KR20200078537A - 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 - Google Patents
가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 Download PDFInfo
- Publication number
- KR20200078537A KR20200078537A KR1020207013475A KR20207013475A KR20200078537A KR 20200078537 A KR20200078537 A KR 20200078537A KR 1020207013475 A KR1020207013475 A KR 1020207013475A KR 20207013475 A KR20207013475 A KR 20207013475A KR 20200078537 A KR20200078537 A KR 20200078537A
- Authority
- KR
- South Korea
- Prior art keywords
- audio
- scene
- user
- streams
- location
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/165—Management of the audio stream, e.g. setting of volume, audio stream path
-
- G—PHYSICS
- G02—OPTICS
- G02B—OPTICAL ELEMENTS, SYSTEMS OR APPARATUS
- G02B27/00—Optical systems or apparatus not provided for by any of the groups G02B1/00 - G02B26/00, G02B30/00
- G02B27/01—Head-up displays
-
- G—PHYSICS
- G02—OPTICS
- G02B—OPTICAL ELEMENTS, SYSTEMS OR APPARATUS
- G02B27/00—Optical systems or apparatus not provided for by any of the groups G02B1/00 - G02B26/00, G02B30/00
- G02B27/0093—Optical systems or apparatus not provided for by any of the groups G02B1/00 - G02B26/00, G02B30/00 with means for monitoring data relating to the user, e.g. head-tracking, eye-tracking
-
- G—PHYSICS
- G02—OPTICS
- G02B—OPTICAL ELEMENTS, SYSTEMS OR APPARATUS
- G02B27/00—Optical systems or apparatus not provided for by any of the groups G02B1/00 - G02B26/00, G02B30/00
- G02B27/01—Head-up displays
- G02B27/0179—Display position adjusting means not related to the information to be displayed
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/012—Head tracking input arrangements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/167—Audio in a user interface, e.g. using voice commands for navigating, audio feedback
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L65/00—Network arrangements, protocols or services for supporting real-time applications in data packet communication
- H04L65/60—Network streaming of media packets
- H04L65/70—Media network packetisation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/20—Image signal generators
- H04N13/293—Generating mixed stereoscopic images; Generating mixed monoscopic and stereoscopic images, e.g. a stereoscopic image overlay window on a monoscopic image background
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/30—Image reproducers
- H04N13/361—Reproducing mixed stereoscopic images; Reproducing mixed monoscopic and stereoscopic images, e.g. a stereoscopic image overlay window on a monoscopic image background
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/21—Server components or server architectures
- H04N21/218—Source of audio or video content, e.g. local disk arrays
- H04N21/21805—Source of audio or video content, e.g. local disk arrays enabling multiple viewpoints, e.g. using a plurality of cameras
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/234—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs
- H04N21/2343—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving reformatting operations of video signals for distribution or compliance with end-user requests or end-user device requirements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/234—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs
- H04N21/2343—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving reformatting operations of video signals for distribution or compliance with end-user requests or end-user device requirements
- H04N21/23439—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving reformatting operations of video signals for distribution or compliance with end-user requests or end-user device requirements for generating different versions
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/439—Processing of audio elementary streams
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/439—Processing of audio elementary streams
- H04N21/4394—Processing of audio elementary streams involving operations for analysing the audio stream, e.g. detecting features or characteristics in audio streams
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/60—Network structure or processes for video distribution between server and client or between remote clients; Control signalling between clients, server and network components; Transmission of management data between server and client, e.g. sending from server to client commands for recording incoming content stream; Communication details between server and client
- H04N21/65—Transmission of management data between client and server
- H04N21/658—Transmission by the client directed to the server
- H04N21/6587—Control parameters, e.g. trick play commands, viewpoint selection
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/81—Monomedia components thereof
- H04N21/8106—Monomedia components thereof involving special audio data, e.g. different tracks for different languages
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/81—Monomedia components thereof
- H04N21/816—Monomedia components thereof involving special video data, e.g 3D video
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/033—Headphones for stereophonic communication
-
- G—PHYSICS
- G02—OPTICS
- G02B—OPTICAL ELEMENTS, SYSTEMS OR APPARATUS
- G02B27/00—Optical systems or apparatus not provided for by any of the groups G02B1/00 - G02B26/00, G02B30/00
- G02B27/01—Head-up displays
- G02B27/0179—Display position adjusting means not related to the information to be displayed
- G02B2027/0187—Display position adjusting means not related to the information to be displayed slaved to motion of at least a part of the body of the user, e.g. head, eye
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Human Computer Interaction (AREA)
- Databases & Information Systems (AREA)
- Optics & Photonics (AREA)
- General Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Computer Networks & Wireless Communication (AREA)
- Acoustics & Sound (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
- Stereophonic System (AREA)
- User Interface Of Digital Computer (AREA)
- Position Input By Displaying (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
일 예에서, 시스템(102)은 사용자로의 VR, AR, MR 또는 360도 비디오 환경 장면들의 표현을 위해 비디오 스트림들로부터의 비디오 신호들을 디코딩하도록 이루어진 적어도 하나의 미디어 비디오 디코더를 포함한다. 시스템은, 적어도 하나의 오디오 스트림(106)으로부터의 오디오 신호들(108)을 디코딩하도록 이루어진 적어도 하나의 오디오 디코더(104)를 포함한다. 시스템(102)은, 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터(110)에 적어도 기초하여, 적어도 하나의 오디오 스트림(106) 및/또는 오디오 스트림의 하나의 오디오 엘리먼트 및/또는 하나의 적응 세트를 서버(120)에 요청(112)하도록 이루어진다.
Description
도 2 내지 도 6은 본 발명의 시나리오들을 도시한다.
도 7a 내지 도 8b는 본 발명의 방법들을 도시한다.
Claims (47)
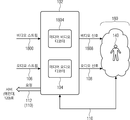
- 미디어 소비 디바이스에서 재생될 비디오 및 오디오 스트림들을 수신하도록 이루어진, 가상 현실(virtual reality; VR), 증강 현실(augmented reality; AR), 혼합 현실(mixed reality; MR), 또는 360도 비디오 환경을 위한 시스템(102)으로서,
상기 시스템(102)은,
사용자로의 VR, AR, MR 또는 360도 비디오 환경 장면들의 표현을 위해 비디오 스트림들로부터의 비디오 신호들을 디코딩하도록 이루어진 적어도 하나의 미디어 비디오 디코더, 및
적어도 하나의 오디오 스트림(106)으로부터의 오디오 신호들(108)을 디코딩하도록 이루어진 적어도 하나의 오디오 디코더(104)를 포함하며,
상기 시스템(102)은, 상기 사용자의 현재 뷰포트(viewport) 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터(110)에 적어도 기초하여, 상기 적어도 하나의 오디오 스트림(106) 및/또는 오디오 스트림의 하나의 오디오 엘리먼트 및/또는 하나의 적응 세트를 서버(120)에 요청(112)하도록 이루어지는, 시스템.
- 제1항에 있어서,
상기 서버(120)로부터 상기 적어도 하나의 오디오 스트림(106) 및/또는 오디오 스트림의 하나의 오디오 엘리먼트 및/또는 하나의 적응 세트를 획득하기 위해, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터(110)를 상기 서버(120)에 제공하도록 이루어지는, 시스템.
- 제1항 또는 제2항에 있어서,
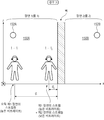
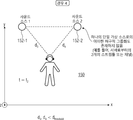
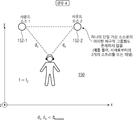
적어도 하나의 장면이 적어도 하나의 오디오 엘리먼트(152)에 연관되며,
각각의 오디오 엘리먼트는, 상기 장면 내의 상이한 사용자의 위치들 및/또는 뷰포트들 및/또는 머리 배향들 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터에 대해 상이한 오디오 스트림들이 제공되도록, 상기 오디오 엘리먼트가 가청적인 시각적 환경 내의 위치 및/또는 영역에 연관되는, 시스템.
- 제1항 내지 제3항 중 어느 한 항에 있어서,
상기 오디오 스트림의 적어도 하나의 오디오 엘리먼트 및/또는 하나의 적응 세트가 상기 장면 내의 현재 사용자의 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치에 대해 재생될지 여부를 판단하도록 이루어지며,
상기 시스템은 현재 사용자의 가상 위치에서 상기 적어도 하나의 오디오 엘리먼트를 요청 및/또는 수신하도록 이루어지는, 시스템.
- 제1항 내지 제4항 중 어느 한 항에 있어서,
상기 시스템은, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터(110)에 적어도 기초하여, 상기 오디오 스트림의 적어도 하나의 오디오 엘리먼트(152) 및/또는 하나의 적응 세트가 관련있게 될지 그리고/또는 가청적이게 될지를 예측적으로(predictively) 판단하도록 이루어지고,
상기 시스템은, 상기 장면 내의 예측된 사용자의 움직임 및/또는 상호작용 이전에 특정한 사용자의 가상 위치에서 상기 적어도 하나의 오디오 엘리먼트 및/또는 오디오 스트림 및/또는 적응 세트를 요청 및/또는 수신하도록 이루어지며,
상기 시스템은, 수신될 경우, 상기 장면 내의 상기 사용자의 움직임 및/또는 상호작용 이후 상기 특정한 사용자의 가상 위치에서 상기 적어도 하나의 오디오 엘리먼트 및/또는 오디오 스트림을 재생하도록 이루어지는, 시스템.
- 제1항 내지 제5항 중 어느 한 항에 있어서,
상기 장면 내의 상기 사용자의 움직임 및/또는 상호작용 이전에 상기 사용자의 가상 위치에서 더 낮은 비트레이트 및/또는 품질 레벨로 상기 적어도 하나의 오디오 엘리먼트(152)를 요청 및/또는 수신하도록 이루어지며,
상기 시스템은, 상기 장면 내의 상기 사용자의 움직임 및/또는 상호작용 이후 상기 사용자의 가상 위치에서 더 높은 비트레이트 및/또는 품질 레벨로 상기 적어도 하나의 오디오 엘리먼트를 요청 및/또는 수신하도록 이루어지는, 시스템.
- 제1항 내지 제6항 중 어느 한 항에 있어서,
상기 적어도 하나의 오디오 엘리먼트(152)는 적어도 하나의 장면에 연관되고, 각각의 오디오 엘리먼트는 상기 장면에 연관된 시각적 환경 내의 위치 및/또는 영역에 연관되며,
상기 시스템은, 상기 사용자로부터 더 멀리있는 오디오 엘리먼트들보다 상기 사용자에 더 가까운 오디오 엘리먼트들에 대해 더 높은 비트레이트 및/또는 품질로 스트림들을 요청 및/또는 수신하도록 이루어지는, 시스템.
- 제1항 내지 제7항 중 어느 한 항에 있어서,
상기 적어도 하나의 오디오 엘리먼트(152)는 적어도 하나의 장면에 연관되고, 상기 적어도 하나의 오디오 엘리먼트는 상기 장면에 연관된 시각적 환경 내의 위치 및/또는 영역에 연관되며,
상기 시스템은, 상기 장면 내의 각각의 사용자의 가상 위치에서의 오디오 엘리먼트들의 관련성 및/또는 가청성 레벨에 기초하여, 상기 오디오 엘리먼트들에 대해 상이한 비트레이트들 및/또는 품질 레벨들로 상이한 스트림들을 요청하도록 이루어지고,
상기 시스템은,
상기 현재 사용자의 가상 위치에서 더 관련있고 그리고/또는 더 가청적인 오디오 엘리먼트들에 대해 더 높은 비트레이트 및/또는 품질 레벨로 오디오 스트림을 요청하고/하거나
상기 현재 사용자의 가상 위치에서 덜 관련있고 덜 가청적인 오디오 엘리먼트들에 대해 더 낮은 비트레이트 및/또는 품질 레벨로 오디오 스트림을
요청하도록 이루어지는, 시스템.
- 제1항 내지 제8항 중 어느 한 항에 있어서,
상기 적어도 하나의 오디오 엘리먼트(152)는 장면에 연관되고, 각각의 오디오 엘리먼트는 상기 장면에 연관된 시각적 환경 내의 위치 및/또는 영역에 연관되며,
상기 시스템은, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터(110)를 상기 서버에 주기적으로 전송하여,
제1 위치에 대해, 더 높은 비트레이트 및/또는 품질의 스트림이 상기 서버로부터 제공되고, 그리고
제2 위치에 대해, 더 낮은 비트레이트 및/또는 품질의 스트림이 상기 서버로부터 제공되도록 이루어지고,
상기 제1 위치는 상기 제2 위치보다 상기 적어도 하나의 오디오 엘리먼트(152)에 더 가까운 것인, 시스템.
- 제1항 내지 제9항 중 어느 한 항에 있어서,
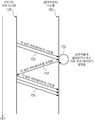
복수의 장면들(150A, 150B)이 인접한 및/또는 이웃한 환경들과 같은 복수의 시각적 환경들에 대해 정의되어,
제1의 현재 장면에 연관된 제1 스트림들이 제공되고, 제2의 추가적인 장면으로의 사용자의 전환의 경우에는, 상기 제1 장면에 연관된 스트림들 및 상기 제2 장면에 연관된 제2 스트림들 둘 모두가 제공되는, 시스템.
- 제1항 내지 제10항 중 어느 한 항에 있어서,
복수의 장면들(150A, 150B)이 제1 시각적 환경 및 제2 시각적 환경에 대해 정의되고, 상기 제1 환경 및 상기 제2 환경은 인접한 및/또는 이웃한 환경들이고,
상기 사용자의 위치 또는 가상 위치가 상기 제1 장면에 연관된 제1 환경에 있는 경우 상기 제1 장면에 연관된 제1 스트림들이 상기 제1 장면의 재생을 위해 상기 서버로부터 제공되고,
상기 사용자의 위치 또는 가상 위치가 상기 제2 장면에 연관된 제2 환경에 있는 경우 상기 제2 장면에 연관된 제2 스트림들이 상기 제2 장면의 재생을 위해 상기 서버로부터 제공되며,
상기 사용자의 위치 또는 가상 위치가 상기 제1 장면과 상기 제2 장면 사이의 전환 위치에 있는 경우 상기 제1 장면에 연관된 제1 스트림들 및 상기 제2 장면에 연관된 제2 스트림들 둘 모두가 제공되는, 시스템.
- 제1항 내지 제11항 중 어느 한 항에 있어서,
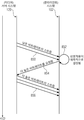
복수의 장면들(150A, 150B)이 인접한 및/또는 이웃한 환경들인 제1 시각적 환경 및 제2 시각적 환경에 대해 정의되며,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제1 환경에 있는 경우 상기 제1 환경에 연관된 제1 장면(150A)의 재생을 위해 상기 제1 장면에 연관된 제1 스트림들을 요청 및/또는 수신하도록 이루어지고,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제2 환경에 있는 경우 상기 제2 환경에 연관된 제2 장면(150B)의 재생을 위해 상기 제2 장면에 연관된 제2 스트림들을 요청 및/또는 수신하도록 이루어지며,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제1 환경과 상기 제2 환경 사이의 전환 위치(150AB)에 있는 경우 상기 제1 장면에 연관된 제1 스트림들 및 상기 제2 장면에 연관된 제2 스트림들 둘 모두를 요청 및/또는 수신하도록 이루어지는, 시스템.
- 제10항 내지 제12항 중 어느 한 항에 있어서,
상기 사용자가 상기 제1 장면에 연관된 제1 환경에 있는 경우 상기 제1 장면에 연관된 제1 스트림들은 더 높은 비트레이트 및/또는 품질로 획득되는 반면,
상기 사용자가 상기 제1 장면으로부터 상기 제2 장면으로의 전환 위치의 시작부에 있는 경우 상기 제2 환경에 연관된 상기 제2 장면에 연관된 제2 스트림들은 더 낮은 비트레이트 및/또는 품질로 획득되고,
상기 사용자가 상기 제1 장면으로부터 상기 제2 장면으로의 전환 위치의 끝에 있는 경우, 상기 제1 장면에 연관된 제1 스트림들은 더 낮은 비트레이트 및/또는 품질로 획득되고, 상기 제2 장면에 연관된 제2 스트림들은 더 높은 비트레이트 및/또는 품질로 획득되며,
상기 더 낮은 비트레이트 및/또는 품질은 상기 더 높은 비트레이트 및/또는 품질보다 낮은 것인, 시스템.
- 제1항 내지 제13항 중 어느 한 항에 있어서,
복수의 장면들(150A, 150B)이 인접한 및/또는 이웃한 환경들과 같은 복수의 환경들에 대해 정의되어,
상기 시스템은, 제1의 현재 환경에 연관된 제1 현재 장면에 연관된 스트림들을 획득하도록 이루어지고,
상기 장면의 경계로부터의 상기 사용자의 위치 또는 가상 위치의 거리가 미리 결정된 임계치 미만인 경우, 상기 시스템은, 제2 장면에 연관된 제2의 인접한 및/또는 이웃한 환경에 연관된 오디오 스트림들을 추가로 획득하는, 시스템.
- 제1항 내지 제14항 중 어느 한 항에 있어서,
복수의 장면들(150A, 150B)이 복수의 시각적 환경들에 대해 정의되어,
상기 시스템은, 더 높은 비트레이트 및/또는 품질로 현재 장면에 연관된 스트림들을 그리고 더 낮은 비트레이트 및/또는 품질로 제2 장면에 연관된 스트림들을 요청 및/또는 획득하며,
상기 더 낮은 비트레이트 및/또는 품질은 상기 더 높은 비트레이트 및/또는 품질보다 낮은 것인, 시스템.
- 제1항 내지 제15항 중 어느 한 항에 있어서,
복수의 N개의 오디오 엘리먼트들이 정의되며,
상기 오디오 엘리먼트들의 위치 또는 영역에 대한 상기 사용자의 거리가 미리 결정된 임계치보다 큰 경우, 상기 N개의 오디오 엘리먼트들은 상기 N개의 오디오 엘리먼트들의 위치 또는 영역에 가까운 위치 또는 영역에 연관된 더 작은 수 M개의 오디오 엘리먼트들(M<N)을 획득하도록 프로세싱되어,
상기 N개의 오디오 엘리먼트들의 위치 또는 영역에 대한 상기 사용자의 거리가 미리 결정된 임계치보다 작은 경우 상기 N개의 오디오 엘리먼트들에 연관된 적어도 하나의 오디오 스트림이 상기 시스템에 제공되거나, 또는
상기 N개의 오디오 엘리먼트들의 위치 또는 영역에 대한 상기 사용자의 거리가 미리 결정된 임계치보다 큰 경우 상기 M개의 오디오 엘리먼트들에 연관된 적어도 하나의 오디오 스트림이 상기 시스템에 제공되는, 시스템.
- 제1항 내지 제16항 중 어느 한 항에 있어서,
적어도 하나의 시각적 환경 장면은 복수의 N개의 오디오 엘리먼트들(N>=2) 중 적어도 하나에 연관되고, 각각의 오디오 엘리먼트는 시각적 환경 내의 위치 및/또는 영역에 연관되며,
적어도, 상기 복수의 N개의 오디오 엘리먼트들 중 적어도 하나는 높은 비트레이트 및/또는 품질 레벨로 적어도 하나의 표현에서 제공되고,
적어도, 상기 복수의 N개의 오디오 엘리먼트들 중 적어도 하나는 낮은 비트레이트 및/또는 품질 레벨로 적어도 하나의 표현에서 제공되고, 상기 적어도 하나의 표현은, 상기 N개의 오디오 엘리먼트들의 위치 또는 영역에 가까운 위치 또는 영역에 연관된 더 작은 수 M개의 오디오 엘리먼트들(M<N)을 획득하도록 상기 N개의 오디오 엘리먼트들을 프로세싱함으로써 획득되고,
상기 시스템은, 상기 오디오 엘리먼트들이 상기 장면 내의 현재 사용자의 가상 위치에서 더 관련있고 그리고/또는 더 가청적인 경우 상기 오디오 엘리먼트들에 대해 더 높은 비트레이트 및/또는 품질 레벨로 상기 표현을 요청하도록 이루어지며,
상기 시스템은, 상기 오디오 엘리먼트들이 상기 장면 내의 현재 사용자의 가상 위치에서 덜 관련있고 그리고/또는 덜 가청적인 경우 상기 오디오 엘리먼트들에 대해 더 낮은 비트레이트 및/또는 품질 레벨로 상기 표현을 요청하도록 이루어지는, 시스템.
- 제16항 또는 제17항에 있어서,
상기 사용자의 거리 및/또는 관련성 및/또는 가청성 레벨 및/또는 각도 배향이 미리 결정된 임계치보다 낮은 경우, 상이한 스트림들이 상이한 오디오 엘리먼트들에 대해 획득되는, 시스템.
- 제1항 내지 제18항 중 어느 한 항에 있어서,
상기 시스템은, 상기 장면 내의 상기 사용자의 배향 및/또는 사용자의 움직임 방향 및/또는 사용자의 상호작용들에 기초하여 스트림들을 요청 및/또는 획득하도록 이루어지는, 시스템.
- 제1항 내지 제19항 중 어느 한 항에 있어서,
상기 뷰포트는 위치 및/또는 가상 위치 및/또는 움직임 데이터 및/또는 머리에 연관되는, 시스템.
- 제1항 내지 제20항 중 어느 한 항에 있어서,
상이한 오디오 엘리먼트들이 상이한 뷰포트들에서 제공되며,
상기 시스템은, 하나의 제1 오디오 엘리먼트(S1)가 뷰포트(160-1) 내에 있는 경우, 상기 뷰포트 내에 있지 않은 제2 오디오 엘리먼트(S2)보다 더 높은 비트레이트로 상기 제1 오디오 엘리먼트를 요청 및/또는 수신하도록 이루어지는, 시스템.
- 제1항 내지 제21항 중 어느 한 항에 있어서,
제1 오디오 스트림들 및 제2 오디오 스트림들을 요청 및/또는 수신하도록 이루어지며,
상기 제1 오디오 스트림들 내의 제1 오디오 엘리먼트들은 상기 제2 오디오 스트림들 내의 제2 오디오 엘리먼트들보다 더 관련있고 그리고/또는 더 가청적이고,
상기 제1 오디오 스트림들은 상기 제2 오디오 스트림들의 비트레이트 및/또는 품질보다 더 높은 비트레이트 및/또는 품질로 요청 및/또는 수신되는, 시스템.
- 제1항 내지 제22항 중 어느 한 항에 있어서,
적어도 2개의 시각적 환경 장면들이 정의되며,
적어도 하나의 제1 및 제2 오디오 엘리먼트들은 제1 시각적 환경에 연관된 제1 장면에 연관되고, 적어도 하나의 제3 오디오 엘리먼트는 제2 시각적 환경에 연관된 제2 장면에 연관되고,
상기 시스템은 상기 적어도 하나의 제2 오디오 엘리먼트가 상기 제2 시각적 환경 장면과 부가적으로 연관된다는 것을 설명하는 메타데이터를 획득하도록 이루어지고,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제1 시각적 환경에 있는 경우 상기 적어도 제1 및 제2 오디오 엘리먼트들을 요청 및/또는 수신하도록 이루어지고,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제2 시각적 환경 장면에 있는 경우 상기 적어도 제2 및 제3 오디오 엘리먼트들을 요청 및/또는 수신하도록 이루어지며,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제1 시각적 환경 장면과 상기 제2 시각적 환경 장면 사이의 전환에 있는 경우 상기 적어도 제1 및 제2 및 제3 오디오 엘리먼트들을 요청 및/또는 수신하도록 이루어지는, 시스템.
- 제23항에 있어서,
상기 적어도 하나의 제1 오디오 엘리먼트는 적어도 하나의 오디오 스트림 및/또는 적응 세트에서 제공되고, 상기 적어도 하나의 제2 오디오 엘리먼트는 적어도 하나의 제2 오디오 스트림 및/또는 적응 세트에서 제공되며, 상기 적어도 하나의 제3 오디오 엘리먼트는 적어도 하나의 제3 오디오 스트림 및/또는 적응 세트에서 제공되고,
상기 적어도 제1 시각적 환경 장면은 상기 적어도 하나의 제1 및 제2 오디오 스트림들 및/또는 적응 세트들을 요구하는 완전한 장면으로서 메타데이터에 의해 설명되고, 상기 제2 시각적 환경 장면은 상기 적어도 제1 시각적 환경 장면과 연관된 상기 적어도 하나의 제3 오디오 스트림 및/또는 적응 세트 및 상기 적어도 하나의 제2 오디오 스트림 및/또는 적응 세트들을 요구하는 불완전한 장면으로서 메타데이터에 의해 설명되며,
상기 시스템은, 상기 사용자의 가상 위치가 상기 제2 시각적 환경에 있는 경우, 상기 제1 시각적 환경에 속하는 상기 제2 오디오 스트림 및 상기 제2 시각적 환경과 연관된 상기 제3 오디오 스트림을 새로운 단일 스트림으로 병합하는 것을 허용하도록 상기 메타데이터를 조작하도록 이루어진 메타데이터 프로세서를 포함하는, 시스템.
- 제1항 내지 제24항 중 어느 한 항에 있어서,
상기 시스템은, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터에 기초하여, 상기 적어도 하나의 오디오 디코더 이전에 적어도 하나의 오디오 스트림에서 메타데이터를 조작하도록 이루어진 메타데이터 프로세서를 포함하는, 시스템.
- 제25항에 있어서,
상기 메타데이터 프로세서는, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터에 기초하여, 상기 적어도 하나의 오디오 디코더 이전에 적어도 하나의 오디오 스트림에서 적어도 하나의 오디오 엘리먼트를 인에이블링 및/또는 디스에이블링시키도록 이루어지며,
상기 메타데이터 프로세서는, 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터의 결과로서 상기 오디오 엘리먼트가 더 이상 재생되지 않을 것이라고 상기 시스템이 판단하는 경우, 상기 적어도 하나의 오디오 디코더 이전에 상기 적어도 하나의 오디오 스트림에서 상기 적어도 하나의 오디오 엘리먼트를 디스에이블링시키도록 이루어지고,
상기 메타데이터 프로세서는, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터의 결과로서 상기 오디오 엘리먼트가 재생될 것이라고 상기 시스템이 판단하는 경우, 상기 적어도 하나의 오디오 디코더 이전에 상기 적어도 하나의 오디오 스트림에서 상기 적어도 하나의 오디오 엘리먼트를 인에이블링시키도록 이루어지는, 시스템.
- 제1항 내지 제26항 중 어느 한 항에 있어서,
상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치에 기초하여 선택된 오디오 엘리먼트들의 디코딩을 디스에이블링시키도록 이루어지는, 시스템.
- 제1항 내지 제27항 중 어느 한 항에 있어서,
현재 오디오 장면에 연관된 적어도 하나의 제1 오디오 스트림을 이웃한, 인접한 및/또는 미래의 오디오 장면에 연관된 적어도 하나의 스트림에 병합하도록 이루어지는, 시스템.
- 제1항 내지 제28항 중 어느 한 항에 있어서,
상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터에 대한 상기 통계 또는 집계된 데이터에 연관된 요청을 상기 서버에 송신하기 위해, 상기 통계 또는 집계된 데이터를 획득 및/또는 수집하도록 이루어지는, 시스템.
- 제1항 내지 제29항 중 어느 한 항에 있어서,
적어도 하나의 스트림에 연관된 메타데이터에 기초하여 그리고 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터에 기초하여 상기 적어도 하나의 스트림의 디코딩 및/또는 재생을 비활성화시키도록 이루어지는, 시스템.
- 제1항 내지 제30항 중 어느 한 항에 있어서,
상기 사용자의 현재 또는 추정된 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터에 적어도 기초하여, 선택된 오디오 스트림들의 그룹과 연관된 메타데이터를 조작해서,
재생될 오디오 장면을 구성(compose)하는 오디오 엘리먼트들을 선택하고 그리고/또는 인에이블링시키고 그리고/또는 활성화시키고; 그리고/또는
모든 선택된 오디오 스트림들의 단일 오디오 스트림으로의 병합을 가능하게 하도록 추가로 이루어지는, 시스템.
- 제1항 내지 제31항 중 어느 한 항에 있어서,
상이한 장면들에 연관된 이웃한 및/또는 인접한 환경들의 경계들로부터의 상기 사용자의 위치의 거리 또는 현재 환경 내의 상기 사용자의 위치에 연관된 다른 메트릭들 또는 미래의 환경에 대한 예측들에 기초하여 상기 서버로의 적어도 하나의 스트림의 요청을 제어하도록 이루어지는, 시스템.
- 제1항 내지 제32항 중 어느 한 항에 있어서,
각각의 오디오 엘리먼트 또는 오디오 오브젝트에 대한 정보가 서버 시스템(120)으로부터 제공되며,
상기 정보는 사운드 장면 또는 오디오 엘리먼트들이 활성인 위치들에 관한 설명 정보를 포함하는, 시스템.
- 제1항 내지 제33항 중 어느 한 항에 있어서,
현재 또는 미래의 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 및/또는 사용자의 선택에 기초하여, 하나의 장면을 재생하는 것과 적어도 2개의 장면들을 구성(compose)하거나 믹싱(mix)하거나 다중화(mux)하거나 중첩시키거나 결합시키는 것 사이에서 선택하도록 이루어지며,
상기 2개의 장면들은 상이한 이웃한 및/또는 인접한 환경들에 연관되는, 시스템.
- 제1항 내지 제34항 중 어느 한 항에 있어서,
적어도 적응 세트들을 생성 또는 사용하여,
복수의 적응 세트들이 하나의 오디오 장면과 연관되고; 그리고/또는
각각의 적응 세트를 하나의 뷰포인트, 또는 상기 하나의 오디오 장면에 관련시키는 부가적인 정보가 제공되며; 그리고/또는
- 상기 하나의 오디오 장면의 경계들에 관한 정보 및/또는,
- 하나의 적응 세트와 하나의 오디오 장면(예를 들어, 상기 오디오 장면은 3개의 적응 세트들로 캡슐화되는 3개의 스트림들로 인코딩됨) 사이의 관계에 관한 정보 및/또는,
- 상기 오디오 장면의 경계들과 상기 복수의 적응 세트들 사이의 연결에 관한 정보를 포함할 수 있는 부가적인 정보가 제공되도록 이루어지는, 시스템.
- 제1항 내지 제35항 중 어느 한 항에 있어서,
이웃한 또는 인접한 환경에 연관된 장면에 대한 스트림을 수신하고;
2개의 환경들 사이의 경계의 전환의 검출 시에 상기 이웃한 또는 인접한 환경에 대한 스트림을 디코딩 및/또는 재생하는 것을 시작하도록 이루어지는,시스템.
- 미디어 소비 디바이스에서 재생될 비디오 및/또는 오디오 스트림들을 전달하도록 이루어진 클라이언트 및 서버로서 동작하도록 이루어진, 제1항 내지 제36항 중 어느 한 항의 시스템을 포함하는, 시스템.
- 제1항 내지 제37항 중 어느 한 항에 있어서,
상기 시스템은,
적어도 하나의 제1 오디오 장면과 연관된 적어도 하나의 오디오 스트림을 포함하는 적어도 하나의 제1 적응 세트를 요청 및/또는 수신하고;
상기 적어도 하나의 제1 오디오 장면을 포함하는 적어도 2개의 오디오 장면들과 연관된 적어도 하나의 제2 오디오 스트림을 포함하는 적어도 하나의 제2 적응 세트를 요청 및/또는 수신하며; 그리고
상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터에 관해 이용가능한 메타데이터, 및/또는 상기 적어도 하나의 제1 적응 세트와 상기 적어도 하나의 제1 오디오 장면의 연관 및/또는 상기 적어도 하나의 제2 적응 세트와 상기 적어도 하나의 제1 오디오 장면의 연관을 설명하는 정보에 기초하여, 상기 적어도 하나의 제1 오디오 스트림과 상기 적어도 하나의 제2 오디오 스트림을 디코딩될 새로운 오디오 스트림으로 병합하는 것을 가능하게 하도록 추가로 이루어지는, 시스템.
- 제1항 내지 제38항 중 어느 한 항에 있어서,
상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터에 관한 정보, 및/또는 상기 사용자의 액션들에 의해 트리거링된 변화들을 특성화하는 임의의 정보를 수신하고;
적어도 하나의 장면 및/또는 뷰포인트 및/또는 뷰포트 및/또는 위치 및/또는 가상 위치 및/또는 움직임 데이터 및/또는 배향에 대한 적어도 하나의 적응 세트의 연관을 설명하는 정보 및 적응 세트들의 이용가능성에 관한 정보를 수신하도록 이루어지는, 시스템.
- 제1항 내지 제39항 중 어느 한 항에 있어서,
적어도 하나의 스트림에 임베딩(embed)된 적어도 하나의 오디오 장면으로부터의 적어도 하나의 오디오 엘리먼트 및 적어도 하나의 부가적인 스트림에 임베딩된 적어도 하나의 부가적인 오디오 장면으로부터의 적어도 하나의 부가적인 오디오 엘리먼트가 재생될지를 판단하고;
긍정적인 판단의 경우, 상기 적어도 하나의 오디오 장면의 적어도 하나의 스트림에 상기 부가적인 오디오 장면의 적어도 하나의 부가적인 스트림을 병합하거나 구성(compose)하거나 다중화하거나 중첩시키거나 결합시키는 동작을 야기하도록 이루어지는, 시스템.
- 제1항 내지 제40항 중 어느 한 항에 있어서,
재생될 것으로 판단되는 오디오 장면을 조립하는 오디오 엘리먼트들을 선택하고 그리고/또는 인에이블링시키고 그리고/또는 활성화시키고 모든 선택된 오디오 스트림들의 단일 오디오 스트림으로의 병합을 가능하게 하기 위해, 상기 사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터에 적어도 기초하여, 선택된 오디오 스트림들과 연관된 오디오 메타데이터를 조작하도록 이루어지는, 시스템.
- 가상 현실(VR), 증강 현실(AR), 혼합 현실(MR), 또는 360도 비디오 환경을 위해 클라이언트에 오디오 및 비디오 스트림들을 전달하기 위한 서버(120)로서,
상기 비디오 및 오디오 스트림들은 미디어 소비 디바이스에서 재생되고,
상기 서버(120)는, 시각적 환경을 설명하기 위한 비디오 스트림들을 인코딩하기 위한 인코더 및/또는 상기 비디오 스트림들을 저장하기 위한 저장소를 포함하고, 상기 시각적 환경은 오디오 장면에 연관되고;
상기 서버는, 상기 클라이언트에 전달될 복수의 스트림들 및/또는 오디오 엘리먼트들 및/또는 적응 세트들을 인코딩하기 위한 인코더 및/또는 상기 복수의 스트림들 및/또는 오디오 엘리먼트들 및/또는 적응 세트들을 저장하기 위한 저장소를 더 포함하고, 상기 스트림들 및/또는 오디오 엘리먼트들 및/또는 적응 세트들은 적어도 하나의 오디오 장면에 연관되고,
상기 서버는,
상기 클라이언트로부터의 요청에 기초하여, 환경에 연관된 비디오 스트림을 선택 및 전달하고;
사용자의 현재 뷰포트 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 상호작용 메타데이터 및/또는 가상 위치 데이터에, 그리고 상기 환경에 연관된 오디오 장면에 적어도 연관된 상기 클라이언트로부터의 요청에 기초하여 오디오 스트림 및/또는 오디오 엘리먼트 및/또는 적응 세트를 선택하며;
상기 오디오 스트림을 상기 클라이언트에 전달하도록 이루어지는, 서버.
- 제42항에 있어서,
상기 스트림들은 적응 세트들로 캡슐화되며, 각각의 적응 세트는 동일한 오디오 콘텐츠의 상이한 비트레이트 및/또는 품질의 상이한 표현들에 연관된 복수의 스트림들을 포함하고,
선택된 적응 세트는 상기 클라이언트로부터의 요청에 기초하여 선택되는, 서버.
- 클라이언트 및 서버로서 동작하는 제1항 내지 제41항 중 어느 한 항의 시스템을 포함하는, 시스템.
- 제44항에 있어서,
제42항 또는 제43항의 서버를 포함하는, 시스템.
- 미디어 소비 디바이스에서 재생될 비디오 및/또는 오디오 스트림들을 수신하도록 이루어진, 가상 현실(VR), 증강 현실(AR), 혼합 현실(MR), 또는 360도 비디오 환경을 위한 방법으로서,
사용자로의 VR, AR, MR 또는 360도 비디오 환경 장면들의 표현을 위해 비디오 스트림들로부터의 비디오 신호들을 디코딩하는 단계, 및
오디오 스트림들로부터의 오디오 신호들을 디코딩하는 단계,
상기 사용자의 현재 뷰포트 및/또는 위치 데이터 및/또는 머리 배향 및/또는 움직임 데이터 및/또는 메타데이터 및/또는 가상 위치 데이터 및/또는 메타데이터에 기초하여 적어도 하나의 오디오 스트림을, 서버에 요청하고 그리고/또는 상기 서버로부터 획득하는 단계를 포함하는, 방법.
- 프로세서에 의해 실행될 경우, 상기 프로세서로 하여금 제46항의 방법을 수행하게 하는 명령들을 포함하는, 컴퓨터 프로그램.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020237027561A KR102707356B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP17196259 | 2017-10-12 | ||
| EP17196259.0 | 2017-10-12 | ||
| PCT/EP2018/077770 WO2019072984A1 (en) | 2017-10-12 | 2018-10-11 | AUDIO DIFFUSION OPTIMIZATION FOR VIRTUAL REALITY APPLICATIONS |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237027561A Division KR102707356B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200078537A true KR20200078537A (ko) | 2020-07-01 |
| KR102568373B1 KR102568373B1 (ko) | 2023-08-18 |
Family
ID=60191107
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237027561A Active KR102707356B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
| KR1020247030446A Active KR102774081B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
| KR1020257005914A Pending KR20250033317A (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
| KR1020207013475A Active KR102568373B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
Family Applications Before (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237027561A Active KR102707356B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
| KR1020247030446A Active KR102774081B1 (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
| KR1020257005914A Pending KR20250033317A (ko) | 2017-10-12 | 2018-10-11 | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 |
Country Status (18)
| Country | Link |
|---|---|
| US (2) | US11354084B2 (ko) |
| EP (2) | EP4329319A3 (ko) |
| JP (3) | JP7295851B2 (ko) |
| KR (4) | KR102707356B1 (ko) |
| CN (5) | CN116193213A (ko) |
| AR (6) | AR113357A1 (ko) |
| AU (2) | AU2018348762B2 (ko) |
| BR (1) | BR112020008073A2 (ko) |
| CA (6) | CA3230205A1 (ko) |
| ES (1) | ES2970490T3 (ko) |
| MX (6) | MX2020003450A (ko) |
| MY (1) | MY205925A (ko) |
| PL (1) | PL3695613T3 (ko) |
| RU (2) | RU2765569C1 (ko) |
| SG (2) | SG10202106080XA (ko) |
| TW (1) | TWI713911B (ko) |
| WO (1) | WO2019072984A1 (ko) |
| ZA (5) | ZA202002064B (ko) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022256828A1 (en) * | 2021-06-02 | 2022-12-08 | Tencent America LLC | Adaptive audio delivery and rendering |
| KR20230013629A (ko) * | 2021-07-19 | 2023-01-26 | 가우디오랩 주식회사 | 멀티-뷰 환경에 있어서 오디오 장면(audio scene)을 전환하는 방법 및 이를 위한 장치 |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10242486B2 (en) * | 2017-04-17 | 2019-03-26 | Intel Corporation | Augmented reality and virtual reality feedback enhancement system, apparatus and method |
| US11232805B2 (en) | 2018-02-22 | 2022-01-25 | Dolby International Ab | Method and apparatus for processing of auxiliary media streams embedded in a MPEGH 3D audio stream |
| US11558708B2 (en) * | 2018-07-13 | 2023-01-17 | Nokia Technologies Oy | Multi-viewpoint multi-user audio user experience |
| CN109151565B (zh) * | 2018-09-04 | 2019-12-20 | 北京达佳互联信息技术有限公司 | 播放语音的方法、装置、电子设备及存储介质 |
| JP2020137044A (ja) * | 2019-02-25 | 2020-08-31 | ソニーセミコンダクタソリューションズ株式会社 | 音声信号処理装置 |
| US11211073B2 (en) * | 2019-04-22 | 2021-12-28 | Sony Corporation | Display control of different verbatim text of vocal deliverance of performer-of-interest in a live event |
| US11429340B2 (en) * | 2019-07-03 | 2022-08-30 | Qualcomm Incorporated | Audio capture and rendering for extended reality experiences |
| US11432097B2 (en) | 2019-07-03 | 2022-08-30 | Qualcomm Incorporated | User interface for controlling audio rendering for extended reality experiences |
| US20210006976A1 (en) * | 2019-07-03 | 2021-01-07 | Qualcomm Incorporated | Privacy restrictions for audio rendering |
| CN111246225B (zh) * | 2019-12-25 | 2022-02-08 | 北京达佳互联信息技术有限公司 | 信息交互方法、装置、电子设备及计算机可读存储介质 |
| CN113585389A (zh) * | 2020-05-01 | 2021-11-02 | 迪尔公司 | 提供机具命令引导的作业车辆磁流变流体操纵杆系统 |
| JP7371595B2 (ja) * | 2020-09-15 | 2023-10-31 | 横河電機株式会社 | 装置、システム、方法およびプログラム |
| GB2599359A (en) | 2020-09-23 | 2022-04-06 | Nokia Technologies Oy | Spatial audio rendering |
| US12010496B2 (en) * | 2020-09-25 | 2024-06-11 | Apple Inc. | Method and system for performing audio ducking for headsets |
| EP4060997A1 (en) * | 2021-03-17 | 2022-09-21 | Koninklijke Philips N.V. | Pre-processing immersive video |
| US11914157B2 (en) | 2021-03-29 | 2024-02-27 | International Business Machines Corporation | Adjustable air columns for head mounted displays |
| US11710491B2 (en) * | 2021-04-20 | 2023-07-25 | Tencent America LLC | Method and apparatus for space of interest of audio scene |
| CN113660347B (zh) * | 2021-08-31 | 2024-05-07 | Oppo广东移动通信有限公司 | 数据处理方法、装置、电子设备和可读存储介质 |
| US20230086248A1 (en) * | 2021-09-21 | 2023-03-23 | Meta Platforms Technologies, Llc | Visual navigation elements for artificial reality environments |
| US11983214B2 (en) * | 2021-11-05 | 2024-05-14 | Tencent America LLC | Reuse of redundant assets with client query |
| US20230260537A1 (en) * | 2022-02-16 | 2023-08-17 | Google Llc | Single Vector Digital Voice Accelerometer |
| US20230394755A1 (en) * | 2022-06-02 | 2023-12-07 | Apple Inc. | Displaying a Visual Representation of Audible Data Based on a Region of Interest |
| US12137335B2 (en) * | 2022-08-19 | 2024-11-05 | Dzco Inc | Method for navigating multidimensional space using sound |
| KR102732148B1 (ko) * | 2022-10-31 | 2024-11-20 | 한국전자통신연구원 | 확대/축소 가능한 스테레오 360vr 영상 제공 방법, 장치, 및 시스템 |
| CN116709162B (zh) * | 2023-08-09 | 2023-11-21 | 腾讯科技(深圳)有限公司 | 音频处理方法及相关设备 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020103554A1 (en) * | 2001-01-29 | 2002-08-01 | Hewlett-Packard Company | Interactive audio system |
| US20100040238A1 (en) * | 2008-08-14 | 2010-02-18 | Samsung Electronics Co., Ltd | Apparatus and method for sound processing in a virtual reality system |
| EP3065406A1 (en) * | 2015-03-05 | 2016-09-07 | Nokia Technologies Oy | Video streaming method |
| US20170127118A1 (en) * | 2014-05-30 | 2017-05-04 | Sony Corporation | Information processing apparatus and information processing method |
| WO2017120681A1 (en) * | 2016-01-15 | 2017-07-20 | Michael Godfrey | Method and system for automatically determining a positional three dimensional output of audio information based on a user's orientation within an artificial immersive environment |
Family Cites Families (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AUPR989802A0 (en) * | 2002-01-09 | 2002-01-31 | Lake Technology Limited | Interactive spatialized audiovisual system |
| JP2004072694A (ja) | 2002-08-09 | 2004-03-04 | Sony Corp | 情報提供システムおよび方法、情報提供装置および方法、記録媒体、並びにプログラム |
| DE102005008366A1 (de) * | 2005-02-23 | 2006-08-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum Ansteuern einer Wellenfeldsynthese-Renderer-Einrichtung mit Audioobjekten |
| JP2007029506A (ja) * | 2005-07-28 | 2007-02-08 | Konami Digital Entertainment:Kk | ゲーム装置、音声データの生成方法及びプログラム |
| US20080022348A1 (en) | 2006-07-03 | 2008-01-24 | Samoa Opulence Investment Inc. | Interactive video display system and a method thereof |
| FR2915177B1 (fr) * | 2007-04-20 | 2009-07-10 | Airbus France Sa | Dispositif d'accrochage de moteur d'aeronef et aeronef comportant au moins un tel dispositif |
| US20090094375A1 (en) * | 2007-10-05 | 2009-04-09 | Lection David B | Method And System For Presenting An Event Using An Electronic Device |
| US8798776B2 (en) * | 2008-09-30 | 2014-08-05 | Dolby International Ab | Transcoding of audio metadata |
| KR20110100640A (ko) * | 2008-12-01 | 2011-09-14 | 노오텔 네트웍스 리미티드 | 3차원 컴퓨터 생성 가상 환경의 비디오 표시를 제공하는 방법 및 장치 |
| US10326978B2 (en) * | 2010-06-30 | 2019-06-18 | Warner Bros. Entertainment Inc. | Method and apparatus for generating virtual or augmented reality presentations with 3D audio positioning |
| EP4404537A3 (en) * | 2011-10-28 | 2024-10-16 | Magic Leap, Inc. | System and method for augmented and virtual reality |
| US20150296247A1 (en) | 2012-02-29 | 2015-10-15 | ExXothermic, Inc. | Interaction of user devices and video devices |
| KR101983432B1 (ko) * | 2013-03-14 | 2019-05-28 | 제너럴 인스트루먼트 코포레이션 | 동적 적응형 스트리밍 오버 http(dash)를 http 라이브 스트리밍(hls)으로 변환 또는 번역하기 위한 장치, 시스템, 및 방법 |
| EP2830052A1 (en) * | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio decoder, audio encoder, method for providing at least four audio channel signals on the basis of an encoded representation, method for providing an encoded representation on the basis of at least four audio channel signals and computer program using a bandwidth extension |
| US20150302651A1 (en) * | 2014-04-18 | 2015-10-22 | Sam Shpigelman | System and method for augmented or virtual reality entertainment experience |
| US9787846B2 (en) * | 2015-01-21 | 2017-10-10 | Microsoft Technology Licensing, Llc | Spatial audio signal processing for objects with associated audio content |
| WO2016138502A1 (en) * | 2015-02-27 | 2016-09-01 | Arris Enterprises, Inc. | Adaptive joint bitrate allocation |
| CA2997789C (en) | 2015-09-16 | 2022-10-04 | Magic Leap, Inc. | Head pose mixing of audio files |
| US20170109131A1 (en) * | 2015-10-20 | 2017-04-20 | Bragi GmbH | Earpiece 3D Sound Localization Using Mixed Sensor Array for Virtual Reality System and Method |
| US10229540B2 (en) | 2015-12-22 | 2019-03-12 | Google Llc | Adjusting video rendering rate of virtual reality content and processing of a stereoscopic image |
| US10229541B2 (en) | 2016-01-28 | 2019-03-12 | Sony Interactive Entertainment America Llc | Methods and systems for navigation within virtual reality space using head mounted display |
| US10291910B2 (en) * | 2016-02-12 | 2019-05-14 | Gopro, Inc. | Systems and methods for spatially adaptive video encoding |
| US11017712B2 (en) * | 2016-08-12 | 2021-05-25 | Intel Corporation | Optimized display image rendering |
| CN116389433A (zh) * | 2016-09-09 | 2023-07-04 | Vid拓展公司 | 用于减少360度视区自适应流媒体延迟的方法和装置 |
| CN106774891A (zh) * | 2016-12-15 | 2017-05-31 | 北京小鸟看看科技有限公司 | 虚拟现实场景的音效产生方法、设备及虚拟现实设备 |
| US10659906B2 (en) * | 2017-01-13 | 2020-05-19 | Qualcomm Incorporated | Audio parallax for virtual reality, augmented reality, and mixed reality |
| GB2560923A (en) * | 2017-03-28 | 2018-10-03 | Nokia Technologies Oy | Video streaming |
| JP7212622B2 (ja) * | 2017-06-15 | 2023-01-25 | ドルビー・インターナショナル・アーベー | コンピュータ媒介式の現実アプリケーションにおける送信器と受信器との間の通信を最適化する方法、装置およびシステム |
| US11164606B2 (en) * | 2017-06-30 | 2021-11-02 | Qualcomm Incorporated | Audio-driven viewport selection |
| WO2019007477A1 (en) * | 2017-07-03 | 2019-01-10 | Telefonaktiebolaget Lm Ericsson (Publ) | 360-DEGREE PERSONALIZED VIDEO DISTRIBUTION METHODS |
| JP7187944B2 (ja) * | 2018-09-28 | 2022-12-13 | トヨタ自動車株式会社 | 処理装置および処理方法 |
-
2018
- 2018-10-11 CN CN202310100084.5A patent/CN116193213A/zh active Pending
- 2018-10-11 EP EP23216937.5A patent/EP4329319A3/en active Pending
- 2018-10-11 RU RU2021117733A patent/RU2765569C1/ru active
- 2018-10-11 BR BR112020008073-0A patent/BR112020008073A2/pt unknown
- 2018-10-11 CN CN202310102807.5A patent/CN116193214A/zh active Pending
- 2018-10-11 CA CA3230205A patent/CA3230205A1/en active Pending
- 2018-10-11 MX MX2020003450A patent/MX2020003450A/es unknown
- 2018-10-11 KR KR1020237027561A patent/KR102707356B1/ko active Active
- 2018-10-11 PL PL18783491.6T patent/PL3695613T3/pl unknown
- 2018-10-11 ES ES18783491T patent/ES2970490T3/es active Active
- 2018-10-11 CA CA3230310A patent/CA3230310A1/en active Pending
- 2018-10-11 SG SG10202106080XA patent/SG10202106080XA/en unknown
- 2018-10-11 AU AU2018348762A patent/AU2018348762B2/en active Active
- 2018-10-11 CN CN201880080196.6A patent/CN111466122B/zh active Active
- 2018-10-11 CN CN202310142677.8A patent/CN116193215A/zh active Pending
- 2018-10-11 RU RU2020115448A patent/RU2750505C1/ru active
- 2018-10-11 CA CA3230231A patent/CA3230231A1/en active Pending
- 2018-10-11 CA CA3230221A patent/CA3230221A1/en active Pending
- 2018-10-11 MY MYPI2020001832A patent/MY205925A/en unknown
- 2018-10-11 JP JP2020520204A patent/JP7295851B2/ja active Active
- 2018-10-11 CA CA3230304A patent/CA3230304A1/en active Pending
- 2018-10-11 WO PCT/EP2018/077770 patent/WO2019072984A1/en active IP Right Grant
- 2018-10-11 CN CN202310099423.2A patent/CN116193212A/zh active Pending
- 2018-10-11 KR KR1020247030446A patent/KR102774081B1/ko active Active
- 2018-10-11 SG SG11202003269SA patent/SG11202003269SA/en unknown
- 2018-10-11 CA CA3078858A patent/CA3078858A1/en active Pending
- 2018-10-11 KR KR1020257005914A patent/KR20250033317A/ko active Pending
- 2018-10-11 EP EP18783491.6A patent/EP3695613B1/en active Active
- 2018-10-11 KR KR1020207013475A patent/KR102568373B1/ko active Active
- 2018-10-12 TW TW107136093A patent/TWI713911B/zh active
- 2018-10-12 AR ARP180102986A patent/AR113357A1/es active IP Right Grant
-
2020
- 2020-04-10 US US16/845,602 patent/US11354084B2/en active Active
- 2020-05-04 ZA ZA2020/02064A patent/ZA202002064B/en unknown
- 2020-07-13 MX MX2023012965A patent/MX2023012965A/es unknown
- 2020-07-13 MX MX2023012966A patent/MX2023012966A/es unknown
- 2020-07-13 MX MX2023012967A patent/MX2023012967A/es unknown
- 2020-07-13 MX MX2023012963A patent/MX2023012963A/es unknown
- 2020-07-13 MX MX2023012964A patent/MX2023012964A/es unknown
-
2022
- 2022-05-02 US US17/734,461 patent/US20220261215A1/en active Pending
- 2022-05-13 AR ARP220101293A patent/AR125883A2/es unknown
- 2022-05-13 AR ARP220101292A patent/AR125882A2/es unknown
- 2022-05-13 AR ARP220101291A patent/AR125881A2/es unknown
- 2022-05-13 AR ARP220101290A patent/AR125880A2/es unknown
- 2022-05-13 AR ARP220101294A patent/AR125884A2/es unknown
- 2022-07-27 ZA ZA2022/08364A patent/ZA202208364B/en unknown
- 2022-07-27 ZA ZA2022/08388A patent/ZA202208388B/en unknown
-
2023
- 2023-05-03 ZA ZA2023/04926A patent/ZA202304926B/en unknown
- 2023-06-09 JP JP2023095140A patent/JP7655688B2/ja active Active
- 2023-11-07 AU AU2023263436A patent/AU2023263436A1/en active Pending
-
2024
- 2024-07-08 ZA ZA2024/05290A patent/ZA202405290B/en unknown
-
2025
- 2025-03-20 JP JP2025046112A patent/JP2025090843A/ja active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020103554A1 (en) * | 2001-01-29 | 2002-08-01 | Hewlett-Packard Company | Interactive audio system |
| US20100040238A1 (en) * | 2008-08-14 | 2010-02-18 | Samsung Electronics Co., Ltd | Apparatus and method for sound processing in a virtual reality system |
| US20170127118A1 (en) * | 2014-05-30 | 2017-05-04 | Sony Corporation | Information processing apparatus and information processing method |
| EP3065406A1 (en) * | 2015-03-05 | 2016-09-07 | Nokia Technologies Oy | Video streaming method |
| WO2017120681A1 (en) * | 2016-01-15 | 2017-07-20 | Michael Godfrey | Method and system for automatically determining a positional three dimensional output of audio information based on a user's orientation within an artificial immersive environment |
Non-Patent Citations (5)
| Title |
|---|
| 3. 현재 솔루션들 |
| ISO/IEC 23008-3:2015, Information technology -- High efficiency coding and media delivery in heterogeneous environments -- Part 3: 3D audio |
| N16950, Study of ISO/IEC DIS 23000-20 Omnidirectional Media Format |
| 현재 솔루션들은 다음과 같다: |
| 현재 솔루션들은, 사용자가 자신의 배향을 변화시키지만 VR 환경에서 이동하지 않도로 허용하는 하나의 고정된 위치에서 독립적인 VR 경험을 제공하는 것으로 제한된다. |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022256828A1 (en) * | 2021-06-02 | 2022-12-08 | Tencent America LLC | Adaptive audio delivery and rendering |
| US12204815B2 (en) | 2021-06-02 | 2025-01-21 | Tencent America LLC | Adaptive audio delivery and rendering |
| KR20230013629A (ko) * | 2021-07-19 | 2023-01-26 | 가우디오랩 주식회사 | 멀티-뷰 환경에 있어서 오디오 장면(audio scene)을 전환하는 방법 및 이를 위한 장치 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102568373B1 (ko) | 가상 현실 애플리케이션들에 대한 오디오 전달의 최적화 | |
| KR102774542B1 (ko) | 고품질의 경험을 위한 오디오 메시지들의 효율적인 전달 및 사용을 위한 방법 및 장치 | |
| RU2801698C2 (ru) | Оптимизация доставки звука для приложений виртуальной реальности | |
| HK40033931A (en) | Optimizing audio delivery for virtual reality applications | |
| HK40033931B (en) | Optimizing audio delivery for virtual reality applications |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200511 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| A201 | Request for examination | ||
| AMND | Amendment | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20200601 Comment text: Request for Examination of Application |
|
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20210603 Patent event code: PE09021S01D |
|
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20211221 Patent event code: PE09021S01D |
|
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| PE0601 | Decision on rejection of patent |
Patent event date: 20221027 Comment text: Decision to Refuse Application Patent event code: PE06012S01D Patent event date: 20211221 Comment text: Notification of reason for refusal Patent event code: PE06011S01I Patent event date: 20210603 Comment text: Notification of reason for refusal Patent event code: PE06011S01I |
|
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20230314 Patent event code: PE09021S01D |
|
| AMND | Amendment | ||
| PX0701 | Decision of registration after re-examination |
Patent event date: 20230516 Comment text: Decision to Grant Registration Patent event code: PX07013S01D Patent event date: 20230510 Comment text: Amendment to Specification, etc. Patent event code: PX07012R01I Patent event date: 20230131 Comment text: Amendment to Specification, etc. Patent event code: PX07012R01I Patent event date: 20221027 Comment text: Decision to Refuse Application Patent event code: PX07011S01I Patent event date: 20220621 Comment text: Amendment to Specification, etc. Patent event code: PX07012R01I Patent event date: 20210803 Comment text: Amendment to Specification, etc. Patent event code: PX07012R01I Patent event date: 20200601 Comment text: Amendment to Specification, etc. Patent event code: PX07012R01I |
|
| X701 | Decision to grant (after re-examination) | ||
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20230814 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20230816 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |