WO2010011918A2 - Methods for prognosing mechanical systems - Google Patents
Methods for prognosing mechanical systems Download PDFInfo
- Publication number
- WO2010011918A2 WO2010011918A2 PCT/US2009/051680 US2009051680W WO2010011918A2 WO 2010011918 A2 WO2010011918 A2 WO 2010011918A2 US 2009051680 W US2009051680 W US 2009051680W WO 2010011918 A2 WO2010011918 A2 WO 2010011918A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- feature space
- prediction
- value
- features
- model
- Prior art date
Links
Classifications
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05B—CONTROL OR REGULATING SYSTEMS IN GENERAL; FUNCTIONAL ELEMENTS OF SUCH SYSTEMS; MONITORING OR TESTING ARRANGEMENTS FOR SUCH SYSTEMS OR ELEMENTS
- G05B23/00—Testing or monitoring of control systems or parts thereof
- G05B23/02—Electric testing or monitoring
- G05B23/0205—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults
- G05B23/0218—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults characterised by the fault detection method dealing with either existing or incipient faults
- G05B23/0243—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults characterised by the fault detection method dealing with either existing or incipient faults model based detection method, e.g. first-principles knowledge model
- G05B23/0254—Electric testing or monitoring by means of a monitoring system capable of detecting and responding to faults characterised by the fault detection method dealing with either existing or incipient faults model based detection method, e.g. first-principles knowledge model based on a quantitative model, e.g. mathematical relationships between inputs and outputs; functions: observer, Kalman filter, residual calculation, Neural Networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/213—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods
- G06F18/2137—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods based on criteria of topology preservation, e.g. multidimensional scaling or self-organising maps
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/232—Non-hierarchical techniques
- G06F18/2321—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2218/00—Aspects of pattern recognition specially adapted for signal processing
Definitions
- the present invention generally relates to prognosing mechanical systems and, specifically, to predicting when a failure may occur.
- unexpected machine downtime is still one of the major issues impacting machining productivity in industry. For example, every minute of downtime in an automotive manufacturing plant could be quite costly, as the breakdown of one machine may result in the halt of the entire production line in a manufacturing facility. As machine tools become more complex and sophisticated, the reliability of the machining equipment becomes more crucial. Most machine maintenance today is either purely reactive (reactive maintenance) or blindly proactive (preventive maintenance), both of which could be extremely wasteful.
- Predictive maintenance focuses on failure prediction in order to prevent failures in advance, and offers sufficient information to improve overall maintenance scheduling.
- researchers and practitioners have been trying to develop and deploy prognostics technologies with ad hoc and trial-and-error approaches. These efforts have resulted in limited success, due to the fact that a systematic approach in deploying the right prognostics models for the right applications has yet to be developed.
- Stability properties and modeling assumptions are important for building physics models for a controller or machine process.
- Operating conditions such as shaft speed, load, feed rate and cutting materials, are also important factors for prognostic models since the degradation patterns of the machine may be distinct under different operating conditions.
- a system's full range of operating states may be decomposed into four overlapping operating conditions based on two principle parameters, which may include shaft speed, load, feed rate, and cutting materials, etc. Under a certain operating condition (e.g. low speed cutting of a soft material), the degradation pattern of the machine may be a slow and stationary process; while under another operating condition (e.g.
- the degradation pattern may show non-stationary characteristics with a faster degradation rate towards failure. It may be difficult for an individual prognostic model to meet the accuracy requirements for prediction when the machine operating condition changes. Many system components can undergo a long degradation process before catastrophic failures occur. If a certain operating condition is continuously examined, the degradation status of the component will change over time. Performance indices (e.g., "1" meaning normal, and "0" meaning unacceptable) may be stable in the range of 0.9 to 1.0 at the beginning. As the initial faults develop over time, a degradation trend appears in the performance indices. At the final stage of the degradation, the trend of the performance indices drops quickly towards 0. An individual model cannot always meet the accuracy requirements for prediction when the machine degradation status changes overtime. Some prediction models are only appropriate for specific degradation patterns. These models may fail to learn and predict for aliasing degradation patterns accurately. A method which incorporates multiple prediction models may solve this issue, while the challenge still remains in how to autonomously shift among these multiple models to improve the prediction accuracy.
- the present disclosure generally relates to a method of prognosing a mechanical system comprising receiving measurement data corresponding to the mechanical system; extracting one or more features from the received measurement data by decomposing the measurement data into a feature space; selecting a prediction model from a plurality of prediction models for one or more features based at least on part on a degradation status of the mechanical system and a reinforcement learning model; generating a predicted feature space by applying the selective prediction model to the feature space; generating a confidence value by comparing the predicted feature space with a normal baseline distribution, a faulty baseline distribution, or a combination thereof; and providing a status of mechanical system based at least in part on the confidence value.
- FIG. 1 depicts an exemplary framework for prognosing mechanical systems according to one or more embodiments shown and described herein;
- FIG. 2 depicts an exemplary DB4 wavelet according to one or more embodiments shown and described herein;
- FIG. 3 depicts an exemplary flowchart of a recurrent neural network according to one or more embodiments shown and described herein;
- FIG. 4 depicts an exemplary adaptive prediction model selection table according to one or more embodiments shown and described herein;
- FIGS. 5A-B depict exemplary confidence value calculations according to one or more embodiments shown and described herein;
- FIG. 6 depicts an exemplary presentation of the self-organizing map structure according to one or more embodiments shown and described herein; and FIG. 7 depicts an exemplary computer system for prognosing a mechanical system according to one or more embodiments shown and described herein.
- the embodiments described herein generally relate to methods for adaptive modeling for robust prognostics for mechanical systems and are aimed at dynamically selecting the most appropriate prediction models under different machine degradation statuses. To tackle these challenges, the disclosed methods comprise three major tasks: identification of the machine degradation status, reinforcement learning-based framework -A-
- the adaptive reinforcement learning-based modeling focuses on providing a recommendation of the most appropriate prediction model according to different machine degradation statuses.
- An effective method to identify the degradation status needs to be developed before applying the reinforcement learning framework.
- the reinforcement learning algorithm will interact with the available historical data and “learn” to select the most appropriate prediction model when the machine is in a certain degradation status. This learning procedure yields a "look-up table” based on which the appropriate prediction models can be selected.
- the reinforcement learning scheme can be updated to provide a new look-up table for prediction model selection when new observations are available. When performing online testing, the appropriate prediction models will be selected according to the results of the look-up table.
- One embodiment of the adaptive modeling for robust prognostics is illustrated in
- the sensors 2 may be those normally used by the mechanical system (e.g., to measure position, velocity, etc.) or may be sensors specifically placed in the mechanical system to measure a particular parameter (e.g., vibration).
- the modeling system may read the measurement data from the sensors 2 and perform a feature extraction method at step 4 which will extract a performance related feature space from the raw sensor data. If the feature space is highly dimensional, reduction methods can be applied to reduce the dimension of the feature space. Based on the recently-obtained features, the degradation status will be identified at step 6.
- the most appropriate prediction model is selected according to the look-up table, which is the result of the reinforcement learning scheme.
- the selected prediction model will be applied to predict future trends of the features at step 8.
- the predicted feature space is generated by sampling between the predicted confidence intervals.
- an enhanced density estimation method is developed to approximate the distribution of the predicted feature space as well as the distributions of the baselines.
- the performance index is calculated at step 16 by the overlap of the distribution of the predicted feature space and the distributions of the baselines. If the predicted performance index drops to a very low level, diagnosis will be applied at step 18 to determine the root causes of the degradation or failures. As part of selecting the appropriate prediction model, the method may reinforce the selection at step 10 by using historical data 20.
- Signal processing and feature extraction algorithms are used to decompose multi- sensory data into a feature space, which is related to the performance assessment or diagnosis tasks.
- a "feature" is a particular characteristic of the measurement signal, which may be extracted using time domain or frequency domain techniques. For example, one feature of a measurement signal may be its maximum amplitude within a given time period. Other features may be extracted as discussed herein.
- Time domain analysis is used to analyze stochastic signals in the time domain, which involves the comparison of two different signals. Time domain analysis uses the waveform for analysis as compared to frequency domain analysis, which instead uses the spectrum. Time domain analysis is useful when two different signals look very similar, even though the characteristics of the time signal are very different.
- the waveform immediately shows the differences, however frequency domain analysis may be used when time domain analysis does not provide enough information for further analysis.
- the Fourier Transform is a well-known algorithm in frequency domain analysis. It is used to decompose or separate the waveform into a sum of sinusoids of different frequencies. When dealing with a discrete or a sampled/digitized analog signal, the Discrete Fourier Transform (DFT) may be an appropriate Fourier analysis algorithm.
- some spectrum analysis tools such as envelope analysis, frequency filters, side band structure analysis, Hubert transform, and Cepstrum analysis, may be applied to various signal processing scenarios. Frequency domain analysis will not preserve the temporal information after the transformation of the time signals. Therefore, it may only be useful for stationary signals that do not contain frequency variations over time.
- Wavelet transform represents time signals in terms of a finite length or fast decaying oscillating waveform, which is scaled and translated to match the input signals.
- Wavelet Packet Transform using a rich library of redundant bases with arbitrary time- frequency resolution, enables the extraction of features from signals that combine non- stationary and stationary characteristics.
- the WPT provides a very powerful tool for non- stationary signal analysis.
- the representation contains information both in time and frequency domain and it may achieve better resolution than time-frequency analysis.
- the RMS may be
- skewness may be calculated as
- N is the number of samples in a dataset
- x is a series of a sampling data
- x is the mean value of the series x .
- a Fast Fourier Transform may be used to decompose or separate the waveform into a sum of sinusoids of different frequencies.
- the Discrete Fourier Transform may be the appropriate Fourier analysis tool.
- the DFT can be computed efficiently in practice using an FFT algorithm.
- the sensor e.g., vibration
- the frequency spectrum can be subdivided into a specific number of sub-bands.
- a sub-band is basically a group of adjacent frequencies.
- the center frequencies of these sub-bands have already been pre- defined as, for example, the ball bearing defect frequencies of a mechanical system: Ball Passing Frequency Inner-race (BPFI), Ball Passing Frequency Outer-race (BPFO), Ball Spin Frequency (BSF) and Foundation Train Frequency (FTF).
- BPFI Ball Passing Frequency Inner-race
- BPFO Ball Passing Frequency Outer-race
- BSF Ball Spin Frequency
- FTF Foundation Train Frequency
- the energy in each of these sub-bands centered at BPFI, BPFO and BSF is computed and passed on to the performance assessment models.
- the Hubert transform is a commonly used transformation to obtain the envelope of the signal.
- Wavelet Packet Analysis provides a powerful method for non-stationary signal analysis. For sustained mechanical defects, a Fourier-based analysis, which uses sinusoidal functions as base functions, provides an ideal candidate for extraction of these narrow-band signals. For intermittent defects, signals often demonstrate a non-stationary and transient nature. Wavelet packet transform, using a rich library of redundant bases with arbitrary time-frequency resolution, enables the extraction of features from signals that combine non- stationary and stationary characteristics. WPA is an extension of the wavelet transform (WT) which provides complete level-by-level decomposition. The wavelet packets are particular linear combinations of wavelets. The wavelet packets inherit properties such as orthogonality, smoothness, and time-frequency localization from their corresponding wavelet functions.
- a wavelet packet is a function ⁇ j ' k (t) with three indices, where integers i, j, and k are the modulation or oscillation parameter, the scale parameter, and the translation parameter, respectively.
- the first wavelet is the so-called mother wavelet or analyzing wavelet.
- Daubechies wavelet 24 (DB4) which is a kind of compactly supported wavelet, is widely used as the mother wavelet. This wavelet is shown in FIG. 2.
- the following wavelets ⁇ ' for i 2, 3 ...
- h(k) and g(k) are the quadrature mirror filters (QMF) associated with the predefined scaling function and the mother wavelet function.
- e k .
- the energies of the nodes are used as the input feature space for performance assessment.
- Wavelet packet analysis may be applied to extract features from the non-stationary vibration data. Other types of analyzing wavelet functions may also be used, as is known in the art.
- Principal component analysis is a statistical method that may be used for reducing feature space dimensionality by transforming the original features into a new set of uncorrelated features.
- the Karhunen-Loeve transform is a linear dimensionality selection procedure that is related to PCA. The goal is to transform a given data set X of dimension N to an alternative data set Y of smaller dimension M in the way that is optimal in a sum-squared error sense.
- SOM Self-Organizing Maps
- SOM provides a way of representing multidimensional feature space in a one or two-dimensional space while preserving the topological properties of the input space.
- SOM is an unsupervised learning neural network which can organize itself according to the nature of the input data.
- the input data vectors, which closely resemble each other, are located next to each other on the map after training.
- the Best Machining Unit (BMU) in the SOM is the neuron whose weight vector is the closest to the input vector in the input space.
- the inner product x ⁇ ⁇ ⁇ can be used as an analytical measure for the match of x with ⁇ ⁇ .
- Euclidean distance may be a better and more convenient measure criterion for the match of x with ⁇ ⁇ .
- the minimum distance defines the BMU. If ⁇ ) c is defined as the weight vector of the neuron that best matches the input vector x, the measure can be represented by
- min
- x - ft>j ⁇ , j l,2,...,m .
- the weight vectors and the topological neighbors of the BMU are updated in order to move them closer to the input vector in the input space.
- a choice of the kernel function may be the
- Gaussian function h j ⁇ in which d , , is the lateral distance between the BMU C ⁇ c and neuron j.
- the parameter ⁇ is the "effective width" of the topological neighborhood.
- the function a(t) is the learning rate which monotonically decreases with the training time. In the initial phase which lasts for a given number of steps (e.g. first 1000 steps), a(t) starts with a value that is close to 1 and it can be linear, exponential, or inversely proportional to t. During the fine-adjustment phase which lasts for the rest of the training, a(t) should keep small values over a long time period.
- MQE minimum quantization error
- V F the input feature vector
- V BMU the weight vector of the BMU.
- Auto-regressive moving average (ARMA) and recurrent neural network (RNN) are considered as two types of prediction models in this disclosure which may be used for prognosing mechanical systems. These two prediction models have different characteristics. Other types of prediction models may be used, as are currently known in -li ⁇
- model uncertainty processing techniques can be classified as active and passive approaches.
- the active approach is based on assumption that the noise can be characterized by some probability density functions.
- the passive approach is based on the adaptive threshold techniques. It may be difficult to identify and model all the objective and subjective uncertainties, but probability theories provide mathematical foundations for solving these issues. For simplicity, this disclosure deals with prediction model uncertainties using confidence boundaries derived from each prediction model.
- the Auto-Regressive Moving Average (ARMA) model consists of two parts, the autoregressive (AR) part and the moving average (MA) part.
- the AR (p) model can be
- Z 1 ⁇ ⁇ ,Z t _, + ⁇ t , in which Z 1 , Z t _ ⁇ , Z t _ 2 ,... , Z t _ p are deviations from ⁇
- an ARMA (p, q) model refers to a model with p autoregressive terms and q moving average terms, which can be
- an F-test statistical hypothesis test method can be applied. Other types of methods may be applied as well.
- X 1 (I) means / steps ahead prediction based on current moment t,a t is the "shock” value, and G t is the value of Green's function. It can be shown that statistically
- a neural network has its own special characteristics, such as non-linear curve fitting, and is also widely used in industrial fields.
- a typical type of RNN consists of an input layer, a hidden layer, a context layer and an output layer. In some situations, the hidden layer contains multiple layers.
- the distinct connections of the context layer in RNN make its output sensitive to not only current input data but also historical input data, which is essentially useful for prediction.
- a popular representative of the transfer function is the logistic function from
- a back propagation (BP) algorithm may be used to train the neural network model.
- the weights will change according to the following equation
- the learning algorithm will update the weights of the network to match the outputs with the desired target values in iterative steps; the iteration stops when a certain criterion (such as maximum iteration step, maximum iteration time, mean square error, etc.) is met.
- PSO Particle swarm optimization
- the particle swarm is an algorithm for finding optimal regions of complex search spaces through the interaction of individuals in a population of particles.
- the scenario of PSO can be supposed as follows: a group of birds are randomly searching food in an area where only one piece of food exists. The birds do not know where the piece of food is, but they know how far the food is in each step of the food searching procedure. The best and effective searching strategy is to follow the bird, which is the nearest to the food, in the entire flock.
- the algorithm is initialized with a population of random solutions, called birds or particles which are updated during each iteration of the searching procedure.
- Each particle i has its current position vector present t and the velocity vector V 1 .
- the velocity vector directs the moving of the particles in the search space.
- the fitness values of all the particles are evaluated by the fitness function which is to be optimized.
- PSO has been proven to be a competitor to genetic algorithm (GA) in optimization problem solving. Both PSO and GA are initialized with random population, update the population with random techniques and share the abilities of handling the nonlinear fitness functions, but PSO doesn't have the genetic operators such as crossover and mutation. PSO only looks for the best solution in the population and shares information in a one-way mechanism, whereas, GA shares information with each other for all chromosomes. Even though the testing results show that PSO and GA outperform each other in different optimization scenarios, PSO tends to converge to the best solution quickly even in the local version in most cases and can be implemented in a much simpler way. 5.3.3 Optimization of the Initial Weights of the RNN with PSO
- FIG. 3 depicts a flowchart of one embodiment of the optimization 30 in which there are two major steps.
- the first step is the optimization of the initial weights of RNN using PSO, shown at step 32.
- the fitness function for PSO may be calculated as the mean square error (MSE) of the training error at step 34.
- MSE mean square error
- the method next finds the best fitness value for pbest t and gbest t at step 36.
- the method updates the particle velocity and positions at steps 38 and 40, respectively.
- the PSO stops when it meets the stop criterion at step 42, where the second step begins to train the RNN with the optimized initial weights at step 44.
- the method calculates the network outputs and errors at step 46.
- the method determines whether the stop criterion has been reached at step 48. If not, the method updates the network weights at step 50 and returns to step 46.
- the trained RNN is used to calculate the prediction results at step 52.
- RNN Uncertainty of Recurrent Neural Network
- the recurrent neural network (RNN) model can be considered as a nonlinear regression model, which can be applied to find a prediction interval by standard asymptotic theory.
- S 2 is asymptotically independent of (y o - y o ).
- t n _ p an approximate l ⁇ (l - a)% level of uncertainty at y o can be obtained as y o ⁇ t "!_ 2 s ⁇ 1 + f o (F' F) l f o
- the prediction model takes into consideration uncertainties by returning predicted results which fall within a confidence interval.
- Monte Carlo sampling method may be used to sample the points within the confidence interval to form the predicted feature space, which is used to calculate a confidence value as discussed herein.
- Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error interactions with a dynamic environment.
- An agent is a learner or decision maker which can interact with the environment via perception or feedback.
- the agent is in a state which is denoted by s t e S represented by the environment, where S is the set of all possible states.
- the agent selects an action which is denoted by a t e A(s t ) , where A(s t ) is the set of all possible actions in the current state s t .
- the state will change from s t to s t+l .
- a state signal that succeeds in retaining all relevant information is said to be Markov, or to have the Markov property.
- state transition is a deterministic Markov decision process
- an action performed in state s t always transitions to the same next state s t+l .
- a probability distribution function defines a set of potential successor states for a given action in a given state. The value of the state transition at time t + 1 is observed by a scalar reinforcement which is denoted by r 1+1 e R .
- the agent selects an action according to the current policy which is denoted by ⁇ , which is a mapping from each possible state to the probabilities of choosing each available action.
- ⁇ is a mapping from each possible state to the probabilities of choosing each available action.
- a policy ⁇ is better or equal to a policy ⁇ ' if its expected return is greater than or equal to that of ⁇ ' for all state-action pairs.
- Q * The optimal action- value function, which is denoted as Q *
- ⁇ * the optimal policy
- the behavior of the agent should learn how to increase the long-run of the r e R over time by a systematic trial-and-error way guided by a variety of algorithms (e.g. Q- learning) as is known in the art.
- the goal of reinforcement learning is to learn the optimal policy Q * from the experiment and maximizing the total amount of reinforcement in a long run.
- the adaptive modeling aims to tackle the problem of selecting appropriate prediction models under different degradation statuses.
- the objective of the adaptive model selection is to obtain a mapping from each state to the probability of all possible prediction models that are taken into consideration in the modeling framework.
- the mapping provides a look-up table for model selection under different states.
- the reinforcement learning framework can be easily adapted for autonomously learning of this mapping.
- a prediction model is first chosen in a certain state according to the current optimal policy (probability of choosing a prediction model in a state). Then, the prediction output of the selected prediction model is compared with the real historical data. If the prediction accuracy is high, a positive reward is assigned to the prediction model; otherwise, the model is given a negative reward.
- the reinforcement learning algorithm learns through the interaction with the environment to maximize the reward in a long run.
- the training results are shown in a look-up table, which shows the Q-value for each state/action (prediction model) pair.
- the Q- value is determined by the sum of the (possibly discounted) reinforcements received when performing an action following a given policy.
- the most appropriate model at a certain state is determined by the largest Q-value for all the state/action pairs in the row of that state in the Q-table. If this reinforcement learning framework is used for a predetermined number of runs, the probability of choosing a certain action (i.e., the prediction model) in a specific state may be calculated via dividing the number of times the action was chosen by the total predefined number of runs, which forms the solution space for the prediction model selection. As an example, as shown in FIG. 4, if the state/action pair is S2, the highest Q-value for that row can be found at M2 (Model 2). 6.2 Problem Domain Mapping
- the map of the relationship is defined as follows:
- the environment of the disclosed reinforcement learning network is defined through historical data.
- the values of the historical data are utilized to calculate the reward of each prediction model that is incorporated in the framework.
- the action is defined as the choice of different prediction models.
- the prediction models include various data-driven prediction algorithms.
- two types of prediction models ARMA and RNN are used.
- ARMA models can have different orders, such as ARMA (2, 1), ARMA (4, 3) and ARMA (12, 11) and so on, with different amounts of historical data used for training.
- RNN models can have various structures which are different in the number of input neurons, the number of hidden neurons, and the number of training samples.
- Each type of the two prediction models with different structures and parameters are considered as the available actions in the reinforcement learning framework.
- the different states are defined by different degradation statuses identified by SOM as described herein.
- the MQE described herein, is used as the indicator of the degradation status.
- the mean value and standard deviation of the MQE are used to define different states for the reinforcement learning framework.
- D L a predefined number of the datasets, denoted by D L , ⁇ ⁇ i ⁇ N , are sampled from the historical data by a fixed interval / from randomly generated start points.
- the maximum mean value of the MQE for all D 1 is denoted by ⁇ max and the minimum mean value of the MQE for all D 1 is denoted by ⁇ mm ; similarly, the maximum standard deviation of the MQE for all D 1 is denoted by (T max and the minimum standard deviation of the MQE for all D 1 is denoted by (T 1111n .
- the interval of (/Z 1111n ju max ] and [ ⁇ mm ⁇ ma ⁇ ] are divided into m(m > l) and n(n > l) sub-intervals, respectively.
- a start point is randomly generated within the length of the historical data.
- a dataset with N data points is sequentially taken from the historical data until it reaches the end of the historical data or the number of the data points left is less than N .
- the reward is based on prediction accuracy.
- a prediction model which has high prediction accuracy, will be assigned a high/positive reward; otherwise, a low/negative reward will be given.
- Mean squared error (MSE), mean absolute deviation (MAD), and mean absolute percentage error (MAPE) can be used as the reward function.
- MSE mean squared error
- MAD mean absolute deviation
- MAE mean absolute percentage error
- R 2 adjusted coefficient of determination
- AIC Akaike's information criterion
- BIC Bayesian information criterion
- FIC Fisher information criterion
- PIC posterior information criterion
- PLS Rissanen's predictive least squares criterion
- ⁇ is the standard deviation of the observed real values.
- Nstep is the number of steps ahead for prediction.
- the reward for a selected prediction model can be calculated as follows
- the policy which defines the behavior of an agent, is the probability of choosing different prediction models in different states.
- the policy can also be seen as a mapping from the perceived environmental state to the actions to be taken.
- the optimal policy will be learned during the reinforcement learning.
- the iterative process of reinforcement learning can be run for a certain predefined number of steps.
- the results will be a "lookup" table (see FIG. 4) in which the rows are different states and the columns are different prediction models.
- the look-up table's values are the probability of choosing a model under a certain state.
- the "look-up" table will be updated when new observations are obtained.
- One-step Q-learning is defined by the following the simplest form: Q ⁇ s t ,a t ) ⁇ r- Q ⁇ s t ,a t )+ a[r 1+1 + ymax ⁇ Q(s t+I ,a)- Q ⁇ s t ,a t )] , in which Q is the action- value function that directly approximates Q * ; Q * is the optimal action- value function that is independent of the policy being followed; a t is the action performed in state a t and the state transits to state s tl ; r t+1 is the reinforcement received when performing action a t at state s t ; a is the learning rate; and ⁇ is a scalar discount factor which functions as a mechanism of weighting the importance of the future rewards and the immediate rewards.
- the confidence value is calculated by evaluating the overlap between the distribution of the most recent feature space and that during normal operation. This overlap is continuously transformed into a confidence value (CV), ranging from 0 to 1 (0- abnormal and 1 -normal) over time for evaluating the deviation of the recent behavior from normal behavior or baseline. After the predicted feature space is sampled between the prediction intervals, it is necessary to calculate the predicted performance index based on the predicted feature space and the baseline. CV is a quantitative measure of the machine degradation, which provides valuable information for the maintenance practitioners to decide whether to take an action or not in a very easy way. The rest of this section describes estimating the distributions of the feature spaces and methods of calculating the CV depending on different data availability.
- GMM is an unsupervised learning method which is used to estimate the density distributions of the predicted feature space.
- GMM consists of a number of Gaussian functions which are combined to provide a multivariate density. Mixtures of Gaussians can be utilized to approximate an arbitrary distribution within an arbitrary accuracy.
- EM expectation maximization
- Bayesian Information Criterion may be used as a criterion to choose the number of mixtures for the GMM.
- Bayesian model comparison calculates the posterior probabilities by using the full information over the priors.
- the evidence for a particular hypothesis may be calculated by: P(D
- ⁇ , ) I H 1 )p ⁇ D, H 1 )d ⁇ , where ⁇ is defined as the parameters in the candidate model h t .
- D represents the training data set.
- the posterior p( ⁇ ⁇ D,h t ) can be peaked at 0 which maximizes the probability of the training data set.
- the previous equation can be approximated as: p ⁇ D I H 1 ) « P(D I ⁇ , H 1 )p( ⁇ I H 1 ) ⁇ , where P(D I ⁇ , H 1 ) is the best-fit likelihood and /?( ⁇ I H 1 )AQ is the Occam factor. If ⁇ is k-dimensional and the posterior can be assumed to be Gaussian, the Occam factor can be calculated directly and yields
- the candidate model which has the largest BIC score, will be selected as the best model.
- Boosting is an algorithm aiming to improve the accuracy of any given learning algorithm or classifiers in a supervised learning scheme, particularly a weak learner algorithm.
- a weak learner class is a class that performs only slightly better than random guessing.
- a weak learner for the training set is created; then new component classifiers are added to form an ensemble with high accuracy on the training set through the use of a weighted decision rule.
- One algorithm comprises a method to continuously add weak learners until a desired low training error is achieved. At this point, each training pattern is assigned a weight which determines the probability of being selected. If the training pattern is correctly classified, the chance of being selected in the subsequent component classifier is reduced.
- DLL log ⁇ a Ji n (x), in which N is the number of mixtures, x is the training dataset and Ct n is the coefficient for each weak learner h n (x).
- BIC is used as a criterion to choose the number of mixtures for weak learners.
- Another boosting GMM has been introduced in which BIC is used to determine the number of mixtures for the GMM model.
- the number of mixtures should not be defined at the very beginning of the boosting procedure, since the sampled dataset will change according to the weights of the dataset at each iteration step.
- the EM algorithm which is utilized to estimate the parameters for GMM, is sensitive to the initial parameters and it will likely converge to a local minimum.
- V' p ⁇ n ⁇ x,, ⁇ k,
- step 8 the fitness function for the PSO is the sum of the within-cluster distances
- the confidence value which indicates the performance of the machine (1 for normal, 0 for abnormal).
- G(x) are the Gaussian mixture functions. If the two distributions overlap extensively, the confidence value will be near 1, which means the performance of the machine does not deviate from the baseline significantly. Otherwise, if the two distributions rarely overlap, the confidence value will be near 0, which means the performance of the machine deviates from the baseline significantly and the machine is probably acting abnormally.
- the calculation of the L2 distance of Gaussian mixtures is depicted in FIG. 5A. If the Gaussian mixture function contains more than two components, the same method can be easily extended to calculate the confidence value by adding necessary items which are the integration parts of the multivariate normal density functions.
- the CV is defined as a normalized average value of the data log-likelihood of both the baselines.
- the concept of the calculation of the CV is illustrated in FIG. 5B.
- DLL N - log — J ⁇ n I 1 F N ⁇ x n
- DLL F - log — ⁇ F F ⁇ x n ) .
- DLL N can be considered as the distance from the predicted feature space to the distribution of the normal feature space F N because DLL N is a positive scalar due to the fact that
- SOM has been introduced herein as a degradation assessment algorithm due to its advantage to deal with high-dimensional feature space.
- a rectangular SOM map is used as an example to demonstrate how SOM is used for diagnosis purposes.
- the weight vector will move towards the input vector at each iteration step according to the neighbor updating rules.
- the input vectors are kept in the map.
- the input vectors which closely resemble one another will locate next to each other on the SOM map after training.
- the weight vectors are grouped into clusters to match the distribution of the input vectors according to their distances to the input vectors.
- a unified distance matrix (U-matrix), which shows the distances between the neighbor units, may be used to visualize the clusters' structure in the SOM map. As shown in FIG. 6, high values of the U-matrix (left-hand side) indicate a cluster boundary; uniform areas of low values indicate clusters themselves.
- the U- matrix visualization has many more hexagons than the map structure. This is because not only the distance values "at” the map units but also distances "between” map units are shown in the U-matrix. Larger distances have darker colors and smaller distances have lighter colors, as seen in the gray bar of FIG. 6.
- the set of hexagons on the right-hand side of FIG. 6 shows the structure of the SOM map itself and is used as a simple method to identify different failure modes for diagnosis. If the label information is available, a variant called "Supervised SOM" can be used to tune the representation of the distribution of all input vector obtained by the unsupervised learning SOM algorithm. Supervised SOM tunes this representation to discriminate better between the classes.
- the SOM units will be labeled with the available label information. Therefore, the testing features can be labeled by finding the BMU in the trained map as "hit points.” The failure modes can be identified by the location of the hit points on the map. This method is illustrated by the bearing example discussed hereinafter.
- the first method is to determine which features were highly correlated with the output.
- the values of correlation coefficient r were calculated and ranked in descending order. The features with the corresponding higher r values were selected as the input to the SOM.
- the second method was the Fisher linear discrimination method which sought the projection directions that were efficient for discrimination. It was used to maximize the ratio of between-class scatter to the within-class scatter, which was preferred in such a multi-class classification task.
- a transformation matrix was obtained by selecting the eigenvectors corresponding to the non-zero eigenvalues of the matrix S w ⁇ l S B .
- roller bearing failure modes generally include roller failure, inner- race failure, outer-race failure, and a combination of these failures. The presence of different failure modes may cause different patterns of contact forces as the bearing rotates, which cause sinusoidal vibrations. Therefore, vibration signals were taken as the measurements for bearing performance assessment, prediction and diagnosis.
- the setup included four test bearings on one shaft.
- the shaft was driven by an AC motor.
- Four bearings were installed on one shaft.
- a PCB 353B33 High Sensitivity Quartz ICPs Accelerometer was installed on each of the bearing housing.
- a Rexnord ® ZA-2115 bearing was used for a run-to-failure test. Vibration data was collected every 20 minutes with sampling rate 20 kHz using a National Instruments ® DAQCardTM-6062E data acquisition card. For each data file, 20,480 data points were obtained.
- a magnetic plug was installed in the oil feedback to accumulate debris; debris is evidence of bearing degradation. At the end of the failure stage, the debris accumulated to a certain level causing an electrical switch to stop the test. In the test, one of the bearings finally developed a roller element defect.
- a SOM was trained only with the feature space from the normal operation data. For each input feature vector, a BMU was found in the SOM. The distance measured between the input feature vector and the weight vector of the BMU, which was defined as the Minimum Quantization Error (MQE), actually indicated how far away the input feature vector deviated from the normal operation state. Hence, the degradation trend was visualized by the trend of the MQE. As the MQE increased, the extent of the degradation became more severe. Data from the first 500 cycles of the normal operation condition were used to train the SOM. After training, the entire life cycle data of the bearing with roller element defect was used for testing and the corresponding MQE values were calculated. In the first 1450 cycles, the bearing was in good condition, and the MQEs were near zero.
- MQE Minimum Quantization Error
- ARMA and RNN are considered two exemplary prediction models due to their different characteristics and prediction capabilities.
- ARMA is applicable to linear time- invariant systems whose performance features display stationary behavior, while it is unfeasible for use in a non-linear or dynamic process.
- RNN is good at modeling complex systems, which involve nonlinear behavior and unstable processes.
- RNN can take more historical data into the training procedure, which makes it is feasible to use for long-term prediction.
- RNN has drawbacks in that there is no standard method to determine the structure of the network and its tendency to over fit.
- the second principle component feature from cycle 1600 to cycle 1820 were normalized, and was used as data for training and testing the prediction models.
- Data from cycle 1600 to cycle 1770 (step 1 to step 170) were used for training and data from cycle 1771 to cycle 1820 (step 171 to step 220) were used for testing.
- Six ARMA models were adopted for prediction in the experiment: ARMA (2, 1), ARMA (4, 3), ARMA (6, 5), ARMA (8, 7), ARMA (10, 9) and ARMA (12, 11).
- a RNN model was also adopted for prediction in the experiment. It had 105 input neurons, 7 hidden neurons, one output neuron, and utilizes 60 training samples.
- the aforementioned six ARMA models and the RNN with PSO initialization were used to predict the normalized feature from step 171 to step 220.
- the testing Mean Square Error (MSE) of each model was shown in the following table.
- the first principle component feature and the MQE values of the entire life cycle were used as the historical data to train the reinforcement algorithm to obtain the "lookup" table for model selection under various degradation statuses.
- the first principle component feature was of interest for prediction.
- MQE data was used to define the degradation status of the machine, which was used to define the state space in the reinforcement learning framework.
- One purpose was to validate whether it is feasible for the reinforcement learning algorithm to learn the optimal policy to select appropriate algorithms in different states after the training.
- the aforementioned six ARMA models were used as agents in the reinforcement learning framework.
- a first order linear model with fixed parameters was also used as another agent in the reinforcement learning framework for comparison with the ARMA models.
- the parameter settings of the Q-learning are described as follows.
- the maximum number of episode was set to be 1000.
- the maximum of steps in each episode was also set to be 1000.
- the state transition interval was set to be 50.
- a state space with 9 different states was generated by different mean values and standard deviations of the MQE values.
- the number of prediction steps ahead was set to be 30 for each agent.
- the learning rate was set to be 0.5. Discount factor was chosen to be 0.2 to weigh more on the current rewards.
- the probability of a random action selection was set to be 0.1 in order to obtain more "exploration" of all the actions in the action set for better choice.
- a Q- value table was obtained for all the state-action pairs, shown in the table below. The most appropriate prediction model can be selected according to the highest Q- value for the state-action pairs.
- ARMA (4, 3) had the highest Q- value in state 1
- ARMA (10, 9) had the highest Q- value in state 2. Therefore, those two models should be selected for prediction in state 1 and state 2, respectively.
- the order one linear model with fixed parameters had all negative Q-values in all the states; hence, it will not be chosen for prediction no matter in which state the machine was.
- the same reinforcement learning frame was run for 9 times repeatedly. For each time, the best action was selected according to the highest Q-value. This showed that the Q-values were similar for the entire state-action space for the 9 runs but not exactly the same.
- the probability of the best state-action pair can be calculated from the 9 runs by calculating the number of times that one action had been chosen as the best action in each state.
- the most appropriate action in each state can be selected according to the highest probability of been chosen in each state. If the probabilities were equal to two actions in the same state, the simpler model will be chosen according to the Occam's razor (i.e., the simplest explanation is the best). The purpose of selecting the simpler model was to avoid over fitting problems.
- Roller bearing failure modes generally include roller failure, inner-race failure, outer-race failure, and a combination of these failures.
- the presence of different failure modes may cause different patterns of contact forces as the bearing rotates, which cause sinusoidal vibrations. If the confidence values predicted drop to a very low level, a very interesting task is trying to determine what kind of failure the bearing has developed.
- the SOM method described herein was employed for diagnosis for bearings. The results were a "health map" which showed different failure modes of the bearing.
- a SKF32208 bearing was used, with an accelerometer installed on the vertical direction of its housing to obtain vibration signals.
- the sampling rate for the vibration signals was 50 kHz.
- 8192 data points were obtained and saved in one data file.
- the bearings were artificially made to have roller defect, inner-race defect and outer-race defect and 4 different combinations of the single failures respectively.
- the vibration signals of 8 different types of bearing states were identified, which were identified based on the following two steps. Step 1: The BPFI, BPFO and BSF for this case were calculated as 131.73 Hz, 95.2
- Step 2 The health map was trained.
- the SOM toolbox developed by Helsinki University of Technology was used.
- the input vector of a specific bearing defect was represented by a cluster of BMUs on the map, which formed a region indicating the defect.
- the first method was to find out which features were highly correlated with the output.
- the values of correlation coefficient r were calculated and ranked in descending order.
- the features with the corresponding higher r values were selected as the input to the SOM. In this case, 7 features with r values higher than 0.5 were selected.
- the selected features were sub bands centered at IX and 2X of BSF, BPFI, and BPFO in the frequency domain, and the RMS value in the time domain.
- the second method was the Fisher linear discrimination method which sought the projection directions that were efficient for discrimination. It was used to maximize the ratio of between-class scatter to the within-class scatter, which was preferred in such a multi-class classification task.
- Repeated holdout validation was used to test the generalization quality of the model. Random samples were selected for each of the 8 classes. The proportion of the samples selected in each class was specified by a certain holdout rate. For example, the holdout rate of 0.1 means that 10% of the samples are randomly selected for testing and the remaining 90% of the samples are used for training. In this case, 5 holdout rates (0.1, 0.2, 0.3, 0.4 and 0.5) were applied. For each holdout rate, 50 trials were carried out repeatedly, and then the average precision rate was calculated.
- microprocessor based systems such as a workstation, a portable computer or other such processing systems, such as personal digital assistants (PDAs), application specific devices, and the likes.
- PDAs personal digital assistants
- a microprocessor executes the above-mentioned processes (e.g., extracting features, decomposing data, selecting a prediction model, generating a predicted feature space, generating a confidence value, providing a status of mechanical system based at least in part on the generated data, etc.), interfacing with memory (e.g., local and/or remote via wired and/or wireless communications) such as for retrieving and storing the processes, results, and data (e.g., measurement data, mechanical system data, prediction models, reinforcement learning model, etc.), interfacing with a display for providing status, selection choices, data, and results, and interfacing with user interface(s) for receiving input (e.g., selection, navigation, etc.).
- processes e.g., extracting features, decomposing data, selecting a prediction model, generating a predicted feature space, generating a confidence value, providing a status of mechanical system based at least in part on the generated data, etc.
- memory e.g., local and/or remote via wired and/or
- Embodiments of the invention may also be provided as a computer product, such as contained in a conventional computer readable medium having stored therein computer instructions to cause a microprocessor to execute the above-mentioned processes of the present invention.
- a computer product such as contained in a conventional computer readable medium having stored therein computer instructions to cause a microprocessor to execute the above-mentioned processes of the present invention.
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Mathematical Physics (AREA)
- Automation & Control Theory (AREA)
- Probability & Statistics with Applications (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Testing Of Devices, Machine Parts, Or Other Structures Thereof (AREA)
- Testing Or Calibration Of Command Recording Devices (AREA)
Abstract
A method of prognosing a mechanical system to predict when a failure may occur is disclosed. Measurement data corresponding to the mechanical system is used to extract one or more features by decomposing the measurement data into a feature space. A prediction model is then selected from a plurality of prediction models for the one or more features based at least on part on a degradation status of the mechanical system and a reinforcement learning model. A predicted feature space is generated by applying the selective prediction model to the feature space as well as a confidence value by comparing the predicted feature space with a normal baseline distribution, a faulty baseline distribution, or a combination thereof. A status of mechanical system based at least in part on the confidence value is then provided.
Description
METHODS FOR PROGNOSING MECHANICAL SYSTEMS
The present invention generally relates to prognosing mechanical systems and, specifically, to predicting when a failure may occur. As background, unexpected machine downtime is still one of the major issues impacting machining productivity in industry. For example, every minute of downtime in an automotive manufacturing plant could be quite costly, as the breakdown of one machine may result in the halt of the entire production line in a manufacturing facility. As machine tools become more complex and sophisticated, the reliability of the machining equipment becomes more crucial. Most machine maintenance today is either purely reactive (reactive maintenance) or blindly proactive (preventive maintenance), both of which could be extremely wasteful.
Predictive maintenance focuses on failure prediction in order to prevent failures in advance, and offers sufficient information to improve overall maintenance scheduling. For decades, researchers and practitioners have been trying to develop and deploy prognostics technologies with ad hoc and trial-and-error approaches. These efforts have resulted in limited success, due to the fact that a systematic approach in deploying the right prognostics models for the right applications has yet to be developed.
Before the deployment of the right prognostics models, several factors for complex systems, such as stability properties and modeling assumptions and operating conditions, must be taken into consideration. Stability properties and modeling assumptions are important for building physics models for a controller or machine process. Operating conditions, such as shaft speed, load, feed rate and cutting materials, are also important factors for prognostic models since the degradation patterns of the machine may be distinct under different operating conditions. A system's full range of operating states may be decomposed into four overlapping operating conditions based on two principle parameters, which may include shaft speed, load, feed rate, and cutting materials, etc. Under a certain operating condition (e.g. low speed cutting of a soft material), the degradation pattern of the machine may be a slow and stationary process; while under
another operating condition (e.g. high speed cutting of a hard material), the degradation pattern may show non-stationary characteristics with a faster degradation rate towards failure. It may be difficult for an individual prognostic model to meet the accuracy requirements for prediction when the machine operating condition changes. Many system components can undergo a long degradation process before catastrophic failures occur. If a certain operating condition is continuously examined, the degradation status of the component will change over time. Performance indices (e.g., "1" meaning normal, and "0" meaning unacceptable) may be stable in the range of 0.9 to 1.0 at the beginning. As the initial faults develop over time, a degradation trend appears in the performance indices. At the final stage of the degradation, the trend of the performance indices drops quickly towards 0. An individual model cannot always meet the accuracy requirements for prediction when the machine degradation status changes overtime. Some prediction models are only appropriate for specific degradation patterns. These models may fail to learn and predict for aliasing degradation patterns accurately. A method which incorporates multiple prediction models may solve this issue, while the challenge still remains in how to autonomously shift among these multiple models to improve the prediction accuracy.
Therefore, novel methods are disclosed to address the challenges of performance degradation identification, adaptive prediction model selection and performance index generation for robust prognostics. These methods leverage the machine prognostics strategy both in autonomy and accuracy.
The present disclosure generally relates to a method of prognosing a mechanical system comprising receiving measurement data corresponding to the mechanical system; extracting one or more features from the received measurement data by decomposing the measurement data into a feature space; selecting a prediction model from a plurality of prediction models for one or more features based at least on part on a degradation status of the mechanical system and a reinforcement learning model; generating a predicted feature space by applying the selective prediction model to the feature space; generating a confidence value by comparing the predicted feature space with a normal baseline
distribution, a faulty baseline distribution, or a combination thereof; and providing a status of mechanical system based at least in part on the confidence value.
The embodiments set forth in the drawings are illustrative and exemplary in nature and not intended to limit the inventions defined by the claims. The following detailed description of the illustrative embodiments can be understood when read in conjunction with the following drawings, where like structure is indicated with like reference numerals and in which:
FIG. 1 depicts an exemplary framework for prognosing mechanical systems according to one or more embodiments shown and described herein; FIG. 2 depicts an exemplary DB4 wavelet according to one or more embodiments shown and described herein;
FIG. 3 depicts an exemplary flowchart of a recurrent neural network according to one or more embodiments shown and described herein;
FIG. 4 depicts an exemplary adaptive prediction model selection table according to one or more embodiments shown and described herein;
FIGS. 5A-B depict exemplary confidence value calculations according to one or more embodiments shown and described herein;
FIG. 6 depicts an exemplary presentation of the self-organizing map structure according to one or more embodiments shown and described herein; and FIG. 7 depicts an exemplary computer system for prognosing a mechanical system according to one or more embodiments shown and described herein.
1 Overview
The embodiments described herein generally relate to methods for adaptive modeling for robust prognostics for mechanical systems and are aimed at dynamically selecting the most appropriate prediction models under different machine degradation statuses. To tackle these challenges, the disclosed methods comprise three major tasks: identification of the machine degradation status, reinforcement learning-based framework
-A-
for adaptive prediction model selection, and a method to improve the accuracy of the predicted performance index calculation.
2 Framework
As discussed herein, the adaptive reinforcement learning-based modeling focuses on providing a recommendation of the most appropriate prediction model according to different machine degradation statuses. An effective method to identify the degradation status needs to be developed before applying the reinforcement learning framework. The reinforcement learning algorithm will interact with the available historical data and "learn" to select the most appropriate prediction model when the machine is in a certain degradation status. This learning procedure yields a "look-up table" based on which the appropriate prediction models can be selected. The reinforcement learning scheme can be updated to provide a new look-up table for prediction model selection when new observations are available. When performing online testing, the appropriate prediction models will be selected according to the results of the look-up table. One embodiment of the adaptive modeling for robust prognostics is illustrated in
FIG. 1. The sensors 2 may be those normally used by the mechanical system (e.g., to measure position, velocity, etc.) or may be sensors specifically placed in the mechanical system to measure a particular parameter (e.g., vibration). The modeling system may read the measurement data from the sensors 2 and perform a feature extraction method at step 4 which will extract a performance related feature space from the raw sensor data. If the feature space is highly dimensional, reduction methods can be applied to reduce the dimension of the feature space. Based on the recently-obtained features, the degradation status will be identified at step 6. The most appropriate prediction model is selected according to the look-up table, which is the result of the reinforcement learning scheme. The selected prediction model will be applied to predict future trends of the features at step 8. The predicted feature space is generated by sampling between the predicted confidence intervals. At step 14, an enhanced density estimation method is developed to approximate the distribution of the predicted feature space as well as the distributions of the baselines. Finally, the performance index is calculated at step 16 by the overlap of the distribution of the predicted feature space and the distributions of the baselines. If the
predicted performance index drops to a very low level, diagnosis will be applied at step 18 to determine the root causes of the degradation or failures. As part of selecting the appropriate prediction model, the method may reinforce the selection at step 10 by using historical data 20. 3 Feature Extraction and Dimension Reduction 3.1 Feature Extraction
Signal processing and feature extraction algorithms are used to decompose multi- sensory data into a feature space, which is related to the performance assessment or diagnosis tasks. A "feature" is a particular characteristic of the measurement signal, which may be extracted using time domain or frequency domain techniques. For example, one feature of a measurement signal may be its maximum amplitude within a given time period. Other features may be extracted as discussed herein. Time domain analysis is used to analyze stochastic signals in the time domain, which involves the comparison of two different signals. Time domain analysis uses the waveform for analysis as compared to frequency domain analysis, which instead uses the spectrum. Time domain analysis is useful when two different signals look very similar, even though the characteristics of the time signal are very different. The waveform immediately shows the differences, however frequency domain analysis may be used when time domain analysis does not provide enough information for further analysis. The Fourier Transform (FT) is a well-known algorithm in frequency domain analysis. It is used to decompose or separate the waveform into a sum of sinusoids of different frequencies. When dealing with a discrete or a sampled/digitized analog signal, the Discrete Fourier Transform (DFT) may be an appropriate Fourier analysis algorithm. In addition, some spectrum analysis tools, such as envelope analysis, frequency filters, side band structure analysis, Hubert transform, and Cepstrum analysis, may be applied to various signal processing scenarios. Frequency domain analysis will not preserve the temporal information after the transformation of the time signals. Therefore, it may only be useful for stationary signals that do not contain frequency variations over time. Wavelet transform represents time signals in terms of a finite length or fast decaying oscillating waveform, which is scaled and translated to match the input signals. Wavelet Packet Transform (WPT), using a rich library of redundant
bases with arbitrary time- frequency resolution, enables the extraction of features from signals that combine non- stationary and stationary characteristics. The WPT provides a very powerful tool for non- stationary signal analysis. The representation contains information both in time and frequency domain and it may achieve better resolution than time-frequency analysis.
3.1.1 Time Domain Analysis
In most of the cases, features from the time domain, such as mean, root mean square (RMS), kurtosis, crest factor, skewness, and entropy, are extracted from the
1 N waveform vibration data. The mean may be calculated as x = — V x . The RMS may be
N tT '
calculated as . The

, , , max(x ) - min(x ) ^ , , , crest factor may be calculated as - — . The skewness may be calculated as
RMS
>, - χ)3
— — . And the entropy may be calculated as - V (x • log(x )). In all of these time
NxRMS' tT domain equations, N is the number of samples in a dataset, x is a series of a sampling data, and x is the mean value of the series x . 3.1.2 Frequency Domain Analysis
A Fast Fourier Transform (FFT) may be used to decompose or separate the waveform into a sum of sinusoids of different frequencies. When dealing with a discrete or a sampled/digitized analog signal, the Discrete Fourier Transform (DFT) may be the appropriate Fourier analysis tool. The DFT can be computed efficiently in practice using an FFT algorithm. The forward DFT of a finite-duration signal x[n] (with N samples)
W-I may be calculated by X[k] = ∑x[«]e~; " πk , k = 0,1,2,... , N - 1 . π=0
By using the FFT algorithm, the sensor (e.g., vibration) signal is translated from time domain into its equivalent frequency domain representation. The frequency spectrum can be subdivided into a specific number of sub-bands. A sub-band is basically a group of adjacent frequencies. The center frequencies of these sub-bands have already been pre- defined as, for example, the ball bearing defect frequencies of a mechanical system: Ball Passing Frequency Inner-race (BPFI), Ball Passing Frequency Outer-race (BPFO), Ball Spin Frequency (BSF) and Foundation Train Frequency (FTF). The energy in each of these sub-bands centered at BPFI, BPFO and BSF is computed and passed on to the performance assessment models. For further analysis on a certain characteristic frequency, the Hubert transform is a commonly used transformation to obtain the envelope of the signal. The Hubert transform is defined as H[x(t)] = — [ dτ , where τ is the dummy time variable, x(t ) is the π J-∞ t - τ time-domain vibration signal, and H[x(t)] is the Hubert transform of x(t) .
3.1.3 Wavelet / Wavelet Packet Analysis Wavelet Packet Analysis (WPA) provides a powerful method for non-stationary signal analysis. For sustained mechanical defects, a Fourier-based analysis, which uses sinusoidal functions as base functions, provides an ideal candidate for extraction of these narrow-band signals. For intermittent defects, signals often demonstrate a non-stationary and transient nature. Wavelet packet transform, using a rich library of redundant bases with arbitrary time-frequency resolution, enables the extraction of features from signals that combine non- stationary and stationary characteristics. WPA is an extension of the wavelet transform (WT) which provides complete level-by-level decomposition. The wavelet packets are particular linear combinations of wavelets. The wavelet packets inherit properties such as orthogonality, smoothness, and time-frequency localization from their corresponding wavelet functions.
A wavelet packet is a function Ψj' k(t) with three indices, where integers i, j, and k are the modulation or oscillation parameter, the scale parameter, and the translation parameter, respectively. The wavelet packet function may be represented by the following
equation: Ψ' k (t) = 21'2 Ψ' (2J t - k) . The first wavelet is the so-called mother wavelet or analyzing wavelet. Daubechies wavelet 24 (DB4), which is a kind of compactly supported wavelet, is widely used as the mother wavelet. This wavelet is shown in FIG. 2. The following wavelets Ψ' for i = 2, 3 ... are obtained from the following recursive relationships: Ψ2' (7) = V2 ∑Λ(fc)Ψ' (2f - fc) and Ψ2ι+1(t) = 4Ϊ ∑g(k)Ψ (2t - k) , where
h(k) and g(k) are the quadrature mirror filters (QMF) associated with the predefined scaling function and the mother wavelet function. The wavelet packet coefficients (of a function/) can be computed by taking the inner product of the signal and the particular basis function c] l k = if, Ψ] k
 = \ f(t)Ψ} ι k (t)dt . The wavelet packet node energy e} k
= \ f(t)Ψ} ι k (t)dt . The wavelet packet node energy e} k
is defined as: e k = . The energies of the nodes are used as the input feature space
 for performance assessment. Wavelet packet analysis may be applied to extract features from the non-stationary vibration data. Other types of analyzing wavelet functions may also be used, as is known in the art.
for performance assessment. Wavelet packet analysis may be applied to extract features from the non-stationary vibration data. Other types of analyzing wavelet functions may also be used, as is known in the art.
3.2 Feature Space Dimension Reduction In some cases, it may be desirable to reduce the number of features in the feature space. Principal component analysis (PCA) is a statistical method that may be used for reducing feature space dimensionality by transforming the original features into a new set of uncorrelated features. The Karhunen-Loeve transform (KLT) is a linear dimensionality selection procedure that is related to PCA. The goal is to transform a given data set X of dimension N to an alternative data set Y of smaller dimension M in the way that is optimal in a sum-squared error sense. Equivalently, it is seeking to find the matrix Y which is the Karhunen-Loeve transform of matrix X: Y=ATX, in which Aτ is the Karhunen-Loeve transform matrix. By choosing the eigenvectors corresponding to the M largest eigenvalues of the correlation matrix of X, the mean square error (MSE) between the input X and its projection X' is minimized.
4 Machine Degradation Assessment by Self-Organizing Maps (SOM)
The purpose of degradation assessment is to evaluate the overlap between the most recent feature space and that during normal product operation. A quantitative measure will be calculated to indicate the degradation of the machine. SOM can generate a performance index to evaluate the degradation status based on the deviation from the baseline of normal condition. SOM is also a powerful classification and visualization tool which can convert multidimensional feature space into a 1-D or 2-D space. It forms a so- called "health map" in which different areas represent different failure modes for diagnosis purposes. The functionality of the SOM is discussed herein. 4.1 Background of Self-Organizing Maps (SOM)
SOM provides a way of representing multidimensional feature space in a one or two-dimensional space while preserving the topological properties of the input space. SOM is an unsupervised learning neural network which can organize itself according to the nature of the input data. The input data vectors, which closely resemble each other, are located next to each other on the map after training. An n-dimensional input data space can be denoted by: x = [x1,x2,...,xn]τ .
The weight vector of each neuron j in the network has the same dimension as the input space and can be represented by ω} = [ωfl , ωj2 , ... , ωjn f , j = 1,2,..., m , in which m is the number of neurons in the network. The Best Machining Unit (BMU) in the SOM is the neuron whose weight vector is the closest to the input vector in the input space. The inner product xτ ω} can be used as an analytical measure for the match of x with ω} . The
Euclidean distance may be a better and more convenient measure criterion for the match of x with ω} . The minimum distance defines the BMU. If ύ)c is defined as the weight vector of the neuron that best matches the input vector x, the measure can be represented by |x - ft>c| = min|x - ft>j}, j = l,2,...,m .
After the BMU is identified in the iterative training process, the weight vectors and the topological neighbors of the BMU are updated in order to move them closer to the
input vector in the input space. The following learning rule is applied u)} (t + Y) = ω} (t) + a(t)hj ω (t)(x - ω} (t)) , in which hj ω denotes the topological neighborhood kernel centered on the BMU Cύc . A choice of the kernel function may be the
Gaussian function hj ω , in which d , ,, is the lateral distance between the
 BMU Cύc and neuron j. The parameter σ is the "effective width" of the topological neighborhood. The function a(t) is the learning rate which monotonically decreases with the training time. In the initial phase which lasts for a given number of steps (e.g. first 1000 steps), a(t) starts with a value that is close to 1 and it can be linear, exponential, or inversely proportional to t. During the fine-adjustment phase which lasts for the rest of the training, a(t) should keep small values over a long time period.
BMU Cύc and neuron j. The parameter σ is the "effective width" of the topological neighborhood. The function a(t) is the learning rate which monotonically decreases with the training time. In the initial phase which lasts for a given number of steps (e.g. first 1000 steps), a(t) starts with a value that is close to 1 and it can be linear, exponential, or inversely proportional to t. During the fine-adjustment phase which lasts for the rest of the training, a(t) should keep small values over a long time period.
4.2 SOM for Machine Degradation Extent Assessment
In most scenarios, only measurement of the normal operating conditions is available. SOM provides a performance index to evaluate the degradation condition when only normal measurement is available. For each input feature vector, a BMU can be found in the SOM trained only with the measurement in the normal operating state. The minimum quantization error (MQE) is defined as the distance between the input feature vector and the weight vector of the BMU. The MQE actually indicates how far away the input feature vector deviates from the normal operating state. The MQE is more particularly defined through the equation MQE = |VF - VBMU\ , in which VF is the input feature vector and VBMU is the weight vector of the BMU. Hence, the degradation trend can be measured by the trend of the MQE.
5 Prediction Models and Their Uncertainties
Auto-regressive moving average (ARMA) and recurrent neural network (RNN) are considered as two types of prediction models in this disclosure which may be used for prognosing mechanical systems. These two prediction models have different characteristics. Other types of prediction models may be used, as are currently known in
-li¬
the art or may be discovered in the future. There always exist errors between the real system and the estimated models by employing a training dataset due to imperfections in model assumptions, noises, and measurement. These errors are notated as model uncertainty. There are many potential root causes of uncertainty associated with fault conditions: faults exhibit varying signatures depending upon the location, cause, prevailing operating conditions, and the state of the component materials. For linear models, the model uncertainty processing techniques can be classified as active and passive approaches. The active approach is based on assumption that the noise can be characterized by some probability density functions. The passive approach is based on the adaptive threshold techniques. It may be difficult to identify and model all the objective and subjective uncertainties, but probability theories provide mathematical foundations for solving these issues. For simplicity, this disclosure deals with prediction model uncertainties using confidence boundaries derived from each prediction model.
5.1 Prediction Model 1 - Auto-Regressive Moving Average (ARMA) The Auto-Regressive Moving Average (ARMA) model consists of two parts, the autoregressive (AR) part and the moving average (MA) part. The AR (p) model can be
P represented by Z1 = ^ Φ,Zt_, + εt , in which Z1 , Zt_γ , Zt_2 ,... , Zt_p are deviations from μ
(the mean about which the process varies), Φt , i = l,2,...,p are the parameters of the model, and εt is the error term. The MA (q) model can be denoted by
1 Zt = εt - ∑ Θ^^ J = l,2,...,q , in which Zt is the deviation from μ, θι , i = \,2,...,q are the
parameters of the model and εt , εt_x ,εt_2,...,εt_ again are the error terms . To achieve greater flexibility in the fitting of the actual time series, it may be advantageous to include both autoregressive and moving average terms in the model. So an ARMA (p, q) model refers to a model with p autoregressive terms and q moving average terms, which can be
P 1 written as Zt = ^O1Z1-1 + εt - ^ #,£,_, . Optimized parameters of an ARMA (p, q) model
can be estimated by historical data. To check the adequacy of the ARMA (p, q) model, an
F-test statistical hypothesis test method can be applied. Other types of methods may be applied as well.
5.2 Uncertainty of ARMA Prediction
For a generalized ARMA (p, q) model, the values of / steps ahead of current time can be described as X1+1 = X1 (l) + et (l) = X1 (l) + (at+l + G1Ci1+^1 + ... + G1-1Ci1+1) , where
X1(I) means / steps ahead prediction based on current moment t,at is the "shock" value, and Gt is the value of Green's function. It can be shown that statistically
(X1+1 I Xn X1^,...) - Norm(X1 (l),VVe1(l)ϊ) ~ Norm(X1 (l),σa 2(\ + G1 + G2 2 + ... + Gι_1 )) , where σa 2 is the mean square error of the modeling process. Therefore the entire prediction with 100(1 - a)% level of uncertainty can be obtained as
Xt(D ± Zanσ 2(\ + G 2 + G 2 + ...+ GJ) .
5.3 Prediction Model 2 - Recurrent Neural Network (RNN) with Particle Swarm Optimization (PSO)
5.3.1 Recurrent Neural Network (RNN) A neural network has its own special characteristics, such as non-linear curve fitting, and is also widely used in industrial fields. A typical type of RNN consists of an input layer, a hidden layer, a context layer and an output layer. In some situations, the hidden layer contains multiple layers. The distinct connections of the context layer in RNN make its output sensitive to not only current input data but also historical input data, which is essentially useful for prediction.
If X1, X2,..., xπ are defined as input neurons and y1, y2,..., yn are defined as hidden layer neurons, the mapping from the input layer to the output layer can be defined as the n following equations S} = ∑ω β χ } + θ} > m which ωμ are the weights of connections
between the input layer neurons and the hidden layer neurons, and θ} is the bias of each
input layer neuron. For RNN, S is described as S = "
 S^W 1A + θ , in which m
is the number of neurons in the context layer, W t is the network weights for the context layer neurons and the hidden layer neurons, and A} is the internal network state at t -1.
S^W 1A + θ , in which m
is the number of neurons in the context layer, W t is the network weights for the context layer neurons and the hidden layer neurons, and A} is the internal network state at t -1.
A transfer function or activation function can be employed, which is described as y = f(S ) . A popular representative of the transfer function is the logistic function from
1 the family of sigmoid functions, which is described as /(S; ) = l + exp(-5; )
A back propagation (BP) algorithm may be used to train the neural network model. The weights will change according to the following equation
Aω = -K Aω = -K , in which Cu is the weight of connections between do>;ι dωβ β neuron j and neuron i, E is the error function, and K is a constant proportionality. The learning algorithm will update the weights of the network to match the outputs with the desired target values in iterative steps; the iteration stops when a certain criterion (such as maximum iteration step, maximum iteration time, mean square error, etc.) is met.
5.3.2 Particle Swarm Optimization (PSO)
Particle swarm optimization (PSO) is a stochastic optimization technique based on a social metaphor of bird flocking or fish schooling. The particle swarm is an algorithm for finding optimal regions of complex search spaces through the interaction of individuals in a population of particles. The scenario of PSO can be supposed as follows: a group of birds are randomly searching food in an area where only one piece of food exists. The birds do not know where the piece of food is, but they know how far the food is in each step of the food searching procedure. The best and effective searching strategy is to follow the bird, which is the nearest to the food, in the entire flock.
The algorithm is initialized with a population of random solutions, called birds or particles which are updated during each iteration of the searching procedure. Each particle i has its current position vector presentt and the velocity vector V1. The velocity vector directs the moving of the particles in the search space. The fitness values of all the particles are evaluated by the fitness function which is to be optimized. For each iteration
step, the particles are updated by following two best fitness values. One is the best fitness value that each particle has achieved so far, which is noted as pbestt . The other one is the best fitness value that is obtained so far by any particle in the population, which is noted as gbestl . After those two best fitness values are found, the velocity of the particle is updated by V1 (t + l) =
V1 (t) + c\ ■ randλ ■ {pbestt (t) - presentt (t)) + cT. ■ randT. ■ (gbestl (t) - presentt (t)) , where c\ and c2 are learning factors which are usually 2, randl and randl are random numbers between 0 and 1. After the velocity of the particle is updated, the position of the particle can be calculated by present \ (t + 1) = present \ (t) + V1 (t + 1) . The PSO algorithm will continue until it achieves the maximum iterations or the minimum error criteria.
PSO has been proven to be a competitor to genetic algorithm (GA) in optimization problem solving. Both PSO and GA are initialized with random population, update the population with random techniques and share the abilities of handling the nonlinear fitness functions, but PSO doesn't have the genetic operators such as crossover and mutation. PSO only looks for the best solution in the population and shares information in a one-way mechanism, whereas, GA shares information with each other for all chromosomes. Even though the testing results show that PSO and GA outperform each other in different optimization scenarios, PSO tends to converge to the best solution quickly even in the local version in most cases and can be implemented in a much simpler way. 5.3.3 Optimization of the Initial Weights of the RNN with PSO
FIG. 3 depicts a flowchart of one embodiment of the optimization 30 in which there are two major steps. The first step is the optimization of the initial weights of RNN using PSO, shown at step 32. The fitness function for PSO may be calculated as the mean square error (MSE) of the training error at step 34. The method next finds the best fitness value for pbestt and gbestt at step 36. The method updates the particle velocity and positions at steps 38 and 40, respectively. The PSO stops when it meets the stop criterion at step 42, where the second step begins to train the RNN with the optimized initial weights at step 44. The method calculates the network outputs and errors at step 46. The
method determines whether the stop criterion has been reached at step 48. If not, the method updates the network weights at step 50 and returns to step 46. After the stop criterion has been reached, the trained RNN is used to calculate the prediction results at step 52. 5.4 Uncertainty of Recurrent Neural Network (RNN) Prediction
The recurrent neural network (RNN) model can be considered as a nonlinear regression model, which can be applied to find a prediction interval by standard asymptotic theory. The nonlinear regression model can be defined as yt = /(x, ; θ) + S1 , i = 1,2, ...,« , where E1 ~ Norm(0, σ 2 ) and X1 and yt are independently and identically distributed (i.i.d.). Therefore the true value y at x = x0 is y0 = /(x0; θ) + ε0 , and the prediction value y is y0 = f(x0 ; θ) , where θ is close to the true value θ for large value n. The first order Taylor expansion of this equation is
f (xo ; θ) ~ f(xo ; θ) + fo'(θ - θ) , where f0 = Since

Ek -jJ~ Ek]-/o'£[θ-θ] and fo (θ -θ) \ ~ σ2 + σ2fo {F' F)'1 fo , where F is the Jacobian matrix of the neural network outputs with respect to its parameters,
F = , in which n is the number of samples and p is the number of
p
parameters. The unbiased estimator of σ2 is S2 = —
 n - p (yo - yo ) ~ Normi 0, σ2 ( 1 + fo (F' F) fo ] ] . S 2 is asymptotically independent of
(yo - yo ). Hence, tn_p . Therefore, an approximate lθθ(l - a)%
n - p (yo - yo ) ~ Normi 0, σ2 ( 1 + fo (F' F) fo ] ] . S 2 is asymptotically independent of
(yo - yo ). Hence, tn_p . Therefore, an approximate lθθ(l - a)%
 level of uncertainty at y o can be obtained as yo ± t "!_2s\ 1 + fo (F' F) l fo
level of uncertainty at y o can be obtained as yo ± t "!_2s\ 1 + fo (F' F) l fo
5.5 Sampling between the Confidence Intervals
The prediction model takes into consideration uncertainties by returning predicted results which fall within a confidence interval. Monte Carlo sampling method may be used to sample the points within the confidence interval to form the predicted feature space, which is used to calculate a confidence value as discussed herein. For example, the dissociation rate may be given by L(q) =— \ dx,dp, p(x, p),δ(y - q) — I \dx,dp,p(x,p) ,
2 J dt J where p(x,p) is the microcanonical density for an energy E, such that pE{x, p) = δ{E - ^,{x, p)) . S represents the Hamiltonian for the system of interest and may contain general potential energy functions. The microcanonical ensemble dissociation rate constants for general interaction potentials may be evaluated by traditional Monte Carlo procedures. Other methods may be used to sample the points, as is known in the art. 6 An Adaptive Reinforcement Learning Framework for Prediction Model Selection 6.1 Overview of the Reinforcement Learning Framework
Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error interactions with a dynamic environment. An agent is a learner or decision maker which can interact with the environment via perception or feedback. For example, at time t , the agent is in a state which is denoted by st e S represented by the environment, where S is the set of all possible states. In each step of iteration, the agent selects an action which is denoted by at e A(st ) , where A(st ) is the set of all possible actions in the current state st . By taking action at , the state will change from st to st+l .
A state signal that succeeds in retaining all relevant information is said to be Markov, or to have the Markov property. Assume there are a finite number of states and reward values for discrete systems, the environmental dynamics can be defined by the probability distribution: P\st+1 = s'e S, rt+l = r e R\st , Ci1 Jn S1-1, Ci1-1 ,... , ^, S0, ao ], for all s'e S, r e R , and all possible past events st , at , rt , S1-1 , Ci1-1 , ... , T1 , so , cιo . If the response of the environment at t + 1 only depends on the state and action at t , the state signal is said to have the Markov property and the environmental dynamics can de defined simpler as

If the state transition is a deterministic Markov decision process, an action performed in state st always transitions to the same next state st+l . Alternatively, in a non- deterministic Markov decision process, a probability distribution function defines a set of potential successor states for a given action in a given state. The value of the state transition at time t + 1 is observed by a scalar reinforcement which is denoted by r1+1 e R .
At each iteration step, the agent selects an action according to the current policy which is denoted by π , which is a mapping from each possible state to the probabilities of choosing each available action. A policy π is better or equal to a policy π' if its expected return is greater than or equal to that of π' for all state-action pairs.
The value of taking action a in state s under policy π , denoted by Qπ (s, a) (that is the action-value function for policy π), is defined as the expected return starting from s , taking action a and, therefore, following policy π is
Qπ{s,a) = Eπ{Rt s, = s,at = a}= En ZA+ st = s, at = a
U=O
The optimal action- value function, which is denoted as Q * , under the optimal policy, which is denoted as π * , is defined as Q * (s, a) = max^ Qπ(s, a), \/se S,a e A(s) .
The behavior of the agent should learn how to increase the long-run of the r e R over time by a systematic trial-and-error way guided by a variety of algorithms (e.g. Q- learning) as is known in the art. The goal of reinforcement learning is to learn the optimal
policy Q * from the experiment and maximizing the total amount of reinforcement in a long run.
The adaptive modeling aims to tackle the problem of selecting appropriate prediction models under different degradation statuses. The objective of the adaptive model selection is to obtain a mapping from each state to the probability of all possible prediction models that are taken into consideration in the modeling framework. The mapping provides a look-up table for model selection under different states. The reinforcement learning framework can be easily adapted for autonomously learning of this mapping. In the iterative process of the reinforcement learning, a prediction model is first chosen in a certain state according to the current optimal policy (probability of choosing a prediction model in a state). Then, the prediction output of the selected prediction model is compared with the real historical data. If the prediction accuracy is high, a positive reward is assigned to the prediction model; otherwise, the model is given a negative reward. As the iteration process proceeds, the reinforcement learning algorithm learns through the interaction with the environment to maximize the reward in a long run.
Finally, as shown in FIG. 4, the training results are shown in a look-up table, which shows the Q-value for each state/action (prediction model) pair. The Q- value is determined by the sum of the (possibly discounted) reinforcements received when performing an action following a given policy. The most appropriate model at a certain state is determined by the largest Q-value for all the state/action pairs in the row of that state in the Q-table. If this reinforcement learning framework is used for a predetermined number of runs, the probability of choosing a certain action (i.e., the prediction model) in a specific state may be calculated via dividing the number of times the action was chosen by the total predefined number of runs, which forms the solution space for the prediction model selection. As an example, as shown in FIG. 4, if the state/action pair is S2, the highest Q-value for that row can be found at M2 (Model 2).
6.2 Problem Domain Mapping
To establish a framework for the adaptive model selection, it is necessary to map the relationship between the prediction task and the domain of reinforcement learning. The map of the relationship is defined as follows: The environment of the disclosed reinforcement learning network is defined through historical data. The values of the historical data are utilized to calculate the reward of each prediction model that is incorporated in the framework.
The action is defined as the choice of different prediction models. The prediction models include various data-driven prediction algorithms. As one example, two types of prediction models (ARMA and RNN) are used. For each type of the prediction models, the structures and parameters are different. ARMA models can have different orders, such as ARMA (2, 1), ARMA (4, 3) and ARMA (12, 11) and so on, with different amounts of historical data used for training. RNN models can have various structures which are different in the number of input neurons, the number of hidden neurons, and the number of training samples. Each type of the two prediction models with different structures and parameters are considered as the available actions in the reinforcement learning framework.
The different states are defined by different degradation statuses identified by SOM as described herein. The MQE, described herein, is used as the indicator of the degradation status. The mean value and standard deviation of the MQE are used to define different states for the reinforcement learning framework. To estimate the maximum/minimum mean value and standard deviation from the historical data, a predefined number (N, positive integer) of the datasets, denoted by DL,\ ≤ i ≤ N , are sampled from the historical data by a fixed interval / from randomly generated start points. The maximum mean value of the MQE for all D1 is denoted by μmax and the minimum mean value of the MQE for all D1 is denoted by μmm ; similarly, the maximum standard deviation of the MQE for all D1 is denoted by (Tmax and the minimum standard deviation of the MQE for all D1 is denoted by (T1111n . The interval of (/Z1111n jumax ] and
[σ mm σ maχ] are divided into m(m > l) and n(n > l) sub-intervals, respectively. If we define Md^ = (Mm** -/O/(™ -!) and σΛv = (σmax - σmn )/(« -l), Iμ ,i e [l,m] and /σ je [l,n] can be denoted as /ft = μmm + (ι - 1) • μdιv and /σ = σmn + ( j - 1) • σΛv .
Therefore, totally (mxn) different states can be defined by the (mxn) combinations of different / and Iσ . To define the state of a dataset, the mean value
{μD ) and standard deviation (σD ) of the last M data points are calculated. The state is defined by the index of the minimum Euclidean distance of the pair {μD σD ) with all the mxn pairs [lμ ,Iσ ).
For state transition of each episode, a start point is randomly generated within the length of the historical data. For each step of an episode, a dataset with N data points is sequentially taken from the historical data until it reaches the end of the historical data or the number of the data points left is less than N .
The reward is based on prediction accuracy. A prediction model, which has high prediction accuracy, will be assigned a high/positive reward; otherwise, a low/negative reward will be given. Mean squared error (MSE), mean absolute deviation (MAD), and mean absolute percentage error (MAPE) can be used as the reward function. Several information criteria, such as adjusted coefficient of determination (R2), Akaike's information criterion (AIC), Bayesian information criterion (BIC), the Fisher information criterion (FIC), the posterior information criterion (PIC), and Rissanen's predictive least squares criterion (PLS), can also be used as the reward function. Another reward function, which may be used due to its simplicity and less computational cost, is described below by the following equations, σ is the standard deviation of the observed real values. The reward is assigned to a prediction model as follows: r' = +10, 01 e (Or1 - σ, Or1 + σ) , or
rl = +5, 01 e (Or1 + σ, Or1 + 2σ)or(Ort - 2σ, Or1 - σ) , or r' = -5, 01 e (Or1 + 2σ, Or1 + 3σ)or(Orι - 3σ, Or1 - 2σ) , or
r' = -10,O, e (-oo,Or, - 3σ)or(Or, + 3σ,∞) ,
where O1Je [l, Nstep] are the output of the selected prediction model and
Or1 J e [l, Nste/?] are the observed values. Nstep is the number of steps ahead for prediction. The reward for a selected prediction model can be calculated as follows

The policy, which defines the behavior of an agent, is the probability of choosing different prediction models in different states. The policy can also be seen as a mapping from the perceived environmental state to the actions to be taken. The optimal policy will be learned during the reinforcement learning. Within the framework defined above, the iterative process of reinforcement learning can be run for a certain predefined number of steps. The results will be a "lookup" table (see FIG. 4) in which the rows are different states and the columns are different prediction models. The look-up table's values are the probability of choosing a model under a certain state. The "look-up" table will be updated when new observations are obtained.
6.3 Q-Learning
One-step Q-learning is defined by the following the simplest form: Q{st ,at ) <r- Q{st ,at )+ a[r1+1 + ymaxα Q(st+I,a)- Q{st ,at )] , in which Q is the action- value function that directly approximates Q * ; Q * is the optimal action- value function that is independent of the policy being followed; at is the action performed in state at and the state transits to state stl ; rt+1 is the reinforcement received when performing action at at state st ; a is the learning rate; and γ is a scalar discount factor which functions as a mechanism of weighting the importance of the future rewards and the immediate rewards.
The pseudo code for Q-learning can be described as follows: (1) Initialize Q values Q(s, a) arbitrarily
(2) Do- (for each episode)
(3) Initialize s
(4) Do- (for each step in an episode)
(5) Select a from s using the policy derived from Q (6) Take action a and observe r and S1+1
(7) Update Q values by: Q(s,a) ^ Q(s,a)+ a[r + /maxα Q(st+I,a)- Q(s,a)]
(8) S <r- S1+1
(9) while s is the termination state (10) while all episodes end. There are two stochastic mechanisms which may be used for action selection. One is the ε -greedy action selection which selects the best action with probability (l - ε) , where εe [θ,l] ; otherwise it will select a random action. The other one is called Softmax action selection, which selects action at with probability eβ's αi' /^ ^e β(s v
6.4 Algorithm of the Reinforcement Learning Framework for Prediction Model Selection
The pseudo code of the reinforcement learning framework for prediction model selection is shown as follows:
(1) Initialize Q values Q(s, a) = 0, Vs e 5", a e A(s)
(2) Do_ (for each episode) (3) Randomly generate a starting point within the length of the historical data
(4) Initialize s for the data points in the first interval with length /
(5) Do_ (for each step in an episode)
(6) Select a prediction model a at state s using the policy derived from Q by ε - greedy selection method
(7) Train prediction model a and calculate the prediction results (8) Calculate the reward r and observe the next state st+1
(9) Update Q values by: Q{s,a) <r- Q{s, a)+ a[r + γmaxa Q{st+I,a)- Q{s,a)]
(10) S <r- S1+1
(11) while s is the termination state
(12) while all episodes end. 7 Improvement in the Accuracy of Confidence Value Calculation
The confidence value is calculated by evaluating the overlap between the distribution of the most recent feature space and that during normal operation. This overlap is continuously transformed into a confidence value (CV), ranging from 0 to 1 (0- abnormal and 1 -normal) over time for evaluating the deviation of the recent behavior from normal behavior or baseline. After the predicted feature space is sampled between the prediction intervals, it is necessary to calculate the predicted performance index based on the predicted feature space and the baseline. CV is a quantitative measure of the machine degradation, which provides valuable information for the maintenance practitioners to decide whether to take an action or not in a very easy way. The rest of this section describes estimating the distributions of the feature spaces and methods of calculating the CV depending on different data availability.
7.1 Density Estimation by Boosting Gaussian Mixture Model (GMM)
GMM is an unsupervised learning method which is used to estimate the density distributions of the predicted feature space. GMM consists of a number of Gaussian functions which are combined to provide a multivariate density. Mixtures of Gaussians can be utilized to approximate an arbitrary distribution within an arbitrary accuracy. The
mathematical model of GMM may be described as: f(x) = ^ pmN(∑m,μm ) , where pm m are the weights for the mth mixture and N(∑m , μ~ m ) denotes multivariate Gaussian distributions with mean vector μm and covariance matrix ∑m . If the number of the mixtures is known, expectation maximization (EM) algorithm is usually used to find the proper parameters for the GMM based on the observed dataset.
7.1.1 Determine the Number of Mixtures by Bayesian Information Criterion (BIC)
Bayesian Information Criterion (BIC) may be used as a criterion to choose the number of mixtures for the GMM. Bayesian model comparison calculates the posterior probabilities by using the full information over the priors. The evidence for a particular hypothesis may be calculated by: P(D|Λ, ) = I
 H1 )p{θ\D, H1 )dθ , where θ is defined as the parameters in the candidate model ht . D represents the training data set. For common cases, the posterior p(θ \ D,ht ) can be peaked at 0 which maximizes the probability of the training data set. Therefore, the previous equation can be approximated as: p{D I H1 ) « P(D I θ, H1 )p(θ I H1 )ΔΘ , where P(D I θ, H1 ) is the best-fit likelihood and /?(θ I H1)AQ is the Occam factor. If θ is k-dimensional and the posterior can be assumed to be Gaussian, the Occam factor can be calculated directly and yields
H1 )p{θ\D, H1 )dθ , where θ is defined as the parameters in the candidate model ht . D represents the training data set. For common cases, the posterior p(θ \ D,ht ) can be peaked at 0 which maximizes the probability of the training data set. Therefore, the previous equation can be approximated as: p{D I H1 ) « P(D I θ, H1 )p(θ I H1 )ΔΘ , where P(D I θ, H1 ) is the best-fit likelihood and /?(θ I H1)AQ is the Occam factor. If θ is k-dimensional and the posterior can be assumed to be Gaussian, the Occam factor can be calculated directly and yields
P(D I /iJ « p(D i e,/i,)/>(e i , where H = 32 ln /?(g 2 I D'/t' ) is a Hessian
 matrix and measures how "peaked" the posterior is around the value θ . Then the BIC score is calculated by: BIC(H1 I D) = log P(D \ hι ) log N , where d represents the
matrix and measures how "peaked" the posterior is around the value θ . Then the BIC score is calculated by: BIC(H1 I D) = log P(D \ hι ) log N , where d represents the
number of parameters in ht and Ν is the size of data set. The candidate model, which has the largest BIC score, will be selected as the best model.
7.1.2 Density Boosting of GMM
Furthermore, a boosting method based on GMM is developed to approximate the distributions in order to achieve higher accuracy. Boosting is an algorithm aiming to improve the accuracy of any given learning algorithm or classifiers in a supervised
learning scheme, particularly a weak learner algorithm. A weak learner class is a class that performs only slightly better than random guessing. A weak learner for the training set is created; then new component classifiers are added to form an ensemble with high accuracy on the training set through the use of a weighted decision rule. One algorithm comprises a method to continuously add weak learners until a desired low training error is achieved. At this point, each training pattern is assigned a weight which determines the probability of being selected. If the training pattern is correctly classified, the chance of being selected in the subsequent component classifier is reduced. If the training pattern is not correctly classified, the chance of being selected in the subsequent component classifier is increased. Patterns are chosen according to the new distribution to train the next classifier and the process is iterated. One issue of this algorithm is that the training error is dependent on the labels of the training patterns, and for unsupervised learning schemes the labels are not available. A gradient boosting methodology for the unsupervised learning scheme of density estimation method can also be used. This methodology will identify the coefficients and parameters of the weak learner which gives the largest local improvement at each iteration step according to the data log-likelihood criterion which is defined as:
DLL = log ^ a Jin (x), in which N is the number of mixtures, x is the training dataset and Ctn is the coefficient for each weak learner hn (x). BIC is used as a criterion to choose the number of mixtures for weak learners. Another boosting GMM has been introduced in which BIC is used to determine the number of mixtures for the GMM model. However, the number of mixtures should not be defined at the very beginning of the boosting procedure, since the sampled dataset will change according to the weights of the dataset at each iteration step. In addition, the EM algorithm, which is utilized to estimate the parameters for GMM, is sensitive to the initial parameters and it will likely converge to a local minimum.
To address the aforementioned issues, the disclosed GMM boosting algorithm is summarized as follows:
(1) Begin initialize L0 (x) to be uniform on the domain of x and set the maximum iteration number T and the maximum iteration number K for EM. Set the maximum number
of mixtures of the GMM as Nmax and stop the iteration if the performance does not improve for Mmax continuous steps
(2) t<-0 (3)dot«-t+l
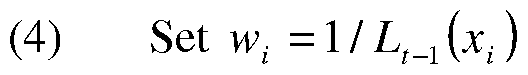
(5) Sample the original dataset according to Cu1
(6) n^O
(7) don^n+1
(8) Use PSO to optimize the initial seeds of the k-means algorithm to initialize GMM (9) Use EM to estimate the distribution of sampled dataset x with a
GMM model
K (*, ) . where Λ," (x, ) = ∑"=i PnNorm{μn,δn ) and )

(9.1) k^O, initialize pn, μn,σn (9.2) dok^k+1

V' p\ω = n\ x,,θk,
(9.4) A =%^ —
Y^ι=ip(ω=n\xι,θ)
(9.5) cr. = _ , where


(9.6) untilk=K
(10) until n=Nmax (11) Use the BIC score to determine the best model ht based on the sampled dataset x
(12) If E1W1^(X1) < n break, where n is the size of training sample
(13) Using line search method to find at = arg min^ y^ L - log((l - Qc)L1^ Jx1 )+ ah, Kx1 ))
(14) Set Lt ={l- (X1)L^1 +a,Lt
(15)untilt= Tmax or log(L,U,
 ))<10"5 for Mmax steps (16) return L.
))<10"5 for Mmax steps (16) return L.
(17) end.
In step 8, the fitness function for the PSO is the sum of the within-cluster distances,
K n d which is described as: Sw = T^ T^ coιk T^ (x, -ck j , where K is the number of clusters, n k=l 1=1 j=l is the number of patterns or samples, d is the number of dimension, X1 is the Hh pattern and ck is the center of the k cluster, a>ιk is 1 if the i •th pattern belongs to the k cluster or
0 otherwise, and ^ ωιk = 1.
7.2 Confidence Value (CV) Calculation Based on Feature Distributions
7.2.1 CV calculation when only normal baseline is available
After the distributions of both the normal baseline and the predicted feature space are approximated through the use of a boosting GMM, the confidence value (CV), which indicates the performance of the machine (1 for normal, 0 for abnormal), is calculated by
the overlap of the distributions following CV where Fix) and
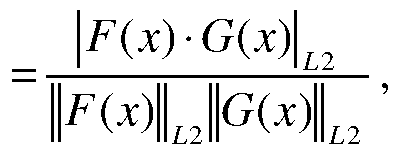
G(x) are the Gaussian mixture functions. If the two distributions overlap extensively, the confidence value will be near 1, which means the performance of the machine does not deviate from the baseline significantly. Otherwise, if the two distributions rarely overlap, the confidence value will be near 0, which means the performance of the machine deviates from the baseline significantly and the machine is probably acting abnormally.
The calculation of the L2 distance of Gaussian mixtures is depicted in FIG. 5A. If the Gaussian mixture function contains more than two components, the same method can be easily extended to calculate the confidence value by adding necessary items which are the integration parts of the multivariate normal density functions.
7.2.2 CV Calculation when Normal Baseline and Faulty Baseline are Both Available
If measurements are available when the machine was running during the normal baseline, or under normal operating conditions, and before the machine was replaced due to a certain failure (i.e. during the faulty baseline), the CV is defined as a normalized average value of the data log-likelihood of both the baselines. The concept of the calculation of the CV is illustrated in FIG. 5B.
The distribution of the normal baseline is denoted by FN (X) and the distribution of the faulty baseline is denoted by FF (x) . Notice that if density booting is applied to the distribution approximation of the baselines, the expression of the distributions is still mixture Gaussian function. The average log-likelihood is calculated by:
DLLN = - log — J^nI1 FN {xn ) and DLLF = - log — ∑^ FF {xn ) . DLLN can be
considered as the distance from the predicted feature space to the distribution of the normal feature space FN because DLLN is a positive scalar due to the fact that
— T^ _ FN (xn ) is between 0 and 1. The larger the DLLN is, the smaller the average mean log-likelihood of the predicted feature space to the distribution of the baseline FN . Similarly, DLLF can be considered as the distance from the predicted feature space to the distribution of the faulty feature space FF . Therefore, CV is defined as:
DLL,, DLL17
CV = I = . According to the definition of CV, the CV is
DLLN + DLLF DLLN + DLLF larger if the distance from the predicted feature space to the normal baseline is smaller; the CV is smaller if the distance from the predicted feature space to the faulty baseline is smaller. This method is illustrated by the bearing example, discussed hereinafter.
8 Machine Failure Diagnosis by Self- Organizing Maps (SOM) 8.1 Diagnosis and Visualization
The purpose of diagnosis is to analyze the patterns embedded in the data to determine what previous observed fault has occurred. SOM has been introduced herein as a degradation assessment algorithm due to its advantage to deal with high-dimensional feature space. A rectangular SOM map is used as an example to demonstrate how SOM is used for diagnosis purposes.
During the training procedure of the SOM, the weight vector will move towards the input vector at each iteration step according to the neighbor updating rules. At the end of the training, the input vectors are kept in the map. In other words, the input vectors which closely resemble one another will locate next to each other on the SOM map after training. In this way, the weight vectors are grouped into clusters to match the distribution of the input vectors according to their distances to the input vectors. A unified distance matrix (U-matrix), which shows the distances between the neighbor units, may be used to visualize the clusters' structure in the SOM map.
As shown in FIG. 6, high values of the U-matrix (left-hand side) indicate a cluster boundary; uniform areas of low values indicate clusters themselves. Note that the U- matrix visualization has many more hexagons than the map structure. This is because not only the distance values "at" the map units but also distances "between" map units are shown in the U-matrix. Larger distances have darker colors and smaller distances have lighter colors, as seen in the gray bar of FIG. 6. The set of hexagons on the right-hand side of FIG. 6 shows the structure of the SOM map itself and is used as a simple method to identify different failure modes for diagnosis. If the label information is available, a variant called "Supervised SOM" can be used to tune the representation of the distribution of all input vector obtained by the unsupervised learning SOM algorithm. Supervised SOM tunes this representation to discriminate better between the classes. In this case, the SOM units will be labeled with the available label information. Therefore, the testing features can be labeled by finding the BMU in the trained map as "hit points." The failure modes can be identified by the location of the hit points on the map. This method is illustrated by the bearing example discussed hereinafter.
8.2 Feature Selection for Diagnosis
An important issue for accurate fault diagnosis is to select the right features as the input of the diagnosis model. Some features might be trivial for diagnosis; these features tend to increase the computational burden and impair the performance of the classifier. Hence, the following two methods are disclosed for feature selection in diagnosis.
The first method is to determine which features were highly correlated with the output. The values of correlation coefficient r were calculated and ranked in descending order. The features with the corresponding higher r values were selected as the input to the SOM. The correlation coefficient r for one pair of input feature and output
({(x, , yt )}: i = l, ... , n) is calculated by r = . '=1 = , in which n is the
 number of samples in a dataset, X1 is a series of a feature, yt is a series of the output, x is the mean value of the series X1 , and y is the mean value of the output.
number of samples in a dataset, X1 is a series of a feature, yt is a series of the output, x is the mean value of the series X1 , and y is the mean value of the output.
The second method was the Fisher linear discrimination method which sought the projection directions that were efficient for discrimination. It was used to maximize the ratio of between-class scatter to the within-class scatter, which was preferred in such a multi-class classification task. A transformation matrix was obtained by selecting the eigenvectors corresponding to the non-zero eigenvalues of the matrix Sw ~lSB . The initial feature space x was then projected to a new feature space y by y = Wx (where
W = Sw ~ SB ). The rank of the matrix Sw ~ SB was c — \ and the projected feature space therefore had c — \ dimensions where c is the number of classes in the dataset.
9 Example
The following provides one example of using the methods described herein for prognosing a mechanical system comprising a rotary machine. Bearings are critical components of the rotary machine since their failures could lead to a chain of serious damages in the machine. Prediction and detection of rolling element-bearing faults has been gaining importance in recent years because of its detrimental effect on the reliability of rotating machines. Different datasets of bearings are utilized in the example to validate the disclosed methods. Roller bearing failure modes generally include roller failure, inner- race failure, outer-race failure, and a combination of these failures. The presence of different failure modes may cause different patterns of contact forces as the bearing rotates, which cause sinusoidal vibrations. Therefore, vibration signals were taken as the measurements for bearing performance assessment, prediction and diagnosis.
9.1 Setup
The setup included four test bearings on one shaft. The shaft was driven by an AC motor. Four bearings were installed on one shaft. A PCB 353B33 High Sensitivity Quartz ICPs Accelerometer was installed on each of the bearing housing. In this case, a Rexnord ® ZA-2115 bearing was used for a run-to-failure test. Vibration data was collected every 20 minutes with sampling rate 20 kHz using a National Instruments ® DAQCard™-6062E
data acquisition card. For each data file, 20,480 data points were obtained. A magnetic plug was installed in the oil feedback to accumulate debris; debris is evidence of bearing degradation. At the end of the failure stage, the debris accumulated to a certain level causing an electrical switch to stop the test. In the test, one of the bearings finally developed a roller element defect.
9.2 Identification of the Degradation Status by SOM
A SOM was trained only with the feature space from the normal operation data. For each input feature vector, a BMU was found in the SOM. The distance measured between the input feature vector and the weight vector of the BMU, which was defined as the Minimum Quantization Error (MQE), actually indicated how far away the input feature vector deviated from the normal operation state. Hence, the degradation trend was visualized by the trend of the MQE. As the MQE increased, the extent of the degradation became more severe. Data from the first 500 cycles of the normal operation condition were used to train the SOM. After training, the entire life cycle data of the bearing with roller element defect was used for testing and the corresponding MQE values were calculated. In the first 1450 cycles, the bearing was in good condition, and the MQEs were near zero. From cycle 1450 to cycle 1650, the initial defects appeared and the MQE started increasing. The MQE continued increasing until approximately cycle 1750, this was an indication that the defects had become more serious. Subsequently, until around cycle 2050, the MQE dropped, this was due to the propagation of the roller defect becoming counterbalanced by the vibration. Shortly thereafter the MQE increased sharply until the bearing failed. It was verified that during the MQE increase that started after cycle 1500, the amount of debris that adhered to the magnetic plug increased. The debris was allowed to continue to increase until it accumulated to a certain level, which caused an electrical switch to stop the running of the test.
9.3 Results of the Prediction Modes
ARMA and RNN are considered two exemplary prediction models due to their different characteristics and prediction capabilities. ARMA is applicable to linear time- invariant systems whose performance features display stationary behavior, while it is
unfeasible for use in a non-linear or dynamic process. Furthermore, since ARMA utilizes a small amount of historical data, it may not be able to provide good long-term prediction. RNN is good at modeling complex systems, which involve nonlinear behavior and unstable processes. RNN can take more historical data into the training procedure, which makes it is feasible to use for long-term prediction. However RNN has drawbacks in that there is no standard method to determine the structure of the network and its tendency to over fit.
To demonstrate the different performances of ARMA and RNN, the second principle component feature from cycle 1600 to cycle 1820 were normalized, and was used as data for training and testing the prediction models. Data from cycle 1600 to cycle 1770 (step 1 to step 170) were used for training and data from cycle 1771 to cycle 1820 (step 171 to step 220) were used for testing. Six ARMA models were adopted for prediction in the experiment: ARMA (2, 1), ARMA (4, 3), ARMA (6, 5), ARMA (8, 7), ARMA (10, 9) and ARMA (12, 11). A RNN model was also adopted for prediction in the experiment. It had 105 input neurons, 7 hidden neurons, one output neuron, and utilizes 60 training samples. Due to the random initialization of the weights of RNN, which made the training performance unstable, PSO was used to optimize the initial weights of the RNN to ensure stable training performance. In the experiment, the swarm size was chosen as 10 and the number of iteration was set to be 500. The comparison of the training performance of RNN with and without PSO indicated that the training performance of RNN with PSO initialization was stable with very small variance for the 25 runs of RNN, while the training performance of RNN without PSO initialization had large variance for the 25 runs.
The aforementioned six ARMA models and the RNN with PSO initialization were used to predict the normalized feature from step 171 to step 220. The testing Mean Square Error (MSE) of each model was shown in the following table.

Table 1
The results indicate that RNN outperforms the other six ARMA models for the prediction under the MSE criterion. The performances of the six ARMA models were very close to each other. The six ARMA models generated larger errors, while RNN achieved better results and captured the drop of the feature very close to the real value. 9.4 Reinforcement Learning for Adaptive Prediction Model Selection
The first principle component feature and the MQE values of the entire life cycle were used as the historical data to train the reinforcement algorithm to obtain the "lookup" table for model selection under various degradation statuses. The first principle component feature was of interest for prediction. MQE data was used to define the degradation status of the machine, which was used to define the state space in the reinforcement learning framework.
One purpose was to validate whether it is feasible for the reinforcement learning algorithm to learn the optimal policy to select appropriate algorithms in different states after the training. The aforementioned six ARMA models were used as agents in the reinforcement learning framework. A first order linear model with fixed parameters was also used as another agent in the reinforcement learning framework for comparison with the ARMA models. The first order linear model was described as y = -10Ox + 0.8. This agent cannot achieve good results for most of the situations; it was added into the reinforcement learning framework in order to determine whether the algorithm can avoid choosing this agent or not after training.
The parameter settings of the Q-learning are described as follows. The maximum number of episode was set to be 1000. The maximum of steps in each episode was also set to be 1000. The state transition interval was set to be 50. A state space with 9 different states was generated by different mean values and standard deviations of the MQE values. The number of prediction steps ahead was set to be 30 for each agent. The learning rate was set to be 0.5. Discount factor was chosen to be 0.2 to weigh more on the current rewards. The probability of a random action selection was set to be 0.1 in order to obtain more "exploration" of all the actions in the action set for better choice. After the learning, a Q- value table was obtained for all the state-action pairs, shown in the table
below. The most appropriate prediction model can be selected according to the highest Q- value for the state-action pairs.

Table 2
ARMA (4, 3) had the highest Q- value in state 1 and ARMA (10, 9) had the highest Q- value in state 2. Therefore, those two models should be selected for prediction in state 1 and state 2, respectively. The order one linear model with fixed parameters had all negative Q-values in all the states; hence, it will not be chosen for prediction no matter in which state the machine was. In the experiment, the same reinforcement learning frame was run for 9 times repeatedly. For each time, the best action was selected according to the highest Q-value. This showed that the Q-values were similar for the entire state-action space for the 9 runs but not exactly the same. The probability of the best state-action pair can be calculated from the 9 runs by calculating the number of times that one action had been chosen as the best action in each state. Hence, the most appropriate action in each state can be selected according to the highest probability of been chosen in each state. If the probabilities were equal to two actions in the same state, the simpler model will be chosen according to the Occam's razor (i.e., the simplest explanation is the best). The purpose of selecting the simpler model was to avoid over fitting problems.
9.5 Diagnosis
Roller bearing failure modes generally include roller failure, inner-race failure, outer-race failure, and a combination of these failures. The presence of different failure modes may cause different patterns of contact forces as the bearing rotates, which cause sinusoidal vibrations. If the confidence values predicted drop to a very low level, a very interesting task is trying to determine what kind of failure the bearing has developed. The
SOM method described herein was employed for diagnosis for bearings. The results were a "health map" which showed different failure modes of the bearing.
In this industrial example, a SKF32208 bearing was used, with an accelerometer installed on the vertical direction of its housing to obtain vibration signals. The sampling rate for the vibration signals was 50 kHz. 8192 data points were obtained and saved in one data file. The bearings were artificially made to have roller defect, inner-race defect and outer-race defect and 4 different combinations of the single failures respectively. The vibration signals of 8 different types of bearing states were identified, which were identified based on the following two steps. Step 1: The BPFI, BPFO and BSF for this case were calculated as 131.73 Hz, 95.2
Hz and 77.44 Hz, respectively. The features were extracted from the raw vibration data, which function as the input vectors for the SOM.
Step 2: The health map was trained. The SOM toolbox developed by Helsinki University of Technology was used. The input vector of a specific bearing defect was represented by a cluster of BMUs on the map, which formed a region indicating the defect.
After training the SOM, a health map was obtained, which showed eight areas indicating the normal status, roller defect, inner-race defect, outer-race defect, outer-race & roller defect, outer-race & inner-race defect, inner-race & roller-defect and outer-race & inner-race & roller defect, respectively. With new data coming in, their extracted features were fed into the trained SOM, and their "hit points" on the health map represented the failure mode of the bearing.
Further examining the 14 features, we found some features might be trivial ones for bearing performance assessment and diagnosis. As such these features tended to increase the computational burden and impaired the performance of the classifier. Hence, the following two methods described herein were applied and compared for feature selection.
The first method was to find out which features were highly correlated with the output. The values of correlation coefficient r were calculated and ranked in descending order. The features with the corresponding higher r values were selected as the input to
the SOM. In this case, 7 features with r values higher than 0.5 were selected. The selected features were sub bands centered at IX and 2X of BSF, BPFI, and BPFO in the frequency domain, and the RMS value in the time domain.
The second method was the Fisher linear discrimination method which sought the projection directions that were efficient for discrimination. It was used to maximize the ratio of between-class scatter to the within-class scatter, which was preferred in such a multi-class classification task.
Repeated holdout validation was used to test the generalization quality of the model. Random samples were selected for each of the 8 classes. The proportion of the samples selected in each class was specified by a certain holdout rate. For example, the holdout rate of 0.1 means that 10% of the samples are randomly selected for testing and the remaining 90% of the samples are used for training. In this case, 5 holdout rates (0.1, 0.2, 0.3, 0.4 and 0.5) were applied. For each holdout rate, 50 trials were carried out repeatedly, and then the average precision rate was calculated. The above-mentioned embodiments of the present invention may be implemented using hardware, software or a combination thereof and may be implemented in one or more microprocessor based systems, such as a workstation, a portable computer or other such processing systems, such as personal digital assistants (PDAs), application specific devices, and the likes. When implemented on a microprocessor based system, a microprocessor executes the above-mentioned processes (e.g., extracting features, decomposing data, selecting a prediction model, generating a predicted feature space, generating a confidence value, providing a status of mechanical system based at least in part on the generated data, etc.), interfacing with memory (e.g., local and/or remote via wired and/or wireless communications) such as for retrieving and storing the processes, results, and data (e.g., measurement data, mechanical system data, prediction models, reinforcement learning model, etc.), interfacing with a display for providing status, selection choices, data, and results, and interfacing with user interface(s) for receiving input (e.g., selection, navigation, etc.). Embodiments of the invention may also be provided as a computer product, such as contained in a conventional computer readable medium having stored therein computer instructions to cause a microprocessor to execute
the above-mentioned processes of the present invention. As taking the embodiments described above and implementing them on such microprocessor based systems and/or a computer readable medium is well within the abilities of one skilled in the related art, for brevity, no further discussion is provided. While particular embodiments and aspects of the present invention have been illustrated and described herein, various other changes and modifications may be made without departing from the spirit and scope of the invention. Moreover, although various inventive aspects have been described herein, such aspects need not be utilized in combination. It is therefore intended that the appended claims cover all such changes and modifications that are within the scope of this invention.
Claims
1. A method of prognosing a mechanical system comprising: receiving measurement data corresponding to the mechanical system; extracting one or more features from the received measurement data by decomposing the measurement data into a feature space; selecting a prediction model from a plurality of prediction models for one or more features based at least on part on a degradation status of the mechanical system and a reinforcement learning model; generating a predicted feature space by applying the selective prediction model to the feature space; generating a confidence value by comparing the predicted feature space with a normal baseline distribution, a faulty baseline distribution, or a combination thereof; and providing a status of mechanical system based at least in part on the confidence value.
2. A method as claimed in claim 1 wherein the measurement data comprises current data, voltage data, vibration data, pressure data, temperature data, acoustic emissions, or combinations thereof.
3. A method as claimed in claim 1 wherein the one or more features comprises one or more time domain features, one or more frequency domain features, or combinations thereof.
4. A method as claimed in claim 3 wherein the method further comprises obtaining the frequency domain features by applying a Fourier transform to stationary signals within the measurement data, and applying a wavelet packet transform to non-stationary signals within the measurement data.
5. A method as claimed in claim 1 wherein the features are extracted by a time domain analysis, a frequency domain analysis or combinations thereof.
6. A method as claimed in claim 1 wherein the method further comprises dimensionally reducing the feature space to generate a reduced set of uncorrelated features from the features within the feature space.
7. A method as claimed in claim 6 wherein dimensionally reducing the feature space further comprises applying a principal component analysis, a Karhunen-Loeve transform, or a combination thereof to the feature space.
8. A method as claimed in claim 1 wherein the degradation status of the mechanical system is determined by comparing the feature space with the normal baseline feature space.
9. A method as claimed in claim 1 wherein the degradation status is based on a performance index generated by a self-organizing map trained with measurement data of a normal operating state.
10. A method as claimed in claim 9 wherein the performance index is the difference between an input vector corresponding with the feature space and a weight vector.
11. A method as claimed in claim 1 wherein the plurality of prediction models comprises one or more auto-regressive moving average models, one or more recurrent neural network models, or combinations thereof.
12. A method as claimed in claim 1 wherein: the reinforcement learning model is defined by a plurality of states, each state corresponding to a particular degradation status; the reinforcement learning model comprises a Q- value for each prediction model at each state; and the selected prediction model is the prediction model having largest Q-value at a particular state.
13. A method as claimed in claim 12 wherein the states are based, at least in part, on a performance index generated by a self-organizing map trained with measurement data of a normal operating state.
14. A method as claimed in claim 13 wherein the Q- values are developed by an iterative learning process.
15. A method as claimed in claim 14 wherein the iterative learning process comprises: choosing a prediction model in a particular state; generating a predicted output; comparing the predicted output with a real value of historical data; and assigning a reward value to the prediction model in the particular state such that a positive reward value is assigned when predicted output has a relatively high prediction accuracy and a negative reward value is assigned when the predicted output has a relatively low prediction accuracy.
16. A method as claimed in claim 15 wherein the Q-value for each predictive model comprises a summation of a plurality of reward values based on a plurality of prediction outputs at the particular state.
17. A method as claimed in claim 1 wherein the predictive feature space is approximated by a density estimation method.
18. A method as claimed in claim 17 wherein the density estimation method comprises a boosting Gaussian mixture model.
19. A method as claimed in claim 1 wherein: the confidence value is a value between zero and one; and the confidence value corresponds to an overlap region of the predicted feature space and the normal baseline distribution such that a relatively high confidence value corresponds with a relatively large overlap region and a relatively low confidence value corresponds with a relatively small overlap region.
20. A method as claimed in claim 1 wherein: the confidence value is a value between zero and one; the confidence value is based on a comparison of the predicted feature space with the normal baseline distribution and the faulty baseline distribution; and the confidence value is greater when the predicted feature space is closer to the normal baseline distribution than the faulty baseline distribution than when the predicted feature space is closer to the faulty baseline distribution than the normal baseline distribution.
21. A method as claimed in claim 1 wherein the method further comprises providing a mechanical system diagnosis indicating one or more faults.
22. A method as claimed in claim 21 wherein providing the mechanical system diagnosis further comprises inputting features into a trained self-organizing map to generate and display a health map.
23. A method as claimed in claim 22 wherein the health map comprises a plurality of regions indication a plurality of corresponding failure modes.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US8334108P | 2008-07-24 | 2008-07-24 | |
| US61/083,341 | 2008-07-24 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2010011918A2 true WO2010011918A2 (en) | 2010-01-28 |
| WO2010011918A3 WO2010011918A3 (en) | 2010-04-22 |
Family
ID=41569429
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2009/051680 WO2010011918A2 (en) | 2008-07-24 | 2009-07-24 | Methods for prognosing mechanical systems |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US8301406B2 (en) |
| WO (1) | WO2010011918A2 (en) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8458525B2 (en) | 2010-03-19 | 2013-06-04 | Hamilton Sundstrand Space Systems International, Inc. | Bayesian approach to identifying sub-module failure |
| EP2696251A2 (en) | 2012-08-07 | 2014-02-12 | Prüftechnik Dieter Busch AG | Method for monitoring rotating machines |
| CN106709149A (en) * | 2016-11-25 | 2017-05-24 | 中南大学 | Neural network-based method and system for predicting shapes of three-dimensional hearths of aluminum cells in real time |
| CN109586239A (en) * | 2018-12-10 | 2019-04-05 | 国网四川省电力公司电力科学研究院 | Intelligent substation real-time diagnosis and fault early warning method |
| CN109800487A (en) * | 2019-01-02 | 2019-05-24 | 北京交通大学 | Life-span prediction method based on obfuscation security domain |
| EP3525176A1 (en) * | 2018-02-08 | 2019-08-14 | GEOTAB Inc. | Telematics predictive vehicle component monitoring system |
| TWI724467B (en) * | 2019-07-19 | 2021-04-11 | 國立中興大學 | The diagnosis method of machine ageing |
| US11176762B2 (en) | 2018-02-08 | 2021-11-16 | Geotab Inc. | Method for telematically providing vehicle component rating |
| US11182987B2 (en) | 2018-02-08 | 2021-11-23 | Geotab Inc. | Telematically providing remaining effective life indications for operational vehicle components |
| US11182988B2 (en) | 2018-02-08 | 2021-11-23 | Geotab Inc. | System for telematically providing vehicle component rating |
| US20230288882A1 (en) * | 2022-03-14 | 2023-09-14 | Microsoft Technology Licensing, Llc | Aging aware reward construct for machine teaching |
| DE102023202109A1 (en) | 2023-03-09 | 2024-09-12 | Siemens Aktiengesellschaft | Procedure for generating a self-organizing map |
Families Citing this family (164)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090326890A1 (en) * | 2008-06-30 | 2009-12-31 | Honeywell International Inc. | System and method for predicting system events and deterioration |
| US8751195B2 (en) * | 2008-09-24 | 2014-06-10 | Inotera Memories, Inc. | Method for automatically shifting a base line |
| NZ572036A (en) * | 2008-10-15 | 2010-03-26 | Nikola Kirilov Kasabov | Data analysis and predictive systems and related methodologies |
| US20100106458A1 (en) * | 2008-10-28 | 2010-04-29 | Leu Ming C | Computer program and method for detecting and predicting valve failure in a reciprocating compressor |
| FR2939170B1 (en) * | 2008-11-28 | 2010-12-31 | Snecma | DETECTION OF ANOMALY IN AN AIRCRAFT ENGINE. |
| US20140052499A1 (en) * | 2009-02-23 | 2014-02-20 | Ronald E. Wagner | Telenostics performance logic |
| US8276106B2 (en) * | 2009-03-05 | 2012-09-25 | International Business Machines Corporation | Swarm intelligence for electrical design space modeling and optimization |
| US7961956B1 (en) * | 2009-09-03 | 2011-06-14 | Thomas Cecil Minter | Adaptive fisher's linear discriminant |
| EP2296062B1 (en) * | 2009-09-09 | 2021-06-23 | Siemens Aktiengesellschaft | Method for computer-supported learning of a control and/or regulation of a technical system |
| US8538901B2 (en) * | 2010-02-05 | 2013-09-17 | Toyota Motor Engineering & Manufacturing North America, Inc. | Method for approximation of optimal control for nonlinear discrete time systems |
| US8521497B2 (en) | 2010-06-03 | 2013-08-27 | Battelle Energy Alliance, Llc | Systems, methods and computer-readable media for modeling cell performance fade of rechargeable electrochemical devices |
| US9015093B1 (en) * | 2010-10-26 | 2015-04-21 | Michael Lamport Commons | Intelligent control with hierarchical stacked neural networks |
| TWI447371B (en) * | 2010-11-18 | 2014-08-01 | Univ Nat Taiwan Science Tech | Real-time detection system and the method thereof |
| US8504493B2 (en) * | 2011-02-15 | 2013-08-06 | Sigma Space Corporation | Self-organizing sequential memory pattern machine and reinforcement learning method |
| US20120215450A1 (en) * | 2011-02-23 | 2012-08-23 | Board Of Regents, The University Of Texas System | Distinguishing between sensor and process faults in a sensor network with minimal false alarms using a bayesian network based methodology |
| CN102324034B (en) * | 2011-05-25 | 2012-08-15 | 北京理工大学 | Sensor-fault diagnosing method based on online prediction of least-squares support-vector machine |
| US9625532B2 (en) * | 2011-10-10 | 2017-04-18 | Battelle Energy Alliance, Llc | Method, system, and computer-readable medium for determining performance characteristics of an object undergoing one or more arbitrary aging conditions |
| CN104067011B (en) * | 2011-11-23 | 2017-07-28 | Skf公司 | Rotary system state monitoring device and method, computer readable medium and management server |
| US20130158912A1 (en) * | 2011-12-15 | 2013-06-20 | Chung-Shan Institute of Science and Technology, Armaments, Bureau, Ministry of National Defence | Apparatus for Measuring the State of Health of a Cell Pack |
| US20130197854A1 (en) * | 2012-01-30 | 2013-08-01 | Siemens Corporation | System and method for diagnosing machine tool component faults |
| US9489636B2 (en) | 2012-04-18 | 2016-11-08 | Tagasauris, Inc. | Task-agnostic integration of human and machine intelligence |
| JP5778087B2 (en) * | 2012-06-19 | 2015-09-16 | 横河電機株式会社 | Process monitoring system and method |
| US9336302B1 (en) * | 2012-07-20 | 2016-05-10 | Zuci Realty Llc | Insight and algorithmic clustering for automated synthesis |
| US20160217628A1 (en) * | 2012-08-29 | 2016-07-28 | GM Global Technology Operations LLC | Method and apparatus for on-board/off-board fault detection |
| US20140180658A1 (en) * | 2012-09-04 | 2014-06-26 | Schlumberger Technology Corporation | Model-driven surveillance and diagnostics |
| US10401164B2 (en) * | 2012-10-16 | 2019-09-03 | Exxonmobil Research And Engineering Company | Sensor network design and inverse modeling for reactor condition monitoring |
| CN103258134B (en) * | 2013-05-14 | 2016-02-24 | 宁波大学 | A kind of dimension-reduction treatment method of vibration signal of higher-dimension |
| US9286573B2 (en) * | 2013-07-17 | 2016-03-15 | Xerox Corporation | Cost-aware non-stationary online learning |
| EP3022612A1 (en) * | 2013-07-19 | 2016-05-25 | GE Intelligent Platforms, Inc. | Model change boundary on time series data |
| US9412075B2 (en) * | 2013-08-23 | 2016-08-09 | Vmware, Inc. | Automated scaling of multi-tier applications using reinforced learning |
| WO2015063435A1 (en) * | 2013-10-30 | 2015-05-07 | Ge Aviation Systems Limited | Method of regression for change detection |
| US20150219530A1 (en) * | 2013-12-23 | 2015-08-06 | Exxonmobil Research And Engineering Company | Systems and methods for event detection and diagnosis |
| US20150204757A1 (en) * | 2014-01-17 | 2015-07-23 | United States Of America As Represented By The Secretary Of The Navy | Method for Implementing Rolling Element Bearing Damage Diagnosis |
| US10653339B2 (en) * | 2014-04-29 | 2020-05-19 | Nxp B.V. | Time and frequency domain based activity tracking system |
| WO2015178820A1 (en) * | 2014-05-19 | 2015-11-26 | Aktiebolaget Skf | A method and device for determining properties of a bearing |
| CN104102773B (en) * | 2014-07-05 | 2017-06-06 | 山东鲁能软件技术有限公司 | A kind of equipment fault early-warning and state monitoring method |
| US10430038B2 (en) * | 2014-07-18 | 2019-10-01 | General Electric Company | Automated data overlay in industrial monitoring systems |
| US20160313216A1 (en) | 2015-04-25 | 2016-10-27 | Prophecy Sensors, Llc | Fuel gauge visualization of iot based predictive maintenance system using multi-classification based machine learning |
| US10481195B2 (en) | 2015-12-02 | 2019-11-19 | Machinesense, Llc | Distributed IoT based sensor analytics for power line diagnosis |
| US10638295B2 (en) | 2015-01-17 | 2020-04-28 | Machinesense, Llc | System and method for turbomachinery preventive maintenance and root cause failure determination |
| US10599982B2 (en) * | 2015-02-23 | 2020-03-24 | Machinesense, Llc | Internet of things based determination of machine reliability and automated maintainenace, repair and operation (MRO) logs |
| US20160245279A1 (en) | 2015-02-23 | 2016-08-25 | Biplab Pal | Real time machine learning based predictive and preventive maintenance of vacuum pump |
| US20160245686A1 (en) | 2015-02-23 | 2016-08-25 | Biplab Pal | Fault detection in rotor driven equipment using rotational invariant transform of sub-sampled 3-axis vibrational data |
| US10613046B2 (en) | 2015-02-23 | 2020-04-07 | Machinesense, Llc | Method for accurately measuring real-time dew-point value and total moisture content of a material |
| US10648735B2 (en) | 2015-08-23 | 2020-05-12 | Machinesense, Llc | Machine learning based predictive maintenance of a dryer |
| JP6620402B2 (en) * | 2015-02-25 | 2019-12-18 | 三菱重工業株式会社 | Event prediction system, event prediction method and program |
| AT515154A2 (en) * | 2015-03-13 | 2015-06-15 | Avl List Gmbh | Method of creating a model ensemble |
| EP3282403A4 (en) * | 2015-04-07 | 2018-04-18 | TLV Co., Ltd. | Maintenance support system and maintenance support method |
| US10984338B2 (en) | 2015-05-28 | 2021-04-20 | Raytheon Technologies Corporation | Dynamically updated predictive modeling to predict operational outcomes of interest |
| US10542961B2 (en) | 2015-06-15 | 2020-01-28 | The Research Foundation For The State University Of New York | System and method for infrasonic cardiac monitoring |
| US10015188B2 (en) | 2015-08-20 | 2018-07-03 | Cyberx Israel Ltd. | Method for mitigation of cyber attacks on industrial control systems |
| CN105140972B (en) * | 2015-09-06 | 2018-01-30 | 河南师范大学 | The frequency method for fast searching of high-transmission efficiency radio energy emission system |
| CN105141016B (en) * | 2015-09-06 | 2017-12-15 | 河南师范大学 | Electric automobile wireless charging stake efficiency extreme point tracking during frequency bifurcated |
| US10641507B2 (en) * | 2015-09-16 | 2020-05-05 | Siemens Industry, Inc. | Tuning building control systems |
| JP6174649B2 (en) * | 2015-09-30 | 2017-08-02 | ファナック株式会社 | Motor drive device with preventive maintenance function for fan motor |
| US10410123B2 (en) * | 2015-11-18 | 2019-09-10 | International Business Machines Corporation | System, method, and recording medium for modeling a correlation and a causation link of hidden evidence |
| US10839302B2 (en) | 2015-11-24 | 2020-11-17 | The Research Foundation For The State University Of New York | Approximate value iteration with complex returns by bounding |
| DE102016201559A1 (en) * | 2016-02-02 | 2017-08-03 | Robert Bosch Gmbh | Method and device for measuring a system to be tested |
| JP6348137B2 (en) * | 2016-03-24 | 2018-06-27 | ファナック株式会社 | Machining machine system for judging the quality of workpieces |
| JP6140331B1 (en) * | 2016-04-08 | 2017-05-31 | ファナック株式会社 | Machine learning device and machine learning method for learning failure prediction of main shaft or motor driving main shaft, and failure prediction device and failure prediction system provided with machine learning device |
| GB2554038B (en) * | 2016-05-04 | 2019-05-22 | Interactive Coventry Ltd | A method for monitoring the operational state of a system |
| CN106021062B (en) * | 2016-05-06 | 2018-08-07 | 广东电网有限责任公司珠海供电局 | The prediction technique and system of relevant fault |
| EP3458926A4 (en) * | 2016-05-16 | 2020-03-25 | Jabil Inc. | DEVICE, MOTOR, SYSTEM AND METHOD FOR PREDICTIVE ANALYTICS IN A MANUFACTURING SYSTEM |
| US11914349B2 (en) | 2016-05-16 | 2024-02-27 | Jabil Inc. | Apparatus, engine, system and method for predictive analytics in a manufacturing system |
| CN106017879B (en) * | 2016-05-18 | 2018-07-03 | 河北工业大学 | Omnipotent breaker mechanical failure diagnostic method based on acoustic signal Fusion Features |
| JP6496274B2 (en) * | 2016-05-27 | 2019-04-03 | ファナック株式会社 | Machine learning device, failure prediction device, machine system and machine learning method for learning life failure condition |
| EP3258333A1 (en) * | 2016-06-17 | 2017-12-20 | Siemens Aktiengesellschaft | Method and system for monitoring sensor data of rotating equipment |
| JP2018004473A (en) * | 2016-07-04 | 2018-01-11 | ファナック株式会社 | Mechanical learning device for learning estimated life of bearing, life estimation device, and mechanical learning method |
| JP6374466B2 (en) * | 2016-11-11 | 2018-08-15 | ファナック株式会社 | Sensor interface device, measurement information communication system, measurement information communication method, and measurement information communication program |
| EP3327419B1 (en) * | 2016-11-29 | 2020-09-09 | STS Intellimon Limited | Engine health diagnostic apparatus and method |
| US11397655B2 (en) * | 2017-02-24 | 2022-07-26 | Hitachi, Ltd. | Abnormality diagnosis system that reconfigures a diagnostic program based on an optimal diagnosis procedure found by comparing a plurality of diagnosis procedures |
| EP3591484A4 (en) * | 2017-03-03 | 2020-03-18 | Panasonic Intellectual Property Management Co., Ltd. | Additional learning method for deterioration diagnosis system |
| CN108694356B (en) * | 2017-04-10 | 2024-05-07 | 京东方科技集团股份有限公司 | Pedestrian detection device and method and auxiliary driving system |
| CN107092987B (en) * | 2017-04-18 | 2020-11-17 | 中国人民解放军空军工程大学 | Method for predicting autonomous landing wind speed of small and medium-sized unmanned aerial vehicles |
| US11132620B2 (en) * | 2017-04-20 | 2021-09-28 | Cisco Technology, Inc. | Root cause discovery engine |
| US10339730B2 (en) * | 2017-05-09 | 2019-07-02 | United Technology Corporation | Fault detection using high resolution realms |
| US20200184373A1 (en) * | 2017-08-30 | 2020-06-11 | Siemens Aktiengesellschaft | Recurrent Gaussian Mixture Model For Sensor State Estimation In Condition Monitoring |
| JP6961424B2 (en) * | 2017-08-30 | 2021-11-05 | 株式会社日立製作所 | Failure diagnosis system |
| CN107545112B (en) * | 2017-09-07 | 2020-11-10 | 西安交通大学 | Complex equipment performance evaluation and prediction method for multi-source label-free data machine learning |
| US10732618B2 (en) * | 2017-09-15 | 2020-08-04 | General Electric Company | Machine health monitoring, failure detection and prediction using non-parametric data |
| EP3701338B1 (en) * | 2017-10-23 | 2024-02-14 | Johnson Controls Tyco IP Holdings LLP | Building management system with automated vibration data analysis |
| US11181898B2 (en) * | 2017-11-10 | 2021-11-23 | General Electric Company | Methods and apparatus to generate a predictive asset health quantifier of a turbine engine |
| CN107832729A (en) * | 2017-11-22 | 2018-03-23 | 桂林电子科技大学 | A kind of bearing rust intelligent diagnosing method |
| US10921792B2 (en) | 2017-12-21 | 2021-02-16 | Machinesense Llc | Edge cloud-based resin material drying system and method |
| CN108416460B (en) * | 2018-01-19 | 2022-01-28 | 北京工商大学 | Blue algae bloom prediction method based on multi-factor time sequence-random depth confidence network model |
| US11568236B2 (en) | 2018-01-25 | 2023-01-31 | The Research Foundation For The State University Of New York | Framework and methods of diverse exploration for fast and safe policy improvement |
| JP6453504B1 (en) * | 2018-02-22 | 2019-01-16 | エヌ・ティ・ティ・コミュニケーションズ株式会社 | Anomaly monitoring device, anomaly monitoring method and anomaly monitoring program |
| US11493913B2 (en) * | 2018-03-28 | 2022-11-08 | L&T Technology Services Limited | System and method for monitoring health and predicting failure of an electro-mechanical machine |
| US10354462B1 (en) | 2018-04-06 | 2019-07-16 | Toyota Motor Engineering & Manufacturing North America, Inc. | Fault diagnosis in power electronics using adaptive PCA |
| US10650616B2 (en) | 2018-04-06 | 2020-05-12 | University Of Connecticut | Fault diagnosis using distributed PCA architecture |
| GB2584570B (en) * | 2018-05-08 | 2023-05-03 | Landmark Graphics Corp | Method for generating predictive chance maps of petroleum system elements |
| US11042145B2 (en) * | 2018-06-13 | 2021-06-22 | Hitachi, Ltd. | Automatic health indicator learning using reinforcement learning for predictive maintenance |
| CN110610226A (en) * | 2018-06-14 | 2019-12-24 | 北京德知航创科技有限责任公司 | A generator failure prediction method and device |
| US11859846B2 (en) | 2018-06-15 | 2024-01-02 | Johnson Controls Tyco IP Holdings LLP | Cost savings from fault prediction and diagnosis |
| US11474485B2 (en) | 2018-06-15 | 2022-10-18 | Johnson Controls Tyco IP Holdings LLP | Adaptive training and deployment of single chiller and clustered chiller fault detection models for connected chillers |
| CN108984893B (en) * | 2018-07-09 | 2021-05-07 | 北京航空航天大学 | A Trend Prediction Method Based on Gradient Boosting |
| US11579588B2 (en) * | 2018-07-30 | 2023-02-14 | Sap Se | Multivariate nonlinear autoregression for outlier detection |
| CN109308343A (en) * | 2018-07-31 | 2019-02-05 | 北京航空航天大学 | A Travel Time Prediction and Reliability Measurement Method Based on Stochastic Fluctuation Model |
| US20200051674A1 (en) * | 2018-08-08 | 2020-02-13 | Fresenius Medical Care Holdings, Inc. | Systems and methods for determining patient hospitalization risk and treating patients |
| JP6845192B2 (en) * | 2018-08-31 | 2021-03-17 | ファナック株式会社 | Processing environment measuring device |
| EP3850551A4 (en) * | 2018-09-12 | 2022-10-12 | Electra Vehicles, Inc. | Systems and methods for managing energy storage systems |
| US12001931B2 (en) | 2018-10-31 | 2024-06-04 | Allstate Insurance Company | Simultaneous hyper parameter and feature selection optimization using evolutionary boosting machines |
| CN109146209A (en) * | 2018-11-02 | 2019-01-04 | 清华大学 | Machine tool spindle thermal error prediction technique based on wavelet neural networks of genetic algorithm |
| US20200193075A1 (en) * | 2018-11-05 | 2020-06-18 | Incucomm, Inc. | System and method for constructing a mathematical model of a system in an artificial intelligence environment |
| CN109753872B (en) * | 2018-11-22 | 2022-12-16 | 四川大学 | Reinforced learning unit matching cyclic neural network system and training and predicting method thereof |
| CN109597401B (en) * | 2018-12-06 | 2020-09-08 | 华中科技大学 | Equipment fault diagnosis method based on data driving |
| CN109740859A (en) * | 2018-12-11 | 2019-05-10 | 国网山东省电力公司淄博供电公司 | Transformer state assessment method and system based on principal component analysis and support vector machine |
| US11842579B2 (en) * | 2018-12-20 | 2023-12-12 | The Regents Of The University Of Colorado, A Body Corporate | Systems and methods to diagnose vehicles based on the voltage of automotive batteries |
| WO2020139588A1 (en) | 2018-12-24 | 2020-07-02 | Dts, Inc. | Room acoustics simulation using deep learning image analysis |
| CN111413030B (en) * | 2019-01-07 | 2021-10-29 | 哈尔滨工业大学 | Measurement and neural network learning control method and device for large-scale high-speed rotary equipment based on spatial projection maximization of stiffness vector |
| CN111413031B (en) * | 2019-01-07 | 2021-11-09 | 哈尔滨工业大学 | Deep learning regulation and assembly method and device for large-scale high-speed rotation equipment based on dynamic vibration response characteristics |
| CN109872249B (en) * | 2019-01-16 | 2023-04-14 | 中国电力科学研究院有限公司 | A method and system for evaluating the operating status of smart electric energy meters based on Bayesian network and genetic algorithm |
| EP3948708A1 (en) * | 2019-03-23 | 2022-02-09 | British Telecommunications public limited company | Automated device maintenance |
| WO2020226921A1 (en) * | 2019-05-07 | 2020-11-12 | Agr International, Inc. | Predictive. preventive maintenance for container-forming production process |
| CN110322048B (en) * | 2019-05-31 | 2023-09-26 | 南京航空航天大学 | Fault early warning method for production logistics conveying equipment |
| US11780609B2 (en) * | 2019-06-12 | 2023-10-10 | Honeywell International Inc. | Maintenance recommendations using lifecycle clustering |
| CN110610245A (en) * | 2019-07-31 | 2019-12-24 | 东北石油大学 | A method and system for leak detection of long oil pipelines based on AFPSO-K-means |
| CN112308278B (en) * | 2019-08-02 | 2024-08-09 | 中移信息技术有限公司 | Optimization method, device, equipment and medium of user off-network prediction model |
| CN110543932A (en) * | 2019-08-12 | 2019-12-06 | 珠海格力电器股份有限公司 | air conditioner performance prediction method and device based on neural network |
| US11494661B2 (en) * | 2019-08-23 | 2022-11-08 | Accenture Global Solutions Limited | Intelligent time-series analytic engine |
| WO2021045749A1 (en) * | 2019-09-04 | 2021-03-11 | Halliburton Energy Services, Inc. | Dynamic drilling dysfunction codex |
| CN110595780B (en) * | 2019-09-20 | 2021-12-14 | 西安科技大学 | Bearing fault identification method based on vibration grayscale image and convolutional neural network |
| JP2021056153A (en) * | 2019-10-01 | 2021-04-08 | 国立大学法人大阪大学 | Remaining life prediction device, remaining life prediction system, and remaining life prediction program |
| CN111178378B (en) * | 2019-11-07 | 2023-05-16 | 腾讯科技(深圳)有限公司 | Equipment fault prediction method and device, electronic equipment and storage medium |
| CN111105005B (en) * | 2019-12-03 | 2023-04-07 | 广东电网有限责任公司 | Wind power prediction method |
| JP2021096639A (en) * | 2019-12-17 | 2021-06-24 | キヤノン株式会社 | Control method, controller, mechanical equipment, control program, and storage medium |
| US20210182738A1 (en) * | 2019-12-17 | 2021-06-17 | General Electric Company | Ensemble management for digital twin concept drift using learning platform |
| EP3865963A1 (en) * | 2020-02-14 | 2021-08-18 | Mobility Asia Smart Technology Co. Ltd. | Method and device for analyzing vehicle failure |
| US11486925B2 (en) * | 2020-05-09 | 2022-11-01 | Hefei University Of Technology | Method for diagnosing analog circuit fault based on vector-valued regularized kernel function approximation |
| CN111985361A (en) * | 2020-08-05 | 2020-11-24 | 武汉大学 | Power system load prediction method and system based on wavelet noise reduction and EMD-ARIMA |
| CN112347571B (en) * | 2020-09-18 | 2022-04-26 | 中国人民解放军海军工程大学 | Rolling bearing residual life prediction method considering model and data uncertainty |
| CN117238453A (en) * | 2020-09-23 | 2023-12-15 | 温州大学 | Storage medium storing medical image feature processing method program |
| US12038354B2 (en) * | 2020-09-25 | 2024-07-16 | Ge Infrastructure Technology Llc | Systems and methods for operating a power generating asset |
| CN112257341B (en) * | 2020-10-20 | 2022-04-26 | 浙江大学 | Customized product performance prediction method based on heterogeneous data difference compensation fusion |
| CN112686366A (en) * | 2020-12-01 | 2021-04-20 | 江苏科技大学 | Bearing fault diagnosis method based on random search and convolutional neural network |
| CN112964355B (en) * | 2020-12-08 | 2023-04-25 | 国电南京自动化股份有限公司 | Instantaneous frequency estimation method based on spline frequency modulation wavelet-synchronous compression algorithm |
| WO2022132898A1 (en) | 2020-12-15 | 2022-06-23 | University Of Cincinnati | Monitoring system for estimating useful life of a machine component |
| WO2022132907A1 (en) | 2020-12-15 | 2022-06-23 | University Of Cincinnati | Tool condition monitoring system |
| CN112528414B (en) * | 2020-12-17 | 2024-10-15 | 震兑工业智能科技有限公司 | SOM-MQE-based aircraft engine fault early warning method |
| EP4057093A1 (en) * | 2021-03-12 | 2022-09-14 | ABB Schweiz AG | Condition monitoring of rotating machines |
| CN112966770B (en) * | 2021-03-22 | 2023-06-27 | 润联智能科技股份有限公司 | Fault prediction method and device based on integrated hybrid model and related equipment |
| US20220334566A1 (en) * | 2021-03-31 | 2022-10-20 | Ats Automation Tooling Systems Inc. | Cloud-based vibratory feeder controller |
| CN113361189B (en) * | 2021-05-12 | 2022-04-19 | 电子科技大学 | Chip performance degradation trend prediction method based on multi-step robust prediction learning machine |
| CN113432875B (en) * | 2021-06-03 | 2022-07-19 | 大连海事大学 | A method for identifying friction state of sliding bearing based on recursive features of friction and vibration |
| CN113705817B (en) * | 2021-08-10 | 2023-07-28 | 石家庄学院 | Remote real-time monitoring data processing method based on high-order Gaussian mixture model |
| DE102021124254A1 (en) | 2021-09-20 | 2023-03-23 | Festo Se & Co. Kg | Machine learning method for leak detection in a pneumatic system |
| DE102021124253A1 (en) | 2021-09-20 | 2023-03-23 | Festo Se & Co. Kg | Machine learning method for anomaly detection in an electrical system |
| CN114091523A (en) * | 2021-10-13 | 2022-02-25 | 江苏今创车辆有限公司 | Grey Fault Diagnosis Method for Key Rotating Parts of Vehicles Driven by Signal Frequency Domain Characteristics |
| CN114297928B (en) * | 2021-12-28 | 2024-07-16 | 南京航空航天大学 | Online fault diagnosis method for wide-forbidden-band aviation power converter |
| JP2023173459A (en) * | 2022-05-26 | 2023-12-07 | 横河電機株式会社 | Model selection system, model selection method, and model selection program |
| JP2024000612A (en) * | 2022-06-21 | 2024-01-09 | 横河電機株式会社 | Estimation apparatus, estimation method, and estimation program |
| CN114875196B (en) * | 2022-07-01 | 2022-09-30 | 北京科技大学 | Method and system for determining converter tapping quantity |
| CN115226027A (en) * | 2022-07-26 | 2022-10-21 | 内蒙古大学 | A WiFi indoor fingerprint positioning method and device |
| KR20240071251A (en) * | 2022-11-14 | 2024-05-22 | 주식회사 마키나락스 | Method for predicting the areas of information needed to be collected |
| CN115514614B (en) * | 2022-11-15 | 2023-02-24 | 阿里云计算有限公司 | Cloud network anomaly detection model training method based on reinforcement learning and storage medium |
| CN116049654B (en) * | 2023-02-07 | 2023-10-13 | 北京奥优石化机械有限公司 | Safety monitoring and early warning method and system for coal preparation equipment |
| DE102023202112A1 (en) * | 2023-03-09 | 2024-09-12 | Siemens Aktiengesellschaft | Procedure for diagnosing the condition of an electric motor |
| CN116415509B (en) * | 2023-06-12 | 2023-08-11 | 华东交通大学 | Bearing performance degradation prediction method, system, computer and storage medium |
| CN116520236B (en) * | 2023-06-30 | 2023-09-22 | 清华大学 | Anomaly detection method and system for smart meters |
| CN116520817B (en) * | 2023-07-05 | 2023-08-29 | 贵州宏信达高新科技有限责任公司 | ETC system running state real-time monitoring system and method based on expressway |
| CN117033912B (en) * | 2023-10-07 | 2024-02-13 | 成都态坦测试科技有限公司 | Equipment fault prediction method and device, readable storage medium and electronic equipment |
| CN117871994B (en) * | 2023-12-22 | 2024-07-23 | 湖南奕坤科技有限公司 | Rapid fault detection method and system for PLC (programmable logic controller) electric cabinet |
| CN118688632B (en) * | 2024-08-29 | 2024-11-01 | 常州博安和达机电科技有限公司 | A push rod motor performance detection system and method based on data analysis |
| CN118824438B (en) * | 2024-09-18 | 2024-11-15 | 西北工业大学 | A composite material stability performance prediction method and related device |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040030524A1 (en) * | 2001-12-07 | 2004-02-12 | Battelle Memorial Institute | Methods and systems for analyzing the degradation and failure of mechanical systems |
| US20050096873A1 (en) * | 2002-12-30 | 2005-05-05 | Renata Klein | Method and system for diagnostics and prognostics of a mechanical system |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7882394B2 (en) * | 2005-07-11 | 2011-02-01 | Brooks Automation, Inc. | Intelligent condition-monitoring and fault diagnostic system for predictive maintenance |
-
2009
- 2009-07-24 US US12/508,836 patent/US8301406B2/en not_active Expired - Fee Related
- 2009-07-24 WO PCT/US2009/051680 patent/WO2010011918A2/en active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040030524A1 (en) * | 2001-12-07 | 2004-02-12 | Battelle Memorial Institute | Methods and systems for analyzing the degradation and failure of mechanical systems |
| US20050096873A1 (en) * | 2002-12-30 | 2005-05-05 | Renata Klein | Method and system for diagnostics and prognostics of a mechanical system |
Non-Patent Citations (1)
| Title |
|---|
| TIAN HAN ET AL.: 'A new condition monitoring and fault diagnosis system of induction motors using artificial intelligence algorithms' ELECTRIC MACHINES AND DRIVES, 2005 IEEE INTERNATIONAL CONFERENCE, SAN ANTONIO: IEEE May 2005, pages 1967 - 1974 * |
Cited By (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8458525B2 (en) | 2010-03-19 | 2013-06-04 | Hamilton Sundstrand Space Systems International, Inc. | Bayesian approach to identifying sub-module failure |
| EP2696251A2 (en) | 2012-08-07 | 2014-02-12 | Prüftechnik Dieter Busch AG | Method for monitoring rotating machines |
| EP2696251A3 (en) * | 2012-08-07 | 2014-02-26 | Prüftechnik Dieter Busch AG | Method for monitoring rotating machines |
| DE102012015485A1 (en) | 2012-08-07 | 2014-05-15 | Prüftechnik Dieter Busch AG | Method for monitoring rotating machines |
| CN106709149B (en) * | 2016-11-25 | 2019-11-19 | 中南大学 | A method and system for real-time prediction of three-dimensional furnace shape of aluminum electrolytic cell based on neural network |
| CN106709149A (en) * | 2016-11-25 | 2017-05-24 | 中南大学 | Neural network-based method and system for predicting shapes of three-dimensional hearths of aluminum cells in real time |
| US11176762B2 (en) | 2018-02-08 | 2021-11-16 | Geotab Inc. | Method for telematically providing vehicle component rating |
| US11282306B2 (en) | 2018-02-08 | 2022-03-22 | Geotab Inc. | Telematically monitoring and predicting a vehicle battery state |
| EP3525177A1 (en) * | 2018-02-08 | 2019-08-14 | GEOTAB Inc. | Telematically monitoring a condition of an operational vehicle component |
| US12080113B2 (en) | 2018-02-08 | 2024-09-03 | Geotab Inc. | Telematically monitoring a condition of an operational vehicle component |
| US10713864B2 (en) | 2018-02-08 | 2020-07-14 | Geotab Inc. | Assessing historical telematic vehicle component maintenance records to identify predictive indicators of maintenance events |
| US12067815B2 (en) | 2018-02-08 | 2024-08-20 | Geotab Inc. | Telematically monitoring a condition of an operational vehicle component |
| US10937257B2 (en) | 2018-02-08 | 2021-03-02 | Geotab Inc. | Telematically monitoring and predicting a vehicle battery state |
| US12056966B2 (en) | 2018-02-08 | 2024-08-06 | Geotab Inc. | Telematically monitoring a condition of an operational vehicle component |
| US11887414B2 (en) | 2018-02-08 | 2024-01-30 | Geotab Inc. | Telematically monitoring a condition of an operational vehicle component |
| US11182987B2 (en) | 2018-02-08 | 2021-11-23 | Geotab Inc. | Telematically providing remaining effective life indications for operational vehicle components |
| US11182988B2 (en) | 2018-02-08 | 2021-11-23 | Geotab Inc. | System for telematically providing vehicle component rating |
| EP3525176A1 (en) * | 2018-02-08 | 2019-08-14 | GEOTAB Inc. | Telematics predictive vehicle component monitoring system |
| US11282304B2 (en) | 2018-02-08 | 2022-03-22 | Geotab Inc. | Telematically monitoring a condition of an operational vehicle component |
| US11544973B2 (en) | 2018-02-08 | 2023-01-03 | Geotab Inc. | Telematically monitoring and predicting a vehicle battery state |
| US11620863B2 (en) | 2018-02-08 | 2023-04-04 | Geotab Inc. | Predictive indicators for operational status of vehicle components |
| US11625958B2 (en) | 2018-02-08 | 2023-04-11 | Geotab Inc. | Assessing historical telematic vehicle component maintenance records to identify predictive indicators of maintenance events |
| US11663859B2 (en) | 2018-02-08 | 2023-05-30 | Geotab Inc. | Telematically providing replacement indications for operational vehicle components |
| CN109586239A (en) * | 2018-12-10 | 2019-04-05 | 国网四川省电力公司电力科学研究院 | Intelligent substation real-time diagnosis and fault early warning method |
| CN109800487B (en) * | 2019-01-02 | 2020-12-29 | 北京交通大学 | A life prediction method for rail transit rolling bearing based on fuzzy safety domain |
| CN109800487A (en) * | 2019-01-02 | 2019-05-24 | 北京交通大学 | Life-span prediction method based on obfuscation security domain |
| TWI724467B (en) * | 2019-07-19 | 2021-04-11 | 國立中興大學 | The diagnosis method of machine ageing |
| US20230288882A1 (en) * | 2022-03-14 | 2023-09-14 | Microsoft Technology Licensing, Llc | Aging aware reward construct for machine teaching |
| US12189350B2 (en) * | 2022-03-14 | 2025-01-07 | Microsoft Technology Licensing, Llc | Aging aware reward construct for machine teaching |
| DE102023202109A1 (en) | 2023-03-09 | 2024-09-12 | Siemens Aktiengesellschaft | Procedure for generating a self-organizing map |
Also Published As
| Publication number | Publication date |
|---|---|
| US8301406B2 (en) | 2012-10-30 |
| WO2010011918A3 (en) | 2010-04-22 |
| US20100023307A1 (en) | 2010-01-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8301406B2 (en) | Methods for prognosing mechanical systems | |
| Goebel et al. | A comparison of three data-driven techniques for prognostics | |
| Zhang et al. | Remaining useful life estimation for mechanical systems based on similarity of phase space trajectory | |
| US10387768B2 (en) | Enhanced restricted boltzmann machine with prognosibility regularization for prognostics and health assessment | |
| Entezari-Maleki et al. | Comparison of classification methods based on the type of attributes and sample size. | |
| Rai et al. | A novel health indicator based on the Lyapunov exponent, a probabilistic self-organizing map, and the Gini-Simpson index for calculating the RUL of bearings | |
| Wang et al. | A generic probabilistic framework for structural health prognostics and uncertainty management | |
| Ishimtsev et al. | Conformal $ k $-NN Anomaly Detector for Univariate Data Streams | |
| Liao et al. | A novel method for machine performance degradation assessment based on fixed cycle features test | |
| Yu | A hybrid feature selection scheme and self-organizing map model for machine health assessment | |
| Wang | Trajectory similarity based prediction for remaining useful life estimation | |
| Li et al. | Data-driven bearing fault identification using improved hidden Markov model and self-organizing map | |
| Richman et al. | Missing data imputation through machine learning algorithms | |
| KR20140041767A (en) | Monitoring method using kernel regression modeling with pattern sequences | |
| KR20140058501A (en) | Monitoring system using kernel regression modeling with pattern sequences | |
| Sani et al. | Redefining selection of features and classification algorithms for room occupancy detection | |
| Yu et al. | Supervised convolutional autoencoder-based fault-relevant feature learning for fault diagnosis in industrial processes | |
| Wang et al. | Health diagnostics using multi-attribute classification fusion | |
| Zhang et al. | A framework for predicting the remaining useful life of machinery working under time-varying operational conditions | |
| Cuentas et al. | An SVM-GA based monitoring system for pattern recognition of autocorrelated processes | |
| Dash et al. | Failure prognosis of the components with unlike degradation trends: A data-driven approach | |
| Dong | A Tutorial on Nonlinear Time‐Series Data Mining in Engineering Asset Health and Reliability Prediction: Concepts, Models, and Algorithms | |
| Tra et al. | Unsupervised fault detection for building air handling unit systems using deep variational mixture of principal component analyzers | |
| Jin | A sequential process monitoring approach using hidden Markov model for unobservable process drift | |
| Gruhl | Novelty Detection for Multivariate Data Streams with Probalistic Models |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09801064 Country of ref document: EP Kind code of ref document: A2 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 09801064 Country of ref document: EP Kind code of ref document: A2 |