KR20120117568A - Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same - Google Patents
Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same Download PDFInfo
- Publication number
- KR20120117568A KR20120117568A KR1020110035384A KR20110035384A KR20120117568A KR 20120117568 A KR20120117568 A KR 20120117568A KR 1020110035384 A KR1020110035384 A KR 1020110035384A KR 20110035384 A KR20110035384 A KR 20110035384A KR 20120117568 A KR20120117568 A KR 20120117568A
- Authority
- KR
- South Korea
- Prior art keywords
- ala
- leu
- arg
- gly
- val
- Prior art date
Links
Images












Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
- C12N15/76—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora for Actinomyces; for Streptomyces
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P17/00—Preparation of heterocyclic carbon compounds with only O, N, S, Se or Te as ring hetero atoms
- C12P17/02—Oxygen as only ring hetero atoms
- C12P17/08—Oxygen as only ring hetero atoms containing a hetero ring of at least seven ring members, e.g. zearalenone, macrolide aglycons
Landscapes
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Plant Pathology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
Description
본 발명은 신규 나르보마이신 유도체 화합물, 상기 화합물을 포함하는 항균용 조성물 및 상기 화합물의 생산 방법에 관한 것이다.The present invention relates to a novel narcamycin derivative compound, an antimicrobial composition comprising the compound and a method of producing the compound.
감염성 세균들이 대부분의 항생제에 대한 내성을 획득하게 되면서, 기존 항생제에 대하여 내성을 갖는 세균이나 곰팡이, 바이러스, 암세포 등을 치료하기 위해, 새로운 종류의 항생제를 얻으려는 노력이 계속되고 있다. 이를 위하여 이제까지는 주로 자연계에 존재하는 미생물을 탐색하여 새로운 항생물질을 만들어내는 균주를 찾았으나, 이러한 신규 항생물질 탐색과정은 그에 들어가는 시간, 노력 및 비용이 엄청나고, 약리작용 및 독성시험까지 완료되어야만 하나의 사용 가능한 항생물질로 인정받을 수 있기 때문에 무척 까다롭고 힘든 작업이다. 따라서 많은 제약회사, 대학 및 연구소에서 기존의 방법과는 다른 돌파구를 기대하고 있다.As infectious bacteria gain resistance to most antibiotics, efforts are being made to obtain new kinds of antibiotics to treat bacteria, fungi, viruses and cancer cells that are resistant to conventional antibiotics. To this end, until now, the strains that search for microorganisms in the natural world to produce new antibiotics have been found.However, the process of searching for new antibiotics requires enormous time, effort, and cost, and pharmacological and toxicological tests must be completed. It is a very difficult and difficult task because it can be recognized as an available antibiotic. As a result, many pharmaceutical companies, universities and research institutes are expecting breakthroughs unlike traditional methods.
그에 따라, 항생물질을 만들어내는 균주의 유전자를 조작하여 새로운 구조의 다양한 생리활성물질을 얻어내려는 방법이 시도되고 있다. 이러한 방법은 주로 폴리케타이드(polyketide) 계열 항생물질의 구조변형에 도입되고 있으며, 다양한 생합성 유전자의 조합을 통하여 다양한 구조를 생성할 수 있으므로 이를 조합 생합성(combinatorial biosynthesis)이라 부른다. 이러한 방법은 기존의 화학 합성법 또는 효소 합성법에 비해 탐색과정에서의 시간과 비용이 절약됨은 물론, 기존 항생제의 구조와 활성과의 관계 등을 응용하여 설계하기 때문에 생물학적 활성을 예상할 수 있어, 많은 시간과 비용을 절감할 수 있다.Accordingly, a method has been attempted to obtain various physiologically active substances with new structures by manipulating the genes of strains producing antibiotics. This method is mainly introduced into the structural modification of polyketide-based antibiotics, and it is called combinatorial biosynthesis because it can generate various structures through the combination of various biosynthetic genes. This method saves time and cost in the screening process compared to the conventional chemical synthesis or enzyme synthesis method, and can be predicted biological activity because it is designed by applying the relationship between the structure and activity of the existing antibiotics, many times Can reduce the cost.
폴리케타이드 계열의 화합물은 미생물로부터 생산되는 복잡한 구조의 화합물로서, 현재까지 약 10,000가지 이상의 화합물이 알려져 있다. 폴리케타이드 계열의 화합물은 폴리케타이드 신타아제(polyketide synthase, PKS)라고 하는 다기능 단백질 복합체(multifunctional protein complex)에 의해 생합성된다. 이러한 PKS 복합체는 연속적인 축합반응에 관여하는 여러 개의 모듈(한 번의 축합반응을 책임지는 촉매 도메인들의 묶음)로 구성되어 있다. 모듈(module)을 구성하는 촉매 도메인(catalytic domain)들의 구성에 따라 폴리케타이드의 구조가 일대일로 대응하여 생합성되므로 PKS 유전자의 변형에 의해 폴리케타이드의 구조를 변형시킬 수 있다.Polyketide-based compounds are complex compounds produced from microorganisms, and more than about 10,000 compounds are known to date. Polyketide-based compounds are biosynthesized by a multifunctional protein complex called polyketide synthase (PKS). These PKS complexes consist of several modules (a bundle of catalytic domains responsible for one condensation reaction) involved in a continuous condensation reaction. Since the structure of the polyketide is biosynthesized in one-to-one correspondence according to the configuration of the catalytic domains constituting the module, the structure of the polyketide may be modified by the modification of the PKS gene.
한편, 마크롤라이드는 폴리케타이드 마크로락톤 환과 그에 부착된 하나 또는 그 이상의 데옥시당으로 구성된다. 상기 마크롤라이드는 스태필로코커스 및 엔테로코커스와 같은 그람-양성 박테리아에 대해 주로 항균 활성을 나타낸다. 마크롤라이드 중에서 데옥시당 부분(moiety)이 표적 분자와 특이적으로 접촉함으로써 분자의 생물학적 활성에 크게 영향을 미치기 때문에, 데옥시 당 부분의 구조가 중요하고, 따라서, 상기 언급한 PKS 유전자 변형에 의한 폴리케타이드 구조 변형 외에도 글리코실화와 같은 후-PKS 테일러링 단계(post-PKS tailoring step)가 반드시 필요하다. 마크롤라이드 계열 항생물질 저항성 병원체의 출현으로 인하여 신규 마크롤라이드 유도체를 발견하기 위한 연구가 계속되고 있다. 기존에는 화학적 및 효소적 합성을 이용한 연구가 많이 진행되어왔으나, 데옥시 당 부분의 화학적 수식 또는 뉴클레오티드-활성화되는 데옥시 당의 시험관 내 효소적 합성이 쉽지 않은 문제가 있다. Macrolides, on the other hand, consist of a polyketide macrolactone ring and one or more deoxysaccharides attached thereto. The macrolides exhibit mainly antimicrobial activity against Gram-positive bacteria such as Staphylococcus and Enterococcus. Since the deoxysugar moiety in macrolides greatly affects the biological activity of the molecule by specific contact with the target molecule, the structure of the deoxy sugar moiety is important, and therefore, it is necessary for the aforementioned PKS gene modification. In addition to polyketide structural modifications, post-PKS tailoring steps such as glycosylation are necessary. Due to the emergence of macrolide antibiotic-resistant pathogens, research continues to find new macrolide derivatives. In the past, many studies using chemical and enzymatic synthesis have been conducted, but there is a problem in that enzymatic synthesis of deoxy sugar moieties or in vitro enzymatic synthesis of nucleotide-activated deoxy sugars is not easy.
나르보마이신은 스트렙토마이세스 베네주엘래에서 형성되는 마크롤라이드 계열 물질로서, PikC에 의하여 네오-, 노바-, 및 피크로마이신으로 전환된다(도 1). 나르보마이신은 스태필로코커스 아우레우스, 스트렙토코커스 피오제네스, 코리네박테리움 디프테리애, 그람-양성 코커스의 에리트로마이신-저항성 균주 등에 대한 우수한 활성을 가지는 것으로 보고되어 왔다. 천연 나르보마이신은 당 부분으로서 데옥시당 D-데소사민을 포함한다. 스트렙토마이세스 베네주엘래의 글리코실트랜스퍼라아제인 DesVII 및 그의 보조 상대인 DevVIII가 나르보마이신의 아글리콘(비당(非糖) 성분)인 나르보놀라이드로 TDP-데옥시 당을 전이시키고, 여섯 개의 오픈 리딩 프레임(open reading frame) desI 내지 desⅥ은 데소사민 생합성에 관여하는 것으로 추정된다. 상기 단백질을 이용하여 시험관 내 및 생체 내에서 나르보마이신 유도체의 글리코실다양화를 유발할 수 있는 것으로 생각되었으나, 생체 내 조합 생합성의 방법으로 나르보마이신에 있어서 다양한 당 부분을 포함하는 나르보마이신 유도체를 합성하여 그의 항균 활성을 보고한 예는 없다.
Narvomycin is Streptomyces As a macrolide material formed in Venezuela , it is converted to neo-, nova-, and pyromycin by PikC (FIG. 1). Narbomycin is Staphylococcus Aureus , Streptococcus piogenes , Corynebacterium Terry deep cliff, gram - have been reported to have excellent activity toward such resistant strains - erythromycin positive Rhodococcus. Natural narbomycin includes deoxysaccharide D-desosamin as the sugar moiety. Streptomyces Venezuela 's glycosyltransferase DesVII and its auxiliary partner DevVIII transfer the TDP-deoxy sugar to the nagliconide, the naglycone (non-sugar component) of narcamycin, and six open readings. Open reading frame desI to desVI are presumed to be involved in desosamin biosynthesis. Although it has been thought that the protein can be used to induce glycosylation of narcoimycin derivatives in vitro and in vivo , narcamycin derivatives containing various sugar moieties in narcamycin by the method of combinatorial biosynthesis in vivo. There is no example of synthesizing and reporting its antimicrobial activity.
이러한 배경에서, 본 발명자들은 다양한 당 생합성 관련 단백질의 조합을 코딩하는 핵산을 포함하는 카세트를 제작하여 나르보놀라이드를 축적하는 스트렙토마이세스 베네주엘래에서 이종 발현시킴으로써 다양하고 신규한 나르보마이신 유도체를 생산할 수 있음을 발견하여 본 발명을 완성하였다. Against this background, the inventors have prepared a cassette comprising a nucleic acid encoding a combination of various sugar biosynthesis related proteins to express a variety of novel navomycin derivatives by heterologous expression in Streptomyces Venezuelan accumulating navonolide . The present invention was completed by discovering that it can be produced.
본 발명은 스트렙토마이세스 속 미생물로서, desVIII, desVII, desIII, desIV, desI, desII, desV, desVI, oleL, oleU, oleV, eryBII, urdR 및 oleW로 구성된 군으로부터 선택되는 단백질의 조합 중 desVIII, desVII, desIII 및 desIV 단백질을 포함하는 단백질의 조합을 코딩하는 핵산이 도입된, 나르보마이신 유도체 생산 재조합 미생물을 제공하고자 한다.The present invention is a microorganism of the genus Streptomyces, desVIII, desVII, desIII, desIV, desI, desII, desV, desVI, oleL, oleU, oleV, eryBII, urdR and oleW among a combination of proteins selected from the group consisting of It is an object of the present invention to provide a recombinant microorganism producing a narcamycin derivative, in which a nucleic acid encoding a combination of proteins, including desIII and desIV proteins, has been introduced.
또한, 본 발명은 desVIII-desVII-desIII-desIV, desVIII-desVII-desIII-desIV-oleL-oleU, desVIII-desVII-desIII-desIV-desI-desII, desVIII-desVII-desIII-desIV-oleV-eryBII-urdR 또는 desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU 의 단백질의 조합을 코딩하는 핵산을 포함하는 발현 벡터를 제공하고자 한다.In addition, the present invention is desVIII-desVII-desIII-desIV, desVIII-desVII-desIII-desIV-oleL-oleU, desVIII-desVII-desIII-desIV-desI-desII, desVIII-desVII-desIII-desIV-oleV-eryBII-urdR Or an expression vector comprising a nucleic acid encoding a combination of proteins of desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU.
또한, 본 발명은 상기 재조합 미생물을 배양하는 단계; 및 배양된 세포 또는 배양액으로부터 나르보마이신 유도체를 회수하는 단계를 포함하는 나르보마이신 유도체의 제조방법을 제공하고자 한다.In addition, the present invention comprises the steps of culturing the recombinant microorganism; And it is to provide a method for producing a narcamycin derivative comprising the step of recovering a narcamycin derivative from the cultured cells or culture medium.
또한, 본 발명은 하기 화학식 1로 표시되는 나르보마이신 유도체 화합물, 그의 약제학적으로 허용가능한 염을 제공하고자 한다.In addition, the present invention is to provide a narbomycin derivative compound represented by the following formula (1), a pharmaceutically acceptable salt thereof.

상기 식에서 R은 


![]()
![]()
또한, 본 발명은 상기 화학식 1의 화합물 또는 약제학적으로 허용가능한 염을 포함하는 항균용 조성물을 제공하고자 한다.
In addition, the present invention is to provide an antimicrobial composition comprising the compound of Formula 1 or a pharmaceutically acceptable salt.
하나의 양태로서, 본 발명은 스트렙토마이세스 속 미생물로서, desVIII, desVII, desIII, desIV, desI, desII, desV, desVI, oleL, oleU, oleV, eryBII, urdR 및 oleW로 구성된 군으로부터 선택되는 단백질의 조합 중 desVIII, desVII, desIII 및 desIV 단백질을 포함하는 단백질의 조합을 코딩하는 핵산이 도입된, 나르보마이신 유도체 생산 재조합 미생물을 제공한다. 상기 단백질의 조합은 desVIII-desVII-desIII-desIV, desVIII-desVII-desIII-desIV-oleL-oleU, desVIII-desVII-desIII-desIV-desI-desII, desVIII-desVII-desIII-desIV-oleV-eryBII-urdR 또는 desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU 의 단백질의 조합일 수 있다. In one embodiment, the present invention provides a microorganism of the genus Streptomyces, the protein selected from the group consisting of desVIII, desVII, desIII, desIV, desI, desII, desV, desVI, oleL, oleU, oleV, eryBII, urdR and oleW Provided is a recombinant microorganism producing a narcamycin derivative, in which a nucleic acid encoding a combination of proteins including desVIII, desVII, desIII and desIV proteins in combination is introduced. The combination of these proteins is desVIII-desVII-desIII-desIV, desVIII-desVII-desIII-desIV-oleL-oleU, desVIII-desVII-desIII-desIV-desI-desII, desVIII-desVII-desIII-desIV-oleV-eryBII-urdR Or a combination of proteins of desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU.
본 발명에서 스트렙토마이세스 속 미생물은, 내재적으로 나르보마이신을 생합성할 수 있는 스트렙토마이세스 속 미생물을 의미한다. 상기 내재적으로 나르보마이신을 생합성할 수 있는 미생물이란, 내재적으로 나르보마이신 생합성에 필요한 모든 효소를 발현하는 미생물을 의미한다. 상기 "내재적"이란 야생형 미생물이 천연의 상태로 가지고 있는 활성을 의미한다. 본 발명에서 나르보마이신은 마크롤라이드 계열 물질로서, 도 1에 도시된 바와 같은 구조를 가진다.Microorganism of the genus Streptomyces in the present invention means a microorganism of the genus Streptomyces capable of biosynthesis of narbomycin intrinsically. The microorganism capable of biosynthesizing narcamycin implicitly means a microorganism that expresses all enzymes necessary for in vivo biosynthesis. The term "intrinsic" refers to the activity of the wild-type microorganism in its natural state. Narvomycin in the present invention is a macrolide-based material, and has a structure as shown in FIG.
본 발명의 스트렙토마이세스 속 미생물은 스트렙토마이세스 베네주엘래일 수 있으나, 이에 한정되지 않고 나르보마이신을 생산할 수 있는 모든 스트렙토마이세스 속 미생물을 포함한다. 스트렙토마이세스 베네주엘래는 유전자 조작이 쉽고 상대적으로 빠른 성장 속도 (doubling time, ca . 1 h)를 가지므로, 대사물질 생산을 위하여 필요한 배양 기간이 짧다. 상기 미생물은 단일 폴리케타이드 신타아제 (PKS) 및 다수의 PKS 후 수식 효소들 (데소사민 당의 생합성 및 전이에 연관된 des 클러스터에 의한 글리코실화 및 PikC P450 모노옥시게나아제에 의한 히드록실화)의 작용을 통하여 12- 및 14-원환 마크롤라이드, 메티마이신 및 피크로마이신을 모두 생산할 수 있다(도 1). 본 발명의 구체적 실시예에서, 스트렙토마이세스 베네주엘 래 ATCC 15439를 사용할 수 있다.Genus Streptomyces microorganism of the present invention is Streptomyces Venezuela Days However, the present invention includes, but is not limited to, all Streptomyces genus microorganisms capable of producing narbomycin. Streptomyces Bene share elrae is so easy to have a relatively fast growth rate genetically modified (doubling time, ca. 1 h ), the shorter the incubation period necessary for the production of metabolites. The microorganism is composed of a single polyketide synthase (PKS) and a number of post-PKS modified enzymes (glycosylation by des clusters involved in biosynthesis and transfer of desosamin sugars and hydroxylation by PikC P450 monooxygenase). Through action it is possible to produce both 12- and 14-membered ring macrolides, methymycin and picromycin (FIG. 1). In a specific embodiment of the invention, Streptomyces Vanessa can use Zwolle below ATCC 15439.
바람직하게는, 상기 스트렙토마이세스 속 미생물은, 내재적으로 나르보마이신을 생합성할 수 있는 스트렙토마이세스 속 미생물에서 나르보마이신의 당 부분인 D-데소사민을 생합성 및 전이시키는 단백질을 코딩하는 유전자 클러스터가 게놈으로부터 결실된 것일 수 있다. 나르보마이신의 당 부분을 생합성 및 전이시키는 단백질을 코딩하는 유전자 클러스터가 게놈으로부터 결실된 스트렙토마이세스 속 미생물은 나르보마이신의 아글리콘(비당(非糖) 성분)인 나르보놀라이드를 축적하게 된다. 상기 유전자 클러스터는 D-데소사민을 생합성 및 전이시키는데 필요한 단백질군을 코딩하는 유전자 클러스터(GenBank: AF079762.1)로서 desVIII-desVII-desIII-desIV-desI-desII-desV-desVI(서열번호 1)로 구성될 수 있다. 상기 미생물은 게놈으로부터 서열번호 1의 염기서열로 구성된 유전자 클러스터가 결실된 것일 수 있다.Preferably, the microorganism of the genus Streptomyces is a gene encoding a protein for biosynthesizing and transferring D-desamine, a sugar portion of narvomycin, in a microorganism of the genus Streptomyces capable of intrinsically biosynthesizing narcamycin. The cluster may be deleted from the genome. Microorganisms of Streptomyces, whose gene clusters encode proteins that biosynthesize and transfer the sugar moiety of narbomycin, result in the accumulation of narbonolide, an aglycone (non-sugar component) of narbomycin. do. The gene cluster is desVIII-desVII-desIII-desIV-desI-desII-desV-desVI (SEQ ID NO: 1), which is a gene cluster (GenBank: AF079762.1) encoding a group of proteins necessary for biosynthesis and metastasis of D-desosamine. It can be configured as. The microorganism may be a gene cluster consisting of the nucleotide sequence of SEQ ID NO: 1 from the genome.
게놈상에서 목적한 유전자만의 특이적 결실은 당 분야에서 확립된 방법을 통하여 수행할 수 있으며, 방법은 특별히 제한되지 않으며, 상동 재조합(homologous recombination)법을 사용할 수도 있다. 목적한 단백질의 N 말단과 C 말단을 코딩하는 핵산 사이에 선별마커를 포함하는 벡터로 스트렙토마이세스 속 균주를 형질전환시켜 게놈과 벡터 사이에 재조합을 유도할 수 있다. 사용되는 선별마커(selection marker)는 특별히 제한되지 않고, 약물 내성, 영양 요구성, 세포독성제에 대한 내성 또는 표면 단백질의 발현과 같은 선택가능 표현형을 부여하는 마커들이 사용될 수 있다. Specific deletion of only the gene of interest in the genome can be carried out through methods established in the art, the method is not particularly limited, homologous recombination method can be used. Recombination may be induced between the genome and the vector by transforming a strain of Streptomyces genus with a vector comprising a selection marker between the N- and C-terminal nucleic acids encoding the protein of interest. The selection marker used is not particularly limited, and markers may be used that confer a selectable phenotype such as drug resistance, nutritional requirements, resistance to cytotoxic agents or expression of surface proteins.
바람직하게는 스트렙토마이세스 베네주엘래 YJ003을 사용할 수 있다. 상기 균주는 본 발명의 실시예에 기재된 방법에 의하여 제조할 수 있다.
Preferably Streptomyces Venezuela YJ003 can be used. The strain can be prepared by the method described in the Examples of the present invention.
본 발명은 나르보마이신 유도체 생산 경로에서 상기 단백질들이 수행하는 기능을 도 2에서 확인할 수 있는 바와 같이 밝혀내었다. 또한, 상기 단백질의 다양하고 신규한 조합을 발현하는 재조합 미생물을 제조함으로써 변형된 당 부분을 가지는 신규 나르보마이신 유도체를 생합성하였고, 그들의 항균 활성도 평가하였다. The present invention has revealed the function of the proteins in the narcamycin derivative production pathway as can be seen in FIG. In addition, by producing recombinant microorganisms expressing a variety of novel combinations of these proteins, new narcommycin derivatives with modified sugar moieties were biosynthesized and their antimicrobial activity was also evaluated.
본 발명의 나르보마이신 유도체 생산에 필요한 단백질 서열정보는 GenBank: AF079762.1, AF055579.2, U77454.1, AF269227.1에서 확인할 수 있다. 구체적으로, 본 발명에서 DesIII는 글루코오스-1-포스페이트를 기질로 하는 Nucleotidylyl transferase(NT)기능을 가지는 단백질로서, 서열번호 2의 아미노산 서열을 가진다. 본 발명에서 DesIV는 4,6-데히드라타아제(4,6-dehydratase, 4,6-DH) 기능을 하는 단백질로서, 서열번호 3의 아미노산 서열을 가진다. 본 발명에서 DesI은 아미노트랜스퍼라아제(aminotrasferase, AT) 기능을 하는 단백질로서, 서열번호 4의 아미노산 서열을 가진다. 본 발명에서 DesII는 데아미나아제(deaminase, DA) 기능을 하는 단백질로서, 서열번호 5의 아미노산 서열을 가진다. 본 발명에서 DesV는 아미노트랜스퍼라아제(aminotransferase, AT) 기능을 하는 단백질로서, 서열번호 6의 아미노산 서열을 가진다. 본 발명에서 DesVI는 N-메틸트랜스퍼라아제(N-methyltransferase, N-MT) 기능을 하는 단백질로서, 서열번호 7의 아미노산 서열을 가진다. 본 발명에서 OleL은 에피머라아제(epimerase, EP) 기능을 하는 단백질로서, 서열번호 8의 아미노산 서열을 가진다. 본 발명에서 OleU는 4-케토리덕타아제(4-ketoreductase, 4-KR) 기능을 하는 단백질로서, 서열번호 9의 아미노산 서열을 가진다. 본 발명에서 OleV는 2,3-데히드라타아제(2,3-dehydratase, 2,3-DH) 기능을 하는 단백질로서, 서열번호 10의 아미노산 서열을 가진다. 본 발명에서 EryBII는 3-케토리덕타아제(3-ketoreductase, 3-KR) 기능을 하는 단백질로서, 서열번호 11의 아미노산 서열을 가진다. 본 발명에서 UrdR은 4-케토리덕타아제(4-ketoreductase, 4-KR) 기능을 하는 단백질로서, 서열번호 12의 아미노산 서열을 가진다. 본 발명에서 OleW는 3-케토리덕타아제(3-ketoreductase, 3-KR) 기능을 하는 단백질로서, 서열번호 13의 아미노산 서열을 가진다. 본 발명에서 DesVIII는 DesVII의 보조 상대 기능을 하는 단백질로서, 서열번호 14의 아미노산 서열을 가진다. 본 발명에서 DesVII은 글리코실트랜스퍼라아제 기능을 하는 단백질로서, 서열번호 15의 아미노산 서열을 가진다. Protein sequence information necessary for the production of the narcamycin derivative of the present invention can be found in GenBank: AF079762.1, AF055579.2, U77454.1, AF269227.1. Specifically, in the present invention, DesIII is a protein having a function of Nucleotidylyl transferase (NT) based on glucose-1-phosphate and has an amino acid sequence of SEQ ID NO. In the present invention, DesIV is a protein having a function of 4,6-dehydratase (4,6-dehydratase, 4,6-DH), and has the amino acid sequence of SEQ ID NO. DesI in the present invention is a protein that functions as an aminotransferase (AT), and has the amino acid sequence of SEQ ID NO. In the present invention, DesII is a protein having a deaminase (DA) function and has an amino acid sequence of SEQ ID NO. In the present invention, DesV is a protein having an aminotransferase (AT) function, and has the amino acid sequence of SEQ ID NO. In the present invention DesVI is N - as the methyl transferase protein kinase (N -methyltransferase, N-MT) function, and has an amino acid sequence of SEQ ID NO: 7. In the present invention, OleL is an epimerase (EP) protein and has an amino acid sequence of SEQ ID NO: 8. In the present invention, OleU is a protein that functions as 4-ketoreductase (4-ketoreductase, 4-KR) and has an amino acid sequence of SEQ ID NO. In the present invention, OleV is a protein having a function of 2,3-dehydratase (2,3-DH) and has an amino acid sequence of SEQ ID NO: 10. In the present invention, EryBII is a protein that functions as 3-ketoreductase (3-KR) and has the amino acid sequence of SEQ ID NO. UrdR in the present invention is a protein that functions as 4-ketoreductase (4-ketoreductase, 4-KR), and has the amino acid sequence of SEQ ID NO: 12. In the present invention, OleW is a protein having a 3-ketoreductase (3-KR) function, and has an amino acid sequence of SEQ ID NO. In the present invention, DesVIII is a protein having an auxiliary relative function of DesVII, and has the amino acid sequence of SEQ ID NO. In the present invention, DesVII is a protein having a glycosyltransferase function and has an amino acid sequence represented by SEQ ID NO: 15.
상기 단백질의 조합을 코딩하는 핵산을 도입하는 것은, 해당 핵산을 염색체상에 추가 도입할 수도 있고, 해당 핵산을 벡터 상에 자가 프로모터 또는 강화된 별개의 프로모터와 함께 도입할 수도 있다. 바람직하게는, 발현벡터를 사용해서 스트렙토마이세스 속 미생물을 형질전환시킬 수 있다. 발현 벡터를 이용하여 형질전환된 재조합 미생물을 제조하기 위한 방법으로는 문헌(Sambrook, J., et al., Molecular Cloning, A Laboratory Manual(2판), Cold Spring Harbor Laboratory, 1. 74, 1989)에 기재된 인산칼슘법 또는 염화캄슘/염화루비듐법, 일렉트로포레이션법(electroporation), 전기주입법(electroinjection), PEG 등의 화학적 처리방법, 유전자 총(gene gun) 등을 이용하는 방법 등이 있다. Introducing a nucleic acid encoding a combination of these proteins may further introduce the nucleic acid on a chromosome, or introduce the nucleic acid on a vector with a self or enhanced discrete promoter. Preferably, an expression vector may be used to transform microorganisms of Streptomyces spp. Methods for preparing transformed recombinant microorganisms using expression vectors include Sambrook, J., et al., Molecular Cloning, A Laboratory Manual (2nd edition), Cold Spring Harbor Laboratory, 1. 74, 1989 The calcium phosphate method or the calcium chloride / rubidium chloride method, the electroporation method, the electroinjection method, the chemical treatment method, such as PEG, the method using a gene gun, etc. are mentioned.
본 발명의 구체적 실시예에서, 재조합 미생물 YJ003/pDDSS(글리코실트랜스퍼라아제 유전자 desVIII/desVII와 함께 D-데소사민 [DDSS] 생합성 유전자 조합(desIII-desIV-desI-desII-desV-desVI)을 발현하는 플라스미드), YJ003/pDQNV(desVIII/desVII와 함께 D-퀴노보오스 [DQNV] 생합성 유전자 조합(desIII - desIV)을 발현하는 플라스미드), 및 YJ003/pODDC(desVIII/desVII와 함께 3'-O-데메틸-D-찰코오스 [ODDC] 생합성 유전자 조합(desIII - desIV - desI - desII)을 발현하는 플라스미드)는 나르보마이신, D-퀴노보오실-나르보놀라이드(DQNVNB), 및 3'-O-데메틸-D-찰코오실-나르보놀라이드(ODDCNB) 을 각각 생산하였다 (도 2 내지 도 4). 그러나, 재조합 YJ003/pLRHM2(desVIII/desVII와 함께 L-람노오스 [LRHM] 생합성 유전자 조합(desIII-desIV-oleL-oleU)을 발현하는 플라스미드)의 발효로부터 2개의 유도체인 L-람노오실-나르보놀라이드(LRHMNB) 및 DQNVNB가 동시에 생산되었다(도 3 및 도 4). 상기 균주에서의 DQNVNB의 동시 생산은 스트렙토마이세스 베네주엘래 경로와 독립적인 4-케토리덕타아제(SvRed)에 의해서 LRHM의 생합성 중간체인 4-케토-6-데옥시-D-글루코오스가 DQNV로 환원되었기 때문이다(도 2). 재조합 YJ003/pDDGT2(desVIII/desVII와 함께 D-디지톡소오스 [DDGT] 생합성 유전자 조합(desIII-desIV-oleV-eryBII-urdR)을 발현하는 플라스미드)는 D-디지톡소오실-나르보놀라이드(DDGTNB) 및 D-보이비노오실-나르보놀라이드(DBVNNB)를 생산하였고, 재조합 YJ003/pLOLV2(desVIII/desVII와 함께 L-올리보오스 [LOLV] 및 L-디지톡소오스 [LDGT] 생합성 유전자 조합(desIII-desIV-oleV-oleW-oleL-oleU)을 발현하는 플라스미드)는 L-올리보오실-나르보놀라이드(LOLVNB), L-디지톡소오실-나르보놀라이드(LDGTNB), 및 DBVNNB를 생산하였다 (도 3 및 도 4). 두 균주에서 DBVNNB를 생산한 것은 천연 스트렙토마이세스 베네주엘래 3-케토리덕타아제가 D-디지톡소오스, L-올리보오스 및 L-디지톡소오스의 중간체로서 2,6-다이데옥시-3,4-다이케토-D-글루코오스를 인식하고, 다른 동정되지 않은 스트렙토마이세스 베네주엘래 4-케토리덕타아제에 의한 4-케토환원과 조합하여, C3에서 환원시켜 D-보이비노오스를 생산한 것으로 생각된다. YJ003/pLOLV2 에서 LOLVNB 및 LDGTNB가 동시에 생산된 것은 OleU 4-케토리덕타아제가 C-3 에서 C-4로의 토오토메리화(tautomerization) 때문에 형성된 TDP-4-케토-LOLV 및 TDP-4-케토-LDGT상에 작용하여 LOLV 및 LDGT를 각각 합성한 것으로 생각된다(도 2). In a specific embodiment of the invention, the recombinant microorganism YJ003 / pDDSS (glycosyltransferase gene desVIII / desVII together with the D -desosamin [DDSS] biosynthetic gene combination ( desIII-desIV-desI-desII-desV-desVI ) plasmid expression), YJ003 / pDQNV (desVIII / desVII and D- quinolyl Novo agarose with [DQNV] biosynthetic gene combinations (desIII - desIV) plasmid expressing), and YJ003 / pODDC (3'- O with desVIII / desVII -Demethyl-D-chalcose [ODDC] biosynthetic gene combination (plasmid expressing desIII - desIV - desI - desII )) is narcamycin , D-quinovoosyl-narbonolide (DQNVNB), and 3 ' O -demethyl-D-chalcoosyl-narbornolide (ODDCNB) was produced respectively (FIGS. 2 to 4). However, recombinant YJ003 / pLRHM2 coming L- ramno the two derivative from the fermentation of (desVIII / L- ramno with desVII OSU [LRHM] biosynthetic gene combinations (desIII-desIV-oleL-oleU ) plasmid expressing) carrying beam Nolide (LRHMNB) and DQNVNB were produced simultaneously (Figures 3 and 4). Simultaneous production of DQNVNB in this strain was achieved by the 4-ketoductase (SvRed) independent of the Streptomyces Venezuela pathway, where 4-keto-6-deoxy-D-glucose, a biosynthetic intermediate of LRHM, was converted to DQNV. Because it was reduced (FIG. 2). Recombinant YJ003 / pDDGT2 (desVIII / D- with desVII digital Messenger source [DDGT] plasmid expressing the biosynthetic gene combinations (desIII-desIV-oleV-eryBII -urdR)) is D- digital Toxoplasma coming-carrying beam surprised Id (DDGTNB ) And D-boibino-osyl-narbonolide (DBVNNB) were produced and combined with recombinant YJ003 / pLOLV2 ( desVIII / desVII L-oliboose [LOLV] and L-digitoxose [LDGT] biosynthetic gene combination ( desIII plasmids expressing -desIV-oleV-oleW-oleL-oleU ) produced L -olibosyl-narbornolide (LOLVNB), L -digitotoxoyl-narbornolide (LDGTNB), and DBVNNB ( 3 and 4). The production of DBVNNB in both strains indicated that the native Streptomyces Venezuelan 3-ketoductase was 2,6-dideoxy-3 as an intermediate of D-digitoxose, L-oliboose and L-digitoxose. Recognizes, 4-diketo-D-glucose and combines with the 4-keto reduction by other unidentified Streptomyces venezuelan 4-ketoductases, reducing at C3 to reduce D-vobinose I think it produced. Simultaneous production of LOLVNB and LDGTNB in YJ003 / pLOLV2 resulted in TDP-4-keto-LOLV and TDP-4-keto formed by OleU 4-ketoductase due to tautomerization from C-3 to C-4 It is thought that LOLV and LDGT were synthesized by acting on -LDGT (Fig. 2).
본 발명의 구체적 실시예에서 제조한 상기 재조합 미생물 중에서, pDDGT2(desVIII/desVII와 함께 D-디지톡소오스 [DDGT] 생합성 유전자 조합(desIII-desIV-oleV-eryBII-urdR)을 발현하는 플라스미드)가 도입된 재조합 미생물 및 pLOLV2(desVIII/desVII와 함께 L-올리보오스 [LOLV] 및 L-디지톡소오스 [LDGT] 생합성 유전자 조합(desIII - desIV - oleV - oleW - oleL - oleU)을 발현하는 플라스미드)가 도입된 재조합 미생물을 한국미생물보존센터(Korean Culture Center of Microorganisms, KCCM)에 2011년 3월 10일자로 각각 기탁번호 KFCC11507P, KFCC11508P로 기탁하였다.
Among the recombinant microorganisms prepared in a specific embodiment of the present invention, pDDGT2 (plasmid expressing the D-digitoxose [DDGT] biosynthetic gene combination ( desIII-desIV-oleV-eryBII-urdR ) together with desVIII / desVII ) is introduced. Introduced recombinant microorganism and pLOLV2 ( plasmid expressing L-oliboose [LOLV] and L-digitoxose [LDGT] biosynthetic gene combination ( desIII - desIV - oleV - oleW - oleL - oleU ) with desVIII / desVII ) The recombinant microorganisms were deposited at the Korean Culture Center of Microorganisms (KCCM) on March 10, 2011 under the accession numbers KFCC11507P and KFCC11508P, respectively.
또 하나의 양태로서, 본 발명은 desVIII-desVII-desIII-desIV, desVIII-desVII-desIII-desIV-oleL-oleU, desVIII-desVII-desIII-desIV-desI-desII, desVIII-desVII-desIII-desIV-oleV-eryBII-urdR 또는 desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU 의 단백질의 조합을 코딩하는 핵산을 포함하는 발현 벡터를 제공한다.In another embodiment, the present invention provides desVIII-desVII-desIII-desIV, desVIII-desVII-desIII-desIV-oleL-oleU, desVIII-desVII-desIII-desIV-desI-desII, desVIII-desVII-desIII-desIV-oleV An expression vector is provided comprising a nucleic acid encoding a combination of proteins of -eryBII-urdR or desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU.
본 발명에서 "발현 벡터"란 적당한 숙주세포에서 목적 단백질을 발현할 수 있는 재조합 벡터로서, 유전자 삽입물이 발현되도록 작동가능하게 연결된 필수적인 조절 요소를 포함하는 유전자 작제물로서, 이러한 유전자 작제물을 제조하기 위해 표준 재조합 DNA 기술을 이용할 수 있다. 본 발명에서 용어, "작동가능하게 연결된(operably linked)"은 일반적 기능을 수행하도록 핵산 발현 조절 서열과 목적하는 단백질을 코딩하는 핵산 서열이 기능적으로 연결(functional linkage)되어 있는 것을 말한다. 예를 들어 프로모터와 단백질을 코딩하는 핵산 서열이 작동가능하게 연결되어 코딩하는 핵산 서열의 발현에 영향을 미칠 수 있다. 발현 벡터의 종류는 원핵세포의 각종 숙주세포에서 목적하는 유전자를 발현하고, 목적하는 단백질을 생산하는 기능을 하면 특별히 한정되지 않지만, 강력한 활성을 나타내는 프로모터와 강한 발현력을 보유하면서 자연 상태와 유사한 형태의 외래 단백질을 대량으로 생산할 수 있는 벡터가 바람직하다. 발현 벡터는 적어도, 프로모터, 개시코돈, 목적하는 단백질을 암호화하는 유전자, 종결코돈 터미네이터를 포함하고 있는 것이 바람직하다. 그 외에 시그널 펩티드를 코딩하는 DNA, 오퍼레이터 서열, 목적하는 유전자의 5측 및 3측의 비해독영역, 선별 마커 영역, 또는 복제가능단위 등을 적절하게 포함할 수도 있다. 개시 코돈 및 종결코돈은 일반적으로 목적 단백질을 코딩하는 핵산 서열의 일부로 간주될 수 있으며, 유전자 작제물이 도입되었을 때 반드시 작용을 나타내야 하며 코딩 서열과 인프레임(in frame)에 있어야 한다. 벡터의 프로모터는 구성적 또는 유도성일 수 있다.In the present invention, an "expression vector" is a recombinant vector capable of expressing a protein of interest in a suitable host cell, and is a gene construct containing essential regulatory elements operably linked to express a gene insert. Standard recombinant DNA techniques can be used for this purpose. As used herein, the term "operably linked" refers to a functional linkage of a nucleic acid expression control sequence and a nucleic acid sequence encoding a protein of interest to perform a general function. For example, a promoter and a nucleic acid sequence encoding a protein can be operably linked to affect the expression of the encoding nucleic acid sequence. The type of expression vector is not particularly limited as long as it expresses a gene of interest in various host cells of prokaryotic cells and produces a protein of interest, but a form similar to that of a natural state with a strong promoter and strong expression ability Vectors capable of producing large amounts of foreign proteins of are preferred. The expression vector preferably contains at least a promoter, an initiation codon, a gene encoding a protein of interest, and a termination codon terminator. In addition, the DNA encoding the signal peptide, an operator sequence, a non-translated region, a selectable marker region, or a replicable unit on the five and three sides of the gene of interest may be appropriately included. The initiation codon and the termination codon can generally be considered part of the nucleic acid sequence encoding the protein of interest and must be functional when the gene construct is introduced and must be in frame with the coding sequence. The promoter of the vector may be constitutive or inducible.
본 발명의 구체적 실시예에서, desVIII-desVII-desIII-desIV의 단백질 조합을 코딩하는 핵산은 서열번호 16, desVIII-desVII-desIII-desIV-oleL-oleU의 단백질 조합을 코딩하는 핵산은 서열번호 17, desVIII-desVII-desIII-desIV-desI-desII의 단백질 조합을 코딩하는 핵산은 서열번호 18, desVIII-desVII-desIII-desIV-oleV-eryBII-urdR의 단백질 조합을 코딩하는 핵산은 서열번호 19, desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU 의 단백질 조합을 코딩하는 핵산은 서열번호 20일 수 있다.In a specific embodiment of the invention, the nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV is SEQ ID NO: 16, the nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV-oleL-oleU is SEQ ID NO: 17, The nucleic acid encoding the protein combination of desVIII-desVII-desIII-desIV-desI-desII is SEQ ID NO: 18, the nucleic acid encoding the protein combination of desVIII-desVII-desIII-desIV-oleV-eryBII-urdR is SEQ ID NO: 19, desVIII- The nucleic acid encoding a protein combination of desVII-desIII-desIV-oleV-oleW-oleL-oleU may be SEQ ID NO: 20.
또한, 본 발명의 구체적 실시예에서, pDQNV(desVIII-desVII-desIII-desIV의 단백질 조합을 코딩하는 서열번호 16의 핵산을 포함하는 발현벡터)는 도 7의 개열지도, pLRHM2(desVIII-desVII-desIII-desIV-oleL-oleU의 단백질 조합을 코딩하는 서열번호 17의 핵산을 포함하는 발현벡터)는 도 8의 개열지도, pODDC(desVIII-desVII-desIII-desIV-desI-desII의 단백질 조합을 코딩하는 서열번호 18의 핵산을 포함하는 발현벡터)는 도 9의 개열지도, pDDGT2(desVIII-desVII-desIII-desIV-oleV-eryBII-urdR의 단백질 조합을 코딩하는 서열번호 19의 핵산을 포함하는 발현벡터)는 도 10의 개열지도, pLOLV2(desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU의 단백질 조합을 코딩하는 서열번호 20의 핵산을 포함하는 발현벡터)는 도 11의 개열지도, pDDSS(desVIII-desVII-desIII-desIV-desI-desII-desV-desVI의 단백질 조합을 코딩하는 서열번호 1의 핵산을 포함하는 발현벡터)는 도 12의 개열지도를 가질 수 있다. Further, in a specific embodiment of the present invention, pDQNV (expression vector comprising nucleic acid of SEQ ID NO: 16 encoding a protein combination of desVIII-desVII-desIII-desIV) is a cleavage map of Figure 7, pLRHM2 (desVIII-desVII-desIII An expression vector comprising a nucleic acid of SEQ ID NO: 17 encoding a protein combination of -desIV-oleL-oleU) is a cleavage map of FIG. 8, a sequence encoding a protein combination of pODDC (desVIII-desVII-desIII-desIV-desI-desII). Expression vector comprising a nucleic acid of No. 18) is a cleavage map of Figure 9, pDDGT2 (expression vector comprising a nucleic acid of SEQ ID NO: 19 encoding a protein combination of desVIII-desVII-desIII-desIV-oleV-eryBII-urdR) The cleavage map of FIG. 10, pLOLV2 (expression vector comprising the nucleic acid of SEQ ID NO: 20 encoding a protein combination of desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU), is a cleavage map of FIG. 11, pDDSS (desVIII). Contains a nucleic acid of SEQ ID NO: 1 encoding a protein combination of -desVII-desIII-desIV-desI-desII-desV-desVI Is an expression vector) may have a cleavage map of FIG.
또 다른 양태로서, 본 발명은 상기 재조합 미생물을 배양하는 단계; 및 배양된 세포 또는 배양액으로부터 나르보마이신 유도체를 회수하는 단계를 포함하는, 나르보마이신 유도체의 제조방법을 제공한다.In another aspect, the present invention comprises the steps of culturing the recombinant microorganism; And it provides a method for producing a narcamycin derivative, comprising the step of recovering a narcamycin derivative from the cultured cells or culture medium.
본 발명에서 용어 "배양"은 미생물을 적당히 인공적으로 조절한 환경조건에서 생육시키는 것을 의미한다. 본 발명의 신규 나르보마이신 유도체를 생산하기 위한 미생물 배양은 통상의 미생물이 사용할 수 있는 영양원을 함유하는 배지에서 배양할 수 있다. 미생물의 영양원으로는 당업계에서 통상적으로 사용되는 영양원을 제한 없이 사용할 수 있으며, 바람직하게는 종래 스트렙토마이세스 속 박테리아의 배양에 이용되고 있는 공지의 영양원을 사용할 수 있다. 예를 들어, 말로닉산(malonic acid), 에탄올, 메치오닌(methionine), 탄소원 및 질소원을 포함하는 배지에서 이루어지는 것이 바람직하다. 이때, 상기 탄소원은 전분, 포도당, 옥수수기름, 글리세롤, 말토스, 만노스 및 이노시톨로 구성된 군으로부터 선택된 하나 이상인 것이 바람직하며, 전분, 포도당 및 옥수수기름인 것이 가장 바람직하다. 또한, 상기 질소원은 면실밀, 옥수수 침지액, 옥수수 침지분, 대두분, 펩톤 및 효모엑기스로 구성된 군으로부터 선택된 하나 이상인 것이 바람직하며, 면실밀 및 옥수수침지액인 것이 가장 바람직하다. 종균배양액을 상기 배양 배지를 포함한 발효조에 식균하여 배양하였다. 배양방법으로는 호기적 조건에서는 진탕배양 혹은 정치배양이 가능하다. 배양온도는 상기의 각 조건들에서 배양할 경우 조건에 따라 약간씩 상이하기는 하나, 보통 20-37℃에서 배양하는 것이 적당하며, 바람직하게는 26-30℃에서 배양할 수 있다. 또한, 배양기간 역시 당업계에서 사용되는 공지의 기간 동안 배양할 수 있으며, 필요에 따라 기간이 조정될 수 있다. 바람직하게 진탕배양, 정치배양의 경우 모두 4일 내지 7일간 배양할 수 있다. The term "culture" in the present invention means to grow microorganisms under environmental conditions that are appropriately artificially controlled. Microbial culture for producing a novel naromycin derivative of the present invention can be cultured in a medium containing nutrients that can be used by conventional microorganisms. As a nutrient source of microorganisms, a nutrient source commonly used in the art may be used without limitation, and a known nutrient source used for culturing bacteria of Streptomyces genus may be used. For example, it is preferably made in a medium containing malonic acid, ethanol, methionine, a carbon source and a nitrogen source. At this time, the carbon source is preferably at least one selected from the group consisting of starch, glucose, corn oil, glycerol, maltose, mannose and inositol, and most preferably starch, glucose and corn oil. In addition, the nitrogen source is preferably at least one selected from the group consisting of cottonseed wheat, corn steep liquor, corn steep flour, soy flour, peptone and yeast extract, it is most preferred that the cottonseed mill and corn steep liquor. The spawn culture was incubated in a fermentor containing the culture medium. As a culture method, shaking culture or political culture is possible under aerobic conditions. The culture temperature is slightly different depending on the conditions when incubated in each of the above conditions, it is usually suitable to incubate at 20-37 ℃, preferably can be cultured at 26-30 ℃. In addition, the culture period can also be cultured for a known period used in the art, the period can be adjusted as necessary. Preferably shaking culture, in the case of stationary culture, all can be cultured for 4 days to 7 days.
배양된 세포 또는 배양액으로부터 나르보마이신 유도체를 회수하는 방법은 당업계에 널리 알려진 방법에 따라 수행할 수 있다. 상기 나르보마이신 유도체 회수 방법에는, 여과, 음이온 교환 크로마토그래피, 결정화 및 HPLC 등이 사용될 수 있으나, 이들 예에 한정되는 것은 아니다.
The method of recovering narbomycin derivatives from cultured cells or cultures can be carried out according to methods well known in the art. Filtration, anion exchange chromatography, crystallization and HPLC may be used as the method for recovering the narcamycin derivative, but is not limited thereto.
또 다른 양태로서, 본 발명은 상기 화학식 1로 표시되는 나르보마이신 유도체 화합물, 그의 약제학적으로 허용가능한 염을 제공한다. 상기 화학식 1로 표시되는 나르보마이신 유도체 중 R이 


![]()
![]()
핵자기공명 스펙트럼을 이용하여 동정한 결과, 상기 화학식 1의 화합물은 신규 나르보마이신 유도체임을 확인하였다.As a result of identification using nuclear magnetic resonance spectra, it was confirmed that the compound of
본 발명의 화합물은 용매화물 또는 전구약물(pro-drug) 형태일 수 있는데, 이는 본 발명의 범위 내에 포함된다. 용매화물은 바람직하게는 수화물 및 에탄올화물을 포함한다. Compounds of the invention may be in the form of solvates or prodrugs, which are included within the scope of the invention. Solvates preferably include hydrates and ethanolates.
본 발명에서의 용어 "약제학적으로 허용가능한 염"은 화합물의 상대적으로 무독성인 무기 및 유기 산 부가염일 수 있다. 상기 염으로는 약학적으로 허용가능한 유리산(free acid)에 의해 형성된 산 부가염이 유용하다. 환자에게 비교적 비독성이고 무해한 유효작용을 갖는 농도로서 이 염에 기인한 부작용이 화학식 1의 화합물의 이로운 효능을 저하시키지 않는 임의의 모든 유기 또는 무기 부가염을 포함한다. The term "pharmaceutically acceptable salt" in the present invention may be a relatively nontoxic inorganic and organic acid addition salt of a compound. As the salts, acid addition salts formed by pharmaceutically acceptable free acid are useful. Concentrations having a relatively nontoxic and harmless effect on a patient include any organic or inorganic addition salt that does not adversely affect the beneficial effects of the compound of formula (I).
산 부가염은 통상의 방법, 예를 들어 화합물을 과량의 산 수용액에 용해시키고, 이 염을 수혼화성 유기 용매, 예를 들어 메탄올, 에탄올, 아세톤 또는 아세토니트릴을 사용하여 침전시켜서 제조한다. 동 몰량의 화합물 및 물 중의 산 또는 알코올(예, 글리콜 모노메틸에테르)을 가열하고, 이어서 상기 혼합물을 증발시켜 건조시키거나, 또는 석출된 염을 흡인 여과시킬 수 있다.Acid addition salts are prepared by conventional methods, for example by dissolving a compound in an excess of aqueous acid solution and precipitating the salt using a water miscible organic solvent such as methanol, ethanol, acetone or acetonitrile. Equivalent molar amounts of the compound and acid or alcohol (eg, glycol monomethyl ether) in water can be heated and the mixture can then be evaporated to dryness or the precipitated salts can be suction filtered.
이때, 유리산으로는 유기산과 무기산을 사용할 수 있으며, 무기산으로는 염산, 인산, 황산, 질산, 주석산 등을 사용할 수 있고 유기산으로는 메탄설폰산, p-톨루엔설폰산, 아세트산, 트라이플루오로아세트산, 말레인산(maleic acid), 석신산, 옥살산, 벤조산, 타르타르산, 푸마르산(fumaric acid), 만데르산, 프로피온산 (propionic acid), 구연산(citric acid), 젖산(lactic acid), 글리콜산(glycollic acid), 글루콘산(gluconic acid), 갈락투론산, 글루탐산, 글루타르산(glutaric acid), 글루쿠론산(glucuronic acid), 아스파르트산, 아스코르브산, 카본산, 바닐릭산, 요오드화수소산(hydroiodic acid) 등을 사용할 수 있으며, 이들에 제한되지 않는다.At this time, an organic acid and an inorganic acid may be used as the free acid, and hydrochloric acid, phosphoric acid, sulfuric acid, nitric acid, tartaric acid, and the like may be used as the inorganic acid, and methanesulfonic acid, p-toluenesulfonic acid, acetic acid, and trifluoroacetic acid may be used as the organic acid. , Maleic acid, succinic acid, oxalic acid, benzoic acid, tartaric acid, fumaric acid, manderic acid, propionic acid, citric acid, lactic acid, glycolic acid , Gluconic acid, galacturonic acid, glutamic acid, glutaric acid, glucuronic acid, glucuronic acid, aspartic acid, ascorbic acid, carbonic acid, vanic acid, hydroiodic acid, etc. Can be used, but not limited to these.
또한, 염기를 사용하여 약제학적으로 허용가능한 금속염을 만들 수 있다. 알칼리 금속염 또는 알칼리 토금속염은, 예를 들어 화합물을 과량의 알칼리 금속 수산화물 또는 알칼리 토금속 수산화물 용액 중에 용해시키고, 비용해 화합물 염을 여과한 후 여액을 증발, 건조시켜 얻는다. 이때, 금속염으로는 특히 나트륨, 칼륨 또는 칼슘염을 제조하는 것이 제약상 적합하나 이들에 제한되는 것은 아니다. 또한, 이에 대응하는 은염은 알칼리 금속 또는 알칼리 토금속 염을 적당한 은염(예, 질산은)과 반응시켜 얻을 수 있다.Bases can also be used to make pharmaceutically acceptable metal salts. Alkali metal salts or alkaline earth metal salts are obtained, for example, by dissolving a compound in an excess of alkali metal hydroxide or alkaline earth metal hydroxide solution, filtering the insoluble compound salt, and then evaporating and drying the filtrate. In this case, as the metal salt, it is particularly suitable to prepare sodium, potassium or calcium salt, but is not limited thereto. Corresponding silver salts may also be obtained by reacting alkali or alkaline earth metal salts with a suitable silver salt (eg, silver nitrate).
화학식 1로 표시되는 화합물의 약제학적으로 허용가능한 염은, 달리 지시되지 않는 한, 상기 화합물에 존재할 수 있는 산성 또는 염기성 기의 염을 포함한다. 예를 들어, 약제학적으로 허용가능한 염으로는 하이드록시기의 나트륨, 칼슘 및 칼륨 염 등이 포함될 수 있고, 아미노기의 기타 약학적으로 허용가능한 염으로는 하이드로브롬화물, 황산염, 수소 황산염, 인산염, 수소 인산염, 이수소 인산염, 아세테이트, 석시네이트, 시트레이트, 타르트레이트, 락테이트, 만델레이트, 메탄설포네이트(메실레이트) 및 p-톨루엔설포네이트(토실레이트) 염 등이 있으며, 당업계에 알려진 염의 제조방법을 통하여 제조될 수 있다.Pharmaceutically acceptable salts of the compounds represented by
본 발명의 화합물은 당업계에서 통상적으로 사용되는 방법에 따라 합성할 수 있으며, 바람직하게는 본 발명의 방법을 사용하여 재조합 미생물로부터 생산할 수 있다. The compounds of the present invention can be synthesized according to methods commonly used in the art, and preferably can be produced from recombinant microorganisms using the methods of the present invention.
또 다른 양태로서, 본 발명은 상기 화학식 1의 화합물 또는 약제학적으로 허용가능한 염을 포함하는 항균용 조성물을 제공한다. 본 발명에서 "항균용 조성물"이란, 미생물의 생존 및/또는 증식을 억제하는 작용을 하는 조성물을 의미한다. 상기 조성물은 에리트로마이신-감수성 균주 및 에리트로마이신-저항성 균주에 대하여 항균 활성을 가지는 것일 수 있고, 구체적으로는, E. 파에시움 ATCC 19434, E. 파에시움 P00558, S. 아우레우스 ATCC 25923 및 S. 아우레우스 P00740로 구성된 군으로부터 선택된 미생물에 대하여 항균 활성을 가질 수 있다. 또한, 상기 조성물은 상기 미생물에 의하여 발생하는 감염성 질환을 치료할 수 있다. As another aspect, the present invention provides a composition for antimicrobial comprising the compound of
상기 조성물은 약제학적으로 허용가능한 담체를 추가로 포함할 수 있다. 본 발명에서의 용어 "약제학적으로 허용가능한 담체"는 임의의 대상 조성물 또는 성분을 하나의 기관, 또는 신체의 부분으로부터 다른 기관, 또는 신체의 부분으로의 운반 또는 수송하는 것에 관여하는 액체 또는 고체 충전제, 희석제, 부형제, 용매 또는 캡슐화 물질과 같은 제약상 허용가능한 물질, 조성물 또는 비히클을 지칭하며, 본 발명의 조성물은, 투여를 위해서 상기 기재한 유효성분 이외에 약제학적으로 허용가능한 담체, 부형제 또는 희석제를 더 포함할 수 있다. 상기 담체, 부형제 및 희석제로는 락토오스, 덱스트로오스, 수크로오스, 소르비톨, 만니톨, 자일리톨, 에리스리톨, 말티톨, 전분, 아카시아 고무, 알지네이트, 젤라틴, 칼슘 포스페이트, 칼슘 실리케이트, 셀룰로오스, 메틸 셀룰로오스, 미정질 셀룰로오스, 폴리비닐 피롤리돈, 물, 메틸히드록시벤조에이트, 프로필히드록시벤조에이트, 탈크, 스테아린산 마그네슘 및 광물유를 들 수 있다.The composition may further comprise a pharmaceutically acceptable carrier. The term "pharmaceutically acceptable carrier" in the present invention refers to liquid or solid fillers involved in the transport or transport of any subject composition or component from one organ or part of the body to another organ or part of the body. Refers to a pharmaceutically acceptable material, composition or vehicle, such as a diluent, excipient, solvent or encapsulating material, wherein the composition of the present invention comprises a pharmaceutically acceptable carrier, excipient or diluent in addition to the active ingredients described above for administration. It may further include. The carrier, excipient and diluent may include lactose, dextrose, sucrose, sorbitol, mannitol, xylitol, erythritol, maltitol, starch, acacia rubber, alginate, gelatin, calcium phosphate, calcium silicate, cellulose, methyl cellulose, microcrystalline cellulose, Polyvinyl pyrrolidone, water, methylhydroxybenzoate, propylhydroxybenzoate, talc, magnesium stearate and mineral oil.
또한, 본 발명의 조성물은 각각 통상의 방법에 따라 산제, 과립제, 정제, 캡슐제, 현탁액, 에멀젼, 시럽, 에어로졸 등의 경구형 제형, 외용제, 좌제 또는 멸균 주사용액의 형태로 제형화하여 사용할 수 있다. 상세하게는, 제형화할 경우 통상 사용하는 충진제, 증량제, 결합제, 습윤제, 붕해제, 계면활성제 등의 희석제 또는 부형제를 사용하여 조제될 수 있다. 경구투여를 위한 고형제제로는 정제, 환제, 산제, 과립제, 캡슐제 등을 포함하나, 이에 한정되는 것은 아니다. 이러한 고형제제는 상기 화학식 1의 화합물 또는 그의 약제학적으로 허용가능한 염에 적어도 하나 이상의 부형제, 예를 들면, 전분, 칼슘 카보네이트, 수크로오스, 락토오스, 젤라틴 등을 섞어 조제될 수 있다. 또한, 단순한 부형제 이외에 스테아린산 마그네슘, 탈크 같은 윤활제들도 사용될 수 있다. 경구를 위한 액상 제제로는 현탁제, 내용 액제, 유제, 시럽제 등을 포함하나, 이에 한정되지 않으며, 흔히 사용되는 단순 희석제인 물, 리퀴드 파라핀 이외에 여러 가지 부형제, 예를 들면 습윤제, 감미제, 방향제, 보존제 등을 첨가하여 조제될 수 있다. 비경구 투여를 위한 제제는 멸균된 수용액, 비수성 용제, 현탁제, 유제, 동결건조 제제 및 좌제를 포함한다. 비수성 용제 및 현탁제로는 프로필렌글리콜, 폴리에틸렌 글리콜, 올리브 오일과 같은 식물성 오일, 에틸올레이트와 같은 주사가능한 에스테르 등이 사용될 수 있다. 좌제의 기제로는 위텝솔, 마크로골, 트윈 61, 카카오지, 라우린지, 글리세로젤라틴 등이 사용될 수 있다.In addition, the compositions of the present invention can be used in the form of powders, granules, tablets, capsules, suspensions, emulsions, syrups, aerosols, oral dosage forms, external preparations, suppositories, or sterile injectable solutions, respectively, according to conventional methods. have. Specifically, when formulated, it may be prepared using conventional diluents or excipients such as fillers, extenders, binders, wetting agents, disintegrating agents, surfactants, and the like. Solid preparations for oral administration include, but are not limited to, tablets, pills, powders, granules, capsules, and the like. Such solid preparations may be prepared by mixing at least one excipient such as starch, calcium carbonate, sucrose, lactose, gelatin and the like with the compound of
또한, 본 발명은 상기 화학식 1의 화합물 또는 그의 약제학적으로 허용가능한 염을 대상에게 투여하는 단계를 포함하는 미생물 감염성 질환의 치료방법을 제공한다. 또한, 본 발명은 상기 화학식 1의 화합물 또는 그의 약제학적으로 허용가능한 염을 이용하여 에리트로마이신-감수성 균주, 에리트로마이신-저항성 균주를 포함하는 미생물의 생존 및/또는 증식을 억제하는 방법을 제공한다. The present invention also provides a method for treating a microbial infectious disease comprising administering to a subject a compound of
본 발명에서의 용어 "치료"란, 질환의 발병을 억제하거나 발병을 지연하는 모든 행위를 말하며, 특히 약리학적 활성 물질에 의해 야기되는 동물, 특히 포유류, 및 더욱 특별히 인간에서의 국소적 또는 전신적인 효과를 가리킨다. As used herein, the term "treatment" refers to any action that inhibits or delays the onset of a disease, and is particularly local or systemic in animals, particularly mammals, and more particularly in humans caused by pharmacologically active substances. Indicates an effect.
본 발명의 구체적 실시예에서, DQNVNB는 S. 아우레우스 P00740의 성장을 저해하는 데에 있어서는 나르보마이신보다 효과적이었다. LOLVNB는 S. 아우레우스 ATCC 25923에 대하여 선택적 활성을 나타내었는 바, LOLVNB의 3'-가로방향(equatorial)-히드록실기가 항균 활성에 긍정적 영향을 미친다는 것을 의미한다. LRHMNB는 강력한 활성 (1.25 - 2.50 μM)을 나타내었다. ODDCNB의 항균 활성(2.5 - 5.0 μM)은 나르보마이신 (10 - 20 μM) 및 DQNVNB (≤ 10 μM) 보다 우수하였다. DBVNNB (≤ 10 μM) 는 E. 파에시움 ATCC 19434, P00558, 및 S. 아우레우스 ATCC 25923에 대하여 높은 항균 활성을 나타내었는 바, 이는 DBVNNB의 4'-세로방향(axial)-히드록실기가 MIC를 감소시킨다는 것을 의미한다.In a specific embodiment of the invention, the DQNVNB is S. aureus. It was more effective than narbomycin in inhibiting the growth of P00740. LOLVNB S. Aureus Selective activity against ATCC 25923 indicates that the 3′-equaltorial-hydroxyl group of LOLVNB has a positive effect on antimicrobial activity. LRHMNB showed strong activity (1.25-2.50 μM). The antimicrobial activity of ODDCNB (2.5-5.0 μM) was better than narbomycin (10-20 μM) and DQNVNB (≦ 10 μM). DBVNNB (≤ 10 μM) is helpful when par E. ATCC 19434, P00558, and S. aureus It showed high antimicrobial activity against ATCC 25923, which means that the 4'-axial-hydroxyl group of DBVNNB reduces MIC.
본 발명의 조성물은 목적 조직에 도달할 수 있는 한 어떠한 일반적인 경로를 통하여 투여될 수 있다. 따라서, 본 발명의 조성물은 국부, 경구, 비경구, 비내, 정맥내, 근육내, 피하, 안내, 경피 등으로 투여될 수 있고, 용액, 현탁액, 정제, 환약, 캡슐, 서방형 제제 등으로 제형할 수 있다. The composition of the present invention may be administered via any general route as long as it can reach the desired tissue. Thus, the compositions of the present invention may be administered topically, orally, parenterally, intranasally, intravenously, intramuscularly, subcutaneously, intraocularly, transdermally, and formulated into solutions, suspensions, tablets, pills, capsules, sustained release formulations, and the like. can do.
본 발명의 조성물은 치료학적 유효량으로 투여될 수 있다. 투여량은 환자의 질병 종류 및 중증도, 연령, 성별, 투여방법, 표적 세포, 발현 정도 등 다양한 요인에 따라 달라질 수 있으며, 당 분야의 전문가들에 의해 용이하게 결정될 수 있다. The composition of the present invention may be administered in a therapeutically effective amount. Dosage may vary depending on various factors such as disease type and severity, age, sex, administration method, target cell, expression level, etc. of the patient, and can be easily determined by those skilled in the art.
본 발명의 생산 방법을 통하여 생체 내 조합 생합성의 방법으로 나르보마이신에 있어서 다양한 당 부분을 포함하는 나르보마이신 유도체를 합성할 수 있고, 특히 신규하고 항균 활성이 우수한 다양한 나르보마이신 유도체를 합성할 수 있다. Through the production method of the present invention, it is possible to synthesize a narcamycin derivative including various sugar moieties in narcamycin by a method of in vivo combinatorial biosynthesis, and in particular to synthesize various narcamycin derivatives having novel and excellent antibacterial activity. Can be.
도 1은 스트렙토마이세스 베네주엘래로부터 나르보마이신이 생합성되는 경로 및 나르보마이신의 구조를 나타내는 도면이다.
도 2는 본 발명의 방법에 의하여 변형된 당 부분을 포함하는 나르보마이신 유도체가 생합성되는 경로를 나타낸다. 상기 생합성에 관여하는 단백질의 기능을 괄호안에 표시하였다. NT, 뉴클레오티딜릴 트랜스퍼라아제; 4,6-DH, 4,6-데하이드라타아제; 2,3-DH, 2,3-데하이드라타아제; AT, 아미노트랜스퍼라아제; DA, 데아미나아제; EP, 에피머라아제; 4-KR, 4-케토리덕타아제; N-MT, N-메틸트랜스퍼라아제; 3-KR, 3-케토리덕타아제; SvRed, 스트렙토마이세스 베네주엘래 경로 독립적인 리덕타아제.
도 3은 나르보마이신 및 그의 유도체의 구조를 나타낸다.
도 4는 스트렙토마이세스 베네주엘래 균주의 배양액으로부터의 HPLC-ESI-MS 크로마토그램을 나타낸다. (A) YJ003/pDDSS로부터 검출된 나르보마이신 ([M + H]+ = 510). (B) YJ003/pDQNV로부터 검출된 DQNVNB ([M + NH4]+ = 516). (C) YJ003/pLRHM2로부터 검출된 LRHMNB ([M + NH4]+ = 516) 및 DQNVNB ([M + NH4]+ = 516). (D) YJ003/pODDC로부터 검출된 ODDCNB ([M + NH4]+ = 500). (E) YJ003/pDDGT2로부터 검출된 DBVNNB ([M + NH4]+ = 500) 및 DDGTNB ([M + NH4]+ = 500). (F) YJ003/pLOLV2로부터 검출된 DBVNNB ([M + NH4]+ = 500), LOLVNB ([M + NH4]+ = 500), 및 LDGTNB ([M + NH4]+ = 500).
도 5는 나르보마이신의 당 부분의 NOE(Nuclear Overhauser effect) 상관관계를 나타낸다.
도 6은 des 클러스터가 결실된 스트렙토마이세스 베네주엘래 결실 돌연변이체를 제조하기 위한 유전자 구조체의 구조를 나타내는 모식도이다.
도 7은 pDQNV(desVIII-desVII-desIII-desIV의 단백질 조합을 코딩하는 핵산을 포함하는 발현벡터)의 개열지도이다.
도 8은 pLRHM2(desVIII-desVII-desIII-desIV-oleL-oleU의 단백질 조합을 코딩하는 핵산을 포함하는 발현벡터)의 개열지도이다.
도 9는 pODDC(desVIII-desVII-desIII-desIV-desI-desII의 단백질 조합을 코딩하는 핵산을 포함하는 발현벡터)의 개열지도이다.
도 10은 pDDGT2(desVIII-desVII-desIII-desIV-oleV-eryBII-urdR의 단백질 조합을 코딩하는 핵산을 포함하는 발현벡터)의 개열지도이다.
도 11은 pLOLV2(desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU의 단백질 조합을 코딩하는 핵산을 포함하는 발현벡터)의 개열지도이다.
도 12는 pDDSS(desVIII-desVII-desIII-desIV-desI-desII-desV-desVI의 단백질 조합을 코딩하는 핵산을 포함하는 발현벡터)의 개열지도이다.1 is Streptomyces Biosynthesis of Narvomycin from Venezuela It is a figure which shows a path | route and the structure of narbomycin.
Figure 2 shows the pathway by which the narcamycin derivative comprising the sugar moiety modified by the method of the present invention is biosynthesized. The functions of the proteins involved in the biosynthesis are shown in parentheses. NT, nucleotidyl transferase; 4,6-DH, 4,6-dehydratase; 2,3-DH, 2,3-dehydratase; AT, aminotransferases; DA, deaminase; EP, epimerase; 4-KR, 4-ketoriductase; N-MT, N -methyltransferase; 3-KR, 3-ketoriductase; SvRed, Streptomyces Venezuela Route independent reductase.
3 shows the structure of narbomycin and its derivatives.
4 is Streptomyces Venezuela HPLC-ESI-MS chromatogram from the culture of the strain is shown. (A) Narvomycin detected from YJ003 / pDDSS ([M + H] + = 510). (B) DQNVNB detected from YJ003 / pDQNV ([M + NH 4 ] + = 516). (C) LRHMNB ([M + NH 4 ] + = 516) and DQNVNB ([M + NH 4 ] + = 516) detected from YJ003 / pLRHM2. (D) ODDCNB detected from YJ003 / pODDC ([M + NH 4 ] + = 500). (E) DBVNNB ([M + NH 4 ] + = 500) and DDGTNB ([M + NH 4 ] + = 500) detected from YJ003 / pDDGT2. (F) DBVNNB detected from YJ003 / pLOLV2 ([M + NH 4 ] + = 500), LOLVNB ([M + NH 4 ] + = 500), and LDGTNB ([M + NH 4 ] + = 500).
Figure 5 shows the Nuclear Overhauser effect (NOE) correlation of the sugar portion of narbomycin.
Figure 6 Streptomyces with deletion of des cluster It is a schematic diagram showing the structure of a gene construct for producing a Venezuelan deletion mutant.
FIG. 7 is a cleavage map of pDQNV (an expression vector comprising a nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV).
8 is a cleavage map of pLRHM2 (an expression vector comprising a nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV-oleL-oleU).
9 is a cleavage map of pODDC (an expression vector comprising nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV-desI-desII).
10 is a cleavage map of pDDGT2 (an expression vector comprising a nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV-oleV-eryBII-urdR).
11 is a cleavage map of pLOLV2 (an expression vector comprising a nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU).
12 is a cleavage map of pDDSS (expression vector comprising nucleic acid encoding a protein combination of desVIII-desVII-desIII-desIV-desI-desII-desV-desVI).
이하 본 발명을 실시예를 통하여 보다 상세하게 설명한다. 그러나, 이들 실시예는 본 발명을 예시적으로 설명하기 위한 것으로 본 발명의 범위가 이들 실시예에 의해 제한되는 것은 아니다.
Hereinafter, the present invention will be described in more detail with reference to examples. However, these examples are for illustrative purposes only and are not intended to limit the scope of the present invention.
박테리아 균주, 배양 조건, 및 유전자 조작Bacterial strains, culture conditions, and genetic engineering
스트렙토마이세스 베네주엘래의 원형질체 제조 및 형질전환은 Kieser, T. et al.의 방법에 따라 수행하였다(Kieser, T. et al., 2000, Practical Streptomyces genetics. John Innes Centre, Norwich, United Kingdom). 스트렙토마이세스 베네주엘래의 형질전환체는 티오스트렙톤으로 보충된 R2YE 아가 플레이트에서 선택하였다. 스트렙토마이세스 베네주엘래 재조합 균주는 SPA 아가(효모 추출물 1 g, 소고기 추출물 1 g, 트립토오스 2 g, 글루코오스 10 g, 미량의 황산철, 및 아가 15 g/리터) 상에서 증식시켰다. 스트렙토마이세스 베네주엘래 ATCC 15439, 스트렙토마이세스 안티비오티커스 ATCC 11891, 및 사카로폴리스포라 에리트래아 NRRL 2338 를 이용하여 게놈 DNA를 획득하였다. Streptomyces Protoplast preparation and transformation in Venezuela were performed according to the method of Kieser, T. et al. (Kieser, T. et al., 2000, Practical Streptomyces) genetics. John Innes Centre, Norwich, United Kingdom). Streptomyces Transformants of Venezuela were selected from R2YE agar plates supplemented with thiostrepton. Streptomyces Venezuela Recombinant strains were grown on SPA agar (1 g yeast extract, 1 g beef extract, 2 g tryptose, 10 g glucose, traces of iron sulfate, and 15 g / liter agar). Streptomyces Venezuela ATCC 15439, Streptomyces Antibioticus ATCC 11891, and Saccharopolis Fora Eritrea Genomic DNA was obtained using NRRL 2338.
대장균(E. coli) DH5α 및 플라스미드 Litmus28 (New England Biolabs)을 이용하여 일반적인 서브클로닝을 하였다. 구성 ermE * 프로모터 (Schmitt-John, T. et al., 1992. Appl. Microbiol. Biotechnol. 36:493-498) 및 티오스트렙톤 저항성 마커를 포함하는 고효율(high-copy-number) 대장균-스트렙토마이세스 셔틀 벡터 pSE34 (Yoon, Y. J. et al., 2002. Chem. Biol. 9:203-214)를 이용하여 데옥시당 및 그들의 부착물의 생합성에 연관된 유전자를 발현시켰다.
E. coli General subcloning was done using DH5α and plasmid Litmus28 (New England Biolabs). Constituent ermE * promoter (Schmitt-John, T. et al., 1992. Appl. Microbiol. Biotechnol. 36: 493-498) and high-copy-number E. coli- streptomyces including thiostrepton resistant markers Seth Shuttle vector pSE34 (Yoon, YJ et al., 2002. Chem. Biol. 9: 203-214) was used to express genes involved in the biosynthesis of deoxysaccharides and their attachments.
desdes 클러스터-결실 돌연변이체의 제조 Preparation of Cluster-Deleted Mutants
복제 플라스미드-매개 상동 재조합(replicative plasmid-mediated homologous recombination) 방법(Xue et al., PNAS USA, 95:12111, 1998)을 통하여, 데소사민 생합성이 결실된 스트렙토마이세스 베네주엘래 결실 돌연변이체(YJ003)를 제조하였다. Streptomyces lacking desosamin biosynthesis via replication plasmid-mediated homologous recombination method (Xue et al., PNAS USA, 95: 12111, 1998) Venezuelan deletion mutant (YJ003) was prepared.
플라스미드는 카나마이신 내성 유전자, aphⅡ(Ward et al., Mol. Gen. Genet., 203:468, 1986)를 가지고 있으며, 전체 des 클러스터 대신에 상기 des 클러스터의 업스트림(upstream)과 다운스트림(downstream) 양측면에 위치한 DNA 단편 (flanking DNA fragment)을 가지도록 제조하였다(도 6). 유전자 교체를 위한 구조체(construct)는 원형질체 형질전환(protoplast transformation)을 통해 스트렙토 마이세스 베네주엘래로 삽입된 pKC1139(Bierman, M. et al., Gene, 116:43-9, 1992)를 사용하여 제조하였다. 스트렙토마이세스 베네주엘래 ATCC 15439를 상기 유전자를 포함하는 플라스미드로 형질전환하였다. 각 형질전환체로부터 얻어진 포자는 카나마이신 선별 아가 플레이트에서 배양하고, 사이클(cycle)은 재조합 가능성을 증대시키기 위하여 3번 반복하였다. 카나마이신-저항성 및 아프라마이신-민감성 표현형을 얻기 위해 목표 유전자를 aphⅡ로 교체한 이중교차(crossover)를 선별 및 스크린하고, 돌연변이 유전자형을 게놈 DNA 서던 블럿 혼성화로 확인하였다.The plasmid has a kanamycin resistance gene, aphII (Ward et al., Mol. Gen. Genet., 203: 468, 1986), which is upstream and downstream of the des cluster instead of the entire des cluster. It was prepared to have a flanking DNA fragment (Fig. 6). By using: (43-9, 1992 Bierman, M. et al, Gene, 116.) Construct (construct) is transformed protoplasts (protoplast transformation) the Streptomyces venetian weeks inserted through pKC1139 elrae for gene replacement Prepared. Streptomyces Venezuelan ATCC 15439 was transformed with a plasmid containing the gene. Spores obtained from each transformant were cultured in kanamycin selective agar plates and the cycle was repeated three times to increase recombination potential. Crossovers in which the target gene was replaced with aphII were selected and screened to obtain a kanamycin-resistant and apramycin-sensitive phenotype, and the mutant genotype was confirmed by genomic DNA Southern blot hybridization.
des 결실 플라스미드(pYJ003)를 제조하기 위하여, SphⅠ으로 자른 스트렙토마이세스 베네주엘래 게놈 DNA를 주형(template)으로 하고, 사용한 5'-des 클러스터 측면에 위치한 부분을 가진 1kb HindⅢ-PstⅠ단편은 서열번호 21 및 22를 프라이머로 사용하고, 3'-des 클러스터 측면에 위치한 부분을 가진 1kb KpnⅠ-EcoRⅠ단편은 서열번호 23 및 24를 프라이머로 사용하여, PCR을 수행하였다. PCR에 사용된 반응성분은 주형 DNA 100ng, 각 프라이머 30pmol, pfu DNA polymerase 2.5unit, 각 dNTP 2mM, Tris-HCl 20mM, (NH4)2SO4 10mM, KCl 10mM, Triton X-100 1%, BSA 1mg/ml, MgSO4 20mM 및 DMSO 10%로, 이들을 섞어서 총 부피가 50㎕가 되도록 하였다.To prepare the des deletion plasmid (pYJ003), a 1 kb HindIII-Pst I fragment having a region flanked by a 5'-des cluster using a Streptomyces Venezuela genomic DNA cut with Sph I was used as a template. PCR was carried out using 21 and 22 as primers, and the 1 kb KpnI-EcoRl fragments having portions located on the 3'-des cluster side, using SEQ ID NOs: 23 and 24 as primers. Reactive components used in PCR were 100ng of template DNA, 30pmol of each primer, 2.5units of pfu DNA polymerase, each dNTP 2mM, Tris-HCl 20mM, (NH 4 ) 2 SO 4 10mM, KCl 10mM, Triton X-100 1%, BSA At 1 mg / ml,
서열번호 21 (forward): 5'-GGCAAGCTTAGCGGGGCGACTGGCGTGCCCACT-3'SEQ ID NO: 21 (forward): 5'-GGCAAGCTTAGCGGGGCGACTGGCGTGCCCACT-3 '
서열번호 22 (reverse): 5'-GGTCTGCAGTCACCGTGGGTTCTGCCATCTCTT-3'SEQ ID NO: 22 (reverse): 5'-GGTCTGCAGTCACCGTGGGTTCTGCCATCTCTT-3 '
서열번호 23 (forward): 5'-GCTGGTACCGGATGTTCCCTCCGGGCCACCGTC-3'SEQ ID NO: 23 (forward): 5'-GCTGGTACCGGATGTTCCCTCCGGGCCACCGTC-3 '
서열번호 24 (reverse): 5'-TGAGAATTCCCTCGCCGTCCTGCCCGCGCTTGG-3'
SEQ ID NO: 24 (reverse): 5'-TGAGAATTCCCTCGCCGTCCTGCCCGCGCTTGG-3 '
발현 플라스미드 및 Expression plasmids and 스트렙토마이세스Streptomyces 베네주엘래Venezuela 재조합 균주의 제조Preparation of Recombinant Strains
복수의 데옥시당 생합성 유전자를 포함하는 DNA 절편을 특이적인 데옥시올리고뉴클레오티드 프라이머 및 주형 DNA를 이용하여 PCR로 증폭하였다 (표 1). PCR은 제조자의 추천 조건 하에서 Pfu 폴리머라아제 (Fermentas)를 이용하여 수행하였다. DNA fragments comprising a plurality of deoxysaccharide biosynthesis genes were amplified by PCR using specific deoxyoligonucleotide primers and template DNA (Table 1). PCR allows Pfu under manufacturer's recommendations It was performed using polymerase (Fermentas).
(GenBank accession No.)DNA origin
(GenBank accession No.)
(GenBank AF079762.1) Streptomyces venezuelae ATCC 15439
(GenBank AF079762.1)
(GenBank AF079762.1) Streptomyces venezuelae ATCC 15439
(GenBank AF079762.1)
(GenBank AF079762.1) Streptomyces venezuelae ATCC 15439
(GenBank AF079762.1)
(GenBank AF079762.1) Streptomyces venezuelae ATCC 15439
(GenBank AF079762.1)
(GenBank AF079762.1) Streptomyces venezuelae ATCC 15439
(GenBank AF079762.1)
(GenBank AF055579.2) Streptomyces antibioticus ATCC 11891
(GenBank AF055579.2)
(GenBank AF055579.2) S. antibioticus ATCC 11891
(GenBank AF055579.2)
(GenBank AF055579.2) S. antibioticus ATCC 11891
(GenBank AF055579.2)
(GenBank U77454.1) Saccharopolyspora erythraea NRRL 2338
(GenBank U77454.1)
pYJ146
(GenBank AF055579.2) S. antibioticus ATCC 11891
(GenBank AF055579.2)
pYJ146는 Hong, J. S. et al., 2004. FEMS Microbiol. Lett. 238:291-299에 기재되어 있음.
pYJ146 is from Hong, JS et al., 2004. FEMS Microbiol. Lett. 238: 291-299.
상기 다양한 데옥시당을 가지는 나르보놀라이드의 글리코실화에 연관되는 유전자들을 복제형 플라스미드 pSE34에 클로닝하였다. 다양한 유전자를 포함하는 플라스미드를 효율적으로 제작하기 위하여 하나의 유전자를 포함하는 PacI/XbaI 절편을 타 유전자를 포함하는 PacI/SpeI-절단되는 Litmus28에 연결하였다. 상기 절차는 나르보놀라이드가 글리코실화 나르보놀라이드로 전환되는데 필요한 모든 유전자들이 Litmus28 내에서 조합되고 PacI/XbaI로 절단되는 pSE34내로 이동될 때까지 회귀적으로 반복되었다. 조합된 유전자 배열을 표 2에 요약하였다. The genes involved in glycosylation of the navonolides having the various deoxysaccharides were cloned into the cloned plasmid pSE34. In order to efficiently construct plasmids containing various genes, PacI / XbaI fragments containing one gene were linked to PacI / SpeI-cleaved Litmus28 containing other genes. The procedure was repeated recursively until all the genes required for the conversion of navonolide to glycosylated narbnolide were transferred into pSE34, which is combined in Litmus28 and cleaved with PacI / XbaI. The combined gene sequence is summarized in Table 2.
LRHMNBDQNVNB
LRHMNB
DBVNNBDDGTNB
DBVNNB
LDGTNB
DBVNNBLOLVNB
LDGTNB
DBVNNB
pDDSS를 제작하기 위하여, DesVII/DesVIII 글리코실트랜스퍼라아제/보조 단백질 쌍 및 TDP-D-데소사민 생합성 효소를 코딩하는 유전자를 Litmus28에 순차적으로 클로닝하여 pDDSS_lit28를 제조하였다. pDDSS_lit28의 삽입 DNA를 PacI/XbaI 로 절단하고 pSE34에 연결하여 pDDSS를 제조하였다. To construct pDDSS, pDDSS_lit28 was prepared by sequentially cloning genes encoding DesVII / DesVIII glycosyltransferase / adjuvant protein pairs and TDP-D-desosamine biosynthetic enzymes into Litmus28. Insertion DNA of pDDSS_lit28 was digested with PacI / XbaI and linked to pSE34 to prepare pDDSS.
pDQNV를 제작하기 위하여, ClaI/EcoRI-절단되는 pDDSS_lit28를 Klenow 절편을 이용하여 둔단으로 만들고 연결하여 desVIII - desVII - desIII - desIV를 포함하는 PacI/XbaI 절편을 pSE34로 클로닝하였다. To construct pDQNV, ClaI / EcoRI-cleaved pDDSS_lit28 was blunted using Klenow fragments and linked to clone PacI / XbaI fragments containing desVIII - desVII - desIII - desIV into pSE34.
다양한 데옥시당의 생합성 및 그들의 전이를 명령하는 다수의 플라스미드(pLRHM2, pODDC, pDDGT2, 및 pLOLV2)를 제작하기 위하여, 다양한 당 유전자 카세트를 포함하는 ClaI/XbaI 절편을 독립적으로 ClaI/XbaI-절단하는 pDDSS_lit28로 클로닝하였다. 제조된 플라스미드의 PacI/XbaI 절편을 pSE34로 각각 클로닝하고, 해당 플라스미드를 스트렙토마이세스 베네주엘래 결실 돌연변이체(YJ003)에 도입하였다. 구체적으로, pDDSS(글리코실트랜스퍼라아제 유전자 desVIII/desVII와 함께 D-데소사민 [DDSS] 생합성 유전자 조합(desIII-desIV-desI-desII-desV-desVI)을 발현하는 플라스미드)를 도입하여 재조합 미생물 YJ003/pDDSS를 제조(나르보마이신 생산); pDQNV(desVIII/desVII와 함께 D-퀴노보오스 [DQNV] 생합성 유전자 조합(desIII-desIV)을 발현하는 플라스미드)를 도입하여 재조합 미생물 YJ003/pDQNV를 제조(D-퀴노보오실-나르보놀라이드(DQNVNB) 생산); pODDC(desVIII/desVII와 함께 3'-O-데메틸-D-찰코오스 [ODDC] 생합성 유전자 조합(desIII-desIV-desI-desII)을 발현하는 플라스미드)를 도입하여 재조합 미생물 YJ003/pODDC를 제조(3'-O-데메틸-D-찰코오실-나르보놀라이드(ODDCNB) 생산); pLRHM2(desVIII/desVII와 함께 L-람노오스 [LRHM] 생합성 유전자 조합(desIII-desIV-oleL-oleU)을 발현하는 플라스미드를 도입하여 재조합 미생물 YJ003/pLRHM2를 제조(L-람노오실-나르보놀라이드(LRHMNB) 및 DQNVNB 생산); pDDGT2(desVIII/desVII와 함께 D-디지톡소오스 [DDGT] 생합성 유전자 조합(desIII-desIV-oleV-eryBII-urdR)을 발현하는 플라스미드를 도입하여 재조합 미생물 YJ003/pDDGT2를 제조(D-디지톡소오실-나르보놀라이드(DDGTNB) 및 D-보이비노오실-나르보놀라이드(DBVNNB) 생산); pLOLV2(desVIII/desVII와 함께 L-올리보오스 [LOLV] 및 L-디지톡소오스 [LDGT] 생합성 유전자 조합(desIII-desIV-oleV-oleW-oleL-oleU)을 발현하는 플라스미드를 도입하여 재조합 미생물 YJ003/pLOLV2를 제조(L-올리보오실-나르보놀라이드(LOLVNB), L-디지톡소오실-나르보놀라이드(LDGTNB), 및 DBVNNB 생산)하였다. In order to construct multiple plasmids (pLRHM2, pODDC, pDDGT2, and pLOLV2) that direct the biosynthesis of various deoxysaccharides and their transition, pDDSS_lit28 to independently ClaI / XbaI-cutting ClaI / XbaI fragments containing various sugar gene cassettes Cloned into. PacI / XbaI fragments of the prepared plasmids were respectively cloned into pSE34 and the plasmids were introduced into Streptomyces Venezuelan deletion mutants (YJ003). Specifically, a recombinant microorganism is introduced by introducing pDDSS ( a plasmid expressing the D-desosamine [DDSS] biosynthetic gene combination ( desIII-desIV-desI-desII-desV-desVI ) together with the glycosyltransferase gene desVIII / desVII ). Preparing YJ003 / pDDSS (producing narcamycin); pDQNV (plasmid expressing the D-quinobose [DQNV] biosynthetic gene combination ( desIII-desIV ) together with desVIII / desVII ) was introduced to prepare the recombinant microorganism YJ003 / pDQNV (D-quinovoosyl-narbonolide ( DQNVNB) production); pODDC ( plasmid expressing 3'- O -demethyl-D-chalcose [ODDC] biosynthetic gene combination ( desIII-desIV-desI-desII ) together with desVIII / desVII) was introduced to prepare recombinant microorganism YJ003 / pODDC ( 3'- 0 -demethyl-D-chalcoosyl-narbornolide (ODDCNB) production); Recombinant microorganism YJ003 / pLRHM2 was prepared by introducing a plasmid expressing pLRHM2 ( desVIII / desVII together with L-rhamnose [LRHM] biosynthetic gene combination ( desIII-desIV-oleL-oleU ) the recombinant microorganism YJ003 / pDDGT2 by introducing a plasmid expressing pDDGT2 (D- digital Messenger source [DDGT] biosynthetic gene combinations (desIII-desIV-oleV-eryBII -urdR with desVIII / desVII); (LRHMNB) and DQNVNB production) Preparation (produces D-Digitoxoosyl-narbonolide (DDGTNB) and D-vobinooxyl-narbornolide (DBVNNB)); pLOLV2 (with L-Olivose [LOLV] and L-Digi with desVIII / desVII ) Recombinant microorganism YJ003 / pLOLV2 was prepared by introducing a plasmid expressing the toxoose [LDGT] biosynthetic gene combination ( desIII-desIV-oleV-oleW-oleL-oleU ) (L -olibosyl-narvonolide (LOLVNB), L Digitoxosol-narbonolide (LDGTNB), and DBVNNB production).
제조한 상기 재조합 미생물 중에서, pDDGT2(desVIII/desVII와 함께 D-디지톡소오스 [DDGT] 생합성 유전자 조합(desIII-desIV-oleV-eryBII-urdR)을 발현하는 플라스미드)가 도입된 재조합 미생물 및 pLOLV2(desVIII/desVII와 함께 L-올리보오스 [LOLV] 및 L-디지톡소오스 [LDGT] 생합성 유전자 조합(desIII-desIV-oleV-oleW-oleL-oleU)을 발현하는 플라스미드)가 도입된 재조합 미생물을 한국미생물보존센터(Korean Culture Center of Microorganisms, KCCM)에 2011년 3월 10일자로 각각 기탁번호 KFCC11507P, KFCC11508P로 기탁하였다.
Among the recombinant microorganism prepared, pDDGT2 (desVIII / with desVII D- digital Messenger source [DDGT] biosynthetic gene combinations (desIII-desIV-oleV-eryBII -urdR) plasmid expressing) a recombinant microorganism, and introducing pLOLV2 (desVIII / L- come with desVII ribose [LOLV] and L- digital Messenger source [LDGT] biosynthetic gene combinations (desIII-desIV-oleV-oleW -oleL-oleU) Korea preserve microorganism a recombinant microorganism the plasmid) is introduced to express the It was deposited with the Korean Culture Center of Microorganisms (KCCM) on March 10, 2011 under the accession numbers KFCC11507P and KFCC11508P, respectively.
HPLCHPLC -- ESIESI -- MSMS 분석 analysis ofof 나르보마이신Narvomycin 및 그의 And his 글리코실화Glycosylation 유도체 derivative
스트렙토마이세스 베네주엘래 배양물에서 생산된 마크롤라이드를 SPE를 이용하여 추출하여 대사물질을 고성능액체크로마토그래피-전자분무이온화-질량분석기 (high-performance liquid chromatography-electrospray ionization-mass spectrometry, HPLC-ESI-MS)로 분석하였다. 각 배양물을 원심분리하였다(10분동안, 5,000 x g). 5 ml 메탄올 및 5 ml 물로 미리 처리된 OASIS HLB (Waters, Milford, MA) SPE 칼럼으로 상등액을 통과시켰다. 칼럼을 5 ml 20% (vol/vol) 메탄올로 세척하고 ca . 30 초동안 공기건조시켰다. 칼럼을 1 ml 0.5% (vol/vol) 메탄올 아세트산으로 3회 용출하였다. 분석 HPLC-ESI-MS를 양이온 모드에서 Waters Nova-Pak C18 칼럼 (150 x 3.9 mm, 5μm)을 사용하여 Waters/Micromass Quattro micro/MS 인터페이스에서 수행하였다. 분석대상물질을 250 μl/분 유속에서 5 mM (wt/vol) 암모늄 아세테이트의 농도 구배를 이용하여 -0.05% (vol/vol) 아세트산 수용액(용액 A) 및 동일한 추가 농도를 가지는 80% (vol/vol) 아세토니트릴 (ACN) (용액 B) 으로서 25분 동안 20 내지 70% 용액 B, 15분 동안 용액 B 90%까지, 9분 동안 90% 용액 B 유지, 및 11분 동안 칼럼 재-평형을 위하여 용액 B 20%까지 - 용출하였다. 다양한 발현 플라스미드를 함유하는 6개의 스트렙토마이세스 베네주엘래 재조합 미생물의 SPE 추출물의 HPLC-ESI-MS 분석 결과, 나르보마이신 및 나르보마이신의 7개의 글리코실화 유도체를 검출하였다(도 4).
Streptomyces Venezuela Macrolides produced in the culture were extracted using SPE and the metabolites were analyzed by high-performance liquid chromatography-electrospray ionization-mass spectrometry (HPLC-ESI-MS). It was. Each culture was centrifuged (5,000 xg for 10 minutes). The supernatant was passed through an OASIS HLB (Waters, Milford, Mass.) SPE column pretreated with 5 ml methanol and 5 ml water. Washing the column with 5
나르보마이신Narvomycin 및 그의 And his 글리코실화Glycosylation 유도체의 추출, 분리 및 확인 Extraction, Separation and Identification of Derivatives
크로마토그래피 분리를 제조용 Spherisorb S5 ODS2 (Waters, 250 x 20 mm, 5 μm) 또는 반-제조용 Watchers 120 ODS-BP (250 x 10 mm, 5 μm, Daiso, Osaka, Japan) 칼럼 상에서 역상 HPLC를 이용하여 수행하였다. 1H, 상관 분광법 (COSY), 이종핵간 다중 결합 상관 (HMBC), 이종핵 단일 양자 상관 (HSQC), 및 핵 오버하우저 효과 분광법 (NOESY) NMR 스펙트럼을 Varian INOVA 500 분광계 (Varian, Inc., Palo Alto, CA)를 이용하여 500 MHz 에서 기록하였다. 13C NMR 스펙트럼을 동일한 기계 상에서 125 MHz 에서 기록하였다. 각각의 용매 피크와 관련하여 화학적 시프트가 보고되었다 (CDCl3에 대하여 δH 7.27 및 δc 77.0; CD3OD에 대하여 δH 3.30 및 δc 49.0).Chromatographic separations were performed using reverse phase HPLC on preparative Spherisorb S5 ODS2 (Waters, 250 x 20 mm, 5 μm) or semi-preparation Watchers 120 ODS-BP (250 x 10 mm, 5 μm, Daiso, Osaka, Japan) column. Was performed. 1 H, Correlation Spectroscopy (COSY), Heteronuclear Multiple Binding Correlation (HMBC), Heteronuclear Single Quantum Correlation (HSQC), and Nuclear Overhauser Effect Spectroscopy (NOESY) NMR Spectra of Varian INOVA 500 Spectrometer (Varian, Inc., Palo Alto, CA) was used to record at 500 MHz. 13 C NMR spectra were recorded at 125 MHz on the same machine. Chemical shifts were reported for each solvent peak (δ H 7.27 and δ c 77.0 for CDCl 3 ; δ H 3.30 and δc 49.0 for CD 3 OD).
나르보마이신-생산 균주 스트렙토마이세스 베네주엘래 YJ003/pDDSS의 전체 배양액 (0.5 L)을 원심 분리하고, 상등액 층을 에틸 아세테이트(Et2OAc)를 이용하여 용매-용매 분배되도록 하였다. 획득된 추출물을 증발시킨 결과 생성된 갈색 잔여물을 구배 용출을 이용하는 제조용 HPLC를 이용하여 분별하였다. 분석대상물질을 0.1% 수성 아세트산 (용액 C) 및 아세토니트릴-아세트산 (99.9:0.1, v/v) (용액 D)의 농도 구배를 이용하여 0부터 15 분까지 용액 D 15%까지, 53 분에서 용액 D 35%까지, 58 분에서 용액 D 60%까지, 63 - 73 분 동안 다시 15% 용액 D로 5 ml/분의 유속으로 용출하였다. 나르보마이신 포함 분획을 이동상으로서 3 ml/분 30% 수성 CAN을 이용하는 반-제조용 HPLC를 사용하여 더욱 정제하여 비정질의 흰색 고체인 순수한 화합물을 생산하였다(0.67 mg; 머무름 시간(Rt), 37.6 분; 화학식; ESI-MS [M + H]+ 510; NMR 데이타는 하기 표 3).The whole culture (0.5 L) of the narbomycin-producing strain Streptomyces Venezuela YJ003 / pDDSS was centrifuged and the supernatant layer was allowed to have solvent-solvent distribution using ethyl acetate (Et 2 OAc). The resulting brown residue, after evaporation of the extract obtained, was fractionated using preparative HPLC using gradient elution. The analyte was subjected to a concentration gradient of 0.1% aqueous acetic acid (solution C) and acetonitrile-acetic acid (99.9: 0.1, v / v) (solution D) from 0 to 15 minutes at

D-퀴노보오실-나르보놀라이드(DQNVNB)-생산 균주 YJ003/pDQNV의 전체 배양액 (1.0 L)을 유사하게 처리하여 갈색의 물질을 획득하였다. 상기 잔여물을 구배 용출 (30 분까지 30% 수성 ACN, 40 - 80 분 동안 50% 수성 ACN, 및 81 - 90 분 동안 다시 30% 수성 ACN)을 이용하는 반-제조용 HPLC를 이용하여 2 ml/분의 유속으로 분별하였다. DQNVNB 포함 분획을 이동상으로서 2 ml/분 30% 수성 ACN을 이용하는 반-제조용 HPLC를 사용하여 더욱 정제하여 비정질의 흰색 고체인 순수한 화합물을 생산하였다(4.25 mg; 머무름 시간(Rt), 25.8 분; 화학식; ESI-MS [M + NH4]+ 516; NMR 데이타는 하기 표 4). The entire culture (1.0 L) of D-quinobosyl-narbonolide (DQNVNB) -producing strain YJ003 / pDQNV was similarly treated to obtain a brownish material. The residue was 2 ml / min using semi-preparative HPLC using gradient elution (30% aqueous ACN up to 30 minutes, 50% aqueous ACN for 40-80 minutes, and 30% aqueous ACN again for 81-90 minutes). Fractionated at a flow rate of. The DQNVNB containing fractions were further purified using semi-preparative HPLC using 2 ml /

L-람노오실-나르보놀라이드(LRHMNB)-생산 균주 YJ003/pLRHM2의 전체 배양액 (0.5 L)으로부터 획득한 잔여물을 구배 용출 (55 분까지 35% 수성 ACN, 55 - 65 분 동안 60% 수성 ACN, 및 70 - 80 분 동안 다시 35% 수성 ACN)을 이용하는 제조용 HPLC 를 이용하여 6 ml/분의 유속으로 분별하였다. LRHMNB 포함 분획을 이동상으로서 30% 수성 ACN을 이용하는 반-제조용 HPLC를 사용하여 정제하여 순수한 화합물을 생산하였다(0.54 mg; 머무름 시간(Rt), 25.2 분; 화학식; ESI-MS [M + NH4]+ 516; NMR 데이타는 하기 표 5).Gradient elution (35% aqueous ACN up to 55 minutes, 60% aqueous for 55-65 minutes) from the residue obtained from the total culture (0.5 L) of L-Rhamonosyl-narbonolide (LRHMNB) -producing strain YJ003 / pLRHM2 Fractionation was performed at a flow rate of 6 ml / min using preparative HPLC using ACN, and again 35% aqueous ACN) for 70-80 minutes. The LRHMNB containing fractions were purified using semi-preparative HPLC using 30% aqueous ACN as mobile phase to yield pure compound (0.54 mg; retention time (Rt), 25.2 min; Formula; ESI-MS [M + NH 4 ] + 516; NMR data is to Table 5).

a: HSQC 및 HMBC 스펙트럼에 기초한 수치
a: numerical value based on HSQC and HMBC spectrum
3'-O-데메틸-D-찰코오실-나르보놀라이드(ODDCNB)-생산 균주 YJ003/pODDC의 전체 배양액 (1.0 L)을 동일한 방식으로 처리하였다. 잔여물을 이동상으로서 45% 수성 ACN을 5 ml/분의 유속으로 이용하는 제조용 HPLC 를 이용하여 분별하였다. ODDCNB 포함 분획을 이동상으로서 30% 수성 ACN을 2 ml/분의 유속으로 이용하는 반-제조용 HPLC를 사용하여 정제하여 순수한 화합물을 생산하였다(2.44 mg; 머무름 시간(Rt), 29.6 분; 화학식; ESI-MS [M + NH4]+ 500; NMR 데이타는 하기 표 6).The whole culture (1.0 L) of 3′- O -demethyl-D-chalcoosyl-narbonolide (ODDCNB) -producing strain YJ003 / pODDC was treated in the same manner. The residue was fractionated using preparative HPLC using 45% aqueous ACN as a mobile phase at a flow rate of 5 ml / min. The ODDCNB containing fractions were purified using semi-preparative HPLC using 30% aqueous ACN as the mobile phase at a flow rate of 2 ml / min to produce pure compounds (2.44 mg; retention time (Rt), 29.6 min; Formula; ESI- MS [M + NH 4 ] + 500; NMR data is shown in Table 6 below.

D-디지톡소오실-나르보놀라이드(DDGTNB) 및 D-보이비노오실-나르보놀라이드 (DBVNNB)-생산 균주 YJ003/pDDGT2의 전체 배양액 (14.6 L)을 유사하게 처리하고 최종 잔여물을 구배 용출 (45 분까지 40% 수성 ACN, 50 - 60 분 동안 45% 수성 ACN, 및 65 - 75 분 동안 다시 40% 수성 ACN)을 이용하는 제조용 HPLC 를 이용하여 6 ml/분의 유속으로 분별하였다. DBVNNB 및 DDGTNB 포함 분획을 35% 수성 ACN을 2 ml/분의 유속으로 이용하는 반-제조용 HPLC 칼럼에 각각 통과시켜 순수한 DBVNNB (9.16 mg; 머무름 시간(Rt), 29.3 분; 화학식; ESI-MS [M + NH4]+ 500; NMR 데이타는 하기 표 7) 및 DDGTNB (4.18 mg; 머무름 시간(Rt), 31.2 분; 화학식; ESI-MS [M + NH4]+ 500; NMR 데이타는 하기 표 8)를 각각 생산하였다.The whole culture (14.6 L) of D-Ditotoxosil-narbonolide (DDGTNB) and D-voinoosino-narbonolide (DBVNNB) -producing strain YJ003 / pDDGT2 was similarly treated and the final residue gradientd. Fractionation was performed at a flow rate of 6 ml / min using preparative HPLC using elution (40% aqueous ACN up to 45 minutes, 45% aqueous ACN for 50-60 minutes, and 40% aqueous ACN again for 65-75 minutes). The fractions containing DBVNNB and DDGTNB were passed through a semi-preparative HPLC column using a 35% aqueous ACN at a flow rate of 2 ml / min to give pure DBVNNB (9.16 mg; retention time (Rt), 29.3 min; chemical formula: ESI-MS [M + NH 4] + 500; NMR data are in Table 7) and DDGTNB (4.18 mg; retention time (Rt), 31.2 min; the formula; ESI-MS [M + NH 4] + 500; NMR data are in Table 8) Respectively.


a: HSQC 및 HMBC 스펙트럼에 기초한 수치
a: numerical value based on HSQC and HMBC spectrum
L-올리보오실-나르보놀라이드(LOLVNB) 및 L-디지톡소오실-나르보놀라이드 (LDGTNB)-생산 균주 YJ003/pLOLV2의 전체 배양액 (2.5 L)으로부터 획득한 잔여물을 구배 용출 (30 분까지 30% 수성 ACN, 40 - 80 분 동안 40% 수성 ACN, 및 81 - 90 분 동안 다시 30% 수성 ACN)을 이용하는 반-제조용 HPLC 를 이용하여 2 ml/분의 유속으로 분별하였다. LOLVNB 포함 분획을 이동상으로서 35% 수성 ACN을 2 ml/분의 유속으로 이용하는 반-제조용 HPLC 칼럼에 통과시켜 순수한 화합물(0.55 mg; 머무름 시간(Rt), 28.7 분; 화학식; ESI-MS [M + NH4]+ 500; NMR 데이타는 하기 표 9)을 생산하였다. Gradient elution of the residue obtained from the total culture (2.5 L) of L-olibosyl-narbonolide (LOLVNB) and L-digitotoxoyl-narbonolide (LDGTNB) -producing strain YJ003 / pLOLV2 (30 min) Fractionation at a flow rate of 2 ml / min using semi-preparative HPLC using 30% aqueous ACN, 40% aqueous ACN for 40-80 minutes, and 30% aqueous ACN again for 81-90 minutes). The LOLVNB containing fractions were passed through a semi-preparative HPLC column using 35% aqueous ACN as the mobile phase at a flow rate of 2 ml / min to give pure compounds (0.55 mg; retention time (Rt), 28.7 min; Formula; ESI-MS [M + NH 4 ] + 500; NMR data produced Table 9).

a: HSQC 및 HMBC 스펙트럼에 기초한 수치
a: numerical value based on HSQC and HMBC spectrum
LOLVNB 및 LDGTNB-생산 균주 YJ003/pLOLV2의 전체 배양액 (21.6 L)을 이전의균주와 동일하게 처리하여 생산된 잔여물을 구배 용출 (50 분까지 38% 수성 ACN, 55 - 75 분 동안 42% 수성 ACN, 및 76 - 85 분 동안 다시 38% 수성 ACN)을 이용하는 제조용 HPLC 를 이용하여 6 ml/분의 유속으로 분별하였다. LDGTNB 포함 분획을 이동상으로서 35% 수성 ACN을 2 ml/분의 유속으로 이용하는 반-제조용 HPLC 칼럼에 통과시켜 순수한 화합물(1.81 mg; 머무름 시간(Rt), 31.0 분; 화학식; ESI-MS [M + NH4]+ 500; NMR 데이타는 하기 표 10)을 생산하였다.Gradient elution (38% aqueous ACN up to 50 minutes, 42% aqueous ACN for 55-75 minutes) by treating the entire culture (21.6 L) of LOLVNB and LDGTNB-producing strain YJ003 / pLOLV2 in the same manner as the previous strain And preparative HPLC using 38% aqueous ACN) again for 76-85 minutes at a flow rate of 6 ml / min. The LDGTNB containing fractions were passed through a semi-preparative HPLC column using 35% aqueous ACN as the mobile phase at a flow rate of 2 ml / min to give pure compounds (1.81 mg; retention time (Rt), 31.0 minutes; Formula; ESI-MS [M + NH 4 ] + 500; NMR data produced Table 10).

a: HSQC 및 HMBC 스펙트럼에 기초한 수치
a: numerical value based on HSQC and HMBC spectrum
나르보마이신Narvomycin 및 그의 유도체 구조 규명 And its derivative structure
분리된 대사물질들의 구조를 NMR 분광법 (1H, 13C, COSY, HSQC, 및 HMBC)을 이용하여 추론하였다. DQNVNB의 13C NMR 데이타를 통하여 나르보마이신과 같은 14-원 마크롤라이드 글리코시드에서 확인할 수 있는 26 탄소의 존재를 확인하였다. COSY, HSQC, 및 HMBC 스펙트럼을 포함하는 2D NMR 데이타의 해석 결과, DQNVNB의 전체 구조를 구상할 수 있었다. 1H NMR 스펙트럼을 통하여 7개의 메틸기 (δH 1.35/ H3-16, 1.30/ H3-6', 1.30/H3-17, 1.10/H3-19, 1.08/H3-20, 0.98/H3-18, 및 0.89/H3-15), 2개의 메틸렌기 (δH 1.48, 1.19/H2-7 및 1.61, 1.52/H2-14), 5개의 메타인(methine) 양성자 (δH 3.82/H-2, 2.89/H-4, 2.81/H-8, 2.72/H-12, 및 1.80/H-6), 7개의 산소 공급된 메타인 양성자 (δH 4.94/H-13, 4.34/H-1', 4.16/H-5, 3.46/H-3', 3.34/H-5', 3.33/H-2', 및 3.16/H-4'), 및 2개의 올레핀 양성자 (δH 6.65/H-11 및 6.05/H-10)에 대한 신호를 확인하였다. COSY 스펙트럼을 통하여 아노머 양성자 (δH 4.34/H-1') 내지 H-6' (δH 1.30)로부터의 6-데옥시헥소오스에 대한 것을 포함하는 5개의 스핀 시스템을 확인하였다. 6-데옥시헥소오스 당의 존재는 13C NMR 및 HSQC 스펙트럼을 통하여 δc 103.1/C-1'에서의 아노머 탄소와 함께 4개의 산소 공급된 탄소 (δc 76.9/C-3', 75.5/C-4', 74.7/C-2', 72.0/C-5') 및 δc 17.8/C-6' 에서의 메틸 신호를 검출함으로써 재차 확인하였다. HMBC 스펙트럼에서, 아노머 양성자 (δH 4.34/H-1')는 탄소 C-5 (δc 78.8)와 연관되어 있었고, 이는 당이 C-5에 부착된 것을 의미한다. 더욱이, 각각의 탄소와 메틸 양성자의 주요 HMBC 상관관계는 그들의 위치를 확인시켜 주었다. The structure of the isolated metabolites was inferred using NMR spectroscopy ( 1 H, 13 C, COZY, HSQC, and HMBC). 13 C NMR data of DQNVNB confirmed the presence of 26 carbons which can be found in 14-membered macrolide glycosides such as narbomycin. Analysis of 2D NMR data including COSY, HSQC, and HMBC spectra revealed the overall structure of DQNVNB. 7 methyl groups through 1 H NMR spectrum (δ H 1.35 / H 3 -16, 1.30 / H 3 -6 ', 1.30 / H 3 -17, 1.10 / H 3 -19, 1.08 / H 3 -20, 0.98 / H 3 -18, and 0.89 / H 3 -15), 2 of a methylene group (δ H 1.48, 1.19 / H 2 -7 and 1.61, 1.52 / H 2 -14) , 5 of the meth (methine) proton (δ H 3.82 / H-2, 2.89 / H-4, 2.81 / H-8, 2.72 / H-12, and 1.80 / H-6), seven oxygenated metain protons (δ H 4.94 / H-13, 4.34 / H-1 ', 4.16 / H-5, 3.46 / H-3', 3.34 / H-5 ', 3.33 / H-2', and 3.16 / H-4 '), and two olefin protons (δ H 6.65 / H-11 and 6.05 / H-10). The COSY spectrum identified five spin systems including those for 6-deoxyhexose from anomer protons (δ H 4.34 / H-1 ′) to H-6 ′ (δ H 1.30). The presence of 6-deoxyhexose sugars was characterized by four oxygenated carbons (δc 76.9 / C-3 ', 75.5 / C- with anomer carbon at δc 103.1 / C-1' through 13 C NMR and HSQC spectra). 4 ', 74.7 / C-2', 72.0 / C-5 '), and confirmed again by detecting the methyl signal in (delta) c 17.8 / C-6'. In the HMBC spectrum, anomer protons (δ H 4.34 / H-1 ′) were associated with carbon C-5 (δc 78.8), meaning that the sugar was attached to C-5. Moreover, the major HMBC correlation of each carbon and methyl proton confirmed their position.
글리코실화의 메커니즘이 알려진 것이라면(입체화학이 반전 또는 보존), 당의 입체배치는 아노머 양성자의 커플링 상수로부터 결정될 수 있다. 글리코실트랜스퍼라아제 DesVII는 활성화된 당의 아노머 탄소에서의 입체화학을 반전시킴으로써 당을 전이시킨다. 따라서, 아노머 양성자에 대한 큰 커플링 상수(ca . 7 Hz)를 가지는 글리코시드는 4C1 입체구조에서 가로방향의(equatorial) β-글리코시드 연결된 D-당을 포함하는 것을 의미하고, 작은 커플링 상수 (< 5 Hz)는 세로방향의(axial) α-글리코시드 결합을 가지는 1C4 입체구조를 가지는 L-당을 의미한다. 올바른 입체구조 (4C1)는 H-1' 및 H-5' 사이의 NOE 크로스 피크를 통하여 재차 확인될 수 있다. 그 결과, 당이 4C1 입체구조를 가지는 D-퀴노보오스로 확인되었다. 아노머 양성자의 큰 커플링 상수 (J 1' ,2' = 7.0 Hz)를 통하여 세로 방향 위치를 확인하였고, 따라서, Klyne의 법칙에 따라 β-글리코시드 연결된 D-당으로 확인되었다. 큰 커플링 상수(J 2' ,3' = 9.0 Hz, J 3' ,4' = 9.0 Hz, 및 J 4' ,5' = 9.0 Hz)는 H-2', H-3', H-4', 및 H-5' 양성자가 세로 방향으로 위치한다는 것을 의미한다. 더욱이, H-1' 및 H-5' 사이의 NOE 상관관계(도 5)가 4C1 입체구조를 뒷받침한다. If the mechanism of glycosylation is known (stereochemistry is reversed or preserved), the stereoconfiguration of the sugar can be determined from the coupling constants of the anomer protons. Glycosyltransferase DesVII transfers sugars by reversing the stereochemistry at the anomer carbon of the activated sugar. Accordingly, a large coupling constant (ca. 7 Hz) having a glycopeptide seed 4 C 1 conformation in a sense that it includes a transverse direction of the (equatorial) β- glycoside-linked sugar and D-, a small couple to the anomeric protons Ring constants (<5 Hz) refer to L-sugars with 1 C 4 conformation with axial α-glycosidic bonds. The correct conformation ( 4 C 1 ) can be identified again via the NOE cross peak between H-1 ′ and H-5 ′. As a result, the sugar was identified as D-quinobose having a 4 C 1 conformation. The longitudinal position was confirmed by the large coupling constant of the anomer protons ( J 1 ′ , 2 ′ = 7.0 Hz), thus identifying β-glycoside linked D-sugars according to Klyne's law. Large coupling constants ( J 2 ' , 3' = 9.0 Hz, J 3 ' , 4' = 9.0 Hz, and J 4 ' , 5' = 9.0 Hz) are H-2 ', H-3', H-4 ', And H-5' protons are located in the longitudinal direction. Moreover, the NOE correlation between H-1 'and H-5' (FIG. 5) supports the 4 C 1 conformation.
ODDCNB의 1D 및 2D NMR 데이타는 DQNVNB와 유사하였다. 이는 상기 물질 역시 나르보마이신 유도체라는 것을 의미한다. 유일한 차이점은 당에서 추가적인 메틸렌기의 존재이고, 이는 다이데옥시헥소오스임을 의미한다. COSY 스펙트럼에서, 양성자 H-1' (δH 4.31)는 H-3' (δH 3.70)에 커플링된 H-2' (δH 3.25)에 커플링되어 있음을 확인하였다. 양성자 H-3'는 메틸렌 H-4' 양성자 (δH 1.95 및 1.42)에 커플링되었고, 차례로 H3-6' 양성자(δH 1.25)에 커플링된 H-5' 양성자 (δH 3.62)에 커플링되어 있음을 확인하였다. 이는 4,6-다이데옥시헥소오스 부분의 존재를 의미한다. 커플링 상수에 의하면, 양성자 H-2', H-3', 및 H-5'는 세로 방향인 것으로 확인되었다. 이는 당이 3-O 데메틸-찰코오스임을 의미한다. 큰 커플링 상수 (J 1' ,2' = 7.5 Hz)는 일반적으로 4C1 입체구조에서 D-당에 대하여 β-글리코시드 결합을 의미한다. 이것은 H-1' 및 H-5' 사이의 NOE 크로스 피크(도 5)에 의하여 뒷받침된다. 이러한 방법으로, 상기 획득된 1D 및 2D NMR 데이타는, 당 부분이 C-5에 부착된 3-O-데메틸-D-찰코오스임을 나타낸다.1D and 2D NMR data of ODDCNB were similar to DQNVNB. This means that the substance is also a narcamycin derivative. The only difference is the presence of additional methylene groups in the sugar, meaning that it is dideoxyhexose. In the COSY spectrum, it was confirmed that proton H-1 '(δ H 4.31) was coupled to H-2' (δ H 3.25) coupled to H-3 '(δ H 3.70). Proton H-3 'was coupled to methylene H-4' protons (δ H 1.95 and 1.42), and in turn to H-5 'proton (δ H 3.62) coupled to H3-6' proton (δ H 1.25) It was confirmed that it was coupled. This means the presence of the 4,6-dideoxyhexose moiety. According to the coupling constants, the protons H-2 ', H-3', and H-5 'were found to be in the longitudinal direction. This means that the sugar is 3- O demethyl-chalcose. Large coupling constants ( J 1 ′ , 2 ′ = 7.5 Hz) generally mean β-glycosidic bonds to D-sugars in the 4 C 1 conformation. This is supported by the NOE cross peak (FIG. 5) between H-1 'and H-5'. In this way, the obtained 1D and 2D NMR data indicate that the sugar moiety is 3- O -demethyl-D-chalcose attached to C-5.
DBVNNB의 NMR 데이타는 ODDCNB와 유사하였다. 이는 다이데옥시헥소오스 당을 포함하는 나르보마이신 유도체의 존재를 의미한다. COSY 스펙트럼에서, 아노머 양성자 H-1' (δH 4.81, dd, J = 8, 4.5 Hz)는 H-3' (δH 4.11)에 커플링된 메틸렌 양성자 (H2-2': δH 1.78/1.80)에 커플링되어 있음을 확인하였다. 양성자 H-3' H-4' (δH 3.26)에 커플링되었고, 또한 차례로 H3-6' 양성자(δH 1.24)에 커플링된 H-5' (δH 4.05)에 커플링되어 있음을 확인하였다. 이는 당 부분이 2,6-다이데옥시헥소오스임을 의미한다. 아노머 양성자의 큰 커플링 상수(δH 4.81, dd, J 1' ,2' = 8.0, 4.5 Hz)는 가로방향의 β-글리코시드 결합을 의미하고 따라서, 4C1 입체구조에 있어서 입체화학이 D-당으로 결정되었다. H-3' (J = 3 Hz) 및 H-4' (brs)의 작은 커플링 상수는 상기 두 양성자가 모두 가로방향으로 위치하고 각각의 히드록실기가 세로방향이라는 것을 의미한다. 따라서, 당은 D-보이비노오스로 확인되었고 상기 데이터는 공지된 보고에 잘 부합하였다. 또한, 4C1 입체구조는 H-1' 및 H-5' 사이의 NOE 크로스 피크(도 5)를 통하여 확인되었다.NMR data of DBVNNB was similar to ODDCNB. This means the presence of narbomycin derivatives, including dideoxyhexose sugars. In the COSY spectrum, anomer proton H-1 '(δ H 4.81, dd, J = 8, 4.5 Hz) is a methylene proton (H 2 -2': δ H coupled to H-3 '(δ H 4.11) 1.78 / 1.80). Coupled to proton H-3 'H-4' (δ H 3.26) and in turn coupled to H-5 '(δ H 4.05) coupled to H3-6' proton (δ H 1.24). Confirmed. This means that the sugar moiety is 2,6-dideoxyhexose. Large coupling constants of the anomer protons (δ H 4.81, dd, J 1 ′ , 2 ′ = 8.0, 4.5 Hz) mean transverse β-glycosidic bonds and thus stereochemistry in the 4 C 1 conformation This was determined as D-sugars. The small coupling constants of H-3 '( J = 3 Hz) and H-4' (brs) mean that both protons are located transversely and each hydroxyl group is longitudinal. Thus, the sugar was identified as D-vobinose and the data corresponded well to known reports. In addition, the 4 C 1 conformation was identified through the NOE cross peak (FIG. 5) between H-1 ′ and H-5 ′.
DDGTNB의 NMR 데이타는 당 양성자의 커플링 상수에서의 차이를 제외하고는 DBVNNB와 유사하였다. NMR 데이터에 기초하여 다이데옥시당은 D-디지톡소오스로 확인되었고, 아노머 양성자의 큰 커플링 상수(J 1' ,2' = 9.5 Hz)는 세로방향의 양성자를 가지는 β-글리코시드 연결된 D 당을 나타낸다. 1H NMR 스펙트럼은 e,a 및 e,e 커플링에 일반적인 H-3' 의 작은 커플링 상수 (δH 4.11, m, J = 3 Hz)를 통하여 3'-OH기의 세로방향을 확증해주었고, 따라서, 디지톡소오스 및 올리보오스 당을 구별하기 위하여 유용하였다. 이축 커플링 (J 4' ,5' = 9.5 Hz)이 H-4' 및 H-5'사이에서 관찰되었는 바, 이는 가로방향의 5'-CH3 및 4'-OH를 의미한다. 디지톡소오스 당의 4C1 입체구조 (D-당에 일반적인)는 H-1' 및 H-5' 사이의 NOE 상관관계를 이용하여 확인하였다(도 5). NMR data of DDGTNB were similar to DBVNNB except for differences in the coupling constants of the sugar protons. Based on the NMR data, dideoxysaccharides were identified as D-digitoxose, and the large coupling constants of the anomer protons ( J 1 ′ , 2 ′ = 9.5 Hz) were β-glycosidically linked with longitudinal protons. D sugar. The 1 H NMR spectrum corroborates the longitudinal direction of the 3'-OH group through the small coupling constant of H-3 '(δ H 4.11, m, J = 3 Hz), which is common for e, a and e, e coupling. And, therefore, was useful for distinguishing digitoxose and oligoose sugars. A biaxial coupling ( J 4 ′ , 5 ′ = 9.5 Hz) was observed between H-4 ′ and H-5 ′, meaning transverse 5′-CH 3 and 4′-OH. The 4 C 1 conformation of digitoxose sugars (common to D-sugars) was confirmed using NOE correlations between H-1 ′ and H-5 ′ (FIG. 5).
LOLVNB의 NMR 데이타는 H-3' (δH 3.90, ddd, J =12.0, 9.0, 5.0 Hz)에 대한 커플링 상수 및 스플릿 패턴에서의 주요 변화를 제외하고는 DDGTNB와 유사하였다. 커플링 상수 J 3' ,2' ax = 12.0 Hz 및 J 3' ,4' = 9.0 Hz는 H-3' 양성자가 세로방향으로 위치하는 반면 3'-OH가 가로방향으로 위치한다는 것을 의미한다. 따라서, DDGTNB에서 디지톡소오스인 것과 달리, 당 부분이 올리보오스로 확인되었다. 당의 입체배치는 아노머 양성자의 커플링 상수(J = 3 Hz) 및 NOE 크로스 피크(도 5)를 통하여 L-올리보오스로 결정되었다. NMR data of LOLVNB were similar to DDGTNB except for the major change in coupling constants and split pattern for H-3 ′ (δ H 3.90, ddd, J = 12.0, 9.0, 5.0 Hz). Coupling Constants J 3 ' , 2' ax = 12.0 Hz and J 3 ' , 4' = 9.0 Hz mean that the H-3 'proton is located longitudinally while the 3'-OH is located transversely. Thus, unlike digitoxose in DDGTNB, the sugar moiety was identified as oligoose. The stereoconfiguration of sugars was determined as L-olivose via the coupling constants of the anomer protons ( J = 3 Hz) and the NOE cross peak (FIG. 5).
LDGTNB의 1H NMR 스펙트럼은 당 부분의 화학적 시프트에 있어서의 약간의 차이를 제외하고는 DDGTNB와 유사하였다. 가장 현저한 차이는 아노머 양성자 신호 (δH 5.03, brs, J 1' ,2' = 3 Hz)이고, 이는 DDGTNB (δH 4.84, J 1' ,2' = 9.5 Hz)에서와 달리, 세로방향의 글리코시드 연결의 존재를 의미한다. 1D 및 2D NMR 데이타는 LDGTNB의 구조를 뒷받침하였다. 또한, 1H NMR 스펙트럼은 커플링 상수 (J 3' ,4' = 3.0 Hz 및 J 4',5' = 10.0 Hz)를 통하여, 가로방향의 H-3' 및 세로방향의 H-4' 및 H-5'를 확인하여, 디지톡소오스 당으로 확인하였다. NOESY 스펙트럼에서, DDGTNB에서 관찰된 H-1' 및 H-5' 사이의 NOE 상관관계 대신에, H-2'ax (δH 1.91, dt, J = 15.0, 3.5 Hz) 및 H-4' (δH 3.15, dd, J = 10.0, 3.0 Hz) 양성자 사이의 상관관계가 관찰되었다(도 5). 따라서, H-1'부터 C-5까지의 HMBC 크로스 피크에 의하여 측정된 바와 같이 당을 C-5 (δC 78.5)에 부착된 L-디지톡소오스로 확인하였다. 상기 데이타는 L-디지톡소오스에 대하여 보고된 데이터에 잘 부합되었다. The 1 H NMR spectrum of LDGTNB was similar to DDGTNB except for a slight difference in the chemical shift of the sugar moiety. The most significant difference is the anomeric proton signal (δ H 5.03, brs, J 1 ′ , 2 ′ = 3 Hz), which is longitudinally unlike DDGTNB (δ H 4.84, J 1 ′ , 2 ′ = 9.5 Hz). Means the presence of a glycoside linkage. 1D and 2D NMR data supported the structure of LDGTNB. In addition, the 1 H NMR spectrum is obtained through the coupling constants ( J 3 ′ , 4 ′ = 3.0 Hz and J 4 ′, 5 ′ = 10.0 Hz), H-3 ′ in the transverse direction and H-4 ′ in the longitudinal direction, and H-5 'was identified and identified as Digitoxose sugar. In the NOESY spectrum, instead of the NOE correlation between H-1 'and H-5' observed in DDGTNB, H-2'ax (δ H 1.91, dt, J = 15.0, 3.5 Hz) and H-4 '( δ H 3.15, dd, J = 10.0, 3.0 Hz) Correlation between protons was observed (FIG. 5). Thus, the sugar was identified as L-digitoxose attached to C-5 (δ C 78.5) as measured by the HMBC cross peak from H-1 ′ to C-5. The data was in good agreement with the data reported for L-digitoxose.
HPLC-ESI-MS 및 1D (1H 및 13C) 및 2D (COSY, HMBC, HSQC, 및 NOESY) NMR 데이터를 통하여 나르보마이신 및 LRHMNB를 확인하였다. 상기 화합물에 있어서 당의 입체배치(configuration) 및 입체구조(conformation)를 커플링 상수 및 NOE 크로스 피크를 통하여 결정하였다.
Narvomycin and LRHMNB were identified through HPLC-ESI-MS and 1D ( 1 H and 13 C) and 2D (COZY, HMBC, HSQC, and NOESY) NMR data. The configuration and conformation of sugars in the compounds were determined through coupling constants and NOE cross peaks.
임상적 균주의 분리 및 항균제 감수성 측정Isolation of Clinical Strains and Measurement of Antimicrobial Susceptibility
에리트로마이신-저항성 균주 E. 파에시움 P00558 및 S. 아우레우스 P00740를 대한민국 대구에 소재한 3차 대학병원에서 분리하였다. 상기 분리물을 속 및 종 동정 및 항균제 감수성 측정을 위하여 MicroScan WalkAway 96 시스템 (Dade Behring, West Sacramento, CA)를 이용하여 처리하였다. MicroScan 그람 양성 MIC/콤보 (PC1A) 패널 (Dade Behring), 그람 음성 MIC/ 콤보 (NC44) 패널 (Dade Behring), 및 그람 음성 구분점(breakpoint) 콤보 (NBC39) 패널 (Dade Behring)을 이용하여 항균제 감수성 및 E. 파에시움 및 S. 아우레우스의 종 레벨을 각각 동정하였다. 시험을 위한 접종물 현탁액을 동일한 깨끗한 18- 내지 24-시간-계대배양 플레이트를 이용하여 같은 날에 처리하였다. 미량희석 항균제 감수성 시험을 위하여 Prompt Inoculation 시스템-D (Dade Behring)를 이용하여 접종물을 표준화하였다. 모든 항균제 감수성 시험은 최신 Clinical and Laboratory Standards Institute 방법에 따라 수행하였다. 품질 관리는 S. 아우레우스 ATCC 25923를 이용하여 관찰하였다.
Erythromycin-resistant strain E. paesium P00558 and S. aureus P00740 was separated from the 3rd university hospital in Daegu, South Korea. The isolates were processed using MicroScan WalkAway 96 system (Dade Behring, West Sacramento, CA) for genus and species identification and antimicrobial susceptibility measurements. Antimicrobials using MicroScan Gram Positive MIC / Combo (PC1A) Panel (Dade Behring), Gram Negative MIC / Combo (NC44) Panel (Dade Behring), and Gram Negative Breakpoint Combo (NBC39) Panel (Dade Behring) Sensitivity and species levels of E. paesium and S. aureus were identified, respectively. Inoculum suspensions for testing were treated on the same day using the same clean 18- to 24-hour-passage plates. Inoculum was standardized using Prompt Inoculation System-D (Dade Behring) for microdilution antimicrobial susceptibility testing. All antimicrobial susceptibility tests were performed according to the latest Clinical and Laboratory Standards Institute methods. Quality Control S. Aureus Observation was made using ATCC 25923.
항균 활성 Antimicrobial activity 어세이Assay
에리트로마이신-감수성 균주 E. 파에시움 ATCC 19434 및 S. 아우레우스 ATCC 25923 및 에리트로마이신-저항성 균주 E. 파에시움 P00558 및 S. 아우레우스 P00740를 이용하여 중성의 데옥시당을 포함하는 나르보마이신 및 그의 유도체의 항균 활성을 측정하였다. 에리트로마이신을 대조군으로서 사용하였다. 박테리아 세포 (2 x 107 /ml)를 LB 또는 Mueller-Hinton 배지에 접종하고 96-웰 미세적정 플레이트로 0.1 ml/웰씩 나누었다. MIC를 National Committee for Clinical Laboratory Standards에 따른 항생제의 연속 2배 희석을 이용하여 측정하였다. 37 ℃에서 접종 24시간 후, 시험 개체의 성장을 방해하는 최소 항생제 농도를 MIC로서 결정하였다. 성장은 미세적정 ELISA Reader (Molecular Devices Emax, CA) 를 이용하여 620 nm에서의 흡광도를 관찰함으로써 어세이하였다. 그 결과를 하기 표 11에 나타내었다.Erythromycin-sensitive strain E. paesium ATCC 19434 and S. Aureus ATCC 25923, and erythromycin-resistant strains E. par when Titanium P00558 and S. aureus P00740 was used to determine the antimicrobial activity of narbomycin and its derivatives including neutral deoxysaccharides. Erythromycin was used as a control. Bacterial cells (2 × 10 7 / ml) were seeded in LB or Mueller-Hinton medium and divided into 0.1 ml / well into 96-well microtiter plates. MIC was measured using serial 2-fold dilutions of antibiotics according to the National Committee for Clinical Laboratory Standards. After 24 hours of inoculation at 37 ° C., the minimum antibiotic concentration that interfered with the growth of the test subject was determined as MIC. Growth was assayed by observing absorbance at 620 nm using a microtiter ELISA Reader (Molecular Devices Emax, CA). The results are shown in Table 11 below.
matter
19434ATCC
19434
25923ATCC
25923
D-데소사민 포함 나르보마이신은 에리트로마이신-감수성 균주에 대하여 에리트로마이신 (10 μM) 과 유사한 항균 활성을 나타내었다. 반면 에리트로마이신-저항성 균주에 대하여는 에리트로마이신 (> 20 μM)보다 더 높은 활성 (10 - 20 μM)이 관찰되었다. DQNVNB는 E. 파에시움 ATCC 19434, E. 파에시움 P00558, 및 S. 아우레우스 ATCC 25923에 대하여 개선된 활성을 나타내지 않았지만, S. 아우레우스 P00740의 성장을 저해하는 데에 있어서는 나르보마이신보다 효과적이었다. LOLVNB는 S. 아우레우스 ATCC 25923에 대하여 선택적 활성을 나타내었다. 본 실험예에서, LRHMNB는 강력한 활성 (1.25 - 2.50 μM)을 나타내었다. ODDCNB 역시 모든 균주에 대하여 유의적인 활성 (2.5 - 5.0 μM)을 나타내었다. LRHMNB 의 시험관 내 항균 활성(1.25 - 2.50 μM) 을 LOLVNB 의 그것(5 - 20 μM)과 비교한 결과, LRHMNB의 2'-히드록실기의 구조-활성 정보를 확인하였고, 이는 항균 활성의 가장 중요한 결정 요인일 수 있다. ODDCNB의 항균 활성(2.5 - 5.0 μM)은 나르보마이신 (10 - 20 μM) 및 DQNVNB (≤ 10 μM) 보다 우수하였다. 이는 나르보마이신의 3'-다이메틸아미노 기가 3'-히드록실기로 교체된 것 및 DQNVNB에 있는 4'-히드록실기가 없는 것이 ODDCNB의 항균 활성을 개선시킨 것임을 확인하였다. S. 아우레우스 ATCC 25923 및 P00740에 대한 LOLVNB (5 - 10 μM) 및 LDGTNB (10 - 20 μM)의 MIC를 비교한 결과, LOLVNB의 3'-가로방향(equatorial)-히드록실기가 항균 활성에 긍정적 영향을 미친다는 것을 의미한다. DBVNNB (≤ 10 μM) 는 E. 파에시움 ATCC 19434, P00558, 및 S. 아우레우 스 ATCC 25923에 대하여 DDGTNB (< 20 μM) 보다 더 높은 항균 활성을 나타내었는 바, 이는 DBVNNB의 4'-세로방향(axial)-히드록실기가 MIC를 감소시킨다는 것을 의미한다.Narvomycin with D-desosamin showed antimicrobial activity similar to erythromycin (10 μM) against erythromycin-sensitive strains. On the other hand, higher activity (10-20 μM) was observed for erythromycin-resistant strains than erythromycin (> 20 μM). DQNVNB is helpful when par E. ATCC 19434, E. paella City Stadium P00558 did not show improved activity against S. aureus ATCC 25923, but S. aureus It was more effective than narbomycin in inhibiting the growth of P00740. LOLVNB showed selective activity against S. aureus ATCC 25923. In this experimental example, LRHMNB showed strong activity (1.25-2.50 μM). ODDCNB also showed significant activity (2.5-5.0 μM) for all strains. In vitro antimicrobial activity of LRHMNB (1.25-2.50 μM) was compared with that of LOLVNB (5-20 μM), confirming the structure-activity information of the 2'-hydroxyl group of LRHMNB, which is the most important of antimicrobial activity. It may be a determining factor. The antimicrobial activity of ODDCNB (2.5-5.0 μM) was better than narbomycin (10-20 μM) and DQNVNB (≦ 10 μM). It was confirmed that the 3'-dimethylamino group of narcamycin was replaced with a 3'-hydroxyl group and the absence of the 4'-hydroxyl group in DQNVNB improved the antimicrobial activity of ODDCNB. S. Aureus Comparing the MICs of LOLVNB (5-10 μM) and LDGTNB (10-20 μM) for ATCC 25923 and P00740, the 3′-equaltorial-hydroxyl group of LOLVNB positively affects antimicrobial activity Means that. DBVNNB (≤ 10 μM) is helpful when par E. ATCC 19434, P00558, and S. Leu brother's ATCC About 25923 DDGTNB (<20 μM) was it exhibited a higher antibacterial activity than the bar, which the DBVNNB 4'- longitudinal (axial) - hydroxyl group reduces the MIC It means.
<110> Ewha University - Industry Collaboration Foundation <120> Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same <130> PA110076/KR <160> 46 <170> KopatentIn 1.71 <210> 1 <211> 9715 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-desI-desII-desV-desVI <400> 1 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tgctagcgac ggtggcccgg agggaacatc 4920 cgtgaaaagc gccttatccg acctcgcatt cttcggcggc cccgccgctt tcgaccagcc 4980 gctcctcgtg gggcggccca accgcatcga ccgcgccagg ctgtacgagc ggctcgaccg 5040 ggccctcgac agccagtggc tgtccaacgg cggcccgctc gtccgcgagt tcgaggagcg 5100 cgtcgccggg ctcgccgggg tccggcatgc cgtggccacc tgcaacgcca cggccgggct 5160 ccagctcctc gcgcacgccg ccggcctcac cggcgaagtg atcatgccgt cgatgacgtt 5220 cgccgccacc ccgcacgcac tgcgctggat cggcctcacc ccggtcttcg ccgacatcga 5280 cccggacacc ggcaacctcg acccggacca ggtggccgcc gcggtcacac cccgcacctc 5340 ggccgtcgtc ggcgtccacc tctggggccg cccctgcgcc gccgaccagc tgcggaaggt 5400 cgccgacgag cacggcctgc ggctgtactt cgacgccgcg cacgccctcg gctgcgcggt 5460 cgacggccgg cccgccggca gcctcggcga cgccgaggtc ttcagcttcc acgccaccaa 5520 ggccgtcaac gccttcgagg gcggcgccgt cgtcaccgac gacgccgacc tcgccgcccg 5580 gatccgcgcc ctccacaact tcggcttcga cctgcccggc ggcagccccg ccggcgggac 5640 caacgccaag atgagcgagg ccgccgccgc catgggcctc acctccctcg acgcgtttcc 5700 cgaggtcatc gaccggaacc ggcgcaacca cgccgcctac cgcgagcacc tcgcggacct 5760 ccccggcgtc ctcgtcgccg accacgaccg ccacggcctc aacaaccacc agtacgtgat 5820 cgtcgagatc gacgaggcca ccaccggcat ccaccgcgac ctcgtcatgg aggtcctgaa 5880 ggccgaaggc gtgcacaccc gcgcctactt ctcgccgggc tgccacgagc tggagccgta 5940 ccgcgggcag ccgcacgccc cgctgccgca caccgaacgc ctcgccgcgc gcgtgctgtc 6000 cctgccgacc ggcaccgcca tcggcgacga cgacatccgc cgggtcgccg acctgctgcg 6060 tctctgcgcg acccgcggcc gcgaactgac cgcgcgccac cgcgacacgg cccccgcccc 6120 gctcgcggcc ccccagacat ccacgcccac gattggacgc tcccgatgac cgcccccgcc 6180 ctttccgcca ccgccccggc cgaacgctgc gcgcaccccg gagccgatct gggggcggcg 6240 gtccacgccg tcggccagac cctcgccgcc ggcggcctcg tgccgcccga cgaggccgga 6300 acgaccgccc gccacctcgt ccggctcgcc gtgcgctacg gcaacagccc cttcaccccg 6360 ctggaggagg cccgccacga cctgggcgtc gaccgggacg ccttccggcg cctcctcgcc 6420 ctgttcgggc aggtcccgga gctccgcacc gcggtcgaga ccggccccgc cggggcgtac 6480 tggaagaaca ccctgctccc gctcgaacag cgcggcgtct tcgacgcggc gctcgccagg 6540 aagcccgtct tcccgtacag cgtcggcctc taccccggcc cgacctgcat gttccgctgc 6600 cacttctgcg tccgtgtgac cggcgcccgc tacgacccgt ccgccctcga cgccggcaac 6660 gccatgttcc ggtcggtcat cgacgagata cccgcgggca acccctcggc gatgtacttc 6720 tccggcggcc tggagccgct caccaacccc ggcctcggga gcctggccgc gcacgccacc 6780 gaccacggcc tgcggcccac cgtctacacg aactccttcg cgctcaccga gcgcaccctg 6840 gagcgccagc ccggcctctg gggcctgcac gccatccgca cctcgctcta cggcctcaac 6900 gacgaggagt acgagcagac caccggcaag aaggccgcct tccgccgcgt ccgcgagaac 6960 ctgcgccgct tccagcagct gcgcgccgag cgcgagtcgc cgatcaacct cggcttcgcc 7020 tacatcgtgc tcccgggccg tgcctcccgc ctgctcgacc tggtcgactt catcgccgac 7080 ctcaacgacg ccgggcaggg caggacgatc gacttcgtca acattcgcga ggactacagc 7140 ggccgtgacg acggcaagct gccgcaggag gagcgggccg agctccagga ggccctcaac 7200 gccttcgagg agcgggtccg cgagcgcacc cccggactcc acatcgacta cggctacgcc 7260 ctgaacagcc tgcgcaccgg ggccgacgcc gaactgctgc ggatcaagcc cgccaccatg 7320 cggcccaccg cgcacccgca ggtcgcggtg caggtcgatc tcctcggcga cgtgtacctg 7380 taccgcgagg ccggcttccc cgacctggac ggcgcgaccc gctacatcgc gggccgcgtg 7440 acccccgaca cctccctcac cgaggtcgtc agggacttcg tcgagcgcgg cggcgaggtg 7500 gcggccgtcg acggcgacga gtacttcatg gacggcttcg atcaggtcgt caccgcccgc 7560 ctgaaccagc tggagcgcga cgccgcggac ggctgggagg aggcccgcgg cttcctgcgc 7620 tgacccgcat ctagtcaggt ctccttcgcg gacggcctcg cgcggaccgt ccgctggtac 7680 cgggagaacc gcggctggtg ggagccgctc aaggcgaccg ccccgcagct gcccgccacc 7740 gccgtggagg tgtccgcgtg agcagccgcg ccgagacccc ccgcgtcccc ttcctcgacc 7800 tcaaggccgc ctacgaggag ctccgcgcgg agaccgacgc cgcgatcgcc cgcgtcctcg 7860 actcggggcg ctacctcctc ggacccgaac tcgaaggatt cgaggcggag ttcgccgcgt 7920 actgcgagac ggaccacgcc gtcggcgtga acagcgggat ggacgccctc cagctcgccc 7980 tccgcggcct cggcatcgga cccggggacg aggtgatcgt cccctcgcac acgtacatcg 8040 ccagctggct cgcggtgtcc gccaccggcg cgacccccgt gcccgtcgag ccgcacgagg 8100 accaccccac cctggacccg ctgctcgtcg agaaggcgat caccccccgc acccgggcgc 8160 tcctccccgt ccacctctac gggcaccccg ccgacatgga cgccctccgc gagctcgcgg 8220 accggcacgg cctgcacatc gtcgaggacg ccgcgcaggc ccacggcgcc cgctaccggg 8280 gccggcggat cggcgccggg tcgtcggtgg ccgcgttcag cttctacccg ggcaagaacc 8340 tcggctgctt cggcgacggc ggcgccgtcg tcaccggcga ccccgagctc gccgaacggc 8400 tccggatgct ccgcaactac ggctcgcggc agaagtacag ccacgagacg aagggcacca 8460 actcccgcct ggacgagatg caggccgccg tgctgcggat ccggctcgcc cacctggaca 8520 gctggaacgg ccgcaggtcg gcgctggccg cggagtacct ctccgggctc gccggactgc 8580 ccggcatcgg cctgccggtg accgcgcccg acaccgaccc ggtctggcac ctcttcaccg 8640 tgcgcaccga gcgccgcgac gagctgcgca gccacctcga cgcccgcggc atcgacaccc 8700 tcacgcacta cccggtaccc gtgcacctct cgcccgccta cgcgggcgag gcaccgccgg 8760 aaggctcgct cccgcgggcc gagagcttcg cgcggcaggt cctcagcctg ccgatcggcc 8820 cgcacctgga gcgcccgcag gcgctgcggg tgatcgacgc cgtgcgcgaa tgggccgagc 8880 gggtcgacca ggcctagtca ggttctagtc aattgcccca ggcctcaccc ctgtatctgc 8940 gccgggggac gcccccggcc caccctccga aagaccgaaa gcaggagcac cgtgtacgaa 9000 gtcgaccacg ccgacgtcta cgacctcttc tacctgggtc gcggcaagga ctacgccgcc 9060 gaggcctccg acatcgccga cctggtgcgc tcccgtaccc ccgaggcctc ctcgctcctg 9120 gacgtggcct gcggtacggg cacgcatctg gagcacttca ccaaggagtt cggcgacacc 9180 gccggcctgg agctgtccga ggacatgctc acccacgccc gcaagcggct gcccgacgcc 9240 acgctccacc agggcgacat gcgggacttc cggctcggcc ggaagttctc cgccgtggtc 9300 agcatgttca gctccgtcgg ctacctgaag acgaccgagg aactcggcgc ggccgtcgcc 9360 tcgttcgcgg agcacctgga gcccggtggc gtcgtcgtcg tcgagccgtg gtggttcccg 9420 gagaccttcg ccgacggctg ggtcagcgcc gacgtcgtcc gccgtgacgg gcgcaccgtg 9480 gcccgtgtct cgcactcggt gcgggagggg aacgcgacgc gcatggaggt ccacttcacc 9540 gtggccgacc cgggcaaggg cgtgcggcac ttctccgacg tccatctcat caccctgttc 9600 caccaggccg agtacgaggc cgcgttcacg gccgccgggc tgcgcgtcga gtacctggag 9660 ggcggcccgt cgggccgtgg cctcttcgtc ggcgtccccg cctgagtcta gaccc 9715 <210> 2 <211> 292 <212> PRT <213> Artificial Sequence <220> <223> DesIII protein <400> 2 Met Lys Gly Ile Val Leu Ala Gly Gly Ser Gly Thr Arg Leu His Pro 1 5 10 15 Ala Thr Ser Val Ile Ser Lys Gln Ile Leu Pro Val Tyr Asn Lys Pro 20 25 30 Met Ile Tyr Tyr Pro Leu Ser Val Leu Met Leu Gly Gly Ile Arg Glu 35 40 45 Ile Gln Ile Ile Ser Thr Pro Gln His Ile Glu Leu Phe Gln Ser Leu 50 55 60 Leu Gly Asn Gly Arg His Leu Gly Ile Glu Leu Asp Tyr Ala Val Gln 65 70 75 80 Lys Glu Pro Ala Gly Ile Ala Asp Ala Leu Leu Val Gly Ala Glu His 85 90 95 Ile Gly Asp Asp Thr Cys Ala Leu Ile Leu Gly Asp Asn Ile Phe His 100 105 110 Gly Pro Gly Leu Tyr Thr Leu Leu Arg Asp Ser Ile Ala Arg Leu Asp 115 120 125 Gly Cys Val Leu Phe Gly Tyr Pro Val Lys Asp Pro Glu Arg Tyr Gly 130 135 140 Val Ala Glu Val Asp Ala Thr Gly Arg Leu Thr Asp Leu Val Glu Lys 145 150 155 160 Pro Val Lys Pro Arg Ser Asn Leu Ala Val Thr Gly Leu Tyr Leu Tyr 165 170 175 Asp Asn Asp Val Val Asp Ile Ala Lys Asn Ile Arg Pro Ser Pro Arg 180 185 190 Gly Glu Leu Glu Ile Thr Asp Val Asn Arg Val Tyr Leu Glu Arg Gly 195 200 205 Arg Ala Glu Leu Val Asn Leu Gly Arg Gly Phe Ala Trp Leu Asp Thr 210 215 220 Gly Thr His Asp Ser Leu Leu Arg Ala Ala Gln Tyr Val Gln Val Leu 225 230 235 240 Glu Glu Arg Gln Gly Val Trp Ile Ala Gly Leu Glu Glu Ile Ala Phe 245 250 255 Arg Met Gly Phe Ile Asp Ala Glu Ala Cys His Gly Leu Gly Glu Gly 260 265 270 Leu Ser Arg Thr Glu Tyr Gly Ser Tyr Leu Met Glu Ile Ala Gly Arg 275 280 285 Glu Gly Ala Pro 290 <210> 3 <211> 337 <212> PRT <213> Artificial Sequence <220> <223> DesIV protein <400> 3 Met Arg Leu Leu Val Thr Gly Gly Ala Gly Phe Ile Gly Ser His Phe 1 5 10 15 Val Arg Gln Leu Leu Ala Gly Ala Tyr Pro Asp Val Pro Ala Asp Glu 20 25 30 Val Ile Val Leu Asp Ser Leu Thr Tyr Ala Gly Asn Arg Ala Asn Leu 35 40 45 Ala Pro Val Asp Ala Asp Pro Arg Leu Arg Phe Val His Gly Asp Ile 50 55 60 Arg Asp Ala Gly Leu Leu Ala Arg Glu Leu Arg Gly Val Asp Ala Ile 65 70 75 80 Val His Phe Ala Ala Glu Ser His Val Asp Arg Ser Ile Ala Gly Ala 85 90 95 Ser Val Phe Thr Glu Thr Asn Val Gln Gly Thr Gln Thr Leu Leu Gln 100 105 110 Cys Ala Val Asp Ala Gly Val Gly Arg Val Val His Val Ser Thr Asp 115 120 125 Glu Val Tyr Gly Ser Ile Asp Ser Gly Ser Trp Thr Glu Ser Ser Pro 130 135 140 Leu Glu Pro Asn Ser Pro Tyr Ala Ala Ser Lys Ala Gly Ser Asp Leu 145 150 155 160 Val Ala Arg Ala Tyr His Arg Thr Tyr Gly Leu Asp Val Arg Ile Thr 165 170 175 Arg Cys Cys Asn Asn Tyr Gly Pro Tyr Gln His Pro Glu Lys Leu Ile 180 185 190 Pro Leu Phe Val Thr Asn Leu Leu Asp Gly Gly Thr Leu Pro Leu Tyr 195 200 205 Gly Asp Gly Ala Asn Val Arg Glu Trp Val His Thr Asp Asp His Cys 210 215 220 Arg Gly Ile Ala Leu Val Leu Ala Gly Gly Arg Ala Gly Glu Ile Tyr 225 230 235 240 His Ile Gly Gly Gly Leu Glu Leu Thr Asn Arg Glu Leu Thr Gly Ile 245 250 255 Leu Leu Asp Ser Leu Gly Ala Asp Trp Ser Ser Val Arg Lys Val Ala 260 265 270 Asp Arg Lys Gly His Asp Leu Arg Tyr Ser Leu Asp Gly Gly Glu Ile 275 280 285 Glu Arg Glu Leu Gly Tyr Arg Pro Gln Val Ser Phe Ala Asp Gly Leu 290 295 300 Ala Arg Thr Val Arg Trp Tyr Arg Glu Asn Arg Gly Trp Trp Glu Pro 305 310 315 320 Leu Lys Ala Thr Ala Pro Gln Leu Pro Ala Thr Ala Val Glu Val Ser 325 330 335 Ala <210> 4 <211> 415 <212> PRT <213> Artificial Sequence <220> <223> DesI protein <400> 4 Met Lys Ser Ala Leu Ser Asp Leu Ala Phe Phe Gly Gly Pro Ala Ala 1 5 10 15 Phe Asp Gln Pro Leu Leu Val Gly Arg Pro Asn Arg Ile Asp Arg Ala 20 25 30 Arg Leu Tyr Glu Arg Leu Asp Arg Ala Leu Asp Ser Gln Trp Leu Ser 35 40 45 Asn Gly Gly Pro Leu Val Arg Glu Phe Glu Glu Arg Val Ala Gly Leu 50 55 60 Ala Gly Val Arg His Ala Val Ala Thr Cys Asn Ala Thr Ala Gly Leu 65 70 75 80 Gln Leu Leu Ala His Ala Ala Gly Leu Thr Gly Glu Val Ile Met Pro 85 90 95 Ser Met Thr Phe Ala Ala Thr Pro His Ala Leu Arg Trp Ile Gly Leu 100 105 110 Thr Pro Val Phe Ala Asp Ile Asp Pro Asp Thr Gly Asn Leu Asp Pro 115 120 125 Asp Gln Val Ala Ala Ala Val Thr Pro Arg Thr Ser Ala Val Val Gly 130 135 140 Val His Leu Trp Gly Arg Pro Cys Ala Ala Asp Gln Leu Arg Lys Val 145 150 155 160 Ala Asp Glu His Gly Leu Arg Leu Tyr Phe Asp Ala Ala His Ala Leu 165 170 175 Gly Cys Ala Val Asp Gly Arg Pro Ala Gly Ser Leu Gly Asp Ala Glu 180 185 190 Val Phe Ser Phe His Ala Thr Lys Ala Val Asn Ala Phe Glu Gly Gly 195 200 205 Ala Val Val Thr Asp Asp Ala Asp Leu Ala Ala Arg Ile Arg Ala Leu 210 215 220 His Asn Phe Gly Phe Asp Leu Pro Gly Gly Ser Pro Ala Gly Gly Thr 225 230 235 240 Asn Ala Lys Met Ser Glu Ala Ala Ala Ala Met Gly Leu Thr Ser Leu 245 250 255 Asp Ala Phe Pro Glu Val Ile Asp Arg Asn Arg Arg Asn His Ala Ala 260 265 270 Tyr Arg Glu His Leu Ala Asp Leu Pro Gly Val Leu Val Ala Asp His 275 280 285 Asp Arg His Gly Leu Asn Asn His Gln Tyr Val Ile Val Glu Ile Asp 290 295 300 Glu Ala Thr Thr Gly Ile His Arg Asp Leu Val Met Glu Val Leu Lys 305 310 315 320 Ala Glu Gly Val His Thr Arg Ala Tyr Phe Ser Pro Gly Cys His Glu 325 330 335 Leu Glu Pro Tyr Arg Gly Gln Pro His Ala Pro Leu Pro His Thr Glu 340 345 350 Arg Leu Ala Ala Arg Val Leu Ser Leu Pro Thr Gly Thr Ala Ile Gly 355 360 365 Asp Asp Asp Ile Arg Arg Val Ala Asp Leu Leu Arg Leu Cys Ala Thr 370 375 380 Arg Gly Arg Glu Leu Thr Ala Arg His Arg Asp Thr Ala Pro Ala Pro 385 390 395 400 Leu Ala Ala Pro Gln Thr Ser Thr Pro Thr Ile Gly Arg Ser Arg 405 410 415 <210> 5 <211> 485 <212> PRT <213> Artificial Sequence <220> <223> DesII protein <400> 5 Met Thr Ala Pro Ala Leu Ser Ala Thr Ala Pro Ala Glu Arg Cys Ala 1 5 10 15 His Pro Gly Ala Asp Leu Gly Ala Ala Val His Ala Val Gly Gln Thr 20 25 30 Leu Ala Ala Gly Gly Leu Val Pro Pro Asp Glu Ala Gly Thr Thr Ala 35 40 45 Arg His Leu Val Arg Leu Ala Val Arg Tyr Gly Asn Ser Pro Phe Thr 50 55 60 Pro Leu Glu Glu Ala Arg His Asp Leu Gly Val Asp Arg Asp Ala Phe 65 70 75 80 Arg Arg Leu Leu Ala Leu Phe Gly Gln Val Pro Glu Leu Arg Thr Ala 85 90 95 Val Glu Thr Gly Pro Ala Gly Ala Tyr Trp Lys Asn Thr Leu Leu Pro 100 105 110 Leu Glu Gln Arg Gly Val Phe Asp Ala Ala Leu Ala Arg Lys Pro Val 115 120 125 Phe Pro Tyr Ser Val Gly Leu Tyr Pro Gly Pro Thr Cys Met Phe Arg 130 135 140 Cys His Phe Cys Val Arg Val Thr Gly Ala Arg Tyr Asp Pro Ser Ala 145 150 155 160 Leu Asp Ala Gly Asn Ala Met Phe Arg Ser Val Ile Asp Glu Ile Pro 165 170 175 Ala Gly Asn Pro Ser Ala Met Tyr Phe Ser Gly Gly Leu Glu Pro Leu 180 185 190 Thr Asn Pro Gly Leu Gly Ser Leu Ala Ala His Ala Thr Asp His Gly 195 200 205 Leu Arg Pro Thr Val Tyr Thr Asn Ser Phe Ala Leu Thr Glu Arg Thr 210 215 220 Leu Glu Arg Gln Pro Gly Leu Trp Gly Leu His Ala Ile Arg Thr Ser 225 230 235 240 Leu Tyr Gly Leu Asn Asp Glu Glu Tyr Glu Gln Thr Thr Gly Lys Lys 245 250 255 Ala Ala Phe Arg Arg Val Arg Glu Asn Leu Arg Arg Phe Gln Gln Leu 260 265 270 Arg Ala Glu Arg Glu Ser Pro Ile Asn Leu Gly Phe Ala Tyr Ile Val 275 280 285 Leu Pro Gly Arg Ala Ser Arg Leu Leu Asp Leu Val Asp Phe Ile Ala 290 295 300 Asp Leu Asn Asp Ala Gly Gln Gly Arg Thr Ile Asp Phe Val Asn Ile 305 310 315 320 Arg Glu Asp Tyr Ser Gly Arg Asp Asp Gly Lys Leu Pro Gln Glu Glu 325 330 335 Arg Ala Glu Leu Gln Glu Ala Leu Asn Ala Phe Glu Glu Arg Val Arg 340 345 350 Glu Arg Thr Pro Gly Leu His Ile Asp Tyr Gly Tyr Ala Leu Asn Ser 355 360 365 Leu Arg Thr Gly Ala Asp Ala Glu Leu Leu Arg Ile Lys Pro Ala Thr 370 375 380 Met Arg Pro Thr Ala His Pro Gln Val Ala Val Gln Val Asp Leu Leu 385 390 395 400 Gly Asp Val Tyr Leu Tyr Arg Glu Ala Gly Phe Pro Asp Leu Asp Gly 405 410 415 Ala Thr Arg Tyr Ile Ala Gly Arg Val Thr Pro Asp Thr Ser Leu Thr 420 425 430 Glu Val Val Arg Asp Phe Val Glu Arg Gly Gly Glu Val Ala Ala Val 435 440 445 Asp Gly Asp Glu Tyr Phe Met Asp Gly Phe Asp Gln Val Val Thr Ala 450 455 460 Arg Leu Asn Gln Leu Glu Arg Asp Ala Ala Asp Gly Trp Glu Glu Ala 465 470 475 480 Arg Gly Phe Leu Arg 485 <210> 6 <211> 379 <212> PRT <213> Artificial Sequence <220> <223> DesV protein <400> 6 Met Ser Ser Arg Ala Glu Thr Pro Arg Val Pro Phe Leu Asp Leu Lys 1 5 10 15 Ala Ala Tyr Glu Glu Leu Arg Ala Glu Thr Asp Ala Ala Ile Ala Arg 20 25 30 Val Leu Asp Ser Gly Arg Tyr Leu Leu Gly Pro Glu Leu Glu Gly Phe 35 40 45 Glu Ala Glu Phe Ala Ala Tyr Cys Glu Thr Asp His Ala Val Gly Val 50 55 60 Asn Ser Gly Met Asp Ala Leu Gln Leu Ala Leu Arg Gly Leu Gly Ile 65 70 75 80 Gly Pro Gly Asp Glu Val Ile Val Pro Ser His Thr Tyr Ile Ala Ser 85 90 95 Trp Leu Ala Val Ser Ala Thr Gly Ala Thr Pro Val Pro Val Glu Pro 100 105 110 His Glu Asp His Pro Thr Leu Asp Pro Leu Leu Val Glu Lys Ala Ile 115 120 125 Thr Pro Arg Thr Arg Ala Leu Leu Pro Val His Leu Tyr Gly His Pro 130 135 140 Ala Asp Met Asp Ala Leu Arg Glu Leu Ala Asp Arg His Gly Leu His 145 150 155 160 Ile Val Glu Asp Ala Ala Gln Ala His Gly Ala Arg Tyr Arg Gly Arg 165 170 175 Arg Ile Gly Ala Gly Ser Ser Val Ala Ala Phe Ser Phe Tyr Pro Gly 180 185 190 Lys Asn Leu Gly Cys Phe Gly Asp Gly Gly Ala Val Val Thr Gly Asp 195 200 205 Pro Glu Leu Ala Glu Arg Leu Arg Met Leu Arg Asn Tyr Gly Ser Arg 210 215 220 Gln Lys Tyr Ser His Glu Thr Lys Gly Thr Asn Ser Arg Leu Asp Glu 225 230 235 240 Met Gln Ala Ala Val Leu Arg Ile Arg Leu Ala His Leu Asp Ser Trp 245 250 255 Asn Gly Arg Arg Ser Ala Leu Ala Ala Glu Tyr Leu Ser Gly Leu Ala 260 265 270 Gly Leu Pro Gly Ile Gly Leu Pro Val Thr Ala Pro Asp Thr Asp Pro 275 280 285 Val Trp His Leu Phe Thr Val Arg Thr Glu Arg Arg Asp Glu Leu Arg 290 295 300 Ser His Leu Asp Ala Arg Gly Ile Asp Thr Leu Thr His Tyr Pro Val 305 310 315 320 Pro Val His Leu Ser Pro Ala Tyr Ala Gly Glu Ala Pro Pro Glu Gly 325 330 335 Ser Leu Pro Arg Ala Glu Ser Phe Ala Arg Gln Val Leu Ser Leu Pro 340 345 350 Ile Gly Pro His Leu Glu Arg Pro Gln Ala Leu Arg Val Ile Asp Ala 355 360 365 Val Arg Glu Trp Ala Glu Arg Val Asp Gln Ala 370 375 <210> 7 <211> 237 <212> PRT <213> Artificial Sequence <220> <223> DesVI protein <400> 7 Met Tyr Glu Val Asp His Ala Asp Val Tyr Asp Leu Phe Tyr Leu Gly 1 5 10 15 Arg Gly Lys Asp Tyr Ala Ala Glu Ala Ser Asp Ile Ala Asp Leu Val 20 25 30 Arg Ser Arg Thr Pro Glu Ala Ser Ser Leu Leu Asp Val Ala Cys Gly 35 40 45 Thr Gly Thr His Leu Glu His Phe Thr Lys Glu Phe Gly Asp Thr Ala 50 55 60 Gly Leu Glu Leu Ser Glu Asp Met Leu Thr His Ala Arg Lys Arg Leu 65 70 75 80 Pro Asp Ala Thr Leu His Gln Gly Asp Met Arg Asp Phe Arg Leu Gly 85 90 95 Arg Lys Phe Ser Ala Val Val Ser Met Phe Ser Ser Val Gly Tyr Leu 100 105 110 Lys Thr Thr Glu Glu Leu Gly Ala Ala Val Ala Ser Phe Ala Glu His 115 120 125 Leu Glu Pro Gly Gly Val Val Val Val Glu Pro Trp Trp Phe Pro Glu 130 135 140 Thr Phe Ala Asp Gly Trp Val Ser Ala Asp Val Val Arg Arg Asp Gly 145 150 155 160 Arg Thr Val Ala Arg Val Ser His Ser Val Arg Glu Gly Asn Ala Thr 165 170 175 Arg Met Glu Val His Phe Thr Val Ala Asp Pro Gly Lys Gly Val Arg 180 185 190 His Phe Ser Asp Val His Leu Ile Thr Leu Phe His Gln Ala Glu Tyr 195 200 205 Glu Ala Ala Phe Thr Ala Ala Gly Leu Arg Val Glu Tyr Leu Glu Gly 210 215 220 Gly Pro Ser Gly Arg Gly Leu Phe Val Gly Val Pro Ala 225 230 235 <210> 8 <211> 204 <212> PRT <213> Artificial Sequence <220> <223> OleL <400> 8 Met Glu Leu Leu Asp Val Asp Gly Ala Trp Leu Tyr Thr Pro Glu Ile 1 5 10 15 Met Arg Asp Glu Arg Gly Glu Phe Leu Glu Trp Phe Arg Gly Arg Thr 20 25 30 Phe Gln Glu Lys Ile Gly His Pro Leu Ser Leu Ala Gln Ala Asn Cys 35 40 45 Ser Val Ser Arg Lys Ala Phe Cys Ala Ala Ser Thr Ser Pro Thr Pro 50 55 60 Pro Pro Gly Gln Ala Lys Tyr Val Thr Cys Ala Ser Gly Thr Val Leu 65 70 75 80 Asp Val Val Val Asp Val Arg Arg Gly Ser Pro Thr Phe Gly Arg Trp 85 90 95 Ala Ala Val Arg Leu Asp Ala Ala Arg His Gln Gly Leu Tyr Leu Ala 100 105 110 Glu Gly Leu Gly His Ala Phe Met Ala Leu Thr Asp Asp Ala Thr Val 115 120 125 Val Tyr Leu Cys Ser Gln Pro Tyr Val Ala Glu Ala Glu Arg Ala Val 130 135 140 Asp Pro Leu Asp Pro Ala Ile Gly Ile Glu Trp Pro Thr Asp Ile Asp 145 150 155 160 Ile Val Pro Val Gly Glu Gly Thr Pro Thr His Arg Pro Trp Arg Arg 165 170 175 Pro Arg Arg Pro Gly Ile Leu Pro Asp Tyr Glu Gly Val Pro Gly Ala 180 185 190 Leu His Arg Gly Gly Gly Arg Arg Gly Thr Gly Pro 195 200 <210> 9 <211> 295 <212> PRT <213> Artificial Sequence <220> <223> OleU protein <400> 9 Met Arg Trp Leu Ile Thr Gly Ala Ala Gly Met Leu Gly Arg Glu Leu 1 5 10 15 Val Arg Arg Leu Ala Glu Asn Glu Glu Asp Val Ala Ala Leu Gly His 20 25 30 Asp His Leu Asp Val Thr Arg Pro Ser Ala Val Arg Ala Ala Leu Ala 35 40 45 Glu His Arg Pro Gly Ile Val Val Asn Cys Ala Ala Tyr Thr Ala Val 50 55 60 Asp Asp Ala Glu Thr Asp Glu Ala Ala Ala Ala Leu Leu Asn Ala Glu 65 70 75 80 Ala Pro Arg Leu Leu Ala Glu Gly Leu Arg Pro His Arg Arg His Gly 85 90 95 Leu Val His Leu Ser Thr Asp Tyr Val Phe Pro Gly Asp Ala Arg Thr 100 105 110 Pro Tyr Ala Glu Asp His Pro Thr Ala Pro Arg Ser Ala Tyr Gly Arg 115 120 125 Thr Lys Arg Asp Gly Glu Gln Ala Val Leu Thr Ala Leu Pro Thr Ala 130 135 140 Thr Val Leu Arg Thr Ala Trp Leu Tyr Gly Arg Thr Gly Arg Ser Phe 145 150 155 160 Val Arg Thr Met Ile Glu Arg Glu Ala Arg Gly Gly Ala Ile Asp Val 165 170 175 Val Ala Asp Gln Arg Gly Gln Pro Thr Trp Thr Gly Asp Leu Ala Asp 180 185 190 Arg Ile Ile Ala Val Gly Arg His Pro Gly Val His Gly Ile Leu His 195 200 205 Ala Thr Asn Ala Gly Ser Ala Thr Trp Tyr Asp Leu Ala Gln Glu Val 210 215 220 Phe Arg Leu Leu Asp Ala Asp Pro Gly Arg Val Arg Pro Thr Thr Gly 225 230 235 240 Ala Ala Phe Arg Arg Pro Ala Pro Arg Pro Ala Tyr Ser Val Leu Gly 245 250 255 His Asp Arg Trp Arg Gly Thr Gly Leu Ala Pro Leu Arg Asp Trp Arg 260 265 270 Ser Ala Leu Arg Glu Ala Phe Pro Asp Ile Leu Ala Ala Glu His Pro 275 280 285 Pro Thr Arg Arg Gly Ala Ala 290 295 <210> 10 <211> 474 <212> PRT <213> Artificial Sequence <220> <223> OleV protein <400> 10 Met Ile Trp Gly Ile Pro Ala Met Ser Glu Ala Met Gly Ser Val Pro 1 5 10 15 Thr Ala Gly Ser Glu Val Ser Ser Thr Cys Ala Phe Leu Ser Trp Leu 20 25 30 Asp Ala Arg Arg Arg Ala Asn Arg Leu Thr Val Glu His Val Pro Phe 35 40 45 Arg Glu Leu Ser Gly Trp Gln Phe Asp Glu Asn Thr Gly Asn Leu Arg 50 55 60 His Thr Ser Gly Arg Phe Phe Ser Ile Glu Gly Leu Arg Val Arg Thr 65 70 75 80 Asp His Cys Trp Phe Gly Ser Trp Thr Gln Pro Ile Ile Val Gln Pro 85 90 95 Glu Ile Gly Ile Leu Gly Leu Leu Val Lys Arg Phe Asp Gly Ile Leu 100 105 110 His Val Leu Val Gln Ala Lys Asn Glu Pro Gly Asn Ile Gly Gly Leu 115 120 125 Gln Leu Ser Pro Thr Val Gln Ala Thr Arg Ser Asn Tyr Thr Arg Val 130 135 140 His Arg Gly Gly Gly Val Arg Tyr Leu Glu Tyr Phe Ala Ser Pro Arg 145 150 155 160 Gly Arg Gly Arg Val Leu Ala Asp Val Leu Gln Ser Glu Gln Gly Ser 165 170 175 Trp Phe Leu His Lys Arg Asn Arg Asn Met Val Val Glu Ala Leu Asp 180 185 190 Asp Val Pro Leu Asp Asp Asp Phe His Trp Ile Ser Leu Gly Gly Leu 195 200 205 Arg Lys Leu Leu Leu Arg Pro His Leu Val Asn Met Asp Thr Arg Thr 210 215 220 Val Leu Ser Cys Leu Pro Pro Asp Pro Ala Pro Asp Gly Arg Gln Pro 225 230 235 240 Pro Ala Pro Ala Ala Pro Phe Ala Ala Ala Val Thr Arg Ser Leu Thr 245 250 255 Arg Gly Ala Thr Ala Leu His Thr Met Gly Glu Ile Leu Gly Trp Leu 260 265 270 Thr Asp Glu Arg Ser Arg Arg Glu Leu Val Gln Gln Arg Val Pro Leu 275 280 285 Glu Glu Thr Ala Phe Ser Gly Trp Arg Arg Asp Asp His Ala Ile Ala 290 295 300 His Lys Asp Gly Asp Tyr Phe Arg Val Ile Gly Val Ser Val Arg Ala 305 310 315 320 Ser Ser Arg Glu Val Ser Ser Trp Ser Gln Pro Leu Leu Ala Pro Val 325 330 335 Gly Pro Gly Leu Ala Ala Phe Val Thr Arg Arg Ile Arg Gly Val Leu 340 345 350 His Val Leu Leu His Ala Arg Thr Glu Ala Gly Leu Leu Asn Gly Pro 355 360 365 Glu Met Ala Pro Thr Val Gln Cys Arg Pro Leu Asn Tyr Arg Ala Val 370 375 380 Pro Ala Glu Tyr Arg Pro Ala Tyr Leu Asp Tyr Val Leu Ser Ala Asp 385 390 395 400 Pro Gly Arg Ile Arg Tyr Asp Thr Leu Gln Ser Glu Glu Gly Gly Arg 405 410 415 Phe His His Ala Glu Asn Arg Tyr Val Val Val Glu Ala Glu Asp Asp 420 425 430 Phe Pro Val Glu Val Pro Arg Asp Phe Arg Trp Leu Thr Leu His Gln 435 440 445 Ile Leu Ala Leu Leu His His Ser Asn Tyr Val Asn Val Glu Ala Arg 450 455 460 Ser Leu Val Ala Cys Ile Gln Ala Leu Ser 465 470 <210> 11 <211> 333 <212> PRT <213> Artificial Sequence <220> <223> EryBII protein <400> 11 Met Thr Thr Asp Ala Ala Thr His Val Arg Leu Gly Arg Ser Ala Leu 1 5 10 15 Leu Thr Ser Arg Leu Trp Leu Gly Thr Val Asn Phe Ser Gly Arg Val 20 25 30 Glu Asp Asp Asp Ala Leu Arg Leu Met Asp His Ala Arg Asp Arg Gly 35 40 45 Ile Asn Cys Leu Asp Thr Ala Asp Met Tyr Gly Trp Arg Leu Tyr Lys 50 55 60 Gly His Thr Glu Glu Leu Val Gly Arg Trp Leu Ala Gln Gly Gly Gly 65 70 75 80 Arg Arg Glu Asp Thr Val Leu Ala Thr Lys Val Gly Gly Glu Met Ser 85 90 95 Glu Arg Val Asn Asp Ser Gly Leu Ser Ala Arg His Ile Ile Ala Ser 100 105 110 Cys Glu Gly Ser Leu Arg Arg Leu Gly Val Asp His Ile Asp Val Tyr 115 120 125 Gln Met His His Ile Asp Arg Ser Ala Pro Trp Asp Glu Val Trp Gln 130 135 140 Ala Met Asp Ser Leu Val Ala Ser Gly Lys Val Ser Tyr Val Gly Ser 145 150 155 160 Ser Asn Phe Ala Gly Trp His Ile Ala Ala Ala Gln Glu Asn Ala Ala 165 170 175 Arg Arg His Ser Leu Gly Met Val Ser His Gln Cys Leu Tyr Asn Leu 180 185 190 Ala Val Arg His Ala Glu Leu Glu Val Leu Pro Ala Ala Gln Ala Tyr 195 200 205 Gly Leu Gly Val Phe Ala Trp Ser Pro Leu His Gly Gly Leu Leu Ser 210 215 220 Gly Ala Leu Glu Lys Leu Ala Ala Gly Thr Ala Val Lys Ser Ala Gln 225 230 235 240 Gly Arg Ala Gln Val Leu Leu Pro Ser Leu Arg Pro Ala Ile Glu Ala 245 250 255 Tyr Glu Lys Phe Cys Arg Asn Leu Gly Glu Asp Pro Ala Glu Val Gly 260 265 270 Leu Ala Trp Val Leu Ser Arg Pro Gly Ile Ala Gly Ala Val Ile Gly 275 280 285 Pro Arg Thr Pro Glu Gln Leu Asp Ser Ala Leu Lys Ala Ser Ala Met 290 295 300 Thr Leu Asp Glu Gln Ala Leu Ser Glu Leu Asp Glu Ile Phe Pro Ala 305 310 315 320 Val Ala Ser Gly Gly Ala Ala Pro Glu Ala Trp Leu Gln 325 330 <210> 12 <211> 247 <212> PRT <213> Artificial Sequence <220> <223> UrdR protein <400> 12 Met Asp Ile Val Gly Asn Gly Phe Leu Ala Arg Asn Leu Arg Pro Leu 1 5 10 15 Ala Glu Arg His Pro Asp Thr Val Ala Leu Ala Ala Gly Val Ser Trp 20 25 30 Ala Ser Gly Thr Ser Asp Ala Asp Phe Ala Arg Glu Ala Ala Leu Leu 35 40 45 Arg Asp Thr Ala Lys Gln Cys Ala Ala Thr Gly Arg Arg Leu Leu Phe 50 55 60 Phe Ser Thr Ala Ala Thr Gly Met Tyr Gly Leu Ala Glu Gly Pro Gly 65 70 75 80 Arg Glu Asp Thr Pro Val Thr Pro Cys Thr Pro Tyr Gly Ala His Lys 85 90 95 Leu Ala Leu Glu Glu Leu Leu Arg Asp Ser Gly Ala Asp His Val Ile 100 105 110 Leu Arg Leu Gly His Leu Val Gly Pro Asp Gln Pro Glu His Gln Leu 115 120 125 Leu Pro Thr Leu Val Arg His Leu Arg Glu Gly Ala Val Arg Ile His 130 135 140 Arg Gly Ala Ala Arg Asp Leu Ile Asp Val Ser Asp Val Val Thr Ile 145 150 155 160 Val Asp Cys Leu Leu Gly Leu Asp Leu Lys Ala Glu Thr Val Asn Val 165 170 175 Ala Ser Gly Tyr Ala Val Pro Val Lys Asp Ile Val Glu Leu Leu Arg 180 185 190 Arg Arg Leu Gly Val Glu Ala Arg Tyr Glu Phe Gln Asp Ala Gly Gly 195 200 205 Gln His Val Ile Ser Ile Glu Lys Leu Arg Ala Leu Val Pro Gln Val 210 215 220 Gln Asp Met Gly Phe Gly Pro Asp Tyr Tyr Arg Arg Ile Leu Ser Asp 225 230 235 240 Phe Thr Ser Ala Val Arg Ile 245 <210> 13 <211> 328 <212> PRT <213> Artificial Sequence <220> <223> OleW protein <400> 13 Met Pro Ser Pro Arg Leu Arg Phe Gly Val Leu Gly Ala Ala Asp Ile 1 5 10 15 Ala Leu Arg Arg Thr Val Pro Ala Leu Leu Ala His Pro Asp Val Thr 20 25 30 Val Val Ala Val Ser Ser Arg Asp Thr Ala Arg Ala Ala Arg Phe Ala 35 40 45 Ala Ala Phe Gly Cys Glu Ala Val Pro Gly His Gln Ala Leu Leu Asp 50 55 60 Arg Asp Asp Ile Asp Ala Leu Tyr Val Pro Leu Pro Val Met Val His 65 70 75 80 Thr Pro Trp Val Glu Ala Ala Leu Leu Arg Gly Arg His Val Leu Val 85 90 95 Glu Lys Pro Leu Thr Ala Thr Arg Ser Gly Ala Glu Asp Leu Ile Ala 100 105 110 Leu Ala Arg Ser Arg Gly Leu Val Leu Met Glu Asn Phe Thr Ser Leu 115 120 125 His His Ala Gln His Gly Thr Val Thr Asp Leu Leu Arg Asp Gly Thr 130 135 140 Ile Gly Glu Leu Arg Ser Leu Ser Ala Ala Phe Thr Ile Pro Pro Lys 145 150 155 160 Pro Glu Gly Asp Ile Arg Tyr Gln Pro Asp Val Gly Gly Gly Ala Leu 165 170 175 Leu Asp Ile Gly Ile Tyr Pro Leu Arg Ala Ala Leu His Phe Leu Gly 180 185 190 Pro Asp Leu His Ala Ala Gly Ala Val Leu Arg Arg Glu Arg Arg Arg 195 200 205 Asn Val Val Val Ser Gly His Val Leu Leu Thr Thr Pro His Gly Val 210 215 220 Val Ala Glu Leu Ala Phe Gly Met Glu His Ala Tyr Arg Ser Glu Tyr 225 230 235 240 Thr Leu Phe Gly Thr Ala Gly Arg Leu Arg Leu Asp Arg Ala Phe Thr 245 250 255 Pro Pro Glu Thr His Arg Pro Arg Val Glu Ile His Arg Gln Asp Ala 260 265 270 Leu Asp Ile Val Asp Leu Pro Pro Asp Ala Gln Phe Ala Asn Leu Val 275 280 285 Arg Asp Phe Val Leu Ala Val Arg Glu Gly Pro Gly Arg Leu Thr Gln 290 295 300 His His Ala Asp Ala Val Arg Gln Ala Asp Leu Val Glu Arg Val Met 305 310 315 320 Ala Val Ala Arg Val Arg Trp Cys 325 <210> 14 <211> 402 <212> PRT <213> Artificial Sequence <220> <223> DesVIII protein <400> 14 Met Thr Asp Asp Leu Thr Gly Ala Leu Thr Gln Pro Pro Leu Gly Arg 1 5 10 15 Thr Val Arg Ala Val Ala Asp Arg Glu Leu Gly Thr His Leu Leu Glu 20 25 30 Thr Arg Gly Ile His Trp Ile His Ala Ala Asn Gly Asp Pro Tyr Ala 35 40 45 Thr Val Leu Arg Gly Gln Ala Asp Asp Pro Tyr Pro Ala Tyr Glu Arg 50 55 60 Val Arg Ala Arg Gly Ala Leu Ser Phe Ser Pro Thr Gly Ser Trp Val 65 70 75 80 Thr Ala Asp His Ala Leu Ala Ala Ser Ile Leu Cys Ser Thr Asp Phe 85 90 95 Gly Val Ser Gly Ala Asp Gly Val Pro Val Pro Gln Gln Val Leu Ser 100 105 110 Tyr Gly Glu Gly Cys Pro Leu Glu Arg Glu Gln Val Leu Pro Ala Ala 115 120 125 Gly Asp Val Pro Glu Gly Gly Gln Arg Ala Val Val Glu Gly Ile His 130 135 140 Arg Glu Thr Leu Glu Gly Leu Ala Pro Asp Pro Ser Ala Ser Tyr Ala 145 150 155 160 Phe Glu Leu Leu Gly Gly Phe Val Arg Pro Ala Val Thr Ala Ala Ala 165 170 175 Ala Ala Val Leu Gly Val Pro Ala Asp Arg Arg Ala Asp Phe Ala Asp 180 185 190 Leu Leu Glu Arg Leu Arg Pro Leu Ser Asp Ser Leu Leu Ala Pro Gln 195 200 205 Ser Leu Arg Thr Val Arg Ala Ala Asp Gly Ala Leu Ala Glu Leu Thr 210 215 220 Ala Leu Leu Ala Asp Ser Asp Asp Ser Pro Gly Ala Leu Leu Ser Ala 225 230 235 240 Leu Gly Val Thr Ala Ala Val Gln Leu Thr Gly Asn Ala Val Leu Ala 245 250 255 Leu Leu Ala His Pro Glu Gln Trp Arg Glu Leu Cys Asp Arg Pro Gly 260 265 270 Leu Ala Ala Ala Ala Val Glu Glu Thr Leu Arg Tyr Asp Pro Pro Val 275 280 285 Gln Leu Asp Ala Arg Val Val Arg Gly Glu Thr Glu Leu Ala Gly Arg 290 295 300 Arg Leu Pro Ala Gly Ala His Val Val Val Leu Thr Ala Ala Thr Gly 305 310 315 320 Arg Asp Pro Glu Val Phe Thr Asp Pro Glu Arg Phe Asp Leu Ala Arg 325 330 335 Pro Asp Ala Ala Ala His Leu Ala Leu His Pro Ala Gly Pro Tyr Gly 340 345 350 Pro Val Ala Ser Leu Val Arg Leu Gln Ala Glu Val Ala Leu Arg Thr 355 360 365 Leu Ala Gly Arg Phe Pro Gly Leu Arg Gln Ala Gly Asp Val Leu Arg 370 375 380 Pro Arg Arg Ala Pro Val Gly Arg Gly Pro Leu Ser Val Pro Val Ser 385 390 395 400 Ser Ser <210> 15 <211> 426 <212> PRT <213> Artificial Sequence <220> <223> DesVII protein <400> 15 Met Arg Val Leu Leu Thr Ser Phe Ala His His Thr His Tyr Tyr Gly 1 5 10 15 Leu Val Pro Leu Ala Trp Ala Leu Leu Ala Ala Gly His Glu Val Arg 20 25 30 Val Ala Ser Gln Pro Ala Leu Thr Asp Thr Ile Thr Gly Ser Gly Leu 35 40 45 Ala Ala Val Pro Val Gly Thr Asp His Leu Ile His Glu Tyr Arg Val 50 55 60 Arg Met Ala Gly Glu Pro Arg Pro Asn His Pro Ala Ile Ala Phe Asp 65 70 75 80 Glu Ala Arg Pro Glu Pro Leu Asp Trp Asp His Ala Leu Gly Ile Glu 85 90 95 Ala Ile Leu Ala Pro Tyr Phe His Leu Leu Ala Asn Asn Asp Ser Met 100 105 110 Val Asp Asp Leu Val Asp Phe Ala Arg Ser Trp Gln Pro Asp Leu Val 115 120 125 Leu Trp Glu Pro Thr Thr Tyr Ala Gly Ala Val Ala Ala Gln Val Thr 130 135 140 Gly Ala Ala His Ala Arg Val Leu Trp Gly Pro Asp Val Met Gly Ser 145 150 155 160 Ala Arg Arg Lys Phe Val Ala Leu Arg Asp Arg Gln Pro Pro Glu His 165 170 175 Arg Glu Asp Pro Thr Ala Glu Trp Leu Thr Trp Thr Leu Asp Arg Tyr 180 185 190 Gly Ala Ser Phe Glu Glu Glu Leu Leu Thr Gly Gln Phe Thr Ile Asp 195 200 205 Pro Thr Pro Pro Ser Leu Arg Leu Asp Thr Gly Leu Pro Thr Val Gly 210 215 220 Met Arg Tyr Val Pro Tyr Asn Gly Thr Ser Val Val Pro Asp Trp Leu 225 230 235 240 Ser Glu Pro Pro Ala Arg Pro Arg Val Cys Leu Thr Leu Gly Val Ser 245 250 255 Ala Arg Glu Val Leu Gly Gly Asp Gly Val Ser Gln Gly Asp Ile Leu 260 265 270 Glu Ala Leu Ala Asp Leu Asp Ile Glu Leu Val Ala Thr Leu Asp Ala 275 280 285 Ser Gln Arg Ala Glu Ile Arg Asn Tyr Pro Lys His Thr Arg Phe Thr 290 295 300 Asp Phe Val Pro Met His Ala Leu Leu Pro Ser Cys Ser Ala Ile Ile 305 310 315 320 His His Gly Gly Ala Gly Thr Tyr Ala Thr Ala Val Ile Asn Ala Val 325 330 335 Pro Gln Val Met Leu Ala Glu Leu Trp Asp Ala Pro Val Lys Ala Arg 340 345 350 Ala Val Ala Glu Gln Gly Ala Gly Phe Phe Leu Pro Pro Ala Glu Leu 355 360 365 Thr Pro Gln Ala Val Arg Asp Ala Val Val Arg Ile Leu Asp Asp Pro 370 375 380 Ser Val Ala Thr Ala Ala His Arg Leu Arg Glu Glu Thr Phe Gly Asp 385 390 395 400 Pro Thr Pro Ala Gly Ile Val Pro Glu Leu Glu Arg Leu Ala Ala Gln 405 410 415 His Arg Arg Pro Pro Ala Asp Ala Arg His 420 425 <210> 16 <211> 4891 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV <400> 16 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag a 4891 <210> 17 <211> 6603 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-oleL-oleU <400> 17 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tatcgctccg agcccgaagg gaaaatcgag 4920 tgcccaattc ggcagaatcg ggatcgatgg agttactcga cgtcgacggg gcctggttat 4980 acaccccgga aatcatgcgg gacgaacggg gagaattcct cgaatggttc cggggtcgga 5040 cattccagga gaagatcggc caccccctct cgctggccca ggccaactgc tcggtgtccc 5100 gcaaggcgtt ctgcgcggca tccacttcgc cgacgccccc gcccggccag gccaagtacg 5160 tcacctgcgc ctccggcacc gtgctcgacg tggtcgtcga cgtacgccgg ggctcgccca 5220 ccttcggccg atgggccgcc gtccgactcg acgcggcccg ccaccagggg ctctacctgg 5280 ccgaaggact cggccacgcg ttcatggccc tcaccgacga cgccacggtc gtctacctct 5340 gctcacagcc ctacgtggcc gaggccgagc gggccgtaga ccctctcgac ccggcgatcg 5400 gcatcgaatg gccgacggac atcgacatcg tccctgtcgg cgaagggaca cccacgcacc 5460 gtccctggcg caggccgcgg agacccggca tcctgccgga ctacgaggga gtgcccggcg 5520 ccttacatcg cggaggcggc cggcgtggga ccggcccgtg aaggccctcg tactggccgg 5580 ctctagttac gtagtaccgc gacaaccgcg cctggtggga acccctgaag aagcggccgg 5640 ccggtcccgc cgcccccccg agaggcagcg gcccatgaga tggctgatca ccggcgccgc 5700 cggaatgctg ggccgggaac tcgtccggcg cctcgccgag aacgaggagg acgtcgcggc 5760 cctcggccac gaccacctcg acgtcacccg accctccgcc gtgcgggcgg cactcgccga 5820 gcaccgtccc gggatcgtcg tcaactgcgc cgcctacacg gccgtcgacg acgccgagac 5880 ggacgaggcc gccgctgccc tcctcaacgc cgaggcgccc cggctgctgg ccgagggcct 5940 gcgcccccac cggcggcacg gcctcgtcca cctgtccacc gactacgtct ttcccggcga 6000 cgcccgcacc ccctacgccg aggaccaccc cacggctccc cgcagcgcct acggacgcac 6060 caaacgggac ggcgagcaag cggtgctgac ggcactgccc accgccaccg tgctgcgcac 6120 cgcctggctg tacgggcgca ccggccgcag cttcgtccgc acgatgatcg aacgggaggc 6180 gcgcggcgga gccatcgacg tcgtcgccga ccagcgcggc cagcccacct ggaccggcga 6240 cctcgccgac cgcatcatcg ccgtcggccg gcaccccggc gtccacggca tcctgcacgc 6300 caccaacgcc ggctccgcca cctggtacga cctggcacaa gaggtcttcc ggctcctcga 6360 cgccgacccc gggcgggtcc ggcccaccac cggcgccgcc ttccgcagac ccgccccccg 6420 ccccgcctac agcgtcctcg gccacgaccg ctggcgcggg accggcctgg cacccctgcg 6480 tgactggcgc tcggccctgc gcgaggcgtt ccccgacatc ctcgccgcgg aacacccacc 6540 gacccggcga ggagcagcat gaaacgaggc gtgcacgacc tggccctctt ccctaggtct 6600 aga 6603 <210> 18 <211> 7635 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-desI-desII <400> 18 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tgctagcgac ggtggcccgg agggaacatc 4920 cgtgaaaagc gccttatccg acctcgcatt cttcggcggc cccgccgctt tcgaccagcc 4980 gctcctcgtg gggcggccca accgcatcga ccgcgccagg ctgtacgagc ggctcgaccg 5040 ggccctcgac agccagtggc tgtccaacgg cggcccgctc gtccgcgagt tcgaggagcg 5100 cgtcgccggg ctcgccgggg tccggcatgc cgtggccacc tgcaacgcca cggccgggct 5160 ccagctcctc gcgcacgccg ccggcctcac cggcgaagtg atcatgccgt cgatgacgtt 5220 cgccgccacc ccgcacgcac tgcgctggat cggcctcacc ccggtcttcg ccgacatcga 5280 cccggacacc ggcaacctcg acccggacca ggtggccgcc gcggtcacac cccgcacctc 5340 ggccgtcgtc ggcgtccacc tctggggccg cccctgcgcc gccgaccagc tgcggaaggt 5400 cgccgacgag cacggcctgc ggctgtactt cgacgccgcg cacgccctcg gctgcgcggt 5460 cgacggccgg cccgccggca gcctcggcga cgccgaggtc ttcagcttcc acgccaccaa 5520 ggccgtcaac gccttcgagg gcggcgccgt cgtcaccgac gacgccgacc tcgccgcccg 5580 gatccgcgcc ctccacaact tcggcttcga cctgcccggc ggcagccccg ccggcgggac 5640 caacgccaag atgagcgagg ccgccgccgc catgggcctc acctccctcg acgcgtttcc 5700 cgaggtcatc gaccggaacc ggcgcaacca cgccgcctac cgcgagcacc tcgcggacct 5760 ccccggcgtc ctcgtcgccg accacgaccg ccacggcctc aacaaccacc agtacgtgat 5820 cgtcgagatc gacgaggcca ccaccggcat ccaccgcgac ctcgtcatgg aggtcctgaa 5880 ggccgaaggc gtgcacaccc gcgcctactt ctcgccgggc tgccacgagc tggagccgta 5940 ccgcgggcag ccgcacgccc cgctgccgca caccgaacgc ctcgccgcgc gcgtgctgtc 6000 cctgccgacc ggcaccgcca tcggcgacga cgacatccgc cgggtcgccg acctgctgcg 6060 tctctgcgcg acccgcggcc gcgaactgac cgcgcgccac cgcgacacgg cccccgcccc 6120 gctcgcggcc ccccagacat ccacgcccac gattggacgc tcccgatgac cgcccccgcc 6180 ctttccgcca ccgccccggc cgaacgctgc gcgcaccccg gagccgatct gggggcggcg 6240 gtccacgccg tcggccagac cctcgccgcc ggcggcctcg tgccgcccga cgaggccgga 6300 acgaccgccc gccacctcgt ccggctcgcc gtgcgctacg gcaacagccc cttcaccccg 6360 ctggaggagg cccgccacga cctgggcgtc gaccgggacg ccttccggcg cctcctcgcc 6420 ctgttcgggc aggtcccgga gctccgcacc gcggtcgaga ccggccccgc cggggcgtac 6480 tggaagaaca ccctgctccc gctcgaacag cgcggcgtct tcgacgcggc gctcgccagg 6540 aagcccgtct tcccgtacag cgtcggcctc taccccggcc cgacctgcat gttccgctgc 6600 cacttctgcg tccgtgtgac cggcgcccgc tacgacccgt ccgccctcga cgccggcaac 6660 gccatgttcc ggtcggtcat cgacgagata cccgcgggca acccctcggc gatgtacttc 6720 tccggcggcc tggagccgct caccaacccc ggcctcggga gcctggccgc gcacgccacc 6780 gaccacggcc tgcggcccac cgtctacacg aactccttcg cgctcaccga gcgcaccctg 6840 gagcgccagc ccggcctctg gggcctgcac gccatccgca cctcgctcta cggcctcaac 6900 gacgaggagt acgagcagac caccggcaag aaggccgcct tccgccgcgt ccgcgagaac 6960 ctgcgccgct tccagcagct gcgcgccgag cgcgagtcgc cgatcaacct cggcttcgcc 7020 tacatcgtgc tcccgggccg tgcctcccgc ctgctcgacc tggtcgactt catcgccgac 7080 ctcaacgacg ccgggcaggg caggacgatc gacttcgtca acattcgcga ggactacagc 7140 ggccgtgacg acggcaagct gccgcaggag gagcgggccg agctccagga ggccctcaac 7200 gccttcgagg agcgggtccg cgagcgcacc cccggactcc acatcgacta cggctacgcc 7260 ctgaacagcc tgcgcaccgg ggccgacgcc gaactgctgc ggatcaagcc cgccaccatg 7320 cggcccaccg cgcacccgca ggtcgcggtg caggtcgatc tcctcggcga cgtgtacctg 7380 taccgcgagg ccggcttccc cgacctggac ggcgcgaccc gctacatcgc gggccgcgtg 7440 acccccgaca cctccctcac cgaggtcgtc agggacttcg tcgagcgcgg cggcgaggtg 7500 gcggccgtcg acggcgacga gtacttcatg gacggcttcg atcaggtcgt caccgcccgc 7560 ctgaaccagc tggagcgcga cgccgcggac ggctgggagg aggcccgcgg cttcctgcgc 7620 tgacccgcat ctaga 7635 <210> 19 <211> 8375 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-oleV-eryBII-urdR <400> 19 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tttaattaag atatccccga ccagccttat 180 cgaaggagcg gcgaagagat ggcagaaccc acggtgaccg acgacctgac gggggccctc 240 acgcagcccc cgctgggccg caccgtccgc gcggtggccg accgtgaact cggcacccac 300 ctcctggaga cccgcggcat ccactggatc cacgccgcga acggcgaccc gtacgccacc 360 gtgctgcgcg gccaggcgga cgacccgtat cccgcgtacg agcgggtgcg tgcccgcggc 420 gcgctctcct tcagcccgac gggcagctgg gtcaccgccg atcacgccct ggcggcgagc 480 atcctctgct cgacggactt cggggtctcc ggcgccgacg gcgtcccggt gccgcagcag 540 gtcctctcgt acggggaggg ctgtccgctg gagcgcgagc aggtgctgcc ggcggccggt 600 gacgtgccgg agggcgggca gcgtgccgtg gtcgagggga tccaccggga gacgctggag 660 ggtctcgcgc cggacccgtc ggcgtcgtac gccttcgagc tgctgggcgg tttcgtccgc 720 ccggcggtga cggccgctgc cgccgccgtg ctgggtgttc ccgcggaccg gcgcgcggac 780 ttcgcggatc tgctggagcg gctccggccg ctgtccgaca gcctgctggc cccgcagtcc 840 ctgcggacgg tacgggcggc ggacggcgcg ctggccgagc tcacggcgct gctcgccgat 900 tcggacgact cccccggggc cctgctgtcg gcgctcgggg tcaccgcagc cgtccagctc 960 accgggaacg cggtgctcgc gctcctcgcg catcccgagc agtggcggga gctgtgcgac 1020 cggcccgggc tcgcggcggc cgcggtggag gagaccctcc gctacgaccc gccggtgcag 1080 ctcgacgccc gggtggtccg cggggagacg gagctggcgg gccggcggct gccggccggg 1140 gcgcatgtcg tcgtcctgac cgccgcgacc ggccgggacc cggaggtctt cacggacccg 1200 gagcgcttcg acctcgcgcg ccccgacgcc gccgcgcacc tcgcgctgca ccccgccggt 1260 ccgtacggcc cggtggcgtc cctggtccgg cttcaggcgg aggtcgcgct gcggaccctg 1320 gccgggcgtt tccccgggct gcggcaggcg ggggacgtgc tccgcccccg ccgcgcgcct 1380 gtcggccgcg ggccgctgag cgtcccggtc agcagctcct gagacaccgg ggccccggtc 1440 cgcccggccc cccttcggac ggaccggacg gctcggacca cggggacggc tcagaccgtc 1500 ccgtgtgtcc ccgtccggct cccgtccgcc ccatcccgcc cctccaccgg caaggaagga 1560 cacgacgcca tgcgcgtcct gctgacctcg ttcgcacatc acacgcacta ctacggcctg 1620 gtgcccctgg cctgggcgct gctcgccgcc gggcacgagg tgcgggtcgc cagccagccc 1680 gcgctcacgg acaccatcac cgggtccggg ctcgccgcgg tgccggtcgg caccgaccac 1740 ctcatccacg agtaccgggt gcggatggcg ggcgagccgc gcccgaacca tccggcgatc 1800 gccttcgacg aggcccgtcc cgagccgctg gactgggacc acgccctcgg catcgaggcg 1860 atcctcgccc cgtacttcca tctgctcgcc aacaacgact cgatggtcga cgacctcgtc 1920 gacttcgccc ggtcctggca gccggacctg gtgctgtggg agccgacgac ctacgcgggc 1980 gccgtcgccg cccaggtcac cggtgccgcg cacgcccggg tcctgtgggg gcccgacgtg 2040 atgggcagcg cccgccgcaa gttcgtcgcg ctgcgggacc ggcagccgcc cgagcaccgc 2100 gaggacccca ccgcggagtg gctgacgtgg acgctcgacc ggtacggcgc ctccttcgaa 2160 gaggagctgc tcaccggcca gttcacgatc gacccgaccc cgccgagcct gcgcctcgac 2220 acgggcctgc cgaccgtcgg gatgcgttat gttccgtaca acggcacgtc ggtcgtgccg 2280 gactggctga gtgagccgcc cgcgcggccc cgggtctgcc tgaccctcgg cgtctccgcg 2340 cgtgaggtcc tcggcggcga cggcgtctcg cagggcgaca tcctggaggc gctcgccgac 2400 ctcgacatcg agctcgtcgc cacgctcgac gcgagtcagc gcgccgagat ccgcaactac 2460 ccgaagcaca cccggttcac ggacttcgtg ccgatgcacg cgctcctgcc gagctgctcg 2520 gcgatcatcc accacggcgg ggcgggcacc tacgcgaccg ccgtgatcaa cgcggtgccg 2580 caggtcatgc tcgccgagct gtgggacgcg ccggtcaagg cgcgggccgt cgccgagcag 2640 ggggcggggt tcttcctgcc gccggccgag ctcacgccgc aggccgtgcg ggacgccgtc 2700 gtccgcatcc tcgacgaccc ctcggtcgcc accgccgcgc accggctgcg cgaggagacc 2760 ttcggcgacc ccaccccggc cgggatcgtc cccgagctgg agcggctcgc cgcgcagcac 2820 cgccgcccgc cggccgacgc ccggcactga gccgcacccc tcgccccagg cctcacccct 2880 gtatctcata tgtctagtta actcgccacg ccgaccgtta tcaccggcgc cctgctgcta 2940 gtttccgaga atgaagggaa tagtcctggc cggcgggagc ggaactcggc tgcatccggc 3000 gacctcggtc atttcgaagc agattcttcc ggtctacaac aaaccgatga tctactatcc 3060 gctgtcggtt ctcatgctcg gcggtattcg cgagattcaa atcatctcga ccccccagca 3120 catcgaactc ttccagtcgc ttctcggaaa cggcaggcac ctgggaatag aactcgacta 3180 tgcggtccag aaagagcccg caggaatcgc ggacgcactt ctcgtcggag ccgagcacat 3240 cggcgacgac acctgcgccc tgatcctggg cgacaacatc ttccacgggc ccggcctcta 3300 cacgctcctg cgggacagca tcgcgcgcct cgacggctgc gtgctcttcg gctacccggt 3360 caaggacccc gagcggtacg gcgtcgccga ggtggacgcg acgggccggc tgaccgacct 3420 cgtcgagaag cccgtcaagc cgcgctccaa cctcgccgtc accggcctct acctctacga 3480 caacgacgtc gtcgacatcg ccaagaacat ccggccctcg ccgcgcggcg agctggagat 3540 caccgacgtc aaccgcgtct acctggagcg gggccgggcc gaactcgtca acctgggccg 3600 cggcttcgcc tggctggaca ccggcaccca cgactcgctc ctgcgggccg cccagtacgt 3660 ccaggtcctg gaggagcggc agggcgtctg gatcgcgggc cttgaggaga tcgccttccg 3720 catgggcttc atcgacgccg aggcctgtca cggcctggga gaaggcctct cccgcaccga 3780 gtacggcagc tatctgatgg agatcgccgg ccgcgaggga gccccgtgag ggcacctcgc 3840 ggccgacgcg ttcccacgac cgacagcgcc accgacagtg cgacccacac cgcgacccgc 3900 accgccaccg acagtgcgac ccacaccgcg acctacagcg cgaccgaaag gaagacggca 3960 gtgcggcttc tggtgaccgg aggtgcgggc ttcatcggct cgcacttcgt gcggcagctc 4020 ctcgccgggg cgtaccccga cgtgcccgcc gatgaggtga tcgtcctgga cagcctcacc 4080 tacgcgggca accgcgccaa cctcgccccg gtggacgcgg acccgcgact gcgcttcgtc 4140 cacggcgaca tccgcgacgc cggcctcctc gcccgggaac tgcgcggcgt ggacgccatc 4200 gtccacttcg cggccgagag ccacgtggac cgctccatcg cgggcgcgtc cgtgttcacc 4260 gagaccaacg tgcagggcac gcagacgctg ctccagtgcg ccgtcgacgc cggcgtcggc 4320 cgggtcgtgc acgtctccac cgacgaggtg tacgggtcga tcgactccgg ctcctggacc 4380 gagagcagcc cgctggagcc caactcgccc tacgcggcgt ccaaggccgg ctccgacctc 4440 gttgcccgcg cctaccaccg gacgtacggc ctcgacgtac ggatcacccg ctgctgcaac 4500 aactacgggc cgtaccagca ccccgagaag ctcatccccc tcttcgtgac gaacctcctc 4560 gacggcggga cgctcccgct gtacggcgac ggcgcgaacg tccgcgagtg ggtgcacacc 4620 gacgaccact gccggggcat cgcgctcgtc ctcgcgggcg gccgggccgg cgagatctac 4680 cacatcggcg gcggcctgga gctgaccaac cgcgaactca ccggcatcct cctggactcg 4740 ctcggcgccg actggtcctc ggtccggaag gtcgccgacc gcaagggcca cgacctgcgc 4800 tactccctcg acggcggcga gatcgagcgc gagctcggct accgcccgca ggtctccttc 4860 gcggacggcc tcgcgcggac cgtccgctgg taccgggaga accgcggctg gtgggagccg 4920 ctcaaggcga ccgccccgca gctgcccgcc accgccgtgg aggtgtccgc gtgagcagcc 4980 gcgccgagac cccccgcgtc cccttcctcg acctcaaggc cgcctacgag gagctctcta 5040 gtgggaatcg cggaagcggc cgggttcggc gccgtcctgg atcacaatga tatggggaat 5100 tcccgcgatg agcgaagcaa tgggatcggt accgacggcc ggcagtgaag tctcctcgac 5160 ctgcgcgttt ctgtcctggt tggacgcgcg ccgccgggcc aatcgcctga cggtggaaca 5220 cgtaccgttc agggagttat cggggtggca attcgacgag aacacgggga acctccgaca 5280 taccagcggt cgtttcttct ccatcgaagg actccgggta cgcacggacc actgctggtt 5340 cggaagctgg acccagccca ttatcgtgca accggagata ggcattctcg gcctcctggt 5400 caagaggttc gacggcatcc tgcacgtcct ggtgcaggca aagaacgaac cgggtaatat 5460 cggcggcctt cagctctccc ccaccgtcca ggccactcgc agcaattaca cccgcgtcca 5520 ccgcggcggc ggtgtcagat acctggagta cttcgcgtcc ccccgcgggc gcggtcgggt 5580 cctcgcggac gtcctccaat ccgagcaggg ctcctggttc ctgcacaagc ggaaccggaa 5640 catggtggtc gaggccctgg acgacgtgcc cctcgacgac gacttccact ggatcagcct 5700 cggcgggctg cggaagctgc tgctgaggcc gcatctggtg aacatggaca cccgcacggt 5760 gctgtcctgc cttcccccgg atccggcacc ggacggccgg cagccgccgg cgcccgcggc 5820 tcccttcgcc gccgcggtca cgcggtccct cacccggggt gccaccgcct tgcacaccat 5880 gggcgagatc ctcggctggc tgaccgacga gcggtcccgg cgggaactgg tgcagcagcg 5940 ggtgccgctg gaggagaccg cgttcagcgg ctggcggcgt gacgaccacg ccatcgcgca 6000 caaggacggc gactacttcc gggtcatcgg ggtgagcgtc cgggccagca gccgggaggt 6060 gtcctcgtgg agccagccgt tgctggcccc cgtcggcccc ggtctggccg ccttcgtcac 6120 caggcggatc cgcggcgtcc tccacgtcct gctgcacgcc cgcaccgaag ccggcctgct 6180 caacggcccg gagatggcac cgaccgtgca gtgccgcccg ctcaactacc gtgcggtgcc 6240 cgccgagtac cggcccgcct acctcgacta cgtgctgtcg gccgatcccg gacgcatccg 6300 ctacgacacc ctccagtcgg aggagggcgg ccgcttccac cacgcggaga accgctacgt 6360 cgtggtggag gccgaggacg acttcccggt cgaggtgccc cgcgacttcc gctggctcac 6420 cctgcaccag atcctcgccc tgctgcacca cagcaactat gtcaacgtgg aggcgcgcag 6480 cctcgtcgcc tgcatccagc ctgagctgat ctagtggtcg tcggcatctg cgaggaactg 6540 gccgcaggaa ggagagaacc acgatgacca ccgacgccgc gacgcacgtg cggctcgggc 6600 gttccgcgct gctcaccagc aggctctggc tcggcacggt gaacttcagc ggacgcgtcg 6660 aggacgacga cgcgctgcgc ctgatggacc acgcccggga ccgcggcatc aactgcctcg 6720 acaccgccga catgtacggc tggcggctct acaagggcca caccgaggag ctggtgggca 6780 ggtggctggc ccagggcggc ggacggcgcg aggacaccgt gctggcgacc aaggtcggcg 6840 gcgagatgag cgagcgcgtc aacgacagcg ggctgtcggc gcggcacatc atcgcctcct 6900 gcgagggatc gctgcgcagg ctgggcgtcg accacatcga cgtctaccag atgcaccaca 6960 tcgaccggtc cgcgccgtgg gacgaggtgt ggcaggccat ggacagcctc gtcgccagcg 7020 gcaaggtctc ctacgtcggc tcgtcgaact tcgcgggctg gcacatcgcc gccgcgcagg 7080 agaacgccgc ccgccgccac tccctgggca tggtctccca ccagtgcctg tacaacctgg 7140 cggtccggca cgccgagctg gaggtgctgc ccgccgcgca ggcctacggg ctcggcgtct 7200 tcgcctggtc gccgctgcac ggcggcctgc tcagcggagc gctggagaag ctggccgcgg 7260 gcaccgcggt gaagtcggcg cagggccgtg cgcaggtgct gttgccgtcc ctgcgcccgg 7320 cgatcgaggc ctacgagaag ttctgccgca acctcggcga agacccggcc gaggtggggc 7380 tcgcatgggt gctgtcccgg cccggcatcg ccggcgccgt catcggcccg cgaacccccg 7440 agcagctcga ctccgcgctg aaggcgtccg cgatgaccct ggacgagcag gcgctgtccg 7500 aactggacga gatcttcccc gcggtggcct ccggcggcgc ggcgccggaa gcctggttgc 7560 agtgagcaca agaggaaccg agtacgtatc tagtgatatc acagagatca ggacgacgca 7620 tggacattgt gggaaatgga ttcctggcgc ggaacctgcg gccgctggcc gaacggcatc 7680 ccgataccgt ggccctcgcc gccggtgtct catgggcgag cggtacctcc gatgccgact 7740 tcgcccggga agccgcactc ctgcgagaca ccgccaagca gtgcgcggcc accggacgac 7800 gactgctgtt cttctcgacc gctgccacgg gcatgtacgg cctggcggag ggacccggcc 7860 gagaggacac gccagtgacg ccgtgcaccc cgtacggcgc gcacaagctg gcgctggagg 7920 aactgctgcg ggactccggt gccgaccatg tgattctcag gctcgggcac ctcgtggggc 7980 ccgaccagcc cgagcaccaa ctgctgccca cgctggtgcg tcacctacgc gaaggcgcgg 8040 tgcgcattca ccgaggcgcg gcccgtgacc tcatcgacgt cagcgacgtc gtcaccattg 8100 tcgactgcct tctcggcctt gacctcaagg ccgagacggt caacgtggcc tccggctacg 8160 ccgttccggt gaaggacatc gtcgaactcc tgcgccgcag gctcggggtc gaggcgcggt 8220 acgagttcca ggatgccggt ggtcagcacg tcatctccat cgagaagctg cgcgcactcg 8280 ttccgcaggt ccaggacatg ggcttcgggc ccgactacta ccggcggatc ctcagtgact 8340 tcacctccgc cgtccgtatc tgacctaggt ctaga 8375 <210> 20 <211> 9085 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU <400> 20 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tgggaatcgc ggaagcggcc gggttcggcg 4920 ccgtcctgga tcacaatgat atggggaatt cccgcgatga gcgaagcaat gggatcggta 4980 ccgacggccg gcagtgaagt ctcctcgacc tgcgcgtttc tgtcctggtt ggacgcgcgc 5040 cgccgggcca atcgcctgac ggtggaacac gtaccgttca gggagttatc ggggtggcaa 5100 ttcgacgaga acacggggaa cctccgacat accagcggtc gtttcttctc catcgaagga 5160 ctccgggtac gcacggacca ctgctggttc ggaagctgga cccagcccat tatcgtgcaa 5220 ccggagatag gcattctcgg cctcctggtc aagaggttcg acggcatcct gcacgtcctg 5280 gtgcaggcaa agaacgaacc gggtaatatc ggcggccttc agctctcccc caccgtccag 5340 gccactcgca gcaattacac ccgcgtccac cgcggcggcg gtgtcagata cctggagtac 5400 ttcgcgtccc cccgcgggcg cggtcgggtc ctcgcggacg tcctccaatc cgagcagggc 5460 tcctggttcc tgcacaagcg gaaccggaac atggtggtcg aggccctgga cgacgtgccc 5520 ctcgacgacg acttccactg gatcagcctc ggcgggctgc ggaagctgct gctgaggccg 5580 catctggtga acatggacac ccgcacggtg ctgtcctgcc ttcccccgga tccggcaccg 5640 gacggccggc agccgccggc gcccgcggct cccttcgccg ccgcggtcac gcggtccctc 5700 acccggggtg ccaccgcctt gcacaccatg ggcgagatcc tcggctggct gaccgacgag 5760 cggtcccggc gggaactggt gcagcagcgg gtgccgctgg aggagaccgc gttcagcggc 5820 tggcggcgtg acgaccacgc catcgcgcac aaggacggcg actacttccg ggtcatcggg 5880 gtgagcgtcc gggccagcag ccgggaggtg tcctcgtgga gccagccgtt gctggccccc 5940 gtcggccccg gtctggccgc cttcgtcacc aggcggatcc gcggcgtcct ccacgtcctg 6000 ctgcacgccc gcaccgaagc cggcctgctc aacggcccgg agatggcacc gaccgtgcag 6060 tgccgcccgc tcaactaccg tgcggtgccc gccgagtacc ggcccgccta cctcgactac 6120 gtgctgtcgg ccgatcccgg acgcatccgc tacgacaccc tccagtcgga ggagggcggc 6180 cgcttccacc acgcggagaa ccgctacgtc gtggtggagg ccgaggacga cttcccggtc 6240 gaggtgcccc gcgacttccg ctggctcacc ctgcaccaga tcctcgccct gctgcaccac 6300 agcaactatg tcaacgtgga ggcgcgcagc ctcgtcgcct gcatccagcc tgagctgatc 6360 tagtgctagc aagggaaccc catgccctcc ccccgtctgc gcttcggtgt gctgggtgcc 6420 gccgacatcg ccctgcgccg caccgtgccc gcgctgctcg cccacccgga cgtcaccgtg 6480 gtcgcggtct ccagccggga cacggcccgc gccgcccgtt tcgccgcggc gttcgggtgc 6540 gaggcggtcc cgggccacca ggcgctgctg gaccgcgacg acatcgacgc gctgtacgtc 6600 ccgctgccgg tgatggtgca cacgccctgg gtggaggcgg cgctgctgcg gggcaggcac 6660 gtcctggtgg agaagccgct gaccgcgacc cgctccggag ccgaggacct gatcgccctg 6720 gcacgctccc gcggcctggt cctgatggag aacttcacgt cgctgcacca cgcacagcac 6780 ggcaccgtca cggacctcct gcgggacggg acgatcggcg aactgcgctc gctgtccgcg 6840 gcgttcacga tcccgccgaa gccggagggc gacatccggt accagcccga cgtgggcgga 6900 ggcgccctgc tcgacatcgg gatctacccc ctgcgggcgg cactgcactt cctgggcccc 6960 gacctgcacg cggccggcgc ggtcctgcgt cgggagcggc gccggaacgt ggtggtctcc 7020 ggccacgtgc tgctcaccac accgcacggc gtcgtggccg agctggcctt cggcatggag 7080 cacgcctacc gctcggagta caccctcttc ggcacggccg gccgcctgcg cctggaccgt 7140 gccttcaccc cgcccgagac ccaccggcca cgtgtggaga tccaccggca ggacgccctg 7200 gacatcgtcg acctgccgcc ggacgcgcaa ttcgccaacc tcgtccggga cttcgtactg 7260 gctgtccgcg agggtcccgg ccggctcaca cagcaccacg ccgacgccgt acgccaagcc 7320 gatctcgtcg agcgcgtcat ggcggtggcg cgggtgcgct ggtgctgtct agtatcgctc 7380 cgagcccgaa gggaaaatcg agtgcccaat tcggcagaat cgggatcgat ggagttactc 7440 gacgtcgacg gggcctggtt atacaccccg gaaatcatgc gggacgaacg gggagaattc 7500 ctcgaatggt tccggggtcg gacattccag gagaagatcg gccaccccct ctcgctggcc 7560 caggccaact gctcggtgtc ccgcaaggcg ttctgcgcgg catccacttc gccgacgccc 7620 ccgcccggcc aggccaagta cgtcacctgc gcctccggca ccgtgctcga cgtggtcgtc 7680 gacgtacgcc ggggctcgcc caccttcggc cgatgggccg ccgtccgact cgacgcggcc 7740 cgccaccagg ggctctacct ggccgaagga ctcggccacg cgttcatggc cctcaccgac 7800 gacgccacgg tcgtctacct ctgctcacag ccctacgtgg ccgaggccga gcgggccgta 7860 gaccctctcg acccggcgat cggcatcgaa tggccgacgg acatcgacat cgtccctgtc 7920 ggcgaaggga cacccacgca ccgtccctgg cgcaggccgc ggagacccgg catcctgccg 7980 gactacgagg gagtgcccgg cgccttacat cgcggaggcg gccggcgtgg gaccggcccg 8040 tgaaggccct cgtactggcc ggctctagtt acgtagtacc gcgacaaccg cgcctggtgg 8100 gaacccctga agaagcggcc ggccggtccc gccgcccccc cgagaggcag cggcccatga 8160 gatggctgat caccggcgcc gccggaatgc tgggccggga actcgtccgg cgcctcgccg 8220 agaacgagga ggacgtcgcg gccctcggcc acgaccacct cgacgtcacc cgaccctccg 8280 ccgtgcgggc ggcactcgcc gagcaccgtc ccgggatcgt cgtcaactgc gccgcctaca 8340 cggccgtcga cgacgccgag acggacgagg ccgccgctgc cctcctcaac gccgaggcgc 8400 cccggctgct ggccgagggc ctgcgccccc accggcggca cggcctcgtc cacctgtcca 8460 ccgactacgt ctttcccggc gacgcccgca ccccctacgc cgaggaccac cccacggctc 8520 cccgcagcgc ctacggacgc accaaacggg acggcgagca agcggtgctg acggcactgc 8580 ccaccgccac cgtgctgcgc accgcctggc tgtacgggcg caccggccgc agcttcgtcc 8640 gcacgatgat cgaacgggag gcgcgcggcg gagccatcga cgtcgtcgcc gaccagcgcg 8700 gccagcccac ctggaccggc gacctcgccg accgcatcat cgccgtcggc cggcaccccg 8760 gcgtccacgg catcctgcac gccaccaacg ccggctccgc cacctggtac gacctggcac 8820 aagaggtctt ccggctcctc gacgccgacc ccgggcgggt ccggcccacc accggcgccg 8880 ccttccgcag acccgccccc cgccccgcct acagcgtcct cggccacgac cgctggcgcg 8940 ggaccggcct ggcacccctg cgtgactggc gctcggccct gcgcgaggcg ttccccgaca 9000 tcctcgccgc ggaacaccca ccgacccggc gaggagcagc atgaaacgag gcgtgcacga 9060 cctggccctc ttccctaggt ctaga 9085 <210> 21 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 21 ggcaagctta gcggggcgac tggcgtgccc act 33 <210> 22 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 22 ggtctgcagt caccgtgggt tctgccatct ctt 33 <210> 23 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 23 gctggtaccg gatgttccct ccgggccacc gtc 33 <210> 24 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 24 tgagaattcc ctcgccgtcc tgcccgcgct tgg 33 <210> 25 <211> 38 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 25 ttaattaaga tatcaccggc aaggaaggac acgacgcc 38 <210> 26 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 26 tctagacata tggcgcagat acaggggtga ggcctg 36 <210> 27 <211> 37 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 27 ttaattaaac tagtatcgat gacggtggcc cggaggg 37 <210> 28 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 28 tctagatgcg ggtcagcgca ggaagccgcg 30 <210> 29 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 29 ttaattaaac tagttaactc gccacgccga ccgtt 35 <210> 30 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 30 tctagagagc tcctcgtagg cggcctt 27 <210> 31 <211> 38 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 31 ttaattaaac tagtcaggtc tccttcgcgg acggcctc 38 <210> 32 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 32 tctagaacct gactaggcct ggtcgacccg 30 <210> 33 <211> 38 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 33 ttaattaaac tagtccccag gcctcacccc tgtatctg 38 <210> 34 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 34 tctagagaat tcgctcaggc ggggacgccg acgaag 36 <210> 35 <211> 41 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 35 ttaattaaac tagtatcgat atcgctccga gcccgaaggg a 41 <210> 36 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 36 tctagagccg gccagtacga gggcctt 27 <210> 37 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 37 ttaattaaac tagtgtaccg cgacaaccgc 30 <210> 38 <211> 29 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 38 tctagagaag agggccaggt cgtgcacgc 29 <210> 39 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 39 ttaattaaac tagtatcgat gggaatcgcg gaagcg 36 <210> 40 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 40 tctagaatca gctcagggcc tggatgc 27 <210> 41 <211> 31 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 41 ttaattaaac tagtggtcgt cggcatctgc g 31 <210> 42 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 42 tctagactcg gttcctcttg tgctcactgc 30 <210> 43 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 43 ttaattaaac tagtacagag atccaggacg acgca 35 <210> 44 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 44 tctagatcag atacggacgg cggaggt 27 <210> 45 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 45 ttaattaaac tagtaaggga accccatgcc ctccc 35 <210> 46 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 46 tctagaatca gcaccagcgc acccgcgcca 30 <110> Ewha University-Industry Collaboration Foundation <120> Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same <130> PA110076 / KR <160> 46 <170> Kopatentin 1.71 <210> 1 <211> 9715 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-desI-desII-desV-desVI <400> 1 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tgctagcgac ggtggcccgg agggaacatc 4920 cgtgaaaagc gccttatccg acctcgcatt cttcggcggc cccgccgctt tcgaccagcc 4980 gctcctcgtg gggcggccca accgcatcga ccgcgccagg ctgtacgagc ggctcgaccg 5040 ggccctcgac agccagtggc tgtccaacgg cggcccgctc gtccgcgagt tcgaggagcg 5100 cgtcgccggg ctcgccgggg tccggcatgc cgtggccacc tgcaacgcca cggccgggct 5160 ccagctcctc gcgcacgccg ccggcctcac cggcgaagtg atcatgccgt cgatgacgtt 5220 cgccgccacc ccgcacgcac tgcgctggat cggcctcacc ccggtcttcg ccgacatcga 5280 cccggacacc ggcaacctcg acccggacca ggtggccgcc gcggtcacac cccgcacctc 5340 ggccgtcgtc ggcgtccacc tctggggccg cccctgcgcc gccgaccagc tgcggaaggt 5400 cgccgacgag cacggcctgc ggctgtactt cgacgccgcg cacgccctcg gctgcgcggt 5460 cgacggccgg cccgccggca gcctcggcga cgccgaggtc ttcagcttcc acgccaccaa 5520 ggccgtcaac gccttcgagg gcggcgccgt cgtcaccgac gacgccgacc tcgccgcccg 5580 gatccgcgcc ctccacaact tcggcttcga cctgcccggc ggcagccccg ccggcgggac 5640 caacgccaag atgagcgagg ccgccgccgc catgggcctc acctccctcg acgcgtttcc 5700 cgaggtcatc gaccggaacc ggcgcaacca cgccgcctac cgcgagcacc tcgcggacct 5760 ccccggcgtc ctcgtcgccg accacgaccg ccacggcctc aacaaccacc agtacgtgat 5820 cgtcgagatc gacgaggcca ccaccggcat ccaccgcgac ctcgtcatgg aggtcctgaa 5880 ggccgaaggc gtgcacaccc gcgcctactt ctcgccgggc tgccacgagc tggagccgta 5940 ccgcgggcag ccgcacgccc cgctgccgca caccgaacgc ctcgccgcgc gcgtgctgtc 6000 cctgccgacc ggcaccgcca tcggcgacga cgacatccgc cgggtcgccg acctgctgcg 6060 tctctgcgcg acccgcggcc gcgaactgac cgcgcgccac cgcgacacgg cccccgcccc 6120 gctcgcggcc ccccagacat ccacgcccac gattggacgc tcccgatgac cgcccccgcc 6180 ctttccgcca ccgccccggc cgaacgctgc gcgcaccccg gagccgatct gggggcggcg 6240 gtccacgccg tcggccagac cctcgccgcc ggcggcctcg tgccgcccga cgaggccgga 6300 acgaccgccc gccacctcgt ccggctcgcc gtgcgctacg gcaacagccc cttcaccccg 6360 ctggaggagg cccgccacga cctgggcgtc gaccgggacg ccttccggcg cctcctcgcc 6420 ctgttcgggc aggtcccgga gctccgcacc gcggtcgaga ccggccccgc cggggcgtac 6480 tggaagaaca ccctgctccc gctcgaacag cgcggcgtct tcgacgcggc gctcgccagg 6540 aagcccgtct tcccgtacag cgtcggcctc taccccggcc cgacctgcat gttccgctgc 6600 cacttctgcg tccgtgtgac cggcgcccgc tacgacccgt ccgccctcga cgccggcaac 6660 gccatgttcc ggtcggtcat cgacgagata cccgcgggca acccctcggc gatgtacttc 6720 tccggcggcc tggagccgct caccaacccc ggcctcggga gcctggccgc gcacgccacc 6780 gaccacggcc tgcggcccac cgtctacacg aactccttcg cgctcaccga gcgcaccctg 6840 gagcgccagc ccggcctctg gggcctgcac gccatccgca cctcgctcta cggcctcaac 6900 gacgaggagt acgagcagac caccggcaag aaggccgcct tccgccgcgt ccgcgagaac 6960 ctgcgccgct tccagcagct gcgcgccgag cgcgagtcgc cgatcaacct cggcttcgcc 7020 tacatcgtgc tcccgggccg tgcctcccgc ctgctcgacc tggtcgactt catcgccgac 7080 ctcaacgacg ccgggcaggg caggacgatc gacttcgtca acattcgcga ggactacagc 7140 ggccgtgacg acggcaagct gccgcaggag gagcgggccg agctccagga ggccctcaac 7200 gccttcgagg agcgggtccg cgagcgcacc cccggactcc acatcgacta cggctacgcc 7260 ctgaacagcc tgcgcaccgg ggccgacgcc gaactgctgc ggatcaagcc cgccaccatg 7320 cggcccaccg cgcacccgca ggtcgcggtg caggtcgatc tcctcggcga cgtgtacctg 7380 taccgcgagg ccggcttccc cgacctggac ggcgcgaccc gctacatcgc gggccgcgtg 7440 acccccgaca cctccctcac cgaggtcgtc agggacttcg tcgagcgcgg cggcgaggtg 7500 gcggccgtcg acggcgacga gtacttcatg gacggcttcg atcaggtcgt caccgcccgc 7560 ctgaaccagc tggagcgcga cgccgcggac ggctgggagg aggcccgcgg cttcctgcgc 7620 tgacccgcat ctagtcaggt ctccttcgcg gacggcctcg cgcggaccgt ccgctggtac 7680 cgggagaacc gcggctggtg ggagccgctc aaggcgaccg ccccgcagct gcccgccacc 7740 gccgtggagg tgtccgcgtg agcagccgcg ccgagacccc ccgcgtcccc ttcctcgacc 7800 tcaaggccgc ctacgaggag ctccgcgcgg agaccgacgc cgcgatcgcc cgcgtcctcg 7860 actcggggcg ctacctcctc ggacccgaac tcgaaggatt cgaggcggag ttcgccgcgt 7920 actgcgagac ggaccacgcc gtcggcgtga acagcgggat ggacgccctc cagctcgccc 7980 tccgcggcct cggcatcgga cccggggacg aggtgatcgt cccctcgcac acgtacatcg 8040 ccagctggct cgcggtgtcc gccaccggcg cgacccccgt gcccgtcgag ccgcacgagg 8100 accaccccac cctggacccg ctgctcgtcg agaaggcgat caccccccgc acccgggcgc 8160 tcctccccgt ccacctctac gggcaccccg ccgacatgga cgccctccgc gagctcgcgg 8220 accggcacgg cctgcacatc gtcgaggacg ccgcgcaggc ccacggcgcc cgctaccggg 8280 gccggcggat cggcgccggg tcgtcggtgg ccgcgttcag cttctacccg ggcaagaacc 8340 tcggctgctt cggcgacggc ggcgccgtcg tcaccggcga ccccgagctc gccgaacggc 8400 tccggatgct ccgcaactac ggctcgcggc agaagtacag ccacgagacg aagggcacca 8460 actcccgcct ggacgagatg caggccgccg tgctgcggat ccggctcgcc cacctggaca 8520 gctggaacgg ccgcaggtcg gcgctggccg cggagtacct ctccgggctc gccggactgc 8580 ccggcatcgg cctgccggtg accgcgcccg acaccgaccc ggtctggcac ctcttcaccg 8640 tgcgcaccga gcgccgcgac gagctgcgca gccacctcga cgcccgcggc atcgacaccc 8700 tcacgcacta cccggtaccc gtgcacctct cgcccgccta cgcgggcgag gcaccgccgg 8760 aaggctcgct cccgcgggcc gagagcttcg cgcggcaggt cctcagcctg ccgatcggcc 8820 cgcacctgga gcgcccgcag gcgctgcggg tgatcgacgc cgtgcgcgaa tgggccgagc 8880 gggtcgacca ggcctagtca ggttctagtc aattgcccca ggcctcaccc ctgtatctgc 8940 gccgggggac gcccccggcc caccctccga aagaccgaaa gcaggagcac cgtgtacgaa 9000 gtcgaccacg ccgacgtcta cgacctcttc tacctgggtc gcggcaagga ctacgccgcc 9060 gaggcctccg acatcgccga cctggtgcgc tcccgtaccc ccgaggcctc ctcgctcctg 9120 gacgtggcct gcggtacggg cacgcatctg gagcacttca ccaaggagtt cggcgacacc 9180 gccggcctgg agctgtccga ggacatgctc acccacgccc gcaagcggct gcccgacgcc 9240 acgctccacc agggcgacat gcgggacttc cggctcggcc ggaagttctc cgccgtggtc 9300 agcatgttca gctccgtcgg ctacctgaag acgaccgagg aactcggcgc ggccgtcgcc 9360 tcgttcgcgg agcacctgga gcccggtggc gtcgtcgtcg tcgagccgtg gtggttcccg 9420 gagaccttcg ccgacggctg ggtcagcgcc gacgtcgtcc gccgtgacgg gcgcaccgtg 9480 gcccgtgtct cgcactcggt gcgggagggg aacgcgacgc gcatggaggt ccacttcacc 9540 gtggccgacc cgggcaaggg cgtgcggcac ttctccgacg tccatctcat caccctgttc 9600 caccaggccg agtacgaggc cgcgttcacg gccgccgggc tgcgcgtcga gtacctggag 9660 ggcggcccgt cgggccgtgg cctcttcgtc ggcgtccccg cctgagtcta gaccc 9715 <210> 2 <211> 292 <212> PRT <213> Artificial Sequence <220> <223> DesIII protein <400> 2 Met Lys Gly Ile Val Leu Ala Gly Gly Ser Gly Thr Arg Leu His Pro 1 5 10 15 Ala Thr Ser Val Ile Ser Lys Gln Ile Leu Pro Val Tyr Asn Lys Pro 20 25 30 Met Ile Tyr Tyr Pro Leu Ser Val Leu Met Leu Gly Gly Ile Arg Glu 35 40 45 Ile Gln Ile Ile Ser Thr Pro Gln His Ile Glu Leu Phe Gln Ser Leu 50 55 60 Leu Gly Asn Gly Arg His Leu Gly Ile Glu Leu Asp Tyr Ala Val Gln 65 70 75 80 Lys Glu Pro Ala Gly Ile Ala Asp Ala Leu Leu Val Gly Ala Glu His 85 90 95 Ile Gly Asp Asp Thr Cys Ala Leu Ile Leu Gly Asp Asn Ile Phe His 100 105 110 Gly Pro Gly Leu Tyr Thr Leu Leu Arg Asp Ser Ile Ala Arg Leu Asp 115 120 125 Gly Cys Val Leu Phe Gly Tyr Pro Val Lys Asp Pro Glu Arg Tyr Gly 130 135 140 Val Ala Glu Val Asp Ala Thr Gly Arg Leu Thr Asp Leu Val Glu Lys 145 150 155 160 Pro Val Lys Pro Arg Ser Asn Leu Ala Val Thr Gly Leu Tyr Leu Tyr 165 170 175 Asp Asn Asp Val Val Asp Ile Ala Lys Asn Ile Arg Pro Ser Pro Arg 180 185 190 Gly Glu Leu Glu Ile Thr Asp Val Asn Arg Val Tyr Leu Glu Arg Gly 195 200 205 Arg Ala Glu Leu Val Asn Leu Gly Arg Gly Phe Ala Trp Leu Asp Thr 210 215 220 Gly Thr His Asp Ser Leu Leu Arg Ala Ala Gln Tyr Val Gln Val Leu 225 230 235 240 Glu Glu Arg Gln Gly Val Trp Ile Ala Gly Leu Glu Glu Ile Ala Phe 245 250 255 Arg Met Gly Phe Ile Asp Ala Glu Ala Cys His Gly Leu Gly Glu Gly 260 265 270 Leu Ser Arg Thr Glu Tyr Gly Ser Tyr Leu Met Glu Ile Ala Gly Arg 275 280 285 Glu Gly Ala Pro 290 <210> 3 <211> 337 <212> PRT <213> Artificial Sequence <220> <223> DesIV protein <400> 3 Met Arg Leu Leu Val Thr Gly Gly Ala Gly Phe Ile Gly Ser His Phe 1 5 10 15 Val Arg Gln Leu Leu Ala Gly Ala Tyr Pro Asp Val Pro Ala Asp Glu 20 25 30 Val Ile Val Leu Asp Ser Leu Thr Tyr Ala Gly Asn Arg Ala Asn Leu 35 40 45 Ala Pro Val Asp Ala Asp Pro Arg Leu Arg Phe Val His Gly Asp Ile 50 55 60 Arg Asp Ala Gly Leu Leu Ala Arg Glu Leu Arg Gly Val Asp Ala Ile 65 70 75 80 Val His Phe Ala Ala Glu Ser His Val Asp Arg Ser Ile Ala Gly Ala 85 90 95 Ser Val Phe Thr Glu Thr Asn Val Gln Gly Thr Gln Thr Leu Leu Gln 100 105 110 Cys Ala Val Asp Ala Gly Val Gly Arg Val Val His Val Ser Thr Asp 115 120 125 Glu Val Tyr Gly Ser Ile Asp Ser Gly Ser Trp Thr Glu Ser Ser Pro 130 135 140 Leu Glu Pro Asn Ser Pro Tyr Ala Ala Ser Lys Ala Gly Ser Asp Leu 145 150 155 160 Val Ala Arg Ala Tyr His Arg Thr Tyr Gly Leu Asp Val Arg Ile Thr 165 170 175 Arg Cys Cys Asn Asn Tyr Gly Pro Tyr Gln His Pro Glu Lys Leu Ile 180 185 190 Pro Leu Phe Val Thr Asn Leu Leu Asp Gly Gly Thr Leu Pro Leu Tyr 195 200 205 Gly Asp Gly Ala Asn Val Arg Glu Trp Val His Thr Asp Asp His Cys 210 215 220 Arg Gly Ile Ala Leu Val Leu Ala Gly Gly Arg Ala Gly Glu Ile Tyr 225 230 235 240 His Ile Gly Gly Gly Leu Glu Leu Thr Asn Arg Glu Leu Thr Gly Ile 245 250 255 Leu Leu Asp Ser Leu Gly Ala Asp Trp Ser Ser Val Arg Lys Val Ala 260 265 270 Asp Arg Lys Gly His Asp Leu Arg Tyr Ser Leu Asp Gly Gly Glu Ile 275 280 285 Glu Arg Glu Leu Gly Tyr Arg Pro Gln Val Ser Phe Ala Asp Gly Leu 290 295 300 Ala Arg Thr Val Arg Trp Tyr Arg Glu Asn Arg Gly Trp Trp Glu Pro 305 310 315 320 Leu Lys Ala Thr Ala Pro Gln Leu Pro Ala Thr Ala Val Glu Val Ser 325 330 335 Ala <210> 4 <211> 415 <212> PRT <213> Artificial Sequence <220> <223> DesI protein <400> 4 Met Lys Ser Ala Leu Ser Asp Leu Ala Phe Phe Gly Gly Pro Ala Ala 1 5 10 15 Phe Asp Gln Pro Leu Leu Val Gly Arg Pro Asn Arg Ile Asp Arg Ala 20 25 30 Arg Leu Tyr Glu Arg Leu Asp Arg Ala Leu Asp Ser Gln Trp Leu Ser 35 40 45 Asn Gly Gly Pro Leu Val Arg Glu Phe Glu Glu Arg Val Ala Gly Leu 50 55 60 Ala Gly Val Arg His Ala Val Ala Thr Cys Asn Ala Thr Ala Gly Leu 65 70 75 80 Gln Leu Leu Ala His Ala Ala Gly Leu Thr Gly Glu Val Ile Met Pro 85 90 95 Ser Met Thr Phe Ala Ala Thr Pro His Ala Leu Arg Trp Ile Gly Leu 100 105 110 Thr Pro Val Phe Ala Asp Ile Asp Pro Asp Thr Gly Asn Leu Asp Pro 115 120 125 Asp Gln Val Ala Ala Ala Val Thr Pro Arg Thr Ser Ala Val Val Gly 130 135 140 Val His Leu Trp Gly Arg Pro Cys Ala Ala Asp Gln Leu Arg Lys Val 145 150 155 160 Ala Asp Glu His Gly Leu Arg Leu Tyr Phe Asp Ala Ala His Ala Leu 165 170 175 Gly Cys Ala Val Asp Gly Arg Pro Ala Gly Ser Leu Gly Asp Ala Glu 180 185 190 Val Phe Ser Phe His Ala Thr Lys Ala Val Asn Ala Phe Glu Gly Gly 195 200 205 Ala Val Val Thr Asp Asp Ala Asp Leu Ala Ala Arg Ile Arg Ala Leu 210 215 220 His Asn Phe Gly Phe Asp Leu Pro Gly Gly Ser Pro Ala Gly Gly Thr 225 230 235 240 Asn Ala Lys Met Ser Glu Ala Ala Ala Ala Met Gly Leu Thr Ser Leu 245 250 255 Asp Ala Phe Pro Glu Val Ile Asp Arg Asn Arg Arg Asn His Ala Ala 260 265 270 Tyr Arg Glu His Leu Ala Asp Leu Pro Gly Val Leu Val Ala Asp His 275 280 285 Asp Arg His Gly Leu Asn Asn His Gln Tyr Val Ile Val Glu Ile Asp 290 295 300 Glu Ala Thr Thr Gly Ile His Arg Asp Leu Val Met Glu Val Leu Lys 305 310 315 320 Ala Glu Gly Val His Thr Arg Ala Tyr Phe Ser Pro Gly Cys His Glu 325 330 335 Leu Glu Pro Tyr Arg Gly Gln Pro His Ala Pro Leu Pro His Thr Glu 340 345 350 Arg Leu Ala Ala Arg Val Leu Ser Leu Pro Thr Gly Thr Ala Ile Gly 355 360 365 Asp Asp Asp Ile Arg Arg Val Ala Asp Leu Leu Arg Leu Cys Ala Thr 370 375 380 Arg Gly Arg Glu Leu Thr Ala Arg His Arg Asp Thr Ala Pro Ala Pro 385 390 395 400 Leu Ala Ala Pro Gln Thr Ser Thr Pro Thr Ile Gly Arg Ser Arg 405 410 415 <210> 5 <211> 485 <212> PRT <213> Artificial Sequence <220> <223> DesII protein <400> 5 Met Thr Ala Pro Ala Leu Ser Ala Thr Ala Pro Ala Glu Arg Cys Ala 1 5 10 15 His Pro Gly Ala Asp Leu Gly Ala Ala Val His Ala Val Gly Gln Thr 20 25 30 Leu Ala Ala Gly Gly Leu Val Pro Pro Asp Glu Ala Gly Thr Thr Ala 35 40 45 Arg His Leu Val Arg Leu Ala Val Arg Tyr Gly Asn Ser Pro Phe Thr 50 55 60 Pro Leu Glu Glu Ala Arg His Asp Leu Gly Val Asp Arg Asp Ala Phe 65 70 75 80 Arg Arg Leu Leu Ala Leu Phe Gly Gln Val Pro Glu Leu Arg Thr Ala 85 90 95 Val Glu Thr Gly Pro Ala Gly Ala Tyr Trp Lys Asn Thr Leu Leu Pro 100 105 110 Leu Glu Gln Arg Gly Val Phe Asp Ala Ala Leu Ala Arg Lys Pro Val 115 120 125 Phe Pro Tyr Ser Val Gly Leu Tyr Pro Gly Pro Thr Cys Met Phe Arg 130 135 140 Cys His Phe Cys Val Arg Val Thr Gly Ala Arg Tyr Asp Pro Ser Ala 145 150 155 160 Leu Asp Ala Gly Asn Ala Met Phe Arg Ser Val Ile Asp Glu Ile Pro 165 170 175 Ala Gly Asn Pro Ser Ala Met Tyr Phe Ser Gly Gly Leu Glu Pro Leu 180 185 190 Thr Asn Pro Gly Leu Gly Ser Leu Ala Ala His Ala Thr Asp His Gly 195 200 205 Leu Arg Pro Thr Val Tyr Thr Asn Ser Phe Ala Leu Thr Glu Arg Thr 210 215 220 Leu Glu Arg Gln Pro Gly Leu Trp Gly Leu His Ala Ile Arg Thr Ser 225 230 235 240 Leu Tyr Gly Leu Asn Asp Glu Glu Tyr Glu Gln Thr Thr Gly Lys Lys 245 250 255 Ala Ala Phe Arg Arg Val Arg Glu Asn Leu Arg Arg Phe Gln Gln Leu 260 265 270 Arg Ala Glu Arg Glu Ser Pro Ile Asn Leu Gly Phe Ala Tyr Ile Val 275 280 285 Leu Pro Gly Arg Ala Ser Arg Leu Leu Asp Leu Val Asp Phe Ile Ala 290 295 300 Asp Leu Asn Asp Ala Gly Gln Gly Arg Thr Ile Asp Phe Val Asn Ile 305 310 315 320 Arg Glu Asp Tyr Ser Gly Arg Asp Asp Gly Lys Leu Pro Gln Glu Glu 325 330 335 Arg Ala Glu Leu Gln Glu Ala Leu Asn Ala Phe Glu Glu Arg Val Arg 340 345 350 Glu Arg Thr Pro Gly Leu His Ile Asp Tyr Gly Tyr Ala Leu Asn Ser 355 360 365 Leu Arg Thr Gly Ala Asp Ala Glu Leu Leu Arg Ile Lys Pro Ala Thr 370 375 380 Met Arg Pro Thr Ala His Pro Gln Val Ala Val Gln Val Asp Leu Leu 385 390 395 400 Gly Asp Val Tyr Leu Tyr Arg Glu Ala Gly Phe Pro Asp Leu Asp Gly 405 410 415 Ala Thr Arg Tyr Ile Ala Gly Arg Val Thr Pro Asp Thr Ser Leu Thr 420 425 430 Glu Val Val Arg Asp Phe Val Glu Arg Gly Gly Glu Val Ala Ala Val 435 440 445 Asp Gly Asp Glu Tyr Phe Met Asp Gly Phe Asp Gln Val Val Thr Ala 450 455 460 Arg Leu Asn Gln Leu Glu Arg Asp Ala Ala Asp Gly Trp Glu Glu Ala 465 470 475 480 Arg Gly Phe Leu Arg 485 <210> 6 <211> 379 <212> PRT <213> Artificial Sequence <220> <223> DesV protein <400> 6 Met Ser Ser Arg Ala Glu Thr Pro Arg Val Pro Phe Leu Asp Leu Lys 1 5 10 15 Ala Ala Tyr Glu Glu Leu Arg Ala Glu Thr Asp Ala Ala Ile Ala Arg 20 25 30 Val Leu Asp Ser Gly Arg Tyr Leu Leu Gly Pro Glu Leu Glu Gly Phe 35 40 45 Glu Ala Glu Phe Ala Ala Tyr Cys Glu Thr Asp His Ala Val Gly Val 50 55 60 Asn Ser Gly Met Asp Ala Leu Gln Leu Ala Leu Arg Gly Leu Gly Ile 65 70 75 80 Gly Pro Gly Asp Glu Val Ile Val Pro Ser His Thr Tyr Ile Ala Ser 85 90 95 Trp Leu Ala Val Ser Ala Thr Gly Ala Thr Pro Val Pro Val Glu Pro 100 105 110 His Glu Asp His Pro Thr Leu Asp Pro Leu Leu Val Glu Lys Ala Ile 115 120 125 Thr Pro Arg Thr Arg Ala Leu Leu Pro Val His Leu Tyr Gly His Pro 130 135 140 Ala Asp Met Asp Ala Leu Arg Glu Leu Ala Asp Arg His Gly Leu His 145 150 155 160 Ile Val Glu Asp Ala Ala Gln Ala His Gly Ala Arg Tyr Arg Gly Arg 165 170 175 Arg Ile Gly Ala Gly Ser Ser Val Ala Ala Phe Ser Phe Tyr Pro Gly 180 185 190 Lys Asn Leu Gly Cys Phe Gly Asp Gly Gly Ala Val Val Thr Gly Asp 195 200 205 Pro Glu Leu Ala Glu Arg Leu Arg Met Leu Arg Asn Tyr Gly Ser Arg 210 215 220 Gln Lys Tyr Ser His Glu Thr Lys Gly Thr Asn Ser Arg Leu Asp Glu 225 230 235 240 Met Gln Ala Ala Val Leu Arg Ile Arg Leu Ala His Leu Asp Ser Trp 245 250 255 Asn Gly Arg Arg Ser Ala Leu Ala Ala Glu Tyr Leu Ser Gly Leu Ala 260 265 270 Gly Leu Pro Gly Ile Gly Leu Pro Val Thr Ala Pro Asp Thr Asp Pro 275 280 285 Val Trp His Leu Phe Thr Val Arg Thr Glu Arg Arg Asp Glu Leu Arg 290 295 300 Ser His Leu Asp Ala Arg Gly Ile Asp Thr Leu Thr His Tyr Pro Val 305 310 315 320 Pro Val His Leu Ser Pro Ala Tyr Ala Gly Glu Ala Pro Pro Glu Gly 325 330 335 Ser Leu Pro Arg Ala Glu Ser Phe Ala Arg Gln Val Leu Ser Leu Pro 340 345 350 Ile Gly Pro His Leu Glu Arg Pro Gln Ala Leu Arg Val Ile Asp Ala 355 360 365 Val Arg Glu Trp Ala Glu Arg Val Asp Gln Ala 370 375 <210> 7 <211> 237 <212> PRT <213> Artificial Sequence <220> <223> DesVI protein <400> 7 Met Tyr Glu Val Asp His Ala Asp Val Tyr Asp Leu Phe Tyr Leu Gly 1 5 10 15 Arg Gly Lys Asp Tyr Ala Ala Glu Ala Ser Asp Ile Ala Asp Leu Val 20 25 30 Arg Ser Arg Thr Pro Glu Ala Ser Ser Leu Leu Asp Val Ala Cys Gly 35 40 45 Thr Gly Thr His Leu Glu His Phe Thr Lys Glu Phe Gly Asp Thr Ala 50 55 60 Gly Leu Glu Leu Ser Glu Asp Met Leu Thr His Ala Arg Lys Arg Leu 65 70 75 80 Pro Asp Ala Thr Leu His Gln Gly Asp Met Arg Asp Phe Arg Leu Gly 85 90 95 Arg Lys Phe Ser Ala Val Val Ser Met Phe Ser Ser Val Gly Tyr Leu 100 105 110 Lys Thr Thr Glu Glu Leu Gly Ala Ala Val Ala Ser Phe Ala Glu His 115 120 125 Leu Glu Pro Gly Gly Val Val Val Glu Pro Trp Trp Phe Pro Glu 130 135 140 Thr Phe Ala Asp Gly Trp Val Ser Ala Asp Val Val Arg Arg Asp Gly 145 150 155 160 Arg Thr Val Ala Arg Val Ser His Ser Val Arg Glu Gly Asn Ala Thr 165 170 175 Arg Met Glu Val His Phe Thr Val Ala Asp Pro Gly Lys Gly Val Arg 180 185 190 His Phe Ser Asp Val His Leu Ile Thr Leu Phe His Gln Ala Glu Tyr 195 200 205 Glu Ala Ala Phe Thr Ala Ala Gly Leu Arg Val Glu Tyr Leu Glu Gly 210 215 220 Gly Pro Ser Gly Arg Gly Leu Phe Val Gly Val Pro Ala 225 230 235 <210> 8 <211> 204 <212> PRT <213> Artificial Sequence <220> <223> OleL <400> 8 Met Glu Leu Leu Asp Val Asp Gly Ala Trp Leu Tyr Thr Pro Glu Ile 1 5 10 15 Met Arg Asp Glu Arg Gly Glu Phe Leu Glu Trp Phe Arg Gly Arg Thr 20 25 30 Phe Gln Glu Lys Ile Gly His Pro Leu Ser Leu Ala Gln Ala Asn Cys 35 40 45 Ser Val Ser Arg Lys Ala Phe Cys Ala Ala Ser Thr Ser Pro Thr Pro 50 55 60 Pro Pro Gly Gln Ala Lys Tyr Val Thr Cys Ala Ser Gly Thr Val Leu 65 70 75 80 Asp Val Val Val Asp Val Arg Arg Gly Ser Pro Thr Phe Gly Arg Trp 85 90 95 Ala Ala Val Arg Leu Asp Ala Ala Arg His Gln Gly Leu Tyr Leu Ala 100 105 110 Glu Gly Leu Gly His Ala Phe Met Ala Leu Thr Asp Asp Ala Thr Val 115 120 125 Val Tyr Leu Cys Ser Gln Pro Tyr Val Ala Glu Ala Glu Arg Ala Val 130 135 140 Asp Pro Leu Asp Pro Ala Ile Gly Ile Glu Trp Pro Thr Asp Ile Asp 145 150 155 160 Ile Val Pro Val Gly Glu Gly Thr Pro Thr His Arg Pro Trp Arg Arg 165 170 175 Pro Arg Arg Pro Gly Ile Leu Pro Asp Tyr Glu Gly Val Pro Gly Ala 180 185 190 Leu His Arg Gly Gly Gly Arg Arg Gly Thr Gly Pro 195 200 <210> 9 <211> 295 <212> PRT <213> Artificial Sequence <220> <223> OleU protein <400> 9 Met Arg Trp Leu Ile Thr Gly Ala Ala Gly Met Leu Gly Arg Glu Leu 1 5 10 15 Val Arg Arg Leu Ala Glu Asn Glu Glu Asp Val Ala Ala Leu Gly His 20 25 30 Asp His Leu Asp Val Thr Arg Pro Ser Ala Val Arg Ala Ala Leu Ala 35 40 45 Glu His Arg Pro Gly Ile Val Val Asn Cys Ala Ala Tyr Thr Ala Val 50 55 60 Asp Asp Ala Glu Thr Asp Glu Ala Ala Ala Ala Leu Leu Asn Ala Glu 65 70 75 80 Ala Pro Arg Leu Leu Ala Glu Gly Leu Arg Pro His Arg Arg His Gly 85 90 95 Leu Val His Leu Ser Thr Asp Tyr Val Phe Pro Gly Asp Ala Arg Thr 100 105 110 Pro Tyr Ala Glu Asp His Pro Thr Ala Pro Arg Ser Ala Tyr Gly Arg 115 120 125 Thr Lys Arg Asp Gly Glu Gln Ala Val Leu Thr Ala Leu Pro Thr Ala 130 135 140 Thr Val Leu Arg Thr Ala Trp Leu Tyr Gly Arg Thr Gly Arg Ser Phe 145 150 155 160 Val Arg Thr Met Ile Glu Arg Glu Ala Arg Gly Gly Ala Ile Asp Val 165 170 175 Val Ala Asp Gln Arg Gly Gln Pro Thr Trp Thr Gly Asp Leu Ala Asp 180 185 190 Arg Ile Ile Ala Val Gly Arg His Pro Gly Val His Gly Ile Leu His 195 200 205 Ala Thr Asn Ala Gly Ser Ala Thr Trp Tyr Asp Leu Ala Gln Glu Val 210 215 220 Phe Arg Leu Leu Asp Ala Asp Pro Gly Arg Val Arg Pro Thr Thr Gly 225 230 235 240 Ala Ala Phe Arg Arg Pro Ala Pro Arg Pro Ala Tyr Ser Val Leu Gly 245 250 255 His Asp Arg Trp Arg Gly Thr Gly Leu Ala Pro Leu Arg Asp Trp Arg 260 265 270 Ser Ala Leu Arg Glu Ala Phe Pro Asp Ile Leu Ala Ala Glu His Pro 275 280 285 Pro Thr Arg Arg Gly Ala Ala 290 295 <210> 10 <211> 474 <212> PRT <213> Artificial Sequence <220> <223> OleV protein <400> 10 Met Ile Trp Gly Ile Pro Ala Met Ser Glu Ala Met Gly Ser Val Pro 1 5 10 15 Thr Ala Gly Ser Glu Val Ser Ser Thr Cys Ala Phe Leu Ser Trp Leu 20 25 30 Asp Ala Arg Arg Arg Ala Asn Arg Leu Thr Val Glu His Val Pro Phe 35 40 45 Arg Glu Leu Ser Gly Trp Gln Phe Asp Glu Asn Thr Gly Asn Leu Arg 50 55 60 His Thr Ser Gly Arg Phe Phe Ser Ile Glu Gly Leu Arg Val Arg Thr 65 70 75 80 Asp His Cys Trp Phe Gly Ser Trp Thr Gln Pro Ile Ile Val Gln Pro 85 90 95 Glu Ile Gly Ile Leu Gly Leu Leu Val Lys Arg Phe Asp Gly Ile Leu 100 105 110 His Val Leu Val Gln Ala Lys Asn Glu Pro Gly Asn Ile Gly Gly Leu 115 120 125 Gln Leu Ser Pro Thr Val Gln Ala Thr Arg Ser Asn Tyr Thr Arg Val 130 135 140 His Arg Gly Gly Gly Val Arg Tyr Leu Glu Tyr Phe Ala Ser Pro Arg 145 150 155 160 Gly Arg Gly Arg Val Leu Ala Asp Val Leu Gln Ser Glu Gln Gly Ser 165 170 175 Trp Phe Leu His Lys Arg Asn Arg Asn Met Val Val Glu Ala Leu Asp 180 185 190 Asp Val Pro Leu Asp Asp Asp Phe His Trp Ile Ser Leu Gly Gly Leu 195 200 205 Arg Lys Leu Leu Leu Arg Pro His Leu Val Asn Met Asp Thr Arg Thr 210 215 220 Val Leu Ser Cys Leu Pro Pro Asp Pro Ala Pro Asp Gly Arg Gln Pro 225 230 235 240 Pro Ala Pro Ala Ala Pro Phe Ala Ala Ala Val Thr Arg Ser Leu Thr 245 250 255 Arg Gly Ala Thr Ala Leu His Thr Met Gly Glu Ile Leu Gly Trp Leu 260 265 270 Thr Asp Glu Arg Ser Arg Arg Glu Leu Val Gln Gln Arg Val Pro Leu 275 280 285 Glu Glu Thr Ala Phe Ser Gly Trp Arg Arg Asp Asp His Ala Ile Ala 290 295 300 His Lys Asp Gly Asp Tyr Phe Arg Val Ile Gly Val Ser Val Arg Ala 305 310 315 320 Ser Ser Arg Glu Val Ser Ser Trp Ser Gln Pro Leu Leu Ala Pro Val 325 330 335 Gly Pro Gly Leu Ala Ala Phe Val Thr Arg Arg Ile Arg Gly Val Leu 340 345 350 His Val Leu Leu His Ala Arg Thr Glu Ala Gly Leu Leu Asn Gly Pro 355 360 365 Glu Met Ala Pro Thr Val Gln Cys Arg Pro Leu Asn Tyr Arg Ala Val 370 375 380 Pro Ala Glu Tyr Arg Pro Ala Tyr Leu Asp Tyr Val Leu Ser Ala Asp 385 390 395 400 Pro Gly Arg Ile Arg Tyr Asp Thr Leu Gln Ser Glu Glu Gly Gly Arg 405 410 415 Phe His His Ala Glu Asn Arg Tyr Val Val Val Glu Ala Glu Asp Asp 420 425 430 Phe Pro Val Glu Val Pro Arg Asp Phe Arg Trp Leu Thr Leu His Gln 435 440 445 Ile Leu Ala Leu Leu His His Ser Asn Tyr Val Asn Val Glu Ala Arg 450 455 460 Ser Leu Val Ala Cys Ile Gln Ala Leu Ser 465 470 <210> 11 <211> 333 <212> PRT <213> Artificial Sequence <220> <223> EryBII protein <400> 11 Met Thr Thr Asp Ala Ala Thr His Val Arg Leu Gly Arg Ser Ala Leu 1 5 10 15 Leu Thr Ser Arg Leu Trp Leu Gly Thr Val Asn Phe Ser Gly Arg Val 20 25 30 Glu Asp Asp Asp Ala Leu Arg Leu Met Asp His Ala Arg Asp Arg Gly 35 40 45 Ile Asn Cys Leu Asp Thr Ala Asp Met Tyr Gly Trp Arg Leu Tyr Lys 50 55 60 Gly His Thr Glu Glu Leu Val Gly Arg Trp Leu Ala Gln Gly Gly Gly 65 70 75 80 Arg Arg Glu Asp Thr Val Leu Ala Thr Lys Val Gly Gly Glu Met Ser 85 90 95 Glu Arg Val Asn Asp Ser Gly Leu Ser Ala Arg His Ile Ile Ala Ser 100 105 110 Cys Glu Gly Ser Leu Arg Arg Leu Gly Val Asp His Ile Asp Val Tyr 115 120 125 Gln Met His His Ile Asp Arg Ser Ala Pro Trp Asp Glu Val Trp Gln 130 135 140 Ala Met Asp Ser Leu Val Ala Ser Gly Lys Val Ser Tyr Val Gly Ser 145 150 155 160 Ser Asn Phe Ala Gly Trp His Ile Ala Ala Ala Gln Glu Asn Ala Ala 165 170 175 Arg Arg His Ser Leu Gly Met Val Ser His Gln Cys Leu Tyr Asn Leu 180 185 190 Ala Val Arg His Ala Glu Leu Glu Val Leu Pro Ala Ala Gln Ala Tyr 195 200 205 Gly Leu Gly Val Phe Ala Trp Ser Pro Leu His Gly Gly Leu Leu Ser 210 215 220 Gly Ala Leu Glu Lys Leu Ala Gla Thr Ala Val Lys Ser Ala Gln 225 230 235 240 Gly Arg Ala Gln Val Leu Leu Pro Ser Leu Arg Pro Ala Ile Glu Ala 245 250 255 Tyr Glu Lys Phe Cys Arg Asn Leu Gly Glu Asp Pro Ala Glu Val Gly 260 265 270 Leu Ala Trp Val Leu Ser Arg Pro Gly Ile Ala Gly Ala Val Ile Gly 275 280 285 Pro Arg Thr Pro Glu Gln Leu Asp Ser Ala Leu Lys Ala Ser Ala Met 290 295 300 Thr Leu Asp Glu Gln Ala Leu Ser Glu Leu Asp Glu Ile Phe Pro Ala 305 310 315 320 Val Ala Ser Gly Gly Ala Ala Pro Glu Ala Trp Leu Gln 325 330 <210> 12 <211> 247 <212> PRT <213> Artificial Sequence <220> <223> UrdR protein <400> 12 Met Asp Ile Val Gly Asn Gly Phe Leu Ala Arg Asn Leu Arg Pro Leu 1 5 10 15 Ala Glu Arg His Pro Asp Thr Val Ala Leu Ala Ala Gly Val Ser Trp 20 25 30 Ala Ser Gly Thr Ser Asp Ala Asp Phe Ala Arg Glu Ala Ala Leu Leu 35 40 45 Arg Asp Thr Ala Lys Gln Cys Ala Ala Thr Gly Arg Arg Leu Leu Phe 50 55 60 Phe Ser Thr Ala Ala Thr Gly Met Tyr Gly Leu Ala Glu Gly Pro Gly 65 70 75 80 Arg Glu Asp Thr Pro Val Thr Pro Cys Thr Pro Tyr Gly Ala His Lys 85 90 95 Leu Ala Leu Glu Glu Leu Leu Arg Asp Ser Gly Ala Asp His Val Ile 100 105 110 Leu Arg Leu Gly His Leu Val Gly Pro Asp Gln Pro Glu His Gln Leu 115 120 125 Leu Pro Thr Leu Val Arg His Leu Arg Glu Gly Ala Val Arg Ile His 130 135 140 Arg Gly Ala Ala Arg Asp Leu Ile Asp Val Ser Asp Val Val Thr Ile 145 150 155 160 Val Asp Cys Leu Leu Gly Leu Asp Leu Lys Ala Glu Thr Val Asn Val 165 170 175 Ala Ser Gly Tyr Ala Val Pro Val Lys Asp Ile Val Glu Leu Leu Arg 180 185 190 Arg Arg Leu Gly Val Glu Ala Arg Tyr Glu Phe Gln Asp Ala Gly Gly 195 200 205 Gln His Val Ile Ser Ile Glu Lys Leu Arg Ala Leu Val Pro Gln Val 210 215 220 Gln Asp Met Gly Phe Gly Pro Asp Tyr Tyr Arg Arg Ile Leu Ser Asp 225 230 235 240 Phe Thr Ser Ala Val Arg Ile 245 <210> 13 <211> 328 <212> PRT <213> Artificial Sequence <220> <223> OleW protein <400> 13 Met Pro Ser Pro Arg Leu Arg Phe Gly Val Leu Gly Ala Ala Asp Ile 1 5 10 15 Ala Leu Arg Arg Thr Val Pro Ala Leu Leu Ala His Pro Asp Val Thr 20 25 30 Val Val Ala Val Ser Ser Ar Ar Asp Thr Ala Arg Ala Ala Arg Phe Ala 35 40 45 Ala Ala Phe Gly Cys Glu Ala Val Pro Gly His Gln Ala Leu Leu Asp 50 55 60 Arg Asp Asp Ile Asp Ala Leu Tyr Val Pro Leu Pro Val Met Val His 65 70 75 80 Thr Pro Trp Val Glu Ala Ala Leu Leu Arg Gly Arg His Val Leu Val 85 90 95 Glu Lys Pro Leu Thr Ala Thr Arg Ser Gly Ala Glu Asp Leu Ile Ala 100 105 110 Leu Ala Arg Ser Arg Gly Leu Val Leu Met Glu Asn Phe Thr Ser Leu 115 120 125 His His Ala Gln His Gly Thr Val Thr Asp Leu Leu Arg Asp Gly Thr 130 135 140 Ile Gly Glu Leu Arg Ser Leu Ser Ala Ala Phe Thr Ile Pro Pro Lys 145 150 155 160 Pro Glu Gly Asp Ile Arg Tyr Gln Pro Asp Val Gly Gly Gly Ala Leu 165 170 175 Leu Asp Ile Gly Ile Tyr Pro Leu Arg Ala Ala Leu His Phe Leu Gly 180 185 190 Pro Asp Leu His Ala Ala Gly Ala Val Leu Arg Arg Glu Arg Arg Arg 195 200 205 Asn Val Val Val Ser Gly His Val Leu Leu Thr Thr Pro His Gly Val 210 215 220 Val Ala Glu Leu Ala Phe Gly Met Glu His Ala Tyr Arg Ser Glu Tyr 225 230 235 240 Thr Leu Phe Gly Thr Ala Gly Arg Leu Arg Leu Asp Arg Ala Phe Thr 245 250 255 Pro Pro Glu Thr His Arg Pro Arg Val Glu Ile His Arg Gln Asp Ala 260 265 270 Leu Asp Ile Val Asp Leu Pro Pro Asp Ala Gln Phe Ala Asn Leu Val 275 280 285 Arg Asp Phe Val Leu Ala Val Arg Glu Gly Pro Gly Arg Leu Thr Gln 290 295 300 His His Ala Asp Ala Val Arg Gln Ala Asp Leu Val Glu Arg Val Met 305 310 315 320 Ala Val Ala Arg Val Arg Trp Cys 325 <210> 14 <211> 402 <212> PRT <213> Artificial Sequence <220> <223> DesVIII protein <400> 14 Met Thr Asp Asp Leu Thr Gly Ala Leu Thr Gln Pro Pro Leu Gly Arg 1 5 10 15 Thr Val Arg Ala Val Ala Asp Arg Glu Leu Gly Thr His Leu Leu Glu 20 25 30 Thr Arg Gly Ile His Trp Ile His Ala Ala Asn Gly Asp Pro Tyr Ala 35 40 45 Thr Val Leu Arg Gly Gln Ala Asp Asp Pro Tyr Pro Ala Tyr Glu Arg 50 55 60 Val Arg Ala Arg Gly Ala Leu Ser Phe Ser Pro Thr Gly Ser Trp Val 65 70 75 80 Thr Ala Asp His Ala Leu Ala Ala Ser Ile Leu Cys Ser Thr Asp Phe 85 90 95 Gly Val Ser Gly Ala Asp Gly Val Pro Val Pro Gln Gln Val Leu Ser 100 105 110 Tyr Gly Glu Gly Cys Pro Leu Glu Arg Glu Gln Val Leu Pro Ala Ala 115 120 125 Gly Asp Val Pro Glu Gly Gly Gln Arg Ala Val Val Glu Gly Ile His 130 135 140 Arg Glu Thr Leu Glu Gly Leu Ala Pro Asp Pro Ser Ala Ser Tyr Ala 145 150 155 160 Phe Glu Leu Leu Gly Gly Phe Val Arg Pro Ala Val Thr Ala Ala Ala 165 170 175 Ala Ala Val Leu Gly Val Pro Ala Asp Arg Arg Ala Asp Phe Ala Asp 180 185 190 Leu Leu Glu Arg Leu Arg Pro Leu Ser Asp Ser Leu Leu Ala Pro Gln 195 200 205 Ser Leu Arg Thr Val Arg Ala Ala Asp Gly Ala Leu Ala Glu Leu Thr 210 215 220 Ala Leu Leu Ala Asp Ser Asp Asp Ser Pro Gly Ala Leu Leu Ser Ala 225 230 235 240 Leu Gly Val Thr Ala Ala Val Gln Leu Thr Gly Asn Ala Val Leu Ala 245 250 255 Leu Leu Ala His Pro Glu Gln Trp Arg Glu Leu Cys Asp Arg Pro Gly 260 265 270 Leu Ala Ala Ala Ala Val Glu Glu Thr Leu Arg Tyr Asp Pro Pro Val 275 280 285 Gln Leu Asp Ala Arg Val Val Arg Gly Glu Thr Glu Leu Ala Gly Arg 290 295 300 Arg Leu Pro Ala Gly Ala His Val Val Val Leu Thr Ala Ala Thr Gly 305 310 315 320 Arg Asp Pro Glu Val Phe Thr Asp Pro Glu Arg Phe Asp Leu Ala Arg 325 330 335 Pro Asp Ala Ala Ala His Leu Ala Leu His Pro Ala Gly Pro Tyr Gly 340 345 350 Pro Val Ala Ser Leu Val Arg Leu Gln Ala Glu Val Ala Leu Arg Thr 355 360 365 Leu Ala Gly Arg Phe Pro Gly Leu Arg Gln Ala Gly Asp Val Leu Arg 370 375 380 Pro Arg Arg Ala Pro Val Gly Arg Gly Pro Leu Ser Val Pro Val Ser 385 390 395 400 Ser Ser <210> 15 <211> 426 <212> PRT <213> Artificial Sequence <220> <223> DesVII protein <400> 15 Met Arg Val Leu Leu Thr Ser Phe Ala His His Thr His Tyr Tyr Gly 1 5 10 15 Leu Val Pro Leu Ala Trp Ala Leu Leu Ala Ala Gly His Glu Val Arg 20 25 30 Val Ala Ser Gln Pro Ala Leu Thr Asp Thr Ile Thr Gly Ser Gly Leu 35 40 45 Ala Ala Val Pro Val Gly Thr Asp His Leu Ile His Glu Tyr Arg Val 50 55 60 Arg Met Ala Gly Glu Pro Arg Pro Asn His Pro Ala Ile Ala Phe Asp 65 70 75 80 Glu Ala Arg Pro Glu Pro Leu Asp Trp Asp His Ala Leu Gly Ile Glu 85 90 95 Ala Ile Leu Ala Pro Tyr Phe His Leu Leu Ala Asn Asn Asp Ser Met 100 105 110 Val Asp Asp Leu Val Asp Phe Ala Arg Ser Trp Gln Pro Asp Leu Val 115 120 125 Leu Trp Glu Pro Thr Thr Tyr Ala Gly Ala Val Ala Ala Gln Val Thr 130 135 140 Gly Ala Ala His Ala Arg Val Leu Trp Gly Pro Asp Val Met Gly Ser 145 150 155 160 Ala Arg Arg Lys Phe Val Ala Leu Arg Asp Arg Gln Pro Pro Glu His 165 170 175 Arg Glu Asp Pro Thr Ala Glu Trp Leu Thr Trp Thr Leu Asp Arg Tyr 180 185 190 Gly Ala Ser Phe Glu Glu Glu Leu Leu Thr Gly Gln Phe Thr Ile Asp 195 200 205 Pro Thr Pro Pro Ser Leu Arg Leu Asp Thr Gly Leu Pro Thr Val Gly 210 215 220 Met Arg Tyr Val Pro Tyr Asn Gly Thr Ser Val Val Pro Asp Trp Leu 225 230 235 240 Ser Glu Pro Pro Ala Arg Pro Arg Val Cys Leu Thr Leu Gly Val Ser 245 250 255 Ala Arg Glu Val Leu Gly Gly Asp Gly Val Ser Gln Gly Asp Ile Leu 260 265 270 Glu Ala Leu Ala Asp Leu Asp Ile Glu Leu Val Ala Thr Leu Asp Ala 275 280 285 Ser Gln Arg Ala Glu Ile Arg Asn Tyr Pro Lys His Thr Arg Phe Thr 290 295 300 Asp Phe Val Pro Met His Ala Leu Leu Pro Ser Cys Ser Ala Ile Ile 305 310 315 320 His His Gly Gly Ala Gly Thr Tyr Ala Thr Ala Val Ile Asn Ala Val 325 330 335 Pro Gln Val Met Leu Ala Glu Leu Trp Asp Ala Pro Val Lys Ala Arg 340 345 350 Ala Val Ala Glu Gln Gly Ala Gly Phe Phe Leu Pro Pro Ala Glu Leu 355 360 365 Thr Pro Gln Ala Val Arg Asp Ala Val Val Arg Ile Leu Asp Asp Pro 370 375 380 Ser Val Ala Thr Ala Ala His Arg Leu Arg Glu Glu Thr Phe Gly Asp 385 390 395 400 Pro Thr Pro Ala Gly Ile Val Pro Glu Leu Glu Arg Leu Ala Ala Gln 405 410 415 His Arg Arg Pro Pro Ala Asp Ala Arg His 420 425 <210> 16 <211> 4891 <212> DNA <213> Artificial Sequence <220> <223> desVIII-des VIII-desIII-desIV <400> 16 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag a 4891 <210> 17 <211> 6603 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-oleL-oleU <400> 17 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tatcgctccg agcccgaagg gaaaatcgag 4920 tgcccaattc ggcagaatcg ggatcgatgg agttactcga cgtcgacggg gcctggttat 4980 acaccccgga aatcatgcgg gacgaacggg gagaattcct cgaatggttc cggggtcgga 5040 cattccagga gaagatcggc caccccctct cgctggccca ggccaactgc tcggtgtccc 5100 gcaaggcgtt ctgcgcggca tccacttcgc cgacgccccc gcccggccag gccaagtacg 5160 tcacctgcgc ctccggcacc gtgctcgacg tggtcgtcga cgtacgccgg ggctcgccca 5220 ccttcggccg atgggccgcc gtccgactcg acgcggcccg ccaccagggg ctctacctgg 5280 ccgaaggact cggccacgcg ttcatggccc tcaccgacga cgccacggtc gtctacctct 5340 gctcacagcc ctacgtggcc gaggccgagc gggccgtaga ccctctcgac ccggcgatcg 5400 gcatcgaatg gccgacggac atcgacatcg tccctgtcgg cgaagggaca cccacgcacc 5460 gtccctggcg caggccgcgg agacccggca tcctgccgga ctacgaggga gtgcccggcg 5520 ccttacatcg cggaggcggc cggcgtggga ccggcccgtg aaggccctcg tactggccgg 5580 ctctagttac gtagtaccgc gacaaccgcg cctggtggga acccctgaag aagcggccgg 5640 ccggtcccgc cgcccccccg agaggcagcg gcccatgaga tggctgatca ccggcgccgc 5700 cggaatgctg ggccgggaac tcgtccggcg cctcgccgag aacgaggagg acgtcgcggc 5760 cctcggccac gaccacctcg acgtcacccg accctccgcc gtgcgggcgg cactcgccga 5820 gcaccgtccc gggatcgtcg tcaactgcgc cgcctacacg gccgtcgacg acgccgagac 5880 ggacgaggcc gccgctgccc tcctcaacgc cgaggcgccc cggctgctgg ccgagggcct 5940 gcgcccccac cggcggcacg gcctcgtcca cctgtccacc gactacgtct ttcccggcga 6000 cgcccgcacc ccctacgccg aggaccaccc cacggctccc cgcagcgcct acggacgcac 6060 caaacgggac ggcgagcaag cggtgctgac ggcactgccc accgccaccg tgctgcgcac 6120 cgcctggctg tacgggcgca ccggccgcag cttcgtccgc acgatgatcg aacgggaggc 6180 gcgcggcgga gccatcgacg tcgtcgccga ccagcgcggc cagcccacct ggaccggcga 6240 cctcgccgac cgcatcatcg ccgtcggccg gcaccccggc gtccacggca tcctgcacgc 6300 caccaacgcc ggctccgcca cctggtacga cctggcacaa gaggtcttcc ggctcctcga 6360 cgccgacccc gggcgggtcc ggcccaccac cggcgccgcc ttccgcagac ccgccccccg 6420 ccccgcctac agcgtcctcg gccacgaccg ctggcgcggg accggcctgg cacccctgcg 6480 tgactggcgc tcggccctgc gcgaggcgtt ccccgacatc ctcgccgcgg aacacccacc 6540 gacccggcga ggagcagcat gaaacgaggc gtgcacgacc tggccctctt ccctaggtct 6600 aga 6603 <210> 18 <211> 7635 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-desI-desII <400> 18 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tgctagcgac ggtggcccgg agggaacatc 4920 cgtgaaaagc gccttatccg acctcgcatt cttcggcggc cccgccgctt tcgaccagcc 4980 gctcctcgtg gggcggccca accgcatcga ccgcgccagg ctgtacgagc ggctcgaccg 5040 ggccctcgac agccagtggc tgtccaacgg cggcccgctc gtccgcgagt tcgaggagcg 5100 cgtcgccggg ctcgccgggg tccggcatgc cgtggccacc tgcaacgcca cggccgggct 5160 ccagctcctc gcgcacgccg ccggcctcac cggcgaagtg atcatgccgt cgatgacgtt 5220 cgccgccacc ccgcacgcac tgcgctggat cggcctcacc ccggtcttcg ccgacatcga 5280 cccggacacc ggcaacctcg acccggacca ggtggccgcc gcggtcacac cccgcacctc 5340 ggccgtcgtc ggcgtccacc tctggggccg cccctgcgcc gccgaccagc tgcggaaggt 5400 cgccgacgag cacggcctgc ggctgtactt cgacgccgcg cacgccctcg gctgcgcggt 5460 cgacggccgg cccgccggca gcctcggcga cgccgaggtc ttcagcttcc acgccaccaa 5520 ggccgtcaac gccttcgagg gcggcgccgt cgtcaccgac gacgccgacc tcgccgcccg 5580 gatccgcgcc ctccacaact tcggcttcga cctgcccggc ggcagccccg ccggcgggac 5640 caacgccaag atgagcgagg ccgccgccgc catgggcctc acctccctcg acgcgtttcc 5700 cgaggtcatc gaccggaacc ggcgcaacca cgccgcctac cgcgagcacc tcgcggacct 5760 ccccggcgtc ctcgtcgccg accacgaccg ccacggcctc aacaaccacc agtacgtgat 5820 cgtcgagatc gacgaggcca ccaccggcat ccaccgcgac ctcgtcatgg aggtcctgaa 5880 ggccgaaggc gtgcacaccc gcgcctactt ctcgccgggc tgccacgagc tggagccgta 5940 ccgcgggcag ccgcacgccc cgctgccgca caccgaacgc ctcgccgcgc gcgtgctgtc 6000 cctgccgacc ggcaccgcca tcggcgacga cgacatccgc cgggtcgccg acctgctgcg 6060 tctctgcgcg acccgcggcc gcgaactgac cgcgcgccac cgcgacacgg cccccgcccc 6120 gctcgcggcc ccccagacat ccacgcccac gattggacgc tcccgatgac cgcccccgcc 6180 ctttccgcca ccgccccggc cgaacgctgc gcgcaccccg gagccgatct gggggcggcg 6240 gtccacgccg tcggccagac cctcgccgcc ggcggcctcg tgccgcccga cgaggccgga 6300 acgaccgccc gccacctcgt ccggctcgcc gtgcgctacg gcaacagccc cttcaccccg 6360 ctggaggagg cccgccacga cctgggcgtc gaccgggacg ccttccggcg cctcctcgcc 6420 ctgttcgggc aggtcccgga gctccgcacc gcggtcgaga ccggccccgc cggggcgtac 6480 tggaagaaca ccctgctccc gctcgaacag cgcggcgtct tcgacgcggc gctcgccagg 6540 aagcccgtct tcccgtacag cgtcggcctc taccccggcc cgacctgcat gttccgctgc 6600 cacttctgcg tccgtgtgac cggcgcccgc tacgacccgt ccgccctcga cgccggcaac 6660 gccatgttcc ggtcggtcat cgacgagata cccgcgggca acccctcggc gatgtacttc 6720 tccggcggcc tggagccgct caccaacccc ggcctcggga gcctggccgc gcacgccacc 6780 gaccacggcc tgcggcccac cgtctacacg aactccttcg cgctcaccga gcgcaccctg 6840 gagcgccagc ccggcctctg gggcctgcac gccatccgca cctcgctcta cggcctcaac 6900 gacgaggagt acgagcagac caccggcaag aaggccgcct tccgccgcgt ccgcgagaac 6960 ctgcgccgct tccagcagct gcgcgccgag cgcgagtcgc cgatcaacct cggcttcgcc 7020 tacatcgtgc tcccgggccg tgcctcccgc ctgctcgacc tggtcgactt catcgccgac 7080 ctcaacgacg ccgggcaggg caggacgatc gacttcgtca acattcgcga ggactacagc 7140 ggccgtgacg acggcaagct gccgcaggag gagcgggccg agctccagga ggccctcaac 7200 gccttcgagg agcgggtccg cgagcgcacc cccggactcc acatcgacta cggctacgcc 7260 ctgaacagcc tgcgcaccgg ggccgacgcc gaactgctgc ggatcaagcc cgccaccatg 7320 cggcccaccg cgcacccgca ggtcgcggtg caggtcgatc tcctcggcga cgtgtacctg 7380 taccgcgagg ccggcttccc cgacctggac ggcgcgaccc gctacatcgc gggccgcgtg 7440 acccccgaca cctccctcac cgaggtcgtc agggacttcg tcgagcgcgg cggcgaggtg 7500 gcggccgtcg acggcgacga gtacttcatg gacggcttcg atcaggtcgt caccgcccgc 7560 ctgaaccagc tggagcgcga cgccgcggac ggctgggagg aggcccgcgg cttcctgcgc 7620 tgacccgcat ctaga 7635 <210> 19 <211> 8375 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-oleV-eryBII-urdR <400> 19 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tttaattaag atatccccga ccagccttat 180 cgaaggagcg gcgaagagat ggcagaaccc acggtgaccg acgacctgac gggggccctc 240 acgcagcccc cgctgggccg caccgtccgc gcggtggccg accgtgaact cggcacccac 300 ctcctggaga cccgcggcat ccactggatc cacgccgcga acggcgaccc gtacgccacc 360 gtgctgcgcg gccaggcgga cgacccgtat cccgcgtacg agcgggtgcg tgcccgcggc 420 gcgctctcct tcagcccgac gggcagctgg gtcaccgccg atcacgccct ggcggcgagc 480 atcctctgct cgacggactt cggggtctcc ggcgccgacg gcgtcccggt gccgcagcag 540 gtcctctcgt acggggaggg ctgtccgctg gagcgcgagc aggtgctgcc ggcggccggt 600 gacgtgccgg agggcgggca gcgtgccgtg gtcgagggga tccaccggga gacgctggag 660 ggtctcgcgc cggacccgtc ggcgtcgtac gccttcgagc tgctgggcgg tttcgtccgc 720 ccggcggtga cggccgctgc cgccgccgtg ctgggtgttc ccgcggaccg gcgcgcggac 780 ttcgcggatc tgctggagcg gctccggccg ctgtccgaca gcctgctggc cccgcagtcc 840 ctgcggacgg tacgggcggc ggacggcgcg ctggccgagc tcacggcgct gctcgccgat 900 tcggacgact cccccggggc cctgctgtcg gcgctcgggg tcaccgcagc cgtccagctc 960 accgggaacg cggtgctcgc gctcctcgcg catcccgagc agtggcggga gctgtgcgac 1020 cggcccgggc tcgcggcggc cgcggtggag gagaccctcc gctacgaccc gccggtgcag 1080 ctcgacgccc gggtggtccg cggggagacg gagctggcgg gccggcggct gccggccggg 1140 gcgcatgtcg tcgtcctgac cgccgcgacc ggccgggacc cggaggtctt cacggacccg 1200 gagcgcttcg acctcgcgcg ccccgacgcc gccgcgcacc tcgcgctgca ccccgccggt 1260 ccgtacggcc cggtggcgtc cctggtccgg cttcaggcgg aggtcgcgct gcggaccctg 1320 gccgggcgtt tccccgggct gcggcaggcg ggggacgtgc tccgcccccg ccgcgcgcct 1380 gtcggccgcg ggccgctgag cgtcccggtc agcagctcct gagacaccgg ggccccggtc 1440 cgcccggccc cccttcggac ggaccggacg gctcggacca cggggacggc tcagaccgtc 1500 ccgtgtgtcc ccgtccggct cccgtccgcc ccatcccgcc cctccaccgg caaggaagga 1560 cacgacgcca tgcgcgtcct gctgacctcg ttcgcacatc acacgcacta ctacggcctg 1620 gtgcccctgg cctgggcgct gctcgccgcc gggcacgagg tgcgggtcgc cagccagccc 1680 gcgctcacgg acaccatcac cgggtccggg ctcgccgcgg tgccggtcgg caccgaccac 1740 ctcatccacg agtaccgggt gcggatggcg ggcgagccgc gcccgaacca tccggcgatc 1800 gccttcgacg aggcccgtcc cgagccgctg gactgggacc acgccctcgg catcgaggcg 1860 atcctcgccc cgtacttcca tctgctcgcc aacaacgact cgatggtcga cgacctcgtc 1920 gacttcgccc ggtcctggca gccggacctg gtgctgtggg agccgacgac ctacgcgggc 1980 gccgtcgccg cccaggtcac cggtgccgcg cacgcccggg tcctgtgggg gcccgacgtg 2040 atgggcagcg cccgccgcaa gttcgtcgcg ctgcgggacc ggcagccgcc cgagcaccgc 2100 gaggacccca ccgcggagtg gctgacgtgg acgctcgacc ggtacggcgc ctccttcgaa 2160 gaggagctgc tcaccggcca gttcacgatc gacccgaccc cgccgagcct gcgcctcgac 2220 acgggcctgc cgaccgtcgg gatgcgttat gttccgtaca acggcacgtc ggtcgtgccg 2280 gactggctga gtgagccgcc cgcgcggccc cgggtctgcc tgaccctcgg cgtctccgcg 2340 cgtgaggtcc tcggcggcga cggcgtctcg cagggcgaca tcctggaggc gctcgccgac 2400 ctcgacatcg agctcgtcgc cacgctcgac gcgagtcagc gcgccgagat ccgcaactac 2460 ccgaagcaca cccggttcac ggacttcgtg ccgatgcacg cgctcctgcc gagctgctcg 2520 gcgatcatcc accacggcgg ggcgggcacc tacgcgaccg ccgtgatcaa cgcggtgccg 2580 caggtcatgc tcgccgagct gtgggacgcg ccggtcaagg cgcgggccgt cgccgagcag 2640 ggggcggggt tcttcctgcc gccggccgag ctcacgccgc aggccgtgcg ggacgccgtc 2700 gtccgcatcc tcgacgaccc ctcggtcgcc accgccgcgc accggctgcg cgaggagacc 2760 ttcggcgacc ccaccccggc cgggatcgtc cccgagctgg agcggctcgc cgcgcagcac 2820 cgccgcccgc cggccgacgc ccggcactga gccgcacccc tcgccccagg cctcacccct 2880 gtatctcata tgtctagtta actcgccacg ccgaccgtta tcaccggcgc cctgctgcta 2940 gtttccgaga atgaagggaa tagtcctggc cggcgggagc ggaactcggc tgcatccggc 3000 gacctcggtc atttcgaagc agattcttcc ggtctacaac aaaccgatga tctactatcc 3060 gctgtcggtt ctcatgctcg gcggtattcg cgagattcaa atcatctcga ccccccagca 3120 catcgaactc ttccagtcgc ttctcggaaa cggcaggcac ctgggaatag aactcgacta 3180 tgcggtccag aaagagcccg caggaatcgc ggacgcactt ctcgtcggag ccgagcacat 3240 cggcgacgac acctgcgccc tgatcctggg cgacaacatc ttccacgggc ccggcctcta 3300 cacgctcctg cgggacagca tcgcgcgcct cgacggctgc gtgctcttcg gctacccggt 3360 caaggacccc gagcggtacg gcgtcgccga ggtggacgcg acgggccggc tgaccgacct 3420 cgtcgagaag cccgtcaagc cgcgctccaa cctcgccgtc accggcctct acctctacga 3480 caacgacgtc gtcgacatcg ccaagaacat ccggccctcg ccgcgcggcg agctggagat 3540 caccgacgtc aaccgcgtct acctggagcg gggccgggcc gaactcgtca acctgggccg 3600 cggcttcgcc tggctggaca ccggcaccca cgactcgctc ctgcgggccg cccagtacgt 3660 ccaggtcctg gaggagcggc agggcgtctg gatcgcgggc cttgaggaga tcgccttccg 3720 catgggcttc atcgacgccg aggcctgtca cggcctggga gaaggcctct cccgcaccga 3780 gtacggcagc tatctgatgg agatcgccgg ccgcgaggga gccccgtgag ggcacctcgc 3840 ggccgacgcg ttcccacgac cgacagcgcc accgacagtg cgacccacac cgcgacccgc 3900 accgccaccg acagtgcgac ccacaccgcg acctacagcg cgaccgaaag gaagacggca 3960 gtgcggcttc tggtgaccgg aggtgcgggc ttcatcggct cgcacttcgt gcggcagctc 4020 ctcgccgggg cgtaccccga cgtgcccgcc gatgaggtga tcgtcctgga cagcctcacc 4080 tacgcgggca accgcgccaa cctcgccccg gtggacgcgg acccgcgact gcgcttcgtc 4140 cacggcgaca tccgcgacgc cggcctcctc gcccgggaac tgcgcggcgt ggacgccatc 4200 gtccacttcg cggccgagag ccacgtggac cgctccatcg cgggcgcgtc cgtgttcacc 4260 gagaccaacg tgcagggcac gcagacgctg ctccagtgcg ccgtcgacgc cggcgtcggc 4320 cgggtcgtgc acgtctccac cgacgaggtg tacgggtcga tcgactccgg ctcctggacc 4380 gagagcagcc cgctggagcc caactcgccc tacgcggcgt ccaaggccgg ctccgacctc 4440 gttgcccgcg cctaccaccg gacgtacggc ctcgacgtac ggatcacccg ctgctgcaac 4500 aactacgggc cgtaccagca ccccgagaag ctcatccccc tcttcgtgac gaacctcctc 4560 gacggcggga cgctcccgct gtacggcgac ggcgcgaacg tccgcgagtg ggtgcacacc 4620 gacgaccact gccggggcat cgcgctcgtc ctcgcgggcg gccgggccgg cgagatctac 4680 cacatcggcg gcggcctgga gctgaccaac cgcgaactca ccggcatcct cctggactcg 4740 ctcggcgccg actggtcctc ggtccggaag gtcgccgacc gcaagggcca cgacctgcgc 4800 tactccctcg acggcggcga gatcgagcgc gagctcggct accgcccgca ggtctccttc 4860 gcggacggcc tcgcgcggac cgtccgctgg taccgggaga accgcggctg gtgggagccg 4920 ctcaaggcga ccgccccgca gctgcccgcc accgccgtgg aggtgtccgc gtgagcagcc 4980 gcgccgagac cccccgcgtc cccttcctcg acctcaaggc cgcctacgag gagctctcta 5040 gtgggaatcg cggaagcggc cgggttcggc gccgtcctgg atcacaatga tatggggaat 5100 tcccgcgatg agcgaagcaa tgggatcggt accgacggcc ggcagtgaag tctcctcgac 5160 ctgcgcgttt ctgtcctggt tggacgcgcg ccgccgggcc aatcgcctga cggtggaaca 5220 cgtaccgttc agggagttat cggggtggca attcgacgag aacacgggga acctccgaca 5280 taccagcggt cgtttcttct ccatcgaagg actccgggta cgcacggacc actgctggtt 5340 cggaagctgg acccagccca ttatcgtgca accggagata ggcattctcg gcctcctggt 5400 caagaggttc gacggcatcc tgcacgtcct ggtgcaggca aagaacgaac cgggtaatat 5460 cggcggcctt cagctctccc ccaccgtcca ggccactcgc agcaattaca cccgcgtcca 5520 ccgcggcggc ggtgtcagat acctggagta cttcgcgtcc ccccgcgggc gcggtcgggt 5580 cctcgcggac gtcctccaat ccgagcaggg ctcctggttc ctgcacaagc ggaaccggaa 5640 catggtggtc gaggccctgg acgacgtgcc cctcgacgac gacttccact ggatcagcct 5700 cggcgggctg cggaagctgc tgctgaggcc gcatctggtg aacatggaca cccgcacggt 5760 gctgtcctgc cttcccccgg atccggcacc ggacggccgg cagccgccgg cgcccgcggc 5820 tcccttcgcc gccgcggtca cgcggtccct cacccggggt gccaccgcct tgcacaccat 5880 gggcgagatc ctcggctggc tgaccgacga gcggtcccgg cgggaactgg tgcagcagcg 5940 ggtgccgctg gaggagaccg cgttcagcgg ctggcggcgt gacgaccacg ccatcgcgca 6000 caaggacggc gactacttcc gggtcatcgg ggtgagcgtc cgggccagca gccgggaggt 6060 gtcctcgtgg agccagccgt tgctggcccc cgtcggcccc ggtctggccg ccttcgtcac 6120 caggcggatc cgcggcgtcc tccacgtcct gctgcacgcc cgcaccgaag ccggcctgct 6180 caacggcccg gagatggcac cgaccgtgca gtgccgcccg ctcaactacc gtgcggtgcc 6240 cgccgagtac cggcccgcct acctcgacta cgtgctgtcg gccgatcccg gacgcatccg 6300 ctacgacacc ctccagtcgg aggagggcgg ccgcttccac cacgcggaga accgctacgt 6360 cgtggtggag gccgaggacg acttcccggt cgaggtgccc cgcgacttcc gctggctcac 6420 cctgcaccag atcctcgccc tgctgcacca cagcaactat gtcaacgtgg aggcgcgcag 6480 cctcgtcgcc tgcatccagc ctgagctgat ctagtggtcg tcggcatctg cgaggaactg 6540 gccgcaggaa ggagagaacc acgatgacca ccgacgccgc gacgcacgtg cggctcgggc 6600 gttccgcgct gctcaccagc aggctctggc tcggcacggt gaacttcagc ggacgcgtcg 6660 aggacgacga cgcgctgcgc ctgatggacc acgcccggga ccgcggcatc aactgcctcg 6720 acaccgccga catgtacggc tggcggctct acaagggcca caccgaggag ctggtgggca 6780 ggtggctggc ccagggcggc ggacggcgcg aggacaccgt gctggcgacc aaggtcggcg 6840 gcgagatgag cgagcgcgtc aacgacagcg ggctgtcggc gcggcacatc atcgcctcct 6900 gcgagggatc gctgcgcagg ctgggcgtcg accacatcga cgtctaccag atgcaccaca 6960 tcgaccggtc cgcgccgtgg gacgaggtgt ggcaggccat ggacagcctc gtcgccagcg 7020 gcaaggtctc ctacgtcggc tcgtcgaact tcgcgggctg gcacatcgcc gccgcgcagg 7080 agaacgccgc ccgccgccac tccctgggca tggtctccca ccagtgcctg tacaacctgg 7140 cggtccggca cgccgagctg gaggtgctgc ccgccgcgca ggcctacggg ctcggcgtct 7200 tcgcctggtc gccgctgcac ggcggcctgc tcagcggagc gctggagaag ctggccgcgg 7260 gcaccgcggt gaagtcggcg cagggccgtg cgcaggtgct gttgccgtcc ctgcgcccgg 7320 cgatcgaggc ctacgagaag ttctgccgca acctcggcga agacccggcc gaggtggggc 7380 tcgcatgggt gctgtcccgg cccggcatcg ccggcgccgt catcggcccg cgaacccccg 7440 agcagctcga ctccgcgctg aaggcgtccg cgatgaccct ggacgagcag gcgctgtccg 7500 aactggacga gatcttcccc gcggtggcct ccggcggcgc ggcgccggaa gcctggttgc 7560 agtgagcaca agaggaaccg agtacgtatc tagtgatatc acagagatca ggacgacgca 7620 tggacattgt gggaaatgga ttcctggcgc ggaacctgcg gccgctggcc gaacggcatc 7680 ccgataccgt ggccctcgcc gccggtgtct catgggcgag cggtacctcc gatgccgact 7740 tcgcccggga agccgcactc ctgcgagaca ccgccaagca gtgcgcggcc accggacgac 7800 gactgctgtt cttctcgacc gctgccacgg gcatgtacgg cctggcggag ggacccggcc 7860 gagaggacac gccagtgacg ccgtgcaccc cgtacggcgc gcacaagctg gcgctggagg 7920 aactgctgcg ggactccggt gccgaccatg tgattctcag gctcgggcac ctcgtggggc 7980 ccgaccagcc cgagcaccaa ctgctgccca cgctggtgcg tcacctacgc gaaggcgcgg 8040 tgcgcattca ccgaggcgcg gcccgtgacc tcatcgacgt cagcgacgtc gtcaccattg 8100 tcgactgcct tctcggcctt gacctcaagg ccgagacggt caacgtggcc tccggctacg 8160 ccgttccggt gaaggacatc gtcgaactcc tgcgccgcag gctcggggtc gaggcgcggt 8220 acgagttcca ggatgccggt ggtcagcacg tcatctccat cgagaagctg cgcgcactcg 8280 ttccgcaggt ccaggacatg ggcttcgggc ccgactacta ccggcggatc ctcagtgact 8340 tcacctccgc cgtccgtatc tgacctaggt ctaga 8375 <210> 20 <211> 9085 <212> DNA <213> Artificial Sequence <220> <223> desVIII-desVII-desIII-desIV-oleV-oleW-oleL-oleU <400> 20 ttaattaaga tatccccgac cagccttatc gaaggagcgg cgaagagatg gcagaaccca 60 cggtgaccga cgacctgacg ggggccctca cgcagccccc gctgggccgc accgtccgcg 120 cggtggccga ccgtgaactc ggcacccacc tcctggagac ccgcggcatc cactggatcc 180 acgccgcgaa cggcgacccg tacgccaccg tgctgcgcgg ccaggcggac gacccgtatc 240 ccgcgtacga gcgggtgcgt gcccgcggcg cgctctcctt cagcccgacg ggcagctggg 300 tcaccgccga tcacgccctg gcggcgagca tcctctgctc gacggacttc ggggtctccg 360 gcgccgacgg cgtcccggtg ccgcagcagg tcctctcgta cggggagggc tgtccgctgg 420 agcgcgagca ggtgctgccg gcggccggtg acgtgccgga gggcgggcag cgtgccgtgg 480 tcgaggggat ccaccgggag acgctggagg gtctcgcgcc ggacccgtcg gcgtcgtacg 540 ccttcgagct gctgggcggt ttcgtccgcc cggcggtgac ggccgctgcc gccgccgtgc 600 tgggtgttcc cgcggaccgg cgcgcggact tcgcggatct gctggagcgg ctccggccgc 660 tgtccgacag cctgctggcc ccgcagtccc tgcggacggt acgggcggcg gacggcgcgc 720 tggccgagct cacggcgctg ctcgccgatt cggacgactc ccccggggcc ctgctgtcgg 780 cgctcggggt caccgcagcc gtccagctca ccgggaacgc ggtgctcgcg ctcctcgcgc 840 atcccgagca gtggcgggag ctgtgcgacc ggcccgggct cgcggcggcc gcggtggagg 900 agaccctccg ctacgacccg ccggtgcagc tcgacgcccg ggtggtccgc ggggagacgg 960 agctggcggg ccggcggctg ccggccgggg cgcatgtcgt cgtcctgacc gccgcgaccg 1020 gccgggaccc ggaggtcttc acggacccgg agcgcttcga cctcgcgcgc cccgacgccg 1080 ccgcgcacct cgcgctgcac cccgccggtc cgtacggccc ggtggcgtcc ctggtccggc 1140 ttcaggcgga ggtcgcgctg cggaccctgg ccgggcgttt ccccgggctg cggcaggcgg 1200 gggacgtgct ccgcccccgc cgcgcgcctg tcggccgcgg gccgctgagc gtcccggtca 1260 gcagctcctg agacaccggg gccccggtcc gcccggcccc ccttcggacg gaccggacgg 1320 ctcggaccac ggggacggct cagaccgtcc cgtgtgtccc cgtccggctc ccgtccgccc 1380 catcccgccc ctccaccggc aaggaaggac acgacgccat gcgcgtcctg ctgacctcgt 1440 tcgcacatca cacgcactac tacggcctgg tgcccctggc ctgggcgctg ctcgccgccg 1500 ggcacgaggt gcgggtcgcc agccagcccg cgctcacgga caccatcacc gggtccgggc 1560 tcgccgcggt gccggtcggc accgaccacc tcatccacga gtaccgggtg cggatggcgg 1620 gcgagccgcg cccgaaccat ccggcgatcg ccttcgacga ggcccgtccc gagccgctgg 1680 actgggacca cgccctcggc atcgaggcga tcctcgcccc gtacttccat ctgctcgcca 1740 acaacgactc gatggtcgac gacctcgtcg acttcgcccg gtcctggcag ccggacctgg 1800 tgctgtggga gccgacgacc tacgcgggcg ccgtcgccgc ccaggtcacc ggtgccgcgc 1860 acgcccgggt cctgtggggg cccgacgtga tgggcagcgc ccgccgcaag ttcgtcgcgc 1920 tgcgggaccg gcagccgccc gagcaccgcg aggaccccac cgcggagtgg ctgacgtgga 1980 cgctcgaccg gtacggcgcc tccttcgaag aggagctgct caccggccag ttcacgatcg 2040 acccgacccc gccgagcctg cgcctcgaca cgggcctgcc gaccgtcggg atgcgttatg 2100 ttccgtacaa cggcacgtcg gtcgtgccgg actggctgag tgagccgccc gcgcggcccc 2160 gggtctgcct gaccctcggc gtctccgcgc gtgaggtcct cggcggcgac ggcgtctcgc 2220 agggcgacat cctggaggcg ctcgccgacc tcgacatcga gctcgtcgcc acgctcgacg 2280 cgagtcagcg cgccgagatc cgcaactacc cgaagcacac ccggttcacg gacttcgtgc 2340 cgatgcacgc gctcctgccg agctgctcgg cgatcatcca ccacggcggg gcgggcacct 2400 acgcgaccgc cgtgatcaac gcggtgccgc aggtcatgct cgccgagctg tgggacgcgc 2460 cggtcaaggc gcgggccgtc gccgagcagg gggcggggtt cttcctgccg ccggccgagc 2520 tcacgccgca ggccgtgcgg gacgccgtcg tccgcatcct cgacgacccc tcggtcgcca 2580 ccgccgcgca ccggctgcgc gaggagacct tcggcgaccc caccccggcc gggatcgtcc 2640 ccgagctgga gcggctcgcc gcgcagcacc gccgcccgcc ggccgacgcc cggcactgag 2700 ccgcacccct cgccccaggc ctcacccctg tatctcatat gtctagttaa ctcgccacgc 2760 cgaccgttat caccggcgcc ctgctgctag tttccgagaa tgaagggaat agtcctggcc 2820 ggcgggagcg gaactcggct gcatccggcg acctcggtca tttcgaagca gattcttccg 2880 gtctacaaca aaccgatgat ctactatccg ctgtcggttc tcatgctcgg cggtattcgc 2940 gagattcaaa tcatctcgac cccccagcac atcgaactct tccagtcgct tctcggaaac 3000 ggcaggcacc tgggaataga actcgactat gcggtccaga aagagcccgc aggaatcgcg 3060 gacgcacttc tcgtcggagc cgagcacatc ggcgacgaca cctgcgccct gatcctgggc 3120 gacaacatct tccacgggcc cggcctctac acgctcctgc gggacagcat cgcgcgcctc 3180 gacggctgcg tgctcttcgg ctacccggtc aaggaccccg agcggtacgg cgtcgccgag 3240 gtggacgcga cgggccggct gaccgacctc gtcgagaagc ccgtcaagcc gcgctccaac 3300 ctcgccgtca ccggcctcta cctctacgac aacgacgtcg tcgacatcgc caagaacatc 3360 cggccctcgc cgcgcggcga gctggagatc accgacgtca accgcgtcta cctggagcgg 3420 ggccgggccg aactcgtcaa cctgggccgc ggcttcgcct ggctggacac cggcacccac 3480 gactcgctcc tgcgggccgc ccagtacgtc caggtcctgg aggagcggca gggcgtctgg 3540 atcgcgggcc ttgaggagat cgccttccgc atgggcttca tcgacgccga ggcctgtcac 3600 ggcctgggag aaggcctctc ccgcaccgag tacggcagct atctgatgga gatcgccggc 3660 cgcgagggag ccccgtgagg gcacctcgcg gccgacgcgt tcccacgacc gacagcgcca 3720 ccgacagtgc gacccacacc gcgacccgca ccgccaccga cagtgcgacc cacaccgcga 3780 cctacagcgc gaccgaaagg aagacggcag tgcggcttct ggtgaccgga ggtgcgggct 3840 tcatcggctc gcacttcgtg cggcagctcc tcgccggggc gtaccccgac gtgcccgccg 3900 atgaggtgat cgtcctggac agcctcacct acgcgggcaa ccgcgccaac ctcgccccgg 3960 tggacgcgga cccgcgactg cgcttcgtcc acggcgacat ccgcgacgcc ggcctcctcg 4020 cccgggaact gcgcggcgtg gacgccatcg tccacttcgc ggccgagagc cacgtggacc 4080 gctccatcgc gggcgcgtcc gtgttcaccg agaccaacgt gcagggcacg cagacgctgc 4140 tccagtgcgc cgtcgacgcc ggcgtcggcc gggtcgtgca cgtctccacc gacgaggtgt 4200 acgggtcgat cgactccggc tcctggaccg agagcagccc gctggagccc aactcgccct 4260 acgcggcgtc caaggccggc tccgacctcg ttgcccgcgc ctaccaccgg acgtacggcc 4320 tcgacgtacg gatcacccgc tgctgcaaca actacgggcc gtaccagcac cccgagaagc 4380 tcatccccct cttcgtgacg aacctcctcg acggcgggac gctcccgctg tacggcgacg 4440 gcgcgaacgt ccgcgagtgg gtgcacaccg acgaccactg ccggggcatc gcgctcgtcc 4500 tcgcgggcgg ccgggccggc gagatctacc acatcggcgg cggcctggag ctgaccaacc 4560 gcgaactcac cggcatcctc ctggactcgc tcggcgccga ctggtcctcg gtccggaagg 4620 tcgccgaccg caagggccac gacctgcgct actccctcga cggcggcgag atcgagcgcg 4680 agctcggcta ccgcccgcag gtctccttcg cggacggcct cgcgcggacc gtccgctggt 4740 accgggagaa ccgcggctgg tgggagccgc tcaaggcgac cgccccgcag ctgcccgcca 4800 ccgccgtgga ggtgtccgcg tgagcagccg cgccgagacc ccccgcgtcc ccttcctcga 4860 cctcaaggcc gcctacgagg agctctctag tgggaatcgc ggaagcggcc gggttcggcg 4920 ccgtcctgga tcacaatgat atggggaatt cccgcgatga gcgaagcaat gggatcggta 4980 ccgacggccg gcagtgaagt ctcctcgacc tgcgcgtttc tgtcctggtt ggacgcgcgc 5040 cgccgggcca atcgcctgac ggtggaacac gtaccgttca gggagttatc ggggtggcaa 5100 ttcgacgaga acacggggaa cctccgacat accagcggtc gtttcttctc catcgaagga 5160 ctccgggtac gcacggacca ctgctggttc ggaagctgga cccagcccat tatcgtgcaa 5220 ccggagatag gcattctcgg cctcctggtc aagaggttcg acggcatcct gcacgtcctg 5280 gtgcaggcaa agaacgaacc gggtaatatc ggcggccttc agctctcccc caccgtccag 5340 gccactcgca gcaattacac ccgcgtccac cgcggcggcg gtgtcagata cctggagtac 5400 ttcgcgtccc cccgcgggcg cggtcgggtc ctcgcggacg tcctccaatc cgagcagggc 5460 tcctggttcc tgcacaagcg gaaccggaac atggtggtcg aggccctgga cgacgtgccc 5520 ctcgacgacg acttccactg gatcagcctc ggcgggctgc ggaagctgct gctgaggccg 5580 catctggtga acatggacac ccgcacggtg ctgtcctgcc ttcccccgga tccggcaccg 5640 gacggccggc agccgccggc gcccgcggct cccttcgccg ccgcggtcac gcggtccctc 5700 acccggggtg ccaccgcctt gcacaccatg ggcgagatcc tcggctggct gaccgacgag 5760 cggtcccggc gggaactggt gcagcagcgg gtgccgctgg aggagaccgc gttcagcggc 5820 tggcggcgtg acgaccacgc catcgcgcac aaggacggcg actacttccg ggtcatcggg 5880 gtgagcgtcc gggccagcag ccgggaggtg tcctcgtgga gccagccgtt gctggccccc 5940 gtcggccccg gtctggccgc cttcgtcacc aggcggatcc gcggcgtcct ccacgtcctg 6000 ctgcacgccc gcaccgaagc cggcctgctc aacggcccgg agatggcacc gaccgtgcag 6060 tgccgcccgc tcaactaccg tgcggtgccc gccgagtacc ggcccgccta cctcgactac 6120 gtgctgtcgg ccgatcccgg acgcatccgc tacgacaccc tccagtcgga ggagggcggc 6180 cgcttccacc acgcggagaa ccgctacgtc gtggtggagg ccgaggacga cttcccggtc 6240 gaggtgcccc gcgacttccg ctggctcacc ctgcaccaga tcctcgccct gctgcaccac 6300 agcaactatg tcaacgtgga ggcgcgcagc ctcgtcgcct gcatccagcc tgagctgatc 6360 tagtgctagc aagggaaccc catgccctcc ccccgtctgc gcttcggtgt gctgggtgcc 6420 gccgacatcg ccctgcgccg caccgtgccc gcgctgctcg cccacccgga cgtcaccgtg 6480 gtcgcggtct ccagccggga cacggcccgc gccgcccgtt tcgccgcggc gttcgggtgc 6540 gaggcggtcc cgggccacca ggcgctgctg gaccgcgacg acatcgacgc gctgtacgtc 6600 ccgctgccgg tgatggtgca cacgccctgg gtggaggcgg cgctgctgcg gggcaggcac 6660 gtcctggtgg agaagccgct gaccgcgacc cgctccggag ccgaggacct gatcgccctg 6720 gcacgctccc gcggcctggt cctgatggag aacttcacgt cgctgcacca cgcacagcac 6780 ggcaccgtca cggacctcct gcgggacggg acgatcggcg aactgcgctc gctgtccgcg 6840 gcgttcacga tcccgccgaa gccggagggc gacatccggt accagcccga cgtgggcgga 6900 ggcgccctgc tcgacatcgg gatctacccc ctgcgggcgg cactgcactt cctgggcccc 6960 gacctgcacg cggccggcgc ggtcctgcgt cgggagcggc gccggaacgt ggtggtctcc 7020 ggccacgtgc tgctcaccac accgcacggc gtcgtggccg agctggcctt cggcatggag 7080 cacgcctacc gctcggagta caccctcttc ggcacggccg gccgcctgcg cctggaccgt 7140 gccttcaccc cgcccgagac ccaccggcca cgtgtggaga tccaccggca ggacgccctg 7200 gacatcgtcg acctgccgcc ggacgcgcaa ttcgccaacc tcgtccggga cttcgtactg 7260 gctgtccgcg agggtcccgg ccggctcaca cagcaccacg ccgacgccgt acgccaagcc 7320 gatctcgtcg agcgcgtcat ggcggtggcg cgggtgcgct ggtgctgtct agtatcgctc 7380 cgagcccgaa gggaaaatcg agtgcccaat tcggcagaat cgggatcgat ggagttactc 7440 gacgtcgacg gggcctggtt atacaccccg gaaatcatgc gggacgaacg gggagaattc 7500 ctcgaatggt tccggggtcg gacattccag gagaagatcg gccaccccct ctcgctggcc 7560 caggccaact gctcggtgtc ccgcaaggcg ttctgcgcgg catccacttc gccgacgccc 7620 ccgcccggcc aggccaagta cgtcacctgc gcctccggca ccgtgctcga cgtggtcgtc 7680 gacgtacgcc ggggctcgcc caccttcggc cgatgggccg ccgtccgact cgacgcggcc 7740 cgccaccagg ggctctacct ggccgaagga ctcggccacg cgttcatggc cctcaccgac 7800 gacgccacgg tcgtctacct ctgctcacag ccctacgtgg ccgaggccga gcgggccgta 7860 gaccctctcg acccggcgat cggcatcgaa tggccgacgg acatcgacat cgtccctgtc 7920 ggcgaaggga cacccacgca ccgtccctgg cgcaggccgc ggagacccgg catcctgccg 7980 gactacgagg gagtgcccgg cgccttacat cgcggaggcg gccggcgtgg gaccggcccg 8040 tgaaggccct cgtactggcc ggctctagtt acgtagtacc gcgacaaccg cgcctggtgg 8100 gaacccctga agaagcggcc ggccggtccc gccgcccccc cgagaggcag cggcccatga 8160 gatggctgat caccggcgcc gccggaatgc tgggccggga actcgtccgg cgcctcgccg 8220 agaacgagga ggacgtcgcg gccctcggcc acgaccacct cgacgtcacc cgaccctccg 8280 ccgtgcgggc ggcactcgcc gagcaccgtc ccgggatcgt cgtcaactgc gccgcctaca 8340 cggccgtcga cgacgccgag acggacgagg ccgccgctgc cctcctcaac gccgaggcgc 8400 cccggctgct ggccgagggc ctgcgccccc accggcggca cggcctcgtc cacctgtcca 8460 ccgactacgt ctttcccggc gacgcccgca ccccctacgc cgaggaccac cccacggctc 8520 cccgcagcgc ctacggacgc accaaacggg acggcgagca agcggtgctg acggcactgc 8580 ccaccgccac cgtgctgcgc accgcctggc tgtacgggcg caccggccgc agcttcgtcc 8640 gcacgatgat cgaacgggag gcgcgcggcg gagccatcga cgtcgtcgcc gaccagcgcg 8700 gccagcccac ctggaccggc gacctcgccg accgcatcat cgccgtcggc cggcaccccg 8760 gcgtccacgg catcctgcac gccaccaacg ccggctccgc cacctggtac gacctggcac 8820 aagaggtctt ccggctcctc gacgccgacc ccgggcgggt ccggcccacc accggcgccg 8880 ccttccgcag acccgccccc cgccccgcct acagcgtcct cggccacgac cgctggcgcg 8940 ggaccggcct ggcacccctg cgtgactggc gctcggccct gcgcgaggcg ttccccgaca 9000 tcctcgccgc ggaacaccca ccgacccggc gaggagcagc atgaaacgag gcgtgcacga 9060 cctggccctc ttccctaggt ctaga 9085 <210> 21 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 21 ggcaagctta gcggggcgac tggcgtgccc act 33 <210> 22 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 22 ggtctgcagt caccgtgggt tctgccatct ctt 33 <210> 23 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 23 gctggtaccg gatgttccct ccgggccacc gtc 33 <210> 24 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 24 tgagaattcc ctcgccgtcc tgcccgcgct tgg 33 <210> 25 <211> 38 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 25 ttaattaaga tatcaccggc aaggaaggac acgacgcc 38 <210> 26 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 26 tctagacata tggcgcagat acaggggtga ggcctg 36 <210> 27 <211> 37 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 27 ttaattaaac tagtatcgat gacggtggcc cggaggg 37 <210> 28 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 28 tctagatgcg ggtcagcgca ggaagccgcg 30 <210> 29 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 29 ttaattaaac tagttaactc gccacgccga ccgtt 35 <210> 30 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 30 tctagagagc tcctcgtagg cggcctt 27 <210> 31 <211> 38 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 31 ttaattaaac tagtcaggtc tccttcgcgg acggcctc 38 <210> 32 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 32 tctagaacct gactaggcct ggtcgacccg 30 <210> 33 <211> 38 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 33 ttaattaaac tagtccccag gcctcacccc tgtatctg 38 <210> 34 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 34 tctagagaat tcgctcaggc ggggacgccg acgaag 36 <210> 35 <211> 41 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 35 ttaattaaac tagtatcgat atcgctccga gcccgaaggg a 41 <210> 36 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 36 tctagagccg gccagtacga gggcctt 27 <210> 37 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 37 ttaattaaac tagtgtaccg cgacaaccgc 30 <210> 38 <211> 29 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 38 tctagagaag agggccaggt cgtgcacgc 29 <210> 39 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 39 ttaattaaac tagtatcgat gggaatcgcg gaagcg 36 <210> 40 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 40 tctagaatca gctcagggcc tggatgc 27 <210> 41 <211> 31 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 41 ttaattaaac tagtggtcgt cggcatctgc g 31 <210> 42 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 42 tctagactcg gttcctcttg tgctcactgc 30 <210> 43 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 43 ttaattaaac tagtacagag atccaggacg acgca 35 <210> 44 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 44 tctagatcag atacggacgg cggaggt 27 <210> 45 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 45 ttaattaaac tagtaaggga accccatgcc ctccc 35 <210> 46 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> primer <400> 46 tctagaatca gcaccagcgc acccgcgcca 30
Claims (16)
배양된 세포 또는 배양액으로부터 나르보마이신 유도체를 회수하는 단계를 포함하는, 나르보마이신 유도체의 제조방법.Culturing the recombinant microorganism of any one of claims 1 to 8; And
A method for producing a narcamycin derivative, comprising recovering a narcamycin derivative from the cultured cells or culture medium.
[화학식 1]

상기 식에서 R은
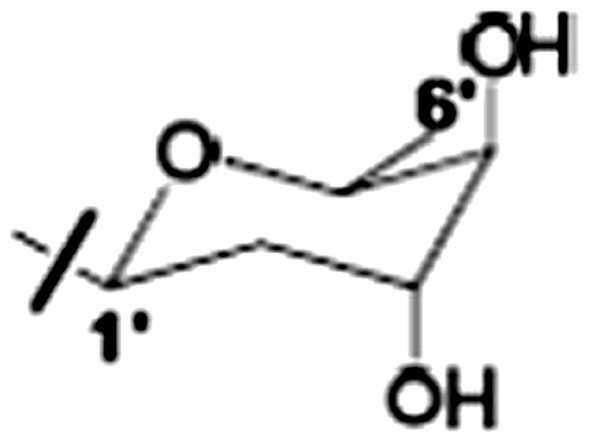


[Formula 1]
In which R is
[화학식 1]

상기 식에서 R은



[Formula 1]
In which R is
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020110035384A KR101347335B1 (en) | 2011-04-15 | 2011-04-15 | Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020110035384A KR101347335B1 (en) | 2011-04-15 | 2011-04-15 | Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020130148025A Division KR101451037B1 (en) | 2013-11-29 | 2013-11-29 | Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20120117568A true KR20120117568A (en) | 2012-10-24 |
| KR101347335B1 KR101347335B1 (en) | 2014-01-06 |
Family
ID=47285508
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020110035384A KR101347335B1 (en) | 2011-04-15 | 2011-04-15 | Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101347335B1 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101721750B1 (en) * | 2015-03-25 | 2017-03-31 | 이화여자대학교 산학협력단 | Novel macrolactam glycoside derivatives, chemoenzymatic method for preparation thereof and antibacterial composition comprising the same |
-
2011
- 2011-04-15 KR KR1020110035384A patent/KR101347335B1/en active IP Right Grant
Also Published As
| Publication number | Publication date |
|---|---|
| KR101347335B1 (en) | 2014-01-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Madduri et al. | Production of the antitumor drug epirubicin (4′-epidoxorubicin) and its precursor by a genetically engineered strain of Streptomyces peucetius | |
| Gaisser et al. | Analysis of seven genes from the eryAI–eryK region of the erythromycin biosynthetic gene cluster in Saccharopolyspora erythraea | |
| Trefzer et al. | Function of glycosyltransferase genes involved in urdamycin A biosynthesis | |
| Salah-Bey et al. | Targeted gene inactivation for the elucidation of deoxysugar biosynthesis in the erythromycin producer Saccharopolyspora erythraea | |
| Blanco et al. | Identification of a sugar flexible glycosyltransferase from Streptomyces olivaceus, the producer of the antitumor polyketide elloramycin | |
| Olano et al. | A two-plasmid system for the glycosylation of polyketide antibiotics: bioconversion of ε-rhodomycinone to rhodomycin D | |
| Wohlert et al. | Insights about the biosynthesis of the avermectin deoxysugar L-oleandrose through heterologous expression of Streptomyces avermitilis deoxysugar genes in Streptomyces lividans | |
| EP2271666B1 (en) | Nrps-pks gene cluster and its manipulation and utility | |
| JP2000515390A (en) | Novel polyketide derivative and recombinant method for producing the same | |
| Rodriguez et al. | Generation of hybrid elloramycin analogs by combinatorial biosynthesis using genes from anthracycline-type and macrolide biosynthetic pathways | |
| KR101272351B1 (en) | New kanamycin compound, kanamycin-producing Streptomyces sp. and kanamycin producing method | |
| Räty et al. | A gene cluster from Streptomyces galilaeus involved in glycosylation of aclarubicin | |
| EP1278881B1 (en) | Hybrid glycosylated products and their production and use | |
| González et al. | The mtmVUC genes of the mithramycin gene cluster in Streptomyces argillaceus are involved in the biosynthesis of the sugar moieties | |
| AU2001248588A1 (en) | Hybrid glycosylated products and their production and use | |
| KR101602195B1 (en) | Method for Production of Non-natural Antibiotic | |
| KR20100010503A (en) | Genetically modified strains producing anthracycline metabolites useful as cancer drugs | |
| US7795001B2 (en) | Midecamycin biosynthesis genes | |
| KR101347335B1 (en) | Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same | |
| KR101451037B1 (en) | Novel narbomycin derivatives compounds, antibacterial composition comprising the same and manufacturing method of the same | |
| Tornus et al. | Identification of four genes from the granaticin biosynthetic gene cluster of Streptomyces violaceoruber Tü22 involved in the biosynthesis of L-rhodinose | |
| EP1443113B1 (en) | Method of obtaining indolocarbazoles using biosynthetic rebeccamycin genes | |
| KR101688235B1 (en) | Novel aminoglycoside antibiotic, process for producing the same, and pharmaceutical use thereof | |
| KR101721750B1 (en) | Novel macrolactam glycoside derivatives, chemoenzymatic method for preparation thereof and antibacterial composition comprising the same | |
| KR100636653B1 (en) | Novel Olivosyl Pikromycin Derivatives and Method for Preparing the Same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| A107 | Divisional application of patent | ||
| AMND | Amendment | ||
| X701 | Decision to grant (after re-examination) | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20170622 Year of fee payment: 4 |
|
| FPAY | Annual fee payment |
Payment date: 20171219 Year of fee payment: 5 |
|
| FPAY | Annual fee payment |
Payment date: 20191001 Year of fee payment: 7 |