JP7433782B2 - Information processing device, information processing method, and program - Google Patents
Information processing device, information processing method, and program Download PDFInfo
- Publication number
- JP7433782B2 JP7433782B2 JP2019110963A JP2019110963A JP7433782B2 JP 7433782 B2 JP7433782 B2 JP 7433782B2 JP 2019110963 A JP2019110963 A JP 2019110963A JP 2019110963 A JP2019110963 A JP 2019110963A JP 7433782 B2 JP7433782 B2 JP 7433782B2
- Authority
- JP
- Japan
- Prior art keywords
- model
- recognition
- evaluation
- information processing
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 65
- 238000003672 processing method Methods 0.000 title claims 5
- 238000011156 evaluation Methods 0.000 claims description 141
- 238000000034 method Methods 0.000 claims description 73
- 230000002159 abnormal effect Effects 0.000 claims description 14
- 230000005856 abnormality Effects 0.000 claims description 11
- 230000006870 function Effects 0.000 claims description 11
- 230000008859 change Effects 0.000 claims description 5
- 230000007704 transition Effects 0.000 claims description 5
- 230000008569 process Effects 0.000 description 48
- 238000007726 management method Methods 0.000 description 33
- 238000012545 processing Methods 0.000 description 32
- 238000004364 calculation method Methods 0.000 description 25
- 230000007423 decrease Effects 0.000 description 15
- 238000010586 diagram Methods 0.000 description 14
- 238000012217 deletion Methods 0.000 description 11
- 230000037430 deletion Effects 0.000 description 11
- 206010000117 Abnormal behaviour Diseases 0.000 description 9
- 230000006399 behavior Effects 0.000 description 9
- 238000012544 monitoring process Methods 0.000 description 9
- 238000012549 training Methods 0.000 description 9
- 230000006866 deterioration Effects 0.000 description 6
- 238000003384 imaging method Methods 0.000 description 6
- 230000000694 effects Effects 0.000 description 5
- 230000003920 cognitive function Effects 0.000 description 4
- 239000000284 extract Substances 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 230000036544 posture Effects 0.000 description 4
- 230000003203 everyday effect Effects 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000005315 distribution function Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 238000010079 rubber tapping Methods 0.000 description 1
- 238000013179 statistical model Methods 0.000 description 1
Images














Landscapes
- Image Analysis (AREA)
Description
本発明は、学習型の認識における情報処理技術に関する。 The present invention relates to information processing technology in learning type recognition.
学習型の認識装置において、稼働時に得られたデータを追加学習することによって、設置された環境に固有のパターンにおける認識精度を高める、いわゆるドメイン適応の手法が知られている。
近年は追加学習の効果を高めるため、不適切な教師データが混入しないよう選別する方法が提案されている。例えば特許文献1には、入力データを教師データとして採用するかどうかを、それまでに収集した教師データが持つ形態素の構成に合致しているかどうかで判断する手法が提案されている。また、特許文献2には、追加学習データの評価値の推移に基づいて過学習かどうかを判定して、過学習の場合は学習しなおす手法が提案されている。
In a learning type recognition device, a so-called domain adaptation method is known in which the recognition accuracy for patterns specific to the installed environment is increased by additionally learning data obtained during operation.
In recent years, in order to increase the effectiveness of additional learning, methods have been proposed to screen out inappropriate teaching data to prevent it from being mixed in. For example,
しかし、前述の特許文献に記載の手法は、教師データの選別や過学習時のやり直し等を行ったとしても、不適切な学習データの混入や過学習の発生を確実に防ぐことが困難である。特に長期間の運用がなされる場合において、不適切な追加学習による認識精度の低下が、一切生じないようにすることは現実的でない。また、このような認識精度の低下による影響は、すぐに顕在化するとは限らない。認識精度の低下は、誤認識あるいは未認識が問題となったことではじめて認知されることになる。そして、認識精度の低下による影響が表れた場合に、その認識精度の低下の原因が、どのような追加学習にあったのかを分析することは容易ではない。このため、認識精度が低下してしまう不適切な追加学習の影響を、適切に排除可能にすることが望まれる。 However, with the method described in the above-mentioned patent document, it is difficult to reliably prevent the mixing of inappropriate training data and the occurrence of overfitting, even if the training data is selected and reworked in case of overfitting. . Particularly in the case of long-term operation, it is not realistic to ensure that there is no reduction in recognition accuracy due to inappropriate additional learning. Further, the effects of such a decrease in recognition accuracy do not necessarily become apparent immediately. A decline in recognition accuracy becomes noticeable only when erroneous recognition or non-recognition becomes a problem. When the influence of a decrease in recognition accuracy appears, it is not easy to analyze what kind of additional learning was the cause of the decrease in recognition accuracy. Therefore, it is desirable to be able to appropriately eliminate the influence of inappropriate additional learning that reduces recognition accuracy.
そこで、本発明は、認識精度を低下させる追加学習の影響を適切に排除可能とし、認識精度の低下を抑えることを目的とする。 Therefore, an object of the present invention is to make it possible to appropriately eliminate the influence of additional learning that reduces recognition accuracy, and to suppress the reduction in recognition accuracy.
本発明の情報処理装置は、モデルに基づいて、画像から特徴を認識する認識手段と、前記モデルの追加学習を行う学習手段と、前記モデルの追加学習の履歴の情報を管理する管理手段と、前記モデルによる前記認識の精度を評価する評価手段と、前記履歴の情報が管理されているモデルのなかから、前記認識の精度に基づいてモデルを選択する選択手段と、を有し、前記評価手段は、認識対象の情報の集合を記録した評価セットを保持し、前記選択手段は、前記評価セットから前記認識対象の情報を抽出した部分集合によって精度を評価した結果に基づいて、追加学習されたモデルを選択し、前記認識手段は、前記選択手段が選択したモデルを前記認識に用いることを特徴とする。 The information processing device of the present invention includes a recognition unit that recognizes features from an image based on a model, a learning unit that performs additional learning of the model, and a management unit that manages information on the history of additional learning of the model. The evaluation means includes an evaluation means for evaluating the accuracy of the recognition by the model, and a selection means for selecting a model from among the models whose history information is managed based on the accuracy of the recognition, and the evaluation means maintains an evaluation set that records a set of information to be recognized, and the selection means performs additional learning based on the result of evaluating accuracy using a subset of information to be recognized from the evaluation set. A model is selected, and the recognition means uses the model selected by the selection means for the recognition.
本発明によれば、認識精度を低下させる追加学習の影響を適切に排除可能とし、認識精度の低下を抑えることが可能となる。 According to the present invention, it is possible to appropriately eliminate the influence of additional learning that reduces recognition accuracy, and it is possible to suppress a reduction in recognition accuracy.
以下、添付の図面を参照して、本発明の実施形態について詳細に説明する。なお、以下の実施形態において示す構成は一例に過ぎず、本発明は図示された構成に限定されるものではない。
<第1の実施形態>
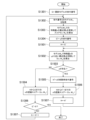
図1は第1の実施形態に係る情報処理装置の概略的な構成例を示した図である。
本実施形態の情報処理装置は、撮影部101、特徴量算出部102、認識部103、学習部104、記憶部105、管理部106、評価部107、選択部108、表示部109、及び操作部110を有する。
Hereinafter, embodiments of the present invention will be described in detail with reference to the accompanying drawings. Note that the configurations shown in the following embodiments are merely examples, and the present invention is not limited to the illustrated configurations.
<First embodiment>
FIG. 1 is a diagram showing a schematic configuration example of an information processing apparatus according to a first embodiment.
The information processing device of this embodiment includes a
撮影部101は、レンズ、撮像素子、レンズ駆動用モータ、および、撮像素子とレンズ駆動用モータを制御するMPU等を有して構成されたカメラ装置である。撮影部101は、例えば動画を撮影し、その動画のデータを出力する。
特徴量算出部102は、MPU等によって構成されている。特徴量算出部102は、撮影部101が撮影した動画に含まれる画像から特徴量を算出する。
The photographing
The feature
認識部103は、MPU等によって構成されている。認識部103は、特徴量算出部102が算出した特徴量を基に、動画の画像内に出現した対象物体を認識する。詳細は後述するが、認識部103は、特徴量算出部102が算出した特徴量について、後述の選択部108によって選択された統計モデルを基に、画像内の対象物体の認識に用いる認識スコアを算出する。そして、認識部103は、撮影された動画内で認識した対象物体について、異常な動作を行った対象物体を認識する。なお、本実施形態の場合、認識部103は、対象物体として人物を認識し、更にそれら人物のなかで異常な行動をとった人物を認識する。
The
学習部104は、MPU等によって構成されている。学習部104は、認識部103が用いるモデルに、教師データから特徴量算出部102が算出した特徴量を追加して再学習することにより、教師データの特徴を追加的に学習したモデルを作成する。
The
記憶部105は、ハードディスクなどの記録メディア、およびMPU等によって構成されている。記憶部105は、撮影部101が撮影した動画のデータ、特徴量算出部102が算出した特徴量、認識部103が認識を行った結果の情報、学習部104が作成したモデル、これらの関係を表現する情報、および作成時刻情報などのメタデータを保存する。なお、記憶部105は、記録メディアの代わりに、NAS(Network Attached Storage)、SAN(Storage Area Network)、クラウドサービスなどのネットワーク上のストレージを用いてもよい。
The
管理部106は、MPU等によって構成されている。管理部106は、学習部104で作成されたモデル、モデルの作成日時、学習に用いた教師データ、および認識部103での使用状況などの各情報を合わせて記録し、学習されたモデルの履歴を管理する。管理部106が管理する情報の詳細は後述する。
評価部107は、MPU等によって構成されている。評価部107は、指定されたモデルについて性能を評価する。性能評価の詳細は後述する。
選択部108は、MPU等によって構成されている。選択部108は、管理部106によって管理されているモデルのなかから、評価部107の評価結果などに基づいて、認識部103が使用するモデルを選択する。モデル選択の詳細は後述する。
The
The
The
表示部109は、液晶画面とこれを制御するMPU等によって構成されている。表示部109は、利用者に様々な情報を提示する。また、表示部109は、利用者が指示を入力する際に用いられるユーザーインターフェース(UI)画面を作成して表示する。UI画面の詳細は後述する。
操作部110は、スイッチとタッチパネル等を有して構成されている。操作部110は、利用者による操作を感知して情報処理装置に入力する。なお、操作部110は、タッチパネルの代わりにマウスやトラックボールなど他のポインティングデバイスを有していてもよい。
The
The
なお、本実施形態では、撮影された動画から対象物体としての人物の異常行動を認識する装置を例に挙げて説明しているが、認識の対象はこれに限らない。認識の対象は、例えば、特定の人物、特定の車両、又は特定の車種などであってもよいし、イベントや時間帯などであってもよい。また認識の対象は、動画の他に、音声、文書、さらにはそれらの組み合わせでもよい。 Note that although the present embodiment has been described using as an example a device that recognizes abnormal behavior of a person as a target object from a captured video, the recognition target is not limited to this. The recognition target may be, for example, a specific person, a specific vehicle, or a specific car model, or may be an event, a time period, or the like. In addition to moving images, the recognition target may also be audio, documents, or a combination thereof.
図2(A)~図2(D)は、本実施形態における表示部109の動作および利用者の操作の一例の説明に用いる図である。図2(A)の映像201、図2(B)の映像204、図2(C)の映像207、及び、図2(D)の映像211は、撮影部101で撮影した動画が表示部109の画面に表示された映像例を示している。
FIGS. 2(A) to 2(D) are diagrams used to explain an example of the operation of the
図2(A)の映像201は通常可動時の動画の映像例を示している。撮影部101は監視カメラとして監視対象箇所に設置されている。表示部109は、その撮影部101が撮影している動画をライブ映像として表示している。利用者は、表示部109に表示されているライブ映像を見て、監視対象箇所に異常が発生していないかどうかを監視している。認識部103は、監視対象箇所に人物が出現した場合に、その出現した人物を認識して表示部109に通知する。表示部109は、その人物の映像に、所定のオブジェクト(例えば人物を内接する矩形オブジェクト)を重畳してライブ映像上に表示する。図2(A)の映像201は、監視対象箇所の動画から認識された人物に対して矩形オブジェクト202,203が重畳表示された例を示している。
An
また表示部109は、映像201の画面上にタイムバー209を表示する。タイムバー209は、操作部110を介して利用者による操作が可能となされている。そして、タイムバー209は、記憶部105に記憶された動画の撮影時間と対応付けられている。例えば利用者は、ライブ映像について例えば過去に表示された映像を見たい場合などに、操作部110を介してタイムバー209を操作することにより、過去の映像の表示を指示することができる。表示部109は、操作部110からタイムバー209が操作されたことの通知を受けると、記憶部105から、タイムバー209の操作位置に応じた撮影時間の動画データを読み出して、その撮影時間の映像を画面上に表示する。
The
また認識部103は、前述したように監視対象箇所に出現した人物の認識処理に加え、その人物における異常な行動を認識する処理も行う。図2(B)の映像204は、人物の異常な行動の一例として、人物205が転倒した場合の映像例を示している。認識部103は、人物205が転倒した場合、通常の歩行とは異なる異常が発生したことを認識して表示部109に通知する。表示部109は、認識部103から人物205において異常が発生したことの通知を受けると、その人物205の近傍に、人物の行動に異常が発生したことを表す警報オブジェクト206を表示する。これにより、利用者は、異常が発生したことを認識可能となり、その異常の状態を確認して必要な措置(例えば転倒者の救護などの必要な措置)をとることが可能となる。なお、図2(B)の例では警報オブジェクト206を画面上に表示したが、警報は、画面上の表示によるものに限らず、例えば警報音の発生でもよいし、利用者や警備員の端末にメールやショートメッセージを送信するようなものでもよい。
Furthermore, the
認識部103は、前述したように人物の異常な行動を認識可能であるが、例えば、正常に歩行している人物について、異常な行動がとったと誤認識してしまう場合があり得る。図2(C)の映像207は、人物が正常に歩行しているのに、異常な行動が発生したと認識部103が誤認識したことにより、画面上に警報オブジェクト208が表示された例を示している。このときの利用者は、画面上の映像を見ることで、警報が誤った警報(つまり誤報)であるかどうかを判断することになる。
Although the
ここで、利用者によりタイムバー209が操作されて過去の撮影時間を選択する指示がなされた上で、さらに利用者によって警報オブジェクト208の表示箇所に対する選択指示がなされたとする。なお、警報オブジェクト208の表示箇所に対する利用者の選択指示は、一例として警報オブジェクト208の位置を例えばタップするような操作であるとする。これらの選択指示がなされた場合、認識部103は、警報オブジェクト208による警報が誤報であると利用者が判断したと認識して、表示部109に通知する。このときの表示部109は、画面上に警報取り消し用のダイアログボックス210を表示する。当該ダイアログボックス210には、例えば「取り消しますか?」のメッセージ、及び「OK」と「キャンセル」のボタンが含まれる。「OK」ボタンは、利用者が警報取り消しを指示する際にタップ等されるボタンである。「キャンセル」ボタンは、利用者が警報取り消しを指示しない場合にタップ等されるボタンである。そして、表示部109は、例えば「OK]のボタンを利用者が選択した旨の情報を操作部110から受け取ると、警報の取り消しを利用者が指示したと判断して、警報オブジェクト208を画面から消す。そして、管理部106は、取り消された誤報に関する情報を記憶部105に保存させる。なお、取り消された誤報に関する情報は、認識部103が異常な行動であると認識した人物の画像領域の特徴量、撮影時間、およびタイムバー209の操作で利用者により選択された過去の撮影時間の情報などを含む。詳細は後述するが、記憶部105に保存された誤報に関する情報は、評価部107がモデルの性能を評価する際に使用される。
Here, it is assumed that the user operates the
また前述したような監視の運用が行われている間、情報処理装置の学習部104は、バックグランド処理として、認識部103による認識結果に対する追加学習を行う。学習部104は、前述のように映像中に出現した各人物に対して認識部103が行った認識結果、人物の撮影時間、人物の画像領域、および特徴量算出部102が取得した特徴量などの情報を、人物に関する情報として記憶部105に蓄積させる。さらに、学習部104は、例えば1日ごとに、記憶部105に蓄積した情報を教師データとして追加学習を行う。そして、認識部103は、その学習によるモデルを、監視対象箇所での人物の認識処理および異常行動の認識処理に用いる。これにより、認識部103における認識精度の向上が図られている。また、認識部103における認識精度が保たれている限り、利用者はそのことを意識する必要がなく、また表示部109には特に追加学習の情報が表示されることはない。
Further, while the above-described monitoring operation is being performed, the
しかしながら、前述のような追加学習を行ったにもかかわらず、認識精度が向上しない場合や、逆に認識精度が低下してしまうことがあり得る。その原因として、例えば人物の行動が正常であるのに異常行動として誤認識されて誤報が発生し、その誤報を利用者が見逃してしまい、その後、当該誤報に係る認識結果を教師データとして追加学習が行われた場合が考えらえる。その他にも、例えば、監視対象箇所において普段と異なるイベント等が催された場合に、そのイベント時の人物の行動、つまり普段とは異なった行動に係る大量の教師データが追加学習された場合などが考えられる。このような学習結果による品質の低いモデルが認識処理に用いられると、認識部103は、例えば人物の異常行動が多数発生しているのに、それらを異常行動として認識せずに見逃してしまうことがある。そして、このように認識精度が低下してしまうと、情報処理装置による監視の運用が困難になる。したがって、認識精度が低下してしまう不適切な追加学習を、適切に除去可能にしてて認識精度の低下を抑えることが望まれる。本実施形態では、認識精度の低下が発生する前の状態に戻すことで、不適切な追加学習が行われる前の、認識精度が高い状態に戻すようにする。
However, even though the above-described additional learning is performed, the recognition accuracy may not improve or may conversely deteriorate. The cause of this is, for example, when a person's behavior is erroneously recognized as abnormal even though it is normal, resulting in a false alarm, which is overlooked by the user, and then additional learning is performed using the recognition results related to the false alarm as training data. I can think of a case where this was done. In addition, for example, when an event that is different from normal is held at a monitored location, a large amount of training data related to the behavior of the person at the time of the event, that is, the behavior that is different from normal, is additionally learned. is possible. If a low-quality model based on such learning results is used for recognition processing, the
このため、本実施形態の情報処理装置では、評価部107が、追加学習によるモデルについて性能評価を行うようになされている。評価部107は、当該モデルの性能評価の結果、そのモデルを用いた場合に認識機能の性能が低下することを検出した場合、その旨を表示部109に通知する。この通知を受けた表示部109は、認識機能の性能が低下したことを表す情報を表示する。これにより利用者は、認識機能の性能低下が生じたことを認識できる。
Therefore, in the information processing apparatus of this embodiment, the
図2(D)の映像211は、認識機能の性能低下が検出された場合に表示部109が表示する映像例を示している。表示部109は、図2(D)に示すダイアログボックス212を映像211内に表示する。ダイアログボックス212は、利用者に提示するメッセージ、「OK」、「キャンセル」、および「詳細確認」のボタンを含む。利用者に提示されるメッセージは、認識機能の低下が生じたことを表すメッセージと、認識機能の低下が生じる前のモデルの状態に戻すかを問うメッセージとからなる。なお、認識機能の低下が生じる前のモデルは、例えば、認識機能の低下が生じた時点より前で且つ現時点から最も近い日時に記憶部105に保存されたモデルであることが望ましい。
An
ここで本実施形態において、学習部104が学習で作成して記憶部105に保存したモデルは、管理部106により管理されている。また本実施形態において、認識部103が認識処理で使用するモデルは、管理部106が管理しているモデルの中から選択部108によって選択される。評価部107により認識機能の性能低下が検出された場合、選択部108は、管理部106が管理しているモデルの中から、認識機能の低下が生じる前のモデルを、認識機能の低下が生じる前のモデルの状態に戻す際の差し戻し候補のモデルとして選択する。そして、選択部108は、その差し戻し候補のモデルを、表示部109に通知する。表示部109は、その差し戻し候補モデルが記憶部105に保存された日時を基に、図2(D)に示したような、認識機能の低下が生じる前のモデルの状態に戻すことを利用者に問うためのメッセージを生成して表示する。このようなダイアログボックス212が表示されることで、利用者は、モデルの劣化によって認識精度の低下が生じたことと、認識精度が低下する前の差し戻し候補の時点のモデルとを知ることができる。
In this embodiment, the model created by learning by the
そして、例えば利用者がダイアログボックス212の「OK」ボタンをタップ等したことの通知を操作部110から受け取ると、選択部108は、認識部103が用いるモデルとして、差し戻し候補モデルを選択する。これにより、認識部103では、差し戻し候補モデル、つまり認識精度が低下する前のモデルを用いた認識処理が行われることになる。また例えば、利用者が「キャンセル」ボタンをタップ等したことの通知を操作部110から受け取ると、選択部108は、認識部103が用いるモデルとして、現在のモデルを選択する。これにより、認識部103では、現在のモデルを用いた認識処理が行われることになる。また例えば、利用者が「詳細確認」ボタンをタップ等した場合、その通知は操作部110から表示部109に送られる。この時の表示部109は、記憶部105から、差し戻し候補モデルに関する詳細情報を表示する。詳細情報は、利用者が差し戻し候補モデルを選択するか否かを判断する際に必要な情報である。詳細情報は、例えば、差し戻し候補モデルが学習された際の日時情報、このモデルを用いて認識部103が認識処理を行った際の認識結果、および、このモデルの学習時に用いられた人物の画像とその画像領域の特徴量などを含んでいてもよい。
For example, when receiving a notification from the
図3は、前述したような本実施形態の情報処理装置における情報処理の流れを示すフローチャートである。本実施形態の情報処理装置は、撮影部101から動画の1フレームが入力されるごとに、図3のフローチャートの処理を実行する。なお、図3のフローチャートによる処理対象のフレームは、撮影部101からの動画のフレームだけに限定されない。例えば、処理対象のフレームは、以前に取得等した個別の動画ファイルのフレームでもよいし、データベース又はビデオマネジメントシステム(VMS)等に蓄積された動画ファイルから日時の範囲が指定されて取り出された動画のフレームでもよい。また例えば、カメラの映像ストリームを指定して、記憶部105に逐次記録された動画データのフレームでもよい。
FIG. 3 is a flowchart showing the flow of information processing in the information processing apparatus of this embodiment as described above. The information processing apparatus of this embodiment executes the process shown in the flowchart of FIG. 3 every time one frame of a moving image is input from the
まずステップS301において、特徴量算出部102は、撮影部101が現在撮影している動画のフレームから画像の特徴量を抽出する。特徴量算出部102は、フレームの画像から人物の領域を公知の人体検出の手法を用いて検出し、その人体の画像領域ごとにHOG(Histogram Of Gradient)を計算して実数値ベクトルを得ることによって特徴量を取得する。なお、特徴量の抽出方法はこれに限るものではない。
First, in step S301, the feature
次にステップS302において、認識部103は、ステップS301で人物ごとに取得された特徴量のそれぞれについて、選択部108によって選択されているモデルを用いた認識処理を行って認識スコアを取得する。本実施形態の場合、モデルは混合ガウス分布モデルを用いる。認識部103は、混合ガウス分布モデルにおける分布関数に特徴量の値を代入して得られる値を認識スコアとして取得する。例えば、認識部103は、モデルMを用いた際の特徴量xの認識スコアS(x;M)を以下の式(1)により算出する。
Next, in step S302, the

式(1)中のKは混合数、N(x;μ,σ)は平均μおよび分散共分散行列σの多変量ガウス分布(正規分布)でのxの値、ωiはモデルMのi番目の分布の重み、μiはモデルMのi番目の分布の平均、σiはモデルMのi番目の分布の分散共分散行列である。重みは正の実数値を取り、ω1からωKの総計は1である。認識スコアの値域は[0,1]の範囲の実数値であり、1に近いほど正常を表し、0に近いほど異常を表す。なおこの例に限らず、モデルは、例えばニューラルネットワークモデルや最近傍モデルでもよい。最近傍モデルについては後述する第3の実施形態において説明する。 In equation (1), K is the number of mixtures, N(x; μ, σ) is the value of x in a multivariate Gaussian distribution (normal distribution) with mean μ and variance-covariance matrix σ, and ω i is i of model M. The weight of the ith distribution, μ i is the mean of the ith distribution of model M, and σ i is the variance-covariance matrix of the ith distribution of model M. The weights take positive real values, and the sum of ω1 to ωK is 1. The range of the recognition score is a real value in the range [0, 1], where the closer it is to 1, the more normal it is, and the closer it is to 0, the more abnormal it is. Note that the model is not limited to this example, and the model may be, for example, a neural network model or a nearest neighbor model. The nearest neighbor model will be explained in the third embodiment described later.
次にステップS303において、認識部103は、ステップS302で算出した認識スコアに基づいた処理を行う。認識部103は、認識スコアが所定の閾値よりも低い場合に人物の行動が異常行動であると判定する。そして、表示部109は、図2(B)の映像204に示したような警報オブジェクト206を表示する。
次に、ステップS304において、記憶部105は、ステップS301で抽出された特徴量の情報を保存する。
Next, in step S303, the
Next, in step S304, the
次にステップS305において、学習部104は、追加学習を実行する条件が満たされたかどうかを判定する。学習部104は、条件が満たされていると判定した場合にはステップS306に処理を進める。一方、ステップS305において、条件が満たされていないと判定した場合、情報処理装置は、図3のフローチャートの処理を終了する。本実施形態において、追加学習を実行する条件は、図3のフローチャートの処理が例えば当日の0時を過ぎて初めて実行されたかどうかである。すなわち追加学習は、当日の0時を過ぎて初めて図3のフローチャートの処理が実行されたという条件が満たされた場合に限って実行される。これにより、追加学習は、毎日1回ずつ、その日に得られた特徴量を用いて行われることになる。
Next, in step S305, the
追加学習を実行する条件は前述した条件に限らない。例えば、追加学習の実行条件としての期間は、1日ごとだけでなく、半日ごとであってもよいし、1週間ごとであってもよい。また追加学習の実行条件は、ステップS304で保存された特徴量が所定個数以上蓄積されたタイミングであってもよい。所定個数が例えば1000個である場合、学習部104は、ステップS304で保存された特徴量が1000個以上蓄積されたタイミングごとに追加学習を実行する。また追加学習の実行条件は、例えば特徴量が得られた時点であってもよい。この場合、学習部104は、特徴量が得られるたびに常に追加学習を実行する。また追加学習の実行条件は、利用者が指示したタイミングであってもよい。さらに追加学習の実行条件は、前述した各条件の二つ以上を組み合わせた条件であってもよい。
The conditions for performing additional learning are not limited to the conditions described above. For example, the period as a condition for performing additional learning may be not only every day, but also every half day, or every week. Further, the execution condition for additional learning may be the timing at which a predetermined number or more of the feature amounts saved in step S304 are accumulated. If the predetermined number is, for example, 1000, the
次にステップS306において、学習部104は、選択部108によって選択されているモデルについて、記憶部105に記憶された特徴量を用いて、EMアルゴリズムによる追加学習を行う。
次にステップS307において、評価部107は、認識部103が認識する認識対象の集合を、性能評価に用いる評価セットとして作成して保持する。評価セットは、特徴量の集合、特徴量ごとの正解ラベル、および、その特徴量を重視する度合いである重みの情報を含む。評価セットの作成方法は後述する。
次にステップS308において、評価部107は、ステップS307において作成した評価セットに基づき、選択部108によって選択されているモデルが劣化しているかどうかを判定する。
このときの評価部107は、ステップS307で作成した評価セットに含まれる特徴量を認識部103で認識した時の認識スコアを、追加学習の前後のモデルでそれぞれ算出して、重み付き平均を取る。モデルMの性能値S(M)は、以下の式(2)で算出する。
Next, in step S306, the
Next, in step S307, the
Next, in step S308, the
At this time, the

式(2)中のTは評価セットの特徴量集合であり、#TはTの要素数である。wxは特徴量xの重みである。pxはxの正解ラベルが正常ならば+1、異常ならば-1である。すなわちモデルの性能値S(M)は、人物の行動が正常で高く、異常で低いスコアを算出するほど大きくなる。例えば、追加学習後のモデルの性能値が、追加学習前のモデルの性能値の0.98倍未満であった場合、評価部107は、モデルが劣化したと判定し、そうでない場合は劣化していないと判定する。なお、本実施形態の場合、追加学習におけるぶれを吸収するために2%程度性能値が下がっても劣化としないこととしているが、これは1.00倍など他の数値でもよい。また、モデルの性能値は、追加学習の進行度合いに応じて変えてもよく、追加学習の履歴が少ない場合はより性能の向上が見込めるため1.02倍とし、履歴が十分に蓄積した後は0.98倍にするなどしてもよい。また、モデルの劣化判定は、これらの例に限らず、モデルの性能値の差によって行ってもよい。また、比較対象は、追加学習前のモデルの性能値ではなく、モデルの履歴で最大の性能値を示すモデルなどにしてもよい。
T in equation (2) is a feature set of the evaluation set, and #T is the number of elements of T. w x is the weight of the feature x. p x is +1 if the correct label of x is normal, and -1 if it is abnormal. That is, the performance value S(M) of the model increases as the score is higher when the person's behavior is normal and lower when the behavior of the person is abnormal. For example, if the performance value of the model after additional learning is less than 0.98 times the performance value of the model before additional learning, the
次にステップS320において、評価部107は、ステップS308での判定結果が劣化かそうでないかを判定し、劣化していると判定していた場合はステップS309に進み、そうでなければステップS313に進む。
ステップS320において劣化していなかったと判定された場合、ステップS313において、管理部106は、ステップS306で追加学習されたモデルをモデル履歴に追加する。そして次のステップS314において、選択部108は、ステップS313において追加されたモデルを現在のモデルとして選択する。このステップ314の後、情報処理装置は、図3のフローチャートの処理を終了する。
Next, in step S320, the
If it is determined in step S320 that there has been no deterioration, in step S313, the
図4は、管理部106が管理するモデル履歴データの模式的に示した図である。
図4に示すように、モデル履歴データは、モデル情報レコードの列からなる。モデル情報レコードは、モデルID、モデルデータ、元モデルID、教師データ、および追加学習日時を含む。
モデルIDはモデル情報レコードを識別する通し番号である。
モデルデータは、図4では図示を省略しているが、認識部103が用いるモデルの本体であり、例えばバイナリやXMLといった形式で格納される。
元モデルIDは、学習部104が追加学習を行う際に元となったモデルのモデルIDである。モデルIDは、出荷時に格納されたモデル、初期設定において作成されたモデルなど、元になったモデルがない場合には「なし」となる。
教師データは、学習部104が追加学習を行う際に用いられた教師データの情報である。教師データは、記憶部105に格納された特徴量であり、モデル情報レコードではファイル名やinode番号などの参照情報の集合を持つ。元になったモデルがない場合、教師データは「なし」となる。
追加学習日時は、学習部104が追加学習を行った日時である。
FIG. 4 is a diagram schematically showing model history data managed by the
As shown in FIG. 4, the model history data consists of a string of model information records. The model information record includes a model ID, model data, original model ID, teacher data, and additional learning date and time.
The model ID is a serial number that identifies the model information record.
Although not shown in FIG. 4, the model data is the main body of the model used by the
The original model ID is the model ID of the model that is the source when the
The teacher data is information on teacher data used when the
The additional learning date and time is the date and time when the
選択部108は、これらのモデル情報レコードのうち1つを、認識部103が用いるモデルとして選択する。
なお、ステップS308において、追加学習したモデルが劣化していないと判定される限りにおいて、管理部106はモデル履歴に追加学習したモデルを追加し、選択部108は追加されたモデルを選択することを続けることになる。すなわち、最新の追加学習が行われたモデルが、認識部103において使用され続ける。
The
Note that as long as it is determined in step S308 that the additionally learned model has not deteriorated, the
一方、ステップS320において、追加学習したモデルが劣化していると評価部107が判定してステップS309に進むと、選択部108は、管理部106が管理しているモデルの中から、差し戻し候補モデルを探索する。差し戻し候補モデルの探索方法は後述する。
On the other hand, in step S320, when the
次にステップS310において、表示部109は、ステップS308において探索した差し戻し候補モデルの情報を表示することで、利用者に確認を促す。このときの利用者は、表示された差し戻し候補モデルに戻すかどうかを判断し、その判断の結果を、操作部110を介して入力する。
Next, in step S310, the
次にステップS311において、選択部108は、ステップS310で提示した差し戻し候補モデルに戻すことの指示が利用者から入力されたかどうかを判定する。そして、差し戻し候補モデルに戻すことの指示が入力された場合、選択部108は、ステップS312において、その差し戻し候補モデルを、認識部103が使用するモデルとして選択する。
Next, in step S311, the
一方、ステップS311において差し戻し候補モデルに戻さないことの指示が利用者から入力された場合、本実施形態の情報処理装置は図3のフローチャートの処理を終了する。この場合、ステップS306で追加学習を行う以前に選択されていたモデルが、認識部103でそのまま使用される。そして、差し戻し候補モデルをそのまま使うことで、その差し戻し候補モデルが得られた時点の状態に戻ることが保証される。なお、差し戻し候補モデルをそのまま使うのではなく、差し戻し候補モデルに対して、差し戻しの指示が入力された時点以降に行われた追加学習をやり直すようにしてもよい。すなわち、差し戻し候補モデルに戻してそのまま使用する場合、モデル履歴をそのまま辿って先ほどステップS306で作られたモデルと同じになってしまう。このため、学習部104は、例えば特許文献1に記載の手法などを用いて教師データの再選別を行ってから追加学習をやり直す。これにより、差し戻しの指示が入力された時点以降に得られた教師データを活用することができることになる。追加学習をやり直すか、差し戻し候補モデルをそのまま使うかは、利用者の操作によって決めるようにしてもよい。
On the other hand, if the user inputs an instruction not to return to the remand candidate model in step S311, the information processing apparatus of this embodiment ends the process of the flowchart of FIG. 3. In this case, the model selected before performing additional learning in step S306 is used as is by the
図5は、ステップS307において評価部107が性能評価に用いるための評価セットを作成する処理の流れを示すフローチャートである。
評価部107は、一般的な人物画像から作られた初期評価セットを出荷時に保持している。評価部107は、この初期評価セットを監視対象箇所へ適応させるために、運用時に得られた情報を用いて随時更新することによって、評価セットを作成する。
FIG. 5 is a flowchart showing the flow of processing in which the
The
図6は、評価セットの一例を示した図である。図6に示すように、評価セットは、評価データレコードの列からなる。評価データレコードは、評価データID、特徴量、重み、正解ラベル、およびスコア履歴を含む。評価IDは評価データレコードを識別する通し番号である。重みは、評価データとしての特徴量の重要度を示し、性能値S(M)の計算に用いる。正解ラベルは、特徴量が示す特徴の正解の情報であり、「正常」または「異常」を示す情報となされる。スコア履歴は、モデルIDとスコアの値のペアの列から成り、モデルIDに対応するモデルを用いて認識部103が特徴量を認識した際のスコアの記録を含む。スコア履歴の内容は後述する図7のステップS702において作られる。
FIG. 6 is a diagram showing an example of an evaluation set. As shown in FIG. 6, the evaluation set consists of a column of evaluation data records. The evaluation data record includes an evaluation data ID, a feature amount, a weight, a correct label, and a score history. The evaluation ID is a serial number that identifies the evaluation data record. The weight indicates the importance of the feature amount as evaluation data, and is used to calculate the performance value S(M). The correct label is information on the correct answer for the feature indicated by the feature amount, and is information indicating "normal" or "abnormal". The score history is made up of a string of pairs of model IDs and score values, and includes records of scores when the
図5のフローチャートのステップS501において、評価部107は、まず優先評価データを決定して取得する。優先評価データは、記憶部105に記憶された特徴量のうち、利用者が操作部110を用いて警報の取り消しを行ったことがある特徴量の集合である。これらの特徴量は、異常という誤報が発生した上で、利用者が直接正常であると判断して指示した特徴量であるから、利用者にとっての正常度が高く、かつ誤報が発生した経緯があることから間違えやすい特徴量であるため、重要な特徴量であると推定される。
In step S501 of the flowchart of FIG. 5, the
次にステップS502において、評価部107は、優先評価データのいずれかに類似した特徴量を、記憶部105に含まれる特徴量から検索する。特徴量の類似度の算出方法は限定しないが、例えば内積を使用することができる。優先評価データの量は一般に少量であるから、評価の正確性を保つため、優先評価データに類似した性質のデータを追加することによって、評価セットが偏らないようにする。なお、評価部107は、特徴量の類似度を直接判断する代わりに、画像から類似性を判断してもよい。例えば、評価部107は、人体の姿勢を推定して、同じような姿勢を取っているかどうかを人体パーツの配置から判断してもよい。また、評価部107は、例えば、一般物体認識を行って同じカテゴリに属せば類似していると判断してもよい。
Next, in step S502, the
次にステップS503において、評価部107は、ステップS501とステップS502で得られた類似データを評価セットに追加する。また、優先評価データの重みは例えば10など大きい値とし、類似データの重みは例えば2など優先評価データよりも低い値とする。なお、初期評価セットに含まれるデータの重みは例えば1などさらに低い値になされてもよい。
Next, in step S503, the
次にステップS504において、評価部107は、評価セットに含まれるデータから、類似したスコア履歴のデータを削減する。つまり、評価セットにデータを追加し続けるとデータ量が肥大化するため、評価部107は、スコア履歴の類似度を用いて重複性の高いデータの削減を行う。
Next, in step S504, the
ここで、モデル履歴の評価の過程で得られたスコア履歴の推移が類似している2つのデータは、異なるモデルにおいても似たようなスコア変化の挙動を示してきていることになる。したがって、これらのデータは、以降の追加学習で作られたモデルでも似たようなスコアを出し続けることが推定される。すなわち、これらのデータは、モデルの評価という目的においては重複性の強いデータであると考えられる。2つのスコア履歴の類似度は、例えば同一モデルIDのスコア間の差の絶対値についての2乗平均の値などとして定める。評価部107は、類似度が例えば0.01以下であれば類似しているものとして片方を削除する。例えば評価部107は、重みが異なる場合は重みの小さい方を削除し、重みが同じ場合はランダムに決めた方を削除する。すなわち評価部107は、類似している少なくとも一つを用いる。なお、評価部107は、例えば評価セットが500個以下など十分に小さい場合、あるいはモデル履歴が10個以下など類似度を信頼できるほど履歴が蓄積していない場合などでは、ステップS504の削除処理を行わないようにしてもよい。
Here, two pieces of data that have similar score history transitions obtained in the process of model history evaluation show similar score change behavior even in different models. Therefore, it is presumed that these data will continue to produce similar scores even with subsequent models created through additional learning. In other words, these data are considered to have strong redundancy for the purpose of model evaluation. The degree of similarity between two score histories is determined, for example, as the root mean square value of the absolute value of the difference between the scores of the same model ID. If the degree of similarity is, for example, 0.01 or less, the
評価部107は、以上のようにして、評価セットを作成する。図3のステップS308における劣化の判定は、この評価セットに基づいて行われる。またステップS309における差し戻し候補モデルの探索処理は、この評価セットに基づいて行われる。
The
図7は、図3のステップS309において選択部108がモデル履歴から差し戻し候補のモデルを探索する処理の流れを示したフローチャートである。
まずステップS701において、選択部108は、ステップS307で作成した評価セットについて、モデル履歴に含まれるそれぞれのモデルを基に性能値S(M)を計算する。
次にステップS702において、評価部107は、ステップS701における性能値のS(M)の計算過程において計算された、それぞれの評価データについての認識スコアを、評価データレコードのスコア履歴に追加する。
FIG. 7 is a flowchart showing the flow of processing in which the
First, in step S701, the
Next, in step S702, the
次にステップS703において、選択部108は、ステップS701で計算した性能値の値から、性能値が極大となるモデルの候補を探索する。性能値が極大となるモデルは、モデル履歴の中で最も性能値の高いモデルMmaxをまず探索する。次いで選択部108は、そのモデルMmaxの性能値S(Mmax)との差が、所定の閾値より小さいモデルがあれば、それらも極大候補モデルとして選び出す。ただし、選択部108は、モデルMmaxが最初のモデル、すなわち追加学習を一度も行っていない初期モデルだった場合、追加学習がまったく効果がなかったことになるため、極大モデルの候補がないものとして、初期モデルの再作成を促す。
Next, in step S703, the
図8(A)~図8(C)は性能値の推移の例を示した図である。
例えば図8(A)に示すように、最も性能値の高いモデルMmaxの性能値S(Mmax)が高く、それに近い性能値のモデルがモデル履歴にない場合、選択部108は、モデルMmaxをそのまま選択する。
例えば図8(B)に示すように、モデルMmaxの性能値S(Mmax)に近い性能値のモデルが、例えば点線804で示す枠内のように複数存在した場合にはモデルMmaxを単純に選択することが有効であるとは自明には言えない。このため、表示部109は、性能値の推移の変化を利用者に提示する。
例えば図8(C)に示すように、モデルMmaxが初期モデルである場合は、そもそも追加学習の効果が一切現れていない。この場合、初期モデルに何らかの異常がある可能性が考えられる。
FIGS. 8(A) to 8(C) are diagrams showing examples of changes in performance values.
For example, as shown in FIG. 8A, when the performance value S (M max ) of the model M max with the highest performance value is high and there is no model with a performance value close to it in the model history, the
For example, as shown in FIG. 8(B), if there are multiple models with performance values close to the performance value S (M max ) of the model M max as shown in the frame indicated by the dotted
For example, as shown in FIG. 8(C), if the model M max is an initial model, no effect of additional learning has appeared in the first place. In this case, there may be some abnormality in the initial model.
図7のフローチャートの説明に戻り、ステップS704において、選択部108は、性能値が極大となる候補のモデルの数を判定する。選択部108は、性能値が極大となる候補のモデル数が1の場合には、ステップS705において、その極大のモデルを選択候補モデルとしてそのまま選んで処理を終了する。一方、選択部108は、性能値が極大となる候補のモデル数が0個、すなわちモデルMmaxが初期モデルだった場合には、表示部109が実行するステップS706に処理を進める。また選択部108は、性能値が極大となる候補のモデルが複数あった場合には、表示部109が実行するステップ709に処理を進める。
Returning to the explanation of the flowchart in FIG. 7, in step S704, the
ステップS706に進むと、表示部109は、利用者にモデルの再作成を促すためのダイアログを表示する。そして次のステップS707において、選択部108は、利用者が操作部110を介してモデルの再作成を指示したか、あるいは、初期モデルに差し戻すことを指示したかを判定する。選択部108は、利用者の指示を基にモデルの再作成が行われた場合にはステップ708の処理に進み、再生成が行われていない場合つまり初期モデルへの差し戻しが指示された場合にはステップS705の処理に進む。
Proceeding to step S706, the
選択部108は、ステップS707においてモデルの再作成が行われたと判定してステップS708に進むと、その再作成されたモデルを選択候補モデルとして処理を終了する。一方、選択部108は、再作成が行われず、初期モデルへ差し戻されてステップS705に進むと、極大のモデルMmaxすなわち初期モデルを選択候補モデルとして処理を終了する。
When the
またステップS704において、性能値が極大となる候補のモデルが複数あってステップS709に進むと、表示部109は、極大候補モデルからの選択画面を表示する。
次にステップS710において、選択部108は、ステップS709で表示された選択画面を介して利用者が選択した極大候補モデルを、選択候補モデルとして処理を終了する。
Further, in step S704, if there are multiple candidate models with maximum performance values and the process proceeds to step S709, the
Next, in step S710, the
図9は、ステップS709において表示部109が表示する極大候補からの選択画面の例を示した図である。
図9の選択画面において、コンボボックス901は、極大候補モデルの作成日時を項目として有する。利用者は、コンボボックス901の作成日時の項目を選択することで、極大候補モデルから1つを選択することができる。サムネイルエリア902および903は、評価セットの中で、現在の認識部103で用いるように選択されているモデルでの認識結果と異なる評価データのサムネイル画像が表示されるエリアである。サムネイルエリア902は、現在のモデルでは異常となるが極大候補モデルでは正常となるデータのサムネイル画像が表示されるエリアである。一方、サムネイルエリア903は、現在のモデルでは正常となるが極大候補モデルでは異常となるデータのサムネイル画像が表示されるエリアである。サムネイルエリア902および903に表示されるサムネイル画像は、コンボボックス901の選択を利用者が操作部110を用いて切り替えることによって変化する。利用者はこれらを見て、どのように結果が変化するかを確認しながらより良いと考えられる極大候補モデルを選択することができる。ボタン904は、利用者がコンボボックス901から選択した作成日時の極大候補モデルを、さらに利用者が選択候補モデルとして決定する際にタップ等されるボタンである。このようにして選択された選択候補モデルは、ステップS310での利用者の確認を経て、差し戻し候補モデルとして以降の認識部103において用いられることになる。
FIG. 9 is a diagram showing an example of a selection screen from maximum candidates displayed on the
In the selection screen of FIG. 9, a
第1の実施形態の情報処理装置は、以上説明したように、追加学習によって認識性能に低下が発生することが判明した時点で、以前の履歴から、精度が高かった時点の状態に差し戻すことができる。すなわち第1の実施形態の情報処理装置は、認識精度を低下させる追加学習を適切に除去可能となり、認識精度の低下を抑えることが可能となる。 As explained above, the information processing device of the first embodiment is capable of reverting to the state at the time when the accuracy was high based on the previous history when it is found that the recognition performance deteriorates due to additional learning. I can do it. That is, the information processing device of the first embodiment can appropriately remove additional learning that lowers recognition accuracy, and can suppress a decrease in recognition accuracy.
<第2の実施形態>
第1の実施形態では、評価セットが作成され、それを使って差し戻し候補モデルが探索される例を説明した。ただし、評価セットをモデル履歴のモデルごとに全て評価する場合、計算量が多くなる可能性がある。
第2の実施形態では、通常運用時の認識結果を再利用してモデルの評価を行う方法を説明する。第2の実施形態の情報処理装置の構成は図1と同様であるため、その図示と説明は省略する。以下、第2の実施形態において、第1の実施形態に対して追加または変更された部分についてのみ説明し、第1の実施形態と共通する部分の説明は省略する。
<Second embodiment>
In the first embodiment, an example has been described in which an evaluation set is created and a remand candidate model is searched for using the evaluation set. However, if the evaluation set is evaluated for each model in the model history, the amount of calculation may increase.
In the second embodiment, a method of evaluating a model by reusing recognition results during normal operation will be described. The configuration of the information processing apparatus of the second embodiment is the same as that in FIG. 1, so illustration and description thereof will be omitted. Hereinafter, in the second embodiment, only the parts added or changed with respect to the first embodiment will be explained, and the explanation of the parts common to the first embodiment will be omitted.
図10は、第2の実施形態の情報処理装置における処理の流れを示すフローチャートである。なお、前述した図3のフローチャートと同様の処理が行われるステップには、図3と同じ参照符号を付してそれらの説明は省略する。図10のフローチャートの処理は、図3と同様に、撮影部101から動画の1フレームの画像データが入力されるごとに実行される。図10のフローチャートの場合、図3のステップS307の処理が省かれている一方で、ステップS305とステップS306との間にステップS1001の処理が加えられている。
FIG. 10 is a flowchart showing the flow of processing in the information processing apparatus of the second embodiment. Note that the steps in which the same processing as in the flowchart of FIG. 3 described above is performed are given the same reference numerals as in FIG. 3, and the description thereof will be omitted. The process in the flowchart of FIG. 10 is executed every time one frame of image data of a moving image is input from the
第2の実施形態の情報処理装置は、ステップS305で追加学習を行う条件が満たされていると判定された場合、ステップS1001の処理に進む。ステップS1001に進むと、評価部107は、現在の認識部103で用いるモデルの性能値を、後述する図11のフローチャートの処理を実行することにより算出する。ステップS1001の処理後、情報処理装置の処理はステップS306に進み、当該ステップS306において前述同様に追加学習が行われる。そして、ステップS306の後、情報処理装置の処理は、ステップS308に進む。
If the information processing apparatus of the second embodiment determines in step S305 that the conditions for performing additional learning are satisfied, the process proceeds to step S1001. Proceeding to step S1001, the
第2の実施形態の場合、図3のステップS307の処理が省かれている。このため、次のステップS308において、評価部107は、第1の実施形態における初期評価セットを常に用いてモデルの劣化判定を行う。なお、第1の実施形態と同様にステップS307を設けて評価セットの更新が行われるようにしてもよいが、その場合、評価セットは本ステップでのみ用いられることになる。
In the case of the second embodiment, the process of step S307 in FIG. 3 is omitted. Therefore, in the next step S308, the
図11は、図10のステップS1001において、評価部107が現在の認識部103で用いているモデルMの性能値S(M)を計算する処理の流れを示すフローチャートである。
まずステップS1101において、評価部107は、ステップS302で認識スコアを計算した特徴量を記憶部105から取得してクラスタリングを行う。ここで、クラスタリングは、認識対象の属性に基づいて特徴量を分類する処理が考えられる。例えば、認識対象が人物である場合、クラスタリングは、人物の属性として、例えば姿勢を検出し、歩いている、走っている、または座っているなどの姿勢カテゴリごとに特徴量を分類する処理が挙げられる。またクラスタリングは、人物の属性として、例えば人物の歩行方向、歩行速度、カメラからの距離、身長、年齢、性別、服装、所持品、または人物密度などの各カテゴリによって特徴量を分類する処理であってもよい。さらにクラスタリングは、それらの各属性のうち、例えば性別と服装、服装と所持品、年齢と性別と歩行速度など、二つ以上の関連性の高い属性の組合せによって特徴量を分類する処理でもよい。その他にも、クラスタリングは、事前知識なしで例えばk平均法などを用いて特徴量を分類する処理であってもよい。
FIG. 11 is a flowchart showing the flow of processing in which the
First, in step S1101, the
次にステップS1102において、評価部107は、ステップS1101でクラスタリングを行ったクラスタから、重要クラスタを決定する。例えば、評価部107は、クラスタのサイズが最も大きいものを選択して重要クラスタに決定する。例えば、走っている人物のクラスタが大きい場合、その監視対象箇所は、走っている人物が多く出現する環境であると考えられる。この場合、重要クラスタの決定は、モデルの評価の基準として、走っている人物を対象として行われることが合理的であると推定される。また、評価に用いる重要クラスタの選び方はこれに限ったものではない。例えば、利用者が、事前知識に基づいて座っている人物が重要であると判断するような場合、評価部107は、座っている人物のクラスタから、重要クラスタを決定する。また重要クラスタは、異常が発生しやすいクラスタが選ばれてもよい。また、これらのクラスタが複数組み合わせされてもよい。
Next, in step S1102, the
次にステップS1103において、評価部107は、ステップS1102で決定した重要クラスタと、そこに含まれる特徴量についてステップS302で計算された認識スコアとを用いて、性能値S(M)を計算する。性能値を計算する際の正解ラベルは、利用者が操作部110を用いて警報の取り消しを行ったことがある特徴量については正常とし、そうでないものは警報が発生したものは異常としそれ以外は正常とする。
Next, in step S1103, the
次にステップS1104において、評価部107は、ステップS1103で計算した現在のモデルの性能値を、モデル履歴レコードに紐づけて記憶部105に記憶する。
第2の実施形態では、以上のようにして、現在の認識部103で用いるモデルの性能値が計算される。
Next, in step S1104, the
In the second embodiment, the performance value of the model currently used by the
本実施形態の情報処理装置の場合、ステップS1001によってモデルの性能値が既に算出されている。このため、第2の実施形態の情報処理装置は、前述した図7のステップS701及びステップS702の処理を省いたフローチャートの処理を行う。すなわち第2の実施形態の場合、図7のステップS701及びステップS702の処理が省かれ、選択部108は、ステップS703からフローチャートの処理を開始し、このステップS703以降の処理を行う。
In the case of the information processing apparatus of this embodiment, the performance value of the model has already been calculated in step S1001. For this reason, the information processing apparatus of the second embodiment performs the processing in the flowchart that omits the processing in step S701 and step S702 in FIG. 7 described above. That is, in the case of the second embodiment, the processing in steps S701 and S702 in FIG. 7 is omitted, and the
このように、第2の実施形態の情報処理装置は、評価セットを用いず、モデルの選択時には重要クラスタでの性能に基づいて選択候補モデルを決定する。重要クラスタを用いた性能の比較は、評価セットを用いるような同一データでの性能比較にはならないものの、クラスタリングによってある程度類似した性質のデータが集まっていると期待される。また重要クラスタの認識スコアは、通常運用時の認識結果であるステップS302で計算したものを用いる。このため、第2の実施形態の情報処理装置は、モデル選択の際に新たに認識部103で計算を行う必要がなく、計算量の制約が強い環境において有用である。
In this manner, the information processing apparatus of the second embodiment does not use an evaluation set, and determines selection candidate models based on performance in important clusters when selecting models. Although comparing performance using important clusters does not compare performance using the same data as using evaluation sets, it is expected that data with somewhat similar properties will be gathered through clustering. Furthermore, the recognition score of the important cluster uses the recognition result calculated in step S302 during normal operation. Therefore, the information processing device of the second embodiment does not require the
なお、第2の実施形態では第1の実施形態で用いていた評価セットをモデル選択において使用しない方法を説明したが、部分的に評価セットを用いる方法でもよい。例えば、情報処理装置は、小規模な評価セットによる性能値を別に求めて、重要クラスタによる性能値を組み合わせたり、評価セットの内容を重要クラスタに類似したものに制限したりするなどの方法でもよい。この場合、評価セットの計算量が軽減可能となる。 Note that although the second embodiment describes a method in which the evaluation set used in the first embodiment is not used in model selection, a method that partially uses the evaluation set may also be used. For example, the information processing device may separately obtain performance values from a small evaluation set and combine the performance values from important clusters, or limit the contents of the evaluation set to those similar to the important clusters. . In this case, the amount of calculation for the evaluation set can be reduced.
<第3の実施形態>
第1の実施形態では、モデルとして混合ガウス分布を例に挙げて説明した。第3の実施形態では、最近傍モデルを用いることによって、モデル履歴の保存容量および差し戻し候補モデルの探索の軽量化を可能とする例について説明する。第3の実施形態の情報処理装置の構成は図1と同様であるため、その図示と説明は省略する。以下、第3の実施形態において、第1の実施形態に対して追加または変更された部分についてのみ説明し、第1の実施形態と共通する部分の説明は省略する。なお、第3の実施形態で説明する手法は、前述した第2の実施形態についても適用可能である。
<Third embodiment>
The first embodiment has been described using a Gaussian mixture distribution as an example of the model. In the third embodiment, an example will be described in which the storage capacity of model history and the search for remand candidate models can be reduced by using a nearest neighbor model. The configuration of the information processing device of the third embodiment is the same as that in FIG. 1, so illustration and description thereof will be omitted. Hereinafter, in the third embodiment, only the parts added or changed with respect to the first embodiment will be explained, and the explanation of the parts common to the first embodiment will be omitted. Note that the method described in the third embodiment is also applicable to the second embodiment described above.
第3の実施形態の場合、モデルは特徴量空間の点の集合である。また第3の実施形態における認識スコアは、特徴量に最も近い点(最近傍)までの距離である。第3の実施形態の場合、モデルMを用いた際の特徴量xの認識スコアS(x;M)は、以下の式(3)により算出する。 In the case of the third embodiment, the model is a set of points in feature space. Furthermore, the recognition score in the third embodiment is the distance to the point closest to the feature amount (nearest neighbor). In the case of the third embodiment, the recognition score S(x;M) of the feature x when using the model M is calculated by the following equation (3).

ここで式(3)のKはモデルの点の数、yiはモデルに含まれる点のベクトル値、d(y,x)はyとxのユークリッド距離である。認識スコアは(0,1]の範囲の実数値を取り、大きいほど正常、小さいほど異常を表す。なお、dの値域は[0,∞)である。ここではスコアとして取り扱うため、dの値域は0から1の範囲を取るよう変形しているが、その方法はここで示したものに限らない。また、dの値域はユークリッド距離に限らず、マンハッタン距離やチェビシェフ距離など擬距離の公理を満たす関係ならばどのような値域であってもよい。また本実施形態の手法は、LSH(Locally-Sensitive Hashing)などの手法を用いてハミング距離で近似する方法でも同様に用いることができる。また第3の実施形態の場合、モデルの点ごとに追加学習の世代番号が、メタデータとして合わせて保持される。初期モデルでは、モデルの点は、すべて世代番号0を持つ。また第3の実施形態において、図3に示したステップS306の追加学習は、正解ラベルが正常である特徴量の点を、モデルに追加することによって行う。世代番号は、ステップS306の実行ごとにインクリメントし、追加学習で追加された点にメタデータとして付与される。
Here, K in equation (3) is the number of points in the model, y i is the vector value of the points included in the model, and d(y, x) is the Euclidean distance between y and x. The recognition score takes a real value in the range of (0, 1), and the larger the score, the more normal it is, and the smaller it is, it is abnormal. Note that the range of d is [0, ∞). Here, since it is handled as a score, the range of d is transformed to take a range from 0 to 1, but the method is not limited to the one shown here. Further, the range of d is not limited to Euclidean distance, but may be any range as long as it satisfies the axiom of pseudo-distance, such as Manhattan distance or Chebyshev distance. Furthermore, the method of this embodiment can be similarly used with a method of approximating using Hamming distance using a method such as LSH (Locally-Sensitive Hashing). Further, in the case of the third embodiment, the generation number of additional learning for each point of the model is also held as metadata. In the initial model, all points in the model have
第3の実施形態における管理部106は、モデル情報レコードにモデルデータを保持せず、代わりに世代番号を保持する。また、管理部106は、最新のモデルに対応する単一のモデルのモデルデータを持ち、他の履歴のモデルデータは最新モデルのモデルデータから再現する。
The
図12は、第3の実施形態における管理部106の履歴管理方法を説明する図である。
図12に示すように、管理部106が管理するモデル履歴データは、モデル情報レコード1201の列からなる。モデル情報レコード1201は、世代番号、元モデルID、教師データ、および追加学習日時を含む。つまり第3の実施形態におけるモデル履歴データは、図4に示したモデル履歴データのモデルデータを含まず、その代わりに、世代番号を含んでいる。
世代番号は、追加学習ごとにインクリメントされる番号である。ただし、世代番号は、履歴の削除や分岐などが発生すればモデルIDと必ずしも一致するとは限らない。
FIG. 12 is a diagram illustrating a history management method of the
As shown in FIG. 12, the model history data managed by the
The generation number is a number that is incremented every time additional learning is performed. However, the generation number does not necessarily match the model ID if the history is deleted or branched.
第3の実施形態の管理部106は、別途、最新モデルのモデルデータ1202を管理する。最新モデルのモデルデータ1202は、モデルの点を表現するベクトル値を含み、それらモデルの点を表現するベクトル値ごとに、メタデータとして世代番号が付与されている。なお図12では、具体的なベクトル値は省略している。同一の世代番号を持つベクトル値の部分集合は、同じ世代番号で追加されたベクトル値の集合を成す。
The
管理部106は、例えば世代番号99のモデルデータを得る場合、最新モデルのモデルデータから、世代番号が99以下のベクトル値のみを抽出する。これにより、初期モデルから世代番号99までの追加学習で追加されたベクトル値の集合、すなわち世代番号99のモデルデータが得られる。図12の例の場合、IDが9501番目から10000番目までのベクトル値が、世代番号が100に対応した追加学習で追加された値である。このため、管理部106は、世代番号99のモデルデータを得る場合、世代番号が100となっているベクトル値を除いた、IDが1番から9500番までの各ベクトル値を取り出すことによって、世代番号99のモデルを得る。
For example, when obtaining model data with a generation number of 99, the
図13は、第3の実施形態の情報処理装置が、モデルの性能値S(M)を計算する際の処理の流れを示したフローチャートである。第3の実施形態の場合、情報処理装置は、前述した図7のステップS701で説明したような、すべてのモデル履歴のモデルの性能値を計算する代わりに、図13に示すフローチャートの処理を行うことで、モデルの性能値の計算効率を高める。以下、図13のフローチャートを参照して、第3の実施形態の情報処理装置が、モデルの性能値を計算する方法について説明する。なお、以下の説明では、世代番号をgとし、その世代番号gのモデルをMgとする。 FIG. 13 is a flowchart showing the flow of processing when the information processing apparatus according to the third embodiment calculates the performance value S(M) of the model. In the case of the third embodiment, the information processing device performs the process of the flowchart shown in FIG. 13 instead of calculating the performance values of the models of all model histories as described in step S701 of FIG. 7 described above. This increases the efficiency of calculating model performance values. Hereinafter, with reference to the flowchart of FIG. 13, a method for the information processing apparatus of the third embodiment to calculate the performance value of the model will be described. In the following description, the generation number is assumed to be g, and the model of the generation number g is assumed to be M g .
まずステップS1301において、選択部108は、管理部106から最新のモデルの世代番号を取得して、世代番号Gとする。
次にステップS1302において、選択部108は、管理部106から、世代番号GのモデルMGを取得する。すなわち先に説明したように、選択部108は、管理部106から世代番号がG以下のベクトル値の集合を取得してモデルMGとする。
次にステップS1303において、評価部107は、認識スコアS(x;MG)を前述の計算式で計算する。また、評価部107は、その計算過程で求める最近傍y、すなわちd(y,x)が最小となるモデルMGの点yを記憶しておく。
First, in step S1301, the
Next, in step S1302, the
Next, in step S1303, the
次にステップS1304において、選択部108は、ステップS1303で求めた最近傍yの世代番号を取得し、世代番号G’とする。
次にステップS1305において、選択部108は、世代番号G’から世代番号Gまでのモデルにおけるxの認識スコアを、ステップS1303で求めた認識スコアS(x;MG)の値で記憶する。すなわち、世代番号gの認識スコアS(x;Mg)は下記の式(4)の値となる。
Next, in step S1304, the
Next, in step S1305, the
S(x;Mg)=S(x;MG)G’≦g≦G 式(4) S(x; M g )=S(x; M G )G'≦g≦G Formula (4)
最近傍yは世代番号G’の追加学習で追加されたベクトル値であり、それが世代番号Gのモデルでも依然として最近傍なのであるから、世代番号G’+1から世代番号Gまでの追加学習において最近傍yよりもxに近いベクトル値は追加されていない。したがって、世代番号G’から世代番号Gまでのモデルの最近傍はすべてyであり、同じ値S(x;MG)を取ることがわかる。
The nearest neighbor y is the vector value added in the additional learning of the generation number G', and since it is still the nearest neighbor in the model of the generation number G, it is the vector value added in the additional learning from the
次にステップS1306において、選択部108は、世代番号G’=0かどうかを判定する。選択部108は、世代番号G’=0であるならば、初期モデルまでのすべてのモデルについて認識スコアが既に計算されたため図13のフローチャートの処理を終了する。一方、選択部108は、世代番号G’=0でない場合にはステップS1307に処理を進める。ステップS1307に進むと、選択部108は、世代番号GにG’-1を設定してからステップS1302の処理に戻り、世代番号G’-1より以前のモデルについて認識スコアを計算する。
Next, in step S1306, the
第3の実施形態の情報処理装置は、以上のようにして、モデル履歴に含まれるモデルのそれぞれについて認識スコアS(x;Mg)を計算することができる。第3の実施形態の情報処理装置は、ステップS1305において世代番号G’からG-1までのモデルの計算を省略できるため、前述した実施形態のようなモデル履歴のモデルそれぞれで逐次計算を行う場合よりも計算効率が高くなる。例えば、ステップS1305で常に世代番号G’=Gとなる最近傍が選ばれ続けるようなワーストケースの場合でも、計算効率は、前述した逐次計算と同等である。
第3の実施形態の情報処理装置は、以上のような処理を行うことで、最近傍モデルを用いた際には、モデル履歴のデータサイズおよびモデル性能の計算の効率を高めることができる。
The information processing device of the third embodiment can calculate the recognition score S(x; M g ) for each model included in the model history as described above. The information processing apparatus of the third embodiment can omit the calculation of the models with generation numbers G' to G-1 in step S1305, so when sequential calculation is performed for each model of the model history as in the embodiment described above. The calculation efficiency is higher than that of For example, even in the worst case where the nearest neighbor with generation number G'=G is always selected in step S1305, the calculation efficiency is equivalent to the sequential calculation described above.
By performing the above-described processing, the information processing apparatus according to the third embodiment can improve the efficiency of calculation of model history data size and model performance when using the nearest neighbor model.
<第4の実施形態>
前述した第3の実施形態の場合、ステップS306の追加学習は、正解ラベルが正常である教師データをモデルに追加することによって最近傍となり得る正常データを増加させるようにしている。これに対し、第4の実施形態の情報処理装置は、正解ラベルが異常である教師データを用いて、モデルの正常データを削減することによって、教師データの近傍におけるスコアを下げるような追加学習を可能とする。第4の実施形態によるモデルは、未認識の異常について認識しやすくする方向に働く。以下、第4の実施形態において正常データを削減する追加学習を行う方法の追加について説明する。なお、第4の実施形態の情報処理装置の構成は図1と同様であるため、その図示と説明は省略する。以下、第4の実施形態において、前述した実施形態に対して追加または変更された部分についてのみ説明し、前述の実施形態と共通する部分の説明は省略する。
<Fourth embodiment>
In the case of the third embodiment described above, the additional learning in step S306 increases the number of normal data that can be nearest neighbors by adding training data whose correct answer label is normal to the model. In contrast, the information processing device of the fourth embodiment performs additional learning that lowers the score in the vicinity of the teaching data by using the teaching data whose correct answer label is abnormal and reducing the normal data of the model. possible. The model according to the fourth embodiment works toward making it easier to recognize unrecognized abnormalities. The addition of a method for performing additional learning to reduce normal data in the fourth embodiment will be described below. Note that since the configuration of the information processing apparatus according to the fourth embodiment is the same as that in FIG. 1, illustration and description thereof will be omitted. Hereinafter, in the fourth embodiment, only the parts added or changed from the above-described embodiment will be explained, and the explanation of the parts common to the above-described embodiment will be omitted.
第4の実施形態の場合、ステップS306において、学習部104は、まず第3の実施形態と同様に正解ラベルが正常である特徴量の点をモデルに追加する。そして、学習部104は、正解ラベルが異常である特徴量が教師データにあれば、それぞれについて、モデルの点のベクトル値のそれぞれとの距離dを計算して、いずれかの距離が所定の閾値tよりも小さいモデルの点については削除する。すなわち、学習部104は、教師データを中心とした半径(閾値t)の超球に含まれるモデルの点を削除する。
In the case of the fourth embodiment, in step S306, the
例えば、学習部104は、削除時の世代番号をモデルの点のメタデータとしてさらに付加することによって削除する。また、学習部104は、削除時の世代番号として付加する世代番号を、別の正解データの追加による追加学習の世代のさらに次の世代とするためインクリメントする。すなわち、同一の世代番号の追加学習の世代は、すべて追加か、すべて削除のいずれかとなる。
For example, the
図14は、第4の実施形態における管理部106の履歴管理方法を説明する図である。
管理部106が管理するモデル履歴データは、モデル情報レコード1201の列からなる。モデル情報レコード1201は、第3の実施形態で説明したものと同様である。モデルデータ1401は、モデルの点を表現するベクトル値ごとに、メタデータとして世代番号および削除時の世代番号が付与されている。なお、削除されていないベクトル値は、削除時の世代番号では「なし」となる。図14の例の場合、IDの2番目と4890番目のベクトル値が、世代番号101の追加学習(削除による)によって削除されたことになる。言い換えると、例えばIDが4890番目のベクトル値は、世代番号55で追加され、世代番号101で削除されたデータである。すなわち、例えばIDが4890番目のベクトル値は、世代番号55から世代番号100までのモデルにおいて存在するベクトル値である。
本実施形態において、このモデルデータから、例えば世代番号99のモデルデータを得るためには、世代番号が99以下で、かつ削除時の世代番号が「なし」または世代番号が99より大きいベクトル値のみを抽出すればよい。
FIG. 14 is a diagram illustrating a history management method of the
The model history data managed by the
In this embodiment, in order to obtain model data with
図15は、第4の実施形態の情報処理装置が、モデルの性能値S(M)を計算する際の処理の流れを示したフローチャートである。以下、図15のフローチャートを参照して、第4の実施形態の情報処理装置が、評価セットのひとつの特徴量xについてモデル履歴に含まれるモデルMgのすべてについて認識スコアS(x;Mg)を計算する方法について説明する。以下の説明では、図13に示したフローチャートとは異なる処理について説明する。 FIG. 15 is a flowchart showing the flow of processing when the information processing apparatus according to the fourth embodiment calculates the performance value S(M) of the model. Hereinafter, with reference to the flowchart of FIG. 15, the information processing apparatus of the fourth embodiment calculates the recognition score S(x; M g ) will be explained. In the following explanation, processing different from the flowchart shown in FIG. 13 will be explained.
第4の実施形態の情報処理装置は、ステップS1304の次はステップS1501の処理に進む。前述した第3の実施形態の場合、ステップS1303で探索した最近傍yは、最近傍yの追加時である世代番号G’から世代番号Gまでずっと最近傍である。一方、第4の実施形態の場合、世代番号G’から世代番号Gまでに削除された点が最近傍yよりも近いかもしれないため、選択部108はその探索を行う。そして、ステップS1501において、選択部108は、世代番号HにG’を設定する。以降、世代番号Hは、ステップS1501からS1507までの一連の流れにおいて、世代番号G’から始まって世代番号Gまで増加する変数である。
After step S1304, the information processing apparatus according to the fourth embodiment proceeds to step S1501. In the case of the third embodiment described above, the nearest neighbor y searched in step S1303 is the nearest neighbor all the way from the generation number G', which is the time when the nearest neighbor y was added, to the generation number G. On the other hand, in the case of the fourth embodiment, the point deleted from generation number G' to generation number G may be closer than the nearest neighbor y, so the
次にステップS1502において、評価部107は、モデルMHからxの最近傍yよりも近い最近傍z、すなわちd(z,x)<d(y,x)なる最近傍zのうちd(z,x)が最小のものを探索して記憶する。そして、評価部107は、そのような最近傍zが存在すれば認識スコアS(x;MH)を前述の計算式で計算する。最近傍zはyよりもxに近いが、世代番号Gの時点では存在しない(zよりも遠いyが最近傍であるから)ので、最近傍zは世代番号HからGの間に削除された点である。逆に、最近傍zの候補はそのような点に限られるため、世代番号HからGの間に削除された点、すなわち削除時世代番号がH以上G以下の点に限って距離を計算することで効率よく最近傍zを探索できる。
Next, in step S1502 , the
次にステップS1503において、選択部108は、ステップS1502の最近傍zが見つかったかどうかを判定する。選択部108は、最近傍zが見つからなかった場合にはステップS1504に処理を進める。
ここで、最近傍zが見つからなかった場合、世代番号Hから世代番号Gまでの間に削除されたデータでyよりも近いものはなかったのだから、世代番号Hから世代番号Gまでの間の最近傍はすべてyであることがわかる。このため、選択部108は、ステップS1504において、世代番号Hから世代番号Gまでのモデルにおけるxの認識スコアを、ステップS1303で求めた認識スコアS(x;MG)の値で記憶する。そして、選択部108は、ステップS1306の処理に進む。
Next, in step S1503, the
Here, if the nearest neighbor z is not found, there is no deleted data between generation number H and generation number G that is closer than y, so the data between generation number H and generation number G is It can be seen that all the nearest neighbors are y. Therefore, in step S1504, the
一方、ステップS1503において最近傍zが見つかった場合、選択部108は、ステップS1505に処理を進める。ステップS1505に進むと、選択部108は、最近傍zの削除時の世代番号を取得し、それを世代番号H'とする。最近傍zは、世代番号Hから、削除される直前である世代番号H'-1までの間はすべて最近傍であることがわかる。
On the other hand, if the nearest neighbor z is found in step S1503, the
次にステップS1506において、選択部108は、世代番号Hから世代番号H’-1までのモデルにおけるxの認識スコアを、ステップS1502で求めた認識スコアS(x;MH)の値で記憶する。
次にステップS1507において、選択部108は、世代番号HにH’を設定してから、ステップS1502の処理に戻る。
Next, in step S1506, the
Next, in step S1507, the
第4の実施形態においては、以上の一連の処理によって、世代番号G’から世代番号Gまでのモデルについて、特徴量xの認識スコアがすべて決定される。これはステップS1305の効果と同様である。
第4の実施形態によれば、以上のようにして、第3の実施形態の処理に、削除による追加学習の処理を追加した上で、前述の第3の実施形態と同様に効率的な処理を行うことができる。
In the fourth embodiment, all the recognition scores of the feature amount x are determined for the models from generation number G' to generation number G through the series of processes described above. This is similar to the effect of step S1305.
According to the fourth embodiment, as described above, the processing of additional learning by deletion is added to the processing of the third embodiment, and the processing is performed efficiently like the third embodiment described above. It can be performed.
<その他の実施形態>
本発明は、前述の各実施形態の1以上の機能を実現するプログラムを、ネットワーク又は記憶媒体を介してシステム又は装置に供給し、そのシステム又は装置のコンピュータにおける1つ以上のプロセッサーがプログラムを読出し実行する処理でも実現可能である。また、1以上の機能を実現する回路(例えば、ASIC)によっても実現可能である。
前述の実施形態は、何れも本発明を実施するにあたっての具体化の例を示したものに過ぎず、これらによって本発明の技術的範囲が限定的に解釈されてはならないものである。即ち、本発明は、その技術思想、又はその主要な特徴から逸脱することなく、様々な形で実施することができる。
<Other embodiments>
The present invention provides a system or device with a program that implements one or more functions of each of the above-described embodiments via a network or a storage medium, and one or more processors in the computer of the system or device reads the program. It can also be realized by executing processing. It can also be realized by a circuit (for example, ASIC) that realizes one or more functions.
The above-described embodiments are merely examples of implementation of the present invention, and the technical scope of the present invention should not be construed as limited by these embodiments. That is, the present invention can be implemented in various forms without departing from its technical idea or main features.
101:撮影部、102:特徴量算出部、103:認識部、104:学習部、105:記憶部、106:管理部、107:評価部、108:選択部、109:表示部、110:操作部 101: Photographing section, 102: Feature calculation section, 103: Recognition section, 104: Learning section, 105: Storage section, 106: Management section, 107: Evaluation section, 108: Selection section, 109: Display section, 110: Operation Department
Claims (18)
前記モデルの追加学習を行う学習手段と、
前記モデルの追加学習の履歴の情報を管理する管理手段と、
前記モデルによる前記認識の精度を評価する評価手段と、
前記履歴の情報が管理されているモデルのなかから、前記認識の精度に基づいてモデルを選択する選択手段と、を有し、
前記評価手段は、前記認識手段が認識する認識対象の情報の集合を記録した評価セットを保持し、
前記選択手段は、前記評価セットから前記認識対象の情報を抽出した部分集合によって精度を評価した結果に基づいて、追加学習されたモデルを選択し、
前記認識手段は、前記選択手段が選択したモデルを前記認識に用いることを特徴とする情報処理装置。 a recognition means for recognizing features from an image based on the model;
learning means for additionally learning the model;
a management means for managing information on the history of additional learning of the model;
evaluation means for evaluating the accuracy of the recognition by the model;
a selection means for selecting a model based on the recognition accuracy from among the models for which the history information is managed;
The evaluation means holds an evaluation set that records a collection of recognition target information recognized by the recognition means,
The selection means selects an additionally learned model based on a result of evaluating accuracy using a subset of information on the recognition target extracted from the evaluation set;
The information processing apparatus is characterized in that the recognition means uses the model selected by the selection means for the recognition.
前記選択手段は、前記履歴の情報が管理されているそれぞれのモデルを用いて、前記評価セットを前記認識手段で認識した精度を前記評価手段で評価した結果に基づいて、前記評価セットに含まれる認識対象のうち、前記モデルのIDと前記スコアが互いに類似する複数の認識対象のいずれかを除いた部分集合によって生成された評価セットを用いて追加学習されたモデルを選択することを特徴とする請求項1に記載の情報処理装置。 The selection means selects models included in the evaluation set based on the results of evaluating the accuracy of recognition of the evaluation set by the recognition means using each model for which the history information is managed. The method is characterized in that a model that has been additionally learned is selected using an evaluation set generated by a subset of recognition targets excluding any of a plurality of recognition targets whose IDs and scores of the models are similar to each other. The information processing device according to claim 1.
前記表示制御手段は、前記評価セットに含まれる前記認識対象の情報を表示することを特徴とする請求項1または2に記載の情報処理装置。 3. The information processing apparatus according to claim 1, wherein the display control means displays information on the recognition target included in the evaluation set.
前記モデルの追加学習を行う学習手段と、 learning means for additionally learning the model;
前記モデルの追加学習の履歴の情報を管理する管理手段と、 a management means for managing information on the history of additional learning of the model;
前記モデルによる前記認識の精度を評価する評価手段と、 evaluation means for evaluating the accuracy of the recognition by the model;
前記履歴の情報が管理されているモデルのなかから、前記認識の精度に基づいてモデルを選択する選択手段と、を有し、 a selection means for selecting a model based on the recognition accuracy from among the models for which the history information is managed;
前記選択手段は、前記認識手段が認識する認識対象の一部を選択し、 The selection means selects a part of the recognition target recognized by the recognition means,
前記評価手段は、前記選択された認識対象の一部における前記認識の結果に基づいて前記認識の精度を評価し、The evaluation means evaluates the accuracy of the recognition based on the recognition results for a part of the selected recognition target,
前記認識手段は、前記選択手段が選択したモデルを前記認識に用いることを特徴とする情報処理装置。 The information processing apparatus is characterized in that the recognition means uses the model selected by the selection means for the recognition.
前記評価手段は、前記選択されたクラスタに属する認識対象における認識の結果に基づいて前記認識の精度を評価することを特徴とする請求項4に記載の情報処理装置。5. The information processing apparatus according to claim 4, wherein the evaluation means evaluates the accuracy of the recognition based on a recognition result of a recognition target belonging to the selected cluster.
前記選択手段は、前記履歴における精度の推移に基づいて決定した複数のモデルを利用者に提示し、利用者が前記選択入力手段によって入力された結果に基づいてモデルを選択することを特徴とする請求項1乃至5のいずれか1項に記載の情報処理装置。 further comprising a selection input means for a user to select a model;
The selection means presents the user with a plurality of models determined based on changes in accuracy in the history, and the user selects a model based on the result input by the selection input means. The information processing device according to any one of claims 1 to 5.
前記管理手段は、前記認識対象に前記追加学習が行われた世代を表す世代番号を付与することによって、前記モデルの履歴を管理し、
前記認識手段は、前記モデルが含むデータの部分集合を前記世代番号に基づいて定め、前記部分集合を前記履歴に含まれるモデルとすることを特徴とする請求項1乃至9のいずれか1項に記載の情報処理装置。 The learning means performs additional learning by adding or deleting a recognition target to the model,
The management means manages the history of the model by assigning a generation number representing a generation in which the additional learning has been performed to the recognition target,
According to any one of claims 1 to 9 , the recognition means determines a subset of data included in the model based on the generation number, and sets the subset as a model included in the history. The information processing device described.
前記認識の精度は、前記世代番号のモデルを用いた際の所定の認識対象のデータに最も近い点までの距離を示すスコアであって、
前記選択手段は、最新のモデルの前記世代番号から初期のモデルまでの各モデルに含まれる前記認識対象のデータと、前記所定の認識対象に基づいて、前記スコアが最小となる前記認識対象のデータを含むモデルを選択し、
前記評価手段は、前記選択されたモデルの前記世代番号が前記初期のモデルの前記世代番号と異なる場合は、前記選択されたモデルの前記世代番号以降のモデルに含まれる前記認識対象のデータを除いた前記認識対象のデータと、前記所定の認識対象に基づいて前記スコアを評価し、前記選択されたモデルの前記世代番号が前記初期のモデルの前記世代番号である場合は、評価を終了することを特徴とする請求項10に記載の情報処理装置。 The model is a collection of data indicating the recognition target in a feature space,
The recognition accuracy is a score indicating the distance to the point closest to the data of the predetermined recognition target when using the model with the generation number,
The selection means selects data of the recognition target that minimizes the score based on the data of the recognition target included in each model from the generation number of the latest model to the initial model and the predetermined recognition target. Select the model containing
If the generation number of the selected model is different from the generation number of the initial model, the evaluation means may exclude the recognition target data included in the models after the generation number of the selected model. evaluating the score based on the data of the recognition target and the predetermined recognition target, and when the generation number of the selected model is the generation number of the initial model, terminating the evaluation; The information processing device according to claim 10 .
前記表示制御手段は、前記認識手段によって正常と認識された物体と、異常が発生したと認識された物体とをそれぞれ示す情報を表示させることを特徴とする請求項1乃至12のいずれか1項に記載の情報処理装置。 further comprising display control means for displaying the image on a display device,
13. The display control means displays information indicating objects recognized as normal and objects recognized as abnormal by the recognition means, respectively. The information processing device described in .
モデルに基づいて、画像から特徴を認識する認識工程と、
前記モデルの追加学習を行う学習工程と、
前記モデルの追加学習の履歴の情報を管理する管理工程と、
前記モデルの前記認識の精度を評価する評価工程と、
前記履歴の情報が管理されているモデルのなかから、前記認識の精度に基づいてモデルを選択する選択工程と、を有し、
前記評価工程は、認識対象の情報の集合を記録した評価セットを保持し、
前記選択工程は、前記評価セットから前記認識対象の情報を抽出した部分集合によって精度を評価した結果に基づいて、追加学習されたモデルを選択し、
前記認識工程は、前記選択工程で選択されたモデルを前記認識に用いることを特徴とする情報処理方法。 An information processing method executed by an information processing device, the method comprising:
a recognition step of recognizing features from the image based on the model;
a learning step of performing additional learning of the model;
a management step of managing information on the history of additional learning of the model;
an evaluation step of evaluating the recognition accuracy of the model;
a selection step of selecting a model based on the recognition accuracy from among the models for which the history information is managed;
The evaluation step includes maintaining an evaluation set that records a collection of information to be recognized;
The selection step selects an additionally learned model based on a result of evaluating accuracy using a subset of information on the recognition target extracted from the evaluation set;
The information processing method is characterized in that the recognition step uses the model selected in the selection step for the recognition.
モデルに基づいて、画像から特徴を認識する認識工程と、a recognition step of recognizing features from the image based on the model;
前記モデルの追加学習を行う学習工程と、a learning step of performing additional learning of the model;
前記モデルの追加学習の履歴の情報を管理する管理工程と、a management step of managing information on the history of additional learning of the model;
前記モデルによる前記認識の精度を評価する評価工程と、an evaluation step of evaluating the accuracy of the recognition by the model;
前記履歴の情報が管理されているモデルのなかから、前記認識の精度に基づいてモデルA model is selected based on the recognition accuracy from among the models for which the history information is managed.
を選択する選択工程と、を有し、a selection step of selecting;
前記選択工程は、前記認識工程が認識する認識対象の一部を選択し、The selection step selects a part of the recognition target to be recognized by the recognition step,
前記評価工程は、前記選択された認識対象の一部における前記認識の結果に基づいて前記認識の精度を評価し、The evaluation step evaluates the accuracy of the recognition based on the recognition results for a part of the selected recognition target,
前記認識工程は、前記選択工程が選択したモデルを前記認識に用いることを特徴とする情報処理方法。The information processing method is characterized in that the recognition step uses the model selected in the selection step for the recognition.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019110963A JP7433782B2 (en) | 2019-06-14 | 2019-06-14 | Information processing device, information processing method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019110963A JP7433782B2 (en) | 2019-06-14 | 2019-06-14 | Information processing device, information processing method, and program |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2020204812A JP2020204812A (en) | 2020-12-24 |
| JP2020204812A5 JP2020204812A5 (en) | 2022-06-17 |
| JP7433782B2 true JP7433782B2 (en) | 2024-02-20 |
Family
ID=73838407
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019110963A Active JP7433782B2 (en) | 2019-06-14 | 2019-06-14 | Information processing device, information processing method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7433782B2 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7612198B2 (en) | 2021-03-01 | 2025-01-14 | 国立大学法人横浜国立大学 | Neural network system, learning control device, calculation method, learning control method and program |
| JP2023149113A (en) * | 2022-03-30 | 2023-10-13 | 株式会社神戸製鋼所 | Abnormality determination method, method for processing at the time of abnormality, information processing apparatus, welding system, and program |
| CN117315565A (en) | 2023-08-31 | 2023-12-29 | 云南电网有限责任公司德宏供电局 | Abnormal behavior identification monitoring method based on increment space-time learning |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010050334A1 (en) | 2008-10-30 | 2010-05-06 | コニカミノルタエムジー株式会社 | Information processing device |
| JP2010257140A (en) | 2009-04-23 | 2010-11-11 | Canon Inc | Apparatus and method for processing information |
| JP2014153906A (en) | 2013-02-08 | 2014-08-25 | Honda Motor Co Ltd | Inspection device, inspection method and program |
| JP2015103144A (en) | 2013-11-27 | 2015-06-04 | 富士ゼロックス株式会社 | Image processing device and program |
| JP2015116319A (en) | 2013-12-18 | 2015-06-25 | パナソニックIpマネジメント株式会社 | Diagnosis support device, diagnosis support method, and diagnosis support program |
| WO2019087791A1 (en) | 2017-10-31 | 2019-05-09 | 富士フイルム株式会社 | Diagnosis support device, endoscope device, management device, diagnosis support method, management method, diagnosis support program, and management program |
-
2019
- 2019-06-14 JP JP2019110963A patent/JP7433782B2/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010050334A1 (en) | 2008-10-30 | 2010-05-06 | コニカミノルタエムジー株式会社 | Information processing device |
| JP2010257140A (en) | 2009-04-23 | 2010-11-11 | Canon Inc | Apparatus and method for processing information |
| JP2014153906A (en) | 2013-02-08 | 2014-08-25 | Honda Motor Co Ltd | Inspection device, inspection method and program |
| JP2015103144A (en) | 2013-11-27 | 2015-06-04 | 富士ゼロックス株式会社 | Image processing device and program |
| JP2015116319A (en) | 2013-12-18 | 2015-06-25 | パナソニックIpマネジメント株式会社 | Diagnosis support device, diagnosis support method, and diagnosis support program |
| WO2019087791A1 (en) | 2017-10-31 | 2019-05-09 | 富士フイルム株式会社 | Diagnosis support device, endoscope device, management device, diagnosis support method, management method, diagnosis support program, and management program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020204812A (en) | 2020-12-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Chen et al. | Order-free rnn with visual attention for multi-label classification | |
| JP6759411B2 (en) | Object tracking method and equipment | |
| AU2016332947B2 (en) | Semi-automatic labelling of datasets | |
| JP7433782B2 (en) | Information processing device, information processing method, and program | |
| JP5889019B2 (en) | Label adding apparatus, label adding method and program | |
| JP6299299B2 (en) | Event detection apparatus and event detection method | |
| US20140201133A1 (en) | Pattern extraction apparatus and control method therefor | |
| CN110413815B (en) | Portrait clustering cleaning method and device | |
| US20210142046A1 (en) | Deep face recognition based on clustering over unlabeled face data | |
| JP2011059898A (en) | Image analysis apparatus and method, and program | |
| Wu et al. | A simple framework for uncertainty in contrastive learning | |
| JP2019185121A (en) | Learning device, learning method and program | |
| JP7315022B2 (en) | Machine learning device, machine learning method, and machine learning program | |
| US20210020310A1 (en) | Information processing apparatus evaluating similarity between medical data, information processing method, and storage medium | |
| Marvasti et al. | Computer-aided medical image annotation: preliminary results with liver lesions in CT | |
| CN114510715B (en) | Method and device for testing functional safety of model, storage medium and equipment | |
| US11748973B2 (en) | Systems and methods for generating object state distributions usable for image comparison tasks | |
| JP2011059897A (en) | Image analysis apparatus and method, and program | |
| JP2023131629A (en) | Image processing program, image processing method, and information processing device | |
| JP2021026406A (en) | Information processing apparatus, information processing method, and program | |
| US12158910B2 (en) | Systems and methods for utilizing object state distributions for image comparison tasks | |
| US20230368534A1 (en) | Method and electronic device for generating a segment of a video | |
| Hua et al. | Microsoft Research Asia TRECVID 2006 High-Level Feature Extraction and Rushes Exploitation. | |
| JPH08305853A (en) | Method and device for object recognition and decision making based upon recognition | |
| WO2023218413A1 (en) | Method and electronic device for generating a segment of a video |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220609 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220609 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230410 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230425 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230623 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20231010 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240109 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240207 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7433782 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |