KR20170011350A - 가상 머신을 지원하는 스토리지 장치, 그것을 포함하는 스토리지 시스템 및 그것의 동작 방법 - Google Patents
가상 머신을 지원하는 스토리지 장치, 그것을 포함하는 스토리지 시스템 및 그것의 동작 방법 Download PDFInfo
- Publication number
- KR20170011350A KR20170011350A KR1020150103853A KR20150103853A KR20170011350A KR 20170011350 A KR20170011350 A KR 20170011350A KR 1020150103853 A KR1020150103853 A KR 1020150103853A KR 20150103853 A KR20150103853 A KR 20150103853A KR 20170011350 A KR20170011350 A KR 20170011350A
- Authority
- KR
- South Korea
- Prior art keywords
- request
- queue
- virtual machines
- time
- job
- Prior art date
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/0671—In-line storage system
- G06F3/0683—Plurality of storage devices
- G06F3/0688—Non-volatile semiconductor memory arrays
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0866—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches for peripheral storage systems, e.g. disk cache
- G06F12/0868—Data transfer between cache memory and other subsystems, e.g. storage devices or host systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/0223—User address space allocation, e.g. contiguous or non contiguous base addressing
- G06F12/023—Free address space management
- G06F12/0238—Memory management in non-volatile memory, e.g. resistive RAM or ferroelectric memory
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
- G06F13/1605—Handling requests for interconnection or transfer for access to memory bus based on arbitration
- G06F13/1642—Handling requests for interconnection or transfer for access to memory bus based on arbitration with request queuing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
- G06F13/1668—Details of memory controller
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/0604—Improving or facilitating administration, e.g. storage management
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0629—Configuration or reconfiguration of storage systems
- G06F3/0631—Configuration or reconfiguration of storage systems by allocating resources to storage systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45504—Abstract machines for programme code execution, e.g. Java virtual machine [JVM], interpreters, emulators
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5077—Logical partitioning of resources; Management or configuration of virtualized resources
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45579—I/O management, e.g. providing access to device drivers or storage
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Techniques For Improving Reliability Of Storages (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Debugging And Monitoring (AREA)
Abstract
스토리지 장치스토리지 장치. 본 출원의 실시 예에 따른 스토리지 장치는 복수의 블록을 포함하는 불휘발성 메모리, 상기 불휘발성 메모리에 연결되어, 상기 불휘발성 메모리 내부에 복수의 가상 머신들 각각에 대응하는 독립된 소거 블록 그룹을 할당하고, 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하는 컨트롤러를 포함한다. 본 출원의 실시예에 따른 스토리지 장치의 작업 스케줄링 방법은 복수의 가상 머신들 각각에 하나의 요청 큐를 할당하고, 상기 요청 큐에 타임버짓을 할당하고, 상기 복수의 가상 머신들이 요청한 작업들을 상기 요청 큐에 저장하고, 상기 요청 큐에 저장된 작업을 수행하고, 상기 저장된 작업의 수행이 완료될 때 상기 타임버짓에서 상기 수행된 작업의 시간비용만큼을 감소시키고, 상기 요청 큐의 타임버짓이 모두 소진되었을 때, 상기 요청 큐의 타임버짓을 재할당할 때까지 상기 요청 큐에 저장된 작업을 대기시킬 수 있다.
Description
본 출원은 스토리지 장치에 관한 것으로, 좀더 자세하게는 가상화 기능을 지원하는 스토리지 장치, 스토리지 장치의 작업 스케줄링 방법 및 스토리지 시스템에 관한 것이다.
불휘발성 메모리 장치를 기반으로 하는 데이터 스토리지 장치의 대표적인 예로써, 솔리스 스테이트 드라이브(solid state drive; SSD)가 있다. SSD와 같은 데이터 스토리지 장치에 사용되는 인터페이스로 SATA, PCIe, SAS 등이 있다. SSD의 성능은 점차 개선되고 있고, 동시에 처리되는 데이터 양도 점차 증가하고 있다. 그러나, SATA와 같은 종래의 인터페이스는 SSD와 같은 데이터 스토리지 장치에 특화된 인터페이스가 아니므로, 근본적으로 한계점을 가지고 있다. 그 결과, SSD에 걸맞는 표준화된 인터페이스를 만들고자 하는 노력의 일환으로써, NVMe가 탄생하게 되었다. NVMe는 SSD와 같은 데이터 스토리지 장치와 호스트 소프트웨어 간에 통신하는 레지스터 레벨의 인터페이스이다. NVMe는 종래의 PCIe 버스를 기반으로 하며, SSD에 최적화된 인터페이스이다.
한편, 반도체 제조 기술이 발전하면서, 스토리지 장치와 통신하는 컴퓨터, 스마트폰, 스마트패드 등과 같은 호스트 장치의 동작 속도가 향상되고 있다. 호스트 장치의 동작 속도가 향상됨에 따라, 하나의 호스트 장치에서 다양한 가상화 기능들을 구동하는 가상화가 도입되고 있다. 그러나 종래의 NVMe는 가상화에서 가상 머신들(virtual machines)간의 분리(isolation) 및 형평성(fairness)을 충분히 보장하지 못하여, 이러한 가상화 기능을 지원하는데 한계가 있다.
본 출원의 목적은 가상화 기능을 지원할 수 있는 스토리지 장치에서 가상 머신들(virtual machines)간의 분리 및 형평성을 보장하는 스토리지 장치, 스토리지 장치를 포함하는 스토리지 시스템 및 스토리지 장치의 가상화 방법을 제공하는데 그 목적이 있다.
본 출원의 실시 예에 따른 스토리지 장치는 복수의 블록을 포함하는 불휘발성 메모리 및 상기 불휘발성 메모리에 연결되어, 상기 불휘발성 메모리 내부에 복수의 가상 머신들 각각에 대응하는 독립된 소거 블록 그룹을 할당하고, 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하는 컨트롤러를 포함할 수 있다.
상기 워크로드 기여도는 상기 소거 블록 그룹내의 유효한 데이터의 저장효율에 기초하여 결정될 수 있다. 상기 유효한 데이터의 저장효율은 상기 소거 블록 그룹내에 사용된 페이지수와 유효 데이터를 저장하는 페이지수의 비율일 수 있다.
상기 스토리지 장치는 상기 복수의 가상 머신들 각각에 대응하고, 상기 복수의 가상 머신들의 요청 작업을 저장하는 복수의 요청 큐를 더 포함할 수 있다. 상기 요청 큐는 DRAM으로 구성될 수 있다.
상기 컨트롤러는, 상기 복수의 가상 머신들 각각에 대응하고, 상기 복수의 가상 머신들의 요청 작업들을 저장하는 복수의 요청 큐들, 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 요청 작업들을 스케줄링하는 스케줄러, 상기 불휘발성 메모리에 저장된 데이터의 주소 맵핑을 관리하는 맵핑관리자 및 상기 불휘발성 메모리에 채널을 통하여 연결된 복수의 플래시 큐들을 포함할 수 있다.
상기 워크로드 기여도는 상기 소거 블록 그룹내의 유효한 데이터 저장효율에 기초하여 결정될 수 있다. 상기 유효한 데이터 저장효율은 상기 소거 블록 그룹내에 사용된 페이지수와 유효 데이터를 저장하는 페이지수의 비율일 수 있다.
상기 스케줄러는 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하기 위하여 상기 복수의 요청 큐들에 타임버짓을 할당할 수 있다. 상기 스케줄러는 상기 요청 작업들 중 선택된 요청 작업의 수행이 완료될 때, 상기 수행된 요청 작업과 관련된 가상 머신의 시간비용을 계산할 수 있다. 상기 시간비용은 상기 요청 작업에 의한 스토리지 장치의 IOPS (Input/Output Per Second)와 반비례관계일 수 있다.
상기 스케줄러는 상기 요청 큐들 중 선택된 요청 큐에서 상기 플래시 큐들 중 선택된 플래시 큐로 데이터를 전송하는데 소용되는 시간에 기초하여 상기 복수의 가상 머신들의 시간비용을 계산할 수 있다. 상기 선택된 요청 큐에서 상기 선택된 플래시 큐로 페이지단위의 데이터가 전송될 때, 상기 스케줄러는 상기 선택된 요청 큐에 할당된 타임버짓을 상기 시간비용만큼 감소시킬 수 있다.
본 출원의 실시 예에 따른 컨트롤러 및 상기 컨트롤러에 연결된 불휘발성 메모리를 포함하는 스토리지 장치의 작업 스케줄링 방법은, 복수의 가상 머신들 각각에 하나의 요청 큐를 할당하는 단계, 상기 요청 큐에 타임버짓을 할당하는 단계, 상기 복수의 가상 머신들이 요청한 작업들을 상기 요청 큐에 저장하는 단계, 상기 요청 큐에 저장된 작업을 수행하는 단계, 상기 저장된 작업의 수행이 완료될 때 상기 타임버짓에서 상기 수행된 작업의 시간비용만큼을 감소시키는 단계 및 상기 요청 큐의 타임버짓이 모두 소진되었을 때, 상기 요청 큐의 타임버짓을 재할당할 때까지 상기 요청 큐에 저장된 작업을 대기시키는 단계를 포함할 수 있다.
상기 타임버짓을 할당하는 단계는, 상기 복수의 가상 머신 각각에 할당된 요청큐에 같은 타임버짓을 할당하는 단계를 포함할 수 있다.
상기 요청 큐에 저장된 작업을 수행하는 단계는, 상기 요청 큐로 부터 상기 저장된 작업을 패치(fetch)하는 단계를 포함할 수 있다. 상기 요청 큐에 저장된 작업을 수행하는 단계는, 상기 저장된 작업과 관련된 데이터를 호스트 장치로 부터 수신하여 상기 컨트롤러에 포함된 플래시 큐로 전송하는 단계를 포함할 수 있다. 상기 요청 큐에 저장된 작업을 수행하는 단계는, 상기 플래시 큐로 전송된 데이터를 상기 컨트롤러와 상기 불휘발성 메모리 사이에 형성된 멀티채널(multi-channel)을 통하여 전송하는 단계를 포함할 수 있다.
상기 복수의 가상 머신 각각에 하나의 요청 큐를 할당하는 단계는, 상기 스토리지 장치에 포함된 DRAM에 상기 각각의 요청 큐들의 영역을 할당하는 단계를 포함할 수 있다.
상기 스토리지 장치의 작업 스케줄링 방법은 상기 요청 큐에 저장된 작업을 패치(fetch)하여 상기 작업의 수행이 완료될 때 소요된 시간을 측정하여 상기 작업의 시간비용을 계산하는 단계를 더 포함할 수 있다.
상기 스토리지 장치의 작업 스케줄링 방법은 상기 호스트 장치로부터 상기 요청 큐에 저장된 작업의 시간비용을 수신하는 단계를 더 포함할 수 있다.
상기 스토리지 장치의 작업 스케줄링 방법은 상기 불휘발성 메모리에 포함된 적어도 하나의 블록을 포함하는 소거 블록 그룹을 상기 복수의 가상 머신들 각각에 전용으로 할당하는 단계를 더 포함할 수 있다. 상기 시간비용은 상기 소거 블록 그룹내의 데이터 저장효율 (storage efficiency)에 기초하여 결정될 수 있다. 상기 데이터 저장효율은 상기 소거 블록 그룹내에 사용된 페이지수와 유효 데이터를 저장하는 페이지수의 비율일 수 있다. 상기 소거 블록 그룹의 데이터 저장효율은 상기 불휘발성 메모리에 포함된 메타블록에 저장될 수 있다. 상기 소거 블록 그룹의 데이터 저장효율은 상기 소거 블록 그룹에 저장될 수 있다.
상기 데이터 저장효율은 상기 소거 블록 그룹에 포함된 각 블록들의 데이터 저장효율의 평균값일 수 있다. 상기 각 블록의 데이터 저장효율은 상기 각 블록의 더미 영역에 저장될 수 있다.
상기 스토리지 장치의 작업 스케줄링 방법은 상기 수행된 작업의 시간비용을 설정하는 단계를 더 포함할 수 있다. 상기 스토리지 장치의 작업 스케줄링 방법은 상기 수행된 작업의 수행시간에 기초하여 상기 시간비용을 초기화하는 단계를 더 포함할 수 있다. 상기 시간비용을 설정하는 단계는, 오버헤드의 시간비용을 계산하는 단계 및 상기 계산된 오버헤드의 시간비용에 기초하여 상기 시간비용을 보상하는 단계를 포함할 수 있다. 상기 오버헤드의 시간비용을 계산하는 단계는, 상기 오버헤드의 수행시간에 기초한 회귀방정식에 의하여 상기 오버헤드의 시간비용을 계산하는 단계일 수 있다. 상기 오버헤드는 불휘발성 메모리의 가비지 컬렉션, 리드 리클레임, 맵핑 테이블 업로드 동작 중 적어도 하나를 포함할 수 있다.
상기 타임버짓을 재할당하는 단계는, 상기 모든 요청 큐에 저장된 작업을 모두 수행한 후에 수행될 수 있다. 상기 타임버짓을 재할당하는 단계는, 상기 모든 요청 큐에 저장된 작업이 없을 경우 새로운 타임버짓을 각 요청 큐에 할당하는 단계일 수 있다.
본 출원의 실시 예에 따른 컨트롤러는 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 저장된 요청 작업들을 스케줄링하는 스케줄러, 복수의 채널을 통하여 외부의 불휘발성 메모리와 연결되는 플래시 큐들 및 상기 외부의 불휘발성 메모리에 저장된 데이터의 주소 맵핑을 관리하는 맵핑관리자를 포함할 수 있다.
상기 컨트롤러는 상기 복수의 가상 머신들 각각에 대응하고, 상기 복수의 가상 머신들의 요청 작업을 저장하는 복수의 요청 큐를 더 포함할 수 있다. 상기 스케줄러는 상기 복수의 가상 머신의 요청 작업을 스케줄링하기 위하여 상기 요청 큐들에 타임버짓을 할당하고, 상기 요청 작업들의 수행이 완료될 때, 상기 수행된 작업의 작업 수행시간에 기초하여 해당 가상 머신의 시간비용을 계산할 수 있다. 상기 시간비용은 상기 수행된 작업에 의한 스토리지 장치컨트롤러의 IOPS (Input/Output Per Second)와 반비례관계일 수 있다. 상기 스케줄러는 상기 요청 큐들 중 선택된 요청 큐에서 상기 플래시 큐들 중 선택된 플래시 큐로 데이터를 전송하는데 소용되는 시간에 기초하여 해당 가상 머신의 시간비용을 계산할 수 있다. 상기 선택된 요청 큐에서 상기 선택된 플래시 큐로 페이지단위의 데이터가 전송될 때, 상기 선택된 요청 큐에 할당된 타임버짓을 상기 시간비용만큼 감소시킬 수 있다.
본 출원의 실시 예에 따른 서버는 복수의 가상 머신들 각각에 대응하는 독립된 소거 블록 그룹을 포함하는 불휘발성 메모리 및 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 요청 작업들을 스케줄링하는 컨트롤러를 포함할 수 있다.
상기 복수의 가상 머신들 각각은 적어도 한 개 이상의 독립된 소거 블록 그룹을 포함할 수 있다.
본 출원의 실시 예에 따른 스토리지 장치 및 스토리지 장치의 동작 방법은 큐 베이스의 인터페이스 방식과 가상화 기능을 효율적으로 지원하여, 가상 머신들간의 성능 분리, 동작 속도 향상 및 리소스 이용 공정성을 증가시킬 수 있다.
도 1은 본 발명의 기술적 사상의 실시 예에 따른 가상화 기능을 지원하는 스토리지 시스템의 일 예를 보여주는 블록도이다
도 2는 본 발명의 기술적 사상의 다른 실시 예에 따른 가상화 기능을 지원하는 스토리지 시스템의 일 예를 보여주는 블록도이다.
도 3은 도 2의 컨트롤러 및 가상화 관리 모듈의 구성 및 동작을 좀더 자세히 보여주는 블록도이다.
도 4는 가상화 기능을 지원하는 스토리지 장치의 블록도이다.
도 5a, 도 5b, 도 5c는 가상 머신이 발생하는 시간 비용을 보상하는 방법에 대한 개념도이다.
도 6은 스토리지 장치(2200)의 불휘발성 메모리 내부에 독립적으로 할당된 블록 그룹(BG)를 나타내는 블록도이다.
도 7은 본 발명의 일 실시예에 따른 도 6의 소거 블록 그룹의 상세 블록도이다.
도 8은 본 발명의 실시 예들에 따른, 타임버짓(TB)에 기초한 작업 스케줄링 방법을 설명하는 순서도이다.
도 9은 요청 작업에 대한 시간 비용을 보상하는 방법에 대한 순서도이다. 도 10은 도 6에서 설명한 저장효율 (예를 들면, 쓰기 확대 요소(WAF))에 기초한 스케줄링 방법에 대한 순서도이다.
도 11는 본 발명의 실시 예에 따른 스토리지 시스템을 나타내는 블록도이다.
도 12는 본 발명의 실시 예에 따른 스토리지 장치가 적용된 컴퓨터 시스템을 나타내는 블록도이다.
도 2는 본 발명의 기술적 사상의 다른 실시 예에 따른 가상화 기능을 지원하는 스토리지 시스템의 일 예를 보여주는 블록도이다.
도 3은 도 2의 컨트롤러 및 가상화 관리 모듈의 구성 및 동작을 좀더 자세히 보여주는 블록도이다.
도 4는 가상화 기능을 지원하는 스토리지 장치의 블록도이다.
도 5a, 도 5b, 도 5c는 가상 머신이 발생하는 시간 비용을 보상하는 방법에 대한 개념도이다.
도 6은 스토리지 장치(2200)의 불휘발성 메모리 내부에 독립적으로 할당된 블록 그룹(BG)를 나타내는 블록도이다.
도 7은 본 발명의 일 실시예에 따른 도 6의 소거 블록 그룹의 상세 블록도이다.
도 8은 본 발명의 실시 예들에 따른, 타임버짓(TB)에 기초한 작업 스케줄링 방법을 설명하는 순서도이다.
도 9은 요청 작업에 대한 시간 비용을 보상하는 방법에 대한 순서도이다. 도 10은 도 6에서 설명한 저장효율 (예를 들면, 쓰기 확대 요소(WAF))에 기초한 스케줄링 방법에 대한 순서도이다.
도 11는 본 발명의 실시 예에 따른 스토리지 시스템을 나타내는 블록도이다.
도 12는 본 발명의 실시 예에 따른 스토리지 장치가 적용된 컴퓨터 시스템을 나타내는 블록도이다.
본 명세서에 개시되어 있는 본 발명의 개념에 따른 실시 예들에 대해서 특정한 구조적 또는 기능적 설명은 단지 본 발명의 개념에 따른 실시 예들을 설명하기 위한 목적으로 예시된 것으로서, 본 발명의 개념에 따른 실시 예들은 다양한 형태들로 실시될 수 있으며 본 명세서에 설명된 실시 예들에 한정되지 않는다.
본 발명의 개념에 따른 실시 예들은 다양한 변경들을 가할 수 있고 여러 가지 형태들을 가질 수 있으므로 실시 예들을 도면에 예시하고 본 명세서에서 상세하게 설명하고자 한다. 그러나, 이는 본 발명의 개념에 따른 실시 예들을 특정한 개시 형태들에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물, 또는 대체물을 포함한다.
제1 또는 제2 등의 용어는 다양한 구성 요소들을 설명하는데 사용될 수 있지만, 상기 구성 요소들은 상기 용어들에 의해 한정되어서는 안 된다. 상기 용어들은 하나의 구성 요소를 다른 구성 요소로부터 구별하는 목적으로만, 예컨대 본 발명의 개념에 따른 권리 범위로부터 벗어나지 않은 채, 제1구성 요소는 제2구성 요소로 명명될 수 있고 유사하게 제2구성 요소는 제1구성 요소로도 명명될 수 있다.
어떤 구성 요소가 다른 구성 요소에 "연결되어" 있다거나 "접속되어" 있다고 언급된 때에는, 그 다른 구성 요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성 요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성 요소가 다른 구성 요소에 "직접 연결되어" 있다거나 "직접 접속되어" 있다고 언급된 때에는 중간에 다른 구성 요소가 존재하지 않는 것으로 이해되어야 할 것이다. 구성 요소들 간의 관계를 설명하는 다른 표현들, 즉 "~사이에"와 "바로 ~사이에" 또는 "~에 이웃하는"과 "~에 직접 이웃하는" 등도 마찬가지로 해석되어야 한다.
본 명세서에서 사용한 용어는 단지 특정한 실시 예를 설명하기 위해 사용된 것으로서, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 명세서에서, "포함하다" 또는 "가지다" 등의 용어는 본 명세서에 기재된 특징, 숫자, 단계, 동작, 구성 요소, 부분품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성 요소, 부분품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.
다르게 정의되지 않는 한, 기술적이거나 과학적인 용어를 포함해서 여기서 사용되는 모든 용어들은 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 가진다. 일반적으로 사용되는 사전에 정의되어 있는 것과 같은 용어들은 관련 기술의 문맥상 가지는 의미와 일치하는 의미를 갖는 것으로 해석되어야 하며, 본 명세서에서 명백하게 정의하지 않는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.
이하에서는 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자가 본 발명의 기술적 사상을 용이하게 실시할 수 있을 정도로 상세히 설명하기 위하여, 본 발명의 실시 예들을 첨부된 도면을 참조하여 설명하기로 한다.
본 발명의 기술적 사상의 실시 예들에 따른 가상화 기능을 지원하는 스토리지 시스템 및 스토리지 장치는 관리를 위한 물리적 기능(Physical function; PF)과 복수의 가상화 기능들(virtual functions; VFs)을 호스트에 제공할 수 있다. 이때, 하나의 가상 머신(virtual machine; VM)에는 적어도 하나의 가상화 기능(virtual functions; VFs)이 할당될 수 있다.
도 1은 본 발명의 기술적 사상의 실시 예에 따른 가상화 기능을 지원하는 스토리지 시스템(1000)의 일 예를 보여주는 블록도이다. 도 1의 스토리지 시스템(1000)은 큐 베이스의 커맨드 인터페이스 방식을 지원하면서 동시에 가상화 기능을 함께 지원할 수 있다. 예를 들어, 도 1의 스토리지 시스템(1000)은 NVMe 프로토콜에 따른 인터페이스 방식을 지원하면서 동시에 SR-IOV(Single-Root IO Virtualization)의 가상화 기능을 함께 지원할 수 있다. 도 1을 참조하면, 스토리지 시스템(1000)은 호스트 장치(1100) 및 스토리지 장치(1200)를 포함할 수 있다. 호스트 장치(1100)는 호스트 코어(1110), 가상화 중재기(Virtualization Intermediary, VI)(1120), 루트 컴플렉스(Root Complex, RC)(1130), 호스트 메모리(1140), 그리고 스토리지 인터페이스(1150)를 포함할 수 있다.
호스트 코어(1110)는 하나의 물리적 기능(Physical Function, PF)(1110_a) 및 복수의 가상화 기능들(Virtual Function, VF)(1111~111n)을 포함할 수 있다. 여기서 물리적 기능(1110_a)는 물리적인 하드웨어로써의 코어 혹은 프로세서일 수 있다. 복수의 가상화 기능들(1111~111n)은 각각 SR-IOV의 가상화 동작에 의하여 생성된 가상화 코어 혹은 프로세서일 수 있으며, 각각 독립적으로 운영체제 및 어플리케이션을 구동할 수 있다. 하나의 가상화 기능에 의하여 구동되는 운영체제는, 예를 들어, 게스트 O/S(Guest O/S)라 칭해질 수 있다.
가상화 중재기(1120)는 호스트 코어(1110) 및 루트 컴플렉스(1130)에 연결되며, 가상화 기능들(1111~111n)을 수행하거나 가상화 기능들(1111~111n)을 관리하는 기능을 수행한다. 예를 들어, 가상화 중재기(1120)는 SR-IOV의 가상화 동작을 위한 주소(address) 정보를 전송하고 관리하는 기능을 수행할 수 있다.
루트 컴플렉스(1130)는 계층(hierarchy)의 루트(root)를 나타내는 것으로, 가상화 중재기(1120), 호스트 메모리(1140), 그리고 스토리지 인터페이스(1150)에 연결될 수 있다. 루트 컴플렉스(1130)는 호스트 코어(1110)를 호스트 메모리(1140)에 연결하거나, 호스트 코어(1110) 및 호스트 메모리(1140)를 스토리지 인터페이스(1150)에 연결하는 역할을 수행할 수 있다.
호스트 메모리(1140)는 루트 컴플렉스(1130)를 통하여 가상화 중재기(1120), 호스트 코어(1110), 그리고 스토리지 인터페이스(1150)에 연결될 수 있다. 호스트 메모리(1140)는, 예를 들어, 호스트 코어(1110)의 물리적 기능(1110_a) 또는 가상화 기능들(1111~111n) 각각을 위한 워킹 메모리(working memory)로 사용될 수 있다. 이 경우, 호스트 메모리(1140)에는 응용 프로그램, 파일 시스템 및 장치 드라이버 등이 로딩될 수 있다.
다른 예로, 호스트 메모리(1140)는 스토리지 장치(1200)로 데이터를 전송하거나 스토리지 장치(1200)로부터 수신된 데이터를 임시로 저장하기 위한 버퍼로 사용될 수 있다. 호스트 메모리(1140)는, 예를 들어, SRAM(Static RAM), DRAM(Dynamic RAM) 등과 같은 휘발성 메모리로 구현될 수 있으며, PRAM(Phase-change RAM), MRAM(Magnetic RAM), RRAM(Resistive RAM), FRAM(Ferrolectric RAM) 등과 같은 불휘발성 메모리이거나, 또는 이들의 조합으로 구현될 수 있다.
스토리지 인터페이스(1150)는 루트 컴플렉스(1130)에 연결되며, 호스트 장치(1100)와 스토리지 장치(1200) 사이의 통신을 제공할 수 있다. 예를 들어, 스토리지 인터페이스(1150)는 NVMe 프로토콜 방식에 따라 큐 베이스의 커맨드들 및 데이터를 스토리지 장치(1200)에 제공하거나, 스토리지 장치(1200)로부터 처리된 커맨드들의 정보 및 데이터를 수신할 것이다.
계속해서 도 1를 참조하면, 스토리지 장치(1200)는 호스트 장치(1100)로부터 제공된 데이터를 저장하거나, 저장된 데이터를 호스트 장치(1100)에 제공할 수 있다. 스토리지 장치(1200)는 컨트롤러(1210) 및 복수의 불휘발성 메모리들(1221~122n)를 포함할 수 있다.
컨트롤러(1210)는 큐 베이스의 인터페이스 방식을 통하여 호스트 장치(1100)와 통신할 수 있다. 컨트롤러(1210)는 호스트 장치(1100)로부터 수신된 커맨드에 따라 데이터를 복수의 불휘발성 메모리들(1221~122n) 중 적어도 하나에 저장하도록 스토리지 장치(1200)를 제어할 수 있다. 또한 컨트롤러(1210)는 복수의 불휘발성 메모리들(1221~122n)에 저장된 데이터를 호스트 장치(1100)로 전송하도록 스토리지 장치(1200)를 제어할 수 있다.
복수의 불휘발성 메모리들(1221~122n)은 각각 대응하는 채널들(CH1~CHn)을 통하여 컨트롤러(1210)에 연결될 수 있다. 복수의 불휘발성 메모리들(1221~122n)은 각각 컨트롤러(1210)의 제어에 따라 데이터를 저장하거나 저장된 데이터를 독출(read)하는 동작을 수행할 수 있다. 복수의 불휘발성 메모리들(1221~122n)은 각각 플래시 메모리(Flash memory), PRAM, MRAM, RRAM, FRAM 등과 같은 불휘발성 메모리로 구현되거나, 혹은 이들이 조합된 형태로 구현될 수 있다.
본 발명의 기술적 사상에 따른 실시 예에 있어서, 호스트 메모리(1140)는 큐 베이스의 인터페이스 방식을 지원하면서 동시에 가상화 기능을 지원하기 위한 큐 커맨드의 저장 영역을 제공할 수 있다. 다시 말하면, 본 발명의 기술적 사상에 따른 호스트 메모리(1140)는 가상화 기능을 구비하는 큐 베이스의 커맨드 인터페이스 방식을 지원하기 위하여, 큐 커맨드를 저장하기 위한 영역을 별도로 제공할 수 있다.
예를 들어 도 2에 도시된 바와 같이, NVMe 프로토콜 인터페이스 방식에서의 SR-IOV 가상화 기능을 지원하기 위하여, 호스트 메모리(1140)는 물리적 기능(1110_a)의 관리 큐를 저장하기 위한 물리적 기능 관리 큐 저장 영역(PF Administrator queue stroage area, PF A_Q Area)(1140_a), 물리적 기능(1110_a)의 입출력 큐를 저장하기 위한 물리적 기능 입출력 큐 저장 영역(PF I/O Queue storage area, PF I/O_Q Area)(1140_b), 가상화 기능들의 입출력 큐들을 저장하기 위한 복수의 가상화 기능 입출력 큐 저장 영역(VF1 I/O_Q Area~VFn I/O_Q Area)(1141~114n)을 제공할 수 있다. 이 경우, 큐 커맨드들은 NVMe 프로토콜 인터페이스 방식에서 주로 사용되는 써큘러 큐(circular queue) 방식을 이용하여 각 저장 영역에 저장될 수 있다.
도 2의 스토리지 시스템(1000)의 각 가상화 기능(1111~111n)의 게스트 O/S 혹은 가상화 중재기(1120)는 가상화 기능들의 입출력 큐들(VF1 I/O Queue~VFn I/O Queue)을 처리할 때마다 물리적 기능 관리 큐 저장 영역(1140_a)에 저장된 물리적 기능(1110_a)의 관리 큐에 접근(access)할 수 있다.
도 2은 본 발명의 기술적 사상의 다른 실시 예에 따른 가상화 기능을 지원하는 스토리지 시스템(2000)의 일 예를 보여주는 블록도이다. 도 2의 스토리지 시스템(2000)의 구성은 도 1의 스토리지 시스템(1000)의 구성과 일정부분 유사하다. 따라서 이하에서는 도 1의 스토리지 시스템(1000)과의 차이점이 중점적으로 설명될 것이다. 도 2을 참조하면, 스토리지 시스템(2000)은 호스트 장치(2100) 및 스토리지 장치(22000)를 포함할 수 있다.
호스트 장치(2100)는 호스트 코어(2110), 가상화 중재기(2120), 루트 컴플렉스(2130), 호스트 메모리(2140), 스토리지 인터페이스(2150)를 포함할 수 있다. 호스트 코어(2110), 가상화 중재기(2120), 루트 컴플렉스(2130) 및 스토리지 인터페이스(2150)의 구성 및 동작은 도 1에서 설명된 것과 유사하므로, 자세한 설명은 생략된다.
본 발명의 기술적 사상에 따른 실시 예에 있어서, 도 2의 복수의 가상화 기능들(2111~211n)에는 각각 별도의 독립적인 관리 큐가 할당될 수 있다. 즉, 복수의 가상화 기능들(2111~211n) 각각에는 독립적인 가상화 기능 관리 큐(VF1 Administrator Queue~VFn Administrator Queue)가 각각 할당된다. 따라서 복수의 가상화 기능들(2111~211n) 각각은 대응하는 가상화 기능 관리 큐를 이용하여 독립적으로 큐 관리(queue management) 및 커맨드/데이터의 교환(CMD/Data transaction) 동작을 수행할 수 있다.
예를 들어, 제 1 가상화 기능(2111)의 게스트 O/S는 제 1 가상화 기능 관리 큐(VF1 Administrator Queue)가 할당되며, 제 1 가상화 기능(2111)는 호스트 메모리(2140)의 제 1 가상화 기능 관리 큐 영역(2141_a)에 저장된 제 1 가상화 기능 관리 큐 및 제 1 가상화 기능 입출력 큐 영역(2141_b)에 저장된 복수의 가상화 기능 입출력 큐들을 이용하여 독립적으로 큐 관리 동작 및 커맨드/데이터 교환 동작을 수행할 수 있다.
이 경우, 가상화 중재기(2120)는 전반적인 가상화 동작에 개입할 필요가 없으며, 예를 들어, 단지 물리적 기능(2110_a)를 통한 SR-IOV 기능 초기화(SR-IOV Capability Initialization)에만 관여하게 되므로, 스토리지 시스템의 성능이 개선될 수 있다.
또한, 복수의 가상화 기능들(2111~211n)에 대응하는 가상화 기능 관리 큐들(2141_a~214n_a)을 저장하기 위하여, 본 발명의 기술적 사상의 실시 예에 따른 호스트 메모리(2140)는 관리 큐 및 입출력 큐들의 큐 페어(queue pair)를 저장하기 위한 영역을 제공할 수 있다. 도 1의 호스트 메모리(2140)는 복수의 가상화 기능 관리 큐 저장 영역(VF1 A_Q Area~VFn A_Q Area)(2141_a~214n_a)을 추가적으로 제공할 수 있다. 이 경우, 각 가상화 기능 관리 큐 및 가상화 기능 입출력 큐는 써큘러 큐 형태로 호스트 메모리(2140)에 저장될 수 있다.
계속해서 도 2를 참조하면, 스토리지 장치(2200)는 컨트롤러(2210) 및 복수의 불휘발성 메모리들(2221~222n)을 포함할 수 있다. 스토리지 장치(2200)의 전반적인 구성 및 동작은 도 1와 유사하므로, 자세한 설명은 생략된다.
본 발명의 기술적 사상에 따른 실시 예에 있어서, 컨트롤러(2210)는 가상화 관리 모듈(VF Manage Module)(2230)을 포함한다. 가상화 관리 모듈(2230)은 복수의 가상화 기능들(2111~211n) 각각에 대응하는 가상화 기능 관리 큐 및 가상화 기능 입출력 큐를 저장하고 처리하는 동작을 수행할 수 있다. 가상화 관리 모듈(2230)은 스케줄러(scheduler) 및 주소 맵핑 관리자(address mapping manager)를 더 포함할 수 있다. 컨트롤러(2210)의 구성 및 동작은 이하의 도 4에서 좀더 자세히 설명될 것이다.
도 1 및 도 2의 스토리지 시스템(1000 및 2000)은 서버(Server), 슈퍼 컴퓨터(Super Computer), 개인용 컴퓨터(Personal Computer), 랩탑(laptop) 컴퓨터, 휴대용 단말기(mobile phone), 스마트폰(smart phone), 태블릿 PC (tablet personal computer), 또는 웨어러블 컴퓨터로 구현될 수 있다.
상술한 바와 같이, 본 발명의 기술적 사상의 실시 예에 따른 스토리지 시스템(2000)은 큐 베이스의 커맨드 인터페이스 방식을 지원하면서 동시에 가상화 기능을 함께 지원할 수 있다.
도 3는 도 2의 컨트롤러(2210) 및 가상화 관리 모듈(2230)의 구성 및 동작을 좀더 자세히 보여주는 블록도이다. 도 3를 참조하면, 컨트롤러(2210)는 가상화 관리 모듈(2230), 복수의 코어들(2211_1~2211_n), 복수의 캐시들(2211_1'~2211_n'), 버퍼 컨트롤러(2212), 버퍼 메모리(2213), 그리고 불휘발성 메모리 인터페이스(2214)를 포함할 수 있다.
본 발명의 기술적 사상에 따른 실시 예에 있어서, 가상화 관리 모듈(2230)은 도 2의 호스트 장치(2100)로부터 수신된 가상화 기능 또는 가상 머신 각각에 대응하는 복수의 관리 큐들 및 복수의 입출력 큐들을 저장하고 처리하는 동작을 수행하도록 구현될 수 있다. 가상화 관리 모듈(2230)은 호스트 인터페이스(2231), 복수의 가상화 커맨드 페처(Command Fetcher, 2232_1~2232_n), 복수의 가상화 커맨드 파서(Command Parser, 2233_1~2233_n), 커맨드 디스패처(Command Dispatcher, 2234), DMA 매니저(DMA manager, 2235), DMA 유닛(DMA unit, 2236), 공통 리스판스 매니저(Response manager, 2237), 복수의 가상화 리스판서(Virtual Responser, 2238_1~2238_n)를 포함할 수 있다.
호스트 인터페이스(2231)는 호스트 장치(2100, 도 2 참조)와 스토리지 장치(2200) 사이의 인터페이싱 동작을 지원한다. 예를 들어, 도 3에 도시된 바와 같이, 제 n 가상화 기능(VFn)에 대응하는 제 n 가상화 기능 관리 서브미션 큐(VFn Administrator Submission Queue, VFn A_SQ) 및 제 n 가상화 기능 입출력 서브미션 큐(VFn I/O Submission Queue, VFn I/O SQ)의 정보는 호스트 인터페이스(2231)를 통하여 호스트(2100)로부터 스토리지 장치(2200)로 송신될 수 있다. 이 경우, 제 n 가상화 기능 관리 서브미션 큐(VFn A_SQ)에는 제 n 가상화 기능이 요구하는 관리(management) 정보가 포함될 수 있으며, 제 n 가상화 기능 입출력 서브미션 큐(VFn I/O_SQ)에는 제 n 가상화 기능이 요구하는 읽기 및 쓰기 동작에 대한 정보가 포함될 수 있다.
또한, 예를 들어, 제 n 가상화 기능(VFn)에 대응하는 제 n 가상화 기능 관리 컴플리션 큐(VFn Administrator Completion Queue, VFn A_CQ) 및 제 n 가상화 기능 입출력 컴플리션 큐(VFn I/O Completion Queue, VFn I/O_CQ)의 정보는 호스트 인터페이스(2231)를 통하여 스토리지 장치(2200)로부터 호스트 장치(2100)로 제공될 수 있다. 이 경우, 제 n 가상화 기능 관리 컴플리션 큐(VFn A_CQ)에는 제 n 가상화 기능 관리 서브미션 큐(VFn A_SQ)의 처리 결과에 대응하는 응답 정보(response information)가 포함될 수 있으며, 제 n 가상화 기능 입출력 컴플리셔 큐(VFn I/O_CQ)에는 제 n 가상화 기능 입출력 서브미션 큐(VFn I/O_SQ)의 처리 결과에 대응하는 응답 정보가 포함될 수 있다.
제 1 내지 제 n 가상화 기능 커맨드 패처들(2232_1~2232_n)은 각각 제 1 내지 제 n 가상화 기능 서브미션 큐의 정보에 대응하며, 대응하는 서브미션 큐에 저장된 커맨드를 패칭(fetching)하는 동작을 지원한다. 예를 들어, 제 1 가상화 기능 커맨드 패처(VF1 CMD Fetcher)(2232_1)는 제 1 가상화 기능 관리 서브미션 큐(VF1 A_SQ) 및 제 1 가상화 기능 입출력 서브미션 큐(VF1 I/O_SQ)의 정보에 대응하며, 링 도어벨(Ring doorbell) 신호에 응답하여 제 1 가상화 기능 관리 서브미션 큐(VF1 A_SQ) 및 제 1 가상화 기능 입출력 서브미션 큐(VF1 I/O_SQ)의 정보를 패칭하는 동작을 수행한다. 예를 들면, 제 1 가상화 기능 또는 제 1 가상 머신은 호스트 장치(1100, 2100)로부터 저장장치(1200, 2200)로 쓰기 또는 읽기 작업 큐를 전송할 수 있으며, 해당 작업은 제 1 가상화 기능 커맨드 패처(2232_1)에 저장될 수 있다. 이때, 제 1 가상화 기능 커맨드 파서(2233_1)은 제 1 가상화 기능 커맨드 패처(2232_1)에 저장된 커맨드 (즉, 요청 작업)을 해석하여 상기 커맨드가 읽기 또는 쓰기 작업인지를 판단할 수 있다. 만약, 상기 커맨드가 쓰기 작업일 경우, 컨트롤러(2210)은 상기 커맨드와 같이 전송된 주소정보를 참조하여 쓰기 DMA(2236_1)을 통하여 호스트의 데이터를 버퍼 메모리(2213)으로 전송할 수 있다. 만약, 상기 커맨드가 읽기 작업일 경우, 컨트롤러(2210)은 상기 커맨드와 같이 전송된 주소정보를 참조하여 읽기 DMA(2236_1)을 통하여 불휘발성 메모리(2221~222n)에서 호스트로 데이터를 전송할 수 있다. 제 1 가상화 기능 커맨드 패처(2232_1~2232_n)은 도 4 이후에 설명될 요청 큐(2290)에 대응될 수 있다. 요청 큐(2290)을 이용한 작업 스케줄링 방법은 도 4이후에 자세히 설명될 것이다.
패칭 동작에 대하여 좀더 자세히 설명하면, 호스트 메모리(2140, 도 2참조)의 제 1 가상화 기능 관리 큐 저장 영역(VF1 A_Q Area)(2141_a)에 서브미션 큐의 정보가 입력되는 경우, 호스트 장치(2100)는 링 도어벨 신호를 컨트롤러(2210)에 전달한다. 이 경우, 제 1 가상화 기능 커맨드 패처(2232_1)는 해당 링 도어벨 신호에 응답하여 제 1 가상화 기능 관리 큐 저장 영역(2141_a)에 접근하며, 제 1 가상화 기능 관리 서브미션 큐(VF1 A_SQ))의 커맨드 정보를 제 1 가상화 기능 커맨드 패처(2232_1) 내의 메모리에 임시로 저장한다.
이와 유사하게, 만약 호스트 메모리(2140)의 제 1 가상화 기능 입출력 큐 저장 영역(VF1 I/O_Q Area)(2141_b)에 서브미션 큐의 정보가 입력되는 경우, 호스트 장치(2100)는 링 도어벨 신호를 컨트롤러(2210)에 전달한다. 이 후, 제 1 가상화 기능 커맨드 패처(2232_1)는 해당 링 도어벨 신호에 응답하여 제 1 가상화 기능 입출력 큐 저장 영역(2141_b)에 접근하며, 제 1 가상화 기능 입출력 서브미션 큐(VF1 I/O_SQ))의 커맨드 정보를 제 1 가상화 기능 커맨드 패처(2232_1) 내의 메모리에 임시로 저장한다.
커맨드 패처들(2232_1~2232_n)은 복수의 레지스터들, 또는 SRAM(Static RAM), DRAM(Dynamic RAM) 등과 같은 휘발성 메모리로 구현될 수 있으며, PRAM(Phase-change RAM), MRAM(Magnetic RAM), RRAM(Resistive RAM), FRAM(Ferrolectric RAM) 등과 같은 불휘발성 메모리이거나, 또는 이들의 조합으로 구현될 수 있다.
제 1 내지 제 n 가상화 기능 커맨드 파서(2233_1~2233_n)는 각각 제 1 내지 제 n 가상화 기능 커맨드 패처(2232_1~2232_n)에 연결된다. 제 1 내지 제 n 가상화 기능 커맨드 파서(2233_1~2233_n)는 각각 제 1 내지 제 n 가상화 기능 커맨드 패처(2232_1~2232_n)로부터 관리 서브미션 큐 또는 입출력 서브미션 큐에 대한 커맨드를 수신하며, 각 커맨드의 특성을 파싱(parsing)하는 동작을 수행할 수 있다. 예를 들어, 제 1 가상화 기능 커맨드 파서(2233_1)는 제 1 가상화 기능 커맨드 패처(2232_1)로부터 커맨드를 수신하고, 수신된 커맨드의 특성, 커맨드가 요구하는 동작 내용 등을 분석하는 동작을 수행할 수 있다.
커맨드 디스패처(2234)는 제 1 내지 제 n 가상화 기능 커맨드 파서(2233_1~2233_n_)에 공통으로 연결된다. 커맨드 디스패처(2234)는 제 1 내지 제 n 가상화 기능 커맨드 파서(2233_1~2233_n)로부터 파싱된 복수의 커맨드들을 수신하며, 이를 그 특성에 따라 복수의 코어들(2211_1~2211_n)에 적절하게 분배하는 동작을 수행한다. 예를 들어, 커맨드 디스패처(2234)는 복수의 코어들(2211_1~2211_n)이 병렬적으로 동작하도록 커맨드들을 분배할 수 있다.
복수의 코어들(2211_1~2211_n)은 각각 버스(2240)를 통하여 커맨드 디스패처(2234)에 연결되며, 커맨드 디스패처(2234)로부터 커맨드를 수신할 수 있다. 또한, 복수의 코어들(2211_1~2211_n)은 각각 복수의 캐시 메모리(2211_1'~2211_n')에 연결되며, 각각 대응하는 캐시 메모리에 저장된 명령어(instruction)를 참조하여 커맨드들을 조정(adjusting)하는 동작을 수행한다. 예를 들어, 수신된 커맨드 및 이에 대응하는 데이터가 DMA 유닛(2236)이 한번에 처리할 수 있는 데이터 용량을 초과하는 경우, 해당 코어는 대응하는 캐시 메모리에 저장된 명령어를 참조하여 해당 커맨드가 DMA 유닛(2236)에서 처리될 수 있도록 적절히 조정하는 동작을 수행할 수 있다. 예를 들면, 상기 처리할 수 있는 데이터 용량은 불휘발성 메모리(2221~222n)의 페이지 단위 (예를 들면, 4Kbyte)일 수 있다. 만약 상기 수신된 커맨드에 대응하는 데이터가 처리할 수 있는 데이터 용량을 넘는다면, 적당한 크기(예를 들면, 4KB)로 분리하여 여러 차례 전송할 수 있다.
DMA 매니저(2235)는 버스(2240)를 통하여 코어들(2211_1~2211_n)로부터 커맨드(예를 들어, 조정된 커맨드)를 수신하며, 수신된 커맨드에 따라 DMA 유닛(2236)을 제어할 수 있다.
DMA 유닛(2236)은 쓰기 DMA(2236_1) 및 읽기 DMA(2236_2)를 포함할 수 있으며, DMA 매니저(2235)의 제어에 따라 데이터 쓰기 동작 혹은 데이터 읽기 동작을 제어할 수 있다. 예를 들어, DMA 매니저(2235)의 제어에 따라 쓰기 동작을 수행하는 경우, 쓰기 DMA(2236_1)는 호스트 인터페이스(2231)를 통하여 데이터를 수신하며, 수신된 데이터가 복수의 불휘발성 메모리(2221~222n) 중 어느 하나에 저장되도록 스토리지 장치(2200)를 제어할 수 있다. 다른 예로, DMA 매니저(2235)의 제어에 따라 읽기 동작을 수행하는 경우, 읽기 DMA(2236_2)는 DMA 매니저(2235)의 제어에 따라 복수의 불휘발성 메모리(2221~222n) 중 어느 하나에 대한 읽기 동작을 수행하며, 독출된 데이터를 호스트 인터페이스(2231)를 통하여 호스트 장치(2100)에 제공한다.
공통 리스판스 매니저(2237)는 DMA 유닛(2236)에 연결되며, 각 커맨드에 대한 응답 정보(response information)를 수신한다. 예를 들어, 제 1 내지 제 n 가상화 기능 입출력 서브미션 큐(VF1 I/O SQ~VFn I/O SQ)가 각각 제 1 내지 제 n 데이터에 대한 쓰기 커맨드에 관한 것인 경우, 공통 리스판스 매니저(2237)는 제 1 내지 제 n 데이터에 대한 쓰기 결과에 대한 정보(예를 들어, 쓰기 실패(write fail) 정보 등)를 DMA 유닛(2236)으로부터 수신할 수 있다.
이 경우, 제 1 가상화 기능 관리 서브미션 큐(VF1 A_SQ)의 처리 결과에 대한 응답 정보는 제 1 가상화 기능 관리 컴플리션 큐(VF1 A_CQ)에 대응할 수 있으며, 제 1 가상화 기능 서브미션 큐(VF1 I/O_SQ)의 처리 결과에 대한 응답 정보는 제 1 가상화 기능 입출력 컴플리션 큐(VF1 I/O_CQ)에 대응할 수 있다. 마찬가지로, 제 n 가상화 기능 관리 서브미션 큐(VFn A_SQ)의 처리 결과에 대한 응답 정보는 제 n 가상화 기능 관리 컴플리션 큐(VFn A_CQ)에 대응할 수 있으며, 제 n 가상화 기능 서브미션 큐(VFn I/O_SQ)의 처리 결과에 대한 응답 정보는 제 n 가상화 기능 입출력 컴플리션 큐(VFn I/O_CQ)에 대응할 수 있다.
또한, 공통 리스판스 매니저(2237)는 수집된 응답 정보를 제 1 내지 제 n 가상화 기능 리스판서(2238_1~2238_n)에 분배하는 동작을 수행한다. 예를 들어, 공통 리스판스 매니저(2237)는 제 1 가상화 기능 관리 컴플리션 큐(VF1 A_CQ) 및 제 1 가상화 기능 입출력 컴플리션 큐(VF1 I/O_CQ)의 정보를 제 1 가상화 기능 리스판서(2238_1)에 분배하며, 제 n 가상화 기능 관리 컴플리션 큐(VFn A_CQ) 및 제 n 가상화 기능 입출력 컴플리션 큐(VFn I/O_CQ)의 정보를 제 n 가상화 기능 리스판서(2238_n)에 분배한다.
제 1 내지 제 n 가상화 기능 리스판서(2238_1~2238_n)는 공통 리스판스 매니저(2237)에 공통으로 연결되며, 대응하는 가상화 기능 관리 컴플리션 큐(VF A_CQ) 및 가상화 기능 입출력 컴플리션 큐(VF I/O_CQ)의 정보를 수신한다. 제 1 내지 제 n 가상화 기능 리스판서(2238_1~2238_n)는 수신한 컴프리션 큐의 정보를 호스트 메모리(2140)에 기록한다.
예를 들어, 제 1 가상화 기능 리스판서(2238_1)는 제 1 가상화 기능 관리 컴플리션 큐(VF1 A_CQ)의 정보 또는 제 1 가상화 기능 입출력 컴플리션 큐(VF1 I/O_CQ)의 정보를 각각 호스트 메모리(2140)의 제 1 가상화 기능 관리 큐 저장 영역(2141_a) 및 제 1 가상화 기능 입출력 큐 저장 영역(2141_b)에 기록할 수 있다. 다른 예로, 제 n 가상화 기능 리스판서(2238_n)는 제 n 가상화 기능 관리 컴플리션 큐(VFn A_CQ)의 정보 또는 제 n 가상화 기능 입출력 컴플리션 큐(VFn I/O_CQ)의 정보를 각각 호스트 메모리(2140)의 제 n 가상화 기능 관리 큐 저장 영역(214n_a) 및 제 n 가상화 기능 입출력 큐 저장 영역(214n_b)에 기록할 수 있다.
또한, 제 1 내지 제 n 가상화 기능 리스판서(2238_1~2238_n)는 각각 컴플리션 큐에 대한 기록 동작을 완료한 후에, 인터럽트 신호를 발생하여 이를 호스트 장치(2100)에 통지할 수 있다. 이 경우, 호스트 장치(2100)는 인터럽트 신호에 응답하여, 호스트 메모리(2140)의 처리 결과에 대한 정보를 확인하고, 이를 처리할 수 있다.
계속해서 도 3을 참조하면, 버퍼 컨트롤러(2212)는 가상화 기능 관리 모듈(2230) 및 버퍼 메모리(2231)에 연결된다. 버퍼 컨트롤러(2212)는 DMA 유닛(2236)의 제어에 응답하여 읽기 동작 또는 쓰기 동작을 수행하도록 버퍼 메모리(2213)를 제어하는 동작을 수행한다.
버퍼 메모리(2213)는 읽기 동작 또는 쓰기 동작에 있어서, 읽기 데이터 또는 쓰기 데이터가 임시로 저장되는 버퍼의 역할을 수행한다. 예를 들어, 버퍼 메모리(2213)는 복수의 레지스터들 또는 SRAM(Static RAM), DRAM(Dynamic RAM) 등과 같은 휘발성 메모리로 구현될 수 있으며, PRAM(Phase-change RAM), MRAM(Magnetic RAM), RRAM(Resistive RAM), FRAM(Ferrolectric RAM) 등과 같은 불휘발성 메모리이거나, 또는 이들의 조합으로 구현될 수 있다..
불휘발성 메모리 인터페이스(2214)는 복수의 채널들(CH1~CHn)을 통하여 불휘발성 메모리들(2221~222n)에 연결되며, 컨트롤러(2210)와 불휘발성 메모리들(2221~222n) 사이의 인터페이싱을 제공한다.
상술한 바와 같이, 본 발명의 실시 예에 따른 컨트롤러(2210)는 호스트 장치(2100)의 복수의 가상화 기능들(2111~211n) 또는 가상 머신들이 각각 독립적으로 구동될 수 있도록, 각 가상화 기능에 대응하는 관리 큐 및 입출력 큐들을 저장하고 처리하는 기능을 지원하는 복수의 요청 큐들(복수의 가상화 장치 커맨드 패처들(2232_1~2232_n))를 포함할 수 있다. 더욱이, 본 발명의 실시 에에 따른 가상화 관리 모듈(2230)은 각 가상화 기능이 요구하는 동작이 스토리지 장치(2200)에서 병렬적으로 처리될 수 있도록, 각 가상화 기능마다 독립적인 패칭(fetching), 파싱(parsing), 응답(responsing) 동작을 수행하도록 구형될 수 있다. 이에 더하여, 본 발명의 실시 예에 따른 스토리지 장치(2200)는 각 가상화 기능이 요구하는 동작에 대한 병렬 처리를 보다 효과적으로 지원하기 위하여, 복수의 코어들(2211_1~2211_n)을 구비할 수 있다.
결국, 본 발명의 실시 예에 따른 스토리지 장치(2200)는 큐 베이스의 커맨드 인터페이스 방식을 지원하면서 동시에 가상화 기능을 함께 지원할 수 있을 뿐만 아니라, 호스트의 요구를 보다 빠르게 처리할 수 있다. 또한, 컨트롤러(2210)는 컨트롤러(2210) 내의 스케줄러를 통하여 각 가상화 기능 또는 가상 머신의 성능을 분리하고, 저장장치(2200) 내의 리소스를 공정하게 사용하도록 제어할 수 있다.
한편, 상술한 설명은 예시적인 것으로 이해되어야 할 것이며, 본 발명의 기술적 사상은 이에 한정되지 않음이 이해될 것이다. 예를 들어, 도 1 내지 도 3에서 스토리지 시스템(1000, 2000)은 SR-IOV 방식의 가상화 기능 또는 가상 머신을 지원하는 것으로 설명되었다. 다만 이는 예시적인 것이며, 본 발명의 스토리지 시스템(2000)은 MR-IOV 방식에도 적용될 수 있음이 이해될 것이다. 또한 도 1 내지 도 3에서 스토리지 시스템(2000)은 NVMe 프로토콜 방식에 따른 인터페이스 방식을 지원하는 것으로 설명되었다. 다만 이는 예시적인 것이며, 본 발명의 스토리지 시스템(2000)은 PCIe 인터페이스를 기반으로 하는 방식, 예를 들어, PQI, PQI/NVMe 방식에도 적용될 수 있음이 이해될 것이다. 또한 도 1 내지 도 3에서 복수의 가상화 기능들 모두에 독립적인 가상화 기능 관리 큐가 할당되는 것으로 설명되었다. 다만 이는 예시적인 것이며, 복수의 가상화 기능들 중 적어도 하나의 가상화 기능에만 가상화 기능 관리 큐가 할당 될 수도 있다.
도 4는 가상화 기능을 지원하는 스토리지 장치의 블록도이다.
도 1 내지 도 4을 참조하면, 스토리지 장치(2200)는 적어도 하나의 요청 큐(2290), 가상화 관리 모듈(2250) 및 적어도 하나의 플래시 큐(2270)를 포함하는 컨트롤러(2210) 및 불휘발성 메모리(Non-volatile memory, 2220)를 포함할 수 있다.
가상화 관리 모듈(2250)은 작업 스케줄러(job scheduler, 2251) 및 주소 맵핑 관리자(address mapping manager)를 포함할 수 있다. 작업 스케줄러(2251)은 요청 큐(2290)와 연결되어, 저장된 요청 작업(RQ)을 스케줄링 알고리즘(scheduling algorithm)에 따라 스케줄링할 수 있다. 주소 맵핑 관리자(FTL, 2252)은 상기 스케줄링 결과에 따라 처리되는 요청 작업과 관련하여 불휘발성 메모리(2220)에 저장되는 데이터의 주소 맵핑 정보를 관리할 수 있다. 플래시 큐(2270)은 불휘발성 메모리(2220)과 복수의 채널(CH1~CH4)을 통하여 연결되어, 상기 스케줄링 알고리즘 및 상기 주소 맵핑 정보에 기초하여 지정된 불휘발성 메모리(2220)에 입력 또는 출력되는 데이터를 임시로 저장할 수 있다. 플래시 큐(2270)은 복수의 채널(CH1~CH4)에 각각 대응하는 복수의 큐(2271~2274)로 구성될 수 있다.
본 발명의 기술적 사상의 실시 예들에 따른 가상화 기능을 지원하는 스토리지 장치(2200)는 관리를 위한 물리적 기능(Physical function; PF)과 복수의 가상화 기능들(virtual functions; VFs)을 호스트에 제공할 수 있다. 이때, 하나의 가상 머신(virtual machine; VM)에는 적어도 하나의 가상화 기능(virtual functions; VFs)이 할당될 수 있다. 예를 들면, 제 1 가상화 기능 (2111)는 제 1 가상 머신(2281)에 할당되고, 제 2 가상화 기능(2112) 및 제 3 가상화 기능(2113)는 제 2 가상 머신(2282)에 할당될 수 있다. 제 3 가상화 기능 (2114)는 제 3 가상 머신(2284)에 할당될 수 있다.
가상화 기능(2111~2114)는 호스트 장치 내에 자기 자신의 인터럽트 및 메모리 영역을 가질 수 있고, 가상 머신(2281~2284)은 가상화 기능(2111~2114)와 직접 통신할 수 있다. 스토리지 장치(2200)는 각각의 가상화 기능(2111~2114) 또는 각각의 가상 머신(2281~2284)에 독립적인 요청 큐 (request queue; 2291~2294)를 할당할 수 있다. 도 4의 요청 큐들(2291~2294)은 도 3에 도시된 제 1 내지 제 n 가상화 기능 커맨드 페처들(2232_1~2232_n) 중 하나에 대응될 수 있다. 가상 머신(2281~2284)의 운영은 호스트에서 관리될 수 있다. 가상 머신(2281~2284)은 자신에게 할당된 가상화 기능(2111~2114)를 통하여 스토리지 장치(2200)에게 작업 요청(job request)을 전송할 수 있다. 상기 전송된 작업 요청은 해당 요청 큐(2291~2294)에 저장된다.
도 4의 실시 예에서, 가상화 관리 모듈(2250)은 도 3의 가상화 관리 모듈(2230)에 대응될 수 있다. 도 4에서, 요청 큐(2290) 및 플래시 큐(2270)은 가상화 관리 모듈(2250)와 분리된 것으로 도시되었으나, 본 발명의 사상에 따른 실시 예들은 이에 한정되지 않고, 가상화 관리 모듈(2250)는 요청 큐(2290) 및 플래시 큐(2270) 중 적어도 하나 포함할 수 있다. 또한, 요청 큐(2290)은 컨트롤러(2210) 외부의 별도의 메모리로 구현될 수도 있다.
요청 큐(2290)는 호스트 장치(1100 또는 2100)와 작업 스케줄러(2251) 사이에 연결될 수 있다. 요청 큐(2290) 각각은 호스트에서 수신된 적어도 하나의 요청 작업을 저장할 수 있다. 예를 들면, 상기 요청 작업은 상기 호스트에서 수신된 가상 머신(2281~2284) 각각의 쓰기 또는 읽기 작업일 수 있다. 요청 큐(2290)는 휘발성 메모리(volatile memory) 또는 불휘발성 메모리(nonvolatile memory)일 수 있다. 상기 휘발성 메모리는 SRAM, DRAM, 래치(latch), 또는 레지스터(register) 중 하나일 수 있다. 상기 불휘발성 메모리는 PRAM, RRAM, MRAM, FRAM 중 하나일 수 있다. 이때, 스토리지 장치(2200)는 각 요청 큐(2291~2294)별로 리드 포인터 (read pointer), 라이트 포인터 (write pointer) 및/또는 베이스 어드레스 (base address)를 관리하기 위한 레지스터(register)를 포함할 수 있다.
요청 큐(2290)은 호스트 장치(2100)으로부터 커맨드(즉, 요청 작업)를 수신할 수 있다. 예를 들면, 도 1 내지 도 3에서 설명한 바와 같이, 호스트 메모리(1140 또는 2140)의 제 1 가상화 기능 입출력 큐 저장 영역(VF1 I/O_Q Area)(2141_b)에 서브미션 큐의 정보가 입력되는 경우, 호스트 장치(2100)는 링 도어벨 신호를 가상화 관리 모듈(2250)에 전달한다. 이 후, 제 1 가상화 기능 커맨드 패처(2232_1)는 해당 링 도어벨 신호에 응답하여 제 1 가상화 기능 입출력 큐 저장 영역(2141_b)에 접근하며, 제 1 가상화 기능 입출력 서브미션 큐(VF1 I/O_SQ))의 커맨드를 제 1 요청 큐(2291_1)에 임시로 저장할 수 있다. 같은 방식으로 복수의 요청 큐(2291~2294)에는 가상 머신들(2281~2284) 또는 가상화 기능들(2111~2114) 각각에 대응되는 요청 작업(커맨드)들이 저장될 수 있다. 실시 예들에서, 각 가상 머신들(2281~2284)은 하나의 가상화 기능(2111~2114)를 갖는 것으로 기술되었으나, 이에 한정되지 않고 하나의 가상 머신은 복수의 가상화 기능을 갖을 수도 있다. 상기 저장된 요청 작업들은 도 3에서 설명된 가상화 기능 커맨드 파서(2233_1~2233_n)에 의하여 해석될 수 있고, 상기 해석된 커맨드는 스케줄러(2251)에 의하여 각 가상 머신들(2281~2284)들의 독립된 성능을 보장하고 스토리지 장치(2200)의 리소스를 공평하게 분배하도록 스케줄링될 수 있다. 이때, 스토리지 장치(2200)은 상기 저장된 요청 작업들의 워크로드 기여도에 따라 스케줄링될 수 있다. 상기 워크로드 기여도는 도 5이후에 자세히 설명될 것이다.
본 발명의 실시 예들에 따른 작업 스케줄러(2251)는 WA-BC (Workload-Aware Budget Compensation) 방식을 이용하여 작업 큐(2231_1~2231_4)에 저장된 요청 작업들을 공평하게 스케줄링할 수 있다. WA-BC 방식은 가상 머신들 각각이 스토리지 장치(2200)의 워크로드에 기여도에 따라 가상 머신들(2281~2284)의 타임버짓 및 시간비용을 계산하여 가상 머신들(2281~2284)의 요청 작업을 스케줄링할 수 있다. 여기서, 워크로드는 컴퓨터 시스템이 처리해야 하는 일의 양. 멀티코어시스템에서는 코어에서 처리해야 하는 일의 양을 의미할 수 있다. 본 발명의 사상에 따른 워크로드 기여도는 복수의 가상 머신이 복수의 워크로드를 발생시킬 때, 각 워크로드들의 상대적인 발생율을 의미할 수 있다. 상기 워크로드는 가상 머신의 요청 작업에 의한 읽기 또는 쓰기 동작과 부가적인 동작 (예를 들면, 가비지 컬랙션, 리드 리클래임 등과 같은 오버헤드)을 포함할 수 있다. WA-BC 방식의 스케줄링 방법은 도 6 내지 도 10을 참조하여 상세히 설명될 것이다.
가상화 관리 모듈(2250)은 요청 큐(2290)와 복수의 플래시 큐(2270) 사이에 연결될 수 있다. 가상화 관리 모듈(2250)은 작업 스케줄러(2251)를 포함할 수 있다. 이때, 작업 스케줄러(2251)는 도 3의 커맨드 디스패처(2234) 및/또는 코어들(2211_1~2211_n) 중 하나에 대응할 수 있다. 작업 스케줄러(2251)는 요청 큐(2290)와 플래시 큐(2270)가 효율적으로 통신할 수 있도록 스케줄링을 수행한다. 예를 들면, 작업 스케줄러(2251)는 요청 큐(2290)에 대기 중인 제 1 요청 작업(RQ)들을 패치(fetch)하여, 코어들(2211_1~2211_n) 중 적어도 하나에 전송할 수 있다. 제 1 요청 작업(RQ)을 수신한 코어(2211_1~2211_n)는 수신한 제 1 요청 작업에 따라 컨트롤러 내의 DMA 유닛(예를 들면, 도 3의 DMA 유닛(2236))를 통하여 호스트 장치(2210)에서 전달된 데이터가 플래시 큐(2270)으로 전송되도록 할 수 있다.
다시 도 4를 참조하면, 가상화 관리 모듈(2250)는 주소 맵핑 관리자, 즉, FTL(Flash Translation Layer, 2252)을 더 포함할 수 있다. 작업 스케줄러(2251)는 요청 큐(2290)에 저장된 요청 작업의 종류를 확인하고 타겟 주소(target address)를 주소 맵핑 관리자(2252)에 전달할 수 있다. 예를 들면, 제 1 요청 큐(2291)에 저장된 요청 작업이 쓰기 명령일 경우, 상기 쓰기 명령과 같이 전송된 쓰기 타겟 주소를 주소 맵핑 관리자(2252)에 전달할 수 있다. 이때, 상기 쓰기 타겟 주소는 논리주소(logical address)일 수 있다.
주소 맵핑 관리자(2252)은 주소변환 알고리즘(algorithm)에 기초하여 수신된 논리 주소를 맵핑 테이블을 이용하여 물리 주소(physical address)로 변환할 수 있다. 상기 물리 주소는 플래시 큐(2270)로 전달할 수 있다. 이때, 플래시 큐(2270)는 작업 스케줄러(2251)가 파악한 작업 명령과 주소 맵핑 관리자 (2252)로부터 수신된 물리 주소에 기초하여 호스트 장치(1100 또는 2100)에서 수신된 데이터를 저장할 수 있다. 상기 맵핑 테이블은 코어들(2211_1~2211_n) 중의 하나의 코어에 의하여 관리될 수 있다.
플래시 큐(2270)는 복수의 플래시 채널(CH1~CH4) 각각에 대응하도록 구비될 수 있다. 복수의 플래시 큐(2270)는 복수의 채널(CH1~CH4)을 통하여 복수의 불휘발성 메모리(2221~2224)에 연결될 수 있다. 복수의 플래시 큐(2270)에 상기 호스트 장치(1100 또는 2100)에서 전달된 데이터를 저장할 때는 하나의 채널(CH1~CH4) 또는 복수개의 채널(CH1~CH4)을 통하여 불휘발성 메모리(2221~2224)에 저장될 수 있다. 예를 들면, 제 1 가상 머신(2281) 및 제 2 가상 머신(2282)과 관련된 데이터는 각각 제 1 채널(CH1) 및 제 2 채널(CH2)에 할당될 수 있다. 다른 실시 예에서, 제 1 가상 머신(2281)과 관련된 제 1 데이터 및 제 2 가상 머신(2282)과 관련된 제 2 데이터는 제 1 채널(CH1)에 모두 할당될 수 있다. 다른 실시 예에서, 제 1 가상 머신(2281)과 관련된 제 1 데이터는 제 1 채널(CH1) 및 제 2 채널(CH2)에 분산되어 할당될 수 있다. 이때, 서로 다른 채널에 할당된 데이터는 동시에 처리 (쓰기 또는 읽기)될 수 있다. 즉, 가상 머신(VM)과 플래시 큐(2270)는 서로 1:1, 1:n 또는 n:1의 맵핑이 가능하다.
작업 스케줄러(2251)가 가상 머신(2281~2284)의 요청 작업(RQ)을 스케줄링할 때, 주소 맵핑 관리자(2252)는 불휘발성 메모리(2221~2224) 내부에 각 가상 머신(2281~2284) 별로 독립된 블록 그룹을 할당할 수 있다. 예를 들면, 상기 독립된 블록 그룹은 소거 블록 그룹(Erase Block Group; EBG)일 수 있다. 소거블록 그룹(EBG) 할당 방식은 도 6를 참조하여 상세히 설명될 것이다.
불휘발성 메모리(2221~2224)에 쓰기 및 읽기의 기본 단위는 불휘발성 메모리의 페이지(page) 단위일 수 있다. 예를 들면, 상기 페이지 단위는 낸드 플래시 메모리(NAND flash memory)의 페이지 단위로 4KB일 수 있다. 따라서, 작업 스케줄러(2251)가 요청 큐(2290)에 저장된 요청 작업(RQ)을 스케줄링할 때 스케줄링의 단위는 상기 페이지 단위일 수 있다. 즉, 호스트 장치(2210)의 요청 작업이 8KB 크기의 데이터 쓰기일 경우, 컨트롤러는 4KB 단위로 2번의 페이지 전송 작업을 수행하도록 스케줄링할 수 있다. 상기 스케줄링의 단위는 불휘발성 메모리(2221~2224)의 페이지 단위에 따라 달라질 수 있다.
본 발명의 사상에 따른 일 실시 예에서, 작업 스케줄러(2251) 및/또는 주소 맵핑 관리자(2252)은 하드웨어(hardware) 또는 소프트웨어(software)로 구현될 수 있다. 예를 들면, 작업 스케줄러(2251)은 도 3의 커맨드 디스패쳐(2234)와 연관된 하드웨어 블록으로 구성될 수 있고, 주소 맵핑 관리자(2252)는 도 3의 버퍼 컨트롤러(2212)와 연관된 하드웨어 블록으로 구성될 수 있다. 또는, 작업 스케줄러(2251) 및/또는 주소 맵핑 관리자(2252)은 도 3의 코어들(2211_1~2211_n) 중 하나에 의하여 수행되는 소프트웨어로 구성될 수 있다. 상기 소프트웨어는 불휘발성 메모리(2220)에 저장되어, 스토리지 장치(2200)의 전원 인가시에 도 3의 버스(2240)을 통하여 캐시 메모리들(2211_1'~2211_n') 중 적어도 하나로 로딩될 수 있다.
작업 스케줄러(2251)는 요청 큐(2290), 가상화 기능 커맨드 파서(2233_1~2233_n), 커맨드 디스패처(2234), 복수의 코어들(2211_1~2211_n) 및 플래시 큐(2270)로 구성될 수 있다. 예를 들면, 요청 큐(2290)에 저장된 제 1 요청 작업(RQ)의 스케줄링을 위하여, 복수의 요청 큐(2290)에 저장된 요청 작업은 가상화 기능 커맨드 파서(2233_1~2233_n)에 의하여 분석되고, 분석된 커맨드는 커맨드 디스패처(2234)에 의하여 적어도 하나의 코어들(2211_1~2211_n)에 분배될 수 있다. 복수의 코어들(2211_1~2211_n) 중 파싱된 커맨드를 처리하는 코어는 상기 수신된 커맨드의 특성, 커맨드가 요구하는 동작 내용 등에 따라 불휘발성 메모리(2220)을 제어하기 위한 제 2 요청 작업(FQ)가 플래시 큐(2270)에 저장될 수 있다. 복수의 코어들(2211_1~2211_n) 중 일부 또는 버퍼 컨트롤러(2212)는 저장된 제 2 요청 작업(FQ)에 기초하여 불휘발성 메모리(2220)의 읽기, 쓰기, 및/또는 소거 동작을 제어할 수 있다.
제 1 요청 작업(RQ)이 읽기, 쓰기 명령일 경우, 컨트롤러(2200)은 제 1 요청 작업 및 제 1 요청 작업에 포함된 제 1 주소를 참조하여 제 2 요청 작업(FQ)과 제 2 주소를 생성시킬 수 있다. 이때 제 2 요청 작업(FQ)는 읽기, 쓰기 및/또는 소거 명령일 수 있다. 이때, 상기 제 1 주소는 논리 주소(logical address)이고, 상기 제 2 주소는 물리적 주소(physical address)일 수 있다.
제 2 요청 작업(FQ)은 제 1 요청 작업(RQ)에서 요청된 작업 외에 불휘발성 메모리(2220)의 관리를 위한 오버헤드관련 동작을 포함할 수 있다. 상기 오버헤드는 예를 들면, 가비지 컬렉션(garbage collection), 리드 리클래임(read reclaim), 웨어 레벨링(wear leveling), 데이터 신뢰성(data reliability), 및 맵핑 테이블 관리(mapping table management) 등과 관련하여 불휘발성 메모리(2200)에서 수행되는 추가적인 데이터의 읽기, 쓰기 및/또는 소거 동작을 포함할 수 있다.
스케줄러(2251)은 제 1 요청 작업(RQ)을 스케줄링하여 제 2 작업을 플래시 큐(2270)에 저장하며, 스케줄러(2251) 및/또는 주소 맵핑 관리자(2252)는 스케줄링 알고리즘 및 주소 맵핑 알고리즘 (address mapping algorithm)에 의하여 상기 제 1 주소에서 상기 제 2 주소로 변환할 수 있다.
만약, 제 1 요청 작업(RQ)가 쓰기 명령일 경우, 호스트 메모리(2140)에 저장된 쓰기 데이터는 컨트롤러(2210) 내의 버퍼메모리(2213)으로 전송될 수 있다. 반대로, 제 1 요청 작업(RQ)가 읽기 명령일 경우, 상기 제 2 주소에 따라 불휘발성 메모리(2220)에서 읽혀진 읽기 데이터는 컨트롤러(2210) 내의 버퍼메모리(2213)에 저장되었다가 호스트 메모리(2140)으로 전송될 수 있다. 여기서, 호스트 메모리(2140)은 호스트 장치(1100 또는 2100)과 연결된 외부 메모리(예를 들면, DRAM)일 수 있다.
요청 큐(2290)에서 제 1 요청 작업(RQ)를 페치(fetch)하여, 제 1 요청 작업(RQ)와 연관된 제 2 요청 작업(FQ)를 플래시 큐에 저장하기까지 스토리지 장치(2200)의 프로세싱 시간이 소요될 수 있다. 상기 프로세싱 시간은 스케줄링을 위한 시간비용으로 사용될 수 있다. 상기 시간비용은 가상 머신에서 요청한 요청 작업에 따라 계산될 수 있으며, 워크로드 기여도에 따라 보상될 수 있다.
도 5a, 도 5b, 도 5c는 가상 머신이 발생하는 시간 비용을 보상하는 방법에 대한 개념도이다. 도 6은 스토리지 장치(2200)의 불휘발성 메모리(2220)의 내부에 독립적으로 할당된 블록 그룹(BG)를 나타내는 블록도이다.
도 3 내지 도 6를 참조하면, 작업 스케줄러(2251)은 요청 큐(2290)에서 선택된 제 1 요청 작업(RQ)에 기초하여 호스트 장치(1100 또는 2100)와 플래시 큐(2270)사이의 데이터 전송을 스케줄링할 수 있다. 작업 스케줄러(2251)는 제 1 요청 작업(RQ)을 스케줄링하기 전에, 각 요청 큐(2290)에 미리 정해진 타임버짓(time budget; TB)을 할당할 수 있다. 이 때 모든 요청 큐(2290)에 할당되는 타임버짓(TB)은 모두 같은 값일 수 있다.
요청 큐(2290)에 저장된 제 1 작업(RQ)이 스케줄링에 의하여 수행되면 타임버짓(TB)은 감소될 수 있다. 감소되는 타임버짓(TB)의 양은 가상 머신(2281~2284)이 요청한 작업(RQ)의 시간 비용(TC)에 따라 달라질 수 있다. 타임버짓(TB)와 시간비용(TC)의 관리 방법에 대해서는 도 5a 내지 도 10을 참조하여 상세히 설명될 것이다. 제 1 작업(RQ)의 수행은 요청 큐(2290)에서 제 1 작업(RQ)가 페치될 때부터 제 1 작업에 대응하는 제 2 작업이 플래시 큐(2270)에 저장되는 때까지의 시간 또는 상기 제 2 작업이 플래시 큐(2270)에 페치되는 때까지의 시간에 대응될 수 있다. 즉, 가상 머신의 시간 비용(TC)은 가상 머신의 요청 작업들의 수행시간에 기초하여 계산될 수 있다. 예를 들면, 상기 수행시간이 10ms일 경우 상기 수행시간에 대응하는 시간비용은 10일 수 있다.
요청 큐(2290)에 저장된 제 1 작업(RQ)이 스케줄링될 때, 처리의 단위는 불휘발성 메모리의 페이지 단위일 수 있다. 즉, 불휘발성 메모리의 페이지 단위의 작업이 처리되면 해당 요청 큐(2291~2294)의 타임버짓(TB)은 수행된 작업의 시간 비용(TC)만큼 감소될 수 있다. 이때, 시간 비용(TC)는 분할된 작업의 시간 비용(TC)에 해당될 수 있다.
요청 큐(2290) 중 타임버짓(TB)을 모두 소진한 큐가 있으면, 해당 큐는 타임버짓(TB)이 다시 재할당(refill)될 때까지 스케줄링에서 제외될 수 있다. 모든 요청 큐(2290)의 타임버짓(TB)이 모두 소진되었을 경우에는, 모든 요청 큐들(2290)에 타임버짓(TB)를 재할당할 수 있다. 이 때 모든 요청 큐(2290)에 재할당되는 타임버짓(TB)는 모두 같은 값일 수 있다.
본 발명의 실시 예에 따른 작업 스케줄러(2251)는 스토리지 장치(2200)의 사용도(utilization)을 높이기 위하여 작업보장성 스케줄링 정책(work conserving scheduling policy)을 가질 수 있다. 즉, 요청 큐들(2290)에 대기하는 적어도 하나의 요청 작업(RQ)이 있다면 작업 스케줄러(2251)는 스케줄링을 계속하지만, 요청 큐들(2290) 중에 대기 작업이 없는 요청 큐가 있으면 작업 스케줄러(2251)는 해당 요청 큐(2290)에 타임버짓(TB)이 남아있더라도 대기 작업이 없는 요청 큐는 스케줄링을 생략하고 나머지 요청 큐들의 요청 작업을 수행할 수 있다. 남아 있는 타임버짓(TB)를 관리하기 위해서, 작업 스케줄러(2251)는 각 요청 큐(2291~2294)에서 소비된 시간비용(Time Cost; TC)을 계산할 수 있다.
시간비용(TC)는 가상 머신(2281~2284)이 발생하는 스토리지 장치(2200)내의 동작의 워크로드(workload)에 기초하여 계산될 수 있다. 예를 들면, 시간비용(TC)는 가상 머신(2281~2284)이 요청한 작업(예를 들어, 쓰기 동작 또는 읽기 동작)에 의한 워크로드와 가비지 컬렉션, 웨어 레벨링, 또는 매핑 테이블 관리와 같은 플래시 관리 동작을 위한 오버헤드관련된 동작에 의한 워크로드를 반영하여 계산될 수 있다. 따라서, 가상 머신의 요청 작업에 의한 워크로드와 상기 요청한 작업과 관련된 오버헤드에 의한 워크로드를 기초로 하여 가상 머신들간의 워크로드의 비율을 계산할 수 있다. 이때, 상기 가상 머신들 간의 워크로드 비율을 워크로드 기여도로 정의할 수 있다. 스토리지 장치(2200)의 워크로드 기여도로 정의할 수 있다. 결과적으로 스케줄러(2251)은 각 가상 머신의 요청 작업의 워크로드 기여도에 따라 가상 머신의 요청 작업들을 스케줄링 할 수 있다.
본 발명의 사상에 따른 워크로드 기여도는 복수의 가상 머신이 복수의 워크로드를 발생시킬 때, 각 워크로드들의 상대적인 발생율을 의미할 수 있다. 상기 워크로드는 가상 머신의 요청 작업에 의한 읽기 또는 쓰기 동작과 부가적인 동작 (예를 들면, 가비지 컬랙션, 리드 리클래임 등과 같은 오버헤드)을 포함할 수 있다. WA-BC 방식의 스케줄링 방법은 도 6 내지 도 10을 참조하여 상세히 설명될 것이다.
시간비용(TC)를 계산하기 위하여 작업 스케줄러(2251)는 회귀분석 기반 비용 모델링(regression based cost modeling) 기법을 이용할 수 있다. 이때, 시간비용(TC)은 요청된 작업의 종류, 요청된 작업의 횟수 및 요청된 작업이 발생하는 시간비용에 기초하여 계산될 수 있다. 수식 (1)은 i번째 프로파일링 간격동안 측정된 가상 머신의 시간비용(TCi)를 나타낸다. 여기서, 프로파일링은 알려진 특징 또는 변수에 따라 추정대상의 정보를 추출하는 과정을 의미한다.


수식 (1)에서 
 및
및 
 는 각각 읽기 요청의 시간비용 및 쓰기 요청의 시간비용을 의미한다.
는 각각 읽기 요청의 시간비용 및 쓰기 요청의 시간비용을 의미한다. 
 및
및 
 는 i번째 프로파일링 간격동안 각각 읽기 요청의 개수 및 쓰기 요청의 개수를 의미한다. 여기서, 읽기 요청 및 쓰기 요청의 단위는 비휘발성 메모리의 페이지 단위일 수 있다.
는 i번째 프로파일링 간격동안 각각 읽기 요청의 개수 및 쓰기 요청의 개수를 의미한다. 여기서, 읽기 요청 및 쓰기 요청의 단위는 비휘발성 메모리의 페이지 단위일 수 있다.
읽기 요청의 시간비용(
 )및 쓰기 요청의 시간비용(
)및 쓰기 요청의 시간비용(
 )은 프로파일링을 통하여 측정된 읽기 요청에 대한 수행시간 및 쓰기 요청에 대한 수행비용에 대응하여 계산된 값들일 수 있다. 즉, i번째 시간비용(TCi)은 i번째 프로파일링 간격동안 읽기 요청 및 쓰기 요청이 수행된 개수에 읽기 요청의 시간비용(
)은 프로파일링을 통하여 측정된 읽기 요청에 대한 수행시간 및 쓰기 요청에 대한 수행비용에 대응하여 계산된 값들일 수 있다. 즉, i번째 시간비용(TCi)은 i번째 프로파일링 간격동안 읽기 요청 및 쓰기 요청이 수행된 개수에 읽기 요청의 시간비용(
 )과 쓰기 요청의 시간비용(
)과 쓰기 요청의 시간비용(
 )을 각각 곱하여 합한 값일 수 있다. 작업 스케줄러(2251)는 K개의 프로파일링 간격동안 K개의 시간비용(
)을 각각 곱하여 합한 값일 수 있다. 작업 스케줄러(2251)는 K개의 프로파일링 간격동안 K개의 시간비용(
 )를 누적하여 가상 머신(2281~2284)의 시간비용을 계산할 수 있다. 예를 들면, 작업 스케줄러(2251)는 K개의 프로파일링 간격동안 읽기 요청의 시간비용(
)를 누적하여 가상 머신(2281~2284)의 시간비용을 계산할 수 있다. 예를 들면, 작업 스케줄러(2251)는 K개의 프로파일링 간격동안 읽기 요청의 시간비용(
 )및 쓰기 요청의 시간비용(
)및 쓰기 요청의 시간비용(
 ) 각각의 K개의 회귀방정식(regression equation)에 기초하여 선형회귀분석을 수행하고, 읽기 요청의 시간비용(
) 각각의 K개의 회귀방정식(regression equation)에 기초하여 선형회귀분석을 수행하고, 읽기 요청의 시간비용(
 ) 및 쓰기 요청의 시간비용(
) 및 쓰기 요청의 시간비용(
 )을 예측할 수 있다. 예측된 읽기 요청의 시간비용(
)을 예측할 수 있다. 예측된 읽기 요청의 시간비용(
 ) 및 예측된 쓰기 요청의 시간비용(
) 및 예측된 쓰기 요청의 시간비용(
 )에 기초하여 읽기 요청 및 쓰기 요청의 수를 측정하면 해당 가상 머신(VM)이 발생시킨 시간비용(TC)를 예측할 수 있다. 본 발명의 실시 예들에서 K가 20일 때 회귀분석에 사용되는 수행시간은 수 us 이하로 매우 짧을 수 있다.
)에 기초하여 읽기 요청 및 쓰기 요청의 수를 측정하면 해당 가상 머신(VM)이 발생시킨 시간비용(TC)를 예측할 수 있다. 본 발명의 실시 예들에서 K가 20일 때 회귀분석에 사용되는 수행시간은 수 us 이하로 매우 짧을 수 있다.
읽기 요청의 시간비용(
 ) 및 쓰기 요청의 시간비용(
) 및 쓰기 요청의 시간비용(
 )은 주기적으로 다시 측정될 수 있다. 예를 들면, 매 K번째 프로파일링 간격마다 다시 측정되어 업데이트 될 수 있다. 읽기 요청의 시간비용(
)은 주기적으로 다시 측정될 수 있다. 예를 들면, 매 K번째 프로파일링 간격마다 다시 측정되어 업데이트 될 수 있다. 읽기 요청의 시간비용(
 ) 및 쓰기 요청의 시간비용(
) 및 쓰기 요청의 시간비용(
 )은 측정 주기는 회기분석 결과의 오류와 워크로드의 변경에 대한 민감도(sensitivity)에 기초하여 결정될 수 있다. 예를 들면, 회기분석 결과의 예측치와 실측치의 오류의 크기가 클 경우 측정 주기는 더 길어질 수 있다. 또한, 워크로드의 변경이 짧은 시간동안 많이 발생할 경우 측정 주기는 짧아질 수 있다.
)은 측정 주기는 회기분석 결과의 오류와 워크로드의 변경에 대한 민감도(sensitivity)에 기초하여 결정될 수 있다. 예를 들면, 회기분석 결과의 예측치와 실측치의 오류의 크기가 클 경우 측정 주기는 더 길어질 수 있다. 또한, 워크로드의 변경이 짧은 시간동안 많이 발생할 경우 측정 주기는 짧아질 수 있다.
읽기 요청의 시간비용(
 )과 쓰기 요청의 시간비용(
)과 쓰기 요청의 시간비용(
 )은 스토리지 장치(2200)의 저장매체의 읽기 및 쓰기의 특성에 따라 변경될 수 있으며 서로 다를 수 있다. 즉, 비휘발성 메모리의 경우, 읽기 요청의 시간비용(
)은 스토리지 장치(2200)의 저장매체의 읽기 및 쓰기의 특성에 따라 변경될 수 있으며 서로 다를 수 있다. 즉, 비휘발성 메모리의 경우, 읽기 요청의 시간비용(
 ) 및 쓰기 요청의 시간비용(
) 및 쓰기 요청의 시간비용(
 )은 메모리 셀의 특성 (읽기 및 쓰기 속도, 쓰기전 지우기 필요성 등)에 따라 결정될 수 있다. 낸드 플래시 메모리의 경우, 메모리 셀(memory cell)의 쓰기 레이턴시(latency)가 읽기 레이턴시(latency)보다 크기 때문에 쓰기 요청의 시간비용(
)은 메모리 셀의 특성 (읽기 및 쓰기 속도, 쓰기전 지우기 필요성 등)에 따라 결정될 수 있다. 낸드 플래시 메모리의 경우, 메모리 셀(memory cell)의 쓰기 레이턴시(latency)가 읽기 레이턴시(latency)보다 크기 때문에 쓰기 요청의 시간비용(
 )은 읽기 요청의 시간비용(
)은 읽기 요청의 시간비용(
 )보다 클 수 있다.
)보다 클 수 있다.
다시 도 5a 내지 도 5c를 참조하면, 각각의 가상 머신(2281~2284) 자신의 시간비용(TC)을 가질 수 있다. 본 발명의 실시 예에 따른 스토리지 장치(2200)는, 각각의 가상 머신(2281~2284)이 가지는 시간비용(TC)에 기초하여 성능 분리(performance isolation) 및 리소스 분배 (resource distribution)을 공정하게 수행할 수 있다.
컨트롤러(2210)가 하나의 가상 머신(2281~2284)의 요청 작업을 수행할 때 쓰기 요청 및 읽기 요청에 의한 작업 수행으로 인한 시간비용(TC)가 발생할 수 있다. 가상 머신(2281~2284)은 상기 읽기 또는 쓰기 작업 수행 외에 내부적인 오버헤드를 발생시킬 수 있다. 여기서, 상기 내부적인 오버헤드는 가비지 컬렉션, 어드레스 메핑 테이블 관리 (address mapping table management), 리드 리클레임(read reclaim), 웨어레벨링(wear leveling) 등과 같이 스토리지 장치(2200) 내부의 관리를 위하여 수행되는 오버헤드일 수 있다. 예를 들면, 스토리지 장치(2200)과 같은 불휘발성 메모리(2220)을 내장한 SSD의 경우, 하나의 가상 머신(2281, 2282, 및 2284)이 불휘발성 메모리에 작고 불규칙한 쓰기 요청(random write request)을 빈번하게 발생시킨다면, 가비지 컬렉션(garbage collection)이 자주 발생할 수 있다. 가비지 컬렉션은 스토리지 장치(2200) 내부에 사용할 수 있는 플래시 블록의 수가 적을 때 (예를 들면 사용된 페이지 수 와 유효한 페이지 수의 비율인 저장효율이 떨어질 때) 발생할 수 있다. 가비지 컬렉션 수행시 스토리지 장치(2200)는 프리 블록 풀(free block pool, 2315)에서 하나의 플래시 블록을 할당하여, 병합동작(Merge operation)을 통하여 유효하지 않은 페이지를 많이 보유한 오래된 플래시 블록의 유효한 페이지만 상기 할당된 플래시 블록에 복사할 수 있다. 이후 상기 오래된 플래시 블록은 소거하여 프리 블록으로 변경될 수 있다. 결과적으로, 가비지 컬렉션시 스토리지 장치(2200)은 가상 머신(2281~2284)이 요청한 작업을 멈추고 상술한 페이지 데이터 복사 및 블록 소거 작업 등을 수행할 수 있기 때문에, 내부적인 오버헤드에 의하여 오버헤드를 발생시킨 요청 작업의 수행시간은 늘어날 수 있다. 스토리지 장치(2200)은 상기 오버헤드를 발생시킨 요청 작업을 다른 요청 작업과 분리하기 위하여 가상 머신들(2281~2284)별로 독립적으로 할당된 블록 그룹을 할당하여 해당 요청 작업을 할당된 블록 그룹안에서 수행할 수 있다.
하나의 가상 머신(VM)에 의하여 내부적으로 발생하는 오버헤드는 다른 가상 머신(VM)의 작업 수행에 영향을 줄 수 있다. 즉, 하나의 가상 머신(VM1)의 작업 수행시 발생되는 오버헤드로 인하여 다른 독립된 가상 머신(VM)의 작업 수행시 지연이 발생할 수 있다. 따라서, 가상 머신들(VMs)간의 공정한 작업 수행을 위해서는 성능 분리(performance isolation) 및 리소스 분배 (resource distribution)의 보장이 필요하다. 이를 위하여, 하나의 가상 머신(2281~2284)이 발생시킬 수 있는 워크로드를 예측할 필요가 있으며, 상기 워크로드는 시간비용(TC)으로 대변될 수 있다. 상기 시간비용(TC)에는 각 가상 머신(VM)의 쓰기 및 읽기 요청을 처리하기 위한 작업에 소요되는 시간비용 및 상기 작업이 유발하는 오버헤드의 시간비용(TC)을 포함할 수 있다.
설명을 쉽게 하기 위하여 스토리지 장치의 오버헤드가 가비지 컬렉션인 경우를 예로 들어 설명한다. 도 5a를 참조하면, 쓰기 요청에 의한 시간비용은 제 1 가상 머신(
 ) 및 제 2 가상 머신(
) 및 제 2 가상 머신(
 ) 각각 제 1 시간비용 (
) 각각 제 1 시간비용 (
 ) 및 제 2 시간비용(
) 및 제 2 시간비용(
 )으로 표현될 수 있다.
)으로 표현될 수 있다.
도 5a는 오버헤드가 발생하지 않았을 경우, 제 1 가상 머신(
 )의 쓰기 요청의 제 1 시간비용(
)의 쓰기 요청의 제 1 시간비용(
 ) 및 제 2 가상 머신(
) 및 제 2 가상 머신(
 )의 쓰기 요청의 제 2 시간비용(
)의 쓰기 요청의 제 2 시간비용(
 )일 수 있다. 예를 들면, 제 1 시간비용(
)일 수 있다. 예를 들면, 제 1 시간비용(
 )은 불규칙 쓰기 (random write)에 의한 시간비용이고, 제 2 시간비용(
)은 불규칙 쓰기 (random write)에 의한 시간비용이고, 제 2 시간비용(
 )은 연속 쓰기(sequential write)에 의한 시간비용일 수 있다. 도 5b는 제 1 가상 머신(
)은 연속 쓰기(sequential write)에 의한 시간비용일 수 있다. 도 5b는 제 1 가상 머신(
 ) 및 제 2 가상 머신(
) 및 제 2 가상 머신(
 )의 요청 작업들을 수행할 때 발생한 오버헤드(예를 들면, 가비지 컬렉션)에 의한 시간비용(
)의 요청 작업들을 수행할 때 발생한 오버헤드(예를 들면, 가비지 컬렉션)에 의한 시간비용(
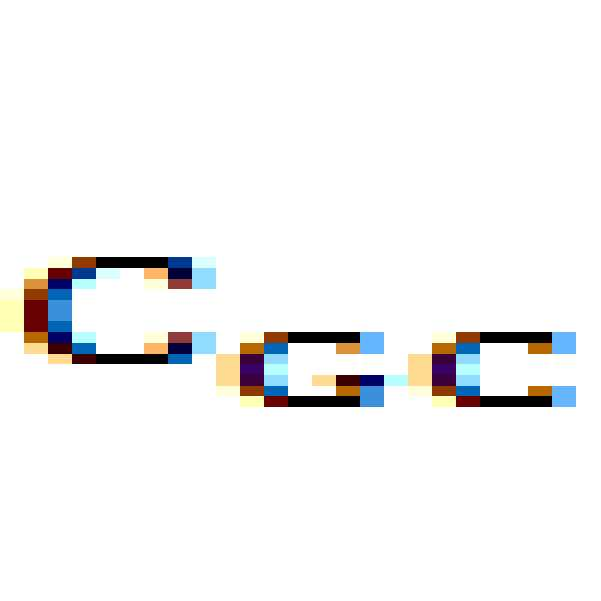 )을 고려한 제 1 가상 머신(
)을 고려한 제 1 가상 머신(
 ) 및 제 2 가상 머신(
) 및 제 2 가상 머신(
 )의 시간비용(TCs)들이다. 만약, 도 5b처럼 전체 오버헤드를 모든 가상 머신들(VMs)이 골고루 분담한다면 각 가상 머신(VM)의 성능 분리를 보장하기 어려울 수 있다. 도 5c를 참조하면, 각 가상 머신(
)의 시간비용(TCs)들이다. 만약, 도 5b처럼 전체 오버헤드를 모든 가상 머신들(VMs)이 골고루 분담한다면 각 가상 머신(VM)의 성능 분리를 보장하기 어려울 수 있다. 도 5c를 참조하면, 각 가상 머신(
 및
및 
 )이 오버헤드에 의한 워크로드에 기여한 정도에 기초하여 해당 가상 머신의 시간비용(TC)을 보상할 경우, 각 가상 머신(VM)의 보상된 시간비용(TC)을 나타낸다. 예를 들면, 제 1 가상 머신(
)이 오버헤드에 의한 워크로드에 기여한 정도에 기초하여 해당 가상 머신의 시간비용(TC)을 보상할 경우, 각 가상 머신(VM)의 보상된 시간비용(TC)을 나타낸다. 예를 들면, 제 1 가상 머신(
 )이 제 2 가상 머신(
)이 제 2 가상 머신(
 )보다 오버헤드 측면에서 워크로드에 기여한 정도가 클 경우, 제 1 가상 머신(
)보다 오버헤드 측면에서 워크로드에 기여한 정도가 클 경우, 제 1 가상 머신(
 )에 오버헤드에 의한 시간비용(TC)을 더 많이 할당할 수 있다.
)에 오버헤드에 의한 시간비용(TC)을 더 많이 할당할 수 있다.
여기서, 가상 머신(2281~2283)별 시간비용(TC)를 계산할 수 있다면, 작업 스케줄러(2251)는 상기 각 가상 머신(2281~2284)의 계산된 시간비용(TC)에 기초하여 해당 가상 머신(2281~2284)의 요청 작업을 공정하게 스케줄링할 수 있다. 예를 들면, 상기 계산된 시간비용(TC)에 기초하여, 해당 가상 머신(VM)의 요청 작업이 수행될 때마다 상기 가상 머신(2281~2284)의 타임버짓(TB)를 상기 계산된 시간비용(TC)만큼 감소시킬 수 있다. 일 실시 예에서, 요청 큐(2231) 에서 플래시 큐(2213)로 페이지 단위(예를 들면, 4KB)로 데이터 전송이 발생할 때마다, 작업 스케줄러(2251)는 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시킬 수 있다. 다른 실시 예에서, 작업 스케줄러(2251)가 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시키는 때는 주소 맵핑 단위일 수 있다. 여기서, 주소 맵핑 단위는 기록된 데이터를 맵핑 테이블에서 관리하는 단위이다. 예를 들면, 페이지 맵핑 방식의 주소 맵핑 관리자(2252)가 사용될 경우 상기 주소 맵핑 단위는 페이지 단위이며, 블록 맵핑 방식의 주소 맵핑 관리자(2252)가 상용될 경우 상기 주소 맵핑 단위는 블록 단위일 수 있다. 상기 주소 맵핑 단위는 페이지 또는 블록 단위에 한정되지 않는다. 예를 들면, 상기 주소 맵핑 단위는 복수의 페이지 그룹 단위일 수 있다.
또 다른 실시 예에서, 하나의 가상 머신(VM)이 오버헤드를 적게 발생시킨다면, 해당 가상 머신(2281~2284)은 더 많은 타임버짓(TC)을 할당받을 수 있다. 즉, 작업 스케줄러(2251)는 스토리지 장치(2200)의 워크로드에 기여도에 기초하여, 가상 머신들(VMs)의 타임버짓(TB)를 조절(adjust)할 수 있다.
만일, 요청 큐(2291~2294) 중 하나의 요청 큐에서 타임버짓(TB)이 더 이상 남아 있지 않으면, 다른 요청 큐의 타임버짓(TB)이 모두 소진될 때까지 대기하거나 다른 요청 큐(2290)의 대기 작업이 없을 경우까지 대기할 수 있다. 만일, 모든 요청 큐의 타임버짓(TB)이 모두 소진되었거나, 타임버짓(TB)이 모두 소진된 요청 큐를 제외하고 나머지 요청 큐의 대기 작업이 없으면, 작업 스케줄러(2251)는 타임버짓(TB)이 모두 소진된 요청 큐의 타임버짓을 재할당(refill)할 수 있다. 이때, 작업 스케줄러(2251)는 타임버짓(TB)이 남아 있는 다른 큐도 같이 타임버짓을 재할당(refill)할 수 있다.
결과적으로, 본 발명의 실시 예들에 따른 작업 스케줄러(2251)는 상대적으로 큰 시간비용을 가진 가상 머신이나 상대적으로 작은 타임버짓(TB)을 가진 가상 머신은 요청 작업이 수행되면서 할당 받은 타임버짓(TB)을 빠른 시간 내에 소진할 수 있기 때문에, 해당 가상 머신은 타임버짓(TB)를 다시 할당 받기까지 대기 시간이 길어 질 수 있어 요청 작업의 수행이 지연되는 효과가 있다. 이와 반대로, 상대적으로 작은 시간비용을 가진 가상 머신 가상 머신이나 상대적으로 큰 타임버짓(TB)을 가진 가상 머신(VM)은 다른 가상 머신에 비하여 요청 작업이 수행되면서 할당 받은 타임버짓(TB)이 상대적으로 더 많이 남아 있기 때문에, 타임버짓(TB)를 다시 할당 받기 위한 대기 시간이 필요없어 요청 작업이 빨리 수행되는 효과가 있다. 결과적으로, 본 발명의 사상에 따른 실시예 들에서, 작업 스케줄링 방법은 가상 머신들(2290)의 타임버짓(TB) 및 시간비용(TC)에 기초하여 가상 머신들(2290)간의 공정한 리소스 분배를 통하여 성능 간섭을 줄여 성능 분리를 보장할 수 있다.
다시 도 5a 내지 도 6을 참조하면, 효율적인 성능 분리 및 공정한 리소스 분배를 위해서는 상술한 바와 같이 가상 머신(2281~2283)이 발생시키는 스토리지 장치(2200)의 오버헤드에 의한 시간비용(TC)를 계산하여 보상된 시간비용(TC)을 계산하는 것이 필요하다. 본 발명의 실시 예에 따른 작업 스케줄링 방법은 스토리지 장치(2200)의 구조적 특징에 기초하여 각 가상 머신(2281~2283)의 보상된 시간비용(TC)를 계산할 수 있다.
도 6을 참조하면, 스토리지 장치 (2200)은 불휘발성 메모리를 포함하는 SSD 장치일 수 있다. 스토리지 장치(2200)는 가상 머신들(2281~2283) 별로 할당된 블록 그룹(Block Group; BG)을 포함할 수 있다. 예를 들면, 블록 그룹(BG)는 소거 단위의 블록의 그룹인 소거 블록 그룹(Erase Block Group; EBG, 2311~2313)일 수 있다. 스토리지 장치(2200)는 가비지 컬렉션을 위한 프리 블록 풀(free block pool, 2315)을 더 포함할 수 있다. 가상 머신들(VMs)에 할당된 소거 블록 그룹(EGB) 내부의 블록들은 유효한 페이지 데이터를 저장하는 유효 페이지 (Valid page) 및 유효하지 않은 예전 페이지 데이터를 저장하는 비유효 페이지(invalid page)를 포함할 수 있다. 여기서, 작업 스케줄러(2251)는 각 소거 블록 그룹(2311~2313) 내부의 사용된 페이지 수와 유효한 페이지 수의 비율에 기초하여 해당 소거 블록 그룹(2311~2313)의 저장효율(Storage efficiency)을 계산할 수 있다. 상기 저장효율은 쓰기 확대 요소(WAF; Write Amplifying Factor)에 대응될 수 있다.
스토리지 장치(2200)는 제 1 가상 머신(2281)에 할당된 4개의 블록들을 포함하는 제 1 소거 블록 그룹(2311)을 포함하고, 제 2 가상 머신(2282)에 할당된 6개의 블록들을 포함하는 제 2 소거 블록 그룹(2312)을 포함하고, 제 3 가상 머신(2284)에 할당된 4개의 블록들을 포함하는 제 3 소거 블록 그룹(2313)을 포함할 수 있다. 또한, 스토리지 장치(2200)는 4개의 소거 블록들을 포함하는 프리 블록 풀(2315)을 더 포함할 수 있다. 프리 블록 풀(2315)에 포함된 프리 블록(free block)들은 소거된 상태의 블록들일 수 있다. 도 6에서 설명의 편의를 위하여 각 블록들은 6개의 페이지를 갖는 것으로 도시하였으나 본 발명의 실시 예들은 이에 한정되는 것은 아니다.
본 발명의 사상에 따른 실시 예에서, 각 소거 블록 그룹(2311~2313)은 하나의 어플리케이션(application) 또는 하나의 가상 머신(2281, 2282, 2284)에만 독립적으로 할당되어 사용될 수 있다. 즉, 하나의 소거 블록 그룹(2311, 2312, 2313) 내의 블록은 다른 가상 머신(2281~2284)과 공유되지 않을 수 있다. 이 경우, 하나의 가상 머신(2281, 2282, 2283)의 데이터는 다른 가상 머신에 할당된 소거 블록 그룹(2311, 2312, 2313)에 분산 저장되지 않도록 타켓 주소가 관리될 수 있다. 상기 타겟 주소의 관리는 스케줄러(2251) 및 주소 맵핑 관리자(2252)에 의하여 수행될 수 있다.
본 발명의 사상에 따른 실시 예에서, 스토리지 장치(2200)내에 하나의 가상 머신(2281, 2282, 2283)의 저장공간이 부족할 경우, 가상화 관리 모듈(2250)은 프리 블록 풀(2315)에서 프리 블록을 해당 가상 머신(2281, 2282, 2283)의 소거 블록 그룹(2311, 2312, 2313) 내에 새로운 블록으로 할당하고 병합(Merge) 동작을 통하여 유효한 페이지 데이터를 새로 할당된 블록으로 복사할 수 있다. 이때, 기존의 유효한 페이지 데이터를 저장하던 해당 페이지는 비유효 페이지로 변경된다. 유효한 페이지 수가 적은 블록은 가비지 컬렉션(garbage collection) 동작을 통하여 프리 블록 풀(2315)의 프리 블록으로 변경될 수 있다. 결과적으로, 하나의 가상 머신(VM)에 할당된 독립적인 블록 그룹은 필요에 따라 포함하는 블록의 수를 가변적으로 운영할 수 있다. 예를 들면, 가상 머신들 각각은 가변적인 전용 소거 블록 그룹(dedicated erase block group)을 할당받을 수 있다.
본 발명의 사상에 따른 실시 예에서, 스토리지 장치(2200)내에 하나의 가상 머신(2281, 2282, 2283)의 저장공간이 부족할 경우, 가상화 관리 모듈(2250)는 프리 블록 풀(2315)에서 복수의 프리 블록들을 해당 가상 머신(2281, 2282, 2284)의 추가적인 소거 블록 그룹으로 할당할 수 있다, 따라서. 하나의 가상 머신(2281, 2282, 2284)은 하나 이상의 독립된 소거 블록 그룹을 할당 받을 수 있다.
작업 스케줄러(2251)는 가상 머신(2281~2283)의 시간비용을 측정하기 위하여, 소거 블록 그룹들(2311~2313)의 시간비용(TC)을 측정할 수 있다. 예를 들면, 소거 블록 그룹들(2311~2313)의 시간비용(TC)은 위에서 언급한 각 소거 블록 그룹(2311, 2312, 2313)의 저장효율에 기초하여 측정될 수 있다. 예를 들면, 저장효율은 쓰기 증폭 요소(Write Amplification Factor; WAF))에 대응될 수 있다. 이때, 상기 저장효율과 쓰기 증폭 요소(WAF)는 서로 반비례 관계일 수 있다. 쓰기 증폭 요소(WAF)은 소거 블록 그룹(EGB)내에 포함된 전체 사용된 공간과 유효한 데이터가 저장된 공간의 비율을 의미할 수 있다. 예를 들면, 도 6의 제 1 소거 블록 그룹(2311)에서 전체 사용된 페이지 수는 22개이고 유효한 페이지 수는 13개 일 때, 저장효율(WAF)은 1.69 (22/13)이다. 이와 마찬가지로 계산하면, 제 2 소거 블록 그룹(2312) 및 제 3 소거 블록 그룹(2313)은, 쓰기 확대 요소(WAF)는 각각 2.13 및 1.11이 된다. 일반적으로 쓰기 확대 요소(WAF)가 클수록 비유효 공간이 많아서 가비지 컬렉션을 발생시킬 가능성이 크다고 할 수 있다. 반대로, 각 소거 블록(2311, 2312, 2313)의 저장효율은 해당 저장효율이 작을수록 비유효 공간이 많아서 가비지 컬렉션을 발생시킬 가능성이 크다고 할 수 있다.
일반적으로 가비지 컬렉션이 스토리지 장치의 오버헤드에 가장 큰 영향을 준다고 가정하고, 쓰기 확대 요소(WAF)를 측정하면 해당 가상 머신(VM)이 발생시킬 수 있는 시간비용(TC)을 효과적으로 예측할 수 있으며, 예측된 시간비용(TC)에 기초하여 작업 스케줄러(2251)는 요청 큐(2290)에 있는 작업 요청을 스케줄링할 수 있다. 이러한 작업 스케줄링 방법은 각 가상 머신(2281~2283)들 간의 간섭을 줄이고, 독립적인 성능을 보장하고 스토리지 장치(2200)내의 리소스 분배를 효율적으로 할 수 있는 효과가 있다.
수식 (2)는 i번째 가상 머신(
 )의 쓰기 확대 요소(WAF)인
)의 쓰기 확대 요소(WAF)인 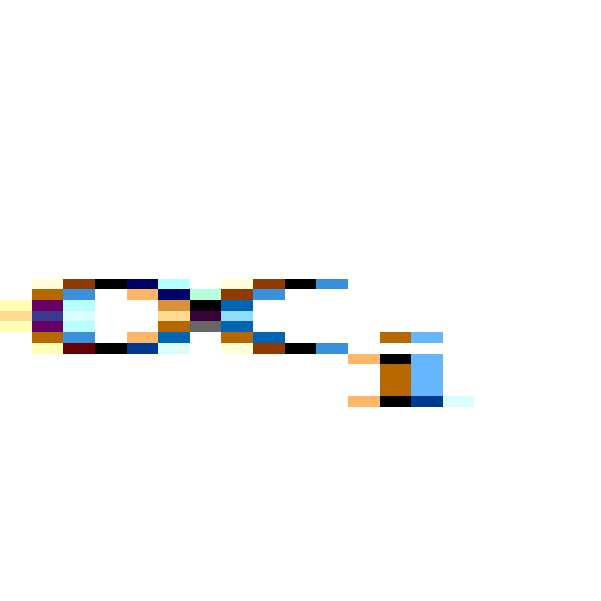
 를 계산하기 위한 수식이다. 쓰기 확대 요소(WAF)인
를 계산하기 위한 수식이다. 쓰기 확대 요소(WAF)인 
 는 소거 블록 그룹(EBGi) 내부에 사용된 페이지수
는 소거 블록 그룹(EBGi) 내부에 사용된 페이지수 
 를 유효 페이지수
를 유효 페이지수 
 로 나눈 값이다. 스토리지 장치(2200)의 쓰기 확대 요소(WAF)인
로 나눈 값이다. 스토리지 장치(2200)의 쓰기 확대 요소(WAF)인 
 는 수식 (3)과 같이 표현될 수 있다. 즉, 스토리지 장치(2200)의 전체 소거 블록 그룹들(EGBs) 내부에 사용된 전체 페이지수(
는 수식 (3)과 같이 표현될 수 있다. 즉, 스토리지 장치(2200)의 전체 소거 블록 그룹들(EGBs) 내부에 사용된 전체 페이지수(
 )를 전체 유효 페이지수(
)를 전체 유효 페이지수(
 )로 나눈 값이다.
)로 나눈 값이다.




각 가상 머신(VM)의 워크로드 기여도를 예측하기 위하여, 오버헤드가 없다고 가정할 때 정규화된 쓰기 요청 시간비용 (normalized write request time cost)인 
 를 정의할 수 있다. 즉, 스토리지 장치(2200)의 전체 쓰기 요청 시간비용(
를 정의할 수 있다. 즉, 스토리지 장치(2200)의 전체 쓰기 요청 시간비용(
 )와 쓰기 확대 요소(WAF)인
)와 쓰기 확대 요소(WAF)인 
 가 서로 비례관계라고 가정하면, 정규화된 쓰기 요청 시간비용(
가 서로 비례관계라고 가정하면, 정규화된 쓰기 요청 시간비용(
 )는 수식 (4)와 같이 표현될 수 있다.
)는 수식 (4)와 같이 표현될 수 있다.
여기서, 각 가상 머신(VM)은 독립적인 소거 블록 그룹(EGB;2311~2313)를 사용하기 때문에, i번째 가상 머신(
 )의 쓰기 요청 시간비용(
)의 쓰기 요청 시간비용(
 )와 쓰기 확대 요소(WAF)인
)와 쓰기 확대 요소(WAF)인 
 가 서로 비례관계라고 가정하면, 정규화된 쓰기 요청 시간비용(
가 서로 비례관계라고 가정하면, 정규화된 쓰기 요청 시간비용(
 )는 수식 (5)와 같이 표현될 수 있다. 따라서, 수식 (4) 및 수식 (5)을 이용하여 i번째 가상 머신(
)는 수식 (5)와 같이 표현될 수 있다. 따라서, 수식 (4) 및 수식 (5)을 이용하여 i번째 가상 머신(
 )의 쓰기 요청 시간비용(
)의 쓰기 요청 시간비용(
 )는 수식 (6)과 같이 표현될 수 있다.
)는 수식 (6)과 같이 표현될 수 있다.






예를 들면, 2개의 가상 머신(
 및
및 
 )이 쓰기 요청을 할 경우, 스토리지 장치(2200)의 전체 쓰기 요청 시간비용(
)이 쓰기 요청을 할 경우, 스토리지 장치(2200)의 전체 쓰기 요청 시간비용(
 ), 전체 쓰기 확대 요소(
), 전체 쓰기 확대 요소(
 ), 제 1 가상 머신(
), 제 1 가상 머신(
 )의 쓰기 확대 요소(
)의 쓰기 확대 요소(
 ), 및 제 2 가상 머신(
), 및 제 2 가상 머신(
 )의 쓰기 확대 요소(
)의 쓰기 확대 요소(
 ) 각각은 16, 1.6, 3.2 및 1.2 일 수 있다. 즉, 제 1 가상 머신(
) 각각은 16, 1.6, 3.2 및 1.2 일 수 있다. 즉, 제 1 가상 머신(
 )의 제 1 쓰기 요청 시간비용(
)의 제 1 쓰기 요청 시간비용(
 ) 및 제 2 가상 머신(
) 및 제 2 가상 머신(
 )의 제 2 쓰기 요청 시간비용(
)의 제 2 쓰기 요청 시간비용(
 )는 각각 32 및 12 임을 예측할 수 있다.
)는 각각 32 및 12 임을 예측할 수 있다.
상술한 바와 같이, 가상 머신(2281~2283)이 요청한 작업에 대한 예측된 시간비용(TC)에 기초하여, 작업 스케줄러(2251)는 상기 요청된 작업을 스케줄링할 수 있다. 예를 들면, 작업 스케줄러(2251)는 각 가상 머신(2281, 2282, 2283)의 쓰기 요청 작업을 수행할 때마다 해당 가상 머신에 할당된 타임버짓(TB)에서 예측된 쓰기 요청 시간비용(
 )만큼을 감소시킬 수 있다. 예를 들면, 요청 큐(2290)의 초기 타임버짓이 100이고, 제 1 가상 머신(
)만큼을 감소시킬 수 있다. 예를 들면, 요청 큐(2290)의 초기 타임버짓이 100이고, 제 1 가상 머신(
 )의 제 1 쓰기 요청 시간비용(
)의 제 1 쓰기 요청 시간비용(
 ) 및 제 2 가상 머신(
) 및 제 2 가상 머신(
 )의 제 2 쓰기 요청 시간비용(
)의 제 2 쓰기 요청 시간비용(
 )는 각각 32 및 12이라 할 때, 제 1 가상 머신(
)는 각각 32 및 12이라 할 때, 제 1 가상 머신(
 )의 쓰기 요청 작업이 수행되면 제 1 요청 큐(2291)의 타임버짓은 68이 될 수 있고, 제 2 가상 머신(
)의 쓰기 요청 작업이 수행되면 제 1 요청 큐(2291)의 타임버짓은 68이 될 수 있고, 제 2 가상 머신(
 )의 쓰기 요청 작업이 수행되면 제 2 요청 큐(2292)의 타임버짓은 88이 될 수 있다.
)의 쓰기 요청 작업이 수행되면 제 2 요청 큐(2292)의 타임버짓은 88이 될 수 있다.
따라서, 적은 시간비용(TC)을 발생시키는 가상 머신의 작업은 많은 시간비용을 발생시키는 가상 머신의 작업에 비하여 상대적으로 오랜 시간동안 리소스를 할당 받을 수 있다. 결과적으로, 본 발명에 실시 예에 따른 작업 스케줄링은 가상 머신들(VMs)간의 간섭을 감소시키고, 각 가상 머신(VM)의 성능 분리 및 공정한 리소스 분배를 구현하는 효과가 있다.
본 발명의 실시 예에서, 쓰기 확대 요소(WAF)로 대변되는 저장효율에 기초하여 가상 머신(VM)의 시간비용(TC)를 측정하는 방법을 설명하였으나, 본 발명은 이에 한정되지 않는다. 예를 들면, 같은 워드라인에 빈번한 읽기 동작에 의하여 발생하는 리드 디스터번스(read disturbance) 또는 블록의 소거횟수 등에 기초하여 스토리지 장치(2200)의 신뢰성(reliability)를 위하여 발생하는 블록의 교체동작인 오버헤드에 기초하여 가상 머신(VM)의 시간비용(TC)을 측정할 수 있다.
다시 도 6을 참조하면, 스토리지 장치(2200)은 메타 블록(Meta Block, 2316)을 더 포함할 수 있다. 메타 블록(2316)은 쓰기 확대 요소(WAF)를 저장할 수 있다. 메타 블록(2316)은 매핑 테이블을 저장할 수 있다. 다른 실시 예에서, 쓰기 확대 요소(WAF)는 소거 블록 그룹(2311~2313)내의 한 블록에 저장될 수 있다. 또 다른 실시 예에서, 쓰기 확대 요소(WAF)는 소거 블록 그룹(2311~2313)마다 포함된 메타블록에 저장될 수 있다. 소거 블록 그룹(EBG)의 쓰기 확대 요소(WAF; 
 )는 각 블록에 저장된 쓰기 확대 요소(WAF;
)는 각 블록에 저장된 쓰기 확대 요소(WAF; 
 )에 기초하여 계산될 수 있다.
)에 기초하여 계산될 수 있다.
본 발명의 사상의 실시 예들에서, 스토리지 장치(2200)의 시간비용(TC)은 스토리지 장치(2200)가 지원하는 가상 머신(2281~2284)이 발생하는 워크로드의 시간비용(TC)에 따라 결정될 수 있다. 각 가상 머신(2281~2284)은 초기에 같은 값의 시간비용(TC)을 가질 수 있다. 다른 실시 예에서, 가상 머신(2281~2284)의 초기 시간비용(TC)은 호스트 장치(1100 또는 2100)으로부터 수신될 수 있다. 또한, 스토리지 장치(2200)에서 계산된 각 가상 머신(2281~2284)의 시간비용(TC)은 호스트 장치(1100 또는 2100)으로 전송되어 호스트 장치(1100 또는 2100)에 저장될 수 있다. 상기 호스트 장치(1100 또는 2100)에 저장된 시간비용(TC)은 나중에 다시 스토리지 장치(2200)으로 전송될 수 있다. 예를 들면, 가상 머신이 종료된 후 다시 이전 가상 머신과 같은 가상 머신이 호스트 장치(1100 또는 2100)에 의해 생성될 때, 상기 호스트 장치(1100 또는 2100)에 저장된 해당 가상 머신의 시간비용(TC)은 다시 호스트 장치(1100 또는 2100)으로부터 스토리지 장치(2200)으로 전송될 수 있다. 상기 전송된 시간비용(TC)은 해당 가상 머신의 초기 시간비용(TC)으로 사용될 수 있다.
예를 들면, 도 6에서 설명된 저장효율 또는 쓰기 확대 요소(WAF)는 해당 가상 머신의 시간비용(TC)에 상응할 수 있으므로, 가상 머신들(2281~2284)에 할당되는 소거 블록 그룹(2311~2313)은 모두 같은 초기값의 쓰기 확대 요소(WAF)를 가질 수 있다. 가상 머신(2281~2284)에 소거 블록 그룹(2311~2313)가 할당될 때 스토리지 장치(2200)은 호스트 장치(1100 또는 2100)으로부터 해당 가상 머신(VM)의 초기 쓰기 확대 요소(WAF)를 수신하여 상기 할당된 소거 블록 그룹(2311~2313) 또는 메타 블록(2315)에 저장할 수 있다.
스토리지 장치(2200)은 상기 수신된 초기 쓰기 확대 요소(WAF)에 기초하여 가상 머신(2281~2284)에 할당되는 소거 블록 그룹(EBG)의 초기 크기(즉, 블록의 개수)를 결정할 수 있다. 스토리지 장치(2200)은 요청 받은 작업을 수행하며, 업데이트되는 쓰기 확대 요소(WAF)에 기초하여 소거 블록 그룹(EBG)의 크기를 재조정할 수 있다. 예를 들면, 쓰기 확대 요소(WAF)의 값이 제 1 한계치를 넘으면 소거 블록 그룹(EGB)의 크기를 새로운 블록을 정해진 개수만큼 증가 시킬 수 있다.
상기 스토리지 장치에 저장된 쓰기 확대 요소(WAF)는 사용된 페이지수(
 ) 및 유효 페이지수(
) 및 유효 페이지수(
 )의 비율이 달라질 때마다 업데이트 될 수 있다. 예를 들면, 상기 스토리지 장치에 저장된 쓰기 확대 요소(WAF)는 상기 소거 블록 그룹(EBG)내의 상기 가상 머신(2281~2284)이 요청한 쓰기 작업이 완료될 때나 상기 소거 블록 그룹(EBG)내에 가비지 컬렉션이 수행 완료되었을 때 업데이트 될 수 있다.
)의 비율이 달라질 때마다 업데이트 될 수 있다. 예를 들면, 상기 스토리지 장치에 저장된 쓰기 확대 요소(WAF)는 상기 소거 블록 그룹(EBG)내의 상기 가상 머신(2281~2284)이 요청한 쓰기 작업이 완료될 때나 상기 소거 블록 그룹(EBG)내에 가비지 컬렉션이 수행 완료되었을 때 업데이트 될 수 있다.
본 발명의 실시예 들에 따른 스토리지 장치(2200)은 가상 머신(2281~2284)이 종료될 때 상기 가상 머신(VM)에 할당된 소거 블록 그룹(EGB)을 해제하면서 소거 블록 그룹(EBG)의 쓰기 확대 요소(WAF)도 같이 삭제 하거나, 또는 호스트로 해당 가상 머신(VM)의 최종 쓰기 확대 요소(WAF)를 전송할 수 있다. 상기 최종 쓰기 확대 요소(WAF)는 최소값 및/또는 최대값을 가질 수 있다. 상기 최소값 및/또는 최대값은 기존 가상 머신(VM)의 작업을 수행하면서 해당 소거 블록 그룹(EBG)내의 쓰기 확대 요소(WAF)가 기록한 최소값 및 최대값을 의미한다. 호스트는 상기 수신된 쓰기 확대 요소(WAF)를 해당 가상 머신(VM)의 요청 작업에 대한 쓰기 확대 요소(WAF)로 저장할 수 있다. 상기 호스트 장치(1100 또는 2100)에 저장된 쓰기 확대 요소(WAF)는 기존 요청 작업과 같은 작업을 수행하는 새로운 가상 머신(VM)이 새로운 소거 블록 그룹을 할당 받기 전에 스토리지 장치(2200)으로 전송될 수 있다.
호스트 장치(1100 또는 2100)으로부터 수신된 상기 수신된 쓰기 확대 요소(WAF)는 최소값 및 최대값을 가질 수 있다. 스토리지 장치(2200)은 상기 수신된 쓰기 확대 요소(WAF)의 최소값 및/또는 최대값에 기초하여 가상 머신(VM)에 할당된 소거 블록 그룹(EBG)의 크기를 결정할 수 있다.
본 발명의 실시 예들에 따른 스토리지 장치(2200)는 갑작스런 전원종료 후 다시 전원이 공급되었을 경우 마지막으로 업데이트된 저장효율(예를 들면, 쓰기 확대 요소(WAF))을 복구할 수 있다. 예를 들면, 마지막으로 저장된 소거 블록 그룹(EBG)을 복구함으로써 복구된 소거 블록 그룹(EBG)내의 사용된 페이지수(
 ) 및 유효 페이지수(
) 및 유효 페이지수(
 )의 비율에 기초하여 전원종료전의 업데이트 된 쓰기 확대 요소(WAF)을 복구할 수 있다. 또는, 다시 전원이 공급된 후, 스토리지 장치(2200)의 복구된 메타블록이나 복구된 소거 블록 그룹(EBG)내의 더미 영역 또는 상태 블록에 저장된 쓰기 확대 요소(WAF)를 복구할 수 있다.
)의 비율에 기초하여 전원종료전의 업데이트 된 쓰기 확대 요소(WAF)을 복구할 수 있다. 또는, 다시 전원이 공급된 후, 스토리지 장치(2200)의 복구된 메타블록이나 복구된 소거 블록 그룹(EBG)내의 더미 영역 또는 상태 블록에 저장된 쓰기 확대 요소(WAF)를 복구할 수 있다.
다시 도 4 내지 도 6을 참조하면, 본 발명의 실시 예들에 따른 스토리지 장치(2200)는 복수의 블록을 포함하는 불휘발성 메모리(2220), 및 상기 불휘발성 메모리(2220)에 연결되어 불휘발성 메모리(2220) 내부에 복수의 가상 머신들(2281~2284) 각각에 대응하는 독립된 소거 블록 그룹(2311~2313)을 할당하고, 복수의 가상 머신들(2281~2284)의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하는 컨트롤러(2210)를 포함할 수 있다. 상기 워크로드 기여도는 상술한 바와 같이 상기 소거 블록 그룹(2311~2313)내의 유효한 데이터의 저장효율에 기초하여 결정될 수 있다. 상기 유효한 데이터의 저장효율은 상기 소거 블록 그룹(2311~2313)내에 사용된 페이지수와 유효 데이터를 저장하는 페이지수의 비율로 결정될 수 있다.
본 발명의 실시 예들에 따른 스토리지 장치(2200)의 컨트롤러(2210)는 시스템온칩으로 구현될 수 있다. 컨트롤러(2210)은 복수의 가상 머신들(2281~2284)의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들(2281~2284)의 요청 작업들(RQ)을 스케줄링하는 스케줄러(2251), 복수의 채널을 통하여 외부의 불휘발성 메모리(2220)와 연결되는 플래시 큐들(2270), 및 외부의 불휘발성 메모리(2220)에 저장된 데이터의 주소 맵핑을 관리하는 맵핑관리자(2252)를 포함할 수 있다. 스케줄러(2251)은 복수의 가상 머신들(2281~2284)의 요청 작업(RQ)을 스케줄링하기 위하여 요청 큐들(2290)에 타임버짓을 할당할 수 있다.
도 7은 본 발명의 일 실시예에 따른 도 6의 소거 블록 그룹의 상세 블록도이다. 상기 소거 블록 그룹의 구조는 제 1 가상 머신(2281)을 예로 하여 설명하도록 하겠다.
도 7을 참조하면, 소거 블록 그룹(2311)은 더미 영역(dummy area, 2322, 2332)을 가진 적어도 하나의 블록(2321 및 2331)을 포함한다. 소거 블록 그룹(2311)은 제 1 가상 머신(2281)에 할당될 수 있다. 일 실시 예에서, 도 6에서 상술한 쓰기 확대 요소 (WAF)는 블록들(2321 및 2331) 중 하나의 더미 영역(2322 및 2332)에 저장될 수 있다.
소거 블록 그룹(2311)은 가상 머신(2281)이 전송한 데이터를 저장하는 데이터 블록(2331) 및, 소거 블록 그룹(2311)과 가상 머신(2281)의 작업을 관리하기 위한 별도의 상태 블록(Status block, 2331)를 포함할 수 있다. 다른 실시 예에서, 소거 블록 그룹(2311)의 저장효율(예를 들면, 쓰기 확대 요소(WAF)) 또는 각 데이터블록(2321)의 쓰기 확대 요소(WAF)는 상태 블록(2331)에 저장될 수 있다.
도 8은 본 발명의 실시 예들에 따른, 타임버짓(TB)에 기초한 작업 스케줄링 방법을 설명하는 순서도이다. 도 3 내지 도 8을 참조하면, 작업 스케줄러(2251)는 각 가상 머신(2281~2284)에 초기 타임버짓(TB)을 할당할 수 있다 (S800). 스토리지 장치(2200)은 각 가상 머신(2281~2284)이 요청한 작업(RQ)을 수행하면서 해당 가상 머신 또는 해당 작업에 대한 시간비용(TC)를 계산할 수 있다 (S810). 일 실시예에서, 시간비용(TC)를 계산하기 위하여 작업 스케줄러(2251)는 회귀분석 기반 비용 모델링(regression based cost modeling) 기법을 이용할 수 있다. 또 다른 실시 예에서, 가상 머신(2281~2284)의 쓰기 요청 작업에 의하여 해당 소거 블록 그룹(EBG)내에서 수행된 페이지 쓰기 결과에 기초하여 계산된 쓰기 확대 요소(WAF)는 쓰기 요청 작업의 시간비용(TC)에 상응할 수 있다.
스토리지 장치(2200)의 작업 스케줄러(2251)는 가상 머신(2281~2284)이 요청한 작업을 수행할 때마다 해당 가상 머신(2281~2284)에 할당된 타임버짓(TB)에서 수행된 작업에 연관된 시간비용(TC)를 감소시킬 수 있다(S820). 일 실시 예에서, 요청 큐(2290) 에서 플래시 큐(2270)로 페이지 단위(예를 들면, 4KB)로 데이터 전송이 발생할 때마다, 작업 스케줄러(2251)는 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시킬 수 있다. 다른 실시 예에서, 작업 스케줄러(2251)가 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시키는 때는 주소 맵핑 단위일 수 있다. 여기서, 주소 맵핑 단위는 기록된 데이터를 맵핑 테이블에서 관리하는 단위이다. 예를 들면, 주소 맵핑 관리자(2252)이 페이지 맵핑 방식의 주소 맵핑을 사용할 경우 상기 주소 맵핑 단위는 페이지 단위일 수 있다. 하지만, 상기 주소 맵핑 단위는 페이지 단위에 한정되지 않고 복수의 페이지 그룹 또는 블록 단위일 수 있다.
만일, 요청 큐(2290)의 타임버짓(TB)이 더 이상 남아 있지 않으면, 다른 요청 큐의 타임버짓(TB)이 모두 소진될 때까지 대기하거나 다른 요청 큐의 대기 작업이 없을 경우까지 대기한다.(S830) 만일, 모든 요청 큐의 타임버짓(TB)이 모두 소진되었거나, 타임버짓(TB)이 모두 소진된 요청 큐를 제외하고 나머지 요청 큐의 대기 작업이 없으면 타임버짓(TB)이 모두 소진된 요청 큐(예를 들면, 2291)의 타임버짓을 리필(refill)할 수 있다. 이때, 타임버짓(TB)이 남아 있는 다른 요청 큐(예를 들면, 2292~2294)도 같이 타임버짓을 리필(refill)할 수 있다.(S840)
결과적으로, 본 발명의 실시 예들에 따른 요청 작업에 대한 시간 비용을 보상하는 방법은, 상대적으로 큰 시간비용을 가진 가상 머신(VM)이나 상대적으로 작은 타임버짓(TB)을 가진 가상 머신(VM)이 다른 가상 머신(VM)에 비하여 요청 작업이 수행되면서 할당 받은 타임버짓(TB)을 더 빨리 소진하기 때문에, 타임버짓(TB)를 다시 할당 받기까지 대기 시간이 길어 질 수 있어 요청 작업이 늦게 수행되는 효과가 있다. 이와 반대로, 상대적으로 작은 시간비용을 가진 가상 머신(VM)이나 상대적으로 큰 타임버짓(TB)을 가진 가상 머신(VM)은 다른 가상 머신(VM)에 비하여 요청 작업이 수행되면서 할당 받은 타임버짓(TB)을 더 늦게 소진하기 때문에, 타임버짓(TB)를 다시 할당 받기위한 대기 시간이 필요없기 때문에 결과적으로 요청 작업이 빨리 수행되는 효과가 있다. 따라서, 본 발명의 실시예 들에 따른 요청 작업에 대한 시간비용(TC)의 보상방법은 가상 머신들(VMs)의 시간비용(TC) 및 타임버짓(TB)에 기초하여 가상 머신들(VMs)간의 공정한 리소스 분배 및 성능 분리를 보장할 수 있다.
도 9은 요청 작업에 대한 시간 비용을 보상하는 방법에 대한 순서도이다. 도 1 내지 도 9을 참조하면, 작업 스케줄러(2251)는 각 가상 머신(VM)에 의해 요청되는 작업에 대해 초기 시간비용을 할당할 수 있다(S900). 예를 들면, 작업 스케줄러(2251)는 요청 작업에 대한 오버헤드가 발생하지 않을 때의 시간비용(TC)을 해당 가상 머신(VM)의 요청 작업에 대한 초기 시간비용(TC)으로 할당할 수 있다. 또한, 작업 스케줄러(2251)는 모든 가상 머신(VM)은 같은 시간비용을 할당 받을 수 있다.
스토리지 장치(2200)은 각 가상 머신(2281~2284)이 요청한 작업을 수행하면서 해당 작업에 대한 오버헤드에 대한 시간비용(TC)를 계산할 수 있다 (S910). 일 실시 예에서, 상기 오버헤드에 시간비용(TC)를 계산하기 위하여 작업 스케줄러(2251)는 도 5a 내지 도 5c에서 설명한 회귀분석 기반 비용 모델링(regression based cost modeling) 기법을 이용할 수 있다.
스토리지 장치(2200)의 작업 스케줄러(2251)는 가상 머신(VM)이 요청한 작업에 대한 보상된 시간비용(TC)을 계산할 수 있다 (S920). 일 실시 예에서, 작업 스케줄러(2251)는 가상 머신(VM)의 요청 작업에 대한 초기 시간비용(TC)과 해당 요청 작업으로 인해 발생한 오버헤드에 대한 시간비용(TC)을 합한 값으로 상기 요청 작업에 대한 시간 비용(TC)으로 할당할 수 있다. 다른 실시 예에서, 도 6에서 설명한 바와 같이, 작업 스케줄러(2251)는 가상 머신(2281~2284)의 쓰기 요청 작업으로 인한 시간 비용(TC)에 상응하는 쓰기 확대 요소(WAF)를 계산할 수 있다.
스토리지 장치(2200)의 작업 스케줄러(2251)는 가상 머신(VM)이 요청한 작업을 수행할 때마다 해당 가상 머신(2281~2284)에 할당된 타임버짓(TB)에서 수행된 작업에 연관된 시간비용(TC)를 감소시킬 수 있다 (S930). 일 실시 예에서, 요청 큐(2290) 에서 플래시 큐(2270)로 페이지 단위(예를 들면, 4KB)로 데이터 전송이 발생할 때마다, 작업 스케줄러(2251)는 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시킬 수 있다. 다른 실시 예에서, 작업 스케줄러(2251)가 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시키는 때는 주소 맵핑 단위일 수 있다. 여기서, 주소 맵핑 단위는 기록된 데이터를 주소 맵핑 테이블에서 관리하는 단위이다. 예를 들면, FTL이 페이지 맵핑 방식을 사용할 경우 상기 주소 맵핑 단위는 페이지 단위일 수 있다. 하지만, 상기 주소 맵핑 단위는 페이지 단위에 한정되지 않고 복수의 페이지 그룹 또는 블록 단위일 수 있다.
만일, 요청 큐(2290)의 타임버짓(TB)이 더 이상 남아 있지 않으면, 다른 요청 큐의 타임버짓(TB)이 모두 소진될 때까지 대기하거나 다른 요청 큐의 대기 작업이 없을 경우까지 대기한다 (S940). 만일, 모든 요청 큐의 타임버짓(TB)이 모두 소진되었거나, 타임버짓(TB)이 모두 소진된 요청 큐를 제외하고 나머지 요청 큐의 대기 작업이 없으면 타임버짓(TB)이 모두 소진된 요청 큐의 타임버짓을 리필(refill)할 수 있다. 이때, 타임버짓(TB)이 남아 있는 다른 큐도 같이 타임버짓을 리필(refill)할 수 있다 (S950).
결과적으로, 본 발명의 실시 예들에 따른 요청 작업에 대한 시간 비용을 보상하는 방법은, 상대적으로 큰 시간비용을 가진 가상 머신(VM)이나 상대적으로 작은 타임버짓(TB)을 가진 가상 머신(VM)이 다른 가상 머신(VM)에 비하여 요청 작업이 수행되면서 할당 받은 타임버짓(TB)을 더 빨리 소진하기 때문에, 타임버짓(TB)를 다시 할당 받기까지 대기 시간이 길어 질 수 있어 요청 작업이 늦게 수행되는 효과가 있다. 이와 반대로, 상대적으로 작은 시간비용을 가진 가상 머신(VM)이나 상대적으로 큰 타임버짓(TB)을 가진 가상 머신(VM)은 다른 가상 머신(VM)에 비하여 요청 작업이 수행되면서 할당 받은 타임버짓(TB)을 더 늦게 소진하기 때문에, 타임버짓(TB)를 다시 할당 받기위한 대기 시간이 필요없기 때문에 결과적으로 요청 작업이 빨리 수행되는 효과가 있다. 따라서, 본 발명의 실시예 들에 따른 요청 작업에 대한 시간비용(TC)의 보상방법은 가상 머신들(VMs)의 시간비용(TC) 및 타임버짓(TB)에 기초하여 가상 머신들(VMs)간의 공정한 리소스 분배 및 성능 분리를 보장할 수 있다.
도 10은 도 6에서 설명한 저장효율 (예를 들면, 쓰기 확대 요소(WAF))에 기초한 스케줄링 방법에 대한 순서도이다. 도 2 내지 도 10을 참조하면, 스토리지 장치(2200)의 작업 스케줄러(2251)는 각 가상 머신(2281~2284)에 할당된 소거 블록 그룹(2311~2313)에 포함된 각 블록의 쓰기 확대 요소(WAF)를 계산할 수 있다 (S1000). 이때, 쓰기 확대 요소(WAF)는 도 6에서 상세히 설명한 바와 같이 소거 블록 그룹(2311~2313)에 포함된 각 블록에서 사용된 페이지수(
 ) 및 유효 페이지수(
) 및 유효 페이지수(
 )의 비율에 기초하여 결정될 수 있다.
)의 비율에 기초하여 결정될 수 있다.
소거 블록 그룹(2311~2313)의 쓰기 확대 요소(WAF)는 소거 블록 그룹(2311~2313)내의 각 블록의 쓰기 확대 요소(WAF)의 평균값일 수 있다. (S1010) 만약, 작업 스케줄러(2251)가 소거 블록 그룹(2311~2313)의 쓰기 확대 요소(WAF)를 계산하기 위하여 소거 블록 그룹(2311~2313)에 포함된 각 블록의 쓰기 확대 요소(WAF)를 계산하지 않고, 소거 블록 그룹(2311~2313)에 포함된 전체 페이지에 대하여 사용된 페이지수(
 ) 및 유효 페이지수(
) 및 유효 페이지수(
 )의 비율을 계산할 경우, 단계 S1000은 생략될 수 있다.
)의 비율을 계산할 경우, 단계 S1000은 생략될 수 있다.
스토리지 장치(2200)의 작업 스케줄러(2251)는 상기 계산된 쓰기 확대 요소(WAF)에 기초하여 상기 가상 머신(VM)에 의하여 요청된 작업의 시간비용(TC)를 계산할 수 있다(S1020). 이때, 상기 계산된 쓰기 확대 요소(WAF)와 상기 시간비용(TC)은 서로 비례관계일 수 있다. 예를 들면, 스토리지 장치(2200)이 불휘발성 메모리(2220)를 사용하는 스토리지 장치인 SSD(Solid State Driver)일 때 각 가상 머신(2281~2284)의 쓰기 요청에 의하여 발생한 페이지 단위의 쓰기 동작이 많아 질수록, 상기 쓰기 요청과 관련된 가상 머신에 할당된 소거 블록 그룹(EBG)은 가비지 컬렉션과 같은 오버헤드가 발생할 확률도 비례해서 커질 수 있다.
스토리지 장치(2200)의 작업 스케줄러(2251)는 가상 머신(2281~2284)이 요청한 작업을 수행할 때마다 해당 가상 머신(VM)에 할당된 타임버짓(TB)에서 수행된 작업에 연관된 시간비용(TC)를 감소시킬 수 있다 (S1030). 일 실시 예에서, 요청 큐(2290) 에서 플래시 큐(2270)로 페이지 단위(예를 들면, 4KB)로 데이터 전송이 발생할 때마다, 작업 스케줄러(2251)는 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시킬 수 있다. 다른 실시 예에서, 요청 큐(2290) 에서 플래시 큐(2270)로 주소 맵핑 단위로 데이터 전송이 발생할 때마다, 작업 스케줄러(2251)는 상기 타임버짓(TB)에서 상기 시간비용(TC)를 감소시킬 수 있다. 여기서, 상기 주소 맵핑 단위는 기록된 데이터를 주소 맵핑 테이블에서 관리하는 단위이다. 예를 들면, 주소 맵핑 관리자(2252)이 페이지 맵핑 방식을 사용될 경우 상기 주소 맵핑 단위는 페이지 단위일 수 있다. 하지만, 상기 주소 맵핑 단위는 페이지 단위에 한정되지 않고 복수의 페이지 그룹 단위일 수 있다.
도 11는 본 발명의 실시 예에 따른 스토리지 시스템을 보여주는 블록도이다. 도 11를 참조하면, 스토리지 시스템(10000)은 스토리지 장치(11000), 전원 장치(12000), 중앙처리장치(13000), 메모리(14000), 사용자 인터페이스(15000) 및 스토리지 인터페이스(16000)를 포함할 수 있다. 그리고 스토리지 장치(11000)은 불휘발성 메모리(11000) 및 메모리 컨트롤러(11200)를 포함한다. 스토리지 시스템(10000)은 보조 전원 장치(12500)를 더 포함할 수 있다. 보조 전원 장치(12500)은 배터리 또는 UPS (Uninterruptible Power Supply)와 같은 보조 전원 장치일 수 있다. 스토리지 시스템(10000)은 도 1 또는 도 2의 스토리지 시스템 (1000 또는 2000)에 대응될 수 있다. 스토리지 장치(11000)은 도 1 내지 도 10에서 설명한 스토리지 장치(1200 또는 2200)에 대응될 수 있다. 스토리지 인터페이스(16000)는 도 1 또는 도 2의 스토리지 인터페이스 (1150 또는 2150)에 대응될 수 있다. 불휘발성 메모리(11000)은 도 1 내지 도 4에 도시된 불휘발성 메모리(1220, 2220)에 대응될 수 있고, 메모리 컨트롤러(11200)은 도 4의 컨트롤러 (2250)에 대응될 수 있다. 메모리(14000)은 도 1 또는 도 2의 호스트 메모리(1140 또는 2140)에 대응할 수 있다. 중앙처리장치(13000)는 도 1 또는 도 2의 호스트 코어(1110 또는 2110)에 대응할 수 있다.
본 발명의 실시 예들에 따른 스토리지 시스템(10000)은 상술한 바와 같이 복수의 가상 머신들 각각에 대응하는 독립된 소거 블록 그룹을 포함하는 불휘발성 메모리(11100) 및 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하는 컨트롤러(11200)를 포함할 수 있다. 스토리지 시스템(10000)은 상기 불휘발성 메모리(11100)를 제어하는 컨트롤러(11200) 및 컨트롤러(11200)와 인터페이스하는 스토리지 인터페이스(16000)를 더 포함할 수 있다. 또한, 스토리지 시스템(10000)은 스토리지 장치(11000)에 전달되는 커맨드 및 데이터를 저장하는 메모리(14000)을 더 포함할 수 있다. 스토리지 시스템(10000) 내의 중앙처리장치(13000)과 스토리지 인터페이스(16000)은 하나의 어플리케이션 프로세서를 형성할 수 있다. 상기 어플리케이션 프로세서는 시스템온칩(System-On-Chip)으로 구현될 수 있다.
본 발명의 실시 예들에 따른 스토리지 시스템(10000)은 상술한 바와 같이 스토리지 장치(11000)가 가상화 기능을 지원함으로써 스토리지 시스템(10000)의 가상 머신들 간의 성능 분리 및 리소스의 공정한 분배를 더욱 효과적으로 구현할 수 있다.
스토리지 시스템(10000)은 서버(Server), 개인용 컴퓨터(Personal Computer), 랩탑(laptop) 컴퓨터, 휴대용 단말기(mobile phone), 스마트폰(smart phone), 태블릿 PC (tablet personal computer), 또는 웨어러블 컴퓨터로 구현될 수 있다. 상기 스토리지 시스템(10000)은 시스템온칩(System-On-Chip)으로 구현될 수 있다. 이때, 불휘발성 메모리(11000)는 별도의 칩으로 구현될 수 있으며, 별도의 불휘발성 메모리(11000)은 상기 시스템온칩에 하나의 패키지(package)로 조립될 수 있다.
도 11에서 스토리지 장치(11000)는 하나의 불휘발성 메모리(11100)를 구비한 것과 같이 도시되어 있으나, 본 발명의 기술적 사상은 이에 한정되는 것이 아님이 이해될 것이다. 예를 들어, 도 11의 스토리지 장치(11000)는 복수의 플래시 메모리들, 또는 플래시 메모리와 다른 불휘발성 메모리들, 또는 이들의 조합을 포함할 수 있다. 또한 스토리지 장치(11000)는 메모리 컨트롤러(11200)와 불휘발성 메모리(11100)가 하나의 패키지 형태로 구현될 수 있다. 도 11에 도시된 스토리지 장치(11000)는 앞에서 설명한 바와 같이, 가상화 기능을 지원할 수 있다.
도 12는 본 발명의 실시 예에 따른 스토리지 장치가 적용된 컴퓨터 시스템을 나타내는 블록도이다. 도 12를 참조하면, 컴퓨터 시스템(20000)은 이미지 처리부(21000), 무선 송수신부(22000), 오디오 처리부(23000), 메모리(24000), 스토리지 장치(25000), 사용자 인터페이스(26000), 그리고 어플리케이션 프로세서(27000)를 포함할 수 있다.
이미지 처리부(21000)는 렌즈(21100), 이미지 센서(21200), 이미지 프로세서(21300), 그리고 디스플레이부(21400)를 포함할 수 있다. 무선 송수신부(22000)는 안테나(22100), RF 부(22200), 모뎀(22300)을 포함할 수 있다. 오디오 처리부(23000)는 오디오 프로세서(23100), 마이크(23200), 그리고 스피커(23300)를 포함할 수 있다. 메모리(24000)은 컴퓨터 시스템(20000)에서 처리되는 데이터를 임시적으로 저장할 수 있다. 또한, 메모리(24000)는 도 11의 메모리(14000)에 대응될 수 있다. 스토리지 장치(25000)는 스토리지 모듈(예를 들면, NVMe, eMMC) 등으로 제공될 수 있다. 스토리지 장치(25000)는 도 11의 스토리지 장치(11000)에 대응될 수 있다.
어플리케이션 프로세서(27000)는 응용 프로그램, 운영 체제 등을 구동하는 시스템 온 칩(SoC)으로 제공될 수 있다. 시스템 온 칩(SoC; System-on-Chip)에서 구동되는 운영 체제의 커널(Kernel)에는 입출력 스케줄러(I/O Scheduler) 및 스토리지 장치(25000)를 제어하기 위한 장치 드라이버(Device Driver)가 포함될 수 있다. 장치 드라이버(Device driver)는 입출력 스케줄러에서 관리되는 동기 큐의 수를 참조하여 스토리지 장치(25000)의 액세스 성능을 제어하거나, SoC 내부의 CPU 모드, DVFS 레벨 등을 제어할 수 있다.
어플리케이션 프로세서 (27000)는 큐 베이스의 인터페이스 방식 및 가상화 기능을 지원하기 위하여 도 11에 도시된 것과 같이 스토리지 인터페이스를 포함할 수 있다.
불휘발성 메모리 장치 및/또는 메모리 컨트롤러는 다양한 형태들의 패키지를 이용하여 실장될 수 있다. 예를 들면, 불휘발성 메모리 장치 및/또는 메모리 컨트롤러는 PoP(Package on Package), Ball grid arrays(BGAs), Chip scale packages(CSPs), Plastic Leaded Chip Carrier(PLCC), Plastic Dual In-Line Package(PDIP), Die in Waffle Pack, Die in Wafer Form, Chip On Board(COB), Ceramic Dual In-Line Package(CERDIP), Plastic Metric Quad Flat Pack(MQFP), Thin Quad Flatpack(TQFP), Small Outline(SOIC), Shrink Small Outline Package(SSOP), Thin Small Outline(TSOP), System In Package(SIP), Multi Chip Package(MCP), Wafer-level Fabricated Package(WFP), Wafer-Level Processed Stack Package(WSP) 등과 같은 패키지들을 이용하여 실장 될 수 있다.
본 발명의 실시 예들에 따른 컴퓨터 시스템(20000)은 상술한 바와 같이 스토리지 장치(25000)가 가상화 기능을 지원함으로써 컴퓨터 시스템(20000)의 가상 머신들 간의 성능 분리 및 리소스의 공정한 분배를 더욱 효과적으로 구현할 수 있다.
컴퓨터 시스템(20000)은 서버(Server), 개인용 컴퓨터(Personal Computer), 랩탑(laptop) 컴퓨터, 휴대용 단말기(mobile phone), 스마트폰(smart phone), 태블릿 PC (tablet personal computer), 또는 웨어러블 컴퓨터로 구현될 수 있다. 어플리케이션 프로세서(27000)는 시스템온칩(System-On-Chip)으로 구현될 수 있다. 이때, 컨트롤러(25200) 및 불휘발성 메모리(25100) 각각은 별도의 칩으로 구현될 수 있으며, 어플리케이션 프로세서(27000), 스토리지 장치(25000)은 하나의 패키지(package)로 조립될 수 있다.
본 발명의 실시 예들에 따른 컴퓨터 시스템(20000)은 상술한 바와 같이 복수의 가상 머신들 각각에 대응하는 독립된 소거 블록 그룹을 포함하는 불휘발성 메모리(25100) 및 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하는 컨트롤러(25200)를 포함할 수 있다. 컴퓨터 시스템(20000)은 어플리케이션 프로세서(27000)을 포함할 수 있다. 어플리케이션 프로세서(27000)은 도 11과 같이 상기 불휘발성 메모리(25100)를 제어하는 컨트롤러(25200)와 인터페이스하는 스토리지 인터페이스(16000)를 포함할 수 있다. 또한, 컴퓨터 시스템(20000)은 스토리지 장치(25000)에 전달되는 커맨드 및 데이터를 저장하는 메모리(24000)을 더 포함할 수 있다.
한편, 본 출원의 상세한 설명에서는 구체적인 실시 예에 관하여 설명하였으나, 본 출원의 범위에서 벗어나지 않는 한도 내에서 여러 가지 변형이 가능함은 물론이다. 그러므로 본 출원의 범위는 상술한 실시예에 국한되어 정해져서는 안되며 후술하는 특허청구범위 뿐만 아니라 이 출원의 특허청구범위와 균등한 것들에 의해 정해져야 한다.
CMD: command
SQ: submission queue
CQ: completion queue
AQ: administrator queue
A_SQ: administrator submission queue
A_CQ: administrator completion queue
I/O_SQ:I/O submission queue
I/O_CQ: I/O completion queue
PF: Physical Function
VF: Virtual Function
VM: Virtual Machine
PF A_Q Area: PF Administrator queue stroage area
PF I/O_Q Area: PF I/O Queue storage area
VF A_Q Area: VF Administrator queue stroage area
VF I/O_Q Area: VF I/O Queue storage area
RQ: Request Queue
FQ: Flash Queue
SQ: submission queue
CQ: completion queue
AQ: administrator queue
A_SQ: administrator submission queue
A_CQ: administrator completion queue
I/O_SQ:I/O submission queue
I/O_CQ: I/O completion queue
PF: Physical Function
VF: Virtual Function
VM: Virtual Machine
PF A_Q Area: PF Administrator queue stroage area
PF I/O_Q Area: PF I/O Queue storage area
VF A_Q Area: VF Administrator queue stroage area
VF I/O_Q Area: VF I/O Queue storage area
RQ: Request Queue
FQ: Flash Queue
Claims (10)
- 복수의 블록을 포함하는 불휘발성 메모리; 및
상기 불휘발성 메모리에 연결되어, 상기 불휘발성 메모리 내부에 복수의 가상 머신들 각각에 대응하는 독립된 소거 블록 그룹을 할당하고, 상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 복수의 가상 머신들의 요청 작업들을 스케줄링하는 컨트롤러를 포함하는 스토리지 장치. - 제 1 항에 있어서,
상기 워크로드 기여도는 상기 소거 블록 그룹내의 유효한 데이터의 저장효율에 기초하여 결정되는 스토리지 장치 - 제 2 항에 있어서,
상기 유효한 데이터의 저장효율은 상기 소거 블록 그룹내에 사용된 페이지수와 유효 데이터를 저장하는 페이지수의 비율인 스토리지 장치. - 제 1 항에 있어서,
상기 컨트롤러는,
상기 복수의 가상 머신들 각각에 대응하고, 상기 복수의 가상 머신들의 요청 작업들을 저장하는 복수의 요청 큐들;
상기 복수의 가상 머신들의 워크로드 기여도에 기초하여 상기 요청 작업들을 스케줄링하는 스케줄러;
상기 불휘발성 메모리에 저장된 데이터의 주소 맵핑을 관리하는 맵핑관리자; 및
상기 불휘발성 메모리에 채널을 통하여 연결된 복수의 플래시 큐들을 포함하는 스토리지 장치. - 컨트롤러 및 상기 컨트롤러에 연결된 불휘발성 메모리를 포함하는 스토리지 장치의 작업 스케줄링 방법에 있어서,
복수의 가상 머신들 각각에 하나의 요청 큐를 할당하는 단계;
상기 요청 큐에 타임버짓을 할당하는 단계;
상기 복수의 가상 머신들이 요청한 작업들을 상기 요청 큐에 저장하는 단계;
상기 요청 큐에 저장된 작업을 수행하는 단계;
상기 저장된 작업의 수행이 완료될 때 상기 타임버짓에서 상기 수행된 작업의 시간비용만큼을 감소시키는 단계;
상기 요청 큐의 타임버짓이 모두 소진되었을 때, 상기 요청 큐의 타임버짓을 재할당할 때까지 상기 요청 큐에 저장된 작업을 대기시키는 스토리지 장치의 작업 스케줄링 방법. - 제 5 항에 있어서,
상기 타임버짓을 할당하는 단계는,
상기 복수의 가상 머신 각각에 할당된 요청 큐에 같은 타임버짓을 할당하는 단계를 포함하는 스토리지 장치의 작업 스케줄링 방법. - 제 5 항에 있어서,
상기 요청 큐에 저장된 작업을 패치(fetch)하여 상기 작업의 수행이 완료될 때 소요된 수행시간을 측정하여 상기 작업의 시간비용을 계산하는 단계를 더 포함하는 스토리지 장치의 작업 스케줄링 방법. - 제 5 항에 있어서,
상기 불휘발성 메모리에 포함된 적어도 하나의 블록을 포함하는 소거 블록 그룹을 상기 복수의 가상 머신들 각각에 전용으로 할당하는 단계를 더 포함하는 스토리지 장치의 작업 스케줄링 방법. - 제 8 항에 있어서,
상기 시간비용는 상기 소거 블록 그룹내의 데이터 저장효율 (storage efficiency)에 기초하여 결정되는 스토리지 장치의 작업 스케줄링 방법. - 제 9 항에 있어서,
상기 데이터 저장효율은 상기 소거 블록 그룹내에 사용된 페이지수와 유효 데이터를 저장하는 페이지수의 비율인 스토리지 장치의 작업 스케줄링 방법.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020150103853A KR102371916B1 (ko) | 2015-07-22 | 2015-07-22 | 가상 머신을 지원하는 스토리지 장치, 그것을 포함하는 스토리지 시스템 및 그것의 동작 방법 |
| CN201610579921.7A CN106371888B (zh) | 2015-07-22 | 2016-07-21 | 支持虚拟机的存储设备,包括其的存储系统和其操作方法 |
| US15/217,270 US10203912B2 (en) | 2015-07-22 | 2016-07-22 | Storage device for supporting virtual machine, storage system including the storage device, and method of operating the same |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020150103853A KR102371916B1 (ko) | 2015-07-22 | 2015-07-22 | 가상 머신을 지원하는 스토리지 장치, 그것을 포함하는 스토리지 시스템 및 그것의 동작 방법 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20170011350A true KR20170011350A (ko) | 2017-02-02 |
| KR102371916B1 KR102371916B1 (ko) | 2022-03-07 |
Family
ID=57837293
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020150103853A KR102371916B1 (ko) | 2015-07-22 | 2015-07-22 | 가상 머신을 지원하는 스토리지 장치, 그것을 포함하는 스토리지 시스템 및 그것의 동작 방법 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US10203912B2 (ko) |
| KR (1) | KR102371916B1 (ko) |
| CN (1) | CN106371888B (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10891073B2 (en) | 2018-04-05 | 2021-01-12 | Research & Business Foundation Sungkyunkwan University | Storage apparatuses for virtualized system and methods for operating the same |
| KR20210056430A (ko) * | 2019-04-24 | 2021-05-18 | 구글 엘엘씨 | 커밋먼트-인식 스케줄러 |
| US11704068B2 (en) | 2021-03-31 | 2023-07-18 | SK Hynix Inc. | Apparatus and method for scheduling operations performed in plural memory devices included in a memory system |
| US12039357B2 (en) | 2021-04-23 | 2024-07-16 | Samsung Electronics Co., Ltd. | Mechanism for distributed resource-based I/O scheduling over storage device |
Families Citing this family (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11036533B2 (en) | 2015-04-17 | 2021-06-15 | Samsung Electronics Co., Ltd. | Mechanism to dynamically allocate physical storage device resources in virtualized environments |
| US10838852B2 (en) | 2015-04-17 | 2020-11-17 | Samsung Electronics Co., Ltd. | System and method to extend NVME queues to user space |
| US20170118293A1 (en) * | 2015-10-26 | 2017-04-27 | Trilliant Networks, Inc. | Method and system for efficient task management |
| US10452279B1 (en) | 2016-07-26 | 2019-10-22 | Pavilion Data Systems, Inc. | Architecture for flash storage server |
| CN107918613B (zh) * | 2016-10-08 | 2022-01-21 | 上海宝存信息科技有限公司 | 因应服务质量的固态硬盘访问方法以及使用该方法的装置 |
| JP6783645B2 (ja) * | 2016-12-21 | 2020-11-11 | キオクシア株式会社 | メモリシステムおよび制御方法 |
| CN108628775B (zh) * | 2017-03-22 | 2021-02-12 | 华为技术有限公司 | 一种资源管理的方法和装置 |
| US10503434B2 (en) * | 2017-04-12 | 2019-12-10 | Micron Technology, Inc. | Scalable low-latency storage interface |
| US10852990B2 (en) * | 2017-08-02 | 2020-12-01 | Samsung Electronics Co., Ltd. | Hybrid framework of NVMe-based storage system in cloud computing environment |
| CN107861894B (zh) * | 2017-11-03 | 2021-08-31 | 郑州云海信息技术有限公司 | NVMe协议的队列命令的执行方法、装置及存储介质 |
| KR102410671B1 (ko) | 2017-11-24 | 2022-06-17 | 삼성전자주식회사 | 스토리지 장치, 스토리지 장치를 제어하는 호스트 장치, 및 스토리지 장치의 동작 방법 |
| TWI643065B (zh) * | 2017-12-20 | 2018-12-01 | 慧榮科技股份有限公司 | 用於動態執行記憶體回收資料儲存裝置與操作方法 |
| KR102528258B1 (ko) * | 2018-04-30 | 2023-05-04 | 에스케이하이닉스 주식회사 | 메모리 컨트롤러 및 그 동작 방법 |
| CN108959127B (zh) * | 2018-05-31 | 2021-02-09 | 华为技术有限公司 | 地址转换方法、装置及系统 |
| CN111902804B (zh) * | 2018-06-25 | 2024-03-01 | 阿里巴巴集团控股有限公司 | 用于管理存储设备的资源并量化i/o请求成本的系统和方法 |
| US10564872B2 (en) * | 2018-06-29 | 2020-02-18 | Western Digital Technologies, Inc. | System and method for dynamic allocation to a host of memory device controller memory resources |
| KR102495539B1 (ko) | 2018-07-16 | 2023-02-06 | 에스케이하이닉스 주식회사 | 메모리 시스템 및 메모리 시스템의 동작방법 |
| US10936199B2 (en) * | 2018-07-17 | 2021-03-02 | Silicon Motion, Inc. | Flash controllers, methods, and corresponding storage devices capable of rapidly/fast generating or updating contents of valid page count table |
| US11372580B2 (en) * | 2018-08-07 | 2022-06-28 | Marvell Asia Pte, Ltd. | Enabling virtual functions on storage media |
| US11656775B2 (en) | 2018-08-07 | 2023-05-23 | Marvell Asia Pte, Ltd. | Virtualizing isolation areas of solid-state storage media |
| KR102541897B1 (ko) | 2018-08-27 | 2023-06-12 | 에스케이하이닉스 주식회사 | 메모리 시스템 |
| US11010314B2 (en) | 2018-10-30 | 2021-05-18 | Marvell Asia Pte. Ltd. | Artificial intelligence-enabled management of storage media access |
| KR20200073122A (ko) * | 2018-12-13 | 2020-06-23 | 에스케이하이닉스 주식회사 | 데이터 저장 장치 및 그것의 동작 방법 |
| US11481118B2 (en) | 2019-01-11 | 2022-10-25 | Marvell Asia Pte, Ltd. | Storage media programming with adaptive write buffer release |
| CN111817818A (zh) * | 2019-04-11 | 2020-10-23 | 中国移动通信集团四川有限公司 | 一种传输数据包的方法和装置 |
| KR20210082705A (ko) * | 2019-12-26 | 2021-07-06 | 삼성전자주식회사 | 미리 정의된 시간을 사용한 스토리지 장치의 작업 스케쥴링 방법 및 이를 이용한 스토리지 시스템의 구동 방법 |
| KR20210099291A (ko) | 2020-02-04 | 2021-08-12 | 삼성전자주식회사 | 다중-호스트를 지원하도록 구성된 스토리지 장치 및 그것의 동작 방법 |
| KR20210105201A (ko) * | 2020-02-18 | 2021-08-26 | 삼성전자주식회사 | 다중-호스트를 지원하도록 구성된 스토리지 장치 및 그것의 동작 방법 |
| CN111562922A (zh) * | 2020-04-29 | 2020-08-21 | 北京中大唯信科技有限公司 | 命令行程序模块化及云端化的方法、系统、电子设备 |
| US11194482B1 (en) * | 2020-06-02 | 2021-12-07 | Western Digital Technologies, Inc. | Storage system and method for segregating outliers in a virtualization system |
| US11494098B2 (en) | 2020-06-30 | 2022-11-08 | Western Digital Technologies, Inc. | Variable performance storage devices |
| KR20220067795A (ko) * | 2020-11-18 | 2022-05-25 | 삼성전자주식회사 | 스토리지 장치 및 이를 포함하는 스토리지 시스템 |
| CN117319242A (zh) * | 2022-06-23 | 2023-12-29 | 华为技术有限公司 | 数据存储方法及电子设备 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8424007B1 (en) * | 2008-09-30 | 2013-04-16 | Symantec Corporation | Prioritizing tasks from virtual machines |
| US20140137104A1 (en) * | 2012-11-12 | 2014-05-15 | Vmware, Inc. | Cooperative Application Workload Scheduling for a Consolidated Virtual Environment |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7953773B2 (en) | 2005-07-15 | 2011-05-31 | Oracle International Corporation | System and method for deterministic garbage collection in a virtual machine environment |
| CN101290583B (zh) * | 2007-04-19 | 2011-03-16 | 国际商业机器公司 | 为虚拟机供应图像的方法和系统 |
| JP4935626B2 (ja) | 2007-10-30 | 2012-05-23 | 富士通株式会社 | 制御プログラム及び方法並びにコンピュータ |
| US8413157B2 (en) * | 2009-08-06 | 2013-04-02 | Charles Palczak | Mechanism for continuously and unobtrusively varying stress on a computer application while processing real user workloads |
| US9389895B2 (en) | 2009-12-17 | 2016-07-12 | Microsoft Technology Licensing, Llc | Virtual storage target offload techniques |
| US8346935B2 (en) * | 2010-01-15 | 2013-01-01 | Joyent, Inc. | Managing hardware resources by sending messages amongst servers in a data center |
| JP4982578B2 (ja) | 2010-02-22 | 2012-07-25 | 西日本電信電話株式会社 | リソース割当装置、リソース割当方法、およびリソース割当制御プログラム |
| KR101658035B1 (ko) | 2010-03-12 | 2016-10-04 | 삼성전자주식회사 | 가상 머신 모니터 및 가상 머신 모니터의 스케줄링 방법 |
| US8707300B2 (en) | 2010-07-26 | 2014-04-22 | Microsoft Corporation | Workload interference estimation and performance optimization |
| US8489699B2 (en) | 2010-08-13 | 2013-07-16 | Vmware, Inc. | Live migration of virtual machine during direct access to storage over SR IOV adapter |
| JP5601516B2 (ja) | 2010-10-06 | 2014-10-08 | 日本電気株式会社 | コンピュータ装置及びメモリリソース割当て方法 |
| US8799554B1 (en) | 2010-10-27 | 2014-08-05 | Amazon Technologies, Inc. | Methods and system for swapping memory in a virtual machine environment |
| US9208071B2 (en) * | 2010-12-13 | 2015-12-08 | SanDisk Technologies, Inc. | Apparatus, system, and method for accessing memory |
| US20120167082A1 (en) | 2010-12-23 | 2012-06-28 | Sanjay Kumar | Direct sharing of smart devices through virtualization |
| JP5538310B2 (ja) | 2011-06-27 | 2014-07-02 | 株式会社エヌ・ティ・ティ・データ | 仮想化システム、および仮想化方法 |
| US8874848B2 (en) * | 2011-09-30 | 2014-10-28 | Net App, Inc. | Intelligence for controlling virtual storage appliance storage allocation |
| US9170849B2 (en) | 2012-01-09 | 2015-10-27 | Microsoft Technology Licensing, Llc | Migration of task to different pool of resources based on task retry count during task lease |
| US9600311B2 (en) * | 2012-03-08 | 2017-03-21 | Nec Corporation | Virtual-machine managing device and virtual-machine managing method |
| US9069640B2 (en) * | 2012-03-23 | 2015-06-30 | Hitachi, Ltd. | Patch applying method for virtual machine, storage system adopting patch applying method, and computer system |
| US9753831B2 (en) | 2012-05-30 | 2017-09-05 | Red Hat Israel, Ltd. | Optimization of operating system and virtual machine monitor memory management |
| JP2014021714A (ja) * | 2012-07-18 | 2014-02-03 | Nec Corp | 仮想マシン管理装置、仮想マシン管理方法、及び、プログラム |
| US9400664B2 (en) * | 2012-12-20 | 2016-07-26 | Hitachi, Ltd. | Method and apparatus for offloading storage workload |
| US9720717B2 (en) | 2013-03-14 | 2017-08-01 | Sandisk Technologies Llc | Virtualization support for storage devices |
| JP5563126B1 (ja) | 2013-06-04 | 2014-07-30 | 日本電信電話株式会社 | 情報処理装置及び検出方法 |
| KR101502225B1 (ko) | 2013-07-31 | 2015-03-12 | 서울대학교산학협력단 | 컴퓨팅 장치에서의 가상머신 간의 성능간섭 감소를 위한 가상머신 할당 방법 |
| US10019352B2 (en) * | 2013-10-18 | 2018-07-10 | Sandisk Technologies Llc | Systems and methods for adaptive reserve storage |
| US10102165B2 (en) * | 2014-11-25 | 2018-10-16 | International Business Machines Corporation | Arbitration in an SRIOV environment |
| US10108339B2 (en) * | 2014-12-17 | 2018-10-23 | Intel Corporation | Reduction of intermingling of input and output operations in solid state drives |
-
2015
- 2015-07-22 KR KR1020150103853A patent/KR102371916B1/ko active IP Right Grant
-
2016
- 2016-07-21 CN CN201610579921.7A patent/CN106371888B/zh active Active
- 2016-07-22 US US15/217,270 patent/US10203912B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8424007B1 (en) * | 2008-09-30 | 2013-04-16 | Symantec Corporation | Prioritizing tasks from virtual machines |
| US20140137104A1 (en) * | 2012-11-12 | 2014-05-15 | Vmware, Inc. | Cooperative Application Workload Scheduling for a Consolidated Virtual Environment |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10891073B2 (en) | 2018-04-05 | 2021-01-12 | Research & Business Foundation Sungkyunkwan University | Storage apparatuses for virtualized system and methods for operating the same |
| KR20210056430A (ko) * | 2019-04-24 | 2021-05-18 | 구글 엘엘씨 | 커밋먼트-인식 스케줄러 |
| US11720403B2 (en) | 2019-04-24 | 2023-08-08 | Google Llc | System for commitment-aware workload scheduling based on anticipated resource consumption levels |
| US11704068B2 (en) | 2021-03-31 | 2023-07-18 | SK Hynix Inc. | Apparatus and method for scheduling operations performed in plural memory devices included in a memory system |
| US12039357B2 (en) | 2021-04-23 | 2024-07-16 | Samsung Electronics Co., Ltd. | Mechanism for distributed resource-based I/O scheduling over storage device |
Also Published As
| Publication number | Publication date |
|---|---|
| US10203912B2 (en) | 2019-02-12 |
| CN106371888A (zh) | 2017-02-01 |
| US20170024132A1 (en) | 2017-01-26 |
| KR102371916B1 (ko) | 2022-03-07 |
| CN106371888B (zh) | 2022-03-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102371916B1 (ko) | 가상 머신을 지원하는 스토리지 장치, 그것을 포함하는 스토리지 시스템 및 그것의 동작 방법 | |
| Lee et al. | Asynchronous {I/O} stack: A low-latency kernel {I/O} stack for {Ultra-Low} latency {SSDs} | |
| US10191759B2 (en) | Apparatus and method for scheduling graphics processing unit workloads from virtual machines | |
| JP5583180B2 (ja) | 仮想gpu | |
| Kwak et al. | Cosmos+ openssd: Rapid prototype for flash storage systems | |
| US20200089537A1 (en) | Apparatus and method for bandwidth allocation and quality of service management in a storage device shared by multiple tenants | |
| US10248322B2 (en) | Memory system | |
| US20180150242A1 (en) | Controller and storage device for efficient buffer allocation, and operating method of the storage device | |
| US11747984B2 (en) | Memory system that constructs virtual storage regions for virtual machines | |
| US20160283116A1 (en) | Sequential write stream management | |
| US9727267B1 (en) | Power management and monitoring for storage devices | |
| KR20160096279A (ko) | 가상화 기능을 지원하는 스토리지 장치 및 사용자 장치 | |
| CA2911982A1 (en) | Resource allocation and deallocation for power management in devices | |
| Zhang et al. | Scalable parallel flash firmware for many-core architectures | |
| US10095432B2 (en) | Power management and monitoring for storage devices | |
| Chang et al. | VSSD: Performance isolation in a solid-state drive | |
| Min et al. | {eZNS}: An elastic zoned namespace for commodity {ZNS}{SSDs} | |
| JP7242170B2 (ja) | メモリープールを有するコンピューティングシステムのためのメモリー分割 | |
| Koh et al. | Faster than flash: An in-depth study of system challenges for emerging ultra-low latency SSDs | |
| Liu et al. | Fair-zns: Enhancing fairness in zns ssds through self-balancing I/O scheduling | |
| KR20210017054A (ko) | 멀티-코어 시스템 및 그 동작 제어 방법 | |
| Kim et al. | FAST I/O: QoS supports for urgent I/Os in NVMe SSDs | |
| KR20210007417A (ko) | 멀티-코어 시스템 및 그 동작 제어 방법 | |
| Liao et al. | A novel memory allocation scheme for memory energy reduction in virtualization environment | |
| KR20160119513A (ko) | 데이터 저장 장치, 이를 포함하는 데이터 처리 시스템, 및 상기 시스템의 작동 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant |