JP7621608B2 - 財務諸表不正推定装置、財務諸表不正推定方法及びプログラム - Google Patents
財務諸表不正推定装置、財務諸表不正推定方法及びプログラム Download PDFInfo
- Publication number
- JP7621608B2 JP7621608B2 JP2024055350A JP2024055350A JP7621608B2 JP 7621608 B2 JP7621608 B2 JP 7621608B2 JP 2024055350 A JP2024055350 A JP 2024055350A JP 2024055350 A JP2024055350 A JP 2024055350A JP 7621608 B2 JP7621608 B2 JP 7621608B2
- Authority
- JP
- Japan
- Prior art keywords
- fraud
- financial statement
- text information
- explanatory variables
- financial
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



























Description
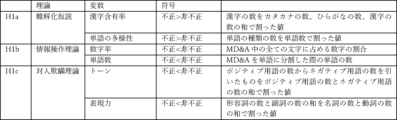
本発明の一実施形態において、財務諸表不正推定装置は、前記説明変数として前記テキスト情報の表現力をさらに含む。
本発明の一実施形態において、財務諸表不正推定装置は、前記説明変数として前記テキスト情報の漢字含有率又は学年をさらに含む。
本発明の一実施形態において、財務諸表不正推定装置は、前記説明変数として前記テキスト情報の単語数をさらに含む。
本発明の一実施形態において、財務諸表不正推定装置は、前記説明変数として前記テキスト情報の表現力、漢字含有率又は学年、単語数をさらに含む。
本発明の一実施形態において、財務諸表不正推定装置は、前記説明変数として前記テキスト情報の単語の多様性及びトーンをさらに含む。
本発明の一実施形態において、財務諸表不正推定装置は、前記説明変数と、前記企業にかかる財務諸表不正の有無と、を入力して両者の相関関係を学習し、前記学習済みモデルを生成する機械学習部をさらに有し、前記機械学習部はアンサンブル学習により前記学習を行う。
本発明の一実施形態において、前記機械学習部は勾配ブースティング決定木(Gradient Boosting Decision Tree)により前記学習を行う。
本発明の一実施形態において、前記機械学習部はランダムフォレストにより前記学習を行う。
本発明の一実施形態において、財務諸表不正推定装置は、前記テキスト情報としてMD&A(Management’s Discussion and Analysis of Financial Condition and Results of Operations)を使用する。
本発明の一実施形態において、財務諸表不正推定方法は、コンピュータにおいて実行される財務諸表不正推定方法であって、企業又はその経営者が開示するテキスト情報を分析して1以上の説明変数を生成するテキスト情報分析ステップと、前記テキスト情報分析ステップにおいて生成された前記説明変数を、前記説明変数と前記企業にかかる財務諸表不正の有無との相関関係を示す学習済みモデル又は統計モデルに入力し、前記企業にかかる財務諸表不正の有無を推定する不正推定ステップと、を有し、前記説明変数として数字率を含む。
本発明の一実施形態において、プログラムは、方法をコンピュータに実行させる。
言語上の複雑性は情報量と難解化の2つの構成要素に分解できる。このうち情報量は情報の非対称性と負の相関があり、難解化は情報の非対称性と正の相関がある。ある研究によれば、赤字企業は、文章を難解にして業績不振を隠蔽する一方で、情報量を増やす開示を行う傾向がある。難解化仮説(Obfuscation Hypothesis)とは、経営者が悪いニュースについては隠蔽したり、より前向きな情報を示したりすることによって投資者をミスリードするという仮説である。情報量については、企業または経営者が関与する財務諸表不正の検出が目的であること、Bad news自体が読みにくいということが別の研究で実証されていることから、本実施の形態では考慮しない。本実施の形態では、経営者の裁量がより働きやすいと考えられる難解化にのみ焦点を合わせる。
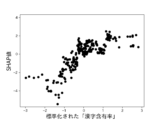
・漢字含有率:テキスト情報に出現する漢字の数を、カタカナの数、ひらがなの数、漢字の数の和で割った値。
・単語の多様性:テキスト情報に出現する単語の種類の数を単語数で割った値。ここで単語の種類の数とは、重複を除いた単語数のことである。
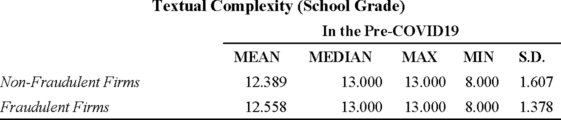
・学年:テキストの複雑さを示す「学年(Grade)」は、“世の中に存在する日本語文章の難易度分布の中で、ある文章がどのような位置にあるのか”を示す指標である(Sato 2008)。佐藤(2011)に依拠して、OBIソフトウェアで、バランスコーパスに基づく相対的な難易度を、日本の学校の学年に対応する13段階に分けて、複雑度を測定する方法を用いている。すなわち、小学校1年次生(複雑さレベル1)から学年高等学校3年次生(複雑さレベル12)、さらに大学(複雑さレベル13)までの13段階のうちどれかの学年で表示される(Sato 2008)。
情報操作理論によれば、受容者をミスリードする目的で提示する情報の量(情報量のコントロール)、質(情報の歪曲)、方法(曖昧なスタイルでの提示)、関連性(無関係な情報)を操作することによって、情報開示の一部または全部を利用することが可能である。不正検出研究として可読性を考察した研究Nakashima et al.(2022)によれば、不正企業と非不正企業間で長さ(文字数)に有意差は観察されていない。不正企業は、財務諸表数値に虚偽があり、その虚偽、特に数字や単語数を隠ぺいすることが予想できる。そこで、仮説H1b「不正企業経営者は、虚偽の数字を示すことができず、隠蔽するので、非不正企業よりも数字率および単語数が低くなる。」を設定する。
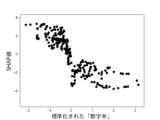
・数字率:テキスト情報に出現する全ての文字に占める数字の割合。
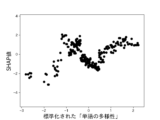
・単語数:テキスト情報を単語に分割した際の単語の数。
ある研究によれば、不正なMD&Aは、真実のMD&Aに比べ、平均して3倍以上のポジティブなセンチメントと4倍以上のネガティブなセンチメントを含んでおり、このことは、不正なMD&Aでは、ポジティブとネガティブの両方のセンチメントがより顕著に使用されていることを示唆している。不正企業はより印象管理に従事し、だましてよりポジティブに企業を描写する。実際に、不正企業経営者はポジティブニュースを大げさにしたり、ネガティブなニュースを最小化したり隠蔽したりして誤った印象を伝えていることが発見されている。
・トーン:テキスト情報に出現するポジティブ用語の数からネガティブ用語の数を引いたものを、ポジティブ用語の数とネガティブ用語の数の和で割った値。ここで、ポジティブ用語及びネガティブ用語の数は以下の手順で測定できる。まず、テキスト情報としての日本語の文章を単語ごとに切断してから、品詞を判断する。そして、辞書を参照し、ポジティブ用語、ネガティブ用語に相当する単語が文章中にいくつあるのかを算定する。辞書は、公知の単語感情極性対応表を使用できる。
・表現力:形容詞の数と副詞の数の和を名詞の数と動詞の数の和で割った値。
単一の木構造を用いた教師あり機械学習による分析の総称である。本実施の形態で用いた他の手法(ランダムフォレスト、XGBoost、LightGBM、CatBoost)と比較して、得られるモデルの精度では劣る傾向がある。しかしながら、モデルの木構造の可視化の点において他手法に勝る。
アンサンブル型学習手法の一種である。元の訓練データから重複を許しつつランダムにいくつかのデータを抽出し、新しい訓練データを構築する。その後、構築された新しい訓練データを元に決定木分析をおこなう。上記の操作を並列に行うことで複数のモデル(弱学習器)を得る。目的変数の推定の際には、複数の弱学習器から得られる出力値に基づいた多数決を行う。より多くの弱学習器が出力した推定結果を最終的な出力とする。この方法により、単一のモデルに比べ、過学習の危険性の軽減が期待される。
以降の手法もランダムフォレストと同様にアンサンブル型学習手法である。各弱学習器が木の構造を持っている点においてもランダムフォレストと類似する。しかし、弱学習器の構成(決定)法・集約法は大きく異なる。ランダムフォレストにおいては、過学習の抑制が目的であったが、以降の手法の主な目的は予測精度の向上である。一方で、以降説明する手法は決定木分析やランダムフォレストよりも、過学習が生じやすい手法である。
LightGBMは、学習アルゴリズムにおいて、XGBoostと類似する手法である。目的変数が1である確率を、木の構造を持つ弱学習器たちの推定値の総和で推定する点において、XGBoostと変わらない。XGBoostとの主な違いは各回帰木の構成方法にある。
XGBoostやLightGBMと同様に、CatBoostも木の構造を持つ弱学習器たちの推定値の総和によって目的変数が1である確率を推定する手法である。勾配ブースティング決定木(Gradient Boosting Decision Tree)の一種である。各弱学習器を構築する際に、訓練データからランダムにサンプリングしたデータを用いるため、XGBoostやLightGBMよりも過学習を起こしにくい手法とされる。
本実施の形態にかかる財務諸表不正推定装置1を使用し、実在する企業が開示したテキスト情報を対象として、財務諸表不正の有無を推定する実験を行なった。その手法と結果を以下に示す。
分析対象企業は、企業はすべて日本取引所に上場している企業3483社のうち、銀行業・保険業(165社)、米国基準およびIFRS基準その他基準(320社)を除外した、日本基準を適用している企業2998社である。不正企業群は、東京商工リサーチ(株)による『2020年不適切な会計・経理」(以下、不適切会計)を開示した上場企業』の2019年に不不適切会計とされた会社73社のうち、会社ぐるみの不正31社、従業員関連の不正が12社、上級経営者個人の不正が3社、子会社関連不正が27社である。会社ぐるみの不正31社のうち、6社が上場廃止企業であり、最終サンプルは25社である。業種と総資産および売上高の類似した企業群をペアの非不正企業としている。図5は、不正企業群25社、非不正企業群25社のt検定結果を示している。図5から、不正企業、非不正企業の総資産、売上高に有意差がなく、ペアサンプルとして妥当であることがわかる。
(2-1)機械学習による財務諸表不正推定の試行
図6に示すフローチャートに従って、財務諸表推定装置1を使用し、機械学習による不正検知モデルの生成及び当該モデルによる財務諸表不正推定を試行した。機械学習手法としては決定木、ランダムフォレスト、XGBoost、LightGBM、CatBoostを用いた。
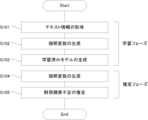
S101:テキスト情報の取得
テキスト情報入力部101が、企業またはその経営者が開示するテキスト情報を取得する。本実験では、(1)サンプル選択とデータにおいて示した企業50社の2013年度から2018年度までの6年分のMD&Aを学習用のテキスト情報として収集、入力した。
テキスト情報分析部102は、テキスト情報入力部101に入力されたテキスト情報を分析し、説明変数を生成する。本実験では、図7に示す6つの説明変数を生成した。
機械学習部104は、S102で生成された6つの説明変数と、財務諸表不正の有無を示す目的変数(2値)と、のセットを学習用データとして繰り返し入力し、学習済みモデルを生成する。本実験では、機械学習手法として決定木、ランダムフォレスト、XGBoost、LightGBM、CatBoostの5種類を採用し、それぞれ学習済みモデルを生成した。
S104:テキスト情報の取得
テキスト情報入力部101が、企業またはその経営者が開示するテキスト情報を取得する。本実験では、(1)サンプル選択とデータにおいて示した企業50社の2019年度のMD&Aを推定用のテキスト情報として収集、入力した。
テキスト情報分析部102は、テキスト情報入力部101に入力されたテキスト情報を分析し、説明変数を生成する。本実験では、図7に示す6つの説明変数を生成した。
不正推定部103は、S105で生成された6つの説明変数をS103で生成された学習済みモデルに入力し、財務諸表不正の有無を示す目的変数(2値)を推定結果として出力する。
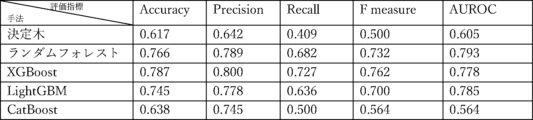
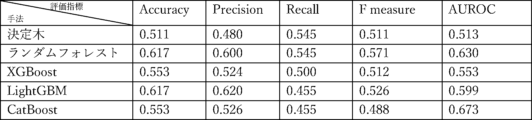
複数の機械学習手法(決定木、ランダムフォレスト、XGBoost、LightGBM、CatBoost)により生成された分類器の有効性を評価するため、Accuracy、Precision、Recall、F measure、AUROCを算出する。Accuracyは、正しく分類されたMD&A開示の総数を分析されたMD&A開示の総数で除したものである。Precisionは、不正と分類されたMD&A開示の総数に対する、不正と正しく分類されたMD&A開示数の比率である。Recallは、実際の不正のMD&A開示の総数に対する、不正と正しく分類されたMD&A開示の数の比率である。RecallはTrue Positive Rate(真陽性率)とも呼ばれる。以下では、True Positive RateをTPRと略記する。対して、実際の非不正のMD&A開示の総数に対する、不正と誤って分類されたMD&A開示の数の比率をFalse Positive Rate(偽陽性率)と呼ぶ。以下では、False Positive RateをFPRと略記する。
(3-1)統計学的検定の結果
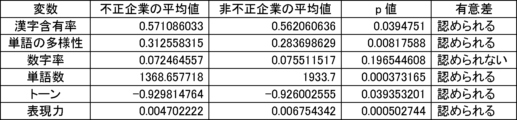
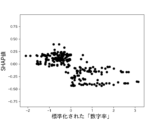
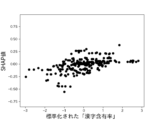
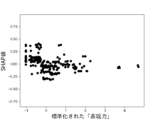
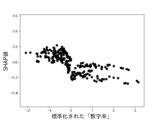
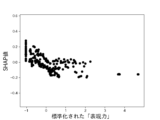
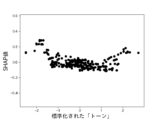
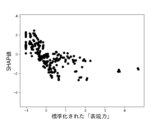
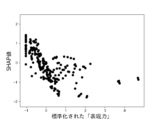
本実験で用いる6個の説明変数に対して、不正企業の群と非不正企業の群の間に有意差があるかをマンホイットニーのU検定(有意水準5%)によって調べた。結果を図10に示す。不正企業は、非不正企業と比べて、漢字含有率が高く、単語の多様性が高く、数字率が低く、単語数が低く、トーンが低く、表現力が低いことがわかった。ただし、数字率については有意差が認められなかった。しかしながら、後述の(3-2)モデルの評価により、数字率は本実験の機械学習モデルの推定に強く寄与していることがわかった。
本実験では、2013年度から2018年度までのデータを訓練データ、2019年度のデータをテストデータとした。また、説明変数として図7に示す6つの説明変数を使用した。
図18は「数字率」及び「単語数」のみを用いた際のモデルの評価指標である。
図19は「数字率」及び「漢字含有率」のみを用いた際のモデルの評価指標である。
図20は「数字率」及び「表現力」のみを用いた際のモデルの評価指標である。
説明変数として、「数字率」のみを用いた際の評価は図21の通りであった。
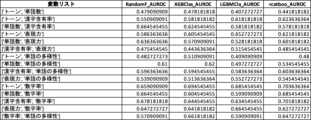
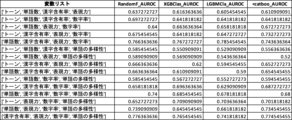
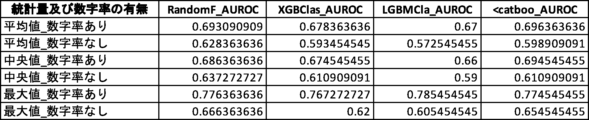
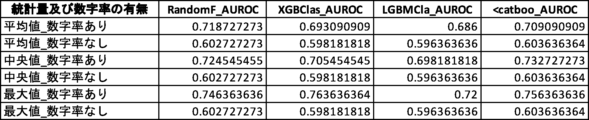
財務諸表不正推定における数字率の有用性をさらに検証するため、数字率を用いずに他の1以上の説明変数を用いた場合の機械学習モデルのAUROC値と、数字率を併用した場合のAUROC値との対比実験を行った(対比実験1)。対比実験1の結果を図23に示す。なお、検証に用いた機械学習アルゴリズムに内在するランダム性により、図17乃至図22において示されている値とは多少の差異がある。
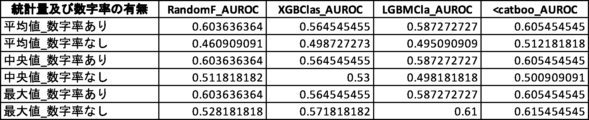
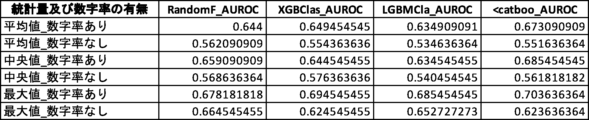
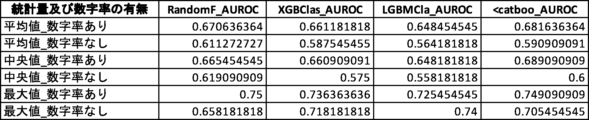
さらなる検証のため、説明変数として数字率を含むグループと、数字率を含まないグループとのAUROC値を比較する対比実験を行った(対比実験2)。対比実験2では、2つのグループの説明変数の数は同じになるようにした。対比実験2の結果を図24及び図25に示す。なお、検証に用いた機械学習アルゴリズムに内在するランダム性により、図17乃至図22において示されている値とは多少の差異がある。
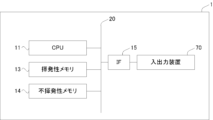
11 CPU
13 揮発性メモリ
14 不揮発性メモリ
15 インタフェース
16 インタフェース
20 バス
70 入出力装置
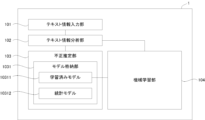
101 テキスト情報入力部
102 テキスト情報分析部
103 不正推定部
1031 モデル格納部
10311 学習済みモデル
10312 統計モデル
104 機械学習部
Claims (12)
- 企業又はその経営者が開示するテキスト情報を分析して1以上の説明変数を生成するテキスト情報分析部と、
前記説明変数と、前記企業にかかる財務諸表不正の有無と、の相関関係を示す学習済みモデルを格納したモデル格納部と、
前記テキスト情報分析部が生成した前記説明変数を、前記学習済みモデルに入力し、前記企業にかかる財務諸表不正の有無を推定する不正推定部と、を有し、
前記説明変数として前記テキスト情報の数字率を含む
財務諸表不正推定装置。 - 前記説明変数として前記テキスト情報の表現力をさらに含み、
前記表現力とは、形容詞の数と副詞の数の和を名詞の数と動詞の数の和で割った値である
請求項1記載の財務諸表不正推定装置。 - 前記説明変数として前記テキスト情報の漢字含有率又は学年をさらに含む
請求項1記載の財務諸表不正推定装置。 - 前記説明変数として前記テキスト情報の単語数をさらに含む
請求項1記載の財務諸表不正推定装置。 - 前記説明変数として前記テキスト情報の表現力、漢字含有率又は学年、単語数をさらに含み、
前記表現力とは、形容詞の数と副詞の数の和を名詞の数と動詞の数の和で割った値である
請求項1記載の財務諸表不正推定装置。 - 前記説明変数として前記テキスト情報の単語の多様性及びトーンをさらに含む
請求項5記載の財務諸表不正推定装置。 - 前記説明変数と、前記企業にかかる財務諸表不正の有無と、を入力して両者の相関関係を学習し、前記学習済みモデルを生成する機械学習部をさらに有し、
前記機械学習部はアンサンブル学習により前記学習を行う
請求項1乃至6いずれか1項記載の財務諸表不正推定装置。 - 前記機械学習部は勾配ブースティング決定木(Gradient Boosting Decision Tree)により前記学習を行う
請求項7記載の財務諸表不正推定装置。 - 前記機械学習部はランダムフォレストにより前記学習を行う
請求項7記載の財務諸表不正推定装置。 - 前記テキスト情報としてMD&A(Management’s Discussion and Analysis of Financial Condition and Results of Operations)を使用する
請求項1乃至6いずれか1項記載の財務諸表不正推定装置。 - コンピュータにおいて実行される財務諸表不正推定方法であって、
企業又はその経営者が開示するテキスト情報を分析して1以上の説明変数を生成するテキスト情報分析ステップと、
前記テキスト情報分析ステップにおいて生成された前記説明変数を、前記説明変数と前記企業にかかる財務諸表不正の有無との相関関係を示す学習済みモデルに入力し、前記企業にかかる財務諸表不正の有無を推定する不正推定ステップと、を有し、
前記説明変数として数字率を含む
財務諸表不正推定方法。 - 請求項11記載の方法をコンピュータに実行させるためのプログラム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023075347 | 2023-04-29 | ||
| JP2023075347 | 2023-04-29 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2024160043A JP2024160043A (ja) | 2024-11-11 |
| JP7621608B2 true JP7621608B2 (ja) | 2025-01-27 |
Family
ID=93429131
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024055350A Active JP7621608B2 (ja) | 2023-04-29 | 2024-03-29 | 財務諸表不正推定装置、財務諸表不正推定方法及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7621608B2 (ja) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050004862A1 (en) | 2003-05-13 | 2005-01-06 | Dale Kirkland | Identifying the probability of violative behavior in a market |
-
2024
- 2024-03-29 JP JP2024055350A patent/JP7621608B2/ja active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050004862A1 (en) | 2003-05-13 | 2005-01-06 | Dale Kirkland | Identifying the probability of violative behavior in a market |
Non-Patent Citations (3)
| Title |
|---|
| 中島真澄,ナラティブ情報(非財務情報)からの会計不正検出,文京学院大学 オピニオンレター,Vol.32,文京学院大学,2022年09月16日,[online],インターネット<URL:https://bgu.ac.jp/about/activity/opinion_letter/>,[令和6年9月10日検索] |
| 市原 直通,外1名,FinTechで変わる会計の世界,企業会計,日本,株式会社中央経済社,2017年06月01日,第69巻 第6号,55-63頁 |
| 首藤昭信,テキスト分析と会計学研究,情報センサー,2019年5月号,日本,EY Japan,2019年04月30日,[online],インターネット<URL:https://ey.com/ja_jp/library/info-sensor/2019/info-sensor-2019-05-02>,[令和6年9月10日検索] |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2024160043A (ja) | 2024-11-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Boskou et al. | Classifying internal audit quality using textual analysis: the case of auditor selection | |
| Han et al. | Artificial intelligence for anti-money laundering: a review and extension | |
| Dong et al. | Leveraging financial social media data for corporate fraud detection | |
| Purda et al. | Accounting variables, deception, and a bag of words: Assessing the tools of fraud detection | |
| Berns et al. | Do changes in MD&A section tone predict investment behavior? | |
| Larcker et al. | Detecting deceptive discussions in conference calls | |
| Bodle et al. | Effect of IFRS adoption on financial reporting quality: Evidence from bankruptcy prediction | |
| Wang et al. | The textual contents of media reports of information security breaches and profitable short-term investment opportunities | |
| Cai et al. | Trends in fintech research and practice: Examining the intersection with the information systems field | |
| Rahrovi Dastjerdi et al. | Detecting manager’s fraud risk using text analysis: evidence from Iran | |
| Li et al. | Financial fraud detection for Chinese listed firms: Does managers' abnormal tone matter? | |
| Küster et al. | The informational content of key audit matters: Evidence from using artificial intelligence in textual analysis | |
| Gianfelici et al. | Exploring the going concern statement, readability and length cues as indicators of distress at Italian companies | |
| Ma et al. | Corporate social responsibility and trade credit: the role of textual features | |
| Yang et al. | Detecting financial statement fraud through multidimensional analysis of text readability | |
| Gkoumas et al. | Bank competition, loan portfolio concentration and stock price crash risk: The role of tone ambiguity | |
| Zheng et al. | The effects of sentiment evolution in financial texts: A word embedding approach | |
| Abbas | Lending by algorithm: Fair or flawed? An information-theoretic view of credit decision pipelines | |
| Fan et al. | Measuring misinformation in financial markets | |
| Huang et al. | Do firms incur financial restatements? A recognition study based on textual features of key audit matters reports | |
| Fedorova et al. | Monetary policy and market interest rates: Literature review using text analysis | |
| Xu et al. | Social media Q&A text semantic similarity and corporate fraud: evidence from the Shanghai Stock Exchange E-interaction platform in China | |
| Zhang et al. | Financial crisis early warning of Chinese listed companies based on MD&A text-linguistic feature indicators | |
| Othman et al. | Text readability and fraud detection | |
| JP7621608B2 (ja) | 財務諸表不正推定装置、財務諸表不正推定方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240405 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20240405 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240711 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240917 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20241118 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20241203 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241230 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7621608 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |