JP7579477B2 - Image encoding device, image decoding device, and bitstream generating device - Google Patents
Image encoding device, image decoding device, and bitstream generating device Download PDFInfo
- Publication number
- JP7579477B2 JP7579477B2 JP2024027119A JP2024027119A JP7579477B2 JP 7579477 B2 JP7579477 B2 JP 7579477B2 JP 2024027119 A JP2024027119 A JP 2024027119A JP 2024027119 A JP2024027119 A JP 2024027119A JP 7579477 B2 JP7579477 B2 JP 7579477B2
- Authority
- JP
- Japan
- Prior art keywords
- partition
- motion vector
- unit
- block
- prediction
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/573—Motion compensation with multiple frame prediction using two or more reference frames in a given prediction direction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/117—Filters, e.g. for pre-processing or post-processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/137—Motion inside a coding unit, e.g. average field, frame or block difference
- H04N19/139—Analysis of motion vectors, e.g. their magnitude, direction, variance or reliability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/182—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a pixel
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/513—Processing of motion vectors
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/537—Motion estimation other than block-based
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/56—Motion estimation with initialisation of the vector search, e.g. estimating a good candidate to initiate a search
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/587—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal sub-sampling or interpolation, e.g. decimation or subsequent interpolation of pictures in a video sequence
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/85—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using pre-processing or post-processing specially adapted for video compression
- H04N19/86—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using pre-processing or post-processing specially adapted for video compression involving reduction of coding artifacts, e.g. of blockiness
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/96—Tree coding, e.g. quad-tree coding
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Apparatus For Radiation Diagnosis (AREA)
- Closed-Circuit Television Systems (AREA)
Description
本開示は、ビデオコーディングに関し、例えば、インター予測を行うことで参照フレームに基づきカレントブロックを構築するか、またはイントラ予測を行うことでカレントフレーム内の符号化/復号済み参照ブロックに基づきカレントブロックを構築する、動画像の符号化および復号におけるシステム、構成要素、ならびに方法などに関する。 The present disclosure relates to video coding, and more particularly to systems, components, and methods for encoding and decoding moving images, for example, by performing inter prediction to construct a current block based on a reference frame, or by performing intra prediction to construct a current block based on an encoded/decoded reference block in a current frame.
ビデオコーディング技術は、H.261およびMPEG-1から、H.264/AVC(Advanced Video Coding)、MPEG-LA、H.265/HEVC(High Efficiency Video Coding)、およびH.266/VVC(Versatile Video Codec)へ進歩している。この進歩に伴い、様々な用途において増え続けるデジタルビデオデータ量を処理するために、ビデオコーディング技術の改良および最適化を提供することが常に必要とされている。本開示は、さらに、ビデオコーディングにおける進歩、改良、および最適化に関し、特に、非矩形形状(例えば三角形)を有する第1パーティションと、第2パーティションとを少なくとも含む複数のパーティションに画像ブロックを分割するインター予測またはイントラ予測に関する。 Video coding techniques have progressed from H.261 and MPEG-1 to H.264/AVC (Advanced Video Coding), MPEG-LA, H.265/HEVC (High Efficiency Video Coding), and H.266/VVC (Versatile Video Codec). With this progress, there is a constant need to provide improvements and optimizations in video coding techniques to handle the ever-increasing amount of digital video data in various applications. The present disclosure further relates to advances, improvements, and optimizations in video coding, and in particular to inter- or intra-prediction that divides an image block into multiple partitions, including at least a first partition having a non-rectangular shape (e.g., a triangle) and a second partition.
一態様に従って、回路と、前記回路に接続されたメモリとを備える画像符号化装置が提供される。前記回路は、動作において、画像ブロック中の非矩形形状を有する第1パーティションについて、前記第1パーティションの第1動きベクトルを動きベクトル候補セットから選択し、前記画像ブロック中のパーティションであり前記第1パーティションと重なる領域を有するパーティションである第2パーティションについて、前記第2パーティションの第2動きベクトルを前記動きベクトル候補セットから選択し、選択した前記第1動きベクトルにより前記第1パーティションを符号化し、選択した前記第2動きベクトルにより前記第2パーティションを符号化し、前記動きベクトル候補セットからは、前記画像ブロックのサイズに関する条件なしに単予測動きベクトルのみが選択される。 According to one aspect, an image encoding device is provided that includes a circuit and a memory connected to the circuit. The circuit, in operation, for a first partition having a non-rectangular shape in an image block, selects a first motion vector for the first partition from a motion vector candidate set, for a second partition in the image block that has an overlapping area with the first partition, selects a second motion vector for the second partition from the motion vector candidate set, encodes the first partition with the selected first motion vector, encodes the second partition with the selected second motion vector, and selects only uni-predictive motion vectors from the motion vector candidate set without any condition regarding the size of the image block.
本開示の実施形態のいくつかの実施例では、符号化効率を改善し、符号化/復号処理を簡素化し、符号化/復号処理速度を加速し、適切なフィルタ、ブロックサイズ、動きベクトル、参照ピクチャ、参照ブロックなどの符号化および復号において用いられる適切なコンポーネント/動作を効率よく選択してもよい。 Some implementations of the present disclosure may improve encoding efficiency, simplify encoding/decoding processes, accelerate encoding/decoding process speeds, and efficiently select appropriate components/operations to be used in encoding and decoding, such as appropriate filters, block sizes, motion vectors, reference pictures, reference blocks, etc.
開示された実施の形態のさらなる利益および利点は、明細書および図面から明らかになる。利益および/または利点は、様々な実施の形態ならびに明細書および図面の特徴によって個別に得られてもよく、このような利益および/または利点を1以上得るために、様々な実施の形態ならびに明細書および図面の特徴全てを設ける必要はない。 Further benefits and advantages of the disclosed embodiments will become apparent from the specification and drawings. Benefits and/or advantages may be obtained by the various embodiments and features of the specification and drawings individually, and it is not necessary that all of the various embodiments and features of the specification and drawings be present in order to obtain one or more of such benefits and/or advantages.
なお、包括的または具体的な実施の形態は、システム、方法、集積回路、コンピュータプログラム、記憶媒体、または、それら任意の組み合わせとして実装されてもよい。 Note that the general or specific embodiments may be implemented as a system, a method, an integrated circuit, a computer program, a storage medium, or any combination thereof.
一態様によれば、回路と、前記回路に接続されたメモリとを備える画像符号化装置が提供される。前記回路は、動作において、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することと、前記第1パーティションについて第1動きベクトルを予測し、前記第2パーティションについて第2動きベクトルを予測することと、前記第1動きベクトルを用いて前記第1パーティションを符号化し、前記第2動きベクトルを用いて前記第2パーティションを符号化することとを行う。 According to one aspect, an image encoding device is provided that includes a circuit and a memory connected to the circuit. The circuit operates to divide an image block into a plurality of partitions, including a first partition having a non-rectangular shape and a second partition, predict a first motion vector for the first partition, predict a second motion vector for the second partition, encode the first partition using the first motion vector, and encode the second partition using the second motion vector.
さらなる態様によれば、前記第2パーティションは、非矩形形状を有する。他の態様によれば、前記非矩形形状は、三角形である。さらなる態様によれば、前記非矩形形状は、三角形、台形、及び、少なくとも5つの辺と角とを有する多角形からなる群から選択される。 According to a further aspect, the second partition has a non-rectangular shape. According to another aspect, the non-rectangular shape is a triangle. According to a further aspect, the non-rectangular shape is selected from the group consisting of a triangle, a trapezoid, and a polygon having at least five sides and angles.
他の態様によれば、前記予測することは、前記第1動きベクトルを第1動きベクトル候補セットから選択することと、前記第2動きベクトルを第2動きベクトル候補セットから選択することとを含む。例えば、前記第1動きベクトル候補セットは、前記第1パーティションに隣接する複数のパーティションの複数の動きベクトルを含んでもよく、前記第2動きベクトル候補セットは、前記第2パーティションに隣接する複数のパーティションの複数の動きベクトルを含んでもよい。前記第1パーティションに隣接する前記複数のパーティションと前記第2パーティションに隣接する前記複数のパーティションとは、前記第1パーティション及び前記第2パーティションに分割される前記画像ブロックの外部であってもよい。前記隣接する複数のパーティションは、空間的に隣接する複数のパーティション、及び、時間的に隣接する複数のパーティションの一方又は両方であってもよい。前記第1動きベクトル候補セットは、前記第2動きベクトル候補セットと同じであっても、異なってもよい。 According to another aspect, the predicting includes selecting the first motion vector from a first motion vector candidate set and selecting the second motion vector from a second motion vector candidate set. For example, the first motion vector candidate set may include a plurality of motion vectors of a plurality of partitions adjacent to the first partition, and the second motion vector candidate set may include a plurality of motion vectors of a plurality of partitions adjacent to the second partition. The plurality of partitions adjacent to the first partition and the plurality of partitions adjacent to the second partition may be outside the image block divided into the first partition and the second partition. The plurality of adjacent partitions may be one or both of a plurality of spatially adjacent partitions and a plurality of temporally adjacent partitions. The first motion vector candidate set may be the same as or different from the second motion vector candidate set.
他の態様によれば、前記予測することは、第1動きベクトル候補を第1動きベクトル候補セットから選択し、前記第1動きベクトル候補に第1差分動きベクトルを加算することによって前記第1動きベクトルを導出することと、第2動きベクトル候補を第2動きベクトル候補セットから選択し、前記第2動きベクトル候補に第2差分動きベクトルを加算することによって前記第2動きベクトルを導出することとを含む。 According to another aspect, the predicting includes selecting a first motion vector candidate from a first motion vector candidate set and deriving the first motion vector by adding a first differential motion vector to the first motion vector candidate, and selecting a second motion vector candidate from a second motion vector candidate set and deriving the second motion vector by adding a second differential motion vector to the second motion vector candidate.
他の態様によれば、動作において、原画像を受信し複数のブロックに分割する分割部と、動作において、前記分割部から前記複数のブロックを受信し、予測制御部から複数の予測を受信し、各予測をその対応ブロックから減算して、残差を出力する加算部と、動作において、前記加算部から出力された複数の残差に変換を行って複数の変換係数を出力する変換部と、動作において、前記複数の変換係数を量子化して複数の量子化変換係数を生成する量子化部と、動作において、前記複数の量子化変換係数を符号化してビットストリームを生成するエントロピー符号化部と、動作において、符号化済み参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部、動作において、カレントピクチャにおける符号化済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部、及び、メモリに接続された前記予測制御部とを備える画像符号化装置を提供する。前記予測制御部は、動作において、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに前記複数のブロックを分割し、前記第1パーティションについて第1動きベクトルを予測し、前記第2パーティションについて第2動きベクトルを予測し、前記第1動きベクトルを用いて前記第1パーティションを符号化し、前記第2動きベクトルを用いて前記第2パーティションを符号化する。 According to another aspect, an image encoding device is provided that includes: a division unit that receives an original image and divides it into a plurality of blocks; an addition unit that receives the plurality of blocks from the division unit and receives a plurality of predictions from a prediction control unit, subtracts each prediction from its corresponding block, and outputs a residual; a transformation unit that performs a transformation on the plurality of residuals output from the addition unit and outputs a plurality of transformation coefficients; a quantization unit that quantizes the plurality of transformation coefficients to generate a plurality of quantized transformation coefficients; an entropy encoding unit that encodes the plurality of quantized transformation coefficients to generate a bitstream; an inter prediction unit that generates a prediction of a current block based on a reference block in an encoded reference picture; an intra prediction unit that generates a prediction of the current block based on an encoded reference block in the current picture; and the prediction control unit connected to a memory. In operation, the prediction control unit divides the multiple blocks into multiple partitions including a first partition having a non-rectangular shape and a second partition, predicts a first motion vector for the first partition, predicts a second motion vector for the second partition, encodes the first partition using the first motion vector, and encodes the second partition using the second motion vector.
他の態様によれば、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することと、前記第1パーティションについて第1動きベクトルを予測し、前記第2パーティションについて第2動きベクトルを予測することと、前記第1動きベクトルを用いて前記第1パーティションを符号化し、前記第2動きベクトルを用いて前記第2パーティションを符号化することとを含む画像符号化方法を提供する。 According to another aspect, an image encoding method is provided that includes dividing an image block into a plurality of partitions including a first partition having a non-rectangular shape and a second partition, predicting a first motion vector for the first partition and a second motion vector for the second partition, encoding the first partition using the first motion vector and encoding the second partition using the second motion vector.
一態様によれば、回路と、前記回路に接続されたメモリとを備える画像復号装置が提供される。前記回路は、動作において、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することと、前記第1パーティションについて第1動きベクトルを予測し、前記第2パーティションについて第2動きベクトルを予測することと、前記第1動きベクトルを用いて前記第1パーティションを復号し、前記第2動きベクトルを用いて前記第2パーティションを復号することとを行う。 According to one aspect, an image decoding device is provided that includes a circuit and a memory connected to the circuit. The circuit, in operation, divides an image block into a plurality of partitions including a first partition having a non-rectangular shape and a second partition, predicts a first motion vector for the first partition, predicts a second motion vector for the second partition, decodes the first partition using the first motion vector, and decodes the second partition using the second motion vector.
さらなる態様によれば、前記第2パーティションは、非矩形形状を有する。他の態様によれば、前記非矩形形状は、三角形である。さらなる態様によれば、前記非矩形形状は、三角形、台形、及び、少なくとも5つの辺と角とを有する多角形からなる群から選択される。 According to a further aspect, the second partition has a non-rectangular shape. According to another aspect, the non-rectangular shape is a triangle. According to a further aspect, the non-rectangular shape is selected from the group consisting of a triangle, a trapezoid, and a polygon having at least five sides and angles.
他の態様によれば、動作において、符号化ビットストリームを受信し復号して複数の量子化変換係数を取得するエントロピー復号部と、動作において、前記複数の量子化変換係数を逆量子化して複数の変換係数を取得し、前記複数の変換係数を逆変換して複数の残差を取得する、逆量子化部及び逆変換部と、動作において、前記逆量子化部及び前記逆変換部から出力された前記複数の残差と、予測制御部から出力された複数の予測とを加算して複数のブロックを再構成する加算部と、動作において、復号済みの参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部、動作において、カレントピクチャにおける復号済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部、及び、メモリに接続された前記予測制御部とを備える画像復号装置が提供される。前記予測制御部は、動作において、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割し、前記第1パーティションについて第1動きベクトルを予測し、前記第2パーティションについて第2動きベクトルを予測し、前記第1動きベクトルを用いて前記第1パーティションを復号し、前記第2動きベクトルを用いて前記第2パーティションを復号する。 According to another aspect, an image decoding device is provided that includes, in operation, an entropy decoding unit that receives and decodes an encoded bitstream to obtain a plurality of quantized transform coefficients; in operation, an inverse quantization unit and an inverse transform unit that inverse quantize the plurality of quantized transform coefficients to obtain a plurality of transform coefficients and inverse transform the plurality of transform coefficients to obtain a plurality of residuals; in operation, an addition unit that adds the plurality of residuals output from the inverse quantization unit and the inverse transform unit to a plurality of predictions output from a prediction control unit to reconstruct a plurality of blocks; in operation, an inter prediction unit that generates a prediction of a current block based on a reference block in a decoded reference picture; in operation, an intra prediction unit that generates a prediction of the current block based on a decoded reference block in the current picture; and the prediction control unit connected to a memory. In operation, the prediction control unit divides an image block into a plurality of partitions including a first partition having a non-rectangular shape and a second partition, predicts a first motion vector for the first partition, predicts a second motion vector for the second partition, decodes the first partition using the first motion vector, and decodes the second partition using the second motion vector.
他の態様によれば、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することと、前記第1パーティションについて第1動きベクトルを予測し、前記第2パーティションについて第2動きベクトルを予測することと、前記第1動きベクトルを用いて前記第1パーティションを復号し、前記第2動きベクトルを用いて前記第2パーティションを復号することとを含む画像復号方法が提供される。 According to another aspect, there is provided an image decoding method including: dividing an image block into a plurality of partitions including a first partition having a non-rectangular shape and a second partition; predicting a first motion vector for the first partition and a second motion vector for the second partition; decoding the first partition using the first motion vector and decoding the second partition using the second motion vector.
一態様によれば、回路と、前記回路に接続されたメモリとを備える画像符号化装置が提供される。前記回路は、動作において、画像ブロックから分割された、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿う境界平滑化動作を行う。当該境界平滑化動作は、前記第1パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの画素セットの複数の第1値を第1予測することと、前記第2パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの前記画素セットの複数の第2値を第2予測することと、前記複数の第1値と前記複数の第2値とを重み付けすることと、重み付けされた前記複数の第1値と重み付けされた前記複数の第2値とを用いて前記第1パーティションを符号化することとを含む。 According to one aspect, an image encoding device is provided that includes a circuit and a memory connected to the circuit. The circuit performs a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition. The boundary smoothing operation includes: first predicting a plurality of first values of a pixel set of the first partition along the boundary using information of the first partition; second predicting a plurality of second values of the pixel set of the first partition along the boundary using information of the second partition; weighting the plurality of first values and the plurality of second values; and encoding the first partition using the weighted plurality of first values and the weighted plurality of second values.
さらなる態様によれば、前記非矩形形状は、三角形である。他の態様によれば、前記非矩形形状は、三角形、台形、及び、少なくとも5つの辺と角とを有する多角形からなる群から選択される。さらに別の態様によれば、前記第2パーティションは、非矩形形状を有する。 According to a further aspect, the non-rectangular shape is a triangle. According to another aspect, the non-rectangular shape is selected from the group consisting of a triangle, a trapezoid, and a polygon having at least five sides and angles. According to yet another aspect, the second partition has a non-rectangular shape.
他の態様によれば、前記第1予測及び前記第2予測の少なくとも一方は、符号化済み参照ピクチャにおける参照パーティションに基づいて前記複数の第1値及び前記複数の第2値を予測するインター予測処理である。前記インター予測処理は、前記画素セットを含む前記第1パーティションの複数の画素の複数の第1値を予測してもよく、前記第1パーティションの前記画素セットのみの前記複数の第2値を予測してもよい。 According to another aspect, at least one of the first prediction and the second prediction is an inter prediction process that predicts the first values and the second values based on a reference partition in a coded reference picture. The inter prediction process may predict the first values of pixels of the first partition that includes the set of pixels, or may predict the second values of only the set of pixels of the first partition.
他の態様によれば、前記第1予測及び前記第2予測の少なくとも一方は、カレントピクチャにおける符号化済み参照パーティションに基づいて前記複数の第1値及び前記複数の第2値を予測するイントラ予測処理である。 According to another aspect, at least one of the first prediction and the second prediction is an intra prediction process that predicts the first values and the second values based on an encoded reference partition in the current picture.
他の態様によれば、前記第1予測に用いられる予測方法は、前記第2予測に用いられる予測方法と異なる。 According to another aspect, the prediction method used for the first prediction is different from the prediction method used for the second prediction.
さらなる態様によれば、前記複数の第1値及び前記複数の第2値を予測する各行又は各列の前記画素セットの数は、整数である。例えば、各行又は各列の前記画素セットの数が4つである場合、1/8、1/4、3/4及び7/8の複数の重みが、それぞれ、前記画素セットにおける4つの画素の複数の第1値に適用されてもよく、7/8、3/4、1/4及び1/8の複数の重みが、それぞれ、前記画素セットにおける4つの画素の複数の第2値に適用されてもよい。他の例として、各行又は各列の前記画素セットの数が2つである場合、1/3及び2/3の複数の重みが、それぞれ、前記画素セットにおける2つの画素の複数の第1値に適用されてもよく、2/3及び1/3の複数の重みが、それぞれ、前記画素セットにおける2つの画素の複数の第2値に適用されてもよい。 According to a further aspect, the number of pixel sets in each row or column for predicting the first values and the second values is an integer. For example, if the number of pixel sets in each row or column is four, weights of 1/8, 1/4, 3/4, and 7/8 may be applied to the first values of the four pixels in the pixel set, respectively, and weights of 7/8, 3/4, 1/4, and 1/8 may be applied to the second values of the four pixels in the pixel set, respectively. As another example, if the number of pixel sets in each row or column is two, weights of 1/3 and 2/3 may be applied to the first values of the two pixels in the pixel set, respectively, and weights of 2/3 and 1/3 may be applied to the second values of the two pixels in the pixel set, respectively.
他の態様によれば、複数の重みは、整数値でもよいし、分数値でもよい。 According to other aspects, the weights may be integer or fractional values.
他の態様によれば、動作において、原画像を受信し複数のブロックに分割する分割部と、動作において、前記分割部から前記複数のブロックを受信し、予測制御部から複数の予測を受信し、各予測をその対応ブロックから減算して、残差を出力する加算部と、動作において、前記加算部から出力された複数の残差に変換を行って複数の変換係数を出力する変換部と、動作において、前記複数の変換係数を量子化して複数の量子化変換係数を生成する量子化部と、動作において、前記複数の量子化変換係数を符号化してビットストリームを生成するエントロピー符号化部と、動作において、符号化済み参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部、動作において、カレントピクチャにおける符号化済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部、及び、メモリに接続された前記予測制御部とを備える画像符号化装置が提供される。前記予測制御部は、動作において、画像ブロックから分割された、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿う境界平滑化動作を行う。前記境界平滑化動作は、前記第1パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの画素セットの複数の第1値を第1予測することと、前記第2パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの前記画素セットの複数の第2値を第2予測することと、前記複数の第1値と前記複数の第2値とを重み付けすることと、重み付けされた前記複数の第1値と重み付けされた前記複数の第2値とを用いて前記第1パーティションを符号化することとを含む。 According to another aspect, an image encoding device is provided that includes a division unit that receives an original image and divides it into a plurality of blocks in an operation, an addition unit that receives the plurality of blocks from the division unit and a plurality of predictions from a prediction control unit, subtracts each prediction from its corresponding block, and outputs a residual in an operation, a transformation unit that performs a transformation on the plurality of residuals output from the addition unit and outputs a plurality of transformation coefficients in an operation, a quantization unit that quantizes the plurality of transformation coefficients to generate a plurality of quantized transformation coefficients in an operation, an entropy encoding unit that encodes the plurality of quantized transformation coefficients to generate a bit stream in an operation, an inter prediction unit that generates a prediction of a current block based on a reference block in an encoded reference picture in an operation, an intra prediction unit that generates a prediction of a current block based on an encoded reference block in a current picture in an operation, and the prediction control unit connected to a memory. The prediction control unit performs a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition in an operation. The boundary smoothing operation includes: first predicting a plurality of first values of the set of pixels of the first partition along the boundary using information of the first partition; second predicting a plurality of second values of the set of pixels of the first partition along the boundary using information of the second partition; weighting the plurality of first values and the plurality of second values; and encoding the first partition using the weighted plurality of first values and the weighted plurality of second values.
他の態様によれば、画像ブロックから分割された、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿う境界平滑化動作を行う画像符号化方法が提供される。当該方法は、前記第1パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの画素セットの複数の第1値を第1予測することと、前記第2パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの前記画素セットの複数の第2値を第2予測することと、前記複数の第1値と前記複数の第2値とを重み付けすることと、重み付けされた前記複数の第1値と重み付けされた前記複数の第2値とを用いて前記第1パーティションを符号化することとの4ステップを通常含む。 According to another aspect, an image encoding method is provided that performs a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition. The method typically includes four steps: first predicting a plurality of first values of a pixel set of the first partition along the boundary using information of the first partition; second predicting a plurality of second values of the pixel set of the first partition along the boundary using information of the second partition; weighting the plurality of first values and the plurality of second values; and encoding the first partition using the weighted plurality of first values and the weighted plurality of second values.
さらなる態様によれば、回路と、前記回路に接続されたメモリとを備える画像復号装置が提供される。前記回路は、動作において、画像ブロックから分割された、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿う境界平滑化動作を行う。前記境界平滑化動作は、前記第1パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの画素セットの複数の第1値を第1予測することと、前記第2パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの前記画素セットの複数の第2値を第2予測することと、前記複数の第1値と前記複数の第2値とを重み付けすることと、重み付けされた前記複数の第1値と重み付けされた前記複数の第2値とを用いて前記第1パーティションを復号することとを含む。 According to a further aspect, an image decoding device is provided that includes a circuit and a memory connected to the circuit. The circuit performs, in operation, a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition. The boundary smoothing operation includes: first predicting a plurality of first values of a set of pixels of the first partition along the boundary using information of the first partition; second predicting a plurality of second values of the set of pixels of the first partition along the boundary using information of the second partition; weighting the plurality of first values and the plurality of second values; and decoding the first partition using the weighted plurality of first values and the weighted plurality of second values.
他の態様によれば、前記非矩形形状は、三角形である。さらなる態様によれば、前記非矩形形状は、三角形、台形、及び、少なくとも5つの辺と角とを有する多角形からなる群から選択される。他の態様によれば、前記第2パーティションは、非矩形形状を有する。 According to another aspect, the non-rectangular shape is a triangle. According to a further aspect, the non-rectangular shape is selected from the group consisting of a triangle, a trapezoid, and a polygon having at least five sides and corners. According to another aspect, the second partition has a non-rectangular shape.
他の態様によれば、前記第1予測及び前記第2予測の少なくとも一方は、符号化済み参照ピクチャにおける参照パーティションに基づいて前記複数の第1値及び前記複数の第2値を予測するインター予測処理である。前記インター予測処理は、前記画素セットを含む前記第1パーティションの複数の画素の複数の第1値を予測してもよく、前記第1パーティションの前記画素セットのみの前記複数の第2値を予測してもよい。 According to another aspect, at least one of the first prediction and the second prediction is an inter prediction process that predicts the first values and the second values based on a reference partition in a coded reference picture. The inter prediction process may predict the first values of pixels of the first partition that includes the set of pixels, or may predict the second values of only the set of pixels of the first partition.
他の態様によれば、前記第1予測及び前記第2予測の少なくとも一方は、カレントピクチャにおける符号化済み参照パーティションに基づいて前記複数の第1値及び前記複数の第2値を予測するイントラ予測処理である。 According to another aspect, at least one of the first prediction and the second prediction is an intra prediction process that predicts the first values and the second values based on an encoded reference partition in the current picture.
他の態様によれば、動作において、符号化ビットストリームを受信し復号して複数の量子化変換係数を取得するエントロピー復号部と、動作において、前記複数の量子化変換係数を逆量子化して複数の変換係数を取得し、前記複数の変換係数を逆変換して複数の残差を取得する、逆量子化部及び逆変換部と、動作において、前記逆量子化部及び前記逆変換部から出力された前記複数の残差と、予測制御部から出力された複数の予測とを加算して複数のブロックを再構成する加算部と、動作において、復号済みの参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部、動作において、カレントピクチャにおける復号済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部、及び、メモリに接続された前記予測制御部とを備える画像復号装置が提供される。前記予測制御部は、動作において、画像ブロックから分割された、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿う境界平滑化動作を行う。前記境界平滑化動作は、前記第1パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの画素セットの複数の第1値を第1予測することと、前記第2パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの前記画素セットの複数の第2値を第2予測することと、前記複数の第1値と前記複数の第2値とを重み付けすることと、重み付けされた前記複数の第1値と重み付けされた前記複数の第2値とを用いて前記第1パーティションを復号することとを含む。 According to another aspect, an image decoding device is provided that includes an entropy decoding unit that receives and decodes an encoded bitstream to obtain a plurality of quantized transform coefficients, an inverse quantization unit and an inverse transform unit that inverse quantize the plurality of quantized transform coefficients to obtain a plurality of transform coefficients and inverse transform the plurality of transform coefficients to obtain a plurality of residuals, an adder that adds the plurality of residuals output from the inverse quantization unit and the inverse transform unit to a plurality of predictions output from a prediction control unit to reconstruct a plurality of blocks, an inter prediction unit that generates a prediction of a current block based on a reference block in a decoded reference picture, an intra prediction unit that generates a prediction of the current block based on a decoded reference block in the current picture, and the prediction control unit connected to a memory. The prediction control unit performs a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition in an operation. The boundary smoothing operation includes: first predicting a plurality of first values of the set of pixels of the first partition along the boundary using information of the first partition; second predicting a plurality of second values of the set of pixels of the first partition along the boundary using information of the second partition; weighting the plurality of first values and the plurality of second values; and decoding the first partition using the weighted plurality of first values and the weighted plurality of second values.
他の態様によれば、画像ブロックから分割された、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿う境界平滑化動作を行う画像復号方法が提供される。当該方法は、前記第1パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの画素セットの複数の第1値を第1予測することと、前記第2パーティションの情報を用いて、前記境界に沿う、前記第1パーティションの前記画素セットの複数の第2値を第2予測することと、前記複数の第1値と前記複数の第2値とを重み付けすることと、重み付けされた前記複数の第1値と重み付けされた前記複数の第2値とを用いて前記第1パーティションを復号することとの4ステップを通常含む。 According to another aspect, an image decoding method is provided that performs a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition. The method typically includes four steps: first predicting a plurality of first values of a pixel set of the first partition along the boundary using information of the first partition; second predicting a plurality of second values of the pixel set of the first partition along the boundary using information of the second partition; weighting the plurality of first values and the plurality of second values; and decoding the first partition using the weighted plurality of first values and the weighted plurality of second values.
一態様によれば、回路と、前記回路に接続されたメモリとを備える画像符号化装置が提供される。前記回路は、動作において、パーティションシンタックス動作を行い、前記パーティションシンタックス動作は、分割を示すパーティションパラメータに基づいて、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することと、前記第1パーティションと前記第2パーティションとを符号化することと、前記パーティションパラメータを含む1つ以上のパラメータをビットストリームに書き込むこととを含む。 According to one aspect, an image encoding device is provided that includes a circuit and a memory coupled to the circuit. The circuit performs a partition syntax operation, the partition syntax operation including: dividing an image block into a plurality of partitions, including a first partition having a non-rectangular shape and a second partition, based on a partition parameter indicating the division; encoding the first partition and the second partition; and writing one or more parameters including the partition parameter to a bitstream.
さらなる態様によれば、前記パーティションパラメータは、前記第1パーティションが三角形形状を有することを示す。 According to a further aspect, the partition parameters indicate that the first partition has a triangular shape.
他の態様によれば、前記パーティションパラメータは、前記第2パーティションが非矩形形状を有することを示す。 According to another aspect, the partition parameters indicate that the second partition has a non-rectangular shape.
他の態様によれば、前記パーティションパラメータは、前記非矩形形状が、三角形、台形、及び、少なくとも5つの辺と角とを有する多角形のうちの1つであることを示す。 According to another aspect, the partition parameters indicate that the non-rectangular shape is one of a triangle, a trapezoid, and a polygon having at least five sides and angles.
他の態様によれば、前記パーティションパラメータは、前記画像ブロックを前記複数のパーティションに分割するために適用される分割方向を一体として符号化する。例えば、前記分割方向は、前記画像ブロックの左上角からその右下角、及び、前記画像ブロックの右上角からその左下角を含んでもよい。前記パーティションパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを一体として符号化してもよい。 According to another aspect, the partition parameters encode a partitioning direction applied to partition the image block into the partitions as a whole. For example, the partitioning direction may include from a top left corner of the image block to a bottom right corner thereof, and from a top right corner of the image block to a bottom left corner thereof. The partition parameters may encode at least a first motion vector of the first partition as a whole.
他の態様によれば、前記パーティションパラメータ以外の1つ以上のパラメータは、前記画像ブロックを前記複数のパーティションに分割するために適用される分割方向を符号化する。前記分割方向を符号化するパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを一体として符号化してもよい。 According to another aspect, one or more parameters other than the partition parameters encode a partitioning direction applied to divide the image block into the plurality of partitions. The parameter encoding the partitioning direction may encode at least a first motion vector of the first partition as a whole.
他の態様によれば、前記パーティションパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを一体として符号化してもよい。前記パーティションパラメータは、前記第2パーティションの第2動きベクトルを一体として符号化してもよい。 According to another aspect, the partition parameters may be encoded as a whole, including at least a first motion vector for the first partition. The partition parameters may be encoded as a whole, including a second motion vector for the second partition.
他の態様によれば、前記パーティションパラメータ以外の1つ以上のパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを符号化してもよい。 According to another aspect, the one or more parameters other than the partition parameters may encode at least a first motion vector for the first partition.
他の態様によれば、前記1つ以上のパラメータは、前記1つ以上のパラメータのうちの少なくとも1つの値に応じて選択される二値化方式に従って、二値化される。 According to another aspect, the one or more parameters are binarized according to a binarization scheme selected depending on the value of at least one of the one or more parameters.
さらなる態様によれば、動作において、原画像を受信し複数のブロックに分割する分割部と、動作において、前記分割部から前記複数のブロックを受信し、予測制御部から複数の予測を受信し、各予測をその対応ブロックから減算して、残差を出力する加算部と、動作において、前記加算部から出力された複数の残差に変換を行って複数の変換係数を出力する変換部と、動作において、前記複数の変換係数を量子化して複数の量子化変換係数を生成する量子化部と、動作において、前記複数の量子化変換係数を符号化してビットストリームを生成するエントロピー符号化部と、動作において、符号化済み参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部、動作において、カレントピクチャにおける符号化済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部、及び、メモリに接続された前記予測制御部とを備える画像符号化装置が提供される。前記予測制御部は、動作において、分割を示すパーティションパラメータに基づいて、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割し、前記第1パーティションと前記第2パーティションとを符号化する。前記エントロピー符号化部は、動作において、前記パーティションパラメータを含む1つ以上のパラメータをビットストリームに書き込む。 According to a further aspect, an image encoding device is provided that includes a partitioning unit that receives an original image and partitions it into a plurality of blocks in an operation, an adder that receives the plurality of blocks from the partitioning unit and a plurality of predictions from a prediction control unit, subtracts each prediction from its corresponding block, and outputs a residual in an operation, a transforming unit that performs a transform on the plurality of residuals output from the adder unit in an operation to output a plurality of transform coefficients in an operation, a quantizing unit that quantizes the plurality of transform coefficients to generate a plurality of quantized transform coefficients in an operation, an entropy encoding unit that encodes the plurality of quantized transform coefficients to generate a bitstream in an operation, an inter prediction unit that generates a prediction of a current block based on a reference block in an encoded reference picture in an operation, an intra prediction unit that generates a prediction of a current block based on an encoded reference block in a current picture in an operation, and the prediction control unit connected to a memory. The prediction control unit divides an image block into a plurality of partitions, including a first partition having a non-rectangular shape and a second partition, based on a partition parameter indicating the partition in an operation, and encodes the first partition and the second partition. In operation, the entropy coding unit writes one or more parameters, including the partition parameters, to a bitstream.
他の態様によれば、パーティションシンタックス動作を含む画像符号化方法が提供される。当該方法は、分割を示すパーティションパラメータに基づいて、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することと、前記第1パーティションと前記第2パーティションとを符号化することと、前記パーティションパラメータを含む1つ以上のパラメータをビットストリームに書き込むこととの3ステップを通常含む。 According to another aspect, an image coding method is provided that includes a partition syntax operation. The method typically includes three steps: partitioning an image block into a plurality of partitions, including a first partition having a non-rectangular shape and a second partition, based on a partition parameter indicating the partition; encoding the first partition and the second partition; and writing one or more parameters including the partition parameter to a bitstream.
他の態様によれば、回路と、前記回路に接続されたメモリとを備える画像復号装置が提供される。前記回路は、動作において、パーティションシンタックス動作を行い、前記パーティションシンタックス動作は、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータを含む1つ以上のパラメータをビットストリームから読み解くことと、前記パーティションパラメータに基づいて、前記画像ブロックを前記複数のパーティションに分割することと、前記第1パーティションと前記第2パーティションとを復号することとを含む。 According to another aspect, an image decoding device is provided that includes a circuit and a memory coupled to the circuit. The circuit performs a partition syntax operation, the partition syntax operation including: interpreting one or more parameters from a bitstream, the partition parameters indicating partitioning of an image block into a plurality of partitions including a first partition having a non-rectangular shape and a second partition; partitioning the image block into the plurality of partitions based on the partition parameters; and decoding the first partition and the second partition.
さらなる態様によれば、前記パーティションパラメータは、前記第1パーティションが三角形形状を有することを示す。 According to a further aspect, the partition parameters indicate that the first partition has a triangular shape.
他の態様によれば、前記パーティションパラメータは、前記第2パーティションが非矩形形状を有することを示す。 According to another aspect, the partition parameters indicate that the second partition has a non-rectangular shape.
他の態様によれば、前記パーティションパラメータは、前記非矩形形状が、三角形、台形、及び、少なくとも5つの辺と角とを有する多角形のうちの1つであることを示す。 According to another aspect, the partition parameters indicate that the non-rectangular shape is one of a triangle, a trapezoid, and a polygon having at least five sides and angles.
他の態様によれば、前記パーティションパラメータは、前記画像ブロックを前記複数のパーティションに分割するために適用される分割方向を一体として符号化する。例えば、前記分割方向は、前記画像ブロックの左上角からその右下角、及び、前記画像ブロックの右上角からその左下角を含む。前記パーティションパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを一体として符号化してもよい。 According to another aspect, the partition parameters encode a partitioning direction applied to partition the image block into the partitions as a whole. For example, the partitioning direction includes from a top left corner of the image block to a bottom right corner thereof and from a top right corner of the image block to a bottom left corner thereof. The partition parameters may encode at least a first motion vector of the first partition as a whole.
他の態様によれば、前記パーティションパラメータ以外の1つ以上のパラメータは、前記画像ブロックを前記複数のパーティションに分割するために適用される分割方向を符号化する。前記分割方向を符号化するパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを一体として符号化してもよい。 According to another aspect, one or more parameters other than the partition parameters encode a partitioning direction applied to divide the image block into the plurality of partitions. The parameter encoding the partitioning direction may encode at least a first motion vector of the first partition as a whole.
他の態様によれば、前記パーティションパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを一体として符号化してもよい。前記パーティションパラメータは、前記第2パーティションの第2動きベクトルを一体として符号化してもよい。 According to another aspect, the partition parameters may be encoded as a whole, including at least a first motion vector for the first partition. The partition parameters may be encoded as a whole, including a second motion vector for the second partition.
他の態様によれば、前記パーティションパラメータ以外の1つ以上のパラメータは、少なくとも、前記第1パーティションの第1動きベクトルを符号化してもよい。 According to another aspect, the one or more parameters other than the partition parameters may encode at least a first motion vector for the first partition.
他の態様によれば、前記1つ以上のパラメータは、前記1つ以上のパラメータのうちの少なくとも1つの値に応じて選択される二値化方式に従って、二値化される。 According to another aspect, the one or more parameters are binarized according to a binarization scheme selected depending on the value of at least one of the one or more parameters.
さらなる態様によれば、動作において、符号化ビットストリームを受信し復号して複数の量子化変換係数を取得するエントロピー復号部と、動作において、前記複数の量子化変換係数を逆量子化して複数の変換係数を取得し、前記複数の変換係数を逆変換して複数の残差を取得する、逆量子化部及び逆変換部と、動作において、前記逆量子化部及び前記逆変換部から出力された前記複数の残差と、予測制御部から出力された複数の予測とを加算して複数のブロックを再構成する加算部と、動作において、復号済みの参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部、動作において、カレントピクチャにおける復号済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部、及び、メモリに接続された前記予測制御部とを備える画像復号装置が提供される。前記エントロピー復号部は、動作において、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータを含む1つ以上のパラメータをビットストリームから読み解き、前記パーティションパラメータに基づいて、前記画像ブロックを前記複数のパーティションに分割し、前記第1パーティションと前記第2パーティションとを復号する。 According to a further aspect, an image decoding device is provided that includes, in operation, an entropy decoding unit that receives and decodes an encoded bitstream to obtain a plurality of quantized transform coefficients; in operation, an inverse quantization unit and an inverse transform unit that inverse quantize the plurality of quantized transform coefficients to obtain a plurality of transform coefficients and inverse transform the plurality of transform coefficients to obtain a plurality of residuals; in operation, an addition unit that adds the plurality of residuals output from the inverse quantization unit and the inverse transform unit to a plurality of predictions output from a prediction control unit to reconstruct a plurality of blocks; in operation, an inter prediction unit that generates a prediction of a current block based on a reference block in a decoded reference picture; in operation, an intra prediction unit that generates a prediction of the current block based on a decoded reference block in the current picture; and the prediction control unit connected to a memory. In operation, the entropy decoding unit decodes one or more parameters from the bitstream, including a partition parameter indicating division of the image block into a plurality of partitions including a first partition having a non-rectangular shape and a second partition, divides the image block into the plurality of partitions based on the partition parameter, and decodes the first partition and the second partition.
他の態様によれば、パーティションシンタックス動作を含む画像復号方法が提供される。当該方法は、非矩形形状を有する第1パーティションと、第2パーティションとを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータを含む1つ以上のパラメータをビットストリームから読み解くことと、前記パーティションパラメータに基づいて、前記画像ブロックを前記複数のパーティションに分割することと、前記第1パーティションと前記第2パーティションとを復号することとの3ステップを通常含む。 According to another aspect, an image decoding method is provided that includes a partition syntax operation. The method typically includes three steps: reading one or more parameters from a bitstream, including a partition parameter indicating partitioning of an image block into a plurality of partitions, including a first partition having a non-rectangular shape and a second partition; partitioning the image block into the plurality of partitions based on the partition parameter; and decoding the first partition and the second partition.
図面において、同一の参照符号は、同じ構成要素を示す。図面における構成要素の大きさおよび相対位置は、必ずしも縮尺比に従うものではない。 In the drawings, identical reference numbers refer to the same components. The sizes and relative positions of components in the drawings are not necessarily to scale.
以下、実施の形態について図面を参照しながら具体的に説明する。なお、以下で説明する実施の形態は、いずれも包括的または具体的な例を示すものである。以下の実施の形態で示される数値、形状、材料、構成要素、構成要素の配置位置及び接続形態、ステップ、ステップの関係及び順序などは、一例であり、請求の範囲を限定する主旨ではない。したがって、以下の実施の形態に開示されているけれども、最も広い発明概念を定義する独立請求項に記載されていない構成要素は、任意の構成要素と理解されてもよい。 The following describes the embodiments in detail with reference to the drawings. Note that the embodiments described below are all comprehensive or specific examples. The numerical values, shapes, materials, components, the arrangement and connection of the components, steps, and the relationship and order of the steps shown in the following embodiments are merely examples and are not intended to limit the scope of the claims. Therefore, components that are disclosed in the following embodiments but are not described in the independent claims that define the broadest inventive concept may be understood as optional components.
以下では、符号化装置および復号化装置の実施の形態を説明する。実施の形態は、本開示の各態様で説明する処理および/または構成を適用可能な符号化装置および復号化装置の例である。処理および/または構成は、実施の形態とは異なる符号化装置および復号化装置においても実施可能である。例えば、実施の形態に対して適用される処理および/または構成に関して、例えば以下のいずれかを実施してもよい。 Below, embodiments of an encoding device and a decoding device are described. The embodiments are examples of encoding devices and decoding devices to which the processes and/or configurations described in each aspect of the present disclosure can be applied. The processes and/or configurations can also be implemented in encoding devices and decoding devices that are different from the embodiments. For example, with regard to the processes and/or configurations applied to the embodiments, for example, any of the following may be implemented.
(1)本開示の各態様で説明する実施の形態の符号化装置または復号装置の複数の構成要素のうちいずれかは、本開示の各態様のいずれかで説明する他の構成要素に置き換えまたは組み合わせられてもよい。 (1) Any of the multiple components of the encoding device or decoding device of the embodiment described in each aspect of the present disclosure may be replaced with or combined with another component described in any of the aspects of the present disclosure.
(2)実施の形態の符号化装置または復号装置において、当該符号化装置または復号装置の複数の構成要素のうち一部の構成要素によって行われる機能または処理に、機能または処理の追加、置き換え、削除などの任意の変更がなされてもよい。例えば、いずれかの機能または処理は、本開示の各態様のいずれかで説明する他の機能または処理に、置き換えまたは組み合わせられてもよい。 (2) In the encoding device or decoding device of the embodiment, any change may be made to the functions or processes performed by some of the multiple components of the encoding device or decoding device, such as adding, replacing, or deleting a function or process. For example, any function or process may be replaced or combined with another function or process described in any of the aspects of the present disclosure.
(3)実施の形態の符号化装置または復号装置が実施する方法において、当該方法に含まれる複数の処理のうちの一部の処理について、追加、置き換えおよび削除などの任意の変更がなされてもよい。例えば、方法におけるいずれかの処理は、本開示の各態様のいずれかで説明する他の処理に、置き換えまたは組み合わせられてもよい。 (3) In the method implemented by the encoding device or decoding device of the embodiment, some of the processes included in the method may be modified in any way, such as by adding, replacing, or deleting. For example, any process in the method may be replaced or combined with another process described in any of the aspects of the present disclosure.
(4)実施の形態の符号化装置または復号装置を構成する複数の構成要素のうちの一部の構成要素は、本開示の各態様のいずれかで説明する構成要素と組み合わせられてもよいし、本開示の各態様のいずれかで説明する機能の一部を備える構成要素と組み合わせられてもよいし、本開示の各態様で説明する構成要素が実施する処理の一部を実施する構成要素と組み合わせられてもよい。 (4) Some of the components among the multiple components constituting the encoding device or decoding device of the embodiment may be combined with components described in any of the aspects of the present disclosure, may be combined with components having some of the functions described in any of the aspects of the present disclosure, or may be combined with components that perform some of the processing performed by the components described in any of the aspects of the present disclosure.
(5)実施の形態の符号化装置または復号装置の機能の一部を備える構成要素、または、実施の形態の符号化装置または復号装置の処理の一部を実施する構成要素は、本開示の各態様いずれかで説明する構成要素と、本開示の各態様でいずれかで説明する機能の一部を備える構成要素と、または、本開示の各態様のいずれかで説明する処理の一部を実施する構成要素と組み合わせまたは置き換えられてもよい。 (5) A component having part of the functionality of the encoding device or decoding device of the embodiment, or a component performing part of the processing of the encoding device or decoding device of the embodiment, may be combined or replaced with a component described in any of the aspects of the present disclosure, a component having part of the functionality described in any of the aspects of the present disclosure, or a component performing part of the processing described in any of the aspects of the present disclosure.
(6)実施の形態の符号化装置または復号装置が実施する方法において、当該方法に含まれる複数の処理のいずれかは、本開示の各態様のいずれかで説明する処理に、または、同様のいずれかの処理に、置き換えまたは組み合わせられてもよい。 (6) In the method implemented by the encoding device or decoding device of the embodiment, any of the multiple processes included in the method may be replaced or combined with any of the processes described in any of the aspects of the present disclosure or any similar processes.
(7)実施の形態の符号化装置または復号装置が実施する方法に含まれる複数の処理のうちの一部の処理は、本開示の各態様のいずれかで説明する処理と組み合わせられてもよい。 (7) Some of the processes among the multiple processes included in the method implemented by the encoding device or decoding device of the embodiment may be combined with the processes described in any of the aspects of the present disclosure.
(8)本開示の各態様で説明する処理および/または構成の実施の仕方は、実施の形態の符号化装置または復号装置に限定されるものではない。例えば、処理および/または構成は、実施の形態において開示する動画像符号化または動画像復号とは異なる目的で利用される装置において実施されてもよい。 (8) The manner in which the processes and/or configurations described in each aspect of the present disclosure are implemented is not limited to the encoding device or decoding device of the embodiments. For example, the processes and/or configurations may be implemented in a device used for a purpose other than the video encoding or video decoding disclosed in the embodiments.
[符号化装置の概要]
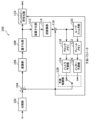
まず、実施の形態に係る符号化装置の概要を説明する。図1は、実施の形態に係る符号化装置100の機能構成を示すブロック図である。符号化装置100は、動画像をブロック単位で符号化する動画像符号化装置である。
[Outline of the encoding device]
First, an overview of a coding device according to an embodiment will be described. Fig. 1 is a block diagram showing a functional configuration of a
図1に示すように、符号化装置100は、画像をブロック単位で符号化する装置であって、分割部102と、減算部104と、変換部106と、量子化部108と、エントロピー符号化部110と、逆量子化部112と、逆変換部114と、加算部116と、ブロックメモリ118と、ループフィルタ部120と、フレームメモリ122と、イントラ予測部124と、インター予測部126と、予測制御部128と、を備える。
As shown in FIG. 1, the
符号化装置100は、例えば、汎用プロセッサ及びメモリにより実現される。この場合、メモリに格納されたソフトウェアプログラムがプロセッサにより実行されたときに、プロセッサは、分割部102、減算部104、変換部106、量子化部108、エントロピー符号化部110、逆量子化部112、逆変換部114、加算部116、ループフィルタ部120、イントラ予測部124、インター予測部126及び予測制御部128として機能する。また、符号化装置100は、分割部102、減算部104、変換部106、量子化部108、エントロピー符号化部110、逆量子化部112、逆変換部114、加算部116、ループフィルタ部120、イントラ予測部124、インター予測部126及び予測制御部128に対応する専用の1以上の電子回路として実現されてもよい。
The
以下に、符号化装置100に含まれる各構成要素について説明する。
The components included in the
[分割部]
分割部102は、入力動画像に含まれる各ピクチャを複数のブロックに分割し、各ブロックを減算部104に出力する。例えば、分割部102は、まず、ピクチャを固定サイズ(例えば128x128)のブロックに分割する。この固定サイズのブロックは、符号化ツリーユニット(CTU)と呼ばれることがある。そして、分割部102は、再帰的な四分木(quadtree)及び/又は二分木(binary tree)ブロック分割に基づいて、固定サイズのブロックの各々を可変サイズ(例えば64x64以下)のブロックに分割する。この可変サイズのブロックは、符号化ユニット(CU)、予測ユニット(PU)あるいは変換ユニット(TU)と呼ばれることがある。様々な処理例では、CU、PU及びTUは区別される必要はなく、ピクチャ内の一部又はすべてのブロックがCU、PU、TUの処理単位となってもよい。
[Divided part]
The
図2は、実施の形態におけるブロック分割の一例を示す図である。図2において、実線は四分木ブロック分割によるブロック境界を表し、破線は二分木ブロック分割によるブロック境界を表す。 Figure 2 is a diagram showing an example of block division in an embodiment. In Figure 2, solid lines represent block boundaries based on quadtree block division, and dashed lines represent block boundaries based on binary tree block division.
ここでは、ブロック10は、128x128画素の正方形ブロック(128x128ブロック)である。この128x128ブロック10は、まず、4つの正方形の64x64ブロックに分割される(四分木ブロック分割)。
Here, block 10 is a square block of 128x128 pixels (128x128 block). This
左上の64x64ブロックは、さらに2つの矩形の32x64ブロックに垂直に分割され、左の32x64ブロックはさらに2つの矩形の16x64ブロックに垂直に分割される(二分木ブロック分割)。その結果、左上の64x64ブロックは、2つの16x64ブロック11、12と、32x64ブロック13とに分割される。
The top-left 64x64 block is further divided vertically into two rectangular 32x64 blocks, and the left 32x64 block is further divided vertically into two rectangular 16x64 blocks (binary tree block division). As a result, the top-left 64x64 block is divided into two
右上の64x64ブロックは、2つの矩形の64x32ブロック14、15に水平に分割される(二分木ブロック分割)。 The top right 64x64 block is split horizontally into two rectangular 64x32 blocks 14 and 15 (binary tree block splitting).
左下の64x64ブロックは、4つの正方形の32x32ブロックに分割される(四分木ブロック分割)。4つの32x32ブロックのうち左上のブロック及び右下のブロックはさらに分割される。左上の32x32ブロックは、2つの矩形の16x32ブロックに垂直に分割され、右の16x32ブロックはさらに2つの16x16ブロックに水平に分割される(二分木ブロック分割)。右下の32x32ブロックは、2つの32x16ブロックに水平に分割される(二分木ブロック分割)。その結果、左下の64x64ブロックは、16x32ブロック16と、2つの16x16ブロック17、18と、2つの32x32ブロック19、20と、2つの32x16ブロック21、22とに分割される。
The bottom left 64x64 block is divided into four square 32x32 blocks (quadtree block division). Of the four 32x32 blocks, the top left and bottom right blocks are further divided. The top left 32x32 block is divided vertically into two rectangular 16x32 blocks, and the right 16x32 block is further divided horizontally into two 16x16 blocks (binary tree block division). The bottom right 32x32 block is divided horizontally into two 32x16 blocks (binary tree block division). As a result, the bottom left 64x64 block is divided into a
右下の64x64ブロック23は分割されない。
The bottom
以上のように、図2では、ブロック10は、再帰的な四分木及び二分木ブロック分割に基づいて、13個の可変サイズのブロック11~23に分割される。このような分割は、QTBT(quad-tree plus binary tree)分割と呼ばれることがある。
As described above, in FIG. 2, block 10 is divided into 13 variable-
図2では、1つのブロックが4つ又は2つのブロックに分割されていたが(四分木又は二分木ブロック分割)、分割はこれらに限定されない。例えば、1つのブロックが3つのブロックに分割されてもよい(三分木ブロック分割)。このような三分木ブロック分割を含む分割は、MBT(multi type tree)分割と呼ばれることがある。 In FIG. 2, one block is divided into four or two blocks (quadtree or binary tree block division), but the division is not limited to this. For example, one block may be divided into three blocks (ternary tree block division). Divisions that include such ternary tree block division are sometimes called MBT (multi type tree) divisions.
[減算部]
減算部104は、分割部102から入力され、分割部102によって分割されたブロック単位で、原信号(原サンプル)から予測信号(以下に示す予測制御部128から入力される予測サンプル)を減算する。つまり、減算部104は、符号化対象ブロック(以下、カレントブロックという)の予測誤差(残差ともいう)を算出する。そして、減算部104は、算出された予測誤差(残差)を変換部106に出力する。
[Subtraction section]
The
原信号は、符号化装置100の入力信号であり、動画像を構成する各ピクチャの画像を表す信号(例えば輝度(luma)信号及び2つの色差(chroma)信号)である。以下において、画像を表す信号をサンプルともいうこともある。
The original signal is an input signal to the
[変換部]
変換部106は、空間領域の予測誤差を周波数領域の変換係数に変換し、変換係数を量子化部108に出力する。具体的には、変換部106は、例えば空間領域の予測誤差に対して予め定められた離散コサイン変換(DCT)又は離散サイン変換(DST)を行う。
[Conversion section]
The
なお、変換部106は、複数の変換タイプの中から適応的に変換タイプを選択し、選択された変換タイプに対応する変換基底関数(transform basis function)を用いて、予測誤差を変換係数に変換してもよい。このような変換は、EMT(explicit multiple core transform)又はAMT(adaptive multiple transform)と呼ばれることがある。
The
複数の変換タイプは、例えば、DCT-II、DCT-V、DCT-VIII、DST-I及びDST-VIIを含む。図3は、各変換タイプに対応する変換基底関数を示す表である。図3においてNは入力画素の数を示す。これらの複数の変換タイプの中からの変換タイプの選択は、例えば、予測の種類(イントラ予測及びインター予測)に依存してもよいし、イントラ予測モードに依存してもよい。 The multiple transform types include, for example, DCT-II, DCT-V, DCT-VIII, DST-I, and DST-VII. FIG. 3 is a table showing the transform basis functions corresponding to each transform type. In FIG. 3, N indicates the number of input pixels. The selection of a transform type from among these multiple transform types may depend, for example, on the type of prediction (intra prediction and inter prediction) or on the intra prediction mode.
このようなEMT又はAMTを適用するか否かを示す情報(例えば、EMTフラグまたはAMTフラグと呼ばれる)及び選択された変換タイプを示す情報は、通常、CUレベルで信号化される。なお、これらの情報の信号化は、CUレベルに限定される必要はなく、他のレベル(例えば、ビットシーケンスレベル、ピクチャレベル、スライスレベル、タイルレベル又はCTUレベル)であってもよい。 Such information indicating whether EMT or AMT is applied (e.g., called an EMT flag or an AMT flag) and information indicating the selected transformation type are typically signaled at the CU level. Note that signaling of this information does not need to be limited to the CU level, but may also be at other levels (e.g., bit sequence level, picture level, slice level, tile level, or CTU level).
また、変換部106は、変換係数(変換結果)を再変換してもよい。このような再変換は、AST(adaptive secondary transform)又はNSST(non-separable secondary transform)と呼ばれることがある。例えば、変換部106は、イントラ予測誤差に対応する変換係数のブロックに含まれるサブブロック(例えば4x4サブブロック)ごとに再変換を行う。NSSTを適用するか否かを示す情報及びNSSTに用いられる変換行列に関する情報は、通常、CUレベルで信号化される。なお、これらの情報の信号化は、CUレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、ピクチャレベル、スライスレベル、タイルレベル又はCTUレベル)であってもよい。
The
変換部106には、Separableな変換と、Non-Separableな変換とが適用されてもよい。Separableな変換とは、入力の次元の数だけ方向ごとに分離して複数回変換を行う方式であり、Non-Separableな変換とは、入力が多次元であった際に2つ以上の次元をまとめて1次元とみなして、まとめて変換を行う方式である。
The
例えば、Non-Separableな変換の一例として、入力が4×4のブロックであった場合にはそれを16個の要素を持ったひとつの配列とみなし、その配列に対して16×16の変換行列で変換処理を行うようなものが挙げられる。 For example, one example of a non-separable transformation would be one in which, if the input is a 4x4 block, it is treated as a single array with 16 elements, and a transformation process is performed on that array using a 16x16 transformation matrix.
また、Non-Separableな変換のさらなる例では、4×4の入力ブロックを16個の要素を持ったひとつの配列とみなした後に、その配列に対してGivens回転を複数回行うような変換(例えば、Hypercube Givens Transform)が行われてもよい。 In another example of a non-separable transformation, a 4x4 input block may be treated as a single array with 16 elements, and then a transformation (e.g., a Hypercube Givens Transform) may be performed on the array by performing multiple Givens rotations.
[量子化部]
量子化部108は、変換部106から出力された変換係数を量子化する。具体的には、量子化部108は、カレントブロックの変換係数を所定の走査順序で走査し、走査された変換係数に対応する量子化パラメータ(QP)に基づいて当該変換係数を量子化する。そして、量子化部108は、カレントブロックの量子化された変換係数(以下、量子化係数という)をエントロピー符号化部110及び逆量子化部112に出力する。
[Quantization section]
The
所定の走査順序は、変換係数の量子化/逆量子化のための順序である。例えば、所定の走査順序は、周波数の昇順(低周波から高周波の順)又は降順(高周波から低周波の順)で定義される。 The predetermined scanning order is the order for quantization/dequantization of the transform coefficients. For example, the predetermined scanning order is defined as ascending frequency (low to high frequency) or descending frequency (high to low frequency).
量子化パラメータ(QP)とは、量子化ステップ(量子化幅)を定義するパラメータである。例えば、量子化パラメータの値が増加すれば量子化ステップも増加する。つまり、量子化パラメータの値が増加すれば量子化誤差が増大する。 The quantization parameter (QP) is a parameter that defines the quantization step (quantization width). For example, as the value of the quantization parameter increases, the quantization step also increases. In other words, as the value of the quantization parameter increases, the quantization error increases.
[エントロピー符号化部]
エントロピー符号化部110は、量子化部108から入力された量子化係数に基づいて符号化信号(符号化ビットストリーム)を生成する。具体的には、例えば、エントロピー符号化部110は、量子化係数を二値化し、二値信号を算術符号化し、圧縮されたビットストリームまたはシーケンスを出力する。
[Entropy coding unit]
The
[逆量子化部]
逆量子化部112は、量子化部108から入力された量子化係数を逆量子化する。具体的には、逆量子化部112は、カレントブロックの量子化係数を所定の走査順序で逆量子化する。そして、逆量子化部112は、カレントブロックの逆量子化された変換係数を逆変換部114に出力する。
[Inverse quantization section]
The
[逆変換部]
逆変換部114は、逆量子化部112から入力された変換係数を逆変換することにより予測誤差(残差)を復元する。具体的には、逆変換部114は、変換係数に対して、変換部106による変換に対応する逆変換を行うことにより、カレントブロックの予測誤差を復元する。そして、逆変換部114は、復元された予測誤差を加算部116に出力する。
[Inverse conversion section]
The
なお、復元された予測誤差は、通常、量子化により情報が失われているので、減算部104が算出した予測誤差と一致しない。すなわち、復元された予測誤差には、通常、量子化誤差が含まれている。
Note that the restored prediction error does not match the prediction error calculated by the
[加算部]
加算部116は、逆変換部114から入力された予測誤差と予測制御部128から入力された予測サンプルとを加算することによりカレントブロックを再構成する。そして、加算部116は、再構成されたブロックをブロックメモリ118及びループフィルタ部120に出力する。再構成ブロックは、ローカル復号ブロックと呼ばれることもある。
[Adder]
The
[ブロックメモリ]
ブロックメモリ118は、イントラ予測で参照されるブロックであって符号化対象ピクチャ(「カレントピクチャ」という)内のブロックを格納するための記憶部である。具体的には、ブロックメモリ118は、加算部116から出力された再構成ブロックを格納する。
[Block Memory]
The
[ループフィルタ部]
ループフィルタ部120は、加算部116によって再構成されたブロックにループフィルタを施し、フィルタされた再構成ブロックをフレームメモリ122に出力する。ループフィルタとは、符号化ループ内で用いられるフィルタ(インループフィルタ)であり、例えば、デブロッキング・フィルタ(DF)、サンプルアダプティブオフセット(SAO)及びアダプティブループフィルタ(ALF)などを含む。
[Loop filter section]
The
ALFでは、符号化歪みを除去するための最小二乗誤差フィルタが適用され、例えばカレントブロック内の2x2サブブロックごとに、局所的な勾配(gradient)の方向及び活性度(activity)に基づいて複数のフィルタの中から選択された1つのフィルタが適用される。 In ALF, a least squared error filter is applied to remove coding artifacts. For example, for each 2x2 subblock in the current block, one filter is selected from among multiple filters based on the local gradient direction and activity.
具体的には、まず、サブブロック(例えば2x2サブブロック)が複数のクラス(例えば15又は25クラス)に分類される。サブブロックの分類は、勾配の方向及び活性度に基づいて行われる。例えば、勾配の方向値D(例えば0~2又は0~4)と勾配の活性値A(例えば0~4)とを用いて分類値C(例えばC=5D+A)が算出される。そして、分類値Cに基づいて、サブブロックが複数のクラスに分類される。 Specifically, first, subblocks (e.g., 2x2 subblocks) are classified into multiple classes (e.g., 15 or 25 classes). The subblocks are classified based on the gradient direction and activity. For example, a classification value C (e.g., C=5D+A) is calculated using the gradient direction value D (e.g., 0-2 or 0-4) and the gradient activity value A (e.g., 0-4). Then, based on the classification value C, the subblocks are classified into multiple classes.
勾配の方向値Dは、例えば、複数の方向(例えば水平、垂直及び2つの対角方向)の勾配を比較することにより導出される。また、勾配の活性値Aは、例えば、複数の方向の勾配を加算し、加算結果を量子化することにより導出される。 The gradient direction value D is derived, for example, by comparing gradients in multiple directions (e.g., horizontal, vertical, and two diagonal directions). The gradient activity value A is derived, for example, by adding gradients in multiple directions and quantizing the sum.
このような分類の結果に基づいて、複数のフィルタの中からサブブロックのためのフィルタが決定される。 Based on the results of this classification, a filter for the subblock is selected from among multiple filters.
ALFで用いられるフィルタの形状としては例えば円対称形状が利用される。図4A~図4Cは、ALFで用いられるフィルタの形状の複数の例を示す図である。図4Aは、5x5ダイヤモンド形状フィルタを示し、図4Bは、7x7ダイヤモンド形状フィルタを示し、図4Cは、9x9ダイヤモンド形状フィルタを示す。フィルタの形状を示す情報は、通常、ピクチャレベルで信号化される。なお、フィルタの形状を示す情報の信号化は、ピクチャレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、スライスレベル、タイルレベル、CTUレベル又はCUレベル)であってもよい。 The filter shape used in ALF is, for example, a circularly symmetric shape. Figures 4A to 4C are diagrams showing several examples of filter shapes used in ALF. Figure 4A shows a 5x5 diamond-shaped filter, Figure 4B shows a 7x7 diamond-shaped filter, and Figure 4C shows a 9x9 diamond-shaped filter. Information indicating the filter shape is usually signaled at the picture level. Note that signaling of information indicating the filter shape does not need to be limited to the picture level, and may be at other levels (e.g., sequence level, slice level, tile level, CTU level, or CU level).
ALFのオン/オフは、ピクチャレベル又はCUレベルで決定されてもよい。例えば、輝度についてはCUレベルでALFを適用するか否かが決定され、色差についてはピクチャレベルでALFを適用するか否かが決定されてもよい。ALFのオン/オフを示す情報は、通常、ピクチャレベル又はCUレベルで信号化される。なお、ALFのオン/オフを示す情報の信号化は、ピクチャレベル又はCUレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、スライスレベル、タイルレベル又はCTUレベル)であってもよい。 The on/off state of ALF may be determined at the picture level or the CU level. For example, whether or not to apply ALF for luminance may be determined at the CU level, and whether or not to apply ALF for chrominance may be determined at the picture level. Information indicating whether ALF is on/off is usually signaled at the picture level or the CU level. Note that the signaling of information indicating whether ALF is on/off does not need to be limited to the picture level or the CU level, and may be at another level (for example, the sequence level, slice level, tile level, or CTU level).
選択可能な複数のフィルタ(例えば15又は25までのフィルタ)の係数セットは、通常、ピクチャレベルで信号化される。なお、係数セットの信号化は、ピクチャレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、スライスレベル、タイルレベル、CTUレベル、CUレベル又はサブブロックレベル)であってもよい。 The coefficient sets of multiple selectable filters (e.g., up to 15 or 25 filters) are typically signaled at the picture level. Note that the signaling of the coefficient sets does not have to be limited to the picture level, but may be at other levels (e.g., sequence level, slice level, tile level, CTU level, CU level, or subblock level).
[フレームメモリ]
フレームメモリ122は、インター予測に用いられる参照ピクチャを格納するための記憶部であり、例えば、フレームバッファと呼ばれることもある。具体的には、フレームメモリ122は、ループフィルタ部120によってフィルタされた再構成ブロックを格納する。
[Frame memory]
The
[イントラ予測部]
イントラ予測部124は、ブロックメモリ118に格納されているようなカレントピクチャ内のブロックを参照してカレントブロックのイントラ予測(画面内予測ともいう)を行うことで、予測信号(イントラ予測信号)を生成する。具体的には、イントラ予測部124は、カレントブロックに隣接するブロックのサンプル(例えば輝度値、色差値)を参照してイントラ予測を行うことでイントラ予測信号を生成し、イントラ予測信号を予測制御部128に出力する。
[Intra prediction unit]
The
例えば、イントラ予測部124は、予め規定された複数のイントラ予測モードのうちの1つを用いてイントラ予測を行う。複数のイントラ予測モードは、通常、1以上の非方向性予測モードと、複数の方向性予測モードと、を含む。
For example, the
1以上の非方向性予測モードは、例えばH.265/HEVC規格で規定されたPlanar予測モード及びDC予測モードを含む。 The one or more non-directional prediction modes include, for example, the planar prediction mode and the DC prediction mode defined in the H.265/HEVC standard.
複数の方向性予測モードは、例えばH.265/HEVC規格で規定された33方向の予測モードを含む。なお、複数の方向性予測モードは、33方向に加えてさらに32方向の予測モード(合計で65個の方向性予測モード)を含んでもよい。 The multiple directional prediction modes include, for example, the 33 prediction modes defined in the H.265/HEVC standard. Note that the multiple directional prediction modes may also include 32 prediction modes in addition to the 33 directions (a total of 65 directional prediction modes).
図5Aは、イントラ予測において用いられ得る全67個のイントラ予測モード(2個の非方向性予測モード及び65個の方向性予測モード)を示す概念図である。実線矢印は、H.265/HEVC規格で規定された33方向を表し、破線矢印は、追加された32方向を表す(2個の「非方向性」予測モードは図5Aには図示されていない)。 Figure 5A is a conceptual diagram showing all 67 intra prediction modes (2 non-directional and 65 directional) that can be used in intra prediction. The solid arrows represent the 33 directions defined in the H.265/HEVC standard, and the dashed arrows represent the additional 32 directions (the two "non-directional" prediction modes are not shown in Figure 5A).
様々な処理例では、色差ブロックのイントラ予測において、輝度ブロックが参照されてもよい。つまり、カレントブロックの輝度成分に基づいて、カレントブロックの色差成分が予測されてもよい。このイントラ予測は、CCLM(cross-component linear model)予測と呼ばれることがある。このような輝度ブロックを参照する色差ブロックのイントラ予測モード(例えばCCLMモードと呼ばれる)は、色差ブロックのイントラ予測モードの1つとして加えられてもよい。 In various processing examples, a luminance block may be referenced in intra prediction of a chrominance block. That is, the chrominance component of the current block may be predicted based on the luminance component of the current block. This intra prediction is sometimes called CCLM (cross-component linear model) prediction. An intra prediction mode of a chrominance block that references such a luminance block (e.g., called a CCLM mode) may be added as one of the intra prediction modes of the chrominance block.
イントラ予測部124は、水平/垂直方向の参照画素の勾配に基づいてイントラ予測後の画素値を補正してもよい。このような補正をともなうイントラ予測は、PDPC(position dependent intra prediction combination)と呼ばれることがある。PDPCの適用の有無を示す情報(例えばPDPCフラグと呼ばれる)は、通常、CUレベルで信号化される。なお、この情報の信号化は、CUレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、ピクチャレベル、スライスレベル、タイルレベル又はCTUレベル)であってもよい。
The
[インター予測部]
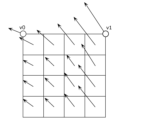
インター予測部126は、フレームメモリ122に格納された参照ピクチャであってカレントピクチャとは異なる参照ピクチャを参照してカレントブロックのインター予測(画面間予測ともいう)を行うことで、予測信号(インター予測信号)を生成する。インター予測は、カレントブロック又はカレントブロック内のカレントサブブロック(例えば4x4ブロック)の単位で行われる。例えば、インター予測部126は、カレントブロック又はカレントサブブロックについて参照ピクチャ内で動き探索(motion estimation)を行い、そのカレントブロック又はサブブロックに最も一致する参照ピクチャ内の参照ブロック又はサブブロックを見つける。そして、インター予測部126は、参照ブロック又はサブブロックからカレントブロック又はサブブロックへの動き又は変化を補償する(又は予測する)動き情報(例えば、動きベクトル)を取得する。そして、インター予測部126は、その動き情報に基づいて、動き補償(又は動き予測)を行い、カレントブロック又はサブブロックのインター予測信号を生成する。そして、インター予測部126は、生成されたインター予測信号を予測制御部128に出力する。
[Inter prediction section]
The
動き補償に用いられた動き情報は、多様な形態でインター予測信号として信号化されてもよい。例えば、動きベクトルが信号化されてもよい。他の例として、動きベクトルと予測動きベクトルとの差分が信号化されてもよい。 The motion information used for motion compensation may be signaled as an inter prediction signal in various forms. For example, a motion vector may be signaled. As another example, the difference between a motion vector and a predicted motion vector may be signaled.
なお、動き探索により得られたカレントブロックの動き情報だけでなく、隣接ブロックの動き情報も用いて、インター予測信号が生成されてもよい。具体的には、(参照ピクチャにおける)動き探索により得られた動き情報に基づく予測信号と、(カレントピクチャにおける)隣接ブロックの動き情報に基づく予測信号と、を重み付け加算することにより、カレントブロック内のサブブロック単位でインター予測信号が生成されてもよい。このようなインター予測(動き補償)は、OBMC(overlapped block motion compensation)と呼ばれることがある。 Note that an inter prediction signal may be generated using not only the motion information of the current block obtained by motion search, but also the motion information of adjacent blocks. Specifically, an inter prediction signal may be generated for each sub-block in the current block by performing a weighted addition of a prediction signal based on the motion information obtained by motion search (in the reference picture) and a prediction signal based on the motion information of adjacent blocks (in the current picture). Such inter prediction (motion compensation) is sometimes called OBMC (overlapped block motion compensation).
OBMCモードでは、OBMCのためのサブブロックのサイズを示す情報(例えばOBMCブロックサイズと呼ばれる)は、シーケンスレベルで信号化されてもよい。また、OBMCモードを適用するか否かを示す情報(例えばOBMCフラグと呼ばれる)は、CUレベルで信号化されてもよい。なお、これらの情報の信号化のレベルは、シーケンスレベル及びCUレベルに限定される必要はなく、他のレベル(例えばピクチャレベル、スライスレベル、タイルレベル、CTUレベル又はサブブロックレベル)であってもよい。 In the OBMC mode, information indicating the size of the subblock for OBMC (e.g., called OBMC block size) may be signaled at the sequence level. Also, information indicating whether or not to apply the OBMC mode (e.g., called OBMC flag) may be signaled at the CU level. Note that the signaling level of these pieces of information does not need to be limited to the sequence level and CU level, and may be other levels (e.g., picture level, slice level, tile level, CTU level, or subblock level).
OBMCモードについて、より具体的に説明する。図5B及び図5Cは、OBMC処理による予測画像補正処理を説明するフローチャート及び概念図である。 The OBMC mode will now be described in more detail. Figures 5B and 5C are a flowchart and a conceptual diagram explaining the predicted image correction process using OBMC processing.
図5Cを参照すると、まず、符号化対象(カレント)ブロックに割り当てられた動きベクトル(MV)を用いて通常の動き補償による予測画像(Pred)を取得する。図5Cにおいて、矢印「MV」は参照ピクチャを指し、予測画像を得るためにカレントピクチャ内のカレントブロックが何を参照しているのかを示している。 Referring to FIG. 5C, first, a predicted image (Pred) is obtained by normal motion compensation using the motion vector (MV) assigned to the block to be coded (current). In FIG. 5C, the arrow "MV" points to the reference picture, indicating what the current block in the current picture is referring to in order to obtain the predicted image.
次に、符号化済みの左隣接ブロックに対して既に導出された動きベクトル(MV_L)を符号化対象(カレント)ブロックに適用(再利用)して予測画像(Pred_L)を取得する。動きベクトル(MV_L)は、カレントブロックから参照ピクチャを指す矢印「MV_L」によって示される。そして、2つの予測画像PredとPred_Lとを重ね合わせることで予測画像の1回目の補正を行う。これは、隣接ブロック間の境界を混ぜ合わせる効果を有する。 Then, the motion vector (MV_L) already derived for the coded left adjacent block is applied (reused) to the block to be coded (current) to obtain a predicted image (Pred_L). The motion vector (MV_L) is indicated by an arrow "MV_L" pointing from the current block to the reference picture. The two predicted images Pred and Pred_L are then superimposed to perform a first correction of the predicted image. This has the effect of blending the boundaries between the adjacent blocks.
同様に、符号化済みの上隣接ブロックに対して既に導出された動きベクトル(MV_U)を符号化対象(カレント)ブロックに適用(再利用)して予測画像(Pred_U)を取得する。動きベクトル(MV_U)は、カレントブロックから参照ピクチャを指す矢印「MV_U」によって示される。そして、予測画像Pred_Uを1回目の補正を行った予測画像(つまり、PredとPred_L)に重ね合わせることで予測画像の2回目の補正を行う。これは、一態様において、隣接ブロック間の境界を混ぜ合わせる効果を有する。2回目の補正によって得られた予測画像は、隣接ブロックとの境界が混ぜ合わされた(スムージングされた)、カレントブロックの最終的な予測画像である。 Similarly, a motion vector (MV_U) already derived for the coded upper adjacent block is applied (reused) to the coding target (current) block to obtain a predicted image (Pred_U). The motion vector (MV_U) is indicated by an arrow "MV_U" pointing from the current block to the reference picture. A second correction of the predicted image is then performed by superimposing the predicted image Pred_U on the predicted image (i.e., Pred and Pred_L) that has been corrected the first time. This has the effect of blending the boundaries between the adjacent blocks, in one aspect. The predicted image obtained by the second correction is the final predicted image of the current block, with the boundaries with the adjacent blocks blended (smoothed).
なお、ここでは左隣接ブロックと上隣接ブロックを用いた2段階の補正方法を説明したが、右隣接ブロックや下隣接ブロックを用いて2段階よりも多い回数の補正を行う構成とすることも可能である。 Note that, although a two-stage correction method using the left adjacent block and the upper adjacent block has been described here, it is also possible to configure the method to perform more than two stages of correction using the right adjacent block or the lower adjacent block.
なお、重ね合わせを行う領域はブロック全体の画素領域ではなく、ブロック境界近傍の一部の領域のみであってもよい。 Note that the area to be overlaid does not have to be the entire pixel area of the block, but may be only a portion of the area near the block boundary.
なお、ここでは1枚の参照ピクチャに基づいて、追加の予測画像Pred_LおよびPred_Uを重ね合せることで1枚の予測画像Predを得るためのOBMCの予測画像補正処理について説明した。しかし、複数の参照ピクチャに基づいて予測画像が補正される場合には、同様の処理が複数の参照ピクチャのそれぞれに適用されてもよい。このような場合、複数の参照ピクチャに基づくOBMCの画像補正を行うことによって、各々の参照ピクチャから、補正された予測画像を取得した後に、その取得された複数の補正予測画像をさらに重ね合わせることで最終的な予測画像を取得する。 Here, we have described the OBMC predicted image correction process for obtaining one predicted image Pred by superimposing additional predicted images Pred_L and Pred_U based on one reference picture. However, when a predicted image is corrected based on multiple reference pictures, a similar process may be applied to each of the multiple reference pictures. In such a case, a corrected predicted image is obtained from each reference picture by performing OBMC image correction based on multiple reference pictures, and then the obtained multiple corrected predicted images are further superimposed to obtain a final predicted image.
なお、OBMCでは、対象ブロックの単位は、予測ブロック単位であっても、予測ブロックをさらに分割したサブブロック単位であってもよい。 In OBMC, the unit of the target block may be a prediction block unit, or a subblock unit obtained by further dividing the prediction block.
OBMC処理を適用するかどうかの判定の方法として、例えば、OBMC処理を適用するかどうかを示す信号であるobmc_flagを用いる方法がある。具体的な一例としては、符号化装置において、符号化対象ブロックが動きの複雑な領域に属しているかどうかを判定し、動きの複雑な領域に属している場合はobmc_flagとして値「1」を設定してOBMC処理を適用して符号化を行い、動きの複雑な領域に属していない場合はobmc_flagとして値「0」を設定してOBMC処理を適用せずに符号化を行う。一方、復号装置では、ストリーム(つまり、圧縮シーケンス)に記述されたobmc_flagを復号することで、その値に応じてOBMC処理を適用するかどうかを切替えて復号を行う。 As a method of determining whether to apply OBMC processing, for example, there is a method of using obmc_flag, which is a signal indicating whether to apply OBMC processing. As a specific example, in an encoding device, it is determined whether the encoding target block belongs to an area with complex motion, and if it belongs to an area with complex motion, the value "1" is set as obmc_flag and OBMC processing is applied and encoding is performed, and if it does not belong to an area with complex motion, the value "0" is set as obmc_flag and encoding is performed without applying OBMC processing. On the other hand, in a decoding device, by decoding obmc_flag described in a stream (i.e., a compressed sequence), decoding is performed by switching whether to apply OBMC processing depending on the value.
なお、動き情報は、符号化装置側から信号化されずに、復号装置側で導出されてもよい。例えば、H.265/HEVC規格で規定されたマージモードが用いられてもよい。また例えば、復号装置側で動き探索を行うことにより動き情報が導出されてもよい。この場合、復号装置側では、カレントブロックの画素値を用いずに動き探索が行われてもよい。 The motion information may be derived on the decoding device side without being signaled from the encoding device side. For example, a merge mode defined in the H.265/HEVC standard may be used. Also, for example, the motion information may be derived by performing a motion search on the decoding device side. In this case, the motion search may be performed on the decoding device side without using pixel values of the current block.
ここで、復号装置側で動き探索を行うモードについて説明する。この復号装置側で動き探索を行うモードは、PMMVD(pattern matched motion vector derivation)モード又はFRUC(frame rate up-conversion)モードと呼ばれることがある。 Here, we will explain the mode in which motion estimation is performed on the decoding device side. This mode in which motion estimation is performed on the decoding device side is sometimes called PMMVD (pattern matched motion vector derivation) mode or FRUC (frame rate up-conversion) mode.
FRUC処理の一例を図5Dに示す。まず、カレントブロックに空間的又は時間的に隣接する符号化済みブロックの動きベクトルを参照して、各々が予測動きベクトル(MV)を有する複数の候補のリスト(マージリストと共通であってもよい)が生成される。次に、候補リストに登録されている複数の候補MVの中からベスト候補MVを選択する。例えば、候補リストに含まれる各候補MVの評価値が算出され、評価値に基づいて1つの候補MVが選択される。 An example of the FRUC process is shown in FIG. 5D. First, a list of multiple candidates (which may be the same as the merge list) each having a predictive motion vector (MV) is generated by referring to the motion vectors of encoded blocks spatially or temporally adjacent to the current block. Next, a best candidate MV is selected from the multiple candidate MVs registered in the candidate list. For example, an evaluation value of each candidate MV included in the candidate list is calculated, and one candidate MV is selected based on the evaluation value.
そして、選択された候補の動きベクトルに基づいて、カレントブロックのための動きベクトルが導出される。具体的には、例えば、選択された候補の動きベクトル(ベスト候補MV)がそのままカレントブロックのための動きベクトルとして導出される。また例えば、選択された候補の動きベクトルに対応する参照ピクチャ内の位置の周辺領域において、パターンマッチングを行うことにより、カレントブロックのための動きベクトルが導出されてもよい。すなわち、ベスト候補MVの周辺の領域に対して、参照ピクチャにおけるパターンマッチングと評価値とを用いた探索を行い、さらに評価値が良い値となるMVがあった場合は、ベスト候補MVを前記MVに更新して、それをカレントブロックの最終的なMVとしてもよい。より良い評価値を有するMVへの更新を行う処理を実施しない構成とすることも可能である。 Then, a motion vector for the current block is derived based on the motion vector of the selected candidate. Specifically, for example, the motion vector of the selected candidate (best candidate MV) is derived as it is as the motion vector for the current block. Also, for example, the motion vector for the current block may be derived by performing pattern matching in the surrounding area of the position in the reference picture corresponding to the motion vector of the selected candidate. That is, a search is performed using pattern matching in the reference picture and the evaluation value for the surrounding area of the best candidate MV, and if an MV with a better evaluation value is found, the best candidate MV may be updated to the MV and used as the final MV for the current block. It is also possible to configure the system without performing the process of updating to an MV with a better evaluation value.
サブブロック単位で処理を行う場合も全く同様の処理としてもよい。 The same process can be used when processing on a subblock basis.
なお、評価値は、様々な方法で算出されてもよい。例えば、動きベクトルに対応する参照ピクチャ内の領域の再構成画像を、所定の領域(例えば、後述するように、他の参照ピクチャの領域、又は、カレントピクチャの隣接ブロックの領域であってもよい)の再構成画像とを比較し、2つの再構成画像の画素値の差分を算出して動きベクトルの評価値として用いてもよい。なお、差分値に加えてそれ以外の情報を用いて評価値を算出してもよい。 The evaluation value may be calculated in various ways. For example, a reconstructed image of an area in a reference picture corresponding to the motion vector may be compared with a reconstructed image of a predetermined area (for example, as described below, this may be an area of another reference picture or an area of an adjacent block of the current picture), and the difference in pixel values between the two reconstructed images may be calculated and used as the evaluation value of the motion vector. The evaluation value may be calculated using other information in addition to the difference value.
次に、パターンマッチングの例について詳細に説明する。まず、候補MVリスト(例えばマージリスト)に含まれる1つの候補MVを、パターンマッチングによる探索のスタートポイントとして選択する。例えば、パターンマッチングとしては、第1パターンマッチング又は第2パターンマッチングが用いられ得る。第1パターンマッチング及び第2パターンマッチングは、それぞれ、バイラテラルマッチング(bilateral matching)及びテンプレートマッチング(template matching)と呼ばれることがある。 Next, an example of pattern matching will be described in detail. First, one candidate MV included in the candidate MV list (e.g., merge list) is selected as a starting point for a search by pattern matching. For example, first pattern matching or second pattern matching can be used as the pattern matching. The first pattern matching and the second pattern matching are sometimes called bilateral matching and template matching, respectively.
第1パターンマッチングでは、異なる2つの参照ピクチャ内の2つのブロックであってカレントブロックの動き軌道(motion trajectory)に沿う2つのブロックの間でパターンマッチングが行われる。したがって、第1パターンマッチングでは、参照ピクチャ内の領域に対し、上述した候補の評価値の算出のための所定の領域として、カレントブロックの動き軌道に沿う他の参照ピクチャ内の領域が用いられる。 In the first pattern matching, pattern matching is performed between two blocks in two different reference pictures that are aligned with the motion trajectory of the current block. Therefore, in the first pattern matching, an area in another reference picture that is aligned with the motion trajectory of the current block is used as a predetermined area for calculating the evaluation value of the above-mentioned candidate for an area in a reference picture.
図6は、動き軌道に沿う2つの参照ピクチャにおける2つのブロック間での第1パターンマッチング(バイラテラルマッチング)の一例を説明するための図である。図6に示すように、第1パターンマッチングでは、カレントブロック(Cur block)の動き軌道に沿う2つのブロックであって異なる2つの参照ピクチャ(Ref0、Ref1)内の2つのブロックのペアの中で最もマッチするペアを探索することにより2つの動きベクトル(MV0、MV1)が導出される。具体的には、カレントブロックに対して、候補MVで指定された第1の符号化済み参照ピクチャ(Ref0)内の指定位置における再構成画像と、前記候補MVを表示時間間隔でスケーリングした対称MVで指定された第2の符号化済み参照ピクチャ(Ref1)内の指定位置における再構成画像との差分を導出し、得られた差分値を用いて評価値を算出する。複数の候補MVの中で最も評価値が良い値となる候補MVを最終MVとして選択することが可能であり、良い結果をもたらし得る。 FIG. 6 is a diagram for explaining an example of the first pattern matching (bilateral matching) between two blocks in two reference pictures along a motion trajectory. As shown in FIG. 6, in the first pattern matching, two motion vectors (MV0, MV1) are derived by searching for a pair of two blocks that are the most matched among pairs of two blocks in two different reference pictures (Ref0, Ref1) along the motion trajectory of the current block (Cur block). Specifically, for the current block, a difference is derived between a reconstructed image at a specified position in a first coded reference picture (Ref0) specified by a candidate MV and a reconstructed image at a specified position in a second coded reference picture (Ref1) specified by a symmetric MV obtained by scaling the candidate MV at a display time interval, and an evaluation value is calculated using the obtained difference value. It is possible to select the candidate MV with the best evaluation value among multiple candidate MVs as the final MV, which can bring about good results.
連続的な動き軌道の仮定の下では、2つの参照ブロックを指し示す動きベクトル(MV0、MV1)は、カレントピクチャ(Cur Pic)と2つの参照ピクチャ(Ref0、Ref1)との間の時間的な距離(TD0、TD1)に対して比例する。例えば、カレントピクチャが時間的に2つの参照ピクチャの間に位置し、カレントピクチャから2つの参照ピクチャへの時間的な距離が等しい場合、第1パターンマッチングでは、2つの鏡映対称な双方向の動きベクトルが導出される。 Under the assumption of continuous motion trajectories, the motion vectors (MV0, MV1) pointing to two reference blocks are proportional to the temporal distances (TD0, TD1) between the current picture (Cur Pic) and the two reference pictures (Ref0, Ref1). For example, if the current picture is located between two reference pictures in time and the temporal distances from the current picture to the two reference pictures are equal, the first pattern matching derives two mirror-symmetric bidirectional motion vectors.
第2パターンマッチング(テンプレートマッチング)では、カレントピクチャ内のテンプレート(カレントピクチャ内でカレントブロックに隣接するブロック(例えば上及び/又は左隣接ブロック))と参照ピクチャ内のブロックとの間でパターンマッチングが行われる。したがって、第2パターンマッチングでは、上述した候補の評価値の算出のための所定の領域として、カレントピクチャ内のカレントブロックに隣接するブロックが用いられる。 In the second pattern matching (template matching), pattern matching is performed between a template in the current picture (a block adjacent to the current block in the current picture (e.g., an upper and/or left adjacent block)) and a block in the reference picture. Therefore, in the second pattern matching, a block adjacent to the current block in the current picture is used as a predetermined area for calculating the evaluation value of the above-mentioned candidate.
図7は、カレントピクチャ内のテンプレートと参照ピクチャ内のブロックとの間でのパターンマッチング(テンプレートマッチング)の一例を説明するための図である。図7に示すように、第2パターンマッチングでは、カレントピクチャ(Cur Pic)内でカレントブロック(Cur block)に隣接するブロックと最もマッチするブロックを参照ピクチャ(Ref0)内で探索することによりカレントブロックの動きベクトルが導出される。具体的には、カレントブロックに対して、左隣接および上隣接の両方もしくはどちらか一方の符号化済み領域の再構成画像と、候補MVで指定された符号化済み参照ピクチャ(Ref0)内の同等位置における再構成画像との差分を導出し、得られた差分値を用いて評価値を算出し、複数の候補MVの中で最も評価値が良い値となる候補MVをベスト候補MVとして選択することが可能である。 Figure 7 is a diagram for explaining an example of pattern matching (template matching) between a template in a current picture and a block in a reference picture. As shown in Figure 7, in the second pattern matching, a motion vector of the current block is derived by searching in the reference picture (Ref0) for a block that best matches a block adjacent to the current block (Cur block) in the current picture (Cur Pic). Specifically, for the current block, the difference between the reconstructed image of both or either of the left and top adjacent coded areas and the reconstructed image at the same position in the coded reference picture (Ref0) specified by the candidate MV is derived, and an evaluation value is calculated using the obtained difference value, and the candidate MV with the best evaluation value among multiple candidate MVs can be selected as the best candidate MV.
このようなFRUCモードを適用するか否かを示す情報(例えばFRUCフラグと呼ばれる)は、CUレベルで信号化されてもよい。また、FRUCモードが適用される場合(例えばFRUCフラグが真の場合)、パターンマッチングの方法(例えば、第1パターンマッチング又は第2パターンマッチング)を示す情報(例えばFRUCモードフラグと呼ばれる)がCUレベルで信号化されてもよい。なお、これらの情報の信号化は、CUレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、ピクチャレベル、スライスレベル、タイルレベル、CTUレベル又はサブブロックレベル)であってもよい。 Information indicating whether or not such a FRUC mode is applied (e.g., when the FRUC flag is true) may be signaled at the CU level. Also, when the FRUC mode is applied (e.g., when the FRUC flag is true), information indicating a pattern matching method (e.g., first pattern matching or second pattern matching) (e.g., when the FRUC mode flag is true) may be signaled at the CU level. Note that the signaling of such information does not need to be limited to the CU level, and may be at other levels (e.g., sequence level, picture level, slice level, tile level, CTU level, or sub-block level).
次に、動きベクトルの導出方法を説明する。まず、等速直線運動を仮定したモデルに基づいて動きベクトルを導出するモードについて説明する。このモードは、BIO(bi-directional optical flow)モードと呼ばれることがある。 Next, we will explain how to derive a motion vector. First, we will explain a mode in which a motion vector is derived based on a model that assumes uniform linear motion. This mode is sometimes called BIO (bi-directional optical flow) mode.
図8は、等速直線運動を仮定したモデルを説明するための図である。図8において、(vx,vy)は、速度ベクトルを示し、τ0、τ1は、それぞれ、カレントピクチャ(Cur Pic)と2つの参照ピクチャ(Ref0,Ref1)との間の時間的な距離を示す。(MVx0,MVy0)は、参照ピクチャRef0に対応する動きベクトルを示し、(MVx1、MVy1)は、参照ピクチャRef1に対応する動きベクトルを示す。 Fig. 8 is a diagram for explaining a model assuming uniform linear motion. In Fig. 8, ( vx , vy ) indicates a velocity vector, and τ0 , τ1 indicate the temporal distance between the current picture (CurPic) and two reference pictures ( Ref0 , Ref1 ), respectively. ( MVx0 , MVy0 ) indicates a motion vector corresponding to reference picture Ref0 , and ( MVx1 , MVy1 ) indicates a motion vector corresponding to reference picture Ref1 .
このとき速度ベクトル(vx,vy)の等速直線運動の仮定の下では、(MVx0,MVy0)及び(MVx1,MVy1)は、それぞれ、(vxτ0,vyτ0)及び(-vxτ1,-vyτ1)と表され、以下のオプティカルフロー等式(1)が成り立つ。 In this case, under the assumption of uniform linear motion of the velocity vector (v x , v y ), (MVx 0 , MVy 0 ) and (MVx 1 , MVy 1 ) are expressed as (v x τ 0 , v y τ 0 ) and (-v x τ 1 , -v y τ 1 ), respectively, and the following optical flow equation (1) holds.

ここで、I(k)は、動き補償後の参照画像k(k=0,1)の輝度値を示す。このオプティカルフロー等式は、(i)輝度値の時間微分と、(ii)水平方向の速度及び参照画像の空間勾配の水平成分の積と、(iii)垂直方向の速度及び参照画像の空間勾配の垂直成分の積と、の和が、ゼロと等しいことを示す。このオプティカルフロー等式とエルミート補間(Hermite interpolation)との組み合わせに基づいて、マージリスト等から得られるブロック単位の動きベクトルが画素単位で補正されてもよい。 Here, I (k) denotes the luminance value of reference image k (k=0,1) after motion compensation. This optical flow equation indicates that the sum of (i) the time derivative of the luminance value, (ii) the product of the horizontal component of the horizontal velocity and the spatial gradient of the reference image, and (iii) the product of the vertical velocity and the vertical component of the spatial gradient of the reference image is equal to zero. Based on a combination of this optical flow equation and Hermite interpolation, block-based motion vectors obtained from a merge list or the like may be corrected pixel by pixel.
なお、等速直線運動を仮定したモデルに基づく動きベクトルの導出とは異なる方法で、復号装置側で動きベクトルが導出されてもよい。例えば、複数の隣接ブロックの動きベクトルに基づいてサブブロック単位で動きベクトルが導出されてもよい。 Note that the motion vector may be derived on the decoding device side using a method other than the method of deriving the motion vector based on a model that assumes uniform linear motion. For example, the motion vector may be derived on a sub-block basis based on the motion vectors of multiple adjacent blocks.
次に、複数の隣接ブロックの動きベクトルに基づいてサブブロック単位で動きベクトルを導出するモードについて説明する。このモードは、アフィン動き補償予測(affine motion compensation prediction)モードと呼ばれることがある。 Next, we will explain a mode in which a motion vector is derived for each sub-block based on the motion vectors of multiple adjacent blocks. This mode is sometimes called an affine motion compensation prediction mode.
図9Aは、複数の隣接ブロックの動きベクトルに基づくサブブロック単位の動きベクトルの導出を説明するための図である。図9Aにおいて、カレントブロックは、16の4x4サブブロックを含む。ここでは、隣接ブロックの動きベクトルに基づいてカレントブロックの左上角制御ポイントの動きベクトルv0が導出される。同様に、隣接サブブロックの動きベクトルに基づいてカレントブロックの右上角制御ポイントの動きベクトルv1が導出される。そして、2つの動きベクトルv0及びv1を用いて、以下の式(2)により、カレントブロック内の各サブブロックの動きベクトル(vx,vy)が導出される。 9A is a diagram for explaining derivation of a motion vector for each subblock based on the motion vectors of multiple adjacent blocks. In FIG. 9A, the current block includes 16 4x4 subblocks. Here, the motion vector v0 of the upper left corner control point of the current block is derived based on the motion vectors of the adjacent blocks. Similarly, the motion vector v1 of the upper right corner control point of the current block is derived based on the motion vectors of the adjacent subblocks. Then, using the two motion vectors v0 and v1 , the motion vectors ( vx , vy ) of each subblock in the current block are derived by the following formula (2).

ここで、x及びyは、それぞれ、サブブロックの水平位置及び垂直位置を示し、wは、予め定められた重み係数を示す。 Here, x and y indicate the horizontal and vertical positions of the subblock, respectively, and w indicates a predetermined weighting coefficient.
このアフィン動き補償予測モードでは、左上及び右上角制御ポイントの動きベクトルの導出方法が異なるいくつかのモードを含んでもよい。このアフィン動き補償予測モードを示す情報(例えばアフィンフラグと呼ばれる)は、CUレベルで信号化されてもよい。なお、このアフィン動き補償予測モードを示す情報の信号化は、CUレベルに限定される必要はなく、他のレベル(例えば、シーケンスレベル、ピクチャレベル、スライスレベル、タイルレベル、CTUレベル又はサブブロックレベル)であってもよい。 This affine motion compensation prediction mode may include several modes with different methods of deriving the motion vectors of the top-left and top-right corner control points. Information indicating this affine motion compensation prediction mode (e.g., called an affine flag) may be signaled at the CU level. Note that the signaling of the information indicating this affine motion compensation prediction mode does not need to be limited to the CU level, and may be at other levels (e.g., sequence level, picture level, slice level, tile level, CTU level, or subblock level).
[予測制御部]
予測制御部128は、(イントラ予測部124から出力される信号)イントラ予測信号及び(インター予測部126から出力される信号)インター予測信号のいずれかを選択し、選択した信号を予測信号として減算部104及び加算部116に出力する。
[Predictive control unit]
The
図1に示すように、種々の処理例では、予測制御部128は、エントロピー符号化部110に入力される予測パラメータを出力してもよい。エントロピー符号化部110は、予測制御部128から入力されるその予測パラメータ、量子化部108から入力される量子化係数に基づいて、符号化ビットストリーム(またはシーケンス)を生成してもよい。予測パラメータは復号装置に使用されてもよい。復号装置は、符号化ビットストリームを受信して復号し、イントラ予測部124、インター予測部126および予測制御部128において行われる予測処理と同じ処理を行ってもよい。予測パラメータは、選択予測信号(例えば、動きベクトル、予測タイプ、または、イントラ予測部124またはインター予測部126で用いられた予測モード)、または、イントラ予測部124、インター予測部126および予測制御部128において行われる予測処理に基づく、あるいはその予測処理を示す、任意のインデックス、フラグ、もしくは値を含んでいてもよい。
As shown in FIG. 1, in various processing examples, the
図9Bは、マージモードでカレントピクチャの動きベクトルを導出する処理の一例を示している。 Figure 9B shows an example of a process for deriving a motion vector for the current picture in merge mode.
まず、予測MVの候補を登録した予測MVリストを生成する。予測MVの候補としては、対象ブロックの空間的に周辺に位置する複数の符号化済みブロックが持つMVである空間隣接予測MV、符号化済み参照ピクチャにおける対象ブロックの位置を投影した近辺のブロックが持つMVである時間隣接予測MV、空間隣接予測MVと時間隣接予測MVのMV値を組み合わせて生成したMVである結合予測MV、および値がゼロのMVであるゼロ予測MV等がある。 First, a prediction MV list is generated in which prediction MV candidates are registered. The prediction MV candidates include spatially adjacent prediction MVs, which are MVs held by multiple encoded blocks located spatially around the target block, temporally adjacent prediction MVs, which are MVs held by nearby blocks projected onto the target block's position in the encoded reference picture, combined prediction MVs, which are MVs generated by combining the MV values of spatially adjacent prediction MVs and temporally adjacent prediction MVs, and zero prediction MVs, which are MVs with a value of zero.
次に、予測MVリストに登録されている複数の予測MVの中から1つの予測MVを選択することで、対象ブロックのMVとして決定する。 Next, one predicted MV is selected from the multiple predicted MVs registered in the predicted MV list and determined as the MV for the target block.
さらに、可変長符号化部では、どの予測MVを選択したかを示す信号であるmerge_idxをストリームに記述して符号化する。 Furthermore, the variable length coding unit writes merge_idx, a signal indicating which predicted MV was selected, into the stream and codes it.
なお、図9Bで説明した予測MVリストに登録する予測MVは一例であり、図中の個数とは異なる個数であったり、図中の予測MVの一部の種類を含まない構成であったり、図中の予測MVの種類以外の予測MVを追加した構成であったりしてもよい。 Note that the predicted MVs registered in the predicted MV list described in FIG. 9B are just an example, and the number may be different from the number shown in the figure, the configuration may not include some of the types of predicted MVs shown in the figure, or the configuration may include predicted MVs other than the types of predicted MVs shown in the figure.
マージモードにより導出した対象ブロックのMVを用いて、後述するDMVR(decoder motion vector refinement)処理を行うことによって最終的なMVを決定してもよい。 The final MV may be determined by performing the DMVR (decoder motion vector refinement) process described below using the MV of the target block derived in merge mode.
図9Cは、MVを決定するためのDMVR処理の一例を説明するための概念図である。 Figure 9C is a conceptual diagram illustrating an example of DMVR processing for determining an MV.
まず、(例えばマージモードにおいて)カレントブロックに設定された最適MVPを、候補MVとする。そして、候補MV(L0)に従って、L0方向の符号化済みピクチャである第1参照ピクチャ(L0)から参照画素を特定する。同様に、候補MV(L1)に従って、L1方向の符号化済みピクチャである第2参照ピクチャ(L1)から参照画素を特定する。これらの参照画素の平均をとることでテンプレートを生成する。 First, the optimal MVP set for the current block (e.g., in merge mode) is set as the candidate MV. Then, according to the candidate MV (L0), reference pixels are identified from the first reference picture (L0), which is an encoded picture in the L0 direction. Similarly, according to the candidate MV (L1), reference pixels are identified from the second reference picture (L1), which is an encoded picture in the L1 direction. A template is generated by taking the average of these reference pixels.
次に、前記テンプレートを用いて、第1参照ピクチャ(L0)および第2参照ピクチャ(L1)の候補MVの周辺領域をそれぞれ探索し、コストが最小となるMVを最終的なMVとして決定する。なお、コスト値は、例えば、テンプレートの各画素値と探索領域の各画素値との差分値および候補MV値等を用いて算出してもよい。 Next, the template is used to search the surrounding areas of the candidate MVs in the first reference picture (L0) and the second reference picture (L1), and the MV with the smallest cost is determined as the final MV. Note that the cost value may be calculated using, for example, the difference value between each pixel value of the template and each pixel value of the search area, the candidate MV value, etc.
なお、典型的には、符号化装置と、後述の復号化装置とでは、ここで説明した処理の構成および動作は基本的に共通である。 Typically, the processing configuration and operation described here are basically the same for the encoding device and the decoding device described below.
ここで説明した処理例そのものでなくても、候補MVの周辺を探索して最終的なMVを導出することができる処理であれば、どのような処理を用いてもよい。 It is not necessary to use the processing example described here, but any processing can be used as long as it can search the area around the candidate MV and derive the final MV.
次に、LIC(local illumination compensation)処理を用いて予測画像(予測)を生成するモードの一例について説明する。 Next, we will explain an example of a mode in which a predicted image (prediction) is generated using LIC (local illumination compensation) processing.
図9Dは、LIC処理による輝度補正処理を用いた予測画像生成方法の一例を説明するための概念図である。 Figure 9D is a conceptual diagram illustrating an example of a method for generating a predicted image using luminance correction processing by LIC processing.
まず、符号化済みの参照ピクチャからMVを導出して、カレントブロックに対応する参照画像を取得する。 First, derive the MV from the encoded reference picture to obtain the reference image corresponding to the current block.
次に、カレントブロックに対して、参照ピクチャとカレントピクチャとで輝度値がどのように変化したかを示す情報を抽出する。この抽出は、カレントピクチャにおける符号化済み左隣接参照領域(周辺参照領域)および符号化済み上隣参照領域(周辺参照領域)の輝度画素値と、導出されたMVで指定された参照ピクチャ内の同等位置における輝度画素値とに基づいて行われる。そして、輝度値がどのように変化したかを示す情報を用いて、輝度補正パラメータを算出する。 Next, information is extracted that indicates how the luminance values of the current block have changed between the reference picture and the current picture. This extraction is performed based on the luminance pixel values of the coded left adjacent reference area (peripheral reference area) and coded upper adjacent reference area (peripheral reference area) in the current picture, and the luminance pixel values at the equivalent positions in the reference picture specified by the derived MV. Then, the luminance correction parameters are calculated using the information that indicates how the luminance values have changed.
MVで指定された参照ピクチャ内の参照画像に対して前記輝度補正パラメータを適用する輝度補正処理を行うことで、カレントブロックに対する予測画像を生成する。 A predicted image for the current block is generated by performing brightness correction processing that applies the brightness correction parameters to the reference image in the reference picture specified by the MV.
なお、図9Dにおける前記周辺参照領域の形状は一例であり、これ以外の形状を用いてもよい。 Note that the shape of the peripheral reference area in FIG. 9D is just an example, and other shapes may be used.
また、ここでは1枚の参照ピクチャから予測画像を生成する処理について説明したが、複数枚の参照ピクチャから予測画像を生成する場合も同様であり、各々の参照ピクチャから取得した参照画像に、上述と同様の方法で輝度補正処理を行ってから予測画像を生成してもよい。 Although the process of generating a predicted image from one reference picture has been described here, the same applies when generating a predicted image from multiple reference pictures, and a predicted image may be generated after performing brightness correction processing on the reference images obtained from each reference picture in the same manner as described above.
LIC処理を適用するかどうかの判定の方法として、例えば、LIC処理を適用するかどうかを示す信号であるlic_flagを用いる方法がある。具体的な一例としては、符号化装置において、カレントブロックが、輝度変化が発生している領域に属しているかどうかを判定し、輝度変化が発生している領域に属している場合はlic_flagとして値「1」を設定してLIC処理を適用して符号化を行い、輝度変化が発生している領域に属していない場合はlic_flagとして値「0」を設定してLIC処理を適用せずに符号化を行う。一方、復号化装置では、ストリームに記述されたlic_flagを復号化することで、その値に応じてLIC処理を適用するかどうかを切替えて復号を行ってもよい。 As a method of determining whether to apply LIC processing, for example, there is a method using lic_flag, which is a signal indicating whether to apply LIC processing. As a specific example, in an encoding device, it is determined whether the current block belongs to an area where a luminance change occurs, and if it belongs to an area where a luminance change occurs, the value "1" is set as lic_flag and LIC processing is applied and encoding is performed, and if it does not belong to an area where a luminance change occurs, the value "0" is set as lic_flag and encoding is performed without applying LIC processing. On the other hand, a decoding device may decode lic_flag described in the stream, and switch whether to apply LIC processing depending on the value and perform decoding.
LIC処理を適用するかどうかの判定の別の方法として、例えば、周辺ブロックでLIC処理を適用したかどうかに従って判定する方法もある。具体的な一例としては、カレントブロックがマージモードであった場合、マージモード処理におけるMVの導出の際に選択した周辺の符号化済みブロックがLIC処理を適用して符号化したかどうかを判定する。その結果に応じてLIC処理を適用するかどうかを切替えて符号化を行う。なお、この例の場合でも、同じ処理が復号装置側の処理に適用される。 As another method of determining whether to apply LIC processing, for example, there is a method of making the determination based on whether LIC processing has been applied to surrounding blocks. As a specific example, when the current block is in merge mode, it is determined whether the surrounding encoded blocks selected when deriving the MV in the merge mode process have been encoded using LIC processing. Depending on the result, the encoding is performed by switching whether or not to apply LIC processing. Note that even in this example, the same processing is applied to the processing on the decoding device side.
[復号装置の概要]
次に、上記の符号化装置100から出力された符号化信号(符号化ビットストリーム)を復号可能な復号装置の概要について説明する。図10は、実施の形態に係る復号装置200の機能構成を示すブロック図である。復号装置200は、動画像をブロック単位で復号する動画像復号装置である。
[Overview of the Decoding Device]
Next, an overview of a decoding device capable of decoding the coded signal (coded bit stream) output from the
図10に示すように、復号装置200は、エントロピー復号部202と、逆量子化部204と、逆変換部206と、加算部208と、ブロックメモリ210と、ループフィルタ部212と、フレームメモリ214と、イントラ予測部216と、インター予測部218と、予測制御部220と、を備える。
As shown in FIG. 10, the
復号装置200は、例えば、汎用プロセッサ及びメモリにより実現される。この場合、メモリに格納されたソフトウェアプログラムがプロセッサにより実行されたときに、プロセッサは、エントロピー復号部202、逆量子化部204、逆変換部206、加算部208、ループフィルタ部212、イントラ予測部216、インター予測部218及び予測制御部220として機能する。また、復号装置200は、エントロピー復号部202、逆量子化部204、逆変換部206、加算部208、ループフィルタ部212、イントラ予測部216、インター予測部218及び予測制御部220に対応する専用の1以上の電子回路として実現されてもよい。
The
以下に、復号装置200に含まれる各構成要素について説明する。
The components included in the
[エントロピー復号部]
エントロピー復号部202は、符号化ビットストリームをエントロピー復号する。具体的には、エントロピー復号部202は、例えば、符号化ビットストリームから二値信号に算術復号する。そして、エントロピー復号部202は、二値信号を多値化(debinarize)する。エントロピー復号部202は、ブロック単位で量子化係数を逆量子化部204に出力する。エントロピー復号部202は、実施の形態におけるイントラ予測部216、インター予測部218および予測制御部220に、符号化ビットストリーム(図1参照)に含まれている予測パラメータを出力してもよい。イントラ予測部216、インター予測部218および予測制御部220は、符号化装置側におけるイントラ予測部124、インター予測部126および予測制御部128で行われる処理と同じ予測処理を実行することができる。
[Entropy Decoding Section]
The
[逆量子化部]
逆量子化部204は、エントロピー復号部202から入力された復号対象ブロック(以下、カレントブロックという)の量子化係数を逆量子化する。具体的には、逆量子化部204は、カレントブロックの量子化係数の各々について、当該量子化係数に対応する量子化パラメータに基づいて当該量子化係数を逆量子化する。そして、逆量子化部204は、カレントブロックの逆量子化された量子化係数(つまり変換係数)を逆変換部206に出力する。
[Inverse quantization section]
The
[逆変換部]
逆変換部206は、逆量子化部204から入力された変換係数を逆変換することにより予測誤差(残差)を復元する。
[Inverse conversion section]
The
例えば符号化ビットストリームから読み解かれた情報がEMT又はAMTを適用することを示す場合(例えばAMTフラグが真)、逆変換部206は、読み解かれた変換タイプを示す情報に基づいてカレントブロックの変換係数を逆変換する。
For example, if the information interpreted from the encoded bitstream indicates that EMT or AMT is to be applied (e.g., the AMT flag is true), the
また例えば、符号化ビットストリームから読み解かれた情報がNSSTを適用することを示す場合、逆変換部206は、変換係数に逆再変換を適用する。
Also, for example, if the information interpreted from the encoded bitstream indicates that NSST should be applied, the
[加算部]
加算部208は、逆変換部206から入力された予測誤差と予測制御部220から入力された予測サンプルとを加算することによりカレントブロックを再構成する。そして、加算部208は、再構成されたブロックをブロックメモリ210及びループフィルタ部212に出力する。
[Adder]
The
[ブロックメモリ]
ブロックメモリ210は、イントラ予測で参照されるブロックであって復号対象ピクチャ(以下、カレントピクチャという)内のブロックを格納するための記憶部である。具体的には、ブロックメモリ210は、加算部208から出力された再構成ブロックを格納する。
[Block Memory]
The
[ループフィルタ部]
ループフィルタ部212は、加算部208によって再構成されたブロックにループフィルタを施し、フィルタされた再構成ブロックをフレームメモリ214及び表示装置等に出力する。
[Loop filter section]
The
符号化ビットストリームから読み解かれたALFのオン/オフを示す情報がALFのオンを示す場合、局所的な勾配の方向及び活性度に基づいて複数のフィルタの中から1つのフィルタが選択され、選択されたフィルタが再構成ブロックに適用される。 If the information indicating ALF on/off read from the encoded bitstream indicates ALF on, one filter is selected from among multiple filters based on the local gradient direction and activity, and the selected filter is applied to the reconstruction block.
[フレームメモリ]
フレームメモリ214は、インター予測に用いられる参照ピクチャを格納するための記憶部であり、フレームバッファと呼ばれることもある。具体的には、フレームメモリ214は、ループフィルタ部212によってフィルタされた再構成ブロックを格納する。
[Frame memory]
The
[イントラ予測部]
イントラ予測部216は、符号化ビットストリームから読み解かれたイントラ予測モードに基づいて、ブロックメモリ210に格納されたカレントピクチャ内のブロックを参照してイントラ予測を行うことで、予測信号(イントラ予測信号)を生成する。具体的には、イントラ予測部216は、カレントブロックに隣接するブロックのサンプル(例えば輝度値、色差値)を参照してイントラ予測を行うことでイントラ予測信号を生成し、イントラ予測信号を予測制御部220に出力する。
[Intra prediction unit]
The
なお、色差ブロックのイントラ予測において輝度ブロックを参照するイントラ予測モードが選択されている場合は、イントラ予測部216は、カレントブロックの輝度成分に基づいて、カレントブロックの色差成分を予測してもよい。
Note that if an intra prediction mode that references a luminance block in intra prediction of a chrominance block is selected, the
また、符号化ビットストリーム(例えば、エントロピー復号部202から出力される予測パラメータ)から読み解かれた情報がPDPCの適用を示す場合、イントラ予測部216は、水平/垂直方向の参照画素の勾配に基づいてイントラ予測後の画素値を補正する。
In addition, when information interpreted from the encoded bitstream (e.g., prediction parameters output from the entropy decoding unit 202) indicates the application of PDPC, the
[インター予測部]
インター予測部218は、フレームメモリ214に格納された参照ピクチャを参照して、カレントブロックを予測する。予測は、カレントブロック又はカレントブロック内のサブブロック(例えば4x4ブロック)の単位で行われる。例えば、インター予測部218は、符号化ビットストリーム(例えば、エントロピー復号部202から出力される予測パラメータ)から読み解かれた動き情報(例えば動きベクトル)を用いて動き補償を行うことでカレントブロック又はサブブロックのインター予測信号を生成し、インター予測信号を予測制御部220に出力する。
[Inter prediction section]
The
符号化ビットストリームから読み解かれた情報がOBMCモードを適用することを示す場合、インター予測部218は、動き探索により得られたカレントブロックの動き情報だけでなく、隣接ブロックの動き情報も用いて、インター予測信号を生成する。
If the information interpreted from the encoded bitstream indicates that the OBMC mode is to be applied, the
また、符号化ビットストリームから読み解かれた情報がFRUCモードを適用することを示す場合、インター予測部218は、符号化ストリームから読み解かれたパターンマッチングの方法(バイラテラルマッチング又はテンプレートマッチング)に従って動き探索を行うことにより動き情報を導出する。そして、インター予測部218は、導出された動き情報を用いて動き補償(予測)を行う。
In addition, if the information interpreted from the encoded bitstream indicates that the FRUC mode is to be applied, the
また、インター予測部218は、BIOモードが適用される場合に、等速直線運動を仮定したモデルに基づいて動きベクトルを導出する。また、符号化ビットストリームから読み解かれた情報がアフィン動き補償予測モードを適用することを示す場合には、インター予測部218は、複数の隣接ブロックの動きベクトルに基づいてサブブロック単位で動きベクトルを導出する。
When the BIO mode is applied, the
[予測制御部]
予測制御部220は、イントラ予測信号及びインター予測信号のいずれかを選択し、選択した信号を予測信号として加算部208に出力する。全体的に、復号装置側の予測制御部220、イントラ予測部216およびインター予測部218の構成、機能、および処理は、符号化装置側の予測制御部128、イントラ予測部124およびインター予測部126の構成、機能、および処理と対応していてもよい。
[Predictive control unit]
The
[非矩形分割]
符号化装置(図1参照)のイントラ予測部124及びインター予測部126に接続された予測制御部128においても、復号装置(図10参照)のイントラ予測部216及びインター予測部218に接続された予測制御部220においても、従来、各ブロックの分割から得られ、動き情報(例えば複数の動きベクトル)が得られる複数のパーティション(又は、複数の可変サイズブロック、又は、複数のサブブロック)は、図2に示されるように、常に矩形である。発明者らは、三角形形状のような非矩形形状を有する複数のパーティションを生成することが、様々な実施において、ピクチャにおける画像の内容に応じて、画質及び符号化効率の改善を導くことを発見した。以下、予測の目的で画像ブロックから分割される少なくとも1つのパーティションが非矩形形状を有する様々な実施の形態が述べられる。なお、これらの実施の形態は、符号化装置側(イントラ予測部124及びインター予測部126に接続された予測制御部128)に対して、及び、復号装置側(イントラ予測部216及びインター予測部218に接続された予測制御部220)に対して、等しく適用可能であり、図1の符号化装置等に、又は、図10の復号装置等に、実装されてもよい。
[Non-rectangular division]
In the
図11は、非矩形形状(例えば三角形)を有する少なくとも第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割し、さらに、第1パーティションと第2パーティションとの再構成された組み合わせとして画像ブロックを符号化(又は復号)する処理を行う処理の一例を示すフローチャートである。 Figure 11 is a flow chart showing an example of a process for dividing an image block into a number of partitions including at least a first partition having a non-rectangular shape (e.g., a triangle) and a second partition, and then encoding (or decoding) the image block as a reconstructed combination of the first and second partitions.
ステップS1001で、画像ブロックは、非矩形形状を有する第1パーティション、及び、非矩形形状を有しても有さなくてもよい第2パーティションを含む複数のパーティションに分割される。例えば、図12に示されるように、画像ブロックは、共に非矩形形状(例えば三角形)を有する第1パーティション及び第2パーティションを作成するため、画像ブロックの左上角から画像ブロックの右下角へ分割されてもよい。あるいは、画像ブロックは、共に非矩形形状(例えば三角形)を有する第1パーティション及び第2パーティションを作成するため、画像ブロックの右上角から画像ブロックの左下角へ分割されてもよい。図12及び図17~図19を参照して、後に、非矩形の分割の様々な例が述べられる。 In step S1001, the image block is divided into a number of partitions including a first partition having a non-rectangular shape and a second partition that may or may not have a non-rectangular shape. For example, as shown in FIG. 12, the image block may be divided from the top left corner of the image block to the bottom right corner of the image block to create a first partition and a second partition, both of which have a non-rectangular shape (e.g., a triangle). Alternatively, the image block may be divided from the top right corner of the image block to the bottom left corner of the image block to create a first partition and a second partition, both of which have a non-rectangular shape (e.g., a triangle). Various examples of non-rectangular divisions are described later with reference to FIG. 12 and FIGS. 17-19.
ステップS1002において、処理は、第1パーティションについて第1動きベクトルを予測し、第2パーティションについて第2動きベクトルを予測する。例えば、第1動きベクトル及び第2動きベクトルを予測することは、第1動きベクトル候補セットから第1動きベクトルを選択すること、及び、第2動きベクトル候補セットから第2動きベクトルを選択することを含んでいてもよい。 In step S1002, the process predicts a first motion vector for the first partition and predicts a second motion vector for the second partition. For example, predicting the first and second motion vectors may include selecting a first motion vector from a first set of motion vector candidates and selecting a second motion vector from a second set of motion vector candidates.
ステップS1003において、上記のステップS1002で導出された第1動きベクトルを用いて第1パーティションを取得し、上記のステップS1002で導出された第2動きベクトルを用いて第2パーティションを取得するため、動き補償処理が行われる。 In step S1003, a motion compensation process is performed to obtain a first partition using the first motion vector derived in step S1002 above, and to obtain a second partition using the second motion vector derived in step S1002 above.
ステップS1004において、第1パーティションと第2パーティションとの(再構成された)組み合わせとして画像ブロックについて予測処理が行われる。予測処理は、第1パーティションと第2パーティションとの間の境界を滑らかにするための境界平滑化処理を含む。例えば、境界平滑化処理は、第1パーティションに基づいて予測される、複数の境界画素の複数の第1値と、第2パーティションに基づいて予測される、複数の境界画素の複数の第2値とを重み付けすることを伴う。境界平滑化処理の様々な実装が、図13、図14、図20及び図21A~図21Dを参照して後に述べられる。 In step S1004, a prediction process is performed on the image block as a (reconstructed) combination of the first and second partitions. The prediction process includes a boundary smoothing process to smooth the boundary between the first and second partitions. For example, the boundary smoothing process involves weighting a plurality of first values of a plurality of boundary pixels predicted based on the first partition and a plurality of second values of a plurality of boundary pixels predicted based on the second partition. Various implementations of the boundary smoothing process are described below with reference to Figures 13, 14, 20, and 21A-21D.
