JP7166370B2 - 音声記録のための音声認識率を向上させる方法、システム、およびコンピュータ読み取り可能な記録媒体 - Google Patents
音声記録のための音声認識率を向上させる方法、システム、およびコンピュータ読み取り可能な記録媒体 Download PDFInfo
- Publication number
- JP7166370B2 JP7166370B2 JP2021014195A JP2021014195A JP7166370B2 JP 7166370 B2 JP7166370 B2 JP 7166370B2 JP 2021014195 A JP2021014195 A JP 2021014195A JP 2021014195 A JP2021014195 A JP 2021014195A JP 7166370 B2 JP7166370 B2 JP 7166370B2
- Authority
- JP
- Japan
- Prior art keywords
- voice
- recording
- user
- custom
- keyword
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images














Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/22—Interactive procedures; Man-machine interfaces
- G10L17/24—Interactive procedures; Man-machine interfaces the user being prompted to utter a password or a predefined phrase
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/225—Feedback of the input speech
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Signal Processing (AREA)
- User Interface Of Digital Computer (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Signal Processing For Digital Recording And Reproducing (AREA)
Description
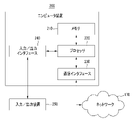
310:音声記録生成部
320:メモマッチング管理部
330:音声記録提供部
Claims (18)
- コンピュータ装置が実行する音声記録管理方法であって、
前記コンピュータ装置は、メモリに含まれるコンピュータ読み取り可能な命令を実行するように構成された少なくとも1つのプロセッサを含み、
前記音声記録管理方法は、
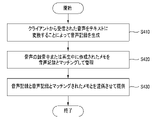
前記少なくとも1つのプロセッサにより、音声をテキストに変換して音声記録を生成する段階、
前記少なくとも1つのプロセッサにより、前記音声の録音中にユーザが作成したメモを前記音声記録とマッチングして管理する段階、および
前記少なくとも1つのプロセッサにより、前記メモからカスタムキーワードを抽出する段階
を含み、
前記生成する段階は、
前記音声と関連して前記カスタムキーワードに加重値を適用した音声認識を実行する段階
を含む、音声記録管理方法。 - 前記実行する段階は、
前記カスタムキーワードに加重値を適用して優先順位を上げ、前記音声認識を実行すること
を特徴とする、請求項1に記載の音声記録管理方法。 - 前記実行する段階は、
前記音声の話者発声区間ごとに、該当の区間にマッチングされたメモから前記カスタムキーワードを抽出して前記音声認識を実行すること
を特徴とする、請求項1に記載の音声記録管理方法。 - 前記実行する段階は、
前記ユーザが前記音声記録に関する情報として入力した単語から前記カスタムキーワードを抽出する段階
を含む、請求項1~3のうちのいずれか一項に記載の音声記録管理方法。 - 前記実行する段階は、
前記ユーザが入力した前記音声記録のタイトルと対話に参加する参加者情報から前記カスタムキーワードを抽出する段階
を含む、請求項1~4のうちのいずれか一項に記載の音声記録管理方法。 - 前記実行する段階は、
前記ユーザが頻繁に使用する単語として登録されたキーワードを前記カスタムキーワードとして抽出する段階
を含む、請求項1~5のうちのいずれか一項に記載の音声記録管理方法。 - 前記音声記録管理方法は、
前記少なくとも1つのプロセッサにより、前記音声記録に含まれたテキストに対して編集機能を提供する段階
をさらに含み、
前記実行する段階は、
前記編集機能を利用して前記ユーザが編集した単語から前記カスタムキーワードを抽出する段階
を含む、請求項1~6のうちのいずれか一項に記載の音声記録管理方法。 - 前記実行する段階は、
前記ユーザが入力した単語の種類または類型に基づく加重値によって前記カスタムキーワードを抽出する段階
を含む、請求項1~7のうちのいずれか一項に記載の音声記録管理方法。 - 前記実行する段階は、
前記ユーザが入力した単語に対する誤字脱字チェックにより、一部の単語を前記カスタムキーワードから除外させる段階
を含む、請求項1~8のうちのいずれか一項に記載の音声記録管理方法。 - 請求項1~9のうちのいずれか一項に記載の音声記録管理方法をコンピュータに実行させるためのプログラムが記録されている、コンピュータ読み取り可能な記録媒体。
- コンピュータ装置であって、
メモリに含まれるコンピュータ読み取り可能な命令を実行するように構成された少なくとも1つのプロセッサ
を含み、
前記少なくとも1つのプロセッサは、
音声をテキストに変換して音声記録を生成する音声記録生成部、および
前記音声の録音中にユーザが作成したメモを前記音声記録とマッチングして管理するメモマッチング管理部
を含み、
前記音声記録生成部は、
前記メモからカスタムキーワードを抽出し、
前記音声記録生成部は、
前記音声と関連して前記カスタムキーワードに加重値を適用した音声認識を実行すること
を特徴とする、コンピュータ装置。 - 前記音声記録生成部は、
前記カスタムキーワードに加重値を適用して優先順位を上げ、前記音声認識を実行すること
を特徴とする、請求項11に記載のコンピュータ装置。 - 前記音声記録生成部は、
前記音声の話者発声区間ごとに、該当の区間にマッチングされたメモから前記カスタムキーワードを抽出して前記音声認識を実行すること
を特徴とする、請求項11に記載のコンピュータ装置。 - 前記音声記録生成部は、
前記ユーザが前記音声記録に関する情報として入力した単語から前記カスタムキーワードを抽出すること
を特徴とする、請求項11~13のうちのいずれか一項に記載のコンピュータ装置。 - 前記音声記録生成部は、
前記ユーザが入力した前記音声記録のタイトルと対話に参加する参加者情報から前記カスタムキーワードを抽出すること
を特徴とする、請求項11~14のうちのいずれか一項に記載のコンピュータ装置。 - 前記音声記録生成部は、
前記ユーザが頻繁に使用する単語として登録されたキーワードを前記カスタムキーワードとして抽出すること
を特徴とする、請求項11~15のうちのいずれか一項に記載のコンピュータ装置。 - 前記少なくとも1つのプロセッサは、
前記音声記録に含まれたテキストに対して編集機能を提供する音声記録提供部
をさらに含み、
前記音声記録生成部は、
前記編集機能を利用して前記ユーザが編集した単語から前記カスタムキーワードを抽出すること
を特徴とする、請求項11~16のうちのいずれか一項に記載のコンピュータ装置。 - 前記音声記録生成部は、
前記ユーザが入力した単語の種類または類型に基づく加重値によって前記カスタムキーワードを抽出すること
を特徴とする、請求項11~17のうちのいずれか一項に記載のコンピュータ装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2020-0137324 | 2020-10-22 | ||
| KR1020200137324A KR102446300B1 (ko) | 2020-10-22 | 2020-10-22 | 음성 기록을 위한 음성 인식률을 향상시키는 방법, 시스템, 및 컴퓨터 판독가능한 기록 매체 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022068817A JP2022068817A (ja) | 2022-05-10 |
| JP7166370B2 true JP7166370B2 (ja) | 2022-11-07 |
Family
ID=81428729
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021014195A Active JP7166370B2 (ja) | 2020-10-22 | 2021-02-01 | 音声記録のための音声認識率を向上させる方法、システム、およびコンピュータ読み取り可能な記録媒体 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7166370B2 (ja) |
| KR (1) | KR102446300B1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102715945B1 (ko) * | 2021-04-07 | 2024-10-10 | 네이버 주식회사 | 음성 녹음 후의 정보에 기초하여 생성된 음성 기록을 제공하는 방법 및 시스템 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007226091A (ja) | 2006-02-27 | 2007-09-06 | Nippon Hoso Kyokai <Nhk> | 音声認識装置及び音声認識プログラム |
| JP2010175765A (ja) | 2009-01-29 | 2010-08-12 | Nippon Hoso Kyokai <Nhk> | 音声認識装置および音声認識プログラム |
| JP2011257878A (ja) | 2010-06-07 | 2011-12-22 | Nippon Telegr & Teleph Corp <Ntt> | 重要語句抽出装置及び方法及びプログラム |
| JP2019105751A (ja) | 2017-12-13 | 2019-06-27 | 大日本印刷株式会社 | 表示制御装置、プログラム、表示システム、表示制御方法及び表示データ |
| US20200403818A1 (en) | 2019-06-24 | 2020-12-24 | Dropbox, Inc. | Generating improved digital transcripts utilizing digital transcription models that analyze dynamic meeting contexts |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4218758B2 (ja) * | 2004-12-21 | 2009-02-04 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 字幕生成装置、字幕生成方法、及びプログラム |
-
2020
- 2020-10-22 KR KR1020200137324A patent/KR102446300B1/ko active Active
-
2021
- 2021-02-01 JP JP2021014195A patent/JP7166370B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007226091A (ja) | 2006-02-27 | 2007-09-06 | Nippon Hoso Kyokai <Nhk> | 音声認識装置及び音声認識プログラム |
| JP2010175765A (ja) | 2009-01-29 | 2010-08-12 | Nippon Hoso Kyokai <Nhk> | 音声認識装置および音声認識プログラム |
| JP2011257878A (ja) | 2010-06-07 | 2011-12-22 | Nippon Telegr & Teleph Corp <Ntt> | 重要語句抽出装置及び方法及びプログラム |
| JP2019105751A (ja) | 2017-12-13 | 2019-06-27 | 大日本印刷株式会社 | 表示制御装置、プログラム、表示システム、表示制御方法及び表示データ |
| US20200403818A1 (en) | 2019-06-24 | 2020-12-24 | Dropbox, Inc. | Generating improved digital transcripts utilizing digital transcription models that analyze dynamic meeting contexts |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102446300B1 (ko) | 2022-09-22 |
| JP2022068817A (ja) | 2022-05-10 |
| KR20220053182A (ko) | 2022-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI807428B (zh) | 一同管理與語音檔有關的文本轉換記錄和備忘錄的方法、系統及電腦可讀記錄介質 | |
| US10902841B2 (en) | Personalized custom synthetic speech | |
| CN107464555B (zh) | 增强包含语音的音频数据的方法、计算装置和介质 | |
| US20210082394A1 (en) | Method, apparatus, device and computer storage medium for generating speech packet | |
| CN103558964B (zh) | 电子设备中的多层次话音反馈 | |
| JP6280312B2 (ja) | 議事録記録装置、議事録記録方法及びプログラム | |
| CN118689347A (zh) | 智能体的生成方法、交互方法、装置、介质及设备 | |
| KR20200011198A (ko) | 대화형 메시지 구현 방법, 장치 및 프로그램 | |
| KR102353797B1 (ko) | 영상 컨텐츠에 대한 합성음 실시간 생성에 기반한 컨텐츠 편집 지원 방법 및 시스템 | |
| JP7166370B2 (ja) | 音声記録のための音声認識率を向上させる方法、システム、およびコンピュータ読み取り可能な記録媒体 | |
| CN108153904A (zh) | 语料收集方法、装置和计算机设备 | |
| JP7225380B2 (ja) | 音声パケット記録機能のガイド方法、装置、デバイス、プログラム及びコンピュータ記憶媒体 | |
| KR102677498B1 (ko) | 음성을 텍스트로 변환한 음성 기록에서 유사 발음의 단어를 포함하여 검색하는 방법, 시스템, 및 컴퓨터 판독가능한 기록 매체 | |
| JP7128222B2 (ja) | 映像コンテンツに対する合成音のリアルタイム生成を基盤としたコンテンツ編集支援方法およびシステム | |
| JP7254842B2 (ja) | アプリとウェブサイトの連動によって音声ファイルに対するメモを作成する方法、システム、およびコンピュータ読み取り可能な記録媒体 | |
| KR102437752B1 (ko) | 인공지능 디바이스와 연동하여 음성 기록을 관리하는 방법, 시스템, 및 컴퓨터 판독가능한 기록 매체 | |
| JP7166373B2 (ja) | 音声ファイルに対するテキスト変換記録とメモをともに管理する方法、システム、およびコンピュータ読み取り可能な記録媒体 | |
| US20060149545A1 (en) | Method and apparatus of speech template selection for speech recognition | |
| KR20260035072A (ko) | 텍스트-음성 변환을 위한 화자 및 감정 조건 정보 생성 시스템 및 방법 | |
| US9471205B1 (en) | Computer-implemented method for providing a media accompaniment for segmented activities | |
| KR20260035071A (ko) | 사용자 인터페이스를 통한 텍스트 기반의 음성의 미세조정 시스템 및 방법 | |
| Hillmann | User Behaviour Model for the Evaluation of Interactive Systems | |
| Henri | Explanatory note |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20210201 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20210414 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20210412 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220315 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220610 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20221004 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20221025 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7166370 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313117 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |