KR101909573B1 - 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 - Google Patents
2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 Download PDFInfo
- Publication number
- KR101909573B1 KR101909573B1 KR1020110138434A KR20110138434A KR101909573B1 KR 101909573 B1 KR101909573 B1 KR 101909573B1 KR 1020110138434 A KR1020110138434 A KR 1020110138434A KR 20110138434 A KR20110138434 A KR 20110138434A KR 101909573 B1 KR101909573 B1 KR 101909573B1
- Authority
- KR
- South Korea
- Prior art keywords
- masking
- spatial domain
- encoding
- spatial
- decoding
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 41
- 238000007906 compression Methods 0.000 claims abstract description 51
- 230000006835 compression Effects 0.000 claims abstract description 51
- 230000000873 masking effect Effects 0.000 claims description 53
- 230000001149 cognitive effect Effects 0.000 claims description 21
- 238000009826 distribution Methods 0.000 claims description 13
- 238000006243 chemical reaction Methods 0.000 claims description 8
- 239000011159 matrix material Substances 0.000 claims description 8
- 230000009466 transformation Effects 0.000 claims description 8
- 230000007480 spreading Effects 0.000 claims description 6
- 238000003892 spreading Methods 0.000 claims description 6
- 238000000354 decomposition reaction Methods 0.000 claims description 4
- 230000001131 transforming effect Effects 0.000 claims description 4
- 230000001419 dependent effect Effects 0.000 claims description 3
- 230000005540 biological transmission Effects 0.000 abstract description 8
- 230000005236 sound signal Effects 0.000 abstract description 6
- 230000000875 corresponding effect Effects 0.000 description 14
- 230000006870 function Effects 0.000 description 14
- 238000012545 processing Methods 0.000 description 10
- 238000004458 analytical method Methods 0.000 description 9
- 238000013459 approach Methods 0.000 description 7
- 230000008569 process Effects 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- 230000000694 effects Effects 0.000 description 4
- 238000009877 rendering Methods 0.000 description 4
- 238000011156 evaluation Methods 0.000 description 3
- 230000004807 localization Effects 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 230000002596 correlated effect Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 238000004091 panning Methods 0.000 description 2
- 238000013139 quantization Methods 0.000 description 2
- 241001499740 Plantago alpina Species 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 235000009508 confectionery Nutrition 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 238000007907 direct compression Methods 0.000 description 1
- 210000005069 ears Anatomy 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 238000000513 principal component analysis Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000009827 uniform distribution Methods 0.000 description 1
Images













Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04H—BROADCAST COMMUNICATION
- H04H20/00—Arrangements for broadcast or for distribution combined with broadcast
- H04H20/86—Arrangements characterised by the broadcast information itself
- H04H20/88—Stereophonic broadcast systems
- H04H20/89—Stereophonic broadcast systems using three or more audio channels, e.g. triphonic or quadraphonic
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Stereophonic System (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
도 1은 B-형식 입력에서의 지향 오디오 코딩(directional audio coding)을 나타낸 도면.
도 2는 B-형식 신호의 직접 인코딩(direct encoding)을 나타낸 도면.
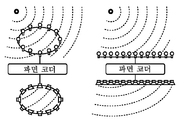
도 3은 공간 스퀴징(spatial squeezing)의 원리를 나타낸 도면.
도 4는 공간 스퀴징 인코딩 처리를 나타낸 도면.
도 5는 파면(Wave Field) 코딩의 원리를 나타낸 도면.
도 6은 파면 인코딩 처리를 나타낸 도면.
도 7은 공간 정보(spatial cue)의 다운믹싱 및 전송을 사용한 공간 오디오 코딩을 나타낸 도면.
도 8은 본 발명의 인코더 및 디코더의 예시적인 실시예를 나타낸 도면.
도 9는 상이한 신호의 BMLD(binaural masking level difference)를 신호의 두 귀 사이의(inter-aural) 위상차 또는 시간차의 함수로서 나타낸 도면.
도 10은 BMLD 모델링을 포함하는 결합 심리 음향적 모델을 나타낸 도면.
도 11은 예시적인 최대의 예상된 재생 시나리오 - 7x5 좌석(일례로서 임의적으로 선택됨)을 갖는 극장 - 를 나타낸 도면.
도 12는 도 11의 시나리오에 대한 최대 상대 지연 및 감쇠의 도출을 나타낸 도면.
도 13은 음장 HOA 성분과 2개의 음 객체 A 및 B의 압축을 나타낸 도면.
도 14는 음장 HOA 성분과 2개의 음 객체 A 및 B에 대한 결합 심리 음향적 모델을 나타낸 도면.

Claims (24)
- HOA 계수들로 표시되는, 2차원 또는 3차원 음장(sound field)의 고차 앰비소닉스 표현(Ambisonics representation)의 수신된 연속 프레임들에 대해 인코딩을 수행하는 방법으로서,
3차원 입력에 대해 프레임의 O = (N+1)2개의 입력 HOA 계수(IHOA)들, 또는 2차원 입력에 대해 프레임의 O = 2N+1개의 입력 HOA 계수(IHOA)들을, 각각 구면 또는 원 상의 기준점들의 정규 분포를 나타내는 O개의 공간 영역 신호들로 변환하는 단계 - 여기서, N은 상기 입력 HOA 계수들의 차수이고 3 이상이며, 상기 O개의 공간 영역 신호들 각각은 공간에서 연관된 방향들로부터 오는 일련의 평면파(set of plane waves)를 나타내고, 대응하는 변환 행렬은 모드 행렬 Ψ의 역이고, 모든 계수들이 상기 모드 행렬 Ψ에서 결합되고, 여기서 i번째 열은 i번째 기준점의 방향에 따른 모드 벡터를 포함함 -,
인지 압축 인코딩(perceptual compression encoding) 단계들 또는 스테이지들을 사용하여, 그로써 코딩 오류가 마스킹된 채로 있도록 선택된 인코딩 파라미터들을 사용하여, 상기 O개의 공간 영역 신호들 각각을 인코딩하는 단계, 및
프레임의 얻어진 비트 스트림들을 결합(joint) 비트 스트림(BS)으로 멀티플렉싱하는 단계
를 포함하는, 인코딩을 수행하는 방법. - 제1항에 있어서, 상기 인지 압축 인코딩에서 사용되는 마스킹은 심리 음향적 마스킹이고, 시간-주파수 마스킹과 공간 마스킹(spatial masking)의 조합인, 인코딩을 수행하는 방법.
- 제1항 또는 제2항에 있어서, O개의 공간 영역 신호들로의 상기 변환은 평면파 분해(plane wave decomposition)인, 인코딩을 수행하는 방법.
- 제1항에 있어서, 상기 O개의 공간 영역 신호들 각각을 상기 인코딩하는 단계는 MPEG-1 오디오 계층 III 또는 AAC 또는 Dolby AC-3 표준에 대응하는, 인코딩을 수행하는 방법.
- 제1항에 있어서, 공간적으로 상이한 방향들로부터의 코딩 오류들의 언마스킹(unmasking)을 방지하기 위해서, 상기 인코딩에서 적용되는 마스킹 임계값들을 계산하는 데 비최적의 청취 위치(non-optimum listening position)들에 대한 음 전파로 인한 방향-의존적 감쇠 및 지연이 고려되는, 인코딩을 수행하는 방법.
- 제1항에 있어서, 상기 인지 압축 인코딩 단계들 또는 스테이지들에서 사용되는 개별 마스킹 임계값들은, 상기 임계값들 각각을, BMLD(Binaural Masking Level Difference)를 고려한 공간 확산 함수와 결합함으로써 변경되고, 상기 개별 마스킹 임계값들의 최대값은 모든 음 방향(sound direction)들에 대해 결합 마스킹 임계값을 얻도록 형성되는, 인코딩을 수행하는 방법.
- 제1항에 있어서, 개별 음 객체들은 개별적으로 인코딩되는, 인코딩을 수행하는 방법.
- HOA 계수들로 표시되는, 2차원 또는 3차원 음장의 고차 앰비소닉스 표현의 수신된 연속 프레임들에 대해 인코딩을 수행하는 장치로서,
3차원 입력에 대해 프레임의 O = (N+1)2개의 입력 HOA 계수(IHOA)들, 또는 2차원 입력에 대해 프레임의 O = 2N+1개의 입력 HOA 계수(IHOA)들을, 각각 구면 또는 원 상의 기준점들의 정규 분포를 나타내는 O개의 공간 영역 신호들로 변환하도록 구성된 변환 수단 - 여기서, N은 상기 입력 HOA 계수들의 차수이고 3 이상이며, 상기 O개의 공간 영역 신호들 각각은 공간에서 연관된 방향들로부터 오는 일련의 평면파를 나타내고, 대응하는 변환 행렬은 모드 행렬 Ψ의 역이고, 모든 계수들이 상기 모드 행렬 Ψ에서 결합되고, 여기서 i번째 열은 i번째 기준점의 방향에 따른 모드 벡터를 포함함 -,
인지 압축 인코딩 단계들 또는 스테이지들을 사용하여, 그로써 코딩 오류가 마스킹된 채로 있도록 선택된 인코딩 파라미터들을 사용하여, 상기 O개의 공간 영역 신호들 각각을 인코딩하도록 구성된 수단, 및
프레임의 얻어진 비트 스트림들을 결합 비트 스트림(BS)으로 멀티플렉싱하도록 구성된 수단
을 포함하는, 인코딩을 수행하는 장치. - 제8항에 있어서, 상기 인지 압축 인코딩에서 사용되는 마스킹은 심리 음향적 마스킹이고, 시간-주파수 마스킹과 공간 마스킹의 조합인, 인코딩을 수행하는 장치.
- 제8항 또는 제9항에 있어서, 상기 O개의 공간 영역 신호들로 변환하는 것은 평면파 분해인, 인코딩을 수행하는 장치.
- 제8항에 있어서, 상기 O개의 공간 영역 신호들 각각을 상기 인코딩하는 것은 MPEG-1 오디오 계층 III 또는 AAC 또는 Dolby AC-3 표준에 대응하는, 인코딩을 수행하는 장치.
- 제8항에 있어서, 공간적으로 상이한 방향들로부터의 코딩 오류들의 언마스킹을 방지하기 위해서, 상기 인코딩에서 적용되는 마스킹 임계값들을 계산하는 데 비최적의 청취 위치들에 대한 음 전파로 인한 방향-의존적 감쇠 및 지연이 고려되는, 인코딩을 수행하는 장치.
- 제8항에 있어서, 상기 인지 압축 인코딩 단계들 또는 스테이지들에서 사용되는 개별 마스킹 임계값들은, 상기 임계값들 각각을, BMLD(Binaural Masking Level Difference)를 고려한 공간 확산 함수와 결합함으로써 변경되고, 상기 개별 마스킹 임계값들의 최대값은 모든 음 방향들에 대해 결합 마스킹 임계값을 얻도록 형성되는, 인코딩을 수행하는 장치.
- 제8항에 있어서, 개별 음 객체들은 개별적으로 인코딩되는, 인코딩을 수행하는 장치.
- 제1항에 따라 인코딩된, 2차원 또는 3차원 음장의 인지 압축 인코딩된 고차 앰비소닉스 표현의 수신된 연속 프레임들을 디코딩하는 방법으로서,
3차원 입력에 대해 수신된 결합 비트 스트림(BS)을 O = (N+1)2개의 인지 압축 인코딩된 공간 영역 신호들로, 또는 2차원 입력에 대해 수신된 결합 비트 스트림(BS)을 O = 2N+1개의 인지 압축 인코딩된 공간 영역 신호들로 디멀티플렉싱하는 단계,
상기 O개의 인코딩된 공간 영역 신호들 각각을, 선택된 인코딩 유형에 대응하는 인지 압축 디코딩 단계들 또는 스테이지들을 사용하여 그리고 인코딩 파라미터들에 상응하는 압축 디코딩 파라미터들을 사용하여, 대응하는 디코딩된 공간 영역 신호로 디코딩하는 단계 - O개의 디코딩된 공간 영역 신호들은 각각 구면 또는 원 상의 기준점들의 정규 분포를 나타냄 -, 및
상기 O개의 디코딩된 공간 영역 신호들을 프레임의 O개의 출력 HOA 계수(OHOA)들로 변환하는 단계 - 여기서, N은 상기 출력 HOA 계수들의 차수임 -
를 포함하는 디코딩 방법. - 제15항에 있어서, 상기 O개의 공간 영역 신호들 각각을 상기 디코딩하는 단계는 MPEG-1 오디오 계층 III 또는 AAC 또는 Dolby AC-3 표준에 대응하는 디코딩 방법.
- 제15항에 있어서, 공간적으로 상이한 방향들로부터의 코딩 오류들의 언마스킹을 방지하기 위해서, 상기 디코딩에서 적용되는 마스킹 임계값들을 계산하는 데 비최적의 청취 위치들에 대한 음 전파로 인한 방향-의존적 감쇠 및 지연이 고려되는 디코딩 방법.
- 제15항에 있어서, 상기 인지 압축 디코딩 단계들 또는 스테이지들에서 사용되는 개별 마스킹 임계값들은, 상기 임계값들 각각을, BMLD(Binaural Masking Level Difference)를 고려한 공간 확산 함수와 결합함으로써 변경되고, 상기 개별 마스킹 임계값들의 최대값은 모든 음 방향들에 대해 결합 마스킹 임계값을 얻도록 형성되는 디코딩 방법.
- 제15항에 있어서, 개별 음 객체들은 개별적으로 디코딩되는 디코딩 방법.
- 제1항에 따라 인코딩된, 2차원 또는 3차원 음장의 인지 압축 인코딩된 고차 앰비소닉스 표현의 수신된 연속 프레임들을 디코딩하는 장치로서,
3차원 입력에 대해 수신된 결합 비트 스트림(BS)을 O = (N+1)2개의 인지 압축 인코딩된 공간 영역 신호들로, 또는 2차원 입력에 대해 수신된 결합 비트 스트림(BS)을 O = 2N+1개의 인지 압축 인코딩된 공간 영역 신호들로 디멀티플렉싱하도록 구성된 수단,
상기 O개의 인코딩된 공간 영역 신호들 각각을, 선택된 인코딩 유형에 대응하는 인지 압축 디코딩 단계들 또는 스테이지들을 사용하여 그리고 인코딩 파라미터들에 상응하는 디코딩 파라미터들을 사용하여, 대응하는 디코딩된 공간 영역 신호로 디코딩하도록 구성된 수단 - O개의 디코딩된 공간 영역 신호들은 각각 구면 또는 원 상의 기준점들의 정규 분포를 나타냄 -, 및
상기 O개의 디코딩된 공간 영역 신호들을 프레임의 O개의 출력 HOA 계수(OHOA)들로 변환하도록 구성된 변환 수단 - 여기서, N은 상기 출력 HOA 계수들의 차수임 -
을 포함하는 디코딩 장치. - 제20항에 있어서, 상기 O개의 공간 영역 신호들 각각을 상기 디코딩하는 것은 MPEG-1 오디오 계층 III 또는 AAC 또는 Dolby AC-3 표준에 대응하는 디코딩 장치.
- 제20항에 있어서, 공간적으로 상이한 방향들로부터의 코딩 오류들의 언마스킹을 방지하기 위해서, 상기 디코딩에서 적용되는 마스킹 임계값들을 계산하는 데 비최적의 청취 위치들에 대한 음 전파로 인한 방향-의존적 감쇠 및 지연이 고려되는 디코딩 장치.
- 제20항에 있어서, 상기 인지 압축 디코딩 단계들 또는 스테이지들을 사용할 때의 개별 마스킹 임계값들은, 상기 임계값들 각각을, BMLD(Binaural Masking Level Difference)를 고려하는 공간 확산 함수와 결합함으로써 변경되고, 상기 개별 마스킹 임계값들의 최대값은 모든 음 방향들에 대해 결합 마스킹 임계값을 얻도록 형성되는 디코딩 장치.
- 제20항에 있어서, 개별 음 객체들은 개별적으로 디코딩되는 디코딩 장치.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP10306472.1 | 2010-12-21 | ||
| EP10306472A EP2469741A1 (en) | 2010-12-21 | 2010-12-21 | Method and apparatus for encoding and decoding successive frames of an ambisonics representation of a 2- or 3-dimensional sound field |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180121677A Division KR102010914B1 (ko) | 2010-12-21 | 2018-10-12 | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20120070521A KR20120070521A (ko) | 2012-06-29 |
| KR101909573B1 true KR101909573B1 (ko) | 2018-10-19 |
Family
ID=43727681
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020110138434A KR101909573B1 (ko) | 2010-12-21 | 2011-12-20 | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 |
| KR1020180121677A KR102010914B1 (ko) | 2010-12-21 | 2018-10-12 | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 |
| KR1020190096615A KR102131748B1 (ko) | 2010-12-21 | 2019-08-08 | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180121677A KR102010914B1 (ko) | 2010-12-21 | 2018-10-12 | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 |
| KR1020190096615A KR102131748B1 (ko) | 2010-12-21 | 2019-08-08 | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9397771B2 (ko) |
| EP (5) | EP2469741A1 (ko) |
| JP (6) | JP6022157B2 (ko) |
| KR (3) | KR101909573B1 (ko) |
| CN (1) | CN102547549B (ko) |
Families Citing this family (109)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2469741A1 (en) * | 2010-12-21 | 2012-06-27 | Thomson Licensing | Method and apparatus for encoding and decoding successive frames of an ambisonics representation of a 2- or 3-dimensional sound field |
| EP2600637A1 (en) * | 2011-12-02 | 2013-06-05 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for microphone positioning based on a spatial power density |
| KR101871234B1 (ko) * | 2012-01-02 | 2018-08-02 | 삼성전자주식회사 | 사운드 파노라마 생성 장치 및 방법 |
| EP2665208A1 (en) | 2012-05-14 | 2013-11-20 | Thomson Licensing | Method and apparatus for compressing and decompressing a Higher Order Ambisonics signal representation |
| US9190065B2 (en) * | 2012-07-15 | 2015-11-17 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for three-dimensional audio coding using basis function coefficients |
| US9288603B2 (en) | 2012-07-15 | 2016-03-15 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for backward-compatible audio coding |
| US9473870B2 (en) * | 2012-07-16 | 2016-10-18 | Qualcomm Incorporated | Loudspeaker position compensation with 3D-audio hierarchical coding |
| EP2688066A1 (en) * | 2012-07-16 | 2014-01-22 | Thomson Licensing | Method and apparatus for encoding multi-channel HOA audio signals for noise reduction, and method and apparatus for decoding multi-channel HOA audio signals for noise reduction |
| KR102201713B1 (ko) | 2012-07-19 | 2021-01-12 | 돌비 인터네셔널 에이비 | 다채널 오디오 신호들의 렌더링을 향상시키기 위한 방법 및 디바이스 |
| US9516446B2 (en) | 2012-07-20 | 2016-12-06 | Qualcomm Incorporated | Scalable downmix design for object-based surround codec with cluster analysis by synthesis |
| US9761229B2 (en) * | 2012-07-20 | 2017-09-12 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for audio object clustering |
| US9460729B2 (en) * | 2012-09-21 | 2016-10-04 | Dolby Laboratories Licensing Corporation | Layered approach to spatial audio coding |
| WO2014052429A1 (en) * | 2012-09-27 | 2014-04-03 | Dolby Laboratories Licensing Corporation | Spatial multiplexing in a soundfield teleconferencing system |
| EP2733963A1 (en) | 2012-11-14 | 2014-05-21 | Thomson Licensing | Method and apparatus for facilitating listening to a sound signal for matrixed sound signals |
| EP2738962A1 (en) * | 2012-11-29 | 2014-06-04 | Thomson Licensing | Method and apparatus for determining dominant sound source directions in a higher order ambisonics representation of a sound field |
| EP2743922A1 (en) | 2012-12-12 | 2014-06-18 | Thomson Licensing | Method and apparatus for compressing and decompressing a higher order ambisonics representation for a sound field |
| KR102143545B1 (ko) * | 2013-01-16 | 2020-08-12 | 돌비 인터네셔널 에이비 | Hoa 라우드니스 레벨을 측정하기 위한 방법 및 hoa 라우드니스 레벨을 측정하기 위한 장치 |
| US9883310B2 (en) * | 2013-02-08 | 2018-01-30 | Qualcomm Incorporated | Obtaining symmetry information for higher order ambisonic audio renderers |
| EP2765791A1 (en) | 2013-02-08 | 2014-08-13 | Thomson Licensing | Method and apparatus for determining directions of uncorrelated sound sources in a higher order ambisonics representation of a sound field |
| US10178489B2 (en) * | 2013-02-08 | 2019-01-08 | Qualcomm Incorporated | Signaling audio rendering information in a bitstream |
| US9609452B2 (en) | 2013-02-08 | 2017-03-28 | Qualcomm Incorporated | Obtaining sparseness information for higher order ambisonic audio renderers |
| US10475440B2 (en) * | 2013-02-14 | 2019-11-12 | Sony Corporation | Voice segment detection for extraction of sound source |
| US9685163B2 (en) | 2013-03-01 | 2017-06-20 | Qualcomm Incorporated | Transforming spherical harmonic coefficients |
| EP2782094A1 (en) * | 2013-03-22 | 2014-09-24 | Thomson Licensing | Method and apparatus for enhancing directivity of a 1st order Ambisonics signal |
| US9667959B2 (en) | 2013-03-29 | 2017-05-30 | Qualcomm Incorporated | RTP payload format designs |
| EP2800401A1 (en) * | 2013-04-29 | 2014-11-05 | Thomson Licensing | Method and Apparatus for compressing and decompressing a Higher Order Ambisonics representation |
| US9412385B2 (en) | 2013-05-28 | 2016-08-09 | Qualcomm Incorporated | Performing spatial masking with respect to spherical harmonic coefficients |
| US9466305B2 (en) | 2013-05-29 | 2016-10-11 | Qualcomm Incorporated | Performing positional analysis to code spherical harmonic coefficients |
| US9384741B2 (en) * | 2013-05-29 | 2016-07-05 | Qualcomm Incorporated | Binauralization of rotated higher order ambisonics |
| US10499176B2 (en) | 2013-05-29 | 2019-12-03 | Qualcomm Incorporated | Identifying codebooks to use when coding spatial components of a sound field |
| EP3923279B1 (en) * | 2013-06-05 | 2023-12-27 | Dolby International AB | Apparatus for decoding audio signals and method for decoding audio signals |
| CN104244164A (zh) * | 2013-06-18 | 2014-12-24 | 杜比实验室特许公司 | 生成环绕立体声声场 |
| US9830918B2 (en) | 2013-07-05 | 2017-11-28 | Dolby International Ab | Enhanced soundfield coding using parametric component generation |
| EP2824661A1 (en) | 2013-07-11 | 2015-01-14 | Thomson Licensing | Method and Apparatus for generating from a coefficient domain representation of HOA signals a mixed spatial/coefficient domain representation of said HOA signals |
| US9466302B2 (en) * | 2013-09-10 | 2016-10-11 | Qualcomm Incorporated | Coding of spherical harmonic coefficients |
| DE102013218176A1 (de) * | 2013-09-11 | 2015-03-12 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und verfahren zur dekorrelation von lautsprechersignalen |
| US8751832B2 (en) * | 2013-09-27 | 2014-06-10 | James A Cashin | Secure system and method for audio processing |
| EP2866475A1 (en) * | 2013-10-23 | 2015-04-29 | Thomson Licensing | Method for and apparatus for decoding an audio soundfield representation for audio playback using 2D setups |
| EP2879408A1 (en) * | 2013-11-28 | 2015-06-03 | Thomson Licensing | Method and apparatus for higher order ambisonics encoding and decoding using singular value decomposition |
| KR101862356B1 (ko) * | 2014-01-03 | 2018-06-29 | 삼성전자주식회사 | 개선된 앰비소닉 디코딩을 수행하는 방법 및 장치 |
| CN118016077A (zh) * | 2014-01-08 | 2024-05-10 | 杜比国际公司 | 包括编码hoa表示的位流的解码方法和装置、以及介质 |
| US9922656B2 (en) * | 2014-01-30 | 2018-03-20 | Qualcomm Incorporated | Transitioning of ambient higher-order ambisonic coefficients |
| US9489955B2 (en) | 2014-01-30 | 2016-11-08 | Qualcomm Incorporated | Indicating frame parameter reusability for coding vectors |
| KR102429841B1 (ko) * | 2014-03-21 | 2022-08-05 | 돌비 인터네셔널 에이비 | 고차 앰비소닉스(hoa) 신호를 압축하는 방법, 압축된 hoa 신호를 압축 해제하는 방법, hoa 신호를 압축하기 위한 장치, 및 압축된 hoa 신호를 압축 해제하기 위한 장치 |
| CN109410963B (zh) * | 2014-03-21 | 2023-10-20 | 杜比国际公司 | 用于对压缩的hoa信号进行解码的方法、装置和存储介质 |
| EP2922057A1 (en) * | 2014-03-21 | 2015-09-23 | Thomson Licensing | Method for compressing a Higher Order Ambisonics (HOA) signal, method for decompressing a compressed HOA signal, apparatus for compressing a HOA signal, and apparatus for decompressing a compressed HOA signal |
| JP6863359B2 (ja) * | 2014-03-24 | 2021-04-21 | ソニーグループ株式会社 | 復号装置および方法、並びにプログラム |
| TWI718979B (zh) | 2014-03-24 | 2021-02-11 | 瑞典商杜比國際公司 | 應用動態範圍壓縮至高階保真立體音響信號之方法和裝置 |
| WO2015145782A1 (en) * | 2014-03-26 | 2015-10-01 | Panasonic Corporation | Apparatus and method for surround audio signal processing |
| US9959876B2 (en) * | 2014-05-16 | 2018-05-01 | Qualcomm Incorporated | Closed loop quantization of higher order ambisonic coefficients |
| US9620137B2 (en) * | 2014-05-16 | 2017-04-11 | Qualcomm Incorporated | Determining between scalar and vector quantization in higher order ambisonic coefficients |
| US10770087B2 (en) | 2014-05-16 | 2020-09-08 | Qualcomm Incorporated | Selecting codebooks for coding vectors decomposed from higher-order ambisonic audio signals |
| US9852737B2 (en) * | 2014-05-16 | 2017-12-26 | Qualcomm Incorporated | Coding vectors decomposed from higher-order ambisonics audio signals |
| US9847087B2 (en) * | 2014-05-16 | 2017-12-19 | Qualcomm Incorporated | Higher order ambisonics signal compression |
| CN106663434B (zh) | 2014-06-27 | 2021-09-28 | 杜比国际公司 | 针对hoa数据帧表示的压缩确定表示非差分增益值所需的最小整数比特数的方法 |
| CN112216292B (zh) * | 2014-06-27 | 2025-01-17 | 杜比国际公司 | 声音或声场的压缩hoa声音表示的解码方法和装置 |
| EP2960903A1 (en) | 2014-06-27 | 2015-12-30 | Thomson Licensing | Method and apparatus for determining for the compression of an HOA data frame representation a lowest integer number of bits required for representing non-differential gain values |
| KR20240050436A (ko) * | 2014-06-27 | 2024-04-18 | 돌비 인터네셔널 에이비 | Hoa 데이터 프레임 표현의 압축을 위해 비차분 이득 값들을 표현하는 데 필요하게 되는 비트들의 최저 정수 개수를 결정하는 장치 |
| US9838819B2 (en) * | 2014-07-02 | 2017-12-05 | Qualcomm Incorporated | Reducing correlation between higher order ambisonic (HOA) background channels |
| KR102363275B1 (ko) * | 2014-07-02 | 2022-02-16 | 돌비 인터네셔널 에이비 | Hoa 신호 표현의 부대역들 내의 우세 방향 신호들의 방향들의 인코딩/디코딩을 위한 방법 및 장치 |
| EP2963949A1 (en) * | 2014-07-02 | 2016-01-06 | Thomson Licensing | Method and apparatus for decoding a compressed HOA representation, and method and apparatus for encoding a compressed HOA representation |
| JP6585095B2 (ja) * | 2014-07-02 | 2019-10-02 | ドルビー・インターナショナル・アーベー | 圧縮hoa表現をデコードする方法および装置ならびに圧縮hoa表現をエンコードする方法および装置 |
| WO2016001355A1 (en) * | 2014-07-02 | 2016-01-07 | Thomson Licensing | Method and apparatus for encoding/decoding of directions of dominant directional signals within subbands of a hoa signal representation |
| EP2963948A1 (en) * | 2014-07-02 | 2016-01-06 | Thomson Licensing | Method and apparatus for encoding/decoding of directions of dominant directional signals within subbands of a HOA signal representation |
| US9847088B2 (en) * | 2014-08-29 | 2017-12-19 | Qualcomm Incorporated | Intermediate compression for higher order ambisonic audio data |
| US9747910B2 (en) | 2014-09-26 | 2017-08-29 | Qualcomm Incorporated | Switching between predictive and non-predictive quantization techniques in a higher order ambisonics (HOA) framework |
| US9875745B2 (en) * | 2014-10-07 | 2018-01-23 | Qualcomm Incorporated | Normalization of ambient higher order ambisonic audio data |
| US10140996B2 (en) | 2014-10-10 | 2018-11-27 | Qualcomm Incorporated | Signaling layers for scalable coding of higher order ambisonic audio data |
| US9984693B2 (en) * | 2014-10-10 | 2018-05-29 | Qualcomm Incorporated | Signaling channels for scalable coding of higher order ambisonic audio data |
| US9794721B2 (en) | 2015-01-30 | 2017-10-17 | Dts, Inc. | System and method for capturing, encoding, distributing, and decoding immersive audio |
| EP3073488A1 (en) | 2015-03-24 | 2016-09-28 | Thomson Licensing | Method and apparatus for embedding and regaining watermarks in an ambisonics representation of a sound field |
| WO2016210174A1 (en) | 2015-06-25 | 2016-12-29 | Dolby Laboratories Licensing Corporation | Audio panning transformation system and method |
| US12087311B2 (en) | 2015-07-30 | 2024-09-10 | Dolby Laboratories Licensing Corporation | Method and apparatus for encoding and decoding an HOA representation |
| EP3329486B1 (en) | 2015-07-30 | 2020-07-29 | Dolby International AB | Method and apparatus for generating from an hoa signal representation a mezzanine hoa signal representation |
| EP3992963B1 (en) | 2015-10-08 | 2023-02-15 | Dolby International AB | Layered coding for compressed sound or sound field representations |
| CA3000781C (en) * | 2015-10-08 | 2024-03-12 | Dolby International Ab | Layered coding and data structure for compressed higher-order ambisonics sound or sound field representations |
| US9959880B2 (en) * | 2015-10-14 | 2018-05-01 | Qualcomm Incorporated | Coding higher-order ambisonic coefficients during multiple transitions |
| EP3375208B1 (en) * | 2015-11-13 | 2019-11-06 | Dolby International AB | Method and apparatus for generating from a multi-channel 2d audio input signal a 3d sound representation signal |
| US9881628B2 (en) | 2016-01-05 | 2018-01-30 | Qualcomm Incorporated | Mixed domain coding of audio |
| EP3408851B1 (en) | 2016-01-26 | 2019-09-11 | Dolby Laboratories Licensing Corporation | Adaptive quantization |
| PL3338462T3 (pl) | 2016-03-15 | 2020-03-31 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Urządzenie, sposób lub program komputerowy do generowania opisu pola dźwięku |
| WO2018001489A1 (en) * | 2016-06-30 | 2018-01-04 | Huawei Technologies Duesseldorf Gmbh | Apparatuses and methods for encoding and decoding a multichannel audio signal |
| MC200186B1 (fr) * | 2016-09-30 | 2017-10-18 | Coronal Encoding | Procédé de conversion, d'encodage stéréophonique, de décodage et de transcodage d'un signal audio tridimensionnel |
| WO2018081829A1 (en) * | 2016-10-31 | 2018-05-03 | Google Llc | Projection-based audio coding |
| FR3060830A1 (fr) * | 2016-12-21 | 2018-06-22 | Orange | Traitement en sous-bandes d'un contenu ambisonique reel pour un decodage perfectionne |
| US10332530B2 (en) * | 2017-01-27 | 2019-06-25 | Google Llc | Coding of a soundfield representation |
| US10904992B2 (en) | 2017-04-03 | 2021-01-26 | Express Imaging Systems, Llc | Systems and methods for outdoor luminaire wireless control |
| EP3622509B1 (en) | 2017-05-09 | 2021-03-24 | Dolby Laboratories Licensing Corporation | Processing of a multi-channel spatial audio format input signal |
| WO2018208560A1 (en) * | 2017-05-09 | 2018-11-15 | Dolby Laboratories Licensing Corporation | Processing of a multi-channel spatial audio format input signal |
| KR102652670B1 (ko) * | 2017-07-14 | 2024-04-01 | 프라운호퍼 게젤샤프트 쭈르 푀르데룽 데어 안겐반텐 포르슝 에. 베. | 다중-층 묘사를 이용하여 증강된 음장 묘사 또는 수정된 음장 묘사를 생성하기 위한 개념 |
| JP7119060B2 (ja) | 2017-07-14 | 2022-08-16 | フラウンホーファー-ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | マルチポイント音場記述を使用して拡張音場記述または修正音場記述を生成するためのコンセプト |
| CN107705794B (zh) * | 2017-09-08 | 2023-09-26 | 崔巍 | 增强型多功能数字音频解码器 |
| US11032580B2 (en) | 2017-12-18 | 2021-06-08 | Dish Network L.L.C. | Systems and methods for facilitating a personalized viewing experience |
| US10365885B1 (en) * | 2018-02-21 | 2019-07-30 | Sling Media Pvt. Ltd. | Systems and methods for composition of audio content from multi-object audio |
| US10672405B2 (en) * | 2018-05-07 | 2020-06-02 | Google Llc | Objective quality metrics for ambisonic spatial audio |
| SG11202012936VA (en) * | 2018-07-04 | 2021-01-28 | Fraunhofer Ges Forschung | Multisignal audio coding using signal whitening as preprocessing |
| KR20230113413A (ko) | 2018-12-07 | 2023-07-28 | 프라운호퍼-게젤샤프트 추르 푀르데룽 데어 안제반텐 포르슝 에 파우 | 방향 컴포넌트 보상을 사용하는 DirAC 기반 공간 오디오코딩과 관련된 인코딩, 디코딩, 장면 처리 및 기타 절차를 위한 장치, 방법 및 컴퓨터 프로그램 |
| US10728689B2 (en) * | 2018-12-13 | 2020-07-28 | Qualcomm Incorporated | Soundfield modeling for efficient encoding and/or retrieval |
| US12143799B2 (en) | 2019-02-19 | 2024-11-12 | Akita Prefectural University | Acoustic signal encoding method, acoustic signal decoding method, program, encoding device, acoustic system, and decoding device |
| US11317497B2 (en) | 2019-06-20 | 2022-04-26 | Express Imaging Systems, Llc | Photocontroller and/or lamp with photocontrols to control operation of lamp |
| US11430451B2 (en) * | 2019-09-26 | 2022-08-30 | Apple Inc. | Layered coding of audio with discrete objects |
| US11212887B2 (en) | 2019-11-04 | 2021-12-28 | Express Imaging Systems, Llc | Light having selectively adjustable sets of solid state light sources, circuit and method of operation thereof, to provide variable output characteristics |
| US11636866B2 (en) * | 2020-03-24 | 2023-04-25 | Qualcomm Incorporated | Transform ambisonic coefficients using an adaptive network |
| CN113593585A (zh) * | 2020-04-30 | 2021-11-02 | 华为技术有限公司 | 音频信号的比特分配方法和装置 |
| CN114582356A (zh) | 2020-11-30 | 2022-06-03 | 华为技术有限公司 | 一种音频编解码方法和装置 |
| CN115376527A (zh) * | 2021-05-17 | 2022-11-22 | 华为技术有限公司 | 三维音频信号编码方法、装置和编码器 |
| CN113903353B (zh) * | 2021-09-27 | 2024-08-27 | 随锐科技集团股份有限公司 | 一种基于空间区分性检测的定向噪声消除方法及装置 |
| WO2024024468A1 (ja) * | 2022-07-25 | 2024-02-01 | ソニーグループ株式会社 | 情報処理装置および方法、符号化装置、音声再生装置、並びにプログラム |
| CN119049482A (zh) * | 2023-05-27 | 2024-11-29 | 华为技术有限公司 | 场景音频解码方法及电子设备 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002093556A1 (en) | 2001-05-11 | 2002-11-21 | Nokia Corporation | Inter-channel signal redundancy removal in perceptual audio coding |
| WO2006052188A1 (en) | 2004-11-12 | 2006-05-18 | Catt (Computer Aided Theatre Technique) | Surround sound processing arrangement and method |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1296504A4 (en) | 2000-05-29 | 2005-02-02 | Ginganet Corp | COMMUNICATION DEVICE |
| US6678647B1 (en) * | 2000-06-02 | 2004-01-13 | Agere Systems Inc. | Perceptual coding of audio signals using cascaded filterbanks for performing irrelevancy reduction and redundancy reduction with different spectral/temporal resolution |
| TWI393120B (zh) * | 2004-08-25 | 2013-04-11 | Dolby Lab Licensing Corp | 用於音訊信號編碼及解碼之方法和系統、音訊信號編碼器、音訊信號解碼器、攜帶有位元流之電腦可讀取媒體、及儲存於電腦可讀取媒體上的電腦程式 |
| KR101237413B1 (ko) * | 2005-12-07 | 2013-02-26 | 삼성전자주식회사 | 오디오 신호의 부호화 및 복호화 방법, 오디오 신호의부호화 및 복호화 장치 |
| US8379868B2 (en) * | 2006-05-17 | 2013-02-19 | Creative Technology Ltd | Spatial audio coding based on universal spatial cues |
| BRPI0807703B1 (pt) * | 2007-02-26 | 2020-09-24 | Dolby Laboratories Licensing Corporation | Método para aperfeiçoar a fala em áudio de entretenimento e meio de armazenamento não-transitório legível por computador |
| EP2168121B1 (fr) * | 2007-07-03 | 2018-06-06 | Orange | Quantification apres transformation lineaire combinant les signaux audio d'une scene sonore, codeur associe |
| US8219409B2 (en) | 2008-03-31 | 2012-07-10 | Ecole Polytechnique Federale De Lausanne | Audio wave field encoding |
| EP2205007B1 (en) | 2008-12-30 | 2019-01-09 | Dolby International AB | Method and apparatus for three-dimensional acoustic field encoding and optimal reconstruction |
| EP2450880A1 (en) * | 2010-11-05 | 2012-05-09 | Thomson Licensing | Data structure for Higher Order Ambisonics audio data |
| EP2469741A1 (en) * | 2010-12-21 | 2012-06-27 | Thomson Licensing | Method and apparatus for encoding and decoding successive frames of an ambisonics representation of a 2- or 3-dimensional sound field |
-
2010
- 2010-12-21 EP EP10306472A patent/EP2469741A1/en not_active Withdrawn
-
2011
- 2011-12-12 EP EP11192998.0A patent/EP2469742B1/en active Active
- 2011-12-12 EP EP24157076.1A patent/EP4343759A3/en active Pending
- 2011-12-12 EP EP21214984.3A patent/EP4007188B1/en active Active
- 2011-12-12 EP EP18201744.2A patent/EP3468074B1/en active Active
- 2011-12-20 JP JP2011278172A patent/JP6022157B2/ja active Active
- 2011-12-20 KR KR1020110138434A patent/KR101909573B1/ko active IP Right Grant
- 2011-12-21 CN CN201110431798.1A patent/CN102547549B/zh active Active
- 2011-12-21 US US13/333,461 patent/US9397771B2/en active Active
-
2016
- 2016-10-05 JP JP2016196854A patent/JP6335241B2/ja active Active
-
2018
- 2018-04-27 JP JP2018086260A patent/JP6732836B2/ja active Active
- 2018-10-12 KR KR1020180121677A patent/KR102010914B1/ko active IP Right Grant
-
2019
- 2019-08-08 KR KR1020190096615A patent/KR102131748B1/ko active IP Right Grant
-
2020
- 2020-02-27 JP JP2020031454A patent/JP6982113B2/ja active Active
-
2021
- 2021-11-18 JP JP2021187879A patent/JP7342091B2/ja active Active
-
2023
- 2023-08-30 JP JP2023139565A patent/JP2023158038A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002093556A1 (en) | 2001-05-11 | 2002-11-21 | Nokia Corporation | Inter-channel signal redundancy removal in perceptual audio coding |
| WO2006052188A1 (en) | 2004-11-12 | 2006-05-18 | Catt (Computer Aided Theatre Technique) | Surround sound processing arrangement and method |
Non-Patent Citations (1)
| Title |
|---|
| Erik Hellerud, et al. Spatial redundancy in Higher Order Ambisonics and its use for lowdelay lossless compression. IEEE International Conference on Acoustics, Speech and Signal Processing. 2009. pp.26* |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2469741A1 (en) | 2012-06-27 |
| JP2016224472A (ja) | 2016-12-28 |
| JP2023158038A (ja) | 2023-10-26 |
| CN102547549A (zh) | 2012-07-04 |
| US20120155653A1 (en) | 2012-06-21 |
| JP2020079961A (ja) | 2020-05-28 |
| EP3468074B1 (en) | 2021-12-22 |
| KR102010914B1 (ko) | 2019-08-14 |
| EP4343759A3 (en) | 2024-06-12 |
| EP2469742A3 (en) | 2012-09-05 |
| JP6732836B2 (ja) | 2020-07-29 |
| KR20190096318A (ko) | 2019-08-19 |
| JP6982113B2 (ja) | 2021-12-17 |
| JP2012133366A (ja) | 2012-07-12 |
| JP6022157B2 (ja) | 2016-11-09 |
| JP7342091B2 (ja) | 2023-09-11 |
| EP2469742B1 (en) | 2018-12-05 |
| EP2469742A2 (en) | 2012-06-27 |
| EP4007188A1 (en) | 2022-06-01 |
| EP3468074A1 (en) | 2019-04-10 |
| KR20180115652A (ko) | 2018-10-23 |
| KR20120070521A (ko) | 2012-06-29 |
| JP2018116310A (ja) | 2018-07-26 |
| EP4007188B1 (en) | 2024-02-14 |
| US9397771B2 (en) | 2016-07-19 |
| CN102547549B (zh) | 2016-06-22 |
| JP6335241B2 (ja) | 2018-05-30 |
| JP2022016544A (ja) | 2022-01-21 |
| EP4343759A2 (en) | 2024-03-27 |
| KR102131748B1 (ko) | 2020-07-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102131748B1 (ko) | 2차원 또는 3차원 음장의 앰비소닉스 표현의 연속 프레임을 인코딩 및 디코딩하는 방법 및 장치 | |
| JP7181371B2 (ja) | レンダリング方法、レンダリング装置及び記録媒体 | |
| JP5081838B2 (ja) | オーディオ符号化及び復号 | |
| RU2551797C2 (ru) | Способы и устройства кодирования и декодирования объектно-ориентированных аудиосигналов | |
| RU2406166C2 (ru) | Способы и устройства кодирования и декодирования основывающихся на объектах ориентированных аудиосигналов | |
| US9478228B2 (en) | Encoding and decoding of audio signals | |
| JP2016530788A (ja) | 符号化表現に基づいて少なくとも4つのオーディオチャネル信号を提供するためのオーディオデコーダ、オーディオエンコーダ、方法、帯域幅拡張を用いた少なくとも4つのオーディオチャネル信号に基づいて符号化表現を提供するための方法およびコンピュータプログラム | |
| JP2012502570A (ja) | マイクロホン信号に基づいて一組の空間手がかりを供給する装置、方法およびコンピュータ・プログラムと2チャンネルのオーディオ信号および一組の空間手がかりを供給する装置 | |
| GB2485979A (en) | Spatial audio coding | |
| Cheng | Spatial squeezing techniques for low bit-rate multichannel audio coding | |
| Väljamäe | A feasibility study regarding implementation of holographic audio rendering techniques over broadcast networks | |
| Mouchtaris et al. | Multichannel Audio Coding for Multimedia Services in Intelligent Environments | |
| Meng | Virtual sound source positioning for un-fixed speaker set up | |
| Ng et al. | A Direct MPEG Surround Encoding Scheme for Surround Sound Recording with Coincident Microphone Techniques | |
| MX2008010631A (es) | Codificacion y decodificacion de audio |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20111220 |
|
| PG1501 | Laying open of application | ||
| PN2301 | Change of applicant |
Patent event date: 20160831 Comment text: Notification of Change of Applicant Patent event code: PN23011R01D |
|
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20161214 Comment text: Request for Examination of Application Patent event code: PA02011R01I Patent event date: 20111220 Comment text: Patent Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20180410 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20180720 |
|
| PA0107 | Divisional application |
Comment text: Divisional Application of Patent Patent event date: 20181012 Patent event code: PA01071R01D |
|
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20181012 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20181015 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee |
Payment date: 20210927 Start annual number: 4 End annual number: 4 |
|
| PR1001 | Payment of annual fee |
Payment date: 20220922 Start annual number: 5 End annual number: 5 |
|
| PR1001 | Payment of annual fee |
Payment date: 20230921 Start annual number: 6 End annual number: 6 |
|
| PR1001 | Payment of annual fee |