KR20230113600A - 수술 능력을 평가하기 위한 시스템들 및 방법들 - Google Patents
수술 능력을 평가하기 위한 시스템들 및 방법들 Download PDFInfo
- Publication number
- KR20230113600A KR20230113600A KR1020237021818A KR20237021818A KR20230113600A KR 20230113600 A KR20230113600 A KR 20230113600A KR 1020237021818 A KR1020237021818 A KR 1020237021818A KR 20237021818 A KR20237021818 A KR 20237021818A KR 20230113600 A KR20230113600 A KR 20230113600A
- Authority
- KR
- South Korea
- Prior art keywords
- corpus
- opi
- score
- surgical data
- data
- Prior art date
Links
Images









































Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H40/00—ICT specially adapted for the management or administration of healthcare resources or facilities; ICT specially adapted for the management or operation of medical equipment or devices
- G16H40/20—ICT specially adapted for the management or administration of healthcare resources or facilities; ICT specially adapted for the management or operation of medical equipment or devices for the management or administration of healthcare resources or facilities, e.g. managing hospital staff or surgery rooms
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H10/00—ICT specially adapted for the handling or processing of patient-related medical or healthcare data
- G16H10/60—ICT specially adapted for the handling or processing of patient-related medical or healthcare data for patient-specific data, e.g. for electronic patient records
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/30—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to physical therapies or activities, e.g. physiotherapy, acupressure or exercising
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/40—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to mechanical, radiation or invasive therapies, e.g. surgery, laser therapy, dialysis or acupuncture
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H30/00—ICT specially adapted for the handling or processing of medical images
- G16H30/40—ICT specially adapted for the handling or processing of medical images for processing medical images, e.g. editing
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H40/00—ICT specially adapted for the management or administration of healthcare resources or facilities; ICT specially adapted for the management or operation of medical equipment or devices
- G16H40/60—ICT specially adapted for the management or administration of healthcare resources or facilities; ICT specially adapted for the management or operation of medical equipment or devices for the operation of medical equipment or devices
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- General Health & Medical Sciences (AREA)
- Primary Health Care (AREA)
- General Business, Economics & Management (AREA)
- Business, Economics & Management (AREA)
- Biomedical Technology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Radiology & Medical Imaging (AREA)
- Urology & Nephrology (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Pathology (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Physical Education & Sports Medicine (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Surgery (AREA)
- Image Analysis (AREA)
- Medical Treatment And Welfare Office Work (AREA)
Abstract
다양한 개시된 실시예들은 수술 성과를 측정하고 모니터링하기 위한 컴퓨터 시스템들 및 컴퓨터에 의해 구현되는 방법들에 관한 것이다. 예를 들어, 시스템은 수술실로부터 취득된 원시 데이터를 수신하고, 분석에 순응하는 데이터로부터 특징들을 생성 및 선택한 다음, 선택된 특징들을 이용하여 기계 학습 분류기를 훈련시켜 다른 외과의들의 성과의 후속 평가를 용이하게 할 수 있다. 특징들의 생성 및 선택은 그 자체로 일부 실시예들에서 기계 학습 분류기의 적용을 수반할 수 있다. 일부 실시예들이 수술 로봇 시스템들로부터 취득된 원시 데이터를 고려하지만, 일부 실시예들은 비-로봇 수술실들로부터 취득된 데이터에 대한 평가들을 용이하게 한다.
Description
관련 출원들에 대한 상호 참조
본 출원은 "SYSTEMS AND METHODS FOR ASSESSING SURGICAL ABILITY"라는 명칭으로 2020년 12월 3일자로 출원된 미국 가출원 제63/121,220호의 이익 및 우선권을 주장하며, 이 가출원은 모든 목적을 위해 그 전체가 본 명세서에 참조로 포함된다.
다양한 개시된 실시예들은 수술 성과(surgical performance)를 측정하고 모니터링하기 위한 컴퓨터 시스템들 및 컴퓨터에 의해 구현되는 방법들에 관한 것이다.
많은 과제들은 수술 기량 평가들을 복잡하게 하여, 외과의들에게 그 수술 성과에 관한 의미 있는 피드백을 제공하는 것을 매우 어렵게 만든다. 예를 들어, 기량과 무관한 다수의 기량들 및 누적 인자들이 최종 결과에 기여하여, 임의의 단일 기량의 영향을 모호하게 하므로, 수술 후 결과들에만 기반하여 특정 수술 기량을 실제로 평가할 수 없다. 대신에 외과 수술 동안 직접 또는 기록된 비디오를 통해 외과의의 기량을 관찰할 수 있지만, 이러한 실시간 및 비디오 기반 검토는 여전히 상급자 외과의와 같은 인간 전문가가 수술실(theater)에서 또는 비디오에 나타나는 수술 기량들을 인식하고 평가할 것을 요구한다. 불행하게도, 이러한 인간 관찰자 평가들은 종종 주관적이고, (적어도 그들이 인간 검토자의 존재를 요구한다는 이유로) 열악하게 스케일링되고, 준비하기 어려울 수 있는데, 왜냐하면 비디오를 생성하는 "초보" 외과의들이 있는 것보다 주어진 유형의 외과 수술에 대해 훨씬 더 적은 "전문가" 외과의들이 종종 있기 때문이다. 그에 부가하여, 많은 전문가 외과의들은 일 부담이 높으며, 스스로 수술들을 수행하는 대신에 이러한 비디오들을 검토하는데 시간을 쏟는 것을 당연히 꺼린다.
새로운 수술 도구들 및 새로운 수술 로봇 시스템들의 데이터 수집 능력들이 막대한 양의 수술 데이터를 이용가능하게 만들었지만, 이 데이터는 위의 과제들을 해결하지 못할 뿐만 아니라, 이제 극복되어야만 하는 그 자신의 과제들을 도입한다. 예를 들어, 원시 데이터는 특정 수술 기량과 직접적으로 거의 상관되지 않으므로, 검토자는 그들이 검사하기를 원하는 기량과 검토를 위해 이용가능한 원시 데이터 사이의 상관을 추론하기 위해 노력해야 한다. 유사하게, "전문가" 및 "초보" 외과의들의 모집단들 사이의 위에서 언급된 상당한 비대칭성은 종종 수집된 데이터에 반영되어, 임의의 자동화된 데이터 분석을 수행하기 위한 노력들을 복잡하게 한다.
이에 따라, 수동 검토에 대한 전문가들의 의존도를 감소시키는, 확장가능하고 자동화된 수술 기량 평가 시스템들이 필요하다. 유사하게, 전문가들과 비전문가들 사이의 이용가능한 데이터에서 상당한 비대칭성을 고려할 수 있는 시스템들이 필요하다. 이러한 시스템들은, 이상적으로는, 또한 액션가능한 피드백을 외과의들에게 제공하기에 적합한 방식으로 그 평가들을 렌더링할 것이다.
본 명세서에서 소개되는 다양한 실시예들은 첨부 도면들과 관련된 아래의 상세한 설명을 참조함으로써 더 잘 이해될 수 있으며, 도면들에서 유사한 참조 번호들은 동일하거나 기능적으로 유사한 요소들을 나타낸다.
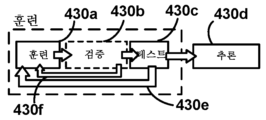
도 1a는 일부 실시예들과 관련하여 발생할 수 있는 바와 같은, 외과 수술 동안 수술실에서 나타나는 다양한 요소들의 개략도이다.
도 1b는 일부 실시예들과 관련하여 발생할 수 있는 바와 같은, 수술 로봇을 이용하는 외과 수술 동안 수술실에서 나타나는 다양한 요소들의 개략도이다.
도 2a는 기계 학습 모델들 및 방법론들의 종래의 그룹화들을 나타내는 개략적인 오일러 다이어그램이다.
도 2b는 도 2a의 종래의 그룹화들에 따른 예시적인 무감독 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2c는 도 2a의 종래의 그룹화들에 따른 예시적인 감독 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2d는 도 2a의 종래의 그룹화들에 따른 예시적인 반감독 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2e는 도 2a의 종래의 분할에 따른 예시적인 강화 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2f는 기계 학습 모델들, 기계 학습 모델 아키텍처들, 기계 학습 방법론들, 기계 학습 방법들, 및 기계 학습 구현들 사이의 관계들을 나타내는 개략적인 블록도이다.
도 3a는 예시적인 지원 벡터 기계(SVM) 기계 학습 모델 아키텍처의 다양한 양태들의 동작의 개략도이다.
도 3b는 예시적인 랜덤 포레스트 기계 학습 모델 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3c는 예시적인 신경망 기계 학습 모델 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3d는 도 3c의 예시적인 신경망 아키텍처의 노드에서의 입력들과 출력들 사이의 가능한 관계의 개략도이다.
도 3e는 베이지안 신경망에서 발생할 수 있는 바와 같은, 예시적인 입력-출력 관계 변화의 개략도이다.
도 3f는 예시적인 심층 학습 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3g는 예시적인 앙상블 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3h는 예시적인 기계 학습 파이프라인 토폴로지의 다양한 동작들을 나타내는 개략적인 블록도이다.
도 4a는 다양한 기계 학습 모델 훈련 방법들에 공통인 다양한 동작들을 나타내는 개략적인 흐름도이다.
도 4b는 다양한 기계 학습 모델 추론 방법들에 공통인 다양한 동작들을 나타내는 개략적인 흐름도이다.
도 4c는 일부 아키텍처들 및 훈련 방법들에서 블록(405b)에서 발생하는 다양한 반복 훈련 동작들을 나타내는 개략적인 흐름도이다.
도 4d는 훈련 및 추론 방법들 사이의 엄격한 구별이 없는 다양한 기계 학습 방법 동작들을 나타내는 개략적인 블록도이다.
도 4e는 아키텍처 훈련 방법들과 추론 방법들 사이의 예시적인 관계를 나타내는 개략적인 블록도이다.
도 4f는 기계 학습 모델 훈련 방법들과 추론 방법들 사이의 예시적인 관계를 나타내는 개략적인 블록도이며, 훈련 방법들은 다양한 데이터 서브세트 동작들을 포함한다.
도 4g는 훈련 데이터를 훈련 서브세트, 검증 서브세트, 및 테스트 서브세트로 분해하는 예를 나타내는 개략적인 블록도이다.
도 4h는 전이 학습을 포함하는 훈련 방법에서의 다양한 동작들을 나타내는 개략적인 블록도이다.
도 4i는 온라인 학습을 포함하는 예시적인 훈련 방법에서의 다양한 동작들을 나타내는 개략적인 블록도이다.
도 4j는 예시적인 생성적 대립쌍 네트워크 방법에서의 다양한 구성요소들을 나타내는 개략적인 블록도이다.
도 5a는 일부 실시예들에서 처리 시스템에서 수신될 수 있는 바와 같은, 수술 데이터의 개략도이다.
도 5b는 다양한 개시된 실시예들과 관련하여 이용될 수 있는 바와 같은, 예시적인 작업들의 표이다.
도 6은 일부 실시예들에서 발생할 수 있는 바와 같은, 수술 기량(또는 작업) 평가를 수행하기 위한 정보 흐름을 나타내는 개략도이다.
도 7a는 일부 실시예들에서 수행될 수 있는 바와 같은, 기량 모델들을 생성 및 적용하기 위한 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 7b는 일부 실시예들에서 구현될 수 있는 바와 같은, 수술 스코어를 결정하기 위한 기량 모델의 예시적인 적용에서 이용되는 다양한 구성요소들을 나타내는 개략도이다.
도 7c는 일부 실시예들에서 구현될 수 있는 바와 같은, 예시적인 윈도잉 스코어 생성 프로세스의 적용을 나타내는 개략도이다.
도 7d는 일부 실시예들에서 생성될 수 있는 바와 같은, 시간 경과에 따른 예시적인 기량 스코어 출력의 플롯이다.
도 8a는 일부 실시예들에서 이용될 수 있는 바와 같은, 다양한 메트릭들과 데이터 구조들 사이의 관계들을 나타내는 개략도이다.
도 8b는 일부 실시예들에서 하나 이상의 객관적 성과 지표(OPI)를 생성하는데 이용될 수 있는 바와 같은, 예시적인 원시 데이터 입력, 구체적으로, 3차원 공간에서의 포스셉스 병진 운동(forceps translational movement)의 개략도이다.
도 8c는 일부 실시예들에서 하나 이상의 OPI를 생성하는데 이용될 수 있는 바와 같은, 예시적인 원시 데이터 입력, 구체적으로, 복수의 포스셉스 구성요소 축을 중심으로 하는 3차원 공간에서의 복수의 회전들의 개략도이다.
도 8d는 일부 실시예들에서 적용될 수 있는 바와 같은, 예시적인 OPI 대 기량 및 기량 대 작업 매핑들을 나타내는 한 쌍의 표들이다.
도 9a는 일부 실시예들에서 구현될 수 있는 바와 같은, 기량들, 기량 모델들, 및 OPI들 사이의 예시적인 관계 세트를 나타내는 개략도이다.
도 9b는 일부 실시예들에서 구현될 수 있는 바와 같은, 주어진 기량 또는 작업에 대한 OPI 서브세트를 필터링하기 위한 OPI 관련성 평가기 시스템의 동작을 나타내는 개략적인 블록도이다.
도 9c는 일부 실시예들에서 OPI 관련성 평가기 시스템에서 구현될 수 있는 바와 같은, 예시적인 필터링 프레임워크를 나타내는 개략도이다.
도 10a는 일부 실시예들에서 구현될 수 있는 바와 같은, 단일 OPI 통계 분포 분석(SOSDA) 또는 다중-OPI 통계 분포 분석(MOSDA) 필터링에 의해 OPI들을 선택하기 위한 예시적인 프로세스를 나타내는 흐름도이다.
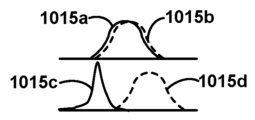
도 10b는 일부 실시예들에서 고려될 수 있는 바와 같은, 예시적인 유사한 그리고 유사하지 않은 전문가 및 비전문가 OPI 값 분포들의 한 쌍의 개략적인 플롯들이다.
도 10c는 일부 실시예들에서 구현될 수 있는 바와 같은, 다중-OPI 예측 모델(MOPM) 필터를 이용하여 OPI 선택을 수행하기 위한 예시적인 프로세스를 나타내는 흐름도이다.
도 11a는 일부 실시예들에서 구현될 수 있는 바와 같은, 예를 들어, 전문 지식 모델을 훈련하기 위해, 기량(또는 작업) 모델 구성들 및 OPI 선택들을 평가하기 위한 예시적인 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
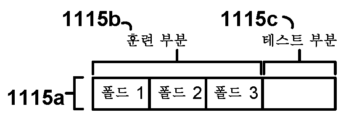
도 11b는 일부 실시예들에서 도 11a의 프로세스에 따라 훈련할 때 적용될 수 있는 바와 같은, 예시적인 훈련 데이터세트 브레이크다운이다.
도 12a는 일부 실시예들에서 발생할 수 있는 바와 같은, 추상적 특징 공간에서의 훈련 특징 벡터들 및 추론 특징 벡터의 개략적인 플롯이다.
도 12b는 일부 실시예들에서 수행될 수 있는 바와 같은, 기준 모집단에 기반하여 모델 출력들로부터 스코어 매핑을 결정하기 위한 예시적인 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 12c는 일부 실시예들에서 수행될 수 있는 바와 같은, 기준 모집단 기반 스코어 결정의 예시적인 적용을 나타내는 개략도이다.
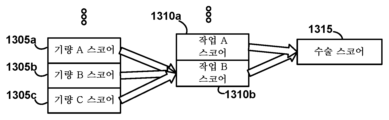
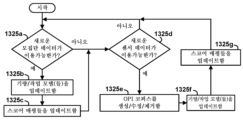
도 13a는 일부 실시예들에서 스코어 생성에 이용될 수 있는 바와 같은, 계층적 입력 및 출력 토폴로지를 나타내는 개략적인 블록도이다.
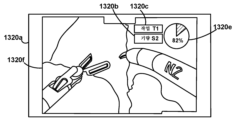
도 13b는 일부 실시예들에서 구현될 수 있는 바와 같은, 외과의의 성과의 비디오에 대한 성과 메트릭 오버레이를 나타내는 그래픽 사용자 인터페이스 스크린샷의 개략적인 표현이다.
도 13c는 일부 실시예들에서 구현될 수 있는 바와 같은, 기량 평가 시스템에 대한 예시적인 업데이트 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 14a는 실시예의 예시적인 실습 축소(reduction to practice)에서 이용하는데 이용가능한 데이터 샘플들의 유형들 및 양의 막대 플롯이다.
도 14b는 실시예의 예시적인 실습 축소에서 기량-작업 및 전체 작업 로지스틱 회귀 모델들 각각에 대한 평균 교차 검증 성과 메트릭들, 구체적으로 균형화된 정확도 및 매튜스 상관 계수들(MCC)을 나타내는 표이다.
도 15는 실시예의 예시적인 구현에서 리샘플링의 적용 전후에 자궁뿔 작업(Uterine Horn task)에서 4개의 기구에 대한 모션 값들의 경제성을 나타내는 한 쌍의 개략적인 도트 플롯들이다.
도 16은 실시예의 예시적인 구현에서 재귀적 특징 제거(Recursive Feature Elimination)(RFE)를 이용한 기량당 다양한 수의 OPI들의 교차 검증된 스코어들 및 예시적인 실습 축소에서의 경험 레벨에 의한 작업 지속기간들의 분포를 나타내는 개략적인 라인 플롯들의 컬렉션이다.
도 17은 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 18은 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 19는 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 20은 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 21은 실시예들 중 일부와 관련하여 이용될 수 있는 바와 같은, 예시적인 컴퓨터 시스템의 블록도이다.
도면들에 도시된 특정 예들은 이해를 용이하게 하기 위해 선택되었다. 결과적으로, 개시된 실시예들은 도면들 또는 대응하는 개시내용에서의 특정 상세들에 제한되지 않아야 한다. 예를 들어, 도면들은 축척에 맞게 그려지지 않을 수 있고, 도면들 내의 일부 요소들의 치수들은 이해를 용이하게 하기 위해 조정되었을 수 있고, 흐름도들과 관련된 실시예들의 동작들은 본 명세서에 도시된 것들보다 추가적인, 대안적인, 또는 더 적은 동작들을 포함할 수 있다. 따라서, 일부 구성요소들 및/또는 동작들은 도시된 것과 다른 방식으로 상이한 블록들로 분리되거나 단일 블록으로 결합될 수 있다. 실시예들은 실시예들을 설명되거나 도시된 특정 예들로 제한하기보다는, 개시된 예들의 범위 내에 있는 모든 수정들, 등가물들, 및 대안들을 커버하도록 의도된다.
도 1a는 일부 실시예들과 관련하여 발생할 수 있는 바와 같은, 외과 수술 동안 수술실에서 나타나는 다양한 요소들의 개략도이다.
도 1b는 일부 실시예들과 관련하여 발생할 수 있는 바와 같은, 수술 로봇을 이용하는 외과 수술 동안 수술실에서 나타나는 다양한 요소들의 개략도이다.
도 2a는 기계 학습 모델들 및 방법론들의 종래의 그룹화들을 나타내는 개략적인 오일러 다이어그램이다.
도 2b는 도 2a의 종래의 그룹화들에 따른 예시적인 무감독 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2c는 도 2a의 종래의 그룹화들에 따른 예시적인 감독 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2d는 도 2a의 종래의 그룹화들에 따른 예시적인 반감독 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2e는 도 2a의 종래의 분할에 따른 예시적인 강화 학습 방법의 다양한 동작들을 나타내는 개략도이다.
도 2f는 기계 학습 모델들, 기계 학습 모델 아키텍처들, 기계 학습 방법론들, 기계 학습 방법들, 및 기계 학습 구현들 사이의 관계들을 나타내는 개략적인 블록도이다.
도 3a는 예시적인 지원 벡터 기계(SVM) 기계 학습 모델 아키텍처의 다양한 양태들의 동작의 개략도이다.
도 3b는 예시적인 랜덤 포레스트 기계 학습 모델 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3c는 예시적인 신경망 기계 학습 모델 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3d는 도 3c의 예시적인 신경망 아키텍처의 노드에서의 입력들과 출력들 사이의 가능한 관계의 개략도이다.
도 3e는 베이지안 신경망에서 발생할 수 있는 바와 같은, 예시적인 입력-출력 관계 변화의 개략도이다.
도 3f는 예시적인 심층 학습 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3g는 예시적인 앙상블 아키텍처의 동작의 다양한 양태들의 개략도이다.
도 3h는 예시적인 기계 학습 파이프라인 토폴로지의 다양한 동작들을 나타내는 개략적인 블록도이다.
도 4a는 다양한 기계 학습 모델 훈련 방법들에 공통인 다양한 동작들을 나타내는 개략적인 흐름도이다.
도 4b는 다양한 기계 학습 모델 추론 방법들에 공통인 다양한 동작들을 나타내는 개략적인 흐름도이다.
도 4c는 일부 아키텍처들 및 훈련 방법들에서 블록(405b)에서 발생하는 다양한 반복 훈련 동작들을 나타내는 개략적인 흐름도이다.
도 4d는 훈련 및 추론 방법들 사이의 엄격한 구별이 없는 다양한 기계 학습 방법 동작들을 나타내는 개략적인 블록도이다.
도 4e는 아키텍처 훈련 방법들과 추론 방법들 사이의 예시적인 관계를 나타내는 개략적인 블록도이다.
도 4f는 기계 학습 모델 훈련 방법들과 추론 방법들 사이의 예시적인 관계를 나타내는 개략적인 블록도이며, 훈련 방법들은 다양한 데이터 서브세트 동작들을 포함한다.
도 4g는 훈련 데이터를 훈련 서브세트, 검증 서브세트, 및 테스트 서브세트로 분해하는 예를 나타내는 개략적인 블록도이다.
도 4h는 전이 학습을 포함하는 훈련 방법에서의 다양한 동작들을 나타내는 개략적인 블록도이다.
도 4i는 온라인 학습을 포함하는 예시적인 훈련 방법에서의 다양한 동작들을 나타내는 개략적인 블록도이다.
도 4j는 예시적인 생성적 대립쌍 네트워크 방법에서의 다양한 구성요소들을 나타내는 개략적인 블록도이다.
도 5a는 일부 실시예들에서 처리 시스템에서 수신될 수 있는 바와 같은, 수술 데이터의 개략도이다.
도 5b는 다양한 개시된 실시예들과 관련하여 이용될 수 있는 바와 같은, 예시적인 작업들의 표이다.
도 6은 일부 실시예들에서 발생할 수 있는 바와 같은, 수술 기량(또는 작업) 평가를 수행하기 위한 정보 흐름을 나타내는 개략도이다.
도 7a는 일부 실시예들에서 수행될 수 있는 바와 같은, 기량 모델들을 생성 및 적용하기 위한 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 7b는 일부 실시예들에서 구현될 수 있는 바와 같은, 수술 스코어를 결정하기 위한 기량 모델의 예시적인 적용에서 이용되는 다양한 구성요소들을 나타내는 개략도이다.
도 7c는 일부 실시예들에서 구현될 수 있는 바와 같은, 예시적인 윈도잉 스코어 생성 프로세스의 적용을 나타내는 개략도이다.
도 7d는 일부 실시예들에서 생성될 수 있는 바와 같은, 시간 경과에 따른 예시적인 기량 스코어 출력의 플롯이다.
도 8a는 일부 실시예들에서 이용될 수 있는 바와 같은, 다양한 메트릭들과 데이터 구조들 사이의 관계들을 나타내는 개략도이다.
도 8b는 일부 실시예들에서 하나 이상의 객관적 성과 지표(OPI)를 생성하는데 이용될 수 있는 바와 같은, 예시적인 원시 데이터 입력, 구체적으로, 3차원 공간에서의 포스셉스 병진 운동(forceps translational movement)의 개략도이다.
도 8c는 일부 실시예들에서 하나 이상의 OPI를 생성하는데 이용될 수 있는 바와 같은, 예시적인 원시 데이터 입력, 구체적으로, 복수의 포스셉스 구성요소 축을 중심으로 하는 3차원 공간에서의 복수의 회전들의 개략도이다.
도 8d는 일부 실시예들에서 적용될 수 있는 바와 같은, 예시적인 OPI 대 기량 및 기량 대 작업 매핑들을 나타내는 한 쌍의 표들이다.
도 9a는 일부 실시예들에서 구현될 수 있는 바와 같은, 기량들, 기량 모델들, 및 OPI들 사이의 예시적인 관계 세트를 나타내는 개략도이다.
도 9b는 일부 실시예들에서 구현될 수 있는 바와 같은, 주어진 기량 또는 작업에 대한 OPI 서브세트를 필터링하기 위한 OPI 관련성 평가기 시스템의 동작을 나타내는 개략적인 블록도이다.
도 9c는 일부 실시예들에서 OPI 관련성 평가기 시스템에서 구현될 수 있는 바와 같은, 예시적인 필터링 프레임워크를 나타내는 개략도이다.
도 10a는 일부 실시예들에서 구현될 수 있는 바와 같은, 단일 OPI 통계 분포 분석(SOSDA) 또는 다중-OPI 통계 분포 분석(MOSDA) 필터링에 의해 OPI들을 선택하기 위한 예시적인 프로세스를 나타내는 흐름도이다.
도 10b는 일부 실시예들에서 고려될 수 있는 바와 같은, 예시적인 유사한 그리고 유사하지 않은 전문가 및 비전문가 OPI 값 분포들의 한 쌍의 개략적인 플롯들이다.
도 10c는 일부 실시예들에서 구현될 수 있는 바와 같은, 다중-OPI 예측 모델(MOPM) 필터를 이용하여 OPI 선택을 수행하기 위한 예시적인 프로세스를 나타내는 흐름도이다.
도 11a는 일부 실시예들에서 구현될 수 있는 바와 같은, 예를 들어, 전문 지식 모델을 훈련하기 위해, 기량(또는 작업) 모델 구성들 및 OPI 선택들을 평가하기 위한 예시적인 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 11b는 일부 실시예들에서 도 11a의 프로세스에 따라 훈련할 때 적용될 수 있는 바와 같은, 예시적인 훈련 데이터세트 브레이크다운이다.
도 12a는 일부 실시예들에서 발생할 수 있는 바와 같은, 추상적 특징 공간에서의 훈련 특징 벡터들 및 추론 특징 벡터의 개략적인 플롯이다.
도 12b는 일부 실시예들에서 수행될 수 있는 바와 같은, 기준 모집단에 기반하여 모델 출력들로부터 스코어 매핑을 결정하기 위한 예시적인 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 12c는 일부 실시예들에서 수행될 수 있는 바와 같은, 기준 모집단 기반 스코어 결정의 예시적인 적용을 나타내는 개략도이다.
도 13a는 일부 실시예들에서 스코어 생성에 이용될 수 있는 바와 같은, 계층적 입력 및 출력 토폴로지를 나타내는 개략적인 블록도이다.
도 13b는 일부 실시예들에서 구현될 수 있는 바와 같은, 외과의의 성과의 비디오에 대한 성과 메트릭 오버레이를 나타내는 그래픽 사용자 인터페이스 스크린샷의 개략적인 표현이다.
도 13c는 일부 실시예들에서 구현될 수 있는 바와 같은, 기량 평가 시스템에 대한 예시적인 업데이트 프로세스에서의 다양한 동작들을 나타내는 흐름도이다.
도 14a는 실시예의 예시적인 실습 축소(reduction to practice)에서 이용하는데 이용가능한 데이터 샘플들의 유형들 및 양의 막대 플롯이다.
도 14b는 실시예의 예시적인 실습 축소에서 기량-작업 및 전체 작업 로지스틱 회귀 모델들 각각에 대한 평균 교차 검증 성과 메트릭들, 구체적으로 균형화된 정확도 및 매튜스 상관 계수들(MCC)을 나타내는 표이다.
도 15는 실시예의 예시적인 구현에서 리샘플링의 적용 전후에 자궁뿔 작업(Uterine Horn task)에서 4개의 기구에 대한 모션 값들의 경제성을 나타내는 한 쌍의 개략적인 도트 플롯들이다.
도 16은 실시예의 예시적인 구현에서 재귀적 특징 제거(Recursive Feature Elimination)(RFE)를 이용한 기량당 다양한 수의 OPI들의 교차 검증된 스코어들 및 예시적인 실습 축소에서의 경험 레벨에 의한 작업 지속기간들의 분포를 나타내는 개략적인 라인 플롯들의 컬렉션이다.
도 17은 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 18은 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 19는 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 20은 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 이들의 관계를 열거하는 표이다.
도 21은 실시예들 중 일부와 관련하여 이용될 수 있는 바와 같은, 예시적인 컴퓨터 시스템의 블록도이다.
도면들에 도시된 특정 예들은 이해를 용이하게 하기 위해 선택되었다. 결과적으로, 개시된 실시예들은 도면들 또는 대응하는 개시내용에서의 특정 상세들에 제한되지 않아야 한다. 예를 들어, 도면들은 축척에 맞게 그려지지 않을 수 있고, 도면들 내의 일부 요소들의 치수들은 이해를 용이하게 하기 위해 조정되었을 수 있고, 흐름도들과 관련된 실시예들의 동작들은 본 명세서에 도시된 것들보다 추가적인, 대안적인, 또는 더 적은 동작들을 포함할 수 있다. 따라서, 일부 구성요소들 및/또는 동작들은 도시된 것과 다른 방식으로 상이한 블록들로 분리되거나 단일 블록으로 결합될 수 있다. 실시예들은 실시예들을 설명되거나 도시된 특정 예들로 제한하기보다는, 개시된 예들의 범위 내에 있는 모든 수정들, 등가물들, 및 대안들을 커버하도록 의도된다.
예시적인 수술실 개요
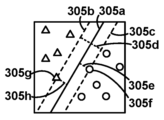
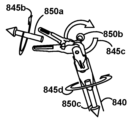
도 1a는 일부 실시예들과 관련하여 발생할 수 있는 외과 수술 동안 수술실(100a)에 나타나는 다양한 요소들의 개략도이다. 특히, 도 1a는 비-로봇 수술실(100a)을 도시하며, 여기서 환자측 외과의(105a)는 그 자신이 외과의, 의사 보조자, 간호사, 기술자 등일 수 있는 한 명 이상의 보조 멤버(105b)의 도움으로 환자(120)에 대한 수술을 수행한다. 외과의(105a)는 다양한 도구들, 예컨대, 복강경 초음파 또는 내시경과 같은 시각화 도구(110b), 및 가위, 리트랙터, 디섹터 등과 같은 기계적 엔드 이펙터(110a)를 이용하여 수술을 수행할 수 있다.
시각화 도구(110b)는, 예컨대, 시각화 도구(110b)와 기계적으로 그리고 전기적으로 결합된 카메라로부터의 시각화 출력을 디스플레이하는 것에 의해, 외과의(105a)에게 환자(120)의 내부 뷰를 제공한다. 외과의는 예를 들어, 시각화 도구(110b)와 결합된 접안경을 통해 또는 시각화 출력을 수신하도록 구성된 디스플레이(125) 상에서 시각화 출력을 볼 수 있다. 예를 들어, 시각화 도구(110b)가 내시경인 경우, 시각화 출력은 컬러 또는 그레이스케일 이미지일 수 있다. 디스플레이(125)는 보조 멤버(105b)가 수술 동안 외과의(105a)의 진행을 모니터링하게 할 수 있다. 시각화 도구(110b)로부터의 시각화 출력은 미래의 검토를 위해, 예를 들면, 시각화 도구(110b) 자체 상의 하드웨어 또는 소프트웨어를 이용하여, 시각화 출력이 디스플레이(125)에 제공될 때 시각화 출력을 병렬로 캡처하는 것, 또는 일단 디스플레이(125)가 스크린 상에 나타나면 디스플레이(125)로부터의 출력을 캡처하는 것 등을 위해 기록되고 저장될 수 있다. 시각화 도구(110b)를 이용한 2차원 비디오 캡처가 본 명세서에서 광범위하게 논의될 수 있지만, 시각화 도구(110b)가 내시경일 때와 같이, 일부 실시예들에서, 시각화 도구(110b)는 (예를 들어, 레이저 거리 측정기, 스테레오스코피 등을 이용하여) 2차원 이미지 데이터 대신에, 또는 그에 더하여 깊이 데이터를 캡처할 수 있다는 것을 알 것이다. 따라서, 필요한 부분만 약간 수정하여, 본 명세서에서 논의된 2차원 수술들을, 이러한 데이터가 이용가능할 때 이러한 3차원 깊이 데이터에 적용하는 것이 가능할 수 있다는 것을 이해할 것이다. 예를 들어, 기계 학습 모델 입력들은 이러한 깊이 데이터로부터 도출된 특징들을 수용하도록 확장 또는 수정될 수 있다.
단일 수술은 액션들의 여러 그룹의 수행을 포함할 수 있으며, 액션들의 각각의 그룹은 본 명세서에서 작업으로 지칭되는 개별 유닛을 형성한다. 예를 들어, 종양의 위치를 찾는 것은 제1 작업을 구성하고, 종양을 절제하는 것은 제2 작업을 구성하고, 수술 부위를 봉합하는 것은 제3 작업을 구성할 수 있다. 각각의 작업은 다수의 액션을 포함할 수 있는데, 예를 들어 종양 절제 작업은 여러 절단 액션 및 여러 소작 액션을 필요로 할 수 있다. 일부 수술들은 작업들이 특정 순서를 취하는 것(예를 들어, 봉합 전에 절제가 발생하는 것)을 요구하지만, 일부 수술들에서의 일부 작업들의 순서 및 존재(예를 들어, 예방 작업의 제거 또는 순서가 영향을 미치지 않는 경우 절제 작업들의 재순서화)는 변화하도록 허용될 수 있다. 작업들 사이의 전이는 외과의(105a)가 환자로부터 도구들을 제거하거나, 도구들을 상이한 도구들로 대체하거나, 새로운 도구들을 도입할 것을 요구할 수 있다. 일부 작업들은 시각화 도구(110b)가 제거되고 이전 작업에서의 그 위치에 대해 재배치될 것을 요구할 수 있다. 일부 보조 멤버들(105b)이 마취제(115)를 환자(120)에게 투여하는 것과 같은 수술 관련 작업들을 도울 수 있지만, 보조 멤버들(105b)은 또한 예를 들어 새로운 도구(110c)에 대한 필요성을 예상하는 것과 같은 이러한 작업 전이들을 도울 수 있다.
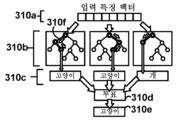
기술의 진보는 도 1a에 도시된 것과 같은 절차들이 비-로봇 수술실(100a)에서 수행될 수 없는 절차들의 수행뿐만 아니라 로봇 시스템들로 수행되는 것을 또한 가능하게 하였다. 구체적으로, 도 1b는 일부 실시예들과 관련하여 발생할 수 있는 바와 같이 da VinciTM 수술 시스템과 같은 수술 로봇을 이용하는 외과 수술 동안 수술실(100b)에 나타나는 다양한 요소들의 개략도이다. 여기서, 복수의 아암(135a, 135b, 135c, 및 135d) 각각에 각각 부착된 도구들(140a, 140b, 140c, 및 140d)을 갖는 환자측 카트(130)는 환자측 외과의(105a)의 위치를 취할 수 있다. 앞에서와 같이, 도구들(140a, 140b, 140c, 및 140d)은 내시경, 복강경 초음파 등과 같은 시각화 도구(140d)를 포함할 수 있다. 외과의일 수 있는 조작자(105c)는 외과의 콘솔(155) 상의 디스플레이(160a)를 통해 시각화 도구(140d)의 출력을 볼 수 있다. 핸드헬드 입력 메커니즘(160b) 및 페달들(160c)을 조작함으로써, 조작자(105c)는 환자(120)에 대한 수술 절차를 수행하기 위해 환자측 카트(130) 상의 도구들(140a-d)과 원격으로 통신할 수 있다. 실제로, 조작자(105c)는 환자측 카트(130) 및 환자(120)와 동일한 물리적 위치에 있거나 그렇지 않을 수 있는데, 그 이유는 외과의 콘솔(155)과 환자측 카트(130) 사이의 통신이 일부 실시예들에서 전기통신 네트워크를 통해 발생할 수 있기 때문이다. 전자기기/제어 콘솔(145)은 또한 환자 바이탈 및/또는 시각화 도구(140d)의 출력을 나타내는 디스플레이(150)를 포함할 수 있다.
비-로봇 수술실(100a)의 작업 전이와 유사하게, 수술실(100b)의 외과 수술은 시각화 도구(140d)를 포함하는 도구(140a-d)가 제거되거나 다양한 작업뿐만 아니라 도입된 새로운 도구, 예를 들어, 새로운 도구(165)를 위해 교체될 것을 요구할 수 있다. 앞에서와 같이, 한 명 이상의 보조 멤버(105d)는 이러한 변화들을 이제 예상할 수 있어서, 수술이 진행됨에 따라 임의의 필요한 조정들을 행하기 위해 조작자(105c)와 함께 작업한다.
또한, 비-로봇 수술실(100a)과 유사하게, 시각화 도구(140d)로부터의 출력은 여기서, 예를 들어, 환자측 카트(130), 외과의 콘솔(155), 디스플레이(150) 등에서 기록될 수 있다. 비-로봇 수술실(100a) 내의 일부 도구들(110a, 110b, 110c)은 온도, 모션, 전도도, 에너지 레벨 등과 같은 추가 데이터를 기록할 수 있지만, 수술실(100b) 내의 외과의 콘솔(155) 및 환자측 카트(130)의 존재는 시각화 도구(140d)로부터만 출력되는 것보다 상당히 더 많은 데이터의 기록을 용이하게 할 수 있다. 예를 들어, 조작자(105c)가 핸드헬드 입력 메커니즘(160b)을 조작하는 것, 페달(160c)을 활성화시키는 것, 디스플레이(160a) 내에서 눈을 움직이는 것 등이 모두 기록될 수 있다. 유사하게, 환자측 카트(130)는 수술 전반에서 도구 활성화들(예로서, 방사 에너지의 인가, 가위 접기 등), 엔드 이펙터의 이동 등을 기록할 수 있다.
기계 학습 기본 개념들 - 개요
이 섹션은 다양한 개시된 실시예들과 관련될 수 있는 기계 학습 모델 아키텍처들 및 방법들의 기본적인 설명을 제공한다. 기계 학습은 방대하고 이질적인 풍경을 포함하고, 많은 갑작스럽고 중복적인 전개들을 경험하였다. 이러한 복잡성을 감안할 때, 실무자들은 용어들을 일관되게 또는 엄격한 명료성으로 항상 사용하지는 않았다. 따라서, 이 섹션은 개시된 실시예들의 실체에 대한 독자의 이해를 더 잘 보장하기 위해 공통 지면을 제공하려고 한다. 본 명세서에서의 아키텍처들, 작업들, 방법들, 및 방법론들의 모든 알려진 가능한 변형들뿐만 아니라, 모든 알려진 기계 학습 모델들을 철저히 다루는 것은 실현가능하지 않다는 것을 알 것이다. 그 대신에, 본 명세서에서 논의된 예들이 단지 대표적인 것이고 다양한 개시된 실시예들이 명시적으로 논의된 것들 이외의 많은 다른 아키텍처들 및 방법들을 이용할 수 있다는 것을 잘 알 것이다.
독자를 기존의 문헌과 관련하여 지향시키기 위해, 도 2a는 종래에 인식된 기계 학습 모델들 및 방법론들(기법들이라고도 함)의 그룹화들을 개략적인 오일러 다이어그램의 형태로 나타내고 있다. 도 2a의 그룹화들은 도 2f와 관련하여 기계 학습 분야의 더 포괄적인 설명이 제공되기 전에, 독자를 지향시키기 위해 그 종래의 방식으로 도 2b 내지 도 2e를 참조하여 설명될 것이다.
통상적으로, 도 2a의 종래의 그룹화들은 모델이 수신할 것으로 예상되는 입력의 성질 또는 방법론이 동작할 것으로 예상되는 것에 기반하여 기계 학습 모델들과 그 방법론들을 구별한다. 무감독 학습 방법론은, 출력 메타데이터("라벨링되지 않은 데이터"라고도 함)가 없는 입력 데이터세트로부터 또는 메타데이터가 존재한다면 이러한 메타데이터를 무시함으로써 추론을 도출한다. 예를 들어, 도 2b에 도시된 바와 같이, 무감독 KNN(K-Nearest-Neighbor) 모델 아키텍처는 특징 공간(205a)에서 원들로 표현된 복수의 라벨링되지 않은 입력들을 수신할 수 있다. 특징 공간은 주어진 모델 아키텍처가 동작하도록 구성되는 입력들의 수학적 공간이다. 예를 들어, 128x128 그레이스케일 픽셀 이미지가 KNN에 입력으로서 제공되었다면, 이것은 16,384개의 "특징"(즉, 원시 픽셀 값)의 선형 어레이로서 취급될 수 있다. 특징 공간은 그러면 16,384차원 공간일 것이다(이해를 용이하게 하기 위해 단지 2차원의 공간이 도 2b에 도시되어 있다). 대신에, 예를 들어, 푸리에 변환이 픽셀 데이터에 적용된다면, 결과적인 주파수 크기 및 위상은 모델 아키텍처에 입력될 "특징"으로서 역할할 수 있다. 특징 공간에서의 입력 값들이 때때로 특징 "벡터들"이라고 지칭될 수 있지만, 모든 모델 아키텍처들이 특징 입력들을 선형 형태로 수신할 것으로 예상하지는 않는다는 것을 알 것이다(예컨대, 일부 심층 학습 네트워크들은 입력 특징들을 행렬들 또는 텐서들로서 예상한다). 이에 따라, 특징들의 벡터, 특징들의 행렬 등에 대한 언급은, 그렇지 않은 것을 나타내는 컨텍스트가 없는 모델 아키텍처에 입력될 수 있는 가능한 형태들의 예시적인 것으로 보아야 한다. 유사하게, "입력"에 대한 참조는 아키텍처에 수용가능한 임의의 가능한 특징 유형 또는 형태를 포함하는 것으로 이해될 것이다. 도 2b의 예를 계속하면, KNN 분류기는 도면에서 표시된 정사각형들, 삼각형들, 및 육각형들에 의해 표현된 바와 같이 KNN 분류기에 의해 결정된 다양한 그룹화들과 입력 벡터들 사이의 연관들을 출력할 수 있다. 따라서, 무감독 방법론들은, 예를 들어, 이 예에서와 같이 데이터 내의 클러스터들을 결정하는 것, 데이터 입력들을 표현하는데 이용되는 특징 차원들을 감소시키거나 변경하는 것 등을 포함할 수 있다.
감독 학습 모델은, 출력 메타데이터("라벨링된 데이터"라고 함)를 수반한 입력 데이터세트를 수신하고, 이 입력 데이터 및 메타데이터에 기반하여 모델 아키텍처의 파라미터(신경망의 바이어스 및 가중치, 또는 SVM의 지원 벡터 등)를 수정하여 후속해서 수신된 입력들을 원하는 출력에 더 양호하게 매핑한다. 예를 들어, SVM 감독 분류기는 도 2c에 도시된 바와 같이 동작하여, 훈련 입력으로서 특징 공간(210a)에서 원들에 의해 표현되는 복수의 입력 특징 벡터들을 수신할 수 있고, 여기서 특징 벡터들은, 예를 들어, 실무자에 의해 제공되는 바와 같은 출력 라벨들 A, B, 또는 C를 수반한다. 감독 학습 방법론에 따르면, SVM은 이러한 라벨 입력들을 이용하여 그 파라미터들을 수정하며, 따라서 SVM이 특징 공간(210a)의 특징 벡터 형태의 새로운 이전에 보이지 않은 입력(210c)을 수신할 때, SVM은 그 출력에서 원하는 분류 "C"를 출력할 수 있다. 따라서, 감독 학습 방법론은, 예를 들어, 이 예에서와 같이 분류를 수행하는 것, 회귀를 수행하는 것 등을 포함할 수 있다.
반감독 학습 방법론은 라벨링된 데이터 및 라벨링되지 않은 데이터 양쪽 모두에 기반하여 그 모델의 아키텍처의 파라미터 조정을 통보한다. 예를 들어, 감독 신경망 분류기는 도 2d에 도시된 바와 같이 동작하여, 분류 A, B, 또는 C로 라벨링된 특징 공간(215a) 내의 일부 훈련 입력 특징 벡터들 및 이러한 라벨이 없는 일부 훈련 입력 특징 벡터들(문자가 없는 원으로 도시됨)을 수신할 수 있다. 라벨링되지 않은 입력들을 고려하지 않으면, 나이브 감독 분류기는 이용가능한 라벨링된 입력들 사이의 특징 공간에서의 단순 평면 분리(215d)에 기반하여 B 및 C 클래스들에서의 입력들을 구별할 수 있다. 그러나, 반감독 분류기는, 라벨링되지 않은 입력 특징 벡터뿐만 아니라 라벨링된 입력 특징 벡터를 고려함으로써, 더 미묘한 분리(215e)를 이용할 수 있다. 단순 분리(215d)와 달리, 미묘한 분리(215e)는 새로운 입력(215c)을 C 클래스에 있는 것으로서 올바르게 분류할 수 있다. 따라서, 반감독 학습 방법들 및 아키텍처들은, 이용가능한 데이터의 적어도 일부가 라벨링되는 감독 및 무감독 학습 양쪽 모두에서의 애플리케이션들을 포함할 수 있다.
마지막으로, 도 2a의 종래의 그룹화들은 강화 학습 방법론들을, 에이전트, 예를 들어, 로봇 또는 디지털 보조기가 에이전트의 환경 컨텍스트(예를 들어, 환경 내의 물체 위치들, 사용자의 배치 등)에 영향을 미치는 일부 액션(예를 들어, 조작자를 이동시키는 것, 사용자에게 제안하는 것 등)을 취하는 것, 새로운 환경 상태 및 일부 연관된 환경 기반 보상(예를 들어, 환경 물체들이 이제 목표 상태에 더 가까운 경우의 긍정적인 보상, 사용자가 거부되는 경우의 부정적인 보상 등)을 촉발시키는 것과 구별한다. 따라서, 강화 학습은, 예를 들어, 사용자의 거동 및 표현된 선호도들, 공장을 통한 자율 로봇 조종, 컴퓨터 플레이 체스 등에 기반하여 디지털 보조기를 업데이트하는 것을 포함할 수 있다.
언급된 바와 같이, 많은 실무자들이 도 2a의 종래의 분류를 인식할 것이지만, 도 2a의 그룹화들은 기계 학습의 풍부한 다양성을 모호하게 하고, 기계 학습 아키텍처들 및 기법들을 부적절하게 특성화할 수 있는데, 이 기계 학습 아키텍처들 및 기법들은 그 그룹들 중 다수에 속하거나 이러한 그룹들의 완전히 외부에 속한다(예를 들어, 랜덤 포레스트들 및 신경망들은 감독 또는 무감독 학습 작업들에 이용될 수 있고; 유사하게, 일부 생성적 대립쌍 네트워크들은, 감독 분류기들을 이용하면서, 그 자체가 도 2a의 그룹화들 중 어느 하나 내에 쉽게 속하지 않을 것이다). 따라서, 본 명세서에서는 독자의 이해를 용이하게 하기 위해 도 2a로부터의 다양한 용어들이 참조될 수 있지만, 이 설명은 도 2a의 획일적 관례들로 제한되지 않아야 한다. 예를 들어, 도 2f는 더 유연한 기계 학습 분류를 제공한다.
특히, 도 1f는 모델들(220a), 모델 아키텍처들(220b), 방법론들(220e), 방법들(220d), 및 구현들(220c)을 포함하는 것과 같이 기계 학습에 접근한다. 상위 레벨에서, 모델 아키텍처들(220b)은 그들 각각의 속 모델들(220a)의 종들(가능한 아키텍처들 A1, A2 등을 갖는 모델 A; 가능한 아키텍처들 B1, B2 등을 갖는 모델 B)로서 보여질 수 있다. 모델들(220a)은 기계 학습 아키텍처들로서 구현하기에 순응적인 수학적 구조들의 설명들을 참조한다. 예를 들어, 박스들 "A", "B", "C" 등에 의해 표현되는 KNN, 신경망들, SVM들, 베이지안 분류기들, PCA(Principal Component Analysis) 등은 모델들의 예들이다(도면들에서의 생략부호들은 추가적인 항목들의 존재를 나타낸다). 모델들이 일반적인 계산 관계들, 예를 들어 SVM이 초평면을 포함하는 것, 신경망이 계층들 또는 뉴런들을 갖는 것 등을 지정할 수 있지만, 모델들은 특정 작업, 예를 들어 SVM이 방사 기저 함수(RBF) 커널을 이용하는 것, 신경망이 차원 256x256x3의 입력들을 수신하도록 구성되는 것 등을 수행하기 위한 아키텍처의 하이퍼파라미터들 및 데이터 흐름의 선택과 같은 아키텍처의 특정 구조를 지정하지 않을 수 있다. 이러한 구조적 특징들은, 예를 들어, 실무자에 의해 선택되거나 또는 훈련 또는 구성 프로세스로부터 초래될 수 있다. 모델(220a)의 유니버스는 또한, 예를 들어, 앙상블 모델(도 3g와 관련하여 이하에서 논의됨)을 생성할 때 또는 모델 파이프라인(도 3h와 관련하여 이하에서 논의됨)을 이용할 때 그 멤버들의 조합을 포함한다는 점에 유의한다.
명확함을 위해, 많은 아키텍처가 파라미터 및 하이퍼파라미터 둘 다를 포함한다는 것을 잘 알 것이다. 아키텍처의 파라미터들은 (훈련 동안 신경망의 가중치들 및 바이어스들의 조정과 같은) 입력 데이터의 수신에 직접 기반하여 조정될 수 있는 아키텍처의 구성 값들을 지칭한다. 상이한 아키텍처들은 파라미터들 및 그 사이의 관계들의 상이한 선택들을 가질 수 있지만, 예를 들어, 훈련 동안의 파라미터의 값에서의 변경들은 아키텍처에서의 변경으로 고려되지 않을 것이다. 대조적으로, 아키텍처의 하이퍼파라미터들은 입력 데이터(예를 들어, KNN 구현에서의 K개의 이웃, 신경망 훈련 구현에서의 학습 레이트, SVM의 커널 유형 등)의 수신에 직접 기반하여 조정되지 않는 아키텍처의 구성 값들을 지칭한다. 따라서, 하이퍼파라미터의 변경은 통상적으로 아키텍처를 변경할 것이다. 후술하는 일부 방법 동작들, 예를 들어 검증은 훈련 동안 하이퍼파라미터들, 및 그 결과의 아키텍처 유형을 조정할 수 있다는 것을 알 것이다. 결과적으로, 일부 구현들은 다수의 아키텍처를 고려할 수 있지만, 이들 중 일부만이 주어진 순간에 이용되도록 구성되거나 이용될 수 있다.
모델들 및 아키텍처들과 유사한 방식으로, 상위 레벨에서, 방법들(220d)은 그 속 방법론들(220e)의 종들로서 보여질 수 있다(방법론 I는 방법들 I.1, I.2 등을 갖고; 방법론 II는 방법들 II.1, II.2 등을 가진다). 방법론들(220e)은, 아키텍처를 훈련하는 것, 아키텍처를 테스트하는 것, 아키텍처를 검증하는 것, 아키텍처로 추론을 수행하는 것, 생성적 대립쌍 네트워크(GAN)에서의 다수의 아키텍처들을 이용하는 것 등과 같은, 하나 이상의 특정 기계 학습 아키텍처를 이용하여 작업들을 수행하는 방법들로서 적응될 수 있는 알고리즘들을 지칭한다. 예를 들어, 기울기 하강은 신경망을 훈련하기 위한 방법들을 설명하는 방법론이고, 앙상블 학습은 아키텍처들의 그룹들을 훈련하기 위한 방법들을 설명하는 방법론 등이다. 방법론들이 일반적인 알고리즘 동작들, 예를 들어, 기울기 하강이 비용 또는 에러 표면을 따라 반복적인 단계들을 취하는 것, 앙상블 학습이 그 아키텍처들의 중간 결과들을 고려하는 것 등을 지정할 수 있지만, 방법들은 특정 아키텍처가 방법론의 알고리즘을 어떻게 수행해야 하는지, 예를 들어, 기울기 하강이 신경망 상의 반복적 역전파 및 특정 하이퍼파라미터들을 갖는 아담을 통한 확률적 최적화를 이용하는 것, 앙상블 시스템이 특정 구성 값들을 갖는 AdaBoost를 적용하는 랜덤 포레스트들의 컬렉션을 포함하는 것, 훈련 데이터가 특정 수의 폴드들로 조직화되는 것 등을 지정한다. 아키텍처들 및 방법들은, 기존의 아키텍처 또는 방법을 추가적인 또는 수정된 기능으로 증강할 때와 같이, 그 자체가 서브아키텍처 및 하위 방법들을 가질 수 있다는 것을 이해할 것이다(예를 들어, GAN 아키텍처 및 GAN 훈련 방법은 심층 학습 아키텍처들 및 심층 학습 훈련 방법들을 포함하는 것으로 볼 수 있다). 또한, 모든 가능한 방법론들이 모든 가능한 모델들에 적용되지는 않을 것임을 이해할 것이다(예를 들어, 추가 설명 없이 PCA 아키텍처에 대해 기울기 하강을 수행하는 제안은 의미없는 것으로 보일 것이다). 방법들은 실무자에 의한 일부 액션들을 포함할 수 있거나 완전히 자동화될 수 있다는 것을 알 것이다.
위의 예들에 의해 입증된 바와 같이, 모델들로부터 아키텍처들로 그리고 방법론들로부터 방법들로 이동함에 따라, 아키텍처의 양태들은 방법 및 아키텍처에서의 방법의 양태들에 나타날 수 있는데, 그 이유는 일부 방법들이 특정 아키텍처들에만 적용될 수 있고 특정 아키텍처들이 특정 방법들에만 순응적일 수 있기 때문이다. 이 상호 작용을 이해하면, 구현(220c)은, 훈련, 추론, GAN을 이용한 새로운 데이터의 생성 등과 같은 하나 이상의 지정된 작업을 수행하도록 구성된 기계 학습 시스템을 형성하기 위한 하나 이상의 방법과의 하나 이상의 아키텍처의 조합이다. 명료성을 위해, 구현의 아키텍처는 그 방법을 능동적으로 수행할 필요는 없고, (예를 들어, 수반되는 훈련 제어 소프트웨어가 아키텍처를 통해 입력을 전달하도록 구성될 때와 같이) 단순히 방법을 수행하도록 구성될 수 있다. 방법을 적용하는 것은 훈련 또는 추론과 같은 작업의 수행을 초래할 것이다. 따라서, 도 2f에 도시된 가상 구현 A("Imp. A"로 표시됨)는 단일 방법을 갖는 단일 아키텍처를 포함한다. 이는, 예를 들어, 16,384 차원의 공간에서 RBF 커널을 이용하는 초평면 지원 벡터 분리 방법을 이용함으로써 128x128 그레이스케일 픽셀 이미지에서 물체들을 인식하도록 구성된 SVM 아키텍처에 대응할 수 있다. RBF 커널의 이용 및 특징 벡터 입력 구조의 선택은 아키텍처의 선택 및 훈련 및 추론 방법들의 선택의 양 양태들을 반영한다. 따라서, 아키텍처 구조의 일부 설명들은 대응하는 방법의 양태들을 암시할 수 있고 그 반대도 가능하다는 것을 알 것이다. 가상 구현 B("Imp. B"로 표시됨)는, 예를 들어, 추론 방법 III.3이 적용되기 전에, 검증 결과들에 기반하여 아키텍처들 B1과 C1 사이에서 스위칭할 수 있는 훈련 방법 II.1에 대응할 수 있다.
구현들 내의 아키텍처들과 방법들 사이의 밀접한 관계는 도 2a의 모호성의 대부분을 촉발시키는데, 그 이유는 그룹들이 주어진 구현에서 방법들과 아키텍처들 사이의 밀접한 관계를 쉽게 캡처하지 않기 때문이다. 예를 들어, 방법 또는 아키텍처의 매우 사소한 변화들은, 실무자가 라벨들을 포함하는 제1 방법(감독)으로 랜덤 포레스트를 훈련한 후, 데이터에 대한 추론을 수행하기보다는 라벨링되지 않은 데이터(무감독)에서 클러스터들을 검출하기 위해 훈련된 아키텍처로 제2 방법을 적용할 때와 같이, 도 2a의 그룹들 사이에서 모델 구현을 이동시킬 수 있다. 유사하게, 도 2a의 그룹들은, 예를 들어 도 2a의 그룹들 중 일부에서 발견되거나, 어느 것에서도 발견되지 않거나, 또는 전부에서 발견되는 기법들을 적용할 수 있는, 도 3f 및 도 3g와 관련하여 이하에서 논의되는 바와 같이, 총합 방법들 및 아키텍처들을 분류하는 것을 어렵게 만들 수 있다. 따라서, 다음 섹션들은 아키텍처들, 방법들, 및 구현들 사이의 관계들의 명확성 및 독자의 인식을 용이하게 하기 위해 도 3a 내지 도 3g 및 도 4a 내지 도 4j를 참조하여 다양한 예시적인 모델 아키텍처들과 예시적인 방법들 사이의 관계들을 논의한다. 논의된 작업들은 예시적이고 따라서, 예를 들어, 이해를 용이하게 하기 위해 분류 동작들을 참조하는 것이 구현이 그 목적을 위해 배타적으로 이용되어야 함을 제안하는 것으로서 해석되어서는 안 된다는 것을 알 것이다.
명확함을 위해, 도 2f와 관련한 이상의 설명이 단지 독자의 이해를 용이하게 하기 위해 제공된 것이고 이에 따라 명시적 언어가 그렇게 표시하지 않는 제한적인 방식으로 해석되어서는 안된다는 것을 잘 알 것이다. 예를 들어, 당연히, "방법들"(220d)은 컴퓨터에 의해 구현되는 방법들이지만, 모든 컴퓨터에 의해 구현되는 방법들이 "방법들"(220d)의 의미에서의 방법들이 아니라는 것을 이해할 것이다. 컴퓨터에 의해 구현되는 방법들은 어떠한 기계 학습 기능도 갖지 않는 로직일 수 있다. 유사하게, 용어 "방법론들"은 "방법론들"(220e)의 의미에서 항상 사용되는 것은 아니지만, 기계 학습 기능이 없는 접근법들을 지칭할 수 있다. 유사하게, 용어들 "모델" 및 "아키텍처" 및 "구현"이 220a, 220b 및 220c에서 위에서 사용되었지만, 그 용어들은 여기서 그 효과에 대한 언어가 없이, 도 2f에서 그 구별들로 제한되지 않고, 일반적으로 기계 학습 구성요소들의 토폴로지를 지칭하는데 사용될 수 있다.
기계 학습 기본 개념들 - 예시적인 구현들
도 3a는 예시적인 SVM 기계 학습 모델 아키텍처의 동작의 개략도이다. 상위 레벨에서, 도 3a의 개략도에서 원들 및 삼각형들에 의해 표현되는, 입력 특징들로서 2개의 클래스로부터의 데이터(예를 들어, 개들의 이미지들 및 고양이들의 이미지들)가 주어지면, SVM들은 각각의 클래스의 멤버들로부터 분리기(305a)까지의 최소 거리를 최대화하는 초평면 분리기(305a)를 결정하려고 시도한다. 여기서, 훈련 특징 벡터(305f)는 분리기(305a)까지의 그 모든 피어들의 최소 거리(305e)를 갖는다. 반대로, 훈련 특징 벡터(305g)는 그 모든 피어들 사이에서 분리기(305a)까지의 최소 거리(305h)를 갖는다. 따라서, 이들 2개의 훈련 특징 벡터 사이에 형성된 마진(305d)은 거리들(305h 및 305e)의 조합이고(명료성을 위해 기준 라인들(305b 및 305c)이 제공됨), 최대 최소 분리이면, 훈련 특징 벡터들(305f 및 305g)을 지원 벡터들로서 식별한다. 이 예가 선형 초평면 분리를 도시하지만, 상이한 SVM 아키텍처들은 비선형 초평면 분리를 용이하게 할 수 있는 상이한 커널들(예를 들어, RBF 커널)을 수용한다. 분리기는 훈련 동안 발견될 수 있고, 후속 추론은 특징 공간에서의 새로운 입력이 분리기에 대해 어디에 속하는지를 고려함으로써 달성될 수 있다. 유사하게, 이 예가 (종이의 2차원 평면에서) 명확함을 위해 2차원의 특징 벡터들을 나타내고 있지만, 아키텍처들이 보다 많은 차원의 특징들을 수용할 수 있다는 것을 잘 알 것이다(예컨대, 128x128 픽셀 이미지가 16,384 차원으로서 입력될 수 있다). 이 예에서의 초평면은 단지 2개의 클래스만을 분리하지만, 다중-클래스 분리는 다양한 방식으로, 예를 들어, 일-대-일, 일-대-전부 등의 구성들에서의 SVM 초평면 분리들의 앙상블 아키텍처를 이용하여 달성될 수 있다. 실무자들은 SVM들을 구현할 때 종종 LIBSVMTM 및 scikit-learnTM 라이브러리들을 이용한다. 많은 상이한 기계 학습 모델들, 예를 들어 로지스틱 회귀 분류기들이 분리된 초평면들을 식별하려고 시도한다는 것을 알 것이다.
위의 예시적인 SVM 구현에서, 실무자는 구현의 아키텍처 및 방법의 일부로서 특징 포맷을 결정했다. 일부 작업들에 대해, 새로운 또는 상이한 특징 형태들 자체를 결정하기 위해 입력들을 처리하는 아키텍처들 및 방법들이 바람직할 수 있다. 일부 랜덤 포레스트 구현들은, 사실상, 이러한 방식으로 특징 공간 표현을 조정할 수 있다. 예를 들어, 도 3b는 각각이 그 루트 노드에서 입력 특징 벡터(310a)의 전부 또는 일부를 수신할 수 있는 복수의 결정 트리(310b)를 포함하는 예시적인 랜덤 포레스트 모델 아키텍처를 상위 레벨에서 도시한다. 이 예시적인 아키텍처에서는 3개의 레벨의 최대 깊이들을 갖는 3개의 트리가 도시되어 있지만, 더 적거나 더 많은 트리들 및 상이한 레벨들(심지어 동일한 포레스트의 트리들 사이)을 갖는 포레스트 아키텍처들이 가능하다는 것을 알 것이다. 각각의 트리는 입력의 그 부분을 고려하므로, 입력 부분이 다양한 노드들과 연관된 조건들을 충족시키거나 충족시키지 않는지에 기반하여 후속 노드, 예로서 경로(310f)에 대한 입력의 전부 또는 일부를 참조한다. 예를 들어, 이미지를 고려할 때, 트리 내의 단일 노드는 특징 벡터 내의 위치에서의 픽셀 값이 특정 임계값 위 또는 아래인지를 질의할 수 있다. 임계 파라미터에 더하여, 일부 트리들은 추가적인 파라미터들을 포함할 수 있고, 그 리프들은 정확한 분류의 확률들을 포함할 수 있다. 트리의 각각의 리프는, 예를 들어, 트리들 사이에서 다수 투표를 취함으로써 또는 각각의 트리의 예측들의 확률 가중 평균에 의해, 투표 메커니즘(310d)에 의한 고려를 위해 잠정적 출력 값(310c)과 연관되어 최종 출력(310e)을 생성할 수 있다. 이 아키텍처 자체는, 예를 들어, 상이한 데이터 서브세트들이 상이한 트리들에 대해 훈련되므로, 다양한 훈련 방법들에 적합할 수 있다.
상이한 트리들뿐만 아니라, 랜덤 포레스트에서의 트리 깊이는 초기 입력에서의 트리들의 직접 비교들을 넘어서 랜덤 포레스트 모델의 특징 관계들의 고려를 용이하게 할 수 있다. 예를 들어, 원래의 특징들이 픽셀 값들이라면, 트리들은, 고양이/개 분류에 대한 "코" 픽셀과 "귀" 픽셀 사이의 관계 등의, 작업에 관련된 픽셀 값들의 그룹들 사이의 관계를 인식할 수 있다. 그러나, 이진 결정 트리 관계들은 이러한 "고차" 특징들을 식별하는 능력에 대한 제한들을 부과할 수 있다.
도 3c의 예시적인 아키텍처에서와 같은 신경망들은 또한 초기 입력 벡터 사이의 고차 특징들 및 관계들을 추론할 수 있다. 그렇지만, 네트워크 내의 각각의 노드는 다양한 파라미터들 및 다른 노드들에의 연결들과 연관되어, 종래의 랜덤 포레스트 트리의 이진 관계들보다 더 복잡한 결정들 및 중간 특징 생성들을 용이하게 할 수 있다. 도 3c에 도시된 바와 같이, 신경망 아키텍처는, 입력 계층, 적어도 하나의 은닉 계층, 및 출력 계층을 포함할 수 있다. 각각의 계층은 다수의 입력을 수신하고, 활성화 값으로도 지칭되는 출력 값을 제공할 수 있는 뉴런들의 컬렉션을 포함하며, 최종 출력 계층의 출력 값들(315b)은 네트워크의 최종 결과의 역할을 한다. 유사하게, 입력 계층에 대한 입력들(315a)은 이전 뉴런 계층보다는 입력 데이터로부터 수신될 수 있다.
도 3d는 도 3c의 노드(315c)에서의 입력 및 출력 관계들을 도시한다. 구체적으로, 노드(315c)의 출력 n out 는 다음과 같이 그 3개의 (제로-베이스 인덱싱된) 입력과 관련될 수 있다:
여기서 w i 는 입력 계층에서의 i번째 노드의 출력에 대한 가중치 파라미터이고, n i 는 입력 계층에서의 i번째 노드의 활성화 함수로부터의 출력 값이고, b는 노드(315c)와 연관된 바이어스 값이고, A는 노드(315c)와 연관된 활성화 함수이다. 이 예에서, 합은 3개의 입력 계층 노드 출력들 및 가중치 쌍들 각각에 대한 것이고 단일 바이어스 값 b만이 가산된다는 점에 유의한다. 활성화 함수 A는 가중치들, 바이어스들 및 이전 계층의 노드 값들의 값들에 기반하여 노드의 출력을 결정할 수 있다. 훈련 동안, 가중치 및 바이어스 파라미터들 각각은 이용되는 훈련 방법에 따라 조정될 수 있다. 예를 들어, 많은 신경망들은 역방향 전파라고 알려진 방법론을 이용하고, 여기서, 일부 방법 형태들에서, 가중치 및 바이어스 파라미터는 랜덤으로 초기화되고, 훈련 입력 벡터가 네트워크를 통과하며, 네트워크의 출력 값과 그 벡터의 메타데이터에 대한 바람직한 출력 값 사이의 차이가 결정된다. 그 다음, 그 차이는 네트워크의 파라미터들이 조정되는 메트릭으로서 이용될 수 있어서, 네트워크가 미래의 조우에서 입력 벡터에 대한 적절한 출력을 생성할 가능성이 더 높도록 네트워크 전반에 걸쳐 정정으로서 에러를 "전파"한다. 명확성을 위해 도 3c의 구현의 입력 계층에는 3개의 노드가 도시되어 있지만, 상이한 아키텍처들에 더 많거나 더 적은 노드들이 있을 수 있다는 것을 알 것이다(예컨대, 위의 128x128 그레이스케일 이미지 예들에서는 픽셀 값들을 수신하는 16,384개의 이러한 노드들이 있을 수 있다). 유사하게, 이 예시적인 아키텍처에서의 계층들 각각이 다음 계층과 완전히 연결되는 것으로 도시되어 있지만, 다른 아키텍처들이 이러한 방식으로 계층들 사이의 노드들 각각을 연결하지 않을 수 있다는 것을 잘 알 것이다. 모든 신경망 아키텍처들이 오로지 좌에서 우로만 데이터를 처리하거나 한 번에 단일 특징 벡터만을 고려하지는 않을 것이다. 예를 들어, 순환 신경망(Recurrent Neural Network)(RNN)들은 현재 인스턴스를 고려할 때 이전 입력 인스턴스들을 고려하는 신경망 방법들 및 아키텍처들의 클래스들을 포함한다. 아키텍처들은 다양한 노드들에서 이용되는 활성화 함수들, 예를 들어 로지스틱 함수들, ReLU(rectified linear unit functions), 소프트플러스 함수들 등에 기반하여 추가로 구별될 수 있다. 따라서, 아키텍처들 사이에는 상당한 다양성이 존재한다.
이 개요에서 지금까지 논의된 예시적인 기계 학습 구현들 중 다수는 "구별적" 기계 학습 모델들 및 방법론들(SVM들, 로지스틱 회귀 분류기들, 도 3d에서와 같은 노드들을 갖는 신경망들 등)이라는 것을 인식할 것이다. 일반적으로, 구별적 접근법들은 아래의 수학식 2의 확률을 찾고자 하는 형태를 가정한다:
즉, 이들 모델들 및 방법론들은 클래스들(예를 들어, SVM 초평면)을 구별하는 구조들을 찾고, 훈련 데이터에 기반하여 그 구조와 연관된 파라미터들(예를 들어, 분리 초평면을 결정하는 지원 벡터들)을 추정한다. 그러나, 본 명세서에서 논의된 모든 모델들 및 방법론들이 이러한 구별적 형태를 가정하는 것이 아니라, 대신에 다수의 "생성적" 기계 학습 모델들 및 대응하는 방법론들(예를 들어, 나이브 베이즈 분류기, 은닉 마르코프 모델, 베이지안 네트워크 등) 중 하나일 수 있다는 것을 이해할 것이다. 이러한 생성적 모델들은 그 대신에 아래의 수학식 3의 확률들을 찾고자 하는 형태를 가정한다:
즉, 이러한 모델들 및 방법론들은 입력들과 출력들 사이의 특성 관계들을 반영하는 구조들(예로서, 그 초기 파라미터들 및 사전을 갖는 베이지안 신경망)을 찾고, 훈련 데이터로부터 이러한 파라미터들을 추정하고, 이어서 베이지 규칙을 이용하여 수학식 2의 값을 계산한다. 이러한 계산들을 직접 수행하는 것이 항상 실현가능한 것은 아니며, 따라서 이러한 생성적 모델들 및 방법론들 중 일부에서 수치 근사화 방법들이 이용될 수 있다는 것을 알 것이다.
이러한 생성적 접근법들은 구별적 구현들로 제시된 결과들을 달성하기 위해 본 명세서에서 필요한 부분만 약간 수정하여 이용될 수 있고 그 반대도 마찬가지라는 것을 알 것이다. 예를 들어, 도 3e는 베이지안 신경망에서 나타날 수 있는 예시적인 노드(315d)를 도시한다. 단순히 수치 값들을 수신하는 노드(315c)와는 달리, 노드(315d)와 같은 베이지안 신경망 내의 노드가 가중된 확률 분포들(315f, 315g, 315h)(예를 들어, 이러한 분포들의 파라미터들)을 수신할 수 있고, 그 자체가 분포(315e)를 출력할 수 있다는 것을 알 것이다. 따라서, 예를 들어, 다양한 후처리 기법들(예를 들어, 드롭아웃의 반복적 적용들을 갖는 출력들을 구별적 신경망과 비교하는 것)을 통해 구별적 모델에서 분류 불확실성을 결정할 수 있지만, 확률 분포를 출력하는 생성적 모델을 이용함으로써, 예를 들어, 분포(315e)의 분산을 고려함으로써 유사한 불확실성 척도들을 달성할 수 있다는 것을 인식할 것이다. 따라서, 본 명세서에서의 하나의 특정 기계 학습 구현에 대한 참조가 임의의 유사하게 기능하는 구현으로의 대체를 배제하도록 의도되지 않는 것처럼, 본 명세서에서의 구별적 구현에 대한 참조도 적용가능한 경우에 생성적 대응물로의 대체를 배제하는 것으로 해석되어서는 안 되며, 그 반대도 마찬가지이다.
기계 학습 접근법들의 일반적인 논의로 돌아가면, 도 3c가 단일 은닉 계층을 갖는 예시적인 신경망 아키텍처를 도시하지만, 많은 신경망 아키텍처들은 하나보다 많은 은닉 계층을 가질 수 있다. 많은 은닉 계층들을 갖는 일부 네트워크들은 놀라울 정도로 효과적인 결과들을 생성하였고, 용어 "심층" 학습은 많은 수의 은닉 계층들을 반영하기 위하여 이 모델들에 적용되었다. 본 명세서에서, 심층 학습은 하나보다 많은 은닉 계층을 갖는 적어도 하나의 신경망 아키텍처를 이용하는 아키텍처들 및 방법들을 지칭한다.
도 3f는 예시적인 심층 학습 모델 아키텍처의 동작의 개략도이다. 이 예에서, 아키텍처는 고양이의 그레이스케일 이미지와 같은 2차원 입력(320a)을 수신하도록 구성된다. 분류에 이용될 때, 이 예에서와 같이, 아키텍처는 일반적으로 2개의 부분, 즉 일련의 계층 동작들을 포함하는 특징 추출 부분 및 추출된 특징들 사이의 관계들에 기반하여 출력 값들을 결정하는 분류 부분으로 분할될 수 있다.
많은 상이한 특징 추출 계층들, 예를 들어 컨볼루션 계층들, 최대 풀링 계층들, 드롭아웃 계층들, 크로핑 계층들 등이 가능하며, 이러한 계층들 중 다수, 예를 들어 2차원 컨볼루션 계층들, 3차원 컨볼루션 계층들, 상이한 활성화 함수들을 갖는 컨볼루션 계층들 등은 물론, 네트워크의 훈련, 추론 등을 위한 상이한 방법들 및 방법론들은 그 자체가 변동에 취약하다. 도시된 바와 같이, 이러한 계층들은 상이한 차원들의 다수의 중간 값(320b-j)을 생성할 수 있으며, 이러한 중간 값들은 다수의 경로를 따라 처리될 수 있다. 예를 들어, 원래의 그레이스케일 이미지(320a)는 차원들 128x128x1의 특징 입력 텐서(예를 들어, 128 픽셀 폭 및 128 픽셀 높이의 그레이스케일 이미지)로서 또는 차원들 128x128x3의 특징 입력 텐서(예를 들어, 128 픽셀 폭 및 128 픽셀 높이의 RGB 이미지)로서 표현될 수 있다. 제1 계층에서 상이한 커널 함수들을 갖는 다수의 컨볼루션들은 이 입력으로부터 다수의 중간 값들(320b)을 촉발시킬 수 있다. 이들 중간 값(320b) 자체는 별개의 경로를 따라 2개의 새로운 중간 값(320c 및 320d)을 형성하기 위해 2개의 상이한 계층에 의해 고려될 수 있다(비록 2개의 경로가 이 예에서 도시되어 있지만, 상이한 아키텍처에서 더 많은 경로 또는 단일 경로가 가능하다는 것을 이해할 것이다). 그에 부가하여, 이미지가, 예를 들어, 128x128x3 특징 텐서에서 "x3" 차원으로 각각의 픽셀에 대해 적색, 녹색 및 청색 값을 가질 때와 같이 데이터가 다수의 "채널"에서 제공될 수 있다(명확함을 위해, 이 입력은 3개의 "텐서" 차원을 갖지만, 49,152개의 개별 "특징" 차원을 가진다). 다양한 아키텍처들은 다양한 계층들에서 개별적으로 또는 집합적으로 채널들 상에서 동작할 수 있다. 도면에서의 생략부호들은 부가의 계층들의 존재를 나타낸다(예컨대, 일부 네트워크들은 수백 개의 계층들을 가진다). 도시된 바와 같이, 중간 값들은 값들(320e)에서와 같이, 예를 들어, 풀링(pooling) 후에, 크기 및 차원들이 변할 수 있다. 일부 네트워크들에서, 중간 값들은 중간 값들(320e, 320f, 320g, 320h) 사이에 도시된 바와 같이 경로들 사이의 계층들에서 고려될 수 있다. 궁극적으로, 최종적인 특징 값 세트는 중간 컬렉션(320i 및 320j)에 나타나고, 계층(320l)의 출력 노드들에서 출력 값들(320m)을 생성하기 위해, 예컨대, 평탄화된 계층들, SoftMax 계층, 완전히 연결된 계층들 등을 통해, 하나 이상의 분류 계층(320k 및 320l)의 컬렉션에 공급된다. 예를 들어, N개의 클래스들이 인식되어야 하는 경우, 각각의 클래스가 정확한 클래스일 확률을 반영하기 위해 N개의 출력 노드들이 존재할 수 있지만(예를 들어, 여기서 네트워크는 3개의 클래스들 중 하나를 식별하고, 클래스 "고양이"를 주어진 입력에 대해 가장 가능성이 있는 것으로서 표시하지만), 일부 아키텍처들은 더 적은 출력들을 갖거나 더 많은 출력들을 가질 수 있다. 유사하게, 일부 아키텍처들은 추가 입력들을 수용할 수 있고(예를 들어, 일부 플러드 필 아키텍처는, 입력 특징 데이터에 추가하여 입력으로서 수신될 뿐만 아니라 분류 출력 값들에 추가하여 출력으로서 수정된 형태로 생성될 수 있는 진화하는 마스크 구조를 이용하고; 유사하게, 일부 순환 신경망은 다른 입력들과 함께 후속 반복에 입력될 하나의 반복으로부터의 값들을 저장할 수 있음), 피드백 루프 등을 포함할 수 있다.
TensorFlowTM, CaffeTM, 및 TorchTM은 심층 신경망을 구현하기 위한 흔한 소프트웨어 라이브러리 프레임워크의 예이지만, 행렬이나 값의 텐서에 관한 연산으로서의 계층과 이러한 행렬이나 텐서 내의 값으로서의 데이터를 단순히 나타내는 많은 아키텍처가 "스크래치로부터" 생성될 수 있다. 심층 학습 네트워크 아키텍처들의 예들은 VGG-19, ResNet, Inception, DenseNet 등을 포함한다.
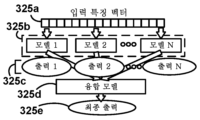
예시적인 전형적 기계 학습 아키텍처들이 도 3a 내지 도 3f와 관련하여 논의되었지만, 동작들 및 구조들을 조합, 수정, 또는 다른 아키텍처들 및 기법들에 첨부함으로써 형성되는 많은 기계 학습 모델들 및 대응하는 아키텍처들이 있다. 예를 들어, 도 3g는 앙상블 기계 학습 아키텍처의 개략도이다. 앙상블 모델들은, 예를 들어, AdaBoost에서와 같이, 더 강한 모델을 집합적으로 형성하기 위해 복수의 약한 학습 모델을 이용하는, 예를 들어, "메타-알고리즘" 모델들을 포함하는, 매우 다양한 아키텍처들을 포함한다. 도 3a의 랜덤 포레스트는 이러한 앙상블 모델의 또 다른 예로서 볼 수 있지만, 랜덤 포레스트 자체가 앙상블 모델에서의 중간 분류기일 수 있다.
도 3g의 예에서, 초기 입력 특징 벡터(325a)는, 전체적으로 또는 부분적으로, 동일한 또는 상이한 모델들(예를 들어, SVM, 신경망, 랜덤 포레스트 등)로부터 온 것일 수 있는 다양한 모델 구현들(325b)에 입력될 수 있다. 이 모델들(325b)로부터의 출력들은 이어서 최종 출력(325e)을 생성하기 위해 "융합" 모델 아키텍처(325d)에 의해 수신될 수 있다. 융합 모델 구현(325d) 자체는 구현들(325b) 중 하나와 동일하거나 상이한 모델 유형일 수 있다. 예를 들어, 일부 시스템들에서, 융합 모델 구현(325d)은 로지스틱 회귀 분류기일 수 있고, 모델들(325b)은 신경망일 수 있다.
앙상블 모델 아키텍처들이 도 3a 내지 도 3f의 전형적 아키텍처들에 비해 더 큰 유연성을 용이하게 할 수 있다는 것을 이해할 수 있는 바와 같이, 아키텍처 또는 그 방법에 대한 때때로 비교적 약간의 수정들이 도 2a의 종래의 그룹화에 쉽게 적합하지 않은 새로운 거동을 용이하게 할 수 있음을 이해해야 한다. 예를 들어, PCA는 라벨들이 없는 입력 데이터의 차원수-감소된 특징 표현들을 식별하므로 일반적으로 무감독 학습 방법 및 대응하는 아키텍처로서 설명된다. 그러나, PCA는, M. Turk 및 A. Pentland의 "Eigenfaces for Recognition", J. Cognitive Neuroscience, vol. 3, no. 1, 1991에 설명된 아이겐페이스(EigenFaces) 애플리케이션에서와 같이, 종종 감독 방식으로 분류를 용이하게 하기 위해 라벨링된 입력들과 함께 이용되었다. 도 3h는 이러한 수정들의 예시적인 기계 학습 파이프라인 토폴로지를 도시한다. 아이겐페이스에서와 같이, 블록(330a)에서 무감독 방법을 이용하여 특징 제시를 결정할 수 있다(예를 들어, 여러 개인들 중 한 명과 연관된 얼굴 이미지들의 각각의 그룹에 대해 PCA를 이용하여 주요 구성요소들을 결정한다). 무감독 방법으로서, 도 2a의 종래의 그룹화는 통상적으로 이 PCA 동작을 "훈련"으로서 해석하지 않을 수 있다. 그러나, 블록(330b)에서 입력 데이터(예를 들어, 얼굴 이미지들)를 새로운 표현(주요 구성요소 특징 공간)으로 변환함으로써, 후속 추론 방법들의 적용에 적합한 데이터 구조를 생성할 수 있다.
예를 들어, 블록(330c)에서, 새로운 들어오는 특징 벡터(새로운 얼굴 이미지)는 무감독 형태(예를 들어, 주요 구성요소 특징 공간)로 변환될 수 있고, 이후 메트릭(예를 들어, 각각의 개인의 얼굴 이미지 그룹 주요 구성요소들과 새로운 벡터의 주요 구성요소 표현 사이의 거리) 또는 다른 후속 분류기(예를 들어, SVM 등)가 블록(330d)에서 적용되어 새로운 입력을 분류할 수 있다. 따라서, 특정 방법론들(예를 들어, 메트릭 기반 훈련 및 추론)의 방법들에 순응하지 않는 모델 아키텍처(예를 들어, PCA)는 파이프라이닝과 같은 방법 또는 아키텍처 수정들을 통해 그렇게 순응하게 될 수 있다. 다시, 이 파이프라인은 일 예일 뿐이며, 도 2b의 KNN 무감독 아키텍처 및 방법은 추론 입력에 대해 특징 공간 내의 가장 가까운 제1 순간을 갖는 그룹의 클래스에 새로운 추론 입력을 할당함으로써 감독 분류에 유사하게 이용될 수 있다는 것을 알 것이다. 따라서, 이러한 파이프라이닝 접근법들은 본 명세서에서 기계 학습 모델들로 고려될 수 있지만, 이들은 통상적으로 이와 같이 지칭되지 않을 수 있다.
일부 아키텍처들은 훈련 방법들과 함께 이용될 수 있고, 이들 훈련된 아키텍처들 중 일부는 이후 추론 방법들과 함께 이용될 수 있다. 그러나, 모든 추론 방법들이 분류를 수행하는 것은 아니고, 모든 훈련된 모델들이 추론에 이용될 수 있는 것은 아니라는 것을 알 것이다. 유사하게, 모든 추론 방법들이 (예를 들어, KNN이 입력 데이터의 직접 고려로부터 클래스들을 생성할 때와 같이) 주어진 작업에 대한 새로운 입력을 처리하기 위해 훈련 방법이 아키텍처에 이전에 적용될 것을 요구하는 것은 아니라는 것을 알 것이다. 훈련 방법들과 관련하여, 도 4a는 다양한 훈련 방법들에서의 공통 동작들을 나타내는 개략적인 흐름도이다. 구체적으로, 블록(405a)에서, 실무자가 직접 또는 아키텍처가 훈련 데이터를 하나 이상의 훈련 입력 특징 벡터로 어셈블링할 수 있다. 예를 들어, 사용자는 감독 학습 방법에 대한 메타데이터 라벨들 또는 무감독 클러스터링에 대한 시간 경과에 따른 라벨링되지 않은 주가를 갖는 개들 및 고양이들의 이미지들을 수집할 수 있다. 논의된 바와 같이, 원시 데이터는 전처리를 통해 특징 벡터로 변환될 수 있거나, 그 원시 형태의 특징들로서 직접 취해질 수 있다.
블록(405b)에서, 훈련 방법은 훈련 데이터에 기반하여 아키텍처의 파라미터들을 조정할 수 있다. 예를 들어, 신경망의 가중치들 및 바이어스들은 역전파를 통해 업데이트될 수 있고, SVM은 초평면 계산들 등에 기반하여 지원 벡터들을 선택할 수 있다. 그러나, 도 3g의 파이프라인 아키텍처들과 관련하여 논의된 바와 같이, 모든 모델 아키텍처들이 "훈련" 동안 아키텍처 자체 내의 파라미터들을 업데이트할 수 있는 것은 아니라는 것을 알 것이다. 예를 들어, 아이겐페이스에서, 얼굴 아이덴티티 그룹들에 대한 주요 구성요소들의 결정은 기존의 파라미터의 조정(예를 들어, 신경망 아키텍처의 가중치들 및 바이어스들을 조정하는 것)으로서가 아니라 새로운 파라미터(주요 구성요소 특징 공간)의 생성으로서 해석될 수 있다. 따라서, 본 명세서에서, 훈련 이미지들로부터의 주요 구성요소들의 아이겐페이스 결정은 여전히 훈련 방법으로서 해석될 것이다.
도 4b는 다양한 기계 학습 모델 추론 방법들에 공통인 다양한 동작들을 나타내는 개략적인 흐름도이다. 언급된 바와 같이, 모든 아키텍처들 또는 모든 방법들이 추론 기능을 포함할 수 있는 것은 아니다. 추론 방법이 적용가능한 경우, 블록(410a)에서, 실무자 또는 아키텍처는 원시 추론 데이터, 예를 들어, 분류될 새로운 이미지를 추론 입력 특징 벡터, 텐서 등으로(예를 들어, 훈련 데이터와 동일한 특징 입력 형태로) 어셈블링할 수 있다. 블록(410b)에서, 시스템은 출력, 예를 들어, 분류, 회귀 결과 등을 결정하기 위해 훈련된 아키텍처를 입력 추론 특징 벡터에 적용할 수 있다.
"훈련"할 때, 일부 방법들 및 일부 아키텍처들은 입력 훈련 특징 데이터를 전체적으로, 단일 패스에서, 또는 반복적으로 고려할 수 있다. 예를 들어, PCA를 통한 분해는 일부 구현들에서 비반복 행렬 연산으로서 구현될 수 있다. SVM은, 그 구현에 따라, 입력들을 통해 단일 반복에 의해 훈련될 수 있다. 마지막으로, 일부 신경망 구현은 기울기 하강 동안에 입력 벡터들에 대한 다수의 반복에 의해 훈련될 수 있다.
반복 훈련 방법들과 관련하여, 도 4c는, 예를 들어, 일부 아키텍처들 및 방법들에서 블록(405b)에서 발생할 수 있는 바와 같은 반복 훈련 동작들을 나타내는 개략적인 흐름도이다. 단일 반복은 흐름도에서 방법을 한 번 적용할 수 있는 반면, 다수의 반복을 수행하는 구현은 다이어그램에서 방법을 여러 번 적용할 수 있다. 블록(415a)에서, 아키텍처의 파라미터들은 디폴트 값들로 초기화될 수 있다. 예를 들어, 일부 신경망들에서, 가중치들 및 바이어스들은 랜덤 값들로 초기화될 수 있다. 일부 SVM 아키텍처들에서, 예를 들어, 대조적으로, 블록(415a)의 동작은 적용되지 않을 수 있다. 훈련 입력 특징 벡터들 각각이 블록(415b)에서 고려됨에 따라, 시스템은 415c에서 모델의 파라미터들을 업데이트할 수 있다. 예를 들어, SVM 훈련 방법은 새로운 입력 특징 벡터들이 지원 벡터 선택에 영향을 주거나 영향을 주지 않도록 고려되고 결정됨에 따라 새로운 초평면을 선택하거나 선택하지 않을 수 있다. 유사하게, 신경망 방법은, 예를 들어, 역전파 및 기울기 하강에 따라 그 가중치 및 바이어스를 업데이트할 수 있다. 모든 입력 특징 벡터들이 고려될 때, 훈련 방법이 수행될 단일 반복에 대해서만 호출된다면 모델은 "훈련된" 것으로 고려될 수 있다. 다수의 반복을 요구하는 방법들은 도 4c의 동작들을 다시 적용할 수 있고(당연히, 이전 반복에서 결정된 파라미터 값들을 위해 블록(415a)에서 다시 초기화하는 것을 피함), 조건이 충족되었을 때, 예를 들어, 예측된 라벨들과 메타데이터 라벨들 사이의 에러 레이트가 임계치 아래로 감소될 때 훈련을 완료할 수 있다.
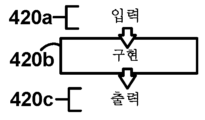
언급된 바와 같이, 매우 다양한 기계 학습 아키텍처들 및 방법들은, 도 4e에 도시된 바와 같이, 명시적 훈련 및 추론 단계들을 갖는 것들, 및 도 4d에 일반화된 바와 같이, 명시적 훈련 및 추론 단계들을 갖지 않는 것들을 포함한다. 도 4e는, 예를 들어, 추론(425b)에서 새롭게 수신된 이미지를 인식하기 위해 신경망 아키텍처를 훈련하는 방법(425a)을 도시하는 반면, 도 4d는, 예를 들어, PCA를 통해 데이터 차원들을 감소시키거나 KNN 클러스터링을 수행하는 구현을 도시하며, 여기서 구현(420b)은 입력(420a)을 수신하고 출력(420c)을 생성한다. 명료성을 위해, 일부 구현들이 데이터 입력을 수신하고 출력(예를 들어, 추론 방법을 갖는 SVM 아키텍처)을 생성할 수 있지만, 일부 구현들은 데이터 입력(예를 들어, 훈련 방법을 갖는 SVM 아키텍처)만을 수신할 수 있고, 일부 구현들은 데이터 입력(예를 들어, 새로운 데이터 인스턴스들을 생성하기 위한 랜덤 생성기 방법을 갖는 훈련된 GAN 아키텍처)을 수신하지 않고 출력만을 생성할 수 있다는 것을 이해할 것이다.
도 4d 및 도 4e의 동작들은 일부 방법들에서 추가로 확장될 수 있다. 예를 들어, 일부 방법들은 도 4f의 개략적인 블록도에 도시된 바와 같이 훈련을 확장하고, 여기서 훈련 방법은 다양한 데이터 서브세트 동작들을 추가로 포함한다. 도 4g에 도시된 바와 같이, 일부 훈련 방법들은 훈련 데이터를 훈련 데이터 서브세트(435a), 검증 데이터 서브세트(435b), 및 테스트 데이터 서브세트(435c)로 분할할 수 있다. 도 4f에 도시된 바와 같이 블록(430a)에서 네트워크를 훈련할 때, 훈련 방법은 먼저, 예를 들어, 훈련 데이터 서브세트(435a)의 전부 또는 일부에 기반한 역전파를 이용하여 네트워크의 파라미터들을 반복적으로 조정할 수 있다. 그러나, 블록(430b)에서, 검증(435b)을 위해 예비된 데이터의 서브세트 부분은 훈련의 유효성을 평가하는데 이용될 수 있다. 모든 훈련 방법들 및 아키텍처들이 주어진 작업에 대한 최적의 아키텍처 파라미터 또는 구성들을 찾도록 보장되는 것은 아니며, 예를 들어, 이들은 국부적 최소값들에 고착될 수 있고, 비효율적인 학습 단계 크기 하이퍼파라미터 등을 이용할 수 있다. 방법들은 이러한 결함들을 예상하는 훈련 데이터 서브세트(435a)와 상이한 훈련 데이터(435b)를 이용하여 블록(430b)에서 현재 하이퍼파라미터 구성을 검증하고, 이에 따라 아키텍처 하이퍼파라미터들 또는 파라미터들을 조정할 수 있다. 일부 방법들에서, 방법은 화살표(430f)에 의해 도시된 바와 같이 훈련과 검증 사이에서, 훈련 데이터 서브세트(435a)의 나머지에 대해 훈련을 계속하기 위해 검증 피드백을 이용하는 것, 훈련 데이터 서브세트(435a)의 전부 또는 일부에 대해 훈련을 재시작하는 것, (추가적인 은닉 계층들이 메타-학습에서 신경망에 추가될 수 있을 때와 같이) 아키텍처의 하이퍼파라미터들 또는 아키텍처의 토폴로지를 조정하는 것 등을 반복할 수 있다. 아키텍처가 훈련되면, 방법은 테스트 데이터 서브세트들(435c)의 전부 또는 일부에 아키텍처를 적용함으로써 아키텍처의 유효성을 평가할 수 있다. 검증 및 테스트를 위해 상이한 데이터 서브세트를 이용하는 것은 또한 과적합(overfitting)을 피하는데 도움을 줄 수 있고, 여기서 훈련 방법은 아키텍처의 파라미터를 훈련 데이터에 너무 가깝게 조정하여, 아키텍처가 새로운 추론 입력에 직면하면 보다 최적의 일반화를 완화시킨다. 테스트 결과들이 바람직하지 않은 경우, 방법은 화살표(430e)에 의해 표시되는 바와 같이 상이한 파라미터 구성, 상이한 하이퍼파라미터 구성을 갖는 아키텍처 등으로 다시 훈련을 시작할 수 있다. 블록(430c)에서의 테스트는 훈련된 아키텍처의 유효성을 확인하는데 이용될 수 있다. 모델이 훈련되면, 추론(430d)은 새롭게 수신된 추론 입력에 대해 수행될 수 있다. 예를 들어, 방법이 가능한 하이퍼파라미터들의 공간의 그리드 검색을 수행하여 작업에 가장 적합한 아키텍처를 결정할 때와 같이, 이러한 검증 방법에 대한 변형들의 존재를 알 것이다.
많은 아키텍처들 및 방법들은 다른 아키텍처들 및 방법들과 통합되도록 수정될 수 있다. 예를 들어, 하나의 작업에 대해 성공적으로 훈련된 일부 아키텍처들은, 예를 들어, 랜덤하게 초기화된 파라미터들로 시작하기보다는 유사한 작업에 대해 더 효과적으로 훈련될 수 있다. 제2 아키텍처(일부 경우들에서, 아키텍처들은 동일할 수 있음)에서 제1 아키텍처로부터의 파라미터들을 이용하는 방법들 및 아키텍처는 "전이 학습(transfer learning)" 방법들 및 아키텍처들이라고 지칭된다. 미리 훈련된 아키텍처(440a)(예를 들어, 이미지들 내의 새들을 인식하도록 훈련된 심층 학습 아키텍처)가 주어지면, 전이 학습 방법들은 추론(440e)이 이 새로운 작업 도메인에서 수행될 수 있도록 새로운 작업 도메인으로부터의 데이터로 추가적인 훈련을 수행할 수 있다(예를 들어, 이미지들 내의 자동차들을 인식하기 위해 자동차들의 이미지들의 라벨링된 데이터를 제공한다). 전이 학습 훈련 방법은 위에 설명된 것과 같은 훈련(440b), 검증(440c), 및 테스트(440d) 하위 방법들 및 데이터 서브세트들뿐만 아니라, 반복 동작들(440f 및 440g)을 구별하거나 구별하지 않을 수 있다. 미리 훈련된 모델(440a)은 전체 훈련된 아키텍처로서, 또는 예를 들어, 동일하거나 유사한 아키텍처의 병렬 인스턴스에 적용될 훈련된 파라미터 값들의 리스트로서 수신될 수 있다는 것을 알 것이다. 일부 전이 학습 애플리케이션들에서, 미리 훈련된 아키텍처의 일부 파라미터들은 훈련 동안 그 조정을 방지하기 위해 "동결"될 수 있는 반면, 다른 파라미터들은 새로운 도메인으로부터의 데이터에 따라 훈련 동안 변화하도록 허용된다. 이 접근법은 아키텍처를 새로운 도메인에 맞추면서, 아키텍처의 원래 훈련의 일반적인 이점들을 유지할 수 있다.
아키텍처들 및 방법들의 조합들이 또한 시간적으로 확장될 수 있다. 예를 들어, "온라인 학습" 방법들은 초기 훈련 방법(445a)을 아키텍처에 적용하는 것, 그 훈련된 아키텍처(445b)에 의한 추론 방법의 후속 적용뿐만 아니라, 다른 훈련 방법(445d), 가능하게는 방법(445a)과 동일한 방법을 전형적으로 새로운 훈련 데이터 입력들에 적용하는 것에 의한 주기적 업데이트들(445c)을 예상한다. 온라인 학습 방법들은, 예를 들어, 로봇이 초기 훈련 방법(445a)에 후속하여 원격 환경에 배치되는 경우에 유용할 수 있고, 여기서 로봇은 445b에서의 추론 방법의 적용을 개선할 수 있는 추가 데이터에 직면할 수 있다. 예를 들어, 몇몇 로봇들이 이러한 방식으로 배치되는 경우, 하나의 로봇이 "진정한 긍정적" 인식(예를 들어, 지리학자에 의해 검증된 분류들을 갖는 새로운 코어 샘플들; 수술 중인 외과의에 의해 검증된 수술 동안의 새로운 환자 특성들)에 직면할 때, 로봇은 방법(445d)과 함께 이용하기 위해 그 데이터 및 결과를 새로운 훈련 데이터 입력들로서 그 피어 로봇들에게 전송할 수 있다. 신경망은 훈련 방법(445d)에서 진정한 긍정적 데이터를 이용하여 역전파 조정을 수행할 수 있다. 유사하게, SVM은 훈련 방법(445d)에서 새로운 데이터가 그 지원 벡터 선택에 영향을 미쳐, 그 초평면의 조정을 촉발시키는지를 고려할 수 있다. 온라인 학습은 종종 강화 학습의 일부이지만, 분류, 회귀, 클러스터링 등과 같은 다른 방법들에서도 온라인 학습이 나타날 수 있다. 초기 훈련 방법은, 훈련(445e), 검증(445f), 및 테스트(445g) 하위 방법, 및 훈련 방법(445a)에서의 반복적 조정(445k, 445l)을 포함하거나 포함하지 않을 수 있다. 유사하게, 온라인 훈련은, 훈련(445h), 검증(445i), 및 테스트 하위 방법(445j) 및 반복적 조정(445m 및 445n)을 포함하거나 포함하지 않을 수 있고, 포함된다면, 하위 방법(445e, 445f, 445g) 및 반복적 조정(445k, 445l)과는 상이할 수 있다. 실제로, 검증 및 테스트를 위해 할당된 훈련 데이터의 서브세트들 및 비율들은 각각의 훈련 방법(445a 및 445d)에서 상이할 수 있다.
위에서 논의된 바와 같이, 많은 기계 학습 아키텍처들 및 방법들은 훈련, 클러스터링, 추론 등과 같은 임의의 하나의 작업에 대해 배타적으로 이용될 필요가 없다. 도 4j는 하나의 이러한 예시적인 GAN 아키텍처 및 방법을 도시한다. GAN 아키텍처들에서, 생성기 서브아키텍처(450b)는 판별기 서브아키텍처(450e)와 경쟁적으로 상호작용할 수 있다. 예를 들어, 생성기 서브아키텍처(450b)는, "가짜" 도전을 실제 진정한 긍정적 데이터(450d), 예를 들어, 실제 사람들의 진정한 초상들과 구별하도록 훈련되는 판별기 서브아키텍처(450e)와 병행하여, 존재하지 않는 개인들의 합성 초상들과 같은 합성 "가짜" 도전들(450c)을 생성하도록 훈련될 수 있다. 이러한 방법들은, 예를 들어, 추가적인 훈련 데이터로서 이용하기 위해, 예를 들어, 실세계 데이터와 유사한 합성 자산들을 생성하는데 이용될 수 있다. 초기에, 생성기 서브아키텍처(450b)는 랜덤 데이터(450a) 및 파라미터 값들로 초기화되어, 매우 설득력이 없는 도전들(450c)을 촉발시킬 수 있다. 판별기 서브아키텍처(450e)는 초기에 진정한 긍정적 데이터(450d)로 훈련될 수 있고 그래서 초기에 가짜 도전들(450c)을 쉽게 구별할 수 있다. 그러나, 각각의 훈련 사이클에서, 생성기의 손실(450g)은 생성기 서브아키텍처(450b)의 훈련을 개선하는데 이용될 수 있고, 판별기의 손실(450f)은 판별기 서브아키텍처(450e)의 훈련을 개선하는데 이용될 수 있다. 이러한 경쟁적 훈련은 궁극적으로 진정한 긍정적 데이터(450d)와 구별하기 매우 어려운 합성 도전들(450c)을 생성할 수 있다. 명확함을 위해, GAN과 관련한 "대립적" 네트워크가 앞서 설명된 생성기들 및 판별기들의 경쟁을 지칭하는 반면, "대립적" 입력이 그 대신에 구현에서 특정의 출력을 달성하도록 특별히 설계된 입력, 가능하게는 구현의 설계자에 의해 의도되지 않은 출력을 지칭한다는 것을 잘 알 것이다.
데이터 개요
도 5a는 일부 실시예들에서 처리 시스템에서 수신될 수 있는 수술 데이터의 개략도이다. 구체적으로, 처리 시스템은 시간(505)에 걸쳐 일련의 개별 프레임들을 포함하는 시각화 도구(110b 또는 140d)로부터의 비디오와 같은 원시 데이터(510)를 수신할 수 있다. 일부 실시예들에서, 원시 데이터(510)는 다수의 외과 수술들(510a, 510b, 510c), 또는 단일 외과 수술만으로부터의 비디오 및 시스템 데이터를 포함할 수 있다.
언급된 바와 같이, 각각의 외과 수술은 액션들의 그룹들을 포함할 수 있고, 각각의 그룹은 본 명세서에서 작업으로서 지칭되는 개별 유닛을 형성한다. 예를 들어, 외과 수술(510b)은 작업들(515a, 515b, 515c, 및 515e)을 포함할 수 있다(생략부호들(515d)은 더 많은 중간 작업들이 있을 수 있다는 것을 나타낸다). 일부 작업들은 수술에서 반복될 수 있거나 그 순서가 변경될 수 있다는 점에 유의한다. 예를 들어, 작업(515a)은 근막의 분절을 찾는 것을 포함할 수 있고, 작업(515b)은 근막의 제1 부분을 절개하는 것을 포함하고, 작업(515c)은 근막의 제2 부분을 절개하는 것을 포함하고, 작업(515e)은 닫기 전에 근막의 영역들을 세척 및 소작하는 것을 포함한다.
작업들(515) 각각은 프레임들(520a, 520b, 520c, 및 520d)의 대응하는 세트, 및 조작자 운동학 데이터(525a, 525b, 525c, 525d), 환자측 디바이스 데이터(530a, 530b, 530c, 530d), 및 시스템 이벤트 데이터(535a, 535b, 535c, 535d)를 포함하는 디바이스 데이터세트들과 연관될 수 있다. 예를 들어, 수술실(100b) 내의 시각화 도구(140d)로부터 취득된 비디오의 경우, 조작자측 운동학 데이터(525)는 외과의 콘솔(155)에서의 하나 이상의 핸드헬드 입력 메커니즘(160b)에 대한 병진 및 회전 값들을 포함할 수 있다. 유사하게, 환자측 운동학 데이터(530)는 환자측 카트(130)로부터의 데이터, 하나 이상의 도구(140a-d, 110a) 상에 배치된 센서들로부터의 데이터, 아암들(135a, 135b, 135c, 및 135d)로부터의 회전 및 병진 데이터 등을 포함할 수 있다. 시스템 이벤트 데이터(535)는 페달들(160c) 중 하나 이상의 활성화, 도구의 활성화, 시스템 알람의 활성화, 에너지 인가들, 버튼 누름들, 카메라 움직임 등과 같이 개별 값들을 취하는 파라미터들에 대한 데이터를 포함할 수 있다. 일부 상황들에서, 작업 데이터는 4개 모두가 아니라 프레임 세트들(520), 조작자측 운동학(525), 환자측 운동학(530) 및 시스템 이벤트들(535) 중 하나 이상을 포함할 수 있다.
명료함을 위해 그리고 이해를 용이하게 하기 위해, 운동학 데이터가 파형으로서 그리고 시스템 데이터가 연속적인 상태 벡터들로서 여기서 도시되지만, 일부 운동학 데이터가 시간 경과에 따른 별개의 값들을 가정할 수 있고(예를 들어, 연속적인 구성요소 위치를 측정하는 인코더가 고정된 간격들로 샘플링될 수 있고), 반대로, 일부 시스템 값들이 시간 경과에 따른 연속적인 값들을 가정할 수 있다(예를 들어, 파라메트릭 함수가 온도 센서의 개별적으로 샘플링된 값들에 맞춤화될 수 있는 때와 같이, 값들이 보간될 수 있다)는 점이 이해될 것이다.
그에 부가하여, 수술들(510a, 510b, 510c) 및 작업들(515a, 515b, 515c)이 이해를 용이하게 하기 위해 여기서 바로 인접한 것으로 도시되어 있지만, 실세계 수술 비디오에서는 수술들과 작업들 간에 갭들이 있을 수 있다는 것을 잘 알 것이다. 따라서, 일부 비디오 및 데이터는 작업과 연계되지 않거나 현재 분석의 대상이 아닌 작업과 연계될 수 있다. 일부 실시예들에서, 이러한 데이터의 "비-작업"/"무관한-작업" 영역들은 그 자체가 주석부기 동안의 작업들, 예를 들어, "진짜" 작업이 발생하지 않는 "갭" 작업들로서 표시될 수 있다.
작업과 연관된 별개의 프레임 세트는 작업의 시작 지점 및 종료 지점에 의해 결정될 수 있다. 각각의 시작 지점 및 각각의 종료 지점은 그 자체가 신체에서의 도구 액션 또는 도구에 의해 달성되는 상태 변화에 의해 결정될 수 있다. 따라서, 이들 2개의 이벤트 사이에 취득된 데이터는 작업과 연관될 수 있다. 예를 들어, 작업(515b)에 대한 시작 및 종료 지점 액션들은 각각 위치들(550a 및 550b)과 연관된 타임스탬프들에서 발생할 수 있다.
도 5b는 개시된 다양한 실시예들과 함께 이용될 수 있는 그 대응하는 시작 지점 및 종료 지점을 갖는 예시적인 작업들을 나타내는 표이다. 구체적으로, 작업 "결장 이동"과 연관된 데이터는 도구가 먼저 결장 또는 주변 조직과 상호작용하는 시간과 도구가 마지막으로 결장 또는 주변 조직과 상호작용하는 시간 사이에서 취득된 데이터이다. 따라서, 프레임 세트들(520), 조작자측 운동학(525), 환자측 운동학(530), 및 이 시작 지점과 종료 지점 사이에 타임스탬프들을 갖는 시스템 이벤트들(535) 중 임의의 것이 작업 "결장 이동"과 연관된 데이터이다. 유사하게, 작업 "골반내 근막 절개(Endopelvic Fascia Dissection)"와 연관된 데이터는 도구가 먼저 골반내 근막(EPF)과 상호작용하는 시간과 전립선이 디패팅되고 분리된 후의 EPF와의 마지막 상호작용의 타임스탬프 사이에서 취득된 데이터이다. 작업 "정단 절개(Apical Dissection)"와 연관된 데이터는 도구가 먼저 전립선에서의 조직과 상호작용하는 시간과 전립선이 환자의 신체에 대한 모든 부착물로부터 자유로워졌을 때 종료하는 시간 사이에 취득된 데이터에 대응한다. 작업 시작 및 종료 시간들은 작업들 사이의 시간적 중첩을 허용하도록 선택될 수 있거나, 또는 이러한 시간적 중첩들을 피하도록 선택될 수 있다는 점이 이해될 것이다. 예를 들어, 일부 실시예들에서, 작업들은 제1 작업을 완료하기 전에 제1 작업에 관여된 외과의가 제2 작업으로 전이하고, 제2 작업을 완료하고, 이후 제1 작업으로 리턴하여 제1 작업을 완료할 때와 같이 "일시중지"될 수 있다. 따라서, 시작 및 종료 지점들이 작업 경계들을 정의할 수 있지만, 데이터는 둘 이상의 작업과 연계된 타임스탬프들을 반영하도록 주석부기될 수 있다는 것을 알 것이다.
작업의 추가적인 예는 양손 기법을 이용하여 4개의 수평 중단된 봉합선을 완료하는 것을 포함하는 "양손 봉합"을 포함한다(즉, 시작 시간은 봉합 바늘이 먼저 조직을 관통할 때이고, 정지 시간은 봉합 바늘이 양손만으로 조직을 빠져나갈 때, 예를 들어, 그 사이에서 일어나는 한 손 봉합 액션이 없을 때이다). "자궁뿔(Uterine Horn)" 작업은 좌측 및 우측 자궁뿔들로부터 넓은 인대를 절개하는 것은 물론, 자궁체(uterine body)의 절단(amputation)을 포함한다(일부 작업들은, 여기서와 같이, 절개 도구가 자궁뿔들 또는 자궁체 중 어느 하나와 접촉할 때 작업이 시작되고, 자궁뿔들 및 자궁체 둘 다가 환자로부터 분리될 때 종료하는, 그 시작 또는 종료 시간을 결정하는 하나 초과의 조건 또는 이벤트를 갖는다는 것을 알 것이다). "한 손 봉합" 작업은 한 손 기법을 이용하여 4개의 수직 중단된 봉합선을 완료하는 것을 포함한다(즉, 시작 시간은 봉합 바늘이 먼저 조직을 관통할 때이고, 정지 시간은 봉합 바늘이 한 손만으로 조직을 빠져나갈 때, 예를 들어, 그 사이에서 일어나는 양손 봉합 액션이 없을 때이다). 작업 "현수 인대"는 요관을 노출시키기 위해 각각의 현수 인대의 측면 소엽들을 절개하는 것을 포함한다(즉, 시작 시간은 첫 번째 소엽의 절개가 시작될 때이고, 정지 시간은 마지막 소엽의 절개가 완료될 때이다). 작업 "러닝 봉합"은 4개의 바이트로 러닝 봉합을 실행하는 것을 포함한다(즉, 시작 시간은 봉합 바늘이 먼저 조직을 관통할 때이고, 정지 시간은 모든 4개의 바이트를 완료한 후에 바늘이 조직을 빠져나갈 때이다). 마지막 예로서, 작업 "직장 동맥/정맥"은 상직장 동맥 및 정맥을 절개하고 결찰하는 것을 포함한다(즉, 시작 시간은 절개가 동맥 또는 정맥에서 시작될 때이고, 정지 시간은 결찰 후에 외과의가 결찰실과의 접촉을 중지할 때이다).
예시적인 조작자 평가 처리 토폴로지
외과의의 기술적 기량들은 최적의 환자 간호를 전달하는데 중요한 인자이다. 불행하게도, 조작자의 기량을 확인하기 위한 많은 기존의 방법들은 주관적, 정성적, 또는 자원 집약적으로 유지된다. 본 명세서에 개시된 다양한 실시예들은 객관적 성과 지표(OPI)들, 조작자의 개별 기량 성과를 검사하는데 적합한 수술 데이터로부터 생성된 정량적 메트릭들, 작업 레벨 성과는 물론, 외과 수술에 대한 성과 전체를 이용하여 조작자 기량들을 분석하는 것에 의한 보다 효과적인 수술 기량 평가들을 고려한다. OPI들이 또한, 데이터 값들로부터 직접 취해지기보다는, 다른 OPI들로부터 생성될 수 있다는 것을 이해할 것이다(예를 들어, 2개의 OPI의 비율이 OPI로 고려될 수 있다). 기량은 수술의 효율 또는 결과에 영향을 미치는 것으로 인식되는 수술 동안 수행되는 액션 또는 액션들의 그룹이다. 초기에, 자동화된 동작의 목적으로, 기량들은 (예를 들어, 전문가에 의해 제안되는 바와 같이) OPI들의 초기 할당에 의해 표현되거나 "정의"될 수 있지만, 이러한 초기 할당들은 본 명세서에 설명되는 다양한 시스템들 및 방법들을 이용하여 조정될 수 있다.
도 6은 일부 실시예들에서 발생할 수 있는 바와 같은 수술 기량 평가를 수행하기 위한 정보 흐름을 나타내는 개략적인 토폴로지 다이어그램이다. 구체적으로는, "기준" 데이터(605a)는 실세계 비-로봇 수술실들(635a), 실세계 로봇 수술실들(635b), 및 시뮬레이션된 동작들(635c)로부터 취득된 데이터일 수 있다(로봇 시뮬레이터가 도시되어 있지만, 비-로봇 수술들이 또한, 예컨대, 적절한 더미 환자 재료들로 시뮬레이션될 수 있다는 것을 잘 알 것이다). 기준 데이터세트들(605a)은 "경험이 있는"(예를 들어, 기량 또는 작업을 수행하는 경험이 100시간보다 많은 조작자들) 및 "초보" 사용자들(예를 들어, 기량 또는 작업을 수행하는 경험이 100시간보다 적은 조작자들) 양자 모두에 대한 데이터를 포함할 수 있다. 기준 데이터세트들(605a)은 성과 평가 시스템(625)의 일부로서 기계 학습 모델 분류기(예를 들어, 본 명세서에서 논의되는 바와 같은 하나 이상의 기량 또는 작업 모델)를 훈련하는데 이용될 수 있다.
나중에, "대상체" 데이터세트(605b)가 취득될 수 있고, 또한 실세계 비-로봇 수술실(640a), 실세계 로봇 수술실(640b), 및 시뮬레이션된 동작(640c)에 의해 제공되는 데이터를 포함할 수 있다(다시 한번, 로봇 시뮬레이터가 도시되어 있지만, 비-로봇 수술이 또한, 예를 들어, 적절한 더미 환자 재료로 시뮬레이션될 수 있다는 것을 이해할 것이다). 대상체 데이터세트들(605b)은 대상체 데이터세트들(605b)에 대한 성과 메트릭들(630)(예를 들어, 기량 스코어들, 작업 스코어들 등)을 생성하기 위해 "기준" 데이터(605a)로 훈련된 성과 평가 시스템(625) 내의 분류기에 마찬가지로 제공될 수 있다. "케이스 캡처" 버튼(640)을 선택하는 것은 일부 실시예들에서 제출 버튼(635)을 선택하는 것과 동일한 효과를 가질 수 있다.
일부 실시예들에서, 기준 데이터세트(605a) 및 대상체 데이터세트(605b)는 성과 평가 시스템(625)에 의한 소비 전에, 각각 데이터 저장소들(610a 및 610b)에 저장될 수 있다. 일부 실시예들에서, 데이터 저장소들(610a 및 610b)은 동일한 데이터 저장소일 수 있다. 일부 실시예들에서, 데이터 저장소들(610a 및 610b)은, 예를 들어, 클라우드 기반 네트워크 서버에서, 데이터가 취득된 위치들로부터 떨어질 수 있다. 처리 시스템들(615a 및 615b)은 데이터 저장소들(610a 및 610b) 내의 저장된 데이터를 처리할 수 있다(예를 들어, 데이터 스트림에서 캡처된 별개의 수술들을 인식하는 것, 스트림에서 인식된 수술들을 별개의 데이터세트들로 분리하는 것, 데이터세트들에 대한 메타데이터 주석부기들을 제공하는 것, 추가 액션 없이 적절한 데이터 저장을 단지 보장하는 것 등이다). 일부 실시예들에서, 인간 주석부기자들은 처리 시스템들(615a 및 615b)의 결과들을 보조, 정정 또는 검증할 수 있다. 일부 실시예들에서, 처리 시스템들(615a 및 615b)은 동일한 처리 시스템일 수 있다.
데이터 저장소들(610a 및 610b) 내의 처리된 기준 데이터(620a) 및 대상체 데이터(620b)는 이후 위에서 언급된 바와 같이 성과 메트릭들(630)을 결정하기 위해 성과 평가 시스템(625)에 의해 이용될 수 있고, 구체적으로, 처리된 데이터(620a)는 성과 평가 시스템(625) 내의 분류기를 훈련하는데 이용될 수 있고, 이후 분류기는 처리된 데이터(620b)에 대한 성과 메트릭들(630)을 생성하는데 이용될 수 있다.
예시적인 처리 개요
도 7a는 일부 실시예들에서 수행될 수 있는 기량(또는 작업) 모델들을 생성하고 적용하기 위한 프로세스(700)에서의 다양한 동작들을 나타내는 흐름도이다. 일반적으로, 동작들은 주석부기된 훈련 데이터를 이용한 기량 모델들의 훈련(705a) 또는 이러한 모델들을 이용한 새로운 주석부기되지 않은 데이터의 추론(705b)을 포함한다. 구체적으로는, 블록(705c)에서, 처리 시스템(예를 들어, 성과 평가 시스템(625))은 데이터세트(605a)에 나타나는 원시 데이터, 예를 들어, 시각화 도구 데이터(520), 조작자측 운동학 데이터(525), 환자측 운동학 데이터(530), 및 시스템 이벤트 데이터(525)를 수신할 수 있지만, 언급된 바와 같이, 일부 실시예들에서는 모든 이들 유형들보다 적은 데이터가 이용가능할 수 있다. 이 데이터가, 외과의의 기량 스코어를 결정하는데 이용될, 기량(또는 작업) 모델들을 훈련시키는데 이용되기 때문에, 데이터가 "전문가" 외과의에 의해 생성되었는지 또는 "비전문가" 외과의에 의해 생성되었는지를 나타내도록 데이터에 주석부기될 수 있다. 본 명세서에서 논의될 바와 같이, 훈련 데이터는 전문가 데이터 값들보다 더 많은 비전문가가 있을 때와 같이, 비대칭성들을 포함할 수 있다. 결과적으로, (예를 들어, imblearnTM 라이브러리 함수 imblearn.over_sampling.SMOTE를 이용하는) SMOTE(Synthetic Minority Oversampling Technique) 등의 리샘플링 방법이 블록(705c)에서의 원시 훈련 데이터 또는 블록(705d)에서의 생성된 메트릭에 적용될 수 있다. SMOTE의 변형들, 예를 들어 SMOTEENN(SMOTE with Edited Nearest Neighbors cleaning), SMOTETomek(SMOTE using Tomek links) 등이 마찬가지로 이용될 수 있다는 것을 알 것이다.
블록(705d)에서, 시스템은, 본 명세서에서 더 상세히 설명될 바와 같이, 원시 데이터를 메트릭들, 예를 들어, OPI들로 변환할 수 있다. 순진하게도, 모든 고려된 외과의 기량들을 평가할 때 모든 메트릭들을 이용할 수 있고, 실제로, 일부 실시예들은 이 접근법을 취할 수 있다. 그러나, 블록(705e)에서, 다양한 실시예들은 그 대응하는 기량(또는 작업)을 평가할 때 이용할 각각의 모델에 대한 특정한 유형의 메트릭을 선택할 것이다. 미래의 계산 오버헤드를 감소시키는 것에 부가하여, 이것은 모델들을 보다 잘 미세 조정하여, 모델들이 그 각각의 기량들에 대한 보다 적절한 특징 벡터들에 대해 동작하는 것을 보장할 수 있다. 블록(705f)에서, 시스템은, 블록(705e)에서 기량 또는 작업 모델들 각각에 대해 선택된 블록(705d)에서 생성된 이들 메트릭 특징 벡터들을 이용하여 각각의 기량 또는 작업 모델을 훈련시킬 수 있다. 명료성을 위해, 기량 모델은 기량과 연관된 비전문가 OPI 값들로부터 전문가를 구별하도록 훈련된 기계 학습 모델인 반면, 작업 모델은 작업과 연관된 비전문가 OPI 값들로부터 전문가를 구별하도록 훈련된 기계 학습 모델이다(그러나, 예를 들어, 도 13a와 관련하여 본 명세서에서 논의된 바와 같이, 기량 모델들로부터의 스코어 결과들은 또한 작업들에 대한 스코어 결과들을 추론하는데 이용될 수 있다). 작업 및 기량 모델들 둘 다가 스코어를 생성하기 위해 OPI 데이터의 컬렉션들에 대해 동작함에 따라, 기량 모델들에 대한 OPI-선택, 훈련, 및 적용에 대한 본 명세서에서의 설명들이 (기량 모델들만이 명료성을 위해 논의될 수 있더라도) 작업 모델들에 마찬가지로 적용된다는 것을 알 것이다.
이러한 훈련된 모델들은 이어서 (예컨대, 대상체 데이터세트(605b)에 반영된 바와 같이) 다른 외과의들의 성과들을 차후에 평가하는데 이용될 수 있다. 구체적으로, 시스템이 블록(705g)에서 추가적인 원시 데이터(추론을 위해, 전문가 또는 비전문가와 연관되는 것으로서 주석부기되지 않을 것임)를 수신함에 따라, 시스템은 이러한 데이터를 통해 반복하여, 블록(705h)에서 이를 각각의 기량 모델에 대한 적절한 메트릭들로 변환하고, 블록(705i)에서 기량 스코어들을 생성할 수 있다(이 예에서, 별개의 작업들은 별개의 기량들과 연관되지만, 일부 실시예들에서, 동일한 기량들이 수술 전체에 걸쳐 적용될 수 있다).
도 7b는 일부 실시예들에서 구현될 수 있는 바와 같은 수술 스코어를 결정하기 위해 기량 모델의 예시적인 적용에서 이용되는 다양한 구성요소들을 나타내는 개략도이다. 구체적으로, 블록들(705c, 705d, 705e, 및 705f)에 따라 훈련되는 기량 모델(710d)이 주어지면, 성과 평가 시스템(625)은 블록들(705h 및 705i)의 동작들을 수행할 수 있다. 예를 들어, 시스템 데이터, 환자측 또는 콘솔측 운동학, 또는 비디오 프레임 데이터를 포함할 수 있는 새로운 원시 데이터(710a)가 주어지면, 변환 구성요소(710b)(예를 들어, 소프트웨어, 하드웨어, 또는 펌웨어에서의 로직)는 원시 데이터를 다양한 메트릭 값들(710c)로 변환할 수 있다. 이 예에서, OPI들(예를 들어, 블록(705e)에서 이 특정 기량 모델(710d)에 대해 선택된 것들)은 각각의 프레임 타임스탬프 값과 연관된 개별 OPI 값들의 어레이들로서 표현된다. 이제 이용가능한 이러한 메트릭들을 이용하여, 시스템은 기량 모델(710d)에 의한 고려를 위해 OPI들의 전부 또는 서브세트를 선택할 수 있다(이러한 실시예들에서, 각각의 기량은 그 자신의 모델과 연관되지만, 단일 모델이 다수의 기량들에 대해 출력하도록 훈련되는 실시예들을 이해할 것이다). 모델(710d)에 대한 OPI 값들의 적용은 모델 출력 값들(710e)을 생성할 수 있다. 모델은 OPI 특징 벡터 입력에 기반하여 "전문가들" 및 "비전문가들"을 인식하도록 훈련되었으므로, 출력(710e)은 2개의 값, 예를 들어, 입력 OPI들(710c)이 전문가 또는 비전문가에 의해 생성된 데이터(710a)로부터 도출되었을 확률일 수 있다. 여기서, 예를 들어, 결과들은 데이터의 생성자가 전문가였을 55% 확률 및 생성자가 비전문가였을 45% 확률을 나타낼 수 있다. 논의될 바와 같이, 모델(710d)은 주어진 OPI 데이터에 대한 전문가들 및 비전문가들을 일반적으로 구별할 수 있는 임의의 적절한 분류기, 예를 들어, 로지스틱 회귀 분류기, SVM, 신경망, 랜덤 포레스트 등일 수 있다. 일부 실시예들에서, 모델(710d)은 이용가능한 원시 데이터(예컨대, 1초 간격들과 연관된 데이터)의 단일 서브세트에 대한 OPI 값들을 수신하도록 구성될 수 있고, 이에 따라, 원시 데이터에 반복적으로 적용될 수 있다. 그러나, 일부 실시예들에서, 모델(710d)은 모든 원시 데이터(710a)를 단일 입력으로서 수신하고 데이터 내의 각각의 타임포인트에 대해(예를 들어, 데이터 내의 프레임들의 각각의 타임스탬프에서) 출력 쌍들(710e)을 생성하도록 구성될 수 있다.
논의될 것인 바와 같이, 원시 모델 확률 출력들(710e)은 해당 기량(즉, 모델(710d)과 연관된 기량)과 관련하여 데이터(710a)를 생성한 외과의에 대한 "스코어"를 결정하는데 항상 바로 적합하지는 않을 수 있다. 따라서, 시스템은 (예컨대, 도 12b 및 도 12c를 참조하여 본 명세서에서 설명된 바와 같이 출력들을 기준 모집단으로부터의 스코어들에 관련시킴으로써) 모델 출력 값들(710e)을 최종 스코어 값(710g)으로 매핑할 수 있는 후처리 모델(710f)을 포함할 수 있다.
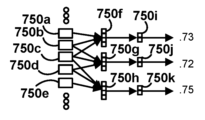
도 7b의 논의로부터, 시스템이 다수의 데이터 세트들(예컨대, 수술의 비디오의 모든 프레임)에 대한 스코어들을 생성하기 위해 어떻게 적용될 수 있는지를 이해할 것이지만, 명확함을 위해, 도 7c는 이러한 데이터를 생성하기 위한 하나의 "윈도잉" 접근법을 예시하고 있다. 구체적으로, 원시 데이터 전체는 연속적인 별개의 시간 간격들 내에 속하는 원시 데이터에 대응할 수 있는 데이터 "세그먼트들"(750a-e)로 조직화될 수 있다. 예를 들어, 데이터 세그먼트(750a)는 기록의 처음 30초 동안의 시스템 및 운동학 데이터일 수 있고, 데이터 세그먼트(750b)는 세그먼트(750a)에 후속하는 30초에서 취득된 시스템 및 운동학 데이터일 수 있고, 데이터 세그먼트(750c)는 마찬가지로 데이터 세그먼트(750b)에 후속할 수 있는 식이다.
모델(710d)은 데이터의 3개의 연속적인 세그먼트로부터 생성된 OPI 값들을 수신하도록 구성될 수 있다. 따라서, 세그먼트들(750a-e)에 걸쳐 3-세그먼트 "윈도우"가 시간적으로 적용될 수 있다. 예를 들어, 세그먼트들(750a, 750b, 및 750c)은 3개의 OPI 값(750f)을 생성하는데 이용될 수 있고, 세그먼트들(750b, 750c, 및 750d)은 3개의 OPI 값(750g)을 생성하는데 이용될 수 있고, 세그먼트들(750c, 750d, 및 750e)은 3개의 OPI 값(750h)을 생성하는데 이용될 수 있다. OPI 값들(750f, 750g, 750h) 각각은 대응하는 예측 출력들(750i, 750j, 750k)(즉, 출력(710e)의 각각의 인스턴스)을 생성하기 위해 모델(710d)에 공급되는 특징 벡터들(즉, OPI들(710c))로서의 역할을 할 수 있다. 이들 출력들 각각은 그 후 후처리 구성요소(710f)에 의해 처리되어 최종 스코어들 0.73, 0.72, 및 0.75를 각각 생성할 수 있다. 윈도우가 데이터의 세그먼트들 대신에 개별 데이터포인트들을 고려할 때, 처리가 계속됨에 따라 윈도우 크기가 조정되는 등의 변형들을 알 것이다.
이러한 방식으로, 최종 스코어들은 시간 경과에 따른 스코어 평가들을 플롯팅하기 위해 대응하는 데이터 세그먼트 타임스탬프들과 연관될 수 있다. 예를 들어, 0.73 기량 스코어는 세그먼트(750b)의 타임스탬프와 연관될 수 있고, 0.72 기량 스코어는 세그먼트(750c)의 타임스탬프와 연관될 수 있고, 0.73 기량 스코어는 세그먼트(750d)의 타임스탬프와 연관될 수 있는 식이다. 이 예가 3-세그먼트 윈도우를 이용하고 이들 3개의 세그먼트에 기반하여 3개의 OPI 값을 생성하지만, 이것이 이해를 용이하게 하기 위해 선택된 단지 하나의 가능한 값임을 쉽게 이해할 것이다. 더 짧은/더 긴 세그먼트 윈도우들 또는 더 많은/더 적은 세그먼트 윈도우들이 이용될 수 있다. 매우 짧은 윈도우들에 대해, 예측 출력들(750i, 750j, 750k)은 인간 검토자에 의한 검사를 용이하게 하기 위해 통합, 예를 들어, 평균화될 수 있다. 반대로, 긴 윈도우들에 대해, 중간 스코어 값들이 보간에 의해 생성될 수 있다.
이에 의해, 이러한 데이터는 도 7d에 도시된 것과 같은 플롯으로 조직화될 수 있고, 여기서 "자궁뿔" 작업에서의 수축 기량에 대한 스코어들이 각각의 대응하는 세그먼트 타임스탬프에 대해 도시된다(기량 모델로부터의 기량 스코어보다는, 시간 경과에 따른 작업 모델로부터의 작업 스코어를 유사하게 조직화할 수 있다는 것을 이해할 것이다). 이러한 방식의 타임스탬프들에 대한 대응하는 스코어들은 수술에서의 특정 시간들과 스코어 값들의 상관, 예를 들어, 작업들(515a, 515b, 515c, 및 515e) 각각 동안의 기량 스코어를 용이하게 할 수 있다. 작업이 이 기량에서 숙련도를 요구하는 것으로 알려져 있는 경우, 도 7d에서와 같은 대응하는 플롯이 매우 유용할 수 있다. 예를 들어, 작업에 대응하는 플롯의 부분들은 외과의에게 강조될 수 있고, 그 피어들에 비해 그 성과가 "양호했는지" 또는 "불량했는지"의 피드백이 제공될 수 있다. 물론, 하나의 작업은 다수의 기량들을 필요로 할 수 있고, 따라서 도 7d와 같은 다수의 플롯들이 외과의에게 함께 제시될 수 있다. 작업들이 발생하는 시간들에 대한 이러한 플롯들은 또한 인간 검토자들에 대한 스코어 값들을 컨텍스트화하는 것을 도울 수 있다. 예를 들어, 외과의들이 그 수술들의 비디오들을 검토할 때, 이러한 세분화된 결과들은, 비디오 전체를 검토하는 것보다는 오히려 성과의 "강조들"을 신속하게 식별하기 위해, 외과의가 그 성과가 더 나은 또는 더 나쁜 비디오에서의 시간들로 점프하게 할 수 있다.
객관적 성과 지표들 - 애플리케이션 개요
이해를 용이하게 하기 위해, 도 8a는 일부 실시예들에서 이용될 수 있는 다양한 메트릭들과 데이터 구조들 사이의 관계들을 나타내는 개략도이다. 구체적으로는, 외과 수술(805a)은 복수의 작업들(예컨대, 작업들(805b, 805c, 및 805d))로 이루어져 있을 수 있다. 각각의 작업은 그 자체가 다수의 기량들을 수반할 수 있다. 예를 들어, 작업(805c)은 기량들(805e, 805f, 및 805g) 각각에 의존할 수 있다. 유사한 방식으로, 각각의 기량은 그 자체가 하나 이상의 OPI 메트릭 값에 기반하여 평가될 수 있다(그러나, 언급된 바와 같이, OPI 값들은 일부 실시예들에서, 개재하는 기량들 없이, 작업들에 직접 관련될 수 있다). 예를 들어, 기량(805f)은 OPI 메트릭들(805h, 805i, 및 805j)에 의해 평가될 수 있다. 각각의 OPI 메트릭은 하나 이상의 원시 데이터 필드로부터 도출될 수 있다. 예를 들어, OPI 메트릭(805i)은 원시 데이터 값들(805k, 805l, 및 805m)에 의존할 수 있다. 따라서, 수술을 의미 있는 작업 분할들로 분할하고, 각각의 작업에 수반되는 기량들을 평가하고, OPI들을 결정하고 이들을 다양한 기량들과 관련시키고, 이용가능한 데이터로부터 OPI들을 정의하는데 주의를 기울일 수 있다.
원시 데이터(구체적으로, 운동학 데이터)의 예로서, 도 8b는 일부 실시예들에서 하나 이상의 OPI를 생성하는데 이용될 수 있는 바와 같은, 3차원 공간에서의 포스셉스(840)의 병진 운동(845a)을 도시한다. 도 8c는 일부 실시예들에서 하나 이상의 OPI를 생성하는데 이용될 수 있는 바와 같은, 예시적인 원시 데이터 입력, 구체적으로는, 복수의 포스셉스 구성요소 축을 중심으로 하는 3차원 공간에서의 복수의 회전이다. 포스셉스(840)는 각각의 축들(850a, 850b, 및 850c)을 중심으로 그 구성요소들 중 다양한 구성요소들을 회전(845b, 845c, 845d)시킬 수 있다. 도 8b 및 도 8c의 병진들 및 회전들은 시간 경과에 따라 원시 운동학 데이터에서 캡처되어, 원시 데이터 값들(805k, 805l, 및 805m)을 형성할 수 있다. OPI 메트릭(805i)은 "포스셉스 팁 움직임 속도" OPI일 수 있고, 원시 값들(805k, 805l, 및 805m)에 기반한 포스셉스 팁의 속도를 나타낼 수 있다(예를 들어, OPI는 도 8b 및 도 8c의 원시 데이터로부터 도출되는 야코비안 행렬로부터 팁 속도를 추론할 수 있다). OPI 메트릭(805i)은 이후 기량(805f)에 대한 기량 스코어(또는, 다시, 작업(805c)에 대한 작업 스코어)를 생성하기 위해 모델에서 특징 벡터의 일부로서 이용되는 몇몇 OPI 메트릭들 중 하나일 수 있다. 일부 실시예들에서, 기량 스코어들의 컬렉션들이 이어서 작업(805c)의 외과의의 성과 및, 궁극적으로는, 모든 작업들을 고려하는 것에 의해, 외과의의 수술(805a) 성과 전체를 평가하는데 이용될 수 있다.
다시 말하지만, 명확함을 위해, 작업들(805b, 805c, 및 805d) 중 하나에 대한 외과의의 성과를 평가하고자 하는 경우, 일부 실시예들은 기량 기반 모델들로부터 생기는 작업의 구성 기량 스코어들을 고려함으로써 작업에 스코어를 부여할 수 있다. 대안적으로, 일부 실시예들에서, 대신, 단순히 OPI들을 작업들에 직접 할당하고, 이후 필요한 부분만 약간 수정하여 기량들에 대해 본 명세서에 개시된 OPI들 및 시스템들 및 방법들을 이용하여 (기량 기반보다는) 작업 기반 모델들을 훈련시킬 수 있다(즉, 전문가들이 기량들에 대해서보다는 작업들에 대해 OPI들을 선택하고, 기량에 대해 선택된 OPI 세트보다는 작업에 대해 선택된 OPI 세트에 대해 OPI 필터링을 수행하게 하는 것 등이다).
예시적인 OPI - 기량/작업 매핑
도 8d는 (예를 들어, 도 11a의 OPI 선택 프로세스들에 따라 또는 전문가 직관 및 경험에 기반한 초기 매핑으로서) 일부 실시예들에서 적용될 수 있는 바와 같은 예시적인 OPI 대 기량 및 기량 대 작업 매핑들을 나타내는 한 쌍의 표들(835a, 835b)이다. 복수의 기량들(855c)에 의해, 표(835b)의 음영 표시된 셀들은 대응하는 OPI들(855b)을 나타낸다. 이와 유사하게, 표(835a)는 작업들(855a)이 어떻게 기량들(855c)에 대응할 수 있는지를 음영 표시된 셀들을 통해 나타낸다.
명확함을 위해, 도 8d에 도시된 예시적인 대응관계에서, 예컨대, 도시된 작업들 중 6개 전부가 "카메라 이용" 기량에 의존하지만, "자궁뿔" 작업만이 "양손 아암 수축" 기량에 의존한다. 유사하게, "우세 팔목 관절(Dominant Arm Wrist Articulation)" OPI는 "봉합" 기량에 관련된다. 이러한 표들로부터, 예를 들어, "카메라 제어 레이트" OPI가 ("카메라 이용"이 표들 각각에서 둘 모두에 공통이기 때문에) "자궁뿔" 작업에 관련된다는 전이적 추론들을 또한 할 수 있다. 따라서, 도 8d와 같은 표들은 기량 모델들 및 작업 모델들 모두에 대한 OPI들을 선택하는데 이용될 수 있다. 이 예에 도시된 것들보다 더 많은 기량들, 작업들, 및 OPI들이 적용될 수 있다는 것을 잘 알 것이다. 또한 유의할 점은, 단일 기량이 다수의 작업들에 적용가능할 수 있다는 것이다. 다시, 초기 OPI 대 기량 대응관계는 본 명세서에 더 상세히 설명되는 데이터-구동 선택을 통해 증강될 수 있다.
언급된 바와 같이, 초기 OPI 대 기량 대응관계, OPI 대 작업 대응관계, 또는 기량 대 작업 대응관계는 검사에 의해 또는 전문가와 협의함으로써 결정될 수 있다. 그러나, 본 명세서에 논의될 바와 같이, 수동 검사만으로 기량 또는 작업에 대한 적절한 OPI들을 선택하는 것은 종종 다루기 힘들 수 있고, 따라서 본 명세서에 제시되는 자동화된 시스템들이 이용될 수 있다.
구체적으로, 모든 OPI들의 특징들에 대해 훈련되는 기계 학습 모델들이 (예를 들어, 신경망이 무관한 특징들과 연관된 가중치들을 감소시키거나 또는 SVM이 초평면 분리를 선택할 때 무관한 차원들을 일반적으로 무시할 때와 같이) 더 두드러진 OPI들에 대해 자연스럽게 이들의 처리를 포커싱할 수 있다는 것이 사실이지만, 모델에 대한 이러한 따르기는 해석 능력을 복잡하게 할 수 있는데, 왜냐하면 모델이 주어진 OPI를 얼마나 정확하게 상향 또는 하향 선택하는지가 실무자에게 불명확할 수 있기 때문이다. 대신에, 도 8d의 방식으로 OPI들을 기량들에 효율적으로 매핑하는 것은 외과의들에게 보고된 기량 스코어들을 보다 일반화가능하고 해석가능하게 만들 수 있다. 따라서, 필요한 것보다 더 많은 OPI들을 기량 또는 작업과 대략적으로 연관시키는 것보다는 오히려, OPI들의 더 효율적인 서브세트를 선택하는 것이 데이터를 외과의들이 더 용이하게 이해하는 카테고리들로 그룹화하는 것을 용이하게 할 수 있고, 이는 그 자체가 외과의 피드백에서의 더 의미 있는 브레이크다운들을 용이하게 할 수 있다. 추가적으로, 입력 특징들에 더 적은 OPI들을 포함시키는 것은 또한 각각의 기량 모델들의 훈련 및 추론 동안 계산 오버헤드를 감소시킬 수 있다. 실제로, 더 적은 OPI들에 의존하는 것은 또한 시스템이 OPI 값들의 전체 세트를 생성하기 위해 모든 데이터 유형들보다 적은 데이터 유형들이 이용가능할 때에도(또는 모든 데이터보다 적은 데이터가 동기화될 수 있을 때에도) 적어도 일부 기량 스코어들을 계속 생성하는 것을 허용할 수 있다.
OPI 선택 - 예시적인 개요
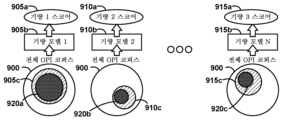
도 9a는 일부 실시예들에서 구현될 수 있는 바와 같은 기량들, 기량 모델들, 및 OPI들 사이의 예시적인 관계 세트를 나타내는 개략도이다. 여기서, 각각의 기량 스코어(905a, 910a, 915a 등)는, 각각, 대응하는 기계 학습 모델(905b, 910b, 915b)로부터 도출될 수 있다(그러나, 언급된 바와 같이, 일부 실시예들에서, 모델의 출력에 대한 후처리가 최종 기량 스코어 값을 결정하기 위해 적용될 수 있다). 일부 실시예들이 모든 기량 모델에 전체 OPI 세트를 제공하는 것을 고려하지만(실제로, 일부 실시예들에서는 모든 고려된 기량들에 대한 출력들을 제공하는 모놀리식 모델이 이용될 수 있음), 여기서, 각각의 모델(905b, 910b, 915b)은 대신 이용가능한 OPI들의 전체 코퍼스(900)로부터의 서브세트(920a, 920b, 920c)를 고려할 수 있다. 구체적으로는, 인간 주석부기기(전문가 외과의 등)는 전문 지식 및 직관에 기반하여 초기 서브세트들(905c, 910c, 915c)을 각각의 기량들과 연관되는 것으로서 선택할 수 있다. 예를 들어, 전문가는 주어진 OPI가 해당 기량에 대한 임의의 관련을 가지는지의 여부를 고려할 수 있다. 기량 "카메라 관리"는 카메라 속도에 관련된 OPI들을 수반할 수 있지만, 말하자면, 가위 활성화에 관련된 OPI들에 의존할 가능성이 없다. 결과적으로, 카메라-관련 기량에 대한 초기 OPI 서브세트 선택은 카메라-관련 데이터로부터 도출되는 모든 OPI들을 포함할 수 있다.
따라서, 일부 실시예들에서, 서브세트들(905c, 910c, 915c)에 대한 OPI 값들은 모델들(905b, 910b, 915b)에 공급되고 기량 스코어들을 결정하는데 이용될 수 있다. 그러나, 위에서 논의된 바와 같이, 중복적인 또는 비정보적인 OPI들을 제거하는 것에 대한 이점들이 존재할 수 있다. 따라서, 일부 실시예들에서, 자동화된 필터링이 905c, 910c, 915c에 적용되어 OPI들의 최종 세트들(920a, 920b, 920c)을 결정한다. 그러나, 때로는 자동화된 필터링이 초기 서브세트 선택과 일치할 것임을 알 것이다(예를 들어, 서브세트들(905c 및 920a)은 동일하다). 유사하게, 일부 실시예들은 초기 인간 주석부기를 포기하고 자동화된 필터링에 완전히 의존할 수 있다(예를 들어, 세트(900) 및 초기 서브세트(905c)는 동일하다).
상이한 작업들에 걸친 서브세트들(920a, 920b, 920c) 각각이 동일한 OPI들 중 하나 이상을 포함할 수 있거나 포함하지 않을 수 있다는 것이 이해될 것이다. 실제로, 일부 경우들에서, 서브세트들(920a, 920b, 920c) 중 2개 이상은 OPI들의 동일한 세트일 수 있다. 일부 실시예들에서, 기량이 상이한 작업에서 이용될 때 상이한 기계 학습 모델로 동일한 기량이 평가될 수 있다. 대안적으로, 훈련 데이터가 작업 레벨에서 주석부기되는(즉, 작업에 관한 데이터의 부분들이 이와 같이 식별되는) 일부 실시예들에서, 모델들(905b, 910b, 915b)은 작업을 나타내는 추가 입력을 수신하도록 구성될 수 있다(이에 의해, 작업-특정 기량 평가들을 생성하도록 이들을 장려한다). 따라서, 일부 실시예들에서, 상이한 작업별 기량 모델들이 상이한 작업별 OPI 서브세트들을 수신할 수 있음을 알 것이다.
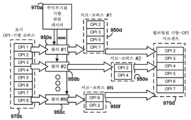
복제가능하고 의미 있는 방식으로 OPI 서브세트들을 효과적으로 선택하기 위해, 다양한 실시예들은 도 9b에 도시된 바와 같이 OPI 관련성 평가기 구성요소(970c)(예를 들어, 소프트웨어, 하드웨어, 또는 펌웨어에서의 로직)를 적용하는 것을 고려한다. 이러한 구성요소는 주석부기된 훈련 데이터(970a)(즉, 해당 특정 기량 또는 작업과 관련하여 전문가 또는 비전문가로부터 온 것으로서 주석부기된 수술 데이터) 및 주어진 기량(또는 작업)에 대한 초기 OPI 선택(970b)을 수신할 수 있다. OPI 관련성 평가기 구성요소(970c)는 최종 필터링된 선택(970d)을 결정하기 위해 초기 OPI 선택(970b)에 하나 이상의 필터링 동작을 적용할 수 있다(예를 들어, 초기 OPI 선택(970b)이 세트(905c)인 경우, 최종 세트(970d)는 세트(920a)일 수 있다).
OPI 관련성 평가기 구성요소(970d)의 예시적인 동작의 상위 레벨 시각화가 도 9c에 도시된다. 여기서, 기량, 예를 들어, 도메인 전문가에 의해 선택된 바와 같은 세트(905c)에 대한 초기 OPI 코퍼스(970b)는 8개의 별개의 OPI("OPI 1", "OPI 2" 등)를 포함할 수 있다. OPI 관련성 평가기 구성요소(970d)는 코퍼스(970b)를 하나 이상의 필터에, 예를 들어, 복수의 필터(950a, 950b, 및 950c) 각각에 제출할 수 있다. 이러한 필터들 각각은 각각의 OPI들에 대한 대응하는 데이터(970a)를 고려함으로써 코퍼스(970b)의 멤버들의 전부 또는 서브세트를 반환할 수 있다. 여기서, 예를 들어, 필터(950a)는 OPIS 1, 4, 6, 및 8을 제거하여 서브-코퍼스(950d)를 생성하였다. 유사하게, 필터(950b)는 서브-코퍼스(950e)를 생성하였고, 필터(950c)는 서브-코퍼스(950f)를 생성하였다. 다시 한번, 필터들(950a, 950b, 및 950c) 중 일부는, (예를 들어, 도 10a 및 도 10c의 예들에 관하여 본 명세서에 더 상세히 설명되는 바와 같이) 그 필터링을 수행할 때 전문가/비전문가 주석부기된 훈련 데이터(970a)를 고려할 수 있다. 예시적인 필터(950a, 950b 및 950c)는 만-휘트니 U 테스트(Mann-Whitney U test), 상관 기반 필터링, 선형 판별 분석, 카이-제곱 테스트 분석, t-테스트(및 Welch와 같은 변형들), LASSO(least absolute shrinkage and selection operator) 회귀, 랜덤 포레스트 또는 결정 트리, RFE/재귀적 특징 제거(로지스틱 회귀 기본 추정기, 기본 추정기로서의 표준 ML 모델 등), PCA/희소 PCA/푸리에 방법/등(예컨대, 훈련 데이터에서 가장 큰 주요 구성요소 또는 신호 기여를 갖는 OPI를 보유하는 것에 의함), t-SNE(t-Distributed Stochastic Neighbor Embedding), UMAP(Uniform Manifold Approximation and Projection) 차원 감소 기반 기법, 릴리프 특징 선택, (예컨대, Boruta RTM 언어 패키지로 구현되는) Boruta 알고리즘 등을 포함한다.
필터들(950a, 950b, 950c)이 서브-코퍼스들(950d, 950e, 및 950f)을 생성한 이후, OPI 관련성 평가기 구성요소(970c)는 서브-코퍼스들(950d, 950e, 및 950f)을 최종 세트(970d)로 통합할 수 있다. 이러한 통합은 상이한 실시예들에서 상이한 형태들을 취할 수 있다. 이 예에서, 구성요소(970c)는 기량 모델이 훈련될 수 있는 최종 서브-코퍼스(970d)를 생성하기 위해 서브-코퍼스들(950d, 950e, 및 950f)의 논리 OR(또는 등가적으로 합집합)을 취한다(즉, 모델은 세트(970d)의 선택된 OPI들에 대응하는 훈련 및 추론을 위해 OPI 데이터를 소비할 것이다). 예를 들어, OPI 2는 양자의 서브세트들(950d 및 950e)에서 나타나고, 따라서, 최종 세트(970d)에서 오직 한번 나타난다. 대조적으로, 세트들(950d, 950e, 또는 950f) 중 어느 것도 OPI 8을 포함하지 않고, 따라서 OPI 8은 최종 세트(970d)에 나타나지 않는다. 여기서, 필터들은 동일하게 취급되지만, 일부 실시예들에서, 일부 필터의 서브세트들은 다른 것들보다 선호도가 주어질 수 있고, 세트(970d)에 나타나는 OPI들은, 예를 들어, 세트들(950d, 950e, 또는 950f)의 가중 투표에 의해 선택될 수 있다(예를 들어, 세트들(950d, 950e, 또는 950f)에서 4개의 가장 공통적인 OPI들을 선택한다). 유사하게, 일부 실시예들은 논리 OR 대신에 세트들의 논리 AND(예를 들어, 각각의 코퍼스의 교차)를 이용할 수 있다. 이 예에서, 논리 AND는 OPI 2만을 가지는 최종 세트(970d)를 생성할 것이다.
서브세트들(가중 투표, 논리 OR, 논리 AND 등)을 어떻게 최상으로 통합할지는 이용되는 기량 모델, OPI들의 성질, 및 부과되는 계산 제약들에 의존할 수 있다. 예를 들어, 계산 자원들이 광범위하고, 기량 모델이 강건(예를 들어, 심층 학습 모델)하고, 다수의 OPI들의 관련성을 식별할 수 있거나, 또는 OPI들이 반드시 상당한 양의 데이터를 캡처하지는 않는 경우, 논리 OR이 더 적합할 수 있다. 대조적으로, 계산 자원들이 제한되거나, 기량 모델이 덜 강건하거나, 또는 OPI들이 상당한 양의 데이터를 캡처하는 경우, 논리 AND가 더 적합할 수 있다. 모델이 로지스틱 회귀 분류기인, 본 명세서에서 논의된, 다양한 실험적 실습 축소들에서, OPI들은 도 17, 도 18, 도 19 및 도 20에 도시된 바와 같았고, 논리 OR이 유리한 결과들을 생성하는 것으로 밝혀졌다.
일부 실시예들에서, 필터들은 또한 처리될 데이터에 대해 예비 검증들을 수행함으로써 선택될 수 있다. 예를 들어, 데이터는 정규성, 동일 분산들 등의 가정들에 대해 테스트될 수 있고, 데이터 소스가 다양한 독립성 요건들을 충족시키는 것으로 발견되면, 다양한 필터들이 단독으로 또는 이에 따라 조합하여 적용될 수 있다.
언급된 바와 같이, 필터들(950a, 950b, 950c)은 다양한 방법들에 따라 OPI들을 선택할 수 있다. 일반적으로, 필터들은 3가지 형태들, 즉 단일 OPI 통계 분포 분석(SOSDA) 필터들, 다중-OPI 통계 분포 분석(MOSDA) 필터들, 및 다중-OPI 예측 모델(MOPM) 필터들 중 하나를 가정할 수 있다. SOSDA 및 MOSDA 필터들은, 각각, 하나 이상의 OPI 값의 선택에 대한 OPI 값들의 세트의 전문가 분포 및 OPI 값들의 세트의 비전문가 분포가, 하나 이상의 OPI가 (예를 들어, 본 명세서에 설명된 도 10a의 방법에 따라) 전문가 데이터를 비전문가 데이터와 구별하는데 유용할 수 있도록 충분히 상이한지의 여부를 결정하는데 이용될 수 있다. 구체적으로, SOSDA 및 MOSDA 필터들 각각에 대한 "차이"는 전문가 및 비전문가 분포들에 적용되는 통계 테스트에 따라 결정될 수 있다. SOSDA 필터에서 이용되는 통계 테스트 및 분석의 예는, 예를 들어, 만-휘트니, t-테스트, Welch의 t-테스트, 상관 방법, 일반화된 선형 모델, 카이-제곱 테스트 등과 같은 가설 테스트를 포함한다. 유사하게, MOSDA 필터에서 이용될 수 있는 통계 테스트 및 분석의 예는, 예를 들어, 월드 테스트(Wald test), ANOVA, 일반화된 선형 모델, PCA, 희소 PCA, t-SNE, UMAP/다른 차원수 감소 기법, 상관 등을 포함한다. MOPM 필터들은, 대조적으로, 예측 모델로 전문가/비전문가 데이터를 구별함에 있어서 하나 이상의 OPI의 선택으로부터의 OPI 값들의 유효성을 고려할 수 있고, 따라서, 예를 들어, log reg 또는 다른 기본 추정기들을 갖는 재귀적 특징 제거(RFE), 릴리프 특징 선택, 선형 판별 분석, LASSO 회귀, 랜덤 포레스트 방법들, 결정 트리들, Boruta 특징 선택 등을 포함할 수 있다. 따라서, 필터(950a, 950b, 950c) 모두가 SOSDA 필터일 수 있고, 모두가 MOSDA 필터일 수 있으며, 모두가 MOPM 필터일 수 있고, 그 일부가 한 유형의 필터일 수 있는 반면 다른 필터가 다른 유형의 필터일 수 있는 것 등을 잘 알 것이다. 유사하게, 통계 테스트들 또는 반복 모델 예측들이 이후 식별된 클러스터들의 비유사도 또는 예측 유효성을 평가하는데 이용될 수 있음에 따라, MOSDA 필터들 및 MOPM 필터들 모두가 K-평균들, K-최근접-이웃들, 계층적 클러스터링, DBSCAN(density-based spatial clustering of applications with noise) 등과 같은 클러스터링 방법들을 이용할 수 있다는 것을 알 것이다.
OPI 선택 - 예시적인 SOSDA/MOSDA OPI 필터링 프로세스
도 10a는 일부 실시예들에서 구현될 수 있는 바와 같은, SOSDA-스타일 OPI 필터링을 위한 예시적인 프로세스(1010)를 나타내는 흐름도이지만, 한 번에 하나의 OPI가 아니라 한 번에 다수의 OPI들을 고려함으로써 MOSDA 필터링을 위한 단계들이 적용될 수 있음을 알 것이다. 여기서, 블록들(1010a 및 1010b)에서, 시스템은 세트(970b) 내의 OPI들을 통해 반복할 수 있다(다시, MOSDA-스타일 필터링 동안, 단일 OPI들보다는 OPI들의 컬렉션들이 블록(1010b)에서 고려될 수 있음을 이해할 것이다). 이러한 OPI들 각각에 대해, 시스템은 기량에 대한 전문가 및 비전문가 데이터세트들 각각에서 OPI 값의 각각의 분포들을 결정하기 위해, 블록(1010c)에서 대응하는 전문가(다시, 해당 기량에 대한 "전문가")/비전문가 주석부기된 데이터(970a)를 참조할 수 있다. 블록(1010d)에서, 시스템은 이어서 분포들이 유사한지 또는 비유사한지를 고려할 수 있다.
예를 들어, 기량이 "카메라 이동"이고 블록(1010b)에서 고려된 OPI가 "카메라 이동의 지속기간"인 경우, 초보 사용자들이 카메라를 종종 신속하고 정밀하게 배치하는 전문가들보다 더 넓은 변동으로 카메라를 위치시키는데 더 많은 시간이 걸릴 수 있으므로, 분포들은 매우 비유사할 수 있다. 반대로, 블록(1010b)에서 고려된 OPI가 (예를 들어, 비디오 이미지의 푸리에 변환으로부터 가장 넓은 주파수 다양성을 찾음으로써 평가되는 바와 같이) "포커스"였던 경우, 전문가들 및 비전문가들 모두는 적절한 포커스를 신속하게 달성할 수 있다. 따라서, 데이터에서의 분포들은 매우 유사할 수 있다. 비유사한 OPI 분포들은 비전문가들로부터 전문가들을 구별하는데 더 유용할 수 있으므로, 블록(1010e)에서 유지될 수 있는 반면, 유사한 분포들은 OPI가 블록(1010f)에서 제거되는 것을 초래할 수 있다. 독자에 대한 명료성을 용이하게 하기 위해, 도 10b는 예시적인 OPI 값 분포들을 도시한다. OPI(예를 들어, "포커스")에 대한 전문가 분포가 분포(1015a)였고, 비전문가 분포가 분포(1015b)였던 경우, OPI는 전문가들과 비전문가들을 구별하기 위한 열악한 수단일 수 있고 세트로부터 제거될 수 있다. 대조적으로, OPI(예컨대, "카메라 이동의 지속기간")에 대한 전문가 분포가 분포(1015c)였고, 비전문가 분포가 분포(1015d)였던 경우, OPI는 전문가들과 비전문가들을 구별하기 위한 양호한 수단일 수 있고 세트에서 유지될 수 있다. 모든 OPI들이 블록(1010a)에서 고려되었다면, 보유된 OPI들의 최종 세트(예를 들어, 서브-코퍼스(950d))가 블록(1010g)에서 출력될 수 있다.
분포들 사이의 "유사도"의 정량적 결정을 평가하기 위한 다양한 메커니즘을 이해할 것이다. 예를 들어, 일부 실시예들은 분포의 평균 및 분산을 직접 비교하고, T-테스트를 수행하며, p-값을 평가하는 것 등을 할 수 있다. 정규 분포를 가정하지 않는 만-휘트니 U 테스트와 같은, 비-파라메트릭 테스트들은, 여기서 고려되는 OPI 값 분포들의 경우일 수 있는 바와 같이, 불균형 데이터를 가지고 작업하는데 특히 유용할 수 있다. 만-휘트니 U 테스트들을 비롯한, 이 테스트들 중 다수를 수행하기 위한 다양한 라이브러리들이 존재한다는 것을 잘 알 것이다. 예를 들어, SciPYTM 라이브러리는 scipy.stats.mannwhitneyu 함수를 제공한다. 이 함수를 이용하고 (예컨대, 블록(1010d)에서) 0.05 미만의 U 통계 p-값들을 갖는 분포들을 "비유사"로서 식별하는 예시적인 실습 축소가 양호한 결과들을 생성하는 것으로 밝혀졌다. 일부 실시예들은 또한 잘못된 결론들을 줄이기 위해 Bonferroni, Bonferroni-Holm과 같은 부류별 에러 정정을 적용할 수 있다(예를 들어, Bonferroni는 잠재적으로 잘못된 부정들을 증가시키는 대가로 잘못된 긍정들을 줄일 수 있다).
OPI 선택 - 예시적인 MOPM OPI 필터링 프로세스
명료성을 위해, 도 10c는 예를 들어, RFE에 따라 이용될 수 있는 바와 같이, MOPM 필터를 이용하여 OPI 선택을 수행하기 위한 예시적인 프로세스(1005)를 나타내는 흐름도이다. 구체적으로, 블록(1005a)에서, 처리 시스템은 OPI 값들(970b)의 모든 초기 세트에 대한 전문가/비전문가 주석부기된 데이터(970a)를 훈련 서브세트 및 검증 서브세트로 분할할 수 있다. 블록(1005b)에서, 처리 시스템은 전문가 및 비전문가 외과의들과 연관된 OPI 값들을 인식하기 위해 OPI 데이터의 이러한 훈련 세트에 대해 기계 학습 모델(예를 들어, 로지스틱 회귀 분류기 모델, SVM 모델 등)을 훈련시킬 수 있다. 블록(1005c)에서, 처리 시스템은 검증 서브세트를 이용하여 모델을 검증할 수 있다. 블록(1005d)에서, 처리 시스템은 검증 동안 정확한 분류에 영향을 미치는 OPI들의 중요도에 기반하여 OPI들의 순서화를 결정할 수 있다. 예를 들어, 초기 OPI들 각각은 선택적으로 제거될 수 있고, 모델 성과가 재고려될 수 있고, 이들 OPI 제거들은 더 중요한 것으로서 고려되는 출력에서 더 큰 분산을 촉발시킨다. 일부 기계 학습 모델들, 예를 들어, 랜덤 포레스트들이 이들의 처리의 일부로서 (예를 들어, OPI가 배제될 때 얼마나 많은 정확도가 감소하는지를 나타내는) 중요도 스코어들을 제공할 수 있다는 점이 이해될 것이다. OPI들의 중요도 순서화를 식별한 이후, 시스템은 블록들(1005f 내지 1005m)에서 덜 중요한 OPI들을 잘라 낼 수 있다(그러나, 다양한 실시예들은 임계치를 넘는 가장 중요한 OPI들을 단순히 선택하기 위해 이들 동작들을 포기할 수 있다).
구체적으로는, 블록(1005e)에서, 서브세트 크기 카운터(CNTS)가 1로 초기화될 수 있다(여기서의 카운터의 이용이 단지 이해를 용이하게 하기 위한 것이고 등가의 기능이 다양한 방식들로 용이하게 구현될 수 있다는 것을 잘 알 것이다). 이 카운터는 (블록(1005d)에서 결정된 바와 같은 중요도의 순서로) 세트(970b)로부터의 S OPI들 중 몇 개가 고려되어야 하는지를 추적할 것이다. 따라서, OPI들의 수는 (블록(1005d)에서 결정되는 바와 같은) 가장 중요한 OPI들의 모든 S가 블록(1005f)에서 고려될 때까지 블록들(1005f 및 1005g)에서 증가될 수 있다.
각각의 반복에서, 블록(1005g)에서의 CNTS 가장 중요한 OPI들이 고려되고 블록(1005h)에서 기계 학습 모델을 훈련하는데 이용될 수 있다. 시스템은 이어서 블록(1005i)에서 훈련된 모델을 검증할 수 있다(예를 들어, 여기서 원시 데이터 및 분할들은 블록(1005a)에서의 것들과 동일하다). 이러한 검증의 유효성은 선택된 OPI 세트 적합성의 추정으로서 이용될 수 있다. 따라서, 결과들, 예를 들어, 검증에서의 모델 정확도가 블록(1005j)에서 기록될 수 있다. CNTS는 블록(1005k)에서 증분될 수 있고, 추가적인 반복들이 수행될 수 있다.
블록(1005i)에서 모든 원하는 OPI들의 세트들이 검증을 통해 평가되었으면, 시스템은 블록(1005l)에서 각각의 세트 선택에 대한 성과 프로파일을 결정할 수 있다. 시스템은 이후, 블록(1005m)에서, 최종 OPI 세트, 예를 들어, 수용가능한 또는 최상의 검증 결과들을 달성하는 가장 작은 세트를 선택할 수 있다.
많은 통계 패키지들이 SOSDA, MOSDA, 또는 MOPM 필터들의 적용을 손쉽게 용이하게 할 수 있다는 것을 알 것이다. 예를 들어, RFE는 scikit-learnTM 라이브러리의 "sklearn.feature_selection.RFE" 클래스를 이용하여 구현될 수 있다. 실시예의 예시적인 실습 축소에서 이용되는 다음의 코드 라인 목록 C1은 이 목적을 위해 양호한 결과들을 생성하는 것으로 밝혀졌다.
다시 말하지만, 코드 목록 C1의 예에서 SVM이 이용되었지만, RFE가 또한 다른 모델들, 예컨대, 랜덤 포레스트, 로지스틱 회귀 분류기 등과 함께 이용될 수 있다는 것을 잘 알 것이다.
OPI 필터링을 이용한 예시적인 기량 모델 훈련 프로세스
도 11a는 일부 실시예들에서 구현될 수 있는 바와 같이, 기량(또는 작업) 모델 구성들 및 OPI 선택들을 평가하여 전문 지식 모델(예를 들어, 기량 모델 또는 작업 모델)을 생성하기 위한 예시적인 프로세스(1100)에서의 다양한 동작들을 나타내는 흐름도이다. 일반적으로, 프로세스(1100)는 OPI 선택을 교차 검증 동작들과 통합함으로써 전문 지식 기계 학습 모델 분류기에 대한 파라미터 선택을 용이하게 할 수 있다. 교차 검증은 이용가능한 데이터의 전부 또는 일부에 대해서만 훈련함으로써 생성될 수 있는 것보다 더 강건한 모델 구성을 달성하기 위해 다수의 모델 구성을 반복적으로 훈련하기 위한 방법이라는 것을 알 것이다. 구체적으로는, 참조 및 명확함을 위해, 도 11b의 예시적인 훈련 데이터(1115a)를 참조하면, 훈련 데이터(1115a)는 선택된 특징들의 포맷으로 되어 있고 본 명세서의 다른 곳에서 논의되는 바와 같이 주석부기될 수 있다(예컨대, 원시 데이터 값들 또는 OPI 값들은 전문가 또는 비전문가와 연관되어 있는 것으로 주석부기된다). 이 데이터는 훈련 부분(1115b) 및 테스트 부분(1115c)으로 분할될 수 있다(일부 실시예들에서, 테스트 부분(1115c)은 생략될 수 있고, 모든 이용가능한 훈련 데이터가 훈련 부분(1115b)으로서 이용될 수 있다). 훈련 부분(1115b) 자체는 모델들의 하이퍼파라미터들 각각을 결정하고 모델들을 검증하는데 이용될 수 있는 반면, 테스트 부분(1115c)은 생성된 모델들의 최종 검증 평가 또는 생성된 모델들로부터 도출된 최종 모델을 제공하도록 보류될 수 있다. 이를 위해, 훈련 부분(1115b) 자체가 대략적으로 동일한 데이터 그룹화의 "폴드들"로 분할될 수 있다(여기서는 3개의 이러한 폴드가 도시되어 있다). 각각의 훈련 반복에서, 모델의 하이퍼파라미터들의 버전은 훈련 부분(1115b)으로부터의 폴드들 중 일부 또는 전부로 모델을 훈련함으로써 결정될 수 있다(예를 들어, 제1 훈련된 모델은 모델을 검증하는데 이용되는 폴드 2 및 폴드 3, 및 폴드 1을 이용하여 생성될 수 있고; 제2 모델은 검증에 이용되는 폴드 1 및 3, 및 폴드 2에 대해 훈련될 수 있는 식이다). 그 다음, 생성된 모델들 및 그 검증 결과들 각각은 선택된 모델 파라미터들의 유효성(예를 들어, 신경망 내의 계층들의 선택, SVM 내의 커널의 선택 등)을 평가하기 위해 분석될 수 있다. 가장 바람직한 파라미터들은 이어서 새로운 모델에 적용될 수 있고, 모델은, 예컨대, 데이터(1115b) 전체에 대해 훈련되고 별개의 예비된 테스트 부분(1115c)을 이용하여 평가될 수 있다.
프로세스(1100)는 검증 결과를 갖는 다수의 이러한 중간 모델, 및 원한다면, 파라미터들이 만족스러운 결과를 생성하는 경우 최종 모델을 유사한 방식으로 생성하는데 이용될 수 있다. 도 9a에 대해 논의된 바와 같이, OPI 코퍼스의 전문가 선택 서브세트(또는 전체 OPI 코퍼스)가 블록(1190)에서 수신될 수 있다. 훈련 데이터(즉, 전문가/비전문가 주석부기된 원시 데이터 값들 또는 OPI 값들)가 또한 제공될 수 있다. 이 데이터는 블록(1186)에서 (부분(1115b)에 대응하는) 훈련 및 (부분(1115c)에 대응하는) 테스트 부분들에 할당될 수 있다. 언급된 바와 같이, 훈련 부분 자체는 원하는 수의 폴드들로 분할될 수 있고, 그로부터 원하는 수(T2)의 선택들이 각각의 반복에서 도출될 수 있다(예를 들어, T2=5이다). 예를 들어, 제1 선택은 폴드들 1 및 2에 대해 훈련할 수 있고, 폴드 3에 대해 검증할 수 있고, 제2 선택은 폴드들 2 및 3에 대해 훈련할 수 있고, 1에 대해 검증할 수 있는 식이다. 따라서, 블록(1105)에서, 외부 카운터 Cnt2는 1로 초기화될 수 있고, 블록(1187)에서 폴드 선택들에 대해 반복하는데 이용될 수 있다(다시, 여기에서의 카운터의 이용은 단지 이해를 용이하게 하기 위한 것이고, 등가의 기능이 다양한 방식들로 용이하게 구현될 수 있다는 것을 알 것이다).
각각의 고려된 폴드들의 선택에 대해, 블록(1110)에서, 시스템은 SOSDA 또는 MOSDA OPI 필터링 방법, 예를 들어, 만-휘트니 U 테스트를 이용한 필터링을 이용하여 제1 OPI 서브세트를 결정할 수 있다. 명확함을 위해, 블록(1110)의 각각의 성과의 SOSDA 또는 MOSDA OPI 필터링의 OPI 값들에 의해 참조되는 원시 데이터가 블록(1187)으로부터의 현재 선택으로부터의 폴드들의 원시 데이터라는 것을 잘 알 것이다(예컨대, 선택에서의 폴드들 전부가 있지만, 일부 실시예들은 모든 폴드들보다 더 적게 이용할 수 있다). 블록(1110)에서 제1 세트의 OPI들이 SOSDA 또는 MOSDA 필터를 통해 선택되었으면, 시스템은 블록(1145)에서 MOPM 필터를 통해 추가적인 OPI 서브세트를 생성하려고 시도할 수 있다. MOPM 필터는 그 자신의 기계 학습 모델을 이용할 수 있기 때문에, 루핑 내부 교차 검증 접근법이 역시 여기서 바람직할 수 있다. 구체적으로는, 블록(1187)으로부터의 현재의 폴드 선택(예를 들어, 훈련을 위해 할당된 폴드와 검증을 위한 폴드 양쪽 모두)은 그 자체가, 블록들(1120, 1125, 1188)에 의해 표시된 바와 같이, 내부 카운터 Cnt1을 통해 고려되는 서브폴드 및 T1의 원하는 수의 반복적 서브폴드 선택으로 분할될 수 있다. 블록(1120)에서 Cnt1이 제1 임계치 T1(예를 들어, 고려될 원하는 수의 서브폴드 선택)보다 작게 유지되는 동안, 블록(1125)에서 Cnt1이 증분될 수 있다.
그러나, 여기서, (블록(1110)에서의 SOSDA 또는 MOSDA 필터에 대한 경우에서와 같이) 블록(1190)에서 수신된 원래의 데이터로부터 "실제" OPI 값 분포들을 참조하기보다는, 블록(1145)에서의 각각의 OPI 선택은 대신, (집합적으로 "중간 합성 데이터세트" 생성 동작들(1195a)로서 지칭되는) 블록들(1130, 1135, 1140)의 동작들을 통해 생성된 합성 데이터세트에 기반하여 결정될 수 있다.
즉, T1 반복들 각각에 대하여, 예를 들어, SMOTE를 통한 업샘플링은 블록(1130)에서 서브폴드 선택의 전문가 주석부기된 부분에 적용되어, 예를 들어, 과소표현된 전문가 데이터를 업샘플링할 수 있다. 전문가 데이터가 업샘플링될 수 있지만, 비전문가 데이터는 반대로 다운샘플링될 수 있다. 예를 들어, 다운샘플링은 2개의 스테이지로 진행될 수 있다. 먼저, 블록(1135)에서, 이웃 클리닝 규칙(Neighborhood Cleaning Rule)(NCR), 다운샘플링 방법은 다른 비전문가 샘플들로부터 먼 이상점들(outlier points)을 제거함으로써 더 큰 비전문가 그룹의 노이지 데이터를 감소시키는데 이용될 수 있다(노이지 샘플들을 효과적으로 클리닝한다). NCR은 일부 실시예들에서 라이브러리, 예를 들어, 라이브러리 imblearnTM의 함수 "imblearn.under_sampling.NeighbourhoodCleaningRule"로 구현될 수 있다. 둘째, 블록(1140)에서, 처리 시스템은 NCR에 의해 제거되지 않은 나머지 비전문가 값들을 랜덤하게 다운샘플링할 수 있다. 이것은 전문가 및 비전문가 그룹들을 대략 50/50 비율로 균형화하는 효과를 가질 수 있다. NCR 방법이 특정 비율로 다운샘플링하지 않을 수 있기 때문에, 블록(1140)은 NCR의 거동을 보상할 수 있다. 클래스 크기가 작을 때, 블록들(1135 및 1140)의 이 조합은 랜덤 다운샘플링 단독보다 더 잘 수행할 수 있지만, 일부 실시예들은 그 대신에 블록(1140)만을 이용하고 블록(1135)을 제거할 수 있거나, 그 반대일 수 있다. 블록들(1130, 1135, 및 1140)의 다운샘플링 프로세스 전후의 OPI 데이터의 예가 도 15에 도시된다.
명확함을 위해, 이러한 동작들이 다양한 라이브러리들을 통해, 예컨대, 예시적인 코드 라인 목록들 C2 내지 C8에 도시된 바와 같은 scikit-learnTM 및 imblearnTM을 통해 통합될 수 있다는 것을 잘 알 것이다:
여기서 "upratio"는, 예를 들어, 3x 업샘플로서 표현된 SMOTE에 대한 비율일 수 있다. 다시, 이러한 라인들은 단지 하나의 예이고, 다른 실시예들은 상이한 수들의 폴드들 또는 모델들을 이용할 수 있다는 것을 이해할 것이다.
언급된 바와 같이, 블록(1145)에서, MOPM 필터, 예를 들어, 본 명세서에 설명되는 바와 같은 RFE는 OPI들의 제2 서브세트를 결정하기 위해 동작들(1195a)에 의해 생성되는 합성 데이터세트에 적용될 수 있다. RFE와 같은 MOPM 필터는 (예를 들어, 도 10c에 관해 논의된 바와 같이) 블록(1145)에서 최대 교차 검증(CV) 스코어 기준들 및 최소 특징 수 기준들 모두를 만족시키는 기량 또는 작업에 대해 이용할 OPI들의 세트를 결정할 수 있다(따라서, 2개의 상이한 크기의 OPI들의 세트들이 동일한 것을 수행하는 것으로 발견되는 경우, 필터는 2개의 세트들 중 더 작은 것을 선택할 수 있다). 명확함을 위해, 블록(1110)에서의 SOSDA 또는 MOSDA 필터는 포함할 가치가 있을 수 있는(즉, 블록(1150)에서 논리 OR을 취함으로써) 블록(1145)에서 생략된 임의의 OPI들에 대한 체크로서 역할할 수 있지만, 본 명세서의 다른 곳에서 논의되는 바와 같이, 세트들이 다른 방식들로 연결되거나 비교될 수 있다. 다시, 여기서 블록(1110)이 명료성을 위해 내부 교차 검증 루프 전에 발생하는 것으로 도시되지만, 일부 실시예들에서는 순서가 반전될 수 있거나, 또는 2개가 병렬로 추구될 수 있다는 것을 알 것이다.
블록(1120)에서 Cnt1이 임계치 T1을 초과할 때(즉, 모든 서브폴드 선택들이 고려되었을 때), 블록(1150)에서, 시스템은 블록(1110)에서 생성된 서브세트 및 블록(1145)의 각각의 반복에서 생성된 서브세트들 각각의 논리 OR을 취할 수 있다. 예를 들어, T1=5인 경우, 블록(1150)은 6개의 OPI 코퍼스 세트, 즉 블록(1110)에서 생성된 세트 및 블록(1145)을 통한 5회의 반복에서 생성된 5개의 세트를 결합할 수 있다. 그렇지만, 다양한 실시예들이 그 대신에 내부 루프로부터의 결과들을 교차 검증하여, 블록(1145)에 의해 생성된 세트들 각각에 기반하여 단일의 가장 적절한 세트를 생성할 수 있는 변형들을 잘 알 것이다. 이들 변형들에서, 당연히, 2개의 세트(블록(1145)에서 생성된 세트들 및 블록(1110)에서 생성된 세트의 내부 교차 검증으로부터의 최적의 세트)만이 블록(1150)에서 결합될 것이다. 그 다음, 블록(1150)의 결합된 코퍼스는 T2 폴드 선택들 중의 (블록(1187)에서 선택된) 현재의 폴드 선택을 위한 기계 학습 모델을 훈련하는데 이용될 수 있다.
구체적으로, 블록(1155)에서, 외부 카운터 Cnt2가 증분될 수 있다. 균형화된 데이터에 대해 훈련된 모델들이 더 강건한 추론 결과들을 제공할 가능성이 더 많으므로, 다른 "훈련" 합성 데이터세트가 다시 생성될 수 있지만, 이번에는 블록(1187)으로부터의 훈련 데이터 폴드(들)의 전체 선택으로부터 온다. 이 훈련 합성 데이터세트는 동작들(1195b), 예컨대, SMOTE, NCR, 및 블록들(1160, 1165, 및 1170) 각각에서, 제각기, 적용된 랜덤 다운샘플링의 시퀀스를 이용하여(예컨대, 서브폴드들의 선택보다는 폴드들의 선택들에 대해, 블록들(1130, 1135, 및 1140)과 관련하여 이전에 논의된 것과 동일한 방식으로) 생성될 수 있다. 내부 검증 루프에 관하여 전술된 바와 같이, 여기서, 일부 실시예들은 마찬가지로, 블록들(1160, 1165, 및 1170) 중 다양한 것을 생략할 수 있다. 그렇지만, 블록들을 유지하는 것이 유익할 수 있는데, 그 이유는, 다시 말하지만, 블록(1170)이 NCR의 거동을 보상할 수 있기 때문이다.
블록(1175)에서, 시스템은 블록(1150)으로부터의 병합된 코퍼스의 OPI 값들에 대응하는 합성 훈련 데이터세트로부터의 데이터로 경험 분류기(작업 또는 기량 모델)를 훈련할 수 있다. 다시 한번, 명료성을 위해, 이들 동작들은 다양한 라이브러리를 통해, 예를 들어, 코드 라인 목록 C9 내지 C14에 도시된 바와 같은 scikit-learnTM 및 imblearnTM을 통해 통합될 수 있다는 것을 이해할 것이다:
여기서, 다시, "upratio"는, 예를 들어, 3x 업샘플로서 표현된 SMOTE에 대한 비율일 수 있다. 다시, 이러한 라인들은 단지 하나의 예이고, 다른 실시예들은 상이한 수들의 폴드들 또는 모델들을 이용할 수 있다는 것을 이해할 것이다.
시스템은 이어서 블록(1180)에서 분류기의 유효성을 평가할 수 있다. 훈련 합성 데이터세트를 이용한 모델의 훈련과는 달리, 블록(1180)에서의 모델의 검증은 현재의 폴드 선택의 데이터를 그 원래의 불균형 형태로 이용할 수 있다는 것을 이해할 것이다. 이것은 전문가들의 샘플 크기를 합성적으로 증가시키는 것이 부정확한 성과 메트릭들을 생성할 수 있으므로, 모델의 성과가 (예컨대, 추론 동안에, 입력 데이터가 합성적으로 균형화되지 않을) 실세계 데이터 상에서의 그 동작에 대하여 평가되고 있는 것을 보장할 수 있다.
다시 한번, 명료성을 위해, 블록들(1175 및 1180)의 각각의 반복은 새로운 훈련된 모델 및 그 모델의 새로운 대응하는 평가를 생성할 수 있다. 예를 들어, 일부 실시예들에서, 블록(1175)에서, (블록(1150)으로부터의) 필터링된 OPI들에 대한 훈련 데이터는 로지스틱 회귀 분류기(또는 예를 들어, 본 명세서에 논의되는 바와 같은, 다른 적절한 모델)를 훈련시키는데 이용되고, 따라서 복수의 이러한 훈련된 분류기들은 각각의 반복(및 블록(1180)에서 이루어지는 대응하는 평가)으로 생성될 수 있다. 이러한 평가들로부터, 유리한 결과들을 생성하는 모델 구성들 및 OPI 선택들을 추론할 수 있다. 예를 들어, "최상의" 모델 구성 및 OPI 선택은 이후 추론을 위해 이용될 수 있거나, 또는 유사하거나 동일한 파라미터들을 가지는 새로운 모델의 생성을 안내하는데 이용될 수 있다. 일부 실시예들에서, 블록(1180)에서 2개의 방법, 즉 -1(불량한 예측) 내지 1(완벽한 예측) 범위의, 분류의 균형화된 품질 척도인, 샘플 크기 및 매튜스 상관 계수(MCC)에서의 큰 차이를 고려하기 위한 균형화된 정확도 스코어(양쪽 그룹들 사이의 리콜의 평균, 예를 들어, ROC-AUC, F1 스코어, Jaccard 등)를 이용하여 성과가 측정될 수 있다. 블록(1185)에서, Cnt2가 외부 임계치 T2를 아직 초과하지 않았다면 외부 루프가 다시 수행될 수 있다.
선택들의 상대적 장점을 평가하기 위해 파라미터들의 다수의 선택들(예를 들어, 블록(1190)에서의 초기 OPI 선택의 변경, 블록(1175)에서의 모델 및 구성 파라미터들의 선택의 변경, MOPM 및 SOSDA/MOSDA의 선택 등)에 대해, 블록(1189)을 저장하여, 프로세스(1100)를 여러 번 실행할 수 있다. 바람직한 결과들을 생성하는 파라미터들이 식별되었으면, 블록(1189)에 표시된 바와 같이, 최종 모델은 파라미터들을 이용하여, 그러나 대신에, 예를 들어, 모델을 훈련하기 위한 훈련 부분(1115b)의 전체, 및 테스트하기 위한 예비된 부분(1115c)을 이용하여 훈련될 수 있다(또는, 예를 들어, 모델은 테스트 없이, 모든 이용가능한 데이터에 대해 훈련될 수 있다).
더 적은 수의 교차 검증 폴드(예를 들어, T1=5, T2=5)가 수행될 수 있고, 여기서, 샘플 크기는 제한된다. 이것은 동일한 데이터 세트들이 여러 번 재이용되었기 때문에 모델의 성과의 과대평가를 방지할 수 있다. 더 많은 전문가 데이터가 이용가능할 때, 더 많은 폴드(예를 들어, T1=10, 20 등)가 이용될 수 있다. 다운(또는 업)샘플링은 그렇게 하는 것이 잘못된 긍정들을 생성할 수 있으므로 블록(1110)에서 일부 실시예들에서 의도적으로 회피될 수 있다는 점에 유의한다. 실제로, 만-휘트니는 비대칭 데이터세트들을 잘 처리할 수 있다. 이 테스트는 일부 실시예들에서 보다 엄격한 필터링(예컨대, Bonferroni, Bonferroni-Holm 등)을 제공하기 위해서 뿐만 아니라, 그러한 이유로 보수적인 다중-테스트 정정들을 이용할 수 있다.
따라서, 이러한 방식으로 SOSDA/MOSDA 및 MOPM 접근법들을 결합하는 것은 어느 하나의 접근법을 분리하여 달성하지 못하는 시너지들을 제공할 수 있다(그러나, 다시, 언급된 바와 같이, 일부 실시예들은 하나 이상의 SOSDA/MOSDA 또는 하나 이상의 MOPM 필터를 단독으로 또는 함께 적용할 수 있다). 전문가들과 비전문가들을 구별하기 위한 OPI들의 최소 유효 수를 단순히 식별하기보다는, SOSDA, MOSDA, 또는 MOPM 접근법들 중 2개 이상을 이용하는 것은 또한 전문가/비전문가 그룹들을 직관적으로 구별하고 또한 모델링을 위해 잘 작동하는 OPI들을, 비록 최소치보다 더 크더라도, 캡처하는 것을 도울 수 있다. 이러한 변경된 OPI 캡처 자체는 교차 검증 동안 모델들의 훈련에 영향을 줄 수 있다. 이러한 결합된 접근법들은 본 명세서에 개시된 리샘플링 기법들(예를 들어, SMOTE, 랜덤 다운샘플링, NCR 등)과 함께 이용될 때 특히 효과적일 수 있다.
예시적인 스코어 생성
일부 실시예들에서, 기량 모델로부터의 직접 출력이 외과의에게 피드백을 제공하는데 이용될 수 있다. 예를 들어, 모델이 외과의의 성과를 전문가의 성과일 가능성이 80%인 것으로 고려한다는 것을 아는 것이 의미 있는 진술일 수 있다. 그러나, 일부 모델들, 예를 들어, 로지스틱 회귀 분류기, 지원 벡터 기계 등의 성질은 기량 레벨에 직접 매핑되는 출력을 제공하지 않을 수 있다.
예를 들어, 도 12a의 추상적 특징 공간(1205b)에 도시된 바와 같이, 제1 상황에서, 전문가 OPI 값들의 그룹(1205a)은 비전문가 OPI 값들의 그룹(1205i)으로부터 특징 공간 내의 큰 거리(1205e)에 위치될 수 있다. 유사하게, 제2 상황에서, 전문가 OPI 값들의 그룹(1205d)은 비전문가 OPI 값들의 그룹(1205h)으로부터 특징 공간 내의 훨씬 더 짧은 거리(1205g)에 위치될 수 있다. 양쪽 상황에서, 여러 기계 학습 모델들이 분리기(1205f)를 결정할 수 있다. 모델이 SVM인 경우, 초평면 분리기로부터 새로운 특징점(1205c)까지의 거리는 그 지점이 클래스에 있을 확률에 대한 프록시로서 이용될 수 있다(일부 SVM들과 같은 많은 이진 분류기들이 전형적으로 백분율 예측 없이 예측된 클래스만을 출력할 수 있다는 것을 이해할 것이다). 그렇지만, 특징 공간에서의 거리는 외과의와 같은 사람의 성과와 직관적으로 유사하지는 않다. 유사하게, 분리기(1205f)가 로지스틱 회귀 분류기의 분리 평면인 경우, 분리기(1205f)로부터의 거리는 시그모이드 함수 및 대응하는 출력 확률의 값에 대응할 수 있다. 직관적으로, 새로운 특징(1205c)이 그룹들의 제2 인스턴스(즉, 1205d 및 1205h)에 비해 그룹들의 제1 인스턴스(즉, 1205a 및 1205i)에서 상이한 확률 할당을 수신하는 것으로 예상할 것이다. 그러나, 시그모이드 함수의 성질이 각각의 인스턴스에서 특징(1205c)에 대해 유사하거나 동일한 확률 값을 촉발시키는 상황들을 상상할 수 있다. 유사하게, 시그모이드 함수는 안정 상태일 수 있고, 분리기로부터 먼 거리에 있는 새로운 특징들에 대해 유사한 확률들을 제공할 수 있다. 따라서, 이러한 시그모이드 매핑은 기량 레벨에 대한 직관적 대응관계를 갖지 않을 수 있다. SVM들 및 로지스틱 회귀 분류기들에 대한 예들이 여기서 주어졌지만, 다른 모델들에 대한 특징 공간에 기반하여 스코어들과 예측 확률들 사이의 유사한 불연속성들을 상상할 수 있다.
모델 출력으로부터의 예측 확률들과 발생할 수 있는 기량에 대한 스코어 사이의 불연속성을 보상하기 위해, 다양한 실시예들은 모델 확률들을 외과의의 기량 레벨들에 매핑하기 위해 (예컨대, 후처리 모듈(710f)에서의) 후처리 단계를 고려한다. 예를 들어, 도 12b는 일부 실시예들에서 수행될 수 있는 바와 같은, 기준 모집단에 기반하여 모델 출력들로부터 스코어 매핑을 결정하기 위한 프로세스를 나타내는 흐름도이다. 블록(1210a)에서, 구성요소는 (상이한 랜덤화된 모집단이 그 대신에 이용될 수 있지만) 전문가 및 비전문가 값들을 표시하기 위해 주석부기될 수 있는, 공지된 외과의들의 모집단에 대한 기량 모델로부터의 출력들, 예컨대, 모델을 훈련시키는데 이용되는 훈련 데이터를 검토할 수 있다. 블록(1210b)에서, 구성요소는 모델 출력들과 외과의 기량 레벨 사이의 매핑을 생성할 수 있다. 블록(1210c)에서, 시스템은, 예컨대, 새로운 대상체 데이터를 고려할 때 미래의 이용을 위해, 매핑을 기록할 수 있다. 예를 들어, 미래의 결과들이 추론 동안 생성될 때, 후처리 모듈(710f)은 블록(1210c)에서 기록된 매핑들에 기반하여, 모델 출력들을 인덱싱하고, 필요하다면 보간할 수 있다.
도 12b의 프로세스를 명확히 하기 위해, 도 12c에서 기준 외과의들(1215b)의 가설의 예시적인 모집단을 고려한다. 이 외과의들 각각은, 기량(또는 작업) 모델을 통해 전달되는, 대응하는 OPI 값들을 생성하는데 이용된, 원시 데이터에서 캡처된 수술 성과들을 제공했을 수 있으며, 이는 차례로 전문가(1215a)일 대응하는 확률들을 생성했다. 이 예에서, 블록(1210b)에서의 매핑은 모델 출력들(1215a)을 감소하는 크기의 순서(1215c)로 순서화한 다음, 선형 스코어링 메트릭(1215d)을 도시된 바와 같은 값들에 매핑할 수 있다(여기서는 이해를 용이하게 하기 위해 선형 메트릭이 이용되지만, 일부 실시예들에서는 기준 모집단(1215b) 내의 전문가들과 비전문가들의 비율에 대응하는 종형 곡선 또는 매핑이 대신 이용될 수 있다는 것을 이해할 것이다). 순위화된 출력들 사이에 속하는 추론 동안 생성된 값들은 스코어링 메트릭으로부터 대응하는 값을 생성할 수 있다. 예를 들어, 새로운 외과의(1215e)의 성과가 동일한 기량 모델에 적용된 경우, 이는 전문가일 확률 0.73을 생성할 수 있다. 이 확률이 순위화된 순서(1215c)에서의 위치(1215f)에 대응하기 때문에, 기량에 대한 최종 스코어는 메트릭(1215d)에서의 대응하는 위치, 예컨대, 87.5와 75의 평균(81.25), 모델 출력 경계 값들 사이의 선형 위치에 의해 스케일링된 평균(즉, (0.73 - 0.5)/(0.75 - 0.5) = 0.92와 0.92 * (87.5 - 75) + 75 = 86.5) 등에 기반하여 출력될 수 있다.
전술한 접근법은 모델 출력들의 확률 분포들이 순위 데이터에서 잘 분리되는 경우에 특히 효과적일 수 있다. 데이터에서 확률들의 그룹들에 더 작은 분산이 있는 경우, 일부 실시예들은 다른 접근법들을 이용할 수 있다. 예를 들어, 일부 실시예들은 확률들의 그룹화들에 대한 국부적 최대치들을 찾기 위해 커널 밀도를 추정하고, 이러한 최대치들을 순위 또는 순위들의 세트와 연관시킬 수 있다(예를 들어, 단일 최대치 예에서, 샘플들의 대부분은 50%를 스코어링할 수 있다). 실시예들은 샘플이 순위에서의 상당한 변화를 구성하기에 충분히 멀리 벗어났을 때를 결정하기 위해 이러한 분포들의 표준 편차를 추정할 수 있다. 이러한 추정이 없으면, 기계 학습 출력에서의 매우 작은 변화는 최종 스코어에서의 바람직하지 않게 넓은 변화를 촉발시킬 수 있다.
분포들의 혼합을 추정함으로써, 실시예들은 순위들의 군집들을 서로 연관시킬 수 있고, 모델 예측에서의 변동들에 대해 더 강건한 스코어들을 렌더링하는 것은 물론, 인간 해석기에 대해 더 직관적인 의미를 부여할 수 있다. 1차원 K-평균 알고리즘의 적용과 유사한, Jenk의 내추럴 브레이크 최적화(natural break optimization)가 일부 실시예들에서 유사하게 적용될 수 있다.
예시적인 스코어 제시 및 유지
외과의의 성과에 관한 피드백을 제공하기 위해 위의 결과들이 외과의에게 제시될 수 있는 복수의 방식들을 잘 알 것이다. 도 13a는 일부 실시예들에서 스코어 생성에 이용될 수 있는 일반적인 계층적 입력 및 출력 토폴로지를 나타내는 개략적인 블록도이다. 논의된 바와 같이, 각각의 기량 모델의 출력(또는 모놀리식 모델이 이용되는 경우, 모델의 기량 특정 출력들)은 기량 스코어를 생성하도록 후처리될 수 있다. 그 후 기량 스코어들은 기량 스코어들이 도출된 그 원시 데이터로부터의 대응하는 작업과 연관될 수 있다. 예를 들어, 작업 B는 기량들 A, B, C에 의존할 수 있다. 따라서, 작업 B를 수행하는 외과의의 데이터는 스코어들(1305a, 1305b, 1305c)을 생성하는데 이용될 수 있다. 이러한 스코어들은 그 자체가 조합되어 외과의의 작업의 성과에 대한 스코어(1310b)를 형성할 수 있다(대안적으로, 또는 상보적인 방식으로, 본 명세서에서 논의된 바와 같은 별도로 훈련된 작업 모델이 스코어를 생성하는데 이용될 수 있고, 최종 작업 스코어는 그 후, 예를 들어, 이 작업 모델 결정 스코어와 누적 기량 결정 스코어(1310b)의 평균일 수 있다). 예를 들어, 스코어들은 작업에 대한 그 상대적 중요도에 의해 가중되고, 합산되고, 정규화되어 스코어(1310b)를 형성할 수 있다. 모든 작업들로부터의 이러한 스코어들, 예를 들어, 1310a, 1310b 등은 마찬가지로 조합되어 전체 수술에 대한 스코어(1315)를 형성할 수 있다. 예를 들어, 조합된 스코어(1315)는 수술에 대한 작업 스코어의 상대적 중요도(및/또는 그 지속기간)에 의해 가중된, 작업 스코어들의 평균일 수 있다.
도 13a의 스코어들은 외과의들이 세분적 피드백 및 전체적 피드백 둘 다를 수신하고 시간 경과에 따른 다양한 상세 레벨들에서 그 진행을 추적하는 것을 허용할 수 있다. 이러한 피드백을 제공하는 것의 일 예로서, 도 13b는, 외과의의 성과의 비디오에 대한 성과 메트릭 오버레이를 나타내는, 그래픽 사용자 인터페이스 스크린샷(1320a)의 개략적인 표현이다. 구체적으로는, 기록된 비디오(1320f)가 외과의의 성과를 재생할 때, 오버레이는 (예컨대, 도 7c와 관련하여 설명된 바와 같은 기량 모델의 윈도잉된 애플리케이션에 따라) 묘사된 수술의 부분에 대한 외과의의 스코어를 나타내는 아이콘, 예컨대, 아이콘(1320e)에 도시된 파이 차트를 포함할 수 있다. 예를 들어, 파이 차트의 일부는 대응하는 스코어의 백분율 값에 따라 상이한 컬러로 음영 표시될 수 있다. 아이콘들(1320b 및 1320c)과 같은 아이콘들은 사용자가 그들이 보고 싶은 스코어들 중 어느 것을 선택하게 할 수 있다. 도 7c 및 도 7d와 관련하여 논의된 바와 같이, 세그먼트별 스코어들이 이용가능한 경우, 아이콘(1320e)에 도시된 스코어의 값은 비디오의 제시 동안 변할 수 있다(유사하게, 아이콘들(1320b 및 1320c)은 비디오가 새로운 작업들 및 대응하는 기량들을 묘사함에 따라 변할 수 있다). 대안적으로, 일부 실시예들에서, 아이콘(1320e)은 비디오에서 현재 묘사된 순간까지 이용가능한 데이터에 기반하여 결정된 최종 스코어 값을 반영할 수 있다. 일부 실시예들에서, 도 7d에 도시된 것과 같은 플롯들은 기량들 중 하나 이상, 및 비디오(1320f)의 현재 보여진 프레임이 플롯에 대응하는 곳을 보여주는데 이용되는 아이콘, 예를 들어 화살표에 대해 오버레이될 수 있다. 이러한 스코어링된 피드백은, 수동 검토 결과들(예를 들어, Goh 등의 Global evaluative assessment of robotic skills: validation of a clinical assessment tool to measure robotic surgical skills. The Journal of Urology, 187(1):247-252, 2012에 설명된 바와 같은 로봇 기량들의 전반적 진화 평가), 기량 스코어 결과들을 다른 전문 지식 카테고리들로 그룹화하는 것(상응하는 수의 절차들이 있는 다른 실무자들에 대한 실무자의 상대적 성과를 나타냄), 잠재적 기량 그룹화들에 대한 데이터를 검색하는 것(예를 들어, 기량 또는 작업 스코어 결과들의 모집단들에 대해 무감독 방법들/클러스터링을 수행하는 것) 등을 포함한, 단지 수술 스코어들을 넘어 확장될 수 있다는 것을 이해할 것이다.
예시적인 진행 중인 훈련 및 스코어 매핑 업데이트들
도 13c는 일부 실시예들에서 구현될 수 있는 바와 같은, 기량 평가 시스템(예를 들어, 성과 평가 시스템(625))에 대한 예시적인 업데이트 프로세스에서의 다양한 동작들을 나타내는 흐름도이다. 구체적으로, 블록(1325a)에서 더 많은 주석부기된 데이터가 이용가능하게 됨에 따라, 시스템은 블록(1325b)에서 기량(및/또는 작업) 모델을 이에 따라 업데이트할 수 있다(예를 들어, 온라인 학습 방법을 신경망 기량 모델에 적용하는 것, 새로운 모집단 데이터가 포함된 로지스틱 회귀 분류기를 재훈련시키는 것 등이다). 시스템은 또한, 예를 들어, 도 12b 및 도 12c와 관련하여 전술한 바와 같이, 블록(1325c)에서 스코어 매핑들을 업데이트할 수 있다.
유사하게, 블록(1325d)에서 수술실에서 새로운 센서들이 이용가능하게 됨에 따라, 다양한 실시예들은 블록(1325e)에서 OPI 코퍼스를 수정할 수 있다. 이것이 새로운 특징 벡터들을 이용가능하게 만들 수 있기 때문에, 블록(1325f)에서 기량(및/또는 작업) 모델들이 재훈련되거나 업데이트될 수 있는 것은 물론, 블록(1325g)에서 대응하는 스코어 매핑들을 업데이트할 수 있다.
결과들을 이용한 예시적인 실습 축소
다양한 실시예들의 구현들은 본 명세서에서 논의되는 시스템들 및 방법들의 효능을 입증하였다. 도 14a는 실시예의 예시적인 실습 축소에서 이용하는데 이용가능한 데이터 샘플들의 유형들 및 양들의 막대 플롯이다. 나타낸 바와 같이, 다양한 작업들, 즉 "양손 봉합", "한 손 봉합", "러닝 봉합", "자궁뿔", "현수 인대", 및 "직장 동맥/정맥 1"과 연관된 기량들 각각에 대해 "전문가들", "훈련생들", 및 "훈련 전문가들"에 대한 주석부기된 데이터가 취득되었다. 훈련생들은 로봇 수술 경험을 갖지 않는 외과의들이었고 따라서 "비전문가들"로서 그룹화되었다. 전문가 외과의들은 >1000 da VinciTM 로봇 절차들을 수행하였다. 훈련 전문가들은 로봇 플랫폼들 상에서 또는 로봇 플랫폼들의 이용에 대해 ~300-600 시간의 실습이 있는 평가된 훈련 작업 연습들에 경험이 있었던 비-외과의의 전문가 조작자들이었다. 따라서, 훈련 전문가들은 마찬가지로 "전문가들"로서 취급되었다. 전문가 외과의들 및 훈련 전문가들("전문가들") 데이터세트로부터의 7-9개의 작업 및 훈련생 그룹("비전문가들")으로부터의 93-122개의 작업이 있었다. 훈련생 참여자들의 수가 많았으므로, 훈련 프로세스로부터 보류될 작업마다 5명의 훈련생이 랜덤하게 선택되었고, 특징 선택을 위해 88-117명을 남겼다. 매핑된 OPI들의 각각의 기량-작업 조합은 4-20개의 OPI로 시작하였고, RFE는 OPI 세트를 1-18개의 OPI로 감소시켰다. 작업 모델들에 대한 RFE는 전형적으로 조기에 안정화된 높은 균형화된 정확도들을 나타내었다. Bonferroni 정정을 이용한 만-휘트니 테스트는 중첩하는 특징 세트들을 생성하였고 최종 모델에 0-11개의 OPI를 추가하였다.
"훈련생들" 및 "훈련 전문가들"에 대한 데이터는 함께 그룹화되어 "비전문가" 데이터를 형성하는 반면, "전문가" 데이터는 "전문가" 데이터 그룹을 형성하였다. 앞서 논의되고 이 실세계 예에 반영된 바와 같이, "전문가" 데이터보다 상당히 더 많은 "비전문가" 데이터가 있었다. 데이터 세트는 da Vinci XiTM 및 da Vinci SiTM 로봇 수술 시스템들 상의 기록 디바이스들로부터 취득되었다.
도 11a에 따라, 6개의 로지스틱 회귀 분류기들은 작업 모델들로서 훈련되었고, 18개의 로지스틱 회귀 분류기들은 기량 모델들(각각의 작업과 연관된 대응하는 기량들을 갖는 도 14b에서 식별된 작업들)로서 훈련되었다. 도 14b는 실시예의 예시적인 실습 축소에서 기량-작업 및 전체 작업 로지스틱 회귀 모델들(즉, 본 명세서에 논의되는 바와 같이, 작업들의 기량들이 아니라 전체 작업들에 대한 OPI들에 대해 훈련되는 모델들) 각각에 대한 평균 교차 검증 성과 메트릭들, 균형화된 정확도 및 MCC를 나타내는 표이다. 여기서 정확도는, 예를 들어, scikit-learnTM 라이브러리의 함수 sklearn.metrics.balanced_accuracy_score를 이용하여 생성될 수 있는, 균형화된 정확도 스코어를 지칭한다는 것을 이해할 것이다. MCC는 scikit-learnTM 라이브러리 함수 sklearn.metrics.matthews_corrcoef를 이용하여 유사하게 생성될 수 있다.
도 15는 도 11a의 블록들(1130, 1135, 및 1140) 또는 블록들(1160, 1165, 및 1170)과 관련하여 논의된 바와 같이 예시적인 실습 축소에서 리샘플링의 적용 전후에 자궁뿔 작업에서 4개의 기구에 대한 모션 OPI 값들의 경제성을 나타내는 한 쌍의 개략적인 도트 플롯들이다. 도 16은 RFE를 이용한 기량당 다양한 수의 OPI들의 교차 검증된 스코어들 및 예시적인 실습 축소에서의 경험 레벨에 의한 작업 지속기간들의 분포를 나타내는 개략적인 라인 플롯들의 컬렉션이다. 구체적으로는, 플롯들(1605a, 1605b, 1605c, 1605d, 1605e, 및 1605f)은 상이한 그룹들의 작업 지속기간을 도시하고, 플롯들(1610a, 1610b, 1610c, 1610d, 1610e, 및 1610f)은 RFE 성과를 도시한다. 나타낸 바와 같이, RFE 플롯들에서의 라인들은 상이한 기량들을 나타낸다. 플롯들(1610a-f)과 관련하여, 수직 축은 모델에 대한 교차 검증 균형화된 예측 정확도인 반면, 수평 축은 플롯에 표시된 기량들 각각에 대한 모델들에서 이용되는 OPI들의 수를 반영한다.
도 17, 도 18, 도 19, 및 도 20은 그 중 일부 또는 전부가 다양한 실시예들에서 이용될 수 있는 OPI들의 예시적인 컬렉션, 각각의 설명, 및 다양한 기량들 및 작업들에 대한 그 관계를 열거하는 표들이다. 로봇 아암들과 관련하여, "SCE"는 "외과의 콘솔"을 지칭하고, "Cam"은 카메라를 잡고 있는 아암을 지칭하고, "D"는 로봇 시스템의 우세 아암을 지칭하고, "N-D"는 로봇 시스템의 비-우세 아암을 지칭하고, "Ret"는 로봇의 수축 아암을 지칭한다. 기량들과 관련하여, "E"는 "에너지"를 나타내고, "S"는 "봉합"을 나타내고, "D"는 "절개"를 나타내고, "CU"는 "카메라 이용"을 나타내고, "AR"은 "아암 수축"을 나타내고, "1-HD"는 "한 손 절개"를 나타내고, "2-HAR"은 "양손 아암 수축"을 나타낸다. 작업들과 관련하여, "SL"은 "현수 인대" 작업을 나타내고, "2-HS"는 "양손 봉합" 작업을 나타내고, "1-HS"는 "한 손 봉합" 작업을 나타내고, "RS"는 "러닝 봉합" 작업을 나타내고, "UH"는 "자궁뿔" 작업을 나타내고, "RA/V"는 "직장 동맥/정맥" 작업을 나타낸다.
이 예시적인 구현에 기반하면, 로지스틱 회귀 모델들의 계수들로부터 계산된 OPI당 오즈비(odds-ratio per OPI)에 기반하여, 더 짧은 시간 기간들에서 더 빈번하게 에너지를 인가하면서(빈도를 증가시킴), 불필요한 에너지 활성화를 축소시켜(전체 이벤트들을 축소시킴) 실습함으로써 외과의들이 그 에너지 기량을 개선할 수 있다는 것이 명백해졌다. 이와 유사하게, 그 결과들은 외과의의 시야를 개선하기 위해 카메라를 조정하는 빈도를 증가시킬 뿐만 아니라 더 빠른 속도로 그렇게 하는 것이 그 카메라 기량을 개선할 수 있다는 것을 나타내었다.
이러한 실습 축소에서, 많은 기량들에 대해, 기술적 기량들을 추정하기 위한 가장 높은 모델 정확도들(80-95%)을 달성하기 위해 OPI들의 작은 서브세트(2-10)만이 요구되었다. 대부분의 기량 특정 모델들은 전체로서 작업에 대한 전문 지식을 예측하도록 훈련된 모델들과 유사한 정확도들(80-98%)을 가졌다.
컴퓨터 시스템
도 21은 실시예들 중 일부와 관련하여 이용될 수 있는 예시적인 컴퓨터 시스템의 블록도이다. 컴퓨팅 시스템(2100)은, 예를 들어, 하나 이상의 프로세서(2110), 하나 이상의 메모리 구성요소(2115), 하나 이상의 입력/출력 시스템(2120), 하나 이상의 저장 시스템(2125), 하나 이상의 네트워크 어댑터(2130) 등과 같은 몇몇 구성요소들을 접속시키는 상호접속부(2105)를 포함할 수 있다. 상호접속부(2105)는, 예를 들어, 하나 이상의 브리지, 트레이스, 버스(예를 들어, ISA, SCSI, PCI, I2C, 파이어와이어 버스 등), 와이어, 어댑터, 또는 제어기일 수 있다.
하나 이상의 프로세서(2110)는, 예를 들어, IntelTM 프로세서 칩, 수학 코프로세서, 그래픽 프로세서 등을 포함할 수 있다. 하나 이상의 메모리 구성요소(2115)는, 예를 들어, 휘발성 메모리(RAM, SRAM, DRAM 등), 비휘발성 메모리(EPROM, ROM, 플래시 메모리 등), 또는 유사한 디바이스들을 포함할 수 있다. 하나 이상의 입력/출력 디바이스(2120)는, 예를 들어, 디스플레이 디바이스들, 키보드들, 포인팅 디바이스들, 터치스크린 디바이스들 등을 포함할 수 있다. 하나 이상의 저장 디바이스(2125)는, 예컨대, 클라우드 기반 저장소들, 이동식 USB 저장소, 디스크 드라이브들 등을 포함할 수 있다. 일부 시스템들에서, 메모리 구성요소들(2115) 및 저장 디바이스들(2125)은 동일한 구성요소들일 수 있다. 네트워크 어댑터들(2130)은, 예를 들어, 유선 네트워크 인터페이스들, 무선 인터페이스들, BluetoothTM 어댑터들, 가시선 인터페이스들 등을 포함할 수 있다.
일부 실시예들에서는 도 21에 도시된 것들보다는 그 구성요소들, 대안 구성요소들 또는 추가 구성요소들 중 일부만이 존재할 수 있다는 것을 인식할 것이다. 유사하게, 구성요소들은 일부 시스템들에서 결합되거나 이중 목적들을 제공할 수 있다. 구성요소들은 예를 들어 하나 이상의 ASIC, PLD, FPGA 등과 같은 특수 목적 하드와이어드 회로를 이용하여 구현될 수 있다. 따라서, 일부 실시예들은, 예를 들어, 소프트웨어 및/또는 펌웨어로 프로그래밍된 프로그래밍가능한 회로(예컨대, 하나 이상의 마이크로프로세서)로, 또는 전적으로 특수 목적 하드와이어드(비-프로그래밍가능한) 회로로, 또는 이러한 형태들의 조합으로 구현될 수 있다.
일부 실시예들에서, 데이터 구조들 및 메시지 구조들은 네트워크 어댑터들(2130)을 통해, 데이터 전송 매체, 예를 들어 통신 링크 상의 신호를 통해 저장되거나 전송될 수 있다. 전송은 다양한 매체들, 예를 들어, 인터넷, 근거리 네트워크, 광역 네트워크, 또는 포인트-투-포인트 다이얼-업 접속 등에 걸쳐 발생할 수 있다. 따라서, "컴퓨터 판독가능한 매체"는 컴퓨터 판독가능한 저장 매체(예를 들어, "비일시적" 컴퓨터 판독가능한 매체) 및 컴퓨터 판독가능한 전송 매체를 포함할 수 있다.
하나 이상의 메모리 구성요소(2115) 및 하나 이상의 저장 디바이스(2125)는 컴퓨터 판독가능한 저장 매체일 수 있다. 일부 실시예들에서, 하나 이상의 메모리 구성요소(2115) 또는 하나 이상의 저장 디바이스(2125)는 본 명세서에서 논의되는 다양한 동작들을 수행하거나 수행되게 할 수 있는 명령어들을 저장할 수 있다. 일부 실시예들에서, 메모리(2115)에 저장된 명령어들은 소프트웨어 및/또는 펌웨어로서 구현될 수 있다. 이러한 명령어들은 본 명세서에 설명된 프로세스들을 수행하기 위해 하나 이상의 프로세서(2110) 상에서 동작들을 수행하는데 이용될 수 있다. 일부 실시예들에서, 이러한 명령어들은 예를 들어 네트워크 어댑터(2130)를 통해 다른 시스템으로부터 명령어들을 다운로드함으로써 하나 이상의 프로세서(2110)에 제공될 수 있다.
비고
본 명세서에서의 도면들 및 설명은 예시적이다. 따라서, 설명도 도면들도 본 개시내용을 제한하는 것으로 해석되어서는 안 된다. 예를 들어, 타이틀들 또는 서브타이틀들은 단순히 독자의 편의를 위해 그리고 이해를 용이하게 하기 위해 제공되었다. 따라서, 타이틀들 또는 서브타이틀들은, 예를 들어, 이해를 용이하게 하기 위해 특정 순서로 또는 함께 단순히 제시된 특징들을 그룹화함으로써, 본 개시내용의 범위를 제한하는 것으로 해석되어서는 안 된다. 본 명세서에서 달리 정의되지 않는 한, 본 명세서에서 사용되는 모든 기술적 및 과학적 용어들은 본 개시내용이 관련되는 본 기술분야의 통상의 기술자에 의해 일반적으로 이해되는 것과 동일한 의미를 갖는다. 충돌의 경우, 본 명세서에서 제공되는 임의의 정의들을 포함하는 본 문서가 우선할 것이다. 본 명세서에서 하나 이상의 동의어에 대한 언급은 다른 동의어들의 사용을 배제하지 않는다. 본 명세서에서 논의되는 임의의 용어의 예들을 포함하는 본 명세서의 어디에서의 예들의 사용은 단지 예시적이며, 본 개시내용 또는 임의의 예시된 용어의 범위 및 의미를 추가로 제한하도록 의도되지 않는다.
유사하게, 본 명세서의 도면들에서의 특정 제시에도 불구하고, 본 기술분야의 통상의 기술자는 정보를 저장하는데 이용되는 실제 데이터 구조들이 도시되는 것과 상이할 수 있다는 점을 이해할 것이다. 예를 들어, 데이터 구조들은 상이한 방식으로 조직화될 수 있고, 도시된 것보다 많거나 적은 정보를 포함할 수 있고, 압축 및/또는 암호화될 수 있는 식이다. 이러한 도면들 및 본 개시내용은 혼동을 피하기 위해 공통 또는 잘 알려진 상세들을 생략할 수 있다. 유사하게, 도면들은 이해를 용이하게 하기 위한 특정한 일련의 동작들을 도시할 수 있으며, 이는 단순히 이러한 동작들의 집합의 더 넓은 클래스를 예시한다. 따라서, 추가적인, 대안적인, 또는 더 적은 동작들이 흐름도들의 일부에 도시되는 동일한 목적 또는 효과를 달성하기 위해 종종 이용될 수 있다는 것을 쉽게 인식할 것이다. 예를 들어, 데이터는 암호화될 수 있지만, 도면들에서는 그와 같이 제시되지 않고, 항목들은 동일하거나 유사한 효과 등을 달성하기 위해, 상이한 루핑 패턴들("for" 루프, "while" 루프 등)로 고려되거나, 상이한 방식으로 정렬될 수 있다.
본 명세서에서 "실시예" 또는 "일 실시예"에 대한 참조는 본 개시내용의 적어도 하나의 실시예가 실시예와 관련하여 설명되는 특정 특징, 구조, 또는 특성을 포함한다는 것을 의미한다. 따라서, 본 명세서의 다양한 곳들에서의 "일 실시예에서"라는 문구는 반드시 이러한 다양한 곳들 각각에서 동일한 실시예를 지칭하는 것은 아니다. 별개의 또는 대안적인 실시예들은 다른 실시예들과 상호 배타적이지 않을 수 있다. 실시예들의 범위로부터 벗어나지 않고 다양한 수정들이 이루어질 수 있다는 것을 인식할 것이다.
Claims (48)
- 수술 데이터(surgical data)에 기반한 스코어를 생성하기 위한 컴퓨터에 의해 구현되는 방법으로서,
수술 데이터를 취득하는 단계;
상기 수술 데이터를 복수의 메트릭 값들로 변환하는 단계; 및
적어도 부분적으로 기계 학습 모델을 이용하여 상기 수술 데이터와 연관된 스코어를 생성하는 단계
를 포함하는, 컴퓨터에 의해 구현되는 방법. - 제1항에 있어서,
스코어를 생성하는 단계는,
상기 메트릭 값들을 상기 기계 학습 모델에 제공하여 예측치를 생성하는 단계; 및
상기 예측치를 스코어에 매핑하는 단계
를 포함하는, 컴퓨터에 의해 구현되는 방법. - 제2항에 있어서,
상기 기계 학습 모델은,
신경망;
지원 벡터 기계;
랜덤 포레스트(random forest);
로지스틱 회귀 분류기; 및
데이터의 패턴들에 기반하여 분류를 예측하도록 구성된 로직
중 하나 이상을 포함하는, 컴퓨터에 의해 구현되는 방법. - 제2항에 있어서,
상기 기계 학습 모델은 로지스틱 회귀 분류기이고,
스코어를 생성하는 단계는 상기 메트릭 값들을 상기 로지스틱 회귀 분류기에 입력하는 단계 및 상기 로지스틱 회귀 분류기의 출력들을 분류기 결과들 대 기량 스코어들(skill scores)의 매핑에 적용하는 단계를 포함하고, 상기 분류기 결과들 대 기량 스코어들의 매핑은 기준 모집단으로부터의 수술 데이터에 기반하여 생성되는, 컴퓨터에 의해 구현되는 방법. - 제2항 또는 제4항에 있어서,
상기 수술 데이터는 환자측 운동학 데이터, 외과의측 운동학 데이터, 시각화 도구 비디오, 및 시스템 이벤트들 중 하나 이상을 포함하는, 컴퓨터에 의해 구현되는 방법. - 제2항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 단일 OPI 통계 분포 분석 필터를 이용하여 선택되는, 컴퓨터에 의해 구현되는 방법. - 제2항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 다중-OPI 통계 분포 분석 필터를 이용하여 선택되는, 컴퓨터에 의해 구현되는 방법. - 제2항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 다중-OPI 예측 모델 필터를 이용하여 선택되는, 컴퓨터에 의해 구현되는 방법. - 제2항, 제6항, 제7항 또는 제8항에 있어서,
상기 메트릭들은 상기 기계 학습 모델의 훈련 동안 교차 검증에서 선택되는, 컴퓨터에 의해 구현되는 방법. - 제2항에 있어서,
상기 방법은 외과의의 수술 성과 과정 동안 생성된 몇 개의 스코어들 중 하나로서 상기 스코어를 제시하는 단계를 더 포함하는, 컴퓨터에 의해 구현되는 방법. - 제10항에 있어서,
상기 스코어는 기량 스코어이고, 상기 기계 학습 모델은 기량 모델인, 컴퓨터에 의해 구현되는 방법. - 제10항에 있어서,
상기 스코어는 작업 스코어이고, 상기 기계 학습 모델은 작업 모델인, 컴퓨터에 의해 구현되는 방법. - 컴퓨터 시스템으로 하여금 방법을 수행하게 하도록 구성된 명령어들을 포함하는 비일시적 컴퓨터 판독가능한 매체로서, 상기 방법은,
수술 데이터를 취득하는 단계;
상기 수술 데이터를 복수의 메트릭 값들로 변환하는 단계; 및
적어도 부분적으로 기계 학습 모델을 이용하여 상기 수술 데이터와 연관된 스코어를 생성하는 단계
를 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제13항에 있어서,
스코어를 생성하는 단계는,
상기 메트릭 값들을 상기 기계 학습 모델에 제공하여 예측치를 생성하는 단계; 및
상기 예측치를 스코어에 매핑하는 단계
를 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제14항에 있어서,
상기 기계 학습 모델은,
신경망;
지원 벡터 기계;
랜덤 포레스트;
로지스틱 회귀 분류기; 및
데이터의 패턴들에 기반하여 분류를 예측하도록 구성된 로직
중 하나 이상을 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제14항에 있어서,
상기 기계 학습 모델은 로지스틱 회귀 분류기이고,
스코어를 생성하는 단계는 상기 메트릭 값들을 상기 로지스틱 회귀 분류기에 입력하는 단계 및 상기 로지스틱 회귀 분류기의 출력들을 분류기 결과들 대 기량 스코어들의 매핑에 적용하는 단계를 포함하고, 상기 분류기 결과들 대 기량 스코어들의 매핑은 기준 모집단으로부터의 수술 데이터에 기반하여 생성되는, 비일시적 컴퓨터 판독가능한 매체. - 제14항 또는 제16항에 있어서,
상기 수술 데이터는 환자측 운동학 데이터, 외과의측 운동학 데이터, 시각화 도구 비디오, 및 시스템 이벤트들 중 하나 이상을 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제14항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 단일 OPI 통계 분포 분석 필터를 이용하여 선택되는, 비일시적 컴퓨터 판독가능한 매체. - 제14항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 다중-OPI 통계 분포 분석 필터를 이용하여 선택되는, 비일시적 컴퓨터 판독가능한 매체. - 제14항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 다중-OPI 예측 모델 필터를 이용하여 선택되는, 비일시적 컴퓨터 판독가능한 매체. - 제14항, 제18항, 제19항 또는 제20항에 있어서,
상기 메트릭들은 상기 기계 학습 모델의 훈련 동안 교차 검증에서 선택되는, 비일시적 컴퓨터 판독가능한 매체. - 제14항에 있어서,
상기 방법은 외과의의 수술 성과 과정 동안 생성된 몇 개의 스코어들 중 하나로서 상기 스코어를 제시하는 단계를 더 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제22항에 있어서,
상기 스코어는 기량 스코어이고, 상기 기계 학습 모델은 기량 모델인, 비일시적 컴퓨터 판독가능한 매체. - 제22항에 있어서,
상기 스코어는 작업 스코어이고, 상기 기계 학습 모델은 작업 모델인, 비일시적 컴퓨터 판독가능한 매체. - 컴퓨터 시스템으로서,
적어도 하나의 프로세서; 및
적어도 하나의 메모리
를 포함하며, 상기 적어도 하나의 메모리는 상기 컴퓨터 시스템으로 하여금 방법을 수행하게 하도록 구성된 명령어들을 포함하고, 상기 방법은,
수술 데이터를 취득하는 단계;
상기 수술 데이터를 복수의 메트릭 값들로 변환하는 단계; 및
적어도 부분적으로 기계 학습 모델을 이용하여 상기 수술 데이터와 연관된 스코어를 생성하는 단계
를 포함하는, 컴퓨터 시스템. - 제25항에 있어서,
스코어를 생성하는 단계는,
상기 메트릭 값들을 상기 기계 학습 모델에 제공하여 예측치를 생성하는 단계; 및
상기 예측치를 스코어에 매핑하는 단계
를 포함하는, 컴퓨터 시스템. - 제26항에 있어서,
상기 기계 학습 모델은,
신경망;
지원 벡터 기계;
랜덤 포레스트;
로지스틱 회귀 분류기; 및
데이터의 패턴들에 기반하여 분류를 예측하도록 구성된 로직
중 하나 이상을 포함하는, 컴퓨터 시스템. - 제26항에 있어서,
상기 기계 학습 모델은 로지스틱 회귀 분류기이고,
스코어를 생성하는 단계는 상기 메트릭 값들을 상기 로지스틱 회귀 분류기에 입력하는 단계 및 상기 로지스틱 회귀 분류기의 출력들을 분류기 결과들 대 기량 스코어들의 매핑에 적용하는 단계를 포함하고, 상기 분류기 결과들 대 기량 스코어들의 매핑은 기준 모집단으로부터의 수술 데이터에 기반하여 생성되는, 컴퓨터 시스템. - 제26항 또는 제28항에 있어서,
상기 수술 데이터는 환자측 운동학 데이터, 외과의측 운동학 데이터, 시각화 도구 비디오, 및 시스템 이벤트들 중 하나 이상을 포함하는, 컴퓨터 시스템. - 제26항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 단일 OPI 통계 분포 분석 필터를 이용하여 선택되는, 컴퓨터 시스템. - 제26항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 다중-OPI 통계 분포 분석 필터를 이용하여 선택되는, 컴퓨터 시스템. - 제26항에 있어서,
상기 메트릭들은, 적어도 부분적으로, 다중-OPI 예측 모델 필터를 이용하여 선택되는, 컴퓨터 시스템. - 제26항, 제30항, 제31항 또는 제32항에 있어서,
상기 메트릭들은 상기 기계 학습 모델의 훈련 동안 교차 검증에서 선택되는, 컴퓨터 시스템. - 제26항에 있어서,
상기 방법은 외과의의 수술 성과 과정 동안 생성된 몇 개의 스코어들 중 하나로서 상기 스코어를 제시하는 단계를 더 포함하는, 컴퓨터 시스템. - 제34항에 있어서,
상기 스코어는 기량 스코어이고, 상기 기계 학습 모델은 기량 모델인, 컴퓨터 시스템. - 제34항에 있어서,
상기 스코어는 작업 스코어이고, 상기 기계 학습 모델은 작업 모델인, 컴퓨터 시스템. - 수술 평가 메트릭들을 선택하기 위한 컴퓨터에 의해 구현되는 방법으로서,
수술 데이터 메트릭 유형들의 제1 코퍼스를 취득하는 단계;
제1 필터를 수술 데이터 메트릭 유형들의 제1 코퍼스에 적용함으로써 수술 데이터 메트릭 유형들의 제2 코퍼스를 생성하는 단계 - 상기 제2 코퍼스는 상기 제1 코퍼스의 서브세트임 -;
제2 필터를 상기 제1 코퍼스에 적용함으로써 수술 데이터 메트릭 유형들의 제3 코퍼스를 생성하는 단계;
상기 제2 코퍼스와 상기 제3 코퍼스의 합집합(union)을 취함으로써 수술 데이터 메트릭 유형들의 제4 코퍼스를 생성하는 단계;
상기 제4 코퍼스의 상기 수술 데이터 메트릭 유형들에 대한 수술 데이터로부터 복수의 메트릭 값들을 생성하는 단계; 및
상기 복수의 메트릭 값들을 이용하여 전문가 수술 데이터 메트릭 값들을 비전문가 수술 데이터 메트릭 값들과 구별하도록 기계 학습 모델을 훈련하는 단계
를 포함하는, 컴퓨터에 의해 구현되는 방법. - 제37항에 있어서,
상기 수술 데이터 메트릭 유형들의 제1 코퍼스는 객관적 성과 지표(OPI) 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제2 코퍼스는 OPI 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제3 코퍼스는 OPI 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제4 코퍼스는 OPI 메트릭 유형들이고,
상기 제1 필터는 통계 분포 분석(SOSDA) 필터 및 다중-OPI 통계 분포 분석(MOSDA) 필터 중 하나이고,
상기 제2 필터는 다중-OPI 예측 모델(MOPM) 필터인, 컴퓨터에 의해 구현되는 방법. - 제38항에 있어서,
상기 제1 필터는 만-휘트니 U 테스트(Mann-Whitney U test)와의 OPI 전문가 및 비전문가 분포들의 비교를 포함하고, 상기 제2 필터는 재귀적 특징 제거(Recursive Feature Elimination)를 포함하는, 컴퓨터에 의해 구현되는 방법. - 제39항에 있어서,
상기 스코어는 기량 스코어 및 작업 스코어 중 하나이고, 상기 기계 학습 모델은 기량 모델 및 작업 모델 중 하나인, 컴퓨터에 의해 구현되는 방법. - 컴퓨터 시스템으로 하여금 방법을 수행하게 하도록 구성된 명령어들을 포함하는 비일시적 컴퓨터 판독가능한 매체로서, 상기 방법은,
수술 데이터 메트릭 유형들의 제1 코퍼스를 취득하는 단계;
제1 필터를 수술 데이터 메트릭 유형들의 제1 코퍼스에 적용함으로써 수술 데이터 메트릭 유형들의 제2 코퍼스를 생성하는 단계 - 상기 제2 코퍼스는 상기 제1 코퍼스의 서브세트임 -;
제2 필터를 상기 제1 코퍼스에 적용함으로써 수술 데이터 메트릭 유형들의 제3 코퍼스를 생성하는 단계;
상기 제2 코퍼스와 상기 제3 코퍼스의 합집합을 취함으로써 수술 데이터 메트릭 유형들의 제4 코퍼스를 생성하는 단계;
상기 제4 코퍼스의 상기 수술 데이터 메트릭 유형들에 대한 수술 데이터로부터 복수의 메트릭 값들을 생성하는 단계; 및
상기 복수의 메트릭 값들을 이용하여 전문가 수술 데이터 메트릭 값들을 비전문가 수술 데이터 메트릭 값들과 구별하도록 기계 학습 모델을 훈련하는 단계
를 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제41항에 있어서,
상기 수술 데이터 메트릭 유형들의 제1 코퍼스는 객관적 성과 지표(OPI) 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제2 코퍼스는 OPI 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제3 코퍼스는 OPI 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제4 코퍼스는 OPI 메트릭 유형들이고,
상기 제1 필터는 통계 분포 분석(SOSDA) 필터 및 다중-OPI 통계 분포 분석(MOSDA) 필터 중 하나이고,
상기 제2 필터는 다중-OPI 예측 모델(MOPM) 필터인, 비일시적 컴퓨터 판독가능한 매체. - 제42항에 있어서,
상기 제1 필터는 만-휘트니 U 테스트와의 OPI 전문가 및 비전문가 분포들의 비교를 포함하고, 상기 제2 필터는 재귀적 특징 제거를 포함하는, 비일시적 컴퓨터 판독가능한 매체. - 제43항에 있어서,
상기 스코어는 기량 스코어 및 작업 스코어 중 하나이고, 상기 기계 학습 모델은 기량 모델 및 작업 모델 중 하나인, 비일시적 컴퓨터 판독가능한 매체. - 컴퓨터 시스템으로서,
적어도 하나의 프로세서; 및
적어도 하나의 메모리
를 포함하며, 상기 적어도 하나의 메모리는 상기 컴퓨터 시스템으로 하여금 방법을 수행하게 하도록 구성된 명령어들을 포함하고, 상기 방법은,
수술 데이터 메트릭 유형들의 제1 코퍼스를 취득하는 단계;
제1 필터를 수술 데이터 메트릭 유형들의 제1 코퍼스에 적용함으로써 수술 데이터 메트릭 유형들의 제2 코퍼스를 생성하는 단계 - 상기 제2 코퍼스는 상기 제1 코퍼스의 서브세트임 -;
제2 필터를 상기 제1 코퍼스에 적용함으로써 수술 데이터 메트릭 유형들의 제3 코퍼스를 생성하는 단계;
상기 제2 코퍼스와 상기 제3 코퍼스의 합집합을 취함으로써 수술 데이터 메트릭 유형들의 제4 코퍼스를 생성하는 단계;
상기 제4 코퍼스의 상기 수술 데이터 메트릭 유형들에 대한 수술 데이터로부터 복수의 메트릭 값들을 생성하는 단계; 및
상기 복수의 메트릭 값들을 이용하여 전문가 수술 데이터 메트릭 값들을 비전문가 수술 데이터 메트릭 값들과 구별하도록 기계 학습 모델을 훈련하는 단계
를 포함하는, 컴퓨터 시스템. - 제45항에 있어서,
상기 수술 데이터 메트릭 유형들의 제1 코퍼스는 객관적 성과 지표(OPI) 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제2 코퍼스는 OPI 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제3 코퍼스는 OPI 메트릭 유형들이고,
상기 수술 데이터 메트릭 유형들의 제4 코퍼스는 OPI 메트릭 유형들이고,
상기 제1 필터는 통계 분포 분석(SOSDA) 필터 및 다중-OPI 통계 분포 분석(MOSDA) 필터 중 하나이고,
상기 제2 필터는 다중-OPI 예측 모델(MOPM) 필터인, 컴퓨터 시스템. - 제46항에 있어서,
상기 제1 필터는 만-휘트니 U 테스트와의 OPI 전문가 및 비전문가 분포들의 비교를 포함하고, 상기 제2 필터는 재귀적 특징 제거를 포함하는, 컴퓨터 시스템. - 제47항에 있어서,
상기 스코어는 기량 스코어 및 작업 스코어 중 하나이고, 상기 기계 학습 모델은 기량 모델 및 작업 모델 중 하나인, 컴퓨터 시스템.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063121220P | 2020-12-03 | 2020-12-03 | |
| US63/121,220 | 2020-12-03 | ||
| PCT/US2021/060900 WO2022119754A1 (en) | 2020-12-03 | 2021-11-26 | Systems and methods for assessing surgical ability |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230113600A true KR20230113600A (ko) | 2023-07-31 |
Family
ID=78828216
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237021818A KR20230113600A (ko) | 2020-12-03 | 2021-11-26 | 수술 능력을 평가하기 위한 시스템들 및 방법들 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20230317258A1 (ko) |
| EP (1) | EP4256579A1 (ko) |
| JP (1) | JP2023552201A (ko) |
| KR (1) | KR20230113600A (ko) |
| CN (1) | CN116711019A (ko) |
| WO (1) | WO2022119754A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116884570B (zh) * | 2023-09-06 | 2023-12-12 | 南京诺源医疗器械有限公司 | 一种基于图像处理的术中实时仿真疗效评估系统 |
| CN117789959A (zh) * | 2023-11-14 | 2024-03-29 | 艾迪普科技股份有限公司 | 一种基于虚拟交互技术的远程医疗测控方法、系统及介质 |
| CN117726541A (zh) * | 2024-02-08 | 2024-03-19 | 北京理工大学 | 一种基于二值化神经网络的暗光视频增强方法及装置 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140220527A1 (en) * | 2013-02-07 | 2014-08-07 | AZ Board of Regents, a body corporate of the State of AZ, acting for & on behalf of AZ State | Video-Based System for Improving Surgical Training by Providing Corrective Feedback on a Trainee's Movement |
-
2021
- 2021-11-26 KR KR1020237021818A patent/KR20230113600A/ko unknown
- 2021-11-26 US US18/037,976 patent/US20230317258A1/en active Pending
- 2021-11-26 WO PCT/US2021/060900 patent/WO2022119754A1/en active Application Filing
- 2021-11-26 CN CN202180088726.3A patent/CN116711019A/zh active Pending
- 2021-11-26 JP JP2023533964A patent/JP2023552201A/ja active Pending
- 2021-11-26 EP EP21823441.7A patent/EP4256579A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20230317258A1 (en) | 2023-10-05 |
| CN116711019A (zh) | 2023-09-05 |
| WO2022119754A1 (en) | 2022-06-09 |
| EP4256579A1 (en) | 2023-10-11 |
| JP2023552201A (ja) | 2023-12-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20230113600A (ko) | 수술 능력을 평가하기 위한 시스템들 및 방법들 | |
| US20200226751A1 (en) | Surgical workflow and activity detection based on surgical videos | |
| US20210307841A1 (en) | Methods, systems, and computer readable media for generating and providing artificial intelligence assisted surgical guidance | |
| Forestier et al. | Classification of surgical processes using dynamic time warping | |
| US20230316756A1 (en) | Systems and methods for surgical data censorship | |
| CN112614571B (zh) | 神经网络模型的训练方法、装置、图像分类方法和介质 | |
| US20240169579A1 (en) | Prediction of structures in surgical data using machine learning | |
| Xi et al. | Forest graph convolutional network for surgical action triplet recognition in endoscopic videos | |
| CN116670726A (zh) | 用于外科手术数据分类的系统和方法 | |
| US20230316545A1 (en) | Surgical task data derivation from surgical video data | |
| Padoy | Workflow and activity modeling for monitoring surgical procedures | |
| WO2023046630A1 (en) | Surgical microscope system and corresponding system, method and computer program for a surgical microscope system | |
| EP4356290A1 (en) | Detection of surgical states, motion profiles, and instruments | |
| Bani et al. | A new classification approach for robotic surgical tasks recognition | |
| Lea | Multi-modal models for fine-grained action segmentation in situated environments | |
| US20230368530A1 (en) | Systems and methods for surgical operation recognition | |
| Konduri et al. | Full resolution convolutional neural network based organ and surgical instrument classification on laparoscopic image data | |
| Qin | Autonomous Temporal Understanding and State Estimation during Robot-Assisted Surgery | |
| Stauder | Context awareness for the operating room of the future | |
| Nandhagopal et al. | Convolutional Neural Networks for Analysis and Recognition of Facial Expressions | |
| Zhang | Vision-based context-aware assistance for minimally invasive surgery. | |
| Jahanbani Fard | Computational Modeling Approaches For Task Analysis In Robotic-Assisted Surgery | |
| Al Hajj | Video analysis for augmented cataract surgery | |
| Jin | Towards Intelligent Surgery: dynamic surgical video analysis with deep learning | |
| Abd Gaus | Artificial intelligence system for continuous affect estimation from naturalistic human expressions |