JP7581358B2 - 適応リターン計算方式を用いた強化学習 - Google Patents
適応リターン計算方式を用いた強化学習 Download PDFInfo
- Publication number
- JP7581358B2 JP7581358B2 JP2022548005A JP2022548005A JP7581358B2 JP 7581358 B2 JP7581358 B2 JP 7581358B2 JP 2022548005 A JP2022548005 A JP 2022548005A JP 2022548005 A JP2022548005 A JP 2022548005A JP 7581358 B2 JP7581358 B2 JP 7581358B2
- Authority
- JP
- Japan
- Prior art keywords
- reward
- return
- environment
- agent
- action
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/004—Artificial life, i.e. computing arrangements simulating life
- G06N3/006—Artificial life, i.e. computing arrangements simulating life based on simulated virtual individual or collective life forms, e.g. social simulations or particle swarm optimisation [PSO]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G06N3/0442—Recurrent networks, e.g. Hopfield networks characterised by memory or gating, e.g. long short-term memory [LSTM] or gated recurrent units [GRU]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/092—Reinforcement learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N7/00—Television systems
- H04N7/002—Special television systems not provided for by H04N7/007 - H04N7/18
- H04N7/005—Special television systems not provided for by H04N7/007 - H04N7/18 using at least one opto-electrical conversion device
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Algebra (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Feedback Control In General (AREA)
- Geophysics And Detection Of Objects (AREA)
Description
Σiγi-t-1ri、
を満足する。ここでiは、エピソード内のtの後の時間ステップのすべてにわたって、またはエピソード内のtの後の時間ステップのいくつかの固定数に対して変動し、γはディスカウントファクタであり、riは時間ステップiにおける総報酬である。上式から分かるように、ディスカウントファクタの値が高いほど、リターン計算に対してより長い計画対象期間をもたらし、すなわち、時間ステップtから時間的により離れた時間ステップからの報酬が、リターン計算においてより大きい重みを与えられることをもたらす。
Q(x, a, j: θ)=Q(x, a, j: θe)+βj・Q(x, a, j: θi)
を満たすことができ、ここでQ(x, a, j: θe)はアクションaに対する外発的アクションスコアであり、Q(x, a, j: θi)はアクションaに対する内発的アクションスコアであり、βjはj番目の方式内のスケーリングファクタである。
Q(x, a, j: θ)=h(h-1(Q(x, a, j: θe))+βjh-1(Q(x, a, j: θi)))
を満たすことができ、ここでhは、ニューラルネットワークのために概算することを容易にするために、状態-アクション値関数、すなわち外発的および内発的報酬関数をスケーリングする単調増加の反転可能なスカッシング関数である。




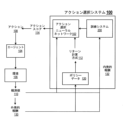
102 アクション選択ニューラルネットワーク
104 エージェント
106 環境
108 アクション
110 観測値
112 リターン計算方式
114 アクションスコア
120 ポリシーデータ
130 外発的報酬
132 内発的報酬
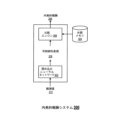
200 訓練システム
202 総報酬
204 外発的報酬
206 内発的報酬、探査報酬
208 訓練エンジン
210 リターン計算方式
212 観測値
300 内発的報酬システム
302 埋め込みニューラルネットワーク
304 外部メモリ
306 比較エンジン
308 可制御性表現
Claims (15)
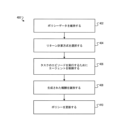
- タスクのエピソードを実行するために環境と相互作用するエージェントを制御するために1つまたは複数のコンピュータにより実行される方法であって、
複数の異なるリターン計算方式の間で選択するためのポリシーを規定するデータを維持するステップであって、各リターン計算方式が、異なる重要度を、前記タスクの前記エピソードを実行しながら前記環境を探査することに対して割り当て、前記ポリシーは、前記リターン計算方式の各々にそれぞれの報酬スコアを割り当てる、ステップと、
前記ポリシーを使用して、前記複数の異なるリターン計算方式からリターン計算方式を選択するステップと、
前記選択されたリターン計算方式に従って計算されたリターンを最大化するように前記タスクの前記エピソードを実行するために前記エージェントを制御するステップと、
前記エージェントが前記タスクの前記エピソードを実行した結果として生成された報酬を識別するステップと、
前記識別された報酬を使用して、複数の異なるリターン計算方式の間で選択するために前記ポリシーを更新するステップと
を含む、方法。 - 前記複数の異なるリターン計算方式が、少なくとも、リターンを生成するために報酬を組み合わせることにおいて使用されるそれぞれのディスカウントファクタをそれぞれ規定する、請求項1に記載の方法。
- 前記複数の異なるリターン計算方式が、リターンを生成するときに前記環境から受信された外発的報酬に対する内発的報酬の重要度を定義する少なくとも1つのそれぞれの内発的報酬スケーリングファクタをそれぞれ規定する、請求項1または2に記載の方法。
- 前記選択されたリターン計算方式に従って計算されたリターンを最大化するように前記タスクの前記エピソードを実行するために前記エージェントを制御するステップが、以下の、
前記環境の現在の状態を特徴づける観測値を受信するステップと、
アクション選択出力を生成するために1つまたは複数のアクション選択ニューラルネットワークを使用して、前記観測値と前記選択されたリターン計算方式を規定するデータとを処理するステップと、
前記アクション選択出力を使用して前記エージェントによって実行されるアクションを選択するステップと
を反復して実行するステップを含む、請求項1から3のいずれか一項に記載の方法。 - 前記環境は実世界の環境であり、各観測値は前記環境を感知するように構成された少なくとも1つのセンサの出力であり、前記エージェントは前記環境と相互作用する機械的エージェントである、請求項4に記載の方法。
- タスクのエピソードを実行するために環境と相互作用するエージェントを制御するために1つまたは複数のコンピュータにより実行される方法であって、
複数の異なるリターン計算方式の間で選択するためのポリシーを規定するデータを維持するステップであって、各リターン計算方式が、異なる重要度を、前記タスクの前記エピソードを実行しながら前記環境を探査することに対して割り当てる、ステップと、
前記ポリシーを使用して、前記複数の異なるリターン計算方式からリターン計算方式を選択するステップと、
前記選択されたリターン計算方式に従って計算されたリターンを最大化するように前記タスクの前記エピソードを実行するために前記エージェントを制御するステップであって、
前記環境の現在の状態を特徴づける観測値を受信するステップと、
アクション選択出力を生成するために1つまたは複数のアクション選択ニューラルネットワークを使用して、前記観測値と、前記選択されたリターン計算方式を規定するデータとを処理するステップと、
前記アクション選択出力を使用して前記エージェントによって実行されるアクションを選択するステップと
を反復して実行するステップを含む、制御するステップと、
前記エージェントが前記タスクの前記エピソードを実行した結果として生成された報酬を識別するステップと、
前記識別された報酬を使用して、複数の異なるリターン計算方式の間で選択するために前記ポリシーを更新するステップと
を含み、
前記1つまたは複数のアクション選択ニューラルネットワークが、
前記環境との相互作用の間に受信された観測値に基づいて内発的報酬システムによって生成された内発的報酬のみから計算された内発的リターンを推定する内発的報酬アクション選択ニューラルネットワークと、
前記環境との相互作用の結果として前記環境から受信された外発的報酬のみから計算された外発的リターンを推定する外発的報酬アクション選択ニューラルネットワークとを含む、方法。 - アクション選択出力を生成するために1つまたは複数のアクション選択ニューラルネットワークを使用して、前記観測値と前記選択されたリターン計算方式を規定するデータとを処理するステップが、アクションのセット内の各アクションに対して、
前記エージェントが前記観測値に応答して前記アクションを実行する場合に受信される推定された内発的リターンを生成するために、前記内発的報酬アクション選択ニューラルネットワークを使用して、前記観測値と、前記アクションと、前記選択されたリターン計算方式を規定する前記データと、を処理するステップと、
前記エージェントが前記観測値に応答して前記アクションを実行する場合に受信される推定された外発的リターンを生成するために、前記外発的報酬アクション選択ニューラルネットワークを使用して、前記観測値と、前記アクションと、前記選択されたリターン計算方式を規定する前記データと、を処理するステップと、
前記推定された内発的報酬および前記推定された外発的報酬から最終リターン推定を決定するステップとを含む、請求項6に記載の方法。 - 前記アクション選択出力を使用して前記エージェントによって実行されるアクションを選択するステップが、
前記アクションのセット内の各アクションに対して決定した最終リターン推定のうち、最高の最終リターン推定に対応するアクションを確率1-εで選択し、確率εでアクションの前記セットからランダムアクションを選択するステップとを含む、請求項7に記載の方法。 - 前記2つのアクション選択ニューラルネットワークは、同じアーキテクチャを有するが異なるパラメータ値を有する、請求項6から8のいずれか一項に記載の方法。
- 前記タスクのエピソードの実行から訓練データを生成するステップと、
強化学習を通して前記訓練データ上で前記1つまたは複数のアクション選択ニューラルネットワークを訓練するステップとをさらに含む、請求項6から9のいずれか一項に記載の方法。 - 前記訓練データ上で前記1つまたは複数のアクション選択ニューラルネットワークを訓練するステップが、
前記タスクのエピソードの前記実行の結果として生成された内発的報酬のみを使用して前記内発的報酬アクション選択ニューラルネットワークを訓練するステップと、
前記タスクのエピソードの前記実行の間に受信された外発的報酬のみを使用して前記外発的報酬アクション選択ニューラルネットワークを訓練するステップとを含む、請求項10に記載の方法。 - タスクのエピソードを実行するために環境と相互作用するエージェントを制御するために1つまたは複数のコンピュータにより実行される方法であって、
複数の異なるリターン計算方式の間で選択するためのポリシーを規定するデータを維持するステップであって、各リターン計算方式が、異なる重要度を、前記タスクの前記エピソードを実行しながら前記環境を探査することに対して割り当てる、ステップと、
前記ポリシーを使用して、前記複数の異なるリターン計算方式からリターン計算方式を選択するステップと、
前記選択されたリターン計算方式に従って計算されたリターンを最大化するように前記タスクの前記エピソードを実行するために前記エージェントを制御するステップと、
前記エージェントが前記タスクの前記エピソードを実行した結果として生成された報酬を識別するステップと、
前記識別された報酬を使用して、複数の異なるリターン計算方式の間で選択するために前記ポリシーを更新するステップであって、前記ポリシーは、前記リターン計算方式の各々に対応するそれぞれの腕を有する非定常多腕バンディットアルゴリズムを使用して更新される、ステップと
を含む、方法。 - 前記識別された報酬を使用して、複数の異なるリターン計算方式の間で選択するために前記ポリシーを更新するステップが、
前記タスクのエピソードの実行の間に受信された外発的報酬からディスカウントされない外発的リターンを決定するステップと、
前記ディスカウントされない外発的報酬を前記非定常多腕バンディットアルゴリズムに対する報酬信号として使用することによって前記ポリシーを更新するステップとを含む、請求項12に記載の方法。 - 1つまたは複数のコンピュータと、命令を記憶する1つまたは複数の記憶デバイスとを含むシステムであって、前記命令が、前記1つまたは複数のコンピュータによって実行されたとき、請求項1から13のいずれか一項に記載の方法の動作を前記1つまたは複数のコンピュータに実行させる、システム。
- 命令を記憶する1つまたは複数の非一時的コンピュータ記憶媒体であって、前記命令が、1つまたは複数のコンピュータによって実行されたとき、請求項1から13のいずれか一項に記載の方法の動作を前記1つまたは複数のコンピュータに実行させる、1つまたは複数の非一時的コンピュータ記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202062971890P | 2020-02-07 | 2020-02-07 | |
| US62/971,890 | 2020-02-07 | ||
| PCT/EP2021/052988 WO2021156518A1 (en) | 2020-02-07 | 2021-02-08 | Reinforcement learning with adaptive return computation schemes |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023512722A JP2023512722A (ja) | 2023-03-28 |
| JP7581358B2 true JP7581358B2 (ja) | 2024-11-12 |
Family
ID=74591970
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022548005A Active JP7581358B2 (ja) | 2020-02-07 | 2021-02-08 | 適応リターン計算方式を用いた強化学習 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20230059004A1 (ja) |
| EP (1) | EP4100881B1 (ja) |
| JP (1) | JP7581358B2 (ja) |
| KR (1) | KR20220137732A (ja) |
| CN (1) | CN115298668A (ja) |
| CA (1) | CA3167201A1 (ja) |
| WO (1) | WO2021156518A1 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220100184A1 (en) * | 2021-12-09 | 2022-03-31 | Intel Corporation | Learning-based techniques for autonomous agent task allocation |
| CN114362773B (zh) * | 2021-12-29 | 2022-12-06 | 西南交通大学 | 一种面向光学射频对消的实时自适应追踪决策方法 |
| GB202202994D0 (en) * | 2022-03-03 | 2022-04-20 | Deepmind Tech Ltd | Agent control through cultural transmission |
| CN114676635B (zh) * | 2022-03-31 | 2022-11-11 | 香港中文大学(深圳) | 一种基于强化学习的光学谐振腔反向设计和优化的方法 |
| CN114492845B (zh) * | 2022-04-01 | 2022-07-15 | 中国科学技术大学 | 资源受限条件下提高强化学习探索效率的方法 |
| EP4569439A1 (en) * | 2022-09-15 | 2025-06-18 | DeepMind Technologies Limited | Data-efficient reinforcement learning with adaptive return computation schemes |
| JP2025534201A (ja) * | 2022-09-26 | 2025-10-15 | ディープマインド テクノロジーズ リミテッド | 報告者ニューラルネットワークを使用したエージェントの制御 |
| CN116050749A (zh) * | 2022-12-26 | 2023-05-02 | 阿里巴巴(中国)有限公司 | 基于深度强化学习的任务调度网络训练方法 |
| CN116225008B (zh) * | 2023-02-24 | 2025-10-21 | 上海大学 | 一种水面水下双模态无人航行器海洋自主巡航路径规划方法及控制系统 |
| CN116360435A (zh) * | 2023-03-24 | 2023-06-30 | 南京大学 | 基于情节记忆的多智能体协同策略的训练方法和系统 |
| CN117010475B (zh) * | 2023-08-07 | 2025-11-14 | 同济大学 | 一种基于最大熵内在奖励的无监督技能学习系统 |
| KR20250098675A (ko) | 2023-12-22 | 2025-07-01 | 고려대학교 산학협력단 | 사람의 노동이 불필요한 인간 피드백 기반 강화학습 언어 모델 생성 방법 |
| KR102696218B1 (ko) * | 2024-02-27 | 2024-08-20 | 한화시스템 주식회사 | 희소보상 전장환경에서의 멀티 에이전트 강화학습 협업 프레임워크 시스템 및 이의 학습 방법 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019537136A (ja) | 2016-11-04 | 2019-12-19 | ディープマインド テクノロジーズ リミテッド | 強化学習を用いた環境予測 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DK3535705T3 (da) * | 2016-11-04 | 2022-05-30 | Deepmind Tech Ltd | Forstærkningslæring med hjælpeopgaver |
| US20180165602A1 (en) * | 2016-12-14 | 2018-06-14 | Microsoft Technology Licensing, Llc | Scalability of reinforcement learning by separation of concerns |
| CN110520868B (zh) * | 2017-04-14 | 2023-06-02 | 渊慧科技有限公司 | 用于分布式强化学习的方法、程序产品和存储介质 |
-
2021
- 2021-02-08 CA CA3167201A patent/CA3167201A1/en active Pending
- 2021-02-08 CN CN202180021105.3A patent/CN115298668A/zh active Pending
- 2021-02-08 KR KR1020227030755A patent/KR20220137732A/ko active Pending
- 2021-02-08 WO PCT/EP2021/052988 patent/WO2021156518A1/en not_active Ceased
- 2021-02-08 EP EP21704741.4A patent/EP4100881B1/en active Active
- 2021-02-08 US US17/797,878 patent/US20230059004A1/en active Pending
- 2021-02-08 JP JP2022548005A patent/JP7581358B2/ja active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019537136A (ja) | 2016-11-04 | 2019-12-19 | ディープマインド テクノロジーズ リミテッド | 強化学習を用いた環境予測 |
Non-Patent Citations (1)
| Title |
|---|
| ZHANG, Jingwei ほか,Scheduled Intrinsic Drive: A Hierarchical Take on Intrinsically Motivated Exploration,arXiv[online],2019年06月21日,[retrieved on 2023.08.17], Retrieved from the Internet: <URL: https://arxiv.org/pdf/1903.07400v2.pdf> |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230059004A1 (en) | 2023-02-23 |
| EP4100881B1 (en) | 2025-12-03 |
| CN115298668A (zh) | 2022-11-04 |
| KR20220137732A (ko) | 2022-10-12 |
| CA3167201A1 (en) | 2021-08-12 |
| JP2023512722A (ja) | 2023-03-28 |
| EP4100881A1 (en) | 2022-12-14 |
| WO2021156518A1 (en) | 2021-08-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7581358B2 (ja) | 適応リターン計算方式を用いた強化学習 | |
| US20240028866A1 (en) | Jointly learning exploratory and non-exploratory action selection policies | |
| US12067491B2 (en) | Multi-agent reinforcement learning with matchmaking policies | |
| US11663441B2 (en) | Action selection neural network training using imitation learning in latent space | |
| CN112119404B (zh) | 样本高效的强化学习 | |
| JP7516666B2 (ja) | パレートフロント最適化を使用する制約付き強化学習ニューラルネットワークシステム | |
| US20220164673A1 (en) | Unsupervised control using learned rewards | |
| CN112119406A (zh) | 利用快速更新循环神经网络和慢速更新循环神经网络的深度强化学习 | |
| US12008077B1 (en) | Training action-selection neural networks from demonstrations using multiple losses | |
| CN110088774A (zh) | 使用强化学习的环境导航 | |
| EP3593292A1 (en) | Training action selection neural networks | |
| JP7354460B2 (ja) | ブートストラップされた潜在性の予測を使用するエージェント制御のための学習環境表現 | |
| JP7818750B2 (ja) | 相対エントロピーq学習を使ったアクション選択システムのトレーニング | |
| JP2025518439A (ja) | 大規模な階層的強化学習 | |
| US20240086703A1 (en) | Controlling agents using state associative learning for long-term credit assignment | |
| WO2023012234A1 (en) | Controlling agents by switching between control policies during task episodes | |
| WO2024056891A1 (en) | Data-efficient reinforcement learning with adaptive return computation schemes |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20221005 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230818 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230904 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231204 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240304 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240604 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240930 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241030 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7581358 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |