WO2001002568A2 - Human genes and gene expression products - Google Patents
Human genes and gene expression products Download PDFInfo
- Publication number
- WO2001002568A2 WO2001002568A2 PCT/US2000/018374 US0018374W WO0102568A2 WO 2001002568 A2 WO2001002568 A2 WO 2001002568A2 US 0018374 W US0018374 W US 0018374W WO 0102568 A2 WO0102568 A2 WO 0102568A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sequence
- seq
- polynucleotides
- expression
- polynucleotide
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/12—Transferases (2.) transferring phosphorus containing groups, e.g. kinases (2.7)
- C12N9/1205—Phosphotransferases with an alcohol group as acceptor (2.7.1), e.g. protein kinases
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4702—Regulators; Modulating activity
- C07K14/4705—Regulators; Modulating activity stimulating, promoting or activating activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6421—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from mammals
- C12N9/6424—Serine endopeptidases (3.4.21)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/90—Isomerases (5.)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
Definitions
- the present invention relates to novel polynucleotides of human origin and the encoded gene products.
- Identification of novel polynucleotides, particularly those that encode an expressed gene product, is important in the advancement of drug discovery, diagnostic technologies, and the understanding of the progression and nature of complex diseases such as cancer. Identification of genes expressed in different cell types isolated from sources that differ in disease state or stage, developmental stage, exposure to various environmental factors, the tissue of origin, the species from which the tissue was isolated, and the like is key to identifying the genetic factors that are responsible for the phenotypes associated with these various differences.
- This invention provides novel human polynucleotides, the polypeptides encoded by these polynucleotides, and the genes and proteins corresponding to these novel polynucleotides.
- This invention relates to novel human polynucleotides and variants thereof, their encoded polypeptides and variants thereof, to genes corresponding to these polynucleotides and to proteins expressed by the genes.
- the invention also relates to diagnostics and therapeutics comprising such novel human polynucleotides, their corresponding genes or gene products, including probes, antisense nucleotides, and antibodies.
- the polynucleotides of the invention correspond to a polynucleotide comprising the sequence information of at least one of SEQ ID NOs: 1-3351.
- the invention relates to polynucleotides comprising the disclosed nucleotide sequences, to full length cDNA, mRNA genomic sequences, and genes corresponding to these sequences and degenerate variants thereof, and to polypeptides encoded by the polynucleotides of the invention and polypeptide variants.
- Polypeptide variants differ from wild type protein in having one or more amino acid substitutions that either enhance, add, or diminish a biological activity of the wild type protein.
- polypeptides disclosed herein encode new members of the MKK kinase family; the coding region is found within the nucleotide region in parentheses: SEQ ID NO:29 (nucleotides 295-421); SEQ ID NO:31 (298-397); SEQ ID NO:196 (37-322); SEQ ID NO:3175 (nucleotides 14-164); SEQ ID NO:3190 (229-390); and SEQ ID NO:3281 (15-182).
- SEQ ID NO:410 (42-191); SEQ ID NO:552 (1 16-288); SEQ ID NO:768 (1 16-288); SEQ ID NO:822 (108- 262); SEQ ID NO:836 (158-353); SEQ 1D N0:1288 (73-234); SEQ 1D N0:1365 (69-257) SEQ ID NO:1540 (289-471); SEQ ID NO:1549 (200-391); SEQ ID NO: 1556 (163-354) SEQ ID NO: 1557 (207-398); SEQ ID NO: 1563 (107-298); SEQ ID NO: 1622 (180-365) SEQ ID NO:1630 (100-291); SEQ ID NO:1704 (184-372); SEQ ID NO:1808 (36-161) SEQ ID NO: 1454 (49-209); SEQ ID NO:2363 (48-21 1); SEQ ID NO:2424 (43-19
- SEQ ID NOs:234 encode polypeptides having an SH2 domain
- SEQ ID NOs:234 encode polypeptides having an SH3 domain
- SEQ ID NOs:234 encode polypeptides having an SH3 domain
- SEQ ID NOs:234 encode polypeptides having an SH3 domain
- SEQ ID NOs:234 encode polypeptides having an SH3 domain.
- Nine polypeptides encode new members of the family of proteins having Ank repeat regions SEQ ID NO:187 (358-432); SEQ ID NO:1268 (238-315); SEQ ID NO:1804 (301-378) SEQ ID NO: 1819 (278-355); SEQ ID NO: 1839 (224-307); SEQ ID NO: 1830 (184-267) SEQ ID NO:2562 (18-101); SEQ ID NO:3015 (131-214); and SEQ ID NO:3267 (97- 180).
- polypeptides having a C2H2 type zinc finger SEQ ID NOs:308 (1 10-172); 807 (339-392); 1324 (294-356); 1503 (154- 216); 1527 (156-212); 1674 (196-258); 1779 (64-126); 1801 (295-351); 3081 (190-252); 3193 (293-355); and 3306 (161-223).
- Polypeptides having a fibronectin type III domain are encoded by SEQ ID NO:746 (209-427) and 1 192 (186-416).
- Polypeptides having an EF-hand domain are encoded by SEQ ID NO:820 (341- 406); 1755 (281-367) and 3285(16-102).
- Six polypeptides of the protein kinase family are encoded by SEQ ID NOs: l 157 (41 -444); 1478 (54-437), 1496 (241 -520); 2286 (12-182); 2969 (5-387); and 3190 (1 18-390).
- LIM domain-containing polypeptides are encoded by SEQ ID NO: 1269 (79-240); 1309 (248-404); 1360 (222-377); and 1386 (243-398).
- Two polypeptides of the family having a C2 domain are encoded by SEQ ID NO: 1325 (1 - 234) and 2282(183-353).
- Polypeptides having a WD domain, G-beta repeat motif are encoded by SEQ ID NOs: 1336 (66-164); 1380 (42-140); 171 1 (263-361 ); 1762 (236-334); 1909 (160-258); 2218 (127-225); 3047 (191-292); 3108 (275-367) and 3292 (208-300).
- SEQ ID NO: 1410 (222-350) encodes a member of the trypsin family.
- SEQ ID NO: 1538 (9-635) encodes a member of the wnt family of developmental signaling proteins.
- polypeptides having a homeobox domain SEQ ID NOs: 1676 (9-86); 1820 (123-299); and 1821 (127-303).
- a novel thioredoxin is encoded by SEQ ID NO: 1677 (316-369).
- Two novel members of the ras family are encoded by SEQ ID NO:1688(109-410) and 3258(138-394).
- a novel polypeptide having a phosphatidylinositol-specific phospholipase C Y-domain is encoded by SEQ ID NO: 1707 (92-439).
- a novel serine carboxypeptidase is encoded by SEQ ID NO: 1744 (238-433).
- a novel polypeptide having N-terminal homology in the Ets domain is encoded by SEQ ID NO: 181 1 (184-315).
- a novel polypeptide having a bromodomain is encoded by SEQ ID NO: 1814 (127-294).
- a novel polypeptide having a double-stranded RNA binding motif is encoded by SEQ ID NO: 1818 (9-146).
- a novel polypeptide having a G-protein alpha subunit is encoded by SEQ ID NO: 1846 (12-398).
- SEQ ID NO:2428 (25-350) encodes a polypeptide member of the dual specificity phosphatase family, having a catalytic domain.
- SEQ ID Nos:2577 (0-31 1); 3183 (14-215); and 3195 (0-215) encode members of the 4 transmembrane segment integral membrane protein family.
- SEQ ID Nos:2826 (116-400) and 2871 (198-392) encode polypeptides of the DEAD and DEAH box helicase family.
- SEQ ID NO:2944 (18-281) encodes a polypeptide having a calpain large subunit, domain III.
- SEQ ID NO: 3274 (11-187) encodes a eukaryotic transcription factor with a fork head domain.
- SEQ ID NO: 3345 (65-271) encodes a polypeptide having a PDZ domain
- SEQ ID NO:3351 (124-270) encodes a polypeptide in the family of phorbol esters/glycerol binding proteins.
- polynucleotide compositions encompassed by the invention, methods for obtaining cDNA or genomic DNA encoding a full-length gene product, expression of these polynucleotides and genes, identification of structural motifs of the polynucleotides and genes, identification of the function of a gene product encoded by a gene corresponding to a polynucleotide of the invention, use of the provided polynucleotides as probes and in mapping and in tissue profiling, use of the corresponding polypeptides and other gene products to raise antibodies, and use of the polynucleotides and their encoded gene products for therapeutic and diagnostic purposes.
- polynucleotide compositions includes, but is not necessarily limited to, polynucleotides having a sequence set forth in any one of SEQ ID NOs: 1-3351; polynucleotides obtained from the biological materials described herein or other biological sources (particularly human sources) by hybridization under stringent conditions (particularly conditions of high stringency); genes corresponding to the provided polynucleotides; variants of the provided polynucleotides and their corresponding genes, particularly those variants that retain a biological activity of the encoded gene product (e.g., a biological activity ascribed to a gene product corresponding to the provided polynucleotides as a result of the assignment of the gene product to a protein family(ies) and/or identification of a functional domain present in the gene product).
- polynucleotides having a sequence set forth in any one of SEQ ID NOs: 1-3351 polynucleotides obtained from the biological materials described herein or other biological sources (particularly human sources) by hybridization under stringent
- nucleic acid compositions contemplated by and within the scope of the present invention will be readily apparent to one of ordinary skill in the art when provided with the disclosure here.
- Polynucleotide and “nucleic acid” as used herein with reference to nucleic acids of the composition is not intended to be limiting as to the length or structure of the nucleic acid unless specifically indicated.
- the invention features polynucleotides that are expressed in human tissue, specifically human colon, breast, and/or lung tissue. Novel nucleic acid
- H- compositions of the invention comprise a sequence set forth in any one of SEQ ID NOs: 1-3351 or an identifying sequence thereof.
- An "identifying sequence” is a contiguous sequence of residues at least about 10 nt to about 20 nt in length, usually at least about 50 nt to about 100 nt in length, that uniquely identifies a polynucleotide sequence, e.g., exhibits less than 90%, usually less than about 80% to about 85% sequence identity to any contiguous nucleotide sequence of more than about 20 nt.
- the subject novel nucleic acid compositions include full length cDNAs or mRNAs that encompass an identifying sequence of contiguous nucleotides from any one of SEQ ID NOs:l-3351.
- the polynucleotides of the invention also include polynucleotides having sequence similarity or sequence identity. Nucleic acids having sequence similarity are detected by hybridization under low stringency conditions, for example, at 50°C and 10XSSC (0.9 M saline/0.09 M sodium citrate) and remain bound when subjected to washing at 55°C in lXSSC.
- Sequence identity can be determined by hybridization under stringent conditions, for example, at 50°C or higher and O.IXSSC (9 mM saline/0.9 mM sodium citrate). Hybridization methods and conditions are well known in the art, see, e.g., U.S. Patent No. 5,707,829. Nucleic acids that are substantially identical to the provided polynucleotide sequences, e.g., allelic variants, genetically altered versions of the gene, etc., bind to the provided polynucleotide sequences (SEQ ID NOs:l-3351) under stringent hybridization conditions. By using probes, particularly labeled probes of DNA sequences, one can isolate homologous or related genes.
- the source of homologous genes can be any species, e.g., primate species, particularly human; rodents, such as rats and mice; canines, felines, bovines, ovines, equines, yeast, nematodes, etc.
- hybridization is performed using at least 15 contiguous nucleotides (nt) of at least one of SEQ ID NOs: 1-3351. That is, when at least 15 contiguous nt of one of the disclosed SEQ ID NOs. is used as a probe, the probe will preferentially hybridize with a nucleic acid comprising the complementary sequence, allowing the identification and retrieval of the nucleic acids that uniquely hybridize to the selected probe. Probes from more than one SEQ ID NO.
- Probes of more than 15 nt can be used, e.g., probes of from about 18 nt to about 100 nt, but 15 nt represents sufficient sequence for unique identification.
- the polynucleotides of the invention also include naturally occurring variants of the nucleotide sequences (e.g., degenerate variants, allelic variants). Variants of the polynucleotides of the invention are identified by hybridization of putative variants with nucleotide sequences disclosed herein, preferably by hybridization under stringent conditions. For example, by using appropriate wash conditions, variants of the polynucleotides of the invention can be identified where the allelic variant exhibits at most about 25-30% base pair (bp) mismatches relative to the selected polynucleotide probe. In general, allelic variants contain 15-25% bp mismatches, and can contain as little as even 5-15%, or 2-5%, or 1-2% bp mismatches, as well as a single bp mismatch.
- allelic variants contain 15-25% bp mismatches, and can contain as little as even 5-15%, or 2-5%, or 1-2% bp mismatches, as
- the invention also encompasses homologs corresponding to the polynucleotides of SEQ ID NOs: 1-3351, where the source of homologous genes can be any mammalian species, e.g., primate species, particularly human; rodents, such as rats; canines, felines, bovines, ovines, equines, yeast, nematodes, etc. Between mammalian species, e.g., human and mouse, homologs generally have substantial sequence similarity, e.g., at least 75% sequence identity, usually at least 90%, more usually at least 95% between nucleotide sequences.
- mammalian species e.g., human and mouse
- homologs generally have substantial sequence similarity, e.g., at least 75% sequence identity, usually at least 90%, more usually at least 95% between nucleotide sequences.
- Sequence similarity is calculated based on a reference sequence, which may be a subset of a larger sequence, such as a conserved motif, coding region, flanking region, etc.
- a reference sequence will usually be at least about 18 contiguous nt long, more usually at least about 30 nt long, and may extend to the complete sequence that is being compared.
- Algorithms for sequence analysis are known in the art, such as BLAST, described in Altschul et al., J. Mol. Biol. (1990) 275:403-10.
- variants of the invention have a sequence identity greater than at least about 65%, preferably at least about 75%, more preferably at least about 85%, and can be greater than at least about 90%, 91%, 92%, 93%, 94%, 95%, or 96%, most preferably 97%, 98% or 99%.
- a preferred method of calculating percent identity is the Smith- Waterman algorithm, using the following. Global DNA sequence identity must be greater than 65% as determined by the Smith- Waterman homology search algorithm as implemented in MPSRCH program (Oxford Molecular) using an affine gap search with the following search parameters: gap open penalty, 12; and gap extension penalty, 1.
- the subject nucleic acids can be cDNAs or genomic DNAs, as well as fragments thereof, particularly fragments that encode a biologically active gene product and/or are useful in the methods disclosed herein (e.g., in diagnosis, as a unique identifier of a differentially expressed gene of interest, etc.).
- cDNA as used herein is intended to include all nucleic acids that share the arrangement of sequence
- a genomic sequence of interest comprises the nucleic acid present between the initiation codon and the stop codon, as defined in the listed sequences, including all of the introns that are normally present in a native chromosome. It can further include the 3' and 5' untranslated regions found in the mature mRNA.
- the genomic DNA can further include specific transcriptional and translational regulatory sequences, such as promoters, enhancers, etc., including about 1 kb, but possibly more, of flanking genomic DNA at either the 5' and 3' end of the transcribed region.
- the genomic DNA can be isolated as a fragment of 100 kbp or smaller; and substantially free of flanking chromosomal sequence.
- the nucleic acid compositions of the subject invention can encode all or a part of the subject polypeptides. Double or single stranded fragments can be obtained from the DNA sequence by chemically synthesizing oligonucleotides in accordance with conventional methods, by restriction enzyme digestion, by PCR amplification, etc.
- Isolated polynucleotides and polynucleotide fragments of the invention comprise at least about 10, about 15, about 20, about 35, about 50, about 100, about 150 to about 200, about 250 to about 300, or about 350 contiguous nt selected from the polynucleotide sequences as shown in SEQ ID NOs: 1-3351.
- the fragments also include those of lengths intermediate to the specifically mentioned lengths, such as 35, 36, 37, 38, 39, etc.; 150, 151 , 152, 153, 154, etc.
- fragments will be of at least 15 nt, usually at least 18 nt or 25 nt, and up to at least about 50 contiguous nt in length or more.
- the polynucleotide molecules comprise a contiguous sequence of at least 12 nt selected from the group consisting of the polynucleotides shown in SEQ ID NOs: 1-3351.
- Probes specific to the polynucleotides of the invention can be generated using the polynucleotide sequences disclosed in SEQ ID NOs: 1-3351.
- the probes are preferably at least about a 12, 15, 16, 18, 20, 22, 24, or 25 nt fragment of a corresponding contiguous sequence of SEQ ID NOs: 1-3351, and can be less than 2, 1, 0.5, 0.1, or 0.05 kb in length.
- the probes can be synthesized chemically or can be generated from longer polynucleotides using restriction enzymes.
- the probes can be labeled, for example, with a radioactive, biotinylated, or fluorescent tag.
- probes are designed based upon an identifying sequence of a polynucleotide of one of SEQ ID NOs: 1-3351. More preferably, probes are designed based on a contiguous sequence of one of the subject polynucleotides that remain unmasked following application of a masking program for masking low complexity (e.g., XBLAST) to the sequence., i.e., one would select an unmasked region, as indicated by the polynucleotides outside the poly-n stretches of the masked sequence produced by the masking program.
- a masking program for masking low complexity e.g., XBLAST
- polynucleotides of the subject invention are isolated and obtained in substantial purity, generally as other than an intact chromosome.
- the polynucleotides either as DNA or RNA, will be obtained substantially free of other naturally-occurring nucleic acid sequences, generally being at least about 50%, usually at least about 90% pure and are typically "recombinant", e.g., flanked by one or more nucleotides with which it is not normally associated on a naturally occurring chromosome.
- the polynucleotides of the invention can be provided as a linear molecule or within a circular molecule, and can be provided within autonomously replicating molecules (vectors) or within molecules without replication sequences. Expression of the polynucleotides can be regulated by their own or by other regulatory sequences known in the art.
- the polynucleotides of the invention can be introduced into suitable host cells using a variety of techniques available in the art, such as transferrin poly cation-mediated DNA transfer, transfection with naked or encapsulated nucleic acids, liposome-mediated DNA transfer, intracellular transportation of DNA- coated latex beads, protoplast fusion, viral infection, electroporation, gene gun, calcium phosphate-mediated transfection, and the like.
- the subject nucleic acid compositions can be used to, for example, produce polypeptides, as probes for the detection of mRNA of the invention in biological samples (e.g. , extracts of human cells) to generate additional copies of the polynucleotides, to generate ribozymes or antisense oligonucleotides, and as single stranded DNA probes or as triple-strand forming oligonucleotides.
- the probes described herein can be used to, for example, determine the presence or absence of the polynucleotide sequences as shown in SEQ ID NOs: 1-3351 or variants thereof in a sample. These and other uses are described in more detail below.
- Full-length cDNA molecules comprising the disclosed polynucleotides are obtained as follows.
- Libraries of cDNA are made from selected tissues, such as normal or tumor tissue, or from tissues of a mammal treated with, for example, a pharmaceutical agent.
- the tissue is the same as the tissue from which the polynucleotides of the invention were isolated, as both the polynucleotides described herein and the cDNA represent expressed genes.
- the cDNA library is made from the biological material described herein in the Examples. The choice of cell type for library construction can be made after the identity of the protein encoded by the gene corresponding to the polynucleotide of the invention is known. This will indicate which tissue and cell types are likely to express the related gene, and thus represent a suitable source for the mRNA for generating the cDNA. As described in the Examples, cDNA of the invention was isolated from specific cell or tissue types, and such cells and tissues are preferable for obtaining related nucleic acids.
- the cDNA can be prepared by using primers based on sequence from SEQ ID NOs: 1-3351.
- the cDNA library can be made from only poly-adenylated mRNA.
- poly-T primers can be used to prepare cDNA from the mRNA.
- Members of the library that are larger than the provided polynucleotides, and preferably that encompass the complete coding sequence of the native message, are obtained.
- RNA protection experiments are performed as follows.
- Hybridization of a full-length cDNA to an mRNA will protect the RNA from RNase degradation. If the cDNA is not full length, then the portions of the mRNA that are not hybridized will be subject to RNase degradation. This is assayed, as is known in the art, by changes in electrophoretic mobility on polyacrylamide gels, or by detection of released monoribonucleotides.
- RNase PCR Protocols: A Guide to Methods and Applications, (1990) Academic Press, Inc.
- Genomic DNA is isolated using the provided polynucleotides in a manner similar to the isolation of full-length cDNAs.
- the provided polynucleotides, or portions thereof are used as probes to libraries of genomic DNA.
- the library is obtained from the cell type that was used to generate the polynucleotides of the invention, but this is not essential.
- the genomic DNA is obtained from the biological material described herein in the Examples.
- Such libraries can be in vectors suitable for carrying large segments of a genome, such as PI or YAC, as described in detail in Sambrook et al., 9.4-9.30.
- genomic sequences can be isolated from human BAC libraries, which are commercially available from Research Genetics, Inc., Huntsville, Alabama, USA, for example.
- chromosome walking is performed, as described in Sambrook et al., such that adjacent and overlapping fragments of genomic DNA are isolated. These are mapped and pieced together, as is known in the art, using restriction digestion enzymes and DNA ligase.
- corresponding full- length genes can be isolated using both classical and PCR methods to construct and probe cDNA libraries.
- Northern blots preferably, are performed on a number of cell types to determine which cell lines express the gene of interest at the highest level.
- Classical methods of constructing cDNA libraries are taught in Sambrook et al., supra. With these methods, cDNA can be produced from mRNA and inserted into viral or expression vectors. Typically, libraries of mRNA comprising poly(A) tails can be produced with poly(T) primers. Similarly, cDNA libraries can be produced using the instant sequences as primers.
- PCR methods are used to amplify the members of a cDNA library that comprise the desired insert.
- the desired insert will contain sequence from the full length cDNA that corresponds to the instant polynucleotides.
- Such PCR methods include gene trapping and RACE methods as described in Gruber et al., WO 95/04745 and Gruber et al., U.S. Patent No. 5,500,356. Kits are commercially available to perform gene trapping experiments from, for example, Life Technologies, Gaithersburg, Maryland, USA.
- a common primer is designed to anneal to an arbitrary adaptor sequence ligated to cDNA ends (Apte and Siebert, Biotechniques (1993) 75:890-893; Edwards et al., Nuc. Acids Res. (1991) 79:5227-5232).
- a single gene-specific RACE primer is paired with the common
- the promoter region of a gene generally is located 5' to the initiation site for RNA polymerase II. Hundreds of promoter regions contain the "TATA" box, a sequence such as TATTA or TATAA, which is sensitive to mutations.
- the promoter region can be obtained by performing 5' RACE using a primer from the coding region of the gene. Alternatively, the cDNA can be used as a probe for the genomic sequence, and the region 5' to the coding region is identified by "walking up.” If the gene is highly expressed or differentially expressed, the promoter from the gene can be of use in a regulatory construct for a heterologous gene.
- DNA encoding variants can be prepared by site-directed mutagenesis, described in detail in Sambrook et al., 15.3-15.63.
- the choice of codon or nucleotide to be replaced can be based on disclosure herein on optional changes in amino acids to achieve altered protein structure and/or function.
- nucleic acid comprising nucleotides having the sequence of one or more polynucleotides of the invention can be synthesized.
- the invention encompasses nucleic acid molecules ranging in length from 15 nt (corresponding to at least 15 contiguous nt of one of SEQ ID NOs:l-3351) up to a maximum length suitable for one or more biological manipulations, including replication and expression, of the nucleic acid molecule.
- the invention includes but is not limited to (a) nucleic acid having the size of a full gene, and comprising at least one of SEQ ID NOs: 1-3351; (b) the nucleic acid of (a) also comprising at least one additional polynucleotide or gene, operably linked to permit expression of a fusion protein; (c) an expression vector comprising (a) or (b); (d) a plasmid comprising (a) or (b) ; and (e) a recombinant viral particle comprising (a) or (b).
- construction or preparation of (a) - (e) are well within the skill in the art.
- sequence of a nucleic acid comprising at least 15 contiguous nt of at least any one of SEQ ID NOs:l-3351, preferably the entire sequence of at least any one of SEQ ID NOs: 1-3351, is not limited and can be any sequence of A, T, G, and/or C (for DNA) and A, U, G, and/or C (for RNA) or modified bases thereof, including inosine and pseudouridine.
- sequence will depend on the desired function and can be dictated by coding regions desired, the intron-like regions desired, and the
- nucleic acid obtained is referred to herein as a polynucleotide comprising the sequence of any one of SEQ ID NOs: 1 -3351.
- polynucleotides e.g., a polynucleotide having a sequence of one of SEQ ID NOs:l-3351
- the corresponding cDNA or the full-length gene is used to express a partial or complete gene product.
- Constructs of polynucleotides having sequences of SEQ ID NOs: 1-3351 can be generated synthetically.
- single-step assembly of a gene and entire plasmid from large numbers of oligodeoxyribonucleotides is described by, e.g., Stemmer et al., Gene (Amsterdam) (1995) 164(l):49-53.
- assembly PCR the synthesis of long DNA sequences from large numbers of oligodeoxyribonucleotides (oligos)
- the method is derived from DNA shuffling (Stemmer, Nature (1994) 570:389-391), and does not rely on DNA ligase, but instead relies on DNA polymerase to build increasingly longer DNA fragments during the assembly process.
- polynucleotide constructs are purified using standard recombinant DNA techniques as described in, for example, Sambrook et al., Molecular Cloning: A Laboratory Manual, 2nd Ed., (1989) Cold Spring Harbor Press, Cold Spring Harbor, NY, and under current regulations described in United States Dept. of HHS, National Institute of Health (NIH) Guidelines for Recombinant DNA Research.
- the gene product encoded by a polynucleotide of the invention is expressed in any expression system, including, for example, bacterial, yeast, insect, amphibian and mammalian systems.
- Vectors, host cells and methods for obtaining expression in same are well known in the art. Suitable vectors and host cells are described in U.S. Patent No. 5,654,173.
- Polynucleotide molecules comprising a polynucleotide sequence provided herein are generally propagated by placing the molecule in a vector.
- Viral and non-viral vectors are used, including plasmids.
- the choice of plasmid will depend on the type of cell in which propagation is desired and the purpose of propagation. Certain vectors are useful for amplifying and making large amounts of the desired DNA sequence.
- Other vectors are suitable for expression in cells in culture.
- Still other vectors are suitable for transfer and expression in cells in a whole animal or person. The choice of appropriate vector is well within the skill of the art. Many such vectors are
- polynucleotides set forth in SEQ ID NOs: 1-3351 or their corresponding full-length polynucleotides are linked to regulatory sequences as appropriate to obtain the desired expression properties. These can include promoters (attached either at the 5' end of the sense strand or at the 3' end of the antisense strand), enhancers, terminators, operators, repressors, and inducers.
- the promoters can be regulated or constitutive. In some situations it may be desirable to use conditionally active promoters, such as tissue-specific or developmental stage-specific promoters. These are linked to the desired nucleotide sequence using the techniques described above for linkage to vectors. Any techniques known in the art can be used.
- the resulting replicated nucleic acid, RNA, expressed protein or polypeptide is within the scope of the invention as a product of the host cell or organism.
- the product is recovered by any appropriate means known in the art.
- the gene corresponding to a selected polynucleotide is identified, its expression can be regulated in the cell to which the gene is native.
- an endogenous gene of a cell can be regulated by an exogenous regulatory sequence as disclosed in U.S. Patent No. 5,641,670.
- Translations of the nucleotide sequence of the provided polynucleotides, cDNAs or full genes can be aligned with individual known sequences. Similarity with individual sequences can be used to determine the activity of the polypeptides encoded by the polynucleotides of the invention. Also, sequences exhibiting similarity with more than one individual sequence can exhibit activities that are characteristic of either or both individual sequences.
- the full length sequences and fragments of the polynucleotide sequences of the nearest neighbors can be used as probes and primers to identify and isolate the full length sequence corresponding to provided polynucleotides.
- the nearest neighbors can indicate a tissue or cell type to be used to construct a library for the full-length sequences corresponding to the provided polynucleotides.
- a selected polynucleotide is translated in all six frames to determine the best alignment with the individual sequences.
- Query and individual sequences can be aligned using the methods and computer programs described above, and include BLAST, available over the world wide web at http://www.ncbi.nlm.nhi.gov/BLAST.
- Another alignment algorithm is Fasta, available in the Genetics Computing Group (GCG) package, Madison, Wisconsin, USA, a wholly owned subsidiary of Oxford Molecular Group, Inc. Other techniques for alignment are described in Doolittle, supra.
- GCG Genetics Computing Group
- an alignment program that permits gaps in the sequence is utilized to align the sequences.
- the Smith- Waterman is one type of algorithm that permits gaps in sequence alignments. See Meth. Mol. Biol. (1997) 70: 173-187.
- the GAP program using the Needleman and Wunsch alignment method can be utilized to align sequences.
- An alternative search strategy uses MPSRCH software, which runs on a MASPAR computer.
- MPSRCH uses a Smith- Waterman algorithm to score sequences on a massively parallel computer. This approach improves ability to identify sequences that are distantly related matches, and is especially tolerant of small gaps and nucleotide sequence errors.
- Amino acid sequences encoded by the provided polynucleotides can be used to search both protein and DNA databases.
- the percent of the alignment region length is typically at least about 55% of total length query sequence; more typically, at least about 58%; even more typically; at least about 60% of the total residue length of the query sequence.
- percent length of the alignment region can be as much as about 62%; more usually, as much as about 64%; even more usually, as much as about 66%.
- the region of alignment typically, exhibits at least about 75% of sequence identity; more typically, at least about 78%; even more typically; at least about 80% sequence identity.
- percent sequence identity can be as much as about 82%; more usually, as much as about 84%; even more usually, as much as about 86%.
- the p value is used in conjunction with these methods. If high similarity is found, the query sequence is considered to have high similarity with a profile
- the p value is less than or equal to about 10 "2 ; more usually; less than or equal to about 10 "3 ; even more usually; less than or equal to about 10 "4 . More typically, the p value is no more than about 10 "5 ; more typically; no more than or equal to about 10 "10 ; even more typically; no more than or equal to about 10 "15 for the query sequence to be considered high similarity.
- Sequence identity alone can be used to determine similarity of a query sequence to an individual sequence and can indicate the activity of the sequence. Such an alignment, preferably, permits gaps to align sequences.
- the query sequence is related to the profile sequence if the sequence identity over the entire query sequence is at least about 15%; more typically, at least about 20%; even more typically, at least about 25%; even more typically, at least about 50%.
- Sequence identity alone as a measure of similarity is most useful when the query sequence is usually, at least 80 residues in length; more usually, 90 residues; even more usually, at least 95 amino acid residues in length. More typically, similarity can be concluded based on sequence identity alone when the query sequence is preferably 100 residues in length; more preferably, 120 residues in length; even more preferably, 150 amino acid residues in length.
- Translations of the provided polynucleotides can be aligned with amino acid profiles that define either protein families or common motifs. Also, translations of the provided polynucleotides can be aligned to multiple sequence alignments (MSA) comprising the polypeptide sequences of members of protein families or motifs. Similarity or identity with profile sequences or MSAs can be used to determine the activity of the gene products (e.g., polypeptides) encoded by the provided polynucleotides or corresponding cDNA or genes. For example, sequences that show an identity or similarity with a chemokine profile or MSA can exhibit chemokine activities.
- MSA sequence alignments
- MSA is an alignment of the amino acid sequence of members that belong to the family and (2) constructing a statistical representation of the alignment.
- MSAs of some protein families and motifs are publicly available. MSAs are described also in Sonnhammer et al., Proteins (1997) 28: 405-420. A brief description of MSAs is reported in Pascarella et al., Prot. Eng. (1996) P(i):249-251.
- Similarity between a query sequence and a protein family or motif can be determined by (a) comparing the query sequence against the profile and/or (b) aligning the query sequence with the members of the family or motif.
- a program such as Searchwise is used to compare the query sequence to the statistical representation of the multiple alignment, also known as a profile (see Birney et al., supra).
- Other techniques to compare the sequence and profile are described in Sonnhammer et al., supra and Doolittle, supra. Next, methods described by Feng et al., J. Mol. Evol. (1987) 25:351 and
- Higgins et al., CABIOS (1989) 5:151 can be used align the query sequence with the members of a family or motif, also known as a MSA. Sequence alignments can be generated using any of a variety of software tools. Examples include PileUp, which creates a multiple sequence alignment, and is described in Feng et al., J. Mol. Evol. (1987) 25:351. Another method, GAP, uses the alignment method of Needleman et al., J. Mol. Biol. (1970) 48:443. GAP is best suited for global alignment of sequences. A third method, BestFit, functions by inserting gaps to maximize the number of matches using the local homology algorithm of Smith et al., Adv. Appl. Math.
- Some alignment programs that both translate and align sequences can make any number of frameshifts when translating the nucleotide sequence to produce the best alignment.
- the fewer frameshifts needed to produce an alignment the stronger the similarity or identity between the query and profile or MSAs.
- a weak similarity resulting from no frameshifts can be a better indication of activity or structure of a query sequence, than a strong similarity resulting from two frameshifts.
- three or fewer frameshifts are found in an alignment; more preferably two or fewer frameshifts; even more preferably, one or fewer frameshifts; even more preferably, no frameshifts are found in an alignment of query and profile or MSAs.
- conserved residues are those amino acids found at a particular position in all or some of the family or motif members. Alternatively, a position is considered conserved if only a certain class of amino acids is found in a particular position in all or some of the family members.
- the N-terminal position can contain a positively charged amino acid, such as lysine, arginine, or histidine.
- a residue of a polypeptide is conserved when a class of amino acids or a single amino acid is found at a particular position in at least about 40% of all class members; more typically, at least about 50%; even more typically, at least about 60% of the members.
- a residue is conserved when a class or single amino acid is found in at least about 70% of the members of a family or motif; more usually, at least about 80%; even more usually, at least about 90%; even more usually, at least about 95%.
- a residue is considered conserved when three unrelated amino acids are found at a particular position in the some or all of the members; more usually, two unrelated amino acids.
- residues are conserved when the unrelated amino acids are found at particular positions in at least about 40% of all class member; more typically, at least about 50%; even more typically, at least about 60% of the members.
- a residue is conserved when a class or single amino acid is found in at least about 70% of the members of a family or motif; more usually, at least about 80%; even more usually, at least about 90%; even more usually, at least about 95%.
- a query sequence has similarity to a profile or MSA when the query sequence comprises at least about 25% of the conserved residues of the profile or MSA; more usually, at least about 30%; even more usually; at least about 40%.
- the query sequence has a stronger similarity to a profile sequence or MSA when the query sequence comprises at least about 45% of the conserved residues of the profile or MSA; more typically, at least about 50%; even more typically; at least about 55%.
- secreted and membrane-bound polypeptides of the present invention are of particular interest.
- levels of secreted polypeptides can be assayed in body fluids that are convenient, such as blood, plasma, serum, and other body fluids such as urine, prostatic fluid and semen.
- Membrane-bound polypeptides are useful for constructing vaccine antigens or inducing an immune response. Such antigens would comprise all or part of the extracellular region of the membrane-bound polypeptides. Because both secreted and membrane-bound polypeptides comprise a fragment of contiguous hydrophobic amino acids, hydrophobicity predicting algorithms can be used to identify such polypeptides.
- a signal sequence is usually encoded by both secreted and membrane- bound polypeptide genes to direct a polypeptide to the surface of the cell.
- the signal sequence usually comprises a stretch of hydrophobic residues.
- Such signal sequences can fold into helical structures.
- Membrane-bound polypeptides typically comprise at least one transmembrane region that possesses a stretch of hydrophobic amino acids that can transverse the membrane. Some transmembrane regions also exhibit a helical structure.
- Hydrophobic fragments within a polypeptide can be identified by using computer algorithms. Such algorithms include Hopp & Woods, Proc. Natl. Acad. Sci. USA (1981) 75:3824-3828; Kyte & Doolittle, J Mol. Biol. (1982) 757: 105-132; and RAOAR algorithm, Degli Esposti et al., Eur. J. Biochem. ( 1990) 190: 207-219.
- Another method of identifying secreted and membrane-bound polypeptides is to translate the polynucleotides of the invention in all six frames and determine if at least 8 contiguous hydrophobic amino acids are present. Those translated polypeptides with at least 8; more typically, 10; even more typically, 12 contiguous hydrophobic amino acids are considered to be either a putative secreted or membrane bound polypeptide.
- Hydrophobic amino acids include alanine, glycine, histidine, isoleucine, leucine, lysine, methionine, phenylalanine, proline, threonine, tryptophan, tyrosine, and valine
- Identification of the Function of an Expression Product of a Full-Length Gene Ribozymes, antisense constructs, and dominant negative mutants can be used to determine function of the expression product of a gene corresponding to a polynucleotide provided herein.
- the phosphoramidite method of oligonucleotide synthesis can be used to construct antisense molecules and ribozymes. See Beaucage et al., Tet. Lett. (1981) 22:1859 and U.S. Patent No. 4,668,777. Automated devices for synthesis are available to create oligonucleotides using this chemistry.
- RNA oligonucleotides can be synthesized, for example, using RNA phosphoramidites. This method can be performed on an automated synthesizer, such as Applied Biosystems, Models 392 and 394, Foster City, California, USA.
- Oligonucleotides of up to 200 nt can be synthesized, more typically, 100 nt, more typically 50 nt; even more typically 30 to 40 nt. These synthetic fragments can be annealed and ligated together to construct larger fragments. See, for example, Sambrook et al., supra.
- Trans-cleaving catalytic RNAs are RNA molecules possessing endoribonuclease activity. Ribozymes are specifically designed for a particular target, and the target message must contain a specific nucleotide sequence. They are engineered to cleave any RNA species site-specifically in the background of cellular RNA. The cleavage event renders the mRNA unstable and prevents protein expression.
- ribozymes can be used to inhibit expression of a gene of unknown function for the purpose of determining its function in an in vitro or in vivo context, by detecting the phenotypic effect.
- Antisense nucleic acids are designed to specifically bind to RNA, resulting in the formation of RNA-DNA or RNA-RNA hybrids, with an arrest of DNA replication, reverse transcription or messenger RNA translation.
- Antisense polynucleotides based on a selected polynucleotide sequence can interfere with expression of the corresponding gene.
- Antisense polynucleotides are typically generated within the cell by expression from antisense constructs that contain the antisense strand as the transcribed strand.
- Antisense polynucleotides based on the disclosed polynucleotides will bind and/or interfere with the translation of mRNA comprising a sequence complementary to the antisense polynucleotide.
- the expression products of control cells and cells treated with the antisense construct are compared to detect the protein product of the gene corresponding to the polynucleotide upon which the antisense construct is based.
- the protein is isolated and identified using routine biochemical methods. Given the extensive background literature and clinical experience in antisense therapy, one skilled in the art can use selected polynucleotides of the invention as additional potential therapeutics.
- the choice of polynucleotide can be narrowed by first testing them for binding to "hot spot" regions of the genome of cancerous cells. If a polynucleotide is identified as binding to a "hot spot,” testing the polynucleotide as an antisense compound in the corresponding cancer cells is warranted.
- a mutant polypeptide will interact with wild-type polypeptides (made from the other allele) and form a non- functional multimer.
- a mutation is in a substrate-binding domain, a catalytic
- mutant polypeptide will be overproduced. Point mutations are made that have such an effect.
- fusion of different polypeptides of various lengths to the terminus of a protein can yield dominant negative mutants.
- General strategies are available for making dominant negative mutants (see, e.g., Herskowitz, Nature (1987) 529:219). Such techniques can be used to create loss of function mutations, which are useful for determining protein function.
- polypeptides of the invention include those encoded by the disclosed polynucleotides, as well as nucleic acids that, by virtue of the degeneracy of the genetic code, are not identical in sequence to the disclosed polynucleotides.
- the invention includes within its scope a polypeptide encoded by a polynucleotide having the sequence of any one of SEQ ID NOs: 1-3351 or a variant thereof.
- polypeptide refers to both the full length polypeptide encoded by the recited polynucleotide, the polypeptide encoded by the gene represented by the recited polynucleotide, as well as portions or fragments thereof.
- Polypeptides also includes variants of the naturally occurring proteins, where such variants are homologous or substantially similar to the naturally occurring protein, and can be of an origin of the same or different species as the naturally occurring protein (e.g., human, murine, or some other species that naturally expresses the recited polypeptide, usually a mammalian species).
- variant polypeptides have a sequence that has at least about 80%, usually at least about 90%, and more usually at least about 98% sequence identity with a differentially expressed polypeptide of the invention, as measured by BLAST using the parameters described above.
- the variant polypeptides can be naturally or non-naturally glycosylated, i.e., the polypeptide has a glycosylation pattern that differs from the glycosylation pattern found in the corresponding naturally occurring protein.
- the invention also encompasses homologs of the disclosed polypeptides (or fragments thereof) where the homologs are isolated from other species, i.e., other animal or plant species, where such homologs, usually mammalian species, e.g., rodents, such as mice, rats; domestic animals, e.g., horse, cow, dog, cat; and humans.
- homolog is meant a polypeptide having at least about 35%, usually at least about 40% and more usually at least about 60% amino acid sequence identity to a particular differentially expressed protein as identified above, where sequence identity is determined using the BLAST algorithm, with the parameters described above.
- the polypeptides of the subject invention are provided in a non-naturally occurring environment, e.g., are separated from their naturally occurring environment.
- the subject protein is present in a composition that is enriched for the protein as compared to a control.
- purified polypeptide is provided, where by purified is meant that the protein is present in a composition that is substantially free of non-differentially expressed polypeptides, where by substantially free is meant that less than 90%, usually less than 60% and more usually less than 50% of the composition is made up of non-differentially expressed polypeptides.
- variants include mutants, fragments, and fusions.
- Mutants can include amino acid substitutions, additions or deletions.
- the amino acid substitutions can be conservative amino acid substitutions or substitutions to eliminate non-essential amino acids, such as to alter a glycosylation site, a phosphorylation site or an acetylation site, or to minimize misfolding by substitution or deletion of one or more cysteine residues that are not necessary for function.
- Conservative amino acid substitutions are those that preserve the general charge, hydrophobicity/ hydrophilicity, and/or steric bulk of the amino acid substituted.
- Variants can be designed so as to retain biological activity of a particular region of the protein (e.g., a functional domain and/or, where the polypeptide is a member of a protein family, a region associated with a consensus sequence). Selection of amino acid alterations for production of variants can be based upon the accessibility (interior vs. exterior) of the amino acid (see, e.g., Go et al., Int. J. Peptide Protein Res. (1980) 75:21 1), the thermostability of the variant polypeptide (see, e.g., Querol et al., Prot. Eng. (1996) 9:265), desired glycosylation sites (see, e.g., Olsen and Thomsen, J.
- Variants also include fragments of the polypeptides disclosed herein, particularly biologically active fragments and/or fragments corresponding to functional domains. Fragments of interest will typically be at least about 10 aa to at least about 15 aa in length, usually at least about 50 aa in length, and can be as long as 300 aa in length or longer, but will usually not exceed about 1000 aa in length, where the fragment will have a stretch of amino acids that is identical to a polypeptide encoded by a
- the protein variants described herein are encoded by polynucleotides that are within the scope of the invention.
- the genetic code can be used to select the appropriate codons to construct the corresponding variants.
- a library of polynucleotides is a collection of sequence information, which information is provided in either biochemical form (e.g., as a collection of polynucleotide molecules), or in electronic form (e.g., as a collection of polynucleotide sequences stored in a computer-readable form, as in a computer system and/or as part of a computer program).
- the sequence information of the polynucleotides can be used in a variety of ways, e.g., as a resource for gene discovery, as a representation of sequences expressed in a selected cell type (e.g., cell type markers), and/or as markers of a given disease or disease state.
- a disease marker is a representation of a gene product that is present in all cells affected by disease either at an increased or decreased level relative to a normal cell (e.g., a cell of the same or similar type that is not substantially affected by disease).
- a polynucleotide sequence in a library can be a polynucleotide that represents an mRNA, polypeptide, or other gene product encoded by the polynucleotide, that is either overexpressed or underexpressed in a breast ductal cell affected by cancer relative to a normal (i.e., substantially disease-free) breast cell.
- the nucleotide sequence information of the library can be embodied in any suitable form, e.g., electronic or biochemical forms.
- a library of sequence information embodied in electronic form comprises an accessible computer data file (or, in biochemical form, a collection of nucleic acid molecules) that contains the representative nucleotide sequences of genes that are differentially expressed (e.g., overexpressed or underexpressed) as between, for example, i) a cancerous cell and a normal cell; ii) a cancerous cell and a dysplastic cell; iii) a cancerous cell and a cell affected by a disease or condition other than cancer; iv) a metastatic cancerous cell and a normal cell and/or non-metastatic cancerous cell; v) a malignant cancerous cell and a non-malignant cancerous cell (or a normal cell) and/or vi) a dysplastic cell relative to a normal cell.
- Other combinations and comparisons of cells affected by various diseases or stages of disease will
- XX the sequences of the genes in the library, where the nucleic acids can correspond to the entire gene in the library or to a fragment thereof, as described in greater detail below.
- the polynucleotide libraries of the subject invention generally comprise sequence information of a plurality of polynucleotide sequences, where at least one of the polynucleotides has a sequence of any of SEQ ID NOs: 1-3351.
- plurality is meant at least 2, usually at least 3 and can include up to all of SEQ ID NOs: 1-3351.
- the length and number of polynucleotides in the library will vary with the nature of the library, e.g., if the library is an oligonucleotide array, a cDNA array, a computer database of the sequence information, etc.
- the library is an electronic library, the nucleic acid sequence information can be present in a variety of media.
- Media refers to a manufacture, other than an isolated nucleic acid molecule, that contains the sequence information of the present invention. Such a manufacture provides the genome sequence or a subset thereof in a form that can be examined by means not directly applicable to the sequence as it exists in a nucleic acid.
- the nucleotide sequence of the present invention e.g., the nucleic acid sequences of any of the polynucleotides of SEQ ID NOs: 1-3351
- Such media include, but are not limited to: magnetic storage media, such as a floppy disc, a hard disc storage medium, and a magnetic tape; optical storage media such as CD-ROM; electrical storage media such as RAM and ROM; and hybrids of these categories such as magnetic/optical storage media.
- magnetic storage media such as a floppy disc, a hard disc storage medium, and a magnetic tape
- optical storage media such as CD-ROM
- electrical storage media such as RAM and ROM
- hybrids of these categories such as magnetic/optical storage media.
- a variety of data processor programs and formats can be used for storage, e.g., word processing text file, database format, etc.
- electronic versions of the libraries of the invention can be provided in conjunction or connection with other computer-readable information and/or other types of computer-readable files (e.g., searchable files, executable files, etc., including, but not limited to, for example, search program software, etc.).
- nucleotide sequence By providing the nucleotide sequence in computer readable form, the information can be accessed for a variety of purposes.
- Computer software to access sequence information is publicly available. For example, the BLAST (Altschul et al.,
- a computer-based system refers to the hardware means, software means, and data storage means used to analyze the nucleotide sequence information of the present invention.
- the minimum hardware of the computer-based systems of the present invention comprises a central processing unit (CPU), input means, output means, and data storage means.
- CPU central processing unit
- input means input means
- output means output means
- data storage means can comprise any manufacture comprising a recording of the present sequence information as described above, or a memory access means that can access such a manufacture.
- Search means refers to one or more programs implemented on the computer-based system, to compare a target sequence or target structural motif, or expression levels of a polynucleotide in a sample, with the stored sequence information. Search means can be used to identify fragments or regions of the genome that match a particular target sequence or target motif.
- a variety of known algorithms are publicly known and commercially available, e.g., MacPattern (EMBL), BLASTN and BLASTX (NCBI).
- a "target sequence” can be any polynucleotide or amino acid sequence of six or more contiguous nucleotides or two or more amino acids, preferably from about 10 to 100 amino acids or from about 30 to 300 nt.
- a variety of comparing means can be used to accomplish comparison of sequence information from a sample (e.g., to analyze target sequences, target motifs, or relative expression levels) with the data storage means.
- a skilled artisan can readily recognize that any one of the publicly available homology search programs can be used as the search means for the computer based systems of the present invention to accomplish comparison of target sequences and motifs.
- Computer programs to analyze expression levels in a sample and in controls are also known in the art.
- target structural motif refers to any rationally selected sequence or combination of sequences in which the sequence(s) are chosen based on a three-dimensional configuration that is formed upon the folding of the target motif, or on consensus sequences of regulatory or active sites.
- target motifs include, but arc not limited to, enzyme active sites and signal sequences.
- Nucleic acid target motifs include, but are not limited to, hairpin structures, promoter sequences and other expression elements such as binding sites for transcription factors.
- a variety of structural formats for the input and output means can be used to input and output the information in the computer-based systems of the present invention.
- One format for an output means ranks the relative expression levels of different polynucleotides. Such presentation provides a skilled artisan with a ranking of relative expression levels to determine a gene expression profile.
- the "library” of the invention also encompasses biochemical libraries of the polynucleotides of SEQ ID NOs: 1-3351, e.g., collections of nucleic acids representing the provided polynucleotides.
- the biochemical libraries can take a variety of forms, e.g., a solution of cDNAs, a pattern of probe nucleic acids stably associated with a surface of a solid support (i.e., an array) and the like.
- nucleic acid arrays in which one or more of SEQ ID NOs: 1-3351 is represented on the array.
- array an article of manufacture that has at least a substrate with at least two distinct nucleic acid targets on one of its surfaces, where the number of distinct nucleic acids can be considerably higher, typically being at least 10 nt, usually at least 20 nt and often at least 25 nt.
- array formats have been developed and are known to those of skill in the art.
- the arrays of the subject invention find use in a variety of applications, including gene expression analysis, drug screening, mutation analysis and the like, as disclosed in the above-listed exemplary patent documents.
- analogous libraries of polypeptides are also provided, where the where the polypeptides of the library will represent at least a portion of the polypeptides encoded by SEQ ID NOs:l-3351.
- Polynucleotide probes generally comprising at least 12 contiguous nt of a polynucleotide as shown in the Sequence Listing, are used for a variety of purposes, such as chromosome mapping of the polynucleotide and detection of transcription levels. Additional disclosure about preferred regions of the disclosed polynucleotide sequences is found in the Examples.
- a probe that hybridizes specifically to a polynucleotide disclosed herein should provide a detection signal at least 5-, 10-, or 20- fold higher than the background hybridization provided with other unrelated sequences. Detection of Expression Levels. Nucleotide probes are used to detect expression of a gene corresponding to the provided polynucleotide. In Northern blots,
- X mRNA is separated electrophoretically and contacted with a probe.
- a probe is detected as hybridizing to an mRNA species of a particular size. The amount of hybridization is quantitated to determine relative amounts of expression, for example under a particular condition.
- Probes are used for in situ hybridization to cells to detect expression. Probes can also be used in vivo for diagnostic detection of hybridizing sequences. Probes are typically labeled with a radioactive isotope. Other types of detectable labels can be used such as chromophores, fluors, and enzymes. Other examples of nucleotide hybridization assays are described in WO92/02526 and U.S. Patent No. 5,124,246.
- PCR Polymerase Chain Reaction
- PCR Polymerase Chain Reaction
- Two primer polynucleotides nucleotides that hybridize with the target nucleic acids are used to prime the reaction.
- the primers can be composed of sequence within or 3' and 5' to the polynucleotides of the Sequence Listing. Alternatively, if the primers are 3' and 5' to these polynucleotides, they need not hybridize to them or the complements.
- the amplified target nucleic acids can be detected by methods known in the art, e.g., Southern blot.
- mRNA or cDNA can also be detected by traditional blotting techniques (e.g., Southern blot, Northern blot, etc.) described in Sambrook et al., "Molecular Cloning: A Laboratory Manual” (New York, Cold Spring Harbor Laboratory, 1989) (e.g., without PCR amplification).
- mRNA or cDNA generated from mRNA using a polymerase enzyme can be purified and separated using gel electrophoresis, and transferred to a solid support, such as nitrocellulose. The solid support is exposed to a labeled probe, washed to remove any unhybridized probe, and duplexes containing the labeled probe are detected.
- Polynucleotides of the present invention can be used to identify a chromosome on which the corresponding gene resides. Such mapping can be useful in identifying the function of the polynucleotide-related gene by its proximity to other genes with known function. Function can also be assigned to the polynucleotide- related gene when particular syndromes or diseases map to the same chromosome. For example, use of polynucleotide probes in identification and quantification of nucleic acid sequence aberrations is described in U.S. Patent No. 5,783,387.
- An exemplary mapping method is fluorescence in situ hybridization (FISH), which facilitates comparative genomic hybridization to allow total genome assessment of changes in relative copy number of DNA sequences (see, e.g., Valdes et al., Methods in Molecular
- Polynucleotides can also be mapped to particular chromosomes using, for example, radiation hybrids or chromosome-specific hybrid panels. See Leach et al., Advances in Genetics, (1995) 55:63-99; Walter et al., Nature Genetics (1994) 7:22; Walter and Goodfellow, Trends in Genetics (1992) 9:352. Panels for radiation hybrid mapping are available from Research Genetics, Inc., Huntsville, Alabama, USA.
- the statistical program RHMAP can be used to construct a map based on the data from radiation hybridization with a measure of the relative likelihood of one order versus another. RHMAP is available via the world wide web at http://www.sph.umich.edu- /group/statgen/software.
- commercial programs are available for identifying regions of chromosomes commonly associated with disease, such as cancer.
- Tissue Typing or Profiling Expression of specific mRNA corresponding to the provided polynucleotides can vary in different cell types and can be tissue-specific. This variation of mRNA levels in different cell types can be exploited with nucleic acid probe assays to determine tissue types. For example, PCR, branched DNA probe assays, or blotting techniques utilizing nucleic acid probes substantially identical or complementary to polynucleotides listed in the Sequence Listing can determine the presence or absence of the corresponding cDNA or mRNA.
- Tissue typing can be used to identify the developmental organ or tissue source of a metastatic lesion by identifying the expression of a particular marker of that organ or tissue. If a polynucleotide is expressed only in a specific tissue type, and a metastatic lesion is found to express that polynucleotide, then the developmental source of the lesion has been identified. Expression of a particular polynucleotide can be assayed by detection of either the corresponding mRNA or the protein product.
- a polynucleotide of the invention can be used in forensics, genetic analysis, mapping, and diagnostic applications where the corresponding region of a gene is polymorphic in the human population. Any means for detecting a polymorphism in a gene can be used, including, but not limited to electrophoresis of protein polymorphic variants, differential sensitivity to restriction enzyme cleavage, and hybridization to allele-specific probes.
- Expression products of a polynucleotide of the invention can be prepared and used for raising antibodies for experimental, diagnostic, and therapeutic purposes.
- this provides an additional
- the polynucleotide or related cDNA is expressed as described above, and antibodies are prepared. These antibodies are specific to an epitope on the polypeptide encoded by the polynucleotide, and can precipitate or bind to the corresponding native protein in a cell or tissue preparation or in a cell-free extract of an in vitro expression system.
- the antibodies specifically bind to epitopes present in the polypeptides encoded by polynucleotides disclosed in the Sequence Listing. Typically, at least 6, 8, 10, or 12 contiguous amino acids are required to form an epitope. Epitopes that involve non-contiguous amino acids may require a longer polypeptide, e.g., at least 15, 25, or 50 amino acids.
- Antibodies that specifically bind to human polypeptides encoded by the provided polynucleotides should provide a detection signal at least 5-, 10-, or 20-fold higher than a detection signal provided with other proteins when used in Western blots or other immunochemical assays.
- antibodies that specifically polypeptides of the invention do not bind to other proteins in immunochemical assays at detectable levels and can immunoprecipitate the specific polypeptide from solution.
- the invention also contemplates naturally occurring antibodies specific for a polypeptide of the invention.
- serum antibodies to a polypeptide of the invention in a human population can be purified by methods well known in the art, e.g., by passing antiserum over a column to which the corresponding selected polypeptide or fusion protein is bound. The bound antibodies can then be eluted from the column, for example using a buffer with a high salt concentration.
- the invention also contemplates genetically engineered antibodies, antibody derivatives (e.g., single chain antibodies, antibody fragments (e.g., Fab, etc.)), according to methods well known in the art.
- antibody derivatives e.g., single chain antibodies, antibody fragments (e.g., Fab, etc.)
- humanized monoclonal antibodies capable of binding to the polypeptides of the invention.
- humanized antibody refers to an antibody derived from a non-human antibody - typically a mouse monoclonal antibody.
- a humanized antibody may be derived from a chimeric antibody that retains or substantially retains the antigen- binding properties of the parental, non-human, antibody but which exhibits diminished immunogenicity as compared to the parental antibody when administered to humans.
- chimeric antibody refers to an antibody containing
- chimeric antibodies comprise human and murine antibody fragments, generally human constant and mouse variable regions. Because humanized antibodies are far less immunogenic in humans than the parental mouse monoclonal antibodies, they can be used for the treatment of humans with far less risk of anaphylaxis. Thus, these antibodies may be preferred in therapeutic applications that involve in vivo administration to a human such as, e.g., use as radiation sensitizers for the treatment of neoplastic disease or use in methods to reduce the side effects of, e.g., cancer therapy.
- Humanized antibodies may be achieved by a variety of methods including, for example: (1) grafting the non-human complementarity determining regions (CDRs) onto a human framework and constant region (a process referred to in the art as “humanizing”), or, alternatively, (2) transplanting the entire non-human variable domains, but “cloaking” them with a human-like surface by replacement of surface residues (a process referred to in the art as “veneering”).
- humanized antibodies will include both “humanized” and “veneered” antibodies. These methods are disclosed in, e.g., Jones et al., Nature 321:522-525 (1986); Morrison et al., Proc. Natl. Acad.
- complementarity determining region refers to amino acid sequences which together define the binding affinity and specificity of the natural Fv region of a native immunoglobulin binding site. See, e.g., Chothia et al., J. Mol. Biol. 79(5:901-917 (1987); Kabat et al., U.S. Dept. of Health and Human Services NIH Publication No. 91-3242 (1991).
- constant region refers to the portion of the antibody molecule that confers effector functions. In the present invention, mouse constant regions are substituted by human constant regions.
- the constant regions of the subject humanized antibodies are derived from human immunoglobulins.
- the heavy chain constant region can be selected from any of the five isotypes: alpha, delta, epsilon, gamma or mu.
- One method of humanizing antibodies comprises aligning the non- human heavy and light chain sequences to human heavy and light chain sequences,
- ⁇ ⁇ selecting and replacing the non-human framework with a human framework based on such alignment, molecular modeling to predict the conformation of the humanized sequence and comparing to the conformation of the parent antibody. This process is followed by repeated back mutation of residues in the CDR region which disturb the structure of the CDRs until the predicted conformation of the humanized sequence model closely approximates the conformation of the non-human CDRs of the parent non-human antibody.
- Such humanized antibodies may be further derivatized to facilitate uptake and clearance, e.g., via Ashwell receptors. See, e.g., U.S. Patent Nos. 5,530,101 and 5,585,089 which patents are incorporated herein by reference.
- Humanized antibodies can also be produced using transgenic animals that are engineered to contain human immunoglobulin loci.
- WO 98/24893 discloses transgenic animals having a human Ig locus wherein the animals do not produce functional endogenous immunoglobulins due to the inactivation of endogenous heavy and light chain loci.
- WO 91/10741 also discloses transgenic non- primate mammalian hosts capable of mounting an immune response to an immunogen, wherein the antibodies have primate constant and/or variable regions, and wherein the endogenous immunoglobulin-encoding loci are substituted or inactivated.
- WO 96/30498 discloses the use of the Cre/Lox system to modify the immunoglobulin locus in a mammal, such as to replace all or a portion of the constant or variable region to form a modified antibody molecule.
- WO 94/02602 discloses non-human mammalian hosts having inactivated endogenous Ig loci and functional human Ig loci.
- U.S. Patent No. 5,939,598 discloses methods of making transgenic mice in which the mice lack endogenous heavy claims, and express an exogenous immunoglobulin locus comprising one or more xenogeneic constant regions.
- an immune response can be produced to a selected antigenic molecule, and antibody-producing cells can be removed from the animal and used to produce hybridomas that secrete human monoclonal antibodies.
- Immunization protocols, adjuvants, and the like are known in the art, and are used in immunization of, for example, a transgenic mouse as described in WO 96/33735.
- This publication discloses monoclonal antibodies against a variety of antigenic molecules including IL-6, IL-8, TNF , human CD4, L-selectin, gp39, and tetanus toxin.
- the monoclonal antibodies can be tested for the ability to inhibit or neutralize the biological activity or physiological effect of the corresponding protein.
- WO 96/33735 discloses that monoclonal antibodies against IL-8, derived from immune cells of transgenic mice immunized with IL-8, blocked IL-8-induced functions of
- Human monoclonal antibodies with specificity for the antigen used to immunize transgenic animals are also disclosed in WO 96/34096.
- Polynucleotides or Arrays for Diagnostics Polynucleotide arrays are created by spotting polynucleotide probes onto a substrate (e.g., glass, nitrocellose, etc.) in a two-dimensional matrix or array having bound probes.
- the probes can be bound to the substrate by either covalent bonds or by non-specific interactions, such as hydrophobic interactions.
- Samples of polynucleotides can be detectably labeled (e.g., using radioactive or fluorescent labels) and then hybridized to the probes.
- Double stranded polynucleotides comprising the labeled sample polynucleotides bound to probe polynucleotides, can be detected once the unbound portion of the sample is washed away.
- Techniques for constructing arrays and methods of using these arrays are described in EP 799 897; WO 97/29212; WO 97/27317; EP 785 280; WO 97/02357; U.S. Patent No. 5,593,839; U.S. Patent No. 5,578,832; EP 728 520; U.S. Patent No. 5,599,695; EP 721 016; U.S. Patent No. 5,556,752; WO 95/22058; and U.S. Patent No.
- arrays can be used to, for example, examine differential expression of genes and can be used to determine gene function.
- arrays can be used to detect differential expression of a polynucleotide between a test cell and control cell (e.g., cancer cells and normal cells).
- a test cell and control cell e.g., cancer cells and normal cells.
- high expression of a particular message in a cancer cell which is not observed in a corresponding normal cell, can indicate a cancer specific gene product.
- Exemplary uses of arrays are further described in, for example, Pappalarado et al., Sem. Radiation Oncol. (1998) 5:217; and Ramsay, Nature Biotechnol. (1998) 7(5:40.
- the polynucleotides of the invention can also be used to detect differences in expression levels between two cells, e.g., as a method to identify abnormal or diseased tissue in a human.
- tissue can be selected according to the putative biological function.
- the expression of a gene corresponding to a specific polynucleotide is compared between a first tissue that is suspected of being diseased and a second, normal tissue of the human.
- the tissue suspected of being abnormal or diseased can be derived from a different tissue type of the human, but preferably it is derived from the same tissue type; for example an intestinal polyp or other abnormal growth should be compared with normal intestinal tissue.
- the normal tissue can be the same tissue as that of the test sample, or any normal tissue of the patient, especially those that express the polynucleotide-related gene of interest (e.g., brain, thymus, testis, heart, prostate, placenta, spleen, small intestine, skeletal muscle, pancreas, and the mucosal lining of the colon).
- a difference between the polynucleotide-related gene, mRNA, or protein in the two tissues which are compared, for example in molecular weight, amino acid or nucleotide sequence, or relative abundance, indicates a change in the gene, or a gene which regulates it, in the tissue of the human that was suspected of being diseased.
- a genetic predisposition to disease in a human can also be detected by comparing expression levels of an mRNA or protein corresponding to a polynucleotide of the invention in a fetal tissue with levels associated in normal fetal tissue.
- Fetal tissues that are used for this purpose include, but are not limited to, amniotic fluid, chorionic villi, blood, and the blastomere of an in v tr ⁇ -fertilized embryo.
- the comparable normal polynucleotide-related gene is obtained from any tissue.
- the mRNA or protein is obtained from a normal tissue of a human in which the polynucleotide- related gene is expressed. Differences such as alterations in the nucleotide sequence or size of the same product of the fetal polynucleotide-related gene or mRNA, or alterations in the molecular weight, amino acid sequence, or relative abundance of fetal protein, can indicate a germline mutation in the polynucleotide-related gene of the fetus, which indicates a genetic predisposition to disease.
- diagnostic, prognostic, and other methods of the invention based on differential expression involve detection of a level or amount of a gene product, particularly a differentially expressed gene product, in a test sample obtained from a patient suspected of having or being susceptible to a disease (e.g. , breast cancer, lung cancer, colon cancer and/or metastatic forms thereof), and comparing the detected levels to those levels found in normal cells (e.g., cells substantially unaffected by cancer) and/or other control cells (e.g., to differentiate a cancerous cell from a cell affected by dysplasia).
- the severity of the disease can be assessed by comparing the detected levels of a differentially expressed gene product with those levels detected in samples representing the levels of differentially gene product associated with varying degrees of severity of disease.
- diagnosis herein is not necessarily meant to exclude “prognostic” or “prognosis,” but rather is used as a matter of convenience.
- the term "differentially expressed gene” is generally intended to encompass a polynucleotide that can, for example, include an open reading frame encoding a gene product (e.g., a polypeptide), and/or introns of such genes and adjacent 5' and 3' non-coding nucleotide sequences involved in the regulation of expression, up to about 20 kb beyond the coding region, but possibly further in either direction.
- the gene can be introduced into an appropriate vector for extrachromosomal maintenance or for integration into a host genome.
- a difference in expression level associated with a decrease in expression level of at least about 25%, usually at least about 50% to 75%, more usually at least about 90% or more is indicative of a differentially expressed gene of interest, i.e., a gene that is underexpressed or down- regulated in the test sample relative to a control sample.
- a difference in expression level associated with an increase in expression of at least about 25%, usually at least about 50% to 75%, more usually at least about 90% and can be at least about 1 ' -fold, usually at least about 2-fold to about 10-fold, and can be about 100-fold to about 1 , 000-fold increase relative to a control sample is indicative of a differentially expressed gene of interest, i.e., an overexpressed or up-regulated gene.
- “Differentially expressed polynucleotide” as used herein means a nucleic acid molecule (RNA or DNA) comprising a sequence that represents a differentially expressed gene, e.g., the differentially expressed polynucleotide comprises a sequence (e.g., an open reading frame encoding a gene product) that uniquely identifies a differentially expressed gene so that detection of the differentially expressed polynucleotide in a sample is correlated with the presence of a differentially expressed gene in a sample.
- RNA or DNA nucleic acid molecule
- the differentially expressed polynucleotide comprises a sequence (e.g., an open reading frame encoding a gene product) that uniquely identifies a differentially expressed gene so that detection of the differentially expressed polynucleotide in a sample is correlated with the presence of a differentially expressed gene in a sample.
- “Differentially expressed polynucleotides” is also meant to encompass fragments of the disclosed polynucleotides, e.g., fragments retaining biological activity, as well as nucleic acids homologous, substantially similar, or substantially identical (e.g., having about 90% sequence identity) to the disclosed polynucleotides.
- Diagnosis generally includes determination of a subject's susceptibility to a disease or disorder, determination as to whether a subject is presently affected by a disease or disorder, as well as to the prognosis of a subject affected by a disease or disorder (e.g. , identification of pre-metastatic or metastatic cancerous states, stages of cancer, or responsiveness of cancer to therapy).
- the present invention particularly encompasses diagnosis of subjects in the context of breast cancer (e.g., carcinoma in situ (e.g., ductal carcinoma in situ), estrogen receptor (ER)-positive breast cancer, ER-negative breast cancer, or other forms and/or stages of breast cancer), lung cancer (e.g., small cell carcinoma, non-small cell carcinoma, mesothelioma, and
- colon cancer e.g., adenomatous polyp, colorectal carcinoma, and other forms and/or stages of colon cancer.
- sample or “biological sample” as used throughout here are generally meant to refer to samples of biological fluids or tissues, particularly samples obtained from tissues, especially from cells of the type associated with the disease for which the diagnostic application is designed (e.g., ductal adenocarcinoma), and the like. “Samples” is also meant to encompass derivatives and fractions of such samples (e.g., cell lysates). Where the sample is solid tissue, the cells of the tissue can be dissociated or tissue sections can be analyzed.
- Methods of the subject invention useful in diagnosis or prognosis typically involve comparison of the abundance of a selected differentially expressed gene product in a sample of interest with that of a control to determine any relative differences in the expression of the gene product, where the difference can be measured qualitatively and/or quantitatively. Quantitation can be accomplished, for example, by comparing the level of expression product detected in the sample with the amounts of product present in a standard curve.
- a comparison can be made visually; by using a technique such as densitometry, with or without computerized assistance; by preparing a representative library of cDNA clones of mRNA isolated from a test sample, sequencing the clones in the library to determine that number of cDNA clones corresponding to the same gene product, and analyzing the number of clones corresponding to that same gene product relative to the number of clones of the same gene product in a control sample; or by using an array to detect relative levels of hybridization to a selected sequence or set of sequences, and comparing the hybridization pattern to that of a control. The differences in expression are then correlated with the presence or absence of an abnormal expression pattern.
- diagnostic assays of the invention involve detection of a gene product of a the polynucleotide sequence (e.g., mRNA or polypeptide) that corresponds to a sequence of SEQ ID NOs: 1-3351.
- the patient from whom the sample is obtained can be apparently healthy, susceptible to disease (e.g., as determined by family history or exposure to certain environmental factors), or can already be identified as having a condition in which altered expression of a gene product of the invention is implicated.
- Diagnosis can be determined based on detected gene product expression levels of a gene product encoded by at least one, preferably at least two or more, at least 3 or more, or at least 4 or more of the polynucleotides having a sequence set forth in SEQ ID NOs: 1-3351, and can involve detection of expression of genes corresponding to all of SEQ ID NOs: 1-3351 and/or additional sequences that can serve as additional diagnostic markers and/or reference sequences.
- the assay preferably involves detection of a gene product encoded by a gene corresponding to a polynucleotide that is differentially expressed in cancer.
- differentially expressed polynucleotides are described in the Examples below. Given the provided polynucleotides and information regarding their relative expression levels provided herein, assays using such polynucleotides and detection of their expression levels in diagnosis and prognosis will be readily apparent to the ordinarily skilled artisan.
- detectable labels include fluorochromes, (e.g., fluorescein isothiocyanate (FITC), rhodamine, Texas Red, phycoerythrin, allophycocyanin, 6-carboxyfluorescein (6-FAM), 2',7'-dimethoxy-4',5'-dichloro-6-carboxyfluorescein, 6-carboxy-X-rhodamine (ROX), 6-carboxy-2',4',7',4,7-hexachlorofluorescein (HEX), 5-carboxyfluorescein (5-FAM) or N,N,N',N'-tetramethyl-6-carboxyrhodamine (TAMRA)), radioactive labels, (e.g., 32' ?, 35 S, 3 H, etc.), and the like.
- the detectable label can involve a two stage systems
- Reagents specific for the polynucleotides and polypeptides of the invention can be supplied in a kit for detecting the presence of an expression product in a biological sample.
- the kit can also contain buffers or labeling components, as well as instructions for using the reagents to detect and quantify expression products in the biological sample. Exemplary embodiments of the diagnostic methods of the invention are described below in more detail.
- the test sample is assayed for the level of a differentially expressed polypeptide.
- Diagnosis can be accomplished using any of a number of methods to determine the absence or presence or altered amounts of the differentially expressed polypeptide in the test sample.
- detection can utilize staining of cells or histological sections with labeled antibodies, performed in accordance with conventional methods. Cells can be permeabilized to stain cytoplasmic molecules.
- antibodies that specifically bind a differentially expressed polypeptide of the invention are added to a sample, and
- the antibody can be detectably labeled for direct detection (e.g., using radioisotopes, enzymes, fluorescers, chemiluminescers, and the like), or can be used in conjunction with a second stage antibody or reagent to detect binding (e.g., biotin with horseradish peroxidase-conjugated avidin, a secondary antibody conjugated to a fluorescent compound, e.g., fluorescein, rhodamine, Texas red, etc.).
- a second stage antibody or reagent e.g., biotin with horseradish peroxidase-conjugated avidin, a secondary antibody conjugated to a fluorescent compound, e.g., fluorescein, rhodamine, Texas red, etc.
- the absence or presence of antibody binding can be determined by various methods, including flow cytometry of dissociated cells, microscopy, radiography, scintillation counting, etc. Any suitable alternative methods can of qualitative or quantitative detection of levels or amounts of differentially expressed polypeptide can be used, for example ELISA, western blot, immunoprecipitation, radioimmunoassay, etc. mRNA detection.
- the diagnostic methods of the invention can also or alternatively involve detection of mRNA encoded by a gene corresponding to a differentially expressed polynucleotides of the invention. Any suitable qualitative or quantitative methods known in the art for detecting specific mRNAs can be used.
- mRNA can be detected by, for example, in situ hybridization in tissue sections, by reverse transcriptase-PCR, or in Northern blots containing poly A+ mRNA.
- mRNA expression levels in a sample can also be determined by generation of a library of expressed sequence tags (ESTs) from the sample, where the EST library is representative of sequences present in the sample (Adams, et al., (1991) Science 252:1651). Enumeration of the relative representation of ESTs within the library can be used to approximate the relative representation of the gene transcript within the starting sample.
- ESTs expressed sequence tags
- EST analysis of a test sample can then be compared to EST analysis of a reference sample to determine the relative expression levels of a selected polynucleotide, particularly a polynucleotide corresponding to one or more of the differentially expressed genes described herein.
- gene expression in a test sample can be performed using serial analysis of gene expression (SAGE) methodology (e.g., Velculescu et al., Science (1995) 270:484) or differential display (DD) methodology (see, e.g., U.S. Patent NOs. 5,776,683 and 5,807,680).
- SAGE serial analysis of gene expression
- DD differential display
- RNA or cDNA can be used to selectively identify or capture DNA or RNA of specific sequence composition, and the amount of RNA or cDNA hybridized to a known capture sequence determined qualitatively or quantitatively, to provide
- Hybridization analysis can be designed to allow for concurrent screening of the relative expression of hundreds to thousands of genes by using, for example, array-based technologies having high density formats, including filters, microscope slides, or microchips, or solution-based technologies that use spectroscopic analysis (e.g. , mass spectrometry).
- array-based technologies having high density formats, including filters, microscope slides, or microchips, or solution-based technologies that use spectroscopic analysis (e.g. , mass spectrometry).
- spectroscopic analysis e.g. , mass spectrometry
- the diagnostic methods of the invention can focus on the expression of a single differentially expressed gene.
- the diagnostic method can involve detecting a differentially expressed gene, or a polymorphism of such a gene (e.g., a polymorphism in an coding region or control region), that is associated with disease.
- Disease-associated polymorphisms can include deletion or truncation of the gene, mutations that alter expression level and/or affect activity of the encoded protein, etc.
- a number of methods are available for analyzing nucleic acids for the presence of a specific sequence, e.g., a disease associated polymorphism. Where large amounts of DNA are available, genomic DNA is used directly.
- the region of interest is cloned into a suitable vector and grown in sufficient quantity for analysis.
- Cells that express a differentially expressed gene can be used as a source of mRNA, which can be assayed directly or reverse transcribed into cDNA for analysis.
- the nucleic acid can be amplified by conventional techniques, such as the polymerase chain reaction (PCR), to provide sufficient amounts for analysis, and a detectable label can be included in the amplification reaction (e.g., using a detectably labeled primer or detectably labeled oligonucleotides) to facilitate detection.
- PCR polymerase chain reaction
- the amplified or cloned sample nucleic acid can be analyzed by one of a number of methods known in the art.
- the nucleic acid can be sequenced by dideoxy or other methods, and the sequence of bases compared to a selected sequence, e.g., to a wild-type sequence.
- Hybridization with the polymorphic or variant sequence can also be used to determine its presence in a sample (e.g., by Southern blot, dot blot, etc.).
- 5,445,934, or in WO 95/35505 can also be used as a means of identifying polymorphic or variant sequences associated with disease.
- Single strand conformational polymorphism (SSCP) analysis, denaturing gradient gel electrophoresis (DGGE), and heteroduplex analysis in gel matrices are used to detect conformational changes created by DNA sequence variation as alterations in electrophoretic mobility.
- SSCP Single strand conformational polymorphism
- DGGE denaturing gradient gel electrophoresis
- heteroduplex analysis in gel matrices are used to detect conformational changes created by DNA sequence variation as alterations in electrophoretic mobility.
- a polymorphism creates or destroys a recognition site for a restriction endonuclease
- the sample is digested with that endonuclease, and the products size fractionated to determine whether the fragment was digested. Fractionation is performed by gel or capillary electrophoresis, particularly acrylamide or agarose gels.
- Screening for mutations in a gene can be based on the functional or antigenic characteristics of the protein. Protein truncation assays are useful in detecting deletions that can affect the biological activity of the protein. Various immunoassays designed to detect polymorphisms in proteins can be used in screening. Where many diverse genetic mutations lead to a particular disease phenotype, functional protein assays have proven to be effective screening tools. The activity of the encoded protein can be determined by comparison with the wild-type protein.
- the diagnostic and/or prognostic methods of the invention involve detection of expression of a selected set of genes in a test sample to produce a test expression pattern (TEP).
- TEP test expression pattern
- REP reference expression pattern
- the selected set of genes includes at least one of the genes of the invention, which genes correspond to the polynucleotide sequences of SEQ ID NOs: l-3351.
- Of particular interest is a selected set of genes that includes genes differentially expressed in the disease for which the test sample is to be screened.
- Reference sequences or “reference polynucleotides” as used herein in the context of differential gene expression analysis and diagnosis/prognosis refers to a selected set of polynucleotides, which selected set includes at least one or more of the differentially expressed polynucleotides described herein.
- a plurality of reference sequences preferably comprising positive and negative control sequences, can be included as reference sequences. Additional suitable reference sequences are found in Genbank, Unigene, and other nucleotide sequence databases (including, e.g., expressed sequence tag (EST), partial, and full-length sequences).
- EST expressed sequence tag
- Reference array means an array having reference sequences for use in hybridization with a sample, where the reference sequences include all, at least one of,
- Arrays of interest can further comprise sequences, including polymorphisms, of other genetic sequences, particularly other sequences of interest for screening for a disease or disorder (e.g., cancer, dysplasia, or other related or unrelated diseases, disorders, or conditions).
- the oligonucleotide sequence on the array will usually be at least about 12 nt in length, and can be of about the length of the provided sequences, or can extend into the flanking regions to generate fragments of 100 nt to 200 nt in length or more.
- Reference arrays can be produced according to any suitable methods known in the art. For example, methods of producing large arrays of oligonucleotides are described in U.S. Patent Nos. 5,134,854 and 5,445,934 using light-directed synthesis techniques. Using a computer controlled system, a heterogeneous array of monomers is converted, through simultaneous coupling at a number of reaction sites, into a heterogeneous array of polymers. Alternatively, microarrays are generated by deposition of pre-synthesized oligonucleotides onto a solid substrate, for example as described in PCT published application no. WO 95/35505.
- a “reference expression pattern” or “REP” as used herein refers to the relative levels of expression of a selected set of genes, particularly of differentially expressed genes, that is associated with a selected cell type, e.g., a normal cell, a cancerous cell, a cell exposed to an environmental stimulus, and the like.
- a “test expression pattern” or “TEP” refers to relative levels of expression of a selected set of genes, particularly of differentially expressed genes, in a test sample (e.g., a cell of unknown or suspected disease state, from which mRNA is isolated). REPs can be generated in a variety of ways according to methods well known in the art.
- REPs can be generated by hybridizing a control sample to an array having a selected set of polynucleotides (particularly a selected set of differentially expressed polynucleotides), acquiring the hybridization data from the array, and storing the data in a format that allows for ready comparison of the REP with a TEP.
- all expressed sequences in a control sample can be isolated and sequenced, e.g., by isolating mRNA from a control sample, converting the mRNA into cDNA, and sequencing the cDNA. The resulting sequence information roughly or precisely reflects the identity and relative number of expressed sequences in the sample.
- the sequence information can then be stored in a format (e.g., a computer-readable format) that allows for ready comparison of the REP with a TEP.
- the REP can be normalized prior to or after data storage, and/or can be processed to selectively remove sequences of expressed genes that are of less interest or that might complicate analysis (e.g., some or all of the sequences associated with housekeeping genes can be eliminated from REP data).
- TEPs can be generated in a manner similar to REPs, e.g., by hybridizing a test sample to an array having a selected set of polynucleotides, particularly a selected set of differentially expressed polynucleotides, acquiring the hybridization data from the array, and storing the data in a format that allows for ready comparison of the TEP with a REP.
- the REP and TEP to be used in a comparison can be generated simultaneously, or the TEP can be compared to previously generated and stored REPs.
- comparison of a TEP with a REP involves hybridizing a test sample with a reference array, where the reference array has one or more reference sequences for use in hybridization with a sample.
- the reference sequences include all, at least one of, or any subset of the differentially expressed polynucleotides described herein.
- Hybridization data for the test sample is acquired, the data normalized, and the produced TEP compared with a REP generated using an array having the same or similar selected set of differentially expressed polynucleotides. Probes that correspond to sequences differentially expressed between the two samples will show decreased or increased hybridization efficiency for one of the samples relative to the other.
- the polynucleotides of the reference and test samples can be generated using a detectable fluorescent label, and hybridization of the polynucleotides in the samples detected by scanning the microarrays for the presence of the detectable label using, for example, a microscope and light source for directing light at a substrate.
- a photon counter detects fluorescence from the substrate, while an x-y translation stage varies the location of the substrate.
- a confocal detection device that can be used in the subject methods is described in U.S. Patent No. 5,631,734.
- a scanning laser microscope is described in Shalon et al., Genome Res. (1996) 6:639.
- the digital images generated from the scan are then combined for subsequent analysis.
- the ratio of the fluorescent signal from one sample e.g., a test sample
- the fluorescent signal from another sample e.g., a reference sample
- the relative signal intensity determined is determined.
- Methods for analyzing the data collected from hybridization to arrays are well known in the art. For example, where detection of hybridization involves a fluorescent label, data analysis can include the steps of determining fluorescent intensity as a function of substrate position from the data collected, removing outliers, i.e., data deviating from a predetermined statistical distribution, and calculating the relative binding affinity of the targets from the remaining data. The resulting data can be displayed as an image with the intensity in each region varying according to the binding affinity between targets and probes.
- the test sample is classified as having a gene expression profile corresponding to that associated with a disease or non-disease state by comparing the TEP generated from the test sample to one or more REPs generated from reference samples (e.g., from samples associated with cancer or specific stages of cancer, dysplasia, samples affected by a disease other than cancer, normal samples, etc.).
- the criteria for a match or a substantial match between a TEP and a REP include expression of the same or substantially the same set of reference genes, as well as expression of these reference genes at substantially the same levels (e.g., no significant difference between the samples for a signal associated with a selected reference sequence after normalization of the samples, or at least no greater than about 25% to about 40% difference in signal strength for a given reference sequence.
- a pattern match between a TEP and a REP includes a match in expression, preferably a match in qualitative or quantitative expression level, of at least one of, all or any subset of the differentially expressed genes of the invention.
- Pattern matching can be performed manually, or can be performed using a computer program.
- Methods for preparation of substrate matrices e.g., arrays
- design of oligonucleotides for use with such matrices labeling of probes, hybridization conditions, scanning of hybridized matrices, and analysis of patterns generated, including comparison analysis, are described in, for example, U.S. Patent No. 5,800,992.
- polynucleotides of the invention and their gene products are of particular interest as genetic or biochemical markers (e.g., in blood or tissues) that will detect the earliest changes along the carcinogenesis pathway and/or to monitor the efficacy of various therapies and preventive interventions.
- biochemical markers e.g., in blood or tissues
- the level of expression of certain polynucleotides can be indicative of a poorer prognosis
- i> therefore warrant more aggressive chemo- or radio-therapy for a patient or vice versa.
- the correlation of novel surrogate tumor specific features with response to treatment and outcome in patients can define prognostic indicators that allow the design of tailored therapy based on the molecular profile of the tumor.
- These therapies include antibody targeting and gene therapy. Determining expression of certain polynucleotides and comparison of a patients profile with known expression in normal tissue and variants of the disease allows a determination of the best possible treatment for a patient, both in terms of specificity of treatment and in terms of comfort level of the patient.
- Surrogate tumor markers, such as polynucleotide expression can also be used to better classify, and thus diagnose and treat, different forms and disease states of cancer. Two classifications widely used in oncology that can benefit from identification of the expression levels of the polynucleotides of the invention are staging of the cancerous disorder, and grading the nature of the cancerous tissue.
- the polynucleotides of the invention can be useful to monitor patients having or susceptible to cancer to detect potentially malignant events at a molecular level before they are detectable at a gross morphological level.
- a polynucleotide of the invention identified as important for one type of cancer can also have implications for development or risk of development of other types of cancer, e.g., where a polynucleotide is differentially expressed across various cancer types.
- expression of a polynucleotide that has clinical implications for metastatic colon cancer can also have clinical implications for stomach cancer or endometrial cancer.
- Staging is a process used by physicians to describe how advanced the cancerous state is in a patient. Generally, if a cancer is only detectable in the area of the primary lesion without having spread to any lymph nodes it is called Stage I. If it has spread only to the closest lymph nodes, it is called Stage II. In Stage III, the cancer has generally spread to the lymph nodes in near proximity to the site of the primary lesion. Cancers that have spread to a distant part of the body, such as the liver, bone, brain or other site, are Stage IV, the most advanced stage.
- the polynucleotides of the invention can facilitate fine-tuning of the staging process by identifying markers for the aggresivity of a cancer, e.g., the metastatic potential, as well as the presence in different areas of the body.
- a Stage II cancer with a polynucleotide signifying a high metastatic potential cancer can be used to change a borderline Stage II tumor to a Stage III tumor, justifying more aggressive
- Grade is a term used to describe how closely a tumor resembles normal tissue of its same type.
- the microscopic appearance of a tumor is used to identify tumor grade based on parameters such as cell morphology, cellular organization, and other markers of differentiation.
- the grade of a tumor corresponds to its rate of growth or aggressiveness, with undifferentiated or high- grade tumors being more aggressive than well differentiated or low-grade tumors.
- the following guidelines are generally used for grading tumors: 1) GX Grade cannot be assessed; 2) Gl Well differentiated; G2 Moderately well differentiated; 3) G3 Poorly differentiated; 4) G4 Undifferentiated.
- the polynucleotides of the invention can be especially valuable in determining the grade of the tumor, as they not only can aid in determining the differentiation status of the cells of a tumor, they can also identify factors other than differentiation that are valuable in determining the aggressivity of a tumor, such as metastatic potential.
- the polynucleotides of the invention can be used to detect lung cancer in a subject.
- the two main types of lung cancer are small cell and nonsmall cell, which encompass about 90% of all lung cancer cases.
- Small cell carcinoma also called oat cell carcinoma
- Nonsmall cell lung cancer NSCLC
- Epidermoid carcinoma also called squamous cell carcinoma
- the size of these tumors can range from very small to quite large.
- Adenocarcinoma starts growing near the outside surface of the lung and can vary in both size and growth rate. Some slowly growing adenocarcinomas are described as alveolar cell cancer. Large cell carcinoma starts near the surface of the lung, grows rapidly, and the growth is usually fairly large when diagnosed. Other less common forms of lung cancer are carcinoid, cylindroma, mucoepidermoid, and malignant mesothelioma.
- polynucleotides of the invention e.g., polynucleotides differentially expressed in normal cells versus cancerous lung cells (e.g., tumor cells of high or low metastatic potential) or between types of cancerous lung cells (e.g., high metastatic versus low metastatic), can be used to distinguish types of lung cancer as well as identifying traits specific to a certain patient's cancer and selecting an appropriate therapy. For example, if the patient's biopsy expresses a polynucleotide that is associated with a low metastatic potential, it may justify leaving a larger portion of the patient's lung in surgery to remove the lesion. Alternatively, a smaller lesion with expression of a polynucleotide that is associated with high metastatic potential may justify a more radical removal of lung tissue and/or the surrounding lymph nodes, even if no metastasis can be identified through pathological examination.
- cancerous lung cells e.g., tumor cells of high or low metastatic potential
- types of cancerous lung cells e.
- ductal carcinoma in situ including comedocarcinoma
- IDC infiltrating (or invasive) ductal carcinoma
- LCIS lobular carcinoma in situ
- ILC infiltrating (or invasive) lobular carcinoma
- inflammatory breast cancer 6) medullary carcinoma; 7) mucinous carcinoma; 8) Paget's disease of the nipple; 9) Phyllodes tumor; and 10) tubular carcinoma.
- polynucleotides of the invention can be used in the diagnosis and management of breast cancer, as well as to distinguish between types of breast cancer. Detection of breast cancer can be determined using expression levels of any of the appropriate polynucleotides of the invention, either alone or in combination. Determination of the aggressive nature and/or the metastatic potential of a breast cancer can also be determined by comparing levels of one or more polynucleotides of the invention and comparing levels of another sequence known to vary in cancerous tissue, e.g., ER expression.
- breast cancer development of breast cancer can be detected by examining the ratio of expression of a differentially expressed polynucleotide to the levels of steroid hormones (e.g., testosterone or estrogen) or to other hormones (e.g., growth hormone, insulin).
- steroid hormones e.g., testosterone or estrogen
- other hormones e.g., growth hormone, insulin.
- expression of specific marker polynucleotides can be used to discriminate between normal and cancerous breast tissue, to discriminate between breast cancers with different cells of origin, to discriminate between breast cancers with different potential metastatic rates, etc.
- Colorectal cancer is one of the most common neoplasms in humans and perhaps the most frequent form of hereditary neoplasia. Prevention and early detection are key factors in controlling and curing colorectal cancer. Colorectal cancer begins as polyps, which are small, benign growths of cells that form on the inner lining of the colon. Over a period of several years, some of these polyps accumulate additional mutations and become cancerous.
- Familial adenomatous polyposis FAP
- Gardner's syndrome Hereditary nonpolyposis colon cancer
- HNPCC Hereditary nonpolyposis colon cancer
- Familial colorectal cancer in Ashkenazi Jews The expression of appropriate polynucleotides of the invention can be used in the diagnosis, prognosis and management of colorectal cancer. Detection of colon cancer can be determined using expression levels of any of these sequences alone or in combination with the levels of expression.
- Determination of the aggressive nature and/or the metastatic potential of a colon cancer can be determined by comparing levels of one or more polynucleotides of the invention and comparing total levels of another sequence known to vary in cancerous tissue, e.g., expression of p53, DCC ras, lor FAP (see, e.g., Fearon ER, et al., Cell (1990) 67(5):759; Hamilton SR et al., Cancer (1993) 72:957; Bodmer W, et al., Nat Genet. (1994) 4(3):2 ⁇ 1; Fearon ER, Ann N Y Acad Sci. (1995) 765:101).
- development of colon cancer can be detected by examining the ratio of any of the polynucleotides of the invention to the levels of oncogenes (e.g., ras) or tumor suppressor genes (e.g., FAP or p53).
- oncogenes e.g., ras
- tumor suppressor genes e.g., FAP or p53.
- Polypeptides encoded by the instant polynucleotides and corresponding full length genes can be used to screen peptide libraries to identify binding partners, such as receptors, from among the encoded polypeptides.
- Peptide libraries can be synthesized according to methods known in the art (see, e.g., U.S. Patent No. 5,010,175, and WO 91/17823).
- Agonists or antagonists of the polypeptides if the invention can be screened using any available method known in the art, such as signal transduction, antibody binding, receptor binding, mitogenic assays, chemotaxis assays, etc.
- the assay conditions ideally should resemble the conditions under which the native activity is exhibited in vivo, that is, under physiologic pH, temperature, and ionic strength. Suitable agonists or antagonists will exhibit strong inhibition or enhancement of the native activity at concentrations that do not cause toxic side effects in the subject. Agonists or antagonists that compete for binding to the native polypeptide can require concentrations equal to or greater than the native concentration, while inhibitors capable of binding irreversibly to the polypeptide can be added in concentrations on the order of the native concentration.
- Such screening and experimentation can lead to identification of a novel polypeptide binding partner, such as a receptor, encoded by a gene or a cDNA corresponding to a polynucleotide of the invention, and at least one peptide agonist or antagonist of the novel binding partner.
- a novel polypeptide binding partner such as a receptor, encoded by a gene or a cDNA corresponding to a polynucleotide of the invention
- agonists and antagonists can be used to modulate, enhance, or inhibit receptor function in cells to which the receptor is native, or in cells that possess the receptor as a result of genetic engineering.
- information about agonist/antagonist binding can facilitate development of improved agonists/antagonists of the known receptor.
- compositions of the invention can comprise polypeptides, antibodies, or polynucleotides (including antisense nucleotides and ribozymes) of the claimed invention in a therapeutically effective amount.
- therapeutically effective amount refers to an amount of a therapeutic agent to treat, ameliorate, or prevent a desired disease or condition, or to exhibit a detectable therapeutic or preventative effect. The effect can be detected by, for example, chemical markers or antigen levels. Therapeutic effects also include reduction in physical symptoms, such as decreased body temperature. The precise effective amount for a subject will depend upon the subject's size and health, the nature and extent of the condition, and the therapeutics or combination of therapeutics selected for administration. Thus, it is not useful to specify an exact effective amount in advance.
- an effective dose will generally be from about 0.01 mg/ kg to 50 mg/kg or 0.05 mg/kg to about 10 mg/kg of the DNA constructs in the individual to which it is administered.
- a pharmaceutical composition can also contain a pharmaceutically acceptable carrier.
- pharmaceutically acceptable carrier refers to a carrier for administration of a therapeutic agent, such as antibodies or a polypeptide, genes, and other therapeutic agents.
- the term refers to any pharmaceutical carrier that does not itself induce the production of antibodies harmful to the individual receiving the composition, and which can be administered without undue toxicity.
- Suitable carriers can be large, slowly metabolized macromolecules such as proteins, polysaccharides, polylactic acids, polyglycolic acids, polymeric amino acids, amino acid copolymers,
- compositions can include liquids such as water, saline, glycerol and ethanol. Auxiliary substances, such as wetting or emulsifying agents, pH buffering substances, and the like, can also be present in such vehicles.
- the therapeutic compositions are prepared as injectables, either as liquid solutions or suspensions; solid forms suitable for solution in, or suspension in, liquid vehicles prior to injection can also be prepared. Liposomes are included within the definition of a pharmaceutically acceptable carrier.
- compositions of the invention can be (1) administered directly to the subject (e.g., as polynucleotide or polypeptides); or (2) delivered ex vivo, to cells derived from the subject (e.g., as in ex vivo gene therapy).
- Direct delivery of the compositions will generally be accomplished by parenteral injection, e.g., subcutaneously, intraperitoneally, intravenously or intramuscularly, intratumoral or to the interstitial space of a tissue.
- parenteral injection e.g., subcutaneously, intraperitoneally, intravenously or intramuscularly, intratumoral or to the interstitial space of a tissue.
- Other modes of administration include oral and pulmonary administration, suppositories, and transdermal applications, needles, and gene guns or hyposprays.
- Dosage treatment can be a single dose schedule or a multiple dose schedule.
- cells useful in ex vivo applications include, for example, stem cells, particularly hematopoetic, lymph cells, macrophages, dendritic cells, or tumor cells.
- nucleic acids for both ex vivo and in vitro applications can be accomplished by, for example, dextran-mediated transfection, calcium phosphate precipitation, polybrene mediated transfection, protoplast fusion, electroporation, encapsulation of the polynucleotide(s) in liposomes, and direct microinjection of the DNA into nuclei, all well known in the art.
- a gene corresponding to a polynucleotide of the invention has been found to correlate with a proliferative disorder, such as neoplasia, dysplasia, and hyperplasia, the disorder can be amenable to treatment by administration of a proliferative disorder, such as neoplasia, dysplasia, and hyperplasia, the disorder can be amenable to treatment by administration of a proliferative disorder, such as neoplasia, dysplasia, and hyperplasia, the disorder can be amenable to treatment by administration of a proliferative disorder, such as neoplasia, dysplasia, and hyperplasia, the disorder can be amenable to treatment by administration of a proliferative disorder, such as neoplasia, dysplasia, and hyperplasia.
- Hi therapeutic agent based on the provided polynucleotide, corresponding polypeptide or other corresponding molecule (e.g., antisense, ribozyme, etc.).
- the dose and the means of administration of the inventive pharmaceutical compositions are determined based on the specific qualities of the therapeutic composition, the condition, age, and weight of the patient, the progression of the disease, and other relevant factors.
- administration of polynucleotide therapeutic compositions agents of the invention includes local or systemic administration, including injection, oral administration, particle gun or catheterized administration, and topical administration.
- the therapeutic polynucleotide composition contains an expression construct comprising a promoter operably linked to a polynucleotide of at least 12, 22, 25, 30, or 35 contiguous nt of the polynucleotide disclosed herein.
- Various methods can be used to administer the therapeutic composition directly to a specific site in the body.
- a small metastatic lesion is located and the therapeutic composition injected several times in several different locations within the body of tumor.
- arteries which serve a tumor are identified, and the therapeutic composition injected into such an artery, in order to deliver the composition directly into the tumor.
- a tumor that has a necrotic center is aspirated and the composition injected directly into the now empty center of the tumor.
- the antisense composition is directly administered to the surface of the tumor, for example, by topical application of the composition.
- X-ray imaging is used to assist in certain of the above delivery methods.
- Receptor-mediated targeted delivery of therapeutic compositions containing an antisense polynucleotide, subgenomic polynucleotides, or antibodies to specific tissues can also be used.
- Receptor-mediated DNA delivery techniques are described in, for example, Findeis et al., Trends Biotechnol. (1993) 77:202; Chiou et al., Gene Therapeutics: Methods And Applications Of Direct Gene Transfer (J. A. Wolff, ed.) (1994); Wu et al., J. Biol. Chem. (1988) 265:621 ; Wu et al., J. Biol. Chem. (1994) 269:542; Zenke et al., Proc. Natl. Acad. Sci.
- compositions containing a polynucleotide are administered in a range of about 100 ng to about 200 mg of DNA for local administration in a gene therapy protocol. Concentration ranges of about 500 ng to about 50 mg, about 1 mg to about 2 mg, about 5 mg to about 500 mg, and about 20 mg to about 100 mg of DNA can also be used during a gene therapy protocol. Factors such as method of action (e.g., for enhancing or inhibiting levels of the encoded gene product) and efficacy of transformation and expression are considerations which will
- the therapeutic polynucleotides and polypeptides of the present invention can be delivered using gene delivery vehicles.
- the gene delivery vehicle can be of viral or non-viral origin (see generally, Jolly, Cancer Gene Therapy (1994) 7:51; Kimura, Human Gene Therapy (1994) 5:845; Connelly, Human Gene Therapy (1995) 7:185; and Kaplitt, Nature Genetics (1994) 6:148). Expression of such coding sequences can be induced using endogenous mammalian or heterologous promoters. Expression of the coding sequence can be either constitutive or regulated.
- Viral-based vectors for delivery of a desired polynucleotide and expression in a desired cell are well known in the art.
- Exemplary viral-based vehicles include, but are not limited to, recombinant retroviruses (see, e.g., WO 90/07936; WO 94/03622; WO 93/25698; WO 93/25234; U.S. Patent No. 5, 219,740; WO 93/1 1230; WO 93/10218; U.S. Patent No. 4,777,127; GB Patent No.
- alphavirus-based vectors e.g., Sindbis virus vectors, Semliki forest virus (ATCC VR-67; ATCC VR-1247), Ross River virus (ATCC VR-373; ATCC VR- 1246) and Venezuelan equine encephalitis virus (ATCC VR-923; ATCC VR-1250; ATCC VR 1249; ATCC VR-532), and adeno-associated virus (AAV) vectors (see, e.g., WO 94/12649, WO 93/03769; WO 93/19191 ; WO 94/28938; WO 95/11984 and WO 95/00655).
- AAV adeno-associated virus
- Non-viral delivery vehicles and methods can also be employed, including, but not limited to, polycationic condensed DNA linked or unlinked to killed adenovirus alone (see, e.g., Curiel, Hum. Gene Ther. (1992) 5:147); ligand-linked DNA(see, e.g., Wu, J. Biol. Chem. 264:16985 (1989)); eukaryotic cell delivery vehicles cells (see, e.g., U.S. Patent No. 5,814,482; WO 95/07994; WO 96/17072; WO 95/30763; and WO 97/42338) and nucleic charge neutralization or fusion with cell membranes. Naked DNA can also be employed.
- Exemplary naked DNA introduction methods are described in WO 90/11092 and U.S. Patent No. 5,580,859.
- Liposomes that can act as gene delivery vehicles are described in U.S. Patent No. 5,422,120; WO 95/13796; WO 94/23697; WO 91/14445; and EP 0524968. Additional approaches are described in Philip, Mol. Cell Biol. 14:24 1 (1994), and in Woffendin, Proc. Natl. Acad. Sci. (1994) 97:1581.
- non-viral delivery suitable for use includes mechanical delivery systems such as the approach described in Woffendin et al., Proc. Natl. Acad. Sci. USA 97(24): 1 1581 (1994).
- the coding sequence and the product of expression of such can be delivered through deposition of photopolymerized hydrogel materials or use of ionizing radiation (see, e.g., U.S. Patent No. 5,206,152 and WO 92/11033).
- Other conventional methods for gene delivery that can be used for delivery of the coding sequence include, for example, use of hand-held gene transfer particle gun (see, e.g., U.S. Patent No.
- the cells lines include Kml2L4-A cell line, a high metastatic colon cancer cell line (Morika, W. A. K. et al., Cancer Research (1988) ⁇ 5:6863).
- the KM 12L4-A cell line is derived from the KM 12C cell line.
- the KM12C cell line, which is poorly metastatic (low metastatic) was established in culture from a Dukes' stage B2 surgical specimen (Morikawa et al. Cancer Res. (1988) ⁇ 5:6863).
- the KML4-A is a highly metastatic subline derived from KM12C (Yeatman et al. Nucl. Acids. Res. (1995) 25:4007; Bao-Ling et al. Proc. Annu. Meet. Am. Assoc. Cancer. Res. (1995) 27:3269).
- the KM12C and KM12C-derived cell lines e.g., KM12L4, KM12L4-A, etc.
- model cell lines for the study of colon cancer see, e.g., Moriakawa et al., supra; Radinsky et al. Clin. Cancer Res.
- Genbank search sequences that exhibited greater than 70% overlap, 99% identity, and a p value of less than 1 x 10 "40 were discarded. Sequences from this search also were discarded if the inclusive parameters were met, but the sequence was ribosomal or vector-derived.
- the resulting sequences from the previous search were classified into three groups (1, 2 and 3 below) and searched in a BLASTX vs. NRP (non-redundant proteins) database search: (1) unknown (no hits in the Genbank search), (2) weak similarity (greater than 45% identity and p value of less than 1 x 10 "5 ), and (3) high similarity (greater than 60% overlap, greater than 80% identity, and p value less than 1 x 10 "5 ). Sequences having greater than 70% overlap, greater than 99% identity, and p value of less than 1 x 10 "40 were discarded.
- sequences were classified as unknown (no hits), weak similarity, and high similarity (parameters as above). Two searches were performed on these sequences. First, a BLAST vs. EST database search was performed and sequences with greater than 99% overlap, greater than 99% similarity and a p value of less than 1 x 10 "40 were discarded. Sequences with a p value of less than 1 x 10 "65 when compared to a database sequence of human origin were also excluded. Second, a BLASTN vs. Patent GeneSeq database was performed and sequences having greater than 99% identity, p value less than 1 x 10 "40 , and greater than 99% overlap were discarded.
- sequences were subjected to screening using other rules and redundancies in the dataset. Sequences with a p value of less than 1 x 10 " "' in relation to a database sequence of human origin were specifically excluded. The final result provided the 3351 sequences listed in the accompanying Sequence Listing. Each identified polynucleotide represents sequence from at least a partial mRNA transcript. Polynucleotides that were determined to be novel were assigned a sequence identification number.
- the novel polynucleotides were assigned sequence identification numbers SEQ ID NOs:l-3351.
- the first 1847 DNA sequences corresponding to the novel polynucleotides are provided in the Sequence Listing in Table 1.
- DNA sequences corresponding to the novel polynucleotides of SEQ ID NOs: 1848-3351 are provided in the Sequence Listing in Table 2.
- Table 4 Each DNA sequence in Table 4 is uniquely identified by a number that is 1847 less than its SEQ ID NO in the Sequence Listing.
- Tables 1 and 2 provide: 1) the SEQ ID NO assigned to each sequence for use in the present specification or a corresponding number; 2) the sequence name used as an internal identifier of the sequence; 3) the name assigned to the clone from which the
- Cluster ID where the cluster ID is 0, the sequence was not assigned to any cluster.
- two or more polynucleotides of the invention may represent different regions of the same mRNA transcript and the same gene. Thus, if two or more SEQ ID NOs: are identified as belonging to the same clone, then either sequence can be used to obtain the full-length mRNA or gene.
- SEQ ID NOs: 1-3351 were translated in all three reading frames to determine the best alignment with the individual sequences. These amino acid sequences and nucleotide sequences are referred to, generally, as query sequences, which are aligned with the individual sequences. Query and individual sequences were aligned using the BLAST programs, available over the world wide web at http://www.ncbi.nlm.nih.gov/BLAST/. Again the sequences were masked to various extents to prevent searching of repetitive sequences or poly-A sequences, using the XBLAST program for masking low complexity as described above in Example 1.
- Tables 3 and 4 show the results of the alignments.
- Table 3 contains alignment information for SEQ ID NOs: 1-1847 and Table 4 contains alignment information for SEQ ID NOs: 1848-3351.
- the DNA sequences of Table 4 while numbered SEQ ID 1-1504, correspond to SEQ ID NOs: 1848-3351.
- Each DNA sequence in Table 4 is uniquely identified by a number that is 1847 less than its SEQ ID NO.
- Tables 3 and 4 refer to each sequence by its SEQ ID NO or a corresponding number, the accession numbers and descriptions of nearest neighbors from the Genbank and Non- Redundant Protein searches, and the p values of the search results.
- SEQ ID NOs:l-1847 For each of SEQ ID NOs:l-1847, the best alignment to a protein or DNA sequence is included in Table 3, and the best alignment for each of SEQ ID NOs: 1848- 3351 is included in Table 4.
- the activity of the polypeptide encoded by SEQ ID NOs: 1-3351 is the same or similar to the nearest neighbor reported in Table 3 or 4.
- the accession number of the nearest neighbor is reported, providing a reference to the activities exhibited by the nearest neighbor.
- the search program and database used for the alignment also are indicated as well as a calculation of the p value.
- ⁇ S Full length sequences or fragments of the polynucleotide sequences of the nearest neighbors can be used as probes and primers to identify and isolate the full length sequence of SEQ ID NOs: 1-3351.
- the nearest neighbors can indicate a tissue or cell type to be used to construct a library for the full-length sequences of SEQ ID NOs:l-3351.
- sequences (SEQ ID NOs:l-3351) were used to conduct a profile search as described in the specification above.
- Several of the polynucleotides of the invention were found to encode polypeptides having characteristics of a polypeptide belonging to a known protein families (and thus represent new members of these protein families) and/or comprising a known functional domain (Table 5).
- “Start” and “stop” in Table 3 indicate the position within the individual sequences that align with the query sequence having the indicated SEQ ID NO.
- the direction indicates the orientation of the query sequence with respect to the individual sequence, where forward (for) indicates that the alignment is in the same direction (left to right) as the sequence provided in the Sequence Listing and reverse (rev) indicates that the alignment is with a sequence complementary to the sequence provided in the Sequence Listing.
- polynucleotides exhibited multiple profile hits because, for example, the particular sequence contains overlapping profile regions, and/or the sequence contains two different functional domains. These profile hits are described in more detail below.
- Ank Repeats (ANK). SEQ ID NOs: 187, 1268, 1804, 1819, 1830, 1839,
- 2652, 3015 and 3267 represent polynucleotides encoding an Ank repeat-containing protein.
- the ankyrin motif is a 33 amino acid sequence named for the protein ankyrin which has 24 tandem 33-amino-acid motifs.
- Ank repeats were originally identified in the cell-cycle-control protein cdclO (Breeden et al., Nature (1987) 529:651).
- Proteins containing ankyrin repeats include ankyrin, myotropin, I-kappaB proteins, cell cycle protein cdclO, the Notch receptor (Matsuno et al., Development (1997) 124(21):4265); G9a (or BAT8) of the class III region of the major histocompatibility complex (Biochem J. 290:811-818, 1993), FABP, GABP, 53BP2, Linl2, glp-1, SW14, and SW16.
- the functions of the ankyrin repeats are compatible with a role in protein- protein interactions (Bork, Proteins (1993) 77( ⁇ ):363; Lambert and Bennet, Eur. J Biochem. (1993) 277:1 ; Kerr et al., Current Op. Cell Biol. (1992) :496; Bennet et al., J. Biol. Chem. (1980) 255:6424).
- AAA protein family is composed of a large number of ATPases that share a conserved region of about 220 amino acids that contains an ATP-binding site (Froehlich et al., J Cell Biol. (1991) 77 ⁇ :443; Erdmann et al., Cell (1991) 6 ⁇ :499; Peters et al., EMBO J.
- the proteins that belong to this family either contain one or two AAA domains. In general, the AAA domains in these proteins act as ATP-dependent protein clamps (Confalonieri et al. (1995) BioEssays 77:639).
- SEQ ID NO: 1814 represents a polynucleotide encoding a polypeptide having a bromodomain region (Haynes et al., 1992, Nucleic Acids Res.
- ID Nos:410, 552, 768, 822, 836, 1288, 1365, 1454, 1540, 1549, 1556, 1557, 1563, 1622, 1630, 1704, 1808, 2363, 2424, 3147, 3152, 3158 and 3208 represent polynucleotides encoding a novel member of the family of basic region plus leucine zipper transcription factors.
- the bZIP superfamily Hurst, Protein Prof. (1995) 2:105; and EUenberger, Curr. Opin. Struct. Biol. (1994) 4:12 of eukaryotic DNA-binding
- ⁇ transcription factors encompasses proteins that contain a basic region mediating sequence-specific DNA-binding followed by a leucine zipper required for dimerization.
- the consensus pattern for this protein family is: [KR]-x(l,3)-[RKSAQ]-N-x(2)- [SAQ](2)-x-[RKTAENQ]-x-R-x-[RK].
- EF Hand (EFhand). SEQ ID NOs:820, 1755 and 3285 correspond to polynucleotides encoding a novel protein in the family of EF-hand proteins. Many calcium-binding proteins belong to the same evolutionary family and share a type of calcium-binding domain known as the EF-hand (Kawasaki et al., Protein. Prof.
- This type of domain consists of a twelve residue loop flanked on both sides by a twelve residue alpha-helical domain.
- the calcium ion is coordinated in a pentagonal bipyramidal configuration.
- the six residues involved in the binding are in positions 1, 3, 5, 7, 9 and 12; these residues are denoted by X, Y, Z, -Y, -X and -Z.
- the invariant Glu or Asp at position 12 provides two oxygens for liganding Ca (bidentate ligand).
- the consensus pattern includes the complete EF-hand loop as well as the first residue which follows the loop and which seem to always be hydrophobic: D-x-[DNS]- ⁇ ILVFYW ⁇ -[DENSTG]-[DNQGHRK]- ⁇ GP ⁇ -[LIVMC]-
- Ets Domain (Ets Nterm).
- SEQ ID NO: 1811 represents a polynucleotide encoding a polypeptide with N-terminal homology in ETS domain. Proteins of this family contain a conserved domain, the "ETS-domain,” that is involved in DNA binding. The domain appears to recognize purine-rich sequences; it is about 85 to 90 amino acids in length, and is rich in aromatic and positively charged residues (Wasylyk, et al., Eur. J. Biochem. (1993) 277:718).
- the ets gene family encodes a novel class of DNA-binding proteins, each of which binds a specific DNA sequence and comprises an ets domain that specifically interacts with sequences containing the common core tri- nucleotide sequence GGA.
- native ets proteins comprise other sequences which can modulate the biological specificity of the protein.
- Ets genes and proteins are involved in a variety of essential biological processes including cell growth, differentiation and development, and three members are implicated in oncogenic process.
- G-Protein Alpha Subunit S ⁇ Q ID NO: 1846 represents a polynucleotide encoding a novel polypeptide of the G-protein alpha subunit family.
- Guanine nucleotide binding proteins are a family of membrane-associated proteins that couple extracellularly-activated integral -membrane receptors to intracellular effectors, such as ion channels and enzymes that vary the concentration of second messenger molecules.
- G-proteins are composed of 3 subunits (alpha, beta and gamma) which, in the resting state, associate as a trimer at the inner face of the plasma membrane. The alpha subunit binds GTP and exhibits GTPase activity.
- G-protein alpha subunits are 350-400 amino acids in length and have molecular weights in the range 40- 45 kDa. Seventeen distinct types of alpha subunit have been identified in mammals, and fall into 4 main groups on the basis of both sequence similarity and function: alpha- s, alpha-q, alpha-i and alpha-12 (Simon et al., Science (1993) 252:802). They are often N-terminally acylated, usually with myristate and or palmitoylate, and these fatty acid modifications can be important for membrane association and high- affinity interactions with other proteins.
- SEQ ID NOs: 1496, 2826 and 2871 represent polynucleotides encoding novel members of the DEAD/H helicase family.
- a number of eukaryotic and prokaryotic proteins have been characterized (Schmid S.R., et al., Mol. Microbiol. (1992) 6:283; Linder P., et al., Nature (1989) 557:121; Wassarman D.A., et al., Nature (1991) 349:463) on the basis of their structural similarity. All are involved in ATP-dependent, nucleic-acid unwinding.
- DEAD box family members of the above proteins share a number of conserved sequence motifs, some of which are specific to the DEAD family while others are shared by other ATP-binding proteins or by proteins belonging to the helicases 'superfamily' (Hodgman T.C., Nature (1988) 555:22 and Nature (1988) 555:578 (Errata).
- One of these motifs called the "D-E-A-D-box", represents a special version of the B motif of ATP-binding proteins.
- signature patterns are used to identify members of both subfamilies: 1) [LIVMF](2)-D- E-A-D-[RKEN]-x-[LIVMFYGSTN]; and 2) [GSAH]-x-[LIVMF](3)-D-E-[ALIV]-H- [NECR].
- Homeobox domain (homeobox).
- SEQ ID NOs: 1676, 1820 and 1821 represent polynucleotides encoding proteins having a homeobox domain.
- the homeobox is a protein domain of 60 amino acids (Gehring In: Guidebook to the Homeobox Genes. Duboule D., Ed., pp. 1-10, Oxford University Press, Oxford, (1994); Buerglin In: Guidebook to the Homeobox Genes, pp25-72, Oxford University Press, Oxford, (1994); Gehring, Trends Biochem. Sci. (1992) 17:277-280; Gehring et al., Annu. Rev. Genet. (1986) 20:147-173; Schofield, Trends Neurosci. (1987) 70:3-6) first
- This domain binds DNA through a helix-turn-helix type of structure.
- proteins that contain a homeobox domain play an important role in development. Most of these proteins are sequence-specific DNA-binding transcription factors.
- the homeobox domain is also very similar to a region of the yeast mating type proteins. These are sequence-specific DNA-binding proteins that act as master switches in yeast differentiation by controlling gene expression in a cell type-specific fashion.
- a schematic representation of the homeobox domain is shown below.
- the helix-turn-helix region is shown by the symbols ⁇ (for helix), and 't' (for turn). xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
- the pattern detects homeobox sequences 24 residues long and spans positions 34 to 57 of the homeobox domain.
- the consensus pattern is as follows: [LIVMFYG]-[ASLVR]-x(2)-[LIVMSTACN]-x-[LIVM]-x(4)-[LIV]-[RKNQESTAIY]- [LIVFSTNKH]-W-[FYVC]-x-[NDQTAH]-x(5)-[RKNAIMW].
- SEQ ID NOs:29, 31, 196, 3175, 3190 and 3281 represent novel members of the MAP kinase kinase family.
- MAP kinases (MAPK) are involved in signal transduction, and are important in cell cycle and cell growth controls.
- the MAP kinase kinases (MAPKK) are dual-specificity protein kinases which phosphorylate and activate MAP kinases.
- MAPKK homologues have been found in yeast, invertebrates, amphibians, and mammals.
- the MAPKK MAPK phosphorylation switch constitutes a basic module activated in distinct pathways in yeast and in vertebrates.
- MAPKKs are essential transducers through which signals must pass before reaching the nucleus.
- Biiques Biol Cell (1993) 79:193-207 Nishida et al., Trends Biochem Sci (1993) 75:128-31; Ruderman, Curr Opin Cell Biol (1993) 5:207-13; Dhanasekaran et al., Oncogene (1998) 77:1447-55; Kiefer et al., Biochem Soc Trans (1997) 25:491-8; and Hill, Cell Signal (1996) 5:533-44.
- Protein Kinase (protkinase).
- SEQ ID NOs: 1 157, 1478, 1496, 2286, 2969 and 3190 represent polynucleotides encoding protein kinases. Protein kinases catalyze phosphorylation of proteins in a variety of pathways, and are implicated in cancer.
- Eukaryotic protein kinases (Hanks S.K., et al., FASEB J. (1995) 9:576; Hunter T., Meth. Enzymol. (1991) 200:3; Hanks S.K., et al., Meth. Enzymol. (1991) 200:38; Hanks S.K.,
- the second region which is located in the central part of the catalytic domain, contains a conserved aspartic acid residue which is important for the catalytic activity of the enzyme (Knighton D.R. et al., Science (1991) 255:407).
- the protein kinase profile includes two signature patterns for this second region: one specific for serine/threonine kinases and the other for tyrosine kinases.
- a third profile is based on the alignment in (Hanks S.K. et al., FASEB J (1995) 9:576) and covers the entire catalytic domain.
- the consensus patterns are as follows: 1) [LIV]-G- ⁇ P ⁇ -G- ⁇ P ⁇ - [FYWMGSTNH]-[SGA]- ⁇ PW ⁇ -[LIVCAT]- ⁇ PD ⁇ -x-[GSTACLIVMFY]-x(5,18)-
- Ras family proteins SEQ ID NOs: 1688 and 3258 represent polynucleotides encoding novel members of the ras family of small GTP/GDP-binding proteins (Valencia et al., 1991, Biochemistry 30:4637-4648). Ras family members generally require a specific guanine nucleotide exchange factor (GEF) and a specific GTPase activating protein (GAP) as stimulators of overall GTPase activity.
- GEF guanine nucleotide exchange factor
- GAP GTPase activating protein
- the first two constitute most of the phosphate and Mg2+ binding site (PM site) and are located in the first half of the G-domain.
- the other two regions are involved in guanosine binding and are located in the C-terminal half of the molecule.
- Motifs and conserved structural features of the ras-related proteins are described in Valencia et al., 1991, Biochemistry 30:4637-4648.
- a major consensus pattern of ras proteins is: D-T-A-G-Q-E-K-[LF]-G- G-L-R-[DE]-G-Y-Y.
- SEQ ID NO: 1677 represents a polynucleotide encoding a protein having a thioredoxin family active site.
- Thioredoxins Holmgren A., Annu. Rev. Biochem. (1985) 54:231; Gleason F.K. et al., FEMS Microbiol. Rev. (1988) 54:271; Holmgren, A. J. Biol. Chem. (1989) 264:13963; Eklund H.
- SEQ ID NO: 1410 corresponds to a novel serine protease of the trypsin family.
- the catalytic activity of the serine proteases from the trypsin family is provided by a charge relay system involving an aspartic acid residue hydrogen-bonded to a histidine, which itself is hydrogen-bonded to a serine.
- the sequences in the vicinity of the active site serine and histidine residues are well conserved in this family of proteases (Brenner S., Nature (1988) 554:528).
- the consensus patterns for this trypsin protein family are: 1) [LIVM]-[ST]-A-[STAG]-H-C, where H is the active site residue; and 2) [DNSTAGC]-[GSTAPIMVQH]-x(2)-G-[DE]- S-G-[GS]-[SAPHV]- [LIVMFYWH]-[LIVMFYSTANQH], where S is the active site residue. All sequences known to belong to this family are detected by the above consensus sequences, except for 18 different proteases which have lost the first conserved glycine. If a protein includes both the serine and the histidine active site signatures, the probability of it being a trypsin family serine protease is 100%.
- G-Beta Repeats (WD domain).
- SEQ ID NOs:1336, 1380, 1711, 1762, 1909, 2218, 3047, 3108 and 3292 represent novel members of the WD domain/G-beta repeat family.
- Beta-transducin (G-beta) is one of the three subunits (alpha, beta, and gamma) of the guanine nucleotide-binding proteins (G proteins) which act as intermediaries in the transduction of signals generated by transmembrane receptors (Gilman, Annu. Rev. Biochem. (1987) 56:615).
- the alpha subunit binds to and hydrolyzes GTP; the functions of the beta and gamma subunits are less clear but they seem to be required for the replacement of GDP by GTP as well as for membrane anchoring and receptor recognition.
- G-beta exists as a small multigene family of highly conserved proteins of about 340 amino acid residues. Structurally, G-beta consists of eight tandem repeats of about 40 residues, each containing a central Trp-Asp motif (this type of repeat is sometimes called a WD-40 repeat).
- the consensus pattern for the WD domain/G-Beta repeat family is: [LIVMSTAC]-[LIVMFYWSTAGC]-[LIMSTAG]-[LIVMSTAGC]-x(2)-[DN]-x(2)- [LIVMWSTAC]-x-[LIVMFSTAG]-W-[DEN]-[LIVMFSTAGCN].
- Wnt dev sign SEQ ID NO: 1538 corresponds to a novel member of the wnt family of developmental signaling proteins.
- Wnt-1 previously known as int-1
- the seminal member of this family (Nusse R., Trends Genet.
- SEQ ID NO:1417 represents a polynucleotide encoding a protein tyrosine kinase.
- Tyrosine specific protein phosphatases (EC 3.1.3.48) (PTPase) (Fischer et al., Science (1991) 255:401; Charbonneau et al., Annu. Rev. Cell Biol. (1992) 5:463; Trowbridge, J. Biol. Chem. (1991) 266:23517; Tonks et al., Trends Biochem. Sci. (1989) 74:497; and Hunter, Cell (1989) 55:1013) catalyze the removal of a phosphate group attached to a tyrosine residue.
- PTPase Tyrosine specific protein phosphatases
- PTPase enzymes that are very important in the control of cell growth, proliferation, differentiation and transformation.
- Multiple forms of PTPase have been characterized and can be classified into two categories: soluble PTPases and transmembrane receptor proteins that contain PTPase domain(s).
- PTPase domains consist of about 300 amino acids. The search of two conserved cysteines has been shown to be absolutely required for activity. Furthermore, a number of conserved residues in its immediate vicinity have also been shown to be important.
- Src homology 2 Src homology 2
- Src homology 2 (SH2) domain is a protein domain of about 100 amino acid residues first identified as a conserved sequence region between the oncoproteins Src and Fps (Sadowski I. et al., Mol. Cell. Biol. 6:4396-4408 (1986)). Similar sequences are found in many other intracellular signal -transducing proteins (Russel R.B. et al., FEBS Lett. 504: 15-20 (1992)).
- SH2 domains function as regulatory modules of intracellular signalling cascades by interacting with high affinity to phosphotyrosine- containing target peptides in a sequence-specific and phosphorylation-dependent manner (Marangere L.E.M., Pawson T., J. Cell Sci. Suppl. 75:97-104 (1994); Pawson T., Schlessinger J., Curr. Biol. 5:434-442 (1993); Mayer B.J., Baltimore D., Trends Cell. Biol. 5:8-13 (1993); Pawson T., Nature 575:573-580 (1995)).
- the SH2 domain has a conserved 3D structure consisting of two alpha helices and six to seven beta-strands.
- the core of the domain is formed by a continuous beta-meander composed of two connected beta-sheets (Kuriyan J., Cowburn D., Curr. Opin. Struct. Biol. 5:828-837(1993)).
- the profile to detect SH2 domains is based on a structural alignment consisting of 8 gap-free blocks and 7 linker regions totaling 92 match positions.
- Src homology 3 SEQ ID NO:234, 1832, and 1835 represent polynucleotides encoding novel members of the family of Src homology 3 (SH3) proteins.
- the Src homology 3 (SH3) domain is a small protein domain of about 60 amino acid residues first identified as a conserved sequence in the non-catalytic part of several cytoplasmic protein tyrosine kinases (e.g., Src, Abl, Lck) (Mayer B.J. et al., Nature 552:272-275 (1988)). Since then, it has been found in a great variety of other intracellular or membrane-associated proteins (Musacchio A. et al., FEBS Lett. 307:55-
- the SH3 domain has a characteristic fold which consists of five or six beta strands arranged as two tightly packed anti-parallel beta sheets.
- the linker regions may contain short helices (Kuriyan J., Cowburn D., Cwrr. Opin. Struct. Biol. 5:828-837
- the function of the SH3 domain may be to mediate assembly of specific protein complexes via binding to proline-rich peptides (Morton C.J., Campbell I.D.,
- SH3 domains are found as single copies in a given protein, but there are a significant number of proteins with two SH3 domains and a few with 3 or 4 copies.
- SEQ ID NOs: 746 and 1 192 represent polynucleotides encoding novel members of the family of fibronectin type III proteins.
- lymphokines A number of receptors for lymphokines, hematopoeitic growth factors and growth hormone-related molecules have been found to share a common binding domain.
- the conserved region constitutes all or part of the extracellular ligand- binding region and is about 200 amino acid residues long.
- cysteines known, in the growth hormone receptor, to be involved in disulfide bonds.
- Two patterns detect this family of receptors The first one is derived from the first N-terminal disulfide loop, the second is a tryptophan-rich pattern located at the C-terminal extremity of the extracellular region.
- a consensus for this protein family is: C-[LVFYR]-x(7,8)-[STIVDN]-C- x-W (The two C's are linked by a disulfide bond].
- a second consensus for this protein family is: [STGL]-x-W-[SG]-x-W-S.
- LIM domain containing proteins SEQ ID NOs: 1269, 1309, 1360, and 1386 represent polynucleotides encoding novel members of the family of LIM domain containing proteins.
- a number of proteins contain a conserved cysteine-rich domain of about 60 amino-acid residues. (Freyd G. et al., Nature 544:876-879 (1990); Baltz R. et al., Plant Cell 4:1465-1466 (1992); Sanchez-Garcia I., Rabbitts T.H., Trends Genet. 70:315-320 (1994)).
- cysteine residues there are seven conserved cysteine residues and a histidine.
- C2 domain protein kinase C like
- SEQ ID NOs: 1325 and 2282 represent polynucleotides encoding novel members of the family of C2 domain containing proteins.
- Some isozymes of protein kinase C (PKC) contain a domain, known as C2, of about 1 16 amino-acid residues, which is located between the two copies of the C 1 domain (that bind phorbol esters and diacylglycerol) and the protein kinase catalytic domain. (Azzi A. et al., Eur. J. Biochem. 208:541-551 (1992); Stabel S., Semin. Cancer Biol. 5:277-284 (1994)).
- the C2 domain is involved in calcium-dependent phospholipid binding (Davletov B.A., Suedhof T.C., J. Biol. Chem. 265:26386-26390 (1993)). Since domains related to the C2 domain are also found in proteins that do not bind calcium, other putative functions for the C2 domain include binding to inositol-1,3,5- tetraphosphate. (Fukuda M., et al., J Biol. Chem. 269:29206-29211 (1994).)
- the consensus pattern for the C2 domain is located in a conserved part of that domain, the connecting loop between beta strands 2 and 3.
- the profile for the C2 domain covers the total domain.
- the consensus for this protein family is:: [ACG]-x(2)- L-x(2,3)-D-x(l,2)-[NGSTLIF]-[GTMR]-x-[STAP]-D- [PA]-[FY]
- SEQ ID NO:1410 represents a polynucleotide encoding a novel member of the family of serine protease, trypsin proteins.
- the catalytic activity of the serine proteases from the trypsin family is
- a second consensus for this protein family is: [DNSTAGC]- [GSTAPIMVQH]-x(2)-G-[DE]-S-G-[GS]-[SAPHV]- [LIVMFYWH]- [LIVMFYSTANQH] [S is the active site residue].
- RNA Recognition Motif Domain RRM. RBD. or RNP.
- SEQ ID NOs: 1464 and 1514 represent polynucleotides encoding novel members of the family of RNA recognition motif domain proteins (Bandziulis R.J. et al., Genes Dev. 5:431-437 (1989); Dreyfuss G. et al., Trends Biochem. Sci. 75:86-91 (1988)).
- RNA-binding domain Inside the putative RNA-binding domain there are two regions which are highly conserved. The first one is a hydrophobic segment of six residues (which is called the RNP-2 motif); the second one is an octapeptide motif (which is called RNP-1 or RNP-CS). The position of both motifs in the domain is shown in the following schematic representation: xxxxxxx### xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx RNP-2 RNP-1
- 1707 represents a polynucleotide encoding a novel member of the phosphatidylinositol- specific phospholipase C, Y domain family of proteins.
- Phosphatidylinositol-specific phospholipase C (EC3.1.4.11), a eukaryotic intracellular enzyme, plays an important role in signal transduction processes (Meldrum E. et al., Biochim. Biophys. Acta 7092:49-71 (1991)). It catalyzes the hydrolysis of 1-phosphatidyl-D-myo-inositol- 3,4,5- triphosphate into the second messenger molecules diacylglycerol and inositol- 1,4,5-triphosphate.
- All eukaryotic PI-PLCs contain two regions of homology, referred to as "X-box” and "Y-box". The order of these two regions is the same (NH2-X-Y-COOH), but the spacing is variable. In most isoforms, the distance between these two regions is only 50-100 residues but in the gamma isoforms one PH domain, two SH2 domains, and one SH3 domain are inserted between the two PLC-specific domains. The two conserved regions have been shown to be important for the catalytic activity. At the C- terminal of the Y-box, there is a C2 domain possibly involved in Ca-dependent membrane attachment.
- Serine Carboxypeptidases SEQ ID NO: 1744 represents a polynucleotide encoding a novel member of the serine carboxypeptidases family of proteins.
- Carboxypeptidases may be either metallo carboxypeptidases or serine carboxypeptidases (EC 3.4.16.5 and EC 3.4.16.6).
- the catalytic activity of the serine carboxypeptidases is provided by a charge relay system involving an aspartic acid residue hydrogen-bonded to a histidine, which is itself hydrogen-bonded to a serine (Liao D.I., Remington S.J., J. Biol. Chem. 265:6528-6531 (1990)).
- a consensus for this protein family is: [LIVM]-x-[GTA]-E-S-Y-[AG]-[GS] [S is the active site residue].
- a second consensus for this protein family is: [LIVF]-x(2)-[LIVSTA]-x-[IVPST]-x-[GSDNQL]- [SAGV]-[SG]-H-x- [IVAQ]-P-x(3)-[PSA] [H is the active site residue].
- SEQ ID NO:1818 represents a polynucleotide encoding a novel member of the dsrm double-stranded RNA binding motif proteins.
- RNA-binding proteins play key roles in the posttranscriptional regulation of gene expression. Characterization of these proteins has led to the identification of several RNA-binding motifs.
- Several human and other vertebrate genetic disorders are caused by aberrant expression of RNA-binding proteins. (C. G. Burd & G. Dreyfuss, Science 265: 615-621 (1994)).
- Double stranded RNA binding motifs are exemplified by interferon- induced protein kinase in humans, which is part of the cellular response to dsRNA.
- SEQ ID NOs:2577, 3183 and 3195 encode members of the 4 transmembrane integral membrane protein family.
- This family consists of type III proteins, which are integral membrane proteins that contain a N-terminal membrane-anchoring domain that is not cleaved during biosynthesis, and which functions as a translocation
- SEQ ID NO:2944 encodes a polypeptide having a calpain large subunit, domain III.
- Calpains are a family of intracellular proteases that play a variety of biological roles.
- Calpain 3 also known as p94, is predominantly expressed in skeletal muscle and plays a role in limb-girdle muscular dystrophy type 2A. (Sorimachi, H. et al., Biochem. J. 328:721-732, 1997).
- SEQ ID NOs: 1911 and 1980 encode polypeptides having a C3HC4 type zinc finger domain (RING finger), which is a cysteine-rich domain of 40 to 60 residues that binds two atoms of zinc, and is believed to be involved in mediating protein-protein interactions.
- Mammalian proteins of this family include V(D)J recombination activating protein, which activates the rearrangement of immunoglobulin and T-cell receptor genes; breast cancer type 1 susceptibility protein (BRCA1); bmi-1 proto- oncogene; cbl proto-oncogene; and mel-18 protein, which is expressed in a variety of tumor cells and is a transcriptional repressor that recognizes and binds a specific DNA sequence.
- the consensus pattern is: C-x-H-x-[LIVMFY]-C-x(2)-C-[LIVMYA].
- SEQ ID NO:3274 encodes a eukaryotic transcription factor with a fork head domain, of about 100 amino acid residues.
- Proteins of this group are transcription factors, including mammalian transcription factors HNF-3 -alpha, -beta, and -gamma; interleukin-enhancer binding factor; and HTLF, which binds to a region of human T- cell leukemia virus long terminal repeat.
- the consensus pattern is [KR]-P-[PTQ]- [FYLVQH]-S-[FY]x(2)-[LIVM]-X(3,4)-[AC]-[LIM].
- SEQ ID NO:3345 encodes a polypeptide having a PDZ domain.
- signaling proteins belong to this group of proteins that have 80-100 residue repeats known as PDZ domains.
- Several of the proteins interact with the C-terminal tetrapeptide motifs X-Ser/Thr/X-Val-COO- of ion channels and/or receptors. (Ponting, C. P., Protein Sci. 6;464-468, 1997.)
- SEQ ID NO:3351 encodes a polypeptide in the family of phorbol esters/glycerol binding proteins.
- Phorbol esters (PE) are analogues of diacylglycerol (DAG) and potent tumor promoters.
- DAG activates a family of serine-threonine protein kinases, known as protein kinase C.
- the N-terminal region of protein kinase C binds PE and DAG, and contains one or two copies of a cysteine-rich domain of about 50 amino acid residues.
- Other proteins having this domain include diacylglycerol kinase; the vav oncogene; and N-chimaerin, a brain-specific protein.
- b1 domain binds two zinc ions through the six cysteines and two histidines that are conserved in the domain.
- the consensus pattern is: H-x-[LIVMFYW]-x(8, 1 l)-C-x(2)- C-x-(3)-[LIVMFC]-x(5, 10)-C-x(2)-C-x(4)-[HD]-x(2)-C-x(5, 9)-C.
- SEQ ID NO:2216 encodes a polypeptide having a WW/rsp5/WWP domain.
- the protein is named for the presence of conserved aromatic positions, generally tryptophan, as well as a conserved proline. Proteins having the domain include dystrophin, vertebrate YAP protein, and IQGAP, a human GTPase activating protein which acts on ras.
- the consensus pattern is: W-x(9,l l)-[VFY]-[FYW]-x(6,7)- [GSTNE]-[GSTQCR]-[FYW]-x(2)-P.
- SEQ ID NO:2428 encodes a member of the dual specificity phosphatase family, having a catalytic domain
- SEQ IDS NOs:2281 and 2310 encode members of the protein tyrosine phosphatase family. These families are related and classified as tyrosine specific protein phosphatases.
- the enzymes catalyze the removal of a phosphate group from a tyrosine residue, and are important in the control of cell growth, proliferation, differentiation, and transformation.
- the consensus pattern is [LIVMF]-H- C-x(2)-G-x-(3)-[STC]-[STAGP]-x-[LIVMFY].
- Mus musculus (U03 137) neuropeptide Pont ⁇ n52 mRNA, precursor FMRFamide-related
- Mus musculus (AF004S35) tyrocidine Pont ⁇ n52 mRNA, synthetase 3 [Brev ibacillus
- the relative expression levels of the polynucleotides of the invention was assessed in several libraries prepared from various sources, including cell lines and patient tissue samples. Table 6 provides a summary of these libraries, including the shortened library name (used hereafter), the mRNA source used to prepare the cDNA library, the abbreviated name of the library that is used in the tables below (in quotes), and the approximate number of clones in the library.
- the KM12L4 and KM12C cell lines are described in Example 1 above.
- the MDA-MB-231 cell line was originally isolated from pleural effusions (Cailleau, J.
- the MCF7 cell line was derived from a pleural effusion of a breast adenocarcinoma and is non-metastatic.
- the MV-522 cell line is derived from a human lung carcinoma and is of high metastatic potential.
- the UCP-3 cell line is a low metastatic human lung carcinoma cell line; the MV-522 is a high metastatic variant of UCP-3.
- the samples of libraries 15-20 are derived from two different patients (UC#2, and UC#3).
- the bFGF -treated HMEC were prepared by incubation with bFGF at lOng/ml for 2 hrs; the VEGF-treated HMEC were prepared by incubation with 20ng/ml VEGF for 2 hrs.
- the GRRpz cell line refers to low passage (3 passages or fewer) human prostate cells
- the WOca cell line refers to low passage (3 passages or fewer) human prostate cancer cells.
- Each of the libraries is composed of a collection of cDNA clones that in turn are representative of the mRNAs expressed in the indicated mRNA source. In order to facilitate the analysis of the millions of sequences in each library, the sequences were assigned to clusters.
- cluster of clones is derived from a sorting/grouping of cDNA clones based on their hybridization pattern to a panel of roughly 300 7bp oligonucleotide probes (see Drmanac et al., Genomics (1996) 57(1):29). Random cDNA clones from a tissue library are hybridized at moderate stringency to 300 7bp oligonucleotides. Each oligonucleotide has some measure of specific hybridization to that specific clone. The combination of 300 of these measures of hybridization for 300 probes equals the "hybridization signature" for a specific clone. Clones with similar sequence will have similar hybridization signatures.
- clusters groups of clones in a library can be identified and brought together computationally. These groups of clones are termed "clusters".
- the "purity" of each cluster can be controlled. For example, artifacts of clustering may
- Differential expression for a selected cluster was assessed by first determining the number of cDNA clones corresponding to the selected cluster in the first library (Clones in 1 st ), and the determining the number of cDNA clones corresponding to the selected cluster in the second library (Clones in 2 nd ). Differential expression of the selected cluster in the first library relative to the second library is expressed as a "ratio" of percent expression between the two libraries.
- the "ratio" is calculated by: 1) calculating the percent expression of the selected cluster in the first library by dividing the number of clones corresponding to a selected cluster in the first library by the total number of clones analyzed from the first library; 2) calculating the percent expression of the selected cluster in the second library by dividing the number of clones corresponding to a selected cluster in a second library by the total number of clones analyzed from the second library; 3) dividing the calculated percent expression from the first library by the calculated percent expression from the second library. If the "number of clones" corresponding to a selected cluster in a library is zero, the value is set at 1 to aid in calculation. The formula used in calculating the ratio takes into account the "depth" of each of the libraries being compared, i.e., the total number of clones analyzed in each library.
- a polynucleotide is said to be significantly differentially expressed between two samples when the ratio value is greater than at least about 2, preferably greater than at least about 3, more preferably greater than at least about 5 , where the ratio value is calculated using the method described above.
- the significance of differential expression is determined using a z score test (Zar, Biostatistical Analysis. Prentice Hall, Inc., USA, "Differences between Proportions," pp 296-298 (1974)).
- a number of polynucleotide sequences have been identified that are differentially expressed between cells derived from high metastatic potential breast cancer tissue and low metastatic breast cancer cells. Expression of these sequences in breast cancer can be valuable in determining diagnostic, prognostic and/or treatment information. For example, sequences that are highly expressed in the high metastatic potential cells can be indicative of increased expression of genes or regulatory sequences involved in the metastatic process. A patient sample displaying an increased level of one or more of these polynucleotides may thus warrant more aggressive treatment.
- sequences that display higher expression in the low metastatic potential cells can be associated with genes or regulatory sequences that inhibit metastasis, and thus the expression of these polynucleotides in a sample may warrant a more positive prognosis than the gross pathology would suggest.
- differential expression of these polynucleotides can be used as a diagnostic marker, a prognostic marker, for risk assessment, patient treatment and the like.
- These polynucleotide sequences can also be used in combination with other known molecular and/or biochemical markers.
- Differentially expressed polynucleotides Higher expression in high metastatic potential breast cancer (lib3) relative to low metastatic breast cancer cells (lib4)
- Differentially expressed polynucleotides Higher expression in w metastatic breast cancer cells (lib4) relative to high metastatic potential breast cancer (lib3)
- a number of polynucleotide sequences have been identified that are differentially expressed between cells derived from high metastatic potential lung cancer cells and low metastatic lung cancer cells. Expression of these sequences in lung cancer tissue can be valuable in determining diagnostic, prognostic and/or treatment information. For example, sequences that are highly expressed in the high metastatic potential cells can be indicative of increased expression of genes or regulatory sequences involved in the metastatic process. A patient sample displaying an increased level of one or more of these polynucleotides may thus warrant more aggressive treatment.
- sequences that display higher expression in the low metastatic potential cells can be associated with genes or regulatory sequences that inhibit metastasis, and thus the expression of these polynucleotides in a sample may warrant a more positive prognosis than the gross pathology would suggest.
- differential expression of these polynucleotides can be used as a diagnostic marker, a prognostic marker, for risk assessment, patient treatment and the like.
- These polynucleotide sequences can also be used in combination with other known molecular and/or biochemical markers.
- Differentially expressed polynucleotides Higher expression in high metastatic potential lung cancer cells (lib8) relative to low metastatic lung cancer cells (lib9)
- a number of polynucleotide sequences have been identified that are differentially expressed between cells derived from high metastatic potential colon cancer cells and low metastatic colon cancer cells. Expression of these sequences in colon cancer tissue can provide diagnostic, prognostic and/or treatment information. For example, sequences that are highly expressed in the high metastatic potential cells can be indicative of increased expression of genes or regulatory sequences involved in the metastatic process. A patient sample displaying an increased level of one or more of these polynucleotides may thus warrant more aggressive treatment.
- sequences that display higher expression in the low metastatic potential cells can be associated with genes or regulatory sequences that inhibit metastasis, and thus the expression of these polynucleotides in a sample may warrant a more positive prognosis than the gross pathology would suggest.
- differential expression of these polynucleotides can be used as a diagnostic marker, a prognostic marker, for risk assessment, patient treatment and the like.
- These polynucleotide sequences can also be used in combination with other known molecular and/or biochemical markers.
- Table 1 1 Differentially expressed polynucleotides: Higher expression in low metastatic colon cancer cells (lib 2) relative to high metastatic potential colon cancer cells (lib 1)
- a number of polynucleotide sequences have been identified that are differentially expressed between cells derived from high metastatic potential colon cancer tissue and normal tissue. Expression of these sequences in colon cancer tissue can provide diagnostic, prognostic and/or treatment information. For example, sequences that are highly expressed in the high metastatic potential cells can be indicative of increased expression of genes or regulatory sequences involved in the advanced disease state which involves processes such as angiogenesis, dedifferentiation, cell replication, and metastasis. A patient sample displaying an increased level of one or more of these polynucleotides may thus warrant more aggressive treatment.
- the differential expression of these polynucleotides can be used as a diagnostic marker, a prognostic marker, for risk assessment, patient treatment and the like. These polynucleotide sequences can also be used in combination with other known molecular and/or biochemical markers.
- a number of polynucleotide sequences have been identified that are differentially expressed between cells derived from colon cancer tissue and cells derived from colon cancer tissue metastases to liver. Expression of these sequences in colon cancer tissue can provide diagnostic, prognostic and/or treatment information associated with the transformation of precancerous tissue to malignant tissue. This information
- a number of polynucleotide sequences have been identified that are differentially expressed between cells derived from high tumor potential colon cancer tissue and normal tissue. Expression of these sequences in colon cancer tissue can provide diagnostic, prognostic and/or treatment information associated with the prevention of the malignant state in these tissues, and can be important in risk assessment for a patient. For example, sequences that are highly expressed in the potential colon cancer cells are associated with or can be indicative of increased expression of genes or regulatory sequences involved in early tumor progression. A patient sample displaying an increased level of one or more of these polynucleotides may thus warrant closer attention or more frequent screening procedures to catch the malignant state as early as possible.
- HMEC human microvascular endothelial cells
- HMEC and untreated HMEC can represent sequences encoding gene products involved in angiogenesis, metastasis (cell migration), and other developmental and oncogenic processes.
- sequences that are more highly expressed in HMEC treated with growth factors (such as bFGF or VEGF) relative to untreated HMEC can serve as markers of cancer cells of higher metastatic potential.
- Detection of expression of these sequences in colon cancer tissue can provide diagnostic, prognostic and/or treatment information associated with the prevention of achieving the malignant state in these tissues, and can be important in risk assessment for a patient.
- a patient sample displaying an increased level of one or more of these polynucleotides may thus warrant closer attention or more frequent screening procedures to catch the malignant state as early as possible.
- the following table summarizes identified polynucleotides with differential expression between growth factor-treated and untreated HMEC.
- polynucleotide sequences have been identified that are differentially expressed between cells derived from normal prostate cells and prostate cancer cells. Expression of these sequences prostate tissue suspected of being cancerous can provide diagnostic, prognostic and/or treatment information. These polynucleotide sequences can also be used in combination with other known molecular and/or biochemical markers.
- the following table summarizes identified polynucleotides with differential expression between high metastatic potential colon cancer cells and low metastatic potential colon cancer cells:
- polynucleotide sequences have been identified that are differentially expressed between cancerous cells and normal cells across two or more tissue types tested (i.e., breast, colon, lung, and prostate). Expression of these sequences in a tissue of any origin can provide diagnostic, prognostic and/or treatment information associated with the prevention of achieving the malignant state in these tissues, and can be important in risk assessment for a patient. These polynucleotides can also serve as non-tissue specific markers of, for example, risk of metastasis of a tumor.
- polynucleotides were differentially expressed but without tissue type-specificity in at least two of the breast, colon, lung, and prostate libraries tested: 53, 105, 355, 412, 614, 836, 1442, 1581, 1647, 1649, 1664, 1772, 1782, 181 1, 1845, 1856, 1875, 1923, 2060, 2071, 2135, 2146, 2239, 2313, 2378, 2393, 2416, 2460, 2490, 2632, 2674, 2704, 2724, 2749, 2784, 2804, 2959, 2976, 2977, 2980, 2987, 3009, 3047, 3128, 3129, 3132, 3146, 3150, 3156, 3210, 3324, 3331, and 3335.
- ATCC American Type Culture Collection
- CMCC Chiron Master Culture Collection: cDNA Libraries Deposited with ATCC
- Table 23 lists the clones for each deposit, designated as "tube” number. This deposit is provided merely as convenience to those of skill in the art, and is not an admission that a deposit is required under 35 U.S.C. ⁇ 112.
- the sequence of the polynucleotides contained within the deposited material, as well as the amino acid sequence of the polypeptides encoded thereby, are incorporated herein by reference and are controlling in the event of any conflict with the written description of sequences herein.
- a license may be required to make, use, or sell the deposited material, and no such license is granted hereby.
- the ATCC deposit is composed of a pool of cDNA clones
- the deposit was prepared by first transfecting each of the clones into separate bacterial cells. The clones were then deposited as a pool of equal mixtures in the composite deposit. Particular clones can be obtained from the composite deposit using methods well known in the art.
- a bacterial cell containing a particular clone can be identified by isolating single colonies, and identifying colonies containing the specific clone through standard colony hybridization techniques, using an oligonucleotide probe or probes designed to specifically hybridize to a sequence of the clone insert (e g , a probe based upon unmasked sequence of the encoded polynucleotide having the indicated SEQ ID NO).
- the probe should be designed to have a T m of approximately 80°C (assuming 2°C for each A or T and 4°C for each G or C). Positive colonies can then be picked, grown in culture, and the recombinant clone isolated.
- probes designed in this manner can be used to PCR to isolate a nucleic acid molecule from the pooled clones according to methods well known in the art, e g , by purifying the cDNA from the deposited culture pool, and using the probes in PCR reactions to produce an amplified product having the corresponding desired polynucleotide sequence.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Wood Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Gastroenterology & Hepatology (AREA)
- Toxicology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Peptides Or Proteins (AREA)
Abstract
Description
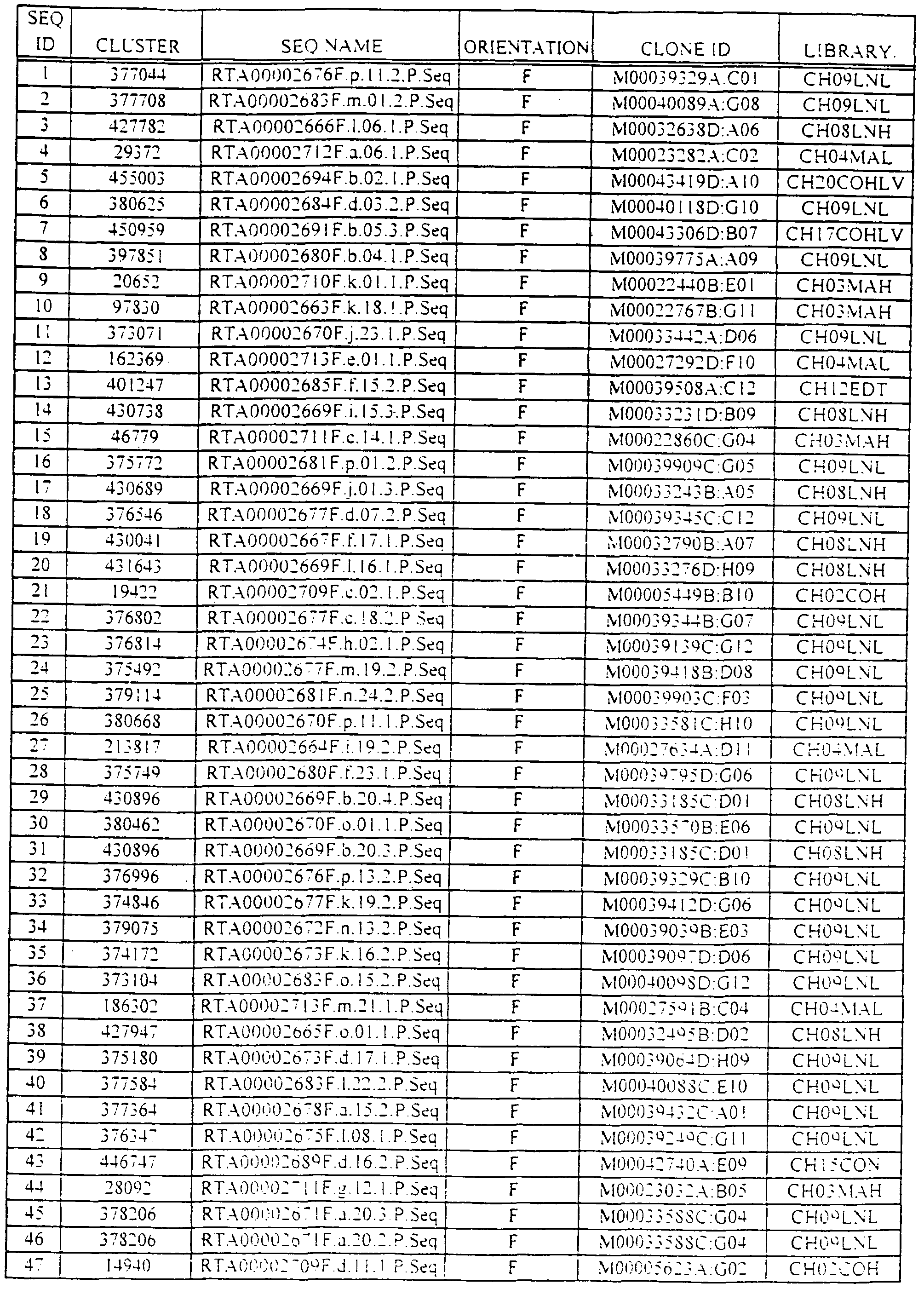



































































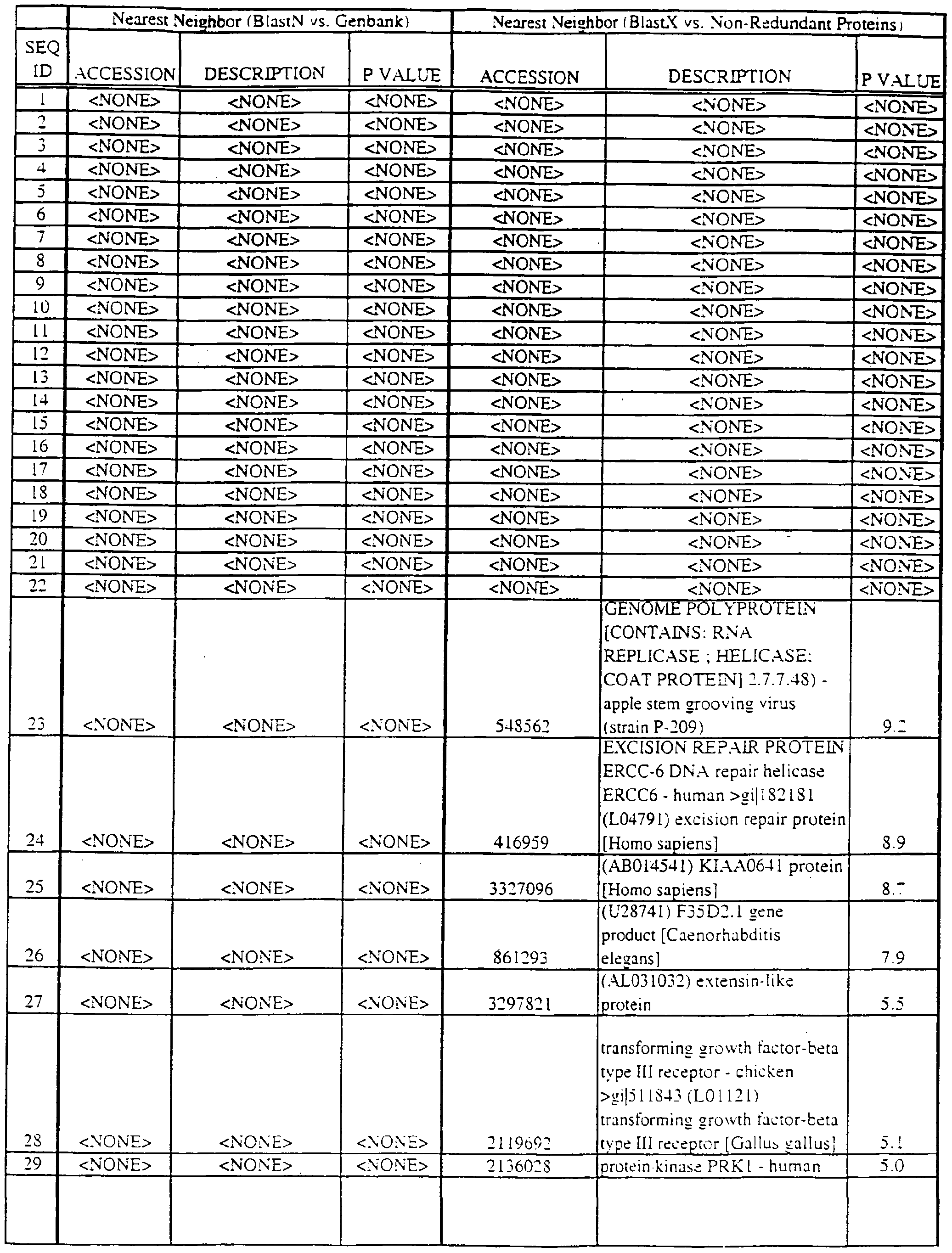




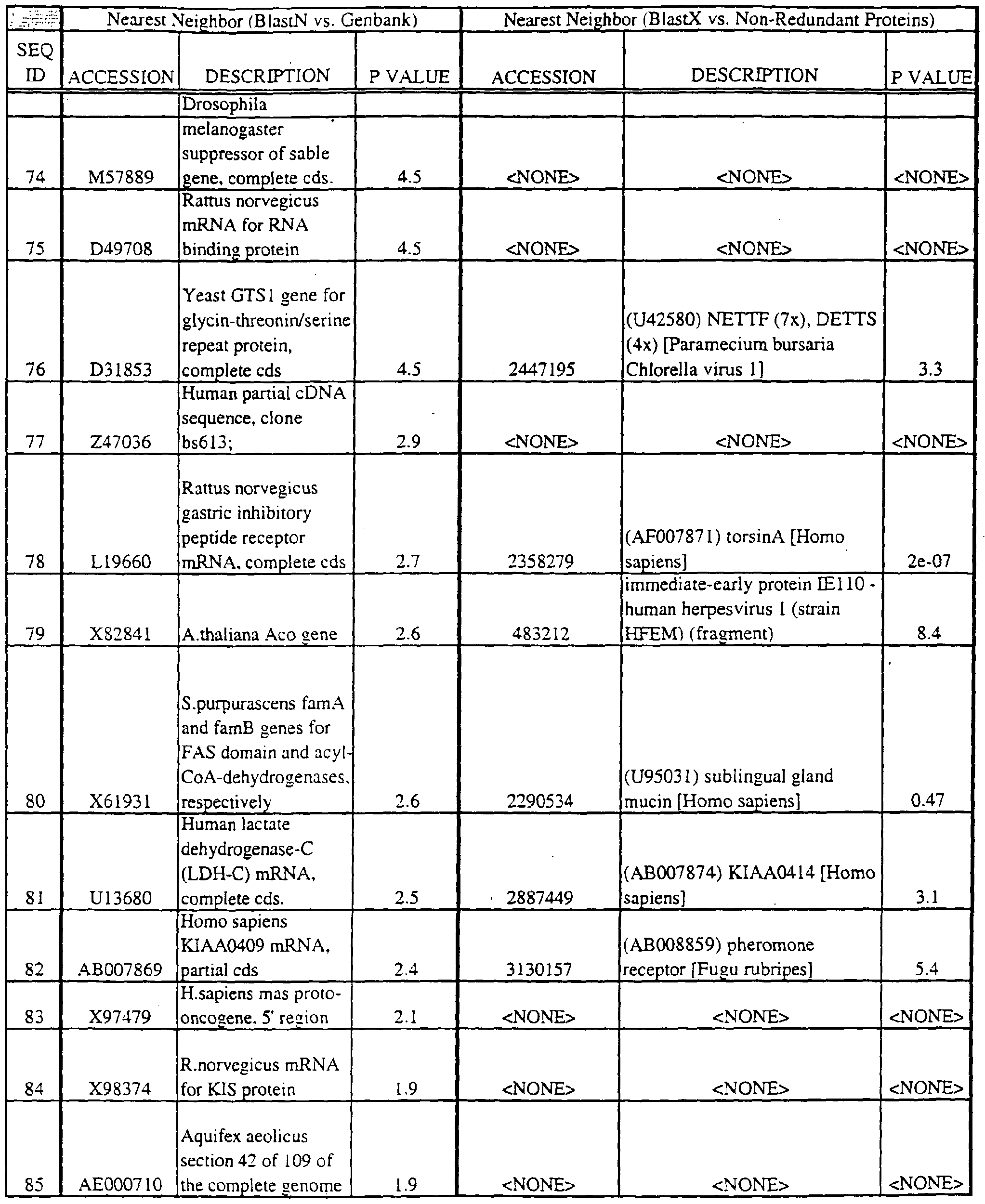


















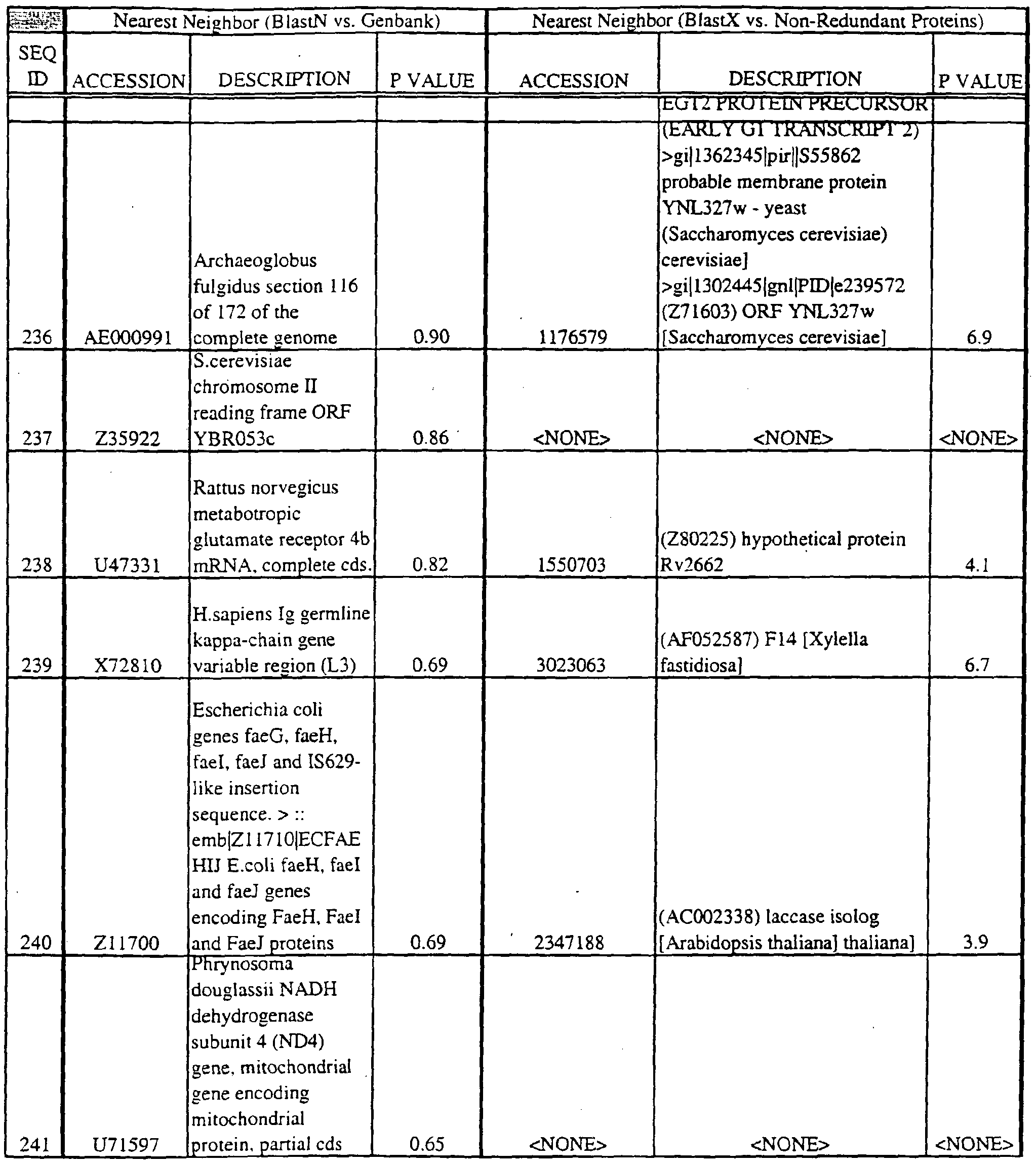

















































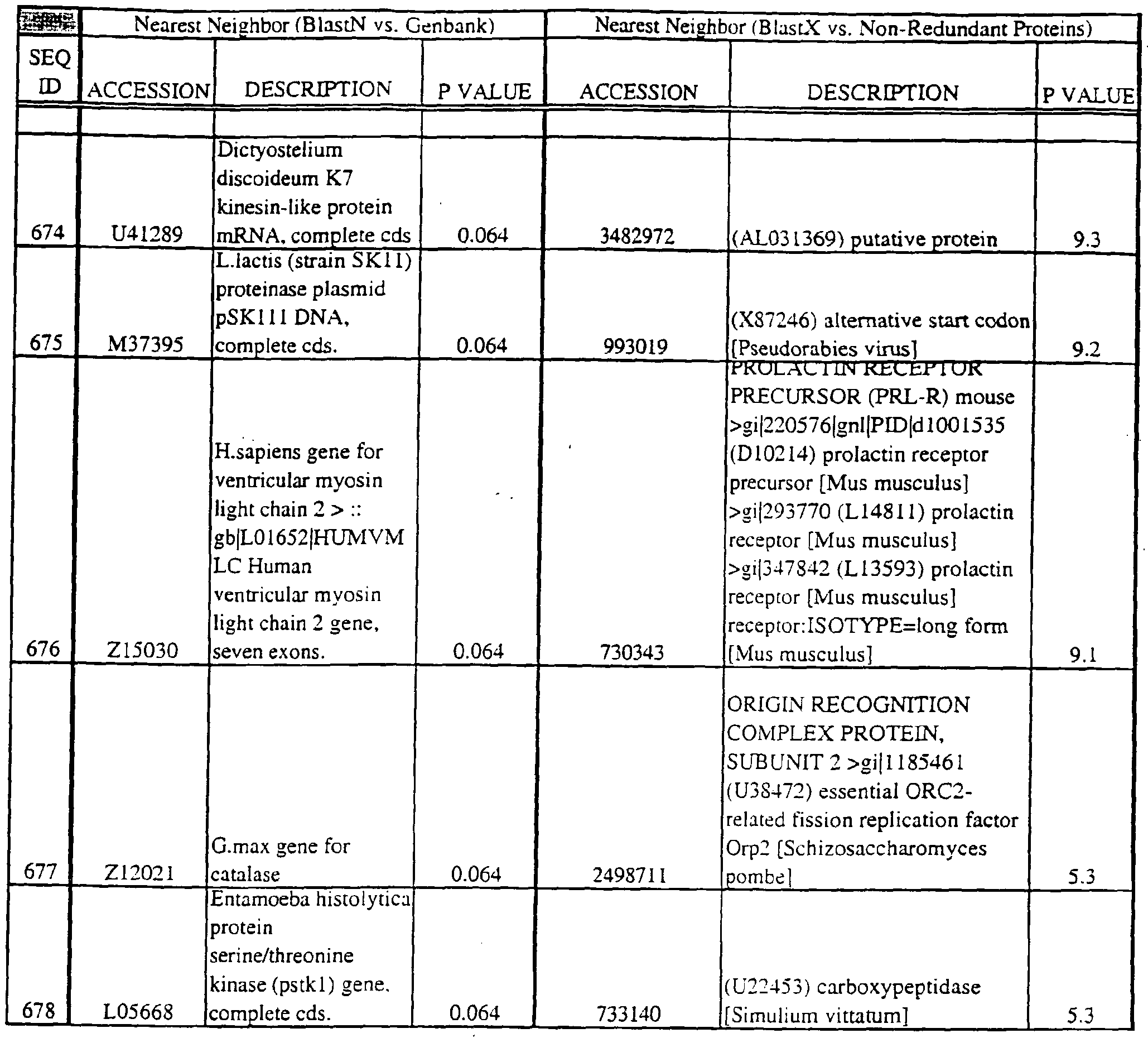









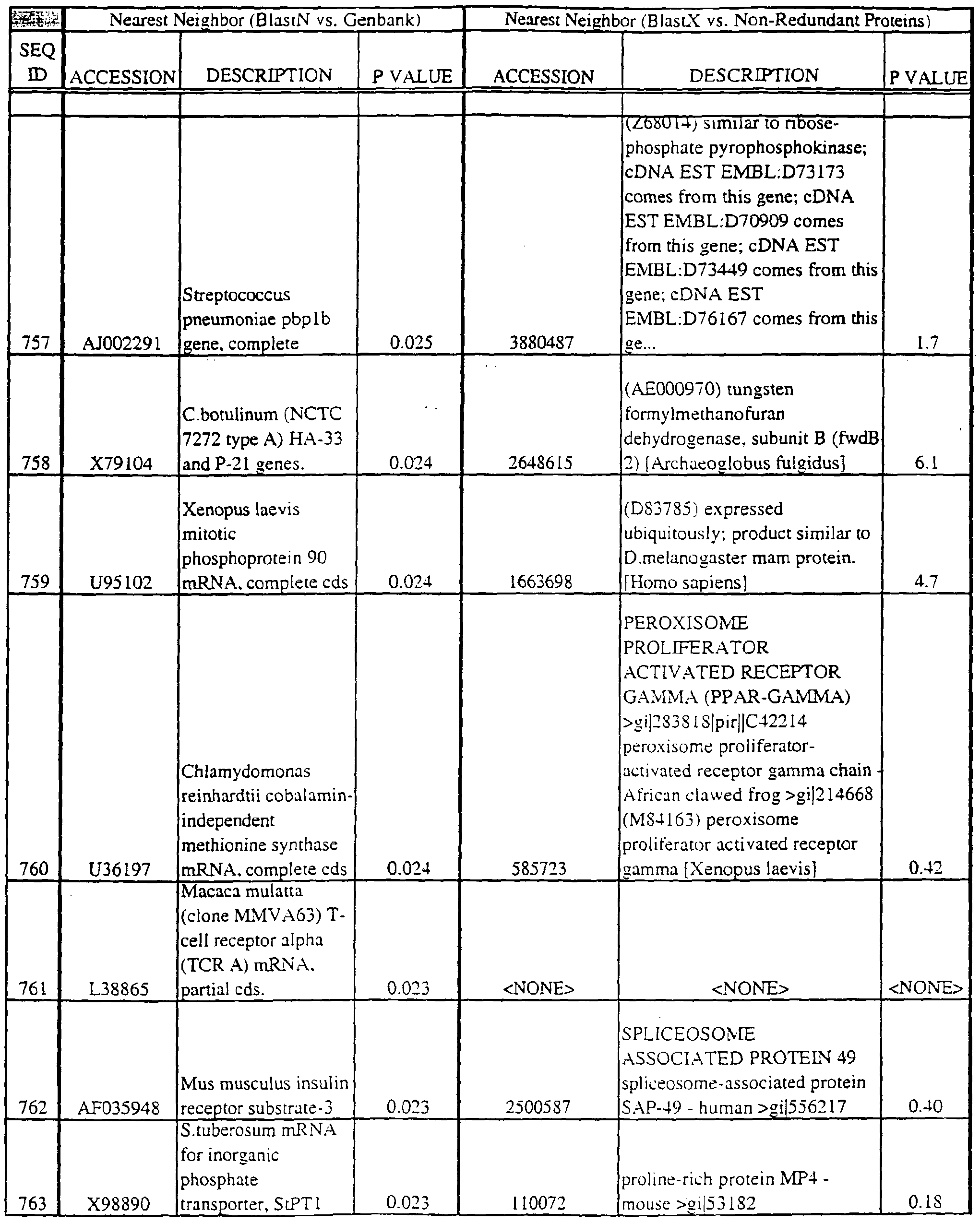


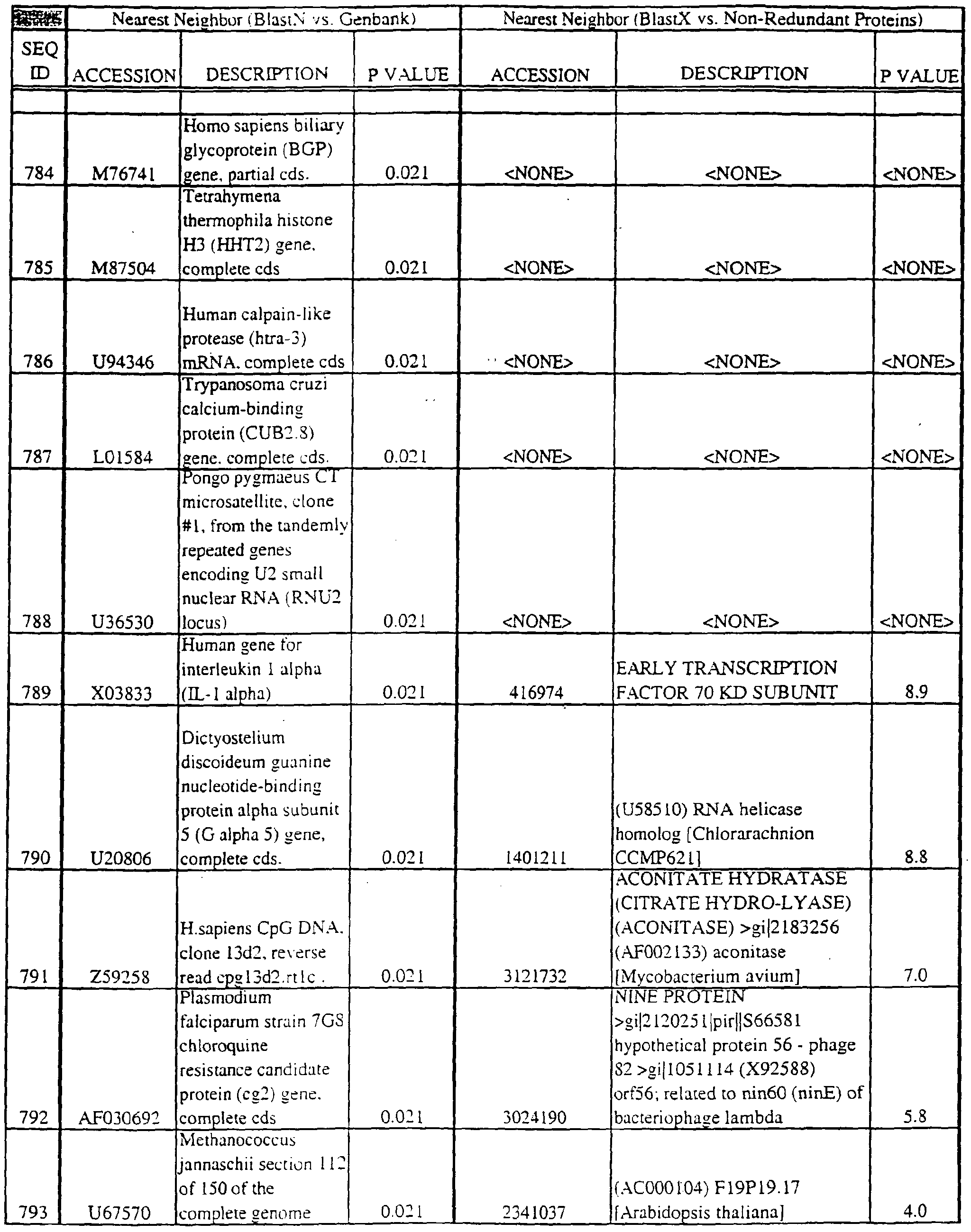























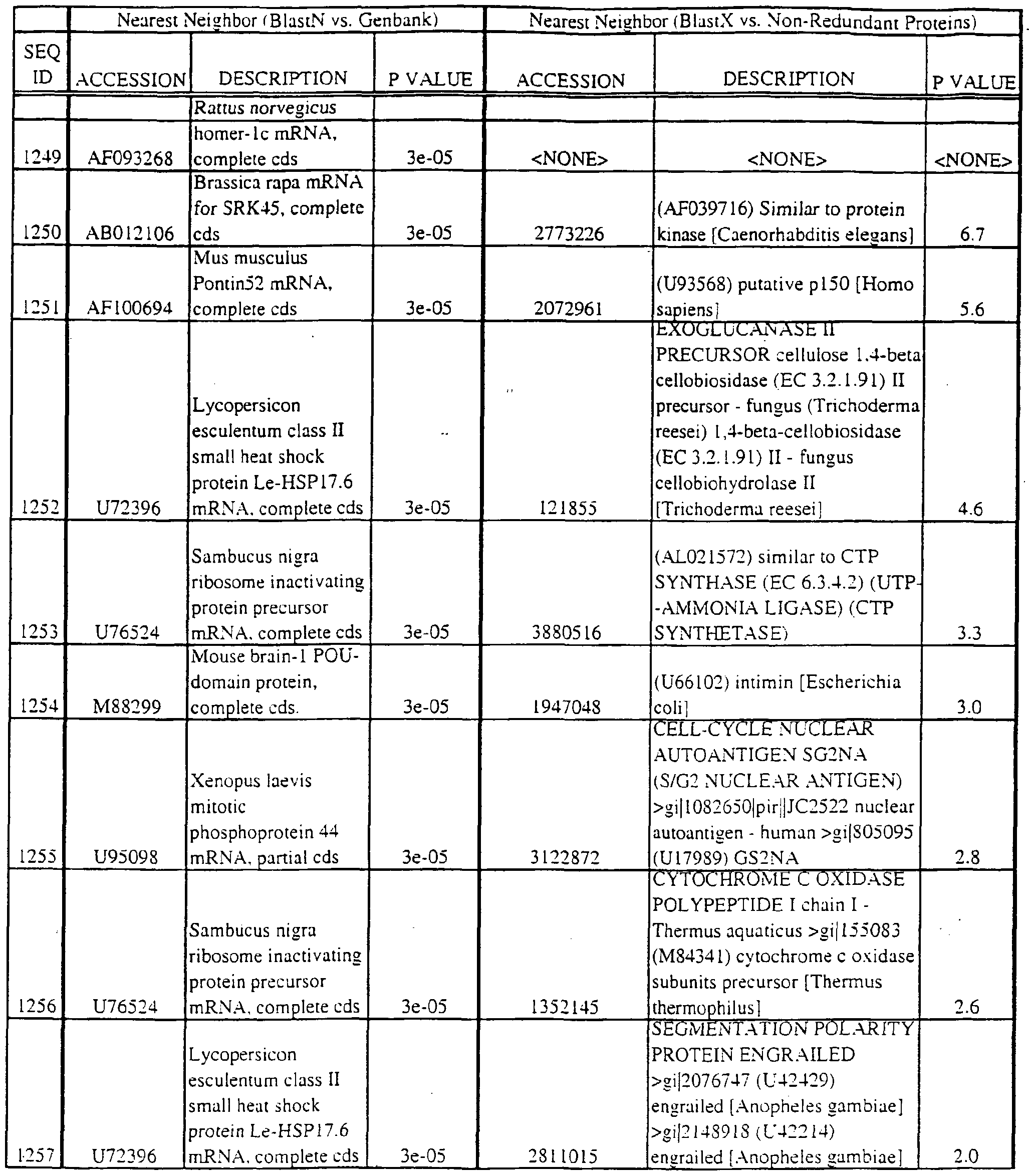
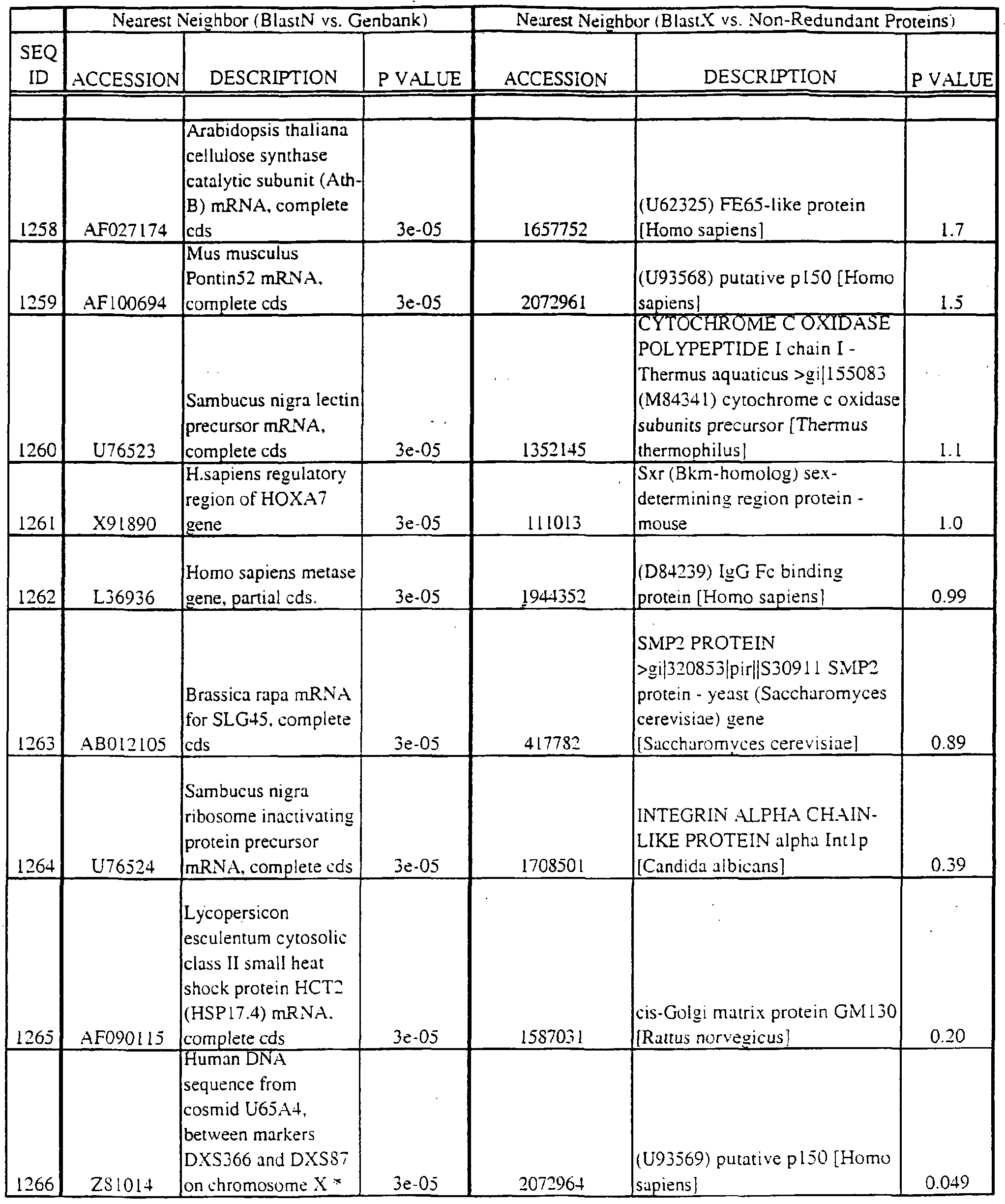






























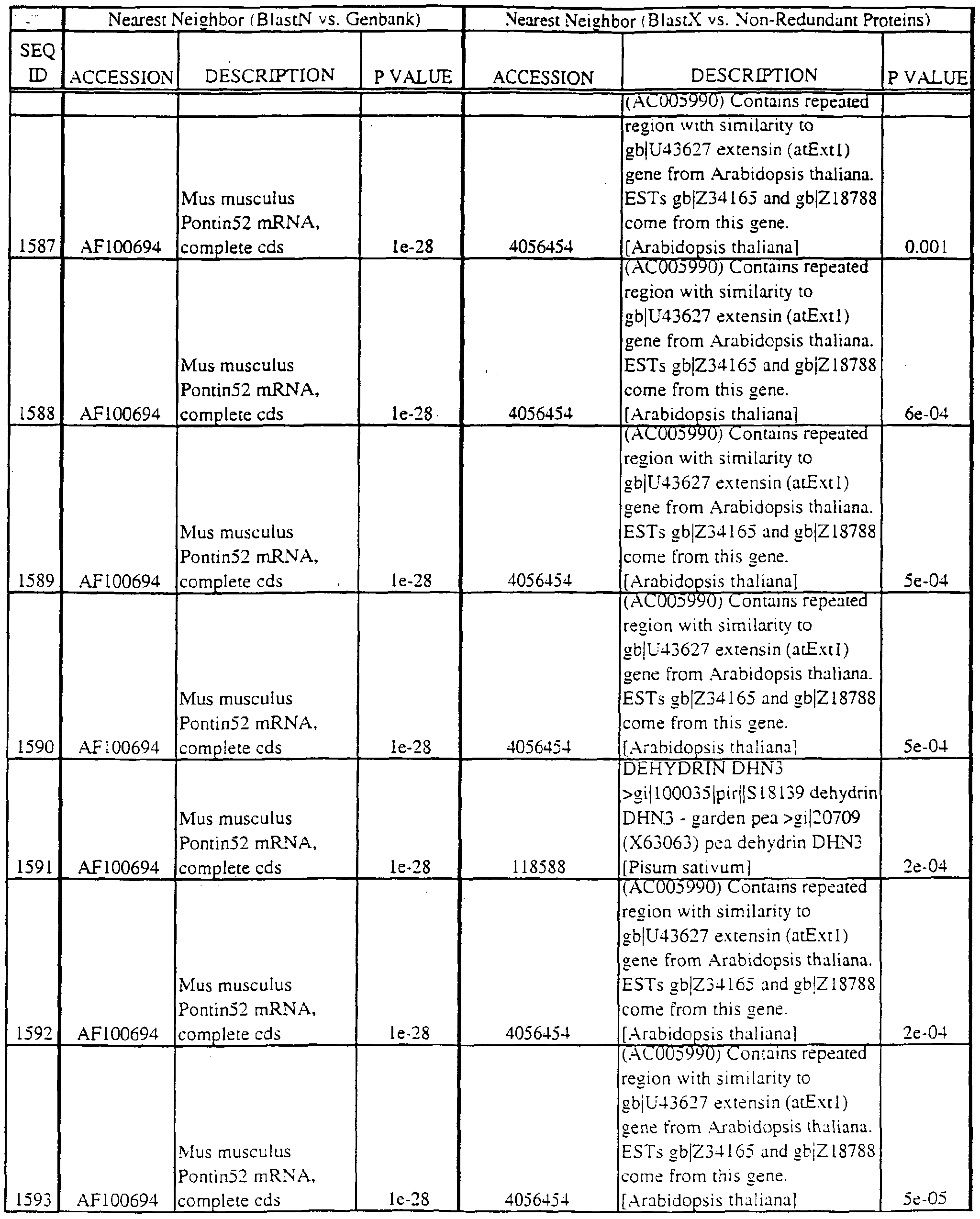











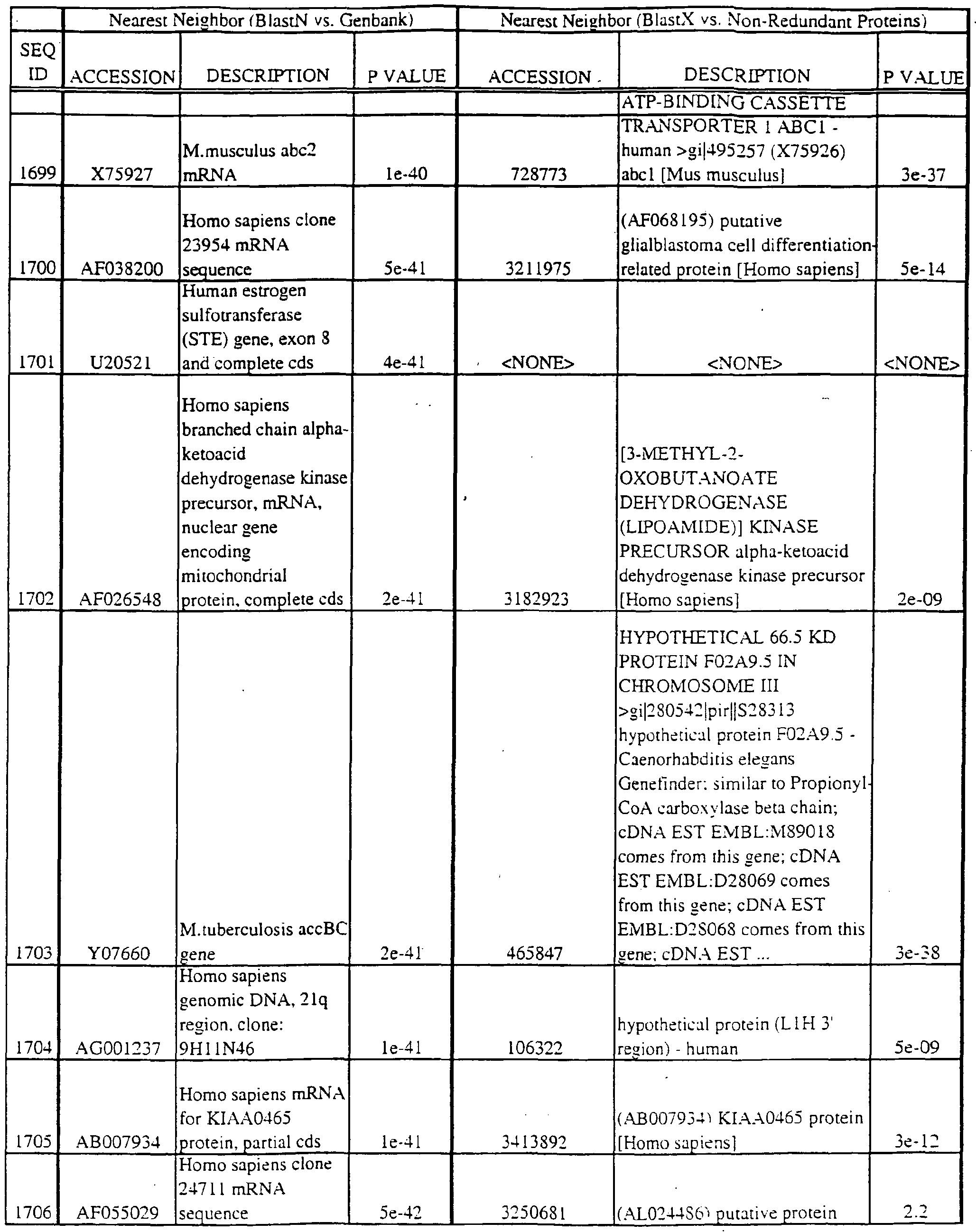




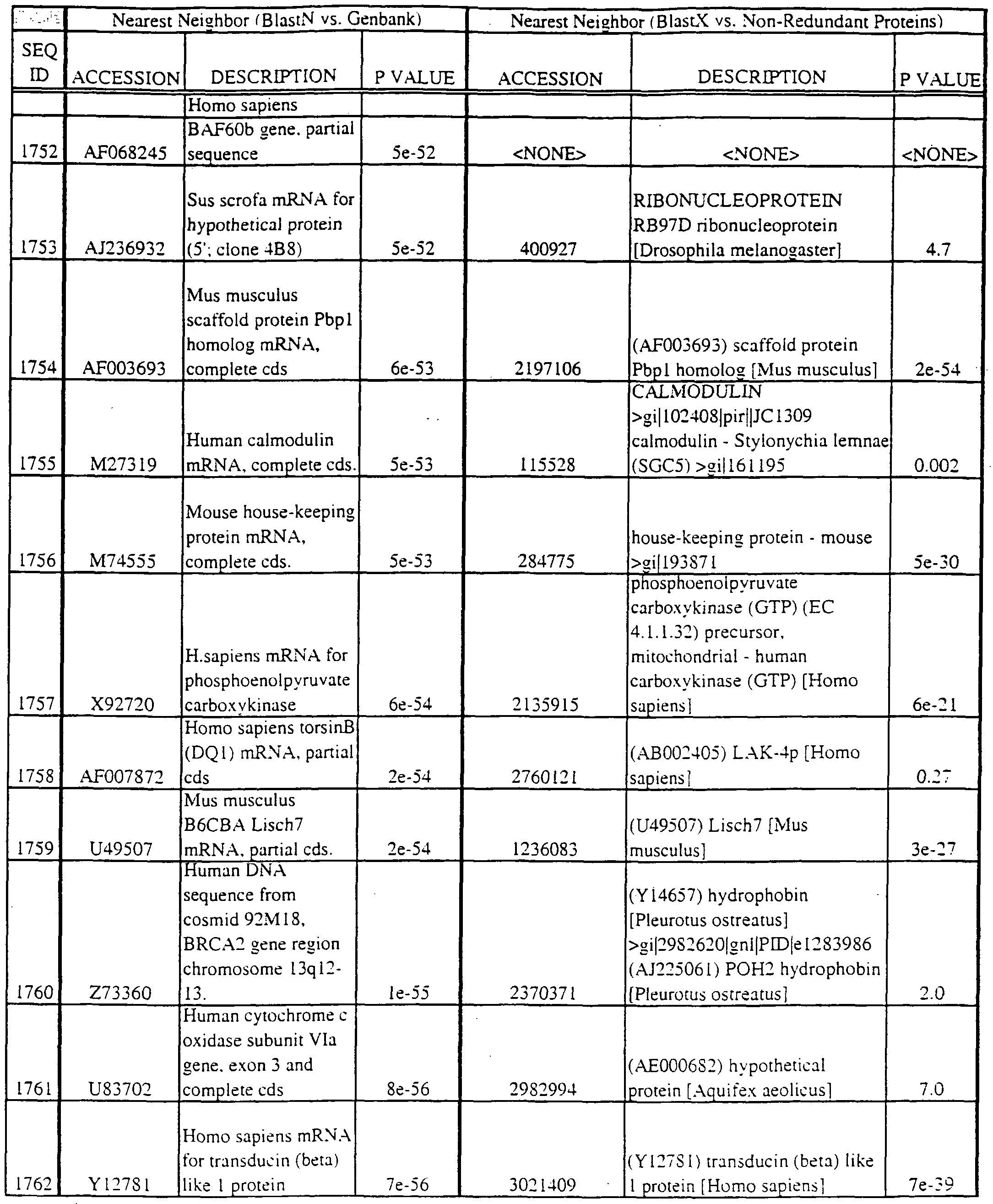


































































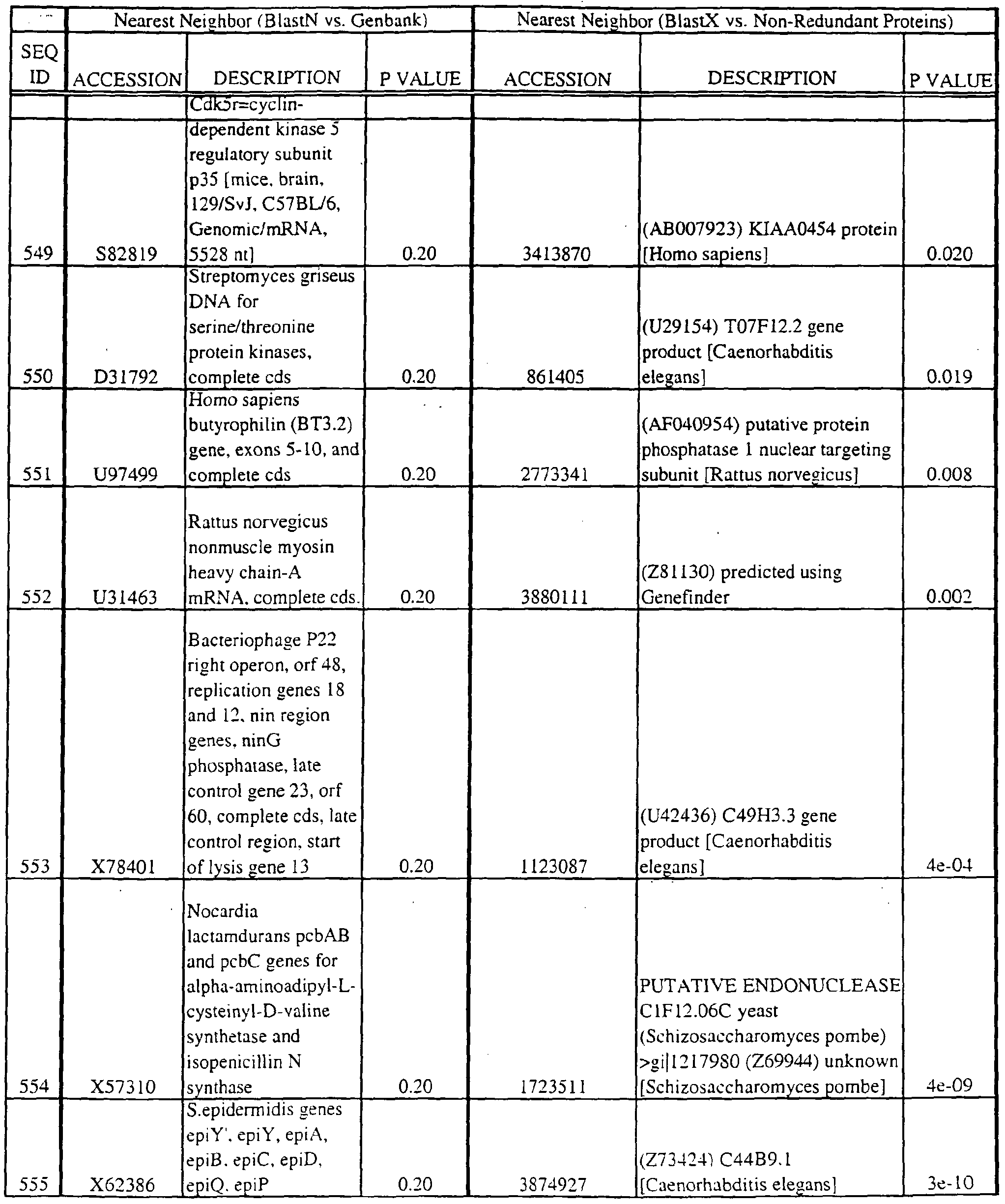
























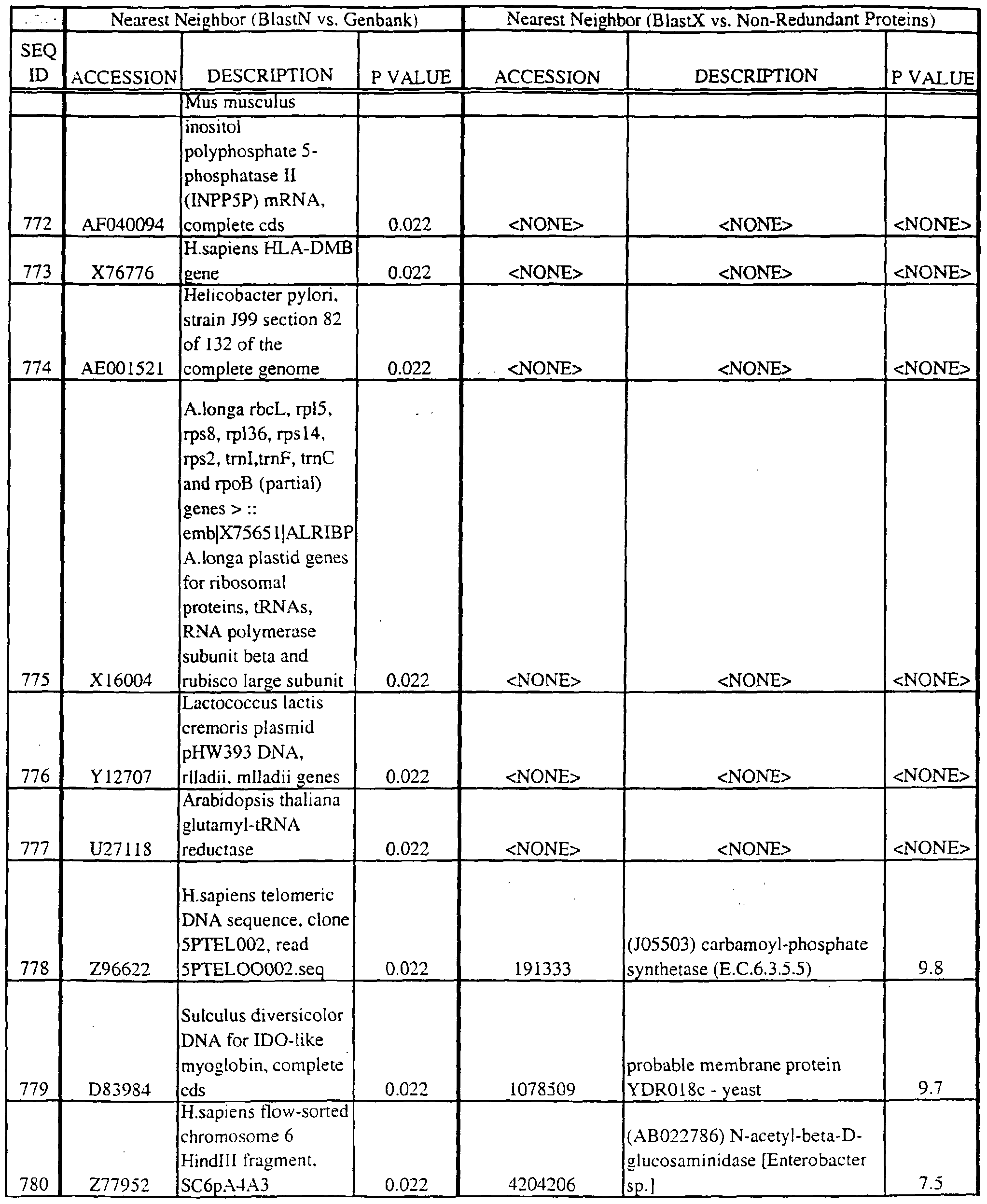
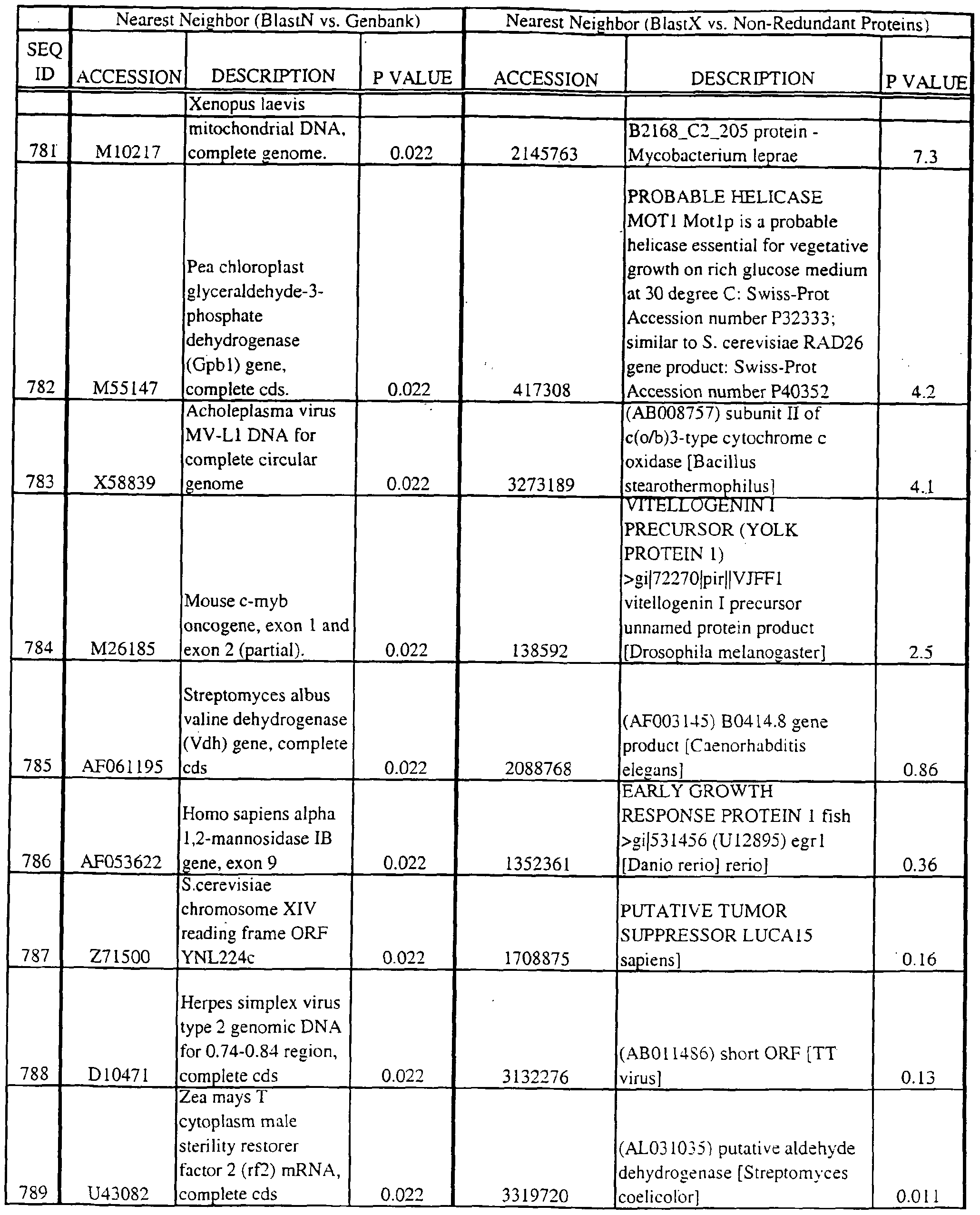


















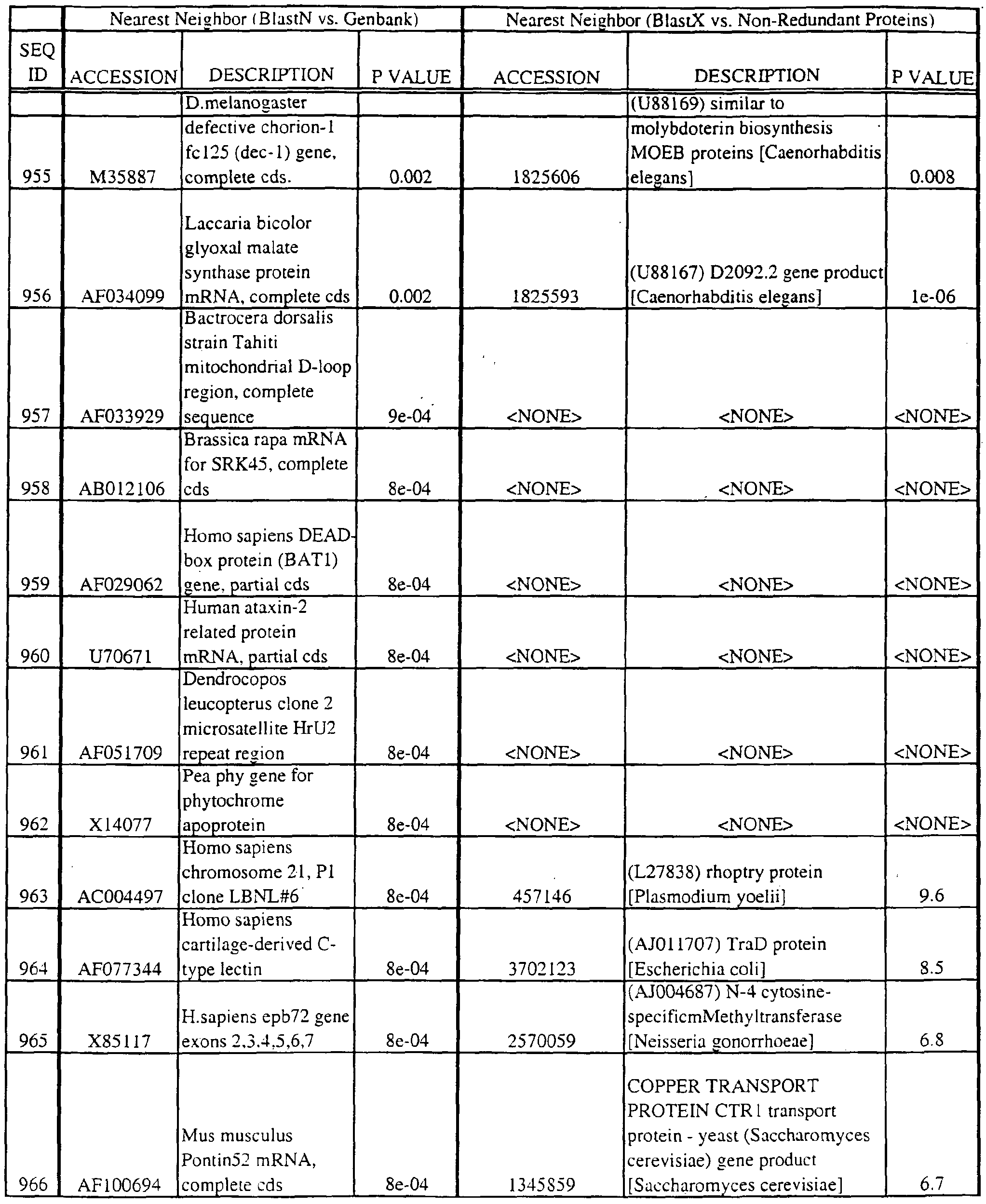

































































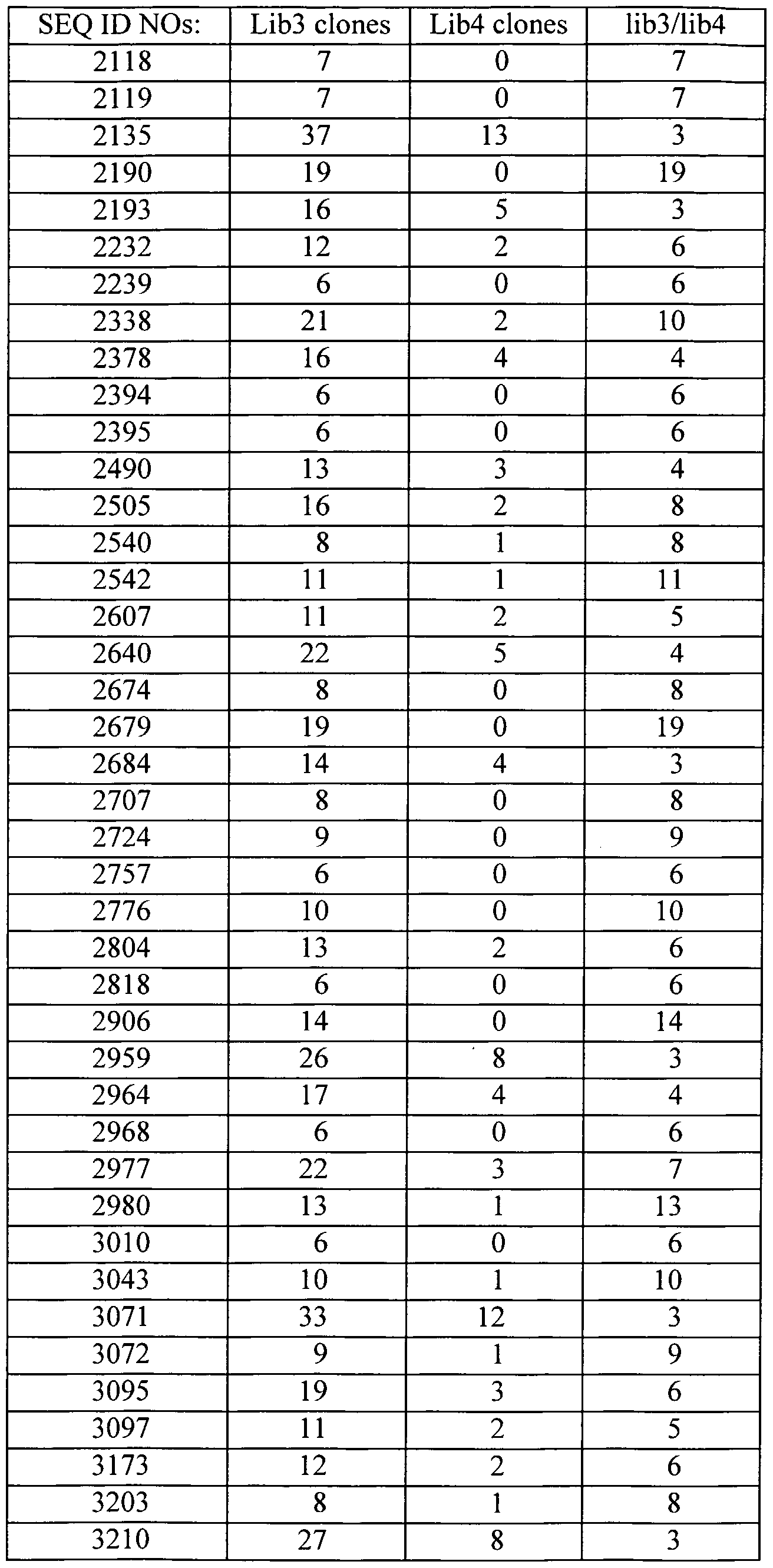












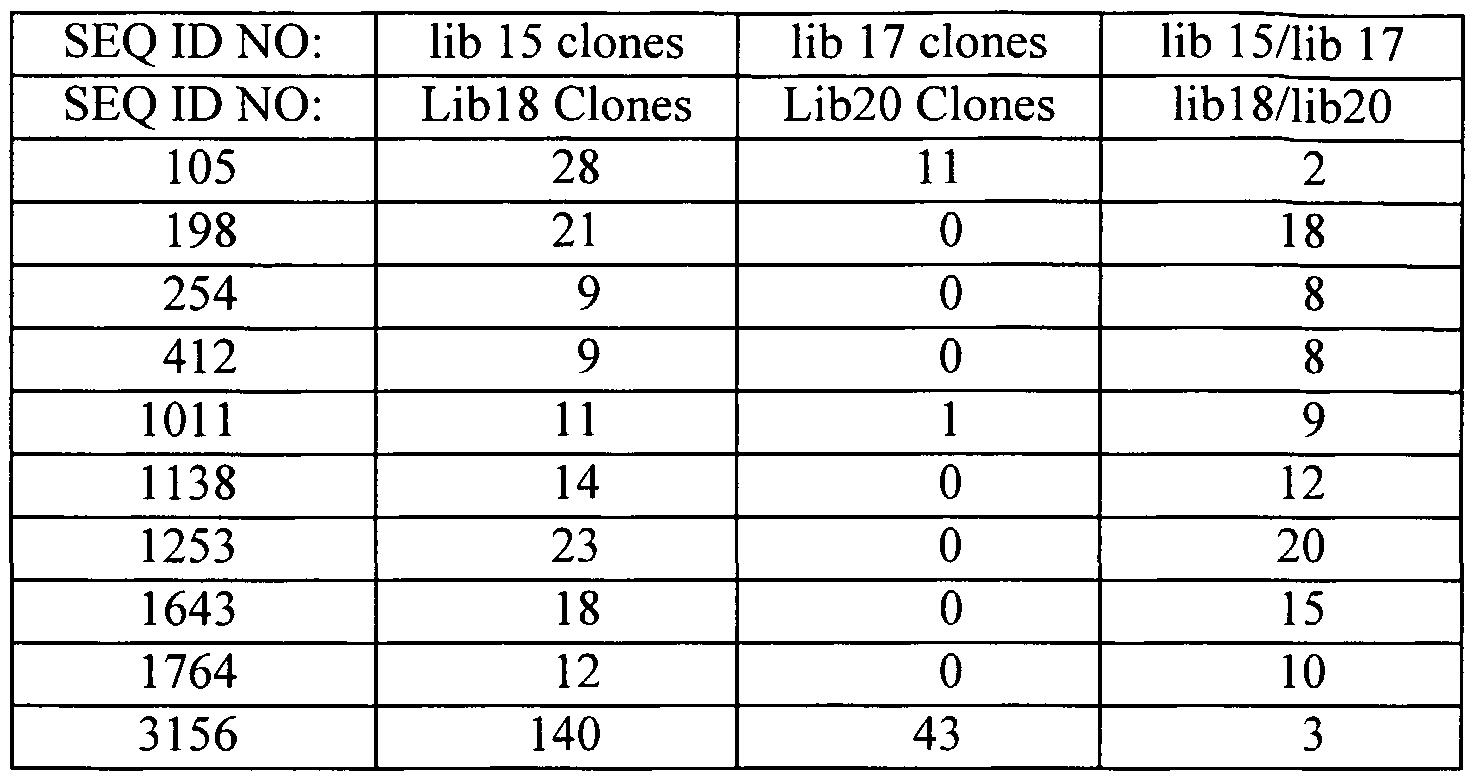









































Claims
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| AU60693/00A AU6069300A (en) | 1999-07-02 | 2000-06-30 | Novel human genes and gene expression products |
| JP2001508340A JP2003518920A (en) | 1999-07-02 | 2000-06-30 | New human genes and gene expression products |
| EP00947021A EP1194549A2 (en) | 1999-07-02 | 2000-06-30 | Human genes and gene expression products |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14231099P | 1999-07-02 | 1999-07-02 | |
| US14231199P | 1999-07-02 | 1999-07-02 | |
| US60/142,310 | 1999-07-02 | ||
| US60/142,311 | 1999-07-02 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2001002568A2 true WO2001002568A2 (en) | 2001-01-11 |
| WO2001002568A3 WO2001002568A3 (en) | 2001-08-30 |
Family
ID=26839967
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2000/018374 WO2001002568A2 (en) | 1999-07-02 | 2000-06-30 | Human genes and gene expression products |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP1194549A2 (en) |
| JP (1) | JP2003518920A (en) |
| AU (1) | AU6069300A (en) |
| WO (1) | WO2001002568A2 (en) |
Cited By (53)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001021836A2 (en) * | 1999-09-23 | 2001-03-29 | Incyte Genomics, Inc. | Molecules for diagnostics and therapeutics |
| WO2001031003A1 (en) * | 1999-10-29 | 2001-05-03 | Pierre Fabre Medicament | Cloning, expression and characterisation of a gene expressed in tumour cells and involved in the regulation of the immune response |
| WO2001042289A2 (en) * | 1999-12-09 | 2001-06-14 | Curagen Corporation | Tetraspan polypetides and polynucleotides encoding same |
| WO2001044472A1 (en) * | 1999-12-16 | 2001-06-21 | Amgen, Inc. | Tnfr/opg-like molecules and uses thereof |
| WO2001062921A2 (en) * | 2000-02-22 | 2001-08-30 | Lexicon Genetics Incorporated | Novel human regulatory protein and polynucleotides encoding the same |
| WO2001062929A2 (en) * | 2000-02-25 | 2001-08-30 | Curagen Corporation | Sodium/solute symporter-like protein and nucleic acids encoding same |
| WO2001064858A2 (en) * | 2000-02-28 | 2001-09-07 | Millennium Pharmaceuticals, Inc. | 25312, a human agmatinase-like homolog |
| WO2001064895A2 (en) * | 2000-02-28 | 2001-09-07 | Millenium Pharmaceuticals, Inc. | 27411, a human phosphatidyl-glycerolphosphate (pgp) synthase |
| WO2001066753A2 (en) * | 2000-03-09 | 2001-09-13 | Chiron Corporation | Human genes and gene expression products |
| WO2001075076A2 (en) * | 2000-03-31 | 2001-10-11 | Millennium Pharmaceuticals, Inc. | 33167, a novel human hydrolase and uses therefor |
| WO2001077150A2 (en) * | 2000-04-10 | 2001-10-18 | Merck Patent Gmbh | Serine-threonine kinase |
| WO2002022777A2 (en) * | 2000-09-15 | 2002-03-21 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Cellular genes involved in oncogenesis, products of said genes and their diagnostic and therapeutic uses |
| FR2814176A1 (en) * | 2000-09-15 | 2002-03-22 | Inst Nat Sante Rech Med | New nucleic acid implicated in oncogenesis, useful for diagnosis and treatment of cancer, also related polypeptides and antibodies |
| WO2002029057A2 (en) * | 2000-10-05 | 2002-04-11 | Millenium Pharmaceuticals, Inc. | 32144, a human fatty acid amide hydrolase and uses thereof |
| WO2002050269A1 (en) * | 2000-12-21 | 2002-06-27 | Genox Research, Inc. | Method of examining allergic disease |
| US6462187B1 (en) | 2000-06-15 | 2002-10-08 | Millennium Pharmaceuticals, Inc. | 22109, a novel human thioredoxin family member and uses thereof |
| EP1277833A2 (en) * | 1999-02-12 | 2003-01-22 | Genentech, Inc. | Costal-2 homologue |
| US6511834B1 (en) | 2000-03-24 | 2003-01-28 | Millennium Pharmaceuticals, Inc. | 32142,21481,25964,21686, novel human dehydrogenase molecules and uses therefor |
| US6534301B2 (en) | 2000-03-07 | 2003-03-18 | Millennium Pharmaceuticals, Inc. | 16835, a novel human phospholipase C family member and uses thereof |
| US6627423B2 (en) | 2000-03-24 | 2003-09-30 | Millennium Pharmaceuticals, Inc. | 21481, a novel dehydrogenase molecule and uses therefor |
| WO2004009837A2 (en) * | 2002-07-19 | 2004-01-29 | Arizona Board Of Regents | A high resolution typing system for pathogenic mycobacterium tuberculosum |
| US6759508B2 (en) | 2000-09-01 | 2004-07-06 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of lung cancer |
| US6787327B2 (en) | 2001-10-05 | 2004-09-07 | Kelk Graduate Of Applied Life Sciences | Methods for determining tyrosine-DNA phosphodiesterase activity |
| US6863892B2 (en) | 2000-08-22 | 2005-03-08 | Agensys, Inc. | Nucleic acid and corresponding protein named 158P1D7 useful in the treatment and detection of bladder and other cancers |
| WO2003057711A3 (en) * | 2001-12-21 | 2005-04-07 | Ludwig Inst Cancer Res | Isolated cytokine receptor licr-2 |
| US6924358B2 (en) | 2001-03-05 | 2005-08-02 | Agensys, Inc. | 121P1F1: a tissue specific protein highly expressed in various cancers |
| US6930172B2 (en) | 1999-01-12 | 2005-08-16 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| US6951738B2 (en) | 1999-07-16 | 2005-10-04 | Human Genome Sciences, Inc. | Human tumor necrosis factor receptors TR13 and TR14 |
| EP1642967A2 (en) * | 1999-03-08 | 2006-04-05 | Genentech, Inc. | Composition and methods for the diagnosis of tumours |
| US7029895B2 (en) | 1999-09-27 | 2006-04-18 | Millennium Pharmaceuticals, Inc. | 27411, a novel human PGP synthase |
| EP1666495A1 (en) * | 1999-12-01 | 2006-06-07 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| EP1666597A3 (en) * | 2000-06-02 | 2006-11-02 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| EP1734051A2 (en) * | 1998-12-01 | 2006-12-20 | Genetech, Inc. | Composition and methods for the diagnosis of tumours |
| US7208267B2 (en) | 2000-11-22 | 2007-04-24 | Diadexus, Inc. | Compositions and methods relating to breast specific genes and proteins |
| US7358353B2 (en) | 2000-08-22 | 2008-04-15 | Agensys, Inc. | Nucleic acid and corresponding protein named 158P1D7 useful in the treatment and detection of bladder and other cancers |
| US7402656B2 (en) | 2001-06-01 | 2008-07-22 | Genentech, Inc. | PRO10013 polypeptides |
| US7601825B2 (en) | 2001-03-05 | 2009-10-13 | Agensys, Inc. | Nucleic acid and corresponding protein entitled 121P1F1 useful in treatment and detection of cancer |
| US7601809B2 (en) | 2000-11-28 | 2009-10-13 | Zymogenetics, Llc | Cytokine receptor zcytor19 |
| US7723298B2 (en) | 2002-04-19 | 2010-05-25 | Zymogenetics, Inc. | Cytokine receptor |
| US7736654B2 (en) | 2001-04-10 | 2010-06-15 | Agensys, Inc. | Nucleic acids and corresponding proteins useful in the detection and treatment of various cancers |
| US7968090B2 (en) | 2001-03-14 | 2011-06-28 | Agensys, Inc. | Nucleic acids and corresponding proteins entitled 191P4D12(b) useful in treatment and detection of cancer |
| US8101349B2 (en) | 1997-12-23 | 2012-01-24 | Novartis Vaccines And Diagnostics, Inc. | Gene products differentially expressed in cancerous cells and their methods of use II |
| EP2325335A3 (en) * | 2001-09-14 | 2012-01-25 | Clinical Genomics Pty. Ltd | Nucleic acid markers for use in determining predisposition to neoplasm and/or adenoma |
| US8216580B2 (en) | 2000-12-27 | 2012-07-10 | The Regents Of The University Of California | Sulfatases and methods of use thereof |
| US8637642B2 (en) | 2010-09-29 | 2014-01-28 | Seattle Genetics, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US8968742B2 (en) | 2012-08-23 | 2015-03-03 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 158P1D7 proteins |
| WO2015084808A1 (en) * | 2013-12-02 | 2015-06-11 | Oncomed Pharmaceuticals, Inc. | Identification of predictive biomarkers associated with wnt pathway inhibitors |
| US9168300B2 (en) | 2013-03-14 | 2015-10-27 | Oncomed Pharmaceuticals, Inc. | MET-binding agents and uses thereof |
| US9228013B2 (en) | 2005-10-31 | 2016-01-05 | OncoMed Pharmaceuticals | Methods of using the FRI domain of human frizzled receptor for inhibiting Wnt signaling in a tumor or tumor cell |
| US9359444B2 (en) | 2013-02-04 | 2016-06-07 | Oncomed Pharmaceuticals Inc. | Methods and monitoring of treatment with a Wnt pathway inhibitor |
| US9499630B2 (en) | 2010-04-01 | 2016-11-22 | Oncomed Pharmaceuticals, Inc. | Frizzled-binding agents and uses thereof |
| US9573998B2 (en) | 2008-09-26 | 2017-02-21 | Oncomed Pharmaceuticals, Inc. | Antibodies against human FZD5 and FZD8 |
| US9579361B2 (en) | 2010-01-12 | 2017-02-28 | Oncomed Pharmaceuticals, Inc. | Wnt antagonist and methods of treatment and screening |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1997040151A2 (en) * | 1996-04-19 | 1997-10-30 | Genetics Institute, Inc. | Secreted proteins and polynucleotides encoding them |
-
2000
- 2000-06-30 AU AU60693/00A patent/AU6069300A/en not_active Abandoned
- 2000-06-30 JP JP2001508340A patent/JP2003518920A/en not_active Withdrawn
- 2000-06-30 EP EP00947021A patent/EP1194549A2/en not_active Withdrawn
- 2000-06-30 WO PCT/US2000/018374 patent/WO2001002568A2/en not_active Application Discontinuation
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1997040151A2 (en) * | 1996-04-19 | 1997-10-30 | Genetics Institute, Inc. | Secreted proteins and polynucleotides encoding them |
Non-Patent Citations (2)
| Title |
|---|
| DATABASE EMBL [Online] ACCESSION NUMBER : AC004067, 31 January 1998 (1998-01-31) N.E. STONE ET AL.: "Homo sapiens chromosome 4 clone B366024 map 4q25, complete sequence" XP002155218 * |
| DATABASE EMBL [Online] ACCESSION NUMBER : R09152, 20 April 1995 (1995-04-20) L. HILLIER ET AL.: "yf25h12.r1 Soares fetal liver spleen 1NFLS Homo sapiens cDNA clone." XP002155219 * |
Cited By (100)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8101349B2 (en) | 1997-12-23 | 2012-01-24 | Novartis Vaccines And Diagnostics, Inc. | Gene products differentially expressed in cancerous cells and their methods of use II |
| EP1734051A2 (en) * | 1998-12-01 | 2006-12-20 | Genetech, Inc. | Composition and methods for the diagnosis of tumours |
| EP1734051A3 (en) * | 1998-12-01 | 2007-09-12 | Genetech, Inc. | Composition and methods for the diagnosis of tumours |
| US6930172B2 (en) | 1999-01-12 | 2005-08-16 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| US6969758B2 (en) | 1999-01-12 | 2005-11-29 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| US7101984B2 (en) | 1999-02-12 | 2006-09-05 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| EP1277833A3 (en) * | 1999-02-12 | 2003-04-23 | Genentech, Inc. | Costal-2 homologue |
| EP1277833A2 (en) * | 1999-02-12 | 2003-01-22 | Genentech, Inc. | Costal-2 homologue |
| EP1642967A3 (en) * | 1999-03-08 | 2006-07-26 | Genentech, Inc. | Composition and methods for the diagnosis of tumours |
| EP1642967A2 (en) * | 1999-03-08 | 2006-04-05 | Genentech, Inc. | Composition and methods for the diagnosis of tumours |
| US6951738B2 (en) | 1999-07-16 | 2005-10-04 | Human Genome Sciences, Inc. | Human tumor necrosis factor receptors TR13 and TR14 |
| WO2001021836A3 (en) * | 1999-09-23 | 2002-01-31 | Incyte Genomics Inc | Molecules for diagnostics and therapeutics |
| WO2001021836A2 (en) * | 1999-09-23 | 2001-03-29 | Incyte Genomics, Inc. | Molecules for diagnostics and therapeutics |
| US7029895B2 (en) | 1999-09-27 | 2006-04-18 | Millennium Pharmaceuticals, Inc. | 27411, a novel human PGP synthase |
| WO2001031003A1 (en) * | 1999-10-29 | 2001-05-03 | Pierre Fabre Medicament | Cloning, expression and characterisation of a gene expressed in tumour cells and involved in the regulation of the immune response |
| EP1666495A1 (en) * | 1999-12-01 | 2006-06-07 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| WO2001042289A3 (en) * | 1999-12-09 | 2002-02-07 | Curagen Corp | Tetraspan polypetides and polynucleotides encoding same |
| WO2001042289A2 (en) * | 1999-12-09 | 2001-06-14 | Curagen Corporation | Tetraspan polypetides and polynucleotides encoding same |
| WO2001044472A1 (en) * | 1999-12-16 | 2001-06-21 | Amgen, Inc. | Tnfr/opg-like molecules and uses thereof |
| WO2001062921A2 (en) * | 2000-02-22 | 2001-08-30 | Lexicon Genetics Incorporated | Novel human regulatory protein and polynucleotides encoding the same |
| WO2001062921A3 (en) * | 2000-02-22 | 2002-02-07 | Lexicon Genetics Inc | Novel human regulatory protein and polynucleotides encoding the same |
| WO2001062929A3 (en) * | 2000-02-25 | 2002-07-25 | Curagen Corp | Sodium/solute symporter-like protein and nucleic acids encoding same |
| WO2001062929A2 (en) * | 2000-02-25 | 2001-08-30 | Curagen Corporation | Sodium/solute symporter-like protein and nucleic acids encoding same |
| US6465230B2 (en) | 2000-02-28 | 2002-10-15 | Millennium Pharmaceuticals, Inc. | 27411, a novel human PGP synthase |
| WO2001064858A3 (en) * | 2000-02-28 | 2002-02-07 | Millennium Pharm Inc | 25312, a human agmatinase-like homolog |
| WO2001064858A2 (en) * | 2000-02-28 | 2001-09-07 | Millennium Pharmaceuticals, Inc. | 25312, a human agmatinase-like homolog |
| US7037671B2 (en) | 2000-02-28 | 2006-05-02 | Millennium Pharmaceuticals, Inc. | 25312, a novel human agmatinase-like homolog |
| WO2001064895A3 (en) * | 2000-02-28 | 2002-02-21 | Millenium Pharmaceuticals Inc | 27411, a human phosphatidyl-glycerolphosphate (pgp) synthase |
| US7060476B2 (en) | 2000-02-28 | 2006-06-13 | Millennium Pharmaceuticals, Inc. | 27411, a novel human PGP synthase |
| US6642039B1 (en) | 2000-02-28 | 2003-11-04 | Millenium Pharmaceuticals, Inc. | 25312, a novel human agmatinase-like homolog |
| US6413757B1 (en) | 2000-02-28 | 2002-07-02 | Millennium Pharmaceuticals, Inc. | 25312, a novel human agmatinase-like homolog |
| WO2001064895A2 (en) * | 2000-02-28 | 2001-09-07 | Millenium Pharmaceuticals, Inc. | 27411, a human phosphatidyl-glycerolphosphate (pgp) synthase |
| US6534301B2 (en) | 2000-03-07 | 2003-03-18 | Millennium Pharmaceuticals, Inc. | 16835, a novel human phospholipase C family member and uses thereof |
| WO2001066753A3 (en) * | 2000-03-09 | 2002-08-15 | Chiron Corp | Human genes and gene expression products |
| WO2001066753A2 (en) * | 2000-03-09 | 2001-09-13 | Chiron Corporation | Human genes and gene expression products |
| US7494793B2 (en) | 2000-03-24 | 2009-02-24 | Millennium Pharmaceuticals, Inc. | 21686, dehydrogenase |
| US6613555B2 (en) | 2000-03-24 | 2003-09-02 | Millennium Pharmaceuticals, Inc. | 32142, 21481, 25964, 21686, novel human dehydrogenase molecules and uses therefor |
| US6627423B2 (en) | 2000-03-24 | 2003-09-30 | Millennium Pharmaceuticals, Inc. | 21481, a novel dehydrogenase molecule and uses therefor |
| US6511834B1 (en) | 2000-03-24 | 2003-01-28 | Millennium Pharmaceuticals, Inc. | 32142,21481,25964,21686, novel human dehydrogenase molecules and uses therefor |
| US7045325B2 (en) | 2000-03-24 | 2006-05-16 | Millennium Pharmaceuticals, Inc. | 32142, 21481, 25964, 21686, novel dehydrogenase molecules and uses therefor |
| WO2001075076A2 (en) * | 2000-03-31 | 2001-10-11 | Millennium Pharmaceuticals, Inc. | 33167, a novel human hydrolase and uses therefor |
| WO2001075076A3 (en) * | 2000-03-31 | 2002-06-20 | Millennium Pharm Inc | 33167, a novel human hydrolase and uses therefor |
| WO2001077150A2 (en) * | 2000-04-10 | 2001-10-18 | Merck Patent Gmbh | Serine-threonine kinase |
| WO2001077150A3 (en) * | 2000-04-10 | 2002-03-28 | Merck Patent Gmbh | Serine-threonine kinase |
| EP1666597A3 (en) * | 2000-06-02 | 2006-11-02 | Genentech, Inc. | Secreted and transmembrane polypeptides and nucleic acids encoding the same |
| US6462187B1 (en) | 2000-06-15 | 2002-10-08 | Millennium Pharmaceuticals, Inc. | 22109, a novel human thioredoxin family member and uses thereof |
| US6863892B2 (en) | 2000-08-22 | 2005-03-08 | Agensys, Inc. | Nucleic acid and corresponding protein named 158P1D7 useful in the treatment and detection of bladder and other cancers |
| US7358353B2 (en) | 2000-08-22 | 2008-04-15 | Agensys, Inc. | Nucleic acid and corresponding protein named 158P1D7 useful in the treatment and detection of bladder and other cancers |
| US8945570B2 (en) | 2000-08-22 | 2015-02-03 | Agensys, Inc. | Nucleic acid and corresponding protein named 158P1D7 useful in the treatment and detection of bladder and other cancers |
| US8951744B2 (en) | 2000-08-22 | 2015-02-10 | Agensys, Inc. | Nucleic acid and corresponding protein named 158P1D7 useful in the treatment and detection of bladder and other cancers |
| US6759508B2 (en) | 2000-09-01 | 2004-07-06 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of lung cancer |
| WO2002022777A3 (en) * | 2000-09-15 | 2002-10-24 | Inst Nat Sante Rech Med | Cellular genes involved in oncogenesis, products of said genes and their diagnostic and therapeutic uses |
| FR2814176A1 (en) * | 2000-09-15 | 2002-03-22 | Inst Nat Sante Rech Med | New nucleic acid implicated in oncogenesis, useful for diagnosis and treatment of cancer, also related polypeptides and antibodies |
| WO2002022777A2 (en) * | 2000-09-15 | 2002-03-21 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Cellular genes involved in oncogenesis, products of said genes and their diagnostic and therapeutic uses |
| WO2002029057A3 (en) * | 2000-10-05 | 2003-01-23 | Millenium Pharmaceuticals Inc | 32144, a human fatty acid amide hydrolase and uses thereof |
| WO2002029057A2 (en) * | 2000-10-05 | 2002-04-11 | Millenium Pharmaceuticals, Inc. | 32144, a human fatty acid amide hydrolase and uses thereof |
| US7208267B2 (en) | 2000-11-22 | 2007-04-24 | Diadexus, Inc. | Compositions and methods relating to breast specific genes and proteins |
| US7608452B2 (en) | 2000-11-28 | 2009-10-27 | Zymogenetics, Llc | Polynucleotides encoding cytokine receptor zcytor19 |
| US7601809B2 (en) | 2000-11-28 | 2009-10-13 | Zymogenetics, Llc | Cytokine receptor zcytor19 |
| US7618791B2 (en) | 2000-11-28 | 2009-11-17 | Zymogenetics, Llc | Methods of detecting cancer with antibodies to cytokine receptor ZCYTOR19 |
| WO2002050269A1 (en) * | 2000-12-21 | 2002-06-27 | Genox Research, Inc. | Method of examining allergic disease |
| US8216580B2 (en) | 2000-12-27 | 2012-07-10 | The Regents Of The University Of California | Sulfatases and methods of use thereof |
| US7892548B2 (en) | 2001-03-05 | 2011-02-22 | Agensys, Inc. | 121P1F1: a tissue specific protein highly expressed in various cancers |
| US7601825B2 (en) | 2001-03-05 | 2009-10-13 | Agensys, Inc. | Nucleic acid and corresponding protein entitled 121P1F1 useful in treatment and detection of cancer |
| US6924358B2 (en) | 2001-03-05 | 2005-08-02 | Agensys, Inc. | 121P1F1: a tissue specific protein highly expressed in various cancers |
| US7309585B2 (en) | 2001-03-05 | 2007-12-18 | Agensys, Inc. | 121P1F1: a tissue specific protein highly expressed in various cancers |
| US8039603B2 (en) | 2001-03-05 | 2011-10-18 | Agensys, Inc. | Nucleic acid and corresponding protein entitled 121P1F1 useful in treatment and detection of cancer |
| US7968090B2 (en) | 2001-03-14 | 2011-06-28 | Agensys, Inc. | Nucleic acids and corresponding proteins entitled 191P4D12(b) useful in treatment and detection of cancer |
| US7736654B2 (en) | 2001-04-10 | 2010-06-15 | Agensys, Inc. | Nucleic acids and corresponding proteins useful in the detection and treatment of various cancers |
| US7402656B2 (en) | 2001-06-01 | 2008-07-22 | Genentech, Inc. | PRO10013 polypeptides |
| US8669050B2 (en) | 2001-09-14 | 2014-03-11 | Clinical Genomics Pty. Ltd. | Nucleic acid markers for use in determining predisposition to neoplasm and/or adenoma |
| EP2325335A3 (en) * | 2001-09-14 | 2012-01-25 | Clinical Genomics Pty. Ltd | Nucleic acid markers for use in determining predisposition to neoplasm and/or adenoma |
| US6787327B2 (en) | 2001-10-05 | 2004-09-07 | Kelk Graduate Of Applied Life Sciences | Methods for determining tyrosine-DNA phosphodiesterase activity |
| WO2003057711A3 (en) * | 2001-12-21 | 2005-04-07 | Ludwig Inst Cancer Res | Isolated cytokine receptor licr-2 |
| US7723298B2 (en) | 2002-04-19 | 2010-05-25 | Zymogenetics, Inc. | Cytokine receptor |
| WO2004009837A3 (en) * | 2002-07-19 | 2007-03-22 | Univ Arizona | A high resolution typing system for pathogenic mycobacterium tuberculosum |
| US7592135B2 (en) | 2002-07-19 | 2009-09-22 | Arizona Board Of Regents | High resolution typing system for pathogenic Mycobacterium tuberculosum |
| US7026467B2 (en) * | 2002-07-19 | 2006-04-11 | Arizona Board Of Regents, Acting For And On Behalf Of, Northern Arizona University | High resolution typing system for pathogenic Mycobaterium tuberculosum |
| WO2004009837A2 (en) * | 2002-07-19 | 2004-01-29 | Arizona Board Of Regents | A high resolution typing system for pathogenic mycobacterium tuberculosum |
| US9228013B2 (en) | 2005-10-31 | 2016-01-05 | OncoMed Pharmaceuticals | Methods of using the FRI domain of human frizzled receptor for inhibiting Wnt signaling in a tumor or tumor cell |
| US9732139B2 (en) | 2005-10-31 | 2017-08-15 | Oncomed Pharmaceuticals, Inc. | Methods of treating cancer by administering a soluble receptor comprising a human Fc domain and the Fri domain from human frizzled receptor |
| US9573998B2 (en) | 2008-09-26 | 2017-02-21 | Oncomed Pharmaceuticals, Inc. | Antibodies against human FZD5 and FZD8 |
| US9579361B2 (en) | 2010-01-12 | 2017-02-28 | Oncomed Pharmaceuticals, Inc. | Wnt antagonist and methods of treatment and screening |
| US9499630B2 (en) | 2010-04-01 | 2016-11-22 | Oncomed Pharmaceuticals, Inc. | Frizzled-binding agents and uses thereof |
| US9314538B2 (en) | 2010-09-29 | 2016-04-19 | Agensys, Inc. | Nucleic acid molecules encoding antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| USRE48389E1 (en) | 2010-09-29 | 2021-01-12 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US10894090B2 (en) | 2010-09-29 | 2021-01-19 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US11559582B2 (en) | 2010-09-29 | 2023-01-24 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US9078931B2 (en) | 2010-09-29 | 2015-07-14 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US9962454B2 (en) | 2010-09-29 | 2018-05-08 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US8637642B2 (en) | 2010-09-29 | 2014-01-28 | Seattle Genetics, Inc. | Antibody drug conjugates (ADC) that bind to 191P4D12 proteins |
| US11634503B2 (en) | 2012-08-23 | 2023-04-25 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 158P1D7 proteins |
| US8968742B2 (en) | 2012-08-23 | 2015-03-03 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 158P1D7 proteins |
| US9926376B2 (en) | 2012-08-23 | 2018-03-27 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 158P1D7 proteins |
| USRE47103E1 (en) | 2012-08-23 | 2018-10-30 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 158P1D7 proteins |
| US10669348B2 (en) | 2012-08-23 | 2020-06-02 | Agensys, Inc. | Antibody drug conjugates (ADC) that bind to 158P1D7 proteins |
| US9987357B2 (en) | 2013-02-04 | 2018-06-05 | Oncomed Pharmaceuticals, Inc. | Methods and monitoring of treatment with a WNT pathway inhibitor |
| US9359444B2 (en) | 2013-02-04 | 2016-06-07 | Oncomed Pharmaceuticals Inc. | Methods and monitoring of treatment with a Wnt pathway inhibitor |
| US9168300B2 (en) | 2013-03-14 | 2015-10-27 | Oncomed Pharmaceuticals, Inc. | MET-binding agents and uses thereof |
| WO2015084808A1 (en) * | 2013-12-02 | 2015-06-11 | Oncomed Pharmaceuticals, Inc. | Identification of predictive biomarkers associated with wnt pathway inhibitors |
Also Published As
| Publication number | Publication date |
|---|---|
| AU6069300A (en) | 2001-01-22 |
| WO2001002568A3 (en) | 2001-08-30 |
| JP2003518920A (en) | 2003-06-17 |
| EP1194549A2 (en) | 2002-04-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2001002568A2 (en) | Human genes and gene expression products | |
| US7122373B1 (en) | Human genes and gene expression products V | |
| US20070243176A1 (en) | Human genes and gene expression products | |
| EP1263956A2 (en) | Human genes and gene expression products | |
| US20020076735A1 (en) | Diagnostic and therapeutic methods using molecules differentially expressed in cancer cells | |
| WO1999038972A2 (en) | Human genes and gene expression products ii | |
| JP2002500010A (en) | Human genes and gene expression products I | |
| KR20060120652A (en) | Nucleic acid molecules and proteins for the identification, assessment, prevention, and therapy of ovarian cancer | |
| JP2011254830A (en) | Polynucleotide related to colon cancer | |
| US20030065156A1 (en) | Novel human genes and gene expression products I | |
| US20030215803A1 (en) | Human genes and gene expression products isolated from human prostate | |
| EP1144636A2 (en) | Human genes and gene expression products | |
| WO2004016317A1 (en) | Use of murine genomic regions identified to be involved in tumor development for the development of anti-cancer drugs and diagnosis of cancer | |
| WO2001072781A2 (en) | Human genes and expression products | |
| CA2430794A1 (en) | Human genes and gene expression products isolated from human prostate | |
| AU2010201655A1 (en) | Use of murine genomic regions identified to be involved in tumor development for the development of anti-cancer drugs and diagnosis of cancer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Kind code of ref document: A2 Designated state(s): AE AG AL AM AT AU AZ BA BB BG BR BY BZ CA CH CN CR CU CZ DE DK DM DZ EE ES FI GB GD GE GH GM HR HU ID IL IN IS JP KE KG KP KR KZ LC LK LR LS LT LU LV MA MD MG MK MN MW MX MZ NO NZ PL PT RO RU SD SE SG SI SK SL TJ TM TR TT TZ UA UG UZ VN YU ZA ZW |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A2 Designated state(s): GH GM KE LS MW MZ SD SL SZ TZ UG ZW AM AZ BY KG KZ MD RU TJ TM AT BE CH CY DE DK ES FI FR GB GR IE IT LU MC NL PT SE BF BJ CF CG CI CM GA GN GW ML MR NE SN TD TG |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| DFPE | Request for preliminary examination filed prior to expiration of 19th month from priority date (pct application filed before 20040101) | ||
| AK | Designated states |
Kind code of ref document: A3 Designated state(s): AE AG AL AM AT AU AZ BA BB BG BR BY BZ CA CH CN CR CU CZ DE DK DM DZ EE ES FI GB GD GE GH GM HR HU ID IL IN IS JP KE KG KP KR KZ LC LK LR LS LT LU LV MA MD MG MK MN MW MX MZ NO NZ PL PT RO RU SD SE SG SI SK SL TJ TM TR TT TZ UA UG UZ VN YU ZA ZW |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A3 Designated state(s): GH GM KE LS MW MZ SD SL SZ TZ UG ZW AM AZ BY KG KZ MD RU TJ TM AT BE CH CY DE DK ES FI FR GB GR IE IT LU MC NL PT SE BF BJ CF CG CI CM GA GN GW ML MR NE SN TD TG |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2000947021 Country of ref document: EP |
|
| ENP | Entry into the national phase in: |
Ref country code: AT Ref document number: 2000 9171 Date of ref document: 20010412 Kind code of ref document: A Format of ref document f/p: F |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 20009171 Country of ref document: AT |
|
| WWP | Wipo information: published in national office |
Ref document number: 2000947021 Country of ref document: EP |
|
| REG | Reference to national code |
Ref country code: DE Ref legal event code: 8642 |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2000947021 Country of ref document: EP |