KR20170069258A - 성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템 - Google Patents
성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템 Download PDFInfo
- Publication number
- KR20170069258A KR20170069258A KR1020177012683A KR20177012683A KR20170069258A KR 20170069258 A KR20170069258 A KR 20170069258A KR 1020177012683 A KR1020177012683 A KR 1020177012683A KR 20177012683 A KR20177012683 A KR 20177012683A KR 20170069258 A KR20170069258 A KR 20170069258A
- Authority
- KR
- South Korea
- Prior art keywords
- information
- user
- text
- grammar
- voice
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 85
- 238000007726 management method Methods 0.000 title abstract description 32
- 238000012545 processing Methods 0.000 claims abstract description 26
- 238000001914 filtration Methods 0.000 claims abstract description 25
- 238000010586 diagram Methods 0.000 description 8
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000012795 verification Methods 0.000 description 5
- 241000272168 Laridae Species 0.000 description 3
- 238000001228 spectrum Methods 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000006854 communication Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000001303 quality assessment method Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/22—Interactive procedures; Man-machine interfaces
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/02—Preprocessing operations, e.g. segment selection; Pattern representation or modelling, e.g. based on linear discriminant analysis [LDA] or principal components; Feature selection or extraction
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/04—Training, enrolment or model building
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/06—Decision making techniques; Pattern matching strategies
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/30—Authentication, i.e. establishing the identity or authorisation of security principals
- G06F21/31—User authentication
- G06F21/32—User authentication using biometric data, e.g. fingerprints, iris scans or voiceprints
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/22—Interactive procedures; Man-machine interfaces
- G10L17/24—Interactive procedures; Man-machine interfaces the user being prompted to utter a password or a predefined phrase
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Quality & Reliability (AREA)
- Computer Security & Cryptography (AREA)
- Theoretical Computer Science (AREA)
- Business, Economics & Management (AREA)
- Game Theory and Decision Science (AREA)
- Computer Hardware Design (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Telephonic Communication Services (AREA)
- Storage Device Security (AREA)
Abstract
본 출원은 제1 사용자의 음성 정보를 얻기 위하여 연관된 시스템 내에 저장된 이력 음성 파일의 필터링, 텍스트 인식 처리에 의한 음성 정보에 대응하는 텍스트 정보 취득, 및 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집을 포함하는 성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템에 관한 것이다. 기준 성문 정보 내의 텍스트 정보 및 음성 정보가 모두 연관된 시스템에 의해 사전 설정되지 않고 상술한 이력 음성 파일 기반으로 취득되므로, 즉, 공개되지 않으므로, 신원 인증이 실행될 때 다시 읽어져야 할 텍스트 정보의 특정한 내용을 사용자가 예견할 수 없고, 따라서 사전 녹음된 음성 파일을 재생하여 성공적인 인증의 목적을 달성할 수 없다. 그러므로, 신원 인증이 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법 기반으로 수행되고, 인증 결과가 더 정확하며, 잠재적인 보안 위험이 존재하지 않으며, 계정의 보안이 강화된다.
Description
본 출원은 성문 인식의 기술 분야에 관한 것이며, 더 구체적으로는, 성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템에 관한 것이다.
성문은 전자 음향 기기로 재생되는(displayed) 구두 정보를 담고 있는 음파 스펙트럼을 말한다. 동일한 단어를 말하는 다른 사람들에 의해 생성되는 음파는 상이하고, 대응하는 음파 스펙트럼, 즉 성문 정보도 상이하다. 따라서, 성문(voiceprint) 정보를 비교함으로써 대응하는 화자가 동일한지 판단할 수 있다. 즉, 성문 인식에 기반한 신원 인증이 구현된다. 성문 인식 기반 신원 인증 방법은 계정의 보안을 보장하기 위해 다양한 계정 관리 시스템에 널리 적용될 수 있다.
관련 기술에서는, 성문 인식 기술을 이용하여 신원 인증을 구현하기 전에, 먼저 사용자가 미리 설정된 텍스트 정보를 읽어야 하며, 이때 사용자의 음성 신호가 수집되고 분석되어 대응하는 성문 정보를 얻고, 이는 사용자의 기준 성문 정보로 사용되며 성문 라이브러리에 저장된다. 신원 인증이 구현될 때, 인증 대상자는 또한 상기 미리 설정된 텍스트 정보를 읽도록 요청되고, 인증 대상자의 음성 신호가 수집되고 분석되어 대응하는 성문 정보를 얻는다. 성문 정보를 성문 라이브러리 내의 기준 성문 정보와 비교함으로써, 인증 대상자가 사용자 자신인지의 여부가 판정될 수 있다.
상기 기술에서는, 성문 라이브러리가 확립되었을 때 신원 인증을 위한 텍스트 정보가 공개되어 있으므로, 이에 따라, 신원 인증을 수행할 때, 인증 대상자가 읽도록 요청되는 텍스트 정보도 알려져 있다. 텍스트 정보를 읽을 사용자 자신의 음성 파일이 미리 녹음되어 있다면, 임의의 사람이 사전에 녹음된 음성 파일을 재생하여 성공적으로 인증할 수 있다. 기존의 성문 인식 기반 신원 인증 방법은 심각한 잠재적인 보안 위험을 갖고 있음을 알 수 있다.
관련 기술에 존재하는 문제점을 극복하기 위하여, 본 출원은 성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템을 제공한다.
본 출원의 제1 양상은 성문 정보 관리 방법을 제공하며, 방법은 다음의 단계를 포함한다:
제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득;
제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리 실행;
음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리 실행; 및
음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집, 및 기준 성문 정보 및 제1 사용자의 신원 식별자 저장.
제1 양상과 함께, 제1 양상의 제1 실현 가능한 실시예에서, 성문 정보 관리 방법은:
텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간 표시; 및
서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 음성 정보로부터 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭(cutting out)을 더 포함한다.
제1 양상의 제1 실현 가능한 실시예와 함께, 제1 양상의 제2 실현 가능한 실시예에서, 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집 단계는:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함한다.
제1 양상과 함께, 제1 양상의 제3 실현 가능한 실시예에서, 기준 성문 정보 및 제1 사용자의 신원 식별자 저장 단계는:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보 및 제1 신원 식별자를 직접 저장;
제2 기준 성문 정보가 존재하면, 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보 삭제; 및
제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제2 기준 성문 정보 삭제, 및 제1 기준 성문 정보 및 제1 신원 식별자 저장을 포함한다.
본 출원의 제2 양상은 성문 정보 관리 장치를 제공하며, 장치는:
제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득, 및 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리를 실행하도록 구성되는 음성 필터;
음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리를 실행하도록 구성되는 텍스트 인식기; 및
음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집, 및 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하도록 구성되는 성문 생성기를 포함한다.
제2 양상과 함께, 제2 양상의 제1 실현 가능한 실시예에서, 성문 정보 관리 장치는:
텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간을 표시하도록 구성되는 텍스트 분할기; 및
서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 음성 정보로부터 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭하도록 구성되는 성문 분할기를 더 포함한다.
제2 양상의 제1 실현 가능한 실시예와 함께, 제2 양상의 제2 실현 가능한 실시예에서, 성문 생성기가 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집은:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함한다.
제2 양상과 함께, 제2 양상의 제3 실현 가능한 실시예에서, 성문 생성기가 기준 성문 정보 및 제1 사용자의 신원 식별자 저장은:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보 및 제1 신원 식별자를 직접 저장;
제2 기준 성문 정보가 존재하면, 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보 삭제; 및
제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제2 기준 성문 정보 삭제, 및 제1 기준 성문 정보 및 제1 신원 식별자 저장을 포함한다.
본 출원의 제3 양상은 신원 인증 방법을 제공하며, 방법은 다음의 단계를 포함한다:
제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득;
제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리 실행;
음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리 실행;
음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집, 및 기준 성문 정보 및 제1 사용자의 신원 식별자 저장;
인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보 획득;
획득된 기준 성문 정보 내의 텍스트 정보 출력, 및 대응하는 인증 대상 음성 정보 수신; 및
획득된 기준 성문 정보 내의 음성 정보를 인증 대상 음성 정보와 매칭, 매칭이 성공하면, 인증 대상 사용자의 인증이 성공한 것으로 판단; 및 매칭이 실패하면, 인증 대상 사용자의 인증이 실패한 것으로 판단.
제3 양상과 함께, 제3 양상의 제1 실현 가능한 실시예에서, 신원 인증 방법은:
텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간 표시; 및
서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 음성 정보로부터 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭을 더 포함한다.
제3 양상의 제1 실현 가능한 실시예와 함께, 제3 양상의 제2 실현 가능한 실시예에서, 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집 단계는:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함한다.
제3 양상과 함께, 제3 양상의 제3 실현 가능한 실시예에서, 기준 성문 정보 및 제1 사용자의 신원 식별자 저장 단계는:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보 및 제1 신원 식별자를 직접 저장;
제2 기준 성문 정보가 존재하면, 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보 삭제; 및
제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제2 기준 성문 정보 삭제, 및 제1 기준 성문 정보 및 제1 신원 식별자 저장을 포함한다.
본 출원의 제4 양상은 신원 인증 시스템을 제공하며, 시스템은:
제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득, 및 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리를 실행하도록 구성되는 음성 필터;
음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리를 실행하도록 구성되는 텍스트 인식기;
음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집, 및 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하도록 구성되는 성문 생성기;
인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보를 획득하도록 구성되는 성문 추출기;
획득된 기준 성문 정보 내의 텍스트 정보를 출력, 및 대응하는 인증 대상 음성 정보를 수신하도록 구성되는 인식 전치(前置)기; 및
획득된 기준 성문 정보 내의 음성 정보를 인증 대상 음성 정보와 매칭, 매칭이 성공하면, 인증 대상 사용자의 인증이 성공한 것으로 판단; 및 매칭이 실패하면, 인증 대상 사용자의 인증이 실패한 것으로 판단하도록 구성되는 성문 매칭기를 포함한다.
제4 양상과 함께, 제4 양상의 제1 실현 가능한 실시예에서, 신원 인증 시스템은:
텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간을 표시하도록 구성되는 텍스트 분할기; 및
서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 음성 정보로부터 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭하도록 구성되는 성문 분할기를 더 포함한다.
제4 양상의 제1 실현 가능한 실시예와 함께, 제4 양상의 제2 실현 가능한 실시예에서, 성문 생성기가 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집은:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함한다.
제4 양상과 함께, 제4 양상의 제3 실현 가능한 실시예에서, 성문 생성기가 기준 성문 정보 및 제1 사용자의 신원 식별자 저장은:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보 및 제1 신원 식별자를 직접 저장;
제2 기준 성문 정보가 존재하면, 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보 삭제; 및
제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제2 기준 성문 정보 삭제, 및 제1 기준 성문 정보 및 제1 신원 식별자 저장을 포함한다.
상기 기술적 해결책으로부터 본 출원이 제1 사용자의 음성 정보를 얻기 위하여 연관된 시스템에 저장된 이력 음성 파일의 필터링, 텍스트 인식 처리에 의한 음성 정보에 대응하는 텍스트 정보 획득, 및 제1 사용자의 기준 성문 정보로 음성 정보 및 대응하는 텍스트 정보 편집을 포함하는 것을 알 수 있다. 기준 성문 정보 내의 텍스트 정보와 음성 정보가 모두 연관된 시스템에 의해 사전 설정되는 것이 아니라 상술한 이력 음성 파일 기반으로 얻어지므로, 즉, 공개되지 않으므로, 제1 사용자, 제2 사용자 또는 임의의 다른 사용자 중 어느 누구도 신원 인증이 실행될 때 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 따라서 대응하는 음성 파일을 미리 녹음할 수 없고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증의 목적을 달성할 수 없다. 그러므로, 기존의 성문 인식 기반 신원 인증 방법과 비교하여, 본 출원에 의해 제공되는 성문 정보 관리 방법에 기반하여 신원 인증이 수행되며, 인증 결과는 더 정확하고, 잠재적인 보안 위험이 존재하지 않으며, 계정의 보안이 강화된다.
상기 일반적 설명 및 이하의 상세한 설명은 단지 예시적이고 설명적인 것이며, 본 출원을 제한할 수 없다는 점을 이해하여야 한다.
이 문서 중의 도면은 명세서에 통합되며 명세서의 일부를 구성하고, 본 발명에 부합하는 실시예를 나타내며, 명세서와 함께 본 발명의 원리를 설명하기 위해 사용된다.
도 1은 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법의 흐름도이다.
도 2는 본 출원의 실시예에 의해 제공되는 다른 성문 정보 관리 방법의 흐름도이다.
도 3은 본 출원의 실시예에 의해 제공되는 기준 성문 정보의 저장 방법의 흐름도이다.
도 4는 본 출원의 실시예에 의해 제공되는 성문 정보 관리 시스템의 구조 블록도이다.
도 5는 본 출원의 실시예에 의해 제공되는 성문 정보 관리 시스템의 구조 블록도이다.
도 6은 본 출원의 실시예에 의해 제공되는 신원 인증 방법의 흐름도이다.
도 7은 본 출원의 실시예에 의해 제공되는 다른 신원 인증 방법의 흐름도이다.
도 8은 본 출원의 실시예에 의해 제공되는 신원 인증 시스템의 구조 블록도이다.
도 9는 본 출원의 실시예에 의해 제공되는 다른 신원 인증 시스템의 구조 블록도이다.
도 1은 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법의 흐름도이다.
도 2는 본 출원의 실시예에 의해 제공되는 다른 성문 정보 관리 방법의 흐름도이다.
도 3은 본 출원의 실시예에 의해 제공되는 기준 성문 정보의 저장 방법의 흐름도이다.
도 4는 본 출원의 실시예에 의해 제공되는 성문 정보 관리 시스템의 구조 블록도이다.
도 5는 본 출원의 실시예에 의해 제공되는 성문 정보 관리 시스템의 구조 블록도이다.
도 6은 본 출원의 실시예에 의해 제공되는 신원 인증 방법의 흐름도이다.
도 7은 본 출원의 실시예에 의해 제공되는 다른 신원 인증 방법의 흐름도이다.
도 8은 본 출원의 실시예에 의해 제공되는 신원 인증 시스템의 구조 블록도이다.
도 9는 본 출원의 실시예에 의해 제공되는 다른 신원 인증 시스템의 구조 블록도이다.
여기에서 예시적인 실시예가 상세하게 기술되며, 실시예의 예는 첨부된 도면에 나타난다. 도면과 연관된 아래의 설명에서, 달리 나타내지 않는 한, 상이한 도면에서 동일한 도면 부호는 동일하거나 유사한 요소를 나타낸다. 아래의 예시적인 실시예에서 기술된 실시예는 본 발명에 부합하는 모든 실시예들을 나타내지는 않는다. 대신, 이들은 첨부된 청구 범위에 상세히 기재된, 본 발명의 일부 양상들에 부합하는 장치 및 방법의 예에 불과하다.
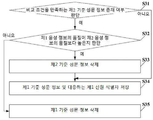
도 1은 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법의 흐름도이다. 성문 정보 관리 방법은 계정 관리 시스템에 적용된다. 도 1에 나타난 바와 같이, 성문 정보 관리 방법은 다음의 단계를 포함한다.
S11, 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득.
상기 제1 사용자는 계정 관리 시스템 내에 대응하는 개인 계정을 갖는 등록된 사용자일 수 있으며, 따라서, 제2 사용자는 계정 관리 시스템의 서비스 직원일 수 있다.
S12, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리 실행.
S13, 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리 실행.
S14, 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집, 및 기준 성문 정보 및 제1 사용자의 신원 식별자 저장.
일반적으로, 성능 통계, 서비스 품질 평가, 분쟁 처리 등을 용이하게 하기 위하여, 계정 관리 시스템은 등록된 사용자와 서비스 직원 사이의 음성 통화 과정을 녹음하고 대응하는 음성 파일을 저장할 수 있다. 이러한 관점에서, 본 출원의 실시예는 등록된 사용자의 음성 정보를 얻기 위하여 계정 관리 시스템 내에 저장된 이력 음성 파일에서 장비 음성 안내(machine prompt tone) 및 서비스 직원의 소리 정보를 필터링하는 것과, 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 대해 텍스트 인식 처리를 수행하는 것을 포함하며, 이에 따라 음성 정보 및 대응하는 텍스트 정보가 등록된 사용자의 기준 성문 정보 그룹의 역할을 할 수 있다. 상기 단계는 각 등록된 사용자에 대해 각각 실행되며, 따라서 각 등록된 사용자에 대응하는 기준 성문 정보가 성문 라이브러리의 생성을 달성하기 위해 얻어질 수 있다.
본 출원의 실시예가 제1 사용자의 음성 정보를 얻기 위하여 연관된 시스템에 저장된 이력 음성 파일의 필터링, 텍스트 인식 처리에 의한 음성 정보에 대응하는 텍스트 정보 획득, 및 제1 사용자의 기준 성문 정보로 음성 정보 및 대응하는 텍스트 정보 편집을 포함하는 것을 상기 방법으로부터 알 수 있다. 기준 성문 정보 내의 텍스트 정보와 음성 정보가 모두, 연관된 시스템에 의해 사전 설정되는 것이 아니라 상술한 이력 음성 파일 기반으로 얻어지므로, 즉, 공개되지 않으므로, 제1 사용자, 제2 사용자 또는 임의의 다른 사용자 중 어느 누구도 신원 인증이 실행될 때 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 따라서 대응하는 음성 파일을 미리 녹음하는 것이 불가능하고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증의 목적을 달성할 수 없다. 그러므로 기존의 성문 인식 기반 신원 인증 방법과 비교하여, 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법에 기반하여 신원 인증이 이루어지며, 인증 결과는 더 정확하고, 잠재적인 보안 위험이 존재하지 않으며, 계정의 보안이 강화된다.
본 출원의 실현 가능한 실시예에서, 제1 사용자 및 제2 사용자 사이의 임의의 통화 과정에 대응하는 이력 음성 파일이 임의로 획득될 수 있어, 성문 라이브러리 내의 신원 식별자가 기준 성문 정보에 일대일 기반으로 대응한다. 어떤 통화 과정이 실제로 획득된 이력 음성 파일에 대응하는지 예측할 수 없으므로, 획득된 기준 성문 정보 내의 텍스트 정보의 구체적인 내용이 예측될 수 없고, 따라서 본 실시예 기반의 신원 인증의 실행은 인증 결과의 정확성을 보장하고 계정의 보안을 개선한다.
본 출원의 다른 실현 가능한 실시예에서, 제1 사용자에 대응하는 모든 이력 음성 파일이 또한 획득될 수 있으며, 각 이력 음성 파일이 기준 성문 정보의 적어도 하나의 그룹에 대응하여, 성문 라이브러리 내의 하나의 신원 식별자가 기준 성문 정보의 복수의 그룹에 대응할 수 있다(즉, 제1 사용자가 복수의 기준 성문 정보 그룹을 가진다). 그리고 이에 따라, 임의의 그룹의 기준 성문 정보가 임의로 획득되어 신원 인증을 실행할 수 있다. 각 그룹의 기준 성문 정보의 텍스트 정보가 공개되지 않으므로, 신원 인증이 실행될 때 획득되는 기준 성문 정보 또한 예측될 수 없으며, 신원 인증 실행을 위한 텍스트 정보의 구체적인 내용이 또한 예측될 수 없고, 따라서, 대응하는 음성 파일을 미리 녹음하고 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성하는 것이 불가능하다. 따라서, 본 실시예 기반의 신원 인증 실행은 인증 결과의 정확성을 보장하며, 계정의 보안을 개선할 수 있다.
도 2는 본 출원의 다른 실시예에 의해 제공되는 성문 정보 관리 방법의 흐름도이다. 성문 정보 관리 방법은 계정 관리 시스템에 적용된다. 도 2에 나타난 바와 같이, 성문 정보 관리 방법은 다음의 단계를 포함한다.
S21, 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득.
S22, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리 실행.
S23, 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리 실행.
S24, 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간 표시.
S25, 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 음성 정보로부터 각 서브 텍스트 정보에 대응하는 서브 음성 정보 각각 절삭.
S26, 서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집, 및 제1 사용자의 각 기준 성문 정보 및 신원 식별자 저장.
이력 음성 파일이 시간 구간 내의 제1 사용자와 제2 사용자 사이의 통화 녹음 파일이므로, 필터링에 의해 얻어진 음성 정보는 제1 사용자의 음성 정보의 복수의 세그먼트를 포함하며, 따라서, 텍스트 인식에 의해 얻어진 텍스트 정보는 복수의 문장 또는 구절을 포함한다. 본 출원의 실시예는 텍스트 정보를 복수의 서브 텍스트 정보(각 서브 텍스트 정보는 문장, 구절 또는 단어일 수 있다)로 분할하는 것을 포함하며, 동시에 분할에 의해 얻어진 각 서브 텍스트 정보의 시작 시간 및 종료 시간이 표시되고, 서브 텍스트 정보에 대응하는 서브 음성 정보가 시작 시간 및 종료 시간에 따라 음성 정보로부터 절삭된다(즉, 음성 정보가 서브 텍스트 정보에 따라 분할된다). 예를 들면, 텍스트 정보 내의 문장 "내 계정이 잠겼습니다"가 음성 정보의 시간 구간 00:03 내지 00:05로부터 인식되어 얻어지면, 문장 "내 계정이 잠겼습니다"는 시작 시간과 종료 시간이 00:03과 00:05인 하나의 서브 텍스트 정보로 분할되고, 따라서 음성 정보 내의 시간 구간 00:03 내지 00:05의 음성 정보가 절삭되면, 서브 텍스트 정보 "내 계정이 잠겼습니다"에 대응하는 서브 음성 정보가 얻어진다. 텍스트 정보와 음성 정보를 분할함으로써, 서브 텍스트 정보와 서브 음성 정보의 복수의 쌍이 얻어질 수 있으며, 각 쌍이 사전 설정된 포맷에 따라 기준 성문 정보로 각각 편집되고, 그리고 나서, 동일한 사용자에 대응하는 복수의 기준 성문 정보가 얻어진다.
본 발명의 실시예에서, 서브 음성 정보 및 대응하는 서브 텍스트 정보의 기준 성문 정보로의 편집은: 서브 음성 정보를 대응하는 서브 성문 정보로 처리, 및 서브 성문 정보에 대한 파일명 설정-파일명의 포맷은 0989X.WAV와 같은 "성문 번호.파일 포맷 접미사"일 수 있음; 및 제1 사용자의 서브 성문 정보 및 신원 식별자와 같은 정보, 및 서브 성문 정보에 대응하는 서브 텍스트 정보의 저장을 포함할 수 있다. 상기 성문 정보 관리 방법 기반으로 얻어진 성문 라이브러리의 저장 구조는 표 1에 나타난 바와 같다.
성문 라이브러리 저장 구조의 예
| 사용자ID | 사용자 성문 번호 | 서브 텍스트 정보 | 서브 성문 정보 |
| 139XXXXXXXX | 1 | 매우 만족합니다 | 0989X.WAV |
| 139XXXXXXXX | 2 | 왜 아직 환불되지 않았나요 | 0389X.WAV |
| 189XXXXXXXX | 1 | 매우 화가 납니다 | 0687X.WAV |
| 189XXXXXXXX | 2 | 계정이 잠겼습니다 | 0361X.WAV |
표 1에서, 각 행은 성문 라이브러리 내의 하나의 기준 성문 정보에 대응하며, 성문 정보 질의 및 통화에 대한 기본 키로서 신원 식별자(즉, 사용자 ID)가 사용되고, 동일한 사용자 ID에 대응하는 다수의 기준 성문 정보를 표시하기 위하여 사용자 성문 번호가 사용된다. 사용자 ID "139XXXXXXXX"를 예로 들면, 사용자 ID에 관한 신원 인증 요청이 수신될 때, 상기 성문 라이브러리로 "139XXXXXXXX"에 대응하는 기준 성문 정보가 질의되고, 복수의 질의 결과가 얻어질 수 있으며, 이 중에서 하나가 본 인증의 기준 성문 정보로 임의로 추출된다. 예를 들면, 사용자 ID에 대응하는 기준 성문 정보 2번이 현재 인증의 기준 성문 정보의 역할을 하도록 추출되고, 그 안의 서브 텍스트 정보 "왜 아직 환불되지 않았나요"가 출력된다. 인증 대상 사용자가 서브 파일 정보를 다시 읽어서 얻어진 인증 대상 음성 정보가 수신되고, 인증 대상 음성 정보가 인증 대상 성문 정보로 처리된다. 인증 대상 성문 정보가 성문 라이브러리로부터 추출된 서브 성문 정보 "0389X.WAV"와 비교된다. 두 가지가 서로 매칭되면, 신원 인증이 성공한 것으로 판단된다. 즉, 인증 대상 사용자가 "139XXXXXXXX"에 대응하는 제1 사용자인 것으로 간주된다. 그렇지 않고, 두 가지가 서로 매칭되지 않으면, 신원 인증이 실패한 것으로 판단한다.
본 출원의 실시예가 제1 사용자의 음성 정보를 얻기 위하여 시스템 내에 저장된 이력 음성 파일을 필터링, 음성 정보에 대해 텍스트 인식 처리를 수행하여 대응하는 텍스트 정보 획득, 인식된 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 각 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라 상기 음성 정보로부터 대응하는 서브 음성 정보 절삭, 서브 텍스트 정보 및 서브 음성 정보의 각 쌍을 하나의 기준 성문 정보로 각각 편집, 및 각 제1 사용자가 복수의 기준 성문 정보를 갖도록 이를 성문 라이브러리에 저장; 및 신원 인증이 실행되어야 할 때, 인증 대상 신원 식별자에 대응하는 복수의 기준 성문 정보로부터 하나가 임의로 선택됨을 포함하는 것을 상기 기술적 해결책으로부터 알 수 있다. 신원 인증이 실행될 때 획득되는 기준 성문 정보가 랜덤이므로, 인증 대상 사용자가 다시 읽어야 할 텍스트 정보의 구체적인 내용이 예측될 수 없으며, 따라서 본 실시예에서 획득된 성문 라이브러리 기반 신원 인증의 실행은 인증 결과의 정확성을 보장하고, 계정 보안을 개선할 수 있다. 또한, 본 실시예에서, 각 기준 성문 정보 내의 서브 텍스트 정보는 간단하고 짧아서 텍스트 정보를 다시 읽는 데 필요한 시간을 줄이고, 성문 비교에 소요되는 시간을 줄이며, 인증 효율성을 개선할 수 있다.
본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법은 새로운 성문 라이브러리를 생성할 수 있을 뿐 아니라, 생성된 성문 라이브러리를 업데이트할 수도 있다. 예를 들면, 새로운 사용자에 대응하는 기준 성문 정보를 추가하고, 기존 사용자에 대해 새로운 기준 성문 정보를 추가할 수 있다. 새로운 사용자에 대해서는, 단지 새로운 사용자에 대응하는 이력 음성 파일만이 획득될 필요가 있으며, 위의 단계 S12 내지 S14 또는 단계 S22 내지 S26가 실행되어, 새로운 사용자에 대응하는 기준 성문 정보가 얻어질 수 있다. 시간이 지남에 따라, 동일한 사용자에 대한 이력 음성 파일이 계속해서 증가하고, 따라서, 기존 사용자에 대해서 대응하는 새롭게 추가된 이력 음성 파일이 획득될 수 있으며, 상기 단계가 실행되고, 기존의 사용자에 대해 새로운 기준 성문 정보가 추가될 수 있다.
본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법에 기반하여, 하나 이상의 기준 성문 정보가 제1 사용자에 대해 설정될 수 있다. 복수의 기준 성문 정보가 동일한 제1 사용자에 대해 설정될 때, 제1 사용자에 대응하는 임의의 두 기준 성문 정보 내의 텍스트 정보가 상이한 것을 보장하여야 한다. 그러나, 실질적인 응용에서, 이하의 경우가 불가피하게 일어난다. 동일한 내용의 텍스트 정보가 상이한 이력 음성 파일에서 인식되거나, 동일한 내용의 복수의 서브 텍스트 정보가 동일한 텍스트 정보로부터 분할되어, 동일한 서브 텍스트 정보가 다수의 서브 음성 정보에 대응하게 된다. 이 때, 본 출원의 실시예에서는 기준 성문 정보의 저장을 달성하기 위하여 도 3에 나타난 방법이 채용된다. 설명의 편의를 위하여, 저장될 기준 성문 정보는 제1 텍스트 정보 및 제1 음성 정보로 구성된 제1 기준 성문 정보로 가정한다. 도 3에 나타난 바와 같이, 본 출원의 실시예에서 제1 기준 성문 정보를 저장하는 과정은 다음의 단계를 포함한다.
S31, 비교 조건을 만족하는 제2 기준 성문 정보가 존재하는지 판단하여, 그러하면, 단계 S32를 실행하고, 그렇지 않으면, 단계 S34를 실행.
상기 비교 조건은: 제2 기준 성문 정보에 대응하는 제2 텍스트 정보가 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일, 및 제2 기준 성문 정보에 대응하는 제2 신원 식별자가 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 동일을 포함한다.
S32, 제1 기준 성문 정보 내의 제1 음성 정보의 품질이 제2 기준 성문 정보 내의 제2 음성 정보의 품질보다 높은지 판단하여, 그러하면, 단계 S33을 실행하고, 그렇지 않으면, 단계 S35를 실행.
S33, 제2 기준 성문 정보 삭제, 및 단계 S34 실행.
S34, 제1 기준 성문 정보 및 대응하는 제1 신원 식별자 저장.
S35, 제1 기준 성문 정보 삭제.
위의 단계 S31에서, 상기한 제2 기준 성문 정보가 존재하는지 판단하기 위하여 검색 범위는 적어도 성문 라이브러리 내에 저장된 기준 성문 정보를 포함하며, 제1 기준 성문 정보와 동시에 생성되었지만 아직 저장되지 않은 기준 성문 정보를 또한 포함할 수 있다. 상기한 제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보가 바로 저장된다. 상기한 제2 기준 성문 정보가 발견되었으면, 이는 동일한 제1 사용자 및 동일한 텍스트 정보에 대해 적어도 두 상이한 음성 정보가 존재하는 것을 나타내며, 이때, 제1 기준 성문 정보 내의 제1 음성 정보의 품질이 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교된다. 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제1 기준 성문 정보가 저장되고, 동시에 제2 기준 성문 정보는 삭제된다. 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보가 바로 삭제된다. 즉, 동일한 텍스트 정보에 대하여 가장 높은 품질의 음성 정보만이 유지되어, 음성 정보의 비교 결과의 정확성을 향상시키며 신원 인증 과정의 비교의 어려움을 줄인다.
상기한 저장 과정에 기반하여, 이하의 세 가지 성문 라이브러리 업데이트 방법이 구현될 수 있다: 1) 새로운 사용자의 기준 성문 정보 추가; 2) 기존 사용자에 대응하는 상이한 텍스트 정보를 갖는 기준 성문 정보 추가; 및 3) 성문 라이브러리 내의 상대적으로 낮은 품질의 음성 정보를 갖는 기준 성문 정보를 더 높은 품질의 음성 정보를 갖는 기준 성문 정보로 대체.
위의 기술적 해결책으로부터, 본 출원의 실시예에서, 얻어진 새로운 기준 성문 정보에 대하여, 정보가 성문 라이브러리에 바로 저장되지 않고, 먼저 기준 성문 정보 내에 있는 것과 텍스트 정보 및 대응하는 신원 식별자가 각각 동일한 다른 기준 성문 정보가 저장되어 있는지 판단하고, 그러하면, 두 기준 성문 정보 내의 음성 정보의 품질이 비교하여, 더 높은 품질의 음성 정보를 갖는 기준 성문 정보가 유지되고, 더 낮은 품질의 음성 정보를 갖는 기준 성문 정보는 삭제된다는 것을 알 수 있다. 따라서, 본 출원의 실시예는, 저장된 기준 성문 정보 내에서, 동일한 신원 식별자(즉, 동일한 제1 사용자)에 대응하는 임의의 두 기준 성문 정보 내의 텍스트 정보가 상이한 것을 보장할 뿐만 아니라, 각 종류의 텍스트 정보에 대응하는 음성 정보의 품질이 최고인 것을 보장하며, 본 출원의 실시예에 기반하여 신원 인증이 실행될 때, 더 높은 품질을 갖는 음성 정보에 기반한 성문 비교의 수행은 인증의 정확성을 보장하고 인증 효율성을 향상시킬 수 있다.
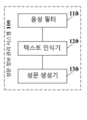
도 4는 본 출원의 실시예에 의해 제공되는 성문 정보 관리 시스템의 구조 블록도이다. 성문 정보 관리 시스템은 계정 관리 시스템에 적용될 수 있다. 도 4에 나타난 바와 같이, 성문 정보 관리 시스템(100)은 음성 필터(110), 텍스트 인식기(120) 및 성문 생성기(130)를 포함한다.
음성 필터(110)는 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득하고, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리를 실행하도록 구성된다.
텍스트 인식기(120)는 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리를 실행하도록 구성된다.
성문 생성기(130)는 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집하고, 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하도록 구성된다.
상기 구조로부터 본 출원의 실시예가 제1 사용자의 음성 정보를 얻기 위하여 연관된 시스템에 저장된 이력 음성 파일을 필터링, 텍스트 인식 처리에 의해 음성 정보에 대응하는 텍스트 정보 획득, 및 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집을 포함하는 것을 알 수 있다. 기준 성문 정보 내의 텍스트 정보와 음성 정보 모두가 연관된 시스템에 의해 사전 설정되는 것이 아니라, 상기한 이력 음성 파일 기반으로 얻어지므로, 즉, 공개되지 않으므로, 제1 사용자나 제2 사용자 또는 임의의 다른 사용자가 누구도 신원 인증이 실행될 때 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 따라서 대응하는 음성 파일을 미리 녹음할 수 없고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성할 수 없다. 그러므로, 기존의 성문 인식 기반 신원 인증 방법과 비교하여, 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법 기반으로 신원 인증이 수행되고, 잠재적 보안 위험이 존재하지 않으며, 계정의 보안이 강화된다.
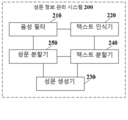
도 5는 본 출원의 실시예에 의해 제공되는 다른 성문 정보 관리 시스템의 구조 블록도이다. 성문 정보 관리 시스템은 계정 관리 시스템에 적용될 수 있다. 도 5에 나타난 바와 같이, 성문 정보 관리 시스템(200)은 음성 필터(210), 텍스트 인식기(220), 텍스트 분할기(240), 성문 분할기(250) 및 성문 생성기(230)를 포함한다.
음성 필터(210)는 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득하고, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리를 실행하도록 구성된다.
텍스트 인식기(220)는 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리를 실행하도록 구성된다.
텍스트 분할기(240)는 텍스트 정보를 복수의 서브 텍스트 정보로 분할하고, 각 서브 텍스트 정보의 시작 시간 및 종료 시간을 표시하도록 구성된다.
성문 분할기(250)는 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 음성 정보로부터 각각 절삭하도록 구성된다.
성문 생성기(230)는 서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집하고, 각 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하도록 구성된다.
상기 구조로부터 본 출원의 실시예가 제1 사용자의 음성 정보를 얻기 위하여 시스템에 저장된 이력 음성 파일을 필터링, 음성 정보에 대한 텍스트 인식 처리에 의해 대응하는 텍스트 정보 획득, 인식된 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 각 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라 상기 음성 정보로부터 대응하는 서브 음성 정보를 절삭, 서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 하나의 기준 성문 정보로 각각 편집하고, 이를 성문 라이브러리에 저장하는 것을 포함하여, 각 제1 사용자가 복수의 기준 성문 정보를 가지고, 신원 인증이 실행되어야 할 때, 인증 대상 신원 식별자에 대응하는 복수의 기준 성문 정보로부터 하나가 임의로 선택되는 것을 알 수 있다. 신원 인증이 실행될 때 획득되는 기준 성문 정보가 랜덤이므로, 인증 대상 사용자가 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 따라서 대응하는 음성 파일을 미리 녹음할 수 없고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성할 수 없다. 그러므로, 본 출원의 실시예에 의해 얻어진 성문 라이브러리 기반 신원 인증의 실행은 인증 결과의 정확성을 보장하고, 계정의 보안을 향상시킬 수 있다. 또한, 본 실시예에서, 각 기준 성문 정보 내의 서브 텍스트 정보는 간단하고 짧아서, 텍스트 정보를 다시 읽는 데 필요한 시간을 줄이고, 성문 비교에 소요되는 시간을 줄이며, 인증 효율성을 개선할 수 있다.
본 출원의 실시예에 의해 제공되는 성문 정보 관리 시스템에서, 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하는 기능을 구현하기 위하여, 상기 성문 생성기(130) 및 성문 생성기(230)는:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보가 존재하는지 판단;
제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보 및 제1 신원 식별자를 직접 저장;
제2 기준 성문 정보가 존재하면, 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교하고, 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보를 삭제; 및
제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제2 기준 성문 정보를 삭제, 및 제1 기준 성문 정보 및 제1 신원 식별자를 저장하도록 구성될 수 있다.
상기와 같이 구성된 성문 생성기에 기반하여, 본 출원의 실시예는, 저장된 기준 성문 정보 내에, 동일한 사용자에 대응하는 임의의 두 기준 성문 정보 내의 텍스트 정보가 상이함을 보장할 뿐만 아니라, 또한 각 종류의 텍스트 정보에 대응하는 음성 정보의 품질이 최고임을 보장할 수 있으며, 따라서 본 출원의 실시예에 기반하여 신원 인증이 실행될 때, 더 높은 품질을 갖는 음성 정보에 기반한 성문 비교의 수행은 인증의 정확성을 보장하고 인증 효율성을 개선할 수 있다.
도 6은 본 출원의 실시예에 의해 제공되는 신원 인증 방법의 흐름도이며, 신원 인증 방법은 계정 관리 시스템에 적용될 수 있다. 도 6을 참조하면, 신원 인증 방법은 다음의 단계를 포함한다.
S41, 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득.
상기 제1 사용자는 계정 관리 시스템 내에 대응하는 개인 계정을 갖는 등록된 사용자일 수 있으며, 따라서, 제2 사용자는 계정 관리 시스템의 서비스 직원일 수 있다.
S42, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리 실행.
S43, 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리 실행.
S44, 텍스트 정보 및 대응하는 음성 정보를 제1 사용자의 기준 성문 정보로 편집, 및 기준 성문 정보 및 제1 사용자의 신원 식별자 저장.
S45, 인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보 획득.
S46, 획득된 기준 성문 정보 내의 텍스트 정보 출력, 및 대응하는 인증 대상 음성 정보 수신.
S47, 획득된 기준 성문 정보 내의 음성 정보를 인증 대상 음성 정보와 매칭; 매칭이 성공하면, 인증 대상 사용자의 인증이 성공한 것으로 판단; 및 매칭이 실패하면, 인증 대상 사용자의 인증이 실패한 것으로 판단.
상기 방법으로부터 본 출원의 실시예가 제1 사용자의 음성 정보를 얻기 위하여 연관된 시스템에 저장된 이력 음성 파일을 필터링, 텍스트 인식 처리에 의해 음성 정보에 대응하는 텍스트 정보 획득, 및 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집을 포함하는 것을 알 수 있다. 기준 성문 정보 내의 텍스트 정보와 음성 정보 모두가 연관된 시스템에 의해 사전 설정되는 것이 아니라, 상기한 이력 음성 파일 기반으로 얻어지므로, 즉, 공개되지 않으므로, 제1 사용자나 제2 사용자 또는 임의의 다른 사용자가 누구도 신원 인증이 실행될 때 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 따라서 대응하는 음성 파일을 미리 녹음할 수 없고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성할 수 없다. 그러므로, 기존의 성문 인식 기반 신원 인증 방법과 비교하여, 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법 기반으로 신원 인증이 수행되고, 잠재적 보안 위험이 존재하지 않으며, 계정의 보안이 강화된다.
도 7은 본 출원의 실시예에 의해 제공되는 다른 신원 인증 방법의 흐름도이며, 신원 인증 방법은 계정 관리 시스템에 적용될 수 있다. 도 7을 참조하면, 신원 인증 방법은 다음의 단계를 포함한다.
S51, 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득.
S52, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리 실행.
S53, 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리 실행.
S54, 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간 표시.
S55, 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 음성 정보로부터 각 서브 텍스트 정보에 대응하는 서브 음성 정보 각각 절삭.
S56, 서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집, 및 각 기준 성문 정보 및 제1 사용자의 신원 식별자 저장.
S57, 인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보 획득.
S58, 획득된 기준 성문 정보 내의 서브 텍스트 정보 출력, 및 대응하는 인증 대상 음성 정보 수신.
S59, 획득된 기준 성문 정보 내의 서브 음성 정보를 인증 대상 음성 정보와 매칭; 매칭이 성공하면, 인증 대상 사용자의 인증이 성공한 것으로 판단; 및 매칭이 실패하면, 인증 대상 사용자의 인증이 실패한 것으로 판단.
상기 방법으로부터 본 출원의 실시예가 인식에 의해 얻어진 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 대응하는 서브 음성 정보를 그 시작 시간 및 종료 시간에 따라 절삭, 각 서브 텍스트 정보 및 대응하는 서브 음성 정보를 하나의 기준 성문 정보로 편집하여, 제1 사용자가 복수의 기준 성문 정보를 가지고, 신원 인증이 실행되어야 할 때, 인증 대상 신원 식별자에 대응하는 복수의 기준 성문 정보로부터 하나를 임의로 선택을 포함하는 것을 알 수 있다. 신원 인증이 실행될 때 획득되는 기준 성문 정보가 랜덤이므로, 인증 대상 사용자가 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 대응하는 음성 파일을 미리 녹음하고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성하는 것이 불가능하다. 그러므로, 본 실시예에 의해 제공되는 신원 인증 방법은 인증 결과의 정확성을 보장하고, 계정의 보안을 향상시킨다. 또한, 본 실시예에서, 각 기준 성문 정보 내의 서브 텍스트 정보는 간단하고 짧아서, 텍스트 정보를 다시 읽는 데 필요한 시간을 줄이고, 성문 비교에 소요되는 시간을 줄이며, 인증 효율성을 개선할 수 있다.
본 출원의 실시예에 의해 제공되는 신원 인증 방법은 또한 기준 성문 정보의 저장을 구현하기 위하여 도 3에 나타난 바와 같은 방법을 채택할 수 있으며, 이는 저장된 기준 성문 정보 내에서, 동일한 사용자에 대응하는 임의의 두 기준 성문 정보 내의 텍스트 정보가 상이함을 보장할 뿐만 아니라, 또한 각 종류의 텍스트 정보에 대응하는 음성 정보의 품질이 최고임을 보장할 수 있으며, 본 출원의 실시예에 기반하여 신원 인증이 실행될 때, 더 높은 품질을 갖는 음성 정보에 기반한 성문 비교의 수행은 인증의 정확성을 보장하고 인증 효율성을 개선할 수 있다.
도 8은 본 출원의 실시예에 의해 제공되는 신원 인증 시스템의 구조 블록도이며, 신원 인증 시스템은 계정 관리 시스템에 적용될 수 있다. 도 8을 참조하면, 신원 인증 시스템(300)은 음성 필터(310), 텍스트 인식기(320), 성문 생성기(330), 성문 추출기(360), 인식 전치(前置)기(370) 및 성문 매칭기(380)를 포함한다.
음성 필터(310)는 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득하고, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리를 실행하도록 구성된다.
텍스트 인식기(320)는 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리를 실행하도록 구성된다.
성문 생성기(330)는 제1 사용자의 기준 성문 정보로 음성 정보 및 대응하는 텍스트 정보를 편집하고, 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하도록 구성된다.
성문 추출기(360)는 인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보를 획득하도록 구성된다.
인식 전치기(370)는 획득된 기준 성문 정보 내의 텍스트 정보를 출력하고, 대응하는 인증 대상 음성 정보를 수신하도록 구성된다.
성문 매칭기(380)는 획득된 기준 성문 정보 내의 음성 정보를 인증 대상 음성 정보와 매칭하여; 매칭이 성공하면, 인증 대상 사용자의 인증이 성공한 것으로 판단하고; 매칭이 실패하면, 인증 대상 사용자의 인증이 실패한 것으로 판단하도록 구성된다.
상기 구조에서, 인식 전치기(370)가 신원 인증 시스템과 인증 대상 사용자 사이의 상호작용을 구현하기 위하여 사용되고, 성문 추출기(360)에 의해 획득된 기준 성문 정보 내의 텍스트 정보 출력 및 인증 대상 사용자에 의해 입력된 인증 대상 음성 정보 수신을 위해 사용되는 것에 추가하여, 이는 또한 인증 대상 사용자의 신원 인증 요청을 수신하고, 신원 인증 요청을 수신한 후에 성문 추출기(360)를 트리거링하며, 성문 매칭기(380)에 의해 얻어진 인증 결과를 인증 대상 사용자에게 출력할 수 있다.
상기 구조로부터 본 출원의 실시예가 제1 사용자의 음성 정보를 얻기 위하여 연관된 시스템에 저장된 이력 음성 파일을 필터링, 텍스트 인식 처리에 의해 음성 정보에 대응하는 텍스트 정보 획득, 및 음성 정보 및 대응하는 텍스트 정보를 제1 사용자의 기준 성문 정보로 편집을 포함하는 것을 알 수 있다. 기준 성문 정보 내의 텍스트 정보와 음성 정보 모두가 연관된 시스템에 의해 사전 설정되는 것이 아니라, 상기한 이력 음성 파일 기반으로 얻어지므로, 즉, 공개되지 않으므로, 제1 사용자나 제2 사용자 또는 임의의 다른 사용자가 누구도 신원 인증이 실행될 때 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 따라서 대응하는 음성 파일을 미리 녹음할 수 없고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성할 수 없다. 그러므로, 기존의 성문 인식 기반 신원 인증 방법과 비교하여, 본 출원의 실시예에 의해 제공되는 성문 정보 관리 방법 기반으로 신원 인증이 수행되고, 인증 결과가 더 정확해지고, 잠재적 보안 위험이 존재하지 않으며, 계정의 보안이 강화된다.
도 9는 본 출원의 실시예에 의해 제공되는 신원 인증 시스템의 구조 블록도이며, 신원 인증 시스템은 계정 관리 시스템에 적용될 수 있다. 도 9를 참조하면, 신원 인증 시스템(400)은 음성 필터(410), 텍스트 인식기(420), 텍스트 분할기(440), 성문 분할기(450), 성문 생성기(430), 성문 추출기(460), 인식 전치기(470) 및 성문 매칭기(480)를 포함한다.
음성 필터(410)는 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득하고, 제1 사용자의 음성 정보를 얻기 위하여 이력 음성 파일에 필터링 처리를 실행하도록 구성된다
텍스트 인식기(420)는 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 음성 정보에 텍스트 인식 처리를 실행하도록 구성된다.
텍스트 분할기(440)는 텍스트 정보를 복수의 서브 텍스트 정보로 분할하고, 각 서브 텍스트 정보의 시작 시간 및 종료 시간을 표시하도록 구성된다.
성문 분할기(450)는 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 음성 정보로부터 각각 절삭하도록 구성된다.
성문 생성기(430)는 서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 제1 사용자의 하나의 기준 성문 정보로 각각 편집하고, 각 기준 성문 정보 및 제1 사용자의 신원 식별자를 저장하도록 구성된다.
성문 추출기(460)는 인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보를 획득하도록 구성된다.
인식 전치기(470)는 획득된 기준 성문 정보 내의 서브 텍스트 정보를 출력하고, 대응하는 인증 대상 음성 정보를 수신하도록 구성된다.
성문 매칭기(480)는 획득된 기준 성문 정보 내의 서브 음성 정보를 인증 대상 음성 정보와 매칭하여; 매칭이 성공하면, 인증 대상 사용자의 인증이 성공한 것으로 판단하고; 매칭이 실패하면, 인증 대상 사용자의 인증이 실패한 것으로 판단하도록 구성된다.
상기 구조로부터 본 출원의 실시예가 인식에 의해 얻어진 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 대응하는 서브 음성 정보를 그 시작 시간 및 종료 시간에 따라 절삭, 각 서브 텍스트 정보 및 대응하는 서브 음성 정보를 하나의 기준 성문 정보로 편집하여, 제1 사용자가 복수의 기준 성문 정보를 가지고; 신원 인증이 실행되어야 할 때, 인증 대상 사용자에 대응하는 신원 식별자에 따라 복수의 대응하는 기준 성문 정보를 결정, 및 이로부터 현재 신원 인증을 위해 하나를 임의로 선택을 포함하는 것을 알 수 있다. 신원 인증이 실행될 때 획득되는 기준 성문 정보가 랜덤이므로, 인증 대상 사용자가 다시 읽어야 할 텍스트 정보의 구체적인 내용을 예측할 수 없으며, 대응하는 음성 파일을 미리 녹음하고, 또한 미리 녹음된 음성 파일을 재생하여 성공적인 인증 목적을 달성하는 것이 불가능하다. 그러므로, 본 실시예에 의해 제공되는 신원 인증 시스템은 인증 결과의 정확성을 보장하고, 계정의 보안을 향상시킬 수 있다. 또한, 본 실시예에서, 각 기준 성문 정보 내의 서브 텍스트 정보는 간단하고 짧아서, 텍스트 정보를 다시 읽는 데 필요한 시간을 줄이고, 성문 비교에 소요되는 시간을 줄이며, 인증 효율성을 개선할 수 있다.
본 출원의 실시예에 의해 제공되는 신원 인증 시스템에서, 기준 성문 정보 및 대응하는 사용자 신원 식별자를 저장하는 기능을 구현하기 위하여, 상기 성문 생성기(330) 및 성문 생성기(430)는:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보가 존재하는지 판단;
제2 기준 성문 정보가 존재하지 않으면, 제1 기준 성문 정보 및 제1 사용자의 신원 식별자를 직접 저장;
제2 기준 성문 정보가 존재하면, 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교하고, 제1 음성 정보의 품질이 제2 음성 정보의 품질보다 낮으면, 제1 기준 성문 정보를 삭제; 및
제1 음성 정보의 품질이 제2 음성 정보의 품질보다 높으면, 제2 기준 성문 정보를 삭제, 및 제1 기준 성문 정보 및 대응하는 사용자 신원 식별자를 저장하도록 구성될 수 있다.
상기와 같이 구성된 성문 생성기에 기반하여, 본 출원의 실시예는, 저장된 기준 성문 정보 내에, 동일한 신원 식별자에 대응하는 임의의 두 기준 성문 정보 내의 텍스트 정보가 상이함을 보장할 뿐만 아니라, 또한 각 종류의 텍스트 정보에 대응하는 음성 정보의 품질이 최고임을 보장할 수 있으며, 본 출원의 실시예에 기반하여 신원 인증이 실행될 때, 더 높은 품질을 갖는 음성 정보에 기반한 성문 비교의 수행은 인증의 정확성을 보장하고 인증 효율성을 개선할 수 있다.
이 분야의 기술자는 명세서를 고려하고 여기에서 개시된 발명을 실시한 후에 본 발명의 다른 구현을 쉽게 생각할 수 있을 것이다. 본 출원은 본 발명의 임의의 변형, 용도 또는 적응적 변경을 포함하도록 의도되며, 이들 변형, 용도 또는 적응적 변경은 본 발명의 일반적인 원리를 따르고 본 출원에서 개시되지 않은 이 분야의 공통적인 지식 또는 관례적인 기술적 수단을 포함한다. 명세서 및 실시예는 단지 예시적인 것으로 간주되며, 본 발명의 진정한 범위 및 취지는 아래의 청구범위에 의해 지적된다.
본 발명은 위에서 설명되고 도면에서 나타난 정확한 구조에 한정되지 않으며, 그 범위로부터 벗어나지 않고 다양한 변경 및 변화가 이루어질 수 있음을 이해하여야 한다. 본 발명의 범위는 첨부된 청구범위에 의해서만 제한된다.
Claims (16)
- 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득;
상기 제1 사용자의 음성 정보를 얻기 위하여 상기 이력 음성 파일에 필터링 처리 실행;
상기 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 상기 음성 정보에 텍스트 인식 처리 실행; 및
상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집, 및 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자 저장을 포함하는 것을 특징으로 하는 성문 정보 관리 방법. - 제1항에 있어서,
상기 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간 표시; 및
상기 서브 텍스트 정보의 시작 시간 및 종료 시간에 따라, 상기 음성 정보로부터 상기 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭을 더 포함하는 것을 특징으로 하는 성문 정보 관리 방법. - 제2항에 있어서, 상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집은:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 상기 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함하는 것을 특징으로 하는 성문 정보 관리 방법. - 제1항에 있어서, 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자 저장 단계는:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 상기 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
상기 제2 기준 성문 정보가 존재하지 않으면, 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자를 직접 저장;
상기 제2 기준 성문 정보가 존재하면, 상기 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 상기 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 만약 상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 낮으면, 상기 제1 기준 성문 정보 삭제; 및
만약 상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 높으면, 상기 제2 기준 성문 정보 삭제, 및 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자 저장을 포함하는 것을 특징으로 하는 성문 정보 관리 방법. - 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득, 및 상기 제1 사용자의 음성 정보를 얻기 위하여 상기 이력 음성 파일에 필터링 처리를 실행하도록 구성되는 음성 필터;
상기 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 상기 음성 정보에 텍스트 인식 처리를 실행하도록 구성되는 텍스트 인식기; 및
상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집, 및 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자를 저장하도록 구성되는 성문 생성기를 포함하는 것을 특징으로 하는 성문 정보 관리 시스템. - 제5항에 있어서,
상기 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간을 표시하도록 구성되는 텍스트 분할기; 및
상기 서브 텍스트 정보의 상기 시작 시간 및 종료 시간에 따라, 상기 음성 정보로부터 상기 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭하도록 구성되는 성문 분할기를 더 포함하는 것을 특징으로 하는 성문 정보 관리 시스템. - 제6항에 있어서, 상기 성문 생성기가 상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집은:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 상기 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함하는 것을 특징으로 하는 성문 정보 관리 시스템. - 제5항에 있어서, 상기 성문 생성기가 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자 저장은:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 상기 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
상기 제2 기준 성문 정보가 존재하지 않으면, 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자를 직접 저장;
상기 제2 기준 성문 정보가 존재하면, 상기 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 상기 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 만약 상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 낮으면, 상기 제1 기준 성문 정보 삭제; 및
만약 상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 높으면, 상기 제2 기준 성문 정보 삭제, 및 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자 저장을 포함하는 것을 특징으로 하는 성문 정보 관리 시스템. - 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일 획득;
상기 제1 사용자의 음성 정보를 얻기 위하여 상기 이력 음성 파일에 필터링 처리 실행;
상기 사용자의 상기 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 상기 사용자의 상기 음성 정보에 텍스트 인식 처리 실행;
상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집, 및 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자 저장;
인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보 획득;
상기 획득된 기준 성문 정보 내의 텍스트 정보 출력, 및 대응하는 인증 대상 음성 정보 수신; 및
획득된 기준 성문 정보 내의 음성 정보를 인증 대상 음성 정보와 매칭, 만약 상기 매칭이 성공하면, 상기 인증 대상 사용자의 인증이 성공한 것으로 판단; 및 만약 상기 매칭이 실패하면, 상기 인증 대상 사용자의 인증이 실패한 것으로 판단을 포함하는 것을 특징으로 하는 신원 인증 방법. - 제9항에 있어서,
상기 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간 표시; 및
상기 서브 텍스트 정보의 상기 시작 시간 및 종료 시간에 따라, 상기 음성 정보로부터 상기 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭을 더 포함하는 것을 특징으로 하는 신원 인증 시스템. - 제10항에 있어서, 상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집 단계는:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 상기 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함하는 것을 특징으로 하는 신원 인증 시스템. - 제9항에 있어서, 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자 저장 단계는:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 상기 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
상기 제2 기준 성문 정보가 존재하지 않으면, 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자를 직접 저장;
상기 제2 기준 성문 정보가 존재하면, 상기 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 상기 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 만약 상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 낮으면, 상기 제1 기준 성문 정보 삭제; 및
상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 높으면, 상기 제2 기준 성문 정보 삭제, 및 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자 저장을 포함하는 것을 특징으로 하는 신원 인증 시스템. - 제1 사용자와 제2 사용자 사이의 통화에 의해 생성된 이력 음성 파일을 획득, 및 상기 제1 사용자의 음성 정보를 얻기 위하여 상기 이력 음성 파일에 필터링 처리를 실행하도록 구성되는 음성 필터;
상기 음성 정보에 대응하는 텍스트 정보를 얻기 위하여 상기 음성 정보에 텍스트 인식 처리를 실행하도록 구성되는 텍스트 인식기; 및
상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집, 및 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자를 저장하도록 구성되는 성문 생성기;
인증 대상 사용자의 신원 식별자에 대응하는 기준 성문 정보를 획득하도록 구성되는 성문 추출기;
상기 획득된 기준 성문 정보 내의 텍스트 정보를 출력, 및 대응하는 인증 대상 음성 정보를 수신하도록 구성되는 인식 전치(前置)기; 및
상기 획득된 기준 성문 정보 내의 음성 정보를 인증 대상 음성 정보와 매칭, 만약 상기 매칭이 성공하면, 상기 인증 대상 사용자의 인증이 성공한 것으로 판단; 및 만약 상기 매칭이 실패하면, 상기 인증 대상 사용자의 인증이 실패한 것으로 판단하도록 구성되는 성문 매칭기를 포함하는 것을 특징으로 하는 신원 인증 시스템. - 제13항에 있어서,
상기 텍스트 정보를 복수의 서브 텍스트 정보로 분할, 및 각 서브 텍스트 정보의 시작 시간 및 종료 시간을 표시하도록 구성되는 텍스트 분할기; 및
상기 서브 텍스트 정보의 상기 시작 시간 및 종료 시간에 따라, 상기 음성 정보로부터 상기 각 서브 텍스트 정보에 대응하는 서브 음성 정보를 각각 절삭하도록 구성되는 성문 분할기를 더 포함하는 것을 특징으로 하는 신원 인증 시스템. - 제14항에 있어서, 상기 성문 생성기가 상기 음성 정보 및 대응하는 텍스트 정보를 상기 제1 사용자의 기준 성문 정보로 편집은:
서브 음성 정보 및 서브 텍스트 정보의 각 쌍을 상기 제1 사용자의 하나의 기준 성문 정보로 각각 편집을 포함하는 것을 특징으로 하는 신원 인증 시스템. - 제13항에 있어서, 상기 성문 생성기가 상기 기준 성문 정보 및 상기 제1 사용자의 신원 식별자 저장은:
저장 대상 제1 기준 성문 정보 내의 제1 텍스트 정보와 동일한 대응하는 제2 텍스트 정보 및 상기 제1 기준 성문 정보에 대응하는 제1 신원 식별자와 또한 동일한 대응하는 제2 신원 식별자를 갖는 제2 기준 성문 정보 존재 여부 판단;
상기 제2 기준 성문 정보가 존재하지 않으면, 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자를 직접 저장;
상기 제2 기준 성문 정보가 존재하면, 상기 제1 기준 성문 정보 내의 제1 음성 정보의 품질을 상기 제2 기준 성문 정보 내의 제2 음성 정보의 품질과 비교, 및 만약 상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 낮으면, 상기 제1 기준 성문 정보 삭제; 및
상기 제1 음성 정보의 품질이 상기 제2 음성 정보의 품질보다 높으면, 상기 제2 기준 성문 정보 삭제, 및 상기 제1 기준 성문 정보 및 상기 제1 신원 식별자 저장을 포함하는 것을 특징으로 하는 신원 인증 시스템.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201410532530.0A CN105575391B (zh) | 2014-10-10 | 2014-10-10 | 声纹信息管理方法、装置以及身份认证方法、系统 |
| CN201410532530.0 | 2014-10-10 | ||
| PCT/CN2015/091260 WO2016054991A1 (zh) | 2014-10-10 | 2015-09-30 | 声纹信息管理方法、装置以及身份认证方法、系统 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20170069258A true KR20170069258A (ko) | 2017-06-20 |
Family
ID=55652587
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177012683A KR20170069258A (ko) | 2014-10-10 | 2015-09-30 | 성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US10593334B2 (ko) |
| EP (1) | EP3206205B1 (ko) |
| JP (1) | JP6671356B2 (ko) |
| KR (1) | KR20170069258A (ko) |
| CN (1) | CN105575391B (ko) |
| HK (1) | HK1224074A1 (ko) |
| SG (2) | SG11201702919UA (ko) |
| WO (1) | WO2016054991A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019143022A1 (ko) * | 2018-01-17 | 2019-07-25 | 삼성전자 주식회사 | 음성 명령을 이용한 사용자 인증 방법 및 전자 장치 |
Families Citing this family (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105575391B (zh) | 2014-10-10 | 2020-04-03 | 阿里巴巴集团控股有限公司 | 声纹信息管理方法、装置以及身份认证方法、系统 |
| CN106156583A (zh) * | 2016-06-03 | 2016-11-23 | 深圳市金立通信设备有限公司 | 一种语音解锁的方法及终端 |
| CN106549947A (zh) * | 2016-10-19 | 2017-03-29 | 陆腾蛟 | 一种即时更新的声纹认证方法及系统 |
| CN106782564B (zh) * | 2016-11-18 | 2018-09-11 | 百度在线网络技术(北京)有限公司 | 用于处理语音数据的方法和装置 |
| CN107147618B (zh) * | 2017-04-10 | 2020-05-15 | 易视星空科技无锡有限公司 | 一种用户注册方法、装置及电子设备 |
| US10592649B2 (en) | 2017-08-09 | 2020-03-17 | Nice Ltd. | Authentication via a dynamic passphrase |
| CN107564531A (zh) * | 2017-08-25 | 2018-01-09 | 百度在线网络技术(北京)有限公司 | 基于声纹特征的会议记录方法、装置及计算机设备 |
| US10490195B1 (en) * | 2017-09-26 | 2019-11-26 | Amazon Technologies, Inc. | Using system command utterances to generate a speaker profile |
| CN107863108B (zh) * | 2017-11-16 | 2021-03-23 | 百度在线网络技术(北京)有限公司 | 信息输出方法和装置 |
| CN108121210A (zh) * | 2017-11-20 | 2018-06-05 | 珠海格力电器股份有限公司 | 家电设备的权限分配方法和装置、存储介质、处理器 |
| CN108257604B (zh) * | 2017-12-08 | 2021-01-08 | 平安普惠企业管理有限公司 | 语音识别方法、终端设备及计算机可读存储介质 |
| CN107871236B (zh) * | 2017-12-26 | 2021-05-07 | 广州势必可赢网络科技有限公司 | 一种电子设备声纹支付方法及装置 |
| CN111177329A (zh) * | 2018-11-13 | 2020-05-19 | 奇酷互联网络科技(深圳)有限公司 | 一种智能终端的用户交互方法、智能终端及存储介质 |
| CN111292733A (zh) * | 2018-12-06 | 2020-06-16 | 阿里巴巴集团控股有限公司 | 一种语音交互方法和装置 |
| CN110660398B (zh) * | 2019-09-19 | 2020-11-20 | 北京三快在线科技有限公司 | 声纹特征更新方法、装置、计算机设备及存储介质 |
| CN112580390B (zh) * | 2019-09-27 | 2023-10-17 | 百度在线网络技术(北京)有限公司 | 基于智能音箱的安防监控方法、装置、音箱和介质 |
| CN110970036B (zh) * | 2019-12-24 | 2022-07-12 | 网易(杭州)网络有限公司 | 声纹识别方法及装置、计算机存储介质、电子设备 |
| US11516197B2 (en) * | 2020-04-30 | 2022-11-29 | Capital One Services, Llc | Techniques to provide sensitive information over a voice connection |
| CN111785280A (zh) * | 2020-06-10 | 2020-10-16 | 北京三快在线科技有限公司 | 身份认证方法和装置、存储介质和电子设备 |
| CN111862933A (zh) * | 2020-07-20 | 2020-10-30 | 北京字节跳动网络技术有限公司 | 用于生成合成语音的方法、装置、设备和介质 |
| US11450334B2 (en) * | 2020-09-09 | 2022-09-20 | Rovi Guides, Inc. | Systems and methods for filtering unwanted sounds from a conference call using voice synthesis |
| US11817113B2 (en) | 2020-09-09 | 2023-11-14 | Rovi Guides, Inc. | Systems and methods for filtering unwanted sounds from a conference call |
| US20220083634A1 (en) * | 2020-09-11 | 2022-03-17 | Cisco Technology, Inc. | Single input voice authentication |
| US11522994B2 (en) | 2020-11-23 | 2022-12-06 | Bank Of America Corporation | Voice analysis platform for voiceprint tracking and anomaly detection |
| CN112565242B (zh) * | 2020-12-02 | 2023-04-07 | 携程计算机技术(上海)有限公司 | 基于声纹识别的远程授权方法、系统、设备及存储介质 |
| US20220246153A1 (en) * | 2021-02-03 | 2022-08-04 | Nice Ltd. | System and method for detecting fraudsters |
| CN115565539B (zh) * | 2022-11-21 | 2023-02-07 | 中网道科技集团股份有限公司 | 一种实现自助矫正终端防伪身份验证的数据处理方法 |
| CN117059092A (zh) * | 2023-10-11 | 2023-11-14 | 北京吉道尔科技有限公司 | 基于区块链的智慧医疗交互式智能分诊方法及系统 |
Family Cites Families (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11344992A (ja) * | 1998-06-01 | 1999-12-14 | Ntt Data Corp | 音声辞書作成方法、個人認証装置および記録媒体 |
| US20040236699A1 (en) | 2001-07-10 | 2004-11-25 | American Express Travel Related Services Company, Inc. | Method and system for hand geometry recognition biometrics on a fob |
| US7158776B1 (en) * | 2001-09-18 | 2007-01-02 | Cisco Technology, Inc. | Techniques for voice-based user authentication for mobile access to network services |
| IL154733A0 (en) | 2003-03-04 | 2003-10-31 | Financial transaction authorization apparatus and method | |
| JP4213716B2 (ja) | 2003-07-31 | 2009-01-21 | 富士通株式会社 | 音声認証システム |
| CN1547191A (zh) * | 2003-12-12 | 2004-11-17 | 北京大学 | 结合语义和声纹信息的说话人身份确认系统 |
| US7386448B1 (en) | 2004-06-24 | 2008-06-10 | T-Netix, Inc. | Biometric voice authentication |
| US8014496B2 (en) | 2004-07-28 | 2011-09-06 | Verizon Business Global Llc | Systems and methods for providing network-based voice authentication |
| US7536304B2 (en) | 2005-05-27 | 2009-05-19 | Porticus, Inc. | Method and system for bio-metric voice print authentication |
| US20060277043A1 (en) | 2005-06-06 | 2006-12-07 | Edward Tomes | Voice authentication system and methods therefor |
| JP4755689B2 (ja) * | 2005-07-27 | 2011-08-24 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 正規受信者への安全なファイル配信のためのシステムおよび方法 |
| CN1852354A (zh) * | 2005-10-17 | 2006-10-25 | 华为技术有限公司 | 收集用户行为特征的方法和装置 |
| JP4466572B2 (ja) * | 2006-01-16 | 2010-05-26 | コニカミノルタビジネステクノロジーズ株式会社 | 画像形成装置、音声コマンド実行プログラムおよび音声コマンド実行方法 |
| CN1808567A (zh) | 2006-01-26 | 2006-07-26 | 覃文华 | 验证真人在场状态的声纹认证设备和其认证方法 |
| US8396711B2 (en) * | 2006-05-01 | 2013-03-12 | Microsoft Corporation | Voice authentication system and method |
| US20080256613A1 (en) | 2007-03-13 | 2008-10-16 | Grover Noel J | Voice print identification portal |
| US8775187B2 (en) | 2008-09-05 | 2014-07-08 | Auraya Pty Ltd | Voice authentication system and methods |
| US8537978B2 (en) * | 2008-10-06 | 2013-09-17 | International Business Machines Corporation | Method and system for using conversational biometrics and speaker identification/verification to filter voice streams |
| US8655660B2 (en) * | 2008-12-11 | 2014-02-18 | International Business Machines Corporation | Method for dynamic learning of individual voice patterns |
| CN102404287A (zh) | 2010-09-14 | 2012-04-04 | 盛乐信息技术(上海)有限公司 | 用数据复用法确定声纹认证阈值的声纹认证系统及方法 |
| US9318114B2 (en) * | 2010-11-24 | 2016-04-19 | At&T Intellectual Property I, L.P. | System and method for generating challenge utterances for speaker verification |
| CN102222502A (zh) * | 2011-05-16 | 2011-10-19 | 上海先先信息科技有限公司 | 一种汉语随机提示声纹验证的有效方式 |
| KR101304112B1 (ko) * | 2011-12-27 | 2013-09-05 | 현대캐피탈 주식회사 | 음성 분리를 이용한 실시간 화자인식 시스템 및 방법 |
| CN102708867A (zh) * | 2012-05-30 | 2012-10-03 | 北京正鹰科技有限责任公司 | 一种基于声纹和语音的防录音假冒身份识别方法及系统 |
| CN102760434A (zh) * | 2012-07-09 | 2012-10-31 | 华为终端有限公司 | 一种声纹特征模型更新方法及终端 |
| US10134400B2 (en) * | 2012-11-21 | 2018-11-20 | Verint Systems Ltd. | Diarization using acoustic labeling |
| JP5646675B2 (ja) * | 2013-03-19 | 2014-12-24 | ヤフー株式会社 | 情報処理装置及び方法 |
| CN103258535A (zh) * | 2013-05-30 | 2013-08-21 | 中国人民财产保险股份有限公司 | 基于声纹识别的身份识别方法及系统 |
| US20140359736A1 (en) | 2013-05-31 | 2014-12-04 | Deviceauthority, Inc. | Dynamic voiceprint authentication |
| CN103679452A (zh) * | 2013-06-20 | 2014-03-26 | 腾讯科技(深圳)有限公司 | 支付验证方法、装置及系统 |
| GB2517952B (en) * | 2013-09-05 | 2017-05-31 | Barclays Bank Plc | Biometric verification using predicted signatures |
| US8812320B1 (en) * | 2014-04-01 | 2014-08-19 | Google Inc. | Segment-based speaker verification using dynamically generated phrases |
| CN105575391B (zh) | 2014-10-10 | 2020-04-03 | 阿里巴巴集团控股有限公司 | 声纹信息管理方法、装置以及身份认证方法、系统 |
-
2014
- 2014-10-10 CN CN201410532530.0A patent/CN105575391B/zh active Active
-
2015
- 2015-09-30 JP JP2017518071A patent/JP6671356B2/ja active Active
- 2015-09-30 SG SG11201702919UA patent/SG11201702919UA/en unknown
- 2015-09-30 EP EP15848463.4A patent/EP3206205B1/en active Active
- 2015-09-30 WO PCT/CN2015/091260 patent/WO2016054991A1/zh active Application Filing
- 2015-09-30 SG SG10201903085YA patent/SG10201903085YA/en unknown
- 2015-09-30 KR KR1020177012683A patent/KR20170069258A/ko not_active Application Discontinuation
-
2016
- 2016-10-26 HK HK16112295.9A patent/HK1224074A1/zh unknown
-
2017
- 2017-04-10 US US15/484,082 patent/US10593334B2/en active Active
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019143022A1 (ko) * | 2018-01-17 | 2019-07-25 | 삼성전자 주식회사 | 음성 명령을 이용한 사용자 인증 방법 및 전자 장치 |
| KR20190087798A (ko) * | 2018-01-17 | 2019-07-25 | 삼성전자주식회사 | 음성 명령을 이용한 사용자 인증 방법 및 전자 장치 |
| US11960582B2 (en) | 2018-01-17 | 2024-04-16 | Samsung Electronics Co., Ltd. | Method and electronic device for authenticating user by using voice command |
Also Published As
| Publication number | Publication date |
|---|---|
| US20170221488A1 (en) | 2017-08-03 |
| WO2016054991A1 (zh) | 2016-04-14 |
| HK1224074A1 (zh) | 2017-08-11 |
| EP3206205A1 (en) | 2017-08-16 |
| CN105575391B (zh) | 2020-04-03 |
| CN105575391A (zh) | 2016-05-11 |
| SG10201903085YA (en) | 2019-05-30 |
| JP6671356B2 (ja) | 2020-03-25 |
| EP3206205A4 (en) | 2017-11-01 |
| US10593334B2 (en) | 2020-03-17 |
| SG11201702919UA (en) | 2017-05-30 |
| EP3206205B1 (en) | 2020-01-15 |
| JP2017534905A (ja) | 2017-11-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20170069258A (ko) | 성문 정보 관리 방법 및 장치, 및 신원 인증 방법 및 시스템 | |
| AU2016216737B2 (en) | Voice Authentication and Speech Recognition System | |
| US10339290B2 (en) | Spoken pass-phrase suitability determination | |
| KR101963993B1 (ko) | 동적 패스워드 음성에 기반한 자체 학습 기능을 구비한 신분 인증 시스템 및 방법 | |
| JP6326490B2 (ja) | 録取された音声データに対する核心語の取出に基づく発話内容の把握システムと、このシステムを用いたインデクシング方法及び発話内容の把握方法 | |
| US8812319B2 (en) | Dynamic pass phrase security system (DPSS) | |
| US7657431B2 (en) | Voice authentication system | |
| US20160372116A1 (en) | Voice authentication and speech recognition system and method | |
| JP2017009980A (ja) | 声紋認証方法および装置 | |
| AU2013203139A1 (en) | Voice authentication and speech recognition system and method | |
| US9311914B2 (en) | Method and apparatus for enhanced phonetic indexing and search | |
| KR101888058B1 (ko) | 발화된 단어에 기초하여 화자를 식별하기 위한 방법 및 그 장치 | |
| KR20170139650A (ko) | 계정 추가 방법, 단말, 서버, 및 컴퓨터 저장 매체 | |
| EP2879130A1 (en) | Methods and systems for splitting a digital signal | |
| TWI536366B (zh) | 新增口說語彙的語音辨識系統與方法及電腦可讀取媒體 | |
| KR101181060B1 (ko) | 음성 인식 시스템 및 이를 이용한 화자 인증 방법 | |
| KR102098956B1 (ko) | 음성인식장치 및 음성인식방법 | |
| JP2011248107A (ja) | 音声認識結果検索方法とその装置とプログラム | |
| WO2018137426A1 (zh) | 用户声音信息的识别方法及装置 | |
| KR102076565B1 (ko) | 화자 식별 노이즈의 삽입을 통해 발화자의 식별이 가능하게 하는 음성 처리 장치 및 그 동작 방법 | |
| US11632345B1 (en) | Message management for communal account | |
| WO2006027844A1 (ja) | 話者照合装置 | |
| JP4807261B2 (ja) | 音声処理装置およびプログラム | |
| KR20230066797A (ko) | 화자 음성 분리에 의한 실시간 자막 및 문서 생성 방법, 그 방법을 이용한 컴퓨터 프로그램 그리고 장치 | |
| CN117151047A (zh) | 一种基于ai识别的会议纪要生成方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |