JP7014129B2 - 推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム - Google Patents
推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム Download PDFInfo
- Publication number
- JP7014129B2 JP7014129B2 JP2018203331A JP2018203331A JP7014129B2 JP 7014129 B2 JP7014129 B2 JP 7014129B2 JP 2018203331 A JP2018203331 A JP 2018203331A JP 2018203331 A JP2018203331 A JP 2018203331A JP 7014129 B2 JP7014129 B2 JP 7014129B2
- Authority
- JP
- Japan
- Prior art keywords
- estimator
- data
- encoder
- learning
- subject
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images














Classifications
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60W—CONJOINT CONTROL OF VEHICLE SUB-UNITS OF DIFFERENT TYPE OR DIFFERENT FUNCTION; CONTROL SYSTEMS SPECIALLY ADAPTED FOR HYBRID VEHICLES; ROAD VEHICLE DRIVE CONTROL SYSTEMS FOR PURPOSES NOT RELATED TO THE CONTROL OF A PARTICULAR SUB-UNIT
- B60W40/00—Estimation or calculation of non-directly measurable driving parameters for road vehicle drive control systems not related to the control of a particular sub unit, e.g. by using mathematical models
- B60W40/08—Estimation or calculation of non-directly measurable driving parameters for road vehicle drive control systems not related to the control of a particular sub unit, e.g. by using mathematical models related to drivers or passengers
- B60W40/09—Driving style or behaviour
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/50—Context or environment of the image
- G06V20/59—Context or environment of the image inside of a vehicle, e.g. relating to seat occupancy, driver state or inner lighting conditions
- G06V20/597—Recognising the driver's state or behaviour, e.g. attention or drowsiness
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/174—Facial expression recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/70—Multimodal biometrics, e.g. combining information from different biometric modalities
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60W—CONJOINT CONTROL OF VEHICLE SUB-UNITS OF DIFFERENT TYPE OR DIFFERENT FUNCTION; CONTROL SYSTEMS SPECIALLY ADAPTED FOR HYBRID VEHICLES; ROAD VEHICLE DRIVE CONTROL SYSTEMS FOR PURPOSES NOT RELATED TO THE CONTROL OF A PARTICULAR SUB-UNIT
- B60W40/00—Estimation or calculation of non-directly measurable driving parameters for road vehicle drive control systems not related to the control of a particular sub unit, e.g. by using mathematical models
- B60W40/08—Estimation or calculation of non-directly measurable driving parameters for road vehicle drive control systems not related to the control of a particular sub unit, e.g. by using mathematical models related to drivers or passengers
- B60W2040/0872—Driver physiology
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60W—CONJOINT CONTROL OF VEHICLE SUB-UNITS OF DIFFERENT TYPE OR DIFFERENT FUNCTION; CONTROL SYSTEMS SPECIALLY ADAPTED FOR HYBRID VEHICLES; ROAD VEHICLE DRIVE CONTROL SYSTEMS FOR PURPOSES NOT RELATED TO THE CONTROL OF A PARTICULAR SUB-UNIT
- B60W2540/00—Input parameters relating to occupants
- B60W2540/22—Psychological state; Stress level or workload
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/15—Biometric patterns based on physiological signals, e.g. heartbeat, blood flow
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Evolutionary Computation (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Mathematical Physics (AREA)
- Databases & Information Systems (AREA)
- Human Computer Interaction (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Automation & Control Theory (AREA)
- Transportation (AREA)
- Mechanical Engineering (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
- Measurement Of The Respiration, Hearing Ability, Form, And Blood Characteristics Of Living Organisms (AREA)
- Measuring And Recording Apparatus For Diagnosis (AREA)
Description
本発明は、推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラムに関する。
近年、居眠り、体調の急変等に起因する自動車の交通事故を防止するため、運転者の状態を監視する技術の開発が進んでいる。また、自動車の自動運転の実現に向けた動きが加速している。自動運転は、システムにより自動車の操舵を制御するものであるが、システムに代わって運転者が運転しなければならない場面もあり得ることから、自動運転中であっても、運転者が運転操作を行える状態にあるか否かを監視する必要性があるとされている。この自動運転中に運転者の状態を監視する必要性があることは、国連欧州経済委員会(UN-ECE)の政府間会合(WP29)においても確認されている。この点からも、運転者の状態を監視する技術の開発が進められている。
運転者の状態を推定する技術として、例えば、特許文献1では、乗員の顔の写る顔画像データをカメラにより取得し、取得した顔画像データを解析することで、乗員の状態(例えば、眠気等)を推定する装置が提案されている。具体的には、特許文献1で提案されている装置は、ニューラルネットワーク等により構成された学習済みモデルを利用し、顔画像データから抽出された顔の特徴点に基づいて乗員の状態を推定する。これにより、この装置は、顔画像データから乗員の状態を推定することができる。
本件発明者らは、特許文献1等のような従来の方法では、次のような問題点があることを見出した。すなわち、機械学習を利用すれば、顔画像データから対象者の状態を推定する推定器を構築することができる。しかしながら、特許文献1のように、抽出する顔の特徴点を人間がデザインした場合には、その特徴点から導出される特徴量に対象者の状態が常に表れるとは限らない。そこで、このような問題点を解決するために、顔画像データから直接的に対象者の状態を推定するようにニューラルネットワーク等の学習モデルを訓練することが考えられる。この方法によれば、学習モデルは、学習の過程で、顔画像から導出する特徴量を自動的にデザインする。そのため、訓練された学習モデルは、顔画像データから対象者の状態を適切に推定することができる。しかしながら、訓練データ(入力データ)から正解データを導出するモデルの局所的な最適解は複数存在し、ニューラルネットワーク等の学習モデルのパラメータは、機械学習の過程において、いずれかの局所解に向かうことが知られている。そのため、機械学習の過程によっては、学習モデルのパラメータは、顔画像データから対象者の状態を推定する精度の比較的に低い局所解に向かう可能性がある。
したがって、従来の方法では、顔画像データから対象者の状態を高精度に推定可能な推定器(学習済みの学習モデル)を構築することができない可能性があるという問題点があることを本件発明者らは見出した。なお、この課題は、上記のような運転者の状態を推定する場面だけではなく、生産ラインにおける作業者の状態を推定する場面等、対象者の活動を観測することで得られた観測データから当該対象者の状態を推定するあらゆる場面で生じ得る。
本発明は、一側面では、このような実情を鑑みてなされたものであり、その目的は、対象者の状態をより高精度に推定可能な推定器を生成するための技術を提供することである。
本発明は、上述した課題を解決するために、以下の構成を採用する。
すなわち、本発明の一側面に係る推定器生成装置は、学習データ取得部及び学習処理部を備える。学習データ取得部は、車両を運転する被験者の顔の写る第1顔画像データ、及び前記車両の運転時における前記被験者の状態を示す第1状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得し、かつ前記被験者の顔の写る第2顔画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた第1生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する、ように構成される。学習処理部は、エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1顔画像データを前記エンコーダに入力すると、入力した前記第1顔画像データに関連付けられた前記第1状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2顔画像データを前記エンコーダに入力すると、入力した前記第2顔画像データに関連付けられた前記第1生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築する、ように構成される。
当該構成によれば、第1推定器及び第2推定器は、共通のエンコーダを有するように構成される。そして、第1推定器は、複数件の第1学習データセットを利用した機械学習により、第1顔画像データから第1状態情報データを導出するように訓練される。一方で、第2推定器は、複数件の第2学習データセットを利用した機械学習により、第2顔画像データから第1生理学的データを導出するように訓練される。そのため、両方の機械学習により、共通のエンコーダの出力(特徴量)は、第1状態情報データ及び第1生理学的データを導出可能にデザインされる。
ここで、生理学的データは、状態情報データに比べて、人間の状態に関する高次な情報を含み得る。したがって、第1状態情報データだけではなく、より高次な情報を含み得る第1生理学的データを導出可能に共通のエンコーダを訓練することで、共通のエンコーダのパラメータが、第1状態情報データを導出する(すなわち、対象者の状態を推定する)精度のよりよい局所解に向かうようにすることができる。よって、当該構成によれば、対象者の状態をより高精度に推定可能な推定器(第1推定器)を生成することができる。
なお、第1顔画像データと第2顔画像データとは共通であってもよいし、互いに異なっていてもよい。状態情報データは、対象者の何らかの状態を示し得るものであれば、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。生理学的データは、状態情報データにより示される対象者の状態に関係し得る生理学的パラメータを1又は複数のセンサで測定することで得られる。生理学的データは、1又は複数のセンサから得られたローデータであってもよいし、何らかの情報処理が適用された加工済みデータであってもよい。生理学的データは、状態情報データよりも人間の状態に関する高次な情報を含むように選択されるのが好ましい。生理学的パラメータは、例えば、脳活動(脳波、脳血流等)、眼球運動(瞳孔径、視線方向等)、筋電位、心電位、血圧、脈拍、心拍、体温、皮膚電気反応(galvanic skin reflex:GSR)又はこれらの組み合わせであってよい。センサは、例えば、脳波計、脳磁計、核磁気共鳴画像装置、カメラ、眼電位センサ、眼球運動計測器、筋電計、心電計、血圧計、脈拍計、心拍計、体温計、皮膚電気反応計又はこれらの組み合わせであってよい。カメラは、RGB画像等の一般的なカメラの他、深度画像を取得可能に構成された深度カメラ(距離カメラ、ステレオカメラ等)、サーモグラフィ画像を取得可能に構成されたサーモカメラ(赤外線カメラ等)等を含んでよい。眼球運動計測器は、瞳孔径の変化、視線方向等の眼球運動を計測するように構成される。眼球運動計測器による計測対象の眼球運動は、随意運動であってもよいし、不随意運動であってもよい。この眼球運動計測器は、例えば、瞳孔径計測装置、視線計測装置等であってよい。瞳孔径計測装置は、対象者の瞳孔径(の時間変化)を計測するように構成される。視線計測装置は、対象者の視線方向(の時間変化)を計測するように構成される。各学習データセットは、学習サンプルと称されてもよい。各顔画像データは、訓練データ又は入力データと称されてもよい。第1状態情報データ及び第1生理学的データはそれぞれ、正解データ又は教師データと称されてもよい。各推定器は、機械学習可能な学習モデルにより構成される。各推定器は、学習器と称されてもよい。
上記一側面に係る推定器生成装置において、前記各件の第1学習データセットを構成する前記第1顔画像データ及び前記第1状態情報データは実環境で収集されてよく、前記各件の第2学習データセットを構成する前記第2顔画像データ及び前記第1生理学的データは仮想環境で収集されてよい。
実環境は、訓練された推定器(第1推定器)を実際に運用する環境又はそれと同等の環境である。実環境は、例えば、車両内の空間、車両を模した構造物内の空間である。一方、仮想環境は、例えば、実験室等の、実環境ではない環境である。仮想環境では、実環境よりも、より高性能なセンサを用いて、人間の状態を示すより高次な情報を収集することが可能である。しかしながら、実環境では、そのような高性能なセンサを運用するのが困難であったり、運用できたとしても、コストがかかり過ぎてしまったり等の問題が生じ得る。
例えば、対象者の眠気の度合いを示す眠気度を対象者の状態として推定するために、生理学的データとして脳血流量の測定データを取得することを想定する。このような場合、生理学的データを収集するためのセンサとして、機能的核磁気共鳴画像法(Functional Magnetic Resonance Imaging, fMRI)により脳活動に関連した血流を撮影するよう構成された磁気共鳴画像装置が用いられる。この磁気共鳴画像装置によれば、対象者の状態(眠気度)をより高精度に推定可能な生理学的データを取得することが可能である。しかしながら、この磁気共鳴画像装置は、非常に大掛りである。そのため、実環境(例えば、車内)で、この磁気共鳴画像装置を運用することは困難である。
そこで、当該構成では、第1推定器の機械学習に利用する各第1学習データセットを実環境で収集するのに対して、第2推定器の機械学習に利用する各第2学習データセットを仮想環境で収集する。これにより、被験者の状態を示すより高次な情報を含み得る第1生理学的データが収集されるようにし、この第1生理学的データを利用した機械学習により、共通のエンコーダのパラメータが、実環境で容易に取得可能な顔画像データから対象者の状態を導出する精度のよりよい局所解に向かうようにすることができる。よって、当該構成によれば、実環境で容易に取得可能なデータから対象者の状態をより高精度に推定可能な推定器を生成することができ、これによって、実環境で推定器を運用するのにかかるコストを低減することができる。
上記一側面に係る推定器生成装置において、前記生理学的パラメータは、脳活動、筋電位、心電位、眼球運動(特に、瞳孔径)又はこれらの組み合わせで構成されてよい。当該構成によれば、被験者の状態を示すより高次な情報を含む第1生理学的データを取得することができ、これによって、共通のエンコーダのパラメータが、第1状態情報データを導出する精度のよりよい局所解に向かうようにすることができる。したがって、当該構成によれば、対象者の状態をより高精度に推定可能な推定器を生成することができる。なお、これらの生理学的データの測定には、例えば、脳波計(Electroencephalograph:EEG)、脳磁計(Magnetoencephalography:MEG)、機能的核磁気共鳴画像法により脳活動に関連した血流を撮影するように構成された核磁気共鳴画像装置、筋電計、心電計、眼電位センサ、眼球運動計測器(特に、瞳孔径計測装置)等が用いられてよい。
上記一側面に係る推定器生成装置において、前記第1状態情報データは、前記被験者の状態として、前記被験者の眠気の度合いを示す眠気度、前記被験者の疲労の度合いを示す疲労度、前記被験者の運転に対する余裕の度合いを示す余裕度、又はこれらの組み合わせを含んでもよい。当該構成によれば、眠気度、疲労度、余裕度、又はこれらの組み合わせをより高精度に推定可能な推定器を生成することができる。
上記一側面に係る推定器生成装置において、前記学習データ取得部は、前記被験者の顔の写る第3顔画像データ、及び前記第1生理学的データとは異なる前記被験者の第2生理学的データの組み合わせによりそれぞれ構成される複数件の第3学習データセットを更に取得するように構成されてよく、前記学習処理部は、前記第1推定器及び前記第2推定器の機械学習と共に、前記第1推定器の前記エンコーダ及び前記第2推定器の前記デコーダとは異なる他のデコーダにより構成される第3推定器であって、前記エンコーダの出力が前記他のデコーダに入力されるように前記エンコーダ及び前記他のデコーダが互いに接続された第3推定器の機械学習を実施することで、前記各件の第3学習データセットを構成する前記第3顔画像データを前記エンコーダに入力すると、入力した前記第3顔画像データに関連付けられた前記第2生理学的データを再現した出力データを前記他のデコーダから出力するように訓練された第3推定器を更に構築するように構成されてよい。当該構成によれば、第3推定器の機械学習の過程で、共通のエンコーダの出力が、第2生理学的データを更に導出可能にデザインされる。これにより、対象者の状態を更に高精度に推定可能な推定器を生成することができる。なお、第3推定器の機械学習に利用される第2生理学的データは、第1生理学的データと同じ生理学的パラメータを測定することで得られたものであってもよい。また、複数の第3推定器が設けられてもよい。
上記一側面に係る推定器生成装置において、前記学習データ取得部は、前記被験者の第3生理学的データ、及び前記被験者の状態を示す第2状態情報データの組み合わせによりそれぞれ構成される複数件の第4学習データセットを更に取得するように構成されてよい。そして、前記学習処理部は、前記第1推定器及び前記第2推定器の機械学習と共に、前記第1推定器の前記エンコーダとは異なる他のエンコーダ及び前記第1推定器の前記推定部により構成される第4推定器であって、前記他のエンコーダの出力が前記推定部に入力されるように前記他のエンコーダ及び前記推定部が互いに接続された第4推定器の機械学習を実施することで、前記各件の第4学習データセットを構成する前記第3生理学的データを前記他のエンコーダに入力すると、入力した前記第3生理学的データに関連付けられた前記第2状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第4推定器を構築し、かつ前記機械学習の過程において、前記第1推定器及び前記第4推定器を、前記第1状態情報データと前記第2状態情報データとが一致する場合に、前記第1状態情報データに関連付けられた前記第1顔画像データを前記エンコーダに入力することで前記エンコーダから得られる出力値と、前記第2状態情報データに関連付けられた前記第3生理学的データを前記他のエンコーダに入力することで前記他のエンコーダから得られる出力値との誤差が閾値よりも小さくなるように訓練する、ように構成されてよい。
当該構成では、第4推定器は、生理学的データから対象者の状態を導出するように訓練される。顔画像データからよりも、生理学的データからの方が対象者の状態をより高精度に推定可能であると期待することができる。そのため、この第4推定器は、顔画像データから対象者の状態を推定する推定器と比べて、対象者の状態をより高精度に推定可能であると期待することができる。そこで、当該構成では、この第4推定器における他のエンコーダの出力を、対象者の状態をより高精度に推定するための第1推定器におけるエンコーダの出力の見本として利用する。つまり、機械学習の過程において、第1推定器及び第4推定器を、エンコーダの出力と他のエンコーダの出力との誤差が閾値よりも小さくなるように訓練する。これにより、第1推定器におけるエンコーダのパラメータが、対象者の状態を推定する精度のよりよい局所解に向かうようにすることができる。よって、当該構成によれば、対象者の状態をより高精度に推定可能な推定器を生成することができる。
また、本発明の一側面に係るモニタリング装置は、車両を運転する対象者の顔の写る顔画像データを取得するデータ取得部と、上記いずれかの形態に係る推定器生成装置により構築された前記第1推定器の前記エンコーダに対して取得した前記顔画像データを入力することで、前記対象者の状態を推定した結果に対応する出力を前記第1推定器の前記推定部から取得する推定処理部と、前記対象者の状態を推定した結果に関連する情報を出力する出力部と、を備える。当該構成によれば、対象者の状態を高精度に推定することができる。
また、上記各形態に係る推定器生成装置及びモニタリング装置は、車両の運転者の状態を推定する場面だけではなく、例えば、生産ラインの作業者の状態を推定する場面等、運転者以外の対象者の状態を推定するあらゆる場面に適用されてよい。更に、上記各形態に係る推定器生成装置及びモニタリング装置は、対象者の顔の写る顔画像データから当該対象者の状態を推定する場面だけではなく、対象者の活動を観測することで得られた観測データから対象者の状態を推定するあらゆる場面に適用されてよい。例えば、上記各形態に係る推定器生成装置及びモニタリング装置は、対象者の写る画像データから当該対象者の状態を推定する場面、画像データ以外の他種のデータから対象者の状態を推定する場面等に適用されてよい。
例えば、本発明の一側面に係る推定器生成装置は、学習データ取得部であって、所定の作業を実行する被験者の写る第1画像データ、及び前記所定の作業を実行している時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得し、かつ前記被験者の写る第2画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する、ように構成される学習データ取得部と、学習処理部であって、エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1画像データを前記エンコーダに入力すると、入力した前記第1画像データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2画像データを前記エンコーダに入力すると、入力した前記第2画像データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築する、ように構成される学習処理部と、を備える。なお、所定の作業は、例えば、車両の運転、生産ラインにおける作業等であってよい。
例えば、本発明の一側面に係る推定器生成装置は、学習データ取得部であって、所定の作業を実行する被験者の活動を第1センサで測定することにより得られた第1観測データ、及び前記所定の作業を実行している時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得し、かつ前記被験者の活動を前記第1センサで測定することにより得られた第2観測データ、及び前記第1センサとは異なる種類の第2センサで前記被験者の生理学的パラメータを測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する、ように構成される学習データ取得部と、学習処理部であって、エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1観測データを前記エンコーダに入力すると、入力した前記第1観測データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2観測データを前記エンコーダに入力すると、入力した前記第2観測データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築する、ように構成される学習処理部と、を備える。
第1センサ及び第2センサは、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。第2センサは、第1センサよりも高機能であり、第1センサよりも人間の状態に関する高次な情報を取得可能に構成されるのが好ましい。一方、第1センサは、第2センサよりも安価であるのが好ましい。なお、2種類のデータのうちより高次な情報を含むデータを判別する方法には、例えば、次のような方法を採用することができる。すなわち、2種類のデータ及び被験者の状態の組み合わせで構成された学習サンプルを用意する。機械学習により、学習サンプルを用いて、一方のデータから被験者の状態を導出するよう訓練された第1学習モデル、及び他方のデータから被験者の状態を導出するように訓練された第2学習モデルを構築する。次に、2種類のデータ及び対象者の状態(正解)の組み合わせで構成された評価サンプルを用意する。学習済みの第1学習モデルを利用して、評価サンプルの一方のデータから対象者の状態を推定する。同様に、学習済みの第2学習モデルを利用して、評価サンプルの他方のデータから対象者の状態を推定する。そして、各学習モデルによる推定の精度を評価する。この評価の結果、第1学習モデルの方が第2学習モデルよりも導出精度が高い場合には、一方のデータの方が他方のデータよりも高次な情報を含んでいると判定することができる。これに対して、第2学習モデルの方が第1学習モデルよりも導出精度が高い場合には、他方のデータの方が一方のデータよりも高次な情報を含んでいると判定することができる。
上記一側面に係る推定器生成装置において、前記各件の第1学習データセットを構成する前記第1観測データ及び前記状態情報データは実環境で収集されてよく、前記各件の第2学習データセットを構成する前記第2観測データ及び前記生理学的データは仮想環境で収集されてよい。当該構成によれば、実環境で容易に取得可能なデータから対象者の状態をより高精度に推定可能な推定器を生成することができ、これによって、実環境で推定器を運用するのにかかるコストを低減することができる。
上記一側面に係る推定器生成装置において、前記第1センサは、カメラ、眼電位センサ、視線計測装置、マイクロフォン、血圧計、脈拍計、心拍計、体温計、皮膚電気反応計、荷重センサ、操作デバイス又はこれらの組み合わせにより構成されてよく、前記第2センサは、脳波計、脳磁計、核磁気共鳴画像装置、筋電計、心電計、瞳孔径計測装置又はこれらの組み合わせにより構成されてよい。当該構成によれば、実環境で容易に取得可能なデータから対象者の状態をより高精度に推定可能な推定器を生成することができ、これによって、実環境で推定器を運用するのにかかるコストを低減することができる。なお、荷重センサは、一点の荷重を計測するように構成されていてもよいし、荷重分布を計測するように構成されていてもよい。操作デバイスは、状態を推定する対象となる対象者が操作可能なデバイスであれば特に限定されなくてもよく、その種類は、実施の形態に応じて適宜選択されてよい。対象者が車両の運転を行うケースでは、操作デバイスは、例えば、ハンドル、ブレーキ、アクセル等であってよい。第1センサにより得られる観測データは、例えば、画像データ、眼電位データ、視線の計測データ、音声データ、血圧データ、脈拍数データ、心拍数データ、体温データ、皮膚電気反射データ、荷重の計測データ、操作ログ又はこれらの組み合わせにより構成される。操作ログは、操作デバイスの操作履歴を示す。
上記各形態に係る推定器生成装置及びモニタリング装置それぞれの別の態様として、本発明の一側面は、以上の各構成を実現する情報処理方法であってもよいし、プログラムであってもよいし、このようなプログラムを記憶した、コンピュータ等が読み取り可能な記憶媒体であってもよい。ここで、コンピュータ等が読み取り可能な記憶媒体とは、プログラム等の情報を、電気的、磁気的、光学的、機械的、又は、化学的作用によって蓄積する媒体である。また、本発明の一側面に係る推定システムは、上記いずれかの形態に係る推定器生成装置及びモニタリング装置により構成されてもよい。
例えば、本発明の一側面に係る推定器生成方法は、コンピュータが、車両を運転する被験者の顔の写る第1顔画像データ、及び前記車両の運転時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得するステップと、前記被験者の顔の写る第2顔画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得するステップと、エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1顔画像データを前記エンコーダに入力すると、入力した前記第1顔画像データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2顔画像データを前記エンコーダに入力すると、入力した前記第2顔画像データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築するステップと、を実行する、情報処理方法である。
また、例えば、本発明の一側面に係る推定器生成プログラムは、コンピュータに、車両を運転する被験者の顔の写る第1顔画像データ、及び前記車両の運転時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得するステップと、前記被験者の顔の写る第2顔画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得するステップと、エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1顔画像データを前記エンコーダに入力すると、入力した前記第1顔画像データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2顔画像データを前記エンコーダに入力すると、入力した前記第2顔画像データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築するステップと、を実行させるための、プログラムである。
本発明によれば、人間の状態をより高精度に推定可能な推定器を生成することができる。
以下、本発明の一側面に係る実施の形態(以下、「本実施形態」とも表記する)を、図面に基づいて説明する。ただし、以下で説明する本実施形態は、あらゆる点において本発明の例示に過ぎない。本発明の範囲を逸脱することなく種々の改良や変形を行うことができることは言うまでもない。つまり、本発明の実施にあたって、実施形態に応じた具体的構成が適宜採用されてもよい。なお、本実施形態において登場するデータを自然言語により説明しているが、より具体的には、コンピュータが認識可能な疑似言語、コマンド、パラメータ、マシン語等で指定される。
§1 適用例
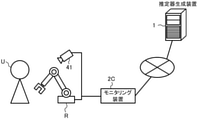
まず、図1を用いて、本発明が適用される場面の一例について説明する。図1は、本実施形態に係る推定システム100の適用場面の一例を模式的に例示する。図1の例では、車両を運転する運転者の状態を顔画像データから導出する場面を想定している。車両の運転は、本発明の「所定の作業」の一例であり、顔画像データは、本発明の「画像データ」及び「観測データ」の一例である。ただし、本発明の適用対象は、このような例に限定されなくてもよい。本発明は、観測データから対象者の状態を推定する場面に広く適用可能である。
まず、図1を用いて、本発明が適用される場面の一例について説明する。図1は、本実施形態に係る推定システム100の適用場面の一例を模式的に例示する。図1の例では、車両を運転する運転者の状態を顔画像データから導出する場面を想定している。車両の運転は、本発明の「所定の作業」の一例であり、顔画像データは、本発明の「画像データ」及び「観測データ」の一例である。ただし、本発明の適用対象は、このような例に限定されなくてもよい。本発明は、観測データから対象者の状態を推定する場面に広く適用可能である。
図1に示されるとおり、本実施形態に係る推定システム100は、ネットワークを介して互いに接続される推定器生成装置1及びモニタリング装置2を備えている。これにより、本実施形態に係る推定システム100は、顔画像データから対象者の状態を推定するための推定器を生成し、生成した推定器により運転者の状態を推定するように構成される。推定器生成装置1及びモニタリング装置2の間のネットワークの種類は、例えば、インターネット、無線通信網、移動通信網、電話網、専用網等から適宜選択されてよい。
本実施形態に係る推定器生成装置1は、機械学習を実施することにより、顔画像データから対象者の状態を推定するための推定器(第1推定器51)を構築するように構成されたコンピュータである。具体的には、まず、本実施形態に係る推定器生成装置1は、複数件の第1学習データセット71及び複数件の第2学習データセット72を取得する。
各件の第1学習データセット71は、車両を運転する被験者Tの顔の写る第1顔画像データ711、及び車両の運転時における被験者Tの状態を示す状態情報データ712の組み合わせにより構成される。第1顔画像データ711は、例えば、車両内の空間(実環境)で、運転席についた被験者Tの顔を撮影可能に配置されたカメラ31により得られてよい。状態情報データ712は、本発明の「第1状態情報データ」の一例である。機械学習の対象となる対象者の状態は、例えば、眠気の度合いを示す眠気度、疲労の度合いを示す疲労度、運転に対する余裕の度合いを示す余裕度、又はこれらの組み合わせであってよい。これに応じて、状態情報データ712は、例えば、被験者Tの状態として、被験者Tの眠気の度合いを示す眠気度、被験者Tの疲労の度合いを示す疲労度、被験者Tの運転に対する余裕の度合いを示す余裕度、又はこれらの組み合わせを含むように構成されてよい。
一方、各件の第2学習データセット72は、被験者Tの顔の写る第2顔画像データ721、及び被験者Tの生理学的パラメータを1又は複数のセンサで測定することにより得られた生理学的データ722の組み合わせにより構成される。例えば、第2顔画像データ721は、実験室等の仮想環境で、被験者Tの顔を撮影可能に配置されたカメラ32により得られてよい。また、生理学的データ722は、本発明の「第1生理学的データ」の一例である。生理学的データ722は、例えば、脳波計33により脳波を測定することで得られてよい。脳波は、本発明の「生理学的パラメータ」の一例であり、脳波計33は、本発明の「センサ」の一例である。各カメラ(31、32)の種類は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。各カメラ(31、32)には、例えば、デジタルカメラ、ビデオカメラ等の一般的なカメラの他、深度画像を取得可能に構成された深度カメラ(距離カメラ、ステレオカメラ等)、サーモグラフィ画像を取得可能に構成されたサーモカメラ(赤外線カメラ等)等が用いられてよい。
続いて、本実施形態に係る推定器生成装置1は、取得した複数件の第1学習データセット71及び複数件の第2学習データセット72を利用して、学習ネットワーク5の機械学習を実施する。本実施形態に係る学習ネットワーク5は、第1推定器51及び第2推定器52を備えている。第1推定器51は、エンコーダ61及び推定部62により構成されている。エンコーダ61及び推定部62は、エンコーダ61の出力が推定部62に入力されるように互いに接続されている。第2推定器52は、第1推定器51のエンコーダ61及びデコーダ63により構成されている。つまり、本実施形態では、第1推定器51及び第2推定器52は、共通のエンコーダ61を有している。エンコーダ61及びデコーダ63は、エンコーダ61の出力がデコーダ63に入力されるように互いに接続されている。
本実施形態に係る推定器生成装置1は、複数件の第1学習データセット71を利用して、第1推定器51の機械学習を実施する。これにより、推定器生成装置1は、各件の第1学習データセット71を構成する第1顔画像データ711をエンコーダ61に入力すると、入力した第1顔画像データ711に関連付けられた状態情報データ712により示される被験者Tの状態に対応する出力値を推定部62から出力するように訓練された第1推定器51を構築する。また、本実施形態に係る推定器生成装置1は、複数件の第2学習データセット72を利用して、第2推定器52の機械学習を実施する。これにより、推定器生成装置1は、各件の第2学習データセット72を構成する第2顔画像データ721をエンコーダ61に入力すると、入力した第2顔画像データ721に関連付けられた生理学的データ722を再現した出力データをデコーダ63から出力するように訓練された第2推定器52を構築する。これらの機械学習により、顔画像データから対象者の状態を推定するための推定器(第1推定器51)が生成される。
一方、本実施形態に係るモニタリング装置2は、推定器生成装置1により生成された学習済みの推定器(第1推定器51)を利用して、車両を運転する運転者Dの状態を顔画像データから推定するように構成されたコンピュータである。具体的には、モニタリング装置2は、まず、車両を運転する運転者Dの顔の写る顔画像データを取得する。運転者Dは、本発明の「対象者」の一例である。顔画像データは、例えば、運転席についた運転者Dの顔を撮影可能に配置されたカメラ41により得られてよい。
続いて、本実施形態に係るモニタリング装置2は、推定器生成装置1により構築された第1推定器51のエンコーダ61に、取得した顔画像データを入力することにより、運転者Dの状態を推定した結果に対応する出力を第1推定器51の推定部62から取得する。これにより、モニタリング装置2は、運転者Dの状態を推定する。そして、モニタリング装置2は、運転者Dの状態を推定した結果に関連する情報を出力する。
以上のとおり、本実施形態では、第1推定器51及び第2推定器52は、共通のエンコーダ61を有するように構成される。第1推定器51は、複数件の第1学習データセット71を利用した機械学習により、顔画像データから対象者の状態を推定するように訓練される。一方で、第2推定器52は、複数件の第2学習データセット72を利用した機械学習により、顔画像データから対象者の生理学的な現象を再現するように訓練される。そのため、両推定器(51、52)の機械学習により、共通のエンコーダ61の出力(特徴量)は、顔画像データから対象者の状態及び生理学的な現象を導出可能にデザインされる。
ここで、生理学的データ722は、状態情報データ712に比べて、人間の状態に関する高次な情報を含み得る。例えば、生理学的データ722が脳波計33により得られる場合、生理学的データ722は、人間の脳活動に関する情報を含む。これに対して、状態情報データ712により示される人間の状態は、眠気度、疲労度、余裕度、又はこれらの組み合わせである。人間の脳活動に関する情報を利用すれば、眠気度、疲労度、及び余裕度を導出することができ、かつその他の人間の状態を導出することも可能である。そのため、生理学的データ722は、状態情報データ712に比べて、人間の状態に関する高次な情報を含む。
したがって、状態情報データ712だけではなく、より高次な情報を含み得る生理学的データ722を導出可能に共通のエンコーダ61を訓練することで、共通のエンコーダ61のパラメータが、状態情報データ712を導出する(すなわち、対象者の状態を推定する)精度のよりよい局所解に向かうようにすることができる。よって、本実施形態に係る推定器生成装置1によれば、対象者の状態をより高精度に推定可能な推定器(第1推定器51)を生成することができる。
加えて、第1学習データセット71及び第2学習データセット72の件数が十分であれば、共通のエンコーダ61は、人間の状態及び生理学的な現象の両方を導出可能な特徴量を出力するように適切に訓練される。そのため、第1学習データセット71及び第2学習データセット72のいずれか一方の件数が少ない場合に、機械学習に利用する学習サンプルの件数を他方により補うことができる。したがって、本実施形態によれば、学習サンプルを収集するコストの大きな増大を招くことなく、対象者の状態をより高精度に推定可能な推定器を生成することができる。本実施形態に係るモニタリング装置2は、このような第1推定器51を利用することで、運転者Dの状態を高精度に推定することができる。
なお、図1の例では、推定器生成装置1及びモニタリング装置2は別個のコンピュータである。しかしながら、推定システム100の構成は、このような例に限定されなくてもよい。推定器生成装置1及びモニタリング装置2は一体のコンピュータで構成されてもよい。また、推定器生成装置1及びモニタリング装置2はそれぞれ複数台のコンピュータにより構成されてもよい。更に、推定器生成装置1及びモニタリング装置2はネットワークに接続されていなくてもよい。この場合、推定器生成装置1及びモニタリング装置2の間のデータのやりとりは、不揮発メモリ等の記憶媒体を介して行われてもよい。
§2 構成例
[ハードウェア構成]
<推定器生成装置>
次に、図2を用いて、本実施形態に係る推定器生成装置1のハードウェア構成の一例について説明する。図2は、本実施形態に係る推定器生成装置1のハードウェア構成の一例を模式的に例示する。
[ハードウェア構成]
<推定器生成装置>
次に、図2を用いて、本実施形態に係る推定器生成装置1のハードウェア構成の一例について説明する。図2は、本実施形態に係る推定器生成装置1のハードウェア構成の一例を模式的に例示する。
図2に示されるとおり、本実施形態に係る推定器生成装置1は、制御部11、記憶部12、通信インタフェース13、入力装置14、出力装置15、及びドライブ16が電気的に接続されたコンピュータである。なお、図2では、通信インタフェースを「通信I/F」と記載している。
制御部11は、ハードウェアプロセッサであるCPU(Central Processing Unit)、RAM(Random Access Memory)、ROM(Read Only Memory)等を含み、プログラム及び各種データに基づいて情報処理を実行するように構成される。記憶部12は、メモリの一例であり、例えば、ハードディスクドライブ、ソリッドステートドライブ等で構成される。本実施形態では、記憶部12は、推定器生成プログラム81、複数件の第1学習データセット71、複数件の第2学習データセット72、学習結果データ121等の各種情報を記憶する。
推定器生成プログラム81は、推定器生成装置1に、後述する機械学習の情報処理(図6)を実行させ、顔画像データから対象者の状態を推定するための学習済みの推定器(第1推定器51)を構築させるためのプログラムである。推定器生成プログラム81は、この情報処理の一連の命令を含む。複数件の第1学習データセット71及び複数件の第2学習データセット72は、この機械学習に利用される。学習結果データ121は、機械学習により構築された学習済みの推定器(第1推定器51)の設定を行うためのデータである。学習結果データ121は、推定器生成プログラム81の実行結果として生成される。詳細は後述する。
通信インタフェース13は、例えば、有線LAN(Local Area Network)モジュール、無線LANモジュール等であり、ネットワークを介した有線又は無線通信を行うためのインタフェースである。推定器生成装置1は、この通信インタフェース13を利用することで、ネットワークを介したデータ通信を他の情報処理装置(例えば、モニタリング装置2)と行うことができる。
入力装置14は、例えば、マウス、キーボード等の入力を行うための装置である。また、出力装置15は、例えば、ディスプレイ、スピーカ等の出力を行うための装置である。オペレータは、入力装置14及び出力装置15を利用することで、推定器生成装置1を操作することができる。
ドライブ16は、例えば、CDドライブ、DVDドライブ等であり、記憶媒体91に記憶されたプログラムを読み込むためのドライブ装置である。ドライブ16の種類は、記憶媒体91の種類に応じて適宜選択されてよい。上記推定器生成プログラム81、複数件の第1学習データセット71、及び複数件の第2学習データセット72の少なくともいずれかは、この記憶媒体91に記憶されていてもよい。
記憶媒体91は、コンピュータその他装置、機械等が、記録されたプログラム等の情報を読み取り可能なように、当該プログラム等の情報を、電気的、磁気的、光学的、機械的又は化学的作用によって蓄積する媒体である。推定器生成装置1は、この記憶媒体91から、上記推定器生成プログラム81、複数件の第1学習データセット71、及び複数件の第2学習データセット72の少なくともいずれかを取得してもよい。
ここで、図2では、記憶媒体91の一例として、CD、DVD等のディスク型の記憶媒体を例示している。しかしながら、記憶媒体91の種類は、ディスク型に限定される訳ではなく、ディスク型以外であってもよい。ディスク型以外の記憶媒体として、例えば、フラッシュメモリ等の半導体メモリを挙げることができる。
なお、推定器生成装置1の具体的なハードウェア構成に関して、実施形態に応じて、適宜、構成要素の省略、置換及び追加が可能である。例えば、制御部11は、複数のハードウェアプロセッサを含んでもよい。ハードウェアプロセッサは、マイクロプロセッサ、FPGA(field-programmable gate array)、DSP(digital signal processor)等で構成されてよい。記憶部12は、制御部11に含まれるRAM及びROMにより構成されてもよい。通信インタフェース13、入力装置14、出力装置15及びドライブ16の少なくともいずれかは省略されてもよい。推定器生成装置1は、各カメラ(31、32)及び脳波計33と接続するための外部インタフェースを更に備えてもよい。この外部インタフェースは、モニタリング装置2の後述する外部インタフェース24と同様に構成されてよい。推定器生成装置1は、複数台のコンピュータで構成されてもよい。この場合、各コンピュータのハードウェア構成は、一致していてもよいし、一致していなくてもよい。また、推定器生成装置1は、提供されるサービス専用に設計された情報処理装置の他、汎用のサーバ装置、PC(Personal Computer)等であってもよい。
<モニタリング装置>
次に、図3を用いて、本実施形態に係るモニタリング装置2のハードウェア構成の一例について説明する。図3は、本実施形態に係るモニタリング装置2のハードウェア構成の一例を模式的に例示する。
次に、図3を用いて、本実施形態に係るモニタリング装置2のハードウェア構成の一例について説明する。図3は、本実施形態に係るモニタリング装置2のハードウェア構成の一例を模式的に例示する。
図3に示されるとおり、本実施形態に係るモニタリング装置2は、制御部21、記憶部22、通信インタフェース23、外部インタフェース24、入力装置25、出力装置26、及びドライブ27が電気的に接続されたコンピュータである。なお、図3では、通信インタフェース及び外部インタフェースをそれぞれ「通信I/F」及び「外部I/F」と記載している。
モニタリング装置2の制御部21~通信インタフェース23及び入力装置25~ドライブ27はそれぞれ、上記推定器生成装置1の制御部11~ドライブ16それぞれと同様に構成されてよい。すなわち、制御部21は、ハードウェアプロセッサであるCPU、RAM、ROM等を含み、プログラム及びデータに基づいて各種情報処理を実行するように構成される。記憶部22は、例えば、ハードディスクドライブ、ソリッドステートドライブ等で構成される。記憶部22は、モニタリングプログラム82、学習結果データ121等の各種情報を記憶する。
モニタリングプログラム82は、学習済みの第1推定器51を利用して、運転者Dの状態を監視する後述の情報処理(図7)をモニタリング装置2に実行させるためのプログラムである。モニタリングプログラム82は、この情報処理の一連の命令を含む。学習結果データ121は、この情報処理の際に、学習済みの第1推定器51を設定するのに利用される。詳細は後述する。
通信インタフェース23は、例えば、有線LANモジュール、無線LANモジュール等であり、ネットワークを介した有線又は無線通信を行うためのインタフェースである。モニタリング装置2は、この通信インタフェース23を利用することで、ネットワークを介したデータ通信を他の情報処理装置(例えば、推定器生成装置1)と行うことができる。
外部インタフェース24は、例えば、USB(Universal Serial Bus)ポート、専用ポート等であり、外部装置と接続するためのインタフェースである。外部インタフェース24の種類及び数は、接続される外部装置の種類及び数に応じて適宜選択されてよい。本実施形態では、モニタリング装置2は、外部インタフェース24を介して、カメラ41に接続される。
カメラ41は、運転者Dの顔を撮影することで、顔画像データを取得するのに利用される。カメラ41の種類及び配置場所は、特に限定されなくてもよく、実施の形態に応じて適宜決定されてよい。カメラ41には、例えば、上記各カメラ(31、32)と同種のカメラが用いられてよい。また、カメラ41は、例えば、少なくとも運転者Dの上半身を撮影範囲とするように、運転席の前方上方に配置されてよい。なお、カメラ41が通信インタフェースを備える場合、モニタリング装置2は、外部インタフェース24ではなく、通信インタフェース23を介して、カメラ41に接続されてもよい。
入力装置25は、例えば、マウス、キーボード等の入力を行うための装置である。また、出力装置26は、例えば、ディスプレイ、スピーカ等の出力を行うための装置である。運転者D等のオペレータは、入力装置25及び出力装置26を利用することで、モニタリング装置2を操作することができる。
ドライブ27は、例えば、CDドライブ、DVDドライブ等であり、記憶媒体92に記憶されたプログラムを読み込むためのドライブ装置である。上記モニタリングプログラム82及び学習結果データ121のうちの少なくともいずれかは、記憶媒体92に記憶されていてもよい。また、モニタリング装置2は、記憶媒体92から、上記モニタリングプログラム82及び学習結果データ121のうちの少なくともいずれかを取得してもよい。
なお、モニタリング装置2の具体的なハードウェア構成に関して、上記推定器生成装置1と同様に、実施の形態に応じて、適宜、構成要素の省略、置換及び追加が可能である。例えば、制御部21は、複数のハードウェアプロセッサを含んでもよい。ハードウェアプロセッサは、マイクロプロセッサ、FPGA、DSP等で構成されてよい。記憶部22は、制御部21に含まれるRAM及びROMにより構成されてもよい。通信インタフェース23、外部インタフェース24、入力装置25、出力装置26及びドライブ27の少なくともいずれかは省略されてもよい。モニタリング装置2は、複数台のコンピュータで構成されてもよい。この場合、各コンピュータのハードウェア構成は、一致していてもよいし、一致していなくてもよい。また、モニタリング装置2は、提供されるサービス専用に設計された情報処理装置の他、汎用のサーバ装置、汎用のデスクトップPC、ノートPC、タブレットPC、スマートフォンを含む携帯電話等が用いられてよい。
[ソフトウェア構成]
次に、図4Aを用いて、本実施形態に係る推定器生成装置1のソフトウェア構成の一例について説明する。図4Aは、本実施形態に係る推定器生成装置1のソフトウェア構成の一例を模式的に例示する。
次に、図4Aを用いて、本実施形態に係る推定器生成装置1のソフトウェア構成の一例について説明する。図4Aは、本実施形態に係る推定器生成装置1のソフトウェア構成の一例を模式的に例示する。
推定器生成装置1の制御部11は、記憶部12に記憶された推定器生成プログラム81をRAMに展開する。そして、制御部11は、RAMに展開された推定器生成プログラム81をCPUにより解釈及び実行して、各構成要素を制御する。これによって、図4Aに示されるとおり、本実施形態に係る推定器生成装置1は、学習データ取得部111、学習処理部112、及び保存処理部113をソフトウェアモジュールとして備えるコンピュータとして動作する。すなわち、本実施形態では、推定器生成装置1の各ソフトウェアモジュールは、制御部11(CPU)により実現される。
学習データ取得部111は、車両を運転する被験者Tの顔の写る第1顔画像データ711、及び車両の運転時における被験者Tの状態を示す状態情報データ712の組み合わせによりそれぞれ構成される複数件の第1学習データセット71を取得する。第1顔画像データ711は、例えば、車両内の空間(実環境)で、運転席についた被験者Tの顔を撮影可能に配置されたカメラ31により得られてよい。状態情報データ712は、例えば、被験者Tの状態として、被験者Tの眠気の度合いを示す眠気度、被験者Tの疲労の度合いを示す疲労度、被験者Tの運転に対する余裕の度合いを示す余裕度、又はこれらの組み合わせを含むように構成されてよい。
また、学習データ取得部111は、被験者Tの顔の写る第2顔画像データ721、及び被験者Tの生理学的パラメータを1又は複数のセンサで測定することにより得られた生理学的データ722の組み合わせによりそれぞれ構成される複数件の第2学習データセット72を取得する。例えば、第2顔画像データ721は、実験室等の仮想環境で、被験者Tの顔を撮影可能に配置されたカメラ32により得られてよい。また、生理学的データ722は、例えば、脳波計33により脳波を測定することで得られてよい。
学習処理部112は、複数件の第1学習データセット71及び複数件の第2学習データセット72を利用して、学習ネットワーク5の機械学習を実施する。具体的には、学習処理部112は、複数件の第1学習データセット71を利用して、第1推定器51の機械学習を実施することで、顔画像データから対象者の状態を推定するように訓練された第1推定器51を構築する。これと共に、学習処理部112は、複数件の第2学習データセット72を利用して、第2推定器52の機械学習を実施することで、顔画像データから生理学的データを再現するように訓練された第2推定器52を構築する。保存処理部113は、構築された学習済みの第1推定器51に関する情報を学習結果データ121として記憶部12に保存する。
なお、「推定」することは、例えば、グループ分け(分類、識別)により離散値(クラス)を導出すること、及び回帰により連続値を導出することのいずれかであってよい。状態情報データ712の形式は、被験者Tの状態を示す形態に応じて適宜選択されてよい。上記のとおり、状態情報データ712は、被験者Tの状態として、被験者Tの眠気度、疲労度、余裕度、又はこれらの組み合わせを含むように構成されてよい。眠気度、疲労度、及び余裕度を連続値で表現する場合、状態情報データ712は、連続値の数値データにより構成されてよい。また、眠気度、疲労度、及び余裕度を離散値で表現する場合、状態情報データ712は、離散値(例えば、クラスを示す)の数値データにより構成されてよい。
(学習ネットワーク)
次に、図4Bを更に用いて、学習ネットワーク5の構成の一例について説明する。図4A及び図4Bに示されるとおり、本実施形態に係る学習ネットワーク5は、エンコーダ61、推定部62、及びデコーダ63を備えている。エンコーダ61は、顔画像データから特徴量を導出するように構成される。推定部62は、特徴量から対象者の状態を導出するように構成される。デコーダ63は、特徴量から生理学的データを再現するように構成される。エンコーダ61及び推定部62は、エンコーダ61の出力が推定部62に入力されるように互いに接続されている。第1推定器51は、エンコーダ61及び推定部62により構成される。一方、エンコーダ61及びデコーダ63は、エンコーダ61の出力がデコーダ63に入力されるように互いに接続されている。第2推定器52は、エンコーダ61及びデコーダ63により構成される。エンコーダ61、推定部62、及びデコーダ63の構成は、機械学習可能な学習モデルが用いられている限り、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。
次に、図4Bを更に用いて、学習ネットワーク5の構成の一例について説明する。図4A及び図4Bに示されるとおり、本実施形態に係る学習ネットワーク5は、エンコーダ61、推定部62、及びデコーダ63を備えている。エンコーダ61は、顔画像データから特徴量を導出するように構成される。推定部62は、特徴量から対象者の状態を導出するように構成される。デコーダ63は、特徴量から生理学的データを再現するように構成される。エンコーダ61及び推定部62は、エンコーダ61の出力が推定部62に入力されるように互いに接続されている。第1推定器51は、エンコーダ61及び推定部62により構成される。一方、エンコーダ61及びデコーダ63は、エンコーダ61の出力がデコーダ63に入力されるように互いに接続されている。第2推定器52は、エンコーダ61及びデコーダ63により構成される。エンコーダ61、推定部62、及びデコーダ63の構成は、機械学習可能な学習モデルが用いられている限り、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。
図4Bに示されるとおり、本実施形態では、エンコーダ61は、いわゆる深層学習に用いられる多層構造のニューラルネットワークにより構成されており、入力層611、中間層(隠れ層)612、及び出力層613を備えている。推定部62は、全結合層621を備えている。デコーダ63は、エンコーダ61と同様に、多層構造のニューラルネットワークにより構成されており、入力層631、中間層(隠れ層)632、及び出力層633を備えている。
なお、図4Bの例では、エンコーダ61を構成するニューラルネットワークは、1層の中間層612を備えている。ただし、エンコーダ61の構成は、このような例に限定されなくてもよい。中間層612の数は、1層に限られなくてもよく、エンコーダ61は、2層以上の中間層612を備えてもよい。デコーダ63についても同様である。中間層632の数は、1層に限られなくてもよく、デコーダ63は、2層以上の中間層632を備えてもよい。同様に、推定部62の構成も、このような例に限定されなくてもよい。推定部62は、多層構造のニューラルネットワークにより構成されてもよい。
各層(611~613、621、631~633)は、1又は複数のニューロン(ノード)を備えている。各層(611~613、621、631~633)のニューロンの数は、実施の形態に応じて適宜設定されてよい。例えば、入力層611のニューロンの数は、入力される顔画像データの画素数に応じて設定されてよい。全結合層621のニューロンの数は、推定の対象となる対象者の状態の種類数、状態の表現方法等に応じて設定されてよい。出力層633のニューロンの数は、生理学的データを再現する形式に応じて設定されてよい。
隣接する層のニューロン同士は適宜結合され、各結合には重み(結合荷重)が設定されている。図4Bの例では、各ニューロンは、隣接する層の全てのニューロンと結合されている。しかしながら、ニューロンの結合は、このような例に限定されなくてもよく、実施の形態に応じて適宜設定されてよい。
各ニューロンには閾値が設定されており、基本的には、各入力と各重みとの積の和が閾値を超えているか否かによって各ニューロンの出力が決定される。各層611~613に含まれる各ニューロン間の結合の重み及び各ニューロンの閾値は、演算処理に利用されるエンコーダ61のパラメータの一例である。全結合層621に含まれる各ニューロン間の結合の重み及び各ニューロンの閾値は、推定部62のパラメータの一例である。各層631~633に含まれる各ニューロン間の結合の重み及び各ニューロンの閾値は、デコーダ63のパラメータの一例である。
第1推定器51の機械学習では、学習処理部112は、各第1学習データセット71について、第1顔画像データ711をエンコーダ61の入力層611に入力し、エンコーダ61及び推定部62のパラメータを利用して、第1推定器51の演算処理を実行する。この演算処理の結果、学習処理部112は、第1顔画像データ711から対象者(この場合は、被験者T)の状態を推定した結果に対応する出力値を推定部62の全結合層621から取得する。続いて、学習処理部112は、取得した出力値と状態情報データ712に対応する値との誤差を算出する。そして、学習処理部112は、算出される誤差の和が小さくなるように、第1推定器51(エンコーダ61及び推定部62)のパラメータの値を調節する。全結合層621から得られる出力値と状態情報データ712に対応する値との誤差の和が閾値以下になるまで、学習処理部112は、第1推定器51のパラメータの値の調節を繰り返す。これにより、学習処理部112は、各件の第1学習データセット71を構成する第1顔画像データ711をエンコーダ61に入力すると、入力した第1顔画像データ711に関連付けられた状態情報データ712により示される被験者Tの状態に対応する出力値を推定部62から出力するように訓練された第1推定器51を構築することができる。
同様に、第2推定器52の機械学習では、学習処理部112は、各第2学習データセット72について、第2顔画像データ721をエンコーダ61の入力層611に入力し、エンコーダ61及びデコーダ63のパラメータを利用して、第2推定器52の演算処理を実行する。この演算処理の結果、学習処理部112は、第2顔画像データ721から対象者(この場合は、被験者T)の生理学的データを再現した結果に対応する出力データをデコーダ63の出力層633から取得する。続いて、学習処理部112は、取得した出力データと生理学的データ722との誤差を算出する。そして、学習処理部112は、算出される誤差の和が小さくなるように、第2推定器52(エンコーダ61及びデコーダ63)のパラメータの値を調節する。出力層633から得られる出力データと生理学的データ722との誤差の和が閾値以下になるまで、学習処理部112は、第2推定器52のパラメータの値の調節を繰り返す。これにより、学習処理部112は、各件の第2学習データセット72を構成する第2顔画像データ721をエンコーダ61に入力すると、入力した第2顔画像データ721に関連付けられた生理学的データ722を再現した出力データをデコーダ63から出力するように訓練された第2推定器52を構築することができる。
これらの機械学習が完了した後、保存処理部113は、構築された学習済みの第1推定器51の構成(例えば、ニューラルネットワークの層数、各層におけるニューロンの個数、ニューロン同士の結合関係、各ニューロンの伝達関数)、及び演算パラメータ(例えば、各ニューロン間の結合の重み、各ニューロンの閾値)を示す学習結果データ121を生成する。そして、保存処理部113は、生成した学習結果データ121を記憶部12に保存する。
<モニタリング装置>
次に、図5を用いて、本実施形態に係るモニタリング装置2のソフトウェア構成の一例について説明する。図5は、本実施形態に係るモニタリング装置2のソフトウェア構成の一例を模式的に例示する。
次に、図5を用いて、本実施形態に係るモニタリング装置2のソフトウェア構成の一例について説明する。図5は、本実施形態に係るモニタリング装置2のソフトウェア構成の一例を模式的に例示する。
モニタリング装置2の制御部21は、記憶部22に記憶されたモニタリングプログラム82をRAMに展開する。そして、制御部21は、RAMに展開されたモニタリングプログラム82をCPUにより解釈及び実行して、各構成要素を制御する。これによって、図5に示されるとおり、本実施形態に係るモニタリング装置2は、データ取得部211、推定処理部212、及び出力部213をソフトウェアモジュールとして備えるコンピュータとして動作する。すなわち、本実施形態では、モニタリング装置2の各ソフトウェアモジュールも、上記推定器生成装置1と同様に、制御部21(CPU)により実現される。
データ取得部211は、車両を運転する運転者Dの顔の写る顔画像データ221を取得する。例えば、データ取得部211は、カメラ41により運転者Dの顔を撮影することで、顔画像データ221を取得する。推定処理部212は、学習結果データ121を保持することで、学習済みの第1推定器51を含んでいる。推定処理部212は、学習結果データ121を参照し、学習済みの第1推定器51の設定を行う。そして、推定処理部212は、学習済みの第1推定器51のエンコーダ61に取得した顔画像データ221を入力することで、運転者Dの状態を推定した結果に対応する出力を第1推定器51の推定部62から取得する。出力部213は、運転者Dの状態を推定した結果に関連する情報を出力する。
<その他>
推定器生成装置1及びモニタリング装置2の各ソフトウェアモジュールに関しては後述する動作例で詳細に説明する。なお、本実施形態では、推定器生成装置1及びモニタリング装置2の各ソフトウェアモジュールがいずれも汎用のCPUによって実現される例について説明している。しかしながら、以上のソフトウェアモジュールの一部又は全部が、1又は複数の専用のプロセッサにより実現されてもよい。また、推定器生成装置1及びモニタリング装置2それぞれのソフトウェア構成に関して、実施形態に応じて、適宜、ソフトウェアモジュールの省略、置換及び追加が行われてもよい。
推定器生成装置1及びモニタリング装置2の各ソフトウェアモジュールに関しては後述する動作例で詳細に説明する。なお、本実施形態では、推定器生成装置1及びモニタリング装置2の各ソフトウェアモジュールがいずれも汎用のCPUによって実現される例について説明している。しかしながら、以上のソフトウェアモジュールの一部又は全部が、1又は複数の専用のプロセッサにより実現されてもよい。また、推定器生成装置1及びモニタリング装置2それぞれのソフトウェア構成に関して、実施形態に応じて、適宜、ソフトウェアモジュールの省略、置換及び追加が行われてもよい。
§3 動作例
[推定器生成装置]
次に、図6を用いて、推定器生成装置1の動作例について説明する。図6は、本実施形態に係る推定器生成装置1の処理手順の一例を示すフローチャートである。以下で説明する処理手順は、本発明の「推定器生成方法」の一例である。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
[推定器生成装置]
次に、図6を用いて、推定器生成装置1の動作例について説明する。図6は、本実施形態に係る推定器生成装置1の処理手順の一例を示すフローチャートである。以下で説明する処理手順は、本発明の「推定器生成方法」の一例である。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
(ステップS101)
ステップS101では、制御部11は、学習データ取得部111として動作し、第1顔画像データ711及び状態情報データ712の組み合わせによりそれぞれ構成される複数件の第1学習データセット71を取得する。また、制御部11は、第2顔画像データ721、及び生理学的データ722の組み合わせによりそれぞれ構成される複数件の第2学習データセット72を取得する。
ステップS101では、制御部11は、学習データ取得部111として動作し、第1顔画像データ711及び状態情報データ712の組み合わせによりそれぞれ構成される複数件の第1学習データセット71を取得する。また、制御部11は、第2顔画像データ721、及び生理学的データ722の組み合わせによりそれぞれ構成される複数件の第2学習データセット72を取得する。
複数件の第1学習データセット71を取得する方法は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、カメラ31を搭載した車両又は車両を模した構造物及び被験者Tを用意し、車両を運転する被験者Tをカメラ31により様々な条件で撮影することで、被験者Tの顔の写る第1顔画像データ711を取得することができる。用意する車両又は車両を模した構造物及び被験者Tの数は、実施の形態に応じて適宜決定されてよい。そして、得られた第1顔画像データ711に対して、被験者Tの状態を示す状態情報データ712を組み合わせることで、各第1学習データセット71を生成することができる。
第1顔画像データ711のデータ形式は、実施の形態に応じて適宜選択されてよい。状態情報データ712は、被験者Tの何らかの状態を示すものであれば特に限定されなくてもよい。状態情報データ712は、例えば、被験者Tの状態として、被験者Tの眠気度、疲労度、余裕度、又はこれらの組み合わせを含むように構成されてよい。また、第1学習データセット71として互いに対応付けられる第1顔画像データ711及び状態情報データ712は必ずしも時間的に一致している必要はない。例えば、状態情報データ712は、第1顔画像データ711を得るために被験者Tの顔を撮影した時刻(以下、撮影時刻)と一致する時刻の被験者Tの状態を示すように構成されてもよいし、第1顔画像データ711の撮影時刻とずれた時刻(例えば、未来の時刻)の被験者Tの状態を示すように構成されてもよい。ただし、第1顔画像データ711から被験者Tの状態を導出可能であることを保証するため、第1顔画像データ711の撮影時刻と状態情報データ712により示される被験者Tの状態の時刻とは関連性があるのが好ましい。
同様に、複数件の第2学習データセット72を取得する方法も、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、カメラ32、脳波計33、及び被験者Tを用意し、被験者Tをカメラ32により様々な条件で撮影すると共に、脳波計33により被験者Tの脳波を計測する。用意するカメラ32、脳波計33、及び被験者Tの数は、実施の形態に応じて適宜決定されてよい。第1学習データセット71の取得に関与した被験者と第2学習データセット72の取得に関与した被験者とは一致していてもよいし、一致していなくてもよい。これにより得られた第2顔画像データ721及び生理学的データ722を組み合わせることで、各第2学習データセット72を生成することができる。
第2顔画像データ721のデータ形式は、実施の形態に応じて適宜選択されてよい。生理学的データ722は、状態情報データ712により示される被験者Tの状態に関係し得る生理学的パラメータを1又は複数のセンサで測定されたものであれば、上記脳波の測定データに限定されなくてもよい。生理学的パラメータは、例えば、脳活動(脳波、脳血流等)、眼球運動(瞳孔径、視線方向等)、筋電位、心電位、血圧、脈拍、心拍、体温、皮膚電気反応又はこれらの組み合わせであってよい。センサは、例えば、脳波計、脳磁計、核磁気共鳴画像装置、カメラ、眼電位センサ、眼球運動計測器、筋電計、心電計、血圧計、脈拍計、心拍計、体温計、皮膚電気反応計又はこれらの組み合わせであってよい。眼球運動計測器は、例えば、瞳孔径の変化、視線方向等の眼球運動を計測するように構成される。眼球運動計測器による計測対象の眼球運動は、随意運動であってもよいし、不随意運動であってもよい。この眼球運動計測器は、例えば、瞳孔径計測装置、視線計測装置等であってよい。瞳孔径計測装置は、対象者の瞳孔径(の時間変化)を計測するように適宜構成される。視線計測装置は、対象者の視線方向(の時間変化)を計測するように適宜構成される。生理学的データ722は、状態情報データ712よりも人間の状態に関する高次な情報を含むように選択されるのが好ましい。生理学的データ722は、1又は複数のセンサから得られたローデータであってもよいし、何らかの情報処理が適用された加工済みデータであってもよい。また、上記第1学習データセット71と同様に、第2学習データセット72として互いに対応付けられる第2顔画像データ721及び生理学的データ722は必ずしも時間的に一致している必要はない。
なお、各件の第1学習データセット71を構成する第1顔画像データ711及び第1状態情報データ712は実環境で収集されるのが好ましい。実環境は、訓練された第1推定器51を実際に運用する環境(例えば、モニタリング装置2を運用する環境)又はそれと同等の環境である。実環境は、例えば、車両内の空間、車両を模した構造物内の空間である。つまり、第1顔画像データ711は、カメラ31を搭載した車両又は車両に模した構造物内で得られるのが好ましい。
これに対して、各件の第2学習データセット72を構成する第2顔画像データ721及び生理学的データ722は仮想環境で収集されるのが好ましい。仮想環境は、例えば、実験室等の、実環境ではない環境である。生理学的データ722は、この仮想環境において、被験者Tの状態を示すより高次な情報を含むように取得されるのが好ましい。この場合、仮想環境で測定される生理学的パラメータは、脳活動、筋電位、心電位、眼球運動(特に、瞳孔径)又はこれらの組み合わせであってよい。これに応じて、仮想環境で利用されるセンサは、脳波計、脳磁計、核磁気共鳴画像装置、筋電計、心電計、眼電位センサ、眼球運動計測器(特に、瞳孔径計測装置)又はこれらの組み合わせであってよい。
また、第1顔画像データ711及び第2顔画像データ721の撮影環境が異なる場合、被験者Tの顔以外の要素(例えば、顔に装着したセンサ)が大きく相違し、この相違が、機械学習により構築される推定器の精度に悪影響を及ぼす可能性がある。撮影環境が異なるケースとは、例えば、上記のように、第1顔画像データ711を実環境で収集し、かつ第2顔画像データ721を仮想環境で収集するケースである。そこで、この場合、第1顔画像データ711及び第2顔画像データ721の顔以外の要素を区別不能なように、第1顔画像データ711及び第2顔画像データ721を適宜加工するのが好ましい。
この加工には、敵対的生成ネットワーク(Generative adversarial network:GAN)等の生成モデルを利用することができる。敵対的生成ネットワークは、生成器及び判別器により構成される。生成器は、ノイズから学習サンプル(画像)に対応する画像を生成するように構成される。判別器は、与えられた画像が学習サンプル由来であるか生成器由来であるかを判別するように訓練される。これに対して、生成器は、判別器による判別が誤るような画像を生成するように訓練される。この判別器及び生成器の学習を交互に繰り返すことで、生成器は、学習サンプルに近い画像を生成する能力を習得する。
そのため、この敵対的生成ネットワークによれば、第1顔画像データ711及び第2顔画像データ721を適宜加工することができる。例えば、第1顔画像データ711を学習サンプルとして、第1顔画像データ711に対応する画像を生成する第1生成器を含む第1敵対的生成ネットワークを構築する。同様に、第2顔画像データ721を学習サンプルとして、第2顔画像データ721に対応する画像を生成する第2生成器を含む第2敵対的生成ネットワークを構築する。第1生成器により生成された画像を加工済みの新たな第1顔画像データ711として元の第1顔画像データ711と置き換え、第2生成器により生成された画像を加工済みの新たな第2顔画像データ721として元の第2顔画像データ721と置き換える。これにより、顔以外の要素を区別不能なように、第1顔画像データ711及び第2顔画像データ721を適宜加工することができる。
ただし、第1顔画像データ711及び第2顔画像データ721を加工する方法は、このような例に限定されなくてもよい。例えば、ガウシアンフィルタ、平均化フィルタ、メディアンフィルタ等の公知のフィルタを適用することで、第1顔画像データ711及び第2顔画像データ721を加工してもよい。また、例えば、画像処理により顔以外の要素を区別可能な領域にマスクをかけることで、第1顔画像データ711及び第2顔画像データ721を加工してもよい。マスクは、例えば、単色ノイズであってもよいし、ランダムノイズであってもよい。また、例えば、顔以外の要素を含まないように、第1顔画像データ711及び第2顔画像データ721それぞれから顔領域(例えば、矩形状の領域)を抽出して、抽出された顔領域の画像をそれぞれ新たな第1顔画像データ711及び第2顔画像データ721それぞれに置き換えてもよい。
ただし、各件の第1学習データセット71及び各件の第2学習データセット72を取得する環境は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。各件の第1学習データセット71及び各件の第2学習データセット72は同一の環境で取得されてもよい。この場合、第1顔画像データ711及び第2顔画像データ721は互いに同一であってよい。また、顔画像データ、状態情報データ712、及び生理学的データ722の組み合わせによりそれぞれ構成された複数件の学習データセットが収集されてよい。各件の第1学習データセット71は、この各件の学習データセットから顔画像データ及び状態情報データ712を抽出することで得られてもよい。各件の第2学習データセット72は、各件の学習データセットから顔画像データ及び生理学的データ722を抽出することで得られてもよい。
上記のような各件の第1学習データセット71及び各件の第2学習データセット72は、自動的に生成されてもよいし、手動的に生成されてもよい。また、各件の第1学習データセット71及び各件の第2学習データセット72の生成は、推定器生成装置1により行われてもよい。或いは、各件の第1学習データセット71及び各件の第2学習データセット72の少なくともいずれかの生成は、推定器生成装置1以外の他のコンピュータにより行われてもよい。
各件の第1学習データセット71及び各件の第2学習データセット72を推定器生成装置1が生成する場合、制御部11は、第1顔画像データ711及び第2顔画像データ721を適宜各カメラ(31、32)から取得する。また、制御部11は、例えば、オペレータによる入力装置14を介する被験者Tの状態の指定を受け付け、指定された被験者Tの状態を示す状態情報データ712を生成する。更に、制御部11は、生理学的データ722を適宜脳波計33から取得する。そして、制御部11は、第1顔画像データ711及び状態情報データ712を組み合わせることで、各件の第1学習データセット71を生成する。制御部11は、第2顔画像データ721及び生理学的データ722を組み合わせることで、各件の第2学習データセット72を生成する。これにより、ステップS101では、制御部11は、複数件の第1学習データセット71及び複数件の第2学習データセット72を取得することができる。
一方、各件の第1学習データセット71及び各件の第2学習データセット72の少なくともいずれかを他のコンピュータが生成する場合、生成された学習データセットは、他のコンピュータから推定器生成装置1に適宜転送される。本ステップ101では、制御部11は、例えば、ネットワーク、記憶媒体91等を介して、他のコンピュータにより生成された各件の第1学習データセット71及び各件の第2学習データセット72の少なくともいずれかを取得してもよい。他のコンピュータでは、上記推定器生成装置1と同様の方法で、各件の第1学習データセット71及び各件の第2学習データセット72の少なくともいずれかが生成されてよい。
また、取得する第1学習データセット71及び第2学習データセット72それぞれの件数は、特に限定されなくてもよく、実施の形態に応じて適宜決定されてよい。複数件の第1学習データセット71及び複数件の第2学習データセット72を取得すると、制御部11は、次のステップS102に処理を進める。
(ステップS102)
ステップS102では、制御部11は、学習処理部112として動作し、複数件の第1学習データセット71及び複数件の第2学習データセット72を利用して、学習ネットワーク5の機械学習を実施する。具体的には、制御部11は、複数件の第1学習データセット71を利用して、第1推定器51の機械学習を実施することで、第1顔画像データ711から状態情報データ712を推定するように訓練された第1推定器51を構築する。これと共に、制御部11は、複数件の第2学習データセット72を利用して、第2推定器52の機械学習を実施することで、第2顔画像データ721から生理学的データ722を再現するように訓練された第2推定器52を構築する。
ステップS102では、制御部11は、学習処理部112として動作し、複数件の第1学習データセット71及び複数件の第2学習データセット72を利用して、学習ネットワーク5の機械学習を実施する。具体的には、制御部11は、複数件の第1学習データセット71を利用して、第1推定器51の機械学習を実施することで、第1顔画像データ711から状態情報データ712を推定するように訓練された第1推定器51を構築する。これと共に、制御部11は、複数件の第2学習データセット72を利用して、第2推定器52の機械学習を実施することで、第2顔画像データ721から生理学的データ722を再現するように訓練された第2推定器52を構築する。
詳細には、まず、制御部11は、学習ネットワーク5を用意する。用意する学習ネットワーク5の構成、各ニューロン間の結合の重みの初期値、及び各ニューロンの閾値の初期値は、テンプレートにより与えられてもよいし、オペレータの入力により与えられてもよい。また、再学習を行う場合には、制御部11は、過去の機械学習を行うことで得られた学習結果データに基づいて、学習ネットワーク5を用意してもよい。
次に、制御部11は、ステップS101で取得した各第1学習データセット71に含まれる第1顔画像データ711を入力データとして利用し、対応する状態情報データ712を教師データとして利用して、第1推定器51の学習処理を実行する。この学習処理には、確率的勾配降下法等が用いられてよい。
例えば、第1のステップでは、制御部11は、各第1学習データセット71について、第1顔画像データ711をエンコーダ61の入力層611に入力し、入力側から順に各層(611~613、621)に含まれる各ニューロンの発火判定を行う。これにより、制御部11は、状態情報データ712により示される被験者Tの状態を第1顔画像データ711から推定した結果に対応する出力値を推定部62の全結合層621から取得する。第2のステップでは、制御部11は、取得した出力値と状態情報データ712に対応する値との誤差を算出する。第3のステップでは、制御部11は、誤差逆伝播(Back propagation)法により、算出した出力値の誤差を用いて、各ニューロン間の結合の重み及び各ニューロンの閾値それぞれの誤差を算出する。第4のステップでは、制御部11は、算出した各誤差に基づいて、各ニューロン間の結合の重み及び各ニューロンの閾値それぞれの値の更新を行う。
制御部11は、各件の第1学習データセット71について、全結合層621から得られる出力値と状態情報データ712に対応する値との誤差の和が閾値以下になるまで、上記第1~第4のステップによる第1推定器51(エンコーダ61及び推定部62)のパラメータの値の調節を繰り返す。閾値は、実施の形態に応じて適宜設定されてよい。これにより、制御部11は、各件の第1学習データセット71を構成する第1顔画像データ711をエンコーダ61に入力すると、入力した第1顔画像データ711に関連付けられた状態情報データ712により示される被験者Tの状態に対応する出力値を推定部62から出力するように訓練された第1推定器51を構築することができる。
同様に、制御部11は、ステップS101で取得した各第2学習データセット72に含まれる第2顔画像データ721を入力データとして利用し、対応する生理学的データ722を教師データとして利用して、第2推定器52の学習処理を実行する。学習処理は、第1推定器51と同様であってよい。すなわち、制御部11は、学習処理の対象を各層(611~613、621)から各層(611~613、631~633)に置き換え、第1顔画像データ711を第2顔画像データ721に置き換え、状態情報データ712を生理学的データ722に置き換えて、上記第1~第4のステップの各処理を実行する。制御部11は、各件の第2学習データセット72について、デコーダ63の出力層633から得られる出力データと生理学的データ722との誤差の和が閾値以下になるまで、上記第1~第4のステップによる第2推定器52(エンコーダ61及びデコーダ63)のパラメータの値の調節を繰り返す。閾値は、実施の形態に応じて適宜設定されてよく、上記第1推定器51の機械学習における閾値と同じであってもよいし、異なっていてもよい。これにより、制御部11は、各件の第2学習データセット72を構成する第2顔画像データ721をエンコーダ61に入力すると、入力した第2顔画像データ721に関連付けられた生理学的データ722を再現した出力データをデコーダ63から出力するように訓練された第2推定器52を構築することができる。
第1推定器51の機械学習及び第2推定器52の機械学習の処理順序は、特に限定されなくてもよく、実施の形態に応じて適宜決定されてよい。第1推定器51の機械学習の処理は、第2推定器52の機械学習の処理の前に実行されてもよいし、第2推定器52の機械学習の処理と共に実行されてもよいし、第2推定器52の機械学習の処理の後に実行されてもよい。第1推定器51及び第2推定器52の機械学習が完了すると、制御部11は、次のステップS103に処理を進める。
なお、上記ステップS101において、対応する第1顔画像データ711の撮影時刻とずれた時刻の被験者Tの状態を示す状態情報データ712が収集された場合、本ステップS102では、第1推定器51は、顔画像データの撮影時刻からずれた時刻における対象者の状態を推定するように訓練される。第2推定器52についても同様である。各第1学習データセット71における第1顔画像データ711及び状態情報データ712の間の時間的な関係と、各第2学習データセット72における第2顔画像データ721及び生理学的データ722の間の時間的な関係とは必ずしも一致していなくてよい。
また、第2推定器52の学習処理の複雑性を低減し、学習データのばらつきにより学習処理が収束しない状態に陥るのを防止するために、教師データとして利用される生理学的データ722は、加工処理により単純化されていてもよい。例えば、生理学的データ722は、勾配の向き(次のサンプル点で値が上昇するか下降するか)を示すように加工されてもよい。また、例えば、生理学的データ722は、整数、対数スケール等の所定の間隔毎に連続値を離散化することで得られてもよいし、クラスタリング等の手法を利用して、データの分布に基づいて離散化することで得られてもよい。また、これらの離散化は、得られたデータそのものに適用されてよいし、上記勾配の大きさに適用されてもよい。
(ステップS103)
ステップS103では、制御部11は、保存処理部113として動作し、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として生成する。そして、制御部11は、生成した学習結果データ121を記憶部12に保存する。これにより、制御部11は、本動作例に係る処理を終了する。
ステップS103では、制御部11は、保存処理部113として動作し、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として生成する。そして、制御部11は、生成した学習結果データ121を記憶部12に保存する。これにより、制御部11は、本動作例に係る処理を終了する。
なお、学習結果データ121の保存先は、記憶部12に限られなくてもよい。制御部11は、例えば、NAS(Network Attached Storage)等のデータサーバに学習結果データ121を格納してもよい。学習結果データ121は、機械学習により構築された第2推定器52(特に、デコーダ63)の構成及びパラメータを示す情報を含んでもよいし、含んでいなくてもよい。
また、学習済みの第1推定器51を構築した後、制御部11は、生成した学習結果データ121を任意のタイミングでモニタリング装置2に転送してもよい。モニタリング装置2は、推定器生成装置1から転送を受けることで学習結果データ121を取得してもよいし、推定器生成装置1又はデータサーバにアクセスすることで学習結果データ121を取得してもよい。学習結果データ121は、モニタリング装置2に予め組み込まれてもよい。
更に、制御部11は、上記ステップS101~S103の処理を定期的に繰り返すことで、学習結果データ121を定期的に更新してもよい。この繰り返す際には、第1学習データセット71及び第2学習データセット72の変更、修正、追加、削除等が適宜実行されてよい。そして、制御部11は、更新した学習結果データ121を学習処理の実行毎にモニタリング装置2に転送することで、モニタリング装置2の保持する学習結果データ121を定期的に更新してもよい。
[モニタリング装置]
次に、図7を用いて、モニタリング装置2の動作例について説明する。図7は、本実施形態に係るモニタリング装置2の処理手順の一例を示すフローチャートである。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
次に、図7を用いて、モニタリング装置2の動作例について説明する。図7は、本実施形態に係るモニタリング装置2の処理手順の一例を示すフローチャートである。ただし、以下で説明する処理手順は一例に過ぎず、各処理は可能な限り変更されてよい。また、以下で説明する処理手順について、実施の形態に応じて、適宜、ステップの省略、置換、及び追加が可能である。
(ステップS201)
ステップS201では、制御部21は、データ取得部211として動作し、車両を運転する運転者Dの顔の写る顔画像データ221を取得する。本実施形態では、モニタリング装置2は、外部インタフェース24を介してカメラ41に接続されている。そのため、制御部21は、カメラ41から顔画像データ221を取得する。この顔画像データ221は、動画像データであってもよいし、静止画像データであってもよい。顔画像データ221を取得すると、制御部21は、次のステップS202に処理を進める。
ステップS201では、制御部21は、データ取得部211として動作し、車両を運転する運転者Dの顔の写る顔画像データ221を取得する。本実施形態では、モニタリング装置2は、外部インタフェース24を介してカメラ41に接続されている。そのため、制御部21は、カメラ41から顔画像データ221を取得する。この顔画像データ221は、動画像データであってもよいし、静止画像データであってもよい。顔画像データ221を取得すると、制御部21は、次のステップS202に処理を進める。
ただし、顔画像データ221を取得する経路は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、モニタリング装置2とは異なる他のコンピュータが、カメラ41に接続されていてもよい。この場合、制御部21は、他のコンピュータから顔画像データ221の送信を受け付けることで、顔画像データ221を取得してもよい。
(ステップS202)
ステップS202では、制御部21は、推定処理部212として動作し、学習済みの第1推定器51の設定を行う。続いて、制御部21は、取得した顔画像データ221を学習済みの第1推定器51に入力し、第1推定器51の演算処理を実行する。すなわち、制御部21は、顔画像データ221をエンコーダ61の入力層611に入力し、入力側から順に各層(611~613、621)に含まれる各ニューロンの発火判定を行う。これにより、制御部21は、運転者Dの状態を推定した結果に対応する出力値を推定部62の全結合層621から取得する。
ステップS202では、制御部21は、推定処理部212として動作し、学習済みの第1推定器51の設定を行う。続いて、制御部21は、取得した顔画像データ221を学習済みの第1推定器51に入力し、第1推定器51の演算処理を実行する。すなわち、制御部21は、顔画像データ221をエンコーダ61の入力層611に入力し、入力側から順に各層(611~613、621)に含まれる各ニューロンの発火判定を行う。これにより、制御部21は、運転者Dの状態を推定した結果に対応する出力値を推定部62の全結合層621から取得する。
これにより、制御部21は、学習済みの第1推定器51を利用して、取得した顔画像データ221から運転者Dの状態を推定することができる。上記機械学習に利用された状態情報データ712が、被験者Tの状態として、被験者Tの眠気度、疲労度、余裕度、又はこれらの組み合わせを含むように構成されている場合、制御部21は、運転者Dの眠気度、疲労度、余裕度、又はこれらの組み合わせを推定することができる。運転者Dの状態を推定すると、制御部21は、次のステップS203に処理を進める。
(ステップS203)
ステップS203では、制御部21は、出力部213として動作し、運転者Dの状態を推定した結果に関連する情報を出力する。出力先及び出力する情報の内容はそれぞれ、実施の形態に応じて適宜決定されてよい。例えば、制御部21は、ステップS202により運転者Dの状態を推定した結果をそのまま出力装置26を介して出力してもよい。
ステップS203では、制御部21は、出力部213として動作し、運転者Dの状態を推定した結果に関連する情報を出力する。出力先及び出力する情報の内容はそれぞれ、実施の形態に応じて適宜決定されてよい。例えば、制御部21は、ステップS202により運転者Dの状態を推定した結果をそのまま出力装置26を介して出力してもよい。
また、例えば、制御部21は、運転者Dの状態を推定した結果に基づいて、何らかの情報処理を実行してもよい。そして、制御部21は、その情報処理を実行した結果を出力してもよい。情報処理の一例として、運転者Dの状態として、眠気度及び疲労度の少なくとも一方を推定した場合、制御部21は、眠気度及び疲労度の少なくとも一方が閾値を超えるか否かを判定してもよい。閾値は適宜設定されてよい。そして、眠気度及び疲労度の少なくとも一方が閾値を超えている場合に、制御部21は、出力装置26を介して、駐車場等に停車し、休憩を取るように運転者Dに促す警告を出力してもよい。
また、情報処理の他の例として、車両が自動運転動作可能に構成されている場合、制御部21は、運転者Dの状態を推定した結果に基づいて、車両の自動運転の動作を制御してもよい。一例として、車両が、システムにより車両の走行を制御する自動運転モード及び運転者Dの操舵により車両の走行を制御する手動運転モードの切り替えが可能に構成されていると想定する。
このケースにおいて、自動運転モードで車両が走行しており、自動運転モードから手動運転モードへの切り替えを運転者D又はシステムから受け付けた際に、制御部21は、運転者Dの推定された余裕度が閾値を超えているか否かを判定してもよい。そして、運転者Dの余裕度が閾値を超えている場合に、制御部21は、自動運転モードから手動運転モードへの切り替えを許可してもよい。一方、運転者Dの余裕度が閾値以下である場合には、制御部21は、自動運転モードから手動運転モードへの切り替えを許可せず、自動運転モードでの走行を維持してもよい。
また、手動運転モードで車両が走行している際に、制御部21は、眠気度及び疲労度の少なくとも一方が閾値を超えるか否かを判定してもよい。そして、眠気度及び疲労度の少なくとも一方が閾値を超えている場合に、制御部21は、手動運転モードから自動運転モードに切り替えて、駐車場等の安全な場所に停車するように指示する指令を車両のシステムに送信してもよい。一方で、そうではない場合には、制御部21は、手動運転モードによる車両の走行を維持してもよい。
また、手動運転モードで車両が走行している際に、制御部21は、余裕度が閾値以下であるか否かを判定してもよい。そして、余裕度が閾値以下である場合に、制御部21は、減速する指令を車両のシステムに送信してもよい。一方で、そうではない場合には、制御部21は、運転者Dの操作による車両の走行を維持してもよい。
情報の出力が完了すると、制御部21は、本動作例に係る処理を終了する。なお、運転者Dが運転席に存在し、車両が走行している間、制御部21は、ステップS201~S203の一連の処理を継続的に繰り返し実行してもよい。これにより、モニタリング装置2は、運転者Dの状態を継続的に監視することができる。
[特徴]
以上のように、本実施形態では、第1推定器51及び第2推定器52は、共通のエンコーダ61を有するように構成される。本実施形態に係る推定器生成装置1は、上記ステップS102の機械学習の処理により、第1顔画像データ711から状態情報データ712を導出するように第1推定器51を訓練すると共に、第2顔画像データ721から生理学的データ722を再現するように第2推定器52を訓練する。そのため、エンコーダ61の出力(特徴量)は、顔画像データから対象者の状態及び生理学的な現象を導出可能にデザインされる。生理学的データ722は、状態情報データ712に比べて、人間の状態に関する高次な情報を含み得る。そのため、ステップS102の機械学習において、状態情報データ712だけではなく、より高次な情報を含み得る生理学的データ722を導出可能に共通のエンコーダ61を訓練することで、共通のエンコーダ61のパラメータが、対象者の状態を推定する精度のよりよい局所解に向かうようにすることができる。したがって、本実施形態に係る推定器生成装置1によれば、対象者の状態をより高精度に推定可能な第1推定器51を生成することができる。
以上のように、本実施形態では、第1推定器51及び第2推定器52は、共通のエンコーダ61を有するように構成される。本実施形態に係る推定器生成装置1は、上記ステップS102の機械学習の処理により、第1顔画像データ711から状態情報データ712を導出するように第1推定器51を訓練すると共に、第2顔画像データ721から生理学的データ722を再現するように第2推定器52を訓練する。そのため、エンコーダ61の出力(特徴量)は、顔画像データから対象者の状態及び生理学的な現象を導出可能にデザインされる。生理学的データ722は、状態情報データ712に比べて、人間の状態に関する高次な情報を含み得る。そのため、ステップS102の機械学習において、状態情報データ712だけではなく、より高次な情報を含み得る生理学的データ722を導出可能に共通のエンコーダ61を訓練することで、共通のエンコーダ61のパラメータが、対象者の状態を推定する精度のよりよい局所解に向かうようにすることができる。したがって、本実施形態に係る推定器生成装置1によれば、対象者の状態をより高精度に推定可能な第1推定器51を生成することができる。
加えて、第1学習データセット71及び第2学習データセット72の件数が十分であれば、共通のエンコーダ61は、人間の状態及び生理学的な現象の両方を導出可能な特徴量を出力するように適切に訓練される。そのため、第1学習データセット71及び第2学習データセット72のいずれか一方の件数が少ない場合に、機械学習に利用する学習サンプルの件数を他方により補うことができる。つまり、上記ステップS101では、第1学習データセット71及び第2学習データセット72のいずれか一方の件数を増やすことにより他方の件数の不足を補うことができる。したがって、本実施形態によれば、学習サンプルを収集するコストの大きな増大を招くことなく、対象者の状態をより高精度に推定可能な第1推定器51を生成することができる。本実施形態に係るモニタリング装置2は、このような第1推定器51を利用することで、運転者Dの状態を高精度に推定することができる。
また、仮想環境では、実環境よりも、より高性能なセンサを用いて、人間の状態を示すより高次な情報を収集することが可能である。しかしながら、実環境では、そのような高性能なセンサを運用するのが困難であったり、運用できたとしても、コストがかかり過ぎてしまったり等の問題が生じ得る。そこで、本実施形態では、上記ステップS101で取得される各件の第1学習データセット71は実環境で収集されてよく、各件の第2学習データセット72は仮想環境で収集されてよい。これにより、被験者Tの状態に関する高次な情報を含み得る生理学的データ722が収集されるようにし、この生理学的データ722を利用した機械学習により、共通のエンコーダ61のパラメータが、実環境で容易に取得可能な顔画像データから対象者の状態を導出する精度のよりよい局所解に向かうようにすることができる。よって、本実施形態によれば、実環境で容易に取得可能なデータから対象者の状態をより高精度に推定可能な第1推定器51を生成することができ、これによって、実環境で第1推定器51を運用するのにかかるコストを低減することができる。
§4 変形例
以上、本発明の実施の形態を詳細に説明してきたが、前述までの説明はあらゆる点において本発明の例示に過ぎない。本発明の範囲を逸脱することなく種々の改良や変形を行うことができることは言うまでもない。例えば、以下のような変更が可能である。なお、以下では、上記実施形態と同様の構成要素に関しては同様の符号を用い、上記実施形態と同様の点については、適宜説明を省略した。以下の変形例は適宜組み合わせ可能である。
以上、本発明の実施の形態を詳細に説明してきたが、前述までの説明はあらゆる点において本発明の例示に過ぎない。本発明の範囲を逸脱することなく種々の改良や変形を行うことができることは言うまでもない。例えば、以下のような変更が可能である。なお、以下では、上記実施形態と同様の構成要素に関しては同様の符号を用い、上記実施形態と同様の点については、適宜説明を省略した。以下の変形例は適宜組み合わせ可能である。
<4.1>
上記実施形態では、エンコーダ61及びデコーダ63は、多層構造の全結合ニューラルネットワークにより構成され、推定部62は、全結合層621により構成されている。しかしながら、エンコーダ61、推定部62、及びデコーダ63それぞれを構成するニューラルネットワークの構造及び種類は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、エンコーダ61及びデコーダ63は、畳み込み層、プーリング層、及び全結合層を備える畳み込みニューラルネットワークにより構成されてよい。また、時系列データを利用する場合には、エンコーダ61及びデコーダ63は、再帰型ニューラルネットワークにより構成されてよい。
上記実施形態では、エンコーダ61及びデコーダ63は、多層構造の全結合ニューラルネットワークにより構成され、推定部62は、全結合層621により構成されている。しかしながら、エンコーダ61、推定部62、及びデコーダ63それぞれを構成するニューラルネットワークの構造及び種類は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。例えば、エンコーダ61及びデコーダ63は、畳み込み層、プーリング層、及び全結合層を備える畳み込みニューラルネットワークにより構成されてよい。また、時系列データを利用する場合には、エンコーダ61及びデコーダ63は、再帰型ニューラルネットワークにより構成されてよい。
また、エンコーダ61、推定部62、及びデコーダ63に利用される学習モデルは、ニューラルネットワークに限られなくてもよく、実施の形態に応じて適宜選択されてよい。エンコーダ61、推定部62、及びデコーダ63にはそれぞれ、例えば、回帰木、サポートベクタ回帰モデル等の回帰モデルが用いられてよい。また、この回帰モデルには、サポートベクタマシン、分類木、ランダムフォレスト、バギング、ブースティング、又はこれらの組み合わせが接続されてもよい。推定部62には、例えば、線形回帰モデルが用いられてよい。推定部62及びデコーダ63にはそれぞれ、例えば、条件付き確率場モデルが用いられてもよい。
<4.2>
上記実施形態では、学習結果データ121は、学習済みのニューラルネットワークの構成を示す情報を含んでいる。しかしながら、学習結果データ121の構成は、このような例に限定されなくてもよく、学習済みの第1推定器51の設定に利用可能であれば、実施の形態に応じて適宜決定されてよい。例えば、利用するニューラルネットワークの構成が各装置で共通化されている場合、学習結果データ121は、学習済みのニューラルネットワークの構成を示す情報を含んでいなくてもよい。
上記実施形態では、学習結果データ121は、学習済みのニューラルネットワークの構成を示す情報を含んでいる。しかしながら、学習結果データ121の構成は、このような例に限定されなくてもよく、学習済みの第1推定器51の設定に利用可能であれば、実施の形態に応じて適宜決定されてよい。例えば、利用するニューラルネットワークの構成が各装置で共通化されている場合、学習結果データ121は、学習済みのニューラルネットワークの構成を示す情報を含んでいなくてもよい。
<4.3>
上記実施形態では、学習ネットワーク5は、互いに共通するエンコーダ61を備える第1推定器51及び第2推定器52により構成されている。これにより、上記実施形態に係る推定器生成装置1は、第2推定器52の機械学習により、共通するエンコーダ61のパラメータをよりよい局所解に向かうようにすることで、第1推定器51の精度の向上を図っている。しかしながら、学習ネットワーク5の構成は、このような例に限定されなくてもよく、実施の形態に応じて適宜変更されてよい。例えば、以下の2つの変形例が採用されてよい。
上記実施形態では、学習ネットワーク5は、互いに共通するエンコーダ61を備える第1推定器51及び第2推定器52により構成されている。これにより、上記実施形態に係る推定器生成装置1は、第2推定器52の機械学習により、共通するエンコーダ61のパラメータをよりよい局所解に向かうようにすることで、第1推定器51の精度の向上を図っている。しかしながら、学習ネットワーク5の構成は、このような例に限定されなくてもよく、実施の形態に応じて適宜変更されてよい。例えば、以下の2つの変形例が採用されてよい。
(第1の変形例)
図8は、本変形例に係る推定器生成装置1Aのソフトウェア構成の一例を模式的に例示する。推定器生成装置1Aのハードウェア構成は、上記実施形態に係る推定器生成装置1と同様である。また、図8に示されるとおり、推定器生成装置1Aのソフトウェア構成も、上記実施形態に係る推定器生成装置1と同様である。上記実施形態に係る学習ネットワーク5と比較して、本変形例に係る学習ネットワーク5Aが第3推定器53を更に備える点、学習データ取得部111が、複数件の第3学習データセット73を更に取得するように構成される点、学習処理部112が、複数件の第3学習データセット73を利用して、第3推定器53の機械学習を更に実行するように構成される点を除き、推定器生成装置1Aは、上記実施形態に係る推定器生成装置1と同様に動作する。
図8は、本変形例に係る推定器生成装置1Aのソフトウェア構成の一例を模式的に例示する。推定器生成装置1Aのハードウェア構成は、上記実施形態に係る推定器生成装置1と同様である。また、図8に示されるとおり、推定器生成装置1Aのソフトウェア構成も、上記実施形態に係る推定器生成装置1と同様である。上記実施形態に係る学習ネットワーク5と比較して、本変形例に係る学習ネットワーク5Aが第3推定器53を更に備える点、学習データ取得部111が、複数件の第3学習データセット73を更に取得するように構成される点、学習処理部112が、複数件の第3学習データセット73を利用して、第3推定器53の機械学習を更に実行するように構成される点を除き、推定器生成装置1Aは、上記実施形態に係る推定器生成装置1と同様に動作する。
すなわち、本変形例に係る学習ネットワーク5Aは、第1推定器51、第2推定器52、及び第3推定器53を備えている。第3推定器53は、第1推定器51のエンコーダ61及び第2推定器52のデコーダ63とは異なるデコーダ64により構成される。デコーダ64は、本発明の「他のデコーダ」の一例である。デコーダ64は、機械学習可能な学習モデルにより構成される。このデコーダ64は、デコーダ63と同様に、ニューラルネットワークにより構成されてよい。エンコーダ61及びデコーダ64は、エンコーダ61の出力がデコーダ64に入力されるように互いに接続される。
推定器生成装置1Aの制御部は、上記推定器生成装置1と同様に、ステップS101の処理を実行し、複数件の第1学習データセット71及び複数件の第2学習データセット72を取得する。加えて、ステップS101において、制御部は、被験者Tの顔の写る顔画像データ731、及び生理学的データ722とは異なる被験者Tの生理学的データ732の組み合わせによりそれぞれ構成される複数件の第3学習データセット73を更に取得する。各件の第3学習データセット73は、各件の第2学習データセット72と同様に収集されてよい。
顔画像データ731は、本発明の「第3顔画像データ」の一例である。顔画像データ731は、第1顔画像データ711及び第2顔画像データ721の少なくとも一方と同一であってよい。また、生理学的データ732は、本発明の「第2生理学的データ」の一例である。生理学的データ732は、生理学的データ722とは異なる生理学的パラメータを測定することで得られてもよいし、生理学的データ722と同一の生理学的パラメータを異なる時刻に測定することで得られてもよい。また、同一の生理学的パラメータを測定することで得られたデータに対して異なる情報処理(例えば、上記単純化処理)を適用することで、各生理学的データ(722、732)は得られてもよい。
ステップS102では、制御部は、第1推定器51及び第2推定器52の機械学習と共に、複数件の第3学習データセット73を利用して、第3推定器53の機械学習を実施する。具体的には、制御部は、各第3学習データセット73に含まれる顔画像データ731を入力データとして利用し、対応する生理学的データ732を教師データとして利用して、第3推定器53の学習処理を実行する。この学習処理は、上記第1推定器51と同様であってよい。すなわち、制御部は、学習処理の対象をエンコーダ61及び推定部62からエンコーダ61及びデコーダ64に置き換え、第1顔画像データ711を顔画像データ731に置き換え、状態情報データ712を生理学的データ732に置き換えて、上記第1~第4のステップの各処理を実行する。制御部は、各件の第3学習データセット73について、デコーダ64から得られる出力データと生理学的データ732との誤差の和が閾値以下になるまで、上記第1~第4のステップによる第3推定器53(エンコーダ61及びデコーダ64)のパラメータの値の調節を繰り返す。閾値は、実施の形態に応じて適宜設定されてよく、上記第1推定器51及び第2推定器52のいずれかの機械学習における閾値と同じであってもよいし、第1推定器51及び第2推定器52の両方の機械学習における閾値と異なっていてもよい。これにより、制御部は、各件の第3学習データセット73を構成する顔画像データ731をエンコーダ61に入力すると、入力した顔画像データ731に関連付けられた生理学的データ732を再現した出力データをデコーダ64から出力するように訓練された第3推定器53を更に構築することができる。なお、上記実施形態と同様に、第1推定器51、第2推定器52、及び第3推定器53それぞれの機械学習の処理順序は、特に限定されなくてもよく、実施の形態に応じて適宜決定されてよい。
ステップS103では、制御部は、上記実施形態と同様に、保存処理部113として動作し、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として記憶部12に保存する。これにより、制御部は、本変形例に係る処理を終了する。生成された学習済みの第1推定器51は、上記実施形態と同様に利用可能である。上記モニタリング装置2は、本変形例により生成された第1推定器51を利用して、顔画像データ221から運転者Dの状態を推定してもよい。
本変形例によれば、第3推定器53の機械学習の過程で、共通のエンコーダ61の出力が、生理学的データ732を更に導出可能にデザインされる。これにより、対象者の状態を更に高精度に推定可能な第1推定器51を生成することができる。
なお、複数の第3推定器53が設けられてもよい。また、第3推定器53を1つずつ学習ネットワーク5Aに追加していき、ステップS102において、制御部は、第1推定器51及び第2推定器52の機械学習と共に、追加した第3推定器53の機械学習を実行するようにしてもよい。そして、機械学習が完了する度に、用意した評価用データセットに対する、生成された学習済みの第1推定器51による推定の正答率を算出してもよい。評価用データセットは、第1学習データセット71と同様に構成される。評価用データセットに含まれる顔画像データを学習済みの第1推定器51に入力し、第1推定器51から出力される出力値が状態情報データに対応する値と一致するか否かに基づいて、学習済みの第1推定器51による推定の正答率を算出することができる。この正答率が低下した場合には、制御部は、追加した第3推定器53を学習ネットワーク5Aから切り離してもよい。これにより、対象者の状態を更に高精度に推定可能な第1推定器51を生成することができる。
(第2の変形例)
図9は、本変形例に係る推定器生成装置1Bのソフトウェア構成の一例を模式的に例示する。推定器生成装置1Bのハードウェア構成は、上記実施形態に係る推定器生成装置1と同様である。また、図9に示されるとおり、推定器生成装置1Bのソフトウェア構成も、上記実施形態に係る推定器生成装置1と同様である。上記実施形態に係る学習ネットワーク5と比較して、本変形例に係る学習ネットワーク5Bが第4推定器54を更に備える点、学習データ取得部111が、複数件の第4学習データセット74を更に取得するように構成される点、学習処理部112が、複数件の第4学習データセット74を利用して、第4推定器54の機械学習を更に実行するように構成される点を除き、推定器生成装置1Bは、上記実施形態に係る推定器生成装置1と同様に動作する。
図9は、本変形例に係る推定器生成装置1Bのソフトウェア構成の一例を模式的に例示する。推定器生成装置1Bのハードウェア構成は、上記実施形態に係る推定器生成装置1と同様である。また、図9に示されるとおり、推定器生成装置1Bのソフトウェア構成も、上記実施形態に係る推定器生成装置1と同様である。上記実施形態に係る学習ネットワーク5と比較して、本変形例に係る学習ネットワーク5Bが第4推定器54を更に備える点、学習データ取得部111が、複数件の第4学習データセット74を更に取得するように構成される点、学習処理部112が、複数件の第4学習データセット74を利用して、第4推定器54の機械学習を更に実行するように構成される点を除き、推定器生成装置1Bは、上記実施形態に係る推定器生成装置1と同様に動作する。
すなわち、本変形例に係る学習ネットワーク5Bは、第1推定器51、第2推定器52、及び第4推定器54を備えている。第4推定器54は、第1推定器51のエンコーダ61とは異なるエンコーダ65及び第1推定器51の推定部62により構成される。エンコーダ65は、本発明の「他のエンコーダ」の一例である。エンコーダ65は、機械学習可能な学習モデルにより、生理学的データから特徴量を導出するように構成される。このエンコーダ65は、エンコーダ61と同様に、ニューラルネットワークにより構成されてよい。エンコーダ65及び推定部62は、エンコーダ65の出力が推定部62に入力されるように互いに接続される。なお、エンコーダ65及びデコーダ63は、エンコーダ65の出力がデコーダ63に入力されるように互いに接続されていてもよい。
推定器生成装置1Bの制御部は、上記推定器生成装置1と同様に、ステップS101の処理を実行し、複数件の第1学習データセット71及び複数件の第2学習データセット72を取得する。加えて、ステップS101において、制御部は、被験者Tの生理学的データ741、及び被験者Tの状態を示す状態情報データ742の組み合わせによりそれぞれ構成される複数件の第4学習データセット74を更に取得する。
生理学的データ741は、本発明の「第3生理学的データ」の一例であり、状態情報データ742は、本発明の「第2状態情報データ」の一例である。生理学的データ741及び生理学的データ722は、同じであってもよいし、互いに異なっていてもよい。状態情報データ742及び状態情報データ712は、同じであってもよいし、互いに異なっていてもよい。生理学的データ741は、生理学的データ722と同様に収集されてよく、状態情報データ742は、状態情報データ712と同様に収集されてよい。
ステップS102では、制御部は、第1推定器51及び第2推定器52の機械学習と共に、複数件の第4学習データセット74を利用して、第4推定器54の機械学習を実施する。具体的には、制御部11は、各第4学習データセット74に含まれる生理学的データ741を入力データとして利用し、対応する状態情報データ742を教師データとして利用して、第4推定器54の学習処理を実行する。この学習処理は、基本的には、上記実施形態と同様であってよい。すなわち、制御部は、学習処理の対象をエンコーダ61及び推定部62からエンコーダ65及び推定部62に置き換え、第1顔画像データ711を生理学的データ741に置き換え、状態情報データ712を状態情報データ742に置き換えて、上記第1~第4のステップの各処理を実行する。制御部は、各件の第4学習データセット74について、推定部62から得られる出力値と状態情報データ742に対応する値との誤差を算出し、算出した各誤差に基づいて、エンコーダ65及び推定部62のパラメータの値を更新する。
加えて、第1推定器51及び第4推定器54の機械学習の過程において、制御部は、第1推定器51及び第4推定器54を、エンコーダ61の出力とエンコーダ65の出力との誤差が最小化されるように訓練する。具体的には、制御部は、状態情報データ712及び状態情報データ742が一致する場合に、状態情報データ712に関連付けられた第1顔画像データ711をエンコーダ61に入力することでエンコーダ61から得られた出力値と、状態情報データ742に関連付けられた生理学的データ741をエンコーダ65に入力することでエンコーダ65から得られた出力値との誤差を算出する。そして、制御部は、算出した各誤差に基づいて、各エンコーダ(61、65)のパラメータの値を更新する。
制御部は、各件の第4学習データセット74について、推定部62から得られる出力値と状態情報データ712との誤差の和が閾値以下であり、かつ同一の状態情報データを導出する際におけるエンコーダ61から得られる出力値とエンコーダ65から得られる出力値との誤差の和が閾値以下になるまで、各パラメータの値の調節を繰り返す。閾値は、実施の形態に応じて適宜設定されてよい。
なお、制御部は、各推定器(51、54)の機械学習を同時に実行してもよいし、いずれか一方の機械学習を先に実行した後に、他方の機械学習を実行してもよい。例えば、制御部は、第4推定器54の機械学習を実行した後に、第1推定器51の機械学習を実行してもよい。この場合、第1推定器51の機械学習では、制御部は、第4推定器54のエンコーダ65のパラメータの値を固定した上で、両エンコーダ(61、65)の出力の誤差が最小化されるように、エンコーダ61のパラメータの値を更新する。
これにより、制御部は、第1推定器51及び第4推定器54を、状態情報データ712と状態情報データ742とが一致する場合に、対応する第1顔画像データ711をエンコーダ61に入力することでエンコーダ61から得られる出力値と、対応する生理学的データ741をエンコーダ65に入力することでエンコーダ65から得られる出力値との誤差の和が閾値よりも小さくなるように訓練することができる。また、制御部は、各件の第4学習データセット74を構成する生理学的データ741をエンコーダ65に入力すると、入力した生理学的データ741に関連付けられた状態情報データ742により示される被験者Tの状態に対応する出力値を推定部62から出力するように訓練された第4推定器54を構築することができる。
なお、エンコーダ65及びデコーダ63が、エンコーダ65の出力がデコーダ63に入力されるように互いに接続されている場合、制御部は、機械学習により、各第4学習データセット74の生理学的データ741をエンコーダ65に入力すると、デコーダ63から生理学的データ741を再現した出力データが出力されるように、エンコーダ65及びデコーダ63を訓練してもよい。制御部は、このエンコーダ65及びデコーダ63の機械学習を、上記各推定器51~54の機械学習と同様に実行可能である。
ステップS103では、制御部は、上記実施形態と同様に、保存処理部113として動作し、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として記憶部12に保存する。これにより、制御部は、本変形例に係る処理を終了する。生成された学習済みの第1推定器51は、上記実施形態と同様に利用可能である。上記モニタリング装置2は、本変形例により生成された第1推定器51を利用して、顔画像データ221から運転者Dの状態を推定してもよい。
本変形例では、第4推定器54は、生理学的データから対象者の状態を推定するように訓練される。生理学的データは顔画像データよりも高次な情報を含み得るため、顔画像データからよりも、生理学的データからの方が対象者の状態をより高精度に推定可能であると期待することができる。そのため、この第4推定器54は、第1推定器51と比べて、対象者の状態をより高精度に推定可能であると期待することができる。つまり、第1推定器51及び第4推定器54を個別に訓練した場合には、第4推定器54におけるエンコーダ65の出力は、第1推定器51におけるエンコーダ61の出力よりも、対象者の状態をより正確に示し得る。
そこで、本変形例では、制御部は、第4推定器54におけるエンコーダ65の出力を、対象者の状態をより高精度に推定するための第1推定器51におけるエンコーダ61の出力の見本として利用する。つまり、制御部は、機械学習の過程において、エンコーダ61の出力とエンコーダ65の出力との誤差が閾値よりも小さくなるように各エンコーダ(61、65)を訓練する。これにより、第1推定器51におけるエンコーダ61のパラメータが、対象者の状態を推定する精度のよりよい局所解に向かうようにすることができる。よって、本変形例によれば、対象者の状態をより高精度に推定可能な第1推定器51を生成することができる。
なお、本変形例では、第4推定器54は、生理学的データ741が入力されるように構成されている。しかしながら、第4推定器54の構成は、このような例に限定されなくてもよく、実施の形態に応じて適宜設定されてよい。例えば、第4推定器54は、顔画像データ及び生理学的データの組み合わせが入力されるように構成されてもよい。この場合、顔画像データ及び生理学的データの両方が第4推定器54の入力として利用されるため、第4推定器54は、第1推定器51よりも優れた性能を有する。また、各推定器(51、54)は、同じ顔画像データを入力するように構成されるため、それぞれのエンコーダ(61、65)のパラメータは類似した値を取り得る。これを利用して、推定器生成装置1Bは、第4推定器54の機械学習を実行した後に、エンコーダ65の振る舞いをエンコーダ61が模倣するように第1推定器51の機械学習を実行するのが好ましい。
<4.4>
上記実施形態に係る推定器生成装置1は、車両の運転者の状態を推定する場面に適用されている。しかしながら、上記実施形態に係る推定器生成装置1は、車両の運転者の顔の写る顔画像データから運転者の状態を推定するための推定器を生成する場面ではなく、何らかの作業を行う対象者の顔の写る顔画像データから対象者の状態を推定するための推定器を生成する場面に広く適用されてよい。
上記実施形態に係る推定器生成装置1は、車両の運転者の状態を推定する場面に適用されている。しかしながら、上記実施形態に係る推定器生成装置1は、車両の運転者の顔の写る顔画像データから運転者の状態を推定するための推定器を生成する場面ではなく、何らかの作業を行う対象者の顔の写る顔画像データから対象者の状態を推定するための推定器を生成する場面に広く適用されてよい。
図10は、本発明が適用される他の場面の一例を模式的に例示する。具体的には、図10は、生産現場で作業する作業者Uの顔を撮影し、得られる顔画像データから作業者Uの状態を推定するための推定器を生成する場面に上記実施形態に係る推定器生成装置1を適用した例を示している。作業者Uは、生産ラインに含まれる各工程のタスクを所定の作業として遂行している。顔画像データに写る対象者が車両の運転者から生産ラインにおける作業者に置き換わる点を除き、本変形例は、上記実施形態と同様である。
すなわち、ステップS101では、制御部11は、所定の作業を遂行する被験者の顔の写る第1顔画像データ、及び所定の作業を遂行している時における被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得する。また、制御部11は、被験者の顔の写る第2顔画像データ、及び被験者の生理学的パラメータを1又は複数のセンサで測定することで得られた生理学的データの組み合わせによりそれぞれ構成された複数件の第2学習データセットを取得する。各件の第1学習データセットは実環境で収集されてよく、各件の第2学習データセットは仮想環境で収集されてよい。本変形例では、所定の作業は、生産ラインにおけるタスクである。しかしながら、所定の作業は、このような例に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。
ステップS102では、制御部11は、取得した複数件の第1学習データセットを利用して、第1推定器51の機械学習を実施する。これと共に、制御部11は、取得した複数件の第2学習データセットを利用して、第2推定器52の機械学習を実施する。これにより、制御部11は、各件の第1学習データセットの第1顔画像データをエンコーダ61に入力すると、対応する状態情報データにより示される被験者の状態に対応する出力値を推定部62から出力するように訓練された第1推定器51を構築する。また、制御部11は、各件の第2学習データセットの第2顔画像データをエンコーダ61に入力すると、対応する生理学的データを再現した出力データをデコーダ63から出力するように訓練された第2推定器52を構築する。機械学習の処理は、上記実施形態と同様であってよい。
ステップS103では、制御部11は、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として記憶部12に保存する。これにより、制御部11は、本変形例に係る処理を終了する。本変形例に係る推定器生成装置1によれば、作業者の状態をより高精度に推定可能な第1推定器51を生成することができる。
モニタリング装置2Cは、本変形例に係る推定器生成装置1により構築された第1推定器51を利用して、生産ラインでロボット装置Rと共に作業を行う作業者Uをカメラ41により撮影し、得られた顔画像データから作業者Uの状態を推定するように構成される。このモニタリング装置2Cのハードウェア構成及びソフトウェア構成は、上記実施形態に係るモニタリング装置2と同様であってよい。モニタリング装置2Cは、運転者以外の対象者の顔画像データを取り扱う点を除いて、上記実施形態に係るモニタリング装置2と同様に動作する。
すなわち、ステップS201では、モニタリング装置2Cの制御部は、作業者Uの顔の写る顔画像データをカメラ41から取得する。次のステップS202では、制御部は、学習済みの第1推定器51に得られた顔画像データを入力し、学習済みの第1推定器51の演算処理を実行することで、作業者Uの状態を推定した結果に対応する出力値を第1推定器51から取得する。次のステップS203では、制御部は、作業者Uの状態を推定した結果に関する情報を出力する。
本変形例に係るステップS203において、出力する情報の内容は、上記実施形態と同様に、実施の形態に応じて適宜選択されてよい。例えば、第1推定器51を利用して、作業者Uの状態として、作業者Uの眠気度、疲労度、余裕度、又はこれらの組み合わせを推定する場合を想定する。この場合、制御部は、眠気度及び疲労度の少なくとも一方が閾値を超えるか否かを判定してもよい。そして、眠気度及び疲労度の少なくとも一方が閾値を超える場合に、制御部は、出力装置を介して、作業を中断し、休憩を取るように促すメッセージを出力してもよい。制御部は、ネットワーク等を介して、作業者U自身、作業者Uを監督する監督者等のユーザ端末にこのメッセージを送信してもよい。
また、制御部は、作業者Uの状態を推定した結果に応じて決定された動作の実行を指示する指令を推定結果に関する情報としてロボット装置Rに出力してもよい。一例として、作業者Uの推定される疲労度が高まっている時に、モニタリング装置2Cの制御部は、ロボット装置Rによる作業支援の割合を向上させる指令をロボット装置Rに出力してもよい。一方、作業者Uの余裕度が高まっている時には、モニタリング装置2Cの制御部は、ロボット装置Rによる作業支援の割合を低下させる指令をロボット装置Rに出力してもよい。これにより、本変形例に係るモニタリング装置2Cは、推定器生成装置1により生成された第1推定器51を利用して、顔画像データから作業者Uの状態を推定することができる。また、モニタリング装置2Cは、推定の結果に基づいて、ロボット装置Rの動作を制御することができる。
<4.5>
上記実施形態及び変形例では、何らかの作業を行う対象者の顔画像データから対象者の状態を推定する場面に本発明を適用した例を示している。しかしながら、本発明の適用可能な範囲は、このような顔画像データから対象者の状態を推定する場面に限られなくてもよく、対象者の写る画像データから対象者の状態を推定するあらゆる場面に広く適用されてよい。
上記実施形態及び変形例では、何らかの作業を行う対象者の顔画像データから対象者の状態を推定する場面に本発明を適用した例を示している。しかしながら、本発明の適用可能な範囲は、このような顔画像データから対象者の状態を推定する場面に限られなくてもよく、対象者の写る画像データから対象者の状態を推定するあらゆる場面に広く適用されてよい。
図11は、本変形例に係る推定器生成装置1Dのソフトウェア構成の一例を模式的に例示する。推定器生成装置1Dのハードウェア構成は、上記実施形態に係る推定器生成装置1と同様である。また、図11に示されるとおり、推定器生成装置1Dのソフトウェア構成も、上記実施形態に係る推定器生成装置1と同様である。第1顔画像データ711が第1画像データ711Dに置き換わり、第2顔画像データ721が第2画像データ721Dに置き換わる点を除き、推定器生成装置1Dは、上記実施形態に係る推定器生成装置1と同様に動作する。
すなわち、ステップS101では、推定器生成装置1Dの制御部は、学習データ取得部111として動作し、所定の作業を実行する被験者の写る第1画像データ711D及び所定の作業を実行している時における被験者の状態を示す状態情報データ712の組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得する。また、制御部は、被験者の写る第2画像データ721D及び被験者の生理学的パラメータを1又は複数のセンサで測定することにより得られた生理学的データ722の組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する。所定の作業は、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。所定の作業は、例えば、車両の運転、生産ラインにおけるタスク等であってよい。
ステップS102では、制御部は、学習処理部112として動作し、取得した複数件の第1学習データセットを利用して、第1推定器51の機械学習を実施する。これと共に、制御部は、取得した複数件の第2学習データセットを利用して、第2推定器52の機械学習を実施する。これにより、制御部は、取得した各件の第1学習データセットを構成する第1画像データ711Dをエンコーダ61に入力すると、入力した第1画像データ711Dに関連付けられた状態情報データ712により示される被験者の状態に対応する出力値を推定部62から出力するように訓練された第1推定器51を構築する。また、制御部は、各件の第2学習データセットを構成する第2画像データ721Dをエンコーダ61に入力すると、入力した第2画像データ721Dに関連付けられた生理学的データ722を再現した出力データをデコーダ63から出力するように訓練された第2推定器52を構築する。機械学習の処理は、上記実施形態と同様であってよい。
ステップS103では、制御部は、保存処理部113として動作し、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として記憶部12に保存する。これにより、制御部は、本変形例に係る処理を終了する。本変形例に係る推定器生成装置1Dによれば、画像データから対象者の状態をより高精度に推定可能な第1推定器51を生成することができる。
図12は、本変形例に係るモニタリング装置2Dのソフトウェア構成の一例を模式的に例示する。モニタリング装置2Dは、本変形例に係る推定器生成装置1Dにより構築された第1推定器51を利用して、画像データから対象者の状態を推定するように構成される。このモニタリング装置2Dのハードウェア構成は、上記実施形態に係るモニタリング装置2と同様であってよい。また、図12に示されるとおり、モニタリング装置2Dのソフトウェア構成も、上記実施形態に係るモニタリング装置2と同様である。顔画像データ221が画像データ221Dに置き換わる点を除き、モニタリング装置2Dは、上記実施形態に係るモニタリング装置2と同様に動作する。
すなわち、ステップS201では、モニタリング装置2Dの制御部は、対象者の写る画像データ221Dをカメラから取得する。次のステップS202では、制御部は、学習済みの第1推定器51に画像データ221Dを入力し、学習済みの第1推定器51の演算処理を実行することで、対象者の状態を推定した結果に対応する出力値を第1推定器51から取得する。次のステップS203では、制御部は、対象者の状態を推定した結果に関する情報を出力する。出力形式は、実施の形態に応じて適宜選択されてよい。本変形例に係るモニタリング装置2Dによれば、画像データから対象者の状態を精度よく推定することができる。
<4.6>
上記実施形態及び変形例では、何らかの作業を行う対象者の写る画像データから当該対象者の状態を推定する場面に本発明を適用した例を示している。しかしながら、本発明の適用範囲は、このような画像データから対象者の状態を推定する場面に限られなくてもよく、対象者の活動を観測することで得られた観測データから対象者の状態を推定するあらゆる場面に適用されてよい。
上記実施形態及び変形例では、何らかの作業を行う対象者の写る画像データから当該対象者の状態を推定する場面に本発明を適用した例を示している。しかしながら、本発明の適用範囲は、このような画像データから対象者の状態を推定する場面に限られなくてもよく、対象者の活動を観測することで得られた観測データから対象者の状態を推定するあらゆる場面に適用されてよい。
図13は、本変形例に係る推定器生成装置1Eのソフトウェア構成の一例を模式的に例示する。推定器生成装置1Eのハードウェア構成は、上記実施形態に係る推定器生成装置1と同様である。図13に示されるとおり、推定器生成装置1Eのソフトウェア構成も、上記実施形態に係る推定器生成装置1と同様である。第1顔画像データ711が第1観測データ711Eに置き換わり、第2顔画像データ721が第2観測データ721Eに置き換わる点を除き、推定器生成装置1Eは、上記実施形態に係る推定器生成装置1と同様に動作する。
すなわち、ステップS101では、推定器生成装置1Eの制御部は、学習データ取得部111として動作し、所定の作業を実行する被験者の活動を1又は複数の第1センサ31Eで測定することにより得られた第1観測データ711E、及び所定の作業を実行している時における被験者Tの状態を示す状態情報データ712の組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得する。また、制御部は、被験者Tの活動を1又は複数の第1センサ32Eで測定することにより得られた第2観測データ721E、及び第1センサ32Eとは異なる種類の1又は複数の第2センサ33Eで被験者Tの生理学的パラメータを測定することにより得られた生理学的データ722Eの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する。
第1センサ(31E、32E)及び第2センサ33Eは、特に限定されなくてもよく、実施の形態に応じて適宜選択されてよい。第1センサ(31E、32E)及び第2センサ33Eは、同じであってもよいし、異なっていてもよい。第2センサ33Eは、第1センサ(31E、32E)よりも高機能であり、第1センサ(31E、32E)よりも人間の状態に関する高次な情報を取得可能に構成されるのが好ましい。一方、第1センサ(31E、32E)は、第2センサ33Eよりも安価であるのが好ましい。
また、各件の第1学習データセットを構成する第1観測データ711E及び状態情報データ712は実環境で収集されるのが好ましい。一方、各件の第2学習データセットを構成する第2観測データ721E及び生理学的データ722Eは仮想環境で収集されるのが好ましい。これに応じて、第1センサ(31E、32E)は、カメラ、眼電位センサ、視線計測装置、マイクロフォン、血圧計、脈拍計、心拍計、体温計、皮膚電気反応計、荷重センサ、操作デバイス又はこれらの組み合わせにより構成されてよい。荷重センサは、一点の荷重を計測するように構成されていてもよいし、荷重分布を計測するように構成されていてもよい。操作デバイスは、状態を推定する対象となる対象者が操作可能なデバイスであれば特に限定されなくてもよく、その種類は、実施の形態に応じて適宜選択されてよい。上記実施形態と同様に対象者が車両の運転を行うケースでは、操作デバイスは、例えば、ハンドル、ブレーキ、アクセル等であってよい。この場合、各観測データ(711E、721E)は、例えば、画像データ、眼電位データ、視線の計測データ、音声データ、血圧データ、脈拍数データ、心拍数データ、体温データ、皮膚電気反射データ、荷重の計測データ、操作ログ又はこれらの組み合わせにより構成される。操作ログは、操作デバイスの操作履歴を示す。一方、第2センサ33Eは、脳波計、脳磁計、核磁気共鳴画像装置、筋電計、心電計、瞳孔径計測装置又はこれらの組み合わせにより構成されてよい。
第1センサは、第1推定器51を実環境で運用する際にも利用される。つまり、所定の作業を実行している対象者から観測データを取得するために第1センサは利用される。そのため、第1センサ(31E、32E)には、被験者Tの活動を測定する間、被験者Tの身体的な動作を制限しないセンサを用いるのが好ましい。身体的な動作を制限しないとは、例えば、カメラ、マイクロフォン等のように、被験者に接触せずに配置されること、及び、例えば、腕時計型デバイス、眼鏡型デバイス等のように、被験者の身体の一部に接触するが、その身体の一部の移動を殆ど阻害しないことを含む。一方、第2センサ33Eには、より高次な情報を収集可能であれば、被験者Tの身体的な動作を制限するセンサが用いられてもよい。身体的な動作を制限するとは、例えば、脳波計等のように、被験者Tの身体の少なくとも一部に取り付けられ、その身体の一部の移動を阻害すること、及び、例えば、核磁気共鳴画像装置等のように、被験者Tの身体に接触しないが、測定のため、所定の作業を行う場所とは異なる一定の場所に被験者Tが留まっていないといけないことを含む。
ステップS102では、制御部は、学習処理部112として動作し、取得した複数件の第1学習データセットを利用して、第1推定器51の機械学習を実施する。これと共に、制御部は、取得した複数件の第2学習データセットを利用して、第2推定器52の機械学習を実施する。これにより、制御部は、各件の第1学習データセットを構成する第1観測データ711Eをエンコーダ61に入力すると、入力した第1観測データ711Eに関連付けられた状態情報データ712により示される被験者Tの状態に対応する出力値を推定部62から出力するように訓練された第1推定器51を構築する。また、制御部は、各件の第2学習データセットを構成する第2観測データ721Eをエンコーダ61に入力すると、入力した第2観測データ721Eに関連付けられた生理学的データ722Eを再現した出力データをデコーダ63から出力するように訓練された第2推定器52を構築する。
ステップS103では、制御部は、ステップS102の機械学習により構築された第1推定器51の構成及びパラメータを示す情報を学習結果データ121として記憶部12に保存する。これにより、制御部は、本変形例に係る処理を終了する。本変形例に係る推定器生成装置1Eによれば、観測データから対象者の状態をより高精度に推定可能な第1推定器51を生成することができる。
図14は、本変形例に係るモニタリング装置2Eのソフトウェア構成の一例を模式的に例示する。モニタリング装置2Eは、本変形例に係る推定器生成装置1Eにより構築された第1推定器51を利用して、観測データから対象者の状態を推定するように構成される。このモニタリング装置2Eのハードウェア構成は、上記実施形態に係るモニタリング装置2と同様であってよい。また、図14に示されるとおり、モニタリング装置2Eのソフトウェア構成も、上記実施形態に係るモニタリング装置2と同様である。顔画像データ221が観測データ221Eに置き換わる点を除き、モニタリング装置2Eは、上記実施形態に係るモニタリング装置2と同様に動作する。
すなわち、ステップS201では、モニタリング装置2Eの制御部は、所定の作業を実行する対象者の活動を1又は複数の第1センサで測定することにより得られた観測データ221Eを取得する。次のステップS202では、制御部は、学習済みの第1推定器51に観測データ221Eを入力し、学習済みの第1推定器51の演算処理を実行することで、対象者の状態を推定した結果に対応する出力値を第1推定器51から取得する。次のステップS203では、制御部は、対象者の状態を推定した結果に関する情報を出力する。出力形式は、実施の形態に応じて適宜選択されてよい。本変形例に係るモニタリング装置2Eによれば、観測データから対象者の状態を精度よく推定することができる。
1…推定器生成装置、
11…制御部、12…記憶部、13…通信インタフェース、
14…入力装置、15…出力装置、16…ドライブ、
111…学習データ取得部、112…学習処理部、
113…保存処理部、
121…学習結果データ、
81…推定器生成プログラム、91…記憶媒体、
2…モニタリング装置、
21…制御部、22…記憶部、23…通信インタフェース、
24…外部インタフェース、
25…入力装置、26…出力装置、
211…データ取得部、212…推定処理部、
213…出力部、
221…顔画像データ、
82…モニタリングプログラム、
31…カメラ、32…カメラ、33…脳波計、
41…カメラ、
5…学習ネットワーク、
51…第1推定器、52…第2推定器、
53…第3推定器、54…第4推定器、
61…エンコーダ、62…推定部、
63…デコーダ、
64…(他の)デコーダ、65…(他の)エンコーダ、
71…第1学習データセット、
711…第1顔画像データ、712…(第1)状態情報データ、
72…第2学習データセット、
721…第2顔画像データ、722…(第1)生理学的データ、
73…第3学習データセット、
731…(第3)顔画像データ、732…(第2)生理学的データ、
74…第4学習データセット、
741…(第3)生理学的データ、742…(第2)状態情報データ、
T…被験者、D…運転者(対象者)
11…制御部、12…記憶部、13…通信インタフェース、
14…入力装置、15…出力装置、16…ドライブ、
111…学習データ取得部、112…学習処理部、
113…保存処理部、
121…学習結果データ、
81…推定器生成プログラム、91…記憶媒体、
2…モニタリング装置、
21…制御部、22…記憶部、23…通信インタフェース、
24…外部インタフェース、
25…入力装置、26…出力装置、
211…データ取得部、212…推定処理部、
213…出力部、
221…顔画像データ、
82…モニタリングプログラム、
31…カメラ、32…カメラ、33…脳波計、
41…カメラ、
5…学習ネットワーク、
51…第1推定器、52…第2推定器、
53…第3推定器、54…第4推定器、
61…エンコーダ、62…推定部、
63…デコーダ、
64…(他の)デコーダ、65…(他の)エンコーダ、
71…第1学習データセット、
711…第1顔画像データ、712…(第1)状態情報データ、
72…第2学習データセット、
721…第2顔画像データ、722…(第1)生理学的データ、
73…第3学習データセット、
731…(第3)顔画像データ、732…(第2)生理学的データ、
74…第4学習データセット、
741…(第3)生理学的データ、742…(第2)状態情報データ、
T…被験者、D…運転者(対象者)
Claims (13)
- 学習データ取得部であって、
車両を運転する被験者の顔の写る第1顔画像データ、及び前記車両の運転時における前記被験者の状態を示す第1状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得し、かつ
前記被験者の顔の写る第2顔画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた第1生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する、
ように構成される学習データ取得部と、
学習処理部であって、
エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1顔画像データを前記エンコーダに入力すると、入力した前記第1顔画像データに関連付けられた前記第1状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、
前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2顔画像データを前記エンコーダに入力すると、入力した前記第2顔画像データに関連付けられた前記第1生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築する、
ように構成される学習処理部と、
を備える、
推定器生成装置。 - 前記各件の第1学習データセットを構成する前記第1顔画像データ及び前記第1状態情報データは実環境で収集され、
前記各件の第2学習データセットを構成する前記第2顔画像データ及び前記第1生理学的データは仮想環境で収集される、
請求項1に記載の推定器生成装置。 - 前記生理学的パラメータは、脳活動、筋電位、心電位、眼球運動又はこれらの組み合わせである、
請求項1又は2に記載の推定器生成装置。 - 前記第1状態情報データは、前記被験者の状態として、前記被験者の眠気の度合いを示す眠気度、前記被験者の疲労の度合いを示す疲労度、前記被験者の運転に対する余裕の度合いを示す余裕度、又はこれらの組み合わせを含む、
請求項1から3のいずれか1項に記載の推定器生成装置。 - 前記学習データ取得部は、前記被験者の顔の写る第3顔画像データ、及び前記第1生理学的データとは異なる前記被験者の第2生理学的データの組み合わせによりそれぞれ構成される複数件の第3学習データセットを更に取得するように構成され、
前記学習処理部は、前記第1推定器及び前記第2推定器の機械学習と共に、前記第1推定器の前記エンコーダ及び前記第2推定器の前記デコーダとは異なる他のデコーダにより構成される第3推定器であって、前記エンコーダの出力が前記他のデコーダに入力されるように前記エンコーダ及び前記他のデコーダが互いに接続された第3推定器の機械学習を実施することで、前記各件の第3学習データセットを構成する前記第3顔画像データを前記エンコーダに入力すると、入力した前記第3顔画像データに関連付けられた前記第2生理学的データを再現した出力データを前記他のデコーダから出力するように訓練された第3推定器を更に構築するように構成される、
請求項1から4のいずれか1項に記載の推定器生成装置。 - 前記学習データ取得部は、前記被験者の第3生理学的データ、及び前記被験者の状態を示す第2状態情報データの組み合わせによりそれぞれ構成される複数件の第4学習データセットを更に取得するように構成され、
前記学習処理部は、
前記第1推定器及び前記第2推定器の機械学習と共に、前記第1推定器の前記エンコーダとは異なる他のエンコーダ及び前記第1推定器の前記推定部により構成される第4推定器であって、前記他のエンコーダの出力が前記推定部に入力されるように前記他のエンコーダ及び前記推定部が互いに接続された第4推定器の機械学習を実施することで、前記各件の第4学習データセットを構成する前記第3生理学的データを前記他のエンコーダに入力すると、入力した前記第3生理学的データに関連付けられた前記第2状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第4推定器を構築し、かつ
前記機械学習の過程において、前記第1推定器及び前記第4推定器を、前記第1状態情報データと前記第2状態情報データとが一致する場合に、前記第1状態情報データに関連付けられた前記第1顔画像データを前記エンコーダに入力することで前記エンコーダから得られる出力値と、前記第2状態情報データに関連付けられた前記第3生理学的データを前記他のエンコーダに入力することで前記他のエンコーダから得られる出力値との誤差が閾値よりも小さくなるように訓練する、
ように構成される、
請求項1から5のいずれか1項に記載の推定器生成装置。 - 車両を運転する対象者の顔の写る顔画像データを取得するデータ取得部と、
請求項1から6のいずれか1項に記載の推定器生成装置により構築された前記第1推定器の前記エンコーダに対して取得した前記顔画像データを入力することで、前記対象者の状態を推定した結果に対応する出力を前記第1推定器の前記推定部から取得する推定処理部と、
前記対象者の状態を推定した結果に関連する情報を出力する出力部と、
を備える、
モニタリング装置。 - コンピュータが、
車両を運転する被験者の顔の写る第1顔画像データ、及び前記車両の運転時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得するステップと、
前記被験者の顔の写る第2顔画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得するステップと、
エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1顔画像データを前記エンコーダに入力すると、入力した前記第1顔画像データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2顔画像データを前記エンコーダに入力すると、入力した前記第2顔画像データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築するステップと、
を実行する、
推定器生成方法。 - コンピュータに、
車両を運転する被験者の顔の写る第1顔画像データ、及び前記車両の運転時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得するステップと、
前記被験者の顔の写る第2顔画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得するステップと、
エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1顔画像データを前記エンコーダに入力すると、入力した前記第1顔画像データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2顔画像データを前記エンコーダに入力すると、入力した前記第2顔画像データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築するステップと、
を実行させるための、
推定器生成プログラム。 - 学習データ取得部であって、
所定の作業を実行する被験者の写る第1画像データ、及び前記所定の作業を実行している時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得し、かつ
前記被験者の写る第2画像データ、及び前記被験者の生理学的パラメータをセンサで測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する、
ように構成される学習データ取得部と、
学習処理部であって、
エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1画像データを前記エンコーダに入力すると、入力した前記第1画像データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、
前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2画像データを前記エンコーダに入力すると、入力した前記第2画像データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築する、
ように構成される学習処理部と、
を備える、
推定器生成装置。 - 学習データ取得部であって、
所定の作業を実行する被験者の活動を第1センサで測定することにより得られた第1観測データ、及び前記所定の作業を実行している時における前記被験者の状態を示す状態情報データの組み合わせによりそれぞれ構成される複数件の第1学習データセットを取得し、かつ
前記被験者の活動を前記第1センサで測定することにより得られた第2観測データ、及び前記第1センサとは異なる種類の第2センサで前記被験者の生理学的パラメータを測定することにより得られた生理学的データの組み合わせによりそれぞれ構成される複数件の第2学習データセットを取得する、
ように構成される学習データ取得部と、
学習処理部であって、
エンコーダ及び推定部により構成される第1推定器であって、前記エンコーダの出力が前記推定部に入力されるように前記エンコーダ及び前記推定部が互いに接続された第1推定器の機械学習を実施することで、前記各件の第1学習データセットを構成する前記第1観測データを前記エンコーダに入力すると、入力した前記第1観測データに関連付けられた前記状態情報データにより示される前記被験者の状態に対応する出力値を前記推定部から出力するように訓練された第1推定器を構築すると共に、
前記第1推定器の前記エンコーダ及びデコーダにより構成される第2推定器であって、前記エンコーダの出力が前記デコーダに入力されるように前記エンコーダ及び前記デコーダが互いに接続された第2推定器の機械学習を実施することで、前記各件の第2学習データセットを構成する前記第2観測データを前記エンコーダに入力すると、入力した前記第2観測データに関連付けられた前記生理学的データを再現した出力データを前記デコーダから出力するように訓練された第2推定器を構築する、
ように構成される学習処理部と、
を備える、
推定器生成装置。 - 前記各件の第1学習データセットを構成する前記第1観測データ及び前記状態情報データは実環境で収集され、
前記各件の第2学習データセットを構成する前記第2観測データ及び前記生理学的データは仮想環境で収集される、
請求項11に記載の推定器生成装置。 - 前記第1センサは、カメラ、眼電位センサ、マイクロフォン、血圧計、脈拍計、心拍計、体温計、皮膚電気反応計、視線計測装置、荷重センサ、操作デバイス又はこれらの組み合わせにより構成され、
前記第2センサは、脳波計、脳磁計、核磁気共鳴画像装置、筋電計、心電計、瞳孔径計測装置又はこれらの組み合わせにより構成される、
請求項11又は12に記載の推定器生成装置。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018203331A JP7014129B2 (ja) | 2018-10-29 | 2018-10-29 | 推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム |
| PCT/JP2019/010185 WO2020090134A1 (ja) | 2018-10-29 | 2019-03-13 | 推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム |
| CN201980058821.1A CN112673378B (zh) | 2018-10-29 | 2019-03-13 | 推断器生成装置、监视装置、推断器生成方法以及推断器生成程序 |
| US17/276,498 US11834052B2 (en) | 2018-10-29 | 2019-03-13 | Estimator generation apparatus, monitoring apparatus, estimator generation method, and computer-readable storage medium storing estimator generation program |
| EP19879158.4A EP3876191B1 (en) | 2018-10-29 | 2019-03-13 | Estimator generation device, monitoring device, estimator generation method, estimator generation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018203331A JP7014129B2 (ja) | 2018-10-29 | 2018-10-29 | 推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2020071550A JP2020071550A (ja) | 2020-05-07 |
| JP7014129B2 true JP7014129B2 (ja) | 2022-02-01 |
Family
ID=70462554
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018203331A Active JP7014129B2 (ja) | 2018-10-29 | 2018-10-29 | 推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11834052B2 (ja) |
| EP (1) | EP3876191B1 (ja) |
| JP (1) | JP7014129B2 (ja) |
| CN (1) | CN112673378B (ja) |
| WO (1) | WO2020090134A1 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102335784B1 (ko) | 2014-10-31 | 2021-12-06 | 아이리듬 테크놀로지스, 아이엔씨 | 무선 생리학적 모니터링 기기 및 시스템 |
| WO2019221654A1 (en) * | 2018-05-17 | 2019-11-21 | Tobii Ab | Autoencoding generative adversarial network for augmenting training data usable to train predictive models |
| US12061971B2 (en) | 2019-08-12 | 2024-08-13 | Micron Technology, Inc. | Predictive maintenance of automotive engines |
| US11853863B2 (en) | 2019-08-12 | 2023-12-26 | Micron Technology, Inc. | Predictive maintenance of automotive tires |
| US10993647B2 (en) * | 2019-08-21 | 2021-05-04 | Micron Technology, Inc. | Drowsiness detection for vehicle control |
| US11250648B2 (en) | 2019-12-18 | 2022-02-15 | Micron Technology, Inc. | Predictive maintenance of automotive transmission |
| JP7406001B2 (ja) | 2020-02-12 | 2023-12-26 | アイリズム・テクノロジーズ・インコーポレイテッド | 患者の生理学的特徴を推論するための、非侵襲的な心臓モニタ、および記録された心臓データの使用方法 |
| KR20210142930A (ko) * | 2020-05-19 | 2021-11-26 | 삼성에스디에스 주식회사 | 퓨 샷 학습 방법 및 이를 수행하기 위한 장치 |
| US11246523B1 (en) | 2020-08-06 | 2022-02-15 | Irhythm Technologies, Inc. | Wearable device with conductive traces and insulator |
| WO2022032117A1 (en) | 2020-08-06 | 2022-02-10 | Irhythm Technologies, Inc. | Adhesive physiological monitoring device |
| JP2022096379A (ja) * | 2020-12-17 | 2022-06-29 | 富士通株式会社 | 画像出力プログラム,画像出力方法および画像出力装置 |
| KR20220120741A (ko) * | 2021-02-22 | 2022-08-31 | 현대자동차주식회사 | 차량 및 그 제어방법 |
| CN116959078B (zh) * | 2023-09-14 | 2023-12-05 | 山东理工职业学院 | 疲劳检测模型的构建方法、疲劳检测方法及其装置 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6264492B1 (ja) | 2017-03-14 | 2018-01-24 | オムロン株式会社 | 運転者監視装置、運転者監視方法、学習装置及び学習方法 |
| US20180116620A1 (en) | 2016-10-31 | 2018-05-03 | Siemens Healthcare Gmbh | Deep Learning Based Bone Removal in Computed Tomography Angiography |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007257043A (ja) * | 2006-03-20 | 2007-10-04 | Nissan Motor Co Ltd | 乗員状態推定装置および乗員状態推定方法 |
| US11017250B2 (en) * | 2010-06-07 | 2021-05-25 | Affectiva, Inc. | Vehicle manipulation using convolutional image processing |
| CN101941425B (zh) * | 2010-09-17 | 2012-08-22 | 上海交通大学 | 对驾驶员疲劳状态的智能识别装置与方法 |
| JP5899472B2 (ja) * | 2012-05-23 | 2016-04-06 | パナソニックIpマネジメント株式会社 | 人物属性推定システム、及び学習用データ生成装置 |
| JP6090129B2 (ja) * | 2013-11-27 | 2017-03-08 | 株式会社デンソー | 視認領域推定装置 |
| CN104408878B (zh) * | 2014-11-05 | 2017-01-25 | 唐郁文 | 一种车队疲劳驾驶预警监控系统及方法 |
| JP6196361B2 (ja) * | 2015-10-15 | 2017-09-13 | ダイキン工業株式会社 | 運転者状態判定装置及び運転者状態判定方法 |
| US10467488B2 (en) * | 2016-11-21 | 2019-11-05 | TeleLingo | Method to analyze attention margin and to prevent inattentive and unsafe driving |
| US11249544B2 (en) * | 2016-11-21 | 2022-02-15 | TeleLingo | Methods and systems for using artificial intelligence to evaluate, correct, and monitor user attentiveness |
| WO2018118958A1 (en) | 2016-12-22 | 2018-06-28 | Sri International | A driver monitoring and response system |
| US11182629B2 (en) * | 2017-01-31 | 2021-11-23 | The Regents Of The University Of California | Machine learning based driver assistance |
| WO2019094843A1 (en) * | 2017-11-10 | 2019-05-16 | Nvidia Corporation | Systems and methods for safe and reliable autonomous vehicles |
| CN108216252B (zh) * | 2017-12-29 | 2019-12-20 | 中车工业研究院有限公司 | 一种地铁司机车载驾驶行为分析方法、车载终端及系统 |
| CN108171176B (zh) * | 2017-12-29 | 2020-04-24 | 中车工业研究院有限公司 | 一种基于深度学习的地铁司机情绪辨识方法及装置 |
| US20190225232A1 (en) * | 2018-01-23 | 2019-07-25 | Uber Technologies, Inc. | Passenger Experience and Biometric Monitoring in an Autonomous Vehicle |
| WO2019182974A2 (en) * | 2018-03-21 | 2019-09-26 | Nvidia Corporation | Stereo depth estimation using deep neural networks |
| US11535262B2 (en) * | 2018-09-10 | 2022-12-27 | Here Global B.V. | Method and apparatus for using a passenger-based driving profile |
| US20200081611A1 (en) * | 2018-09-10 | 2020-03-12 | Here Global B.V. | Method and apparatus for providing a user reaction user interface for generating a passenger-based driving profile |
-
2018
- 2018-10-29 JP JP2018203331A patent/JP7014129B2/ja active Active
-
2019
- 2019-03-13 CN CN201980058821.1A patent/CN112673378B/zh active Active
- 2019-03-13 US US17/276,498 patent/US11834052B2/en active Active
- 2019-03-13 EP EP19879158.4A patent/EP3876191B1/en active Active
- 2019-03-13 WO PCT/JP2019/010185 patent/WO2020090134A1/ja unknown
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180116620A1 (en) | 2016-10-31 | 2018-05-03 | Siemens Healthcare Gmbh | Deep Learning Based Bone Removal in Computed Tomography Angiography |
| JP6264492B1 (ja) | 2017-03-14 | 2018-01-24 | オムロン株式会社 | 運転者監視装置、運転者監視方法、学習装置及び学習方法 |
Non-Patent Citations (1)
| Title |
|---|
| 安達紘子, 外2名,"CNNを用いた顔面熱画像に基づく眠気レベルの判別",電子情報通信学会技術研究報告,日本,一般社団法人電子情報通信学会,2017年03月06日,第116巻, 第520号,p.83-86 |
Also Published As
| Publication number | Publication date |
|---|---|
| US11834052B2 (en) | 2023-12-05 |
| JP2020071550A (ja) | 2020-05-07 |
| EP3876191A4 (en) | 2022-03-02 |
| EP3876191A1 (en) | 2021-09-08 |
| CN112673378B (zh) | 2024-01-30 |
| US20210269046A1 (en) | 2021-09-02 |
| WO2020090134A1 (ja) | 2020-05-07 |
| EP3876191B1 (en) | 2024-01-24 |
| CN112673378A (zh) | 2021-04-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7014129B2 (ja) | 推定器生成装置、モニタリング装置、推定器生成方法及び推定器生成プログラム | |
| JP7020156B2 (ja) | 評価装置、動作制御装置、評価方法、及び評価プログラム | |
| Singh et al. | A comprehensive review on critical issues and possible solutions of motor imagery based electroencephalography brain-computer interface | |
| US20240236547A1 (en) | Method and system for collecting and processing bioelectrical and audio signals | |
| JP6264492B1 (ja) | 運転者監視装置、運転者監視方法、学習装置及び学習方法 | |
| Stopczynski et al. | The smartphone brain scanner: a portable real-time neuroimaging system | |
| US20200187841A1 (en) | System and Method for Measuring Perceptual Experiences | |
| KR102221264B1 (ko) | 인간 감정 인식을 위한 딥 생리적 정서 네트워크를 이용한 인간 감정 추정 방법 및 그 시스템 | |
| Kucukyildiz et al. | Design and implementation of a multi sensor based brain computer interface for a robotic wheelchair | |
| KR20180099434A (ko) | 환자를 모니터링하는 방법 및 장치 | |
| WO2013019997A1 (en) | Methods for modeling neurological development and diagnosing a neurological impairment of a patient | |
| WO2023112384A1 (ja) | 計算機システム及び情動推定方法 | |
| Ktistakis et al. | Applications of ai in healthcare and assistive technologies | |
| EP3203904B1 (en) | Adaptive cognitive prosthetic and applications thereof | |
| KR102142183B1 (ko) | 사용자의 심리활동과 생체신호에 기반한 감정 추정 방법 및 그 시스템 | |
| Paul et al. | A study on the application domains of electroencephalogram for the deep learning-based transformative healthcare | |
| Sant’Ana et al. | A decentralized sensor fusion approach to human fatigue monitoring in maritime operations | |
| Eker et al. | EEG Signals and Spectrogram with Deep Learning Approaches Emotion Analysis with Images | |
| JP7454163B2 (ja) | 対象の脳波の強度を推定するシステム、方法、およびプログラム | |
| WO2023199422A1 (ja) | 内面状態推定装置、内面状態推定方法及び記憶媒体 | |
| US20240223884A1 (en) | Image capturing method | |
| Zaman et al. | Emotion detection for children on the autism Spectrum using BCI and web technology | |
| EP4394555A1 (en) | Sensation transmission system, sensation transmission method, and sensation transmission program | |
| JP2023066304A (ja) | 電子機器、電子機器の制御方法、及びプログラム | |
| Tseng et al. | Modified frequency-partitioned spectrum estimation for a wireless health advanced monitoring bio-diagnosis system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20201214 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20211221 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220103 |