ステップS1005において、処理は、非矩形形状を有する第1パーティション、及び、第2パーティションに画像ブロックを分割することを示すパーティションパラメータを含む1つ以上のパラメータを用いて画像ブロックを符号化又は復号する。図15の表に集約されるように、例えば、パーティションパラメータ(「第1インデックス値」)は、例えば、(例えば図12に示されるように左上から右下へ又は右上から左下への)分割に適用される分割方向と、上述されたステップS1002で導出された第1動きベクトル及び第2動きベクトルとを一体として符号化してもよい。パーティションパラメータを含む1つ以上のパラメータを伴うこのようなパーティションシンタックス動作の詳細は、図15、図16及び図22~図25を参照して、後に詳細に述べられる。 In step S1005, the process encodes or decodes the image block using one or more parameters including a partition parameter indicating partitioning of the image block into a first partition having a non-rectangular shape and a second partition. As summarized in the table of FIG. 15, for example, the partition parameter ("first index value") may encode, for example, a partition direction to be applied to the partition (e.g., from top left to bottom right or top right to bottom left as shown in FIG. 12) together with the first and second motion vectors derived in step S1002 described above. Details of such partition syntax operations involving one or more parameters including the partition parameter are described in more detail below with reference to FIGS. 15, 16, and 22-25.
図17は、画像ブロックを分割する処理2000を示すフローチャートである。ステップS2001において、処理は、非矩形形状を有する第1パーティション、及び、非矩形形状を有しても有さなくてもよい第2パーティションを含む複数のパーティションに画像を分割する。図12に示されるように、画像ブロックは、三角形形状を有する第1パーティション、及び、同じく三角形形状を有する第2パーティションに分割される。少なくとも第1パーティションが非矩形形状を有する、第1パーティション及び第2パーティションを含む複数のパーティションに画像ブロックが分割される多数の他の例がある。非矩形形状は、三角形であってもよいし、台形であってもよいし、少なくとも5つの辺と角とを有する多角形であってもよい。
Figure 17 is a flow chart illustrating a
例えば、図18に示されるように、画像ブロックは、2つの三角形形状パーティションに分割されてもよい。画像ブロックは、2つの三角形形状パーティションよりも多く(例えば3つの三角形形状パーティション)に分割されてもよい。画像ブロックは、1つ又は複数の三角形形状パーティションと、1つ又は複数の矩形形状パーティションとの組み合わせに分割されてもよい。あるいは、画像ブロックは、1つ又は複数の三角形形状パーティションと、1つ又は複数の多角形形状パーティションとの組み合わせに分割されてもよい。 For example, as shown in FIG. 18, an image block may be divided into two triangular partitions. An image block may be divided into more than two triangular partitions (e.g., three triangular partitions). An image block may be divided into a combination of one or more triangular partitions and one or more rectangular partitions. Alternatively, an image block may be divided into a combination of one or more triangular partitions and one or more polygonal partitions.
さらに図19に示されるように、画像ブロックは、L形状(多角形形状)パーティションと、矩形形状パーティションとに分割されてもよい。画像ブロックは、五角形(多角形)形状パーティションと、三角形形状パーティションとに分割されてもよい。画像ブロックは、六角形(多角形)形状パーティションと、五角形(多角形)形状パーティションとに分割されてもよい。あるいは、画像ブロックは、複数の多角形形状パーティションに分割されてもよい。 As further shown in FIG. 19, the image block may be partitioned into L-shaped (polygonal) partitions and rectangular shaped partitions. The image block may be partitioned into pentagonal (polygonal) shaped partitions and triangular shaped partitions. The image block may be partitioned into hexagonal (polygonal) shaped partitions and pentagonal (polygonal) shaped partitions. Alternatively, the image block may be partitioned into multiple polygonal shaped partitions.
図17を再び参照し、ステップS2002において、処理は、第1パーティションについて、例えば第1動きベクトル候補セットから第1パーティションを選択することによって、第1動きベクトルを予測し、第2パーティションについて、例えば第2動きベクトル候補セットから第2パーティションを選択することによって、第2動きベクトルを予測する。例えば、第1動きベクトル候補セットは、第1パーティションに隣接する複数のパーティションの複数の動きベクトルを含んでいてもよく、第2動きベクトル候補セットは、第2パーティションに隣接する複数のパーティションの複数の動きベクトルを含んでいてもよい。隣接する複数のパーティションは、空間的に隣接する複数のパーティションと、時間的に隣接する複数のパーティションとの一方又は両方であってもよい。空間的に隣接する複数のパーティションのいくつかの例は、処理されるパーティションの左、左下、下、右下、右、右上、上又は左上に位置するパーティションを含む。時間的に隣接する複数のパーティションの複数の例は、画像ブロックの複数の参照ピクチャにおける複数のco-locatedパーティションを含む。 Referring again to FIG. 17, in step S2002, the process predicts a first motion vector for the first partition, e.g., by selecting a first partition from a first motion vector candidate set, and predicts a second motion vector for the second partition, e.g., by selecting a second partition from a second motion vector candidate set. For example, the first motion vector candidate set may include motion vectors of partitions adjacent to the first partition, and the second motion vector candidate set may include motion vectors of partitions adjacent to the second partition. The adjacent partitions may be one or both of spatially adjacent partitions and temporally adjacent partitions. Some examples of spatially adjacent partitions include partitions located to the left, bottom left, bottom, bottom right, right, top right, top, or top left of the partition being processed. Examples of temporally adjacent partitions include co-located partitions in reference pictures of the image block.
様々な実装において、第1パーティションに隣接する複数のパーティション、及び、第2パーティションに隣接する複数のパーティションは、第1パーティション及び第2パーティションに分割される画像ブロックの外部であってもよい。第1動きベクトル候補セットは、第2動きベクトル候補セットと、同じであってもよいし、異なっていてもよい。さらに、第1動きベクトル候補セット、及び、第2動きベクトル候補セットの少なくとも1つは、画像ブロックについて準備された他の第3動きベクトル候補セットと同じであってもよい。 In various implementations, the partitions adjacent to the first partition and the partitions adjacent to the second partition may be outside the image block divided into the first partition and the second partition. The first motion vector candidate set may be the same as or different from the second motion vector candidate set. Furthermore, at least one of the first motion vector candidate set and the second motion vector candidate set may be the same as another third motion vector candidate set prepared for the image block.
いくつかの実装では、ステップS2002において、第1パーティションと同様に第2パーティションも非矩形形状(例えば三角形)を有するとの判定に応じて、処理2000は、第1パーティションを除く(つまり第1パーティションの動きベクトルを除く)、第2パーティションに隣接する複数のパーティションの複数の動きベクトルを含む第2動きベクトル候補セットを(非矩形形状第2パーティションについて)作成する。一方、第1パーティションと同様でなく第2パーティションが矩形形状を有するとの判定に応じて、処理2000は、第1パーティションを含む、第2パーティションに隣接する複数のパーティションの複数の動きベクトルを含む第2動きベクトル候補セットを(矩形形状第2パーティションについて)作成する。
In some implementations, in response to determining in step S2002 that the second partition has a non-rectangular shape (e.g., a triangle) similar to the first partition,
ステップS2003において、処理は、上述されたステップS2002で導出された第1動きベクトルを用いて第1パーティションを符号化又は復号し、上述されたステップS2002で導出された第2動きベクトルを用いて第2パーティションを符号化又は復号する。 In step S2003, the process encodes or decodes the first partition using the first motion vector derived in step S2002 described above, and encodes or decodes the second partition using the second motion vector derived in step S2002 described above.
図17の処理2000のような画像ブロック分割処理は、例えば図1に示されたような回路及び回路に接続されたメモリを含む画像符号化装置によって行われてもよい。回路は、動作において、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割すること(ステップS2001)、第1パーティションについて第1動きベクトル、及び、第2パーティションについて第2動きベクトルを予測すること(ステップS2002)、第1動きベクトルを用いて第1パーティションを、及び、第2動きベクトルを用いて第2パーティションを符号化すること(ステップS2003)を行う。
An image block division process such as
他の実施の形態に従って、図1に示されたような、画像符号化装置は、動作において原画像を受信し複数のブロックに分割する分割部102、動作において分割部から複数のブロック、及び、予測制御部128から複数の予測を受信し、各予測をその対応ブロックから減算して、残差を出力する加算部104、動作において加算部104から出力された複数の残差に変換を行って複数の変換係数を出力する変換部106、動作において複数の変換係数を量子化して複数の量子化変換係数を生成する量子化部108、動作において複数の量子化変換係数を符号化してビットストリームを生成するエントロピー符号化部110、及び、動作において符号化済み参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部126と、動作においてカレントピクチャにおける符号化済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部124と、メモリ118、122とに接続された予測制御部128を含んで、提供される。予測制御部128は、動作において、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに複数のブロックを分割し(図17、ステップS2001)、第1パーティションについて第1動きベクトル、及び、第2パーティションについて第2動きベクトルを予測し(ステップS2002)、第1動きベクトルを用いて第1パーティションを、及び、第2動きベクトルを用いて第2パーティションを符号化する(ステップS2003)。
According to another embodiment, an image coding device as shown in FIG. 1 is provided, which includes a
他の実施の形態に従って、例えば図10に示されるような回路及び回路に接続されたメモリを含む画像復号装置が提供される。回路は、動作において、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割すること(図17、ステップS2001)と、第1パーティションについて第1動きベクトル、及び、第2パーティションについて第2動きベクトルを予測すること(ステップS2002)と、第1動きベクトルを用いて第1パーティションを、及び、第2動きベクトルを用いて第2パーティションを復号すること(ステップS2003)とを行う。 According to another embodiment, an image decoding device is provided that includes a circuit, such as that shown in FIG. 10, and a memory connected to the circuit. The circuit operates to divide an image block into a plurality of partitions, including a first partition and a second partition, each having a non-rectangular shape (FIG. 17, step S2001), predict a first motion vector for the first partition and a second motion vector for the second partition (step S2002), and decode the first partition using the first motion vector and the second partition using the second motion vector (step S2003).
さらに実施の形態に従って、図10に示された画像復号装置は、動作において符号化ビットストリームを受信し復号して複数の量子化変換係数を取得するエントロピー復号部202、動作において、複数の量子化変換係数を逆量子化して複数の変換係数を取得し、複数の変換係数を逆変換して複数の残差を取得する逆量子化部204及び逆変換部206、動作において、逆量子化部204及び逆変換部206から出力された複数の残差と、予測制御部220から出力された複数の予測とを加算して複数のブロックを再構成する加算部208、及び、動作において復号済みの参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部218と、動作においてカレントピクチャにおける復号済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部216と、メモリ210、214とに接続された予測制御部220を含んで、提供される。予測制御部220は、動作において、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割し(図17、ステップS2001)、第1パーティションについて第1動きベクトル、及び、第2パーティションについて第2動きベクトルを予測し(ステップS2002)、第1動きベクトルを用いて第1パーティションを、及び、第2動きベクトルを用いて第2パーティションを復号する(ステップS2003)。
Further, according to an embodiment, the image decoding device shown in FIG. 10 is provided including an
[境界平滑化]
図11、ステップS1004において上述されたように、様々な実施の形態に従って、非矩形形状を有する第1パーティションと、第2パーティションとの(再構成された)組み合わせとして画像ブロックについて予測処理を行うことは、第1パーティションと第2パーティションとの間の境界に沿う境界平滑化処理の適用を伴ってもよい。
[Boundary Smoothing]
As described above in FIG. 11 , step S1004, according to various embodiments, performing prediction processing on an image block as a (reconstructed) combination of a first partition having a non-rectangular shape and a second partition may involve application of a boundary smoothing process along the boundary between the first partition and the second partition.
例えば、図21Bは、第1パーティションに基づいて第1予測された複数の境界画素の複数の第1値と、第2パーティションに基づいて第2予測された複数の境界画素の複数の第2値とを重み付けすることを伴う境界平滑化処理の一例を示す。 For example, FIG. 21B shows an example of a boundary smoothing process that involves weighting a plurality of first values of a plurality of boundary pixels that are first predicted based on a first partition and a plurality of second values of a plurality of boundary pixels that are second predicted based on a second partition.
図20は、一実施形態に従って、第1パーティションに基づいて第1予測された複数の境界画素の複数の第1値と、第2パーティションに基づいて第2予測された複数の境界画素の複数の第2値とを重み付けすることを伴う全体の境界平滑化処理3000を示すフローチャートである。ステップS3001において、図21A、又は、上述された図12、図18及び図19に示されたように、画像ブロックは、少なくとも第1パーティションが非矩形形状を有する、第1パーティション及び第2パーティションに、境界に沿って分割される。
20 is a flow diagram illustrating an overall
ステップS3002において、境界に沿う、第1パーティションの画素セット(図21Aにおける「複数の境界画素」)の複数の第1値(例えば色、輝度、透明性等)は、第1パーティションの情報を用いて、第1予測される。ステップS3003において、境界に沿う、第1パーティションの(同じ)画素セットの複数の第2値は、第2パーティションの情報を用いて第2予測される。いくつかの実施の形態において、第1予測及び第2予測の少なくとも1つが、符号化済み参照ピクチャにおける参照パーティションに基づいて複数の第1値及び複数の第2値を予測するインター予測処理である。図21Dを参照して、いくつか実装では、予測処理は、第1パーティション及び第2パーティションが重なる画素セットを含む第1パーティション(「第1サンプルセット」)の全ての画素の複数の第1値を予測し、第1パーティションと第2パーティションとが重なる画素セット(「第2サンプルセット」)のみの第2値を予測する。他の実装において、第1予測及び第2予測の少なくとも1つは、カレントピクチャにおける符号化済み参照パーティションに基づいて複数の第1値及び複数の第2値を予測するイントラ予測処理である。いくつかの実装において、第1予測に用いられる予測方法は、第2予測に用いられる予測方法とは異なる。例えば、第1予測は、インター予測処理を含んでいてもよいし、第2予測は、イントラ予測処理を含んでいてもよい。複数の第1値の第1予測、又は、複数の第2値の第2予測に用いられる情報は、第1パーティション又は第2パーティションの複数の動きベクトル、複数のイントラ予測方向等であってもよい。 In step S3002, a plurality of first values (e.g., color, luminance, transparency, etc.) of a set of pixels of a first partition along the boundary ("boundary pixels" in FIG. 21A) are first predicted using information of the first partition. In step S3003, a plurality of second values of a (same) set of pixels of the first partition along the boundary are second predicted using information of the second partition. In some embodiments, at least one of the first prediction and the second prediction is an inter-prediction process that predicts the plurality of first values and the plurality of second values based on a reference partition in the encoded reference picture. With reference to FIG. 21D, in some implementations, the prediction process predicts the plurality of first values of all pixels of the first partition ("first sample set") that includes a set of pixels where the first partition and the second partition overlap, and predicts the second values only of a set of pixels where the first partition and the second partition overlap ("second sample set"). In other implementations, at least one of the first prediction and the second prediction is an intra prediction process that predicts the first values and the second values based on a coded reference partition in the current picture. In some implementations, the prediction method used for the first prediction is different from the prediction method used for the second prediction. For example, the first prediction may include an inter prediction process, and the second prediction may include an intra prediction process. Information used for the first prediction of the first values or the second prediction of the second values may be motion vectors of the first partition or the second partition, multiple intra prediction directions, etc.
ステップS3004において、第1パーティションを用いて予測される複数の第1値、及び、第2パーティションを用いて予測される複数の第2値は、重み付けされる。ステップS3005において、第1パーティションは、重み付けされた複数の第1値及び複数の第2値を用いて符号化又は復号される。 In step S3004, the first values predicted using the first partition and the second values predicted using the second partition are weighted. In step S3005, the first partition is encoded or decoded using the weighted first values and second values.
図21Bは、第1パーティション及び第2パーティションが各行又は各行の(最大)5画素で重なる境界平滑化動作の例を示す。すなわち、複数の第1値が第1パーティションに基づいて予測され、複数の第2値が第2パーティションに基づいて予測される各行又は各列の画素セットの数は、最大で5つである。図21Cは、第1パーティション及び第2パーティションが各行又は各列の(最大)3画素で重なる境界平滑化動作の他の例を示す。すなわち、複数の第1値が第1パーティションに基づいて予測され、複数の第2値が第2パーティションに基づいて予測される各行又は各列の画素セットの数は、最大で3つである。 Figure 21B shows an example of a boundary smoothing operation in which the first partition and the second partition overlap at (maximum) five pixels in each row or at (maximum) five pixels in each row. That is, the number of pixel sets in each row or column for which the multiple first values are predicted based on the first partition and the multiple second values are predicted based on the second partition is at most five. Figure 21C shows another example of a boundary smoothing operation in which the first partition and the second partition overlap at (maximum) three pixels in each row or column. That is, the number of pixel sets in each row or column for which the multiple first values are predicted based on the first partition and the multiple second values are predicted based on the second partition is at most three.
図13は、第1パーティション及び第2パーティションが各行又は各列の(最大)4画素で重なる境界平滑化動作の他の例を示す。すなわち、複数の第1値が第1パーティションに基づいて予測され、複数の第2値が第2パーティションに基づいて予測される各行又は各列の画素セットの数は、最大で4つである。示された例において、1/8、1/4、3/4及び7/8の複数の重みが、それぞれ、セットにおける4つの画素の複数の第1値に、7/8、3/4、1/4及び1/8の複数の重みが、それぞれ、セットにおける4つの画素の複数の第2値に、適用されてもよい。 13 shows another example of a boundary smoothing operation in which the first and second partitions overlap at (maximum) four pixels in each row or column. That is, the number of pixel sets in each row or column for which the first values are predicted based on the first partition and the second values are predicted based on the second partition is at most four. In the example shown, weights of 1/8, 1/4, 3/4 and 7/8 may be applied to the first values of the four pixels in the set, respectively, and weights of 7/8, 3/4, 1/4 and 1/8 may be applied to the second values of the four pixels in the set, respectively.
図14は、さらに、第1パーティション及び第2パーティションが各行又は各列の0画素で重なる(つまりそれらが重ならい)、各行又は各列の(最大)1画素で重なる、及び、各行又は各列の(最大)2画素で重なる境界平滑化動作の複数の例を示す。第1パーティション及び第2パーティションが重ならない例において、複数のゼロ重みが適用される。第1パーティション及び第2パーティションが各行又は各列の1画素で重なる例において、第1パーティションに基づいて予測されるセットにおける複数の画素の複数の第1値に1/2の重みが適用されてもよく、第2パーティションに基づいて予測されるセットにおける複数の画素の複数の第2値に1/2の重みが適用されてもよい。第1パーティション及び第2パーティションが各行又は各列の2画素で重なる例において、第1パーティションに基づいて予測されるセットにおける2つの画素の複数の第1値に、それぞれ、1/3及び2/3の重みが適用されてもよく、第2パーティションに基づいて予測されるセットにおける2つの画素の複数の第2値に、それぞれ、2/3及び1/3の重みが適用されてもよい。 14 further illustrates several examples of boundary smoothing operations in which the first and second partitions overlap (i.e., they do not overlap) at 0 pixels in each row or column, overlap at (at most) 1 pixel in each row or column, and overlap at (at most) 2 pixels in each row or column. In examples in which the first and second partitions do not overlap, zero weights are applied. In examples in which the first and second partitions overlap at 1 pixel in each row or column, a weight of 1/2 may be applied to the first values of the pixels in the set predicted based on the first partition, and a weight of 1/2 may be applied to the second values of the pixels in the set predicted based on the second partition. In an example where the first and second partitions overlap by two pixels in each row or column, weights of 1/3 and 2/3 may be applied to the first values of the two pixels in the set predicted based on the first partition, respectively, and weights of 2/3 and 1/3 may be applied to the second values of the two pixels in the set predicted based on the second partition, respectively.
上述された複数の実施の形態に従って、第1パーティション及び第2パーティションが重なるセットにおける複数の画素の数は整数である。他の複数の実装において、セットにおいて重なる画素の数は、例えば、非整数であってもよいし、分数であってもよい。画素セットの複数の第1値及び複数の第2値に適用される複数の重みも、各適用に応じて、分数又は整数であってもよい。 In accordance with the embodiments described above, the number of pixels in the set where the first partition and the second partition overlap is an integer. In other implementations, the number of overlapping pixels in the set may be, for example, a non-integer number or a fraction. The weights applied to the first values and second values of the pixel set may also be fractional or integer, depending on the respective application.
図20の処理3000のような境界平滑化処理は、例えば図1に示されたような回路及び回路に接続されたメモリを含む画像符号化装置によって行われてもよい。回路は、動作において、画像ブロックから分割される、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿って境界平滑化動作を行う(図20、ステップS3001)。境界平滑化動作は、境界に沿う、第1パーティションの画素セットの複数の第1値を第1パーティションの情報を用いて予測すること(ステップS3002)と、境界に沿う、第1パーティションの画素セットの複数の第2値を第2パーティションの情報を用いて第2予測すること(ステップS3003)と、複数の第1値及び複数の第2値を重み付けすること(ステップS3004)と、重み付けされた複数の第1値、及び、重み付けされた複数の第2値を用いて、第1パーティションを符号化すること(ステップS3005)とを含む。
The boundary smoothing process such as
他の実施の形態に従って、図1に示されたような、画像符号化装置は、動作において原画像を受信し複数のブロックに分割する分割部102、動作において分割部から複数のブロック、及び、予測制御部128から複数の予測を受信し、各予測をその対応ブロックから減算して、残差を出力する加算部104、動作において加算部104から出力された複数の残差に変換を行って複数の変換係数を出力する変換部106、動作において複数の変換係数を量子化して複数の量子化変換係数を生成する量子化部108、動作において複数の量子化変換係数を符号化してビットストリームを生成するエントロピー符号化部110、及び、動作において符号化済み参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部126と、動作においてカレントピクチャにおける符号化済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部124と、メモリ118、122とに接続された予測制御部128を含んで、提供される。予測制御部128は、動作において、画像ブロックから分割される、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿って境界平滑化動作を行う(図20、ステップS3001)。境界平滑化動作は、境界に沿う、第1パーティションの画素セットの複数の第1値を、第1パーティションの情報を用いて第1予測すること(ステップS3002)と、境界に沿う、第1パーティションの画素セットの複数の第2値を、第2パーティションの情報を用いて第2予測すること(ステップS3003)と、複数の第1値及び複数の第2値を重み付けすること(ステップS3004)と、重み付けされた複数の第1値、及び、重み付けされた複数の第2値を用いて第1パーティションを符号化すること(ステップS3005)とを含む。
According to another embodiment, an image coding device as shown in FIG. 1 is provided, which includes a
他の実施の形態に従って、例えば、図10に示されたような、回路及び回路に接続されたメモリを含む画像復号装置が提供される。回路は、動作において、画像ブロックから分割される、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿って境界平滑化動作を行う(図20、ステップS3001)。境界平滑化動作は、境界に沿う、第1パーティションの画素セットの複数の第1値を第1パーティションの情報を用いて第1予測すること(ステップS3002)と、境界に沿う、第1パーティションの画素セットの複数の第2値を第2パーティションの情報を用いて第2予測すること(ステップS3003)と、複数の第1値及び複数の第2値を重み付けすること(ステップS3004)と、重み付けされた複数の第1値、及び、重み付けされた複数の第2値を用いて、第1パーティションを復号すること(ステップS3005)とを含む。 According to another embodiment, an image decoding device is provided that includes a circuit and a memory connected to the circuit, for example as shown in FIG. 10. In operation, the circuit performs a boundary smoothing operation along a boundary between a first partition having a non-rectangular shape divided from an image block and a second partition (FIG. 20, step S3001). The boundary smoothing operation includes first predicting a plurality of first values of a pixel set of the first partition along the boundary using information of the first partition (step S3002), second predicting a plurality of second values of a pixel set of the first partition along the boundary using information of the second partition (step S3003), weighting the plurality of first values and the plurality of second values (step S3004), and decoding the first partition using the weighted plurality of first values and the weighted plurality of second values (step S3005).
他の実施の形態に従って、図10に示された画像復号装置は、動作において符号化ビットストリームを受信し復号して複数の量子化変換係数を取得するエントロピー復号部202、動作において、複数の量子化変換係数を逆量子化して複数の変換係数を取得し、複数の変換係数を逆変換して複数の残差を取得する逆量子化部204及び逆変換部206、動作において、逆量子化部204及び逆変換部206から出力された複数の残差と、予測制御部220から出力された複数の予測とを加算して複数のブロックを再構成する加算部208、及び、動作において復号済みの参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部218と、動作においてカレントピクチャにおける復号済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部216と、メモリ210、214とに接続された予測制御部220を含んで、提供される。予測制御部220は、動作において、画像ブロックから分割される、非矩形形状を有する第1パーティションと、第2パーティションとの間の境界に沿って境界平滑化動作を行う(図20、ステップS3001)。境界平滑化動作は、境界に沿う、第1パーティションの画素セットの複数の第1値を第1パーティションの情報を用いて第1予測すること(ステップS3002)と、境界に沿う、第1パーティションの画素セットの複数の第2値を第2パーティションの情報を用いて第2予測すること(ステップS3003)と、複数の第1値及び複数の第2値を重み付けすること(ステップS3004)と、重み付けされた複数の第1値、及び、重み付けされた複数の第2値を用いて、第1パーティションを復号すること(ステップS3005)とを含む。
According to another embodiment, the image decoding device shown in FIG. 10 is provided including an
[パーティションパラメータシンタックスを用いるエントロピー符号化及び復号]
図11、ステップS1005に示されるように、様々な実施の形態に従って、非矩形形状を有する第1パーティション、及び、第2パーティションに分割された画像ブロックは、画像ブロックの非矩形分割を示すパーティションパラメータを含む1つ以上のパラメータを用いて符号化又は復号されてもよい。様々な実施の形態において、このようなパーティションパラメータは、後により十分に述べられるように、例えば、分割に適用される分割方向(例えば、左上から右下へ、又は、右上から左下へ、図12参照)と、ステップS1002で予測された第1動きベクトル及び第2動きベクトルとを一体として符号化してもよい。
Entropy Encoding and Decoding Using Partition Parameter Syntax
As shown in Figure 11, step S1005, according to various embodiments, an image block divided into a first partition and a second partition having a non-rectangular shape may be encoded or decoded using one or more parameters including a partition parameter indicating the non-rectangular division of the image block. In various embodiments, such partition parameters may be encoded jointly with, for example, a division direction applied to the division (e.g., from upper left to lower right or from upper right to lower left, see Figure 12) and the first and second motion vectors predicted in step S1002, as described more fully below.
図15は、複数のサンプルパーティションパラメータ(「第1インデックス値」)及び複数のパーティションパラメータによってそれぞれ一体として符号化される複数の情報セットの表である。複数のパーティションパラメータ(「第1インデックス値」)は、0から6に入り、共に三角形である第1パーティション及び第2パーティションに画像ブロックを分割する方向(図12参照)、第1パーティションについて予測された第1動きベクトル(図11、ステップS1002)、及び、第2パーティションについて予測された第2動きベクトル(図11、ステップS1002)を一体として符号化する。特に、パーティションパラメータ0は、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。
15 is a table of sample partition parameters ("first index values") and information sets that are each encoded together by the partition parameters. The partition parameters ("first index values") range from 0 to 6 and encode the direction of partitioning the image block into a first partition and a second partition, both of which are triangular (see FIG. 12), a first motion vector predicted for the first partition (FIG. 11, step S1002), and a second motion vector predicted for the second partition (FIG. 11, step S1002). In particular,
パーティションパラメータ1は、分割方向が右上角から左下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第1」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第2」動きベクトルであることを符号化する。パーティションパラメータ2は、分割方向が右上角から左下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。パーティションパラメータ3は、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第2」動きベクトルであることを符号化する。パーティションパラメータ4は、分割方向が右上角から左下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第3」動きベクトルであることを符号化する。パーティションパラメータ5は、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第3」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。パーティションパラメータ6は、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第4」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。
図22は、符号化装置側で行われる方法4000を示すフローチャートである。ステップS4001において、処理は、分割を示すパーティションパラメータに基づいて、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割する。例えば、上述された図15に示されたように、パーティションパラメータは、画像ブロックを分割する方向(例えば、右上角から左下角、又は、左上角から右下角)を示してもよい。ステップS4002において、処理は、第1パーティション及び第2パーティションを符号化する。ステップS4003において、処理は、復号装置側が1つ以上のパラメータを取得して復号装置側の第1パーティション及び第2パーティションについて(符号化装置側で行われたものと)同じ予測処理を行うため受信でき復号できるビットストリームにパーティションパラメータを含む1つ以上のパラメータを書き込む。パーティションパラメータを含む1つ以上のパラメータは、第1パーティションの非矩形形状、第2パーティションの形状、第1パーティション及び第2パーティションを取得するための画像ブロックの分割に用いられる分割方向、第1パーティションの第1動きベクトル、第2パーティションの第2動きベクトル等のような、様々な情報を一体として又は別々に符号化する。
FIG. 22 is a flowchart showing a
図23は、復号装置側で行われる方法5000を示すフローチャートである。ステップS5001において、処理は、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータを1つ以上のパラメータが含むビットストリームから、1つ以上のパラメータを読み解く。ビットストリームから読み解かれるパーティションパラメータを含む1つ以上のパラメータは、第1パーティションの非矩形形状、第2パーティションの形状、第1パーティション及び第2パーティションを取得するため画像ブロックの分割に用いられる分割方向、第1パーティションの第1動きベクトル、第2パーティションの第2動きベクトル等のような、復号装置側が符号化装置側で行われたものと同じ予測処理行うため必要とされる様々な情報を一体として又は別々に符号化してもよい。ステップS5002において、処理5000は、ビットストリームから読み解かれたパーティションパラメータに基づいて、画像ブロックを複数のパーティションに分割する。ステップS5003において、処理は、画像ブロックから分割されるような、第1パーティション及び第2パーティションを復号する。
23 is a flow chart showing a
図24は、図15において上述されたサンプル表に特性が類似し、複数のサンプルパーティションパラメータ(「第1インデックス値」)及びそれぞれ複数のパーティションパラメータによって一体として符号化された複数の情報セットの表である。図24において、パーティションパラメータ(「第1インデックス値」)は、0から6に入り、画像ブロックから分割される第1パーティション及び第2パーティションの形状、画像ブロックを第1パーティション及び第2パーティションに分割する方向、第1パーティションについて予測される第1動きベクトル(図11、ステップS1002)、及び、第2パーティションについて予測される第2動きベクトル(図11、ステップS1002)を一体として符号化する。特に、パーティションパラメータ0は、第1パーティションも第2パーティションも三角形形状を有さないこと、従って、分割方向情報が「N/A」であること、第1動きベクトル情報が「N/A」であること、及び、第2動きベクトル情報が「N/A」であることを符号化する。
24 is a table of sample partition parameters ("first index values") and information sets encoded together by the respective partition parameters, similar in characteristics to the sample table described above in FIG. 15. In FIG. 24, the partition parameters ("first index values") range from 0 to 6 and encode the shape of the first and second partitions divided from the image block, the direction of dividing the image block into the first and second partitions, the first motion vector predicted for the first partition (FIG. 11, step S1002), and the second motion vector predicted for the second partition (FIG. 11, step S1002) together. In particular, the
パーティションパラメータ1は、第1パーティション及び第2パーティションが三角形であること、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。パーティションパラメータ2は、第1パーティション及び第2パーティションが三角形であること、分割方向が右上角から左下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第1」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第2」動きベクトルであることを符号化する。パーティションパラメータ3は、第1パーティション及び第2パーティションが三角形であること、分割方向が右上角から左下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。パーティションパラメータ4は、第1パーティション及び第2パーティションが三角形であること、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第2」動きベクトルであることを符号化する。パーティションパラメータ5は、第1パーティション及び第2パーティションが三角形であること、分割方向が右上角から左下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第2」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第3」動きベクトルであることを符号化する。パーティションパラメータ6は、第1パーティション及び第2パーティションが三角形であること、分割方向が左上角から右下角であること、第1動きベクトルが第1パーティションについて第1動きベクトル候補セットに列挙された「第3」動きベクトルであること、及び、第2動きベクトルが第2パーティションについて第2動きベクトル候補セットに列挙された「第1」動きベクトルであることを符号化する。
いくつかの実装に従って、複数のパーティションパラメータ(複数のインデックス値)は、少なくとも1つ、又は、1つ以上のパラメータの値に応じて選択される二値化方式に従って、二値化されてもよい。図16は、複数のインデックス値(複数のパーティションパラメータ値)を二値化する二値化方式例を示す。 According to some implementations, the partition parameters (index values) may be binarized according to a binarization scheme selected depending on the value of at least one or more parameters. FIG. 16 shows an example binarization scheme for binarizing the index values (partition parameter values).
図25は、第1パラメータ及び第2パラメータの組み合わせ例の表であり、第1パラメータ及び第2パラメータの一方が、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータである。この例において、パーティションパラメータは、他の複数のパラメータの1つ以上によって符号化される他の情報を一体として符号化することなく画像ブロックを分割することを示すことに用いられてもよい。 25 is a table showing an example combination of a first parameter and a second parameter, in which one of the first parameter and the second parameter is a partition parameter indicating that the image block is to be divided into a plurality of partitions including a first partition and a second partition having a non-rectangular shape. In this example, the partition parameter may be used to indicate that the image block is to be divided without encoding other information encoded by one or more of the other parameters as a whole.
図25における第1例において、第1パラメータは、画像ブロックサイズを示すことに用いられ、第2パラメータは、画像ブロックから分割された複数のパーティションの少なくとも1つが三角形形状を有することを示すためのパーティションパラメータ(フラグ)として用いられる。第1パラメータ及び第2パラメータのこのような組み合わせは、例えば、1)画像ブロックサイズが64×64よりも大きい場合に三角形形状パーティションがないこと、又は、2)画像ブロックの幅と高さとの比率が4よりも大きい場合(例えば64×4)に三角形形状パーティションがないことを示すために用いられてもよい。 In the first example in FIG. 25, the first parameter is used to indicate the image block size, and the second parameter is used as a partition parameter (flag) to indicate that at least one of the partitions divided from the image block has a triangular shape. Such a combination of the first and second parameters may be used, for example, to indicate that 1) there is no triangular shaped partition when the image block size is larger than 64x64, or 2) there is no triangular shaped partition when the width to height ratio of the image block is larger than 4 (e.g., 64x4).
図25の第2例において、第1パラメータは、予測モードを示すために用いられ、第2パラメータは、画像ブロックから分割された複数のパーティションの少なくとも1つが三角形形状を有することを示すためのパーティションパラメータ(フラグ)として用いられる。第1パラメータ及び第2パラメータのこのような組み合わせは、例えば、1)画像ブロックがイントラモードで符号化される場合に三角形パーティションがないことを示すために用いられてもよい。 In the second example of FIG. 25, the first parameter is used to indicate a prediction mode, and the second parameter is used as a partition parameter (flag) to indicate that at least one of the partitions divided from the image block has a triangular shape. Such a combination of the first and second parameters may be used, for example, to indicate that 1) there is no triangular partition when the image block is coded in intra mode.
図25の第3例において、第1パラメータは、画像ブロックから分割された複数のパーティションの少なくとも1つが三角形形状を有することを示すためのパーティションパラメータ(フラグ)として用いられ、第2パラメータは、予測モードを示すために用いられる。第1パラメータ及び第2パラメータのこのような組み合わせは、例えば、1)画像ブロックから分割された複数のパーティションの少なくとも1つが三角形形状を有する場合に画像ブロックがインター符号化されなければならいことを示すために用いられてもよい。 In the third example of FIG. 25, the first parameter is used as a partition parameter (flag) to indicate that at least one of the partitions divided from the image block has a triangular shape, and the second parameter is used to indicate the prediction mode. Such a combination of the first and second parameters may be used, for example, to indicate that the image block should be inter-coded if 1) at least one of the partitions divided from the image block has a triangular shape.
図25の第4例において、第1パラメータは、隣接ブロックの動きベクトルを示し、第2パラメータは、画像ブロックを2つの三角形に分割する方向を示すパーティションパラメータとして用いられる。第1パラメータ及び第2パラメータのこのような組み合わせは、例えば、1)隣接ブロックの動きベクトルが斜め方向である場合に画像ブロックを2つの三角形に分割する方向が左上角から右下角であることを示すために用いられてもよい。 In the fourth example of FIG. 25, the first parameter indicates the motion vector of the adjacent block, and the second parameter is used as a partition parameter indicating the direction of partitioning the image block into two triangles. Such a combination of the first and second parameters may be used, for example, to indicate that 1) if the motion vector of the adjacent block is diagonal, the direction of partitioning the image block into two triangles is from the top left corner to the bottom right corner.
図25の第5例において、第1パラメータは、隣接ブロックのイントラ予測方向を示し、第2パラメータは、画像ブロックを2つの三角形に分割する方向を示すパーティションパラメータとして用いられる。第1パラメータ及び第2パラメータのこのような組み合わせは、例えば、1)隣接ブロックのイントラ予測方向が逆斜め方向である場合、画像ブロックを2つの三角形に分割する方向が右上角から左下角であることを示すために用いられてもよい。 In the fifth example of FIG. 25, the first parameter indicates the intra prediction direction of the neighboring block, and the second parameter is used as a partition parameter indicating the direction of partitioning the image block into two triangles. Such a combination of the first and second parameters may be used to indicate, for example, that 1) if the intra prediction direction of the neighboring block is reverse diagonal, the direction of partitioning the image block into two triangles is from the top right corner to the bottom left corner.
パーティションパラメータを含む1つ以上のパラメータの複数の表、及び、図15、図24及び図25に示されたような、どの情報が一体として又は別々に符号化されるかは、複数の例のみとして提示され、上述されたパーティションシンタックス動作の部分として様々な情報を一体として又は別々に符号化する他の多数の方法が本開示の範囲内であると理解されるべきである。例えば、パーティションパラメータが、第1パーティションが三角形、台形、又は、少なくとも5つの辺及び角を有する多角形であることを示してもよい。パーティションパラメータは、第2パーティションが、三角形、台形、及び、少なくとも5つの辺及び角を有する多角形のような、非矩形形状を有することを示してもよい。第1パーティションの非矩形形状、第2パーティションの形状(非矩形又は矩形であってもよい)、画像ブロックを複数のパーティションに分割するために適用される分割方向(例えば、画像ブロックの左上角からその右下角、及び、画像ブロックの右上角からその左下角)のような、分割についての1つ以上の情報をパーティションパラメータが示してもよい。パーティションパラメータは、第1パーティションの第1動きベクトル、第2パーティションの第2動きベクトル、画像ブロックサイズ、予測モード、隣接ブロックの動きベクトル、隣接ブロックのイントラ予測方向等のような、さらなる情報を一体として符号化する。あるいは、さらなる情報のいずれかが、パーティションパラメータ以外の1つ以上のパラメータによって別々に符号化されてもよい。 It should be understood that the tables of one or more parameters including partition parameters and which information is coded together or separately as shown in Figures 15, 24, and 25 are presented as examples only, and that numerous other ways of coding various information together or separately as part of the partition syntax operations described above are within the scope of this disclosure. For example, the partition parameters may indicate that the first partition is a triangle, a trapezoid, or a polygon having at least five sides and corners. The partition parameters may indicate that the second partition has a non-rectangular shape, such as a triangle, a trapezoid, and a polygon having at least five sides and corners. The partition parameters may indicate one or more pieces of information about the partition, such as the non-rectangular shape of the first partition, the shape of the second partition (which may be non-rectangular or rectangular), and the partition direction applied to divide the image block into multiple partitions (e.g., from the top left corner of the image block to its bottom right corner, and from the top right corner of the image block to its bottom left corner). The partition parameters jointly encode further information, such as a first motion vector for the first partition, a second motion vector for the second partition, an image block size, a prediction mode, motion vectors of neighboring blocks, intra-prediction directions of neighboring blocks, etc. Alternatively, any of the further information may be encoded separately by one or more parameters other than the partition parameters.
図22の処理4000のようなパーティションシンタックス動作は、例えば図1に示されたような、回路及び回路に接続されたメモリを含む画像符号化装置によって行われてもよい。回路は、動作において、分割を示すパーティションパラメータに基づいて、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割すること(図22、ステップS4001)と、第1パーティション及び第2パーティションを符号化すること(S4002)と、パーティションパラメータを含む1つ以上のパラメータをビットストリーム書き込むこと(S4003)とを含むパーティションシンタックス動作を行う。
A partition syntax operation such as
他の実施の形態に従って、図1に示されたような、画像符号化装置は、動作において原画像を受信し複数のブロックに分割する分割部102、動作において分割部から複数のブロック、及び、予測制御部128から複数の予測を受信し、各予測をその対応ブロックから減算して、残差を出力する加算部104、動作において加算部104から出力された複数の残差に変換を行って複数の変換係数を出力する変換部106、動作において複数の変換係数を量子化して複数の量子化変換係数を生成する量子化部108、動作において複数の量子化変換係数を符号化してビットストリームを生成するエントロピー符号化部110、及び、動作において符号化済み参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部126と、動作においてカレントピクチャにおける符号化済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部124と、メモリ118、122とに接続された予測制御部128を含んで、提供される。予測制御部128は、動作において、分割を示すパーティションパラメータに基づいて、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割し(図22、ステップS4001)、第1パーティション及び第2パーティションを符号化する(ステップS4002)。エントロピー符号化部110は、動作において、パーティションパラメータを含む1つ以上のパラメータをビットストリーム書き込む(ステップS4003)。
According to another embodiment, an image coding device as shown in FIG. 1 is provided, which includes a
他の実施の形態に従って、例えば、図10に示されたような、回路及び回路に接続されたメモリを含む画像復号装置が提供される。回路は、動作において、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータを含む1つ以上のパラメータをビットストリームから読み解くこと(図23、ステップS5001)と、パーティションパラメータに基づいて、画像ブロックを複数のパーティションに分割すること(S5002)と、第1パーティション及び第2パーティションを復号すること(S5003)とを含むパーティションシンタックス動作を行う。 According to another embodiment, an image decoding device is provided that includes a circuit and a memory coupled to the circuit, for example as shown in FIG. 10. In operation, the circuit performs partition syntax operations including: reading one or more parameters from the bitstream, including a partition parameter indicating partitioning of an image block into a plurality of partitions, including a first partition having a non-rectangular shape and a second partition (FIG. 23, step S5001); partitioning the image block into a plurality of partitions based on the partition parameter (S5002); and decoding the first partition and the second partition (S5003).
さらに実施の形態に従って、図10に示された画像復号装置は、動作において符号化ビットストリームを受信し復号して複数の量子化変換係数を取得するエントロピー復号部202、動作において、複数の量子化変換係数を逆量子化して複数の変換係数を取得し、複数の変換係数を逆変換して複数の残差を取得する逆量子化部204及び逆変換部206、動作において、逆量子化部204及び逆変換部206から出力された複数の残差と、予測制御部220から出力された複数の予測とを加算して複数のブロックを再構成する加算部208、及び、動作において復号済みの参照ピクチャにおける参照ブロックに基づいてカレントブロックの予測を生成するインター予測部218と、動作においてカレントピクチャにおける復号済み参照ブロックに基づいてカレントブロックの予測を生成するイントラ予測部216と、メモリ210、214とに接続された予測制御部220を含んで、提供される。エントロピー復号部202は、動作において、いくつかの実装では予測制御部220と協力して、非矩形形状を有する第1パーティション、及び、第2パーティションを含む複数のパーティションに画像ブロックを分割することを示すパーティションパラメータを含む1つ以上のパラメータをビットストリームから読み解き(図23、ステップS5001)、パーティションパラメータに基づいて、画像ブロックを複数のパーティションに分割し(S5002)、第1パーティション及び第2パーティションを復号する(S5003)。
Further, according to an embodiment, the image decoding device shown in FIG. 10 is provided including an
他の複数の例に従って、インター予測部は、次の処理を行ってもよい。 In accordance with several other examples, the inter prediction unit may perform the following processing:
第1動きベクトル候補セットに含まれる全ての動きベクトル候補は、複数の単予測動きベクトルであってもよい。つまり、インター予測部は、複数の単予測動きベクトルのみを第1動きベクトル候補セットにおける複数の動きベクトル候補として決定してもよい。 All of the motion vector candidates included in the first motion vector candidate set may be multiple uni-predictive motion vectors. In other words, the inter prediction unit may determine only multiple uni-predictive motion vectors as the multiple motion vector candidates in the first motion vector candidate set.
インター予測部は、第1動きベクトル候補セットから、複数の単予測動きベクトル候補のみを選択してもよい。 The inter prediction unit may select only multiple uni-prediction motion vector candidates from the first motion vector candidate set.
小さいブロックの予測に単予測動きベクトルのみが用いられてもよい。大きいブロックの予測に双予測動きベクトルが用いられてもよい。一例として、予測処理は、画像ブロックのサイズを判定することを含んでいてもよい。画像ブロックのサイズが閾値よりも大きいと判定された場合、予測が、第1動きベクトル候補セットから第1動きベクトルを選択することを含んでいてもよいし、第1動きベクトル候補セットが、単予測動きベクトル及び/又は双予測動きベクトルを含んでいてもよい。画像ブロックのサイズが閾値よりも大きくないと判定された場合、予測が、第1動きベクトル候補セットから第1動きベクトルを選択することを含んでいてもよいし、第1動きベクトル候補セットが、複数の単予測動きベクトルのみを含んでいてもよい。 Only uni-predictive motion vectors may be used to predict small blocks. Bi-predictive motion vectors may be used to predict large blocks. As an example, the prediction process may include determining a size of the image block. If the size of the image block is determined to be greater than a threshold, the prediction may include selecting a first motion vector from a first motion vector candidate set, and the first motion vector candidate set may include uni-predictive and/or bi-predictive motion vectors. If the size of the image block is determined to be not greater than a threshold, the prediction may include selecting a first motion vector from a first motion vector candidate set, and the first motion vector candidate set may include only uni-predictive motion vectors.
[実施及び応用]
以上の各実施の形態において、機能的又は作用的なブロックの各々は、通常、MPU(micro proccessing unit)及びメモリ等によって実現可能である。また、機能ブロックの各々による処理は、ROM等の記録媒体に記録されたソフトウェア(プログラム)を読み出して実行するプロセッサなどのプログラム実行部として実現されてもよい。当該ソフトウェアは、配布されてもよい。当該ソフトウェアは、半導体メモリなどの様々な記録媒体に記録されてもよい。なお、各機能ブロックをハードウェア(専用回路)によって実現することも可能である。ハードウェア及びソフトウェアの様々な組み合わせが採用され得る。
[Implementation and Application]
In each of the above embodiments, each of the functional or operational blocks can usually be realized by an MPU (micro processing unit) and a memory, etc. Furthermore, the processing by each of the functional blocks may be realized as a program execution unit such as a processor that reads and executes software (programs) recorded in a recording medium such as a ROM. The software may be distributed. The software may be recorded in various recording media such as semiconductor memories. It is also possible to realize each of the functional blocks by hardware (dedicated circuits). Various combinations of hardware and software may be adopted.
各実施の形態において説明した処理は、単一の装置(システム)を用いて集中処理することによって実現してもよく、又は、複数の装置を用いて分散処理することによって実現してもよい。また、上記プログラムを実行するプロセッサは、単数であってもよく、複数であってもよい。すなわち、集中処理を行ってもよく、又は分散処理を行ってもよい。 The processing described in each embodiment may be realized by centralized processing using a single device (system), or may be realized by distributed processing using multiple devices. Furthermore, the processor that executes the above program may be either single or multiple. In other words, centralized processing or distributed processing may be performed.
本開示の態様は、以上の実施例に限定されることなく、種々の変更が可能であり、それらも本開示の態様の範囲内に包含される。 The aspects of this disclosure are not limited to the above examples, and various modifications are possible, all of which are within the scope of the aspects of this disclosure.
さらにここで、上記各実施の形態で示した動画像符号化方法(画像符号化方法)又は動画像復号化方法(画像復号方法)の応用例、及び、その応用例を実施する種々のシステムを説明する。このようなシステムは、画像符号化方法を用いた画像符号化装置、画像復号方法を用いた画像復号装置、又は、両方を備える画像符号化復号装置を有することを特徴としてもよい。このようなシステムの他の構成について、場合に応じて適切に変更することができる。 Furthermore, here, application examples of the video encoding method (image encoding method) or video decoding method (image decoding method) shown in each of the above embodiments, and various systems implementing the application examples will be described. Such a system may be characterized by having an image encoding device using the image encoding method, an image decoding device using the image decoding method, or an image encoding/decoding device that includes both. Other configurations of such a system can be appropriately changed depending on the case.
[使用例]
図26は、コンテンツ配信サービスを実現する適切なコンテンツ供給システムex100の全体構成を示す図である。通信サービスの提供エリアを所望の大きさに分割し、各セル内にそれぞれ、図示された例における固定無線局である基地局ex106、ex107、ex108、ex109、ex110が設置されている。
[Example of use]
26 is a diagram showing the overall configuration of a suitable content supply system ex100 for realizing a content distribution service. The area where communication services are provided is divided into cells of a desired size, and base stations ex106, ex107, ex108, ex109, and ex110, which are fixed wireless stations in the illustrated example, are installed in each cell.
このコンテンツ供給システムex100では、インターネットex101に、インターネットサービスプロバイダex102又は通信網ex104、及び基地局ex106~ex110を介して、コンピュータex111、ゲーム機ex112、カメラex113、家電ex114、及びスマートフォンex115などの各機器が接続される。当該コンテンツ供給システムex100は、上記のいずれかの装置を組合せて接続するようにしてもよい。種々の実施において、基地局ex106~ex110を介さずに、各機器が電話網又は近距離無線等を介して直接的又は間接的に相互に接続されていてもよい。さらに、ストリーミングサーバex103は、インターネットex101等を介して、コンピュータex111、ゲーム機ex112、カメラex113、家電ex114、及びスマートフォンex115などの各機器と接続されてもよい。また、ストリーミングサーバex103は、衛星ex116を介して、飛行機ex117内のホットスポット内の端末等と接続されてもよい。 In this content supply system ex100, devices such as a computer ex111, a game machine ex112, a camera ex113, a home appliance ex114, and a smartphone ex115 are connected to the Internet ex101 via an Internet service provider ex102 or a communication network ex104, and base stations ex106 to ex110. The content supply system ex100 may be configured to connect a combination of any of the above devices. In various implementations, each device may be directly or indirectly connected to each other via a telephone network or short-range wireless communication, etc., without going through the base stations ex106 to ex110. Furthermore, the streaming server ex103 may be connected to each device such as a computer ex111, a game machine ex112, a camera ex113, a home appliance ex114, and a smartphone ex115 via the Internet ex101, etc. In addition, the streaming server ex103 may be connected to a terminal in a hotspot on an airplane ex117 via a satellite ex116.
なお、基地局ex106~ex110の代わりに、無線アクセスポイント又はホットスポット等が用いられてもよい。また、ストリーミングサーバex103は、インターネットex101又はインターネットサービスプロバイダex102を介さずに直接通信網ex104と接続されてもよいし、衛星ex116を介さず直接飛行機ex117と接続されてもよい。 In addition, wireless access points or hot spots may be used instead of the base stations ex106 to ex110. Also, the streaming server ex103 may be directly connected to the communication network ex104 without going through the Internet ex101 or the Internet service provider ex102, or may be directly connected to the airplane ex117 without going through the satellite ex116.
カメラex113はデジタルカメラ等の静止画撮影、及び動画撮影が可能な機器である。また、スマートフォンex115は、2G、3G、3.9G、4G、そして今後は5Gと呼ばれる移動通信システムの方式に対応したスマートフォン機、携帯電話機、又はPHS(Personal Handy-phone System)等である。 The camera ex113 is a device capable of taking still images and videos, such as a digital camera. The smartphone ex115 is a smartphone, mobile phone, or PHS (Personal Handy-phone System) that supports the mobile communication system standards of 2G, 3G, 3.9G, 4G, and in the future, 5G.
家電ex114は、冷蔵庫、又は家庭用燃料電池コージェネレーションシステムに含まれる機器等である。 The home appliance ex114 is a refrigerator or an appliance included in a home fuel cell cogeneration system.
コンテンツ供給システムex100では、撮影機能を有する端末が基地局ex106等を通じてストリーミングサーバex103に接続されることで、ライブ配信等が可能になる。ライブ配信では、端末(コンピュータex111、ゲーム機ex112、カメラex113、家電ex114、スマートフォンex115、及び飛行機ex117内の端末等)は、ユーザが当該端末を用いて撮影した静止画又は動画コンテンツに対して上記各実施の形態で説明した符号化処理を行ってもよく、符号化により得られた映像データと、映像に対応する音を符号化した音データと多重化してもよく、得られたデータをストリーミングサーバex103に送信してもよい。即ち、各端末は、本開示の一態様に係る画像符号化装置として機能する。 In the content supply system ex100, a terminal having a photographing function is connected to a streaming server ex103 via a base station ex106 or the like, thereby enabling live distribution and the like. In live distribution, a terminal (such as a computer ex111, a game machine ex112, a camera ex113, a home appliance ex114, a smartphone ex115, or a terminal in an airplane ex117) may perform the encoding process described in each of the above embodiments on still image or video content captured by a user using the terminal, may multiplex the video data obtained by encoding with audio data obtained by encoding the sound corresponding to the video, and may transmit the obtained data to the streaming server ex103. That is, each terminal functions as an image encoding device according to one aspect of the present disclosure.
一方、ストリーミングサーバex103は要求のあったクライアントに対して送信されたコンテンツデータをストリーム配信する。クライアントは、上記符号化処理されたデータを復号化することが可能な、コンピュータex111、ゲーム機ex112、カメラex113、家電ex114、スマートフォンex115、又は飛行機ex117内の端末等である。配信されたデータを受信した各機器は、受信したデータを復号化処理して再生してもよい。即ち、各機器は、本開示の一態様に係る画像復号装置として機能してもよい。 Meanwhile, the streaming server ex103 streams the transmitted content data to the requesting client. The client is a computer ex111, a game console ex112, a camera ex113, a home appliance ex114, a smartphone ex115, or a terminal in an airplane ex117, etc., capable of decoding the encoded data. Each device that receives the distributed data may decode and play back the received data. In other words, each device may function as an image decoding device according to one aspect of the present disclosure.
[分散処理]
また、ストリーミングサーバex103は複数のサーバ又は複数のコンピュータであって、データを分散して処理したり記録したり配信するものであってもよい。例えば、ストリーミングサーバex103は、CDN(Contents Delivery Network)により実現され、世界中に分散された多数のエッジサーバとエッジサーバ間をつなぐネットワークによりコンテンツ配信が実現されていてもよい。CDNでは、クライアントに応じて物理的に近いエッジサーバが動的に割り当てられ得る。そして、当該エッジサーバにコンテンツがキャッシュ及び配信されることで遅延を減らすことができる。また、いくつかのタイプのエラーが発生した場合又はトラフィックの増加などにより通信状態が変わる場合に複数のエッジサーバで処理を分散したり、他のエッジサーバに配信主体を切り替えたり、障害が生じたネットワークの部分を迂回して配信を続けることができるので、高速かつ安定した配信が実現できる。
[Distributed Processing]
The streaming server ex103 may be a plurality of servers or computers that process, record, and distribute data in a distributed manner. For example, the streaming server ex103 may be realized by a CDN (Contents Delivery Network), and content distribution may be realized by a network that connects a large number of edge servers distributed around the world. In the CDN, a physically close edge server may be dynamically assigned according to the client. The content is cached and distributed to the edge server, thereby reducing delays. In addition, when some types of errors occur or the communication state changes due to an increase in traffic, the processing can be distributed among multiple edge servers, the distribution entity can be switched to another edge server, or distribution can be continued by bypassing the part of the network where a failure has occurred, thereby realizing high-speed and stable distribution.
また、配信自体の分散処理にとどまらず、撮影したデータの符号化処理を各端末で行ってもよいし、サーバ側で行ってもよいし、互いに分担して行ってもよい。一例として、一般に符号化処理では、処理ループが2度行われる。1度目のループでフレーム又はシーン単位での画像の複雑さ、又は、符号量が検出される。また、2度目のループでは画質を維持して符号化効率を向上させる処理が行われる。例えば、端末が1度目の符号化処理を行い、コンテンツを受け取ったサーバ側が2度目の符号化処理を行うことで、各端末での処理負荷を減らしつつもコンテンツの質と効率を向上させることができる。この場合、ほぼリアルタイムで受信して復号する要求があれば、端末が行った一度目の符号化済みデータを他の端末で受信して再生することもできるので、より柔軟なリアルタイム配信も可能になる。 In addition to the distributed processing of the distribution itself, the encoding process of the captured data may be performed by each terminal, by the server, or by sharing among them. As an example, in the encoding process, a processing loop is generally performed twice. In the first loop, the complexity of the image or the amount of code is detected for each frame or scene. In the second loop, processing is performed to improve the encoding efficiency while maintaining the image quality. For example, the terminal performs the first encoding process, and the server side that receives the content performs the second encoding process, thereby improving the quality and efficiency of the content while reducing the processing load on each terminal. In this case, if there is a request to receive and decode almost in real time, the data encoded the first time by the terminal can be received and played by another terminal, making more flexible real-time distribution possible.
他の例として、カメラex113等は、画像から特徴量(特徴又は特性の量)を抽出し、特徴量に関するデータをメタデータとして圧縮してサーバに送信する。サーバは、例えば特徴量からオブジェクトの重要性を判断して量子化精度を切り替えるなど、画像の意味(又は内容の重要性)に応じた圧縮を行う。特徴量データはサーバでの再度の圧縮時の動きベクトル予測の精度及び効率向上に特に有効である。また、端末でVLC(可変長符号化)などの簡易的な符号化を行い、サーバでCABAC(コンテキスト適応型二値算術符号化方式)など処理負荷の大きな符号化を行ってもよい。 As another example, the camera ex113 etc. extracts features (amount of features or characteristics) from an image, compresses the data related to the features as metadata, and transmits it to the server. The server performs compression according to the meaning of the image (or the importance of the content), for example by determining the importance of an object from the features and switching the quantization precision. The feature data is particularly effective in improving the accuracy and efficiency of motion vector prediction when the server re-compresses. Alternatively, the terminal may perform simple encoding such as VLC (variable length coding), and the server may perform encoding with a high processing load such as CABAC (context-adaptive binary arithmetic coding).
さらに他の例として、スタジアム、ショッピングモール、又は工場などにおいては、複数の端末によりほぼ同一のシーンが撮影された複数の映像データが存在する場合がある。この場合には、撮影を行った複数の端末と、必要に応じて撮影をしていない他の端末及びサーバを用いて、例えばGOP(Group of Picture)単位、ピクチャ単位、又はピクチャを分割したタイル単位などで符号化処理をそれぞれ割り当てて分散処理を行う。これにより、遅延を減らし、よりリアルタイム性を実現できる。 As another example, in a stadium, shopping mall, or factory, multiple video data may exist that show almost the same scene captured by multiple terminals. In this case, the multiple terminals that captured the video and, as necessary, other terminals and servers that did not capture the video are used to perform distributed processing, for example, by GOP (group of picture) unit, picture unit, or tile unit into which a picture is divided. This reduces delays and achieves better real-time performance.
複数の映像データはほぼ同一シーンであるため、各端末で撮影された映像データを互いに参照し合えるように、サーバで管理及び/又は指示をしてもよい。また、各端末からの符号化済みデータを、サーバが受信し複数のデータ間で参照関係を変更、又はピクチャ自体を補正或いは差し替えて符号化しなおしてもよい。これにより、一つ一つのデータの質と効率を高めたストリームを生成できる。 Since the multiple video data are of almost the same scene, the server may manage and/or instruct the video data shot on each terminal to be mutually referenced. The server may also receive encoded data from each terminal and change the reference relationships between the multiple data, or correct or replace the pictures themselves and re-encode them. This makes it possible to generate a stream that improves the quality and efficiency of each piece of data.
さらに、サーバは、映像データの符号化方式を変更するトランスコードを行ったうえで映像データを配信してもよい。例えば、サーバは、MPEG系の符号化方式をVP系(例えばVP9)に変換してもよいし、H.264をH.265に変換等してもよい。 Furthermore, the server may distribute the video data after performing transcoding to change the encoding method of the video data. For example, the server may convert the MPEG-based encoding method to the VP-based encoding method (e.g., VP9), or convert H.264 to H.265, etc.
このように、符号化処理は、端末、又は1以上のサーバにより行うことが可能である。よって、以下では、処理を行う主体として「サーバ」又は「端末」等の記載を用いるが、サーバで行われる処理の一部又は全てが端末で行われてもよいし、端末で行われる処理の一部又は全てがサーバで行われてもよい。また、これらに関しては、復号処理についても同様である。 In this way, the encoding process can be performed by a terminal or one or more servers. Therefore, in the following, descriptions such as "server" or "terminal" are used to indicate the entity performing the processing, but some or all of the processing performed by the server may be performed by the terminal, and some or all of the processing performed by the terminal may be performed by the server. The same applies to the decoding process.
[3D、マルチアングル]
互いにほぼ同期した複数のカメラex113及び/又はスマートフォンex115などの端末により撮影された異なるシーン、又は、同一シーンを異なるアングルから撮影した画像或いは映像を統合して利用することが増えてきている。各端末で撮影した映像は、別途取得した端末間の相対的な位置関係、又は、映像に含まれる特徴点が一致する領域などに基づいて統合され得る。
[3D, multi-angle]
It is becoming increasingly common to integrate and use images or videos of different scenes or the same scene taken from different angles by multiple devices such as a camera ex113 and/or a smartphone ex115 that are approximately synchronized with each other. The videos taken by each device can be integrated based on the relative positional relationship between the devices obtained separately, or on areas where feature points included in the videos match.
サーバは、2次元の動画像を符号化するだけでなく、動画像のシーン解析などに基づいて自動的に、又は、ユーザが指定した時刻において、静止画を符号化し、受信端末に送信してもよい。サーバは、さらに、撮影端末間の相対的な位置関係を取得できる場合には、2次元の動画像だけでなく、同一シーンが異なるアングルから撮影された映像に基づき、当該シーンの3次元形状を生成できる。サーバは、ポイントクラウドなどにより生成した3次元のデータを別途符号化してもよいし、3次元データを用いて人物又はオブジェクトを認識或いは追跡した結果に基づいて、受信端末に送信する映像を、複数の端末で撮影した映像から、選択、又は、再構成して生成してもよい。 The server may not only encode two-dimensional video images, but may also encode still images automatically or at a time specified by the user based on scene analysis of the video images and transmit them to the receiving terminal. Furthermore, if the server can obtain the relative positional relationship between the capturing terminals, the server may generate a three-dimensional shape of the scene based on not only two-dimensional video images but also images of the same scene captured from different angles. The server may separately encode three-dimensional data generated by a point cloud or the like, or may select or reconstruct images to be transmitted to the receiving terminal from images captured by multiple terminals based on the results of recognizing or tracking people or objects using the three-dimensional data.
このようにして、ユーザは、各撮影端末に対応する各映像を任意に選択してシーンを楽しむこともできるし、複数画像又は映像を用いて再構成された3次元データから選択視点の映像を切り出したコンテンツを楽しむこともできる。さらに、映像と共に、音も複数の相異なるアングルから収音され、サーバは、特定のアングル又は空間からの音を対応する映像と多重化して、多重化された映像と音とを送信してもよい。 In this way, the user can enjoy a scene by arbitrarily selecting each video corresponding to each shooting terminal, or can enjoy content in which a video from a selected viewpoint is cut out from three-dimensional data reconstructed using multiple images or videos. Furthermore, together with the video, sound may also be collected from multiple different angles, and the server may multiplex the sound from a particular angle or space with the corresponding video and transmit the multiplexed video and sound.
また、近年ではVirtual Reality(VR)及びAugmented Reality(AR)など、現実世界と仮想世界とを対応付けたコンテンツも普及してきている。VRの画像の場合、サーバは、右目用及び左目用の視点画像をそれぞれ作成し、Multi-View Coding(MVC)などにより各視点映像間で参照を許容する符号化を行ってもよいし、互いに参照せずに別ストリームとして符号化してもよい。別ストリームの復号時には、ユーザの視点に応じて仮想的な3次元空間が再現されるように互いに同期させて再生するとよい。 In recent years, content that associates the real world with a virtual world, such as Virtual Reality (VR) and Augmented Reality (AR), has also become popular. In the case of VR images, the server creates viewpoint images for the right eye and the left eye, respectively, and may perform encoding that allows reference between each viewpoint video using Multi-View Coding (MVC) or the like, or may encode them as separate streams without mutual reference. When decoding the separate streams, it is preferable to play them in synchronization with each other so that a virtual three-dimensional space is reproduced according to the user's viewpoint.
ARの画像の場合には、サーバは、現実空間のカメラ情報に、仮想空間上の仮想物体情報を、3次元的位置又はユーザの視点の動きに基づいて重畳してもよい。復号装置は、仮想物体情報及び3次元データを取得又は保持し、ユーザの視点の動きに応じて2次元画像を生成し、スムーズにつなげることで重畳データを作成してもよい。または、復号装置は仮想物体情報の依頼に加えてユーザの視点の動きをサーバに送信してもよい。サーバは、サーバに保持される3次元データから受信した視点の動きに合わせて重畳データを作成し、重畳データを符号化して復号装置に配信してもよい。なお、重畳データは、典型的には、RGB以外に透過度を示すα値を有し、サーバは、3次元データから作成されたオブジェクト以外の部分のα値が0などに設定し、当該部分が透過する状態で、符号化してもよい。もしくは、サーバは、クロマキーのように所定の値のRGB値を背景に設定し、オブジェクト以外の部分は背景色にしたデータを生成してもよい。所定の値のRGB値は、予め定められていてもよい。 In the case of an AR image, the server may superimpose virtual object information in the virtual space on camera information in the real space based on the three-dimensional position or the movement of the user's viewpoint. The decoding device may acquire or hold virtual object information and three-dimensional data, generate a two-dimensional image according to the movement of the user's viewpoint, and smoothly connect the two-dimensional image to create superimposed data. Alternatively, the decoding device may transmit the movement of the user's viewpoint to the server in addition to the request for virtual object information. The server may create superimposed data according to the movement of the viewpoint received from the three-dimensional data held by the server, encode the superimposed data, and distribute it to the decoding device. Note that the superimposed data typically has an α value indicating the transparency in addition to RGB, and the server may set the α value of the part other than the object created from the three-dimensional data to 0, etc., and encode the part in a state where the part is transparent. Alternatively, the server may generate data in which a predetermined value of RGB value is set to the background like a chromakey, and the part other than the object is the background color. The predetermined value of RGB value may be determined in advance.
同様に配信されたデータの復号処理はクライアント(例えば、端末)で行っても、サーバ側で行ってもよいし、互いに分担して行ってもよい。一例として、ある端末が、一旦サーバに受信リクエストを送り、そのリクエストに応じたコンテンツを他の端末で受信し復号処理を行い、ディスプレイを有する装置に復号済みの信号が送信されてもよい。通信可能な端末自体の性能によらず処理を分散して適切なコンテンツを選択することで画質のよいデータを再生することができる。また、他の例として大きなサイズの画像データをTV等で受信しつつ、鑑賞者の個人端末にピクチャが分割されたタイルなど一部の領域が復号されて表示されてもよい。これにより、全体像を共有化しつつ、自身の担当分野又はより詳細に確認したい領域を手元で確認することができる。 Similarly, the decoding process of the distributed data may be performed by the client (e.g., a terminal), by the server, or by both parties sharing the task. As an example, a terminal may first send a reception request to the server, and the content corresponding to the request may be received by another terminal, which may then decode the content, and the decoded signal may be sent to a device having a display. By distributing the processing and selecting the appropriate content regardless of the performance of the communication-capable terminal itself, data with good image quality can be reproduced. As another example, large-sized image data may be received on a TV or the like, while a portion of the image, such as tiles into which the picture is divided, is decoded and displayed on the viewer's personal terminal. This allows the viewer to share the overall picture while checking their own area of responsibility or areas they wish to check in more detail.
屋内外の近距離、中距離、又は長距離の無線通信が複数使用可能な状況下で、MPEG-DASHなどの配信システム規格を利用して、シームレスにコンテンツを受信することが可能かもしれない。ユーザは、ユーザの端末、屋内外に配置されたディスプレイなどの復号装置又は表示装置を自由に選択しながらリアルタイムで切り替えてもよい。また、自身の位置情報などを用いて、復号する端末及び表示する端末を切り替えながら復号を行うことができる。これにより、ユーザが目的地へ移動している間に、表示可能なデバイスが埋め込まれた隣の建物の壁面又は地面の一部に情報をマップ及び表示することが可能になる。また、符号化データが受信端末から短時間でアクセスできるサーバにキャッシュされている、又は、コンテンツ・デリバリー・サービスにおけるエッジサーバにコピーされている、などの、ネットワーク上での符号化データへのアクセス容易性に基づいて、受信データのビットレートを切り替えることも可能である。 In a situation where multiple short-distance, medium-distance, or long-distance wireless communication is available indoors and outdoors, it may be possible to receive content seamlessly using a distribution system standard such as MPEG-DASH. A user may freely select and switch in real time between a decoding device or a display device such as a user's terminal or a display device placed indoors or outdoors. Decoding can also be performed while switching between a decoding device and a display device using the user's own location information, etc. This makes it possible to map and display information on a part of the wall or ground of a neighboring building in which a displayable device is embedded while the user is moving to a destination. It is also possible to switch the bit rate of received data based on the accessibility of the encoded data on the network, such as when the encoded data is cached on a server that can be accessed from the receiving terminal in a short time, or copied to an edge server in a content delivery service.
[スケーラブル符号化]
コンテンツの切り替えに関して、図27に示す、上記各実施の形態で示した動画像符号化方法を応用して圧縮符号化されたスケーラブルなストリームを用いて説明する。サーバは、個別のストリームとして内容は同じで質の異なるストリームを複数有していても構わないが、図示するようにレイヤに分けて符号化を行うことで実現される時間的/空間的スケーラブルなストリームの特徴を活かして、コンテンツを切り替える構成であってもよい。つまり、復号側が性能という内的要因と通信帯域の状態などの外的要因とに応じてどのレイヤを復号するかを決定することで、復号側は、低解像度のコンテンツと高解像度のコンテンツとを自由に切り替えて復号できる。例えばユーザが移動中にスマートフォンex115で視聴していた映像の続きを、例えば帰宅後にインターネットTV等の機器で視聴したい場合には、当該機器は、同じストリームを異なるレイヤまで復号すればよいので、サーバ側の負担を軽減できる。
[Scalable Coding]
Regarding the switching of contents, a scalable stream compressed and coded by applying the video coding method shown in each of the above embodiments shown in FIG. 27 will be used for explanation. The server may have multiple streams with the same content but different qualities as individual streams, but may be configured to switch contents by taking advantage of the characteristics of a temporal/spatial scalable stream realized by coding in layers as shown in the figure. In other words, the decoding side can freely switch and decode low-resolution content and high-resolution content by determining which layer to decode according to an internal factor such as performance and an external factor such as the state of the communication band. For example, if a user wants to continue watching a video that he or she was watching on the smartphone ex115 while on the move on a device such as an Internet TV after returning home, the device can decode the same stream up to a different layer, thereby reducing the burden on the server side.
さらに、上記のように、レイヤ毎にピクチャが符号化されており、ベースレイヤの上位のエンハンスメントレイヤでスケーラビリティを実現する構成以外に、エンハンスメントレイヤが画像の統計情報などに基づくメタ情報を含んでいてもよい。復号側が、メタ情報に基づきベースレイヤのピクチャを超解像することで高画質化したコンテンツを生成してもよい。超解像は、解像度を維持及び/又は拡大しつつ、SN比を向上してもよい。メタ情報は、超解像処理に用いるような線形或いは非線形のフィルタ係数を特定するため情報、又は、超解像処理に用いるフィルタ処理、機械学習或いは最小2乗演算におけるパラメータ値を特定する情報などを含む。 Furthermore, as described above, pictures are coded for each layer, and in addition to the configuration in which scalability is achieved in an enhancement layer above the base layer, the enhancement layer may include meta-information based on image statistical information, etc. The decoding side may generate high-quality content by super-resolving pictures in the base layer based on the meta-information. Super-resolution may improve the signal-to-noise ratio while maintaining and/or increasing the resolution. The meta-information includes information for specifying linear or non-linear filter coefficients to be used in super-resolution processing, or information for specifying parameter values in filter processing, machine learning, or least-squares calculations to be used in super-resolution processing.
または、画像内のオブジェクトなどの意味合いに応じてピクチャがタイル等に分割される構成が提供されてもよい。復号側が、復号するタイルを選択することで一部の領域だけを復号する。さらに、オブジェクトの属性(人物、車、ボールなど)と映像内の位置(同一画像における座標位置など)とをメタ情報として格納することで、復号側は、メタ情報に基づいて所望のオブジェクトの位置を特定し、そのオブジェクトを含むタイルを決定できる。例えば、図28に示すように、メタ情報は、HEVCにおけるSEI(supplemental enhancement information)メッセージなど、画素データとは異なるデータ格納構造を用いて格納されてもよい。このメタ情報は、例えば、メインオブジェクトの位置、サイズ、又は色彩などを示す。 Alternatively, a configuration may be provided in which a picture is divided into tiles or the like according to the meaning of an object or the like in the image. The decoding side selects tiles to decode and decodes only a portion of the area. Furthermore, by storing the object attributes (person, car, ball, etc.) and their positions in the video (coordinate positions in the same image, etc.) as meta information, the decoding side can identify the position of a desired object based on the meta information and determine the tile containing the object. For example, as shown in FIG. 28, the meta information may be stored using a data storage structure different from pixel data, such as a supplemental enhancement information (SEI) message in HEVC. This meta information indicates, for example, the position, size, or color of the main object.
ストリーム、シーケンス又はランダムアクセス単位など、複数のピクチャから構成される単位でメタ情報が格納されてもよい。復号側は、特定人物が映像内に出現する時刻などを取得でき、ピクチャ単位の情報と時間情報を合わせることで、オブジェクトが存在するピクチャを特定でき、ピクチャ内でのオブジェクトの位置を決定できる。 Meta information may be stored in units consisting of multiple pictures, such as streams, sequences, or random access units. The decoding side can obtain the time when a specific person appears in the video, and by combining the picture-by-picture information with the time information, it is possible to identify the picture in which the object exists and determine the position of the object within the picture.
[Webページの最適化]
図29は、コンピュータex111等におけるwebページの表示画面例を示す図である。図30は、スマートフォンex115等におけるwebページの表示画面例を示す図である。図29及び図30に示すようにwebページが、画像コンテンツへのリンクであるリンク画像を複数含む場合があり、閲覧するデバイスによってその見え方は異なっていてもよい。画面上に複数のリンク画像が見える場合には、ユーザが明示的にリンク画像を選択するまで、又は画面の中央付近にリンク画像が近付く或いはリンク画像の全体が画面内に入るまで、表示装置(復号装置)は、リンク画像として各コンテンツが有する静止画又はIピクチャを表示してもよいし、複数の静止画又はIピクチャ等でgifアニメのような映像を表示してもよいし、ベースレイヤのみを受信し、映像を復号及び表示してもよい。
[Web page optimization]
FIG. 29 is a diagram showing an example of a display screen of a web page on a computer ex111 or the like. FIG. 30 is a diagram showing an example of a display screen of a web page on a smartphone ex115 or the like. As shown in FIG. 29 and FIG. 30, a web page may include a plurality of link images that are links to image content, and the appearance may differ depending on the device used to view the page. When a plurality of link images are visible on the screen, the display device (decoding device) may display a still image or I picture that each content has as a link image, or may display an image such as a GIF animation using a plurality of still images or I pictures, or may receive only the base layer and decode and display the image.
ユーザによりリンク画像が選択された場合、表示装置は、例えばベースレイヤを最優先にしつつ復号を行う。なお、webページを構成するHTMLにスケーラブルなコンテンツであることを示す情報があれば、表示装置は、エンハンスメントレイヤまで復号してもよい。さらに、リアルタイム性を担保するために、選択される前又は通信帯域が非常に厳しい場合には、表示装置は、前方参照のピクチャ(Iピクチャ、Pピクチャ、前方参照のみのBピクチャ)のみを復号及び表示することで、先頭ピクチャの復号時刻と表示時刻との間の遅延(コンテンツの復号開始から表示開始までの遅延)を低減できる。またさらに、表示装置は、ピクチャの参照関係を敢えて無視して、全てのBピクチャ及びPピクチャを前方参照にして粗く復号し、時間が経ち受信したピクチャが増えるにつれて正常の復号を行ってもよい。 When a link image is selected by the user, the display device performs decoding, for example, giving top priority to the base layer. Note that if the HTML constituting the web page contains information indicating that the content is scalable, the display device may decode up to the enhancement layer. Furthermore, in order to ensure real-time performance, before selection or when the communication bandwidth is very tight, the display device decodes and displays only forward-reference pictures (I pictures, P pictures, and B pictures with forward reference only), thereby reducing the delay between the decoding time of the first picture and the display time (the delay from the start of content decoding to the start of display). Furthermore, the display device may intentionally ignore the reference relationship of pictures and roughly decode all B pictures and P pictures with forward reference, and then perform normal decoding as the number of received pictures increases over time.
[自動走行]
また、車の自動走行又は走行支援のため2次元又は3次元の地図情報などのような静止画又は映像データを送受信する場合、受信端末は、1以上のレイヤに属する画像データに加えて、メタ情報として天候又は工事の情報なども受信し、これらを対応付けて復号してもよい。なお、メタ情報は、レイヤに属してもよいし、単に画像データと多重化されてもよい。
[Autonomous Driving]
Furthermore, when transmitting and receiving still image or video data such as two-dimensional or three-dimensional map information for automatic driving or driving assistance of a vehicle, the receiving terminal may receive weather or construction information as meta information in addition to image data belonging to one or more layers, and may associate and decode these. Note that the meta information may belong to a layer, or may simply be multiplexed with the image data.
この場合、受信端末を含む車、ドローン又は飛行機などが移動するため、受信端末は、当該受信端末の位置情報を送信することで、基地局ex106~ex110を切り替えながらシームレスな受信及び復号の実行を実現できる。また、受信端末は、ユーザの選択、ユーザの状況及び/又は通信帯域の状態に応じて、メタ情報をどの程度受信するか、又は地図情報をどの程度更新していくかを動的に切り替えることが可能になる。 In this case, since a car, drone, or airplane including a receiving terminal is moving, the receiving terminal can transmit location information of the receiving terminal, thereby achieving seamless reception and decoding while switching between base stations ex106 to ex110. In addition, the receiving terminal can dynamically switch how much meta information to receive or how much to update map information depending on the user's selection, the user's situation, and/or the state of the communication bandwidth.
コンテンツ供給システムex100では、ユーザが送信した符号化された情報をリアルタイムでクライアントが受信して復号し、再生することができる。 In the content supply system ex100, the client can receive, decode, and play back the encoded information sent by the user in real time.
[個人コンテンツの配信]
また、コンテンツ供給システムex100では、映像配信業者による高画質で長時間のコンテンツのみならず、個人による低画質で短時間のコンテンツのユニキャスト、又はマルチキャスト配信が可能である。このような個人のコンテンツは今後も増加していくと考えられる。個人コンテンツをより優れたコンテンツにするために、サーバは、編集処理を行ってから符号化処理を行ってもよい。これは、例えば、以下のような構成を用いて実現できる。
[Distribution of personal content]
Furthermore, the content supply system ex100 allows not only high-quality, long-duration content from video distributors, but also low-quality, short-duration content from individuals via unicast or multicast distribution. Such personal content is expected to continue to increase in the future. To improve the quality of personal content, the server may perform editing before encoding. This can be achieved, for example, by using the following configuration.
撮影時にリアルタイム又は蓄積して撮影後に、サーバは、原画データ又は符号化済みデータから撮影エラー、シーン探索、意味の解析、及びオブジェクト検出などの認識処理を行う。そして、サーバは、認識結果に基づいて手動又は自動で、ピントずれ又は手ブレなどを補正したり、明度が他のピクチャに比べて低い又は焦点が合っていないシーンなどの重要性の低いシーンを削除したり、オブジェクトのエッジを強調したり、色合いを変化させるなどの編集を行う。サーバは、編集結果に基づいて編集後のデータを符号化する。また撮影時刻が長すぎると視聴率が下がることも知られており、サーバは、撮影時間に応じて特定の時間範囲内のコンテンツになるように上記のように重要性が低いシーンのみならず動きが少ないシーンなどを、画像処理結果に基づき自動でクリップしてもよい。または、サーバは、シーンの意味解析の結果に基づいてダイジェストを生成して符号化してもよい。 In real time during shooting or after accumulating, the server performs recognition processing such as shooting errors, scene search, semantic analysis, and object detection from the original image data or encoded data. Then, based on the recognition results, the server manually or automatically corrects out-of-focus or camera shake, deletes less important scenes such as scenes that are less bright than other pictures or out of focus, emphasizes object edges, changes color, and performs other editing. The server encodes the edited data based on the editing results. It is also known that if the shooting time is too long, the viewer rating will decrease, so the server may automatically clip not only scenes with less importance as described above but also scenes with little movement based on the image processing results so that the content will be within a specific time range depending on the shooting time. Alternatively, the server may generate a digest based on the results of the semantic analysis of the scene and encode it.
個人コンテンツには、そのままでは著作権、著作者人格権、又は肖像権等の侵害となるものが写り込んでいるケースもあり、共有する範囲が意図した範囲を超えてしまうなど個人にとって不都合な場合もある。よって、例えば、サーバは、画面の周辺部の人の顔、又は家の中などを敢えて焦点が合わない画像に変更して符号化してもよい。さらに、サーバは、符号化対象画像内に、予め登録した人物とは異なる人物の顔が映っているかどうかを認識し、映っている場合には、顔の部分にモザイクをかけるなどの処理を行ってもよい。または、符号化の前処理又は後処理として、著作権などの観点からユーザが画像を加工したい人物又は背景領域を指定してもよい。サーバは、指定された領域を別の映像に置き換える、又は焦点をぼかすなどの処理を行ってもよい。人物であれば、動画像において人物をトラッキングして、人物の顔の部分の映像を置き換えることができる。 In some cases, personal content may contain content that, if left as is, violates copyright, moral rights, or portrait rights, and may cause the scope of sharing to exceed the intended scope, which may be inconvenient for individuals. Therefore, for example, the server may change the image to one that is out of focus, such as the face of a person on the periphery of the screen or the inside of a house, and encode it. Furthermore, the server may recognize whether the face of a person other than a person registered in advance is shown in the image to be encoded, and if so, may perform processing such as blurring the face part. Alternatively, as pre-processing or post-processing of encoding, the user may specify a person or background area that he or she wants to process in the image from the viewpoint of copyright, etc. The server may replace the specified area with another image or blur the focus. If it is a person, the person can be tracked in the video and the image of the person's face replaced.
データ量の小さい個人コンテンツの視聴はリアルタイム性の要求が強いため、帯域幅にもよるが、復号装置は、まずベースレイヤを最優先で受信して復号及び再生を行ってもよい。復号装置は、この間にエンハンスメントレイヤを受信し、再生がループされる場合など2回以上再生される場合に、エンハンスメントレイヤも含めて高画質の映像を再生してもよい。このようにスケーラブルな符号化が行われているストリームであれば、未選択時又は見始めた段階では粗い動画だが、徐々にストリームがスマートになり画像がよくなるような体験を提供することができる。スケーラブル符号化以外にも、1回目に再生される粗いストリームと、1回目の動画を参照して符号化される2回目のストリームとが1つのストリームとして構成されていても同様の体験を提供できる。 Because viewing of personal content with a small amount of data requires real-time performance, depending on the bandwidth, the decoding device may first receive the base layer as a top priority and decode and play it. The decoding device may receive the enhancement layer during this time, and if the content is played more than twice, such as when playback is looped, play high-quality video including the enhancement layer. With a stream that has been scalably encoded in this way, it is possible to provide an experience in which the video is rough when not selected or when viewing begins, but the stream gradually becomes smarter and the image quality improves. In addition to scalable encoding, a similar experience can be provided even if a rough stream that is played the first time and a second stream that is encoded with reference to the first video are configured as a single stream.
[その他の実施応用例]
また、これらの符号化又は復号処理は、一般的に各端末が有するLSIex500において処理される。LSI(large scale integration circuitry)ex500(図26参照)は、ワンチップであっても複数チップからなる構成であってもよい。なお、動画像符号化又は復号用のソフトウェアをコンピュータex111等で読み取り可能な何らかの記録メディア(CD-ROM、フレキシブルディスク、又はハードディスクなど)に組み込み、そのソフトウェアを用いて符号化又は復号処理を行ってもよい。さらに、スマートフォンex115がカメラ付きである場合には、そのカメラで取得した動画データを送信してもよい。このときの動画データはスマートフォンex115が有するLSIex500で符号化処理されたデータであってもよい。
[Other application examples]
Moreover, these encoding or decoding processes are generally processed in the LSIex500 possessed by each terminal. The LSI (large scale integration circuitry) ex500 (see FIG. 26) may be a one-chip or a multi-chip configuration. In addition, software for encoding or decoding moving images may be incorporated into some recording medium (such as a CD-ROM, a flexible disk, or a hard disk) that can be read by the computer ex111, etc., and the encoding or decoding process may be performed using the software. Furthermore, if the smartphone ex115 has a camera, video data acquired by the camera may be transmitted. The video data at this time may be data encoded and processed by the LSIex500 possessed by the smartphone ex115.
なお、LSIex500は、アプリケーションソフトをダウンロードしてアクティベートする構成であってもよい。この場合、端末は、まず、当該端末がコンテンツの符号化方式に対応しているか、又は、特定サービスの実行能力を有するかを判定する。端末がコンテンツの符号化方式に対応していない場合、又は、特定サービスの実行能力を有さない場合、端末は、コーデック又はアプリケーションソフトをダウンロードし、その後、コンテンツ取得及び再生してもよい。 The LSIex500 may be configured to download and activate application software. In this case, the terminal first determines whether the terminal supports the content encoding method or has the ability to execute a specific service. If the terminal does not support the content encoding method or does not have the ability to execute a specific service, the terminal may download a codec or application software, and then acquire and play the content.
また、インターネットex101を介したコンテンツ供給システムex100に限らず、デジタル放送用システムにも上記各実施の形態の少なくとも動画像符号化装置(画像符号化装置)又は動画像復号化装置(画像復号装置)のいずれかを組み込むことができる。衛星などを利用して放送用の電波に映像と音が多重化された多重化データを載せて送受信するため、コンテンツ供給システムex100のユニキャストがし易い構成に対してマルチキャスト向きであるという違いがあるが符号化処理及び復号処理に関しては同様の応用が可能である。 Furthermore, at least one of the video encoding devices (image encoding devices) or video decoding devices (image decoding devices) of the above embodiments can be incorporated into a digital broadcasting system, not limited to the content supply system ex100 via the Internet ex101. Since multiplexed data in which video and audio are multiplexed is transmitted and received over broadcast radio waves using a satellite or the like, there is a difference in that it is more suited to multicast compared to the content supply system ex100, which has a configuration that is easy to use for unicast, but similar applications are possible with regard to the encoding and decoding processes.
[ハードウェア構成]
図31は、図26に示されたスマートフォンex115のさらに詳細を示す図である。また、図32は、スマートフォンex115の構成例を示す図である。スマートフォンex115は、基地局ex110との間で電波を送受信するためのアンテナex450と、映像及び静止画を撮ることが可能なカメラ部ex465と、カメラ部ex465で撮像した映像、及びアンテナex450で受信した映像等が復号されたデータを表示する表示部ex458とを備える。スマートフォンex115は、さらに、タッチパネル等である操作部ex466と、音声又は音響を出力するためのスピーカ等である音声出力部ex457と、音声を入力するためのマイク等である音声入力部ex456と、撮影した映像或いは静止画、録音した音声、受信した映像或いは静止画、メール等の符号化されたデータ、又は、復号化されたデータを保存可能なメモリ部ex467と、ユーザを特定し、ネットワークをはじめ各種データへのアクセスの認証をするためのSIMex468とのインタフェース部であるスロット部ex464とを備える。なお、メモリ部ex467の代わりに外付けメモリが用いられてもよい。
[Hardware configuration]
Fig. 31 is a diagram showing further details of the smartphone ex115 shown in Fig. 26. Fig. 32 is a diagram showing a configuration example of the smartphone ex115. The smartphone ex115 includes an antenna ex450 for transmitting and receiving radio waves to and from the base station ex110, a camera unit ex465 capable of taking videos and still images, and a display unit ex458 for displaying the video captured by the camera unit ex465 and the decoded data of the video and the like received by the antenna ex450. The smartphone ex115 further includes an operation unit ex466 such as a touch panel, an audio output unit ex457 such as a speaker for outputting voice or sound, an audio input unit ex456 such as a microphone for inputting voice, a memory unit ex467 capable of storing encoded data such as captured video or still images, recorded voice, received video or still images, and e-mail, or decoded data, and a slot unit ex464 which is an interface unit with a SIM ex468 for identifying a user and authenticating access to various data including a network. An external memory may be used instead of the memory unit ex467.
表示部ex458及び操作部ex466等を統括的に制御し得る主制御部ex460と、電源回路部ex461、操作入力制御部ex462、映像信号処理部ex455、カメラインタフェース部ex463、ディスプレイ制御部ex459、変調/復調部ex452、多重/分離部ex453、音声信号処理部ex454、スロット部ex464、及びメモリ部ex467とが同期バスex470を介して接続されている。 The main control unit ex460, which can comprehensively control the display unit ex458 and the operation unit ex466, etc., is connected to the power supply circuit unit ex461, the operation input control unit ex462, the video signal processing unit ex455, the camera interface unit ex463, the display control unit ex459, the modulation/demodulation unit ex452, the multiplexing/separation unit ex453, the audio signal processing unit ex454, the slot unit ex464, and the memory unit ex467 via a synchronization bus ex470.
電源回路部ex461は、ユーザの操作により電源キーがオン状態にされると、スマートフォンex115を動作可能な状態に起動し、バッテリパックから各部に対して電力を供給する。 When the power key is turned on by the user, the power supply circuit unit ex461 starts up the smartphone ex115 into an operational state and supplies power to each unit from the battery pack.
スマートフォンex115は、CPU、ROM及びRAM等を有する主制御部ex460の制御に基づいて、通話及データ通信等の処理を行う。通話時は、音声入力部ex456で収音した音声信号を音声信号処理部ex454でデジタル音声信号に変換し、変調/復調部ex452でスペクトラム拡散処理を施し、送信/受信部ex451でデジタルアナログ変換処理及び周波数変換処理を施し、その結果の信号を、アンテナex450を介して送信する。また受信データを増幅して周波数変換処理及びアナログデジタル変換処理を施し、変調/復調部ex452でスペクトラム逆拡散処理し、音声信号処理部ex454でアナログ音声信号に変換した後、これを音声出力部ex457から出力する。データ通信モード時は、本体部の操作部ex466等の操作に基づいてテキスト、静止画、又は映像データが操作入力制御部ex462を介して主制御部ex460の制御下で送出され得る。同様の送受信処理が行われる。データ通信モード時に映像、静止画、又は映像と音声を送信する場合、映像信号処理部ex455は、メモリ部ex467に保存されている映像信号又はカメラ部ex465から入力された映像信号を上記各実施の形態で示した動画像符号化方法によって圧縮符号化し、符号化された映像データを多重/分離部ex453に送出する。音声信号処理部ex454は、映像又は静止画をカメラ部ex465で撮像中に音声入力部ex456で収音した音声信号を符号化し、符号化された音声データを多重/分離部ex453に送出する。多重/分離部ex453は、符号化済み映像データと符号化済み音声データを所定の方式で多重化し、変調/復調部(変調/復調回路部)ex452、及び送信/受信部ex451で変調処理及び変換処理を施してアンテナex450を介して送信する。所定の方式は、予め定められていてもよい。 The smartphone ex115 performs processes such as telephone calls and data communications under the control of the main control unit ex460 having a CPU, ROM, and RAM. During a telephone call, the voice signal collected by the voice input unit ex456 is converted into a digital voice signal by the voice signal processing unit ex454, and then the signal is subjected to spectrum spreading processing by the modulation/demodulation unit ex452, and then to digital-to-analog conversion processing and frequency conversion processing by the transmission/reception unit ex451, and the resulting signal is transmitted via the antenna ex450. In addition, the received data is amplified and subjected to frequency conversion processing and analog-to-digital conversion processing, and then subjected to spectrum inverse spreading processing by the modulation/demodulation unit ex452, and then converted into an analog voice signal by the voice signal processing unit ex454, and then output from the voice output unit ex457. During a data communication mode, text, still images, or video data can be sent under the control of the main control unit ex460 via the operation input control unit ex462 based on the operation of the operation unit ex466 of the main unit. Similar transmission and reception processing is performed. When transmitting video, still images, or video and audio in the data communication mode, the video signal processing unit ex455 compresses and codes the video signal stored in the memory unit ex467 or the video signal input from the camera unit ex465 by the moving image coding method shown in each of the above embodiments, and sends the coded video data to the multiplexing/separation unit ex453. The audio signal processing unit ex454 codes the audio signal collected by the audio input unit ex456 while the camera unit ex465 is capturing the video or still image, and sends the coded audio data to the multiplexing/separation unit ex453. The multiplexing/separation unit ex453 multiplexes the coded video data and coded audio data by a predetermined method, and transmits the data through the antenna ex450 after performing modulation and conversion processing in the modulation/demodulation unit (modulation/demodulation circuit unit) ex452 and the transmission/reception unit ex451. The predetermined method may be determined in advance.
電子メール又はチャットに添付された映像、又はウェブページにリンクされた映像を受信した場合等において、アンテナex450を介して受信された多重化データを復号するために、多重/分離部ex453は、多重化データを分離することにより、多重化データを映像データのビットストリームと音声データのビットストリームとに分け、同期バスex470を介して符号化された映像データを映像信号処理部ex455に供給するとともに、符号化された音声データを音声信号処理部ex454に供給する。映像信号処理部ex455は、上記各実施の形態で示した動画像符号化方法に対応した動画像復号化方法によって映像信号を復号し、ディスプレイ制御部ex459を介して表示部ex458から、リンクされた動画像ファイルに含まれる映像又は静止画が表示される。音声信号処理部ex454は、音声信号を復号し、音声出力部ex457から音声が出力される。リアルタイムストリーミングがますます普及しだしているため、ユーザの状況によっては音声の再生が社会的にふさわしくないこともあり得る。そのため、初期値としては、音声信号は再生せず映像データのみを再生する構成の方が望ましく、ユーザが映像データをクリックするなど操作を行った場合にのみ音声を同期して再生してもよい。 In the case of receiving a video attached to an e-mail or chat, or a video linked to a web page, etc., in order to decode the multiplexed data received via the antenna ex450, the multiplexing/separation unit ex453 separates the multiplexed data into a bit stream of video data and a bit stream of audio data by separating the multiplexed data, and supplies the encoded video data to the video signal processing unit ex455 via the synchronization bus ex470, and supplies the encoded audio data to the audio signal processing unit ex454. The video signal processing unit ex455 decodes the video signal by a video decoding method corresponding to the video encoding method shown in each of the above embodiments, and the video or still image contained in the linked video file is displayed on the display unit ex458 via the display control unit ex459. The audio signal processing unit ex454 decodes the audio signal, and audio is output from the audio output unit ex457. As real-time streaming becomes more and more popular, audio playback may not be socially appropriate depending on the user's situation. Therefore, it is preferable to initially configure the device to play only the video data without playing any audio signals, and to play audio in sync only when the user performs an operation such as clicking on the video data.
またここではスマートフォンex115を例に説明したが、端末としては符号化器及び復号化器を両方持つ送受信型端末の他に、符号化器のみを有する送信端末、及び、復号化器のみを有する受信端末という他の実装形式が考えられる。デジタル放送用システムにおいて、映像データに音声データが多重化された多重化データを受信又は送信するとして説明した。ただし、多重化データには、音声データ以外に映像に関連する文字データなどが多重化されてもよい。また、多重化データではなく映像データ自体が受信又は送信されてもよい。 Although the smartphone ex115 has been used as an example here, other implementation formats are possible, such as a transmitting terminal having only an encoder and a receiving terminal having only a decoder, in addition to a transmitting/receiving terminal having both an encoder and a decoder. In the digital broadcasting system, multiplexed data in which audio data is multiplexed onto video data is received or transmitted. However, in addition to audio data, text data related to the video may also be multiplexed into the multiplexed data. Also, video data itself may be received or transmitted instead of multiplexed data.
なお、CPUを含む主制御部ex460が符号化又は復号処理を制御するとして説明したが、種々の端末はGPUを備えることも多い。よって、CPUとGPUで共通化されたメモリ、又は共通に使用できるようにアドレスが管理されているメモリにより、GPUの性能を活かして広い領域を一括して処理する構成でもよい。これにより符号化時間を短縮でき、リアルタイム性を確保し、低遅延を実現できる。特に動き探索、デブロックフィルタ、SAO(Sample Adaptive Offset)、及び変換・量子化の処理を、CPUではなく、GPUでピクチャなどの単位で一括して行うと効率的である。 Although the main control unit ex460 including the CPU has been described as controlling the encoding or decoding process, various terminals often include a GPU. Therefore, a configuration may be used in which a wide area is processed collectively by utilizing the performance of the GPU using a memory shared by the CPU and GPU, or a memory whose addresses are managed so that they can be used in common. This can shorten the encoding time, ensure real-time performance, and achieve low latency. It is particularly efficient to perform the processes of motion search, deblocking filter, SAO (Sample Adaptive Offset), and conversion/quantization collectively in units such as pictures by the GPU, rather than by the CPU.
Claims (3)
前記回路に接続されたメモリとを備え、
前記回路は、動作において、
画像ブロック中の非矩形形状を有する第1パーティションについて、前記第1パーティションの第1動きベクトルを動きベクトル候補セットから選択し、
前記画像ブロック中のパーティションであり前記第1パーティションと重なる領域を有するパーティションである第2パーティションについて、前記第2パーティションの第2動きベクトルを前記動きベクトル候補セットから選択し、
選択した前記第1動きベクトルにより前記第1パーティションを符号化し、
選択した前記第2動きベクトルにより前記第2パーティションを符号化し、
前記動きベクトル候補セットからは、前記画像ブロックのサイズに関する条件なしに単予測動きベクトルのみが選択される、
画像符号化装置。 The circuit,
a memory connected to the circuit;
The circuit, in operation,
For a first partition having a non-rectangular shape in the image block, selecting a first motion vector for the first partition from a set of motion vector candidates;
For a second partition, the second partition being a partition in the image block and having an overlapping area with the first partition, selecting a second motion vector for the second partition from the motion vector candidate set;
encoding the first partition with the selected first motion vector;
encoding the second partition with the selected second motion vector;
from the motion vector candidate set, only uni-predictive motion vectors are selected without any constraint on the size of the image block;
Image encoding device.
前記回路に接続されたメモリとを備え、
前記回路は、動作において、
画像ブロック中の非矩形形状を有する第1パーティションについて、前記第1パーティションの第1動きベクトルを動きベクトル候補セットから選択し、
前記画像ブロック中のパーティションであり前記第1パーティションと重なる領域を有するパーティションである第2パーティションについて、前記第2パーティションの第2動きベクトルを前記動きベクトル候補セットから選択し、
選択した前記第1動きベクトルにより前記第1パーティションを復号し、
選択した前記第2動きベクトルにより前記第2パーティションを復号し、
前記動きベクトル候補セットからは、前記画像ブロックのサイズに関する条件なしに単予測動きベクトルのみが選択される、
画像復号装置。 The circuit,
a memory connected to the circuit;
The circuit, in operation,
For a first partition having a non-rectangular shape in the image block, selecting a first motion vector for the first partition from a set of motion vector candidates;
For a second partition, the second partition being a partition in the image block and having an overlapping area with the first partition, selecting a second motion vector for the second partition from the motion vector candidate set;
Decoding the first partition using the selected first motion vector;
Decoding the second partition with the selected second motion vector;
from the motion vector candidate set, only uni-predictive motion vectors are selected without any constraint on the size of the image block;
Image decoding device.
前記回路に接続されたメモリとを備え、
前記回路は、動作において、
パーティション処理を復号装置に実行させるためのパラメータを生成し、
前記パラメータをビットストリームに含め、
前記パーティション処理は、
画像ブロック中の非矩形形状を有する第1パーティションの第1動きベクトルが動きベクトル候補セットから選択されることと、
前記画像ブロック中のパーティションであり前記第1パーティションと重なる領域を有するパーティションである第2パーティションの第2動きベクトルが前記動きベクトル候補セットから選択されることと、
選択した前記第1動きベクトルにより前記第1パーティションが復号されることと、
選択した前記第2動きベクトルにより前記第2パーティションが復号されることとを含み、
前記動きベクトル候補セットからは、前記画像ブロックのサイズに関する条件なしに単予測動きベクトルのみが選択される、
ビットストリーム生成装置。 The circuit,
a memory connected to the circuit;
The circuit, in operation,
generating parameters for causing a decoding device to execute partition processing;
including said parameters in a bitstream;
The partition process includes:
A first motion vector of a first partition having a non-rectangular shape in the image block is selected from a motion vector candidate set;
selecting a second motion vector for a second partition, the second partition being a partition in the image block and having an overlapping area with the first partition, from the motion vector candidate set;
the first partition is decoded using the selected first motion vector; and
and decoding the second partition using the selected second motion vector;
from the motion vector candidate set, only uni-predictive motion vectors are selected without any constraint on the size of the image block;
Bitstream generator.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024188064A JP7710081B2 (en) | 2017-08-22 | 2024-10-25 | Image encoding device, image decoding device, and bitstream generating device |
| JP2025114262A JP2025143441A (en) | 2017-08-22 | 2025-07-07 | Image encoding device, image decoding device, and bitstream generation device |
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762548631P | 2017-08-22 | 2017-08-22 | |
| US62/548,631 | 2017-08-22 | ||
| US201862698785P | 2018-07-16 | 2018-07-16 | |
| US62/698,785 | 2018-07-16 | ||
| JP2020511395A JP7179832B2 (en) | 2017-08-22 | 2018-08-10 | image coding device |
| PCT/JP2018/030059 WO2019039322A1 (en) | 2017-08-22 | 2018-08-10 | Image encoder, image decoder, image encoding method, and image decoding method |
| JP2022183267A JP7446393B2 (en) | 2017-08-22 | 2022-11-16 | Image encoding device, image decoding device, and bitstream generation device |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022183267A Division JP7446393B2 (en) | 2017-08-22 | 2022-11-16 | Image encoding device, image decoding device, and bitstream generation device |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024188064A Division JP7710081B2 (en) | 2017-08-22 | 2024-10-25 | Image encoding device, image decoding device, and bitstream generating device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2024054401A JP2024054401A (en) | 2024-04-16 |
| JP7579477B2 true JP7579477B2 (en) | 2024-11-07 |
Family
ID=65438980
Family Applications (5)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020511395A Active JP7179832B2 (en) | 2017-08-22 | 2018-08-10 | image coding device |
| JP2022183267A Active JP7446393B2 (en) | 2017-08-22 | 2022-11-16 | Image encoding device, image decoding device, and bitstream generation device |
| JP2024027119A Active JP7579477B2 (en) | 2017-08-22 | 2024-02-27 | Image encoding device, image decoding device, and bitstream generating device |
| JP2024188064A Active JP7710081B2 (en) | 2017-08-22 | 2024-10-25 | Image encoding device, image decoding device, and bitstream generating device |
| JP2025114262A Pending JP2025143441A (en) | 2017-08-22 | 2025-07-07 | Image encoding device, image decoding device, and bitstream generation device |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020511395A Active JP7179832B2 (en) | 2017-08-22 | 2018-08-10 | image coding device |
| JP2022183267A Active JP7446393B2 (en) | 2017-08-22 | 2022-11-16 | Image encoding device, image decoding device, and bitstream generation device |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024188064A Active JP7710081B2 (en) | 2017-08-22 | 2024-10-25 | Image encoding device, image decoding device, and bitstream generating device |
| JP2025114262A Pending JP2025143441A (en) | 2017-08-22 | 2025-07-07 | Image encoding device, image decoding device, and bitstream generation device |
Country Status (10)
| Country | Link |
|---|---|
| US (8) | US11223844B2 (en) |
| EP (2) | EP4676057A2 (en) |
| JP (5) | JP7179832B2 (en) |
| KR (2) | KR20250024127A (en) |
| CN (7) | CN116527934B (en) |
| BR (1) | BR112020001991A2 (en) |
| ES (1) | ES3055707T3 (en) |
| MX (6) | MX2020001886A (en) |
| TW (2) | TWI836681B (en) |
| WO (1) | WO2019039322A1 (en) |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116527934B (en) * | 2017-08-22 | 2025-11-11 | 松下电器(美国)知识产权公司 | Image encoder, image decoder, and bit stream generating device |
| CN117478879A (en) * | 2017-10-16 | 2024-01-30 | 数字洞察力有限公司 | Method for encoding/decoding images and recording medium for storing bit stream |
| CN108198145B (en) * | 2017-12-29 | 2020-08-28 | 百度在线网络技术(北京)有限公司 | Method and device for point cloud data restoration |
| MX2020013782A (en) * | 2018-06-15 | 2021-04-13 | Huawei Tech Co Ltd | Method and apparatus for intra prediction. |
| US11695967B2 (en) * | 2018-06-22 | 2023-07-04 | Op Solutions, Llc | Block level geometric partitioning |
| KR102648038B1 (en) * | 2018-07-04 | 2024-03-18 | 파나소닉 인텔렉츄얼 프로퍼티 코포레이션 오브 아메리카 | Encoding device, decoding device, encoding method, and decoding method |
| CN112514394B (en) * | 2018-07-17 | 2024-10-29 | 松下电器(美国)知识产权公司 | System and method for video coding |
| CN112913247B (en) * | 2018-10-23 | 2023-04-28 | 北京字节跳动网络技术有限公司 | Video processing using local illumination compensation |
| WO2020084508A1 (en) | 2018-10-23 | 2020-04-30 | Beijing Bytedance Network Technology Co., Ltd. | Harmonization between local illumination compensation and inter prediction coding |
| US10778977B2 (en) | 2018-12-05 | 2020-09-15 | Qualcomm Incorporated | Triangle motion information for video coding |
| US20200213595A1 (en) * | 2018-12-31 | 2020-07-02 | Comcast Cable Communications, Llc | Methods, Systems, And Apparatuses For Adaptive Processing Of Non-Rectangular Regions Within Coding Units |
| CN113302918B (en) | 2019-01-15 | 2025-01-17 | 北京字节跳动网络技术有限公司 | Weighted Prediction in Video Codecs |
| WO2020147804A1 (en) | 2019-01-17 | 2020-07-23 | Beijing Bytedance Network Technology Co., Ltd. | Use of virtual candidate prediction and weighted prediction in video processing |
| AR118250A1 (en) * | 2019-03-08 | 2021-09-22 | Jvckenwood Corp | MOTION PICTURE CODING AND DECODING DEVICES, METHODS AND PROGRAMS |
| CN113557739B (en) * | 2019-03-08 | 2023-07-11 | 知识产权之桥一号有限责任公司 | Image encoding device, image encoding method, and image encoding program, image decoding device, image decoding method, and image decoding program |
| US11973966B2 (en) * | 2019-03-12 | 2024-04-30 | Hyundai Motor Company | Method and apparatus for efficiently coding residual blocks |
| CN118118657A (en) | 2019-03-13 | 2024-05-31 | Lg 电子株式会社 | Inter prediction method and device based on DMVR |
| EP3944623A4 (en) | 2019-03-22 | 2022-06-08 | LG Electronics Inc. | Dmvr-based inter prediction method and apparatus |
| EP3745725A1 (en) | 2019-03-22 | 2020-12-02 | LG Electronics Inc. -1- | Method and device for inter prediction on basis of dmvr and bdof |
| US11140409B2 (en) | 2019-03-22 | 2021-10-05 | Lg Electronics Inc. | DMVR and BDOF based inter prediction method and apparatus thereof |
| CN113163204B (en) * | 2019-06-24 | 2022-11-01 | 杭州海康威视数字技术股份有限公司 | Encoding and decoding method, device and equipment |
| KR102925158B1 (en) | 2019-06-25 | 2026-02-09 | 에스케이텔레콤 주식회사 | Method and apparatus for deriving motion information |
| WO2020260766A1 (en) * | 2019-06-26 | 2020-12-30 | Nokia Technologies Oy | Method, apparatus, computer program product for storing motion vectors for video encoding |
| WO2021003126A1 (en) * | 2019-07-02 | 2021-01-07 | Beijing Dajia Internet Information Technology Co., Ltd. | Methods and apparatuses for video coding using triangle partition |
| CN119299678A (en) * | 2019-08-06 | 2025-01-10 | 交互数字Ce专利控股有限公司 | Secondary transform for video encoding and decoding |
| WO2021040037A1 (en) | 2019-08-29 | 2021-03-04 | 日本放送協会 | Encoding apparatus, decoding apparatus, and program |
| CN114731409A (en) | 2019-09-20 | 2022-07-08 | 韩国电子通信研究院 | Image encoding/decoding method and apparatus, and recording medium storing bit stream |
| KR102766987B1 (en) * | 2019-09-23 | 2025-02-13 | 주식회사 케이티 | Method and apparatus for processing a video |
| EP4022908A4 (en) | 2019-09-25 | 2022-11-09 | Huawei Technologies Co., Ltd. | SIMPLIFIED GEOMETRIC FUSION MODE METHOD AND APPARATUS FOR INTER-PREDICTION |
| WO2021134393A1 (en) * | 2019-12-31 | 2021-07-08 | Huawei Technologies Co., Ltd. | Method and apparatus of deblocking filtering between boundaries of blocks predicted using weighted prediction and non-rectangular merge modes |
| EP4091324A1 (en) | 2020-04-30 | 2022-11-23 | Huawei Technologies Co., Ltd. | Triangulation-based adaptive subsampling of dense motion vector fields |
| TWI749676B (en) | 2020-08-03 | 2021-12-11 | 緯創資通股份有限公司 | Image quality assessment apparatus and image quality assessment method thereof |
| TWI743919B (en) | 2020-08-03 | 2021-10-21 | 緯創資通股份有限公司 | Video processing apparatus and processing method of video stream |
| WO2022047117A1 (en) * | 2020-08-28 | 2022-03-03 | Op Solutions, Llc | Methods and systems of adaptive geometric partitioning |
| WO2022077495A1 (en) * | 2020-10-16 | 2022-04-21 | Oppo广东移动通信有限公司 | Inter-frame prediction methods, encoder and decoders and computer storage medium |
| TWI786497B (en) | 2020-12-22 | 2022-12-11 | 宏正自動科技股份有限公司 | Image output device, image receiving device and image transmission method |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080101707A1 (en) | 2006-10-30 | 2008-05-01 | Debargha Mukherjee | Method for decomposing a video sequence frame |
| JP2012023597A (en) | 2010-07-15 | 2012-02-02 | Sony Corp | Image processing device and image processing method |
| WO2013047805A1 (en) | 2011-09-29 | 2013-04-04 | シャープ株式会社 | Image decoding apparatus, image decoding method and image encoding apparatus |
| WO2015006884A1 (en) | 2013-07-19 | 2015-01-22 | Qualcomm Incorporated | 3d video coding with partition-based depth inter coding |
| JP2015216632A (en) | 2014-04-22 | 2015-12-03 | ソニー株式会社 | Coding device and coding method |
| US20160234503A1 (en) | 2013-10-16 | 2016-08-11 | Huawei Technologies Co., Ltd. | Method for Determining a Corner Video Part of a Partition of a Video Coding Block |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE69630643T2 (en) * | 1995-08-29 | 2004-10-07 | Sharp Kk | The video coding apparatus |
| JP4448167B2 (en) * | 2007-12-28 | 2010-04-07 | フェリカネットワークス株式会社 | Communication device, remote server and terminal device |
| JP2011023885A (en) * | 2009-07-14 | 2011-02-03 | Canon Inc | Video encoder and video encoding method |
| CN104967857B (en) * | 2010-01-19 | 2019-08-23 | 三星电子株式会社 | Method and apparatus for encoding/decoding images |
| US8879632B2 (en) * | 2010-02-18 | 2014-11-04 | Qualcomm Incorporated | Fixed point implementation for geometric motion partitioning |
| JP2012019447A (en) * | 2010-07-09 | 2012-01-26 | Sony Corp | Image processor and processing method |
| MX367864B (en) * | 2010-07-20 | 2019-09-05 | Ntt Docomo Inc | PICTURE PREDICTION ENCODING DEVICE, PICTURE PREDICTION ENCODING METHOD, PICTURE PREDICTION ENCODING PROGRAM, IMAGE PREDICTION DECODING DEVICE, PREDICTION PREDICTION PICTURE DECODING METHOD, AND PREDICTION IMAGE DECODING PROGRAM. |
| JP2012034213A (en) * | 2010-07-30 | 2012-02-16 | Toshiba Corp | Image processing device, image processing system and image processing method |
| WO2012039136A1 (en) * | 2010-09-24 | 2012-03-29 | パナソニック株式会社 | Image encoding method, image decoding method, image encoding apparatus, and image decoding apparatus |
| JP5698541B2 (en) * | 2011-01-12 | 2015-04-08 | 株式会社Nttドコモ | Image predictive encoding device, image predictive encoding method, image predictive encoding program, image predictive decoding device, image predictive decoding method, and image predictive decoding program |
| JP5857244B2 (en) * | 2011-03-07 | 2016-02-10 | パナソニックIpマネジメント株式会社 | Motion compensation device, video encoding device, video decoding device, motion compensation method, program, and integrated circuit |
| WO2013069990A1 (en) * | 2011-11-08 | 2013-05-16 | 삼성전자 주식회사 | Method and device for determining motion vector for video coding or video decoding |
| EP4161078A1 (en) * | 2011-11-11 | 2023-04-05 | GE Video Compression, LLC | Effective wedgelet partition coding using spatial prediction |
| WO2013099244A1 (en) * | 2011-12-28 | 2013-07-04 | 株式会社Jvcケンウッド | Video encoding device, video encoding method, video encoding program, video decoding device, video decoding method, video decoding program |
| US20150098508A1 (en) * | 2011-12-30 | 2015-04-09 | Humax Co., Ltd. | Method and device for encoding three-dimensional image, and decoding method and device |
| US20130287093A1 (en) * | 2012-04-25 | 2013-10-31 | Nokia Corporation | Method and apparatus for video coding |
| KR20140089486A (en) * | 2013-01-04 | 2014-07-15 | 삼성전자주식회사 | Motion compensation method and motion compensation apparatus for encoding and decoding of scalable video |
| US10390034B2 (en) * | 2014-01-03 | 2019-08-20 | Microsoft Technology Licensing, Llc | Innovations in block vector prediction and estimation of reconstructed sample values within an overlap area |
| JP6308449B2 (en) * | 2014-06-26 | 2018-04-11 | ホアウェイ・テクノロジーズ・カンパニー・リミテッド | Method and apparatus for reducing computational load in high efficiency video coding |
| US10271057B2 (en) * | 2014-11-04 | 2019-04-23 | Vahagn Nurijanyan | System and methods for image/video compression |
| EP3293975A4 (en) * | 2015-09-08 | 2018-10-10 | Samsung Electronics Co., Ltd. | Device and method for entropy encoding and decoding |
| JP6638366B2 (en) * | 2015-12-14 | 2020-01-29 | 日本電気株式会社 | Video coding apparatus, video coding method, and video coding program |
| US10306258B2 (en) * | 2016-01-29 | 2019-05-28 | Google Llc | Last frame motion vector partitioning |
| CN116527934B (en) * | 2017-08-22 | 2025-11-11 | 松下电器(美国)知识产权公司 | Image encoder, image decoder, and bit stream generating device |
| WO2020094052A1 (en) * | 2018-11-06 | 2020-05-14 | Beijing Bytedance Network Technology Co., Ltd. | Side information signaling for inter prediction with geometric partitioning |
| EP3847814A4 (en) * | 2018-11-06 | 2021-07-14 | Beijing Bytedance Network Technology Co. Ltd. | POSITION-DEPENDENT STORAGE OF MOVEMENT INFORMATION |
| US10893298B2 (en) | 2018-12-12 | 2021-01-12 | Tencent America LLC | Method and apparatus for video coding |
| US11463693B2 (en) * | 2019-08-30 | 2022-10-04 | Qualcomm Incorporated | Geometric partition mode with harmonized motion field storage and motion compensation |
-
2018
- 2018-08-10 CN CN202310720431.4A patent/CN116527934B/en active Active
- 2018-08-10 KR KR1020257004063A patent/KR20250024127A/en active Pending
- 2018-08-10 JP JP2020511395A patent/JP7179832B2/en active Active
- 2018-08-10 MX MX2020001886A patent/MX2020001886A/en unknown
- 2018-08-10 CN CN201880054452.4A patent/CN110999303B/en active Active
- 2018-08-10 BR BR112020001991-7A patent/BR112020001991A2/en unknown
- 2018-08-10 CN CN202310722029.XA patent/CN116527935B/en active Active
- 2018-08-10 ES ES18848245T patent/ES3055707T3/en active Active
- 2018-08-10 CN CN202310720553.3A patent/CN116582682B/en active Active
- 2018-08-10 CN CN202310720512.4A patent/CN116567265B/en active Active
- 2018-08-10 WO PCT/JP2018/030059 patent/WO2019039322A1/en not_active Ceased
- 2018-08-10 CN CN202310714655.4A patent/CN116527933A/en active Pending
- 2018-08-10 EP EP25207148.5A patent/EP4676057A2/en active Pending
- 2018-08-10 CN CN202310720863.5A patent/CN116567266B/en active Active
- 2018-08-10 KR KR1020207004566A patent/KR20200038943A/en not_active Ceased
- 2018-08-10 EP EP18848245.9A patent/EP3673656B1/en active Active
- 2018-08-17 TW TW111140567A patent/TWI836681B/en active
- 2018-08-17 TW TW107128782A patent/TWI782073B/en active
-
2019
- 2019-09-16 US US16/572,323 patent/US11223844B2/en active Active
-
2020
- 2020-02-18 MX MX2024004990A patent/MX2024004990A/en unknown
- 2020-02-18 MX MX2024004987A patent/MX2024004987A/en unknown
- 2020-02-18 MX MX2024004992A patent/MX2024004992A/en unknown
- 2020-02-18 MX MX2024004989A patent/MX2024004989A/en unknown
- 2020-02-18 MX MX2024004988A patent/MX2024004988A/en unknown
-
2021
- 2021-10-20 US US17/506,443 patent/US11563969B2/en active Active
-
2022
- 2022-11-16 JP JP2022183267A patent/JP7446393B2/en active Active
- 2022-12-12 US US18/064,774 patent/US11856217B2/en active Active
- 2022-12-13 US US18/065,513 patent/US12114004B2/en active Active
- 2022-12-14 US US18/065,977 patent/US11812049B2/en active Active
- 2022-12-15 US US18/066,873 patent/US11924456B2/en active Active
- 2022-12-16 US US18/067,519 patent/US12483720B2/en active Active
-
2024
- 2024-02-27 JP JP2024027119A patent/JP7579477B2/en active Active
- 2024-10-25 JP JP2024188064A patent/JP7710081B2/en active Active
-
2025
- 2025-04-04 US US19/170,549 patent/US20250234028A1/en active Pending
- 2025-07-07 JP JP2025114262A patent/JP2025143441A/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080101707A1 (en) | 2006-10-30 | 2008-05-01 | Debargha Mukherjee | Method for decomposing a video sequence frame |
| JP2012023597A (en) | 2010-07-15 | 2012-02-02 | Sony Corp | Image processing device and image processing method |
| WO2013047805A1 (en) | 2011-09-29 | 2013-04-04 | シャープ株式会社 | Image decoding apparatus, image decoding method and image encoding apparatus |
| WO2015006884A1 (en) | 2013-07-19 | 2015-01-22 | Qualcomm Incorporated | 3d video coding with partition-based depth inter coding |
| US20160234503A1 (en) | 2013-10-16 | 2016-08-11 | Huawei Technologies Co., Ltd. | Method for Determining a Corner Video Part of a Partition of a Video Coding Block |
| JP2015216632A (en) | 2014-04-22 | 2015-12-03 | ソニー株式会社 | Coding device and coding method |
Non-Patent Citations (1)
| Title |
|---|
| Xiaozhen Zheng, et al.,CE2: Test results of non-rectangular motion partitioning (NRMP) with overlapped block motion compens,Joint Collaborative Team on Video Coding (JCT-VC)of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11,JCTVC-E373,2011年03月23日,pp.1-3 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7710081B2 (en) | Image encoding device, image decoding device, and bitstream generating device | |
| JP7705989B2 (en) | Image encoding device, image decoding device, and bitstream generating device | |
| JP7658002B2 (en) | Image encoding device, image decoding device, and bitstream generating device | |
| JP7570544B2 (en) | BITSTREAM TRANSMISSION DEVICE AND BITSTREAM TRANSMISSION METHOD | |
| JP7712984B2 (en) | Image encoding device, image decoding device, and bitstream generating device | |
| JP7675143B2 (en) | Image encoding device, image decoding device, and bitstream generating device | |
| JP7692520B2 (en) | Encoding device and decoding device | |
| JP7509975B2 (en) | Encoding device and decoding device | |
| JP7713579B2 (en) | Encoding device and decoding device | |
| JP7681160B2 (en) | Transmitting device and transmitting method | |
| JP7656128B2 (en) | Encoding device and decoding device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240227 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20241008 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241025 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7579477 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |