KR20200054138A - 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 - Google Patents
어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 Download PDFInfo
- Publication number
- KR20200054138A KR20200054138A KR1020200016770A KR20200016770A KR20200054138A KR 20200054138 A KR20200054138 A KR 20200054138A KR 1020200016770 A KR1020200016770 A KR 1020200016770A KR 20200016770 A KR20200016770 A KR 20200016770A KR 20200054138 A KR20200054138 A KR 20200054138A
- Authority
- KR
- South Korea
- Prior art keywords
- annotation
- slide image
- task
- panel
- present disclosure
- Prior art date
Links
Images






















Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H30/00—ICT specially adapted for the handling or processing of medical images
- G16H30/20—ICT specially adapted for the handling or processing of medical images for handling medical images, e.g. DICOM, HL7 or PACS
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/20—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for computer-aided diagnosis, e.g. based on medical expert systems
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/70—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for mining of medical data, e.g. analysing previous cases of other patients
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Public Health (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Epidemiology (AREA)
- Data Mining & Analysis (AREA)
- Primary Health Care (AREA)
- Databases & Information Systems (AREA)
- Pathology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Radiology & Medical Imaging (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
어노테이션 작업을 효율적으로 수행할 수 있는 어노테이션 작업 관리 방법이 제공된다. 상기 어노테이션 작업 관리 방법은, 신규의 병리 슬라이드 이미지에 대한 정보를 얻는 단계, 상기 병리 슬라이드 이미지의 데이터셋 타입 및 패널을 결정하는 단계 및 상기 병리 슬라이드 이미지, 상기 결정된 데이터셋 타입, 어노테이션 태스크(annotation task) 및 상기 병리 슬라이드 이미지의 일부 영역인 패치로 정의되는 어노테이션 작업(job)을 어노테이터(annotator) 계정에 할당하는 단계를 포함할 수 있다. 이때, 상기 어노테이션 태스크는, 상기 결정된 패널을 포함하여 정의되는 것이고, 상기 패널은, 세포(cell) 패널, 조직(tissue) 패널 및 스트럭쳐(structure) 패널 중 어느 하나로 지정되는 것이며, 상기 데이터셋 타입은, 상기 병리 슬라이드 이미지의 용도를 가리키는 것으로서, 기계학습 모델의 학습(training) 용도 또는 상기 기계학습 모델의 검증(validation) 용도 중 어느 하나로 지정되는 것일 수 있다.
Description
본 개시는 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템에 관한 것이다. 보다 자세하게는, 어노테이션(annotation) 작업을 보다 효율적으로 관리함과 동시에 어노테이션 결과의 정확성을 담보할 수 있는 방법, 그 방법을 지원하는 장치 및 시스템을 제공하는 것이다.
지도 학습(supervised learning)이란 도 1에 도시된 바와 같이 레이블 정보(즉, 정답 정보)가 주어진 데이터셋(2)을 학습하여 목적 태스크를 수행하는 타깃 모델(3)을 구축하는 기계 학습 방법이다. 따라서, 레이블 정보(태그 아이콘으로 표시됨)가 주어지지 않은 데이터셋(1)에 대해 지도 학습을 수행하기 위해서는, 어노테이션(annotation) 작업이 필수적으로 선행되어야 한다.
어노테이션 작업은 학습 데이터셋을 생성하기 위해 데이터 별로 레이블 정보를 태깅하는 작업을 의미한다. 어노테이션 작업은 일반적으로 사람에 의해 수행되기 때문에, 대량의 학습 데이터셋을 생성하기 위해서는 상당한 인적 비용과 시간 비용이 소모된다. 특히, 병리 이미지에서 병변의 종류 또는 위치 등을 진단하는 기계 학습 모델을 구축하는 경우라면, 숙련된 전문의에 의해 어노테이션 작업이 수행되어야 하기 때문에, 다른 도메인에 비해 훨씬 더 많은 비용이 소모된다.
종래에는, 체계적인 작업 프로세스가 정립되지 않은 체로 어노테이션 작업이 수행되었다. 가령, 종래의 방식은 관리자가 각 병리 이미지의 특성을 육안으로 확인하여 어노테이션 수행 여부를 결정하고, 손수 병리 이미지를 분류한 다음 적절한 어노테이터(annotator)에게 병리 이미지를 할당하는 방식이었다. 뿐만 아니라, 종래에는 관리자가 일일이 병리 이미지 상의 어노테이션 영역을 지정한 다음, 어노테이터에게 작업을 할당하였다. 즉, 종래에는 병리 이미지 분류, 작업 할당, 어노테이션 영역 지정 등의 제반 과정이 관리자에 의해 수동으로 이루어졌고, 이로 인해 어노테이션 작업에 상당한 시간 비용과 인적 비용이 소모되는 문제가 있었다.
나아가, 기계 학습 기법 자체는 충분히 고도화되었음에도 불구하고, 어노테이션 작업의 시간적, 비용적 문제로 인해 다양한 분야에 기계 학습 기법을 적용하는데 많은 어려움이 있었다.
따라서, 기계 학습 기법의 활용성을 더욱 증대시키기 위해, 보다 효율적이고 체계적으로 어노테이션 작업을 수행할 수 있는 방법이 요구된다.
본 개시의 몇몇 실시예들을 통해 해결하고자 하는 기술적 과제는, 어노테이션 작업의 자동화를 통해 어노테이션 작업을 보다 효율적이고 체계적으로 수행하고 관리할 수 있는 방법, 그 방법을 지원하는 장치 및 시스템을 제공하는 것이다.
본 개시의 몇몇 실시예들을 통해 해결하고자 하는 다른 기술적 과제는, 어노테이션 작업을 체계적으로 관리할 수 있는 데이터 설계 산출물 또는 데이터 모델링 산출물을 제공하는 것이다.
본 개시가 해결하고자 하는 또 다른 기술적 과제는, 어노테이션 작업을 적절한 어노테이터에게 자동으로 할당하는 방법, 그 방법을 지원하는 장치 및 시스템을 제공하는 것이다.
본 개시가 해결하고자 하는 또 다른 기술적 과제는, 병리 슬라이드 이미지에서 어노테이션 작업이 수행될 패치 이미지를 자동으로 추출하는 방법, 그 방법을 지원하는 장치 및 시스템을 제공하는 것이다.
본 개시가 해결하고자 하는 또 다른 기술적 과제는, 어노테이션 결과의 정확성을 담보할 수 있는 방법, 그 방법을 지원하는 장치 및 시스템을 제공하는 것이다.
본 개시의 기술적 과제들은 이상에서 언급한 기술적 과제들로 제한되지 않으며, 언급되지 않은 또 다른 기술적 과제들은 아래의 기재로부터 본 개시의 기술분야에서의 통상의 기술자에게 명확하게 이해될 수 있을 것이다.
상기 기술적 과제를 해결하기 위한, 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 방법은, 컴퓨팅 장치에 의하여 수행되는 방법에 있어서, 신규의 병리 슬라이드 이미지에 대한 정보를 얻는 단계, 상기 병리 슬라이드 이미지의 데이터셋 타입 및 패널을 결정하는 단계 및 상기 병리 슬라이드 이미지, 상기 결정된 데이터셋 타입, 어노테이션 태스크(annotation task) 및 상기 병리 슬라이드 이미지의 일부 영역인 패치로 정의되는 어노테이션 작업(job)을 어노테이터(annotator) 계정에 할당하는 단계를 포함하되, 상기 어노테이션 태스크는, 상기 결정된 패널을 포함하여 정의되는 것이고, 상기 패널은, 세포(cell) 패널, 조직(tissue) 패널 및 스트럭처(structure) 패널 중 어느 하나로 지정되는 것이며, 상기 데이터셋 타입은, 상기 병리 슬라이드 이미지의 용도를 가리키는 것으로서, 기계학습 모델의 학습(training) 용도 또는 상기 기계학습 모델의 검증(validation) 용도 중 어느 하나로 지정되는 것일 수 있다.
몇몇 실시예에서, 상기 어노테이션 태스크는, 태스크 클래스를 더 포함하여 정의되는 것이고, 상기 태스크 클래스는, 상기 패널의 관점에서 정의되는 어노테이션 대상을 가리키는 것일 수 있다.
몇몇 실시예에서, 상기 데이터셋 타입은, 상기 기계학습 모델의 학습(training) 용도, 상기 기계학습 모델의 검증(validation) 용도 또는 OPT(Observer Performance Test) 용도 중 어느 하나로 지정되는 것일 수 있다.
몇몇 실시예에서, 상기 데이터셋 타입 및 패널을 결정하는 단계는, 상기 병리 슬라이드 이미지를 기계학습 모델에 입력하고, 그 결과로 출력된 출력 값에 기반하여, 상기 병리 슬라이드 이미지의 데이터셋 타입 및 패널을 결정하는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 신규의 병리 슬라이드 이미지에 대한 정보를 얻는 단계는, 지정된 위치의 스토리지에 병리 슬라이드 이미지 파일이 추가되는 것을, 상기 스토리지를 모니터링 하는 워커 에이전트가 감지하는 단계, 상기 워커 에이전트에 의하여 상기 신규의 병리 슬라이드 이미지에 대한 정보가 데이터베이스에 삽입되는 단계 및 상기 데이터베이스로부터 상기 병리 슬라이드 이미지에 대한 정보를 얻는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 할당하는 단계는, 상기 어노테이션 작업의 데이터셋 타입 및 어노테이션 태스크의 패널의 조합과 연관된 어노테이션 수행 이력을 기준으로 선정된 어노테이터 계정에 상기 어노테이션 작업을 자동 할당하는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 어노테이션 태스크는, 태스크 클래스를 더 포함하여 정의되는 것이고, 상기 태스크 클래스는, 상기 패널의 관점에서 정의되는 어노테이션 대상을 가리키는 것이며, 상기 할당하는 단계는, 상기 어노테이션 작업의 어노테이션 태스크의 패널 및 태스크 클래스의 조합과 연관된 어노테이션 수행 이력을 기준으로 선정된 어노테이터 계정에 상기 어노테이션 작업을 자동 할당하는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 할당하는 단계는, 상기 병리 슬라이드 이미지의 후보 패치들을 얻는 단계 및 각각의 후보 패치를 상기 기계학습 모델에 입력하고, 그 결과로 출력된 각 클래스 별 출력 값에 기반하여, 상기 후보 패치들 중에서 상기 어노테이션 작업의 패치를 자동으로 선정하는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 어노테이션 작업의 패치를 상기 후보 패치들 중에서 자동으로 선정하는 단계는, 상기 각각의 후보 패치에 대한 각 클래스 별 출력 값을 이용하여 엔트로피 값을 연산하는 단계 및 상기 엔트로피 값이 기준치 이상인 후보 패치를, 상기 어노테이션 작업의 패치로 선정하는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 할당하는 단계는, 상기 병리 슬라이드 이미지의 후보 패치들을 얻는 단계, 각각의 후보 패치에 대한 상기 기계학습 모델의 오예측(miss-prediction) 확률을 산출하는 단계 및 상기 산출된 오예측 확률이 기준치 이상인 후보 패치를, 상기 어노테이션 작업의 패치로 선정하는 단계를 포함할 수 있다.
몇몇 실시예에서, 상기 어노테이션 작업을 할당받은 어노테이터 계정의 제1 어노테이션 결과 데이터를 얻는 단계, 상기 제1 어노테이션 결과 데이터와 상기 어노테이션 작업의 패치를 상기 기계학습 모델에 입력한 결과를 비교하는 단계 및 상기 비교 결과, 두 결과의 차이가 기준치를 초과하면 상기 어노테이션 작업을 다른 어노테이터 계정에 재할당하는 단계를 더 포함할 수 있다.
몇몇 실시예에서, 상기 어노테이션 작업을 할당받은 어노테이터 계정의 제1 어노테이션 결과 데이터를 얻는 단계, 다른 어노테이터 계정의 제2 어노테이션 결과 데이터를 얻는 단계 및 상기 제1 어노테이션 결과 데이터와 상기 제2 어노테이션 결과 데이터의 유사도가 기준치 미만이면 상기 제1 어노테이션 결과 데이터를 미승인 처리하는 단계를 더 포함할 수 있다.
상술한 기술적 과제를 해결하기 위한 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 장치는, 하나 이상의 인스트럭션들(instructions)을 포함하는 메모리 및 상기 하나 이상의 인스트럭션들을 실행함으로써, 신규의 병리 슬라이드 이미지에 대한 정보를 얻어오고, 상기 병리 슬라이드 이미지의 데이터셋 타입 및 패널을 결정하며, 상기 병리 슬라이드 이미지, 상기 결정된 데이터셋 타입, 어노테이션 태스크(annotation task) 및 상기 병리 슬라이드 이미지의 일부 영역인 패치로 정의되는 어노테이션 작업(job)을 어노테이터(annotator) 계정에 할당하는 프로세서를 포함하되, 상기 어노테이션 태스크는, 상기 결정된 패널을 포함하여 정의되는 것이고, 상기 패널은, 세포(cell) 패널, 조직(tissue) 패널 및 스트럭처(structure) 패널 중 어느 하나로 지정되는 것이며, 상기 데이터셋 타입은, 상기 병리 슬라이드 이미지의 용도를 가리키는 것으로서, 기계학습 모델의 학습(training) 용도 또는 상기 기계학습 모델의 검증(validation) 용도 중 어느 하나로 지정되는 것일 수 있다.
상술한 기술적 과제를 해결하기 위한 본 개시의 몇몇 실시예들에 따른 컴퓨터 프로그램을 포함하는 비일시적(non-transitory) 컴퓨터 판독가능 기록매체는, 상기 컴퓨터 프로그램의 명령어들이 프로세서에 의해 실행될 때, 상기 프로세서로 하여금, 신규의 병리 슬라이드 이미지에 대한 정보를 얻는 단계, 상기 병리 슬라이드 이미지의 데이터셋 타입 및 패널을 결정하는 단계 및 상기 병리 슬라이드 이미지, 상기 결정된 데이터셋 타입, 어노테이션 태스크(annotation task) 및 상기 병리 슬라이드 이미지의 일부 영역인 패치로 정의되는 어노테이션 작업(job)을 어노테이터(annotator) 계정에 할당하는 단계를 수행하도록 할 수 있다. 이때, 상기 어노테이션 태스크는, 상기 결정된 패널을 포함하여 정의되는 것이고, 상기 패널은, 세포(cell) 패널, 조직(tissue) 패널 및 스트럭처(structure) 패널 중 어느 하나로 지정되는 것이며, 상기 데이터셋 타입은, 상기 병리 슬라이드 이미지의 용도를 가리키는 것으로서, 기계학습 모델의 학습(training) 용도 또는 상기 기계학습 모델의 검증(validation) 용도 중 어느 하나로 지정되는 것일 수 있다.
상술한 본 개시의 다양한 실시예들에 따르면, 어노테이션 작업이 전반적으로 자동화됨에 따라 관리자의 편의성이 증대되고, 전반적인 작업 효율성이 크게 향상될 수 있다. 이에 따라, 어노테이션 작업에 소요되는 시간 비용 및 인적 비용이 크게 절감될 수 있다. 또한, 어노테이션 작업의 부담이 감소됨에 따라, 기계 학습 기법의 활용성은 더욱 증대될 수 있다.
또한, 데이터 모델링 산출물에 기반하여 어노테이션 작업과 연관된 각종 데이터가 체계적으로 관리될 수 있다. 이에 따라, 데이터 관리 비용은 감소되고, 전반적인 어노테이션 작업 프로세스가 원활하게 진행될 수 있다.
또한, 어노테이션 작업을 적절한 어노테이터에게 자동으로 할당함으로써, 관리자의 업무 부담이 감소될 수 있고, 어노테이션 결과의 정확성은 향상될 수 있다.
또한, 어노테이션 작업 결과를 기계학습 모델 또는 다른 어노테이터의 결과와 비교 검증함으로써, 어노테이션 결과의 정확성이 담보될 수 있다. 이에 따라, 어노테이션 결과를 학습한 기계학습 모델의 성능도 향상될 수 있다.
또한, 어노테이션이 수행될 영역을 가리키는 패치가 자동으로 추출될 수 있다. 따라서, 관리자의 업무 부담이 최소화될 수 있다.
또한, 기계 학습 모델의 오예측 확률, 엔트로피 값 등에 기반하여 복수의 후보 패치 중에서 학습에 효과적인 패치만이 어노테이션 대상으로 선정된다. 이에 따라, 어노테이션 작업량이 감소되고, 양질의 학습 데이터셋이 생성될 수 있다.
본 개시의 기술적 사상에 따른 효과들은 이상에서 언급한 효과들로 제한되지 않으며, 언급되지 않은 또 다른 효과들은 아래의 기재로부터 통상의 기술자에게 명확하게 이해될 수 있을 것이다.
도 1은 지도 학습과 어노테이션 작업 간의 관계를 설명하기 위한 예시도이다.
도 2 및 도 3은 본 개시의 다양한 실시예들에 따른 어노테이션 작업 관리 시스템을 나타내는 예시적인 구성도이다.
도 4는 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리를 위한 예시적인 데이터 모델의 설계도이다.
도 5는 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 방법을 나타내는 예시적인 흐름도이다.
도 6은 본 개시의 몇몇 실시예들에 따른 어노테이터 선정 방법을 설명하기 위한 예시도이다.
도 7은 본 개시의 몇몇 실시예들에서 참조될 수 있는 어노테이션 툴을 나타내는 예시도이다.
도 8은 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 생성 방법을 나타내는 예시적인 흐름도이다.
도 9는 본 개시의 몇몇 실시예들에 따른 병리 슬라이드 이미지에 대한 데이터셋 타입 결정 방법을 나타내는 예시적인 흐름도이다.
도 10 내지 도 13은 본 개시의 몇몇 실시예들에 따른 패널 유형 결정 방법을 설명하기 위한 도면이다.
도 14는 본 개시의 제1 실시예들에 따른 패치 자동 추출 방법을 나타내는 예시적인 흐름도이다.
도 15 내지 도 19는 본 개시의 제1 실시예들에 따른 패치 자동 추출 방법을 부연 설명하기 위한 예시도이다.
도 20은 본 개시의 제2 실시예들에 따른 패치 자동 추출 방법을 나타내는 예시적인 흐름도이다.
도 21 내지 도 23은 본 개시의 제2 실시예들에 따른 패치 자동 추출 방법을 부연 설명하기 위한 예시도이다.
도 24는 본 개시의 다양한 실시예들에 따른 장치/시스템을 구현할 수 있는 예시적인 컴퓨팅 장치를 나타내는 예시적인 하드웨어 구성도이다.
도 2 및 도 3은 본 개시의 다양한 실시예들에 따른 어노테이션 작업 관리 시스템을 나타내는 예시적인 구성도이다.
도 4는 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리를 위한 예시적인 데이터 모델의 설계도이다.
도 5는 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 방법을 나타내는 예시적인 흐름도이다.
도 6은 본 개시의 몇몇 실시예들에 따른 어노테이터 선정 방법을 설명하기 위한 예시도이다.
도 7은 본 개시의 몇몇 실시예들에서 참조될 수 있는 어노테이션 툴을 나타내는 예시도이다.
도 8은 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 생성 방법을 나타내는 예시적인 흐름도이다.
도 9는 본 개시의 몇몇 실시예들에 따른 병리 슬라이드 이미지에 대한 데이터셋 타입 결정 방법을 나타내는 예시적인 흐름도이다.
도 10 내지 도 13은 본 개시의 몇몇 실시예들에 따른 패널 유형 결정 방법을 설명하기 위한 도면이다.
도 14는 본 개시의 제1 실시예들에 따른 패치 자동 추출 방법을 나타내는 예시적인 흐름도이다.
도 15 내지 도 19는 본 개시의 제1 실시예들에 따른 패치 자동 추출 방법을 부연 설명하기 위한 예시도이다.
도 20은 본 개시의 제2 실시예들에 따른 패치 자동 추출 방법을 나타내는 예시적인 흐름도이다.
도 21 내지 도 23은 본 개시의 제2 실시예들에 따른 패치 자동 추출 방법을 부연 설명하기 위한 예시도이다.
도 24는 본 개시의 다양한 실시예들에 따른 장치/시스템을 구현할 수 있는 예시적인 컴퓨팅 장치를 나타내는 예시적인 하드웨어 구성도이다.
이하, 첨부된 도면을 참조하여 본 개시의 바람직한 실시예들을 상세히 설명한다. 본 개시의 이점 및 특징, 그리고 그것들을 달성하는 방법은 첨부되는 도면과 함께 상세하게 후술되어 있는 실시예들을 참조하면 명확해질 것이다. 그러나 본 개시의 기술적 사상은 이하의 실시예들에 한정되는 것이 아니라 서로 다른 다양한 형태로 구현될 수 있으며, 단지 본 실시예들은 본 개시가 완전하도록 하고, 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자에게 본 개시의 범주를 완전하게 알려주기 위해 제공되는 것이며, 본 개시의 기술적 사상은 청구항의 범주에 의해 정의될 뿐이다.
각 도면의 구성요소들에 참조부호를 부가함에 있어서, 동일한 구성요소들에 대해서는 비록 다른 도면상에 표시되더라도 가능한 한 동일한 부호를 가지도록 하고 있음에 유의해야 한다. 또한, 본 개시를 설명함에 있어, 관련된 공지 구성 또는 기능에 대한 구체적인 설명이 본 개시의 요지를 흐릴 수 있다고 판단되는 경우에는 그 상세한 설명은 생략한다.
다른 정의가 없다면, 본 명세서에서 사용되는 모든 용어(기술 및 과학적 용어를 포함)는 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자에게 공통적으로 이해될 수 있는 의미로 사용될 수 있다. 또 일반적으로 사용되는 사전에 정의되어 있는 용어들은 명백하게 특별히 정의되어 있지 않는 한 이상적으로 또는 과도하게 해석되지 않는다. 본 명세서에서 사용된 용어는 실시예들을 설명하기 위한 것이며 본 개시를 제한하고자 하는 것은 아니다. 본 명세서에서, 단수형은 문구에서 특별히 언급하지 않는 한 복수형도 포함한다.
또한, 본 개시의 구성 요소를 설명하는 데 있어서, 제1, 제2, A, B, (a), (b) 등의 용어를 사용할 수 있다. 이러한 용어는 그 구성 요소를 다른 구성 요소와 구별하기 위한 것일 뿐, 그 용어에 의해 해당 구성 요소의 본질이나 차례 또는 순서 등이 한정되지 않는다. 어떤 구성 요소가 다른 구성요소에 "연결", "결합" 또는 "접속"된다고 기재된 경우, 그 구성 요소는 그 다른 구성요소에 직접적으로 연결되거나 또는 접속될 수 있지만, 각 구성 요소 사이에 또 다른 구성 요소가 "연결", "결합" 또는 "접속"될 수도 있다고 이해되어야 할 것이다.
명세서에서 사용되는 "포함한다 (comprises)" 및/또는 "포함하는 (comprising)"은 언급된 구성 요소, 단계, 동작 및/또는 소자는 하나 이상의 다른 구성 요소, 단계, 동작 및/또는 소자의 존재 또는 추가를 배제하지 않는다.
본 명세서에 대한 설명에 앞서, 본 명세서에서 사용되는 몇몇 용어들에 대하여 명확하게 하기로 한다.
본 명세서에서, 레이블 정보(label information)란, 데이터 샘플의 정답 정보로써 어노테이션 작업의 결과로 획득된 정보이다. 상기 레이블은 당해 기술 분야에서 어노테이션(annotation), 태그 등의 용어와 혼용되어 사용될 수 있다.
본 명세서에서, 어노테이션(annotation)이란, 데이터 샘플에 레이블 정보를 태깅하는 작업 또는 태깅된 정보(즉, 주석) 그 자체를 의미한다. 상기 어노테이션은 당해 기술 분야에서 태깅(tagging), 레이블링(labeling) 등의 용어와 혼용되어 사용될 수 있다.
본 명세서에서, 오예측(miss-prediction) 확률이란, 주어진 데이터 샘플에 대한 특정 모델이 예측을 수행할 때, 상기 예측 결과에 오류가 포함될 확률(즉, 예측이 틀릴 확률) 또는 가능성을 의미한다.
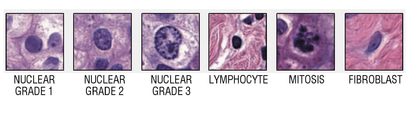
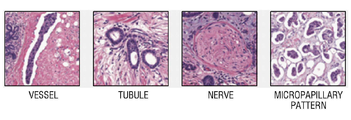
본 명세서에서, 패널(panel)이란, 병리 슬라이드 이미지에서 추출될 패치(patch) 또는 병리 슬라이드 이미지의 타입을 의미한다. 상기 패널은 세포(cell) 패널, 조직(tissue) 패널 및 스트럭처(structure) 패널로 구분될 수 있으나, 본 개시의 기술적 범위가 이에 한정되는 것은 아니다. 각 패널 유형에 대응되는 패치의 예는 도 10 내지 도 12를 참조하도록 한다.
본 명세서에서 인스트럭션(instruction)이란, 기능을 기준으로 묶인 일련의 명령어들로서 컴퓨터 프로그램의 구성 요소이자 프로세서에 의해 실행되는 것을 가리킨다.
이하, 본 개시의 몇몇 실시예들에 대하여 첨부된 도면에 따라 상세하게 설명한다.
도 2는 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 시스템을 나타내는 예시적인 구성도이다.
도 2에 도시된 바와 같이, 상기 어노테이션 작업 관리 시스템은 스토리지 서버(10), 적어도 하나의 어노테이터 단말(20-1 내지 20-n) 및 어노테이션 작업 관리 장치(100)를 포함할 수 있다. 단, 이는 본 개시의 목적을 달성하기 위한 바람직한 실시예일뿐이며, 필요에 따라 일부 구성 요소가 추가되거나 삭제될 수 있음은 물론이다. 가령, 다른 몇몇 실시예에서는, 도 3에 도시된 바와 같이, 상기 어노테이션 작업 관리 시스템은 어노테이션 작업에 대한 리뷰(즉, 평가)를 담당하는 리뷰자의 단말(30)을 더 포함할 수 있다.
도 2 또는 도3에 도시된 시스템의 각각의 구성 요소들은 기능적으로 구분되는 기능 요소들을 나타낸 것으로서, 복수의 구성 요소가 실제 물리적 환경에서는 서로 통합되는 형태로 구현될 수도 있다. 또는, 상기 각각의 구성 요소들은 실제 물리적 환경에서는 복수의 세부 기능 요소로 분리되는 형태로 구현될 수도 있다. 예컨대, 어노테이션 작업 관리 장치(100)의 제1 기능은 제1 컴퓨팅 장치에서 구현되고, 제2 기능은 제2 컴퓨팅 장치에서 구현될 수도 있다. 이하, 상기 각각의 구성 요소에 대하여 설명한다.
상기 어노테이션 작업 관리 시스템에서, 스토리지 서버(10)는 어노테이션 작업과 연관된 각종 데이터를 저장하고 관리하는 서버이다. 데이터의 효율적인 관리를 위해, 스토리지 서버(10)는 데이터베이스를 이용하여 상기 각종 데이터를 저장되고 관리할 수 있다.
상기 각종 데이터는 병리 슬라이드 이미지의 파일, 병리 슬라이드 이미지의 메타 데이터(e.g. 이미지 형식, 연관된 병명, 연관된 조직, 연관된 환자 정보 등), 어노테이션 작업에 관한 데이터, 어노테이터에 관한 데이터, 어노테이션 작업 결과물 등을 포함할 수 있을 것이나, 본 개시의 기술적 범위가 이에 한정되는 것은 아니다.
몇몇 실시예에서, 스토리지 서버(10)는 작업 관리 웹 페이지를 제공하는 웹 서버로 동작할 수도 있다. 이와 같은 경우, 관리자는 상기 작업 관리 웹 페이지를 통해 어노테이션 작업에 대한 할당, 관리 등을 수행하고, 어노테이터는 상기 작업 관리 웹 페이지를 통해 할당된 작업을 확인하고 수행할 수 있다.
몇몇 실시예에서, 어노테이션 작업 관리를 위한 데이터 모델(e.g. DB 스키마)은 도 4에 도시된 바와 같이 설계될 수 있다. 도 4에서 박스형 객체는 엔티티(entity)를 가리키고, 박스형 객체를 연결하는 선은 관계(relationship)를 가리키며, 선 위의 글자는 관계 유형을 가리킨다. 도 4에 도시된 바와 같이, 어노테이션 작업 엔티티(44)는 다양한 엔티티(43, 45, 46, 47, 49)와 연관될 수 있다. 보다 이해의 편의를 제공하기 위해, 작업 엔티티(44)를 중심으로 도 4에 도시된 데이터 모델에 대하여 간략하게 설명하도록 한다.
슬라이드 엔티티(45)는 병리 슬라이드 이미지에 관한 엔티티이다. 슬라이드 엔티티(45)는 병리 슬라이드 이미지와 연관된 각종 정보를 속성(attribute)으로 가질 수 있다. 하나의 병리 슬라이드 이미지로부터 다수의 어노테이션 작업이 생성될 수 있기 때문에, 슬라이드 엔티티(45)와 작업 엔티티(44) 간의 관계는 1:n이 된다.
데이터셋 엔티티(49)는 어노테이션이 수행된 데이터의 활용 용도를 나타내는 엔티티이다. 가령, 상기 활용 용도는 학습(training) 용도(즉, 학습 데이터셋으로 활용됨), 검증(validation) 용도(즉, 검증 데이터셋으로 활용됨), 테스트 용도(즉, 테스트 데이터셋으로 활용됨) 또는 OPT(Observer Performance Test) 용도(즉, OPT 테스트에 활용됨)로 구분될 수 있으나, 본 개시의 기술적 범위가 이에 한정되는 것은 아니다.
어노테이터 엔티티(47)는 어노테이터를 나타내는 엔티티이다. 어노테이터 엔티티(47)는 상기 어노테이터의 현재 작업 현황, 과거 작업 수행 이력, 기 수행된 작업에 대한 평가 결과, 어노테이터의 인적 정보(e.g. 학력, 전공 등) 등을 속성으로 가질 수 있다. 한 명의 어노테이터는 다수의 작업을 수행할 수 있으므로, 어노테이터 엔티티(47)와 작업 엔티티(44) 간의 관계는 1:n이 된다.
패치 엔티티(46)는 병리 슬라이드 이미지로부터 파생된 패치에 관한 엔티티이다. 상기 패치에는 복수개의 어노테이션이 포함될 수 있기 때문에, 패치 엔티티(46)와 어노테이션 엔티티(48) 간의 관계는 1:n이 된다. 또한, 하나의 어노테이션 작업이 복수개의 패치에 대해 수행될 수 있기 때문에, 패치 엔티티(46)와 작업 엔티티(44) 간의 관계는 n:1이 된다.
어노테이션 태스크 엔티티(43)는 세부적인 어노테이션 작업 유형인 어노테이션 태스크(annotation task)를 나타내는 엔티티이다. 예를 들어, 상기 어노테이션 태스크 유사 분열 세포(mitosis)인지 여부를 태깅하는 태스크, 유사 분열 세포의 개수를 태깅하는 태스크, 병변의 종류를 태깅하는 태스크, 병변의 위치를 태깅하는 태스크, 병명을 태깅하는 태스크 등과 같이 다양하게 정의되고 세분화될 수 있다. 상기 어노테이션 작업의 세부 유형은 패널에 따라 달라질 수 있고(즉, 세포 패널과 조직 패널에 태깅되는 어노테이션은 달라질 수 있음), 동일한 패널이더라도 서로 다른 태스크가 수행될 수 있기 때문에, 태스크 엔티티((43)는 패널 엔티티(41)와 태스크 클래스(42) 엔티티를 속성으로 가질 수 있다. 여기서, 태스크 클래스 엔티티(42)는 패널의 관점에서 정의되는 어노테이션 대상(e.g. 유사 분열 세포, 병변의 위치) 또는 패널의 관점에서 정의되는 태스크 유형을 나타내는 엔티티이다. 하나의 어노테이션 태스크에서 복수의 어노테이션 작업이 생성될 수 있기 때문에(즉, 동일한 태스크를 수행하는 복수의 작업이 존재할 수 있음), 어노테이션 태스크 엔티티(43)와 어노테이션 작업 엔티티(44) 간의 관계는 1:n이 된다. 프로그래밍적 관점에서, 어노테이션 태스크 엔티티(43)는 클래스(class) 또는 프로그램(program)에 대응되고, 어노테이션 작업 엔티티(44)는 상기 클래스의 인스턴스(instance) 또는 프로그램 실행에 의해 생성된 프로세스(process)에 대응되는 것으로 이해될 수 있다.
몇몇 실시예에서, 스토리지 서버(10)는 전술한 데이터 모델에 기반하여 데이터베이스를 구축하고, 어노테이션 작업과 연관된 각종 데이터를 체계적으로 관리할 수 있다. 이에 따라, 데이터 관리 비용은 감소되고, 전반적인 어노테이션 작업 프로세스가 원활하게 진행될 수 있다.
지금까지 어노테이션 작업 관리를 위한 데이터 모델에 대하여 설명하였다. 다시 도 2 및 도 3을 참조하여 어노테이션 작업 관리 시스템의 구성 요소에 대한 설명을 이어가도록 한다.
상기 어노테이션 작업 관리 시스템에서, 어노테이션 작업 관리 장치(100)는 어노테이터 단말(20-1 내지 20-n)에게 어노테이션 작업을 할당하는 등의 제반 관리 기능을 수행하는 컴퓨팅 장치이다. 여기서, 상기 컴퓨팅 장치는, 노트북, 데스크톱(desktop), 랩탑(laptop) 등이 될 수 있으나, 이에 국한되는 것은 아니며 컴퓨팅 기능이 구비된 모든 종류의 장치를 포함할 수 있다. 상기 컴퓨팅 장치의 일 예는 도 24를 참조하도록 한다. 이하에서는, 설명의 편의상 어노테이션 작업 관리 장치(100)를 관리 장치(100)로 약칭하도록 한다. 또한, 이하의 서술에서, 어노테이터 단말을 총칭하거나 구분 없이 임의의 어노테이터 단말을 지칭할 때는 참조 번호 20을 이용하도록 한다.
작업 관리 장치(100)는 관리자에 의해 이용되는 장치일 수 있다. 가령, 관리자는 작업 관리 장치(100)를 통해 작업 관리 웹 페이지 접속하고, 관리자 계정으로 로그인 한 다음, 전반적인 작업에 대한 관리를 수행할 수 있다. 가령, 관리자는 어노테이션 작업을 특정 어노테이터의 계정에 할당하거나, 어노테이션 결과를 리뷰자의 계정으로 전송하여 리뷰를 요청하는 등의 관리 행위를 수행할 수 있다. 물론, 위와 같은 제반 관리 과정은 작업 관리 장치(100)에 의해 자동으로 수행될 수도 잇는데, 이에 대한 설명은 도 5 이하의 도면을 참조하여 후술하도록 한다.
상기 어노테이션 작업 관리 시스템에서, 어노테이터 단말(20)은 어노테이터에 의해 어노테이션 작업이 수행되는 단말이다. 단말(20)에는 어노테이션 툴(annotation tool)이 설치되어 있을 수 있다. 물론, 작업 관리 웹 페이지를 통해 어노테이션을 위한 각종 기능이 제공될 수도 있다. 이와 같은 경우, 어노테이터는 단말(20)을 통해 상기 작업 관리 웹 페이지에 접속한 다음, 웹 상에서 어노테이션 작업을 수행할 수 있다. 상기 어노테이션 툴의 일 예시는 도 7을 참조하도록 한다.
상기 어노테이션 작업 관리 시스템에서, 리뷰자 단말(30)은 어노테이션 결과에 대한 리뷰를 수행하는 리뷰자 측의 단말이다. 리뷰자는 리뷰자 단말(30)을 이용하여 어노테이션 결과에 대한 리뷰를 수행하고, 리뷰 결과를 관리 장치(100)에게 제공할 수 있다.
몇몇 실시예에서, 어노테이션 작업 관리 시스템의 적어도 일부의 구성 요소들은 네트워크를 통해 통신할 수 있다. 여기서, 상기 네트워크는 근거리 통신망(Local Area Network; LAN), 광역 통신망(Wide Area Network; WAN), 이동 통신망(mobile radio communication network), Wibro(Wireless Broadband Internet) 등과 같은 모든 종류의 유/무선 네트워크로 구현될 수 있다.
지금까지 도 2 내지 도 4를 참조하여 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 시스템에 대하여 설명하였다. 이하에서는, 도 5 내지 도 23의 도면을 참조하여 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 방법에 대하여 설명하도록 한다.
상기 어노테이션 작업 관리 방법의 각 단계는 컴퓨팅 장치에 의해 수행될 수 있다. 다시 말하면, 상기 어노테이션 작업 관리 방법의 각 단계는 컴퓨팅 장치의 프로세서에 의해 실행되는 하나 이상의 인스트럭션들로 구현될 수 있다. 이해의 편의를 제공하기 위해, 상기 어노테이션 작업 관리 방법이 도 3 또는 도 4에 도시된 환경에서 수행되는 것을 가정하여 설명을 이어가도록 한다.
도 5는 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 방법을 나타내는 예시적인 흐름도이다. 단, 이는 본 개시의 목적을 달성하기 위한 바람직한 실시예일뿐이며, 필요에 따라 일부 단계가 추가되거나 삭제될 수 있음은 물론이다.
도 5에 도시된 바와 같이, 상기 어노테이션 작업 관리 방법은 신규의 병리 슬라이드 이미지에 대한 정보를 얻는 단계 S100에서 시작된다. 상기 병리 슬라이드 이미지에 대한 정보는 상기 병리 슬라이드 이미지의 메타 데이터만을 포함할 수 있고, 병리 슬라이드 이미지 파일을 더 포함할 수도 있다.
몇몇 실시예에서, 워커 에이전트(worker agent)를 통해 상기 신규의 병리 슬라이드 이미지에 대한 정보가 실시간으로 획득될 수 있다. 구체적으로, 상기 워커 에이전트에 의해 지정된 위치의 스토리지(e.g. 스토리지 서버 10 or 병리 슬라이드 이미지를 제공하는 의료 기관의 스토리지)에 병리 슬라이드 이미지 파일이 추가되는 것이 감지될 수 있다. 또한, 상기 워커 에이전트에 의하여 상기 신규의 병리 슬라이드 이미지에 대한 정보가 작업 관리 장치(100) 또는 스토리지 서버(10)의 데이터베이스에 삽입될 수 있다. 그러면, 상기 데이터베이스로부터 상기 신규의 병리 슬라이드 이미지에 대한 정보가 획득될 수 있다.
단계 S200에서, 관리 장치(100)는 상기 병리 슬라이드 이미지에 대한 어노테이션 작업을 생성한다. 여기서, 상기 어노테이션 작업은 상기 병리 슬라이드 이미지, 데이터셋 타입, 어노테이션 태스크 및 상기 병리 슬라이드 이미지의 일부 영역(즉, 어노테이션 대상 영역)인 패치 등의 정보에 기초하여 정의될 수 있다(도 4 참조). 본 단계 S200에 대한 자세한 설명은 도 8 내지 도 23을 참조하여 후술하도록 한다.
단계 S300에서, 관리 장치(100)는 상기 생성된 어노테이션 작업을 수행할 어노테이터를 선정한다.
몇몇 실시예에서, 도 6에 도시된 바와 같이, 관리 장치(100)는 어노테이터(51 내지 53)의 작업 수행 이력(e.g. 자주 진행했던 어노테이션 작업 등), 기 수행한 작업의 평가 결과(또는 검증 결과), 현재 작업 현황(e.g. 현재 할당된 작업의 진행 상태) 등의 관리 정보(54 내지 56) 에 기초하여 어노테이터를 자동으로 선정할 수 있다. 예를 들어, 관리 장치(100)는 상기 생성된 어노테이션 작업과 연관된 작업을 자주 수행했던 제1 어노테이터, 연관 작업에 대한 어노테이션 결과가 우수했던 제2 어노테이터, 현재 진행 중인 작업이 많지 않은 제3 어노테이터 등을 상기 생성된 어노테이션 작업의 어노테이터로 선정할 수 있다.
여기서, 작업 수행 이력에 상기 생성된 어노테이션 작업과 연관된 작업이 포함되어 있는지 여부는 각 작업의 데이터셋 타입과 어노테이션 태스크의 패널의 조합이 서로 유사한지 여부에 기초하여 판정될 수 있다. 또는, 어노테이션 태스크의 패널 및 태스크 클래스의 조합이 서로 유사한지 여부에 기초하여 판정될 수도 있다. 물론, 상기 두가지 조합이 모두 유사한지 여부에 기초하여 판정될 수도 있다.
몇몇 실시예에서, 상기 신규의 병리 슬라이드 이미지가 중요 데이터(e.g. 희귀병과 연관된 슬라이드 이미지, 고품질의 슬라이드 이미지 등)인 경우, 복수의 어노테이터가 선정될 수 있다. 또한, 어노테이터의 사람 수는 상기 중요도에 비례하여 증가될 수도 있다. 이와 같은 경우, 상기 복수의 어노테이터의 작업 결과를 상호 비교함으로써, 어노테이션 결과에 대한 검증이 수행될 수 있다. 본 실시예에 따르면, 중요 데이터에 대하여 보다 엄격한 검증이 수행됨으로써, 어노테이션 결과의 정확성이 향상될 수 있다.
단계 S400에서, 관리 장치(100)는 선정된 어노테이터의 단말(20)에게 어노테이션 작업을 할당한다. 가령, 관리 장치(100)는 상기 선정된 어노테이터의 계정에 어노테이션 작업을 할당할 수 있다.
단계 S500에서, 어노테이터 단말(20)에서 어노테이션이 수행된다. 어노테이터는 단말(20)에 설치된 어노테이터 툴 또는 웹(e.g. 작업 관리 웹 페이지)을 통해 제공되는 어노테이션 서비스를 이용하여 어노테이션을 수행할 수 있을 것이나, 본 개시의 기술적 범위가 이에 한정되는 것은 아니다.
상기 어노테이터 툴의 몇몇 예시는 도 6에 도시되어 있다. 도 6에 도시된 바와 같이, 어노테이션 툴(60)은 제1 영역(63)과 제2 영역(61)을 포함할 수 있다. 제2 영역(61)에는 실제 어노테이션이 수행될 패치 영역(68)과 확대/축소 인디케이터(65)가 포함될 수 있다. 도 6에 도시된 바와 같이, 패치 영역(68)에는 박스 라인 등의 하이라이트 처리가 이루어질 수 있다. 제1 영역(63)에는 작업 정보(67)가 표시되고, 도구 영역(69)이 더 포함될 수 있다. 도구 영역(69)에는 각 어노테이션에 대응되는 선택 가능한 도구들이 포함될 수 있다. 따라서, 어노테이터는 패치 영역(68)에 직접 어노테이션을 기입하지 않고, 간편하게 선택된 도구를 이용하여 패치 영역(68)에 어노테이션을 태깅할 수 있다(e.g. 클릭을 통해 제1 도구를 선택하고, 패치 영역 68을 다시 클릭하여 태깅 수행). 도구 영역(63)에 표시되는 어노테이션의 종류는 어노테이션 작업에 따라 달라질 것이므로, 어노테이션 툴(60)은 어노테이션 작업 정보에 기초하여 적절한 어노테이션 도구를 세팅할 수 있다.
도 6에 도시된 어노테이션 툴(60)은 어노테이터의 편의성을 위해 고안된 툴의 일 예시를 도시하고 있을 뿐임에 유의하여야 한다. 즉, 어노테이션 툴은 어떠한 방식으로 구현되더라도 무방하다. 다시 도 5를 참조하여 설명을 이어가도록 한다.
단계 S600에서, 어노테이터 단말(20)은 어노테이션 작업의 결과를 제공한다. 어노테이션 작업의 결과는 해당 패치에 태깅된 레이블 정보가 될 수 있다.
단계 S700에서, 관리 장치(100)는 작업 결과에 대한 검증(평가)을 수행한다. 상기 검증 결과는 해당 어노테이터의 평가 결과로 기록될 수 있다. 상기 검증을 수행하는 구체적인 방식은 실시예에 따라 달라질 수 있다.
몇몇 실시예에서, 기계학습 모델의 출력 결과에 기초하여 자동으로 검증이 수행될 수 있다. 구체적으로, 작업을 할당받은 어노테이터로부터 제1 어노테이션 결과 데이터가 획득되면, 상기 제1 어노테이션 결과 데이터와 상기 어노테이션 작업의 패치를 상기 기계학습 모델에 입력한 결과가 비교될 수 있다. 상기 비교 결과, 두 결과의 차이가 기준치를 초과하면 상기 제1 어노테이션 결과 데이터의 승인은 보류되거나 미승인 처리될 수 있다.
여기서, 상기 기준치는 기 설정된 고정 값 또는 상황에 따라 변동되는 변동 값일 수 있다. 가령, 상기 기준치는 상기 기계학습 모델의 정확도가 높을수록 더 작은 값으로 변동되는 값일 수 있다.
단계 S800에서, 관리 장치(100)는 어노테이션 작업이 다시 수행되어야 하는지 여부를 판정한다. 가령, 단계 S700에서 검증이 성공적으로 수행되지 않은 경우, 관리 장치(100)는 재작업이 필요하다는 결정을 내릴 수 있다.
단계 S900에서, 재작업 필요 결정에 응답하여, 관리 장치(100)는 다른 어노테이터를 선정하고, 상기 다른 어노테이터에게 어노테이션 작업을 재할당한다. 이때, 상기 다른 어노테이터는 단계 S300에서 설명한 바와 유사한 방식으로 선정될 수 있다. 또는, 상기 다른 어노테이터는 리뷰자 또는 성능이 가장 우수한 기계학습 모델이 될 수도 있다.
도 5에는 도시되어 있지 않으나, 단계 S900 이후에, 상기 다른 어노테이터의 제2 어노테이션 결과 데이터에 기초하여 상기 제1 어노테이션 결과 데이터에 대한 검증이 다시 수행될 수 있다. 구체적으로, 상기 제2 어노테이션 결과 데이터가 획득되면, 상기 제1 어노테이션 결과 데이터와 상기 제2 어노테이션 결과 데이터의 유사도가 산출될 수 있다. 또한, 상기 유사도가 기준치 미만이면 상기 제1 어노테이션 결과 데이터는 최종적으로 미승인 처리될 수 있다. 이와 같은 처리 결과는 해당 어노테이터의 작업 수행 이력에 기록될 수 있다.
지금까지 도 4 내지 도 7을 참조하여 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 관리 방법에 대하여 설명하였다. 상술한 방법에 따르면, 어노테이션 작업이 전반적으로 자동화됨에 따라 관리자의 편의성이 증대되고, 전반적인 작업 효율성이 크게 향상될 수 있다. 이에 따라, 어노테이션 작업에 소요되는 시간 비용 및 인적 비용이 크게 절감될 수 있다. 또한, 어노테이션 작업의 부담이 감소됨에 따라, 기계 학습 기법의 활용성은 더욱 증대될 수 있다.
나아가, 어노테이션 작업 결과를 기계학습 모델 또는 다른 어노테이터의 결과와 비교 검증함으로써, 어노테이션 결과의 정확성이 담보될 수 있다. 이에 따라, 어노테이션 결과를 학습한 기계학습 모델의 성능도 향상될 수 있다.
이하에서는, 도 8 내지 도 22를 참조하여 어노테이션 작업 생성 단계 S200의 세부 과정에 대하여 상세하게 설명하도록 한다.
도 8은 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 생성 방법을 나타내는 예시적인 흐름도이다. 단, 이는 본 개시의 목적을 달성하기 위한 바람직한 실시예일뿐이며, 필요에 따라 일부 단계가 추가되거나 삭제될 수 있음은 물론이다.
도 8에 도시된 바와 같이, 상기 어노테이션 작업 생성 방법은 신규의 병리 슬라이드 이미지의 데이터셋 타입을 결정하는 단계 S210에서 시작된다. 전술한 바와 같이, 상기 데이터셋 타입은 상기 병리 슬라이드 이미지의 활용 용도를 가리키는 것으로, 용도는 학습 용도, 검증 용도, 테스트 용도 또는 OPT(Observer Performance Test) 용도 등으로 구분될 수 있다.
몇몇 실시예에서, 상기 데이터셋 타입은 관리자의 선택에 의해 결정될 수 있다.
다른 몇몇 실시예에서, 상기 데이터셋 타입은 병리 슬라이드 이미지에 대한 기계학습 모델의 컨피던스 스코어에 기초하여 결정될 수 있다. 여기서, 상기 기계학습 모델은 병리 슬라이드 이미지에 기초하여 특정 태스크(e.g. 병변 분류, 병변 위치 인식 등)를 수행하는 모델(즉, 학습 대상 모델)을 의미한다. 본 실시예에 대한 자세한 내용은 도 9에 도시되어 있다. 도 9에 도시된 바와 같이, 관리 장치(100)는 병리 슬라이드 이미지를 기계학습 모델에 입력하고, 그 결과로 컨피던스 스코어를 획득하며(S211), 상기 컨피던스 스코어가 기준치 이상인지 여부를 판정한다(S213). 또한, 기준치 미만이라는 판정에 응답하여, 관리 장치(100)는 상기 병리 슬라이드 이미지의 데이터셋 타입을 학습 용도로 결정한다(S217). 컨피던스 스코어가 기준치 미만이라는 것은 기계학습 모델이 상기 병리 슬라이드 이미지를 명확하게 판단하지 못한다는 것을 의미하기 때문이다(즉, 해당 병리 슬라이드 이미지에 대한 학습이 필요하다는 것을 의미하기 때문이다). 반대의 경우, 상기 병리 슬라이드 이미지의 데이터셋 타입은 검증 용도(또는 테스트 용도)로 결정된다(S215).
또 다른 몇몇 실시예에서, 상기 데이터셋 타입은 병리 슬라이드 이미지에 대한 기계학습 모델의 엔트로피(entropy) 값에 기초하여 결정될 수 있다. 상기 엔트로피 값은 불확실성(uncertainty)를 나타내는 지표로, 컨피던스 스코어가 클래스 별로 고르게 분포할수록 큰 값을 가질 수 있다. 본 실시예에서, 상기 엔트로피 값이 기준치 이상이라는 판정에 응답하여, 상기 데이터셋 타입은 학습 용도로 결정될 수 있다. 반대의 경우라면, 검증 용도로 결정될 수 있다.
다시 도 8을 참조하면, 단계 S230에서, 관리 장치(100)는 병리 슬라이드 이미지의 패널 유형을 결정한다. 전술한 바와 같이, 상기 패널 유형은 세포 패널, 조직 패널 및 스트럭처 패널 등으로 구분될 수 있다. 상기 세포 패널 유형의 이미지의 예는 도 10에 도시되어 있고, 상기 조직 패널의 이미지의 예는 도 11에 도시되어 있으며, 상기 스트럭처 패널의 이미지의 예는 도 12에 도시되어 있다. 도 10 내지 도 12에 도시된 바와 같이, 세포 패널은 세포 레벨의 어노테이션이 수행되는 패치 유형이고, 조직 패널은 조직 레벨의 어노테이션이 수행되는 패치 유형이며, 조직 패널은 세포 또는 조직 등의 구조와 연관된 어노테이션이 수행되는 패치 유형이다.
몇몇 실시예에서, 상기 패널 유형은 관리자의 선택에 의해 결정될 수 있다.
몇몇 실시예에서, 상기 패널 유형은 기계학습 모델의 출력 값에 기초하여 결정될 수 있다. 도 13을 참조하여 부연 설명하면, 기계학습 모델에는 세포 패널에 대응되는 제1 기계학습 모델(75-1, 즉 세포 레벨의 어노테이션을 학습한 모델), 조직 패널에 대응되는 제2 기계학습 모델(75-2) 및 스트럭처 패널에 대응되는 제3 기계학습 모델(75-3)이 포함될 수 있다. 이와 같은 경우, 관리 장치(100)는 주어진 병리 슬라이드 이미지(71)에서 각각의 패널에 대응되는 제1 내지 제3 이미지(73-1 내지 73-3)를 추출(또는 샘플링)하고, 각 이미지를 대응되는 모델(75-1 내지 75-3)에 입력하며, 그 결과로 출력 값(77-1 내지 77-3)을 획득할 수 있다. 또한, 관리 장치(100)는 출력 값(77-1 내지 77-3)과 기준치와의 비교 결과에 따라 병리 슬라이드 이미지(71)의 패널 유형을 결정할 수 있다. 가령, 제1 출력 값(77-1)이 상기 기준치 미만인 경우, 병리 슬라이드 이미지(71)의 패널 유형은 세포 패널로 결정될 수 있다. 병리 슬라이드 이미지(71)에서 추출되는 세포 패치들이 제1 기계학습 모델(75-1)의 학습 성능을 올리는데 효과적일 것이기 때문이다.
몇몇 실시예에서, 병리 슬라이드 이미지가 복수의 패널 유형을 가질 수도 있다. 이와 같은 경우, 상기 병리 슬라이드 이미지로부터 각 패널에 대응되는 패치들이 추출될 수 있다.
다시 도 8을 참조하면, 단계 S250에서, 관리 장치(100)는 어노테이션 태스크를 결정한다. 전술한 바와 같이, 어노테이션 태스크는 세부 작업 유형이 정의해 놓은 엔티티를 의미한다.
몇몇 실시예에서, 상기 어노테이션 태스크는 관리자의 선택에 의해 결정될 수 있다.
몇몇 실시예에서, 상기 어노테이션 태스크는 상기 결정된 데이터셋 타입과 패널 유형의 조합에 기초하여 자동으로 결정될 수도 있다. 가령, 데이터셋 타입과 패널 유형의 조합에 매칭되는 어노테이션 태스크가 미리 정의되어 있는 경우, 상기 조합에 에 기초하여 상기 매칭되는 어노테이션 태스크가 자동으로 결정될 수 있다.
단계 S270에서, 관리 장치(100)는 병리 슬라이드 이미지에서 실제 어노테이션이 수행될 패치를 자동으로 추출한다. 물론, 관리자에 의해 지정된 영역이 패치로 추출될 수도 있다. 상기 패치를 자동으로 추출하는 구체적인 방법은 실시예에 따라 달라질 수 있는데, 패치 추출과 관련된 다양한 실시예들은 도 14 내지 도 23을 참조하여 후술하도록 한다.
도 8에는 도시되어 있지 않으나, 단계 S270 이후에, 관리 장치(100)는 단계 S210 내지 S270에서 결정된 데이터셋 타입, 패널 유형, 어노테이션 태스크 및 패치에 기반하여 어노테이션 작업을 생성할 수 있다. 전술한 바와 같이, 생성된 어노테이션 작업은 적절한 어노테이터의 계정에 할당될 수 있다.
지금까지 도 8 내지 도 13을 참조하여 본 개시의 몇몇 실시예들에 따른 어노테이션 작업 생성 방법에 대하여 설명하였다. 이하에서는, 패치 자동 추출과 관련된 본 개시의 다양한 실시예들에 대하여 도 14 내지 도 23을 참조하여 설명하도록 한다.
도 14는 본 개시의 제1 실시예에 따른 패치 자동 추출 방법을 나타내는 예시적인 흐름도이다. 단, 이는 본 개시의 목적을 달성하기 위한 바람직한 실시예일뿐이며, 필요에 따라 일부 단계가 추가되거나 삭제될 수 있음은 물론이다.
도 14에 도시된 바와 같이, 상기 패치 자동 추출 방법은 신규의 병리 슬라이드 이미지에서 복수의 후보 패치를 샘플링하는 단계 S271에서 시작된다. 상기 복수의 후보 패치를 샘플링하는 구체적인 방식은 실시예에 따라 달라질 수 있다.
몇몇 실시예에서, 특정 조직을 구성하는 적어도 세포 영역들을 후보 패치(즉, 세포 패널 유형의 패치들)로 샘플링하는 경우, 도 15에 도시된 바와 같이, 병리 슬라이드 이미지(81)에서 영상 분석을 통해 조직 영역(83)을 추출하고, 추출된 영역(83) 내에서 복수의 후보 패치들(85)이 샘플링될 수 있다. 샘플링 결과의 몇몇 예시는 도 16 및 도 17에 도시되어 있다. 도 16 및 도 17에 도시된 병리 슬라이드 이미지(87, 89)에서, 각 포인트는 샘플링 포인트를 의미하고, 사각형의 도형은 샘플링 영역(즉, 후보 패치 영역)을 의미한다. 도 16 및 도 17에 도시된 바와 같이, 복수의 후보 패치들은 적어도 일부가 중첩되는 형태로 샘플링될 수도 있다.
몇몇 실시예에서, 병리 슬라이드 이미지의 전체 영역을 균일하게 분할하고, 분할된 각각의 영역들을 샘플링하여 후보 패치들이 생성될 수 있다. 즉, 균등 분할 방식으로 샘플링이 수행될 수 있다. 이때, 각 후보 패치들의 크기는 기 설정된 고정 값 또는 병리 슬라이드 이미지의 크기, 해상도, 패널 유형 등에 기초하여 결정되는 변동 값일 수 있다.
몇몇 실시예에서, 병리 슬라이드 이미지의 전체 영역을 랜덤하게 분할하고, 분할된 각각의 영역들을 샘플링하여 후보 패치들이 생성될 수 있다.
몇몇 실시예에서, 객체의 개수가 기준치를 초과하도록 후보 패치들이 형성될 수 있다. 가령, 상기 병리 슬라이드 이미지의 전체 영역에 대하여 객체 인식을 수행하고, 상기 객체 인식의 결과 산출된 객체의 개수가 기준치를 초과하는 영역이 후보 패치로 샘플링될 수 있다. 이와 같은 경우, 후보 패치의 크기는 서로 다를 수도 있다.
몇몇 실시예에서, 병리 슬라이드 이미지의 메타 데이터에 기반하여 결정된 정책에 따라 분할된 후보 패치가 샘플링될 수 있다. 여기서, 상기 메타 데이터는 상기 병리 슬라이드 이미지와 연관된 병명, 조직(tissue), 환자의 인구통계학적 정보, 의료기관의 위치, 상기 병리 슬라이드 이미지의 품질(e.g. 해상도), 포맷 형식 등이 될 수 있다. 구체적인 예를 들어, 병리 슬라이드 이미지가 종양 환자의 조직에 관한 이미지인 경우, 유사 분열 세포 검출을 위한 기계학습 모델의 학습 데이터로 이용하기 위해, 세포 레벨로 후보 패치가 샘플링될 수 있다. 다른 예를 들어, 병리 슬라이드 이미지와 연관된 병명의 예후를 진단할 때 조직 내 병변의 위치가 중요한 경우, 조직 레벨로 후보 패치가 샘플링될 수도 있다.
몇몇 실시예에서, 병리 슬라이드 이미지에서 스트럭처 패널 유형의 후보 패치들을 샘플링하는 경우, 영상 분석을 통해 상기 병리 슬라이드 이미지에서 외곽선이 추출되고, 상기 추출된 외곽선 중에서 서로 연결된 외곽선들이 하나의 후보 패치를 형성하도록 샘플링이 수행될 수도 있다.
이와 같이, 단계 S271에서 복수의 후보 패치를 샘플링하는 구체적인 방식은 실시예에 따라 달라질 수 있다. 다시 도 14를 참조하여 설명을 이어가도록 한다.
단계 S273에서, 기계학습 모델의 출력 값에 기반하여 어노테이션 대상 패치가 선정된다. 상기 출력 값은 예를 들어 컨피던스 스코어(또는 클래스 별 컨피던스 스코어)가 될 수 있는데, 상기 컨피던스 스코어에 기초하여 패치를 선정하는 구체적인 방식은 실시예에 따라 달라질 수 있다.
몇몇 실시예에서, 클래스 별 컨피던스 스코어에 의해 산출된 엔트로피 값에 기초하여 어노테이션 대상 패치가 선정될 수 있다. 본 실시예에 대한 자세한 내용은 도 18 및 도 19에 도시되어 있다.
도 18에 도시된 바와 같이, 병리 슬라이드 이미지(91)에서 샘플링된 후보 패치들(92)로부터 엔트로피 값 기반의 불확실성 샘플링을 통해 어노테이션 대상 패치(93)가 선정될 수 있다. 보다 구체적으로, 도 19에 도시된 바와 같이, 기계학습 모델(95)로부터 출력된 각 후보 패치(94-1 내지 94-n)의 클래스 별 컨피던스 스코어(96-1 내지 96-n)를 기초로 엔트로피 값(97-1 내지 97-n)이 산출될 수 있다. 전술한 바와 같이, 엔트로피 값은 컨피던스 스코어가 클래스 별로 고르게 분포할수록 큰 값을 갖게 된다. 가령, 도 19에 도시된 경우라면, 엔트로피 A(97-1)가 가장 큰 값으로 연산되고, 엔트로피 C(97-n)가 가장 작은 값으로 연산된다. 또한, 엔트로피 값이 기준치 이상인 후보 패치들이 어노테이션 대상으로 자동 선정될 수 있다. 엔트로피 값이 높다는 것은 기계학습 모델의 예측 결과가 불확실하다는 것을 의미하고, 이는 곧 학습에 보다 효과적인 데이터라는 것을 의미하기 때문이다.
몇몇 실시예에서, 상기 컨피던스 스코어 자체에 기초하여 어노테이션 대상 패치가 선정될 수도 있다. 가령, 복수의 후보 패치 중에서, 컨피던스 스코어가 기준치 미만인 후보 패치가 상기 어노테이션 대상 패치로 선정될 수 있다.
도 20은 본 개시의 제2 실시예들에 따른 패치 자동 추출 방법을 나타내는 예시적인 흐름도이다. 단, 이는 본 개시의 목적을 달성하기 위한 바람직한 실시예일뿐이며, 필요에 따라 일부 단계가 추가되거나 삭제될 수 있음은 물론이다. 명세서의 명료함을 위해, 전술한 실시예와 중복되는 내용에 대한 설명은 생략하도록 한다.
도 20에 도시된 바와 같이, 상기 제2 실시예 또한 복수의 후보 패치를 샘플링하는 단계 S271에서 시작된다. 다만, 상기 제2 실시예에서는 기계학습 모델의 오예측 확률에 기반하여 어노테이션 대상 패치가 선정된다는 점에서(S275 참조), 전술한 실시예와 차이가 있다.
상기 기계학습 모델의 오예측 확률은 기계 학습을 통해 구축된 오예측 확률 산출 모델(이하, "산출 모델"로 약칭함)에 의해 산출될 수 있는데, 이해의 편의를 제공하기 위해, 먼저 상기 산출 모델을 구축하는 방법에 대하여 도 21 및 도 22를 참조하여 설명하도록 한다.
도 21에 도시된 바와 같이, 상기 산출 모델은 상기 기계학습 모델의 평가 결과(e.g. 검증 결과, 테스트 결과)를 학습함으로써 구축될 수 있다(S291 내지 S295). 구체적으로, 평가용 데이터로 상기 기계학습 모델을 평가하고(S291), 평가 결과가 상기 평가용 데이터에 레이블 정보로 태깅되면(S293), 상기 평가용 데이터를 상기 레이블 정보로 학습함으로써 상기 산출 모델이 구축될 수 있다(S295).
평가용 데이터에 레이블 정보를 태깅하는 몇몇 예시는 도 22에 도시되어 있다. 도 22는 혼동 행렬(confusion matrix)을 도시하고 있는데, 상기 기계학습 모델이 분류 태스크를 수행하는 모델인 경우, 평가 결과는 혼동 행렬 내의 특정 셀에 대응될 수 있다. 도 22에 도시된 바와 같이, 평가 결과가 FP(false positive) 또는 FN(false negative)인 이미지(101)에는 제1 값(e.g. 1)이 레이블 값(102)으로 태깅되고, 평가 결과가 TP(true positive) 또는 TN(true negative)인 이미지(103)에는 제2 값(e.g. 0)이 레이블 값(104)으로 태깅될 수 있다. 즉, 기계학습 모델의 예측이 정답과 일치한 경우에는 "1"이 태깅되고, 불일치한 경우에는 "0"이 태깅될 수 있다.
위와 같은 이미지(101, 102)와 레이블 정보를 학습하게 되면, 산출 모델은 기계학습 모델이 정확하게 예측했던 이미지와 유사한 이미지가 입력될 때 높은 컨피던스 스코어를 출력하게 된다. 또한, 반대의 경우 산출 모델은 낮은 컨피던스 스코어를 출력하게 된다. 따라서, 산출 모델은 입력된 이미지에 대한 기계학습 모델의 오예측 확률을 산출할 수 있게 된다.
한편, 도 22는 레이블 정보를 태깅하는 몇몇 예시를 도시하고 있을 뿐임에 유의하여야 한다. 본 개시의 다른 몇몇 실시예들에 따르면, 예측 오차가 레이블 정보로 태깅될 수도 있다. 여기서, 상기 예측 오차는 예측 값(즉, 컨피던스 스코어)과 실제 값(즉, 정답 정보)의 차이를 의미한다.
또한, 본 개시의 또 다른 몇몇 실시예들에 따르면, 평가용 이미지의 예측 오차가 임계 값 이상인 경우 제1 값(e.g. 0)이 태깅되고, 상기 예측 오차가 상기 임계 값 미만인 경우 제2 값(e.g. 1)이 레이블 정보로 태깅될 수도 있다.
다시 도 20을 참조하여 설명을 이어가도록 한다.
전술한 방법에 따라 산출 모델이 구축되면, 단계 S275에서, 관리 장치(100)는 복수의 후보 패치들 각각에 대한 오예측 확률을 산출할 수 있다. 가령, 도 23에 도시된 바와 같이, 관리 장치(100)는 각 데이터 샘플(111-1 내지 111-n)을 산출 모델(113)에 입력하여 산출 모델(113)의 컨피던스 스코어(115-1 내지 115-n)를 획득하고, 획득된 컨피던스 스코어(115-1 내지 115-n)에 기초하여 상기 오예측 확률을 산출할 수 있다.
다만, 도 23에 도시된 바와 같이, 후보 패치(11-1 내지 111-n)가 입력될 때, 정답 및 오답 클래스에 대한 컨피던스 스코어(115-1 내지 115-n)를 출력하도록 산출 모델(113)이 학습된 경우(e.g. 정답과 일치 시 레이블 1로 학습하고, 불일치 시 레이블 0으로 학습한 경우)라면, 오답 클래스의 컨피던스 스코어(밑줄로 도시됨)가 오예측 확률로 이용될 수도 있다.
각 후보 패치의 오예측 확률이 산출되면, 관리 장치(100)는 복수의 후보 패치 중에서 상기 산출된 오예측 확률이 기준치 이상인 후보 패치를 어노테이션 대상으로 선정할 수 있다. 오예측 확률이 높다는 것은 상기 기계학습 모델의 예측 결과가 틀릴 가능성이 높다는 것을 의미하고, 이는 곧 해당 패치가 상기 기계학습 모델의 성능을 개선하는데 중요한 데이터라는 것을 의미하기 때문이다. 이와 같이, 오예측 확률에 기반하여 패치를 선정하면, 학습에 효과적인 패치들이 어노테이션 대상으로 선정됨으로써 양질의 학습 데이터셋이 생성될 수 있다.
지금까지 도 14 내지 도 23을 참조하여 본 개시의 다양한 실시예들에 따른 패치 자동 추출 방법에 대하여 설명하였다. 상술한 방법에 따르면, 어노테이션이 수행될 영역을 가리키는 패치가 자동으로 추출될 수 있다. 따라서, 관리자의 업무 부담이 최소화될 수 있다. 또한, 기계 학습 모델의 오예측 확률, 엔트로피 값 등에 기반하여 복수의 후보 패치 중에서 학습에 효과적인 패치만이 어노테이션 대상으로 선정된다. 이에 따라, 어노테이션 작업량이 감소되고, 양질의 학습 데이터셋이 생성될 수 있다
이하에서는, 도 24를 참조하여 본 개시의 다양한 실시예들에 따른 장치(e.g. 관리 장치 100)/시스템을 구현할 수 있는 예시적인 컴퓨팅 장치(200)에 대하여 설명하도록 한다.
도 24는 본 개시의 다양한 실시예들에 따른 장치를 구현할 수 있는 예시적인 컴퓨팅 장치(200)를 나타내는 예시적인 하드웨어 구성도이다.
도 24에 도시된 바와 같이, 컴퓨팅 장치(200)는 하나 이상의 프로세서(210), 버스(250), 통신 인터페이스(270), 프로세서(210)에 의하여 수행되는 컴퓨터 프로그램을 로드(load)하는 메모리(230)와 컴퓨터 프로그램(291)를 저장하는 스토리지(290)를 포함할 수 있다. 다만, 도 24에는 본 개시의 실시예와 관련 있는 구성요소들만이 도시되어 있다. 따라서, 본 개시가 속한 기술분야의 통상의 기술자라면 도 24에 도시된 구성요소들 외에 다른 범용적인 구성 요소들이 더 포함될 수 있음을 알 수 있다.
프로세서(210)는 컴퓨팅 장치(200)의 각 구성의 전반적인 동작을 제어한다. 프로세서(210)는 CPU(Central Processing Unit), MPU(Micro Processor Unit), MCU(Micro Controller Unit), GPU(Graphic Processing Unit) 또는 본 개시의 기술 분야에 잘 알려진 임의의 형태의 프로세서를 포함하여 구성될 수 있다. 또한, 프로세서(210)는 본 개시의 실시예들에 따른 방법을 실행하기 위한 적어도 하나의 애플리케이션 또는 프로그램에 대한 연산을 수행할 수 있다. 컴퓨팅 장치(200)는 하나 이상의 프로세서를 구비할 수 있다.
메모리(230)는 각종 데이터, 명령 및/또는 정보를 저장한다. 메모리(230)는 본 개시의 다양한 실시예들에 따른 방법/동작을 실행하기 위하여 스토리지(290)로부터 하나 이상의 프로그램(291)을 로드할 수 있다. 메모리(230)는 RAM과 같은 휘발성 메모리로 구현될 수 있을 것이나, 본 개시의 기술적 범위는 이에 한정되지 아니한다.
버스(250)는 컴퓨팅 장치(200)의 구성 요소 간 통신 기능을 제공한다. 버스(250)는 주소 버스(Address Bus), 데이터 버스(Data Bus) 및 제어 버스(Control Bus) 등 다양한 형태의 버스로 구현될 수 있다.
통신 인터페이스(270)는 컴퓨팅 장치(200)의 유무선 인터넷 통신을 지원한다. 또한, 통신 인터페이스(270)는 인터넷 통신 외의 다양한 통신 방식을 지원할 수도 있다. 이를 위해, 통신 인터페이스(270)는 본 개시의 기술 분야에 잘 알려진 통신 모듈을 포함하여 구성될 수 있다.
스토리지(290)는 상기 하나 이상의 프로그램(291)을 비임시적으로 저장할 수 있다. 스토리지(290)는 ROM(Read Only Memory), EPROM(Erasable Programmable ROM), EEPROM(Electrically Erasable Programmable ROM), 플래시 메모리 등과 같은 비휘발성 메모리, 하드 디스크, 착탈형 디스크, 또는 본 개시가 속하는 기술 분야에서 잘 알려진 임의의 형태의 컴퓨터로 읽을 수 있는 기록 매체를 포함하여 구성될 수 있다.
컴퓨터 프로그램(291)은 메모리(230)에 로드될 때 프로세서(210)로 하여금 본 개시의 다양한 실시예들에 따른 동작/방법을 수행하도록 하는 하나 이상의 인스트럭션들(instructions)을 포함할 수 있다. 즉, 프로세서(210)는 상기 하나 이상의 인스트럭션들을 실행함으로써, 본 개시의 다양한 실시예들에 따른 동작/방법들을 수행할 수 있다.
예를 들어, 컴퓨터 프로그램(291)은 신규의 병리 슬라이드 이미지에 대한 정보를 얻는 동작, 상기 병리 슬라이드 이미지의 데이터셋 타입 및 패널을 결정하는 동작 및 상기 병리 슬라이드 이미지, 상기 결정된 데이터셋 타입, 어노테이션 태스크(annotation task) 및 상기 병리 슬라이드 이미지의 일부 영역인 패치로 정의되는 어노테이션 작업(job)을 어노테이터(annotator) 계정에 할당하는 동작을 수행하도록 하는 하나 이상의 인스트럭션들을 포함할 수 있다. 이와 같은 경우, 컴퓨팅 장치(200)를 통해 본 개시의 몇몇 실시예들에 따른 관리 장치(100)가 구현될 수 있다.
지금까지 도 24를 참조하여 본 개시의 다양한 실시예들에 따른 장치를 구현할 수 있는 예시적인 컴퓨팅 장치에 대하여 설명하였다.
지금까지 도 1 내지 도 24를 참조하여 설명된 본 개시의 기술적 사상은 컴퓨터가 읽을 수 있는 매체 상에 컴퓨터가 읽을 수 있는 코드로 구현될 수 있다. 상기 컴퓨터로 읽을 수 있는 기록 매체는, 예를 들어 이동형 기록 매체(CD, DVD, 블루레이 디스크, USB 저장 장치, 이동식 하드 디스크)이거나, 고정식 기록 매체(ROM, RAM, 컴퓨터 구비 형 하드 디스크)일 수 있다. 상기 컴퓨터로 읽을 수 있는 기록 매체에 기록된 상기 컴퓨터 프로그램은 인터넷 등의 네트워크를 통하여 다른 컴퓨팅 장치에 전송되어 상기 다른 컴퓨팅 장치에 설치될 수 있고, 이로써 상기 다른 컴퓨팅 장치에서 사용될 수 있다.
이상에서, 본 개시의 실시예를 구성하는 모든 구성 요소들이 하나로 결합되거나 결합되어 동작하는 것으로 설명되었다고 해서, 본 개시의 기술적 사상이 반드시 이러한 실시예에 한정되는 것은 아니다. 즉, 본 개시의 목적 범위 안에서라면, 그 모든 구성요소들이 하나 이상으로 선택적으로 결합하여 동작할 수도 있다.
도면에서 동작들이 특정한 순서로 도시되어 있지만, 반드시 동작들이 도시된 특정한 순서로 또는 순차적 순서로 실행되어야만 하거나 또는 모든 도시 된 동작들이 실행되어야만 원하는 결과를 얻을 수 있는 것으로 이해되어서는 안 된다. 특정 상황에서는, 멀티태스킹 및 병렬 처리가 유리할 수도 있다. 더욱이, 위에 설명한 실시예들에서 다양한 구성들의 분리는 그러한 분리가 반드시 필요한 것으로 이해되어서는 안 되고, 설명된 프로그램 컴포넌트들 및 시스템들은 일반적으로 단일 소프트웨어 제품으로 함께 통합되거나 다수의 소프트웨어 제품으로 패키지 될 수 있음을 이해하여야 한다.
이상 첨부된 도면을 참조하여 본 개시의 실시예들을 설명하였지만, 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자는 그 기술적 사상이나 필수적인 특징을 변경하지 않고서 본 개시가 다른 구체적인 형태로도 실시될 수 있다는 것을 이해할 수 있다. 그러므로 이상에서 기술한 실시예들은 모든 면에서 예시적인 것이며 한정적인 것이 아닌 것으로 이해해야만 한다. 본 개시의 보호 범위는 아래의 청구범위에 의하여 해석되어야 하며, 그와 동등한 범위 내에 있는 모든 기술 사상은 본 개시에 의해 정의되는 기술적 사상의 권리범위에 포함되는 것으로 해석되어야 할 것이다.
Claims (1)
- 적어도 하나의 컴퓨팅 장치에 의해 수행되는 어노테이션 작업 관리 방법에 있어서,
어노테이션 대상인 병리 슬라이드 이미지를 획득하는 단계;
결정된 데이터셋 타입 및 패널 유형 중 적어도 하나를 기초로, 상기 병리 슬라이드 이미지에 포함되는 복수의 후보 패치 중에서 적어도 하나의 어노테이션 작업 대상 패치를 적어도 하나의 어노테이터 계정에 할당하는 단계를 포함하는
어노테이션 작업 관리 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020200016770A KR102413583B1 (ko) | 2020-01-28 | 2020-02-12 | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020200009995A KR102081037B1 (ko) | 2020-01-28 | 2020-01-28 | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 |
| KR1020200016770A KR102413583B1 (ko) | 2020-01-28 | 2020-02-12 | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020200009995A Division KR102081037B1 (ko) | 2020-01-28 | 2020-01-28 | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200054138A true KR20200054138A (ko) | 2020-05-19 |
| KR102413583B1 KR102413583B1 (ko) | 2022-06-27 |
Family
ID=82247407
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020200016770A KR102413583B1 (ko) | 2020-01-28 | 2020-02-12 | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102413583B1 (ko) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102204829B1 (ko) * | 2020-06-12 | 2021-01-19 | 인하대학교 산학협력단 | 딥러닝 기반의 어노테이션 툴을 제공하는 방법 및 시스템 |
| KR102241724B1 (ko) * | 2020-05-22 | 2021-04-19 | 주식회사 루닛 | 레이블 정보를 보정하는 방법 및 시스템 |
| KR20220001204A (ko) | 2020-06-29 | 2022-01-05 | (주)휴톰 | 복수의 학습모델을 이용한 어노테이터 평가 및 어노테이션 분석 방법, 전자 장치 및 프로그램 |
| KR20220006292A (ko) | 2020-07-08 | 2022-01-17 | 주식회사 메가젠임플란트 | 학습 데이터 생성장치 및 그 장치의 구동방법, 그리고 컴퓨터 판독가능 기록매체 |
| KR20220068316A (ko) | 2020-11-18 | 2022-05-26 | (주)휴톰 | 어노테이션 평가 방법 및 장치 |
| KR102403617B1 (ko) * | 2021-10-20 | 2022-05-30 | 주식회사 애자일소다 | 학습 데이터 생성 장치 및 방법 |
| KR20220105545A (ko) * | 2021-01-20 | 2022-07-27 | 주식회사 한글과컴퓨터 | 기계학습용 데이터의 분류 저장 및 검색을 지원하는 데이터 처리 장치, 및 그 동작 방법 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20090006295A (ko) * | 2007-07-11 | 2009-01-15 | 하숙태 | 세포 슬라이드 판독 장치, 세포 슬라이드 판독 시스템,이를 이용하는 세포 슬라이드 판독 방법 및 기록매체 |
| KR20140093974A (ko) | 2011-11-08 | 2014-07-29 | 비디노티 에스아 | 이미지 주석 방법 및 시스템 |
| JP2016049327A (ja) * | 2014-09-01 | 2016-04-11 | 富士フイルム株式会社 | 医用画像計測装置および方法並びにプログラム |
| KR101623431B1 (ko) * | 2015-08-06 | 2016-05-23 | 주식회사 루닛 | 의료 영상의 병리 진단 분류 장치 및 이를 이용한 병리 진단 시스템 |
| KR20170046104A (ko) * | 2015-09-24 | 2017-04-28 | 주식회사 뷰노코리아 | 질환 모델 기반의 의료 정보 서비스 제공 방법 및 장치 |
-
2020
- 2020-02-12 KR KR1020200016770A patent/KR102413583B1/ko active IP Right Grant
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20090006295A (ko) * | 2007-07-11 | 2009-01-15 | 하숙태 | 세포 슬라이드 판독 장치, 세포 슬라이드 판독 시스템,이를 이용하는 세포 슬라이드 판독 방법 및 기록매체 |
| KR20140093974A (ko) | 2011-11-08 | 2014-07-29 | 비디노티 에스아 | 이미지 주석 방법 및 시스템 |
| JP2016049327A (ja) * | 2014-09-01 | 2016-04-11 | 富士フイルム株式会社 | 医用画像計測装置および方法並びにプログラム |
| KR101623431B1 (ko) * | 2015-08-06 | 2016-05-23 | 주식회사 루닛 | 의료 영상의 병리 진단 분류 장치 및 이를 이용한 병리 진단 시스템 |
| KR20170046104A (ko) * | 2015-09-24 | 2017-04-28 | 주식회사 뷰노코리아 | 질환 모델 기반의 의료 정보 서비스 제공 방법 및 장치 |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102241724B1 (ko) * | 2020-05-22 | 2021-04-19 | 주식회사 루닛 | 레이블 정보를 보정하는 방법 및 시스템 |
| US11710552B2 (en) | 2020-05-22 | 2023-07-25 | Lunit Inc. | Method and system for refining label information |
| KR102204829B1 (ko) * | 2020-06-12 | 2021-01-19 | 인하대학교 산학협력단 | 딥러닝 기반의 어노테이션 툴을 제공하는 방법 및 시스템 |
| KR20220001204A (ko) | 2020-06-29 | 2022-01-05 | (주)휴톰 | 복수의 학습모델을 이용한 어노테이터 평가 및 어노테이션 분석 방법, 전자 장치 및 프로그램 |
| KR20220006292A (ko) | 2020-07-08 | 2022-01-17 | 주식회사 메가젠임플란트 | 학습 데이터 생성장치 및 그 장치의 구동방법, 그리고 컴퓨터 판독가능 기록매체 |
| KR20220068316A (ko) | 2020-11-18 | 2022-05-26 | (주)휴톰 | 어노테이션 평가 방법 및 장치 |
| KR20220105545A (ko) * | 2021-01-20 | 2022-07-27 | 주식회사 한글과컴퓨터 | 기계학습용 데이터의 분류 저장 및 검색을 지원하는 데이터 처리 장치, 및 그 동작 방법 |
| KR102403617B1 (ko) * | 2021-10-20 | 2022-05-30 | 주식회사 애자일소다 | 학습 데이터 생성 장치 및 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102413583B1 (ko) | 2022-06-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11062800B2 (en) | Method for managing annotation job, apparatus and system supporting the same | |
| KR102075270B1 (ko) | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 | |
| KR102413583B1 (ko) | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 | |
| KR102081037B1 (ko) | 어노테이션 작업 관리 방법, 이를 지원하는 장치 및 시스템 | |
| US20200356901A1 (en) | Target variable distribution-based acceptance of machine learning test data sets | |
| JP6967512B2 (ja) | 画像解釈ワークフローにおけるサードパーティアプリケーションの統合のための構造化所見オブジェクト | |
| US20230148374A1 (en) | Code development management system | |
| US12067720B2 (en) | Quality control of automated whole-slide analyses | |
| US10971255B2 (en) | Multimodal learning framework for analysis of clinical trials | |
| US20190087744A1 (en) | Automatic Selection of Variables for a Machine-Learning Model | |
| US20210342735A1 (en) | Data model processing in machine learning using a reduced set of features | |
| US11244761B2 (en) | Accelerated clinical biomarker prediction (ACBP) platform | |
| JP2018507450A (ja) | 自動スキーマ不整合検出 | |
| US10019681B2 (en) | Multidimensional recursive learning process and system used to discover complex dyadic or multiple counterparty relationships | |
| US10936801B2 (en) | Automated electronic form generation with context cues | |
| KR20210080224A (ko) | 정보 처리 장치 및 정보 처리 방법 | |
| US11593700B1 (en) | Network-accessible service for exploration of machine learning models and results | |
| US20230290485A1 (en) | Artificial intelligence prioritization of abnormal radiology scans | |
| US20230237380A1 (en) | Multivariate outlier detection for data privacy protection | |
| US11742081B2 (en) | Data model processing in machine learning employing feature selection using sub-population analysis | |
| US20170039266A1 (en) | Methods and systems for multi-code categorization for computer-assisted coding | |
| US9189465B2 (en) | Documentation of system monitoring and analysis procedures | |
| WO2024193195A1 (zh) | 硬件兼容性测试方法、装置、计算设备集群和程序产品 | |
| JP2024150151A (ja) | 作業情報管理装置、作業情報管理システム及び作業情報管理方法 | |
| CN115934042A (zh) | 一种研发需求评估方法及装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant |