KR20060041165A - Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers - Google Patents
Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers Download PDFInfo
- Publication number
- KR20060041165A KR20060041165A KR1020057020870A KR20057020870A KR20060041165A KR 20060041165 A KR20060041165 A KR 20060041165A KR 1020057020870 A KR1020057020870 A KR 1020057020870A KR 20057020870 A KR20057020870 A KR 20057020870A KR 20060041165 A KR20060041165 A KR 20060041165A
- Authority
- KR
- South Korea
- Prior art keywords
- datagram
- network
- data
- server
- authentication
- Prior art date
Links
Images








Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/08—Network architectures or network communication protocols for network security for authentication of entities
- H04L63/0861—Network architectures or network communication protocols for network security for authentication of entities using biometrical features, e.g. fingerprint, retina-scan
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/30—Authentication, i.e. establishing the identity or authorisation of security principals
- G06F21/31—User authentication
- G06F21/34—User authentication involving the use of external additional devices, e.g. dongles or smart cards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L63/00—Network architectures or network communication protocols for network security
- H04L63/04—Network architectures or network communication protocols for network security for providing a confidential data exchange among entities communicating through data packet networks
- H04L63/0428—Network architectures or network communication protocols for network security for providing a confidential data exchange among entities communicating through data packet networks wherein the data content is protected, e.g. by encrypting or encapsulating the payload
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
- H04L9/08—Key distribution or management, e.g. generation, sharing or updating, of cryptographic keys or passwords
Landscapes
- Engineering & Computer Science (AREA)
- Computer Security & Cryptography (AREA)
- Theoretical Computer Science (AREA)
- Computer Hardware Design (AREA)
- General Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Computer Networks & Wireless Communication (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Computer And Data Communications (AREA)
- Storage Device Security (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
- Telephonic Communication Services (AREA)
- Mobile Radio Communication Systems (AREA)
Abstract
Description
배경기술Background
실시형태의 분야Field of Embodiments
본 발명은 일반적으로 디지털 네트워크 통신에 관한 것이다. 상세하게는, 본 발명은 공개 또는 비공개 네트워크 설정에서 원격 애플리케이션 서비스의 제공 및 보안 데이터 송신에 관한 것이다. 더 상세하게는, 개선된 액세스 제어, 관리 모니터링, 네트워크를 통한 데이터 송신 및 원격 애플리케이션 공유의 신뢰도 및 통합을 위한 방법 및 통합된 시스템이 제공된다. 개시된 방법 및 시스템은, 다수의 애플리케이션 및 네트워크 서비스가 지원되는 네트워크 트랜잭션에서 동적 데이터 스위칭을 가능하게 하는 데이터그램 스키마를 사용한다. 인증 및 암호화 방식의 구현을 가능하게 하는 이동식 지능형 데이터 캐리어가 다양한 실시형태에서 제공된다. 개시된 방법 및 시스템에 의해 가능한 퍼베이시브, 사용자 중심 네트워크 보안은, 금융 및 은행 환경, 국가 보안 및 군사적 정보 기술 (IT) 시스템, 건강 관리 네트워크, 법률 및 다른 전문 자문 서비스를 위한 IT 기반구조 및 다양한 온라인 상업 트랜잭션 시스템 등에 편리하게 배치될 수도 있다. 본 발명에 따른 시스템 및 방법은 생체인식 및 다른 적절한 인증 수단과 결합하여 구현될 수도 있다.The present invention relates generally to digital network communications. Specifically, the present invention relates to the provision of remote application services and secure data transmission in public or private network settings. More specifically, methods and integrated systems are provided for improved access control, management monitoring, data transmission over a network and reliability and integration of remote application sharing. The disclosed methods and systems use a datagram schema that enables dynamic data switching in network transactions where multiple applications and network services are supported. Removable intelligent data carriers are provided in various embodiments that enable the implementation of an authentication and encryption scheme. Pervasive, user-centric network security enabled by the disclosed methods and systems, IT infrastructure and various online commerce for financial and banking environments, national security and military information technology (IT) systems, healthcare networks, legal and other professional advisory services It may be conveniently disposed in a transaction system or the like. Systems and methods in accordance with the present invention may be implemented in combination with biometrics and other suitable authentication means.
관련 분야의 설명Description of the related field
국제화에 따른 디지털 혁명이 전례없는 방식으로 인간의 생활을 변화시키고 있다. 인터넷의 성장 및 진화가 새로운 국가간의 사업의 등장을 촉진하면서 기존 사업의 팽창을 가속시키고 있다. 현재의 국제 경제에서, 사업 또는 연구 기관의 생존능력은 정보를 프로세싱하고 관리하는 효율성에 크게 의존하고 있다. 데이터 송신 및 관리는 다양한 산업분야에서 점차 중요한 역할을 하고 있다. 엔지니어 및 사업 구상자들은, 안정되고 효율적인 데이터 송신, 효과적인 액세스 제어, 및 다수의 사용자에게 서비스되는 분산된 컴퓨터간에 애플리케이션의 원격 공유 및 관리를 가능하게 하는 기관 보안 네트워크 시스템에 대한 중요한 시도에 직면했다.The digital revolution of internationalization is changing human life in an unprecedented way. The growth and evolution of the Internet is accelerating the expansion of existing businesses, facilitating the emergence of businesses between new countries. In the current international economy, the viability of a business or research institution depends heavily on the efficiency of processing and managing information. Data transmission and management are playing an increasingly important role in various industries. Engineers and business people have faced important attempts at institutional security network systems that enable reliable and efficient data transmission, effective access control, and remote sharing and management of applications between distributed computers served to multiple users.
다양한 네트워크 구성이 규격화된 IT 기반구조에 사용되어 왔다. 예를 들어, 이더넷, 토큰 링 및 클라이언트-서버 아키텍쳐가 널리 채택되었다. 데이터 암호화 및 압축에 대한 관련 기술들이 유사하게 공지되고, 보안 데이터 송신을 용이하게 하는데 사용되어 왔다. 기존의 네트워크 시스템은 흔히 데이터 트랜잭션의 인터셉트 및 네트워크 접속의 손실을 겪는다. 일반적으로 손실된 접속을 복구하는 것은 어렵다. 손실된 접속의 파라미터를 정확하게 재확립하여 재접속의 무결성을 보장하는 것은 더 힘들다. 데이터는 유실될 수도 있고, 데이 터 송신은 다시 시작될 필요가 있다. 복구를 허용하는 정보의 시작 레벨을 추적하고 모을 수 없다면, 손실은 영속적일 수도 있다. 이러한 안정도의 부족이 데이터 송신의 신뢰도를 크게 위협하고 따라서, 분산적인 데이터 프로세싱 및 관리에 대한 치명적인 문제점을 제시한다. 이러한 실패에 대처하는데에 현저한 비용이 발생된다. 최근에 온라인 전자 사업이 직면한 어려움들에서 명백한 바와 같이, 이러한 문제점은 전체 산업을 방해할 수 있다.Various network configurations have been used for standardized IT infrastructure. For example, Ethernet, token ring, and client-server architectures have been widely adopted. Related techniques for data encryption and compression are similarly known and have been used to facilitate secure data transmission. Existing network systems often suffer from intercepts of data transactions and loss of network connectivity. In general, it is difficult to recover a lost connection. It is more difficult to accurately reestablish the parameters of the lost connection to ensure the integrity of the reconnection. Data may be lost and data transmission needs to be restarted. If the starting level of information allowing recovery can not be tracked and collected, the loss may be permanent. This lack of stability greatly threatens the reliability of data transmission and thus presents a fatal problem for distributed data processing and management. There is a significant cost in dealing with this failure. As is evident in the difficulties faced by the online electronics business in recent times, this problem can hinder the entire industry.
불안정하고 - 따라서 신뢰할 수 없는 - 네트워크 통신의 문제점은, 분산된 사업적 IT 환경에서 안전한 정보의 배포 및 애플리케이션 관리를 위한 포괄적이고, 견고하고, 사용자 친화적이며, 비용면에서 효율적인 네트워크 보안 솔루션의 부족에 의해 심화된다. 비공개 사업 및 공개 기관은 흔히 보안 침해로부터 현저한 금전전 손실을 겪는다. 또한, 통합되지 않은 정보 및 애플리케이션 관리때문에 비효율적인 IT 보안 솔루션에 많은 돈이 낭비되고 있다.The problem of unstable—and therefore unreliable—network communication is the lack of comprehensive, robust, user-friendly, and cost-effective network security solutions for secure information distribution and application management in distributed business IT environments. Deepened by Private businesses and public agencies often suffer significant financial losses from security breaches. In addition, a lot of money is wasted on inefficient IT security solutions because of unintegrated information and application management.
현재의 네트워크 보안 솔루션의 단점은 명백하다. 주로, 4 개의 양태가 현저하다: 첫째로, 현저하게 사업 성장을 제한하지 않고 전체 네트워크를 보호하는 통합 시스템이 부족하다. 상이한 보안 기능을 수행하기 위해, 조직은 상이한 판매자로부터 다수의 상품을 사용하는 것이 강요된다. 이러한 상품 각각은 전반적인 네트워크 보안 요구의 개별적인 면만을 해결한다. 예를 들어, 방화벽은 인터넷을 통해 송신되고 있는 데이터를 암호화하지 않고; 침입 탐지 시스템 (IDS) 은, 인증된 로그인 명칭 및 패스워드를 입력하여 가상 비공개 네트워크 (VPN) 를 여는 사람이 실제로 의도된 사용자인 것을 입증하고 보장하지 못하며; VPN 은 IT 부가 사용자 권리 및 액세스 정책을 모니터링하는 것을 돕지 않는다. 따라서, 기존의 시스템 또는 방법은 네트워크의 모든 면을 단독으로 보호하지 못한다. 경쟁하는 판매자들로부터의 다수의 보안 상품에 의존하는 것은 비호환성 문제를 발생시킨다. 또한, 가변적인 주변 보안 디바이스 및 소프트웨어 패키지를 유지하는 것은 매우 복잡하고 지나치게 고가이다. 대체로, 이러한 패치워크 솔루션은 규격화된 IT 프레임워크를 보호하는데 효과적이지 못하다.The disadvantages of current network security solutions are obvious. Primarily, four aspects are significant: First, there is a lack of integrated systems that protect the entire network without significantly limiting business growth. To perform different security functions, organizations are forced to use multiple products from different vendors. Each of these products addresses only the individual aspects of the overall network security needs. For example, a firewall does not encrypt data being transmitted over the internet; Intrusion Detection System (IDS) does not verify and guarantee that the person opening the virtual private network (VPN) by entering an authenticated login name and password is actually the intended user; VPNs do not help IT monitor user rights and access policies. Thus, existing systems or methods do not protect every aspect of the network alone. Relying on multiple security products from competing sellers creates incompatibilities. In addition, maintaining variable peripheral security devices and software packages is very complex and overly expensive. In general, these patchwork solutions are not effective in protecting standardized IT frameworks.
둘째로, 기존의 촛점은 디바이스 및 데이터를 보호하는데 있다. 이러한 시스템 중심 접근방식은 디바이스를 사용하는 개별 사용자의 액세스 지점을 보호할 수 없다. 현재의 접근방식의 이러한 내재된 문제점은, 디바이스의 수 및 사용자 이동성이 증가함에 따라 - 세계는 퍼베이시브 컴퓨팅으로 전이하고 있기 때문에 피할 수 없다 - 더 현저해진다.Second, the existing focus is on protecting devices and data. This system-centric approach cannot protect the access points of individual users of the device. This inherent problem of the current approach becomes more pronounced as the number of devices and user mobility increases—the world is inevitable because it is transitioning to pervasive computing.
시스템 중심 시스템에 내재하는 단점을 평가하기 위해, 사이버 범죄의 다양한 시나리오를 고려할 수 있다. 사이버 범죄는, 다른 사람으로 가장하거나 또는 라우팅 상에서 흔적을 감추어서, 그 아이텐티티를 위장하는 침입자의 시도로 흔히 표현된다. 사용자의 아이덴티티를 확립하고 입증하는데 사용되는 기술은 적어도 부분적으로는 오류가 있기 때문에, 이러한 시도는 너무나 자주 성공한다. 예를 들어, 대부분의 패스워드는 깨기 쉬우며; 패스워드는 흔히 분명하거나 또는 쉽게 위협받을 수 있는 디바이스 상에 저장되어 있다. 기존의 기반구조 지원 디지털 인증 및 공개/비공개 키 또한 남용될 수 있다. 따라서, 네트워크 디바이스의 사용자를 식별하고 이러한 사용자에 대한 디바이스를 보호하는 - 따라서 시 스템 중심인 - 기존의 방법은 내재적인 보안 장애를 나타낸다. 보호되는 네트워크에 액세스를 시도하는 사용자의 아이덴티티를 정확하게 하기 위해 효과적인 수단이 채택되지 않으면, 높은 레벨의 보안성은 환상으로 남을 것이다. 따라서, 더 양호한 네트워크 보안을 위해, 디바이스 및 데이터 보호로부터 사용자 보호로의 주요한 패러다임 변화가 정당화되고 있다. 사용자 아이덴티티를 확립하고 입증하여, 이동형 액세스 및 이벤트 기반 사용자 중심 보안을 가능하게 하는 사용자 중심 방식이 바람직하다.To assess the shortcomings inherent in system-centric systems, various scenarios of cybercrime can be considered. Cybercrime is often expressed as an intruder's attempt to disguise that identity, either by impersonating another person or hiding a trace on a route. Since the techniques used to establish and verify the identity of a user are at least partially error-prone, these attempts succeed too often. For example, most passwords are easy to break; Passwords are often stored on devices that are obvious or easily compromised. Existing infrastructure support digital certificates and public / private keys can also be abused. Thus, existing methods of identifying the users of network devices and protecting the devices for these users-and thus system-centric-represent inherent security barriers. Unless effective measures are taken to accurately identify the identity of a user attempting to access a protected network, a high level of security will remain an illusion. Thus, for better network security, a major paradigm shift from device and data protection to user protection is justified. A user-centric approach to establishing and validating user identities to enable mobile access and event-based user-centric security is desirable.
세째로, 기존의 IT 보안 솔루션은 일반 사용자에게는 너무 복잡하다. 평균적인 사용자가 복잡한 보안 과정을 수행하도록 기대되고, 이는 흔히 사업적 IT 환경에서 에러 및 보안 실패를 유발한다. 예를 들어, VPN 은 인스톨, 동작 또는 유지가 용이하지 않다. 암호화 이메일은 과도한 작업을 포함하여, 사용자가 거의 없다. 좋은 패스워드를 선택하고 기억하는 것조차 많은 사람들에게는 매우 귀찮을 수 있다. 복잡한 보안 과정을 수행하는 IT 전문가가 아닌 사용자에게 의존하는 것은 효과가 없다. 일반적인 사용자는 보안 과정을 우회하거나 이들을 완전히 무시하는 방법을 찾으려 할 수도 있다. 또한, 소프트웨어 패치의 범람을 유지하고 동작하는 것은 많은 IT 부의 자원을 고갈시키고, 용량을 초과하게 한다. 따라서, 사용자에게 친근하고 최소의 동작 및 관리로 충분한 효과적인 보안 솔루션이 요구된다.Third, traditional IT security solutions are too complex for the end user. The average user is expected to perform a complex security process, which often leads to errors and security failures in a business IT environment. For example, a VPN is not easy to install, operate or maintain. Encrypted emails include excessive work, with very few users. Even choosing and remembering a good password can be very annoying for many. Relying on non-IT professionals for complex security processes is ineffective. The average user may want to find a way to bypass the security process or ignore them completely. In addition, maintaining and operating a flood of software patches exhausts the resources of many IT departments and causes them to exceed capacity. Thus, there is a need for an effective security solution that is user friendly and sufficient with minimal operation and management.
마지막으로, 다른 분야에서와 같이, IT 보안 산업에는 특정한 관성이 존재한다. 변화 및 새로운 방법론은 어느 정도 저항받는다. 기존의 방식이 널리 보급되어 있고, 제공자측 및 소비자측 모두에서 네트워크 보안 솔루션을 지배하고 있다. 기존의 기술에 대한 집착, 및 개선과 변형에 대한 임시변통적인 접근방식이 진정으로 혁신적인 솔루션의 발전을 방해하고 있다.Finally, as in other areas, there is a certain inertia in the IT security industry. Changes and new methodologies are somewhat resisted. Traditional approaches are widespread and dominate network security solutions on both the provider and consumer sides. Obsession with existing technologies and ad hoc approaches to improvements and transformations are really hampering the development of innovative solutions.
전술한 이유 때문에, 소망하는 신뢰도, 효율, 및 사용자 친화력을 전달하는 새로운 네트워크 보안 패러다임이 요구되고 있다. 분산적인 IT 프레임워크의 요구를 충족시키고 퍼베이시브 컴퓨팅 및 정보 프로세싱을 지원할 수 있는 종류의 보안 솔루션이 기존의 오류에 대처해야 한다.For the reasons mentioned above, there is a need for a new network security paradigm that delivers the desired reliability, efficiency, and user friendliness. The kind of security solutions that can meet the needs of distributed IT frameworks and support pervasive computing and information processing must cope with existing errors.
숙련된 네트워크 엔지니어 또는 비지니스 IT 네트워크에 정통한 사용자는 더 뛰어난 IT 보안 솔루션의 중요성을 인식할 것이다. 이러한 목적으로, 규격화된 컴퓨팅 및 IT 네트워크의 연혁을 간략하게 리뷰하는 것이 유용할 것이다.Experienced network engineers or users familiar with business IT networks will recognize the importance of better IT security solutions. For this purpose, it would be useful to briefly review the history of standardized computing and IT networks.
제 1 컴퓨터는 메인프레임이었다. 이 복잡한 모놀리스 디바이스는 적절하게 기능하기 위해 보호된 환경을 요구했다. 이러한 디바이스들은 매우 특수한 지식을 가진 숙련된 기술자들에 의해서만 동작될 수 있었다. 이 디바이스들로의 액세스는 제한되었고, 이 디바이스들은 다른 디바이스와 제한된 접속성을 제공했다. 그 결과, 이들은 쉽게 보호되었다.The first computer was the mainframe. This complex monolithic device required a protected environment to function properly. These devices could only be operated by skilled technicians with very specific knowledge. Access to these devices was limited, and these devices provided limited connectivity with other devices. As a result, they were easily protected.
퍼스널 컴퓨터 (PC) 의 도래, 네트워크 기술의 진화, 및 특히 최근 인터넷의 폭발적인 성장은, 사람들이 컴퓨터를 사용하고 컴퓨터에 관련되는 방식을 변화시켰다. 컴퓨터 디바이스의 크기는 감소했고; 디바이스들은 쉽게 이동가능하게 되었고, 친근한 사용자 인터페이스의 도움으로 평범한 개인에 의해 동작가능하게 되었다. 정보 및 애플리케이션의 공유를 가능하게 하는 컴퓨터 네트워크를 생성 하기 위해 컴퓨터들은 접속되었다. 인터넷은 네트워크의 접속성을 그 정점 - 집합체가 될 수 있는 전세계적 접속성 - 까지 이끌었다. 데스크탑 및 랩탑 PC 에 추가하여, 가정 및 사무실의 외부에서 네트워크 액세스를 원하는 사람들 사이에 개인 휴대 단말기 (PDA), 테이블 PC, 및 이동 전화가 보편화되었다.The advent of personal computers (PCs), the evolution of network technologies, and especially the recent explosive growth of the Internet, have changed the way people use computers and relate to them. The size of the computer device has decreased; The devices have become easily mobile and can be operated by ordinary individuals with the help of a friendly user interface. Computers are connected to create a computer network that enables sharing of information and applications. The Internet has driven network connectivity to its climax-global connectivity that can be aggregates. In addition to desktop and laptop PCs, personal digital assistants (PDAs), table PCs, and mobile phones have become commonplace among people who want network access from outside of homes and offices.
기술의 급속한 진보 및 사업적 요구의 증대가 전세계적으로 IT 분야에 대한 전례없는 시도를 제공했다. 끊임없이 증가하는 데이터의 양 - 방대한 디바이스로부터 액세스가능한 - 이 보호될 필요가 있다. 또한, 이러한 보호는 "올웨이즈-온" 접속의 배경에 대해 실행되어야 한다. 또한, 인터넷에 관련한 사생활보호 및 정보 소유권을 다루는 많은 국가에서 규제 개시가 현저하다. 명백하게, 특히 퍼베이시브 컴퓨팅에 의해 표시되는 IT 진화의 불가피한 다음 국면의 관점에서, 기술적으로 견고하고 포괄적으로 비즈니스-와이즈한 네트워크 보안 솔루션이 요구된다. 모든 아날로그 디바이스는 디지털 디바이스에 의해 대체되고 있으며, 대체될 것이다. 텔레비젼, 전화기, CD 및 DVD, 디지털 카메라, 비디오 카메라, 및 컴퓨터 게임 플랫폼 등은 - 아직 아니라면 - 모두 인터넷 액세스를 지원할 것이다. 네트워크 데이터 액세스가 언제 어디서나 가능해짐에 따라, 사적인 통합 데이터 및 민감한 비공개 정보를 보호하기 위한 요구가 더 강해지고 있고, 이러한 요구를 충족시키는 어려움의 정도는 그에 따라 증가되고 있다.Rapid advances in technology and growing business demands have provided an unprecedented attempt in the global IT sector. The ever-increasing amount of data-accessible from vast devices-needs to be protected. This protection must also be carried out against the background of an "always-on" connection. In addition, regulatory initiation is prominent in many countries dealing with privacy and information ownership over the Internet. Clearly, there is a need for a technically robust and comprehensive business-wise network security solution, particularly in view of the inevitable next phase of the IT evolution represented by pervasive computing. All analog devices are being replaced by digital devices and will be replaced. Televisions, telephones, CDs and DVDs, digital cameras, video cameras, and computer game platforms—all if not yet—will support Internet access. As network data access becomes available anytime, anywhere, the need to protect private unified data and sensitive private information is growing, and the difficulty of meeting these needs is increasing accordingly.
요약하면, 조직화된 IT 기반구조의 진화, 및 보안 네트워크 통신에서의 현재의 결함을 반영하여, 당업자들은, 네트워크 데이터 송신의 보안성, 안정성, 효율성 및 유동성을 개선하는 시스템 및 방법에 대한 요구, 및 안전하고 신뢰할만한 전사 적 정보 관리 및 애플리케이션 공유를 위한 새로운 네트워크 패러다임의 필요를 인식할 것이다.In summary, reflecting the evolution of organized IT infrastructures and current deficiencies in secure network communications, those skilled in the art will appreciate the need for systems and methods for improving the security, stability, efficiency, and fluidity of network data transmission, and It will recognize the need for a new network paradigm for secure and reliable enterprise-wide information management and application sharing.
다양한 실시형태의 요약Summary of Various Embodiments
따라서, 본 발명의 목적은 보안 데이터 송신의 신뢰도, 유동성 및 효율성, 및 네트워크 상에서의 애플리케이션 공유를 개선하는 시스템 및 방법을 제공하는 것이다. 더 상세하게는, 본 명세서에 개시된 방법 및 시스템은, 안전하고 유동적인 네트워크 접속, 및 다수의 사용자들 사이에서 신뢰할 수 있고 효율적인 네트워크 트랜잭션을 지원하는 공개 클라이언트-서버 아키텍쳐를 가능하게 한다. 이러한 IT 네트워크 플랫폼은 퍼베이시브 보안, 즉, 다양한 네트워크 접속 디바이스에 요구되는 보안을 전달하고, 사용자 중심, 즉, 네트워크에 접속하기 위해 사용자가 사용하는 디바이스보다 사용자를 더 보호한다. 퍼베이시브 및 사용자 중심 보안은 본 명세서에 개시된 시스템 및 방법의 일 실시형태에 따라 언제 어디서든, 어떠한 네트워크 디바이스를 사용하든 실행될 수도 있다.It is therefore an object of the present invention to provide a system and method for improving the reliability, fluidity and efficiency of secure data transmission, and application sharing over a network. More specifically, the methods and systems disclosed herein enable open client-server architectures that support secure and flexible network connections, and reliable and efficient network transactions among multiple users. These IT network platforms deliver pervasive security, i.e. the security required for a variety of networked devices, and are more user-centric, i.e., more user-protected than the devices the user uses to connect to the network. Pervasive and user-centric security may be implemented anytime, anywhere, using any network device, in accordance with one embodiment of the systems and methods disclosed herein.
일 실시형태에서는, 데이터그램 스키마가 제공되고, 데이터그램 스키마는, 다수의 애플리케이션 및 네트워크 서비스를 지원하는 동적 데이터그램 스위칭의 구현을 허용한다. 또 다른 실시형태에서는, 이동식 지능형 데이터 캐리어가 제공되어, 사용자 인증을 위한 인증 및 암호화 방식을 구현한다. 본 발명에 따른 퍼베이시브, 사용자 중심 네트워크 보안은, 분산적인 컴퓨터 네트워크가 사용되는, 예를 들어, 정부, 군대, 공장을 포함하는 전사적 IT 환경에서, 또한 금융 서비스, 보험, 컨설팅, 건강관리 및 제약 산업에서 편리하게 배치될 수도 있다. 다양한 실시형태에 따르면, 이러한 IT 보안 플랫폼은, 특히 창고업, 세일즈, 고객 서비스, 마케팅 및 광고, 원격 전자 회의, 다양한 애플리케이션의 원격 공유를 포함하는 광범위한 비즈니스 동작들을 용이하게 할 수도 있다. 본 발명의 시스템 및 방법은 특정한 실시형태에서 생체인식법 및 또 다른 적절한 인증 방법론과 결합하여 구현될 수도 있다.In one embodiment, a datagram schema is provided, which allows for the implementation of dynamic datagram switching supporting multiple applications and network services. In another embodiment, a mobile intelligent data carrier is provided to implement an authentication and encryption scheme for user authentication. Pervasive, user-centric network security in accordance with the present invention is used in enterprise IT environments, including, for example, government, military, and factories where distributed computer networks are used, as well as in the financial services, insurance, consulting, healthcare and pharmaceutical industries. It may be conveniently arranged in. According to various embodiments, such an IT security platform may facilitate a wide range of business operations, particularly including warehousing, sales, customer service, marketing and advertising, teleconferencing, remote sharing of various applications. The systems and methods of the present invention may be implemented in combination with biometrics and another suitable authentication methodology in certain embodiments.
따라서, 본 발명은, 기존의 패치워크 솔루션에 비해 분산된 네트워크 보안 플랫폼을 제공한다. 네트워크가 다양한 어레이의 디바이스 또는 애플리케이션 인터페이스를 통해 접속하는 전세계적인 사용자들에게 자원을 동적으로 확장함에 따라, 조직이 전체 네트워크를 보호할 수 있게 하는 전체적인 접근방식이 얻어지고 단일한 솔루션이 제공된다. 본 발명의 네트워크 보안 플랫폼은, 사용자에 의해 사용되는 다양한 네트워크 호스트 디바이스가 아닌 사용자의 보호에 중점을 둔다. 이러한 사용자 중심 방식은 전례없는 단순화와 유동성을 제공하고, 네트워크 시스템에 개선된 사용자 친화력을 부여한다. 강화된 보안은 사용자에게 평이하다. 그러나, 사용자의 활동은 필요에 따라 효과적으로 모니터링될 수도 있다. IT 부는 모든 사용자 액세스에 대해 완전한 제어를 가진다.Thus, the present invention provides a distributed network security platform over existing patchwork solutions. As the network dynamically scales resources to global users connecting through various arrays of devices or application interfaces, a holistic approach is provided and organizations can provide a single solution to protect the entire network. The network security platform of the present invention focuses on the protection of a user rather than the various network host devices used by the user. This user-centric approach provides unprecedented simplicity and flexibility, and gives network systems improved user friendliness. Enhanced security is easy for the user. However, the user's activity may be effectively monitored as needed. The IT department has complete control over all user access.
본 발명에 따라, 일 실시형태에서는, 하나 이상의 사용자와 하나 이상의 네트워크 서버 사이에 보안 네트워크 접속 시스템이 제공된다. 이 시스템은: 하나의 사용자에게 송신되고, 적어도 (i) 데이터를 저장하기 위한 메모리 (ii) 데이터를 입력 및 출력하기 위한 하나의 입력-출력 장치 (iii) 메모리에 저장된 데이터를 프로세싱하기 위한 하나의 프로세서를 포함하고, 호스트 컴퓨터 디바이스에 접 속하여 입력-출력 장치를 통해 네트워크 상에서 데이터를 송신할 수 있고, 인증 및 암호화 방식을 통해 사용자에 대한 네트워크 아이덴티티를 확립하도록 구성되는 지능형 데이터 캐리어; 및 하나 이상의 사용자에게 서비스되는 다수의 애플리케이션에 대한 데이터그램을 동적으로 할당하고 스와핑하기 위한 동적 데이터그램 스위치를 포함한다.In accordance with the present invention, in one embodiment, a secure network connection system is provided between one or more users and one or more network servers. The system comprises: (i) a memory for storing data, (ii) one input-output device for inputting and outputting data, and (iii) one for processing data stored in the memory. An intelligent data carrier comprising a processor, coupled to the host computer device, capable of transmitting data on the network via the input-output device, and configured to establish a network identity for the user via authentication and encryption schemes; And a dynamic datagram switch for dynamically allocating and swapping datagrams for multiple applications serviced to one or more users.
일 실시형태에 따르면, 지능형 데이터 캐리어는 이동형이다. 또 다른 실시형태에 따르면, 지능형 데이터 캐리어는 USB 키, 컴팩트 플래시, 스마트 미디어, 컴팩트 디스크, DVD, PDA, 파이어와이어 디바이스 및 토큰 디바이스 중 하나로 구현된다.According to one embodiment, the intelligent data carrier is mobile. According to another embodiment, the intelligent data carrier is implemented with one of a USB key, compact flash, smart media, compact disk, DVD, PDA, Firewire device and token device.
또 다른 실시형태에 따르면, 인증 및 암호화 방식은: (a) 지능형 데이터 캐리어로부터 지능형 데이터 캐리어가 인증되는 네트워크 서버로 요청이 포워딩되는 단계; (b) 네트워크 서버가 지능형 데이터 캐리어에 복수의 인증 방법을 제공하는 단계; (c) 지능형 데이터 캐리어가 이벤트를 통한 복수의 인증 방법으로부터 하나를 선택하는 단계; (d) 선택된 방법에 기초하여, 네트워크 서버가 지능형 데이터 캐리어로부터의 인증 데이터에 대한 요구를 지능형 데이터 캐리어에 전송하는 단계; (e) 네트워크 서버가 지능형 데이터 캐리어로부터 수신된 인증 데이터를 하나 이상의 데이터 인증 객체로 변환하며, 각 데이터 인증 객체는 하나 이상의 분류자를 사용하여 분석될 수 있는 데이터 벡터 객체인 단계; (f) 하나 이상의 분류자에 따라 네트워크 서버가 데이터 인증 객체를 분석하여 인증 결과를 결정하는 단계; 및 (g) 네트워크 서버가 성공한 인증 시도 또는 실패한 인증 시도를 나타내는 결과 를 지능형 데이터 캐리어에 전송하는 단계를 포함한다.According to yet another embodiment, an authentication and encryption scheme includes: (a) forwarding a request from an intelligent data carrier to a network server where the intelligent data carrier is authenticated; (b) the network server providing a plurality of authentication methods to the intelligent data carrier; (c) the intelligent data carrier selecting one from the plurality of authentication methods through the event; (d) based on the selected method, the network server sending a request for authentication data from the intelligent data carrier to the intelligent data carrier; (e) the network server converting authentication data received from the intelligent data carrier into one or more data authentication objects, each data authentication object being a data vector object that can be analyzed using one or more classifiers; (f) the network server analyzing the data authentication object according to one or more classifiers to determine an authentication result; And (g) the network server transmitting a result indicating the successful authentication attempt or the failed authentication attempt to the intelligent data carrier.
또 다른 실시형태에 따르면, 단계 (c) 의 이벤트는 마우스 클릭, 스크린 상의 터치, 키스트로크, 발성, 또는 생체인식 측정값이다.According to another embodiment, the event of step (c) is a mouse click, a touch on the screen, a keystroke, speech, or biometric measurement.
또 다른 실시형태에 따르면, 단계 (e) 의 요구는 의사 랜덤 및 순수 (true) 랜덤 코드 중 적어도 하나를 포함한다. 의사 랜덤 코드는 수학적으로 미리 계산된 리스트에 기초하여 생성된다. 순수 랜덤 코드는 시스템 외부에서 엔트로피 소스를 샘플링하고 프로세싱함으로써 생성된다. According to another embodiment, the requirement of step (e) comprises at least one of pseudo random and true random codes. Pseudo random codes are generated based on a mathematically precomputed list. Pure random code is generated by sampling and processing entropy sources outside the system.
또 다른 실시형태에 따르면, 랜덤화는 하나 이상의 랜덤 생성기 및 하나 이상의 독립 시드로 수행된다.According to another embodiment, randomization is performed with one or more random generators and one or more independent seeds.
또 다른 실시형태에 따르면, 단계 (f) 의 분석은 하나 이상의 분석 룰에 기초한다. 또 다른 실시형태에서, 하나 이상의 분석 룰은 단계 (e) 의 하나 이상의 분류자에 따른 분류를 포함한다.According to another embodiment, the analysis of step (f) is based on one or more analysis rules. In yet another embodiment, the one or more analysis rules comprise classification according to one or more classifiers of step (e).
또 다른 실시형태에 따르면, 분류는 화자 입증이고, 데이터 객체 벡터는 2 개의 클래스, 즉, 목표 화자 및 사칭자를 포함한다. 각 클래스는 확률 밀도 함수에 의해 특징지어지고, 단계 (f) 의 결정은 2 진 판정의 문제이다.According to another embodiment, the classification is speaker verification and the data object vector comprises two classes, a target speaker and a surname. Each class is characterized by a probability density function, and the decision of step (f) is a matter of binary decision.
또 다른 실시형태에 따르면, 단계 (f) 의 결정은, 단계 (e) 의 하나 이상의 분류자에 기초하여 하나 이상의 데이터 벡터 객체로부터 합, 우위 및 확률 중 적어도 하나를 계산하는 것을 포함한다. 또 다른 실시형태에서, 합은 하나 이상의 데이터 벡터 객체로부터 계산된 최고 및 랜덤 합 중 하나이다.According to yet another embodiment, the determination of step (f) comprises calculating at least one of a sum, an advantage and a probability from one or more data vector objects based on the one or more classifiers of step (e). In another embodiment, the sum is one of the highest and random sums calculated from one or more data vector objects.
또 다른 실시형태에 따르면, 단계 (e) 의 하나 이상의 분류자는 2 이상의 데 이터 벡터 객체로부터 유도된 수퍼 분류자를 포함한다.According to another embodiment, the one or more classifiers of step (e) comprise a super classifier derived from two or more data vector objects.
또 다른 실시형태에 따르면, 수퍼 분류자는, 음성 인식, 지문, 핸드프린트, 혈액형, DNA 테스트, 망막 또는 홍채 스캔, 및 얼굴 인식 중 적어도 하나를 포함하는 물리적 생체인식법에 기초한다. 또 다른 실시형태에 따르면, 수퍼 분류자는 개인적 행동의 습관 또는 패턴을 포함하는 행위적 생체인식법에 기초한다.According to another embodiment, the super classifier is based on physical biometrics, including at least one of voice recognition, fingerprint, handprint, blood type, DNA test, retinal or iris scan, and face recognition. According to another embodiment, the super classifier is based on behavioral biometrics that includes habits or patterns of personal behavior.
또 다른 실시형태에 따르면, 인증 및 암호화 방식은 비대칭적 및 대칭적 다중-암호 암호화를 포함한다. 또 다른 실시형태에 따르면, 암호화는 출력 피드백, 암호 피드백, 암호 블록 체인 및 암호 포워딩 중 적어도 하나를 사용한다. 또 다른 실시형태에서, 암호화는 차세대 암호화 표준 (AES) 륀다엘 (Rijndael) 에 기초한다.According to another embodiment, the authentication and encryption scheme comprises asymmetric and symmetric multi-password encryption. According to yet another embodiment, encryption uses at least one of output feedback, cipher feedback, cipher blockchain, and cipher forwarding. In another embodiment, the encryption is based on the Next Generation Encryption Standard (AES) Rijndael.
또 다른 실시형태에 따르면, 인증 및 암호화 방식은 보안 키 교환 (SKE) 을 사용한다. 일 실시형태에서 SKE 는 공개 키 시스템을 사용한다. 또 다른 실시형태에서 SKE 는 타원 곡선 암호시스템 (ECC) 비공개 키를 사용한다.According to yet another embodiment, the authentication and encryption scheme uses secure key exchange (SKE). In one embodiment, the SKE uses a public key system. In another embodiment, the SKE uses an elliptic curve cryptosystem (ECC) private key.
또 다른 실시형태에서, 인증 및 암호화 방식은, 지능형 데이터 캐리어가 서버에 등록되었음을 검증하는 논리 테스트, 지능형 데이터 캐리어 및 호스트 컴퓨터 디바이스에서 물리적 파라미터를 검증하기 위한 디바이스 테스트, 및 이벤트 레벨 데이터에 기초하여 사용자를 인증하기 위한 개인적 테스트 중 적어도 하나를 포함한다.In yet another embodiment, the authentication and encryption scheme is based on a logical test that verifies that the intelligent data carrier has been registered with the server, a device test for verifying physical parameters at the intelligent data carrier and host computer device, and a user based on event level data. At least one of a personal test for authenticating.
또 다른 실시형태에 따르면, 다수의 애플리케이션은, 윈도우 기반 원격 단말 서버 애플리케이션, 메인프레임을 위한 3270/5250 단말 에뮬레이터 상의 애플리케 이션, 직접 내장된 애플리케이션, 및 멀티미디어 애플리케이션 중 적어도 하나를 포함하고, 직접 내장된 애플리케이션은, 데이터베이스 애플리케이션, 데이터 분석 툴, 고객 관련 관리 (CRM) 툴, 및 전사적 자원 관리 (ERP) 패키지 중 적어도 하나를 포함한다.According to yet another embodiment, the plurality of applications includes at least one of a Windows-based remote terminal server application, an application on a 3270/5250 terminal emulator for the mainframe, a direct embedded application, and a multimedia application. The application includes at least one of a database application, a data analysis tool, a customer relationship management (CRM) tool, and an enterprise resource planning (ERP) package.
또 다른 실시형태에 따르면, 동적 데이터그램 스위치는 데이터그램 스키마 및 파서를 포함한다. 데이터그램 스키마는 하나 이상의 데이터그램 타입에 속하는 2 이상의 데이터그램을 포함한다. 데이터그램은, (i) 네트워크 송신에 대한 콘텐츠 데이터, 및 (ii) 네트워크 접속을 관리하고 제어하기 위한 또 다른 정보를 반송하고 네트워크 애플리케이션을 지원하도록 구성된다. 각 데이터그램 타입은 복수의 함수를 가진다. 파서는 하나 이상의 데이터그램 타입을 파싱하도록 구성된다.According to another embodiment, the dynamic datagram switch includes a datagram schema and parser. The datagram schema includes two or more datagrams belonging to one or more datagram types. The datagram is configured to carry (i) content data for network transmissions, and (ii) further information for managing and controlling network connections and to support network applications. Each datagram type has multiple functions. The parser is configured to parse one or more datagram types.
또 다른 실시형태에 따르면, 데이터그램 스키마는 하나 이상의 주 (major) 데이터그램 타입, 및 하나의 주 데이터그램 타입 내의 하나 이상의 부 (minor) 데이터그램 타입을 포함한다.According to another embodiment, the datagram schema includes one or more major datagram types, and one or more minor datagram types within one primary datagram type.
또 다른 실시형태에 따르면, 파서는 데이터그램 타입의 매트릭스를 파싱할 수 있다. 또 다른 실시형태에 따르면, 매트릭스는, 제 1 다수의 주 데이터그램 타입, 및 제 1 다수의 각 주 데이터그램 타입 내의 제 2 다수의 부 데이터그램 타입를 포함한다.According to yet another embodiment, the parser may parse a matrix of datagram types. According to yet another embodiment, the matrix comprises a first plurality of primary datagram types and a second plurality of secondary datagram types within the first plurality of primary datagram types.
또 다른 실시형태에 따르면, 주 데이터그램 타입은, (i) 사용자 접속을 인증하는 서버 메시지 및 접속 제어 데이터그램, (ii) 콘텐츠 데이터를 송신하는 콘텐 츠 데이터그램, (iii) 포인트 대 포인트, 포인트 대 멀티포인트, 및 멀티포인트 대 멀티포인트 데이터 송신을 관리하는 통지 데이터그램, (iv) 네트워크 서버와 지능형 데이터 캐리어 사이에 프록시 데이터를 전달하는 접속 프록시 데이터그램, (v) 실시간으로 메시지를 송신하는 인스턴트 메시지 타입, (vi) 대량의 데이터 및 미디어 파일을 전달하는 대량 콘텐츠 전달 데이터그램, (vii) 네트워크 사용자를 탐색하는 사용자 디렉토리 데이터그램, 및 (viii) 원격으로 네트워크 사용자를 제어하는 원격 관리 데이터그램을 포함하는 그룹으로부터 선택된다.According to yet another embodiment, the primary datagram type includes (i) a server message and a connection control datagram authenticating a user connection, (ii) a content datagram transmitting content data, (iii) point to point, point Notification datagrams for managing multipoint-to-multipoint and multipoint-to-multipoint data transmissions, (iv) Connection proxy datagrams that carry proxy data between network servers and intelligent data carriers, and (v) Instant sending messages in real time Message types, (vi) bulk content delivery datagrams carrying large amounts of data and media files, (vii) user directory datagrams to navigate network users, and (viii) remotely managed datagrams to remotely control network users. It is selected from the group containing.
또 다른 실시형태에 따르면, 데이터그램 스키마의 각 데이터그램은, (A) (i) 하나 이상의 주 데이터그램 타입, (ii) 하나 이상의 부 데이터그램 타입, (iii) 데이터그램 길이, 및 (iv) 데이터그램 체크섬에 대한 헤더 필드, 및 (B) 송신에서 데이터를 반송하기 위한 데이터그램 페이로드를 포함하는 일반 레이아웃을 가진다.According to yet another embodiment, each datagram in the datagram schema includes (A) (i) one or more primary datagram types, (ii) one or more secondary datagram types, (iii) datagram lengths, and (iv) A header field for the datagram checksum, and (B) a general layout comprising a datagram payload for carrying data in the transmission.
또 다른 실시형태에서, 일반 레이아웃은 하나 이상의 추가 헤더 필드를 포함한다. 또 다른 실시형태에서, 일반 레이아웃은 TCP 헤더에 후속한다.In yet another embodiment, the general layout includes one or more additional header fields. In another embodiment, the general layout follows the TCP header.
또 다른 실시형태에서, 지능형 데이터 캐리어는, 레이더 접속기를 더 포함하고; 레이더 접속기는 네트워크와 인터페이싱하며 네트워크 접속을 모니터링하고 제어하도록 구성된다. 또 다른 실시형태에서, 네트워크 서버는 네트워크 접속을 모니터링하고 제어하는 레이더 접속기를 더 포함한다. 네트워크 서버의 레이더 접속기는 네트워크를 통해 지능형 데이터 캐리어의 레이더 접속기에 접속된다. 또 다른 실시형태에서, 레이더 접속기는 손실된 접속을 검출하고, 네트워크 서버에의 콘택트를 개시하여 접속을 재확립하도록 더 구성된다.In yet another embodiment, the intelligent data carrier further comprises a radar connector; The radar connector interfaces with the network and is configured to monitor and control the network connection. In yet another embodiment, the network server further includes a radar connector that monitors and controls network connections. The radar connector of the network server is connected to the radar connector of the intelligent data carrier via the network. In yet another embodiment, the radar connector is further configured to detect the lost connection, initiate a contact to the network server and reestablish the connection.
또 다른 실시형태에 따르면, 보안 네트워크 접속 시스템은, 기존의 네트워크를 네트워크 서버에 접속시키고 기존의 네트워크와 지능형 데이터 캐리어 사이에서 네트워크 서버를 통해 데이터를 송신하도록 구성되는 인젝터를 더 포함하며, 기존의 네트워크는 무선 또는 유선이다. 또 다른 실시형태에서, 인젝터는, 네트워크와 인터페이싱하고, 네트워크 접속을 모니터링하고 제어하는 레이더 접속기를 더 포함한다.According to another embodiment, the secure network connection system further comprises an injector configured to connect the existing network to the network server and to transmit data via the network server between the existing network and the intelligent data carrier, the existing network Is wireless or wired. In yet another embodiment, the injector further comprises a radar connector that interfaces with the network and monitors and controls the network connection.
본 발명에 따르면, 또 다른 실시형태에서는, 하나 이상의 서버 및 하나의 클라이언트를 포함하는 클라이언트-서버 통신 시스템이 제공된다. 서버는, 복수의 네트워크 애플리케이션에 대한 데이터그램을 동적으로 할당하고 스와핑하는 동적 데이터그램 스위치를 포함한다. 클라이언트는, 호스트 컴퓨터 디바이스와 접속하여, 네트워크 상에서 입력-출력 장치를 통해 데이터를 송신할 수 있는 지능형 데이터 캐리어이다. 지능형 데이터 캐리어는 서버와 클라이언트 사이에서 보안 데이터 송신을 위한 인증 및 암호화 스킴을 통해 네트워크 사용자 아이덴티티를 확립하도록 구성된다.In accordance with the present invention, in another embodiment, a client-server communication system is provided that includes one or more servers and one client. The server includes a dynamic datagram switch that dynamically allocates and swaps datagrams for a plurality of network applications. A client is an intelligent data carrier capable of connecting with a host computer device and sending data over an input-output device on a network. The intelligent data carrier is configured to establish network user identity through an authentication and encryption scheme for secure data transmission between the server and the client.
또 다른 실시형태에 따르면, 클라이언트-서버 통신 시스템은, 기존의 네트워크를 서버에 접속시키고, 서버를 통해 기존의 네트워크와 클라이언트 사이에 데이터를 송신하도록 구성되는 인젝터를 더 포함한다. 기존의 네트워크는 유선 또는 무선이다.According to yet another embodiment, the client-server communication system further comprises an injector configured to connect the existing network to the server and to transmit data between the existing network and the client via the server. Existing networks are wired or wireless.
또 다른 실시형태에 따르면, 서버, 클라이언트 및 인젝터 각각은 레이더 접속기를 포함한다. 레이더 접속기는 네트워크와 인터페이싱하며 네트워크 접속 을 모니터링하고 제어하도록 구성된다. 클라이언트의 레이더 접속기는 네트워크를 통해 서버의 레이더 접속기에 접속되고, 인젝터의 레이더 접속기는 네트워크를 통해 서버의 레이더 접속기에 접속된다.According to yet another embodiment, each of the server, client and injector comprises a radar connector. The radar interface interfaces with the network and is configured to monitor and control the network connection. The radar connector of the client is connected to the radar connector of the server via the network, and the radar connector of the injector is connected to the radar connector of the server via the network.
또 다른 실시형태에 따르면, 클라이언트-서버 통신 시스템의 서버는, 클라이언트를 위한 전용 데이터 저장을 위한 암호화 가상 파일 시스템을 더 포함한다.According to yet another embodiment, the server of the client-server communication system further comprises an encrypted virtual file system for storing dedicated data for the client.
본 발명에 따라, 또 다른 실시형태에서는, 적어도 (i) 데이터를 저장하는 하나의 메모리, (ii) 데이터를 입력 및 출력하는 하나의 입력-출력 장치, 및 (iii) 메모리에 저장된 데이터를 프로세싱하는 하나의 프로세서를 포함하는 지능형 데이터 캐리어가 제공된다. 지능형 데이터 캐리어는 호스트 컴퓨터 디바이스에 접속되어 입력-출력 장치를 통해 네트워크 상에서 데이터를 송신할 수 있다. 데이터 송신은 동적 스위치 데이터그램을 통해 이루어진다. 지능형 데이터 캐리어는 보안 네트워크 데이터 송신을 위한 인증 및 암호화 방식을 통해 네트워크 사용자 아이덴티티를 확립하도록 구성된다.According to the invention, in another embodiment, at least (i) one memory for storing data, (ii) one input-output device for inputting and outputting data, and (iii) processing data stored in the memory An intelligent data carrier is provided that includes one processor. An intelligent data carrier can be connected to a host computer device to transmit data on a network via an input-output device. Data transmission is via dynamic switch datagrams. The intelligent data carrier is configured to establish a network user identity through an authentication and encryption scheme for secure network data transmission.
본 발명에 따라, 또 다른 실시형태에서는, 보안 네트워크 통신을 위한 방법이 제공된다. 이 방법은: 네트워크 상의 호스트 컴퓨터 디바이스에 접속되어, IO 장치를 통해 네트워크 상에서 데이터를 송신하고 인증 및 암호화 방식을 통해 네트워크 사용자에 대한 네트워크 아이덴티티를 확립할 수 있는 지능형 데이터 캐리어를 네트워크 사용자에게 송신하는 단계; 및 다수의 애플리케이션 지원시에 데이터그램의 동적 할당 및 스와핑을 위한 동적 데이터그램 스위치를 네트워크 상의 서버에 제공하는 단계를 포함한다. 다양한 실시형태에서, 이 방법은 데이터 벡 터 객체와 결합하여 인증, 암호화, 및 랜덤화를 수행한다. 특정한 실시형태에서는, 특히 물리적 및 행위적 생체인식 측정값을 가진 수퍼 분류자가 사용된다.In accordance with the present invention, in another embodiment, a method for secure network communication is provided. The method comprises the steps of: sending an intelligent data carrier to a network user, which is connected to a host computer device on the network, which can transmit data on the network via an IO device and establish a network identity for the network user via authentication and encryption schemes. ; And providing a server on the network with a dynamic datagram switch for dynamic allocation and swapping of datagrams in support of multiple applications. In various embodiments, the method combines with a data vector object to perform authentication, encryption, and randomization. In particular embodiments, super classifiers are used that have physical and behavioral biometric measurements in particular.
본 발명에 따라, 또 다른 실시형태에서는, 하나 이상의 애플리케이션을 사용자에게 목표 전달하는 방법이 제공된다. 이 방법은, 네트워크 서버가 배치되는 네트워크에 접속되며 네트워크를 통해 네트워크 서버와 통신하는 호스트 컴퓨터 디바이스에 도킹하도록 구성되는 지능형 데이터 캐리어를 사용자에게 송신하고, 네트워크 서버는 동적 스위치 데이터그램을 통해 지능형 데이터 캐리어와 통신하는 단계; 서버가 인증 및 암호화 방식을 통해 사용자를 인증하는 단계; 및 인증 성공시에 사용자에게 하나 이상의 애플리케이션에의 액세스를 승인하는 단계를 포함한다.In accordance with the present invention, in another embodiment, a method of delivering one or more applications to a user is provided. The method sends an intelligent data carrier to a user connected to a network on which the network server is deployed and configured to dock over a network to a host computer device that communicates with the network server, the network server sending the intelligent data carrier via a dynamic switch datagram. Communicating with; The server authenticating the user through an authentication and encryption scheme; And authorizing the user to access one or more applications upon successful authentication.
또 다른 실시형태에 따르면, 하나 이상의 애플리케이션은 지능형 데이터 캐리어 상에 미리 로드되거나 네트워크 서버 또는 호스트 컴퓨터 디바이스 상에 인스톨된다. 또 다른 실시형태에서, 호스트 컴퓨터 디바이스는 유선 또는 무선 수단을 통해 네트워크에 접속된다. 호스트 컴퓨터 디바이스는 데스크탑 또는 랩탑 컴퓨터, 개인 휴대 단말기 (PDA), 이동 전화, 디지털 TV, 오디오 또는 비디오 플레이어, 컴퓨터 게임 콘솔, 디지털 카메라, 카메라폰, 및 네트워크 가능 가전기기일 수도 있다.According to yet another embodiment, one or more applications are preloaded on an intelligent data carrier or installed on a network server or host computer device. In yet another embodiment, the host computer device is connected to the network via wired or wireless means. The host computer device may be a desktop or laptop computer, a personal digital assistant (PDA), a mobile phone, a digital TV, an audio or video player, a computer game console, a digital camera, a camera phone, and a network capable home appliance.
또 다른 실시형태에 따르면, 하나 이상의 애플리케이션은 윈도우 기반 원격 단말 서버 애플리케이션, 메인프레임에 대한 3270/5250 단말 에뮬레이터 상의 애플리케이션, 직접 내장된 애플리케이션, 및 멀티미디어 애플리케이션일 수도 있다. 직접 내장된 애플리케이션은 데이터베이스 애플리케이션, 데이터 분석 툴, 고객 관 련 관리 (CRM) 툴, 및 전사적 자원 관리 (ERP) 패키지 중 하나 이상을 포함한다.According to yet another embodiment, the one or more applications may be a Windows-based remote terminal server application, an application on a 3270/5250 terminal emulator for the mainframe, a directly embedded application, and a multimedia application. Directly embedded applications include one or more of database applications, data analysis tools, customer relationship management (CRM) tools, and enterprise resource planning (ERP) packages.
도면의 간단한 설명Brief description of the drawings
도 1 은 본 발명의 일 실시형태에 따른 클라이언트, 서버, 및 인젝터 사이의 상호작용을 도시한다.1 illustrates the interaction between a client, a server, and an injector in accordance with one embodiment of the present invention.
도 2 는 본 발명의 또 다른 실시형태에 따른 객체 벡터 수퍼 분류자를 도시한다. 2 illustrates an object vector super classifier in accordance with another embodiment of the present invention.
도 3 은 본 발명의 또 다른 실시형태에 따른, 다양한 구성요소, 모듈 및 그와 관련된 프로세스를 포함하는 데이터그램 파서를 도시한다.3 illustrates a datagram parser that includes various components, modules, and associated processes, in accordance with another embodiment of the present invention.
도 4 는 본 발명의 또 다른 실시형태에 따른 데이터그램의 일반 레이아웃이다.4 is a general layout of a datagram according to another embodiment of the invention.
도 5 는 본 발명의 또 다른 실시형태에 따른, 지능형 데이터 캐리어, 다양한 모듈 및 그에 따라 구현되는 프로세스를 도시한다.5 illustrates an intelligent data carrier, various modules, and a process implemented according to another embodiment of the present invention.
도 6 은 본 발명의 또 다른 실시형태에 따른, 다양한 구성요소, 모듈 및 그와 관련된 프로세스를 포함하는 클라이언트를 도시한다.6 illustrates a client including various components, modules, and associated processes, in accordance with another embodiment of the present invention.
도 7 은 본 발명의 또 다른 실시형태에 따른, 다양한 구성요소, 모듈 및 그와 관련된 프로세스를 포함하는 서버를 도시한다.7 illustrates a server including various components, modules, and processes associated therewith, in accordance with another embodiment of the present invention.
도 8 은 본 발명의 또 다른 실시형태에 따른, 다양한 구성요소, 모듈 및 그와 관련된 프로세스를 포함하는 인젝터를 도시한다.8 illustrates an injector including various components, modules and processes associated therewith, in accordance with another embodiment of the present invention.
다양한 실시형태의 상세한 설명Detailed Description of Various Embodiments
관련 용어의 간단한 설명Brief description of related terms
다음의 용어들, 네트워크, 클라이언트, 서버, 데이터, 데이터 벡터 객체 (또한 데이터 객체 벡터, 객체 벡터라고도 한다), 분류자, 의사 결정, 결정 분석, 객체 기반 결정 분석 (또한 객체 분석이라고도 한다), 난수, 난수 생성기, 시드, 랜덤화, 확률, 확률 밀도 함수, 인증, 비공개 키, 공개 키, 타원 곡선 암호화 (ECC; Elliptic Curve Cryptography), ECC 서명, 파서 (parser), 패킷, 헤더, TCP, UDP, 방화벽, 범용 직렬 버스 (USB; Universal Serial Bus), 애플 직렬 버스 (ASB), 직렬 포트, 병렬 포트, 토큰, 파이어와이어, 및 본 발명의 명세서 전체에 걸친 또 다른 관련 용어는 종래 기술, 즉, 수학, 컴퓨터과학, 정보 기술 (IT), 물리학, 통계학, 인공 지능, 디지털 네트워크, 네트워크 통신, 인터넷 기술, 암호해독법, 암호 및 해독, 압축 및 압축해제, 분류 이론, 예측 모델링, 의사 결정, 음성 인식 및 생체인식법에서 확립된 통상의 의미와 일관되게 이해되어야 한다.The following terms: network, client, server, data, data vector object (also known as data object vector, object vector), classifier, decision making, decision analysis, object based decision analysis (also called object analysis), random numbers Random number generator, seed, randomization, probability, probability density function, authentication, private key, public key, elliptic curve cryptography (ECC), ECC signature, parser, packet, header, TCP, UDP, Firewall, Universal Serial Bus (USB), Apple Serial Bus (ASB), Serial Port, Parallel Port, Token, Firewire, and other related terms throughout the specification of the present invention are known in the art, i. , Computer Science, Information Technology (IT), Physics, Statistics, Artificial Intelligence, Digital Networks, Network Communications, Internet Technology, Decryption, Encryption & Decryption, Compression & Decompression, Classification Theory, Predictive Modeling, Decision Making, Speech Expression, and to be understood consistently with the normal meaning in the established biometric method.
다음의 용어들, 안전 키 교환 (SKE; Secure Key Exchange), 차세대 암호화 방식 (AES; Advance Encryption Standard), 공개 키 기반구조 (PKI; Public Key Infrastructure), 암호화 가상 파일 시스템 (EVFS; Encrypted Virtual Files Systems), 가상 사설 네트워크 (VPN; Virtual Private Network), 침입 탐지 시스템 (IDS; Intrusion Detection System), 비무장 지대 (DMZ), 개인 휴대 단말기 (PDA), USB 키, USB 토큰, USB 동글 (dongle), 병렬 포트 동글, 직렬 포트 동글, 파이어와이어 디바이스, 토큰 디바이스, 스마트 카드, 스마트 미디어, 컴팩트 플래시, 스마트 디지털 미디어, DVD, 컴팩트 디스크, 멀티프로토콜 레이블 스위칭 표준 (MPLS), 라이트웨이트 디렉토리 액세스 프로토콜 (LDAP; Lightweight Directory Access Protocol), 전자 데이터 교환 (EDI), 인터넷 릴레이 챗 (IRC; Internet Relay Chat), 순환 중복 검사 (CRC; Cyclic Redundancy Checksum), 터미널 식별자 (TID; Terminal Identifier), 및 본 발명의 명세서 전체에 걸친 또 다른 관련 용어들은, IT 산업, 전자 또는 온라인 상업 및 특정한 네트워크 보안 및 특정 관련 분야에서 확립된 통상의 의미와 일관되게 이해되어야 한다.The following terms: Secure Key Exchange (SKE), Advance Encryption Standard (AES), Public Key Infrastructure (PKI), Encrypted Virtual Files Systems (EVFS) ), Virtual Private Network (VPN), Intrusion Detection System (IDS; Intrusion Detection System), DMZ, Personal Digital Assistant (PDA), USB Key, USB Token, USB Dongle, Parallel Port Dongle, Serial Port Dongle, Firewire Device, Token Device, Smart Card, Smart Media, Compact Flash, Smart Digital Media, DVD, Compact Disc, Multiprotocol Label Switching Standard (MPLS), Lightweight Directory Access Protocol (LDAP) Directory Access Protocol (EDI), Internet Relay Chat (IRC), Cyclic Redundancy Checksum (CRC), Terminal Identifier (TID; Terminal Identifier), and other related terms across the entire context of the present invention are to be consistently understood and the IT industry, electronic or online commerce, and the specific network security and common sense is established in certain related areas.
본 명세서에서 사용하는 네트워크는 원격으로 디지털 및/또는 아날로그 데이터를 송신하도록 구성되는 매체 (광섬유 등) 를 통해 상호접속되는 임의의 네트워크 가능 디바이스의 그룹을 말한다. 네트워크는 인터넷과 같은 공개 네트워크일 수도 있고, 기업 인트라넷 시스템과 같은 비공개 네트워크일 수도 있다. 네트워크 접속 디바이스, 접속 디바이스 또는 디바이스라고도 하는 네트워크 가능 디바이스는 컴퓨터, 디지털 이동 전화, PDA, 디지털 카메라, 디지털 오디오-비디오 통신기 또는 유무선 수단을 통해 네트워크에 접속할 수도 있는 임의의 다른 디바이스일 수도 있다. 네트워크 접속 디바이스는 본 명세서에서 말하는 클라이언트 또는 서버일 수도 있다. 일 실시형태에서, 접속 디바이스는 지능형 데이터 캐리어와 같은 이동 클라이언트를 위한 호스트 컴퓨터일 수도 있다. 지능형 데이터 캐리어로서의 클라이언트에 대한 다음의 설명을 참조한다. 특정한 실시형태에서, 네트워크는 하나 이상의 이러한 클라이언트 및 하나 이상의 이러한 서버를 포함할 수도 있다. 또 다른 실시형태에서는, 네트워크는, 이하 본 명세서의 상세한 설명에서 설명하는 하나 이상의 인젝터를 또한 포함한다.As used herein, a network refers to any group of network capable devices that are interconnected through a medium (such as optical fiber) that is configured to transmit digital and / or analog data remotely. The network may be a public network, such as the Internet, or a private network, such as a corporate intranet system. A network capable device, also referred to as a network connected device, connected device or device, may be a computer, digital mobile phone, PDA, digital camera, digital audio-video communicator, or any other device that may connect to the network via wired or wireless means. The network connection device may be a client or server as referred to herein. In one embodiment, the connecting device may be a host computer for a mobile client, such as an intelligent data carrier. See the following description of the client as an intelligent data carrier. In a particular embodiment, the network may include one or more such clients and one or more such servers. In another embodiment, the network also includes one or more injectors described in the detailed description herein below.
본 명세서에서 사용되는 가상 사설 네트워크 (VPN) 는 보안 과정 및 터널링 을 적용하여 인터넷과 같은 공개 네트워크 기반구조를 공유하면서 네트워크 트랜잭션에서 프라이버시를 달성한다. 터널링은 보호된 데이터 - 비즈니스에 대한 사유물 또는 개인에 대한 비밀 - 의 공개 네트워크를 통한 송신을 말한다. 공개 네트워크에서의 라우팅 노드는, 송신이 사설 네트워크의 일부임을 인식하지 못한다. 통상적으로, 사설 네트워크 데이터 및 프로토콜 정보를 공개 네트워크 송신 유닛 내에 캡슐화함으로써 터널링이 달성되어, 사설 네트워크 프로토콜 정보는 데이터로서 공개 네트워크에 나타난다. 터널링은 인터넷을 사용하여 사설 네트워크를 대신하여 데이터를 송신할 수 있다. 다양한 터널링 프로토콜이 개발되었으며, 그 중 일부 예로, 마이크로소프트 및 다수의 다른 회사에 의해 개발된 포인트 대 포인트 터널링 프로토콜 (PPTP); 시스코 시스템에 의해 개발된 GRE (generic routing encapsulation); 및 레이어 투 터널링 프로토콜 (L2TP) 이 있다. 터널링, 및 VPN 의 사용은 보안 데이터 송신을 보장하는데 있어서 암호화를 대체하지 못한다. 암호화는 VPN 에 접속되고 VPN 내에서 사용될 수도 있다.As used herein, a virtual private network (VPN) applies security procedures and tunneling to achieve privacy in network transactions while sharing public network infrastructure, such as the Internet. Tunneling refers to the transmission of data over a public network of protected data—property for a business or secret for an individual. The routing node in the public network does not recognize that the transmission is part of a private network. Typically, tunneling is achieved by encapsulating private network data and protocol information in a public network transmission unit so that the private network protocol information appears in the public network as data. Tunneling can send data on behalf of a private network using the Internet. Various tunneling protocols have been developed, some of which include point-to-point tunneling protocols (PPTP) developed by Microsoft and many other companies; Generic routing encapsulation (GRE) developed by Cisco systems; And Layer to Tunneling Protocol (L2TP). Tunneling, and the use of VPNs, do not replace encryption in ensuring secure data transmission. Encryption may be connected to a VPN and used within the VPN.
본 명세서에 사용되는 생체인식법은, 사용자를 인증하고, 보호된 기관 네트워크 또는 보호된 정보 소스로의 액세스를 적절히 인증하거나 거부하기 위해 사용자 아이덴티티를 확립하는데 사용되는 개인적 특징 - 물리적 또는 행위적 - 을 말한다. 물리적 생체인식법은 음성 인식 (즉, 화자 확인), 지문, 핸드프린트, 혈액형, DNA 데스트, 망막 또는 홍채 스캔, 및 얼굴 인식 등을 포함한다. 행위 생체인식법은 개인적 행동의 습관 또는 패턴을 포함한다.As used herein, biometrics refers to personal features-physical or behavioral-used to establish a user identity to authenticate a user and to properly authenticate or deny access to a protected institutional network or protected information source. Say. Physical biometrics include speech recognition (ie, speaker identification), fingerprints, handprints, blood types, DNA tests, retina or iris scans, and facial recognition. Behavioral biometrics include habits or patterns of personal behavior.
본 명세서에서 사용하는 데이터는 네트워크를 통해 송신될 수 있는 임의의 정보를 말한다. 데이터는 다양한 실시형태에서 디지털 정보 또는 정보라는 용어와 상호교환가능하게 사용된다. 콘텐츠 데이터는 사용자에 의한 네트워크를 통한 송신에 지정되는 임의의 데이터를 말한다. 예를 들어, 금융기관 또는 은행에서, 고객 계좌 정보는, 다양한 인증 계좌 관리자 및 시스템 관리자에 의해 사용되거나 조작되는 하나 이상의 클라이언트 및 서버 사이에서 송신될 수도 있는 일 타입의 콘텐츠 데이터로 구성된다. 계좌 지급 정보는 EDI 트랜잭션의 경우에 일 타입의 콘텐츠 데이터일 수 있다. 다른 종류의 콘텐츠 데이터의 또 다른 예로는 제조 설비에서 원재료 또는 완성된 생산품에 대한 재고 정보가 있으며; 이러한 데이터는 흔히, 제조 엔지니어 및 사업 계획 직원에 의한 액세스를 위해 이러한 설비 전체에 걸쳐 클라이언트 및 서버 사이에서 송신된다. 오디오, 비디오 파일과 같은 멀티미디어 데이터가 또 다른 형태의 콘텐츠 데이터이다. 본 명세서에서 트랜잭션 데이터 - 접속 데이터라고도 함 - 는, 클라이언트와 서버 사이의 네트워크 접속의 상태 및 이들간의 데이터 송신을 나타내는 임의의 정보를 의미한다. 이 정보는 사용자 인증 상태 및 인증 방법에 대한 정보 등을 포함한다.Data used herein refers to any information that can be transmitted over a network. Data is used interchangeably with the term digital information or the information in various embodiments. Content data refers to any data specified for transmission over a network by a user. For example, in a financial institution or bank, customer account information consists of one type of content data that may be transmitted between one or more clients and servers used or manipulated by various authentication account managers and system administrators. The account payment information may be one type of content data in the case of an EDI transaction. Another example of another kind of content data is inventory information for raw materials or finished products at a manufacturing facility; Such data is often sent between clients and servers throughout this facility for access by manufacturing engineers and business planning personnel. Multimedia data, such as audio and video files, is another form of content data. Transaction data, also referred to herein as connection data, means any information that indicates the status of a network connection between a client and a server and the data transmission between them. This information includes information about the user authentication status and the authentication method.
본 명세서에서의 데이터 압축 및 암호화는 통상의 산업 관례에 따라 구현될 수도 있다. 압축/압축해제 및 암호/해독에 대한 다양한 사양 및 알고리즘이 종래 기술에 공지되어 있고, 다양한 관련 상품이 공개적으로 또는 상업적으로 사용가능하며; 본 명세서의 다양한 실시형태에 따른 방법 및 시스템에서 사용될 수도 있다.Data compression and encryption herein may be implemented according to conventional industry practice. Various specifications and algorithms for compression / decompression and encryption / decryption are known in the art, and various related products are publicly or commercially available; It may be used in methods and systems in accordance with various embodiments herein.
본 명세서에서 사용되는 사용자 인터페이스는 사용자와 상호작용할 수 있는 임의의 컴퓨터 애플리케이션 또는 프로그램을 말한다. 사용자 인터페이스는 브라우져와 같은 그래픽 사용자 인터페이스 (GUI) 일 수도 있다. 이러한 브라우져의 예로는 마이크로소프트 인터넷 익스플로어러TM 및 네스케이프 네비게이터TM 가 포함된다. 또한, 사용자 인터페이스는 또 다른 실시형태에서는 단순한 커맨드 라인 인터페이스일 수도 있다. 또한 사용자 인터페이스는, 기존의 애플리케이션을 확장하고 마이크로소프트 오피스, ERP 시스템 등과 같은 표준 데스크탑 애플리케이션과의 상호작용을 지원하는 플러그인 툴을 포함할 수도 있다. 또한, 임의의 실시형태에서의 사용자 인터페이스는 키패드, PDA, 마이크로폰 또는 임의의 다른 타입의 생체인식 입력 유닛과 같은 정보 입력기의 임의의 지점일 수도 있다.As used herein, a user interface refers to any computer application or program that can interact with a user. The user interface may be a graphical user interface (GUI) such as a browser. Examples of such browsers include Microsoft Internet Explorer ™ and Netscape Navigator ™ . Also, the user interface may be a simple command line interface in another embodiment. The user interface may also include plug-in tools that extend existing applications and support interaction with standard desktop applications such as Microsoft Office, ERP systems, and the like. In addition, the user interface in any embodiment may be any point of an information input device such as a keypad, PDA, microphone, or any other type of biometric input unit.
본 명세서에서 사용되는 레이더 접속기는, 네트워크 접속을 모니터링하고 제어하도록 구성되는 모듈을 말한다. 레이더 접속기는 다양한 실시형태에 따라 클라이언트, 서버 또는 인젝터에 포함되거나 접속될 수도 있다. 특정한 실시형태에서 클라이언트의 레이더 접속기는 실패한 접속을 검출하고 서버에의 콘택트를 개시하여 접속을 재확립하도록 더 구성된다. 레이더 접속기는 우선, 포트에 접속을 시도하고; 그 후 네트워크 접속을 연속적으로 모니터링하고 접속 실패가 검출된 경우 서버를 호출함으로써 접속 재확립을 시도한다. 서버측에서는, 레이더 접속기가 항상 활성화 상태로 남아, 다양한 클라이언트와의 접속 상태를 모니터링할 수도 있다.Radar connector as used herein refers to a module configured to monitor and control network connections. The radar connector may be included or connected to a client, server or injector in accordance with various embodiments. In a particular embodiment the radar connector of the client is further configured to detect the failed connection and initiate a contact to the server to reestablish the connection. The radar connector first attempts to connect to the port; It then continuously monitors the network connection and attempts to reestablish the connection by calling the server if a connection failure is detected. On the server side, the radar connector may remain active at all times to monitor the connection status with various clients.
본 명세서에서 사용되는 퍼베이시브 컴퓨팅은 사람들의 사업 및 가정내 사무 에서의 네트워크 컴퓨터 또는 또 다른 디지털 디바이스의 증가되고 널리 보급된 사용을 말한다. 디지털 및 웹 가능 전자제품 및 가전제품 (예를 들어, 이동 전화, 디지털 TV, PDA, GPS (Global Positioning System), 카메라 폰, 및 네트워크 전자레인지, 냉장고, 세탁기, 건조기, 식기세척기 등) 및 광대역 인터넷 접속의 보편화가 퍼베이시브 컴퓨팅의 시대를 나타낸다.Pervasive computing as used herein refers to the increased and widespread use of networked computers or other digital devices in people's business and home offices. Digital and web-enabled electronics and appliances (e.g., mobile phones, digital TVs, PDAs, Global Positioning System (GPS), camera phones, and network microwaves, refrigerators, washing machines, dryers, dishwashers, etc.) and broadband Internet Universalization of connectivity represents an era of pervasive computing.
다양한 실시형태에서 사용되는 퍼베이시브 보안은, 하나 이상의 네트워크 호스트 또는 접속 디바이스를 사용하여 요구되는 보안을 전달하는 네트워크 보안 플랫폼을 말한다. 본 명세서에 따른 사용자 중심 보안은, 시스템이 네트워크 서버에 접속하기 위한 사용자에 의해 사용되는 하나 이상의 컴퓨터 호스트 디바이스 대신에 하나 이상의 사용자를 보호하는 것을 말한다. 퍼베이시브 및 사용자 중심 보안은 언제 어디서나 본 명세서의 시스템 및 방법을 사용하고 임의의 네트워크 디바이스를 사용하여 일 실시형태에서 실행될 수도 있다.Pervasive security as used in various embodiments refers to a network security platform that delivers the required security using one or more network hosts or access devices. User-centric security in accordance with the present description refers to protecting one or more users instead of one or more computer host devices used by a user to access a network server. Pervasive and user-centric security may be implemented in one embodiment using any of the network devices and methods herein and anytime, anywhere.
데이터그램은 "소스와 수신지 컴퓨터 사이에서의 사전 교환 및 전달 네트워크에 의존하지 않고, 소스로부터 수신지 컴퓨터로 라우팅되는 충분한 정보를 반송하는, 자체포함되고 독립적인 데이터 엔티티" 로서 정의된다. 2001년 11월 Whatis.Com, QUE 의 기술용어 백과사전 참조. 데이터그램 및 패킷은 상호교환가능한 ID 로 사용될 수 있다.A datagram is defined as "a self-contained and independent data entity that carries sufficient information routed from a source to a destination computer without relying on a pre-exchange and delivery network between the source and destination computer." See November 2001, Whatis.Com, QUE, Technical Encyclopedia. Datagrams and packets can be used as interchangeable IDs.
용어 "지능형 데이터 캐리어" (IDC) 는 본 명세서의 다양한 실시형태에서 용어 "클라이언트" 와 상호교환가능하게 사용된다. 지능형 데이터 캐리어는 적어도 (i) 데이터를 저장하도록 구성되는 하나의 메모리, (ii) 데이터를 입력하고 출 력하도록 구성되는 하나의 입력-출력 장치, 및 (iii) 전술한 메모리에 저장된 데이터를 프로세싱하도록 구성되는 하나의 프로세서를 구비한다. 지능형 데이터 캐리어는 호스트 컴퓨터 디바이스와 접속하여 네트워크 상의 IO 장치를 통해 데이터를 송신할 수 있다. 또한, 지능형 데이터 캐리어는 본 명세서의 특정한 실시형태에 따라, 인증 및 암호 방식을 통해 네트워크 사용자의 네트워크 아이덴티티를 확립하도록 구성된다. 일 실시형태에서, 지능형 데이터 캐리어는 이동형이다. 지능형 데이터 캐리어는 USB 키, 파이어와이어 디바이스, 스마트 카드, 컴팩트 디스크, DVD, 스마트 미디어, 컴팩트 플래시, PDA, 스마트 디지털 미디어, 또는 토큰 디바이스로 또는 이러한 장치 상에서 구현될 수도 있다. 토큰 디바이스는 직렬 포트 동글 또는 병렬 포트 동글과 같은 소프트웨어 동글, 임의의 일회성 패스워드 생성 디바이스 또는 시스템 액세스 디바이스일 수도 있다. 또 다른 디지털 미디어 판독기는 본 명세서에 따른 지능형 데이터 캐리어로서 구현될 수도 있다. 이는 상이한 방식으로 다양한 포트 또는 드라이브를 통해 다양한 호스트 컴퓨터 디바이스에 접속할 수 있다. 지능형 데이터 캐리어는, 사용자가 서버에 의해 적절히 인증되면, 사용자를 대표하여 보안 네트워크 접속의 확립 및 요구되는 애플리케이션의 론치를 위해 모든 데이터 및 기능을 보유한다. 지능형 데이터 캐리어로서 클라이언트에 대한 다음의 상세한 설명 참조.The term "intelligent data carrier" (IDC) is used interchangeably with the term "client" in various embodiments herein. An intelligent data carrier comprises at least (i) one memory configured to store data, (ii) one input-output device configured to input and output data, and (iii) data stored in the aforementioned memory. It has one processor configured. The intelligent data carrier can connect with a host computer device and send data through an IO device on the network. In addition, the intelligent data carrier is configured to establish the network identity of the network user through an authentication and encryption scheme, in accordance with certain embodiments herein. In one embodiment, the intelligent data carrier is mobile. The intelligent data carrier may be implemented as or on a USB key, Firewire device, smart card, compact disc, DVD, smart media, compact flash, PDA, smart digital media, or token device. The token device may be a software dongle, such as a serial port dongle or a parallel port dongle, any one-time password generation device or system access device. Another digital media reader may be implemented as an intelligent data carrier in accordance with the present disclosure. It can connect to various host computer devices through various ports or drives in different ways. An intelligent data carrier holds all the data and functions on behalf of the user, for the establishment of a secure network connection and for the launching of the required application, once the user is properly authenticated by the server. See the following detailed description of the client as an intelligent data carrier.
클라이언트-서버-인젝터 네트워크 통신 시스템Client-Server-Injector Network Communication System
클라이언트-서버 통신 시스템이, 하나 이상의 클라이언트 및 하나 이상의 서버를 포함하는 본 명세서의 일 실시형태에 제공된다. 각 클라이언트는 네트워 크 서버로의 보안 접속을 위한 인증 및 암호 방식을 지원할 수 있는 지능형 데이터 캐리어이다. 지능형 데이터 캐리어로서 클라이언트에 대한 다음의 상세한 설명 참조. 시스템은 지능형 데이터 캐리어를 통해 직접 각각의 사용자를 인증하고 보호하기 때문에 사용자 중심 보안이 가능하다. 어떠한 종류의 접속 디바이스 또는 로컬 호스트 컴퓨터가 사용된다 하더라도, 사용자는 지능형 데이터 캐리어를 호스트에 도킹시키고, 목표 서버에 접속하기 위해 인증 세션을 론치할 수도 있다. 따라서, 액세스 안전장치의 중요한 점은 접속 디바이스 또는 로컬 호스트 머신이 아니고, 지능형 데이터 캐리어로 송신되는 개별 사용자에 있다. 지능형 데이터 캐리어는 이동형일 수도 있으며; 이러한 이동성은 시스템에 의해 부여되는 보안 솔루션에서의 퍼베이시브니스 (pervasiveness) 를 강화시킨다. 이것이 임의의 접속 디바이스 또는 로컬 호스트 머신을 사용하는 요구되는 보안이다.A client-server communication system is provided in one embodiment of the present disclosure that includes one or more clients and one or more servers. Each client is an intelligent data carrier capable of supporting authentication and encryption schemes for secure access to network servers. See the following detailed description of the client as an intelligent data carrier. The system authenticates and protects each user directly through intelligent data carriers, enabling user-centric security. No matter what kind of connection device or local host computer is used, the user may dock an intelligent data carrier to the host and launch an authentication session to connect to the target server. Thus, an important aspect of access safeguards lies in the individual user being transmitted on the intelligent data carrier, not the connecting device or the local host machine. The intelligent data carrier may be mobile; This mobility enhances the pervasiveness in the security solution imparted by the system. This is the required security of using any connected device or local host machine.
또 다른 실시형태에서는, 클라이언트-서버 통신 시스템에 인젝터가 포함된다. 클라이언트-서버-인젝터 시스템은 기존의 네트워크 기반구조와의 편리한 통합을 가능하게 하고, 데이터 송신 및 애플리케이션 공유의 전반적인 보안을 용이하게 한다. 서버 및 클라이언트와 접속하는 인젝터에 대한 다음의 상세한 설명 참조. 하나 이상의 클라이언트, 하나 이상의 서버, 및 하나 이상의 인젝터가 이러한 네트워크 통신 시스템에 설비될 수도 있다. 각 인젝터는 하나 이상의 서버와 링크되고 통신한다. 각 서버는 하나 이상의 클라이언트와 접속하고 서비스한다. 시스템의 다수의 서버는 전체 네트워크의 데이터 흐름을 관리하는데 있어서 서로 통신할 수도 있다.In yet another embodiment, an injector is included in the client-server communication system. Client-server-injector systems enable convenient integration with existing network infrastructures and facilitate overall security of data transmission and application sharing. See the following detailed description of the injector connecting to the server and client. One or more clients, one or more servers, and one or more injectors may be equipped in such network communication systems. Each injector links and communicates with one or more servers. Each server connects and services one or more clients. Multiple servers in the system may communicate with each other in managing the data flow of the entire network.
도 1 은 일 실시형태에 따라 인젝터 (105), 클라이언트 (103) 및 한 쌍의 피어 (peer) 서버 (101) 간의 접속을 개략적으로 도시한다. 각 서버, 클라이언트 및 인젝터는 네트워크와 인터페이싱하는 레이더 접속기 (107) 를 가진다. 레이더 접속기 (107) 는 네트워크 접속의 상태를 계속하여 모니터링한다. 접속 실패가 검출되면, 클라이언트 측의 레이더 접속기 (107) 는 서버를 호출함으로써 접속을 재확립하기 위한 하나 이상의 시도를 한다. 클라이언트는 가장 최근의 접속에 대한 접속 상태의 파라미터를 기록했기 때문에 - 따라서, 기억함 - 실패한 접속은 소망하는 정확도로 빠르게 복구될 수도 있다. 그 결과, 데이터 송신의 무결성이 보호될 수도 있고, 실패 비율은 감소될 수도 있다.1 schematically illustrates a connection between an injector 105, a
레이더 접속기 (107) 에 부가하여, 임의의 다른 모듈 및 프로세스는 도 1 에 도시된 클라이언트 (103), 인젝터 (105) 및 2 개의 피어 서버 (101) 간에 공통된다. 승인 매니저 (109) 는 사용자 승인을 할당하고 관리한다. 서비스 촉진기 (111) 는, 특정한 애플리케이션 또는 서비스가 요청된 사용자에게 제공되는 것을 보장한다. 데이터그램 파서 엔진 (113) 은 도 1 에 도시된 바와 같이, 각 클라이언트 (103), 서버 (101) 및 인젝터 (105) 에 포함되어 있다. 파서 엔진 (113) 은 시스템의 동적 데이터그램 스위치 및 파서를 구비할 수도 있다. 도 7 및 8 을 참조하면, 동적 데이터그램 스위치 (701, 801) 및 프레임 파서 (703, 803) 는 각각 서버 (101) 및 인젝터 (105) 에 포함된다. 따라서, 서비스 파서 (601) 및 서비스 프레임 (603) 은 도 6 에 도시된 바와 같이 클라이언트 (103) 에 포함된다. 데이터그램 (701, 801) 은 클라이언트측 및 서버측 모두에서 레이더 접속 기 (107) 와 함께 동작하여, 데이터그램 송신의 다수의 인스턴스를 프로세싱한다. 이하, 동적 데이터그램 스위치 (701, 801) 에 대해 상세히 설명한다. 암호 엔진 (115) 은 네트워크를 통한 데이터 트랜잭션의 암호 및 해독을 프로세싱한다. 클라이언트 (103), 서버 (101) 및 인젝터 (105) 시스템에서, 암호 엔진 (115) 은, 네트워크와 인터페이싱하는 레이더 접속기 (107) 뒤의 하나의 레벨이다. 서버 (101) 및 인젝터 (105) 모두에서 구현되는 파싱 엔진 (113) 및 서비스 촉진기 (111) 는, 전반적인 시스템이 다수의 네트워크 서비스 및 애플리케이션뿐 아니라 다양한 타입의 데이터 송신을 지원할 수 있게 한다. 이러한 모듈 및 프로세스, 및 또 다른 모듈 및 프로세스를 이하 클라이언트 (103), 서버 (101) 및 인젝터 (105) 에 대한 개별적인 절에서 설명한다.In addition to the radar connector 107, any other modules and processes are common between the
지능형 데이터 캐리어로서의 클라이언트Client as an intelligent data carrier
클라이언트는, 유선 또는 무선 네트워크를 통해 서버 컴퓨터 또는 디바이스에 접속할 수 있는 임의의 컴퓨터 또는 디바이스이다. 또한, 클라이언트는, 서버를 호출하고 접속하는 컴퓨터 소프트웨어 또는 펌웨어일 수도 있다. 클라이언트는 일 실시형태에 따른 지능형 데이터 캐리어 (IDC) 이다. 클라이언트 또는 IDC 는 네트워크에 링크된 호스트 컴퓨터 디바이스 상에서 소프트웨어, 펌웨어 또는 플래시 메모리를 실행시킴으로써 구현될 수도 있다. 사용자 인터페이스가 일 실시형태에서 호스트 컴퓨터 디바이스 또는 IDC 에 의해 제공되고, 일단 사용자가 IDC 를 통해 네트워크 서버에 접속하면 사용자가 네트워크 트랜잭션을 모니터링하고 데이터 송신을 제어할 수 있게 한다. 예를 들어, 사용자 인터페이스는 사 용자가 네트워크에 로그온하도록 로그인 형태를 제공할 수도 있다. 이 형태는 텍스트, 객체 또는 그래프 등의 상이한 포맷의 입력을 수용할 수도 있다. 또한 사용자 인터페이스는 사용자가 네트워크 트랜잭션 및 데이터 송신을 제어하기 위한 명령을 송신할 수 있게 한다.A client is any computer or device capable of connecting to a server computer or device via a wired or wireless network. The client may also be computer software or firmware that invokes and connects to the server. The client is an intelligent data carrier (IDC) according to one embodiment. The client or IDC may be implemented by running software, firmware or flash memory on a host computer device linked to a network. The user interface is provided by the host computer device or IDC in one embodiment and allows the user to monitor network transactions and control data transmission once the user connects to the network server via IDC. For example, the user interface may provide a login form for the user to log on to the network. This form may accept different formats of input such as text, objects or graphs. The user interface also allows the user to send commands to control network transactions and data transmission.
지능형 데이터 캐리어는 본 명세서의 일 실시형태에 따라 이동형일 수도 있다. 다양한 실시형태에서, 지능형 데이터 캐리어는 USB 키, 컴팩트 플래시, 스마트 미디어, 컴팩트 디스크, DVD, PDA, 파이어와이어 디바이스, 직렬 포트 동글 또는 병렬 포트 동글과 같은 토큰 디바이스, 또는 다른 디지털, 아날로그 디바이스 또는 매체 판독기로 또는 이러한 장치 상에서 구현될 수도 있다.The intelligent data carrier may be mobile according to one embodiment of the present disclosure. In various embodiments, the intelligent data carrier may be a USB key, compact flash, smart media, compact disc, DVD, PDA, firewire device, token device such as serial port dongle or parallel port dongle, or other digital, analog device or media reader. Or on such a device.
일 실시형태에 따라 지능형 데이터 캐리어는 3 개의 주요 구성요소: 디지털 정보를 저장하도록 구성되는 메모리, 디지털 정보를 입력하고 출력하도록 구성되는 입력-출력 (IO) 장치, 및 메모리에 저장된 디지털정보를 프로세싱하도록 구성되는 프로세서를 가진다. IDC 는, 네트워크에 배치된 컴퓨터 호스트 디바이스에 접속하여 IO 장치를 통해 네트워크 상에서 데이터를 송신할 수 있다.According to one embodiment, an intelligent data carrier comprises three main components: a memory configured to store digital information, an input-output (IO) device configured to input and output digital information, and a digital information stored in the memory. Have a processor configured. The IDC may connect to a computer host device disposed in the network and transmit data on the network via the IO device.
IDC 의 메모리는, CD, 플로피 디스크, DVD, EPROM (Erasable Programmable Read-Only Memory), 및 플래시 메모리 (컴팩트 플래시, 스마트 미디어, USB 키 등) 와 같은 임의의 컴퓨터 판독가능 미디어의 형태를 가질 수도 있다.The memory of the IDC may take the form of any computer readable media such as CD, floppy disk, DVD, erasable programmable read-only memory (EPROM), and flash memory (compact flash, smart media, USB key, etc.). .
IDC 의 IO 장치는, 예를 들어, 마우스 포트, 키보드 포트, 직렬 포트 (USB 포트 또는 ASB 포트), 병렬 포트, 적외선 포트, 및 펌웨어 접속 (IEEE 1394) 등을 포함하는 임의의 IO 접속 또는 포트를 통해 호스트 컴퓨터 디바이스에 접속할 수 있다. IO 접속은 다양한 실시형태에 따라 유선 또는 무선일 수도 있다. 예를 들어, 일 실시형태에서, 근거리 무선 접속이 IDC 와 블루투스 사양에 따른 호스트 디바이스 사이에 확립될 수도 있다. www.bluetooth.org 참조. 또 다른 실시형태에서는 802.11b-g 및 적외선 통신이 사용된다. IO 장치는, 또 다른 실시형태에서 음성 또는 이미지 데이터를 전송하고 수신하도록 구성되는 트랜시버를 포함한다. 따라서 IDC 는 VoIP 애플리케이션을 지원한다.IDC's IO devices can be configured with any IO connection or port, including, for example, a mouse port, keyboard port, serial port (USB port or ASB port), parallel port, infrared port, and firmware connection (IEEE 1394). It can be connected to the host computer device through. The IO connection may be wired or wireless according to various embodiments. For example, in one embodiment, a short range wireless connection may be established between the IDC and the host device according to the Bluetooth specification. See www.bluetooth.org. In another embodiment, 802.11b-g and infrared communication are used. The IO device, in another embodiment, includes a transceiver configured to transmit and receive voice or image data. IDC therefore supports VoIP applications.
IDC 프로세서는 일 실시형태에서 집적회로 (IC) 를 구비한다. 또 다른 실시형태에서는, IC 가 주문형 집적회로 (ASIC) 이다. IC 는 IDC 상에 미리 로드된 애플리케이션뿐만 아니라 호스트 컴퓨터 디바이스 상에 인스톨되는 애플리케이션 또는 원격 서버로부터 사용가능한 애플리케이션의 실행을 지원한다. 또 다른 실시형태에서, IDC 의 프로세서는 IC 를 포함하지 않고; 호스트 컴퓨터 디바이스의 IC 에 의존하며, 호스트 컴퓨터 디바이스에 인스톨되는 애플리케이션으로부터의 IDC 메모리에 로딩되는 정보 및 IDC 메모리에 저장된 정보를 프로세싱하도록 구성된다. 애플리케이션 전달에 대한 다음의 상세한 설명 참조.The IDC processor has an integrated circuit (IC) in one embodiment. In yet another embodiment, the IC is an application specific integrated circuit (ASIC). The IC supports the execution of applications available from remote servers or applications installed on the host computer device as well as applications preloaded on IDC. In yet another embodiment, the processor of IDC does not include an IC; It relies on the IC of the host computer device and is configured to process information loaded into the IDC memory and information stored in the IDC memory from an application installed on the host computer device. See the following detailed description of application delivery.
본 명세서에 따른 지능형 데이터 캐리어는 인증 및 암호 방식을 통해 사용자를 위한 네트워크 아이덴티티를 확립하도록 구성된다. 지능형 데이터 캐리어는 서버 위치를 결정하고, 인증 프로세스를 개시함으로써 서버에 자신을 제공한다. 인증 및 암호에 대한 다음의 설명 참조. 본 명세서의 보안 네트워크 시스템에서, 각 사용자는, 사용자가 네트워크 서버에 접속할 수 있게 하고 데이터 및 애플리케이션에 액세스할 수 있게 하는 IDC 로 송신될 수도 있다. 사용자는 IDC 를 사용하여, 필요에 따라 의도한 서버에 접속하고, 접속종료하고, 재접속할 수도 있다. 접속은 일 실시형태에 따라, 임의의 시간에 임의의 네트워크 호스트 디바이스로부터 이루어질 수도 있다. 호스트 컴퓨터 디바이스는 데스크탑 또는 랩탑 컴퓨터, 개인 휴대 단말기 (PDA), 이동 전화, 디지털 TV, 오디오 또는 비디오 플레이어, 컴퓨터 게임 콘솔, 디지털 카메라, 카메라 폰, 및 네트워크화된 냉장고, 전자레인지, 세척기, 건조기 및 식기세척기와 같은 네트워크 가능 가전기기일 수도 있다. 임의의 실시형태에서, IDC 는 호스트 디바이스에 직접 내장되어 네트워크를 통한 애플리케이션 공유 또는 보안 데이터 교환을 제공할 수도 있다. 네트워크 액세스는 각 사용자에 대해 비공개이며 보안되어 있다. 암호화 가상 파일 시스템에 대한 다음의 설명 참조. 따라서, IDC 는 네트워크 통신에 큰 이동성, 및 강화된 사용자 중심 보안을 부여한다.The intelligent data carrier according to the present specification is configured to establish a network identity for a user through an authentication and encryption scheme. The intelligent data carrier provides itself to the server by determining the server location and initiating the authentication process. See the following description of authentication and password. In the secure network system herein, each user may be sent to IDC that allows the user to access a network server and to access data and applications. Using IDC, the user can connect, terminate, and reconnect to the intended server as needed. The connection may be from any network host device at any time, according to one embodiment. Host computer devices include desktop or laptop computers, personal digital assistants (PDAs), mobile phones, digital TVs, audio or video players, computer game consoles, digital cameras, camera phones, and networked refrigerators, microwaves, washers, dryers, and tableware. It may also be a network capable home appliance such as a washer. In some embodiments, the IDC may be embedded directly in the host device to provide application sharing or secure data exchange over the network. Network access is private and secure for each user. See the following description of the encrypted virtual file system. Thus, IDC imparts great mobility and enhanced user-centric security to network communications.
애플리케이션은 보안되고 제어된 방식으로 IDC 를 통해 의도된 사용자에게 전달될 수도 있다. 일 실시형태에서는, 임의의 허가된 애플리케이션이, 인증된 사용자에게 송신되는 IDC 에 사전 로딩되고, 인증된 사용자는 서버로 등록될 수도 있다. 사용자는, IDC 가 어떠한 로컬 호스트에 도킹되는지에 무관하게, 서버에 의한 적절한 인증에 따라 IDC 로부터 애플리케이션을 실행시킬 수도 있다. 즉, 예를 들어, 사용자는 하나의 위치에서 USB 키 IDC 를 컴퓨터 - 인터넷에 접속된 - 에 삽입하고, 일단 서버 - 또한 인터넷에 위치하는 - 에 성공적으로 접속되면 USB 키 IDC 로부터 애플리케이션을 론치할 수도 있다. 사용자는 애플리케이션을 종료하고 파일을 서버 또는 USB 키 IDC 상에 저장할 수도 있다. 파일은 네트워크 서버에 접속된 암호화 가상 파일 시스템 (EVFS) 에 저장된다. EVFS 의 다음의 설명 참조. 또 다른 위치인 경우, 사용자는 상이한 컴퓨터 호스트 디바이스를 사용하여 USB 키 IDC 로부터 애플리케이션을 론치하고 - 서버에 의한 적절한 인증에 따라 - 동일한 파일에서 작업을 계속할 수도 있다. 따라서, IDC 와 네트워크 서버간의 이러한 보안되고, 이동형인 사용자 중심 접속성은 데이터 액세스 및 애플리케이션 전달을 관리하고 제어하는 패러다임을 제공한다.The application may be delivered to the intended user via IDC in a secure and controlled manner. In one embodiment, any authorized application may be preloaded in an IDC sent to an authenticated user, and the authenticated user may be registered with the server. A user may run an application from IDC upon proper authentication by the server, regardless of which local host the IDC is docked to. That is, for example, a user may insert a USB key IDC into a computer-connected to the Internet-in one location, and launch an application from the USB key IDC once it is successfully connected to the server-also located on the Internet. have. The user may exit the application and save the file on a server or USB key IDC. The file is stored in an encrypted virtual file system (EVFS) connected to a network server. See the following description of EVFS. In another location, the user may use a different computer host device to launch the application from the USB key IDC and continue working on the same file—according to proper authentication by the server. Thus, this secure, mobile, user-centric connectivity between IDC and network servers provides a paradigm for managing and controlling data access and application delivery.
지능형 데이터 캐리어는 일 실시형태에 따라 독립형 애플리케이션 또는 동작 시스템을 전달하는데 사용될 수도 있다. 사용자는, 판독전용 (read-only) 이며 복사방지된 애플리케이션 및/또는 동작 시스템을 가진 IDC 로 송신될 수도 있다. 사용자는 IDC 를 사용하여, 동작 시스템 또는 저장 디바이스를 가지지 않는 호스트 시스템을 부팅하고, IDC 상에 액세스 서버기반 애플리케이션 또는 미리 로딩된 애플리케이션에 액세스할 수도 있다.Intelligent data carriers may be used to deliver standalone applications or operating systems according to one embodiment. The user may be sent to IDC with a read-only and copy protected application and / or operating system. A user may use IDC to boot a host system that does not have an operating system or storage device, and access an access server-based application or preloaded application on IDC.
지능형 데이터 캐리어는 또 다른 실시형태에 따른 애플리케이션 미디어 콘텐츠를 전달하는데 사용될 수도 있다. 예를 들어, 고유의 시리얼 넘버뿐만 아니라, 복사방지 및 판독전용인 애플리케이션을 포함하는 IDC 가 사용자에게 제공되어 애플리케이션의 초기 인스톨을 허용할 수도 있다. 인스톨이 완료되면, IDC 는 시스템 명칭, MAC 넘버, 프로세서 시리얼 넘버, 또는 또 다른 정적 시스템 기반 정보를 요청하여 복사방지 코드를 생성하여, 이를 사용자에게는 감춰진 암호화된 코드의 형태로 IDC 에 저장할 수도 있다. 이 코드는, 애플리케이션이 오리지널 호스트 디바이스 상에만 인스톨되는 것을 보장할 수도 있다.Intelligent data carriers may be used to deliver application media content according to another embodiment. For example, an IDC that includes an application that is copy-protected and read-only, as well as a unique serial number, may be provided to the user to allow initial installation of the application. Once installed, IDC may request a system name, MAC number, processor serial number, or other static system based information to generate a copy protection code, which may be stored in IDC in the form of encrypted code hidden from the user. This code may ensure that the application is only installed on the original host device.
지능형 데이터 캐리어는 또 다른 실시형태에 따른 미디어 특정 분포에 적합하다. 각 사용자는, DVD, CD, 또는 MP3 데이터 파일과 같은 특정한 디지털 미디어 소스에의 액세스를 인증하는 하나 이상의 특정한 디코더로 작동하는 IDC 로 송신될 수도 있다. 서버는 IDC 를 통해 특정한 데이터 파일의 액세스 및 사용을 트래킹할 수도 있다.Intelligent data carriers are suitable for media specific distribution according to another embodiment. Each user may be sent to an IDC operating with one or more specific decoders that authorize access to a particular digital media source, such as a DVD, CD, or MP3 data file. The server may track access and use of specific data files via IDC.
따라서, 본 명세서에 따른 애플리케이션 전달 패러다임은, 특수 데이터베이스 애플리케이션, 데이터 분석 툴, 및 다양한 고객 관계 관리 (CRM; Customer Relation Management), 및 전사적 자원 관리 (ERP; Enterprise Resource Planning) 패킷 등을 포함하는 IT 툴 및 상업적 소프트웨어 패킷뿐만 아니라 사유 데이터 콘텐츠에 특히 유용하다. 중앙집중된 데이터 및 파일 관리뿐 아니라 엄격한 인증 및 암호화와 결합된 제어되고 목표화된 전달은 이러한 패러다임을 전사적 라이센스 및 플로우팅 라이센스와 같은 기존의 소프트웨어 라이센싱 방식의 실질적 경쟁자로 만든다. 이러한 능력에서, IDC 는 사유 데이터, 애플리케이션 및 서비스에 대한 디지털 권리 관리 (DRM) 를 가능하게 한다.Accordingly, the application delivery paradigm according to the present specification may include special database applications, data analysis tools, and IT tools including various customer relationship management (CRM), enterprise resource planning (ERP) packets, and the like. And commercial software packets as well as proprietary data content. Controlled and targeted delivery combined with strict authentication and encryption, as well as centralized data and file management, make this paradigm a real competitor to traditional software licensing approaches such as enterprise and floating licenses. In this capability, IDC enables digital rights management (DRM) for proprietary data, applications and services.
도 5 를 참조하면, 지능형 데이터 캐리어는 본 명세서의 일 실시형태에 따른 다수의 모듈 및 프로세스를 구현한다. 예를 들어, 애플리케이션 부팅 로더 (501) 는, 시스템 통합자 (SI) 및 OEM 제조자들이 호스트 컴퓨터 디바이스에 인스톨되는 애플리케이션 또는 IDC 에 저장된 애플리케이션에 대한 커스항 부팅 호출을 생성하게 한다. 애플리케이션 부팅 로더 (501) 는 본 실시형태에 따른 IDC 의 프로세서의 일부이다. 이것을 애플리케이션을 부팅하기 위한 config 파일, SYS 파일 또는 실행 파일 등이라 할 수도 있다.Referring to FIG. 5, an intelligent data carrier implements multiple modules and processes in accordance with one embodiment of the present disclosure. For example,
IDC 의 메모리는 일 실시형태에 따라 - 예를 들어, SI 또는 OEM 에 의해 - 사용자 데이터 저장영역 (503), 애플리케이션 데이터 저장영역 (505) 및 관리 config 분할영역 (507) 으로 분할될 수도 있다. 사용자 데이터 저장영역 (503) 은 기록 및 판독이 가능하다. 애플리케이션 데이터 저장영역 (505) 은 판독만 가능하다. 관리 config 분할영역 (507) 은 판독전용이고 복사방지되어 있다. 분할 정보는, 사용자의 관점이 아닌 방식 또는 사용자가 직접 액세스할 수 없는 방식으로 IDC 에 저장된다.The memory of the IDC may be partitioned into
사용자 인증을 위한 온 디바이스 인증 클라이언트 모듈 (509), 네트워크 접속의 모니터링 및 제어를 위한 레이더 접속기 (511), 및 암호화 모듈 (513) 등을 포함하는 추가적인 모듈이 포함된다. 인증 클라이언트 (509) 는, 객체 방법 (515), 패스워드 시스템 (517), 및 또 다른 권리 정책 (519) 등을 포함하는 다양한 사용자 인증 수단을 사용할 수도 있다. 이하, 인증 및 암호화에 대해 상세히 설명한다.Additional modules are included, including an on device authentication client module 509 for user authentication, a radar connector 511 for monitoring and control of network connections, an encryption module 513, and the like. Authentication client 509 may use various user authentication means, including object method 515, password system 517, another rights policy 519, and the like. Hereinafter, authentication and encryption will be described in detail.
도 6 은 본 명세서의 일 실시형태에 따른 클라이언트의 또 다른 예시를 제공한다. 프로세스에 포함된 바와 같이 다양한 모듈 및 구성요소가 도시되어 있다. 예를 들어, 서버와의 접속에 따라, 클라이언트는 메시징 (605), 스트리밍 (607), 및 또 다른 커스항 통신 (609) 을 포함하는 상이한 타입의 송신을 지원한다. 일 실시형태의 네트워크 서버에서 데이터그램 스위치 (701, 703) 에 대응하는 데이터그램 파서 (서비스 파서 (601)) 가 사용된다. 동적 데이터그램 스 위치를 가진 서버에 대한 다음의 설명 참조. 보안 키 교환 (611) 및 암호화 (613) 가 클라이언트에 구현된다. 인증 및 암호화에 대한 다음의 설명 참조. 인증 및 암호화 방식에 결합하여 랜덤화가 사용된다. 데이터 객체의 생성 및 분석에서 랜덤화에 대한 다음의 설명 참조. 또한, 레이더 접속기 (615) 가 클라이언트를 서버에 링크시키는 클라이언트의 일부로서 포함된다. 레이더 접속기 (615) 는 클라이언트와 서버 사이의 접속을 모니터링한다. 접속은 인터넷과 같은 공개 네트워크를 통할 수도 있다. 또한 접속은 사설, 사업자 네트워크, 특히 배분적 계산을 포함하는 네트워크 내에서 확립될 수 있다.6 provides another example of a client, according to one embodiment of the present disclosure. Various modules and components are shown as included in the process. For example, depending on the connection with the server, the client supports different types of transmissions, including messaging 605, streaming 607, and another custom communication 609. In the network server of one embodiment, a datagram parser (service parser 601) corresponding to the datagram switches 701 and 703 is used. See the following description of a server with a dynamic datagram switch. Secure key exchange 611 and encryption 613 are implemented in the client. See the following description of authentication and encryption. Randomization is used in combination with authentication and encryption schemes. See the following description of randomization in the creation and analysis of data objects. Radar connector 615 is also included as part of the client linking the client to the server. Radar connector 615 monitors the connection between the client and the server. The connection may be through a public network, such as the Internet. Connections can also be established within private, operator networks, especially networks that include distributed calculations.
동적 데이터그램 스위치를 갖는 서버Server with Dynamic Datagram Switch
서버는, 클라이언트에 접속하고 클라이언트를 인증하고 데이터 및 애플리케이션 액세스를 클라이언트에 제공할 수 있는, 공개 - 예를 들어, 인터넷 - 또는 비공개 - 예를 들어, 기관 환경 - 네트워크 상에 배치된 임의의 컴퓨터 또는 디지털 디바이스일 수 있다. 네트워크는 유선일 수도 있고, 또는 일부 또는 전체로 무선일 수도 있다. 서버는 시스템에서 다양한 클라이언트 또는 사용자의 승인 또는 권리를 규정한다. 승인은 물리적인 사용자 아이덴티티 - 예를 들어, 생체인식 측정결과에 따라 - 및 지리적 위치 - 예를 들어, 로컬 호스트명, 로컬 시간, 또는 임의의 다른 검출가능한 파라미터 - 에 기초하여 컴파일되고 송신될 수도 있다. 클라이언트가 성공적으로 인증되면, 서버는 클라이언트로부터의 접속을 허용하고, 사용자에게 속하거나 사용자가 액세스하도록 인증된 데이터 또는 애플리케이션으로의 액세스를 허용한다. 데이터 파일은, 각각의 사용자에게 보안되고 비공개된 액세스를 제공하는 EVFS 내에 존재한다. EVFS 에 대한 다음의 설명 참조. 또 다른 실시형태에서는, 전술한 바와 같이, 접속이 확립되면, 서버는 인증된 사용자에게 애플리케이션을 전달할 수도 있다.The server may be any computer deployed on a public-for example, Internet-or private-e.g., institutional environment-network that can connect to the client, authenticate the client, and provide data and application access to the client, or It may be a digital device. The network may be wired, or may be wireless in part or in whole. The server defines the approval or rights of various clients or users in the system. The grant may be compiled and transmitted based on the physical user identity-eg, depending on the biometric measurement result-and the geographic location-eg, local host name, local time, or any other detectable parameter. . If the client is successfully authenticated, the server allows a connection from the client and allows access to data or applications belonging to or authorized by the user. The data file resides in the EVFS which provides each user with secure and private access. See the following description of EVFS. In another embodiment, as described above, once a connection is established, the server may deliver the application to the authenticated user.
도 7 에 도시된 바와 같이, 일 실시형태에 따른 서버는 일련의 모듈 및 구성요소들을 포함하고, 이들 중 일부는 도 6 에 도시된 클라이언트에 포함된 모듈 및 구성요소와 유사하다. 예를 들어, SKE (705) 및 암호화 (707) 는 서버에 구현된다. 또한, 랜덤화는 인증 및 암호화 방식과 결합하여 사용된다. 전술한 바와 같이, EVFS (709) 는 서버에 링크되어, 데이터 액세스 및 저장을 위한 비공개 파일 시스템을 각 클라이언트에 제공한다. EVFS (709) 는 EVFS 인터페이스 (711) 를 통해 서버에 링크된다. 다음의 상세한 설명 참조. 또한, 레이더 접속기 (713) 는 서버의 일부로서 포함되어, 클라이언트측에서 레이더 접속기 (615) 와 인터페이싱한다. 각 측에 레이더 접속기를 가진 서버와 클라이언트간의 네트워크 접속은 네트워크 접속의 효과적인 모니터링 및 제어를 가능하게 한다. 또한, 본 명세서의 또 다른 실시형태에 따라, 레이더 접속기는 접속 실패를 검출하여 필요한 경우 접속을 재확립한다. 예를 들어, 메시징 (715), 스트리밍 (717), 및 커스항 통신 (719) 을 포함하는 다양한 애플리케이션 또는 서비스가 지원된다.As shown in FIG. 7, the server according to one embodiment includes a series of modules and components, some of which are similar to the modules and components included in the client shown in FIG. 6. For example, SKE 705 and encryption 707 are implemented in a server. Randomization is also used in combination with authentication and encryption schemes. As noted above, EVFS 709 is linked to the server, providing each client with a private file system for data access and storage. The EVFS 709 is linked to the server via the EVFS interface 711. See detailed description below. The radar connector 713 is also included as part of the server and interfaces with the radar connector 615 on the client side. Network connections between servers and clients with radar connectors on each side enable effective monitoring and control of network connections. Further, according to another embodiment of the present specification, the radar connector detects a connection failure and reestablishes a connection if necessary. Various applications or services are supported, including, for example, messaging 715, streaming 717, and custom communications 719.
클라이언트와 서버간의 데이터 송신은 임의의 실시형태에 따른 데이터그램 방식에 기초한 동적 데이터그램에 의해 실시된다. 다음의 예 1 참조. 서버를 통한 전달을 위해 의도된 모든 데이터 - 콘텐츠 데이터 또는 트랜잭션 데이터 - 는 데이터그램으로 포맷된다. 각 데이터그램은 일 실시형태에 따른 TCP 패킷 내에서 반송된다. 또 다른 실시형태에서는, UDP, HTTP, 및 HTTPS 와 같은 또 다른 네트워크 프로토콜이 사용될 수도 있다. 다수의 데이터그램 타입이 일 실시형태에 따른 데이터그램 방식에 규정된다. 주 데이터그램 타입은 복수의 부 또는 서브 타입을 가질 수도 있다. 또 다른 실시형태에서, 부 데이터그램 타입은 더 낮은 레벨의 데이터그램 서브타입을 더 포함할 수도 있다. 일련의 방법 및 기능이 각각의 데이터그램 타입 또는 서브타입에 대해 규정될 수도 있다. 각 데이터그램 타입 또는 서브타입은 하나 이상의 특정한 애플리케이션을 지원하고 하나 이상의 특정한 종류의 데이터를 반송할 수 있다. 다양한 타입은 상이하고 특정한 특권 및/또는 승인을 요구할 수도 있다.Data transmission between the client and server is performed by dynamic datagrams based on the datagram scheme in accordance with certain embodiments. See example 1 below. All data intended for delivery through the server-content data or transaction data-is formatted as a datagram. Each datagram is carried in a TCP packet according to one embodiment. In another embodiment, other network protocols such as UDP, HTTP, and HTTPS may be used. Multiple datagram types are defined in the datagram scheme according to one embodiment. The primary datagram type may have multiple sub or subtypes. In another embodiment, the secondary datagram type may further include lower level datagram subtypes. A series of methods and functions may be defined for each datagram type or subtype. Each datagram type or subtype supports one or more specific applications and may carry one or more specific kinds of data. Various types may be different and require specific privileges and / or approvals.
데이터그램은 동적 데이터그램 스위치 (701) 에 의해 서버에서 프로세싱된다. 동적 데이터그램 스위치는 실시간으로 데이터그램을 생성 (701), 할당, 프로세싱 및 스와핑할 수 있다. 데이터그램 할당 및 할당해제는 동적으로 수행된다. 일 실시형태에서는, 하나의 데이터그램이 할당되면서 다른 데이터그램은 할당해제될 때 동일한 메모리 공간이 사용된다. 메모리 포인터가 다수의 데이터그램에 대해 사용된다. 하나의 데이터그램이 서비스중일 때, 그 포인터는 할당된 메모리를 지정한다. 메모리 포인터의 사용은, 다수의 네트워크 애플리케이션을 사용하고, 하나 이상의 사용자에게 서비스중인 네트워크 데이터 송신을 지원할 때에 높은 레벨의 효율성 및 속도를 제공한다. 특정한 실시형태에서는, 데이터그램의 스위치가 하나의 포트를 통한 네트워크 접속 내에서 구현될 수도 있 고; 또 다른 실시형태에서는, 데이터그램의 스위치가 다수의 포트와 접속되어 구현될 수도 있다.The datagram is processed at the server by the dynamic datagram switch 701. The dynamic datagram switch can generate, assign, process and swap datagrams in real time. Datagram allocation and deallocation are performed dynamically. In one embodiment, the same memory space is used when one datagram is allocated while the other datagram is deallocated. Memory pointers are used for multiple datagrams. When a datagram is in service, the pointer points to the allocated memory. The use of memory pointers provides a high level of efficiency and speed when using multiple network applications and supporting the transmission of network data in service to one or more users. In a particular embodiment, a switch of datagrams may be implemented within a network connection through one port; In another embodiment, a switch of datagrams may be implemented in connection with multiple ports.
동적 데이터그램 스위치 (701) 는 일 실시형태에 따른 데이터그램 파서 엔진 (113) 을 구비한다. 또한 파서 엔진 (113) 은, 주 및 부 타입에 기초한 데이터그램을 필터링하는 파서 (703) 를 포함한다. 예를 들어, 우선 데이터는 소켓으로부터 판독되고, 그 소켓에 대한 인-큐 에 첨부된다. 그 후, 파서 엔진 (113) 은 그 소켓이 큐 내에 완전한 데이터그램을 가지는지 여부를 알기 위해 체크한다. 완전한 데이터그램을 가지지 않는 경우, 파서 엔진은 휴지상태가 되어 소켓에 도달하는 다음 패킷을 대기한다. 완전한 데이터그램을 가지는 경우, 파서 엔진은 소켓의 인-큐로부터 완전한 데이터그램을 제거하여, 이를 해독 및 파싱 유닛에 전송하여 해독하고 파싱한다.The dynamic datagram switch 701 includes a datagram parser engine 113 according to one embodiment. The parser engine 113 also includes a
그 후, 파서 엔진 (113) 은, 데이터그램이 해독 및 검증을 통과했는지 여부를 묻는다. 통과하지 않은 경우, 파서 엔진은, 데이터그램이 변경 또는 인젝션의 신호를 나타내는지 여부를 알기 위해 체크한다. 변경 또는 인젝션이 검출되면, 데이터그램은 폐기되고 그 데이터그램을 전송한 사용자는 접속해제될 수도 있다. 데이터그램이 성공적으로 해독되고 검증된 경우, 파서 엔진 (113) 은 그 데이터그램의 의도된 수신자의 결정을 시도한다. 데이터그램이 또 다른 접속 서버에 의도된 경우, 데이터그램은 그 피어 서버 상에서 피어 파서 엔진 (113) 에 포워딩된다. 데이터그램이 로컬 서버에 의도된 경우, 로컬 파서 (703) 로 전달된다.The parser engine 113 then asks whether the datagram passed the decryption and verification. If it does not pass, the parser engine checks to see if the datagram indicates a signal of a change or injection. If a change or injection is detected, the datagram may be discarded and the user sending the datagram may be disconnected. If the datagram has been successfully decrypted and verified, the parser engine 113 attempts to determine the intended recipient of that datagram. If the datagram is intended for another connection server, the datagram is forwarded to peer parser engine 113 on that peer server. If the datagram is intended for the local server, it is passed to the
그 후, 파서 (703) 는, 전송자가 그 특정 타입의 데이터그램을 전송할 권한을 가지는지 여부를 체크한다. 일 실시형태에서, 이것은 객체 분류자를 사용하여 수행된다. 인증 및 암호화에 대한 설명 및 다음의 예 2 참조. 전송자가 특정한 타입의 데이터그램을 전송할 권한을 가지지 않은 경우, 그 데이터그램은 폐기되고 로그파일이 생성된다. 전송자가 그 데이터그램 타입에 대한 권한을 가지는 경우, 파서는, 그 전송자가 특정한 데이터그램을 전송할 권한을 가지는지 여부 및 수신자가 그 데이터그램을 수신할 권한을 가지는지 여부를 알기 위해 더 체크한다. 권한을 가지지 않고, 그 부정적인 권한이 영구적이면, 데이터그램은 폐기되고 로그파일이 생성된다. 권한을 가지지 않지만 그 부정적 권한이 일시적이면, 데이터그램은 후속적인 검색 및 프로세싱을 위해 저장될 수도 있다. 전송자가 데이터그램을 전송할 권한을 가지고 수신자가 그 데이터그램을 수신할 권한을 가지는 경우, 파서는 계속 진행하여 데이터그램 타입을 결정한다.The
도 3 은 일 실시형태에 따른 파서 (703) 에서 구현되는 데이터그램 타입 결정 (301) 및 데이터그램 파싱에 대한 관련 프로세스를 도시한다. 각 데이터그램 타입은, 인스턴트 메시징 엔진 (303), 브로드캐스트 엔진 (305), 접속 프록시 엔진 (307), 사용자 인증 엔진 (309), 사용자 관리 엔진 (311), 사용자 디렉토리 엔진 (313) 등과 같은 대응하는 프로세싱 엔진을 가진다. 데이터그램 타입이 결정되면, 데이터그램은 대응하는 데이터그램 타입에 대한 지정된 엔진에 공급되어 프로세싱된다.3 illustrates a related process for
피어링 엔진 (315) 은 또 다른 접속 서버, 피어 서버에 상주하는 피어 파싱 엔진을 말한다. 사용자 로그온 및 로그오프가 모든 피어에 브로드캐스트된다 (317). 각 피어 서버로의 사용자 액세스는 의도에 따라 통합되어 관리될 수도 있다. 예를 들어, 사용자가, 더 높은 레벨의 액세스 특권을 승인하는 피어 서버에 의해 인증되고 그 피어 서버에 접속되는 경우, 서버에 대해 사용자가 가진 기존의 접속은 해제될 수도 있다. 사용자 관리 엔진 (311) 과 접속된 권한 엔진 (319) 은 모든 사용자에 대한 권한을 관리하고 기록한다. 필요에 따라 추가적인 기능성을 제공하는 또 다른 실시형태에서는, 예를 들어, VPN 터널링 엔진 (321) 을 포함하는 또 다른 모듈 또는 프로세스를 포함할 수도 있다.Peering engine 315 refers to another connection server, a peer parsing engine residing on the peer server. User logon and logoff are broadcast to all peers (317). User access to each peer server may be integrated and managed according to intent. For example, if a user is authenticated by a peer server granting a higher level of access privileges and is connected to that peer server, the existing connection the user has to the server may be released. The authorization engine 319 connected with the user management engine 311 manages and records the privileges for all users. In another embodiment that provides additional functionality as needed, it may include another module or process that includes, for example, the VPN tunneling engine 321.
일 실시형태에서, 서버는 데이터그램 타입의 매트릭스를 동적으로 프로세싱한다. 매트릭스는 제 1 의 소정수 (예를 들어, 256) 의 주 데이터그램 타입을 포함하고, 주 데이터그램 타입 각각은 제 2 의 소정수 (예를 들어, 256) 의 부 데이터그램 타입을 가진다. 또 다른 실시형태에서는, 파서 (703) 가, 3 이상의 차원 또는 층을 가진 데이터그램 타입의 매트릭스를 파싱할 수 있다. 따라서, 파싱은 데이터그램 타입, 필드 및 층에 기초하여 구현될 수도 있다.In one embodiment, the server dynamically processes the matrix of datagram types. The matrix includes a first predetermined number (eg, 256) of primary datagram types, each of which has a second predetermined number (eg, 256) of secondary datagram types. In yet another embodiment, the
데이터그램의 일반 레이아웃에 따라, 데이터그램이 적절히 파싱되면 각각의 데이터그램에 대해 적절한 기능 또는 방법이 실행될 수도 있다. 도 4 는 일 실시형태에 따른 데이터그램의 일반 레이아웃을 제공한다. 데이터그램 레이아웃은 주 데이터그램 타입 (403), 부 데이터그램 타입 또는 서브타입 (405), 데이터그램 길이 (407) 및 데이터그램 체크섬 (409) 과 같은 헤더 필드 및 페이로드 필드 (401) 를 포함한다. 페이로드 (401) 는 송신에서 콘텐츠 데이터를 반송한다. 추가적인 헤더 필드 (411) 가 또 다른 데이터그램 타입에 대해 포함될 수도 있다.Depending on the general layout of the datagram, the proper function or method may be executed for each datagram if the datagram is properly parsed. 4 provides a general layout of a datagram according to one embodiment. The datagram layout includes header fields such as primary datagram type 403, sub datagram type or subtype 405, datagram length 407, and datagram checksum 409 and payload field 401. . Payload 401 carries the content data in the transmission. Additional header field 411 may be included for another datagram type.
일 실시형태에서, 다음의 예 1 를 참조하면, 주 데이터그램 타입은: 사용자 접속을 인증하고 제어할 수 있는 서버 메시지 및 접속 제어 데이터그램; 콘텐츠 데이터 송신을 관리할 수 있는 콘텐츠 데이터그램; 포인트 대 멀티포인트 및 멀티포인트 대 멀티포인트 송신을 실시간 관리할 수 있는 브로드캐스트 데이터그램; 및 네트워크 서버와 지능형 데이터 캐리어간의 프록시 데이터를 송신할 수 있는 접속 프록시 데이터그램 등을 포함한다.In one embodiment, referring to Example 1 below, the primary datagram type includes: a server message and a connection control datagram capable of authenticating and controlling a user connection; A content datagram capable of managing content data transmission; Broadcast datagrams capable of real-time management of point-to-multipoint and multipoint-to-multipoint transmissions; And a connection proxy datagram capable of transmitting proxy data between the network server and the intelligent data carrier.
서버 메시지 및 접속 제어 데이터그램은: 인증 요청을 개시할 수 있는 인증 요청 데이터그램; 인증 요청시에 응답을 전송할 수 있는 인증 응답 데이터그램; 및 인증 세션의 결과를 전송할 수 있는 인증 결과 데이터그램과 같은 부 또는 서브 데이터그램 타입을 포함한다.The server message and access control datagram may include: an authentication request datagram capable of initiating an authentication request; An authentication response datagram capable of sending a response upon authentication request; And a sub or sub datagram type such as an authentication result datagram that can transmit the result of the authentication session.
콘텐츠 데이터그램은: 콘텐츠 데이터를 송신할 수 있는 정규 콘텐츠 데이터그램; 네트워크 서버와 통신하고 로그인 세션을 확립할 수 있는 원격 로깅 데이터그램; 및 원격 접속으로부터 데이터를 송신할 수 있는 원격 데이터 집합 데이터그램; 송신된 콘텐츠 데이터의 검증을 요청할 수 있는 콘텐츠 승인 요청 데이터그램; 및 송신된 콘텐츠 데이터의 검증 요청에 응답할 수 있는 콘텐츠 승인 응답 데이터그램과 같은 부 또는 서브 데이터그램 타입을 포함한다.The content datagram includes: canonical content datagram capable of transmitting content data; A remote logging datagram capable of communicating with a network server and establishing a login session; And a remote data set datagram capable of transmitting data from the remote connection; A content approval request datagram that can request verification of the transmitted content data; And a sub or sub datagram type such as a content acknowledgment response datagram that can respond to the verification request of the transmitted content data.
접속 프록시 데이터그램은: 지능형 데이터 캐리어로부터 네트워크 서버로 프록시 데이터를 전달할 수 있는 서버로의 프록시 데이터; 및 네트워크 서버로부터 지능형 데이터 캐리어로 프록시 데이터를 전달할 수 있는 서버로부터의 프록시 데 이터와 같은 부 또는 서브 데이터그램 타입을 포함한다. 주 데이터그램 타입의 또 다른 예는 인스턴트 메시지 타입이다. 이것은, 파일 송신 타입, 오디오-비디오 송신 타입, 인스턴트 메일 메시지 타입 및 원격 데이터 집합 타입과 같은 부 데이터그램 타입을 포함한다.The connection proxy datagram may comprise: proxy data from an intelligent data carrier to a server capable of delivering proxy data to a network server; And sub or sub datagram types such as proxy data from a server capable of delivering proxy data from a network server to an intelligent data carrier. Another example of a primary datagram type is the instant message type. This includes secondary datagram types such as file transmission type, audio-video transmission type, instant mail message type and remote data set type.
서버 및 클라이언트와 접속하는 인젝터Injector connecting to server and client
또 다른 실시형태에서, 본 명세서의 보안 네트워크 시스템은 서버를 기존 네트워크 기반구조에 접속시키도록 구성되는 인젝터를 포함한다. 인젝터는 네트워크 접속성을 제공하는 소프트웨어 또는 펌웨어일 수 있다. 인젝터는 물리적 접속 데이터를 논리적 네트워크 자원으로 변환한다. 이것이 기존 네트워크와의 편리한 통합을 허용하고, 기존 IT 기반구조를 변형할 필요성을 감소시킨다.In yet another embodiment, the secure network system herein includes an injector configured to connect a server to an existing network infrastructure. The injector may be software or firmware that provides network connectivity. The injector transforms the physical connection data into logical network resources. This allows for easy integration with existing networks and reduces the need to modify existing IT infrastructure.
도 8 을 참조하면, 일 실시형태에서의 인젝터는 클라이언트 (도 6) 또는 서버 (도 7) 에서의 인젝터와 유사한 모듈 및 프로세스를 포함한다. 예를 들어, SKE (805) 및 암호화 (807) 가 인젝터에서 구현된다. 또한, 인증 및 암호화 방식에 결합하여 랜덤화가 사용된다. 서버와 같이, 인젝터는 EVFS (809) 에 링크되어, 기존 네트워크에의 데이터 액세스를 위한 가상 비공개 파일 시스템을 사용자에게 제공한다. EVFS (809) 는 가상 파일 시스템 (VFS) 인터페이스 (811) 를 통해 인젝터에 링크된다. 클라이언트 및 서버와 같이, 인젝터는 예를 들어, 메시징 (813), 스트리밍 (815), 및 또 다른 커스항 통신 (817) 을 포함하는 상이한 타입의 통신을 지원한다.Referring to FIG. 8, the injector in one embodiment includes modules and processes similar to the injector at a client (FIG. 6) or a server (FIG. 7). For example, SKE 805 and encryption 807 are implemented in the injector. In addition, randomization is used in combination with authentication and encryption schemes. Like the server, the injector is linked to the EVFS 809 to provide the user with a virtual private file system for data access to the existing network. The EVFS 809 is linked to the injector via the virtual file system (VFS) interface 811. Like the client and server, the injector supports different types of communication, including, for example, messaging 813, streaming 815, and another custom communication 817.
또한, 인젝터는 동적 데이터그램 스위치 (801) 를 사용하고 데이터그램 또는 프레임 파서 (803) 를 가진다. 데이터그램 스위치 (801) 및 프레임 파서 (803) 는 네트워크 서버에서의 데이터그램 스위치 (701) 및 데이터그램 파서 (703) 에 대응한다. 또한, 레이더 접속기 (819) 는 인젝터의 일부로서 포함되어 서버측의 레이더 접속기 (713) 와 인터페이싱한다. 레이더 접속기 (819) 는 인젝터와 서버 사이에서 네트워크 접속을 모니터링하고 제어한다. 또한, 또 다른 실시형태에 따라 레이더 접속기 (819) 는 접속 실패를 검출하고 필요에 따라 접속을 재확립할 수도 있다.The injector also uses a dynamic datagram switch 801 and has a datagram or
인증 및 암호화Authentication and encryption
본 명세서의 다양한 실시형태에서, 보안 네트워크 시스템은, 예를 들어, 암호화된 또는 암호화되지 않은 ASCII 스트링, 단일 분류 모델 및 수퍼 분류 모델을 포함하는 다양한 인증 및 암호화 수단을 사용할 수도 있다. 대칭적 및 비대칭적 다중암호 암호화가 사용될 수도 있다. 암호화는 출력 피드백, 암호 피드백, 암호 블록 체인화, 암호 포워딩 또는, 암호 및 해독 엔진 모두가 예측하거나 재생산할 수 있는 방식으로 암호 및/또는 키를 변형하는 임의의 다른 방식에 의해 시간에 따라 변경될 수도 있다. 특정한 실시형태에서는, 보안 키 교환 (SKE) 이 사용될 수도 있다. SKE 는 한번만 사용되고 그 후에 폐기되는 랜덤한 키의 쌍 생성을 포함한다. SKE 에 따르면, 서버에 의해 소유되고 제어되는 공개-비공개 키 쌍을 제외하고는 어떠한 키도 임의의 디바이스 또는 시스템에 저장되지 않는다. SKE 는, 다수의 사용자에게 공급하기 위해 공개 키 저장 시스템을 요구하는 공개 키 기반구조 (PKI) 와 다르다. 개재되는 공개 키 저장 시스템 - 네트워크 해커 의 통상적인 목표 - 의 생략이 강화된 네트워크 보안을 허용한다.In various embodiments of the present disclosure, a secure network system may use various authentication and encryption means, including, for example, an encrypted or unencrypted ASCII string, a single classification model, and a super classification model. Symmetric and asymmetric multipassword encryption may be used. Encryption may change over time by output feedback, cipher feedback, cipher block chaining, cipher forwarding, or any other way of transforming ciphers and / or keys in a way that the cipher and decryption engine can all predict or reproduce. have. In a particular embodiment, secure key exchange (SKE) may be used. SKE involves generating a pair of random keys that are used only once and then discarded. According to SKE, no key is stored on any device or system except for a public-private key pair that is owned and controlled by a server. SKE is different from public key infrastructure (PKI), which requires a public key storage system to serve multiple users. Omission of the intervening public key storage system-the common goal of network hackers-allows for enhanced network security.
특정한 실시형태에 따른 보안 네트워크 시스템의 SKE 모듈은 상업용 (COTS) 시스템을 포함하는 다양한 공개 키 시스템을 사용한다. 일 실시형태에서는, 차세대 암호화 표준 (AES) 륀다엘 이 사용된다. 2001년 11월, Announcing the Advanced Encryption Standard 의 Federal Information, Processing Standards Publication 197 참조 (csrc.nist.gov/publications/fips/fips197/fips-197.pdf 에서 이용가능). 또한, 웹사이트, csrc.nist.gov/CryptoToolkit/aes/; csrc.nist.gov/CryptoToolkit/aes/rijindael/; 및 csrc.nist.gov/CryptoToolkit/aes/rijindael/rijindael-ip.pdf 참조. 또 다른 실시형태에서는, 163 비트 타원 곡선 암호화 (ECC) 키가 사용될 수도 있다. ECC 기술은 공지되어 있다. 예를 들어, 1999년 3월 Tatsuaki Okamoto 등의 PSEC: Provably Secure Elliptic Curve Encryption Scheme (P1363a 에 제안) 참조 (grouper.ieee.org/groups/1363/P1363a/contributions/psec.pdf). 또한, 웹사이트, world.std.com/~dpj/elliptic.html 및 csrc.nist.gov/cryptval/dss/fr000215.html 참조.The SKE module of the secure network system according to a particular embodiment uses a variety of public key systems, including commercial (COTS) systems. In one embodiment, Next Generation Encryption Standard (AES) Fenderel is used. See, November 2001, Federal Information, Processing Standards Publication 197, Announcing the Advanced Encryption Standard (available at csrc.nist.gov/publications/fips/fips197/fips-197.pdf). In addition, the website, csrc.nist.gov/CryptoToolkit/aes/; csrc.nist.gov/CryptoToolkit/aes/rijindael/; And csrc.nist.gov/CryptoToolkit/aes/rijindael/rijindael-ip.pdf. In another embodiment, a 163 bit elliptic curve cryptography (ECC) key may be used. ECC techniques are known. See, eg, March 1999, Tatsuaki Okamoto et al., PSEC: Provably Secure Elliptic Curve Encryption Scheme (proposed in P1363a) (grouper.ieee.org/groups/1363/P1363a/contributions/psec.pdf). See also the websites, world.std.com/~dpj/elliptic.html and csrc.nist.gov/cryptval/dss/fr000215.html.
또 다른 실시형태에서는, 다양한 암호화 방법이 랜덤 기반 및 조합으로 사용될 수도 있다. 예를 들어, 또 다른 암호에는: Gost, Cast128, Cast256, Blowfish, IDEA, Mars, Misty 1, RC2, RC4, RC5, FROG, SAFER, SAFER-K40, SAFER-SK40, SAFER-K64, SAFER-SK64, SAFER-K128, SAFER-SK128, TEA, TEAN, Skipjack, SCOP, Q128, 3Way, Shark, Square, Single DES, Double DES, Triple DES, Double DES16, Triple DES16, Triple DES24, DESX, NewDES, Diamond Ⅱ, Diamond Ⅱ Lite 및 Sapphire Ⅱ 등이 포함된다. 또 다른 해시에는: MD2, SH4, SHA-2, RipeMD128, RipeMD160, RipeMD256, RipeMD320, Haval (128, 160, 192, 224 및 256 비트) with Rounds, Snefru, Square, Tiger, 및 Sapphire Ⅱ (128, 160, 192, 224, 256, 288 및 320 비트) 가 포함된다.In another embodiment, various encryption methods may be used on a random basis and in combination. For example, another cipher includes: Gost, Cast128, Cast256, Blowfish, IDEA, Mars,
일 실시형태에서의 인증은 이벤트 레벨 데이터에 기초한다. 인증 이벤트는 마우스 클릭, 키스트로크, 스크린상에서의 터치, 발성, 또는 생체인식 측정값의 선택을 포함한다. 이벤트 레벨 데이터는 이벤트 이전 및 이후에 생성된 데이터 및 이벤트시에 생성되는 데이터를 포함한다. 이벤트 윈도우는 이벤트의 기록시 또는 측정시에 특정될 수도 있다. 즉, 예를 들어, 음향 샘플이 시간 제한 내에 선택될 수도 있다. 이러한 데이터는 일 실시형태에 따른 수퍼 분류자를 컴파일링하는데 사용될 수도 있다.Authentication in one embodiment is based on event level data. Authentication events include mouse clicks, keystrokes, touch on screen, speech, or selection of biometric measurements. Event level data includes data generated before and after the event and data generated at the event. The event window may be specified at the time of recording or measuring the event. That is, for example, an acoustic sample may be selected within a time limit. Such data may be used to compile the super classifier according to one embodiment.
수퍼 분류자의 사용은 3 개의 양태: 분류 (다음의 부록 1 참조), 분석 (다음의 부록 2 참조), 및 판정 (다음의 부록 3 참조) 을 포함한다. 수퍼 분류자의 기능은 입력 벡터 데이터의 특성 추출이다. 입력 벡터 데이터는 2 진수일 수도 있고, 2 진수가 아닐 수도 있다. 예를 들어, 부록 3 참조. 일 실시형태에서는 객체 벡터 기반 수퍼 분류자가 사용된다. 다음의 예 2 참조. 다음 절에서 설명하는 수퍼 분류자 기반 객체 분석에 랜덤화가 적용된다.The use of super classifiers includes three aspects: classification (see
클라이언트 또는 IDC 가 네트워크 서버로의 접속을 시도할 때마다 인증이 수행된다. 일 실시형태에 따르면, 인증 및 암호화 방식은 IDC 로 사용가능하다. 인증 및 암호화 방식은 일련의 단계를 포함한다. 1 단계로, 사용자는 클라이언트 또는 IDC 를 통해 요청을 전송하여, 인증을 요청한다. 따라서, 인증 세션의 개시는 클라이언트 또는 IDC 로부터이다. 2 단계로, 서버는 사용가능한 인증 방식의 리스트를 IDC 에 전송하고, 사용자는 이벤트 - 예를 들어, 마우스 클릭, 스크린 상에서의 터치, 발성, 키스트로크 또는 임의의 다른 적절한 통지 이벤트를 통해 리스트로부터 하나를 선택한다. 카메라 또는 생체인식 디바이스와 같은 디지타이저로부터의 입력은 적절한 통지 이벤트의 또 다른 예를 구성한다. 3 단계로, 선택된 인증 방식에 기초하여, 서버는 인증 데이터에 대한 요구를 IDC 에 전송한다. 요구는, 다양한 실시형태에 따라 순수 랜덤 또는 의사 랜덤인 패스워드일 수도 있다. 의사 랜덤 패스워드는 수학적으로 미리 계산된 리스트에 기초하여 생성되고, 순수 랜덤 패스워드는 시스템 외부에서 엔트로피 소스를 샘플링하고 프로세싱함으로써 생성된다. 5 단계로, 서버는 IDC 로부터 수신된 인증 데이터를 하나 이상의 데이터 객체 또는 객체 벡터로 변환한다. 6 단계로, 서버는 하나 이상의 분류자 또는 수퍼 분류자를 사용하여 데이터 객체에 대한 객체 분석을 수행한다. 생체인식 측정결과에 기초한 수퍼 분류자가 사용될 수도 있다. 마지막으로, 분석 결과 또는 분류자에 기초한 판정이 서버로부터 IDC 에 전송되어, 사용자의 적절한 인증을 확인하여 IDC 의 서버로의 접속을 허용하거나 또는 IDC 로부터의 인증 시도가 실패했음을 선언한다.Authentication is performed whenever a client or IDC attempts to connect to a network server. According to one embodiment, the authentication and encryption scheme is available with IDC. The authentication and encryption scheme includes a series of steps. In a first step, the user sends a request via client or IDC to request authentication. Thus, the initiation of the authentication session is from the client or IDC. In step two, the server sends a list of available authentication methods to IDC, and the user sends one from the list via an event-for example, a mouse click, a touch on the screen, a voice, a keystroke, or any other suitable notification event. Select. Input from a digitizer, such as a camera or biometric device, constitutes another example of a suitable notification event. In step 3, based on the selected authentication scheme, the server sends a request for authentication data to the IDC. The request may be a pure random or pseudo random password, in accordance with various embodiments. Pseudo random passwords are generated based on a mathematically precomputed list, and pure random passwords are generated by sampling and processing entropy sources outside the system. In a fifth step, the server converts authentication data received from IDC into one or more data objects or object vectors. In step 6, the server uses one or more classifiers or super classifiers to perform object analysis on the data object. Super classifiers based on biometric measurements may be used. Finally, a decision based on analysis results or classifiers is sent from the server to the IDC to confirm proper authentication of the user to allow the IDC to connect to the server or declare that the authentication attempt from the IDC has failed.
또 다른 실시형태에 따르면, 3 상태의 인증 또는 3 개의 인증 테스트: 클라이언트-서버 매칭에 대한 논리 테스트, IDC 에 대한 디바이스 테스트, 및 사용자에 대한 개인적 테스트가 구현될 수도 있다. 랜덤화는 데이터 객체 분류자와 함께 또는 분류자없이, 3 개의 테스트 중 하나 이상과 결합되어 사용될 수도 있다.According to yet another embodiment, three state authentication or three authentication tests: logic tests for client-server matching, device tests for IDC, and personal tests for users may be implemented. Randomization may be used in conjunction with one or more of the three tests, with or without a data object classifier.
클라이언트 서버 매칭에 대한 논리 테스트는, IDC 또는 클라이언트가 정확한 서버를 발견하게 하는 테스트이다. 이것은 다수의 단계를 포함한다. 우선, 서버가 인스톨되거나 개시된 경우, 검증 목적으로만 사용되는 공개/비공개 ECC 키 쌍이 서버에 생성된다. IDC 가 구성되거나 생성된 때, IDC 가 서버의 "일반 코드" 로 프린트되고 지정된 서버로 "등록" 되도록, 이러한 서버의 임의의 클라이언트 또는 IDC 에 서버 공개 키 (PK1) 가 제공된다. 그 후, IDC 가 사용자에 할당되고 네트워크를 통해 원격으로 서버에 접속을 시도할 때, 서버의 랜덤화기는 대량의 랜덤 데이터 스트림을 생성하여, 접속 세션을 위한 새로운 ECC (PK2) 공개/비공개 키 쌍의 생성시에 시드로 사용한다. 그 후, 이 공개 키는 검증만을 목적으로한 미리 생성된 서버 비공개 키로 표시된다. 그 후, 서버는 IDC 에 대한 서명 및 새롭게 생성된 공개 ECC 키 모두를 전송한다. 이러한 정보의 수신시에, IDC 는 "검증 전용" 공개 키를 사용하고 키에 의해 프린트되어, 공개 ECC 키의 서명을 입증한다. 서명이 "프린트" 와 매칭되지 않으면, 서버는 올바른 서버가 아니고, IDC 는 접속해제된다. 서명이 매칭되면, IDC 는 세션을 위한 새로운 ECC (PK3) 공개/비공개 키 쌍을 생성하고, 그 공개 키를 클라이언트 아이덴티티 및 설비 (CIF, 전술한 예 1 참조) 의 일부로서 전송한다. CIF 는 서버의 공개 키 PK2 를 사용하여 차례로 암호화된다.Logical testing for client server matching is a test that allows an IDC or client to find the correct server. This involves a number of steps. First, when the server is installed or started, a public / private ECC key pair is generated on the server that is used only for verification purposes. When IDC is configured or created, the server public key PK1 is provided to any client or IDC of such server so that the IDC is printed with the "general code" of the server and "registered" with the designated server. Then, when IDC is assigned to the user and attempts to connect to the server remotely over the network, the server's randomizer generates a large amount of random data streams, creating a new ECC (PK2) public / private key pair for the connection session. Used as a seed in the creation of. This public key is then represented as a pre-generated server private key for verification purposes only. The server then sends both the signature for the IDC and the newly generated public ECC key. Upon receipt of this information, the IDC uses the "verify only" public key and is printed by the key to verify the signature of the public ECC key. If the signature does not match "print", the server is not a valid server and IDC is disconnected. If the signature matches, the IDC generates a new ECC (PK3) public / private key pair for the session and sends that public key as part of the client identity and facility (CIF, see Example 1 above). The CIF is in turn encrypted using the server's public key PK2.
IDC 에 대한 디바이스 테스트는 입증을 위한 IDC 의 물리적 파라미터에 중점 을 둔다. 예를 들어, 캐리어 디바이스 상에 클라이언트 소프트웨어를 배치할 때, 즉, 캐리어 또는 저장 디바이스가 IDC 가 되는 경우, IDC 는 서버에 등록되고, 그 파라미터 중 특정한 파라미터가 서버 데이터베이스 내부와 같은 서버 상에 저장된다. IDC 가 CIF 패킷을 생성하는 경우, IDC 가 도킹되는 호스트 컴퓨터 디바이스 또는 네트워크 접속 디바이스 상에 모을 수도 있는 임의의 정보를 CIF 상에 저장하고, 이전의 논리 테스트에서 검증되었던 공개 키 PK1 으로 전체 CIF 패킷을 암호화하고, 암호화된 CIF 를 서버에 전송한다. 해독후, 서버는, CIF 내의 데이터가 서버에 미리 등록된 파라미터에 매칭되는지 여부 및 IDC 가 공지의 또는 정규의 네트워크 호스트로부터 접속되었는지 여부를 입증할 수도 있다. 입증이 실패하면, 서버는 세션을 종료하고 IDC 를 접속해제한다.Device testing for IDC focuses on IDC's physical parameters for verification. For example, when deploying client software on a carrier device, i.e. when the carrier or storage device becomes an IDC, the IDC is registered with the server and certain of those parameters are stored on the server, such as inside a server database. . When IDC generates a CIF packet, it stores any information on the CIF that may be collected on the host computer device or network attached device to which the IDC is docked and stores the entire CIF packet with the public key PK1 that was validated in the previous logical test. Encrypt and send the encrypted CIF to the server. After decryption, the server may verify whether the data in the CIF matches a parameter previously registered with the server and whether the IDC is connected from a known or regular network host. If the verification fails, the server terminates the session and disconnects IDC.
사용자에 대한 개인적 테스트는 특정한 사용자의 인증에 중점을 둔다. 이 테스트는 분류자 또는 수퍼 분류자로 또는 분류자 없이 구현될 수도 있다. 수퍼 분류자를 사용하지 않는 분류자는 다수의 단계를 포함할 수도 있다. 예를 들어, 성공적 SKE 에 수반하여, 인증 요청 데이터그램이 IDC 에 전송되어, 인증 방법의 리스트, 및 이 방법들 중 하나가 시도-응답 기반 인증인 경우, IDC 가 인증될 시도를 포함한다. 그 후, IDC 는 인증 방법 중 하나를 선택한다. 양방향성 로그인을 위해 사용자를 프롬프트하거나 프롬프트하지 않을 수도 있다. IDC 가 인증을 위한 충분한 정보를 가지고 있는 경우, 자동 로그인이 제공된다. 인증에 계속하여, IDC 는 서버에 인증 객체를 전송하고, 인증 객체는 서버에 의해 조사되어야 하는 검증 데이터를 포함하는 또 다른 데이터그램 타입에서 구현된다. 인증 데이터 객체의 분석은 사용되는 인증 방법에 기초하여 변화한다.Personal testing of users focuses on authentication of specific users. This test may be implemented with or without a classifier or super classifier. Classifiers that do not use super classifiers may include multiple steps. For example, following a successful SKE, an authentication request datagram is sent to IDC to include a list of authentication methods, and an attempt to be authenticated if one of these methods is challenge-response based authentication. The IDC then chooses one of the authentication methods. You may or may not be prompted for a two-way login. If IDC has enough information for authentication, automatic login is provided. Following authentication, IDC sends an authentication object to the server, which is implemented in another datagram type that contains validation data that should be examined by the server. The analysis of the authentication data object changes based on the authentication method used.
한편, 수퍼 분류자를 사용하는 사용자 테스트는 다음과 같이 진행할 수도 있다. 수퍼 분류자는 다양한 타입의 데이터그램 타입 및 서버에서의 데이터그램에 기초하여 구현된다. 성공적인 SKE 시에, 인증 요청 데이터그램은 수퍼 분류자로부터 IDC 로 전송되고, 인증 요청 데이터그램은, 인증 방법의 리스트 및 인증 방법 중 하나가 시도-응답 기반 인증인 경우 IDC 가 인증되어야 하는 시도를 포함한다. 그 후, IDC 는 인증 방법을 유사하게 선택한다. 인증에 대하여, 서버는 이벤트 레벨 작업의 실행에 대한 요청을 IDC 에 전송한다. 요청은 랜덤화기로부터의 입력에 기초하여 수퍼 분류자로 성립된다. IDC 가 작업을 수행하고, 결과로 얻어진 이벤트 레벨 데이터가 인증 데이터 객체로 랩 (wrap) 된다. 일 실시형태에서, 이 데이터 객체는, 세션을 위협하는 가능성을 최소화하도록, 특정한 네트워크 교환 세션에 대해 랜덤하게 생성된 개별적인 식별자를 포함한다. 그 후, 인증 객체는 IDC 로부터 복귀되고, 수퍼 분류자에 기초하여 서버의 "입증자" 에 의해 분석된다. 데이터 객체 분석은 사용되는 특정한 인증 방법에 따라 변화할 수도 있다.On the other hand, the user test using the super classifier may proceed as follows. Super classifiers are implemented based on various types of datagram types and datagrams on the server. Upon successful SKE, the authentication request datagram is sent from the super classifier to IDC, and the authentication request datagram includes an attempt to be authenticated by the IDC if one of the authentication methods and the list of authentication methods is challenge-response based authentication. do. The IDC then similarly chooses an authentication method. For authentication, the server sends a request to the IDC for execution of the event level task. The request is made with the super classifier based on the input from the randomizer. IDC does the work, and the resulting event level data is wrapped in an authentication data object. In one embodiment, this data object includes a randomly generated individual identifier for a particular network switched session to minimize the possibility of threatening the session. The authentication object is then returned from IDC and resolved by the server's "certifier" based on the super classifier. Data object analysis may vary depending on the specific authentication method used.
데이터 벡터 객체의 생성 및 분석에서의 랜덤화Randomization in the Creation and Analysis of Data Vector Objects
랜덤화 기술은 이론 수학 및 응용 수학 분야에서 공지되어 있다. 이것은, 명백한 공통 분모가 존재하지 않는 의사 결정 프로세스에 흔히 적용된다. 랜덤화의 사용은, 오늘날 사용가능한 거대한 계산 능력에 의해 용이해진다. 통상적으로 랜덤화는 시드의 사용을 포함한다. 난수 생성기는 하나 이상의 시드 의 공급에 기초하여 난수의 풀을 생성한다. 시드의 특징에 따라, 랜덤화는 의사 랜덤 또는 순수 랜덤으로 분류될 수도 있다. 대부분의 난수 생성기는 의사 난수 생성기이다. 이것은 수학적으로 미리 계산된, 절충될 수 있는 리스트에 기초한다. 대조적으로, 순수한 난수는 흔히 관련된 컴퓨터 시스템 또는 네트워크 외부에서 엔트로피의 소스를 샘플링하고 프로세싱함으로써 생성된다. 순수 랜덤화기를 깨기 위해서는 엔트로피의 소스 및 엔트로피가 시드를 생성한 방법을 식별해야 한다.Randomization techniques are known in the field of theoretical mathematics and applied mathematics. This often applies to decision making processes where there is no obvious common denominator. The use of randomization is facilitated by the huge computational power available today. Randomization typically involves the use of seeds. The random number generator generates a pool of random numbers based on the supply of one or more seeds. Depending on the characteristics of the seed, randomization may be classified as pseudo random or pure random. Most random number generators are pseudo random number generators. This is based on a mathematically precomputed, negotiable list. In contrast, pure random numbers are often generated by sampling and processing a source of entropy outside an associated computer system or network. To break a pure randomizer, one must identify the source of entropy and how the entropy generated the seed.
또한, 랜덤화는 컴퓨터 또는 네트워크 보안에서 적용된다. 기존의 데이터 보안에서의 랜덤화의 적용은 대개 정적이다. 예를 들어, 난수는 클라이언트, 서버 또는 또 다른 컴퓨터 디바이스에 의해 생성되어 순차적으로 사용자에 의해 컴퓨터 상으로 이동될 수도 있다. 수가 시스템 특정 난수 생성기에 의해 허용되는 난수 "프레임" 내의 수와 매칭되면, 사용자는 액세스가 승인될 것이다. 이것은, 2 개의 비공개로 생성된 키가 공유 검증 지점에서 매칭되고 검증되는 공개 키 기반구조 (PKI) 와 유사하다. 이러한 패러다임에서 하나의 문제는, 공유 검증 지점은 상대적으로 쉽게 위협될 수도 있다는 것이다. 소정의 시드에 기반한 수들의 프레임 (또는 문자 숫자와 같은 임의의 원하는 출력 조합) 을 포함하는 난수 생성기는 시스템 공유 검증 지점에 존재한다. 난수 생성기는 무한한 난수를 발생시키는 것처럼 보이지만, 생성되는 난수의 총 수는 생성기가 생성되면 (시드되면) 미리 결정된다. 즉, 랜덤인 것은 난수가 생성되는 순서만이다. 이러한 랜덤화는 정적이다. 각 난수는 이론적으로 예측된다.Randomization also applies in computer or network security. The application of randomization in existing data security is usually static. For example, the random number may be generated by the client, server or another computer device and sequentially moved onto the computer by the user. If the number matches a number in the random number "frame" allowed by the system specific random number generator, the user will be granted access. This is similar to a public key infrastructure (PKI) in which two privately generated keys are matched and verified at a shared verification point. One problem with this paradigm is that shared verification points may be threatened relatively easily. A random number generator that includes a frame of numbers based on a given seed (or any desired output combination, such as alphanumeric), is present at the system shared verification point. The random number generator appears to generate infinite random numbers, but the total number of random numbers generated is predetermined when the generator is generated (seed). In other words, it is only the order in which random numbers are generated that are random. This randomization is static. Each random number is theoretically predicted.
본 명세서의 특정한 실시형태에 따른 랜덤화는 비정적 방식에서 적용된다. 랜덤화는 하나 이상의 분류자 또는 수퍼 분류자를 통해 데이터 객체에서 구현된다. 후술하는 예 2 참조. 순수한 난수 생성기는 데이터 벡터 객체의 분석을 위한 난수를 제공하도록 시드된다. 데이터 객체는 전술한 바와 같은 인증을 위한 특정한 테스트에 사용된다.Randomization according to certain embodiments herein is applied in a non-static manner. Randomization is implemented in data objects through one or more classifiers or super classifiers. See example 2 below. Pure random number generators are seeded to provide random numbers for analysis of data vector objects. The data object is used for a specific test for authentication as described above.
다양한 실시형태에서, 다수의 개별적인 비공개 키가 순수 랜덤 값에 기초하여 생성된다. 이벤트 레벨에서 컴퓨터 외부의 엔트로피에 기초하여 데이터 객체가 수를 데이터 이미지 또는 값으로 변환하기 때문에, 이 키들은 초기 서버 검증 키에 기초한 어떠한 정보도 포함하지 않는다. 따라서, 키들은 랜덤화기 또는 난수 생성기의 환경 외부에 존재하고 비정적이 된다. 랜덤화 기반 객체 변환에 사용되는 것은 키 자체이기 때문에, 2 개의 미지의 키 (비공개 키) 를 매칭하고 인식하는 것이 가능하다. 또 다른 실시형태에서는, 3 개 이상의 비공개 키가 유사하게 생성되고 사용될 수도 있다. 또한, 임의의 수의 비공개 키가 분류자에서의 객체에 의해 생성되어 비공개 키의 수를 알려지지 않게 할 수도 있다.In various embodiments, multiple individual private keys are generated based on pure random values. Since the data object converts the number to a data image or value based on entropy outside the computer at the event level, these keys do not contain any information based on the initial server verification key. Thus, the keys are outside the environment of the randomizer or random number generator and become non-static. Since the key itself is used for randomization-based object transformation, it is possible to match and recognize two unknown keys (private keys). In another embodiment, three or more private keys may be similarly generated and used. In addition, any number of private keys may be generated by the object in the classifier to make the number of private keys unknown.
이 실시형태에서, 랜덤화는, (i) 사용자 또는 클라이언트가 순수 난수 생성기에 기초한 인증 시도에 직면하도록, 그리고 (ii) 수행될 객체 분석이 선택되고, 선택된 분석이 수행되도록 구현된다.In this embodiment, randomization is implemented such that (i) the user or client faces an authentication attempt based on a pure random number generator, and (ii) the object analysis to be performed is selected and the selected analysis is performed.
통상적인 사전 프로그래밍된 난수 생성기는 다음의 형태:A typical preprogrammed random number generator is of the form:

를 가질 수도 있다.May have
예를 들어, 캠브리지 대학에서 출판한 W.H. Press 등의 Numerical Recipes 참조. 단순한 선형 합동 생성기가 사용되든 개선된 생성기가 사용되든지 간에, 시드의 계산이 예를 들어, 시퀀스에서 생성되는 다수의 난수를 관찰하는 것을 방지하기 위해, 다수의 난수 생성기가 사용될 수도 있다 - 따라서 결합의 문제를 발생시킨다. 특정한 실시형태에서는, 시퀀스에서 최소 유효숫자가 절단되어, 어떠한 힌트를 남길 가능성을 최소화한다. 또한 이러한 실시형태에서는, 시드에 부가하여, 생성기 특정 상수 a, c 및 m 이 전술한 공식에 따라 제공된다. 상수 a 및 m 에 대해 많은 가능한 값을 가지는 표가 생성될 수도 있다. 일부 잡음 입력을 사용하여 상수가 선택되는 경우, 이러한 접근방식은 더 견고한 랜덤화기를 유도할 것이다. 또 다른 실시형태에서는, 다수의 미리 선택된 난수 생성기가 N 개의 독립된 시드와 결합하여 사용될 수도 있다. 단순 합이 다음의 식:For example, W.H., published by the University of Cambridge. See Numerical Recipes, such as Press. Whether a simple linear joint generator is used or an improved generator is used, multiple random number generators may be used to prevent the calculation of the seed, for example, from observing the multiple random numbers generated in the sequence-thus the combination of Cause problems. In certain embodiments, the least significant digits in the sequence are truncated to minimize the possibility of leaving any hints. Also in this embodiment, in addition to the seed, generator specific constants a, c and m are provided according to the above formula. A table with many possible values for the constants a and m may be generated. If a constant is chosen using some noise input, this approach will lead to a more robust randomizer. In yet another embodiment, multiple preselected random number generators may be used in combination with N independent seeds. The simple sum is the following expression:

으로서 사용될 수도 있다.It may also be used as.
약 2.3 × 1018 의 결합 주기를 가지는 2 개의 선형 합동 생성기를 결합시키기 위한 유용한 알고리즘의 예는 Numerical Recipes 에서 설명하는 ran2 이다. 이 알고리즘은 2 개의 독립 시드를 사용하여 변형될 수도 있다. 3 또는 N 개의 생성기를 사용하여 더 변형될 수도 있다. 일 실시형태에서는, 침입자가 쉽게 액세스하지 못하는 비결정 소스를 사용하여 하나 이상의 시드가 획득된다. 비결정 소스는 랜덤화기 외부의 것일 수도 있고, 예를 들어, 외부 디바이스, 외부 이벤트의 발생, 제 3 자, 및 컴퓨터의 최근 기록으로부터 유도되는 비트 등과 같은 해당 네트워크 시스템 외의 것일 수도 있다.An example of a useful algorithm for combining two linear joint generators with a coupling period of about 2.3 × 10 18 is ran2, described in Numerical Recipes. This algorithm may be modified using two independent seeds. It may be further modified using 3 or N generators. In one embodiment, one or more seeds are obtained using an amorphous source that is not easily accessible by an intruder. The non-deterministic source may be external to the randomizer, or may be external to that network system, such as, for example, an external device, the occurrence of an external event, a third party, and a bit derived from a recent record of the computer.
하나의 특정 분류자가 객체 기반 벡터의 분석에 사용되는 경우, 예측성이 상대적으로 높아서, 침입자가 분류자 및 시드를 해결할 수도 있다. 특정한 실시형태에서는, 분류자의 총체 - 즉, 다수의 분류자 또는 수퍼 분류자 - 가 사용되어, 더 낮은 예측성을 달성할 수도 있다. 클래스 결정적이 아닌 변량이 폐기되기 때문에 특성 벡터의 차원이 감소될 수도 있다. 후술하는 부록 1 및 2 참조.If one particular classifier is used in the analysis of object-based vectors, the predictability is relatively high, allowing an attacker to resolve the classifier and seed. In certain embodiments, the totality of classifiers, ie multiple classifiers or super classifiers, may be used to achieve lower predictability. The dimension of the feature vector may be reduced because the non-class deterministic is discarded. See
요약하면, 본 명세서에 따른 랜덤화는 데이터 액세스에 대한 보호를 개선한다. 데이터 객체는 이벤트 레벨에서 사용자에게만 알려진 특정한 값 - 일 실시형태에서 생체인식 측정값과 같은 - 에 기초한다. 디바이스보다 사용자에 대해 중점을 두는 것이 본 명세서에 따른 사용자 중심 보안을 나타낸다. 순수 랜덤화 방식에서 이벤트 레벨에서 변환되고 수퍼 분류자에서 분석되는 데이터 객체가 사용자 아이덴티티를 확립하고 입증하기 위한 더 우수한 토대를 제공한다.In summary, randomization according to the present specification improves protection for data access. The data object is based on a specific value known only to the user at the event level, such as in one embodiment a biometric measurement. Focusing on the user rather than on the device represents user-centric security in accordance with the present specification. In pure randomization, data objects transformed at the event level and analyzed at the super classifier provide a better foundation for establishing and validating user identities.
암호화 가상 파일 시스템 (EVFS)Encryption Virtual File System (EVFS)
다양한 실시형태에 따른 EVFS 는 파일 리포지토리라고도 불리는 사용자마다 (또는 사용자 그룹 마다), 클라이언트마다의 가상 파일 시스템이다. 이것은 서버 기반 파일 시스템 또는 파일 및 데이터 저장 설비이며, 네트워크 시스템의 사용자가 그들의 로컬 호스트 또는 클라이언트 캐리어로부터 파일 또는 데이터를 저장 할 수 있게 한다. EVFS 는 예를 들어, 로컬 호스트에서 저장 용량이 부족한 경우에 유용할 수도 있다. EVFS 의 사용 및 구현의 예는 공개적으로 사용가능하다. 웹사이트, www.microsoft.com/technet/treeview/default.asp?url=/TechNet/prodtechnol/windows2000serv/deploy/confeat/nt5efs.asp; www.serverwatch.com/tutorials/article.php/2106831; 및 www.freebsddiary.org/encrypted-fs.php 참조.According to various embodiments, EVFS is a virtual file system per user (or per user group), also per client, also referred to as a file repository. It is a server-based file system or file and data storage facility and allows users of network systems to store files or data from their local host or client carriers. EVFS may be useful, for example, when there is insufficient storage capacity on the local host. Examples of the use and implementation of EVFS are publicly available. Website, www.microsoft.com/technet/treeview/default.asp?url=/TechNet/prodtechnol/windows2000serv/deploy/confeat/nt5efs.asp; www.serverwatch.com/tutorials/article.php/2106831; And www.freebsddiary.org/encrypted-fs.php.
본 명세서의 일 실시형태에 따르면, 보안 네트워크 시스템의 서버는 도 7 에 도시된 바와 같이, EVFS 인터페이스 (711) 를 통해 EVFS (709) 에 접속된다. EVFS (709) 는 사용자 디렉토리 (721), 사용자마다의 파일 데이터베이스 (723) 및 파일 저장영역 (725) 을 포함한다. 사용자 디렉토리는, 패스워드, 로그인 파라미터, 생체인식 프로파일, 물리적 또는 지리적 위치, 온라인 및 오프라인 상태, EVFS 에 저장된 암호 파일에 사용되는 공개 ECC 키를 포함하는 모든 사용자에 대한 관련 정보를 포함한다. 사용자는, 클라이언트 또는 IDC 를 통해 네트워크 서버에 접속했으며 네트워크에 의해 지원되는 특정한 애플리케이션을 사용했거나 사용중인 개인이다. 애플리케이션은 본 명세서의 일 실시형태에 따른 IDC 에 전달되고 실행될 수도 있다. 또한 애플리케이션은 IDC 또는 클라이언트가 접속되는 호스트 컴퓨터 또는 디바이스를 실행시킬 수도 있다. 또는, 애플리케이션은 클라이언트 대신 서버 상에서 원격으로 실행될 수도 있다.According to one embodiment of the present disclosure, the server of the secure network system is connected to the EVFS 709 via the EVFS interface 711, as shown in FIG. 7. EVFS 709 includes a user directory 721, a file database 723 for each user, and a
서버는 디렉토리 인터페이스 (727) - 서버에 상주 - 를 사용하여 사용자 디 렉토리 (721) 에 액세스한다. 파일 저장영역 (725) 은, 사용자에게 관심있는 파일 및 임의의 다른 데이터를 저장한 디지털 미디어이다. 이는 임의의 종류의 컴퓨터 메모리일 수도 있다. 이는, 사용자 애플리케이션으로부터 생성되고 변형된 파일 또는 데이터가 저장되는 물리적 위치이며; 사용자 애플리케이션은 IDC, 호스트 컴퓨터 또는 원격의 서버 상에서 실행된다. 파일 저장영역 (725) 은 빠르고 편리한 액세스를 위해 최적화될 수도 있다.The server accesses the user directory 721 using the directory interface 727-which resides on the server.
사용자마다의 파일 데이터베이스 (723) 는, 원시 파일명, 데이터 및 시간, 및 파일 암호화에 사용되는 암호 키의 암호화된 표현과 같은 사용자 파일 정보를 포함한다. EVFS (709) 에 저장된 모든 파일은 순수 랜덤 명칭 및 순수 랜덤 암호 키로 할당되고; 파일 저장영역 (725) 에서 서로 혼합된다. 데이터 액세스는 각 사용자에 대해 비공개이고 보안되어 있다. 각 개별 사용자는, 사용자가 소유권을 가지거나 사용자가 액세스할 권한을 가진 파일 또는 데이터를 찾거나 검색만 할 수도 있다. 사용자가 각 파일 또는 기록에 대해 가지는 액세스 레벨은 서버에 의해 제어된다. 즉, 특정한 실시형태에서는, 사용자가 파일을 판독하고 편집하기 위해서만 승인되고, 파일을 서버 - 애플리케이션이 지능형 데이터 캐리어로부터 실행되는 경우에는 IDC - 로부터 이동시키거나 복사하도록 승인되지는 않을 수도 있다. 이와 같이, 각 사용자는 서버에 접속된 가상의 비공개 데이터베이스 - 즉, 사용자마다의 데이터베이스 (723) - 를 가진다.File database 723 per user includes user file information such as source file name, data and time, and an encrypted representation of an encryption key used for file encryption. All files stored in the EVFS 709 are assigned a pure random name and a pure random encryption key; Files are mixed with each other in
본 명세서에서 개시되는 보안 네트워크 시스템 (709) 은 각 사용자에게 속하는 데이터 및 애플리케이션에 대한 강화된 보호를 제공한다. 물리적 위협의 경 우, 예를 들어, IDC 가 분실되거나 도난당한 경우, EVFS (709) 에 저장된 데이터는, 파일을 열 수 있는 비공개 ECC 암호 키로의 액세스를 가지는 파일을 소유자인 적절히 인증된 사용자를 제외하고는 누구에게도 판독될 수 - 또는 시인될 수 - 없을 것이다.The secure network system 709 disclosed herein provides enhanced protection for data and applications belonging to each user. In the case of a physical threat, for example, if IDC is lost or stolen, the data stored in EVFS 709 excludes properly authenticated users who are owners of the file with access to a private ECC encryption key that can open the file. No one can read or admit it to anyone.
따라서, EVFS (709) 의 제공은 다양한 실시형태에 따른 보안 네트워크 시스템의 사용자 중심 양태를 강화한다. 암호화, 인증, 및 본 명세서 전반에 걸쳐 설명하는 다른 특성과 함께, EVFS (709) 는 IDC 를 통해 애플리케이션의 안전한 전달 및 독립형 동작을 가능하게 한다.Thus, provision of EVFS 709 enhances the user-centric aspect of a secure network system according to various embodiments. Along with encryption, authentication, and other features described throughout this specification, EVFS 709 enables secure delivery and standalone operation of applications via IDC.
다음의 예에서 다양한 실시형태를 더 설명하고, 개시된 실시형태들은 예시적인 것이며 한정적인 것이 아니다.The following examples further illustrate various embodiments, and the disclosed embodiments are illustrative and not restrictive.
실시예 1 : 데이터그램의 예, 및 주 및 부 (서브) 데이터그램 타입의 사양Example 1 Example of Datagram, and Specification of Primary and Sub (Sub) Datagram Types
데이터그램의 예Example of datagram
인스턴트 메시지 타입Instant message type
인스턴트 메시지Instant message
원격 로깅Remote logging
원격 데이터-집합Remote data-set
원격 커맨드 실행Remote command execution
파일 송신Send file
오디오-비디오 통신Audio-Video Communication
EDI 트랜잭션EDI Transaction
브로드캐스트 타입Broadcast type
비 실시간 포인트 대 멀티포인트 송신Non real-time point-to-multipoint transmission
증권 시세 표시기 (Stock ticker)Stock ticker
비 실시간 멀티포인트 대 멀티포인트 송신Non real-time multipoint-to-multipoint transmission
채널 기반 챗 (IRC 스타일)Channel based chat (IRC style)
실시간 포인트 대 포인트 송신Real time point-to-point transmission
사용자 대 사용자 챗User to User Chat
오디오-비디오 회의 (오디오 또는 음성 전화통신)Audio-Video Conferencing (Audio or Voice Telephony)
실시간 포인트 대 멀티포인트 송신 (브로드캐스트)Real-time point-to-multipoint transmission (broadcast)
오디오 비디오 브로드캐스트Audio video broadcast
실시간 멀티포인트 대 멀티포인트 송신Real-time multipoint-to-multipoint transmission
오디오 비디오 회의Audio video conferencing
사용자 디렉토리 타입User directory type
조회Lookup
업데이트update
서버 큐 타입Server queue type
오프라인 저장Offline save
서버 스와핑 영역Server swapping area
콘텐츠 필터 제어Content filter control
필터 상태Filter status
필터 통계Filter statistics
필터 업데이트 (룰의 추가/제거)Filter Update (Add / Remove Rule)
필터 설정Filter settings
필터 재설정Reset filter
강제 데이터그램 필드Forced Datagram Field
각 데이터그램의 시작은 다음과 같이 레이아웃될 수도 있다:The beginning of each datagram may be laid out as follows:
바이트 타입 상주 콘텐츠Byte type resident content
1 클라이언트 데이터그램 주 타입1 Client Datagram Main Type
1 클라이언트 데이터그램 부 타입(서브 타입)1 Client datagram subtype (subtype)
8 서버 서버로부터 수신된 데이터그램 (타임스탬프)8 Server Datagram received from server (timestamp)
4 서버 데이터그램 발신자(전송자의 클라이언트-ID)4 Server datagram sender (sender's client-ID)
1 클라이언트 서명/CRC 타입1 Client Signature / CRC Type
n 클라이언트 서명/체크섬 필드n Client signature / checksum field
(예컨대, ECC 서명, MD4, MD5, SHA, SHA1 등)(E.g., ECC signature, MD4, MD5, SHA, SHA1, etc.)
추가 헤더 필드가 데이터그램의 타입에 따라 전술한 필드에 첨부될 수도 있다. 통상적으로 추가 헤더 필드는 클라이언트에 상주하고, 서버에 의해 검증될 수도 있다.An additional header field may be attached to the above-described field according to the type of datagram. Typically additional header fields reside on the client and may be verified by the server.
서명/CRC 타입:Signature / CRC Type:
타입 CRC 필드의 길이The length of the type CRC field
0: 체크섬 없음 0 바이트 (무시됨)0: No checksum 0 bytes (ignored)
1: ECC 서명 87 바이트1: ECC signature 87 bytes
2: SHA 20 바이트2: 20 bytes of SHA
3: SHA1 20 바이트3: SHA1 20 bytes
4: MD44: MD4
5: MD5 16 바이트5: MD5 16 bytes
6:6:
7:7:
8: CRC328: CRC32
다양한 데이터그램에서 추가 헤더가 첨부된다. 헤더는 클라이언트에 상주하고 서버에 의해 검증될 수도 있다.Additional headers are attached in various datagrams. The header may reside in the client and be verified by the server.
대칭적 암호 타입Symmetric cipher type
SKE (보안 키 교환) 의 일부가 절충된다. 대칭적 암호는 클라이언트 및 서버 모두에 의해 지원될 수도 있고, 승인 및 암호 타입 우선권에 기초하여 선택될 수도 있다.Part of the SKE (Security Key Exchange) is compromised. Symmetric cryptography may be supported by both client and server, and may be selected based on grant and cipher type priority.
타입 명칭Type name
1 Rijndael1 Rijndael
2 Blowfish2 Blowfish
3 RC63 RC6
4 Twofish4 Twofish
보안 키 교환Security key exchange
특정한 실시형태에서, SKE 는 대칭적 암호키가 클라이언트에 저장되어 위협에 놓이지 않도록, 랜덤한 일회성 (폐기되는) 암호 키를 구현하는데 사용된다.In a particular embodiment, the SKE is used to implement random one-time (discarded) cryptographic keys so that symmetric cryptographic keys are stored on the client and not put in threat.
SKE 가 실행되는 경우, 또 다른 정보 또는 데이터가 네트워크 상에서 교환된다. 이 정보 또는 데이터는 사용자에 대한 강화된 특권 또는 제한을 구체화할 수도 있다.When the SKE is executed, another information or data is exchanged on the network. This information or data may embody enhanced privileges or restrictions on the user.
SKE 프로세스 개관SKE Process Overview
1. 클라이언트가 서버에 접속함1. Client connects to server
2. 서버가 SPK 데이터그램을 클라이언트에 전송함2. Server sends SPK datagram to client
3. 클라이언트가 서버 서명을 검증하고 CIF 데이터그램을 리턴함.3. The client verifies the server signature and returns a CIF datagram.
4. 서버가 클라이언트 데이터를 검증하고, SKP 데이터그램을 리턴함.4. The server verifies the client data and returns a SKP datagram.
5. 클라이언트가 리시트 (Receipt) 를 전송함5. Client sends Receipt
6. 서버가 리시트를 전송함6. The server sends a record
SPK 데이터그램SPK datagram
서버 공개 키 (SPK) 데이터그램은 클라이언트에 세션에 대한 서버 공개 키를 전송하는데 사용된다. 서버는, 침입하는 해킹으로부터 보호하기 위해 서버 인스톨동안 생성되는 미리 공유된 공개/비공개 ECC 키로부터 비공개 키를 가진 키를 표시할 수도 있다.Server Public Key (SPK) datagrams are used to send the server public key for a session to the client. The server may present a key with a private key from a pre-shared public / private ECC key generated during server installation to protect against invading hacking.
바이트 크기 설명Byte size Description
2 세션에 대한 서버의 공개 키의 길이 (16진수)Length of server's public key for 2 sessions (hexadecimal)
n 세션에 대한 서버 공개 키Server public key for n sessions
n 서명n signature
CIF 데이터그램CIF datagram
클라이언트 아이덴티티 및 성능 (CIF) 데이터그램은, IDC 가 실행되는 호스트에 대한 정보, 및 클라이언트가 세션에 대해 사용하기를 원하는 공개 키를 포함하는, 클라이언트에 관한 데이터 (IDC) 를 인코딩한다.The Client Identity and Capability (CIF) datagram encodes data about the client (IDC), including information about the host on which IDC runs, and the public key that the client wants to use for the session.
데이터는 CSV 형 방식으로 인코딩된다.The data is encoded in CSV format.
필드 설명Field description
1 세션에 대한 클라이언트 공개 키Client public key for
2 암호 방법 및 지원되는 키길이의 공간적으로 분리된 리스트2 Spatially separated list of cipher methods and supported key lengths
3 해시 방법의 공간적으로 분리된 리스트3 Spatially separated list of hash methods
4 클라이언트 디바이스 타입 (2 진 데이터로 인코딩될 수도 있다)4 client device type (may be encoded as binary data)
5 클라이언트 식별자 (2 진 데이터로 인코딩될 수도 있다)5 client identifier (may be encoded as binary data)
6 클라이언트에 대한 대칭 암호 키 -> 서버 스트림6 Symmetric encryption key for client-> server stream
7 대칭 암호에 대한 IV7 IV for Symmetric Password
암호 및 키길이는 다음과 같이 포맷된다.The password and key length are formatted as follows.
<암호 방법>-<키길이><암호 방법>-<키길이><Password method>-<key length> <password method>-<key length>
클라이언트 데이터 타입은 (윈도우 기반 호스트에 대한 PNP 디바이스-ID 와 같은) IDC 하드웨어 환경의 설명을 말한다. IDC 가 접속된 호스트 상에서, 예를 들어, 호스트 프로세서 시리얼 넘버, 마더보드 (마더보드 BIOS) 의 펌웨어 개정 시리얼 넘버, 상이한 하드웨어 토큰 (생체인식 입력 디바이스, 스마트카드 판독기, 플래시 판독기) 으로부터의 인증 데이터, 및 호스트가 서버와 통신하는 네트워크 인터페이스의 MAC 등을 포함하는 임의의 정보가 사용될 수 있다.Client data type refers to the description of an IDC hardware environment (such as a PNP device-ID for a Windows-based host). On the host to which the IDC is connected, for example, the host processor serial number, firmware revision serial number of the motherboard (motherboard BIOS), authentication data from different hardware tokens (biometric input devices, smart card readers, flash readers), And any information including the MAC of the network interface through which the host communicates with the server and the like.
전체 CIF 데이터그램은 서버 공개 키를 사용하여 암호화된다. 교환된 값 (EV) 은 암호화된 패키지를 따라 전송된다. 전송된 암호화된 데이터그램은 다음과 같이 판독될 수도 있다:The entire CIF datagram is encrypted using the server public key. The exchanged value (EV) is sent along the encrypted package. The transmitted encrypted datagram may be read as follows:
제 1 및 제 2 옥테트는 (16진수의) EV 의 길이임The first and second octets are of length (in hexadecimal) EV
n 옥테트가 EV 에 후속함n Octet follows EV
n 옥테트가 암호화된 CIF 데이터에 후속함n Octet follows encrypted CIF data
SKP 데이터그램SKP datagram
서버 키 패키지 (SKP) 데이터그램은 암호, 비트 길이 및 키에 대한 정보를 유지하지만, 다른 목적으로는 확장될 수 없다.Server key package (SKP) datagrams maintain information about ciphers, bit lengths, and keys, but cannot be extended for other purposes.
서버는 SKP 데이터그램의 정보를 표시할 필요가 없다. SKP 는 클라이언트의 공개 키로 암호화되며, 차례로 서버에 전송되고 서버의 공개 키로 암호화된다. 이 데이터그램은 CSV 형 방식으로 인코딩된다.The server does not need to display information from SKP datagrams. The SKP is encrypted with the client's public key, which in turn is sent to the server and encrypted with the server's public key. This datagram is encoded in CSV format.
필드 설명Field description
1 SKP 데이터그램 타입1 SKP datagram type
SKP 타입 0SKP type 0
이것은 정규의 SKP 데이터그램이다. 이것은 업스트림 및 다운스트림을 위해, 암호, 키길이 및 암호모드에 대한 정보를 클라이언트에 유지한다.This is a regular SKP datagram. This maintains information on the client about the cipher, key length and cipher mode, for upstream and downstream.
필드 설명Field description
2 서버에 대해 선택된 암호 -> 클라이언트 스트림2 Password selected for server-> client stream
3 서버에 대한 비트길이 -> 클라이언트 스트림3 Bit length for server-> client stream
4 서버에 대한 암호모드(ECB, CBC, CFB, OFB)->클라이언트 스트림4 Cipher Mode (ECB, CBC, CFB, OFB)-> Client Streams for Server
5 클라이언트에 대해 선택된 암호 -> 서버 스트림5 Password selected for client-> server stream
6 클라이언트에 대한 비트길이 -> 서버 스트림6 Bit Length for Client-> Server Stream
7 클라이언트에 대한 암호모드(ECB, CBC, CFB, OFB)->서버 스트림7 Cipher Mode (ECB, CBC, CFB, OFB)-> Server Stream for Client
8 서버에 대한 대칭 암호 키 -> 클라이언트 스트림Symmetric Cryptographic Key-> Client Streams for Server 8
9 서버에 대한 대칭적 IV -> 스트림Symmetric IV-> Streams for 9 Servers
SKP 타입 1
IDC 가 특정한 서버로부터 "클라이언트 아이덴티티" 업데이트 (또는 추가 아 이덴티티) 를 검색하도록 한다.Instructs IDC to retrieve "client identity" updates (or additional identities) from a particular server.
필드 설명Field description
2 추가 아이덴티티를 유지하는 서버의 IP 어드레스2 IP address of the server holding the additional identity
3 서버가 경청하고 있는 포트3 Port on which the server is listening
4 SKE 동안 서버에 부여되는 옵션적인 "클라이언트 아이덴티티"Optional "client identity" granted to server during 4 SKE
SKP 타입 8SKP type 8
현재의 위치로부터 시스템에 접속하도록 허용되지 않음을 IDC 에 통지한다. 타입 8 SKP 데이터그램의 성공적인 전송시에, 서버는 접속을 자동으로 해제한다.Notify IDC that it is not allowed to connect to the system from its current location. Upon successful transmission of a Type 8 SKP datagram, the server automatically releases the connection.
필드 설명Field description
2 사용자에게 나타내기 위한 메시지 (옵션)2 Message to the user (optional)
SKP 타입 9SKP Type 9
펌웨어 업데이트의 검색을 시도할 것을 IDC 에 요청한다.Ask IDC to try to search for firmware updates.
필드 설명Field description
2 펌웨어 업데이트를 유지하는 서버의 IP 어드레스2 IP address of the server holding the firmware update
3 서버가 경청하고 있는 포트3 Port on which the server is listening
4 SKE 동안 서버에 부여되는 옵션적인 "클라이언트 아이덴티티"Optional "client identity" granted to server during 4 SKE
SKP 타입 10SKP Type 10
누락 또는 손실로 리포트되었을 때, IDC 가 사용자에게 IDC 디바이스를 리턴시킬 것을 요청하도록 지시한다.When reported as missing or lost, IDC instructs the user to request to return the IDC device.
필드 설명Field description
2 사용자에게 나타내기 위한 메시지2 Message to display to user
SKP 타입 11SKP Type 11
IDC 가 "자체 파괴" 를 시도하도록 지시한다Instructs IDC to try to "destroy itself"
필드 설명Field description
2 방법 (비트 필드)2 way (bitfield)
3 쿠키 (옵션)3 cookies (optional)
SKP 타입 11 방법SKP type 11 method
비트 설명Bit description
0 드라이브를 언링크시킴0 unlink drive
1 와이프 (wipe)1 wipe
2 "쿠키" 를 추가함2 added "cookies"
SKP 데이터그램은 클라이언트의 공개 키로 암호화된다. 교환값 (EV) 은 암호화된 패키지를 따라 전송된다. 전송된 암호화된 데이터그램은 다음과 같이 판독될 수도 있다:SKP datagrams are encrypted with the client's public key. The exchange value EV is transmitted along with the encrypted package. The transmitted encrypted datagram may be read as follows:
제 1 및 제 2 옥테트는 (16진수의) EV 의 길이임 The first and second octets are of length (in hexadecimal) EV
n 옥테트는 EV 에 후속함n Octet follows EV
n 옥테트는 암호화된 SPK 데이터에 후속함n Octet follows encrypted SPK data
CR 데이터그램CR datagram
클라이언트 리시트 (CR) 데이터그램은, 대칭 암호, 비트길이 및 서버에 의해 제공되는 방법에 의해 암호화되는, 전체 (암호화되지 않은) SKP 데이터그램의 SHA- 1 해시이다.Client Receive (CR) datagrams are SHA-1 hashes of entire (unencrypted) SKP datagrams, encrypted by symmetric ciphers, bit lengths, and methods provided by the server.
SR 데이터그램SR datagram
서버 리시트 (SR) 데이터그램은 서버로부터 클라이언트로의 암호 스트림의 테스트, 및 리스트로서 동일한 해시를 리턴시킨다.The server record (SR) datagram tests the cipher stream from the server to the client, and returns the same hash as a list.
주 타입 0: 서버 메시지 및 접속 제어Main type 0: server messages and access control
데이터그램 타입은, 서버가 메시지, 에러 통지, 및 네트워크 접속에 대한 서버-클라이언트 특정 정보를 전송하는데 사용된다.The datagram type is used by the server to send messages, error notifications, and server-client specific information about the network connection.
서브타입 1: 인증 요청Subtype 1: Authentication Request
서버에의 접속시에, 서버는, 클라이언트가 클라이언트 자신을 식별하도록 요구하는 타입 0, 1 데이터그램을 송신할 수도 있다. 이 데이터그램은, 서버에 의해 인증되도록 요구되는 인증 방식을 접속된 클라이언트에 통지한다.Upon connection to the server, the server may send
서브타입 2: 인증 응답Subtype 2: Authentication Response
이 데이터그램은 사용자를 검증하기 위해 클라이언트에 의해 사용된다.This datagram is used by the client to verify the user.
복수의 인증 방법은 다음 리스트에 예시하는 바와 같이 데이터그램의 서브타입들과 결합하여 사용될 수도 있다:Multiple authentication methods may be used in combination with subtypes of datagrams as illustrated in the following list:
0 사용자명 및 패스워드0 username and password
1 사용자명 및 패스워드 + x.509 클라이언트 인증 서명 (예를 들어, www.webopedia.com/TERM/X/X_509.html 참조)1 Username and password + x.509 client certificate signature (see www.webopedia.com/TERM/X/X_509.html for example)
2 사용자명 및 패스워드 + ECC 서명2 Username and Password + ECC Signature
3 패스워드3 password
4 패스워드 + X.509 클라이언트 인증 서명4 Password + X.509 Client Certificate Signing
5 패스워드 + ECC 서명5 Password + ECC Signature
6 일회성 패스워드 (S-Key, 패스워드의 소정의 순서화된 리스트)6 one-time password (S-Key, predetermined ordered list of passwords)
7 일회성 패스워드 + x.509 클라이언트 인증 서명7 one-time password + x.509 client certificate signature
8 일회성 패스워드 + ECC 서명8 one-time password + ECC signature
9 음성키9 Voice Key
10 음성키 + x.509 클라이언트 인증 서명10 voice keys + x.509 client certificate signature
11 음성키 + ECC 서명11 Voice Keys + ECC Signature
12 생체인식 해시12 Biometric Hash
13 생체인식 해시 + x.509 인증 서명13 Biometric Hash + x.509 Certificate Signature
14 생체인식 해시 + ECC 서명14 Biometric Hash + ECC Signature
15 x.509 클라이언트 인증 (서명)15 x.509 Client Authentication (Signature)
16 ECC 서명16 ECC Signature
17 콘텐츠 전달 ID (TID)17 Content Delivery ID (TID)
18 대안적인 캐리어에 의해 송신되는 일회성 패스워드18 One-time password sent by alternative carrier
19 일시적인 인증-토큰 (auth-token)19 auth-token
사용되는 특정한 인증 방법은 이 데이터그램의 추가 데이터 필드의 수를 결정한다. 이하, 특정한 방법이 사용되는 경우의 다양한 필드의 예를 나타낸다:The specific authentication method used determines the number of additional data fields of this datagram. The following is an example of various fields when a particular method is used:
방법 0Method 0
바이트 크기 설명Byte size Description
1 사용자명 필드의 길이The length of the username field
n 사용자명n username
1 패스워드 필드의 길이The length of one password field
n 패스워드n password
방법 1
바이트 크기 설명Byte size Description
1 사용자명 필드의 길이The length of the username field
n 사용자명n username
1 패스워드 필드의 길이The length of one password field
n 패스워드n password
n 사용자명 및 패스워드 필드에 대한 x.509 서명x.509 signature for username and password fields
방법 2
바이트 크기 설명Byte size Description
1 사용자명 필드의 길이The length of the username field
n 사용자명n username
1 패스워드 필드의 길이The length of one password field
n 패스워드n password
n 사용자명 및 패스워드 필드에 대한 ECC 서명n ECC signatures for username and password fields
방법 8Method 8
바이트 크기 설명Byte size Description
1 패스워드 필드의 길이The length of one password field
n 일회성 패스워드n one-time password
n ECC 클라이언트 인증 서명n ECC client certificate signature
방법 11Method 11
바이트 크기 설명Byte size Description
1 ECC 서명의 길이1 ECC signature length
n 음성키 데이터에 대한 ECC 서명n ECC signature for voice key data
n 음성키 데이터n Voice Key Data
방법 12Method 12
바이트 크기 설명Byte size Description
n 생체인식 해시biometric hash
방법 14Method 14
바이트 크기 설명Byte size Description
1 ECC 서명의 길이1 ECC signature length
n 생체인식 해시에 대한 ECC 서명ECC signature for biometric hash
n 생체인식 해시biometric hash
방법 16Method 16
바이트 크기 설명Byte size Description
n 시도에 대한 ECC 서명n ECC signature for attempt
서브타입 3: 인증 결과Subtype 3: Authentication Result
인증 요청이 프로세싱된 후, 클라이언트는, 인증 결과를 전달하는 0,3 데이터그램을 수신할 것이다. 이 데이터그램은 특정한 정적 필드를 가진다:After the authentication request has been processed, the client will receive 0,3 datagrams carrying the authentication result. This datagram has certain static fields:
바이트 크기 설명Byte size Description
1 1=승인, 0=거부1 1 = Approve, 0 = Reject
성공적인 인증에 대해, 추가 필드가 포함될 수도 있다:For successful authentication, additional fields may be included:
바이트 크기 설명Byte size Description
1 전송된 사용자 프로파일1 User Profile Sent
4 프로파일이 전송되면, 프로파일 필드의 길이를 표시함4 If profile is sent, indicates the length of the profile field
n 마임인코딩된 (mime-encoded) 사용자 프로파일n mime-encoded user profiles
서브타입 4: 일반적 에러Subtype 4: General Error
서버가 클라이언트 세션동안 임의의 에러를 직면한 경우, 이러한 타입의 데이터그램이 에러를 포착한다. 포함된 필드는 다음과 같다:If the server encounters any error during the client session, this type of datagram catches the error. The fields included are:
바이트 크기 설명Byte size Description
n 에러 메시지n error message
서브타입 5: 무효 데이터그램Subtype 5: Invalid Datagram
서버를 통과한 데이터그램이 어떠한 이유때문에 무효인 것으로 간주되면, 이러한 타입의 데이터그램은 페이로드에 그 이유를 포함한다.If the datagram passed through the server is considered invalid for some reason, this type of datagram includes the reason in the payload.
바이트 크기 설명Byte size Description
n 에러 설명n Error description
서브타입 6: 부적당한 허용Subtype 6: Improper Allow
데이터그램은, 네트워크 액세스가 거부되었음을 나타낸다.The datagram indicates that network access is denied.
바이트 크기 설명Byte size Description
1 주 타입1 week type
1 부 타입1 type
n 에러 메시지n error message
서브타입 7: 킵-얼라이브Subtype 7: Keep-Alive
이 데이터그램은 소정의 간격으로 서버 및/또는 클라이언트에 의해 서로에게 전송되어, TCP 접속을 개방상태로 유지한다. 이것은 시스템이 다양한 프록시-방화벽을 통해 실행될 때 (예를 들어, FW-1) 또는 다이얼-업 접속을 통해 실행될 때 (예를 들어, 다이얼-업 라우터) 유용하다.These datagrams are sent to each other by the server and / or client at predetermined intervals to keep the TCP connection open. This is useful when the system is running through various proxy-firewalls (eg, FW-1) or when running through a dial-up connection (eg, dial-up routers).
또한 이 타입의 데이터그램은, 클라이언트가 얼라이브인지 여부를 검출하기 위해, 클라이언트가 킵-얼라이브 데이터그램을 리턴하도록 서버가 요청하는데 유용하다.This type of datagram is also useful for the server to request that the client return a keep-alive datagram to detect whether the client is alive.
바이트 크기 설명Byte size Description
0,1 0=필요한 답 없음; 1=응답 요구0,1 0 = No answer required; 1 = response request
주 타입 1: 콘텐츠 데이터그램Primary Type 1: Content Datagram
서브타입 1: 정규의 콘텐츠 데이터그램Subtype 1: Canonical Content Datagram
이 데이터그램은 송신될 실질적 콘텐츠 데이터를 포함한다.This datagram contains the actual content data to be transmitted.
바이트 크기 콘텐츠Byte size content
4 최종 수신-ID4 Last Receive-ID
n 마임인코딩된 로그-데이터mime-encoded log-data
서브타입 2: 원격 로깅Subtype 2: remote logging
특정한 실시형태에 따라, 이 데이터그램은, 또 다른 네트워크에 클라이언트가 될 수도 있는 로깅 서버로 향하는, 인스톨된 "로그-집합자" 클라이언트를 가진 접속 디바이스로부터 로그-엔트리를 포함한다.According to a particular embodiment, this datagram includes a log-entry from a connecting device with an installed "log-aggregator" client, which is directed to a logging server that may be a client to another network.
바이트 크기 콘텐츠Byte size content
8 최종 수신-ID8 Final Receive-ID
n 마임인코딩된 데이터n mime-encoded data
서브타입 3: 원격 데이터-집합자Subtype 3: remote data-aggregator
이 데이터그램은, 접속을 확립하는 클라이언트로부터 데이터를 획득하기 위해, 서버의 "원격 데이터 집합자" 엔진으로부터 클라이언트에 대한 조회를 나타낸다.This datagram represents a query to the client from the server's "remote data aggregator" engine to obtain data from the client establishing the connection.
바이트 크기 콘텐츠Byte size content
8 최종 수신-ID8 Final Receive-ID
1 데이터그램 타입 (조회 또는 답)1 datagram type (query or answer)
n 마임인코딩된 데이터n mime-encoded data
서브타입 4: 콘텐츠 승인 요청Subtype 4: Content Approval Request
이 데이터그램은, 종결 기록, 비용 리포트, 및 전자적 금융 트랜잭션 승인 등과 같은 송신된 콘텐츠 데이터의 승인을 요청하는데 이용된다.This datagram is used to request approval of transmitted content data, such as closing records, expense reports, and electronic financial transaction approvals.
바이트 크기 콘텐츠Byte size content
8 최종 수신-ID8 Final Receive-ID
n 승인에 대한 마임인코딩되고 XML 포맷된 콘텐츠n Mim-encoded and XML formatted content for approval
서브타입 5: 콘텐츠 승인 응답Subtype 5: Content Approval Response
이 데이터그램은 콘텐츠 승인 요청 (서브타입 4) 에 대한 응답에 사용된다.This datagram is used in response to a content approval request (subtype 4).
바이트 크기 콘텐츠Byte size content
8 최종 수신-ID8 Final Receive-ID
1 승인 또는 거부1 Approve or Reject
1 서명 필드의 길이Length of the signature field
n "타입 8" 패킷의 데이터 필드에 대한 ECC 서명n ECC signature for the data field of a "Type 8" packet
주 타입 2: 브로드캐스트 데이터그램Main type 2: broadcast datagram
이 타입의 데이터그램은 다양한 회의 및 브로드캐스트 애플리케이션에 사용된다. 비실시간 포인트 대 멀티포인트 송신: 실시간 포인트 대 포인트 송신 (예를 들어, 사용자 대 사용자 챗, 오디오 비디오 회의); 실시간 포인트 대 멀티포인트 송신 (예를 들어, 증권 시세 표시기, 오디오 비디오 브로드캐스트); 실시간 멀티포인트 대 멀티포인트 송신 (예를 들어, 오디오 비디오 회의) 를 포함하는 다수의 서브타입이 구현될 수도 있다.This type of datagram is used in a variety of conferencing and broadcast applications. Non-real-time point-to-multipoint transmission: real-time point-to-point transmission (eg, user-to-user chat, audio video conferencing); Real-time point-to-multipoint transmission (eg, stock tickers, audio video broadcasts); Multiple subtypes may be implemented that include real-time multipoint to multipoint transmissions (eg, audio video conferencing).
주 타입 3: 접속 프록시Main type 3: Connection proxy
접속 프록시 데이터그램은 원시 접속 데이터를 반송하고, 클라이언트 상에 내장되거나 빌트-인 (built-in) 된 애플리케이션으로부터 동일한 것을 네트워크 서버로 전송하는데 사용된다.Connection proxy datagrams are used to carry raw connection data and send the same from the built-in application on the client to the network server.
통상적으로 프록시 접속은 제어 채널, 즉, 서버에 대한 제 1 접속 상에서 요청되고, 성공적으로 프로세싱된 요청시에 서버에 대한 새로운 접속이 시작될 때 확립된다. 그 후, 또한 인증 목적으로 사용되는 "프록시 접속-ID" 가 부여된다. 또 다른 실시형태에서, 프록시 접속은 제어 채널 상에서 직접 확립될 수도 있다. 이것은 단일 접속을 통한 데이터 송신을 지원한다. 이것은, 단말 서버 또는 텔넷 접속이 사용되는 경우와 같이, 프록시 접속이 매우 적은 데이터를 반송하는 경우, 서버 및 클라이언트 상의 부하를 감소시킨다.Typically a proxy connection is requested on the control channel, i.e., the first connection to the server, and is established when a new connection to the server is initiated upon a successfully processed request. Thereafter, the "proxy connection-ID" is also given, which is used for authentication purposes. In yet another embodiment, the proxy connection may be established directly on the control channel. This supports data transmission over a single connection. This reduces the load on the server and client when the proxy connection carries very little data, such as when a terminal server or telnet connection is used.
접속 타입Connection type
접속 프로토콜의 상이한 타입이 사용될 수도 있다.Different types of connection protocols may be used.
0: TCP0: TCP
1: UDP1: UDP
서브타입 1: 클라이언트로부터의 프록시 데이터Subtype 1: Proxy Data from Client
이 데이터그램은 클라이언트단으로부터 입력되는 프록시 접속에 대한 실질적 데이터를 반송한다. 하나의 사용자는 동시에 오픈되는 하나 이상의 프록시 접속을 가질 수도 있다. 접속 ID (CID) 필드가 각 접속을 식별하기 위해 포함된다.This datagram carries the actual data for the proxy connection coming from the client end. One user may have more than one proxy connection open at the same time. A Connection ID (CID) field is included to identify each connection.
바이트 크기 설명Byte size Description
2 프록시 접속 ID2 proxy connection ID
n 데이터n data
서브타입 2: 클라이언트로의 프록시 데이터Subtype 2: Proxy Data to Client
이것은 프록시 접속으로부터 클라이언트 (접속의 소유자) 로 역으로 입력되는 접속 데이터이다. 프록시 접속만이 접속의 소유자에게 접속 데이터를 송신하고 수신하기 때문에, 실제 데이터와 다른 어떠한 필드도 포함되지 않는다. 어떠한 원격 접속 (즉, 서버) 이 응답하는지를 클라이언트가 식별하기 위해, CID 가 데이터그램의 발신자 필드에 포함된다.This is the connection data input back from the proxy connection to the client (the owner of the connection). Since only the proxy connection sends and receives connection data to the owner of the connection, no fields other than the actual data are included. In order for the client to identify which remote connection (ie, server) responds, the CID is included in the sender field of the datagram.
바이트 크기 설명Byte size Description
N 데이터N data
타입 송신자 설명Type Sender Description
0: 서버 원격 소켓을 접속0: connect to server remote socket
1: 서버 원격 소켓을 접속해제1: Disconnect the server remote socket
2: 클라이언트 원격 소켓을 접속해제하지만, 프록시 접속 (CID) 은 유지.2: Disconnects the client remote socket but maintains the proxy connection (CID).
3: 클라이언트 프록시 소켓 접속을 종료 (완전한 종료)3: terminate client proxy socket connection (complete termination)
4: 서버 프록시 소켓을 종료 (완전한 종료)4: terminate the server proxy socket (complete shutdown)
주 타입 4: 대량 콘텐츠 전송Week Type 4: Mass Content Delivery
이 데이터그램은 오디오 비디오 미디어 및 데이터 파일과 같은 대량의 콘텐츠 데이터를 전송하기 위해 설계된다.This datagram is designed to transfer large amounts of content data such as audio, video media and data files.
서브타입 0: 전송에 대한 리시트Subtype 0: Resume for Transfer
전송자가 최종 수신자로부터 리시트를 요청하면, 최종 수신자는 송신에 대한 리시트를 가진 4,0 타입 데이터그램을 송신할 수도 있다.If the sender requests a record from the final receiver, the final receiver may transmit a 4,0 type datagram with a record for the transmission.
리턴된 리시트는 CRC 필드 및 전송-ID 의 콘텐츠를 포함한다.The returned return contains the CRC field and the content of the transport-ID.
바이트 크기 설명Byte size Description
1 CRC 필드의 길이Length of 1 CRC field
n 전송된 콘텐츠에 대한 체크섬n Checksum for transferred content
n 전송-IDn transport-id
서브타입 1: 콘텐츠 전송 요청Subtype 1: Content Delivery Request
대량 콘텐츠의 전송을 요청하기 위해 클라이언트에 의해 사용된다. 클라이언트의 요청 수신시에, 서버는 클라이언트에 대해 사용할 전송-ID (TID) 를 리턴하여, 클라이언트는 콘텐츠를 전송하기 위해 서버에 대한 추가 접속을 오픈할 수 있다. 이와 같이, 제어 접속은 장기간의 전송동안 방해받지 않을 것이다.Used by clients to request the delivery of bulk content. Upon receiving the client's request, the server returns a transport-ID (TID) to use for the client, so that the client can open an additional connection to the server to deliver the content. As such, the control connection will not be interrupted for long periods of transmission.
바이트 크기 설명Byte size Description
4 전송될 콘텐츠의 바이트 크기4 Byte size of content to be transferred
2 전송될 청크 (chunk) 의 총 수2 Total number of chunks to be sent
4 최종 수신자-ID4 final recipient-ID
서브 타입 2: 콘텐츠 전송 응답Subtype 2: Content Delivery Response
바이트 크기 설명Byte size Description
1 0=전송 거부, 1=전송 승인1 0 = transmit rejected, 1 = transmit acknowledged
n 전송이 승인되면, 클라이언트가 파일을 전송하기 위한 또 다른 접속을 오픈할 때, 이 필드가 제공되고, 서버에 부여될 전송 ID (TID) 를 포 함할 것이다.n If the transfer is approved, this field is provided when the client opens another connection to transfer the file and will contain the transfer ID (TID) to be granted to the server.
서브타입 3: 콘텐츠 전송 세그먼트Subtype 3: Content Delivery Segment
바이트 크기 설명Byte size Description
2 세그먼트 수2 segments
n 세그먼트 청크n segment chunk
서브타입 4: 재송신 요청Subtype 4: Resend Request
이것은 일반적으로 전송된 콘텐츠가 체크섬 체크를 통과하는데 실패한 경우, 콘텐츠의 세그먼트를 재요청하는데 사용된다. 또한, 전송 접속의 손실로부터 복구하는데에 사용될 수도 있다.This is generally used to re-request a segment of content if the transmitted content fails to pass the checksum check. It may also be used to recover from loss of the transport connection.
바이트 크기 설명Byte size Description
2 재전송될 청크2 Chunks to be Resent
n TIDn TID
주 타입 5: 사용자 디렉토리Primary type 5: user directory
이 타입의 데이터그램은 사용자, 사용자 그룹을 탐색하거나, 사용자 디렉토리 내의 정보를 업데이트하는데 사용된다.This type of datagram is used to search for users, user groups, or update information in the user directory.
조회에서 탐색 필드는 마스크로서 취급된다. 내재된 데이터베이스 기반구조가 지원하는 경우, 탐색은 정규의 표현으로 취급되는 탐색 마스크로 수행된다.In the query, the search field is treated as a mask. If the underlying database infrastructure supports it, the search is performed with a search mask treated as a regular expression.
정규의 표현 탐색이 지원되는 디폴트 데이터베이스 기반 시스템을 제공하기 위해 MySQL 이 구현될 수도 있다. 따라서, 시스템 구성은 정규의 표현을 사용하는 모든 탐색을 지원한다.MySQL can also be implemented to provide a default database-based system with regular expression search. Thus, the system configuration supports all searches using regular expressions.
서브타입 1: 사용자 온라인Subtype 1: User Online
이 데이터그램은 사용자가 네트워크에 접속될 때, 시스템에 통지하기 위해 사용된다.This datagram is used to notify the system when the user is connected to the network.
바이트 크기 설명Byte size Description
4 사용자의 사용자ID4 User ID of the user
서브타입 2: 사용자 오프라인Subtype 2: User Offline
이 데이터그램은 사용자가 네트워크로부터 접속해제할 때 시스템에 통지하기 위해 사용된다.This datagram is used to notify the system when the user disconnects from the network.
바이트 크기 설명Byte size Description
4 사용자의 사용자ID4 User ID of the user
서브타입 3: 사용자 탐색 요청Subtype 3: User Search Request
이것은 특정한 데이터 마스크에 기초하여 전체 사용자 디렉토리 내에서 사용자를 탐색하기 위해 접속된 클라이언트에 의해 사용된다. 이 타입의 탐색은 타입 5,10 데이터그램을 리턴한다.This is used by connected clients to search for users within the entire user directory based on specific data masks. This type of search returns a
바이트 크기 설명Byte size Description
n 탐색을 위한 마스크n Mask for navigation
서브타입 4: 개별 사용자 탐색Subtype 4: individual user navigation
서브타입 3 과 유사하지만, 사용자에 대한 더 정확한 매칭을 리턴한다. 이 타입의 탐색은 타입 5,10 데이터그램을 리턴한다.Similar to subtype 3, but returns a more accurate match for the user. This type of search returns a
바이트 크기 설명Byte size Description
4 사용자ID4 User ID
8 최후의 로그인8 Last login
1 온라인 상태1 online
n 디스플레이 명칭n Display designation
주 타입 6: 원격 관리Week type 6: remote management
이 데이터그램은, 네트워크 시스템의 관리자 또는 특권화된 사용자가 원격으로 또 다른 접속 클라이언트를 제어하고, 접속된 클라이언트 상에서 애플리케이션을 실행하고, 업데이트를 푸시하는 것을 가능하게 한다.This datagram enables an administrator or privileged user of a network system to remotely control another connecting client, to run an application on the connected client, and to push updates.
서브타입 1: 원격 콘솔 애플리케이션 실행Subtype 1: Running a Remote Console Application
6,1 데이터그램은 규정된 애플리케이션을 실행시키고, 애플리케이션에의 오픈 조작을 유지하며, 애플리케이션의 프로세스-id 는 성공적 실행시에 개시자에게 리턴된다. 이 프로세스-id 는 프로세스에 대한 모든 후속 커맨드 또는 제어 데이터그램에서 사용되어야 한다.The 6,1 datagram runs the specified application, maintains open operations on the application, and the process-id of the application is returned to the initiator upon successful execution. This process-id must be used in all subsequent commands or control datagrams for the process.
바이트 크기 설명Byte size Description
8 목표 사용자-ID8 Target User-ID
n 실행될 애플리케이션의 전체 경로 및 명칭n Full path and name of the application to be run
서브타입 2: 원격 실행 결과Subtype 2: result of remote execution
6,1 데이터그램의 성공적인 실행시에 6,1 데이터그램의 개시자에게 역으로 전송된다.Upon successful execution of the 6,1 datagram, it is sent back to the initiator of the 6,1 datagram.
바이트 크기 설명Byte size Description
8 수신 사용자-ID8 Receive User-ID
2 프로세스-ID2 process-ID
서브타입 3: 종료된 원격 프로세스Subtype 3: terminated remote process
6,1 데이터그램에 의해 개시되는 원격 프로세스가 종료된 경우, 6,3 데이터그램이 애플리케이션으로부터 종료 코드로 전송된다.When the remote process initiated by the 6,1 datagram terminates, the 6,3 datagram is sent from the application to the exit code.
바이트 크기 설명Byte size Description
8 수신 사용자-ID8 Receive User-ID
2 프로세스-ID2 process-ID
2 애플리케이션 종료 코드2 application exit code
서브타입 10: 원격 툴 요청Subtype 10: Remote Tool Request
원격 클라이언트로부터 데이터의 검색을 단순화하거나 원격 디바이스에 대한 기본 제어를 수행하기 위해, 실행중인 프로세스, 로그인한 사용자(들), 데이터 저장영역 등의 리스트 상의 정보를 포함하는, 원격 디바이스로부터의 정보를 검색하는데 기본 툴-세트가 사용가능하다.Retrieve information from a remote device, including information on a list of running processes, logged-in user (s), data storage, etc. to simplify retrieval of data from the remote client or to perform basic control over the remote device. A basic set of tools is available.
바이트 크기 설명Byte size Description
8 목표 사용자-ID8 Target User-ID
1 툴 식별자1 tool identifier
n 옵션적인 파라미터 (특정한 툴이 필요로한다면)n Optional parameters (if a particular tool is needed)
툴 식별자Tool identifier
0 실행 프로세스 리스트0 process list
1 숨겨진 프로세스를 포함하는 실행 프로세스 리스트1 list of running processes, including hidden processes
2 프로세스 (파라미터로서 주어지는 PID) 킬 (Kill) 2 Process (PID given as parameters) Kill
3 서비스 리스트3 Service List
4 서비스 (파라미터로서 서비스 명칭) 정지4 Stop service (service name as parameter)
5 서비스 (파라미터로서 서비스 명칭) 시작5 Start service (service name as parameter)
6 서비스 (파라미터로서 서비스 명칭) 재시작6 Restart service (service name as parameter)
7 볼륨 레이블, 크기, 블록 크기, 사용되는 공간 및 파일 시스템 타입을 포함하는 로컬 저장 디바이스 리스트.7 List of local storage devices, including volume label, size, block size, space used, and file system type.
서브타입 11: 원격 툴 응답Subtype 11: Remote Tool Response
요청된 툴에 따라 CSV 포맷 응답을 포함한다.Include CSV format responses according to the requested tool.
바이트 크기 설명Byte size Description
8 수신 사용자-ID8 Receive User-ID
n 원격 툴로부터 출력된 CSV 데이터n CSV data output from remote tool
서브타입 20: 애플리케이션 전송 요청Subtype 20: Application Transfer Request
애플리케이션의 전송 또는 애플리케이션 업데이트를 개시하는데 사용된다.Used to initiate the transfer of an application or an application update.
바이트 크기 설명Byte size Description
1 전송 타입1 transmission type
수신 사용자-IDIncoming User-ID
1 옵션 (비트필드)1 option (bitfield)
4 콘텐츠의 크기4 Size of content
n 파일의 경로 및 명칭 목표 (옵션, 클라이언트의 루트 (root) 에 대한 디폴트)n File path and name target (optional, default to client's root)
옵션 비트필드Optional bitfield
비트 설명Bit description
1 자동 실행 (또한, 자동 업데이트, 자동 확장 등을 커버)1 autorun (also covers auto update, auto expand, etc.)
2 사용자 프롬프트 (실행/업데이트 전)2 User Prompt (Before Run / Update)
3 전송 후 리시트 리턴3 Return after transfer
전송 타입Transmission type
1 파일의 전송 (업데이트동안, 기존 파일이 제시될 것이 요구됨)1 File transfer (during update, existing file is required to be presented)
2 클라이언트 펌웨어 전송 (현재의 것을 대체)2 client firmware transfer (replaces current one)
3 클라이언트 ISO 코드의 전송 (현재의 것을 대체하고, ISO 코드는, 예를 들어, ISO 9660 및 국제 표준화 기구 www.iso.org 에 대한 또 다른 데이터 표준과 같은 CD ROM 데이터 포맷을 포함)3 Transfer of client ISO codes (replaces current ones, ISO codes include CD ROM data formats such as, for example, ISO 9660 and another data standard for the International Organization for Standardization www.iso.org)
4 압축된 어카이브의 전송 (목표 위치에서 연장되도록)4 Transfer the compressed archive (to extend from the target position)
서브타입 21: 애플리케이션 전송 응답Subtype 21: Application Transfer Response
승인 또는 거부를 시그널링하는데 사용됨Used to signal acknowledgment or rejection
바이트 크기 설명Byte size Description
1 승인/거부1 Approve / Reject
8 전송-ID (전송이 승인된 경우에만 첨부)8 transfer-ID (attach only if transfer is approved)
서브타입 22: 애플리케이션 전송 콘텐츠 부분Subtype 22: Application Delivery Content Part
이 데이터그램은 전송을 위한 실제 데이터를 유지한다.This datagram holds the actual data for transmission.
4 개의 옥테트 '콘텐츠 부분' 필드가 단일 전송에서 256^4 부분까지 허용할 것이고, 애플리케이션의 전송을 위해, 4 기가바이트 크기를 초과하는 이미지 및 어카이브를 제공할 것이다 (예를 들어, 데이터 각각 1K 를 유지하는 데이터그램을 사용하면).Four octet 'content portion' fields will allow up to 256 ^ 4 portions in a single transmission, and will provide images and archives over 4 gigabytes in size for the application's delivery (e.g. 1K data each) Using a datagram to keep it).
'송신 부분' 필드는 1 에서 시작하고, 전송되는 모든 부분에 대해 1 씩 증가하며, 전송의 종점을 시그널링하기 위해 0 (zero) 의 '전송 부분' 을 가진 6,22 데이터그램을 전송한다.The 'transmit part' field starts at 1 and increments by 1 for every part transmitted, and transmits 6,22 datagrams with a 'transmit part' of zero (zero) to signal the end of the transmission.
바이트 크기 설명Byte size Description
8 전송-ID8 Transport-ID
4 전송 부분4 transmission parts
n 데이터 콘텐츠n data content
서브타입 23: 전송 리시트Subtype 23: Transfer List
전송된 애플리케이션의 체크섬Checksum of the transferred application
바이트 크기 설명Byte size Description
1 CRC-타입1 CRC-type
n 전송된 애플리케이션에 대한 체크섬n Checksum for transferred application
주 타입 7: 실시간 멀티미디어 전송Week type 7: Real time multimedia transmission
이 타입의 데이터그램은 멀티미디어 콘텐츠의 클라이언트 대 클라이언트 송신을 지원하기 위해 사용된다.This type of datagram is used to support client-to-client transmission of multimedia content.
서브타입 1: 전송 요청Subtype 1: Request to Send
송신을 시작하기 위한 승인을 요청하는데 사용된다.Used to request an acknowledgment to begin transmission.
바이트 크기 설명Byte size Description
4 수신 사용자ID4 Receive User ID
2 미디어 콘텐츠 타입2 Media content type
4 Kbit/s 에 요구되는 최소 대역폭Minimum bandwidth required for 4 Kbit / s
미디어 콘텐츠 타입Media content type
타입 설명Type Description
1 5 KHz, 8 비트, 1 채널 오디오1 5 KHz, 8 bit, 1 channel audio
2 8 KHz, 8 비트, 1 채널 오디오2 8 KHz, 8 bit, 1 channel audio
3 11 KHz, 8 비트, 1 채널 오디오3 11 KHz, 8 bit, 1 channel audio
4 11 KHz, 8 비트, 2 채널 오디오4 11 KHz, 8 bit, 2 channel audio
5 22 KHz, 16 비트, 2 채널 오디오5 22 KHz, 16 bit, 2 channel audio
6 44 KHz, 16 비트, 2 채널 오디오6 44 KHz, 16 bit, 2 channel audio
서브타입 2: 전송 응답Subtype 2: Transmission Response
바이트 크기 설명Byte size Description
4 수신 사용자ID4 Receive User ID
1 승인 (1) 또는 거부 (0)1 Approved (1) or Rejected (0)
4 콘텐츠 스트림 ID (클라이언트를 수신함으로써 송신되고, 요청이 승인된 경우에만 존재해야 한다)4 content stream ID (sent by receiving the client, and should only exist if the request is approved)
서브타입 3: 미디어 스트림 패킷Subtype 3: Media Stream Packets
이 데이터그램은 송신을 구성하는 개별 패킷을 반송한다This datagram carries the individual packets that make up the transmission.
바이트 크기 설명Byte size Description
4 수신 사용자ID (수신자 리스트 사용에 대해서 0)4 Receive User ID (0 for use of recipient list)
4 콘텐츠 스트림 ID4 Content Stream ID
n 스트림 패킷 (콘텐츠 데이터)n stream packets (content data)
서브타입 4: 송신 종료Subtype 4: End Transmission
송신의 종료 (송신 소스에 의해 전송되는 경우) 또는 송신 포기 (수신자에 의해 전송되는 경우) 를 나타내기 위해 전송자 또는 수신자 모두에 의해 송신될 수 있다.It may be sent by both the sender or the receiver to indicate the end of the transmission (if sent by the sending source) or the abandonment of the transmission (if sent by the receiver).
바이트 크기 설명Byte size Description
4 수신 사용자ID (수신자 리스트 사용에 대해서 zero)4 Receive User ID (zero for use of recipient list)
4 콘텐츠 스트림 ID4 Content Stream ID
서브타입 5: 수신자 리스트 관리Subtype 5: Recipient List Management
강의, 회의 전화 (VoIP) 와 같은 일 대 다수의 송신을 수행하는 경우, 전체 수신자 리스트에 대한 데이터 분포를 관리하기 위해 이 데이터그램에 의존할 수도 있다.If you are doing one-to-many transmissions, such as lectures, conference calls (VoIPs), you may rely on this datagram to manage the distribution of data for the entire list of recipients.
바이트 크기 설명Byte size Description
1 액션1 action
n 데이터n data
액션의 정의:Action Definition:
액션 설명Action description
0 수신자 리스트 삭제 (설정되었다면)0 Delete recipient list (if set)
1 사용자(들)를 리스트에 추가 (데이터로서 사용자ID 의 공간적으로 분리된 리스트)1 Add user (s) to the list (spatially separated list of user IDs as data)
2 리스트로부터 사용자(들) 제거 (데이터로서 사용자ID 의 공간적으로 분리된 리스트)2 Remove user (s) from list (spatially separated list of user IDs as data)
서브타입 6: 송신 전환 요청Subtype 6: Transmit Switch Request
이 데이터그램은, 클라이언트가 "송신의 종점" 통지를 또 다른 사용자에게 전송할 수 있게 한다.This datagram allows the client to send a "end of transmission" notification to another user.
바이트 크기 설명Byte size Description
4 수신자 ID4 Receiver ID
2 미디어 콘텐츠 타입2 Media content type
4 Kbit/S 에 요구되는 최소 대역폭Minimum bandwidth required for 4 Kbit / S
실시예 2: 객체 벡터 기반 수퍼 분류자 및 생체인식 측정법Example 2: Object Vector Based Super Classifier and Biometric Measurement
도 2 를 참조하면, 객체 벡터 수퍼 분류자 (또한 다중 분류자라고도 한다) 가 도시되어 있다. 하나 이상의 데이터 객체 벡터가 이벤트 레벨 인증에 사용된다. 분류 판정은, 도 2 의 객체 벡터 1, 2 및 3 을 포함하는 데이터 벡터 객체로부터 계산되는 최고 또는 랜덤 합에 기초하여 이루어진다. 여기서, 각 객체 벡터는 분류자 1 내지 N 으로부터 하나 이상의 분류자에 접속된다. 즉, 특 성 추출이 다수의 객체 벡터로부터 이루어지고, 집합적으로 수퍼 분류자를 구성하는 일련의 분류자로 변환된다. 이벤트 특정 변환은, 이벤트 기반 특성을 특징짓는 상대적으로 단순한 분포를 제공한다.Referring to FIG. 2, an object vector super classifier (also referred to as multiple classifier) is shown. One or more data object vectors are used for event level authentication. The classification decision is made based on the highest or random sum calculated from the data vector objects comprising the
수퍼 분류자를 사용한 사용자 인증의 일 예로 생체인식 측정법이 포함된다. 본 발명의 일 실시형태에서, 수퍼 분류자는, 음성 인식, 지문, 핸드프린트, 혈액형, DNA 테스트, 망막 또는 홍채 스캔 및 얼굴 인식 등을 포함하는 물리적 생체인식 측정값과 결합하여 사용된다. 또 다른 실시형태에서, 수퍼 분류자는 개인적 행동의 습관 또는 패턴을 포함하는 행위적 생체인식 측정값과 결합하여 사용된다.An example of user authentication using a super classifier includes biometrics. In one embodiment of the present invention, the super classifier is used in combination with physical biometric measurements, including voice recognition, fingerprints, handprints, blood types, DNA tests, retinal or iris scans, face recognition, and the like. In another embodiment, the super classifier is used in conjunction with behavioral biometric measurements that include habits or patterns of personal behavior.
이벤트 기반 인증 세션, 및 이러한 사용자 특정 이벤트에 기초한 객체 분석의 선택 및 실행은 객체 판정 분석의 2 진 구조를 식별하거나 유도하는 가능성을 증가시킨다. 2 진 구조가 수퍼 분류자에 추가되기 때문에, 인증 세션은 높은 확률의 레이트로 평가될 수도 있다.The selection and execution of event based authentication sessions, and object analysis based on such user specific events, increases the likelihood of identifying or driving the binary structure of object decision analysis. Since the binary structure is added to the super classifier, the authentication session may be evaluated at a high probability rate.
예시적인 실시형태를 나타내는 설명, 특정한 실시예 및 데이터는 예시의 방식으로 주어진 것이며, 본 발명의 다양한 실시형태를 한정하려는 의도가 아니다. 본 명세서에서 인용하는 모든 참조는 구체적이며 전체적으로 참조로서 통합되어 있다. 본 발명에서의 다양한 변경 및 변형은 본 명세서에 포함된 설명 및 데이터로부터 당업자에게 명백할 것이고, 따라서 본 발명의 다양한 실시형태의 일부로 고려된다.The descriptions, the specific examples, and the data representing the exemplary embodiments are given by way of example and are not intended to limit the various embodiments of the invention. All references cited herein are specific and incorporated by reference in their entirety. Various modifications and variations in the present invention will be apparent to those skilled in the art from the description and data contained herein and are therefore considered to be part of various embodiments of the present invention.
부록 1 : 화자 (speaker) 검증에서의 객체 (object) 분류Appendix 1: Object Classification in Speaker Verification
분류 및 확률 밀도 추정Classification and probability density estimation
화자 검증은 임의의 다른 데이터 객체 벡터와 마찬가지로, 2 개의 클래스들, 즉, 목표 화자들 (I) (객체의 사용자) 및 사칭자들 (-I) (객체의 침입자) 에 관련되는 분류 문제이다. 이 경우, 분류를 하기 위해 화자들의 음성의 녹음으로부터 얻어지는 한 세트의 측정값이 필요하다. 이 측정값들은 D-차원 벡터,Speaker verification, like any other data object vector, is a classification problem involving two classes: target speakers I (the user of the object) and impersonators ( -I ) (the intruder of the object). In this case, a set of measurements from the recording of the speaker's voice is needed for classification. These measures are D-dimensional vectors,
![]()
![]()
로 편리하게 나타낼 수 있다.It can be represented conveniently.
각 화자는 관측값들의 라이클리후드 (likelihood) 를 측정하는 확률 밀도 함수,Each speaker is a probability density function that measures the likelihood of the observations,
![]()
![]()
로 특징된다. 이 확률 밀도는,It is characterized by. This probability density is
![]()
![]()
![]()
![]()

로 특징되며, 여기서 P(I) 및 P(-I) 는 각각 목표 화자의 시도들 및 사칭자 시도들의 선험확률 (priori probability) 들이다. 화자 검증을 위해, 관측값 ![]()
![]()
사후확률은 베이즈 룰에 의해 계산될 수 있다. The posterior probability can be calculated by Bayes' rules.

I 및 -I 는 상호 배타적이므로, 다음 식을 얻을 수 있다. Since I and -I are mutually exclusive, the following equations can be obtained.
![]()
![]()
즉, 관측값 ![]()
![]()
![]()
![]()


[도 1] 2 개의 클래스, I 및 -I 에 대한 확률 밀도. 1 Probability density for two classes, I and -I.
밀도는 다음의 영역에서 오버랩되며,Density overlaps in the following areas,

이것은 베이즈 에러 레이트를 0 보다 크게 만든다. 이 결정 룰을 사용하는 분류자는 베이즈 분류자로 칭해진다. 베이즈 분류자의 에러 레이트는,This makes the Bayesian error rate greater than zero. The classifier using this decision rule is called a Bayes classifier. The error rate of the Bayes classifier is

수식: 1.8Formula: 1.8

과 동일하며, 여기서,Is the same as where
![]()
![]()
![]()
![]()
이다.to be.
실제로, 확률 함수들 Indeed, probability functions
![]()
![]()
![]()
![]()
는 미지수이고, 단지 추정될 수 있다. 따라서, 어떠한 실제 결정 방법에서의 에러 레이트도 평균적으로 베이즈 에러 레이트 이상의 에러 레이트를 가지는 것으로 제한된다.Is unknown and can only be estimated. Thus, the error rate in any actual determination method is limited to having an error rate above the Bayes error rate on average.
선험확률 & 리스크 최소화Priority probability & risk minimization
평균 에러는, 목표 화자의 거부 (TA 에러): The average error is the target speaker's rejection (TA error):

및 사칭자의 승인 (IR 에러):And impersonator's approval (IR error):

의 2 개의 항으로 구성된다.It consists of two terms.
샘플들을 분류하기 위해 사후확률을 사용하는 것은 최대 라이클리후드에 따 라 분류하는 것과 본질적으로 동일하다. 그러나, 전체 에러 레이트는 사칭자 및 목표 화자의 시도의 상대적인 횟수에 의존한다. 사칭자 시도가 목표 화자 시도보다 훨씬 더 빈도가 높은 경우, 절대 에러 전체는 EI 보다 E-I 에 더욱 의존하므로, 클래스 I 일 확률이 더 높더라도, 클래스 -I 로 어떤 샘플을 분류할 가능성이 높다. 즉, EI 를 희생함으로써 E-I 가 최소화된다. 이들 에러 레이트를 최적으로 밸랜싱하는 방법은, 사칭자/목표 화자 시도 (객체 시도들) 의 상대적인 회수를 반영하도록 선험확률을 고정하는 것이다. Using post-probability to classify samples is essentially the same as classifying according to maximum Lyclihood. However, the overall error rate depends on the relative number of attempts by the impersonator and the target speaker. If the impostor attempts are much higher than the target frequency speaker attempts, total absolute error, so more and more dependent on the E -I E I, although a higher probability of class I, are likely to be classified as a class to which the sample -I high. In other words, E -I is minimized by sacrificing E I. A method of optimally balancing these error rates is to fix the prior probability to reflect the relative number of impersonator / target speaker attempts (object attempts).
선험확률들을 할당하는 것이 TA 및 IR 에러를 밸런싱하는 유일한 방법이다. 일반적으로, 2 가지 타입의 에러들은 상이한 결과들을 가질 수도 있고, 따라서, 오분류 (misclassification) 의 비용을 반영하는 밸런스를 획득하는 것이 바람직할 수도 있다. 이 경우, P(I) 및 P(-I) 는,Assigning prior probabilities is the only way to balance TA and IR errors. In general, the two types of errors may have different results, and therefore, it may be desirable to obtain a balance that reflects the cost of misclassification. In this case, P (I) and P (-I) are
![]()
![]()
![]()
![]()
으로 치환되며,Is replaced by
여기서, ![]()
![]()

수식 1.6 에 유사하게, 다음의 결정 룰을 얻는다.Similar to Equation 1.6, the following decision rule is obtained.

TA 및 IR 에러 밸런싱 문제에 대한 더욱 실용적인 접근방법은, EI 또는 E-I 에 대한 적당한 에러 레이트를 선험적으로 결정하고1, 그 후, 그것을 이용해 결정 평면들을 판정하는 것이다 (그리고, P(I) 및 P(-I) 의 확장에 의해). 어떤 방법을 선택하더라도, 클래스 라이클리후드More practical approach to balancing TA and IR errors problem is to decide a priori to an appropriate error rate for the I or E -I E is determined by using the crystal plane 1, then, it (and, P (I) And by expansion of P (−I) ). Regardless of which method you choose, the class lyclihood

및And

를 추정하는 실제 문제는 동일하게 남는다.The actual problem of estimating remains the same.
확률 추정Probability estimation
결정 룰을 구현하는 한 접근방법은, 개별적으로 확률 밀도들 및 One approach to implementing decision rules is to individually determine probability densities and
![]()
![]()
및And
![]()
![]()
를 테스트 환경에서 추정하고 - 라이클리후드들을 Estimates in a test environment
![]()
![]()
대신에 이용될 수 있는 확률들로 변환하기 위해 베이즈 룰을 사용한다.Instead, use Bayes' rules to convert to probabilities that can be used.
그러나, 이 해결방법은, 검증 (발성(utterance) 변환이 2 진 데이터 객체로 되는 것에 의한) 문제는 라이클리후드 비율에만 의존하기 때문에, 요구되는 것에 비해 더욱 광범위하며, 이 라이클리후드 비율은,However, this solution is more extensive than required because the verification (by the utterance conversion being binary data objects) depends only on the Lyclihood ratio, which is

로 주어진다.Is given by
LR(~x) 의 관점에서, 결정 함수 2.6 은,In terms of LR (~ x), the decision function 2.6 is

으로 된다.Becomes
클래스 I 와 클래스 -I 사이의 베이즈 결정 평면은,The Bayesian decision plane between class I and class -I is
![]()
![]()
으로 특징된다.It is characterized by.
분류 목적을 위해, 테스트 샘플 ![]()
![]()
파라미터적 및 비-파라미터적 분류사이에서 구별이 이루어진다. 그 차이는 클래스 분포에 관하여 이루어지는 선 (prior) 가정들에 있다. 파라미터적 분류는 분류될 샘플들이 좁게 (narrowly) 정의된 확률 밀도 함수들 패밀리에 속하는 것으로 가정하고, 반면에, 비-파라미터적 분류는 선 (prior) 분포들에 관한 약한 (weak) 추정만을 만든다. 따라서, 비-파라미터적 분류는 더욱 일반적이고, 반면에, 파라미터적 분류자들은 더 낮은 자유도를 가지기 때문에 구성이 용이하다.A distinction is made between parametric and non-parametric classifications. The difference lies in the assumptions made about the class distribution. Parametric classification assumes that the samples to be classified belong to a narrowly defined family of probability density functions, while non-parametric classification only makes a weak estimate of the prior distributions. Thus, non-parametric classification is more general, whereas parametric classifiers are easier to construct because they have lower degrees of freedom.
파라미터적 분류Parametric Classification
파라미터적 분류의 예로서, 클래스들 (j = 1, 2) 이 정규 확률 밀도들As an example of parametric classification, classes (j = 1, 2) are normal probability densities

수식: 1.19Formula: 1.19
에 의해 특징되는 것을 가정할 수 있다.It can be assumed that it is characterized by.
이 경우,in this case,
![]()
![]()
은 다음과 같이 주어진다.Is given by
![]()
![]()

이것은 2 차 함수 (quadratic function) 이다. 또한, 2 개의 분포가 동일한 공분산 (covariance) 매트릭스 S1 = S2 = S 를 공유하는 것으로 가정하는 경우, 이것은 This is a quadratic function. In addition, if we assume that two distributions share the same covariance matrix S1 = S2 = S

으로 단순화된다.Is simplified.

[도 2] 2 개의 클래스들은 2 차 결정 평면들을 이용하는 베이즈 분류자였다.2 The two classes were Bayes classifiers using quadratic decision planes.
좌측 : 클래스들은 유사한 평균들을 가진다.Left: Classes have similar averages.
![]()
![]()
우측 : 클래스들은 상이한 평균들을 가진다.Right: Classes have different averages.
![]()
![]()
우측 예에서, 베이즈 결정 평면은 선형 함수로 양호하게 근사될 수 있으며, 여기서,In the right example, the Bayesian crystal plane can be approximated well with a linear function, where
![]()
![]()

이다.to be.
이것은 선형 함수이다. 식별 분석에서, 식 1.22 는 피셔 (Fisher) 선형 식별 함수로 알려져 있다. 지금까지 살펴본 바와 같이, 이 식별 함수는 동일한 공분산 매트릭스들로 특징되는 정규 분포된 클래스들에 대해 최적이지만, 그 유용함은 이것을 넘어선다. 그것은 클래스 분포들이 "구형 구름" 형태를 가지는 경우에 좋은 결과를 낼 수 있는 (비록 최적은 아니지만) 로버스트한 함수이다. 사실, 수식 1.21 -그리고 수식 1.22 는 아닌- 이 최적의 식별 함수로 알려져 있더라도, 수식 1.22 는 더 우수한 결과를 나타낼 수도 있다 (Raudys 및 Pikelis 1980). 수식 1.21 을 이용할 때의 문제는 제한된 샘플 세트로부터 기인하며, S1 및 S2 에 대한 우수한 추정들을 획득하기 어럽다. 특히, 이것은 고차원 공간에서 사실이다.This is a linear function. In identification analysis, Equation 1.22 is known as a Fisher linear identification function. As we have seen, this identification function is optimal for normally distributed classes characterized by the same covariance matrices, but its usefulness goes beyond this. It is a robust function (although not optimal) that can produce good results when class distributions have a "spherical cloud" shape. In fact, even though Equation 1.21-and not Equation 1.22-is known as the optimal identification function, Equation 1.22 may give better results (Raudys and Pikelis 1980). The problem with using Equation 1.21 stems from a limited set of samples and is difficult to obtain good estimates for S1 and S2. In particular, this is true in high dimensional space.
선형 분류자는 우선적으로 1 차 모멘트들 (평균들)Linear classifier preferentially first-order moments (means)
![]()
![]()
에 의존하기 때문에, 추정 에러들에 덜 민감하며, 이 모멘트들은 S1 및 S2 (2차 모멘트들) 보다 추정이 용이하다. 필요한 경우, S 가 대각선이거나, 심지어 아이덴티티 매트릭스와 동일한 것으로 가정하여, 선형 분류자가 더욱 단순화될 수도 있다.Is less sensitive to estimation errors, and these moments are easier to estimate than S1 and S2 (secondary moments). If necessary, the linear classifier may be further simplified, assuming that S is diagonal or even equal to the identity matrix.
예Yes
도 2 는 2 개의 정규 분포된 클래스들에 대한 1-차 밀도 함수들의 2 개의 예를 나타낸다. 2 개의 예에서 모두, 분산들이 2 shows two examples of first-order density functions for two normally distributed classes. In both examples, the variances
![]()
![]()
로 상이하기 때문에 베이즈 결정 평면들은 2 차이다.Bayes crystal planes are quadratic because they differ from each other.
평균은, 케이스 1 에서 Average, in
![]()
![]()
케이스 2 에서In
![]()
![]()
이다.to be.
동일한 선험 (priors) 을 가정하면, 수식 1.21 을 이용하여 결정 룰을 판정할 수 있다.Assuming the same priors, the decision rule can be determined using Equation 1.21.
![]()
![]()

따라서, 결정 룰은Therefore, the decision rule

이다.to be.
에러 레이트는 The error rate is

이다.to be.
1.22 에서 살펴봤던 선형 케이스에서,In the linear case we saw in 1.22,


이므로, 다음의 결정 룰을 얻을 수 있으며,Therefore, the following decision rule can be obtained.

이때, 에러 레이트는 ![]()
![]()

이 되고,Become,
선형 분류자에 대해,For the linear classifier,

이 된다. 평균 에러 레이트들은 각각 0.007 % 및 0.03 % 로, 양 결정 룰 모두에 대해 매우 작은 값이다. 그러나, 2 차 결정 룰이 상대적으로 훨씬 더 정확하다. 이것은 그것이 2 차이기 때문이 아니며,Becomes Average error rates are 0.007% and 0.03%, respectively, which are very small values for both decision rules. However, the second decision rule is relatively much more accurate. This is not because it is 2 difference,

와 같은 선형 결정 룰도 2 차 결정 룰 처럼 작은 에러 레이트를 가진다. 따라서, 여기서 성능 차이는 선험 분포들에 관한 가정에서 기인한다.A linear decision rule, such as, has a small error rate as a second decision rule. Thus, the difference in performance here is due to the assumptions about prior distributions.
선형 대 비선형 결정 평면들Linear vs Nonlinear Crystal Planes
![]()
![]()
에 대한 해가 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
에서 최적의 결정 평면은 The optimal decision plane at
![]()
![]()
의 형태를 가지는 것으로 가정하자.Assume that it has the form of.
x1 및 x2 에 관한 것보다는,Rather than about x 1 and x 2 ,
![]()
![]()
에 관하여 분류가 수행되는 경우, 선형 분류자는 이 결정 평면을 구현할 수 있으며, 여기서,When classification is performed with respect to, the linear classifier can implement this decision plane, where

이다.to be.
즉, 2D 의 2 차 결정 함수는 5D 공간에서 선형 함수에 의해 구현될 수 있다.That is, the 2D quadratic decision function can be implemented by a linear function in 5D space.
비-파라미터적 분류Non-parametric classification
도 3 은 화자 인식 시스템 또는 객체 인식 엔진의 클래스 (화자 또는 객체) 의 분포가 어떤 형태일 수 있는지 실제적인 예를 나타낸다.3 shows a practical example of how the distribution of the class (the speaker or the object) of the speaker recognition system or the object recognition engine may be.
여기서, 주어진 화자로부터의 관측들이 정규 분포로부터 얻어진다는 가정은 합리적이다.Here, the assumption that observations from a given speaker are obtained from a normal distribution is reasonable.
피셔 식별 함수는 임의의 2 명의 화자 (그리고 이 경우 임의의 주어진 데이터 소스를 포함하는 객체에 비교되는) 사이의 식별에 적합하지만, 한 목표 화자와 군중속의 나머지 화자들 사이의 식별에 대해서는 명확하게 부적합한 모델 (2D 에서) 이다 (독립된 한 명의 화자를 군중속의 대부분의 다른 화자들로부터 분리하는 선은 그어질 수 없다). 사실, 사칭자 클래스는 어떠한 단순한 파라미터적 분포로 모델링하기에는 너무 복잡하다. 이것은 많은 패턴 분류 문제들에서 공통적인 상황이다. 비-파라미터적 분류 및 확률 밀도 추정에 대한 많은 테크닉들이 존재한다.The Fisher identification function is suitable for identification between any two speakers (and in this case compared to an object containing any given data source), but clearly unsuitable for identification between one target speaker and the rest of the speakers in the crowd. It is a model (in 2D) (the line that separates one independent speaker from most other speakers in the crowd cannot be drawn). In fact, the impersonator class is too complex to model with any simple parametric distribution. This is a common situation in many pattern classification problems. There are many techniques for non-parametric classification and probability density estimation.

[도 3] 10 개의 다른 샘플의 세트로부터 얻어지는 2D 샘플들의 확률 분포FIG. 3 is a probability distribution of 2D samples obtained from a set of 10 different samples
비-파라미터적 확률 밀도 추정Non-parametric probability density estimation
클래스 멤버쉽이 알려진 샘플들의 트레이닝 세트가 주어지면, 비-파라미터적 확률 밀도 추정은, 존재하는 것 이외에 어떠한 것에 관해서도 가정하지 않고 클래스들을 특징짓는 실제 PDF 를 근사하는 PDF 를 구성하는 문제이다.Given a training set of samples for which class membership is known, non-parametric probability density estimation is a matter of constructing a PDF that approximates the actual PDF characterizing the classes without assuming anything about what exists.
히스토그램 룰Histogram rule
비-파라미터적 밀도 추정에 가장 단순한 접근 방법은 특징 공간 (feature space) 을 크기 hD 의 볼륨들 v 로 나누는 것이며, 여기서, h 는 D-차원 하이퍼큐브의 측면 길이이다. 그 후, 주어진 테스트 샘플 ![]()
![]()
![]()
![]()

여기서, ![]()
![]()
![]()
![]()
![]()
![]()
최인접 이웃 (nearest neighbour) PDF 추정은 상이한 볼륨들의 크기들을 다르게 하여 고정된 수의 트레이닝 샘플들 (k) 이 각 볼륨들에 위치하게 함으로써, 파라미터 h 를 선택하는 문제를 제거한다. 그 결과를 특징 공간의 보로니 (Voroni) 파티션 (모자이크 배열 (tessellation)) 이라 한다. 예 (k=1) 가 도 4 에 주어져 있다.The nearest neighbor PDF estimation eliminates the problem of selecting the parameter h by varying the sizes of the different volumes so that a fixed number of training samples (k) are placed in each of the volumes. The result is called a Voroni partition (tessellation) in the feature space. An example (k = 1) is given in FIG. 4.
그러나, 히스토그램 룰과 마찬가지로, 확률 밀도 추정은 불연속적이며,However, like the histogram rule, the probability density estimate is discontinuous,
셀 경계의 서로 다른 사이드의 2 개의 인접 샘플들은, 그 사이의 간격이 룰에 무관 하게 (Rule arbitrarily) 작을 수도 있다는 사실에도 불구하고, 서로 다른 라이클리후드를 가진다. 또한, 어떤 셀들은 무한 볼륨을 가질 수도 있기 때문에, 즉, 이것은 이들 셀들에 위치하는 샘플들은 추정된 라이클리후드 0 을 가지는 것을 의미하는 것으로서, 보로니 파티션은 경계 문제를 가진다.Two adjacent samples on different sides of the cell boundary have different Lyclihoods, despite the fact that the spacing between them may be small (Rule arbitrarily). Also, because some cells may have infinite volume, that is, this means that the samples located in these cells have an estimated Lyclihood 0, and the Voroni partition has a boundary problem.

[도 4] 1-최인접 이웃으로부터 기인하는 특징 공간의 보로니 파티션Fig. 4 Vorony partition of feature space resulting from 1-nearest neighbors
커널 함수Kernel functions
히스토 그램 룰의 다른 일반화는 커널 함수들의 합으로서 ![]()
![]()

커널 ![]()
![]()
![]()
![]()

는 본질적으로 히스토그램 룰로 귀결되고, 반면에 ![]()
![]()
![]()
![]()

![]()
![]()

![]()
![]()
를 요구하는 것이 편리하고, 이것은 자동적으로 ![]()
![]()

[도 5] 라이클리후드[Fig. 5] Lycli Hood
라이클리후드Lycli Hood
도 5 : 도 3 에 대응하는 밀도 함수의 커널 추정. 일반적으로, 커널 함수들은 특징 공간에 불균일하게 배치된다. 따라서, 단순한 히스토그램 룰에 대비되는 바와 같이, 특징 공간의 어떤 영역은 전혀 "모델링" 되지 않고, 다른 영역들에서는 -밀도 함수가 복잡한- 복수의 커널 함수들이 밀도를 모델링하기 위해 오버랩될 수도 있다.5: Kernel estimation of the density function corresponding to FIG. 3. In general, kernel functions are placed unevenly in the feature space. Thus, as opposed to simple histogram rules, some regions of the feature space are not "modeled" at all, and in other regions multiple kernel functions-complex density functions-may overlap to model density.
예를 들어, 도 3 에 나타낸 밀도 함수를 근사하기 위해서, 중심들이 특정 화자의 샘플들이 위치하는 원형 영역들의 중심에 각각 대응하는 10 개의 커널을 이용 하는 것이 합리적이다. 이 경우, h 는 주어진 화자들 데이터의 표준편차에 합리적으로 대응되어야 한다. 이것의 예가 도 1.5 에 나타나 있으며, 여기서, 가우시안 커널들이 사용되었다.For example, to approximate the density function shown in FIG. 3, it is reasonable to use 10 kernels whose centers respectively correspond to the centers of the circular regions in which samples of a particular speaker are located. In this case, h must reasonably correspond to the standard deviation of the given speaker data. An example of this is shown in Figure 1.5, where Gaussian kernels were used.
비-파라미터적 분류Non-parametric classification
PDF 들을 추정하는 목적은 결정 룰 1.6 에서 사용될 수 있는 사후 (postheory) 확률들을 계산할 수 있기 위한 것이다. 그러나, 이 중간 단계 없이 1.6 을 직접 구현하는 것이 가능하다. 이렇게 하는 방법은, 기본적으로, 특징 공간를 영역들로 파디션하고, 이 영역으로 위치하는 어떤 클래스 샘플들이 (분명히) 속하는 지에 따라 각 영역을 레이블링하는 것이다.The purpose of estimating the PDFs is to be able to calculate the posterior probabilities that can be used in decision rule 1.6. However, it is possible to implement 1.6 directly without this intermediate step. The way to do this is, basically, to partition the feature space into regions, and label each region according to which class samples (obviously) belong to it.
k-최인접 이웃 룰이 어떻게 분류를 위해 사용될 수 있는지를 살피는 것은 어려운 것이 아닌 것으로서, 셀의 k 샘플들의 대다수가 어떤 클래스 속하는지에 따라 각 보로니 셀을 단순하게 레이블링한다. 그 결과 결정 평면들은 부분적으로 선형이 될 것이다.It is not difficult to see how the k-nearest neighbor rule can be used for classification, simply labeling each Voroni cell according to which class the majority of k samples of the cell belong to. As a result the crystal planes will be partially linear.

[도 6] 페셉트론 (우측) 은 하이퍼 평면을 형성하고, 샘플들이 하이퍼 평면의 어느 측에 위치하는지에 따라 샘플들을 분류한다.Fig. 6 The perceptron (right) forms a hyperplane and sorts the samples according to which side of the hyperplane the samples are located.
또한, 분류자들은 커널 함수들에 기초할 수 있다. 이 경우, PDF 의 제한들이 만족될 필요가 없기 때문에, 커널 함수들 K() 에 대한 요구조건들은 덜 제한적이다. 방사형 기저 함수 (RBF) 네트워크가 커널 함수들에 기초하는 분류자의 한 예이다.Classifiers may also be based on kernel functions. In this case, the requirements for kernel functions K () are less restrictive, because the restrictions of PDF need not be satisfied. The Radial Basis Function (RBF) network is an example of a classifier based on kernel functions.
기저 함수 반경 최대화Maximize Basis Function Radius
RBF 네트워크들에 대해, 기저 함수들,For RBF networks, basis functions,

의 직경을 고려함으로써 한 구조가 기저 함수들에 부과될 수 있으며, h 가 작을 수록 기저 함수가 더욱 "스파이크 (spiked)" 된다. 스파이크된 기저 함수는 단지 특징 공간의 매우 작은 영역에 민감하고, 트레이닝 동안 중요해 질수도 있다. 넓은 기저 함수 (큰 h) 는 특징 공간의 큰 볼륨을 커버하고, h 가 클수록 기저 함수가 언제나 액티브한 단순한 바이어스를 더욱 닮게 된다. 따라서, 큰 직경을 가지도록 트레이닝된 네트워크가 더욱 잘 일반화될 수 있고, 직경은 트레이닝 세트에서 분류 성능을 중대하게 열화시키지 않는 포인트까지 확대되어야 한다.By taking into account the diameter of a structure can be imposed on the basis functions, the smaller the h, the more "spiked" the basis function. The spiked basis function is only sensitive to very small areas of the feature space and may be important during training. The wide basis function (large h) covers a large volume of feature space, and the larger h, the more like the simple bias the basis function is always active. Thus, a network trained to have a large diameter can be better generalized, and the diameter should be extended to the point where it does not significantly degrade classification performance in the training set.
분류자 총체Classifier total
파라미터들을 추정하기 위해 사용되는 트레이닝 알고리즘들이 최적화 조건의 글로벌 최소값을 판정할 수 없고 단지 로컬 최소값만 판정할 수 있다는 사실은, 단순히 한정된 복잡도를 가지는 많은 모델들 -특히, 신경 네트워크에서- 에서 문제가 된다. 이러한 이유로, 동일한 데이터에 대해 복수의 분류자들을 트레이닝시키고, 이들 네트워크들을 사용하여 새로운 "수퍼" 분류자를 생성하는 것이 유용할 수 있다. 상이한 네트워크들의 조합은 파라미터 도메인에서는 쉽게 행해질 수 없으나, 상이한 로컬 최소값을 나타내는 네트워크들은 문제의 상이한 부분들을 모델링할 수 있고, 개별 분류자들의 평균 출력으로 정의된 분류자는 일반적으로 어떠한 개별 분류자들보다 우수하게 수행할 것이며, N 개의 분류자들의 개별 제곱 평균 (mean square) 에러 레이트들 (수식 1.40) 이The fact that the training algorithms used to estimate the parameters cannot determine the global minimum value of the optimization condition and can only determine the local minimum value is problematic in many models, especially in neural networks, which have only limited complexity. . For this reason, it may be useful to train multiple classifiers on the same data and use these networks to create new "super" classifiers. Combinations of different networks cannot be done easily in the parameter domain, but networks representing different local minimums can model different parts of the problem, and a classifier defined by the average output of individual classifiers is generally superior to any individual classifiers. The individual mean square error rates of N classifiers (Equation 1.40)
![]()
![]()
으로 나타내어지며, 분류자 총체의 제곱 평균 에러 레이트의 기대값은, 네트워크들이 에러를 독립적으로 만드는 것으로 가정하면, 다음 식에 의해 주어진다 (Perrone 및 Cooper 1994).The expected value of the squared mean error rate of the classifier total is given by the following equation, assuming that the networks make the error independent (Perrone and Cooper 1994).

따라서, 에러들이 상호관련되어있지 않는 한 (uncorrelated), 분류자 총체의 성능은 더 많은 네트워크들을 추가함으로써 향상될 수 있고, 네트워크의 수가 2 배가 될 때마다 제곱 평균 에러 레이트가 반으로 줄어든다.Thus, unless the errors are correlated (uncorrelated), the performance of the classifier aggregate can be improved by adding more networks, and the squared mean error rate is cut in half each time the number of networks is doubled.
퍼셉트론 타입 모델들에 대해, 상이한 로컬 최소값을 나타내는 네트워크들은, 가중치들 (weights) 을 상이하게 초기화함으로써 단순하게 생성될 수 있다 (Hansen 및 Salamon 1990; Battiti 및 Colla 1994). Benediktsson 등 (1997) 에서, 개별 네트워크들 (퍼셉트론들) 은 상이한 데이터 변환들을 이용해 변환된 데이터에 대해 트레이닝된다. Ji 및 Ma (1997) 는 약한 분류자들 (퍼셉트론들) 을 선택하고 결합하는데 특화된 알고리즘을 제안했다.For Perceptron type models, networks representing different local minimums can be generated simply by initializing the weights differently (Hansen and Salamon 1990; Battiti and Colla 1994). In Benediktsson et al. (1997), individual networks (perceptrons) are trained on transformed data using different data transforms. Ji and Ma (1997) proposed algorithms specialized for selecting and combining weak classifiers (perceptrons).
화자 검증Speaker Verification
랜덤화된 환경에서 화자 검증 및 객체 핸들링은 패턴 식별 문제이고, 단지 2 개의 클래스들 (패턴들), 즉 목표 화자들 또는 객체와 사칭자들만이 구별될 필요가 있기 때문에, 개념적으로 매우 단순하다. 그러나, 특징 공간에서 2 개의 클래스들을 분류하는 것은 쉽지 않다. 클래스 분포들은 복잡하고 비-파라미터적 테 크닉들을 이용하여 실제로 모델링되어야만 한다. 신경 네트워크들은 이 종류의 문제들에 대해 매력적인 분류자들이며, 그 식별 트레이닝 방식은 화자들 또는 객체를 식별하는 특징 공간의 영역에 모델링의 초점을 두는 것을 가능하게 한다.Speaker verification and object handling in a randomized environment is a pattern identification problem and is conceptually very simple because only two classes (patterns), namely target speakers or objects and impersonators, need to be distinguished. However, it is not easy to classify two classes in the feature space. Class distributions must be actually modeled using complex and non-parametric techniques. Neural networks are attractive classifiers for this kind of problem, and their identification training approach makes it possible to focus modeling on the area of the feature space that identifies the speaker or object.
그러나, 많은 트레이닝 또는 객체 학습 알고리즘들의 문제는 그것들이 모델링 파라미터들의 최적 값들을 보장할 수 없다는 것이다. 이 경우, 구조적 리스크 최소화 테크닉을 사용하여 모델링에 제한들을 부과함으로써 일반화 능력을 향상시킬 수 있다. 파라미터 문제에 대한 다른 접근 방법 -차선책- 은 총체 테크닉들을 사용하는 것으로서, 단순 차선 분류자들의 총체이 결합되어 더욱 강력하고 로버스트한 새로운 분류자를 형성할 수 있다. 분류자 총체의 에러 레이트가 원리상 총체 멤버들의 수의 역수에 비례하기 때문에 총체 방법이 매력적인 것이다.However, a problem with many training or object learning algorithms is that they cannot guarantee optimal values of modeling parameters. In this case, structural risk minimization techniques can be used to impose restrictions on modeling to improve generalization capabilities. Another approach to the parametric problem-the next best thing-is to use gross techniques, in which the gross of simple lane classifiers can be combined to form a more powerful and robust new classifier. The aggregation method is attractive because the error rate of the classifier aggregate is in principle proportional to the inverse of the number of aggregate members.
부록 2 : RBF 기반 음운 (phoneme) 모델링에 의해 예시화된 객체 분석Appendix 2: Object Analysis Illustrated by RBF-based Phoneme Modeling
이 예는 이벤트 레벨에서 화자 검증에 적용될 수 있는 분류자 아키텍쳐를 나타내지만, 임의의 주어진 객체 데이터 타입에 대해서도 사용될 수 있는 방법의 예로 보아야 한다. 분류자 - RBF 네트워크 - 는 그것이 동작하는 이벤트들을 스스로 식별할 수 없고, 이것을 하기 위해서는 특징 추출 프로세스에 의존한다. 도 1.1 은 분류자 아키텍쳐를 개략적으로 나타낸다. 히든 마르코프 모델 (Hidden Markov Model) 들이 스피치 (speech) 신호를 세그먼트하기 위해 사용된다. 히든 마르코프 음운 모델은 음운 세그먼트들을 정규 분포의 혼합으로 모델링하며, 여기서, 이 혼합의 평균 및 분산은 시간의 불연속 포인트들에서, 상태 천이에서 변한다. 이 불연속 변화들은 이상적으로 연속적이어야 하지만 이것은 모델링이 어렵다.This example shows a classifier architecture that can be applied to speaker verification at the event level, but should be seen as an example of a method that can be used for any given object data type. The classifier-the RBF network-cannot self identify the events it operates on and relies on a feature extraction process to do this. 1.1 schematically illustrates a classifier architecture. Hidden Markov Models are used to segment the speech signal. The Hidden Markov phonological model models phonological segments as a mix of normal distributions, where the mean and variance of this blend varies in state transitions, at discrete points in time. These discrete changes should ideally be continuous, but this is difficult to model.
음운 세그먼트들이 식별된 후에, 새로운 특징 추출이 수행되며 (섹션 1.1), 여기서, 각 개별 음운 세그먼트들은 특징들의 단일 벡터에 의해 다시 나타내어진다. 여기서, 전체 음운 관측을 나타내는 특징 벡터는 음운 벡터,After phonological segments are identified, new feature extraction is performed (section 1.1), where each individual phonological segments are represented again by a single vector of features. Here, the feature vector representing the entire phonological observation is a phonological vector,
![]()
![]()
라고 할 것이다.I will say.
음운 벡터들이 추출되면, 신호는 더 이상 시간 정보를 포함하지 않으며, 음운 벡터들이 한 주기의 시간 동안 순차적으로 측정된다는 사실은 부적절하고, 화자 아이덴티티에 관한 정보를 포함하지 않는다. 또한1, 음성 프린트의 2 진 폼이 ( 순수) 랜덤 발성 모델에 "생성"되며, 이것은 2 진 객체를 완전히 유일하게 만든다. 이것이 실질적으로 의미하는 것은 벡터 모델이 랜덤 벡터 nn 이 된다는 것이다.Once phonological vectors are extracted, the signal no longer contains time information, and the fact that the phonological vectors are measured sequentially over a period of time is inappropriate and does not contain information about the speaker identity. 1 also, the binary form of the voice print, and "create" in the (pure) random utterance model, which makes the binary object entirely unique. What this actually means is that the vector model is a random vector n n .
여기서, 기본 특징은 필터 뱅크 에너지에 의해 나타낸 것이고, 따라서, 신호 이득 (섹션 1.2) 을 제거하기 위해 음은 벡터들은 정규화될 필요가 있다. 이를 위해, 화자 확률,Here, the basic feature is represented by the filter bank energy, so that negative vectors need to be normalized to remove the signal gain (section 1.2). To this end, speaker probability,
![]()
![]()
을 계산하는 RBF 네트워크로의 입력으로서 최종적으로 전달되기 전에 이것들은 변환 1,These are converted 1, before finally passed as input to the RBF network to compute
![]()
![]()
을 거쳐야 한다.Should go through.
프레임 선택Frame selection
음운 지속시간들 (durations) 은 음운 콘텍스트, 전체 스피치 템포 및 다른 인자들의 함수이며, 음운 지속시간들은 매우 가변적이다. 정적 모델링 접근을 위해 음운들을 고정된 수의 특징들에 의해 나타낼 필요가 있다. 이것은 마르코프 세그멘테이션을 이용해 수행될 수 있으며, 여기서, 각 음운은, 음운 모델의 상이한 방출 마르코프 상태들에 대응하는 다수의 서브-세그먼트들로 세그먼트된다. 가능한 리프리젠테이션 방식들은 아래와 같다.Phonological durations are a function of phonological context, overall speech tempo, and other factors, and phonological durations are very variable. For a static modeling approach it is necessary to represent the phonemes by a fixed number of features. This can be done using Markov segmentation, where each phoneme is segmented into a number of sub-segments corresponding to different emitting Markov states of the phoneme model. Possible representations are as follows:
1. 새로운 "가변" 프레임 세그멘테이션 (그리고 스피치 파라미터화) 을 계산하며, 여기서 새로운 프레임 길이는 전체 음운 세그먼트의 정수 비율이 되도록 조 정된다. 산술적으로 이것은 상대적으로 고가이지만, 전체 음운 세그먼트가 이용된다는 이점이 있다.1. Compute a new "variable" frame segmentation (and speech parameterization), where the new frame length is adjusted to be an integer ratio of the entire phonetic segment. Arithmically this is relatively expensive, but the advantage is that the entire phonetic segment is used.
2. 존재 프레임들의 고정된 수 (N) 를 음운 세그먼트의 대표값으로 선택한다. 몇 가지 프레임 선택 방법이 고려될 수 있다.2. Select a fixed number N of existing frames as the representative of phonetic segments. Several frame selection methods can be considered.
a. 선형 선택 : 선형적으로 스페이스된 N 개의 프레임들을 음운 세그먼트로부터 선택한다.a. Linear Selection: Select linearly spaced N frames from phonetic segments.
b. 서브-세그먼트 선택 : 각 서브-음운 세그먼트로부터 하나의 프레임을 선택한다. 리프리젠테이션의 균등성을 증진시키기 위해서, 선택은 일관되게, 예를 들어, 분리 HMM 상태들에 의해 모델링된 각 서브-음운 세그먼트에서 항상 중심 프레임들을 선택함으로써 수행되어야 한다.b. Sub-segment selection: Select one frame from each sub-phonic segment. In order to promote uniformity of representation, the selection must be performed consistently, for example by always selecting center frames in each sub-phonic segment modeled by separate HMM states.
c. 최대 라이클리후드 선택 : 가장 높은 라이클리후드를 가지는 각 서브-음운 세그먼트로부터 프레임을 선택한다.c. Maximum Riclid Hood Selection: Select a frame from each sub-phonic segment with the highest riclihood.
적당한 프레임들이 식별된 후에, 대응하는 특징 벡터들은 하나의 긴 벡터를 형성하기 위해 "연결된다."After the appropriate frames are identified, the corresponding feature vectors are "concatenated" to form one long vector.
선택 방식 2A 및 2B 는 상당히 유사하고, 총체 방법들 (섹션 2.7 참조) 과 관련하여 프레임 선택 방법에서의 변형들이 동일 음운에 대해 "상이한" 음운 모델들을 생성하는데 사용될 수 있기 때문에, 여기서는 프레임 선택 방법으로 2B 를 사용하는 것으로 선택하였다. 선택 방식 2B 는, 예를 들어, 중심 프레임 대신에 각 서브 세그먼트에서 가장 우측 또는 가장 좌측 프레임들을 선택함으로써, 용이하게 변형될 수 있다.The selection schemes 2A and 2B are quite similar, and here we refer to the frame selection scheme since variations in the frame selection scheme in relation to the aggregate methods (see section 2.7) can be used to generate "different" phonological models for the same phonology. It was chosen to use 2B. The selection scheme 2B can be easily modified by, for example, selecting the rightmost or leftmost frames in each subsegment instead of the center frame.
정규화Normalization
스피치 신호의 필터 뱅크 리프리젠테이션과 관련한 문제는 신호 이득이 잘 제어되지 않는다는 것이다. 신호 이득은 화자들의 스피킹 레벨, 마이크와의 간격, 입과 마이크 및 녹음 도구들 사이의 각도에 의존한다. 이것은 화자 식별용으로 절대 이득이 사용될 수 없고, 정규화되어야만 함을 효율적으로 의미한다. 스피치 프로세싱에 관해 일반적인 것으로서, 여기서, 로그 필터 뱅크 리프리젠테이션이 사용된다.The problem with filter bank representation of speech signals is that the signal gain is not well controlled. Signal gain depends on the speaker's speaking level, distance from the microphone, and the angle between the mouth and microphone and recording tools. This effectively means that absolute gain cannot be used for speaker identification and must be normalized. As is common with respect to speech processing, log filter bank representation is used.

[도 7] RBF 네트워크[Figure 7] RBF Network
이것은 각 필터 뱅크로부터의 에너지 출력의 로그값이 사용되는 것을 의미한다. 1 미만의 에너지 출력들은 폐기되며, 그것들은 대부분 노이즈를 나타내며, 로그 함수의 특이 행위 (singular behaviour)2 때문에, 이들 에너지를 모델링하지 않는 것이 최선이다.This means that the logarithm of the energy output from each filter bank is used. Energy outputs below 1 are discarded, most of them represent noise, and because of the singular behavior 2 of the logarithmic function, It is best not to model these energies.
로그 에너지 도메인에서, 이득 인자는 가산 바이어스 (additive bias),In the log energy domain, the gain factor is additive bias,
![]()
![]()
가 된다.Becomes
여기서, 벡터의 log() 를 취하는 것은 log() 함수가 벡터의 모든 요소 (element) 들에 적용되는 것을 의미한다. 또한, 스칼라 및 벡터의 가산 (승산) 은 스케일러가 벡터의 모든 요소들에 가산 (승산) 되는 것을 의미한다. 스케일이 적절하지 않기 때문에 음운 벡터들은 놈 (norm) 1 을 가지는 것으로 가정한다.Here, taking log () of a vector means that the log () function is applied to all elements of the vector. Also, addition (multiplication) of scalars and vectors means that the scaler is added (multiplication) to all elements of the vector. The phonological vectors are assumed to have

스케일링 후, 놈은,After scaling, he

이 된다.Becomes
따라서, 놈Therefore, bastard
![]()
![]()
을 계산하고Calculate
로그 놈을 필터 뱅크들로부터 감산Subtract the log norm from the filter banks

함으로써 이득이 제거될 수 있다.The gain can be eliminated by doing so.
데이터를 더욱 균등화하기 위해, 벡터To make the data more even, vector
![]()
![]()
는 여기서 놈 1 을 가지도록 정규화된다.Is normalized to have
독립적인 이득 인자가 각 필터 뱅크 채널과 관련된 경우, 이것은 특징 벡터들에 가산된 바이어스 벡터들을 유발한다. 이 타입의 이득은 하나의 특정 특징 벡터를 살핌으로써 제거될 수는 없으나, 대신, 한 발성 동안 평균 에너지 출력을 추정함으로써 보상될 수 있다.If an independent gain factor is associated with each filter bank channel, this results in bias vectors added to the feature vectors. This type of gain cannot be eliminated by looking at one particular feature vector, but can instead be compensated by estimating the average energy output during one vocalization.
실제로, 바이어스 제거는 유용한 휴리스틱이지만, 추정되는 바이어스는 발성의 발음 내용 (phonetic content) 에 의존하기 때문에 (Zhao 1994), 이것은 실제로 평범하지 않은 문제이다. 이 휴리스틱은 여기서는 사용되지 않는다.Indeed, bias removal is a useful heuristic, but since the estimated bias depends on the phonetic content of the vocalization (Zhao 1994), this is actually a trivial problem. This heuristic is not used here.
RBF 트레이닝 :RBF Training:
정규화된 음운 벡터들은 음운Normalized phoneme vectors are phonemes

및 화자 의존 (speaker dependent) RBF 네트워크에 입력되기 전에 변환되며, 이 RBF 네트워크는,And before being input into a speaker dependent RBF network, the RBF network
함수function

를 계산하기 위해 사용되며,Is used to calculate
여기서 S 는 활성화 함수 스케일이고,Where S is the activation function scale,

이며, 여기서, D 는 입력 벡터들의 차원이다. 기저 함수 스케일들 Ci 및 분산들Where D is the dimension of the input vectors. Basis Function Scales Ci and Variances
![]()
![]()
은silver

에 의해 한정되고, 이것은 네트워크가 최적 베이즈 판별 함수Defined by the network, the optimal Bayesian discriminant function

를 근사하는 것을 보장한다.Ensure to approximate it.
이들 위해 많은 테크닉들이 사용되었다 (Press 등 1995; Bishop 1995). 이 경우, 여기서는 기울기 계산이 용이하기 때문에 가장 단순한 접근방법은 기울기 감소 (gradient descent) 를 이용하는 것으로서, 네트워크의 크기 때문에 트레이닝 알고리즘은 매우 빠르게 수렴하여 켤레 (conjugate) 기울기 또는 준-뉴튼 (Quasi-Newton) 방법들이 요구되지 않는다. 기울기 감소는 반복적 (iterative) 테크닉이며, 여기서, 반복 t 의 파라미터들은 다음 식에 따라 업데이트 되며,Many techniques have been used for these (Press et al. 1995; Bishop 1995). In this case, the simplest approach here is to use gradient descent because the slope calculations are easy, and because of the size of the network, the training algorithm converges very quickly, resulting in conjugate slope or quasi-Newton. No methods are required. Gradient reduction is an iterative technique, where the parameters of the iteration t are updated according to





여기서,here,

이고,ego,







및And

이다.to be.
여기서, 기울기들은 전체 트레이닝 샘플들에 대한 합산으로서 계산되는 것으로 내타내었다. 트레이닝 프로세스를 빠르게 하기 위해, 이 요구조건은 보통 완화됨으로써 서브세트들 또는 심지어 개별 샘플들이, 기울기를 계산하고 파라미터들을 업데이트하기 위한 기저로서 사용된다. 이것은 트레이닝 데이터가 "주기적"1 인 경우 합리적이다.Here, the slopes are shown to be calculated as the summation for the entire training samples. To speed up the training process, this requirement is usually relaxed so subsets or even individual samples are used as the basis for calculating the slope and updating the parameters. This is reasonable if the training data is "periodic" 1 .
기울기 수식들의 형태들은 상대적으로 이해하기 쉽다. 기울기 수식들은 일부 공통 항들 및 일부 특정 항들을 가진다.The forms of the slope equations are relatively easy to understand. Gradient equations have some common terms and some specific terms.
모든 기울기들이 포함하는 공통항은 에러 항,The common term that all the slopes contain is the error term,
![]()
![]()
으로서, 이것은 샘플들이 오분류되지 않으면 0 이다. 따라서, 샘플들이 정확하 게 분류된 경우, 파라미터들은 업데이트되지 않는다. 오분류의 경우, 목표 출력이 음수이면 에러 항은 양수이고, 목표 출력이 양수이면 에러항은 음수이다. 하나의 클래스 에러 레이트를 다른 에러 레이트들에 대해 강조하기 위해 클래스 의존 가중치 (weight) 가 에러 항에 주어질 수 있다. 예를 들어, 트레이닝 세트는 상대적으로 적은 목표 화자 패턴들을 포함하기 때문에 목표 화자 패턴들은 더 높은 가중치를 받을 수도 있고, 따라서, 분류자는 이들 패턴들을 풍부한 사칭 화자 패턴들에 비해 "과다 학습 (over learn)" 하는 경향이 높다.This is zero if the samples are not misclassified. Thus, if the samples are sorted correctly, the parameters are not updated. In the case of misclassification, the error term is positive if the target output is negative and the error term is negative if the target output is positive. A class dependent weight may be given in the error term to emphasize one class error rate over other error rates. For example, the target speaker patterns may be weighted higher because the training set contains relatively fewer target speaker patterns, so the classifier may "over learn" these patterns compared to the richly impersonated speaker patterns. "I tend to.
모든 기울기에 나타난 제 2 항은The second term that appears in every slope

이다.to be.
이 항은 This term
![]()
![]()
인 경우, 즉 파라미터들이 큰 마진으로 오분류된 경우에, 파라미터 변경을 방지하는 효과를 가진다., I.e., if the parameters are misclassified with a large margin, they have the effect of preventing parameter changes.
![]()
![]()
( 주석 1: 여기서, 주기는 2 개 이상이어서, 목표 화자 패턴 및 사칭 화자 패턴이 각 주기에 나타나야 한다. 보다 일반적으로는, 각 업데이트가 개별 음운 관측 들 - 예를 들어 상이한 음운 콘텍스들에 대응하는 - 의 세트에 기초하도록 -주기- 가 증가될 수 있다. 이것이 행하지 않는 경우 학습은 "이상"해 지는 경향일 수 있으며, 네트워크는 가장 최근에 나타난 트레이닝 토큰으로 바이어스되고, 최근에 학습한 정보 중 일부를 - 잊어버린다-.)(Note 1: Here, there are two or more periods, so that the target speaker pattern and the impersonator speaker pattern must appear in each period. More generally, each update corresponds to individual phonetic observations-e.g. different phonetic contexts. -Period- may be increased to be based on a set of-which, if this is not done, learning may tend to be "abnormal", and the network is biased with the most recently shown training token, and among the recently learned information Forget some-forget it.)
모든 기울기들이 공유하는 제 3 항은 기저 함수 출력,The third term shared by all the slopes is the basis function output,

이고, 이것은 0 과 1 사이의 값이다. 따라서, 샘플, Which is a value between 0 and 1. Thus, the sample
![]()
![]()
이 this

가 활성화되는 하이퍼 타원 (hyper elliptical) 영역에 위치하지 않으면 주어진 기저 함수에 관련된 파라미터들이 업데이트 되지 않는다.If is not located in the hyper elliptical region where it is active, the parameters associated with a given base function are not updated.
가중치 (Weights)Weights
가중치들이 업데이트됨으로써, 오분류된 샘플들에 대해, 목표 출력이 양수인 경우 가중치가 증가하고 반대의 경우 감소한다. 최종 분류자에서, 양수 가중치를 가지는 기저 함수들은 클래스 I 를 나타내고, 음수의 가중치를 가지는 기저 함수들은 클래스 ![]()
![]()
평균Average
목표 클래스,Target class,
![]()
![]()
를 나타내는 기저 함수들은 오분류된 샘플에 더욱 가깝게 이동되고, 반대 클래스를 나타내는 기저 함수들은 멀어진다. 단계 크기는 개별 기저 함수들,The base functions representing ε are moved closer to the misclassified sample, and the base functions representing the opposite class are farther away. The step size is the individual basis functions,
![]()
![]()
을 어떻게 "활성화" 시키는지에 의존하고, 기저 함수들의 반경, Depends on how to "activate" the radius of the basis functions,
![]()
![]()
, 오분류된 포인트와의 간격 및 분류 에러의 통상 크기., Spacing with misclassified points and the normal magnitude of the classification error.
기저 함수 스케일 Basis Function Scale
기저 함수들의 폭은 The width of the basis functions
![]()
![]()
목표 클래스를 나타내는 기저 함수들에 대해,For the base functions that represent the target class,
![]()
![]()
가 그 샘플을 그 기저 함수들의 영향의 구 내부에 포함하도록 감소된다 (폭은 증가된다). 반대 클래스를 나타내는 기저 함수들에 대해,Is reduced to include the sample inside the sphere of influence of the basis functions (the width is increased). For base functions that represent opposite classes,
![]()
![]()
가 샘플을 이들 기저 함수들의 영향 구로부터 배제하도록 증가된다 (폭은 감소된다).Is increased to exclude the sample from the effect sphere of these basis functions (width is reduced).
분산들을 업데이트 하는 것은 목표 클래스를 나타내는 기저 함수들에 대한 기저 함수들의 폭을 넓히는 것 및 반대 클래스를 나타내는 기저 함수들의 폭을 감소시키는 것과 동일한 효과를 가진다.Updating variances has the same effect as widening the base functions for base functions representing the target class and reducing the width of the base functions representing the opposite class.
분산Dispersion
분산들, Dispersions,
![]()
![]()
은 개별 특징 요소들의 상대적인 분산을 나타낸다. 분산들은 개별 요소들의 통계적인 분산들에 반드시 대응하지는 않으나, 특징들의 중요도에는 대응한다. 분류를 위해 작은 중요도를 가지는 특징 요소들은 큰 "분산" 을 받음으로써 기저 함수의 활성화에 대해 상대적으로 적은 영향을 가질 수도 있다.Represents the relative variance of the individual feature elements. The variances do not necessarily correspond to the statistical variances of the individual elements, but to the importance of the features. Feature elements with small importance for classification may have a relatively small impact on the activation of the basis function by receiving a large "variance".
활성화 함수 스케일Activation function scale
활성화 함수 S 의 스케일은 퍼셉트론에 의해 구현된 하이퍼 평면의 정확한 사이드의 샘플들에 대해 증가하고, 정확하지 않은 사이드의 샘플들에 대해 감소한다. 그러나, 샘플들의 분류는 S 를 업데이트함으로써 개선되거나 변경되지 않는다. 따라서, 학습 알고리즘은 에러 레이트 최소화 목적으로 S 의 값을 변경하지 않는다. 그러나, 활성화 함수 스케일은 RBF 모델을 확률 추정자로서 향상시키기 위해 순차적으로 조정될 수도 있다.The scale of the activation function S increases for samples of the correct side of the hyper plane implemented by the perceptron and decreases for samples of the incorrect side. However, the classification of the samples is not improved or changed by updating S. Thus, the learning algorithm does not change the value of S for the purpose of minimizing the error rate. However, the activation function scale may be adjusted sequentially to improve the RBF model as a probability estimator.
초기화reset
반복적인 트레이닝 알고리즘은 네트워크 파라미터들의 초기 추정을 요구한다. RBF 네트워크의 파라미터들은 MLP 의 가중치들보다 훨씬 더 해석하기 쉽고, 따라서, 반드시 랜덤 값들을 이용하여 초기화할 필요가 없다. 특히, 클러스터링 알고리즘이 목표 화자 및 그룹 (cohort) 화자들을 각각 나타내는 적합한 기저 함수들을 계산하기 위해 이용될 수 있다. 목표 화자 기저 함수들에 대응하는 가중치들은 Iterative training algorithms require an initial estimation of network parameters. The parameters of the RBF network are much easier to interpret than the weights of the MLP and therefore do not necessarily need to be initialized with random values. In particular, a clustering algorithm can be used to calculate suitable basis functions representing the target speaker and the cohort speakers, respectively. The weights corresponding to the target speaker basis functions are

으로 초기화될 수 있으며, 여기서,Can be initialized to, where
![]()
![]()
는 i 번째 목표 화자 클러스터에 위치하는 트레이닝 샘플들의 개수이다. 유사하게, 그룹 화자 기저 함수들에 대응하는 가중치들은 Is the number of training samples located in the i th target speaker cluster. Similarly, the weights corresponding to the group speaker basis functions are

로 초기화될 수 있다.Can be initialized to
바이어스 가중치Bias weights
![]()
![]()
는 0 미만의 값으로 초기화 되어야 하며, 네트워크에 어떠한 기저 함수들도 액티베이트하지 않는 음운 벡터가 제공된 경우, 분류는 ![]()
![]()
트레이닝 알고리즘의 수렴은 기저 함수들의 초기화에 임계적으로 의존하지만, 실제로 가중치 초기화에 강하다. 따라서, 가중치들은 랜덤 값들 ([-1;1] 범위 의) 로 단순하게 초기화될 수도 있다.The convergence of the training algorithm depends critically on the initialization of the basis functions, but is actually strong in weight initialization. Thus, the weights may simply be initialized to random values (in the range [-1; 1]).
사후확률Post probability
RBF 네트워크들은 트레이닝 세트의 제곱 평균 에러 레이트 (수식 1.9) 를 최소화하도록 트레이닝된다. 이 에러 조건의 최소화는 RBF 네트워크가 다음 식으로 주어지는 최적 (베이즈) 식별 함수를 근사하게 한다.RBF networks are trained to minimize the root mean square error rate of the training set (Equation 1.9). Minimization of this error condition allows the RBF network to approximate the optimal (baize) identification function given by
![]()
![]()
이 중요한 사실은 여러 저자들에 의해 증명 되었다 (Ruck 등 1990; Richard 와 Lippmann 1991; Gish 1990a; Ney 1991).This important fact has been demonstrated by several authors (Ruck et al. 1990; Richard and Lippmann 1991; Gish 1990a; Ney 1991).
![]()
![]()
![]()
![]()
와 같은 일반 함수는, 비록 유한 개수의 기저 함수들을 가진다 하더라도, 위 타입 의 RBF 네트워크에 의해 구현될 수 없다. ![]()
![]()
그러나, 기초적인 (underlying) 함수 ![]()
![]()

그러나, tanh(x) 를 활성화 함수로 선택하는 것은 임의적이지 않다. 예를 들어, 2-클래스 분류 문제에서, 식별될 2 개의 클래스가 가우시안 확률 분포들However, choosing tanh (x) as the activation function is not arbitrary. For example, in a two-class classification problem, two classes to be identified are Gaussian probability distributions.

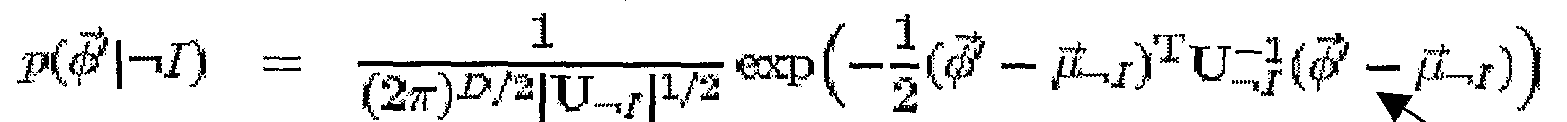
에 의해 특징되는 경우를 고려하자.Consider the case characterized by.
베이즈 룰에 따르면, 클래스 I 의 사후확률은, 다음 식에 의해 주어지며,According to Bayes' rule, the posterior probability of class I is given by

여기서,here,

이다.to be.
RBF 네트워크가 식별 함수RBF network identification function
![]()
![]()
를 근사하는 경우, 다음 식을 얻을 수 있기 때문에 (2.5 를 이용하여),If we approximate, we get the following equation (using 2.5),
![]()
![]()

이것은 정확히 우리가 원하는 형태이며,This is exactly what we want,
여기서here
![]()
![]()
이다.to be.
활성화 함수 스케일의 조정Activation function scaling
확률 추정으로서, 수식 33 및 34 는 다소 미완성이다. 스티프 (steep) 한 활성화 함수 (큰 활성화 함수 스케일 S) 가 사용되는 경우, 출력은 필수적으로 2 진 변수이다. 활성화 함수 스케일 (S) 는, 먼저, -이상적으로는- 독립적인 테스트 세트,As probability estimation, Equations 33 and 34 are somewhat incomplete. If a steep activation function (large activation function scale S) is used, the output is essentially a binary variable. The activation function scale (S) is, first of all, ideally an independent test set,


로부터 경험적 활성화 함수를 추정하고, 여기서 ![]()
![]()

인 계단함수 이고, 여기서, ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

이 되도록 활성화 함수 스케일이 조정된다.The activation function scale is adjusted so that
이것은 this is

를 선택함으로써 수행되며, 여기서Is performed by selecting, where

이다.to be.
잠재적으로 더욱 정확한 다른 접근방법은 tahh() 를 경험적 (empirical) 활성화 함수로 단순하게 치환하는 것이다 (수식 36).Another potentially more accurate approach is to simply substitute tahh () with an empirical activation function (Eq. 36).
잠재적으로 더욱 정확한 다른 접근방법은 tahh() 를 경험적 활성화 함수로 단순하게 치환하는 것이다 (수식 36).Another potentially more accurate approach is to simply substitute tahh () with an empirical activation function (Eq. 36).
바이어스 조정Bias adjustment
제한된 트레이닝 세트로부터 RBF 네트워크를 트레이닝하는 것은 어렵다. 일반적으로, 문제는 트레이닝 세트의 사칭자 부분이 아닌 목표 화자 부분이다. 물론, 이것은 화자 모델을 트레이닝하는 것을 어렵게 만들지만, 특히, TA 와 IR 에러들 사이에서 원하는 밸런스를 획득하도록 모델을 조정하는 것을 어렵게 만든다. 밸런스는 다양한 트레이닝 파라미터들에 의해 다소 제어될 수 있으며, 예를 들어, 에러 항![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

이 된다.Becomes
이 해는 다음 식의 근들을 판정함으로써 찾을 수 있으며,This solution can be found by determining the roots of

여기서, 다음과 같은 약어를 사용하였다.Here, the following abbreviations were used.
![]()
![]()
![]()
![]()
![]()
![]()
B = 1 에 대해 이것은 수식 1.26 (객체 분류의 예시) 과 동일한 식이다. 우리가 관심있는 해는 ![]()
![]()
![]()
![]()
다른 방법 - 가우시안 추정이 부실한 경우 - 은 경험적 활성화 함수 (수식 x.36) 를 사용하는 것이다. 상이한 에러 밸런스 B 가 요구되는 경우, 다음 식에 따라 바이어스가 조정될 수 있다.Another way-if Gaussian estimation is poor-is to use the empirical activation function (Equation x.36). If a different error balance B is required, the bias can be adjusted according to the following equation.

![]()
![]()

따라서, 밸런스 B 를 가지도록 교차비 (odds ratio) 를 조정하기 위해, 수식 48 의 해, ![]()
![]()
![]()
![]()
B = 1 에 대해 동일한 에러 레이트가 근사되고, B < 1 에 대해 IR 에러들의 비용으로 TA 에러들의 수가 최소화되고, B > 1 에 대해 TA 에러들의 비용으로 IR 에러들이 최소화된다.The same error rate is approximated for B = 1, the number of TA errors at the cost of IR errors for B <1 is minimized, and IR errors at the cost of TA errors for B> 1.
도 8 은 한 세트의 화자 모델들에 대한, 클래스 조건 경험적 분포 함수들,8 shows class condition empirical distribution functions, for a set of speaker models,
![]()
![]()
및 And
![]()
![]()
및 경험적 활성화 함수 And heuristic activation function
![]()
![]()
를 나타낸다. 이 도면은 트레이닝 데이터 및 테스트 데이터에 대한 양 함수들을 모두 나타낸다.Indicates. This figure shows both functions for training data and test data.
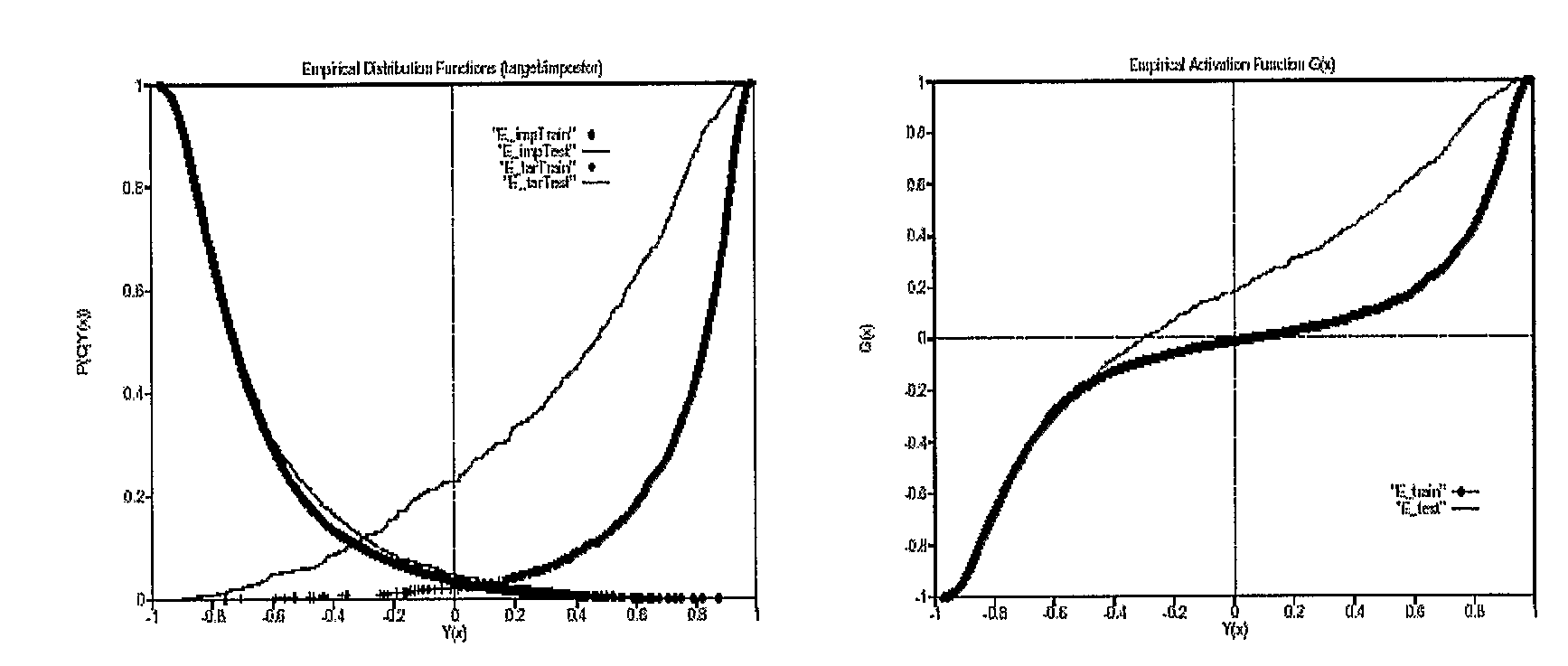
[도 8] 경험적 분포 함수Figure 8 empirical distribution function
트레이닝 데이터를 위해, 각각 1622 및 6488 로컬 목표 화자 및 사칭 화자 결정들이 사용되었다. 테스트 데이터를 위해, 각각 394 및 1576 로컬 결정들이 사용되었다.For the training data, 1622 and 6488 local target speaker and impersonated speaker decisions were used, respectively. For test data, 394 and 1576 local decisions were used, respectively.

[도 9] 바이어스 보상 후의 경험분포함수들[Figure 9] Empirical Distribution Functions after Bias Compensation
트레이닝 데이터에 대해, ![]()
![]()
요약하면, 음운 기반 화자 모델을 설명하였다. 이 모델은 음운 관측을 특징 요소들 스펙트럼의 고정된 벡터들로서 나타내는 "특징 추출기들"로서 HMM 들을 사용하며, 모델의 이 부분은 화자 독립적이다. 음운 벡터들은 변환되고 마 침내 음운 독립 RBF 네트워크의 입력으로서 전달되고, 트레이닝 되어 음운 벡터들로부터 화자 확률을 추정한다. 화자 확률은 (로컬) 화자 식별 결정을 생성하는데 직접 사용되거나, 다른 음운 관측으로부터 추정된 다른 화자 확률들과 결합되어 보다 로버스트한 결정을 생성할 수 있다. 입력 벡터 (음운) 는 객체가 무엇에 기초하는지, 즉, 식별이 가능한지 예시하기 위해서만 언급되었다. 따라서, 임의의 다른 타입의 생체측정 벡터들이 트레이닝 필터들에 사용될 수 있다.In summary, a phonological-based speaker model has been described. This model uses the HMMs as "feature extractors" that represent phonological observations as fixed vectors of the feature elements spectrum, and this part of the model is speaker independent. Phonological vectors are transformed and finally delivered as input to a phonological independent RBF network, trained to estimate speaker probability from the phonological vectors. Speaker probabilities may be used directly to generate a (local) speaker identification decision or may be combined with other speaker probabilities estimated from other phonological observations to produce a more robust decision. The input vector (phonology) is only mentioned to illustrate what the object is based on, i. Thus, any other type of biometric vectors can be used in the training filters.
부록 3 : 화자 검증에 의해 예시된 객체 기반 결정 과정 (decision making)Appendix 3: Object-Based Decision Making Illustrated by Speaker Verification
객체 검증 - 또는 이 경우 화자 검증은 2 진 결정 문제이고, 따라서, 결국, 스코어를 계산하고, 스코어가 주어진 임계값 t 보다 큰지 작은지를 판정하여 아이덴티티 주장을 검증하는 것으로 귀착된다.Object Verification-or Speaker Verification in this case is a binary decision problem, and consequently results in verifying the identity claim by calculating the score and determining whether the score is greater than or less than a given threshold t.

이 스코어, 즉 객체 값을 계산할 때, 스피치 신호의 각 음운 세그먼트가 기여한다 (음운들이 명확하게 모델링되지 않는 때라도). 종래의 텍스트 독립 화자 검증 알고리즘에서, 상이한 음운들의 전체 스코어 (예를 들어, 발성 라이클리후드) 에 대한 기여는 알 수 없었고, 전체 스코어는 테스트 발성에서 각 음운 세그먼트 지속시간 동안 음운들이 나타내어지는 특정 주파수에 의존한다.When calculating this score, i. E. Object value, each phonetic segment of the speech signal contributes (even when the phonemes are not explicitly modeled). In conventional text-independent speaker verification algorithms, the contribution to the overall score of different phonologies (e.g. vocal lyclie hood) is unknown, and the overall score is the specific frequency at which phonologies are represented during each phonological segment duration in the test utterance. Depends on
개별 음운 세그먼트들이 기여한 로컬 스코어들이 화자 아이덴티티를 표현하고, 상이한 음운들이 화자에 관한 동일한 정보를 표현하는 것이 고려되지 않았기 때문에, 이것이 최적이 아님이 명백한 것으로, 예를 들어, 추측컨데, 비음 및 모음은 크게 부각되는 정보를 나타내고, 반면에, 예를 들어, 2 개의 후설모음은 화자에 관해 높게 상호연관된 정보를 나타낸다.It is evident that this is not optimal because local scores contributed by individual phonological segments represent the speaker identity and different phonologies are not considered to represent the same information about the speaker, e.g. While the information is greatly highlighted, on the other hand, two rear-bottom collections, for example, represent highly correlated information about the speaker.
여기서 개시된 알고리즘은, 먼저, 음운 세그먼트들이 식별되고, 화자 아이덴티티가 각 음운 세그먼트에 대해 독립적으로 모델링되는 2 부분을 가진다. 이것의 결과는 다수의 로컬 스코어들 -각각 발성의 상이한 음운에 대한- 로서, 글로 벌 식별 결정 또는 객체 데이터의 클래스를 생성하기 위해 결합되어야만 한다.The algorithm disclosed herein first has two parts in which phonological segments are identified and the speaker identity is modeled independently for each phonological segment. The result of this is a number of local scores, each for a different phoneme of speech, which must be combined to generate a global identification decision or a class of object data.
스코어들의 결합Combination of Scores
RBF 네트워크들은 아래 판별 함수를 근사하기 위해 트레이닝 되며,RBF networks are trained to approximate the following discriminant function,

여기서, here,
![]()
![]()
는 음운 관측이다.Is a phonological observation.
![]()
![]()
이기 때문에, 아래 식들을 얻을 수 있고,Because of this, we can get


이 식들은 단일 음운 관측용 결정 룰을 구현하는데 사용될 수 있다. 몇몇 독립 음운 관측이 가능한 경우, 로컬 스코어들을 하나의 글로벌 스코어로 결합함으로써 보다 로버스트한 결정이 만들어 질 수 있다. 2 개의 기본적으로 상이한 접근방법은, 총체 조합과 확률 조합이다.These equations can be used to implement decision rules for single phonological observations. If several independent phonological observations are possible, more robust decisions can be made by combining local scores into one global score. The two fundamentally different approaches are aggregate and probability combinations.
총체 조합Gross combination
로컬 식별 스코어들을 결합하는 접근방법 중 하나는 단순하게 로컬 스코어들 을 "평균"내는 것으로서,One approach to combining local identification scores is to simply "average" the local scores,

여기서,here,
![]()
![]()
는 알파벳에서 상이한 음운의 개수이고,Is the number of different phonemes in the alphabet,
![]()
![]()
는 음운![]()
![]()
![]()
![]()
![]()
![]()
확률 조합Probability combination
총체 조합외의 다른 방법은 네트워크들이 사후확률을 계산하는 사실을 이용하는 것이다. 몇몇 독립적인 관측들, ![]()
![]()
![]()
![]()
이기 때문에, 아래 식과 같이 교차비를 정의함으로써 표현될 수 있다.Because of this, it can be expressed by defining an intersection ratio as in the following equation.

또한, 다음의 수식이 성립한다.In addition, the following formula holds.


따라서, 스코어링하는 다른 방법은, 다음 식을 이용하는 것이다.Therefore, another method of scoring uses the following formula.
![]()
![]()
실제로, 더 많은 수의 음운 관측들이 더해질수록 이것은 -1 또는 +1 로 수렴하는 것이 이 스코어링 룰의 특징이다.Indeed, as more phonological observations are added, it is characteristic of this scoring rule to converge to -1 or +1.
수식 6 과 수식 11 사이의 주된 차이점은 관측들의 독립성에 관한 가정이다. 주어진 음운 벡터 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
동일한 사칭 화자들이 기본적으로 목표 화자와 동일한 음운 벡터들을 생성할 수 있는 경우, 더 많은 관측 (동일한 이벤트의) 이 확률 추정을 향상시키는 것으로 기대될 수 없는 반면에 노이즈는 "평균" (유도) 되므로, 이 차이는 중요한 것이다.If the same impersonal speakers can basically produce the same phonological vectors as the target speaker, the noise is "averaged" (induced), while more observations (of the same event) cannot be expected to improve the probability estimates. This difference is important.
그러나, 양 수식 1.6 및 1.11 모두의 문제는 전체 스코어는 가장 빈도가 높은 음운에 의해 좌우된다는 것이다. 이것은 상이한 음운들이 출처가 상이한 화자의 정보로 간주될 수 있다는 점에서 부적합하다 (Olsen 1997b; Olsen 1996b).However, the problem with both Equations 1.6 and 1.11 is that the overall score depends on the most frequent phonemes. This is inappropriate in that different phonologies can be regarded as information of speakers of different origin (Olsen 1997b; Olsen 1996b).
그러나, 실제로, 음운들의 특정 클래스에 의해 좌우되는 "병리 (pathological)" 문장들은 자주 발생하지 않기 때문에, 수식 1.6 및 1.11 을 사용하여 좋은 결과를 얻을 수 있다. 어떠한 이성적인 문장도 나타내어지는 음운들의 넓은 선택을 전형적으로 가질 것이지만, 각 음운 관측에 의해 제공되는 증거들을 어떻게 가중하는지의 기회가 여전히 남겨져서는 안된다.In practice, however, since "pathological" sentences that depend on a particular class of phonologies do not occur often, good results can be obtained using Equations 1.6 and 1.11. No rational sentence will typically have a wide selection of phonologies represented, but there should still be no chance of how to weight the evidence provided by each phonological observation.
커미티 (committee) 머신들Commit machines
각 음운 모델은 특정 타입의 정보, 즉 특정 음운의 관측들이 주어진 화자 식별 전문가 (expert) 로 간주될 수 있다. 개별 전문가들은 화자의 상이한 "양상들 (aspects)" 을 모델링하는 것으로 가정되기 때문에, 각 전문가가 글로벌 스코어에 미칠 수 있는 영향을 제한하는 것이 합리적이다. 이에 대한 한 접근방법은 동일 전문가로부터의 스코어들을 음운 레벨 로컬 스코어로 결합하도록 수식 1.6 또는 1.11 을 이용하는 것이다. 로컬 2 진 결정 - 정확할 확률은 경험적으로 알려진- 은 테스트 발성에 나타난 각 음운에 대해 만들어질 수 있다.Each phonological model can be considered a speaker identification expert given a particular type of information, i. Since individual experts are assumed to model different "aspects" of the speaker, it is reasonable to limit the effect each expert can have on a global score. One approach to this is to use Equation 1.6 or 1.11 to combine scores from the same expert into phonological level local scores. A local binary decision-an exact probability known empirically-can be made for each phonology shown in the test vocalization.

이 접근방법을 따라서, 로컬 결정들을 글로벌 결정으로 결합하는 가장 단순한 방법은 "대다수" 투표 (vote) 를 만드는 것에 의하는 것으로,Following this approach, the simplest way to combine local decisions into global decisions is to make a "most likely" vote.


[도 1] 커미티 구성원들의 수에 대한 함수로서 커미티 머신이 정확한 결정을 만들 확률 Figure 1: Probability of the community machine making an accurate decision as a function of the number of community members
여기서, ![]()
![]()
개별 결정들이 독립적이고, 그 결정이 정확할 확률 P 가 모두 동일한 경우, 커미티 머신이 정확한 결정을 할 확률은 다음 식으로 주어지며, If the individual decisions are independent and the probability P that the decisions are correct is the same, then the probability that the community machine makes the correct decision is given by

여기서, N 은 커미티 구성원들의 수이다. 확률 함수 ![]()
![]()
![]()
![]()
개별 분류자들이 상이한 분류 정확성를 가지는 경우에도 그런 것은 아니지만, 그 경우의 모델도 상당히 로버스트하다. 예를 들어, 정확성이 각각 P1, P2 및 P3 인 3 개의 분류자들이 결합된 것으로 가정하자. This is not the case even if the individual classifiers have different classification accuracy, but the model in that case is quite robust. For example, suppose that three classifiers of accuracy P1, P2 and P3 are combined.


인 경우, 커미티 머신은 적어도 개별 분류자들 중에서 가장 정확한 것 만큼은 정확하다 (P1 이라 하자)., The commit machine is at least as accurate as the individual classifiers (let's say P1).
예를 들어, P2 = P3 = 0.9 인 경우, 그것이 홀로 P1, P2 및 P3 의 조합보다 더 정확한 것으로 가정되는 경우, P1 은 0.99 보다 높은 정확성을 가져야만 한다.For example, if P2 = P3 = 0.9, if it is assumed to be more accurate than the combination of P1, P2 and P3 alone, then P1 must have a higher accuracy than 0.99.
전문가 가중 (weighting)Expert weighting
상이한 전문가들로부터의 투표들이 동일하게 중요한 것은 아니고, 상이한 음운 의존 화자 모델들은 상이한 정확성을 가진다. 따라서, 개별 투표들을 상이하게 가중함으로써 기본 투표 방식이 향상될 수 있다. 이에 대한 "정적" 접근방법은 동일오류율 (equal accuracy rate) 의 기대값, AEER = 1 - EER 만큼 각 투표를 단순하게 가중하는 것이다.Votes from different experts are not equally important, and different phonological dependent speaker models have different accuracy. Thus, by weighting individual votes differently, the basic voting scheme can be improved. The "static" approach to this is to simply weight each vote by the expected value of equal accuracy rate, A EER = 1-EER.

이에 대응하는 "동적" 가중 방식은 분류자에 의해 계산된 차동 화자 확률만큼 각 투표를 가중하는 것이다.The corresponding "dynamic" weighting method is to weight each vote by the differential speaker probability calculated by the classifier.
![]()
![]()
확률 추정 ![]()
![]()
전문가 그룹핑 (Groupling)Expert Grouping
음운들은 상이한 그룹들, 예를 들어, 비음, 마찰음, 파열음, 모음 등으로 나누어 질 수 있다. 예를 들어, 직관적으로, 2 개의 비음 음운들에 특화된 2 개의 전문가는 투표 도메인에서 상관관계를 나타낼 것이고, 반면에, 상이한 음운, 예 를 들어, 비음 및 마찰음 음운에 각각 특화된 2 개의 전문가들은 상관관계를 덜 나타낼 것이다. 따라서, 전문가들을 상이한 음운 클래스들을 나타내는 그룹들로 나누는 것이 합리적이다. 따라서, 화자 식별 스코어, DC;L 는 각 음운 그룹 (C) 에 대해 계산될 수 있으며,Phonemes can be divided into different groups, for example, nasal, rubbing, rupturing, vowel, etc. For example, intuitively, two experts who specialize in two nonphonic phonologies will correlate in the voting domain, while two experts who each specialize in different phonologies, eg, nonphonic and rubbing phonology, Will represent less. Thus, it is reasonable to divide the experts into groups representing different phonological classes. Thus, the speaker identification score, D C; L , can be calculated for each phonological group (C),

여기서, #C 는 그룹 C 의 음운들의 개수를 나타낸다. 수식 19 는 새로운 전문가들 세트를 정의한다. 글로벌 식별 결정은 "음운" 전문가들로부터가 아닌, 그룹 전문가들로부터의 투표들을 앞에서와 마찬가지로 결합함으로써 만들어질 수 있다. 원리상, 이 결정 방법은 몇 개의 전문가들 층을 포함하는 것으로 확장될 수 있으며, 여기서 가장 낮은 층의 전문가들은 상이한 개별 음운들을 나타내고, 상위 레벨의 전문가들은 더 넓은 사운드 클래스들 (비음, 모음, 마찰음 등) 을 나타내는 것이다.Here, #C represents the number of phonemes of group C. Equation 19 defines a new set of experts. The global identification decision can be made by combining votes from group experts, not from "phonological" experts as before. In principle, this decision method can be extended to include several layers of experts, where the experts of the lowest layer represent different individual phonologies, and the higher levels of experts represent broader sound classes (noise, vowels, friction sounds). Etc.).
전문가 투표들의 모델링Modeling of Expert Votes
N 개의 전문가 투표들을 결합하는 매력적인 방법은 네트워크 (RBF 또는 MLP) 가 경험적으로 최적 결합 방법을 학습하도록 트레이닝시키는 것이다 (Wolpert 1992). 이 방법은 개별 전문가들의 정확성 및 상이한 전문가 투표들 사이의 상관관계가 모두 직접 고려될 수 있다. 이 접근방법을 따랐을 때, 전문가 투표가 결합되어야 하는 포인트까지 발생한 모든 것은 본질적으로 특징 추출로 간주되며, 여기서, 특징 벡터들은 결정 벡터들이다.An attractive way to combine N expert votes is to train the network (RBF or MLP) to empirically learn the best combining method (Wolpert 1992). This method allows both the accuracy of individual experts and the correlation between different expert votes to be considered directly. Following this approach, everything that occurs up to the point where expert votes should be combined is considered essentially feature extraction, where the feature vectors are decision vectors.

그러나, 이 접근방법과 관련하여 2 가지 문제점이 있다.However, there are two problems with this approach.
첫 번째 문제점은, 로컬 전문가 투표들을 결합하는 "수퍼" 네트워크가, 그들이 트레이닝 되는 데이터들에 대해 로컬 전문가들을 평가함으로써 단순하게 생성되는 결정 벡터들에 대해, 트레이닝 될 수 없다는 것으로서, -전문가들은 오버 트레이닝 되는 경향이 있고, 그들의 - 트레이닝 데이터 투표들은 - 너무 "낙관적" 이다. 따라서, 추가적인 트레이닝 데이터가 제공되거나, 또는, 수퍼 네트워크가 화자에 독립적이어야 한다.The first problem is that a "super" network that combines local expert votes cannot be trained on decision vectors that are simply generated by evaluating local experts for the data they are trained on. Tend to become, and their-training data votes-are too "optimistic." Thus, additional training data must be provided, or the super network must be speaker independent.
두 번째 문제점은, 여기서 로컬 전문가 투표들이 상이한 음운들을 나타내고, 상이한 테스트 발성들의 음성 메이크 (make) 는 매우 다양하게 변할 수 있고, 이것은 특정 테스트 발성들로부터 유발되는 투표들을 최적으로 결합하는 네트워크를 트레이닝시키는 것을 불가능하게 만든다.A second problem is that local expert votes represent different phonologies, and the voice make of different test vocals can vary widely, which trains a network that optimally combines voting resulting from specific test vocals. Makes things impossible
제한된 수의 트레이닝 발성들이 주어지면, 당연히, 상이한 트레이닝 발성들로부터 추출된 관련된 전문가 결정들을 결합함으로써, 훨씬 더 많은 결정 벡터들을 시뮬레이션하는 것이 가능하다. 그러나, 발생 가능한 음운 조합들은 여전히 매우 많다. 예를 들어, 임의의 주어진 발성를 가정하면, 30 개의 가능한 것 중 정확히 15 개의 상이한 음운들이 나타날 수 있다. 따라서, Given a limited number of training utterances, of course, it is possible to simulate even more decision vectors by combining relevant expert decisions extracted from different training utterances. However, there are still many phonological combinations that can occur. For example, assuming any given utterance, exactly 15 different phonologies may appear out of the 30 possible ones. therefore,

개 까지의 상이한 투표 조합이 고려되어야만 할 수 있다. 이 계산은 투표들이 하나 이상의 음운 관측에 기초할 수도 있고 - 따라서 더욱 신뢰할 수 있고 -, 실제 상이한 음운들의 수는 더 많거나 15 보다 작을 수도 있다는 사실을 무시한다.Up to three different voting combinations may have to be considered. This calculation ignores the fact that the votes may be based on one or more phonological observations—and thus more reliable—and in fact the number of different phonologies may be more or less than fifteen.
이 딜레마에 대해 가능한 해결방법은 특정 발성용 수퍼 분류자를 만드는 것으로서, 즉, 어떤 텍스트가 바로 다음에 발생할지 결정할 때까지, 또는, 더욱 편리하게는, 실제 스피치 발성에 대해 음운 세그멘테이션이 계산될 때까지, 트레이닝을 미루는 것이다. 이 경우의 수퍼 분류자는 단순 퍼셉트론일 수 있고, 따라서, 트레이닝은 심각한 계산 문제가 아니다. 도 2 는 이것의 예를 나타낸다.A possible solution to this dilemma is to create a superspeaker for a particular speech, i.e. until it decides which text will occur immediately, or, more conveniently, until a phonetic segmentation is calculated for the actual speech speech. Put off training. The super classifier in this case may be a simple perceptron, so training is not a serious computational problem. 2 shows an example of this.
다른 방법으로는 -반복적 퍼셉트론 트레이닝 알고리즘을 피하기 위해- 피셔 선형 판별 함수가 개별 전문가 가중치들을 학습하는데 이용될 수 있다.Alternatively, the Fischer linear discriminant function can be used to learn individual expert weights-to avoid repeated perceptron training algorithms.
요약하면, 이 예는 로컬 화자 확률들이 어떻게 개별 음운 관측들 (이것은 본질적으로 글로벌 화자 검증 결정들을 생성하기 위해 결합될 수 있는 객체이다) 로부터 추정될 수 있는지를 검토한다. 성공적인 조함 방식들은, 어떤 특정 음운들이 나머지 음운들보다 많은 정보를 가지고 있을 수 있는 점을 고려하는 한편, 다른 한편으로는, 상이한 음운들이 화자에 관해 부각되는 정보를 다소 제공할 수도 있다는 점을 고려해야만 한다.In summary, this example examines how local speaker probabilities can be estimated from individual phonetic observations (which are essentially objects that can be combined to produce global speaker verification decisions). Successful collusion schemes should take into account that certain phonologies may have more information than the rest of the phonologies, while on the other hand, different phonologies may provide some more noticeable information about the speaker. do.
로컬 결정을 어떻게 가중할지 결정할 때 처하게 되는 주 난점은, -화자들에게 주어진 다음 텍스트들이 심히 제약되어 있지 않다면- 테스트 발성에서 발생할 수 있는 상이한 음운 조합들의 전체 수가 극히 많다는 것이다. 따라서, 이들 가중치들은 미리 용이하게 계산될 수 없다.The main difficulty in deciding how to weight local decisions is that the total number of different phonological combinations that can occur in the test utterance—unless the following texts given to the speakers—are very limited. Therefore, these weights cannot be easily calculated in advance.

[도 2] 수퍼 분류자[FIG. 2] Super Classifier
분류자는 개별 음운 모델들로부터의 차동 화자 확률들을 입력으로 취하고 그것들을 글로벌 스코어로 결합한다.The classifier takes as input the differential speaker probabilities from the individual phonological models and combines them into a global score.
![]()
![]()
Claims (160)
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/428,895 US7103772B2 (en) | 2003-05-02 | 2003-05-02 | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers |
| US10/428,895 | 2003-05-02 | ||
| US10/759,789 US7360087B2 (en) | 2003-05-02 | 2004-01-16 | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers |
| US10/759,789 | 2004-01-16 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20060041165A true KR20060041165A (en) | 2006-05-11 |
| KR100825241B1 KR100825241B1 (en) | 2008-04-25 |
Family
ID=35432873
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020057020870A KR100825241B1 (en) | 2003-05-02 | 2004-01-28 | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers |
Country Status (9)
| Country | Link |
|---|---|
| EP (1) | EP1620773A4 (en) |
| JP (1) | JP4430666B2 (en) |
| KR (1) | KR100825241B1 (en) |
| AU (1) | AU2004237046B2 (en) |
| BR (1) | BRPI0409844A (en) |
| CA (1) | CA2525490C (en) |
| NO (1) | NO335789B1 (en) |
| RU (1) | RU2308080C2 (en) |
| WO (1) | WO2004099940A2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015026829A1 (en) * | 2013-08-20 | 2015-02-26 | Janus Technologies, Inc. | Method and apparatus for securing computer mass storage data |
| KR20170142647A (en) * | 2016-06-20 | 2017-12-28 | 시너지시티 주식회사 | Valet parking system and the method utilizing parking location map |
Families Citing this family (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8255223B2 (en) | 2004-12-03 | 2012-08-28 | Microsoft Corporation | User authentication by combining speaker verification and reverse turing test |
| FR2882506B1 (en) | 2005-02-25 | 2007-05-18 | Oreal | MAKE-UP PROCESS USING A VIBRANT APPLICATOR |
| JP4138808B2 (en) | 2006-01-10 | 2008-08-27 | 株式会社エヌ・ティ・ティ・ドコモ | Communication system and communication method |
| US20080208806A1 (en) * | 2007-02-28 | 2008-08-28 | Microsoft Corporation | Techniques for a web services data access layer |
| US20090099827A1 (en) * | 2007-10-16 | 2009-04-16 | Sony Corporation | System and method for effectively performing a network simulation procedure |
| CN100488099C (en) | 2007-11-08 | 2009-05-13 | 西安西电捷通无线网络通信有限公司 | Bidirectional access authentication method |
| CN101222328B (en) | 2007-12-14 | 2010-11-03 | 西安西电捷通无线网络通信股份有限公司 | Entity bidirectional identification method |
| US20100263022A1 (en) * | 2008-10-13 | 2010-10-14 | Devicescape Software, Inc. | Systems and Methods for Enhanced Smartclient Support |
| US9094721B2 (en) | 2008-10-22 | 2015-07-28 | Rakuten, Inc. | Systems and methods for providing a network link between broadcast content and content located on a computer network |
| US8160064B2 (en) | 2008-10-22 | 2012-04-17 | Backchannelmedia Inc. | Systems and methods for providing a network link between broadcast content and content located on a computer network |
| RU2484531C2 (en) * | 2009-01-22 | 2013-06-10 | Государственное научное учреждение центральный научно-исследовательский и опытно-конструкторский институт робототехники и технической кибернетики (ЦНИИ РТК) | Apparatus for processing video information of security alarm system |
| US8631070B2 (en) | 2009-03-27 | 2014-01-14 | T-Mobile Usa, Inc. | Providing event data to a group of contacts |
| US8428561B1 (en) | 2009-03-27 | 2013-04-23 | T-Mobile Usa, Inc. | Event notification and organization utilizing a communication network |
| FR2947404B1 (en) * | 2009-06-30 | 2011-12-16 | Sagem Securite | CRYPTOGRAPHY BY PARAMETRISATION ON AN ELLIPTICAL CURVE |
| CN101808096B (en) * | 2010-03-22 | 2012-11-07 | 北京大用科技有限责任公司 | Method for sharing and controlling large screen among local area networks in different positions |
| RU2457535C2 (en) * | 2010-05-25 | 2012-07-27 | Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования "Санкт-Петербургский государственный политехнический университет" (ФГБОУ ВПО "СПбГПУ") | Method of generating and verifying electronic digital signature based on elliptic or hyperelliptic curve |
| CN101931626B (en) * | 2010-08-25 | 2012-10-10 | 深圳市傲冠软件股份有限公司 | Service terminal realizing safe auditing function in remote control process |
| WO2012035451A1 (en) * | 2010-09-16 | 2012-03-22 | International Business Machines Corporation | Method, secure device, system and computer program product for securely managing files |
| US9152815B2 (en) * | 2010-10-29 | 2015-10-06 | International Business Machines Corporation | Method, secure device, system and computer program product for securely managing user access to a file system |
| EP2754290B1 (en) | 2011-09-09 | 2019-06-19 | Rakuten, Inc. | Systems and methods for consumer control over interactive television exposure |
| US9549024B2 (en) * | 2012-12-07 | 2017-01-17 | Remote Media, Llc | Routing and synchronization system, method, and manager |
| WO2014092441A1 (en) | 2012-12-13 | 2014-06-19 | Samsung Electronics Co., Ltd. | Device control method for registering device information of peripheral device, and device and system thereof |
| KR101881926B1 (en) * | 2012-12-13 | 2018-07-26 | 삼성전자주식회사 | Device Control Method for Registering Device Information of Peripheral Device, Device and System Thereof |
| US10326734B2 (en) | 2013-07-15 | 2019-06-18 | University Of Florida Research Foundation, Incorporated | Adaptive identity rights management system for regulatory compliance and privacy protection |
| RU2589861C2 (en) * | 2014-06-20 | 2016-07-10 | Закрытое акционерное общество "Лаборатория Касперского" | System and method of user data encryption |
| KR101655448B1 (en) * | 2014-12-24 | 2016-09-07 | 주식회사 파수닷컴 | Apparatus and method for authenticating user by using authentication proxy |
| RU2683184C2 (en) * | 2015-11-03 | 2019-03-26 | Общество с ограниченной ответственностью "ДОМКОР" | Software-hardware complex of electronic real estate system and method of data exchange in it |
| US10262164B2 (en) | 2016-01-15 | 2019-04-16 | Blockchain Asics Llc | Cryptographic ASIC including circuitry-encoded transformation function |
| US20170332395A1 (en) * | 2016-05-11 | 2017-11-16 | Sharp Laboratories Of America, Inc. | Systems and methods for physical uplink shared channel (pusch) format signaling and contention access |
| RU2638779C1 (en) * | 2016-08-05 | 2017-12-15 | Общество С Ограниченной Ответственностью "Яндекс" | Method and server for executing authorization of application on electronic device |
| CN106730835A (en) * | 2016-12-16 | 2017-05-31 | 青岛蘑菇网络技术有限公司 | A kind of network game accelerated method and system based on router and vpn server |
| RU2653231C1 (en) * | 2016-12-16 | 2018-05-07 | Общество с ограниченной ответственностью "Иридиум" | Method and system of communication of components for management of objects of automation |
| US10256974B1 (en) | 2018-04-25 | 2019-04-09 | Blockchain Asics Llc | Cryptographic ASIC for key hierarchy enforcement |
| RU2697646C1 (en) * | 2018-10-26 | 2019-08-15 | Самсунг Электроникс Ко., Лтд. | Method of biometric authentication of a user and a computing device implementing said method |
| RU2714856C1 (en) * | 2019-03-22 | 2020-02-19 | Общество с ограниченной ответственностью "Ак Барс Цифровые Технологии" | User identification system for performing electronic transaction for provision of service or purchase of goods |
| WO2021182985A1 (en) * | 2020-03-13 | 2021-09-16 | Сергей Станиславович ЧАЙКОВСКИЙ | Peripheral device with an integrated security system using artificial intelligence |
| CN111951783B (en) * | 2020-08-12 | 2023-08-18 | 北京工业大学 | Speaker recognition method based on phoneme filtering |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06282527A (en) * | 1993-03-29 | 1994-10-07 | Hitachi Software Eng Co Ltd | Network control system |
| US5550984A (en) * | 1994-12-07 | 1996-08-27 | Matsushita Electric Corporation Of America | Security system for preventing unauthorized communications between networks by translating communications received in ip protocol to non-ip protocol to remove address and routing services information |
| US5958010A (en) * | 1997-03-20 | 1999-09-28 | Firstsense Software, Inc. | Systems and methods for monitoring distributed applications including an interface running in an operating system kernel |
| DE19812215A1 (en) * | 1998-03-19 | 1999-09-23 | Siemens Ag | Controlling link related security functions |
| US6405203B1 (en) * | 1999-04-21 | 2002-06-11 | Research Investment Network, Inc. | Method and program product for preventing unauthorized users from using the content of an electronic storage medium |
| ATE297645T1 (en) * | 1999-10-22 | 2005-06-15 | Ericsson Telefon Ab L M | MOBILE PHONE WITH BUILT-IN SECURITY FIRMWARE |
| KR100376618B1 (en) * | 2000-12-05 | 2003-03-17 | 주식회사 싸이버텍홀딩스 | Intelligent security system for network based on agent |
| US7941669B2 (en) * | 2001-01-03 | 2011-05-10 | American Express Travel Related Services Company, Inc. | Method and apparatus for enabling a user to select an authentication method |
| US6732278B2 (en) * | 2001-02-12 | 2004-05-04 | Baird, Iii Leemon C. | Apparatus and method for authenticating access to a network resource |
| KR20020075319A (en) * | 2002-07-19 | 2002-10-04 | 주식회사 싸이버텍홀딩스 | Intelligent Security Engine and Intelligent and Integrated Security System Employing the Same |
-
2004
- 2004-01-28 JP JP2006508631A patent/JP4430666B2/en not_active Expired - Lifetime
- 2004-01-28 BR BRPI0409844-7A patent/BRPI0409844A/en active Search and Examination
- 2004-01-28 RU RU2005137570/09A patent/RU2308080C2/en not_active IP Right Cessation
- 2004-01-28 EP EP04706073A patent/EP1620773A4/en not_active Withdrawn
- 2004-01-28 KR KR1020057020870A patent/KR100825241B1/en not_active IP Right Cessation
- 2004-01-28 WO PCT/US2004/002438 patent/WO2004099940A2/en active Application Filing
- 2004-01-28 CA CA2525490A patent/CA2525490C/en not_active Expired - Fee Related
- 2004-01-28 AU AU2004237046A patent/AU2004237046B2/en not_active Ceased
-
2005
- 2005-10-31 NO NO20055067A patent/NO335789B1/en not_active IP Right Cessation
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015026829A1 (en) * | 2013-08-20 | 2015-02-26 | Janus Technologies, Inc. | Method and apparatus for securing computer mass storage data |
| US9424443B2 (en) | 2013-08-20 | 2016-08-23 | Janus Technologies, Inc. | Method and apparatus for securing computer mass storage data |
| US10395044B2 (en) | 2013-08-20 | 2019-08-27 | Janus Technologies, Inc. | Method and apparatus for securing computer mass storage data |
| KR20170142647A (en) * | 2016-06-20 | 2017-12-28 | 시너지시티 주식회사 | Valet parking system and the method utilizing parking location map |
Also Published As
| Publication number | Publication date |
|---|---|
| NO335789B1 (en) | 2015-02-16 |
| RU2308080C2 (en) | 2007-10-10 |
| NO20055067L (en) | 2006-02-02 |
| AU2004237046A1 (en) | 2004-11-18 |
| JP4430666B2 (en) | 2010-03-10 |
| CA2525490A1 (en) | 2004-11-18 |
| BRPI0409844A (en) | 2006-05-16 |
| RU2005137570A (en) | 2006-06-10 |
| NO20055067D0 (en) | 2005-10-31 |
| WO2004099940A2 (en) | 2004-11-18 |
| WO2004099940A8 (en) | 2006-08-03 |
| JP2007524892A (en) | 2007-08-30 |
| EP1620773A2 (en) | 2006-02-01 |
| KR100825241B1 (en) | 2008-04-25 |
| WO2004099940A3 (en) | 2006-05-18 |
| AU2004237046B2 (en) | 2008-02-28 |
| EP1620773A4 (en) | 2011-11-23 |
| CA2525490C (en) | 2012-01-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100825241B1 (en) | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers | |
| Syed et al. | Zero trust architecture (zta): A comprehensive survey | |
| US20040221163A1 (en) | Pervasive, user-centric network security enabled by dynamic datagram switch and an on-demand authentication and encryption scheme through mobile intelligent data carriers | |
| Schiller et al. | Landscape of IoT security | |
| Kumar et al. | TP2SF: A Trustworthy Privacy-Preserving Secured Framework for sustainable smart cities by leveraging blockchain and machine learning | |
| Waheed et al. | Security and privacy in IoT using machine learning and blockchain: Threats and countermeasures | |
| Attkan et al. | Cyber-physical security for IoT networks: a comprehensive review on traditional, blockchain and artificial intelligence based key-security | |
| CN112970236B (en) | Collaborative risk awareness authentication | |
| Puthal et al. | SEEN: A selective encryption method to ensure confidentiality for big sensing data streams | |
| JP2023171851A (en) | Extending secure key storage for transaction confirmation and cryptocurrency | |
| Liu et al. | MACA: A privacy-preserving multi-factor cloud authentication system utilizing big data | |
| US20090083826A1 (en) | Unsolicited communication management via mobile device | |
| Khalil et al. | A comparative analysis on blockchain versus centralized authentication architectures for IoT-enabled smart devices in smart cities: a comprehensive review, recent advances, and future research directions | |
| Acar et al. | A privacy‐preserving multifactor authentication system | |
| US11418338B2 (en) | Cryptoasset custodial system using power down of hardware to protect cryptographic keys | |
| Cherbal et al. | Security in internet of things: a review on approaches based on blockchain, machine learning, cryptography, and quantum computing | |
| KR102665644B1 (en) | Method for authentication and device thereof | |
| Ahmad et al. | An efficient and secure key management with the extended convolutional neural network for intrusion detection in cloud storage | |
| Khan et al. | A brief review on cloud computing authentication frameworks | |
| Moradi et al. | Security‐Level Improvement of IoT‐Based Systems Using Biometric Features | |
| Chatterjee et al. | A framework for development of secure software | |
| Verma et al. | A novel model to enhance the data security in cloud environment | |
| US20220343095A1 (en) | Fingerprint-Based Device Authentication | |
| Cooper | Security for the Internet of Things | |
| Reshmi et al. | A survey of authentication methods in mobile cloud computing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20130222 Year of fee payment: 6 |
|
| FPAY | Annual fee payment |
Payment date: 20131112 Year of fee payment: 7 |
|
| FPAY | Annual fee payment |
Payment date: 20150112 Year of fee payment: 8 |
|
| FPAY | Annual fee payment |
Payment date: 20151221 Year of fee payment: 9 |
|
| FPAY | Annual fee payment |
Payment date: 20161222 Year of fee payment: 10 |
|
| LAPS | Lapse due to unpaid annual fee |