RU2308080C2 - Всеобъемлющая, ориентированная на пользователя сетевая безопасность, обеспечиваемая динамической коммутацией датаграмм и схемой аутентификации и шифрования по требованию через переносные интеллектуальные носители информации - Google Patents
Всеобъемлющая, ориентированная на пользователя сетевая безопасность, обеспечиваемая динамической коммутацией датаграмм и схемой аутентификации и шифрования по требованию через переносные интеллектуальные носители информации Download PDFInfo
- Publication number
- RU2308080C2 RU2308080C2 RU2005137570/09A RU2005137570A RU2308080C2 RU 2308080 C2 RU2308080 C2 RU 2308080C2 RU 2005137570/09 A RU2005137570/09 A RU 2005137570/09A RU 2005137570 A RU2005137570 A RU 2005137570A RU 2308080 C2 RU2308080 C2 RU 2308080C2
- Authority
- RU
- Russia
- Prior art keywords
- network
- datagram
- data
- server
- datagrams
- Prior art date
Links
Images







Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/08—Network architectures or network communication protocols for network security for authentication of entities
- H04L63/0861—Network architectures or network communication protocols for network security for authentication of entities using biometrical features, e.g. fingerprint, retina-scan
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/30—Authentication, i.e. establishing the identity or authorisation of security principals
- G06F21/31—User authentication
- G06F21/34—User authentication involving the use of external additional devices, e.g. dongles or smart cards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/04—Network architectures or network communication protocols for network security for providing a confidential data exchange among entities communicating through data packet networks
- H04L63/0428—Network architectures or network communication protocols for network security for providing a confidential data exchange among entities communicating through data packet networks wherein the data content is protected, e.g. by encrypting or encapsulating the payload
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
- H04L9/08—Key distribution or management, e.g. generation, sharing or updating, of cryptographic keys or passwords
Abstract
Изобретение относится к защищенной передаче данных и предоставлению услуг в открытых или закрытых сетевых настройках. Техническим результатом является повышение надежности и гибкости передачи данных в сети. Безопасные, устойчивые сетевые соединения и эффективные сетевые транзакции среди множества пользователей поддерживаются открытой и распределенной архитектурой клиент-сервер. Схема датаграмм приспособлена для обеспечения динамической коммутации датаграмм в поддержку множества сетевых приложений и услуг. Предоставлены мобильные интеллектуальные носители данных, которые обеспечивают возможность реализации схемы аутентификации и шифрования. Интеллектуальные носители данных выполнены с возможностью целевой доставки приложений уполномоченным пользователям. Схема аутентификации и кодирования в одном варианте воплощения основана на физической или рабочей биометрии. Способы и системы предназначены для использования в сетевой среде предприятия для поддержки широкого спектра деловых, исследовательских и административных операций. 5 н. и 48 з.п. ф-лы, 8 ил.
Description
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное раскрытие имеет отношение, в общем случае, к цифровым сетевым коммуникациям. Более определенно, данное раскрытие имеет отношение к защищенной передаче данных и предоставлению удаленных прикладных услуг в открытых или закрытых сетевых настройках. Более определенно, способы и интегрированные системы предназначены для того, чтобы улучшить контроль доступа, административный контроль, надежность и целостность передачи данных и совместное использование удаленных приложений по сети. Раскрытые способы и системы используют схему датаграмм, которая обеспечивает динамическую коммутацию датаграмм в сетевой транзакции для поддержки множества приложений и сетевых услуг. Мобильные интеллектуальные носители информации предоставляются в различных вариантах воплощения, которые предназначены для реализации схемы шифрования и аутентификации. Всеобъемлющая, ориентированная на пользователя сетевая безопасность, обеспечиваемая раскрытыми способами и системами, может быть выгодным образом развернута, наряду с другими, в финансовой и банковской среде, в системах национальной безопасности и военных информационных технологиях (IT), сетях управления здравоохранением, инфраструктуре IT для юридических и других профессиональных консультационных служб, и различных интерактивных коммерческих транзакционных системах. Системы и способы согласно этому раскрытию могут быть осуществлены в связи с биометрическим и другими подходящими средствами аутентификации.
ОПИСАНИЕ ПРЕДШЕСТВУЮЩЕГО УРОВНЯ ТЕХНИКИ
Цифровая революция, сопровождаемая глобализацией, изменила жизнь людей беспрецедентным образом. Рост и развитие Интернета питает расширение существующих фирм, способствуя появлению новых инициатив, пересекающих национальные границы. В сегодняшней мировой экономике жизнеспособность бизнеса или исследовательских институтов обращается, в большей части, к их эффективности в обработке и управлении информацией. Передача данных и управление играют все более и более жизненную роль в разнообразных отраслях промышленности. Инженеры и прогнозисты в бизнесе столкнулись с существенным вызовом в области установления защищенных сетевых систем, которые обеспечивают устойчивую и эффективную передачу данных, эффективный контроль доступа и удаленное совместное использование и управление ресурсами приложений среди распределенных компьютеров при обслуживании множества пользователей.
В установленных инфраструктурах IT были использованы различные конфигурации сети. Широко распространены, например, Ethernet, token ring и архитектура клиент-сервер. Связанные технологии для шифрования и сжатия данных являются известными, сходным образом, и используются, чтобы облегчить безопасную передачу данных. Существующие сетевые системы часто страдают от перехвата данных транзакций и потери сетевых соединений. Вообще, трудно восстановить потерянную связь. Еще более стимулирующим является точное восстановление параметров потерянного соединения, гарантируя, таким образом, целостность восстановления соединения. Данные могут быть потеряны, и передача данных должна начаться с начала. Потери могут быть постоянными, если никто не сможет проследить и определить пороговый уровень информации, который позволит восстановить данные. Эта нехватка стабильности сильно ставит под угрозу верность передачи данных, и, таким образом, представляет собой фатальную проблему распределенной обработки данных и управления. В связи с таким отказом следуют существенные затраты. Как заявляется в списке трудностей, с которыми сталкиваются в последние годы интерактивные фирмы в области электроники, эта проблема может препятствовать развитию всей промышленности.
Проблема неустойчивости, а следовательно, ненадежности - сетевых взаимодействий состоит из желания иметь всесторонние, ясные, легкие в использовании и эффективные по стоимости решения для сетевой безопасности для сохранения распространения информации и управления приложениями в распределенной IT среде предприятия. Частные фирмы и публичные учреждения часто несут существенные финансовые потери от нарушений безопасности. Много денег также тратится впустую на неэффективных решениях для безопасности IT из-за нескоординированного управления информацией и приложениями.
Недостатки текущих решений для сетевой безопасности многообразны. В основном, примечательны четыре аспекта: во-первых, когда испытывается недостаток в интегрированной системе, которая защищает всю сеть, не ограничивая строго рост бизнеса. Организации вынуждены использовать разнообразные продукты от различных поставщиков, чтобы выполнять различные функции защиты. Каждый из этих продуктов решает только определенный аспект из всех потребностей сетевой безопасности. Например, брандмауэр не шифрует данные, передающиеся через сеть Интернет; система обнаружения вторжения (IDS) не может проверить и гарантировать, что человек, который предоставляет имя учетной записи и пароль для авторизации для открытия соединения по персональной частной сети (VPN), является, по факту, намеченным пользователем; и VPN не помогает отделу IT в контроле пользовательских прав и политики доступа. Таким образом, никакая существующая система или способ не способны к исключительной защите каждого аспекта сети. Обращение к множеству продуктов по защите от конкурирующих производителей создает проблемы несовместимости. Поддержание переменного числа периферийных устройств защиты и пакетов программ может также быть чрезвычайно сложным и чрезмерно дорогостоящим. В целом, такое лоскутное решение менее чем эффективно в защите установленной IT структуры.
Во-вторых, существующие решения сфокусированы на защите устройств и данных. Такой ориентированный на систему подход не в состоянии защитить точку доступа для отдельных пользователей, которые используют устройства. Эта характерная проблема текущего подхода станет более заметной при увеличении числа устройств и степени подвижности пользователей, что неизбежно, поскольку мир эволюционирует в распространяющееся вычисление.
Чтобы оценивать характерные недостатки ориентированных на систему систем, можно рассмотреть различные сценарии киберпреступлений. Киберпреступления часто отмечаются попыткой преступника замаскировать свой идентификатор либо замаскироваться под кого-либо еще или скрыть свои следы по различным направлениям. Такая попытка слишком часто становится удачной, потому что, по меньшей мере частично, способы установить и проверить идентификационные данные пользователя являются ошибочными. Например, большинство паролей легко взламываются; они часто слишком очевидны или сохранены на устройстве, которое может быть легко скомпрометировано. Существующая инфраструктура, поддерживающая цифровые сертификаты и открытые/личные ключи, также может быть скомпрометирована. Поэтому существующие пути для идентификации пользователей сетевого устройства и защиты устройства в отношении этих пользователей - в данном случае, ориентированные на систему - имеют характерные ограничения безопасности. Высокий уровень безопасности останется иллюзией, если никакие эффективные средства не будут приняты для точной идентификации тех, кто пытается осуществить доступ к защищенной сети. Основное смещение парадигмы осуществляется, таким образом, к лучшей сетевой безопасности, от защиты устройств и данных к защите пользователей. Желательно иметь ориентированную на пользователей схему для установления и проверки пользовательских идентификаторов, допускающую, таким образом, мобильный доступ и основанную на событиях, ориентированную на пользователя, безопасность.
В-третьих, существующие решения для безопасности IT слишком сложны для обычных пользователей. Средние пользователи, как ожидается, выполнят усложненные процедуры безопасности, которые часто приводят к ошибкам и упущениям в безопасности в IT среде предприятия. Например, VPN далеки от очевидности в их установке, функционировании или обслуживании. Шифрование электронных писем требует дополнительной работы, таким образом, очень немногие когда-либо потрудились сделать это. Даже отбор и запоминание хорошего пароля может быть слишком большой неприятностью для многих людей. Передача пользователям, которые не являются экспертами IT, выполнения усложненных процедур безопасности просто не работает. Обычный пользователь может найти способы обойти процедуры безопасности или напрямую игнорировать их. Кроме того, поддержание и функционирование потопа заплаток программного обеспечения также иссушает ресурсы во многих IT отделах и превосходит их возможности. Поэтому необходимым является эффективное решение для безопасности, которое является дружественным к пользователю и которое дает минимальные эксплуатационные и административные расходы.
И наконец, как и в других областях, определенная инерция существует в индустрии IT безопасности. Изменениям и новым методологиям до некоторой степени оказывается сопротивление. Существующий способ сделать что-либо преобладает и доминирует над перспективой решений для сетевой безопасности и на стороне поставщика, и на стороне потребителя. Приверженность существующим технологиям и временному подходу для усовершенствований и модификаций препятствует развитию истинно инновационных решений.
По упомянутым выше причинам существует потребность в новой парадигме сетевой безопасности, которая дает желательную надежность, эффективность и дружественность для пользователя. Вид решения для безопасности, которое может соответствовать потребности распределенной IT инфраструктуры и поддерживать распределенные вычисления и обработку информации, должен быть обращен на ошибки существующих систем.
Квалифицированный сетевой инженер или обученный пользователь промышленных сетей IT оценят важность лучших решений для безопасности IT. С этой целью будет полезен краткий обзор истории становления компьютеров и сетей IT.
Первые компьютеры были универсальными ЭВМ (мейнфреймами). Эти сложные монолитные устройства требовали, чтобы защищенная среда функционировала должным образом. Они могли эксплуатироваться только квалифицированными техниками с высокоспециализированными знаниями. Доступ к ним был ограничен, и они давали ограниченную возможность соединения с другими устройствами. Как результат, их было легко защитить.
Появление персонального компьютера (PC), развитие сетевых технологий и, особенно, недавний взрывной рост Интернета преобразовал способ, которым люди используют и относятся к компьютерам. Размер компьютерных устройств уменьшился; они стали как без труда перемещаемыми, так и допускающими эксплуатацию обычными людьми с помощью дружественных пользовательских интерфейсов. Компьютеры были связаны, чтобы создать компьютерные сети, необходимые для совместного использования информации и приложений. Интернет привел возможность сетевого соединения к ее высшей точке - истинному глобальному соединению, которое является доступным для масс. В дополнение к настольному и портативному компьютеру, персональные цифровые ассистенты (PDA), планшетные PC и мобильные телефоны становятся популярными среди людей, которые нуждаются в сетевом доступе вне дома или офиса.
Быстрый прогресс технологий и расширение деловых нужд дали беспрецедентный вызов для отделов IT во всем мире. Постоянно увеличивающееся объемы данных, доступных из огромного числа устройств, требуют защиты. И такая защита должна быть задействована на фоне широкополосной, постоянно работающей сети. Также примечательными являются регулирующие инициативы в различных странах, относящиеся к секретности и проблемам информационной собственности в Интернете. Ясно, что необходимо решение для сетевой безопасности, которое является технически здравым и всесторонним для деловых нужд, особенно ввиду следующей неизбежной фазы развития IT, отмеченной распространяющимся вычислением. Все аналоговые устройства уже заменены или должны быть заменены цифровыми. Телевидение, телефоны, компакт-диски и DVD, цифровые камеры, видеокамеры и платформы для компьютерных игр будут все поддерживать, если уже не поддерживают, доступ в Интернет. Поскольку сетевые данные становятся доступными отовсюду и все время, потребность в том, чтобы защищать частные корпоративные данные и важную частную информацию становится все более необходимой, и уровень трудностей, соответствующий таким потребностям, соответственно поднимается.
В сумме, размышляя над развитием организационной инфраструктуры IT и текущего дефицита в безопасных сетевых коммуникациях, специалист в данной области техники оценит потребность в системах и методах, которые улучшают безопасность, стабильность, эффективность и гибкость передачи сетевых данных и связанную с этим потребность в новой парадигме сети для безопасного и надежного информационного управления и совместного использования приложений уровня предприятия.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задача этого раскрытия заключается в предоставлении систем и способов для повышения надежности, гибкости и эффективности защищенной передачи данных и совместного использования приложений по сети. В частности, способы и системы, раскрытые здесь, обеспечивают открытую архитектуру клиент-сервер, которая поддерживает безопасные, гибкие сетевые соединения и надежные, эффективные сетевые транзакции среди множества пользователей. Эта сетевая IT платформа обеспечивает всеобъемлющую безопасность, то есть безопасность по требованию, с помощью разнообразных подсоединяющихся к сети устройств, и она является ориентированной на пользователя, то есть она защищает пользователей, а не устройства, используемые пользователями для соединения с сетью. Всеобъемлющая и ориентированная на пользователя безопасность может быть установлена согласно одному варианту воплощения с помощью раскрытых здесь систем и способов в любое время в любом месте, используя любое сетевое устройство.
Схема датаграмм предоставляется в одном варианте воплощения, которая предназначена для реализации динамической коммутации датаграмм для поддержки множества приложений и сетевых услуг. В другом варианте воплощения предоставляются мобильные интеллектуальные носители информации, которые реализуют схему аутентификации и шифрования для аутентификации пользователя. Всеобъемлющая, ориентированная на пользователя сетевая безопасность согласно этому раскрытию может быть развернута в любой IT среде предприятия, где используется распределенная компьютерная сеть, включая, например, правительственные, военные, промышленные учреждения в финансовых службах, службах страхования, консультации, здравоохранения, а также в фармацевтической отрасли промышленности. Согласно различным вариантам воплощения, эта платформа безопасности IT может облегчить множество деловых операций, включая, среди прочего, материальные запасы, обслуживание потребителей, продажу и рекламу, организацию телеконференций и удаленное совместное использование различных приложений. Системы и способы согласно этому раскрытию могут быть реализованы в связи с биометрическими и другими подходящими методологиями аутентификации в определенных вариантах воплощения.
Данное раскрытие обеспечивает, таким образом, платформу сетевой безопасности, которая является отличной по сравнению с существующими лоскутными решениями. Предпринят целостный подход, и предоставляется единое решение, позволяющее организациям защищать всю сеть по мере того, как сеть динамически расширяет свои ресурсы для пользователей во всем мире, которые подсоединяются через множество разнообразных устройств или интерфейсов приложений. Платформа сетевой безопасности согласно этому раскрытию сосредотачивается на защите пользователя, а не различных сетевых главных устройств, используемых пользователем. Такая ориентированная на пользователя схема предоставляет беспрецедентную простоту и гибкость, которая, в свою очередь, обеспечивает улучшенную, легкую в использовании, сетевую систему. Расширенная безопасность прозрачна пользователю. И все же, пользовательские действия могут быть эффективно отслежены, когда это необходимо. Отделы IT имеют полный контроль над всем пользовательским доступом.
В соответствии с этим раскрытием обеспечивается, в одном варианте воплощения, система безопасного сетевого соединения между одним или более пользователями и, по меньшей мере, одним сервером сети. Система включает в себя по меньшей мере один интеллектуальный носитель информации, выданный одному пользователю, где интеллектуальный носитель информации включает в себя, по меньшей мере, (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в указанном запоминающем устройстве, при этом интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера, передавая таким образом данные через указанное устройство ввода-вывода по сети, и при этом интеллектуальный носитель информации выполнен с возможностью установления сетевых идентификационных данных пользователя посредством схемы шифрования и аутентификации; и динамический коммутатор датаграмм для динамического выделения датаграмм и обмена датаграммами для разнообразных приложений при обслуживании одного или более пользователей.
Согласно одному варианту воплощения интеллектуальный носитель информации данных является переносным. Согласно другому варианту воплощения интеллектуальный носитель информации реализован с помощью одного из следующих устройств: ключ универсальной последовательной шины (USB), носитель стандарта Compact Flash, носитель стандарта Smart Media, компакт-диск, цифровой многофункциональный диск (DVD), PDA, устройство-брандмауэр и устройство-жетон.
Согласно еще одному варианту воплощения, схема аутентификации и шифрования включает в себя следующие последовательные этапы: (a) отправка запроса от интеллектуального носителя информации серверу сети в отношении того, что интеллектуальный носитель информации должен быть аутентифицирован; (b) представление сервером сети интеллектуальному носителю информации множества способов аутентификации; (c) выбор интеллектуальным носителем информации в зависимости от конкретного случая, один способ аутентификации из данного множества; (d) сервер сети посылает интеллектуальному носителю информации требование, основанное на выбранном способе, в отношении данных аутентификации интеллектуального носителя информации; (e) сервер сети преобразует данные аутентификации, принятые от интеллектуального носителя информации, в один или более объектов аутентификации данных, где каждый объект аутентификации данных является объектом вектора данных, предназначенным для анализа с использованием одного или более классификаторов; (f) сервер сети анализирует объекты аутентификации данных согласно одному или более классификаторам, определяя таким образом результат аутентификации; и (g) сервер сети посылает этот результат интеллектуальному носителю информации, показывая успешную или неуспешную попытку аутентификации.
Согласно дополнительному варианту воплощения, событием на этапе c) является щелчок клавишей мыши, касание экрана, нажатие клавиши, произнесение фрагмента речи или биометрическое измерение.
Согласно еще одному дополнительному варианту воплощения, требование на этапе d) включает в себя по меньшей мере один из псевдослучайного и истинно случайного кода. Псевдослучайный код генерируется, основываясь на предварительно математически вычисленном списке, а истинно случайный код генерируется с помощью дискретизации и обработки в отношении источника энтропии вне системы.
Согласно другому варианту воплощения, генерация случайных чисел выполняется с помощью одного или более генераторов случайных чисел и одного или более независимых начальных значений.
Согласно дополнительному варианту воплощения, анализ на этапе f) основан на одном или более правилах анализа. В еще одном дополнительном варианте воплощения, эти одно или более правил анализа включают в себя классификацию согласно одному или более классификаторам по этапу e).
Согласно другому варианту воплощения, классификация является верификацией говорящего (диктора), при этом векторы объектов данных задействуют два класса, а именно целевого говорящего и самозванца. Каждый класс характеризуется функцией плотности вероятности, и определение на этапе (f) задачей выбора из двух альтернатив.
Согласно еще одному варианту воплощения, определение на этапе (f) включает в себя вычисление по меньшей мере одной из суммы, старшинства и вероятности одного или более объектов векторов данных на основе одного или более классификаторов по этапу (e). В еще одном варианте воплощения сумма является одной из верхней и случайной сумм, вычисленных из одного или более объектов векторов данных.
Согласно дополнительному варианту воплощения, один или более классификаторов по этапу e) включают в себя суперклассификатор, полученный из более чем одного объекта вектора данных.
Согласно еще одному дополнительному варианту воплощения, суперклассификатор основан на физической биометрии, включающей в себя по меньшей мере одно из распознавания голоса, отпечатков пальцев, отпечатка руки, узоров кровеносных сосудов, тестов ДНК, сканирования сетчатки глаза или радужной оболочки и распознавания лица. В другом варианте воплощения, суперклассификатор основан на биометрических данных, включая привычки или модели индивидуального поведения.
Согласно дополнительному варианту воплощения, схема аутентификации и шифрования включает в себя асимметричное и симметричное шифрование на основе мультишифра. В еще одном дополнительном варианте воплощения при шифровании используют по меньшей мере одно из следующего: обратную связь по выходным данным, обратную связь по шифру, формирование цепочек блоков шифра и пересылку шифра. В другом варианте воплощения шифрование основано на алгоритме Rijndael Усовершенствованного Стандарта Шифрования (AES).
Согласно еще одному варианту воплощения, в схеме аутентификации и шифрования используют защищенный обмен ключами (SKE). SKE использует систему открытых ключей в одном варианте воплощения. SKE использует личные ключи криптосистемы на основе эллиптических кривых (ЕСС) в другом варианте воплощения.
Согласно еще одному варианту воплощения, схема аутентификации и шифрования включает в себя по меньшей мере одно из следующего: логический тест, адаптированный для проверки действительности того, что интеллектуальный носитель информации зарегистрирован сервером, тест устройства, адаптированный для проверки действительности физических параметров в интеллектуальном носителе информации и устройстве главного компьютера, и персональный тест, адаптированный для аутентификации пользователя, основываясь на данных уровня события.
Согласно дополнительному варианту воплощения, разнообразие приложений включает по меньшей мере одно из следующего: основывающиеся на windows приложения удаленного терминального сервера, приложения на терминальных эмуляторах 3270/5250 для универсальной ЭВМ, непосредственно встроенные приложения и мультимедийные приложения, где непосредственно встроенные приложения включают в себя по меньшей мере одно из приложений баз данных, инструментов анализа данных, инструментов управления взаимодействием с потребителями (CRM) и пакетов планирования ресурсов предприятия (ERP).
Согласно другому варианту воплощения, динамический коммутатор датаграмм включает в себя схему датаграмм и анализатор. Схема датаграмм включает в себя две или больше датаграмм, принадлежащих одному или более типам датаграмм. Датаграмма приспособлена для того, чтобы переносить (i) данные содержимого для сетевой передачи и (ii) другую информацию для управления и контроля сетевых соединений и поддержки сетевых приложений. Каждый тип датаграмм включает множество функций. Анализатор выполнен с возможностью разбора одного или более типов датаграмм.
Согласно еще одному варианту воплощения, схема датаграмм включает в себя по меньшей мере один главный тип датаграмм и, в пределах одного главного типа датаграмм, по меньшей мере один младший тип датаграмм.
Согласно еще одному варианту воплощения, анализатор выполнен с возможностью разбора матрицы типов датаграмм. В дополнительном варианте воплощения, эта матрица включает в себя первое множество главных типов датаграмм и, в каждом главном типе датаграмм этого первого множества, второе множество младших типов датаграмм.
Согласно другому варианту воплощения, главный тип датаграмм выбран из группы, состоящей из (i) датаграммы управления сообщениями сервера и соединением, приспособленной для аутентификации и управления пользовательскими соединениями, (ii) датаграммы содержимого, приспособленной для передачи данных содержимого, (iii) широковещательной датаграммы, приспособленной для управления передачей данных от точки к точке, от точки к множеству точек и от множества точек к множеству точек, (iv) датаграммы посредника соединения, приспособленная для передачи посреднических данных между сервером сети и интеллектуальным носителем информации, (v) типа мгновенного сообщения, приспособленного для передачи сообщений в реальном времени, (vi) большой датаграммы передачи содержимого, приспособленной для передачи данных большого размера и файлов мультимедиа, (vii) датаграммы пользовательского каталога, приспособленной для поиска пользователей сети и (viii) датаграммы удаленного управления, приспособленной для удаленного управления пользователями сети.
Согласно другому варианту воплощения, каждая датаграмма в схеме датаграмм имеет общую компоновку, которая включает в себя (A) поля заголовка для (i) одного или более главных типов датаграмм, (ii) одного или более младших типов датаграмм, (iii) длины датаграммы и (iv) контрольной суммы датаграммы, и (B) полезную нагрузку датаграммы для переноса данных при передаче.
В еще одном варианте воплощения, общая компоновка включает в себя одно или более дополнительных полей заголовка. В дополнительном варианте воплощения общая компоновка следует за заголовком TCP (протокола управления передачей).
Согласно другому варианту воплощения, интеллектуальный носитель информации дополнительно содержит следящий соединитель, который сопряжен с сетью и выполнен с возможностью мониторинга и контроля сетевых соединений. В еще одном варианте воплощения сервер сети дополнительно содержит следящий соединитель, выполненный с возможностью мониторинга и контроля сетевых соединений. Следящий соединитель сервера сети соединен со следящим соединителем интеллектуального носителя информации по сети. В дополнительном варианте воплощения следящий соединитель дополнительно выполнен с возможностью обнаружения потерянных соединений и инициализации обращения к серверу сети, тем самым вновь устанавливая соединения.
Согласно еще одному варианту воплощения, система защищенного сетевого соединения дополнительно содержит средство сопряжения, выполненное с возможностью соединения существующих сетей с сервером сети и передачи данных между существующей сетью и интеллектуальным носителем информации через сервер сети, причем указанная существующая сеть является проводной или беспроводной. В еще одном варианте воплощения средство сопряжения дополнительно содержит следящий соединитель, сопряженный с сетью, и выполненный с возможностью мониторинга и контроля сетевых соединений.
В соответствии с данным раскрытием, в другом варианте воплощения предоставляется система связи клиент-сервер, которая включает в себя, по меньшей мере, один сервер и один клиент. Сервер включает в себя динамический коммутатор датаграмм для динамического выделения датаграмм и обмена датаграммами для разнообразных сетевых приложений. Клиент является интеллектуальным носителем информации, выполненным с возможностью соединения с устройством главного компьютера, передавая таким образом данные через устройство ввода-вывода по сети. Интеллектуальный носитель информации выполнен с возможностью установления идентификационных данных пользователя сети посредством схемы аутентификации и шифрования для безопасной передачи данных между сервером и клиентом.
Согласно другому варианту воплощения, система связи клиент-сервер дополнительно содержит средство сопряжения, выполненное с возможностью соединения существующей сети с сервером и передачи данных между существующими сетями и клиентом через сервер. Существующая сеть является проводной или беспроводной сетью.
Согласно еще одному варианту воплощения каждый из сервера, клиента и средства сопряжения включает в себя следящий соединитель. Следящий соединитель сопряжен с сетью и выполнен с возможностью мониторинга и контроля сетевых соединений. Следящий соединитель клиента соединен со следящим соединителем сервера по сети, и следящий соединитель средства сопряжения соединен со следящим соединителем сервера по сети.
Согласно дополнительному варианту воплощения, сервер в системе связи клиент-сервер дополнительно содержит зашифрованную виртуальную файловую систему для специализированного хранения данных для клиента.
В соответствии с данным раскрытием, в еще одном варианте воплощения предоставляется интеллектуальный носитель информации, который включает в себя по меньшей мере (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве. Интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера в сети, передавая таким образом данные через свое устройство ввода-вывода по сети. Передача данных осуществляется посредством динамически коммутируемых датаграмм. Интеллектуальный носитель информации выполнен с возможностью установления идентификационных данных пользователя сети посредством схемы аутентификации и шифрования для защищенной сетевой передачи данных.
В соответствии с данным раскрытием, в еще одном варианте воплощения обеспечивается способ защищенной сетевой связи. Способ содержит: выдачу пользователю сети интеллектуального носителя информации, который выполнен с возможностью соединения с устройством главного компьютера в сети, передавая тем самым данные через его устройство ввода-вывода (I/O) по сети и устанавливая сетевые идентификационные данные для пользователя сети посредством схемы шифрования и аутентификации; и предоставление динамического коммутатора датаграмм в сервере сети для динамического выделения датаграмм и обмена датаграммами для поддержки разнообразных приложений. В различных вариантах воплощения способ выполняет аутентификацию, шифрование и генерацию случайных чисел в связи с объектами векторов данных. Используются суперклассификаторы, особенно вместе с физическими и поведенческими биометрическими измерениями в определенных вариантах воплощения.
В соответствии с данным раскрытием, в дополнительном варианте воплощения обеспечивается способ целевой доставки одного или более приложений пользователю. Способ включает в себя этапы, на которых выдают пользователю интеллектуальный носитель информации, выполненный с возможностью подстыковки к устройству главного компьютера, которое соединено с сетью, в которой находится сервер сети, и с возможностью осуществления связи с сервером сети по сети, при этом сервер сети взаимодействует с интеллектуальным носителем информации посредством динамически коммутируемых датаграмм; аутентифицируют пользователя с помощью сервера, посредством схемы аутентификации и шифрования; и предоставляют пользователю доступ к одному или более приложений после успешной аутентификации.
Согласно другому варианту воплощения, одно или более приложений являются предварительно загруженными на интеллектуальном носителе информации или установлены на сервере сети или устройстве главного компьютера. В еще одном варианте воплощения, устройство главного компьютера соединено с сетью через проводные или беспроводные средства. Устройство главного компьютера может быть настольным или переносным компьютером, персональным цифровым ассистентом (PDA), мобильным телефоном, цифровым телевизором (TV), звуковым или видеопроигрывателем, компьютерной игровой консолью, цифровой камерой, камерой в телефоне и рассчитанным на работу в сетевой среде бытовым прибором.
Согласно дополнительному варианту воплощения, одно или более приложений могут быть основывающимися на windows приложениями удаленного терминального сервера, приложениями на терминальных эмуляторах 3270/5250 для универсальной ЭВМ, непосредственно встроенными приложениями, и мультимедийными приложениями. Непосредственно встроенные приложения включают в себя, по меньшей мере, одно из приложений баз данных, инструментов анализа данных, инструментов управления взаимодействием с потребителями (CRM) и пакетами планирования ресурсов предприятия (ERP).
ПЕРЕЧЕНЬ ФИГУР ЧЕРТЕЖЕЙ
Фиг.1 - изображение взаимодействия между клиентом, сервером и средством сопряжения согласно одному варианту воплощения данного раскрытия.
Фиг.2 - иллюстрация вектора объекта суперклассификатора согласно другому варианту воплощения этого раскрытия.
Фиг.3 - изображение анализатора датаграмм согласно другому варианту воплощения этого раскрытия, включая различные компоненты, модули и процессы, задействуемые в нем.
Фиг.4 - общая компоновка датаграммы согласно другому варианту воплощения этого раскрытия.
Фиг.5 - иллюстрация интеллектуального носителя информации, различных модулей и процессов, задействуемых в нем, согласно другому варианту воплощения этого раскрытия.
Фиг.6 - изображение клиента согласно другому варианту воплощения этого раскрытия, включая различные компоненты, модули и процессы, задействуемые в нем.
Фиг.7 - изображение сервера согласно другому варианту воплощения этого раскрытия, включая различные компоненты, модули и процессы, задействуемые в нем.
Фиг.8 - изображение средства сопряжения согласно другому варианту воплощения этого раскрытия, включая различные компоненты, модули и процессы, задействуемые в нем.
ПОДРОБНОЕ ОПИСАНИЕ РАЗЛИЧНЫХ ВАРИАНТОВ ВОПЛОЩЕНИЯ
Краткое описание соответствующих терминов
Следующие термины: сеть, клиент, сервер, данные, объект вектора данных (также называемый вектором объекта данных, вектор объекта), классификатор, принятие решения, детерминированный анализ, основанный на объектах, детерминированный анализ (также называемый объектным анализом), случайное число, генератор случайных чисел, начальное значение, генерация случайных чисел, вероятность, функция плотности вероятности, аутентификация, личный ключ, открытый ключ, криптография на основе эллиптических кривых (ЕСС), сигнатура ЕСС, анализатор, пакет, заголовок, TCP, UDP (протокол датаграмм пользователя), брандмауэр, универсальная последовательная шина (USB), последовательная шина Apple (ASB), последовательный порт, параллельный порт, маркер, firewire (стандарт высокопроизводительной последовательной шины IEEE 1394), а также и другие соответствующие термины по всему настоящему раскрытию - должны быть поняты сообразно с их типичными значениями, установленными в соответствующей области техники, то есть области математики, информатики, информационной технологии (IT), физики, статистики, искусственного интеллекта, цифровых сетей, сетевых коммуникаций, интернет-технологии, криптографии, шифрования и дешифрования, уплотнения и разуплотнения, теорий классификации, моделирования с предсказанием, принятия решения, голосовой идентификации и биометрии.
Следующие термины: защищенный обмен ключами (SKE), усовершенствованный стандарт шифрования (AES), инфраструктура открытых ключей (PKI), шифрованные виртуальные файловые системы (EVFS), виртуальная частная сеть (VPN), система обнаружения вторжения (IDS), демилитаризованная зона (DMZ), персональный цифровой ассистент (PDA), ключ USB, маркер USB, заглушка USB, заглушка параллельного порта, заглушка последовательного порта, устройство стандарта firewire, устройство-жетон, носитель стандарта Smart Card, Smart Media, Compact Flash, Smart Digital Media, DVD, компакт-диск, Стандарт многопротокольной коммуникации с использованием меток (MPLS), облегченный протокол службы каталогов (LDAP), электронный обмен данными (EDI), интернет-система общения в реальном времени (IRC), контроль с помощью циклического избыточного кода (CRC), терминальный идентификатор (TID), а также и другие соответствующие термины по всему настоящему раскрытию - должны быть поняты сообразно с их типичными значениями, установленными в отраслях промышленности IT, электронной или онлайн-торговле, и особенно сетевой безопасности и любых связанных областях.
Понятие «сеть», как оно используется здесь, относится к любой группе устройств, рассчитанных на работу в сетевой среде и соединенных между собой через среду связи (типа оптоволоконного кабеля), подходящую для передачи цифровых и/или аналоговых данных на расстояние. Сеть может быть открытой сетью, типа Интернета, или закрытой сетью, типа системы интранет предприятия. Устройство, рассчитанное на работу в сетевой среде, также называемое устройством с возможностью соединения с сетью, подсоединяющимся устройством или устройством, может быть компьютером, цифровым мобильным телефоном, PDA, цифровой камерой, цифровым аудио-, видеокоммуникатором или любыми другими устройствами, которые могут быть соединены с сетью через проводные или беспроводные средства. Устройство с возможностью соединения с сетью может быть клиентом или сервером, как упомянуто в этом раскрытии. В одном варианте воплощения, подсоединяющееся устройство может также относиться к главному компьютеру для мобильного клиента, такого как интеллектуальный носитель информации. См. обсуждение ниже клиента как интеллектуального носителя информации. В определенных вариантах воплощения сеть может включать в себя один или более таких клиентов и один или более таких серверов. В других вариантах воплощения, сеть также включает в себя одно или более устройств сопряжения, обсуждаемых ниже в подробном описании этого раскрытия.
В используемом здесь контексте виртуальная частная сеть (VPN) применяет процедуры безопасности и туннелирование, чтобы достигнуть конфиденциальности в сетевых транзакциях, при совместном использовании инфраструктуры общедоступной сети, типа Интернет. Туннелирование относится к передаче защищенных данных типа составляющих собственность бизнеса или частных для человека через общедоступную сеть. Узлы маршрутизации в открытой сети не знают, что передача является частью частной сети. Туннелирование обычно достигается инкапсуляцией частных сетевых данных и информации протокола в модули передачи общедоступной сети так, чтобы частная информация сетевого протокола появилась в общедоступной сети в виде данных. Туннелирование позволяет использовать Интернет для передачи данных от имени частной сети. Были развиты многочисленные протоколы туннелирования, среди которого некоторыми примерами являются протокол туннелирования «точка-точка» (PPTP), разработанный Microsoft и несколькими другими компаниями; протокол общей инкапсуляции при маршрутизации (GRE), разработанный Cisco Systems; и протокол тунелирования Layer Two (L2TP). Туннелирование и использование VPN не заменяют шифрование для обеспечения защищенной передачи данных. Шифрование может использоваться в связи с и в пределах VPN.
Понятие «биометрия», как оно используется в данном раскрытии, относится к индивидуальным характеристикам - физическим или поведенческим, - которые используются, чтобы идентифицировать пользователя для аутентификации пользователя и подлежащего разрешения или запрета доступа к защищенной сети учреждения или к защищенному источнику информации. Физическая биометрия включает в себя голосовую идентификацию (то есть верификацию говорящего), отпечатки пальцев, отпечатки руки, узоры кровеносных сосудов, тесты ДНК, сканирование сетчатки глаза или радужной оболочки и распознавание лица, среди прочих вещей. Выполнение биометрии включает привычки или модели индивидуального поведения.
Понятие «данные», как оно используется здесь, относится к любой информации, которую можно передать по сети. Данные используются в различных вариантах воплощения попеременно с термином «цифровая информация» или «информация». Данные содержимого относятся к любым данным, которые определены для передачи пользователем по сети. Например, в финансовом учреждении или банке информация о счете клиента составляет один тип данных содержимого, которые могут передаваться среди одного или более клиентов и серверов, используемых или управляемых с помощью различных уполномоченных менеджеров счетов и системных администраторов. Информация об оплате счета должна быть одним типом данных содержимого в контексте транзакций EDI (электронного обмена данными). Другим примером различного вида данных содержимого является информация инвентаризации относительно сырья и готовых изделий в производственном предприятии, эти данные часто передаются среди клиентов и серверов по всему предприятию для доступа со стороны инженеров производства и персонала планирования бизнеса. Мультимедийные данные, типа звуковых и видеофайлов, представляют собой еще одну форму данных содержимого. Транзакционные данные, также называемые данными соединения, означают, в данном раскрытии, любую информацию, которая показывает состояние сетевого соединения между клиентом и сервером и передачи данных между ними. Она включает в себя информацию относительно состояния полномочий пользователя и способов аутентификации, среди прочего.
Уплотнение и шифрование данных, как упоминаются в этом раскрытии, могут быть реализованы в соответствии с обычной промышленной практикой. Разнообразие спецификаций и алгоритмов для уплотнения/разуплотнения и шифрования/дешифрования известно в данной области техники, и много связанных продуктов находятся в открытом или коммерческом доступе; они могут использоваться в способах и системах согласно различным вариантам воплощения этого раскрытия.
Понятие «пользовательский интерфейс», как оно используется здесь, относится к любому виду компьютерных приложений или программ, которые обеспечивают взаимодействие с пользователем. Пользовательский интерфейс может быть графическим пользовательским интерфейсом (GUI), типа браузера. Примеры такого браузера включают в себя Microsoft Internet Explorer™ и Netscape Navigator™. Пользовательский интерфейс также может быть интерфейсом простой командной строки в альтернативных вариантах воплощения. Пользовательский интерфейс может также включать в себя инструменты для расширения программ, которые расширяют существующие приложения и поддерживают взаимодействие со стандартными настольными приложениями, типа Microsoft Office, системы ERP и т.д. Дополнительно, пользовательский интерфейс в определенном варианте воплощения может также относиться к любому пункту информационного ввода, типа, среди прочего, клавишной панели, PDA, микрофона или любого типа модуля биометрического ввода.
Понятие «следящий соединитель», как оно используется здесь, относится к модулю, который выполнен с возможностью мониторинга и управления сетевыми соединениями. Он может быть включен в состав или подсоединен к клиенту, серверу или устройству сопряжения согласно различным вариантам воплощения. Следящий соединитель клиента в определенных вариантах воплощения дополнительно выполнен с возможностью обнаруживать потерянные соединения и инициализировать контакт с сервером, вновь устанавливая таким образом соединения. Вначале он стремится соединиться с портом; после этого он непрерывно отслеживает сетевые соединения и, когда обнаружена потеря соединения, пытается вновь установить соединение, вызывая сервер. На стороне сервера следящий соединитель может всегда оставаться активным, отслеживая состояние соединений с различными клиентами.
Понятие «всеобъемлющие» вычисления, как оно используется в данном раскрытии, относится к нарастающему и широко распространенному использованию сетевых компьютеров или других цифровых устройств в бизнесе и быту людей. Быстрый рост цифровых и предназначенных для web электронных и внутренних приборов (таких как мобильный телефон, цифровой телевизор, PDA, глобальная система определения местоположения (GPS), камера в телефоне и сетевые микроволновая печь, холодильник, стиральная машина, сушилка и посудомоечная машина и т.д.) и постоянно работающих широкополосных соединений с Интернет отмечает эру всеобъемлющих вычислений.
Понятие «всеобъемлющая безопасность», как оно используется в различных вариантах воплощения, относится к платформе сетевой безопасности, которая поставляет безопасность по требованию, используя одно или более главных сетевых устройств или подсоединяющихся устройств. Ориентированная на пользователя безопасность, согласно этому раскрытию, относится к тому, что система защищает одного или более пользователей вместо одного или более главных компьютерных устройств, используемых пользователями для соединения с сервером сети. Всеобъемлющая и ориентированная на пользователя безопасность может быть обеспечена в одном варианте воплощения, используя системы и способы согласно этому раскрытию в любом месте, в любое время, с использованием любого сетевого устройства.
Датаграмма определена как «автономный, независимый элемент данных, несущих достаточную информацию для маршрутизации от источника в компьютер назначения, не полагаясь на более ранние обмены между этим источником и компьютером назначения и транспортной сетью». См. Encyclopedia of Technology Terms, Whatis.Com, QUE, ноябрь 2001. Понятия «датаграмма» и «пакет» могут использоваться попеременно. Id.
Термин «интеллектуальный носитель информации» (IDC) используется попеременно с термином «клиент» в различных вариантах воплощения этого раскрытия. Интеллектуальный носитель информации включает в себя, по меньшей мере, (i) одно запоминающее устройство (память), выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве. Интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера, передавая таким образом данные через это устройство ввода-вывода по сети. Он также выполнен с возможностью установления сетевых идентификационных данных сетевого пользователя через схему аутентификации и шифрования согласно определенным вариантам воплощения данного раскрытия. В одном варианте воплощения интеллектуальный носитель информации является переносным. Интеллектуальный носитель информации может быть реализован с помощью ключа USB, устройства стандарта firewire, носителя стандарта Smart Card, Compact Disk, DVD, Smart Media, Compact Flash, PDA, Smart Digital Media или устройства-жетона. Устройство-жетон может быть программной заглушкой, типа заглушки последовательного порта или заглушки параллельного порта, любого устройства генерации одноразового пароля или устройства доступа к системе. Другое устройство чтения цифрового носителя может быть реализовано как интеллектуальный носитель информации согласно этому раскрытию. Они выполнены с возможностью соединения с разнообразными устройствами главного компьютера через различные порты или управляющие программы и в различной манере. Интеллектуальный носитель информации несет все данные и полномочия для установления защищенного сетевого соединения от имени пользователя и запуска приложения по требованию, как только пользователь должным образом аутентифицирован сервером. См. ниже подробное обсуждение клиента как интеллектуального носителя информации.
Коммуникационная сетевая система клиент-сервер-устройство сопряжения
Коммуникационная система клиент-сервер, предоставленная в одном варианте воплощения этого раскрытия, включает в себя один или более клиентов и один или более серверов. Каждый клиент является интеллектуальным носителем информации, выполненным с возможностью поддержки схемы аутентификации и шифрования защищенных соединений с сервером сети. См. ниже обсуждение клиента как интеллектуального носителя информации. Система делает возможной ориентированную на пользователя безопасность, аутентифицируя и защищая каждого пользователя непосредственно через интеллектуальный носитель информации. Независимо от того, какие подсоединяющие устройства или локальные главные компьютеры используются, пользователь может подстыковать интеллектуальный носитель информации к главной машине и начать сеанс аутентификации, чтобы соединиться с целевым сервером. Таким образом, фокус гарантии безопасности доступа находится не на подсоединяющемся устройстве или локальной главной машине, а, скорее, непосредственно на отдельном пользователе, которому выдан интеллектуальный носитель информации. Интеллектуальный носитель информации может быть переносным; такая переносимость увеличивает всеобъемлемость в решении для безопасности, предоставленном системой. Это является безопасностью по требованию, использующей любое подсоединяющееся устройство или локальную главную машину.
В другом варианте воплощения средство сопряжения включено в коммуникационную систему клиент-сервер. Система клиент-сервер-средство сопряжения обеспечивает удобную интеграцию с существующими инфраструктурами сети и облегчает полную защищенную передачу данных и совместное использование приложений. См. ниже подробное обсуждение по средству сопряжения, соединяющемуся с сервером и клиентом. Один или более клиентов, один или более серверов и одно или более средств сопряжения могут быть введены в такую коммуникационную сетевую систему. Каждое средство сопряжения связывается и сообщается с одним или более серверами. Каждый сервер соединяется с и обслуживает одного или более клиентов. Множество серверов в системе могут сообщаться друг с другом при управлении потоками данных по всей сети.
Фиг.1 обрисовывает соединения между средством сопряжения 105, клиентом 103 и парой одноранговых серверов 101 согласно одному варианту воплощения. Каждый сервер, клиент и средство сопряжения имеет следящий соединитель 107, сопряженный с сетью. Следящий соединитель 107 постоянно отслеживает состояние сетевых соединений. Когда обнаружена потеря соединения, следящий соединитель 107 на стороне клиента делает одну или более попыток вновь установить соединение, вызывая сервер. Так как клиент сделал запись параметров состояния соединения для наиболее недавнего соединения и, следовательно, помнит их, потерянное соединение может быть быстро восстановлено с желательной точностью. Следовательно, целостность передачи данных может быть защищена и частота отказов может быть уменьшена.
В дополнение к следящему соединителю 107, некоторые другие модули и процессы обычны среди клиента 103, средства 105 сопряжения и двух одноранговых серверов 101, изображенных на Фиг.1. Менеджер средства управления 109 разрешений назначает и управляет пользовательскими разрешениями. Средство 111 обеспечения услуг гарантирует, что определенные приложения или услуги предоставляются пользователю по его запросу. Средство 113 анализа датаграмм включено в каждый клиент 103, сервер 101 и средства 105 сопряжения, как показано на Фиг.1. Средство 113 анализа может состоять из анализатора и динамического коммутатора датаграмм системы. См., фиг.7 и 8, где динамические коммутаторы 701, 801 датаграмм и анализаторы 703, 803 кадров включены в сервер 101 и средство 105 сопряжения, соответственно. Соответственно, анализатор 601 услуг и кадры 603 услуг включены в клиент 103, как показано на Фиг.6. Коммутатор 701, 801 датаграмм работают совместно со следящим соединителем 107 и на стороне клиента, и на стороне сервера, чтобы обработать множество событий передач датаграмм. Подробное обсуждение динамических коммутаторов 701, 801 датаграмм сформулировано ниже. Средство 115 шифрования обрабатывает шифрование и дешифрование данных транзакций по сети. В системах клиента 103, сервера 101 и средства 105 сопряжения, средство 115 шифрования находится на один уровень за следящим соединителем 107, который сопряжен с сетью. Средство 113 анализа и средство 111 обеспечения услуг, реализованные и в сервере 101, и в средстве 105 сопряжения, позволяют всей системе поддерживать множество сетевых услуг и приложений, а также передачу различных типов данных. Дополнительные подробности относительно этих и других модулей и процессов обсуждаются ниже в отдельных секциях для клиента 103, сервера 101 и средства 105 сопряжения.
Клиент как интеллектуальный носитель информации
Клиент является любым компьютером или устройством, которое выполнено с возможностью соединения с серверным компьютером или устройством по сети, проводной или беспроводной. Клиент может также относиться к программному обеспечению или программно-аппаратным средствам, которые вызывают сервер, и соединяется с сервером. Клиент является интеллектуальным носителем информации (IDC) согласно одному варианту воплощения. Клиент или IDC могут быть реализованы посредством выполнения программного обеспечения в виде программно-аппаратных средств или флэш-памяти на устройстве главного компьютера, связанного с сетью. Пользовательский интерфейс, предоставленный в одном варианте воплощения с помощью устройства главного компьютера или IDC, позволяет пользователю отслеживать сетевые транзакции и передачу управляющих данных, как только пользователь соединяется с сервером сети через IDC. Например, пользовательский интерфейс может предоставить пользователю форму для осуществления логического входа, чтобы зарегистрироваться в сети. Форма может принять вводы в различных форматах либо в виде текста, либо объекта, либо графики. Пользовательский интерфейс также позволяет пользователю выдавать инструкции для управления сетевой транзакцией и передачей данных.
Интеллектуальный носитель информации может быть переносным согласно одному варианту воплощения этого раскрытия. В различных вариантах воплощения интеллектуальный носитель информации может быть реализован с помощью ключа USB, носителя стандарта Compact Flash, Smart Media, компакт-диска, DVD, PDA, устройства firewire, устройства-жетона, заглушки последовательного порта или заглушки параллельного порта, либо других цифровых, аналоговых устройств или устройств для чтения носителей информации.
Интеллектуальный носитель информации имеет три принципиальных компонента согласно одному варианту воплощения: память, выполненную с возможностью хранения цифровой информации, устройство ввода-вывода (IO), выполненное с возможностью ввода и вывода цифровой информации, и процессор, выполненный с возможностью обработки цифровой информации, хранящейся в памяти. IDC выполнен с возможностью соединения с главным компьютерным устройством, которое находится в сети, и, таким образом, выполнен с возможностью передачи данных по сети через свое устройство ввода-вывода.
Память IDC может принимать форму любых читаемых компьютером носителей, например компакт-дисков, дискет, DVD, стираемой программируемой постоянной памяти 21 (EPROM) и флэш-памяти (Compact Flash, Smart Media, ключ USB и т.д.).
Устройство ввода-вывода IDC выполнено с возможностью соединения с устройством главного компьютера через любой вид соединения или порта ввода-вывода, включая, например, порты мыши, порты клавиатуры, последовательные порты (порты USB или порты ASB), параллельные порты, инфракрасные порты и соединения firewire (IEEE 1394), среди прочих. Соединение ввода-вывода может быть проводным или беспроводным согласно различным вариантам воплощения. Например, в одном варианте воплощения, беспроводное соединение ближнего действия может быть установлено между IDC и главным устройством в соответствии с спецификацией Bluetooth. См., www.bluetooth.org. В других вариантах воплощения используется связь согласно 802.1-Ib-g и инфракрасная связь. Устройство ввода-вывода включает в себя приемопередатчик в дополнительном варианте воплощения, который выполнен с возможностью отправки и приема голосовых данных или данных изображения. IDC таким образом поддерживает приложения VoIP (передача голоса поверх межсетевого протокола (IP)).
Процессор IDC включает в себя интегральную схему (IC) в одном варианте воплощения. В другом варианте воплощения, IC является специализированной интегральной схемой (ASIC). IC поддерживает выполнение предварительно загруженных приложений на IDC, так же, как и приложений, установленных на устройстве главного компьютера или сделанных доступными с удаленного сервера. В альтернативных вариантах воплощения процессор IDC самостоятельно не включает IC; он основывается на IC устройства главного компьютера и выполнен с возможностью обработки информации, хранящейся в памяти IDC, и информации, загруженной в память IDC из приложений, установленных на устройстве главного компьютера. См. ниже подробные обсуждения доставки приложений.
Интеллектуальный носитель информации согласно этому раскрытию выполнен с возможностью установления сетевых идентификационных данных для пользователя через схему шифрования и аутентификации. Интеллектуальный носитель информации определяет местонахождение сервера и представляется серверу, начиная процесс аутентификации. См. ниже обсуждение аутентификации и шифрования. В защищенной сетевой системе согласно этому раскрытию каждому пользователю может быть выдан IDC, который позволяет пользователю соединяться с сервером сети и осуществлять доступ к данным и приложениям вслед за тем. Пользователь может использовать IDC, чтобы подсоединяться, отсоединиться и повторно подсоединиться к серверу по желанию и необходимости. Соединение может быть сделано из любого главного сетевого устройства и в любое время согласно одному варианту воплощения. Устройство главного компьютера может быть настольным или переносным компьютером, персональным цифровым ассистентом (PDA), мобильным телефоном, цифровым телевизором, аудио- или видеопроигрывателем, компьютерной игровой консолью, цифровой камерой, камерой в телефоне и рассчитанным на работу в сетевой среде бытовым прибором типа сетевых холодильника, микроволновой печи, стиральной машины, сушилки и посудомоечной машины. В определенных вариантах воплощения IDC может быть непосредственно встроен в главное устройство, обеспечивая, таким образом, безопасный обмен данными или совместное использование приложений в сети. Доступ в сеть является частным и защищенным для каждого пользователя. См. ниже обсуждение по виртуальной шифрованной файловой системе. IDC предоставляет, таким образом, большую мобильность и всеобъемлющую, ориентированную на пользователя безопасность для сетевых коммуникаций.
Приложения могут быть доставлены намеченному пользователю через IDC в защищенной, контролируемой манере. В одном варианте воплощения определенные лицензированные приложения могут быть предварительно загружены в IDC, который выдается зарегистрированному пользователю, который зарегистрирован на сервере. Пользователь может выполнять приложение с IDC после надлежащей аутентификации сервером, независимо от того, с каким локальным главным устройством IDC состыкован. Таким образом, например, пользователь может вставить IDC в виде ключа USB в компьютер, который соединен с Интернетом, в одном местоположении и запустить приложение с IDC в виде ключа USB, после единожды успешного соединения с сервером, также находящимся в Интернет. Пользователь может закрыть приложение и сохранить файл на сервере или IDC в виде ключа USB. Файлы сохраняются в виртуальной шифрованной файловой системе (EVFS), связанной с сервером сети. См. ниже обсуждение EVFS. Находясь в другом местоположении, пользователь может запустить приложение после надлежащей аутентификации сервером с IDC в виде ключа USB, используя другое главное компьютерное устройство, и продолжить работать с тем же самым файлом. Такая защищенная, мобильная и ориентированная на пользователя возможность соединения между IDC и сервером сети обеспечивает, таким образом, парадигму для управления и контроля не только в отношении доступа к данным, но также и доставки приложений.
Интеллектуальные носители информации могут использоваться для доставки автономных приложений или операционных систем согласно одному варианту воплощения. Пользователю может быть выдан IDC с приложениями и/или операционной системой, которая предназначена только для чтения и является защищенной от копирования. Пользователь может использовать IDC для начальной загрузки главной системы, которая не имеет операционной системы или устройства хранения данных, установленного в ней, и осуществить доступ к основывающимся на сервере приложениям или предварительно загруженным на IDC приложениям.
Интеллектуальный носитель информации может использоваться для доставки приложений и мультимедийного содержимого согласно другому варианту воплощения. Например, пользователю можно предоставить IDC, содержащий приложение, которое является защищенным от копирования и разрешенным только для чтения, а также уникальный регистрационный номер, разрешающий начальную установку приложения. Когда установка закончена, IDC может запросить название системы, MAC-номер, регистрационный номер процессора или другую статическую информацию системы для создания кода, защищающего от копирования, который после этого сохраняется на IDC в форме зашифрованного кода, скрытого от пользователя. Этот код может гарантировать, что приложение будет установлено только на исходном главном устройстве.
Интеллектуальные носители информации используются для специфического для конкретных мультимедийных данных распространения согласно еще одному варианту воплощения. Каждому пользователю может быть выдан IDC, который работает с одним или более определенными декодерами, разрешающими доступ к определенным источникам цифровой мультимедийной информации, таким как DVD, компакт-диск (CD) или файлы данных в формате MP3. Сервер может отследить доступ и использование определенных файлов данных через IDC.
Парадигма доставки приложений согласно этому раскрытию является особенно полезной для составляющих частную собственность данных содержимого, а также пакетов коммерческих программ и инструментов IT, включая, среди прочего, специализированные приложения баз данных, инструменты анализа данных и различные пакеты управления взаимоотношениями с клиентами (CRM) и планирования ресурсов предприятия (ERP). Контролируемая и управляемая доставка, связанная с тщательной аутентификацией и шифрованием, а также с централизованным управлением данными и файлами, делает эту парадигму практическим конкурентом существующих схем лицензирования программного обеспечения, типа лицензий для предприятия и плавающих лицензий (нестрогое лицензионное соглашение). В связи с этими возможностями, IDC обеспечивает управление цифровыми правами (DRM) для составляющих частную собственность данных, приложений и услуг.
Что касается Фиг.5, интеллектуальный носитель информации реализует некоторое количество модулей и процессов согласно одному варианту воплощения этого раскрытия. Например, начальный загрузчик 501 приложения позволяет системным интеграторам (SI) и изготовителям комплектного оборудования (OEM) создавать настраиваемые вызовы начальной загрузки к приложениям, которые сохранены на IDC или в приложениях, установленных на устройстве главного компьютера. Начальный загрузчик 501 приложения является частью процессора IDC согласно этому варианту воплощения. Он может вызвать конфигурационный файл, файл SYS или исполняемый файл, среди прочего, с целью начальной загрузки приложения.
Память IDC может быть разделена на разделы, интеграторами SI или производителями OEM, для примера, на пользовательское хранилище 503 данных, хранилище 505 данных приложений и административный конфигурационный раздел 507, согласно одному варианту воплощения. В отношении пользовательского хранилища 503 данных разрешены чтение и запись. Хранилище 505 данных приложений доступно только для чтения. Административный конфигурационный раздел 507 доступен только для чтения и защищен от копирования. Информация о разделах сохраняется на IDC таким способом, что она недоступна для просмотра пользователем и не является непосредственно доступной пользователю.
Также включены дополнительные модули, включая клиентский модуль 509 аутентификации на устройстве для аутентификации пользователя, следящий соединитель 511 для мониторинга и контроля сетевых соединений и модуль 513 шифрования, среди прочего. Клиент 509 аутентификации может использовать различные средства аутентификации пользователя, включая объектный способ 515, систему 517 паролей и другие политики 519 установления прав, среди прочего. Подробное обсуждение аутентификации и шифрования сформулировано ниже.
Фиг.6 предоставляет другую иллюстрацию клиента согласно одному варианту воплощения этого раскрытия. Также изображены различные модули и компоненты, а также задействуемые процессы. Например, в зависимости от соединения с сервером, клиент поддерживает различные типы передачи, включая передачу 605 сообщений, поточную передачу 607 и другие специализированные виды связи 609. Используется анализатор датаграмм (анализатор 601 услуг), соответствующий анализатору датаграмм из состава коммутатора датаграмм (701, 703) в сервере сети в одном варианте воплощения. См. ниже обсуждение сервера с динамическим коммутатором датаграмм. Защищенный обмен 611 ключами и шифрование 613 реализованы на клиенте. См. ниже обсуждение аутентификации и шифрования. Генерация случайных чисел используется в связи со схемой шифрования и аутентификации. См. ниже обсуждение генерации случайных чисел при создании и анализе объектов данных. Дополнительно, следящий соединитель 615 включен как часть клиента, связывая клиента с сервером. Следящий соединитель 615 отслеживает соединения между клиентом и сервером. Соединение может проходить через открытую сеть, такую как Интернет. Оно может также быть установлено в пределах частной сети предприятия, особенно в сети, которая задействует распределенные вычисления.
Сервер с динамическим коммутатором датаграмм
Сервер может быть любым компьютерным или цифровым устройством, которое находится в открытой, например Интернет, или закрытой, например в среде учреждения, сети, которое выполнено с возможностью соединения с клиентом, аутентификации клиента и предоставления данных и доступа к приложениям клиенту. Сеть может быть проводной или, частично или в целом, беспроводной. Сервер задает разрешения или права различных клиентов или пользователей в системе. Разрешения могут быть скомпонованы и выданы, основываясь на физических идентификационных данных пользователя, например, согласно биометрическим измерениям, и географическом местоположении, например, именах локальных хостов, местном времени или любых других обнаружимых параметрах. Как только клиент успешно аутентифицирован, сервер принимает соединение от клиента и позволяет доступ к данным или приложениям, которые принадлежат пользователю или к которым пользователю разрешен доступ. Файлы данных находятся в EVFS, которая обеспечивает безопасный частный доступ для каждого пользователя. См. ниже обсуждение EVFS. В других вариантах воплощения сервер может доставить приложения уполномоченному (авторизированному) пользователю, как только соединение будет установлено, как обсуждалось выше.
Как показано на Фиг.7, сервер, согласно одному варианту воплощения, включает в себя ряд модулей и компонентов, некоторые из которых аналогичны тем, что включены в клиент, показанный на Фиг.6. Например, SKE 705 и шифрование 707 реализованы на сервере. Генерация случайных чисел также используется в связи со схемой шифрования и аутентификации. Как обсуждалось выше, EVFS 709 связана с сервером, предоставляя каждому клиенту виртуальную частную файловую систему для доступа к данным и хранения. EVFS 709 связана с сервером через интерфейс 711 EVFS. См. ниже подробное обсуждение. Дополнительно, следящий соединитель 713 включен как часть сервера, сопряженная со следящим соединителем 615 на стороне клиента. Сетевое соединение между клиентом и сервером с помощью следящего соединителя на каждой стороне позволяет проводить эффективный мониторинг и контроль сетевых соединений. Следящий соединитель может также обнаружить потерянные соединения и вновь установить соединения, когда это необходимо, согласно другому варианту воплощения этого раскрытия. Различные приложения или услуги включают в себя, например, передачу 715 сообщений, поточную передачу 717 и специализированные виды связи 719.
Передача данных между клиентом и сервером выполняется динамическим коммутатором датаграмм, на основе схемы датаграмм в определенных вариантах воплощения. См. ниже пример 1. Все данные - данные ли содержимого или данные транзакции - предназначенные для транспортировки через сервер, форматированы в датаграмму. Каждая датаграмма переносится внутри пакета TCP согласно одному варианту воплощения. В альтернативных вариантах воплощения могут использоваться другие протоколы сети, такие как UDP, HTTP и HTTPS. Множество типов датаграмм задано в схеме датаграмм согласно одному варианту воплощения. Главный тип датаграмм может иметь множество подтипов или младших типов. Младший тип датаграмм может дополнительно содержать подтипы датаграмм более низкого уровня в альтернативных вариантах воплощения. Ряд методов и функций может быть определен для каждого типа или подтипа датаграмм. Каждый тип или подтип датаграмм может поддерживать одно или более конкретных приложений и переносить один или более конкретных видов данных. Различные типы могут потребовать различных и определенных привилегий и/или разрешений.
Датаграммы обрабатываются на сервере динамическим коммутатором 701 датаграмм. Динамический коммутатор 701 датаграмм выполнен с возможностью создания, выделения, обработки и обмена датаграммами в режиме реального времени. Выделение и высвобождение датаграмм выполняется динамически. В одном варианте воплощения используется одно и то же пространство памяти, когда одна датаграмма высвобождается, в то время как другая выделяется. Указатели памяти используются для множества датаграмм. Когда одна датаграмма находится в обслуживании, ее указатель указывает на выделенную память. Использование указателя на память обеспечивает эффективность и скорость высокого уровня при развертывании множества сетевых приложений и поддержке передачи сетевых данных при обслуживании одного или более пользователей. Коммутация датаграмм может быть осуществлена, в определенных вариантах воплощения, в пределах сетевого соединения через один порт; и в альтернативных вариантах воплощения, коммутация датаграмм может быть осуществлена через множество портов.
Динамический коммутатор 701 датаграмм составляет средство 113 анализа датаграмм согласно одному варианту воплощения. Средство 113 анализа также включает в себя анализатор 703, который фильтрует датаграммы, основываясь на их главных и младших типах. Например, данные сначала считываются из сокета и добавляются к очереди для этого сокета. Средство 113 анализа тогда проверяет, видит ли этот сокет всю датаграмму в очереди. В противном случае оно возвращается в спящее состояние и ждет прибытия следующего пакета в сокет. Если да, оно удаляет законченную датаграмму из очереди сокета и посылает ее модулю дешифрования и анализа для дешифрования и анализа.
Средство 113 анализа после этого запрашивает, прошла ли датаграмма дешифрование и подтверждение действительности. Если нет, оно проверяет, проявляет ли датаграмма какие-нибудь признаки изменения или добавления. Если изменение или добавление обнаружено, датаграмму сбрасывают, и пользователь, который посылает датаграмму, может быть отключен. Если датаграмма успешно дешифрована и ее действительность подтверждена, средство 113 анализа после этого пытается определить намеченного получателя датаграммы. Если датаграмма предназначена для другого подсоединенного сервера, датаграмма после этого отправляется одноранговому средству 113 анализа на этом одноранговом сервере. Если датаграмма предназначена для локального сервера, тогда она передается локальному анализатору 703.
Анализатор 703 тогда проверяет, имеет ли отправитель разрешение посылать этот специфический тип датаграммы. Это выполняется, используя классификатор объектов в одном варианте воплощения. См. ниже пример 2 и обсуждение аутентификации и шифрования. Если отправитель не имеет никакого разрешения посылать этот специфический тип датаграммы, датаграмму сбрасывают и создают файл журнала регистрации. Если отправитель имеет разрешение для данного типа датаграммы, анализатор дополнительно проверяет, имеет ли отправитель разрешение посылать специфическую датаграмму и имеет ли получатель разрешение принимать датаграмму. Если нет и если негативное разрешение постоянно, то датаграмму сбрасывают и создают файл журнала регистрации. Если нет, но если негативное разрешение является временным, то датаграмма может быть сохранена для более позднего извлечения и обработки. Если отправитель имеет разрешения послать датаграмму и получатель имеет разрешение принять датаграмму, анализатор после этого продолжает определять тип датаграммы.
Фиг.3 показывает соответствующие процессы для определения типов 301 датаграмм и разбора датаграмм, осуществляемые в анализаторе 703 согласно одному варианту воплощения. Каждый тип датаграмм имеет соответствующее средство обработки, такое как средство 303 мгновенной передачи сообщений, средство 305 широковещательной рассылки, средство 307 посредника соединения, средство 309 аутентификации пользователя, средство 311 администрирования пользователей, средство 313 пользовательского каталога, и т.д. Как только тип датаграммы определен, датаграмма подается и обрабатывается специальным для соответствующего типа датаграмм средством.
Средство 315 одноранговой связи относится к одноранговому средству анализа, находящемуся в другом подсоединенном сервере, одноранговом сервере. Логические входы и выходы пользователя транслируются 317 по всем одноранговым узлам. Пользовательский доступ к каждому одноранговому серверу может быть скоординирован и управляем, как это желательно. Например, существующее соединение, которое пользователь имеет с сервером, может быть завершено, когда пользователь успешно аутентифицирован и соединен с одноранговым сервером, который предоставляет более высокий уровень привилегии доступа. Связанное со средством 311 управления пользователями средство 319 разрешений управляет разрешениями и записывает разрешения для всех пользователей. Другие модули или процессы могут быть включены в другие варианты воплощения, которые предоставляют дополнительные функциональные возможности, когда это необходимо, включая, например, средство 321 туннелирования VPN.
В одном варианте воплощения сервер может динамически обрабатывать матрицу типов датаграмм. Эта матрица включает в себя первое предопределенное количество (например, 256) главных типов датаграмм, каждый из которых имеет второе предопределенное количество (например, 256) младших типов датаграмм. В альтернативных вариантах воплощения, анализатор 703 выполнен с возможностью анализа матрицы типов датаграмм, которая имеет больше чем две размерности или слоя. Анализ, поэтому, может быть реализован, основываясь на типах датаграмм, полях и слоях.
Соответствующие функции или методы могут быть исполнены для каждой датаграммы, после того как датаграмма должным образом разобрана, согласно общей компоновке датаграммы. Фиг.4 предоставляет общую компоновку датаграмм согласно одному варианту воплощения. Компоновка датаграммы включает в себя полезную нагрузку 401 и поля заголовка, такие как главный тип 403 датаграммы, младший тип или подтип 405 датаграммы, длина 407 датаграммы и контрольная сумма 409 датаграммы. Полезная нагрузка 401 несет данные содержимого при передаче. Дополнительные поля 411 заголовка могут быть включены для различных типов датаграмм.
Согласно примеру 1 ниже, в одном варианте воплощения, главные типы датаграмм включают в себя, среди прочих: датаграмму управлениями сообщениями сервера и соединением, адаптированную для аутентификации и управления пользовательскими соединениями; датаграмму содержимого, адаптированную для управления передачей данных содержимого; широковещательную датаграмму, адаптированную для управления в реальном времени передачами данных точка-множество точек и множество точек-множество точек; и датаграмму посредника соединения, адаптированную для передачи посреднических данных между сервером сети и интеллектуальным носителем информации.
Датаграмма управления сообщениями сервера и соединением включает младшие типы или подтипы датаграмм, такие как датаграмма запроса аутентификации, адаптированная для инициирования запроса аутентификации; датаграмма ответа на запрос аутентификации, адаптированная для посылки ответа после запроса аутентификации; и датаграмма результата аутентификации, адаптированная для посылки результата сеанса аутентификации.
Датаграмма содержимого включает младшие типы или подтипы датаграмм, такие как нормальная датаграмма содержимого, адаптированная для передачи данных содержимого; датаграмма с удаленного логического входа, адаптированная для осуществления связи с сервером сети и установления сеанса логического входа; датаграмма удаленного сбора данных, адаптированная для передачи данных из удаленного соединения; датаграмма запроса одобрения содержимого, адаптированная для запрашивания верификации переданных данных содержимого; и датаграмма ответа на запрос одобрения содержимого, адаптированная для ответа на запрос верификации переданных данных содержимого.
Датаграмма посредника соединения включает в себя младшие типы или подтипы датаграмм, такие как посреднические данные к серверу, этот тип адаптирован пропускать посреднические данные к серверу сети от интеллектуального носителя информации; и посреднические данные от сервера, этот тип адаптирован пропускать посреднические данные от сервера сети к интеллектуальному носителю информации. Другим примером главного типа датаграмм является тип мгновенного сообщения. Он включает младшие типы датаграмм, такие как тип передачи файла, тип передачи аудио-, видеоданных, тип мгновенного почтового сообщения и тип удаленного сбора данных.
Средство сопряжения, соединяющееся с сервером и клиентом
Защищенная сетевая система согласно этому раскрытию включает в себя средство сопряжения в дополнительном варианте воплощения, выполненное с возможностью соединения сервера с существующей инфраструктурой сети. Средство сопряжения может быть программным обеспечением или программно-аппаратным обеспечением, которое обеспечивает возможность сетевого соединения. Средство сопряжения преобразовывает физические данные соединения в логические ресурсы сети. Это допускает удобную интеграцию с существующими сетями и уменьшает потребность в модифицировании существующих инфраструктур IT.
Обратимся к Фиг.8, где средство сопряжения в одном варианте воплощения включает в себя модули и процессы, сходные с оными клиента (Фиг.6) или сервера (Фиг.7). Например, SKE 805 и шифрование 807 реализованы в средстве сопряжения. Генерация случайных чисел также используется в связи со схемой шифрования и аутентификации. Как и сервер, средство сопряжения также связано с EVFS 809, предоставляя пользователям виртуальную частную файловую систему для доступа к данным в отношении существующих сетей. EVFS 809 связана с средством сопряжения через интерфейс 811 виртуальной файловой системы (VFS). Средство сопряжения как клиент и сервер, также поддерживает различные типы связи, включая, например, передачу сообщений 813, поточную передачу 815 и другие специализированные виды связи 817.
Кроме того, средство сопряжения использует динамический коммутатор 801 датаграмм и имеет анализатор 803 кадров или датаграмм. Коммутатор 801 датаграмм и анализатор 803 кадров соответствуют коммутатору 701 датаграмм и анализатору 703 датаграмм в сервере сети. Следящий соединитель 819 также включен как часть средства сопряжения, взаимодействующий со следящим соединителем 713 на стороне сервера. Следящий соединитель 819 отслеживает и управляет сетевыми соединениями между средством сопряжения и сервером. Следящий соединитель 819 может также обнаруживать потерянные соединения и вновь устанавливать соединения, когда это необходимо, согласно другому варианту воплощения.
Аутентификация и шифрование
В различных вариантах воплощения этого раскрытия, защищенная сетевая система может использовать разнообразные средства аутентификации и шифрования, включая, например, шифрованную или нешифрованную строку ASCII, модель единого классификатора и модель суперклассификатора. Может использоваться симметричное и асимметричное шифрование на основе мультишифра. Шифрование может изменяться со временем посредством обратной связи по выходным данным, обратной связи по шифру, сцепления блоков шифра, перенаправления шифра или любого другого способа, который изменяет шифр и/или ключ в манере, которую средство шифрования или средство дешифрования может предсказать или воспроизвести. В определенных вариантах воплощения используется защищенный обмен ключами (SKE). SKE задействует генерацию случайных пар ключей, которые используются только однажды и после того сбрасывается. В соответствии с SKE, никакие ключи не сохраняются ни на каком устройстве или системе, за исключением пары открытый ключ-личный ключ, находящейся на сервере или управляемой сервером. SKE отличается от инфраструктуры открытых ключей (PKI), которая требует, чтобы система хранения открытых ключей обслуживала множество пользователей. Исключение промежуточной системы хранения открытых ключей, которая является типичной целью для сетевых хакеров, обеспечивает усиленную безопасность сети.
Модуль SKE в защищенной сетевой системе согласно определенным вариантам воплощения использует различные системы открытых ключей, включая коммерческие системы (COTS). В одном варианте воплощения используется алгоритм Rijndael усовершенствованного стандарта шифрования (AES). См. Federal Information, Processing Standards Publication 197, Announcing the Advanced Encryption Standard, ноябрь 2001, (доступная по адресу csrc.nist.gov/publications/fips/fipsl97/fips-197.pdf). См. также, web-сайты csrc.nist.gov/CryptoToolkit/aes/; csrc.nist.gov/CryptoToolkit/aes/rijndael/; и csrc.nist.gov/CryptoToolkit/aes/rijndael/rijndael-ip.pdf. В другом варианте воплощения может использоваться 163-битный ключ криптографии на основе эллиптических кривых с ЕСС. Технология ЕСС известна. См., например, Tatsuaki Okamoto и другие, PSEC: Provably Secure Elliptic Curve Encryption Scheme, (Submission to P1363a), март 1999 (доступный по адресу grouper.ieee.org/groups/1363/P1363a/contributions/psec.pdf). См. также web-сайты world.std.com/~dpj/elliptic.html и csrc.nist.gov/cryptval/dss/fr000215.html.
В альтернативных вариантах воплощения могут использоваться различные способы шифрования на случайной основе и в комбинации. Например, альтернативные шифры включают в себя, среди прочего: Gost, Castl28, Cast256, Blowfish, IDEA, Mars, Misty 1, RC2, RC4, RC5, FROG, SAFER, SAFER-K40, SAFER-SK40, SAFER-K64, SAFER-SK64, SAFER-K128, SAFER-SK128, TEA, TEAN, Skipjack, SCOP, Q128, 3Way, Shark, Square, Single DES, Double DES, Triple DES, Double DES16, Triple DES16, TripleDES24, DESX, NewDES, Diamond II, Diamond II Lite и Sapphire II. Альтернативные алгоритмы хэширования включают в себя, среди прочего: MD4, SHA, SHA-2, RipeMD128, RipeMD160, RipeMD256, RipeMD320, Haval (128, 160, 192, 224 и 256 битов) с Rounds, Snefru, Square, Tiger, and Sapphire II (128, 160, 192, 224, 256, 288 и 320 битов).
Аутентификация в одном варианте воплощения основана на данных уровня события. Событие аутентификации включает в себя щелчок клавишей мыши, нажатие клавиши, прикосновение к экрану, произнесение фрагмента речи или получение биометрических данных. Данные уровня события охватывают данные, сгенерированные при событии, а также данные, сгенерированные до и после события. Окно события может быть задано при регистрации или измерении события. Таким образом, например, взятие выборки звука может быть осуществлено в пределах некоторого лимита времени. Эти данные могут использоваться при компилировании суперклассификаторов согласно одному варианту воплощения.
Использование суперклассификатора задействует три аспекта: классификация (см. ниже Приложение 1), анализ (см. ниже Приложение 2) и решение (см. ниже Приложение 3). Функция суперклассификатора - выделение признаков данных входного вектора. Данные входного вектора могут быть бинарными или не бинарными. См., например, приложение 3. Вектор объекта, основанный на суперклассификаторе, используется в одном варианте воплощения. См. ниже пример 2. Генерация случайных чисел применяется в основанном на суперклассификаторе объектном анализе, обсуждаемом в следующем разделе.
Аутентификация выполняется каждый раз, когда клиент или IDC пытается соединиться с сервером сети. Согласно одному варианту воплощения, схема аутентификации и шифрования представляется с помощью IDC. Схема аутентификации и шифрования вовлекает ряд этапов. Сначала пользователь посылает, через клиент или IDC, запрос к серверу сети, запрашивая выполнение аутентификации в отношении себя. Инициирование сеанса аутентификации исходит, таким образом, от клиента или IDC. Во-вторых, сервер посылает IDC список доступных способов аутентификации, из которого пользователь выбирает один на основе события, например, щелчка клавишей мыши, касания экрана, произнесения фрагмента речи, нажатия клавиши или любого другого подходящего события уведомления. Ввод от цифрового преобразователя, типа камеры или биометрического устройства дает другие примеры подходящих событий уведомления. В-третьих, основываясь на выбранном способе аутентификации, сервер посылает IDC запрос на данные аутентификации. Запрос может быть в отношении пароля, который является истинно случайным или псевдослучайным, согласно различным вариантам воплощения. Псевдослучайный пароль генерируется, основываясь на предварительно рассчитанном математически списке, и истинно случайный пароль генерируется посредством дискретизации и обработки в отношении источника энтропии вне системы. В-пятых, сервер преобразовывает данные аутентификации, принятые от IDC, в один или более объектов данных или векторов объектов. В-шестых, сервер выполняет объектный анализ в отношении объектов данных, используя один или более классификаторов или суперклассификатор. Может использоваться суперклассификатор, основывающийся на биометрических измерениях. И наконец, результат этого анализа или решения, основанного на классификаторе, посылают от сервера к IDC, который или подтверждает надлежащую аутентификацию пользователя, разрешая, таким образом, соединение IDC с сервером, или объявляет, что попытка аутентификации от IDC провалилась.
Согласно другим вариантам воплощения, могут быть осуществлены три фазы аутентификации или три теста аутентификации: логический тест для соответствия клиент-сервер, тест устройства для IDC и персональный тест для пользователя. Генерация случайных чисел может использоваться в связи с одним или более из этих трех тестов, с или без классификаторов объектов данных.
Логический тест на соответствие клиент-сервера является тестом, который позволяет IDC или клиенту находить свой правильный сервер. Это вовлекает множество шагов. В начале, когда сервер устанавливается или инициализируется, пара открытый ключ/личный ключ ЕСС создается в сервере, используемая только в целях проверки действительности. Любому клиенту или IDC этого сервера дают открытый серверный ключ (PK1), когда IDC конфигурируется или создается, так, чтобы в IDC был зашит «генетический код» сервера и, следовательно, «имелась регистрация» на своем намеченном сервере. Позже, когда IDC выдан пользователю и пытается удаленно соединиться с сервером по сети, средство генерации случайных чисел сервера генерирует большой поток случайных данных и использует его для задания начального значения в создании новой пары (PK2) открытого/личного ключей ЕСС для этого сеанса соединения. Этот открытый ключ затем подписывается ранее созданным личным ключом сервера, который используется только в целях проверки действительности. Сервер после этого посылает в IDC и вновь созданный открытый ключ ЕСС, и подпись. После приема такой информации IDC использует открытый ключ «только для проверки действительности», который в него зашит, для проверки подписи открытого ключа ЕСС. Если подпись не соответствует «зашитому коду», сервер не является правильным сервером, и IDC отсоединяется. Если подпись соответствует, IDC генерирует новую пару открытого/личного ключей ЕСС (PK3) для сеанса и посылает открытый ключ как часть идентификационных данных и возможностей клиента (CIF, см. пример 1 выше). CIF, в свою очередь, зашифрован с использованием открытого ключа PK2 сервера.
Тест устройства для IDC сосредотачивается на физических параметрах IDC для проверки. Например, во время развертывания программного обеспечения клиента на устройстве-носителе, то есть, когда носитель или устройство хранения данных становится IDC, IDC регистрируется на сервере, и ряд его параметров сохраняется на сервере, например, в базе данных сервера. Когда IDC генерирует пакет CIF, он сохраняет в CIF любую информацию, которую может собрать на устройстве главного компьютера, соединенном с сетью устройством соединения, к которому он подстыкован, шифрует весь пакет CIF открытым ключом PK1, действительность которого была проверена в предыдущем логическом тесте, и посылает зашифрованный CIF серверу. После дешифрования сервер может проверить, соответствуют ли данные в CIF параметрам, предварительно зарегистрированным в сервере, и подсоединен ли IDC от известного или законного главного сетевого устройства. Если проверка терпит неудачу, сервер может закончить сеанс и отсоединить IDC.
Персональный тест пользователя сосредотачивается на аутентификации конкретного пользователя. Этот тест может быть осуществлен с или без классификаторов или суперклассификатора. Тест без использования суперклассификатора может вовлекать множество шагов. Например, после успешного SKE, на IDC посылают датаграмму запроса аутентификации, включающую в себя список способов аутентификации, и, если одним из этих способов является аутентификация, основанная на механизме «опознавательный запрос-ответ», - опознавательный запрос для аутентификации IDC. IDC тогда выбирает один из способов аутентификации. Он может предложить или не предложить пользователю интерактивный логический вход. В случаях, когда IDC уже имеет достаточно информации для аутентификации, обеспечивается автоматический логический вход. Продолжая аутентификацию, IDC посылает объект аутентификации серверу, реализованный в другом типе датаграмм, который содержит данные проверки действительности, подлежащие исследованию сервером. Анализ объектов данных аутентификации варьируется, основываясь на способе аутентификации, который используется.
Пользовательский тест с использованием суперклассификатора, с другой стороны, может пройти следующим образом. Суперклассификатор реализован, основываясь на различных типах типов датаграмм и датаграмм на сервере. При успешном SKE, датаграмму запроса аутентификации посылают от суперклассификатора к IDC, включая список способов аутентификации и опознавательный запрос для аутентификации IDC, если один из способов аутентификации является аутентификацией на основе механизма «опознавательный запрос-ответ». IDC тогда, подобным способом, выбирает способ аутентификации. Для аутентификации сервер посылает IDC запрос на исполнение задачи уровня события. Запрос построен с помощью суперклассификатора на основе ввода от средства генерации случайных чисел. IDC выполняет задачу, и получаемые данные уровня события после этого заключаются в объект данных аутентификации. Этот объект данных включает в себя, в одном варианте воплощения, отдельный, случайно сгенерированный, идентификатор для этого конкретного сеанса сетевого обмена, так чтобы минимизировать вероятность компрометации этого сеанса. Объект аутентификации тогда возвращается из IDC, который проанализирован «средством верификации» сервера на основе суперклассификатора. Анализ объекта данных может варьироваться в зависимости от конкретного используемого способа аутентификации.
Генерация случайных чисел при создании и анализе векторных объектов данных
Способы генерации случайных чисел известны в области теоретической и прикладной математики. Они часто применяются в процессах принятия решения, где не существует никакого очевидного общего знаменателя. Использование генерации случайных чисел облегчено большой вычислительной мощностью, доступной сегодня. Генерация случайных чисел обычно использует привлечение начального значения. Генераторы случайных чисел выдают совокупности случайных чисел, основываясь на предоставлении одного или более начальных значений. В зависимости от характеристик начальных значений, генерацию случайных чисел можно классифицировать как псевдослучайную или истинно случайную. Большинство генераторов случайных чисел являются псевдослучайными генераторами чисел. Они основаны на предварительно рассчитанном математически списке, который может быть скомпрометирован. В отличие от этого, истинно случайные числа обычно генерируются дискретизацией и обработкой в отношении источника энтропии вне задействуемых компьютерных систем или сетей. Нужно идентифицировать источник энтропии и то, как энтропия создала начальное значение, чтобы взломать истинный генератор случайных чисел.
Генерация случайных чисел также применяется в сетевой или компьютерной безопасности. Существующее приложение генерации случайных чисел в защите данных является, в значительной степени, статическим. Например, случайное число может быть сгенерировано клиентом, сервером или другим компьютерным устройством и впоследствии передано на компьютер пользователем. Если число будет соответствовать числу в пределах «фрейма» случайных чисел, разрешенного специфическим для конкретной системы генератором случайных чисел, то пользователю будет предоставлен доступ. Это аналогично инфраструктуре открытого ключа (PKI), где два секретным образом сгенерированных ключа сопоставляются и проверяются на предмет действительности в совместно используемом пункте проверки действительности. Проблема этой парадигмы состоит в том, что совместно используемый пункт проверки действительности может быть скомпрометирован относительно легко: в системе совместно используемый пункт проверки действительности является генератором случайных чисел, который содержит фрейм чисел (или любую желательную выходную комбинацию, типа алфавитных цифр), основанный на заданном начальном значении. Хотя кажется, что генератор случайных чисел производит бесконечное число случайных чисел, общее количество случайных чисел, которые будут сгенерированны, предопределено, как только генератор создан (инициализирован начальным значением). Таким образом, случайным является только порядок, в котором генерируются случайные числа. Такая генерация случайных чисел является статической. Каждое случайное число теоретически предсказуемо.
Генерация случайных чисел, согласно определенным воплощениям этого раскрытия, применяется в нестатической манере. Генерация случайных чисел реализуется в объектах данных через один или более классификаторов или суперклассификаторов. См. ниже пример 2. Истинный генератор случайных чисел инициализируется начальным значением с целью обеспечения случайных чисел для анализа объектов векторов данных. Объекты данных используются в ряде тестов на аутентификацию, как обсуждалось выше.
Множественные и отдельные личные ключи генерируются, основываясь на истинно случайных значениях в различных вариантах воплощения. Эти ключи не содержат никакой информации, основанной на начальном ключе подтверждения действительности сервера, потому что объект данных преобразовывает число в значение или образ данных, основываясь на энтропии вне компьютера на уровне события. Поэтому генерация случайных чисел находится вне среды или генератора случайных чисел и становится нестатической. Поскольку то, что используется для преобразования объекта на основе генерации случайных чисел, является само по себе ключом, становится возможным сопоставить два неизвестных (личных ключа) и сделать их известными. В альтернативных вариантах воплощения, могут сходным образом генерироваться и использоваться более чем два личных ключа. Кроме того, любое количество личных ключей может быть сгенерированно объектами в классификаторе и таким образом сделать количество личных неизвестным.
В этом варианте воплощения генерация случайных чисел осуществляется и для (i) сопоставления пользователя или клиента с вызовом аутентификации на основе истинно случайного генератора, и для (ii) выбора объектного анализа, подлежащего выполнению, и выполнения выбранного анализа.
Типичный предопределенный генератор случайных чисел может принять следующую форму:

См., например, Numeric Recipes, W.H. Press at all, Cambridge University Press. Независимо от того, используются ли простые линейные конгруэнтные генераторы или улучшенные генераторы, множественные генераторы случайных чисел могут использоваться, создавая, таким образом, комбинаторную проблему, чтобы предотвратить вычисление начального значения на основе, например, наблюдения некоторого количества случайных чисел, сгенерированных в последовательности. В определенных вариантах воплощения самые младшие разряды обрезаются в последовательности, сводя к минимуму возможность пропуска каких-либо подсказок. В других вариантах воплощения, помимо начального значения, специфические для конкретного генератора константы а, с и m также предоставляются, согласно вышеупомянутой формуле. Может быть создана таблица с большим количеством возможных значений для констант a и m. Когда константы выбираются, используя некоторый шумовой ввод, согласно этому подходу будут получены более устойчивые генераторы случайных чисел. В других вариантах воплощения может использоваться некоторое количество предварительно выбранных генераторов случайных чисел в сочетании с N независимыми начальными значениями. Простая сумма может использоваться следующим образом:

Примером полезного алгоритма для комбинирования двух линейных конгруэнтных генераторов с объединенным периодом приблизительно 2,3×1018 является ran2, описанный в Numerical Recipes. Алгоритм может быть изменен, используя два независимых начальных значения. Он может быть дополнительно изменен, используя 3 или N генераторов. В одном варианте воплощения, по меньшей мере одно начальное значение получают, используя недетерминистический источник, к которому преступник не имеет свободного доступа. Недетерминистический источник может быть чем-нибудь вне генератора случайных чисел и вне системы сети, представляющей интерес, типа, например, внешнего устройства, возникновение внешнего события, третьего лица и битов, полученных из ближайшей предыстории компьютера.
Когда один конкретный классификатор используется при анализе основывающегося на объекте вектора, предсказуемость может быть относительно высокой, так что преступник может найти решение классификатора и начального значения. В определенных вариантах воплощения группа классификаторов, то есть множественные классификаторы или суперклассификаторы, используется, когда может быть достигнута более низкая предсказуемость. Размерность векторов признаков может быть уменьшена по мере того, как вариации, которые не являются различительными в отношении классов, сбрасываются. См. ниже Приложения 1 и 2.
В итоге, генерация истинно случайных чисел согласно этому раскрытию улучшает защиту доступа к данным. Объекты данных основываются на специальных значениях, таких как биометрические измерения в одном варианте воплощения, которые известны только пользователю на уровне события. Эта фокусировка на пользователе, а не устройствах, делает защиту ориентированной на пользователя согласно этому раскрытию. Объекты данных, преобразованных на уровне события с помощью генератора истинно случайных чисел и проанализированные в суперклассификаторе, обеспечивают превосходную основу для установления и верификации идентификационных данных пользователя.
Зашифрованная виртуальная файловая система (EVFS)
EVFS, согласно различным вариантам воплощения, является заданной для каждого пользователя (или группы пользователей), для каждого клиента виртуальной файловой системой, также называемой файловым хранилищем. Она является серверной файловой системой или средством хранения данных или файлов, которое позволяет пользователям сетевой системы хранить файлы или данные вне локальных главных машин или клиентских носителей. EVFS может быть полезной, когда, например, емкость запоминающего устройства является недостаточной на локальной машине. Примеры использования и реализации систем EVFS доступны в открытых источниках. См., например, web-сайты www.microsoft.com/technet/treeview/default.asp?url=/TechNet/prodtechnol/windows2000serv/deploy/confeat/nt5efs.asp; www.serverwatch.com/tutorials/article.php/2106831; и www.freebsddiary.org/encrypted-fs.php.
Согласно одному варианту воплощения этого раскрытия сервер защищенной сетевой системы связан с EVFS 709 через интерфейс 711 EVFS, как показано на Фиг.7. EVFS 709 включает в себя пользовательский каталог 721, предоставляемую для каждого пользователя базу 723 данных файлов и хранилище 725 файлов. Пользовательский каталог содержит релевантную информацию для всех пользователей, включая пароль, параметры логического входа, биометрический профиль, физическое или географическое местоположение, неавтономный и автономный статус, открытый ключ ЕСС, используемый для шифрования файлов, которые хранятся в EVFS. Пользователями являются индивидуумы, которые подсоединены к серверу сети через клиент или IDC и использовали или используют определенные приложения, поддерживаемые сетью. Приложения можно поставить и запустить с IDC, согласно одному варианту воплощения этого раскрытия. Приложения можно также запустить на главном компьютере или устройстве, к которому IDC или клиент подсоединен. Или, альтернативно, приложения можно запустить удаленно на сервере от имени клиента.
Сервер использует интерфейс 727 пользовательского каталога, который находится на сервере, для доступа к пользовательскому каталогу 721. Хранилищем 725 файлов является цифровой носитель, на котором хранятся файлы и любые другие данные, представляющие интерес для пользователей. Это может быть любой вид машинной памяти. Оно является физическим местоположением, где файлы или данные, созданные или измененные пользовательскими приложениями, сохраняются; пользовательские приложения выполняются на IDC, главном компьютере или удаленно на сервере. Хранилище 725 файлов может быть оптимизировано для скорости и удобства доступа.
Предназначенная для каждого пользователя база 723 данных файлов содержит пользовательскую информацию о файлах, типа исходного имени файла, даты и времени, и зашифрованное представление ключа шифрования, используемого для шифрования файла. Всем файлам, хранящимся в EVPS 709, назначены истинно случайные имена, а также истинно случайные ключи шифрования; они смешиваются между собой в хранилище 725 файлов. Доступ к данным является конфиденциальным и безопасным для каждого пользователя. Каждый отдельный пользователь может видеть и осуществлять доступ только к тем файлам или данным, в отношении которых пользователь является владельцем или для которых пользователь получил разрешения на доступ. Уровнем доступа, который пользователь имеет для каждого файла или документа, управляет сервер. Таким образом, пользователю может быть разрешено только читать и редактировать файл, но не перемещать или копировать его с сервера или IDC, если приложение исполняется с интеллектуального носителя данных, в определенных вариантах воплощения. По существу, каждый пользователь фактически имеет личную базу данных, то есть предоставляемую для каждого пользователя базу 723 данных, связанную с сервером.
EVFS 709, используемая в защищенной сетевой системе, раскрытой здесь, обеспечивает улучшенную защиту для данных и приложений, принадлежащих каждому пользователю. В случае физической компрометации, например, если IDC потерян или украден, данные, сохраненные в EVFS 709, будут не читаемы или без возможности представления для любого, но не для аутентифицированного должным образом пользователя, владельца файла, который имеет доступ к личному ключу шифрования ЕСС, который может деблокировать файлы.
Предоставление EVFS 709 усиливает, таким образом, ориентированный на пользователя аспект защищенной сетевой системы согласно различным вариантам воплощения. Наряду с шифрованием, аутентификацией и другими особенностями, обсужденными в данном раскрытии, EVFS 709 обеспечивает защищенное распространение и автономное функционирование приложений через IDC.
Различные варианты воплощения дополнительно описываются следующими примерами, которые являются иллюстрацией раскрытых вариантов воплощения, но не ограничивают их каким-либо образом.
Пример 1: Пример датаграммы и спецификации главных и младших типов (под)датаграмм
Примеры датаграмм
Типы мгновенного сообщения
Мгновенное сообщение
Удаленное протоколирование
Удаленный сбор данных
Выполнение удаленной команды
Передача файла
Аудио-, видеокоммуникация
Транзакция EDI
Типы широковещательной рассылки
Передача типа точка-много точек не в реальном времени
Биржевое сообщение
Передача типа много точек-много точек не в реальном времени
Интерактивный обмен на основе канала (стиль IRC)
Передача типа точка-точка в реальном времени
Интерактивный обмен от пользователя к пользователю
Аудио-, видеоконференция (аудио- или видеотелефония)
Передача типа точка-много точек в реальном времени (широковещательная рассылка)
Широковещательная рассылка аудио-, видео
Передача типа много точек-много точек в реальном времени
Аудио-, видеоконференция
Типы пользовательских каталогов
Запрос
Обновление
Типы запросов к серверу
Автономное хранилище
Область обмена сервера
Устройство контроля фильтром содержания
Статус фильтра
Статистика фильтра
Обновление фильтра (правила добавления/обновления)
Установка фильтра
Перезагрузка фильтра
Обязательные поля датаграмм
Начало каждой датаграммы может быть систематизировано следующим образом:
| Размер в байтах | Кем заполняется | Содержимое |
| 1 | Клиент | Главный тип датаграммы |
| 1 | Клиент | Младший тип датаграммы (подтип) |
| 8 | Сервер | Получение датаграммы на сервере (временная метка) |
| 4 | Сервер | Создатель датаграммы (ID клиента-отправителя) |
| 1 | Клиент | Сигнатура/тип CRC |
| n | Клиент | Сигнатура/поле контрольной суммы (например, сигнатура ECC, MD4, MD5, SHA, SHA1, и т.д.) |
Дополнительные поля заголовка могут быть добавлены к вышеупомянутым полям, в зависимости от типа датаграммы. Дополнительные поля заголовка обычно заполняются клиентом и могут быть утверждены сервером.
Типы Подписи/ CRC:
| Тип | Длина поля CRC |
| 0: нет контрольной суммы | 0 байтов (недооцененных) |
| 1: Сигнатура ЕСС | 87 байтов |
| 2: SHA | 20 байтов |
| 3: SHA1 | 20 байтов |
| 4: MD4 | |
| 5: MD5 | 16 байтов |
| 6: | |
| 7: | |
| 8: CRC32 |
Здесь добавлены дополнительные заголовки в различных датаграммах. Заголовки заполняются клиентом и могут быть утверждены сервером.
Типы симметричного шифра
Частью SKE (Защищенного обмена ключами) являются переговоры. Симметричные шифры могут поддерживаться и клиентом, и сервером и выбираются, основываясь на разрешениях и приоритете типа шифра.
| Тип | Название |
| 1 | Rijndael |
| 2 | Blowfish |
| 3 | RC6 |
| 4 | Twofish |
Защищенный обмен ключами
SKE используется для реализации случайных, одноразовых (невосстановимых) ключей шифрования в определенных вариантах воплощения, так что никакие симметричные ключи шифрования не сохраняются на клиенте, которые могут быть подвергнуть риску компрометации.
Обмен другой информацией или данными осуществляется по сети, когда выполнен SKE. Эта информация или данные могут существенно ограничить или увеличить привилегии для пользователя.
Краткий обзор Процесса SKE
1. Клиент соединяется с сервером
2. Сервер посылает датаграмму SPK клиенту
3. Клиент подтверждает сигнатуру сервера и возвращает датаграмму CIF
4. Сервер подтверждает данные клиента и возвращает датаграмму SKP
5. Клиент посылает уведомление о доставке
6. Сервер посылает уведомление о доставке
Датаграмма SPK
Датаграмма открытого серверного ключа (SPK) используется, чтобы передать открытый серверный ключ для сеанса клиенту. Сервер может подписать ключ личным ключом из предварительно разделенной пары открытого/личного ключей ЕСС, которая сгенерированна во время установки сервера, чтобы принять меры против вторжения хакера.
| Размер в байтах | Описание |
| 2 | Размера открытого серверного ключа для сеанса (в шестнадцатиричном формате) |
| n | Открытый серверный ключ для сеанса |
| n | Сигнатура |
Датаграмма CIF
Датаграмма идентифицированных данных и возможностей клиента (CIF) кодирует данные относительно клиента (IDC), включая информацию относительно главной машины, где работает IDC, а также открытый клиентский ключ, который желательно использовать для сеанса.
Данные закодированы в CSV-подобной манере.
| Поле | Описание |
| 1 | Открытый клиентский ключ для сеанса |
| 2 | Разделенный пробелами список способов шифрования и поддерживаемой длины ключей |
| 3 | Разделенный пробелами список способов хеширования |
| 4 | Тип устройства клиента (могут быть закодированные двоичные данные) |
| 5 | Идентификатор клиента (могут быть закодированные двоичные данные) |
| 6 | Симметричный ключ шифра для клиента ->серверный поток |
| 7 | IV для симметричного Шифра |
Шифр и длина ключа отформатированы следующим образом:
<способ шифрования>-<длина ключа><способ шифрования>-<длина ключа>
Тип устройства клиента ссылается на описание среды аппаратных средств IDC (типа ID устройства PNP для машин на основе windows). Любая информация может использоваться на главной машине, к которой IDC подсоединен, включая, например, серийный номер процессора главной машины, номер версии микропрограммы и серийный номер материнской платы (или BIOS материнской платы), данные аутентификации от различных аппаратных жетонов (например, биометрических устройств ввода, устройств чтения SmartCard, устройств чтения флеш-памяти), и MAC-адрес сетевого интерфейса, через который главная машина сообщается с сервером.
Вся датаграмма CIF может быть зашифрована, используя открытый серверный ключ. Подлежащую обмену величину (EV) посылают в зашифрованном пакете. Посланная зашифрованная датаграмма может быть прочтена следующим образом:
1-й и 2-й октет (в шестнадцатеричном исчислении) являются длиной EV
n октетов следует с EV
n октетов следует с зашифрованными данными CIF
Датаграмма SKP
Датаграмма пакета серверного ключа (SKP) хранит информацию относительно шифра, битовой длины и ключа, но может быть расширена для других целей.
Серверу не требуется подписывать информацию в датаграмме SKP. SKP шифруется открытым клиентским ключом, который, в свою очередь, посылается серверу и шифруется открытым серверным ключом. Эта датаграмма закодирована в CSV-подобной манере:
| Поле | Описание |
| 1 | Тип датаграммы SKP |
SKP типа 0
Это является нормальной датаграммой SKP. Она хранит информацию клиента о шифре, длине ключа и режиме шифра для поднимающегося потока в восходящем и нисходящем направлении.
| Поле | Описание |
| 2 | Шифр, выбранный для сервера → клиентский поток |
| 3 | Битовая длина для сервера → клиентский поток |
| 4 | Режим шифра (ECB, CBC, CFB, OFB) для сервера → клиентский поток |
| 5 | Шифр, выбранный для клиента → серверный поток |
| 6 | Битовая длина для клиента → серверный поток |
| 7 | Режим шифра (ECB, CBC, CFB, OFB) для клиента → серверный поток |
| 8 | Симметричный шифровальный ключ для сервера → клиентский поток |
| 9 | Симметричный IV для сервера → поток |
SKP типа 1
Инструктируя IDC, извлечь «идентификационные данные клиента» из определенного сервера (или дополнительные идентификационные данные).
| Поле | Описание |
| 2 | IP адрес сервера, содержащего дополнительные идентификационные данные |
| 3 | Порт, который слушает сервер |
| 4 | Необязательные «идентификационные данные клиента» для выдачи серверу во время SKE |
SKP типа 8
Сообщает IDC, что ему не позволено соединиться с системой из его текущего местоположения. Сервер может автоматически закончить соединение при успешной передаче датаграммы SKP типа 8.
| Поле | Описание |
| 2 | Сообщение для показа пользователю (необязательное) |
SKP типа 9
Просит, чтобы IDC сделал попытку поиска обновления микропрограммы.
| Поле | Описание |
| 2 | Адрес IP сервера, содержащего обновление микропрограммы |
| 3 | Порт, который слушает сервер |
| 4 | Необязательные «идентификационные данные клиента», выдаваемые серверу во время SKE |
SKP типа 10
Инструктирует IDC запросить от пользователя возврат устройства IDC, поскольку сообщено о его отсутствии или потере.
| Поле | Описание |
| 2 | Сообщение для показа пользователю |
SKP типа 11
Инструктирует IDC сделать попытку «самоуничтожения».
| Поле | Описание |
| 2 | Способ (битовое поле) |
| 3 | Cookie (фрагмент данных, порождаемый сервером при первом подключении и отсылаемый пользователю; при последующих подключениях этот фрагмент автоматически предоставляется серверу) (необязательно) |
SKP Типа 11
| Бит | Описание |
| 0 | Отсоединить приводы |
| 1 | Стереть |
| 2 | Добавить «Cookie» |
SKP датаграмма шифруется открытым клиентским ключом. Подлежащую обмену величину (EV) посылают в зашифрованном пакете. Посланная зашифрованная датаграмма может читаться следующим образом:
1-й и 2-й октет (в шестнадцатеричном значении) являются длиной EV
n октетов следует с EV
n октетов следует с зашифрованными данными SPK
CR датаграмма
Датаграмма уведомления клиента о получении (CR) является SHA-1. Хэш всей (незашифрованной) датаграммы SKP, зашифрованной симметричным шифром, битовая длина и способ предоставляются сервером.
SR датаграмма
Датаграмма уведомления сервера о получении (SR) возвращает тот же хэш и как уведомление, и как тест шифропотока от сервера к клиенту.
Главный тип 0: контроль сообщений сервера и соединений
Тип датаграмм используется для сервера для отправки сообщений, уведомлений об ошибках и специфическую для клиента и сервера информацию по сетевому соединению.
Подтип 1: Запрос аутентификации
После соединения с сервером, сервер может выдать датаграмму Типа 0,1, требуя от клиента идентифицировать себя. Эта датаграмма сообщает соединенному клиенту способ аутентификации, требуемый для аутентификации сервером.
Подтип 2: Ответ на запрос аутентификации
Эта датаграмма используется клиентом, чтобы проверить действительность пользователя.
Множество способов аутентификации может использоваться в связи с этими подтипами датаграмм, как иллюстрируется следующим списком:
0 Имя пользователя и пароль
1 Имя пользователя и пароль + сертификат клиента x.509 (см., например, www.webopedia.com/TERM/X/X_509.html)
2 Имя пользователя и пароль + сигнатура ECC
3 Пароль
4 Пароль + сигнатура сертификата клиента x.509
5 Пароль + сигнатура ЕСС
6 Одноразовый пароль (стиль S-ключа, предопределенный, упорядоченный список паролей)
7 Одноразовый пароль + сигнатура сертификата клиента x.509
8 Одноразовый пароль + сигнатура ECC
9 Голосовой ключ
10 Голосовой ключ + сигнатура сертификата клиента x.509
11 Голосовой ключ + сигнатура ECC
12 Биометрический хэш
13 Биометрический хэш + сигнатура сертификата клиента x.509
14 Биометрический хэш + сигнатура ECC
15 Сигнатура сертификата клиента x.509
16 Сигнатура ECC
17 ID переноса содержимого
18 Одноразовый пароль, передаваемый альтернативным способом доставки.
19 Временный маркер подлинности
Определенный способ аутентификации использует предопределенное число дополнительных полей данных в этих датаграммах. Примеры различных полей, когда используются определенные способы, показаны ниже:
Способ 0
| Размер в байтах | Описание |
| 1 | Длина поля UserName (имя пользователя) |
| n | UserName |
| 1 | Длина поля Password |
| n | Password |
Способ 1
| Размер в байтах | Описание |
| 1 | Длина поля UserName |
| n | UserName |
| 1 | Длина поля Password |
| n | Password |
| n | x.509 сигнатура для полей UserName и Password |
Способ 2
| Размер в байтах | Описание |
| 1 | Длина поля UserName |
| n | UserName |
| 1 | Длина поля Password |
| n | Password |
| n | Сигнатура ECC для UserName и Password |
Способ 8
| Размер в байтах | Описание |
| 1 | Длина поля Password |
| n | Одноразовый Пароль |
| n | Сигнатура сертификата клиента ECC |
Способ 11
| Размер в байтах | Описание |
| 1 | Длина сигнатуры ECC |
| n | Сигнатура ECC для данных Voicekey (голосового ключа) |
| n | Данные Voicekey |
Способ 12
| Размер в байтах | Описание |
| n | Биометрический хеш |
Способ 14
| Размер в байтах | Описание |
| 1 | Длина сигнатуры ECC |
| n | Сигнатура ECC для биометрического хеша |
| n | Биометрический хеш |
Способ 16
| Размер в байтах | Описание |
| n | Сигнатура ECC для вызова |
Подтип 3: Результат аутентификации
После обработки запроса аутентификации клиент принимает датаграммы 0,3, которые доставляют результат аутентификации. Эта датаграмма имеет определенные статические поля:
| Размер в байтах | Описание |
| 1 | l=Разрешено, 0=Отклонено |
Для успешной аутентификации могут быть включены дополнительные поля:
| Размер в байтах | Описание |
| 1 | Отправленный профиль пользователя |
| 4 | Если профиль отправлен, указывает длину поля профиля |
| n | Закодированный согласно Mime профиль пользователя |
Подтип 4: Общая ошибка
Если сервер сталкивается с какой-нибудь ошибкой во время клиентского сеанса, этот тип датаграммы фиксирует ошибку. Поля содержат:
| Размер в байтах | Описание |
| n | Сообщение об ошибке |
Подтип 5: Неверная датаграмма
Если датаграмма, которую передают к серверу, считается неверной по какой-либо причине, этот тип датаграммы будет содержать причину в своей полезной нагрузке.
| Размер в байтах | Описание |
| n | Описание ошибки |
Подтип 6: Неподходящие разрешения
Эта датаграмма обозначает, что сетевой доступ запрещен.
| Размер в байтах | Описание |
| 1 | Главный тип |
| 1 | Младший тип |
| n | Сообщение об ошибке |
Подтип 7: Подтверждение активности
Эту датаграмму посылают сервер и/или клиент друг другу в предопределенном интервале, поддерживая соединение TCP открытым. Это полезно, когда система запускается через различные брандмауэры-посредники (например, FW-1) или запускается через коммутируемое соединение (например, через маршрутизатор коммутируемого соединения).
Этот тип датаграмм также полезен для сервера, запрашивающего, чтобы клиент вернул датаграмму, подтверждающую активность, чтобы обнаружить, «жив» ли клиент. Сервер может отсоединить, когда не получен ответ от клиента.
| Размер в байтах | Описание |
| 0,1 | 0=ответ не требуется; l=пожалуйста, ответьте |
Главный тип 1: Датаграмма содержимого
Подтип 1: Датаграмма нормального содержимого
Эта датаграмма содержит фактические данные содержимого, которые будут переданы.
| Размер в байтах | Содержимое |
| 4 | Заключительный ID Получателя |
| n | Закодированные согласно Mime данные |
Подтип 2: Удаленное протоколирование
Эта датаграмма содержит записи журнала регистрации от подсоединяющегося устройства, с установленным клиентом-«сборщиком записей журнала регистрации», предназначенным для ведения журнала регистрации в отношении сервера, который сам может быть клиентом для другой сети, согласно определенным вариантам воплощения.
| Размер в байтах | Содержимое |
| 8 | Финальный ID Получателя |
| n | Закодированные согласно Mime данные регистрации |
Подтип 3: Удаленный сборщик данных
Эта датаграмма представляет собой запрос к клиенту от «удаленного средства сбора данных» на сервере для сбора данных от клиента для установления соединения.
| Размер в байтах | Содержимое |
| 8 | Финальный ID Получателя |
| 1 | Данные датаграммы (запрос или ответ) |
| n | Закодированные согласно Mime данные |
Подтип 4: Запрос одобрения содержимого
Эта датаграмма используется для того, чтобы запросить одобрение переданных данных содержимого, например, подписание документов, сообщений о расходах, и одобрение электронной финансовой транзакции.
| Размер в байтах | Содержимое |
| 8 | Финальный ID Получателя |
| n | Закодированное согласно Mime и форматированное в XML содержимое для одобрения |
Подтип 5: Ответ на запрос одобрения содержимого
Эта датаграмма используется для ответа на запросы одобрения содержимого (Подтип 4).
| Размер в байтах | Содержимое |
| 8 | Финальный ID Получателя |
| 1 | Одобрение или отклонение |
| 1 | Длина поля сигнатуры |
| n | Сигнатура ECC для поля данных пакета «Тип 8» |
Главный Тип 2: Широковещательная датаграмма
Этот тип датаграмм используется для разнообразных приложений конференц-связи и широковещательной рассылки. Может быть реализовано множество подтипов, включая: передачу точка-много точек не в реальном времени; передачу точка-точка в реальном времени (например, чат пользователь-пользователь, аудио-, видеоконференция); передачу точка-много точек в реальном времени (например, биржевой тикер, аудио-, видеошироковещательная рассылка); передачу много точек-много точек (например, аудио-, видеоконференция).
Главный Тип 3: Посредник соединения
Датаграммы посредника соединения используются, чтобы нести необработанные данные соединения и посылать их из вложенных или встроенных приложений на клиенте серверу сети.
Соединения через посредника обычно запрашиваются по каналу управления, то есть первому соединению с сервером, и устанавливаются, когда новое соединение с сервером открыто после запроса, который успешно обработан. Затем дается «ID соединения через посредника», который также используется в целях аутентификации. В альтернативных вариантах воплощения соединения через посредника могут быть установлены непосредственно по каналу управления. Это поддерживает передачу данных через единственное соединение. Это уменьшает нагрузку на сервер и клиент, если соединение через посредника несет очень немного данных, типа случая, когда используются терминальный сервер или соединение telnet.
Типы соединений
Могут использоваться различные типы протоколов связи.
0: TCP
1: UDP
Подтип 1: Данные через посредника от клиента
Эти датаграммы несут фактические данные для соединения через посредника, приходящие от конечного клиента. Пользователь может иметь одно или более соединений через посредника, открытых в одно и то же время. Поле ID соединения (CID) включено для идентификации каждого соединения.
| Размер в байтах | Описание |
| 2 | ID соединения через посредника |
| n | Данные |
Подтип 2: Данные через посредника к клиенту
Это данные соединения, возвращающиеся от соединения через посредника клиенту (или владельцу соединения). Никакое другое поле, кроме как фактические данные, не включается, так как соединение через посредника только посылает и получает данные соединения для владельца соединения. Для того чтобы клиент идентифицировал, какое удаленное соединение (то есть сервер) ответило, CID включен в поле источника датаграммы.
| Размер в байтах | Описание | |
| N | Данные | |
| Тип | Отправитель | Описание |
| 0: | Сервер | Удаленный сокет (объект, являющийся конечным элементом соединения, обеспечивающего взаимодействие между процессами транспортного уровня сети) подсоединен. |
| 1: | Сервер | Удаленный сокет отсоединен. |
| 2: | Клиент | Отсоединить удаленный сокет, но сохранить соединение через посредника (CID). |
| 3: | Клиент | Разорвать соединение через сокет посредника (полный разрыв). |
| 4: | Сервер | Соединение через сокет посредника разорвано (полный разрыв). |
Главный тип 4: Передача большого объема содержимого
Эти датаграммы разработаны, чтобы передать большие порции данных содержимого, типа аудио-, видеоданных и файлов данных.
Подтип 0: Уведомление о приеме при передаче
Если отправитель запросил уведомление о приеме от конечного получателя, конечный получатель может выдать датаграмму типа 4,0 с уведомлением о приеме при передаче.
Возвращаемое уведомление о приеме содержит содержимое поля CRC и ID передачи.
| Размер в байтах | Описание |
| 1 | Длина поля CRC |
| n | Контрольная сумма для переданного содержимого |
| n | ID передачи |
Подтип 1: Запрос на передачу содержания
Используется клиентом для запроса передачи большого объема содержимого. После приема запроса клиента сервер возвращает ID передачи (TID) для использования клиентом, таким образом клиент может открыть дополнительное соединение с сервером для передачи содержимого. Также соединение управления не будет блокировано во время длительных передач.
| Размер в байтах | Описание |
| 4 | Размер в байтах содержимого, которое будет передано |
| 2 | Общее число порций для отправления |
| 4 | Финальный ID получателя |
Подтип 2: Ответ на запрос на передачу содержимого
| Размер в байтах | Описание |
| 1 | 0 =передача запрещена, l = передача разрешена |
| n | Если передача разрешена, это поле будет присутствовать и содержать ID передачи (TID), подлежащий выдаче серверу, когда клиент открывает другое соединение для передачи файла |
Подтип 3: Сегмент передачи содержимого
| Размер в байтах | Описание |
| 2 | Номер сегмента |
| n | Порция сегмента |
Подтип 4: Запрос на повторную передачу
Используется, чтобы повторно запросить сегмент содержимого, обычно в случае, когда переданное содержимое не проходит проверку контрольной суммы. Может также использоваться для восстановления при потере соединения передачи.
| Размер в байтах | Описание |
| 2 | Порция для повторной передачи |
| n | TID |
Главный Тип 5: Пользовательский каталог
Датаграммы этого типа используются, чтобы искать пользователей, пользовательские группы или обновлять пользовательскую информацию в пользовательском каталоге.
Поля поиска в запросе рассматриваются в качестве маски. Поиски проводятся с масками поиска, которые рассматриваются как регулярное выражение, когда поддерживается основной инфраструктурой базы данных.
Может быть реализован MySQL, чтобы обеспечить используемую по умолчанию систему базы данных, в которой поддерживается поиск регулярных выражений. Таким образом, конфигурация системы поддерживает все поиски, используя регулярные выражения.
Подтип 1: Пользователь в режиме онлайн
Эта датаграмма используется для уведомления системы, когда пользователь становится соединенным с сетью.
| Размер в байтах | Описание |
| 4 | UserID пользователя |
Подтип 2: Пользователь в автономном режиме
Эта датаграмма используется для уведомления системы, когда пользователь отсоединен от сети.
| Размер в байтах | Описание |
| 4 | UserID пользователя |
Подтип 3: Запрос на поиск пользователя
Используется подсоединенным клиентом для поиска пользователей во всем пользовательском каталоге, на основе определенной маски данных. Этот тип поиска возвращает датаграммы типа 5,10.
| Размер в байтах | Описание |
| n | Маска для поиска |
Подтип 4: Поиск отдельного пользователя
Подобен подтипу 3, но возвращает более точное соответствие для пользователя. Этот тип поиска возвращает датаграммы типа 5,10.
| Размер в байтах | Описание |
| 4 | UserID |
| 8 | Последний логический вход |
| 1 | Статус режима онлайн |
| n | Дисплейное имя |
Главный Тип 6: Удаленное управление
Этот тип датаграмм позволяет администраторам или привилегированным пользователям в сетевой системе удаленно управлять другими подсоединенными клиентами, выполнять приложения на подсоединенных клиентах и проталкивать обновления.
Подтип 1: Выполнение удаленного консольного приложения
Датаграмма 6,1 выполняет определенное приложение и поддерживает открытым дескриптор для приложения, куда id процесса приложения возвращается инициатору после успешного выполнения. Этот id процесса должен использоваться во всех последующих командных или контрольных датаграммах для процесса.
| Размер в байтах | Описание |
| 8 | Целевой User-ID |
| n | Полный путь и имя приложения для выполнения |
Подтип 2: Результат удаленного выполнения
Посылаются обратно инициатору датаграммы 6,1 после успешного выполнения датаграммы 6,1.
| Размер в байтах | Описание |
| 8 | User-ID адресата информации |
| 2 | Process-ID |
Подтип 3: Завершение удаленного процесса
Когда удаленный процесс, начатый датаграммой 6,1, завершается, датаграмма 6,3 посылается с кодом завершения от приложения.
| Размер в байтах | Описание |
| 8 | User-ID адресата информации |
| 2 | Process-ID |
| 2 | Код завершения приложения |
Подтип 10: Запрос удаленного инструмента
Для упрощения поиска данных на удаленном клиенте или выполнения основного контроля на удаленном устройстве основной набор инструментов сделан доступным для извлечения информации от удаленного устройства, включая информацию о списке управления процессами, зарегистрированном пользователе(ях), хранилище данных и т.д.
| Размер в байтах | Описание |
| 8 | Целевой User-ID |
| 1 | Идентификатор инструмента |
| n | Необязательные параметры (если специфицированный инструмент нуждается в них) |
Идентификаторы инструмента
| 0 | Список запущенных процессов |
| 1 | Список запущенных процессов, включая скрытые процессы |
| 2 | Убить процесс (PID дается как параметр) |
| 3 | Список служб |
| 4 | Остановить службу (имя службы как параметр) |
| 5 | Запустить службу (имя службы как параметр) |
| 6 | Перезапустить службу (имя службы как параметр) |
| 7 | Перечисляет локальные устройства хранения, включая имена томов, размер, размер блока, использованное пространство и тип файловой системы |
Подтип 11: Ответ на запрос удаленного инструмента
Содержит форматированный в CSV ответ в зависимости от запрошенного инструмента.
| Размер в байтах | Описание |
| 8 | User-ID адресата информации |
| n | Вывод данных CSV от удаленного инструмента |
Подтип 20: Запрос передачи приложения
Используется для начала передачи приложения или обновления приложения.
| Размер в байтах | Описание |
| 1 | Тип передачи |
User-ID адресата информации
| 1 | Варианты (битовое поле) |
| 4 | Размер содержимого |
| n | Путь и имя целевого файла (необязательно, к умолчанию к корню клиента) |
Варианты битовое поле
| Бит | Описание |
| 1 | Автовыполнение (также охватывает автообновление, авторасширение и т.д.) |
| 2 | Предложение пользователю (перед выполнением/обновлением) |
| 3 | Возвращение уведомления о приеме после передачи |
Типы передачи
| 1 | Передача файла (для обновления, присутствие существующих файлов не требуется) |
| 2 | Передача микропрограммы клиента (заменяет поток) |
| 3 | Передача клиентских.ISO кодов (заменяет поток, ISO коды включают в себя формат данных CD-ROM, например, ISO 9660 и другие стандарты данных Международной Организации по Стандартизации, www.iso.org) |
| 4 | Передачи уплотненного архива (для разуплотнения в целевом местоположении) |
Подтип 21: Ответ на запрос передачи приложения
Используется для сигнализации о разрешении или запрете.
| Размер в байтах | Описание |
| 1 | Разрешено/запрещено |
| 8 | Transfer ID (добавляется только, если передача разрешена) |
Подтип 22: Часть содержимого передачи приложения
Эти датаграммы содержат фактические данные для передачи.
Поле «Content Part» («часть содержимого») с четырьмя октетами должно допускать 2564 частей в одной передаче, которая предоставляется для передачи приложений, изображений и архивов, превышающих по размеру 4 гигабайта (если, например, используются датаграммы, содержащие 1K данных каждая).
Поле «Transfer Part» («часть передачи») начинается в 1 и увеличивается на единицу для каждой части передачи, посылая датаграмму 6,22 с «Transfer Part» 0 (ноль), чтобы просигнализировать конец передачи.
| Размер в байтах | Описание |
| 8 | Transfer-ID |
| 4 | Transfer Part |
| n | Содержимое данных |
Подтип 23: Уведомление о приеме передачи
Контрольная сумма переданного приложения.
| Размер в байтах | Описание |
| 1 | Тип CRC |
| n | Контрольная сумма переданного приложения |
Главный тип 7: Передача мультимедийных данных в реальном времени
Этот тип датаграмм используется, чтобы поддерживать клиент-серверные передачи мультимедийного содержимого.
Подтип 1: Запрос передачи
Используется для запроса разрешения на начало передачи.
| Размер в байтах | Описание |
| 4 | UserID получателя |
| 2 | Тип мультимедийного содержимого |
| 4 | Минимальная требуемая ширина канала, в Кбит/С |
Типы мультимедийного содержимого
| Тип | Описание |
| 1 | 5 кГц, 8 битов, одноканальное аудио |
| 2 | 8 кГц, 8 битов, одноканальное аудио |
| 3 | 11 кГц, 8 битов, одноканальное аудио |
| 4 | 11 кГц, 8 битов, двухканальное аудио |
| 5 | 22 кГц, 16 битов, двухканальное аудио |
| 6 | 44 кГц, 16 битов, двухканальное аудио |
Подтип 2: Ответ на запрос передачи
| Размер в байтах | Описание |
| 4 | UserID получателя |
| 1 | Принято (1) или отклонено (0) |
| 4 | ID потока содержимого (выданный принимающим клиентом и существующий, только если запрос был принят) |
Подтип 3: Пакет мультимедийного потока
Эти датаграммы несут отдельные пакеты, которые составляют передачу.
| Размер в байтах | Описание |
| 4 | UserID получателя (0 для использования списка получателей) |
| 4 | ID потока содержимого |
| n | Пакет потока (данные содержимого) |
Подтип 4: Завершение передачи
Может быть выдан и отправителем, и получателем, чтобы указать или конец передачи (если послано источником передачи), или аварийное прекращение передачи (если послано получателем).
| Размер в байтах | Описание |
| 4 | UserID получателя (0 для использования списка получателей) |
| 4 | ID потока содержимого |
Подтип 5: Управление списком получателей
Когда выполняется передача «один к многим», типа лекции, группового совещания (VoIP), можно положиться на эти датаграммы, чтобы управлять распространением данных для всего списка получателей.
| Размер в байтах | Описание |
| 1 | Действие |
| n | Данные |
Определение действия:
| Действие | Описание |
| 0 | Удаляет список получателей (если установлен) |
| 1 | Добавляет пользователя(ей) в список (разделенный пробелами список UserID в качестве данных) |
| 2 | Удаляет пользователя(ей) из списка (разделенный пробелами список UserID в качестве данных) |
Подтип 6: Запрос на отклонение передачи
Эти датаграммы позволяют клиенту передать свое уведомление «конец передачи» другому пользователю.
| Размер в байтах | Описание |
| 4 | ID получателя |
| 2 | Тип мультимедийного содержимого |
| 4 | Минимальная требуемая ширина канала, в Кбит/С |
Пример 2: Основанные на векторе объекта суперклассификатор и биометрия
Обратимся к фиг.2, где показан основанный на векторе объекта суперклассификатор (также называемый множественными классификаторами). Больше чем один вектор объекта данных используется для аутентификации уровня события. Выбор классификации может быть сделан на основе верхней или случайной суммы, вычисленной из объектов векторов данных, включая вектор объекта 1, 2 и 3 по фиг.2. Здесь каждый вектор объекта связан с одним или более классификаторами из классификаторов 1-N. Таким образом, извлечение признаков может быть сделано из множественных векторов объектов и затем преобразовано в ряд классификаторов, которые все вместе составляют суперклассификатор. Специфическое для конкретного события преобразование обеспечивает относительно простые распределения, которые характеризуют признаки на основывающиеся события.
Один из примеров аутентификации пользователя, использующий суперклассификаторы, задействует биометрию. В одном варианте воплощения этого раскрытия, суперклассификатор используется в связи с физическими биометрическими измерениями, включая голосовую идентификацию, отпечатки пальца, отпечатки руки, образцы кровеносного сосуда, тесты ДНК, сканирование сетчатки глаза или радужной оболочки и распознавание лица, среди прочего. В альтернативном воплощении, суперклассификатор используется в связи с выполнением биометрических измерений, включая привычки или модели индивидуального поведения.
Сеанс аутентификации на основе события и выбор и выполнение анализа объекта, основанного на этих специфических для конкретного пользователя событиях, увеличивают вероятность идентификации или получения бинарных структур в анализе решения объекта. Поскольку бинарные структуры добавлены к суперклассификатору, сеанс аутентификации может быть проведен с высокой нормой вероятности.
Необходимо понимать, что описание, определенные примеры и данные, указывающие на примерные варианты воплощения, даются только в качестве иллюстраций и не предназначены для ограничения различных вариантов воплощений данного раскрытия. Все ссылки, процитированные здесь, определенно и полностью включены по ссылке. Различные изменения и модификации в пределах данного раскрытия станут очевидными специалисту в данной области техники из описания и данных, содержащихся здесь, и таким образом считаются частью различных вариантов воплощения этого раскрытия.
Приложение 1: Классификация объекта в проверке говорящего (диктора)
Классификация и плотность вероятности оценки
Проверка диктора является проблемой классификации, как и любые другие вектора объектов данных, вовлекающей два класса: целевой диктор (I) (пользователь объекта) и самозванец (-I) (нарушитель объекта). Чтобы сделать классификацию необходим, в этом случае, ряд измерений, полученных из записи голосов дикторов. Эти измерения удобно представить как векторы D-размерности:

Каждый диктор характеризуется функцией плотности вероятности:

которая измеряет вероятность наблюдений. Плотность вероятности характеризована

где P(I) и P(-I) являются априорными вероятностями соответственно испытания целевого диктора и испытания самозванца. Для проверки диктора представляет интерес апостериорная вероятность запрашиваемого диктора, I, при данном наблюдении  .
.
Апостериорная вероятность может быть вычислена по правилу Байеса:

Поскольку I и -I взаимно исключающие, мы имеем

то есть вероятность того, что требование идентичности было правильным при данном наблюдении, , плюс вероятность того, что говорил некоторый другой диктор (не I), даст в сумме единицу. Привлекательно использовать апостериорную вероятность 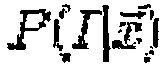 в целях классификации: требование идентичности принимается или отклоняется по правилу:
в целях классификации: требование идентичности принимается или отклоняется по правилу:


Фиг.1. Плотности вероятности для двух этих классов, I и -I
Плотности частично перекрываются в областях:

это обусловливает то, что частоты ошибок Байеса больше чем 0. Классификатор, который использует это правило принятия решения, называют классификатором Байеса. Частота ошибок классификатора Баеса равна

где

На практике, функции вероятности:
неизвестны и могут только быть приближенными. Следовательно, частота ошибок любой практической стратегии решения обязана иметь частоту ошибок, которая в среднем не меньше, чем частота ошибок Байеса.
Априорные минимизации вероятностей и риска
Средняя ошибка состоит из двух членов; отклонений целевых дикторов (ошибки ТА):

и принятий самозванцев (ошибки IR):

Использование апостериорных вероятностей для классификации образцов является, по существу, той же самой классификацией, что и максимальная вероятность. Полная частота ошибок, однако, зависит от относительного числа испытаний самозванца и целевого диктора. Если испытания самозванца намного более часты, чем испытания целевого диктора, то платой за это является классификация некоторых образцов как класс -I, даже если класс I более вероятен, поскольку полная абсолютная ошибка более зависит от E-I, чем от EI. Другими словами, E-I минимизирована в затратах EI. Способом оптимально уравновесить эти частоты ошибок является установление априорных вероятностей для отражения относительного числа испытаний целевого диктора/самозванца (пробы объекта).
Назначение предшествующих вероятностей является только одним из способов уравновесить ТА и ошибки IR. Вообще, два типа ошибок могут иметь различные последствия, и поэтому может быть желательно достигнуть баланса, который отражает стоимость мультиклассификаторов. В этом случае P(I) и P(-I) заменяются на:

где  является стоимостью классификации
является стоимостью классификации  образца как I. Классификация здесь является соответствующей риску, а не апостериорной вероятности:
образца как I. Классификация здесь является соответствующей риску, а не апостериорной вероятности:

Аналогично уравнению 1.6, мы имеем правило принятия решения:

Более прагматический подход к проблеме уравновешивания ошибок ТА и IR состоит в том, чтобы принять решение относительно априорно приемлемой частоте ошибок либо для EI, либо для E-I 1, и затем использовать ее для определения поверхностей решения (и расширением P(I) и P(-I)). Независимо от того, какой путь выбран, реальная проблема оценки вероятностей класса

и
остается той же самой.
Оценка Вероятности
Одним из подходов к реализации правила принятия решения является раздельная оценка плотностей вероятности

и
в ситуации испытания - используя правило Байеса для преобразования вероятности в вероятность, которая может использоваться вместо
Это решение, однако, более широкое, чем необходимо, начиная с проблемы проверки (которая, вследствие трансляции фрагмента речи становится бинарным объектом данных), зависящей от отношения вероятности:

В терминах LR(-x), функция решения 2.6 становится:

Поверхность решения Байеса между классом I и классом -I характеризуется как:
В целях классификации, мы должны знать только, на какую сторону поверхности решения падает тестовый образец  . В примере, данном на фиг.2.1, эта поверхность является самой простой: единственная точка x = t, где t является порогом решения.
. В примере, данном на фиг.2.1, эта поверхность является самой простой: единственная точка x = t, где t является порогом решения.
Сделано различие между параметрической и непараметрической классификацией. Различие заключается в предшествующих предположениях, которые сделаны для распределений по классам. Параметрическая классификация предполагает, что образцы, которые будут классифицированы, принадлежат узко определенной семье функций плотности вероятности, тогда как непараметрическая классификация делает только слабые предположения о предшествующих распределениях. Следовательно, непараметрическая классификация является более общей, тогда как параметрические классификаторы легче строить, потому что они имеют меньше степеней свободы.
Параметрическая Классификация
В качестве примера параметрической классификации мы могли бы предположить, что классы  характеризуются нормальными удельными весами вероятности:
характеризуются нормальными удельными весами вероятности:

В этом случае:
дается

Это является квадратичной функцией. Если мы, кроме того, предполагаем, что эти два распределения совместно используют одну и ту же ковариантную матрицу S1=S2=S, это упрощает до
Фиг.2. Два класса были классификаторами Байеса, использующими квадратические поверхности принятия решения.
Слева: Классы имеют сходные средние:
Справа: Классы имеют различные средние:

В правом примере, поверхность принятия решения Байеса может быть хорошо приближена линейной функцией,
где

Это является линейной функцией. В дискриминационном анализе уравнение 1.22 является известным как линейная дискриминационная функция Фишера. Как мы видели, эта дискриминационная функция оптимальна для нормально распределенных классов, характеризуемых одной и той же ковариантной матрицей, но ее полезность для использования выходит за эти границы. Это является устойчивой функцией, которая (хотя и не оптимально) может использоваться с хорошими результатами, если распределения классов имеют форму «сферических облаков». Фактически, даже если известно, что уравнение 1.21, а не уравнение 1.22, является оптимальной дискриминационной функцией, уравнение 1.22 может привести к лучшим результатам (Raudys и Pikelis 1980). Проблема при использовании уравнения 1.21 состоит в том, что из ограниченного набора образцов трудно получить хорошие оценки для S1 и S2. Это особенно верно в пространствах высокой размерности.
Линейный классификатор менее чувствителен к ошибкам оценки, так как зависимость находится, прежде всего, имеет место от моментов первого порядка (средние):

которые легче оценить, чем S1 и S2 (моменты второго порядка). Если нужно, линейный классификатор может быть дополнительно упрощен, принимая S в виде диагональной матрицы или даже принимая S равной единичной матрице.
Пример
Фиг.2 показывает два примера одномерных функций плотности для двух нормально распределенных классов. В обоих примерах поверхности принятия решения Байеса квадратичные, потому что дисперсии различны
В случае один средние равны:
и в случае два:
Предполагая равные предшествующие распределения, мы можем определить правило принятия решения, используя уравнение 1.21:

Следовательно, мы имеем правило принятия решения:

Частота ошибок

В линейном случае мы имеем из уравнения: 1.22
которые приводят к правилу решения

С частотой ошибок (0,40+0,16)/2≈28%. Квадратичный классификатор здесь значительно лучше, чем линейный классификатор. В случае 2 соответствующее правило принятия решения становится

для квадратичного классификатора и

для линейного классификатора. Средние частоты ошибок равны соответственно 0,007% и 0,03%, что очень мало для обоих правил принятия решения. Соответственно, квадратичное правило принятия решения, однако, все еще значительно более точное. Это не потому, что оно квадратично: линейное правило принятия решения, типа

имеет ту же самую малую частоту ошибок, что и квадратичное правило принятия решения. Следовательно, различия в эффективности здесь обусловлены предположениями о предшествующих распределениях.
Линейные поверхности принятия решения по отношению
к нелинейным поверхностям принятия решения
Априорное предположение, что решение
линейно по  , упрощает структуру классификатора. Нелинейные классификаторы более мощные, потому что они позволяют решению 1.29 быть созданным из большего набора (который обычно включает в себя линейное решение в виде специального случая). Здесь, однако, ничего не ограничивает предположения о линейных поверхностях принятия решения, так как линейность относится к
, упрощает структуру классификатора. Нелинейные классификаторы более мощные, потому что они позволяют решению 1.29 быть созданным из большего набора (который обычно включает в себя линейное решение в виде специального случая). Здесь, однако, ничего не ограничивает предположения о линейных поверхностях принятия решения, так как линейность относится к  но вектор
но вектор  может быть «предварительно обработан» прежде, чем быть переданным классификатору. Предположим, например, что оптимальная поверхность решения - в данной 2-мерной проблеме
может быть «предварительно обработан» прежде, чем быть переданным классификатору. Предположим, например, что оптимальная поверхность решения - в данной 2-мерной проблеме
имеет форму

Линейный классификатор в состоянии реализовать эту поверхность решения, если классификация, лучше, чем в терминах x1 и x2, сделана в терминах

где

Другими словами, 2-мерная квадратичная функция решения может быть реализована линейной функцией в 5-мерном пространстве.
Непараметрическая классификация
Фиг.3 показывает реалистичный пример того, как могут выглядеть распределения классов (диктора или объекта) в системе распознавания диктора или механизме распознавания объекта.
Предположение о том, что наблюдения от заданного диктора получены из нормального распределения, разумно здесь.
Дискриминационная функция Фишера является подходящей для проведения различия между любыми двумя дикторами (и в этом случае относительно объекта, содержащего любой данный источник данных), но очевидно является недостаточной моделью (в 2-мерном пространстве) для проведения различия между одним целевым диктором и оставшимися дикторами в совокупности (не может быть проведена линия, которая отделяет отдельного диктора от большинства других дикторов в совокупности). Фактически, класс самозванца слишком усложнен, чтобы быть хорошо смоделированным любым простым параметрическим распределением. Это является общей ситуацией для многих задач классификации образца. Существует множество способов для непараметрической классификации и оценки плотности вероятности.

Фиг.3. Распределение вероятности двумерных образцов, выбранных из набора десяти различных образцов
Непараметрическая оценка плотности вероятности
При заданном обучающем наборе образцов с известным членством в классе, непараметрическая оценка плотности вероятности является проблемой построения PDF (функции распределения вероятностей), которая аппроксимирует реальную PDF, характеризующую классы, без какого-либо предположения об этой функции, кроме того, что она существует.
Правила гистограммы
Самый простой подход к непараметрической оценке плотности состоит в том, чтобы разделить пространство признаков на объемы v размера hD, где h является длиной стороны гиперкуба размерности D. Вероятность данного пробного образца,  может тогда быть вычислена, идентифицируя объем,
может тогда быть вычислена, идентифицируя объем,  которому он принадлежит, и вычисляя относительное количество обучающих образцов, которые попадают в этот объем:
которому он принадлежит, и вычисляя относительное количество обучающих образцов, которые попадают в этот объем:

где  является количеством образцов, попадающих в этот объем
является количеством образцов, попадающих в этот объем  , которому
, которому  принадлежит, и N - общее количество образцов в обучающем наборе 1.2.2 k-ближайших соседей.
принадлежит, и N - общее количество образцов в обучающем наборе 1.2.2 k-ближайших соседей.
PDF оценка ближайших соседей устраняет проблему отбора параметра h, позволяя размерам различных объемов изменяться так, чтобы фиксированное число обучающих образцов (k) попало в каждый объем. Результатом является так называемое разделение Вороного (Vorono:) (составление мозаики) пространства признаков. Пример (k=1) дается в фиг.4.
Подобно правилу гистограммы, однако, оценка плотности вероятности дискретна:
два соседних образца на различных сторонах границы ячейки в общем случае имеют различные вероятности, несмотря на то, что расстояние между ними может быть произвольно малым правилом. Разделение Вороного также имеет краевую задачу, потому что некоторые ячейки могут иметь бесконечный объем, что означает, что образцы, падающие в эти ячейки, имеют предполагаемую нулевую вероятность.
Фиг.4. Разделение Вороного пространства признаков, полученное из предположения об одном ближайшем соседе
Функции ядра
Альтернативное обобщение правила гистограммы должно вычислить  как сумму функций ядра (Hand 1982):
как сумму функций ядра (Hand 1982):

Форма ядра  определяет характеристики
определяет характеристики  . Например, однородное ядро
. Например, однородное ядро

по существу приводит к правилу гистограммы, тогда как, если  является непрерывной функцией, тогда
является непрерывной функцией, тогда  является также непрерывной. Гауссовы ядра являются популярным выбором:
является также непрерывной. Гауссовы ядра являются популярным выбором:

Поскольку  аппроксимирует PDF, удобно потребовать
аппроксимирует PDF, удобно потребовать

поскольку это автоматически означает, что является PDF.

Фиг.5. Вероятность
Вероятность
Фиг.5: Оценка ядра функции плотности, соответствующей фиг.3. Функции ядра, в общем случае, размещаются неравномерно в пространстве признаков. Следовательно, в противоположность простому правилу гистограммы, некоторые области пространства признаков не «моделированы» вообще, а в других, где функция плотности усложнена, несколько функций ядра могут наложиться, чтобы смоделировать плотность.
Например, чтобы аппроксимировать функцию плотности, показанную на фиг.3, было бы разумно использовать 10 ядер с центрами, соответствующими центру каждой из круглых областей, в которые попадают образцы определенного диктора. В этом случае h должен разумно соответствовать стандартному отклонению данных для представленных дикторов. Пример этого показан на фиг.1.5, где использовались Гауссовы ядра.
Непараметрическая классификация
Цель оценки PDF состоит в том, чтобы быть в состоянии вычислить вероятности, которые могут использоваться в правиле 1.6 принятия решения. Возможно, однако, осуществить 1.6 непосредственно, без этого промежуточного шага. Способ сделать это состоит в том, чтобы, в основном, разделить пространство признаков на области и маркировать каждую область согласно тому, кому образцы класса, попадающие в эту область (вероятно), принадлежат.
Нетрудно заметить, как правило k-ближайших соседей может использоваться для классификации: просто маркируем каждую ячейку Вороного согласно тому, какому классу принадлежит большинство из k образцов в ячейке. Получающиеся поверхности принятия решения будут кусочно линейными.

Фиг.6. Перцептрон (справа) формирует гиперплоскость и классифицирует образцы согласно тому, на какую сторону гиперплоскости они попадают.
Классификаторы могут также быть основанными на функциях ядра. В этом случае требования к функциям ядра K() менее ограничительные, потому что не должны выполняться ограничения PDF. Сеть радиальных базисных функций (RBF) является примером классификатора, основанного на функциях ядра.
Максимизация радиуса базисной функции
Для сетей RBF структура может быть наложена на базисные функции с помощью рассмотрения радиусов базисных функций:

при меньшей h является более «заостренной», является базисной функцией. Остроконечная базисная функция чувствительна только к очень малой области пространства признаков и может хорошо прогнозировать при обучении. Широкие базисные функции (с большой h) покрывают большой объем пространства признаков; чем больше h, тем в большей степени базисная функция напоминает простое смещение, которое всегда является активным. Следовательно, обучаемая сеть, имеющая большие радиусы, более вероятно будет в состоянии сделать обобщение; радиусы должны быть расширены к точке, где это сильно не влияет на эффективность по классификации на обучающем наборе.
Ансамбли классификаторов
Проблемой для многих моделей - в специфических нейронных сетях - даже только с ограниченной сложностью, является то, что алгоритмы обучения, используемые для оценки их параметров, неспособны определить глобальный минимум критериев оптимизации, но преуспевают только в определении локального минимума. По этой причине может быть полезно обучать несколько классификаторов на тех же самых данных и использовать эти сети, чтобы создать новый «супер» классификатор. Комбинация различных сетей не может быть легко сделана в области параметров, но сети, представляющие различные локальные минимумы, вероятно, будут моделировать различные части проблемы, и классификатор, определенный как средний вывод отдельных классификаторов, в общем случае выполнит это лучше, чем любой из отдельных классификаторов: если отдельные среднеквадратичные частоты ошибок (уравнение 1.40) N классификаторов обозначены,

можно показать, что ожидаемая среднеквадратичная частота ошибок ансамбля классификаторов дается как (Perrone и Cooper 1994):

при условии, что сети делают ошибки независимо. Следовательно, пока ошибки являются некоррелированными, эффективность ансамбля классификаторов может быть повышена, добавляя больше сетей: среднеквадратичная частота ошибок сокращается на половину каждый раз, когда удваивается число сетей.
Для моделей типа персептрона сети, представляющие различные локальные минимумы, могут быть созданы просто посредством разной инициализации весов (Hansen и Salamon 1990; Battiti и Colla 1994). В Benediktsson и др. (1997) отдельные сети (персептроны) обучаются на данных, которые были преобразованы, используя различные преобразования данных. Ji и Ma (1997) предлагают алгоритм, предназначенный для выбора и комбинирования слабых классификаторов (персептроны).
Проверка диктора
Проверка диктора и обработка объекта в случайной среде является проблемой распознавания образцов, и концептуально это является очень простым, так как требуется различать только два класса (образца): целевых дикторов или объектов и самозванцев. Однако нелегко отделить эти два класса в пространстве признаков. Распределения классов сложны и должны, на практике, быть смоделированы, используя непараметрические способы. Нейронные сети являются привлекательными классификаторами для проблем этого вида: их дискриминационные схемы обучения позволяют им сосредоточить моделирование на областях пространства признаков, которые хорошо различают дикторов или объекты.
Проблема со многими алгоритмами обучения или изучения объектов, однако, состоит в том, что они не являются способными гарантировать оптимальные значения параметров моделирования. В этом случае могут использоваться структурные способы минимизации риска для того, чтобы наложить ограничения на модели, которые увеличивают их способности делать выводы. Другой подход к проблеме с субоптимальными параметрами состоит в использовании способов ансамбля: ансамбль простых субоптимальных классификаторов может быть объединен, чтобы сформировать новый более мощный и устойчивый классификатор. Способы ансамбля привлекательны, потому что частота ошибок ансамбля классификаторов, в принципе, обратно пропорциональна числу членов ансамбля.
Приложение 2: Объемный анализ, иллюстрируемый основывающимся на RBF моделированием фонемы
Этот пример представляет собой архитектуру классификатора, которая может применяться для проверки диктора на уровне события, однако должно рассматриваться как пример способа, который может использоваться для любого типа представленного объекта данных. Классификатор - сеть RBF - является самостоятельно не способным идентифицировать события, на которых он работает, и полагается на процесс излечения признаков, чтобы сделать это. Фиг.1.1 схематично показывает архитектуру классификатора. Скрытые модели Маркова используются для сегментации речевого сигнала. Скрытая модель фонемы Маркова моделирует сегменты фонемы как смесь нормальных распределений, где средние и ковариации смесей изменяются в дискретных точках во времени: в переходах между состояниями. Дискретные изменения в идеальном случае должны быть непрерывными, но это трудно смоделировать.
После того как сегменты фонемы идентифицированы, выполняется новое извлечение признаков (секция 1.1), посредством чего каждый отдельный сегмент фонемы представляется единственным вектором признаков. Вектор признаков, представляющий наблюдение за целой фонемой, здесь упоминается как вектор фонемы:

Когда векторы фонемы извлечены, сигнал больше не содержит информацию времени; тот факт, что векторы фонемы были измерены последовательно в течение периода времени, является нерелевантным и не содержит никакой информации о подлинности диктора. Дополнительная бинарная форма отпечатка голоса «создана» на (истинно) случайной модели фрагмента речи, что делает бинарный объект полностью уникальным. Это по существу означает, что векторная модель становится случайным вектором.
Основное представление признака, используемое здесь, реализовано в терминах энергии группы фильтров, и векторы фонемы, поэтому, должны быть нормированы, чтобы устранить усиление сигнала (секция 1.2). После этого они подвергаются преобразованию 1:

перед передачей, в конечном итоге, в качестве ввода в сеть RBF, которая вычисляет вероятность диктора:

Выбор фрейма
Длительность фонемы является функцией контекста фонемы, полного темпа речи и других факторов; продолжительности фонем являются очень разными. Для статического подхода моделирования необходимо представить фонемы фиксированным числом признаков. Это может быть сделано при использовании сегментации Маркова, где каждая фонема сегментирована на множество субсегментов, соответствующих различным испускающим состояниям Маркова в модели фонемы. Возможные схемы представления:
1. Вычисление новой «переменной» сегментации фрейма (и параметризации речи), где новой фрейм структуры приспособлен, чтобы быть целой долей полного сегмента фонемы. В вычислительном отношении это может быть относительно дорогостоящим, но преимущество состоит в том, что используется весь сегмент фонемы.
2. Выбор фиксированного числа (N) существующих фреймов как представителей сегмента фонемы. Можно рассмотреть несколько стратегий выбора фрейма:
a. Линейный выбор: выбрать N линейно раздельных фреймов из сегмента фонемы.
b. Выбор субсегмента: выбрать один фрейм из каждого сегмента субфонемы. Для помощи в достижении однородности представления выбор должен делаться последовательно; например, всегда выбирая центральные фреймы в каждом сегменте субфонемы, моделируемой отдельными состояниями HMM. Это мотивируется, в соответствии с гипотезой, тем, что центры фреймов представляют одну и ту же точку в переходе «скользящего среднего значения», которым речевой сигнал подвергается в сегменте фонемы.
c. Выбор максимальной вероятности: выбрать фрейм из каждого сегмента субфонемы, который имеет самую высокую вероятность.
После того как релевантные фреймы идентифицированы, соответствующие векторы признаков являются «сцепленными» для формирования одного длинного вектора.
Схемы 2A и 2B выбора по существу подобны; они были выбраны здесь, чтобы использовать 2B как стратегию выбора фрейма, поскольку, в связи с изменением способов ансамбля (см. секцию 2.7), стратегии выбора фрейма могут использоваться для генерации «различных» моделей фонемы для той же самой фонемы. Схема 2B выбора может легко варьироваться, выбирая, например, самые правые или самые левые фреймы в каждом суб-сегменте вместо центрального фрейма.
Нормировка
Проблема с представлением набора фильтров сигнала речи состоит в том, что управление усилением сигнала реализуется недостаточно хорошо. Коэффициент усиления сигнала зависит от уровня говорящих дикторов, расстояния до микрофона, угла между ртом и микрофоном и оборудования записи. Это эффективно означает, что абсолютный коэффициент усиления не может использоваться для распознавания диктора, и он должен быть нормирован. Как обычно для обработки речи, здесь используется логарифмическое представление набора фильтров. Это означает, что используется логарифм энергии, выдаваемой из каждого набора фильтров. Выходная энергия меньше единицы отбрасывается; они наиболее вероятно представляют шум и из-за сингулярного поведения логарифмической функции, лучшим вариантом является не моделировать эти энергии.

Фиг.7. Сеть RBF
В логарифмической области энергии коэффициент усиления становится аддитивным смещением:

Взятие log() вектора означает здесь, что функция log() применена к каждому элементу вектора. Аналогично, дополнение (умножение) скаляра и вектора означает, что скаляр добавляется к (умножается на) каждому элементу вектора. Так как масштаб не релевантный, векторы фонемы, как предполагается, имеют норму 1:

после масштабирования норма равна:

Поэтому коэффициент усиления может быть удален вычислением нормы

и вычитанием логарифмической нормы из выхода группы фильтров

Чтобы дополнительно гомогенизировать данные, вектор
нормализуется так, чтобы его норма была равна 1.
Если независимый коэффициент усиления ассоциирован с каждым каналом группы фильтров, это приводит к вектору смещения, добавляемому к векторам признаков. Этот тип усиления может не быть устранен при фокусировании на одном конкретном векторе, но может вместо этого быть скомпенсирован посредством средней выходной энергии для одного фрагмента речи.
Удаление смещения является полезной эвристикой на практике, но фактически является нетривиальной проблемой, потому что смещение, которое оценивается, зависит от фонетического содержимого фрагмента речи (Zhao 1994). Эта эвристика не используется здесь.
Обучение RBF:
Нормированные векторы фонемы подвергаются преобразованию перед введением в фонему,

и зависимая от диктора сеть RBF, которая используется для вычисления функции:

где S - масштаб функции активации и

где D - размерность входных векторов. Масштабы базисных функций, Сj, и дисперсии
ограничены следующим образом:
Уравнение: 7
что гарантирует, что сеть будет аппроксимировать оптимальную дискриминационную функцию Байеса:

Для этого может использоваться множество способов (Press и др. 1995; Bishop 1995). В этом случае самый простой подход состоит в том, чтобы использовать спадание градиента, потому что градиент здесь легко вычислить; из-за размера сети алгоритм обучения сходится настолько быстро, что методы сопряженного градиента, или квази-Ньютоновские методы не требуются. Спадание градиента является итерационным способом, где параметры итерации t обновляются согласно:

где

И



и

Здесь градиенты показаны, как вычисляемые суммированием по всем обучающим образцам. Для того чтобы ускорить процесс обучения, это требование обычно смягчается так, чтобы подмножества или даже отдельные образцы использовались как основание для вычисления градиента и обновления параметров. Это разумно, если данные обучения «периодические».
Форма уравнений градиента относительно легко понимаема. Уравнения градиента имеют некоторые общие члены и некоторые специальные члены.
Общие члены. Все градиенты включают член ошибки,
который является нулем, если образцы классифицированы ошибочно. Следовательно, параметры не обновляются, если образцы классифицированы правильно. В случае ошибочной классификации ошибочный член положителен, если целевые выходные данные отрицательны, и отрицателен, если целевые выходные данные положительны. Ошибочному члену можно дать зависящий от класса вес, чтобы выделить частоту ошибок одного класса над другим. Например, образцам целевого диктора можно дать более высокий вес, потому что обучающий набор содержит относительно немного образцов целевых дикторов, и, следовательно, классификатор более вероятно будет «переобучен» этими образцами, по сравнению с избыточными образцами дикторов-самозванцев.
Второй член, который присутствует во всех градиентах, это

Этот член имеет эффект предотвращения изменений параметров, если

то есть, если параметры,

классифицированы ошибочно с большим отклонением. Интуитивно это полезно, если обучающий набор содержит выбросы, которые не могут быть правильно классифицированы малым изменением существующих параметров.
Третий член, совместно используемый всеми градиентами, является выходом базисной функции,

который является значением между нулем и единицей. Следовательно, параметры, связанные с данной базисной функцией, не обновляются, если образец

не попадает в гиперэллиптическую область, где

активируется.
Веса
Веса обновляются так, чтобы для ошибочно классифицированных образцов вес был бы увеличен, если целевые выходные данные положительны, и уменьшен в противном случае. В окончательном классификаторе базисные функции с положительным весом представляют класс I, и базисные функции с отрицательным весом представляют класс  .
.
Средние
Базисные функции, представляющие целевой класс,
сдвигаются ближе к ошибочно классифицированному образцу, и базисные функции, представляющие противоположный класс, отодвигаются в противоположном направлении. Размер шага зависит от того, как «активированы» отдельные базисные функции,

радиуса базисных функций,

расстояния до ошибочно классифицированной точки и, как обычно, размера ошибки классификации.
Масштабы базисных функций
Ширина базисных функций контролируется
Для базисных функций, представляющих целевой класс,
уменьшается (ширина увеличивается) так, чтобы включить этот образец в сферу влияния этих базисных функций. Для базисных функций, представляющих противоположный класс,
увеличивается (ширина уменьшается) так, чтобы исключить образец из сферы влияния этих базисных функций.
Обновление дисперсий имеет тот же самый эффект расширения ширины базисных функций для базисных функций, представляющих целевой класс, и уменьшения ширины базисных функций, представляющих противоположный класс.
Дисперсии
Дисперсии,
задают относительное отклонение отдельных элементов признаков. Дисперсии не обязательно соответствуют статистическим дисперсиям отдельных элементов, а, скорее, важности признаков. Компонентам признаков, которые имеют небольшую важность для классификации, можно дать большую «дисперсию» так, чтобы они имели относительно меньше влияния на активацию базисной функции.
Масштаб функции активации
Масштаб функции активации S увеличен для образцов на правильной стороне гиперплоскости, реализуемой персептроном, и уменьшен для образцов на неправильной стороне. Классификация образцов, однако, не улучшается и не изменяется при обновлении S. Следовательно, алгоритм обучения не изменяет значение S с целью уменьшения частоты ошибок. Масштаб функции активации может, однако, быть приспособлен впоследствии для улучшения модели RBF как средства оценки вероятности.
Инициализация
Итерационный обучающий алгоритм требует начальных оценок параметров сети. Параметры сети RBF намного легче интерпретировать, чем веса MLP, и, следовательно, нет необходимости инициализировать, используя случайные значения. Определенно, алгоритм кластеризации может использоваться для вычисления приемлемых базисных функций, представляющих, соответственно, целевого диктора и дикторов группы. Веса, соответствующие базисным функциям целевого диктора, могут инициализироваться

где
является количеством образцов обучения, попадающих в i-тый кластер целевого диктора. Аналогично, веса, соответствующие базисным функциям диктора группы, могут инициализироваться как:

Вес смещения,
должен инициализироваться значением меньшим, чем ноль: если сеть предоставлена вектором фонемы, который не активирует никаких базисных функций, классификация должна быть  (отклонить).
(отклонить).
Сходимость обучающего алгоритма критически зависит от инициализации базисных функций, но, на практике, является нечувствительной к инициализации веса. Следовательно, веса могут просто инициализироваться случайными значениями (в диапазоне [-1;1]).
Апостериорные вероятности
Сети RBF обучаются для минимизации средней квадратичной частоты ошибок на обучающем наборе (уравнение 1.9). Минимизация этих критериев ошибки заставляет сеть RBF аппроксимировать оптимальную дискриминационную функцию (Байес), задаваемую:

Этот важный факт был доказан несколькими авторами (Ruck и др. 1990; Richard и Lippmann 1991; Gish 1990a; Ney 1991).
Даже при том, что  аппроксимирует оптимальную дискриминационную функцию, все еще остаются вопросы, действительно ли она, в принципе, способна к точной реализации этой функции. Ограничивающая функция tanh(), представленная на выходе сети RBF, ограничивает число преобразований от RD к [-1; 1], которые могут быть осуществлены. Например, общая функция, типа
аппроксимирует оптимальную дискриминационную функцию, все еще остаются вопросы, действительно ли она, в принципе, способна к точной реализации этой функции. Ограничивающая функция tanh(), представленная на выходе сети RBF, ограничивает число преобразований от RD к [-1; 1], которые могут быть осуществлены. Например, общая функция, типа

не может быть реализована сетью RBF вышеупомянутого типа, даже если бы она имела бесконечное число базисных функций. Было бы неудачно, если бы  имело этот тип, потому что это означало бы, что оно не может, даже в принципе, быть вычислено. Основная функция
имело этот тип, потому что это означало бы, что оно не может, даже в принципе, быть вычислено. Основная функция  , однако, очень гибка. Применением теоремы Stone-Weierstrass можно фактически показать, что эта функция может аппроксимировать любое отображение от R0 до R1 произвольно хорошо (Hornik 1989; Cotter 1990). Поскольку tanh(x) является монотонной функцией, которая может принимать любое значение в интервале [0; 1], можно аппроксимировать функцию:
, однако, очень гибка. Применением теоремы Stone-Weierstrass можно фактически показать, что эта функция может аппроксимировать любое отображение от R0 до R1 произвольно хорошо (Hornik 1989; Cotter 1990). Поскольку tanh(x) является монотонной функцией, которая может принимать любое значение в интервале [0; 1], можно аппроксимировать функцию:

Выбор tanh(x) в качестве функции активации, однако, не произволен. Положим, например, что в задаче классификации с 2 классами, эти два класса, подлежащие различению, характеризуются Гауссовыми распределениями вероятности:

Согласно правилу Байеса, апостериорная вероятность класса I задается:

где

Это является точной формой того, что мы хотели бы иметь, поскольку если сеть RBF аппроксимирует дискриминационную функцию:

тогда мы имеем (используя 2.5):

где

Подгонка масштаба функции активации
Как оценки вероятности, уравнения 33 и 34 являются несколько грубыми. Если используется крутая функция активации (большой масштаб функции активации S), выход, по существу, является бинарной переменной. Масштаб функции активации (S) может быть подогнан первой оценкой эмпирической функции активации от идеально независимого тестового набора:


где  является шаговой функцией:
является шаговой функцией:

и где  и
и  - векторы фонемы в независимом тестовом наборе. Теперь значение
- векторы фонемы в независимом тестовом наборе. Теперь значение  , для которого
, для которого  идентифицируется
идентифицируется  и масштаб функции активации подогнан так, чтобы
и масштаб функции активации подогнан так, чтобы
Это сделано, выбирая:

где

Альтернативный и потенциально более точный подход состоит в том, чтобы просто заменить tanh() эмпирической функцией активации (уравнение 36).
Подгонка смещения
Обучение сети RBF на основе ограниченного обучающего набора является трудной задачей. Проблема обычно заключается не в соответствующей самозванцу части обучающего набора, а, скорее, части, соответствующей целевому диктору. Это, конечно, может само по себе сделать трудным обучение модели диктора, но в особенности это делает трудным скорректировать модель для достижения желательного баланса между ошибками ТА и IR. Балансом можно до некоторой степени управлять различными учебными параметрами, например, масштабируя ошибочный член  по-разному для образцов целевого диктора и образцов дикторов группы, представляя образцы цели/группы с разными частотами, или путем ограничения модели, используя штрафы веса/радиусов. Эти меры, однако, довольно грубы, и более точный подход состоит в подгонке смещения
по-разному для образцов целевого диктора и образцов дикторов группы, представляя образцы цели/группы с разными частотами, или путем ограничения модели, используя штрафы веса/радиусов. Эти меры, однако, довольно грубы, и более точный подход состоит в подгонке смещения  моделей RBF. Это может быть сделано, оценивая среднее значение и дисперсию данных
моделей RBF. Это может быть сделано, оценивая среднее значение и дисперсию данных  при заданном целевом дикторе,
при заданном целевом дикторе,  , и заданных дикторах-самозванцах,
, и заданных дикторах-самозванцах,  . Принимая Гауссово распределение этих двух переменных, смещение уменьшается
. Принимая Гауссово распределение этих двух переменных, смещение уменьшается
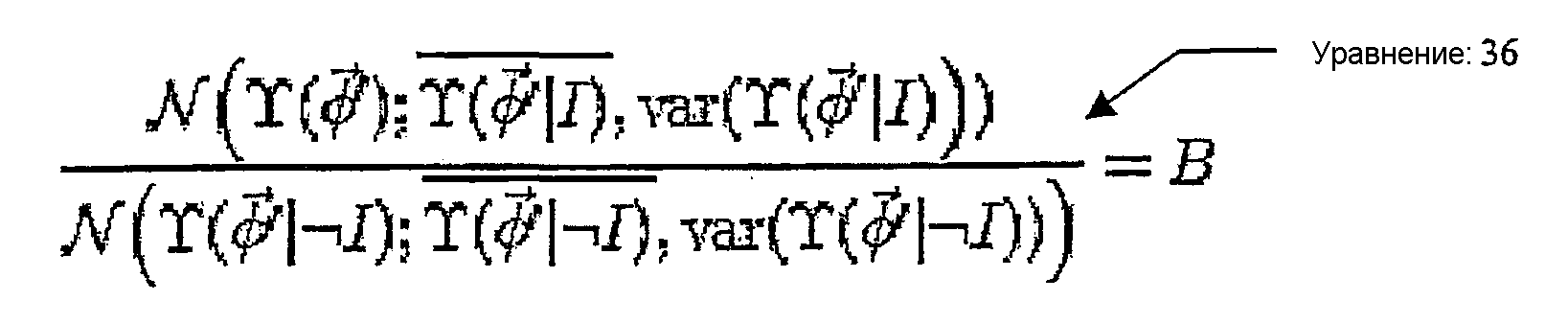
Это решение может быть найдено, определяя корни:

где использовались следующие сокращения:

Для B=1 это является тем же самым уравнением, что и уравнение 1.26 (пример на классификацию объекта). Решение, которым мы интересуемся, одно между  .
.
Альтернативно, если предположение о Гауссовом распределении неудовлетворительно, можно использовать эмпирическую функцию активации (уравнение x.36). Если желателен другой баланс ошибок, B, смещение может быть подогнано согласно:

Следовательно, чтобы подогнать отношение разногласий так, чтобы оно имело баланс B, определяется решение  для уравнения 48 и вычитается из смещения:
для уравнения 48 и вычитается из смещения:
Для B=1, эквивалентная частота ошибок аппроксимирована, для B<1, число ошибок ТА минимизировано за счет ошибок IR, и для В>1, ошибки IR минимизированы за счет ошибок ТА.
Фиг.8 показывает пример, где условные эмпирические функции распределения классов,

и

и эмпирическая функция активации,
для набора моделей диктора. Фигура показывает обе функции.

Фиг.8. Эмпирические функции распределения
Для данных обучения использовались, соответственно, решения 1622 и 6488 локальных целевых дикторов и дикторов-самозванцев. Для тестовых данных, соответственно, использовались 394 и 1576 локальных решений для обучающих данных и для тестовых данных.

Фиг.9. Эмпирические функции распределения после компенсации смещения
Для обучающих данных эмпирическая функция активации является приблизительно нулем для  но не для тестовых данных (модели диктора «перетренированы»). Фиг.9 показывает те же самые функции, что и фиг.8, но после компенсации смещения.
но не для тестовых данных (модели диктора «перетренированы»). Фиг.9 показывает те же самые функции, что и фиг.8, но после компенсации смещения.
В заключении, была описана модель диктора на основе фонемы. Модель использует HMM как «средства извлечения признаков», которые представляют собой наблюдения фонемы в качестве фиксированных векторов (векторы фонемы) элементов спектральных признаков; эта часть модели является независимой от диктора. Векторы фонемы преобразуются и окончательно передаются в качестве ввода зависящей от фонемы сети RBF, обучаемой для оценки вероятности диктора из векторов фонемы. Вероятность диктора может использоваться непосредственно для принятия (локально) решения в отношении проверки диктора, или она может быть объединена с другими вероятностями диктора, оцененными из других наблюдений фонемы, чтобы принять более надежное решение. Входной вектор (фонема) приведен только для иллюстрации того, какой может быть проверка, основанная на объектах. Любой другой тип биометрических векторов, соответственно, может использоваться при обучении фильтров.
Приложение 3: Основанное на объекте принятие решения, иллюстрируемое проверкой диктора
Проверка объекта или, в данном случае, проверка диктора является задачей бинарного выбора (выбора из двух альтернатив), и поэтому может быть в конце концов приведена к вычислению оценки и подтверждения требований идентичности, определяя, действительно ли оценка больше или меньше чем заданный порог, t

При вычислении этой оценки или значения объекта каждый сегмент фонемы в сигнале речи делает свой вклад (даже когда фонемы не модулируются явно). В обычном алгоритме независящей от текста проверки диктора вклад различных фонем в полную оценку (например, вероятность фрагмента речи) неизвестен; полная оценка зависит от конкретной частоты, с которой фонемы представлены в тестовом фрагменте речи, и от продолжительности каждого сегмента фонемы.
Ясно, что это не оптимально, так как не принимается во внимание то, в какой степени локальные оценки, внесенные в качестве вклада отдельными сегментами фонемы, выражают подлинность диктора, и до какой степени разные фонемы выражают одну и ту же с информацию о дикторе, например, носовое и гласное представление информации, которая является в значительной степени приветственной, тогда как, скажем, два гласных заднего ряда представляют высоко коррелированную информацию о дикторе.
Алгоритм, описанный здесь, имеет две части: первые сегменты фонемы идентифицируются, и подлинность диктора моделируется для каждого сегмента фонемы независимо. Результатом этого является множество локальных оценок - одной для каждой отличающейся от других фонемы в фрагменте речи - которые, впоследствии, должны быть объединены, чтобы принять глобальное решение при проверке или в отношении класса данных объекта.
Комбинирование оценок
Сети RBF обучаются для аппроксимирования дискриминационной функции:

где
является наблюдением фонемы. Поскольку:

мы имеем

которые можно использовать для реализации правила принятия решения для единственного наблюдения фонемы. Когда несколько независимых наблюдений фонемы доступны, более надежные решения могут быть приняты, комбинируя локальные оценки в глобальную оценку. Можно следовать двум основным различным подходам: комбинации ансамбля и комбинации вероятности.
Комбинация ансамбля
Одним из подходов к объединению локальных оценок проверки является простое «усреднение» локальных оценок:
| Оценка |
 |
Уравнение: 6 |
где

является числом отличающихся фонем в алфавите,

количество наблюдений фонемы  и
и  - j-е наблюдение {вектор фонемы) фонемы
- j-е наблюдение {вектор фонемы) фонемы  . Это является характеристикой этого правила оценивания, что для увеличивающегося количества наблюдений оценка будет сходиться к значению в диапазоне [-1; 1]. Величина непосредственно не затрагивается количеством наблюдений.
. Это является характеристикой этого правила оценивания, что для увеличивающегося количества наблюдений оценка будет сходиться к значению в диапазоне [-1; 1]. Величина непосредственно не затрагивается количеством наблюдений.
Комбинация вероятности
Альтернативой комбинации ансамбля является эксплуатация того факта, что сети вычисляют апостериорные вероятности. Когда сделаны несколько независимых наблюдений,  , доверие к классификации, как ожидается, повысится. Это может быть выражено, определяя вероятность успешного исхода:
, доверие к классификации, как ожидается, повысится. Это может быть выражено, определяя вероятность успешного исхода:

поскольку

Из этого следует, что

Следовательно, альтернативная стратегия оценки состоит в том, чтобы использовать
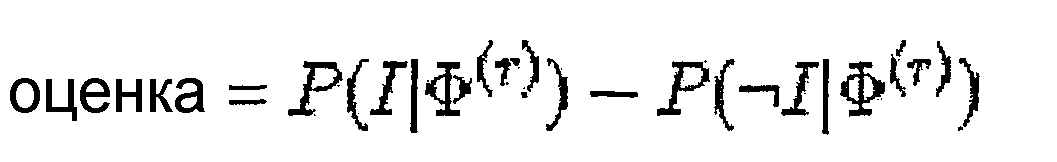
Характеристикой этого правила оценки является то, что, на практике, оно будет сходиться или к -1, или+1, когда добавляется больше наблюдений фонемы.
Различием между уравнениями 6 и 11 является, главным образом, предположение о независимости наблюдений. Предположим для заданного вектора фонемы,  , что вероятность диктора оценена, скажем, как
, что вероятность диктора оценена, скажем, как  . Если используется уравнение 11 (комбинация вероятности), мы предполагаем, что вероятность есть только 0.7, а не 1.0, потому что наблюдение было затронуто «случайным» шумом, тогда как если используется уравнение 1.6 (комбинация ансамбля), мы предполагаем, что определенная пропорция сообщества самозванцев способна к созданию векторов фонемы, подобных .
. Если используется уравнение 11 (комбинация вероятности), мы предполагаем, что вероятность есть только 0.7, а не 1.0, потому что наблюдение было затронуто «случайным» шумом, тогда как если используется уравнение 1.6 (комбинация ансамбля), мы предполагаем, что определенная пропорция сообщества самозванцев способна к созданию векторов фонемы, подобных .
Это различие важно, потому что шум может быть отброшен «усреднением», тогда как ожидание того, что получение большего количества наблюдений (одного и того же события) для улучшения оценки вероятности не может быть оправданным, если те же самые дикторы-самозванцы фундаментальным образом могут сгенерировать те же самые векторы фонемы, что и целевой диктор.
Проблема и с уравнением 1.6 и с 1.11, однако, состоит в том, что доминирующее влияние на полную оценку будет оказывать наиболее часто имеющая место фонема. Это неблагоразумно до той степени, что различные фонемы могут быть расценены как разные источники информации диктора (Olsen 1997b; Olsen 1996b).
На практике, однако, можно использовать уравнение 1.6 и 1.11 с хорошими результатами, потому что «патологические» предложения, которые являются доминирующими для определенного класса фонем, имеют место нечасто. Для любого разумного предложения будет обычно характерен широкий выбор представленных фонем, но при этом все еще не следует полагаться на то, как взвешивать данные, предоставленные каждым наблюдением фонемы.
Машины комитета
Каждая модель фонемы может быть расценена как эксперт проверки диктора, при заданном конкретном типе информации: наблюдениях определенной фонемы. Так как отдельные эксперты, как предполагается, моделируют различные «аспекты» диктора, имеет смысл ограничивать влияние, которое каждый эксперт может иметь на глобальную оценку. Один из подходов к этому состоит в том, чтобы использовать или уравнение 1.6, или 1.11, чтобы комбинировать локальные оценки от одного и того же эксперта, в локальную оценку уровня фонемы. Локальный бинарный выбор - с известной из опыта вероятностью быть правым - может тогда быть сделан для каждой фонемы, представленной в тестовом фрагменте речи:

Следуя этому подходу, самым простым способом объединить локальные оценки в глобальную оценку является голосование «большинства»:


Фиг.1. вероятность машины комитета, принимающей правильное решение, как функция числа членов комитета.
где  является числом отличающихся фонем, представленных в тестовом фрагменте речи. Этот тип глобального классификатора называют машиной комитета (Nilsson 1965; Mazurov и др. 1987).
является числом отличающихся фонем, представленных в тестовом фрагменте речи. Этот тип глобального классификатора называют машиной комитета (Nilsson 1965; Mazurov и др. 1987).
Если отдельные решения независимы и все имеют одну и ту же вероятность, P, принятия правильного решения, вероятность принятия правильного решения машиной комитета дается как:

где N - число членов комитета. Функция вероятности  показана на Фиг.1. График имеет пилообразную форму, потому что для четного N совпадение
показана на Фиг.1. График имеет пилообразную форму, потому что для четного N совпадение  подсчитывается как ошибка, даже при том, что вероятность ошибки фактически равна только 50%. Пока ошибки являются некоррелированными, эффективность машины комитета может быть повышена добавлением большего числа членов. Если P>0,5, машина комитета всегда работает эффективнее, чем отдельные члены комитета.
подсчитывается как ошибка, даже при том, что вероятность ошибки фактически равна только 50%. Пока ошибки являются некоррелированными, эффективность машины комитета может быть повышена добавлением большего числа членов. Если P>0,5, машина комитета всегда работает эффективнее, чем отдельные члены комитета.
Это не является обязательным в случае, когда отдельные классификаторы имеют различные точности классификации, но модель является, однако, достаточно устойчивой в этом случае. Предположим, например, что три классификатора с индивидуальными точностями P1; P2 и P3 должны быть объединены. Машина комитета работает, по меньшей мере, так же точно, как и самые точные из отдельных классификаторов (допустим, P1), при условии, что:

Например, если P2=P3=0,9, то P1 должен иметь точность выше, чем 0,99, если, согласно допущению, он один должен быть более точным, чем комбинация P1, P2 и P3.
Взвешивание экспертов
Голоса от различных экспертов не одинаково важны; разные модели дикторов, зависящие от фонемы, имеют разную точность. Основная схема голосования, поэтому, может быть улучшена с помощью различного взвешивания отдельных голосов. «Статический» подход к этому состоит в том, чтобы просто взвесить каждый голос ожидаемой равной степенью точности, AEER=1-EER, соответствующего классификатора:

Соответствующая «динамическая» схема взвешивания состоит в том, чтобы взвесить каждый голос дифференциальной вероятностью диктора, вычисленной классификатором:

Даже если оценка вероятности  несколько груба, преимуществом здесь является то, что вес зависит от фактических наблюдений фонемы.
несколько груба, преимуществом здесь является то, что вес зависит от фактических наблюдений фонемы.
Группирование экспертов
Фонемы могут быть разделены на различные группы, например носовые, фрикативные, взрывные, гласные и т.д. Два эксперта, специализирующиеся, скажем, на двух носовых фонемах, интуитивно покажут корреляции в голосующей области, тогда как два эксперта, специализующихся в различных фонемах, скажем, соответственно, носовой и фрикативной фонемах, с меньшей вероятностью покажут корреляцию. Поэтому может быть разумным разделить экспертов на группы, представляющие разные классы фонем. Оценка проверки диктора, DС,L, может тогда быть вычислена для каждой группы фонем (C):

где #C обозначает число фонем в группе C. Уравнение 19 эффективно определяет новый набор экспертов. Глобальное решение проверки может быть принято, как и прежде, комбинируя голоса от экспертов группы, а не от экспертов «фонемы». В принципе эта стратегия решения может быть расширена, включая несколько слоев экспертов, где эксперты на самом низком уровне представляют разные отдельные фонемы, и эксперты на верхних уровнях представляют более широкие звуковые классы (носовые, гласные, фрикативные и т.д.).
Моделирование голосования экспертов
Привлекательный способ объединять N голосов экспертов состоит в том, чтобы обучить сеть (RBF или MLP) опытным путем наилучшей стратегии комбинирования (Wolpert 1992). Таким путем и точность отдельных экспертов, и корреляция между разными голосами экспертов могут быть приняты во внимание непосредственно. Тогда, когда следуют этому подходу, все, что имело место до точки, где голоса экспертов должны быть объединены, по существу расценивается как извлечение признаков; векторы признаков являются здесь векторами принятия решения:

Есть, однако, две проблемы, связанные с этим подходом.
Первая проблема состоит в том, что «супер» сеть, которая комбинирует локальные голоса экспертов, не может обучаться на векторах принятия решения, произведенных просто оцениванием локальных экспертов по данным, на которых они обучались; эксперты, вероятно, будут переобученными и их голоса данных обучения будут поэтому «слишком оптимистическими». Следовательно, или нужно обеспечить дополнительные обучающие данные, или, альтернативно, суперсеть должна быть независимой от диктора.
Вторая проблема состоит в том, что здесь голоса локальных экспертов представляют различные фонемы, и фонетика, составленная из разных тестовых фрагмента речи, может сильно варьироваться, и это лишает нас возможности обучить сеть, которая оптимально комбинирует голоса, следующие из конкретного тестового фрагмента речи.
При ограниченном количестве обучающих фрагментов речи можно смоделировать намного большее число векторов принятия решения, комбинируя релевантные решения экспертов, полученные из разных обучающих фрагментов речи. Однако число возможных комбинаций фонем, которые могут иметь место, является все еще очень большим. Предположим, например, что в любом заданном фрагменте речи будут представлены ровно 15 различных фонем из 30 возможных. Тогда

различных комбинаций голосов должны быть рассмотрены. Это вычисление игнорирует то, что голоса могут быть основаны на больше чем одном наблюдении фонемы и, следовательно, могут быть более надежным и что фактическое число разных фонем может быть больше или может быть меньше, чем 15.
Возможное решение этой дилеммы состоит в том, чтобы сделать суперклассификатор специфическим для конкретного фрагмента речи, то есть откладывать обучение до момента, когда будет принято решение, какой подсказывающий текст выдать после этого, или, что более удобно, пока сегментация фонемы не будет вычислена для фактического фрагмента речи. Суперклассификатор может в этом случае быть простым персептроном, и обучение, поэтому, не является само по себе серьезной вычислительной проблемой. Фиг.2 показывает пример этого.
Альтернативно, чтобы избежать итеративного алгоритма обучения персептрона, линейная дискриминационная функция Фишера может использоваться для изучения весов отдельных экспертов.
В заключении, в этом примере обсуждается, как локальные вероятности диктора оцениваются из отдельных наблюдений фонемы (которые по существу являются объектом, который может быть объединен, чтобы принять глобальные решения проверки диктора). Успешные схемы комбинирования должны принимать во внимание то, что, с одной стороны, некоторые определенные фонемы более информативны, чем другие, и, с другой стороны, что различные фонемы до некоторой степени обеспечивают приветственную информацию о дикторе.
Главная трудность при принятии решения о том, как взвешивать каждое локальное решение, состоит в том, что, если подсказывающие тексты, даваемые дикторам, серьезно не ограничены, и общее количество различных комбинаций фонем, которые могут иметь место в тестовых фрагментах речи, является чрезвычайно большим. Следовательно, эти веса не могут быть легко вычислены априори.

Фиг.2. Суперклассификатор
Классификатор берет различные вероятности диктора от отдельных моделей фонемы в качестве ввода и комбинирует их в глобальную оценку:
Claims (53)
1. Система, предназначенная для обеспечения возможности защищенного сетевого соединения между одним или более пользователями и по меньшей мере одним сервером сети, содержащая
по меньшей мере один интеллектуальный носитель информации, выданный одному пользователю, при этом упомянутый интеллектуальный носитель информации содержит по меньшей мере (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве, причем упомянутый интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера, передавая, таким образом, данные через упомянутое устройство ввода-вывода по сети, и упомянутый интеллектуальный носитель информации выполнен с возможностью установления сетевых идентификационных данных для пользователя через схему шифрования и аутентификации; и
динамический коммутатор датаграмм для динамического выделения датаграмм и обмена датаграммами для множества приложений при обслуживании одного или более пользователей, при этом упомянутый динамический коммутатор датаграмм содержит схему датаграмм и анализатор, причем упомянутая схема датаграмм содержит две или более датаграмм, принадлежащих одному или более типам датаграмм, где каждый тип датаграмм содержит множество функций, и упомянутый анализатор выполнен с возможностью разбора этих одного или более типов датаграмм.
2. Система по п.1, в которой упомянутый интеллектуальный носитель информации является переносным.
3. Система по п.1, в которой интеллектуальный носитель информации реализован с помощью одного из ключа USB, носителя стандарта Compact Flash, носителя стандарта Smart Media, компакт-диска, DVD, PDA, устройства-брандмауэра и устройства-жетона.
4. Система по п.1, в которой упомянутое множество приложений содержит по меньшей мере одно из основывающихся на Windows приложений удаленного терминального сервера, приложений на терминальных эмуляторах 3270/5250 для универсальной ЭВМ, непосредственно встроенных приложений и мультимедийных приложений, при этом непосредственно встроенные приложения включают в себя по меньшей мере одно из приложений баз данных, инструментов анализа данных, инструментов управления взаимодействием с потребителями и пакетов планирования ресурсов предприятия.
5. Система по п.1, в которой схема датаграмм содержит по меньшей мере один главный тип датаграмм и, в пределах главного типа датаграмм по меньшей мере один младший тип датаграмм.
6. Система по п.5, в которой анализатор выполнен с возможностью разбора матрицы типов датаграмм, причем упомянутая матрица содержит первое множество главных типов датаграмм и, в каждом главном типе датаграмм упомянутого первого множества, второе множество младших типов датаграмм.
7. Система по п.6, в которой главный тип датаграмм выбран из группы, состоящей из (i) датаграммы управления сообщениями сервера и соединением, приспособленной для аутентификации и управления пользовательскими соединениями, (ii) датаграммы содержимого, приспособленной для передачи данных содержимого, (iii) широковещательной датаграммы, приспособленной для управления передачей данных от точки к точке, от точки к множеству точек и от множества точек к множеству точек, (iv) датаграммы посредника соединения, приспособленной для передачи посреднических данных между сервером сети и интеллектуальным носителем информации, (v) типа мгновенного сообщения, выполненного с возможностью передачи сообщения в реальном времени, (vi) датаграммы передачи большого объема содержимого, приспособленной для передачи данных большого объема и мультмедийных файлов, (vii) датаграммы пользовательского каталога, приспособленной для поиска пользователей сети, и (viii) датаграммы удаленного управления, приспособленной для удаленного управления пользователями сети.
8. Система по п.7, в которой датаграмма управления сообщениями сервера и соединением содержит младшие типы датаграмм, выбранные из группы, состоящей из (i) датаграммы запроса аутентификации, приспособленной для инициирования запроса аутентификации, (ii) датаграммы ответа на запрос аутентификации, приспособленной для отправки ответа после запроса аутентификации, и (iii) датаграммы результата аутентификации, приспособленной для отправки результата сеанса аутентификации.
9. Система по п.8, в которой датаграмма содержимого содержит младшие типы датаграмм, выбранные из группы, состоящей из (i) нормальной датаграммы содержимого, приспособленной для передачи данных содержимого, (ii) датаграммы удаленного логического входа, приспособленной для сообщения с сервером сети и установления сеанса логического входа, (iii) удаленной датаграммы сбора данных, приспособленной для передачи данных от удаленного соединения, (iv) датаграммы запроса одобрения содержимого, приспособленной для запроса верификации переданных данных содержимого, и (v) датаграммы ответа на запрос одобрения содержимого, приспособленной для ответа на запрос верификации переданных данных содержимого.
10. Система по п.7, в которой датаграмма посредника соединения содержит младшие типы датаграмм, выбранные из группы, состоящей из (i) посреднических данных к серверу, причем этот тип приспособлен для передачи посреднических данных к серверу сети от интеллектуального носителя информации, и (ii) посреднических данных от сервера, причем этот тип приспособлен для передачи посреднических данных от сервера сети к интеллектуальному носителю информации.
11. Система по п.7, в которой тип мгновенного сообщения содержит младшие типы датаграмм, выбранные из группы, состоящей из (i) типа передачи файла, (ii) типа передачи аудио/видео данных, (iii) типа мгновенных почтовых сообщений и (iv) типа удаленного сбора данных.
12. Система по п.1, в которой каждая датаграмма в схеме датаграмм имеет основную компоновку, содержащую
(A) поля заголовка для (i) одного или более главных типов датаграмм, (ii) одного или более младших типов датаграмм, (ii) длины датаграммы и (iii) контрольной суммы датаграммы, и
(B) полезную нагрузку датаграммы для переноса данных в передаче.
13. Система по п.12, в которой общая компоновка содержит одно или более дополнительных полей заголовка.
14. Система по п.12, в которой основная компоновка следует за заголовком TCP.
15. Система по п.1, в которой интеллектуальный носитель информации дополнительно содержит следящий соединитель, который сопряжен с сетью и выполнен с возможностью мониторинга и контроля сетевых соединений.
16. Система по п.15, в которой сервер сети дополнительно содержит следящий соединитель, выполненный с возможностью мониторинга и контроля сетевых соединений, при этом следящий соединитель сервера сети соединен со следящим соединителем интеллектуального носителя информации по сети.
17. Система по п.16, в которой следящий соединитель дополнительно выполнен с возможностью обнаружения потерянных соединений и инициализации обращения к серверу сети, тем самым вновь устанавливая соединения.
18. Система по п.1, дополнительно содержащая средство сопряжения, выполненное с возможностью соединения существующих сетей с сервером сети и передачи данных между существующей сетью и интеллектуальным носителем информации через сервер сети, при этом данная существующая сеть является проводной или беспроводной.
19. Система по п.18, в которой средство сопряжения дополнительно содержит следящий соединитель, сопряженный с сетью и выполненный с возможностью мониторинга и контроля сетевых соединений.
20. Система связи клиент-сервер, содержащая
по меньшей мере один сервер, содержащий динамический коммутатор датаграмм для динамического выделения датаграмм и обмена датаграммами для множества сетевых приложений, при этом упомянутый динамический коммутатор датаграмм содержит схему датаграмм и анализатор, причем упомянутая схема датаграмм содержит две или более датаграмм, принадлежащих одному или более типам датаграмм, где каждый тип датаграмм содержит множество функций, и упомянутый анализатор выполнен с возможностью разбора этих одного или более типов датаграмм; и
по меньшей мере один клиент, причем клиент является интеллектуальным носителем информации, содержащим по меньшей мере (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве, при этом упомянутый интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера, передавая, таким образом, данные через упомянутое устройство ввода-вывода по сети, и при этом упомянутый интеллектуальный носитель информации выполнен с возможностью установления идентификационных данных пользователя сети посредством схемы аутентификации и шифрования для защищенной передачи данных между упомянутым сервером и упомянутым клиентом.
21. Система связи клиент-сервер по п.20, в которой интеллектуальный носитель информации реализован с помощью одного из ключа USB, носителя стандарта Compact Flash, носителя стандарта Smart Media, компакт-диска, DVD, PDA, устройства брандмауэра и устройства-жетона.
22. Система связи клиент-сервер по п.20, в которой схема датаграмм содержит по меньшей мере один главный тип датаграмм и, в пределах главного типа датаграмм по меньшей мере один младший тип датаграмм.
23. Система связи клиент-сервер по п.20, в которой анализатор выполнен с возможностью разбора матрицы типов датаграмм, причем эта матрица содержит первое множество главных типов датаграмм и в каждом главном типе датаграмм упомянутого первого множества второе множество младших типов датаграмм.
24. Система связи клиент-сервер по п.20, в которой каждая датаграмма в схеме датаграмм имеет основную компоновку, содержащую
(A) поля заголовка для (i) одного или более главных типов датаграмм, (ii) одного или более младших типов датаграмм, (ii) длины датаграммы и (iii) контрольной суммы датаграммы, и
(B) полезную нагрузку датаграммы для переноса данных в передаче.
25. Система связи клиент-сервер по п.20, дополнительно содержащая средство сопряжения, выполненное с возможностью соединения существующей сети с сервером и передачи данных между этой существующей сетью и клиентом через сервер, причем данная существующая сеть является проводной или беспроводной.
26. Система связи клиент-сервер по п.25, в которой каждый из сервера, клиента и средства сопряжения содержит следящий соединитель, который сопряжен с сетью и выполнен с возможностью мониторинга и контроля сетевых соединений, при этом следящий соединитель клиента соединен со следящим соединителем сервера по сети, и следящий соединитель средства сопряжения соединен со следящим соединителем сервера по сети.
27. Система связи клиент-сервер по п.26, в которой следящий соединитель клиента дополнительно выполнен с возможностью обнаружения потерянных соединении и инициализации обращения к серверу, тем самым вновь устанавливая соединения.
28. Система связи клиент-сервер по п.20, в которой сервер дополнительно содержит зашифрованную виртуальную файловую систему для специализированного хранения данных для клиента.
29. Интеллектуальный носитель информации, содержащий по меньшей мере (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве, при этом интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера в сети, передавая таким образом данные через упомянутое устройство ввода-вывода по сети, при этом передача данных выполняется посредством динамически коммутируемых датаграмм согласно схеме датаграмм, причем интеллектуальный носитель информации выполнен с возможностью аутентификации пользователя сети посредством схемы аутентификации и шифрования для защищенной сетевой передачи данных.
30. Интеллектуальный носитель информации по п.29, который реализован с помощью одного из ключа USB, носителя стандарта Compact Flash, носителя стандарта Smart Media, компакт-диска, DVD, PDA, устройства-брандмауэра и устройства-жетона.
31. Интеллектуальный носитель информации по п.29, в котором динамически коммутируемые датаграммы принадлежат одному или более типам датаграмм и приспособлены для переноса (i) данных содержимого для сетевой передачи и (ii) другой информации для управления сетевыми соединениями и их контроля и поддержки сетевых приложений, причем каждый тип датаграмм содержит множество функций.
32. Интеллектуальный носитель информации по п.31, в котором типы датаграмм содержат по меньшей мере один главный тип датаграмм и в пределах главного типа датаграмм по меньшей мере один младший тип датаграмм.
33. Интеллектуальный носитель информации по п.32, в котором датаграммы соответствуют основной компоновке, причем данная основная компоновка содержит
(A) поля заголовка для (i) одного или более главных типов датаграмм, (ii) одного или более младших типов датаграмм, (ii) длины датаграммы и (iii) контрольной суммы датаграммы, и
(B) полезную нагрузку датаграммы для переноса данных в передаче.
34. Способ защищенной сетевой связи, содержащий
выдачу пользователю сети интеллектуального носителя информации, где интеллектуальный носитель информации содержит по меньшей мере (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве, при этом интеллектуальный носитель информации выполнен с возможностью соединения с устройством главного компьютера в сети, передавая, таким образом, данные через упомянутое устройство ввода-вывода по сети, причем интеллектуальный носитель информации выполнен с возможностью установления сетевых идентификационных данных для пользователя сети посредством схемы шифрования и аутентификации; и
обеспечение динамического коммутатора датаграмм на сервере сети для динамического выделения датаграмм и обмена датаграммами для поддержки множества приложений, при этом упомянутый динамический коммутатор датаграмм содержит схему датаграмм и анализатор, причем упомянутая схема датаграмм содержит две или более датаграмм, принадлежащих одному или более типам датаграмм, где каждый тип датаграмм содержит множество функций, и упомянутый анализатор выполнен с возможностью разбора этих одного или более типов датаграмм.
35. Способ по п.34, в котором схема аутентификации и шифрования содержит следующие последовательные этапы:
(a) отправка запроса от интеллектуального носителя информации серверу в отношении того, что интеллектуальный носитель информации должен быть аутентифицирован;
(b) представление сервером интеллектуальному носителю информации множества способов аутентификации;
(c) выбор интеллектуальным носителем информации одного способа аутентификации из упомянутого множества на основе события;
(d) отправка сервером интеллектуальному носителю информации требования, основанного на выбранном способе, в отношении данных аутентификации от интеллектуального носителя информации;
(e) преобразование сервером данных аутентификации, принятых от интеллектуального носителя информации, в один или более объектов аутентификации данных, причем каждый из объектов аутентификации данных является объектом вектора данных, который можно проанализировать, используя один или более классификаторов;
(f) анализ сервером упомянутых объектов аутентификации данных согласно упомянутым одному или более классификаторам, определяя, таким образом, результат аутентификации; и
(g) посылка сервером упомянутого результата интеллектуальному носителю информации, показывая успешную или неуспешную попытку аутентификации.
36. Способ по п.35, в котором упомянутое событие на этапе (с) содержит по меньшей мере одно событие из щелчка клавишей мыши, касания экрана, нажатия клавиши, произнесения фрагмента речи и биометрического измерения.
37. Способ по п.35, в котором упомянутое требование на этапе (d) содержит по меньшей мере один из псевдослучайного и истинно случайного кода, при этом псевдослучайный код генерируется на основе предварительно рассчитанного математически списка, а истинно случайный код генерируется посредством дискретизации и обработки в отношении источника энтропии вне системы.
38. Способ по п.35, в котором анализ на этапе (f) выполняется на основе одного или более правил анализа, при этом упомянутые одно или более правил анализа включают в себя классификацию согласно одному или более классификаторам по этапу (е).
39. Способ по п.38, в котором упомянутая классификация содержит проверку говорящего, при этом векторы объектов данных задействуют два класса, а именно целевого говорящего и самозванца, причем каждый класс характеризуется функцией плотности вероятности, и определение на этапе (f) является задачей выбора из двух альтернатив.
40. Способ по п.35, в котором определение на этапе (f) содержит вычисление по меньшей мере одного из суммы, старшинства и вероятности из упомянутых одного или более объектов векторов данных на основе одного или более классификаторов по этапу (е), при этом сумма является одной из верхней и случайной сумм, вычисленных из одного или более объектов векторов данных.
41. Способ по п.35, в котором упомянутые один или более классификаторов по этапу (е) включают в себя суперклассификатор, полученный из более чем одного объекта вектора данных, при этом упомянутый суперклассификатор основан либо на физической биометрии, либо на рабочей биометрии, причем физическая биометрия содержит по меньшей мере одно из распознавания голоса, отпечатков пальцев, отпечатков руки, узоров кровеносных сосудов, тестов ДНК, сканирования сетчатки глаза или радужной оболочки и распознавания лица, а рабочая биометрия содержит привычки или модели индивидуального поведения.
42. Способ по п.34, в котором схема аутентификации и шифрования содержит симметричное и асимметричное шифрование на основе мультишифра, при этом упомянутое шифрование использует по меньшей мере одно из обратной связи по выходным данным, обратной связи по шифру, перенаправления шифра и формирования цепочек блоков шифра.
43. Способ по п.42, в котором шифрование основано на алгоритме Rijndael усовершенствованного стандарта шифрования (AES).
44. Способ по п.34, в котором схема аутентификации и шифрования реализует защищенный обмен ключами, при этом защищенный обмен ключами использует либо систему открытых ключей, либо личные ключи криптосистемы на основе эллиптических кривых.
45. Способ по п.34, в котором схема аутентификации и шифрования содержит по меньшей мере одно из логического теста, приспособленного для проверки действительности того, что интеллектуальный носитель информации зарегистрирован сервером, теста устройства, приспособленного для проверки действительности физических параметров в интеллектуальном носителе информации и устройстве главного компьютера, и персонального теста, приспособленного для аутентификации пользователя, на основе данных уровня события.
46. Способ по п.34, дополнительно содержащий этап предоставления первого следящего соединителя в интеллектуальном носителе информации и второго следящего соединителя на сервере, при этом первый следящий соединитель выполнен с возможностью соединения со вторым следящим соединителем по сети, и первый и второй следящие соединители выполнены с возможностью мониторинга и контроля сетевых соединений.
47. Способ по п.46, в котором первый следящий соединитель дополнительно выполнен с возможностью обнаружения потерянных соединений и инициализации обращения ко второму следящему соединителю, тем самым вновь устанавливая соединения.
48. Способ целевой доставки одного или более приложений пользователю, содержащий
выдачу пользователю интеллектуального носителя информации, выполненного с возможностью подстыковки к устройству главного компьютера, которое соединено с сетью, в которой находится сервер сети, и сообщения с сервером сети по сети, при этом сервер сети сообщается с интеллектуальным носителем информации посредством динамически коммутируемых датаграмм согласно схеме датаграмм, причем интеллектуальный носитель информации содержит по меньшей мере (i) одно запоминающее устройство, выполненное с возможностью хранения данных, (ii) одно устройство ввода-вывода, выполненное с возможностью ввода и вывода данных, и (iii) один процессор, выполненный с возможностью обработки данных, хранящихся в упомянутом запоминающем устройстве;
аутентификацию сервером пользователя посредством схемы аутентификации и шифрования; и
предоставление пользователю доступа к одному или более приложениям после успешной аутентификации.
49. Способ по п.48, в котором упомянутые одно или более приложений предварительно загружены на интеллектуальный носитель информации или установлены на сервере сети или устройстве главного компьютера.
50. Способ по п.49, в котором устройство главного компьютера соединено с сетью через проводные или беспроводные средства.
51. Способ по п.49, в котором устройство главного компьютера содержит по меньшей мере одно устройство из настольного или переносного компьютера, персонального цифрового ассистента (PDA), мобильного телефона, цифрового телевизора, аудио- или видеопроигрывателя, компьютерной игровой консоли, цифровой камеры, камеры в телефоне и предназначенного для работы в сети бытового прибора.
52. Способ по п.51, в котором предназначенный для работы в сети бытовой прибор является одним из предназначенных для работы в сети холодильника, микроволновой печи, стиральной машины, сушилки и посудомоечной машины.
53. Способ по п.48, в котором упомянутые одно или более приложений включают в себя по меньшей мере одно из основывающихся на Windows приложений удаленного терминального сервера, приложений на терминальных эмуляторах 3270/5250 для универсальной ЭВМ, непосредственно встроенных приложений и мультимедийных приложений, при этом непосредственно встроенные приложения содержат по меньшей мере одно из приложений баз данных, инструментов анализа данных, инструментов управления взаимодействием с потребителями и пакетов планирования ресурсов предприятия.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/428,895 | 2003-05-02 | ||
| US10/428,895 US7103772B2 (en) | 2003-05-02 | 2003-05-02 | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers |
| US10/759,789 | 2004-01-16 | ||
| US10/759,789 US7360087B2 (en) | 2003-05-02 | 2004-01-16 | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2005137570A RU2005137570A (ru) | 2006-06-10 |
| RU2308080C2 true RU2308080C2 (ru) | 2007-10-10 |
Family
ID=35432873
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2005137570/09A RU2308080C2 (ru) | 2003-05-02 | 2004-01-28 | Всеобъемлющая, ориентированная на пользователя сетевая безопасность, обеспечиваемая динамической коммутацией датаграмм и схемой аутентификации и шифрования по требованию через переносные интеллектуальные носители информации |
Country Status (9)
| Country | Link |
|---|---|
| EP (1) | EP1620773A4 (ru) |
| JP (1) | JP4430666B2 (ru) |
| KR (1) | KR100825241B1 (ru) |
| AU (1) | AU2004237046B2 (ru) |
| BR (1) | BRPI0409844A (ru) |
| CA (1) | CA2525490C (ru) |
| NO (1) | NO335789B1 (ru) |
| RU (1) | RU2308080C2 (ru) |
| WO (1) | WO2004099940A2 (ru) |
Cited By (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2444143C2 (ru) * | 2007-11-08 | 2012-02-27 | Чайна Ивнкомм Ко., Лтд | Способ двусторонней аутентификации доступа |
| RU2445741C1 (ru) * | 2007-12-14 | 2012-03-20 | Чайна Ивнкомм Ко., Лтд. | Способ и система двухсторонней аутентификации субъектов |
| RU2457535C2 (ru) * | 2010-05-25 | 2012-07-27 | Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования "Санкт-Петербургский государственный политехнический университет" (ФГБОУ ВПО "СПбГПУ") | Способ формирования и проверки электронной цифровой подписи на основе эллиптической или гиперэллиптической кривой |
| RU2484531C2 (ru) * | 2009-01-22 | 2013-06-10 | Государственное научное учреждение центральный научно-исследовательский и опытно-конструкторский институт робототехники и технической кибернетики (ЦНИИ РТК) | Устройство обработки видеоинформации системы охранной сигнализации |
| RU2492522C2 (ru) * | 2007-10-16 | 2013-09-10 | Сони Корпорейшн | Система и способ эффективного выполнения процедуры имитации сети |
| RU2533087C2 (ru) * | 2009-06-30 | 2014-11-20 | Морфо | Криптография с параметризацией на эллиптической кривой |
| RU2589861C2 (ru) * | 2014-06-20 | 2016-07-10 | Закрытое акционерное общество "Лаборатория Касперского" | Система и способ шифрования данных пользователя |
| RU2633111C1 (ru) * | 2012-12-07 | 2017-10-11 | Грегори Х. ЛИКЛЕЙ | Одноранговая сеть доставки контента, способ и управляющее устройство |
| RU2638779C1 (ru) * | 2016-08-05 | 2017-12-15 | Общество С Ограниченной Ответственностью "Яндекс" | Способ и сервер для вьполнения авторизации приложения на электронном устройстве |
| RU2653231C1 (ru) * | 2016-12-16 | 2018-05-07 | Общество с ограниченной ответственностью "Иридиум" | Способ и система объединения компонентов для управления объектами автоматизации |
| RU2653280C2 (ru) * | 2012-12-13 | 2018-05-07 | Самсунг Электроникс Ко., Лтд. | Способ управления устройством для регистрации информации об устройстве для периферийного устройства и устройство и система для этого |
| US10116505B2 (en) | 2012-12-13 | 2018-10-30 | Samsung Electronics Co., Ltd. | Device control method for registering device information of peripheral device, and device and system thereof |
| RU2683184C2 (ru) * | 2015-11-03 | 2019-03-26 | Общество с ограниченной ответственностью "ДОМКОР" | Программно-аппаратный комплекс системы электронных продаж недвижимости и способ обмена данными в нем |
| RU2697646C1 (ru) * | 2018-10-26 | 2019-08-15 | Самсунг Электроникс Ко., Лтд. | Способ биометрической аутентификации пользователя и вычислительное устройство, реализующее упомянутый способ |
| RU2714856C1 (ru) * | 2019-03-22 | 2020-02-19 | Общество с ограниченной ответственностью "Ак Барс Цифровые Технологии" | Система идентификации пользователя для совершения электронной сделки для предоставления услуги или покупки товара |
| RU2735637C2 (ru) * | 2016-05-11 | 2020-11-05 | Шарп Кабусики Кайся | Системы и способы для сигнализации формата физического совместно применяемого канала для передачи данных по восходящей линии связи (pusch) и конкурентного доступа |
| RU2738823C1 (ru) * | 2020-03-13 | 2020-12-17 | Сергей Станиславович Чайковский | Периферийное устройство с интегрированной системой безопасности с применением искусственного интеллекта |
| US10936758B2 (en) | 2016-01-15 | 2021-03-02 | Blockchain ASICs Inc. | Cryptographic ASIC including circuitry-encoded transformation function |
| US11042669B2 (en) | 2018-04-25 | 2021-06-22 | Blockchain ASICs Inc. | Cryptographic ASIC with unique internal identifier |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8255223B2 (en) | 2004-12-03 | 2012-08-28 | Microsoft Corporation | User authentication by combining speaker verification and reverse turing test |
| FR2882506B1 (fr) | 2005-02-25 | 2007-05-18 | Oreal | Procede de maquillage au moyen d'un applicateur vibrant |
| JP4138808B2 (ja) | 2006-01-10 | 2008-08-27 | 株式会社エヌ・ティ・ティ・ドコモ | 通信システムおよび通信方法 |
| US20080208806A1 (en) * | 2007-02-28 | 2008-08-28 | Microsoft Corporation | Techniques for a web services data access layer |
| US20100263022A1 (en) * | 2008-10-13 | 2010-10-14 | Devicescape Software, Inc. | Systems and Methods for Enhanced Smartclient Support |
| US9094721B2 (en) | 2008-10-22 | 2015-07-28 | Rakuten, Inc. | Systems and methods for providing a network link between broadcast content and content located on a computer network |
| US8160064B2 (en) | 2008-10-22 | 2012-04-17 | Backchannelmedia Inc. | Systems and methods for providing a network link between broadcast content and content located on a computer network |
| US8631070B2 (en) | 2009-03-27 | 2014-01-14 | T-Mobile Usa, Inc. | Providing event data to a group of contacts |
| US8428561B1 (en) | 2009-03-27 | 2013-04-23 | T-Mobile Usa, Inc. | Event notification and organization utilizing a communication network |
| CN101808096B (zh) * | 2010-03-22 | 2012-11-07 | 北京大用科技有限责任公司 | 一种大规模异地局域网间屏幕共享及控制的方法 |
| CN101931626B (zh) * | 2010-08-25 | 2012-10-10 | 深圳市傲冠软件股份有限公司 | 远程控制过程中实现安全审计功能的服务终端 |
| WO2012035451A1 (en) * | 2010-09-16 | 2012-03-22 | International Business Machines Corporation | Method, secure device, system and computer program product for securely managing files |
| US9152815B2 (en) * | 2010-10-29 | 2015-10-06 | International Business Machines Corporation | Method, secure device, system and computer program product for securely managing user access to a file system |
| CN103797811B (zh) | 2011-09-09 | 2017-12-12 | 乐天株式会社 | 用于消费者对交互式电视接触的控制的系统和方法 |
| US10326734B2 (en) | 2013-07-15 | 2019-06-18 | University Of Florida Research Foundation, Incorporated | Adaptive identity rights management system for regulatory compliance and privacy protection |
| US9424443B2 (en) | 2013-08-20 | 2016-08-23 | Janus Technologies, Inc. | Method and apparatus for securing computer mass storage data |
| KR101655448B1 (ko) * | 2014-12-24 | 2016-09-07 | 주식회사 파수닷컴 | 인증 프록시를 이용한 사용자 인증 장치 및 방법 |
| KR102128303B1 (ko) * | 2016-06-20 | 2020-06-30 | 시너지시티 주식회사 | 주차위치맵을 활용한 주차대리 시스템 및 그 방법 |
| CN106730835A (zh) * | 2016-12-16 | 2017-05-31 | 青岛蘑菇网络技术有限公司 | 一种基于路由器和vpn服务器的网游加速方法及系统 |
| CN111951783B (zh) * | 2020-08-12 | 2023-08-18 | 北京工业大学 | 一种基于音素滤波的说话人识别方法 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06282527A (ja) * | 1993-03-29 | 1994-10-07 | Hitachi Software Eng Co Ltd | ネットワーク管理システム |
| US5550984A (en) * | 1994-12-07 | 1996-08-27 | Matsushita Electric Corporation Of America | Security system for preventing unauthorized communications between networks by translating communications received in ip protocol to non-ip protocol to remove address and routing services information |
| US5958010A (en) * | 1997-03-20 | 1999-09-28 | Firstsense Software, Inc. | Systems and methods for monitoring distributed applications including an interface running in an operating system kernel |
| DE19812215A1 (de) * | 1998-03-19 | 1999-09-23 | Siemens Ag | Verfahren, Mobilstation und Funk-Kommunikationssystem zur Steuerung von sicherheitsbezogenen Funktionen bei der Verbindungsbehandlung |
| US6405203B1 (en) * | 1999-04-21 | 2002-06-11 | Research Investment Network, Inc. | Method and program product for preventing unauthorized users from using the content of an electronic storage medium |
| DE69925732T2 (de) * | 1999-10-22 | 2006-03-16 | Telefonaktiebolaget Lm Ericsson (Publ) | Mobiltelefon mit eingebauter Sicherheitsfirmware |
| KR100376618B1 (ko) * | 2000-12-05 | 2003-03-17 | 주식회사 싸이버텍홀딩스 | 에이전트 기반의 지능형 보안 시스템 |
| US7941669B2 (en) * | 2001-01-03 | 2011-05-10 | American Express Travel Related Services Company, Inc. | Method and apparatus for enabling a user to select an authentication method |
| US6732278B2 (en) * | 2001-02-12 | 2004-05-04 | Baird, Iii Leemon C. | Apparatus and method for authenticating access to a network resource |
| KR20020075319A (ko) * | 2002-07-19 | 2002-10-04 | 주식회사 싸이버텍홀딩스 | 지능형 보안 엔진과 이를 포함하는 지능형 통합 보안 시스템 |
-
2004
- 2004-01-28 RU RU2005137570/09A patent/RU2308080C2/ru not_active IP Right Cessation
- 2004-01-28 CA CA2525490A patent/CA2525490C/en not_active Expired - Fee Related
- 2004-01-28 JP JP2006508631A patent/JP4430666B2/ja not_active Expired - Lifetime
- 2004-01-28 BR BRPI0409844-7A patent/BRPI0409844A/pt active Search and Examination
- 2004-01-28 EP EP04706073A patent/EP1620773A4/en not_active Withdrawn
- 2004-01-28 KR KR1020057020870A patent/KR100825241B1/ko not_active IP Right Cessation
- 2004-01-28 WO PCT/US2004/002438 patent/WO2004099940A2/en active Application Filing
- 2004-01-28 AU AU2004237046A patent/AU2004237046B2/en not_active Ceased
-
2005
- 2005-10-31 NO NO20055067A patent/NO335789B1/no not_active IP Right Cessation
Cited By (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2492522C2 (ru) * | 2007-10-16 | 2013-09-10 | Сони Корпорейшн | Система и способ эффективного выполнения процедуры имитации сети |
| US8412943B2 (en) | 2007-11-08 | 2013-04-02 | China Iwncomm Co., Ltd. | Two-way access authentication method |
| RU2444143C2 (ru) * | 2007-11-08 | 2012-02-27 | Чайна Ивнкомм Ко., Лтд | Способ двусторонней аутентификации доступа |
| US8417955B2 (en) | 2007-12-14 | 2013-04-09 | China Iwncomm Co., Ltd. | Entity bidirectional authentication method and system |
| RU2445741C1 (ru) * | 2007-12-14 | 2012-03-20 | Чайна Ивнкомм Ко., Лтд. | Способ и система двухсторонней аутентификации субъектов |
| RU2484531C2 (ru) * | 2009-01-22 | 2013-06-10 | Государственное научное учреждение центральный научно-исследовательский и опытно-конструкторский институт робототехники и технической кибернетики (ЦНИИ РТК) | Устройство обработки видеоинформации системы охранной сигнализации |
| RU2533087C2 (ru) * | 2009-06-30 | 2014-11-20 | Морфо | Криптография с параметризацией на эллиптической кривой |
| RU2457535C2 (ru) * | 2010-05-25 | 2012-07-27 | Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования "Санкт-Петербургский государственный политехнический университет" (ФГБОУ ВПО "СПбГПУ") | Способ формирования и проверки электронной цифровой подписи на основе эллиптической или гиперэллиптической кривой |
| RU2633111C1 (ru) * | 2012-12-07 | 2017-10-11 | Грегори Х. ЛИКЛЕЙ | Одноранговая сеть доставки контента, способ и управляющее устройство |
| RU2653280C2 (ru) * | 2012-12-13 | 2018-05-07 | Самсунг Электроникс Ко., Лтд. | Способ управления устройством для регистрации информации об устройстве для периферийного устройства и устройство и система для этого |
| US10116505B2 (en) | 2012-12-13 | 2018-10-30 | Samsung Electronics Co., Ltd. | Device control method for registering device information of peripheral device, and device and system thereof |
| US9596221B2 (en) | 2014-06-20 | 2017-03-14 | AO Kaspersky Lab | Encryption of user data for storage in a cloud server |
| RU2589861C2 (ru) * | 2014-06-20 | 2016-07-10 | Закрытое акционерное общество "Лаборатория Касперского" | Система и способ шифрования данных пользователя |
| RU2683184C2 (ru) * | 2015-11-03 | 2019-03-26 | Общество с ограниченной ответственностью "ДОМКОР" | Программно-аппаратный комплекс системы электронных продаж недвижимости и способ обмена данными в нем |
| RU2746014C2 (ru) * | 2016-01-15 | 2021-04-05 | БЛОКЧЕЙН АСИКС ЭлЭЛСи | Криптографическая интегральная схема специального назначения, включающая в себя закодированную в цепи функцию преобразования |
| US10936758B2 (en) | 2016-01-15 | 2021-03-02 | Blockchain ASICs Inc. | Cryptographic ASIC including circuitry-encoded transformation function |
| RU2735637C2 (ru) * | 2016-05-11 | 2020-11-05 | Шарп Кабусики Кайся | Системы и способы для сигнализации формата физического совместно применяемого канала для передачи данных по восходящей линии связи (pusch) и конкурентного доступа |
| RU2638779C1 (ru) * | 2016-08-05 | 2017-12-15 | Общество С Ограниченной Ответственностью "Яндекс" | Способ и сервер для вьполнения авторизации приложения на электронном устройстве |
| RU2653231C1 (ru) * | 2016-12-16 | 2018-05-07 | Общество с ограниченной ответственностью "Иридиум" | Способ и система объединения компонентов для управления объектами автоматизации |
| WO2018111139A1 (ru) * | 2016-12-16 | 2018-06-21 | Общество с ограниченной ответственностью "Иридиум" | Способ и система построения вычислительной сети для связи между множеством устройств |
| US11042669B2 (en) | 2018-04-25 | 2021-06-22 | Blockchain ASICs Inc. | Cryptographic ASIC with unique internal identifier |
| US11093654B2 (en) | 2018-04-25 | 2021-08-17 | Blockchain ASICs Inc. | Cryptographic ASIC with self-verifying unique internal identifier |
| US11093655B2 (en) | 2018-04-25 | 2021-08-17 | Blockchain ASICs Inc. | Cryptographic ASIC with onboard permanent context storage and exchange |
| RU2697646C1 (ru) * | 2018-10-26 | 2019-08-15 | Самсунг Электроникс Ко., Лтд. | Способ биометрической аутентификации пользователя и вычислительное устройство, реализующее упомянутый способ |
| RU2714856C1 (ru) * | 2019-03-22 | 2020-02-19 | Общество с ограниченной ответственностью "Ак Барс Цифровые Технологии" | Система идентификации пользователя для совершения электронной сделки для предоставления услуги или покупки товара |
| RU2738823C1 (ru) * | 2020-03-13 | 2020-12-17 | Сергей Станиславович Чайковский | Периферийное устройство с интегрированной системой безопасности с применением искусственного интеллекта |
| WO2021182985A1 (ru) * | 2020-03-13 | 2021-09-16 | Сергей Станиславович ЧАЙКОВСКИЙ | Периферийное устройство с интегрированной системой безопасности с применением искусственного интеллекта |
Also Published As
| Publication number | Publication date |
|---|---|
| CA2525490A1 (en) | 2004-11-18 |
| EP1620773A2 (en) | 2006-02-01 |
| JP2007524892A (ja) | 2007-08-30 |
| WO2004099940A3 (en) | 2006-05-18 |
| KR100825241B1 (ko) | 2008-04-25 |
| AU2004237046B2 (en) | 2008-02-28 |
| JP4430666B2 (ja) | 2010-03-10 |
| RU2005137570A (ru) | 2006-06-10 |
| CA2525490C (en) | 2012-01-24 |
| NO335789B1 (no) | 2015-02-16 |
| WO2004099940A8 (en) | 2006-08-03 |
| AU2004237046A1 (en) | 2004-11-18 |
| BRPI0409844A (pt) | 2006-05-16 |
| EP1620773A4 (en) | 2011-11-23 |
| NO20055067D0 (no) | 2005-10-31 |
| KR20060041165A (ko) | 2006-05-11 |
| WO2004099940A2 (en) | 2004-11-18 |
| NO20055067L (no) | 2006-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2308080C2 (ru) | Всеобъемлющая, ориентированная на пользователя сетевая безопасность, обеспечиваемая динамической коммутацией датаграмм и схемой аутентификации и шифрования по требованию через переносные интеллектуальные носители информации | |
| US20040221163A1 (en) | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers | |
| Syed et al. | Zero trust architecture (zta): A comprehensive survey | |
| CN101375284B (zh) | 安全数据分析方法和系统 | |
| CN102932136B (zh) | 用于管理加密密钥的系统和方法 | |
| CN114144781A (zh) | 身份验证和管理系统 | |
| CN112084256A (zh) | 用于数据库的聚合机器学习验证 | |
| EP1351113A2 (en) | A biometric authentication system and method | |
| US11188637B1 (en) | Systems and methods for link device authentication | |
| CN105224417A (zh) | 改进的磁带备份方法 | |
| CN105743930A (zh) | 安全数据解析方法和系统 | |
| CN112084255A (zh) | 机器学习应用的有效验证 | |
| US11418338B2 (en) | Cryptoasset custodial system using power down of hardware to protect cryptographic keys | |
| Verma et al. | A novel model to enhance the data security in cloud environment | |
| US11870917B2 (en) | Systems and methods for facilitating policy-compliant end-to-end encryption for individuals between organizations | |
| US11522842B2 (en) | Central trust hub for interconnectivity device registration and data provenance | |
| Reshmi et al. | A survey of authentication methods in mobile cloud computing | |
| Cooper | Security for the Internet of Things | |
| NURUS SALAM | Modelling of a Communication Protocol for IoT based Applications | |
| Rull Jariod | Authorization and authentication strategy for mobile highly constrained edge devices | |
| Merzeh et al. | Secure Mutual Authentication Scheme for IoT Smart Home Environment Using Biometric and Group Signature Verification Methods | |
| Kuznetsov et al. | Deep learning-based biometric cryptographic key generation with post-quantum security | |
| Kumar et al. | Performance Analysis of User Authentication Schemes in Wireless Sensor Networks | |
| MXPA05011778A (es) | Seguridad penetrante de red de usuario central permitida por el conmutador dinamico de datagrama y esquema de autentificacion y cifrado en demanda a traves de portadores inteligentes y moviles de datos | |
| Cao et al. | DeepWAF: Detecting Web Attacks Based on CNN and LSTM Models |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| MM4A | The patent is invalid due to non-payment of fees |
Effective date: 20180129 |