KR20150128804A - 하드웨어 테이블 워크를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 방법들 및 시스템들 - Google Patents
하드웨어 테이블 워크를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 방법들 및 시스템들 Download PDFInfo
- Publication number
- KR20150128804A KR20150128804A KR1020157027417A KR20157027417A KR20150128804A KR 20150128804 A KR20150128804 A KR 20150128804A KR 1020157027417 A KR1020157027417 A KR 1020157027417A KR 20157027417 A KR20157027417 A KR 20157027417A KR 20150128804 A KR20150128804 A KR 20150128804A
- Authority
- KR
- South Korea
- Prior art keywords
- ipa
- function
- vmid
- hwtw
- tlb
- Prior art date
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G06F12/1027—Address translation using associative or pseudo-associative address translation means, e.g. translation look-aside buffer [TLB]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/15—Use in a specific computing environment
- G06F2212/151—Emulated environment, e.g. virtual machine
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/17—Embedded application
- G06F2212/171—Portable consumer electronics, e.g. mobile phone
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/50—Control mechanisms for virtual memory, cache or TLB
- G06F2212/507—Control mechanisms for virtual memory, cache or TLB using speculative control
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/65—Details of virtual memory and virtual address translation
- G06F2212/654—Look-ahead translation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/68—Details of translation look-aside buffer [TLB]
- G06F2212/684—TLB miss handling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45545—Guest-host, i.e. hypervisor is an application program itself, e.g. VirtualBox
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Software Systems (AREA)
Abstract
변환 색인 버퍼 (TLB) 미스가 발생할 경우에 하드웨어 테이블 워크 (HWTW) 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키는 컴퓨터 시스템 및 방법이 제공된다. 스테이지 1 (SI) 페이지 테이블이 저장되는 물리적 어드레스 (PA) 를 발견하기 위해 스테이지 2 (S2) HWTW 를 수행할 경우에 TLB 미스가 발생하면, MMU 는 중간 물리적 어드레스 (IPA) 를 이용하여 대응하는 PA 를 예측하고, 이에 의해, S2 테이블 룩업들 중 임의의 룩업을 수행하기 위한 필요성을 회피시킨다. 이는 이들 타입들의 HWTW 판독 트랜잭션들을 수행할 경우에 수행될 필요가 있는 룩업들의 수를 크게 감소시키고, 이는 이들 타입들의 트랜잭션들을 수행하는 것과 연관된 프로세싱 오버헤드 및 성능 페널티들을 크게 감소시킨다.
Description
본 발명은 컴퓨터 시스템들에 관한 것으로서, 더 상세하게는, 하드웨어 테이블 워크 (HWTW) 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 컴퓨터 시스템들 및 컴퓨터 시스템에서의 사용 방법들에 관한 것이다.
현대 컴퓨팅 시스템들은 메모리 관리 유닛들 (MMU들) 을 사용하여, 예를 들어, 솔리드 스테이트 메모리 디바이스들과 같은 하나 이상의 물리적 메모리 디바이스들에 데이터를 기입하고 물리적 메모리 디바이스들로부터 데이터를 판독하는 것을 관리한다. 컴퓨터 시스템의 MMU 는 컴퓨터 시스템의 중앙 프로세싱 유닛 (CPU) 에 가상 메모리를 제공하여, 종종 단편화되거나 불연속적인 물리적 메모리 어드레스 공간을 어플리케이션 프로그램들 모두가 공유하게 하는 것보다는 CPU 로 하여금 그 자신의 전용된 연속적인 가상 메모리 어드레스 공간에서 각각의 어플리케이션 프로그램을 구동하게 한다. MMU 의 목적은 CPU 에 대하여 가상 메모리 어드레스들 (VA들) 을 물리적 메모리 어드레스들 (PA들) 로 변환하는 것이다. CPU 는 VA들을 직접 판독하고 MMU 에 기입함으로써 PA들을 간접적으로 판독 및 기입하며, 이 MMU 는 VA들을 PA들로 변환하고 그 후 PA들을 기입 또는 판독한다.
변환들을 수행하기 위해, MMU 는 시스템 메인 메모리에 저장된 페이지 테이블들에 액세스한다. 페이지 테이블들은 페이지 테이블 엔트리들로 이루어진다. 페이지 테이블 엔트리들은 VA들을 PA들로 매핑하기 위해 MMU 에 의해 사용되는 정보이다. MMU 는 통상적으로, 최근에 사용된 매핑들을 캐시하도록 사용되는 캐시 메모리 엘리먼트인 변환 색인 버퍼 (TLB) 를 포함한다. MMU 가 VA 를 PA 로 변환할 필요가 있을 경우, MMU 는 먼저 TLB 를 체크하여 VA 에 대한 매칭이 존재하는지 여부를 결정한다. 매칭이 존재한다면, MMU 는 TLB 에서 발견된 매핑을 이용하여 PA 를 산출하고 그 후 PA 에 액세스한다 (즉, PA 를 판독 또는 기입함). 이는 TLB "히트 (hit)" 로서 공지된다. MMU 가 TLB 에서 매칭을 발견하지 않으면, 이는 TLB "미스 (miss)" 로서 공지된다.
TLB 미스의 경우, MMU 는 하드웨어 테이블 워크 (HWTW) 로서 공지된 것을 수행한다. HWTW 는, "테이블 워크" 를 수행하여 MMU 에서 대응하는 페이지 테이블을 발견하고, 그 후, 페이지 테이블에서 다중의 위치들을 판독하여 대응하는 VA-투-PA 어드레스 매핑을 발견하는 것을 수반하는 시간 소모적이고 계산상으로 고가인 프로세스이다. 그 후, MMU 는 그 매핑을 사용하여 대응하는 PA 를 산출하고 그 매핑을 역으로 TLB 에 기입한다.
오퍼레이팅 시스템 (OS) 가상화를 구현하는 컴퓨터 시스템들에 있어서, 하이퍼바이저로서 일반적으로 또한 지칭되는 가상 메모리 모니터 (VMM) 가 컴퓨터 시스템의 하드웨어와 컴퓨터 시스템의 시스템 OS 사이에 개재된다. 하이퍼바이저는 특권 모드 (privileged mode) 에서 실행하고, 하나 이상의 게스트 하이-레벨 OS들을 호스팅할 수 있다. 그러한 시스템들에 있어서, OS들 상에서 구동하는 어플리케이션 프로그램들은 어드레스 메모리에 대한 가상 메모리의 제 1 계층의 VA들을 이용하고, 하이퍼바이저 상에서 구동하는 OS들은 어드레스 메모리에 대한 가상 메모리의 제 2 계층의 중간 물리적 어드레스들 (IPA들) 을 이용한다. MMU 에 있어서, 스테이지 1 (SI) 변환들은 각각의 VA 를 IPA 로 변환하도록 수행되고, 스테이지 2 (S2) 변환들은 각각의 IPA 를 PA 로 변환하도록 수행된다.
그러한 변환들을 수행할 경우에 TLB 미스가 발생하면, 멀티-레벨 2차원 (2-D) HWTW 가, 대응하는 IPA 및 PA 를 산출하는데 필요한 테이블 엔트리들을 획득하도록 수행된다. 이들 멀티-레벨 2-D HWTW들을 수행하는 것은 MMU 에 대한 현저한 양의 계산상 오버헤드를 발생시킬 수 있으며, 이는 통상적으로 성능 페널티들을 발생시킨다.
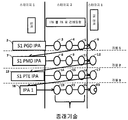
도 1 은 판독 트랜잭션을 수행하는 동안 TLB 미스가 발생할 경우에 수행되는 공지된 3레벨 2-D HWTW 의 도식적 예시이다. 도 1 에 도시된 HWTW 는, 데이터가 물리적 메모리에 저장되는 PA 를 획득하기 위해 15개 테이블 룩업들의 수행을 요구하는 3레벨 2-D HWTW 에 대한 최악 케이스 시나리오를 나타낸다. 이 예에 대해, 컴퓨터 시스템의 MMU 는 적어도 하나의 게스트 하이-레벨 OS (HLOS) 를 호스팅하고 있는 하이퍼바이저를 구동하고 있으며, 이 HLOS 는 결국, 적어도 하나의 어플리케이션 프로그램을 구동하고 있다. 그러한 구성에 있어서, 게스트 HLOS 에 의해 할당되고 있는 메모리는 시스템의 실제 물리적 메모리가 아니지만, 대신, 전술된 중간 물리적 메모리이다. 하이퍼바이저는 실제 물리적 메모리를 할당한다. 따라서, 각각의 VA 는 IPA 로 변환되고, 이 IPA 는 그 후, 판독되는 데이터가 실제로 저장되는 실제 물리적 메모리의 PA 로 변환된다.
그 프로세스는 MMU 가 SI 페이지 글로벌 디렉토리 (PGD) IPA (2) 를 수신하는 것으로 시작한다. 이러한 최악 케이스 시나리오 예에 대해, MMU 가 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 HWTW 를 수행해야 한다. HWTW 는 IPA (2) 를 PA 로 컨버팅하는데 필요한 매핑을 획득하기 위한 3개의 S2 테이블 룩업들 (3, 4 및 5) 및 PA 를 판독하기 위한 하나의 부가적인 룩업 (6) 을 수행하는 것을 수반한다. 테이블 룩업들 (3, 4 및 5) 은 각각, S2 PGD, 페이지 중간 디렉토리 (PMD) 및 페이지 테이블 엔트리 (PTE) 를 판독하는 것을 수반한다. 룩업 (6) 에서 PA 를 판독하는 것은 MMU 에게 SI PMD IPA (7) 를 제공한다. 이러한 최악 케이스 시나리오 예에 대해, MMU 가 SI PMD IPA (7) 와의 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 다른 HWTW 를 수행해야 한다. HWTW 는 S1 PMD IPA (7) 를 PA 로 컨버팅하는데 필요한 매핑을 획득하기 위한 3개의 S2 테이블 룩업들 (8, 9 및 11) 및 PA 를 판독하기 위한 하나의 부가적인 룩업 (12) 을 수행하는 것을 수반한다. 테이블 룩업들 (8, 9 및 11) 은 각각, S2 PGD, PMD 및 PTE 를 판독하는 것을 수반한다. 룩업 (12) 에서 PA 를 판독하는 것은 MMU 에게 SI PTE IPA (13) 를 제공한다.
이러한 최악 케이스 시나리오 예에 대해, MMU 가 SI PTE IPA (13) 와의 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 다른 HWTW 를 수행해야 한다. HWTW 는 SI PTE IPA (13) 를 PA 로 컨버팅하는데 필요한 매핑을 획득하기 위한 3개의 S2 테이블 룩업들 (14, 15 및 16) 및 PA 를 판독하기 위한 하나의 부가적인 룩업 (17) 을 수행하는 것을 수반한다. 테이블 룩업들 (14, 15 및 16) 은 각각, S2 PGD, PMD 및 PTE 를 판독하는 것을 수반한다. 룩업 (17) 에서 PA 를 판독하는 것은 MMU 에게 실제 IPA (18) 를 제공한다. 이러한 최악 케이스 시나리오 예에 대해, MMU 가 실제 IPA (18) 와의 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 다른 HWTW 를 수행해야 한다. HWTW 는 실제 IPA (18) 를 PA 로 컨버팅하는데 필요한 매핑을 획득하기 위한 3개의 S2 테이블 룩업들 (19, 21 및 22) 을 수행하는 것을 수반한다. 테이블 룩업들 (19, 21 및 22) 은 각각, S2 PGD, PMD 및 PTE 를 판독하는 것을 수반한다. 그 후, PA 는 대응하는 판독 데이터를 획득하도록 판독된다. 룩업 (18) 에서 PA 를 판독하는 것은 MMU 에게 SI PTE IPA (13) 를 제공한다.
따라서, 3레벨 2-D HWTW 에 대한 최악 케이스 시나리오에 있어서, 12개의 S2 테이블 룩업들 및 3개의 SI 테이블 룩업들이 수행되며, 이는 다량의 시간을 소모하고 성능 페널티들을 발생시키는 다량의 계산상 오버헤드임을 알 수 있다. 예를 들어, TLB 의 사이즈를 증가시키는 것, 다중의 TLB들을 이용하는 것, 플랫 네스팅된 페이지 테이블들을 이용하는 것, 섀도우 페이징 또는 사변적 섀도우 페이징을 이용하는 것 및 페이지 워크 캐시를 이용하는 것을 포함하여, HWTW들을 수행하는 것에 관련된 시간 및 프로세싱 오버헤드의 양을 감소시키기 위해 다양한 기술들 및 아키텍처들이 사용되었다. 이들 기술들 및 아키텍처들 모두가 HWTW들을 수행하는 것과 연관된 프로세싱 오버헤드를 감소시킬 수 있지만, 이들은 종종, 컴퓨터 시스템에서의 다른 어떤 곳에서 프로세싱 오버헤드의 증가를 발생시킨다.
이에 따라, HWTW 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 컴퓨터 시스템들 및 방법들에 대한 필요성이 존재한다.
본 발명은 HWTW 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 컴퓨터 시스템 및 컴퓨터 시스템에서의 사용 방법에 관한 것이다. 컴퓨터 시스템은 적어도 하나의 중앙 프로세싱 유닛 (CPU), 적어도 하나의 물리적 메모리, 적어도 하나의 TLB, 및 적어도 하나의 MMU 를 포함한다. CPU 는 호스트 OS 및 하이퍼바이저를 구동한다. 하이퍼바이저는 CPU 상에서 적어도 제 1 게스트 OS 의 실행을 제어한다. 하이퍼바이저는 제 1 게스트 OS 와 연관된 적어도 제 1 VM 을 구동한다. 물리적 메모리는, PA들에 의해 어드레싱가능한 물리적 메모리 위치들을 갖는다. 적어도 하나의 페이지 테이블은 물리적 메모리의 물리적 메모리 위치들에 저장된다. 페이지 테이블은 IPA 를 물리적 메모리의 실제 PA 로 매핑하기 위한 매핑들에 대응하는 페이지 테이블 엔트리들을 포함한다. TLB 는 페이지 테이블 엔트리들의 서브세트를 저장한다. 메모리 액세스가 수행되고 있을 경우, MMU 는 IPA 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되는지 여부를 결정한다. IPA 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되지 않으면, TLB 미스가 발생하였다. TLB 미스가 발생하면, MMU 는 IPA 와 연관된 데이터가 저장되는 물리적 메모리의 PA 를 예측하고, 이에 의해, PA 를 산출하기 위해 HWTW 를 수행하기 위한 필요성을 제거한다.
그 방법은:
MMU 에 있어서:
IPA 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되는지 여부를 결정하는 단계;
IPA 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되지 않는다고 결정되면, TLB 미스가 발생하였다고 판정하는 단계; 및
TLB 미스가 발생하였다고 판정되었으면, IPA 와 연관된 데이터가 저장되는 물리적 메모리의 PA 를 예측하는 단계를 포함한다.
본 발명은 또한 HWTW 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키기 위해 하나 이상의 프로세서들에 의한 실행을 위한 컴퓨터 코드를 저장하는 컴퓨터 판독가능 매체 (CRM) 를 제공한다. 컴퓨터 코드는 제 1 및 제 2 코드 부분들을 포함한다. 제 1 코드 부분은, IPA 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되는지 여부를 결정한다. IPA 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되지 않는다고 결정되면, 제 1 코드 부분은 TLB 미스가 발생하였다고 판정한다. 제 2 코드 부분은, 제 1 코드 부분이 TLB 미스가 발생하였다고 판정하면, IPA 와 연관된 데이터가 저장되는 물리적 메모리의 PA 를 예측한다.
이들 및 다른 특징들, 및 이점들은 다음의 설명, 도면들, 및 청구항들로부터 명백하게 될 것이다.
도 1 은 본 발명의 예시적인 실시형태에 따른 컴퓨터 시스템의 블록 다이어그램이다.
도 2 는, HWTW 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 방법을 수행하도록 구성된 예시적인 또는 전형적인 실시형태에 따른 컴퓨터 시스템의 블록 다이어그램을 도시한다.
도 3 은, HWTW 판독 트랜잭션을 수행하는데 요구된 시간 및 프로세싱 오버헤드의 양을 감소시키기 위해 도 2 에 도시된 하이퍼바이저에 의해 수행된 예시적인 실시형태에 따른 방법을 나타낸 플로우차트이다.
도 4 는, 예시적인 실시형태에 따라 도 3 에 도시된 플로우차트에 의해 나타낸 방법을 이용하여 HWTW 판독 트랜잭션이 수행되는 방식을 나타내는 도식적 다이어그램이다.
도 5 는, 도 3 에 도시된 플로우차트에 의해 나타낸 방법을 수행하는 예시적인 실시형태에 따른 하드웨어 예측기의 블록 다이어그램이다.
도 6 은, 도 2 에 도시된 컴퓨터 시스템이 통합된 모바일 스마트폰의 블록 다이어그램을 도시한다.
도 2 는, HWTW 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 방법을 수행하도록 구성된 예시적인 또는 전형적인 실시형태에 따른 컴퓨터 시스템의 블록 다이어그램을 도시한다.
도 3 은, HWTW 판독 트랜잭션을 수행하는데 요구된 시간 및 프로세싱 오버헤드의 양을 감소시키기 위해 도 2 에 도시된 하이퍼바이저에 의해 수행된 예시적인 실시형태에 따른 방법을 나타낸 플로우차트이다.
도 4 는, 예시적인 실시형태에 따라 도 3 에 도시된 플로우차트에 의해 나타낸 방법을 이용하여 HWTW 판독 트랜잭션이 수행되는 방식을 나타내는 도식적 다이어그램이다.
도 5 는, 도 3 에 도시된 플로우차트에 의해 나타낸 방법을 수행하는 예시적인 실시형태에 따른 하드웨어 예측기의 블록 다이어그램이다.
도 6 은, 도 2 에 도시된 컴퓨터 시스템이 통합된 모바일 스마트폰의 블록 다이어그램을 도시한다.
본 명세서에서 설명된 예시적인 실시형태들에 따르면, HWTW 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 컴퓨터 시스템 및 컴퓨터 시스템에서의 사용 방법이 제공된다. 본 명세서에서 설명된 실시형태들에 따르면, SI 페이지 테이블이 저장되는 PA 를 발견하기 위해 S2 HWTW 를 수행할 때 TLB 미스가 발생할 경우, MMU 는 IPA 를 이용하여 대응하는 PA 를 예측하고, 이에 의해, S2 테이블 룩업들 중 임의의 룩업을 수행하기 위한 필요성을 회피시킨다. 이는 이들 타입들의 HWTW 판독 트랜잭션들을 수행할 경우에 수행될 필요가 있는 룩업들의 수를 크게 감소시키고, 이는 이들 타입들의 트랜잭션들을 수행하는 것과 연관된 프로세싱 오버헤드 및 성능 페널티들을 크게 감소시킨다.
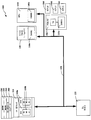
도 2 는, S1 페이지 테이블이 저장되는 PA 를 발견하기 위해 S2 HWTW 를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 방법을 수행하도록 구성된 예시적인 또는 전형적인 실시형태에 따른 컴퓨터 시스템 (100) 의 블록 다이어그램을 도시한다. 도 2 에 도시된 컴퓨터 시스템 (100) 의 예는 CPU 클러스터 (110), 메인 메모리 (120), 비디오 카메라 디스플레이 (130), 그래픽 프로세싱 유닛 (GPU) (140), 주변기기 접속 인터페이스 익스프레스 (PCIe) 입력/출력 (IO) 디바이스 (150), 복수의 IO TLB들 (IOTLB들) (160), 및 시스템 버스 (170) 를 포함한다. CPU 클러스터 (110) 는 복수의 CPU 코어들 (110a) 을 가지며, CPU 코어들 각각은 MMU (110b) 를 갖는다. 각각의 CPU 코어 (110a) 는 마이크로프로세서 또는 임의의 다른 적합한 프로세서일 수도 있다. 비디오 카메라 디스플레이 (130) 는 시스템 MMU (SMMU) (130a) 를 갖는다. GPU (140) 는 그 자신의 SMMU (140a) 를 갖는다. 유사하게, PCIe IO 디바이스 (150) 는 그 자신의 SMMU (150a) 를 갖는다.
프로세서 코어들 (110a) 의 MMU들 (110b) 은 VA들을 IPA들로 변환하고 IPA들을 PA들로 변환하는 태스크들을 수행하도록 구성된다. 페이지 테이블들은 메인 메모리 (120) 에 저장된다. MMU들 (110b) 및 SMMU들 (130a, 140a 및 150a) 각각은, 메인 메모리 (120) 에 저장되는 페이지 테이블들의 서브세트들을 저장하는 그 자신의 TLB (명료화의 목적을 위해 도시 안됨) 를 갖는다. 이러한 예시적인 실시형태에 따르면, TLB 미스의 발생 이후, MMU들 (110b) 은, IPA 를 프로세싱하여 PA 를 예측하는 예측 알고리즘을 수행한다. 예측 알고리즘은
와 같이 수학적으로 표현될 수도 있으며, 여기서, f 는 수학적 함수를 나타낸다. 이러한 목적을 위해 사용될 수도 있는 함수들 (f) 은 도 5 를 참조하여 하기에서 상세히 설명된다. 어구 "예측하는 것" 은, 그 어구가 본 명세서에서 사용될 때, "결정하는 것" 을 의미하고, 비록 통계적 또는 확률적 결정들이 본 발명의 범위로부터 반드시 배제되는 것은 아니지만, 통계적 또는 확률적 결정을 암시하지는 않는다. 예측 알고리즘에 의해 행해진 예측들은 통상적으로 결정론적이지만 반드시 결정론적일 필요는 없다.
CPU 클러스터 (110) 는 시스템 OS (200) 및 가상 머신 모니터 (VMM) 또는 하이퍼바이저 (210) 를 구동한다. 하이퍼바이저 (210) 는, 변환들을 수행하는 것에 부가하여, MMU들 (110b) 및 SMMU들 (130a, 140a 및 150a) 에 저장된 페이지 테이블들을 업데이트하는 것을 포함하는 변환 태스크들을 관리한다. 하이퍼바이저 (210) 는 또한, 게스트 HLOS (220) 및/또는 게스트 디지털 권리 관리자 (DRM) (230) 를 구동한다. HLOS (220) 는 비디오 카메라 디스플레이 (130) 와 연관될 수도 있고, DRM (230) 은 GPU (140) 와 연관될 수도 있다. 하이퍼바이저 (210) 는 HLOS (220) 및 DRM (230) 을 관리한다.
TLB 미스가 발생한 이후, 하이퍼바이저 (210) 는, 예측 알고리즘을 수행하여 IPA 를 PA 로 컨버팅하도록 MMU들 (110b) 및 SMMU들 (130a, 140a 및 150a) 을 구성한다. 그러한 경우들에 있어서, TLB 미스와 연관된 VA 에 대한 시작 IPA 는, SI 변환이 통상적으로 시작하는 통상의 방식으로 CPU 클러스터 (110) 의 하드웨어 베이스 레지스터 (명료화의 목적을 위해 도시 안됨) 로부터 획득된다. 그 후, 예측 알고리즘은, 하기에서 더 상세히 설명될 바와 같이, 수학식 1 에 따라 PA 를 예측한다. SMMU들 (130a, 140a 및 150a) 을 관리 및 업데이트하기 위해, CPU MMU (110b) 는 분산형 가상 메모리 (DVM) 메시지들을 버스 (170) 를 통해 SMMU들 (130a, 140a 및 150a) 로 전송한다. MMU들 (110b) 및 SMMU들 (130a, 140a 및 150a) 은 메인 메모리 (120) 에 액세스하여 HWTW들을 수행한다.
예시적인 실시형태에 따르면, CPU MMU (110b) 는 MMU 트래픽을 3개의 트랜잭션 클래스들, 즉, (1) SI 페이지 테이블이 저장되는 PA 를 발견하기 위한 S2 HWTW 판독 트랜잭션들; (2) 클라이언트 트랜잭션들; 및 (3) 어드레스 결함 (AF)/더티 플래그 (dirty flag) 기입 트랜잭션들; 로 분류한다. 이러한 예시적인 실시형태에 따르면, 예측 알고리즘은 오직 클래스 1 트랜잭션들, 즉, HWTW 판독 트랜잭션들을 위해 IPA들을 PA들로만 컨버팅한다. 트랜잭션들의 다른 모든 클래스들에 대해, 이러한 예시적인 실시형태에 따라, MMU들 (110b) 및 SMMU들 (130a, 140a 및 150a) 은 다른 모든 변환들 (예를 들어, SI 및 클라이언트 트랜잭션 S2 변환들) 을 통상적인 방식으로 수행한다.
도 3 은, HWTW 판독 트랜잭션을 수행하는데 요구된 시간 및 프로세싱 오버헤드의 양을 감소시키기 위해 CPU MMU (110b) 에 의해 수행된 예시적인 실시형태에 따른 방법을 나타낸 플로우차트이다. 블록 301 은 방법 시작을 나타내며, 이는, CPU 클러스터 (110) 가 부스트 업하고 시스템 OS (200) 및 하이퍼바이저 (210) 를 구동하기 시작할 경우에 통상적으로 발생한다. MMU들 (110b) 은, 블록 302 에 의해 표시된 바와 같이, 트래픽을 전술된 트랜잭션 클래스들 (1), (2) 및 (3) 으로 분류한다. 분류 프로세스는 트랙잭션들을 이들 3개보다 더 많거나 더 적은 클래스들로 분류할 수도 있지만, 분류들 중 적어도 하나는 클래스 (1) 트랜잭션들, 즉, SI 페이지 테이블이 저장되는 PA 를 발견하기 위한 S2 HWTW 판독 트랜잭션들일 것이다. 블록 303 에 의해 나타낸 단계에서, 클래스 (1) 트랜잭션을 수행할 경우에 TLB 미스가 발생하였는지 여부에 관한 결정이 행해진다. 만약 발생하지 않았으면, 방법은 블록 306 으로 진행하고, 블록 306 에서, MMU들 (110b) 또는 SMMU들 (130a, 140a 또는 150a) 은 HWTW 를 정규의 방식으로 수행한다.
블록 303 에 의해 나타낸 단계에서, 클래스 (1) 트랜잭션을 수행할 경우에 미스가 발생하였다고 CPU MMU (110b) 가 결정하면, 그 방법은 블록 305 에 의해 나타낸 단계로 진행한다. 블록 305 에 의해 나타낸 단계에서, 전술된 예측 알고리즘이 IPA 를 PA 로 컨버팅 또는 변환하기 위해 수행된다.
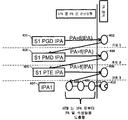
도 4 는, 예시적인 실시형태에 따라 HWTW 판독 트랜잭션이 수행되는 방식을 나타내는 도식적 다이어그램이다. 이 예시적인 실시형태에 대해, 페이지 테이블들은 3레벨 페이지 테이블들이고 HWTW들은 2-D HWTW들이라고 예시적인 목적들을 위해 가정된다. 그 예는 또한 TLB 미스 최악 케이스 시나리오를 가정한다. 프로세스는, MMU 가 VA 를 수신하고 그 후 제어 레지스터 (명료화의 목적을 위해 도시 안됨) 로부터 SI PGD IPA (401) 를 취출하는 것으로 시작한다. 그 후, MMU 는 SI PGD IPA (401) 와의 매칭을 위해 TLB 를 체크한다. 이러한 최악 케이스 시나리오 예에 대해, MMU 가 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 예측 알고리즘을 수행하여, SI PGD IPA (401) 를, SI PMD IPA (403) 가 저장되는 PA (402) 로 컨버팅한다. 따라서, 단일 룩업이 SI PGD IPA (401) 를 PA (402) 로 컨버팅하는데 사용된다.
이러한 최악 케이스 시나리오 예에 대해, MMU 가 SI PMD IPA (403) 와의 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 예측 알고리즘을 수행하여, SI PMD IPA (403) 를, SI PTE IPA (405) 가 저장되는 PA (404) 로 컨버팅한다. 따라서, 단일 룩업이 SI PMD IPA (403) 를 PA (404) 로 컨버팅하는데 사용된다. 이러한 최악 케이스 시나리오 예에 대해, MMU 가 SI PTE IPA (405) 와의 매칭을 위해 TLB 를 체크할 경우에 TLB 미스가 발생한다고 가정될 것이다. 미스 때문에, MMU 는 예측 알고리즘을 수행하여, SI PTE IPA (405) 를, IPA1 (407) 이 저장되는 PA (406) 로 컨버팅한다. 일단 IPA1 (407) 이 획득되었으면, 3개의 룩업들 (408, 409 및 411) 이 수행되어, 판독될 데이터가 저장되는 최종 PA (412) 를 획득한다.
따라서, 이 실시형태에 따르면, 룩업들의 총 수가 15개 (도 1) 로부터 6개로 감소되었음을 알 수 있으며, 이는 프로세싱 오버헤드에 있어서 60% 감소를 나타낸다. 물론, 본 발명은, 특정 수의 레벨들 또는 특정 수의 HWTW 치수들을 갖는 MMU 구성들로 한정되지 않는다. 당업자는 본 발명의 개념들 및 원리들이 페이지 테이블들의 구성에 관계없이 적용됨을 이해할 것이다. 또한, 비록 본 방법 및 시스템이 IPA-투-PA 변환을 참조하여 본 명세서에서 설명되고 있지만, 본 발명 및 시스템은 IPA들을 사용하지 않는 시스템들에서의 직접 VA-투-PA 변환들에 동일하게 적용가능하다.
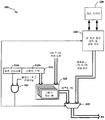
도 5 는 예측 알고리즘을 수행하는 예측기 (500) 의 예시적인 실시형태의 블록 다이어그램이다. 예측기 (500) 는 통상적으로, MMU들 (110b) 에서 그리고 SMMU들 (130a, 140a 및 150a) 에서 구현된다. 상기에서 나타낸 바와 같이, 예시적인 실시형태에 따르면, 예측 알고리즘은 오직 클래스 1 판독 트랜잭션을 수행할 경우에만 수행된다. 도 5 에 도시된 예측기 (500) 의 구성은, 예측기 (500) 가 클래스 1 트랜잭션들에 대해 인에이블되게 하고 클래스 2 및 3 트랜잭션들을 포함한 트랜잭션들의 다른 모든 클래스들에 대해 디스에이블되게 하는 일 구성의 예이다.
도 5 에 도시된 예측기 (500) 의 구성은 또한, 예측기 (500) 로 하여금 IPA 에 기초하여 PA 를 산출하도록 상기 수학식 1 에서 사용되는 함수 (f) 를 선택하게 한다. 각각의 가상 머신 (VM) 은 함수들 (f) 의 상이한 세트를 사용하고 있을 수도 있어서, 사용되는 함수들의 세트들이 IPA 의 범위에 걸쳐 IPA 와 PA 간에 1대1 매핑이 존재함을 보장한다는 것이 중요하다. 하이퍼바이저 (210) 는 다중의 HLOS들 또는 DRM들을 관리하고 있을 수도 있으며, 그들 각각은 하이퍼바이저 (210) 에서 구동하는 대응하는 VM 를 가질 것이다. 사용되는 함수들의 세트들은, 예측된 PA 가 다른 VM 에 할당된 예측된 PA 를 중첩하지 않음을 보장한다.
함수 (f) 의 예들은
PA=IPA;
PA=IPA + Offset_function(VMID) (여기서, VMID 는 HWTW 판독 트랜잭션과 연관된 VM 을 식별하는 모든 VM들에 걸친 고유의 식별자이고, Offset_function 은 VMID 와 연관된 특정 오프셋 값에 기초하여 선택되는 출력을 갖는 함수임); 및
PA=IPA XOR Extended_VMID (여기서, XOR 는 배타적 OR 연산을 나타내고 Extended_VMID 는 확장된 VMID 임) 이다. 하이퍼바이저 (210) 는, VM들 간의 충돌들이 회피되도록 함수 (f) 를 선택한다.
도 5 에 있어서, 함수 (f) 는 다항식이고 하이퍼바이저 (210) 는 복수의 다항식들로부터 함수 (f) 로서 사용될 다항식을 선택한다고 가정된다. 선택되는 다항식은, 예를 들어, HWTW 판독 트랜잭션이 수행되고 있는 VM 의 VMID 에 기초할 수도 있다. 예측기 (500) 의 구성 레지스터 (510) 는 하나 이상의 예측 인에이블 비트들 (510a) 및 하나 이상의 다항식 선택 비트들 (510b) 을 보유한다. 예측기 (500) 의 다항식 계산 하드웨어 (520) 는, 레지스터 (510) 로부터 수신된 다항식 선택 비트들 (510b) 의 값에 기초하여 다항식 함수를 선택하는 하드웨어를 포함한다. 다항식 계산 하드웨어 (520) 는 또한, IPA-투-PA 변환 요청을 수신하고 선택된 다항식 함수에 따라 그 요청을 프로세싱하여 예측된 PA 를 생성한다.
예측 인에이블 비트 (510a) 및 클래스 1 인에이블 비트는 AND 게이트 (530) 의 입력들로 수신된다. 클래스 1 인에이블 비트는, 클래스 1 판독 트랜잭션을 수행할 경우 미스가 발생하였을 때에 어서팅(assert)된다. 예측기 (500) 의 멀티플렉서 (MUX) (540) 는 MUX (540) 의 선택기 포트에서 AND 게이트 (530) 의 출력을 수신하고, 정규의 방식으로 획득된 IPA-투-PA 변환 결과 및 예측된 PA 를 수신한다. 예측 인에이블 비트 (510a) 및 클래스 1 인에이블 비트 양자가 어서팅될 경우, S2 워크 제어 로직 및 상태 머신 (550) 은 디스에이블되고, MUX (540) 는 MUX (540) 로부터 출력될 예측된 PA 를 선택한다.
예측 인에이블 비트 (510a) 및/또는 클래스 1 인에이블 비트가 디-어서팅될 경우, S2 워크 제어 로직 및 상태 머신 (550) 은 인에이블된다. S2 워크 제어 로직 및 상태 머신 (550) 이 인에이블될 경우, S2 워크들의 다른 타입들 (예를 들어, 클래스 2 및 클래스 3) 이 S2 워크 제어 로직 및 상태 머신 (550) 에 의해 메인 메모리 (120) 에서 수행될 수도 있다. 따라서, S2 워크 제어 로직 및 상태 머신 (550) 이 인에이블될 경우, MUX (540) 는, S2 워크 제어 로직 및 상태 머신 (550) 으로부터 출력되는 IPA-투-PA 변환 결과를 출력한다.
예측기 (500) 는 다수의 상이한 구성들을 가질 수도 있음이 주목되어야 한다. 도 5 에 도시된 예측기 (500) 의 구성은 예측 알고리즘을 수행하기 위한 다수의 적합한 구성들 중 단지 하나일 뿐이다. 당업자는 도 5 에 도시된 것과는 다른 다수의 구성들이 예측 알고리즘을 수행하기 위해 사용될 수도 있음을 이해할 것이다.
도 2 에 도시된 컴퓨터 시스템 (100) 은, 예를 들어, 데스크탑 컴퓨터들, 서버들 및 모바일 스마트폰들을 포함하여 메모리 가상화가 수행되는 임의의 타입의 시스템에서 구현될 수도 있다. 도 6 은, 컴퓨터 시스템 (100) 이 통합된 모바일 스마트폰 (600) 의 블록 다이어그램을 도시한다. 스마트폰 (600) 은, 본 명세서에서 설명된 방법들을 수행 가능해야 하는 점을 제외하면, 임의의 특정 타입의 스마트폰이거나 임의의 특정 구성을 갖는 것으로 한정되지 않는다. 또한, 도 6 에 도시된 스마트폰 (600) 은, 본 명세서에서 설명된 방법들을 수행하기 위해 컨텍스트 인식 및 프로세싱 능력을 갖는 셀룰러 전화기의 간략화된 예이도록 의도된다. 당업자는 스마트폰의 동작 및 구성 그리고 그에 따른 구현 상세들이 생략되었음을 이해할 것이다.
이 예시적인 실시형태에 따르면, 스마트폰 (600) 은 시스템 버스 (612) 를 통해 함께 접속되는 기저대역 서브시스템 (610) 및 무선 주파수 (RF) 서브시스템 (620) 을 포함한다. 시스템 버스 (612) 는 통상적으로, 상기 설명된 엘리먼트들을 함께 커플링시키고 그 상호운용가능성을 가능케 하는 물리적 및 논리적 커넥션들을 포함한다. RF 서브시스템 (620) 은 무선 트랜시버일 수도 있다. 비록 상세들이 명료화를 위해 설명되진 않지만, RF 서브시스템 (620) 은 일반적으로 송신용 기저대역 정보 신호를 준비하기 위한 변조, 상향변환 및 증폭 회로를 갖는 송신 (Tx) 모듈 (630) 을 포함하고, RF 신호를 수신하고 기저대역 정보 신호로 하향변환하여 데이터를 복원하기 위한 증폭, 필터링 및 하향변환 회로를 갖는 수신 (Rx) 모듈 (640) 을 포함하며, 다이플렉서 회로, 듀플렉서 회로, 또는 당업자에게 공지된 바와 같이 송신 신호를 수신 신호로부터 분리할 수 있는 임의의 다른 회로를 포함하는 프론트 엔드 모듈 (FEM) (650) 을 포함한다. 안테나 (660) 는 FEM (650) 에 접속된다.
기저대역 서브시스템 (610) 은 일반적으로, 시스템 버스 (612) 를 통해 함께 전기적으로 커플링되는 컴퓨터 시스템 (100), 아날로그 회로 엘리먼트들 (616), 및 디지털 회로 엘리먼트들 (618) 을 포함한다. 시스템 버스 (612) 는 통상적으로, 상기 설명된 엘리먼트들을 함께 커플링시키고 그 상호운용가능성을 가능케 하기 위한 물리적 및 논리적 커넥션들을 포함한다.
입력/출력 (I/O) 엘리먼트 (621) 는 커넥션 (624) 을 통해 기저대역 서브시스템 (610) 에 접속된다. I/O 엘리먼트 (621) 는 통상적으로, 예를 들어, 마이크로폰, 키패드, 스피커, 포인팅 디바이스, 사용자 인터페이스 제어 엘리먼트들, 및 사용자로 하여금 입력 커맨드들을 제공하게 하고 스마트폰 (600) 으로부터 출력들을 수신하게 하는 임의의 다른 디바이스들 또는 시스템들을 포함한다. 메모리 (628) 는 커넥션 (629) 을 통해 기저대역 서브시스템 (610) 에 접속된다. 메모리 (628) 는 임의의 타입의 휘발성 또는 비휘발성 메모리일 수도 있다. 메모리 (628) 는 스마트폰 (600) 에 영구적으로 설치될 수도 있거나, 또는 착탈가능 메모리 카드와 같이 착탈가능 메모리 엘리먼트일 수도 있다.
아날로그 회로 (616) 및 디지털 회로 (618) 는 신호 프로세싱, 신호 변환, 및 I/O 엘리먼트 (621) 에 의해 제공된 입력 신호를 송신될 정보 신호로 컨버팅하는 로직을 포함한다. 유사하게, 아날로그 회로 (616) 및 디지털 회로 (618) 는, 수신된 신호로부터 복원된 정보를 포함하는 정보 신호를 생성하는데 사용되는 신호 프로세싱 엘리먼트들을 포함한다. 디지털 회로 (618) 는, 예를 들어, 디지털 신호 프로세서 (DSP), 필드 프로그래밍가능 게이트 어레이 (FPGA), 또는 임의의 다른 프로세싱 디바이스를 포함할 수도 있다. 기저대역 서브시스템 (610) 이 아날로그 및 디지털 엘리먼트들 양자를 포함하기 때문에, 기저대역 서브시스템은 혼합형 신호 디바이스 (MSD) 로서 지칭될 수도 있다.
스마트폰 (600) 은, 예를 들어, 카메라 (661), 마이크로폰 (662), 글로벌 포지셔닝 시스템 (GPS) 센서 (663), 가속도계 (665), 자이로스코프 (667) 및 디지털 컴파스 (668) 와 같은 다양한 센서들 중 하나 이상을 포함할 수도 있다. 이들 센서들은 버스 (612) 를 통해 기저대역 서브시스템 (610) 과 통신한다.
컴퓨터 시스템 (100) 을 스마트폰 (600) 에 내장되게 하는 것은 다중의 OS들 및 다중의 개별 VM들로 하여금 스마트폰 (600) 상에서 구동하게 한다. 이러한 환경에 있어서, 컴퓨터 시스템 (100) 의 하이퍼바이저 (210) (도 2) 는 스마트폰 (600) 의 하드웨어와 VM들에 의해 실행되고 있는 어플리케이션 소프트웨어 간의 안전한 분리를 제공한다.
도 3 을 참조하여 상기 설명된 방법은 하드웨어에서 단독으로, 또는 하드웨어와 소프트웨어 또는 하드웨어와 펌웨어의 조합에서 구현될 수도 있다. 유사하게, 도 2 에 도시된 컴퓨터 시스템 (100) 의 컴포넌트들 중 다수가 하드웨어에서 단독으로, 또는 하드웨어와 소프트웨어 또는 펌웨어와의 조합에서 구현될 수도 있다. 예를 들어, 하이퍼바이저 (210) 는 하드웨어에서 단독으로, 또는 하드웨어와 소프트웨어 또는 펌웨어와의 조합에서 구현될 수도 있다. 컴퓨터 시스템 (100) 의 컴포넌트 또는 방법이 소프트웨어 또는 펌웨어에서 구현되는 경우들에 있어서, 대응하는 코드는, 컴퓨터 판독가능 매체인 메인 메모리 (120) (도 2) 에 저장된다. 메인 메모리 (120) 는 통상적으로, 비휘발성 랜덤 액세스 메모리 (RAM), 판독 전용 메모리 (ROM) 디바이스, 프로그래밍가능 ROM (PROM), 소거가능한 PROM (EPROM) 등과 같은 솔리드 스테이트 컴퓨터 판독가능 매체이다. 하지만, 다른 타입들의 컴퓨터 판독가능 매체들이, 예를 들어, 자기 및 광학 저장 디바이스들과 같이 코드를 저장하기 위해 사용될 수도 있다.
다수의 변동들이 본 발명의 범위로부터 일탈함없이 도 2 내지 도 6 을 참조하여 상기 설명된 방법들에 대해 행해질 수도 있음이 또한 주목되어야 한다. 예를 들어, 도 2 에 도시된 컴퓨터 시스템 (100) 의 구성은, 당업자에 의해 이해될 바와 같이, 다수의 방식들로 변형될 수도 있다. 또한, 도 6 에 도시된 스마트폰 (600) 은, 본 발명을 수행하기 위해 적합한 구성 및 기능을 갖는 모바일 디바이스의 단지 일 예일 뿐이다. 당업자는, 본 명세서에서 제공된 설명의 관점에서, 다수의 변동들이 본 발명의 범위로부터 일탈함없이 도 6 에 도시된 스마트폰 (600) 에 대해 행해질 수도 있음을 이해할 것이다. 이들 및 다른 변동들은 본 발명의 범위 내에 있다. 본 명세서에서 설명된 예시적인 실시형태들은 본 발명의 원리들 및 개념들을 나타내도록 의도되지만, 당업자에 의해 이해될 바와 같이, 본 발명은 이들 실시형태들로 한정되지 않는다.
Claims (28)
- 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템으로서,
호스트 오퍼레이팅 시스템 (OS) 및 하이퍼바이저를 구동하는 적어도 하나의 중앙 프로세싱 유닛 (CPU) 으로서, 상기 하이퍼바이저는 상기 CPU 상에서 적어도 제 1 게스트 OS 의 실행을 제어하고, 상기 하이퍼바이저는 상기 제 1 게스트 OS 와 연관된 적어도 제 1 가상 머신 (VM) 을 구동하는, 상기 적어도 하나의 중앙 프로세싱 유닛 (CPU);
상기 CPU 와 통신하는 물리적 메모리로서, 상기 물리적 메모리는 물리적 어드레스들 (PA들) 에 의해 어드레싱가능한 물리적 메모리 위치들을 가지며 적어도 하나의 페이지 테이블이 상기 물리적 메모리의 물리적 메모리 위치들에 저장되며 상기 페이지 테이블은 중간 물리적 어드레스 (IPA) 를 상기 물리적 메모리의 실제 PA 로 매핑하기 위한 매핑들에 대응하는 페이지 테이블 엔트리들을 포함하는, 상기 물리적 메모리;
상기 페이지 테이블 엔트리들의 서브세트를 저장하는 적어도 하나의 변환 색인 버퍼 (TLB); 및
상기 CPU, 상기 물리적 메모리 및 상기 TLB 와 통신하는 적어도 하나의 메모리 관리 유닛 (MMU) 으로서, 상기 MMU 는 IPA 와 연관된 페이지 테이블 엔트리들이 상기 TLB 에 저장되는지 여부를 결정하고, 상기 IPA 와 연관된 페이지 테이블 엔트리들이 상기 TLB 에 저장되지 않으면, TLB 미스가 발생하였고, TLB 미스가 발생하면, 상기 MMU 는 상기 IPA 와 연관된 데이터가 저장되는 상기 물리적 메모리의 PA 를 예측하는, 상기 적어도 하나의 메모리 관리 유닛 (MMU) 을 포함하는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 1 항에 있어서,
상기 MMU 는 PA = f(IPA) 와 같은 상기 IPA 의 함수 (f) 로서 상기 PA 를 예측하는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 2 항에 있어서,
상기 함수 (f) 는 복수의 함수들로부터 선택되고, 상기 복수의 함수들의 각각의 함수는 상기 IPA 와 예측된 상기 PA 간에 1대1 매핑을 제공하는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 3 항에 있어서,
상기 함수 (f) 는 다항식인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 3 항에 있어서,
상기 함수 (f) 는 PA = IPA 이도록 유니티 함수인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 3 항에 있어서,
상기 하이퍼바이저는 디지털 권리 관리자 (DRM) 컴퓨터 프로그램과 연관된 적어도 제 2 VM 을 구동하고 있고,
상기 함수 (f) 는 IPA_Offset_function(VMID) 이며, 상기 VMID 는 상기 TLB 미스와 연관된 VM 을 식별하는 상기 제 1 및 제 2 VM들에 걸친 고유의 식별자이고, 상기 IPA_Offset_function 은 상기 TLB 미스가 발생하였을 경우에 메모리에 액세스하도록 상기 IPA 를 사용하고 있었던 상기 제 1 또는 제 2 VM 의 상기 VMID 와 연관된 특정 오프셋 값에 기초하여 선택되는 출력을 갖는 함수이며,
상기 예측된 PA 는 PA = IPA_Offset_function(VMID) 로서 예측되는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 3 항에 있어서,
상기 하이퍼바이저는 디지털 권리 관리자 (DRM) 컴퓨터 프로그램과 연관된 적어도 제 2 VM 을 구동하고 있고,
상기 함수 (f) 는 IPA XOR Extended_VMID 이며, 상기 XOR 는 배타적 OR 연산을 나타내고 상기 Extended_VMID 는 확장된 VMID 이며,
상기 예측된 PA 는 PA = IPA XOR Extended_VMID 로서 예측되는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 1 항에 있어서,
상기 컴퓨터 시스템은 모바일 디바이스의 부분인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 8 항에 있어서,
상기 모바일 디바이스는 모바일 전화기인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 제 9 항에 있어서,
상기 모바일 전화기는 스마트 폰인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 컴퓨터 시스템. - 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법으로서,
적어도 하나의 중앙 프로세싱 유닛 (CPU), 적어도 하나의 물리적 메모리, 적어도 하나의 변환 색인 버퍼 (TLB), 및 적어도 하나의 메모리 관리 유닛 (MMU) 을 제공하는 단계로서, 상기 CPU, 상기 물리적 메모리, 상기 TLB, 및 상기 MMU 는 서로 통신하고, 상기 CPU 는 호스트 오퍼레이팅 시스템 (OS) 및 하이퍼바이저를 구동하고, 상기 하이퍼바이저는 상기 CPU 상에서 적어도 제 1 게스트 OS 의 실행을 제어하고, 상기 하이퍼바이저는 상기 제 1 게스트 OS 와 연관된 적어도 제 1 가상 머신 (VM) 을 구동하고, 상기 물리적 메모리는 물리적 어드레스들 (PA들) 에 의해 어드레싱가능한 물리적 메모리 위치들을 가지며 적어도 하나의 페이지 테이블이 상기 물리적 메모리의 물리적 메모리 위치들에 저장되고 상기 페이지 테이블은 중간 물리적 어드레스 (IPA) 를 상기 물리적 메모리의 실제 PA 로 매핑하기 위한 매핑들에 대응하는 페이지 테이블 엔트리들을 포함하고, 상기 TLB 는 상기 페이지 테이블 엔트리들의 서브세트를 저장하는, 상기 제공하는 단계; 및
상기 MMU 에 있어서:
IPA 와 연관된 페이지 테이블 엔트리들이 상기 TLB 에 저장되는지 여부를 결정하는 단계;
상기 IPA 와 연관된 페이지 테이블 엔트리들이 상기 TLB 에 저장되지 않는다고 결정되면, TLB 미스가 발생하였다고 판정하는 단계; 및
TLB 미스가 발생하였다고 판정되었으면, 상기 IPA 와 연관된 데이터가 저장되는 상기 물리적 메모리의 PA 를 예측하는 단계를 포함하는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 11 항에 있어서,
상기 MMU 는 PA = f(IPA) 와 같은 상기 IPA 의 함수 (f) 로서 상기 PA 를 예측하는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 12 항에 있어서,
상기 함수 (f) 는 복수의 함수들로부터 선택되고, 상기 복수의 함수들의 각각의 함수는 상기 IPA 와 예측된 상기 PA 간에 1대1 매핑을 제공하는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 13 항에 있어서,
상기 함수 (f) 는 다항식인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 13 항에 있어서,
상기 함수 (f) 는 PA = IPA 이도록 유니티 함수인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 13 항에 있어서,
상기 하이퍼바이저는 디지털 권리 관리자 (DRM) 컴퓨터 프로그램과 연관된 적어도 제 2 VM 을 구동하고 있고,
상기 함수 (f) 는 IPA_Offset_function(VMID) 이며, 상기 VMID 는 상기 TLB 미스와 연관된 VM 을 식별하는 상기 제 1 및 제 2 VM들에 걸친 고유의 식별자이고, 상기 IPA_Offset_function 은 상기 TLB 미스가 발생하였을 경우에 메모리에 액세스하도록 상기 IPA 를 사용하고 있었던 상기 제 1 또는 제 2 VM 의 상기 VMID 와 연관된 특정 오프셋 값에 기초하여 선택되는 출력을 갖는 함수이며,
상기 예측된 PA 는 PA = IPA_Offset_function(VMID) 로서 예측되는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 13 항에 있어서,
상기 하이퍼바이저는 디지털 권리 관리자 (DRM) 컴퓨터 프로그램과 연관된 적어도 제 2 VM 을 구동하고 있고,
상기 함수 (f) 는 IPA XOR Extended_VMID 이며, 상기 XOR 는 배타적 OR 연산을 나타내고 상기 Extended_VMID 는 확장된 VMID 이며,
상기 예측된 PA 는 PA = IPA XOR Extended_VMID 로서 예측되는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 13 항에 있어서,
상기 하이퍼바이저는 상기 CPU 상에서의 적어도 제 1 및 제 2 게스트 OS들의 실행을 제어하고, 상기 하이퍼바이저는 또한 상기 제 2 게스트 OS 와 연관된 적어도 제 2 VM 을 구동하고 있고,
PA들을 예측하기 위해 상기 MMU 에 의해 사용되는 상기 함수 (f) 는 상기 제 1 VM 과 연관된 미스에 대한 PA들의 제 1 범위에 있는 PA들을 예측하고 그리고 상기 제 2 VM 과 연관된 미스에 대한 PA들의 제 2 범위에 있는 PA들을 예측하며, 상기 PA 들의 제 1 및 제 2 범위들은 서로 상이한, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 13 항에 있어서,
상기 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법은 모바일 디바이스의 컴퓨터 시스템에 의해 수행되는, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 19 항에 있어서,
상기 모바일 디바이스는 모바일 전화기인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 제 20 항에 있어서,
상기 모바일 전화기는 스마트 폰인, 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키는 방법. - 하드웨어 테이블 워크 (HWTW) 를 수행하는 것과 연관된 프로세싱 오버헤드를 감소시키기 위해 하나 이상의 프로세서들에 의한 실행을 위해 컴퓨터 코드가 저장된 비-일시적인 컴퓨터 판독가능 매체 (CRM) 로서,
상기 컴퓨터 코드는
중간 물리적 어드레스 (IPA) 와 연관된 페이지 테이블 엔트리들이 TLB 에 저장되는지 여부를 결정하기 위한 제 1 코드 부분으로서, 상기 IPA 와 연관된 페이지 테이블 엔트리들이 상기 TLB 에 저장되지 않는다고 결정되면, 상기 제 1 코드 부분은 TLB 미스가 발생하였다고 판정하는, 상기 제 1 코드 부분; 및
상기 제 1 코드 부분이 TLB 미스가 발생하였다고 판정하면, 상기 IPA 와 연관된 데이터가 저장되는 물리적 메모리의 물리적 어드레스 (PA) 를 예측하기 위한 제 2 코드 부분을 포함하는, 비-일시적인 컴퓨터 판독가능 매체 (CRM). - 제 21 항에 있어서,
상기 제 2 코드 부분은 PA = f(IPA) 와 같은 상기 IPA 의 함수 (f) 로서 상기 PA 를 예측하는, 비-일시적인 컴퓨터 판독가능 매체 (CRM). - 제 23 항에 있어서,
상기 제 2 코드 부분은 상기 함수 (f) 를 복수의 함수들로부터 선택하고, 상기 복수의 함수들의 각각의 함수는 상기 IPA 와 예측된 상기 PA 간에 1대1 매핑을 제공하는, 비-일시적인 컴퓨터 판독가능 매체 (CRM). - 제 24 항에 있어서,
상기 함수 (f) 는 다항식인, 비-일시적인 컴퓨터 판독가능 매체 (CRM). - 제 24 항에 있어서,
상기 함수 (f) 는 PA = IPA 이도록 유니티 함수인, 비-일시적인 컴퓨터 판독가능 매체 (CRM). - 제 24 항에 있어서,
상기 함수 (f) 는 IPA_Offset_function(VMID) 이며, 상기 VMID 는 제 1 및 제 2 가상 머신들 (VM들) 중 하나를 상기 TLB 미스와 연관된 VM 으로서 식별하는 상기 제 1 및 제 2 가상 머신들 (VM들) 에 걸친 고유의 식별자이고, 상기 IPA_Offset_function 은 상기 TLB 미스가 발생하였을 경우에 메모리에 액세스하도록 상기 IPA 를 사용하고 있었던 상기 제 1 또는 제 2 VM 의 상기 VMID 와 연관된 특정 오프셋 값에 기초하여 선택되는 출력을 갖는 함수이며,
상기 예측된 PA 는 PA = IPA_Offset_function(VMID) 로서 예측되는, 비-일시적인 컴퓨터 판독가능 매체 (CRM). - 제 24 항에 있어서,
상기 함수 (f) 는 IPA XOR Extended_VMID 이며, 상기 XOR 는 배타적 OR 연산을 나타내고 상기 Extended_VMID 는 확장된 VMID 이며,
상기 예측된 PA 는 PA = IPA XOR Extended_VMID 로서 예측되는, 비-일시적인 컴퓨터 판독가능 매체 (CRM).
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/785,877 | 2013-03-05 | ||
| US13/785,877 US9015400B2 (en) | 2013-03-05 | 2013-03-05 | Methods and systems for reducing the amount of time and computing resources that are required to perform a hardware table walk (HWTW) |
| PCT/US2014/020101 WO2014137970A1 (en) | 2013-03-05 | 2014-03-04 | Methods and systems for reducing the amount of time and computing resources that are required to perform a hardware table walk |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150128804A true KR20150128804A (ko) | 2015-11-18 |
Family
ID=50382619
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020157027417A KR20150128804A (ko) | 2013-03-05 | 2014-03-04 | 하드웨어 테이블 워크를 수행하는데 요구된 시간 및 컴퓨팅 리소스들의 양을 감소시키기 위한 방법들 및 시스템들 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9015400B2 (ko) |
| EP (1) | EP2965210A1 (ko) |
| JP (1) | JP6298083B2 (ko) |
| KR (1) | KR20150128804A (ko) |
| CN (1) | CN105027095B (ko) |
| TW (1) | TWI526832B (ko) |
| WO (1) | WO2014137970A1 (ko) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9330026B2 (en) | 2013-03-05 | 2016-05-03 | Qualcomm Incorporated | Method and apparatus for preventing unauthorized access to contents of a register under certain conditions when performing a hardware table walk (HWTW) |
| US9805194B2 (en) | 2015-03-27 | 2017-10-31 | Intel Corporation | Memory scanning methods and apparatus |
| US10474589B1 (en) * | 2016-03-02 | 2019-11-12 | Janus Technologies, Inc. | Method and apparatus for side-band management of security for a server computer |
| US10261916B2 (en) * | 2016-03-25 | 2019-04-16 | Advanced Micro Devices, Inc. | Adaptive extension of leases for entries in a translation lookaside buffer |
| US10386904B2 (en) * | 2016-03-31 | 2019-08-20 | Qualcomm Incorporated | Hardware managed power collapse and clock wake-up for memory management units and distributed virtual memory networks |
| US20180069767A1 (en) * | 2016-09-06 | 2018-03-08 | Advanced Micro Devices, Inc. | Preserving quality of service constraints in heterogeneous processing systems |
| EP3355188B1 (en) | 2017-01-31 | 2021-08-25 | OpenSynergy GmbH | Instrument display on a car dashboard by checking frames of a gui by a realtime os |
| US10754790B2 (en) * | 2018-04-26 | 2020-08-25 | Qualcomm Incorporated | Translation of virtual addresses to physical addresses using translation lookaside buffer information |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2933628B2 (ja) * | 1988-07-25 | 1999-08-16 | 株式会社日立製作所 | 主記憶装置管理方法および計算機システム |
| GB2260004B (en) | 1991-09-30 | 1995-02-08 | Apple Computer | Memory management unit for a computer system |
| US7124170B1 (en) | 1999-08-20 | 2006-10-17 | Intertrust Technologies Corp. | Secure processing unit systems and methods |
| US20030079103A1 (en) | 2001-10-24 | 2003-04-24 | Morrow Michael W. | Apparatus and method to perform address translation |
| US8051301B2 (en) | 2001-11-13 | 2011-11-01 | Advanced Micro Devices, Inc. | Memory management system and method providing linear address based memory access security |
| AU2003276399A1 (en) | 2002-11-18 | 2004-06-15 | Arm Limited | Virtual to physical memory address mapping within a system having a secure domain and a non-secure domain |
| US7089397B1 (en) * | 2003-07-03 | 2006-08-08 | Transmeta Corporation | Method and system for caching attribute data for matching attributes with physical addresses |
| US7117290B2 (en) * | 2003-09-03 | 2006-10-03 | Advanced Micro Devices, Inc. | MicroTLB and micro tag for reducing power in a processor |
| US8156343B2 (en) * | 2003-11-26 | 2012-04-10 | Intel Corporation | Accessing private data about the state of a data processing machine from storage that is publicly accessible |
| US7162609B2 (en) * | 2003-12-03 | 2007-01-09 | Marvell International Ltd. | Translation lookaside buffer prediction mechanism |
| EP1870814B1 (en) | 2006-06-19 | 2014-08-13 | Texas Instruments France | Method and apparatus for secure demand paging for processor devices |
| US7340582B2 (en) | 2004-09-30 | 2008-03-04 | Intel Corporation | Fault processing for direct memory access address translation |
| US7428626B2 (en) | 2005-03-08 | 2008-09-23 | Microsoft Corporation | Method and system for a second level address translation in a virtual machine environment |
| US20060224815A1 (en) | 2005-03-30 | 2006-10-05 | Koichi Yamada | Virtualizing memory management unit resources |
| US20070226795A1 (en) | 2006-02-09 | 2007-09-27 | Texas Instruments Incorporated | Virtual cores and hardware-supported hypervisor integrated circuits, systems, methods and processes of manufacture |
| US7822941B2 (en) | 2006-06-05 | 2010-10-26 | Oracle America, Inc. | Function-based virtual-to-physical address translation |
| US7594079B2 (en) * | 2006-09-29 | 2009-09-22 | Mips Technologies, Inc. | Data cache virtual hint way prediction, and applications thereof |
| US8615643B2 (en) * | 2006-12-05 | 2013-12-24 | Microsoft Corporation | Operational efficiency of virtual TLBs |
| EP2075696A3 (en) | 2007-05-10 | 2010-01-27 | Texas Instruments Incorporated | Interrupt- related circuits, systems and processes |
| US8661181B2 (en) * | 2007-06-28 | 2014-02-25 | Memory Technologies Llc | Memory protection unit in a virtual processing environment |
| US8595465B1 (en) * | 2009-09-09 | 2013-11-26 | Marvell Israel (M.I.S.L) Ltd. | Virtual address to physical address translation using prediction logic |
| US9098700B2 (en) | 2010-03-01 | 2015-08-04 | The Trustees Of Columbia University In The City Of New York | Systems and methods for detecting attacks against a digital circuit |
| US9405700B2 (en) | 2010-11-04 | 2016-08-02 | Sonics, Inc. | Methods and apparatus for virtualization in an integrated circuit |
| US20120246381A1 (en) * | 2010-12-14 | 2012-09-27 | Andy Kegel | Input Output Memory Management Unit (IOMMU) Two-Layer Addressing |
| US9092358B2 (en) * | 2011-03-03 | 2015-07-28 | Qualcomm Incorporated | Memory management unit with pre-filling capability |
| US9009445B2 (en) * | 2011-10-20 | 2015-04-14 | Apple Inc. | Memory management unit speculative hardware table walk scheme |
| CN102722451B (zh) * | 2012-06-25 | 2015-04-15 | 杭州中天微系统有限公司 | 采用物理地址预测访问高速缓存的装置 |
| US9330026B2 (en) | 2013-03-05 | 2016-05-03 | Qualcomm Incorporated | Method and apparatus for preventing unauthorized access to contents of a register under certain conditions when performing a hardware table walk (HWTW) |
-
2013
- 2013-03-05 US US13/785,877 patent/US9015400B2/en active Active
-
2014
- 2014-03-03 TW TW103107028A patent/TWI526832B/zh not_active IP Right Cessation
- 2014-03-04 WO PCT/US2014/020101 patent/WO2014137970A1/en active Application Filing
- 2014-03-04 KR KR1020157027417A patent/KR20150128804A/ko not_active Application Discontinuation
- 2014-03-04 EP EP14712879.7A patent/EP2965210A1/en not_active Withdrawn
- 2014-03-04 CN CN201480011808.8A patent/CN105027095B/zh not_active Expired - Fee Related
- 2014-03-04 JP JP2015561519A patent/JP6298083B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN105027095B (zh) | 2019-01-22 |
| JP2016513835A (ja) | 2016-05-16 |
| US20140258586A1 (en) | 2014-09-11 |
| US9015400B2 (en) | 2015-04-21 |
| TWI526832B (zh) | 2016-03-21 |
| WO2014137970A1 (en) | 2014-09-12 |
| EP2965210A1 (en) | 2016-01-13 |
| CN105027095A (zh) | 2015-11-04 |
| TW201447583A (zh) | 2014-12-16 |
| JP6298083B2 (ja) | 2018-03-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6298083B2 (ja) | ハードウェアテーブルウォークを実行するのに要求される時間およびコンピューティングリソースの量を低減するための方法およびシステム | |
| US10437733B2 (en) | Method and apparatus to allow secure guest access to extended page tables | |
| JP6301378B2 (ja) | ハードウェアテーブルウォーク(hwtw)を実行する際にいくつかの条件下でレジスタの内容に対する許可のないアクセスを防止するための方法および装置 | |
| US9858198B2 (en) | 64KB page system that supports 4KB page operations | |
| US10540306B2 (en) | Data copying method, direct memory access controller, and computer system | |
| US10558584B2 (en) | Employing intermediary structures for facilitating access to secure memory | |
| US8521919B2 (en) | Direct memory access in a computing environment | |
| US10216533B2 (en) | Efficient virtual I/O address translation | |
| US10310759B2 (en) | Use efficiency of platform memory resources through firmware managed I/O translation table paging | |
| CN114860329B (zh) | 动态一致性偏置配置引擎及方法 | |
| US20150277782A1 (en) | Cache Driver Management of Hot Data | |
| US20140237144A1 (en) | Method to emulate message signaled interrupts with interrupt data | |
| US9384154B2 (en) | Method to emulate message signaled interrupts with multiple interrupt vectors | |
| US8751724B2 (en) | Dynamic memory reconfiguration to delay performance overhead | |
| US10102135B2 (en) | Dynamically-adjusted host memory buffer | |
| US20190238656A1 (en) | Consolidated cloud system for virtual machine | |
| US20200348874A1 (en) | Memory-fabric-based data-mover-enabled memory tiering system | |
| US11009841B2 (en) | Initialising control data for a device | |
| KR20240067880A (ko) | 프로세서 기반 디바이스에서의 메모리 블록 액세스 빈도 추적 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Withdrawal due to no request for examination |