KR20160115944A - 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들 - Google Patents
오디오 패스워드의 강도를 평가하는 시스템들 및 방법들 Download PDFInfo
- Publication number
- KR20160115944A KR20160115944A KR1020167023068A KR20167023068A KR20160115944A KR 20160115944 A KR20160115944 A KR 20160115944A KR 1020167023068 A KR1020167023068 A KR 1020167023068A KR 20167023068 A KR20167023068 A KR 20167023068A KR 20160115944 A KR20160115944 A KR 20160115944A
- Authority
- KR
- South Korea
- Prior art keywords
- password
- audio
- electronic device
- strength
- user
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 114
- 230000005236 sound signal Effects 0.000 claims abstract description 160
- 238000011156 evaluation Methods 0.000 claims abstract description 65
- 238000004590 computer program Methods 0.000 claims description 5
- 230000000593 degrading effect Effects 0.000 claims description 2
- 238000004891 communication Methods 0.000 description 38
- 238000005259 measurement Methods 0.000 description 25
- 238000013459 approach Methods 0.000 description 18
- 238000012795 verification Methods 0.000 description 18
- 238000012549 training Methods 0.000 description 17
- 230000006870 function Effects 0.000 description 13
- 238000010586 diagram Methods 0.000 description 10
- 230000001419 dependent effect Effects 0.000 description 6
- 238000000605 extraction Methods 0.000 description 6
- 230000006978 adaptation Effects 0.000 description 5
- 238000013507 mapping Methods 0.000 description 5
- 239000013598 vector Substances 0.000 description 5
- 238000012935 Averaging Methods 0.000 description 4
- 208000030984 MIRAGE syndrome Diseases 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- TVLSRXXIMLFWEO-UHFFFAOYSA-N prochloraz Chemical compound C1=CN=CN1C(=O)N(CCC)CCOC1=C(Cl)C=C(Cl)C=C1Cl TVLSRXXIMLFWEO-UHFFFAOYSA-N 0.000 description 4
- 239000002131 composite material Substances 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000013528 artificial neural network Methods 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000001360 synchronised effect Effects 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000005401 electroluminescence Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 229920001690 polydopamine Polymers 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000003825 pressing Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 238000012706 support-vector machine Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/30—Authentication, i.e. establishing the identity or authorisation of security principals
- G06F21/31—User authentication
- G06F21/32—User authentication using biometric data, e.g. fingerprints, iris scans or voiceprints
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/30—Authentication, i.e. establishing the identity or authorisation of security principals
- G06F21/45—Structures or tools for the administration of authentication
- G06F21/46—Structures or tools for the administration of authentication by designing passwords or checking the strength of passwords
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Security & Cryptography (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Software Systems (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Telephone Function (AREA)
- Collating Specific Patterns (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
전자 디바이스에 의해 오디오 패스워드의 강도를 평가하는 방법이 설명된다. 방법은, 하나 이상의 마이크로폰들에 의해 캡처된 오디오 신호를 획득하는 단계를 포함한다. 오디오 신호는 오디오 패스워드를 포함한다. 방법은, 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가하는 단계를 또한 포함한다. 방법은, 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지하는 단계를 더 포함한다.
Description
본 개시는 일반적으로 전자 디바이스들에 관한 것이다. 더욱 구체적으로, 본 개시는 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들에 관한 것이다.
최근 수십 년간, 전자 디바이스들의 사용이 일반화되었다. 특히, 전자 기술의 진보들은 더욱더 복잡하고 유용한 전자 디바이스들의 비용을 감소시켰다. 비용 감소 및 소비자 요구가 전자 디바이스들의 사용을 만연시켜서, 전자 디바이스들은 현대 사회에서 실질적으로 유비쿼터스하다. 전자 디바이스들의 사용이 확장함에 따라, 전자 디바이스들의 신규하고 향상된 특징들에 대한 요구를 갖게 된다. 더욱 구체적으로, 신규한 기능들을 수행하고 그리고/또는 기능들을 더 빠르고, 더욱 효율적으로 또는 더 높은 품질로 수행하는 전자 디바이스들이 종종 추구된다.
일부 전자 디바이스들 (예를 들어, 셀룰러 폰들, 스마트폰들, 오디오 리코더들, 캠코더들, 컴퓨터들 등) 이 오디오 신호들을 활용한다. 이들 전자 디바이스들은 오디오 신호들을 캡처하고, 인코딩하고, 저장하고, 그리고/또는 송신할 수도 있다. 예를 들어, 스마트폰은 폰 호출을 위한 스피치 신호를 획득하고, 인코딩하며, 송신할 수도 있는 반면에, 다른 스마트폰은 그 스피치 신호를 수신하고 디코딩할 수도 있다.
그러나, 보안 목적을 위해 오디오 신호들을 활용하는 전자 디바이스들에 대해 특정한 도전과제들이 발생할 수도 있다. 예를 들어, 다수의 오디오 신호들은 전자 디바이스 액세스를 적절히 보안하는데 불충분할 수도 있다. 이러한 논의로부터 알 수 있는 바와 같이, 보안성을 향상시킨 시스템들 및 방법들이 유익할 수도 있다.
전자 디바이스에 의해 오디오 패스워드의 강도를 평가하는 방법이 설명된다. 방법은, 하나 이상의 마이크로폰들에 의해 캡처된 오디오 신호를 획득하는 단계를 포함한다. 오디오 신호는 오디오 패스워드를 포함한다. 방법은, 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가하는 단계를 또한 포함한다. 방법은, 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지하는 단계를 더 포함한다. 오디오 신호는 적어도 하나의 스피치 컴포넌트를 포함할 수도 있다. 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것은 일반 스피치 모델에 기초할 수도 있다.
사용자에게 통지하는 단계는, 오디오 패스워드의 강도와 연관된 라벨을 디스플레이하는 단계를 포함할 수도 있다. 사용자에게 통지하는 단계는 패스워드 강도 스코어를 디스플레이하는 단계를 포함할 수도 있다. 사용자에게 통지하는 단계는 적어도 하나의 후보 스피치 컴포넌트를 디스플레이하는 단계를 포함할 수도 있다.
방법은 패스워드 강도 스코어를 다른 값과 비교하는 단계를 포함할 수도 있다. 다른 값은 임계치 또는 이전 패스워드 강도 스코어일 수도 있다.
방법은 적어도 하나의 추가 인증 입력을 획득하는 단계를 포함할 수도 있다. 방법은 오디오 신호 및 추가 인증 입력 중 적어도 하나를 저하시키는 단계를 포함할 수도 있다. 방법은 지리적 위치, 사용자 나이, 사용자 성 (gender), 사용자 언어, 및 지역 방언 중 하나 이상에 기초하여 일반 스피치 모델을 업데이트하는 단계를 포함할 수도 있다.
오디오 패스워드의 강도를 평가하는 전자 디바이스가 또한 설명된다. 전자 디바이스는 오디오 신호를 캡처하는 하나 이상의 마이크로폰들을 포함한다. 오디오 신호는 오디오 패스워드를 포함한다. 전자 디바이스는 하나 이상의 마이크로폰들에 결합된 패스워드 평가 회로를 또한 포함한다. 패스워드 평가 회로는, 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가한다. 전자 디바이스는 패스워드 평가 회로에 결합된 패스워드 피드백 회로를 더 포함한다. 패스워드 피드백 회로는, 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지한다.
오디오 패스워드의 강도를 평가하는 컴퓨터 프로그램 제품이 또한 설명된다. 컴퓨터 프로그램 제품은 명령들을 갖는 비일시적인 유형의 컴퓨터 판독가능 매체를 포함한다. 명령들은 전자 디바이스로 하여금, 하나 이상의 마이크로폰들에 의해 캡처된 오디오 신호를 획득하게 하는 코드를 포함한다. 오디오 신호는 오디오 패스워드를 포함한다. 명령들은 전자 디바이스로 하여금, 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가하게 하는 코드를 또한 포함한다. 명령들은 전자 디바이스로 하여금, 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지하게 하는 코드를 더 포함한다.
오디오 패스워드의 강도를 평가하는 장치가 또한 설명된다. 장치는 오디오 신호를 획득하는 수단을 포함한다. 오디오 신호는 오디오 패스워드를 포함한다. 장치는, 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가하는 수단을 또한 포함한다. 장치는, 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지하는 수단을 더 포함한다.
도 1 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스의 일 구성을 예시하는 블록도이다.
도 2 는 오디오 패스워드의 강도를 평가하는 방법의 일 구성을 예시하는 흐름도이다.
도 3 은 고유성 측정치의 예를 예시하는 그래프들을 포함한다.
도 4 는 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스의 더 구체적인 구성을 예시하는 블록도이다.
도 5 는 오디오 패스워드의 강도를 평가하는 방법의 더 구체적인 구성을 예시하는 흐름도이다.
도 6 은 오디오 패스워드의 강도를 평가하는 방법의 다른 더 구체적인 구성을 예시하는 흐름도이다.
도 7 은 오디오 패스워드의 강도를 평가하는 방법의 다른 더 구체적인 구성을 예시하는 흐름도이다.
도 8 은 오디오 패스워드의 강도를 평가하는 방법의 다른 더 구체적인 구성을 예시하는 흐름도이다.
도 9 는 화자 (예를 들어, 사용자) 인식 모델들의 일례를 예시하는 블록도이다.
도 10 은 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 방법의 일 구성을 예시하는 흐름도이다.
도 11 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스의 다른 더 구체적인 구성을 예시하는 블록도이다.
도 12 는 오디오 패스워드의 강도를 평가하는 방법의 더 구체적인 구성을 예시하는 흐름도이다.
도 13 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 무선 통신 디바이스의 일 구성을 예시하는 블록도이다.
도 14 는 전자 디바이스에서 활용될 수도 있는 다양한 컴포넌트들을 예시한다.
도 2 는 오디오 패스워드의 강도를 평가하는 방법의 일 구성을 예시하는 흐름도이다.
도 3 은 고유성 측정치의 예를 예시하는 그래프들을 포함한다.
도 4 는 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스의 더 구체적인 구성을 예시하는 블록도이다.
도 5 는 오디오 패스워드의 강도를 평가하는 방법의 더 구체적인 구성을 예시하는 흐름도이다.
도 6 은 오디오 패스워드의 강도를 평가하는 방법의 다른 더 구체적인 구성을 예시하는 흐름도이다.
도 7 은 오디오 패스워드의 강도를 평가하는 방법의 다른 더 구체적인 구성을 예시하는 흐름도이다.
도 8 은 오디오 패스워드의 강도를 평가하는 방법의 다른 더 구체적인 구성을 예시하는 흐름도이다.
도 9 는 화자 (예를 들어, 사용자) 인식 모델들의 일례를 예시하는 블록도이다.
도 10 은 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 방법의 일 구성을 예시하는 흐름도이다.
도 11 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스의 다른 더 구체적인 구성을 예시하는 블록도이다.
도 12 는 오디오 패스워드의 강도를 평가하는 방법의 더 구체적인 구성을 예시하는 흐름도이다.
도 13 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 무선 통신 디바이스의 일 구성을 예시하는 블록도이다.
도 14 는 전자 디바이스에서 활용될 수도 있는 다양한 컴포넌트들을 예시한다.
본 명세서에 개시된 시스템들 및 방법들의 일부 구성들은 스피치-기반 생체 (biometric) 인증을 위한 패스워드 강도 평가 및 제안을 제공한다. 인증을 위해 음성을 사용할 때, 사용자는 발음하여 (utter) 패스워드를 설정하기를 원할 수도 있다. 그러나, 동일한 패스워드가 발음되는 것이 발생될 때 누군지 다른 사람이 시스템을 중단할 수 없도록 패스워드가 음성 음색에 관하여 충분히 고유한지를 아는 것은 어려울 수도 있다. 이것은 발음된 패스워드가 사용자 자신의 독특한 생체 구별을 포함하는 경우에 임의로 설정된 패스워드 보다는 훨씬 양호하다. 추가의 수단들이 이용가능한 경우에, 이들은 보안성을 강화시키기 위해 적절하게 활용될 수도 있다.
본 명세서에 개시된 시스템들 및 방법들은, 사용자가 충분히 고유한 패스워드를 선택할 수도 있도록 "고유성"의 강도를 평가하는 접근방식을 제공할 수도 있다. 일부 구성들에서, 본 명세서에 개시된 시스템들 및 방법들은 사용자의 강화된 고유성을 보존하는 발음 (utterance) 들을 사용하여 일부 후보들을 제안할 수도 있다. 본 명세서에 개시된 시스템들 및 방법들은 사용자의 자신의 강화된 고유성을 보존하는 발음들을 사용할 뿐만 아니라 일부 구성들에서 하나 이상의 다른 가용 양식들 (modalities) 을 레버리징함으로써 일부 후보들을 제안할 수도 있다.
일부 화자 검증 시스템들은, 화자 데이터를 유니버셜 배경 모델 (UBM) 에 적응시킴으로써 화자 모델들을 트레이닝한다. 검증의 단계에서, 화자 모델들과 UBM 사이의 관측된 프레임들의 우도비가 산출될 수도 있다. 전체 발음/문장 프레임들에 걸친 요약 통계가, 스피치 프레임들이 참 (true) 화자로부터인지를 결정하기 위해 계산될 수도 있다. 그러나, 발음/음소/음절 당 또는 심지어 프레임 당 "로컬" 우도는, 일부가 높은 구별을 갖지만, 일부는 갖지 않는다는 것을 나타낸다. 많은 구별을 갖지 않은 부분은, 다른 모델들로부터 또한 설명된 부분으로서 해석될 수도 있으며, 이는 검증 성능을 손상시킨다는 것을 의미한다. 또는, 이것은 타겟 모델에 의해 보이지 않는 데이터 (unseen data) 로서 설명될 수도 있고, 이것은 사용자에 의해 반복되는 것이 어려울 수도 있다는 것을 의미한다. 이에 따라, 충분히 강하고 용이하게 재생가능한 패스워드를 갖는 것이 유익할 수도 있다.
이제, 동일한 참조 부호들이 기능적으로 유사한 엘리먼트들을 나타낼 수도 있는 도면들을 참조하여 다양한 구성들이 설명된다. 본 명세서의 도면들에 일반적으로 설명하고 예시된 바와 같은 시스템들 및 방법들은 매우 다양한 상이한 구성들로 배열되고 설계될 수 있다. 따라서, 도면들에 표현된 바와 같은, 여러 구성들의 아래의 더욱 상세한 설명은, 청구하는 바와 같이 범위를 한정하려는 의도가 아니라, 시스템들 및 방법들을 단지 나타낸다.
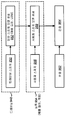
도 1 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스 (102) 의 일 구성을 예시하는 블록도이다. 전자 디바이스 (102) 의 예들은, 스마트폰들, 셀룰러 폰들, 태블릿 디바이스들, 컴퓨터들 (예를 들어, 랩탑 컴퓨터들, 데스크탑 컴퓨터들 등), 게임 시스템들, 전자 자동 콘솔들, 휴대 정보 단말기들 (PDA들) 등을 포함한다.
전자 디바이스 (102) 는 하나 이상의 마이크로폰들 (104), 패스워드 평가 모듈 (108), 패스워드 피드백 모듈 (112), 및 하나 이상의 출력 디바이스들 (116) 을 포함한다. 마이크로폰(들) (104) 은 음향 신호들을 전자 신호들로 변환하는 하나 이상의 트랜스듀서들일 수도 있다. 하나 이상의 출력 디바이스들 (116) 은 전자 디바이스 (102) 로부터의 출력을 제공하는 디바이스들일 수도 있다. 하나 이상의 출력 디바이스들 (116) 의 예들은, 디스플레이들 (예를 들어, 디스플레이 패널들, 터치스크린들), 스피커들 (예를 들어, 전자 신호들을 음향 신호들로 변환하는 트랜스듀서들), 햅틱 디바이스들 (예를 들어, 힘, 모션 및/또는 진동을 생성하는 디바이스들) 등을 포함한다. "모듈" 은 하드웨어 (예를 들어, 회로) 또는 하드웨어와 소프트웨어의 조합 (예를 들어, 명령들을 갖는 프로세서들) 으로 구현될 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 및/또는 패스워드 피드백 모듈 (112) 은 하드웨어 또는 하드웨어와 소프트웨어의 조합으로 구현될 수도 있다.
하나 이상의 마이크로폰들 (104) 은 패스워드 평가 모듈 (108) 에 결합될 수도 있다. 패스워드 평가 모듈 (108) 은 패스워드 피드백 모듈 (112) 에 결합될 수도 있다. 패스워드 피드백 모듈 (112) 은 하나 이상의 출력 디바이스들 (116) 에 결합될 수도 있다. 본 명세서에서 사용되는 바와 같이, 용어 "결합" 및 관련 용어들은, 하나의 컴포넌트가 다른 컴포넌트에 직접적으로 연결 (예를 들어, 개재 컴포넌트들 없이) 되거나 간접적으로 연결 (예를 들어, 하나 이상의 개재 컴포넌트들로) 되는 것을 의미할 수도 있다. 도면들에 도시된 화살표들 및/또는 라인들은 결합들을 표기할 수도 있다.
하나 이상의 마이크로폰들 (104) 은 오디오 신호 (106) 를 캡처할 수도 있다. 예를 들어, 하나 이상의 마이크로폰들 (104) 은 음향 신호를 캡처하여, 그 음향 신호를 전자 오디오 신호 (106) 로 변환할 수도 있다. 오디오 신호 (106) 는 오디오 패스워드를 포함할 수도 있다. 오디오 패스워드는 사용자의 아이덴티티를 검증하는 하나 이상의 사운드들 (예를 들어, 음소들, 음절들, 단어들, 어구들, 문장들, 발음들 등과 같은 하나 이상의 스피치 컴포넌트들) 을 포함할 수도 있다. 예를 들어, 오디오 패스워드는 사용자를 식별하기 위해 사용될 수도 있는 하나 이상의 특징들 (예를 들어, 생체 특징들, 음색 등) 을 포함할 수도 있다. 오디오 신호 (106) 는 패스워드 평가 모듈 (108) 에 제공될 수도 있다.
패스워드 평가 모듈 (108) 은 하나 이상의 마이크로폰들 (104) 에 의해 캡처된 오디오 신호 (106) 를 획득 (예를 들어, 수신) 할 수도 있다. 상술한 바와 같이, 오디오 신호 (106) 는 오디오 패스워드를 포함할 수도 있다. 패스워드 평가 모듈 (108) 은, 오디오 신호 (106) 의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가할 수도 있다. 패스워드 "강도" 는 패스워드가 얼마나 안전한지를 나타내는 특성일 수도 있다. 예를 들어, 강한 오디오 패스워드 (예를 들어, 높은 강도를 갖는 오디오 패스워드) 는, 사기꾼이 참 사용자로서 부정확하게 식별되는 경우에, 사기꾼이 본질적으로 모방하거나 복제하는 것이 매우 어렵거나 거의 불가능할 수도 있다. 그러나, 약한 오디오 패스워드 (예를 들어, 낮은 강도를 갖는 오디오 패스워드) 는, 사기꾼이 참 사용자로서 부정확하게 식별되는 경우에, 사기꾼이 본질적으로 모방하거나 복제하는 것이 더 용이할 수도 있다. 일부 구성들에서, 오디오 패스워드 강도는 고유성 면에서 표현될 수도 있다. 예를 들어, 오디오 패스워드의 하나 이상의 스피치 컴포넌트들이 더욱 고유할수록, 패스워드는 더 강하다. 그러나, 오디오 패스워드의 하나 이상의 스피치 컴포넌트들이 덜 고유할수록, 패스워드는 더 약하다. 이에 따라, 오디오 패스워드 강도는 정량화될 수도 있으며 약한 정도로부터 강한 정도까지의 범위일 수도 있다. 예를 들어, 더욱 고유한 스피치 컴포넌트들이 덜 고유한 스피치 컴포넌트들 보다 더욱 높게 (예를 들어, 더욱 강하게) 스코어링될 수도 있다.
일부 구성들에서, 패스워드 평가 모듈 (108) 은 하나 이상의 일반 스피치 모델들 (예를 들어, UBM) 로부터의 고유성 또는 구별성의 정도를 갖는 오디오 패스워드의 하나 이상의 스피치 컴포넌트들 (예를 들어, 발음들, 음소들 등) 의 강도를 평가할 수도 있다. 일반 스피치 모델은 사람들의 그룹의 스피치를 나타내는 스피치 모델 (예를 들어, 통계적 스피치 모델) 일 수도 있다. 하나 이상의 UBM들이 일반 스피치 모델의 예들이다.
일부 구성들에서, 패스워드 평가 모듈 (108) 은 다중의 일반 스피치 모델들 (예를 들어, UBM들) 을 활용할 수도 있다. 예를 들어, 다중의 일반 스피치 모델들은 지리적 위치 (예를 들어, 우편 번호, 도시, 군, 주, 나라 등), 성, 나이, 언어, 지역 방언 등과 같은 사용자의 입력 및/또는 특징들에 기초하여 활용 (예를 들어, 선택 및/또는 적응 등) 될 수도 있다. 사용자의 특징들은 사용자의 스피치의 음향 특징들에 영향을 미칠 수도 있다. 일부 구성들에서, 사용자 제공 정보가 저장된 일반 스피치 모델(들)과 매칭되지 않으면, 전자 디바이스 (102) 는 사용자의 확인응답 하에서 사용자 및/또는 적절한 모델이 대신 사용될 수도 있다는 것을 통지할 수도 있다. 고유성을 측정하기 위해 더욱 구체적으로 매칭된 일반 스피치 모델들 (예를 들어, UBM들) 을 사용함으로써, 전자 디바이스 (102) (예를 들어, 패스워드 평가 모듈 (108)) 는 더욱 정확한 고유성 측정치들 및/또는 스코어들을 제공할 수도 있다. 일부 구성들에서, 전자 디바이스 (102) (예를 들어, 패스워드 평가 모듈 (108)) 은 참여하는 하나 이상의 사용자의 데이터에 기초하여 대응하는 일반 스피치 모델(들) (예를 들어, UBM들) 을 업데이트할 수도 있다.
패스워드 평가 모듈 (108) 은, 일부 구성들에서, 아래와 같이 오디오 신호 (106) 의 하나 이상의 특징들 (예를 들어, 고유 특징들) 을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가할 수도 있다. 패스워드 평가 모듈 (108) 은 오디오 신호 (106) 로부터 하나 이상의 특징들 (예를 들어, 특징 벡터들) 을 추출할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 오디오 신호 (106) 에 기초하여 하나 이상의 MFCC (Mel-Frequency Cepstral Coefficients) 를 결정할 수도 있다. 일부 구성들에서, MFCC들은 오디오 신호 (106) 의 mel-주파수 평활화된 스펙트럼의 로그 크기에 이산 코사인 변환 (DCT) 을 적용함으로써 획득된 계수들일 수도 있다. 본 명세서에 개시된 시스템들 및 방법들에 따르면, 화자/스피치 인식을 위해 활용될 수 있는 임의의 또는 모든 특징들이 사용을 위해 추출될 수도 있다. MFCC들은, 이들이 이러한 애플리케이션들에서 사용된 관련 특징 벡터일 수도 있기 때문에 예로서 제공된다. 일부 구성들에서, 본 명세서에 개시된 시스템들 및 방법들에 따라 추출되고 그리고/또는 활용된 특징(들)은 (데이터에 관계없이, 예를 들어, 특징(들)이 획득되는 방식이 고정될 수도 있는 것을 의미하는) 결정론적 특징들에 한정되지 않을 수도 있다. 예를 들어, 특징 벡터들은 일부 접근방식들에서 심층 신경 네트워크들과 같은 데이터-구동 방법들을 사용하여 추출 (예를 들어, 학습) 될 수도 있다.
패스워드 평가 모듈 (108) 은 하나 이상의 일반 스피치 모델들 (예를 들어, UBM들) 에 기초하여 오디오 신호 (106) 의 고유성 측정치를 획득할 수도 있다. 고유성 측정치는 오디오 신호 (106) (예를 들어, 오디오 패스워드) 에 걸친 고유성을 나타낼 수도 있다. 예를 들어, 고유성 측정치는 오디오 신호 (106) (예를 들어, 오디오 패스워드) 의 시간 주기에 걸쳐 변할 수도 있다. 일부 구성들에서, 고유성 측정치는 각각의 스피치 컴포넌트 (예를 들어, 음소, 음절, 단어 등) 및/또는 오디오 신호 (106) (예를 들어, 오디오 패스워드) 의 프레임에 걸쳐 획득될 수도 있다. 일부 구성들에서, 오디오 신호 (106) (예를 들어, 입력파) 는 고유성 측정치 및/또는 패스워드 강도 스코어를 획득하기 위해 활용될 수도 있는 특징 벡터들 (예를 들어, MFCC들) 로 변환될 수도 있다.
일부 구성들에서, 고유성 측정치는 오디오 신호 (106) 와 일반 스피치 모델(들) 사이의 우도비일 수도 있다. 예를 들어, 우도비는 수학식 (1) 에 따라 결정될 수도 있다.

수학식 (1) 에서, t 는 시간이고, X 는 오디오 신호 (또는 예를 들어, 오디오 신호에 기초한 특징 벡터(들)) 이고,  는 타겟 (예를 들어, 참 사용자) 모델이고,
는 타겟 (예를 들어, 참 사용자) 모델이고,  는 일반 스피치 모델(들) (예를 들어, UBM(들)) 이고,
는 일반 스피치 모델(들) (예를 들어, UBM(들)) 이고,  는 X 가 참 사용자에게 대응하는 확률이며,
는 X 가 참 사용자에게 대응하는 확률이며,  는 X 가 일반 사용자 (예를 들어, 사기꾼, 참이 아닌 사용자 등) 에 대응하는 확률이다. 일반항 (예를 들어,
는 X 가 일반 사용자 (예를 들어, 사기꾼, 참이 아닌 사용자 등) 에 대응하는 확률이다. 일반항 (예를 들어,  ) 은 사기꾼 및/또는 참이 아닌 사용자 등의 모델일 수도 있다. 사기꾼 및/또는 참이 아닌 사용자의 모델은 실제 사용자 모델들을 비교하기 위해 활용될 수도 있다. 실제 사용자 모델들을 비교하는 것은, 계산 집중적이고 그리고/또는 소모적일 수도 있어서, 일부 계층이 탐색 범위 (예를 들어, 성, 나이, 위치 등) 를 정의하기 위해 활용될 수도 있다. 추가로 또는 대안으로, 일반항 (예를 들어,
) 은 사기꾼 및/또는 참이 아닌 사용자 등의 모델일 수도 있다. 사기꾼 및/또는 참이 아닌 사용자의 모델은 실제 사용자 모델들을 비교하기 위해 활용될 수도 있다. 실제 사용자 모델들을 비교하는 것은, 계산 집중적이고 그리고/또는 소모적일 수도 있어서, 일부 계층이 탐색 범위 (예를 들어, 성, 나이, 위치 등) 를 정의하기 위해 활용될 수도 있다. 추가로 또는 대안으로, 일반항 (예를 들어,  ) 은 비사용자 의존 모델 (예를 들어, 일반 화자 모델) 일 수도 있다. 비사용자 의존 모델은 비교를 단순화하기 위해 활용될 수도 있고, 여기서, 하나의 모델만이 비교를 위해 필요할 수도 있다. 전자 디바이스 (102) 에서 그리고/또는 원격 디바이스 (예를 들어, 원격 서버) 에서 일반항 (예를 들어,
) 은 비사용자 의존 모델 (예를 들어, 일반 화자 모델) 일 수도 있다. 비사용자 의존 모델은 비교를 단순화하기 위해 활용될 수도 있고, 여기서, 하나의 모델만이 비교를 위해 필요할 수도 있다. 전자 디바이스 (102) 에서 그리고/또는 원격 디바이스 (예를 들어, 원격 서버) 에서 일반항 (예를 들어,  ) 이 (예를 들어, 필요한 경우에) 업데이트될 수도 있다는 것에 유의해야 한다. 일부 예들에서, 일반 모델은 하나 이상의 파라미터들 (예를 들어, 평균 및/또는 믹싱 가중치들) 을 업데이트함으로써 업데이트될 수도 있다. 업데이트하는 것은, 주기적으로 (예를 들어, 정규적으로) 그리고/또는 비주기적으로 (예를 들어, 요구시에, 업데이트 결정에 기초하여, 등) 수행될 수도 있다.
) 이 (예를 들어, 필요한 경우에) 업데이트될 수도 있다는 것에 유의해야 한다. 일부 예들에서, 일반 모델은 하나 이상의 파라미터들 (예를 들어, 평균 및/또는 믹싱 가중치들) 을 업데이트함으로써 업데이트될 수도 있다. 업데이트하는 것은, 주기적으로 (예를 들어, 정규적으로) 그리고/또는 비주기적으로 (예를 들어, 요구시에, 업데이트 결정에 기초하여, 등) 수행될 수도 있다.
다른 구성들에서, 고유성 측정치 (예를 들어, 우도비) 는 임의의 감소하지 않는 함수 (f) 로서 일반화될 수도 있다. 예를 들어, 고유성 측정치는 수학식 (2) 에 따라 결정될 수도 있다.

일부 구성들에서, 일반 스피치 모델은 아래와 같이 획득되고 그리고/또는 업데이트될 수도 있다. 일반 스피치 모델은 (예를 들어, 참 사용자 이외의) 다른 사용자들의 스피치를 모델링할 수도 있다. 일부 구성들에서, 일반 스피치 모델은 다른 사용자들의 "상시 적응 모델 (always adapting model)" 일 수도 있다. 추가로 또는 대안으로, 오디오 신호 (106) (예를 들어, 오디오 패스워드) 는, 다른 사용자들의 모델들이 (예를 들어, 동일한 원격 서버를 갖는) 동일한 시스템을 사용하는 경우에, 다른 사용자들의 모델들에 대해 (예를 들어, 전자 디바이스 (102) 또는 원격 디바이스에 의해) 비교될 수도 있다. 이것은 일부 구성들에서 UBM 에 대해 오디오 신호 (106) 를 비교하는 대신에 수행될 수도 있다.
복잡성이 탐색 범위를 좁힘으로써 줄어들 수도 있더라도, 복잡성은 이러한 접근방식이 갖는 하나의 문제일 수도 있다. 예를 들어, 성, 나이, 지역 방언들 포함하는 언어 등과 같은 기본 정보 검색이 먼저 수행될 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (102) 또는 원격 디바이스 (예를 들어, 서버) 는 사용자의 거주의 물리적 지역 또는 그것의 일부 이력의 로케이팅을 시도할 수도 있다. 그 후, 오디오 신호 (106) (예를 들어, 오디오 패스워드) 는 고정된 또는 동적으로 변화할 수도 있는 (예를 들어, 성, 나이, 언어, 지역 방언, 물리적 지역 등의) 동일한 카테고리를 갖는 다른 사람들에 대한 실제 모델들의 훨씬 더 작은 세트와 비교될 수도 있다. 전자 디바이스 (102) 는 (예를 들어, 거주 지역 또는 말하는 언어 등에 따라) 동적으로 패스워드에 대한 상이한 제안들을 (사용자에게) 제공할 수도 있다.
일부 구성들에서, 일반 스피치 모델은 다중의 모델들에 기초할 수도 있다. 예를 들어, 일반 스피치 모델은, 원래의 단일 UBM으로부터 업데이트된 높은 우도를 갖는 가우시안 혼합 모델 (GMM) 상태들에 기초한 다중의 UBM들을 클러스터링하는 것에 기초할 수도 있다. 추가로 또는 대안으로, 일반 스피치 모델은 사용될 수도 있는 물리적 지역 (예를 들어, 샌디에고 92121) 에 기반한 그룹화에 기초할 수도 있으며, 사용자의 모델은 동일한 지역에서의 사람들에 대한 모델들과 비교될 수도 있다.
패스워드 평가 모듈 (108) 은 고유성 측정치에 기초하여 하나 이상의 패스워드 강도 스코어들을 결정할 수도 있다. 패스워드 강도 스코어(들)는 오디오 패스워드의 강도를 나타낼 수도 있다. 예를 들어, 패스워드 강도 스코어는 전체 오디오 패스워드의 강도의 표시일 수도 있다. 추가로 또는 대안으로, 하나 이상의 서브레벨 패스워드 강도 스코어들이 결정될 수도 있다. 일부 구성들에서, 패스워드 강도 스코어는 고유성 측정치의 요약 통계에 기초하여 결정될 수도 있다.
일부 구성들에서, 패스워드 강도 스코어는 고유성 측정치 자체일 수도 있다. 추가로 또는 대안으로, 패스워드 강도 스코어를 결정하는 것은, 고유성 측정치의 부분들을 조합하는 것 (예를 들어, 합산하는 것) 을 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 강도 스코어를 결정하는 것은, 수치값(들) (예를 들어, 퍼센티지), 단어(들) (예를 들어, "약한", "중간", "강한" 등) 및/또는 일부 다른 표시자(들) (예를 들어, 컬러, 형상 등) 에 고유성 측정치를 매핑하는 것, 고유성 측정치의 하나 이상의 부분들을 매핑하는 것 및/또는 하나 이상의 요약 통계들을 매핑하는 것을 포함할 수도 있다.
일부 구성들에서, 패스워드 강도 스코어는 고유성 측정치일 수도 있다. 예를 들어, 수학식 (1) 및/또는 수학식 (2) 는 패스워드 강도 스코어를 획득하기 위해 활용될 수도 있다. t 가 요약 통계의 길이를 결정할 수도 있다는 것에 유의해야 한다. 예를 들어, 일부 작은 상수 t (예를 들어, 프레임 길이) 는 고유성 측정치 (예를 들어, 연속 스코어) 를 획득하기 위해 활용될 수도 있다. 작은 상수 t 로 획득된 고유성 측정치의 일례가 도 3 과 관련하여 설명된다.
일부 구성들에서, 패스워드 강도 스코어를 결정하는 것은, 고유성 측정치의 부분들을 조합하는 것 (예를 들어, 합산하는 것, 평균화하는 것 등) 을 포함할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 패스워드 강도 스코어를 결정하기 위해 고유성 측정치의 특정한 주기에 걸쳐 조합 (예를 들어, 합산, 평균화 등) 할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 평활화된 스코어를 얻기 위해 전체 고유성 측정치 또는 고유성 측정치의 하나 이상의 충분히 긴 시간 프레임들을 사용할 수도 있다. 이 평활화된 스코어는 패스워드 강도 스코어의 일례일 수도 있다.
일부 구성들에서, t 가 충분히 긴 경우에, 패스워드 강도 스코어는 고유성 측정치의 부분들을 조합하지 않은 고유성 측정치 자체일 수도 있다. 그러나, 스피치 컴포넌트-레벨 (예를 들어, 음소-레벨) 고유성을 권장하고 그리고/또는 액세스하도록 활용될 수도 있는 (예를 들어, 음소 레벨에서) 하나 이상의 스피치 컴포넌트들에 대응하는 고유성 측정치의 부분들을 획득하는 것이 유익할 수도 있다. 그 후, 고유성 측정치의 이들 부분들은 전체 패스워드 강도 스코어를 결정하기 위해 조합될 수도 있다.
일부 구성들에서, 하나 이상의 서브레벨 패스워드 강도들이 획득될 수도 있다. 예를 들어, 서브레벨 패스워드 강도들 각각은 고유성 측정치의 부분들일 수도 있거나 그 부분들에 기초할 수도 있다. 이것은 고유성 측정치를 스피치-컴포넌트 (예를 들어, 음소) 레벨로 좁히는데 유용할 수도 있다. 추가로 또는 대안으로, 패스워드 평가 모듈 (108) 은 (예를 들어, 고유성 측정치 모두가 아닌) 고유성 측정치의 부분들을 조합 (예를 들어, 합산, 평균화 등) 함으로써 하나 이상의 서브레벨 패스워드 강도들을 획득할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 스피치 컴포넌트들에 각각 대응하는 고유성 측정치의 부분들을 조합할 수도 있다. 일 접근방식에서, 패스워드 평가 모듈 (108) 은 더 큰 세트 (예를 들어, 단어, 어구, 문장 등) 내의 음소들에 대응하는 고유성 측정치의 부분들을 합산하고 그리고/또는 평균화할 수도 있다. 이러한 방식으로, 하나 이상의 더 높은 레벨 (예를 들어, 단어-레벨, 어구-레벨, 문장-레벨 등) 패스워드 강도 스코어들이 결정될 수도 있다.
일부 구성들에서, 패스워드 강도 스코어를 결정하는 것은, 패스워드 강도 스코어(들)를 수치값 (예를 들어, 10%, 43%, 65%, 90% 등), 단어 (예를 들어, "약한", "중간", "강한" 등) 및/또는 일부 다른 표시자 (예를 들어, 레드, 옐로우, 그린 등) 로서 표현하는 것 그리고/또는 패스워드 강도 스코어(들)를 수치값 (예를 들어, 10%, 43%, 65%, 90% 등), 단어 (예를 들어, "약한", "중간", "강한" 등) 및/또는 일부 다른 표시자 (예를 들어, 레드, 옐로우, 그린 등) 에 매핑하는 것을 포함할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 패스워드 강도 스코어를 결정하기 위해 고유성 측정치의 요약 통계 (및/또는 고유성 측정치의 부분들) 를 일부 팩터 (예를 들어, 100) 로 승산할 수도 있다. 추가로 또는 대안으로, 패스워드 평가 모듈 (108) 은 패스워드 강도 스코어를 결정하기 위해 고유성 측정치, 고유성 측정치의 부분들 및/또는 고유성 측정치의 요약 통계에 기초하여 특정한 수치값, 단어 및/또는 일부 다른 표시자를 선택 (예를 들어, 룩업) 할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 고유성 측정치에 기초한 패스워드 강도 스코어(들), 고유성 측정치의 하나 또는 부분들 및/또는 고유성 측정치에 기초한 하나 이상의 수량들 (예를 들어, 합들, 평균들, 통계들 등) 을 결정할 수도 있다. 이들 수량들 중 하나 이상은 패스워드 강도 스코어(들)를 결정하기 위해 하나 이상의 임계치들에 비교될 수도 있고 그리고/또는 패스워드 강도 스코어(들)는 이들 수량들 중 하나 이상에 기초하여 (예를 들어, 테이블에서) 룩업될 수도 있다.
일부 구성들에서, 패스워드 평가 모듈 (108) 은 (예를 들어, 임의의 확률에 따라, 사용자 선호도에 따라 그리고/또는 사기꾼이 오디오 패스워드를 발음함으로써 참 사용자로서 통과하는 것이 아주 가능성이 없을 만큼) 오디오 패스워드가 충분히 강한지를 결정할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 패스워드 강도 스코어를 값과 비교할 수도 있다. 예를 들어, 값은 이전의 패스워드 강도 스코어 및/또는 임계치일 수도 있다. 값은 정적 (예를 들어, 미리 결정됨) 이고 그리고/또는 동적일 수도 있다. 일부 구성들에서, 값은 제조자에 의해 설정되고 그리고/또는 사용자에 의해 구성될 수도 있다. 값은 수치값 (예를 들어, 60%, 80%, 90% 등) 및/또는 단어 (예를 들어, "중간", "강한" 등) 로서 표현될 수도 있다. 값은 패스워드 강도가 충분하거나 불충분한 것으로 여겨지는지를 서술하는 판정 포인트를 확립할 수도 있다.
일부 구성들에서, 패스워드 강도 스코어는 오디오 패스워드와 조합하여 하나 이상의 추가의 인증 입력들을 고려할 수도 있다. 예를 들어, 오디오 패스워드가 영숫자 코드 또는 지문 스캔과 함께 사용되는 경우에, 강도 스코어는 활용되는 경우에, 오디오 패스워드와 하나 이상의 추가의 인증 입력들의 조합에 의해 제공된 추가의 인증 강도를 반영할 수도 있다.
일부 구성들에서, 전자 디바이스 (102) (예를 들어, 패스워드 평가 모듈 (108)) 는 하나 이상의 추가의 인증 입력들을 수신할 수도 있다. 예를 들어, 일부 구성들은 비디오, 자이로/가속도계 센서들, 키보드들, 지문 센서 등과 같은 다른 양식들의 사용을 허용할 수도 있다. 일부 접근방식들에서, 하나 이상의 이러한 양식들은 작은 고유성 또는 구별 강도를 갖는 (어구, 문장 등의) 하나 이상의 부분들에 대해 활용될 수도 있다. 예를 들어, 사용자가 낮은 고유성을 갖는 단어 (예를 들어, 덜 특징적인 스코어를 갖는 "스쿨") 를 발음할 때, 전자 디바이스 (102) 는 하나 이상의 추가의 인증 입력들을 획득하거나 수신할 수도 있다.
하나 이상의 추가의 인증 입력들의 예들이 아래와 같이 제공된다. 전자 디바이스 (102) 가 제스처 인식을 갖는 구성들에서, 전자 디바이스 (102) 는 사용자에 의해 입력된 제스처 (예를 들어, 터치스크린 패턴, 터치패드 패턴, 카메라에 의해 캡처된 시각적 핸드 제스처 패턴 등) 를 수신할 수도 있다. 제스처는 사용자-생성되거나 사전정의될 수도 있다. 전자 디바이스 (102) 가 카메라를 포함하는 구성들에서, 전자 디바이스 (102) 는 오디오 신호 (106) 로 사용자의 얼굴, 눈, 코, 입술, 형상 및/또는 홍채와 같은 더욱 고유한 정보와 같은 사용자의 하나 이상의 이미지들을 캡처할 수도 있다. 예를 들어, 전자 디바이스 (102) 에 포함된 카메라는 사용자의 얼굴의 모두 또는 일부를 캡처하기 위해 (예를 들어, 사용자에 의해) 포인팅될 수도 있다.
전자 디바이스 (102) 가 하나 이상의 모션 및/또는 배향 센서들 (예를 들어, 자이로들, 가속도계들, 기울기 센서들 등) 을 포함하는 구성들에서, 전자 디바이스 (102) 는 모션 및/또는 배향 정보를 획득할 수도 있다. 예를 들어, 사용자는 전자 디바이스 (102) (예를 들어, 폰) 를 사용자-생성되거나 사전정의된 방식으로 배향하고 그리고/또는 이동시킬 수도 있다. 예를 들어, 전자 디바이스 (102) 는 오디오 신호 (106) 와 함께 자이로 및/또는 가속도계 센서 정보를 인코딩할 수도 있다.
전자 디바이스 (102) 가 물리적 또는 소프트웨어 키패드 또는 키보드를 포함하는 구성들에서, 전자 디바이스 (102) 는 오디오 신호 (106) 와 함께 (예를 들어, 사용자에 의해 타이핑된) 수치 코드, 텍스트 및/또는 영숫자 스트링을 수신할 수도 있다. 전자 디바이스 (102) 가 지문 센서를 포함하는 구성들에서, 전자 디바이스 (102) 는 (예를 들어, 사용자가 지문 센서를 터치하거나 홀딩할 때) 지문을 수신할 수도 있다.
전자 디바이스 (102) 가 다중의 마이크로폰들 (104) 을 포함하는 구성들에서, 전자 디바이스 (102) 는 오디오 신호 (106) 의 공간적 방향성 정보를 획득 (예를 들어, 수신 및/또는 결정) 할 수도 있다. 예를 들어, 사용자는 전자 디바이스 (102) 에 대해 방향들 (예를 들어, 위, 아래, 왼쪽, 오른쪽, 앞, 뒤, 오른쪽 위, 왼쪽 아래 등) 의 시퀀스로 오디오 패스워드를 발화할 수도 있다. 예를 들어, 사용자는 전자 디바이스 (102) 의 아래를 향해 제 1 단어를 말할 수도 있고, 전자 디바이스 (102) 의 위를 향해 제 2 단어를 말할 수도 있고, 전자 디바이스 (102) 의 왼쪽을 향해 제 3 단어를 말할 수도 있으며, 전자 디바이스 (102) 의 오른쪽을 향해 제 4 단어를 말할 수도 있다.
하나 이상의 추가의 인증 입력들은 타이밍 및/또는 시퀀스 제약들과 또는 타이밍 및/또는 시퀀스 제약들 없이 활용될 수도 있다. 일부 예들에서, 하나 이상의 추가의 인증 입력들은 오디오 신호 (106) 가 수신되기 이전에, 수신되는 동안, 또는 수신된 이후 임의의 시간에 전자 디바이스 (102) 에 의해 획득될 수도 있다.
다른 예들에서, 전자 디바이스 (102) 는 하나 이상의 추가의 인증 입력들이 특정한 타이밍 제약들로 그리고/또는 오디오 신호 (106) 의 수신에 대해 특정한 시퀀스로 수신되는 것을 요구할 수도 있다(또는 요구하도록 구성될 수도 있다). 일례에서, 전자 디바이스 (102) 는 하나 이상의 추가의 인증 입력들이 오디오 신호 (106) 가 수신되기 이전의, 수신되는 동안 그리고/또는 수신된 이후의 기간 내에 수신되는 것을 요구할 수도 있다(또는 요구하도록 구성될 수도 있다). 예를 들어, 전자 디바이스 (102) 는 추가의 인증 입력이 오디오 패스워드의 더 약한 스피치 컴포넌트 동안 수신되는 것을 요구할 수도 있다. 예를 들어, 오디오 패스워드 "오아시스 워즈 어 미라지 (oasis was a mirage)" 에 대해, 부분 "워즈 어 (was a)" 는 오디오 패스워드의 다른 부분 보다 덜 고유하거나 더 약할 수도 있다. 전자 디바이스 (102) 는 사용자가 "워즈 어" 를 발음하면서 추가의 인증 입력 (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간적 방향성 및/또는 (지문 스캔, 사용자의 얼굴 또는 홍채의 카메라 이미지 등과 같은) 추가의 생체특성) 이 수신되는 것을 요구할 수도 있다 (또는 요구하도록 구성될 수도 있다). 추가로 또는 대안으로, 전자 디바이스 (102) 는 추가의 인증 입력이 특정한 시퀀스로 (예를 들어, 스피치 컴포넌트 이전에, 스피치 컴포넌트 이후에, 스피치 컴포넌트들 사이에, 다른 추가의 인증 입력(들)과 시퀀스로 등) 수신되는 것을 요구할 수도 있다 (또는 요구하도록 구성될 수도 있다).
일부 구성들에서, 전자 디바이스 (102) (예를 들어, 패스워드 평가 모듈 (108)) 는 오디오 신호 (106) 및/또는 추가의 인증 입력을 저하시킬 수도 있다. 예를 들어, 전자 디바이스 (102) 는 오디오 신호 (106) 로부터 정보를 제거할 수도 있다 (예를 들어, 오디오 신호 (106) 의 하나 이상의 부분들을 다운샘플링하고, 필터링할 수도 있다). 추가로 또는 대안으로, 전자 디바이스 (102) 는 지문 스캔으로부터 또는 사용자의 얼굴 또는 홍채의 이미지로부터 정보를 제거할 수도 있다. 이러한 접근방식의 하나의 이점은, 사용자들이 그들의 보안성 또는 프라이버시 이유로 정확하거나 고품질의 정보 (예를 들어, 음성 샘플, 스캐닝된 지문, 이미지 등과 같은 정확하거나 고품질 생체 정보) 를 공유하기를 원하지 않을 수도 있다는 것이다. 추가로, 저하된 정보는 캡처된 정보의 단순화되거나 저하된 버전들일 수도 있다. 일부 구성들에서, 단일 양식 또는 입력 타입 (예를 들어, 음성 또는 스피치, 지문, 홍채 스캔 등) 자체의 저하된 정보는 신뢰가능한 사용자 식별을 위해 사용될 수 없다. 그러나, 다중의 양식들 또는 입력 타입들로부터의 저하된 정보의 조합은 강한 인증을 여전히 제공할 수도 있다. 따라서, 저하되지 않은 버전들이 높은 고유성 강도를 자체적으로 제공할 수도 있더라도, "홍채" 또는 "지문" 스캐닝도 음성 패스워드와 같은 추가의 양식을 활용할 수도 있다.
패스워드 평가 모듈 (108) 은 평가 정보 (110) 를 패스워드 피드백 모듈 (112) 에 제공할 수도 있다. 평가 정보 (110) 는 패스워드 강도를 나타내는 정보 및/또는 패스워드 평가에서 획득된 정보를 포함할 수도 있다. 예를 들어, 평가 정보 (110) 는 추출된 특징(들), 고유성 측정치, 패스워드 강도 스코어 및/또는 다른 정보를 포함할 수도 있다.
패스워드 피드백 모듈 (112) 은 패스워드 피드백 (114) 을 제공할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (112) 은, 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지할 수도 있다. 패스워드 피드백 (114) 을 제공하는 것은, 사용자가 충분하게 강한 오디오 패스워드를 결정 (예를 들어, 선택, 제공 또는 생성) 할 수 있게 할 수도 있다. 패스워드 피드백 (114) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 예를 들어, 패스워드 피드백 (114) 은, 오디오 패스워드가 약하다는 것을 나타내는 패스워드 강도 스코어 및 메시지를 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (114) 은 사용자가 더 강한 오디오 패스워드를 생성하기 위해 활용할 수도 있는 하나 이상의 제안된 스피치 컴포넌트들을 포함할 수도 있다. 일부 구성들에서, 전자 디바이스 (102) 는 패스워드 피드백 (114) 으로서 제안된 스피치 컴포넌트들로 이루어진 제안된 합성 (예를 들어, 미지의) 단어를 제공할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (114) 은 사용자가 추가의 인증 입력 (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간 방향성, 추가의 생체특징 (예를 들어, 얼굴 스캔, 홍채 스캔, 지문 등)) 을 제공할 수도 있는 제안된 액션을 포함할 수도 있다.
일부 구성들에서, 패스워드 피드백 모듈 (112) 은 하나 이상의 패스워드 제안들을 제공할 수도 있다. 예를 들어, 전자 디바이스 (102) (예를 들어, 패스워드 피드백 모듈 (112)) 은 충분히 높은 고유성 또는 하나 이상의 다른 모델들 (예를 들어, 일반 스피치 모델, 유니버셜 모델, UBM 등) 으로부터 구별성을 갖는 하나 이상의 스피치 컴포넌트들 (예를 들어, 발음들, 음소들 등) 을 식별할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (112) 은 한 쌍의 스피치 인식 및 화자 검증 시스템들을 통해 각각의 음소에 대한 사용자의 음성의 고유성에 기초하여 하나 이상의 스피치 컴포넌트들을 식별할 수도 있다. 그 후, 패스워드 피드백 모듈 (112) 은, 사용자가 하나 이상의 후보 스피치 컴포넌트들을 선택하여 패스워드를 생성할 수도 있도록, 높은 "고유성" 을 갖는 일부 가능한 후보 스피치 컴포넌트(들) (예를 들어, 음소들, 음절들, 발음들, 패스워드들 등) 를 생성할 수도 있다. 예를 들어, 전자 디바이스 (102) 는 "당신은 /아/, /크/,... , <트라이앵귤러>, <퀄컴>, ..., 을 사용할 수 있다" 와 같은 패스워드 피드백 (114) 을 디스플레이할 수도 있다. 추가로 또는 대안으로, 상세한 패스워드 피드백 (114) 이 사용자에 의해 발음된 패스워드를 더욱 강화시키기 위해 (예를 들어, "당신의 패스워드는 60% 강도를 갖는다. 발음 /에/ 가 /아/ 로 대체될 수도 있고, … .") 사용자에 의해 발음된 패스워드에 대해 제공될 수도 있다.
일부 구성들에서, 전자 디바이스 (102) (예를 들어, 패스워드 피드백 모듈 (112)) 는 멀티-양식을 갖는 패스워드 제안을 제공할 수도 있다. 상술한 바와 같이, 예를 들어, 패스워드 피드백 모듈 (112) 은 하나 이상의 추가의 인증 입력들 (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간 방향성, 추가의 생체특징 (예를 들어, 얼굴 스캔, 홍채 스캔, 지문 등)) 을 제안하는 패스워드 피드백 (114) 을 제공할 수도 있다.
일부 구성들에서, 패스워드 피드백 모듈 (112) 은 패스워드 피드백 (114) 을 생성하기 위해 아래의 동작들 중 하나 이상을 수행할 수도 있다. 패스워드 피드백 모듈 (112) 은 하나 이상의 추출된 특징들에 기초하여 스피치 인식을 수행할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (112) 은 하나 이상의 추출된 특징들에 기초하여 하나 이상의 인식된 스피치 컴포넌트들을 결정할 수도 있다. 입력에 기초한 시간 정렬을 갖는 음소들의 시퀀스를 제공하는 임의의 알려진 스피치 인식기가 하나 이상의 인식된 스피치 컴포넌트들을 결정하기 위해 활용될 수도 있다. 활용될 수도 있는 스피치 인식기의 일례가 Hidden Markov Model Toolkit (HTK) 이다.
패스워드 피드백 모듈 (112) 은 고유성 측정치와 하나 이상의 인식된 스피치 컴포넌트들을 정렬할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (112) 은 하나 이상의 인식된 스피치 컴포넌트들의 발생을 고유성 측정치와 시간에서 정렬할 수도 있다. 일부 구성들에서, 각각의 스피치 컴포넌트 (예를 들어, 음소) 경계에 대한 시간 정렬이 스피치 인식의 부산물들 중 하나이다. 특히, 패스워드 피드백 모듈 (112) 은 정렬된 스피치 및 고유성을 생성하기 위해 인식된 스피치 컴포넌트들 (예를 들어, 음소들) 에 대한 경계 정보 및 대응하는 기간들 동안 고유성 측정치를 활용할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (112) 은 스피치 인식에 의해 제공된 스피치 컴포넌트 경계들에 의해 표시된 바와 같은 스피치 컴포넌트 경계로서 고유성 측정치의 하나 이상의 시점들을 지정할 수도 있다.
패스워드 피드백 모듈 (112) 은 고유성 측정치에 기초하여 하나 이상의 스피치 컴포넌트들을 분류할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (112) 은 하나 이상의 스피치 컴포넌트들 각각의 고유성 (예를 들어, 강함 또는 약함) 을 결정할 수도 있다. 일부 구성들에서, 패스워드 피드백 모듈 (112) 은 정렬된 스피치 컴포넌트들 각각에서의 고유성 측정치 (또는 예를 들어, 평균, 최대, 최소 등과 같은 고유성 측정치에 기초한 일부 값) 를 하나 이상의 임계치들에 비교할 수도 있다. 스피치 컴포넌트에 대응하는 고유성 측정치 (또는 고유성 측정치에 기초한 값) 가 임계치 보다 큰 경우에, 대응하는 스피치 컴포넌트는 충분히 고유하거나 충분히 강한 것으로서 분류될 수도 있다. 일부 구성들에서, 충분히 고유하거나 충분히 강한 것으로서 분류되는 (예를 들어, 임계치 보다 큰) 스피치 컴포넌트(들)는 제안들로서 패스워드 피드백 (114) 에 제공될 수도 있다. 또한, 유사한 스피치 컴포넌트(들) 및/또는 스피치 컴포넌트 또는 유사한 스피치 컴포넌트들을 포함하는 발음(들), 단어(들), 어구(들) 및/또는 패스워드(들)가 제안들로서 패스워드 피드백 (114) 에 제공될 수도 있다.
패스워드 피드백 모듈 (112) 은 패스워드 피드백 (114) 을 하나 이상의 출력 디바이스들 (116) 에 제공할 수도 있다. 이에 따라, 하나 이상의 출력 디바이스들 (116) 은 패스워드 피드백 (114) 을 사용자에게 중계하거나 전달할 수도 있다. 예를 들어, 출력 디바이스(들) (116) (예를 들어, 디스플레이, 터치스크린, 스피커 등) 는 오디오 패스워드의 강도와 연관된 라벨을 중계할 수도 있다. 일 접근방식에서, 디스플레이 패널이 패스워드 강도 스코어를 디스플레이할 수도 있다. 추가로 또는 대안으로, 스피커는 패스워드 강도 스코어 (예를 들어, "당신의 패스워드가 약하다", "당신의 패스워드가 60% 강하다" 등) 를 나타내는 음향 신호 (예를 들어, 텍스트-스피치) 를 출력할 수도 있다.
일부 구성들에서, 출력 디바이스(들) (116) 는 하나 이상의 제안들을 중계할 수도 있다. 예를 들어, 디스플레이 패널은, 음소들, 음절들, 단어들, 발음들 및/또는 어구들 (예를 들어, "/아/, /에/, /크/, /트라이앵귤러/, /미라지/") 과 같은 하나 이상의 제안된 스피치 컴포넌트들을 디스플레이할 수도 있다. 추가로 또는 대안으로, 스피커는 하나 이상의 제안들 (예를 들어, "/아/, /에/, /크/, /트라이앵귤러/, /미라지/ 및/또는 추가의 입력 타입을 당신의 패스워드에 추가하세요") 을 중계하기 위해 음향 신호를 출력할 수도 있다.
일부 구성들에서, 패스워드 피드백 (114) 은 하나 이상의 그래픽 사용자 인터페이스들 (GUI들) 을 통해 제공될 수도 있다. 예를 들어, 라벨 (예를 들어, 패스워드 강도 스코어), 하나 이상의 제안들 및/또는 하나 이상의 메시지들이 GUI 상에 제공될 수도 있다. 일부 구성들에서, GUI 는 사용자 입력을 수신하는 인터페이스를 또한 제공할 수도 있다. 예를 들어, 사용자는 GUI 를 통해 하나 이상의 제안들 (예를 들어, 하나 이상의 후보 스피치 컴포넌트들, 합성 단어, 제안된 패스워드, 하나 이상의 추가의 인증 입력 옵션들 등) 을 선택할 수도 있다.
일부 구성들에서, 전자 디바이스 (102) 는 검증 모듈 (미도시) 을 포함할 수도 있다. 검증 모듈은 오디오 패스워드에 기초하여, 말하는 사용자가 참 사용자인지 여부를 검증할 수도 있다. 검증 절차가 패스워드 평가 절차와는 별개일 수도 있다는 것에 유의해야 한다. 예를 들어, 검증은 패스워드 (예를 들어, 오디오 패스워드 및/또는 하나 이상의 추가의 인증 입력들) 가 설정될 때까지는 발생하지 않을 수도 있다. 그에 따라, 본 명세서에 개시된 바와 같은 패스워드 평가 및 제안은 예를 들어, 패스워드가 설정된 이후에만 발생할 수도 있는 패스워드 검증과는 별개인 절차들을 포함할 수도 있다.
도 2 는 오디오 패스워드의 강도를 평가하는 방법 (200) 의 일 구성을 예시하는 흐름도이다. 도 1 과 관련하여 설명한 전자 디바이스 (102) 가 방법 (200) 을 수행할 수도 있다.
전자 디바이스 (102) 는 하나 이상의 마이크로폰들 (104) 에 의해 캡처된 오디오 신호 (106) 를 획득할 수도 있다 (202). 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 오디오 신호 (106) 는 오디오 패스워드를 포함할 수도 있다.
전자 디바이스 (102) 는, 오디오 신호 (106) 의 하나 이상의 특징들 (예를 들어, 고유 특징들) 을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가할 수도 있다 (204). 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (102) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM) 로부터의 고유성 또는 구별성의 정도를 갖는 오디오 패스워드의 하나 이상의 스피치 컴포넌트들 (예를 들어, 발음들, 음소들 등) 의 강도를 평가할 수도 있다 (204). 일부 구성들에서, 패스워드 평가 모듈 (108) 은 상술한 바와 같은 다중의 일반 스피치 모델들 (예를 들어, UBM들) 을 활용할 수도 있다. 예를 들어, 다중의 일반 스피치 모델들은 지리적 위치 (예를 들어, 우편 번호, 도시, 군, 주, 나라 등), 성, 나이, 언어, 지역 방언 등과 같은 사용자의 입력 및/또는 특징들에 기초하여 활용 (예를 들어, 선택 및/또는 적응 등) 될 수도 있다.
전자 디바이스 (102) 는, 일부 구성들에서, 아래와 같이 오디오 신호 (106) 의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가할 수도 있다 (204). 전자 디바이스 (102) 는 오디오 신호 (106) 로부터 하나 이상의 특징들을 추출할 수도 있다. 전자 디바이스 (102) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM들) 에 기초하여 오디오 신호 (106) 의 고유성 측정치를 획득할 수도 있다. 전자 디바이스 (102) 는 고유성 측정치에 기초하여 패스워드 강도 스코어를 결정할 수도 있다.
일부 구성들에서, 전자 디바이스 (102) 는 (예를 들어, 임의의 확률에 따라, 사용자 선호도에 따라 그리고/또는 사기꾼이 오디오 패스워드를 발음함으로써 참 사용자로서 통과하는 것이 아주 가능성이 없을 만큼) 오디오 패스워드가 충분히 강한지를 결정할 수도 있다. 예를 들어, 패스워드 평가 모듈 (108) 은 패스워드 강도 스코어를 값과 비교할 수도 있다. 값은 이전의 패스워드 강도 스코어 및/또는 임계치일 수도 있다.
전자 디바이스 (102) 는 패스워드 피드백 (114) 을 제공할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (102) 는 오디오 패스워드의 강도의 평가에 기초하여 (예를 들어, 패스워드 강도 스코어가 값 보다 크지 않을 때) 오디오 패스워드가 약하다는 것을 사용자에게 통지할 수도 있다 (206). 패스워드 피드백 (114) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 예를 들어, 패스워드 피드백 (114) 은, 오디오 패스워드가 약하다는 것을 나타내는 패스워드 강도 스코어 및 메시지를 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (114) 은 사용자가 더 강한 오디오 패스워드를 생성하기 위해 활용할 수도 있는 하나 이상의 제안된 스피치 컴포넌트들을 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (114) 은 사용자가 추가의 인증 입력 (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간 방향성, 추가의 생체특징 (예를 들어, 얼굴 스캔, 홍채 스캔, 지문 등)) 을 제공할 수도 있는 제안된 액션을 포함할 수도 있다.
패스워드 피드백 (114) 은 하나 이상의 출력 디바이스들 (116) 에 제공될 수도 있다. 그에 따라, 하나 이상의 출력 디바이스들 (116) 은, 도 1 과 관련하여 상술한 바와 같이, 패스워드 피드백 (114) (예를 들어, 라벨, 하나 이상의 제안된 스피치 컴포넌트들, 하나 이상의 제안된 액션들 등) 을 사용자에게 중계하거나 전달할 수도 있다.
전자 디바이스 (102) 는 사용자 입력을 옵션으로 검증할 수도 있다. 예를 들어, 전자 디바이스 (102) 는 패스워드 (예를 들어, 오디오 패스워드 및/또는 하나 이상의 추가의 인증 입력들) 가 설정된 이후에 사용자 입력을 수신할 수도 있다. 전자 디바이스 (102) 는 사용자 입력이 충분하게 (예를 들어, 충분히 높은 확률로) 패스워드에 매칭하는지를 결정할 수도 있다. 오디오 패스워드 검증에 대한 하나의 접근방식이 도 9 와 관련하여 제공된다. 사용자 입력이 충분히 (예를 들어, 임계 확률로 그리고/또는 추가의 인증 입력(들)에 대한 하나 이상의 추가의 기준에 따라) 패스워드에 매칭하면, 전자 디바이스 (102)는 액세스를 승인할 수도 있다. 예를 들어, 전자 디바이스는 사용자 입력이 충분히 패스워드에 매칭하면 하나 이상의 기능들 (예를 들어, 애플리케이션들, 호출 등) 에 대한 사용자 액세스를 허용할 수도 있다.
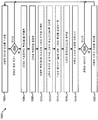
도 3 은 고유성 측정치의 예를 예시하는 그래프들을 포함한다. 특히, 도 3 은 그래프 A (318a), 그래프 B (318b) 및 그래프 C (318c) 를 포함한다. 그래프 A (318a) 의 수직축은 mel-주파수 스케일로 예시되고, 그래프 A (318a) 의 수평축은 시간 (프레임들) 으로 예시된다. 그래프 B (318b) 의 수직축은 우도비를 예시하며, 그래프 B (318b) 의 수평축은 시간 (프레임들) 으로 예시된다. 그래프 C (318c) 의 수직축은 우도비를 예시하며, 그래프 C (318c) 의 수평축은 시간 (프레임들) 으로 예시된다.
그래프 A (318a) 는 오디오 신호의 시간에 따른 mel-주파수에서의 스펙트로그램을 예시한다. 오디오 신호는 어구 (예를 들어, 오디오 패스워드) "오아시스 워즈 어 미라지" 를 포함한다. 스피치 컴포넌트 A (320) 는 발음 "워즈 어" 를 포함한다. 스피치 컴포넌트 B (322) 는 단어 "미라지" 에서 발음 "아" 를 포함한다.
그래프 B (318b) 는 시간에 따른 참 사용자 (예를 들어, 인증될 참 화자 또는 사용자) 에 대한 고유성 측정치 (예를 들어, 우도비) 의 일례를 예시한다. 고유성 측정치는 그래프 A (318a) 에 대응한다. 이러한 예에서, 고유성 측정치는 참 사용자의 스피치 (예를 들어, 사용자 스피치 모델) 와 UBM 사이의 우도비이다. 그래프 B (318b) 에서 관측될 수 있는 바와 같이, 스피치 컴포넌트 A (320) (예를 들어, "워즈 어") 는 낮은 고유성을 갖는다. 그러나, 스피치 컴포넌트 B (322) (예를 들어, "미라지" 에서 "아") 는 참 사용자에 대한 높은 고유성을 갖는다.
그래프 C (318c) 는 시간에 따른 사기꾼에 대한 고유성 측정치 (예를 들어, 우도비) 의 일례를 예시한다. 고유성 측정치는 그래프 A (318a) 에 대응한다. 이러한 예에서, 고유성 측정치는 사기꾼의 스피치 (예를 들어, 사기꾼 스피치 모델) 와 UBM 사이의 우도비이다. 그래프 C (318c) 에서 관측될 수 있는 바와 같이, 스피치 컴포넌트 A (320) (예를 들어, "워즈 어") 및 스피치 컴포넌트 B (322) 는 낮은 고유성을 갖는다. 도 3 에 예시되어 있는 바와 같이, 참 사용자에 대한 향상된 고유성 (예를 들어, 우도비) 를 제공하지만 사기꾼에 대한 낮은 우도비를 제공하는 스피치 컴포넌트들 (예를 들어, 음소들, 음절들, 단어들 등) 은 더 강한 패스워드들을 생성하기 위해 활용될 수도 있다.
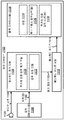
도 4 는 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스 (402) 의 더 구체적인 구성을 예시하는 블록도이다. 도 4 와 관련하여 설명하는 전자 디바이스 (402) 는 도 1 과 관련하여 설명한 전자 디바이스 (102) 의 일례일 수도 있다.
전자 디바이스 (402) 는 하나 이상의 마이크로폰들 (404), 패스워드 평가 모듈 (408), 패스워드 피드백 모듈 (412), 및 하나 이상의 출력 디바이스들 (416) 을 포함한다. 전자 디바이스 (402) 에 포함된 컴포넌트들 중 하나 이상은 도 1 과 관련하여 설명한 전자 디바이스 (102) 에 포함된 컴포넌트들 중 하나 이상에 대응할 수도 있고 그리고/또는 그와 유사하게 기능할 수도 있다.
전자 디바이스 (402) 는 통신 모듈 (436) 을 옵션으로 포함할 수도 있다. 통신 모듈 (436) 은 전자 디바이스 (402) 가 하나 이상의 디바이스들 (예를 들어, 다른 전자 디바이스들, 기지국들, 서버들, 컴퓨터들, 네트워크 인프라구조 등) 과 통신할 수 있게 할 수도 있다. 통신 모듈 (436) 은 무선 및/또는 유선 통신을 제공할 수도 있다. 예를 들어, 통신 모듈 (436) 은 하나 이상의 무선 사양들 (예를 들어, 3세대 파트너쉽 프로젝트 (3GPP) 사양들, 전기 전자 기술자 협회 (IEEE) 802.11 사양들 등) 에 따라 하나 이상의 다른 디바이스들과 무선으로 통신할 수도 있다. 추가로 또는 대안으로, 통신 모듈 (436) 은 유선 링크 (예를 들어, 이더넷, 유선 통신 등) 를 통해 다른 디바이스들과 통신할 수도 있다.
하나 이상의 마이크로폰들 (404) 은 오디오 신호 (406) 를 캡처할 수도 있다. 오디오 신호 (406) 는 오디오 패스워드를 포함할 수도 있다. 오디오 패스워드는 사용자의 아이덴티티를 검증하는 하나 이상의 사운드들 (예를 들어, 음소들, 음절들, 단어들, 어구들, 문장들, 발음들 등과 같은 하나 이상의 스피치 컴포넌트들) 을 포함할 수도 있다. 오디오 신호 (406) 는 패스워드 평가 모듈 (408) 에 제공될 수도 있다.
패스워드 평가 모듈 (408) 은 특징 추출 모듈 (424), 고유성 측정 모듈 (428) 및/또는 패스워드 강도 스코어링 모듈 (432) 을 포함할 수도 있다.
패스워드 평가 모듈 (408) (예를 들어, 특징 추출 모듈 (424)) 은 하나 이상의 마이크로폰들 (404) 에 의해 캡처된 오디오 신호 (406) 를 획득 (예를 들어, 수신) 할 수도 있다. 특징 추출 모듈 (424) 은 오디오 신호 (406) 로부터 하나 이상의 특징들을 추출하여 추출된 특징(들) (426) 을 획득할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 특징 추출 모듈 (424) 은 오디오 신호 (406) 에 기초하여 하나 이상의 MFCC들을 결정할 수도 있다. MFCC들은 추출된 특징(들) (426) 의 일례일 수도 있다. 특징 추출 모듈 (424) 은 고유성 측정 모듈 (428) 에 결합될 수도 있다. 특징 추출 모듈 (424) 은 추출된 특징(들) (426) 을 고유성 측정 모듈 (428) 에 제공할 수도 있다.
고유성 측정 모듈 (428) 은 하나 이상의 일반 스피치 모델들 (예를 들어, UBM들) 에 기초하여 오디오 신호 (406) 의 고유성 측정치 (430) 를 획득할 수도 있다. 일부 구성들에서, 고유성 측정치는 오디오 신호 (406) 와 일반 스피치 모델(들) 사이의 우도비일 수도 있다. 도 3 에서의 그래프 B (318b) 는 고유성 측정치 (430) (예를 들어, 우도비) 의 일례를 예시한다. 일부 구성들에서, 전자 디바이스 (402) 는 고유성 측정치 (430) 를 로컬하게 결정 (예를 들어, 산출) 할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 고유성 측정치 (430) 를 결정하기 위해 활용될 수도 있는 하나 이상의 일반 스피치 모델들을 로컬하게 저장할 수도 있다. 다른 구성들에서, 전자 디바이스 (402) 는 원격 디바이스 (예를 들어, 서버, 중앙 서버) 로부터 고유성 측정치 (430) 를 수신할 수도 있다. 예를 들어, 원격 디바이스 (예를 들어, 서버, 중앙 서버) 는 고유성 측정치 (430) 를 원격으로 결정하기 위해 사용될 수도 있는 하나 이상의 일반 스피치 모델들을 저장할 수도 있다.
일부 구성들에서, 일반 스피치 모델은 도 1 과 관련하여 상술한 바와 같이 획득되고 그리고/또는 업데이트될 수도 있다. 예를 들어, 전자 디바이스 (402) 및/또는 원격 디바이스 (예를 들어, 서버) 는 일반 스피치 모델(들)을 획득하고 그리고/또는 업데이트할 수도 있다. 일부 구성들에서, 전자 디바이스 (402) 는 일반 스피치 모델(들)을 획득하고 그리고/또는 업데이트할 수도 있다. 예를 들어, 전자 디바이스 (402) (예를 들어, 고유성 측정 모듈 (428)) 는 일반 스피치 모델(들)에 대한 미리 결정된 데이터를 저장할 수도 있다. 전자 디바이스 (402) 는 통신 모듈 (436) 을 통해 원격 디바이스 (예를 들어, 서버, 중앙 서버 등) 로부터 데이터를 수신함으로써 일반 스피치 모델(들)을 옵션으로 업데이트할 수도 있다.
일부 구성들에서, 전자 디바이스 (402) (예를 들어, 고유성 측정 모듈 (428)) 는 사용자 특징들 (예를 들어, 성, 나이, 위치, 등) 을 수신하고 그리고/또는 결정할 수도 있다. 예를 들어, 고유성 측정 모듈 (428) 은 하나 이상의 입력 디바이스들을 통해 사용자에 의한 입력으로서 사용자 특징들을 획득할 수도 있다. 전자 디바이스 (402) (예를 들어, 고유성 측정 모듈 (428)) 는 일반 스피치 모델 (예를 들어, UBM) 업데이트 요청을 원격 디바이스 (예를 들어, 서버, 중앙 서버 등) 에 옵션으로 전송할 수도 있다. 일부 접근방식들에서, 일반 스피치 모델 업데이트 요청은 사용자 특징들의 하나 이상의 표시자들을 포함할 수도 있다. 원격 디바이스는 (예를 들어, 사용자 특징(들)에 기초하여) 전자 디바이스 (402) 의 일반 스피치 모델(들)에 대한 업데이트들을 옵션으로 결정할 수도 있다. 원격 디바이스는 일반 스피치 모델 (예를 들어, UBM) 업데이트 데이터를 전자 디바이스 (402) 에 전송할 수도 있다. 일반 스피치 모델 업데이트 데이터는 전자 디바이스 (402) (예를 들어, 고유성 측정 모듈 (428)) 에 의해 사용된 일반 스피치 모델(들)을 적응시키거나 변형하기 위해 전자 디바이스 (402) 에 의해 활용될 수도 있는 사용자 특징들에 기초할 수도 있다.
일부 구성들에서, 전자 디바이스 (402) 는 고유성 측정치 요청을 원격 디바이스에 전송할 수도 있다. 예를 들어, 고유성 측정 모듈 (428) 은 고유성 측정치 요청을 통신 모듈 (436) 에 제공할 수도 있고, 이 통신 모듈은 고유성 측정치 요청을 원격 디바이스 (예를 들어, 서버) 에 전송할 수도 있다. 고유성 측정치 요청은 오디오 신호 (106) 에 관한 정보 (예를 들어, 추출된 특징(들) (426)) 를 포함할 수도 있다. 이러한 접근방식에서, 원격 디바이스 (예를 들어, 서버) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM들) 에 기초하여 고유성 측정치 (430) (예를 들어, 우도비) 를 결정 (예를 들어, 산출) 할 수도 있다. 전자 디바이스 (402) (예를 들어, 통신 모듈 (436)) 는 고유성 측정치 (430) 를 수신할 수도 있으며, 그 고유성 측정치 (430) 를 고유성 측정 모듈 (428) 에 제공할 수도 있다.
원격 디바이스가 일부 구성들에서 사용자 정보 (예를 들어, 위치, 나이, 성 등) 에 기초하여 그것의 일반 스피치 모델(들)을 획득하고, 유지하고 그리고/또는 적응시킬 수도 있다는 것에 유의해야 한다. 사용자 정보는 전자 디바이스 (402), 하나 이상의 다른 디바이스 및/또는 하나 이상의 3자들로부터 원격 디바이스에 의해 수신될 수도 있다. 그 후, 원격 디바이스는 고유성 측정치를 전자 디바이스 (402) 에 전송할 수도 있다.
고유성 측정 모듈 (428) 은 고유성 측정치 (430) 를 패스워드 강도 스코어링 모듈 (432) 에 제공할 수도 있다. 패스워드 강도 스코어링 모듈 (432) 은 고유성 측정치 (430) 에 기초하여 하나 이상의 패스워드 강도 스코어들 (434) 을 결정할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 패스워드 강도 스코어는 고유성 측정치일 수도 있고 그리고/또는 패스워드 강도 스코어를 결정하는 것은, 고유성 측정치의 부분들을 조합하는 것 (예를 들어, 합산하는 것, 평균화하는 것 등) 을 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 강도 스코어를 결정하는 것은, 수치값 (예를 들어, 퍼센티지), 단어 (예를 들어, "약한", "중간", "강한" 등) 및/또는 일부 다른 표시자 (예를 들어, 컬러, 형상 등) 에 고유성 측정치를 매핑하는 것, 고유성 측정치의 하나 이상의 부분들을 매핑하는 것 및/또는 하나 이상의 요약 통계들을 매핑하는 것을 포함할 수도 있다.
패스워드 강도 스코어링 모듈 (432) 은, 도 1 과 관련하여 상술한 바와 같이 오디오 패스워드가 충분하게 강한지를 결정할 수도 있다. 예를 들어, 패스워드 강도 스코어링 모듈 (432) 은 패스워드 강도 스코어(들) (434) 를 하나 이상의 값들 (예를 들어, 이전의 패스워드 강도 스코어 및/또는 임계치) 과 비교할 수도 있다. 일부 구성들에서, 패스워드 강도 스코어는 오디오 패스워드와 조합하여 하나 이상의 추가의 인증 입력들 (예를 들어, 공간적 방향성, 텍스트, 수치 코드, 영숫자 스트링, 추가의 생체특징 등) 을 반영할 수도 있다. 일부 구성들에서, 전자 디바이스 (402) (예를 들어, 패스워드 평가 모듈 (408)) 는 오디오 신호 (406) 및/또는 추가의 인증 입력을 저하시킬 수도 있다.
패스워드 평가 모듈 (408) 은 평가 정보를 패스워드 피드백 모듈 (412) 에 제공할 수도 있다. 예를 들어, 평가 정보 (410) 는 추출된 특징(들) (426), 고유성 측정치 (430), 패스워드 강도 스코어(들) (434) 및/또는 다른 정보를 포함할 수도 있다.
패스워드 피드백 모듈 (412) 은 스피치 인식 모듈 (438), 정렬 모듈 (442) 및/또는 스피치 컴포넌트 분류 모듈 (446) 을 옵션으로 포함할 수도 있다. 스피치 인식 모듈 (438) 은 하나 이상의 추출된 특징들 (426) 에 기초하여 스피치 인식을 수행할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (412) 은 하나 이상의 추출된 특징들 (426) 에 기초하여 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 결정할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 스피치 인식 모듈 (438) 은 인식된 스피치 컴포넌트(들) (440) 를 정렬 모듈 (442) 에 제공할 수도 있다.
정렬 모듈 (442) 은 고유성 측정치 (430) 와 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 정렬할 수도 있다. 예를 들어, 정렬 모듈 (442) 은 하나 이상의 인식된 스피치 컴포넌트들 (440) 의 발생을 고유성 측정치와 시간에서 정렬하여 정렬된 스피치 및 고유성 (444) 을 생성할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 정렬 모듈 (442) 은 정렬된 스피치 및 고유성 (444) 을 스피치 컴포넌트 분류 모듈 (446) 에 제공할 수도 있다.
스피치 컴포넌트 분류 모듈 (446) 은 고유성 측정치에 기초하여 하나 이상의 스피치 컴포넌트들 (예를 들어, 인식된 스피치 컴포넌트들 (440)) 을 분류할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (412) 은 정렬된 스피치 및 고유성 (444) 에서 하나 이상의 인식된 스피치 컴포넌트들 각각의 고유성 (예를 들어, 강함 또는 약함) 을 결정할 수도 있다. 일부 구성들에서, 패스워드 피드백 모듈 (412) 은 정렬된 스피치 컴포넌트들 각각에서의 고유성 측정치 (또는 예를 들어, 평균, 최대, 최소 등과 같은 고유성 측정치에 기초한 일부 값) 를 하나 이상의 임계치들에 비교할 수도 있다. 스피치 컴포넌트에 대응하는 고유성 측정치 (또는 고유성 측정치에 기초한 값) 가 임계치 보다 큰 경우에, 대응하는 스피치 컴포넌트는 충분히 고유하거나 충분히 강한 것으로서 분류될 수도 있다. 일부 구성들에서, 충분히 고유하거나 충분히 강한 것으로서 분류되는 (예를 들어, 임계치 보다 큰) 스피치 컴포넌트(들)는 제안들로서 패스워드 피드백 (414) 에 제공될 수도 있다. 또한, 유사한 스피치 컴포넌트(들) 및/또는 스피치 컴포넌트 또는 유사한 스피치 컴포넌트들을 포함하는 발음(들), 단어(들), 어구(들) 및/또는 패스워드(들)가 제안들로서 패스워드 피드백 (414) 에 제공될 수도 있다.
패스워드 피드백 모듈 (412) 은 패스워드 피드백 (414) 을 하나 이상의 출력 디바이스들 (416) 에 제공할 수도 있다. 패스워드 피드백 (414) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 (예를 들어, 하나 이상의 추가의 인증 입력들을 제안하는 것) 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 이에 따라, 하나 이상의 출력 디바이스들 (416) 은 패스워드 피드백 (414) 을 사용자에게 중계하거나 전달할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 출력 디바이스(들) (416) 는 패스워드 피드백 (414) 을 텍스트, 이미지 및/또는 사운드로서 출력할 수도 있다. 출력은 라벨 (예를 들어, 패스워드 강도 스코어), 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 (예를 들어, 하나 이상의 추가의 인증 입력들을 제안하는 것) 및/또는 하나 이상의 메시지들을 중계할 수도 있다.
도 5 는 오디오 패스워드의 강도를 평가하는 방법 (500) 의 더 구체적인 구성을 예시하는 흐름도이다. 도 1 및 도 4 와 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상이 방법 (500) 을 수행할 수도 있다.
전자 디바이스 (402) 는 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 옵션으로 제공할 수도 있다 (502). 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 것 (502) 의 예가 도 10 과 관련하여 설명된다.
전자 디바이스 (402) 는 하나 이상의 마이크로폰들 (404) 에 의해 캡처된 오디오 신호 (406) 를 획득할 수도 있다 (504). 이것은 도 1, 도 2 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 오디오 신호 (106) 는 오디오 패스워드를 포함할 수도 있다. 오디오 패스워드는 사용자의 아이덴티티를 검증하는 하나 이상의 사운드들 (예를 들어, 음소들, 음절들, 단어들, 어구들, 문장들, 발음들 등과 같은 하나 이상의 스피치 컴포넌트들) 을 포함할 수도 있다.
전자 디바이스 (402) 는 오디오 신호 (406) 로부터 하나 이상의 특징들을 추출하여 추출된 특징(들) (426) 을 획득할 수도 있다 (506). 이것은 도 1 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (402) 는 오디오 신호 (406) 에 기초하여 하나 이상의 MFCC들을 결정할 수도 있다. MFCC들은 추출된 특징(들) (426) 의 일례일 수도 있다.
전자 디바이스 (402) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM) 에 기초하여 오디오 신호 (406) 의 고유성 측정치 (430) 를 획득할 수도 있다 (508). 이것은 도 1 내지 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 일부 구성들에서, 고유성 측정치는 오디오 신호 (406) 와 일반 스피치 모델(들) 사이의 우도비일 수도 있다. 일부 구성들에서, 전자 디바이스 (402) 는 고유성 측정치 (430) 를 로컬하게 결정 (예를 들어, 산출) 할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 고유성 측정치 (430) 를 결정하기 위해 활용될 수도 있는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM(들)) 을 로컬하게 저장할 수도 있다. 다른 구성들에서, 전자 디바이스 (402) 는 원격 디바이스 (예를 들어, 서버, 중앙 서버) 로부터 고유성 측정치 (430) 를 수신할 수도 있다. 예를 들어, 원격 디바이스 (예를 들어, 서버, 중앙 서버) 는 고유성 측정치 (430) 를 원격으로 결정하기 위해 사용될 수도 있는 하나 이상의 일반 스피치 모델들을 저장할 수도 있다. 일부 구성들에서, 전자 디바이스 (402) 는 고유성 측정치 요청을 원격 디바이스에 전송할 수도 있다. 고유성 측정치 요청은 오디오 신호 (406) 에 관한 정보 (예를 들어, 추출된 특징(들) (426)) 를 포함할 수도 있다. 이러한 접근방식에서, 원격 디바이스 (예를 들어, 서버) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM들) 에 기초하여 고유성 측정치 (430) (예를 들어, 우도비) 를 결정 (예를 들어, 산출) 할 수도 있다. 전자 디바이스 (402) 는 고유성 측정치 (430) 를 수신할 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 패스워드 강도 스코어 (434) 를 결정할 수도 있다 (510). 이것은 도 1 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 패스워드 강도 스코어가 값 보다 큰지를 결정할 수도 있다 (512). 이것은 도 1 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (402) 는 패스워드 강도 스코어 (434) 를 값 (예를 들어, 이전의 패스워드 강도 스코어 및/또는 임계치) 과 비교할 수도 있다.
패스워드 강도 스코어 (434) 가 값 (예를 들어, 이전의 패스워드 강도 스코어 및/또는 임계치) 보다 큰 경우에, 전자 디바이스 (402) 는 오디오 신호 (406) 에 기초하여 패스워드를 설정할 수도 있다 (516). 일부 구성들에서, 전자 디바이스 (402) 는 패스워드로서 오디오 신호 (406) 를 저장할 수도 있고 그리고/또는 오디오 신호 (406) 를 지정할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (402) 는 패스워드로서 오디오 신호 (406) 에 포함된 인식된 스피치 컴포넌트들의 조합을 저장하고 그리고/또는 지정할 수도 있다.
패스워드 강도 스코어 (434) 가 값 보다 크지 않으면 (예를 들어, 값 이하이면), 전자 디바이스 (402) 는 패스워드 피드백을 제공할 수도 있다 (514). 이것은 도 1, 도 2 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (402) 는 패스워드 피드백 (414) 을 제공하고 그리고/또는 출력할 수도 있다. 패스워드 피드백 (414) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 (예를 들어, 하나 이상의 추가의 인증 입력들을 제안하는 것) 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 패스워드 피드백 (414) 을 텍스트, 이미지 및/또는 사운드로서 출력할 수도 있다. 출력은 라벨 (예를 들어, 패스워드 강도 스코어), 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 (예를 들어, 하나 이상의 추가의 인증 입력들을 제안하는 것) 및/또는 하나 이상의 메시지들을 중계할 수도 있다.
도 6 은 오디오 패스워드의 강도를 평가하는 방법 (600) 의 다른 더 구체적인 구성을 예시하는 흐름도이다. 특히, 이러한 구성은 하나 이상의 제안들을 제공하기 위해 수행될 수도 있는 동작들의 예를 제공한다. 도 1 및 도 4 와 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상이 방법 (600) 을 수행할 수도 있다.
전자 디바이스 (402) 는 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 옵션으로 제공할 수도 있다 (602). 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 것 (602) 의 예가 도 10 과 관련하여 설명된다.
전자 디바이스 (402) 는 하나 이상의 마이크로폰들 (404) 에 의해 캡처된 오디오 신호 (406) 를 획득할 수도 있다 (604). 이것은 도 1, 도 2, 도 4 및 도 5 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 오디오 신호 (406) 로부터 하나 이상의 특징들을 추출하여 추출된 특징(들) (426) 을 획득할 수도 있다 (606). 이것은 도 1, 도 4 및 도 5 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM) 에 기초하여 오디오 신호 (406) 의 고유성 측정치 (430) 를 획득할 수도 있다 (608). 이것은 도 1, 도 4 및 도 5 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 패스워드 강도 스코어 (434) 를 결정할 수도 있다 (610). 이것은 도 1, 도 4 및 도 5 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 패스워드 강도 스코어가 값 보다 큰지를 결정할 수도 있다 (612). 이것은 도 1, 도 4 및 도 5 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 강도 스코어 (434) 가 값 (예를 들어, 이전의 패스워드 강도 스코어 및/또는 임계치) 보다 큰 경우에, 전자 디바이스 (402) 는 오디오 신호 (406) 에 기초하여 패스워드를 설정할 수도 있다 (622). 이것은 도 5 과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 강도 스코어 (434) 가 값 보다 크지 않으면 (예를 들어, 값 이하이면), 전자 디바이스 (402) 는 하나 이상의 추출된 특징들 (426) 에 기초하여 스피치 인식을 수행할 수도 있다 (614). 예를 들어, 전자 디바이스 (402) 는 하나 이상의 추출된 특징들 (426) 에 기초하여 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 결정할 수도 있다. 이것은 도 1 과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 와 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 정렬할 수도 있다 (616). 예를 들어, 전자 디바이스 (402) 는 하나 이상의 인식된 스피치 컴포넌트들의 발생을 고유성 측정치와 시간에서 정렬하여 정렬된 스피치 및 고유성 (444) 을 생성할 수도 있다. 이것은 도 1 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 하나 이상의 스피치 컴포넌트들 (예를 들어, 인식된 스피치 컴포넌트들 (440)) 을 분류할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 정렬된 스피치 및 고유성 (444) 에서 하나 이상의 인식된 스피치 컴포넌트들 각각의 고유성 (예를 들어, 강함 또는 약함) 을 결정할 수도 있다. 일부 구성들에서, 패스워드 피드백 모듈 (412) 은 정렬된 스피치 컴포넌트들 각각에서의 고유성 측정치 (또는 예를 들어, 평균, 최대, 최소 등과 같은 고유성 측정치에 기초한 일부 값) 를 하나 이상의 임계치들에 비교할 수도 있다. 스피치 컴포넌트에 대응하는 고유성 측정치 (또는 고유성 측정치에 기초한 값) 가 임계치 보다 큰 경우에, 대응하는 스피치 컴포넌트는 충분히 고유하거나 충분히 강한 것으로서 분류될 수도 있다. 일부 구성들에서, 충분히 고유하거나 충분히 강한 것으로서 분류되는 (예를 들어, 임계치 보다 큰) 스피치 컴포넌트(들)는 제안들로서 패스워드 피드백 (414) 에 제공될 수도 있다 (620). 또한, 유사한 스피치 컴포넌트(들) 및/또는 스피치 컴포넌트 또는 유사한 스피치 컴포넌트들을 포함하는 발음(들), 단어(들), 어구(들) 및/또는 패스워드(들)가 제안들로서 패스워드 피드백 (414) 에 제공될 수도 있다 (620).
전자 디바이스 (402) 는 패스워드 피드백을 제공할 수도 있다 (620). 이것은 도 1, 도 4 및 도 5 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (402) 는 패스워드 피드백 (414) 을 제공하고 그리고/또는 출력할 수도 있다. 패스워드 피드백 (414) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 (예를 들어, 하나 이상의 추가의 인증 입력들을 제안하는 것) 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 패스워드 피드백 (414) 을 텍스트, 이미지 및/또는 사운드로서 출력할 수도 있다. 출력은 라벨 (예를 들어, 패스워드 강도 스코어), 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 (예를 들어, 하나 이상의 추가의 인증 입력들을 제안하는 것) 및/또는 하나 이상의 메시지들을 중계할 수도 있다. 일부 구성들에서, 전자 디바이스 (402) 는 패스워드 피드백으로서 제안된 스피치 컴포넌트들로 이루어진 제안된 합성 (예를 들어, 미지의) 단어를 제공할 수도 있다 (620).
도 7 은 오디오 패스워드의 강도를 평가하는 방법 (700) 의 다른 더 구체적인 구성을 예시하는 흐름도이다. 특히, 이러한 구성은 다른 사용자의 모델들로 패스워드 강도 평가 및 제안을 위해 수행될 수도 있는 동작들의 예를 제공한다. 도 1 및 도 4 와 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상이 방법 (700) 을 수행할 수도 있다.
전자 디바이스 (402) 는 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 옵션으로 제공할 수도 있다 (702). 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 것 (702) 의 예가 도 10 과 관련하여 설명된다.
전자 디바이스 (402) 는 하나 이상의 마이크로폰들 (404) 에 의해 캡처된 오디오 신호 (406) 를 획득할 수도 있다 (704). 이것은 도 1, 도 2, 도 4, 도 5 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 오디오 신호 (406) 로부터 하나 이상의 특징들을 추출하여 추출된 특징(들) (426) 을 획득할 수도 있다 (706). 이것은 도 1, 도 4, 도 5 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 요청을 (예를 들어, 원격 디바이스에) 전송할 수도 있다 (708). 이것은 도 4 과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (402) 는 유선 및/또는 무선 통신을 통해 고유성 측정치 요청을 원격 디바이스 (예를 들어, 서버) 에 전송할 수도 있다. 고유성 측정치 요청은 오디오 신호 (406) 에 관한 정보 (예를 들어, 추출된 특징(들) (426)) 를 포함할 수도 있다. 이러한 접근방식에서, 원격 디바이스 (예를 들어, 서버) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM들, 다른 사용자의 스피치 모델들 등) 에 기초하여 고유성 측정치 (430) (예를 들어, 우도비) 를 결정 (예를 들어, 산출) 할 수도 있다. 원격 디바이스가 일부 구성들에서 사용자 정보 (예를 들어, 위치, 나이, 성 등) 에 기초하여 그것의 일반 스피치 모델(들)을 획득하고, 유지하고 그리고/또는 적응시킬 수도 있다는 것에 유의해야 한다. 사용자 정보는 전자 디바이스 (402), 하나 이상의 다른 디바이스 및/또는 하나 이상의 3자들로부터 원격 디바이스에 의해 수신될 수도 있다. 그 후, 원격 디바이스는 고유성 측정치를 전자 디바이스 (402) 에 전송할 수도 있다.
전자 디바이스 (402) (예를 들어, 통신 모듈 (436)) 는 고유성 측정치 (430) 를 수신할 수도 있다 (710). 예를 들어, 전자 디바이스 (402) 는 유선 및/또는 무선 통신을 통해 원격 디바이스 (예를 들어, 서버) 로부터 고유성 측정치 (430) 를 수신할 수도 있다 (710).
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 패스워드 강도 스코어 (434) 를 결정할 수도 있다 (712). 이것은 도 1, 도 4, 도 5 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 패스워드 강도 스코어가 값 보다 큰지를 결정할 수도 있다 (714). 이것은 도 1, 도 4, 도 5 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 강도 스코어 (434) 가 값 (예를 들어, 이전의 패스워드 강도 스코어 및/또는 임계치) 보다 큰 경우에, 전자 디바이스 (402) 는 오디오 신호 (406) 에 기초하여 패스워드를 설정할 수도 있다 (724). 이것은 도 5 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 강도 스코어 (434) 가 값 보다 크지 않으면 (예를 들어, 값 이하이면), 전자 디바이스 (402) 는 하나 이상의 추출된 특징들 (426) 에 기초하여 스피치 인식을 옵션으로 수행할 수도 있다 (716). 이것은 도 1 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 와 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 옵션으로 정렬할 수도 있다 (718). 이것은 도 1, 도 4 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 하나 이상의 스피치 컴포넌트들 (예를 들어, 인식된 스피치 컴포넌트들 (440)) 을 옵션으로 분류할 수도 있다 (720). 이것은 도 1, 도 4 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 패스워드 피드백을 제공할 수도 있다 (722). 이것은 도 1, 도 4, 도 5 및 도 6 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
도 8 은 오디오 패스워드의 강도를 평가하는 방법 (800) 의 다른 더 구체적인 구성을 예시하는 흐름도이다. 특히, 이러한 구성은 일반 스피치 모델을 업데이트하기 위해 수행될 수도 있는 동작들의 예를 제공한다. 도 1 및 도 4 와 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상이 방법 (800) 을 수행할 수도 있다.
전자 디바이스 (402) 는 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 옵션으로 제공할 수도 있다 (802). 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 것 (802) 의 예가 도 10 과 관련하여 설명된다.
전자 디바이스 (402) 는 하나 이상의 마이크로폰들 (404) 에 의해 캡처된 오디오 신호 (406) 를 획득할 수도 있다 (804). 이것은 도 1, 도 2, 도 4, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 오디오 신호 (406) 로부터 하나 이상의 특징들을 추출하여 추출된 특징(들) (426) 을 획득할 수도 있다 (806). 이것은 도 1, 도 4, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 하나 이상의 사용자 특징들을 획득할 수도 있다 (808). 사용자 특징들의 예들은, 지리적 위치 (예를 들어, 우편 번호, 도시, 군, 주, 나라 등), 성, 나이, 언어 및/또는 지역 방언 등을 포함한다. 예를 들어, 전자 디바이스 (402) 는 하나 이상의 사용자 특징들을 나타내는 (예를 들어, 사용자로부터의) 하나 이상의 입력들을 수신할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (402) 는 하나 이상의 센서들로부터 하나 이상의 사용자 특징들을 획득할 수도 있다 (808). 예를 들어, 전자 디바이스 (402) 는 마이크로폰(들) (404) 으로부터 캡처된 오디오에 기초하여 사용자의 성, 언어 및/또는 지역 방언을 결정할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (402) 는 마이크로폰(들) (404) 으로부터 캡처된 오디오에 기초하여 사용자 나이를 추정할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (402) 는 글로벌 포지셔닝 시스템 (GPS) 모듈로부터의 데이터에 기초하여 지리적 위치를 결정할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (402) 는 원격 디바이스 (예를 들어, 서비스 제공자 서버) 로부터 하나 이상의 사용자 특징들을 요청할 수도 있다.
전자 디바이스 (402) 는 하나 이상의 사용자 특징들에 기초하여 일반 스피치 모델을 업데이트할 수도 있다 (810). 이것은 도 1 및 도 4 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (402) 및/또는 원격 디바이스 (예를 들어, 서버) 는 일반 스피치 모델(들)을 업데이트할 수도 있다 (810). 일부 구성들에서, 전자 디바이스 (402) 는 사용자 특징들에 기초하여 일반 스피치 모델(들)을 로컬하게 업데이트할 수도 있다 (810). 예를 들어, 전자 디바이스 (402) 는, 전자 디바이스 (402) 가 사용자의 특징들과 유사한 특징들을 갖는 다른 사용자들의 데이터를 단지 포함함으로써 로컬하게 업데이트할 수도 있는 일반 스피치 모델(들)에 대한 미리 결정된 데이터를 옵션으로 저장할 수도 있다.
전자 디바이스 (402) 는 통신 모듈 (436) 을 통해 사용자 특징들을 원격 디바이스 (예를 들어, 서버) 에 전송하고 그리고/또는 원격 디바이스 (예를 들어, 서버, 중앙 서버 등) 로부터 데이터를 수신함으로써 사용자 특징(들)에 기초하여 일반 스피치 모델(들)을 옵션으로 업데이트할 수도 있다 (810). 예를 들어, 전자 디바이스 (402) 는 일반 스피치 모델 (예를 들어, UBM) 업데이트 요청을 원격 디바이스 (예를 들어, 서버, 중앙 서버 등) 에 전송할 수도 있다. 일부 접근방식들에서, 일반 스피치 모델 업데이트 요청은 사용자 특징들의 하나 이상의 표시자들을 포함할 수도 있다. 일부 구성들에서, 원격 디바이스는 사용자 특징(들)에 기초하여 원격 디바이스상에 저장된 하나 이상의 일반 스피치 모델(들)을 업데이트할 수도 있다. 추가로 또는 대안으로, 원격 디바이스는 (예를 들어, 사용자 특징(들)에 기초하여) 전자 디바이스 (402) 의 일반 스피치 모델(들)에 대한 업데이트들을 옵션으로 결정할 수도 있다. 원격 디바이스는 일반 스피치 모델 (예를 들어, UBM) 업데이트 데이터를 전자 디바이스 (402) 에 전송할 수도 있다.
전자 디바이스 (402) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM) 에 기초하여 오디오 신호 (406) 의 고유성 측정치 (430) 를 획득할 수도 있다 (812). 이것은 도 1, 도 4, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 패스워드 강도 스코어 (434) 를 결정할 수도 있다 (814). 이것은 도 1, 도 4, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 패스워드 강도 스코어가 값 보다 큰지를 결정할 수도 있다 (816). 이것은 도 1, 도 4, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 강도 스코어 (434) 가 값 (예를 들어, 이전의 패스워드 강도 스코어 및/또는 임계치) 보다 큰 경우에, 전자 디바이스 (402) 는 오디오 신호 (406) 에 기초하여 패스워드를 설정할 수도 있다 (826). 이것은 도 5 내지 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 강도 스코어 (434) 가 값 보다 크지 않으면 (예를 들어, 값 이하이면), 전자 디바이스 (402) 는 하나 이상의 추출된 특징들 (426) 에 기초하여 스피치 인식을 옵션으로 수행할 수도 있다 (818). 이것은 도 1, 도 6, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 와 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 옵션으로 정렬할 수도 있다 (820). 이것은 도 1, 도 4, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 에 기초하여 하나 이상의 스피치 컴포넌트들 (예를 들어, 인식된 스피치 컴포넌트들 (440)) 을 옵션으로 분류할 수도 있다 (822). 이것은 도 1, 도 4, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
전자 디바이스 (402) 는 패스워드 피드백을 제공할 수도 있다 (824). 이것은 도 1, 도 4, 도 5, 도 6 및 도 7 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
도 9 는 화자 (예를 들어, 사용자) 인식 모델들의 일례를 예시하는 블록도이다. 화자 인식 모델들은 텍스트-독립 화자 인식에 기초할 수도 있다. 하나의 모델이 MFCC 및 UBM-GMM 에 기초한다. 이것은 GMM 을 사용하여 UBM 을 트레이닝하는 것을 포함한다. 도 9 에 예시되어 있는 바와 같이, 트레이닝하는 것 (948) 은 일반 스피치 모델 생성 (952) 을 위해 트레이닝 스피치 (950) 를 활용하는 것을 포함할 수도 있다.
일부 접근방식들에서, 화자 등록 (954) 은 일반 스피치 모델 (예를 들어, UBM) 에 대한 최대 사후 (MAP) 적응을 사용하여 수행될 수도 있다. 도 9 에 예시되어 있는 바와 같이, 등록 (954) (예를 들어, 적응) 은 사용자 스피치 모델 생성 (958) 에 대해 사용자 스피치 (956) 를 활용하는 것을 포함할 수도 있다.
일부 접근방식들에서, 각각의 스피치 발음 (962) 은 일반 스피치 모델 (예를 들어, UBM) 과 각각의 등록된 화자 모델 사이의 우도비를 비교함으로써 검증될 수도 있다. 도 9 에 예시되어 있는 바와 같이, 각각의 발음 (962) 은 검증 (964) 절차에서 활용될 수도 있다. 예를 들어, 검증 (964) 절차는 수학식 (1) 및/또는 수학식 (2) 에 따라 수행될 수도 있다. 예를 들어, 검증 (964) 절차는  에 따라 수행될 수도 있고, 여기서, t 는 시간이고, X 는 발음 (962) 또는 오디오 신호이고,
에 따라 수행될 수도 있고, 여기서, t 는 시간이고, X 는 발음 (962) 또는 오디오 신호이고,  는 타겟 (예를 들어, 참 사용자 스피치) 모델이고,
는 타겟 (예를 들어, 참 사용자 스피치) 모델이고,  는 일반 스피치 모델(들) (예를 들어, UBM(들))이고,
는 일반 스피치 모델(들) (예를 들어, UBM(들))이고,  는 X 가 참 사용자에 대응하는 확률이고,
는 X 가 참 사용자에 대응하는 확률이고,  는 X 가 일반 사용자 (예를 들어, 사기꾼, 참이 아닌 사용자, 비사용자 의존 모델 또는 일반 화자 모델) 에 대응하는 확률이며,
는 X 가 일반 사용자 (예를 들어, 사기꾼, 참이 아닌 사용자, 비사용자 의존 모델 또는 일반 화자 모델) 에 대응하는 확률이며,  는 검증 임계치이다. 다중의 화자들이 식별될 때, 가장 높은 가능성을 생성하는 화자가 선택될 수도 있다. 추가로 또는 대안으로, 다른 분류기들 (예를 들어, 서포트 벡터 머신 또는 신경망들) 이 활용될 수도 있다.
는 검증 임계치이다. 다중의 화자들이 식별될 때, 가장 높은 가능성을 생성하는 화자가 선택될 수도 있다. 추가로 또는 대안으로, 다른 분류기들 (예를 들어, 서포트 벡터 머신 또는 신경망들) 이 활용될 수도 있다.
도 10 은 사전-트레이닝에 기초하여 하나 이상의 후보 스피치 컴포넌트들을 제공하는 방법 (1000) 의 일 구성을 예시하는 흐름도이다. 예를 들어, 도 10 과 관련하여 설명하는 절차들 중 하나 이상은 등록에 대한 사전-트레이닝에서 활용될 수도 있다. 예를 들어, 등록에 대한 사전-트레이닝은, (예를 들어, 도 5 내지 8 중 하나 이상과 관련하여 설명한 단계들 (502, 602, 702 및 802) 중 하나 이상에서) 평가를 위해 오디오 패스워드를 수신하기 이전에 발생할 수도 있다.
이하, 등록 및 비교에 대한 더 많은 상세가 제공된다. 사용자를 등록하는 것에 대한 하나의 접근방식은, 충분한 음소들을 제공하여 일반 스피치 모델 (예를 들어, UBM) 로부터 사용자의 모델을 적응시키기 위해 당분간 사용자 말하게 두는 것을 포함할 수도 있다. 일부 구성들에서, 전자 디바이스(들) (102, 402) 는 트레이닝 시간을 최소화하기 위해 일부 미리 정의된 음성적으로 밸런싱된 문장들을 제공할 수도 있다. 추가로 또는 대안으로, 사용자는 (예를 들어, 일반 스피치 모델을 사용자의 스피치 모델에 적응시키는 것을 적절히 트레이닝하기에) 충분히 긴 스크립트를 판독할 수도 있다.
추가로 또는 대안으로, 전자 디바이스(들) (102, 402) 는, 사용자가 디바이스의 소유자 (예를 들어, 참 사용자) 라는 것을 가정하여, 호출 동안 사용자의 데이터 (예를 들어, 스피치) 를 수집할 수도 있다. 데이터의 사이즈에 관하여 특정한 레벨이 도달되면, 전자 디바이스(들) (102, 402) 는 음성 패스워드가 인에이블될 수도 있다는 것을 사용자에게 통지하거나 알려줄 수도 있다 (예를 들어, 메시지를 디스플레이할 수도 있고, 메시지를 제공하는 스피치를 출력할 수도 있다). 일부 구성들에서, 전자 디바이스(들)는 사용자의 스피치 모델을 계속 업데이트할 수도 있다. 이러한 방식으로, 시간에 따른 사용자의 음색 변화 (예를 들어, 나이-의존 변화) 가 모니터링될 수도 있다.
도 1 및 도 4 중 하나 이상과 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상이 방법 (1000) 을 수행할 수도 있다. 도 10 과 관련하여 설명한 바와 같은 사전-트레이닝 또는 등록 동안 수행된 절차들 중 하나 이상이 (예를 들어, 도 1, 도 2, 도 4, 도 5, 도 6, 도 7 및 도 8 중 하나 이상과 관련하여 설명한 바와 같은) 오디오 패스워드를 획득하고 평가할시에 수행된 절차들 중 하나 이상과 유사할 수도 있지만, 도 10 과 관련하여 설명한 절차들 중 하나 이상이 상술한 바와 같은 오디오 패스워드를 획득시에 수행된 절차들과는 개별적으로 그리고/또는 그 이전에 수행될 수도 있다는 것에 유의해야 한다.
전자 디바이스 (402) 는 사용자 오디오 신호 (406) 를 수신할 수도 있다 (1002). 예를 들어, 사용자 오디오 신호 (406) 는 하나 이상의 마이크로폰들 (404) 에 의해 캡처될 수도 있다. 사용자 오디오 신호 (406) 는, 예를 들어, 사용자가 스크립트를 판독하거나 전화 호출을 하는 동안 수신될 수도 있다.
전자 디바이스 (402) 는 사용자 오디오 신호 (406) 가 양호한 음향 조건으로 수신되는지를 결정할 수도 있다 (1004). 예를 들어, 전자 디바이스 (402) 는 사용자 오디오 신호 (406) 의 신호 대 잡음비 (SNR) 를 결정할 수도 있다. SNR 이 SNR 임계치 위이면, 전자 디바이스 (402) 는 사용자 오디오 신호 (406) 가 양호한 음향 조건으로 수신된다는 것을 결정할 수도 있다 (1004). SNR 이 SNR 임계치 위가 아니면 (예를 들어, 이하이면), 전자 디바이스 (402) 는 사용자 오디오 신호 (406) 가 양호한 음향 조건으로 수신되지 않는다는 것을 결정할 수도 있다 (1004). 사용자 오디오 신호 (406) 가 양호한 음향 조건으로 수신되지 않으면, 전자 디바이스 (402) 는 수신된 오디오 신호 (406) 를 폐기할 수도 있으며 후속 사용자 오디오 신호 (406) 를 수신하는 것 (1002) 으로 복귀할 수도 있다.
사용자 오디오 신호 (406) 가 양호한 음향 조건으로 수신되면, 전자 디바이스 (402) 는 오디오 신호 (406) 로부터 하나 이상의 특징들을 추출하여 추출된 특징(들) (426) 을 획득할 수도 있다 (1006). 예를 들어, 전자 디바이스 (402) 는 오디오 신호 (406) 에 기초하여 하나 이상의 MFCC들을 결정할 수도 있다.
전자 디바이스 (402) 는 하나 이상의 일반 스피치 모델들 (예를 들어, UBM) 에 기초하여 오디오 신호 (406) 의 고유성 측정치 (430) 를 결정할 수도 있다 (1008). 일부 구성들에서, 고유성 측정치는 오디오 신호 (406) 와 일반 스피치 모델(들) 사이의 우도비일 수도 있다. 일부 구성들에서, 전자 디바이스 (402) 는 고유성 측정치 (430) 를 로컬하게 결정 (예를 들어, 산출) 할 수도 있다. 다른 구성들에서, 전자 디바이스 (402) 는 고유성 측정치 (430) 를 요청하여 원격 디바이스 (예를 들어, 서버) 로부터 수신할 수도 있다.
전자 디바이스 (402) 는 하나 이상의 추출된 특징들 (426) 에 기초하여 스피치 인식을 수행할 수도 있다 (1010). 예를 들어, 전자 디바이스 (402) 는 하나 이상의 추출된 특징들 (426) 에 기초하여 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 결정할 수도 있다.
전자 디바이스 (402) 는 고유성 측정치 (430) 와 하나 이상의 인식된 스피치 컴포넌트들 (440) 을 정렬할 수도 있다 (1012). 예를 들어, 전자 디바이스 (402) 는 하나 이상의 인식된 스피치 컴포넌트들의 발생을 고유성 측정치와 시간에서 정렬하여 정렬된 스피치 및 고유성 (444) 을 생성할 수도 있다.
전자 디바이스 (402) 는 하나 이상의 스피치 컴포넌트들 (예를 들어, 인식된 스피치 컴포넌트들) 에 대한 고유성 통계를 업데이트할 수도 있다 (1014). 예를 들어, 전자 디바이스 (402) 는 그 스피치 컴포넌트에 대응하는 고유성 측정치에 기초하여 스피치 컴포넌트에 대한 고유성 통계를 업데이트할 수도 있다 (1014). 일부 구성들에서, 전자 디바이스 (402) 는 하나 이상의 인식된 스피치 컴포넌트들이 캡처되고 인식될 때 하나 이상의 인식된 스피치 컴포넌트들에 대응하는 고유성 측정치 (또는 예를 들어, 최대, 최소 또는 평균과 같은 고유성 측정치에 기초한 값) 을 저장할 수도 있다. 인식된 스피치 컴포넌트가 획득된 이후 각각의 다음의 경우에, 전자 디바이스 (402) 는 고유성 통계를 업데이트할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 저장된 고유성 측정치 (또는 값) 및 현재 고유성 측정치 (또는 값) 에 기초하여 일부 통계적 측정치 (예를 들어, 평균 등) 를 산출할 수도 있다. 그 후, 전자 디바이스 (402) 는 업데이트된 통계적 측정치를 저장할 수도 있다.
전자 디바이스 (402) 는 하나 이상의 스피치 컴포넌트들을 등록할 수도 있다 (1016). 예를 들어, 전자 디바이스 (402) 는 하나 이상의 인식된 스피치 컴포넌트들 각각에 대한 데이터를 저장할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (402) 는 (예를 들어, 스피치 컴포넌트가 임계치 보다 큰 대응하는 고유성 측정치 또는 고유성 통계를 갖는 경우에) 패스워드 권장을 위해 충분히 고유하거나 강한 것으로서 인식된 스피치 컴포넌트들 중 하나 이상을 지정할 수도 있다. 예를 들어, 전자 디바이스 (402) 는 일부 구성들에서 패스워드 평가를 위해 오디오 패스워드를 초기에 수신하기 이전에 하나 이상의 제안된 스피치 컴포넌트들을 제공할 수도 있다.
전자 디바이스 (402) 는 사용자 스피치 모델을 적응시킬 수도 있다 (1018). 예를 들어, 전자 디바이스 (402) 는 사용자 스피치 모델의 음소 데이터 및/또는 가중치들을 업데이트함으로써 (예를 들어, 일반 스피치 모델에 초기에 기초할 수도 있는) 사용자 스피치 모델을 적응시키거나 변형시킬 수도 있다. 일부 구성들에서, 사용자 스피치 모델을 적응시키는 것 (1018) 은 하나 이상의 모델 파라미터들 (예를 들어, GMM 컴포넌트들) 을 업데이트하는 것을 포함할 수도 있다. 구체적으로, 적응 (1018) 은 GMM 의 평균 및/또는 믹싱 가중치들을 업데이트함으로써 수행될 수도 있다.
전자 디바이스 (402) 는 사용자의 스피치를 정확하게 설명하기 위해 사용자 스피치 모델에 대한 충분한 데이터가 존재하는지를 결정할 수도 있다 (1020). 예를 들어, 전자 디바이스 (402) 는 사용자 스피치 모델이 참 사용자의 스피치를 정확하게 반영하기 위해 충분히 개량되도록 임계 수 및/또는 특정한 음소들이 캡처되었는지를 결정할 수도 있다. 충분한 데이터가 존재하지 않으면, 전자 디바이스 (402) 는 사용자 오디오 신호를 계속 수신할 수도 있다 (1002).
충분한 데이터가 존재하면, 전자 디바이스 (402) 는 사용자 스피치 모델을 제공할 수도 있다 (1022). 예를 들어, 전자 디바이스 (402) 는 상술한 바와 같이 사용자 스피치 모델이 오디오 패스워드 강도 평가 및/또는 제안을 위해 이용가능하게 할 수도 있다. 사용자 스피치 모델이 사용을 위해 제공될 수도 있지만 (1022), 방법 (1000) 은 사용자 스피치 모델을 더 적응시키고 그리고/또는 개량하기 위해 다수 회 그리고/또는 지속적으로 반복될 수도 있다는 것에 유의해야 한다.
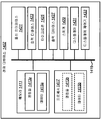
도 11 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 전자 디바이스 (1102) 의 다른 더 구체적인 구성을 예시하는 블록도이다. 도 11 과 관련하여 설명하는 전자 디바이스 (1102) 는 도 1 및 도 4 와 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상의 예일 수도 있다.
전자 디바이스 (1102) 는 하나 이상의 마이크로폰들 (1104), 패스워드 평가 모듈 (1108), 패스워드 피드백 모듈 (1112), 및 하나 이상의 출력 디바이스들 (1116) 을 포함한다. 전자 디바이스 (1102) 에 포함된 컴포넌트들 중 하나 이상은 도 1 및 도 4 중 하나 이상과 관련하여 설명한 전자 디바이스들 (102, 402) 중 하나 이상에 에 포함된 컴포넌트들 중 하나 이상에 대응할 수도 있고 그리고/또는 그와 유사하게 기능할 수도 있다.
전자 디바이스 (1102) 는 하나 이상의 입력 디바이스들 (1166) 을 포함할 수도 있다. 입력 디바이스들 (1166) 의 예들은, 터치스크린들, 터치패드들, 이미지 센서들 (예를 들어, 카메라들), 키보드들 (예를 들어, 물리적 및/또는 소프트웨어 키보드들), 키패드들 (예를 들어, 물리적 및/또는 소프트웨어 키패드들), 지문 스캐너들, 추가의 마이크로폰들, 배향 센서들 (예를 들어, 기울기 센서들), 모션 센서들 (예를 들어, 가속도계들), GPS 모듈들, 압력 센서들 등을 포함한다. 하나 이상의 입력 디바이스들 (1166) 은 하나 이상의 입력들 (1168) 을 획득하거나 수신할 수도 있다. 하나 이상의 입력들 (1168) 은 패스워드 평가 모듈 (1108) 에 제공될 수도 있다.
하나 이상의 마이크로폰들 (1104) 은 오디오 신호 (1106) 를 캡처할 수도 있다. 오디오 신호 (1106) 는 오디오 패스워드를 포함할 수도 있다. 오디오 신호 (1106) 는 패스워드 평가 모듈 (1108) 에 제공될 수도 있다.
패스워드 평가 모듈 (1108) 은 하나 이상의 마이크로폰 (1104) 에 의해 캡처된 오디오 신호 (1106) 를 획득 (예를 들어, 수신) 할 수도 있다. 상술한 바와 같이, 오디오 신호 (1106) 는 오디오 패스워드를 포함할 수도 있다. 패스워드 평가 모듈 (1108) 은, 오디오 신호 (1106) 의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 오디오 패스워드의 강도를 평가할 수도 있다. 이것은 도 1, 도 2, 도 4, 도 5, 도 6, 도 7 및 도 8 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다.
패스워드 평가 모듈 (1108) 은 추가의 인증 입력 평가 모듈 (1170) 을 옵션으로 포함할 수도 있다. 추가의 인증 입력 평가 모듈 (1170) 은 오디오 패스워드와 조합하여 하나 이상의 추가의 인증 입력들 (1168) 을 고려할 수도 있다. 예를 들어, 오디오 패스워드가 영숫자 코드 또는 지문 스캔과 함께 사용되는 경우에, 강도 스코어는 활용되는 경우에, 오디오 패스워드와 하나 이상의 추가의 인증 입력들의 조합에 의해 제공된 추가의 인증 강도를 반영할 수도 있다. 일부 구성들에서, 전자 디바이스 (1102) (예를 들어, 패스워드 평가 모듈 (1108)) 는 하나 이상의 추가의 인증 입력들 (1168) 을 획득할 수도 있다. 예를 들어, 일부 구성들은 비디오, 자이로/가속도계 센서들, 키보드들, 지문 센서 등과 같은 다른 양식들의 사용을 허용할 수도 있다. 일부 접근방식들에서, 하나 이상의 이러한 양식들은 작은 고유성 또는 구별 강도를 갖는 (어구, 문장 등의) 하나 이상의 부분들에 대해 활용될 수도 있다. 예를 들어, 사용자가 낮은 고유성을 갖는 단어 (예를 들어, 작은 특징적인 스코어를 갖는 "스쿨") 를 발음할 때, 전자 디바이스 (1102) 는 하나 이상의 추가의 인증 입력들 (1168) 을 획득하거나 수신할 수도 있다.
하나 이상의 추가의 인증 입력들 (1168) 의 예들이 아래와 같이 제공된다. 전자 디바이스 (1102) 가 제스처 인식을 갖는 구성들에서, 전자 디바이스 (1102) 는 사용자에 의해 입력된 제스처 (예를 들어, 터치스크린 패턴, 터치패드 패턴, 카메라에 의해 캡처된 시각적 핸드 제스처 패턴 등) 를 수신할 수도 있다. 제스처는 사용자-생성되거나 사전정의될 수도 있다. 전자 디바이스 (1102) 가 카메라를 포함하는 구성들에서, 전자 디바이스 (1102) 는 오디오 신호 (1106) 로 사용자의 얼굴, 눈, 코, 입술, 형상 및/또는 홍채와 같은 더욱 고유한 정보와 같은 사용자의 하나 이상의 이미지들을 캡처할 수도 있다. 예를 들어, 전자 디바이스 (1102) 에 포함된 카메라는 사용자의 얼굴의 모두 또는 일부를 캡처하기 위해 (예를 들어, 사용자에 의해) 포인팅될 수도 있다.
전자 디바이스 (1102) 가 하나 이상의 모션 및/또는 배향 센서들 (예를 들어, 자이로들, 가속도계들, 기울기 센서들 등) 을 포함하는 구성들에서, 전자 디바이스 (1102) 는 모션 및/또는 배향 정보를 획득할 수도 있다. 예를 들어, 사용자는 전자 디바이스 (1102) (예를 들어, 폰) 를 사용자-생성되거나 사전정의된 방식으로 배향하고 그리고/또는 이동시킬 수도 있다. 예를 들어, 전자 디바이스 (1102) 는 오디오 신호 (1106) 와 함께 자이로 및/또는 가속도계 센서 정보를 인코딩할 수도 있다.
전자 디바이스 (1102) 가 물리적 또는 소프트웨어 (예를 들어, 터치스크린 또는 디스플레이 상의) 키패드 또는 키보드를 포함하는 구성들에서, 전자 디바이스 (1102) 는 오디오 신호 (1106) 와 함께 (예를 들어, 사용자에 의해 타이핑된) 수치 코드, 텍스트 및/또는 영숫자 스트링을 수신할 수도 있다. 전자 디바이스 (1102) 가 지문 센서를 포함하는 구성들에서, 전자 디바이스 (1102) 는 (예를 들어, 사용자가 지문 센서를 터치하거나 홀딩할 때) 지문을 수신할 수도 있다.
전자 디바이스 (1102) 가 다중의 마이크로폰들 (1104) 을 포함하는 구성들에서, 전자 디바이스 (1102) 는 오디오 신호 (1106) 의 공간적 방향성 정보를 획득 (예를 들어, 수신 및/또는 결정) 할 수도 있다. 예를 들어, 사용자는 전자 디바이스 (1102) 에 대해 방향들 (예를 들어, 위, 아래, 왼쪽, 오른쪽, 앞, 뒤, 오른쪽 위, 왼쪽 아래 등) 의 시퀀스로 오디오 패스워드를 발화할 수도 있다. 예를 들어, 사용자는 전자 디바이스 (1102) 의 아래를 향해 제 1 단어를 말할 수도 있고, 전자 디바이스 (1102) 의 위를 향해 제 2 단어를 말할 수도 있고, 전자 디바이스 (1102) 의 왼쪽을 향해 제 3 단어를 말할 수도 있으며, 전자 디바이스 (1102) 의 오른쪽을 향해 제 4 단어를 말할 수도 있다.
이하, 공간적 방향성에 관한 추가의 상세가 제공된다. 일부 구성들에서, 전자 디바이스 (1102) 는 보안성을 위해 공간적 오디오의 통합을 활용할 수도 있다. 예를 들어, 전자 디바이스 (1102) 를 잠금해제하기 위해, 사용자는 (예를 들어, 전자 디바이스 (1102) (예를 들어, 폰) 에 관하여) 특정한 공간적 섹터 또는 상이한 공간적 섹터로 시퀀스를 발음할 수도 있다.
전자 디바이스 (1102) (예를 들어, 도 11 에는 도시되지 않은 검증 모듈) 는 (화자 인식으로) 사용자를 식별할 수도 있으며, 공간적 대화 방향들의 시퀀스가 정확한지를 식별할 수도 있다. 충분히 높은 화자 인식 가능성과 정확한 공간적 시퀀스의 조합만이 전자 디바이스 (1102) 를 잠금해제한다. 예를 들어, 전자 디바이스 (1102) 는 아래와 같은 공간적 오디오/화자 인식의 일부 구성들에서 검증을 수행할 수도 있다. 전자 디바이스 (1102) 는 프롬프트를 초기화할 수도 있고, 전자 디바이스 (1102) 의 전면으로부터 발음을 수신할 수도 있고, 전자 디바이스 (1102) 의 왼쪽으로부터 발음을 수신할 수도 있고, 전자 디바이스 (1102) 의 위로부터 발음을 수신할 수도 있으며, 전자 디바이스 (1102) 의 왼쪽으로부터 발음을 수신할 수도 있다. 초기 프롬프트 이후에, (다중의 마이크로폰들을 갖는) 전자 디바이스 (1102) 는 공간적 오디오 픽업의 사전정의된 시퀀스를 제공한다. 이들 구성들에서, 사용자는 오디오 패스워드 (예를 들어, 문장) 를 정확한 공간적 섹터들로 발음할 시퀀스를 알 필요가 있을 수도 있다. 예를 들어, 사용자는: "나의 가장 좋아하는" - 스위치 섹터 - "애완동물의" - 스위치 섹터 - "이름은" - 스위치 섹터 - "바니이다" 라고 말할 수도 있다.
일부 구성들에서, 각각의 공간적 섹터에서 발음의 타이밍 및/또는 지속기간은 검증 절차의 일부 (예를 들어, 앞 섹터에서 2초, 위 섹터에서 5초, 오른쪽 섹터에서 3초 등) 일 수도 있다. 예를 들어, 전자 디바이스 (1102) 는 음성 프롬프트를 통해 또는 버튼 또는 스크린의 누름을 검출함으로써 음성 기록 프로세스를 개시할 수도 있다. 전자 디바이스 (1102) 는 사전정의된 시퀀스 (예를 들어, 활성화된 공간적 섹터들의 시퀀스 및/또는 각각의 공간적 섹터의 타이밍 (지속기간)) 에 따라 상이한 공간적 섹터들에서 청취를 시작할 수도 있다. 전자 디바이스 (1102) 가 각각의 공간적 섹터 (컨텍스트 의존 또는 독립 발음) 에서 참 사용자를 인식하는 경우에, 전자 디바이스 (1102) 는 액세스를 승인한다.
더욱 구체적으로, 전자 디바이스 (1102) 는 아래의 방법 또는 절차에 따라 동작할 수도 있다. 전자 디바이스 (1102) 는 음성 프롬프트로 그리고/또는 (예를 들어, 버튼 또는 터치스크린의) 입력이 수신될 때 음성 기록을 개시할 수도 있다. 전자 디바이스 (1102) 는 사전정의된 시퀀스에 따라 상이한 공간적 시퀀스에서 청취를 시작할 수도 있다. 예를 들어, 전자 디바이스 (1102) 는 활성화된 공간적 섹터들의 시퀀스에서 오디오를 수신할 수도 있다. 일부 구성들에서, 전자 디바이스 (1102) 는 각각의 공간적 섹터에서의 타이밍 (예를 들어, 지속기간) 시퀀스에 따라 오디오를 수신할 수도 있다.
전자 디바이스 (1102) 가 각각의 공간적 섹터 (컨텍스트 의존 또는 독립 발음) 에서 참 사용자 (소망하는 화자) 를 인식하는 경우에, 전자 디바이스 (1102) 는 액세스를 승인한다. 예를 들어, 전자 디바이스 (1102) 는 사용자가 전자 디바이스 (1102) 의 더 많은 기능 (예를 들어, 애플리케이션들, 음성 호출들 등) 에 액세스하는 것을 허용할 수도 있다.
일례에서, 사용자는 디바이스에 대해 하나의 특정한 방향으로부터 패스워드, 패스프레이즈 (passphrase) 또는 단어들의 시퀀스 (예를 들어, "문장") 을 발음할 수도 있다. 다른 예에서, 사용자는 방향들의 시퀀스에서 문장의 부분들을 발음할 수도 있다. 추가로 또는 대안으로, 사용자는 특정한 타이밍으로 문장의 상이한 부분들을 발음하는 것이 요구될 수도 있다. 추가로 또는 대안으로, 다중의 사용자의 음성들이 활용될 수도 있다. 예를 들어, 제 1 사용자가 전자 금고의 왼쪽으로부터 패스워드를 발음할 수도 있는 반면에, 제 2 사용자가 금고를 잠금해제하기 위해 전자 금고의 오른쪽으로부터 패스워드를 발음할 수도 있다. 공간적 오디오 보안 특징이 다른 수단들 (예를 들어, 안면 인식, 지문 인식 등) 과 독립적으로 또는 그와 조합하여 구현될 수도 있다.
일부 구성들에서, 하나 이상의 추가의 인증 입력들과 조합한 오디오 패스워드가 설정될 패스워드 (예를 들어, 하나 이상의 추가의 인증 입력들 (1168) 과의 조합된 오디오 패스워드) 에 대한 다중의 기준을 통과하도록 요구될 수도 있다. 예를 들어, 패스워드 평가 모듈 (1108) 은, 오디오 패스워드가 최소의 고유성을 제공하고, 하나 이상의 추가의 인증 입력들 (1168) 이 하나 이상의 추가의 기준들을 충족한다는 것을 요구할 수도 있다. 고유성 임계치 및/또는 하나 이상의 추가의 기준들은 가중될 수도 있다.
일부 구성들에서, 추가의 인증 입력 평가 모듈 (1170) 은 오디오 신호 (1106) 및/또는 하나 이상의 추가의 인증 입력들 (1168) 에 기초하여 하나 이상의 임계치들을 디스카운트할 수도 있다. 예를 들어, 지문 스캔이 추가의 인증 강도를 제공하는 경우에, 패스워드 평가 모듈 (1108) 은 더 낮은 고유성 임계치 또는 오디오 패스워드 강도를 요구할 수도 있다. 추가로 또는 대안으로, 오디오 신호 (1106) 가 높은 고유성을 제공하는 경우에, 패스워드 평가 모듈 (1108) 은 추가의 인증 입력 (1168) 에 의해 기여된 더 낮은 강도를 요구할 수도 있다. 예를 들어, 오디오 신호 (1106) 가 상대적으로 양호한 고유성을 제공하는 경우에, 패스워드 평가 모듈 (1108) 은 2-자리 수치 코드가 활용되는 것을 제안할 수도 있다. 그러나, 예를 들어, 오디오 신호 (1106) 가 상대적으로 약한 고유성을 제공하는 경우에, 패스워드 평가 모듈 (1108) 은 4-자리 수치 코드 및/또는 지문 스캔이 활용되는 것을 제안할 수도 있다.
하나 이상의 추가의 인증 입력들 (1168) 은 타이밍 및/또는 시퀀스 제약들과 또는 타이밍 및/또는 시퀀스 제약들 없이 활용될 수도 있다. 일부 예들에서, 하나 이상의 추가의 인증 입력들 (1168) 은 오디오 신호 (1106) 가 수신되기 이전에, 수신되는 동안, 또는 수신된 이후 임의의 시간에 전자 디바이스 (1102) 에 의해 획득될 수도 있다.
다른 예들에서, 전자 디바이스 (1102) 는 하나 이상의 추가의 인증 입력들 (1168) 이 특정한 타이밍 제약들로 그리고/또는 오디오 신호 (1106) 의 수신에 대해 특정한 시퀀스로 수신되는 것을 요구할 수도 있다(또는 요구하도록 구성될 수도 있다). 일례에서, 전자 디바이스 (1102) 는 하나 이상의 추가의 인증 입력들 (1168) 이 오디오 신호 (1106) 가 수신되기 이전의, 수신되는 동안 그리고/또는 수신된 이후의 기간 내에 수신되는 것을 요구할 수도 있다(또는 요구하도록 구성될 수도 있다). 예를 들어, 전자 디바이스 (1102) 는 추가의 인증 입력 (1168) 이 오디오 패스워드의 더 약한 스피치 컴포넌트 동안 수신되는 것을 요구할 수도 있다. 추가로 또는 대안으로, 전자 디바이스 (1102) 는 추가의 인증 입력 (1168) 이 특정한 시퀀스로 (예를 들어, 스피치 컴포넌트 이전에, 스피치 컴포넌트 이후에, 스피치 컴포넌트들 사이에, 다른 추가의 인증 입력(들)과 시퀀스로 등) 수신되는 것을 요구할 수도 있다 (또는 요구하도록 구성될 수도 있다). 일부 구성들에서, 전자 디바이스 (1102) 는 하나 이상의 추가의 인증 입력들 (1168) 을 증가하는 복잡성의 순서로 추가할 수도 있다 (그리고/또는 추가하도록 제한할 수도 있다). 추가로 또는 대안으로, 전자 디바이스 (1102) 는, 패스워드 (예를 들어, 하나 이상의 추가의 인증 입력들) 이 최소 요구 강도를 초과할 때까지 하나 이상의 추가의 인증 입력들 (1168) 이 추가되는 것을 요구할 수도 있다.
일부 구성들에서, 패스워드 평가 모듈 (1108) 은 입력 저하 모듈 (1172) 을 옵션으로 포함할 수도 있다. 입력 저하 모듈 (1172) 은 오디오 신호 (1106) 및/또는 추가의 인증 입력(들) (1168) 을 저하시킬 수도 있다. 예를 들어, 패스워드 평가 모듈 (1108) 은 오디오 신호 (1106) 로부터 정보를 제거할 수도 있다 (예를 들어, 오디오 신호 (1106) 의 하나 이상의 부분들을 다운샘플링하고, 필터링할 수도 있다). 추가로 또는 대안으로, 패스워드 평가 모듈 (1108) 은 지문 스캔으로부터 또는 사용자의 얼굴 또는 홍채의 이미지로부터 정보를 제거할 수도 있다.
패스워드 평가 모듈 (1108) 은 평가 정보 (1110) 를 패스워드 피드백 모듈 (1112) 에 제공할 수도 있다. 평가 정보 (1110) 는 패스워드 강도를 나타내는 정보 및/또는 패스워드 평가에서 획득된 정보를 포함할 수도 있다. 예를 들어, 평가 정보 (1110) 는 추출된 특징(들), 고유성 측정치, 패스워드 강도 스코어 및/또는 다른 정보를 포함할 수도 있다.
패스워드 피드백 모듈 (1112) 은 패스워드 피드백 (1114) 을 제공할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (1112), 오디오 패스워드의 강도의 평가에 기초하여 오디오 패스워드가 약하다는 것을 사용자에게 통지할 수도 있다. 패스워드 피드백 (1114) 을 제공하는 것은, 사용자가 충분하게 강한 오디오 패스워드를 결정 (예를 들어, 선택, 제공 또는 생성) 할 수 있게 할 수도 있다. 패스워드 피드백 (1114) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 예를 들어, 패스워드 피드백 (1114) 은, 오디오 패스워드가 약하다는 것을 나타내는 패스워드 강도 스코어 및 메시지를 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (1114) 은 사용자가 더 강한 오디오 패스워드를 생성하기 위해 활용할 수도 있는 하나 이상의 제안된 스피치 컴포넌트들을 포함할 수도 있다. 일부 구성들에서, 전자 디바이스 (1102) 는 패스워드 피드백 (1114) 으로서 제안된 스피치 컴포넌트들로 이루어진 제안된 합성 (예를 들어, 미지의) 단어를 제공할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (1114) 은 사용자가 추가의 인증 입력 (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간 방향성, 추가의 생체특징 (예를 들어, 얼굴 스캔, 홍채 스캔, 지문 등)) 을 제공할 수도 있는 제안된 액션을 포함할 수도 있다.
일부 구성들에서, 패스워드 피드백 모듈 (1112) 은 하나 이상의 패스워드 제안들을 제공할 수도 있다. 예를 들어, 전자 디바이스 (1102) (예를 들어, 패스워드 피드백 모듈 (1112)) 은 충분히 높은 고유성 또는 하나 이상의 다른 모델들 (예를 들어, 일반 스피치 모델, 유니버셜 모델, UBM 등) 으로부터 구별성을 갖는 하나 이상의 스피치 컴포넌트들 (예를 들어, 발음들, 음소들 등) 을 식별할 수도 있다. 예를 들어, 패스워드 피드백 모듈 (1112) 은 한 쌍의 스피치 인식 및 화자 검증 시스템들을 통해 각각의 음소에 대한 사용자의 음성의 고유성에 기초하여 하나 이상의 스피치 컴포넌트들을 식별할 수도 있다. 그 후, 패스워드 피드백 모듈 (1112) 은, 사용자가 하나 이상의 후보 스피치 컴포넌트들을 선택하여 패스워드를 생성할 수도 있도록, 높은 "고유성" 을 갖는 일부 가능한 후보 스피치 컴포넌트(들) (예를 들어, 음소들, 음절들, 발음들, 패스워드들 등) 를 생성할 수도 있다. 예를 들어, 전자 디바이스 (1102) 는 "당신은 /아/, /크/,…, <트라이앵귤러>, <퀄컴>, …, 을 사용할 수 있다" 와 같은 패스워드 피드백 (1114) 을 디스플레이할 수도 있다. 추가로 또는 대안으로, 상세한 패스워드 피드백 (1114) 이 사용자에 의해 발음된 패스워드를 더욱 강화시키기 위해 (예를 들어, "당신의 패스워드는 60% 강도를 갖는다. 발음 /에/ 가 /아/ 로 대체될 수도 있고, ... .") 사용자에 의해 발음된 패스워드에 대해 제공될 수도 있다.
일부 구성들에서, 전자 디바이스 (1102) (예를 들어, 패스워드 피드백 모듈 (1112)) 는 멀티-양식을 갖는 패스워드 제안을 제공할 수도 있다. 상술한 바와 같이, 예를 들어, 패스워드 피드백 모듈 (1112) 은 하나 이상의 추가의 인증 입력들 (1168) (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간 방향성, 추가의 생체특징 (예를 들어, 얼굴 스캔, 홍채 스캔, 지문 등)) 을 제안하는 패스워드 피드백 (1114) 을 제공할 수도 있다.
패스워드 피드백 모듈 (1112) 은 패스워드 피드백 (1114) 을 하나 이상의 출력 디바이스들 (1116) 에 제공할 수도 있다. 이에 따라, 하나 이상의 출력 디바이스들 (1116) 은 패스워드 피드백 (1114) 을 사용자에게 중계하거나 전달할 수도 있다. 예를 들어, 출력 디바이스(들) (1116) (예를 들어, 디스플레이, 터치스크린, 스피커 등) 는 오디오 패스워드의 강도와 연관된 라벨 (1174) 을 중계할 수도 있다. 일부 구성들에서, 이것은 도 1 과 관련하여 상술한 바와 같이 하나 이상의 GUI들을 통해 수행될 수도 있다. 일 접근방식에서, 디스플레이 패널이 패스워드 강도 스코어를 디스플레이할 수도 있다. 추가로 또는 대안으로, 스피커는 패스워드 강도 스코어 (예를 들어, "당신의 패스워드가 약하다", "당신의 패스워드가 60% 강하다" 등) 를 나타내는 음향 신호 (예를 들어, 텍스트-스피치) 를 출력할 수도 있다.
일부 구성들에서, 출력 디바이스(들) (1116) 는 하나 이상의 제안들 (예를 들어, 후보 스피치 컴포넌트(들) (1176), 추가의 인증 입력 옵션(들) (1178) 등) 을 중계할 수도 있다. 예를 들어, 디스플레이 패널은, 음소들, 음절들, 단어들, 발음들 및/또는 어구들 (예를 들어, "/아/, /에/, /크/, /트라이앵귤러/, /미라지/") 과 같은 하나 이상의 제안된 스피치 컴포넌트들을 디스플레이할 수도 있다. 추가로 또는 대안으로, 스피커는 하나 이상의 제안들 (예를 들어, "/아/, /에/, /크/, /트라이앵귤러/, /미라지/ 및/또는 추가의 입력 타입을 당신의 패스워드에 추가하세요") 을 중계하기 위해 음향 신호를 출력할 수도 있다.
보안성을 위한 오디오 패스워드들 (예를 들어, 독립적 오디오 패스워드들 및/또는 공간적 방향성 등과 같은 하나 이상의 추가의 인증 입력들 (1168) 을 갖는 오디오 패스워드들) 의 사용이 (예를 들어, 마이크로폰들 (1104) 의 어레이를 포함할 수도 있는) 다수의 상이한 타입들의 전자 디바이스들 (1102) 에 적용될 수도 있다. 예를 들어, 이러한 보안성 특징은 스마트폰들, 태블릿 디바이스들, 전자 도어 락들, 도어 센서들, 카메라들, 스마트 키들, 랩탑 컴퓨터들, 데스크탑 컴퓨터들, 게임 시스템들, 자동차들, (예를 들어, 거래를 인증하는 방식으로서) 지불 키오스크들, 텔레비전들, 오디오 디바이스들 (예를 들어, mp3 플레이어들, iPod들, 컴팩트 디스크 (CD) 플레이어들 등), 오디오/비디오 디바이스들 (예를 들어, 디지털 비디오 리코더들 (DVR들), 블루-레이 플레이어들, 디지털 다기능 디스크 (DVD) 플레이어들 등), 가전제품들, 서모스탯들, 금고들 등에 적용될 수도 있다. 추가로 또는 대안으로, 이러한 보안성 특징은 (예를 들어, 원격 디바이스에) 원격으로 적용될 수도 있다. 예를 들어, 사용자는 도어 (예를 들어, 홈 도어, 자동차 도어, 사무실 도어 등) 를 잠금해제/잠금하기 위해 전자 도어 락에 인증 크리덴셜들 또는 커맨드를 제공할 수도 있는 스마트폰상에 오디오 패스워드 (예를 들어, 문장, 패스프레이즈, 패스워드 등) 를 제공할 수도 있다. 다른 예에서, 사용자는 웹사이트 인증, 거래 (예를 들어, 구매, 뱅킹) 인증 등을 위한 원격 서버를 인증하기 위해 스마트폰, 랩탑 또는 태블릿상에 공간적 오디오 코드를 제공할 수도 있다.
도 12 는 오디오 패스워드의 강도를 평가하는 방법 (1200) 의 더 구체적인 구성을 예시하는 흐름도이다. 도 1, 도 4 및 도 11 과 관련하여 설명한 전자 디바이스들 (102, 402, 1102) 중 하나 이상이 방법 (1200) 을 수행할 수도 있다.
전자 디바이스 (1102) 는 하나 이상의 마이크로폰들 (1104) 에 의해 캡처된 오디오 신호 (1106) 를 획득할 수도 있다 (1202). 이것은 도 1, 도 2, 도 4, 도 5, 도 6, 도 7, 도 8 및 도 11 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 오디오 신호 (1106) 는 오디오 패스워드를 포함할 수도 있다.
전자 디바이스 (1102) 는 적어도 하나의 추가의 인증 입력 (1168) 을 획득할 수도 있다. 이것은 도면들 (예를 들어, 도 1, 도 4 및 도 11) 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스는 텍스트, 수치 코드, 영숫자 스트링, 공간적 방향성 및/또는 (지문 스캔, 사용자의 얼굴 또는 홍채의 카메라 이미지 등과 같은) 추가의 생체특성과 같은 하나 이상의 추가의 인증 입력들 (1168) 을 획득할 수도 있다 (1204).
전자 디바이스 (1102) 는 오디오 신호 (1106) 및/또는 추가의 인증 입력(들) (1168) 을 옵션으로 저하시킬 수도 있다 (1206). 이것은 도면들 (예를 들어, 도 1, 도 4 및 도 11) 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (1102) 는 오디오 신호 (1106) 로부터 정보를 제거할 수도 있다 (예를 들어, 오디오 신호 (106) 의 하나 이상의 부분들을 다운샘플링하고, 필터링할 수도 있다). 추가로 또는 대안으로, 패스워드 평가 모듈 (1108) 은 지문 스캔으로부터 또는 사용자의 얼굴 또는 홍채의 이미지로부터 정보를 제거할 수도 있다.
전자 디바이스 (1102) 는 적어도 하나의 추가의 인증 입력 (1168) 과 조합하여 오디오 패스워드의 강도를 평가할 수도 있다 (1208). 예를 들어, 전자 디바이스 (1102) 는 오디오 패스워드와 조합하여 하나 이상의 추가의 인증 입력들 (1168) 을 고려할 수도 있다. 예를 들어, 오디오 패스워드가 영숫자 코드 또는 지문 스캔과 함께 사용되는 경우에, 강도 스코어는, 오디오 패스워드와 하나 이상의 추가의 인증 입력들의 조합에 의해 제공된 추가의 인증 강도를 반영할 수도 있다.
전자 디바이스 (1102) 는, 적어도 하나의 추가의 인증 입력 (1168) 과 조합한 오디오 패스워드의 강도가 약한 경우에 패스워드 피드백 (1114) 을 제공할 수도 있다 (1210). 이것은 도 1, 도 2, 도 4, 도 5, 도 6, 도 7, 도 8 및 도 11 중 하나 이상과 관련하여 상술한 바와 같이 수행될 수도 있다. 예를 들어, 전자 디바이스 (1102) 는 적어도 하나의 추가의 인증 입력 (1168) 과 조합하여 오디오 패스워드의 강도의 평가에 기초하여 (예를 들어, 패스워드 강도 스코어가 값 보다 크지 않을 때) 오디오 패스워드가 약하다는 것을 사용자에게 통지할 수도 있다 (1206). 패스워드 피드백 (1114) 은 패스워드 강도 스코어, 하나 이상의 스피치 컴포넌트 후보들 (예를 들어, 권장되거나 제안된 스피치 컴포넌트(들)), 하나 이상의 제안된 액션들 및/또는 하나 이상의 메시지들을 포함할 수도 있다. 예를 들어, 패스워드 피드백 (1114) 은, 오디오 패스워드가 약하다는 것을 나타내는 패스워드 강도 스코어 및 메시지를 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (1114) 은 사용자가 더 강한 오디오 패스워드를 생성하기 위해 활용할 수도 있는 하나 이상의 제안된 스피치 컴포넌트들을 포함할 수도 있다. 추가로 또는 대안으로, 패스워드 피드백 (1114) 은 사용자가 추가의 인증 입력 (1168) (예를 들어, 텍스트, 수치 코드, 영숫자 스트링, 공간 방향성, 추가의 생체특징 (예를 들어, 얼굴 스캔, 홍채 스캔, 지문 등)) 을 제공할 수도 있는 제안된 액션을 포함할 수도 있다.
도 13 은 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들이 구현될 수도 있는 무선 통신 디바이스 (1302) 의 일 구성을 예시하는 블록도이다. 도 13 에 예시된 무선 통신 디바이스 (1302) 는 본 명세서에 설명한 전자 디바이스들 (102, 402, 1102) 중 하나 이상의 예일 수도 있다. 무선 통신 디바이스 (1302) 는 애플리케이션 프로세서 (1384) 를 포함할 수도 있다. 애플리케이션 프로세서 (1384) 는 무선 통신 디바이스 (1302) 상에서 기능들을 수행하기 위해 명령들을 일반적으로 프로세싱한다 (예를 들어, 프로그램들을 구동한다). 애플리케이션 프로세서 (1384) 는 오디오 코더/디코더 (코덱) (1382) 에 결합될 수도 있다.
오디오 코덱 (1382) 은 오디오 신호들을 코딩하고 그리고/또는 디코딩하기 위해 사용될 수도 있다. 오디오 코덱 (1382) 은 적어도 하나의 스피커 (1335), 이어피스 (1337), 출력 잭 (1339) 및/또는 적어도 하나의 마이크로폰 (1380) 에 결합될 수도 있다. 스피커들 (1335) 은 전기 또는 전자 신호들을 음향 신호들로 변환하는 하나 이상의 전기 음향 트랜스듀서들을 포함할 수도 있다. 예를 들어, 스피커들 (1335) 은 음악을 재생하거나 스피커폰 대화 등을 출력하기 위해 사용될 수도 있다. 이어피스 (1337) 는 음향 신호들 (예를 들어, 스피치 신호들) 을 사용자에게 출력하기 위해 사용될 수 있는 다른 스피커 또는 전기 음향 트랜스듀서일 수도 있다. 예를 들어, 이어피스 (1337) 는 사용자만이 음향 신호를 신뢰가능하게 들을 수도 있도록 사용될 수도 있다. 출력 잭 (1339) 은 다른 디바이스들을 헤드폰들과 같은 오디오를 출력하는 무선 통신 디바이스 (1302) 에 결합하기 위해 사용될 수도 있다. 스피커들 (1335), 이어피스 (1337) 및/또는 출력 잭 (1339) 은 오디오 코덱 (1382) 으로부터 오디오 신호를 출력하기 위해 일반적으로 사용될 수도 있다. 적어도 하나의 마이크로폰 (1380) 은 (사용자의 음성과 같은) 음향 신호를 오디오 코덱 (1382) 에 제공되는 전기 또는 전자 신호들로 변환하는 음향 전기 트랜스듀서일 수도 있다.
일부 구성들에서, 오디오 코덱 (1382) 은 패스워드 평가 모듈 (1308a) 및 패스워드 피드백 모듈 (1312a) 을 포함할 수도 있다. 추가로 또는 대안으로, 애플리케이션 프로세서 (1384) 는 패스워드 평가 모듈 (1308b) 및 패스워드 피드백 모듈 (1312b) 을 포함할 수도 있다. 패스워드 평가 모듈(들) (1308a-b) 및/또는 패스워드 피드백 모듈(들) (1312a-b) 은 도 1, 도 4 및 도 11 중 하나 이상과 관련하여 상술한 패스워드 평가 모듈(들) (108, 408, 1108) 및/또는 패스워드 피드백 모듈(들) (112, 412, 1112) 의 예들일 수도 있다. 다른 구성들에서, 패스워드 평가 모듈 (1308a) 및 패스워드 피드백 모듈 (1312a) 중 하나 이상은 오디오 코덱 (1382) 및 애플리케이션 프로세서 (1384) 로부터 별개로 무선 통신 디바이스 (1302) 상에서 구현될 수도 있다.
애플리케이션 프로세서 (1384) 는 전력 관리 회로 (1394) 에 또한 결합될 수도 있다. 전력 관리 회로 (1394) 의 일례가, 무선 통신 디바이스 (1302) 의 전력 소모를 관리기 위해 사용될 수도 있는 전력 관리 집적 회로 (PMIC) 이다. 전력 관리 회로 (1394) 는 배터리 (1396) 에 결합될 수도 있다. 배터리 (1396) 는 전력을 무선 통신 디바이스 (1302) 에 일반적으로 제공할 수도 있다. 예를 들어, 배터리 (1396) 및/또는 전력 관리 회로 (1394) 는 무선 통신 디바이스 (1302) 에 포함된 엘리먼트들 중 적어도 하나에 결합될 수도 있다.
애플리케이션 프로세서 (1384) 는 입력을 수신하는 적어도 하나의 입력 디바이스 (1398) 에 결합될 수도 있다. 입력 디바이스들 (1398) 의 예들이 적외선 센서들, 이미지 센서들, 가속도계들, 터치 센서들, 키패드들 등을 포함한다. 입력 디바이스들 (1398) 은 무선 통신 디바이스 (1302) 와의 사용자 상호작용을 허용할 수도 있다. 애플리케이션 프로세서 (1384) 는 하나 이상의 출력 디바이스들 (1301) 에 또한 결합될 수도 있다. 출력 디바이스들 (1301) 의 예들이 프린터들, 프로젝터들, 스크린들, 햅틱 디바이스들 등을 포함한다. 출력 디바이스들 (1301) 은 무선 통신 디바이스 (1302) 가 사용자가 경험할 수도 있는 출력을 생성하게 할 수도 있다.
애플리케이션 프로세서 (1384) 는 애플리케이션 메모리 (1303) 에 결합될 수도 있다. 애플리케이션 메모리 (1303) 는 전자 정보를 저장할 수 있는 임의의 전자 디바이스일 수도 있다. 애플리케이션 메모리 (1303) 의 예들이, 더블 데이터 레이트 동기 동적 랜덤 액세스 메모리 (DDRAM), 동기 동적 랜덤 액세스 메모리 (SDRAM), 플래시 메모리 등을 포함한다. 애플리케이션 메모리 (1303) 는 애플리케이션 프로세서 (1384) 에 대한 저장부를 제공할 수도 있다. 예를 들어, 애플리케이션 메모리 (1303) 는 애플리케이션 프로세서 (1384) 상에서 구동되는 프로그램들의 기능을 위한 데이터 및/또는 명령들을 저장할 수도 있다.
애플리케이션 프로세서 (1384) 는 디스플레이 (1307) 에 차례로 결합될 수도 있는 디스플레이 제어기 (1305) 에 결합될 수도 있다. 디스플레이 제어기 (1305) 는 디스플레이 (1307) 상에 이미지들을 생성하기 위해 사용되는 하드웨어 블록일 수도 있다. 예를 들어, 디스플레이 제어기 (1305) 은 명령들 및/또는 데이터를 애플리케이션 프로세서 (1384) 로부터 디스플레이 (1307) 상에 제공될 수 있는 이미지들로 전환할 수도 있다. 디스플레이 (1307) 의 예들은, 액정 디스플레이 (LCD) 패널들, 발광 다이오드 (LED) 패널들, 음극선관 (CRT) 디스플레이들, 플라즈마 디스플레이들 등을 포함한다.
애플리케이션 프로세서 (1384) 는 기저대역 프로세서 (1386) 에 결합될 수도 있다. 기저대역 프로세서 (1386) 는 통신 신호들을 일반적으로 프로세싱한다. 예를 들어, 기저대역 프로세서 (1386) 는 수신된 신호들을 복조하고 그리고/또는 디코딩할 수도 있다. 추가로 또는 대안으로, 기저대역 프로세서 (1386) 는 송신의 준비로 신호들을 인코딩하고 그리고/또는 변조할 수도 있다.
기저대역 프로세서 (1386) 는 기저대역 메모리 (1309) 에 결합될 수도 있다. 기저대역 메모리 (1309) 는 SDRAM, DDRAM 플래시 메모리 등과 같은 전자 정보를 저장할 수 있는 임의의 전자 디바이스일 수도 있다. 기저대역 프로세서 (1386) 는 기저대역 메모리 (1309) 로부터 정보 (예를 들어, 명령들 및/또는 데이터) 를 판독할 수도 있고 그리고/또는 기저대역 메모리 (1309) 에 정보를 기입할 수도 있다. 추가로 또는 대안으로, 기저대역 프로세서 (1386) 는 통신 동작들을 수행하기 위해 기저대역 메모리 (1309) 에 저장된 명령들 및/또는 데이터를 사용할 수도 있다.
기저대역 프로세서 (1386) 는 무선 주파수 (RF) 트랜시버 (1388) 에 결합될 수도 있다. RF 트랜시버 (1388) 는 전력 증폭기 (1390) 및 하나 이상의 안테나들 (1392) 에 결합될 수도 있다. RF 트랜시버 (1388) 는 무선 주파수 신호들을 송신하고 그리고/또는 수신할 수도 있다. 예를 들어, RF 트랜시버 (1388) 는 전력 증폭기 (1390) 및 적어도 하나의 안테나 (1392) 를 사용하여 RF 신호를 송신할 수도 있다. RF 트랜시버 (1388) 는 하나 이상의 안테나들 (1392) 을 사용하여 RF 신호들을 또한 수신할 수도 있다.
도 14 는 전자 디바이스 (1402) 에서 활용될 수도 있는 다양한 컴포넌트들을 예시한다. 예시된 컴포넌트들은 동일한 물리적 구조 내에 또는 개별 하우징들 또는 구조들에 위치될 수도 있다. 도 14 와 관련하여 설명하는 전자 디바이스 (1402) 는 본 명세서에 설명한 전자 디바이스들 (102, 402, 1102) 및 무선 통신 디바이스 (1302) 중 하나 이상에 따라 구현될 수도 있다. 전자 디바이스 (1402) 는 프로세서 (1407) 를 포함한다. 프로세서 (1417) 는 범용 단일 또는 멀티-칩 마이크로프로세서 (예를 들어, ARM), 특수용 마이크로프로세서 (예를 들어, 디지털 신호 프로세서 (DSP)), 마이크로제어기, 프로그램가능한 게이트 어레이 등일 수도 있다. 프로세서 (1417) 는 중앙 처리 장치 (CPU) 로서 지칭될 수도 있다. 단일 프로세서 (1417) 만이 도 14 의 전자 디바이스 (1402) 에 도시되어 있지만, 대안의 구성에서는, 프로세서들 (예를 들어, ARM 및 DSP) 의 조합이 사용될 수 있다.
전자 디바이스 (1402) 는 프로세서 (1417) 와 통신하는 메모리 (1411) 를 또한 포함한다. 즉, 프로세서 (1417) 는 메모리 (1411) 로부터 정보를 판독할 수 있고 그리고/또는 메모리 (1411) 에 정보를 기입할 수 있다. 메모리 (1411) 는 전자 정보를 저장할 수 있는 임의의 전자 컴포넌트일 수도 있다. 메모리 (1411) 는 랜덤 액세스 메모리 (RAM), 판독 전용 메모리 (ROM), 자기 디스크 저장 매체, 광학 저장 매체, RAM 에서의 플래시 메모리 디바이스들, 프로세서에 포함된 온-보드 메모리, 프로그램가능한 판독 전용 메모리 (PROM), 소거가능한 프로그램가능 판독 전용 메모리 (EPROM), 전기적으로 소거가능한 PROM (EEPROM), 레지스터들 등일 수도 있고, 이들의 조합들을 포함한다.
데이터 (1415a) 및 명령들 (1413a) 이 메모리 (1411) 에 저장될 수도 있다. 명령들 (1413a) 은 하나 이상의 프로그램들, 루틴들, 서브-루틴들, 함수들, 절차들 등을 포함할 수도 있다. 명령들 (1413a) 은 단일 컴퓨터 판독가능 구문 또는 다수의 컴퓨터 판독가능 구문들을 포함할 수도 있다. 명령들 (1413a) 은 상술한 방법들, 기능들 및 절차들 중 하나 이상을 구현하기 위해 프로세서 (1417) 에 의해 실행가능할 수도 있다. 명령들 (1413a) 을 실행하는 것은, 메모리 (1411) 에 저장된 데이터 (1415a) 의 사용을 수반할 수도 있다. 도 14 는 (명령들 (1413a) 및 데이터 (1415a) 로부터 올 수도 있는) 일부 명령들 (1413b) 및 데이터 (1415b) 가 프로세서 (1417) 에 로딩되는 것을 도시한다.
전자 디바이스 (1402) 는 다른 전자 디바이스들과 통신하는 하나 이상의 통신 인터페이스들 (1421) 을 또한 포함할 수도 있다. 통신 인터페이스들 (1421) 은 유선 통신 기술, 무선 통신 기술, 또는 양자에 기초할 수도 있다. 상이한 타입들의 통신 인터페이스들 (1421) 의 예는, 직렬 포트, 병렬 포트, 유니버셜 시리얼 버스 (USB), 이더넷 어댑터, 전기 전자 기술자 협회 (IEEE) 1494 버스 인터페이스, 소형 컴퓨터 시스템 인터페이스 (SCSI) 버스 인터페이스, 적외선 (IR) 통신 포트, 블루투스 무선 통신 어댑터, 3세대 파트너쉽 프로젝트 (3GPP) 트랜시버, IEEE 802. 11 ("Wi-Fi") 트랜시버 등을 포함한다. 예를 들어, 통신 인터페이스 (1421) 는 무선 신호들을 송신하고 수신하는 하나 이상의 안테나들 (미도시) 에 결합될 수도 있다.
전자 디바이스 (1402) 는 하나 이상의 입력 디바이스들 (1423) 및 하나 이상의 출력 디바이스들 (1427) 을 포함할 수도 있다. 상이한 종류의 입력 디바이스들 (1423) 의 예들은, 키보드, 마우스, 마이크로폰, 원격 제어 디바이스, 버튼, 조이스틱, 트랙볼, 터치패드, 라이트펜 등을 포함한다. 예를 들어, 전자 디바이스 (1402) 는 오디오 신호들을 캡처하는 하나 이상의 마이크로폰들 (1425) 을 포함할 수도 있다. 일 구성에서, 마이크로폰 (1425) 은 음향 신호들 (예를 들어, 음성, 스피치) 을 전기 또는 전자 신호들로 변환하는 트랜스듀서일 수도 있다. 상이한 종류의 출력 디바이스들 (1427) 의 예들이 스피커, 프린터 등을 포함한다. 예를 들어, 전자 디바이스 (1402) 는 하나 이상의 스피커들 (1429) 을 포함할 수도 있다. 일 구성에서, 스피커 (1429) 는 전기 또는 전자 신호들을 음향 신호들로 변환하는 트랜스듀서일 수도 있다. 전자 디바이스 (1402) 에 통상적으로 포함될 수도 있는 하나의 특정한 타입의 출력 디바이스가 디스플레이 디바이스 (1431) 이다. 본 명세서에 개시된 구성들과 사용되는 디스플레이 디바이스 (1431) 는 음극선관 (CRT), 액정 디스플레이 (LCD), 발광 다이오드 (LED), 가스 플라즈마 전기 발광 등과 같은 임의의 적합한 이미지 프로젝션 기술을 활용할 수도 있다. 메모리 (1411) 에 저장된 데이터를 디스플레이 디바이스 (1431) 상에 도시된 텍스트, 그래픽, 및/또는 동영상들 (적절한 경우) 로 변환하는 디스플레이 제어기 (1433) 또한 제공될 수도 있다.
전자 디바이스 (1402) 의 다양한 컴포넌트들이 전력 버스, 제어 신호 버스, 상태 신호 버스, 데이터 버스 등을 포함할 수도 있는 하나 이상의 버스들에 의해 함께 결합될 수도 있다. 간략화를 위해, 다양한 버스들은 도 14 에 버스 시스템 (1419) 으로서 예시된다. 도 14 가 전자 디바이스 (1402) 의 단지 하나의 가능한 구성을 예시한다는 것에 유의해야 한다. 다양한 다른 아키텍처들 및 컴포넌트들이 활용될 수도 있다.
상기 설명에 있어서, 참조부호들은 종종, 다양한 용어들과 관련하여 사용되었다. 용어가 참조부호와 관련하여 사용된 경우, 이는, 도면들 중 하나 이상에 도시된 특정 엘리먼트를 지칭하도록 의도될 수도 있다. 용어가 참조부호 없이 사용된 경우, 이는, 그 용어를 임의의 특정 도면으로의 한정없이 일반적으로 지칭하도록 의도될 수도 있다.
용어 "결정하는 것" 은 매우 다양한 액션들을 포괄하며, 따라서, "결정하는 것" 은 계산하는 것, 산출하는 것, 프로세싱하는 것, 도출하는 것, 조사하는 것, 검색하는 것 (예를 들어, 표, 데이터베이스, 또는 다른 데이터 구조에서 검색하는 것), 확인하는 것 등을 포함할 수 있다. 또한, "결정하는 것" 은 수신하는 것 (예를 들어, 정보를 수신하는 것), 액세스하는 것 (예를 들어, 메모리 내 데이터에 액세스하는 것) 등을 포함할 수 있다. 또한, "결정하는 것" 은 해결하는 것, 선택하는 것, 선출하는 것, 확립하는 것 등을 포함할 수 있다.
어구 "~에 기초하는" 은, 달리 명백히 명시되지 않으면, "~에만 기초하는" 을 의미하지 않는다. 즉, 어구 "~에 기초하는" 은 "~에만 기초하는" 및 "~에 적어도 기초하는" 양자를 기술한다.
본 명세서에 설명한 구성들 중 어느 하나와 관련하여 설명한 특징들, 기능들, 절차들, 컴포넌트들, 엘리먼트들, 구조들 등 중 하나 이상이, 호환가능한 경우에, 본 명세서 설명한 다른 구성들 중 임의의 것과 관련하여 설명한 기능들, 절차들, 컴포넌트들, 엘리먼트들, 절차들 등 중 하나 이상과 조합될 수도 있다는 것에 유의해야 한다. 즉, 본 명세서에 설명한 기능들, 절차들, 컴포넌트들, 엘리먼트들 등 중 임의의 호환가능한 조합이 본 명세서에 개시된 시스템들 및 방법들에 따라 구현될 수도 있다.
본 명세서에서 설명된 기능들은 프로세서 판독가능 또는 컴퓨터 판독가능 매체 상에 하나 이상의 명령들로서 저장될 수도 있다. 용어 "컴퓨터 판독가능 매체" 는, 컴퓨터 또는 프로세서에 의해 액세스될 수 있는 임의의 가용 매체를 지칭한다. 한정이 아닌 예로서, 그러한 매체는 RAM, ROM, EEPROM, 플래시 메모리, CD-ROM 또는 다른 광학 디스크 저장부, 자기 디스크 저장부 또는 다른 자기 저장 디바이스들, 또는 원하는 프로그램 코드를 명령들 또는 데이터 구조들의 형태로 저장하는데 이용될 수 있고 컴퓨터에 의해 액세스될 수 있는 임의의 다른 매체를 포함할 수도 있다 본 명세서에서 사용된 바와 같은 디스크 (disk) 및 디스크 (disc) 는 컴팩트 디스크 (CD), 레이저 디스크, 광학 디스크, 디지털 다기능 디스크 (DVD), 플로피 디스크 및 블루레이® 디스크를 포함하며, 여기서, 디스크 (disk) 는 통상적으로 데이터를 자기적으로 재생하지만 디스크 (disc) 는 레이저를 이용하여 데이터를 광학적으로 재생한다. 컴퓨터 판독가능 매체는 유형의 및 비-일시적일 수도 있음을 주목해야 한다. 용어 "컴퓨터 프로그램 제품" 은, 컴퓨팅 디바이스 또는 프로세서에 의해 실행, 프로세싱, 또는 산출될 수도 있는 코드 또는 명령들 (예를 들어, "프로그램") 과 결합한 컴퓨팅 디바이스 또는 프로세서를 지칭한다. 본 명세서에서 사용된 바와 같이, 용어 "코드" 는 컴퓨팅 디바이스 또는 프로세서에 의해 실행가능한 소프트웨어, 명령들, 코드 또는 데이터를 지칭할 수도 있다.
소프트웨어 또는 명령들은 또한 송신 매체 상으로 송신될 수도 있다. 예를 들어, 동축 케이블, 광섬유 케이블, 꼬임쌍선, 디지털 가입자 라인 (DSL), 또는 적외선, 무선, 및 마이크로파와 같은 무선 기술들을 이용하여 웹사이트, 서버, 또는 다른 원격 소스로부터 소프트웨어가 송신된다면, 동축 케이블, 광섬유 케이블, 꼬임쌍선, DSL, 또는 적외선, 무선, 및 마이크로파와 같은 무선 기술들은 매체의 정의에 포함된다.
본 명세서에 개시된 방법들은 설명된 방법을 달성하기 위한 하나 이상의 단계들 또는 액션들을 포함한다 그 방법 단계들 및/또는 액션들은 청구항들의 범위로부터 일탈함없이 서로 대체될 수도 있다. 즉, 단계들 또는 액션들의 특정 순서가, 설명되고 있는 방법의 적절한 동작을 위해 필수적이지 않다면, 특정 단계들 및/또는 액션들의 순서 및/또는 그 사용은 청구항들의 범위로부터 일탈함없이 변경될 수도 있다
청구항들은 상기 예시된 정확한 구성 및 컴포넌트들로 한정되지 않음을 이해해야 한다. 다양한 변형들, 변경들 및 변이들이 청구항들의 범위로부터 일탈함없이, 본 명세서에서 설명된 시스템들, 방법들, 및 장치의 배열, 동작 및 상세들에서 행해질 수도 있다.
Claims (30)
- 전자 디바이스에 의해 오디오 패스워드의 강도를 평가하는 방법으로서,
하나 이상의 마이크로폰들에 의해 캡처된 오디오 신호를 획득하는 단계로서, 상기 오디오 신호는 상기 오디오 패스워드를 포함하는, 상기 오디오 신호를 획득하는 단계;
상기 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 상기 오디오 패스워드의 상기 강도를 평가하는 단계; 및
상기 오디오 패스워드의 상기 강도의 상기 평가에 기초하여 상기 오디오 패스워드가 약하다는 것을 사용자에게 통지하는 단계를 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
상기 오디오 신호는 적어도 하나의 스피치 컴포넌트를 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
상기 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것은 일반 스피치 모델에 기초하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
상기 사용자에게 통지하는 단계는 상기 오디오 패스워드의 상기 강도와 연관된 라벨을 디스플레이하는 단계를 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
상기 사용자에게 통지하는 단계는 패스워드 강도 스코어를 디스플레이하는 단계를 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
패스워드 강도 스코어를 다른 값과 비교하는 단계를 더 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 6 항에 있어서,
상기 다른 값은 임계치 또는 이전의 패스워드 강도 스코어인, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
상기 사용자에게 통지하는 단계는 적어도 하나의 후보 스피치 컴포넌트를 디스플레이하는 단계를 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
적어도 하나의 추가의 인증 입력을 획득하는 단계를 더 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 9 항에 있어서,
상기 오디오 신호 및 상기 추가의 인증 입력 중 적어도 하나를 저하시키는 단계를 더 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 제 1 항에 있어서,
지리적 위치, 사용자 나이, 사용자 성 (gender), 사용자 언어, 및 지역 방언 중 하나 이상에 기초하여 일반 스피치 모델을 업데이트하는 단계를 더 포함하는, 오디오 패스워드의 강도를 평가하는 방법. - 오디오 패스워드의 강도를 평가하는 전자 디바이스로서,
오디오 신호를 캡처하는 하나 이상의 마이크로폰들로서, 상기 오디오 신호는 상기 오디오 패스워드를 포함하는, 상기 하나 이상의 마이크로폰들;
상기 하나 이상의 마이크로폰들에 결합된 패스워드 평가 회로로서, 상기 패스워드 평가 회로는 상기 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 상기 오디오 패스워드의 상기 강도를 평가하는, 상기 패스워드 평가 회로; 및
상기 패스워드 평가 회로에 결합된 패스워드 피드백 회로로서, 상기 패스워드 피드백 회로는 상기 오디오 패스워드의 상기 강도의 상기 평가에 기초하여 상기 오디오 패스워드가 약하다는 것을 사용자에게 통지하는, 상기 패스워드 피드백 회로를 포함하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 오디오 신호는 적어도 하나의 스피치 컴포넌트를 포함하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것은 일반 스피치 모델에 기초하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 사용자에게 통지하는 것은 상기 오디오 패스워드의 상기 강도와 연관된 라벨을 디스플레이하는 것을 포함하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 사용자에게 통지하는 것은 패스워드 강도 스코어를 디스플레이하는 것을 포함하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 패스워드 평가 회로는 추가로, 패스워드 강도 스코어를 다른 값과 비교하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 17 항에 있어서,
상기 다른 값은 임계치 또는 이전의 패스워드 강도 스코어인, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 사용자에게 통지하는 것은 적어도 하나의 후보 스피치 컴포넌트를 디스플레이하는 것을 포함하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 패스워드 평가 회로에 결합된 하나 이상의 입력 디바이스들을 더 포함하며,
상기 하나 이상의 입력 디바이스들은 적어도 하나의 추가의 인증 입력을 획득하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 20 항에 있어서,
상기 패스워드 평가 회로는 추가로, 상기 오디오 신호 및 상기 추가의 인증 입력 중 적어도 하나를 저하시키는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 제 12 항에 있어서,
상기 패스워드 평가 회로는 추가로, 지리적 위치, 사용자 나이, 사용자 성, 사용자 언어, 및 지역 방언 중 하나 이상에 기초하여 일반 스피치 모델을 업데이트하는, 오디오 패스워드의 강도를 평가하는 전자 디바이스. - 명령들을 갖는 비일시적인 유형의 컴퓨터 판독가능 매체를 포함하는, 오디오 패스워드의 강도를 평가하는 컴퓨터 프로그램 제품으로서,
상기 명령들은,
전자 디바이스로 하여금 하나 이상의 마이크로폰들에 의해 캡처된 오디오 신호를 획득하게 하기 위한 코드로서, 상기 오디오 신호는 상기 오디오 패스워드를 포함하는, 상기 오디오 신호를 획득하게 하기 위한 코드;
상기 전자 디바이스로 하여금 상기 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 상기 오디오 패스워드의 상기 강도를 평가하게 하기 위한 코드; 및
상기 전자 디바이스로 하여금 상기 오디오 패스워드의 상기 강도의 상기 평가에 기초하여 상기 오디오 패스워드가 약하다는 것을 사용자에게 통지하게 하기 위한 코드를 포함하는, 비일시적인 유형의 컴퓨터 판독가능 매체를 포함하는 컴퓨터 프로그램 제품. - 제 23 항에 있어서,
상기 사용자에게 통지하는 것은 상기 오디오 패스워드의 상기 강도와 연관된 라벨을 디스플레이하는 것을 포함하는, 비일시적인 유형의 컴퓨터 판독가능 매체를 포함하는 컴퓨터 프로그램 제품. - 제 23 항에 있어서,
상기 사용자에게 통지하는 것은 적어도 하나의 후보 스피치 컴포넌트를 디스플레이하는 것을 포함하는, 비일시적인 유형의 컴퓨터 판독가능 매체를 포함하는 컴퓨터 프로그램 제품. - 제 23 항에 있어서,
상기 전자 디바이스로 하여금 적어도 하나의 추가의 인증 입력을 획득하게 하기 위한 코드를 더 포함하는, 비일시적인 유형의 컴퓨터 판독가능 매체를 포함하는 컴퓨터 프로그램 제품. - 오디오 패스워드의 강도를 평가하는 장치로서,
오디오 신호를 획득하는 수단으로서, 상기 오디오 신호는 상기 오디오 패스워드를 포함하는, 상기 오디오 신호를 획득하는 수단;
상기 오디오 신호의 하나 이상의 고유 특징들을 측정하는 것에 기초하여 상기 오디오 패스워드의 상기 강도를 평가하는 수단; 및
상기 오디오 패스워드의 상기 강도의 상기 평가에 기초하여 상기 오디오 패스워드가 약하다는 것을 사용자에게 통지하는 수단을 포함하는, 오디오 패스워드의 강도를 평가하는 장치. - 제 27 항에 있어서,
상기 사용자에게 통지하는 것은 상기 오디오 패스워드의 상기 강도와 연관된 라벨을 디스플레이하는 것을 포함하는, 오디오 패스워드의 강도를 평가하는 장치. - 제 27 항에 있어서,
상기 사용자에게 통지하는 것은 적어도 하나의 후보 스피치 컴포넌트를 디스플레이하는 것을 포함하는, 오디오 패스워드의 강도를 평가하는 장치. - 제 27 항에 있어서,
적어도 하나의 추가의 인증 입력을 획득하는 수단을 더 포함하는, 오디오 패스워드의 강도를 평가하는 장치.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/172,619 US10157272B2 (en) | 2014-02-04 | 2014-02-04 | Systems and methods for evaluating strength of an audio password |
| US14/172,619 | 2014-02-04 | ||
| PCT/US2015/013126 WO2015119806A1 (en) | 2014-02-04 | 2015-01-27 | Systems and methods for evaluating strength of an audio password |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20160115944A true KR20160115944A (ko) | 2016-10-06 |
Family
ID=52469335
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167023068A KR20160115944A (ko) | 2014-02-04 | 2015-01-27 | 오디오 패스워드의 강도를 평가하는 시스템들 및 방법들 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US10157272B2 (ko) |
| EP (1) | EP3103050A1 (ko) |
| JP (1) | JP6452708B2 (ko) |
| KR (1) | KR20160115944A (ko) |
| CN (1) | CN105940407B (ko) |
| WO (1) | WO2015119806A1 (ko) |
Families Citing this family (81)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9318108B2 (en) | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| US8977255B2 (en) | 2007-04-03 | 2015-03-10 | Apple Inc. | Method and system for operating a multi-function portable electronic device using voice-activation |
| US8676904B2 (en) | 2008-10-02 | 2014-03-18 | Apple Inc. | Electronic devices with voice command and contextual data processing capabilities |
| US10255566B2 (en) | 2011-06-03 | 2019-04-09 | Apple Inc. | Generating and processing task items that represent tasks to perform |
| US10276170B2 (en) | 2010-01-18 | 2019-04-30 | Apple Inc. | Intelligent automated assistant |
| US10417037B2 (en) | 2012-05-15 | 2019-09-17 | Apple Inc. | Systems and methods for integrating third party services with a digital assistant |
| DE112014000709B4 (de) | 2013-02-07 | 2021-12-30 | Apple Inc. | Verfahren und vorrichtung zum betrieb eines sprachtriggers für einen digitalen assistenten |
| US10652394B2 (en) | 2013-03-14 | 2020-05-12 | Apple Inc. | System and method for processing voicemail |
| US10748529B1 (en) | 2013-03-15 | 2020-08-18 | Apple Inc. | Voice activated device for use with a voice-based digital assistant |
| US10176167B2 (en) | 2013-06-09 | 2019-01-08 | Apple Inc. | System and method for inferring user intent from speech inputs |
| EP3937002A1 (en) | 2013-06-09 | 2022-01-12 | Apple Inc. | Device, method, and graphical user interface for enabling conversation persistence across two or more instances of a digital assistant |
| DE112014003653B4 (de) | 2013-08-06 | 2024-04-18 | Apple Inc. | Automatisch aktivierende intelligente Antworten auf der Grundlage von Aktivitäten von entfernt angeordneten Vorrichtungen |
| US20150255068A1 (en) * | 2014-03-10 | 2015-09-10 | Microsoft Corporation | Speaker recognition including proactive voice model retrieval and sharing features |
| CN103841108B (zh) * | 2014-03-12 | 2018-04-27 | 北京天诚盛业科技有限公司 | 用户生物特征的认证方法和系统 |
| US10170123B2 (en) | 2014-05-30 | 2019-01-01 | Apple Inc. | Intelligent assistant for home automation |
| TWI566107B (zh) | 2014-05-30 | 2017-01-11 | 蘋果公司 | 用於處理多部分語音命令之方法、非暫時性電腦可讀儲存媒體及電子裝置 |
| US9715875B2 (en) | 2014-05-30 | 2017-07-25 | Apple Inc. | Reducing the need for manual start/end-pointing and trigger phrases |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| KR20160026317A (ko) * | 2014-08-29 | 2016-03-09 | 삼성전자주식회사 | 음성 녹음 방법 및 장치 |
| CN104616655B (zh) * | 2015-02-05 | 2018-01-16 | 北京得意音通技术有限责任公司 | 声纹模型自动重建的方法和装置 |
| US9977884B2 (en) * | 2015-02-27 | 2018-05-22 | Plantronics, Inc. | Authentication server for a probability-based user authentication system and method |
| US9886953B2 (en) | 2015-03-08 | 2018-02-06 | Apple Inc. | Virtual assistant activation |
| US10460227B2 (en) | 2015-05-15 | 2019-10-29 | Apple Inc. | Virtual assistant in a communication session |
| US10200824B2 (en) | 2015-05-27 | 2019-02-05 | Apple Inc. | Systems and methods for proactively identifying and surfacing relevant content on a touch-sensitive device |
| US20160378747A1 (en) | 2015-06-29 | 2016-12-29 | Apple Inc. | Virtual assistant for media playback |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US10740384B2 (en) | 2015-09-08 | 2020-08-11 | Apple Inc. | Intelligent automated assistant for media search and playback |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US10331312B2 (en) | 2015-09-08 | 2019-06-25 | Apple Inc. | Intelligent automated assistant in a media environment |
| US11587559B2 (en) | 2015-09-30 | 2023-02-21 | Apple Inc. | Intelligent device identification |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10956666B2 (en) | 2015-11-09 | 2021-03-23 | Apple Inc. | Unconventional virtual assistant interactions |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| US10510350B2 (en) * | 2016-03-30 | 2019-12-17 | Lenovo (Singapore) Pte. Ltd. | Increasing activation cue uniqueness |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| CN107579947A (zh) * | 2016-07-05 | 2018-01-12 | 中兴通讯股份有限公司 | 一种访客终端的控制方法、装置、服务器及移动终端 |
| KR102575634B1 (ko) * | 2016-07-26 | 2023-09-06 | 삼성전자주식회사 | 전자 장치 및 전자 장치의 동작 방법 |
| EP3287921B1 (en) * | 2016-08-26 | 2020-11-04 | Nxp B.V. | Spoken pass-phrase suitability determination |
| US9852287B1 (en) | 2016-10-04 | 2017-12-26 | International Business Machines Corporation | Cognitive password pattern checker to enforce stronger, unrepeatable passwords |
| US10672403B2 (en) * | 2017-02-07 | 2020-06-02 | Pindrop Security, Inc. | Age compensation in biometric systems using time-interval, gender and age |
| US10726832B2 (en) | 2017-05-11 | 2020-07-28 | Apple Inc. | Maintaining privacy of personal information |
| DK180048B1 (en) | 2017-05-11 | 2020-02-04 | Apple Inc. | MAINTAINING THE DATA PROTECTION OF PERSONAL INFORMATION |
| DK201770428A1 (en) | 2017-05-12 | 2019-02-18 | Apple Inc. | LOW-LATENCY INTELLIGENT AUTOMATED ASSISTANT |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| DK201770411A1 (en) | 2017-05-15 | 2018-12-20 | Apple Inc. | MULTI-MODAL INTERFACES |
| US20180336275A1 (en) | 2017-05-16 | 2018-11-22 | Apple Inc. | Intelligent automated assistant for media exploration |
| US20180336892A1 (en) | 2017-05-16 | 2018-11-22 | Apple Inc. | Detecting a trigger of a digital assistant |
| KR102338376B1 (ko) * | 2017-09-13 | 2021-12-13 | 삼성전자주식회사 | 디바이스 그룹을 지정하기 위한 전자 장치 및 이의 제어 방법 |
| KR102585231B1 (ko) | 2018-02-02 | 2023-10-05 | 삼성전자주식회사 | 화자 인식을 수행하기 위한 음성 신호 처리 방법 및 그에 따른 전자 장치 |
| US10818288B2 (en) | 2018-03-26 | 2020-10-27 | Apple Inc. | Natural assistant interaction |
| US10909991B2 (en) * | 2018-04-24 | 2021-02-02 | ID R&D, Inc. | System for text-dependent speaker recognition and method thereof |
| US11145294B2 (en) | 2018-05-07 | 2021-10-12 | Apple Inc. | Intelligent automated assistant for delivering content from user experiences |
| US10928918B2 (en) | 2018-05-07 | 2021-02-23 | Apple Inc. | Raise to speak |
| US10826906B2 (en) * | 2018-05-10 | 2020-11-03 | Nidec Motor Corporation | System and computer-implemented method for controlling access to communicative motor |
| DK179822B1 (da) | 2018-06-01 | 2019-07-12 | Apple Inc. | Voice interaction at a primary device to access call functionality of a companion device |
| DK180639B1 (en) | 2018-06-01 | 2021-11-04 | Apple Inc | DISABILITY OF ATTENTION-ATTENTIVE VIRTUAL ASSISTANT |
| DK201870355A1 (en) | 2018-06-01 | 2019-12-16 | Apple Inc. | VIRTUAL ASSISTANT OPERATION IN MULTI-DEVICE ENVIRONMENTS |
| US10892996B2 (en) | 2018-06-01 | 2021-01-12 | Apple Inc. | Variable latency device coordination |
| US10757095B1 (en) * | 2018-06-07 | 2020-08-25 | Sprint Communications Company L.P. | Unix password replication to a set of computers |
| US11462215B2 (en) | 2018-09-28 | 2022-10-04 | Apple Inc. | Multi-modal inputs for voice commands |
| US11055398B2 (en) * | 2018-11-02 | 2021-07-06 | Rsa Security Llc | Monitoring strength of passwords |
| US11348573B2 (en) | 2019-03-18 | 2022-05-31 | Apple Inc. | Multimodality in digital assistant systems |
| DK201970509A1 (en) | 2019-05-06 | 2021-01-15 | Apple Inc | Spoken notifications |
| US11307752B2 (en) | 2019-05-06 | 2022-04-19 | Apple Inc. | User configurable task triggers |
| US11140099B2 (en) | 2019-05-21 | 2021-10-05 | Apple Inc. | Providing message response suggestions |
| DK180129B1 (en) | 2019-05-31 | 2020-06-02 | Apple Inc. | USER ACTIVITY SHORTCUT SUGGESTIONS |
| DK201970510A1 (en) | 2019-05-31 | 2021-02-11 | Apple Inc | Voice identification in digital assistant systems |
| US11468890B2 (en) | 2019-06-01 | 2022-10-11 | Apple Inc. | Methods and user interfaces for voice-based control of electronic devices |
| KR20210009596A (ko) * | 2019-07-17 | 2021-01-27 | 엘지전자 주식회사 | 지능적 음성 인식 방법, 음성 인식 장치 및 지능형 컴퓨팅 디바이스 |
| US11537708B1 (en) * | 2020-01-21 | 2022-12-27 | Rapid7, Inc. | Password semantic analysis pipeline |
| US11061543B1 (en) | 2020-05-11 | 2021-07-13 | Apple Inc. | Providing relevant data items based on context |
| US11038934B1 (en) | 2020-05-11 | 2021-06-15 | Apple Inc. | Digital assistant hardware abstraction |
| US11755276B2 (en) | 2020-05-12 | 2023-09-12 | Apple Inc. | Reducing description length based on confidence |
| US11490204B2 (en) | 2020-07-20 | 2022-11-01 | Apple Inc. | Multi-device audio adjustment coordination |
| US11438683B2 (en) | 2020-07-21 | 2022-09-06 | Apple Inc. | User identification using headphones |
| US11665169B2 (en) * | 2021-01-28 | 2023-05-30 | Dell Products, Lp | System and method for securely managing recorded video conference sessions |
| US20240303030A1 (en) * | 2021-03-09 | 2024-09-12 | Webtalk Ltd | Dynamic audio content generation |
| JP7376127B2 (ja) * | 2021-05-06 | 2023-11-08 | Necプラットフォームズ株式会社 | 情報処理装置、情報処理システム、情報処理方法及びプログラム |
Family Cites Families (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5450524A (en) * | 1992-09-29 | 1995-09-12 | At&T Corp. | Password verification system based on a difference of scores |
| JP2003050783A (ja) | 2001-05-30 | 2003-02-21 | Fujitsu Ltd | 複合認証システム |
| FR2842643B1 (fr) | 2002-07-22 | 2004-09-03 | France Telecom | Normalisation de score de verification dans un dispositif de reconnaissance vocale de locuteur |
| KR100554788B1 (ko) * | 2002-10-15 | 2006-02-22 | 엘지전자 주식회사 | 광디스크 장치에서의 패스워드 관리방법 |
| US7299359B2 (en) * | 2003-04-23 | 2007-11-20 | Apple Inc. | Apparatus and method for indicating password quality and variety |
| US7536304B2 (en) | 2005-05-27 | 2009-05-19 | Porticus, Inc. | Method and system for bio-metric voice print authentication |
| CN1905445B (zh) * | 2005-07-27 | 2012-02-15 | 国际商业机器公司 | 使用可移动的语音标识卡的语音认证系统及语音认证方法 |
| US7516074B2 (en) * | 2005-09-01 | 2009-04-07 | Auditude, Inc. | Extraction and matching of characteristic fingerprints from audio signals |
| CN1963917A (zh) | 2005-11-11 | 2007-05-16 | 株式会社东芝 | 评价语音的分辨力、说话人认证的注册和验证方法及装置 |
| US8504366B2 (en) * | 2005-12-19 | 2013-08-06 | Nuance Communications, Inc. | Joint factor analysis scoring for speech processing systems |
| JP4717872B2 (ja) * | 2006-12-06 | 2011-07-06 | 韓國電子通信研究院 | 話者の音声特徴情報を利用した話者情報獲得システム及びその方法 |
| US8099288B2 (en) * | 2007-02-12 | 2012-01-17 | Microsoft Corp. | Text-dependent speaker verification |
| US20080244272A1 (en) | 2007-04-03 | 2008-10-02 | Aten International Co., Ltd. | Hand cryptographic device |
| US8200978B2 (en) * | 2007-07-06 | 2012-06-12 | Gong Ling LI | Security device and method incorporating multiple varying password generator |
| US8826396B2 (en) * | 2007-12-12 | 2014-09-02 | Wells Fargo Bank, N.A. | Password reset system |
| US8108932B2 (en) * | 2008-06-12 | 2012-01-31 | International Business Machines Corporation | Calculating a password strength score based upon character proximity and relative position upon an input device |
| US8775187B2 (en) * | 2008-09-05 | 2014-07-08 | Auraya Pty Ltd | Voice authentication system and methods |
| JP5293460B2 (ja) * | 2009-07-02 | 2013-09-18 | ヤマハ株式会社 | 歌唱合成用データベース生成装置、およびピッチカーブ生成装置 |
| US20120066650A1 (en) * | 2010-09-10 | 2012-03-15 | Motorola, Inc. | Electronic Device and Method for Evaluating the Strength of a Gestural Password |
| FR2965377A1 (fr) | 2010-09-24 | 2012-03-30 | Univ D Avignon Et Des Pays De Vaucluse | Procede de classification de donnees biometriques |
| WO2012075641A1 (en) | 2010-12-10 | 2012-06-14 | Panasonic Corporation | Device and method for pass-phrase modeling for speaker verification, and verification system |
| US9471772B2 (en) * | 2011-06-01 | 2016-10-18 | Paypal, Inc. | Password check by decomposing password |
| WO2013109330A2 (en) * | 2011-10-31 | 2013-07-25 | The Florida State University Research Foundation, Inc. | System and methods for analyzing and modifying passwords |
| US9147401B2 (en) | 2011-12-21 | 2015-09-29 | Sri International | Method and apparatus for speaker-calibrated speaker detection |
| US9147400B2 (en) * | 2011-12-21 | 2015-09-29 | Sri International | Method and apparatus for generating speaker-specific spoken passwords |
| KR101971697B1 (ko) | 2012-02-24 | 2019-04-23 | 삼성전자주식회사 | 사용자 디바이스에서 복합 생체인식 정보를 이용한 사용자 인증 방법 및 장치 |
| US9129591B2 (en) | 2012-03-08 | 2015-09-08 | Google Inc. | Recognizing speech in multiple languages |
| US8918836B2 (en) * | 2012-04-23 | 2014-12-23 | Microsoft Corporation | Predicting next characters in password generation |
| US9489950B2 (en) | 2012-05-31 | 2016-11-08 | Agency For Science, Technology And Research | Method and system for dual scoring for text-dependent speaker verification |
| US8863260B2 (en) * | 2012-06-07 | 2014-10-14 | International Business Machines Corporation | Enhancing password protection |
| US9536528B2 (en) * | 2012-07-03 | 2017-01-03 | Google Inc. | Determining hotword suitability |
| KR20140021415A (ko) * | 2012-08-10 | 2014-02-20 | 삼성전기주식회사 | 실리콘 기판 및 그 제조 방법 |
| US20140188468A1 (en) * | 2012-12-28 | 2014-07-03 | Dmitry Dyrmovskiy | Apparatus, system and method for calculating passphrase variability |
| US20140379525A1 (en) * | 2013-06-20 | 2014-12-25 | Bank Of America Corporation | Utilizing voice biometrics |
| US9437195B2 (en) * | 2013-09-18 | 2016-09-06 | Lenovo (Singapore) Pte. Ltd. | Biometric password security |
-
2014
- 2014-02-04 US US14/172,619 patent/US10157272B2/en active Active
-
2015
- 2015-01-27 CN CN201580006253.2A patent/CN105940407B/zh not_active Expired - Fee Related
- 2015-01-27 WO PCT/US2015/013126 patent/WO2015119806A1/en active Application Filing
- 2015-01-27 JP JP2016549463A patent/JP6452708B2/ja not_active Expired - Fee Related
- 2015-01-27 KR KR1020167023068A patent/KR20160115944A/ko not_active Application Discontinuation
- 2015-01-27 EP EP15704160.9A patent/EP3103050A1/en not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| EP3103050A1 (en) | 2016-12-14 |
| CN105940407B (zh) | 2019-02-15 |
| US10157272B2 (en) | 2018-12-18 |
| JP6452708B2 (ja) | 2019-01-16 |
| US20150220715A1 (en) | 2015-08-06 |
| CN105940407A (zh) | 2016-09-14 |
| WO2015119806A1 (en) | 2015-08-13 |
| JP2017511915A (ja) | 2017-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10157272B2 (en) | Systems and methods for evaluating strength of an audio password | |
| EP3210205B1 (en) | Sound sample verification for generating sound detection model | |
| US11403065B2 (en) | User interface customization based on speaker characteristics | |
| US10950245B2 (en) | Generating prompts for user vocalisation for biometric speaker recognition | |
| US10468032B2 (en) | Method and system of speaker recognition using context aware confidence modeling | |
| US9147400B2 (en) | Method and apparatus for generating speaker-specific spoken passwords | |
| US20150302856A1 (en) | Method and apparatus for performing function by speech input | |
| JP2019194713A (ja) | 話者検証のためのニューラルネットワーク | |
| CN111566729A (zh) | 用于远场和近场声音辅助应用的利用超短语音分段进行的说话者标识 | |
| CN111699528A (zh) | 电子装置及执行电子装置的功能的方法 | |
| US20090119103A1 (en) | Speaker recognition system | |
| KR20160011709A (ko) | 지불 확인을 위한 방법, 장치 및 시스템 | |
| CN112509598B (zh) | 音频检测方法及装置、存储介质 | |
| CN111684521B (zh) | 用于说话者识别的处理语音信号方法及实现其的电子装置 | |
| US20200201970A1 (en) | Biometric user recognition | |
| CN111344783A (zh) | 说话人识别系统中的注册 | |
| KR102394912B1 (ko) | 음성 인식을 이용한 주소록 관리 장치, 차량, 주소록 관리 시스템 및 음성 인식을 이용한 주소록 관리 방법 | |
| KR20230156145A (ko) | 하이브리드 다국어 텍스트 의존형 및 텍스트 독립형 화자 검증 | |
| US11227601B2 (en) | Computer-implement voice command authentication method and electronic device | |
| WO2021147018A1 (en) | Electronic device activation based on ambient noise | |
| WO2022024188A1 (ja) | 音声登録装置、制御方法、プログラム及び記憶媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |