JP7689748B2 - 確率信号生成要素、確率ニューロン及びそのニューラルネットワーク - Google Patents
確率信号生成要素、確率ニューロン及びそのニューラルネットワーク Download PDFInfo
- Publication number
- JP7689748B2 JP7689748B2 JP2022549079A JP2022549079A JP7689748B2 JP 7689748 B2 JP7689748 B2 JP 7689748B2 JP 2022549079 A JP2022549079 A JP 2022549079A JP 2022549079 A JP2022549079 A JP 2022549079A JP 7689748 B2 JP7689748 B2 JP 7689748B2
- Authority
- JP
- Japan
- Prior art keywords
- signal
- probability
- stochastic
- binary
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/544—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices for evaluating functions by calculation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/60—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers
- G06F7/70—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers using stochastic pulse trains, i.e. randomly occurring pulses the average pulse rates of which represent numbers
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Neurology (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
- Sanitary Device For Flush Toilet (AREA)
- Complex Calculations (AREA)
- Electrophonic Musical Instruments (AREA)
Description
- LeCun, Y., Bottou, L., Bengio, Y., Haffner, P. Gradient-based learning applied to document recognition (1998) Proceedings of the IEEE, 86 (11), pp. 2278-2323.
- Lawrence, S., Giles, C.L., Tsoi, A.C., Back, A.D. Face recognition: A convolutional neural-network approach (1997) IEEE Transactions on Neural Networks, 8 (1), pp. 98-113.

-Zhang, C., Li, P., Sun, G., Guan, Y., Xiao, B., Cong, J. "Optimizing FPGA-based accelerator design for deep convolutional neural networks" (2015) FPGA 2015 - 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, pp. 161-170.
-Sanni, K., Garreau, G., Molin, J.L., Andreou, A.G. "FPGA implementation of a Deep Belief Network architecture for character recognition using stochastic computation", (2015) 2015 49th Annual Conference on Information Sciences and Systems, CISS 2015, art. no. 7086904.
-Alawad, M., Lin, M. "Stochastic-Based Deep Convolutional Networks with Reconfigurable Logic Fabric" (2016) IEEE Transactions on Multi-Scale Computing Systems, 2 (4), art. no. 7547913, pp. 242-256.
この研究では、確率論の特定の特性が用いられており、この確率論の特定の特性は、2つの独立した確率変数の和の確率密度関数と、これらの変数個々の確率密度(双方の畳み込みに関連する)との間の関係といったものである。CNN処理の高速化の基礎は個々のニューラル要素を用いる代わりにこの確率特性の実装にある。
-Ren, A., Li, Z., Ding, C., Qiu, Q., Wang, Y., Li, J., Qian, X., Yuan, B. "SC-DCNN: Highly-scalable deep convolutional neural network using stochastic computing" (2017) International Conference on Architectural Support for Programming Languages and Operating Systems - ASPLOS, Part F127193, pp. 405-418.
この研究では、確率論理は畳み込み処理及びマックスプーリング処理双方の実装に用いられる。一方、正接バイポーラ関数(前述の式である関数f)の実装にステートマシンを用い、構成をかなり複雑化しうる(図6に見られるように)。また、相関信号の使用も活用せず、活性化関数の実装を簡潔化もしない。
-Li, Z., Li, J., Ren, A., Cai, R., Ding, C., Qian, X., Draper, J., Yuan, B., Tang, J., Qiu, Q., Wang, Y. "HEIF: Highly Efficient Stochastic Computing-Based Inference Framework for Deep Neural Networks" (2019) IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 38 (8), art. no. 8403283, pp. 1543-1556.
この研究では、図4cに示すように、近似的並列カウンタ(Approximate Parallel Counter:APC)として知られるバイナリブロックが用いられる。これは、ニューラル入力の重み付け和を実行するのに用いられるが、複雑な回路はReLU型活性化関数又はマックスプーリングブロック(前記文献の図6における)の実装において実行される。実際に、得られた活性化関数は古典的ReLUでなく、「クリップされたReLU」、すなわち飽和されたReLUである。
a)各ニューロンの異なる乱数生成器の実装を要求しないことによる、結果の精度を落とすことのない使用ハードウェア資源の節約をすること(確率論による実装において、資源の最大割合はランダム/乱数の生成に用いられる)
b)論理ゲートのような単純な計算ユニットのみ含むマックスプーリング関数及び畳み込みの実装の簡略化(いろいろな取り組み及び設計が文献で紹介され、ニューラルネットワークにおいてこの関数が実装可能となったが、無相関信号を用いる場合、提案された設計は相当なハードウェアスペースを要求する)
c)ネットワークの層の数に拘わらず生成器の数は一定であるため、各々の乱数生成器の使用を必要とせずにニューラルネットワークにおけるさらなる深さの層の加算が可能なこと(ネットワークの層が増えると、乱数生成器の数が増える他の実装と異なる)
から構成される。
-FPGA16. S. I. Venieris and C. Bouganis, “fpgaconvnet: A framework for mapping convolutional neural networks on fpgas,” in 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM) , May 2016, pp. 40-47.
-FPGA17a. Z. Liu, Y. Dou, J. Jiang, J. Xu, S. Li, Y. Zhou, and Y. Xu, “Throughput-optimized fpga accelerator for deep convolutional neural networks,”TRETS, vol. 10, pp. 17:1-17:23, 2017.
-FPGA17b. Z. Li, L. Wang, S. Guo, Y. Deng, Q. Dou, H. Zhou, and W. Lu, “Laius: An 8-bit fixed-point cnn hardware inference engine,” in 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Dec 2017, pp. 143-150.
-FPGA18.S.-S. Park, K.-B. Park, and K. Chung, “Implementation of a cnn accelerator on an embedded soc platform using sdsoc,” 02 2018, pp.161-165.
Claims (16)
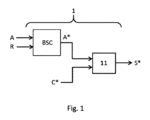
- バイナリ信号(A)を受信する、第1入力と、ランダム信号(R)を受信する、第2入力と、を順に有し、前記ランダム信号(R)を用いて前記バイナリ信号(A)を第1確率信号(A*)に変換する、第1バイナリ-確率変換器(BSC)、
を備え、
前記第1確率信号(A*)を受信する、第1入力と、第2確率信号である参照確率信号(C*)を受信する第2入力であって前記参照確率信号(C*)は定数値信号(C)から前記ランダム信号(R)を用いて生成される、第2入力と、を備える、処理ユニット(11)であって、前記第1確率信号(A*)及び前記参照確率信号(C*)を少なくとも1つの算術関数に従って処理し、前記処理を表す確率出力信号(S*)を生成する、処理ユニット(11)、
を備え、
前記処理ユニット(11)は、OR型論理ゲートであり、適用される前記算術関数は、正規化線形ユニット(ReLU)型の活性化関数から構成される、
確率信号生成要素(1)。 - バイナリ信号(A)を受信する、第1入力と、ランダム信号(R)を受信する、第2入力と、を順に有し、前記ランダム信号(R)を用いて前記バイナリ信号(A)を第1確率信号(A*)に変換する、第1バイナリ-確率変換器(BSC)、
を備え、
前記第1確率信号(A*)を受信する、第1入力と、第2確率信号である参照確率信号(C*)を受信する第2入力であって前記参照確率信号(C*)は定数値信号(C)から前記ランダム信号(R)を用いて生成される、第2入力と、を備える、処理ユニット(11)であって、前記第1確率信号(A*)及び前記参照確率信号(C*)を少なくとも1つの算術関数に従って処理し、前記処理を表す確率出力信号(S*)を生成する、処理ユニット(11)、
を備え、
前記処理ユニット(11)は、AND型論理ゲートであり、適用される前記算術関数は、最小値型の活性化関数(A*、C*)から構成される、
確率信号生成要素(1)。 - 請求項1又は請求項2に記載された確率信号生成要素(1)を備える、
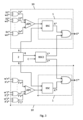
計算ニューラルネットワーク用の確率ニューロン(10)。 - 複数の確率の入力信号(Y1* - Yn*)を受信する近似的並列カウンタ(APC)を備え、前記複数の入力信号(Y1* - Yn*)の和をとり、その出力において2の補数に符号化されたバイナリの出力信号に変換し、
前記出力信号は、前記第1バイナリ-確率変換器(BSC)に入力された前記バイナリ信号(A)である、
請求項3に記載の計算ニューラルネットワーク用の確率ニューロン(10)。 - 複数の処理サブユニットを備え、それぞれの処理サブユニットが外部確率信号(X1* - Xn*)及び確率重み信号(w1* - wn*)を受信し、算術関数を適用することでそれらを処理し、前記近似的並列カウンタ(APC)の前記入力信号(Y1* - Yn*)を構成する出力信号を生成する、
請求項4に記載の計算ニューラルネットワーク用の確率ニューロン(10)。 - 前記処理サブユニットは、XNOR論理ゲートから構成され、それぞれのXNOR論理ゲートは、前記外部確率信号(X1* - Xn*)と対応する前記確率重み信号(w1* - wn*)とをバイポーラ的に乗算する、
請求項5に記載の計算ニューラルネットワーク用の確率ニューロン(10)。 - 前記処理サブユニットは、AND論理ゲートから構成され、それぞれのAND論理ゲートは、前記外部確率信号(X1* - Xn*)と対応する前記確率重み信号(w1* - wn*)とをユニポーラ的に乗算する、
請求項5に記載の計算ニューラルネットワーク用の確率ニューロン(10)。 - 請求項3から請求項7のいずれかに記載の複数の確率ニューロン(10)を備え、
前記複数の確率ニューロン(10)の一部は、他と演算的に相互接続する、
計算ニューラルネットワーク。 - 第2バイナリ-確率変換器(BSC2)を備え、前記第2バイナリ-確率変換器(BSC2)は、前記参照確率信号(C*)を前記定数値信号(C)及び前記ランダム信号(R)から生成し、前記複数の確率ニューロン(10)の異なる前記処理ユニット(11)に一斉に送信する、
請求項8に記載の計算ニューラルネットワーク。 - 乱数生成器(2)を備え、前記乱数生成器(2)は前記ランダム信号(R)を生成し、前記複数の確率ニューロン(10)の異なる前記第1、第2バイナリ-確率変換器(BSC、BSC2)に一斉に前記ランダム信号(R)を送信する、
請求項9に記載の計算ニューラルネットワーク。 - 前記乱数生成器(2)は線形フィードバックシフトレジスタ型である、
請求項10に記載の計算ニューラルネットワーク。 - ORグループゲート(3)を備え、前記ORグループゲート(3)は確率出力信号(S0* - S3*)を確率ニューロン(n0 - n3)のグループから受信し、その出力(Smax*)における最大値を取得する、
請求項8から請求項11のいずれかに記載の計算ニューラルネットワーク。 - バイナリ-確率変換器のアレイ(BSCアレイ)を備え、前記バイナリ-確率変換器のアレイは、それぞれの第1入力で受信される初期信号(x)を変換し、それぞれの第2入力で受信される前記ランダム信号(R)を用いてそれらの出力としてそれぞれ初期確率信号(x*)に変換する、
請求項8から請求項12のいずれかに記載の計算ニューラルネットワーク。 - 第2乱数生成器(2’)と、バイナリ-確率重み変換器のアレイ(BSCアレイ’)と、を備え、前記バイナリ-確率重み変換器のアレイは第1入力で受信される重み信号(w)を変換し、前記第2乱数生成器(2’)から受信される第2乱数信号を用いてその出力として前記確率重み信号(w*)に変換する、
請求項5を引用する請求項8から請求項13のいずれかに記載の計算ニューラルネットワーク。 - 請求項1に記載の確率ニューロン(10)を複数備え、
前記処理ユニット(11)がOR型論理ゲートである確率信号生成要素(1)を備える確率ニューロン(10)を有する、マックスプーリング型層を備える、
請求項8から請求項14のいずれかに記載の計算ニューラルネットワーク。 - 請求項2に記載の確率ニューロン(10)を複数備え、
前記処理ユニット(11)がAND型論理ゲートである確率信号生成要素(1)を備える確率ニューロン(10)を有する、ミニマムプーリング型層を備える、
請求項8から請求項14のいずれかに記載の計算ニューラルネットワーク。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| ES202030120A ES2849123B2 (es) | 2020-02-13 | 2020-02-13 | Elemento de generación de señales estocásticas, neurona estocástica y red neuronal a partir de esta |
| ESP202030120 | 2020-02-13 | ||
| PCT/ES2021/070096 WO2021160914A1 (es) | 2020-02-13 | 2021-02-11 | Elemento de generación de señales estocásticas, neurona estocástica y red neuronal a partir de esta |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023513596A JP2023513596A (ja) | 2023-03-31 |
| JP7689748B2 true JP7689748B2 (ja) | 2025-06-09 |
Family
ID=77245003
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022549079A Active JP7689748B2 (ja) | 2020-02-13 | 2021-02-11 | 確率信号生成要素、確率ニューロン及びそのニューラルネットワーク |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20230079289A1 (ja) |
| EP (1) | EP4105834A4 (ja) |
| JP (1) | JP7689748B2 (ja) |
| ES (1) | ES2849123B2 (ja) |
| WO (1) | WO2021160914A1 (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7438994B2 (ja) * | 2021-01-07 | 2024-02-27 | 株式会社東芝 | ニューラルネットワーク装置及び学習方法 |
| CN114553242B (zh) * | 2022-03-04 | 2023-04-25 | 电子科技大学 | 基于半概率计算的部分并行ldpc译码器 |
| US20230419093A1 (en) * | 2022-06-23 | 2023-12-28 | International Business Machines Corporation | Stochastic Bitstream Generation with In-Situ Function Mapping |
| WO2025048815A1 (en) * | 2023-08-31 | 2025-03-06 | Stem Ai, Inc. | Logic interpretation of dynamic machine learning model |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7499588B2 (en) | 2004-05-20 | 2009-03-03 | Microsoft Corporation | Low resolution OCR for camera acquired documents |
-
2020
- 2020-02-13 ES ES202030120A patent/ES2849123B2/es active Active
-
2021
- 2021-02-11 JP JP2022549079A patent/JP7689748B2/ja active Active
- 2021-02-11 US US17/760,480 patent/US20230079289A1/en not_active Abandoned
- 2021-02-11 WO PCT/ES2021/070096 patent/WO2021160914A1/es not_active Ceased
- 2021-02-11 EP EP21754657.1A patent/EP4105834A4/en active Pending
Non-Patent Citations (3)
| Title |
|---|
| T. LEE, Vincent et al.,Energy-Efficient Hybrid Stochastic-Binary Neural Networkds For Near-Sensor Computing,arXiv [online],2017年,all 6 pages,Retrieved from The Internet: <URL: https://arxiv.org/pdf/1706.02344 > |
| Te-Hsuan Chen and John P. Hayes,Design of Division Circuits for Stochastic Computing,2016 IEEE Computer Society Annual Symposium on VLSI,IEEE [online],2016年07月13日,pp.116-121,https://ieeexplore.ieee.org/abstract/document/7560183 |
| Yi Xie, et al.,Fully-Parallel Area-Efficient Deep Neural Network Design using Stochastic Computing,IEEE Transactions on Circuits and Systems II: Express Briefs,IEEE [online],2017年08月30日,pp.1382-1386,https://ieeexplore.ieee.org/document/8022910 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021160914A1 (es) | 2021-08-19 |
| ES2849123A8 (es) | 2021-11-05 |
| US20230079289A1 (en) | 2023-03-16 |
| ES2849123B2 (es) | 2023-03-07 |
| EP4105834A1 (en) | 2022-12-21 |
| JP2023513596A (ja) | 2023-03-31 |
| EP4105834A4 (en) | 2024-04-03 |
| ES2849123A1 (es) | 2021-08-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7689748B2 (ja) | 確率信号生成要素、確率ニューロン及びそのニューラルネットワーク | |
| Hassantabar et al. | SCANN: Synthesis of compact and accurate neural networks | |
| Kleyko et al. | Density encoding enables resource-efficient randomly connected neural networks | |
| Canals et al. | A new stochastic computing methodology for efficient neural network implementation | |
| Bethge et al. | BinaryDenseNet: Developing an architecture for binary neural networks | |
| Wang et al. | Deep spiking neural networks with binary weights for object recognition | |
| JP7803594B2 (ja) | 機械学習タスクを実施するためのニューラル・ネットワークの訓練 | |
| Jia et al. | An energy-efficient Bayesian neural network implementation using stochastic computing method | |
| CN105913118A (zh) | 一种基于概率计算的人工神经网络硬件实现装置 | |
| Moran et al. | Digital implementation of radial basis function neural networks based on stochastic computing | |
| Nowshin et al. | Recent advances in reservoir computing with a focus on electronic reservoirs | |
| Rosselló et al. | Probabilistic-based neural network implementation | |
| Rossello et al. | Highly optimized hardware morphological neural network through stochastic computing and tropical pruning | |
| Morán et al. | Reservoir computing hardware with cellular automata | |
| Kim et al. | Two-step spike encoding scheme and architecture for highly sparse spiking-neural-network | |
| Luu et al. | Improvement of spiking neural network with bit plane coding | |
| Cherniuk et al. | Quantization aware factorization for deep neural network compression | |
| Chen et al. | Universal adder neural networks | |
| US20250181886A1 (en) | Method and electronic system for inferring a morphological neural network | |
| Dogaru et al. | Fast training of light binary convolutional neural networks using chainer and cupy | |
| Rosselló et al. | Hardware implementation of stochastic computing-based morphological neural systems | |
| Golbabaei et al. | A non-deterministic training approach for memory-efficient stochastic neural networks | |
| Rosselló et al. | Stochastic Computing Applications to Artificial Neural Networks | |
| Tang et al. | OneSpike: Ultra-low latency spiking neural networks | |
| Zu et al. | Generalwise separable convolution for mobile vision applications |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240130 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240927 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20241219 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20250128 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20250416 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250509 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250521 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7689748 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |