JP7575813B2 - 文書生成システム、文書生成方法およびプログラム - Google Patents
文書生成システム、文書生成方法およびプログラム Download PDFInfo
- Publication number
- JP7575813B2 JP7575813B2 JP2023019540A JP2023019540A JP7575813B2 JP 7575813 B2 JP7575813 B2 JP 7575813B2 JP 2023019540 A JP2023019540 A JP 2023019540A JP 2023019540 A JP2023019540 A JP 2023019540A JP 7575813 B2 JP7575813 B2 JP 7575813B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- trained model
- document
- generation unit
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 21
- 238000012549 training Methods 0.000 claims description 70
- 238000000605 extraction Methods 0.000 claims description 36
- 238000013480 data collection Methods 0.000 claims description 35
- 238000010801 machine learning Methods 0.000 claims description 31
- 238000012545 processing Methods 0.000 claims description 19
- 239000000284 extract Substances 0.000 claims description 16
- 230000007115 recruitment Effects 0.000 claims description 4
- 238000010586 diagram Methods 0.000 description 8
- 230000006870 function Effects 0.000 description 6
- 230000005540 biological transmission Effects 0.000 description 4
- 238000004891 communication Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 241000797344 Carlia pulla Species 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
Images


Landscapes
- Machine Translation (AREA)
Description
機械学習を用いたシステムでは、推論の対象を特定する要件を定め、予め多数の教師データを用いて、当該推論を行うためのモデルを学習する(例えば、非特許文献1参照)。
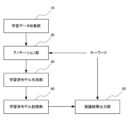
図7に示すように、文書生成システムは、学習データ収集部10と、アノテーション部20と、学習済モデル生成部30と、学習済モデル記憶部40と、推論結果出力部50と、を含んで構成され、学習データ収集部10と、アノテーション部20と、学習済モデル生成部30と、学習済モデル記憶部40と、により実行される処理工程が学習工程、推論結果出力部50と、によって実行される処理工程が推論工程となっている。
アノテーション部20において処理された学習データは、学習済モデル生成部30において機械学習が実行され、学習済モデルが生成される。
そして、生成された学習済モデルを学習済モデル記憶部40に格納して、処理を終了する。
そのため、こうしたノイズを含んだ文書データを用いて学習済みモデルを生成するために、文書の生成精度が低くなるという課題があった。
以下、図1、図2を用いて、本実施形態に係る文書生成システム1について、説明する。
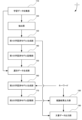
図1に示すように、本実施形態に係る文書生成システム1は、学習データ収集部110と、抽出部120と、第1の学習済モデル生成部130と、第1の学習済モデル記憶部140と、選別データ生成部150と、第2の学習済モデル生成部160と、第2の学習済モデル記憶部170と、推論結果出力部180と、文書データ出力部190と、を含んで構成されている。
学習データ収集部110において収集された学習データは、後述する抽出部120に出力される。
なお、文書データとしては、例えば、報告書やプレゼン資料等のビジネス文書をはじめとする種々の文書を例示できるが、以下では、求人票の募集要項を文書データとして例示して、説明する。
抽出部120において抽出された教師データは、後述する第1の学習済モデル生成部130に出力される。
また、抽出部120において抽出された教師データは、図示しない記憶部に記憶保存される。
教師データは、例えば、特定の学習データにラベルが付された文書データであり、ラベルには、文書に種別に応じた複数のパラメータに対する充足度が示されている。
また、パラメータに対する充足度は、例えば、2値で示される。
例えば、文書データを求人票の募集要項とした場合、パラメータとしては、自社の現状、やってほしい仕事、ポジション、仕事の進め方、将来像等を例示でき、充足度は、各パラメータに関する記載が文書データに記載されているか否かを2値で示している。
抽出部120は、学習データ収集部110において収集された学習データの中から、複数のパラメータに対して、その充足度が少なくとも、1つ満たされた厳選された少量の教師データを抽出する。
ここで、第1の学習済モデル生成部130において生成される第1の学習済モデルは、後述する選別データ生成部において、選別データを生成するために用いられる学習済モデルである。
第1の学習済モデル生成部130において生成された第1の学習済モデルは、後述する第1の学習済モデル記憶部140に記憶される。
選別データ生成部150において生成された選別データは、膨大な量の文書データとなる。
選別データ生成部150において生成された選別データは、後述する第2の学習済モデル生成部160に出力される。
キーワードは文書の種別や内容に応じたものであり、予め準備されたものである。
第2の学習済モデル生成部160において生成された第2の学習済モデルは、後述する第2の学習済モデル記憶部170に記憶される。
推論結果出力部180における推論結果としての文書データは、後述する文書データ出力部190に出力される。
なお、文書データ出力部190の評価としては、ラベルに示された文書に種別に応じた複数のパラメータに対する充足度が高いもの、具体的には、充足度の高いパラメータの数により、評価を行う。
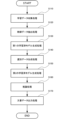
図2を用いて、本実施形態に係る文書生成システム1の処理について説明する。
学習データ収集部110において収集された学習データは、抽出部120に出力される。
抽出部120において抽出された教師データは、第1の学習済モデル生成部130に出力される。
第1の学習済モデル生成部130において生成された第1の学習済モデルは、第1の学習済モデル記憶部140に記憶される。
選別データ生成部150において生成された膨大な量の選別データは、第2の学習済モデル生成部160に出力される。
第2の学習済モデル生成部160において生成された第2の学習済モデルは、第2の学習済モデル記憶部170に記憶される。
推論結果出力部180における推論結果としての文書データは、文書データ出力部190に出力される。
以上、説明したように、本実施形態に係る文書生成システム1は、文書データとしての学習データを収集する学習データ収集部110と、該収集された学習データの中から特定の学習データを教師データとして抽出する抽出部120と、該抽出された教師データを入力し、第1の機械学習を実行して、第1の学習済モデルを生成する第1の学習済モデル生成部130と、該生成された第1の学習済モデルを用いて、学習データから選別した文書データを生成する選別データ生成部150と、該生成された選別データとキーワードとを入力し、第2の機械学習を実行して、第2の学習済モデルを生成する第2の学習済モデル生成部160と、第2の学習済モデルとキーワードと用いて、推論結果としての文書データを出力する推論結果出力部180と、第1の学習済モデルを用いて、推論結果としての文書データを評価し、評価の高い文書データを出力する文書データ出力部190と、を備えている。
抽出部120は、収集された学習データの中から特定の学習データを教師データとして抽出する。
ここで、教師データは、例えば、特定の学習データにラベルが付された文書データであり、ラベルには、文書に種別に応じた複数のパラメータに対する充足度が示されている。
抽出部120は、学習データ収集部110において収集された学習データの中から、複数のパラメータに対して、その充足度が少なくとも1つ満たされた厳選された少量の教師データを抽出する。
つまり、抽出部120は、学習データ収集部110において収集された学習データの中から、複数のパラメータに対して、その充足度が少なくとも1つ満たされた厳選された少量の教師データを抽出するため、工数を大幅に削減できる。
なお、これが実現できるのは、後述する第1の学習済モデル生成部130、選別データ生成部150、第2の学習済モデル生成部160、推論結果出力部180、文書データ出力部190を備えているためである。
第1の学習済モデル生成部130は、抽出部120において抽出された教師データを入力し、第1の機械学習を実行して、第1の学習済モデルを生成し、選別データ生成部150は、該生成された第1の学習済モデルを用いて、学習データから選別した文書データを生成し、第2の学習済モデル生成部160は、該生成された選別データとキーワードとを入力し、第2の機械学習を実行して、第2の学習済モデルを生成する。
つまり、第1の学習済モデル生成部130は、教師データを入力し、第1の学習済モデルを生成し、選別データ生成部150は、第1の学習済モデルを用いて、学習データから選別した膨大な選別データを生成し、第2の学習済モデル生成部160は、選別データとキーワードとを入力し、第2の学習済モデルを生成する。
そのため、厳選された少量の教師データから第1の学習済モデルが生成することによって、精度の高い学習済モデルを生成することができる。
また、第1の学習済モデルを用いて、学習データから選別した膨大な文書データが生成されるため、少ない工数で、精度が高く、従来のアノテーション処理を凌駕する文書データを生成することができる。
さらに、選別データとキーワードとを入力し、第2の学習済モデルが生成されるため、精度の高い処理が実現できる。
推論結果出力部180は、第2の学習済モデルとキーワードと用いて、推論結果としての文書データを出力し、文書データ出力部190は、第1の学習済モデルを用いて、推論結果としての文書データを評価し、評価の高い文書データを出力する。
つまり、推論結果出力部180は、第1の学習済モデルを用いて、学習データから選別した膨大な選別データから生成された第2の学習済モデルから推論結果としての文書データを出力し、文書データ出力部190は、第1の学習済モデル生成部130において生成された第1の学習済モデルを用いて、推論結果としての文書データを評価し、評価の高い文書データを出力するため、確度の高い推論と評価によって、高い品質の文書データを生成することができる。
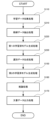
以下、図3、図4を用いて、本実施形態に係る文書生成システム1Aについて、説明する。
図3に示すように、本実施形態に係る文書生成システム1Aは、学習データ収集部110と、抽出部120Aと、第1の学習済モデル生成部130Aと、第1の学習済モデル記憶部140Aと、選別データ生成部150Aと、第2の学習済モデル生成部160と、第2の学習済モデル記憶部170と、推論結果出力部180と、文書データ出力部190と、を含んで構成されている。
なお、第1の実施形態と同一の符号を付す構成要素については、同様の機能を有することから、その詳細な説明は、省略する。
抽出部120Aは、抽出された教師データを学習データとラベルとに分離して、後述する第1の学習済モデル生成部130Aに出力する。
第1の学習済モデル生成部130において生成された第1の学習済モデルは、後述する第1の学習済モデル記憶部140Aに記憶される。
なお、第1の学習済モデル生成部130Aは、特定の学習データと複数のパラメータのうち、1つのパラメータに対する充足度とを組み合わせた文書データに対して、繰り返し処理を実行する。
選別データ生成部150Aにおいて生成される選別データは、膨大な量の文書データとなる。
選別データ生成部150Aにおいて生成された選別データは、後述する第2の学習済モデル生成部160に出力される。
なお、選別データ生成部150Aは、特定の学習データと複数のパラメータのうち、1つのパラメータに対する充足度とを組み合わせた文書データに対して、繰り返し処理を実行する。
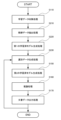
図2を用いて、本実施形態に係る文書生成システム1の処理について説明する。
学習データ収集部110において収集された学習データは、抽出部120に出力される。
抽出部120Aは、抽出された教師データを学習データとラベルとに分離して、後述する第1の学習済モデル生成部130Aに出力する。
なお、第1の学習済モデル生成部130Aは、特定の学習データと複数のパラメータのうち、1つのパラメータに対する充足度とを組み合わせた文書データに対して、繰り返し処理を実行する。
第1の学習済モデル生成部130Aにおいて生成された第1の学習済モデルは、第1の学習済モデル記憶部140Aに記憶される。
選別データ生成部150Aにおいて生成された膨大な量の選別データは、第2の学習済モデル生成部160に出力される。
なお、選別データ生成部150Aは、特定の学習データと複数のパラメータのうち、1つのパラメータに対する充足度とを組み合わせた文書データに対して、繰り返し処理を実行する。
第2の学習済モデル生成部160において生成された第2の学習済モデルは、第2の学習済モデル記憶部170に記憶される。
推論結果出力部180における推論結果としての文書データは、文書データ出力部190に出力される。
以上、説明したように、本実施形態に係る文書生成システム1Aにおいて、教師データは、特定の学習データにラベルが付された文書データであり、ラベルには、文書の種別に応じた複数のパラメータに対する充足度が示されており、第1の学習済モデル生成部130Aは、教師データとして、特定の学習データとラベルとを入力し、選別データ生成部150Aは、第1の学習済モデルを用いて、特定の学習データ以外の学習データにラベルを付し、パラメータごとの充足度が高い学習データを選別データとして生成する。
つまり、第1の学習済モデル生成部130Aは、教師データとして、特定の学習データとラベルとを入力し、選別データ生成部150Aは、第1の学習済モデルを用いて、特定の学習データ以外の学習データにラベルを付し、パラメータごとの充足度が高い学習データを選別データとして生成する。
そのため、パラメータごとの充足度が高い学習データを選別データとして生成することにより、教師データが従来よりも少数であっても、文書生成の精度を向上させることができる。
また、教師データが従来よりも少数であることから、教師データを得るための工数が削減され、システム全体のコストを低減することができる。
つまり、第1の機械学習により、ラベルが付された学習データを生成し、その中からパラメータごとの充足度が高い学習データを選別データとして生成する。
そのため、パラメータごとの充足度が高い学習データを選別データとして生成することにより、教師データが従来よりも少数であっても、文書生成の精度を向上させることができる。
以下、図5、図6を用いて、本実施形態に係る文書生成システム1Bについて、説明する。
図5に示すように、本実施形態に係る文書生成システム1Bは、学習データ収集部110と、抽出部120Aと、第1の学習済モデル生成部130Aと、第1の学習済モデル記憶部140Aと、選別データ生成部150Aと、第2の学習済モデル生成部160と、第2の学習済モデル記憶部170と、推論結果出力部180と、文書データ出力部190Aと、を含んで構成されている。
なお、第1の実施形態および第2の実施形態と同一の符号を付す構成要素については、同様の機能を有することから、その詳細な説明は、省略する。
また、文書データ出力部190Aから出力される評価の高い文書データは、選別データ生成部150Aの学習データとしてフィードバックされる。
図6を用いて、本実施形態に係る文書生成システム1Bの処理について説明する。
学習データ収集部110において収集された学習データは、抽出部120に出力される。
抽出部120Aは、抽出された教師データを学習データとラベルとに分離して、後述する第1の学習済モデル生成部130Aに出力する。
第1の学習済モデル生成部130Aにおいて生成された第1の学習済モデルは、第1の学習済モデル記憶部140Aに記憶される。
なお、第1の学習済モデル生成部130Aは、特定の学習データと複数のパラメータのうち、1つのパラメータに対する充足度とを組み合わせた文書データに対して、繰り返し処理を実行する。
選別データ生成部150Aにおいて生成された膨大な量の選別データは、第2の学習済モデル生成部160に出力される。
なお、選別データ生成部150Aは、特定の学習データと複数のパラメータのうち、1つのパラメータに対する充足度とを組み合わせた文書データに対して、繰り返し処理を実行する。
第2の学習済モデル生成部160において生成された第2の学習済モデルは、第2の学習済モデル記憶部170に記憶される。
推論結果出力部180における推論結果としての文書データは、文書データ出力部190に出力される。
また、文書データ出力部190Aから出力される文書データは、選別データ生成部150Aの学習データとしてフィードバックされる。
以上、説明したように、本実施形態に係る文書生成システム1Bにおいて、文書データ出力部190Aから出力される文書データは、選別データ生成部150Aの学習データとしてフィードバックされる。
つまり、文書データ出力部190Aにおいて、評価が高いとされる文書データを選別データ生成部150Aで用いられる学習データに加える。
そのため、更に精度の高い文書データの作成が期待できる。
本実施形態に係る文書生成システム1、1A、1Bを用いることによって、Webサイトや求人サイトあるいは報告書、プレゼン資料等の種々の文書を自動的に生成することができる。
また、文書生成の観点やポイントを教育するためのツールとして活用することも期待できる。
また、文書を添削するためのツールや記載されている文書の構成や内容を分析するためのツールとして活用することも期待できる。
ここでいうコンピュータシステムとは、OSや周辺装置等のハードウェアを含む。
1A;文書データ生成システム
1B;文書データ生成システム
110;学習データ収集部
120;抽出部
120A;抽出部
130;第1の学習済モデル生成部
130A;第1の学習済モデル生成部
140;第1の学習済モデル記憶部
140A;第1の学習済モデル記憶部
150;選別データ生成部
150A;選別データ生成部
160;第2の学習済モデル生成部
170;第2の学習済モデル記憶部
180;推論結果出力部
190;文書データ出力部
190A;文書データ出力部
Claims (8)
- 文書データとしての学習データを収集する学習データ収集部と、
該収集された前記学習データの中から特定の前記学習データを教師データとして抽出する抽出部と、
該抽出された前記教師データを入力し、第1の機械学習を実行して、第1の学習済モデルを生成する第1の学習済モデル生成部と、
該生成された前記第1の学習済モデルを用いて、前記学習データから選別データを生成する選別データ生成部と、
該生成された前記選別データとキーワードとを入力し、第2の機械学習を実行して、第2の学習済モデルを生成する第2の学習済モデル生成部と、
前記第2の学習済モデルとキーワードと用いて、推論結果としての文書データを出力する推論結果出力部と、
前記第1の学習済モデルを用いて、推論結果としての文書データを評価し、評価の高い文書データを出力する文書データ出力部と、
を備え、
前記教師データは、前記特定の前記学習データにラベルが付されたデータであり、前記ラベルには、文書に種別に応じた複数のパラメータに対する充足度が示されており、
前記第1の学習済モデル生成部は、前記教師データとして、前記特定の前記学習データとラベルとを入力し、
前記選別データ生成部は、前記第1の学習済モデルを用いて、前記特定の学習データ以外の前記学習データに前記ラベルを付し、前記パラメータごとの充足度が高い前記ラベルが多く付された前記学習データを前記選別データとして生成することを特徴とする文書生成システム。 - 前記第1の学習済モデル生成部および前記選別データ生成部は、前記特定の前記学習データと前記複数のパラメータのうち、1つの前記パラメータに対する充足度とを組み合わせた文書データに対して、処理を実行することを特徴とする請求項1に記載の文書生成システム。
- 前記文書データ出力部から出力される前記文書データは、前記選別データ生成部の前記学習データとしてフィードバックされることを特徴とする請求項1に記載の文書生成システム。
- 前記パラメータに対する充足度は、2値で示されることを特徴とする請求項1に記載の文書生成システム。
- 前記文書データが求人票の募集要項であることを特徴とする請求項1から4のいずれか1項に記載の文書生成システム。
- 前記パラメータが、自社の現状、やってほしい仕事、ポジション、仕事の進め方、将来像を含み、前記充足度は、各パラメータに関する記載が前記文書データに記載されているか否かを2値で示していることを特徴とする請求項4に記載の文書生成システム。
- 学習データ収集部と、抽出部と、第1の学習済モデル生成部と、選別データ生成部と、第2の学習済モデル生成部と、推論結果出力部と、文書データ出力部と、を含む文書生成システムにおける文書生成方法であって、
前記学習データ収集部が、文書データとしての学習データを収集する第1の工程と、前記抽出部が、該収集された前記学習データの中から特定の前記学習データを教師データとして抽出する第2の工程と、
前記第1の学習済モデル生成部が、該抽出された前記教師データを入力し、第1の機械学習を実行して、第1の学習済モデルを生成する第3の工程と、
前記選別データ生成部が、該生成された前記第1の学習済モデルを用いて、前記学習データから選別データを生成する第4の工程と、
前記第2の学習済モデル生成部が、該生成された前記選別データとキーワードとを入力し、第2の機械学習を実行して、第2の学習済モデルを生成する第5の工程と、
前記推論結果出力部が、前記第2の学習済モデルとキーワードと用いて、推論結果としての学習済モデルを出力する第6の工程と、
前記文書データ出力部が、前記第1の学習済モデルを用いて、推論結果としての学習済モデルを評価し、評価の高い文書データを出力する第7の工程と、
を備え、
前記教師データは、前記特定の前記学習データにラベルが付されたデータであり、前記ラベルには、文書に種別に応じた複数のパラメータに対する充足度が示されており、
前記第3の工程において、前記第1の学習済モデル生成部は、前記教師データとして、前記特定の前記学習データとラベルとを入力し、
前記第4の工程において、前記選別データ生成部は、前記第1の学習済モデルを用いて、前記特定の学習データ以外の前記学習データに前記ラベルを付し、前記パラメータごとの充足度が高い前記ラベルが多く付された前記学習データを前記選別データとして生成することを特徴とする文書生成方法。 - 学習データ収集部と、抽出部と、第1の学習済モデル生成部と、選別データ生成部と、第2の学習済モデル生成部と、推論結果出力部と、文書データ出力部と、を含む文書生成システムにおける文書生成方法をコンピュータに実行させるためのプログラムであって、
前記学習データ収集部が、文書データとしての学習データを収集する第1の工程と、前記抽出部が、該収集された前記学習データの中から特定の前記学習データを教師データとして抽出する第2の工程と、
前記第1の学習済モデル生成部が、該抽出された前記教師データを入力し、第1の機械学習を実行して、第1の学習済モデルを生成する第3の工程と、
前記選別データ生成部が、該生成された前記第1の学習済モデルを用いて、前記学習データから選別データを生成する第4の工程と、
前記第2の学習済モデル生成部が、該生成された前記選別データとキーワードとを入力し、第2の機械学習を実行して、第2の学習済モデルを生成する第5の工程と、
前記推論結果出力部が、前記第2の学習済モデルとキーワードと用いて、推論結果としての学習済モデルを出力する第6の工程と、
前記文書データ出力部が、前記第1の学習済モデルを用いて、推論結果としての学習済モデルを評価し、評価の高い文書データを出力する第7の工程と、
を備え、
前記教師データは、前記特定の前記学習データにラベルが付されたデータであり、前記ラベルには、文書に種別に応じた複数のパラメータに対する充足度が示されており、
前記第3の工程において、前記第1の学習済モデル生成部は、前記教師データとして、前記特定の前記学習データとラベルとを入力し、
前記第4の工程において、前記選別データ生成部は、前記第1の学習済モデルを用いて、前記特定の学習データ以外の前記学習データに前記ラベルを付し、前記パラメータごとの充足度が高い前記ラベルが多く付された前記学習データを前記選別データとして生成するプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023019540A JP7575813B2 (ja) | 2023-02-10 | 2023-02-10 | 文書生成システム、文書生成方法およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023019540A JP7575813B2 (ja) | 2023-02-10 | 2023-02-10 | 文書生成システム、文書生成方法およびプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2024114102A JP2024114102A (ja) | 2024-08-23 |
| JP7575813B2 true JP7575813B2 (ja) | 2024-10-30 |
Family
ID=92456409
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023019540A Active JP7575813B2 (ja) | 2023-02-10 | 2023-02-10 | 文書生成システム、文書生成方法およびプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7575813B2 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014136316A1 (ja) | 2013-03-04 | 2014-09-12 | 日本電気株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2019159576A (ja) | 2018-03-09 | 2019-09-19 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
| JP2020119044A (ja) | 2019-01-18 | 2020-08-06 | 富士通株式会社 | 学習方法、学習プログラムおよび学習装置 |
| JP2021179859A (ja) | 2020-05-14 | 2021-11-18 | 株式会社日立製作所 | 学習モデル生成システム、及び学習モデル生成方法 |
-
2023
- 2023-02-10 JP JP2023019540A patent/JP7575813B2/ja active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014136316A1 (ja) | 2013-03-04 | 2014-09-12 | 日本電気株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2019159576A (ja) | 2018-03-09 | 2019-09-19 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
| JP2020119044A (ja) | 2019-01-18 | 2020-08-06 | 富士通株式会社 | 学習方法、学習プログラムおよび学習装置 |
| JP2021179859A (ja) | 2020-05-14 | 2021-11-18 | 株式会社日立製作所 | 学習モデル生成システム、及び学習モデル生成方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2024114102A (ja) | 2024-08-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230334254A1 (en) | Fact checking | |
| Wu et al. | Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis | |
| US11663409B2 (en) | Systems and methods for training machine learning models using active learning | |
| Carmichael et al. | Data science vs. statistics: two cultures? | |
| CN112257841B (zh) | 图神经网络中的数据处理方法、装置、设备及存储介质 | |
| US8498950B2 (en) | System for training classifiers in multiple categories through active learning | |
| US20200143265A1 (en) | Systems and methods for automated conversations with feedback systems, tuning and context driven training | |
| Rai | Identifying key product attributes and their importance levels from online customer reviews | |
| JP6976910B2 (ja) | データ分類システム、データ分類方法、および、データ分類装置 | |
| JP7365267B2 (ja) | 広告文自動作成システム | |
| US20160140106A1 (en) | Phrase-based data classification system | |
| US8650143B2 (en) | Determination of document credibility | |
| WO2019113122A1 (en) | Systems and methods for improved machine learning for conversations | |
| KR20050035066A (ko) | 컴퓨터를 이용한 질의-태스크 매핑 | |
| US20250103919A1 (en) | Systems and methods for applying rules via artificial intelligence for document processing | |
| CN118193851B (zh) | 一种电子书文档的处理方法及系统 | |
| KR20120087881A (ko) | 웹 페이지에 키워드를 할당하기 위한 방법 및 장치 | |
| JP7703599B2 (ja) | 意見分析システム、意見分析方法、及びプログラム | |
| JP6201792B2 (ja) | 情報処理装置及び情報処理プログラム | |
| US12277162B1 (en) | Using generative AI models for content searching and generation of confabulated search results | |
| JP2020013541A (ja) | 会話型の文書を要約するために表題を生成するためのシステム及び方法、文書用に表題を生成する方法、プログラム、演算装置、及びコンピュータ機器 | |
| CN117725458A (zh) | 一种获取威胁情报样本数据生成模型的方法及装置 | |
| Sun et al. | Docagent: An agentic framework for multi-modal long-context document understanding | |
| Nigatu et al. | Co-designing for transparency: Lessons from building a document organization tool in the criminal justice domain | |
| US20240211518A1 (en) | Automated document intake system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230213 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240430 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20240701 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240828 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240910 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241010 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7575813 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |