DNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, as a biomarker in the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including
diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, wherein the gene is selected from one of the groups described herein, in particular to the group described in claim 1 , and the use is preferably performed for monitoring the therapeutic treatment of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer. Within the context of using said biomarkers a method for diagnosing, prognosing and/or staging metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer and/or monitoring the treatment of at least one of said diseases, is provided by
(a) measuring the level of expression of at least one biomarker, wherein the biomarker is a gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 in a patient or in a sample of a patient suffering from or being susceptible to a metabolic and/or tumorous disease, and
(b) comparing the level of said at least one biomarker in said patient or in said sample to a reference level of said at least one biomarker.
Accordingly, the first aspect of the invention may also be used in a method of qualifying the HNF4α activity in a patient suffering or being susceptible to metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one said diseases, comprising determining in a sample of a subject suffering from or being susceptible to one of said diseases the level of at least one biomarker, wherein the biomarker is the gene product encoded by a gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , and/or the biomarker is the mRNA sequence encoding the gene product of said selected gene, and wherein the sample level of the at least one biomarker being significantly higher or lower than the level of said biomarker(s) in the sample of a subject without a disease associated with increased activity of HNF4α is indicative of induced HNF4α activity in the subject.
Such method of qualifying the HNF4α activity in a patient suffering from metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating such diseases preferably comprises administering a drug identified by the first aspect of the invention, or by the second aspect of the invention as described hereinafter, or
administering a HNF4α activity modulator, wherein the level of the at least one biomarker being significantly higher or lower than the level of said biomarker(s) in a subject without cancer associated with increased activity of HNF4α is indicative that the subject will respond therapeutically to a method of treating cancer comprising administering said drug or administering a HNF4α activity modulator.
Such methods of qualifying the HNF4α activity may be also used for monitoring the therapeutically response of a patient suffering from metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of said diseases comprising administering a drug identified by the first aspect of the invention, or by the second aspect of the invention as described hereinafter, or administering a HNF4α activity modulator, wherein the level of the at least one biomarker before and after the treatment is determined, and a significant decrease or increase of said level(s), preferably a decrease or increase to the normal level(s), of the at least one biomarker after the treatment is indicative that the subject therapeutically responds to the administration said drug or to the administration of the HNF4α activity modulator.
In a preferred embodiment, preferably a RT-PCR (RT = real time) is performed for the afore mentioned methods of qualifying the HNF4α activity , in particular by using the kit described hereinafter.
Within the context of diagnosis of the first aspect, the invention is also directed to a composition for qualifying the HNF4α activity in a patient suffering or being susceptible to a metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases, wherein the composition comprises an effective amount of at least one biomarker, and wherein the biomarker is a gene selected from one of the groups of genes described herein, in particular of the group described in claim 1 , and/or the biomarker is the gene product encoded by said gene, and/or wherein the composition comprises an effective amount of an antibody directed against said gene product.
Within the context of the invention it is thus understood that the gene according to the invention, or the DNA sequences hybridizing to said gene and encoding a polypeptide having the function of the gene product of said gene, may be part of a recombinant DNA molecule for use in cloning a DNA sequence in bacteria, yeasts or animal cells.
Within the context of the invention it is further understood that the gene according to the invention, or the DNA sequences hybridizing to said gene and encoding a polypeptide having the function of the gene product of said gene, may be part by a vector. The invention is thus also directed to the use of a vector for the therapy and/or diagnosis of metabolic and/or cancerous diseases and/or to screen for and to identify drugs against metabolic and/or cancerous diseases, such as diabetes mellitus and/or colorectal cancer may be, wherein the vector comprises a gene selected from one of the goups of genes described herein, in particular the group according to claim 1 , or the vector comprises DNA sequences hybridizing to said gene and encoding a polypeptide having the function of the gene product of said gene.
In particular, the composition for qualifying the HNF4α activity is used for the production of a diagnostic agent, in particular of a diagnostic standard.
In a preferred embodiment, this composition is used for the production of a diagnostic agent for qualifying the HNF4α activity in a patient suffering or being susceptible to a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases. In another preferred embodiment this compositon is used for the production of a diagnostic agent for predicting or monitoring the response of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of said diseases with a drug, in particular a drug identified according to the first aspect of the invention , or according to the second aspect of the invention as described hereinafter, and/or with a HNF4α activity modulator.
Accordingly the first aspect of the invention is, in another example, directed to the use, in particular the in vitro use, of
(A) a human gene, or
(B) the coding region of (A), or
(C) the template strand of a (A) or (B), wherein (C) is preferably a recombinant DNA molecule, or
(D) the coding strand of (A) or (B), wherein (D) is preferably a recombinant DNA molecule, or
(E) the gene product encoded by (A) - (D), or
(F) DNA or RNA sequences hybridizing with (C), and encoding a polypeptide having the biological activity of (E)1) for the screening of drugs directed against adenocarcinoma of the colon, wherein (A) is selected from one of the groups of genes described herein and, in particular, wherein a biological sample
of a subject suffering from adenocarcinoma of the colon, such as a histological sample may be, is contacted with a drug to be tested, and wherein the level of expression of (A) is detected in the sample by measuring the level of (E) or (F) in the sample, preferably by the use of antibodies directed against (E) or by the use of primers directed against (F), and wherein a level of (E) or (F), being significantly lower or higher in the sample contacted with the drug to be sceened than the level of (E) or (F) in a control sample of the same subject, is indicative of a downregulation or upregulation of (A) in the biological sample, contacted with the drug, and wherein the drug is then identified as a drug to be used in the medication of said subject, preferably in a medication for normalizing the level of (A) to the level of (A) in a healthy individual.
Accordingly the first aspect of the invention is, in a further example, directed to the use, in particular the in vitro use, of
(A) human gene, or
(B) the coding region of (A), or
(C) the template strand of a (A) or (B)1 wherein (C) is preferably a recombinant DNA molecule, or
(D) the coding strand of (A) or (B), wherein (D) is preferably a recombinant DNA molecule, or
(E) the gene product encoded by (A) - (D), or
(F) DNA or RNA sequences hybridizing with (C), and encoding a polypeptide having the biological activity of (E)1) for the identification of drugs directed against adenocarcinoma of the colon, wherein (A) is selected from the group of human chromosomal genes as described herein and, in particular, wherein a biological sample of a subject suffering from adenocarcinoma of the colon, such as CACO2 cells may be, is contacted with a drug to be tested, and wherein the level of expression of (A) is detected in the sample by measuring the level of (E) or (F) in the sample, preferably by the use of antibodies directed against (E) or by the use of primers directed against (F), and wherein a level of (E) or (F), being significantly lower or higher in the sample contacted with the drug to be sceened than the level of (E) or (F) in a control sample of the same subject, is indicative of a downregulation or upregulation of (A) in the biological sample contacted with the drug, and wherein the drug is then identified as a drug to be used in the medication of adenocarcinomas of the colon, preferably in a medication for normalizing the level of (A) to the level of (A) in a healthy individual.
Still according to the first aspect of the invention the gene is preferably selected from the group of genes identified by the method according to the second aspect of the invention.
Within the first aspect of the invention and/or within the second aspect of the invention, as described hereinafter, an agent selected from the group consisting of: the agonists, antagonists, drugs, agents, antiestrogens, and compounds according to Tables 36-54, sulfonlyurea derivates, and Aroclor 1254,
is used and/or tested and/or screened as the drug and/or as the HNF4α activity modulator.
As disclosed by Mehlmann et al. Toxicology 5 89-95 (1975), the administration of Aroclor 1254 decreases the activity of pyruvate carboxylase (PC), phosphoenolpyrutvate carboxykinase (PEPCK) and glucose-6-phosphatase in diabetic liver.
Since the rate of hepatic gluconeogenesis is increased dramatically in the diabetic state, concomitant with increases in the activities of all gluconeogenic enzymes, i.e. phosphoenolpyrutvate carboxykinase, fructose-1 ,6-bisphosphatase, glucose-6-phosphatase and pyruvate carboxylase, Arocolor 1254 is thus a, at least putative, drug against diabetes mellitus. For comparison, also the administration of insulin to diabetic rats brings the increased amount of pyruvate carboxylase back to the normal level, as disclosed by Wallace & Jitrapakdee Biochemical Journal 340 1-16 (1999).
Further, it is known from the prior art that Aroclor 1254 can inhibit tumor growth in rats, as described, for example, by the article "Inhibition of tumor growth in rats by feeding a polychlorinated biphenyl, Aroclor 1254" by Kervliet & Kimeldorf in Bull Environ Contam 1977 Aug , 18 (2) :243-6. Aroclor 1254 is thus a, at least putative, drug against cancerous diseases.
Consequently, Aroclor 1254 is thus a, at least putative, drug against metabolic diseases, in particular against diabetes mellitus, and/or against cancerous diseases.
The second aspect of the invention provides a method for a genomewide identification of functional binding sites at targeted DNA sequences bound to DNA complexes in cells, healthy and diseased tissues and/or organs, wherein the method comprises, or preferably consists of, the steps of a. chromatin immunoprecipitation and b. DNA-DNA hybridisation for the c. de novo identification of gene targets.
In a preferred embodiment the method according to invention is used for the identification of the functional binding sites of a protein of interest, preferably of a transcription factor, and/or the method is characterized in that a. the chromatin immunoprecipitation comprises or consists of two rounds of sequential chromatin immunoprecipitation, b. a genome wide tiling array is used for the DNA-DNA hybridisation, and/or c. the de novo identification of gene targets comprises reducing the number of false enhancer-gene associations.
In another preferred embodiment the method according to invention is used for determining a region of ChIP enrichment in the immunoprecipitated sample (enrichment site), with respect to a
control or to genomic DNA, preferably a HNF4α binding site, and/or the method is characterized in that a. an anti HNF4α antibody is used for the immunoprecipiation b. a human or murine array with a genome-wide 20-50 bp resolution is used, and/or c. all genes, which are separated from their associated enhancer by a CTCF-binding site, are removed from the group of the de novo identified genes (target list).
In a further preferred embodiment the method according to invention is used for mapping the in vivo enrichment sites' of a specific protein of interest, and/or the method is characterized in that a. Caco-2 cells are used, b. human tiling arrays with a genome-wide 35 bp resolution are used, and/or c. all genes, which are separated from their associated enhancer by the CTCF-binding site according to matrix 2, are removed from the target list.
In particular, it is preferred if the method according to the invention further comprises the use of DNA-sequences and/or genes identified by the second aspect of the invention to screen for and to identify novel drug targets for the treatment of metabolic and cancerous diseases, preferably comprising the use according to the first aspect of the invention.
In another preferred embodiment of the method according to the invention novel identified sequences and genes encoding DNA are used.
In yet another preferred embodiment of the method according to the invention polypeptides encoded by novel identified sequences and genes are used.
Still further according to the second aspect of the invention it is preferred, if
-Caco-2 cells cultures treated with Aroclor 1254 are used,
-Protein A Sepharose is used for the chromatin immunoprecipitation
- a quantile normalization is performed and subsequently the raw data is analyzed for enriched regions by three independent algorithms, in particular TAS, MAT and Tilemap, and the results from all three algorithms are intersected,
- parameters for enrichment site (ES) detection are further improved based on the frequency of motives of the protein of interest, in particular of HNF4α -motives, within the enriched regions, which is determined by application of the MATCH algorithm,
- the distribution of the binding sites of the protein of interest, in particular the HNF4α binding sites, relative to transcription start sites (TSS) is analyzed, and the distance from the center of each ES to the closest TSS of a RefSeq gene is determined,
- the enrichment allows an easy 'de novo' identification of the DNA binding motif of the protein HNF4α motif,
- regions of 500bp surrounding the identified binding sites are analyzed for DNA binding motifs of the protein of interest, in particular for HNF4α motives
- wherein the ChIP regions are analyzed for overrepresented motifs, in particular using motif analysis programs, such as from Biobase and Genomatix, as well as the tool CEAS -transcription factors cross-talking with the protein of interest, in particular with HNF4α, are determinded
-a relative increase of the frequency of binding motifs for AP1 , GATA, ER and HNFI a, and/or a negative relationship between HNF4α and CART binding motifs is observed.
- the genomic position of the highest scoring motif of the protein of interest (highest likelihood ratio) , in particular of the HNF4α motif (highest likelihood ratio), within the ChIP regions is retrieved and extended for 500 nucleotides to both flanks, and within these sequences, other enriched motifs are detected and preferably the distance to the DNA- binding motif of the protein of interest, in particular to the HNF4α motif, is calculated
- ER motifs co-locate with HNF4α motifs,
- HNF1 , AP1 an GATA motifs have their highest enrichment in a distance of 20 to 60 nucleotides to the DNA-binding motifs of the protein of interest, in particular to the HNF4α motifs,
- all RefSeq genes with a TSS separated by less than 100000 nucleotides from these binding sites are selected for associating the binding sites of the protein of interest, in particular the HNF4α binding sites, identified by the ChlP-chip approach with target genes,
- the potential RefSeq target genes of the protein of interest, in particular of HNF4α, are identified,
- the following parameter are chosen for ES identification with the different programs: for MAT bandwidth = 200, maximum gap = 300, minimum probes = 8, P-value < 0.00001 and MAT score > 5, for Tilemap truncation =-1000000, 1000000, transform = none, GAP<=300/probes between peaks <=5, minimum length 200nt/5 probes, region summary method = HMM (A peak 28 probes on average, cutoff 0,5), FDR = left tail and FDR < 0.015, and for TAS bandwidth = 400, P-value < 0.01 , minimum run = 200 and maximum gap = 250,
- the resulting regions are intersected using the Galaxy tool and after intersection resulting enriched regions shorter than 200 nt are removed,
- the ChIP regions are scanned for transcription factor motifs using position-specific score matrices (PSSM) from TRANSFAC, in particular 533 well-defined PSSM,
- for each matrix, all PSSM matches with cutoff scores from 5.0 (90% of relative entropy) up to 12.0, in increments of 0.5 are considered,
- at each cutoff level, the resulting two sets of motifs are tested for significance and minimum change (with respect to control) of 1.5-fold,
- association of binding sites identified by ChlP-chip with RefSeq annotated genes is performed with the software tool CisGenome,
- ES are associated with all RefSeq genes with transcript coding regions within 100000 nt from the center of the ES using Cisgenome,
- all genes with an TSS further than 10OOOOnt from the center of the ES were removed from this list,
-genomic positions of insulator sites retrieved from Kim et al., (2007) are used and converted to the hg18 assembly,
- it is tested if an insulator site is located between ES and the associated TSS, and if this is the case, then the association is removed,
- all RefSeq genes associated with an ES are joined into a single list, which then is used for Gene Ontology categorization, and/or
-gene Ontology categorization is performed with GOFFA and DAVID, -de novo identified genes associated with the DNA binding sites of the protein of interest , in particular with the HNF4α binding sites, are grouped by Ontology terms, in particular in genes in metabolic and cancerous disease,
- the de novo identified genes involved in metabolic processes (lipid metabolism, organic acid metabolism, carboxylic acid metabolism, phosphate, alcohol and carbohydrate metabolism), in particular genes coding for steroid metabolism, are grouped,
- the de novo identified genes involved in developmental (e.g., kidney development) and differentiation categories are grouped,
- the de novo identified genes related to transport, especially lipid transport, are grouped,
- the de novo identified genes involved in signaling, in particular insulin receptor signaling, and regulation of cellular processes are grouped
- the de novo identified genes involved in regulation of different signaling pathways are grouped, and/or
- the de novo identified genes involved in cell death and apoptosis are grouped.
In particular, it is preferred if the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to develop new medications for the treatment of disease as a result of HNF4α dysfunction.
Preferably, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to develop new drug candidates for treatment of metabolic and tumorous diseases by interfering with the activity of polypeptides, as described herein, encoded by novel identified sequences and genes are used for the purpose of normalizing its activity and to restore a healthy condition.
In another preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to optimize novel chemical entities for the purpose of drug development.
In yet another preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting chromatin and its regulation by interfering with protein-DNA, protein-protein and multiprotein- DNA complexes for the purpose of normalizing gene activities in metabolic and cancerous diseases.
In a particular preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting carbohydrate metabolism in metabolic and tumorous diseases for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of
ACLY, ACO1 , ACO2, ADPGK, AKR1A1 , ALDH2, ALDOB, AMDHD2, APOA2, ARPP-19, ARSB, B3GAT1 , B4GALT1 , B4GALT4, B4GALT5, B4GALT6, B4GALT7, C9orf103, CARKL, ChGn, CHST12, CHST13, CHST3, CHST9, CMAS, COG2, DLST, EXT1 , FBP1 , FBP2, FLJ10986, FN3K, FUCA2, FUT4, FUT8, G6PC, GALK1 , GALM, GALNT3, GALNT4, GALNT5, GALT, GANAB, GANC, GBA3, GBGT1 , GCNT2, GCNT3, GENX-3414, GK, GLCE, GMDS1 GNPDA1 , GNS, GPD1 , GPD2, GSK3B, GUSB, GYS2, H6PD, HECA, HEXB, HIBADH, HK1 , HK2, HKDC1 , HS3ST4, HS3ST5, IDH1 , IDH3A, IDS, IMPA1 , INSR, IRS2, ITIH1 , ITIH2, ITIH3, ITIH5, KHK, KIAA0100, KL, KLB1 LARGE, LCT, LCTL, LDHA, LDHAL6B, MAN2A1 , MAN2C1 , MANBA, MDH2, ME1 , ME2, ME3, MGAM, MGAT1 , MGAT2, MGC40579, MMP15, MMP16, MMP17, MMP2, MMP20, NAALADL2, NAGK, NANS, NDST1 , OGDH1 PC, PCK1 , PCK2, PDK1 , PDK3, PDK4, PFKFB1 , PFKFB2, PFKFB3, PFKM, PFKP, PGAM4, PGD, PGK2, PGLYRP2, PGM1 , PGM2, PGM2L1 , PGM3, PHKB1 PKM2, PMM1 , POFUT1 , PPARD, PPP1 CB, PPP1 R2, PRKAA1 , PRKAB1 , PTEN1 PYGB, PYGL, RBKS, RPIA1 SDHB1 Sl, SLC2A2, SLC2A3, SLC2A8, SLC35A2, SLC35A3, SLC35D1 , SLC37A4, SLC3A1 , SMA4, SORD, SPAM1 , ST3GAL2, ST3GAL6, ST6GAL1 , ST8SIA2, ST8SIA4, SUCLA2, SUCLG1 , SUCLG2, SULF2, TFF1 , UAP1 , and UGP2 is used or a gene product encoded by a gene selected from said group of genes, in particular encoded by the coding region of said gene, is used, or RNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
In a particular preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting lipid metabolism in metabolic and tumorous disease for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of A4GALT, ABCA1 , ABCD2, ABCG1 , ABHD4, ACAA2, ACACA, ACADM, ACADS, ACAT2, ACBD3, ACLY, ACOT1 , ACOT11 , ACOT12, ACOT2, ACOT7, ACOX1 , ACOX2, ACSL1 , ACSL3, ACSL4, ACSL5, ACSL6, ACSS2, ADIPOR2, ADM, AGPAT1 , AGPAT2, AGPAT3, AKR1 B10, AKR1C1 , AKR1C3, AKR1C4, AKR1 D1 , ALDH3A2, ALOX5AP, ALOXE3, ANGPTL3, AOAH, APOA1 , AP0A2, AP0A4, APOB, APOBEC1 , APOC3, APOF, APOM, ASAH1 , ASAH2,
ATP8B1, AYTL2, B3GALT1, B4GALNT2, B4GALT4, BAAT, BTN2A1, BTNL3, C11orf11, C14orf1, CD36, CD74, CDC91L1, CDS1, CDS2, CEL, CERK, CHKA, CLU, CMAS, COQ2, CPNE3, CPNE7, CPT2, CRLS1, CROT, CUBN, CYP19A1, CYP2J2, CYP3A4, CYP3A5, CYP4A11, CYP4F3, CYP51A1, CYP7A1, DCTN6, DEGS1, DGAT1, DGKD, DHCR24, DHRS3, DHRS8, DPAGT1, EBP, EBPL, EHHADH, ELOVL2, ELOVL4, ENPP6, ENPP7, ETNK1, FABP1, FABP2, FABP5, FABP6, FADS1, FDFT1, FDX1, FLJ25084, GALC, GPAM, GPX4, HACL1, HADH, HADHA, HADHB, HAO2, HEXB, HMGCR, HMGCS1, HNF4A, HPGD, HSD17B2, HSD17B3, HSD17B4, HSD17B6, HSD3B1, HSD3B2, IHPK3, IMPA1, LARGE, LASS2, LASS5, LIPA, LIPC, LIPF, LOC340204, LPGAT1, LRP1, LRP2, LRP5, LYPLA2, MGC26963, MGLL, MGST2, MGST3, MIF, MTMR10, MTMR11, MTMR12, MTMR2, MTMR4, MTTP, MVK, NANS, NPC1, NPC2, NR1H4, NR1I2, NR2F2, NR5A1, OSBP, OSBP2, OSBPL10, OSBPL11, OSBPL1A, OSBPL3, OSBPL5, OSBPL6, OSBPL8, OSBPL9, PAFAH2, PBX1, PC, PCCA, PCCB, PCSK9, PCYT1A, PCYT1B, PCYT2, PDE3A, PDSS1, PECl, PECR, PEMT1 PGDS, PHYH, PIGC, PIGF, PIGH, PIGK, PIGL, PIGM, PIGY, PIGZ, PIK3C2A, PIK3R1, PIK4CB, PIP5K2A, PISD, PITPNA, PITPNB, PLA2G12B, PLA2G2A, PLA2G2E, PLA2G4A, PLA2G4D, PLA2G6, PLB1, PLCB1, PLCE1, PLCG1, PLCH1, PLCZ1, PLD1, PLIN, PMVK, PNLIPRP1, PNLIPRP2, PNPLA3, PNPLA8, PPAP2A, PPAP2B, PPARD, PPARG, PPP2CA, PPP2R1B, PRDX6, PRKAA1, PRKAA2, PRKAB1, PRKAB2, PRKAG2, PRLR, PSAP, PTDSS1, PTEN, PTGES, PTGIS1 RBP3, RDH12, SAMD8, SC4MOL, SC5DL, SCAP, SCARB1, SCD, SCD5, SCP2, SEC14L2, SELI, SERINC2, SERPINA3, SGPL1, SHH, SLC27A2, SLC27A3, SMPD1, SMPD3, SOAT1, SOAT2, SORL1, SQLE, SRD5A2, SREBF1, ST3GAL6, STARD4, STARD5, SULT1A1, SULT1B1, SULT1E1, SULT2A1, TBXAS1, TMEM23.TNFRSF1A, TPP1, TRERF1, UCP3, UGCG, UGT1A1, UGT2B11, UGT2B7, UGT8, VLDLR, WWOX, YWHAH, and ZNF202 is used or a gene product encoded by a gene selected from said group of genes, in particular encoded by the coding region of said gene, is used, or RNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
In a further preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting intracellular signaling in metabolic and tumorous disease for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of ABL1, ABL2, ABR, ABRA1 ACOT11, ACR, ADCY5, ADCY6, ADCY8, ADCY9, ADIPOR2, ADORA2A, ADORA2B, ADORA3, ADRA1B, ADRA1D, ADRB1, AGTR1, AKAP13, AKAP7, AMBP, ANP32A, APBB2, ARF1, ARF6, ARFGEF2, ARHGAP29, ARHGAP5, ARHGAP6, ARHGEF1, ARHGEF10L, ARHGEF11, ARHGEF12, ARHGEF17, ARHGEF18, ARHGEF3, ARHGEF5, ARHGEF7, ARID1A, ARL1, ARL4A, ARL4C, ARL4D, ARL5A, ARL5B, ARL8B, ASB1, ASB13, ASB14, ASB2, ASB4, ASB7, ASB9, ASIP, ATP2C1, AVPR1A, BCAR3, BCL10, BIRC2, BLNK, BRAF, BRCA1, C20orf23, C5AR1, CALCR, CALCRL, CAP1, CARD10, CARD4, CARHSP1, CBLB1 CCKAR, CCM2, CCNE1, CCR1, CDC42BPA, CDK7, CENTD3, CERK, CERKL1 CFL1, CFLAR1 CHN1, CHN2, CHP1 CHRM1, CHRM2, CNIH, CNIH3, CNIH4,
CORO2A, CRKL, CRSP2, CRSP6, CSK, CTNNB1, DAB2IP, DAPK1, DAPK2, DAPP1, DDAH1, DEPDC7, DERL1, DGKA, DGKB, DGKD, DGKH, DGKI, DIRAS3, DLG5, DNMBP, DRD2, DRD5, DSCR1, DSCR1L1, DUSP16, DUSP22, DUSP6, DUSP9, DVL3, DYNC1LI1, EDD1, EDG2, EDNRB, EGF1 EGFR, ELMO1, ERBB2, ERN1, ESR1, F2, F2R, FARP2, FGD2, FGD4, FGD5, FGF2, FHL2, FLJ20184, FLJ30934, FLJ38964, FLJ41603, FRK, FYN, G3BP, GADD45B, GADD45G, GAP43, GAPVD1, GBF1, GCC2, GEM, GHRH, GJA1, GLP1R, GNAQ, GNB1L, GPR89A, GRAP, GRB10, GRB14, GRB2, GRB7, GRK5, GRLF1, GTPBP4, GUCY2C, GUCY2D, HIPK2, HIST4H4, HMOX1, HRH2, HS1BP3, ICK, IFNAR2, IGF1, IHPK3, IL10, IL22RA2, IQGAP2, IQGAP3, IQSEC1, IQSEC3, IRAKI BP1, ITSN1, JAK1, KALRN, KIAA1804, KRAS, KSR1, KSR2, LAT, LATS 1, LATS2, LAX1, LGALS9, LHCGR, LTB4R2, LYN, MAGI3, MAP3K11, MAP3K13, MAP3K4, MAP3K7IP2, MAP3K9, MAP4K3, MAP4K4, MAP4K5, MAPK13, MAPK14, MAPK8, MAPKAPK2, MARK1, MARK2, MBIP, MC3R, MCF2L, MCTP1, MCTP2, MED4, MFHAS1, MGC39715, MINK1, MIST, NCK2, NCOA1, NCOA3, NCOA4, NDFIP1, NEK11, NEK6, NET1, NF1, NFAM1, NFKBIA, NKIRAS1, NKIRAS2, NLK, NMUR2, NOTCH2, NPR2, NPY, NRAS, NRIP1, NUDT4, OPRK1, OPRM1, OTUD7B, P2RY1, P2RY2, P2RY4, P2RY6, PAK1, PARD3, PARK7, PDCD11, PDK1, PDZD8, PIK3C2A, PIK3C2G, PIK3CB, PIK3R1, PIP5K3, PLCB1, PLCE1, PLCG1, PLCH1, PLCZ1, PLD1, PLEK2, PLEKHG1, PLEKHG2, PLEKHG3, PLEKHM1, PLK2, PPAP2A, PPARBP, PPARGC1B, PPM1A, PPP2CA, PPP2R1B, PRDX4, PRKAA1, PRKAR1A, PRKAR2B, PRKCA1 PRKCD, PRKCE, PRKCI, PRKCSH, PRKCZ, PRLR1 PSCD4, PSD3, PSD4, PSEN1, PTEN, PTPLAD1, PTPN11, RAB10, RAB11A, RAB17, RAB1A, RAB20, RAB27A, RAB30, RAB31, RAB32, RAB33A, RAB35, RAB37, RAB38, RAB3B, RAB3D, RAB43, RAB4A, RAB5A, RAB5C, RAB6C, RAB7, RAB7L1, RAB8B, RAB9A, RABIF1 RABL3, RAF1, RALB, RALGPS1, RALGPS2, RAN, RANBP3, RAP1A, RAP1B, RAP2A, RAP2B, RAPGEF1, RAPGEF4, RASA1, RASA2, RASA3, RASAL2, RASGEF1C, RASGRF1, RASGRF2, RBJ, RBM9, RGL1, RGS1, RGS3, RGS9, RHEB, RHOBTB2, RHOC, RHOF, RHOH, RHOT1, RIN2, RIPK1, RND1, RND3, ROCK1, ROCK2, RP1L1, RPS6KA5, RRAGC, RREB1, S100A1, SAC, SAR1B, SCAP, SDCBP2, SELS, SGEF, SGK2, SH2D1A, SH2D3A, SH2D4A, SH2D6, SH3BP5, SH3PXD2A, SHANK2, SHC1, SHE, SHF, SHOC2, SIAH2, SLA, SLC20A1, SMAD2, SNF1LK2, SNX1, SNX10, SNX11, SNX12, SNX13, SNX14, SNX19, SNX24, SNX27, SNX3, SNX4, SNX5, SNX7, SNX9, SOCS5, SOCS6, SOCS7, SOS1, SPAG5, SPRED1, SPRED2, SRPK1, SRPK2, SSTR1 , STAT5B, STAT6, STK17A, STK17B, STK3, STK38, STK38L, STK4, STMN4, SYNGAP1, TACR1, TAOK3, TBK1, TEC, TESK2, TFG, THRAP1, TIAM1, TIAM2, TMED4, TMEPAI, TMPRSS6, TNFAIP3, TNFRSF10B, TNFRSF19, TNFRSF1A, TNFSF10, TNFSF15, TNIK, TNK2, TNS1, TNS3, TRAF3IP2, TRAF5, TRAF6, TRIO, TRIP6, TSSK3, TULP4, UBE2V1, USH1C, VAPA, VAV2, VAV3, VIPR1, WASF2, WNK1, WNK2, WNK4, WSB1, WSB2, YES1, YWHAH1 ZAK, and ZDHHC13 is used or a gene product encoded by a gene selected from said group of genes, in particular encoded by the coding region of said gene, is used, or RNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
In another preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting cell cycle and cell proliferation in metabolic and tumorous disease for the purpose of its normalization , wherein a gene, in particular the coding region thereof, selected from the group consisting of
ABM, ABL1, ACHE, ACPP1 ACTN4, ADRA1B, ADRA1D, AGGF1, AHR, AIF1, ALS2CR19, ANAPC4, ANKRD15, APBB1, APBB2, APC, AR, AREG, ARHGEF1, ATM, ATPIF1, AXIN1, B4GALT7, BCAR1, BCAR3, BCL10, BCL2, BCL6, BHLHB3, BIN1, BRCA1, BRCA2, BRIP1, BTC, BTG1, BTG2, BUB1, C10orf46, C10orf9, C2orf29, C9orf127, CABLES1, CCL14, CCNA2, CCND1, CCND2, CCNE1, CCNE2, CCNH, CCNJL, CCNL1, CCNT1, CCNT2, CCRK, CD160, CD164, CD28, CD3E, CD74, CD86, CDC14A, CDC2, CDC25A, CDC25B, CDC25C, CDC37L1, CDC6, CDK10, CDK3, CDK4, CDK5R1, CDK5RAP3, CDK7, CDKL1, CDKN1A, CDKN1B, CDKN2A, CDKN2B, CDKN3, CDT1, CDV3, CENPF, CEP250, CETN2, CETN3, CHAF1A, CHES1, ChGn, CHRM1, CHRM4, CITED2, CLASP1, COL18A1, CREG1, CRTAM, CSF1, CSF1R, CSK, CTCFL, CUL1, CUL3, CUL4A, CXCL5, CYR61, DAB2, DBC1, DCC, DCTN2, DHCR24, DIP13B, DIRAS3, DLEC1, DLG1, DLG3, DLG5, DST, DUSP1, DUSP22, DUSP6, E2F3, E2F7, EDD1, EDN1, EGF, EGFR, ELF4, ELN, EML4, EMP1, ENPEP, ENPP7, EP300, EPS15, EPS8, ERBB2, ERBB2IP, ERG, ERN1, ESCO1, ESR1, ETS1, EXT1, F2, F2R, FABP6, FGA, FGB, FGF2, FGF8, FGF9, FGFR1OP, FGG, FHIT, FLCN, FLJ16793, FLJ40432, FLT1, FRK, G0S2, GAB1, GADD45A, GAS2, GAS6, GMNN, GNRH1, GRLF1, HBP1, HDAC6, HDAC7A, HDAC9, HDGF, HECA, HEXIM1, HIC1, HIPK2, HK2, HOXC10, HPGD, IGF1, IGF1R, IGFBP4, IL10, IL12RB1, IL12RB2, IL18, IL28RA, IL2RA, IL6R, IL9R, ING1, INHBA, INSIG1, IRF1, IRF2, IRS2, ISG20, JAG1, KATNB1, KIAA0367, KIAA0376, KIF25, KITLG, KLF4, KPNA2, KRAS, LAMB1, LAMC1, LATS1, LATS2, LIF, LIG4, LMO1, LRP1, LRP5, LTBP2, LYN, LZTS2, MACF1, MAD2L1, MAP2K6, MAP3K11, MAPK13, MAPK6, MAPRE1, MAPRE2, MAPRE3, MCC, MCM3, MCM8, MCRS1, MDM2, MDM4, MET, MIF, MKI67, MLH3, MNAT1, MNT, MOS, MPL, MSH5, MTSS1, MUTYH, MXD1, MXM, MYB, MYC, NBL1, NCK2, NDP, NEDD9, NEK11, NEK2, NEK6, NF1, NFYC, NIPBL, NME1, NOTCH2, NPY, NR6A1, NRAS, NRD1, NRP1, NUMA1, OPRM1, OSM, PAM, PAPD5, PARD3, PARD6B, PBEF1, PBK, PDCD4, PDF, PDGFB, PDGFRA, PEMT, PFDN1, PGF, PIK3CB, PIM1, PLAGL1, PLCB1, PLG, PMP22, POLA, POLS, POU3F2, PPAP2A, PPARD, PPM1D, PPP1CB, PPP1R9B, PPP2CA, PPP2R1B, PPP3CB, PPP6C, PRDX1, PRKCA, PRKG2, PRKRIR, PRL, PRM1, PROK1, PSMD1, PTEN, PTHLH, PTK2B, PTMA, PTMS, PTP4A1, PTPRC, PTTG1, QSCN6, RAD17, RAD50, RAD51, RAD51L1, RAD54L, RAD9B, RAF1, RAN, RAP1A, RASSF4, RB1CC1, RBL1, RBM5, RBM9, RCBTB1, RCC2, RECK, RFP, RGS2, RINT1, RPS27, RSN, RUNX3, S100A6, SASH1, SCIN, SEPT11, SEPT3, SEPT4, SEPT7, SESN1, SESN3, SGOL1, SH3BP4, SHC1, SHH, SIAH1, SIAH2, SKP2, SLAMF1, SLC12A6, SMARCB1, SMC3, SMPD3, SPAG5, SPHAR, SSR1, SSTR1, STARD13, STIM1, STRN3, SUPT3H, SYCP2, SYCP3, TACC1, TADA3L, TAL1, TBC1D8, TCF7L2, TCFL5, TERF2, TFDP1, TFDP2, TGFB3, TGFBI, TGFBR2, THY1, TM4SF4,
TNFRSF11A, TNFRSF8, TNFSF13B, TNFSF15, TNFSF4, TOB1, TOB2, TSGA2, TSPAN2, TSPAN3, TUBG1, TXLNA, TXN, UBE2V1, UHRF1, UHRF2, UNC84B, UNG2, USP8, UTP14C, VEGF, VIPR1, WEE1, WT1, WWOX, XRN1, YWHAG, YWHAH, YWHAQ, ZAK, ZFP36L2, ZW10, andZZEFI is used or a gene product encoded by a gene selected from said group of genes, in particular encoded by the coding region of said gene, is used, or RNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
In a particular preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting programmed cell death in metabolic and tumorous disease for the purpose of its normalization, wherein a gene, in particular the coding region thereof, selected from the group consisting of ABL1, ACIN1, ACTN1, ACTN4, ADORA2A, AHR, ALB, AMID, AMIG02, ANXA4, ANXA5, APOE, APP1 ASAH2, ATG5, AXIN1, BAD, BAG2, BAG3, BBC3, BCAR1, BCL10, BCL2, BCL2A1, BCL2L1, BCL2L10, BCL2L11, BCL2L14, BCLAF1, BID, BIRC2, BIRC3, BIRC4, BMF, BRAF, BRCA1, BRE, BTG1, CARD10, CARD4, CASP10, CASP3, CASP6, CBX4, CD28, CD3E, CD74, CDC2, CDK5R1, CDKN1A, CDKN2A, CEBPG, CFL1, CFLAR, CIAS1, CLU, COP1, CRADD, CROP, CRTAM, CTNNBL1, CTSB, CUL1, CUL3, CUL4A, CYCS, DAD1, DAP, DAPK1, DAPK2, DCC, DHCR24, DIDO1, DNASE1, DNASE1L3, DUSP22, EBAG9, EDAR1 EFHC1, EGLN3, ELMO1, ELMO2, EP300, ERCC3, ERN1, F2, F2R, FAIM, FAIM3, FASTKD1, FOXL2, FOXO1A, FOXO3A, GADD45A, GADD45B, GADD45G, GAS2, GPR65, GSTP1, HBXIP, HIPK2, HMGB1, ICEBERG, IER3, IGF1R, IHPK2, IHPK3, IL10, IL18, IL2RA, INHBA, KIAA0367, KNG1, MAGEH1, MAGI3, MCL1, MDM4, MIF, MOAP1, MRPS30, MTP18, NCKAP1, NEK6, NFKB1, NFKBIA, NME1, NME6, NOTCH2, NRG2, NTF3, NUAK2, NUDT2, OPA1, PAK1, PAWR, PAX7, PDCD10, PDCD11, PDCD2, PDCD4, PDCD6, PECR, PERP, PHLDA1, PHLPP, PIM1, PLAGL1, PLG, PPARD, PPP2CA, PPP2R1B, PRF1, PRKAA1, PRKCA, PRKCE, PRKCZ, PRLR, PROC, PRODH, PSEN1, PTEN, PTH, PTK2B, PTPRC, PTRH2, RAF1, RASA1, RFFL1 RHOT1, RIPK1, RIPK3, RNF7, ROCK1, RP6-213H19.1, RRAGC, RTN4, RUNX3, RYBP, SCARB1, SCIN, SEMA4D, SEMA6A, SEPT4, SERPINB9, SGK, SGPL1, SH3GLB1, SIAH1, SIAH2, SIRT1, SMNDC1, SNRK, STK17A, STK17B, STK3, STK4, TAIP-2, TAX1BP1, TEGT1 TESK2, THY1, TIA1, TIAL1, TIMP3, TLR2, TNFAIP3, TNFAIP8, TNFRSF10B, TNFRSF11B, TNFRSF19, TNFRSF1A, TNFRSF21, TNFRSF25, TNFSF10, TNFSF15, TNFSF18, TP53INP1, TP73L, TPT1, TRAF3, TRAF5, TRAF6, TRIB3, TXNDC5, UBE4B, UNC5B, VDAC1, VEGF, YWHAG, YWHAH, ZAK, ZBTB16, ZDHHC16, and ZNF346 is used or a gene product encoded by a gene selected from said group of genes, in particular encoded by the coding region of said gene, is used, or RNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
In a particular preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to identify drugs targeting
cell morphogenesis and cell / organ development in metabolic and tumorous disease for the purpose of its normalization , wherein a gene, in particular the coding region thereof, selected from the group consisting of
ABLIM1, ABTB2, ACHE, ACIN1, ACTL6A, AGGF1, AHSG, ALX4, AMELX, AMIGOi, AMOT, ANGPTL3, ANKH, ANXA2, APBB1 , APBB2, APOE, AR, ARF6, ARHGEF11 , ARTS-1 , ASH2L, ATP10A, ATPIF1, AXIN1, BCAR1, BCL11A, BHLHB3, BMP2, BMP3, BMP4, BMP6, BMP7, BMP8A, BMP8B, BRAF, BRD8, BTG1, BVES, CACNB2, CALCR, CAMK2D, CANX, CAP1, CAPN3, CART1, CASC5, CASQ2, CCL4, CCM2, CD164, CD1D, CD74, CD86, CD9, CDC42EP4, CDC42EP5, CDH11, CDK5R1, CDK5RAP2, CDK5RAP3, CDX2, CEACAM1, CEBPA, CEBPG, CENPF, CENTD3, CHRDL2, CITED2, CLASP1, CLEC3A, CNTN4, COL11A2, COL12A1, COL18A1, COL1A1, COL1A2, COL2A1, COL9A1, COVA1, CRB1, CREG1, CRIM1, CSDE1, CSF1, CSRP3, CTGF, CYR61, DAZL, DCC, DDX5, DGAT1, DGKD, DLC1, DLG1, DMAP1, DMD, DVL3, DZIP1, EBAG9, EBP, EGFR, ELN, EMP1, EPAS1, ERBB2, ERBB2IP, ESR1, ETS1, ETS2, EVL, EXT1, EYA2, FABP1, FARP2, FBLIM1, FBN1, FCMD, FEZ2, FGD2, FGD4/FGD5, FGF2, FGFR2, FHL1, FLNB, FLT1, F0XL2, FOXN1, FOXO3A, FRZB, GAP43, GAS2, GAS6, GATA4, GATA6, GDF10, GHR1 GJA1, GLCE, GNAO1, GRLF1, HAND1, HBEGF, HCCS, HDAC7A, HDAC9, HECA, HEY1, HILS1, HMGCR, HOXA13, HSD17B3, IFRD1, IGF1, IGFBP2, IGFBP4, IHPK2, IL10, IL18, ING1, ING2, INHBA, IPF1, ITCH, ITGA11, ITGA2, ITGB1BP2, JAG1, KAZALD1, KDR, KIRREL3, KITLG, KL, KLF6, KRT19, LAMB1, LARGE, LECT2, LHCGR, LHX3, LIMA1, LTBP4, LYN, MAFB, MAP7, MARK2, MATN1, MBNL1, MBP, MEF2A, MEF2C, MKKS, MKL2, MPZ, MSX1, MSX2, MTSS1, MUSK, MYF6, MYH10, MYH14, MYST3, NCOA4, NEDD9, NET1, NFAM1, NKX2-2, NOTCH2, NOTCH4, NR5A1, NRCAM, NRD1, NRP1, NRP2, NRXN3, NTNG1, OKL38, OSM, PAPPA2, PAPSS1, PAPSS2, PARD3, PARD6B, PAX1, PAX2, PBX1, PBX3, PDLIM5, PGF, PHEX, PHGDH, PITX1, PITX2, PITX3, PLEKHC1, PLG, POU3F1, P0U4F1, POU6F1, PPARD, PPP1R9B, PPP2CA, PPP2R1B, PRDX1, PRELP, PRKCI1 PRL1 PTEN, PTH1 PTPRC1 QSCN6, RAB3D, RASA1, RHOH, RND1, ROBO1, ROBO2, RPS6KA3, RRAGC, RTN4, RTN4RL1, RTN4RL2, RUNX1, RUNX2, RUVBL1, S100A6, SCGB1A1, SCIN1 SEMA6A, SGCB1 SGCE1 SHC1, SHH, SIAH1, SIRT1, SIX1, SLIT1, SMARCA1, SNAH1 SNRK1 SOCS5, SOCS6, SOCS7, S0RT1, SOX6, SOX9, SPAG6, SPARC, SPINK5, SPN1 SPRY2, SRD5A2, SRI1 STIM2, SVIL, SYCP3, TAGLN3, TBX3, TCF12, TC0F1, TGFB3, THY1, TINAG, TLE1, TLE3, TMEM97, TMPRSS6, TNFAIP2, TNFRSF11B, TNN, TNP1, TNR1 TPD52, TRAPPC4, TSSK3, TUFT1, UBE3A, UTRN, VCL, VCX3A, VEGF1 VIL2, WISP1, WISP3, XRN2, YEATS4, YWHAH, ZBTB16, ZNF160 and ZNF22. is used or a gene product encoded by a gene selected from said group of genes, in particular encoded by the coding region of said gene, is used, or RNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, are used.
In yet a further preferred embodiment, the use according to the first aspect of the invention or the method according to the second aspect of the invention is performed to select drug
candidates of an antisense molecule, ribozyme, triple helix molecule or other new chemical entities targeting the chromatin.
Within the context of diagnosis and therapy, the invention further comprises a kit for qualifying the HNF4α activity in a patient suffering or being susceptible to metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases, in particular for predicting or monitoring the response of a patient to suffering from at least one of said diseases by a method of treating metabolic and/or tumorous diseases comprising administering a HNF4α activity modulator, comprising at least one standard indicative of the level of a biomarker selected from the groups of genes described herein, preferably the group according to claim 1 , or from the group of gene products encoded by said groups of genes in normal individuals or individuals having metabolic and/or tumorous disease associated with increased HNF4α activity, and instructions for the use of the kit, and, preferably, wherein the at least one standard comprises an indicative amount of at least one gene selected from one of the groups of the genes and/or at least one gene product encoded thereby.
In particular it is preferred if the kit according to the invention further comprises at least one primer or primer pair specifically hybridizing with the mRNA of a biomarker selected from one of the groups of genes and/or at least one antibody specific for a biomarker selected from the group of gene products encoded by said genes, and reagents effective to detect said biomarker(s) in a serum sample.
Within the context of the therapy according to the first aspect of the invention, a medicament for the treatment of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer is provided, wherein the medicament comprises a composition that decreases the expression or activity of a HNF4α modulated gene selected from one of the groups of genes described herein, preferably from the group specified in claim 1.
Within the context of the therapy also an SiRNA composition is provided, wherein the siRNA composition reduces the expression of a de novo identified HNF4α modulated gene selected from one of the groups of genes described herein, preferably from the group specified in claim
1.
The present invention thus employs SiRNA oligonucleotides directed to said genes specifically hybridizing with nucleic acids encoding the gene products of said genes and interfering with gene expression of said genes.
Preferably, the siRNA composition comprises siRNA (double stranded RNA) that corresponds to the nucleic acid ORF sequence of the gene product coded by one of said human genes or a subsequence thereof; wherein the subsequence is 19, 20, 21 , 22, 23, 24, or 25 contiguous RNA nucleotides in length and contains sequences that are complementary and non-complementary to at least a portion of the mRNA coding sequence.
The nucleotide sequences and siRNA according to the invention may be prepared by any standard method for producing a nucleotide sequence or siRNA, such as by recombinant methods, in particular synthetic nucleotide sequences and siRNA is preferred.
Further, an antisense composition is provided, wherein the antisense composition comprises a nucleotide sequence complementary to a coding sequence of a HNF4α modulated gene selected from one of the groups of genes described herein, preferably from the group specified in claim 1.
In this regard, the term "coding sequence" is directed to the portion of an mRNA which actually codes for a protein. The term "nucleotide sequence complementary to a coding sequence" in particular is directed to an oligonucleotide compound, preferably RNA or DNA, more preferably DNA, which is complementary to a portion of an mRNA, and which hybridizes to and prevents translation of the mRNA. Preferably, the antisense DNA is complementary to the 5' regulatory sequence or the 5' portion of the coding sequence of said mRNA. It is preferred that the antisense composition comprises a nucleotide sequence containing between 10-40 nucleotides , preferably 12 to 25 nucleotides, and having a base sequence effective to hybridize to a region of processed or preprocessed human mRNA.
In particular, the composition comprises a nucleotide sequence effective to form a base-paired heteroduplex structure composed of human RNA transcript and the oligonucleotide compound, whereby this structure is characterized by a Tm of dissociation of at least 450C.
Preferably, the siRNA composition and/or the antisense composition is/are used for the preparation of a medicament, in particular for the preparation of a medicament for preventing, treating, or ameliorating metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer.
Within the context of using drugs according to the invention it is preferred, if said siRNA composition and/or said antisense composition a composition is used.
Within the context of using a HNF4α acitivity modulator according to the invention, it is preferred, if a nucleic acid, in particular DNA, hybridizing with the expression regulatory sequence of matrix 1 is used.
Further scope of applicability of the present invention will become apparent from the detailed description given hereinafter. However, it should be understood that the detailed description and specific examples, while indicating preferred embodiments of the invention, are given by way of illustration only, since various changes and modifications within the spirit and scope of the invention will become apparent to those skilled in the art from this detailed description.
Detailed description
Because of its master regulatory function and its role in malignant disease a new method was probed were particularly interested to search genome-wide for genes regulated by HNF4α. Here a comprehensive genome-wide scan for the de novo identification of HNF4α gene targets by use of the ChlP-chip human genome tiling arrays is reported. With high resolution (on average 35 bp) it was possible to map greater than 17000 binding sites for HNF4α in a human intestinal adeno-carcinoma cell line. Notably, the enterocyte-like Caco-2 cell line has been widely used as a model for intestinal epithelial cells (Delie and Rubas, 1997) and was found to express a high level of HNF4α. This cell line differentiates into enterocytes upon confluence (Soutoglou et al., 2002). Furthermore, in differentiated Caco-2 cells HNF4α protein expression is comparable to its expression in liver (Niehof and Borlak, 2008). Therefore, Caco-2 cells are an interesting system to study the HNF4α gene regulatory network.
The study according to the invention is the first genome-wide approach to identify nearby 6600 RefSeq genes targeted by HNF4α. The importance of promoter-distal regions in HNF4α mediated transcriptional control is highlighted, and a basis for elucidation of transcriptional networks formed by cooperating transcription factors acting in concert with HNF4α is offered. Finally, based on induction of HNF4α protein expression and a genome-wide transcriptome analysis, good agreement between de novo identified genes and their expression in Caco-2 cells is demonstrated. Taken collectively, the studies according to the invention will help to determine the role of HNF4α gene regulatory networks in cancerous and metabolic diseases and can therefore be applied for an identification of new drug targets in the development of genome based medicines.
Results:
ChIP experiments were performed with Caco-2 cell culture as described by Niehof et al. (2005). An antibody with high specificity against HNF4α (Santa Cruz sc 6556x) was used for the IP. Enrichment of two known positive controls, binding sites in the promoter regions of HNFIa and AGT, was confirmed by quantitative real time PCR.
Total input DNA from three independent biological replicates, which served as a control, was diluted to 1 ng/μl, and amplified in parallel with IP-DNA from three independent biological replicates following a PCR amplification protocol optimized for unbiased amplification. After labeling, the samples were hybridized to Affymetrix Human tiling 2.0R arrays with a genome- wide 35 bp resolution. After quantile normalization, raw data were analyzed for enriched regions by three independent algorithms (TAS (Affymetrix), MAT (Johnson et al., 2006) and Tilemap (Ji et al., 2005)). Initial cut off criteria were determined based on the detection of a weakly enriched positive control (OTC). Parameters for enrichment site (ES) detection were further improved based on the frequency of HNF4α -motives within the enriched regions, which was determined by application of the MATCH algorithm (KeI et al., 2003). To increase confidence in the identified intervals, results from all three algorithms were intersected. However, the overlap of ES identified by the three approaches was very high (Fig. S1), and differences partially due to the use of different repeat libraries. Intersecting of the different data sets lead to the identification of 17.561 enrichment sites, which agrees well with the high number of ES described by Rada-lglesis et al. (2005).
To determine the reliability of the identified ES, 15 ES were randomly chosen and enrichment in the primary IP-DNA was confirmed by realtime PCR (Fig. 1). For all selected sites, enrichment could be confirmed, indicating a low false discovery rate.
Among the identified ES were many HNF4α binding sites described in literature and present in the Biobase database, including /WT (R00114), GCC (R08885), PCK (R12074), APOB (R01612), CYP2C9 (R15905), AKR1C4 (R13037), ACADM (R15923) or CYP27A1 (R15917). In several cases, like SHBG (R15941), enrichment sites were found within a few hundred basepairs relative to the reported binding sites. Other binding sites described in literature, like ALDH2 (R15845), could not be confirmed. Quantification by real time PCR showed that the ALDH2 site was also not enriched in the primary IP-DNA. This does not necessarily mean that these sites are not bound by HNF4α in Caco-2 cells, as interacting factors may mask the HNF4α epitope.
However, as HNF4α binding sites described in literature were identified in many different tissues/cell lines, it must be expected that some are not bound in Caco-2 cells, as accessibility of binding sites depends on chromatin organization, which in turn depends on the cell type. This is supported by ChlP-chip publications on other transcription factors, where different cell types were tested in parallel, and significant differences in DNA binding sites in these different cell types were reported (e.g. Xu et al., 2007).
HNF4α binds predominantly to enhancer elements
To analyze the distribution of HNF4α binding sites relative to transcription start sites (TSS), the distance from the center of each ES to the closest TSS of a RefSeq gene was determined. In the study according to the invention, an ~4.7-fold overrepresentation of promoter-proximal ES was observed (Table 1 ; Fig. 2). However, only 4 % of the ES mapped to promoter-proximal
regions, and 3 % of all RefSeq promoters are bound (Table 1). This agrees well with the findings reported by Rada-lglesias et al. (2005), but contradicts results reported by Odom et al. (2004), where >12% of all promoters were bound by HNF4α. The overall distribution of ES is very similar to that observed in genome-wide ChlP-chip for another member of the nuclear receptor family, i. e. the estrogen receptor (Carroll et al., 2006). A significant lack of preference for binding to 5' promoter-proximal regions has also been reported for other transcription factors, e.g. p53, cMyc or p63 (Table 7; Cawley et al., 2004; Wei et al., 2006; Yang et al., 2006). Thus, some transcription factors like E2F1 show a clear preference for binding to 5' promoter- proximal regions (Bieda et al., 2006), but accumulating evidence is highly suggestive for promoter-proximal regions to constitute only a small fraction of mammalian gene regulatory sequences. Indeed, members of the nuclear receptor family clearly display higher activity at enhancer rather than promoter binding sites, as evidenced by the invention and other investigators (e.g. Bolton et al., 2007). Consequently, studies based on promoter sequence containing arrays can be misleading.
Indeed, for many transcription factor, binding sites are located in first introns. Therefore the frequency of binding sites in introns of RefSeq annotated genes was analyzed in more detail (Fig. 2). A clear overrepresentation for binding sites in the first introns was observed, but less so for second introns, while binding sites in third (or more distant) introns were not significantly enriched as compared to the random control set.
The distribution of identified ES across the chromosomes shows a clear under representation for the Y chromosome (Table 2). Noteworthy, even when excluding the sex chromosomes, the ES/gene ratio varied greater than 6 fold between the chromosomes. Therefore, further the chromosomal distribution of ES was analyzed, and it was found that they are not randomly distributed, rather clusters are formed (Fig. 3a). These clusters are not related to differences in the gene density within these regions, as shown for on chromosome 10 (Fig. 3b).
The HNF4α motif is highly enriched within the ChIP regions:
Known HNF4α binding motifs are highly abundant within the ChIP regions. Using stringent criteria to minimize false positives, an up to > 14-fold enrichment was detected for different HNF4α matrices compared to the genomic background (Table 3). This enrichment allowed an easy 'de novo' identification of the HNF4α motif: Among 5 motifs identified by a Gibbs motif sampler, 2 motifs represented HNF4α binding sites (Fig. 4).
When the regions of 500bp surrounding the 17561 identified binding sites were analyzed for HNF4α motifs with settings to minimize false negatives, 23145 motifs more than in random control sequences (i.e. above background) were counted. This equals 1.32 motifs / ChIP region. Further, in 98.1% of all ChIP regions at least one motif was detected. Minimize false negatives (MinFN) cut off criteria of the Transfac matrix were set to a value that provides recognition of 90% of binding sites used to create the matrix, accepting 10% false negatives. As the fraction of sequences without detected motifs is significantly smaller than 10%, it is possible that these
sequences may also contain HNF4α binding sites. This indicates that most of the ChIP regions are enriched due to direct binding of HNF4α.
Then the binding sites reported by Rada-lglesias et al. (2005) were analyzed by the same approach, and 1.13 motifs / Chip region (500bp surrounding the 194 identified binding sites) were counted. This is significantly less than seen with the data set according to the invention. Therefore, the use of high resolution tiling arrays enabled better identification of high quality binding sites.
Rada-lglesias et al. (2005) speculated that the identified ES within 5000 nt from the closest transcription start site are due to indirect interactions of HNF4α with other transcription factors. Consequently, they developed a model where HNF4α binds to distant (>5000 nt) enhancer elements, that create chromatin loops by interacting with other, promoter-bound transcription factors. Unfortunately, this model is based on less than 1 % of genomic sequences. However, using the high statistical power of the genome-wide data according to the invention, indeed a higher representation of HNF4α binding motifs was shown in promoter-distal regions compared to promoter-proximal regions (Figure S3a). Further, regions with a low enrichment, indicated by a high P-Value given by the detection algorithm, show a higher percentage of promoter- proximal binding sites, and a lower number of HNF4α motifs, than regions with higher enrichment (Figure S3b). Therefore, it was demonstrated that often HNF4α binding to promoter- proximal regions is indirect (due to interaction with other transcription factors), and therefore weaker. However, as HNF4α motifs are still enriched in promoter-proximal regions it seems likely that HNF4α can act as a promoter binding as well as an enhancer binding transcription factor.
Enhancer elements defined by HNF4α display high conservation
An analysis of the average conservation of the HNF4α binding sites identified in this study was performed by use of the tool CEAS (Ji et al., 2006), which extends binding sites in both directions, and calculates the average conservation score for each nucleotide (Fig. 5a). Nucleotides in the center, were an enhancer element could be expected, show a two times higher conservation than those at the ends of the plot (genomic background). The increased conservation supports the idea that the detected HNF4α binding sites are situated within evolutionary maintained enhancer elements. When the same analysis was performed by aligning the ES peak position detected by MAT, instead of the center position of the ES, the conservation peak was even more clearly defined. The sharp drop at a distance of ~250 nucleotides to the peak position may be suggestive for these enhancer elements to have a size of ~500 nucleotides.
Subsequently, the distribution of HNF4α motifs around the peak and center positions of the ChIP regions was analyzed (Fig. 5b). Again, distribution of motifs around the peak position showed less scattering than the distribution around the center position, supporting that the peak
position gives a better prediction of the actual binding site. An enrichment of motifs above background was restricted to a region of 600-1000 nucleotides around the peak position.
Transcription factors cross-talk with HNF4α
To identify transcription factor binding sites that might form composite modules together with detected HNF4α binding sites, the ChIP regions for overrepresented motifs were analyzed, using motif analysis programs from Biobase and Genomatix, as well as the tool CEAS. Among the motifs with the highest fold enrichment are matrices similar to the HNF4α binding motif, e. g. the binding motifs for COUP-TF, PPAR or LEF1 (Table 3; Fig. 6). These transcription factors are known to compete with HNF4α for common binding sites (Galson et al., 1995; Hertz et al., 1995; Hertz et al., 1996; Dongol et al., 2007; For motif similarity see also Kielbasa et al., 2005). However, many motifs dissimilar to HNF4α, e.g. the binding motifs for HNF1 , AP1 , GATA transcription factors or CREB, where also enriched within the ChIP regions (Table 3; Supplementary tables S1 , S2 and S3; Fig. 7). Significant overrepresentation of these motifs has been further confirmed with different sets of ChIP regions defined by high- and low stringency cut-off criteria (data not shown). The corresponding transcription factors can therefore be expected to form composite modules with HNF4α. If these factors act combinatorial with HNF4α, it could be further expected that the frequency of their motifs increases with decreasing distance to the HNF4α binding sites. Therefore, the frequency of their motifs relative to the HNF4α binding sites was analyzed identified in this study.
A histogram of the density of binding motifs for the transcription factors AP1 , GATA, ER and HNF1 relative to the peak position of the regions detected by ChlP-chip was created (Fig.8). This histogram shows that the enrichment of these motifs is restricted to a region of a few hundred basepairs around the peak position, supporting the idea that they are part of enhancer elements defined by HNF4α. Interestingly, besides relative increase of the frequency of binding motifs for AP1 , GATA, ER and HNFIa, a negative relationship between HNF4α and CART binding motifs was also observed. It is tempting to speculate that this significant drop in CART motif frequency is of regulatory importance for HNF4α.
Other analyzed motifs showed only a slight correlation between the number of motifs and the distance to the peak position, although they were clearly enriched or depleted in ChIP regions compared to background controls (e.g. USF, HNF6, CREB). Future studies need to delineate their cooperativity with HNF4α, even though their motifs are wider spread and no clear peak formation is detectable.
Additionally, sequence similarity of HNF4α and estrogen receptor (ER) binding motifs at flanking sequences was observed (Fig. 9). Enrichment of ER motifs, and possibly other motifs as well, could therefore be coincidental for enrichment of HNF4α. To analyze the probability of cooccurrences of enriched motifs, and to get a better idea about the distances between AP1 , GATA, ER and HNF4α binding sites, it was aimed to locate the exact HNF4α binding sites by motif analysis. The genomic position of the highest scoring HNF4α motif (highest likelihood
ratio) within the ChIP regions was retrieved and extended for 500 nucleotides to both flanks. Within these sequences, other enriched motifs were detected and the distance to the HNF4α motif (i.e. the centre) was calculated (Fig. 10). As expected, most ER motifs co-locate with HNF4α motifs, leading to the high peak at the center. In contrast, HNF1 , AP1 an GATA motifs have their highest enrichment in a distance of 20 to 60 nucleotides to the HNF4α motifs, and are underrepresented in the center due their mutual exclusion by the presence of the HNF4α motif. As the ER motif partially overlaps with the HNF4α motif, it is difficult to judge whether enrichment within the ChIP regions is due to a functional connection between the two factors. Recently, a genome-wide map of ER binding sites was obtained (Carroll et al, 2006). Binding sites for ER and HNF4α were compared, and a considerable overlap was found (Fig. 1 1). Using the low stringency set of HNF4α binding sites binding, 15% of the ER binding sites were also targeted by HNF4α, supporting the idea of cooperation between HNF4α and the ER nuclear receptor.
A genome-wide ChlP-chip scan reveals HNF4α's master function
As mentioned above, ChlP-chip experiments were employed by Rada-lglesias et al (2005) to identify HNF4α binding sites within the ENCODE regions in HepG2 hepatoma cells. Likewise, a ChlP-chip protocol was used by Odom et al. (2004) to identify binding sites within promoter regions in human hepatocytes and pancreatic islets. Here the genomewide approach according to the invention was compared with the aforementioned studies to identify regions which overlap amongst these platforms, and the data according to the invention was compared to the binding sites reported in these publications (Fig. 12; Table 7).
Of the 194 enrichment sites reported by Rada-lglesias et al (2005), 76 overlapped with 244 enrichment regions identified according to the invention within the ENCODE region. This equals to 39 % agreement as compared to an overlap with a random control group of 1 %. Nonetheless, in the study according to the invention and that of Rada-lglesias different cells were used and the platforms and protocols employed may not bedirectly comparable. Furthermore, in the study of Odom et al. (2004) 1553 HNF4α bound promoter sequences were reported for hepatocytes. In the study according to the invention, and when compared with the sequences used on the Hu13K arrays of Odom et al., a total of 575 binding sites were detected (Fig 12; Table 7). Of these, 200 binding sites overlapped with the data according to the invention. Therefore 13 % of the promoter binding sites proposed by Odom et al. are confirmed, but no evidence for the remaining ~ 1300 HNF4α binding sites suggested by Odom et al. was obtained. Given the fact that the authors proposed a 16% false discovery rate the need for quality controls becomes apparent. Furthermore, the overlap with a random control group of 5% is comparably high. Actually, of HNF4α binding sites reported in pancreatic islets only 9 % could be confirmed for Caco-2 cells. This is much less significant than the overlap obtained with the data reported by Rada-lglesias et al.(2005).
Search for insulators in HNF4α targeted genes
Most enhancers appear to be promiscuous and can regulate multiple genes (West et al., 2005). Additionally, the genes with the TSS closest to the enhancer are not necessarily the ones regulated by this enhancer (Blackwood, 1998). Enhancer action can thus take place over hundreds of kilobases (Dekker et al.2008), and even cases of inter-chromosomal regulation by enhancers are known (Spilianakis et al., 2005). Nonetheless, most known enhancer elements are within 100000 nt of their respective TSS.
Activity of an enhancer is defined by enhancer-blocking insulators. If an active insulator is placed between an enhancer and a promoter, no communication between them, and therefore no activation of transcription by the enhancer, is possible. In vertebrates, binding of the protein CTCF to an insulator element is required for insulator function. Recently, genome-wide data of insulator regions became available. Kim et al. (2007) identified 13.804 CTCF binding sites. Furthermore, they compared insulator activity between different cell types, and found that CTCF localization is largely invariant.
To associate the HNF4α binding sites identified by the ChlP-chip approach according to the invention with target genes, all RefSeq genes with a TSS separated by less than 100000 nucleotides from these binding sites were selected. It was then considered reasonable to reduce the number of false enhancer-gene associations by removing all genes from the target list according to the invention which were separated from their associated enhancer by a CTCF- binding site originally identified by Kim et al. (2007). With this approach 5936 potential RefSeq target genes of HNF4α were identified.
Ontology of de novo identified HNF4α gene targets
Based on RefSeq annotations it was possible to group de novo identified genes associated with HNF4α binding sites by Ontology terms. As expected, many genes identified in the present study are involved in different metabolic processes (lipid metabolism, organic acid metabolism, carboxylic acid metabolism, phosphate, alcohol and carbohydrate metabolism), with the highest significance for genes coding for steroid metabolism. Categories related to transport, especially lipid transport, were also significantly overrepresented. The pivotal role of HNF4α in the regulation of a wide range of metabolic and transport processes (e.g., fatty acid and cholesterol metabolism) is well known (Watt et al., 2003; Schrem et al., 2002). Likewise, significant overrepresentation of developmental (e.g., kidney development) and differentiation categories was found. HNF4α is well known to have an important role in development (Sladek et al., 1990; Sladek et al, 1993), and is an essential driver for epithelial differentiation (Watt et al., 2003). Needless to say, HNF4α ko mice die around E 8_5 due to deficient organ development. In general, HNF4α can be seen as a regulator of an epithelial phenotype, and several lines of evidence suggest HNF4α to play an essential role in activation of the expression of genes
encoding cell junction molecules (Spa'th and Weiss, 1998; Chiba et al., 2003; Parviz et al., 2003; Satohisa et al., 2005; Battle et al., 2006).
Another overrepresented GO category is insulin receptor signaling. HNF4α is well known to control the insulin secretory pathway (Miura et al., 2006), and was linked to rare monogenic disorder, maturity-onset diabetes of the young (MODY), confirming its role in insulin signaling (Yamagata et al., 1996). The overrepresentation of GO categories representing well known functions of HNF4α supports the general biological significance of the association of binding sites according to the invention with target genes.
Furthermore, overrepresentation of categories involved in signaling and regulation of cellular processes was found. Few direct targets in these categories are known for HNF4α, however, the role of HNF4α in development is likely to involve regulation of different signaling pathways. Also a highly significant overrepresentation of the categories cell death and apoptosis was found, which might be related to HNF4α -functions in development. Indeed, genes from these categories might be important in context of a tumor suppressor activity of HNF4α which was recently suggested (Grigo et al., 2008). Overall, the data according to the invention can help to identify genes in metabolic and cancerous disease.
Correlation of genome-wide HNF4α ChlP-chip and gene expression data
Besides ChlP-chip, the most common approach to identify targeted genes is to analyze changes in transcript abundance caused by its increased or diminished expression or activity. Several investigators have thus used this approach to identify genes targeted by HNF4α. Among these, three publications used human cells (Lucas et al, 2005: HEK293 human embryonic kidney cells; Naiki et al., 2002: HUH7 human hepatoma cells and Sumi et al., 2007: HepG2 human hepatoma cells). Surprisingly, the authors reported that HNF4α activity influenced the transcript levels of only a small number of genes. However, it is known from yeast, that most transcription factors bind under 'non-activating' conditions, and that often transcriptional regulation is not mediated at the level of DNA binding alone (Harbison et al., 2004). A further limitation of expression studies is that they only recover target genes that respond to analyzed transcription factor under the chosen, often unphysiological experimental conditions, e. g. exaggerated expression etc.. Furthermore, such expression analyses cannot differentiate between direct and indirect targets.
Therefore, to confirm functional binding sites of de novo identified HNF4α gene targets, Caco-2 cell cultures were treated with Aroclor 1254, a known HNF4α inducer (Borlak et al., 2001). Indeed, after Aroclor 1254 treatment of Caco-2 cells, binding of the HNF4α protein to the HNF1 promoter was increased (Niehof and Borlak, 2008). Caco-2 cells were treated with Aroclor 1254 for 48 and 72 hours. Strong induction of HNF4α was confirmed by western blot analysis (Fig. 12) and increased binding activity by EMSA, and genome-wide expression profiling by microarray analyses was performed to search for regulated genes. Using stringent criteria (llogarithmized signal ratio| > 1.5, both after 48 and 72 hours), 536 unique RefSeq-annotated
genes were identified to be regulated (Suppl. table 4). Of these, 383 genes were upregulated and 153 genes were downregulated. These were compared to the list of potential targets identified by the ChlP-chip study according to the invention, and a highly significant overlap of 63 % or 336 genes was found (Table 6). This stresses the importance of HNF4α in the Aroclor 1254 response, and supports the biological significance of HNF4α binding sites identified by ChlP-chip tiling arrays.
Finally, published data for HNF4α targets based on its overexpression in mammalian cell lines were compared. Essentially, a high overlap, ranging from 65 to 94 %, of the genes identified by expression profiling experiments was found (Table 6). Interestingly, the highest overlap was found with the targets identified by Sumi et al. (2007). The approach used in this study differs from the others in the point that targets were not only identified by overexpression of HNF4α, but also by knock down by si'RNA, and only genes increased by overexpression and decreased by siRNA were reported as target genes. Therefore, targets reported here might be considered more reliable.
Discussion
For technical as well as practical reason, research on trans-acting factors and their corresponding c/s-elements focused on promoter-proximal binding sites. With the availability of
ChlP-chip assays, genome-wide scans for transcription factor binding sites becomes feasible.
This highly significant improvement will translate to better understanding of basic mechanisms of transcriptional control and an identification of promoter distal binding sites in facilitating RNA processing events.
In the study according to the invention it was focused on the transcription factor HNF4α, as this protein plays a critical role in liver development and its metabolic competence. This Zinc-finger protein is also of highest interest in drug discovery and cancer research, as highly malignant hepatocellular carcinomes could be reverted to a less aggressive phenotype by overexpression of HNF4α (Lazarevich et al., 2004). For the first time an unbiased, genome-wide set of HNF4α binding sites is reported, and a valuable resource for interrogating HNF4α gene regulatory networks is established.
In the study according to the invention, it was possible to evidence > 95% of the HNF4α binding sites to be located in promoter-distal regions, a distribution similar to that described for the estrogen receptor (Carrol et al., 2006). Therefore, ChlP-chip assays focusing only on promoter regions (e.g. Odom, 2004 or Cheng, 2006) are limited.
Furthermore, an analyses of HNF4α motifs within the regions identified show an enrichment of motifs in regions confined to ~600 bp, which demonstrates the high accuracy in identification of
HNF4α binding sites achieved by the use of high resolution tiling array.
The use of genome-wide ChlP-chip tiling arrays enabled an identification of an unexpected high number of HNF4α binding sites. Even with stringent criteria, i.e. reproducible identification of enriched regions by three different algorithms, and stringent exclusion of repetitive elements, >
17000 binding sites for HNF4α were identified. The high number of HNF4α motifs which were counted within these ChlP-chip identified regions further supports that the vast majority of these sites are direct HNF4α binding sites. Additionally, it is shown that the HNF4α binding sites identified in this study are conserved between species (see conservation score reported in fig. 5), which is an accepted indicator of the biological relevance of sequences. Enhancer elements are constituted by clusters of binding sites for different transcription factors (Michelson, 2002). The fact that it was possible to identify a highly significant enrichment or even depletion of binding motifs of several other transcription factors in the close vicinity of the detected HNF4α binding sites, together with the conservation across species, stresses that the identified binding sites are biologically functional enhancer elements.
The regions surrounding the HNF4α binding sites were analyzed for overrepresentation of transcription factor binding motifs from different databases with different algorithms, and it was shown for several motifs to be significantly overrepresented in these regions. Moreover, there are also motifs which are significantly underrepresented, such as CART. Based on a thorough and detailed analysis, it was possible to evidence a close relationship between HNF4α and AP1 , GATA, ER or HNF1 binding sites. The close association of these motifs enabled to predict composite models formed by the corresponding transcription factors on bound enhancer elements. While single cases of synergistic action of HNF4α with HNF1 (Fourel et al.,1996), ER (Harnish et al., 1996) or GATA transcription factors (Sumi et al., 2007; Alrefai et al., 2007) are already known, to the best of our knowledge the data according to the invention is the first report to suggest a collaborative action of HNF4α and AP1. While over 95% of the identified binding sites are promoter distal sequences identified as enhancer elements, promoter proximal sites are highly enriched compared to random controls. This suggests that HNF4α can also interact directly with the basal transcriptional machinery. The actual number of promoter-proximal binding sites will even be higher, as transcription start sites only of RefSeq annotated genes were included.
In the past enhancers could hardly be identified by available methods; their genome-wide mapping is only possible through the advent of ChlP-chip technology. One of the most promising aspects of future research will therefore be the integration of all the transcription factor binding sites into a genome-wide map of enhancer elements, like it is currently done within the ENCODE regions (See The ENCODE Project Consortium, 2007). Current methods for association of enhancers and their target genes are mostly restricted to CCC or related methods, which allow only the analysis of single enhancer elements, and are technically challenging (Dekker, 2006). In recent publications, association of promoter-distal transcription factor binding sites with their target genes is mostly based on the search for the closest transcription start site or the closest gene. In this regard, the importance of insulator elements in determining enhancer activity has just been unravelled; Their position can be analyzed genome-wide (Dorman et al., 2007; Kim et al., 2007). Therefore, available data on insulator elements was used to narrow down the number of genes associated with the HNF4α
binding sites identified in the study according to the invention. Based on such analysis ~6000 RefSeq annotated gene targets were determined.
Because of its master function knowledge on HNF4α targeted genes will help to identify novel drug targets for the treatment of cancerous and metabolic disease. This principle has been demonstrated by the invention and other investigators based on identification of novel HNF4α gene targets in liver cancer and metabolic diseases (Niehof and Borlak, 2005; Niehof and Borlak, 2005; Niehof and Borlak, 2008)
Methods
Caco-2 Cell Culture and Aroclor 1254 treatment
Caco-2 cells were obtained from and cultivated as recommended by Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH (Braunschweig, Germany), seeded with a density of 4 X 106 cells/75 cm2 flask, and harvested after 11 days. Aroclor 1254 treatment was performed as described in Borlak et al. (2001).
Chromatin immunoprecipitation (ChIP)
All chromatin immunoprecipitation (ChIP) procedures were carried out as described by Weinmann et al. (2001) with some modifications. The samples were sonicated on ice until cross-linked chromatin was fragmented to approximately 0.2 to 1.6 kilobase pairs. Protein A Sepharose CLB4 (Amersham Biosciences, Freiburg, Germany) was blocked with 1 mg/ml bovine serum albumin and washed extensively before use. Chromatin preparations were precleared by incubation with "blocked" Protein A-Sepharose for 1 h at 4°C. Precleared chromatin from 2.5 X 107 cells was incubated with 1 μg of HNF4α antibody and rotated at 4°C overnight. After recovering of immunocomplexes, extensive washing, and elution, two samples were pooled for a second immunoprecipitation step with the HNF4α antibody. Two rounds of sequential chromatin immunoprecipitations (Weinmann et al., 2001) were used to increase purity and specificity of target DNA for ChlP-cloning and for validation of ChlP-derived clones. Other investigators used a single immunoprecipitation step with obvious limitations for validation of targets (Horak et al., 2002; Tomaru et al., 2003).
[Caco-2 cell culture, ChIP and chromatin preparation were performed as previously described (Niehof et al., 2005), with the exception that the blocking steps With herring sperm DNA were omitted. Aroclor 1254 treatment was performed as described in Borlak et al. (2001).].
ChlP-chip assay
High specificity of the antibody against HNF4α (Santa Cruz sc 6556x) used for the IP was confirmed by Western blot analysis. Enrichment of two known positive controls, binding sites in
the promoter regions of HNF1 and AGT, was confirmed by quantitative real time PCR, to ensure that the ChIP was successful. The three samples showing the highest enrichment were selected for ChlP-chip. Total input DNA from three independent biological replicates, which served as a control, was diluted to 1ng/μl, and amplified in parallel with IP-DNA from the three independent biological replicates. Amplifikation was performed according to the Affymetrix protocol, however, cycle number and amount of taq polymerase have been optimized for unbiased amplification. For fragmentation and labeling of the amplified DNA, the GeneChlP WT Double-Stranded DNA Terminal Labeling Kit (P/N 900812) from Affymetrix was used. Fragmentation success was confirmed with the Agilent Bioanalyzer. The labeled samples were hybridized to Affymetrix Human tiling 2.0R arrays with a 35 base pair resolution.
Raw data (CEL-files generated by GCOS after scanning) were analyzed for enriched regions by three independent algorithms, TAS (Affymetrix/Cawley et al., 2004), MAT (Johnson et al., 2006) and Tilemap (Ji et al., 2005). Initial cut off criteria were determined based on the detection of a weakly enriched positive control (OTC). Parameters for enrichment site (ES) detection were further improved based on the rate of HNF4α -motives within the enriched regions, which was determined by application of the MATCH algorithm (KeI et al., 2003). Finally, following parameter were chosen for ES identification with the different programs: for MAT bandwidth = 200, maximum gap = 300, minimum probes = 8, P-value < 0.00001 and MAT score > 5, for Tilemap truncation =-1000000, 1000000, transform = none, GAP<=300/probes between peaks <=5, minimum length 200nt/5 probes, region summary method = HMM (A peak 28 probes on average, cutoff 0,5), FDR = left tail and FDR < 0.015, and for TAS bandwidth = 400, P-value < 0.01 , minimum run = 200 and maximum gap = 250. Resulting regions were intersected using the Galaxy tool (Giardine et al., 2005). After intersection resulting enriched regions shorter than 200 nt were removed.
ChIP and enrichment validation by real-time PCR
ChIP was performed as previously described (Niehof et al., 2005). ChIP-DNA from three independent experiments (122, 124 and f3) was used for enrichment validation. Realtime PCR was performed on the Light Cycler (Roche Diagnostics, Mannheim, Germany) with the following conditions denaturation at 94°C for 120 s, extension at 720C for different times, and fluorescence at different temperatures. Primer sequences, annealing times and temperatures, extension times and fluorescence temperatures are summarized in Table M1. The reaction was stopped after a total of 45 cycles, and at the end of each extension phase, fluorescence was observed and used for quantification within the linear range of amplification. Δct-values were calculated versus diluted total input, and normalization, i. e. calculation of ΔΔct-values was performed using a β-actin negative control, HNF1 upstream. No enrichment of on negative control against the other was observed.
Sequence conservation analysis
Enrichment site centers (left) or Peak positions detected by MAT (right) were extend to 200 bp in both directions, and analyzed with CEAS (Ji et al., 2006) for conservation and motif content. For conservation analysis, CEAS extends the 200 bp genomic regions to 3000 bp, and calculates for each nucleotide the average conservation score, based on the high-quality phast- Cons (Siepel et al., 2005) information from the UCSC GoldenPath genome Resource. The average conservation scores were plotted against the nucleotides position.
Analysis of ChlP-chip enriched regions for overrepresented motifs
Sequence analyses for the detection of TF binding motifs were performed with MATCH (KeI et al., 2003) and Cisgenome (http://www.biostat.jhsph.edu/~hji/cisgenome/). Further, identification of enriched motifs within ChlP-chip detected regions was performed by use of CEAS (Ji et al., 2006) and Genomatix Region Miner (http://www.genomatix.de/index.html).
Correlation of HNF4α binding sites to RefSeq annotated genes and Gene Ontology categorization
Association of binding sites identified by ChlP-chip with RefSeq annotated genes was performed with the software tool CisGenome (http://www.biostat.jhsph.edu/~hji/cisgenome/). ES were associated with all RefSeq genes with transcript coding regions within 100000 nt from the center of the ES using Cisgenome (http://www.biostat.jhsph.edu/~hji/cisgenome/). All genes with an TSS further than IOOOOOnt from the center of the ES were removed from this list. Genomic positions of insulator sites where retrieved from Kim et al., (2007), and converted to the hg18 assembly at http://main.g2.bx.psu.edu/. Subsequently, it was tested if an insulator site was located between ES and the associated TSS, and if this was the case, then the association was removed. All RefSeq genes associated with an ES where joined into a single list, which then was used for Gene Ontology categorization. Gene Ontology categorization was performed with GOFFA (Tong et al., 2003) and DAVID (Dennis et al., 2003).
To analyze enrichment of binding sites in introns, a list of all RefSeq genes and their intron/exon structure was obtained from http://genome.ucsc.edu/. The number of ChIP regions and of regions from the random control set, which overlap introns, was determined using the Galaxy tool (http://g2.trac.bx.psu.edu/).
Expression profiling:
Total RNA was isolated using QIAGEN's RNeasy total RNA isolation kit according to the manufacturer's recommendations. 10 μg of total RNA were prepared for hybridization using the respective Affymetrix kits according to the manufacturer's recommendations. Samples were hybridized to Affymetrix U133Plus2.0 genechip arrays. GCOS 1.4 was used to calculate the level of differential expression at each time point relative to 0 h.


Aroclor experiments:
To confirm functional binding sites of de novo identified HNF4α gene targets, Caco-2 cell cultures were treated with Aroclor 1254, a known HNF4α inducer36. After Aroclor 1254 treatment of Caco-2 cells, binding of the HNF4α protein to the HNF1 promoter was increased7. Caco-2 cells were treated with Aroclor 1254 for 48 and 72 hours, respectively. Strong induction of HNF4α was confirmed by western blot analysis and increased binding activity was observed by EMSA (Fig. 7). A genome-wide expression profiling was performed by microarray analyses to search for regulated genes. Using stringent criteria, 536 RefSeq-annotated genes were identified to be regulated (Supplementary Table 4). Of these, 383 genes were upregulated and 153 downregulated. These were compared to the list of potential targets identified by ChlP-chip, and it was found a significant overlap of 63 % or 336 genes (Supplementary Table 6). This stresses the importance of HNF4α in the Aroclor 1254 response, and supports the biological significance of HNF4α binding sites identified by ChlP-chip.
References






Figure legends:
Fig. 1 : HNF4α ChIP was performed and enrichment of novel HNF4α binding sites detected by ChlP-chip was confirmed by real time PCR. ChIP-DNA from three independent experiments was used. Normalization was performed using a β-actin negative control, and the values are shown as fold enrichment versus total input. HNF1 upstream is a second negative control, located upstream of the known HNF4α binding site in the HNF1 promoter, and is used to confirm the β-actin negative control.
Fig. 2: Distribution of ES relative to RefSeq loci. a) Location of HNF4α binding sites relative to the closest transcription start sites (TSS) of RefSeq genes, compared to random distribution. The Y-axis gives the number of binding sites, and the X-axis the distance to closest TSS in nucleotides, b) Overrepresentation of HNF4α ES in first, second an third introns of RefSeq annotated genes, relative to a random control regions.
Fig. 3: A) Each chromosome was divided into 150 'bins', and within each bin the number of ES was counted. In the grey line chart, the number of HNF4α binding sites within each bin is represented as a single data point. Below each chromosome the minimum and maximum number of binding sites located in a single bin is given.
B) The distribution of HNF4α binding sites (grey line chart, upper half) is compared to the distribution of known genes on chromosome 10. Green arrows mark two gene-sparse regions, in which also hardly ES are found. The red arrows mark two region with a high number of HNF4α binding sites and a low number of genes. Analyses where performed using the Ensembl tool Karyoview ( http://www.ensembl.org/Homo_sapiens/karyoview ).
Fig. 4: HNF4α ChlP-chip enrichment sites allow easy 'de novo' prediction of the HNF4α binding motif. After analysis of the sequence of regions enriched by HNF4α ChlP-chip with Gibbs motif sampler, the HNF4α-motif, as described by the TRANSFAC matrices M01031or M00134, was actually detected two times, with the second motif presenting only a half site.
Fig. 5: a) Conservation of all HNF4α binding sites (blue line). Enrichment site centers (blue) or Peak positions (red) were extend to 1000 bp in both directions, and for each nucleotide the average conservation score, based on the high-quality phast-Cons (Siepel et al., 2005) information from the UCSC GoldenPath genome Resource, was calculated. The average conservation scores were plotted against the nucleotides position. Analyses where performed with CEAS (Ji et al., 2006). b) HNF4α motifs in the area of 1000 bp surrounding enrichment site peak or center positions were detected with MATCH, using cut offs to minimize false positives. The distance of the center of detected motifs to the peak or center position of the enrichment sites was calculated. A Histogram was created using bins of 50 nucleotides around the center or peak positions. The blue line shows the deviation of HNF4α motifs relative to the enrichment site center, the red line shows the deviation relative to the peak position.
Fig. 6: Computational screens were performed for motifs which are enriched within the detected HNF4α ChlP-chip enriched regions. Binding sites were defined as the area of 300 surround the peak positions. Besides the expected overrepresentation of HNF4α-motifs, an enrichment of HNF4α-similiar motifs like COUP-TF, PPAR or LEF was found. Similarity of the motifs is visualized by using Weblogo depiction (http://weblogo.berkeley.edu/). A complete list of enriched motifs can be found in Table 3.
Fig. 7: As described in Fig. 6, HNF4α-dissimilar motifs are displayed. Dissimilarity is visiualized by using Weblogo.
Fig. 8: Distribution of AP1 , CART, ER, GATA2, HNF1 and SREBP motifs within the regions enriched by HNF4α-ChlP, relative to the peak position (represented as 0). Enrichment site centers were extend to 500 nt in both directions, and Motifs were detected by use of the MATCH algorithm using cutoff criteria to minimize the sum of false positives and false negatives. Regions were segmented into bins of 25 nt, and the number of occurrences of the different motifs within each bin was counted.
Fig. 9: Display of the overlap between the binding motifs of HNF4α and the estrogen receptor by use of Weblogo illustrations. Both motifs show an partial overlap.
Fig. 10: Plot of the relative distance of HNF4α motifs to other motifs enriched in the ChIP region. Within ChIP regions the most conserved HNF4α motifs where identified. The sequences of the 500 nucleotides surrounding these most conserved HNF4α motifs where retrieved and analyzed for those motifs of other TF that were also enriched in the ChIP regions. Then, the distance between these motifs and the HNF4α motif was calculated using Cisgenome for motif detection, and plotted as histogram, using bins of 20 nt. The HNF4α motif is found at the center, reaching from nt -6 to nt +6.
Fig. 11 : Overlap between estrogen receptor (ER) binding sites and HNF4α binding sites. The high stringency set of ER binding sites identified by ChlP-chip, described in Carrol et al. (2006), was obtained. Thereafter, the percentage of ER binding sites which were identified in this study to by also bound by HNF4α was calculated, and displayed in a bar chart. To give an estimation of random background, further the overlap of ER binding sites was calculated with the random control regions described herein.
Fig. 12: For Rada Iglesias, the Random Control group (600nt) was used. For Odom et al, a number of promoter regions from the Huk13 array used in their study equal to the number of promoters they detected as binding sites was selected by random. This was necessary, because Odom et al. tested only promoter regions, and these regions are highly enriched within binding sites identified in this study. Therefore, comparison to the Random Control group (600nt) would have a high negative bias.
Fig. S1 : Venn diagram of overlap between ES identified by variable algorithms. ES were identified by use of three different algorithms. Although different parameter settings (e. g. band width of 200, 300 and 400 nucleotides) and different algorithms were used, the overlap was surprisingly high. The Venn diagram was calculated using the intersect function of Galaxy (Giardine et al., 2005).
Figure S2: HNF4α induction in Caco-2 cells. a) HNF4α Western blotting of 20 μg Caco-2 cell extract. A clear induction of HNF4α protein expression can be seen after 48 and 72h of ArocloM 254 treatment. b) Electrophoretic mobility shift assays with 2.5 μg Caco-2 cell nuclear extract and oligonucleotides corresponding to the A-site of the HNF1_ promoter (HNFI pro) as 32P labeled probes. In supershift assays an antibody directed against HNF4α (+) was added. Binding of HNF4α is significantly increased after 72h of Araclor1254 induction.
Figure S3: Promoter-proximal ES might be indirect HNF4α binding sites, a) Bootstrapping analysis of HNF4α binding motif (matrix M01031) occurrences in promoter-proximal and promoter distal regions. 100 promoter-proximal ES (-138 to -2 relative to the TSS) were compared to 100 promoter-distal ES (-24972 to -23489 relative to the TSS) by the bootstrapping analysis tool POBO (Kankainen and Holm, 2004). Promoter-proximal ES show a significantly lower number of HNF4α motifs, b) ES (300bp surround the peak position) were sorted by their Pvalue (as calculated by the MAT algorithm) and divided into bins of 1000 ES. For each bin the number of HNF4α motif occurrences and the percentage of promoter-proximal ES was calculated. As can be clearly seen, ES with a high Pvalue (weak ES) are more likely to be located promoter-proximal, and to contain no HNF4α binding motif.
Tables:































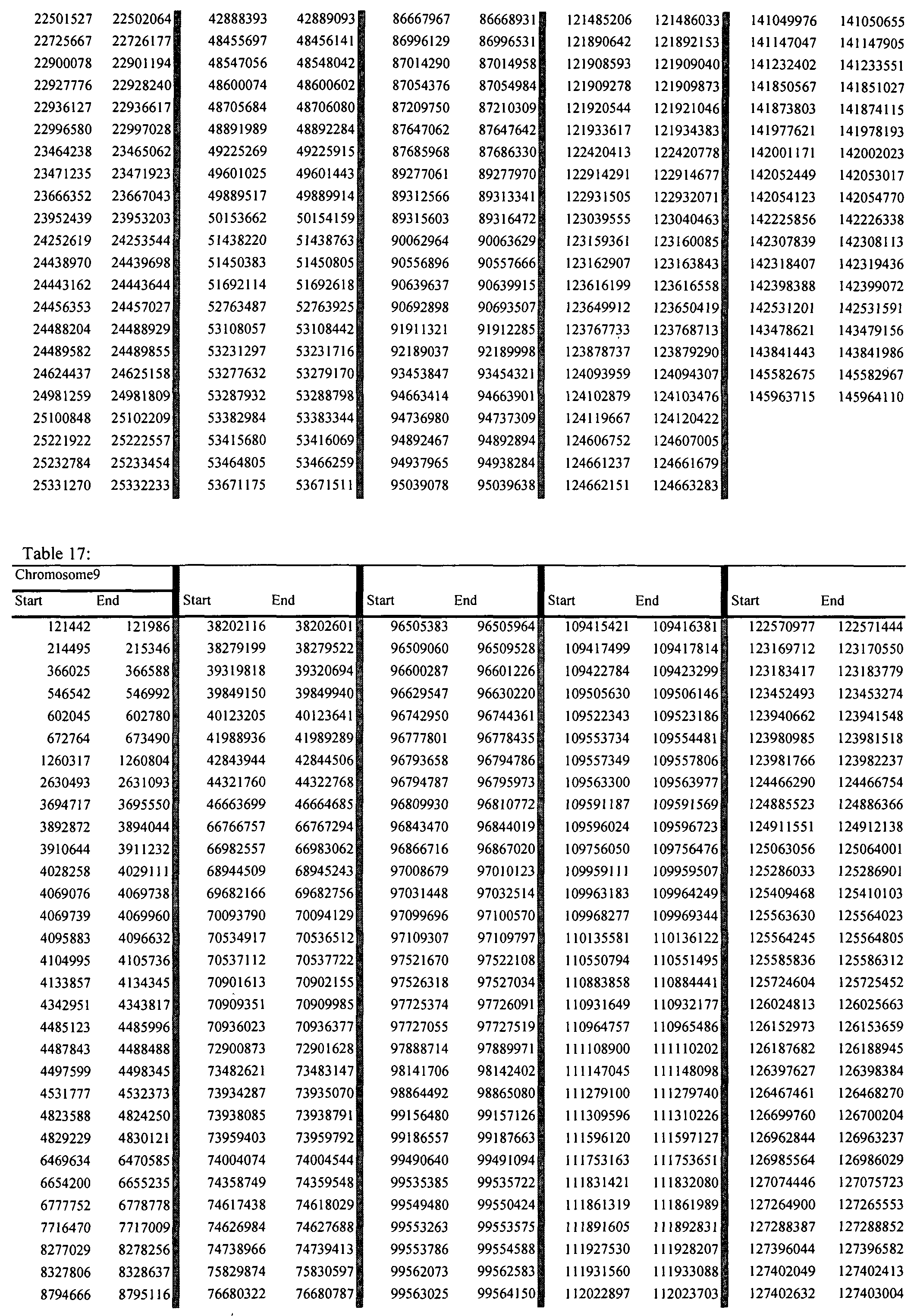

























Further evidence of the applicability ot the invention is given by the disclosure of the articles Borlak J, Niehof M. HNF4alpha and HNF1 alpha dysfunction as a molecular rational for cyclosporine induced posttransplantation diabetes mellitus. PLoS One. 2009;4(3):e4662 and
Niehof M, Borlak J. Expression of HNF4alpha in the human and rat choroid plexus: implications for drug transport across the blood-cerebrospinal-fluid (CSF) barrier. BMC MoI Biol. 2009; 10:68, which have been published after the priority date, and which are incorporated herein by reference.
The characteristics of the invention being disclosed in the preceding description, the subsequent tables, drawings, and claims can be of importance both singularly and in arbitrary combination for the implementation of the invention in its different embodiments.



















Claims
1. Use of a human gene, in particular the coding region thereof, or a gene product encoded thereby or of RNA or DNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, or of an antibody directed against said gene product, for the therapy and/or diagnosis of metabolic and/or cancerous diseases and/or to screen for and to identify drugs against metabolic and/or cancerous diseases, such as diabetes mellitus and/or colorectal cancer may be, wherein the gene is selected from the group of the human chromosomal genes having at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4α matrix) in the range of 100000 nucleotides upstream or downstream of their transcription start site in the human genome, and wherein the at least one expression regulatory sequence according to matrix 1 is located within the chromosomal position specified by the start and end sites according to Tables 9-32 (chromosomes 1-22, X-, Y- chromosome).
2. Use as claimed in claim 1 , wherein genes having an expression regulatory sequence according to matrix 2 (CTCF matrix) between the transcription start site and the at least one expression regulatory sequence (matrix 1 ("de novo" HNF4α matrix)) in the human genome are excluded from the group of genes.
3. Use as claimed in one the claims 1-2, wherein the gene is selected from the group of genes further having at least one expression regulatory sequence according to matrices 3-6 (AP1 , GATA2, ER, HNF1 matrices), preferably according to matrix 3, in the range of 20-60 nucleotides upstream or downstream of the at least one expression regulatory sequence according to matrix 1 ("de novo" HNF4α matrix)) in the human genome.
4. Use as claimed in one of the claims 1-3, wherein genes having an expression regulatory sequence according to matrix 7 (CART1 matrix) in the range of 20-60 nucleotides upstream or downstream of the transcription start site in the human genome are excluded from the group of genes.
5. Use as claimed in one the claims 1-4, wherein the gene is selected from the group of genes located on chromosomes 6 or 10.
6. Use as claimed in one of the claims 1-5, wherein the gene is selected from the group of genes coded at least partially in the genomic regions according to table 33.
7. Use as claimed in one of the claims 1-6, wherein the gene is selected from the group of genes according to Table 34.
8. Use as claimed in one of the claims 1-7, wherein the gene is selected from the group of genes according to Table 35.
9. Use as claimed in one of the claims 1-8, wherein the group of genes is identified by the method according to one of the claims 10-16.
10. Method for a genomewide identification of functional binding sites at targeted DNA sequences bound to DNA complexes in cells, healthy and diseased tissues and/or organs comprising the steps of a. chromatin immunoprecipitation and b. DNA-DNA hybridisation for the c. de novo identification of gene targets (RefSeq genes).
11. Method as claimed in claim 10, in particular for the identification of the functional binding sites of a protein of interest, preferably of a transcription factor, wherein a. the chromatin immunoprecipitation comprises or consists of two rounds of sequential chromatin immunoprecipitation, b. a genome wide tiling array is used for the DNA-DNA hybridisation, and/or c. the de novo identification of gene targets comprises reducing the number of false enhancer-gene associations.
12. Method as claimed in one of the claims 10-11 , in particular for determining a region of ChIP enrichment in the immunoprecipitated sample (enrichment site), with respect to a control or to genomic DNA, preferably a HNF4α binding site, wherein a. an anti HNF4α antibody is used for the immunoprecipiation b. a human or murine array with a genome-wide 20-50 bp resolution is used, and/or c. all genes, which are separated from their associated enhancer by a CTCF- binding site, are removed from the group of the de novo identified genes (target list).
13. Method as claimed in one of the claims 10-12, in particular for mapping the in vivo enrichment sites of a specific protein of interest, wherein a. Caco-2 cells are used, b. human tiling arrays with a genome-wide 35 bp resolution are used, and/or c. all genes, which are separated from their associated enhancer by the CTCF- binding site according to matrix 2, are removed from the target list.
14. Method as claimed in one of the claims 10-13, further comprising the use of DNA- sequences and/or genes identified by the method according to one of the claims 9-12 to screen for and to identify novel drug targets for the treatment of metabolic and cancerous diseases, preferably comprising the use according to one of the claims 1- 7.
15. Method as claimed in one of the claims 10-14, wherein novel identified sequences and genes encoding DNA are used.
16. Method as claimed in one of the claims 10-15, wherein polypeptides encoded by novel identified sequences and genes are used.
17. Use or method as claimed in one of the preceding claims to develop new medications for the treatment of disease as a result of HNF4α dysfunction.
18. Use or method as claimed in one of the preceding claims to develop new drug candidates for treatment of metabolic and tumorous diseases by interfering with the activity of polypeptides according to claim 16 for the purpose of normalizing its activity and to restore a healthy condition.
19. Use or method as claimed in one of the preceding claims to optimize novel chemical entities for the purpose of drug development.
20. Use or method as claimed in one of the preceding claims to identify drugs targeting chromatin and its regulation by interfering with protein-DNA, protein-protein and multiprotein-DNA complexes for the purpose of normalizing gene activities in metabolic and cancerous diseases.
21. Use or method as claimed in one of the preceding claims to identify drugs targeting carbohydrate metabolism in metabolic and tumorous disease for the purpose of its
normalization as exemplified by but not limited to the following genes and gene products: ACLY1 ACO1, ACO2, ADPGK1 AKR1A1, ALDH2, ALDOB, AMDHD2, APOA2, ARPP-19, ARSB, B3GAT1, B4GALT1, B4GALT4, B4GALT5, B4GALT6, B4GALT7, C9orf103, CARKL, ChGn, CHST12, CHST13, CHST3, CHST9, CMAS, COG2, DLST, EXT1, FBP1, FBP2, FLJ10986, FN3K, FUCA2, FUT4, FUT8, G6PC, GALK1, GALM, GALNT3, GALNT4, GALNT5, GALT, GANAB, GANC, GBA3, GBGT1, GCNT2, GCNT3, GENX-3414, GK, GLCE, GMDS, GNPDA1, GNS, GPD1, GPD2, GSK3B, GUSB, GYS2, H6PD, HECA, HEXB, HIBADH, HK1, HK2, HKDC1, HS3ST4, HS3ST5, IDH1, IDH3A, IDS, IMPA1, INSR, IRS2, ITIH1, ITIH2, ITIH3, ITIH5, KHK, KIAA0100, KL, KLB1 LARGE, LCT, LCTL, LDHA, LDHAL6B, MAN2A1, MAN2C1, MANBA, MDH2, ME1, ME2, ME3, MGAM, MGAT1, MGAT2, MGC40579, MMP15, MMP16, MMP17, MMP2, MMP20, NAALADL2, NAGK, NANS, NDST1, OGDH1 PC, PCK1, PCK2, PDK1, PDK3, PDK4, PFKFB1, PFKFB2, PFKFB3, PFKM, PFKP1 PGAM4, PGD, PGK2, PGLYRP2, PGM1, PGM2, PGM2L1, PGM3, PHKB, PKM2, PMM1, POFUT1, PPARD, PPP1CB, PPP1R2, PRKAA1, PRKAB1, PTEN, PYGB, PYGL, RBKS, RPIA, SDHB, Sl, SLC2A2, SLC2A3, SLC2A8, SLC35A2, SLC35A3, SLC35D1, SLC37A4, SLC3A1, SMA4, SORD, SPAM1, ST3GAL2, ST3GAL6, ST6GAL1, ST8SIA2, ST8SIA4, SUCLA2, SUCLG1, SUCLG2, SULF2, TFF1, UAP1 and UGP2.
22. Use or method as claimed in one of the preceding claims to identify drugs targeting lipid metabolism in metabolic and tumorous disease for the purpose of its normalization as exemplified by but not limited to the following genes and gene products: A4GALT, ABCA1, ABCD2, ABCG1, ABHD4, ACAA2, ACACA, ACADM, ACADS, ACAT2, ACBD3, ACLY, ACOT1, ACOT11, ACOT12, ACOT2, ACOT7, ACOX1, ACOX2, ACSL1, ACSL3, ACSL4, ACSL5, ACSL6, ACSS2, ADIPOR2, ADM, AGPAT1, AGPAT2, AGPAT3, AKR1B10, AKR1C1, AKR1C3, AKR1C4, AKR1D1, ALDH3A2, ALOX5AP, ALOXE3, ANGPTL3, AOAH, APOA1, APOA2, APOA4, APOB1 APOBEC1, APOC3, APOF1 APOM, ASAH1, ASAH2, ATP8B1, AYTL2, B3GALT1, B4GALNT2, B4GALT4, BAAT, BTN2A1, BTNL3, C11orf11, C14orf1, CD36, CD74, CDC91L1, CDS1, CDS2, CEL1 CERK, CHKA1 CLU, CMAS, C0Q2, CPNE3, CPNE7, CPT2, CRLS1, CROT, CUBN, CYP19A1, CYP2J2, CYP3A4, CYP3A5, CYP4A11, CYP4F3, CYP51A1, CYP7A1, DCTN6, DEGS1, DGAT1, DGKD, DHCR24, DHRS3, DHRS8, DPAGT1, EBP, EBPL, EHHADH, EL0VL2, ELOVL4, ENPP6, ENPP7, ETNK1, FABP1, FABP2, FABP5, FABP6, FADS1, FDFT1, FDX1, FLJ25084, GALC, GPAM, GPX4, HACL1, HADH, HADHA, HADHB, HAO2, HEXB, HMGCR, HMGCS1, HNF4A, HPGD, HSD17B2, HSD17B3, HSD17B4, HSD17B6, HSD3B1, HSD3B2,
IHPK3, IMPA1, LARGE, LASS2, LASS5, LIPA, LIPC, LIPF, LOC340204, LPGAT1, LRP1, LRP2, LRP5, LYPLA2, MGC26963, MGLL, MGST2, MGST3, MIF, MTMR10, MTMR11, MTMR12, MTMR2, MTMR4, MTTP, MVK, NANS, NPC1, NPC2, NR1H4, NR1I2, NR2F2, NR5A1, OSBP, OSBP2, OSBPL10, OSBPL11, OSBPL1A, OSBPL3, OSBPL5, OSBPL6, OSBPL8, OSBPL9, PAFAH2, PBX1, PC, PCCA, PCCB, PCSK9, PCYT1A, PCYT1B, PCYT2, PDE3A, PDSS1, PECI, PECR, PEMT, PGDS, PHYH, PIGC, PIGF1 PIGH, PIGK, PIGL, PIGM, PIGY, PIGZ, PIK3C2A, PIK3R1, PIK4CB, PIP5K2A, PISD, PITPNA, PITPNB, PLA2G12B, PLA2G2A, PLA2G2E, PLA2G4A, PLA2G4D, PLA2G6, PLB1, PLCB1, PLCE1, PLCG1, PLCH1, PLCZ1, PLD1, PLIN, PMVK, PNLIPRP1, PNLIPRP2, PNPLA3, PNPLA8, PPAP2A, PPAP2B, PPARD, PPARG, PPP2CA, PPP2R1B, PRDX6, PRKAA1, PRKAA2, PRKAB1, PRKAB2, PRKAG2, PRLR, PSAP, PTDSS1, PTEN, PTGES, PTGIS, RBP3, RDH12, SAMD8, SC4MOL, SC5DL, SCAP, SCARB1, SCD, SCD5, SCP2, SEC14L2, SELI, SERINC2, SERPINA3, SGPL1, SHH, SLC27A2, SLC27A3, SMPD1, SMPD3, SOAT1, SOAT2, SORL1, SQLE, SRD5A2, SREBF1, ST3GAL6, STARD4, STARD5, SULT1A1, SULT1B1, SULT1E1, SULT2A1, TBXAS1, TMEM23, TNFRSF1A, TPP1, TRERF1, UCP3, UGCG, UGT1A1, UGT2B11, UGT2B7, UGT8, VLDLR, WWOX, YWHAH and ZNF202.
23. Use or method as claimed in one of the preceding claims to identify drugs targeting intracellular signaling in metabolic and tumorous disease for the purpose of its normalization as exemplified by but not limited to the following genes and gene products: ABL1, ABL2, ABR, ABRA, ACOT11, ACR, ADCY5, ADCY6, ADCY8, ADCY9, ADIPOR2, ADORA2A, ADORA2B, AD0RA3, ADRA1B, ADRA1D, ADRB1, AGTR1, AKAP13, AKAP7, AMBP, ANP32A, APBB2, ARF1, ARF6, ARFGEF2, ARHGAP29, ARHGAP5, ARHGAP6, ARHGEF1, ARHGEF10L, ARHGEF11, ARHGEF12, ARHGEF17, ARHGEF18, ARHGEF3, ARHGEF5, ARHGEF7, ARID1A, ARL1, ARL4A, ARL4C, ARL4D, ARL5A, ARL5B, ARL8B, ASB1, ASB13, ASB14, ASB2, ASB4, ASB7, ASB9, ASIP, ATP2C1, AVPR1A, BCAR3, BCL10, BIRC2, BLNK, BRAF, BRCA1, C20orf23, C5AR1, CALCR, CALCRL, CAP1, CARD10, CARD4, CARHSP1, CBLB, CCKAR, CCM2, CCNE1, CCR1, CDC42BPA, CDK7, CENTD3, CERK, CERKL, CFL1, CFLAR, CHN1, CHN2, CHP, CHRM1, CHRM2, CNIH, CNIH3, CNIH4, CORO2A, CRKL, CRSP2, CRSP6, CSK, CTNNB1, DAB2IP, DAPK1, DAPK2, DAPP1, DDAH1, DEPDC7, DERL1, DGKA, DGKB, DGKD, DGKH, DGKI, DIRAS3, DLG5, DNMBP, DRD2, DRD5, DSCR1, DSCR1L1, DUSP16, DUSP22, DUSP6, DUSP9, DVL3, DYNC1LI1, EDD1, EDG2, EDNRB, EGF, EGFR, ELMO1, ERBB2, ERN1, ESR1, F2, F2R, FARP2, FGD2, FGD4, FGD5, FGF2, FHL2,
FLJ20184, FLJ30934, FLJ38964, FLJ41603, FRK, FYN, G3BP, GADD45B, GADD45G, GAP43, GAPVD1, GBF1, GCC2, GEM, GHRH, GJA1, GLP1R, GNAQ, GNB1L, GPR89A, GRAP1 GRB10, GRB14, GRB2, GRB7, GRK5, GRLF1, GTPBP4, GUCY2C, GUCY2D, HIPK2, HIST4H4, HMOX1, HRH2, HS1BP3, ICK, IFNAR2, IGF1, IHPK3, IL10, IL22RA2, IQGAP2, IQGAP3, IQSEC1, IQSEC3, IRAKI BP1, ITSN1, JAK1, KALRN, KIAA1804, KRAS, KSR1, KSR2, LAT, LATS 1, LATS2, LAX1, LGALS9, LHCGR, LTB4R2, LYN, MAGI3, MAP3K11, MAP3K13, MAP3K4, MAP3K7IP2, MAP3K9, MAP4K3, MAP4K4, MAP4K5, MAPK13, MAPK14, MAPK8, MAPKAPK2, MARK1, MARK2, MBIP, MC3R, MCF2L, MCTP1, MCTP2, MED4, MFHAS1, MGC39715, MINK1, MIST, NCK2, NCOA1, NCOA3, NCOA4, NDFIP1, NEK11, NEK6, NET1, NF1, NFAM1, NFKBIA, NKIRAS1, NKIRAS2, NLK1 NMUR2, NOTCH2, NPR2, NPY1 NRAS, NRIP1, NUDT4, OPRK1, OPRM1, OTUD7B, P2RY1, P2RY2, P2RY4, P2RY6, PAK1, PARD3, PARK7, PDCD11, PDK1, PDZD8, PIK3C2A, PIK3C2G, PIK3CB, PIK3R1, PIP5K3, PLCB1, PLCE1, PLCG1, PLCH1, PLCZ1, PLD1, PLEK2, PLEKHG1, PLEKHG2, PLEKHG3, PLEKHM1, PLK2, PPAP2A, PPARBP, PPARGC1B, PPM1A, PPP2CA, PPP2R1B, PRDX4, PRKAA1, PRKAR1A, PRKAR2B, PRKCA, PRKCD, PRKCE, PRKCI, PRKCSH, PRKCZ, PRLR, PSCD4, PSD3, PSD4, PSEN1, PTEN, PTPLAD1, PTPN11, RAB10, RAB11A, RAB17, RAB1A, RAB20, RAB27A, RAB30, RAB31, RAB32, RAB33A, RAB35, RAB37, RAB38, RAB3B, RAB3D, RAB43, RAB4A, RAB5A, RAB5C, RAB6C, RAB7, RAB7L1, RAB8B, RAB9A, RABIF, RABL3, RAF1, RALB, RALGPS1, RALGPS2, RAN, RANBP3, RAP1A, RAP1B, RAP2A, RAP2B, RAPGEF1, RAPGEF4, RASA1, RASA2, RASA3, RASAL2, RASGEF1C, RASGRF1, RASGRF2, RBJ, RBM9, RGL1, RGS1, RGS3, RGS9, RHEB, RHOBTB2, RHOC, RHOF, RHOH, RHOT1, RIN2, RIPK1, RND1, RND3, ROCK1, ROCK2, RP1L1, RPS6KA5, RRAGC, RREB1, S100A1, SAC, SAR1B, SCAP, SDCBP2, SELS, SGEF, SGK2, SH2D1A, SH2D3A, SH2D4A, SH2D6, SH3BP5, SH3PXD2A, SHANK2, SHC1, SHE, SHF, SHOC2, SIAH2, SLA, SLC20A1, SMAD2, SNF1LK2, SNX1, SNX10, SNX11, SNX12, SNX13, SNX14, SNX19, SNX24, SNX27, SNX3, SNX4, SNX5, SNX7, SNX9, SOCS5, SOCS6, SOCS7, SOS1, SPAG5, SPRED1, SPRED2, SRPK1, SRPK2, SSTR1, STAT5B, STAT6, STK17A, STK17B, STK3, STK38, STK38L, STK4, STMN4, SYNGAP1, TACR1, TAOK3, TBK1, TEC, TESK2, TFG, THRAP1, TIAM1, TIAM2, TMED4, TMEPAI, TMPRSS6, TNFAIP3, TNFRSF10B, TNFRSF19, TNFRSF1A, TNFSF10, TNFSF15, TNIK, TNK2, TNS1, TNS3, TRAF3IP2, TRAF5, TRAF6, TRIO, TRIP6, TSSK3, TULP4, UBE2V1, USH1C, VAPA1 VAV2, VAV3, VIPR1, WASF2, WNK1, WNK2, WNK4, WSB1, WSB2, YES1, YWHAH, ZAK and ZDHHC13.
4. Use or method as claimed in one of the preceding claims to identify drugs targeting cell cycle and cell proliferation in metabolic and tumorous disease for the purpose of its normalization as exemplified by but not limited to the following genes and gene products: ABH, ABL1, ACHE, ACPP, ACTN4, ADRA1B, ADRA1D, AGGF1, AHR, AIF1, ALS2CR19, ANAPC4, ANKRD15, APBB1, APBB2, APC, AR, AREG, ARHGEF1, ATM, ATPIF1, AXIN1, B4GALT7, BCAR1, BCAR3, BCL10, BCL2, BCL6, BHLHB3, BIN1, BRCA1, BRCA2, BRIP1, BTC, BTG1, BTG2, BUB1, C10orf46, C10orf9, C2orf29, C9orf127, CABLES1, CCL14, CCNA2, CCND1, CCND2, CCNE1, CCNE2, CCNH, CCNJL, CCNL1, CCNT1, CCNT2, CCRK, CD160, CD164, CD28, CD3E, CD74, CD86, CDC14A, CDC2, CDC25A, CDC25B, CDC25C, CDC37L1, CDC6, CDK10, CDK3, CDK4, CDK5R1, CDK5RAP3, CDK7, CDKL1, CDKN1A, CDKN1B, CDKN2A, CDKN2B, CDKN3, CDT1, CDV3, CENPF, CEP250, CETN2, CETN3, CHAF1A, CHES1, ChGn, CHRM1, CHRM4, CITED2, CLASP1, COL18A1, CREG1, CRTAM, CSF1, CSF1R, CSK, CTCFL, CUL1, CUL3, CUL4A, CXCL5, CYR61, DAB2, DBC1, DCC, DCTN2, DHCR24, DIP13B, DIRAS3, DLEC1, DLG1, DLG3, DLG5, DST, DUSP1, DUSP22, DUSP6, E2F3, E2F7, EDD1, EDN1, EGF, EGFR, ELF4, ELN, EML4, EMP1, ENPEP, ENPP7, EP300, EPS15, EPS8, ERBB2, ERBB2IP, ERG1 ERN1, ESCO1, ESR1, ETS1, EXT1, F2, F2R, FABP6, FGA1 FGB, FGF2, FGF8, FGF9, FGFR1OP, FGG, FHIT, FLCN, FLJ16793, FLJ40432, FLT1, FRK1 G0S2, GAB1, GADD45A, GAS2, GAS6, GMNN, GNRH1, GRLF1, HBP1, HDAC6, HDAC7A, HDAC9, HDGF, HECA, HEXIM1, HIC.1, HIPK2, HK2, HOXC10, HPGD, IGF1, IGF1R, IGFBP4, IL10, IL12RB1, IL12RB2, IL18, IL28RA, IL2RA, IL6R, IL9R, ING1, INHBA1 INSIG1, IRF1, IRF2, IRS2, ISG20, JAG1, KATNB1, KIAA0367, KIAA0376, KIF25, KITLG, KLF4, KPNA2, KRAS1 LAMB1, LAMC1, LATS1, LATS2, LIF, LIG4, LMO1, LRP1, LRP5, LTBP2, LYN1 LZTS2, MACF1, MAD2L1, MAP2K6, MAP3K11, MAPK13, MAPK6, MAPRE1, MAPRE2, MAPRE3, MCC1 MCM3, MCM8, MCRS1, MDM2, MDM4, MET, MIF1 MKI67, MLH3, MNAT1, MNT, MOS, MPL, MSH5. MTSS1, MUTYH, MXD1, MXM1 MYB, MYC, NBL1, NCK2, NDP, NEDD9, NEK11, NEK2, NEK6, NF1, NFYC, NIPBL, NME1, NOTCH2, NPY, NR6A1, NRAS, NRD1, NRP1, NUMA1, OPRM1, OSM, PAM, PAPD5, PARD3, PARD6B, PBEF1, PBK, PDCD4, PDF, PDGFB, PDGFRA, PEMT1 PFDN1, PGF, PIK3CB, PIM1, PLAGL1, PLCB1, PLG1 PMP22, POLA, POLS, POU3F2, PPAP2A, PPARD1 PPM1D, PPP1CB, PPP1R9B, PPP2CA, PPP2R1B, PPP3CB, PPP6C, PRDX1, PRKCA, PRKG2, PRKRIR1 PRL1 PRM1, PROK1, PSMD1, PTEN, PTHLH, PTK2B, PTMA, PTMS1 PTP4A1, PTPRC, PTTG1, QSCN6, RAD17, RAD50, RAD51, RAD51L1, RAD54L, RAD9B, RAF1, RAN, RAP1A, RASSF4, RB1CC1, RBL1, RBM5, RBM9, RCBTB1, RCC2, RECK, RFP, RGS2, RINT1, RPS27, RSN, RUNX3, S100A6, SASH1, SCIN,
SEPT11, SEPT3, SEPT4, SEPT7, SESN1, SESN3, SGOL1, SH3BP4, SHC1, SHH, SIAH1, SIAH2, SKP2, SLAMF1, SLC12A6, SMARCB1, SMC3, SMPD3, SPAG5, SPHAR, SSR1, SSTR1, STARD13, STIM1, STRN3, SUPT3H, SYCP2, SYCP3, TACC1, TADA3L, TAL1, TBC1D8, TCF7L2, TCFL5, TERF2, TFDP1, TFDP2, TGFB3, TGFBI1 TGFBR2, THY1 , TM4SF4, TNFRSF11A, TNFRSF8, TNFSF13B, TNFSF15, TNFSF4, TOB1, TOB2, TSGA2, TSPAN2, TSPAN3, TUBG1, TXLNA, TXN, UBE2V1, UHRF1, UHRF2, UNC84B, UNG2, USP8, UTP14C, VEGF, VIPR1, WEE1, WT1, WWOX, XRN1, YWHAG, YWHAH, YWHAQ, ZAK, ZFP36L2, ZW10 and ZZEF1.
25. Use or method as claimed in one of the preceding claims to identify drugs targeting programmed cell death in metabolic and tumorous disease for the purpose of its normalization as exemplified by but not limited to the following genes and gene products: ABL1, ACIN1, ACTN1, ACTN4, ADORA2A, AHR, ALB, AMID, AMIG02, ANXA4, ANXA5, APOE, APP, ASAH2, ATG5, AXIN1, BAD, BAG2, BAG3, BBC3, BCAR1, BCL10, BCL2, BCL2A1, BCL2L1, BCL2L10, BCL2L11, BCL2L14, BCLAF1, BID, BIRC2, BIRC3, BIRC4, BMF, BRAF, BRCA1, BRE, BTG1, CARD10, CARD4, CASP10, CASP3, CASP6, CBX4, CD28, CD3E, CD74, CDC2, CDK5R1, CDKN1A, CDKN2A, CEBPG, CFL1, CFLAR, CIAS1, CLU, COP1, CRADD, CROP, CRTAM, CTNNBL1, CTSB, CUL1, CUL3, CUL4A, CYCS1 DAD1, DAP, DAPK1, DAPK2, DCC, DHCR24, DIDO1, DNASE1, DNASE1L3, DUSP22, EBAG9, EDAR, EFHC1, EGLN3, ELMO1, ELMO2, EP300, ERCC3, ERN1, F2, F2R, FAIM, FAIM3, FASTKD1, FOXL2, FOXO1A, FOXO3A, GADD45A, GADD45B, GADD45G, GAS2, GPR65, GSTP1, HBXIP, HIPK2, HMGB1, ICEBERG, IER3, IGF1R, IHPK2, IHPK3, IL10, IL18, IL2RA, INHBA, KIAA0367, KNG1, MAGEH1, MAGI3, MCL1, MDM4, MIF, MOAP1, MRPS30, MTP18, NCKAP1, NEK6, NFKB1, NFKBIA1 NME1, NME6, NOTCH2, NRG2, NTF3, NUAK2, NUDT2, OPA1, PAK1, PAWR1 PAX7, PDCD10, PDCD11, PDCD2, PDCD4, PDCD6, PECR, PERP, PHLDA1, PHLPP, PIM1, PLAGL1, PLG, PPARD, PPP2CA, PPP2R1B, PRF1, PRKAA1, PRKCA1 PRKCE, PRKCZ, PRLR, PROC, PRODH, PSEN1, PTEN, PTH, PTK2B, PTPRC1 PTRH2, RAF1, RASA1, RFFL, RHOT1, RIPK1, RIPK3, RNF7, ROCK1, RP6-213H19.1, RRAGC1 RTN4, RUNX3, RYBP, SCARB1, SCIN1 SEMA4D, SEMA6A, SEPT4, SERPINB9, SGK1 SGPL1, SH3GLB1, SIAH1, SIAH2, SIRT1, SMNDC1, SNRK1 STK17A, STK17B, STK3, STK4, TAIP-2, TAX1BP1, TEGT, TESK2, THY1, TIA1, TIAL1, TIMP3, TLR2, TNFAIP3, TNFAIP8, TNFRSF10B, TNFRSF11B, TNFRSF19, TNFRSF1A, TNFRSF21, TNFRSF25, TNFSF10, TNFSF15, TNFSF18, TP53INP1, TP73L, TPT1, TRAF3, TRAF5, TRAF6, TRIB3, TXNDC5, UBE4B, U.NC5B, VDAC1, VEGF, YWHAG, YWHAH, ZAK, ZBTB16, ZDHHC16andZNF346.
6. Use or method as claimed in one of the preceding claims to identify drugs targeting cell morphogenesis and cell / organ development in metabolic and tumorous disease for the purpose of its normalization as exemplified by but not limited to the following genes and gene products: ABLIM1, ABTB2, ACHE, ACIN1, ACTL6A, AGGF1, AHSG, ALX4, AMELX, AMIGO1, AMOT, ANGPTL3, ANKH, ANXA2, APBB1, APBB2, APOE, AR, ARF6, ARHGEF11, ARTS-1, ASH2L, ATP10A, ATPIF1, AXIN1, BCAR1, BCL11A, BHLHB3, BMP2, BMP3, BMP4, BMP6, BMP7, BMP8A, BMP8B, BRAF, BRD8, BTG1, BVES, CACNB2, CALCR, CAMK2D, CANX, CAP1, CAPN3, CART1, CASC5, CASQ2, CCL4, CCM2, CD164, CD1D, CD74, CD86, CD9, CDC42EP4, CDC42EP5, CDH11, CDK5R1, CDK5RAP2, CDK5RAP3, CDX2, CEACAM1, CEBPA, CEBPG, CENPF, CENTD3, CHRDL2, CITED2, CLASP1, CLEC3A, CNTN4, COL11A2, COL12A1, COL18A1, COL1A1, COL1A2, COL2A1, COL9A1, COVA1, CRB1, CREG1, CRIM1, CSDE1, CSF1, CSRP3, CTGF, CYR61, DAZL, DCC, DDX5, DGAT1, DGKD, DLC1, DLG1, DMAP1, DMD, DVL3, DZIP1, EBAG9, EBP, EGFR1 ELN, EMP1, EPAS1, ERBB2, ERBB2IP, ESR1, ETS1, ETS2, EVL1 EXT1, EYA2, FABP1, FARP2, FBLIM1, FBN1, FCMD, FEZ2, FGD2, FGD4, FGD5, FGF2, FGFR2, FHL1, FLNB1 FLT1, F0XL2, FOXN1, FOXO3A, FRZB, GAP43, GAS2, GAS6, GATA4, GATA6, GDF10, GHR, GJA1, GLCE, GNAO1, GRLF1, HAND1, HBEGF1 HCCS, HDAC7A, HDAC9, HECA1 HEY1, HILS1, HMGCR, HOXA13, HSD17B3, IFRD1, IGF1, IGFBP2, IGFBP4, IHPK2, IL10, IL18, ING1, ING2, INHBA, IPF1, ITCH, ITGA11, ITGA2, ITGB1BP2, JAG1, KAZALD1, KDR, KIRREL3, KITLG, KL, KLF6, KRT19, LAMB1, LARGE, LECT2, LHCGR, LHX3, LIMA1, LTBP4, LYN, MAFB, MAP7, MARK2, MATN1, MBNL1, MBP, MEF2A, MEF2C, MKKS, MKL2, MPZ, MSX1, MSX2, MTSS1, MUSK, MYF6, MYH10, MYH14, MYST3, NCOA4, NEDD9, NET1, NFAM1, NKX2-2, NOTCH2, NOTCH4, NR5A1, NRCAM, NRD1, NRP1, NRP2, NRXN3, NTNG1, OKL38, OSM, PAPPA2, PAPSS1, PAPSS2, PARD3, PARD6B, PAX1, PAX2, PBX1, PBX3, PDLIM5, PGF, PHEX, PHGDH, PITX1, PITX2, PITX3, PLEKHC1, PLG, P0U3F1, P0U4F1, P0U6F1, PPARD, PPP1R9B, PPP2CA, PPP2R1B, PRDX1, PRELP, PRKCI, PRL, PTEN, PTH, PTPRC, QSCN6, RAB3D, RASA1, RHOH1 RND1, ROBO1, ROBO2, RPS6KA3, RRAGC, RTN4, RTN4RL1, RTN4RL2, RUNX1, RUNX2, RUVBL1, S100A6, SCGB1A1, SCIN1 SEMA6A, SGCB, SGCE, SHCI, SHH, SIAH1, SIRT1, SIX1, SLIT1, SMARCA1, SNAM1 SNRK, SOCS5, SOCS6, SOCS7, SORT1, SOX6, SOX9, SPAG6, SPARC, SPINK5, SPN, SPRY2, SRD5A2, SRI, STIM2, SVIL, SYCP3, TAGLN3, TBX3, TCF12, TCOF1, TGFB3, THY1, TINAG1 TLE1, TLE3, TMEM97, TMPRSS6, TNFAIP2, TNFRSF11B, TNN, TNP1, TNR, TPD52, TRAPPC4, TSSK3, TUFT1, UBE3A, UTRN, VCL, VCX3A,
VEGF, VIL2, WISP1 , WISP3, XRN2, YEATS4, YWHAH, ZBTB16, ZNF160 and ZNF22.
27. Use or method as claimed in one of the preceding claims to select drug candidates of an antisense molecule, ribozyme, triple helix molecule or other new chemical entities targeting the chromatin.
28. Use of a human gene, in particular the coding region thereof, or a gene product encoded thereby or of RNA or DNA sequences, which hybridize to said gene and which code for a polypeptide having the function of said gene product, as a biomarker, or of an antibody directed against said gene product, in the diagnosis, prognosis and/or treatment monitoring of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer, wherein the gene is selected from the group of genes according to one of the claims 1-9 or is selected from the genes specified in the claims 21-26.
29. Use as claimed in claim 28 for monitoring the therapeutic treatment of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer.
30. A method for diagnosing, prognosing and/or staging metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer and/or monitoring the treatment of at least one of said diseases, comprising
(a) measuring the level of expression of at least one biomarker, wherein the biomarker is selected from the genes specified in the claims 1-9 and/or 21-26 in a patient or in a sample of a patient suffering from or being susceptible to a metabolic and/or tumorous disease, and
(b) comparing the level of said at least one biomarker in said patient or in said sample to a reference level of said at least one biomarker, in particular by the use according to one of the claims 28-29.
31. A composition for qualifying the HNF4α activity in a patient suffering or being susceptible to a metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases, comprising an effective amount of at least one biomarker selected from the genes specified in the claims 1-9 and/or 21-26 or from the group of gene products encoded by said genes, and/or comprising an effective amount of at least one antibody directed against at least one biomarker selected from said group of gene products.
32. Use of a composition as claimed in claims 31 for the production of a diagnostic agent, in particular of a diagnostic standard.
33. Use as claimed in claim 32 for the production of a diagnostic agent for qualifying the HNF4α activity in a patient suffering or being susceptible to a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases.
34. Use as claimed in one of the claims 32-33 for the production of a diagnostic agent for predicting or monitoring the response of a patient suffering from a metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of said diseases with a drug, in particular a drug identified by the use or by the method according to one of the claims 1-27 and/or a HNF4α activity modulator.
35. A kit for qualifying the the HNF4α activity in a patient suffering or being susceptible to metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one of said diseases, in particular for predicting or monitoring the response
of a patient to suffering from at least one of said diseases by a method of treating metabolic and/or tumorous diseases comprising administering a HNF4α activity modulator, comprising at least one standard indicative of the level of a biomarker selected from the genes specified in the claims 1-9 and/or 21-26 or from the group of gene products encoded by said genes in normal individuals or individuals having metabolic and/or tumorous disease associated with increased HNF4α activity, and instructions for the use of the kit.
36. The kit as claimed in claim 35, wherein the at least one standard comprises an indicative amount of at least one biomarker selected from the genes specified in the claims 1-9 and/or 21-26 or from the group of gene products encoded by said genes.
37. The kit as claimed in one of the claims 35-36, further comprising at least one primer or primer pair specifically hybridizing with the mRNA of a biomarker selected from the genes specified in the claims 1-9 and/or 21-26, preferably a primer or primer pair selected from Table M1 , and/or at least one antibody specific for a biomarker selected from the group of gene products encoded by said genes, and reagents effective to detect said biomarker(s) in a serum sample.
38. A method of qualifying the HNF4α activity in a patient suffering or being susceptible to metabolic and/or tumorous disease, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer or for classifying a patient suffering from or being susceptible to at least one said diseases, comprising determining in a sample of a subject suffering from or being susceptible to one of said diseases at least one biomarker wherein the biomarker is the gene product encoded by a gene selected from the genes specified in the claims 1-9 and/or 21-26 or and/or the biomarker is the mRNA sequence encoding the gene product of said selected gene, and wherein the sample level , of the at least one biomarker being significantly higher or lower than the level of said biomarker(s) in the sample of subjects without a disease associated with increased activity of HNF4α is indicative of induced HNF4α activity in the subject.
39. Method as claimed in claim 38 for predicting the response of a patient suffering from metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina,
and/or colorectal cancer to a method of treating such diseases comprising administering a drug identified by the use or method according to one the claims 1-27 or a HNF4α activity modulator, wherein the level of the at least one biomarker being significantly higher or lower than the level of said biomarker(s) in subjects without cancer associated with increased activity of HNF4α is indicative that the subject will respond therapeutically to a method of treating cancer comprising administering a drug identified by the use or method according to one the claims 1-27 or administering a HNF4α activity modulator.
40. Method as claimed in one of the claims 38-39 for monitoring the therapeutically response of a patient suffering from metabolic and/or tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer to a method of treating at least one of said diseases comprising administering a drug identified by the use or method according to one the claims 1-27 or administering a HNF4α activity modulator, wherein the level of the at least one biomarker before and after the treatment is determined, and a significant decrease or increse of said level(s), preferably a decrease or increase to the normal level(s), of the at least one biomarker after the treatmentis indicative that the subject therapeutically responds to the administration of the drug identified by the use or method according to one the claims 1-27 to the administration of the HNF4α activity modulator.
41. The method as claimed in one of the claims 38-40, wherein a RT-PCR is performed, in particular by using the kit as claimed in one of the claims 35-37.
42. Medicament for the treatment of metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer comprising a composition that decreases the expression or activity of a HNF4α modulated gene selected from the genes specified in the claims 1-9 and/or 21-26.
43. SiRNA composition, wherein the siRNA composition reduces the expression of a de novo identified HNF4α modulated gene selected from the genes specified in the claims 1-9 or 21-26.
44. Antisense composition, wherein the antisense composition comprises a nucleotide sequence complementary to a coding sequence of a HNF4α modulated gene selected from the genes specified in the claims 1-9 or 21-26
45. Use of an siRNA composition as claimed in claim 43 or of an antisense composition as claimed in claim 44 for the preparation of a medicament.
46. Use as claimed in claim 45 for the preparation of a medicament for preventing, treating, or ameliorating metabolic and tumorous diseases, in particular type 1 and/or type 2 diabetes mellitus, and/or diabetes-caused diseases, including diabetic nephropathy, hearing dysfunction, diabetic neuropathy, cardiovascular diseases or diseases of the retina, and/or colorectal cancer.
47. Method or use or medicament or kit as claimed in one of the preceding claims, wherein a composition according to one of the claims 44-45 is used as the drug or wherein an agent selected from the group consisting of the agonists, antagonists, drugs, agents, antiestrogens, and compounds listed in the
Tables 36-54, sulfonlyurea dehvates, and Aroclor 1254, is used and/or tested and/or screened as the drug and/or as the HNF4α activity modulator.
48. Method according to one of the claims 1-9 and 14-16 or use or method according to one of the claims 17-29, wherein Aroclor 1254 is screened and identified.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP08075816A EP2177615A1 (en) | 2008-10-10 | 2008-10-10 | Method for a genome wide identification of expression regulatory sequences and use of genes and molecules derived thereof for the diagnosis and therapy of metabolic and/or tumorous diseases |
| DE08075816.2 | 2008-10-10 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| WO2010040571A2 true WO2010040571A2 (en) | 2010-04-15 |
| WO2010040571A3 WO2010040571A3 (en) | 2010-07-08 |
| WO2010040571A4 WO2010040571A4 (en) | 2010-08-26 |
Family
ID=40852381
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2009/007431 WO2010040571A2 (en) | 2008-10-10 | 2009-10-12 | Method for a genome wide identification of expression regulatory sequences and use of genes and molecules derived thereof for the diagnosis and therapy of metabolic and/or tumorous diseases |
Country Status (2)
| Country | Link |
|---|---|
| EP (1) | EP2177615A1 (en) |
| WO (1) | WO2010040571A2 (en) |
Cited By (90)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102183655A (en) * | 2011-01-24 | 2011-09-14 | 中国人民解放军军事医学科学院生物医学分析中心 | New molecular marker CUEDC2 (CUE Domain Containing 2) protein for prognosis judgement in endocrine therapy of breast cancer |
| WO2011150976A1 (en) * | 2010-06-04 | 2011-12-08 | bioMérieux | Method and kit for the prognosis of colorectal cancer |
| US8153606B2 (en) | 2008-10-03 | 2012-04-10 | Opko Curna, Llc | Treatment of apolipoprotein-A1 related diseases by inhibition of natural antisense transcript to apolipoprotein-A1 |
| WO2012131301A1 (en) * | 2011-03-28 | 2012-10-04 | The University Of Surrey | Compositions and methods for treating, diagnosing and monitoring disease |
| US8288354B2 (en) | 2005-12-28 | 2012-10-16 | The Scripps Research Institute | Natural antisense and non-coding RNA transcripts as drug targets |
| WO2012154567A2 (en) * | 2011-05-06 | 2012-11-15 | Albert Einstein College Of Medicine Of Yeshiva University | Human invasion signature for prognosis of metastatic risk |
| US20130296191A1 (en) * | 2010-12-23 | 2013-11-07 | Paul Roepman | Methods and Means for Molecular Classification of Colorectal Cancers |
| WO2013166373A1 (en) * | 2012-05-03 | 2013-11-07 | Zhong Wu | Gene expression signature for il-6/stat3 signaling pathway and use thereof |
| WO2014097584A1 (en) * | 2012-12-17 | 2014-06-26 | 独立行政法人医薬基盤研究所 | Method for determining colon cancer |
| US8791085B2 (en) | 2009-05-28 | 2014-07-29 | Curna, Inc. | Treatment of antiviral gene related diseases by inhibition of natural antisense transcript to an antiviral gene |
| US8791087B2 (en) | 2009-08-21 | 2014-07-29 | Curna, Inc. | Treatment of ‘C terminus of HSP70-interacting protein’ (CHIP)related diseases by inhibition of natural antisense transcript to CHIP |
| US8859515B2 (en) | 2009-06-24 | 2014-10-14 | Curna, Inc. | Treatment of tumor necrosis factor receptor 2 (TNFR2) related diseases by inhibition of natural antisense transcript to TNFR2 |
| US8895528B2 (en) | 2010-05-26 | 2014-11-25 | Curna, Inc. | Treatment of atonal homolog 1 (ATOH1) related diseases by inhibition of natural antisense transcript to ATOH1 |
| US8895527B2 (en) | 2009-05-22 | 2014-11-25 | Curna, Inc. | Treatment of transcription factor E3 (TFE3) and insulin receptor substrate 2(IRS2) related diseases by inhibition of natural antisense transcript to TFE3 |
| US8912157B2 (en) | 2010-01-06 | 2014-12-16 | Curna, Inc. | Treatment of pancreatic developmental gene related diseases by inhibition of natural antisense transcript to a pancreatic developmental gene |
| US8921329B2 (en) | 2008-12-04 | 2014-12-30 | Curna, Inc. | Treatment of erythropoietin (EPO) related diseases by inhibition of natural antisense transcript to EPO |
| US8921330B2 (en) | 2009-06-26 | 2014-12-30 | Curna, Inc. | Treatment of down syndrome gene related diseases by inhibition of natural antisense transcript to a down syndrome gene |
| US8921334B2 (en) | 2009-12-29 | 2014-12-30 | Curna, Inc. | Treatment of nuclear respiratory factor 1 (NRF1) related diseases by inhibition of natural antisense transcript to NRF1 |
| US8927511B2 (en) | 2008-12-04 | 2015-01-06 | Curna, Inc. | Treatment of vascular endothelial growth factor (VEGF) related diseases by inhibition of natural antisense transcript to VEGF |
| US8940708B2 (en) | 2009-12-23 | 2015-01-27 | Curna, Inc. | Treatment of hepatocyte growth factor (HGF) related diseases by inhibition of natural antisense transcript to HGF |
| US8946181B2 (en) | 2010-01-04 | 2015-02-03 | Curna, Inc. | Treatment of interferon regulatory factor 8 (IRF8) related diseases by inhibition of natural antisense transcript to IRF8 |
| US8946182B2 (en) | 2010-01-25 | 2015-02-03 | Curna, Inc. | Treatment of RNASE H1 related diseases by inhibition of natural antisense transcript to RNASE H1 |
| US8951981B2 (en) | 2009-06-16 | 2015-02-10 | Curna, Inc. | Treatment of paraoxonase 1 (PON1) related diseases by inhibition of natural antisense transcript to PON1 |
| US8957037B2 (en) | 2009-05-18 | 2015-02-17 | Curna, Inc. | Treatment of reprogramming factor related diseases by inhibition of natural antisense transcript to a reprogramming factor |
| US8962585B2 (en) | 2009-12-29 | 2015-02-24 | Curna, Inc. | Treatment of tumor protein 63 (p63) related diseases by inhibition of natural antisense transcript to p63 |
| US8962586B2 (en) | 2010-02-22 | 2015-02-24 | Curna, Inc. | Treatment of pyrroline-5-carboxylate reductase 1 (PYCR1) related diseases by inhibition of natural antisense transcript to PYCR1 |
| US8980857B2 (en) | 2010-05-14 | 2015-03-17 | Curna, Inc. | Treatment of PAR4 related diseases by inhibition of natural antisense transcript to PAR4 |
| US8980860B2 (en) | 2010-07-14 | 2015-03-17 | Curna, Inc. | Treatment of discs large homolog (DLG) related diseases by inhibition of natural antisense transcript to DLG |
| US8980856B2 (en) | 2010-04-02 | 2015-03-17 | Curna, Inc. | Treatment of colony-stimulating factor 3 (CSF3) related diseases by inhibition of natural antisense transcript to CSF3 |
| US8980858B2 (en) | 2010-05-26 | 2015-03-17 | Curna, Inc. | Treatment of methionine sulfoxide reductase a (MSRA) related diseases by inhibition of natural antisense transcript to MSRA |
| US8987225B2 (en) | 2010-11-23 | 2015-03-24 | Curna, Inc. | Treatment of NANOG related diseases by inhibition of natural antisense transcript to NANOG |
| US8993533B2 (en) | 2010-10-06 | 2015-03-31 | Curna, Inc. | Treatment of sialidase 4 (NEU4) related diseases by inhibition of natural antisense transcript to NEU4 |
| US9012139B2 (en) | 2009-05-08 | 2015-04-21 | Curna, Inc. | Treatment of dystrophin family related diseases by inhibition of natural antisense transcript to DMD family |
| US9023822B2 (en) | 2009-08-25 | 2015-05-05 | Curna, Inc. | Treatment of 'IQ motif containing GTPase activating protein' (IQGAP) related diseases by inhibition of natural antisense transcript to IQGAP |
| US9044494B2 (en) | 2010-04-09 | 2015-06-02 | Curna, Inc. | Treatment of fibroblast growth factor 21 (FGF21) related diseases by inhibition of natural antisense transcript to FGF21 |
| US9044493B2 (en) | 2009-08-11 | 2015-06-02 | Curna, Inc. | Treatment of Adiponectin related diseases by inhibition of natural antisense transcript to an Adiponectin |
| US9068183B2 (en) | 2009-12-23 | 2015-06-30 | Curna, Inc. | Treatment of uncoupling protein 2 (UCP2) related diseases by inhibition of natural antisense transcript to UCP2 |
| US9074210B2 (en) | 2009-02-12 | 2015-07-07 | Curna, Inc. | Treatment of brain derived neurotrophic factor (BDNF) related diseases by inhibition of natural antisense transcript to BDNF |
| US9089588B2 (en) | 2010-05-03 | 2015-07-28 | Curna, Inc. | Treatment of sirtuin (SIRT) related diseases by inhibition of natural antisense transcript to a sirtuin (SIRT) |
| US9155754B2 (en) | 2009-05-06 | 2015-10-13 | Curna, Inc. | Treatment of ABCA1 gene related diseases by inhibition of a natural antisense transcript to ABCA1 |
| US9163285B2 (en) | 2009-05-06 | 2015-10-20 | Curna, Inc. | Treatment of tristetraproline (TTP) related diseases by inhibition of natural antisense transcript to TTP |
| US9173895B2 (en) | 2009-12-16 | 2015-11-03 | Curna, Inc. | Treatment of membrane bound transcription factor peptidase, site 1 (MBTPS1) related diseases by inhibition of natural antisense transcript to MBTPS1 |
| US9200277B2 (en) | 2010-01-11 | 2015-12-01 | Curna, Inc. | Treatment of sex hormone binding globulin (SHBG) related diseases by inhibition of natural antisense transcript to SHBG |
| US9222088B2 (en) | 2010-10-22 | 2015-12-29 | Curna, Inc. | Treatment of alpha-L-iduronidase (IDUA) related diseases by inhibition of natural antisense transcript to IDUA |
| US9234199B2 (en) | 2009-08-05 | 2016-01-12 | Curna, Inc. | Treatment of insulin gene (INS) related diseases by inhibition of natural antisense transcript to an insulin gene (INS) |
| EP2877214A4 (en) * | 2012-07-26 | 2016-03-09 | Joslin Diabetes Center Inc | Predicting and treating diabetic complications |
| US9464287B2 (en) | 2009-03-16 | 2016-10-11 | Curna, Inc. | Treatment of nuclear factor (erythroid-derived 2)-like 2 (NRF2) related diseases by inhibition of natural antisense transcript to NRF2 |
| JP2017018108A (en) * | 2011-03-25 | 2017-01-26 | ビオメリューBiomerieux | Method and kit for determining in vitro probability for individual to suffer from colorectal cancer |
| US9562906B2 (en) | 2010-06-10 | 2017-02-07 | National University Of Singapore | Methods for detection of gastric cancer |
| US9567641B2 (en) | 2013-07-03 | 2017-02-14 | Samsung Electronics Co., Ltd. | Combination therapy for the treatment of cancer using an anti-C-met antibody |
| US9593330B2 (en) | 2011-06-09 | 2017-03-14 | Curna, Inc. | Treatment of frataxin (FXN) related diseases by inhibition of natural antisense transcript to FXN |
| US9677074B2 (en) | 2009-12-31 | 2017-06-13 | Curna, Inc. | Treatment of insulin receptor substrate 2 (IRS2) related diseases by inhibition of natural antisense transcript to IRS2 and transcription factor E3 (TFE3) |
| US9708604B2 (en) | 2009-03-17 | 2017-07-18 | Curna, Inc. | Treatment of delta-like 1 homolog (DLK1) related diseases by inhibition of natural antisense transcript to DLK1 |
| CN107144620A (en) * | 2017-03-31 | 2017-09-08 | 兰州百源基因技术有限公司 | Diabetic nephropathy detects mark |
| US9771579B2 (en) | 2010-06-23 | 2017-09-26 | Curna, Inc. | Treatment of sodium channel, voltage-gated, alpha subunit (SCNA) related diseases by inhibition of natural antisense transcript to SCNA |
| US9834609B2 (en) | 2008-11-07 | 2017-12-05 | Galaxy Biotech, Llc | Methods of detecting a tumor expressing fibroblast growth factor receptor 2 |
| KR101808658B1 (en) * | 2010-07-22 | 2017-12-13 | 한국생명공학연구원 | Diagnostic Kit for Cancer and Pharmaceutical Composition for Prevention and Treatment of Cancer |
| WO2017216391A1 (en) | 2016-06-17 | 2017-12-21 | F. Hoffmann-La Roche Ag | Papd5 and papd7 inhibitors for treating a hepatitis b infection |
| WO2017217807A3 (en) * | 2016-06-16 | 2018-02-01 | 울산대학교 산학협력단 | Biomarker comprising nckap1 as effective ingredient for diagnosing colorectal cancer or for predicting metastasis and prognosis of colorectal cancer |
| US10000752B2 (en) | 2010-11-18 | 2018-06-19 | Curna, Inc. | Antagonat compositions and methods of use |
| KR20180092135A (en) * | 2017-02-08 | 2018-08-17 | 가톨릭대학교 산학협력단 | Use of VLDLR for preventing, diagnosing or treating colorectal and rectal cancer |
| US10113166B2 (en) | 2009-09-25 | 2018-10-30 | Curna, Inc. | Treatment of filaggrin (FLG) related diseases by modulation of FLG expression and activity |
| US10172937B2 (en) | 2013-08-01 | 2019-01-08 | Five Prime Therapeutics, Inc. | Method of treatment of malignant solid tumors with afucosylated anti-FGFR2IIIb antibodies |
| US10214745B2 (en) | 2012-03-15 | 2019-02-26 | The Scripps Research Institute | Treatment of brain derived neurotrophic factor (BDNF) related diseases by inhibition of natural antisense transcript to BDNF |
| WO2019078634A3 (en) * | 2017-10-18 | 2019-06-20 | 한국생명공학연구원 | Pharmaceutical composition for prevention or treatment of insulin resistance or fatty liver, comprising ptp4a1 protein |
| US10358646B2 (en) | 2008-12-04 | 2019-07-23 | Curna, Inc. | Treatment of tumor suppressor gene related diseases by inhibition of natural antisense transcript to the gene |
| US10370657B2 (en) | 2009-06-16 | 2019-08-06 | Curna, Inc. | Treatment of Collagen gene related diseases by inhibition of natural antisense transcript to a collagen gene |
| KR20190116930A (en) * | 2018-04-05 | 2019-10-15 | 주식회사 지놈앤컴퍼니 | Novel target for anti-cancer and immune-enhancing |
| RU2707533C2 (en) * | 2013-03-27 | 2019-11-27 | Ф. Хоффманн-Ля Рош Аг | Genetic markers for prediction of susceptibility to therapy |
| US10563202B2 (en) | 2009-07-24 | 2020-02-18 | GuRNA, Inc. | Treatment of Sirtuin (SIRT) related diseases by inhibition of natural antisense transcript to a Sirtuin (SIRT) |
| CN110859967A (en) * | 2019-11-11 | 2020-03-06 | 上海市东方医院(同济大学附属东方医院) | Application of human CDC37L1 gene and protein coded by same in preparation of medicine for treating gastric cancer |
| US10583128B2 (en) | 2011-09-06 | 2020-03-10 | Curna, Inc. | Treatment of diseases related to alpha subunits of sodium channels, voltage-gated (SCNxA) with small molecules |
| US10584385B2 (en) | 2014-07-30 | 2020-03-10 | Hoffmann-La Roche Inc. | Genetic markers for predicting responsiveness to therapy with HDL-raising or HDL mimicking agent |
| US20200199575A1 (en) * | 2017-09-13 | 2020-06-25 | Children's Hospital Medical Center | Role of exosomes, extracellular vesicles, in the regulation of metabolic homeostasis |
| KR20200085390A (en) * | 2019-01-04 | 2020-07-15 | 순천향대학교 산학협력단 | A biomarker for diagnosing diabetic nephropathy comprising RIPK3 and the uses thereof |
| CN112229999A (en) * | 2020-09-01 | 2021-01-15 | 浙江省肿瘤医院 | Prognostic diagnosis marker Claudin21 for ovarian cancer and application thereof |
| CN112229998A (en) * | 2020-09-01 | 2021-01-15 | 浙江省肿瘤医院 | Prognostic diagnosis marker Claudin22 for ovarian cancer and application thereof |
| US10953034B2 (en) | 2017-10-16 | 2021-03-23 | Hoffmann-La Roche Inc. | Nucleic acid molecule for reduction of PAPD5 and PAPD7 mRNA for treating hepatitis B infection |
| CN113030472A (en) * | 2021-02-01 | 2021-06-25 | 深圳市人民医院 | Application of mitochondrial protein SUCLG2 in diagnosis and prognosis judgment of colorectal cancer |
| US11058767B2 (en) | 2018-02-21 | 2021-07-13 | Bristol-Myers Squibb Company | CAMK2D antisense oligonucleotides and uses thereof |
| US11091555B2 (en) | 2017-05-16 | 2021-08-17 | Five Prime Therapeutics, Inc. | Method of treating gastric cancer with anti-FGFR2-IIIb antibodies and modified FOLFOX6 chemotherapy |
| CN114134091A (en) * | 2021-11-08 | 2022-03-04 | 中国科学院武汉病毒研究所 | Identification method and application of bacterial genome insulation site |
| US11279929B2 (en) | 2018-07-03 | 2022-03-22 | Hoffmann-La Roche, Inc. | Oligonucleotides for modulating Tau expression |
| CN114788869A (en) * | 2022-04-18 | 2022-07-26 | 中山大学肿瘤防治中心(中山大学附属肿瘤医院、中山大学肿瘤研究所) | Medicine for treating recurrent or metastatic nasopharyngeal carcinoma and curative effect evaluation marker thereof |
| US11447553B2 (en) | 2015-11-23 | 2022-09-20 | Five Prime Therapeutics, Inc. | FGFR2 inhibitors alone or in combination with immune stimulating agents in cancer treatment |
| US11479802B2 (en) | 2017-04-11 | 2022-10-25 | Regeneron Pharmaceuticals, Inc. | Assays for screening activity of modulators of members of the hydroxy steroid (17-beta) dehydrogenase (HSD17B) family |
| US11485958B2 (en) | 2017-01-23 | 2022-11-01 | Regeneron Pharmaceuticals, Inc. | HSD17B13 variants and uses thereof |
| CN115927605A (en) * | 2023-03-09 | 2023-04-07 | 山东大学齐鲁医院 | PLA2G12B as diabetic nephropathy biomarker and application thereof |
| US11702700B2 (en) | 2017-10-11 | 2023-07-18 | Regeneron Pharmaceuticals, Inc. | Inhibition of HSD17B13 in the treatment of liver disease in patients expressing the PNPLA3 I148M variation |
| US11939635B2 (en) | 2020-08-15 | 2024-03-26 | Regeneron Pharmaceuticals, Inc. | Treatment of obesity in subjects having variant nucleic acid molecules encoding Calcitonin Receptor (CALCR) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FI20096188A0 (en) * | 2009-11-16 | 2009-11-16 | Mas Metabolic Analytical Servi | Nutrigenetic biomarkers for obesity and type 2 diabetes |
| EA019599B1 (en) * | 2010-09-13 | 2014-04-30 | Федеральное государственное бюджетное учреждение науки Институт биологии гена Российской академии наук | Method for diagnosis of melanoma of a human based on determination of phf 10 gene expression level, diagnostic kit |
| CN103443295B (en) * | 2011-03-25 | 2016-08-17 | 生物梅里埃公司 | External method and the test kit determining that individuality suffers from colorectal cancer probability |
| US20140243403A1 (en) * | 2011-06-03 | 2014-08-28 | The General Hospital Corporation | Treating colorectal, pancreatic, and lung cancer |
| US8859517B2 (en) | 2011-08-08 | 2014-10-14 | Fondazione Salvatore Maugeri Clinica Del Lavoro E Della Riabilitazione | Method of gene transfer for the treatment of recessive catecholaminergic polymorphic ventricular tachycardia (CPVT) |
| US9677072B2 (en) | 2011-09-14 | 2017-06-13 | Georgetown University | Methods of inhibiting proliferation of estrogen-independent cancer cells |
| CN102495214B (en) * | 2011-11-30 | 2014-06-11 | 厦门大学 | Application of prosaposin (psap) serving as effect marker in detection of male reproductive toxicity of polychlorinated biphenyl |
| US20150152421A1 (en) * | 2012-06-14 | 2015-06-04 | Medhexim, Llc | Hexim-1 as a target of leptin signaling to regulate obesity and diabetes |
| CN104583422A (en) | 2012-06-27 | 2015-04-29 | 博格有限责任公司 | Use of markers in the diagnosis and treatment of prostate cancer |
| JP6781507B2 (en) * | 2014-09-08 | 2020-11-04 | 国立研究開発法人国立がん研究センター | Cancer cell-specific antibodies, anticancer drugs, and cancer testing methods |
| WO2016048138A1 (en) * | 2014-09-22 | 2016-03-31 | Rijksuniversiteit Groningen | Biomarkers for cervical cancer. |
| EP4242329A3 (en) | 2014-12-08 | 2023-10-25 | Berg LLC | Use of markers including filamin a in the diagnosis and treatment of prostate cancer |
| TWI793151B (en) | 2017-08-23 | 2023-02-21 | 瑞士商諾華公司 | 3-(1-oxoisoindolin-2-yl)piperidine-2,6-dione derivatives and uses thereof |
| AR116109A1 (en) | 2018-07-10 | 2021-03-31 | Novartis Ag | DERIVATIVES OF 3- (5-AMINO-1-OXOISOINDOLIN-2-IL) PIPERIDINE-2,6-DIONA AND USES OF THE SAME |
| BR122022012697B1 (en) | 2018-07-10 | 2023-04-04 | Novartis Ag | USES OF 3-(5-HYDROXY-1-OXOISOINDOLIN-2-IL)PIPERIDINE-2,6- DIONE DERIVATIVES, AND KIT |
-
2008
- 2008-10-10 EP EP08075816A patent/EP2177615A1/en not_active Withdrawn
-
2009
- 2009-10-12 WO PCT/EP2009/007431 patent/WO2010040571A2/en active Application Filing
Non-Patent Citations (1)
| Title |
|---|
| KEL ALEXANDER E ET AL: "Genome wide prediction of HNF4I+- functional binding sites by the use of local and global sequence context" GENOME BIOLOGY, BIOMED CENTRAL LTD., LONDON, GB, vol. 9, no. 2, 21 February 2008 (2008-02-21), page R36, XP021041580 ISSN: 1465-6906 * |
Cited By (183)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9803195B2 (en) | 2005-12-28 | 2017-10-31 | The Scripps Research Institute | Natural antisense and non-coding RNA transcripts as drug targets |
| US8288354B2 (en) | 2005-12-28 | 2012-10-16 | The Scripps Research Institute | Natural antisense and non-coding RNA transcripts as drug targets |
| US10472627B2 (en) | 2005-12-28 | 2019-11-12 | The Scripps Research Institute | Natural antisense and non-coding RNA transcripts as drug targets |
| US8153606B2 (en) | 2008-10-03 | 2012-04-10 | Opko Curna, Llc | Treatment of apolipoprotein-A1 related diseases by inhibition of natural antisense transcript to apolipoprotein-A1 |
| US10689448B2 (en) | 2008-11-07 | 2020-06-23 | Galaxy Biotech, Llc | Monoclonal antibodies to fibroblast growth factor receptor 2 |
| US9834609B2 (en) | 2008-11-07 | 2017-12-05 | Galaxy Biotech, Llc | Methods of detecting a tumor expressing fibroblast growth factor receptor 2 |
| US10138301B2 (en) | 2008-11-07 | 2018-11-27 | Galaxy Biotech, Llc | Monoclonal antibodies to fibroblast growth factor receptor 2 |
| US8927511B2 (en) | 2008-12-04 | 2015-01-06 | Curna, Inc. | Treatment of vascular endothelial growth factor (VEGF) related diseases by inhibition of natural antisense transcript to VEGF |
| US10358646B2 (en) | 2008-12-04 | 2019-07-23 | Curna, Inc. | Treatment of tumor suppressor gene related diseases by inhibition of natural antisense transcript to the gene |
| US9765336B2 (en) | 2008-12-04 | 2017-09-19 | Curna, Inc. | Treatment of erythropoietin (EPO) related diseases by inhibition of natural antisense transcript to EPO |
| US8921329B2 (en) | 2008-12-04 | 2014-12-30 | Curna, Inc. | Treatment of erythropoietin (EPO) related diseases by inhibition of natural antisense transcript to EPO |
| US10358645B2 (en) | 2008-12-04 | 2019-07-23 | Curna, Inc. | Treatment of erythropoietin (EPO) related diseases by inhibition of natural antisense transcript to EPO |
| US9410155B2 (en) | 2008-12-04 | 2016-08-09 | Curna, Inc. | Treatment of vascular endothelial growth factor (VEGF) related diseases by inhibition of natural antisense transcript to VEGF |
| US11697814B2 (en) | 2008-12-04 | 2023-07-11 | Curna, Inc. | Treatment of tumor suppressor gene related diseases by inhibition of natural antisense transcript to the gene |
| US9074210B2 (en) | 2009-02-12 | 2015-07-07 | Curna, Inc. | Treatment of brain derived neurotrophic factor (BDNF) related diseases by inhibition of natural antisense transcript to BDNF |
| US10519448B2 (en) | 2009-02-12 | 2019-12-31 | Curna, Inc. | Treatment of brain derived neurotrophic factor (BDNF) related diseases by inhibition of natural antisense transcript to BDNF |
| US10995334B2 (en) | 2009-03-16 | 2021-05-04 | Curna Inc. | Treatment of nuclear factor (erythroid-derived 2)-like 2 (NRF2) related diseases by inhibition of natural antisense transcript to NRF2 |
| US9464287B2 (en) | 2009-03-16 | 2016-10-11 | Curna, Inc. | Treatment of nuclear factor (erythroid-derived 2)-like 2 (NRF2) related diseases by inhibition of natural antisense transcript to NRF2 |
| US9834769B2 (en) | 2009-03-17 | 2017-12-05 | Curna, Inc. | Treatment of delta-like 1 homolog (DLK1) related diseases by inhibition of natural antisense transcript to DLK1 |
| US9708604B2 (en) | 2009-03-17 | 2017-07-18 | Curna, Inc. | Treatment of delta-like 1 homolog (DLK1) related diseases by inhibition of natural antisense transcript to DLK1 |
| US9163285B2 (en) | 2009-05-06 | 2015-10-20 | Curna, Inc. | Treatment of tristetraproline (TTP) related diseases by inhibition of natural antisense transcript to TTP |
| US9611477B2 (en) | 2009-05-06 | 2017-04-04 | Curna, Inc. | Treatment of tristetraproline (TTP) related diseases by inhibition of natural antisense transcript to TTP |
| US9155754B2 (en) | 2009-05-06 | 2015-10-13 | Curna, Inc. | Treatment of ABCA1 gene related diseases by inhibition of a natural antisense transcript to ABCA1 |
| US9957503B2 (en) | 2009-05-06 | 2018-05-01 | Curna, Inc. | Treatment of LCAT gene related diseases by inhibition of a natural antisense transcript to LCAT |
| US10604755B2 (en) | 2009-05-06 | 2020-03-31 | Curna, Inc. | Treatment of lipid transport and metabolism gene related diseases by inhibition of natural antisense transcript to a lipid transport and metabolism gene |
| US9012139B2 (en) | 2009-05-08 | 2015-04-21 | Curna, Inc. | Treatment of dystrophin family related diseases by inhibition of natural antisense transcript to DMD family |
| US9533004B2 (en) | 2009-05-08 | 2017-01-03 | Curna, Inc. | Treatment of dystrophin family related diseases by inhibition of natural antisense transcript to DMD family |
| US9914923B2 (en) | 2009-05-18 | 2018-03-13 | Curna, Inc. | Treatment of reprogramming factor related diseases by inhibition of natural antisense transcript to a reprogramming factor |
| US10487327B2 (en) | 2009-05-18 | 2019-11-26 | Curna, Inc. | Treatment of reprogramming factor related diseases by inhibition of natural antisense transcript to a reprogramming factor |
| US8957037B2 (en) | 2009-05-18 | 2015-02-17 | Curna, Inc. | Treatment of reprogramming factor related diseases by inhibition of natural antisense transcript to a reprogramming factor |
| US8895527B2 (en) | 2009-05-22 | 2014-11-25 | Curna, Inc. | Treatment of transcription factor E3 (TFE3) and insulin receptor substrate 2(IRS2) related diseases by inhibition of natural antisense transcript to TFE3 |
| US9725717B2 (en) | 2009-05-22 | 2017-08-08 | Curna, Inc. | Treatment of transcription factor E3 (TFE3) and insulin receptor substrate 2 (IRS2) related diseases by inhibition of natural antisense transcript to TFE3 |
| US9512427B2 (en) | 2009-05-28 | 2016-12-06 | Curna, Inc. | Treatment of antiviral gene related diseases by inhibition of natural antisense transcript to an antiviral gene |
| US9133456B2 (en) | 2009-05-28 | 2015-09-15 | Curna, Inc. | Treatment of antiviral gene related diseases by inhibition of natural antisense transcript to an antiviral gene |
| US8791085B2 (en) | 2009-05-28 | 2014-07-29 | Curna, Inc. | Treatment of antiviral gene related diseases by inhibition of natural antisense transcript to an antiviral gene |
| US10370657B2 (en) | 2009-06-16 | 2019-08-06 | Curna, Inc. | Treatment of Collagen gene related diseases by inhibition of natural antisense transcript to a collagen gene |
| US8951981B2 (en) | 2009-06-16 | 2015-02-10 | Curna, Inc. | Treatment of paraoxonase 1 (PON1) related diseases by inhibition of natural antisense transcript to PON1 |
| US9714423B2 (en) | 2009-06-16 | 2017-07-25 | Curna, Inc. | Treatment of Paraoxonase 1 (PON1) related diseases by inhibition of natural antisense transcript to PON1 |
| US11339394B2 (en) | 2009-06-16 | 2022-05-24 | Curna, Inc. | Treatment of collagen gene related diseases by inhibition of natural antisense transcript to a collagen gene |
| US8859515B2 (en) | 2009-06-24 | 2014-10-14 | Curna, Inc. | Treatment of tumor necrosis factor receptor 2 (TNFR2) related diseases by inhibition of natural antisense transcript to TNFR2 |
| US9771593B2 (en) | 2009-06-24 | 2017-09-26 | Curna, Inc. | Treatment of tumor necrosis factor receptor 2 (TNFR2) related diseases by inhibition of natural antisense transcript to TNFR2 |
| US10036014B2 (en) | 2009-06-26 | 2018-07-31 | Curna, Inc. | Treatment of down syndrome gene related diseases by inhibition of natural antisense transcript to a down syndrome gene |
| US8921330B2 (en) | 2009-06-26 | 2014-12-30 | Curna, Inc. | Treatment of down syndrome gene related diseases by inhibition of natural antisense transcript to a down syndrome gene |
| US10450567B2 (en) | 2009-06-26 | 2019-10-22 | Curna, Inc. | Treatment of down syndrome gene related diseases by inhibition of natural antisense transcript to a down syndrome gene |
| US10876117B2 (en) | 2009-06-26 | 2020-12-29 | Curna, Inc. | Treatment of down syndrome gene related diseases by inhibition of natural antisense transcript to a down syndrome gene |
| US10563202B2 (en) | 2009-07-24 | 2020-02-18 | GuRNA, Inc. | Treatment of Sirtuin (SIRT) related diseases by inhibition of natural antisense transcript to a Sirtuin (SIRT) |
| US9234199B2 (en) | 2009-08-05 | 2016-01-12 | Curna, Inc. | Treatment of insulin gene (INS) related diseases by inhibition of natural antisense transcript to an insulin gene (INS) |
| US10316317B2 (en) | 2009-08-11 | 2019-06-11 | Curna, Inc. | Treatment of adiponectin (ADIPOQ) related diseases by inhibition of natural antisense transcript to an adiponectin (ADIPOQ) |
| US9909126B2 (en) | 2009-08-11 | 2018-03-06 | Curna, Inc. | Treatment of Adiponectin (ADIPOQ) related diseases by inhibition of natural antisense transcript to an Adiponectin (ADIPOQ) |
| US9044493B2 (en) | 2009-08-11 | 2015-06-02 | Curna, Inc. | Treatment of Adiponectin related diseases by inhibition of natural antisense transcript to an Adiponectin |
| US9290766B2 (en) | 2009-08-11 | 2016-03-22 | Curna, Inc. | Treatment of adiponectin (ADIPOQ) related diseases by inhibition of natural antisense transcript to an adiponectin (ADIPOQ) |
| US9725756B2 (en) | 2009-08-21 | 2017-08-08 | Curna, Inc. | Treatment of ‘C terminus of HSP7O-interacting protein’ (CHIP) related diseases by inhibition of natural antisense transcript to CHIP |
| US8791087B2 (en) | 2009-08-21 | 2014-07-29 | Curna, Inc. | Treatment of ‘C terminus of HSP70-interacting protein’ (CHIP)related diseases by inhibition of natural antisense transcript to CHIP |
| US9528110B2 (en) | 2009-08-25 | 2016-12-27 | Curna, Inc. | Treatment of ‘IQ motif containing gtpase activating protein’ (IQGAP) related diseases by inhibition of natural antisense transcript to IQGAP |
| US9023822B2 (en) | 2009-08-25 | 2015-05-05 | Curna, Inc. | Treatment of 'IQ motif containing GTPase activating protein' (IQGAP) related diseases by inhibition of natural antisense transcript to IQGAP |
| US11390868B2 (en) | 2009-09-25 | 2022-07-19 | Curna, Inc. | Treatment of filaggrin (FLG) related diseases by modulation of FLG expression and activity |
| US10113166B2 (en) | 2009-09-25 | 2018-10-30 | Curna, Inc. | Treatment of filaggrin (FLG) related diseases by modulation of FLG expression and activity |
| US9173895B2 (en) | 2009-12-16 | 2015-11-03 | Curna, Inc. | Treatment of membrane bound transcription factor peptidase, site 1 (MBTPS1) related diseases by inhibition of natural antisense transcript to MBTPS1 |
| US9879264B2 (en) | 2009-12-16 | 2018-01-30 | Curna, Inc. | Treatment of membrane bound transcription factor peptidase, site 1 (MBTPS1) related diseases by inhibition of natural antisense transcript to MBTPS1 |
| US9879256B2 (en) | 2009-12-23 | 2018-01-30 | Curna, Inc. | Treatment of hepatocyte growth factor (HGF) related diseases by inhibition of natural antisense transcript to HGF |
| US8940708B2 (en) | 2009-12-23 | 2015-01-27 | Curna, Inc. | Treatment of hepatocyte growth factor (HGF) related diseases by inhibition of natural antisense transcript to HGF |
| US10221413B2 (en) | 2009-12-23 | 2019-03-05 | Curna, Inc. | Treatment of uncoupling protein 2 (UCP2) related diseases by inhibition of natural antisense transcript to UCP2 |
| US9068183B2 (en) | 2009-12-23 | 2015-06-30 | Curna, Inc. | Treatment of uncoupling protein 2 (UCP2) related diseases by inhibition of natural antisense transcript to UCP2 |
| US9732339B2 (en) | 2009-12-29 | 2017-08-15 | Curna, Inc. | Treatment of tumor protein 63 (p63) related diseases by inhibition of natural antisense transcript to p63 |
| US8921334B2 (en) | 2009-12-29 | 2014-12-30 | Curna, Inc. | Treatment of nuclear respiratory factor 1 (NRF1) related diseases by inhibition of natural antisense transcript to NRF1 |
| US8962585B2 (en) | 2009-12-29 | 2015-02-24 | Curna, Inc. | Treatment of tumor protein 63 (p63) related diseases by inhibition of natural antisense transcript to p63 |
| US9663785B2 (en) | 2009-12-29 | 2017-05-30 | Curna, Inc. | Treatment of nuclear respiratory factor 1 (NRF1) related diseases by inhibition of natural antisense transcript to NRF1 |
| US9677074B2 (en) | 2009-12-31 | 2017-06-13 | Curna, Inc. | Treatment of insulin receptor substrate 2 (IRS2) related diseases by inhibition of natural antisense transcript to IRS2 and transcription factor E3 (TFE3) |
| US8946181B2 (en) | 2010-01-04 | 2015-02-03 | Curna, Inc. | Treatment of interferon regulatory factor 8 (IRF8) related diseases by inhibition of natural antisense transcript to IRF8 |
| US9834767B2 (en) | 2010-01-04 | 2017-12-05 | Curna, Inc. | Treatment of interferon regulatory factor 8 (IRF8) related diseases by inhibition of natural antisense transcript to IRF8 |
| US9267136B2 (en) | 2010-01-06 | 2016-02-23 | Curna, Inc. | Treatment of pancreatic developmental gene related diseases by inhibition of natural antisense transcript to a pancreatic developmental gene |
| US8912157B2 (en) | 2010-01-06 | 2014-12-16 | Curna, Inc. | Treatment of pancreatic developmental gene related diseases by inhibition of natural antisense transcript to a pancreatic developmental gene |
| US9200277B2 (en) | 2010-01-11 | 2015-12-01 | Curna, Inc. | Treatment of sex hormone binding globulin (SHBG) related diseases by inhibition of natural antisense transcript to SHBG |
| US10696966B2 (en) | 2010-01-11 | 2020-06-30 | Curna, Inc. | Treatment of sex hormone binding globulin (SHBG) related diseases by inhibition of natural antisense transcript to SHBG |
| US10337013B2 (en) | 2010-01-25 | 2019-07-02 | Curna, Inc. | Treatment of RNASE H1 related diseases by inhibition of natural antisense transcript to RNASE H1 |
| US8946182B2 (en) | 2010-01-25 | 2015-02-03 | Curna, Inc. | Treatment of RNASE H1 related diseases by inhibition of natural antisense transcript to RNASE H1 |
| US9745582B2 (en) | 2010-01-25 | 2017-08-29 | Curna, Inc. | Treatment of RNASE H1 related diseases by inhibition of natural antisense transcript to RNASE H1 |
| US9382543B2 (en) | 2010-02-22 | 2016-07-05 | Curna, Inc. | Treatment of pyrroline-5-carboxylate reductase 1 (PYCR1) related diseases by inhibition of natural antisense transcript to PYCR1 |
| US8962586B2 (en) | 2010-02-22 | 2015-02-24 | Curna, Inc. | Treatment of pyrroline-5-carboxylate reductase 1 (PYCR1) related diseases by inhibition of natural antisense transcript to PYCR1 |
| US9902995B2 (en) | 2010-02-22 | 2018-02-27 | Curna, Inc. | Treatment of pyrroline-5-carboxylate reductase 1 (PYCR1) related disease by inhibition of natural antisense transcript to PYCR1 |
| US8980856B2 (en) | 2010-04-02 | 2015-03-17 | Curna, Inc. | Treatment of colony-stimulating factor 3 (CSF3) related diseases by inhibition of natural antisense transcript to CSF3 |
| US9920369B2 (en) | 2010-04-02 | 2018-03-20 | Curna, Inc. | Treatment of colony-stimulating factor 3 (CSF3) related diseases by inhibition of natural antisene transcript to CSF3 |
| US9382538B2 (en) | 2010-04-02 | 2016-07-05 | Curna, Inc. | Treatment of colony-stimulating factor 3 (CSF3) related diseases by inhibition of natural antisense transcript to CSF3 |
| US9745580B2 (en) | 2010-04-09 | 2017-08-29 | Curna, Inc. | Treatment of fibroblast growth factor 21 (FGF21) related diseases by inhibition of natural antisense transcript to FGF21 |
| US10337011B2 (en) | 2010-04-09 | 2019-07-02 | Curna, Inc. | Treatment of fibroblast growth factor 21 (FGF21) related diseases by inhibition of natural antisense transcript to FGF21 |
| US9044494B2 (en) | 2010-04-09 | 2015-06-02 | Curna, Inc. | Treatment of fibroblast growth factor 21 (FGF21) related diseases by inhibition of natural antisense transcript to FGF21 |
| US9089588B2 (en) | 2010-05-03 | 2015-07-28 | Curna, Inc. | Treatment of sirtuin (SIRT) related diseases by inhibition of natural antisense transcript to a sirtuin (SIRT) |
| US11408004B2 (en) | 2010-05-03 | 2022-08-09 | Curna, Inc. | Treatment of Sirtuin (SIRT) related diseases by inhibition of natural antisense transcript to a Sirtuin (SIRT) |
| US10100315B2 (en) | 2010-05-14 | 2018-10-16 | Curna, Inc. | Treatment of PAR4 related diseases by inhibition of natural antisense transcript to PAR4 |
| US8980857B2 (en) | 2010-05-14 | 2015-03-17 | Curna, Inc. | Treatment of PAR4 related diseases by inhibition of natural antisense transcript to PAR4 |
| US9745584B2 (en) | 2010-05-14 | 2017-08-29 | Curna, Inc. | Treatment of PAR4 related diseases by inhibition of natural antisense transcript to PAR4 |
| US9970008B2 (en) | 2010-05-26 | 2018-05-15 | Curna, Inc. | Treatment of atonal homolog 1 (ATOH1) related diseases by inhibition of natural antisense transcript to ATOH1 |
| US9624493B2 (en) | 2010-05-26 | 2017-04-18 | Curna, Inc. | Treatment of atonal homolog 1 (ATOH1) related diseases by inhibition of natural antisense transcript to ATOH1 |
| US10253320B2 (en) | 2010-05-26 | 2019-04-09 | Curna, Inc. | Treatment of atonal homolog 1 (ATOH1) related diseases by inhibition of natural antisense transcript to ATOH1 |
| US10174324B2 (en) | 2010-05-26 | 2019-01-08 | Curna, Inc. | Treatment of Methionine sulfoxide reductase a (MSRA) related diseases by inhibition of natural antisense transcript to MSRA |
| US8895528B2 (en) | 2010-05-26 | 2014-11-25 | Curna, Inc. | Treatment of atonal homolog 1 (ATOH1) related diseases by inhibition of natural antisense transcript to ATOH1 |
| US8980858B2 (en) | 2010-05-26 | 2015-03-17 | Curna, Inc. | Treatment of methionine sulfoxide reductase a (MSRA) related diseases by inhibition of natural antisense transcript to MSRA |
| WO2011150976A1 (en) * | 2010-06-04 | 2011-12-08 | bioMérieux | Method and kit for the prognosis of colorectal cancer |
| US9771621B2 (en) | 2010-06-04 | 2017-09-26 | Biomerieux | Method and kit for performing a colorectal cancer assay |
| US9422598B2 (en) | 2010-06-04 | 2016-08-23 | Biomerieux | Method and kit for the prognosis of colorectal cancer |
| US9562906B2 (en) | 2010-06-10 | 2017-02-07 | National University Of Singapore | Methods for detection of gastric cancer |
| US9771579B2 (en) | 2010-06-23 | 2017-09-26 | Curna, Inc. | Treatment of sodium channel, voltage-gated, alpha subunit (SCNA) related diseases by inhibition of natural antisense transcript to SCNA |
| US10793857B2 (en) | 2010-06-23 | 2020-10-06 | Curna, Inc. | Treatment of sodium channel, voltage-gated, alpha subunit (SCNA) related diseases by inhibition of natural antisense transcript to SCNA |
| US9902958B2 (en) | 2010-07-14 | 2018-02-27 | Curna, Inc. | Treatment of discs large homolog (DLG) related diseases by inhibition of natural antisense transcript to DLG |
| US8980860B2 (en) | 2010-07-14 | 2015-03-17 | Curna, Inc. | Treatment of discs large homolog (DLG) related diseases by inhibition of natural antisense transcript to DLG |
| US9394542B2 (en) | 2010-07-14 | 2016-07-19 | Curna, Inc. | Treatment of discs large homolog (DLG) related diseases by inhibition of natural antisense transcript to DLG |
| KR101808658B1 (en) * | 2010-07-22 | 2017-12-13 | 한국생명공학연구원 | Diagnostic Kit for Cancer and Pharmaceutical Composition for Prevention and Treatment of Cancer |
| US8993533B2 (en) | 2010-10-06 | 2015-03-31 | Curna, Inc. | Treatment of sialidase 4 (NEU4) related diseases by inhibition of natural antisense transcript to NEU4 |
| US9222088B2 (en) | 2010-10-22 | 2015-12-29 | Curna, Inc. | Treatment of alpha-L-iduronidase (IDUA) related diseases by inhibition of natural antisense transcript to IDUA |
| US9873873B2 (en) | 2010-10-22 | 2018-01-23 | Curna, Inc. | Treatment of alpha-L-iduronidase (IDUA) related diseases by inhibition of natural antisense transcript to IDUA |
| US10000752B2 (en) | 2010-11-18 | 2018-06-19 | Curna, Inc. | Antagonat compositions and methods of use |
| US8987225B2 (en) | 2010-11-23 | 2015-03-24 | Curna, Inc. | Treatment of NANOG related diseases by inhibition of natural antisense transcript to NANOG |
| US9809816B2 (en) | 2010-11-23 | 2017-11-07 | Curna, Inc. | Treatment of NANOG related diseases by inhibition of natural antisense transcript to NANOG |
| US10036070B2 (en) * | 2010-12-23 | 2018-07-31 | Agendia N.V. | Methods and means for molecular classification of colorectal cancers |
| US20130296191A1 (en) * | 2010-12-23 | 2013-11-07 | Paul Roepman | Methods and Means for Molecular Classification of Colorectal Cancers |
| WO2012100573A1 (en) * | 2011-01-24 | 2012-08-02 | 中国人民解放军军事医学科学院生物医学分析中心 | New molecular marker cuedc2 protein for prognostic determination of breast cancer endocrinology therapy |
| CN102183655A (en) * | 2011-01-24 | 2011-09-14 | 中国人民解放军军事医学科学院生物医学分析中心 | New molecular marker CUEDC2 (CUE Domain Containing 2) protein for prognosis judgement in endocrine therapy of breast cancer |
| JP2017018108A (en) * | 2011-03-25 | 2017-01-26 | ビオメリューBiomerieux | Method and kit for determining in vitro probability for individual to suffer from colorectal cancer |
| US9689041B2 (en) | 2011-03-25 | 2017-06-27 | Biomerieux | Method and kit for determining in vitro the probability for an individual to suffer from colorectal cancer |
| CN103502453B (en) * | 2011-03-28 | 2017-06-09 | Hox治疗有限公司 | For treat, diagnose and monitoring of diseases composition and method |
| US9803196B2 (en) | 2011-03-28 | 2017-10-31 | Hox Therapeutics Limited | Compositions and methods for treating, diagnosing and monitoring disease |
| WO2012131301A1 (en) * | 2011-03-28 | 2012-10-04 | The University Of Surrey | Compositions and methods for treating, diagnosing and monitoring disease |
| AU2012235986B2 (en) * | 2011-03-28 | 2017-05-04 | Hox Therapeutics Limted | Compositions and methods for treating, diagnosing and monitoring disease |
| CN103502453A (en) * | 2011-03-28 | 2014-01-08 | Hox治疗有限公司 | Compositions and methods for treating, diagnosing and monitoring disease |
| KR20140045345A (en) * | 2011-03-28 | 2014-04-16 | 혹스 테라퓨틱스 리미티드 | Compositions and methods for treating, diagnosing and monitoring disease |
| WO2012154567A2 (en) * | 2011-05-06 | 2012-11-15 | Albert Einstein College Of Medicine Of Yeshiva University | Human invasion signature for prognosis of metastatic risk |
| WO2012154567A3 (en) * | 2011-05-06 | 2014-05-08 | Albert Einstein College Of Medicine Of Yeshiva University | Human invasion signature for prognosis of metastatic risk |
| US9970057B2 (en) | 2011-05-06 | 2018-05-15 | Albert Einstein College Of Medicine, Inc. | Human invasion signature for prognosis of metastatic risk |
| US9902959B2 (en) | 2011-06-09 | 2018-02-27 | Curna, Inc. | Treatment of Frataxin (FXN) related diseases by inhibition of natural antisense transcript to FXN |
| US9593330B2 (en) | 2011-06-09 | 2017-03-14 | Curna, Inc. | Treatment of frataxin (FXN) related diseases by inhibition of natural antisense transcript to FXN |
| US10583128B2 (en) | 2011-09-06 | 2020-03-10 | Curna, Inc. | Treatment of diseases related to alpha subunits of sodium channels, voltage-gated (SCNxA) with small molecules |
| US10214745B2 (en) | 2012-03-15 | 2019-02-26 | The Scripps Research Institute | Treatment of brain derived neurotrophic factor (BDNF) related diseases by inhibition of natural antisense transcript to BDNF |
| US10081838B2 (en) * | 2012-05-03 | 2018-09-25 | Qiagen Sciences, Llc | Gene expression signature for IL-6/STAT3 signaling pathway and use thereof |
| US20150232926A1 (en) * | 2012-05-03 | 2015-08-20 | Zhong Wu | Gene expression signature for il-6/stat3 signaling pathway and use thereof |
| WO2013166373A1 (en) * | 2012-05-03 | 2013-11-07 | Zhong Wu | Gene expression signature for il-6/stat3 signaling pathway and use thereof |
| EP2877214A4 (en) * | 2012-07-26 | 2016-03-09 | Joslin Diabetes Center Inc | Predicting and treating diabetic complications |
| US9921221B2 (en) | 2012-07-26 | 2018-03-20 | Joslin Diabetes Center, Inc. | Predicting and treating diabetic complications |
| WO2014097584A1 (en) * | 2012-12-17 | 2014-06-26 | 独立行政法人医薬基盤研究所 | Method for determining colon cancer |
| RU2707533C2 (en) * | 2013-03-27 | 2019-11-27 | Ф. Хоффманн-Ля Рош Аг | Genetic markers for prediction of susceptibility to therapy |
| US11549142B2 (en) | 2013-03-27 | 2023-01-10 | Hoffmann-La Roche Inc. | CETP inhibitors for therapeutic use |
| US10711303B2 (en) | 2013-03-27 | 2020-07-14 | Hoffman-La Roche Inc. | CETP inhibitors for therapeutic use |
| US9567641B2 (en) | 2013-07-03 | 2017-02-14 | Samsung Electronics Co., Ltd. | Combination therapy for the treatment of cancer using an anti-C-met antibody |
| US10172937B2 (en) | 2013-08-01 | 2019-01-08 | Five Prime Therapeutics, Inc. | Method of treatment of malignant solid tumors with afucosylated anti-FGFR2IIIb antibodies |
| US11235059B2 (en) | 2013-08-01 | 2022-02-01 | Five Prime Therapeutics, Inc. | Afucosylated anti-FGFR2IIIB antibodies |
| US10584385B2 (en) | 2014-07-30 | 2020-03-10 | Hoffmann-La Roche Inc. | Genetic markers for predicting responsiveness to therapy with HDL-raising or HDL mimicking agent |
| US11401554B2 (en) | 2014-07-30 | 2022-08-02 | Hoffman-La Roche Inc. | Genetic markers for predicting responsiveness to therapy with HDL-raising or HDL mimicking agent |
| US11447553B2 (en) | 2015-11-23 | 2022-09-20 | Five Prime Therapeutics, Inc. | FGFR2 inhibitors alone or in combination with immune stimulating agents in cancer treatment |
| WO2017217807A3 (en) * | 2016-06-16 | 2018-02-01 | 울산대학교 산학협력단 | Biomarker comprising nckap1 as effective ingredient for diagnosing colorectal cancer or for predicting metastasis and prognosis of colorectal cancer |
| EP4219767A1 (en) | 2016-06-17 | 2023-08-02 | F. Hoffmann-La Roche AG | Papd5 and papd7 inhibitors for treating a hepatitis b infection |
| WO2017216390A1 (en) | 2016-06-17 | 2017-12-21 | F. Hoffmann-La Roche Ag | Nucleic acid molecules for reduction of papd5 or papd7 mrna for treating hepatitis b infection |
| US11534452B2 (en) | 2016-06-17 | 2022-12-27 | Hoffmann-La Roche Inc. | Nucleic acid molecules for reduction of PAPD5 or PAPD7 mRNA for treating hepatitis B infection |
| WO2017216391A1 (en) | 2016-06-17 | 2017-12-21 | F. Hoffmann-La Roche Ag | Papd5 and papd7 inhibitors for treating a hepatitis b infection |
| US11191775B2 (en) | 2016-06-17 | 2021-12-07 | Hoffmann-La Roche Inc. | PAPD5 and PAPD7 inhibitors for treating a hepatitis B infection |
| US11753628B2 (en) | 2017-01-23 | 2023-09-12 | Regeneron Pharmaceuticals, Inc. | HSD17B13 variants and uses thereof |
| US11485958B2 (en) | 2017-01-23 | 2022-11-01 | Regeneron Pharmaceuticals, Inc. | HSD17B13 variants and uses thereof |
| KR102358385B1 (en) | 2017-02-08 | 2022-02-04 | 가톨릭대학교 산학협력단 | Use of VLDLR for preventing, diagnosing or treating colorectal and rectal cancer |
| KR20180092135A (en) * | 2017-02-08 | 2018-08-17 | 가톨릭대학교 산학협력단 | Use of VLDLR for preventing, diagnosing or treating colorectal and rectal cancer |
| CN107144620A (en) * | 2017-03-31 | 2017-09-08 | 兰州百源基因技术有限公司 | Diabetic nephropathy detects mark |
| US11479802B2 (en) | 2017-04-11 | 2022-10-25 | Regeneron Pharmaceuticals, Inc. | Assays for screening activity of modulators of members of the hydroxy steroid (17-beta) dehydrogenase (HSD17B) family |
| US11091555B2 (en) | 2017-05-16 | 2021-08-17 | Five Prime Therapeutics, Inc. | Method of treating gastric cancer with anti-FGFR2-IIIb antibodies and modified FOLFOX6 chemotherapy |
| US20200199575A1 (en) * | 2017-09-13 | 2020-06-25 | Children's Hospital Medical Center | Role of exosomes, extracellular vesicles, in the regulation of metabolic homeostasis |
| US11702700B2 (en) | 2017-10-11 | 2023-07-18 | Regeneron Pharmaceuticals, Inc. | Inhibition of HSD17B13 in the treatment of liver disease in patients expressing the PNPLA3 I148M variation |
| US11484546B2 (en) | 2017-10-16 | 2022-11-01 | Hoffman-La Roche Inc. | Nucleic acid molecule for reduction of PAPD5 and PAPD7 mRNA for treating hepatitis B infection |
| US10953034B2 (en) | 2017-10-16 | 2021-03-23 | Hoffmann-La Roche Inc. | Nucleic acid molecule for reduction of PAPD5 and PAPD7 mRNA for treating hepatitis B infection |
| WO2019078634A3 (en) * | 2017-10-18 | 2019-06-20 | 한국생명공학연구원 | Pharmaceutical composition for prevention or treatment of insulin resistance or fatty liver, comprising ptp4a1 protein |
| US11058767B2 (en) | 2018-02-21 | 2021-07-13 | Bristol-Myers Squibb Company | CAMK2D antisense oligonucleotides and uses thereof |
| KR102308980B1 (en) | 2018-04-05 | 2021-10-06 | 주식회사 지놈앤컴퍼니 | Novel target for anti-cancer and immune-enhancing |
| KR20190116930A (en) * | 2018-04-05 | 2019-10-15 | 주식회사 지놈앤컴퍼니 | Novel target for anti-cancer and immune-enhancing |
| US11753640B2 (en) | 2018-07-03 | 2023-09-12 | Hoffmann-La Roche Inc. | Oligonucleotides for modulating Tau expression |
| US11279929B2 (en) | 2018-07-03 | 2022-03-22 | Hoffmann-La Roche, Inc. | Oligonucleotides for modulating Tau expression |
| KR102185987B1 (en) | 2019-01-04 | 2020-12-04 | 순천향대학교 산학협력단 | A biomarker for diagnosing diabetic nephropathy comprising RIPK3 and the uses thereof |
| KR20200085390A (en) * | 2019-01-04 | 2020-07-15 | 순천향대학교 산학협력단 | A biomarker for diagnosing diabetic nephropathy comprising RIPK3 and the uses thereof |
| CN110859967A (en) * | 2019-11-11 | 2020-03-06 | 上海市东方医院(同济大学附属东方医院) | Application of human CDC37L1 gene and protein coded by same in preparation of medicine for treating gastric cancer |
| US11939635B2 (en) | 2020-08-15 | 2024-03-26 | Regeneron Pharmaceuticals, Inc. | Treatment of obesity in subjects having variant nucleic acid molecules encoding Calcitonin Receptor (CALCR) |
| CN112229998B (en) * | 2020-09-01 | 2022-04-22 | 浙江省肿瘤医院 | Prognostic diagnosis marker Claudin22 for ovarian cancer and application thereof |
| CN112229999B (en) * | 2020-09-01 | 2022-04-22 | 浙江省肿瘤医院 | Prognostic diagnosis marker Claudin21 for ovarian cancer and application thereof |
| CN112229998A (en) * | 2020-09-01 | 2021-01-15 | 浙江省肿瘤医院 | Prognostic diagnosis marker Claudin22 for ovarian cancer and application thereof |
| CN112229999A (en) * | 2020-09-01 | 2021-01-15 | 浙江省肿瘤医院 | Prognostic diagnosis marker Claudin21 for ovarian cancer and application thereof |
| CN113030472A (en) * | 2021-02-01 | 2021-06-25 | 深圳市人民医院 | Application of mitochondrial protein SUCLG2 in diagnosis and prognosis judgment of colorectal cancer |
| CN114134091A (en) * | 2021-11-08 | 2022-03-04 | 中国科学院武汉病毒研究所 | Identification method and application of bacterial genome insulation site |
| CN114134091B (en) * | 2021-11-08 | 2024-04-12 | 中国科学院武汉病毒研究所 | Identification method and application of bacterial genome insulation sites |
| CN114788869A (en) * | 2022-04-18 | 2022-07-26 | 中山大学肿瘤防治中心(中山大学附属肿瘤医院、中山大学肿瘤研究所) | Medicine for treating recurrent or metastatic nasopharyngeal carcinoma and curative effect evaluation marker thereof |
| CN115927605A (en) * | 2023-03-09 | 2023-04-07 | 山东大学齐鲁医院 | PLA2G12B as diabetic nephropathy biomarker and application thereof |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2010040571A3 (en) | 2010-07-08 |
| WO2010040571A4 (en) | 2010-08-26 |
| EP2177615A1 (en) | 2010-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20200399714A1 (en) | Cancer-related biological materials in microvesicles | |
| US20220025369A1 (en) | Rna encoding a therapeutic protein | |
| US11485743B2 (en) | Protein degraders and uses thereof | |
| US20210363525A1 (en) | Sarna compositions and methods of use | |
| EP2177615A1 (en) | Method for a genome wide identification of expression regulatory sequences and use of genes and molecules derived thereof for the diagnosis and therapy of metabolic and/or tumorous diseases | |
| US20210147831A1 (en) | Sequencing-based proteomics | |
| US20220401460A1 (en) | Modulating resistance to bcl-2 inhibitors | |
| US20230115184A1 (en) | Protein degraders and uses thereof | |
| CN110499364A (en) | A kind of probe groups and its kit and application for detecting the full exon of extended pattern hereditary disease | |
| US20240165239A1 (en) | Covalent Binding Compounds for the Treatment of Disease | |
| CN106232833A (en) | The haplotyping that methylates (MONOD) for non-invasive diagnostic | |
| WO2012087983A1 (en) | Polycomb-associated non-coding rnas | |
| WO2023286305A1 (en) | Cell quality management method and cell production method | |
| WO2019008412A1 (en) | Utilizing blood based gene expression analysis for cancer management | |
| WO2019008414A1 (en) | Exosome based gene expression analysis for cancer management | |
| WO2019008415A1 (en) | Exosome and pbmc based gene expression analysis for cancer management | |
| US20240233867A1 (en) | Quality management method for specific cell and method of producing specific cell | |
| US20240191294A1 (en) | Quality management method for cell and method of producing cell | |
| US12054756B2 (en) | Engineered nucleases, compositions, and methods of use thereof | |
| WO2023183893A1 (en) | Engineered gene effectors, compositions, and methods of use thereof | |
| CN117677707A (en) | Quality control method for specific cells and method for producing specific cells | |
| CN117730164A (en) | Method for managing cell quality and method for producing cell | |
| Gillis et al. | Exceptional Edges matrices from" Guilt by Association" Is the Exception Rather Than the Rule in Gene Networks Gillis, J. and Pavlidis, P.(2012) PLoS Computational Biology, 8 (3). |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09752724 Country of ref document: EP Kind code of ref document: A2 |
|
| NENP | Non-entry into the national phase in: |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 09752724 Country of ref document: EP Kind code of ref document: A2 |