KR20230042315A - 리간드-수용체 쌍 및 생물학적 기능성 단백질을 포함하는 융합 단백질 - Google Patents
리간드-수용체 쌍 및 생물학적 기능성 단백질을 포함하는 융합 단백질 Download PDFInfo
- Publication number
- KR20230042315A KR20230042315A KR1020237005797A KR20237005797A KR20230042315A KR 20230042315 A KR20230042315 A KR 20230042315A KR 1020237005797 A KR1020237005797 A KR 1020237005797A KR 20237005797 A KR20237005797 A KR 20237005797A KR 20230042315 A KR20230042315 A KR 20230042315A
- Authority
- KR
- South Korea
- Prior art keywords
- fusion protein
- ligand
- receptor
- amino acid
- seq
- Prior art date
Links
- 108020001507 fusion proteins Proteins 0.000 title claims abstract description 311
- 102000037865 fusion proteins Human genes 0.000 title claims abstract description 311
- 108090000623 proteins and genes Proteins 0.000 title claims description 105
- 102000004169 proteins and genes Human genes 0.000 title claims description 101
- 230000027455 binding Effects 0.000 claims abstract description 289
- 239000000427 antigen Substances 0.000 claims abstract description 155
- 108091007433 antigens Proteins 0.000 claims abstract description 155
- 102000036639 antigens Human genes 0.000 claims abstract description 155
- 238000000034 method Methods 0.000 claims abstract description 69
- 230000002519 immonomodulatory effect Effects 0.000 claims abstract description 20
- 102000037982 Immune checkpoint proteins Human genes 0.000 claims abstract description 15
- 230000004913 activation Effects 0.000 claims abstract description 13
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 456
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 256
- 229920001184 polypeptide Polymers 0.000 claims description 253
- 102000005962 receptors Human genes 0.000 claims description 198
- 108020003175 receptors Proteins 0.000 claims description 198
- 239000003446 ligand Substances 0.000 claims description 179
- 238000003776 cleavage reaction Methods 0.000 claims description 169
- 230000007017 scission Effects 0.000 claims description 169
- 102000035195 Peptidases Human genes 0.000 claims description 162
- 108091005804 Peptidases Proteins 0.000 claims description 162
- 239000004365 Protease Substances 0.000 claims description 162
- 150000001413 amino acids Chemical group 0.000 claims description 155
- 210000004027 cell Anatomy 0.000 claims description 106
- 108060003951 Immunoglobulin Proteins 0.000 claims description 79
- 102000018358 immunoglobulin Human genes 0.000 claims description 79
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 claims description 64
- 102100040678 Programmed cell death protein 1 Human genes 0.000 claims description 61
- 206010028980 Neoplasm Diseases 0.000 claims description 57
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 54
- 108010032595 Antibody Binding Sites Proteins 0.000 claims description 49
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 46
- 230000002829 reductive effect Effects 0.000 claims description 34
- 102000001301 EGF receptor Human genes 0.000 claims description 26
- 108060006698 EGF receptor Proteins 0.000 claims description 26
- 201000011510 cancer Diseases 0.000 claims description 23
- 210000002865 immune cell Anatomy 0.000 claims description 21
- 102100037942 Suppressor of tumorigenicity 14 protein Human genes 0.000 claims description 20
- 239000012634 fragment Substances 0.000 claims description 20
- 108010000499 Thromboplastin Proteins 0.000 claims description 19
- 230000035772 mutation Effects 0.000 claims description 19
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 18
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 18
- 102000003735 Mesothelin Human genes 0.000 claims description 18
- 108090000015 Mesothelin Proteins 0.000 claims description 18
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 18
- 230000004069 differentiation Effects 0.000 claims description 18
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 claims description 17
- 230000000694 effects Effects 0.000 claims description 17
- 239000013598 vector Substances 0.000 claims description 17
- 102000000905 Cadherin Human genes 0.000 claims description 15
- 108050007957 Cadherin Proteins 0.000 claims description 15
- 108010091175 Matriptase Proteins 0.000 claims description 15
- 108091008036 Immune checkpoint proteins Proteins 0.000 claims description 14
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 claims description 14
- 102220258496 rs1553638805 Human genes 0.000 claims description 14
- 101000863873 Homo sapiens Tyrosine-protein phosphatase non-receptor type substrate 1 Proteins 0.000 claims description 13
- 102100029948 Tyrosine-protein phosphatase non-receptor type substrate 1 Human genes 0.000 claims description 13
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 claims description 13
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 12
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 12
- 102220229708 rs876660131 Human genes 0.000 claims description 12
- 108010088842 Fibrinolysin Proteins 0.000 claims description 11
- 229940012957 plasmin Drugs 0.000 claims description 11
- 101001011896 Homo sapiens Matrix metalloproteinase-19 Proteins 0.000 claims description 10
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 claims description 10
- 102100030218 Matrix metalloproteinase-19 Human genes 0.000 claims description 10
- 230000005888 antibody-dependent cellular phagocytosis Effects 0.000 claims description 10
- 230000007423 decrease Effects 0.000 claims description 10
- 108010022683 guanidinobenzoate esterase Proteins 0.000 claims description 10
- 230000028993 immune response Effects 0.000 claims description 10
- 101000798702 Homo sapiens Transmembrane protease serine 4 Proteins 0.000 claims description 9
- 102100032471 Transmembrane protease serine 4 Human genes 0.000 claims description 9
- 230000001419 dependent effect Effects 0.000 claims description 9
- 102200037607 rs771019366 Human genes 0.000 claims description 9
- 230000011664 signaling Effects 0.000 claims description 9
- 102100023832 Prolyl endopeptidase FAP Human genes 0.000 claims description 8
- 108091008874 T cell receptors Proteins 0.000 claims description 8
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 8
- 230000003013 cytotoxicity Effects 0.000 claims description 8
- 231100000135 cytotoxicity Toxicity 0.000 claims description 8
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 claims description 7
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 claims description 7
- 102000012479 Serine Proteases Human genes 0.000 claims description 7
- 108010022999 Serine Proteases Proteins 0.000 claims description 7
- 230000033228 biological regulation Effects 0.000 claims description 7
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 claims description 7
- 230000004927 fusion Effects 0.000 claims description 6
- 102200067724 rs369125667 Human genes 0.000 claims description 6
- 230000000638 stimulation Effects 0.000 claims description 6
- 102100026802 72 kDa type IV collagenase Human genes 0.000 claims description 5
- 108030001653 Adamalysin Proteins 0.000 claims description 5
- 102000034473 Adamalysin Human genes 0.000 claims description 5
- 102000030431 Asparaginyl endopeptidase Human genes 0.000 claims description 5
- 108010032088 Calpain Proteins 0.000 claims description 5
- 102000007590 Calpain Human genes 0.000 claims description 5
- 108090000397 Caspase 3 Proteins 0.000 claims description 5
- 102000004018 Caspase 6 Human genes 0.000 claims description 5
- 108090000425 Caspase 6 Proteins 0.000 claims description 5
- 108090000567 Caspase 7 Proteins 0.000 claims description 5
- 108090000426 Caspase-1 Proteins 0.000 claims description 5
- 102100035904 Caspase-1 Human genes 0.000 claims description 5
- 102000004068 Caspase-10 Human genes 0.000 claims description 5
- 108090000572 Caspase-10 Proteins 0.000 claims description 5
- 108090000570 Caspase-12 Proteins 0.000 claims description 5
- 102000004066 Caspase-12 Human genes 0.000 claims description 5
- 102000004958 Caspase-14 Human genes 0.000 claims description 5
- 108090001132 Caspase-14 Proteins 0.000 claims description 5
- 102000004046 Caspase-2 Human genes 0.000 claims description 5
- 108090000552 Caspase-2 Proteins 0.000 claims description 5
- 102100029855 Caspase-3 Human genes 0.000 claims description 5
- 102100025597 Caspase-4 Human genes 0.000 claims description 5
- 101710090338 Caspase-4 Proteins 0.000 claims description 5
- 102100038916 Caspase-5 Human genes 0.000 claims description 5
- 101710090333 Caspase-5 Proteins 0.000 claims description 5
- 102100038902 Caspase-7 Human genes 0.000 claims description 5
- 108090000538 Caspase-8 Proteins 0.000 claims description 5
- 102000004039 Caspase-9 Human genes 0.000 claims description 5
- 108090000566 Caspase-9 Proteins 0.000 claims description 5
- 108010059081 Cathepsin A Proteins 0.000 claims description 5
- 102000005572 Cathepsin A Human genes 0.000 claims description 5
- 108090000712 Cathepsin B Proteins 0.000 claims description 5
- 102000004225 Cathepsin B Human genes 0.000 claims description 5
- 102000003908 Cathepsin D Human genes 0.000 claims description 5
- 108090000258 Cathepsin D Proteins 0.000 claims description 5
- 102000004178 Cathepsin E Human genes 0.000 claims description 5
- 108090000611 Cathepsin E Proteins 0.000 claims description 5
- 108090000625 Cathepsin K Proteins 0.000 claims description 5
- 102000004171 Cathepsin K Human genes 0.000 claims description 5
- 102100035654 Cathepsin S Human genes 0.000 claims description 5
- 108090000613 Cathepsin S Proteins 0.000 claims description 5
- 102100027995 Collagenase 3 Human genes 0.000 claims description 5
- 102100031111 Disintegrin and metalloproteinase domain-containing protein 17 Human genes 0.000 claims description 5
- 101710088083 Glomulin Proteins 0.000 claims description 5
- 102000004989 Hepsin Human genes 0.000 claims description 5
- 108090001101 Hepsin Proteins 0.000 claims description 5
- 101000627872 Homo sapiens 72 kDa type IV collagenase Proteins 0.000 claims description 5
- 101000577887 Homo sapiens Collagenase 3 Proteins 0.000 claims description 5
- 101000777461 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 17 Proteins 0.000 claims description 5
- 101001013150 Homo sapiens Interstitial collagenase Proteins 0.000 claims description 5
- 101000577881 Homo sapiens Macrophage metalloelastase Proteins 0.000 claims description 5
- 101000990912 Homo sapiens Matrilysin Proteins 0.000 claims description 5
- 101001011906 Homo sapiens Matrix metalloproteinase-14 Proteins 0.000 claims description 5
- 101001011884 Homo sapiens Matrix metalloproteinase-15 Proteins 0.000 claims description 5
- 101001011886 Homo sapiens Matrix metalloproteinase-16 Proteins 0.000 claims description 5
- 101001011887 Homo sapiens Matrix metalloproteinase-17 Proteins 0.000 claims description 5
- 101001013139 Homo sapiens Matrix metalloproteinase-20 Proteins 0.000 claims description 5
- 101001013142 Homo sapiens Matrix metalloproteinase-21 Proteins 0.000 claims description 5
- 101000627852 Homo sapiens Matrix metalloproteinase-25 Proteins 0.000 claims description 5
- 101000990902 Homo sapiens Matrix metalloproteinase-9 Proteins 0.000 claims description 5
- 101000990908 Homo sapiens Neutrophil collagenase Proteins 0.000 claims description 5
- 101000990915 Homo sapiens Stromelysin-1 Proteins 0.000 claims description 5
- 101000577874 Homo sapiens Stromelysin-2 Proteins 0.000 claims description 5
- 101000577877 Homo sapiens Stromelysin-3 Proteins 0.000 claims description 5
- 101000661807 Homo sapiens Suppressor of tumorigenicity 14 protein Proteins 0.000 claims description 5
- 101000798700 Homo sapiens Transmembrane protease serine 3 Proteins 0.000 claims description 5
- 102100027998 Macrophage metalloelastase Human genes 0.000 claims description 5
- 102100030417 Matrilysin Human genes 0.000 claims description 5
- 102000000380 Matrix Metalloproteinase 1 Human genes 0.000 claims description 5
- 102100030216 Matrix metalloproteinase-14 Human genes 0.000 claims description 5
- 102100030201 Matrix metalloproteinase-15 Human genes 0.000 claims description 5
- 102100030200 Matrix metalloproteinase-16 Human genes 0.000 claims description 5
- 102100030219 Matrix metalloproteinase-17 Human genes 0.000 claims description 5
- 102100024130 Matrix metalloproteinase-23 Human genes 0.000 claims description 5
- 102100024131 Matrix metalloproteinase-25 Human genes 0.000 claims description 5
- 102100030412 Matrix metalloproteinase-9 Human genes 0.000 claims description 5
- NPPQSCRMBWNHMW-UHFFFAOYSA-N Meprobamate Chemical compound NC(=O)OCC(C)(CCC)COC(N)=O NPPQSCRMBWNHMW-UHFFFAOYSA-N 0.000 claims description 5
- 101000933115 Mus musculus Caspase-4 Proteins 0.000 claims description 5
- 108090000028 Neprilysin Proteins 0.000 claims description 5
- 102000003729 Neprilysin Human genes 0.000 claims description 5
- 102100030411 Neutrophil collagenase Human genes 0.000 claims description 5
- 102000016387 Pancreatic elastase Human genes 0.000 claims description 5
- 108010067372 Pancreatic elastase Proteins 0.000 claims description 5
- 229920000037 Polyproline Polymers 0.000 claims description 5
- 108010072866 Prostate-Specific Antigen Proteins 0.000 claims description 5
- 102100030416 Stromelysin-1 Human genes 0.000 claims description 5
- 102100028848 Stromelysin-2 Human genes 0.000 claims description 5
- 102100028847 Stromelysin-3 Human genes 0.000 claims description 5
- 102100032452 Transmembrane protease serine 6 Human genes 0.000 claims description 5
- 108010055066 asparaginylendopeptidase Proteins 0.000 claims description 5
- 108010018550 caspase 13 Proteins 0.000 claims description 5
- BFPSDSIWYFKGBC-UHFFFAOYSA-N chlorotrianisene Chemical compound C1=CC(OC)=CC=C1C(Cl)=C(C=1C=CC(OC)=CC=1)C1=CC=C(OC)C=C1 BFPSDSIWYFKGBC-UHFFFAOYSA-N 0.000 claims description 5
- 108010047374 matriptase 2 Proteins 0.000 claims description 5
- 108091007169 meprins Proteins 0.000 claims description 5
- 108010026466 polyproline Proteins 0.000 claims description 5
- 101100520152 Arabidopsis thaliana PIR gene Proteins 0.000 claims description 4
- 102000001398 Granzyme Human genes 0.000 claims description 4
- 108060005986 Granzyme Proteins 0.000 claims description 4
- 102100022623 Hepatocyte growth factor receptor Human genes 0.000 claims description 4
- 101710184069 Hepatocyte growth factor receptor Proteins 0.000 claims description 4
- 102100021768 Phosphoserine aminotransferase Human genes 0.000 claims description 4
- RASZIXQTZOARSV-BDPUVYQTSA-N astacin Chemical compound CC=1C(=O)C(=O)CC(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)C(=O)C(=O)CC1(C)C RASZIXQTZOARSV-BDPUVYQTSA-N 0.000 claims description 4
- 230000001413 cellular effect Effects 0.000 claims description 4
- 230000021008 regulation of antibody-dependent cellular cytotoxicity Effects 0.000 claims description 4
- 230000036755 cellular response Effects 0.000 claims description 3
- DQMZLTXERSFNPB-UHFFFAOYSA-N primidone Chemical compound C=1C=CC=CC=1C1(CC)C(=O)NCNC1=O DQMZLTXERSFNPB-UHFFFAOYSA-N 0.000 claims description 3
- 102220231785 rs148036492 Human genes 0.000 claims description 3
- 102220334449 rs1554010636 Human genes 0.000 claims description 3
- 102200113210 rs759408749 Human genes 0.000 claims description 3
- 102220254288 rs767276648 Human genes 0.000 claims description 3
- 102220077433 rs797044910 Human genes 0.000 claims description 3
- 102000034498 Astacin Human genes 0.000 claims description 2
- 108090000658 Astacin Proteins 0.000 claims description 2
- FMKGDHLSXFDSOU-BDPUVYQTSA-N Dienon-Astacin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)C(=O)C(=CC1(C)C)O)C=CC=C(/C)C=CC2=C(C)C(=O)C(=CC2(C)C)O FMKGDHLSXFDSOU-BDPUVYQTSA-N 0.000 claims description 2
- 101001091385 Homo sapiens Kallikrein-6 Proteins 0.000 claims description 2
- 102100034866 Kallikrein-6 Human genes 0.000 claims description 2
- 206010057249 Phagocytosis Diseases 0.000 claims description 2
- 108090000899 Serralysin Proteins 0.000 claims description 2
- 235000003676 astacin Nutrition 0.000 claims description 2
- 230000005764 inhibitory process Effects 0.000 claims description 2
- 230000008782 phagocytosis Effects 0.000 claims description 2
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 claims 4
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 claims 4
- 102100031358 Urokinase-type plasminogen activator Human genes 0.000 claims 4
- 102100026548 Caspase-8 Human genes 0.000 claims 2
- 102220550848 Chromatin modification-related protein MEAF6_I58S_mutation Human genes 0.000 claims 2
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims 2
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims 2
- 102000002262 Thromboplastin Human genes 0.000 claims 2
- 102220411563 c.209T>C Human genes 0.000 claims 2
- 102200118279 rs36008922 Human genes 0.000 claims 2
- 102100036360 Cadherin-3 Human genes 0.000 claims 1
- 101000762242 Homo sapiens Cadherin-15 Proteins 0.000 claims 1
- 101000714553 Homo sapiens Cadherin-3 Proteins 0.000 claims 1
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 claims 1
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 claims 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 claims 1
- 230000005887 cellular phagocytosis Effects 0.000 claims 1
- 229910052698 phosphorus Inorganic materials 0.000 claims 1
- 239000011574 phosphorus Substances 0.000 claims 1
- 230000008685 targeting Effects 0.000 abstract description 16
- 108091008034 costimulatory receptors Proteins 0.000 abstract description 7
- 230000001988 toxicity Effects 0.000 abstract description 5
- 231100000419 toxicity Toxicity 0.000 abstract description 5
- 230000004957 immunoregulator effect Effects 0.000 abstract description 4
- 108091008028 Immune checkpoint receptors Proteins 0.000 abstract description 3
- 230000009471 action Effects 0.000 abstract description 3
- 230000002411 adverse Effects 0.000 abstract description 3
- 231100000331 toxic Toxicity 0.000 abstract description 3
- 230000002588 toxic effect Effects 0.000 abstract description 3
- 230000000873 masking effect Effects 0.000 abstract description 2
- 125000000524 functional group Chemical group 0.000 abstract 2
- 125000003275 alpha amino acid group Chemical group 0.000 description 235
- 235000001014 amino acid Nutrition 0.000 description 145
- 229940024606 amino acid Drugs 0.000 description 123
- 235000019419 proteases Nutrition 0.000 description 118
- 235000018102 proteins Nutrition 0.000 description 88
- 230000004048 modification Effects 0.000 description 60
- 238000012986 modification Methods 0.000 description 60
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 53
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 description 39
- 108091033319 polynucleotide Proteins 0.000 description 32
- 102000040430 polynucleotide Human genes 0.000 description 32
- 239000002157 polynucleotide Substances 0.000 description 32
- 238000006467 substitution reaction Methods 0.000 description 32
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 27
- 210000004881 tumor cell Anatomy 0.000 description 27
- 238000011282 treatment Methods 0.000 description 24
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 20
- 239000003814 drug Substances 0.000 description 18
- 230000006870 function Effects 0.000 description 18
- 102100030859 Tissue factor Human genes 0.000 description 17
- 238000013368 capillary electrophoresis sodium dodecyl sulfate analysis Methods 0.000 description 15
- 230000013595 glycosylation Effects 0.000 description 14
- 238000006206 glycosylation reaction Methods 0.000 description 14
- 229940079593 drug Drugs 0.000 description 13
- 230000001965 increasing effect Effects 0.000 description 13
- 238000013459 approach Methods 0.000 description 12
- 238000003556 assay Methods 0.000 description 12
- -1 epitope Substances 0.000 description 12
- 230000001225 therapeutic effect Effects 0.000 description 11
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 10
- 102000004190 Enzymes Human genes 0.000 description 10
- 108090000790 Enzymes Proteins 0.000 description 10
- 102100035943 HERV-H LTR-associating protein 2 Human genes 0.000 description 10
- 101001021491 Homo sapiens HERV-H LTR-associating protein 2 Proteins 0.000 description 10
- 229940088598 enzyme Drugs 0.000 description 10
- 238000000746 purification Methods 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 101150029707 ERBB2 gene Proteins 0.000 description 9
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 9
- 102100034980 ICOS ligand Human genes 0.000 description 9
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 9
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 9
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 description 9
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 description 9
- 238000010586 diagram Methods 0.000 description 9
- 239000013604 expression vector Substances 0.000 description 9
- 238000000684 flow cytometry Methods 0.000 description 9
- 125000003729 nucleotide group Chemical group 0.000 description 9
- 238000002965 ELISA Methods 0.000 description 8
- 101001019455 Homo sapiens ICOS ligand Proteins 0.000 description 8
- 101710099301 Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 8
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 8
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 8
- 230000015572 biosynthetic process Effects 0.000 description 8
- 238000004422 calculation algorithm Methods 0.000 description 8
- 239000012636 effector Substances 0.000 description 8
- 238000005755 formation reaction Methods 0.000 description 8
- 239000002773 nucleotide Substances 0.000 description 8
- 230000004481 post-translational protein modification Effects 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 7
- 108010073807 IgG Receptors Proteins 0.000 description 7
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 7
- 108010004222 Natural Cytotoxicity Triggering Receptor 3 Proteins 0.000 description 7
- 102100032852 Natural cytotoxicity triggering receptor 3 Human genes 0.000 description 7
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 235000018417 cysteine Nutrition 0.000 description 7
- 238000001727 in vivo Methods 0.000 description 7
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 6
- 102000009490 IgG Receptors Human genes 0.000 description 6
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 6
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 6
- 102000002274 Matrix Metalloproteinases Human genes 0.000 description 6
- 108010000684 Matrix Metalloproteinases Proteins 0.000 description 6
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 6
- 229940049595 antibody-drug conjugate Drugs 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 230000004068 intracellular signaling Effects 0.000 description 6
- 230000001105 regulatory effect Effects 0.000 description 6
- 238000003571 reporter gene assay Methods 0.000 description 6
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 5
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 5
- 101000764622 Homo sapiens Transmembrane and immunoglobulin domain-containing protein 2 Proteins 0.000 description 5
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 5
- 241000699666 Mus <mouse, genus> Species 0.000 description 5
- 102100026224 Transmembrane and immunoglobulin domain-containing protein 2 Human genes 0.000 description 5
- 238000007792 addition Methods 0.000 description 5
- 210000004899 c-terminal region Anatomy 0.000 description 5
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 5
- 108020001756 ligand binding domains Proteins 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 239000000203 mixture Substances 0.000 description 5
- 239000013642 negative control Substances 0.000 description 5
- 230000037361 pathway Effects 0.000 description 5
- 230000009467 reduction Effects 0.000 description 5
- 230000009870 specific binding Effects 0.000 description 5
- 238000010561 standard procedure Methods 0.000 description 5
- 239000000758 substrate Substances 0.000 description 5
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 4
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 description 4
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 4
- 101000914321 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 7 Proteins 0.000 description 4
- 101000617725 Homo sapiens Pregnancy-specific beta-1-glycoprotein 2 Proteins 0.000 description 4
- 101000652359 Homo sapiens Spermatogenesis-associated protein 2 Proteins 0.000 description 4
- 102100029527 Natural cytotoxicity triggering receptor 3 ligand 1 Human genes 0.000 description 4
- 102100022019 Pregnancy-specific beta-1-glycoprotein 2 Human genes 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 239000000611 antibody drug conjugate Substances 0.000 description 4
- 230000000903 blocking effect Effects 0.000 description 4
- 150000001720 carbohydrates Chemical class 0.000 description 4
- 230000021615 conjugation Effects 0.000 description 4
- 238000004132 cross linking Methods 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 201000010099 disease Diseases 0.000 description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 230000005847 immunogenicity Effects 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 210000003734 kidney Anatomy 0.000 description 4
- 238000012004 kinetic exclusion assay Methods 0.000 description 4
- 210000000265 leukocyte Anatomy 0.000 description 4
- 150000007523 nucleic acids Chemical class 0.000 description 4
- 229920001542 oligosaccharide Polymers 0.000 description 4
- 150000002482 oligosaccharides Chemical class 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 4
- 102100027207 CD27 antigen Human genes 0.000 description 3
- 102100038078 CD276 antigen Human genes 0.000 description 3
- 101710185679 CD276 antigen Proteins 0.000 description 3
- 241000282836 Camelus dromedarius Species 0.000 description 3
- 102000004091 Caspase-8 Human genes 0.000 description 3
- 102000000844 Cell Surface Receptors Human genes 0.000 description 3
- 108010001857 Cell Surface Receptors Proteins 0.000 description 3
- 241000699802 Cricetulus griseus Species 0.000 description 3
- 102100035139 Folate receptor alpha Human genes 0.000 description 3
- 108010070675 Glutathione transferase Proteins 0.000 description 3
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 description 3
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 3
- 101001023230 Homo sapiens Folate receptor alpha Proteins 0.000 description 3
- 101000633520 Homo sapiens Natural cytotoxicity triggering receptor 3 ligand 1 Proteins 0.000 description 3
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 3
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- 108091005735 TGF-beta receptors Proteins 0.000 description 3
- 102000016715 Transforming Growth Factor beta Receptors Human genes 0.000 description 3
- 102100033579 Trophoblast glycoprotein Human genes 0.000 description 3
- 102100033732 Tumor necrosis factor receptor superfamily member 1A Human genes 0.000 description 3
- 102100033733 Tumor necrosis factor receptor superfamily member 1B Human genes 0.000 description 3
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 3
- 101001011890 Xenopus laevis Matrix metalloproteinase-18 Proteins 0.000 description 3
- 239000005557 antagonist Substances 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 229960003852 atezolizumab Drugs 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 229960002685 biotin Drugs 0.000 description 3
- 235000020958 biotin Nutrition 0.000 description 3
- 239000011616 biotin Substances 0.000 description 3
- 239000006143 cell culture medium Substances 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 230000000139 costimulatory effect Effects 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 230000005593 dissociations Effects 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 210000004602 germ cell Anatomy 0.000 description 3
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 229910052738 indium Inorganic materials 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 238000000111 isothermal titration calorimetry Methods 0.000 description 3
- 210000003292 kidney cell Anatomy 0.000 description 3
- 210000004698 lymphocyte Anatomy 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 102000039446 nucleic acids Human genes 0.000 description 3
- 108020004707 nucleic acids Proteins 0.000 description 3
- 210000001672 ovary Anatomy 0.000 description 3
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 238000009738 saturating Methods 0.000 description 3
- 230000004083 survival effect Effects 0.000 description 3
- 239000003053 toxin Substances 0.000 description 3
- 231100000765 toxin Toxicity 0.000 description 3
- 108700012359 toxins Proteins 0.000 description 3
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- 108010077805 Bacterial Proteins Proteins 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 108010029697 CD40 Ligand Proteins 0.000 description 2
- 102100032937 CD40 ligand Human genes 0.000 description 2
- 102100025221 CD70 antigen Human genes 0.000 description 2
- 229940045513 CTLA4 antagonist Drugs 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 201000009030 Carcinoma Diseases 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 108050000299 Chemokine receptor Proteins 0.000 description 2
- 102000009410 Chemokine receptor Human genes 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 2
- 102000009109 Fc receptors Human genes 0.000 description 2
- 108010087819 Fc receptors Proteins 0.000 description 2
- 102100037362 Fibronectin Human genes 0.000 description 2
- 108010067306 Fibronectins Proteins 0.000 description 2
- 102000006471 Fucosyltransferases Human genes 0.000 description 2
- 108010019236 Fucosyltransferases Proteins 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102100034459 Hepatitis A virus cellular receptor 1 Human genes 0.000 description 2
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 2
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 2
- 101000801228 Homo sapiens Tumor necrosis factor receptor superfamily member 1A Proteins 0.000 description 2
- 101000801232 Homo sapiens Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 2
- 208000029462 Immunodeficiency disease Diseases 0.000 description 2
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 102100021317 Inducible T-cell costimulator Human genes 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 102100027754 Mast/stem cell growth factor receptor Kit Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 2
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 2
- 108010077854 Natural Killer Cell Receptors Proteins 0.000 description 2
- 102000010648 Natural Killer Cell Receptors Human genes 0.000 description 2
- KDLHZDBZIXYQEI-UHFFFAOYSA-N Palladium Chemical compound [Pd] KDLHZDBZIXYQEI-UHFFFAOYSA-N 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 102100026547 Platelet-derived growth factor receptor beta Human genes 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 206010039491 Sarcoma Diseases 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 208000009956 adenocarcinoma Diseases 0.000 description 2
- 230000009824 affinity maturation Effects 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- 238000012867 alanine scanning Methods 0.000 description 2
- 230000009435 amidation Effects 0.000 description 2
- 238000007112 amidation reaction Methods 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000005094 computer simulation Methods 0.000 description 2
- 150000001945 cysteines Chemical class 0.000 description 2
- 102000003675 cytokine receptors Human genes 0.000 description 2
- 108010057085 cytokine receptors Proteins 0.000 description 2
- 206010052015 cytokine release syndrome Diseases 0.000 description 2
- 230000001085 cytostatic effect Effects 0.000 description 2
- 229940127089 cytotoxic agent Drugs 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 238000002296 dynamic light scattering Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 239000012091 fetal bovine serum Substances 0.000 description 2
- 108010072257 fibroblast activation protein alpha Proteins 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 229910052731 fluorine Inorganic materials 0.000 description 2
- 108020005243 folate receptor Proteins 0.000 description 2
- 102000006815 folate receptor Human genes 0.000 description 2
- 230000002496 gastric effect Effects 0.000 description 2
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 102000054751 human RUNX1T1 Human genes 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 230000002757 inflammatory effect Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 210000005229 liver cell Anatomy 0.000 description 2
- 230000035800 maturation Effects 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 238000000569 multi-angle light scattering Methods 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- 210000004985 myeloid-derived suppressor cell Anatomy 0.000 description 2
- 210000000822 natural killer cell Anatomy 0.000 description 2
- 230000001323 posttranslational effect Effects 0.000 description 2
- 230000009145 protein modification Effects 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 230000006337 proteolytic cleavage Effects 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 241000894007 species Species 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 239000013589 supplement Substances 0.000 description 2
- 230000001629 suppression Effects 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 210000004981 tumor-associated macrophage Anatomy 0.000 description 2
- 238000011179 visual inspection Methods 0.000 description 2
- JPSHPWJJSVEEAX-OWPBQMJCSA-N (2s)-2-amino-4-fluoranylpentanedioic acid Chemical compound OC(=O)[C@@H](N)CC([18F])C(O)=O JPSHPWJJSVEEAX-OWPBQMJCSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 1
- FSPQCTGGIANIJZ-UHFFFAOYSA-N 2-[[(3,4-dimethoxyphenyl)-oxomethyl]amino]-4,5,6,7-tetrahydro-1-benzothiophene-3-carboxamide Chemical compound C1=C(OC)C(OC)=CC=C1C(=O)NC1=C(C(N)=O)C(CCCC2)=C2S1 FSPQCTGGIANIJZ-UHFFFAOYSA-N 0.000 description 1
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- 102100022464 5'-nucleotidase Human genes 0.000 description 1
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 1
- CJIJXIFQYOPWTF-UHFFFAOYSA-N 7-hydroxycoumarin Natural products O1C(=O)C=CC2=CC(O)=CC=C21 CJIJXIFQYOPWTF-UHFFFAOYSA-N 0.000 description 1
- 230000005730 ADP ribosylation Effects 0.000 description 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 1
- 102000012440 Acetylcholinesterase Human genes 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- 108010000239 Aequorin Proteins 0.000 description 1
- 241000122170 Aliivibrio salmonicida Species 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102100023635 Alpha-fetoprotein Human genes 0.000 description 1
- 229930183010 Amphotericin Natural products 0.000 description 1
- QGGFZZLFKABGNL-UHFFFAOYSA-N Amphotericin A Natural products OC1C(N)C(O)C(C)OC1OC1C=CC=CC=CC=CCCC=CC=CC(C)C(O)C(C)C(C)OC(=O)CC(O)CC(O)CCC(O)C(O)CC(O)CC(O)(CC(O)C2C(O)=O)OC2C1 QGGFZZLFKABGNL-UHFFFAOYSA-N 0.000 description 1
- 108010083359 Antigen Receptors Proteins 0.000 description 1
- 102000006306 Antigen Receptors Human genes 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 108050001427 Avidin/streptavidin Proteins 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 1
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 208000037914 B-cell disorder Diseases 0.000 description 1
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 108700012439 CA9 Proteins 0.000 description 1
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 1
- 108091008927 CC chemokine receptors Proteins 0.000 description 1
- 102000005674 CCR Receptors Human genes 0.000 description 1
- 102100024210 CD166 antigen Human genes 0.000 description 1
- 102100038077 CD226 antigen Human genes 0.000 description 1
- 102100032912 CD44 antigen Human genes 0.000 description 1
- 102100036008 CD48 antigen Human genes 0.000 description 1
- 108010065524 CD52 Antigen Proteins 0.000 description 1
- 108010062802 CD66 antigens Proteins 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 108091008925 CX3C chemokine receptors Proteins 0.000 description 1
- 108091008928 CXC chemokine receptors Proteins 0.000 description 1
- 102000054900 CXCR Receptors Human genes 0.000 description 1
- 102100029756 Cadherin-6 Human genes 0.000 description 1
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 1
- 102100024533 Carcinoembryonic antigen-related cell adhesion molecule 1 Human genes 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- 102000005600 Cathepsins Human genes 0.000 description 1
- 108010084457 Cathepsins Proteins 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 241000819038 Chichester Species 0.000 description 1
- 241000282552 Chlorocebus aethiops Species 0.000 description 1
- 102100039496 Choline transporter-like protein 4 Human genes 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 102000016989 Ciliary Neurotrophic Factor Receptor Human genes 0.000 description 1
- 108010000063 Ciliary Neurotrophic Factor Receptor Proteins 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- XPDXVDYUQZHFPV-UHFFFAOYSA-N Dansyl Chloride Chemical compound C1=CC=C2C(N(C)C)=CC=CC2=C1S(Cl)(=O)=O XPDXVDYUQZHFPV-UHFFFAOYSA-N 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 102100036466 Delta-like protein 3 Human genes 0.000 description 1
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 description 1
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 1
- 208000030453 Drug-Related Side Effects and Adverse reaction Diseases 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 102100031788 E3 ubiquitin-protein ligase MYLIP Human genes 0.000 description 1
- 101710190174 E3 ubiquitin-protein ligase MYLIP Proteins 0.000 description 1
- 102100029722 Ectonucleoside triphosphate diphosphohydrolase 1 Human genes 0.000 description 1
- 108010055196 EphA2 Receptor Proteins 0.000 description 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 241000282324 Felis Species 0.000 description 1
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 description 1
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 description 1
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 description 1
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- GYHNNYVSQQEPJS-UHFFFAOYSA-N Gallium Chemical compound [Ga] GYHNNYVSQQEPJS-UHFFFAOYSA-N 0.000 description 1
- 102220560597 Glucose-6-phosphate 1-dehydrogenase_V68M_mutation Human genes 0.000 description 1
- 108010051815 Glutamyl endopeptidase Proteins 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- 102100032530 Glypican-3 Human genes 0.000 description 1
- 101150112082 Gpnmb gene Proteins 0.000 description 1
- 108010054017 Granulocyte Colony-Stimulating Factor Receptors Proteins 0.000 description 1
- 102100039622 Granulocyte colony-stimulating factor receptor Human genes 0.000 description 1
- 108010092372 Granulocyte-Macrophage Colony-Stimulating Factor Receptors Proteins 0.000 description 1
- 102000016355 Granulocyte-Macrophage Colony-Stimulating Factor Receptors Human genes 0.000 description 1
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 102100029360 Hematopoietic cell signal transducer Human genes 0.000 description 1
- 108010007712 Hepatitis A Virus Cellular Receptor 1 Proteins 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 101000678236 Homo sapiens 5'-nucleotidase Proteins 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000884298 Homo sapiens CD226 antigen Proteins 0.000 description 1
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 1
- 101000716130 Homo sapiens CD48 antigen Proteins 0.000 description 1
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 1
- 101000928513 Homo sapiens Delta-like protein 3 Proteins 0.000 description 1
- 101001012447 Homo sapiens Ectonucleoside triphosphate diphosphohydrolase 1 Proteins 0.000 description 1
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 1
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 description 1
- 101000990188 Homo sapiens Hematopoietic cell signal transducer Proteins 0.000 description 1
- 101001068136 Homo sapiens Hepatitis A virus cellular receptor 1 Proteins 0.000 description 1
- 101000606465 Homo sapiens Inactive tyrosine-protein kinase 7 Proteins 0.000 description 1
- 101001103039 Homo sapiens Inactive tyrosine-protein kinase transmembrane receptor ROR1 Proteins 0.000 description 1
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 description 1
- 101000994378 Homo sapiens Integrin alpha-3 Proteins 0.000 description 1
- 101000852870 Homo sapiens Interferon alpha/beta receptor 1 Proteins 0.000 description 1
- 101000852865 Homo sapiens Interferon alpha/beta receptor 2 Proteins 0.000 description 1
- 101001001420 Homo sapiens Interferon gamma receptor 1 Proteins 0.000 description 1
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 1
- 101001018034 Homo sapiens Lymphocyte antigen 75 Proteins 0.000 description 1
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 description 1
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 1
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 description 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 1
- 101001103036 Homo sapiens Nuclear receptor ROR-alpha Proteins 0.000 description 1
- 101001126417 Homo sapiens Platelet-derived growth factor receptor alpha Proteins 0.000 description 1
- 101000692455 Homo sapiens Platelet-derived growth factor receptor beta Proteins 0.000 description 1
- 101001117312 Homo sapiens Programmed cell death 1 ligand 2 Proteins 0.000 description 1
- 101001123448 Homo sapiens Prolactin receptor Proteins 0.000 description 1
- 101001136592 Homo sapiens Prostate stem cell antigen Proteins 0.000 description 1
- 101000831286 Homo sapiens Protein timeless homolog Proteins 0.000 description 1
- 101000752245 Homo sapiens Rho guanine nucleotide exchange factor 5 Proteins 0.000 description 1
- 101000633786 Homo sapiens SLAM family member 6 Proteins 0.000 description 1
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 1
- 101000809875 Homo sapiens TYRO protein tyrosine kinase-binding protein Proteins 0.000 description 1
- 101000835093 Homo sapiens Transferrin receptor protein 1 Proteins 0.000 description 1
- 101000610604 Homo sapiens Tumor necrosis factor receptor superfamily member 10B Proteins 0.000 description 1
- 101000611185 Homo sapiens Tumor necrosis factor receptor superfamily member 5 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 241000578472 Human endogenous retrovirus H Species 0.000 description 1
- 101000954493 Human papillomavirus type 16 Protein E6 Proteins 0.000 description 1
- 101000767631 Human papillomavirus type 16 Protein E7 Proteins 0.000 description 1
- 101710093458 ICOS ligand Proteins 0.000 description 1
- 102100039813 Inactive tyrosine-protein kinase 7 Human genes 0.000 description 1
- 102100039615 Inactive tyrosine-protein kinase transmembrane receptor ROR1 Human genes 0.000 description 1
- 101710205775 Inducible T-cell costimulator Proteins 0.000 description 1
- 108700001097 Insect Genes Proteins 0.000 description 1
- 102100025305 Integrin alpha-2 Human genes 0.000 description 1
- 102100032819 Integrin alpha-3 Human genes 0.000 description 1
- 102100036714 Interferon alpha/beta receptor 1 Human genes 0.000 description 1
- 102100036718 Interferon alpha/beta receptor 2 Human genes 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 102100035678 Interferon gamma receptor 1 Human genes 0.000 description 1
- 102100036157 Interferon gamma receptor 2 Human genes 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 1
- 108010056045 K cadherin Proteins 0.000 description 1
- 102000002698 KIR Receptors Human genes 0.000 description 1
- 108010043610 KIR Receptors Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- 102000017578 LAG3 Human genes 0.000 description 1
- 101150030213 Lag3 gene Proteins 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 102100021747 Leukemia inhibitory factor receptor Human genes 0.000 description 1
- 101710142062 Leukemia inhibitory factor receptor Proteins 0.000 description 1
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- 102100033486 Lymphocyte antigen 75 Human genes 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 description 1
- 101710150918 Macrophage colony-stimulating factor 1 receptor Proteins 0.000 description 1
- 101710087603 Mast/stem cell growth factor receptor Kit Proteins 0.000 description 1
- 102000001776 Matrix metalloproteinase-9 Human genes 0.000 description 1
- 108010015302 Matrix metalloproteinase-9 Proteins 0.000 description 1
- 102000000440 Melanoma-associated antigen Human genes 0.000 description 1
- 108050008953 Melanoma-associated antigen Proteins 0.000 description 1
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 241000579835 Merops Species 0.000 description 1
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- ZOKXTWBITQBERF-UHFFFAOYSA-N Molybdenum Chemical compound [Mo] ZOKXTWBITQBERF-UHFFFAOYSA-N 0.000 description 1
- 101100502475 Mus musculus Fblim1 gene Proteins 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 1
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 1
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 description 1
- 101710201161 Natural cytotoxicity triggering receptor 3 ligand 1 Proteins 0.000 description 1
- 102100035486 Nectin-4 Human genes 0.000 description 1
- 101710043865 Nectin-4 Proteins 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 238000012879 PET imaging Methods 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 241000235648 Pichia Species 0.000 description 1
- 108010051742 Platelet-Derived Growth Factor beta Receptor Proteins 0.000 description 1
- 102100030485 Platelet-derived growth factor receptor alpha Human genes 0.000 description 1
- 102100029740 Poliovirus receptor Human genes 0.000 description 1
- 101710094000 Programmed cell death 1 ligand 1 Proteins 0.000 description 1
- 102100029000 Prolactin receptor Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 102100036735 Prostate stem cell antigen Human genes 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 101710151245 Receptor-type tyrosine-protein kinase FLT3 Proteins 0.000 description 1
- 102100020718 Receptor-type tyrosine-protein kinase FLT3 Human genes 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 102100029197 SLAM family member 6 Human genes 0.000 description 1
- 108091006938 SLC39A6 Proteins 0.000 description 1
- 108091007561 SLC44A4 Proteins 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 101100215487 Sus scrofa ADRA2A gene Proteins 0.000 description 1
- 102100035721 Syndecan-1 Human genes 0.000 description 1
- 230000006043 T cell recruitment Effects 0.000 description 1
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 1
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 1
- 102100038717 TYRO protein tyrosine kinase-binding protein Human genes 0.000 description 1
- 102100027188 Thyroid peroxidase Human genes 0.000 description 1
- 101710113649 Thyroid peroxidase Proteins 0.000 description 1
- 206010070863 Toxicity to various agents Diseases 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 1
- 101710190034 Trophoblast glycoprotein Proteins 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 102100040653 Tryptophan 2,3-dioxygenase Human genes 0.000 description 1
- 101710136122 Tryptophan 2,3-dioxygenase Proteins 0.000 description 1
- 102100040112 Tumor necrosis factor receptor superfamily member 10B Human genes 0.000 description 1
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 1
- 101710187743 Tumor necrosis factor receptor superfamily member 1A Proteins 0.000 description 1
- 101710187830 Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 1
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 1
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 1
- 102100027212 Tumor-associated calcium signal transducer 2 Human genes 0.000 description 1
- 206010054094 Tumour necrosis Diseases 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 244000000188 Vaccinium ovalifolium Species 0.000 description 1
- 102100023144 Zinc transporter ZIP6 Human genes 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 239000007801 affinity label Substances 0.000 description 1
- 230000008484 agonism Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 229940009444 amphotericin Drugs 0.000 description 1
- APKFDSVGJQXUKY-INPOYWNPSA-N amphotericin B Chemical compound O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 APKFDSVGJQXUKY-INPOYWNPSA-N 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 230000010516 arginylation Effects 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000012575 bio-layer interferometry Methods 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 229960003008 blinatumomab Drugs 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 238000007707 calorimetry Methods 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 1
- 229940127276 delta-like ligand 3 Drugs 0.000 description 1
- 230000017858 demethylation Effects 0.000 description 1
- 238000010520 demethylation reaction Methods 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 238000001938 differential scanning calorimetry curve Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 108020001096 dihydrofolate reductase Proteins 0.000 description 1
- 238000000375 direct analysis in real time Methods 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 231100000371 dose-limiting toxicity Toxicity 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 230000000857 drug effect Effects 0.000 description 1
- 238000012063 dual-affinity re-targeting Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 230000003176 fibrotic effect Effects 0.000 description 1
- 150000002211 flavins Chemical class 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000022244 formylation Effects 0.000 description 1
- 238000006170 formylation reaction Methods 0.000 description 1
- 150000008267 fucoses Chemical class 0.000 description 1
- 230000033581 fucosylation Effects 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 229910052733 gallium Inorganic materials 0.000 description 1
- 230000006251 gamma-carboxylation Effects 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000009036 growth inhibition Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 150000003278 haem Chemical group 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 102000048776 human CD274 Human genes 0.000 description 1
- 102000048362 human PDCD1 Human genes 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 125000004435 hydrogen atom Chemical class [H]* 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- 230000005934 immune activation Effects 0.000 description 1
- 230000005746 immune checkpoint blockade Effects 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 230000002584 immunomodulator Effects 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 230000001024 immunotherapeutic effect Effects 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 108091008042 inhibitory receptors Proteins 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 108010085650 interferon gamma receptor Proteins 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 230000026045 iodination Effects 0.000 description 1
- 238000006192 iodination reaction Methods 0.000 description 1
- PNDPGZBMCMUPRI-UHFFFAOYSA-N iodine Chemical compound II PNDPGZBMCMUPRI-UHFFFAOYSA-N 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 231100001231 less toxic Toxicity 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 210000005265 lung cell Anatomy 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- 229920012128 methyl methacrylate acrylonitrile butadiene styrene Polymers 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 238000012737 microarray-based gene expression Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 229910052750 molybdenum Inorganic materials 0.000 description 1
- 239000011733 molybdenum Substances 0.000 description 1
- 238000012243 multiplex automated genomic engineering Methods 0.000 description 1
- 210000000066 myeloid cell Anatomy 0.000 description 1
- ZTLGJPIZUOVDMT-UHFFFAOYSA-N n,n-dichlorotriazin-4-amine Chemical compound ClN(Cl)C1=CC=NN=N1 ZTLGJPIZUOVDMT-UHFFFAOYSA-N 0.000 description 1
- 229950006780 n-acetylglucosamine Drugs 0.000 description 1
- 210000000581 natural killer T-cell Anatomy 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 229910052763 palladium Inorganic materials 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 231100000683 possible toxicity Toxicity 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 230000013823 prenylation Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000000770 proinflammatory effect Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 230000018883 protein targeting Effects 0.000 description 1
- 229940024999 proteolytic enzymes for treatment of wounds and ulcers Drugs 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 229940043131 pyroglutamate Drugs 0.000 description 1
- 230000006340 racemization Effects 0.000 description 1
- 239000012857 radioactive material Substances 0.000 description 1
- 230000007420 reactivation Effects 0.000 description 1
- 210000003370 receptor cell Anatomy 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 238000006722 reduction reaction Methods 0.000 description 1
- 230000019908 regulation of T cell activation Effects 0.000 description 1
- 230000018928 regulation of interferon-gamma production Effects 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 238000007363 ring formation reaction Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 206010041823 squamous cell carcinoma Diseases 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 230000019635 sulfation Effects 0.000 description 1
- 238000005670 sulfation reaction Methods 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 210000000225 synapse Anatomy 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- 229910052716 thallium Inorganic materials 0.000 description 1
- BKVIYDNLLOSFOA-UHFFFAOYSA-N thallium Chemical compound [Tl] BKVIYDNLLOSFOA-UHFFFAOYSA-N 0.000 description 1
- 229940124598 therapeutic candidate Drugs 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 108091052247 type I cytokine receptor family Proteins 0.000 description 1
- 102000042286 type I cytokine receptor family Human genes 0.000 description 1
- 102000042287 type II cytokine receptor family Human genes 0.000 description 1
- 108091052254 type II cytokine receptor family Proteins 0.000 description 1
- 238000010798 ubiquitination Methods 0.000 description 1
- 230000034512 ubiquitination Effects 0.000 description 1
- 238000013060 ultrafiltration and diafiltration Methods 0.000 description 1
- ORHBXUUXSCNDEV-UHFFFAOYSA-N umbelliferone Chemical compound C1=CC(=O)OC2=CC(O)=CC=C21 ORHBXUUXSCNDEV-UHFFFAOYSA-N 0.000 description 1
- HFTAFOQKODTIJY-UHFFFAOYSA-N umbelliferone Natural products Cc1cc2C=CC(=O)Oc2cc1OCC=CC(C)(C)O HFTAFOQKODTIJY-UHFFFAOYSA-N 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 229910052724 xenon Inorganic materials 0.000 description 1
- FHNFHKCVQCLJFQ-UHFFFAOYSA-N xenon atom Chemical compound [Xe] FHNFHKCVQCLJFQ-UHFFFAOYSA-N 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images
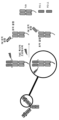
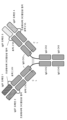





















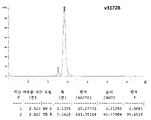




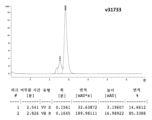




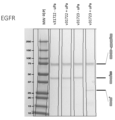










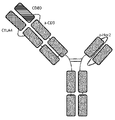






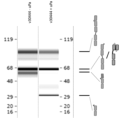

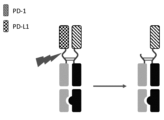








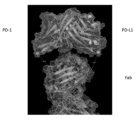













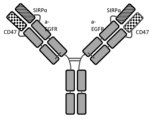















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70521—CD28, CD152
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2878—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70532—B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/66—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a swap of domains, e.g. CH3-CH2, VH-CL or VL-CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/32—Fusion polypeptide fusions with soluble part of a cell surface receptor, "decoy receptors"
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Cell Biology (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Gastroenterology & Hepatology (AREA)
- Toxicology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Oncology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicinal Preparation (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
본 개시내용은 프로그래밍된 표적 결합(programmed target engagement)을 위한 다기능성 생물학적 설계된 융합 단백질을 제공한다. 특정 실시양태에서, 본원에 기술된 융합 단백질은 동시 표적 항원 결합 및 면역 체크포인트 또는 공동자극 수용체 표적화를 제공한다. 특정 측면에서, 상기 융합 단백질은 표적 결합과 관련된 임의의 온타겟 조직 외 작용(on-target off-tissue action)(즉, 독성)이 차폐된다. 특정 실시양태에서, 상기 융합 단백질은 차폐된 항원 결합 도메인은 물론 차폐된 면역조절 표적 결합 도메인을 제공하여, 하나의 결합 작용기의 프로그래밍된 활성화가 다른 결합 작용기의 활성화를 야기함으로써 이중특이성 분자를 생성한다. 따라서, 본 개시내용은 또한 심각한 유해 독성 효과 없이 특정 표적 조직 설정 및 면역조절 표적의 표적화 및 활성화에서 항원 결합 도메인의 차폐 및 조건부 활성화 방법을 제공한다.
Description
단클론 항체 및 기타 생물의약품(biologics)이 약물(drug)로 개발됨에 따라 매우 특이적이고 표적화된 치료제가 설계될 수 있다. 그러나 이러한 약물의 사용은 어느 정도 차등 발현되더라도 암과 같은 병든 세포를 표시(mark)할 수 있는 대부분의 분자 표적이 환자 신체에서 병들지 않은(정상적인) 세포에도 나타날 수 있다는 사실로 인해 종종 방해를 받는다. 그 결과, 치료제로 사용되는 활성 표적 생체분자는 치료 효과를 위해 작용할 것으로 예상되는 위치 외부에서 의도하지 않은 활성을 나타낼 수 있으며, 이는 잠재적 독성 및 바람직하지 않은 부작용을 초래할 수 있다. 이것을 온타겟 종양 외(on-target off-tumor)(온타겟 조직 외(on-target off-tissue)라고도 알려짐) 작용이라고 하며 투여 요법은 물론 약물의 효능과 독성 사이의 균형에 영향을 미친다. 온타겟 종양 외 작용은 병들지 않은 세포에 의한 치료제의 의도하지 않은 흡수 및 가속화된 클리어런스(clearance)로 이어질 수 있으며, 그 결과 표적 매개 약물 처리(target mediated drug disposition, TMDD)라고도 하는 치료제의 바람직하지 않은 약동학 프로파일을 초래할 수 있다. 따라서, 이러한 도전은 분자 표적에 대한 높은 특이성을 넘어 동일한 표적 발현된 종양 외 조직에 대한 약물의 영향을 피하면서 병든 세포/조직에 대해 치료제가 조건부 및 국소적으로 작용하도록 하는 치료 설계의 특징을 요구한다.
양성 또는 음성 공동자극 분자를 통한 면역 체크포인트 경로의 표적화는 환자의 면역 시스템의 능동적 개입으로 지속적인 치료 반응을 제공할 수 있다. 불행하게도, 체크포인트 경로 표적화 요법은 또한 표적 매개 약물 독성 및 클리어런스 문제의 쟁점으로 어려움을 겪을 수 있다. 또한, 이러한 체크포인트 및/또는 공동자극 경로 중 하나 이상을 공동 표적화할 때 또는 이러한 체크포인트 표적이 다른 비-면역 관련 표적 및 요법과 결합될 때 더욱 효과적인 면역 반응 재활성화가 있을 수 있다는 인식이 커지고 있다. 따라서, 체크포인트 표적을 포함하는 치료 전략을 설계하는 데 큰 관심이 있지만 면역 관련 이상반응(immune related adverse event, irAE), 즉 독성 및 클리어런스와 관한 쟁점은 여전히 해결해야 할 과제로 남아 있다. 치료제의 조건부 개입을 제공하는 설계는 면역조절 분자의 표적화를 위해 덜 독성이고 더 효과적인 해결책을 제공할 수 있다.
본원에는 생물학적 기능성 단백질, 리간드-수용체 쌍, 제1 펩티드 링커 및 제2 펩티드 링커를 포함하는 융합 단백질로서, 상기 생물학적 기능성 단백질은 적어도 제1 폴리펩티드 및 제2 폴리펩티드를 포함하고; 상기 리간드-수용체 쌍은 면역글로불린 수퍼패밀리(immunoglobulin superfamily, IgSF) 수용체의 세포외 부분 및 이의 동족 리간드(cognate ligand) 또는 이의 수용체 결합 단편을 포함하고; 상기 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 말단에 융합되고; 상기 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 동일한 각각의 말단에 융합되고; 상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링(pairing)을 허용하기에 충분한 길이이고, 상기 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하는 융합 단백질이 기술되어 있다. 일부 실시양태에서, 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함한다. 특정 실시양태에서 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 N-말단에 융합되고, 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 N-말단에 융합된다.
특정 실시양태에서, 생물학적 기능성 단백질은 항체 또는 항원 결합 항체 단편을 포함한다. 특정 실시양태에서, 생물학적 기능성 단백질은 폴리펩티드 스캐폴드(polypeptide scaffold)로 이루어진다. 특정 실시양태에서 폴리펩티드 스캐폴드는 이량체 Fc 영역이고, 제1 폴리펩티드는 제1 Fc 폴리펩티드로 이루어지고 제2 폴리펩티드는 제2 Fc 폴리펩티드로 이루어지고, 제1 및 제2 Fc 폴리펩티드는 이량체 Fc 영역을 형성한다. 특정 실시양태에서, 생물학적 기능성 단백질은 폴리펩티드 스캐폴드를 포함한다.
특정 실시양태에서, 폴리펩티드 스캐폴드는 이량체 Fc 영역을 포함한다. 특정 실시양태에서, 이량체 Fc 영역은 이종이량체 Fc이다. 특정 실시양태에서, 리간드-수용체 쌍에서 리간드 또는 수용체 중 적어도 하나는 면역조절 표적에 결합할 수 있다.
일부 실시양태에서, 리간드 수용체 쌍은 면역 체크포인트의 조절, 면역 세포 활성의 조절, T 세포 수용체 신호전달의 조절, T 세포 의존성 세포독성(T-cell dependent cytotoxicity, TDCC)의 조절, 항체 의존성 세포 식세포작용(antibody-dependent cellular phagocytosis, ADCP)의 조절 및 항체 의존성 세포 세포독성(antibody-dependent cellular cytotoxicity, ADCC)의 조절로 이루어진 군으로부터 선택된 세포 반응에 관여한다. 일부 실시양태에서, 수용체는 야생형 수용체와 비교하여 동족 리간드에 대한 수용체의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함한다.
일부 실시양태에서, 리간드는 야생형 리간드와 비교하여 동족 수용체에 대한 리간드의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 리간드-수용체 쌍은 PD1-PDL1, PD1-PDL2, CTLA4-CD80, CD28-CD80, CD28-CD86, CTLA4-CD86, PDL1-CD80, ICOS-ICOSL, NCRSRLG1-NKp30 및 CD47-SIRPα로 이루어진 군으로부터 선택된다. 특정 실시양태에서, 리간드-수용체 쌍은 PD1-PDL1이다. 특정 실시양태에서, 리간드 PDL1은 서열번호 8에 따른 아미노산 서열을 포함한다. 특정 실시양태에서, 수용체 PD1은 서열번호 9에 따른 아미노산 서열을 포함한다.
특정 실시양태에서, 리간드-수용체 쌍은 CTLA4-CD80이다. 특정 실시양태에서, 리간드 CD80은 서열번호 25, 서열번호 185, 서열번호 187 또는 서열번호 189에 따른 아미노산 서열을 포함한다. 특정 실시양태에서, 수용체 CTLA4는 서열번호 26에 따른 아미노산 서열을 포함한다.
특정 실시양태에서, 수용체 및 리간드는 제1 및 제2 폴리펩티드의 각각의 N-말단에 융합된다. 특정 실시양태에서, 제1 또는 제2 펩티드 링커 중 하나는 하나 초과의 프로테아제 절단 부위를 포함한다. 특정 실시양태에서, 리간드 또는 수용체에 융합된 펩티드 링커 중 하나는 하나 이상의 추가의 프로테아제 절단 부위를 포함하도록 조작되고, 리간드 또는 수용체의 하나 이상의 프로테아제 절단 부위 및 제1 또는 제2 펩티드 링커의 프로테아제 절단 부위는 동일한 프로테아제 또는 상이한 프로테아제에 의해 절단 가능하다.
특정 실시양태에서, 프로테아제는 세린 프로테아제, MMP1, MMP2, MMP3, MMP7, MMP8, MMP9, MMP10, MMP11, MMP12, MMP13, MMP14, MMP15, MMP16, MMP17, MMP18(콜라게나제 4), MMP19, MMP20, MMP21, 아다말리신(adamalysin), 세랄리신(serralysin), 아스타신(astacin), 카스파제(caspase) 1, 카스파제 2, 카스파제 3, 카스파제 4, 카스파제 5, 카스파제 6, 카스파제 7, 카스파제 8, 카스파제 9, 카스파제 10, 카스파제 11, 카스파제 12, 카스파제 13, 카스파제 14, 카텝신(cathepsin) A, 카텝신 B, 카텝신 D, 카텝신 E, 카텝신 K, 카텝신 S, 그랜자임(granzyme) B, 구아니디노벤조아타제(guanidinobenzoatase, GB), 헵신(hepsin), 엘라스타제(elastase), 레구마인(legumain), 매트립타제(matriptase), 매트립타제 2, 메프린(meprin), 뉴로신(neurosin), MT-SP1, 네프릴리신(neprilysin), 플라스민(plasmin), PSA, PSMA, TACE, TMPRSS3, TMPRSS4, uPA, 칼페인(calpain), FAP 및 KLK로 이루어진 군으로부터 선택된다. 특정 실시양태에서, 프로테아제는 uPA 또는 매트립타제이다.
특정 실시양태에서, 펩티드 링커는 길이가 3-50개 또는 5-20개의 아미노산이다. 특정 실시양태에서, 제1 또는 제2 펩티드 링커 중 하나는 프로테아제 절단 부위를 갖지 않는다. 특정 실시양태에서, 펩티드 링커는 (GlynSer) 링커이고, (GlynSer) 링커는 (Gly3Ser)n(Gly4Ser)1, (Gly3Ser)1(Gly4Ser)n, (Gly3Ser)n(Gly4Ser)n 및 (Gly4Ser)n으로 이루어진 군으로부터 선택된 아미노산 서열을 포함하고, n은 1 내지 5의 정수이다. 특정 실시양태에서, 펩티드 링커는 (EAAAK)n 링커이고, n은 1 내지 5의 정수이다. 특정 실시양태에서, 펩티드 링커는 아미노산 서열 EAAAKEAAAK(서열번호 38)를 포함한다. 특정 실시양태에서, 펩티드 링커는 폴리프롤린 링커(polyproline linker), 선택적으로 PPP 또는 PPPP이다. 특정 실시양태에서, 펩티드 링커는 야생형 면역글로불린 힌지 영역 아미노산 서열과 비교하여 아미노산 서열 동일성이 최대 30% 차이나는 아미노산 서열을 포함하는 면역글로불린 힌지 영역 서열을 포함한다. 특정 실시양태에서, 펩티드 링커는 아미노산 서열 MSGRSANA(서열번호 28)를 포함하는 프로테아제 절단 부위를 포함한다.
또한, 본원에는 Fab 영역 및 Fc 영역과 면역글로불린 수퍼패밀리 수용체의 세포외 부분 및 이의 동족 리간드 또는 이의 수용체 결합 단편을 포함하는 리간드-수용체 쌍을 포함하는 융합 단백질로서, 상기 Fab 영역은 항원 결합 도메인을 형성하는 VH 폴리펩티드 및 VL 폴리펩티드를 포함하고; 상기 리간드는 제1 펩티드 링커를 통해 VH 또는 VL 폴리펩티드 중 하나의 N-말단에 융합되고 상기 수용체는 제2 펩티드 링커를 통해 VH 또는 VL 폴리펩티드 중 다른 하나의 N-말단에 융합되고; 상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링을 허용하기에 충분한 길이이고; 상기 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하고; 상기 리간드-수용체 쌍은 항원 결합 도메인과 이의 동족 항원의 결합을 입체적으로 방해하는 융합 단백질이 기술되어 있다.
일부 실시양태에서, 제1 및 제2 폴리펩티드 중 적어도 하나는 제1 VH 폴리펩티드 및 제1 VL 폴리펩티드를 포함하고, 제1 VH 및 VL 폴리펩티드는 항체의 제1 항원 결합 도메인을 형성하고, 리간드는 제1 펩티드 링커를 통해 VH 또는 VL 폴리펩티드 중 하나에 융합되고 수용체는 제2 펩티드 링커를 통해 VH 또는 VL 폴리펩티드 중 다른 하나에 융합되고, 리간드-수용체 쌍은 제1 항원 결합 도메인과 이의 동족 항원의 결합을 입체적으로 방해한다. 특정 실시양태에서, 제1 및 제2 폴리펩티드는 이량체 Fc를 추가로 포함한다. 특정 실시양태에서, 이량체 Fc 영역은 이종이량체 Fc이다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커-VL, 수용체-링커-VL, 리간드-링커-VH 또는 수용체-링커-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-절단성 링커-VL, 수용체-절단성 링커-VL, 리간드-절단성 링커-VH 또는 수용체-절단성 링커-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 114)-VL, 수용체-링커(서열번호 114)-VL, 리간드-링커(서열번호 14)-VH 또는 수용체-링커(서열번호 14)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 145)-VL, 수용체-링커(서열번호 145)-VL, 리간드-링커(서열번호 145)-VH 또는 수용체-링커(서열번호 145)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 147)-VL, 수용체-링커(서열번호 147)-VL, 리간드-링커(서열번호 147)-VH 또는 수용체-링커(서열번호 147)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 154)-VL, 수용체-링커(서열번호 154)-VL, 리간드-링커(서열번호 154)-VH 또는 수용체-링커(서열번호 154)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 203)-VL, 수용체-링커(서열번호 203)-VL, 리간드-링커(서열번호 203)-VH 또는 수용체-링커(서열번호 203)-VH를 포함한다.
특정 실시양태에서, 리간드-수용체 쌍의 리간드 또는 수용체 중 적어도 하나는 면역조절 표적에 결합할 수 있다. 특정 실시양태에서, 리간드 수용체 쌍은 면역 체크포인트의 조절, 면역 세포 활성의 조절, T 세포 수용체 신호전달의 조절, T 세포 의존성 세포독성(TDCC)의 조절, 항체 의존성 세포 식세포작용(ADCP)의 조절 및 항체 의존성 세포 세포독성(ADCC)의 조절로 이루어진 군으로부터 선택되는 세포 반응에 관여한다.
특정 실시양태에서, 수용체는 야생형 수용체와 비교하여 동족 리간드에 대한 수용체의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 리간드는 야생형 리간드와 비교하여 동족 수용체에 대한 리간드의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 리간드-수용체 쌍은 PD1-PDL1, PD1-PDL2, CTLA4-CD80, CD28-CD80, CD28-CD86, CTLA4-CD86, PDL1-CD80, ICOS-ICOSL, NCRSRLG1-NKp30 및 CD47-SIRPα로 이루어진 군으로부터 선택된다. 특정 실시양태에서, 리간드-수용체 쌍은 PD1-PDL1이다. 특정 실시양태에서, 리간드 PDL1은 서열번호 8에 따른 아미노산 서열을 포함한다. 특정 실시양태에서, 수용체 PD1은 서열번호 9에 따른 아미노산 서열을 포함한다. 특정 실시양태에서, 리간드-수용체 쌍은 CTLA4-CD80이다. 특정 실시양태에서, 리간드 CD80은 서열번호 25에 따른 아미노산 서열을 포함한다. 특정 실시양태에서, 수용체 CTLA4는 서열번호 26에 따른 아미노산 서열을 포함한다.
일부 실시양태에서, 수용체 및 리간드는 제1 및 제2 폴리펩티드의 각각의 N-말단에 융합된다. 특정 실시양태에서, 제1 또는 제2 펩티드 링커 중 하나는 하나 초과의 프로테아제 절단 부위를 포함한다. 특정 실시양태에서, 리간드 또는 수용체 중 하나는 하나 이상의 추가의 프로테아제 절단 부위를 포함하도록 조작되고, 리간드 또는 수용체의 하나 이상의 프로테아제 절단 부위 및 제1 또는 제2 펩티드 링커의 프로테아제 절단 부위는 동일한 프로테아제 또는 다른 프로테아제에 의해 절단 가능하다.
특정 실시양태에서, 프로테아제는 세린 프로테아제, MMP1, MMP2, MMP3, MMP7, MMP8, MMP9, MMP10, MMP11, MMP12, MMP13, MMP14, MMP15, MMP16, MMP17, MMP18(콜라게나제 4), MMP19, MMP20, MMP21, 아다말리신, 세랄리신, 아스타신, 카스파제 1, 카스파제 2, 카스파제 3, 카스파제 4, 카스파제 5, 카스파제 6, 카스파제 7, 카스파제 8, 카스파제 9, 카스파제 10, 카스파제 11, 카스파제 12, 카스파제 13, 카스파제 14, 카텝신 A, 카텝신 B, 카텝신 D, 카텝신 E, 카텝신 K, 카텝신 S, 그랜자임 B, 구아니디노벤조아타제(GB), 헵신, 엘라스타제, 레구마인, 매트립타제, 매트립타제 2, 메프린, 뉴로신, MT-SP1, 네프릴리신, 플라스민, PSA, PSMA, TACE, TMPRSS3, TMPRSS4, uPA, 및 칼페인, FAP 및 KLK로 이루어진 군으로부터 선택된다. 특정 실시양태에서, 프로테아제는 uPA 또는 매트립타제이다. 특정 실시양태에서, 펩티드 링커는 길이가 3-50개 또는 5-20개의 아미노산이다. 특정 실시양태에서, 제1 또는 제2 펩티드 링커 중 하나는 프로테아제 절단 부위를 갖지 않는다. 특정 실시양태에서, 펩티드 링커는 (GlynSer) 링커이고, (GlynSer) 링커는 (Gly3Ser)n(Gly4Ser)1, (Gly3Ser)1(Gly4Ser)n, (Gly3Ser)n(Gly4Ser)n 및 (Gly4Ser)n으로 이루어진 군으로부터 선택된 아미노산 서열을 포함하고, n은 1 내지 5의 정수이다. 특정 실시양태에서, 펩티드 링커는 (EAAAK)n 링커이고, n은 1 내지 5의 정수이다. 특정 실시양태에서, 프로테아제 절단 부위를 갖지 않는 펩티드 링커는 아미노산 서열 EAAAKEAAAK(서열번호 38)를 포함한다. 특정 실시양태에서, 펩티드 링커는 폴리프롤린 링커, 선택적으로 PPP 또는 PPPP이다. 특정 실시양태에서 링커는 글리신(G) 프롤린(P) 폴리펩티드 링커, 선택적으로 GPPPG, GGPPPGG, GPPPPG 또는 GGPPPGG이다. 특정 실시양태에서, 펩티드 링커는 야생형 면역글로불린 힌지 영역 아미노산 서열과 비교하여 아미노산 서열 동일성이 최대 30% 차이나는 아미노산 서열을 포함하는 면역글로불린 힌지 영역 서열을 포함한다. 특정 실시양태에서, 프로테아제 절단 부위를 포함하는 펩티드 링커는 아미노산 서열 MSGRSANA(서열번호 28)를 포함한다.
특정 실시양태에서, 제1 항원 결합 도메인과 이의 동족 항원의 결합은 리간드-수용체 쌍에 융합되지 않은 모(parental) 항원 결합 도메인과 비교하여 10배 이상 감소된다. 특정 실시양태에서, 세포 환경에서 프로테아제 절단 부위의 절단은 융합 단백질로부터 리간드-수용체 쌍의 한 구성원을 방출함으로써 항원 결합 도메인이 이의 동족 항원에 결합하도록 한다.
특정 실시양태에서, 제1 항원 결합 도메인은 Fab이다. 특정 실시양태에서, 제1 항원 결합 도메인은 암세포 또는 면역 세포에서 발현되는 항원에 결합한다. 특정 실시양태에서, 제1 항원 결합 도메인은 T 세포에서 발현되는 항원에 결합한다. 특정 실시양태에서, 제1 항원 결합 도메인은 종양 관련 항원(tumor-associated antigen, TAA)에 결합한다. 특정 실시양태에서, 제1 항원 결합 도메인은 분화 클러스터 3(Cluster of Differentiation 3, CD3), 인간 표피 성장 인자 수용체 2(Human Epidermal Growth Factor Receptor 2, HER2), 표피 성장 인자 수용체(Epidermal Growth Factor Receptor, EGFR), 메소텔린(Mesothelin, MSLN), 조직 인자(Tissue Factor, TF), 분화 클러스터 19(CD19), 티로신-단백질 키나제 Met(c-Met), 분화 클러스터 40(CD40) 및 카드헤린 3(Cadherin 3, CDH3)로 이루어진 군으로부터 선택된 항원에 결합한다.
특정 실시양태에서, 항체 또는 항체 단편은 제2 VH 폴리펩티드 및 제2 VL 폴리펩티드를 포함하는 제2 항원 결합 도메인을 포함한다. 특정 실시양태에서, 융합 단백질은 제2 리간드-수용체 쌍을 포함하고, 제2 리간드-수용체 쌍의 리간드는 제3 펩티드 링커를 통해 제2 VH 또는 VL 폴리펩티드 중 하나에 융합되고 제2 리간드-수용체 쌍의 수용체는 제4 펩티드 링커를 통해 제2 VH 또는 VL 폴리펩티드 중 다른 하나에 융합되고, 제3 및 제4 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하고, 리간드-수용체 쌍은 제2 항원 결합 도메인과 이의 동족 항원의 결합을 입체적으로 방해한다. 특정 실시양태에서, 융합 단백질은 2개의 별개의 항원에 결합한다. 특정 실시양태에서, 하나의 항원은 T 세포에 의해 발현되는 항원이고 다른 항원은 암세포에 의해 발현되는 항원이다. 특정 실시양태에서, 융합 단백질은 CD3 및 HER2에 결합한다.
또한, 본원에는 제1 Fc 폴리펩티드 및 제2 Fc 폴리펩티드를 포함하는 Fc 영역, 및 면역글로불린 수퍼패밀리 수용체의 세포외 부분 및 이의 동족 리간드 또는 이의 수용체 결합 단편을 포함하는 리간드-수용체 쌍을 포함하는 융합 단백질로서, 상기 리간드는 제1 펩티드 링커를 통해 제1 Fc 폴리펩티드의 말단에 융합되고 상기 수용체는 제2 펩티드 링커를 통해 제2 Fc 폴리펩티드의 동일한 각각의 말단에 융합되고; 상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링을 허용하기에 충분한 길이이고; 상기 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하는 융합 단백질이 기술되어 있다.
본 발명의 이러한 특징 및 다른 특징, 측면 및 장점은 다음의 설명 및 첨부 도면과 관련하여 더 잘 이해될 것이다:
도 1a는 본원에 기술된 특정 융합 단백질 구조의 개략도를 나타낸다. PD-1(체크무늬) 및 PD-L1(줄무늬)을 각각 중쇄 및 경쇄의 N 말단에 융합함으로써, Fab의 파라토프(paratope)(회색)는 상기 둘 사이에 형성되는 Ig 수퍼패밀리 이종이량체에 의해 입체적으로 차단될 수 있다. 차폐 도메인과 Fab 사이에 도입된 링커 중 하나의 TME 특이적 단백질분해 절단(볼트)을 통해 이 마스크의 한 면을 제거하면 상기 마스크의 일부가 해제되고 표적과의 결합이 복원될 수 있다. 또한, Fab에 공유적으로 부착된 상태로 남아 있는 상기 마스크의 일부는 이의 면역조절 파트너에 결합하여 기능성을 추가한다. 도 1b는 TME 프로테아제 절단성 또는 비절단성 링커로 N-말단에 부착된 IgSF 도메인 쌍을 사용하여 차폐된 2개의 Fab 암(arm)을 가진 항체의 개략도를 나타낸다. Fab 파라토프 α-TAA 1 및 α-TAA 2는 동일하거나 상이할 수 있으며 IgSF 쌍 1:2 및 3:4는 동일하거나 상이할 수 있다. 도 1c는 표적 1에 특이적인 Fab 암과 표적 2에 특이적인 scFv 암이 있는 Fab × scFv 작제물의 개략도를 나타낸다. Fab 암과 표적 1에 대한 결합은 TME 프로테아제 절단성 또는 비절단성 링커를 사용하여 N-말단에 부착된 IgSF 도메인 쌍에 의해 차폐된다.
도 2는 본원에 기술된 변형된 이중특이성 CD3 × Her2 Fab × scFv Fc 융합 단백질의 개략도를 나타낸다. 항체 유사 분자의 한쪽 암은 PD-1/PD-L1 마스크에 의해 차단되는 항 CD3 Fab를 함유하는 반면, 다른 암은 항-Her2 scFv를 함유한다.
도 3은 대표적인 이중특이성 CD3 × Her2 Fab × scFv Fc 변이체에 대한 UPLC-SEC 크로마토그램과 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 3a) 차폐되지 않은 변이체 30421의 UPLC-SEC 크로마토그램, (도 3b) 차폐되지 않은 변이체 30421의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 3c) 차폐된 비절단성 변이체 30423의 UPLC-SEC 크로마토그램, (도 3d) 차폐된 비절단성 변이체 30423의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로필, (도 3e) 차폐된 경쇄 절단성 변이체 30430의 UPLC-SEC 크로마토그램, (도 3f) 차폐된 경쇄 절단성 변이체 30430의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 3g) 차폐된 중쇄 절단성 변이체 30436의 UPLC-SEC 크로마토그램, (도 3h) 차폐된 중쇄 절단성 변이체 30436의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일.
도 4는 조사된 CD3 × Her2 Fab × scFv Fc 시스템의 변형되지 않은 변이체(30421) 및 PD-1:PD-L1 차폐된 변이체(30430, 30436)에 대한 DSC 서모그램(thermogram)의 오버레이를 보여준다.
도 5는 1:50의 uPa:변이체 비율에서 37℃에서 24시간 동안 uPa 처리하지 않은(-uPa) 대표적인 변이체 및 uPa 처리한(+uPa) 대표적인 변이체의 감소하는 CE-SDS 프로파일을 보여준다. 차폐되지 않은 변이체(30421), 차폐되었지만 비절단성 변이체(30423) 및 차폐된 절단성 변이체(30430, 30436, 31934)에 대한 프로파일이 표시되어 있다.
도 6은 ELISA로 측정한 Jurkat 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), PD-L1 또는 PD-1 모이어티만 부착된 작제물(31929, 31931), 및 전체 비절단성 마스크가 있는 변이체(30423), 또는 전체 마스크 및 절단성 PD-L1 또는 PD-1 모이어티가 있는 변이체(30430, 30436)에 대한 결과가 표시되어 있다. 변이체 30423, 30430, 30436의 샘플에 대해 uPa 미처리(-uPa) 샘플 및 처리(+uPa) 샘플을 테스트하였다.
도 7은 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 TDCC 검정으로 측정한 Pan T 세포에 의한 JIMT-1 종양 세포의 세포 사멸을 나타낸다. 차폐되지 않은 변이체(30421), 중쇄에 PD-1 모이어티만 부착된 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423), 또는 전체 마스크 및 경쇄 상의 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 8은 (도 8a) PD-L1 형질감염 CHO-S 세포 및 (도 8b) PD-1 형질감염 CHO-S 세포에 대한 선별 CD3 표적화 변이체의 유세포분석에 의한 고유 결합 연구의 결과를 나타낸다. 차폐되지 않은 변이체(30421), PD-L1 또는 PD-1 모이어티만 부착된 작제물(31929, 31931), 및 완전한 비절단성 마스크가 있는 변이체(30423, 30426), 또는 전체 마스크 및 절단성 PD-L1 또는 PD-1 모이어티가 있는 변이체(30430, 30436)에 대한 결과가 표시되어 있다. 친화성 성숙된 PD-1 모이어티의 Fc-융합도 포함된다(31829). 변이체 30423, 30426, 30430, 30436의 샘플에 대해, uPa 미처리(-uPa) 샘플 및 처리(+uPa) 샘플을 테스트하였다.
도 9는 T 세포 및 JIMT-1 세포의 가교결합 및 PD-1:PD-L1 체크포인트 결합의 차단을 조사하는 하이브리드(hybrid) PD-1/PD-L1 리포터 유전자 검정의 개략도(도 9a) 및 이의 분석(도 9b)을 나타낸다. 차폐되지 않은 변이체(30421) 및 과량의 항-PD-L1 항체와 조합된 동일한 차폐되지 않은 변이체(30421 + 150nM 항-PD-L1)에 대한 결과가 표시되어 있다. 중쇄에 PD-1 모이어티만 부착된 작제물(31929), 및 전체 마스크가 있는 변이체(30423), 또는 전체 마스크 및 경쇄 상의 절단성 PD-L1 모이어티가 있는 변이체(30430)도 조사하였다. 변이체 30430에 대해 uPa 미처리(-uPa) 샘플 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다. 측정은 3중으로 수행하였으며 표준 편차를 반영하는 오차 막대가 표시되어 있다.
도 10은 종양 관련 항원(TAA)에 대해 표적화된 변형된 단일특이성, 2가 융합 단백질을 나타내는 도면이다. Fab의 파라토프는 PD-1/PD-L1 마스크에 의해 입체적으로 차단된다.
도 11은 EGFR, MSLN, TF, CD19, cMet, CDH3에 대해 표적화된 차폐된 융합 단백질의 UPLC-SEC 크로마토그램(도 11a-j) 및 비환원 SDS-PAGE(도 11k) 또는 비환원 및 환원 CE-SDS 프로파일(도 11l)을 나타낸다. 모든 융합 단백질에 대해 비절단성 변이체에 대한 데이터가 표시되어 있고(31722, 31728, 31736, 31732, 28647, 28662), EGFR, MSLN, TF 및 CD19에 대해 절단성 변이체의 샘플도 포함된다(31723, 31729, 31737, 31733).
도 12는 (도 12a) EGFR, (도 12b) MSLN, (도 12c) TF, (도 12d) CD19에 대해 표적화된 대표적인 융합 단백질의 환원 SDS-PAGE 프로파일을 나타낸다. uPa 처리하지 않은(-uPa) 샘플 및 uPa 처리한(+uPa) 샘플을 조사한다. 각 시스템에 대해 uPa 비절단성 변이체(31722, 31728, 31736, 31732) 및 VL과 PD-L1 모이어티 사이에 u-Pa 절단 서열이 있는 변이체(31723, 31729, 31737, 31733)에 대한 데이터가 표시되어 있다.
도 13은 해당 항원을 발현하는 다음 세포주에 대한 상이한 항원에 대해 표적화된 선별 융합 단백질의 고유 결합에 대한 유세포분석에 의한 결과를 나타낸다: (도 13a) MDA-MB-468의 경우 EGFR, (도 13b) OVCAR3의 경우 MSLN, (도 13c) MDA-MB-231의 경우 TF, (도 13d) Raji의 경우 CD19, (도 13e) EBC1의 경우 cMet, (도 13f) JIMT1의 경우 CDH3. 모든 시스템에 대해 비절단성 변이체에 대한 데이터가 표시되어 있다(31722, 31728, 31736, 31732, 28647, 28662), EGFR, MSLN, TF 및 CD19에 대해 절단성 변이체의 샘플도 포함(31723, 31729, 31737, 31733)되어 있으며 uPa 처리 없이(-uPa) 및 uPa 처리(+uPa)하여 테스트하였다. 모든 시스템에 대해 변형되지 않은 대조군(32474, 16427 16417, 6323, 4372, 17606, 17214)은 물론 cMet 및 CDH3(22277)에 대해 무관한 대조군도 포함된다. 이용 가능한 경우(EGFR, MSLN, TF) SPR의 데이터가 비교를 위해 포함된다.
도 14는 EGFR 표적화 변이체로 처리된 NCI-H292 세포의 성장 억제 연구 결과를 나타낸다. 차폐되지 않은 변이체(32474) 및 PD-1:PD-L 차폐된 변이체에 대한 데이터가 표시되어 있다. 차폐된 변이체는 비절단성 형태(31722)는 물론 경쇄에 절단성 PD-L1 모이어티가 있는 형태(31723)도 포함한다. 무관한 대조군(22277)도 포함된다. 모든 변이체에 대해 샘플은 처리(-uPa) 및 처리 없이(+uPa) 테스트한다. 오류 막대는 3중 측정의 표준 편차를 반영한다.
도 15는 본원에서 조사된 변형된 이중특이성 CD3 × Her2 Fab × scFv Fc 변이체의 개략도를 나타낸다. 융합 단백질의 한쪽 암은 CD80/CTLA4 마스크에 의해 차단되는 항 CD3 Fab를 함유하고 다른 암은 항-Her2 scFv를 함유한다.
도 16은 변이체 30444의 UPLC-SEC 크로마토그램과 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 16a) 차폐된 경쇄 절단성 변이체 30444의 UPLC-SEC 크로마토그램, (도 16b) 차폐된 경쇄 절단성 변이체 30444의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 16c) 차폐된 경쇄 절단성 변이체 30444의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 16d-도 16f) 단백질 A 정제 후 차폐된 경쇄 절단성 변이체 33525, 33526, 33527의 UPLC-SEC 크로마토그램.
도 17은 uPa 처리하지 않은(-uPa) 및 uPa 처리한(+uPa) 변이체 30444의 감소하는 CE-SDS 프로파일을 나타낸다.
도 18은 ELISA로 측정한 Jurkat 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), 전체 PD-1/PD-L1 기반 마스크와 절단성 PD-L1 모이어티가 있는 변이체(30430) 및 전체 CD80/CTLA4 기반 마스크와 절단성 CTLA4 모이어티가 있는 변이체(30444)에 대한 결과가 표시되어 있다. 변이체 30430 및 30444의 샘플에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다.
도 19는 힌지를 통해 이종이량체 IgG Fc에 융합된 면역조절인자 쌍(예를 들어, PD-1:PD-L1)의 IgV의 개략도를 나타낸다. uPa와 같은 TME 관련 프로테아제에 의한 두 링커 중 하나의 절단은 하나의 모이어티(예를 들어, PD-L1)를 방출하고 여전히 Fc에 부착되어 있으며 세포에서 파트너와 결합 가능한 원하는 기능이 있는 모이어티(예를 들어, PD-1)는 남긴다. PD-1의 경우 PD-L1을 표적 세포에 결합시켜 체크포인트 기능을 억제할 수 있다.
도 20은 CD40 표적화 변이체의 (도 20a-도 20c) UPLC-SEC 크로마토그램 및 (도 20d) 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 20e) 환원 CE-SDS, (도 20f) 유세포분석 결합 데이터 및 (도 20g) CD40 RGA 검정으로부터의 결과는 uPa로 처리하지 않은(-uPa) 및 uPa로 처리한(+uPa) 동일한 변이체에 대해서도 표시되어 있다. 테스트 항목에는 차폐되지 않은 변이체(32477), 비절단성 PD-1/PD-L1 기반 마스크가 있는 변이체(32478) 및 uPa로 절단하여 PD-L1 부분을 제거할 수 있는 PD-1/PD-L1 기반 마스크가 있는 변이체(32479)가 포함된다. RGA 검정(도 20g)을 통한 기능 조사에서, 고유 CD40 결합 파트너 CD40L 및 무관한 대조군(v22277)도 포함된다. CD40 RGA 검정에 대한 데이터는 도 20h의 표에 요약되어 있다.
도 21a: PD1 및 PDL1은 복합체를 형성하는 면역글로불린 도메인으로 구성된다. 이미지에서 결합 Fab는 파라토프 말단의 PD1-PDL1 복합체와 도킹된다. PD1 및 PDL1을 적절한 링커로 VH 및 VL 사슬에 연결하면 항원 결합을 차단할 수 있다. 도 21b: 마스크 역할을 할 수 있는 다른 예시적인 면역조절인자 쌍의 구조: PD-1/PD-L1(PDB:4ZQK), PD-1/PD-L2(PDB:3BP5), CTLA4/CD86(PDB:1I85), NCRSRLG1/NKp30(PDB: 3PV6), SIRPα/CD47(PDB:4KJY), CTLA4/CD80(PDB:1I8L).
도 22는 유세포분석으로 측정한 Pan T 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), 항-CD3 원 암(one-armed) 항체(18560), PD-1 모이어티만 부착된 작제물(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 절단성 PD-L1 모이어티가 있는 변이체(30430, 30436)에 대한 결과가 표시되어 있다. 변이체 30423, 30430의 샘플에 대해, uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 대조군(22277)에 대한 데이터도 표시되어 있다.
도 23a 및 도 23b는 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 TDCC 검정을 2회 반복하여 측정한 Pan T 세포에 의한 HCC1954, JIMT-1, HCC827 및 MCF-7 종양 세포의 세포 사멸을 나타낸다. 차폐되지 않은 변이체(30421)는 물론 포화량의 항-PD-L1 항체와 차폐되지 않은 변이체의 조합(30421 + 120nM 아테졸리주맙), 중쇄에 PD-1 모이어티만 부착된 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 경쇄에 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430 및 30423에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 24는 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 HCC1954, JIMT-1, HCC827 및 MCF-7 암세포를 사용한 TDCC 검정의 2회 반복으로 측정한 Pan T 세포의 IFNγ 방출을 나타낸다. 차폐되지 않은 변이체(30421)는 물론 포화량의 항-PD-L1 항체와 차폐되지 않은 변이체의 조합(30421 + 120nM 아테졸리주맙), 중쇄에 PD-1 모이어티만 부착된 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 경쇄에 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430 및 30423에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 25는 유세포분석으로 측정한, TDCC 및 RGA 검정에서 사용된 암 세포주 세트에 대한 Her2 및 PD-L1 세포당 수용체 수를 나타낸다.
도 26a 내지 도 26d는 T 세포와 4개의 상이한 암 세포주(HCC1954, JIMT-1, HCC827, MCF-7)의 가교결합 및 PD-1:PD-L1 체크포인트 결합 차단을 조사하는 하이브리드 PD-1/PD-L1 리포터 유전자 검정 결과를 나타낸다. 차폐되지 않은 변이체(30421)는 물론 포화량의 항-PD-L1 항체와 차폐되지 않은 변이체의 조합(30421 + 150nM 아테졸리주맙), 중쇄에 PD-1 모이어티만 부착되어 있는 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 경쇄에 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 27은 EGFR(a-EGFR)을 표적으로 하는 변형된 단일특이성, 2가 융합 단백질을 나타내는 도면이다. Fab의 파라토프는 SIRPα/CD47 마스크에 의해 입체적으로 차단된다.
도 28은 EGFR 표적화되고 SIRPα/CD47 차폐된 완전 절단성 변이체(34164)의 (도 28a) UPLC-SEC 크로마토그램 및 (도 28b) 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 28c) 환원 CE-SDS는 uPa로 처리하지 않은(-uPa) 및 uPa로 처리한 동일한 변이체에 대해서도 나타냈다.
도 29는 EGFR 양성 H292 세포에 대한 고함량 분석에 의한 고유 결합 분석 결과를 나타낸다. 테스트 항목에는 차폐되지 않은 EGFR 표적화 대조군(v32474), uPa로 처리하지 않은(-uPa) 및 uPa로 처리한(+uPa) EGFR 표적화 SIRPα/CD47 차폐된 완전 절단성 변이체(34164) 및 무관한 대조군(v22277)이 포함된다.
도 30은 (도 30a) Her2+/PD-L1+ JIMT-1 세포에 대한 유세포분석 결합 실험에서 단일 적정점(1nM)으로부터의 데이터 및 (도 30b) 인간 Pan T 세포와 Her2+/PD-L1+ JIMT-1 세포의 브릿징 실험으로부터의 데이터를 나타낸다. 데이터는 중쇄에 PD-1 모이어티만 부착된 삼중특이성 변이체(v31929) 및 동일한 형식이지만 PD-L1 또는 Her2에 결합할 수 없는 이중특이성 변이체(각각 v32497 및 v33551)에 대해 표시되어 있다. 무관한 대조군(v22277)에 대한 데이터는 브릿징 검정(도 30b)에 포함된다.
도 31은 PD-1:PD-L1 차폐된 CD3 × Her2 Fab × scFv Fc 변이체의 T 세포 동원 및 활성화의 메커니즘을 나타낸다. (도 31a) 치료용 항체는 TAA 결합을 통해 종양 미세환경(TME)으로 향하게 된다. (도 31b) 마스크의 PD-L1 모이어티는 TME 특이적 프로테아제의 절단을 통해 방출된다. (도 31c) 활성화된 치료제는 차폐되지 않은 α-CD3 파라토프를 통해 종양 세포 사멸을 위해 T 세포와 결합하고 활성화하며 종양 세포에서 PD-L1에 결합하여 체크포인트 활성을 억제한다.
도 32는 유세포분석으로 측정한 Pan T 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), PD-1 모이어티만 부착된 작제물(31929) 및 중쇄에 비기능적(non-functional) PD-1 도메인이 부착된 변이체(32497)에 대한 결과가 표시되어 있다. 무관한 대조군(22277)에 대한 데이터도 표시되어 있다.
도 33은 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 TDCC 검정에서 측정한 Pan T 세포에 의한 JIMT-1 종양 세포의 세포 사멸을 나타낸다. 차폐되지 않은 변이체(30421), 중쇄에 PD-1 모이어티만 부착된 변이체(31929) 및 중쇄에 비기능적 PD-1 도메인이 부착된 변이체(32497)에 대한 결과가 표시되어 있다.
도 34a는 IgSF 코어 Ig-폴드(Ig-fold)의 개략도로서, 3개의 스트랜드(strand)와 4개의 스트랜드의 두 베타 시트(beta-sheet)로 배열된 총 7개의 역평행 베타 스트랜드로 구성된 베타 샌드위치(beta-sandwich)를 보여준다. 도 34b는 스트랜드의 배열이 다른 IgSF IgC1 서브그룹 도메인 (상단) 및 IgC2 서브그룹 도메인 (하단)을 나타내는 개략도이다. 도 34c 및 34d는 4개의 스트랜드와 5개의 스트랜드의 두 시트로 배열된 9개의 베타 스트랜드(beta-strands)를 포함하는 IgV 도메인의 개략도이다.
도 1a는 본원에 기술된 특정 융합 단백질 구조의 개략도를 나타낸다. PD-1(체크무늬) 및 PD-L1(줄무늬)을 각각 중쇄 및 경쇄의 N 말단에 융합함으로써, Fab의 파라토프(paratope)(회색)는 상기 둘 사이에 형성되는 Ig 수퍼패밀리 이종이량체에 의해 입체적으로 차단될 수 있다. 차폐 도메인과 Fab 사이에 도입된 링커 중 하나의 TME 특이적 단백질분해 절단(볼트)을 통해 이 마스크의 한 면을 제거하면 상기 마스크의 일부가 해제되고 표적과의 결합이 복원될 수 있다. 또한, Fab에 공유적으로 부착된 상태로 남아 있는 상기 마스크의 일부는 이의 면역조절 파트너에 결합하여 기능성을 추가한다. 도 1b는 TME 프로테아제 절단성 또는 비절단성 링커로 N-말단에 부착된 IgSF 도메인 쌍을 사용하여 차폐된 2개의 Fab 암(arm)을 가진 항체의 개략도를 나타낸다. Fab 파라토프 α-TAA 1 및 α-TAA 2는 동일하거나 상이할 수 있으며 IgSF 쌍 1:2 및 3:4는 동일하거나 상이할 수 있다. 도 1c는 표적 1에 특이적인 Fab 암과 표적 2에 특이적인 scFv 암이 있는 Fab × scFv 작제물의 개략도를 나타낸다. Fab 암과 표적 1에 대한 결합은 TME 프로테아제 절단성 또는 비절단성 링커를 사용하여 N-말단에 부착된 IgSF 도메인 쌍에 의해 차폐된다.
도 2는 본원에 기술된 변형된 이중특이성 CD3 × Her2 Fab × scFv Fc 융합 단백질의 개략도를 나타낸다. 항체 유사 분자의 한쪽 암은 PD-1/PD-L1 마스크에 의해 차단되는 항 CD3 Fab를 함유하는 반면, 다른 암은 항-Her2 scFv를 함유한다.
도 3은 대표적인 이중특이성 CD3 × Her2 Fab × scFv Fc 변이체에 대한 UPLC-SEC 크로마토그램과 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 3a) 차폐되지 않은 변이체 30421의 UPLC-SEC 크로마토그램, (도 3b) 차폐되지 않은 변이체 30421의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 3c) 차폐된 비절단성 변이체 30423의 UPLC-SEC 크로마토그램, (도 3d) 차폐된 비절단성 변이체 30423의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로필, (도 3e) 차폐된 경쇄 절단성 변이체 30430의 UPLC-SEC 크로마토그램, (도 3f) 차폐된 경쇄 절단성 변이체 30430의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 3g) 차폐된 중쇄 절단성 변이체 30436의 UPLC-SEC 크로마토그램, (도 3h) 차폐된 중쇄 절단성 변이체 30436의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일.
도 4는 조사된 CD3 × Her2 Fab × scFv Fc 시스템의 변형되지 않은 변이체(30421) 및 PD-1:PD-L1 차폐된 변이체(30430, 30436)에 대한 DSC 서모그램(thermogram)의 오버레이를 보여준다.
도 5는 1:50의 uPa:변이체 비율에서 37℃에서 24시간 동안 uPa 처리하지 않은(-uPa) 대표적인 변이체 및 uPa 처리한(+uPa) 대표적인 변이체의 감소하는 CE-SDS 프로파일을 보여준다. 차폐되지 않은 변이체(30421), 차폐되었지만 비절단성 변이체(30423) 및 차폐된 절단성 변이체(30430, 30436, 31934)에 대한 프로파일이 표시되어 있다.
도 6은 ELISA로 측정한 Jurkat 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), PD-L1 또는 PD-1 모이어티만 부착된 작제물(31929, 31931), 및 전체 비절단성 마스크가 있는 변이체(30423), 또는 전체 마스크 및 절단성 PD-L1 또는 PD-1 모이어티가 있는 변이체(30430, 30436)에 대한 결과가 표시되어 있다. 변이체 30423, 30430, 30436의 샘플에 대해 uPa 미처리(-uPa) 샘플 및 처리(+uPa) 샘플을 테스트하였다.
도 7은 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 TDCC 검정으로 측정한 Pan T 세포에 의한 JIMT-1 종양 세포의 세포 사멸을 나타낸다. 차폐되지 않은 변이체(30421), 중쇄에 PD-1 모이어티만 부착된 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423), 또는 전체 마스크 및 경쇄 상의 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 8은 (도 8a) PD-L1 형질감염 CHO-S 세포 및 (도 8b) PD-1 형질감염 CHO-S 세포에 대한 선별 CD3 표적화 변이체의 유세포분석에 의한 고유 결합 연구의 결과를 나타낸다. 차폐되지 않은 변이체(30421), PD-L1 또는 PD-1 모이어티만 부착된 작제물(31929, 31931), 및 완전한 비절단성 마스크가 있는 변이체(30423, 30426), 또는 전체 마스크 및 절단성 PD-L1 또는 PD-1 모이어티가 있는 변이체(30430, 30436)에 대한 결과가 표시되어 있다. 친화성 성숙된 PD-1 모이어티의 Fc-융합도 포함된다(31829). 변이체 30423, 30426, 30430, 30436의 샘플에 대해, uPa 미처리(-uPa) 샘플 및 처리(+uPa) 샘플을 테스트하였다.
도 9는 T 세포 및 JIMT-1 세포의 가교결합 및 PD-1:PD-L1 체크포인트 결합의 차단을 조사하는 하이브리드(hybrid) PD-1/PD-L1 리포터 유전자 검정의 개략도(도 9a) 및 이의 분석(도 9b)을 나타낸다. 차폐되지 않은 변이체(30421) 및 과량의 항-PD-L1 항체와 조합된 동일한 차폐되지 않은 변이체(30421 + 150nM 항-PD-L1)에 대한 결과가 표시되어 있다. 중쇄에 PD-1 모이어티만 부착된 작제물(31929), 및 전체 마스크가 있는 변이체(30423), 또는 전체 마스크 및 경쇄 상의 절단성 PD-L1 모이어티가 있는 변이체(30430)도 조사하였다. 변이체 30430에 대해 uPa 미처리(-uPa) 샘플 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다. 측정은 3중으로 수행하였으며 표준 편차를 반영하는 오차 막대가 표시되어 있다.
도 10은 종양 관련 항원(TAA)에 대해 표적화된 변형된 단일특이성, 2가 융합 단백질을 나타내는 도면이다. Fab의 파라토프는 PD-1/PD-L1 마스크에 의해 입체적으로 차단된다.
도 11은 EGFR, MSLN, TF, CD19, cMet, CDH3에 대해 표적화된 차폐된 융합 단백질의 UPLC-SEC 크로마토그램(도 11a-j) 및 비환원 SDS-PAGE(도 11k) 또는 비환원 및 환원 CE-SDS 프로파일(도 11l)을 나타낸다. 모든 융합 단백질에 대해 비절단성 변이체에 대한 데이터가 표시되어 있고(31722, 31728, 31736, 31732, 28647, 28662), EGFR, MSLN, TF 및 CD19에 대해 절단성 변이체의 샘플도 포함된다(31723, 31729, 31737, 31733).
도 12는 (도 12a) EGFR, (도 12b) MSLN, (도 12c) TF, (도 12d) CD19에 대해 표적화된 대표적인 융합 단백질의 환원 SDS-PAGE 프로파일을 나타낸다. uPa 처리하지 않은(-uPa) 샘플 및 uPa 처리한(+uPa) 샘플을 조사한다. 각 시스템에 대해 uPa 비절단성 변이체(31722, 31728, 31736, 31732) 및 VL과 PD-L1 모이어티 사이에 u-Pa 절단 서열이 있는 변이체(31723, 31729, 31737, 31733)에 대한 데이터가 표시되어 있다.
도 13은 해당 항원을 발현하는 다음 세포주에 대한 상이한 항원에 대해 표적화된 선별 융합 단백질의 고유 결합에 대한 유세포분석에 의한 결과를 나타낸다: (도 13a) MDA-MB-468의 경우 EGFR, (도 13b) OVCAR3의 경우 MSLN, (도 13c) MDA-MB-231의 경우 TF, (도 13d) Raji의 경우 CD19, (도 13e) EBC1의 경우 cMet, (도 13f) JIMT1의 경우 CDH3. 모든 시스템에 대해 비절단성 변이체에 대한 데이터가 표시되어 있다(31722, 31728, 31736, 31732, 28647, 28662), EGFR, MSLN, TF 및 CD19에 대해 절단성 변이체의 샘플도 포함(31723, 31729, 31737, 31733)되어 있으며 uPa 처리 없이(-uPa) 및 uPa 처리(+uPa)하여 테스트하였다. 모든 시스템에 대해 변형되지 않은 대조군(32474, 16427 16417, 6323, 4372, 17606, 17214)은 물론 cMet 및 CDH3(22277)에 대해 무관한 대조군도 포함된다. 이용 가능한 경우(EGFR, MSLN, TF) SPR의 데이터가 비교를 위해 포함된다.
도 14는 EGFR 표적화 변이체로 처리된 NCI-H292 세포의 성장 억제 연구 결과를 나타낸다. 차폐되지 않은 변이체(32474) 및 PD-1:PD-L 차폐된 변이체에 대한 데이터가 표시되어 있다. 차폐된 변이체는 비절단성 형태(31722)는 물론 경쇄에 절단성 PD-L1 모이어티가 있는 형태(31723)도 포함한다. 무관한 대조군(22277)도 포함된다. 모든 변이체에 대해 샘플은 처리(-uPa) 및 처리 없이(+uPa) 테스트한다. 오류 막대는 3중 측정의 표준 편차를 반영한다.
도 15는 본원에서 조사된 변형된 이중특이성 CD3 × Her2 Fab × scFv Fc 변이체의 개략도를 나타낸다. 융합 단백질의 한쪽 암은 CD80/CTLA4 마스크에 의해 차단되는 항 CD3 Fab를 함유하고 다른 암은 항-Her2 scFv를 함유한다.
도 16은 변이체 30444의 UPLC-SEC 크로마토그램과 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 16a) 차폐된 경쇄 절단성 변이체 30444의 UPLC-SEC 크로마토그램, (도 16b) 차폐된 경쇄 절단성 변이체 30444의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 16c) 차폐된 경쇄 절단성 변이체 30444의 비환원(왼쪽) 및 환원(오른쪽) CE-SDS 프로파일, (도 16d-도 16f) 단백질 A 정제 후 차폐된 경쇄 절단성 변이체 33525, 33526, 33527의 UPLC-SEC 크로마토그램.
도 17은 uPa 처리하지 않은(-uPa) 및 uPa 처리한(+uPa) 변이체 30444의 감소하는 CE-SDS 프로파일을 나타낸다.
도 18은 ELISA로 측정한 Jurkat 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), 전체 PD-1/PD-L1 기반 마스크와 절단성 PD-L1 모이어티가 있는 변이체(30430) 및 전체 CD80/CTLA4 기반 마스크와 절단성 CTLA4 모이어티가 있는 변이체(30444)에 대한 결과가 표시되어 있다. 변이체 30430 및 30444의 샘플에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다.
도 19는 힌지를 통해 이종이량체 IgG Fc에 융합된 면역조절인자 쌍(예를 들어, PD-1:PD-L1)의 IgV의 개략도를 나타낸다. uPa와 같은 TME 관련 프로테아제에 의한 두 링커 중 하나의 절단은 하나의 모이어티(예를 들어, PD-L1)를 방출하고 여전히 Fc에 부착되어 있으며 세포에서 파트너와 결합 가능한 원하는 기능이 있는 모이어티(예를 들어, PD-1)는 남긴다. PD-1의 경우 PD-L1을 표적 세포에 결합시켜 체크포인트 기능을 억제할 수 있다.
도 20은 CD40 표적화 변이체의 (도 20a-도 20c) UPLC-SEC 크로마토그램 및 (도 20d) 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 20e) 환원 CE-SDS, (도 20f) 유세포분석 결합 데이터 및 (도 20g) CD40 RGA 검정으로부터의 결과는 uPa로 처리하지 않은(-uPa) 및 uPa로 처리한(+uPa) 동일한 변이체에 대해서도 표시되어 있다. 테스트 항목에는 차폐되지 않은 변이체(32477), 비절단성 PD-1/PD-L1 기반 마스크가 있는 변이체(32478) 및 uPa로 절단하여 PD-L1 부분을 제거할 수 있는 PD-1/PD-L1 기반 마스크가 있는 변이체(32479)가 포함된다. RGA 검정(도 20g)을 통한 기능 조사에서, 고유 CD40 결합 파트너 CD40L 및 무관한 대조군(v22277)도 포함된다. CD40 RGA 검정에 대한 데이터는 도 20h의 표에 요약되어 있다.
도 21a: PD1 및 PDL1은 복합체를 형성하는 면역글로불린 도메인으로 구성된다. 이미지에서 결합 Fab는 파라토프 말단의 PD1-PDL1 복합체와 도킹된다. PD1 및 PDL1을 적절한 링커로 VH 및 VL 사슬에 연결하면 항원 결합을 차단할 수 있다. 도 21b: 마스크 역할을 할 수 있는 다른 예시적인 면역조절인자 쌍의 구조: PD-1/PD-L1(PDB:4ZQK), PD-1/PD-L2(PDB:3BP5), CTLA4/CD86(PDB:1I85), NCRSRLG1/NKp30(PDB: 3PV6), SIRPα/CD47(PDB:4KJY), CTLA4/CD80(PDB:1I8L).
도 22는 유세포분석으로 측정한 Pan T 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), 항-CD3 원 암(one-armed) 항체(18560), PD-1 모이어티만 부착된 작제물(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 절단성 PD-L1 모이어티가 있는 변이체(30430, 30436)에 대한 결과가 표시되어 있다. 변이체 30423, 30430의 샘플에 대해, uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 대조군(22277)에 대한 데이터도 표시되어 있다.
도 23a 및 도 23b는 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 TDCC 검정을 2회 반복하여 측정한 Pan T 세포에 의한 HCC1954, JIMT-1, HCC827 및 MCF-7 종양 세포의 세포 사멸을 나타낸다. 차폐되지 않은 변이체(30421)는 물론 포화량의 항-PD-L1 항체와 차폐되지 않은 변이체의 조합(30421 + 120nM 아테졸리주맙), 중쇄에 PD-1 모이어티만 부착된 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 경쇄에 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430 및 30423에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 24는 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 HCC1954, JIMT-1, HCC827 및 MCF-7 암세포를 사용한 TDCC 검정의 2회 반복으로 측정한 Pan T 세포의 IFNγ 방출을 나타낸다. 차폐되지 않은 변이체(30421)는 물론 포화량의 항-PD-L1 항체와 차폐되지 않은 변이체의 조합(30421 + 120nM 아테졸리주맙), 중쇄에 PD-1 모이어티만 부착된 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 경쇄에 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430 및 30423에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 25는 유세포분석으로 측정한, TDCC 및 RGA 검정에서 사용된 암 세포주 세트에 대한 Her2 및 PD-L1 세포당 수용체 수를 나타낸다.
도 26a 내지 도 26d는 T 세포와 4개의 상이한 암 세포주(HCC1954, JIMT-1, HCC827, MCF-7)의 가교결합 및 PD-1:PD-L1 체크포인트 결합 차단을 조사하는 하이브리드 PD-1/PD-L1 리포터 유전자 검정 결과를 나타낸다. 차폐되지 않은 변이체(30421)는 물론 포화량의 항-PD-L1 항체와 차폐되지 않은 변이체의 조합(30421 + 150nM 아테졸리주맙), 중쇄에 PD-1 모이어티만 부착되어 있는 변이체(31929), 및 전체 비절단성 마스크가 있는 변이체(30423) 또는 전체 마스크와 경쇄에 절단성 PD-L1 모이어티가 있는 변이체(30430)에 대한 결과가 표시되어 있다. 변이체 30430에 대해 uPa 미처리(-uPa) 및 처리(+uPa) 샘플을 테스트하였다. 무관한 항-RSV 항체(22277)를 음성 대조군으로 사용하였다.
도 27은 EGFR(a-EGFR)을 표적으로 하는 변형된 단일특이성, 2가 융합 단백질을 나타내는 도면이다. Fab의 파라토프는 SIRPα/CD47 마스크에 의해 입체적으로 차단된다.
도 28은 EGFR 표적화되고 SIRPα/CD47 차폐된 완전 절단성 변이체(34164)의 (도 28a) UPLC-SEC 크로마토그램 및 (도 28b) 비환원 및 환원 CE-SDS 프로파일을 나타낸다. (도 28c) 환원 CE-SDS는 uPa로 처리하지 않은(-uPa) 및 uPa로 처리한 동일한 변이체에 대해서도 나타냈다.
도 29는 EGFR 양성 H292 세포에 대한 고함량 분석에 의한 고유 결합 분석 결과를 나타낸다. 테스트 항목에는 차폐되지 않은 EGFR 표적화 대조군(v32474), uPa로 처리하지 않은(-uPa) 및 uPa로 처리한(+uPa) EGFR 표적화 SIRPα/CD47 차폐된 완전 절단성 변이체(34164) 및 무관한 대조군(v22277)이 포함된다.
도 30은 (도 30a) Her2+/PD-L1+ JIMT-1 세포에 대한 유세포분석 결합 실험에서 단일 적정점(1nM)으로부터의 데이터 및 (도 30b) 인간 Pan T 세포와 Her2+/PD-L1+ JIMT-1 세포의 브릿징 실험으로부터의 데이터를 나타낸다. 데이터는 중쇄에 PD-1 모이어티만 부착된 삼중특이성 변이체(v31929) 및 동일한 형식이지만 PD-L1 또는 Her2에 결합할 수 없는 이중특이성 변이체(각각 v32497 및 v33551)에 대해 표시되어 있다. 무관한 대조군(v22277)에 대한 데이터는 브릿징 검정(도 30b)에 포함된다.
도 31은 PD-1:PD-L1 차폐된 CD3 × Her2 Fab × scFv Fc 변이체의 T 세포 동원 및 활성화의 메커니즘을 나타낸다. (도 31a) 치료용 항체는 TAA 결합을 통해 종양 미세환경(TME)으로 향하게 된다. (도 31b) 마스크의 PD-L1 모이어티는 TME 특이적 프로테아제의 절단을 통해 방출된다. (도 31c) 활성화된 치료제는 차폐되지 않은 α-CD3 파라토프를 통해 종양 세포 사멸을 위해 T 세포와 결합하고 활성화하며 종양 세포에서 PD-L1에 결합하여 체크포인트 활성을 억제한다.
도 32는 유세포분석으로 측정한 Pan T 세포에 대한 CD3 표적화 변이체의 고유 결합 결과를 나타낸다. 차폐되지 않은 변이체(30421), PD-1 모이어티만 부착된 작제물(31929) 및 중쇄에 비기능적(non-functional) PD-1 도메인이 부착된 변이체(32497)에 대한 결과가 표시되어 있다. 무관한 대조군(22277)에 대한 데이터도 표시되어 있다.
도 33은 T 세포와 종양 세포를 가교결합하는 조작된 변이체로 처리한 후 TDCC 검정에서 측정한 Pan T 세포에 의한 JIMT-1 종양 세포의 세포 사멸을 나타낸다. 차폐되지 않은 변이체(30421), 중쇄에 PD-1 모이어티만 부착된 변이체(31929) 및 중쇄에 비기능적 PD-1 도메인이 부착된 변이체(32497)에 대한 결과가 표시되어 있다.
도 34a는 IgSF 코어 Ig-폴드(Ig-fold)의 개략도로서, 3개의 스트랜드(strand)와 4개의 스트랜드의 두 베타 시트(beta-sheet)로 배열된 총 7개의 역평행 베타 스트랜드로 구성된 베타 샌드위치(beta-sandwich)를 보여준다. 도 34b는 스트랜드의 배열이 다른 IgSF IgC1 서브그룹 도메인 (상단) 및 IgC2 서브그룹 도메인 (하단)을 나타내는 개략도이다. 도 34c 및 34d는 4개의 스트랜드와 5개의 스트랜드의 두 시트로 배열된 9개의 베타 스트랜드(beta-strands)를 포함하는 IgV 도메인의 개략도이다.
정의
청구범위 및 명세서에 사용된 용어는 여기에서 간략하게 정의되며, 더욱 상세하게는 아래에서 정의된다.
"융합 단백질"은, 예를 들어, 펩티드 결합에 의해 서로 연결된 하나 이상의 폴리펩티드 영역 또는 도메인을 포함하는 단백질을 지칭한다. 따라서, 본원에서 사용되는 "융합된"은 펩티드 결합을 통해 서로 연결된 폴리펩티드 서열을 지칭한다. 예로는 면역조절 리간드/수용체 쌍에 융합된 항체 또는 스캐폴드를 포함한다. 본원에 기술된 융합 단백질은 때때로 "변이체" 또는 "작제물"로 지칭된다.
"생물학적 기능성 단백질"은 생물학적 기능이 있는 폴리펩티드 또는 단백질, 예를 들어, 항체, 예를 들어, 이량체 Fc를 광범위하게 지칭한다.
"리간드-수용체 쌍"은 서로 특이적으로 결합하는 수용체 폴리펩티드와 리간드 폴리펩티드를 지칭한다. 예로는 PD-1-PD-L1, CTLA4-CD80 또는 CD28-CD80을 포함한다.
"수용체 결합 단편"은 리간드-수용체 쌍의 수용체에 특이적으로 결합하는 임의의 폴리펩티드를 지칭한다. 수용체 결합 단편은 자연 발생 또는 비자연 발생일 수 있다.
"면역조절" 분자는 면역 반응의 상향조절 또는 하향조절과 같이 면역 반응을 직접 또는 간접적으로 조절하는 능력 및/또는 면역 세포 활성이 있는 분자를 지칭한다.
"펩티드 링커"는 다른 펩티드 또는 폴리펩티드를 잇거나 연결하는 펩티드를 의미한다.
용어 "Fc 영역", "Fc" 및 "Fc 도메인"은 본원에서 상호교환적으로 사용되며 불변 영역의 적어도 일부를 함유하는 면역글로불린 중쇄의 C-말단 영역을 지칭한다.
"이중특이성"은 2개의 별개의 에피토프에 특이적으로 결합할 수 있는 생물학적 기능성 단백질을 의미한다.
"다중특이성"은 2개 이상의 별개의 표적 분자 또는 에피토프에 특이적으로 결합할 수 있는 생물학적 기능성 단백질을 의미한다.
"차폐된"은 표적 서열에 대한 결합이 입체적으로 방해되는 폴리펩티드 도메인, 예를 들어, 항체의 항원 결합 도메인, 또는 동족 결합 파트너, 예를 들어, 수용체에 대한 결합이 입체적으로 방해되는 리간드를 지칭한다.
"프로테아제 활성화된" 또는 "프로테아제 절단된" 또는 "절단된"은 프로테아제에 의해 절단된 후의 프로테아제 절단 부위를 포함하는 융합 단백질을 지칭한다.
"프로테아제 절단 부위"는 프로테아제 인식 서열을 함유하고 프로테아제에 의해 절단되는 융합 단백질 내의 아미노산 서열을 지칭한다.
"면역 체크포인트"는 면역계 활성화를 조절하는 면역계의 조절 경로를 의미한다.
특정 항원, 에피토프, 리간드 또는 수용체의 결합을 언급할 때 "특이적으로 결합한다"(및 이의 문법적 변형)는 비특이적 상호작용과 상당히 다른 결합을 의미한다.
하기에 더 상세히 설명되는 바와 같이, "포유동물"은 인간 및 인간이 아닌 것 둘 다 포함하고 인간, 인간이 아닌 영장류, 개, 고양이과 동물, 뮤린(murine), 소, 말 및 돼지를 포함하지만 이에 제한되지 않는다.
명세서 및 첨부된 청구범위에 사용된 바와 같이, 단수형 "a", "an" 및 "the"는 문맥상 명백하게 달리 지시하지 않는 한 복수 지시 대상을 포함한다는 점에 유의해야 한다.
본 출원에서 사용된 약어는 다음을 포함한다: PD-1(세포예정사 단백질(Programmed Cell Death Protein) 1); PDL-1(예정사 리간드(Programmed death-ligand) 1); CD3(분화 클러스터(Cluster of Differentiation) 3); CTLA4(세포독성 T-림프구 관련 단백질(Cytotoxic T-lymphocyte-Associated Protein) 4 또는 분화 클러스터 152); CD80(분화 클러스터 80); CD28(분화 클러스터 28); CD86(분화 클러스터 86); ICOS(유도성 T 세포 공동자극자(Inducible T Cell Costimulator)); ICOSL(유도성 T 세포 공동자극자 리간드(Inducible T Cell Costimulator Ligand)); CD47(분화 클러스터 47); SIRPA(신호 조절 단백질 알파(Signal-Regulatory Protein Alpha)), HHLA2(인간 내재성 레트로바이러스-H 긴 반복부위 결합 2(Human endogenous retro virus-H Long repeat-associating 2)), NKp30(자연살해 세포 수용체(Natural Killer cell Receptor) 3), NCR3LG1(자연살해 세포 세포독성 수용체 3 리간드 1(Natural Killer Cell Cytotoxicity Receptor 3 Ligand 1)), HHLA2(HERV-H LTR 결합 2(HERV-H LTR-associating 2)), VISTA(T 세포 활성화의 V-도메인 Ig 억제인자(V-domain Ig Suppressor of T cell Activation)), VTCN1(V-세트 도메인 함유 T 세포 활성화 억제제 1(V-set domain-containing T-cell activation inhibitor 1)), CD276(분화 클러스터 276), 인간 표피 성장 인자 수용체 2(Human Epidermal Growth Factor Receptor 2, HER2), 표피 성장 인자 수용체(Epidermal Growth Factor Receptor, EGFR), 메소텔린(Mesothelin, MSLN), 조직 인자(Tissue Factor, TF), 분화 클러스터 19(CD19), 티로신-단백질 키나제 Met(c-Met) 및 카드헤린 3(CDH3).
본원에서 사용되는 용어 "약"은 주어진 값의 대략 +/- 10% 편차를 지칭한다. 이러한 편차는 그것이 구체적으로 언급되는지 여부에 관계없이 본원에 제공된 임의의 주어진 값에 항상 포함된다는 것을 이해해야 한다.
본원에 사용된 용어 "포함하는(comprising)", "갖는(having)", "포함하는(including)" 및 "함유하는(containing)", 및 이들의 문법적 변형은 포괄적이거나 개방형이며 추가의 인용되지 않은 요소 및/또는 방법 단계를 배제하지 않는다. 구성, 용도 또는 방법과 관련하여 본원에서 사용될 때 용어 "본질적으로 이루어진"은 추가 요소 및/또는 방법 단계가 존재할 수 있지만 이러한 추가가 인용된 구성, 방법 또는 용도가 기능하는 방식에 실질적으로 영향을 미치지 않음을 나타낸다. 본원에서 구성, 용도 또는 방법과 관련하여 사용될 때 "~로 이루어진"이라는 용어는 추가 요소 및/또는 방법 단계의 존재를 배제한다. 특정 요소 및/또는 단계를 포함하는 것으로 본원에 기술된 구성, 용도 또는 방법은 또한 특정 실시양태에서 이러한 요소 및/또는 단계로 본질적으로 이루어질 수 있고, 다른 실시양태에서는 이러한 실시양태가 구체적으로 언급되는지 여부에 관계없이 이러한 요소 및/또는 단계로 이루어질 수 있다.
본원에 논의된 임의의 실시양태는 본원에 개시된 임의의 방법, 용도 또는 구성과 관련하여 구현될 수 있고 그 반대도 가능함이 고려된다.
또한, 한 실시양태에서 하나의 특징의 긍정적인 언급은 다른 실시양태에서 그 특징을 배제하기 위한 근거로 작용함을 이해해야 한다. 특히, 주어진 실시양태 또는 청구범위에 대해 옵션 목록이 제공되는 경우, 하나 이상의 옵션이 목록에서 삭제될 수 있고 축약된 목록이 대체 실시양태가 구체적으로 언급되는지 여부에 관계없이 이러한 대체 실시양태를 형성할 수 있음을 이해해야 한다.
본원에서 언급된 다양한 아미노산 서열 및 클론의 서열은 표 AA에서 찾을 수 있다.
융합 단백질
본원에는 리간드-수용체 쌍에 융합된 생물학적 기능성 단백질, 예를 들어, 항체 또는 폴리펩티드 스캐폴드를 포함하는 융합 단백질이 개시되어 있다. 본 개시내용에 따른 융합 단백질에서, 생물학적 기능성 단백질은 적어도 제1 폴리펩티드 및 제2 폴리펩티드를 포함하고, 리간드는 제1 펩티드 링커를 통해 폴리펩티드 중 하나의 말단에 융합되고 수용체는 제2 펩티드 링커를 통해 다른 폴리펩티드의 동일한 각각의 말단에 융합된다. 일부 실시양태에서, 제1 및 제2 펩티드 링커 중 적어도 하나는 표적 세포 환경, 예를 들어, 종양 미세환경에서 자연적으로 발생하는 프로테아제에 대한 절단 부위를 포함한다. 또한 본원에 개시된 융합 단백질을 사용하는 방법이 개시되어 있다.
본 개시내용에 따른 융합 단백질은 표적 결합과 관련된 임의의 온-타겟 조직 외(예를 들어, 종양 외) 작용(즉, 독성)을 감소시키기 위해 차폐된다. 표적 세포 환경에서 프로테아제 절단 부위를 포함하는 펩티드 링커(들)의 절단은 융합 단백질의 차폐를 해제시킨다(unmasking). 특정 실시양태에서, 본 발명에 따른 융합 단백질은 리간드-수용체 쌍에 융합된 폴리펩티드 스캐폴드를 포함한다. 이와 관련하여, 융합 단백질은 리간드-수용체 쌍의 각각의 리간드 및 수용체가 서로의 회합을 통해 고유 동족 수용체 또는 리간드와 결합하는 것을 방해한다는 점에서 차폐된다. 표적 세포 환경에서 프로테아제 절단 부위를 포함하는 펩티드 링커(들)의 절단은 융합 단백질로부터 리간드-수용체 쌍의 한 구성원을 방출함으로써 융합 단백질의 차폐를 해제하여 리간드-수용체 쌍의 다른 구성원이 이의 동족 파트너에 결합되도록 한다. 따라서, 특정 실시양태에서, 본 개시내용은 프로그래밍된 체크포인트 또는 공동자극 수용체 표적화를 위한 생물학적 설계를 제공한다.
특정 실시양태에서, 본 개시내용에 따른 융합 단백질은 리간드-수용체 쌍에 융합된 항원 결합 도메인을 포함하는 항체 또는 항원 결합 항체 단편을 포함한다. 이와 관련하여, 융합 단백질은 리간드-수용체 쌍이 항원 결합 도메인이 동족 항원에 결합하는 것을 입체적으로 방해한다는 점에서 차폐된다. 융합 단백질은 리간드-수용체 쌍의 각각의 리간드 및 수용체가 서로의 회합을 통해 고유 동족 수용체 또는 리간드와 결합하는 것이 방해된다는 점에서 추가로 차폐된다. 표적 세포 환경에서 프로테아제 절단 부위를 포함하는 펩티드 링커(들)의 절단은 융합 단백질로부터 리간드-수용체 쌍의 한 구성원을 방출함으로써 융합 단백질의 차폐를 해제하여 리간드-수용체의 다른 구성원이 이의 동족 파트너에 결합하고 항원 결합 도메인이 동족 항원에 결합하도록 한다. 따라서, 특정 실시양태에서, 본 개시내용은 프로그래밍된 표적 항원 결합 및 동시 체크포인트 또는 공동자극 수용체 표적화를 위한 다기능 생물학적 설계를 제공한다. 특정 측면에서, 본원에 기술된 융합 단백질의 설계는 표적 매개 약물 처리를 감소시킨다. 특정 실시양태에서, 융합 단백질은 차폐된 항원 결합 도메인, 예를 들어, 생물학적 기능성 단백질은 물론 차폐된 면역조절 표적 결합 도메인, 예를 들어, 리간드-수용체 쌍을 제공하여 하나의 결합 기능성의 프로그래밍된 활성화가 다른 결합 기능성도 활성화함으로써 이중기능성 분자를 생성한다. 따라서, 특정 실시양태에서, 본 개시내용은 특정 표적 조직 환경에서 항원 결합 도메인의 차폐 및 조건부 활성화는 몰론 유해 독성 효과가 감소된 면역조절 표적의 표적화 및 활성화 방법을 제공한다.
리간드-수용체 쌍
본원에는 리간드-수용체 쌍을 각각 포함하는 융합 단백질이 기술되어 있다. 특정 측면에서, 리간드 수용체 쌍은 면역글로불린 수퍼패밀리(IgSF)에 속하는 리간드-수용체 도메인의 면역조절 쌍이다(Natarajan, Kannan; Mage, Michael G; 및 Margulies, David H (April 2015) Immunoglobulin Superfamily. In: eLS. John Wiley & Sons, Ltd: Chichester., A F Williams 1, A N Barclay (1988) The Immunoglobulin Superfamily--Domains for Cell Surface Recognition Annu Rev Immunol 6:381-405).
면역글로불린 수퍼패밀리(IgSF)는 코어 면역글로불린(Ig) 폴드(fold)에 기반한 단백질에서 일반적으로 발견되는 도메인을 분류한다. 이 Ig 폴드는 3개의 스트랜드(strand)와 4개의 스트랜드의 두 베타 시트(beta-sheet)로 배열된 총 7개의 역평행 베타 스트랜드로 구성된 베타 샌드위치(beta-sandwich)로 이루어진다(도 34a). 두 베타 샌드위치는 스트랜드 B와 F 사이의 디설파이드 브릿지를 통해 상호연결된다. Ig 폴드에서 통상 식별되는 구조적 모티프는 "그리스 열쇠(Greek Key)" 모티프이다. IgSF의 통상의 하위 그룹은 IgV, IgC1 및 IgC2 도메인이다. 구성원은 통상의 구조적 특징과 베타 스트랜드의 배열에 따라 식별된다. IgC 도메인은 3개의 스트랜드와 4개의 스트랜드의 두 시트로 배열된 7개의 베타 스트랜드를 포함하는 반면(도 34b), IgV 도메인은 4개의 스트랜드와 5개의 스트랜드의 두 시트로 배열된 9개의 베타 스트랜드를 포함한다(도 34c, 34d). IgC1과 IgC2는 스트랜드의 구조적 배열이 다르다. IgSF 도메인은 항원 수용체, 면역글로불린 및 면역조절 수용체를 포함하여 생물학적으로 중요한 다양한 단백질에서 찾을 수 있다. 코어 베타 샌드위치의 표면 노출된 잔기는 물론 베타 스트랜드를 연결하는 루프는 항원 인식을 위한 상호작용 인터페이스, 3차/4차 어셈블리 또는 수용체/리간드 쌍의 다른 구조적 도메인 역할을 할 수 있다. 면역글로불린의 항원 인식 부위(IgG1과 같은 항체의 VH-VL 쌍)는 2개의 IgV 도메인 이량체를 포함하기 때문에 IgSF 또는 IgV 도메인 이량체는 항체의 N-말단에 공유결합으로 부착되는 경우 해당 항원 인식 부위에 대한 입체 마스크를 형성하기에 구조적으로 적합하다(도 21).
특정 실시양태에서, 리간드-수용체 쌍은 면역조절성이며, 예를 들어, 면역 체크포인트이고, 면역 세포 이펙터 기능을 조절하고, T 세포 수용체 신호전달을 조절하며, 항원 제시 세포와 이펙터 세포 또는 이들의 조합 사이의 상호작용을 조절한다. 특정 실시양태에서, 리간드-수용체 쌍은 IgSF 수용체의 세포외 부분 및 이의 동족 리간드, 또는 이의 수용체 결합 단편을 포함한다. 수용체 결합 단편은 리간드-수용체 쌍의 수용체에 특이적으로 결합하는 임의의 폴리펩티드를 지칭하며, 자연 발생 또는 비자연 발생일 수 있다. 본원에서 사용되고 대상에 적용되는 "자연 발생"은 대상이 자연에서 발견될 수 있다는 사실을 지칭한다. 예를 들어, 자연의 공급원으로부터 분리될 수 있고 실험실에서 인간에 의해 의도적으로 변형되지 않은 유기체에 존재하는 폴리펩티드 또는 폴리뉴클레오티드 서열은 자연 발생적이다. 특정 실시양태에서, 리간드-수용체 쌍은 면역글로불린 도메인 수퍼패밀리에 속하는 2개의 상호작용하는 단백질 도메인일 수 있다. 본원에서 사용된 "비자연 발생"은 자연 발생 단백질의 돌연변이체와 같은 IgSF와의 구조적 유사성이 있는 조작된 폴리펩티드 서열을 지칭한다.
특정 실시양태에서, 본원의 개시내용은 IgSF에 속하는 리간드-수용체 도메인의 면역조절 쌍을 항체 또는 항체 단편의 마스크로서 사용함으로써 표적 항원 결합을 방해하는 것에 관한 것이다. 면역글로불린 수퍼패밀리에 속하는 리간드-수용체 도메인의 면역조절 쌍의 예는 B7/CD28 패밀리의 쌍(예컨대 PD1-PDL1, PD1-PDL2, CTLA4-CD80, CD28-CD80, CD28-CD86, CTLA4-CD86, PDL1-CD80 및 ICOS-ICOSL, NCR3LG1-NKp30, HHLA2-CD28H 및 CD47-SIRPα를 포함하지만 이에 제한되지 않는다. CD80(B7-1로도 알려짐), CD86(B7-2), PDL1(B7-H1), ICOSL(B7-H2), PDL2(B7-DC), CD276(B7-H3), VTCN1(B7-H4), VISTA(B7-H5), NCR3LG1(B7-H6), HHLA2(B7-H7)은 B7 패밀리에 속한다. 단백질의 B7 패밀리는 전형적으로 리간드로 간주되며 CD28, CTLA4, CD28H, NKp30, PD1 및 ICOS를 포함하는 CD28 패밀리의 구성원과 페어링된다. (S.M.West 및 X.A.Deng. Considering B7-CD28 as a family through sequence and structure. Exp Biol Med (Maywood) 2019; 244(17): 1577-1583; doi: 10.1177/1535370219855970).
특정 실시양태에서, 리간드-수용체 쌍은 IgSF B7/CD28 패밀리의 구성원을 포함한다. 특정 실시양태에서, 리간드 및 수용체는 면역글로불린 수퍼패밀리(IgSF) 폴리펩티드의 세포외 부분을 포함한다. 특정 실시양태에서, 리간드 및 수용체는 IgSF 면역글로불린 가변(IgV) 폴리펩티드의 세포외 부분을 포함한다. 특정 실시양태에서, 리간드는 IgSF B7 패밀리의 구성원이고 수용체는 IgSF CD28 패밀리의 구성원이다.
특정 실시양태에서, 리간드-수용체 쌍은 백혈구 공동자극 수용체를 포함한다. B7/CD28 패밀리에 속하는 백혈구 공동자극 수용체의 예는 ICOS(CD278로도 알려짐) 및 CD28을 포함한다. 공동자극 리간드-수용체 쌍의 예는 CD80:CD28, CD86:CD28 및 ICOS:ICOSL(ICOS 리간드)을 포함한다. 공동억제 리간드-수용체 쌍의 예는 PD1-PDL1, PD1-PDL2, CTLA4-CD80, CTLA4-CD86, PDL1-CD80 및 CD47-SIRPα를 포함한다. Fab의 N-말단에 연결된 경우, 본원에 기술된 결과는 이들이 CDR에 대한 접근을 차단하여 항원으로의 결합을 차단함을 나타낸다(도 21a).
이 큰 IgSF의 다른 구성원은 유사한 방식으로 사용될 수 있고 면역 조절 기능을 수행할 수 있다. 도 21b는 공지된 B7-CD28 구성원의 공지된 구조를 나타낸 것이다. 다른 쌍의 도메인의 크기와 방향은 PD-1 및 PD-L1과 매우 유사하므로 PD-1/PD-L1 수용체-리간드 쌍과 유사한 결합 또는 기능적 차단에 사용될 수 있다.
기능성 마스크의 개념은 B7-패밀리의 구성원을 넘어서 확장된다. 예를 들어, 도 21b는 IgSF에 속하는 도메인을 가진 또 다른 리간드 수용체 쌍인 SIRPα/CD47의 구조를 나타내며, 이는 Fab의 N-말단에 위치하여 결합을 차단하는 양호한 공간 호환성을 보여준다. 많은 치료 후보가 암세포의 식세포작용을 증가시키기 위해 이 축에서 길항제의 사용을 평가하여 기능성 마스크에 대한 좋은 후보가 되도록 한다. (Murata Y, Saito Y, Kotani T, Matozaki T. (2018) CD47-signal regulatory protein α signaling system and its application to cancer immunotherapy. Cancer Sci. 2018 Aug;109(8):2349-2357).
특정 실시양태에서, 융합 단백질의 리간드-수용체 쌍에서 리간드-수용체 도메인의 친화도는 야생형 리간드 및 수용체와 비교하여 변경된다. 특정 실시양태에서, 리간드 및 수용체가 야생형 리간드 또는 수용체와 구별되는 서열을 포함하도록 차폐 쌍의 리간드-수용체 도메인 중 하나 또는 둘 다 조작된다. 특정 실시양태에서, 리간드는 이의 동족 수용체에 대한 리간드의 결합 친화도를 증가시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 야생형 리간드와 비교하여 리간드-수용체 쌍의 리간드의 상대적 결합 친화도는 자연 발생 동족 수용체에 대한 야생형 리간드의 1, 1.5, 2, 2.5, 3, 5, 10, 20, 30, 40, 50, 100, 500, 1000, 5,000, 10,000, 50,000 또는 100,000배 초과이다.
특정 실시양태에서, 수용체는 이의 동족 리간드에 대한 수용체의 결합 친화도를 증가시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 야생형 수용체와 비교하여 리간드-수용체 쌍의 수용체의 상대적 결합 친화도는 자연 발생 동족 리간드에 대한 야생형 수용체의 1, 1.5, 2, 2.5, 3, 5, 10, 20, 30, 40, 50, 100, 500, 1000, 5,000, 10,000 또는 100,000배 초과이다.
특정 실시양태에서, 리간드는 이의 동족 수용체에 대한 리간드의 결합 친화도를 감소시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 야생형 리간드와 비교하여 리간드-수용체 쌍의 리간드의 상대적 결합 친화도는 자연 발생 동족 수용체에 대한 야생형 리간드보다 1, 1.5, 2, 2.5, 3, 5, 10, 20, 30, 40, 50, 100, 500, 1000, 5,000, 10,000, 50,000 또는 100,000배 초과로 더 낮다.
특정 실시양태에서, 수용체는 이의 동족 리간드에 대한 수용체의 결합 친화도를 감소시키는 하나 이상의 돌연변이를 포함한다. 특정 실시양태에서, 야생형 수용체와 비교하여 리간드-수용체 쌍의 수용체의 상대적 결합 친화도는 자연 발생 동족 리간드에 대한 야생형 수용체의 1, 1.5, 2, 2.5, 3, 5, 10, 20, 30, 40, 50, 100, 500, 1000, 5,000, 10,000 또는 100,000배 초과로 더 낮다.
리간드-수용체 쌍은, 예를 들어, PD-L1(Uniprot ID Q9NZQ7, 33-146) 및 PD-1(Uniprot ID Q15116, 18-132)의 IgV 도메인일 수 있다. 일부 실시양태에서, 리간드는 PD-L1이고, 예를 들어, 서열번호 8 또는 서열번호 10에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, PD-L1은 서열번호 8과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, PD-L1은 서열번호 8과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, PD-L1은 서열번호 8과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다. 임의의 PD-L1 변이체, 예를 들어, 당업계에 공지된 고친화성 변이체, 예를 들어, Z. Laing 등, High-affinity human PD-L1 variants attenuate the suppression of T cell activation; Oncotarget 8, 88360-88375 (2017) 또는 WO2018/170021A1에 제공된 변이체가 사용될 수 있다. 특정 실시양태에서, 수용체는 고친화성 PD-L1 변이체이다. 일부 실시양태에서, 수용체는 서열번호 10에 상응하는 아미노산 서열 또는 서열번호 10과 실질적으로 동일한 아미노산 서열을 갖는 고친화성 PD-L1 변이체이다.
일부 실시양태에서, 수용체는 PD-1이고, 예를 들어, 서열번호 7 또는 11에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, PD-1은 서열번호 7 또는 11과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, PD-1은 서열번호 7 또는 11과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, PD-1은 서열번호 7 또는 11과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다. 임의의 PD-1 변이체, 예를 들어. 당업계에 공지된 고친화성 변이체, 예를 들어, R. L. Maute 등, Engineering high-affinity PD-1 variants for optimized immunotherapy and immuno-PET imaging. Proc Natl Acad Sci U S A 112, E6506-6514 (2015), WO2016/022994A2 또는 E. Lazar-Molnar 등, Structure-guided development of a high affinity human Programmed Cell Death-1: Implications for tumor immunotherapy EBIOMedicine 17. 30-44 (2017) 및 WO2019/241758A1에 제공된 변이체가 사용될 수 있다.
특정 실시양태에서, 수용체는 고친화성 PD-1 변이체이다. 일부 실시양태에서, 수용체는 서열번호 9에 상응하는 아미노산 서열 또는 서열번호 9와 실질적으로 동일한 아미노산 서열을 갖는 고친화성 PD-1 변이체이다.
특정 일부 실시양태에서, 리간드는 CD80이고, 예를 들어, 서열번호 25에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CD80은 서열번호 25와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD80은 서열번호 25와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD80은 서열번호 25와 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다. 일부 실시양태에서, CD80은 서열번호 185, 서열번호 187 또는 서열번호 189와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD80은 서열번호 185, 서열번호 187 또는 서열번호 189와 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD80은 이의 수용체에 대한 친화도를 증가시키거나 제조 동안 동종이량체를 형성하는 경향을 감소시키는 돌연변이를 갖는다. 특정 실시양태에서, CD80은 하기 돌연변이 세트 중 하나를 갖는 서열번호 25에 상응하는 아미노산 서열을 갖는다: (a) H18Y, A26E, E35D, M47S, I61S 및 D90G; (b) E35D, M47S, N48K, I61S, K89N; (c) E35D, D46V, M47S, I61S, D90G, K93E; 또는 (d) H18Y, A26E, E35D, M47S, I61S, V68M, A71G, D90G.
특정 실시양태에서, 리간드는 PD-L2이고, 예를 들어, 서열번호 250에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, PD-L2는 서열번호 250과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, PD-L2는 서열번호 250과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, PD-L2는 서열번호 250과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 CD86이고, 예를 들어, 서열번호 248에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CD86은 서열번호 248과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD86은 서열번호 248과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD86은 서열번호 248과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 ICOSL이고, 예를 들어, 서열번호 256에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, ICOSL은 서열번호 256과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, ICOSL은 서열번호 256과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, ICOSL은 서열번호 256과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 CD276이고, 예를 들어, 서열번호 258에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CD276은 서열번호 258과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD276은 서열번호 258과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD276은 서열번호 258과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 VTCN1이고, 예를 들어, 서열번호 259에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, VTCN1은 서열번호 259와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, VTCN1은 서열번호 259와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, VTCN1은 서열번호 259와 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 VISTA이고, 예를 들어, 서열번호 260에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, VISTA는 서열번호 260과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, VISTA는 서열번호 260과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, VISTA는 서열번호 260과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 HHLA2이고, 예를 들어, 서열번호 262에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, HHLA2는 서열번호 262와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, HHLA2는 서열번호 262와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, HHLA2는 서열번호 262와 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, 리간드는 SIRPα이고, 예를 들어, 서열번호 255에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, SIRPα는 서열번호 255와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, SIRPα는 서열번호 255와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, SIRPα는 서열번호 255와 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 수용체는 CTLA4이고, 예를 들어, 서열번호 26에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CTLA4는 서열번호 26과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CTLA4는 서열번호 26과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CTLA4는 서열번호 26과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 수용체는 CD28이고, 예를 들어, 서열번호 253에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CD28은 서열번호 253과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD28은 서열번호 253과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD28은 서열번호 253과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 수용체는 CD28H이고, 예를 들어, 서열번호 263에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CD28H는 서열번호 263과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD28H는 서열번호 263과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CD28H는 서열번호 263과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 수용체는 NKp30이고, 예를 들어, 서열번호 264에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, NKp30은 서열번호 264와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, NKp30은 서열번호 264와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, NKp30은 서열번호 264와 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 수용체는 ICOS이고, 예를 들어, 서열번호 257에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, ICOS는 서열번호 257과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, ICOS는 서열번호 257과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, ICOS는 서열번호 257과 약 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는다.
특정 실시양태에서, IgSF 리간드 및/또는 수용체는 면역글로불린 가변 도메인(IgV) 유사 구조를 갖는다. 본원에 기술된 일부 예시적인 자연 발생 IgV 도메인 수용체 및 리간드의 아미노산 서열은 표 CC에 제시되어 있다.
특정 실시양태에서, 조작된 비자연 발생 리간드-수용체 쌍의 페어링 리간드 및/또는 수용체는 자연 발생 면역조절 수용체에 대해 친화성이 있는 도메인 중 적어도 하나를 갖는 면역글로불린 도메인을 포함한다.
특정 실시양태에서, 면역조절 리간드-수용체 쌍은 이의 동족 표적 쌍의 길항제 또는 작용제로서 기능하도록 선택된다. 특정 실시양태에서, 면역조절 리간드-수용체 쌍은 종양 환경에서 이의 동족 표적 쌍의 길항제 또는 작용제로서 기능하도록 선택된다. 특정 실시양태에서, 리간드-수용체 쌍의 리간드 또는 수용체 중 하나 또는 둘 다는 프로테아제 절단에 의한 활성화 후에 기능적 역할을 하도록 설계된다.
융합 단백질 형식
본원에 기술된 융합 단백질은 다수의 상이한 형식일 수 있다. 융합 단백질은 적어도 리간드 수용체 쌍을 포함하는 모듈식 구조를 갖는 것으로 간주될 수 있으며, 각각의 리간드 및 수용체는 펩티드 링커를 통해 생물학적 기능성 단백질에 융합된다. 궁극적으로 생물학적 기능성 단백질은 적어도 제1 및 제2 폴리펩티드를 포함한다. 예를 들어, 리간드-수용체 쌍의 리간드 또는 수용체의 N-말단 또는 C-말단은, 예를 들어, 펩티드 링커를 통해 생물학적 기능성 단백질의 제1 및 제2 폴리펩티드에 융합될 수 있다. 리간드는 제1 폴리펩티드에 융합되고 수용체는 제2 폴리펩티드의 동일한 각각의 말단에 융합된다. 폴리펩티드에 융합되는 리간드-수용체 쌍을 설명할 때 용어 "동일한 각각의 말단"은 리간드와 수용체가 각각 제1 및 제2 폴리펩티드의 N-말단 또는 제1 및 제2 폴리펩티드의 C-말단에 융합되는 것을 지칭한다. 따라서, 특정 실시양태에서, 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 N-말단에 융합되고, 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 N-말단에 융합된다. 특정 실시양태에서, 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 C-말단에 융합되고, 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 C-말단에 융합된다. 리간드와 수용체는 이의 C-말단 또는 이의 N-말단을 통해 융합될 수 있다. 리간드와 수용체는 둘 다 이의 N-말단 또는 C-말단을 통해 융합될 수 있거나 리간드 또는 수용체 중 하나는 이의 N-말단을 통해 융합될 수 있고 리간드 또는 수용체 중 다른 하나는 이의 C-말단을 통해 융합될 수 있다.
특정 실시양태에서, 리간드의 N-말단은 제1 펩티드 링커를 통해 제1 폴리펩티드의 N-말단에 융합되고, 수용체의 N-말단은 제2 펩티드 링커를 통해 제2 폴리펩티드의 N-말단에 융합된다. 특정 실시양태에서, 리간드의 C-말단은 제1 펩티드 링커를 통해 제1 폴리펩티드의 C-말단에 융합되고, 수용체의 C-말단은 제2 펩티드 링커를 통해 제2 폴리펩티드에 융합된다.
특정 실시양태에서, 리간드는 프로테아제 절단 부위를 포함하는 제1 펩티드 링커를 통해 생물학적 기능성 단백질의 제1 폴리펩티드의 말단에 융합된다. 특정 실시양태에서, 수용체는 프로테아제 절단 부위를 포함하는 제2 펩티드 링커를 통해 생물학적 기능성 단백질의 제2 폴리펩티드의 말단에 융합된다. 특정 실시양태에서, 리간드는 프로테아제 절단 부위를 포함하는 제1 펩티드 링커를 통해 생물학적 기능성 단백질의 제1 폴리펩티드의 말단에 융합되고, 수용체는 프로테아제 절단 부위를 포함하는 제2 펩티드 링커를 통해 생물학적 기능성 단백질의 제2 폴리펩티드의 말단에 융합된다. 제1 및 제2 펩티드 링커 둘 다 프로테아제 절단 부위를 포함하는 경우, 프로테아제 절단 부위는 동일한 프로테아제에 의해 절단될 수 있거나 상이한 프로테아제에 의해 절단될 수 있다.
특정 실시양태에서, 리간드는 프로테아제 절단 부위를 포함하는 제1 펩티드 링커를 통해 생물학적 기능성 단백질의 제1 폴리펩티드의 말단에 융합되고 리간드는 제1 펩티드 링커의 절단 부위와 동일하거나 상이할 수 있는 내부 프로테아제 절단 부위를 포함하도록 조작된다. 특정 실시양태에서, 수용체는 프로테아제 절단 부위를 포함하는 제2 펩티드 링커를 통해 생물학적 기능성 단백질의 제2 폴리펩티드의 말단에 융합되고 수용체는 제1 펩티드 링커의 절단 부위와 동일하거나 상이할 수 있는 내부 프로테아제 절단 부위를 포함하도록 조작된다. 링커에 의해 생물학적 기능성 단백질에 연결된 리간드-수용체 쌍의 구성원과 펩티드 링커 둘 다 프로테아제 절단 부위를 포함하면 표적 세포 환경에서 리간드-수용체 쌍의 구성원의 절단 및 불활성화가 가능하지만, 생물학적 활성 단백질에 여전히 융합되어 있는 리간드-수용체 쌍의 구성원은 차폐되지 않는다(즉, 조건부로 활성화됨).
특정 실시양태에서, 융합 단백질은 또 다른 치료 및/또는 진단 모이어티, 예를 들어, 화학요법제 또는 방사성동위원소에 접합된다.
생물학적 기능성 단백질
생물학적 기능성 단백질은 스캐폴드로서 기능할 수 있고/있거나 결합 도메인을 포함할 수 있다. 폴리펩티드 스캐폴드의 예는 면역글로불린 Fc 영역, 알부민, 알부민 유사체 및 유도체, 독소(toxin), 사이토카인, 케모카인, 성장 인자, 및 류신 지퍼 도메인(leucine zipper domain)과 같은 단백질 쌍을 포함한다. 특정 실시양태에서, 생물학적 기능성 단백질은 표지, 약물 또는 이들의 조합을 포함한다. 본원에 기술된 융합 단백질의 검출에 적합한 당업계에 공지된 임의의 표지가 사용될 수 있다. 생물학적 기능성 단백질은 단백질에 접합할 수 있고 원하는 생물학적 결과를 달성할 수 있는 당업계에 공지된 임의의 약물, 독소 또는 화학물질을 포함할 수 있다.
특정 실시양태에서, 본원에 기술된 융합 단백질의 생물학적 기능성 단백질은 적어도 하나의 항원 결합 도메인을 포함한다. 이 결합 도메인은, 예를 들어, 면역글로불린 기반 결합 도메인 또는 비-면역글로불린 기반 항체 모방체(mimetics), 또는 이의 표적, 예를 들어, 천연 또는 조작된 리간드에 특이적으로 결합할 수 있는 다른 폴리펩티드 또는 소분자일 수 있다. 비-면역글로불린 기반 항체 모방체 형식은, 예를 들어, 안티칼린(anticalin), 파이노머(fynomer), 아피머(affimer), 알파바디(alphabody), DARPin 및 아비머(avimer)를 포함한다.
본원에 기술된 융합 단백질은 생물학적 기능성 단백질을 포함한다. 생물학적 기능성 단백질의 예는 항체, 예를 들어, 항원 결합 도메인을 갖는 폴리펩티드, 및 폴리펩티드 스캐폴드, 예를 들어, 이량체 Fc를 포함하지만 이에 제한되지 않는다. 따라서, 특정 실시양태에서, 생물학적 기능성 단백질의 제1 및 제2 폴리펩티드는 항체의 가변 및/또는 불변 도메인, 또는 항원 결합 기능 또는 스캐폴딩 기능을 융합 단백질에 부여하는 다른 도메인을 포함하는 폴리펩티드이다.
항체
특정 실시양태에서, 생물학적 기능성 단백질은 항체, 즉 면역글로빈이다. 본 개시내용에 따른 항체는 항체 단편을 포함하여 본원에 기술된 바와 같은 다양한 형식을 취할 수 있다. 따라서, 특정 실시양태에서, 생물학적 기능성 단백질은 항체 단편이다. 용어 "항체" 및 "면역글로불린"은 본원에서 면역글로불린 유전자 또는 유전자들에 의해 암호화되는 폴리펩티드, 또는 폴리펩티드가 항원에 특이적으로 결합하는 면역글로불린 유전자의 변형된 버전을 지칭하기 위해 상호교환적으로 사용된다.
특이적 결합은, 예를 들어, 효소 결합 면역흡착제 검정(enzyme-linked immunosorbent assay, ELISA), 표면 플라스몬 공명(surface plasmon resonance, SPR) 기술(예를 들어 BIAcore 기기 사용)(Liljeblad 등, 2000, Glyco J, 17:323-329), 또는 전통적인 결합 검정(Heeley, 2002, Endocr Res, 28:217-229)을 통해 측정할 수 있다. 특정 실시양태에서, 특이적 결합은 관련되지 않은 단백질에 대한 결합 정도가, 예를 들어, SPR로 측정했을 때 표적 항원에 대한 결합의 약 10% 미만인 것으로 정의된다. 특정 실시양태에서, 특정 항원 또는 에피토프에 대한 항체 또는 항체 단편의 특이적 결합은 ≤1μM, 예를 들어, ≤100nM, ≤10nM, ≤1nM, ≤0.1nM, ≤0.01nM 또는 ≤0.001nM의 해리 상수(KD)로 정의된다. 특정 실시양태에서, 특정 항원 또는 에피토프에 대한 항체 또는 항체 단편의 특이적 결합은 10-6M 이하, 예를 들어, 10-7M 이하 또는 10-8M 이하의 해리 상수(KD)로 정의된다. 일부 실시양태에서, 특정 항원 또는 에피토프에 대한 항체 또는 항체 단편의 특이적 결합은 10-6M 내지 10-13M, 예를 들어, 10-7M 내지 10-13M, 10-8M 내지 10-13M 또는 10-9M 내지 10-13M의 해리 상수(KD)로 정의된다.
전통적인 면역글로불린 구조 단위는 전형적으로 두 쌍의 폴리펩티드 사슬로 구성되며, 각 쌍은 하나의 "경"쇄(약 25kD) 및 하나의 "중"쇄(약 50-70kD)를 갖는다. 경쇄는 카파 또는 람다로 분류된다. 면역글로불린의 "클래스"는 중쇄가 소유한 불변 도메인의 유형을 지칭한다. 항체의 5가지 주요 클래스에는 IgA, IgD, IgE, IgG 및 IgM이 있으며, 이들 중 일부는, 예를 들어, IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2와 같은 서브클래스(아이소타입)로 더 나뉠 수 있다. 상이한 클래스의 면역글로불린에 상응하는 중쇄 불변 도메인은 각각 알파(α), 델타(δ), 엡실론(ε), 감마(γ) 및 뮤(μ)라고 한다.
특정 실시양태에서, 본원에 기술된 항체는 IgG 클래스 면역글로불린, 예를 들어, IgG1, IgG2, IgG3 또는 IgG4 면역글로불린에 기반한다. 일부 실시양태에서, 본원에 기술된 항체는 IgG1, IgG2 또는 IgG4 면역글로불린을 기반으로 한다. 일부 실시양태에서, 본원에 기술된 항체는 IgG1 면역글로불린을 기반으로 한다. 본 개시내용과 관련하여, 항체가 특정 면역글로불린 아이소타입을 기반으로 할 때, 이는 항체가 특정 면역글로불린 아이소타입의 불변 영역의 전부 또는 일부를 포함함을 의미한다. 항체는 또한 일부 실시양태에서 아이소타입 및/또는 서브클래스의 하이브리드를 포함할 수 있음을 이해해야 한다.
면역글로불린의 각각의 폴리펩티드 사슬의 N-말단 도메인은 주로 항원 인식을 담당하는 길이가 약 100 내지 110개 이상의 아미노산인 가변 영역을 정의한다. 가변 경쇄(VL) 및 가변 중쇄(VH)라는 용어는 각각 경쇄 및 중쇄에 있는 이러한 도메인을 의미한다.
따라서, 면역글로불린은 중쇄 및 경쇄 내에 상이한 도메인을 포함함을 알 수 있다. 이러한 도메인은 중첩될 수 있으며 Fc 도메인(또는 Fc 영역), CH1 도메인, CH2 도메인, CH3 도메인, 힌지 도메인, 중쇄 불변 도메인(CH1-힌지-Fc 또는 CH1-힌지-CH2-CH3), 가변 중쇄 도메인(VH), 가변 경쇄 도메인(VL) 및 경쇄 불변 도메인(CL)을 포함한다. "Fc 도메인"은 CH2 및 CH3 도메인, 및 선택적으로 힌지 도메인(또는 힌지 영역)을 포함한다.
면역글로불린의 각각의 VH 및 VL 도메인에는 서열이 초가변적이고 항원 결합 부위를 형성하는 3개의 루프가 있다. 이러한 각 루프를 "초가변 영역(hypervariable region)" 또는 "HVR"이라고 한다. 초가변 영역(HVR) 및 상보성 결정 영역(complementarity determining region, CDR)이라는 용어는 항원 결합 도메인을 형성하는 가변 영역의 부분과 관련하여 본원에서 상호교환적으로 사용된다. VH의 CDR1을 제외하고, CDR은 일반적으로 초가변 루프를 형성하는 아미노산 잔기를 포함한다. VH 및 VL 도메인은 각각의 길이가 전형적으로 약 5 내지 15개의 아미노산(종종 이보다 더 길거나 더 짧음)인 더 짧은 CDR에 의해 분리된, 길이가 약 15 내지 30개의 아미노산인 프레임워크 영역(framework region, FR)이라고 하는 상대적으로 불변인 스트레치로 구성된다. VH 및 VL 도메인 각각을 구성하는 3개의 CDR 및 4개의 FR은 다음과 같이 N-말단에서 C-말단 쪽으로 배열된다: FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4.
Kabat 등(1983, Sequences of Proteins of Immunological Interest, NIH Publication No. 369-847, Bethesda, MD), Chothia 등(1987, J Mol Biol, 196:901-917)에 의해 기술된 정의는 물론 IMGT, AbM 및 Contact 정의를 포함하여 CDR 영역의 다수의 상이한 정의가 통상 사용된다. 이러한 상이한 정의에는 서로 비교할 때 아미노산 잔기의 중첩 또는 하위 집합이 포함된다. 예를 들어, Kabat, Chothia, IMGT, AbM 및 Contact에 따른 CDR 정의는 아래 표 1에 제공되어 있다. 따라서, 당업자에게 자명한 바와 같이, CDR의 정확한 넘버링 및 배치는 사용된 넘버링 시스템에 따라 상이할 수 있다. 그러나 본원의 가변 중쇄 도메인(VH)의 개시는 임의의 공지된 넘버링 시스템에 의해 정의된 바와 같은 연관된(고유) 중쇄 CDR(HCDR)의 개시를 포함하는 것으로 이해해야 한다. 유사하게, 본원의 가변 경쇄 도메인(VL)의 개시는 임의의 공지된 넘버링 시스템에 의해 정의된 바와 같은 연관된(고유) 중쇄 CDR(HCDR)의 개시를 포함한다.
[표 1]

당업자는 항체가 이의 표적에 결합하는 능력을 상실하지 않으면서 공지된 항체의 CDR 서열에 또는 VH 또는 VL 서열에 제한된 수의 아미노산 치환이 도입될 수 있음을 이해할 것이다. 후보 아미노산 치환은 컴퓨터 모델링에 의해 또는 전술한 바와 같은 알라닌 스캐닝과 같은 기술에 의해 확인될 수 있으며, 생성된 변이체는 표준 기술에 의해 결합 활성에 대해 테스트된다. 예를 들어, 특정 실시양태에서 융합 단백질에 포함된 EGFR 결합 도메인은 결합 도메인이 EGFR에 결합하는 능력을 보유하는 세툭시맙(cetuximab) 또는 파니투무맙(panitumumab)으로부터의 CDR 세트에 대해 서열 동일성이 90% 이상, 95% 이상, 98% 이상, 99% 이상 또는 100%인 CDR 세트(즉, 중쇄 CDR1, CDR2 및 CDR3, 및 경쇄 CDR1, CDR2 및 CDR3)를 포함한다. 특정 실시양태에서, 융합 단백질에 포함된 EGFR 결합 도메인은 3개의 CDR에 걸쳐 1 내지 10개의 아미노산 치환, 예를 들어, 상기 CDR에 걸쳐 1 내지 7개의 아미노산 치환, 1 내지 5개의 아미노산 치환, 1 내지 4개의 아미노산 치환, 1 내지 3개의 아미노산 치환, 1 내지 2개의 아미노산 치환 또는 1개의 아미노산 치환을 포함하는 이러한 CDR 서열의 변이체를 포함하며(즉, CDR은 변형되는 CDR의 임의의 조합으로 최대 10개의 아미노산 치환을 포함하여 변형될 수 있음), 변이체는 EGFR에 결합하는 능력을 보유한다. 전형적으로, 이러한 아미노산 치환은 하기 표 4의 1열 또는 2열에 약술된 것과 같은 보존적 아미노산 치환일 것이다.
특정 실시양태에서, 본원에 기술된 항체는 소 면역글로불린, 인간 면역글로불린, 낙타 면역글로불린, 래트 면역글로불린 또는 마우스 면역글로불린과 같은 포유동물 면역글로불린으로부터의 적어도 하나의 면역글로불린 도메인을 포함한다. 일부 실시양태에서, 생물학적 기능성 단백질은 키메라 항체일 수 있고 2개 이상의 면역글로불린 도메인을 포함하며, 적어도 하나의 도메인은 제1 포유동물 면역글로불린, 예를 들어, 인간 면역글로불린에서 유래하고 적어도 제2 도메인은 제2 포유동물 면역글로불린, 예를 들어, 마우스 또는 래트 면역글로불린에서 유래한다. 일부 실시양태에서, 생물학적 기능성 단백질은 인간 면역글로불린으로부터의 적어도 하나의 면역글로불린 불변 도메인을 포함한다.
당업자는 상이한 형식의 다중특이성 항체를 포함하여 상이한 형식의 항체를 제공하기 위해 이러한 도메인이 다양한 방식으로 조합될 수 있음을 이해할 것이다. 이러한 형식은 일반적으로 당업계에 공지된 항체 형식을 기반으로 한다(예를 들어, Brinkmann & Kontermann, 2017, MABS, 9(2):182-212, 및 Muller & Kontermann, "Bispecific Antibodies" in Handbook of Therapeutic Antibodies, Wiley-VCH Verlag GmbH & Co. (2014) 참조).
본원에 기술된 생물학적 기능성 단백질의 항체는 원자가가 상이할 수 있다. 특정 실시양태에서, 생물학적 기능성 단백질은 단일 항원 결합 도메인을 포함한다. 특정 실시양태에서, 생물학적 기능성 단백질은 2개 이상의 항원 결합 도메인을 포함한다. 특정 실시양태에서, 생물학적 기능성 단백질은 원자가 및 특이성이 상이한 항체를 포함한다. 본원에서 사용되는 "이중특이성 항체"는 2개의 결합 도메인을 포함한다. 특정 실시양태에서, 2개의 결합 도메인 각각은 결합 특이성이 독특하다. 본원에서 사용된 "다중특이성 항체"는 2개 이상의 결합 도메인을 포함한다. 특정 실시양태에서, 2개 이상의 결합 도메인 각각은 결합 특이성이 독특하다. 일부 실시양태에서, 2개 이상의 결합 도메인 중 적어도 2개는 결합 특이성이 독특하다. 예를 들어, 항체는 2가이고 이중특이성일 수 있거나, 2가이고 단일특이성일 수 있다. 대안적으로, 항체는 3가이고 이중특이성일 수 있는데, 즉 항체는 3개의 결합 도메인을 포함한다. 항체는 또한 이중특이성이고 4가일 수 있는데, 즉 항체는 4개의 결합 도메인을 포함한다. 다른 원자가도 가능하다.
항체가 동일한 표적 분자에 결합하는 2개의 결합 도메인을 포함하는 경우, 결합 도메인은 표적 분자 상의 동일한 에피토프에 결합할 수 있거나 표적 분자 상의 상이한 에피토프에 결합할 수 있다. 일부 실시양태에서, 항체는 표적 분자 상의 상이한 에피토프에 결합하는 2개의 결합 도메인을 포함한다. 용어 "이중파라토프성(biparatopic)"은 동일한 표적 분자(항원) 상의 상이한 에피토프에 결합하는 2개의 결합 도메인을 포함하는 항체를 지칭하기 위해 사용될 수 있다. 이중파라토프성 항체는 2개의 상이한 에피토프를 통해 단일 항원 분자에 결합할 수 있거나, 각각 상이한 에피토프를 통해 2개의 개별 항원 분자에 결합할 수 있다.
특정 실시양태에서, 항체는 제1 표적 분자 상의 상이한 에피토프에 각각 결합하는 제1 결합 도메인과 제2 결합 도메인, 및 제2 표적 분자에 결합하는 제3 결합 도메인을 포함한다는 점에서 이중파라토프성이고 이중특이성이다. 대안적으로, 이중특이성 이중파라토프성 항체는 제1 표적 분자 상의 상이한 에피토프에 각각 결합하는 제1 결합 도메인과 제2 결합 도메인, 및 제2 표적 분자 상의 상이한 에피토프에 각각 결합하는 제3 결합 도메인과 제4 결합 도메인을 포함할 수 있다.
일부 실시양태에서, 항체는 스캐폴드를 추가로 포함하고 결합 도메인은 스캐폴드에 작동 가능하게 연결된다. 본원에서 사용된 "작동 가능하게 연결된"은 기술된 구성요소가 각각이 의도한 방식으로 기능하도록 허용하는 관계에 있음을 의미한다. 결합 도메인은 스캐폴드에 직접 또는 간접적으로 연결될 수 있다. 간접적으로 연결된다는 것은 주어진 결합 도메인이 다른 구성요소, 예를 들어, 링커 또는 다른 결합 도메인 중 하나를 통해 스캐폴드에 연결됨을 의미한다. 스캐폴드를 포함하는 융합 단백질에 대한 다양한 형식은 아래에 더 자세히 설명되어 있다.
항원 결합 도메인 형식
일부 실시양태에서, 본원에 기술된 융합 단백질은 Fab, Fab', 단일 사슬 Fab(scFab), 단일 사슬 Fv(scFv) 또는 단일 도메인 항체(sdAb)와 같은 항체 단편인 적어도 하나의 항원 결합 도메인을 갖는 항체를 포함한다.
"Fab" 또는 "Fab 단편"은 CDR을 포함하는, 각각 경쇄 및 중쇄 상의 가변 도메인 VL 및 VH와 함께 경쇄의 불변 도메인(CL) 및 중쇄의 제1 불변 도메인(CH1)을 함유한다. Fab' 또는 Fab' 단편은 힌지 영역에서 하나 이상의 시스테인 잔기를 포함하여 중쇄 CH1 도메인의 C-말단에 몇 개의 아미노산 잔기가 추가된다는 점에서 Fab 단편과 다르다.
Fab 단편은 2개의 별개의 폴리펩티드 사슬(경쇄 및 중쇄)을 포함할 수 있거나 단일 사슬 Fab일 수 있다. 단일 사슬 Fab는 Fab 경쇄와 Fab 중쇄가 펩티드 링커에 의해 연결되어 단일 펩티드 사슬을 형성하는 Fab 분자이다. 전형적으로 Fab 경쇄의 C-말단은 단일 사슬 Fab 분자에서 Fab 중쇄의 N-말단에 연결되지만 다른 형식도 가능하다.
"scFv"는 단일 폴리펩티드 사슬에 항체의 중쇄 가변 도메인(VH) 및 경쇄 가변 도메인(VL)을 포함한다. scFv는 선택적으로 scFv가 항원 결합을 위한 원하는 구조를 형성하는 것을 도울 수 있는 VH 도메인과 VL 도메인 사이의 폴리펩티드 링커를 포함할 수 있다. scFv는 링커에 의해 C-말단에서 VH의 N-말단 쪽으로 연결된 VL, 즉 VL-링커-VH을 포함할 수 있거나, 대안적으로 scFv는 링커에 의해 C-말단에서 VL의 N-말단 쪽으로 연결된 VH, 즉 VH-링커-VL을 포함할 수 있다. scFv의 검토를 위해 Pluckthun in The Pharmacology of Monoclonal Antibodies, vol. 113, Rosenburg 및 Moore eds., Springer-Verlag, New York, pp. 269-315 (1994) 참조.
용어 "sdAb"는 단일 면역글로불린 도메인을 의미한다. sdAb는, 예를 들어, 낙타 기원일 수 있다. 낙타 항체에는 경쇄가 없으며 항원 결합 부위는 "VHH"라고 하는 단일 도메인으로 이루어져 있다. sdAb는 항원 결합 부위를 형성하는 3개의 CDR/초가변 루프 CDR1, CDR2 및 CDR3를 포함한다. sdAbs는, 예를 들어, 항체의 Fc 사슬과의 융합체로서 상당히 안정하고 발현하기 쉽다(예를 들어, Harmsen & De Haard, 2007, Appl. Microbiol Biotechnol. 77(1):13-22 참조).
일부 실시양태에서, 항체에 포함된 하나 이상의 결합 도메인은 표적 수용체에 대한 천연 또는 조작된 리간드, 또는 이러한 리간드의 기능적 단편, 즉 표적 수용체에 특이적으로 결합할 수 있는 단편일 수 있다.
항원 결합 도메인은 개별 scFv, Fab, sdAb의 조합 형태일 수 있다. 예를 들어, 결합 도메인이 scFv의 형태인 경우, 탠덤(tandem) scFv((scFv)2 또는 taFv) 또는 트리플바디(3개의 scFv)와 같은 형식이 작제될 수 있으며, scFv는 유연한 링커에 의해 함께 연결된다. scFv는 짧은 링커에 의해 연결된 각각 2, 3 및 4개의 scFv를 포함하는 디아바디, 트리아바디 및 테트라바디(탠덤 디아바디 또는 TandAb) 형식을 구성하는 데 사용될 수도 있다. 링커의 제한된 길이(보통 약 5개의 아미노산 길이)는 헤드-투-테일(head-to-tail) 방식으로 scFv를 이량체화한다. 임의의 전술한 형식에서, scFv는 도메인간 디설파이드 결합을 포함함으로써 추가로 안정화될 수 있다. 예를 들어, 디설파이드 결합은 각 사슬에 추가의 시스테인 잔기의 도입을 통해 VL과 VH 사이에 도입될 수 있거나(예를 들어, VH에서 44번 위치 및 VL에서 100번 위치)(예를 들어, Fitzgerald 등, 1997, Protein Engineering, 10:1221-1225 참조) 디설파이드 결합이 2개의 VH 사이에 도입되어 DART 형식의 항원 결합 도메인을 제공할 수 있다(예를 들어, Johnson 등, 2010, J Mol. Biol., 399: 436-449 참조).
유사하게, 적합한 링커를 통해 함께 연결된 VH 또는 VHH와 같은 2개 이상의 sdAb를 포함하는 형식이 생물학적 기능성 단백질에 사용될 수 있다. 스캐폴드가 없는 항체 형식의 다른 예에는 Fab 단편, 예를 들어, Fab2, F(ab')2 및 F(ab')3 형식을 기반으로 하는 것들이 포함되며, Fab 단편은 링커 또는 IgG 힌지 영역을 통해 연결된다.
상이한 형태의 항원 결합 도메인의 조합이 또한 대체 형식을 생성하기 위해 사용될 수 있다. 예를 들어, scFv 또는 sdAb는 Fab 단편의 경쇄 및 중쇄 중 하나 또는 둘 다의 C-말단에 융합되어 2가(Fab-scFv) 또는 (Fab-sdAb) 또는 3가(Fab- (scFv)2 또는 Fab-(sdAb)2)를 생성한다. 유사하게, 1개 또는 2개의 scFv 또는 sdAb는 F(ab') 단편의 힌지 영역에서 융합되어 3가 또는 4가 F(ab')2-scFv/sdAb를 생성할 수 있다. 결합 도메인은 상술한 형태 중 하나 또는 조합일 수 있다(예를 들어, scFv, Fab 및/또는 sdAb, 또는 리간드 기반 결합 도메인).
특정의 구체적인 실시양태에서, 생물학적 기능성 단백질은 면역 세포 항원, 예를 들어, CD3, 및 종양 관련 항원(TAA), 예를 들어, HER2에 결합하는 이중특이성 항체를 포함한다. 특정의 더욱 구체적인 실시양태에서, 생물학적 기능성 단백질은 Fab-scFv 형식의 이중특이성 항체를 포함하며, Fab는 면역 세포 항원에 결합하고 scFv는 TAA에 결합한다. 특정의 더욱 구체적인 실시양태에서, 생물학적 기능성 단백질은 Fab가 CD3에 결합하고 scFv가 HER2에 결합하는 Fab-scFv 형식의 이중특이성 항체를 포함한다. 일부 실시양태에서, 생물학적 기능성 단백질은 하나의 Fab가 CD3에 결합하고 다른 Fab가 HER2에 결합하는 Fab-Fab 형식의 이중특이성 항체를 포함한다.
특정 실시양태에서, 생물학적 기능성 단백질은 이종이량체 Fc에 작동 가능하게 연결된 2개 이상의 항원 결합 도메인을 포함한다. 이와 관련하여, 생물학적 기능성 단백질은 2가, 3가 또는 4가일 수 있다. 형식의 비제한적 예는 아래에 기술되어 있다. 다른 구성은 당업계에 공지되어 있다(예를 들어, Spiess 등, 2015, Mol Immunol., 67:95-106 참조).
이종이량체 Fc, 즉 2가 항체에 작동 가능하게 연결된 2개의 결합 도메인을 포함하는 생물학적 기능성 단백질에 대한 예시적인 구성은 다음을 포함하지만 이에 제한되지 않는다: a) 제1 결합 도메인이 이종이량체 Fc의 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이고 제2 결합 도메인이 제2 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab인 mAb 형식; b) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab인 하이브리드 형식, 및 c) 제1 결합 도메인이 이종이량체 Fc의 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 제2 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv인 이중 scFv 형식.
다른 예는 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab 또는 scFv로서의 하나의 결합 도메인(제1 또는 제2) 및 제2 Fc 폴리펩티드의 C-말단에 작동 가능하게 연결된 Fab 또는 scFv로서의 다른 결합 도메인을 포함하는 항체를 포함한다.
이종이량체 Fc에 작동 가능하게 연결된 3개의 결합 도메인을 포함하는 다중특이성 항체(즉, 3가 항체)에 대한 예시적인 구성은 다음을 포함하지만 이에 제한되지 않는다:
A) 제1 결합 도메인이 이종이량체 Fc의 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이고 제2 결합 도메인이 제2 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 하나의 Fc 폴리펩티드의 C-말단에 부착된 VH 도메인 및 다른 Fc 폴리펩티드의 C-말단에 부착된 VL 도메인으로 구성되는 mAb-Fv 형식;
B) 제1 결합 도메인이 이종이량체 Fc의 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이고 제2 결합 도메인이 제2 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 Fc 폴리펩티드의 C-말단에 작동가능하게 연결된 scFv인 mAb-scFv 형식;
C) 제1 결합 도메인이 이종이량체 Fc의 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이고 제2 결합 도메인이 제2 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 결합 도메인의 N-말단에 작동 가능하게 연결된 scFv인 scFv-mAb 형식;
D) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 결합 도메인(scFv)에 작동 가능하게 연결된 Fab인 중심 scFv 형식;
E) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 결합 도메인의 N-말단에 작동 가능하게 연결된 Fab인 Fab-하이브리드 형식;
F) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 결합 도메인의 N-말단에 작동 가능하게 연결된 scFv인 scFv-하이브리드 형식;
G) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 Fc 폴리펩티드의 C-말단에 작동 가능하게 연결된 scFv인 하이브리드-scFv 형식;
H) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 Fc 폴리펩티드의 C-말단에 작동 가능하게 연결된 Fab인 하이브리드-Fab 형식; 및
I) 제1 결합 도메인이 이종이량체 Fc의 제1 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이고 제2 결합 도메인이 제2 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 제1 또는 제2 결합 도메인의 N-말단에 작동 가능하게 연결된 Fab인 Fab-mAb 형식.
이종이량체 Fc에 작동 가능하게 연결된 4개의 결합 도메인을 포함하는 다중특이성 항체, 즉 4가 항체에 대한 예시적인 구성은 다음을 포함하지만 이에 제한되지 않는다: ⅰ) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 scFv이며 제3 결합 도메인이 scFv 중 하나에 작동 가능하게 연결된 Fab이고 제4 결합 도메인이 다른 scFv에 작동 가능하게 연결된 Fab인 중심-scFv2 형식, 및 ⅱ) 제1 결합 도메인이 이종이량체 Fc의 하나의 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이고 제2 결합 도메인이 다른 Fc 폴리펩티드의 N-말단에 작동 가능하게 연결된 Fab이며 제3 결합 도메인이 Fab 중 하나에 작동 가능하게 연결된 scFv이고 제4 결합 도메인이 다른 Fab에 작동 가능하게 연결된 scFv인 이중 가변 도메인 형식.
본원에 기술된 생물학적 기능성 단백질의 항체는 표지, 약물 또는 이들의 조합을 포함할 수 있다. 본원에 기술된 융합 단백질의 검출에 적합한 당업계에 공지된 임의의 표지가 사용될 수 있다. 항체 약물 접합체는 아래에 더 자세히 기술되어 있다.
특정 실시양태에서, 본원에 기술된 생물학적 기능성 단백질의 항체의 항원 결합 도메인은 동일한 세포 상의 동일한 항원에 결합한다. 특정 실시양태에서, 항원 결합 도메인은 동일한 세포 상의 하나 초과의 항원에 결합한다. 특정 실시양태에서, 항원 결합 도메인은 하나 초과의 항원에 결합하며, 적어도 하나의 항원은 다른 항원과는 또 다른 세포 상에 있다. 특정 실시양태에서, 항체의 항원 결합 도메인(들)은 종양 세포 또는 면역 세포에 결합한다. 특정 실시양태에서, 항체의 항원 결합 도메인은 종양 세포 및 면역 세포에 결합한다.
키메라 항체, 인간화 항체 및 변이체 항체
일부 실시양태에서, 항체는 상이한 종으로부터의 면역글로불린에서 유래할 수 있으며, 예를 들어, 항체는 키메라 항체 또는 인간화 항체일 수 있다. "키메라 항체"는 전형적으로 설치류 항체(보통 뮤린 항체)로부터의 적어도 하나의 가변 도메인 및 인간 항체로부터의 적어도 하나의 불변 도메인을 포함하는 항체를 지칭한다. "인간화 항체"는 비인간 항체에서 유래한 최소한의 서열을 함유하는 일종의 키메라 항체이다.
키메라 항체의 인간 불변 도메인은 이것이 대체하는 비인간 불변 도메인과 동일한 아이소타입일 필요는 없다. 키메라 항체는, 예를 들어, Morrison 등, 1984, Proc. Natl. Acad. Sci. USA, 81:6851-55 및 미국 특허 제4,816,567호에 논의되어 있다. 일반적으로 인간화 항체는 수용자의 초가변 영역의 잔기가 표적 항원에 대해 원하는 특이성과 친화성을 갖는 비인간 종(공여자 항체), 예컨대 마우스, 래트 또는 비인간 영장류의 초가변 영역의 잔기로 대체된 인간 면역글로불린(수용자 항체)이다. 인간화 항체를 만드는 이 기술은 종종 "CDR 이식(grafting)"이라고 지칭된다. "키메라 항체" 및 "인간화 항체"는 둘 다 일반적으로 하나 초과의 종으로부터의 면역글로불린 영역 또는 도메인을 결합한 항체를 지칭한다.
일부 경우에, 항체 성능을 추가로 개선하기 위해 추가 변형이 이루어진다. 예를 들어, 인간 면역글로불린의 프레임워크 영역(FR) 잔기는 상응하는 비인간 잔기로 대체되거나, 인간화 항체는 수용자 항체 또는 공여자 항체에서 발견되지 않는 잔기를 포함할 수 있다. 일반적으로, 인간화 항체의 가변 도메인은 비인간 면역글로불린으로부터의 모든 또는 실질적으로 모든 초가변 영역 및 인간 면역글로불린 서열로부터의 모든 또는 실질적으로 모든 FR을 포함할 것이다. 인간화 항체는, 예를 들어, Jones, 등, 1986, Nature, 321:522-525; Riechmann, 등, 1988, Nature, 332:323-329 및 Presta, 1992, Curr. Op. Struct. Biol., 2:593-596에 더 상세히 기술되어 있다.
비인간 CDR을 이식하기 위한 가장 적절한 인간 프레임워크를 선택하기 위한 다수의 접근법이 당업계에 공지되어 있다. 초기 접근법은 CDR을 제공하는 비인간 항체에 대한 서열 동일성에 관계없이 특성이 잘 규명된 인간 항체의 제한된 하위 집합을 사용하였다("고정 프레임워크(fixed framework)" 접근법). 좀 더 최근의 접근법은 CDR을 제공하는 비인간 항체의 가변 영역에 대해 아미노산 서열 동일성이 높은 가변 영역을 사용하였다("상동 매칭(homology matching)" 또는 "최적합(best-fit)" 접근법). 대안적인 접근법은 여러 상이한 인간 항체로부터 각각의 경쇄 또는 중쇄 가변 영역 내의 프레임워크 서열의 단편을 선택하는 것이다. CDR-이식은 일부 경우에 표적 항원에 대한 이식된 분자의 친화도를 부분적으로 또는 완전히 상실하게 할 수 있다. 이러한 경우, 인간 기원의 잔기 중 일부를 상응하는 비인간 잔기로 역돌연변이시킴으로써 친화도를 회복할 수 있다. 이러한 접근법에 의해 인간화 항체를 제조하는 방법은 당업계에 잘 알려져 있다(예를 들어, Tsurushita & Vasquez, 2004, Humanization of Monoclonal Antibodies, Molecular Biology of B Cells, 533-545, Elsevier Science (USA); Jones 등, 1986, Nature, 321:522-525; Riechmann 등, 1988, Nature, 332:323-329; Presta 등, 1997, Cancer Res, 57(20):4593-4599 참조).
대안적으로 또는 이러한 전통적인 접근법에 더하여, CDR 이식된 인간화 항체의 면역원성을 추가로 감소시키기 위해 더 최근의 기술이 사용될 수 있다. 예를 들어, 인간 생식계열 서열 또는 공통 서열에 기반한 프레임워크는 체세포 돌연변이(들)를 갖는 인간 프레임워크보다는 억셉터 인간 프레임워크(acceptor human framework)로서 사용될 수 있다. 비인간 CDR의 잠재적인 면역원성을 감소시키는 것을 목표로 하는 또 다른 기술은 특이성 결정 잔기(specificity-determining residue, SDR)만 이식하는 것이다. 이 접근법에서는 항원 결합 활성에 필요한 최소 CDR 잔기("SDR")만이 인간 생식계열 프레임워크에 이식된다. 이 방법은 인간화 항체의 "인간성"(즉, 인간 생식계열 서열과의 유사성)을 개선하여 가변 영역의 면역원성 위험을 줄이는 데 도움이 된다. 이러한 기술은 다양한 간행물에 기술되어 있다(예를 들어, Almagro & Fransson, 2008, Front Biosci, 13:1619-1633; Tan, 등, 2002, J Immunol, 169:1119-1125; Hwang, 등, 2005, Methods, 36:35-42; Pelat, 등, 2008, J Mol Biol, 384:1400-1407; Tamura, 등, 2000, J Immunol, 164:1432-1441; Gonzales, 등, 2004, Mol Immunol, 1:863-872, 및 Kashmiri, 등, 2005, Methods, 36:25-34 참조).
특정 실시양태에서, 항체는 인간화 항체 서열, 예를 들어, 하나 이상의 인간화 가변 도메인을 포함한다. 일부 실시양태에서, 항체는 인간화 항체이다.
특정 실시양태에서, 융합 단백질에 포함된 항원 결합 도메인은 모 항체의 CDR에서 하나 이상의 아미노산 치환을 포함하는 공지된 항체의 치환 변이체이다. 특정 실시양태에서, 치환 변이체는 모 항체에 비해 특정 생물학적 특성이 변형(예를 들어, 개선)된 것이다. 예를 들어, 치환 변이체는 표적 단백질에 대해 친화도가 증가될 수 있거나 면역원성이 감소될 수 있다. 일부 실시양태에서, 치환 변이체는 모 항체의 특정 생물학적 특성을 실질적으로 유지한다.
CDR 핫스팟(hotspot)은 체세포 성숙 과정 동안 높은 빈도로 돌연변이를 겪는 코돈에 의해 암호화된 잔기이다(예를 들어, Chowdhury, 2008, Methods Mol. Biol., 207:179-196 참조). 2차 라이브러리로부터의 구성 및 재선택에 의한 친화성 성숙(affinity maturation)이 기술되었다(예를 들어, Hoogenboom 등, Methods in Molecular Biology, 178:1-37, O'Brien 등, ed., Human Press, Totowa, N.J. (2001) 참조).
친화성 성숙 방법은 당업계에 잘 알려져 있다. 예를 들어, 다양성을, 예를 들어, 오류가 발생하기 쉬운 PCR, 사슬 셔플링(chain shuffling) 또는 올리고뉴클레오티드 지향 돌연변이유발(oligonucleotide-directed mutagenesis)을 포함하는 다양한 기술로 성숙을 위해 선택된 가변 유전자에 도입할 수 있다. 이어서 2차 라이브러리를 생성하고 이 라이브러리를 스크리닝하여 원하는 친화도의 임의의 항체 변이체를 식별한다. 다양성을 도입하는 또 다른 방법은 여러 CDR 잔기(예를 들어, 한 번에 2개, 3개, 4개 이상의 잔기)를 무작위화하는 CDR 유도 접근법을 포함한다. 중쇄 또는 경쇄 중 하나 또는 둘 다의 CDR3는 종종 CDR 유도 접근법을 위해 표적이 된다. 항원 결합에 관련된 CDR 잔기는, 예를 들어, 알라닌 스캐닝 돌연변이유발(예를 들어, Cunningham 및 Wells, 1989, Science, 244:1081-1085 참조)을 사용하거나 항원-항체 복합체의 결정 구조를 사용한 컴퓨터 모델링을 통해 항체와 항원 사이의 접점을 식별한다.
특정 실시양태에서, 치환 변이체는 치환이 표적 항원에 결합하는 결합 도메인의 능력을 실질적으로 감소시키지 않는 한, 하나 이상의 CDR 내에 하나 이상의 치환을 포함한다. 예를 들어, 치환 변이체는 결합 친화도를 실질적으로 감소시키지 않는 하나 이상의 CDR 내에 본원에 기술된 바와 같은 하나 이상의 보존적 치환(conservative substitution)을 포함할 수 있다. 일부 실시양태에서, 치환 변이체는 항원 접촉 아미노산을 포함하지 않는 CDR 내의 하나 이상의 아미노산 치환을 포함한다. 일부 실시양태에서, 치환 변이체는 각각의 CDR이 변경되지 않거나 1개, 2개 또는 3개 이하의 아미노산 치환을 함유하는 변이체 VH 또는 VL 서열을 포함한다.
글리코실화 변이체
특정 실시양태에서, 본원에 기술된 융합 단백질은 고유 글리코실화가 변형된 IgG Fc에 기반한 생물학적 기능성 단백질을 포함한다. 당업계에 공지된 바와 같이, Fc의 글리코실화는 이펙터 기능을 증가시키거나 감소시키도록 변형될 수 있다.
예를 들어, 위치 297에서 보존된 아스파라긴 잔기의 알라닌, 글루타민, 리신 또는 히스티딘(즉, N297A, Q, K 또는 H)으로의 돌연변이는 모든 이펙터 기능이 결여된 비글리코실화 Fc를 초래한다(Bolt 등, 1993, Eur. J. Immunol., 23:403-411; Tao & Morrison, 1989, J. Immunol., 143:2595-2601).
반대로, 중쇄 N297 연결된 올리고당으로부터의 푸코스의 제거는 FcγRIIIa에 대한 개선된 결합을 기반으로 ADCC를 강화시키는 것으로 나타났다(예를 들어, Shields 등, 2002, J Biol Chem., 277:26733-26740, 및 Niwa 등, 2005, J. Immunol. Methods, 306:151-160 참조). 이러한 적은 푸코스 항체는, 예를 들어, 푸코실트랜스퍼라제(FUT8)가 결여된 녹아웃 차이니즈 햄스터 난소(Chinese hamster ovary, CHO) 세포(Yamane-Ohnuki 등, 2004, Biotechnol. Bioeng., 87:614-622), 푸코스를 N297 연결된 탄수화물에 부착시키는 능력이 감소된 변이체 CHO 세포주 Lec 13(국제 공개 번호 WO 03/035835), 또는 비푸코실화 항체를 생성하는 다른 세포(예를 들어, Li 등, 2006, Nat Biotechnol, 24:210-215; Shields 등, 2002, ibid, 및 Shinkawa 등, 2003, J. Biol. Chem., 278:3466-3473)에서 생성될 수 있다. 또한, 국제 공개 번호 WO 2009/135181에는 푸코스가 항체 상의 탄수화물로 혼입되는 것을 억제하기 위해 항체 생성 동안 배양 배지에 푸코스 유사체를 첨가하는 것이 기술되어 있다.
Fc 글리코실화 부위(N297)에 푸코스가 거의 없거나 전혀 없는 항체를 생성하는 다른 방법은 당업계에 잘 알려져 있다. 예를 들어, GlymaX® 기술(ProBioGen AG)(von Horsten 등, 2010, Glycobiology, 20(12):1607-1618 및 미국 특허 제8,409,572호 참조).
다른 글리코실화 변이체는 이등분된 올리고당을 갖는 변이체, 예를 들어, 항체의 Fc 영역에 부착된 바이안테너리(biantennary) 올리고당이 N-아세틸글루코사민(GlcNAc)에 의해 이등분된 변이체를 포함한다. 이러한 글리코실화 변이체는 감소된 푸코실화 및/또는 개선된 ADCC 기능을 가질 수 있다. 예를 들어, 국제 공개 번호 WO 2003/011878, 미국 특허 제6,602,684호 및 미국 특허 출원 공개 번호 US 2005/0123546 참조. 유용한 글리코실화 변이체는 또한 개선된 CDC 기능을 가질 수 있는, Fc 영역에 부착된 올리고당에 적어도 하나의 갈락토스 잔기를 갖는 변이체를 포함한다(예를 들어, 국제 공개 번호 WO 1997/030087, WO 1998/58964 및 WO 1999/22764 참조).
폴리펩티드 스캐폴드
특정 실시양태에서, 본원에 기술된 융합 단백질의 생물학적 기능성 단백질은, 예를 들어, 리간드 수용체 쌍의 생체 내 반감기를 안정화시키거나 연장시키는 기능을 할 수 있는 폴리펩티드 스캐폴드이다.
특정 실시양태에서, 생물학적 기능성 단백질은 이량체 Fc 영역으로 이루어진다. 특정 실시양태에서, 생물학적 기능성 단백질의 제1 및 제2 폴리펩티드는 이량체 Fc로 이루어지고, 제1 폴리펩티드는 제1 Fc 폴리펩티드로 이루어지고 제2 폴리펩티드는 제2 Fc 폴리펩티드로 이루어지며, 제1 및 제2 Fc 폴리펩티드는 이량체 Fc 영역을 형성한다. 특정 실시양태에서, 이량체 Fc 영역은 이종이량체 Fc이다. 이종이량체 Fc 영역은 본원에서 더욱 상세히 기술된다.
특정 실시양태에서, 폴리펩티드 스캐폴드는 제1 및 제2 폴리펩티드로 구성된다. 특정 실시양태에서, 리간드 수용체 쌍의 리간드는 펩티드 링커를 통해 제1 폴리펩티드에 융합되고 수용체는 펩티드 링커를 통해 제2 폴리펩티드의 동일한 각각의 말단에 융합된다. 따라서, 특정 실시양태에서, 리간드는 펩티드 링커를 통해 제1 폴리펩티드의 N-말단에 융합되고, 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 N-말단에 융합된다. 반대로, 특정 실시양태에서, 리간드는 펩티드 링커를 통해 제1 폴리펩티드의 C-말단에 융합되고, 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드에 융합된다.
특정의 더욱 구체적인 실시양태에서, 생물학적 기능성 단백질은 이량체 Fc 영역 및 리간드-수용체 쌍으로 이루어진 PDL-1 및 PD-1인 폴리펩티드 스캐폴드를 포함한다. 특정 실시양태에서, 융합 단백질은 이량체 Fc 영역 및 리간드-수용체 쌍으로 이루어진 CD80 및 CTLA4인 생물학적 기능성 단백질을 포함한다. 특정 실시양태에서, 폴리펩티드 스캐폴드의 Fc 도메인은 서열번호 4 및 5, 및 선택적으로 서열번호 6에 상응하는 아미노산 서열을 포함한다. 특정 실시양태에서, 폴리펩티드 스캐폴드는 서열번호 4 및 서열번호 5를 포함하는 이종이량체 Fc로 이루어지고; 제1 Fc 폴리펩티드는 서열번호 4를 포함하고 제2 Fc 폴리펩티드는 서열번호 5를 포함한다. 일부 실시양태에서, 이종이량체 Fc로 이루어진 폴리펩티드 스캐폴드는 각각 표 2 및 표 3의 변형된 CH3 및/또는 CH2 도메인을 포함한다.
FC 도메인
특정 실시양태에서, 본원에 기술된 융합 단백질은 이량체성 면역글로불린 Fc 영역을 포함하는 생물학적 기능성 단백질, 예를 들어, 항체 또는 폴리펩티드 스캐폴드를 포함한다. 용어 "Fc 영역"은 고유 서열 Fc 영역 및 변이체 Fc 영역을 포함한다. 본원에서 달리 명시되지 않는 한, Fc 영역 또는 불변 영역에서 아미노산 잔기의 넘버링은 Kabat 등, Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991)에 기술된 바와 같이, EU 인덱스로도 불리는 EU 넘버링을 따른다. 이량체 Fc의 "Fc 폴리펩티드"는 이량체 Fc 영역을 형성하는 2개의 폴리펩티드 중 하나, 즉 안정적인 자가 결합이 가능한 면역글로불린 중쇄의 C-말단 불변 영역을 포함하는 폴리펩티드를 지칭한다.
Fc 영역은 CH3 도메인 또는 CH3 및 CH2 도메인을 포함할 수 있다. CH3 도메인은 2개의 CH3 서열을 포함하며, 각각은 이량체 Fc의 2개의 Fc 폴리펩티드 중 하나로 구성된다. 유사하게, CH2 도메인은 2개의 CH2 서열을 포함하며, 각각은 이량체 Fc의 2개의 Fc 폴리펩티드 중 하나로 구성된다.
특정 실시양태에서, 융합 단백질은 인간 IgG Fc에 기반한 Fc를 포함한다. 일부 실시양태에서, 융합 단백질은 인간 IgG1 Fc에 기반한 Fc를 포함한다. 일부 실시양태에서, 융합 단백질은 2개의 상이한 Fc 폴리펩티드를 포함하는 이종이량체 Fc에 기반한 Fc를 포함한다.
특정 실시양태에서, 융합 단백질은 CH3 도메인이 하나 이상의 아미노산 변형을 포함하는 변형된 IgG Fc에 기반한 Fc를 포함한다. 일부 실시양태에서, 융합 단백질은 CH2 도메인이 하나 이상의 아미노산 변형을 포함하는 변형된 IgG Fc에 기반한 Fc를 포함한다. 일부 실시양태에서, 융합 단백질은 CH3 도메인이 하나 이상의 아미노산 변형을 포함하고 CH2 도메인이 하나 이상의 아미노산 변형을 포함하는 변형된 IgG Fc에 기반한 Fc를 포함한다.
변형된 Fc CH3 도메인
특정 실시양태에서, 융합 단백질은 변형된 CH3 도메인을 포함하는 이종이량체 면역글로불린 Fc를 포함하고, 변형된 CH3 도메인은 하나 이상의 비대칭 아미노산 변형을 포함한다. 본원에 사용된 "비대칭 아미노산 변형"은 제1 Fc 폴리펩티드 상의 특정 위치에 있는 아미노산이 제2 Fc 폴리펩티드 상의 상응하는 위치에 있는 아미노산과 상이한 변형을 지칭한다. 이러한 비대칭 아미노산 변형은 각각의 Fc 폴리펩티드 상의 상응하는 위치에서 2개의 아미노산 중 하나만의 변형을 포함할 수 있거나, 각각의 제1 및 제2 Fc 폴리펩티드 상의 상응하는 위치에서 두 아미노산의 변형을 포함할 수 있다.
특정 실시양태에서, 융합 단백질은 변형된 CH3 도메인을 포함하는 이종이량체 Fc를 포함하고, 변형된 CH3 도메인은 동종이량체 Fc의 형성보다 이종이량체 Fc의 형성을 촉진하는 하나 이상의 비대칭 아미노산 변형을 포함한다. 이종이량체 Fc의 형성을 촉진하기 위해 Fc의 CH3 도메인에 만들어질 수 있는 아미노산 변형은 당업계에 공지되어 있고, 예를 들어, 국제 공개 번호 WO 96/027011("knobs into hole"), Gunasekaran 등, 2010, J Biol Chem, 285, 19637-46("electrostatic steering"), Davis 등, 2010, Prot Eng Des Sel, 23(4):195-202(strand exchange engineered domain (SEED) technology) 및 Labrijn 등, 2013, Proc Natl Acad Sci USA, 110(13):5145-50(Fab-arm exchange)에 기술된 것을 포함한다. 다른 예는 국제 공개 번호 WO 2012/058768 및 WO 2013/063702에 기술된 바와 같이 안정한 비대칭적으로 변형된 Fc 영역을 생성하기 위한 포지티브 설계 전략과 네거티브 설계 전략을 조합한 접근법을 포함한다.
특정 실시양태에서, 융합 단백질은 국제 공개 번호 WO 2012/058768 또는 국제 특허 공개 번호 WO 2013/063702에 기술된 바와 같이 변형된 CH3 도메인을 갖는 이종이량체 Fc를 포함한다.
일부 실시양태에서, 융합 단백질은 변형된 CH3 도메인을 갖는 이종이량체 인간 IgG1 Fc를 포함한다. 하기 표 2는 전장 인간 IgG1 중쇄의 아미노산 231 내지 447에 상응하는 인간 IgG1 Fc 서열의 아미노산 서열을 제공한다. CH2 도메인은 전형적으로 전장 인간 IgG1 중쇄의 아미노산 231-340을 포함하는 것으로 정의되고 CH3 도메인은 전형적으로 전장 인간 IgG1 중쇄의 아미노산 341-447을 포함하는 것으로 정의된다.
특정 실시양태에서, 융합 단백질은 동종이량체 Fc의 형성보다 이종이량체 Fc의 형성을 촉진하는 하나 이상의 비대칭 아미노산 변형을 포함하는 변형된 CH3 도메인을 갖는 이종이량체 Fc를 포함하며, 변형된 CH3 도메인은 위치 F405 및 Y407에서의 아미노산 변형을 포함하는 제1 Fc 폴리펩티드, 및 위치 T366 및 T394에서의 아미노산 변형을 포함하는 제2 Fc 폴리펩티드를 포함한다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 Fc 폴리펩티드의 위치 F405에서의 아미노산 변형은 F405A, F405I, F405M, F405S, F405T 또는 F405V이다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 Fc 폴리펩티드의 위치 Y407에서의 아미노산 변형은 Y407I 또는 Y407V이다. 일부 실시양태에서, 변형된 CH3 도메인의 제2 Fc 폴리펩티드의 위치 T366에서의 아미노산 변형은 T366I, T366L 또는 T366M이다. 일부 실시양태에서, 변형된 CH3 도메인의 제2 Fc 폴리펩티드의 위치 T394에서의 아미노산 변형은 T394W이다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 Fc 폴리펩티드는 위치 L351에서의 아미노산 변형을 추가로 포함한다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 Fc 폴리펩티드의 위치 L351에서의 아미노산 변형은 L351Y이다. 일부 실시양태에서, 변형된 CH3 도메인의 제2 Fc 폴리펩티드는 위치 K392에서의 아미노산 변형을 추가로 포함한다. 일부 실시양태에서, 변형된 CH3 도메인의 제2 Fc 폴리펩티드의 위치 K392에서의 아미노산 변형은 K392F, K392L 또는 K392M이다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 및 제2 Fc 폴리펩티드 중 하나 또는 둘 다는 아미노산 변형 T350V를 추가로 포함한다.
특정 실시양태에서, 융합 단백질은 동종이량체 Fc의 형성보다 이종이량체 Fc의 형성을 촉진하는 하나 이상의 비대칭 아미노산 변형을 포함하는 변형된 CH3 도메인을 갖는 이종이량체 Fc를 포함하며, 변형된 CH3 도메인은 아미노산 변형 Y407I 또는 Y407V와 함께 아미노산 변형 F405A, F405I, F405M, F405S, F405T 또는 F405V를 포함하는 제1 Fc 폴리펩티드, 및 아미노산 변형 T394W와 함께 아미노산 변형 T366I, T366L 또는 T366M을 포함하는 제2 Fc 폴리펩티드를 포함한다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 Fc 폴리펩티드는 아미노산 변형 L351Y를 추가로 포함한다. 일부 실시양태에서, 변형된 CH3 도메인의 제2 Fc 폴리펩티드는 아미노산 변형 K392F, K392L 또는 K392M을 추가로 포함한다. 일부 실시양태에서, 변형된 CH3 도메인의 제1 및 제2 Fc 폴리펩티드 중 하나 또는 둘 다는 아미노산 변형 T350V를 추가로 포함한다.
특정 실시양태에서, 융합 단백질은 상술한 바와 같이 위치 F405 및 Y407에서의 아미노산 변형을 포함하고 선택적으로 위치 L351에서의 아미노산 변형을 추가로 포함하는 제1 Fc 폴리펩티드, 및 위치 T366 및 T394에서의 아미노산 변형을 포함하고 선택적으로 위치 K392에서의 아미노산 변형을 추가로 포함하는 제2 Fc 폴리펩티드를 갖는 변형된 CH3 도메인을 포함하는 이종이량체 Fc를 포함하고, 제1 Fc 폴리펩티드는 위치 S400 또는 Q347 중 하나 또는 둘 다에서의 아미노산 변형을 추가로 포함하고/하거나 제2 Fc 폴리펩티드는 위치 K360 또는 N390 중 하나 또는 둘 다에서의 아미노산 변형을 추가로 포함하며, 위치 S400에서의 아미노산 변형은 S400E, S400D, S400R 또는 S400K이고; 위치 Q347에서의 아미노산 변형은 Q347R, Q347E 또는 Q347K이며; 위치 K360에서의 아미노산 변형은 K360D 또는 K360E이고, 위치 N390에서의 아미노산 변형은 N390R, N390K 또는 N390D이다.
특정 실시양태에서, 융합 단백질은 표 2에 나타낸 바와 같이 변이체 1, 변이체 2, 변이체 3, 변이체 4 또는 변이체 5 중 어느 하나의 변형을 포함하는 변형된 CH3 도메인을 포함하는 이종이량체 Fc를 포함한다. 특정 실시양태에서, CH3 도메인은 서열번호 4 또는 서열번호 5에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CH3은 서열번호 4 또는 서열번호 5와 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CH3 도메인은 서열번호 4 또는 서열번호 5와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다.
[표 2]

변형된 Fc CH2 도메인
특정 실시양태에서, 융합 단백질은 변형된 CH2 도메인을 갖는 IgG Fc에 기반한 Fc를 포함한다. 일부 실시양태에서, 융합 단백질은 변형된 CH2 도메인을 갖는 IgG Fc에 기반한 Fc를 포함하며, CH2 도메인의 변형은 하나 이상의 Fc 수용체(FcR), 예컨대 FcγRⅠ, FcγRⅡ 및 FcγRⅢ 서브클래스에 대한 변경된 결합을 초래한다.
상이한 Fcγ 수용체에 대한 Fc의 친화도를 선택적으로 변경하는 CH2 도메인에 대한 다수의 아미노산 변형이 당업계에 공지되어 있다. 증가된 결합을 초래하는 아미노산 변형 및 감소된 결합을 초래하는 아미노산 변형은 둘 다 특정 적응증에서 유용할 수 있다. 예를 들어, FcγRⅢa(활성화 수용체)에 대한 Fc의 결합 친화도가 증가하면 항체 의존성 세포 매개 세포독성(ADCC)이 증가하고, 이는 다시 표적 세포의 용해를 증가시킨다. 마찬가지로 FcγRⅡb(억제 수용체)에 대한 감소된 결합이 일부 상황에서 유익할 수 있다. 특정 적응증에서, ADCC 및 보체 매개 세포독성(complement-mediated cytotoxicity, CDC)의 감소 또는 제거가 바람직할 수 있다. 이러한 경우에, FcγRⅡb에 대한 증가된 결합을 초래하는 아미노산 변형 또는 모든 Fcγ 수용체에 대한 Fc 영역의 결합을 감소시키거나 제거하는 아미노산 변형을 포함하는 변형된 CH2 도메인("녹아웃" 변이체)이 유용할 수 있다.
Fcγ 수용체에 의한 Fc의 결합을 변경하는, CH2 도메인에 대한 아미노산 변형의 예는 다음을 포함하지만 이에 제한되지 않는다: S298A/E333A/K334A 및 S298A/E333A/K334A/K326A(FcγRⅢa에 대한 증가된 친화도)(Lu, 등, 2011, J Immunol Methods, 365(1-2):132-41); F243L/R292P/Y300L/V305I/P396L(FcγRⅢa에 대한 증가된 친화도)(Stavenhagen, 등, 2007, Cancer Res, 67(18):8882-90); F243L/R292P/Y300L/L235V/P396L(FcγRⅢa에 대한 증가된 친화도)(Nordstrom JL, 등, 2011, Breast Cancer Res, 13(6):R123); F243L(FcγRⅢa에 대한 증가된 친화도)(Stewart, 등, 2011, Protein Eng Des Sel., 24(9):671-8); S298A/E333A/K334A(FcγRⅢa에 대한 증가된 친화도)(Shields, 등, 2001, J Biol Chem, 276(9):6591-604); S239D/I332E/A330L 및 S239D/I332E(FcγRⅢa에 대한 증가된 친화도)(Lazar, 등, 2006, Proc Natl Acad Sci USA, 103(11):4005-10), 및 S239D/S267E 및 S267E/L328F(FcγRⅡb에 대한 증가된 친화도)(Chu, 등, 2008, Mol Immunol, 45(15):3926-33).
Fcγ 수용체에 결합하는 Fc에 영향을 미치는 추가 변형은 Therapeutic Antibody Engineering(Strohl & Strohl, Woodhead Publishing series in Biomedicine No 11, ISBN 1 907568 37 9, Oct 2012, page 283)에 기술되어 있다.
특정 실시양태에서, 융합 단백질은 변형된 CH2 도메인을 갖는 IgG Fc에 기반한 Fc를 포함하며, 변형된 CH2 도메인은 모든 Fcγ 수용체에 대한 Fcγ 영역의 결합을 감소시키거나 제거하는 하나 이상의 아미노산 변형을 포함한다(즉, "녹아웃" 변이체).
다양한 간행물은 항체를 조작하여 "녹아웃" 변이체를 생성하는 데 사용된 전략을 기술한다(예를 들어, Strohl, 2009, Curr Opin Biotech 20:685-691, 및 Strohl & Strohl, "Antibody Fc engineering for optimal antibody performance" In Therapeutic Antibody Engineering, Cambridge: Woodhead Publishing, 2012, pp 225-249 참조). 이러한 전략에는 글리코실화의 변형(아래에 더 자세히 기술됨), IgG2/IgG4 스캐폴드의 사용, 또는 Fc의 힌지 또는 CH2 도메인에서의 돌연변이 도입을 통한 이펙터 기능의 감소가 포함된다(미국 특허 공개 번호 2011/0212087, 국제 공개 번호 WO 2006/105338, 미국 특허 공개 번호 2012/0225058, 미국 특허 공개 번호 2012/0251531 및 Strop 등, 2012, J. Mol. Biol., 420: 204-219 참조).
FcγR 및/또는 Fc에 대한 보체 결합을 감소시키기 위한 공지된 아미노산 변형의 구체적이고 비제한적인 예는 표 3에서 확인되는 것을 포함한다.
[표 3]

추가 예는 아미노산 변형 L235A/L236A/D265S를 포함하도록 조작된 Fc 영역을 포함한다. 또한, 모든 Fcγ 수용체에 대한 Fc의 결합을 감소시키는 CH2 도메인의 비대칭 아미노산 변형이 국제 공개 번호 WO 2014/190441에 기술되어 있다.
특정 실시양태에서, CH2 도메인은 서열번호 6에 상응하는 아미노산 서열을 갖는다. 특정 실시양태에서, CH2는 서열번호 6과 실질적으로 동일한 아미노산 서열을 갖는다. 특정 실시양태에서, CH2 도메인은 서열번호 6과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 아미노산 서열을 갖는다.
항체 약물 접합체
본원에 기술된 융합 단백질의 특정 실시양태는 약물에 접합된 항체, 즉 항체 약물 접합체(antibody drug conjugate, ADC)인 생물학적 기능성 단백질을 포함한다. ADC의 약물은 임의의 치료 분자, 예를 들어, 독소, 화학요법제, 소분자 억제제일 수 있다. ADC는 절단성 링커 또는 비절단성 링커일 수 있는 링커를 통해 약물에 접합될 수 있다. 절단성 링커는, 예를 들어, 리소좀 과정을 통해 세포내 조건 하에서 절단되기 쉬울 수 있다. 절단성 링커의 예는 프로테아제-민감성, 산-민감성, 환원-민감성 또는 광불안정한 링커를 포함한다. 약물의 접합은 라이신 또는 시스테인 접합, 비스-티올 링커, 항체의 글리코실화 부위를 이용한 접합, 자외선 접합 및 비천연 아미노산의 사용을 포함하지만 이에 제한되지 않는 당업계에 공지된 임의의 방법에 의해 수행될 수 있다.
펩티드 링커, 프로테아제 및 프로테아제 절단 부위
본원에 기술된 융합 단백질은 적어도 제1 및 제2 펩티드 링커를 포함한다. 펩티드 링커는 다른 펩티드 또는 폴리펩티드를 잇거나 연결하는 펩티드이다. 특정 실시양태에서, 펩티드 링커는 생물학적 기능성 단백질의 폴리펩티드, 예를 들어, 항체 또는 이량체 Fc 스캐폴드를 리간드-수용체 쌍의 리간드 및/또는 수용체에 융합시킨다.
특정 실시양태에서, 생물학적 기능성 단백질이 Fc 영역을 포함하는 경우, Fc 폴리펩티드는 리간드-수용체 쌍의 리간드 또는 수용체에 융합되거나, 링커가 Fc 폴리펩티드를 리간드-수용체 쌍의 리간드 또는 수용체에 결합시킬 수 있다. 특정 실시양태에서, 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 말단에 융합되고; 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 동일한 각각의 말단에 융합된다. 본원에 기술된 융합 단백질의 특정 실시양태에서, 수용체 및 리간드는 둘 다 펩티드 링커를 통해 제1 및 제2 폴리펩티드의 각각의 N-말단에 융합된다. 본원에 기술된 융합 단백질의 특정 실시양태에서, 수용체 및 리간드는 둘 다 펩티드 링커를 통해 제1 및 제2 폴리펩티드의 각각의 C-말단에 융합된다.
펩티드 링커는 리간드와 수용체의 페어링을 허용하기에 충분한 길이이다. 펩티드 링커는 간격 기능을 제공하는 것 외에도 융합 단백질 내에서 및 융합 단백질과 이의 표적(들)간에 또는 그 중에서 본원의 융합 단백질의 하나 이상의 도메인을 적절하게 배향시키기에 적합한 유연성 또는 강성을 제공할 수 있다. 또한, 펩티드 링커는 전장 융합 단백질의 발현 및 정제된 단백질의 안정성을 인간과 같이 이것이 필요한 대상체에게 투여한 후 시험관 내 및 생체 내 모두에서 지원할 수 있고, 바람직하게는 이러한 동일한 대상체에서 비면역원성이거나 낮은 면역원성이다. 특정 실시양태에서, 펩티드 링커는 인간 면역글로불린 힌지, C형 렉틴(lectin)의 스톡 부위(stalk region), Ⅱ형 막 단백질 패밀리 또는 이들의 조합의 일부 또는 전부를 포함할 수 있다.
특정 실시양태에서, 펩티드 링커는 리간드와 수용체의 페어링을 허용하기에 충분한 길이이고 약 2 내지 약 150개의 아미노산이다. 특정 실시양태에서, 펩티드 링커의 길이는 약 3 내지 약 50개의 아미노산, 또는 약 5 내지 약 20개의 아미노산, 또는 약 10 내지 약 50개의 아미노산, 또는 약 2 내지 약 40개의 아미노산, 또는 약 8 내지 약 20개의 아미노산, 약 10개 내지 약 60개의 아미노산, 약 10개 내지 약 30개의 아미노산, 또는 약 15개 내지 약 25개의 아미노산 범위이다. 일부 실시양태에서, 펩티드 링커는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59 또는 60개의 아미노산이다.
본원에 기술된 융합 단백질의 펩티드 링커 중 적어도 하나는 절단 서열이라고도 하는 프로테아제 절단 부위를 포함한다. 특정 실시양태에서, 융합 단백질은 프로테아제 절단 부위를 포함하는 적어도 하나의 펩티드 링커 및 프로테아제 절단 부위를 포함하지 않는 적어도 하나의 펩티드 링커를 포함한다. 사용되는 경우, 프로테아제 절단 부위는 원하는 프로테아제 또는 프로테아제들에 의한 인식 및 절단을 최대화하고 다른 프로테아제에 의한 인식 및 비특이적 절단을 최소화하도록 펩티드 링커 내에 위치한다. 펩티드 링커는 하나 이상의 절단 부위를 포함할 수 있다. 이와 관련하여, 융합 단백질은 1, 2, 3, 4, 5개 이상의 프로테아제에 의해 절단될 수 있다. 추가로, 프로테아제 절단 부위 또는 부위들은 펩티드 링커 내에 위치할 수 있고(또는 달리 말하면, 링커에 의해 둘러싸일 수 있음) 융합 단백질 단편(예를 들어, 수용체 리간드 쌍의 리간드, 리간드 수용체 쌍의 수용체 또는 리간드와 수용체 모두)의 최상의 원하는 절단 및 절단 후 방출을 달성하기 위해 전체적으로 융합 단백질 내에 위치할 수 있다. 펩티드 링커에 의해 융합 단백질에 융합되고 펩티드 링커의 절단 후 융합 단백질로부터 방출되는 폴리펩티드 모이어티는 본원에서 절단성 모이어티(cleavable moiety, CM)로 언급될 수 있다. 융합 단백질이 하나 이상의 CM을 포함하는 특정 실시양태에서, 이는 동일한 절단 부위 또는 상이한 절단 부위를 갖는 동일하거나 상이한 펩티드 링커에 의해 융합 단백질에 융합될 수 있다.
프로테아제 절단 부위 또는 절단 서열은 융합 단백질 또는 생물학적 기능성 단백질의 활성이 요구되는 조직에서 공동 위치하는 프로테아제에 기반하여 선택될 수 있다. 절단 부위는 다중 프로테아제에 대한 기질, 예를 들어, 세린 프로테아제 및 제2의 상이한 프로테아제, 예를 들어, 매트릭스 메탈로프로테이나제(matrix metalloproteinase, MMP)에 대한 기질로서 작용할 수 있다. 일부 실시양태에서, 절단 부위는 하나 초과의 세린 프로테아제, 예를 들어, 매트립타제 및 우로키나제형 플라스미노겐 활성제(urokinase-type plasminogen activator, uPA)에 대한 기질로서 작용할 수 있다. 일부 실시양태에서, 펩티드 링커는 하나 초과의 MMP, 예를 들어, MMP9 및 MMP 14에 대한 기질로서 작용할 수 있다.
특정 실시양태에서, 펩티드 링커는 약 0.001-1500 × 104M-1S-1, 또는 적어도 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1, 2.5, 5, 7.5, 10, 15, 20, 25, 50, 75, 100, 125, 150, 200, 250, 500, 750, 1000, 1250 또는 1500 × 104 M-1S-1의 비율로 프로테아제에 의해 특이적으로 절단된다.
효소에 의한 특이적 절단의 경우, 효소와 펩티드 링커 사이에 접촉이 이루어진다. 특정 실시양태에서, 융합 단백질이 적어도 제1 펩티드 링커를 포함하고 충분한 효소 활성이 존재하는 경우, 펩티드 링커가 절단된다. 충분한 효소 활성은 효소가 펩티드 링커와 접촉하여 절단을 일으키는 능력을 의미할 수 있다. 효소가 펩티드 링커 근처에 있을 수 있지만 다른 세포 인자나 효소의 단백질 변형으로 인해 절단할 수 없다는 것을 쉽게 상상할 수 있다.
특정 실시양태에서, 펩티드 링커는 길이가 5-10개의 아미노산, 또는 7-10개의 아미노산, 또는 8-10개의 아미노산인 프로테아제 절단 부위를 포함한다. 다른 실시양태에서, 펩티드 링커는 길이가 5-10개의 아미노산, 또는 7-10개의 아미노산, 또는 8-10개의 아미노산인 프로테아제 절단 부위로 이루어진다. 한 실시양태에서, 프로테아제 절단 부위는 길이가 약 1-20개의 아미노산, 2-5개의 아미노산, 5-10개의 아미노산, 10-15개의 아미노산, 10-20개의 아미노산, 12-16개의 아미노산, 또는 약 5개 또는 약 10개의 아미노산인 링커 서열이 N-말단에서 선행한다. 다른 실시양태에서, 프로테아제 절단 부위는 길이가 약 1-20개의 아미노산, 2-5개의 아미노산, 5-10개의 아미노산, 10-15개의 아미노산, 10-20개의 아미노산, 12-16개의 아미노산 아미노산, 또는 일부 경우에는 약 5개 또는 약 10개의 아미노산인 링커 서열이 C-말단에서 뒤따른다. 또 다른 실시양태에서, 프로테아제 절단 부위는 N-말단에서 링커 서열이 선행하고 C-말단에서 링커 서열이 뒤따른다. 따라서, 특정 실시양태에서, 프로테아제 절단 부위는 2개의 링커 사이에 위치한다. 프로테아제 절단 부위의 N 또는 C-말단 엔드에 있는 링커는 길이가 다양할 수 있으며, 예를 들어, 길이가 약 2-20개, 6-20개, 8-15개, 8-10개, 10-18개 또는 12-16개의 아미노산일 수 있다. 특정 실시양태에서, N- 또는 C-말단 링커 서열은 길이가 약 3개 또는 약 5개의 아미노산이다.
본 개시내용의 예시적인 펩티드 링커는 세린 프로테아제, MMP(MMP1, MMP2, MMP3, MMP7, MMP8, MMP9, MMP10, MMP11, MMP12, MMP13, MMP14, MMP15, MMP16, MMP17, MMP18(콜라게나제 4), MMP19, MMP20, MMP21 등), 아다말리신, 세랄리신, 아스타신, 카스파제(예를 들어, 카스파제 1, 카스파제 2, 카스파제 3, 카스파제 4, 카스파제 5, 카스파제 6, 카스파제 7, 카스파제 8, 카스파제 9, 카스파제 10, 카스파제 11, 카스파제 12, 카스파제 13, 카스파제 14), 카텝신(예를 들어, 카텝신 A, 카텝신 B, 카텝신 D, 카텝신 E, 카텝신 K, 카텝신 S), 그래님 B, 구아니디노벤조아타제(GB), 헵신, 엘라스타제, 레구마인, 매트립타제, 매트립타제 2, 메프린, 뉴로신, MT-SP1, 네프릴리신, 플라스민, PSA, PSMA, TACE, TMPRSS3/4, uPA, 및 칼페인, FAP 및 KLK와 같은, 그러나 이에 제한되지 않는 임의의 다양한 프로테아제에 의해 인식되는 하나 이상의 프로테아제 절단 부위를 포함한다. 일부 실시양태에서 프로테아제는 uPA 또는 매트립타제이다.
특정 실시양태에서, 펩티드 링커는 하나 초과의 프로테아제에 의해 절단되는 절단 부위를 포함한다. 이와 관련하여, 개별 절단 부위는 1, 2, 3, 4, 5개 이상의 프로테아제에 의해 절단될 수 있다. 다른 실시양태에서, 펩티드 링커는 하나의 효소에 의해 실질적으로 절단되지만 다른 효소에 의해서는 절단되지 않는 절단 부위를 포함할 수 있다. 따라서, 일부 실시양태에서, 펩티드 링커는 높은 특이성의 절단 부위를 포함한다. "높은 특이성"은 특정 프로테아제에 의해서는 >90%의 절단이 관찰되고 다른 프로테아제에 의해서는 50% 미만의 절단이 관찰되는 것을 의미한다. 특정 실시양태에서, 펩티드 링커는 하나의 프로테아제에 의해서는 >80%의 절단을 나타내지만 다른 프로테아제에 의해서는 50% 미만의 절단을 나타내는 절단 부위를 포함한다. 특정 실시양태에서, 펩티드 링커는 하나의 프로테아제에 의해서는 >70%, 75%, 76%, 77%, 78% 또는 79%의 절단을 나타내지만 다른 프로테아제에 의해서는 65%, 60%, 55%, 54%, 53%, 52%, 51%, 50%, 49%, 48%, 47%, 46% 또는 45% 미만의 절단을 나타내는 절단 부위를 포함한다. 예로서, 한 실시양태에서, 절단 부위는 매트립타제에 의해 >90% 절단될 수 있고 uPa 및 플라스민에 의해 약 75% 절단될 수 있다. 다른 실시양태에서, 절단 부위는 uPa 및 매트립타제에 의해 절단될 수 있지만 플라스민에 의한 특이적 절단은 관찰되지 않는다. 또 다른 실시양태에서, 절단 부위는 uPa에 의해 절단될 수 있지만 매트립타제 또는 플라스민에 의해 절단될 수 없다. 한 실시양태에서, 절단 부위는 비특이적 프로테아제 절단, 예를 들어, 플라스민 또는 다른 비특이적 프로테아제에 의한 절단에 대한 어느 정도의 저항성을 나타낼 수 있다. 이와 관련하여, 프로테아제 절단 부위는 "높은 비특이적 프로테아제 저항성"(플라스민 또는 동등한 비특이적 프로테아제에 의한 <25%의 절단), "보통의 비특이적 프로테아제 저항성"(플라스민 또는 동등한 비특이적 프로테아제에 의한 <75%의 절단) 또는 "낮은 비특이적 프로테아제 저항성"(플라스민 또는 동등한 비특이적 프로테아제에 의한 최대 약 90%의 절단)을 가질 수 있다. 이러한 절단 활성은 적절한 프로테아제와 함께 인큐베이션한 후 SDS-PAGE 또는 다른 분석과 같은 당업계에 공지된 검정을 사용하여 측정할 수 있다. 특정 실시양태에서, 프로테아제 절단 부위는 프로테아제와의 24시간 접촉에 대해 프로테아제 절단에 대한 완전한 저항성을 나타낼 수 있다. 다른 실시양태에서, 프로테아제 절단 서열은 프로테아제와의 0.5시간 내지 36시간 접촉 후에 비특이적 프로테아제 절단에 대해 완전한 저항성을 나타낼 수 있다. 다른 실시양태에서, 프로테아제 절단 서열은 적절한 프로테아제와의 0.5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 20, 24, 36, 48 또는 72시간 접촉 후 비특이적 프로테아제 절단에 대해 완전한 저항성을 나타낸다.
따라서, 특정 실시양태에서, 절단 부위는 원하는 다양한 프로테아제에 대한 선호도에 기반하여 선택된다. 이러한 방식으로, 절단 부위를 포함하는 특정 펩티드 링커에 대한 원하는 절단 프로파일은 특정 프로테아제 또는 프로테아제 세트가 펩티드 링커 내의 특정 절단 부위의 높은, 특이적, 상승된, 효율적, 중간, 낮은 절단 또는 절단 없음을 나타낼 수 있다. 절단을 측정하는 방법은 당업계에 공지되어 있다.
특정 실시양태에서, 펩티드 링커는 각각의 절단 부위 사이에 추가 링커가 있거나 없는 일렬로 배열된 하나 이상의 절단 부위를 포함할 수 있다. 특정 실시양태에서, 펩티드 링커는 제1 절단 부위 및 제2 절단 부위를 포함하며, 제1 절단 부위는 제1 프로테아제에 의해 절단되고 제2 절단 부위는 제2 프로테아제에 의해 절단된다. 비제한적 예로서, 펩티드 링커는 매트립타제 및 uPa에 의해 절단되는 제1 절단 부위와 MMP에 의해 절단되는 제2 절단 부위를 포함할 수 있다. 특정 실시양태에서, 펩티드 링커는 제1 절단 부위, 제2 절단 부위 및 제3 절단 부위를 포함하고, 제1 절단 부위는 제1 프로테아제에 의해 절단되고 제2 절단 부위는 제2 프로테아제에 의해 절단되고 제3 절단 부위는 제3 프로테아제에 의해 절단된다.
본원의 융합 단백질에 유용한 예시적인 단백질분해 효소 및 이의 인식 서열은 당업자에 의해 식별될 수 있고, MEROPS 데이터베이스(예를 들어, Rawlings, 등 Nucleic Acids Research, Volume 46, Issue D1, 4 January 2018, Pages D624-D632) 및 다른 곳(Hoadley 등, Cell, 2018; GTEX Consortium, Nature, 2017; Robinson 등, Nature, 2017)에 기술된 것과 같이 당해 분야에 공지되어 있다.
미국 특허 제9,453,078호, 제10,138,272호, 제9,562,073호 및 공개된 국제 출원 번호 WO 2015048329; WO2015116933; WO2016118629에 기술된 것과 같은, 본원에서 사용하기 위한 절단 부위를 확인하기 위해 다른 방법도 사용될 수 있다.
따라서, 본 개시내용의 실시양태는 적어도 2개의 펩티드 링커를 포함하는 융합 단백질로서, 펩티드 링커 중 적어도 하나가 본원에 제시된 절단 부위를 하나 이상 포함하는 융합 단백질을 제공한다. 한 실시양태에서, 본 개시내용은 하나의 펩티드 링커를 포함하는 융합 단백질로서, 펩티드 링커가 프로테아제 절단 부위를 포함하고 uPA에 의해 절단될 수 있는 융합 단백질을 제공한다. 한 실시양태에서, 본 개시내용은 하나의 펩티드 링커를 포함하는 융합 단백질로서, 펩티드 링커가 아미노산 서열 MSGRSANA(서열번호 28)를 포함하는 융합 단백질을 제공한다. 특정 실시양태에서 펩티드 링커 서열은 TSGRSANP, LSGRSDNH, GSGRSAQV, GSSRNADV, GTARSDNV, GTARSDNV. GGGRVNNV, MSARILQV 또는 GKGRSANA(각각 서열번호 30-37)로부터 선택된 적어도 하나의 프로테아제 절단 부위를 포함한다.
특정 실시양태에서, 본원에 기술된 펩티드 링커를 포함하는 융합 단백질은 2개의 이종 폴리펩티드, 즉 펩티드 링커 쪽으로 말단에 아미노(N)가 위치한 제1 폴리펩티드 및 펩티드 링커 쪽으로 말단에 카복실(C)이 위치한 제2 폴리펩티드를 포함하고, 따라서 2개의 이종 폴리펩티드는 펩티드 링커에 의해 분리된다.
특정 실시양태에서, 융합 단백질은 프로테아제 절단 부위를 포함하지 않는 적어도 하나의 펩티드 링커를 포함한다. 특정 실시양태에서, 펩티드 링커는 아미노산 서열 (EAAAK)n을 포함하며, n은 1 내지 5의 정수이다. 일부 실시양태에서, 펩티드 링커는 EAAAK(서열번호 39)이다. 일부 실시양태에서 펩티드 링커는 EAAAKEAAAK(서열번호 38)이다. 일부 실시양태에서, 펩티드 링커는 선택적으로 PPP(서열번호 41) 또는 PPPP(서열번호 40)의 아미노산 서열을 갖는 폴리프롤린 링커를 포함한다. 특정 실시양태에서 링커는 글리신(G)-프롤린(P) 폴리펩티드 링커, 선택적으로 GPPPG, GGPPPGG, GPPPPG 또는 GGPPPGG이다. 특정 실시양태에서, 펩티드 링커는 GlynSer 링커이다. 특정 실시양태에서, 펩티드 링커는 (Gly3Ser)n(Gly4Ser)1, (Gly3Ser)1(Gly4Ser)n, (Gly3Ser)n(Gly4Ser)n 또는 (Gly4Ser)n의 아미노산 서열을 포함하며, n은 1 내지 5의 정수이다. 특정 실시양태에서, 펩티드 링커는 상이한 도메인을 연결하는데 적합하고 글리신-세린 링커, 예를 들어, 제한되지는 않지만 (GmS)n-GG, (SGn)m, (SEGn)m을 포함하는 서열을 포함하고, m 및 n은 0-20이다.
특정 실시양태에서, 펩티드 링커는 항체 힌지 영역 서열, 결합 도메인을 수용체에 연결하는 서열, 또는 결합 도메인을 세포 표면 막관통 영역 또는 막 앵커에 연결하는 서열로부터 획득, 유래 또는 설계된 아미노산 서열이다. 일부 실시양태에서, 펩티드 링커는 생리학적 조건 또는 다른 표준 펩티드 조건(예를 들어, 펩티드 정제 조건, 펩티드 저장을 위한 조건) 하에 적어도 하나의 디설파이드 결합에 참여할 수 있는 적어도 하나의 시스테인을 갖는다. 특정 실시양태에서, 면역글로불린 힌지 펩티드에 상응하거나 유사한 펩티드 링커는 해당 힌지의 아미노 말단을 향해 배치된 힌지 시스테인에 상응하는 시스테인을 보유한다. 추가 실시양태에서, 펩티드 링커는 IgG1 힌지에서 유래하고 임의의 시스테인 잔기를 제거하도록 변형되었거나 힌지 시스테인에 상응하는 1개의 시스테인 또는 2개의 시스테인을 갖는 IgG1 힌지이다.
특정 실시양태에서, 본원에서 사용하기 위한 펩티드 링커는 "변경된 야생형 면역글로불린 힌지 영역" 또는 "변경된 면역글로불린 힌지 영역"을 포함할 수 있다. 이러한 변경된 힌지 영역은 (a) 최대 30%의 아미노산 변화(예를 들어, 최대 25%, 20%, 15%, 10% 또는 5%의 아미노산 치환 또는 결실)를 갖는 야생형 면역글로불린 힌지 영역, (b) 길이가 적어도 10개의 아미노산(예를 들어, 12, 13, 14 또는 15개의 아미노산)이고 최대 30%의 아미노산 변화(예를 들어, 최대 25%, 20%, 15%, 10% 또는 5%의 아미노산 치환 또는 결실)를 갖는 야생형 면역글로불린 힌지 영역의 일부, 또는 (c) 코어 힌지 영역을 포함하는 야생형 면역글로불린 힌지 영역의 일부(이 부분은 길이가 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개의 아미노산, 또는 적어도 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개의 아미노산일 수 있음)를 지칭한다. 특정 실시양태에서, 상부 및 코어 영역을 포함하는 IgG1 힌지와 같은 야생형 면역글로불린 힌지 영역 내의 하나 이상의 시스테인 잔기는 하나 이상의 다른 아미노산 잔기(예를 들어, 하나 이상의 세린 잔기)로 치환될 수 있다. 변경된 면역글로불린 힌지 영역은 다른 아미노산 잔기(예를 들어, 세린 잔기)로 치환된, 상부 및 코어 영역을 포함하는 IgG1 힌지와 같은 야생형 면역글로불린 힌지 영역의 프롤린 잔기를 대안적으로 또는 추가로 가질 수 있다.
연결 영역으로 사용될 수 있는 대안적인 힌지 및 링커 서열은 IgV 유사 또는 IgC 유사 도메인을 연결하는 세포 표면 수용체의 일부로부터 만들 수 있다. 세포 표면 수용체가 일렬로 다수의 IgV 유사 도메인을 함유하는 IgV 유사 도메인 사이의 영역 및 세포 표면 수용체가 다수의 일렬형 IgC 유사 영역을 함유하는 IgC 유사 도메인 사이의 영역은 연결 영역 또는 링커 펩티드로서도 사용될 수 있다. 특정 실시양태에서, 힌지 및 링커 서열은 길이가 5 내지 60개의 아미노산이고, 주로 유연할 수 있지만, 더 단단한 특징도 제공할 수 있고, 주로 최소 베타 시트 구조의 나선형 구조를 함유할 수 있다.
특정 실시양태에서, 본원에 기술된 프로테아제는 생체 내 특정 관심 표적 세포 근처, 예를 들어, 표적 종양 세포의 종양 미세환경에서 더 많은 양으로 발현된다. 관심 표적(예컨대 특정 종양 유형, 특정 종양 관련 항원을 발현하는 특정 종양)이 프로테아제와 함께 공동 위치하는 다양한 상이한 병태 또는 질환이 알려져 있으며, 프로테아제의 기질은 당해 분야에 알려져 있다. 암의 예에서, 표적 조직은 암성 조직, 특히 고형 종양의 암성 조직일 수 있다. 다수의 암, 예를 들어, 액체 종양 또는 고형 종양에서 증가된 수준의 프로테아제는 문헌에 보고되어 있다. 예를 들어, La Rocca 등, (2004) British J. of Cancer 90(7): 1414-1421 참조.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커-VL, 수용체-링커-VL, 리간드-링커-VH 또는 수용체-링커-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-절단성 링커-VL, 수용체-절단성 링커-VL, 리간드-절단성 링커-VH 또는 수용체-절단성 링커-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 114)-VL, 수용체-링커(서열번호 114)-VL, 리간드-링커(서열번호 14)-VH 또는 수용체-링커(서열번호 14)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 145)-VL, 수용체-링커(서열번호 145)-VL, 리간드-링커(서열번호 145)-VH 또는 수용체-링커(서열번호 145)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 147)-VL, 수용체-링커(서열번호 147)-VL, 리간드-링커(서열번호 147)-VH 또는 수용체-링커(서열번호 147)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 154)-VL, 수용체-링커(서열번호 154)-VL, 리간드-링커(서열번호 154)-VH 또는 수용체-링커(서열번호 154)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커(서열번호 203)-VL, 수용체-링커(서열번호 203)-VL, 리간드-링커(서열번호 203)-VH 또는 수용체-링커(서열번호 203)-VH를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커-Fc 또는 수용체-링커-Fc를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-절단성 링커-Fc 또는 수용체-절단성 링커-Fc를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-절단성 링커(서열번호 28)-Fc 또는 수용체-절단성 링커(서열번호 28)-Fc를 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-링커-Fc1 또는 수용체-링커-Fc1을 포함한다.
특정 실시양태에서, 융합 단백질은 N 말단에서 C 말단 쪽으로 리간드-절단성 링커-Fc2 또는 수용체-절단성 링커-Fc2를 포함한다.
특정 실시양태에서, Fc1 및 Fc2는 이종이량체를 형성할 수 있다. 특정 실시양태에서, Fc1은 리간드에 연결되고 Fc2는 수용체에 연결된다. 특정 실시양태에서, 리간드를 Fc1과 연결하는 링커는 절단성이고 수용체를 Fc2와 연결하는 링커는 비절단성이다. 특정 실시양태에서, 리간드를 Fc1과 연결하는 링커는 비절단성이고 수용체를 Fc2와 연결하는 링커는 절단성이다. 특정 실시양태에서, 리간드를 Fc1과 연결하는 링커는 절단성이고 수용체를 Fc2와 연결하는 링커는 절단성이다. 특정 실시양태에서, 리간드를 Fc1과 연결하는 링커는 비절단성이고 수용체를 Fc2와 연결하는 링커는 비절단성이다.
표적
일부 실시양태에서, 본원에 기술된 융합 단백질의 항원 결합 도메인은 세포 표면 분자에 특이적으로 결합한다. 특정 실시양태에서, 융합 단백질의 항원 결합 도메인은 종양 관련 항원(TAA)에 특이적으로 결합한다. TAA는 종양 세포 표면 상에서 발현되는 항원성 물질이다. 일부 실시양태에서, 항원 결합 도메인은 섬유아세포 활성화 단백질 알파(Fibroblast activation protein alpha, FAPα), 영양막 당단백질(Trophoblast glycoprotein)(5T4), 종양 관련 칼슘 신호 변환자(Tumor-associated calcium signal transducer) 2(Trop2), 피브로넥틴 EDB(EDB-FN), 피브로넥틴 F.ⅢB 도메인, CGS-2, EpCAM, EGER, HER-2, HER-3, cMet, CEA 및 FOLR1, EpCAM, EGFR, HER-2, HER-3, cMet, CEA 및 FOLR1, EpCAM, EGFR, HER-2, HER-3, c-Met, FOLR1, PSMA, CD38, BCMA 및 CEA. 5T4, AFP, B7-H3, 카드헤린-6, CAIX, CD117, CD123, CD138, CD166, CD19, CD20, CD205, CD22, CD30, CD33, CD40, CD352, CD37, CD44, CD52, CD56, CD70, CD71, CD74, CD79b, DLL3, DR5, EphA2, FAP, FGFR2, FGFR3, GPC3, gpA33, FLT-3, gpNMB, HPV-16 E6, HPV-16 E7, ITGA2, ITGA3, SLC39A6, MAGE, 메소텔린(MSLN), Mucl, Mucl6, NaPi2b, Nectin-4, P-카드헤린, NY-ESO-1, PRLR, PSCA, PTK7, ROR1, SLC44A4, SLTRK5, SLTRK6, STEAP1, TIM1, 조직 인자(TF), Trop2, WT1로부터 선택된 TAA에 특이적으로 결합한다.
일부 실시양태에서, 항원 결합 도메인은 면역 체크포인트 단백질에 특이적으로 결합한다. 면역 체크포인트 단백질의 예는 CD27, CD137, 2B4, TIGIT, CD155, ICOS, HVEM, CD40L, LIGHT, TIM-1, 0X40, DNAM-1, PD-L1, PD1, PD-L2, CTLA-4, CD80, CD40, CEACAM1, CD48, CD70, A2AR, CD39, CD73, B7-H3, B7-H4, BTLA, IDOl, ID02, TDO, KIR, LAG-3, TIM-3, VISTA, CD47 또는 SIRPα를 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 항원 결합 도메인은 바이러스 감염된 세포, 박테리아 감염된 세포, 손상된 적혈구, 동맥 플라크 세포, 염증 또는 섬유성 조직 세포 상에서 발현되는 항원에 특이적으로 결합한다.
특정 실시양태에서, 항원 결합 도메인은 사이토카인 수용체에 특이적으로 결합한다. 사이토킨 수용체의 예는 GM-CSF 수용체, G-CSF 수용체, Ⅰ형 IL 수용체, Epo 수용체, LIF 수용체, CNTF 수용체, TPO 수용체와 같은 Ⅰ형 사이토킨 수용체; IFN-알파 수용체(IFNAR1, IFNAR2), IFB-베타 수용체, IFN-감마 수용체(IFNGR1, IFNGR2), Ⅱ형 IF 수용체와 같은 Ⅱ형 사이토카인 수용체; CC 케모카인 수용체, CXC 케모카인 수용체, CX3C 케모카인 수용체, XC 케모카인 수용체와 같은 케모카인 수용체; TNFRSF5/CD40, TNFRSF8/CD30, TNFRSF7/CD27, TNFRSFlA/TNFRl/CD120a, TNFRSF1B/TNFR2/CD120b와 같은 종양 괴사 수용체 수퍼패밀리 수용체; TGF-베타 수용체 1, TGF-베타 수용체 2와 같은 TGF-베타 수용체; Ig 수퍼패밀리 수용체, 예컨대 IF-1 수용체, CSF-1R, PDGFR(PDGFRA, PDGFRB), SCFR을 포함하지만 이에 제한되지 않는다.
특정 실시양태에서, 본원에 기술된 융합 단백질의 항원 결합 도메인은 생체 내에서 적어도 하나의 관심 분자 또는 표적에 특이적으로 결합한다. 특정 실시양태에서, 관심 표적은 분화 클러스터 3(CD3), 인간 표피 성장 인자 수용체 2(HER2), 표피 성장 인자 수용체(EGFR), 메소텔린(MSLN), 조직 인자(TF), 분화 클러스터 19(CD19), 티로신-단백질 키나제 Met(c-Met), 분화 클러스터 40(CD40), 카드헤린 3(CDH3) 또는 이들의 조합이다. 특정 실시양태에서, 융합 단백질은 항체를 포함하고 항체의 적어도 하나의 항원 결합 도메인은 CD3, HER2, EGFR, MSLN, TF, CD19, c-Met, CD40, CDH3 또는 이들의 조합 상의 에피토프에 결합한다.
일부 실시양태에서, 관심 표적은 HER2이고, 융합 단백질의 항-HER2 파라토프는 서열번호 120에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 124에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-HER2 파라토프는 서열번호 120과 실질적으로 동일한 VH 아미노산 서열 및 서열번호 124와 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서 항-HER2 파라토프는 서열번호 120과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 124와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-HER2 파라토프는 서열번호 120과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 및 서열번호 124와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-HER2 파라토프는 서열번호 3에 상응하는 아미노산 서열을 갖는 scFv를 포함한다. 일부 실시양태에서, 항-HER2는 각각 서열번호 121, 122 및 123에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 125, 126 및 127에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 EGFR이고, 융합 단백질의 항-EGFR 파라토프는 서열번호 14에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 13에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-EGFR 파라토프는 서열번호 14와 실질적으로 동일한 VH 아미노산 서열 및 서열번호 13과 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-EGFR 파라토프는 서열번호 14와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 13과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-EGFR 파라토프는 서열번호 14와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 13과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-EGFR은 각각 서열번호 84, 85 및 86에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 59, 60 및 61에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 MSLN이고, 융합 단백질의 항-MSLN 파라토프는 서열번호 16에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 15에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-MSLN 파라토프는 서열번호 16과 실질적으로 동일한 VH 아미노산 서열 및 서열번호 15와 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서 항-MSLN 파라토프는 서열번호 16과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 15와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-MSLN 파라토프는 서열번호 16과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 15와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-MSLN은 각각 서열번호 69, 70 및 71에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 74, 75 및 76에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 TF(조직 인자)이고, 융합 단백질의 항-TF 파라토프는 서열번호 18에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 17에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-TF 파라토프는 서열번호 18과 실질적으로 동일한 VH 아미노산 서열 및 서열번호 17과 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-TF 파라토프는 서열번호 18과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 17과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-TF 파라토프는 서열번호 18과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 17과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-TF는 각각 서열번호 54, 55 및 56에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 48, 49 및 50에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 CD19이고 융합 단백질의 항-CD19 파라토프는 서열번호 20에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 19에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-CD19 파라토프는 서열번호 20과 실질적으로 동일한 VH 아미노산 서열 및 서열번호 19와 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-CD19 파라토프는 서열번호 20과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 19와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-CD19 파라토프는 서열번호 20과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 19와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-CD19는 각각 서열번호 64, 65 및 66에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 74, 75 및 165에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 c-Met이고 융합 단백질의 항-c-Met 파라토프는 서열번호 22에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 21에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-c-Met 파라토프는 서열번호 22와 실질적으로 동일한 VH 아미노산 서열 및 서열번호 21과 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-c-Met 파라토프는 서열번호 22와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 21과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-c-Met 파라토프는 서열번호 22와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 21과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-c-Met는 각각 서열번호 99, 100 및 101에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 94, 95 및 96에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 CDH3이고 융합 단백질의 항-CDH3 파라토프는 서열번호 24에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 23에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-CDH3 파라토프는 서열번호 24와 실질적으로 동일한 VH 아미노산 서열 및 서열번호 23과 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-CDH3 파라토프는 서열번호 24와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 23과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-CDH3 파라토프는 서열번호 24와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 23과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-CDH3은 각각 서열번호 89, 90 및 91에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 94, 95 및 96에 상응하는 아미노산을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL을 갖는다.
일부 실시양태에서, 관심 표적은 CD40이고 융합 단백질의 항-CD40 파라토프는 서열번호 172에 상응하는 아미노산 서열을 갖는 VH 및 서열번호 177에 상응하는 아미노산 서열을 갖는 VL을 갖는다. 특정 실시양태에서, 항-CD40 파라토프는 서열번호 172와 실질적으로 동일한 VH 아미노산 서열 및 서열번호 177과 실질적으로 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-CD40 파라토프는 서열번호 172와 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VH 아미노산 서열 및 서열번호 177과 약 80%, 약 85%, 약 90% 또는 약 95% 동일한 VL 아미노산 서열을 갖는다. 특정 실시양태에서, 항-CD40 파라토프는 서열번호 172와 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 아미노산 서열 및 서열번호 177과 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VL 아미노산 서열을 갖는다. 일부 실시양태에서, 항-CD40은 각각 서열번호 173, 174 및 175에 상응하는 아미노산 서열을 갖는 3개의 CDR인 HCDR1, HDR2 및 HCDR3을 갖는 VH, 및 각각 서열번호 178, 179 및 180에 상응하는 아미노산 서열을 갖는 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 갖는 VL를 갖는다.
특정 실시양태에서, 융합 단백질의 항원 결합 도메인은 면역 세포 상의 분자, 예를 들어, 폴리펩티드에 특이적으로 결합한다. 특정 실시양태에서, 융합 단백질은 면역 세포 상의 분자, 예를 들어, 폴리펩티드에 특이적으로 결합하는 항원 결합 도메인 및 TAA 둘 다에 특이적으로 결합하는 항원 결합 도메인을 포함한다. 따라서, 특정 실시양태에서, 융합 단백질은 종양 세포 및 면역 세포 둘 다에 결합한다. 특정 실시양태에서, 면역 세포는 T 세포이다. 특정 실시양태에서 면역 세포는 대식세포, 수지상 세포, 호중구, B-세포 또는 NK 세포이다.
특정 실시양태에서 융합 단백질은 T 세포 상의 CD3 항원 및 종양 세포 상의 하나 이상의 TAA에 결합한다.
차폐된 T 세포 인게이저
T 세포 인게이저(T cell engager, TCE)는 종양 세포 상의 TAA 및 T 세포 상의 CD3 에피토프에 동시에 결합하여 TCR 독립적 인공 면역 시냅스를 형성하는 폴리펩티드 작제물, 종종 이중특이성 항체이다. 이로 인해 T 세포가 활성화되어 종양 세포에 세포독성 효과를 발휘한다. T 세포를 종양 세포에 표적화할 수 있는 이중특이성 항체가 확인되었고 암 치료에서 효능에 대해 테스트되었다. 블리나투모맙(blinatumomab)은 재발된 B 세포 비호지킨 림프종(relapsed B-cell non-Hodgkin lymphoma) 및 만성 림프성 백혈병(chronic lymphocytic leukemia)과 같은 B 세포 질환의 치료를 위해 확인된 BiTE™(이중특이성 T 세포 인게이저)라는 형식의 이중특이성 항-CD3-CD19 항체의 예(Baeuerle 등 (2009) Cancer Research12:4941-4944)이며 FDA 승인을 받았다. 다른 종양 관련 표적 항원에 대한 T 세포 인게이저도 만들어졌으며 몇 가지가 임상 시험에 들어갔다: 폐암, 위암 및 대장암에 대한 AMG110/MT110 EpCAM; 위장 선암종(gastrointestinal adenocarcinoma)에 대한 AMG211/MEDI565 CEA; 및 전립선암에 대한 AMG 212/BAY2010112 PSMA(Suruadevara, C. M. 등, Oncoimmunology. 2015 Jun;4(6): e1008339 참조). 이러한 연구는 유망한 임상 효능을 보였지만 주로 사이토카인 방출 증후군(cytokine release syndrome, CRS)으로 인한 심각한 용량 제한 독성으로 인해 방해를 받았다. 이로 인해 치료 범위가 좁아졌다. 종양 미세 환경에서 주로 활성화되는 차폐된 T 세포 결합 파라토프를 사용하면 TCE의 독성을 줄일 수 있다.
특정 실시양태에서 융합 단백질은 T 세포 상의 CD3 항원 및 종양 세포 상의 TAA에 결합한다. 특정 실시양태에서 융합 단백질은 T 세포 상의 CD3 항원, 종양 세포 상의 TAA 및 종양 세포 상의 IgSF 세포외 도메인에 결합한다. 특정 실시양태에서, 융합 단백질은 T 세포 상의 CD3 항원, 종양 세포 상의 TAA 및 T 세포 상의 IgSF 세포외 도메인에 결합한다.
특정 실시양태에서, 융합 단백질은 실시예 20에서 입증되는 바와 같이 종양 미세환경에서 프로테아제에 의해 차폐되지 않게 되고, 종양 세포 상의 TAA 및 T 세포 상의 CD3 항원에 결합하여 T 세포와 종양 세포의 가교를 야기한다. 특정 실시양태에서, 차폐되지 않은 융합 단백질은 도 31에 예시된 바와 같이 T 세포 상의 CD3 항원 및 종양 세포 상의 TAA 및 IgSF 리간드 둘 다에 결합한다. 특정 실시양태에서, 종양 세포 상의 IgSF 리간드(예를 들어, PD-L1)는 T 세포 상의 IgSF 수용체(예를 들어, PD-1)의 결합을 방지하여 체크포인트 억제를 차단한다(도 31c).
특정 실시양태에서 융합 단백질은 표 BB에 나타낸 파라토프의 것과 실질적으로 동일한 항-CD3 파라토프 VH 및 VL을 포함한다. 특정 실시양태에서, CD3 파라토프는 다음의 VH 및 VL 아미노산 서열을 포함한다:
(a) 서열번호 2에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 1에 따른 아미노산 서열을 포함하는 VL;
(b) 서열번호 206에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 210에 따른 아미노산 서열을 포함하는 VL;
(c) 서열번호 215에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 219에 따른 아미노산 서열을 포함하는 VL;
(d) 서열번호 223에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 227에 따른 아미노산 서열을 포함하는 VL;
(d) 서열번호 231에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 235에 따른 아미노산 서열을 포함하는 VL; 또는
(e) 서열번호 239에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 243에 따른 아미노산 서열을 포함하는 VL.
특정 실시양태에서, CD3 파라토프는 다음과 약 90%, 약 91%, 약 92%, 약 93%, 약 94%, 약 95%, 약 96%, 약 97%, 약 98% 또는 약 99% 동일한 VH 및 VL을 포함한다:
(a) 서열번호 2에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 1에 따른 아미노산 서열을 포함하는 VL;
(b) 서열번호 206에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 210에 따른 아미노산 서열을 포함하는 VL;
(c) 서열번호 215에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 219에 따른 아미노산 서열을 포함하는 VL;
서열번호 223에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 227에 따른 아미노산 서열을 포함하는 VL;
서열번호 231에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 235에 따른 아미노산 서열을 포함하는 VL; 또는
서열번호 239에 상응하는 아미노산 서열을 포함하는 VH 및 서열번호 243에 따른 아미노산 서열을 포함하는 VL.
특정 실시양태에서, 항-CD3 파라토프는 서열번호 207, 208 및 209에 상응하는 아미노산 서열을 포함하는 3개의 중쇄 CDR인 HCDR1, HCDR2 및 HCDR3을 포함하는 VH, 및 서열번호 211, 212 및 214에 상응하는 아미노산 서열을 포함하는 3개의 경쇄 CDR인 LCDR1, LCDR2 및 LCDR3을 포함하는 VL을 포함한다. 특정 실시양태에서, 항-CD3 파라토프는 서열번호 224, 225 및 226에 상응하는 아미노산 서열을 포함하는 3개의 중쇄 CDR인 HCDR1, HCDR2 및 HCDR3을 포함하는 VH, 및 서열번호 228, 229 및 230에 상응하는 아미노산 서열을 포함하는 3개의 경쇄 CDR인 LCDR1, LCDR2 및 LCDR3을 포함하는 VL을 포함한다. 특정 실시양태에서, 항-CD3 파라토프는 서열번호 232, 233 및 234에 상응하는 아미노산 서열을 포함하는 3개의 중쇄 CDR인 HCDR1, HCDR2 및 HCDR3을 포함하는 VH, 및 서열번호 236, 237 및 238에 상응하는 아미노산 서열을 포함하는 3개의 경쇄 CDR인 LCDR1, LCDR2 및 LCDR3을 포함하는 VL을 포함한다. 특정 실시양태에서, 항-CD3 파라토프는 서열번호 240, 241 및 242에 상응하는 아미노산 서열을 포함하는 3개의 중쇄 CDR인 HCDR1, HCDR2 및 HCDR3을 포함하는 VH, 및 서열번호 244, 245 및 246에 상응하는 아미노산 서열을 포함하는 3개의 경쇄 CDR인 LCDR1, LCDR2 및 LCDR3을 포함하는 VL을 포함한다.
CAR 작제물
특정 실시양태에서, 융합 단백질은 키메라 항원 수용체(chimeric antigen receptor, CAR) 또는 CAR 단편에 포함될 수 있다. CAR은 하나 이상의 세포외 리간드 결합 도메인, 선택적으로 힌지 영역, 막관통 영역 및 세포내 신호전달 영역을 포함할 수 있다. 하나 이상의 세포외 리간드 결합 도메인은 하나 이상의 융합 단백질을 포함할 수 있다. 세포외 리간드 결합 도메인은 전형적으로 단일 사슬 면역글로불린 가변 단편(single-chain immunoglobulin variable fragment, scFv), 또는 Fab 또는 천연 단백질 리간드와 같은 다른 리간드 결합 도메인을 포함할 수 있다. 힌지 영역은 일반적으로 하나 이상의 아미노산, CD8 알파 힌지 영역 또는 IgG4 영역(또는 기타), 및 이들의 조합과 같은 가변 길이의 폴리펩티드 힌지를 포함할 수 있다. 막관통 도메인은 전형적으로 CD8 알파, CD28, 또는 DAP10, DAP12 또는 NKG2D와 같은 다른 막관통 단백질 및 이들의 조합으로부터 유도된 막관통 영역을 포함할 수 있다. 세포내 신호전달 영역은 CD28, 4-1BB, CD3 제타, OX40, 2B4 또는 다른 세포내 신호전달 도메인, 및 이들의 조합과 같은 하나 이상의 세포내 신호전달 도메인을 포함할 수 있다. 예를 들어, 하나 이상의 세포내 신호전달 도메인은 CD28 및 CD3 제타, 4-1BB 및 CD3 제타, 또는 CD3 제타를 포함할 수 있다. T 세포 및 NK 세포와 같은 림프구는 키메라 항원 수용체 세포(예를 들어, CAR-T)를 생성하도록 변형될 수 있다. CAR-T 세포는 특정 가용성 항원, 또는 종양 세포 표면과 같은 표적 세포 표면 또는 종양 미세환경의 세포 상의 항원을 인식할 수 있다. 세포외 리간드 결합 도메인이 동족 리간드에 결합하면 CAR의 세포내 신호전달 도메인이 림프구를 활성화할 수 있다. 예를 들어, Brudno 등, Nature Rev. Clin. Oncol. (2018) 15:31-46; Maude 등, N. Engl. J. Med. (2014) 371:1507-1517; Sadelain 등, Cancer Disc. (2013) 3:388-398 (2018); 미국 특허 제7,446,190호 및 제8,399,645호 참조.
특정 실시양태에서, 본원에 기술된 바와 같은 리간드 수용체 쌍 작제물을 포함하는 CAR 작제물이 제공된다. 특정 실시양태에서, CAR 작제물은 리간드 수용체 쌍 작제물에 융합될 수 있는 scFv를 포함한다. 특정 실시양태에서, 리간드 수용체 쌍 작제물은 scFv의 N-말단에 링커와 함께 또는 링커 없이 융합될 수 있는 단일 사슬 리간드 수용체 쌍 작제물이다. 특정 실시양태에서, 단일 사슬 리간드 수용체 쌍 작제물은 프로테아제 절단성 링커를 포함한다. 특정 실시양태에서, 수용체는 scFv의 N-말단에 제1 링커와 함께 또는 없이 융합되고 리간드는 scFv의 중쇄와 경쇄를 연결하는 제2 링커에 내부적으로 융합된다. 특정 실시양태에서 링커는 프로테아제에 의해 절단 가능한 프로테아제 절단 부위를 포함한다. 특정 실시양태에서, 리간드는 scFv의 N-말단에 제1 링커와 함께 또는 없이 융합되고 수용체는 scFv의 중쇄와 경쇄를 연결하는 제2 링커에 내부적으로 융합된다. 특정 실시양태에서 제1 링커는 프로테아제에 의해 절단 가능하고 제2 링커는 절단 불가능하다. 특정 실시양태에서 T 세포는 리간드 수용체 쌍 CAR을 발현하도록 변형될 수 있다.
서열 상동성
본 개시내용의 특정 실시양태는 본원에 기술된 융합 단백질을 암호화하는 분리된 폴리뉴클레오티드 또는 폴리뉴클레오티드 세트에 관한 것이다. 이러한 맥락에서 폴리뉴클레오티드는 융합 단백질의 전부 또는 일부를 암호화할 수 있다.
용어 "핵산", "핵산 분자" 및 "폴리뉴클레오티드"는 본원에서 상호교환적으로 사용되며 데옥시리보뉴클레오티드 또는 리보뉴클레오티드 또는 이들의 유사체 중 임의의 길이의 뉴클레오티드의 중합체 형태를 지칭한다. 폴리뉴클레오티드의 비제한적 예는 유전자, 유전자 단편, 메신저 RNA(mRNA), cDNA, 재조합 폴리뉴클레오티드, 플라스미드, 벡터, 임의의 서열의 분리된 DNA, 임의의 서열의 분리된 RNA, 핵산 프로브 및 프라이머를 포함한다.
주어진 폴리펩티드를 "암호화"하는 폴리뉴클레오티드는 적절한 조절 서열의 제어 하에 놓였을 때 생체 내에서 폴리펩티드로 전사되고(DNA의 경우) 번역되는(mRNA의 경우) 폴리뉴클레오티드이다. 코딩 서열의 경계는 5'(아미노) 말단의 시작 코돈과 3'(카복시) 말단의 번역 정지 코돈에 의해 결정된다. 전사 종결 서열은 코딩 서열에 대해 3'에 위치할 수 있다.
특정 실시양태에서, 본 개시내용은 본원에 기술된 융합 단백질의 적어도 일부, 예를 들어, 생물학적 기능성 단백질의 제1 또는 제2 폴리펩티드를 암호화하는 폴리펩티드와 동일하거나 실질적으로 동일한 폴리뉴클레오티드 및 폴리펩티드 서열에 관한 것이다. 2개 이상의 폴리뉴클레오티드 또는 폴리펩티드 서열과 관련하여 "동일한"이라는 용어는 동일한 2개 이상의 서열 또는 하위서열을 지칭한다. 서열은 당업자에게 공지된 통상 사용되는 서열 비교 알고리즘 중 하나를 사용하거나 수동 정렬 및 육안 검사로 측정했을 때 비교 범위(comparison window) 또는 지정된 영역에 걸쳐 비교하고 최대 상관(maximum correspondence)을 위해 정렬하는 경우 동일한 아미노산 잔기 또는 뉴클레오티드의 백분율(예를 들어, 특정 영역에 대해 약 80%, 약 85%, 약 90% 또는 약 95%의 동일성)을 갖는다면 "실질적으로 동일"하다. 이 정의는 또한 테스트 폴리뉴클레오티드 서열의 보체를 지칭한다. 동일성은 길이가 적어도 약 50개의 아미노산 또는 뉴클레오티드인 영역에 걸쳐, 또는 길이가 75-100개의 아미노산 또는 뉴클레오티드인 영역에 걸쳐, 또는 명시되지 않은 경우, 폴리펩티드 또는 폴리뉴클레오티드의 전체 서열에 걸쳐 존재할 수 있다. 서열 비교를 위해, 전형적으로 테스트 서열을 지정된 기준 서열과 비교한다. 서열 비교 알고리즘을 사용하는 경우 테스트 및 기준 서열을 컴퓨터에 입력하고, 필요에 따라 서열 좌표를 지정하고, 서열 알고리즘 프로그램 매개변수를 지정한다. 기본 프로그램 매개변수(default program parameter)를 사용하거나 대체 매개변수를 지정할 수 있다. 그런 다음 서열 비교 알고리즘은 프로그램 매개변수에 기반하여 기준 서열에 대한 테스트 서열의 서열 동일성 백분율을 계산한다.
본원에 사용된 "비교 범위"는 테스트 서열과 기준 서열이 최적으로 정렬된 후 테스트 서열이 동일한 수의 인접 위치의 기준 서열과 비교될 수 있는 20 내지 1000개의 연속 아미노산 또는 뉴클레오티드 위치, 예를 들어, 약 50 내지 약 600개 또는 약 100개 내지 약 300개 또는 약 150개 내지 약 200개의 인접 아미노산 또는 뉴클레오티드 위치일 수 있는 연속 아미노산 또는 뉴클레오티드 위치를 포함하는 서열 세그먼트를 지칭한다. 전장 서열까지 포함하는 더 긴 세그먼트도 특정 실시양태에서 비교 범위로 사용될 수 있다. 비교를 위한 서열 정렬 방법은 당업자에게 공지되어 있다. 비교를 위한 최적의 서열 정렬은, 예를 들어, Smith & Waterman, 1970, Adv. Appl. Math., 2:482c의 로컬 상동성 알고리즘(local homology algorithm); Needleman & Wunsch, 1970, J. Mol. Biol., 48:443의 상동성 정렬 알고리즘(homology alignment algorithm); Pearson & Lipman, 1988, Proc. Natl. Acad. Sci. USA, 85:2444의 유사성 검색 방법, 또는 이러한 알고리즘의 전산화된 구현(예를 들어, Genetics Computer Group(Madison, WI)의 Wisconsin Genetics Software Package 내 GAP, BESTFIT, FASTA 또는 TFASTA), 또는 수동 정렬 및 육안 검사(예를 들어, Ausubel 등, Current Protocols in Molecular Biology, (1995 supplement), Cold Spring Harbor Laboratory Press 참조)에 의해 수행될 수 있다. 서열 동일성 %를 측정하는데 적합한 이용 가능한 알고리즘의 예는 Altschul 등, 1997, Nuc. Acids Res., 25:3389-3402, 및 Altschul 등, 1990, J. Mol. Biol., 215:403-410에 각각 기술되어 있는 BLAST 및 BLAST 2.0 알고리즘이다. BLAST 분석을 수행하기 위한 소프트웨어는 NCBI(National Center for Biotechnology Information) 웹 사이트를 통해 공개적으로 사용할 수 있다.
본원에 기술된 특정 실시양태는 하나 이상의 아미노산 치환을 포함하는 변이체 서열에 관한 것이다. 일부 실시양태에서, 아미노산 치환은 보존적 치환이다. 일반적으로, "보존적 치환"은 하나의 아미노산을 물리적, 화학적 및/또는 구조적 특성이 유사한 또 다른 아미노산으로 치환하는 것으로 간주된다. 통상의 보존적 치환은 표 4의 1열에 나열되어 있다. 당업자는 무엇이 보존적 치환을 구성하는지 결정하는 주요 요인이 보통 아미노산 측쇄의 크기 및 이의 물리적/화학적 특성이지만 특정 환경은 주어진 아미노산을 1열에 나열된 것보다 더 넓은 범위의 아미노산으로 대체할 수 있도록 한다는 것을 이해할 것이다. 이러한 추가 아미노산은 대체되는 아미노산과 특성은 유사하지만 크기가 더 광범위하게 달라지는 경향이 있거나, 크기는 비슷하지만 물리적/화학적 특성이 더 다양한 경향이 있다. 이러한 더 광범위한 보존적 치환은 표 4의 2열에 나열되어 있다. 당업자는 아미노산 치환이 이루어지는 특정 단백질 환경을 고려하여 선택할 가장 적절한 치환기 그룹을 쉽게 확인할 수 있다.
[표 4]

융합 단백질의 제조
본원에 기술된 융합 단백질은 당업계에 공지된 표준 재조합 방법을 사용하여 생성할 수 있다(예를 들어, 미국 특허 제4,816,567호 및 "Antibodies: A Laboratory Manual," 2nd Edition, Ed. Greenfield, Cold Spring Harbor Laboratory Press, New York, 2014 참조).
융합 단백질을 암호화하는 벡터
본원에 기술된 융합 단백질의 재조합 생성을 위해, 융합 단백질을 암호화하는 폴리뉴클레오티드 또는 폴리뉴클레오티드 세트가 생성되고 추가 클로닝 및/또는 숙주 세포에서의 발현을 위해 하나 이상의 벡터에 삽입된다. 융합 단백질을 암호화하는 폴리뉴클레오티드(들)은 당업계에 공지된 표준 방법에 의해 생성될 수 있다(예를 들어, Ausubel 등, Current Protocols in Molecular Biology, John Wiley & Sons, New York, 1994 & update, 및 "Antibodies: A Laboratory Manual," 2nd Edition, Ed. Greenfield, Cold Spring Harbor Laboratory Press, New York, 2014 참조). 당업자가 이해할 수 있는 바와 같이, 융합 단백질의 발현에 필요한 폴리뉴클레오티드의 수는 융합 단백질이 항체를 포함하는지 여부 및 융합 단백질 내의 폴리펩티드의 수를 포함한 융합 단백질의 형식에 따라 달라질 것이다. 예를 들어, 융합 단백질이 2개의 폴리펩티드 사슬을 포함하는 경우, 각각 하나의 폴리펩티드 사슬을 암호화하는 2개의 폴리뉴클레오티드가 필요할 것이다. 유사하게, 특정 실시양태에서, 융합 단백질이 mAb 형식의 생물학적 기능성 단백질을 포함하는 경우, 각각 하나의 폴리펩티드 사슬을 암호화하는 2개의 폴리뉴클레오티드가 필요하다. 다중 폴리뉴클레오티드가 필요한 경우, 이는 하나의 벡터 또는 하나 초과의 벡터에 통합될 수 있다.
일반적으로, 발현을 위해, 폴리뉴클레오티드 또는 폴리뉴클레오티드 세트는 폴리뉴클레오티드의 효율적인 전사에 필요한 하나 이상의 조절 요소, 예컨대 전사 요소와 함께 발현 벡터에 통합된다. 이러한 조절 요소의 예는 프로모터(promoter), 인핸서(enhancer), 종결자(terminator) 및 폴리아데닐화 신호를 포함하지만 이에 제한되지 않는다. 당업자는 조절 요소의 선택이 융합 단백질의 폴리펩티드의 발현을 위해 선택된 숙주 세포에 의존하고 이러한 조절 요소가 박테리아, 진균, 바이러스, 포유동물 또는 곤충 유전자를 포함하여 다양한 공급원으로부터 유도될 수 있음을 이해할 것이다. 발현 벡터는 발현된 단백질의 발현 또는 정제를 용이하게 하는 이종 핵산 서열을 선택적으로 추가로 함유할 수 있다. 이의 예는 금속 친화성 태그(metal-affinity tag), 히스티딘 태그(histidine tag), 아비딘/스트렙트아비딘 암호화 서열(avidin/streptavidin encoding sequence), 글루타티온-S-트랜스퍼라제(glutathione-S-transferase, GST) 암호화 서열 및 비오틴 암호화 서열과 같은 신호 펩티드 및 친화성 태그를 포함하지만 이에 제한되지 않는다. 발현 벡터는 염색체외 벡터 또는 통합 벡터일 수 있다.
본 개시내용의 특정 실시양태는 본원에 기술된 융합 단백질의 적어도 일부를 암호화하는 하나 이상의 폴리뉴클레오티드를 포함하는 벡터(예컨대 발현 벡터)에 관한 것이다. 폴리뉴클레오티드(들)는 단일 벡터 또는 하나 초과의 벡터에 의해 구성될 수 있다. 일부 실시양태에서, 폴리뉴클레오티드는 멀티시스트론 벡터(multicistronic vector)로 구성된다.
폴리뉴클레오티드를 발현하기 위해 사용되는 발현 벡터는 융합 단백질을 암호화하는 벡터를 포함하는 세포에 대한 pTT5 및 pUC15를 포함하지만 이에 제한되지 않는다.
융합 단백질 폴리펩티드의 클로닝 또는 발현에 적합한 숙주 세포는 당업계에 공지된 바와 같은 다양한 원핵 또는 진핵 세포를 포함한다. 진핵 숙주 세포는, 예를 들어, 포유동물 세포, 식물 세포, 곤충 세포 및 효모 세포(예컨대 사카로마이세스(Saccharomyces) 또는 피키아(Pichia) 세포)를 포함한다. 원핵 숙주 세포는, 예를 들어, 대장균(E. coli), A. 살모니시다(A. Salmonicida) 또는 B. 서브틸리스(B. subtilis) 세포를 포함한다.
특정 실시양태에서, 융합 단백질은 특히 글리코실화 및 Fc 이펙터 기능이 필요하지 않을 때, 예를 들어, 미국 특허 제5,648,237호, 제5,789,199호 및 제5,840,523호, 및 Charlton, Methods in Molecular Biology, Vol. 248, pp. 245-254, B.K.C. Lo, ed., Humana Press, Totowa, N.J., 2003에 기술된 바와 같이 박테리아에서 생성된다.
사상 진균(filamentous fungi) 또는 효모와 같은 진핵 미생물은 특정 실시양태에서 적합한 발현 숙주 세포, 특히 글리코실화 경로가 "인간화"되어 부분적으로 또는 완전히 인간 글리코실화 패턴을 갖는 항체를 생성하는 진균 및 효모 균주이다(예를 들어, Gerngross, 2004, Nat. Biotech. 22:1409-1414 및 Li 등, 2006, Nat. Biotech. 24:210-215 참조).
글리코실화 융합 단백질의 발현에 적합한 숙주 세포는 보통 진핵 세포이다. 예를 들어, 미국 특허 제5,959,177호, 제6,040,498호, 제6,420,548호, 제7,125,978호 및 제6,417,429호는 트랜스제닉 식물에서 항체를 생성하기 위한 PLANTIBODIES™ 기술을 설명한다. 현탁액에서 성장하도록 조정된 포유동물 세포주는 융합 단백질의 발현에 특히 유용하다. 이의 예는 SV40(COS-7)에 의해 형질전환된 원숭이 신장 CV1 계통, 인간 배아 신장(human embryonic kidney, HEK) 계통 293 또는 293 세포(예를 들어, Graham 등, 1977, J. Gen Virol., 36:59 참조), 베이비 햄스터 신장(baby hamster kidney, BHK) 세포, 마우스 세르톨리 TM4 세포(예를 들어, Mather, 1980, Biol Reprod, 23:243-251 참조); 원숭이 신장 세포(CV1), 아프리카 녹색 원숭이 신장 세포(VERO-76), 인간 자궁경부암(HeLa) 세포, 개 신장 세포(MDCK), 버팔로 래트 간 세포(BRL 3A), 인간 폐 세포(W138), 인간 간 세포(Hep G2), 마우스 유방 종양(MMT 060562), TRI 세포(예를 들어, Mather 등, 1982, Annals N.Y. Acad Sci, 383:44-68 참조), MRC 5 세포, FS4 세포, 차이니즈 햄스터 난소(CHO) 세포(DHFR- CHO 세포 포함, Urlaub 등, 1980, Proc Natl Acad Sci USA, 77:4216 참조) 및 골수종 세포주(예컨대 Y0, NS0 및 Sp2/0)를 포함하지만 이에 제한되지 않는다. 항체 생성에 적합한 예시적인 포유동물 숙주 세포주는 Yazaki & Wu, Methods in Molecular Biology, Vol. 248, pp. 255-268 (B.K.C. Lo, ed., Humana Press, Totowa, N.J., 2003)에 검토되어 있다.
특정 실시양태에서, 숙주 세포는 포유동물 세포주와 같은 일시적 또는 안정한 고등 진핵 세포주이다. 일부 실시양태에서, 숙주 세포는 포유류 HEK293T, CHO, HeLa, NS0 또는 COS 세포이다. 일부 실시양태에서, 숙주 세포는 융합 단백질의 성숙한 글리코실화를 허용하는 안정한 세포주이다.
융합 단백질을 암호화하는 발현 벡터(들)를 포함하는 숙주 세포는 융합 단백질을 생성하기 위해 통상적인 방법을 사용하여 배양할 수 있다. 대안적으로, 일부 실시양태에서, 융합 단백질을 암호화하는 발현 벡터(들)를 포함하는 숙주 세포는 대상체에게 융합 단백질을 전달하기 위해 치료적 또는 예방적으로 사용될 수 있거나, 폴리뉴클레오티드 또는 발현 벡터는 생체 외에서 대상체로부터의 세포에 투여된 다음 상기 세포가 대상체의 몸으로 돌아갈 수 있다.
일부 실시양태에서, 숙주 세포는 본원에 기술된 결합 도메인의 VL 및 결합 도메인의 VH를 암호화하는 폴리뉴클레오티드를 포함하는 벡터를 포함한다(예를 들어, 형질전환되었다). 일부 실시양태에서, 숙주 세포는 본원에 기술된 결합 도메인의 VL을 암호화하는 폴리뉴클레오티드를 포함하는 제1 벡터 및 결합 도메인의 상응하는 VH를 암호화하는 폴리뉴클레오티드를 포함하는 제2 벡터를 포함한다. 일부 실시양태에서, 숙주 세포는 진핵 세포, 예를 들어, 차이니즈 햄스터 난소(CHO) 세포, 인간 배아 신장(HEK) 세포 또는 림프계 세포(lymphoid cell)(예를 들어, Y0, NS0, Sp20 세포)이다.
특정 실시양태에서, 숙주 세포는 Expi293™(Thermo Fisher, Waltham, MA)이다. 특정 실시양태에서, 숙주 세포는 CHO-S 세포(National Research Council Canada) 또는 HEK293 세포이다.
본 개시내용의 특정 실시양태는 융합 단백질을 암호화하는 하나 이상의 폴리뉴클레오티드 또는 융합 단백질을 암호화하는 하나 이상의 발현 벡터가 도입된 숙주 세포를 융합 단백질의 발현에 적합한 조건 하에서 배양하는 단계 및 선택적으로 숙주 세포로부터(또는 숙주 세포 배양 배지로부터) 융합 단백질을 회수하는 단계를 포함하는, 융합 단백질을 제조하는 방법에 관한 것이다.
사용될 수 있는 세포 배양 배지는 DMEM(Thermo Fisher, Waltham, MA), Opti-MEM™(Thermo Fisher, Waltham, MA), Opti-MEM™ I Reduced Serum Medium(Thermo Fisher, Waltham, MA), RPMI-1640 배지, Expi293™ Expression Medium(Thermo Fisher, Waltham, MA) 및 FreeStyle CHO expression medium(Thermo Fisher Scientific, Waltham, MA)를 포함하지만 이에 제한되지 않는다.
세포 배양 배지에는 혈청, 예를 들어, 소 태아 혈청(FBS), 아미노산, 예를 들어, L-글루타민, 항생제, 예를 들어, 페니실린 및 스트렙토마이신 및/또는 항진균제, 예를 들어, 암포테리신, 또는 세포 배양을 지원하기 위해 일상적으로 사용되는 임의의 다른 보충제가 보충될 수 있다.
융합 단백질의 정제
전형적으로, 융합 단백질은 발현 후에 정제된다. 단백질은 당업자에게 공지된 다양한 방식으로 분리 또는 정제될 수 있다(예를 들어, Protein Purification: Principles and Practice, 3rd Ed., Scopes, Springer-Verlag, NY, 1994 참조). 표준 정제 방법은 FPLC 및 HPLC와 같은 시스템을 사용하여 대기압 또는 고압에서 수행되는 이온 교환, 소수성 상호작용, 친화성, 사이징 또는 겔 여과 및 역상을 포함하는 크로마토그래피 기술을 포함하다. 추가의 정제 방법은 전기영동, 면역학적, 침전, 투석 및 크로마토포커싱(chromatofocusing) 기술을 포함한다. 단백질 농축과 함께 한외여과 및 정용여과 기술도 유용하다. 당업계에 잘 알려진 바와 같이, 다양한 천연 단백질이 Fc 및 항체에 결합하고, 이러한 단백질은 특정 항체의 정제에 사용된다. 예를 들어, 박테리아 단백질 A와 G는 Fc 영역에 결합한다. 마찬가지로, 박테리아 단백질 L은 일부 항체의 Fab 영역에 결합한다. 정제는 특정 융합 파트너에 의해서도 활성화될 수 있다. 예를 들어, 항체는 GST 융합을 사용하는 경우 글루타티온 수지를 사용하여 정제할 수 있거나, His-태그를 사용하는 경우 Ni+2 친화성 크로마토그래피를 사용하여 정제할 수 있거나, 플래그 태그(flag-tag)를 사용하는 경우 고정된 항플래그 항체(anti-flag antibody)를 사용하여 정제할 수 있다. 필요한 정제 정도는 항체의 용도에 따라 달라진다. 일부 경우에 정제가 필요하지 않을 수 있다.
특정 실시양태에서, 융합 단백질은 실질적으로 순수하다. 본원에 기술된 융합 단백질과 관련하여 사용될 때 "실질적으로 순수한"(또는 "실질적으로 정제된")이라는 용어는 융합 단백질이 이의 자연 발생 환경에서, 예컨대 재조합적으로 생성된 융합 단백질의 경우에는 고유 세포 또는 숙주 세포에서 발견되는 단백질이 일반적으로 동반되거나 이와 상호작용하는 성분이 실질적으로 또는 본질적으로 없다는 것을 의미한다. 특정 실시양태에서, 실질적으로 순수한 융합 단백질은 오염 단백질이 약 30% 미만, 약 25% 미만, 약 20% 미만, 약 15% 미만, 약 10% 미만 또는 약 5% 미만(건조 중량 기준)인 단백질 제제이다.
단백질 정제 및/또는 균질성의 평가는 비환원/환원 CE-SDS, 비환원/환원 SDS-PAGE, 초고성능 액체 크로마토그래피-크기 배제 크로마토그래피(UPLC-SEC), 고성능 액체 크로마토그래피(HPLC), 질량 분석법, 다각도 광산란(multi angle light scattering, MALS), 동적 광산란(DLS)을 포함하지만 이에 제한되지 않는 당업계에 공지된 임의의 방법으로 수행할 수 있다.
번역 후 변형
특정 실시양태에서, 본원에 기술된 융합 단백질은 하나 이상의 번역 후 변형(post-translational modification)을 포함한다. 이러한 번역 후 변형은 생체 내에서 발생할 수 있거나 숙주 세포에서 융합 단백질을 분리한 후 시험관 내에서 수행될 수 있다.
번역 후 변형은 당업계에 공지된 다양한 변형을 포함한다(예를 들어, Proteins - Structure and Molecular Properties, 2nd Ed., T. E. Creighton, W. H. Freeman and Company, New York, 1993; Post-Translational Covalent Modification of Proteins, B. C. Johnson, Ed., Academic Press, New York, pgs. 1-12, 1983; Seifter 등, 1990, Meth. Enzymol., 182:626-646, 및 Rattan 등, 1992, Ann. N.Y. Acad. Sci., 663:48-62 참조). 융합 단백질이 하나 이상의 번역 후 변형을 포함하는 실시양태에서, 융합 단백질은 하나 또는 여러 부위에서 동일한 유형의 변형을 포함할 수 있거나, 상이한 부위에서 상이한 변형을 포함할 수 있다.
번역 후 변형의 예는 글리코실화, 아세틸화, 인산화, 아미드화, 공지된 보호/차단 그룹에 의한 유도체화, 포르밀화, 산화, 환원, 단백질분해 절단, 또는 브롬화시아노겐, 트립신, 키모트립신, 파파인, V8 프로테아제 또는 NaBH4에 의한 특정 화학적 절단을 포함한다.
번역 후 변형의 다른 예는, 예를 들어, N-연결되거나 O-연결된 탄수화물 사슬의 추가 또는 제거, N-연결되거나 O-연결된 탄수화물 사슬의 화학적 변형, N-말단 또는 C-말단 엔드의 처리, 아미노산 백본으로의 화학적 잔기의 부착, 및 원핵 숙주 세포 발현으로 인한 N-말단 메티오닌 잔기의 첨가 또는 결실을 포함한다. 번역 후 변형은 또한 단백질의 검출 및 분리를 가능하게 하는 효소, 형광, 동위원소 또는 친화성 표지와 같은 검출 가능한 표지를 사용한 변형을 포함할 수 있다. 적합한 효소 표지의 예는 호스래디쉬 퍼옥시다제, 알칼리 포스파타제, 베타-갈락토시다제 및 아세틸콜린에스테라제를 포함하지만 이에 제한되지 않는다. 적합한 보결 그룹 복합체(prosthetic group complex)의 예는 스트렙트아비딘/비오틴(streptavidin/biotin) 및 아비딘/비오틴(avidin/biotin)을 포함하지만 이에 제한되지 않는다. 적합한 형광 물질의 예는 움벨리페론(umbelliferone), 플루오레세인(fluorescein), 플루오레세인 이소티오시아네이트(fluorescein isothiocyanate), 로다민(rhodamine), 디클로로트리아지닐아민 플루오레세인(dichlorotriazinylamine fluorescein), 단실 클로라이드(dansyl chloride) 및 피코에리트린(phycoerythrin)을 포함하지만 이에 제한되지 않는다. 발광 물질의 예는 루미놀(luminol)이고, 생물발광 물질의 예는 루시퍼라제(luciferase), 루시페린(luciferin) 및 에쿼린(aequorin)을 포함하고, 적합한 방사성 물질의 예는 요오드, 탄소, 황, 삼중수소, 인듐, 테크네튬(technetium), 탈륨, 갈륨, 팔라듐, 몰리브덴, 크세논 및 불소를 포함한다.
번역 후 변형의 추가 예는 아실화, ADP-리보실화, 아미드화, 플라빈의 공유 부착, 헴(heme) 모이어티의 공유 부착, 뉴클레오티드 또는 뉴클레오티드 유도체의 공유 부착, 지질 또는 지질 유도체의 공유 부착, 포스포티딜이노시톨의 공유 부착, 가교결합, 고리화, 디설파이드 결합 형성, 탈메틸화, 공유 가교결합 형성, 시스테인 형성, 피로글루타메이트 형성, 감마-카복실화, GPI 앵커 형성, 하이드록실화, 요오드화, 메틸화, 미리스틸화, 페길화, 프레닐화, 라세미화, 셀레노일화, 황산화, 단백질에 대한 아미노산의 전달-RNA 매개 첨가, 예컨대 아르기닐화 및 유비퀴틴화를 포함한다.
융합 단백질의 차폐 및 프로그래밍된 활성화
본 개시내용에 따르면, 융합 단백질은 이의 의도된 표적(들)과 결합하지 않도록 차폐된다. 표적(들)에 대한 융합 단백질의 결합이 감소되는 정도는 효소 결합 면역흡착제 검정(ELISA), 생체층 간섭계(bio-layer interferometery, BLI), 표면 플라스몬 공명(SPR), 형광 활성화 세포 분리(fluorescence-activated cell sorting, FACS), 유세포분석, 키네틱 배제 검정(kinetic exclusion assay, KinExA), 메조 스케일 디스커베이(meso scale discovey, MSD)), 미세 유체 공학(microfluidics) 또는 등온 적정 열량 측정법(isothermal titration calorimetry, ITC)과 같은 표준 기술로 측정할 수 있다. 특정 실시양태에서, 융합 단백질은 리간드-수용체 쌍에 의해 차폐되는 항원 결합 도메인을 포함하고 항원 결합 도메인과 이의 동족 항원의 결합은 상응하는 차폐되지 않은 항원 결합 도메인에 비해 적어도 3배 감소되는데, 예를 들어, 항원 결합 도메인과 이의 동족 항원의 결합은 적어도 5배, 적어도 10배, 적어도 20배, 적어도 25배 또는 적어도 30배, 또는 적어도 40배, 또는 적어도 50배, 또는 적어도 70배 또는 적어도 80배, 또는 적어도 90배 또는 적어도 100배, 또는 적어도 200배 또는 적어도 400배, 또는 적어도 600배 또는 적어도 800배 또는 적어도 1000배 또는 적어도 2000배 또는 적어도 5000배 또는 적어도 10,000배 감소된다.
본 개시내용에 따르면, 리간드-수용체 쌍의 리간드 또는 수용체와 생물학적 기능성 단백질 사이의 펩티드 링커 중 적어도 하나의 프로테아제 절단은 융합 단백질이 의도된 표적(들)에 결합할 수 있도록 융합 단백질을 차폐 해제(활성화)시킨다. 절단에 대한 펩티드 링커의 감수성은 본원의 실시예에 기술된 것을 포함하는 표준 기술로 시험관 내에서 테스트할 수 있다. 프로테아제 절단 후 융합 단백질과 표적(들)의 결합이 회복되는 정도는 효소 결합 면역흡착제 검정(ELISA), 생체층 간섭계(BLI), 표면 플라스몬 공명(SPR), 형광 활성화 세포 분리(FACS), 유세포분석, 키네틱 배제 검정(KinExA), 메조 스케일 디스커베이(MSD)), 미세 유체 공학 또는 등온 적정 열량 측정법(ITC)과 같은 표준 기술로 테스트할 수 있다. 표적(들)에 대한 융합 단백질의 결합 회복은 부분적이거나 완전할 수 있다. 결합의 부분적 회복은 융합 단백질의 관련 도메인(예를 들어, 리간드, 수용체 또는 항원 결합 도메인)과 이의 의도된 표적의 측정 가능한 결합으로 정의되며, 예를 들어, 모 도메인의 결합보다 100배 내지 2배 작을 수 있다. 부분적 회복은 모 도메인의 결합보다 약 100배, 75배, 50배, 25배, 10배, 5배 또는 2배 작을 수 있다.
치료 방법
특정 측면에서, 본 개시내용은 본원에 기술된 융합 단백질을 이것이 필요한 대상체에게 투여하는 것을 포함하는, 질환 또는 병태의 치료 방법을 포함한다. 특정 실시양태에서, 대상체는 포유동물이다. 특정 실시양태에서, 대상체는 인간이다.
특정 실시양태에서, 본원에 개시된 방법은 암 치료를 위한 것이다. 암은 혈액 신생물(백혈병, 골수종 및 림프종 포함), 암종(선암종 및 편평 세포 암종 포함), 흑색종 및 육종을 포함할 수 있지만 이에 제한되지 않는다. 암종 및 육종은 종종 "고형 종양"이라고도 한다. 특정 실시양태에서, 암은 고형 종양이다. 특정 실시양태에서, 암은 백혈병이다. 특정 실시양태에서, 암은 림프종이다.
융합 단백질은 세포독성 또는 세포증식억제(cytostatic) 효과를 발휘할 수 있고 종양 크기 감소, 종양 크기 증가의 지연 또는 예방, 종양의 소실 또는 제거와 재발생 사이의 무질병 생존 시간의 증가, 종양의 초기 또는 후속 발생(예를 들어, 전이)의 예방, 종양 진행 시간의 증가, 종양과 관련된 하나 이상의 부작용의 감소, 또는 종양이 있는 대상체의 전체 생존 시간의 증가 중 하나 이상을 초래할 수 있다.
특정 실시양태에서, 본원에 개시된 방법은 면역결핍 장애 또는 질환의 치료를 위한 것이다.
특정 실시양태에서, 본원에 개시된 방법은 자가면역 질환 또는 병태의 치료를 위한 것이다.
본원에 기술된 방법은 본원에 기술된 융합 단백질을 이것이 필요한 대상체에게 투여하는 것을 포함한다. 융합 단백질은 적절한 투여 경로에 의해 대상체에게 투여될 수 있다. 당업자가 이해하는 바와 같이, 투여 경로 및/또는 방식은 원하는 결과에 따라 달라질 것이다. 전형적으로, 면역치료 항체는 전신 투여 또는 국소 투여에 의해 투여된다. 국소 투여는 종양 부위에서 또는 종양 배액 림프절(tumor draining lymph node) 내로 이루어질 수 있다. 일반적으로, 융합 단백질은 비경구 투여, 예를 들어, 정맥내, 근육내, 피내, 복강내, 피하 또는 척수 투여에 의해, 예컨대 주사 또는 주입에 의해 투여될 것이다.
융합 단백질의 "치료적 유효량"을 투여함으로써 치료가 달성된다. "치료적 유효량"은 원하는 치료 결과를 달성하기 위해 필요한 투여량 및 기간 동안 효과적인 양을 의미한다. 치료적 유효량은 대상체의 질환 상태, 연령, 성별 및 체중과 같은 인자에 따라 달라질 수 있다. 치료적 유효량은 또한 치료적으로 유익한 효과가 융합 단백질의 임의의 독성 또는 해로운 효과를 능가하는 양이다. "충분한 양"은 원하는 효과를 생성하기에 충분한 양, 예를 들어, 면역 세포에 대한 면역조절 리간드-수용체 결합에 의해 표적 세포 또는 조직에 대한 면역 반응을 조절하기에 충분한 양을 의미한다.
융합 단백질의 적합한 투여량은 숙련된 의사가 결정할 수 있다. 선택된 투여량 수준은 사용된 특정 융합 단백질의 활성, 투여 경로, 투여 시간, 폴리펩티드의 분비 속도, 치료 기간, 기타 약물, 융합 단백질과 조합하여 사용되는 화합물 및/또는 물질, 예를 들어 항암제, 치료 대상체의 연령, 성별, 체중, 병태, 일반 건강 및 이전 병력, 및 의학 분야에 잘 알려진 유사 인자를 포함한 다양한 약동학 인자에 따라 달라질 것이다.
면역 세포 또는 면역 반응을 조절하는 방법
특정 실시양태에서, 본원에 기술된 융합 단백질은 이것이 필요한 대상체, 예를 들어, 암을 앓고 있는 대상체에게 투여되어 대상체의 면역계를 조절한다. 따라서, 특정 실시양태에서, 본원에 기술된 융합 단백질은 면역 반응을 하향조절하거나 면역 반응을 상향조절한다.
이 실시양태에 따르면, 충분한 양의 융합 단백질을 대상체에게 투여하면 면역 반응을 활성화하거나 상향조절하기 위해 다음 중 하나 이상에 영향을 미칠 수 있다: 면역 체크포인트의 조절, T 세포 수용체 신호전달의 조절, T 세포 활성화의 조절, 전염증성 사이토카인의 조절, T 세포에 의한 인터페론-γ 생성의 조절, T 세포 억제의 조절, M2형 종양 관련 대식세포(TAM) 또는 골수 유래 억제 세포(myeloid-derived suppressor cell, MDSC) 생존 및/또는 분화의 조절, 및/또는 세포에 대한 세포독성 또는 세포증식억제 효과의 조절.
특정 실시양태에서, 본원에는 면역 체크포인트의 억제, 면역 체크포인트의 자극, 면역 세포 활성화, T 세포 수용체 신호전달의 자극, 및 항체 의존성 세포 세포독성(ADCC), T 세포 의존성 세포독성(TDCC)), 세포 의존성 세포독성(CDC) 또는 항체 의존성 세포 식세포작용(ADCP)의 자극을 포함하는, 면역 반응을 조절하는 방법이 제공되어 있다.
특정 실시양태에서, 융합 단백질은 프로테아제에 의해 활성화되는 경우 표적 백혈구 공동자극 수용체를 작용시킬 수 있다. 백혈구 공동자극 수용체 효능 작용(agonism)의 기능적 효과는 T 이펙터 세포의 활성화, 염증성 골수 세포의 분화 및 활성화, 및/또는 B 세포 및/또는 NKT 세포의 동원을 포함한다. T 이펙터 세포의 활성화는 인터페론 감마(IFN-γ), 인터루킨-2(IL-2), 인터루킨-12(IL-12), 인터루킨-17(IL-17), 인터루킨-21(IL-21), 과립구 대식세포 콜로니 자극 인자(granulocyte-macrophage colony-stimulating factor, GM-CSF), 종양 괴사 인자-α(TNF-α), 대식세포 염증 단백질 1β(MIP-1β) 및/또는 C-X-C 모티프 리간드 13(CXCL13)과 같은 T 세포에 의한 하나 이상의 사이토카인의 생성 증가를 조래할 수 있다. T 이펙터 세포에 의한 IL-21 및 CXCL13의 생성 증가는, 예를 들어, TME에서 염증성 골수 세포의 분화 및 활성화를 지원하며, B 및 NKT 세포와 같은 항종양 림프구 세포를 동원하고/하거나 3차 림프 구조의 형성을 지원할 수 있다.
특정 실시양태에서, 융합 단백질은 T 이펙터 세포를 활성화한다. 일부 실시양태에서, 융합 단백질은 T 이펙터 세포에 의한 GM-CSF, TNF-α, MIP-1β, IL-17, IL-12, IL-21 및/또는 C-X-C 모티프 리간드 13(CXCL13)의 생성을 증가시킨다.
특정 실시양태에서, 융합 단백질은 단핵구의 CSF1 의존성 생존력을 감소시키고 T 이펙터 세포를 활성화시킨다.
본 개시내용의 특정 실시양태는, 예를 들어, 암을 치료하기 위해 생체 내에서 백혈구 공동자극 수용체 효능 작용을 조절하기 위해 융합 단백질을 사용하는 방법에 관한 것이다.
특정 실시양태에서, 상기 방법은, 예를 들어, 자가면역 질환 또는 장애를 치료하기 위한 면역 세포 또는 면역 반응의 억제 또는 하향조절에 관한 것이다. 따라서 특정 실시양태에서, 융합 단백질은 면역 세포를 조절하기에 충분한 양으로 투여된다. 특정 실시양태에서, 면역 반응의 하향조절은 면역 체크포인트의 조절, T 세포 수용체 신호전달의 조절, T 세포 활성화의 조절, 전염증성 사이토카인의 조절, T 세포에 의한 인터페론-γ 생성의 조절, T 세포 억제의 조절, M2형 종양 관련 대식세포(TAM) 또는 골수 유래 억제 세포(MDSC) 생존 및/또는 분화의 조절, 및/또는 세포에 대한 세포독성 또는 세포증식억제 효과의 조절에 의한 것이다.
표적 세포의 ADCC를 변경하는 방법
특정 실시양태에서, 본원에 기술된 융합 단백질은 항체 의존성 세포 매개 세포독성(ADCC)을 유도하고, 이는 결국 표적 세포의 용해를 증가시킨다. 특정 실시양태에서, 융합 단백질은 FcγRⅢa(활성화 수용체)에 대한 Fc의 결합 친화도가 증가된 Fc 영역을 포함하여 증가된 항체 의존성 세포 매개 세포독성(ADCC) 및 표적 세포의 용해를 증가시킨다. 특정 실시양태에서, Fc 영역은 FcγRⅢa(활성화 수용체)에 대한 Fc의 결합 친화도를 증가시켜 항체 의존성 세포 매개 세포독성(ADCC)을 증가시키는 아미노산 변형을 포함하는 변형된 CH2 도메인을 갖는다.
특정 실시양태에서, 본원에 기술된 융합 단백질은 항체 의존성 세포 매개 세포독성(ADCC)을 감소시킨다. 특정 적응증에서 ADCC 및 보체 매개 세포독성(CDC)의 감소 또는 제거가 바람직하다. 특정 실시양태에서, 융합 단백질은 FcγRⅡb에 대한 결합을 증가시키는 아미노산 변형 또는 모든 Fcγ 수용체에 대한 Fc 영역의 결합을 감소시키거나 제거하는 아미노산 변형("놋아웃" 변이체)을 포함하는 변형된 CH2 도메인을 갖는 Fc 영역을 포함하는 것이 유용할 수 있다. 특정 실시양태에서, 융합 단백질은 FcγRⅡb(억제 수용체)에 대한 결합이 감소된 Fc 영역을 포함한다.
약제학적 조성물
본 발명에 따른 융합 단백질은 약제학적 조성물로 제형화될 수 있다. 이러한 조성물은 융합 단백질 중 하나 이상에 더하여, 약제학적으로 허용되는 부형제, 담체, 버퍼, 안정제 또는 당업자에게 잘 알려진 다른 물질을 포함할 수 있다. 이러한 물질은 무독성이어야 하며 활성 성분의 효능을 방해하지 않아야 한다. 담체 또는 기타 물질의 정확한 특성은 투여 경로, 예를 들어, 경구, 정맥내, 피부 또는 피하, 비강, 근육내, 복강내 경로에 따라 달라질 수 있다.
경구 투여용 약제학적 조성물은 정제, 캡슐, 분말 또는 액체 형태일 수 있다. 정제는 젤라틴과 같은 고체 담체 또는 보조제를 포함할 수 있다. 액체 약제학적 조성물은 일반적으로 물, 석유, 동물성 또는 식물성 오일, 광유 또는 합성 오일과 같은 액체 담체를 포함한다. 생리 식염수, 덱스트로스 또는 기타 당류 용액 또는 글리콜, 예컨대 에틸렌 글리콜, 프로필렌 글리콜 또는 폴리에틸렌 글리콜이 포함될 수 있다.
정맥내, 피부 또는 피하 주사, 또는 통증 부위 주사의 경우, 활성 성분은 발열원이 없고 pH, 등장성 및 안정성이 적합한 비경구적으로 허용되는 수용액의 형태일 것이다. 당업자는, 예를 들어, 염화나트륨 주사액, 링거 주사액, 락테이트 링거 주사액(Lactated Ringer's Injection)과 같은 등장성 비히클을 사용하여 적합한 용액을 잘 제조할 수 있다. 필요에 따라 방부제, 안정제, 버퍼, 항산화제 및/또는 기타 첨가제를 포함할 수 있다.
개체에게 제공되는 본 개시내용에 따른 융합 단백질의 경우, 투여는 바람직하게는 개체에게 이점을 나타내기에 충분한 "치료적 유효량"으로 이루어진다. 개체에게 이익을 주기에 충분한 경우 "예방적 유효량"도 투여할 수 있다. 투여되는 실제 양, 투여 속도 및 투여 기간은 치료되는 단백질 응집 질환의 특성 및 중증도에 따라 달라질 것이다. 치료 처방, 예를 들어, 투여량 등의 결정은 일반의 및 기타 의사의 책임이며, 전형적으로 치료할 장애, 개별 환자의 상태, 전달 부위, 투여 방법 및 실무자에게 알려진 기타 요인을 고려한다. 상기 언급된 기술 및 프로토콜의 예는 Remington's Pharmaceutical Sciences, 16th edition, Osol, A. (ed), 1980에서 찾을 수 있다.
조성물은 치료될 병태에 따라 동시에 또는 순차적으로 단독으로 또는 다른 치료와 함께 투여될 수 있다.
키트
본 개시내용은 또한 본원에 기술된 하나 이상의 조성물 및 사용 설명서를 포함하는 키트를 제공한다. 따라서, 특정 실시양태에서, 본원에 기술된 융합 단백질을 발현하기 위한 벡터 및 사용 설명서를 포함하는 키트가 본원에 기술된다. 특정 실시양태에서, 본원에는 융합 단백질 발현용 벡터를 포함하는 숙주 세포 및 사용 설명서를 포함하는 키트가 기술되어 있다. 특정 실시양태에서, 정제된 융합 단백질 및 사용 설명서를 포함하는 키트가 있다. 정제된 융합 단백질은 동결건조되거나 분말 또는 과립과 같은 건조 형태로 제공될 수 있고, 키트는 추가로 동결건조되거나 건조된 성분(들)의 재구성을 위한 적합한 용매를 함유할 수 있다.
키트는 전형적으로 용기 및 용기 위의 또는 용기와 관련된 라벨 및/또는 패키지 삽입물을 포함할 것이다. 라벨 또는 패키지 삽입물은 치료 제품의 상업용 패키지에 관례적으로 포함되는 지침이 함유되며, 이러한 치료 제품의 사용에 관한 적응증, 용법, 투여량, 투여, 금기 사항 및/또는 경고에 대한 정보 또는 지침을 제공한다. 라벨 또는 패키지 삽입물은 의약품 또는 생물학적 제제의 제조, 사용 또는 판매를 규제하는 정부 기관에서 규정한 형식의 통지를 추가로 포함할 수 있으며, 이 통지는 인간 또는 동물 투여를 위한 사용 또는 판매에 대한 제조 기관의 승인을 반영한다. 용기는 융합 단백질을 포함하는 조성물을 보유한다. 일부 실시양태에서, 용기에는 멸균 접근 포트(sterile access port)가 있을 수 있다. 예를 들어, 용기는 피하 주사바늘에 의해 뚫릴 수 있는 마개가 있는 바이알 또는 정맥내 수액 백일 수 있다.
키트는 융합 단백질을 포함하는 조성물을 함유하는 용기 이외에 키트의 다른 구성요소를 포함하는 하나 이상의 추가 용기를 포함할 수 있다. 예를 들어, 약제학적으로 허용되는 버퍼(예컨대 주사용 정균수(bacteriostatic water for injection, BWFI), 인산염 완충 식염수, 링거액 또는 덱스트로스 용액), 기타 버퍼 또는 희석제.
적합한 용기에는, 예를 들어, 병, 바이알, 주사기, 정맥내 수액 백 등이 포함된다. 용기는 유리 또는 플라스틱과 같은 다양한 재료로 형성될 수 있다. 적절한 경우, 키트의 하나 이상의 구성요소는 동결건조되거나 분말 또는 과립과 같은 건조 형태로 제공될 수 있으며, 키트는 추가로 동결건조되거나 건조된 구성요소(들)의 재구성을 위한 적절한 용매를 포함할 수 있다.
키트는 필터, 바늘 및 주사기와 같은 상업적 또는 사용자 관점에서 바람직한 다른 재료를 추가로 포함할 수 있다.
실시예
다음 실시예는 예시 목적으로만 제공되며 어떤 식으로든 본 개시내용의 범위를 제한하려는 의도가 아니다. 사용된 숫자(예를 들어, 양, 온도 등)와 관련하여 정확성을 보장하기 위해 노력했지만 일부 실험 오차 및 편차가 물론 허용되어야 한다.
본 개시내용의 실시는 달리 나타내지 않는 한, 당업계의 기술 내에서 단백질 화학, 생화학, 재조합 DNA 기술 및 약리학의 통상적인 방법을 사용할 것이다. 이러한 기술은 문헌에 충분히 설명되어 있다. 예를 들어, T.E. Creighton, Proteins: Structures and Molecular Properties (W.H. Freeman and Company, 1993); A.L. Lehninger, Biochemistry (Worth Publishers, Inc., current addition); Sambrook, 등, Molecular Cloning: A Laboratory Manual (2nd Edition, 1989); Methods In Enzymology (S. Colowick and N. Kaplan eds., Academic Press, Inc.); Remington's Pharmaceutical Sciences, 18th Edition (Easton, Pennsylvania: Mack Publishing Company, 1990); Carey 및 Sundberg Advanced Organic Chemistry 3 rd Ed. (Plenum Press) Vols A 및 B(1992) 참조.
실시예 1 차폐된 항-CD3 × 항-HER2 T 세포-인게이저 융합 단백질의 설계
항-CD3 Fab × 항-Her2 scFv Fc는 리간드-수용체 쌍 PD-1-PDL-1 중 하나를 Fab의 경쇄의 N-말단에 연결하고 다른 하나를 중쇄의 N-말단에 연결함으로써 마스크가 항-CD3 Fab에 부착되었다. 융합 단백질 작제물은 다음과 같이 설계하였다.
방법
융합 단백질은 Fc에 융합된 항-Her2 scFv와 이종이량체를 형성하는 항-CD3 중쇄 및 경쇄를 포함하는 반항체(half-antibody)가 있는 변형된 이중특이성 Fab × scFv Fc 형식이었다. 항-CD3 파라토프는 US20150232557A1(VL 서열번호 1, VH 서열번호 2)에 기술되어 있다. 항-Her2 파라토프는 US10000576B1(서열번호 3)에 기술된 바와 같이 글리신 세린 링커에 의해 연결된 트라스투주맙(trastuzumab) VL 및 VH에 기반한 scFv 형식이었다(Carter, P. 등 Humanization of an anti-p185HER2 antibody for human cancer therapy. Proc Natl Acad Sci U S A 89, 4285-4289, doi:10.1073/pnas.89.10.4285 (1992)). 선택적인 이종이량체 페어링을 허용하기 위해, 돌연변이를 이전에 기술된 바와 같이 항-CD3 CH3은 물론 항-Her2 scFv-Fc CH3 사슬에 도입하였다(Von Kreudenstein, T. S. 등, Improving biophysical properties of a bispecific antibody scaffold to aid developability: quality by molecular design. MAbs 5, 646-654, doi:10.4161/mabs.25632 (2013); (A 사슬 CH3 도메인, 서열번호 4, B 사슬 CH3 도메인 서열번호 5). 또한, Fc 감마 수용체(서열번호 6)에 대한 결합을 감소시키기 위해 돌연변이(야생형 인간 IgG1 CH2와 비교하여 L234A_L235A_D265S)를 두 CH2 도메인에 도입하였다. 추가로, 인간 PD-1(서열번호 7) 및/또는 PD-L1(서열번호 8)의 IgV 도메인의 변형된 단백질 서열에 기반한 폴리펩티드(West, S. M. & Deng, X. A. Considering B7-CD28 as a family through sequence and structure. Exp Biol Med (Maywood), 1535370219855970, doi:10.1177/1535370219855970 (2019)는 나선형 회전(helical turn)을 형성할 것으로 예상되는 가변 개수의 반복 서열로 구성된 링커를 사용하여 각각 항-CD3 가변 도메인의 중쇄(VH-CH1-힌지-CH2-CH3)와 카파 경쇄(VL-CL)의 N-말단에 융합시켰다((EAAAK)n, Chen, X., Zaro, J. L. & Shen, W. C. Fusion protein linkers: property, design and functionality. Adv Drug Deliv Rev 65, 1357-1369, doi:10.1016/j.addr.2012.09.039 (2013)). 이러한 PD-1 및 PD-L1 모이어티는 이량체화되고 에피토프 결합을 입체적으로 차단하는 것으로 예측되었다. 모든 변이체에서 마스크의 절반으로 사용된 PD-1 또는 PD-L1 서열은 앞서 기술된 바와 같이 PD-1:PD-L1 복합체의 친화도를 증가시키는 돌연변이를 함유하였다(Maute, R. L. 등, Engineering high-affinity PD-1 variants for optimized immunotherapy and immuno-PET imaging. Proc Natl Acad Sci U S A 112, E6506-6514, doi:10.1073/pnas.1519623112 (2015); 서열번호 9; Liang, Z. 등, High-affinity human PD-L1 variants attenuate the suppression of T cell activation. Oncotarget 8, 88360-88375, doi:10.18632/oncotarget.21729 (2017); 서열번호 10). 추가로, 모든 WT PD-1 모이어티에서, 노출된 환원 그룹(서열번호 11)의 책임(liability)을 없애기 위해 페어링되지 않은 시스테인을 세린으로 돌연변이시켰다. 일부 변이체는 또한 종양 미세환경(TME) 관련 프로테아제 uPa(MSGRSANA 서열번호 28)에 대한 절단 서열을 함유하여 융합 단백질을 프로테아제에 노출시킴으로써 마스크의 일부 또는 전부를 제거할 수 있게 하였다. 차폐된 Fab에 대한 작제물 설계 도식은 물론 의도된 작용 메커니즘이 도 1에 나와 있다. 최종 설계는 차폐된 항-CD3 Fab는 물론 항-Her2 scFv를 함유하는 이중특이성 Fab × scFv Fc 분자였다. 도식은 도 2에 나와 있으며 사용된 서열은 표 A에 나열되어 있다.
[표 A]


실시예 2 차폐된 항-CD3 변이체의 생성
실시예 1에서 설계된 변형된 CD3 × Her2 Fab × scFv 변이체의 서열을 발현 벡터에 이식하고 다음과 같이 발현 및 정제하였다.
방법
신호 펩티드(Barash 등, 2002, Biochem and Biophys Res. Comm., 294:835-842, 서열번호 27) 및 CH3의 G446(EU 넘버링)에서 끝나는 중쇄 클론을 포함하는 중쇄 벡터 삽입체를 pTT5 벡터에 결찰하여 중쇄 발현 벡터를 생성하였다. 동일한 신호 펩티드 및 경쇄 클론을 포함하는 경쇄 벡터 삽입체를 pTT5 벡터에 결찰하여 경쇄 발현 벡터를 생성하였다. 생성된 중쇄 및 경쇄 발현 벡터를 시퀀싱하여 정확한 리딩 프레임 및 코딩 DNA 서열을 확인하였다.
변형된 CD3 × Her2 Fab × scFv Fc 변이체의 중쇄 및 경쇄는 25mL의 Expi29 3F™ 세포(Thermo Fisher, Waltham, MA) 배양물에서 공동발현시켰다. Expi293™ 세포를 Expi293™ 발현 배지(Thermo Fisher, Waltham, MA) 중 37℃ 및 8% CO2의 가습 분위기에서 125rpm으로 회전하는 오비탈 진탕기에 배양하였다. 총 세포 수가 7.5 × 107개의 세포인 25mL 부피를 H1:L1:H2에 대해 40:40:20의 형질감염 비율로 총 25μg의 DNA로 형질감염시켰다. 형질감염 전에 DNA를 1.5mL의 Opti-MEM™ I 저혈청 배지(Thermo Fisher, Waltham, MA)에 희석하였다. 1.42mL 부피의 Opti-MEM™ I 저혈청 배지에 80μL의 ExpiFectamine™ 293 시약(Thermo Fisher, Waltham, MA)을 희석하고, 5분 동안 인큐베이션한 후, 총 부피 3mL로 DNA 형질감염 믹스와 합하였다. 10 내지 20분 후 DNA-ExpiFectamine™ 293 시약 혼합물을 세포 배양액에 첨가하였다. 37℃에서 18-22시간 동안 인큐베이션한 후, 150μL의 ExpiFectamine™ 293 Enhancer 1 및 1.5mL의 ExpiFectamine™ 293 Enhancer 2(Thermo Fisher, Waltham, MA)를 각 배양액에 첨가하였다. 세포를 5 내지 7일 동안 인큐베이션하고 상등액을 단백질 정제를 위해 수확하였다.
정화된 상등액 샘플을 배치 모드로 50% mAb Select SuRe 수지(GE Healthcare, Chicago, IL)를 함유하는 1mL의 슬러리에 적용하였다. 컬럼을 PBS에서 평형화하였다. 로딩 후, 컬럼을 PBS로 세척하고 단백질을 100mM 나트륨 시트레이트 버퍼(pH 3.5)로 용출하였다. 용출된 샘플은 10%(v/v) 1M Tris pH 9를 첨가하여 pH를 조정하여 6-7의 최종 pH를 산출하였다. 농축 후, 모든 물질을 AKTA Pure FPLC System(GE Life Sciences)에 주입하고 PBS pH 7.4로 사전 평형화한 Superdex 200 Increase 10/300 GL(GE Life Sciences) 컬럼에서 실행하였다. 단백질을 0.75mL/분의 속도로 컬럼에서 용출하였고 0.5mL 분획으로 수집하였다. 피크 분획을 모아 Vivaspin 20, 30kDa MWCO 폴리에테르설폰 농축기(MilliporeSigma Burlington MA, USA)를 사용하여 농축하였다. 0.2μm PALL Acrodisc™ Syringe Filters with Supor™ Membrane을 통해 멸균 여과한 후 A280nm(Nanodrop)를 기준으로 단백질을 정량하고 냉동하여 추가 사용 전까지 -80℃에서 보관하였다.
결과
단백질 A 정제(나타내지 않음) 후 UPLC-SEC로 측정했을 때 샘플은 상당한 양의 고분자량 종을 함유하였고 고순도 샘플을 얻기 위해 분취 SEC를 사용하였다. 분취 SEC 후 수율은 변이체당 1.5-5mg 범위였다. 샘플 순도 및 안정성을 실시예 3 및 실시예 4에서 평가하였다.
실시예 3 차폐된 항-CD3 변이체의 순도 및 균질성 평가
정제된 변이체를 하기 기술된 바와 같이 비환원/환원 CE-SDS UPLC-SEC로 순도 및 샘플 균질성에 대해 평가하였다.
방법
정제 후, CE-SDS LabChip® GXII(Perkin Elmer, Waltham, MA)를 사용한 비환원 및 환원 고처리량 단백질 발현(High Throughput Protein Express) 검정으로 샘플의 순도를 평가하였다. HT Protein Express LabChip® 사용자 가이드 버전 2에 따라 다음과 같이 수정하여 절차를 수행하였다. 2uL 또는 5uL(농도 범위 5-2000ng/ul)의 mAb 샘플을 7uL의 HT 단백질 발현 샘플 버퍼(Protein Express Sample Buffer)(Perkin Elmer # 760328)와 함께 96웰 플레이트(BioRad, Hercules, CA)의 개별 웰에 첨가하였다. 환원 버퍼는 100μl의 HT 단백질 발현 샘플 버퍼에 3.5μl의 DTT(1M)를 첨가하여 제조한다. 이어서 mAb 샘플을 90℃에서 5분 동안 변성시키고 35μl의 물을 각 샘플 웰에 첨가한다. LabChip® 기기는 HT Protein Express Chip(Perkin Elmer #760499) 및 HT Protein Express 200 검정 설정(14kDa-200kDa)을 사용하여 작동시켰다.
UPLC-SEC를 25℃에서 Agilent Technologies AdvanceBio SEC 300A 컬럼을 사용하여 Agilent Technologies 1260 Infinity LC 시스템에서 수행하였다. 주입 전에 샘플을 10000g에서 5분 동안 원심분리한 후 5μl를 컬럼에 주입하였다. 샘플을 PBS(pH 7.4)에서 1mL/분의 유속으로 7분 동안 실행하고 용출을 190-400nm에서 UV 흡광도로 모니터링하였다. 크로마토그램을 280nm에서 추출하였다. OpenLAB CDS ChemStation 소프트웨어를 사용하여 피크 통합을 수행하였다.
결과
도 3a, 3c, 3e 및 3g의 변이체의 분취 SEC 정제 후 샘플의 대표적인 UPLC-SEC 흔적은 정확한 종의 89%-94%를 함유하는 매우 균질한 샘플을 나타냈다. 주요 종에 비해 짧은 머무름 시간의 작은 피크의 존재는 모든 샘플에서 올리고머 및 응집체와 같은 고분자량 종이 소량 존재함을 나타낸다.
비환원 CE-SDS의 분석(도 3b, 3d, 3e 및 3f)은 단일 우세 종을 나타냈고 모든 변이체의 온전한 사슬에 상응하는 밴드만이 환원 CE-SDS 실행에서 발견되었다. 특히, 차폐된 중쇄 및 경쇄는 예상되는 것보다 상당히 더 높은 겉보기 분자량을 나타냈다(HC의 경우 110kDa 대 63kDa, LC의 경우 54kDa 대 37kDa). 이는 비환원 디설파이드 결합 종의 높은 겉보기 분자량에도 반영되었다(215 kDa 대 152 kDa). 설계에서 PD1 및 PD-L1 모이어티 둘 다의 글리코실화는 겉보기 분자량의 증가를 야기할 가능성이 있다(Tan, S. 등, An unexpected N-terminal loop in PD-1 dominates binding by nivolumab. Nat Commun 8, 14369, doi:10.1038/ncomms14369 (2017), Li, C. W. 등, Glycosylation and stabilization of programmed death ligand-1 suppresses T-cell activity. Nat Commun 7, 12632, doi:10.1038/ncomms12632 (2016)).
실시예 4 차폐된 항-CD3 변이체의 안정성 평가
정제된 변이체를 하기 기술된 바와 같이 시차 주사 열량측정법(DSC)으로 열 안정성에 대해 평가하였다.
방법
변형된 CD3 × Her2 Fab × scFv Fc 변이체의 대표적 세트의 샘플을 PBS에서 0.5-1mg/ml로 희석하였다. NanoDSC(TA Instruments, New Castle, DE, USA)를 사용하는 DSC 분석을 위해, 950μl의 샘플 및 매칭 버퍼(PBS)를 각각 샘플 및 기준 96웰 플레이트에 첨가하였다. DSC 실행 시작 시 기준선을 안정화하기 위해 버퍼(PBS) 블랭크 주입을 수행하였다. 이어서 각 샘플을 주입하고 60psi 질소 압력을 사용하여 1℃/분으로 25 내지 95℃에서 스캔하였다. 서모그램은 NanoAnalyze 소프트웨어를 사용하여 분석하였다. S자형 곡선을 사용하여 매칭 버퍼 서모그램을 샘플 서모그램 및 기준선 피트(baseline fit)에서 뺐다. 이어서 데이터를 2-상태 스케일링된 DSC 모델에 맞췄다.
결과
변형되지 않은 CD3 × Her2 Fab × scFv Fc 변이체(30421, 도 4)의 DSC 서모그램은 68℃ 및 83℃에서 전이를 나타냈다. Tm이 68℃인 전이는 항-CD3 Fab, 항-Her2 scFv 및 CH2 도메인의 언폴딩(unfolding)에 대한 확인되지 않은 개별 전이(unresolved individual transition)에 해당하는 반면, Tm = 83℃에서의 전이는 중쇄의 CH3 도메인의 언폴딩에 해당할 가능성이 높다. PD-1:PD-L1 마스크(30430, 30436; 도 4)를 보유하는 변이체의 서모그램은 유사한 온도에서 차폐되지 않은 변이체에 대한 유사한 서모그램 흔적과 함께 두 가지 전이를 보여주었다. 이는 융합된 차폐 도메인이 항-CD3 Fab의 Tm에 영향을 미치지 않고 Fab와 협력적으로 언폴딩되거나 비협력적으로 언폴딩되지만 Fab, scFv 및 CH2와 유사한 Tm을 가지고 언폴딩됨을 나타낸다.
실시예 5 항-CD3 변이체의 UPA 절단
링커에 도입된 프로테아제 절단 부위의 절단에 의한 융합 단백질의 항-CD3 Fab로부터의 마스크의 일부 또는 전부의 방출을 평가하기 위해, 샘플을 uPa로 시험관 내에서 처리하였다. 다음과 같이 환원 CE-SDS로 반응을 모니터링하였다.
방법
변이체의 분취 절단을 위해, 25-100ug의 정제된 샘플을 PBS + 0.05% Tween 20에서 0.2mg/mL의 최종 변이체 농도로 희석하고 재조합 인간 u-플라스미노겐 활성제(uPa)/유로키나제(R&D 시스템 번호 P00749)를 프로테아제:기질=1:50(몰:몰)의 비율로 첨가하였다. 37℃에서 24시간 동안 인큐베이션한 후, 실시예 2에 기술된 바와 같이 환원 CE-SDS에서 샘플 단편을 분석한 다음 추가 사용 시까지 -80℃에서 동결 및 보관하였다.
결과
uPa 처리 유무에 따른 차폐된 변이체의 환원 CE-SDS 프로파일의 분석은 조사된 조건 하에서 마스크의 일부 또는 전부가 도입된 절단 부위에서의 절단에 의해 Fab로부터 효과적으로 제거되었음을 나타냈다(도 5). 성공적으로 절단된 변이체(30430, 30436, 31934)의 경우, 차폐된 중쇄 및/또는 경쇄의 단편을 나타내는 밴드는 절단 시 완전히 사라지지만 차폐되지 않은 중쇄 및/또는 경쇄의 단편이 나타난다. 변이체 30430에서는 유리 PD-1의 단편에 상응하는 저강도의 광대역이 관찰될 수 있지만, 변이체 30436에서는 방출된 PD-L1의 경우에 그렇지 않았다. 글리코실화로 인한 작은 크기 및 크기 불균일(Tan, S. 등, An unexpected N-terminal loop in PD-1 dominates binding by nivolumab. Nat Commun 8, 14369, doi:10.1038/ncomms14369 (2017), Li, C. W. 등, Glycosylation and stabilization of programmed death ligand-1 suppresses T-cell activity. Nat Commun 7, 12632, doi:10.1038/ncomms12632 (2016))은 유리 PD-1 단편을 거의 검출할 수 없고 PD-L1 단편을 검출할 수 없도록 만들었을 가능성이 있다. 절단 서열을 함유하지 않는 변이체(30421, 30423)에서는 절단이 관찰되지 않았다.
실시예 6 CD3-결합의 차폐/차폐 해제
실시예 5로부터의 항-CD3 변이체의 절단되지 않은 샘플 및 절단된 샘플을 다음과 같이 CD3 발현하는 Jurkat 세포에 대한 결합에 대해 ELISA로 테스트하고 Pan T 세포에 대한 결합에 대해 유세포분석으로 테스트하였다.
방법
ELISA
인간 Jurkat 세포(Fujisaki Cell Center, Japan)를 2mM L-글루타민 및 1X 페니실린/스트렙토마이신을 함유하는 10% 열 불활성화 태아 소 혈청(FBS)이 보충된 RPMI-1640 배지 중 37℃에서 가습 + 5% CO2 인큐베이터에서 유지하였다. 실시예 5로부터의 변형된 CD3 × Her2 변이체 샘플을 포화량의 무관한 인간 Ig를 함유하는 차단 버퍼에서 2배 희석한 다음, 총 8개의 농도 지점에 대해 차단 버퍼에서 7번의 3배 연속 희석을 하였다. 세포에 대한 백그라운드 신호를 측정하기 위해 차단 버퍼만 대조군 웰에 첨가하였다(음성/블랭크 대조군).
모든 인큐베이션은 4℃에서 수행하였다. 검정 당일, 기하급수적으로 성장하는 세포를 원심분리하고 완전 배양 배지와 차단 버퍼의 1:1 혼합물 중 96웰 필터 플레이트(MilliporeSigma, Burlington, MA, USA)에 접종하였다. 동일한 부피의 2X 변이체 또는 대조군을 세포에 첨가하고 1시간 동안 인큐베이션하였다. 이어서, 진공 여과를 사용하여 플레이트를 4회 세척하였다. HRP 접합된 항-인간 IgG Fc 감마 특이적 2차 항체(Jackson ImmunoResearch, West Grove, PA, USA)를 웰에 첨가하고 1시간 동안 더 인큐베이션하였다. 플레이트를 진공 여과로 7회 세척한 후 실온에서 TMB 기질(Thermo Scientific, Waltham MA, USA)을 첨가하였다. 0.5 부피의 1M 황산을 첨가하여 반응을 중단시키고 상등액을 여과하여 투명한 96웰 플레이트(Corning, Corning, NY, USA)로 옮겼다. 450nm에서의 흡광도는 경로 검사 보정 기능(path-check correction)이 있는 Spectramax 340PC 플레이트 판독기로 판독하였다.
블랭크를 뺀 OD450 대 선형 또는 로그 항체 농도의 결합 곡선을 GraphPad Prism 8(GraphPad Software, La Jolla, CA, USA)로 피팅하였다. 각 테스트 항목에 대한 Bmax 및 겉보기 Kd 값을 측정하기 위해 Hill 기울기가 있는 원-사이트 특이적 4-매개변수 비선형 회귀 곡선 피팅 모델(one-site specific, four-parameter nonlinear regression curve fitting model)을 사용하였다.
유세포분석
항체는 v자 바닥 96웰 플레이트(Sarstedt AG, Numbrecht, Germany)에서 FACS 버퍼 - 2% FBS 함유 PBS(Thermo Fisher Scientific, Waltham, MA)에 총 20uL/웰로 1:3 희석하여 300nM에서 1.7pM까지 적정하였다. 건강한 공여자 말초 혈액 pan T 세포(BioIVT, Westbury, NY)를 해동하고 10% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA)이 보충된 RPMI 1640 배지(A1049101, ATCC 변형)(Thermo Fisher Scientific, Waltham, MA)로 이루어진 배지로 세척하였다. 세포를 계수하고, FACS 버퍼에 재현탁하고, 웰당 50,000개의 세포로 96웰 플레이트에 첨가하였다. 세포를 변이체와 함께 4℃에서 1시간 동안 인큐베이션한 다음 FACS 버퍼 및 1mg/mL의 2차 항체 AF647 염소 항-인간 IgG Fc(Jackson ImmunoResearch, West Grove, PA)로 2회 세척하였다. 1000배 희석된 생존 염료(Biolegend, San Diego, CA)도 웰에 첨가하였다. 플레이트를 실온에서 30분 동안 진탕하면서(200rpm) 인큐베이션하였다. 이어서, 세포를 FACS 버퍼로 2회 세척하고 100uL의 FACS 버퍼에 재현탁하였다. 검정 판독을 위해 APC 형광의 기하 평균을 BD LSRFortessa(BD Biosciences, San Jose, CA)에서 유세포분석으로 측정하였다. 원시 데이터는 FlowJo, LLC Software(Becton, Dickinson & Company, Ashland, OR)에서 분석하였다. 그래프는 Mac OS X용 GraphPad Prism 버전 8.1.2(GraphPad Software, La Jolla, CA)를 사용하여 생성하였다.
결과
ELISA
도 6에서 볼 수 있는 바와 같이, CD3 Fab에 부착된 전체 PD1:PD-L1 기반 마스크를 함유하는 변이체(30423, 30430, 30436)는 차폐되지 않은 대조군(30421)과 비교하여 40-180배 감소된 결합을 나타냈다. uPa로 처리하면 절단성 변이체 30430 및 30436의 CD3 결합이 부분적으로 회복되었다(차폐되지 않은 대조군의 6-7배 이내). 이 부분적 회복은 절단 후 마스크에 남아 있는 마스크 부분에 의한 에피토프 결합의 입체적 방해로 인해 발생할 수 있다. 동시에, PD-1 또는 PD-L1만 각각 중쇄 또는 경쇄에 부착된 대조군(31929, 31931)은 완전히 차폐된 변이체의 uPa 절단된 샘플로서 차폐되지 않은 대조군과 비교하여 유사한 결합 감소(4-5배)를 나타냈다.
유세포분석
도 22에서 볼 수 있는 바와 같이, CD3 Fab에 부착된 전체 PD1:PD-L1 기반 마스크를 함유하는 변이체(30423, 30430)는 차폐되지 않은 대조군(30421)과 비교하여 >43배 감소된 결합을 나타냈다. uPa로 처리하면 절단성 변이체 30430의 CD3 결합이 부분적으로 회복되었다(차폐되지 않은 대조군의 29배 이내). 이 부분적 회복은 절단 후 마스크에 남아 있는 마스크 부분에 의한 에피토프 결합의 입체적 방해로 인해 발생할 수 있다. 동시에, PD-1만 중쇄에 부착된 대조군(31929)은 완전히 차폐된 변이체의 uPa 절단된 샘플로서 차폐되지 않은 대조군과 비교하여 유사한 결합 감소(14배)를 나타냈다. 별도의 실험에서, 중쇄에 부착된 비기능적 PD-1 도메인이 있는 변이체(32497)는 기능적 PD-1이 있는 동등한 변이체(31929, 5배)에서 볼 수 있는 것처럼 차폐되지 않은 대조군과 비교하여 유사한 결합 감소(6배)를 나타냈다(도 32).
실시예 7 차폐된 변이체 및 차폐되지 않은 변이체의 T 세포 의존성 세포 세포독성
Her2 보유 세포의 사멸을 위해 T 세포와 결합하고 활성화하는 CD3 × Her2 Fab × scFv Fc 변이체의 능력에 대한 PD-1:PD-L1 기반 마스크의 기능적 영향을 다음과 같이 T 세포 의존성 세포 세포독성(TDCC) 검정으로 평가하였다.
방법
공동배양 검정
10% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA)이 보충된 DMEM 배지(Thermo Fisher Scientific, Waltham, MA)로 이루어진 성장 배지에서 배양된 JIMT-1(Leibniz Institute, Braunschweig, Germany), 10% 태아 소 혈청이 보충된 RPMI-1640 ATCC 변형(Thermo Fisher Scientific, Waltham, MA)으로 이루어진 성장 배지에서 배양된 HCC1954(ATCC, Manassas, VA)와 HCC827(ATCC, Manassas, VA), 및 10% 태아 소 혈청과 0.01mg/mL의 인간 재조합 인슐린(Thermo Fisher Scientific, Waltham, MA)이 보충된 MEM 배지(Thermo Fisher Scientific, Waltham, MA)로 이루어진 성장 배지에서 배양된 MCF-7(ATCC, Manassas, VA)을 37℃에서 5% 이산화탄소를 함유하는 인큐베이터 내 T-175 플라스크(Corning, Corning, NY)에서 수평으로 유지하였다. 검정 설정 당일, 변이체를 384웰 세포 배양 처리된 광학 바닥 플레이트(ThermoFisher Scientific, Waltham, MA)에서 직접 1:3 희석하여 5nM에서 0.08pM까지 3중 적정하였다. 종양 세포를 PBS(Thermo Fisher Scientific, Waltham, MA)로 헹구고, TrypLE Express(Thermo Fisher Scientific, Waltham, MA)로 수확하고, 배지에 희석하고, Vi-Cell(Beckman Coulter, Indianapolis, IN)을 사용하여 계수하였다. 1차 인간 pan-T 세포(BioIVT, Westbury, NY)의 바이알을 37℃ 수조에서 해동하고, 배지에서 세척하고 Vi-Cell을 사용하여 계수하였다. Pan T 세포 현탁액을 5:1의 이펙터 대 표적 비율로 종양 세포와 혼합하고, 세척하고, 0.55 E6 세포/ml로 재현탁하였다. 20uL의 혼합된 세포 현탁액을 적정 변이체를 함유하는 플레이트에 첨가하였다. 플레이트를 37℃에서 5% 이산화탄소를 함유하는 인큐베이터에서 48시간 동안 인큐베이션하였다. 이어서 샘플을 고함량 세포독성 평가에 적용하고 IFNγ 분석을 위해 상등액을 수집하였다.
고함량 세포독성 분석
핵의 시각화 및 생존력 평가를 위해 세포를 Hoechst33342로 염색하였다. 10μL의 Hoechst33342(Thermo Fisher Scientific, Waltham, MA)를 배지에서 1:1000으로 희석하고, 48시간 후 세포에 첨가하고 37℃에서 추가로 1시간 동안 인큐베이션하였다. 이어서, 플레이트를 CellInsight CX-5(ThermoFisher Scientific, Waltham, MA)에서 고함량 이미지 분석하여 생존 종양 세포와 죽은 종양 세포는 물론 이펙터 세포를 구별하고 정량화하였다. 플레이트는 다음 설정으로 SpotAnalysis.V4 Bioapplication을 사용하여 CellInsightCX5 고함량 기기로 스캔하였다: 대물렌즈: 10x, 채널 1 - 386nm: Hoechst(고정 노출 시간 0.008ms, 게인(Gain) 2).
IFNγ 정량화
MSD U-PLEX 384웰 단일 스팟 검정에서 IFNγ 정량화를 위해, 스트렙트아비딘 코팅된 다중 어레이 플레이트(MA6000 384 SA 플레이트, Meso Scale Diagnostics, Rockville, MD)를 50uL의 Diluent 100으로 차단하고, 밀봉하고, 30분 동안 진탕(800rpm)하면서 실온에서 인큐베이션하였다. 인큐베이션 종료 시, 모든 웰을 흡인하였다. 비오틴화 포획 IFNγ 항체를 Diluent 100에 1:16.5 비율로 첨가하고, 10uL의 포획 항체 용액을 차단된 플레이트의 각 웰에 첨가하였다. 플레이트를 밀봉하고 4℃에서 밤새 인큐베이션하였다. 다음날, 공동배양 검정으로부터의 동결된 상등액을 젖은 얼음 상에서 해동시켰다. 플레이트를 세척하고 5μl의 Diluent 43을 각 웰에 첨가한 다음 5μl의 해동된 상등액 샘플 또는 표준을 첨가하였다. 플레이트를 밀봉하고 실온에서 1시간 동안 진탕하면서(800rpm) 인큐베이션하였다. 인큐베이션 후, 플레이트를 세척하고 Diluent 3에 1:1000으로 희석된 10uL의 SULFO-TAG 검출 항체를 각 웰에 첨가하였다. 플레이트를 밀봉하고 진탕(800rpm)하면서 실온에서 1시간 동안 인큐베이션하였다. 인큐베이션 후, 플레이트를 세척하고 40μl의 MSD GOLD Read Buffer를 각 웰에 첨가하였다. 플레이트는 MESO SECTOR R600 기기(Meso Scale Diagnostics, Rockville, MD)에서 판독하였다.
PD-L1 및 Her2 수용체 정량화
Her2 및 PD-L1 수용체 정량화는 각각 Quantum Simply Cellular 항-인간 및 항-마우스 IgG 키트(Bangs Laboratories, Fishers, Indiana)를 사용하여 유세포분석을 통해 수행하였다. 종양 세포를 PBS(Thermo Fisher Scientific, Waltham, MA)로 헹구고 TrypLE Express(Thermo Fisher Scientific, Waltham, MA)로 수확하였다. Vi-Cell(Beckman Coulter, Indianapolis, IN)을 사용하여 세포를 계수하고, 세척하고, FACS 버퍼 - 2% FBS 함유 PBS(Thermo Fisher Scientific, Waltham, MA)에 4x10^6 c/mL로 재현탁하였다. 25uL의 종양 세포 현탁액을 96웰 V형 바닥 플레이트(Sarstedt AG, Numbrecht, Germany)에 3중 첨가하였다. 15ug/mL의 항-Her2-AF647(Trastuzumab, 1가 항체, Zymeworks, Vancouver, BC), 항-PDL1-APC(Clone MIH1, BD Biosciences, San Jose, CA) 또는 무관한 음성 대조군 IgG-AF657(Zymeworks, Vancouver, BC) 항체를 Quantum Simply Cellular IgG 비드(항-인간 또는 항-마우스) 및 블랭크 비드를 함유하는 웰 및 에펜도르프 튜브(Eppendorf tube)(Thermo Fisher Scientific, Waltham, MA)에 첨가하였다. 세포와 비드를 4℃, 암실에서 1시간 동안 항체와 함께 인큐베이션하였다. 세포와 비드를 세척하고, 재현탁하고, 유세포분석으로 분석하였다. 분석을 위해 특정 로트의 비드에 대해 Bangs Laboratories(Fishers, Indiana)에서 제공한 스프레드시트를 사용하여 표준 곡선을 생성하고, 동일한 스프레드시트를 이용하여 세포군의 기하 평균을 입력하여 표면 항원 결합능(ABC)을 생성하였다. ABC 값은 1가 결합 모델을 가정하여 세포 표면에 발현된 수용체 분자의 수를 나타낸다. 수용체 수의 확실한 측정을 위한 범위를 결정하는 표준 곡선은 Her2의 경우 3500개의 수용체/세포에서 330000개의 수용체/세포, PD-L1의 경우 4400개의 수용체/세포에서 630000개의 수용체/세포 범위였다.
결과
실시예 6에서 CD3에 대한 결합에서 CD3 × Her2 Fab × scFv Fc 변이체에 대해 나타난 차폐 효과는 동일한 샘플이 Her2 발현 JIMT-1 세포를 이용한 TDCC 검정에서 기능에 대해 조사되었을 때 재현되었다(도 7). 차폐되지 않은 변이체(30421)는 낮은 변이체 농도에서 강력한 종양 세포 사멸을 보인 반면, 차폐된 비절단성 변이체(30423)의 효능은 49000배까지 감소하였다. 경쇄(30430)에 절단성 PD-L1 모이어티가 있는 완전히 차폐된 변이체는 또한 uPa 처리 없이 5800배까지 효능이 감소되었다. 비절단성 변이체와 절단성 변이체 사이의 차폐의 이러한 불일치는 CD3 결합에서도 나타났다(실시예 6). 마스크가 uPa에 의해 절단되었을 때 30430의 효능은 차폐되지 않은 변이체(30421)의 효능으로 돌아갔다. 마스크의 PD-1 부분만 부착된 대조군 변이체(31929)는 30421 및 uPa 처리된 30430과 유사한 효능을 나타냈다. 무관한 항 호흡기 세포융합 바이러스(Respiratory Syncytial Virus, RSV) 항체(22277)는 종양 세포 사멸에 대한 T 세포의 활성화를 나타내지 않았다.
Her2 및 PD-L1 양성 세포주로서 JIMT-1을 사용하는 TDCC를 반복하였고 이전 실험에서와 상이한 T 세포 공여자를 사용하고 이들 수용체의 수준이 상이한 3개의 다른 세포주로 확대시켰다. 2회 반복에 대한 세포독성 데이터는 도 23에 제시되어 있다. 사이토카인 IFNγ 수준도 반복 n=1에 대한 T 세포의 면역 활성화의 프록시로서 모니터링하였다(도 24). 사용된 모든 세포주에 대해 수용체 수를 측정하였고 도 25에 나타냈다. 차폐되지 않은 대조군(30421)의 효능은 상이한 세포주의 세포독성에 대해 0.03pM(HCC1954: 높은 Her2, 높은 PD-L1) 내지 3pM(MCF-7: 중간 Her2, 낮은 PD-L1)인 것으로 측정되었다. IFNγ 방출로 측정했을 때 이 차폐되지 않은 대조군의 효능은 8.4pM(HCC1954: 높은 Her2, 높은 PD-L1) 내지 50pM(HCC829: 낮은 Her2, 중간 PD-L1)이었다. 비절단성(30423) 및 절단성(30430) 차폐된 변이체에 대한 EC50의 증가로 측정된 차폐는 모든 세포주에서 확인되었으며 세포독성 판독에서 72 내지 >450배 범위였고 IFNγ 판독에서 8.2 내지 >350배 범위였다. PD-1 모이어티만 중쇄에 부착된 변이체(31929), uPa 처리 후 절단성 차폐된 변이체(30430 +uPa)는 물론 차폐되지 않은 대조군과 포화량의 항-PD-L1 항체의 조합(30421 + 120nM 아테졸리주맙(atezolizumab))은 PD-L1 발현이 현저한 세포주(HCC1954, JIMT-1, HCC827)에서 PD-L1에 결합하는 능력으로 인해 차폐되지 않은 대조군(30421)에 비해 더 높은 효능(세포독성에서 0.019 내지 0.84배 더 낮은 EC50)을 나타냈다. PD-L1 발현이 매우 낮은 세포주(MCF-7)는 차폐되지 않은 대조군(30421)과 PD-L1에 결합할 수 있는 변이체(31929, 30421 + 120nM 아테졸리주맙, 30430 + uPa) 사이의 세포독성 판독값에서 유의미한 차이를 보이지 않았다. 그러나 항-PD-L1 모이어티가 있는 이러한 변이체는 차폐되지 않은 대조군(30421)과 비교하여 모든 테스트된 세포주에 대해 IFNγ 방출에서 더 높은 효능을 보였다. 무관한 항-RSV 항체(22277)는 어느 세포주에 대해서도 TDCC에서 활성을 나타내지 않았다.
실시예 8 차폐된 항-CD3 변이체의 PD1 및 PD-L1 결합 분석
차폐 도메인으로 사용된 PD-1 및 PD-L1 모이어티의 생물학적 활성에 대한 프록시로서, PD-L1 및 PD-1을 발현하는 CHO 세포에 대한 변형된 변이체의 결합을 다음과 같이 측정하였다.
방법
CHO 세포의 형질감염
CHO-S 세포(National Research Council Canada)를 1% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA)을 함유하는 FreeStyle CHO 발현 배지(Thermo Fisher Scientific, Waltham, MA)에서 배양하였다. Neon Transfection 시스템(Thermo Fisher Scientific, Waltham, MA)을 사용하여 형질감염을 수행하였다. CHO-S 세포를 계수하고 PBS로 2회 세척하고 Resuspension buffer R(Thermo Fisher Scientific, Waltham, MA)에서 1회 세척한 후 100 E6 세포/mL로 재현탁하였다. PD-1, PDL-1 또는 GFP 플라스미드 DNA(GenScript, Piscataway, NJ)를 1ug/1 E6 세포로 첨가하였다. Neon 튜브를 3mL Electrolytic buffer E2(Thermo Fisher Scientific, Waltham, MA)로 채웠다. 100μL의 Neon 팁(Thermo Fisher Scientific, Waltham, MA)을 사용하여 다음 설정으로 각 플라스미드에 대한 형질감염을 수행하였다: 전압 - 1620, 폭 - 10, 펄스 - 3. 형질감염된 세포를 각 조건에 대해 1 E6 세포/mL의 농도로 예열된 플라스크로 옮겼다.
유세포분석에 의한 PD1/PDL1 결합
실시예 2에서 정제된 변이체 및 실시예 5에서 uPa 처리된 변이체를 v형 바닥 96웰 플레이트(VWR, Radnor, PA, USA)에서 1:3 희석하여 200nM에서 직접 적정하였다. CHO-PD1, CHO-PDL-1 및 CHO-GFP 세포를 해동하고 10% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA, USA)이 보충된 RPMI 1640 배지(A1049101, ATCC 변형)로 세척하고 FACS 버퍼(PBS + 2% FBS)에 재현탁하였다. CHO-PD1 및 CHO-PDL-1 세포 각각을 CHO-GFP 세포와 2:1로 조합하고 20uL의 세포 현탁액을 적정된 변이체가 있는 플레이트에 첨가하였다. 세포를 4℃에서 1시간 동안 변이체와 함께 인큐베이션하였다. 인큐베이션 후, 세포를 FACS 버퍼로 2회 세척하고 1000배 희석된 생존력 염료(Biolegend, San Diego, CA, USA)와 함께 1ug/mL의 2차 항체 AF647 염소 항-인간 IgG Fc(Jackson ImmunoResearch, West Grove, PA, USA)를 웰에 첨가하였다. 플레이트를 실온에서 30분 동안 인큐베이션하였다. 세포를 FACS 버퍼로 2회 세척하고 50uL의 FACS 버퍼에 재현탁하엿다.
검정 판독을 위해, APC 형광의 기하 평균을 BD LSRFortessa(BD Life Sciences, Gurugram, India)에서 유세포분석으로 측정하였다. GFP 양성 세포의 APC 형광 기하 평균을 측정하여 비특이적 결합을 결정하였다. 그래프는 Mac OS X용 GraphPad Prism 버전 8.1.2(GraphPad Software, La Jolla, CA, USA)를 사용하여 생성하였다.
결과
도 8에 나타낸 바와 같이, uPa 처리 없는(-uPa) 차폐된 변이체(30423, 30426, 30430, 30436)에 대해 PD-L1(도 8a) 또는 PD-1(도 8b)에 대한 결합이 관찰되지 않았다. 중쇄 또는 경쇄에 부착된 친화성 성숙된 PD-1 또는 PD-L1 모이어티만 있는 변이체는 각각 0.3nM 및 6nM의 IC50으로 결합을 나타냈다. 비절단성 변이체(30423, 30426)는 프로테아제로 처리했을 때(+uPa) PD-L1 또는 PD-1에 결합하지 않은 반면, Fab와 PD-1:PD-L1 마스크 사이에 uPa 절단 서열을 함유하는 uPa 처리된 샘플에 대해서는 부분적 결합이 회복되었다. 구체적으로, PD-L1에 대한 결합은 관련된 한 쪽(one-sided) 마스크 대조군 31929의 53배 이내에서 30430에 대해 부분적으로 회복되었다(도 8a). PD-1에 대한 결합은 한 쪽 마스크 대조군 31931의 12배 이내에서 30436에 대해 부분적으로 회복되었다(도 8b). 이는 프로테아제에 의해 절단될 때 이러한 변이체에 남도록 설계된 면역 조절제의 정체와 일치한다(30430의 PD-1, 30436의 PD-L1). PD-1:PD-L1 기반 마스크가 없는 변이체(30421) 및 무관한 대조군(22277)은 예상대로 PD-L1 또는 PD-1에 결합하지 않는 것으로 나타났다. JIMT-1을 표적 세포로 사용한 별도의 실험에서 중쇄에 비기능적 PD-1 도메인이 부착된 변이체(32497)는 차폐되지 않은 대조군과 비교하여 TDCC 효능의 감소(55배의 EC50, 도 33)를 나타냈지만, 기능적 PD-1이 있는 동등한 변이체(31929)는 이전에 보았던 차폐되지 않은 대조군(v30421)에 비해 증가된 TDCC 효능(0.2배의 EC50)을 나타냈다.
실시예 9 하이브리드 PD-1/PD-L1 리포터 유전자 검정에서 PD-1 마스크의 추가된 기능성 조사
변이체의 T 세포 결합 기능에 더하여 마스크의 PD-1 모이어티에 의한 PD-1:PD-L1 체크포인트 결합의 차단을 조사하기 위해 맞춤형 하이브리드 PD-1/PD-L1 리포터 유전자 검정(RGA)을 다음과 같이 수행하였다.
방법
10% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA)이 보충된 DMEM 배지(Thermo Fisher Scientific, Waltham, MA)로 이루어진 성장 배지에서 배양된 JIMT-1(Leibniz Institute, Braunschweig, Germany), 10% 태아 소 혈청이 보충된 RPMI-1640 ATCC 변형(Thermo Fisher Scientific, Waltham, MA)으로 이루어진 성장 배지에서 배양된 HCC1954 (ATCC, Manassas, VA) 및 HCC827 (ATCC, Manassas, VA), 10% 태아 소 혈청 및 0.01mg/mL의 인간 재조합 인슐린(Thermo Fisher Scientific, Waltham, MA)이 보충된 MEM 배지(Thermo Fisher Scientific, Waltham, MA)로 이루어진 성장 배지에서 배양된 MCF-7 (ATCC, Manassas, VA), 및 10% 태아 소 혈청이 보충된 RPMI-1640 배지 ATCC 변형에서 배양된 인간 PD-1 및 NFAT-유도된 루시퍼라제(PD-1/PD-L1 Blockade Bioassay Promega Cat# J1250, Madison, WI)를 안정하게 발현하는 Jurkat T 세포를 검정 설정 전에 37℃에서 5% 이산화탄소를 함유하는 인큐베이터 내 T-75 또는 T-175 플라스크(Corning, Corning, NY)에 유지하였다. 실험 당일, 변이체를 384웰 로우 플랜지 백색 평면 바닥 폴리스티렌(Low Flange White Flat Bottom Polystyrene) TC-처리된 마이크로플레이트(Corning Cat# 3570, Corning, NY)에서 웰당 총 부피 20uL로 직접 1:3 희석하여 150nM에서 0.85pM까지 3중 적정하였다. 종양 세포를 세포 해리 버퍼를 사용하여 해리하고 1% 태아 소 혈청이 보충된 RPMI 1640에서 Jurkat 세포와 1:1 비율로 혼합하였다. 20uL의 혼합된 세포 현탁액을 적정된 변이체를 함유하는 플레이트에 첨가하였다. 플레이트를 5% 이산화탄소와 함께 37℃에서 16시간 동안 인큐베이션하였다. 인큐베이션 후, 40uL의 Bio-Glo™ 루시퍼라제 검정 시약(Promega Cat# G7940, Madison, WI)을 모든 웰에 첨가하여 기포가 형성되지 않도록 하고 게인 150으로 마이크로플레이트 판독기(Biotek Synergy H1, Winooski, VT)에서 발광 모드로 10분 후에 플레이트를 판독하였다. 검정 설정의 개략도는 도 9a에 나와 있다.
결과
마스크에 의해 추가된 기능을 조사하기 위한 맞춤형 RGA의 분석이 도 9b에 나와 있다. 포화량(150nM)의 항-PD-L1 항체와 조합하여 T 세포와 종양 세포를 가교결합할 수 있는 차폐되지 않은 변이체(30421)로 세포를 처리한 경우, 높은 RGA 반응이 나타났다. 차폐되지 않은 이중특이성 CD3 × Her2 항체가 T 세포와 종양 세포를 생산적으로 가교결합할 수 있는 반면, 고농도의 항 PD-L1 항체는 PD-1:PD-L1 체크포인트 결합을 강력하게 차단하여 모든 테스트된 변이체 농도에 걸쳐 높은 신호를 생성하였다. 반대로, 차폐되지 않은 변이체(30421)로만 처리한 경우에는 변형된 T 세포와 JIMT-1 세포 사이의 PD-1과 PD-L1의 결합으로 인해 신호가 크게 감소하였다. uPa로 처리되지 않은(-uPa) 비절단성(30423) 및 절단성(30430) 차폐된 변이체는 차폐되지 않은 30421과 비교했을 때 10nM 변이체 농도 미만에서 현저하게 감소된 활성을 나타내며, 이는 CD3 파라토프의 입체적 차단에 의한 T 세포 인게이저 기능의 생산적인 억제를 가리킨다. uPa 미처리 샘플 30430은 30423보다 RGA 반응을 유도하는 데 더 강력하였다. uPa로 처리했을 때(+uPa) 절단성 차폐된 변이체(30430)는 100pM보다 높은 변이체 농도에서 차폐되지 않은 대조군(30421)보다 RGA에서 더 높은 활성을 나타내며, 이는 CD3 파라토프의 차폐 해제는 물론 절단 후 변이체에 남아 있는 마스크의 기능적 PD-1 모이어티에 의한 PD-1:PD-L1 체크포인트 결합의 차단을 가리킨다. 이 결과와 일치하게도 CD3 Fab의 중쇄에 부착된 PD-1 도메인만 있는 대조군은 차폐되지 않은 대조군(30421)과 비교할 때 100pM보다 높은 변이체 농도에서 RGA에서 유사한 프로파일 및 증가된 활성을 나타냈다. 무관한 항-RSV 항체(22277)는 RGA에서 활성을 나타내지 않았다.
Her2 및 PD-L1 양성 세포주로서 JIMT-1을 사용하여 RGA를 반복하고 실시예 7에서 측정된 바와 같이 상이한 수준의 이러한 수용체를 갖는 3개의 다른 세포주로 확장시켰다. 여기에서 수행된 RGA에 대한 데이터는 도 26에 나타나 있다. 비절단성(30423) 및 절단성(30430) 차폐된 변이체에 대한 EC50 증가에 의해 측정된 차폐는 모든 세포주에서 확인되었고 차폐되지 않은 대조군(30421)에 비해 4 내지 530배 범위였다. 차폐되지 않은 대조군(30421)의 효능은 세포주 사이에서 유사했지만(EC50 = 20-50pM), Her2 및/또는 PD-L1 수용체 수가 더 적은 세포주(HCC827 및 MCF-7)에서 테스트된 변이체는 수용체 발현이 더 높은 것(HCC1954 및 JIMT-1)보다 더 강한 차폐를 나타냈다. uPa 처리(+uPa) 시 절단성 차폐된 변이체(30430)는 차폐되지 않은 대조군의 1.7 내지 3.6배 내에서 효능을 회복하였다. PD-1 모이어티만 중쇄에 부착된 변이체(31929), uPa 처리 후의 절단성 차폐된 변이체(30430 + uPa)는 물론 차폐되지 않은 대조군과 포화량의 항-PD-L1 항체의 조합(30421 + 120nM 아테졸리주맙)은 PD-L1에도 결합하는 능력으로 인해 PD-L1 발현이 현저한 세포주(HCC1954, JIMT-1, HCC827)에서 더 높은 효능(1.6 내지 3.3배 더 높은 최대 RLU)을 나타냈다. TAA 및 PD-L1 발현이 높은 세포주(HCC1954, JIMT-1)에서도 이러한 변이체에 대해 더 높은 효능이 관찰되었다(0.2 내지 0.4배의 EC50). PD-L1 발현이 매우 낮은 세포주(MCF-7)는 차폐되지 않은 대조군(30421) 및 PD-L1에 결합할 수 있는 세포(31929, 30421 + 120nM 아테졸리주맙, 30430 + uPa)와 구별되지 않았다. 무관한 항-RSV 항체(22277)는 어느 세포주에 대해서도 RGA에서 활성을 나타내지 않았다.
실시예 10 차폐된 항-EGFR, 항-메소텔린, 항-TF, 항-CD19, 항-CMET 및 항-CDH3 변이체의 제조
상이한 항원을 표적으로 하는 항체에 대한 차폐 기술의 적용 가능성을 조사하기 위해, 여러 상이한 에피토프를 표적으로 하는 mAb의 가변 도메인에 PD-1:PD-L1 복합체를 포함하는 차폐 도메인을 추가하였다. 융합 단백질 구조는 다음과 같이 설계하였다.
방법
WT의 단백질 서열과 인간 PD-1 및 PD-L1의 변형된 IgV 도메인을 비절단성 및 uPa 절단성 링커를 통해 실시예 1에 기술된 바와 같은 여러 상이한 에피토프(EGFR, 메소텔린, TF, CD19, cMet, CDH3)에 대해 표적화된 항체의 IgG1 중쇄 및 카파 경쇄(VL-CL)의 N-말단에 각각 융합시켰다. VL 및 VH의 서열 및 이들의 공급원은 표 2에 기술되어 있다. 실시예 1의 작제물과의 현저한 차이점은 야생형(WT) CH3(서열번호 12)를 사용하여 동종이량체 전체 크기 항체의 조립을 가능하게 한 것이다. 차폐된 Fab에 대한 작제물 설계의 개략도는 물론 의도된 작용 메커니즘(MoA)이 도 1에 나와 있다. 2개의 동일한 중쇄 및 경쇄가 있는 2가의 완전히 차폐된 mAb의 최종 설계의 개략도가 도 10에 나와 있다. 최종 변이체의 사용된 서열은 표 B에 나열되어 있다.
[표 B]

[표 C]



실시예 11 차폐된 항-EGFR, 항-메소텔린, 항-TF, 항-CD19, 항-CMET 및 항-CDH3 변이체의 생성
실시예 10에서 설계된 변형된 변이체의 서열을 발현 벡터에 클로닝하고 다음과 같이 발현 및 정제하였다.
방법
실시예 10으로부터의 여러 상이한 에피토프(EGFR, MSLN, TF, CD19, cMet, CDH3)에 대해 표적화된 변형된 변이체의 중쇄 및 경쇄 서열을 동일한 몰 비로 Expi293F™ 세포에 형질감염시키고, 그 외에는 실시예 2에 기술된 바와 같이 발현하고 정제하였다.
결과
고순도 샘플을 얻기 위해 실시예 2에 기술된 바와 같이 분취 SEC를 사용하였다. 분취 SEC 후 수율은 변이체당 1.5-6mg 범위였다. 실시예 12에 기술된 바와 같이 샘플 순도를 평가하였다.
실시예 12 차폐된 항-EGFR, 항-메소텔린, 항-TF, 항-CD19, 항-CMET 및 항-CDH3 변이체의 품질 평가
실시예 10으로부터의 정제된 샘플을 하기 기술된 바와 같이 UPLC-SEC 및 비환원 SDS-PAGE로 순도 및 샘플 균질성에 대해 평가하였다.
방법
비환원 SDS-PAGE의 경우, 2μL의 샘플을 10μL의 PBS로 희석한 다음 4μL의 4X Laemmli 버퍼(BioRad, Hercules, CA)와 혼합하였다. 이어서 샘플을 95℃에서 5분 동안 가열하고 쿠마시(Coomassie) G-250으로 염색하기 전에 제공된 Tris/글리신/SDS 버퍼 중 mini-PROTEAN 4-20% Precast Gel(BioRad, Hercules, CA)에서 실행하고 탈색 및 이미징한다. UPLC-SEC와 비환원 및 환원 CE-SDS를 실시예 3에 기술된 바와 같이 수행하였다.
결과
도 11a-11j에서 분취 SEC 정제 후 샘플의 UPLC-SEC 흔적은 샘플이 정확한 종의 85% - 98%를 함유함을 나타냈다. 주요 종에 비해 짧은 머무름 시간의 작은 피크의 존재는 모든 샘플에서 올리고머 및 응집체와 같은 소량의 고분자량 종의 존재를 나타낸다. 이러한 고분자량 종은 MSLN, TF, c-Met 및 CDH3을 표적으로 하는 것과 비교하여 CD19 및 EGFR을 표적으로 하는 샘플에서 더 일반적이었다.
비환원 SDS-PAGE 및 CE-SDS(도 11k, 11l)의 분석은 모든 변이체에 대해 단일 우세 종을 나타냈다. 특히, 이 종의 겉보기 분자량은 예상되는 것보다 상당히 높다(>250kDa 대 200kDa). c-Met 및 CDH3에 대해 표적화된 대표적인 변이체의 환원 CE-SDS는 온전한 중쇄 및 경쇄에 상응하는 밴드만을 나타냈다. 이들은 실시예 3에 기술된 것과 동일한 높은 겉보기 분자량을 나타낸다. 설계에서 PD1 및 PD-L1 모이어티 둘 다의 글리코실화는 겉보기 분자량을 증가시킬 가능성이 있다(Tan, S. 등, An unexpected N-terminal loop in PD-1 dominates binding by nivolumab. Nat Commun 8, 14369, doi:10.1038/ncomms14369 (2017), Li, C. W. 등, Glycosylation and stabilization of programmed death ligand-1 suppresses T-cell activity. Nat Commun 7, 12632, doi:10.1038/ncomms12632 (2016)).
실시예 13 차폐된 항-EGFR, 항-메소텔린, 항-TF, 항-CD19, 항-CMET 및 항-CDH3 변이체의 UPA 절단
링커에서 의도된 프로테아제 부위의 절단에 의해 여러 상이한 파라토프의 Fab로부터 마스크의 일부 또는 전부의 방출을 평가하기 위해, 실시예 11에서 생성된 선별 샘플을 시험관 내에서 uPa로 처리하였다. 다음과 같이 환원 SDS-PAGE로 반응을 모니터링하였다.
방법
상이한 에피토프를 표적으로 하는 변형된 변이체의 분취 절단 검정을 실시예 5에 기술된 바와 같이 설정하고 비환원 SDS-PAGE로 분석하였다. SDS-PAGE는 샘플의 변성을 위해 환원 Laemmli 버퍼를 사용하는 것을 제외하고는 실시예 12에 기술된 바와 같이 설정하였다. 환원 버퍼는 10% β-ME로 4X Laemmli 버퍼를 보충하여 얻었다.
결과
uPa 절단 서열을 함유하지 않는 변이체는 테스트된 조건 하에서 어떠한 프로세싱(processing)도 나타내지 않았지만, PD-L1 모이어티와 Fab의 VL 사이에 uPa 특이적 서열을 포함하는 모든 변이체는 경쇄에서 PD-L1 도메인의 완전한 절단(도 12) 및 방출을 나타냈다. 이는 보호되지 않은 카파 경쇄에 대해 예상된 바와 같이 uPa 처리 후 LC의 겉보기 MW가 약 25kDa로 감소한 것으로 볼 수 있다. 이종 글리코실화(Li, C. W. 등, Glycosylation and stabilization of programd death ligand-1 suppresses T-cell activity. Nat Commun 7, 12632, doi:10.1038/ncomms12632 (2016)) 및 소분자량(약 13kDa)으로 인해 유리 PD-L1 모이어티는 EGFR 및 TF를 표적으로 하는 변이체에 대해 검출되지 않았을 가능성이 높다. MSLN 및 CD19에 대해 15-20kDa의 겉보기 분자량 종을 나타내는 희미한 밴드가 감지되었다.
실시예 14 항-EGFR, 항-메소텔린, 항-TF, 항-CD19, 항-CMET 및 항-CDH3 변이체의 차폐/차폐 해제
상이한 파라토프/에피토프 쌍의 표적 결합은 실시예 11에서 생성되고 실시예 13에서 uPa로 처리된 샘플에 대해 SPR 및 유동세포분석으로 다음과 같이 평가하였다.
방법
유세포분석에 의한 고유 결합
관심 대상(MDA-MB231, OVCAR3, MDA-MB468, Raji)을 함유하는 표면 단백질을 발현하는 다양한 암 세포주를 37℃에서 가습 + 5% CO2 인큐베이터 내 L-글루타민 및 적절한 농도의 혈청(완전 배지)이 보충된 권장 배양 배지에서 유지하였다.
상이한 에피토프에 대해 표적화된 변형된 변이체를 완전 배지에서 2배 희석한 다음, 300nM 또는 150nM에서 시작하여 총 8 내지 10개의 농도 지점에 대해 차가운 완전 배지에서 3배 연속 희석하였다.
모든 배지를 4℃로 유지하였고 모든 인큐베이션은 젖은 얼음에서 수행하였다. 검정 당일, 기하급수적으로 성장하는 세포를 따뜻한 비효소 세포 해리 용액을 사용하여 수확하고, 원심분리하고, 2E+06 세포/mL의 세포 밀도로 완전 배지에 재현탁하였다. 50μL/웰의 세포를 폴리프로필렌 v형 바닥 96웰 플레이트(Corning, Corning, NY, USA)에 분배하였다. 동일한 부피의 2배 테스트 항체 또는 대조군을 세포에 첨가하고 2시간 동안 인큐베이션하였다. 이어서 세포를 원심분리로 2회 세척하고 상등액을 제거하였다. 결합된 변이체의 검출은 1시간 동안 형광 표지된 Fc 특이적 2차 항체(Jackson ImmunoResearch, West Grove, PA, USA)와 함께 추가 인큐베이션하여 달성하였다. 세포를 원심분리로 2회 세척하고 세포 펠릿을 요오드화프로피듐(Invitrogen, Carlsbad, CA, USA)과 함께 완전 배지에 재현탁하고, 0.60μm 크기 기공의 96웰 필터 플레이트(MilliporeSigma, Burlington, MA, USA)를 사용하여 여과하고 HTS 자동 샘플러 장치(BD-LSRII 또는 BD-LSRFortessa에 설치됨)를 사용하여 유세포분석으로 분석하였다. 샘플당 2,000개의 살아있는/단일 세포 이벤트를 획득하였다.
음성 대조군(백그라운드)의 MFI 값을 빼서 각 샘플 포인트에 대해 특정 MFI를 계산하였다. 결합 곡선(특정 MFI 대 선형 또는 로그 항체 농도)은 각 테스트 항목에 대한 Bmax 및 겉보기 Kd 값을 측정하기 위해 Hill 기울기가 있는 원-사이트 특이적 4-매개변수 비선형 회귀 곡선 피팅 모델을 사용하여 GraphPad Prism 8(GraphPad Software, La Jolla, CA, USA)로 피팅하였다.
SPR
변형된 mAb 변이체에 대한 상이한 항원의 서브세트(EGFR, TF, 메소텔린)의 키네틱 및 친화도를 측정하기 위한 SPR(표면 플라스몬 공명) 결합 검정을 25℃의 온도에서 PBS-T(PBS + 0.05%(v/v) Tween 20, pH 7.4) 실행 버퍼를 사용하여 Biacore™ T200 기기(GE Healthcare, Mississauga, ON, Canada)에서 수행하였다. CM5 시리즈 S 센서 칩, Biacore 아민 커플링 키트(NHS, EDC 및 1M 에탄올아민) 및 10mM 나트륨 아세테이트 버퍼는 모두 GE Healthcare에서 구입하였다. 0.05%(v/v) Tween 20(PBS-T)이 포함된 PBS 실행 버퍼는 Teknova Inc.(Hollister, CA)에서 구입하였다. 염소 다클론 항-인간 Fc 항체는 Jackson Immuno Research Laboratories Inc.(West Grove, PA)에서 구입하였다. 인간 EGFR의 세포외 도메인의 재조합 단백질(Genscript, Cat# Z03194-50) 및 성숙한 인간 메소텔린(R&D systems, Cat# 3265-MS-050)을 구입하고 SPR 분석 전에 SEC로 정제하여 분석물의 순도 및 균질성을 보장하였다. 인간 TF의 재조합 단백질을 HEK293 세포에서 발현시키고 음이온 교환(Q Sepharose HP, GE Healthcare)으로 정제한 다음 SPR에 사용하기 전에 SEC 정제를 수행하였다.
상이한 항원에 대한 결합에 대한 mAb 변이체의 스크리닝은 두 단계로 실행하였다: 항-인간 Fc 특이적 다클론 항체 표면으로의 mAb 변이체의 간접 포획에 이은 SEC 정제된 항원의 5가지 농도의 주입. 항-인간 Fc 표면은 제조사(GE Healthcare)가 기술한 표준 아민 커플링 방법으로 CM5 시리즈 S 센서 칩 상에 제조하였다. 간략하게, EDC/NHS 활성화 직후, 10mM NaOAc(pH 4.5) 중 항-인간 Fc의 25μg/mL 용액을 약 4500 공명 단위(RU)가 4개의 플로우 셀(flow cell) 모두에 고정될 때까지 7분 동안 10μL/분의 유량으로 주입하였다. 나머지 활성 그룹은 7분 동안 10uL/분의 1M 에탄올아민의 주입에 의해 켄칭되었다. 분석을 위한 MAb는 60초 동안 10μL/분의 유량으로 2-20μg/mL 용액을 주입함으로써 항-Fc 표면(플로우 셀 2-4)으로 간접적으로 포획되어 mAb 변이체에 따라 130-470 RU 범위의 mAb 포획 수준을 야기하였다. 단일 주기 키네틱을 사용하여 항원의 2배 희석 시리즈의 5개 농도를 기준 플로우 셀 1을 포함한 모든 플로우 셀에 40μL/분으로 순차적으로 주입하고 모든 플로우 셀에 버퍼 블랭크를 대조군으로 주입하였다. 분석물의 농도 범위와 접촉 및 해리 시간에 대한 자세한 내용은 표 53 참조. 30μL/분에서 120초 동안 10mM 글리신/HCl, pH 1.5의 1회 펄스에 의해 항-인간 Fc 표면을 재생시켜 다음 주입 주기를 준비하였다. Biacore™ T200 평가 소프트웨어 v3.0을 사용하여 이중 기준 감산 센소그램을 분석한 다음 1:1 Langmuir 결합 모델에 피팅하였다.
[표 D]

결과
도 13은 모든 비절단성 변이체에 대한 항원 결합(EGFR, MSLN, TF, CD19, cMet, CDH3의 경우 각각 변이체 31722, 31728, 31736, 31732, 28647, 28664)이 세포 결합(on-cell binding) 연구로 측정했을 때 각각의 차폐되지 않은 대조군(EGFR, MSLN, TF, CD19, cMet, CDH3의 경우 각각 변이체 32474, 16417, 6323, 4372, 17606, 17214)과 비교하여 30-190배 감소되었음을 나타낸다. 절단성 변이체가 포함된 경우, 샘플을 uPa 처리 없이(-uPa) 및 uPa 처리하고(+uPa) 테스트하였다. 비절단성 변이체(EGFR, MSLN, TF, CD19의 경우 각각 31722, 31728, 31736, 31732)는 절단되지 않은 샘플과 uPa 처리된 샘플 사이에 약간의 차이만 보였지만, 절단성 샘플(EGFR, MSLN, TF, CD19의 경우 각각 31723, 31729, 31737, 31733)은 uPa 처리 시 결합을 현저하게 회복하였다. 구체적으로, 결합 수준은 프로테아제에 적용되기 전에 비절단성 변이체와 유사했지만, uPa 절단 시에 결합은 차폐되지 않은 대조군의 1.3-85배 내에서 회복되었다. 이용 가능한 경우(EGFR, TF, 메소텔린), SPR 결합 결과는 절단 후 동일한 경향의 차폐 및 결합의 회복을 보여준다.
실시예 15 차폐된 항-EGFR 변이체의 기능적 분석
세포 기반 검정에서 마스크가 실시예 11에서 생성되고 실시예 13에서 uPa로 처리되고 실시예 14에서 표적 결합에 대해 테스트된 EGFR 표적 변이체의 기능에 미치는 영향을 조사하기 위해 NCI-H292 세포에 대한 성장 억제 연구를 다음과 같이 수행하였다.
방법
이 검정을 위해, NCI-H292 세포를 37℃ + 5% CO2에서 75㎠(T75) 플라스크에서 일상적으로 성장시키고 항생제를 첨가하지 않은 FBS 배양 배지에서 주 2회 계대하였다. 항체를 첨가하기 전날 세포를 mL당 1000 단위의 페니실린, 1000μg의 스트렙토마이신 및 2.5μg의 암포테리신(Amphotericin) B가 첨가된 배양 배지 중 384웰 플레이트(Corning 3570)에 300개, 1000개 및 125개의 세포/25μL/웰로 접종하였다. 검정 당일에 항체 및 대조군을 원하는 최종 농도의 6배로 11-지점 용량-반응 곡선으로 연속 희석한 다음, 표 5: 변이체 농도 범위에 기술된 최종 인큐베이션 농도를 위해 플레이팅된 세포에 첨가하였다. 세포 증식에 대한 이의 효과는 37℃, 5% CO2에서 5일 동안 인큐베이션한 후에 측정하였다. 무관한 항체(22277)와의 인큐베이션을 비-표적 지향 세포독성을 평가하는데 사용하였다. Cell TiterGlo™(Promega, Madison)를 사용하여 각 웰에 존재하는 ATP의 정량을 기반으로 세포 생존력을 측정하였으며, 이는 대사 활성 세포의 존재를 나타낸다. 신호 출력은 0.1초의 통합 시간으로 설정된 발광 플레이트 판독기(Envision, Perkin Elmer)에서 측정하였다. 통합 시간은 높은 ATP 농도에서 신호 포화를 최소화하도록 조정된다.
상대적 발광 단위(Relative Luminescence Unit, RLU)로 표현된 데이터를 미처리 대조군 웰에 대해 정규화하고 다음 공식에 따라 계산한 생존 %로 표현한다.
생존 % = RLU Ab/RLU 미처리 × 100.
GraphPad Prism 소프트웨어를 사용하여 용량-반응 곡선을 생성하여 효능(efficacy)(고농도에서 관찰된 최대 포화 성장 억제 반응) 및 효력(potency)(상대 IC50, 최대 효능의 절반에 도달하는 데 필요한 농도)을 측정하였다.
[표 E]

결과
도 14에 나타낸 바와 같이, 세툭시맙에 기반한 항-EGFR 항체(32474)는 0.11nM의 IC50으로 NCI-H292 세포의 성장을 억제하였다. uPa 처리는 이 기능에 최소한의 영향만 미쳤다. PD-1:PD-L1 차폐된 변이체(31722, 31723)는 uPa 처리 없이는 덜 강력하였다(40-80배 증가된 IC50). uPa로 처리했을 때, 비절단성 변이체 31722는 여전히 기능이 상당히 억제(100배)된 반면, 절단성 변이체 31723은 차폐되지 않은 v32474의 2.5배 이내의 기능 회복을 보였다. 무관한 항체(22277)는 성장 억제 검정에서 기능을 나타내지 않았다.
실시예 16 마스크로서의 B7:CD28 패밀리 리간드 수용체 쌍 - CTLA4:CD80
B7:CD28 패밀리의 다른 구성원이 Fab를 효율적으로 차폐하는데 이용될 수 있는지 결정하기 위해, 실시예 1로부터의 CD3 × Her2 Fab × scFv Fc 항체의 CTLA4:CD80 차폐된 버전을 생성하고 CD3 결합에 대해 다음과 같이 평가하였다.
방법
차폐된 CTLA4:CD80 CD3 Fab를 실시예 1의 PD1:PD-L1 차폐된 변이체와 동등하도록 설계하였다. 간략하게, 인간 CD80 및 CTLA4의 IgV 도메인의 서열(West, S. M. & Deng, X. A. Considering B7-CD28 as a family through sequence and structure. Exp Biol Med (Maywood), 1535370219855970, doi:10.1177/1535370219855970 (2019); 서열번호 25, 26)을 실시예 1 및 실시예 10에 기술된 링커 조합 중 하나를 사용하여 CD3 Fab의 중쇄 및 경쇄의 N-말단 각각에 부착하였다. 구체적으로, CD80 모이어티는 프로테아제에 의해 제거될 수 없는 반면 CTLA4 IgV 도메인은 uPa 절단성 서열이 있는 LC에 융합되었다. 조사된 변이체 구조의 도식은 도 15에 나와 있다. 또한, 이전에 기술된 CD80을 통한 동종이량체화를 감소시키기 위해(C. C. Stamper 등, Crystal structure of the B7-1/CTLA-4 complex that inhibits human immune responses. Nature 410, 608-611 (2001)), 일부 변이체에서 CD80 모이어티에 돌연변이가 도입되었다. 변이체의 개별 쇄의 서열은 표 F에 나열되어 있다. 항체가 생성되었고, 실시예 2, 실시예 3, 실시예 5 및 실시예 6 각각에서와 같이 이의 샘플 순도 및 uPa에 의한 절단을 평가하였으며 CD3 함유 Jurkat 세포에 대한 결합을 평가하였다.
[표 F]

결과
CTLA4:CD80 기반 마스크(30444)를 포함하는 변형된 CD3 × Her2 Fab × scFv Fc 변이체의 생성은 분취 SEC 후 6.7mg을 산출했으며, 이는 실시예 2에서의 동등한 PD-1:PD-L1 차폐된 변이체와 유사한 양이다. 단백질 A 정제 후 UPLC-SEC 분석(도 16a)은 이량체를 주요 종으로 나타냈고, 이는 이종이량체 계면으로부터 멀리 떨어져 있는 CD80 및 CTLA4 상의 동종이량체화 계면과 일치한다(Trang, V. H. 등, A coiled-coil masking domain for selective activation of therapeutic antibodies. Nat Biotechnol 37, 761-765, doi:10.1038/s41587-019-0135-x (2019)). 응집체 및 올리고머와 같은 고분자량 종도 상당량 관찰되었으며 이러한 바람직하지 않은 입자를 제거하기 위해 분취 SEC를 수행하였다. 최종 SEC 정제된 샘플의 UPLC-SEC(도 16b)는 84%의 이량체 및 9%의 단량체 종을 나타냈다. 또한, 7%의 고분자량 종이 여전히 존재하였다. 비환원 CE-SDS(도 16c)는 온전한 분자에 대해 예상되는 것보다 상당히 더 높은 분자량의 단일 우세 종에 해당하는 프로파일을 보였다. 변형된 중쇄 및 경쇄에 대한 밴드는 환원 CE-SDS 프로파일에서 예상된 겉보기 분자량보다 훨씬 더 높게 나타난다. 실시예 3의 PD-1:PD-L1 기반 변형과 유사하게, 이는 CD80 및 CTLA4의 광범위한 글리코실화로 인해 발생했을 가능성이 높다(Stamper, C. C. 등, Crystal structure of the B7-1/CTLA-4 complex that inhibits human immune responses. Nature 410, 608-611, doi:10.1038/35069118 (2001)). CD80 모이어티의 동종이량체화 계면에 돌연변이가 도입되었을 때 단백질 A 정제 후 UPLC-SEC에서 발견되는 이량체 종의 양은 19-59%로 감소한 반면 단량체 종의 양은 28-66%로 증가하였다(도 16d-16f).
uPa로 처리했을 때, CTLA4 모이어티는 도 17에 나타낸 바와 같이 경쇄로부터 효과적으로 제거되었다. 여기서, 변형된 경쇄에 상응하는 밴드는 절단 시 사라졌고 차폐되지 않은 경쇄의 분자량에 상응하는 밴드가 나타났다. 방출된 CTLA4 성분은 절단 후에 검출되지 않았는데, 글리코실화로 인한 작은 크기 및 이질성 때문일 가능성이 크다.
Jurkat 세포 상의 CD3에 대한 결합의 평가는 실시예 6(도 18)에 기술된 바와 같이 ELISA로 평가하였으며, CD80:CTLA4 기반 변형(v30444)이 표적 결합을 약 80배 감소시켰음을 나타냈다. 이는 PD-1:PD-L1 기반 마스크(실시예 6, 참조로 여기에 포함된 v30430)가 있는 동등한 변이체에 대해 표시되는 것과 유사하다. CTLA4 모이어티의 uPa 절단 시, CD3 결합이 부분적으로 복원된다(WT의 약 4배 이내).
실시예 17 차폐된 면역조절인자-FC-융합에 기반한 조건부 활성 면역조절인자
면역조절 쌍(예를 들어, PD-1:PD-L1(표 G), CD80:CTLA-4)은 본 실시예에서 비표적 조건부 활성화 분자로 사용된다. 여기서, 면역조절 쌍은 특정 파라토프에 대해 차폐 기능을 수행하지 않고 다음과 같이 Fc에 직접 융합된다.
방법
여기서 조사된 작제물은 이종이량체 IgG Fc의 힌지에 N-말단이 융합된 PD-1:PD-L1과 같은 면역조절인자 쌍의 IgV 도메인을 기반으로 한다. 이러한 작제물의 Fc 부분은 이전에 기술된 바와 같이 2개의 사슬의 이종이량체 페어링을 만드는 CH3 도메인의 돌연변이를 포함한다(예를 들어, Von Kreudenstein, T. S. 등, Improving biophysical properties of a bispecific antibody scaffold to aid developmentability: quality by molecular design MAbs 5, 646-654, doi:10.4161/mabs.25632 (2013); 서열번호 4,5; 다른 이종이량체 Fc 형성 돌연변이도 문헌에서 이용 가능함). 한 실시양태에서, 돌연변이는 또한 Fc 감마 수용체(서열번호 6)에 대한 결합을 없애기 위해 두 CH2 도메인에 도입된다. 하나의 면역조절인자 IgV 도메인(예를 들어, PD-1의 고친화성 버전, Maute, R. L. 등, Engineering high-affinity PD-1 variants for optimized immunotherapy and immuno-PET imaging. Proc Natl Acad Sci U S A 112, E6506-6514, doi:10.1073/pnas.1519623112 (2015), 서열번호 9)은 IgG 힌지의 N 말단에 직접 융합되고, uPa(MSGRSANA)에 의해 인식되고 절단되는 아미노산 서열은 나머지 사슬의 힌지와 또 다른 면역조절 IgV 도메인(예를 들어, WT PD-L1, 서열번호 8) 사이에 도입된다.
이 설계는 프로테아제 절단성 펩티드 링커를 통해 IgG Fc에 직접 융합되는 조건부 활성의 1가 PD-L1 표적화 분자를 생성한다(도 19). uPa가 없는 경우, 고친화성 PD-1:PD-L1 이량체가 분자 내에서 형성되고 PD-L1에 대한 바람직하지 않은 전신 결합이 방지된다. 예를 들어, 종양 미세환경(TME)에서 uPa에 노출되면 PD-L1이 방출되고 PD-1 모이어티가 종양 세포에서 발현된 PD-L1에 결합할 수 있다. 이로써 TME에서는 체크포인트 활성이 선택적으로 차단되고 세포독성 T 세포에 대한 종양 세포의 감수성이 향상된다. CD80:CTLA-4 또는 SIRPα:CD47과 같은 다른 면역조절 리간드 수용체 쌍도 마스크로 사용된다. CD80:CTLA-4의 경우, 올바른 TME 관련 프로테아제가 있는 경우에만 CTLA-4가 방출되고 나머지 CD80은 T 세포의 CD28 또는 CTLA-4에 결합하여 면역조절 기능을 발휘할 수 있다. SIRPα:CD47 마스크의 경우, CD47 모이어티는 TME에서 단백질분해 절단에 의해 방출되어 SIRPα가 대식세포의 CD47에 자유롭게 결합하도록 함으로써 체크포인트 활성을 억제하고 식세포작용 및 종양 세포 사멸을 증가시킨다.
uPa로 처리하거나 처리하지 않은 변이체를 실시예 8에 기술된 바와 같이 유세포분석으로 PD-L1에 대한 결합에 대해 테스트하였다. 동일한 샘플을 PD-1:PD-L1 체크포인트 억제에 민감한 리포터 유전자 검정(RGA)으로 테스트하였다(Promega, Madison, WI, USA). RGA는 실시예 9의 RGA와 유사하게 수행되지만, PD-L1 발현 및 TCR 지향 CHO 세포는 제조사 프로토콜에 따라 변형된 Jurkat T 세포와 함께 사용된다.
[표 G]

결과
uPa로 처리하지 않으면 ZW Fc1은 유세포분석 검정에서 PD-L1에 결합하지 않는다. 이는 Fc 어셈블리에서 PD-L1과 PD-1 IgV 도메인의 고친화성 버전의 긴밀한 분자 내 상호작용 때문이다. uPa로 처리하면 ZW Fc1은 SPR 및 유세포분석 검정에서 PD-L1에 단단히 결합한다. 이는 링커에서 uPa 특이적 서열이 절단된 후 PD-L1 모이어티가 방출되고 Fc에 남아 있는 PD-1 도메인이 검정에서 PD-L1에 자유롭게 결합하기 때문인 것으로 예상된다. 유사하게, uPa에 의해 절단되지 않는 ZW Fc1은 PD-1:PD-L1 RGA에서 활성이 없지만 uPa로 처리되면 강력한 활성을 나타낸다.
실시예 18 항-CD40 시스템에서 차폐 기술의 평가
실시예 1-15에 기술된 PD-1:PD-L1 기반 마스크를 CD40 표적화 파라토프에 적용하고 생성된 변이체의 샘플 품질, 표적 결합 및 기능에 대한 마스크의 영향을 다음과 같이 평가하였다.
방법
변이체 설계 및 생성
이전에 기술된 항-CD40 파라토프를 함유하는 풀 사이즈 항체의 PD-1:PD-L1 차폐된 버전(R. H. Vonderheide 등, Clinical activity and immune modulation in cancer patients treated with CP-870,893, a novel CD40 agonist monoclonal antibody. J Clin Oncol 25, 876-883 (2007))을 실시예 10에 기술된 바와 같이 작제하였다. 생성된 작제물 및 그 서열은 표 H에 요약되어 있다.
[표 H]

기술된 변이체의 중쇄 및 경쇄 서열을 발현 벡터에 운반(port)하고, Expi293F™ 세포에서 발현시키고 실시예 11에 기술된 2단계 정제 공정을 사용하여 정제하였다. 이어서, 정제된 샘플을 실시예 3에 기술된 바와 같이 UPLC-SEC 및 비환원 겔 전기영동으로 순도 및 샘플 균질성에 대해 평가하였다. 정제 후, 샘플을 uPa로 처리하고 이러한 처리를 실시예 5에 기술된 바와 같이 비환원 CE-SDS로 평가하였다. 이어서, uPa 미처리된 샘플과 uPa 처리된 샘플 둘 다를 실시예 14에 기술된 바와 같이 Raji 세포에 대한 표적 결합에 대해 유세포분석으로 평가하였다.
CD40 RGA
uPa 미처리(-uPA) 변이체 및 uPa 처리(+uPA) 변이체를 기능적으로 평가하기 위해, CD40 리포터 유전자 검정(RGA)을 수행하였다. HEK Blue CD40L 세포(Invivogen, San Diego, CA, USA, hkb-cd40 Lot 38-01-hkbcd40) 세포를 PBS로 분리한 다음 예열된 테스트 배지(Gibco™ DMEM(Thermo Fisher Scientific, Waltham, MS, USA, 1195-040) + 10% 열 불활성화 Gibco™ FBS(Thermo Fisher Scientific, Waltham, MS, USA, 12483-020 Lot 1996160)(56℃, 30분) 및 100U/mL Gibco™ Pen-Strep(Thermo Fisher Scientific, Waltham, MS, USA, 15070-063 Lot 1989510))에서 2.78 × 105개의 세포/mL로 재현탁하였다. WT-CHOK1(ATCC, Manassas, VA, USA, ATCC CCL-61, Lot 70014310) 및 FcgR2B-CHOK1 세포(BPS Bioscience, San Diego, CA, USA, 79511, Lot 191104-41)를 트립신으로 분리하고, 테스트 배지와 함께 5.56 × 105개의 세포/mL로 재현탁하였다. 이어서, 25,000개의 HEK Blue CD40 세포(90μL)를 테스트 배지(10μg/mL-0.000001μg/mL)에 연속 희석된 20μL의 변이체에 첨가한 다음, 50,000개의 WT-CHOK1, FcYR2B-CHOK1 세포(90μL) 또는 90μL의 테스트 배지를 첨가하였다. 37℃, 5% CO2에서 20-24시간 동안 인큐베이션한 후, 20μL의 상등액을 180μL의 Quanti-Blue™ 용액(Invivogen, San Diego, CA, USA)과 혼합하고, 37℃, 5% CO2에서 3시간 동안 인큐베이션하고 OD620nm를 측정하였다. 테스트 항목에는 uPa 미처리 및 uPa 처리 CD40 표적화 변이체는 물론 각각 음성 대조군 및 양성 대조군으로서 RSV 및 CD40L(Invivogen, San Diego, CA, USA)에 대해 표적화된 무관한 대조군 항체가 포함되었다.
결과
도 20a-20c에 나타낸 바와 같이, SEC 정제 후, 항 CD40 변이체는 UPLC-SEC에서 92%-100%의 순도로 하나의 우세 종을 나타냈고, 차폐된 변이체 v32478 및 v32479에 대해 적은 양의 고분자량 종(7-8%)이 존재하였다. 비환원 CE-SDS 분석(도 20d)은 또한 모든 변이체에 대해 단일 우세 종을 나타냈다. 차폐되지 않은 v32477의 주요 종의 겉보기 분자량은 예상대로 약 150kDa인 반면, PD-1:PD-L1 차폐된 변이체 v32478 및 v32479는 상당히 더 높은 겉보기 분자량(> 250kDa)을 나타냈는데, 실시예 3 및 실시예 12에서 동일한 차폐 도메인을 사용한 작제물에서 볼 수 있는 바와 같이 글리코실화 때문일 가능성이 크다. 환원 CE-SDS(도 20d)는 모든 변이체에 대해 중쇄 및 경쇄에 상응하는 2종의 뚜렷한 분자량을 나타냈다. 차폐된 변이체 v32478 및 v32479의 경우, 중쇄 및 경쇄 모두의 겉보기 분자량도 예상보다 높았는데(HC의 경우 약 100kDa 대 63kDa, LC의 경우 약 50kDa 대 37kDa), 실시예 3 및 실시예 12에서 볼 수 있는 바와 같이 PD-1 및 PD-L1 둘 다의 글리코실화 때문일 가능성이 크다.
여기에서 조사된 3개의 항-CD40 변이체를 생성 후 uPa로 처리하고 절단을 환원 CE-SDS로 모니터링하였다(도 20e). v32477 및 v32478은 특정 절단 부위의 결여로 인해 uPa와의 인큐베이션 시 어떠한 변화도 나타내지 않았지만, v32479의 경쇄에 대한 프로세싱이 관찰되었다. 여기서, PD-L1 모이어티는 PD-L1의 C-말단과 VL 도메인의 N-말단 사이의 링커에서 uPa 특이적 서열의 절단에 의해 제거되었다. 이로써 절단 후 환원 CE-SDS에서 검출된 3개의 단편이 생성되었다: uPa 부위가 결여된 변경되지 않은 PD-1 차폐된 중쇄, 카파 경쇄의 VL-CL에 상응하는 사슬 및 방출된 PD-L1모이어티에 상응하는 사슬.
uPa 처리된 샘플 및 uPa 미처리된 샘플을 Raji 세포의 CD40에 대한 결합에 대해 유세포분석으로 테스트하였다. 도 20f에 나타낸 바와 같이, 차폐되지 않은 v32477은 EC50 값이 1nM인 결합 곡선을 나타낸 반면, 차폐된 v32478은 결합이 40-70배 감소하였다. 두 변이체 모두 uPa 절단 부위가 결여되어 결합은 uPa 처리에 의해 영향을 받지 않았다. uPa 미처리된 v32479의 경우 결합이 14배 감소했지만, uPa로 처리했을 때 5배 이내로 회복되었다.
동일한 샘플을 기능성에 대해 CD40 특이적 RGA(도 20g)로 조사했을 때의 경향이 재현되었다. v32477은 FcγR2B-CHOK1에 의해 추가로 강화될 수 있는 강력한 독립적 활성을 나타냈지만, v32478에 대해서는 기능이 90-110배 감소된 것을 볼 수 있다. 두 변이체 모두 uPa 절단 부위가 결여되어 uPa 처리 유무에 관계없이 RGA 실험에서 동일한 활성을 나타냈다. uPa 미처리된 v32479의 경우 v32478과 유사한 수준의 활성 차폐를 나타냈다(55배). uPa 처리된 v32487에서 v32477의 2배 이내의 활성을 검출할 수 있었다. 검정에서 양성 대조군 CD40L은 FcγR2B의 존재와 독립적으로 CD40 활성을 유도했고 음성 대조군(v22277)은 CD40을 활성화할 수 없었다. 검정에서 테스트된 변이체에 대해 관찰된 활성의 최대 수준(Bmax)은 2차 세포주에 FcgR2B가 존재하지 않는 경우와 반대로 FcgR2B 양성 세포주의 존재 시 더 컸다. FcgR2B 양성 세포주가 없는 경우에도 CD40L로 처리하면 Bmax가 동일하게 증가한다.
실시예 19: 마스크로서의 SIRPα:CD47 면역조절 쌍
B7:CD28 패밀리 외의 면역조절 쌍이 Fab를 효율적으로 차폐하는 데 이용될 수 있는지 측정하기 위해, 실시예 10에 기술된 항-EGFR 항체의 CD47:SIRPα 차폐된 버전을 생성하고 다음과 같이 EGFR 결합에 대해 평가하였다.
방법
CD47:SIRPα 차폐된 항-EGFR 항체를 실시예 10에 기술된 PD1:PD-L1 차폐된 변이체와 동등하도록 설계하였다. 간략하게, 인간 CD47 및 인간 SIRPα의 변형되고 친화도 증가된 변이체의 IgV 도메인의 서열(K. Weiskopf 등, Engineered SIRPalpha variants as immunotherapeutic adjuvants to anticancer antibody. Science 341, 88-91 (2013))을 실시예 1 및 실시예 10에 기술된 uPa 절단성 링커를 사용하여 항-EGFR Fab의 중쇄 및 경쇄 각각의 N-말단에 부착시켰다. 조사된 변이체 구조의 도식은 도 27에 나와 있다. 변이체의 개별 사슬의 서열은 표 I에 열거되어 있다. 항체가 생성되었고, 실시예 2, 실시예 3 및 실시예 5 각각에서와 같이 이의 샘플 순도 및 uPa에 의한 절단을 평가하였다. EGFR 함유 H292 세포에 대한 결합을 정량적 형광 현미경으로 평가하였다.
[표 I]

형광 현미경검사에 의한 H292 세포에 대한 고유 결합
EGFR을 발현하는 NCI-H292 세포주를 37℃에서 가습 + 5% CO2 인큐베이터에서 L-글루타민 및 10% FBS(완전 배지)가 보충된 RPMI-1640에 유지하였다. 검정 전날, 기하급수적으로 성장하는 세포를 0.05% 트립신(Gibco®)을 사용하여 수확하고, 1.2×105개의 세포/mL의 세포 밀도로 완전 배지에 재현탁하였다. 50μL의 세포를 Corning® 96 Half Area Well Flat Clear Bottom Black Polystyrene TC-처리된 마이크로플레이트(Code 3882, Corning, Corning, NY, USA)에 6000개의 세포/웰의 최종 농도로 분배하고 37℃에서 가습 + 5% CO2 인큐베이터에서 밤새 인큐베이션하였다. 실험 당일, 검정을 수행하기 전에 세포가 있는 플레이트를 30분 동안 4℃로 식혔다. 변형된 변이체를 Ca2+ 및 Mg2+를 함유하는 차가운 DPBS(Wisent Bioproduct, St-Bruno, Quebec, Canada)에서 최종 농도의 2배로 희석한 다음, 100nM에서 시작하여 총 11개의 농도 지점에 대해 3배 연속 희석하였다. 모든 용액은 4℃로 유지하고 모든 인큐베이션을 4℃에서 수행하였다. 동일한 부피의 2X 시험 변이체 또는 대조군을 세포에 첨가하고 2시간 동안 인큐베이션하였다. 이어서, 세포를 150μL/웰/주기로 3주기 세척을 위해 BioTek EL405 Select 플레이트 세척기(BioTek, Winooski, VT, USA)에서 Ca2+ 및 Mg2+를 함유하는 차가운 DPBS로 세척하여 잔류 최종 부피를 25uL로 하였다. 결합된 변이체의 검출은 FBS(Wisent Bioproduct, St-Bruno, Quebec, Canada)의 존재하에 1시간 동안 AF488 표지된 인간 Fc 특이적 2차 항체(Jackson ImmunoResearch, West Grove, PA, USA), Deep Red CellMask(Molecular Probes, Eugene, Oregon, USA) 및 Hoechst33342(Molecular probes, Eugene, Oregon, USA)를 함유하는 형광 표지 혼합물과의 추가 인큐베이션으로 달성하였다. BioTek EL405 Select(BioTek, Winooski, VT, USA) 플레이트 세척기에서 세포를 2회 세척(3주기, 매번 150μL/웰로 세척)하였다. 투과광, DAPI(청색 채널), Cy5(근적외선 채널) 및 FITC(녹색 채널)를 사용하여 ImageXpress Micro XLS(Molecular Devices, San Jose, CA, USA)에서 이미지를 캡처하였다. 이미지 분석은 MetaXpress 분석 소프트웨어 Custom Module Editor(CME)(Molecular Devices, San Jose, CA, USA)를 사용하여 수행하였다. 각 웰에 대해, 세포로 덮인 웰 영역에서 총 녹색 형광 강도를 측정한 다음 세포 영역으로 정규화하였다. 이 정규화된 값 "세포 면적당 총 강도"는 GraphPad Prism 8(GraphPad Software, La Jolla, CA, USA)의 곡선 피팅 분석에 사용되었다. 대조군 웰(이 웰은 2차 항체의 형광 표지 믹스로만 인큐베이션한 웰임)의 평균 정규화된 녹색 백그라운드 형광 신호를 사용하여 기준선 값을 계산하였다. 비선형 피팅 모델을 적용하기 전에 각 플레이트의 기준선 값을 모든 데이터에서 뺐다. 세포 면적당 특정 총 강도(기준선 보정됨) 대 로그 항체 농도를 각각의 테스트 항목에 대해 "Hill 기울기가 있는 원-사이트 특이적 결합" 비선형 회귀 곡선 피팅 모델로 피팅하였다.
결과
분취 SEC 후 CD47:SIRPα 기반 마스크를 함유하는 변형된 항-EGFR 변이체(34164)가 0.33mg 생성되었다. 단백질 A 정제 후 UPLC-SEC 분석은 주요 종 이외에 응집체 및 올리고머와 같은 고분자량 종을 상당량 나타냈고, 이러한 바람직하지 않은 입자를 제거하기 위해 분취 SEC를 수행하였다. 최종 SEC 정제된 샘플의 UPLC-SEC(도 28a)는 원하는 종을 91% 나타냈다. 비환원 CE-SDS(도 28b)는 온전한 분자에 대해 예상되는 것보다 상당히 더 높은 분자량에서 단일 우세 종에 해당하는 프로파일을 나타냈다. CD47 변형된 경쇄에 대한 밴드는 환원 CE-SDS 프로파일에서 예상된 겉보기 분자량보다 상당히 더 높게 나타내며, 이는 변형된 중쇄와 중첩된다. 실시예 3의 PD-1:PD-L1 기반 변형과 유사하게, 이것은 CD47의 광범위한 글리코실화 때문일 것이다(W. J. Mawby, C. H. Holmes, D. J. Anstee, F. A. Spring, M. J. Tanner, Isolation and characterization of CD47 glycoprotein: a multispanning membrane protein which is the same as integrin-associated protein (IAP) and the ovarian tumour marker OA3. Biochem J 304 (Pt 2), 525-530 (1994)).
uPa로 처리했을 때, CD47는 물론 SIRPα 모이어티 둘 다 도 29에 나타낸 바와 같이 경쇄로부터 효과적으로 제거되었다. 여기서, 변형된 중쇄 및 경쇄에 상응하는 밴드는 절단 시 사라지고, 차폐되지 않은 중쇄와 경쇄의 분자량에 응하는 밴드가 나타났다. 방출된 CD47 및 SIRPα 성분은 절단 후 명확하게 식별할 수 없었는데, 글리코실화로 인한 작은 크기 및 불균일 때문일 가능성이 크다.
고함량 분석(도 30)에 의해 평가된 H292 세포 상의 EGFR에 대한 결합은 v34164에서 CD47:SIRPα 기반 마스크가 표적 결합을 37배 감소시켰음을 나타냈다. 이는 PD-1:PD-L1 기반 마스크를 사용한 동등한 변이체에 대해 실시예 14에 나타낸 것과 유사하다. 두 마스크 성분의 uPa 절단 시, EGFR 결합은 WT의 1.1배 이내로 회복되었다.
실시예 20: 항-CD3 삼중특이성 변이체에 의한 표적의 공동결합 및 브릿징
PD-L1, Her2 및 CD3이 실시예 1-9에 기술된 항-CD3 변이체에 의해 동시에 결합될 수 있는지 측정하기 위해, Her2-PD-L1 공동결합 및 T 세포 브릿징 연구를 다음과 같이 수행하였다.
방법
유세포분석에 의한 동시 Her2 및 PD-L1 결합의 평가
10% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA)이 보충된 DMEM 배지(Thermo Fisher Scientific, Waltham, MA)로 이루어진 성장 배지에서 배양된 JIMT-1(Leibniz Institute, Braunschweig, Germany)을 37℃에서 5% 이산화탄소를 함유하는 인큐베이터 내 T-175 플라스크(Corning, Corning, NY)에서 수평으로 유지하였다. 항체를 96웰 v형 바닥 플레이트(Thermo Fisher Scientific, Waltham, MA)에서 FACS 버퍼 - 2% FBS를 함유하는 PBS(Thermo Fisher Scientific, Waltham, MA)로 1:3 희석하여 총 20uL/웰로 100nM에서 1.7pM까지 적정하였다. 종양 세포를 PBS(Thermo Fisher Scientific, Waltham, MA)로 헹구고, TrypLE Express(Thermo Fisher Scientific, Waltham, MA)로 수확하고, 배지에 희석하고, Countess 자동 세포 계수기(Thermo Fisher Scientific, Waltham, MA)를 사용하여 계수하였다. 종양 세포를 세척하고 FACS 버퍼에 재현탁하고, 웰당 50,000개의 세포로 96웰 플레이트에 첨가하였다. 세포를 변이체와 함께 4℃에서 1시간 동안 인큐베이션하였다. 인큐베이션 후, 세포를 FACS 버퍼로 2회 세척하고 1000배 희석된 생존 염료(Thermo Fisher Scientific, Waltham, MA)와 함께 1mg/mL의 2차 항체 AF647 염소 항-인간 IgG Fc(Jackson ImmunoResearch, West Grove, PA)를 웰에 첨가하였다. 플레이트를 실온에서 30분 동안 인큐베이션하였다. 세포를 FACS 버퍼로 2회 세척하고 100uL의 FACS 버퍼에 재현탁하였다. 검정 판독을 위해 APC 형광의 기하 평균을 BD Celesta(BD Biosciences, San Jose, CA)에서 유세포분석으로 측정하였다. 원시 데이터는 FlowJo, LLC Software(Becton, Dickinson & Company, Ashland, OR)로 분석하였다. 그래프는 Mac OS X용 GraphPad Prism 버전 8.1.2(GraphPad Software, La Jolla, CA)를 사용하여 생성하였다.
CD3/Her2/PD-L1 브릿징 검정
10% 태아 소 혈청(Thermo Fisher Scientific, Waltham, MA)이 보충된 DMEM 배지(Thermo Fisher Scientific, Waltham, MA)로 이루어진 성장 배지에서 배양된 JIMT-1(Leibniz Institute, Braunschweig, Germany)을 37℃에서 5% 이산화탄소를 함유하는 인큐베이터 내 T-175 플라스크(Corning, Corning, NY)에서 수평으로 유지하였다. 종양 세포를 PBS(Thermo Fisher Scientific, Waltham, MA)로 헹구고, TrypLE Express(Thermo Fisher Scientific, Waltham, MA)로 수확하고, PBS로 희석하고, PBS로 2회 세척하였다. 1차 인간 Pan-T 세포(BioIVT, Westbury, NY) 바이알을 37℃ 수조에서 해동하고, 10% 태아 소 혈청이 보충된 RPMI-1640 ATCC 변형(Thermo Fisher Scientific, Waltham, MA)으로 이루어진 성장 배지에서 세척한 다음 PBS로 세척하고 PBS에 재현탁하였다. T 세포 및 종양 세포를 Countess 자동 세포 계수기(Thermo Fisher Scientific, Waltham, MA)를 사용하여 계수하고 PBS에서 5M/mL로 재현탁하였다. 세포 증식 염료-eF670(Thermo Fisher Scientific, Waltham, MA)을 1.25uM로 종양 세포에 첨가하였다. Cell Tracker Green(Thermo Fisher Scientific, Waltham, MA)을 2uM로 T 세포에 첨가하였다. T 세포 및 종양 세포를 암실에서 20분 동안 37℃에서 인큐베이션하고 FACS 버퍼 - 2% FBS를 함유하는 PBS(Thermo Fisher Scientific, Waltham, MA)에서 2회 세척하였다. 항체를 FACS 버퍼에서 총 50uL/웰로 1:6 희석하여 v형 바닥 96웰 플레이트(Thermo Fisher Scientific, Waltham, MA)에서 10nM에서 0.2pM까지 적정하였다. Pan T 세포를 1.44 E6 세포/mL로 5:1의 이펙터 대 표적 비율로 종양 세포와 혼합하였다. 50uL의 혼합된 세포 현탁액을 적정 변이체를 함유하는 플레이트에 첨가하였다. 세포를 변이체와 함께 4℃에서 1시간 동안 인큐베이션하였다. 검정 판독을 위해, 이중 양성 세포군을 BD Celesta(BD Biosciences, San Jose, CA)에서 유세포분석으로 측정하였다. 원시 데이터는 FlowJo, LLC Software(Becton, Dickinson & Company, Ashland, OR)로 분석하였다. 그래프는 Mac OS X용 GraphPad Prism 버전 8.1.2(GraphPad Software, La Jolla, CA)를 사용하여 생성하였다.
결과
내인성 Her2+/PD-L1+ 암 세포주(JIMT-1, Her2 및 PD-L1 수용체 정량화에 대한 실시예 7 참조)에 대한 결합을 유세포분석으로 측정하였다(도 30a). 중쇄에 PD-1만 부착되어 있고 차폐된 변이체 30430의 완전히 차폐 해제된 버전을 나타내는 삼중특이성(PD-1-CD3-Her2) 변이체(31929)는 이중특이성 대조군(v32497(CD3-Her2), v33551(PD-L1-CD3))과 비교하여 더 높은 MFI를 나타낸다. 동일한 형식의 이중특이성 대조군을 달성하기 위해, PD-L1 결합을 없애는 PD-1 모이어티의 돌연변이를 v32497에 도입한 반면, 헤마글루티닌을 표적으로 하는 무관한 scFv는 v33551에서 Her2 표적화 scFv를 대체하였다. 이것은 PD-L1과 Her2 둘 다 삼중특이성 변이체에 의해 암세포에 동시에 결합한다는 증거이다.
또한, Her2+/PDL1+ 암 세포주 및 Pan T 세포의 항체 의존성 브릿징은 유세포분석에서 이중 양성 신호(동시에 T 세포 및 표적 세포 둘 다에 대한 형광 신호)의 존재로 평가하였다(도 30b). 이중특이성 대조군(v32497(CD3-Her2), v33551(PD-L1-CD3))과 비교하여 삼중특이성(PD-1-CD3-Her2) 변이체(v31929)에 대한 이중 양성 신호의 더 높은 백분율은 여기에 기술된 변이체가 T 세포와 암세포를 브릿징할 수 있으며 v31929에 의한 세 가지 표적 모두의 동시 결합은 이러한 T 세포 브릿징을 증가시킴을 나타낸다.
실시예 21: 항-CD3 × 항-HER2 T 세포-인게이저 융합 단백질의 생체 내 기능 평가
Her2 보유 종양 세포의 사멸을 위해 T 세포와 결합하고 활성화하는 실시예 1-9에 기술된 CD3 × Her2 Fab × scFv Fc 변이체의 능력에 대한 PD-1:PD-L1 기반 마스크의 기능적 영향을 다음과 같이 인간화 마우스 모델에서의 생체 내 연구로 평가한다.
방법
마우스(NSG[NOD-scid-감마])에 인간 Her2+ 종양 세포주(JIMT-1)로부터의 5×106개의 세포를 피하 이식하고 동시에 건강한 인간 공여자의 1×107개의 PBMC를 정맥 내 이식하였다. 종양의 확립 및 대략 150-200㎣까지의 종양의 초기 성장 후, 실시예 1-9에서 기술되고 생성된 항체 변이체를 마우스에 정맥 내 투여하였다. 마우스를 연구 기간 동안 주당 2회 체중 및 종양 성장(캘리퍼로 측정)에 대해 모니터링한다.
결과
실시예 6-9에서 CD3에 대한 결합 및 기능적 연구에서 차폐된 및 차폐되지 않은 CD3 × Her2 Fab × scFv Fc 변이체에 대해 나타난 경향은 건강한 공여자의 PBMC는 물론 이식된 Her2 양성 인간 암 세포주와 함께 인간화 마우스 모델을 사용하는 생체 내 연구에서 항-종양 활성에 대해 동일한 샘플을 조사할 때 재현된다. 약물을 투여하지 않거나 무관한 대조군 항체(22277)로 처리한 동물에서 종양이 빠르게 성장하는 반면, 중쇄에 비기능성 PD-L1 도메인만 부착된 변이체(32497)는 사멸을 위해 T 세포를 동원하는 능력으로 인해 강력한 종양 성장 억제를 나타낸다. 동일한 변이체가 항 PD-L1 항체(32497 + 33449)와 조합하여 페어링되는 경우, 추가 체크포인트 활성으로 인해 추가 억제가 나타날 수 있다. 또한, 기능적 PD-1 도메인이 있는 변이체(31929)는 비기능적 PD-1 도메인이 있는 동등한 작제물(32497)과 비교할 때 추가적인 종양 성장 억제를 나타낸다. 완전한 PD-1:PD-L1 기반 마스크가 있는 변이체를 평가할 때, 추가된 두 도메인 모두에 비절단성 링커가 있는 작제물(30423)은 빠른 종양 성장을 나타낸다. 반대로, Fab와 PD-L1(30430) 사이에 절단성 링커가 있는 작제물(30430)은 관련 프로테아제가 고발현되는 종양 세포주가 상기 모델에서 사용될 때 차페되지 않은 삼중특이성 대조군(31929)과 유사하게 높은 항종양 활성을 나타낸다. 프로테아제 발현이 낮은 종양 세포주를 사용하는 경우 동일한 절단성 변이체(30430)는 비절단성 작제물(30430)과 유사하게 빠른 종양 성장을 나타낸다.
실시예 22: 마스크로서의 CD80-CTLA-4, CD80-CD28 및 CD80-PD-L1 리간드-수용체 쌍
CTLA-4, CD28 및 PD-L1에 대한 CD80 친화도는 각각 0.2uM, 4uM 및 1.7uM이다(Butte, M. J. 등, Programmed death-1 ligand 1 interacts specifically with the B7-1 costimulatory molecule to inhibit T cell responses. Immunity, 27, 111-122, doi:10.1016/j.immuni.2007.05.016 (2007)). CD80과 CD28의 우선적 결합을 유도하기 위해 CD28에 대한 친화도를 선택적으로 증가시키는 것으로 알려진 돌연변이를 CD80 IgV 도메인에 도입한다(특허: US20210155668A1). "한 쪽" CD80 마스크 형식에서 T 세포 활성화를 최적으로 강화하는 기하 구조를 평가하기 위해 여러 작제물을 설계하였다. 간략하게, (상술된 바와 같은) CD80 동종이량체화를 방지하기 위한 돌연변이가 있는 인간 CD80의 IgV 도메인 및/또는 CD28에 대한 친화도를 증가시킬 것으로 예상되는 돌연변이가 있는 CD80을 (EAAAK)2 링커를 사용하여 항-CD3 Fab의 중쇄 또는 경쇄의 N-말단에 부착하고 항-TAA scFv × Fc와 이종이량체 Fc 형식으로 페어랑한다. 대안적으로, CD80 IgV 도메인을 (EAAAK)2 링커를 사용하여 항-TAA Fab의 중쇄 또는 경쇄의 N-말단에 부착하고 항-CD3 scFv × Fc와 이종이량체 Fc 형식으로 페어랑한다. 상술된 형식은 표 J에 설명되어 있다.
CD80은 CTLA-4, CD28 및 PD-L1에 결합할 수 있으므로 세 가지 모두 이량체 마스크 파트너(CD80:CTLA-4, CD80:CD28, CD80:PD-L1)로 사용된다. CD80 동종이량체화를 방지하고 CD28에 대한 친화도를 증가시키는 것으로 알려진 돌연변이가 있는 CD80 IgV 도메인을 사용하여 생성된 차폐된 작제물을 설계하였다. 모든 경우에 CTLA-4, CD28 또는 PD-L1 IgV 도메인은 프로테아제 절단성 서열로 중쇄 또는 경쇄에 융합되는 반면 CD80 모이어티는 내인성 프로테아제에 의해 제거되지 않도록 설계된 알파 나선형 펩티드 링커 서열로 경쇄 또는 중쇄에 융합된다. CD80:CTLA-4 마스크 설계의 경우, CD80 IgV 도메인의 고친화성 버전과 야생형 인간 CTLA-4 IgV 도메인을 펩티드 링커를 사용하여 항-CD3 Fab의 중쇄 및 경쇄 각각의 N-말단에 부착하고 항-TAA scFv Fc와 페어링한다. CD80:CD28 마스크의 경우, CD80 IgV 도메인의 고친화성 버전과 야생형 인간 CD28 IgV 도메인을 펩티드 링커를 사용하여 항-CD3 Fab의 중쇄 및 경쇄 각각의 N-말단에 부착하고 항-TAA scFv Fc와 페어링한다. 마지막으로, CD80:PD-L1 마스크의 경우 CD80 동종이량체화를 방지하고 CD28 및 PD-L1(특허: US20210155668A1)에 대한 친화도를 증가시킬 것으로 예측되는 돌연변이가 있는 CD80 IgV 도메인과 야생형 인간 PD-L1 IgV 도메인을 펩티드 링커를 사용하여 항-CD3 Fab의 중쇄 및 경쇄 각각의 N-말단에 부착하고 항-TAA scFv Fc와 페어링한다. 또한, CD80 함유 마스크(CD80:CTLA-4, CD80:CD28 또는 CD80:PD-L1)가 항-TAA Fab 파라토프를 차단하는 데 사용되고 사슬이 항-CD3 scFv와 페어링되는 분자를 설계한다. 상기 기술된 차폐된 변이체는 표 J에 예시되어 있다.
상기 예에서, 작제물은 항-CD3 암(arm)(Fab 또는 scFv) 및 항-TAA 암(Fab 또는 scFv)을 포함하는 분자에서 사용되는 한 쪽 또는 이량체성 CD80 기반 마스크(CD80:CTLA-4, CD80:CD28, CD80:PD-L1)로 기술된다. 이러한 설계는 다양한 항-CD3 파라토프 및 임의의 TAA 파라토프와 함께 플랫폼 역할을 할 수 있다.
[표 J]


당업자에게 명백할 본원에 기술된 특정 실시양태의 수정은 아래 청구항의 범위 내에 포함되는 것으로 의도된다.
본 명세서의 본문 내에서 인용된 모든 참고문헌, 특허 및 특허 출원은 모든 목적을 위해 그 전체가 참고로 포함된다.
서열
표 AA 파트 1




표 AA 파트 2
클론 서열


































표 BB 항-CD3 파라토프 서열


표 CC IgSF IgV 도메인 서열


SEQUENCE LISTING
<110> ZYMEWORKS INC.
<120> FUSION PROTEINS COMPRISING A LIGAND-RECEPTOR PAIR AND A
BIOLOGICALLY FUNCTIONAL PROTEIN
<130> V816961WO
<140> PCT/CA2021/051006
<141> 2021-07-20
<150> 63/172,626
<151> 2021-04-08
<150> 63/054,180
<151> 2020-07-20
<160> 268
<170> PatentIn version 3.5
<210> 1
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> CRIS7 CD3 VL
<400> 1
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Ser Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Gln Ile Thr
100 105
<210> 2
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> CRIS7 CD3 VH
<400> 2
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe
65 70 75 80
Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys
85 90 95
Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Pro Val Thr Val Ser Ser
115 120
<210> 3
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> Trastuzumab scFv
<400> 3
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Gly Gly Ser Gly Gly
100 105 110
Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Glu
115 120 125
Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
130 135 140
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr Tyr
145 150 155 160
Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala
165 170 175
Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val Lys
180 185 190
Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr Leu
195 200 205
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ser
210 215 220
Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln Gly
225 230 235 240
Thr Leu Val Thr Val Ser Ser
245
<210> 4
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Chain A CH3 region
<400> 4
Gly Gln Pro Arg Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Ala Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 5
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> ChainB CH3 region
<400> 5
Gly Gln Pro Arg Glu Pro Gln Val Tyr Val Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Leu Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Leu Thr Trp Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 6
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> CH2 region with L234A-L235A_D265S mutations
<400> 6
Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
100 105 110
<210> 7
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> Wild type PD-1
<400> 7
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu
<210> 8
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Wild type PD-L1
<400> 8
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala
115
<210> 9
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> High affinity PD-1
<400> 9
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu
<210> 10
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> High affinity PD-L1
<400> 10
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Gln Val Phe Trp Met Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Thr
85 90 95
Cys Leu Ile Ala Tyr Lys Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala
115
<210> 11
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> WT CS PD-1
<400> 11
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu
<210> 12
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Wild type CH3 region
<400> 12
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
100 105
<210> 13
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VL
<400> 13
Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser
65 70 75 80
Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 14
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> EGFR VH
<400> 14
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 15
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> MSLN VL
<400> 15
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Lys His Pro Leu Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 16
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> MSLN VH
<400> 16
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Leu Ile Thr Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys Phe
50 55 60
Arg Gly Lys Ala Thr Met Thr Val Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Asp Gly Arg Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 17
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> TF VL
<400> 17
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Asp Ile Lys Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile
35 40 45
Tyr Tyr Ala Thr Ser Leu Ala Glu Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Gly Glu Ser Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 18
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> TF VH
<400> 18
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Glu Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Leu Ile Asp Pro Glu Gln Gly Asn Thr Ile Tyr Asp Pro Lys Phe
50 55 60
Gln Asp Arg Ala Thr Ile Ser Ala Asp Asn Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Thr Ala Ala Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 19
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> CD19A VL
<400> 19
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Phe Gln Gly Ser Val Tyr Pro Phe Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 20
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> CD19A VH
<400> 20
Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Asp Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Ala Tyr Tyr
85 90 95
Cys Ala Arg Met Glu Leu Trp Ser Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 21
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> cMET VL
<400> 21
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Glu Ser Val Asp Ser Tyr
20 25 30
Ala Asn Ser Phe Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Thr Arg Glu Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Asp Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 22
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> cMET VH
<400> 22
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Ala Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Lys Pro Asn Asn Gly Leu Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Glu Ile Thr Thr Glu Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 23
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> CDH3 VL
<400> 23
Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Asn Asp Val Gly Ala Tyr
20 25 30
Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Ser Glu Val Asn Lys Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Thr Ser Gly
85 90 95
Leu Pro Trp Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 24
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> CDH3 VH
<400> 24
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Trp Gly Asp Gly Thr Leu Asn Pro Trp Gly Gln Gly Thr Met
100 105 110
Val Thr Val Ser Ser
115
<210> 25
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> WT CD80
<400> 25
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala
100 105
<210> 26
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> WT CTLA4
<400> 26
Met His Val Ala Gln Pro Ala Val Val Leu Ala Ser Ser Arg Gly Ile
1 5 10 15
Ala Ser Phe Val Cys Glu Tyr Ala Ser Pro Gly Lys Ala Thr Glu Val
20 25 30
Arg Val Thr Val Leu Arg Gln Ala Asp Ser Gln Val Thr Glu Val Cys
35 40 45
Ala Ala Thr Tyr Met Met Gly Asn Glu Leu Thr Phe Leu Asp Asp Ser
50 55 60
Ile Cys Thr Gly Thr Ser Ser Gly Asn Gln Val Asn Leu Thr Ile Gln
65 70 75 80
Gly Leu Arg Ala Met Asp Thr Gly Leu Tyr Ile Cys Lys Val Glu Leu
85 90 95
Met Tyr Pro Pro Pro Tyr Tyr Leu Gly Ile Gly Asn Gly Thr Gln Ile
100 105 110
Tyr Val Ile Asp Pro Glu
115
<210> 27
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> Signal peptide
<400> 27
Glu Phe Ala Thr Met Arg Pro Thr Trp Ala Trp Trp Leu Phe Leu Val
1 5 10 15
Leu Leu Leu Ala Leu Trp Ala Pro Ala Arg Gly
20 25
<210> 28
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 28
Met Ser Gly Arg Ser Ala Asn Ala
1 5
<210> 29
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG1 Fc sequence 231-447 (EU-numbering)
<400> 29
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 30
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 30
Thr Ser Gly Arg Ser Ala Asn Pro
1 5
<210> 31
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 31
Leu Ser Gly Arg Ser Asp Asn His
1 5
<210> 32
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 32
Gly Ser Gly Arg Ser Ala Gln Val
1 5
<210> 33
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 33
Gly Ser Ser Arg Asn Ala Asp Val
1 5
<210> 34
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 34
Gly Thr Ala Arg Ser Asp Asn Val
1 5
<210> 35
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage sequence
<400> 35
Gly Gly Gly Arg Val Asn Asn Val
1 5
<210> 36
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 36
Met Ser Ala Arg Ile Leu Gln Val
1 5
<210> 37
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Protease cleavage site
<400> 37
Gly Lys Gly Arg Ser Ala Asn Ala
1 5
<210> 38
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 38
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys
1 5 10
<210> 39
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 39
Glu Ala Ala Ala Lys
1 5
<210> 40
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 40
Pro Pro Pro Pro
1
<210> 41
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 41
Pro Pro Pro
1
<210> 42
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 42
Gly Gly Gly Gly Ser
1 5
<210> 43
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker with C-terminal protease cleavage site
<400> 43
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly Arg Ser Ala
1 5 10 15
Asn Ala
<210> 44
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker with N-terminal protease cleavage site
<400> 44
Met Ser Gly Arg Ser Ala Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala
1 5 10 15
Ala Lys
<210> 45
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker with N-terminal protease cleavage sequence
<400> 45
Met Ser Gly Arg Ser Ala Asn Ala Glu Ala Ala Ala Lys
1 5 10
<210> 46
<211> 215
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 787 Full
<400> 46
Gly Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val
1 5 10 15
Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Asp Ile Lys Ser
20 25 30
Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu
35 40 45
Ile Tyr Tyr Ala Thr Ser Leu Ala Glu Gly Val Pro Ser Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln
65 70 75 80
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Gly Glu Ser Pro
85 90 95
Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 47
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 787, 23262, 23264 VL
<400> 47
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Asp Ile Lys Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile
35 40 45
Tyr Tyr Ala Thr Ser Leu Ala Glu Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Gly Glu Ser Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 48
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 787, 23262, 23264 LCDR1
<400> 48
Arg Ala Ser Arg Asp Ile Lys Ser Tyr Leu Asn
1 5 10
<210> 49
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 787, 23262, 23264 LCDR2
<400> 49
Tyr Ala Thr Ser Leu Ala Glu
1 5
<210> 50
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 787, 23262, 23264 LCDR3
<400> 50
Leu Gln His Gly Glu Ser Pro Trp Thr
1 5
<210> 51
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 1380 Full
<400> 51
Gly Glu Pro Lys Ser Ser Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
20 25 30
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
35 40 45
Val Val Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
50 55 60
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
65 70 75 80
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
85 90 95
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
100 105 110
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
115 120 125
Pro Arg Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu
130 135 140
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
145 150 155 160
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
165 170 175
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Ala Leu
180 185 190
Val Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
195 200 205
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
210 215 220
Lys Ser Leu Ser Leu Ser Pro Gly Lys
225 230
<210> 52
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 2932 Full
<400> 52
Gly Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly
1 5 10 15
Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Glu
20 25 30
Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Gly Leu Ile Asp Pro Glu Gln Gly Asn Thr Ile Tyr Asp Pro Lys
50 55 60
Phe Gln Asp Arg Ala Thr Ile Ser Ala Asp Asn Ser Lys Asn Thr Ala
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Asp Thr Ala Ala Tyr Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
210 215 220
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 53
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 2932, 23261 VH
<400> 53
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Glu Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Leu Ile Asp Pro Glu Gln Gly Asn Thr Ile Tyr Asp Pro Lys Phe
50 55 60
Gln Asp Arg Ala Thr Ile Ser Ala Asp Asn Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Thr Ala Ala Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 54
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 2932, 23261 HCDR1
<400> 54
Glu Tyr Tyr Met His
1 5
<210> 55
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 2932, 23261 HCDR2
<400> 55
Leu Ile Asp Pro Glu Gln Gly Asn Thr Ile Tyr Asp Pro Lys Phe Gln
1 5 10 15
Asp
<210> 56
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 2932, 23261 HCDR3
<400> 56
Asp Thr Ala Ala Tyr Phe Asp Tyr
1 5
<210> 57
<211> 215
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3232, 3357 Full
<400> 57
Gly Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser Pro
1 5 10 15
Gly Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr
20 25 30
Asn Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu
35 40 45
Ile Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu
65 70 75 80
Ser Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro
85 90 95
Thr Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 58
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3232, 3357, 23247, 23248 VL
<400> 58
Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser
65 70 75 80
Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 59
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3232, 3357, 23247, 23248 LCDR1
<400> 59
Arg Ala Ser Gln Ser Ile Gly Thr Asn Ile His
1 5 10
<210> 60
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3232, 3357, 23247, 23248 LCDR2
<400> 60
Tyr Ala Ser Glu Ser Ile Ser
1 5
<210> 61
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3232,3357, 23247, 23248 LCDR3
<400> 61
Gln Gln Asn Asn Asn Trp Pro Thr Thr
1 5
<210> 62
<211> 451
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3345 Full
<400> 62
Gly Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr
1 5 10 15
Gln Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr
20 25 30
Ser Gly Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu
35 40 45
Glu Trp Leu Ala His Ile Trp Trp Asp Asp Asp Lys Arg Tyr Asn Pro
50 55 60
Ala Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln
65 70 75 80
Val Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Ala Tyr
85 90 95
Tyr Cys Ala Arg Met Glu Leu Trp Ser Tyr Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Val Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
355 360 365
Leu Leu Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Leu Thr Trp Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys
450
<210> 63
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3345, 23257 VH
<400> 63
Gln Val Thr Leu Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Asp Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Ala Tyr Tyr
85 90 95
Cys Ala Arg Met Glu Leu Trp Ser Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 64
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3345, 23257 HCDR1
<400> 64
Thr Ser Gly Met Gly Val Gly
1 5
<210> 65
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3345, 23257 HCDR2
<400> 65
His Ile Trp Trp Asp Asp Asp Lys Arg Tyr Asn Pro Ala Leu Lys Ser
1 5 10 15
<210> 66
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 3345, 23257 HCDR3
<400> 66
Met Glu Leu Trp Ser Tyr Tyr Phe Asp Tyr
1 5 10
<210> 67
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10564 Full
<400> 67
Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly
1 5 10 15
Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly
20 25 30
Tyr Thr Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp
35 40 45
Met Gly Leu Ile Thr Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys
50 55 60
Phe Arg Gly Lys Ala Thr Met Thr Val Asp Thr Ser Thr Ser Thr Val
65 70 75 80
Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Gly Gly Tyr Asp Gly Arg Gly Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Val Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Leu Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Leu Thr Trp Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 68
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10564, 23253 VH
<400> 68
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Leu Ile Thr Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys Phe
50 55 60
Arg Gly Lys Ala Thr Met Thr Val Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Asp Gly Arg Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 69
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10564, 23253 HCDR1
<400> 69
Gly Tyr Thr Met Asn
1 5
<210> 70
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10564, 23253 HCDR2
<400> 70
Leu Ile Thr Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys Phe Arg
1 5 10 15
Gly
<210> 71
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10564, 23253 HCDR3
<400> 71
Gly Gly Tyr Asp Gly Arg Gly Phe Asp Tyr
1 5 10
<210> 72
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10565 Full
<400> 72
Gly Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val
1 5 10 15
Gly Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr
20 25 30
Met His Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Lys His Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 73
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10565, 23256 VL
<400> 73
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Lys His Pro Leu Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 74
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10565, 23256, 23258, 23260 LCDR1
<400> 74
Ser Ala Ser Ser Ser Val Ser Tyr Met His
1 5 10
<210> 75
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10565, 23256, 23258, 23260 LCDR2
<400> 75
Asp Thr Ser Lys Leu Ala Ser
1 5
<210> 76
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10565, 23256 LCDR3
<400> 76
Gln Gln Trp Ser Lys His Pro Leu Thr
1 5
<210> 77
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10567 Full
<400> 77
Gly Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly
1 5 10 15
Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Asn Asp Val Gly Ala
20 25 30
Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys
35 40 45
Leu Met Ile Ser Glu Val Asn Lys Arg Pro Ser Gly Val Ser Asn Arg
50 55 60
Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly
65 70 75 80
Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Thr Ser
85 90 95
Gly Leu Pro Trp Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
115 120 125
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
130 135 140
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
145 150 155 160
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
165 170 175
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
180 185 190
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
195 200 205
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
210 215
<210> 78
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10567, 20871 VL
<400> 78
Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Asn Asp Val Gly Ala Tyr
20 25 30
Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Ser Glu Val Asn Lys Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Thr Ser Gly
85 90 95
Leu Pro Trp Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 79
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10567, 20871 LCDR1
<400> 79
Thr Gly Thr Ser Asn Asp Val Gly Ala Tyr Asn Tyr Val Ser
1 5 10
<210> 80
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10567, 20871 LCDR2
<400> 80
Glu Val Asn Lys Arg Pro Ser
1 5
<210> 81
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10567, 20871 LCDR3
<400> 81
Ser Ser Phe Thr Ser Gly Leu Pro Trp Val Val
1 5 10
<210> 82
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10606 Full
<400> 82
Gly Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser
1 5 10 15
Gln Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn
20 25 30
Tyr Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp
35 40 45
Leu Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe
50 55 60
Thr Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe
65 70 75 80
Phe Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ala Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Val Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Leu Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Leu Thr Trp Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly
<210> 83
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10606, 23246, 23567 VH
<400> 83
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 84
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10606, 23246, 23567 HCDR1
<400> 84
Asn Tyr Gly Val His
1 5
<210> 85
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10606, 23246, 23567 HCDR2
<400> 85
Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr Ser
1 5 10 15
<210> 86
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 10606, 23246, 23567 HCDR3
<400> 86
Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5 10
<210> 87
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11274 Full
<400> 87
Gly Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly
1 5 10 15
Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys Trp Gly Asp Gly Thr Leu Asn Pro Trp Gly Gln Gly Thr
100 105 110
Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
210 215 220
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 88
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11274, 20875 VH
<400> 88
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Trp Gly Asp Gly Thr Leu Asn Pro Trp Gly Gln Gly Thr Met
100 105 110
Val Thr Val Ser Ser
115
<210> 89
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11274, 20875 HCDR1
<400> 89
Ser Tyr Ala Met Ser
1 5
<210> 90
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11274, 20875 HCDR2
<400> 90
Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 91
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11274, 20875 HCDR3
<400> 91
Trp Gly Asp Gly Thr Leu Asn Pro
1 5
<210> 92
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11462 Full
<400> 92
Gly Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu
1 5 10 15
Gly Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Glu Ser Val Asp Ser
20 25 30
Tyr Ala Asn Ser Phe Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Pro
35 40 45
Pro Lys Leu Leu Ile Tyr Arg Ala Ser Thr Arg Glu Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Ser
85 90 95
Lys Glu Asp Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 93
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11462, 20855 VL
<400> 93
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Glu Ser Val Asp Ser Tyr
20 25 30
Ala Asn Ser Phe Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Thr Arg Glu Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Asp Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 94
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11462, 20855 LCDR1
<400> 94
Lys Ser Ser Glu Ser Val Asp Ser Tyr Ala Asn Ser Phe Leu His
1 5 10 15
<210> 95
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11462, 20855 LCDR2
<400> 95
Arg Ala Ser Thr Arg Glu Ser
1 5
<210> 96
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11462, 20855 LCDR3
<400> 96
Gln Gln Ser Lys Glu Asp Pro Leu Thr
1 5
<210> 97
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11509 Full
<400> 97
Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly
1 5 10 15
Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Ala
20 25 30
Tyr Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp
35 40 45
Met Gly Trp Ile Lys Pro Asn Asn Gly Leu Ala Asn Tyr Ala Gln Lys
50 55 60
Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala
65 70 75 80
Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Ser Glu Ile Thr Thr Glu Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Cys
210 215 220
His Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 98
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11509, 20859 VH
<400> 98
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Ala Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Lys Pro Asn Asn Gly Leu Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Glu Ile Thr Thr Glu Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 99
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11509, 20859 HCDR1
<400> 99
Ala Tyr Thr Met His
1 5
<210> 100
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11509, 20859 HCDR2
<400> 100
Trp Ile Lys Pro Asn Asn Gly Leu Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 101
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11509, 20859 HCDR3
<400> 101
Ser Glu Ile Thr Thr Glu Phe Asp Tyr
1 5
<210> 102
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12985 Full
<400> 102
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Ser Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Gln Ile Thr Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys
210
<210> 103
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12985, 22091, 22092, 22094, 22105 VL
<400> 103
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Ser Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Gln Ile Thr
100 105
<210> 104
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12985, 22091, 22092, 22094, 22105 LCDR1
<400> 104
Ser Ala Ser Ser Ser Val Ser Tyr Met Asn
1 5 10
<210> 105
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12985, 22091, 22092, 22094, 22105 LCDR2
<400> 105
Asp Ser Ser Lys Leu Ala Ser
1 5
<210> 106
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12985, 22091, 22092, 22094, 22105 LCDR3
<400> 106
Gln Gln Trp Ser Arg Asn Pro Pro Thr
1 5
<210> 107
<211> 450
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12989 Full
<400> 107
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe
65 70 75 80
Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys
85 90 95
Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ser Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
355 360 365
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly
450
<210> 108
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12989, 22080, 22082, 22083, 22086, 22088, 24659, 24660,
24661 VH
<400> 108
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe
65 70 75 80
Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys
85 90 95
Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Pro Val Thr Val Ser Ser
115 120
<210> 109
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12989, 22080, 22082, 22083, 22086, 22088, 24659, 24660,
24661 HCDR1
<400> 109
Arg Ser Thr Met His
1 5
<210> 110
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12989, 22080, 22082, 22083, 22086, 22088, 24659, 24660,
24661 HCDR2
<400> 110
Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Asp
<210> 111
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 12989, 22080, 22082, 22083, 22086, 22088, 24659, 24660,
24661 HCDR3
<400> 111
Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr
1 5 10
<210> 112
<211> 343
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20855 Full
<400> 112
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Asp Ile Val
115 120 125
Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly Glu Arg Ala
130 135 140
Thr Ile Asn Cys Lys Ser Ser Glu Ser Val Asp Ser Tyr Ala Asn Ser
145 150 155 160
Phe Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu
165 170 175
Ile Tyr Arg Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Ser
180 185 190
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln
195 200 205
Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Ser Lys Glu Asp Pro
210 215 220
Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
225 230 235 240
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
245 250 255
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
260 265 270
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
275 280 285
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
290 295 300
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
305 310 315 320
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
325 330 335
Ser Phe Asn Arg Gly Glu Cys
340
<210> 113
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20855, 20871, 22091, 22094, 23247, 23248, 23256, 23258,
23260, 23262, 23264, 23715, 23716 Mask
<400> 113
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala
115
<210> 114
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20855, 20859, 20871, 20875, 22080, 22082, 22088, 22091,
22092, 23246, 23247, 23253, 23257, 23258, 23261, 23262, 23714,
23715, 24659, 24660, 24661 Mask Linker
<400> 114
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys
1 5 10
<210> 115
<211> 569
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20859 Full
<400> 115
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val
130 135 140
Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Ala Tyr Thr Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Trp Ile Lys
165 170 175
Pro Asn Asn Gly Leu Ala Asn Tyr Ala Gln Lys Phe Gln Gly Arg Val
180 185 190
Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr Met Glu Leu Ser
195 200 205
Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Glu
210 215 220
Ile Thr Thr Glu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
225 230 235 240
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
245 250 255
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
260 265 270
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
275 280 285
Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
290 295 300
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr
305 310 315 320
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val
325 330 335
Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Cys His Cys Pro Pro Cys
340 345 350
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
355 360 365
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
370 375 380
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
385 390 395 400
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
405 410 415
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
420 425 430
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
435 440 445
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
450 455 460
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
465 470 475 480
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
485 490 495
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
500 505 510
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
515 520 525
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
530 535 540
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
545 550 555 560
Gln Lys Ser Leu Ser Leu Ser Pro Gly
565
<210> 116
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20859, 20875, 22080, 23246, 23253, 23257, 23261, 23714
Mask
<400> 116
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu
<210> 117
<211> 342
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20871 Full
<400> 117
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Ser Ala
115 120 125
Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln Ser Ile Thr
130 135 140
Ile Ser Cys Thr Gly Thr Ser Asn Asp Val Gly Ala Tyr Asn Tyr Val
145 150 155 160
Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu Met Ile Ser
165 170 175
Glu Val Asn Lys Arg Pro Ser Gly Val Ser Asn Arg Phe Ser Gly Ser
180 185 190
Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu Gln Ala Glu
195 200 205
Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Phe Thr Ser Gly Leu Pro Trp
210 215 220
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys
225 230 235 240
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
245 250 255
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
260 265 270
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
275 280 285
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
290 295 300
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
305 310 315 320
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
325 330 335
Ala Pro Thr Glu Cys Ser
340
<210> 118
<211> 570
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 20875 Full
<400> 118
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Val Gln Leu
115 120 125
Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu
130 135 140
Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ala Met Ser Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ala Ile Ser
165 170 175
Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe
180 185 190
Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn
195 200 205
Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys Trp Gly
210 215 220
Asp Gly Thr Leu Asn Pro Trp Gly Gln Gly Thr Met Val Thr Val Ser
225 230 235 240
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
245 250 255
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
260 265 270
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
275 280 285
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
290 295 300
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
305 310 315 320
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
325 330 335
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
340 345 350
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
355 360 365
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
370 375 380
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
385 390 395 400
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
405 410 415
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
420 425 430
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
435 440 445
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
450 455 460
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
465 470 475 480
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
485 490 495
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
500 505 510
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
515 520 525
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
530 535 540
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
545 550 555 560
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 119
<211> 478
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 Full
<400> 119
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Gly Gly Ser Gly Gly
100 105 110
Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Glu
115 120 125
Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
130 135 140
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr Tyr
145 150 155 160
Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala
165 170 175
Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val Lys
180 185 190
Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr Leu
195 200 205
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ser
210 215 220
Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln Gly
225 230 235 240
Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Ser Asp Lys Thr His
245 250 255
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
260 265 270
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
275 280 285
Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu Asp Pro Glu
290 295 300
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
305 310 315 320
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
325 330 335
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
340 345 350
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
355 360 365
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Val Leu Pro
370 375 380
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Leu Cys Leu
385 390 395 400
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
405 410 415
Gly Gln Pro Glu Asn Asn Tyr Leu Thr Trp Pro Pro Val Leu Asp Ser
420 425 430
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
435 440 445
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
450 455 460
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470 475
<210> 120
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 VH
<400> 120
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 121
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 HCDR1
<400> 121
Asp Thr Tyr Ile His
1 5
<210> 122
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 HCDR2
<400> 122
Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 123
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 HCDR3
<400> 123
Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr
1 5 10
<210> 124
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 VL
<400> 124
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 125
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 LCDR1
<400> 125
Arg Ala Ser Gln Asp Val Asn Thr Ala Val Ala
1 5 10
<210> 126
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 LCDR2
<400> 126
Ser Ala Ser Phe Leu Tyr Ser
1 5
<210> 127
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21490 LCDR3
<400> 127
Gln Gln His Tyr Thr Thr Pro Pro Thr
1 5
<210> 128
<211> 706
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 Full
<400> 128
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Gly Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ala Trp Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Tyr Glu Gly Arg Ser Thr Tyr Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Arg Ala Glu Gly Met Asp Phe Asp Tyr Trp Gly Gln Gly Val
100 105 110
Met Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro Ser Val Tyr Pro
115 120 125
Leu Ala Pro Gly Ser Ala Ala Gln Thr Asn Ser Met Val Thr Leu Gly
130 135 140
Cys Leu Val Lys Gly Tyr Phe Pro Glu Pro Val Thr Val Thr Trp Asn
145 150 155 160
Ser Gly Ser Leu Ser Ser Gly Val His Thr Phe Pro Ala Val Leu Glu
165 170 175
Ser Asp Leu Tyr Thr Leu Ser Ser Ser Val Thr Val Pro Ser Ser Pro
180 185 190
Arg Pro Ser Glu Thr Val Thr Cys Asn Val Ala His Pro Ala Ser Ser
195 200 205
Thr Lys Val Asp Lys Lys Ile Val Pro Arg Asp Cys Gly Cys Pro Pro
210 215 220
Cys Ile Cys Thr Val Pro Glu Val Ser Ser Val Phe Ile Phe Pro Pro
225 230 235 240
Lys Pro Lys Asp Val Leu Thr Ile Thr Leu Thr Pro Lys Val Thr Cys
245 250 255
Val Val Val Ala Ile Ser Lys Asp Asp Pro Glu Val Gln Phe Ser Trp
260 265 270
Phe Val Asp Asp Val Glu Val His Thr Ala Gln Thr Gln Pro Arg Glu
275 280 285
Glu Gln Phe Asn Ser Thr Phe Arg Ser Val Ser Glu Leu Pro Ile Met
290 295 300
His Gln Asp Trp Leu Asn Gly Lys Glu Phe Lys Cys Arg Val Asn Ser
305 310 315 320
Ala Ala Phe Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly
325 330 335
Arg Pro Lys Ala Pro Gln Val Tyr Val Ile Pro Pro Ser Lys Glu Gln
340 345 350
Met Ala Lys Asp Lys Val Ser Leu Leu Cys Met Ile Thr Asp Phe Phe
355 360 365
Pro Glu Asp Ile Thr Val Glu Trp Gln Trp Asn Gly Gln Pro Ala Glu
370 375 380
Asn Tyr Leu Thr Trp Pro Pro Ile Met Asp Thr Asp Gly Ser Tyr Phe
385 390 395 400
Val Tyr Ser Lys Leu Asn Val Gln Lys Ser Asn Trp Glu Ala Gly Asn
405 410 415
Thr Phe Thr Cys Ser Val Leu His Glu Gly Leu His Asn His His Thr
420 425 430
Glu Lys Ser Leu Ser His Ser Pro Gly Gly Gly Ser Gly Gly Gly Ser
435 440 445
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Asp Ile Val Met
450 455 460
Thr Gln Thr Pro Ala Ser Val Glu Ala Ala Val Gly Gly Thr Val Thr
465 470 475 480
Ile Lys Cys Gln Ala Ser Gln Ser Ile Tyr Ser Ser Leu Ala Trp Tyr
485 490 495
Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr Asp Ala Ser
500 505 510
His Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Arg Tyr Gly
515 520 525
Thr Glu Phe Thr Leu Thr Ile Ser Gly Val Gln Cys Asp Asp Ala Ala
530 535 540
Thr Tyr Tyr Cys Gln Gly Gly Trp Tyr Ser Ser Ala Ala Thr Tyr Val
545 550 555 560
Pro Asn Thr Phe Gly Gly Gly Thr Glu Val Val Val Lys Gly Gly Gly
565 570 575
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Glu Gln Leu
580 585 590
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Glu Gly Ser Leu Thr Leu
595 600 605
Thr Cys Lys Ala Ser Gly Phe Thr Ile Ser Asn Asn Tyr Tyr Met Cys
610 615 620
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Ala Cys Ile
625 630 635 640
Tyr Gly Gly Ile Ser Gly Arg Thr Tyr Tyr Ala Ser Trp Ala Lys Gly
645 650 655
Arg Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Thr Leu Gln Met
660 665 670
Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe Cys Val Arg Gly
675 680 685
Tyr Val Gly Thr Ser Asn Leu Trp Gly Pro Gly Thr Leu Val Thr Val
690 695 700
Ser Ser
705
<210> 129
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 VH
<400> 129
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Gly Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ala Trp Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Tyr Glu Gly Arg Ser Thr Tyr Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Arg Ala Glu Gly Met Asp Phe Asp Tyr Trp Gly Gln Gly Val
100 105 110
Met Val Thr Val Ser Ser
115
<210> 130
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 HCDR1
<400> 130
Asp Tyr Tyr Met Ala
1 5
<210> 131
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 HCDR2
<400> 131
Ser Ile Ser Tyr Glu Gly Arg Ser Thr Tyr Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 132
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 HCDR3
<400> 132
Arg Ala Glu Gly Met Asp Phe Asp Tyr
1 5
<210> 133
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 VH
<400> 133
Gln Glu Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Glu Gly
1 5 10 15
Ser Leu Thr Leu Thr Cys Lys Ala Ser Gly Phe Thr Ile Ser Asn Asn
20 25 30
Tyr Tyr Met Cys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Ala Cys Ile Tyr Gly Gly Ile Ser Gly Arg Thr Tyr Tyr Ala Ser
50 55 60
Trp Ala Lys Gly Arg Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val
65 70 75 80
Thr Leu Gln Met Thr Ser Leu Thr Ala Ala Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Val Arg Gly Tyr Val Gly Thr Ser Asn Leu Trp Gly Pro Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 134
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 HCDR1
<400> 134
Asn Asn Tyr Tyr Met Cys
1 5
<210> 135
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 HCDR2
<400> 135
Cys Ile Tyr Gly Gly Ile Ser Gly Arg Thr Tyr Tyr Ala Ser Trp Ala
1 5 10 15
Lys Gly
<210> 136
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 HCDR3
<400> 136
Gly Tyr Val Gly Thr Ser Asn Leu
1 5
<210> 137
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 VL
<400> 137
Asp Ile Val Met Thr Gln Thr Pro Ala Ser Val Glu Ala Ala Val Gly
1 5 10 15
Gly Thr Val Thr Ile Lys Cys Gln Ala Ser Gln Ser Ile Tyr Ser Ser
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser His Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Tyr Gly Thr Glu Phe Thr Leu Thr Ile Ser Gly Val Gln Cys
65 70 75 80
Asp Asp Ala Ala Thr Tyr Tyr Cys Gln Gly Gly Trp Tyr Ser Ser Ala
85 90 95
Ala Thr Tyr Val Pro Asn Thr Phe Gly Gly Gly Thr Glu Val Val Val
100 105 110
Lys
<210> 138
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 LCDR1
<400> 138
Gln Ala Ser Gln Ser Ile Tyr Ser Ser Leu Ala
1 5 10
<210> 139
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 LCDR2
<400> 139
Asp Ala Ser His Leu Ala Ser
1 5
<210> 140
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 21496 LCDR3
<400> 140
Gln Gly Gly Trp Tyr Ser Ser Ala Ala Thr Tyr Val Pro Asn Thr
1 5 10 15
<210> 141
<211> 574
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22080 Full
<400> 141
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg Ser Leu Arg Leu
130 135 140
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser Thr Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn
165 170 175
Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Arg Phe
180 185 190
Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe Leu Gln Met Asp
195 200 205
Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys Ala Arg Pro Gln
210 215 220
Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly Gln Gly Thr Pro
225 230 235 240
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
245 250 255
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
260 265 270
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
275 280 285
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
290 295 300
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
305 310 315 320
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
325 330 335
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
340 345 350
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
355 360 365
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
370 375 380
Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu Asp Pro Glu
385 390 395 400
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
405 410 415
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
420 425 430
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
435 440 445
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
450 455 460
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Val Tyr Pro
465 470 475 480
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
485 490 495
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
500 505 510
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
515 520 525
Asp Gly Ser Phe Ala Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg
530 535 540
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
545 550 555 560
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 142
<211> 574
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22082 Full
<400> 142
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg Ser Leu Arg Leu
130 135 140
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser Thr Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn
165 170 175
Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Arg Phe
180 185 190
Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe Leu Gln Met Asp
195 200 205
Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys Ala Arg Pro Gln
210 215 220
Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly Gln Gly Thr Pro
225 230 235 240
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
245 250 255
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
260 265 270
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
275 280 285
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
290 295 300
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
305 310 315 320
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
325 330 335
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
340 345 350
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
355 360 365
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
370 375 380
Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu Asp Pro Glu
385 390 395 400
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
405 410 415
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
420 425 430
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
435 440 445
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
450 455 460
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Val Tyr Pro
465 470 475 480
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
485 490 495
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
500 505 510
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
515 520 525
Asp Gly Ser Phe Ala Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg
530 535 540
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
545 550 555 560
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 143
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22082, 22083, 22086 Mask
<400> 143
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu
<210> 144
<211> 577
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22083 Full
<400> 144
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Met Ser Gly Arg Ser Ala Asn Ala Glu Ala Ala Ala Lys Gln
115 120 125
Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg Ser
130 135 140
Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser Thr
145 150 155 160
Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile Gly
165 170 175
Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe Lys
180 185 190
Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe Leu
195 200 205
Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys Ala
210 215 220
Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly Gln
225 230 235 240
Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
245 250 255
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
260 265 270
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
275 280 285
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
290 295 300
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
305 310 315 320
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
325 330 335
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
340 345 350
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly
355 360 365
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
370 375 380
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu
385 390 395 400
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
405 410 415
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
420 425 430
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
435 440 445
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
450 455 460
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
465 470 475 480
Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
485 490 495
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
500 505 510
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
515 520 525
Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser Lys Leu Thr Val Asp
530 535 540
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
545 550 555 560
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
565 570 575
Gly
<210> 145
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22083 Mask Linker
<400> 145
Met Ser Gly Arg Ser Ala Asn Ala Glu Ala Ala Ala Lys
1 5 10
<210> 146
<211> 582
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22086 Full
<400> 146
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly Arg
115 120 125
Ser Ala Asn Ala Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
130 135 140
Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr
145 150 155 160
Phe Thr Arg Ser Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly
165 170 175
Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr
180 185 190
Asn Gln Lys Phe Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys
195 200 205
Ser Thr Ala Phe Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly
210 215 220
Val Tyr Phe Cys Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe
225 230 235 240
Pro Tyr Trp Gly Gln Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr
245 250 255
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
260 265 270
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
275 280 285
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
290 295 300
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
305 310 315 320
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
325 330 335
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
340 345 350
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
355 360 365
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
370 375 380
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
385 390 395 400
Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
405 410 415
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
420 425 430
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
435 440 445
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
450 455 460
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
465 470 475 480
Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys
485 490 495
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
500 505 510
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
515 520 525
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser
530 535 540
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
545 550 555 560
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
565 570 575
Leu Ser Leu Ser Pro Gly
580
<210> 147
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22086, 22105, 23248, 23256, 23260, 23264, 23716 Mask
Linker
<400> 147
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly Arg Ser Ala
1 5 10 15
Asn Ala
<210> 148
<211> 566
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22088 Full
<400> 148
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala Glu Ala Ala Ala Lys Glu
100 105 110
Ala Ala Ala Lys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
115 120 125
Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr
130 135 140
Phe Thr Arg Ser Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly
145 150 155 160
Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr
165 170 175
Asn Gln Lys Phe Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys
180 185 190
Ser Thr Ala Phe Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly
195 200 205
Val Tyr Phe Cys Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe
210 215 220
Pro Tyr Trp Gly Gln Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr
225 230 235 240
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
245 250 255
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
260 265 270
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
275 280 285
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
290 295 300
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
305 310 315 320
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
325 330 335
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
340 345 350
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
355 360 365
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
370 375 380
Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
385 390 395 400
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
405 410 415
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
420 425 430
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
435 440 445
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
450 455 460
Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys
465 470 475 480
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
485 490 495
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
500 505 510
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser
515 520 525
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
530 535 540
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
545 550 555 560
Leu Ser Leu Ser Pro Gly
565
<210> 149
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22088 Mask
<400> 149
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala
100 105
<210> 150
<211> 338
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22091 Full
<400> 150
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Asp Ile Gln
115 120 125
Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val
130 135 140
Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr
145 150 155 160
Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Trp Ile Tyr Asp Ser Ser
165 170 175
Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly
180 185 190
Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
195 200 205
Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr Phe Gly Gly
210 215 220
Gly Thr Lys Leu Gln Ile Thr Arg Thr Val Ala Ala Pro Ser Val Phe
225 230 235 240
Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val
245 250 255
Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp
260 265 270
Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr
275 280 285
Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr
290 295 300
Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val
305 310 315 320
Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
325 330 335
Glu Cys
<210> 151
<211> 338
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22092 Full
<400> 151
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Gln Val Phe Trp Met Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Thr
85 90 95
Cys Leu Ile Ala Tyr Lys Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Asp Ile Gln
115 120 125
Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val
130 135 140
Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr
145 150 155 160
Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Trp Ile Tyr Asp Ser Ser
165 170 175
Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly
180 185 190
Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
195 200 205
Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr Phe Gly Gly
210 215 220
Gly Thr Lys Leu Gln Ile Thr Arg Thr Val Ala Ala Pro Ser Val Phe
225 230 235 240
Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val
245 250 255
Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp
260 265 270
Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr
275 280 285
Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr
290 295 300
Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val
305 310 315 320
Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
325 330 335
Glu Cys
<210> 152
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22092 Mask
<400> 152
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Gln Val Phe Trp Met Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Thr
85 90 95
Cys Leu Ile Ala Tyr Lys Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala
115
<210> 153
<211> 341
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22094 Full
<400> 153
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Met Ser Gly Arg Ser Ala Asn Ala
115 120 125
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
130 135 140
Asp Arg Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
145 150 155 160
Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Trp Ile Tyr
165 170 175
Asp Ser Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr
210 215 220
Phe Gly Gly Gly Thr Lys Leu Gln Ile Thr Arg Thr Val Ala Ala Pro
225 230 235 240
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
245 250 255
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
260 265 270
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
275 280 285
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
290 295 300
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
305 310 315 320
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
325 330 335
Asn Arg Gly Glu Cys
340
<210> 154
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22094 Mask Linker
<400> 154
Glu Ala Ala Ala Lys Met Ser Gly Arg Ser Ala Asn Ala
1 5 10
<210> 155
<211> 349
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22105 Full
<400> 155
Met His Val Ala Gln Pro Ala Val Val Leu Ala Ser Ser Arg Gly Ile
1 5 10 15
Ala Ser Phe Val Cys Glu Tyr Ala Ser Pro Gly Lys Ala Thr Glu Val
20 25 30
Arg Val Thr Val Leu Arg Gln Ala Asp Ser Gln Val Thr Glu Val Cys
35 40 45
Ala Ala Thr Tyr Met Met Gly Asn Glu Leu Thr Phe Leu Asp Asp Ser
50 55 60
Ile Cys Thr Gly Thr Ser Ser Gly Asn Gln Val Asn Leu Thr Ile Gln
65 70 75 80
Gly Leu Arg Ala Met Asp Thr Gly Leu Tyr Ile Cys Lys Val Glu Leu
85 90 95
Met Tyr Pro Pro Pro Tyr Tyr Leu Gly Ile Gly Asn Gly Thr Gln Ile
100 105 110
Tyr Val Ile Asp Pro Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys
115 120 125
Met Ser Gly Arg Ser Ala Asn Ala Asp Ile Gln Met Thr Gln Ser Pro
130 135 140
Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Met Thr Cys Ser
145 150 155 160
Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Arg Trp Ile Tyr Asp Ser Ser Lys Leu Ala Ser Gly
180 185 190
Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Trp Ser Arg Asn Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Gln
225 230 235 240
Ile Thr Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser
245 250 255
Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn
260 265 270
Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
275 280 285
Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
290 295 300
Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
305 310 315 320
Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu
325 330 335
Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
340 345
<210> 156
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 22105 Mask
<400> 156
Met His Val Ala Gln Pro Ala Val Val Leu Ala Ser Ser Arg Gly Ile
1 5 10 15
Ala Ser Phe Val Cys Glu Tyr Ala Ser Pro Gly Lys Ala Thr Glu Val
20 25 30
Arg Val Thr Val Leu Arg Gln Ala Asp Ser Gln Val Thr Glu Val Cys
35 40 45
Ala Ala Thr Tyr Met Met Gly Asn Glu Leu Thr Phe Leu Asp Asp Ser
50 55 60
Ile Cys Thr Gly Thr Ser Ser Gly Asn Gln Val Asn Leu Thr Ile Gln
65 70 75 80
Gly Leu Arg Ala Met Asp Thr Gly Leu Tyr Ile Cys Lys Val Glu Leu
85 90 95
Met Tyr Pro Pro Pro Tyr Tyr Leu Gly Ile Gly Asn Gly Thr Gln Ile
100 105 110
Tyr Val Ile Asp Pro Glu
115
<210> 157
<211> 572
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23246 Full
<400> 157
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln Ser Leu Ser Ile
130 135 140
Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr Gly Val His Trp
145 150 155 160
Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp
165 170 175
Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr Ser Arg Leu Ser
180 185 190
Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe Lys Met Asn Ser
195 200 205
Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala Arg Ala Leu Thr
210 215 220
Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr
225 230 235 240
Val Ser Ala Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
245 250 255
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
260 265 270
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
275 280 285
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
290 295 300
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
305 310 315 320
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
325 330 335
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
340 345 350
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
355 360 365
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
370 375 380
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
385 390 395 400
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
405 410 415
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
420 425 430
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
435 440 445
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
450 455 460
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
465 470 475 480
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
485 490 495
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
500 505 510
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
515 520 525
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
530 535 540
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
545 550 555 560
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 158
<211> 339
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23247 Full
<400> 158
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Asp Ile Leu
115 120 125
Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser Pro Gly Glu Arg Val
130 135 140
Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp
145 150 155 160
Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile Lys Tyr Ala
165 170 175
Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser
180 185 190
Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser Glu Asp Ile
195 200 205
Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly
210 215 220
Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro Ser Val
225 230 235 240
Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser
245 250 255
Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln
260 265 270
Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val
275 280 285
Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu
290 295 300
Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu
305 310 315 320
Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg
325 330 335
Gly Glu Cys
<210> 159
<211> 347
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23248 Full
<400> 159
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly
115 120 125
Arg Ser Ala Asn Ala Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu
130 135 140
Ser Val Ser Pro Gly Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln
145 150 155 160
Ser Ile Gly Thr Asn Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser
165 170 175
Pro Arg Leu Leu Ile Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile
195 200 205
Asn Ser Val Glu Ser Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn
210 215 220
Asn Asn Trp Pro Thr Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
225 230 235 240
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
245 250 255
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
260 265 270
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
275 280 285
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
290 295 300
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
305 310 315 320
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
325 330 335
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
340 345
<210> 160
<211> 572
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23253 Full
<400> 160
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val
130 135 140
Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr Thr Met Asn Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Leu Ile Thr
165 170 175
Pro Tyr Asn Gly Ala Ser Ser Tyr Asn Gln Lys Phe Arg Gly Lys Ala
180 185 190
Thr Met Thr Val Asp Thr Ser Thr Ser Thr Val Tyr Met Glu Leu Ser
195 200 205
Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Gly
210 215 220
Tyr Asp Gly Arg Gly Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
225 230 235 240
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
245 250 255
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
260 265 270
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
275 280 285
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
290 295 300
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
305 310 315 320
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
325 330 335
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
340 345 350
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
355 360 365
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
370 375 380
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
385 390 395 400
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
405 410 415
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
420 425 430
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
435 440 445
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
450 455 460
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
465 470 475 480
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
485 490 495
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
500 505 510
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
515 520 525
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
530 535 540
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
545 550 555 560
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 161
<211> 346
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23256 Full
<400> 161
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly
115 120 125
Arg Ser Ala Asn Ala Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Ser
145 150 155 160
Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro
165 170 175
Lys Leu Leu Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ser
180 185 190
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
195 200 205
Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser
210 215 220
Lys His Pro Leu Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
225 230 235 240
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
245 250 255
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
260 265 270
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
275 280 285
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
290 295 300
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
305 310 315 320
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
325 330 335
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
340 345
<210> 162
<211> 573
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23257 Full
<400> 162
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Thr Leu
115 120 125
Arg Glu Ser Gly Pro Ala Leu Val Lys Pro Thr Gln Thr Leu Thr Leu
130 135 140
Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser Gly Met Gly Val
145 150 155 160
Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu Trp Leu Ala His
165 170 175
Ile Trp Trp Asp Asp Asp Lys Arg Tyr Asn Pro Ala Leu Lys Ser Arg
180 185 190
Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val Val Leu Thr Met
195 200 205
Thr Asn Met Asp Pro Val Asp Thr Ala Ala Tyr Tyr Cys Ala Arg Met
210 215 220
Glu Leu Trp Ser Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
225 230 235 240
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
245 250 255
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
260 265 270
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
275 280 285
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
290 295 300
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
305 310 315 320
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
325 330 335
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
340 345 350
Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe
355 360 365
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
370 375 380
Glu Val Thr Cys Val Val Val Ser Val Ser His Glu Asp Pro Glu Val
385 390 395 400
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
405 410 415
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
420 425 430
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
435 440 445
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
450 455 460
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
465 470 475 480
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
485 490 495
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
500 505 510
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
515 520 525
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
530 535 540
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
545 550 555 560
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 163
<211> 338
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23258 Full
<400> 163
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ile Val
115 120 125
Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly Glu Arg Ala
130 135 140
Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Tyr
145 150 155 160
Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Asp Thr Ser
165 170 175
Lys Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly
180 185 190
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro Glu Asp Phe Ala
195 200 205
Val Tyr Tyr Cys Phe Gln Gly Ser Val Tyr Pro Phe Thr Phe Gly Gln
210 215 220
Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala Pro Ser Val Phe
225 230 235 240
Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val
245 250 255
Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp
260 265 270
Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr
275 280 285
Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr
290 295 300
Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val
305 310 315 320
Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
325 330 335
Glu Cys
<210> 164
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23258, 23260 VL
<400> 164
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Phe Gln Gly Ser Val Tyr Pro Phe Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 165
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23258, 23260 LCDR3
<400> 165
Phe Gln Gly Ser Val Tyr Pro Phe Thr
1 5
<210> 166
<211> 346
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23260 Full
<400> 166
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly
115 120 125
Arg Ser Ala Asn Ala Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu
130 135 140
Ser Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser
145 150 155 160
Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
165 170 175
Arg Leu Leu Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly Ile Pro Ala
180 185 190
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
195 200 205
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Phe Gln Gly Ser
210 215 220
Val Tyr Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
225 230 235 240
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
245 250 255
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
260 265 270
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
275 280 285
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
290 295 300
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
305 310 315 320
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
325 330 335
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
340 345
<210> 167
<211> 570
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23261 Full
<400> 167
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Val Gln Leu
115 120 125
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu
130 135 140
Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Glu Tyr Tyr Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Gly Leu Ile Asp
165 170 175
Pro Glu Gln Gly Asn Thr Ile Tyr Asp Pro Lys Phe Gln Asp Arg Ala
180 185 190
Thr Ile Ser Ala Asp Asn Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn
195 200 205
Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Thr
210 215 220
Ala Ala Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
225 230 235 240
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
245 250 255
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
260 265 270
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
275 280 285
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
290 295 300
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
305 310 315 320
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
325 330 335
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
340 345 350
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
355 360 365
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
370 375 380
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
385 390 395 400
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
405 410 415
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
420 425 430
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
435 440 445
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
450 455 460
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
465 470 475 480
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
485 490 495
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
500 505 510
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
515 520 525
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
530 535 540
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
545 550 555 560
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 168
<211> 339
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23262 Full
<400> 168
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Asp Ile Gln
115 120 125
Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val
130 135 140
Thr Ile Thr Cys Arg Ala Ser Arg Asp Ile Lys Ser Tyr Leu Asn Trp
145 150 155 160
Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile Tyr Tyr Ala
165 170 175
Thr Ser Leu Ala Glu Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser
180 185 190
Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe
195 200 205
Ala Thr Tyr Tyr Cys Leu Gln His Gly Glu Ser Pro Trp Thr Phe Gly
210 215 220
Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala Pro Ser Val
225 230 235 240
Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser
245 250 255
Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln
260 265 270
Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val
275 280 285
Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu
290 295 300
Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu
305 310 315 320
Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg
325 330 335
Gly Glu Cys
<210> 169
<211> 347
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23264 Full
<400> 169
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly
115 120 125
Arg Ser Ala Asn Ala Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg
145 150 155 160
Asp Ile Lys Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Lys Val Leu Ile Tyr Tyr Ala Thr Ser Leu Ala Glu Gly Val Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His
210 215 220
Gly Glu Ser Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
225 230 235 240
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
245 250 255
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
260 265 270
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
275 280 285
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
290 295 300
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
305 310 315 320
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
325 330 335
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
340 345
<210> 170
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23567 Full
<400> 170
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Leu Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Lys Met Asn Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
<210> 171
<211> 455
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23712 Full
<400> 171
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asp Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Asn Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gln Pro Leu Gly Tyr Cys Thr Asn Gly Val Cys Ser Tyr
100 105 110
Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser
115 120 125
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
130 135 140
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
145 150 155 160
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
165 170 175
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
180 185 190
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
195 200 205
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
210 215 220
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
225 230 235 240
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
245 250 255
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
260 265 270
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
275 280 285
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
290 295 300
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
305 310 315 320
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
325 330 335
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
340 345 350
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
355 360 365
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
370 375 380
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
385 390 395 400
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
405 410 415
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
420 425 430
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
435 440 445
Ser Leu Ser Leu Ser Pro Gly
450 455
<210> 172
<211> 126
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23712, 23714 VH
<400> 172
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Asp Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Asn Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gln Pro Leu Gly Tyr Cys Thr Asn Gly Val Cys Ser Tyr
100 105 110
Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 173
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23712, 23714 HCDR1
<400> 173
Gly Tyr Tyr Met His
1 5
<210> 174
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23712, 23714 HCDR2
<400> 174
Trp Ile Asn Pro Asp Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 175
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23712, 23714 HCDR3
<400> 175
Asp Gln Pro Leu Gly Tyr Cys Thr Asn Gly Val Cys Ser Tyr Phe Asp
1 5 10 15
Tyr
<210> 176
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23713 Full
<400> 176
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Tyr Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Asn Leu Leu Ile
35 40 45
Tyr Thr Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ile Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 177
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23713, 23715, 23716 VL
<400> 177
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Tyr Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Asn Leu Leu Ile
35 40 45
Tyr Thr Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ile Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 178
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23713, 23715, 23716 LCDR1
<400> 178
Arg Ala Ser Gln Gly Ile Tyr Ser Trp Leu Ala
1 5 10
<210> 179
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23713, 23715, 23716 LCDR2
<400> 179
Thr Ala Ser Thr Leu Gln Ser
1 5
<210> 180
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23713, 23715, 23716 LCDR3
<400> 180
Gln Gln Ala Asn Ile Phe Pro Leu Thr
1 5
<210> 181
<211> 579
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23714 Full
<400> 181
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe His
20 25 30
Val Val Trp His Arg Glu Ser Pro Ser Gly Gln Thr Asp Thr Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ala Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Val Cys Gly Val Ile Ser Leu
85 90 95
Ala Pro Lys Ile Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val
130 135 140
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr Tyr Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Trp Ile Asn
165 170 175
Pro Asp Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe Gln Gly Arg Val
180 185 190
Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr Met Glu Leu Asn
195 200 205
Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Gln
210 215 220
Pro Leu Gly Tyr Cys Thr Asn Gly Val Cys Ser Tyr Phe Asp Tyr Trp
225 230 235 240
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
245 250 255
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
260 265 270
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
275 280 285
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
290 295 300
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
305 310 315 320
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
325 330 335
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
340 345 350
Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
355 360 365
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
370 375 380
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
385 390 395 400
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
405 410 415
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
420 425 430
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
435 440 445
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
450 455 460
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
465 470 475 480
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
485 490 495
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
500 505 510
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
515 520 525
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
530 535 540
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
545 550 555 560
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
565 570 575
Ser Pro Gly
<210> 182
<211> 339
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23715 Full
<400> 182
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Asp Ile Gln
115 120 125
Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly Asp Arg Val
130 135 140
Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Tyr Ser Trp Leu Ala Trp
145 150 155 160
Tyr Gln Gln Lys Pro Gly Lys Ala Pro Asn Leu Leu Ile Tyr Thr Ala
165 170 175
Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser
180 185 190
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe
195 200 205
Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ile Phe Pro Leu Thr Phe Gly
210 215 220
Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala Pro Ser Val
225 230 235 240
Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser
245 250 255
Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln
260 265 270
Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val
275 280 285
Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu
290 295 300
Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu
305 310 315 320
Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg
325 330 335
Gly Glu Cys
<210> 183
<211> 347
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23716 Full
<400> 183
Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly
1 5 10 15
Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp
20 25 30
Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile
35 40 45
Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr
50 55 60
Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala
65 70 75 80
Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg
85 90 95
Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys
100 105 110
Val Asn Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Met Ser Gly
115 120 125
Arg Ser Ala Asn Ala Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln
145 150 155 160
Gly Ile Tyr Ser Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Asn Leu Leu Ile Tyr Thr Ala Ser Thr Leu Gln Ser Gly Val Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala
210 215 220
Asn Ile Phe Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
225 230 235 240
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
245 250 255
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
260 265 270
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
275 280 285
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
290 295 300
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
305 310 315 320
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
325 330 335
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
340 345
<210> 184
<211> 566
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 24659 Full
<400> 184
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ser Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Ser Ile Ser Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala Glu Ala Ala Ala Lys Glu
100 105 110
Ala Ala Ala Lys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
115 120 125
Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr
130 135 140
Phe Thr Arg Ser Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly
145 150 155 160
Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr
165 170 175
Asn Gln Lys Phe Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys
180 185 190
Ser Thr Ala Phe Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly
195 200 205
Val Tyr Phe Cys Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe
210 215 220
Pro Tyr Trp Gly Gln Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr
225 230 235 240
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
245 250 255
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
260 265 270
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
275 280 285
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
290 295 300
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
305 310 315 320
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
325 330 335
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
340 345 350
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
355 360 365
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
370 375 380
Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
385 390 395 400
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
405 410 415
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
420 425 430
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
435 440 445
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
450 455 460
Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys
465 470 475 480
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
485 490 495
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
500 505 510
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser
515 520 525
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
530 535 540
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
545 550 555 560
Leu Ser Leu Ser Pro Gly
565
<210> 185
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 24659 Mask
<400> 185
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ser Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Ser Ile Ser Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala
100 105
<210> 186
<211> 566
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 24660 Full
<400> 186
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Ser Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ser Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala Glu Ala Ala Ala Lys Glu
100 105 110
Ala Ala Ala Lys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
115 120 125
Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr
130 135 140
Phe Thr Arg Ser Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly
145 150 155 160
Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr
165 170 175
Asn Gln Lys Phe Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys
180 185 190
Ser Thr Ala Phe Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly
195 200 205
Val Tyr Phe Cys Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe
210 215 220
Pro Tyr Trp Gly Gln Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr
225 230 235 240
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
245 250 255
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
260 265 270
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
275 280 285
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
290 295 300
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
305 310 315 320
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
325 330 335
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
340 345 350
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
355 360 365
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
370 375 380
Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
385 390 395 400
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
405 410 415
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
420 425 430
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
435 440 445
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
450 455 460
Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys
465 470 475 480
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
485 490 495
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
500 505 510
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser
515 520 525
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
530 535 540
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
545 550 555 560
Leu Ser Leu Ser Pro Gly
565
<210> 187
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 24660 Mask
<400> 187
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Ser Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ser Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala
100 105
<210> 188
<211> 566
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 24661 Full
<400> 188
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Ser Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala Glu Ala Ala Ala Lys Glu
100 105 110
Ala Ala Ala Lys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
115 120 125
Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr
130 135 140
Phe Thr Arg Ser Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly
145 150 155 160
Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr
165 170 175
Asn Gln Lys Phe Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ser Lys
180 185 190
Ser Thr Ala Phe Leu Gln Met Asp Ser Leu Arg Pro Glu Asp Thr Gly
195 200 205
Val Tyr Phe Cys Ala Arg Pro Gln Val His Tyr Asp Tyr Asn Gly Phe
210 215 220
Pro Tyr Trp Gly Gln Gly Thr Pro Val Thr Val Ser Ser Ala Ser Thr
225 230 235 240
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
245 250 255
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
260 265 270
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
275 280 285
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
290 295 300
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
305 310 315 320
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
325 330 335
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
340 345 350
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
355 360 365
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
370 375 380
Ser Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
385 390 395 400
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
405 410 415
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
420 425 430
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
435 440 445
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
450 455 460
Glu Pro Gln Val Tyr Val Tyr Pro Pro Ser Arg Asp Glu Leu Thr Lys
465 470 475 480
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
485 490 495
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
500 505 510
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Ala Leu Val Ser
515 520 525
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
530 535 540
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
545 550 555 560
Leu Ser Leu Ser Pro Gly
565
<210> 189
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 24661 Mask
<400> 189
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Ser Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr Leu Ser Val Lys Ala
100 105
<210> 190
<211> 574
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23734
<400> 190
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Ala Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ala Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Gln Val Gln Leu
115 120 125
Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg Ser Leu Arg Leu
130 135 140
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser Thr Met His Trp
145 150 155 160
Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn
165 170 175
Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Arg Phe
180 185 190
Thr Ile Ser Ala Asp Lys Ser Lys Ser Thr Ala Phe Leu Gln Met Asp
195 200 205
Ser Leu Arg Pro Glu Asp Thr Gly Val Tyr Phe Cys Ala Arg Pro Gln
210 215 220
Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly Gln Gly Thr Pro
225 230 235 240
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
245 250 255
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
260 265 270
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
275 280 285
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
290 295 300
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
305 310 315 320
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
325 330 335
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
340 345 350
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
355 360 365
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
370 375 380
Pro Glu Val Thr Cys Val Val Val Ser Val Ser His Glu Asp Pro Glu
385 390 395 400
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
405 410 415
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
420 425 430
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
435 440 445
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
450 455 460
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Val Tyr Pro
465 470 475 480
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
485 490 495
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
500 505 510
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
515 520 525
Asp Gly Ser Phe Ala Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg
530 535 540
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
545 550 555 560
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 191
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 23734 Mask
<400> 191
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
1 5 10 15
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
20 25 30
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Ala Leu Ala
35 40 45
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Ser Arg Phe Arg
50 55 60
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
65 70 75 80
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ala Ser Leu
85 90 95
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
100 105 110
Thr Glu
<210> 192
<211> 487
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018Full
<400> 192
Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly
1 5 10 15
Ala Ser Val Arg Val Ser Cys Arg Ala Ser Gly Tyr Ile Phe Thr Glu
20 25 30
Ser Gly Ile Thr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp
35 40 45
Met Gly Trp Ile Ser Gly Tyr Ser Gly Asp Thr Lys Tyr Ala Gln Lys
50 55 60
Leu Gln Gly Arg Val Thr Met Thr Lys Asp Thr Ser Thr Thr Thr Ala
65 70 75 80
Tyr Met Glu Leu Arg Ser Leu Arg Tyr Asp Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Asp Val Gln Tyr Ser Gly Ser Tyr Leu Gly Ala Tyr Tyr
100 105 110
Phe Asp Tyr Trp Ser Pro Gly Thr Leu Val Thr Val Ser Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
145 150 155 160
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Thr Asn
165 170 175
Tyr Val Tyr Trp Tyr Gln Gln Phe Pro Gly Thr Ala Pro Lys Leu Leu
180 185 190
Ile Tyr Arg Ser Tyr Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
195 200 205
Gly Ser Lys Ser Gly Ser Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
210 215 220
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Thr Trp Asp Asp Ser Leu
225 230 235 240
Asp Gly Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Ala Ala
245 250 255
Glu Pro Lys Ser Ser Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
260 265 270
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
275 280 285
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
290 295 300
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
305 310 315 320
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
325 330 335
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
340 345 350
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
355 360 365
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
370 375 380
Arg Glu Pro Gln Val Tyr Val Leu Pro Pro Ser Arg Asp Glu Leu Thr
385 390 395 400
Lys Asn Gln Val Ser Leu Leu Cys Leu Val Lys Gly Phe Tyr Pro Ser
405 410 415
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
420 425 430
Leu Thr Trp Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
435 440 445
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
450 455 460
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
465 470 475 480
Ser Leu Ser Leu Ser Pro Gly
485
<210> 193
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 VH
<400> 193
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Arg Val Ser Cys Arg Ala Ser Gly Tyr Ile Phe Thr Glu Ser
20 25 30
Gly Ile Thr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Gly Tyr Ser Gly Asp Thr Lys Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Lys Asp Thr Ser Thr Thr Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Tyr Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Val Gln Tyr Ser Gly Ser Tyr Leu Gly Ala Tyr Tyr Phe
100 105 110
Asp Tyr Trp Ser Pro Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 194
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 VL
<400> 194
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Thr Asn
20 25 30
Tyr Val Tyr Trp Tyr Gln Gln Phe Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Arg Ser Tyr Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Ser Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Thr Trp Asp Asp Ser Leu
85 90 95
Asp Gly Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 195
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 HCDR1
<400> 195
Glu Ser Gly Ile Thr
1 5
<210> 196
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 HCDR2
<400> 196
Trp Ile Ser Gly Tyr Ser Gly Asp Thr Lys Tyr Ala Gln Lys Leu Gln
1 5 10 15
Gly
<210> 197
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 HCDR3
<400> 197
Asp Val Gln Tyr Ser Gly Ser Tyr Leu Gly Ala Tyr Tyr Phe Asp Tyr
1 5 10 15
<210> 198
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 LCDR1
<400> 198
Ser Gly Ser Ser Ser Asn Ile Gly Thr Asn Tyr Val Tyr
1 5 10
<210> 199
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 LCDR2
<400> 199
Arg Ser Tyr Gln Arg Pro Ser
1 5
<210> 200
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 11018 LCDR3
<400> 200
Ala Thr Trp Asp Asp Ser Leu Asp Gly Trp Val
1 5 10
<210> 201
<211> 571
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 25321 Full
<400> 201
Glu Glu Glu Leu Gln Ile Ile Gln Pro Asp Lys Ser Val Ser Val Ala
1 5 10 15
Ala Gly Glu Ser Ala Ile Leu His Cys Thr Ile Thr Ser Leu Phe Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Ala Arg Val Leu
35 40 45
Ile Tyr Asn Gln Arg Gln Gly Pro Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Glu Thr Thr Lys Arg Glu Asn Met Asp Phe Ser Ile Ser Ile Ser Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Thr Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser
100 105 110
Val Arg Ala Met Ser Gly Arg Ser Ala Asn Ala Gln Val Gln Leu Lys
115 120 125
Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln Ser Leu Ser Ile Thr
130 135 140
Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr Gly Val His Trp Val
145 150 155 160
Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Ser
165 170 175
Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr Ser Arg Leu Ser Ile
180 185 190
Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe Lys Met Asn Ser Leu
195 200 205
Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala Arg Ala Leu Thr Tyr
210 215 220
Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
225 230 235 240
Ser Ala Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
245 250 255
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
260 265 270
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
275 280 285
Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
290 295 300
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr
305 310 315 320
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val
325 330 335
Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro
340 345 350
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
355 360 365
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
370 375 380
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
385 390 395 400
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
405 410 415
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
420 425 430
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
435 440 445
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
450 455 460
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
465 470 475 480
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
485 490 495
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
500 505 510
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
515 520 525
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
530 535 540
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
545 550 555 560
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
565 570
<210> 202
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 25321 Mask
<400> 202
Glu Glu Glu Leu Gln Ile Ile Gln Pro Asp Lys Ser Val Ser Val Ala
1 5 10 15
Ala Gly Glu Ser Ala Ile Leu His Cys Thr Ile Thr Ser Leu Phe Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Ala Arg Val Leu
35 40 45
Ile Tyr Asn Gln Arg Gln Gly Pro Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Glu Thr Thr Lys Arg Glu Asn Met Asp Phe Ser Ile Ser Ile Ser Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Thr Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser
100 105 110
Val Arg Ala
115
<210> 203
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 25321 Mask Linker
<400> 203
Met Ser Gly Arg Ser Ala Asn Ala
1 5
<210> 204
<211> 337
<212> PRT
<213> Artificial Sequence
<220>
<223> Clone ID 25325 Full
<400> 204
Gln Leu Leu Phe Asn Lys Thr Lys Ser Val Glu Phe Thr Phe Gly Asn
1 5 10 15
Asp Thr Val Val Ile Pro Cys Phe Val Thr Asn Met Glu Ala Gln Asn
20 25 30
Thr Thr Glu Val Tyr Val Lys Trp Lys Phe Lys Gly Arg Asp Ile Tyr
35 40 45
Thr Phe Asp Gly Ala Leu Asn Lys Ser Thr Val Pro Thr Asp Phe Ser
50 55 60
Ser Ala Lys Ile Glu Val Ser Gln Leu Leu Lys Gly Asp Ala Ser Leu
65 70 75 80
Lys Met Asp Lys Ser Asp Ala Val Ser His Thr Gly Asn Tyr Thr Cys
85 90 95
Glu Val Thr Glu Leu Thr Arg Glu Gly Glu Thr Ile Ile Glu Leu Lys
100 105 110
Tyr Arg Val Met Ser Gly Arg Ser Ala Asn Ala Asp Ile Leu Leu Thr
115 120 125
Gln Ser Pro Val Ile Leu Ser Val Ser Pro Gly Glu Arg Val Ser Phe
130 135 140
Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn Ile His Trp Tyr Gln
145 150 155 160
Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile Lys Tyr Ala Ser Glu
165 170 175
Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr
180 185 190
Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser Glu Asp Ile Ala Asp
195 200 205
Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr Thr Phe Gly Ala Gly
210 215 220
Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile
225 230 235 240
Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val
245 250 255
Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys
260 265 270
Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu
275 280 285
Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu
290 295 300
Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr
305 310 315 320
His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu
325 330 335
Cys
<210> 205
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> 25325 Mask
<400> 205
Gln Leu Leu Phe Asn Lys Thr Lys Ser Val Glu Phe Thr Phe Gly Asn
1 5 10 15
Asp Thr Val Val Ile Pro Cys Phe Val Thr Asn Met Glu Ala Gln Asn
20 25 30
Thr Thr Glu Val Tyr Val Lys Trp Lys Phe Lys Gly Arg Asp Ile Tyr
35 40 45
Thr Phe Asp Gly Ala Leu Asn Lys Ser Thr Val Pro Thr Asp Phe Ser
50 55 60
Ser Ala Lys Ile Glu Val Ser Gln Leu Leu Lys Gly Asp Ala Ser Leu
65 70 75 80
Lys Met Asp Lys Ser Asp Ala Val Ser His Thr Gly Asn Tyr Thr Cys
85 90 95
Glu Val Thr Glu Leu Thr Arg Glu Gly Glu Thr Ile Ile Glu Leu Lys
100 105 110
Tyr Arg Val
115
<210> 206
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 VH
<400> 206
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Val Thr Phe Asn Tyr Tyr
20 25 30
Gly Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Thr Ser Ser Gly Gly Arg Ile Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Glu Asn Thr Gln Lys Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Leu Asp Gly Arg Asp Gly Trp Val Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 207
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 Kabat HCDR1
<400> 207
Tyr Tyr Gly Met Ser
1 5
<210> 208
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 Kabat HCDR2
<400> 208
Ser Ile Thr Ser Ser Gly Gly Arg Ile Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Gly
<210> 209
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 Kabat HCDR3
<400> 209
Asp Gly Arg Asp Gly Trp Val Ala Tyr
1 5
<210> 210
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 VL
<400> 210
Asn Phe Met Leu Thr Gln Pro His Ser Val Ser Glu Ser Pro Gly Lys
1 5 10 15
Thr Val Thr Ile Ser Cys Lys Arg Asn Thr Gly Asn Ile Gly Ser Asn
20 25 30
Tyr Val Asn Trp Tyr Gln Gln His Glu Gly Ser Ser Pro Thr Thr Ile
35 40 45
Ile Tyr Arg Asn Asp Lys Arg Pro Asp Gly Val Ser Asp Arg Phe Ser
50 55 60
Gly Ser Ile Asp Arg Ser Ser Lys Ser Ala Ser Leu Thr Ile Ser Asn
65 70 75 80
Leu Lys Thr Glu Asp Glu Ala Asp Tyr Phe Cys Gln Ser Tyr Ser Ser
85 90 95
Gly Phe Ile Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 211
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 Kabat LCDR1
<400> 211
Lys Arg Asn Thr Gly Asn Ile Gly Ser Asn Tyr Val Asn
1 5 10
<210> 212
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 Kabat LCDR2
<400> 212
Arg Asn Asp Lys Arg Pro Asp
1 5
<210> 213
<400> 213
000
<210> 214
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 1 Kabat LCDR3
<400> 214
Gln Ser Tyr Ser Ser Gly Phe Ile
1 5
<210> 215
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 VH
<400> 215
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Val Thr Phe Asn Tyr Tyr
20 25 30
Gly Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Thr Arg Ser Gly Gly Arg Ile Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Glu Asn Thr Gln Lys Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Leu Asp Gly Arg Asp Gly Trp Val Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 216
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 Kabat HCDR1
<400> 216
Tyr Tyr Gly Met Ser
1 5
<210> 217
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 Kabat HCDR2
<400> 217
Ser Ile Thr Arg Ser Gly Gly Arg Ile Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Gly
<210> 218
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 Kabat HCDR3
<400> 218
Asp Gly Arg Asp Gly Trp Val Ala Tyr
1 5
<210> 219
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 VL
<400> 219
Asn Phe Met Leu Thr Gln Pro Ser Ser Val Ser Gly Val Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Thr Gly Asn Thr Gly Asn Ile Gly Ser Asn
20 25 30
Tyr Val Asn Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Arg Asp Asp Lys Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Phe Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Ser Ser Gly Phe
85 90 95
Ile Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 220
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 Kabat LCDR1
<400> 220
Thr Gly Asn Thr Gly Asn Ile Gly Ser Asn Tyr Val Asn
1 5 10
<210> 221
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 Kabat LCDR2
<400> 221
Arg Asp Asp Lys Arg Pro Ser
1 5
<210> 222
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 2 Kabat LCDR3
<400> 222
Gln Ser Tyr Ser Ser Gly Phe Ile
1 5
<210> 223
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 VH
<400> 223
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 224
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 Kabat HCDR1
<400> 224
Lys Tyr Ala Met Asn
1 5
<210> 225
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 Kabat HCDR2
<400> 225
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys Asp
<210> 226
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 Kabat HCDR3
<400> 226
His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 227
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 VL
<400> 227
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
1 5 10 15
Thr Val Thr Leu Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Ser Gly
20 25 30
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
35 40 45
Leu Ile Gly Gly Thr Lys Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe
50 55 60
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
65 70 75 80
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn
85 90 95
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 228
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 Kabat LCDR1
<400> 228
Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 229
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 Kabat LCDR2
<400> 229
Gly Thr Lys Phe Leu Ala Pro
1 5
<210> 230
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 3 Kabat LCDR3
<400> 230
Val Leu Trp Tyr Ser Asn Arg Trp Val
1 5
<210> 231
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 VH
<400> 231
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Val Ser Trp Phe
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 232
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 Kabat HCDR1
<400> 232
Thr Tyr Ala Met Asn
1 5
<210> 233
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 Kabat HCDR2
<400> 233
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys Gly
<210> 234
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 Kabat HCDR3
<400> 234
His Gly Asn Phe Gly Asn Ser Tyr Val Ser Trp Phe Ala Tyr
1 5 10
<210> 235
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 VL
<400> 235
Gln Ala Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
1 5 10 15
Thr Val Thr Leu Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Thr Ser
20 25 30
Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Gly Gln Ala Phe Arg Gly
35 40 45
Leu Ile Gly Gly Thr Asn Lys Arg Ala Pro Gly Thr Pro Ala Arg Phe
50 55 60
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Ala
65 70 75 80
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Ala Leu Trp Tyr Ser Asn
85 90 95
Leu Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105
<210> 236
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 Kabat LCDR1
<400> 236
Gly Ser Ser Thr Gly Ala Val Thr Thr Ser Asn Tyr Ala Asn
1 5 10
<210> 237
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 Kabat LCDR2
<400> 237
Gly Thr Asn Lys Arg Ala Pro
1 5
<210> 238
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 4 Kabat LCDR3
<400> 238
Ala Leu Trp Tyr Ser Asn Leu Trp Val
1 5
<210> 239
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 VH
<400> 239
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 240
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 Kabat HCDR1
<400> 240
Arg Ser Thr Met His
1 5
<210> 241
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 Kabat HCDR2
<400> 241
Tyr Ile Asn Pro Ser Ser Ala Tyr Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Asp
<210> 242
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 Kabat HCDR3
<400> 242
Pro Gln Val His Tyr Asp Tyr Asn Gly Phe Pro Tyr
1 5 10
<210> 243
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 VL
<400> 243
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile Tyr
35 40 45
Asp Ser Ser Lys Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
65 70 75 80
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Arg Asn Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 244
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 Kabat LCDR1
<400> 244
Ser Ala Ser Ser Ser Val Ser Tyr Met Asn
1 5 10
<210> 245
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 Kabat LCDR2
<400> 245
Asp Ser Ser Lys Leu Ala Ser
1 5
<210> 246
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-CD3 paratope 5 Kabat LCDR3
<400> 246
Gln Gln Trp Ser Arg Asn Pro Pro Thr
1 5
<210> 247
<211> 101
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CD80 Residue 35-135
<400> 247
Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu Ser Cys
1 5 10 15
Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile Tyr Trp
20 25 30
Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp Met Asn
35 40 45
Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr Asn Asn
50 55 60
Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly Thr Tyr
65 70 75 80
Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg Glu His
85 90 95
Leu Ala Glu Val Thr
100
<210> 248
<211> 99
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CD86 Residue 33-131
<400> 248
Asn Glu Thr Ala Asp Leu Pro Cys Gln Phe Ala Asn Ser Gln Asn Gln
1 5 10 15
Ser Leu Ser Glu Leu Val Val Phe Trp Gln Asp Gln Glu Asn Leu Val
20 25 30
Leu Asn Glu Val Tyr Leu Gly Lys Glu Lys Phe Asp Ser Val His Ser
35 40 45
Lys Tyr Met Gly Arg Thr Ser Phe Asp Ser Asp Ser Trp Thr Leu Arg
50 55 60
Leu His Asn Leu Gln Ile Lys Asp Lys Gly Leu Tyr Gln Cys Ile Ile
65 70 75 80
His His Lys Lys Pro Thr Gly Met Ile Arg Ile His Gln Met Asn Ser
85 90 95
Glu Leu Ser
<210> 249
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member PD-L1 Residue 19-127
<400> 249
Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly Ser
1 5 10 15
Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp Leu
20 25 30
Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile Gln
35 40 45
Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr Arg
50 55 60
Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala Ala
65 70 75 80
Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg Cys
85 90 95
Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr
100 105
<210> 250
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member PD-L2 Residue 21-118
<400> 250
Phe Thr Val Thr Val Pro Lys Glu Leu Tyr Ile Ile Glu His Gly Ser
1 5 10 15
Asn Val Thr Leu Glu Cys Asn Phe Asp Thr Gly Ser His Val Asn Leu
20 25 30
Gly Ala Ile Thr Ala Ser Leu Gln Lys Val Glu Asn Asp Thr Ser Pro
35 40 45
His Arg Glu Arg Ala Thr Leu Leu Glu Glu Gln Leu Pro Leu Gly Lys
50 55 60
Ala Ser Phe His Ile Pro Gln Val Gln Val Arg Asp Glu Gly Gln Tyr
65 70 75 80
Gln Cys Ile Ile Ile Tyr Gly Val Ala Trp Asp Tyr Lys Tyr Leu Thr
85 90 95
Leu Lys
<210> 251
<211> 102
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CTLA-4 Residue 39-140
<400> 251
His Val Ala Gln Pro Ala Val Val Leu Ala Ser Ser Arg Gly Ile Ala
1 5 10 15
Ser Phe Val Cys Glu Tyr Ala Ser Pro Gly Lys Ala Thr Glu Val Arg
20 25 30
Val Thr Val Leu Arg Gln Ala Asp Ser Gln Val Thr Glu Val Cys Ala
35 40 45
Ala Thr Tyr Met Met Gly Asn Glu Leu Thr Phe Leu Asp Asp Ser Ile
50 55 60
Cys Thr Gly Thr Ser Ser Gly Asn Gln Val Asn Leu Thr Ile Gln Gly
65 70 75 80
Leu Arg Ala Met Asp Thr Gly Leu Tyr Ile Cys Lys Val Glu Leu Met
85 90 95
Tyr Pro Pro Pro Tyr Tyr
100
<210> 252
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member PD-1 Residue 35-145
<400> 252
Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp Asn Ala
1 5 10 15
Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val Leu Asn
20 25 30
Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala Ala Phe
35 40 45
Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg Val Thr
50 55 60
Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg Ala Arg
65 70 75 80
Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu Ala Pro
85 90 95
Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val Thr
100 105 110
<210> 253
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CD28 Residue 28-137
<400> 253
Met Leu Val Ala Tyr Asp Asn Ala Val Asn Leu Ser Cys Lys Tyr Ser
1 5 10 15
Tyr Asn Leu Phe Ser Arg Glu Phe Arg Ala Ser Leu His Lys Gly Leu
20 25 30
Asp Ser Ala Val Glu Val Cys Val Val Tyr Gly Asn Tyr Ser Gln Gln
35 40 45
Leu Gln Val Tyr Ser Lys Thr Gly Phe Asn Cys Asp Gly Lys Leu Gly
50 55 60
Asn Glu Ser Val Thr Phe Tyr Leu Gln Asn Leu Tyr Val Asn Gln Thr
65 70 75 80
Asp Ile Tyr Phe Cys Lys Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu
85 90 95
Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val Lys Gly
100 105 110
<210> 254
<211> 109
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CD47 Residue 19-127
<400> 254
Gln Leu Leu Phe Asn Lys Thr Lys Ser Val Glu Phe Thr Phe Cys Asn
1 5 10 15
Asp Thr Val Val Ile Pro Cys Phe Val Thr Asn Met Glu Ala Gln Asn
20 25 30
Thr Thr Glu Val Tyr Val Lys Trp Lys Phe Lys Gly Arg Asp Ile Tyr
35 40 45
Thr Phe Asp Gly Ala Leu Asn Lys Ser Thr Val Pro Thr Asp Phe Ser
50 55 60
Ser Ala Lys Ile Glu Val Ser Gln Leu Leu Lys Gly Asp Ala Ser Leu
65 70 75 80
Lys Met Asp Lys Ser Asp Ala Val Ser His Thr Gly Asn Tyr Thr Cys
85 90 95
Glu Val Thr Glu Leu Thr Arg Glu Gly Glu Thr Ile Ile
100 105
<210> 255
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member SIRPa Residue 32-137
<400> 255
Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala
1 5 10 15
Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro Val
20 25 30
Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile
35 40 45
Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Asp
50 55 60
Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn Ile
65 70 75 80
Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly
85 90 95
Ser Pro Asp Asp Val Glu Phe Lys Ser Gly
100 105
<210> 256
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member ICOSL Residue 19-129
<400> 256
Asp Thr Gln Glu Lys Glu Val Arg Ala Met Val Gly Ser Asp Val Glu
1 5 10 15
Leu Ser Cys Ala Cys Pro Glu Gly Ser Arg Phe Asp Leu Asn Asp Val
20 25 30
Tyr Val Tyr Trp Gln Thr Ser Glu Ser Lys Thr Val Val Thr Tyr His
35 40 45
Ile Pro Gln Asn Ser Ser Leu Glu Asn Val Asp Ser Arg Tyr Arg Asn
50 55 60
Arg Ala Leu Met Ser Pro Ala Gly Met Leu Arg Gly Asp Phe Ser Leu
65 70 75 80
Arg Leu Phe Asn Val Thr Pro Gln Asp Glu Gln Lys Phe His Cys Leu
85 90 95
Val Leu Ser Gln Ser Leu Gly Phe Gln Glu Val Leu Ser Val Glu
100 105 110
<210> 257
<211> 103
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member ICOS Residue 30-132
<400> 257
Met Phe Ile Phe His Asn Gly Gly Val Gln Ile Leu Cys Lys Tyr Pro
1 5 10 15
Asp Ile Val Gln Gln Phe Lys Met Gln Leu Leu Lys Gly Gly Gln Ile
20 25 30
Leu Cys Asp Leu Thr Lys Thr Lys Gly Ser Gly Asn Thr Val Ser Ile
35 40 45
Lys Ser Leu Lys Phe Cys His Ser Gln Leu Ser Asn Asn Ser Val Ser
50 55 60
Phe Phe Leu Tyr Asn Leu Asp His Ser His Ala Asn Tyr Tyr Phe Cys
65 70 75 80
Asn Leu Ser Ile Phe Asp Pro Pro Pro Phe Lys Val Thr Leu Thr Gly
85 90 95
Gly Tyr Leu His Ile Tyr Glu
100
<210> 258
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CD276 Residue 29-139
<400> 258
Leu Glu Val Gln Val Pro Glu Asp Pro Val Val Ala Leu Val Gly Thr
1 5 10 15
Asp Ala Thr Leu Cys Cys Ser Phe Ser Pro Glu Pro Gly Phe Ser Leu
20 25 30
Ala Gln Leu Asn Leu Ile Trp Gln Leu Thr Asp Thr Lys Gln Leu Val
35 40 45
His Ser Phe Ala Glu Gly Gln Asp Gln Gly Ser Ala Tyr Ala Asn Arg
50 55 60
Thr Ala Leu Phe Pro Asp Leu Leu Ala Gln Gly Asn Ala Ser Leu Arg
65 70 75 80
Leu Gln Arg Val Arg Val Ala Asp Glu Gly Ser Phe Thr Cys Phe Val
85 90 95
Ser Ile Arg Asp Phe Gly Ser Ala Ala Val Ser Leu Gln Val Ala
100 105 110
<210> 259
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member VTCN1 35-146 Residue 35-146
<400> 259
His Ser Ile Thr Val Thr Thr Val Ala Ser Ala Gly Asn Ile Gly Glu
1 5 10 15
Asp Gly Ile Leu Ser Cys Thr Phe Glu Pro Asp Ile Lys Leu Ser Asp
20 25 30
Ile Val Ile Gln Trp Leu Lys Glu Gly Val Leu Gly Leu Val His Glu
35 40 45
Phe Lys Glu Gly Lys Asp Glu Leu Ser Glu Gln Asp Glu Met Phe Arg
50 55 60
Gly Arg Thr Ala Val Phe Ala Asp Gln Val Ile Val Gly Asn Ala Ser
65 70 75 80
Leu Arg Leu Lys Asn Val Gln Leu Thr Asp Ala Gly Thr Tyr Lys Cys
85 90 95
Tyr Ile Ile Thr Ser Lys Gly Lys Gly Asn Ala Asn Leu Glu Tyr Lys
100 105 110
<210> 260
<211> 136
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member VISTA Residue 33-168
<400> 260
Phe Lys Val Ala Thr Pro Tyr Ser Leu Tyr Val Cys Pro Glu Gly Gln
1 5 10 15
Asn Val Thr Leu Thr Cys Arg Leu Leu Gly Pro Val Asp Lys Gly His
20 25 30
Asp Val Thr Phe Tyr Lys Thr Trp Tyr Arg Ser Ser Arg Gly Glu Val
35 40 45
Gln Thr Cys Ser Glu Arg Arg Pro Ile Arg Asn Leu Thr Phe Gln Asp
50 55 60
Leu His Leu His His Gly Gly His Gln Ala Ala Asn Thr Ser His Asp
65 70 75 80
Leu Ala Gln Arg His Gly Leu Glu Ser Ala Ser Asp His His Gly Asn
85 90 95
Phe Ser Ile Thr Met Arg Asn Leu Thr Leu Leu Asp Ser Gly Leu Tyr
100 105 110
Cys Cys Leu Val Val Glu Ile Arg His His His Ser Glu His Arg Val
115 120 125
His Gly Ala Met Glu Leu Gln Val
130 135
<210> 261
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member NCR3LG1 Residue 27-138
<400> 261
Lys Val Glu Met Met Ala Gly Gly Thr Gln Ile Thr Pro Leu Asn Asp
1 5 10 15
Asn Val Thr Ile Phe Cys Asn Ile Phe Tyr Ser Gln Pro Leu Asn Ile
20 25 30
Thr Ser Met Gly Ile Thr Trp Phe Trp Lys Ser Leu Thr Phe Asp Lys
35 40 45
Glu Val Lys Val Phe Glu Phe Phe Gly Asp His Gln Glu Ala Phe Arg
50 55 60
Pro Gly Ala Ile Val Ser Pro Trp Arg Leu Lys Ser Gly Asp Ala Ser
65 70 75 80
Leu Arg Leu Pro Gly Ile Gln Leu Glu Glu Ala Gly Glu Tyr Arg Cys
85 90 95
Glu Val Val Val Thr Pro Leu Lys Ala Gln Gly Thr Val Gln Leu Glu
100 105 110
<210> 262
<211> 71
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member HHLA2 Residue 61-131
<400> 262
Ile His Trp Lys Tyr Gln Asp Ser Tyr Lys Val His Ser Tyr Tyr Lys
1 5 10 15
Gly Ser Asp His Leu Glu Ser Gln Asp Pro Arg Tyr Ala Asn Arg Thr
20 25 30
Ser Leu Phe Tyr Asn Glu Ile Gln Asn Gly Asn Ala Ser Leu Phe Phe
35 40 45
Arg Arg Val Ser Leu Leu Asp Glu Gly Ile Tyr Thr Cys Tyr Val Gly
50 55 60
Thr Ala Ile Gln Val Ile Thr
65 70
<210> 263
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member CD28H Residue 23-129
<400> 263
Leu Ser Val Gln Gln Gly Pro Asn Leu Leu Gln Val Arg Gln Gly Ser
1 5 10 15
Gln Ala Thr Leu Val Cys Gln Val Asp Gln Ala Thr Ala Trp Glu Arg
20 25 30
Leu Arg Val Lys Trp Thr Lys Asp Gly Ala Ile Leu Cys Gln Pro Tyr
35 40 45
Ile Thr Asn Gly Ser Leu Ser Leu Gly Val Cys Gly Pro Gln Gly Arg
50 55 60
Leu Ser Trp Gln Ala Pro Ser His Leu Thr Leu Gln Leu Asp Pro Val
65 70 75 80
Ser Leu Asn His Ser Gly Ala Tyr Val Cys Trp Ala Ala Val Glu Ile
85 90 95
Pro Glu Leu Glu Glu Ala Glu Gly Asn Ile Thr
100 105
<210> 264
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> IgSF Member NKp30 Residue 19-126
<400> 264
Leu Trp Val Ser Gln Pro Pro Glu Ile Arg Thr Leu Glu Gly Ser Ser
1 5 10 15
Ala Phe Leu Pro Cys Ser Phe Asn Ala Ser Gln Gly Arg Leu Ala Ile
20 25 30
Gly Ser Val Thr Trp Phe Arg Asp Glu Val Val Pro Gly Lys Glu Val
35 40 45
Arg Asn Gly Thr Pro Glu Phe Arg Gly Arg Leu Ala Pro Leu Ala Ser
50 55 60
Ser Arg Phe Leu His Asp His Gln Ala Glu Leu His Ile Arg Asp Val
65 70 75 80
Arg Gly His Asp Ala Ser Ile Tyr Val Cys Arg Val Glu Val Leu Gly
85 90 95
Leu Gly Val Gly Thr Gly Asn Gly Thr Arg Leu Val
100 105
<210> 265
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Mask linker
<400> 265
Gly Pro Pro Pro Gly
1 5
<210> 266
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Mask linker
<400> 266
Gly Gly Pro Pro Pro Gly Gly
1 5
<210> 267
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Mask linker
<400> 267
Gly Pro Pro Pro Pro Gly
1 5
<210> 268
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Mask linker
<400> 268
Gly Gly Pro Pro Pro Gly Gly
1 5
Claims (98)
- 생물학적 기능성 단백질, 리간드-수용체 쌍, 제1 펩티드 링커 및 제2 펩티드 링커를 포함하는 융합 단백질로서,
상기 생물학적 기능성 단백질은 적어도 제1 폴리펩티드 및 제2 폴리펩티드를 포함하고;
상기 리간드-수용체 쌍은 면역글로불린 수퍼패밀리(immunoglobulin superfamily) 수용체의 세포외 부분 및 이의 동족 리간드(cognate ligand) 또는 이의 수용체 결합 단편을 포함하고;
상기 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 말단에 융합되고;
상기 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 동일한 각각의 말단에 융합되고; 상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링(pairing)을 허용하기에 충분한 길이이고, 상기 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하는 융합 단백질. - 제1항에 있어서, 리간드 및 수용체가 면역글로불린 수퍼패밀리(IgSF) 폴리펩티드의 세포외 부분을 포함하는 융합 단백질.
- 제1항에 있어서, 리간드 및 수용체가 면역글로불린 가변(IgV) 폴리펩티드의 세포외 부분을 포함하는 융합 단백질.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 생물학적 기능성 단백질이 항체 또는 항원 결합 항체 단편을 포함하는 융합 단백질.
- 제1항에 있어서, 생물학적 기능성 단백질이 폴리펩티드 스캐폴드로 이루어지는 융합 단백질.
- 제5항에 있어서, 폴리펩티드 스캐폴드가 이량체 Fc 영역이고, 제1 폴리펩티드가 제1 Fc 폴리펩티드로 이루어지고 제2 폴리펩티드가 제2 Fc 폴리펩티드로 이루어지며, 제1 및 제2 Fc 폴리펩티드는 이량체 Fc 영역을 형성하는 융합 단백질.
- 제1항에 있어서, 생물학적 기능성 단백질이 폴리펩티드 스캐폴드를 포함하는 융합 단백질.
- 제7항에 있어서, 폴리펩티드 스캐폴드가 이량체 Fc 영역을 포함하는 융합 단백질.
- 제6항 또는 제8항에 있어서, 이량체 Fc 영역이 이종이량체 Fc인 융합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 리간드-수용체 쌍에서 리간드 또는 수용체 중 적어도 하나가 면역조절 표적에 결합할 수 있는 융합 단백질.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 리간드 수용체 쌍이 면역 체크포인트의 조절, 면역 세포 활성의 조절, T 세포 수용체 신호전달의 조절, T 세포 의존성 세포독성(T-cell dependent cytotoxicity, TDCC)의 조절, 항체 의존성 세포 식세포작용(antibody-dependent cellular phagocytosis, ADCP)의 조절 및 항체 의존성 세포 세포독성(antibody-dependent cellular cytotoxicity, ADCC)의 조절로 이루어진 군으로부터 선택된 세포 반응에 관여하는 융합 단백질.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 수용체가 야생형 수용체와 비교하여 동족 리간드에 대한 수용체의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함하는 융합 단백질.
- 제1항 내지 제12항 중 어느 한 항에 있어서, 리간드가 야생형 리간드와 비교하여 동족 수용체에 대한 리간드의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함하는 융합 단백질.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 리간드-수용체 쌍이 PD1-PDL1, PD1-PDL2, CTLA4-CD80, CD28-CD80, CD28-CD86, CTLA4-CD86, PDL1-CD80, ICOS-ICOSL, NCRSRLG1-NKp30 및 CD47-SIRPα로 이루어진 군으로부터 선택되는 융합 단백질.
- 제14항에 있어서, 리간드-수용체 쌍이 PD1-PDL1인 융합 단백질.
- 제15항에 있어서, 리간드 PDL1이 서열번호 8에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제15항 또는 제16항에 있어서, 수용체 PD1이 서열번호 9에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제14항에 있어서, 리간드-수용체 쌍이 CTLA4-CD80인 융합 단백질.
- 제18항에 있어서, 리간드 CD80이 서열번호 25, 서열번호 185, 서열번호 187 또는 서열번호 189에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제18항 또는 제19항에 있어서, 수용체 CTLA4가 서열번호 26에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제14항에 있어서, 리간드-수용체 쌍이 CTLA4-CD80, PDL1-CD80 및 CD28-CD80으로 이루어진 군으로부터 선택되고, 리간드 CD80이 다음으로 이루어진 군으로부터 선택된 돌연변이를 갖는 서열번호 25에 따른 아미노산 서열을 포함하는 융합 단백질:
(a) H18Y, A26E, E35D, M47S, I61S 및 D90G; (b) E35D, M47S, N48K, I61S, K89N; (c) E35D, D46V, M47S, I61S, D90G, K93E; 또는 (d) H18Y, A26E, E35D, M47S, I61S, V68M, A71G, D90G; (e) I58S, V68S, L70S; (f) M47S, I61S 또는 (g) V22S. - 제1항 내지 제21항 중 어느 한 항에 있어서, 수용체 및 리간드가 제1 및 제2 폴리펩티드의 각각의 N-말단에 융합된 융합 단백질.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 제1 또는 제2 펩티드 링커 중 하나가 하나 초과의 프로테아제 절단 부위를 포함하는 융합 단백질.
- 제1항 내지 제23항 중 어느 한 항에 있어서, 리간드 또는 수용체에 융합된 펩티드 링커 중 하나가 하나 이상의 추가 프로테아제 절단 부위를 포함하도록 조작되고, 리간드 또는 수용체의 하나 이상의 프로테아제 절단 부위 및 제1 또는 제2 펩티드 링커의 프로테아제 절단 부위는 동일한 프로테아제 또는 상이한 프로테아제에 의해 절단 가능한 융합 단백질.
- 제1항 내지 제24항 중 어느 한 항에 있어서, 프로테아제가 세린 프로테아제, MMP1, MMP2, MMP3, MMP7, MMP8, MMP9, MMP10, MMP11, MMP12, MMP13, MMP14, MMP15, MMP16, MMP17, MMP18(콜라게나제 4), MMP19, MMP20, MMP21, 아다말리신(adamalysin), 세랄리신(serralysin), 아스타신(astacin), 카스파제(caspase) 1, 카스파제 2, 카스파제 3, 카스파제 4, 카스파제 5, 카스파제 6, 카스파제 7, 카스파제 8, 카스파제 9, 카스파제 10, 카스파제 11, 카스파제 12, 카스파제 13, 카스파제 14, 카텝신(cathepsin) A, 카텝신 B, 카텝신 D, 카텝신 E, 카텝신 K, 카텝신 S, 그랜자임(granzyme) B, 구아니디노벤조아타제(guanidinobenzoatase, GB), 헵신(hepsin), 엘라스타제(elastase), 레구마인(legumain), 매트립타제(matriptase), 매트립타제 2, 메프린(meprin), 뉴로신(neurosin), MT-SP1, 네프릴리신(neprilysin), 플라스민(plasmin), PSA, PSMA, TACE, TMPRSS3, TMPRSS4, uPA, 칼페인(calpain), FAP 및 KLK로 이루어진 군으로부터 선택되는 융합 단백질.
- 제25항에 있어서, 프로테아제가 uPA 또는 매트립타제인 융합 단백질.
- 제1항 내지 제26항 중 어느 한 항에 있어서, 펩티드 링커는 길이가 3-50개 또는 5-20개의 아미노산인 융합 단백질.
- 제1항 내지 제27항 중 어느 한 항에 있어서, 제1 또는 제2 펩티드 링커 중 하나가 프로테아제 절단 부위를 갖지 않는 융합 단백질.
- 제1항 내지 제28항 중 어느 한 항에 있어서, 펩티드 링커가 (GlynSer) 링커이고, (GlynSer) 링커는 (Gly3Ser)n(Gly4Ser)1, (Gly3Ser)1(Gly4Ser)n, (Gly3Ser)n(Gly4Ser)n 및 (Gly4Ser)n으로 이루어진 군으로부터 선택된 아미노산 서열을 포함하고, n은 1 내지 5의 정수인 융합 단백질.
- 제1항 내지 제29항 중 어느 한 항에 있어서, 펩티드 링커가 (EAAAK)n 링커이고, n은 1 내지 5의 정수인 융합 단백질.
- 제30항에 있어서, 펩티드 링커가 아미노산 서열 EAAAKEAAAK(서열번호 38)를 포함하는 융합 단백질.
- 제1항 내지 제31항 중 어느 한 항에 있어서, 펩티드 링커가 폴리프롤린 링커(polyproline linker), 선택적으로 PPP 또는 PPPP, 또는 글리신-프롤린 링커, 선택적으로 GPPPG, GGPPPGG, GPPPPG 또는 GGPPPPGG인 융합 단백질.
- 제1항 내지 제32항 중 어느 한 항에 있어서, 펩티드 링커가 야생형 면역글로불린 힌지 영역 아미노산 서열과 비교하여 아미노산 서열 동일성이 최대 30% 차이나는 아미노산 서열을 포함하는 면역글로불린 힌지 영역 서열을 포함하는 융합 단백질.
- 제1항 내지 제33항 중 어느 한 항에 있어서, 펩티드 링커가 아미노산 서열 MSGRSANA(서열번호 28)를 포함하는 프로테아제 절단 부위를 포함하는 융합 단백질.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 제1 및 제2 폴리펩티드 중 적어도 하나가 제1 VH 폴리펩티드 및 제1 VL 폴리펩티드를 포함하고, 제1 VH 및 VL 폴리펩티드는 항체의 제1 항원 결합 도메인을 형성하고, 리간드는 제1 펩티드 링커를 통해 제1 VH 또는 VL 폴리펩티드 중 하나에 융합되고 수용체는 제2 펩티드 링커를 통해 제1 VH 또는 VL 폴리펩티드 중 다른 하나에 융합되며, 리간드-수용체 쌍은 제1 항원 결합 도메인과 이의 동족 항원의 결합을 입체적으로 방해하는 융합 단백질.
- 제35항에 있어서, 제1 및 제2 폴리펩티드가 이량체 Fc를 추가로 포함하는 융합 단백질.
- 제36항에 있어서, 이량체 Fc 영역이 이종이량체 Fc인 융합 단백질.
- 제35항 내지 제37항 중 어느 한 항에 있어서, 리간드-수용체 쌍의 리간드 또는 수용체 중 적어도 하나가 면역조절 표적에 결합할 수 있는 융합 단백질.
- 제35항 내지 제38항 중 어느 한 항에 있어서, 리간드 수용체 쌍이 면역 체크포인트의 조절, 면역 세포 활성의 조절, T 세포 수용체 신호전달의 조절, T 세포 의존성 세포독성(TDCC)의 조절, 항체 의존성 세포 식세포작용(ADCP)의 조절 및 항체 의존성 세포 세포독성(ADCC)의 조절로 이루어진 군으로부터 선택된 세포 반응에 관여하는 융합 단백질.
- 제35항 내지 제38항 중 어느 한 항에 있어서, 수용체가 야생형 수용체와 비교하여 동족 리간드에 대한 수용체의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함하는 융합 단백질.
- 제35항 내지 제40항 중 어느 한 항에 있어서, 리간드가 야생형 리간드와 비교하여 동족 수용체에 대한 리간드의 결합 친화도를 증가시키거나 감소시키는 하나 이상의 돌연변이를 포함하는 융합 단백질.
- 제35항 내지 제41항 중 어느 한 항에 있어서, 리간드-수용체 쌍이 PD1-PDL1, PD1-PDL2, CTLA4-CD80, CD28-CD80, CD28-PDL1, CD28-CD86, CTLA4-CD86, PDL1-CD80, ICOS-ICOSL, NCRSRLG1-NKp30 및 CD47-SIRPα로 이루어진 군으로부터 선택되는 융합 단백질.
- 제42항에 있어서, 리간드-수용체 쌍이 PD1-PDL1인 융합 단백질.
- 제43항에 있어서, 리간드 PD-L1이 서열번호 8에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제43항 또는 제44항에 있어서, 수용체 PD1이 서열번호 9에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제42항에 있어서, 리간드-수용체 쌍이 CTLA4-CD80인 융합 단백질.
- 제46항에 있어서, 리간드 CD80이 서열번호 25에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제42항에 있어서, 리간드-수용체 쌍이 CTLA4-CD80, PDL1-CD80 및 CD28-CD80으로 이루어진 군으로부터 선택되고, 리간드 CD80이 다음으로 이루어진 군으로부터 선택된 돌연변이를 갖는 서열번호 25에 따른 아미노산 서열을 포함하는 융합 단백질:
(a) H18Y, A26E, E35D, M47S, I61S 및 D90G; (b) E35D, M47S, N48K, I61S, K89N; (c) E35D, D46V, M47S, I61S, D90G, K93E; (d) H18Y, A26E, E35D, M47S, I61S, V68M, A71G, D90G; (e) I58S, V68S, L70S; (f) M47S, I61S 또는 (g) V22S. - 제46항 내지 제48항 중 어느 한 항에 있어서, 수용체 CTLA4가 서열번호 26에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제48항에 있어서, 리간드-수용체 쌍이 PDL1-CD80이고 PDL1이 서열번호 8에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제48항에 있어서, 리간드-수용체 쌍이 CD28-CD80이고 CD28이 서열번호 254에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제43항에 있어서, 리간드-수용체 쌍이 CD28-PDL1인 융합 단백질.
- 제52항에 있어서, CD28이 서열번호 254에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제52항 또는 제53항에 있어서, PDL1이 서열번호 8에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제42항에 있어서, 리간드-수용체 쌍이 CD47-SIRPα인 융합 단백질.
- 제55항에 있어서, SIRPα가 서열번호 255에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제55항 또는 제56항에 있어서, CD47이 서열번호 254에 따른 아미노산 서열을 포함하는 융합 단백질.
- 제35항 내지 제57항 중 어느 한 항에 있어서, 수용체 및 리간드가 제1 및 제2 폴리펩티드의 각각의 N-말단에 융합된 융합 단백질.
- 제35항 내지 제58항 중 어느 한 항에 있어서, 제1 또는 제2 펩티드 링커 중 하나가 하나 초과의 프로테아제 절단 부위를 포함하는 융합 단백질.
- 제35항 내지 제59항 중 어느 한 항에 있어서, 리간드 또는 수용체 중 하나가 하나 이상의 추가의 프로테아제 절단 부위를 포함하도록 조작되고, 리간드 또는 수용체의 하나 이상의 프로테아제 절단 부위 및 제1 또는 제2 펩티드 링커의 프로테아제 절단 부위가 동일한 프로테아제 또는 상이한 프로테아제에 의해 절단 가능한 융합 단백질.
- 제35항 내지 제60항 중 어느 한 항에 있어서, 프로테아제가 세린 프로테아제, MMP1, MMP2, MMP3, MMP7, MMP8, MMP9, MMP10, MMP11, MMP12, MMP13, MMP14, MMP15, MMP16, MMP17, MMP18(콜라게나제 4), MMP19, MMP20, MMP21, 아다말리신, 세랄리신, 아스타신, 카스파제 1, 카스파제 2, 카스파제 3, 카스파제 4, 카스파제 5, 카스파제 6, 카스파제 7, 카스파제 8, 카스파제 9, 카스파제 10, 카스파제 11, 카스파제 12, 카스파제 13, 카스파제 14, 카텝신 A, 카텝신 B, 카텝신 D, 카텝신 E, 카텝신 K, 카텝신 S, 그랜자임 B, 구아니디노벤조아타제(GB), 헵신, 엘라스타제, 레구마인, 매트립타제, 매트립타제 2, 메프린, 뉴로신, MT-SP1, 네프릴리신, 플라스민, PSA, PSMA, TACE, TMPRSS3, TMPRSS4, uPA, 칼페인, FAP 및 KLK로 이루어진 군으로부터 선택되는 융합 단백질.
- 제61항에 있어서, 프로테아제가 uPA 또는 매트립타제인 융합 단백질.
- 제35항 내지 제62항 중 어느 한 항에 있어서, 펩티드 링커는 길이가 3-50개 또는 5-20개의 아미노산인 융합 단백질.
- 제35항 내지 제63항 중 어느 한 항에 있어서, 제1 또는 제2 펩티드 링커 중 하나가 프로테아제 절단 부위를 갖지 않는 융합 단백질.
- 제35항 내지 제64항 중 어느 한 항에 있어서, 펩티드 링커가 (GlynSer) 링커이고, (GlynSer) 링커는 (Gly3Ser)n(Gly4Ser)1, (Gly3Ser)1(Gly4Ser)n, (Gly3Ser)n(Gly4Ser)n 및 (Gly4Ser)n으로 이루어진 군으로부터 선택된 아미노산 서열을 포함하고, n은 1 내지 5의 정수인 융합 단백질.
- 제35항 내지 제64항 중 어느 한 항에 있어서, 펩티드 링커가 (EAAAK)n 링커이고, n은 1 내지 5의 정수인 융합 단백질.
- 제64항에 있어서, 프로테아제 절단 부위를 갖지 않는 펩티드 링커가 아미노산 서열 EAAAKEAAAK(서열번호 38)를 포함하는 융합 단백질.
- 제51항 또는 제52항에 있어서, 펩티드 링커가 폴리프롤린 링커, 선택적으로 PPP 또는 PPPP, 또는 글리신-프롤린 링커, 선택적으로 GPPPG, GGPPPGG, GPPPPG 또는 GGPPPPGG인 융합 단백질.
- 제35항 내지 제64항 중 어느 한 항에 있어서, 펩티드 링커가 야생형 면역글로불린 힌지 영역 아미노산 서열과 비교하여 아미노산 서열 동일성이 최대 30% 차이나는 아미노산 서열을 포함하는 면역글로불린 힌지 영역 서열을 포함하는 융합 단백질.
- 제35항 내지 제69항 중 어느 한 항에 있어서, 프로테아제 절단 부위를 포함하는 펩티드 링커가 아미노산 서열 MSGRSANA(서열번호 28)를 포함하는 융합 단백질.
- 제35항 내지 제70항 중 어느 한 항에 있어서, 제1 항원 결합 도메인과 이의 동족 항원의 결합이 리간드-수용체 쌍에 융합되지 않은 모(parental) 항원 결합 도메인과 비교하여 10배 이상 감소되는 융합 단백질.
- 제35항 내지 제71항 중 어느 한 항에 있어서, 세포 환경에서 프로테아제 절단 부위의 절단이 융합 단백질로부터 리간드-수용체 쌍의 한 구성원을 방출함으로써 항원 결합 도메인이 이의 동족 항원에 결합되도록 하는 융합 단백질.
- 제35항 내지 제72항 중 어느 한 항에 있어서, 제1 항원 결합 도메인이 Fab인 융합 단백질.
- 제35항 내지 제73항 중 어느 한 항에 있어서, 제1 항원 결합 도메인이 암세포 또는 면역 세포에서 발현되는 항원에 결합하는 융합 단백질.
- 제35항 내지 제74항 중 어느 한 항에 있어서, 제1 항원 결합 도메인이 T 세포에서 발현되는 항원에 결합하는 융합 단백질.
- 제35항 내지 제74항 중 어느 한 항에 있어서, 제1 항원 결합 도메인이 종양 관련 항원(tumor-associated antigen, TAA)에 결합하는 융합 단백질.
- 제35항 내지 제74항 중 어느 한 항에 있어서, 제1 항원 결합 도메인이 TAA에 결합하고, 리간드-수용체 쌍에서 리간드 또는 수용체 중 적어도 하나가 면역조절 표적에 결합할 수 있는 융합 단백질.
- 제35항 내지 제77항 중 어느 한 항에 있어서, 제1 항원 결합 도메인이 분화 클러스터 3(Cluster of Differentiation 3, CD3), 인간 표피 성장 인자 수용체 2(Human Epidermal Growth Factor Receptor 2, HER2), 표피 성장 인자 수용체(Epidermal Growth Factor Receptor, EGFR), 메소텔린(Mesothelin, MSLN), 조직 인자(Tissue Factor, TF), 분화 클러스터 19(CD19), 티로신-단백질 키나제 Met(c-Met) 및 카드헤린 3(Cadherin 3, CDH3)으로 이루어진 군으로부터 선택된 항원에 결합하는 융합 단백질.
- 제32항 내지 제78항 중 어느 한 항에 있어서, 항체 또는 항체 단편이 제2 VH 폴리펩티드 및 제2 VL 폴리펩티드를 포함하는 제2 항원 결합 도메인을 포함하는 융합 단백질.
- 제79항에 있어서, 융합 단백질이 제2 리간드-수용체 쌍을 포함하고, 제2 리간드-수용체 쌍의 리간드는 제3 펩티드 링커를 통해 제2 VH 또는 VL 폴리펩티드 중 하나에 융합되고 제2 리간드-수용체 쌍의 수용체는 제4 펩티드 링커를 통해 제2 VH 또는 VL 폴리펩티드 중 다른 하나에 융합되고, 제3 및 제4 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하고, 리간드-수용체 쌍은 제2 항원 결합 도메인과 이의 동족 항원의 결합을 입체적으로 방해하는 융합 단백질.
- 제79항 또는 제80항에 있어서, 융합 단백질이 2개의 별개의 항원에 결합하는 융합 단백질.
- 제81항에 있어서, 하나의 항원이 T 세포에 의해 발현되는 항원이고 다른 항원이 암세포에 의해 발현되는 항원인 융합 단백질.
- 제82항에 있어서, T 세포에 의해 발현되는 항원이 CD3인 융합 단백질.
- 제83항에 있어서, (a) VH 및 VL을 포함하는 항-CD3 파라토프(paratope)를 포함하고, VH는 3개의 CDR인 HCDR1, HCDR2 및 HCDR3을 포함하고 VL은 3개의 CDR인 LCDR1, LCDR2 및 LCDR3을 포함하며,
(a) HCDR1, HCDR2 및 HCDR3은 각각 서열번호 207, 208 및 209이고, LCDR1, LCDR2 및 LCDR3은 각각 211, 212 및 214이거나;
(b) HCDR1, HCDR2 및 HCDR3은 각각 서열번호 224, 225 및 226이고, LCDR1, LCDR2 및 LCDR3은 각각 228, 229 및 230이거나;
(c) HCDR1, HCDR2 및 HCDR3은 각각 서열번호 232, 233 및 234이고, LCDR1, LCDR2 및 LCDR3은 각각 236, 237 및 238이거나;
(d) HCDR1, HCDR2 및 HCDR3은 각각 서열번호 240, 241 및 242이고, LCDR1, LCDR2 및 LCDR3은 각각 244, 245 및 246인 융합 단백질. - 제81항 내지 제84항 중 어느 한 항에 있어서, 융합 단백질이 CD3 및 HER2에 결합하는 융합 단백질.
- 제1 Fc 폴리펩티드 및 제2 Fc 폴리펩티드를 포함하는 Fc 영역, 및
면역글로불린 수퍼패밀리 수용체의 세포외 부분 및 이의 동족 리간드 또는 이의 수용체 결합 단편을 포함하는 리간드-수용체 쌍을 포함하는 융합 단백질로서,
상기 리간드는 제1 펩티드 링커를 통해 제1 Fc 폴리펩티드의 말단에 융합되고 상기 수용체는 제2 펩티드 링커를 통해 제2 Fc 폴리펩티드의 동일한 각각의 말단에 융합되고;
상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링을 허용하기에 충분한 길이이고;
상기 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하는 융합 단백질. - 생물학적 기능성 단백질, 리간드-수용체 쌍, 제1 펩티드 링커 및 제2 펩티드 링커를 포함하는 융합 단백질로서,
상기 생물학적 기능성 단백질은 적어도 제1 폴리펩티드 및 제2 폴리펩티드를 포함하고;
상기 리간드-수용체 쌍은 면역글로불린 수퍼패밀리 수용체의 세포외 부분 및 이의 동족 리간드 또는 이의 수용체 결합 단편을 포함하고;
상기 리간드는 제1 펩티드 링커를 통해 제1 폴리펩티드의 말단에 융합되고;
상기 수용체는 제2 펩티드 링커를 통해 제2 폴리펩티드의 동일한 각각의 말단에 융합되고; 상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링을 허용하기에 충분한 길이인 융합 단백질. - 제86항에 있어서, 리간드 및 수용체가 제1 및 제2 Fc 폴리펩티드의 각각의 N-말단에 융합된 융합 단백질.
- Fab 영역 및 Fc 영역, 및
면역글로불린 수퍼패밀리 수용체의 세포외 부분 및 이의 동족 리간드 또는 이의 수용체 결합 단편을 포함하는 리간드-수용체 쌍을 포함하는 융합 단백질로서,
상기 Fab 영역은 항원 결합 도메인을 형성하는 VH 폴리펩티드 및 VL 폴리펩티드를 포함하고,
상기 리간드는 제1 펩티드 링커를 통해 VH 또는 VL 폴리펩티드 중 하나의 N-말단에 융합되고 상기 수용체는 제2 펩티드 링커를 통해 VH 또는 VL 폴리펩티드 중 다른 하나의 N-말단에 융합되고;
상기 제1 및 제2 펩티드 링커는 상기 리간드와 수용체의 페어링을 허용하기에 충분한 길이이고;
상기 제1 및 제2 펩티드 링커 중 적어도 하나는 프로테아제 절단 부위를 포함하고;
상기 리간드-수용체 쌍은 항원 결합 도메인과 이의 동족 항원의 결합을 입체적으로 방해하는 융합 단백질. - 제89항에 있어서, 추가의 Fab 영역 또는 scFv를 추가로 포함하는 융합 단백질.
- 암 치료가 필요한 환자에게 충분한 양의 청구항 제1항 내지 제90항 중 어느 한 항의 융합 단백질을 투여하는 것을 포함하는, 암 치료 방법.
- 면역 반응의 조절이 필요한 환자에게 충분한 양의 청구항 제1항 내지 제90항 중 어느 한 항의 융합 단백질을 투여하는 것을 포함하는, 면역 반응의 조절 방법.
- 제92항에 있어서, 면역 반응이 면역 체크포인트의 억제, 면역 체크포인트의 자극, 면역 세포 활성화, T 세포 수용체 신호전달의 자극, T 세포 의존성 세포독성(TDCC), 항체 의존성 세포 식세포작용(ADCP) 및 항체 의존성 세포 세포독성(ADCC)의 자극으로 이루어진 군으로부터 선택되는 방법.
- 제91항 내지 제93항 중 어느 한 항에 있어서, 융합 단백질이 정맥내로 투여되는 방법.
- 제1항 내지 제90항 중 어느 한 항의 융합 단백질의 적어도 하나의 폴리펩티드를 포함하는 아미노산 서열을 암호화하는 벡터.
- 제95항에 따른 벡터를 포함하는 세포.
- 제95항에 따른 벡터, 제96항에 따른 세포, 제1항 내지 제90항 중 어느 한 항에 따른 정제된 융합 단백질 또는 이들의 조합, 및 사용 설명서를 포함하는 키트.
- 제1항 내지 제90항 중 어느 한 항에 있어서, 세포 환경에서 프로테아제 절단 부위의 절단이 융합 단백질로부터 리간드-수용체 쌍의 하나의 구성원을 방출함으로써 리간드-수용체 쌍의 다른 구성원이 세포 표면 상의 이의 동족 파트너에 결합하도록 하는 융합 단백질.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063054180P | 2020-07-20 | 2020-07-20 | |
| US63/054,180 | 2020-07-20 | ||
| US202163172626P | 2021-04-08 | 2021-04-08 | |
| US63/172,626 | 2021-04-08 | ||
| PCT/CA2021/051006 WO2022016270A1 (en) | 2020-07-20 | 2021-07-20 | Fusion proteins comprising a ligand-receptor pair and a biologically functional protein |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230042315A true KR20230042315A (ko) | 2023-03-28 |
Family
ID=79729591
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237005797A KR20230042315A (ko) | 2020-07-20 | 2021-07-20 | 리간드-수용체 쌍 및 생물학적 기능성 단백질을 포함하는 융합 단백질 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US20230331809A1 (ko) |
| EP (1) | EP4182357A1 (ko) |
| JP (1) | JP2023541771A (ko) |
| KR (1) | KR20230042315A (ko) |
| CN (1) | CN116171167A (ko) |
| AU (1) | AU2021312554A1 (ko) |
| CA (1) | CA3145387A1 (ko) |
| MX (1) | MX2023000839A (ko) |
| WO (1) | WO2022016270A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024047218A1 (en) * | 2022-09-02 | 2024-03-07 | Novimmune Sa | Reciprocally masked antibody-cytokine fusion proteins and methods of use thereof |
| WO2024082060A1 (en) * | 2022-10-19 | 2024-04-25 | Zymeworks Bc Inc. | Trivalent and trispecific antibody constructs and methods of use thereof |
| CN116574748B (zh) * | 2023-07-10 | 2023-09-12 | 昆明医科大学 | 一种用于靶向KRAS高频突变肿瘤的嵌合型nTCR-T构建方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3897851A2 (en) * | 2018-12-17 | 2021-10-27 | Revitope Limited | Twin immune cell engager |
-
2021
- 2021-07-20 KR KR1020237005797A patent/KR20230042315A/ko active Search and Examination
- 2021-07-20 MX MX2023000839A patent/MX2023000839A/es unknown
- 2021-07-20 US US18/017,319 patent/US20230331809A1/en active Pending
- 2021-07-20 WO PCT/CA2021/051006 patent/WO2022016270A1/en unknown
- 2021-07-20 EP EP21845766.1A patent/EP4182357A1/en active Pending
- 2021-07-20 AU AU2021312554A patent/AU2021312554A1/en active Pending
- 2021-07-20 CN CN202180051531.1A patent/CN116171167A/zh active Pending
- 2021-07-20 JP JP2023504005A patent/JP2023541771A/ja active Pending
- 2021-07-20 CA CA3145387A patent/CA3145387A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| EP4182357A1 (en) | 2023-05-24 |
| CN116171167A (zh) | 2023-05-26 |
| MX2023000839A (es) | 2023-04-18 |
| WO2022016270A1 (en) | 2022-01-27 |
| CA3145387A1 (en) | 2022-01-20 |
| JP2023541771A (ja) | 2023-10-04 |
| AU2021312554A1 (en) | 2023-03-09 |
| WO2022016270A9 (en) | 2023-02-02 |
| US20230331809A1 (en) | 2023-10-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11377477B2 (en) | PD-1 targeted IL-15/IL-15RALPHA fc fusion proteins and uses in combination therapies thereof | |
| KR102607909B1 (ko) | 항-cd28 조성물 | |
| EP3988577A1 (en) | Anti-cd137 antibodies | |
| US20230331809A1 (en) | Fusion proteins comprising a ligand-receptor pair and a biologically functional protein | |
| JP2022551081A (ja) | 癌処置のための多重特異性結合タンパク質 | |
| CA3147126A1 (en) | Masked il12 fusion proteins and methods of use thereof | |
| TW202233673A (zh) | 含調節免疫細胞功能之cd8抗原結合分子之融合物 | |
| US20230052369A1 (en) | Antibody constructs binding 4-1bb and tumor-associated antigens and uses thereof | |
| WO2022026939A2 (en) | Single and dual targeting ligand induced t-cell engager compositions | |
| JP2023518241A (ja) | ガイダンス及びナビゲーションコントロール(gnc)抗体様タンパク質、その製造方法及び使用方法 | |
| WO2022150792A1 (en) | Indinavir based chemical dimerization t cell engager compositions | |
| EP4240494A1 (en) | Anti-cd19 agent and b cell targeting agent combination therapy for treating b cell malignancies | |
| KR20240137058A (ko) | 면역조절 삼중특이성 t 세포 인게이저 융합 단백질 | |
| CA3226428A1 (en) | Anti-cd38 antibodies, anti-cd3 antibodies, and bispecific antibodies, and uses thereof | |
| US20230265202A1 (en) | Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof | |
| CN118715248A (zh) | 免疫调节三特异性t细胞接合器融合蛋白 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |