JP7621675B2 - トラスト環境ベースの人工知能装置 - Google Patents
トラスト環境ベースの人工知能装置 Download PDFInfo
- Publication number
- JP7621675B2 JP7621675B2 JP2023129058A JP2023129058A JP7621675B2 JP 7621675 B2 JP7621675 B2 JP 7621675B2 JP 2023129058 A JP2023129058 A JP 2023129058A JP 2023129058 A JP2023129058 A JP 2023129058A JP 7621675 B2 JP7621675 B2 JP 7621675B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- memory
- dnn
- artificial intelligence
- type
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images
Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/20—Handling requests for interconnection or transfer for access to input/output bus
- G06F13/28—Handling requests for interconnection or transfer for access to input/output bus using burst mode transfer, e.g. direct memory access DMA, cycle steal
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/50—Monitoring users, programs or devices to maintain the integrity of platforms, e.g. of processors, firmware or operating systems
- G06F21/57—Certifying or maintaining trusted computer platforms, e.g. secure boots or power-downs, version controls, system software checks, secure updates or assessing vulnerabilities
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L2209/00—Additional information or applications relating to cryptographic mechanisms or cryptographic arrangements for secret or secure communication H04L9/00
- H04L2209/12—Details relating to cryptographic hardware or logic circuitry
- H04L2209/125—Parallelization or pipelining, e.g. for accelerating processing of cryptographic operations
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L2209/00—Additional information or applications relating to cryptographic mechanisms or cryptographic arrangements for secret or secure communication H04L9/00
- H04L2209/12—Details relating to cryptographic hardware or logic circuitry
- H04L2209/127—Trusted platform modules [TPM]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- General Physics & Mathematics (AREA)
- Computer Security & Cryptography (AREA)
- Computer Hardware Design (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Bioethics (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Neurology (AREA)
- Storage Device Security (AREA)
Description
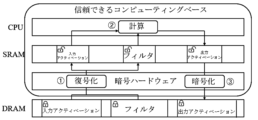
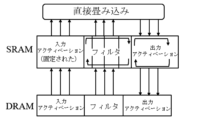
前記暗号処理フロント-エンドプロセッサは、前記人工知能演算の過程で前記プロセッサによるオン-デマンド要求を受信し、前記第1類型のメモリにアクセスして前記暗号化入力データを取り込むことができる。
前記第2類型のメモリは、前記第1類型のメモリよりも相対的に速い動作速度及び少ない格納容量を有することができる。
前記プロセッサは、直接畳み込みベースのニューラルネットワーク演算を行って前記第1類型のメモリのアクセス数を減らすことができる。
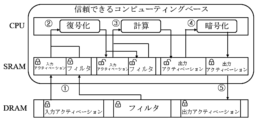
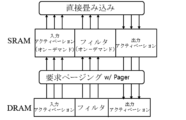
前記プロセッサは、前記第2類型のメモリに復号化入力アクティベーションを固定的に格納し、復号化フィルタ及び非暗号出力アクティベーションを循環キュー方式で格納することができる。
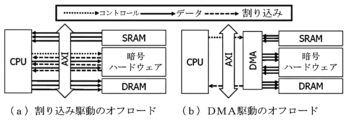
前記プロセッサは、前記暗号処理フロント-エンドプロセッサの割り込み駆動のオフロード(interrupt driven offloading)を介して、前記第1類型のメモリ及び前記第2類型のメモリとデータ送受信を行うことができる。
前記プロセッサは、DMA(Direct Memory Access)コントローラのDMA駆動のオフロードを介して、前記暗号処理フロント-エンドプロセッサと前記第1類型のメモリ及び前記第2類型のメモリとデータ送受信を行うことができる。
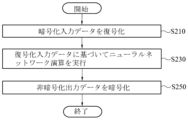
前記プロセッサは、前記暗号処理フロント-エンドプロセッサの暗号化及び復号化演算の実行にオーバーラップするように前記ニューラルネットワーク演算を実行してイントラ-レイヤパイプライニングを実現することができる。
前記プロセッサは、前記ニューラルネットワーク演算の実行中に前記暗号処理フロント-エンドプロセッサが前記暗号化入力データの復号化演算を行うようにして、前記ニューラルネットワーク演算を途切れることなく行うことができる。
前記プロセッサは、前記イントラ-レイヤパイプライニングのために、データ復号化ステップ、演算ステップ、及びデータ暗号化ステップに細分化して、前記ニューラルネットワーク演算を途切れることなく行うことができる。
前記プロセッサは、前記第2類型のメモリに復号化入力アクティベーションを固定的に格納し、復号化フィルタ及び非暗号出力アクティベーションを循環キュー方式で格納することができる。
前記プロセッサは、前記暗号処理フロント-エンドプロセッサの暗号化及び復号化演算の実行にオーバーラップするように前記ニューラルネットワーク演算を実行してイントラ-レイヤパイプライニングを実現することができる。
[この発明を支援した国家研究開発事業]
[課題固有番号] 1711193986
[課題番号] 2020-0-01361-004
[省庁名] 科学技術情報通信部
[課題管理(専門)機関名] 情報通信企画評価院
[研究事業名] 情報通信放送革新人材養成
[研究課題名] 人工知能大学院支援(延世大学校)
[寄与率] 1/2
[課題実行機関名] 延世大学校産学協力団
[研究期間] 2023.01.01~2023.12.31
[この発明を支援した国家研究開発事業]
[課題固有番号] 1415177659
[課題番号] P0016150
[省庁名] 産業通商資源部
[課題管理(専門)機関名] 韓国産業技術振興院
[研究事業名] 産業技術国際協力(R&D)
[研究課題名] スマートIoTネットワークセキュリティのための攻撃探知及び防御技術開発
[寄与率] 1/2
[課題実行機関名] 韓国電子技術研究院
[研究期間] 2021.12.01~2022.11.30

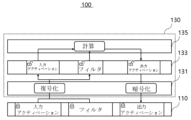
110 第1類型のメモリ
130 トラスト人工知能処理部
131 暗号処理フロント-エンドプロセス
133 第2類型のメモリ
135 プロセッサ
Claims (6)
- 暗号化入力データを送信し、暗号化出力データを受信する第1類型のメモリと、
トラスト信頼空間で動作し、前記暗号化入力データ及び前記暗号化出力データの人工知能演算を行うトラスト人工知能処理部と、を備え、
前記トラスト人工知能処理部は、
前記暗号化入力データの復号化を介して復号化入力データを生成し、前記暗号化出力データを生成するために非暗号化出力データの暗号化を行う暗号処理フロント-エンドプロセッサと、
前記復号化入力データ及び前記非暗号化出力データに対するバッファを提供し、前記第1類型のメモリよりも相対的に速い動作速度及び少ない格納容量を有する第2類型のメモリと、
前記復号化入力データに基づいてニューラルネットワーク演算を行って前記非暗号化出力データを生成するプロセッサと、を含み、
前記プロセッサは、
直接畳み込みベースのニューラルネットワーク演算を行って前記第1類型のメモリのアクセス数を減らし、
前記第2類型のメモリを、畳み込みレイヤの入力アクティベーション、復号化フィルタ、及び非暗号出力アクティベーションのアクセス領域により管理し、
前記第2類型のメモリに畳み込みレイヤの実行全体で繰り返しアクセスするときに、全ての前記復号化入力データを前記入力アクティベーションの領域に固定的に格納し、残りの前記第2類型のメモリを、前記復号化フィルタ及び前記非暗号出力アクティベーションの領域の2つの循環キューで構成された循環キュー方式で格納し、
前記暗号処理フロント-エンドプロセッサの暗号化及び復号化演算の実行にオーバーラップするように前記ニューラルネットワーク演算を実行してイントラ-レイヤパイプライニングを実現し、
前記イントラ-レイヤパイプライニングのために、データ復号化ステップ、演算ステップ、及びデータ暗号化ステップに細分化して、前記ニューラルネットワーク演算を途切れることなく行うことを特徴とするトラスト環境ベースの人工知能装置。 - 前記暗号処理フロント-エンドプロセッサは、前記第1類型のメモリから前記暗号化入力データとして暗号化入力アクティベーション及び暗号化フィルタの入力を受けて、前記第2類型のメモリに復号化入力アクティベーション及び復号化フィルタを格納することを特徴とする請求項1に記載のトラスト環境ベースの人工知能装置。
- 前記暗号処理フロント-エンドプロセッサは、前記人工知能演算の過程で前記プロセッサによるオン-デマンド要求を受信し、前記第1類型のメモリにアクセスして前記暗号化入力データを取り込むことを特徴とする請求項1に記載のトラスト環境ベースの人工知能装置。
- 前記プロセッサは、前記暗号処理フロント-エンドプロセッサの割り込み駆動のオフロード(interrupt driven offloading)を介して、前記第1類型のメモリ及び前記第2類型のメモリとデータ送受信を行うことを特徴とする請求項1に記載のトラスト環境ベースの人工知能装置。
- 前記プロセッサは、DMA(Direct Memory Access)コントローラのDMA駆動のオフロードを介して、前記暗号処理フロント-エンドプロセッサと前記第1類型のメモリ及び前記第2類型のメモリとデータ送受信を行うことを特徴とする請求項1に記載のトラスト環境ベースの人工知能装置。
- 前記プロセッサは、前記ニューラルネットワーク演算の実行中に前記暗号処理フロント-エンドプロセッサが前記暗号化入力データの復号化演算を行うようにして、前記ニューラルネットワーク演算を途切れることなく行うことを特徴とする請求項1に記載のトラスト環境ベースの人工知能装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020230058605A KR20240161452A (ko) | 2023-05-04 | 2023-05-04 | 트러스트 환경 기반 인공지능 장치 |
| KR10-2023-0058605 | 2023-05-04 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2024160912A JP2024160912A (ja) | 2024-11-15 |
| JP7621675B2 true JP7621675B2 (ja) | 2025-01-27 |
Family
ID=93292602
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023129058A Active JP7621675B2 (ja) | 2023-05-04 | 2023-08-08 | トラスト環境ベースの人工知能装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240370563A1 (ja) |
| JP (1) | JP7621675B2 (ja) |
| KR (1) | KR20240161452A (ja) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005018434A (ja) | 2003-06-26 | 2005-01-20 | Toshiba Corp | マイクロプロセッサ |
| US10956584B1 (en) | 2018-09-25 | 2021-03-23 | Amazon Technologies, Inc. | Secure data processing |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10706349B2 (en) * | 2017-05-25 | 2020-07-07 | Texas Instruments Incorporated | Secure convolutional neural networks (CNN) accelerator |
| US11295205B2 (en) * | 2018-09-28 | 2022-04-05 | Qualcomm Incorporated | Neural processing unit (NPU) direct memory access (NDMA) memory bandwidth optimization |
| US11003606B2 (en) * | 2019-06-21 | 2021-05-11 | Microchip Technology Incorporated | DMA-scatter and gather operations for non-contiguous memory |
| US11341066B2 (en) * | 2019-12-12 | 2022-05-24 | Electronics And Telecommunications Research Institute | Cache for artificial intelligence processor |
| US11847507B1 (en) * | 2020-12-02 | 2023-12-19 | Amazon Technologies, Inc. | DMA synchronization using alternating semaphores |
| KR102474875B1 (ko) | 2021-04-09 | 2022-12-06 | 충남대학교 산학협력단 | Arm 프로세서 기반 모바일 디바이스에서 안정적인 휘발성 데이터 획득 방법 및 시스템 |
| US12265492B2 (en) * | 2023-02-21 | 2025-04-01 | Meta Platforms, Inc. | Circular buffer for input and output of tensor computations |
-
2023
- 2023-05-04 KR KR1020230058605A patent/KR20240161452A/ko active Pending
- 2023-08-03 US US18/229,765 patent/US20240370563A1/en active Pending
- 2023-08-08 JP JP2023129058A patent/JP7621675B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005018434A (ja) | 2003-06-26 | 2005-01-20 | Toshiba Corp | マイクロプロセッサ |
| US10956584B1 (en) | 2018-09-25 | 2021-03-23 | Amazon Technologies, Inc. | Secure data processing |
Non-Patent Citations (3)
| Title |
|---|
| Meiyu Zhang et al.,SoftME: A Software-Based Memory Protection Approach for TEE System to Resist Physical Attacks,Security and Communication Networks,Hindawi [オンライン],2019年01月,Volume 2019, Issue 1,(2024.10.29 検索)、インターネット,URL: https://onlinelibrary.wiley.com/doi/epdf/10.1155/2019/8690853 |
| Yunjie Deng et al.,StrangBox: A GPU TEE on Arm Endpoints,CCS'22: Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security,2022年11月07日,pp. 769-783 |
| 中井 綱人,"ОP-TEEを用いた隔離AIハードウェアアクセラレーションの実装評価",2022年 暗号と情報セキュリティシンポジウム予稿集,2022年01月21日,pp.1-8 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20240161452A (ko) | 2024-11-12 |
| US20240370563A1 (en) | 2024-11-07 |
| JP2024160912A (ja) | 2024-11-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11088846B2 (en) | Key rotating trees with split counters for efficient hardware replay protection | |
| Lee et al. | Occlumency: Privacy-preserving remote deep-learning inference using SGX | |
| Mo et al. | Darknetz: towards model privacy at the edge using trusted execution environments | |
| US9893881B2 (en) | Efficient sharing of hardware encryption pipeline for multiple security solutions | |
| US9524249B2 (en) | Memory encryption engine integration | |
| US8819455B2 (en) | Parallelized counter tree walk for low overhead memory replay protection | |
| EP3274848B1 (en) | Providing enhanced replay protection for a memory | |
| US11531772B2 (en) | Support for increased number of concurrent keys within multi-key cryptographic engine | |
| JP2019191575A (ja) | 準同型暗号を用いた処理動作の委託 | |
| US20120260102A1 (en) | System and method for executing an encrypted binary from a memory pool | |
| Islam et al. | Confidential execution of deep learning inference at the untrusted edge with arm trustzone | |
| US11886350B2 (en) | System memory context determination for integrity monitoring and related techniques | |
| US20190215160A1 (en) | Managing a set of cryptographic keys in an encrypted system | |
| Huang et al. | ThinORAM: towards practical oblivious data access in fog computing environment | |
| WO2020242689A1 (en) | Execution of deep-learning model | |
| US10810137B2 (en) | Physical address randomization for secure encrypted memory | |
| EP4202748A1 (en) | Data oblivious cryptographic computing | |
| US10528746B2 (en) | System, apparatus and method for trusted channel creation using execute-only code | |
| JP7621675B2 (ja) | トラスト環境ベースの人工知能装置 | |
| Choi et al. | GuardiaNN: Fast and Secure On-Device Inference in TrustZone Using Embedded SRAM and Cryptographic Hardware | |
| WO2017166206A1 (en) | Techniques for accelerated secure storage capabilities | |
| Omar et al. | Breaking the oblivious-ram bandwidth wall | |
| KR20190091606A (ko) | Gpu를 이용한 파일 시스템 레벨 암호화 장치 및 방법 | |
| Haifeng et al. | Memory confidentiality and integrity protection method based on variable length counter | |
| Kurdziel et al. | Minimizing performance overhead in memory encryption |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230808 |
|
| A80 | Written request to apply exceptions to lack of novelty of invention |
Free format text: JAPANESE INTERMEDIATE CODE: A80 Effective date: 20230823 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240618 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240913 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20241217 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250107 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7621675 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |