JP7220914B2 - コンピュータに実装する方法、コンピュータ可読媒体および異種計算システム - Google Patents
コンピュータに実装する方法、コンピュータ可読媒体および異種計算システム Download PDFInfo
- Publication number
- JP7220914B2 JP7220914B2 JP2019547267A JP2019547267A JP7220914B2 JP 7220914 B2 JP7220914 B2 JP 7220914B2 JP 2019547267 A JP2019547267 A JP 2019547267A JP 2019547267 A JP2019547267 A JP 2019547267A JP 7220914 B2 JP7220914 B2 JP 7220914B2
- Authority
- JP
- Japan
- Prior art keywords
- processing unit
- data
- runtime
- information
- run
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 111
- 238000012545 processing Methods 0.000 claims description 262
- 230000006870 function Effects 0.000 claims description 137
- 239000013598 vector Substances 0.000 claims description 82
- 230000015654 memory Effects 0.000 claims description 47
- 238000012546 transfer Methods 0.000 claims description 22
- 239000011159 matrix material Substances 0.000 claims description 15
- 230000014509 gene expression Effects 0.000 claims description 8
- 238000005259 measurement Methods 0.000 claims description 7
- 230000001360 synchronised effect Effects 0.000 claims description 5
- 235000019800 disodium phosphate Nutrition 0.000 claims 3
- 239000000872 buffer Substances 0.000 description 48
- 238000003491 array Methods 0.000 description 24
- 238000003860 storage Methods 0.000 description 24
- 238000013459 approach Methods 0.000 description 14
- 230000008569 process Effects 0.000 description 11
- 238000011156 evaluation Methods 0.000 description 10
- 230000008859 change Effects 0.000 description 9
- 238000004088 simulation Methods 0.000 description 9
- 238000007726 management method Methods 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 7
- 238000005457 optimization Methods 0.000 description 7
- 230000008901 benefit Effects 0.000 description 6
- 239000000047 product Substances 0.000 description 5
- 238000004364 calculation method Methods 0.000 description 4
- 230000011218 segmentation Effects 0.000 description 4
- 108010074506 Transfer Factor Proteins 0.000 description 3
- 230000001133 acceleration Effects 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 230000004888 barrier function Effects 0.000 description 3
- 230000006378 damage Effects 0.000 description 3
- 238000000354 decomposition reaction Methods 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000007667 floating Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 230000003068 static effect Effects 0.000 description 3
- 230000000153 supplemental effect Effects 0.000 description 3
- 230000001960 triggered effect Effects 0.000 description 3
- 238000013500 data storage Methods 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- HPTJABJPZMULFH-UHFFFAOYSA-N 12-[(Cyclohexylcarbamoyl)amino]dodecanoic acid Chemical compound OC(=O)CCCCCCCCCCCNC(=O)NC1CCCCC1 HPTJABJPZMULFH-UHFFFAOYSA-N 0.000 description 1
- 241000272525 Anas platyrhynchos Species 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000004931 aggregating effect Effects 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 238000000429 assembly Methods 0.000 description 1
- 230000000712 assembly Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000013075 data extraction Methods 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000002408 directed self-assembly Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 238000009499 grossing Methods 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000008450 motivation Effects 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 230000036316 preload Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- WFKWXMTUELFFGS-UHFFFAOYSA-N tungsten Chemical compound [W] WFKWXMTUELFFGS-UHFFFAOYSA-N 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5044—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering hardware capabilities
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/52—Program synchronisation; Mutual exclusion, e.g. by means of semaphores
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/48—Indexing scheme relating to G06F9/48
- G06F2209/486—Scheduler internals
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Devices For Executing Special Programs (AREA)
- Complex Calculations (AREA)
- Stored Programmes (AREA)
Description
この出願の発明に関連する先行技術文献情報としては、以下のものがある(国際出願日以降国際段階で引用された文献及び他国に国内移行した際に引用された文献を含む)。
(先行技術文献)
(特許文献)
(特許文献1) 国際公開第2017/016590号
(特許文献2) 米国特許出願公開第2011/0173155号明細書
(特許文献3) 米国特許出願公開第2007/0283358号明細書
(非特許文献)
(非特許文献1) Philchaya Mangpo Phothilimthana,et al."Portable Performance on Heterogeneous Architectures",In: Proceedings of the ASPLOS’13,Houston,Texas,USA,March 16-20,2013,S.1-13.
(非特許文献2) J.Ansel,et al.: PetaBricks:"A Language and Compiler for Algorithmic Choice.In: Proceedings of the PLDI’09,Dublin,Ireland,June 15-20,2009,S.38-49.
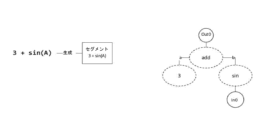
C = sum(abs(A- B[full,i]))

-要素#0:入力次元数による関数の仕事量、
-要素#1:入力要素の数による仕事量、
-...
-要素#2...(n-3):対応する次元の長さによる仕事量。
-要素#0:次元数(n)、
-要素#1:要素の数、
-...
-要素#2...(n + 1):次元1...nの長さ。
-セグメント仕事量ベクトル、
-セグメントサイズベクトル、そして
-セグメントカーネルテンプレート。
この段階では、個々の処理ユニットのカテゴリ用に作成された仕事量ベクトルは、具体的なデバイスに固有の情報をまだ運んでいないことに注意が必要である。むしろ、個々の仕事量ベクトルは、さまざまな処理ユニットのカテゴリで命令を実装および実行する個々の方法を取り得る。たとえば、一部のデバイスカテゴリでは、一部の命令を効率的に実行するためにループ構造やスレッド管理オーバーヘッドを実装するカーネルコードを必要とするが、他のデバイスカテゴリでは必要としない。
[1] {
[2] ILArray<double> A = rand(1000,2000);
[3] ...
[4] B = Abs(Sin(A * A));
[5] var c = A.GetArrayForRead();
[6] ...
[7] }
ソフトウェアコード(通常、GPLまたはMATLABやNumPyなどの科学計算言語で記述されたユーザーコード)を取得し、そのソフトウェアコードで、一般データの複数の要素を格納できる最初のデータ構造の数値演算を含むプログラムセグメントを識別すること、
数値演算の出力、特に出力のサイズ、出力の構造、およびまたは出力を生成するための仕事量を参照する関数メタ情報を決定すること、
数値演算を実行するのに適したコンピュータまたは別の異種コンピューティングシステムの処理ユニットを決定すること、そして
プログラムセグメントを中間表現、特にバイトコード表現、またはコンピュータまたは他の異種コンピューティングシステムで実行可能な表現、特にプログラムセグメントの実行時セグメントに変換すること。
Claims (18)
- コンピューターに実装する方法であって、次の複数のステップ:
異種計算システムの第1の計算カーネル(140-144)を持つ第1の処理ユニット(71)と第2の計算カーネル(150-154)を持つ第2の処理ユニット(72)を初期化するステップであって、
なおそこで第1の計算カーネル(140-144)と第2の計算カーネル(150-154)の各々は、複数の一般データタイプの要素を保存する第1のデータ構造(A)を受け取るように形成されたプログラムセグメント(220)から供給される数値演算を実行するように形成され、このプログラムセグメント(220)は、前記数値演算の出力を生成する演算的仕事量と、前記出力のサイズに関するデータ及び前記出力の構造に関するデータの内の少なくとも1つと、を含む関数メタ情報を有する、初期化するステップと、
上記関数メタ情報と第1データ構造(A)の実行時インスタンス(A1)のデータメタ情報を用いて、
実行時インスタンス(A1)で数値演算を実行するための第1計算カーネル(140-144)を第1処理ユニット(71)で実行するための第1の予測コストを計算し、
そして同じく実行時インスタンス(A1)で数値演算を実行するための第2計算カーネル(150-154)を第2処理ユニット(72)で実行するための第2の予測コストを計算するステップと、
なおそこで上記データメタ情報は、実行時インスタンス(A1)の実行時の大きさの情報と実行時インスタンス(A1)の実行時の場所の情報を含む、
およびつぎの2つのステップ:
第1の予測コストが第2の予測コストより低いまたは等しい場合に、実行時インスタンス(A1)で数値演算を実行するための第1計算カーネル(140-144)を第1処理ユニット(71)で実行するステップ、および
第1の予測コストが第2の予測コストより高い場合に、実行時インスタンス(A1)で数値演算を実行するための第2計算カーネル(150-154)を第2処理ユニット(72)で実行するステップ
のどちらか一方のステップと、
から構成される方法。 - 請求項1の方法であって、上記プログラムセグメント(220)は、さらに上記一般データタイプまたはその他の一般データタイプの複数の要素を保存することができる第2のデータ構造を受け取るように形成され、
そこで上記第2のデータ構造の実行時インスタンスのデータメタ情報は第1の予測コストおよび第2の予測コストを数値的に計算するために用いられ、そして第2データ構造情報の上記実行時インスタンスの上記データメタ情報は、第2データ構造情報の上記実行時インスタンスの実行時の大きさ情報と第2データ構造情報の上記実行時インスタンスの実行時の場所情報を含む方法。 - 請求項1~2のいずれか1つに記載の方法であって、そこで各々のデータメタ情報はさらに上記各々の実行時インスタンス(A1)の同期状態か非同期状態かを示す情報を含み同期の方法を示す同期オブジェクト、およびまたは上記各々の実行時インスタンス(A1)の実行時タイプ情報をも含む方法。
- 請求項1~3のいずれか1つに記載の方法であって、そこで第1データ構造(A)、第1データ構造 (A)の実行時インスタンス(A1)、第2データ構造の実行時インスタンスと第2データ構造の少なくとも一つが各々の一般データタイプの可変数個の要素を保存することができ、
なおそこで、前記第1データ構造(A)、前記第1データ構造(A)の実行時インスタンス(A1)、前記第2データ構造の実行時インスタンス、及び前記第2データ構造の少なくとも一つは、コレクション、ベクトル、行列、リスト、キュー、スタック、グラフ、トリーそしてn次元直方のデータ構造の少なくとも1つを保存しおよびまたは含み、
そこで、第1データ構造(A)の実行時インスタンス(A1)と、第2データ構造の実行時インスタンスは画像を含み、
そこで、第1データ構造 (A)実行時インスタンス(A1)と、第2データ構造の実行時インスタンスは測定データを含み、
およびまたは、
そこで数値演算は行列演算である
方法。 - 請求項1~4のいずれか1つに記載の方法であって、
そこで第1データ構造(A)、第1データ構造(A)の実行時インスタンス(A1)、第2データ構造の実行時インスタンス及び第2データ構造の内の少なくとも一つが各々の実行時メタ情報を保存することができ、この実行時メタ情報は、実行時大きさ情報、実行時場所情報、実行時同期情報およびまたは実行時タイプ情報を含む
方法。 - 請求項1~5のいずれか1つに記載の方法であって、
そこで多項式コスト関数が第1および第2の予測コストを計算するために用いられ、
そこで第1及び第2の予測コストの計算は、計算コストの決定および転送コストの決定の少なくとも1つを含み、
およびまたは、
そこで第1及び第2の予測コストは実行時中およびまたは第1処理ユニット(71)と第2処理ユニット(72)の初期化の後に計算される
方法 - 請求項1~6のいずれか1つに記載の方法であって、
そこで出力を生成する仕事量は、第1の予測コストおよび第2の予測コストを計算するために用いられ、
そこで出力を生成する仕事量は、上記第1処理ユニット(71)上の一般データタイプの1要素への数値演算を実行するための第1の数値的仕事量と上記第2処理ユニット(72)上の一般データタイプの1要素への数値演算を実行するための第2の数値的仕事量を含み、
そこで第1の数値的仕事量は上記第1処理ユニット(71)の決定された特性に応じて更新され、
およびまたは、
そこで第2の数値的仕事量は上記第2処理ユニット(72)の決定された特性に応じて更新される
方法 - 請求項1~7のいずれか1つに記載の方法であって、
さらに前記第1処理ユニット(71)および前記第2処理ユニット(72)を初期化する前に、前記異種計算システム上で制御カーネルを実行するステップを含み、
そこで上記制御カーネルは、第1処理ユニット(71)および第2処理ユニット(72)の特性を決定し、
第1処理ユニット(71)および第2処理ユニット(72)の決定された特性に従って関数メタ情報を更新し、
第1の予想コストおよび第2の予想コストを計算し、
第1の予想コストおよび第2の予想コストに基づいて、それぞれの計算カーネルを実行するための第1の処理ユニット(71)または第2の処理ユニット(72)を選択し、およびまたは、
選択された処理ユニット(71、72)上でそれぞれの計算カーネルの実行を開始するするように形成される方法。 - 請求項1~8のいずれか1つに記載の方法であって、さらに次のステップ、
第1処理ユニット(71)およびまたは第2処理ユニット(72)の特性を決定するステップ、
第1処理ユニット(71)の決定された特性およびまたは第2処理ユニット(72)の決定された特性に従ってそれぞれの関数メタ情報を更新するステップ、
その数値演算を実行するのに適したものとして第1処理ユニット(71)および第2処理ユニット(72)を決定するステップ、
実行時に、そして第1および第2の予想コストを計算する前に、第1のデータ構造の次元および第1データ構造内の記憶された要素の数のうちの少なくとも一つを決定するステップ、
そして実行時に、かつ第1および第2の予想コストを計算する前に、第2のデータ構造の実行時インスタンスの次元および第2のデータ構造の実行時インスタンス内の記憶された要素の数のうちの少なくとも一つ
を決定するステップ、
の少なくとも1つを含む方法。 - 請求項1~9のいずれか1つに記載の方法であって、さらに、
さらなる第1の計算カーネル(140―144)を用いて第1の処理ユニット(71)を初期化し、さらなる第2の計算カーネル(150―154)を用いて第2の処理
ユニット(72)を初期化するステップ、
そこで、さらなる第1の計算カーネル(140―144)およびさらなる第2の計算カーネル(150―154)は、第1のデータ構造(A)およびまたは一般データタイプあるいはもう一つの一般データタイプそして数値演算の出力を表す複数のデータ構造を格納するさらなるデータ構造を受け取るように構成された引き続くプログラムセグメント(221)から導出されるさらなる数値演算を実行するように構成され、
そこで、上記引き続くプログラムセグメント(221)は、さらなる数値演算の出力のサイズに関するデータを含むさらなる関数メタ情報、さらなる数値演算の出力の構造、およびまたはさらなる数値演算の出力を生成するための仕事量を含む、
およびまたは
さらなる関数メタ情報と、さらなるデータ構造のさらなる実行時インスタンスのデータメタ情報および第1のデータ構造(A)の実行時インスタンス(A1)のデータメタ情報の少なくとも1つを用いて、
実行時インスタンス(A1)およびまたはさらなる実行時インスタンスに対してさらなる数値演算を実行するために、さらなる第1の計算カーネル(140―144)を第1の処理ユニット(71)上で実行する第1の予想コストを数値的に計算し、
およびまたは、実行時インスタンス(A1)およびまたはさらなる実行時インスタンスに対してさらなる数値演算を実行するために、第2の計算カーネル(150―154)を第2の処理ユニット(72)上で実行する第2の予想コストを数値的に計算する
ステップを含み、
そこでさらなる実行時インスタンスのデータメタ情報は、さらなる実行時インスタンスの実行時サイズ情報およびまたはさらなる実行時インスタンスの実行時場所情報を含む
方法 - 請求項10に記載の方法であって、さらに
そこで前記数値演算は、第1のデータ構造(A)およびまたは第2のデータ構造に対する計算命令の縮小セットの命令であり、
およびまたは、そこで前記さらなる数値演算は、第1のデータ構造(A)およびまたはさらなるデータ構造に対する計算命令の縮小セットの命令である
方法。 - 請求項1~11のいずれか1つに記載の方法であって、さらに
プログラムコード内の前記プログラムセグメント(220)を識別するステップ、
プログラムコード内の引き続くプログラムセグメント(221)を識別するステップ、
前記プログラムセグメント(220)から前記第1の計算カーネル(142)、前記第2の計算カーネル(152)、および関数メタ情報を含む実行時セグメント(32)を作成するステップ、
引き続くプログラムセグメント(221)から、さらなる第1の計算カーネル、さらなる第2の計算カーネル(152)、およびさらなる関数メタ情報を含む引き続く実行時セグメントを作成するステップ、
それぞれのプログラムセグメント(220、221)を中間表現、特にバイトコード表現、または第1の処理ユニット(71)および第2の処理ユニット(72)上での実行を円滑に進めるそれぞれの表現に翻訳するステップ、
決定された第1処理ユニット(71)の特性およびまたは第2処理ユニット(72)の特性に従ってそれぞれの実行時セグメントを更新するステップ、そして
第1処理ユニット(71)および第2処理ユニット(72)での実行を容易にする中間表現、バイトコード表現、およびそれぞれの表現のうちの少なくとも1つをそれぞれの計算カーネル(130―134、140―144、150―154)にコンパイルするステップ、
の少なくとも1つを含む方法。 - 請求項1~12のいずれか1つに記載の方法であって、さらに前記プログラムセグメント(220)は前記異種計算システムのホストプロセッサー(73)上での実行を容易にする以下の表現、
異種計算システムのシングルコアCPU上での実行を容易にする表現、
異種計算システムのマルチコアCPU上での実行を容易にする表現、
異種計算システムのCPUベクトル拡張上での実行を容易にする表現、
異種計算システムのGPU上での実行を容易にする表現、
異種計算システムのSIMDアクセラレータ上での実行を容易にする表現、
異種計算システムのDSP上での実行を容易にする表現、
異種計算システムのマイクロプロセッサ上での実行を容易にする表現、
異種計算システムのマイクロコントローラ上での実行を容易にする表現、
異種計算システムの仮想デバイス上での実行を容易にする表現、
異種計算システムのFPGA上での実行を容易にする表現、
の少なくとも1つに翻訳されている方法。 - 請求項1~13のいずれか1つに記載の方法であって、さらに次の複数のステップ、
一般データ型またはその他の一般データタイプの複数の要素を格納する第1のデータ構造(A)およびまたは第2のデータ構造(B)を受け取るようにそれぞれ構成されたいくつかのプログラムセグメント(220―222)を含み、また数値演算の出力のサイズ、出力の構造、およびまたは出力を生成するための仕事量に関連するデータを含む関数メタ情報を含むシーケンス(210)をプログラムコード内で特定するステップ、
各実行時セグメント(30―34)がそれぞれの第1の計算カーネル、それぞれの第2の計算カーネル、および第1データ構造(A1)の実行時インスタンスおよびまたは第2データ構造の実行時インスタンスに対するそれぞれの数値演算を参照してそれぞれの関数メタ情報を含むように、各プログラムセグメント(220―222)からそれぞれの実行時セグメント(30―34)を作成するステップ、
各実行時セグメント(30-34)の第1および第2の計算カーネルを実行するためのそれぞれの第1および第2予想コストを計算するステップ、そして
それぞれの第1の予想コストとそれぞれの第2の予想コストを使用して
それぞれの計算カーネルが第1の処理ユニット(71)と第2の処理ユニット(72)のどちらで実行するかを決定するステップ、
の少なくとも1つを含む方法。 - 第1処理ユニット(71)および第2処理ユニット(72)を備えるコンピュータによって実行されるときに、前記請求項1~14のいずれかに記載の方法を上記コンピュータに実行させる命令を含むコンピュータ可読媒体。
- 異種計算システムであって、
一般データ型の複数の要素を格納することができる第1のデータ構造(A)を受け取るように構成されたプログラムセグメントの実行時セグメント(30―34)を格納するメモリであって、前記プログラムセグメントは、数値演算の出力を生成する演算的仕事量と、前記出力のサイズに関するデータ及び前記出力の構造に関するデータの内の少なくとも1つと、を含む関数メタ情報を有する、メモリと、
少なくとも2つの異種の処理ユニット(71,72)と、
を含み、
そこで少なくとも2つの異なる処理ユニット(71、72)のそれぞれは、上記実行時セグメント(30―34)のそれぞれの計算カーネルを格納するメモリにアクセスしかつまたはその一部を形成し、各計算カーネルは数値演算を実行し、
そこで上記実行時セグメント(30―34)は、第1のデータ構造(A)の実行時インスタンス(A1)のデータメタ情報を決定するための実行可能コードを含み、そのデータメタ情報は、実行時インスタンス(A1)の実行時サイズ情報および実行時インスタンス(A1)の実行時場所情報を含み、
そこで実行時セグメント(30―34)は、関数メタ情報およびデータメタ情報を使用して、少なくとも2つの異なる処理ユニットのそれぞれについて、実行時インスタンス(A1)を用いて数値演算を実行するためのそれぞれの計算カーネル(130-134,140-144、150-154)を実行するそれぞれの予想コストを計算する実行可能コードを含み、そして
そこで実行時セグメント(30―34)は、それぞれの計算カーネルを実行するために少なくとも2つの異なる処理ユニットのうちの1つを選択するための実行可能コードを含み、少なくとも2つの処理ユニットのうちの選択された1つの計算された期待コストは決定された予想コストの最低値に対応する
システム。 - 請求項16の異種計算システムであって、さらに
上記異種計算システムは、少なくとも2つの異なる処理ユニット(71、72)と結合されたベースプロセッサを備え
そこで上記ベースプロセッサは、少なくとも2つの異なる処理ユニット(71、72)のうちの少なくとも1つにそれぞれの計算カーネルをロードするように構成され、
そこで異種計算システムは異種コンピュータであり、
そこでベースプロセッサは異種コンピュータのホストコントローラのホストプロセッサであり、
ベースプロセッサは、少なくとも2つの異なる処理ユニットのうちの1つを形成し、
少なくとも2つの異なる処理ユニットのうちの少なくとも1つは、シングルコアCPU、マルチコアCPU、CPUベクトル拡張、GPU、SIMDアクセラレータ、DSP、マイクロプロセッサ、マイクロコントローラ、およびFPGAからなる群から選択され、
そしてまたは
そこで少なくとも2つの異なる処理ユニットのうちの少なくとも1つは、少なくとも1つのシングルコアCPU、少なくとも1つのマルチコアCPU、少なくとも1つのCPUベクトル拡張、少なくとも1つのGPU、少なくとも1つのSIMDアクセラレータ、少なくとも1つのDSP、少なくとも1つのマイクロプロセッサ、少なくとも1つのマイクロコントローラ、およびまたは少なくとも1つのFPGAを含む
システム。 - 請求項16または17に記載の異種計算システムであって、
そこで前記データメタ情報は、実行時インスタンス(A1)の実行時同期情報、および実行時インスタンス(A1)の実行時タイプ情報の少なくとも1つを含み、
そしてまたは
そこで異種計算システムは、請求項1から10のいずれかに記載の方法を実行するように形成される
システム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102017109239.0 | 2017-04-28 | ||
| DE102017109239.0A DE102017109239A1 (de) | 2017-04-28 | 2017-04-28 | Computerimplementiertes verfahren, computerlesbares medium und heterogenes rechnersystem |
| PCT/EP2018/060932 WO2018197695A1 (en) | 2017-04-28 | 2018-04-27 | A computer-implemented method, a computer-readable medium and a heterogeneous computing system |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2020518881A JP2020518881A (ja) | 2020-06-25 |
| JP2020518881A5 JP2020518881A5 (ja) | 2021-05-20 |
| JP7220914B2 true JP7220914B2 (ja) | 2023-02-13 |
Family
ID=62063083
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019547267A Active JP7220914B2 (ja) | 2017-04-28 | 2018-04-27 | コンピュータに実装する方法、コンピュータ可読媒体および異種計算システム |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US11144348B2 (ja) |
| EP (1) | EP3443458B1 (ja) |
| JP (1) | JP7220914B2 (ja) |
| CN (1) | CN110383247B (ja) |
| DE (1) | DE102017109239A1 (ja) |
| WO (1) | WO2018197695A1 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11188348B2 (en) * | 2018-08-31 | 2021-11-30 | International Business Machines Corporation | Hybrid computing device selection analysis |
| US11604757B2 (en) * | 2019-07-17 | 2023-03-14 | International Business Machines Corporation | Processing data in memory using an FPGA |
| CN111090508B (zh) * | 2019-11-29 | 2023-04-14 | 西安交通大学 | 一种基于OpenCL的异构协同并行计算中设备间动态任务调度方法 |
| CN113590086B (zh) * | 2020-04-30 | 2023-09-12 | 广东中砼物联网科技有限公司 | 快速开发软件的方法、计算机设备、及存储介质 |
| CN112083956B (zh) * | 2020-09-15 | 2022-12-09 | 哈尔滨工业大学 | 一种面向异构平台的复杂指针数据结构自动管理系统 |
| CN112364053B (zh) * | 2020-11-25 | 2023-09-05 | 成都佳华物链云科技有限公司 | 一种搜索优化方法、装置、电子设备及存储介质 |
| CN112486684B (zh) * | 2020-11-30 | 2022-08-12 | 展讯半导体(成都)有限公司 | 行车影像显示方法、装置及平台、存储介质、嵌入式设备 |
| CN112783503B (zh) * | 2021-01-18 | 2023-12-22 | 中山大学 | 一种基于Arm架构的NumPy运算加速优化方法 |
| CN114003973A (zh) * | 2021-10-13 | 2022-02-01 | 杭州趣链科技有限公司 | 数据处理方法、装置、电子设备和存储介质 |
| CN114185687B (zh) * | 2022-02-14 | 2022-05-24 | 中国人民解放军国防科技大学 | 一种面向共享内存式协处理器的堆内存管理方法和装置 |
| EP4227795A1 (en) | 2022-02-15 | 2023-08-16 | ILNumerics GmbH | A computer-implemented method and a computer-readable medium |
| CN115167637B (zh) * | 2022-09-08 | 2022-12-13 | 中国电子科技集团公司第十五研究所 | 一种易扩展可重构的计算机系统及计算机 |
| CN116089050B (zh) * | 2023-04-13 | 2023-06-27 | 湖南大学 | 一种异构自适应任务调度方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007328415A (ja) | 2006-06-06 | 2007-12-20 | Univ Waseda | ヘテロジニアス・マルチプロセッサシステムの制御方法及びマルチグレイン並列化コンパイラ |
| US20110173155A1 (en) | 2010-01-12 | 2011-07-14 | Nec Laboratories America, Inc. | Data aware scheduling on heterogeneous platforms |
| JP2012525753A (ja) | 2009-05-01 | 2012-10-22 | ミリクス リミテッド | 通信システム及び方法 |
| JP2014102683A (ja) | 2012-11-20 | 2014-06-05 | Fujitsu Ltd | 情報処理装置の制御プログラム、情報処理装置の制御方法および情報処理装置 |
| JP2015509622A (ja) | 2012-02-08 | 2015-03-30 | インテル・コーポレーション | 電力を使用するダイナミックcpugpuロードバランシング |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8074059B2 (en) * | 2005-09-02 | 2011-12-06 | Binl ATE, LLC | System and method for performing deterministic processing |
| US8522217B2 (en) * | 2010-04-20 | 2013-08-27 | Microsoft Corporation | Visualization of runtime analysis across dynamic boundaries |
| US20150309808A1 (en) * | 2010-12-31 | 2015-10-29 | Morphing Machines Pvt Ltd | Method and System on Chip (SoC) for Adapting a Reconfigurable Hardware for an Application in Runtime |
| US8782645B2 (en) * | 2011-05-11 | 2014-07-15 | Advanced Micro Devices, Inc. | Automatic load balancing for heterogeneous cores |
| US8566559B2 (en) * | 2011-10-10 | 2013-10-22 | Microsoft Corporation | Runtime type identification of native heap allocations |
| US9235801B2 (en) * | 2013-03-15 | 2016-01-12 | Citrix Systems, Inc. | Managing computer server capacity |
| US11243816B2 (en) * | 2014-03-30 | 2022-02-08 | UniversiteitGent | Program execution on heterogeneous platform |
| WO2017016590A1 (en) * | 2015-07-27 | 2017-02-02 | Hewlett-Packard Development Company, L P | Scheduling heterogenous processors |
-
2017
- 2017-04-28 DE DE102017109239.0A patent/DE102017109239A1/de not_active Withdrawn
-
2018
- 2018-04-27 WO PCT/EP2018/060932 patent/WO2018197695A1/en active Application Filing
- 2018-04-27 CN CN201880016139.1A patent/CN110383247B/zh active Active
- 2018-04-27 EP EP18720259.3A patent/EP3443458B1/en active Active
- 2018-04-27 US US16/607,263 patent/US11144348B2/en active Active
- 2018-04-27 JP JP2019547267A patent/JP7220914B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007328415A (ja) | 2006-06-06 | 2007-12-20 | Univ Waseda | ヘテロジニアス・マルチプロセッサシステムの制御方法及びマルチグレイン並列化コンパイラ |
| JP2012525753A (ja) | 2009-05-01 | 2012-10-22 | ミリクス リミテッド | 通信システム及び方法 |
| US20110173155A1 (en) | 2010-01-12 | 2011-07-14 | Nec Laboratories America, Inc. | Data aware scheduling on heterogeneous platforms |
| JP2015509622A (ja) | 2012-02-08 | 2015-03-30 | インテル・コーポレーション | 電力を使用するダイナミックcpugpuロードバランシング |
| JP2014102683A (ja) | 2012-11-20 | 2014-06-05 | Fujitsu Ltd | 情報処理装置の制御プログラム、情報処理装置の制御方法および情報処理装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110383247B (zh) | 2023-04-28 |
| US20200301736A1 (en) | 2020-09-24 |
| WO2018197695A1 (en) | 2018-11-01 |
| EP3443458B1 (en) | 2024-02-28 |
| EP3443458A1 (en) | 2019-02-20 |
| CN110383247A (zh) | 2019-10-25 |
| US11144348B2 (en) | 2021-10-12 |
| DE102017109239A1 (de) | 2018-10-31 |
| EP3443458C0 (en) | 2024-02-28 |
| JP2020518881A (ja) | 2020-06-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7220914B2 (ja) | コンピュータに実装する方法、コンピュータ可読媒体および異種計算システム | |
| Wang et al. | Supporting very large models using automatic dataflow graph partitioning | |
| Planas et al. | Self-adaptive OmpSs tasks in heterogeneous environments | |
| EP2710467B1 (en) | Automatic kernel migration for heterogeneous cores | |
| WO2015150342A1 (en) | Program execution on heterogeneous platform | |
| US11579905B2 (en) | Systems and methods for automatic data management for an asynchronous task-based runtime | |
| Zhang et al. | Optimizing the Barnes-Hut algorithm in UPC | |
| Sabne et al. | Scaling large-data computations on multi-GPU accelerators | |
| JP2019049843A (ja) | 実行ノード選定プログラム、実行ノード選定方法及び情報処理装置 | |
| Edmonds et al. | Expressing graph algorithms using generalized active messages | |
| Cui et al. | Directive-based partitioning and pipelining for graphics processing units | |
| KR20240090423A (ko) | 최적화된 레이턴시를 가진 멀티-프로세서 시스템을 위한 프로세싱 코드들의 자동-병렬화를 위한 시스템 및 그의 방법 | |
| Baskaran et al. | Automatic code generation and data management for an asynchronous task-based runtime | |
| Fumero et al. | Using compiler snippets to exploit parallelism on heterogeneous hardware: a Java reduction case study | |
| US20230259338A1 (en) | Computer-implemented method and a computer-readable medium | |
| Ying | Compiler-Hardware Co-Design for Pervasive Parallelization | |
| Parsa et al. | Nested-loops tiling for parallelization and locality optimization | |
| Sarkar | The era of GPU Computing using CUDA C and JCUDA | |
| Clucas et al. | Ripple: Simplified Large-Scale Computation on Heterogeneous Architectures with Polymorphic Data Layout | |
| Li | Facilitating emerging applications on many-core processors | |
| Wu | Facilitating the Deployment of Irregular Applications on Parallel Manycore Architecture by Identifying Irregular Patterns | |
| Garcia de Gonzalo | Techniques for enabling GPU code generation of low-level optimizations and dynamic parallelism from high-level abstractions | |
| Planas et al. | Selection of task implementations in the Nanos++ runtime | |
| Hong | Code Optimization on GPUs | |
| Barigou | On Communication-Computation Overlap in High-Performance Computing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210406 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20210406 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220224 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220315 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220614 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20221018 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221203 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230110 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230125 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7220914 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |