US20080312911A1 - Dictionary word and phrase determination - Google Patents
Dictionary word and phrase determination Download PDFInfo
- Publication number
- US20080312911A1 US20080312911A1 US11/870,089 US87008907A US2008312911A1 US 20080312911 A1 US20080312911 A1 US 20080312911A1 US 87008907 A US87008907 A US 87008907A US 2008312911 A1 US2008312911 A1 US 2008312911A1
- Authority
- US
- United States
- Prior art keywords
- candidate
- dictionary
- words
- characters
- count
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/3332—Query translation
- G06F16/3338—Query expansion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/53—Processing of non-Latin text
Definitions
- This disclosure relates to input methods.
- a logographic script in which one or two characters, for example, glyphs, correspond roughly to one word or meaning have more characters than keys on a standard input device, such as a computer keyboard on a mobile device keypad.
- a standard input device such as a computer keyboard on a mobile device keypad.
- the Chinese language contains thousands of characters defined by base Pinyin characters and five tones.
- the mapping of these many-to-one associations can be implemented by input methods that facilitate entry of characters and symbols not found on input devices.
- a Western-style keyboard can be used to input Chinese, Japanese, or Korean characters.
- an input method editor IME
- a computer-implemented method includes identifying context signals in documents, identifying characters bounded by the context signals, identifying one or more candidate words defined by the characters bounded by the context signals, and adding one or more of the candidate words to an input method editor dictionary.
- Implementations of the method can include one or more of the following features. Identifying context signals in documents includes identifying Chinese book title marks. Identifying characters bounded by the context signals includes identifying Hanzi characters bounded by the context signals. The candidate words include Chinese words. Identifying context signals in documents includes identifying hypertext markup language tags in electronic documents.
- the input method editor dictionary includes a Chinese input method editor dictionary. The method includes determining a count of each candidate word. Adding one or more of the candidate words to the input method editor dictionary includes adding candidate words having a count that exceeds a threshold to the input method editor dictionary. Identifying context signals in documents includes identifying non-duplicative documents.
- Determining a count of each candidate word includes determining the count of each candidate word based on only the non-duplicative documents.
- the documents include web documents obtained from the Internet.
- the method includes identifying candidate words in search queries and adding one or more of the candidate words to the input method editor dictionary. Identifying candidate words in search queries includes, for each candidate word, determining a first count representing a number of times that the candidate word is the only word in the search queries, and determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. Identifying candidate words in search queries includes adding one or more of the candidate words to the input method editor dictionary based on a relationship between the first count and the second count.
- a computer-implemented method includes identifying pairs of Chinese book title marks in documents, identifying a candidate word defined by one or more characters marked by each pair of Chinese book title marks, and adding one or more candidate words to an input method editor dictionary.
- Implementations of the method can include one or more of the following features.
- the Chinese book title marks include single book title marks or double book title marks.
- the method includes determining a count of each candidate word. Adding one or more candidate words to an input method editor dictionary includes adding candidate words having a count that exceeds a threshold to the input method editor dictionary.
- the method includes identifying candidate words in search queries and adding one or more of the candidate words to the input method editor dictionary. Identifying candidate words in search queries includes, for each candidate word, determining a first count representing a number of times that the candidate word is the only word in the search queries, and determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. Identifying candidate words in search queries includes adding one or more of the candidate words to the input method editor dictionary based on a relationship between the first count and the second count.
- a method in another aspect, includes establishing a dictionary having words that are identified based on characters bounded by context signals, and providing an input method editor configured to select words from the dictionary.
- Implementations of the method can include one or more of the following features.
- Establishing the dictionary includes identifying words based on characters bounded by Chinese book title marks.
- an apparatus in another aspect, includes a dictionary that has words identified based on candidate words associated with characters found in documents, in which each candidate word is associated with one or more characters enclosed in a pair of Chinese book title marks.
- the apparatus includes an input method editor configured to select words from the dictionary.
- Implementations of the apparatus can include one or more of the following features.
- the candidate words include Hanzi characters.
- the Chinese book title marks include at least one of single book title marks or double book title marks.
- the dictionary includes words identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are in each of the search queries.
- a system in another aspect, in general, includes a data store and a processing engine.
- the data store stores a document corpus.
- the processing engine is stored in computer readable medium and includes instructions executable by a processing device that upon such execution cause the processing device to identify candidate words by finding characters in documents of the document corpus in which the characters are enclosed in pairs of Chinese book title marks, and add one or more of the candidate words to an input method editor dictionary.
- a system in another aspect, in general, includes a data store and the processing device.
- the data store stores a document corpus.
- the processing device identifies candidate words by finding characters in documents in the document corpus in which the characters are enclosed in pairs of Chinese book title marks, and adds one or more of the candidate words to an input method editor dictionary.
- a system in another aspect, includes means for identifying context signals in documents, means for identifying characters bounded by the context signals, means for identifying one or more candidate words defined by the characters bounded by the context signals, and means for adding one or more of the candidate words to an input method editor dictionary.
- a system in another aspect, includes means for identifying pairs of Chinese book title marks in documents, means for identifying a string of one or more characters bounded by each pair of Chinese book title marks, means for identifying a candidate word defined by each string of one or more characters, and means for adding one or more of the candidate words to an input method editor dictionary.
- a computer-implemented method in another aspect, includes identifying candidate words in search queries, each candidate word including one or more consecutive characters, and for each candidate word, determining a first count representing a number of times that the candidate word is the only word in the search queries, and determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries.
- the method includes adding one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count.
- Implementations of the method can include one or more of the following features. Adding one or more of the candidate words to the input method editor dictionary includes adding a candidate word to the input method editor dictionary when the first count is larger than the second count. Adding one or more of the candidate words to the input method editor dictionary includes adding a candidate word to the input method editor dictionary when the first count is larger than the second count and the first count is larger than a threshold value. Determining the second count includes counting a number of search queries that each includes the candidate word and one or more other words, in which the candidate word and the one or more other words are separated by one or more white spaces or punctuation marks entered by users who submitted the search queries. The method includes obtaining the search queries from a search log. The search log includes search queries submitted by users of a search service.
- an apparatus in another aspect, includes a data store to store search queries, and a processing device to identify candidate words in the search queries, each candidate word including one or more consecutive characters. For each candidate word, the processing device determines a first count representing a number of times that the candidate word is the only word in the search queries, and determines a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. The processing device adds one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count.
- Implementations of the apparatus can include one or more of the following features.
- the processing device adds a candidate word to the input method editor dictionary when the first count is larger than the second count.
- the processing device adds a candidate word to the input method editor dictionary when the first count is larger than the second count and the first count is larger than a threshold value.
- the processing engine counts a number of search queries that each includes the candidate word and one or more other words, in which the candidate word and the one or more other words are separated by one or more white spaces or punctuation marks entered by users who submitted the search queries.
- a system in another aspect, includes a data store to store search queries, and a processing engine stored in computer readable medium and including instructions executable by a processing device that upon such execution cause the processing device to identify candidate words in the search queries, each candidate word comprising one or more consecutive characters.
- the processing engine includes instructions that upon execution cause the processing device to, for each candidate word, determine a first count representing a number of times that the candidate word is the only word in the search queries, and determine a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries.
- the processing engine includes instructions that upon execution cause the processing device to add one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count.
- Implementations of the system can include one or more of the following features.
- the processing engine includes instructions executable by the processing device and upon such execution cause the processing device to add a candidate word to the input method editor dictionary when the first count is larger than the second count.
- the processing engine includes instructions executable by the processing device and upon such execution cause the processing device to add a candidate word to the input method editor dictionary when the first count is larger than the second count and the first count is larger than a threshold value.
- the processing engine includes instructions executable by the processing device and upon such execution cause the processing device to count a number of search queries that each includes the candidate word and one or more other words, in which the candidate word and the one or more other words are separated by one or more white spaces or punctuation marks entered by users who submitted the search queries.
- an apparatus in another aspect, includes a dictionary having words identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are in each of the search queries.
- the apparatus includes an input method editor configured to select words from the dictionary.
- Implementations of the apparatus can include one or more of the following features.
- the input method editor includes a Chinese input method editor.
- the words include Hanzi characters.
- the search queries are identified from a search log.
- a system in another aspect, in general, includes a data store and a processing engine.
- the data store stores a dictionary that includes words that are identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are included in each of the search queries.
- the processing engine is stored in computer readable medium and includes instructions executable by a processing device that upon such execution cause the processing device to provide an input method editor to enable a user to select words from the dictionary.
- a system in another aspect, in general, includes a data store and a processing engine.
- the data store stores a dictionary that includes words that are identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are included in each of the search queries.
- the processing engine causes a processing device to provide an input method editor to enable a user to select words from the dictionary.
- a system in another aspect, includes means for identifying candidate words based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are included in each of the search queries, and means for adding one or more of the candidate words to an input method editor dictionary.
- a dictionary can be automatically established or enhanced based on a corpus of documents and query logs.
- IME utilizing the dictionary can provide more accurate identifications of candidate words for selection.
- the dictionary can be efficiently updated, and the speed and efficiency for the computer processing the logographic script, for example, Chinese characters, can be improved, and therefore the user's input speed of the logographic script can be increased.
- FIG. 1 is a block diagram of an example device that can be used to implement the systems and methods described herein.
- FIG. 2 is a block diagram of an example editor system.
- FIG. 3 is a diagram of an example input method editor environment.
- FIG. 4 is a diagram of an example word and phrase determination engine.
- FIG. 5 is a flow diagram of an example process for determining words and phrases based on a document corpus.
- FIG. 6 is a flow diagram of an example process for determining words and phrases based on search query logs.
- FIG. 7 is a flow diagram of an example process for determining words and phrases.
- FIG. 8 is a diagram of an example word and phrase determination engine.
- FIG. 1 is a block diagram of an example device 100 that can be utilized to implement the systems and methods described herein.
- the device 100 can, for example, be implemented in a computer device, such as a personal computer device, or other electronic devices, such as a mobile phone, mobile communication device, personal digital assistant (PDA), and the like.
- a computer device such as a personal computer device
- PDA personal digital assistant
- the example device 100 includes a processing device 102 , a first data store 104 , a second data store 106 , input devices 108 , output devices 110 , and a network interface 112 .
- a bus system 114 including, for example, a data bus and a motherboard, can be used to establish and control data communication between the components 102 , 104 , 106 , 108 , 110 and 112 .
- Other example system architectures can also be used.
- the processing device 102 can, for example, include one or more microprocessors.
- the first data store 104 can, for example, include a random access memory storage device, such as a dynamic random access memory, or other types of computer-readable medium memory devices.
- the second data store 106 can, for example, include one or more hard drives, a flash memory, and/or a read only memory, or other types of computer-readable medium memory devices.
- Example input devices 108 can include a keyboard, a mouse, a stylus, etc.
- example output devices 110 can include a display device, an audio device, etc.
- the network interface 112 can, for example, include a wired or wireless network device operable to communicate data to and from a network 116 .
- the network 116 can include one or more local area networks (LANs) and/or a wide area network (WAN), such as the Internet.
- LANs local area networks
- WAN wide area network
- the device 100 can include input method editor (IME) code 101 in a data store, such as the data store 106 .
- the input method editor code 101 can be defined by instructions that upon execution cause the processing device 102 to carry out input method editing functions.
- the input method editor code 101 can, for example, include interpreted instructions, such as script instructions, for example, JavaScript or ECMAScript instructions, that can be executed in a web browser environment.
- Other implementations can also be used, for example, compiled instructions, a stand-alone application, an applet, a plug-in module, etc.
- Execution of the input method editor code 101 generates or launches an input method editor instance 103 .
- the input method editor instance 103 can define an input method editor environment, for example, user interface, and can facilitate the processing of one or more input methods at the device 100 , during which time the device 100 can receive composition inputs for input characters, ideograms, or symbols, such as, for example, Hanzi characters.
- the user can use one or more of the input devices 108 (for example, a keyboard, such as a Western-style keyboard, a stylus with handwriting recognition engines, etc.) to input composition inputs for identification of Hanzi characters.
- a Hanzi character can be associated with more than one composition input.
- the first data store 104 and/or the second data store 106 can store an association of composition inputs and characters. Based on a user input, the input method editor instance 103 can use information in the data store 104 and/or the data store 106 to identify one or more candidate characters represented by the input. In some implementations, if more than one candidate character is identified, the candidate characters are displayed on an output device 110 . Using the input device 108 , the user can select from the candidate characters a Hanzi character that the user desires to input.
- the input method editor instance 103 on the device 100 can receive one or more Pinyin composition inputs and convert the composition inputs into Hanzi characters.
- the input method editor instance 103 can, for example, use compositions of Pinyin syllables or characters received from keystrokes to represent the Hanzi characters.
- Each Pinyin syllable can, for example, correspond to a key in the Western style keyboard.
- a Pinyin input method editor a user can input a Hanzi character by using composition inputs that include one or more Pinyin syllables representing the sound of the Hanzi character.
- the user can also input a word that includes two or more Hanzi characters by using composition inputs that include two or more Pinyin syllables representing the sound of the Hanzi characters. Input methods for other languages, however, can also be facilitated.
- Other application software 105 can also be stored in data stores 104 and/or 106 , including web browsers, word processing programs, e-mail clients, etc. Each of these applications can generate a corresponding application instance 107 . Each application instance can define an environment that can facilitate a user experience by presenting data to the user and facilitating data input from the user. For example, web browser software can generate a search engine environment; e-mail software can generate an e-mail environment; a word processing program can generate an editor environment; etc.
- a remote computing system 118 having access to the device 100 can also be used to edit a logographic script.
- the device 100 may be a server that provides logographic script editing capability via the network 116 .
- a user can edit a logographic script stored in the data store 104 and/or the data store 106 using a remote computing system, for example, a client computer.
- the device 100 can, for example, select a character and receive a composition input from a user over the network interface 112 .
- the processing device 102 can, for example, identify one or more characters adjacent to the selected character, and identify one or more candidate characters based on the received composition input and the adjacent characters.
- the device 100 can transmit a data communication that includes the candidate characters back to the remote computing system.
- FIG. 2 is a block diagram of an example input method editor system 120 .
- the input method editor system 120 can, for example, be implemented using the input method editor code 101 and associated data stores 104 and 106 .
- the input method editor system 120 includes an input method editor engine 122 , a dictionary 124 , and a composition input table 126 .
- Other storage architectures can also be used.
- a user can use the IME system 120 to enter, for example, Chinese words or phrases by typing Pinyin characters, and the IME engine 122 will search the dictionary 124 to identify candidate dictionary entries each including one or more Chinese words or phrases that match the Pinyin characters.
- the dictionary 124 includes entries 128 that correspond to characters, words, or phrases of a logographic script used in one or more language models, and characters, words, and phrases in Roman-based or western-style alphabets, for example, English, German, Spanish, etc.
- Each word corresponds to a meaning and may include one or more characters.
- a word having the meaning “apple” includes two Hanzi characters and that correspond to Pinyin inputs “ping” and “guo,” respectively.
- the character is also a word that has the meaning “fruit.”
- the dictionary entries 128 may include, for example, idioms (for example, proper names (for example, names of historical characters or famous people (for example, terms of art (for example, phrases (for example, book titles (for example, titles of art works (for example, or movie titles (for example, etc., each including one or more characters.
- the dictionary entries 128 may include, for example, names of geographical entities or political entities, names of business concerns, names of educational institutions, names of animals or plants, names of machinery, song names, titles of plays, names of software programs, names of consumer products, etc.
- the dictionary 124 may include, for example, thousands of characters, words and phrases.
- the dictionary 124 includes information about relationships between characters.
- the dictionary 124 can include scores or probability values assigned to a character depending on other characters adjacent to the character.
- the dictionary 124 can include entry scores or entry probability values each associated with one of the dictionary entries 128 to indicate how often the entry 128 is used in general.
- the composition input data store 126 includes an association of composition inputs and the entries 128 stored in the dictionary 124 .
- the composition input data store 126 can link each of the entries 128 in the dictionary 124 to a composition input (for example, Pinyin input) used by the input method editor engine 122 .
- the input method editor engine 122 can use the information in the dictionary 124 and the composition input data store 126 to associate and/or identify one or more entries 128 in the dictionary 124 with one or more composition inputs in the composition input data store 126 .
- Other associations can also be used.
- the candidate selections in the IME system 120 can be ranked and presented in the input method editor according to the rank.
- FIG. 3 is a diagram of an example input method editor environment 300 presenting five ranked candidate selections 302 .
- Each candidate selection can be a dictionary entry 128 or a combination of dictionary entries 128 .
- the candidate selections 302 are identified based on the Pinyin inputs 304 .
- a selection indicator 308 surrounds the first candidate selection, i.e., indicating that the first candidate selection is selected. The user can also use a number key to select a candidate selection, or use up and down arrow keys to move the selection indicator 308 to select the candidate selection.
- the IME engine 122 accesses the dictionary 124 to identify candidate entries that are associated with Pinyin characters entered by the user.
- the dictionary 124 can be updated with new words or names periodically. For example, names and words that are commonly typed by users of the IME system 120 may change over time in response to news events and changes in the society.
- the dictionary 124 can be established and/or updated based on characters, words, and phrases that are identified from documents and search queries.
- FIG. 4 is a diagram of an example of a word and phrase determination engine 400 that identifies dictionary entries 128 (for example, Chinese characters, words, and phrases).
- the engine 400 identifies Chinese words and phrases using a context signal based determination engine 406 and/or a query based determination engine 408 .
- the context signal based determination engine 406 processes the documents 420 in a document corpus 402 to identify words and phrases using context signals.
- the query based determination engine 408 searches queries 418 in search query logs 404 to identify Chinese words and phrases based on whether the words or phrases appear in the search queries alone or in combination with one or more other words or phrases.
- the identified words and phrases can be merged in a merger engine 414 and added as entries 128 to the dictionary 124 .
- only one of the update methods can be used, for example, the dictionary 124 can be updated by use of either the document corpus 402 or the search query logs 404 .
- the context signal determination engine 406 is configured to determine candidate dictionary entries 422 from the documents 420 using context signals that identify bounded content.
- Example context signals include marks, characters, hypertext mark up language tags, and/or formatting that identify bounded content, such as quotation marks, special identifier characters, underlining, etc.
- An example context signal can include Chinese double book title marks, for example, ⁇ >>, and/or Chinese single book title marks, for example, ⁇ >.
- Chinese book title marks are commonly used to mark titles or names of documents and/or cultural works, for example, books, articles, newspapers, journals, and magazines.
- Chinese book title marks can also be used to mark the titles or names of cultural works such as, for example, songs, movies, television shows, plays, operas, dramas, symphonies, dances, paintings, statutes, and regulations, etc.
- the book title marks can identify multiple titles, for example, when a first title includes a second title, the first title is marked using the double book title mark, and the second title is marked using the single book title mark.
- Chinese book title marks are context signals that mark the boundaries of words or phrases. Thus, when one or more characters (for example, Hanzi characters) appear inside a pair of Chinese book title marks, there is a high likelihood that the one or more characters correspond to one or more words or phrases.
- names or titles of cultural works being marked by Chinese book title marks are illustrative: (“Dream of the Red Chamber” book), (“Upper River During the Qing Ming Festival” painting), (“Crouching Tiger, Hidden Dragon” movie), and (“Beethoven's Ninth Symphony”).
- the documents 420 can, for example, include documents that can be accessed over a network.
- the documents 420 can include, for example, web pages, e-books, journal articles, e-mail messages, advertisements, instant messages, blogs, legal documents, or other types of documents.
- the document corpus 402 may include documents 420 that cover a wide variety of subjects, such as news, literature, movies, music, political debates, scientific discoveries, legal issues, health issues, environmental issues, etc.
- the document corpus 402 can be established by gathering the documents 420 from, for example, a local area network or a wide area network, such as a corporate Intranet or the public Internet.
- the number of documents 420 processed can thus be in the range of millions of documents, or more.
- the documents 420 may include, for example, Hanzi characters, English characters, numbers, punctuation marks, symbols, HTML codes, etc. Other documents can also be used, for example, an electronic collection of literary works, an electronic library, etc.
- the context signal determination engine 406 scans each of the documents 420 to identify pairs of Chinese book title marks. For each pair of Chinese book title marks that are identified, the engine 406 identifies a candidate entry 422 defined by a string of characters, for example, one or more Hanzi bounded by the pair of Chinese book title marks, and adds the candidate entry 422 to a first dictionary 410 .
- the candidate entry 422 may include one or more words or phrases. If a term within a pair of Chinese book title marks is separated by a punctuation mark, such as a hyphen or colon, the term can be treated as two separated terms.
- the engine 406 may process (the Chinese title for the computer game “Need for Speed: Underground”) and determine that there are two candidate entries 422 : is one candidate entry 422 and is another candidate entry 422 .
- Each candidate entry 422 is associated with a count that represents the number of occurrences of the candidate entry 422 in the documents 420 .
- the engine 406 is configured such that each occurrence of the candidate entry 422 in the same document 420 causes the count to be increased by one. Thus, for example, if a candidate entry 422 occurs three times in one document 420 and five times in another document 420 , the count for the candidate entry is increased by eight.
- the engine 406 is configured such that the count is increased by one each time a candidate entry 422 occurs in a separate document, regardless of the number of the times that the candidate entry 422 occurs within each document. In this case, for example, if the candidate entry 422 occurs three times in one document 420 and five times in another document 420 , the count associated with the candidate entry 422 is increased by two.
- the engine 406 identifies pairs of Chinese book title marks that bound Chinese characters and do not bound characters of other languages. In this case, if a pair of Chinese book title marks bound a Chinese word and an English word, the Chinese word is not considered to be a candidate entry. In some implementations, the engine 406 processes the text bound by each pair of Chinese book title marks to remove non-Chinese characters and adds the remaining Chinese characters as a candidate entry 422 to the first dictionary 410 .
- the engine 406 sets a range for the number of characters included in each candidate entry 422 .
- the engine 406 may require that each candidate entry 422 has at least three Chinese characters and not more than ten Chinese characters.
- the engine 406 After processing all the documents 420 to identify all the candidate entries 422 that are marked by Chinese book title marks, the engine 406 filters the candidate entries 422 to remove the candidate entries with counts less than a threshold value.
- the threshold value can be set between 20 to 40, for example, 30.
- the threshold can, for example, be utilized to remove candidate entries 422 that contain errors, have word(s) or phrase(s) that are rarely used, or that occur infrequently for some other reason.
- the query based determination engine 408 is configured to identify candidate dictionary entries 416 from the search query logs 404 .
- the search query logs 404 can include search queries 418 submitted by multiple users of one or more search services (for example, Google search) over a period of time.
- the engine 408 identifies candidate entries 416 by finding consecutive strings of characters in the search queries 418 .
- a search query 418 may include one or more candidate entries 416 that are separated by one or more white spaces or punctuation marks that are entered by a user who submitted the search query 418 .
- a search query includes the phrase (meaning “world's fastest”) and the word (meaning “supercomputer”) that are separated by a white space. Each of the phrase and the word is identified by the engine 408 as a candidate entry 416 .
- the engine 408 assigns two count numbers to each candidate entry 416 , a query count qf and a user-segmented count sf.
- the query count qf is used to represent the number of times that the candidate entry 416 is the only word or phrase in the search queries.
- the query count qf associated with the entry represents the number of search queries 418 that include only the word .
- the user-segmented count sf is used to represents the number of search queries 418 that each include the candidate entry 416 and one or more other words or phrases, where the candidate entry 416 and the one or more other words or phrases can be separated by, for example, one or more white spaces or punctuation marks entered by users who submitted the search queries.
- the candidate entry 416 and the associated query count qf and user-segmented count sf are stored in a second dictionary 412 .
- the engine 408 finds a search query 418 that includes the user-segmented count sf for the candidate entry is incremented by 1, and the user-segmented count sf for the candidate entry is also incremented by 1. If the engine 408 finds a search query 418 that includes only , the query count qf for the candidate entry is incremented by 1.
- the engine 408 After the engine 408 processes all of the search queries to determine all of the candidate entries 416 and associated query counts qf and user-segmented counts sf, the engine 408 removes from the dictionary 412 candidate entries 416 in which the user-segmented count sf is equal to or greater than the query count sf (i.e., sf ⁇ qf). The engine 408 also removes candidate entries 416 in which the query count qf is less than a threshold value (i.e., qf ⁇ threshold). In some implementations, the threshold value can be set to a value in the range of 3 to 10. The query count qf is a measure of frequentness of the candidate word in the search queries. Removing candidate entries having a low query count qf can remove candidate entries 416 that contain errors or are rarely used.
- the candidate entries 416 remaining in the dictionary 412 are ones whose query count qf is greater than the user-segmented count sf (i.e., qf>sf) and have occurred at least a certain number of times in the search queries 418 (i.e., qf ⁇ threshold).
- qf the number of times a particular string of consecutive characters appears by itself in the search queries 418 is greater than the number of times that the string appears with one or more other strings or characters in the search queries 418 , there is a high likelihood that the particular string of consecutive characters correspond to one or more words or phrases, and is suitable as a dictionary entry 128 in the IME dictionary 124 .
- the engine 400 includes a merger engine 414 that merges the dictionary entries 422 and 416 from the first and second dictionaries 410 and 412 , respectively, by removing duplicate dictionary entries.
- the non-duplicative dictionary entries are added to the IME dictionary 124 .
- FIG. 5 is a flow diagram of an example process 500 for determining words and phrases based on a document corpus (for example, document corpus 402 ).
- the process 500 can, for example, be implemented in a system that includes one or more server computers.
- the process 500 identifies context signals in documents ( 502 ), and identifies characters bounded by the context signals ( 504 ).
- the context signals can be Chinese book title marks
- the characters can be Hanzi characters
- the documents can be the documents 420 in the document corpus 402 of FIG. 4 .
- the engine 406 of FIG. 4 can identify the context signals and the characters bounded by the context signals.
- the process 500 identifies one or more candidate words defined by the characters bounded by the context signals ( 506 ).
- the candidate words can be the entries 422 of FIG. 4 .
- the process 500 adds one or more candidate word to an input method editor dictionary ( 508 ).
- the dictionary can be the first dictionary 410 of FIG. 4 or the IME dictionary 124 of FIG. 2 .
- FIG. 6 is a flow diagram of an example process 600 for determining words and phrases based on search query logs (for example, search query logs 404 ).
- the process 600 can, for example, be implemented in a system that includes one or more server computers.
- the process 600 identifies candidate words in search queries, each candidate word including one or more consecutive characters ( 602 ).
- the characters can be Hanzi characters
- the candidate words can be the entry 416
- the search queries can be the search queries 418 of search query logs 404 FIG. 4 .
- the engine 408 can identify the candidate words in the search queries 418 .
- the process 600 determines a first count representing a number of times that the candidate word is the only word in the search queries ( 604 ), and determines a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries ( 606 ).
- the candidate word and the one or more other words can be separated by one or more white spaces or punctuation marks entered by the user.
- the engine 408 can determine the first count and the second count, for example, qf and sf.
- the process 600 adds one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count ( 610 ).
- the dictionary can be the first dictionary 410 of FIG. 4 or the IME dictionary 124 of FIG. 2 .
- the engine 408 may add a candidate word to the dictionary when the first count is greater than the second count.
- the processes 500 and 600 can be combined and the words and phrases can be added to a dictionary by a merger process.
- FIG. 7 is a flow diagram of an example process 700 for determining words and phrases based on a document corpus (for example, document corpus 402 ) and search query logs (for example, search query logs 404 ).
- the process 700 can, for example, be implemented in a system that includes one or more server computers.
- the process 700 includes two processes 722 and 724 that can be performed in parallel to generate first and second dictionaries that are merged into a final dictionary.
- the process 722 identifies documents ( 702 ).
- the documents can be the documents 420 in the document corpus 402 of FIG. 4 .
- the process 722 identifies pairs of Chinese book title marks in the documents 420 , and identifies strings of characters marked by the pairs of Chinese book title marks ( 704 ).
- the Chinese book title marks can be ⁇ >> or ⁇ >, and the string of characters can include Hanzi characters.
- the engine 406 of FIG. 4 can identify the Chinese book title marks and strings of characters.
- the process 722 designates each string of characters marked by the Chinese book title marks as a candidate entry, and adds the candidate entry to a first dictionary ( 706 ).
- the process 722 also associates a count with the candidate entry, in which the count represents the number of occurrences of the candidate entry in the documents.
- the first dictionary can be the first dictionary 410 of FIG. 4
- the engine 406 can add or update the candidate entries 422 and associated counts in the first dictionary 410 .
- the process 722 filters the candidate entries in the first dictionary by comparing the counts with a threshold value ( 708 ). If a count is lower than the threshold value, the candidate entry associated with the count is removed from the first dictionary. For example, the engine 406 can filter the candidate entries 422 in the first dictionary 410 .
- the process 724 identifies search queries ( 710 ).
- the search queries can be the search queries 418 of the search logs 404 of FIG. 4 .
- the process 724 identifies a string of consecutive characters, or strings of consecutive characters that are separated by white space(s) or symbol(s) that are not characters, where the white space(s) or symbol(s) are entered by the user ( 712 ).
- the characters can be Hanzi characters
- the search queries can be the search queries 418 of FIG. 4 .
- the engine 408 can identify the string of consecutive characters, or the strings of consecutive characters in each of the search queries 418 .
- the process 724 identifies a candidate entry as being defined by each string of consecutive characters, and adds the candidate entry to a second dictionary ( 714 ).
- the process 724 also associates a query count qf and a user-segmented count sf with each candidate entry.
- the query count qf represents the number of search queries that include only the candidate entry
- the user-segmented count sf represents the number of search queries that each includes the candidate entry and one or more other strings of characters.
- the candidate entries can be the candidate entries 416 of FIG. 4
- the second dictionary can be the second dictionary 412
- the engine 408 can add or update the candidate entries 416 in the second dictionary 412 , and can initialize or update the query counts qf and user-segmented counts sf associated with the candidate entries 416 .
- the process 724 filters the candidate entries in the second dictionary ( 716 ).
- the process 724 compares the query count qf to the user-segmented count sf, and compares the query count qf to a threshold value. For example, the process 722 removes from the second dictionary the candidate entries in which the query count qf is less than a threshold, and removes candidate entries in which the query count qf is equal to or less than the user-segmented count sf.
- the candidate entries in the second dictionary are ones in which the query count qf is greater than the user-segmented count sf, and the query count qf is at least the threshold value.
- engine 408 filters the candidate entries 416 in the second dictionary 412 .
- each of the first and second dictionaries have candidate entries.
- the process 700 merges the first and second dictionaries by removing duplicate candidate entries to generate a final dictionary ( 718 ).
- the candidate entries in the final dictionary are added to an IME dictionary ( 720 ).
- the merger engine 414 of FIG. 4 can be used to merge the first and second dictionaries 410 and 412 , and the candidate entries in the final dictionary can be added to the IME dictionary 124 of FIG. 2 .
- hypertext markup language (HTML) title tags can be used to identify candidate dictionary entries from web documents. For example, a pair of HTML tags ⁇ title> and ⁇ /title> mark the title of an HTML document. A string of characters bounded by the ⁇ title> and ⁇ /title> HTML tags can be identified as a candidate dictionary entry and added to the dictionary 124 if a threshold criterion is met (for example, the number of times that the string of characters appear in the web documents is greater than a threshold value).
- a threshold criterion for example, the number of times that the string of characters appear in the web documents is greater than a threshold value.
- the input engine 122 can be capable of mapping composition inputs from a western keyboard to input Chinese, Japanese, Korean and/or Indic characters.
- some or all implementations described can be applicable to other input methods, such as Cangjie input method, Jiufang input method, Wubi input method, or other input methods.
- the weight values for different types of documents, and the classification of types of documents, can be different from those described above.
- the number of words and documents being processed, and the sources of the documents in the document corpus 402 can be different from those described above.
- the processes 722 and 724 in FIG. 7 can be performed sequentially.
- the engine 406 may identify non-duplicative documents 420 in the document corpus 402 , and identify candidate entries and associated counts based on the non-duplicative documents.
- the dictionary 124 can include characters, words, and phrases obtained from pre-existing dictionaries.
- the context signal based engine 406 of FIG. 4 can be configured such that the count increases as a function of the number of times that the candidate entry 422 occurs in each document. For example, the count can be increased by one each time that the candidate entry 422 occurs in the same document, up to a limit (for example, three) for each document. Thus, if the upper limit is three and the candidate entry 422 occurs five times in the same document, the count is increased by three. For example, the count can be increased as a log function of the number of times that the candidate entry 422 occurs within the same document. In some implementations, the engine 406 is configured such that the count increases as a function of the location where the candidate entry 422 occurs in each document.
- the count can be increased by 1.5 if the candidate entry 422 appears in the title of the document 420 (or subject line of an e-mail message), and the count can be increased by 1 if the candidate entry 422 appears in other places of the document 420 .
- Other methods for modifying the count based on occurrences of the candidate entry 422 in the documents 420 can also be used.
- dictionaries for example, a legal dictionary, a medical dictionary, a science dictionary, and a general dictionary.
- Each dictionary can be established by starting with a dictionary associated with a particular field.
- the word and phrase determination engine 400 is used to process a document corpus having documents and search query logs having search queries biased toward the field associated with the dictionary.
- a document corpus having documents and search query logs having search queries biased toward the legal field can be used.
- the IME system 120 can allow the user to select the field of interest (for example, legal, medical, science) when entering characters, and the candidate words can be selected from the dictionary related to the field of interest.
- the context signal based engine 406 and the search query based engine 408 write to a single dictionary 800 .
- the engine 406 processes the documents 420 and adds or updates candidate entries 802 to the dictionary 800 .
- Each candidate entry 802 processed by the engine 406 is associated with a document occurrence count, representing the number of occurrences of the candidate entry 802 in the documents 420 .
- the engine 408 processes the search queries 418 and adds or updates the candidate entries 802 to the dictionary 800 .
- Each candidate entry 802 processed by the engine 408 is associated with a query count and a user-segmented count.
- the engine 400 removes from the dictionary 800 the candidate entries 802 in which certain criteria are met, for example: (1) the document occurrence count is less than a first threshold value, (2) the user-segmented count is equal to or greater than the query count, or (3) the query count is less than a second threshold value.
- the remaining candidate entries 802 are added to the IME dictionary 124 .
- the engines 406 and 408 can write to the IME dictionary 124 directly, and add, update, or filter the entries 128 in the dictionary 124 .
- Embodiments of the subject matter and the functional operations described in this specification can be implemented in digital electronic circuitry, or in computer software, firmware, or hardware, including the structures disclosed in this specification and their structural equivalents, or in combinations of one or more of them.
- Embodiments of the subject matter described in this specification can be implemented as one or more computer program products, i.e., one or more modules of computer program instructions encoded on a tangible program carrier for execution by, or to control the operation of, data processing apparatus.
- the tangible program carrier can be a propagated signal or a computer readable medium.
- the propagated signal is an artificially generated signal, for example, a machine generated electrical, optical, or electromagnetic signal, that is generated to encode information for transmission to suitable receiver apparatus for execution by a computer.
- the computer readable medium can be a machine readable storage device, a machine readable storage substrate, a memory device, a composition of matter effecting a machine readable propagated signal, or a combination of one or more of them.
- data processing apparatus encompasses all apparatus, devices, and machines for processing data, including by way of example a programmable processor, a computer, or multiple processors or computers.
- the apparatus can include, in addition to hardware, code that creates an execution environment for the computer program in question, for example, code that constitutes processor firmware, a protocol stack, a database management system, an operating system, or a combination of one or more of them.
- a computer program (also known as a program, software, software application, script, or code) can be written in any form of programming language, including compiled or interpreted languages, or declarative or procedural languages, and it can be deployed in any form, including as a stand alone program or as a module, component, subroutine, or other unit suitable for use in a computing environment.
- a computer program does not necessarily correspond to a file in a file system.
- a program can be stored in a portion of a file that holds other programs or data (for example, one or more scripts stored in a markup language document), in a single file dedicated to the program in question, or in multiple coordinated files (for example, files that store one or more modules, sub programs, or portions of code).
- a computer program can be deployed to be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a communication network.
- the processes and logic flows described in this specification can be performed by one or more programmable processors executing one or more computer programs to perform functions by operating on input data and generating output.
- the processes and logic flows can also be performed by, and apparatus can also be implemented as, special purpose logic circuitry, for example, an FPGA (field programmable gate array) or an ASIC (application specific integrated circuit).
- FPGA field programmable gate array
- ASIC application specific integrated circuit
- processors suitable for the execution of a computer program include, by way of example, both general and special purpose microprocessors, and any one or more processors of any kind of digital computer.
- a processor will receive instructions and data from a read only memory or a random access memory or both.
- the essential elements of a computer are a processor for performing instructions and one or more memory devices for storing instructions and data.
- a computer will also include, or be operatively coupled to receive data from or transfer data to, or both, one or more mass storage devices for storing data, for example, magnetic, magneto optical disks, or optical disks.
- mass storage devices for storing data, for example, magnetic, magneto optical disks, or optical disks.
- a computer need not have such devices.
- a computer can be embedded in another device, for example, a mobile telephone, a personal digital assistant (PDA), a mobile audio or video player, a game console, a Global Positioning System (GPS) receiver, to name just a few.
- PDA personal digital
- Computer readable media suitable for storing computer program instructions and data include all forms of non volatile memory, media and memory devices, including by way of example semiconductor memory devices, for example, EPROM, EEPROM, and flash memory devices; magnetic disks, for example, internal hard disks or removable disks; magneto optical disks; and CD ROM and DVD ROM disks.
- semiconductor memory devices for example, EPROM, EEPROM, and flash memory devices
- magnetic disks for example, internal hard disks or removable disks
- magneto optical disks and CD ROM and DVD ROM disks.
- the processor and the memory can be supplemented by, or incorporated in, special purpose logic circuitry.
- embodiments of the subject matter described in this specification can be implemented on a computer having a display device, for example, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor, for displaying information to the user and a keyboard and a pointing device, for example, a mouse or a trackball, by which the user can provide input to the computer.
- a display device for example, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor
- keyboard and a pointing device for example, a mouse or a trackball
- Other kinds of devices can be used to provide for interaction with a user as well; for example, feedback provided to the user can be any form of sensory feedback, for example, visual feedback, auditory feedback, or tactile feedback; and input from the user can be received in any form, including acoustic, speech, or tactile input.
- Embodiments of the subject matter described in this specification can be implemented in a computing system that includes a back end component, for example, as a data server, or that includes a middleware component, for example, an application server, or that includes a front end component, for example, a client computer having a graphical user interface or a Web browser through which a user can interact with an implementation of the subject matter described is this specification, or any combination of one or more such back end, middleware, or front end components.
- the components of the system can be interconnected by any form or medium of digital data communication, for example, a communication network. Examples of communication networks include a local area network (“LAN”) and a wide area network (“WAN”), for example, the Internet.
- LAN local area network
- WAN wide area network
- the computing system can include clients and servers.
- a client and server are generally remote from each other and typically interact through a communication network.
- the relationship of client and server arises by virtue of computer programs running on the respective computers and having a client server relationship to each other.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Document Processing Apparatus (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Context signals in documents are identified, characters bounded by the context signals are identified, one or more candidate words defined by the characters bounded by the context signals are identified, and one or more of the candidate words are added to an input method editor dictionary.
Description
- This application is a continuation of International Application No. PCT/CN2007/001871, titled “DICTIONARY WORD AND PHRASE DETERMINATION”, filed on Jun. 14, 2007, the contents of which are incorporated herein by reference.
- This disclosure relates to input methods.
- Languages that use a logographic script in which one or two characters, for example, glyphs, correspond roughly to one word or meaning have more characters than keys on a standard input device, such as a computer keyboard on a mobile device keypad. For example, the Chinese language contains thousands of characters defined by base Pinyin characters and five tones. The mapping of these many-to-one associations can be implemented by input methods that facilitate entry of characters and symbols not found on input devices. Accordingly, a Western-style keyboard can be used to input Chinese, Japanese, or Korean characters. In some examples, an input method editor (IME) can be used to search a dictionary to find candidate characters, words, or phrases that correspond to the Pinyin characters typed by a user.
- In one aspect, in general, a computer-implemented method includes identifying context signals in documents, identifying characters bounded by the context signals, identifying one or more candidate words defined by the characters bounded by the context signals, and adding one or more of the candidate words to an input method editor dictionary.
- Implementations of the method can include one or more of the following features. Identifying context signals in documents includes identifying Chinese book title marks. Identifying characters bounded by the context signals includes identifying Hanzi characters bounded by the context signals. The candidate words include Chinese words. Identifying context signals in documents includes identifying hypertext markup language tags in electronic documents. The input method editor dictionary includes a Chinese input method editor dictionary. The method includes determining a count of each candidate word. Adding one or more of the candidate words to the input method editor dictionary includes adding candidate words having a count that exceeds a threshold to the input method editor dictionary. Identifying context signals in documents includes identifying non-duplicative documents. Determining a count of each candidate word includes determining the count of each candidate word based on only the non-duplicative documents. The documents include web documents obtained from the Internet. The method includes identifying candidate words in search queries and adding one or more of the candidate words to the input method editor dictionary. Identifying candidate words in search queries includes, for each candidate word, determining a first count representing a number of times that the candidate word is the only word in the search queries, and determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. Identifying candidate words in search queries includes adding one or more of the candidate words to the input method editor dictionary based on a relationship between the first count and the second count.
- In another aspect, in general, a computer-implemented method includes identifying pairs of Chinese book title marks in documents, identifying a candidate word defined by one or more characters marked by each pair of Chinese book title marks, and adding one or more candidate words to an input method editor dictionary.
- Implementations of the method can include one or more of the following features. The Chinese book title marks include single book title marks or double book title marks. The method includes determining a count of each candidate word. Adding one or more candidate words to an input method editor dictionary includes adding candidate words having a count that exceeds a threshold to the input method editor dictionary. The method includes identifying candidate words in search queries and adding one or more of the candidate words to the input method editor dictionary. Identifying candidate words in search queries includes, for each candidate word, determining a first count representing a number of times that the candidate word is the only word in the search queries, and determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. Identifying candidate words in search queries includes adding one or more of the candidate words to the input method editor dictionary based on a relationship between the first count and the second count.
- In another aspect, in general, a method includes establishing a dictionary having words that are identified based on characters bounded by context signals, and providing an input method editor configured to select words from the dictionary.
- Implementations of the method can include one or more of the following features. Establishing the dictionary includes identifying words based on characters bounded by Chinese book title marks.
- In another aspect, in general, an apparatus includes a dictionary that has words identified based on candidate words associated with characters found in documents, in which each candidate word is associated with one or more characters enclosed in a pair of Chinese book title marks. The apparatus includes an input method editor configured to select words from the dictionary.
- Implementations of the apparatus can include one or more of the following features. The candidate words include Hanzi characters. The Chinese book title marks include at least one of single book title marks or double book title marks. The dictionary includes words identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are in each of the search queries.
- In another aspect, in general, a system includes a data store and a processing engine. The data store stores a document corpus. The processing engine is stored in computer readable medium and includes instructions executable by a processing device that upon such execution cause the processing device to identify candidate words by finding characters in documents of the document corpus in which the characters are enclosed in pairs of Chinese book title marks, and add one or more of the candidate words to an input method editor dictionary.
- In another aspect, in general, a system includes a data store and the processing device. The data store stores a document corpus. The processing device identifies candidate words by finding characters in documents in the document corpus in which the characters are enclosed in pairs of Chinese book title marks, and adds one or more of the candidate words to an input method editor dictionary.
- In another aspect, in general, a system includes means for identifying context signals in documents, means for identifying characters bounded by the context signals, means for identifying one or more candidate words defined by the characters bounded by the context signals, and means for adding one or more of the candidate words to an input method editor dictionary.
- In another aspect, in general, a system includes means for identifying pairs of Chinese book title marks in documents, means for identifying a string of one or more characters bounded by each pair of Chinese book title marks, means for identifying a candidate word defined by each string of one or more characters, and means for adding one or more of the candidate words to an input method editor dictionary.
- In another aspect, in general, a computer-implemented method includes identifying candidate words in search queries, each candidate word including one or more consecutive characters, and for each candidate word, determining a first count representing a number of times that the candidate word is the only word in the search queries, and determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. The method includes adding one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count.
- Implementations of the method can include one or more of the following features. Adding one or more of the candidate words to the input method editor dictionary includes adding a candidate word to the input method editor dictionary when the first count is larger than the second count. Adding one or more of the candidate words to the input method editor dictionary includes adding a candidate word to the input method editor dictionary when the first count is larger than the second count and the first count is larger than a threshold value. Determining the second count includes counting a number of search queries that each includes the candidate word and one or more other words, in which the candidate word and the one or more other words are separated by one or more white spaces or punctuation marks entered by users who submitted the search queries. The method includes obtaining the search queries from a search log. The search log includes search queries submitted by users of a search service.
- In another aspect, in general, an apparatus includes a data store to store search queries, and a processing device to identify candidate words in the search queries, each candidate word including one or more consecutive characters. For each candidate word, the processing device determines a first count representing a number of times that the candidate word is the only word in the search queries, and determines a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. The processing device adds one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count.
- Implementations of the apparatus can include one or more of the following features. The processing device adds a candidate word to the input method editor dictionary when the first count is larger than the second count. The processing device adds a candidate word to the input method editor dictionary when the first count is larger than the second count and the first count is larger than a threshold value. The processing engine counts a number of search queries that each includes the candidate word and one or more other words, in which the candidate word and the one or more other words are separated by one or more white spaces or punctuation marks entered by users who submitted the search queries.
- In another aspect, in general, a system includes a data store to store search queries, and a processing engine stored in computer readable medium and including instructions executable by a processing device that upon such execution cause the processing device to identify candidate words in the search queries, each candidate word comprising one or more consecutive characters. The processing engine includes instructions that upon execution cause the processing device to, for each candidate word, determine a first count representing a number of times that the candidate word is the only word in the search queries, and determine a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries. The processing engine includes instructions that upon execution cause the processing device to add one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count.
- Implementations of the system can include one or more of the following features. The processing engine includes instructions executable by the processing device and upon such execution cause the processing device to add a candidate word to the input method editor dictionary when the first count is larger than the second count. The processing engine includes instructions executable by the processing device and upon such execution cause the processing device to add a candidate word to the input method editor dictionary when the first count is larger than the second count and the first count is larger than a threshold value. The processing engine includes instructions executable by the processing device and upon such execution cause the processing device to count a number of search queries that each includes the candidate word and one or more other words, in which the candidate word and the one or more other words are separated by one or more white spaces or punctuation marks entered by users who submitted the search queries.
- In another aspect, in general, an apparatus includes a dictionary having words identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are in each of the search queries. The apparatus includes an input method editor configured to select words from the dictionary.
- Implementations of the apparatus can include one or more of the following features. The input method editor includes a Chinese input method editor. The words include Hanzi characters. The search queries are identified from a search log.
- In another aspect, in general, a system includes a data store and a processing engine. The data store stores a dictionary that includes words that are identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are included in each of the search queries. The processing engine is stored in computer readable medium and includes instructions executable by a processing device that upon such execution cause the processing device to provide an input method editor to enable a user to select words from the dictionary.
- In another aspect, in general, a system includes a data store and a processing engine. The data store stores a dictionary that includes words that are identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are included in each of the search queries. The processing engine causes a processing device to provide an input method editor to enable a user to select words from the dictionary.
- In another aspect, in general, a system includes means for identifying candidate words based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are included in each of the search queries, and means for adding one or more of the candidate words to an input method editor dictionary.
- The systems and methods disclosed herein may have one or more of the following advantages. A dictionary can be automatically established or enhanced based on a corpus of documents and query logs. IME utilizing the dictionary can provide more accurate identifications of candidate words for selection. Also, by using the system and method disclosed herein, the dictionary can be efficiently updated, and the speed and efficiency for the computer processing the logographic script, for example, Chinese characters, can be improved, and therefore the user's input speed of the logographic script can be increased.
- The details of one or more embodiments of the subject matter described in this specification are set forth in the accompanying drawings and the description below. Other features, aspects, and advantages of the subject matter will become apparent from the description, the drawings, and the claims.
-
FIG. 1 is a block diagram of an example device that can be used to implement the systems and methods described herein. -
FIG. 2 is a block diagram of an example editor system. -
FIG. 3 is a diagram of an example input method editor environment. -
FIG. 4 is a diagram of an example word and phrase determination engine. -
FIG. 5 is a flow diagram of an example process for determining words and phrases based on a document corpus. -
FIG. 6 is a flow diagram of an example process for determining words and phrases based on search query logs. -
FIG. 7 is a flow diagram of an example process for determining words and phrases. -
FIG. 8 is a diagram of an example word and phrase determination engine. - Like reference numbers and designations in the various drawings indicate like elements.
-
FIG. 1 is a block diagram of anexample device 100 that can be utilized to implement the systems and methods described herein. Thedevice 100 can, for example, be implemented in a computer device, such as a personal computer device, or other electronic devices, such as a mobile phone, mobile communication device, personal digital assistant (PDA), and the like. - The
example device 100 includes aprocessing device 102, afirst data store 104, asecond data store 106,input devices 108,output devices 110, and anetwork interface 112. Abus system 114, including, for example, a data bus and a motherboard, can be used to establish and control data communication between thecomponents - The
processing device 102 can, for example, include one or more microprocessors. Thefirst data store 104 can, for example, include a random access memory storage device, such as a dynamic random access memory, or other types of computer-readable medium memory devices. Thesecond data store 106 can, for example, include one or more hard drives, a flash memory, and/or a read only memory, or other types of computer-readable medium memory devices. -
Example input devices 108 can include a keyboard, a mouse, a stylus, etc., andexample output devices 110 can include a display device, an audio device, etc. Thenetwork interface 112 can, for example, include a wired or wireless network device operable to communicate data to and from anetwork 116. Thenetwork 116 can include one or more local area networks (LANs) and/or a wide area network (WAN), such as the Internet. - In some implementations, the
device 100 can include input method editor (IME)code 101 in a data store, such as thedata store 106. The inputmethod editor code 101 can be defined by instructions that upon execution cause theprocessing device 102 to carry out input method editing functions. In an implementation, the inputmethod editor code 101 can, for example, include interpreted instructions, such as script instructions, for example, JavaScript or ECMAScript instructions, that can be executed in a web browser environment. Other implementations can also be used, for example, compiled instructions, a stand-alone application, an applet, a plug-in module, etc. - Execution of the input
method editor code 101 generates or launches an inputmethod editor instance 103. The inputmethod editor instance 103 can define an input method editor environment, for example, user interface, and can facilitate the processing of one or more input methods at thedevice 100, during which time thedevice 100 can receive composition inputs for input characters, ideograms, or symbols, such as, for example, Hanzi characters. For example, the user can use one or more of the input devices 108 (for example, a keyboard, such as a Western-style keyboard, a stylus with handwriting recognition engines, etc.) to input composition inputs for identification of Hanzi characters. In some examples, a Hanzi character can be associated with more than one composition input. - The
first data store 104 and/or thesecond data store 106 can store an association of composition inputs and characters. Based on a user input, the inputmethod editor instance 103 can use information in thedata store 104 and/or thedata store 106 to identify one or more candidate characters represented by the input. In some implementations, if more than one candidate character is identified, the candidate characters are displayed on anoutput device 110. Using theinput device 108, the user can select from the candidate characters a Hanzi character that the user desires to input. - In some implementations, the input
method editor instance 103 on thedevice 100 can receive one or more Pinyin composition inputs and convert the composition inputs into Hanzi characters. The inputmethod editor instance 103 can, for example, use compositions of Pinyin syllables or characters received from keystrokes to represent the Hanzi characters. Each Pinyin syllable can, for example, correspond to a key in the Western style keyboard. Using a Pinyin input method editor, a user can input a Hanzi character by using composition inputs that include one or more Pinyin syllables representing the sound of the Hanzi character. Using the Pinyin IME, the user can also input a word that includes two or more Hanzi characters by using composition inputs that include two or more Pinyin syllables representing the sound of the Hanzi characters. Input methods for other languages, however, can also be facilitated. -
Other application software 105 can also be stored indata stores 104 and/or 106, including web browsers, word processing programs, e-mail clients, etc. Each of these applications can generate acorresponding application instance 107. Each application instance can define an environment that can facilitate a user experience by presenting data to the user and facilitating data input from the user. For example, web browser software can generate a search engine environment; e-mail software can generate an e-mail environment; a word processing program can generate an editor environment; etc. - In some implementations, a
remote computing system 118 having access to thedevice 100 can also be used to edit a logographic script. For example, thedevice 100 may be a server that provides logographic script editing capability via thenetwork 116. In some examples, a user can edit a logographic script stored in thedata store 104 and/or thedata store 106 using a remote computing system, for example, a client computer. Thedevice 100 can, for example, select a character and receive a composition input from a user over thenetwork interface 112. Theprocessing device 102 can, for example, identify one or more characters adjacent to the selected character, and identify one or more candidate characters based on the received composition input and the adjacent characters. Thedevice 100 can transmit a data communication that includes the candidate characters back to the remote computing system. -
FIG. 2 is a block diagram of an example inputmethod editor system 120. The inputmethod editor system 120 can, for example, be implemented using the inputmethod editor code 101 and associateddata stores method editor system 120 includes an inputmethod editor engine 122, adictionary 124, and a composition input table 126. Other storage architectures can also be used. A user can use theIME system 120 to enter, for example, Chinese words or phrases by typing Pinyin characters, and theIME engine 122 will search thedictionary 124 to identify candidate dictionary entries each including one or more Chinese words or phrases that match the Pinyin characters. - The
dictionary 124 includesentries 128 that correspond to characters, words, or phrases of a logographic script used in one or more language models, and characters, words, and phrases in Roman-based or western-style alphabets, for example, English, German, Spanish, etc. Each word corresponds to a meaning and may include one or more characters. For example, a wordhaving the meaning “apple” includes two Hanzi characters and
and that correspond to Pinyin inputs “ping” and “guo,” respectively. The character
that correspond to Pinyin inputs “ping” and “guo,” respectively. The character is also a word that has the meaning “fruit.” The
is also a word that has the meaning “fruit.” Thedictionary entries 128 may include, for example, idioms (for example,proper names (for example, names of historical characters or famous people (for example,
names of historical characters or famous people (for example, terms of art (for example,
terms of art (for example, phrases (for example,
phrases (for example, book titles (for example,
book titles (for example, titles of art works (for example,
titles of art works (for example, or movie titles (for example,
or movie titles (for example, etc., each including one or more characters.
etc., each including one or more characters.
- Similarly, the
dictionary entries 128 may include, for example, names of geographical entities or political entities, names of business concerns, names of educational institutions, names of animals or plants, names of machinery, song names, titles of plays, names of software programs, names of consumer products, etc. Thedictionary 124 may include, for example, thousands of characters, words and phrases. - In some implementations, the
dictionary 124 includes information about relationships between characters. For example, thedictionary 124 can include scores or probability values assigned to a character depending on other characters adjacent to the character. Thedictionary 124 can include entry scores or entry probability values each associated with one of thedictionary entries 128 to indicate how often theentry 128 is used in general. - The composition
input data store 126 includes an association of composition inputs and theentries 128 stored in thedictionary 124. In some implementations, the compositioninput data store 126 can link each of theentries 128 in thedictionary 124 to a composition input (for example, Pinyin input) used by the inputmethod editor engine 122. For example, the inputmethod editor engine 122 can use the information in thedictionary 124 and the compositioninput data store 126 to associate and/or identify one ormore entries 128 in thedictionary 124 with one or more composition inputs in the compositioninput data store 126. Other associations can also be used. - In some implementations, the candidate selections in the
IME system 120 can be ranked and presented in the input method editor according to the rank. -
FIG. 3 is a diagram of an example inputmethod editor environment 300 presenting five rankedcandidate selections 302. Each candidate selection can be adictionary entry 128 or a combination ofdictionary entries 128. Thecandidate selections 302 are identified based on thePinyin inputs 304. Aselection indicator 308 surrounds the first candidate selection, i.e.,indicating that the first candidate selection is selected. The user can also use a number key to select a candidate selection, or use up and down arrow keys to move the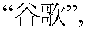
selection indicator 308 to select the candidate selection. - As described above, the
IME engine 122 accesses thedictionary 124 to identify candidate entries that are associated with Pinyin characters entered by the user. Thedictionary 124 can be updated with new words or names periodically. For example, names and words that are commonly typed by users of theIME system 120 may change over time in response to news events and changes in the society. In some implementations, thedictionary 124 can be established and/or updated based on characters, words, and phrases that are identified from documents and search queries. -
FIG. 4 is a diagram of an example of a word andphrase determination engine 400 that identifies dictionary entries 128 (for example, Chinese characters, words, and phrases). In some implementations, theengine 400 identifies Chinese words and phrases using a context signal baseddetermination engine 406 and/or a query baseddetermination engine 408. The context signal baseddetermination engine 406 processes thedocuments 420 in adocument corpus 402 to identify words and phrases using context signals. The query baseddetermination engine 408searches queries 418 in search query logs 404 to identify Chinese words and phrases based on whether the words or phrases appear in the search queries alone or in combination with one or more other words or phrases. The identified words and phrases can be merged in amerger engine 414 and added asentries 128 to thedictionary 124. In some implementations, only one of the update methods can be used, for example, thedictionary 124 can be updated by use of either thedocument corpus 402 or the search query logs 404. - In some implementations, the context
signal determination engine 406 is configured to determinecandidate dictionary entries 422 from thedocuments 420 using context signals that identify bounded content. Example context signals include marks, characters, hypertext mark up language tags, and/or formatting that identify bounded content, such as quotation marks, special identifier characters, underlining, etc. - An example context signal can include Chinese double book title marks, for example, << >>, and/or Chinese single book title marks, for example, < >. Chinese book title marks are commonly used to mark titles or names of documents and/or cultural works, for example, books, articles, newspapers, journals, and magazines. Chinese book title marks can also be used to mark the titles or names of cultural works such as, for example, songs, movies, television shows, plays, operas, dramas, symphonies, dances, paintings, statutes, and regulations, etc. The book title marks can identify multiple titles, for example, when a first title includes a second title, the first title is marked using the double book title mark, and the second title is marked using the single book title mark.
- Chinese book title marks are context signals that mark the boundaries of words or phrases. Thus, when one or more characters (for example, Hanzi characters) appear inside a pair of Chinese book title marks, there is a high likelihood that the one or more characters correspond to one or more words or phrases. The following examples of names or titles of cultural works being marked by Chinese book title marks are illustrative:(“Dream of the Red Chamber” book),
 (“Upper River During the Qing Ming Festival” painting),
(“Upper River During the Qing Ming Festival” painting), (“Crouching Tiger, Hidden Dragon” movie), and
(“Crouching Tiger, Hidden Dragon” movie), and (“Beethoven's Ninth Symphony”).
(“Beethoven's Ninth Symphony”).
- The
documents 420 can, for example, include documents that can be accessed over a network. Thedocuments 420 can include, for example, web pages, e-books, journal articles, e-mail messages, advertisements, instant messages, blogs, legal documents, or other types of documents. Thedocument corpus 402 may includedocuments 420 that cover a wide variety of subjects, such as news, literature, movies, music, political debates, scientific discoveries, legal issues, health issues, environmental issues, etc. Thedocument corpus 402 can be established by gathering thedocuments 420 from, for example, a local area network or a wide area network, such as a corporate Intranet or the public Internet. The number ofdocuments 420 processed can thus be in the range of millions of documents, or more. Thedocuments 420 may include, for example, Hanzi characters, English characters, numbers, punctuation marks, symbols, HTML codes, etc. Other documents can also be used, for example, an electronic collection of literary works, an electronic library, etc. - In some implementations, the context
signal determination engine 406 scans each of thedocuments 420 to identify pairs of Chinese book title marks. For each pair of Chinese book title marks that are identified, theengine 406 identifies acandidate entry 422 defined by a string of characters, for example, one or more Hanzi bounded by the pair of Chinese book title marks, and adds thecandidate entry 422 to afirst dictionary 410. Thecandidate entry 422 may include one or more words or phrases. If a term within a pair of Chinese book title marks is separated by a punctuation mark, such as a hyphen or colon, the term can be treated as two separated terms. For example, theengine 406 may process (the Chinese title for the computer game “Need for Speed: Underground”) and determine that there are two candidate entries 422:
(the Chinese title for the computer game “Need for Speed: Underground”) and determine that there are two candidate entries 422: is one
is one
candidate entry 422 andis another
candidate entry 422. - Each
candidate entry 422 is associated with a count that represents the number of occurrences of thecandidate entry 422 in thedocuments 420. In some implementations, theengine 406 is configured such that each occurrence of thecandidate entry 422 in thesame document 420 causes the count to be increased by one. Thus, for example, if acandidate entry 422 occurs three times in onedocument 420 and five times in anotherdocument 420, the count for the candidate entry is increased by eight. In some implementations, theengine 406 is configured such that the count is increased by one each time acandidate entry 422 occurs in a separate document, regardless of the number of the times that thecandidate entry 422 occurs within each document. In this case, for example, if thecandidate entry 422 occurs three times in onedocument 420 and five times in anotherdocument 420, the count associated with thecandidate entry 422 is increased by two. - In some implementations, the
engine 406 identifies pairs of Chinese book title marks that bound Chinese characters and do not bound characters of other languages. In this case, if a pair of Chinese book title marks bound a Chinese word and an English word, the Chinese word is not considered to be a candidate entry. In some implementations, theengine 406 processes the text bound by each pair of Chinese book title marks to remove non-Chinese characters and adds the remaining Chinese characters as acandidate entry 422 to thefirst dictionary 410. - In some implementations, the
engine 406 sets a range for the number of characters included in eachcandidate entry 422. For example, theengine 406 may require that eachcandidate entry 422 has at least three Chinese characters and not more than ten Chinese characters. - After processing all the
documents 420 to identify all thecandidate entries 422 that are marked by Chinese book title marks, theengine 406 filters thecandidate entries 422 to remove the candidate entries with counts less than a threshold value. In some implementations, the threshold value can be set between 20 to 40, for example, 30. The threshold can, for example, be utilized to removecandidate entries 422 that contain errors, have word(s) or phrase(s) that are rarely used, or that occur infrequently for some other reason. - In some implementations, the query based
determination engine 408 is configured to identifycandidate dictionary entries 416 from the search query logs 404. The search query logs 404 can include search queries 418 submitted by multiple users of one or more search services (for example, Google search) over a period of time. Theengine 408 identifiescandidate entries 416 by finding consecutive strings of characters in the search queries 418. Asearch query 418 may include one ormore candidate entries 416 that are separated by one or more white spaces or punctuation marks that are entered by a user who submitted thesearch query 418. For example, a search queryincludes the phrase (meaning “world's fastest”) and the word
(meaning “world's fastest”) and the word (meaning “supercomputer”) that are separated by a white space. Each of the phrase
(meaning “supercomputer”) that are separated by a white space. Each of the phrase and the wordis identified by the
and the wordis identified by theengine 408 as acandidate entry 416. - In some implementations, the
engine 408 assigns two count numbers to eachcandidate entry 416, a query count qf and a user-segmented count sf. The query count qf is used to represent the number of times that thecandidate entry 416 is the only word or phrase in the search queries. For example, the query count qf associated with the entryrepresents the number of search queries 418 that include only the word. The user-segmented count sf is used to represents the number of search queries 418 that each include thecandidate entry 416 and one or more other words or phrases, where thecandidate entry 416 and the one or more other words or phrases can be separated by, for example, one or more white spaces or punctuation marks entered by users who submitted the search queries. Thecandidate entry 416 and the associated query count qf and user-segmented count sf are stored in asecond dictionary 412. - For example, if the
engine 408 finds asearch query 418 that includesthe user-segmented count sf for the candidate entryis incremented by 1, and the user-segmented count sf for the candidate entryis also incremented by 1. If theengine 408 finds asearch query 418 that includes only, the query count qf for the candidate entryis incremented by 1. - After the
engine 408 processes all of the search queries to determine all of thecandidate entries 416 and associated query counts qf and user-segmented counts sf, theengine 408 removes from thedictionary 412candidate entries 416 in which the user-segmented count sf is equal to or greater than the query count sf (i.e., sf≧qf). Theengine 408 also removescandidate entries 416 in which the query count qf is less than a threshold value (i.e., qf<threshold). In some implementations, the threshold value can be set to a value in the range of 3 to 10. The query count qf is a measure of frequentness of the candidate word in the search queries. Removing candidate entries having a low query count qf can removecandidate entries 416 that contain errors or are rarely used. - The
candidate entries 416 remaining in thedictionary 412 are ones whose query count qf is greater than the user-segmented count sf (i.e., qf>sf) and have occurred at least a certain number of times in the search queries 418 (i.e., qf≧threshold). When the number of times a particular string of consecutive characters appears by itself in the search queries 418 is greater than the number of times that the string appears with one or more other strings or characters in the search queries 418, there is a high likelihood that the particular string of consecutive characters correspond to one or more words or phrases, and is suitable as adictionary entry 128 in theIME dictionary 124. - In some implementations, the
engine 400 includes amerger engine 414 that merges thedictionary entries second dictionaries IME dictionary 124. -
FIG. 5 is a flow diagram of anexample process 500 for determining words and phrases based on a document corpus (for example, document corpus 402). Theprocess 500 can, for example, be implemented in a system that includes one or more server computers. - The
process 500 identifies context signals in documents (502), and identifies characters bounded by the context signals (504). For example, the context signals can be Chinese book title marks, the characters can be Hanzi characters, and the documents can be thedocuments 420 in thedocument corpus 402 ofFIG. 4 . For example, theengine 406 ofFIG. 4 can identify the context signals and the characters bounded by the context signals. - The
process 500 identifies one or more candidate words defined by the characters bounded by the context signals (506). For example, the candidate words can be theentries 422 ofFIG. 4 . - The
process 500 adds one or more candidate word to an input method editor dictionary (508). For example, the dictionary can be thefirst dictionary 410 ofFIG. 4 or theIME dictionary 124 ofFIG. 2 . -
FIG. 6 is a flow diagram of anexample process 600 for determining words and phrases based on search query logs (for example, search query logs 404). Theprocess 600 can, for example, be implemented in a system that includes one or more server computers. - The
process 600 identifies candidate words in search queries, each candidate word including one or more consecutive characters (602). For example, the characters can be Hanzi characters, the candidate words can be theentry 416, and the search queries can be the search queries 418 of search query logs 404FIG. 4 . For example, theengine 408 can identify the candidate words in the search queries 418. - For each candidate word, the
process 600 determines a first count representing a number of times that the candidate word is the only word in the search queries (604), and determines a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries (606). For example, in each of the search queries counted by the second count, the candidate word and the one or more other words can be separated by one or more white spaces or punctuation marks entered by the user. Theengine 408 can determine the first count and the second count, for example, qf and sf. - After determining all the words have been processed (608), the
process 600 adds one or more of the candidate words to an input method editor dictionary based on a relationship between the first count and the second count (610). For example, the dictionary can be thefirst dictionary 410 ofFIG. 4 or theIME dictionary 124 ofFIG. 2 . For example, theengine 408 may add a candidate word to the dictionary when the first count is greater than the second count. - In some implementations, the
processes -
FIG. 7 is a flow diagram of anexample process 700 for determining words and phrases based on a document corpus (for example, document corpus 402) and search query logs (for example, search query logs 404). Theprocess 700 can, for example, be implemented in a system that includes one or more server computers. Theprocess 700 includes twoprocesses - The
process 722 identifies documents (702). For example, the documents can be thedocuments 420 in thedocument corpus 402 ofFIG. 4 . - The
process 722 identifies pairs of Chinese book title marks in thedocuments 420, and identifies strings of characters marked by the pairs of Chinese book title marks (704). For example, the Chinese book title marks can be << >> or < >, and the string of characters can include Hanzi characters. For example, theengine 406 ofFIG. 4 can identify the Chinese book title marks and strings of characters. - The
process 722 designates each string of characters marked by the Chinese book title marks as a candidate entry, and adds the candidate entry to a first dictionary (706). Theprocess 722 also associates a count with the candidate entry, in which the count represents the number of occurrences of the candidate entry in the documents. For example, the first dictionary can be thefirst dictionary 410 ofFIG. 4 , and theengine 406 can add or update thecandidate entries 422 and associated counts in thefirst dictionary 410. - After all the documents have been processed to identify all the pairs of Chinese book title marks, and all the strings of characters marked by the Chinese book title marks have been added as candidate entries to the first dictionary, the
process 722 filters the candidate entries in the first dictionary by comparing the counts with a threshold value (708). If a count is lower than the threshold value, the candidate entry associated with the count is removed from the first dictionary. For example, theengine 406 can filter thecandidate entries 422 in thefirst dictionary 410. - The
process 724 identifies search queries (710). For example, the search queries can be the search queries 418 of the search logs 404 ofFIG. 4 . - For each search query, the
process 724 identifies a string of consecutive characters, or strings of consecutive characters that are separated by white space(s) or symbol(s) that are not characters, where the white space(s) or symbol(s) are entered by the user (712). For example, the characters can be Hanzi characters, and the search queries can be the search queries 418 ofFIG. 4 . For example, theengine 408 can identify the string of consecutive characters, or the strings of consecutive characters in each of the search queries 418. - The
process 724 identifies a candidate entry as being defined by each string of consecutive characters, and adds the candidate entry to a second dictionary (714). Theprocess 724 also associates a query count qf and a user-segmented count sf with each candidate entry. The query count qf represents the number of search queries that include only the candidate entry, and the user-segmented count sf represents the number of search queries that each includes the candidate entry and one or more other strings of characters. - For example, the candidate entries can be the
candidate entries 416 ofFIG. 4 , and the second dictionary can be thesecond dictionary 412. For example, theengine 408 can add or update thecandidate entries 416 in thesecond dictionary 412, and can initialize or update the query counts qf and user-segmented counts sf associated with thecandidate entries 416. - After all the search queries have been processed and all the strings of consecutive characters have been added as candidate entries to the second dictionary, the
process 724 filters the candidate entries in the second dictionary (716). Theprocess 724 compares the query count qf to the user-segmented count sf, and compares the query count qf to a threshold value. For example, theprocess 722 removes from the second dictionary the candidate entries in which the query count qf is less than a threshold, and removes candidate entries in which the query count qf is equal to or less than the user-segmented count sf. After filtering, the candidate entries in the second dictionary are ones in which the query count qf is greater than the user-segmented count sf, and the query count qf is at least the threshold value. For example,engine 408 filters thecandidate entries 416 in thesecond dictionary 412. - After the
processes process 700 merges the first and second dictionaries by removing duplicate candidate entries to generate a final dictionary (718). The candidate entries in the final dictionary are added to an IME dictionary (720). For example, themerger engine 414 ofFIG. 4 can be used to merge the first andsecond dictionaries IME dictionary 124 ofFIG. 2 . - In some implementations, rather than using Chinese book title marks to identify candidate dictionary entries, hypertext markup language (HTML) title tags can be used to identify candidate dictionary entries from web documents. For example, a pair of HTML tags <title> and </title> mark the title of an HTML document. A string of characters bounded by the <title> and </title> HTML tags can be identified as a candidate dictionary entry and added to the
dictionary 124 if a threshold criterion is met (for example, the number of times that the string of characters appear in the web documents is greater than a threshold value). - Although various implementations have been described, other implementations can also be used. For example, various forms of the flows shown above may be used, with steps re-ordered, added, or removed. Also, although several implementations and methods have been described, it should be recognized that numerous other implementations are contemplated. For example, the
input engine 122 can be capable of mapping composition inputs from a western keyboard to input Chinese, Japanese, Korean and/or Indic characters. In some examples, some or all implementations described can be applicable to other input methods, such as Cangjie input method, Jiufang input method, Wubi input method, or other input methods. The weight values for different types of documents, and the classification of types of documents, can be different from those described above. The number of words and documents being processed, and the sources of the documents in thedocument corpus 402, can be different from those described above. Theprocesses FIG. 7 can be performed sequentially. In some implementations, theengine 406 may identifynon-duplicative documents 420 in thedocument corpus 402, and identify candidate entries and associated counts based on the non-duplicative documents. In some implementations, thedictionary 124 can include characters, words, and phrases obtained from pre-existing dictionaries. - In some implementations, the context signal based
engine 406 ofFIG. 4 can be configured such that the count increases as a function of the number of times that thecandidate entry 422 occurs in each document. For example, the count can be increased by one each time that thecandidate entry 422 occurs in the same document, up to a limit (for example, three) for each document. Thus, if the upper limit is three and thecandidate entry 422 occurs five times in the same document, the count is increased by three. For example, the count can be increased as a log function of the number of times that thecandidate entry 422 occurs within the same document. In some implementations, theengine 406 is configured such that the count increases as a function of the location where thecandidate entry 422 occurs in each document. For example, the count can be increased by 1.5 if thecandidate entry 422 appears in the title of the document 420 (or subject line of an e-mail message), and the count can be increased by 1 if thecandidate entry 422 appears in other places of thedocument 420. Other methods for modifying the count based on occurrences of thecandidate entry 422 in thedocuments 420 can also be used. - In some implementations, several dictionaries, for example, a legal dictionary, a medical dictionary, a science dictionary, and a general dictionary, can be used. Each dictionary can be established by starting with a dictionary associated with a particular field. The word and
phrase determination engine 400 is used to process a document corpus having documents and search query logs having search queries biased toward the field associated with the dictionary. For example, to establish the probability values of the words in the legal dictionary, a document corpus having documents and search query logs having search queries biased toward the legal field can be used. TheIME system 120 can allow the user to select the field of interest (for example, legal, medical, science) when entering characters, and the candidate words can be selected from the dictionary related to the field of interest. - Referring to
FIG. 8 , in some implementations, the context signal basedengine 406 and the search query basedengine 408 write to asingle dictionary 800. For example, theengine 406 processes thedocuments 420 and adds orupdates candidate entries 802 to thedictionary 800. Eachcandidate entry 802 processed by theengine 406 is associated with a document occurrence count, representing the number of occurrences of thecandidate entry 802 in thedocuments 420. Theengine 408 processes the search queries 418 and adds or updates thecandidate entries 802 to thedictionary 800. Eachcandidate entry 802 processed by theengine 408 is associated with a query count and a user-segmented count. - After the
engines documents 420 andsearch queries 418 to determine all of thecandidate entries 802 and associated document occurrence counts, query counts, and user-segmented counts, theengine 400 removes from thedictionary 800 thecandidate entries 802 in which certain criteria are met, for example: (1) the document occurrence count is less than a first threshold value, (2) the user-segmented count is equal to or greater than the query count, or (3) the query count is less than a second threshold value. The remainingcandidate entries 802 are added to theIME dictionary 124. In some implementations, theengines IME dictionary 124 directly, and add, update, or filter theentries 128 in thedictionary 124. - Embodiments of the subject matter and the functional operations described in this specification can be implemented in digital electronic circuitry, or in computer software, firmware, or hardware, including the structures disclosed in this specification and their structural equivalents, or in combinations of one or more of them. Embodiments of the subject matter described in this specification can be implemented as one or more computer program products, i.e., one or more modules of computer program instructions encoded on a tangible program carrier for execution by, or to control the operation of, data processing apparatus. The tangible program carrier can be a propagated signal or a computer readable medium. The propagated signal is an artificially generated signal, for example, a machine generated electrical, optical, or electromagnetic signal, that is generated to encode information for transmission to suitable receiver apparatus for execution by a computer. The computer readable medium can be a machine readable storage device, a machine readable storage substrate, a memory device, a composition of matter effecting a machine readable propagated signal, or a combination of one or more of them.
- The term “data processing apparatus” encompasses all apparatus, devices, and machines for processing data, including by way of example a programmable processor, a computer, or multiple processors or computers. The apparatus can include, in addition to hardware, code that creates an execution environment for the computer program in question, for example, code that constitutes processor firmware, a protocol stack, a database management system, an operating system, or a combination of one or more of them.
- A computer program (also known as a program, software, software application, script, or code) can be written in any form of programming language, including compiled or interpreted languages, or declarative or procedural languages, and it can be deployed in any form, including as a stand alone program or as a module, component, subroutine, or other unit suitable for use in a computing environment. A computer program does not necessarily correspond to a file in a file system. A program can be stored in a portion of a file that holds other programs or data (for example, one or more scripts stored in a markup language document), in a single file dedicated to the program in question, or in multiple coordinated files (for example, files that store one or more modules, sub programs, or portions of code). A computer program can be deployed to be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a communication network.
- The processes and logic flows described in this specification can be performed by one or more programmable processors executing one or more computer programs to perform functions by operating on input data and generating output. The processes and logic flows can also be performed by, and apparatus can also be implemented as, special purpose logic circuitry, for example, an FPGA (field programmable gate array) or an ASIC (application specific integrated circuit).
- Processors suitable for the execution of a computer program include, by way of example, both general and special purpose microprocessors, and any one or more processors of any kind of digital computer. Generally, a processor will receive instructions and data from a read only memory or a random access memory or both. The essential elements of a computer are a processor for performing instructions and one or more memory devices for storing instructions and data. Generally, a computer will also include, or be operatively coupled to receive data from or transfer data to, or both, one or more mass storage devices for storing data, for example, magnetic, magneto optical disks, or optical disks. However, a computer need not have such devices. Moreover, a computer can be embedded in another device, for example, a mobile telephone, a personal digital assistant (PDA), a mobile audio or video player, a game console, a Global Positioning System (GPS) receiver, to name just a few.
- Computer readable media suitable for storing computer program instructions and data include all forms of non volatile memory, media and memory devices, including by way of example semiconductor memory devices, for example, EPROM, EEPROM, and flash memory devices; magnetic disks, for example, internal hard disks or removable disks; magneto optical disks; and CD ROM and DVD ROM disks. The processor and the memory can be supplemented by, or incorporated in, special purpose logic circuitry.
- To provide for interaction with a user, embodiments of the subject matter described in this specification can be implemented on a computer having a display device, for example, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor, for displaying information to the user and a keyboard and a pointing device, for example, a mouse or a trackball, by which the user can provide input to the computer. Other kinds of devices can be used to provide for interaction with a user as well; for example, feedback provided to the user can be any form of sensory feedback, for example, visual feedback, auditory feedback, or tactile feedback; and input from the user can be received in any form, including acoustic, speech, or tactile input.
- Embodiments of the subject matter described in this specification can be implemented in a computing system that includes a back end component, for example, as a data server, or that includes a middleware component, for example, an application server, or that includes a front end component, for example, a client computer having a graphical user interface or a Web browser through which a user can interact with an implementation of the subject matter described is this specification, or any combination of one or more such back end, middleware, or front end components. The components of the system can be interconnected by any form or medium of digital data communication, for example, a communication network. Examples of communication networks include a local area network (“LAN”) and a wide area network (“WAN”), for example, the Internet.
- The computing system can include clients and servers. A client and server are generally remote from each other and typically interact through a communication network. The relationship of client and server arises by virtue of computer programs running on the respective computers and having a client server relationship to each other.
- While this specification contains many specific implementation details, these should not be construed as limitations on the scope of any invention or of what may be claimed, but rather as descriptions of features that may be specific to particular embodiments of particular inventions. Certain features that are described in this specification in the context of separate embodiments can also be implemented in combination in a single embodiment. Conversely, various features that are described in the context of a single embodiment can also be implemented in multiple embodiments separately or in any suitable subcombination. Moreover, although features may be described above as acting in certain combinations and even initially claimed as such, one or more features from a claimed combination can in some cases be excised from the combination, and the claimed combination may be directed to a subcombination or variation of a subcombination.
- Similarly, while operations are depicted in the drawings in a particular order, this should not be understood as requiring that such operations be performed in the particular order shown or in sequential order, or that all illustrated operations be performed, to achieve desirable results. In certain circumstances, multitasking and parallel processing may be advantageous. Moreover, the separation of various system components in the embodiments described above should not be understood as requiring such separation in all embodiments, and it should be understood that the described program components and systems can generally be integrated together in a single software product or packaged into multiple software products.
- Particular embodiments of the subject matter described in this specification have been described. Other embodiments are within the scope of the following claims. For example, the actions recited in the claims can be performed in a different order and still achieve desirable results. As one example, the processes depicted in the accompanying figures do not necessarily require the particular order shown, or sequential order, to achieve desirable results. In certain implementations, multitasking and parallel processing may be advantageous.
Claims (25)
1. A computer-implemented method, comprising:
identifying context signals in documents;
identifying characters bounded by the context signals;
identifying one or more candidate words defined by the characters bounded by the context signals; and
adding one or more of the candidate words to an input method editor dictionary.
2. The method of claim 1 wherein identifying context signals in documents comprises identifying Chinese book title marks.
3. The method of claim 2 wherein the Chinese book title marks comprise single book title marks or double book title marks.
4. The method of claim 1 wherein identifying characters bounded by the context signals comprises identifying Hanzi characters bounded by the context signals.
5. The method of claim 1 wherein the candidate words comprise Chinese words.
6. The method of claim 1 , wherein identifying context signals in documents comprises identifying hypertext markup language tags in electronic documents.
7. The method of claim 1 wherein the input method editor dictionary comprises a Chinese input method editor dictionary.
8. The method of claim 1 , comprising determining a count of each candidate word.
9. The method of claim 8 wherein adding one or more of the candidate words to the input method editor dictionary comprises adding candidate words having a count that exceeds a threshold to the input method editor dictionary.
10. The method of claim 8 , wherein identifying context signals in documents comprises identifying non-duplicative documents.
11. The method of claim 10 , wherein determining a count of each candidate word comprises determining the count of each candidate word based on only the non-duplicative documents.
12. The method of claim 1 wherein the documents comprise web documents obtained from the Internet.
13. The method of claim 1 , comprising identifying candidate words in search queries and adding one or more of the candidate words to the input method editor dictionary.
14. The method of claim 13 wherein identifying candidate words in search queries comprises:
for each candidate word,
determining a first count representing a number of times that the candidate word is the only word in the search queries, and
determining a second count representing a number of times that the candidate word and one or more other words are included in each of the search queries, and
adding one or more of the candidate words to the input method editor dictionary based on a relationship between the first count and the second count.
15. A method, comprising:
establishing a dictionary that includes words that are identified based on characters bounded by context signals; and
providing an input method editor configured to select words from the dictionary.
16. The method of claim 15 wherein establishing the dictionary comprises identifying words based on characters bounded by Chinese book title marks.
17. The method of claim 15 , comprising identifying candidate words in search queries and adding one or more of the candidate words to the dictionary.
18. An apparatus, comprising:
a dictionary that includes words that are identified based on candidate words that are associated with characters found in documents, in which each candidate word is associated with one or more characters bounded by the context signals; and
an input method editor configured to select words from the dictionary
19. The apparatus of claim 18 wherein the candidate words comprise Hanzi characters.
20. The apparatus of claim 18 wherein the context signals comprise Chinese book title marks.
21. The apparatus of claim 20 wherein the Chinese book title marks comprise at least one of single book title marks or double book title marks.
22. The apparatus of claim 18 wherein the dictionary comprises words identified based on a first count representing a number of times that the word is the only word in search queries and a second count representing a number of times that the word and one or more other words are in each of the search queries.
23. The apparatus of claim 18 wherein the input method editor dictionary comprises a Chinese input method editor dictionary.
24. A system, comprising:
a data store to store a document corpus; and
a processing engine stored in computer readable medium and comprising instructions executable by a processing device that upon such execution cause the processing device to:
identify candidate words by finding characters in documents of the document corpus in which the characters are enclosed in pairs of Chinese book title marks, and
add one or more of the candidate words to an input method editor dictionary.
25. A system, comprising:
means for identifying context signals in documents;
means for identifying characters bounded by the context signals;
means for identifying one or more candidate words defined by the characters bounded by the context signals; and
means for adding one or more of the candidate words to an input method editor dictionary.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/191,410 US8412517B2 (en) | 2007-06-14 | 2011-07-26 | Dictionary word and phrase determination |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2007/001871 WO2008151466A1 (en) | 2007-06-14 | 2007-06-14 | Dictionary word and phrase determination |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2007/001871 Continuation WO2008151466A1 (en) | 2007-06-14 | 2007-06-14 | Dictionary word and phrase determination |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/191,410 Division US8412517B2 (en) | 2007-06-14 | 2011-07-26 | Dictionary word and phrase determination |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| US20080312911A1 true US20080312911A1 (en) | 2008-12-18 |
Family
ID=40129201
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US11/870,089 Abandoned US20080312911A1 (en) | 2007-06-14 | 2007-10-10 | Dictionary word and phrase determination |
| US13/191,410 Expired - Fee Related US8412517B2 (en) | 2007-06-14 | 2011-07-26 | Dictionary word and phrase determination |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/191,410 Expired - Fee Related US8412517B2 (en) | 2007-06-14 | 2011-07-26 | Dictionary word and phrase determination |
Country Status (3)
| Country | Link |
|---|---|
| US (2) | US20080312911A1 (en) |
| CN (1) | CN101779200B (en) |
| WO (1) | WO2008151466A1 (en) |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090292689A1 (en) * | 2008-05-20 | 2009-11-26 | Yahoo! Inc. | System and method of providing electronic dictionary services |
| US20100088303A1 (en) * | 2008-10-03 | 2010-04-08 | Microsoft Corporation | Mining new words from a query log for input method editors |
| US20110289115A1 (en) * | 2010-05-20 | 2011-11-24 | Board Of Regents Of The Nevada System Of Higher Education On Behalf Of The University Of Nevada | Scientific definitions tool |
| US20120016658A1 (en) * | 2009-03-19 | 2012-01-19 | Google Inc. | Input method editor |
| US20120078631A1 (en) * | 2010-09-26 | 2012-03-29 | Alibaba Group Holding Limited | Recognition of target words using designated characteristic values |
| US20120110518A1 (en) * | 2010-10-29 | 2012-05-03 | Avago Technologies Ecbu Ip (Singapore) Pte. Ltd. | Translation of directional input to gesture |
| US20120296631A1 (en) * | 2011-05-20 | 2012-11-22 | Microsoft Corporation | Displaying key pinyins |
| US20130132871A1 (en) * | 2010-05-21 | 2013-05-23 | Jian Zeng | Input method editor |
| CN103365833A (en) * | 2012-03-28 | 2013-10-23 | 百度在线网络技术(北京)有限公司 | Context scene based candidate word input prompt method and system for implementing same |
| US20150088493A1 (en) * | 2013-09-20 | 2015-03-26 | Amazon Technologies, Inc. | Providing descriptive information associated with objects |
| US20150106702A1 (en) * | 2012-06-29 | 2015-04-16 | Microsoft Corporation | Cross-Lingual Input Method Editor |
| US9183192B1 (en) * | 2011-03-16 | 2015-11-10 | Ruby Investments Properties LLC | Translator |
| US9886433B2 (en) * | 2015-10-13 | 2018-02-06 | Lenovo (Singapore) Pte. Ltd. | Detecting logograms using multiple inputs |
| US10509862B2 (en) * | 2016-06-10 | 2019-12-17 | Apple Inc. | Dynamic phrase expansion of language input |
| US10572586B2 (en) * | 2018-02-27 | 2020-02-25 | International Business Machines Corporation | Technique for automatically splitting words |
| US11379669B2 (en) * | 2019-07-29 | 2022-07-05 | International Business Machines Corporation | Identifying ambiguity in semantic resources |
Families Citing this family (60)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9318108B2 (en) | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| US8977255B2 (en) | 2007-04-03 | 2015-03-10 | Apple Inc. | Method and system for operating a multi-function portable electronic device using voice-activation |
| US8676904B2 (en) | 2008-10-02 | 2014-03-18 | Apple Inc. | Electronic devices with voice command and contextual data processing capabilities |
| US10255566B2 (en) | 2011-06-03 | 2019-04-09 | Apple Inc. | Generating and processing task items that represent tasks to perform |
| US9378290B2 (en) | 2011-12-20 | 2016-06-28 | Microsoft Technology Licensing, Llc | Scenario-adaptive input method editor |
| US9275636B2 (en) | 2012-05-03 | 2016-03-01 | International Business Machines Corporation | Automatic accuracy estimation for audio transcriptions |
| US10417037B2 (en) | 2012-05-15 | 2019-09-17 | Apple Inc. | Systems and methods for integrating third party services with a digital assistant |
| CN110488991A (en) | 2012-06-25 | 2019-11-22 | 微软技术许可有限责任公司 | Input Method Editor application platform |
| KR101911999B1 (en) | 2012-08-30 | 2018-10-25 | 마이크로소프트 테크놀로지 라이센싱, 엘엘씨 | Feature-based candidate selection |
| KR20150104615A (en) | 2013-02-07 | 2015-09-15 | 애플 인크. | Voice trigger for a digital assistant |
| US10652394B2 (en) | 2013-03-14 | 2020-05-12 | Apple Inc. | System and method for processing voicemail |
| US10748529B1 (en) | 2013-03-15 | 2020-08-18 | Apple Inc. | Voice activated device for use with a voice-based digital assistant |
| CN104133815B (en) * | 2013-05-02 | 2018-09-04 | 张岩 | The method and system of input and search |
| US10176167B2 (en) | 2013-06-09 | 2019-01-08 | Apple Inc. | System and method for inferring user intent from speech inputs |
| DE112014003653B4 (en) | 2013-08-06 | 2024-04-18 | Apple Inc. | Automatically activate intelligent responses based on activities from remote devices |
| US10656957B2 (en) | 2013-08-09 | 2020-05-19 | Microsoft Technology Licensing, Llc | Input method editor providing language assistance |
| US9715875B2 (en) | 2014-05-30 | 2017-07-25 | Apple Inc. | Reducing the need for manual start/end-pointing and trigger phrases |
| EP3149728B1 (en) | 2014-05-30 | 2019-01-16 | Apple Inc. | Multi-command single utterance input method |
| US10170123B2 (en) | 2014-05-30 | 2019-01-01 | Apple Inc. | Intelligent assistant for home automation |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| US9886953B2 (en) | 2015-03-08 | 2018-02-06 | Apple Inc. | Virtual assistant activation |
| US10460227B2 (en) | 2015-05-15 | 2019-10-29 | Apple Inc. | Virtual assistant in a communication session |
| US10200824B2 (en) | 2015-05-27 | 2019-02-05 | Apple Inc. | Systems and methods for proactively identifying and surfacing relevant content on a touch-sensitive device |
| US20160378747A1 (en) | 2015-06-29 | 2016-12-29 | Apple Inc. | Virtual assistant for media playback |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US10740384B2 (en) | 2015-09-08 | 2020-08-11 | Apple Inc. | Intelligent automated assistant for media search and playback |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US10331312B2 (en) | 2015-09-08 | 2019-06-25 | Apple Inc. | Intelligent automated assistant in a media environment |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10956666B2 (en) | 2015-11-09 | 2021-03-23 | Apple Inc. | Unconventional virtual assistant interactions |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| US11204787B2 (en) | 2017-01-09 | 2021-12-21 | Apple Inc. | Application integration with a digital assistant |
| US10726832B2 (en) | 2017-05-11 | 2020-07-28 | Apple Inc. | Maintaining privacy of personal information |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| DK201770427A1 (en) | 2017-05-12 | 2018-12-20 | Apple Inc. | Low-latency intelligent automated assistant |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| US20180336892A1 (en) | 2017-05-16 | 2018-11-22 | Apple Inc. | Detecting a trigger of a digital assistant |
| US20180336275A1 (en) | 2017-05-16 | 2018-11-22 | Apple Inc. | Intelligent automated assistant for media exploration |
| CN108536480B (en) * | 2017-12-28 | 2021-05-28 | Oppo广东移动通信有限公司 | Input method configuration method and related product |
| US10818288B2 (en) | 2018-03-26 | 2020-10-27 | Apple Inc. | Natural assistant interaction |
| US10928918B2 (en) | 2018-05-07 | 2021-02-23 | Apple Inc. | Raise to speak |
| US11145294B2 (en) | 2018-05-07 | 2021-10-12 | Apple Inc. | Intelligent automated assistant for delivering content from user experiences |
| DK179822B1 (en) | 2018-06-01 | 2019-07-12 | Apple Inc. | Voice interaction at a primary device to access call functionality of a companion device |
| DK180639B1 (en) | 2018-06-01 | 2021-11-04 | Apple Inc | DISABILITY OF ATTENTION-ATTENTIVE VIRTUAL ASSISTANT |
| US10892996B2 (en) | 2018-06-01 | 2021-01-12 | Apple Inc. | Variable latency device coordination |
| US11475898B2 (en) | 2018-10-26 | 2022-10-18 | Apple Inc. | Low-latency multi-speaker speech recognition |
| CN109858011B (en) * | 2018-11-30 | 2022-08-19 | 平安科技(深圳)有限公司 | Standard word bank word segmentation method, device, equipment and computer readable storage medium |
| DK201970509A1 (en) | 2019-05-06 | 2021-01-15 | Apple Inc | Spoken notifications |
| US11423908B2 (en) | 2019-05-06 | 2022-08-23 | Apple Inc. | Interpreting spoken requests |
| US11140099B2 (en) | 2019-05-21 | 2021-10-05 | Apple Inc. | Providing message response suggestions |
| US11496600B2 (en) | 2019-05-31 | 2022-11-08 | Apple Inc. | Remote execution of machine-learned models |
| US11289073B2 (en) | 2019-05-31 | 2022-03-29 | Apple Inc. | Device text to speech |
| DK180129B1 (en) | 2019-05-31 | 2020-06-02 | Apple Inc. | User activity shortcut suggestions |
| DK201970510A1 (en) | 2019-05-31 | 2021-02-11 | Apple Inc | Voice identification in digital assistant systems |
| US11488406B2 (en) | 2019-09-25 | 2022-11-01 | Apple Inc. | Text detection using global geometry estimators |
| US11038934B1 (en) | 2020-05-11 | 2021-06-15 | Apple Inc. | Digital assistant hardware abstraction |
| US11755276B2 (en) | 2020-05-12 | 2023-09-12 | Apple Inc. | Reducing description length based on confidence |
Citations (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3484751A (en) * | 1966-07-19 | 1969-12-16 | Fma Inc | Storage and retrieval of graphic information |
| US5111398A (en) * | 1988-11-21 | 1992-05-05 | Xerox Corporation | Processing natural language text using autonomous punctuational structure |
| US5113341A (en) * | 1989-02-24 | 1992-05-12 | International Business Machines Corporation | Technique for creating and expanding element marks in a structured document |
| US5544049A (en) * | 1992-09-29 | 1996-08-06 | Xerox Corporation | Method for performing a search of a plurality of documents for similarity to a plurality of query words |
| US5594642A (en) * | 1993-12-22 | 1997-01-14 | Object Technology Licensing Corp. | Input methods framework |
| US5708829A (en) * | 1991-02-01 | 1998-01-13 | Wang Laboratories, Inc. | Text indexing system |
| US5819265A (en) * | 1996-07-12 | 1998-10-06 | International Business Machines Corporation | Processing names in a text |
| US5952942A (en) * | 1996-11-21 | 1999-09-14 | Motorola, Inc. | Method and device for input of text messages from a keypad |
| US6003050A (en) * | 1997-04-02 | 1999-12-14 | Microsoft Corporation | Method for integrating a virtual machine with input method editors |
| US6009382A (en) * | 1996-08-19 | 1999-12-28 | International Business Machines Corporation | Word storage table for natural language determination |
| US6014615A (en) * | 1994-08-16 | 2000-01-11 | International Business Machines Corporaiton | System and method for processing morphological and syntactical analyses of inputted Chinese language phrases |
| US6073146A (en) * | 1995-08-16 | 2000-06-06 | International Business Machines Corporation | System and method for processing chinese language text |
| US6169999B1 (en) * | 1997-05-30 | 2001-01-02 | Matsushita Electric Industrial Co., Ltd. | Dictionary and index creating system and document retrieval system |
| US6182066B1 (en) * | 1997-11-26 | 2001-01-30 | International Business Machines Corp. | Category processing of query topics and electronic document content topics |
| US6282508B1 (en) * | 1997-03-18 | 2001-08-28 | Kabushiki Kaisha Toshiba | Dictionary management apparatus and a dictionary server |
| US6490563B2 (en) * | 1998-08-17 | 2002-12-03 | Microsoft Corporation | Proofreading with text to speech feedback |
| US6687689B1 (en) * | 2000-06-16 | 2004-02-03 | Nusuara Technologies Sdn. Bhd. | System and methods for document retrieval using natural language-based queries |
| US6704698B1 (en) * | 1994-03-14 | 2004-03-09 | International Business Machines Corporation | Word counting natural language determination |
| US6789057B1 (en) * | 1997-01-07 | 2004-09-07 | Hitachi, Ltd. | Dictionary management method and apparatus |
| US20040215465A1 (en) * | 2003-03-28 | 2004-10-28 | Lin-Shan Lee | Method for speech-based information retrieval in Mandarin chinese |
| US6822585B1 (en) * | 1999-09-17 | 2004-11-23 | Nokia Mobile Phones, Ltd. | Input of symbols |
| US20040254920A1 (en) * | 2003-06-16 | 2004-12-16 | Brill Eric D. | Systems and methods that employ a distributional analysis on a query log to improve search results |
| US20050071148A1 (en) * | 2003-09-15 | 2005-03-31 | Microsoft Corporation | Chinese word segmentation |
| US6879951B1 (en) * | 1999-07-29 | 2005-04-12 | Matsushita Electric Industrial Co., Ltd. | Chinese word segmentation apparatus |
| US6917910B2 (en) * | 1999-12-27 | 2005-07-12 | International Business Machines Corporation | Method, apparatus, computer system and storage medium for speech recognition |
| US20050197829A1 (en) * | 2004-03-03 | 2005-09-08 | Microsoft Corporation | Word collection method and system for use in word-breaking |
| US20050209844A1 (en) * | 2004-03-16 | 2005-09-22 | Google Inc., A Delaware Corporation | Systems and methods for translating chinese pinyin to chinese characters |
| US6964014B1 (en) * | 2001-02-15 | 2005-11-08 | Networks Associates Technology, Inc. | Method and system for localizing Web pages |
| US20050289463A1 (en) * | 2004-06-23 | 2005-12-29 | Google Inc., A Delaware Corporation | Systems and methods for spell correction of non-roman characters and words |
| US20060100856A1 (en) * | 2004-11-09 | 2006-05-11 | Samsung Electronics Co., Ltd. | Method and apparatus for updating dictionary |
| US7058626B1 (en) * | 1999-07-28 | 2006-06-06 | International Business Machines Corporation | Method and system for providing native language query service |
| US20060150069A1 (en) * | 2005-01-03 | 2006-07-06 | Chang Jason S | Method for extracting translations from translated texts using punctuation-based sub-sentential alignment |
| US20060248459A1 (en) * | 2002-06-05 | 2006-11-02 | Rongbin Su | Input method for optimizing digitize operation code for the world characters information and information processing system thereof |
| US7158930B2 (en) * | 2002-08-15 | 2007-01-02 | Microsoft Corporation | Method and apparatus for expanding dictionaries during parsing |
| US20070118356A1 (en) * | 2003-05-28 | 2007-05-24 | Leonardo Badino | Automatic segmentation of texts comprising chunks without separators |
| US20070265382A1 (en) * | 2004-03-09 | 2007-11-15 | Mitsubishi Chemical Corporation | Polybutylene Terephthalate Pellet, Compound Product and Molded Product Using the Same, and Processes for Producing the Compound Product and Molded Product |
| US20070265832A1 (en) * | 2006-05-09 | 2007-11-15 | Brian Bauman | Updating dictionary during application installation |
| US7299228B2 (en) * | 2003-12-11 | 2007-11-20 | Microsoft Corporation | Learning and using generalized string patterns for information extraction |
| US7315982B2 (en) * | 2003-02-26 | 2008-01-01 | Xerox Corporation | User-tailorable romanized Chinese text input systems and methods |
| US20080046405A1 (en) * | 2006-08-16 | 2008-02-21 | Microsoft Corporation | Query speller |
| US20080077588A1 (en) * | 2006-02-28 | 2008-03-27 | Yahoo! Inc. | Identifying and measuring related queries |
| US20080312910A1 (en) * | 2007-06-14 | 2008-12-18 | Po Zhang | Dictionary word and phrase determination |
| US20080319738A1 (en) * | 2007-06-25 | 2008-12-25 | Tang Xi Liu | Word probability determination |
| US7490034B2 (en) * | 2002-04-30 | 2009-02-10 | Microsoft Corporation | Lexicon with sectionalized data and method of using the same |
| US7512533B2 (en) * | 2002-07-03 | 2009-03-31 | Research In Motion Limited | Method and system of creating and using chinese language data and user-corrected data |
| US7783476B2 (en) * | 2004-05-05 | 2010-08-24 | Microsoft Corporation | Word extraction method and system for use in word-breaking using statistical information |
| US8122034B2 (en) * | 2005-06-30 | 2012-02-21 | Veveo, Inc. | Method and system for incremental search with reduced text entry where the relevance of results is a dynamically computed function of user input search string character count |
| US8126874B2 (en) * | 2006-05-09 | 2012-02-28 | Google Inc. | Systems and methods for generating statistics from search engine query logs |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003178260A (en) * | 2001-12-10 | 2003-06-27 | Canon Inc | Data processing method |
| CN1303564C (en) * | 2003-06-12 | 2007-03-07 | 摩托罗拉公司 | Identification of character input in improved electronic device |
| JP4120550B2 (en) | 2003-09-29 | 2008-07-16 | 富士通株式会社 | User dictionary registration program, apparatus, and method |
| US7836044B2 (en) * | 2004-06-22 | 2010-11-16 | Google Inc. | Anticipated query generation and processing in a search engine |
| CN100405371C (en) | 2006-07-25 | 2008-07-23 | 北京搜狗科技发展有限公司 | Method and system for abstracting new word |
| US8290967B2 (en) * | 2007-04-19 | 2012-10-16 | Barnesandnoble.Com Llc | Indexing and search query processing |
| US8312032B2 (en) * | 2008-07-10 | 2012-11-13 | Google Inc. | Dictionary suggestions for partial user entries |
-
2007
- 2007-06-14 WO PCT/CN2007/001871 patent/WO2008151466A1/en active Application Filing
- 2007-06-14 CN CN2007801002407A patent/CN101779200B/en not_active Expired - Fee Related
- 2007-10-10 US US11/870,089 patent/US20080312911A1/en not_active Abandoned
-
2011
- 2011-07-26 US US13/191,410 patent/US8412517B2/en not_active Expired - Fee Related
Patent Citations (51)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3484751A (en) * | 1966-07-19 | 1969-12-16 | Fma Inc | Storage and retrieval of graphic information |
| US5111398A (en) * | 1988-11-21 | 1992-05-05 | Xerox Corporation | Processing natural language text using autonomous punctuational structure |
| US5113341A (en) * | 1989-02-24 | 1992-05-12 | International Business Machines Corporation | Technique for creating and expanding element marks in a structured document |
| US5708829A (en) * | 1991-02-01 | 1998-01-13 | Wang Laboratories, Inc. | Text indexing system |
| US5544049A (en) * | 1992-09-29 | 1996-08-06 | Xerox Corporation | Method for performing a search of a plurality of documents for similarity to a plurality of query words |
| US5594642A (en) * | 1993-12-22 | 1997-01-14 | Object Technology Licensing Corp. | Input methods framework |
| US6704698B1 (en) * | 1994-03-14 | 2004-03-09 | International Business Machines Corporation | Word counting natural language determination |
| US6014615A (en) * | 1994-08-16 | 2000-01-11 | International Business Machines Corporaiton | System and method for processing morphological and syntactical analyses of inputted Chinese language phrases |
| US6073146A (en) * | 1995-08-16 | 2000-06-06 | International Business Machines Corporation | System and method for processing chinese language text |
| US5819265A (en) * | 1996-07-12 | 1998-10-06 | International Business Machines Corporation | Processing names in a text |
| US6009382A (en) * | 1996-08-19 | 1999-12-28 | International Business Machines Corporation | Word storage table for natural language determination |
| US5952942A (en) * | 1996-11-21 | 1999-09-14 | Motorola, Inc. | Method and device for input of text messages from a keypad |
| US6789057B1 (en) * | 1997-01-07 | 2004-09-07 | Hitachi, Ltd. | Dictionary management method and apparatus |
| US6282508B1 (en) * | 1997-03-18 | 2001-08-28 | Kabushiki Kaisha Toshiba | Dictionary management apparatus and a dictionary server |
| US6003050A (en) * | 1997-04-02 | 1999-12-14 | Microsoft Corporation | Method for integrating a virtual machine with input method editors |
| US6169999B1 (en) * | 1997-05-30 | 2001-01-02 | Matsushita Electric Industrial Co., Ltd. | Dictionary and index creating system and document retrieval system |
| US6182066B1 (en) * | 1997-11-26 | 2001-01-30 | International Business Machines Corp. | Category processing of query topics and electronic document content topics |
| US6490563B2 (en) * | 1998-08-17 | 2002-12-03 | Microsoft Corporation | Proofreading with text to speech feedback |
| US7058626B1 (en) * | 1999-07-28 | 2006-06-06 | International Business Machines Corporation | Method and system for providing native language query service |
| US6879951B1 (en) * | 1999-07-29 | 2005-04-12 | Matsushita Electric Industrial Co., Ltd. | Chinese word segmentation apparatus |
| US6822585B1 (en) * | 1999-09-17 | 2004-11-23 | Nokia Mobile Phones, Ltd. | Input of symbols |
| US6917910B2 (en) * | 1999-12-27 | 2005-07-12 | International Business Machines Corporation | Method, apparatus, computer system and storage medium for speech recognition |
| US6687689B1 (en) * | 2000-06-16 | 2004-02-03 | Nusuara Technologies Sdn. Bhd. | System and methods for document retrieval using natural language-based queries |
| US6964014B1 (en) * | 2001-02-15 | 2005-11-08 | Networks Associates Technology, Inc. | Method and system for localizing Web pages |
| US7490034B2 (en) * | 2002-04-30 | 2009-02-10 | Microsoft Corporation | Lexicon with sectionalized data and method of using the same |
| US20060248459A1 (en) * | 2002-06-05 | 2006-11-02 | Rongbin Su | Input method for optimizing digitize operation code for the world characters information and information processing system thereof |
| US7512533B2 (en) * | 2002-07-03 | 2009-03-31 | Research In Motion Limited | Method and system of creating and using chinese language data and user-corrected data |
| US7158930B2 (en) * | 2002-08-15 | 2007-01-02 | Microsoft Corporation | Method and apparatus for expanding dictionaries during parsing |
| US7315982B2 (en) * | 2003-02-26 | 2008-01-01 | Xerox Corporation | User-tailorable romanized Chinese text input systems and methods |
| US20040215465A1 (en) * | 2003-03-28 | 2004-10-28 | Lin-Shan Lee | Method for speech-based information retrieval in Mandarin chinese |
| US20070118356A1 (en) * | 2003-05-28 | 2007-05-24 | Leonardo Badino | Automatic segmentation of texts comprising chunks without separators |
| US20040254920A1 (en) * | 2003-06-16 | 2004-12-16 | Brill Eric D. | Systems and methods that employ a distributional analysis on a query log to improve search results |
| US20050071148A1 (en) * | 2003-09-15 | 2005-03-31 | Microsoft Corporation | Chinese word segmentation |
| US7299228B2 (en) * | 2003-12-11 | 2007-11-20 | Microsoft Corporation | Learning and using generalized string patterns for information extraction |
| US7424421B2 (en) * | 2004-03-03 | 2008-09-09 | Microsoft Corporation | Word collection method and system for use in word-breaking |
| US20050197829A1 (en) * | 2004-03-03 | 2005-09-08 | Microsoft Corporation | Word collection method and system for use in word-breaking |
| US20070265382A1 (en) * | 2004-03-09 | 2007-11-15 | Mitsubishi Chemical Corporation | Polybutylene Terephthalate Pellet, Compound Product and Molded Product Using the Same, and Processes for Producing the Compound Product and Molded Product |
| US7478033B2 (en) * | 2004-03-16 | 2009-01-13 | Google Inc. | Systems and methods for translating Chinese pinyin to Chinese characters |
| US20050209844A1 (en) * | 2004-03-16 | 2005-09-22 | Google Inc., A Delaware Corporation | Systems and methods for translating chinese pinyin to chinese characters |
| US7783476B2 (en) * | 2004-05-05 | 2010-08-24 | Microsoft Corporation | Word extraction method and system for use in word-breaking using statistical information |
| US20050289463A1 (en) * | 2004-06-23 | 2005-12-29 | Google Inc., A Delaware Corporation | Systems and methods for spell correction of non-roman characters and words |
| US20060100856A1 (en) * | 2004-11-09 | 2006-05-11 | Samsung Electronics Co., Ltd. | Method and apparatus for updating dictionary |
| US20060150069A1 (en) * | 2005-01-03 | 2006-07-06 | Chang Jason S | Method for extracting translations from translated texts using punctuation-based sub-sentential alignment |
| US8122034B2 (en) * | 2005-06-30 | 2012-02-21 | Veveo, Inc. | Method and system for incremental search with reduced text entry where the relevance of results is a dynamically computed function of user input search string character count |
| US20080077588A1 (en) * | 2006-02-28 | 2008-03-27 | Yahoo! Inc. | Identifying and measuring related queries |
| US20070265832A1 (en) * | 2006-05-09 | 2007-11-15 | Brian Bauman | Updating dictionary during application installation |
| US8126874B2 (en) * | 2006-05-09 | 2012-02-28 | Google Inc. | Systems and methods for generating statistics from search engine query logs |
| US20080046405A1 (en) * | 2006-08-16 | 2008-02-21 | Microsoft Corporation | Query speller |
| US20080312910A1 (en) * | 2007-06-14 | 2008-12-18 | Po Zhang | Dictionary word and phrase determination |
| US8010344B2 (en) * | 2007-06-14 | 2011-08-30 | Google Inc. | Dictionary word and phrase determination |
| US20080319738A1 (en) * | 2007-06-25 | 2008-12-25 | Tang Xi Liu | Word probability determination |
Non-Patent Citations (3)
| Title |
|---|
| Nianwen Xue. Chinese Word Segmentation as Character Taggin. Computation linguistics and Chinese Language processing. Vol. 8, No. 1, Feb 2003. * |
| Shu-Kai Hsieh. Hanzi, Concept and Computation: A preliminary survey of Chinese Characters as a knowledge resource in NLP. Dissertation of Universitat Tubingen. Published 2006. * |
| Unicode Standard v. 3.2, 1991-2002 Unicode Inc. * |
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090292689A1 (en) * | 2008-05-20 | 2009-11-26 | Yahoo! Inc. | System and method of providing electronic dictionary services |
| US20100088303A1 (en) * | 2008-10-03 | 2010-04-08 | Microsoft Corporation | Mining new words from a query log for input method editors |
| US8407236B2 (en) * | 2008-10-03 | 2013-03-26 | Microsoft Corp. | Mining new words from a query log for input method editors |
| US9026426B2 (en) * | 2009-03-19 | 2015-05-05 | Google Inc. | Input method editor |
| US20120016658A1 (en) * | 2009-03-19 | 2012-01-19 | Google Inc. | Input method editor |
| US20110289115A1 (en) * | 2010-05-20 | 2011-11-24 | Board Of Regents Of The Nevada System Of Higher Education On Behalf Of The University Of Nevada | Scientific definitions tool |
| US20130132871A1 (en) * | 2010-05-21 | 2013-05-23 | Jian Zeng | Input method editor |
| US9552125B2 (en) * | 2010-05-21 | 2017-01-24 | Google Inc. | Input method editor |
| US20120078631A1 (en) * | 2010-09-26 | 2012-03-29 | Alibaba Group Holding Limited | Recognition of target words using designated characteristic values |
| EP2619651A4 (en) * | 2010-09-26 | 2017-12-27 | Alibaba Group Holding Limited | Recognition of target words using designated characteristic values |
| US8744839B2 (en) * | 2010-09-26 | 2014-06-03 | Alibaba Group Holding Limited | Recognition of target words using designated characteristic values |
| US20120110518A1 (en) * | 2010-10-29 | 2012-05-03 | Avago Technologies Ecbu Ip (Singapore) Pte. Ltd. | Translation of directional input to gesture |
| US9104306B2 (en) * | 2010-10-29 | 2015-08-11 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Translation of directional input to gesture |
| US9183192B1 (en) * | 2011-03-16 | 2015-11-10 | Ruby Investments Properties LLC | Translator |
| US20120296631A1 (en) * | 2011-05-20 | 2012-11-22 | Microsoft Corporation | Displaying key pinyins |
| CN103365833A (en) * | 2012-03-28 | 2013-10-23 | 百度在线网络技术(北京)有限公司 | Context scene based candidate word input prompt method and system for implementing same |
| US20150106702A1 (en) * | 2012-06-29 | 2015-04-16 | Microsoft Corporation | Cross-Lingual Input Method Editor |
| US20150088493A1 (en) * | 2013-09-20 | 2015-03-26 | Amazon Technologies, Inc. | Providing descriptive information associated with objects |
| US9886433B2 (en) * | 2015-10-13 | 2018-02-06 | Lenovo (Singapore) Pte. Ltd. | Detecting logograms using multiple inputs |
| US10509862B2 (en) * | 2016-06-10 | 2019-12-17 | Apple Inc. | Dynamic phrase expansion of language input |
| US10572586B2 (en) * | 2018-02-27 | 2020-02-25 | International Business Machines Corporation | Technique for automatically splitting words |
| US11379669B2 (en) * | 2019-07-29 | 2022-07-05 | International Business Machines Corporation | Identifying ambiguity in semantic resources |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2008151466A1 (en) | 2008-12-18 |
| US20110282903A1 (en) | 2011-11-17 |
| CN101779200A (en) | 2010-07-14 |
| US8412517B2 (en) | 2013-04-02 |
| CN101779200B (en) | 2013-03-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8412517B2 (en) | Dictionary word and phrase determination | |
| US8010344B2 (en) | Dictionary word and phrase determination | |
| US8463598B2 (en) | Word detection | |
| KR101465770B1 (en) | Word probability determination | |
| US7983902B2 (en) | Domain dictionary creation by detection of new topic words using divergence value comparison | |
| US10169453B2 (en) | Automatic document summarization using search engine intelligence | |
| US8745051B2 (en) | Resource locator suggestions from input character sequence | |
| WO2009145988A1 (en) | Techniques for input recognition and completion | |
| WO2015047920A1 (en) | Title and body extraction from web page | |
| WO2009026850A1 (en) | Domain dictionary creation | |
| US8862602B1 (en) | Systems and methods for improved readability of URLs | |
| US10621261B2 (en) | Matching a comment to a section of a content item based upon a score for the section | |
| CN103455572A (en) | Method and device for acquiring movie and television subjects from web pages | |
| US20170060846A1 (en) | Linguistic based determination of text creation date | |
| CN100422987C (en) | Method and system of intelligent information processing in network | |
| US20230090601A1 (en) | System and method for polarity analysis | |
| CN113743098A (en) | Input method and terminal based on cloud platform | |
| Gali | Summarizing the content of web pages | |
| Sha et al. | Automatic Chinese Topic Term Spelling Correction in Online Pinyin Input |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: GOOGLE INC., CALIFORNIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:ZHANG, PO;REEL/FRAME:020074/0097 Effective date: 20070806 |
|
| STCB | Information on status: application discontinuation |
Free format text: ABANDONED -- FAILURE TO PAY ISSUE FEE |
|
| AS | Assignment |
Owner name: GOOGLE LLC, CALIFORNIA Free format text: CHANGE OF NAME;ASSIGNOR:GOOGLE INC.;REEL/FRAME:044142/0357 Effective date: 20170929 |