JP6962105B2 - 対話装置、サーバ装置、対話方法及びプログラム - Google Patents
対話装置、サーバ装置、対話方法及びプログラム Download PDFInfo
- Publication number
- JP6962105B2 JP6962105B2 JP2017186013A JP2017186013A JP6962105B2 JP 6962105 B2 JP6962105 B2 JP 6962105B2 JP 2017186013 A JP2017186013 A JP 2017186013A JP 2017186013 A JP2017186013 A JP 2017186013A JP 6962105 B2 JP6962105 B2 JP 6962105B2
- Authority
- JP
- Japan
- Prior art keywords
- voice
- response
- unit
- information
- server device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 99
- 230000004044 response Effects 0.000 claims description 342
- 238000004891 communication Methods 0.000 claims description 180
- 230000008569 process Effects 0.000 claims description 84
- 238000012545 processing Methods 0.000 claims description 32
- 238000000605 extraction Methods 0.000 claims description 16
- 239000000284 extract Substances 0.000 claims description 10
- 230000005540 biological transmission Effects 0.000 claims description 7
- 230000006870 function Effects 0.000 description 17
- 230000009471 action Effects 0.000 description 4
- 230000002452 interceptive effect Effects 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 230000008859 change Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 239000003607 modifier Substances 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 241000282412 Homo Species 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 230000009118 appropriate response Effects 0.000 description 1
- 238000005352 clarification Methods 0.000 description 1
- 210000005069 ears Anatomy 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000002045 lasting effect Effects 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
Images

















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63H—TOYS, e.g. TOPS, DOLLS, HOOPS OR BUILDING BLOCKS
- A63H3/00—Dolls
- A63H3/28—Arrangements of sound-producing means in dolls; Means in dolls for producing sounds
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/167—Audio in a user interface, e.g. using voice commands for navigating, audio feedback
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1815—Semantic context, e.g. disambiguation of the recognition hypotheses based on word meaning
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/30—Distributed recognition, e.g. in client-server systems, for mobile phones or network applications
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Machine Translation (AREA)
- Toys (AREA)
- Telephonic Communication Services (AREA)
Description
また、本発明に係る対話方法は、外部のサーバ装置との間で通信する通信部を有し、ユーザが発話した音声に対する応答文を前記通信部を介して前記サーバ装置と通信しながら作成する対話装置が実行する対話方法であって、自己の位置データを取得する位置取得処理と、ユーザが発話した音声に基づく音声情報を記録する音声記録処理と、前記通信部を介した前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録処理で記録した音声情報及び通信切断中に前記位置取得処理で取得した位置データを前記サーバ装置に送信し、前記音声情報に対する応答文情報及び前記位置データに対応する場所名を前記サーバ装置から取得する、応答文情報取得処理と、前記応答文情報取得処理で取得した応答文情報を用いて所定の応答文作成ルールに従って作成された応答文に前記応答文情報取得処理で取得した場所名を含む前置きを追加した応答文でユーザに応答する応答処理と、を含むことを特徴とする。
また、本発明に係るサーバ装置は、ユーザが発話した音声に対する応答文をサーバ装置と通信しながら作成する対話装置と、前記サーバ装置と、を備える対話システムにおけるサーバ装置であって、前記対話装置と通信する通信部と、前記ユーザが発話した音声に基づく音声情報を前記対話装置から前記通信部を介して受信する受信部と、前記受信部が受信した音声情報に含まれる音声データを音声認識してテキストデータを生成する音声認識部と、前記音声認識部が生成したテキストデータから該テキストデータに含まれる特徴的な単語である特徴単語を抽出する特徴単語抽出部と、前記特徴単語抽出部が抽出した特徴単語と所定の応答文作成ルールとに基づき、応答文情報を作成する応答作成部と、前記応答作成部が作成した応答文情報を前記通信部を介して送信する送信部と、を備え、前記通信部による前記対話装置との通信が一時的に切断した後に回復した状態において、通信切断中の音声情報及び通信切断中の前記対話装置の位置データを前記対話装置から受信し、前記受信した音声情報に対して作成した応答文情報及び前記受信した位置データに対応する場所名を前記対話装置に送信する、ことを特徴とする。
また、本発明に係るプログラムは、外部のサーバ装置との間で通信する通信部を有し、ユーザが発話した音声に対する応答文を前記通信部を介して前記サーバ装置と通信しながら作成する対話装置のコンピュータに、自己の位置データを取得する位置取得処理、ユーザが発話した音声を音声データとして取得する音声取得処理、前記音声取得処理で取得した音声データに基づく音声情報を記録する音声記録処理、前記通信部を介した前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録処理で記録した音声情報及び通信切断中に前記位置取得処理で取得した位置データを前記サーバ装置に送信し、前記音声情報に対する応答文情報及び前記位置データに対応する場所名を前記サーバ装置から取得する、応答文情報取得処理、及び、前記応答文情報取得処理で取得した応答文情報を用いて所定の応答文作成ルールに従って作成された応答文に前記応答文情報取得処理で取得した場所名を含む前置きを追加した応答文でユーザに応答する応答処理、を実行させることを特徴とする。
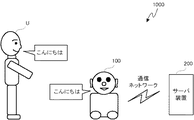
図1に示すように、本発明の第1実施形態に係る対話システム1000は、音声でユーザUと対話するロボットである対話装置100と、対話装置100がユーザUと対話する際に必要な各種処理(例えば音声認識処理、応答文作成処理等)を行うサーバ装置200と、を備える。対話装置100はユーザが発話した音声のデータ(音声データ)を外部のサーバ装置200に送信し、該サーバ装置200に音声認識処理や応答文情報作成等を行ってもらうことにより、ユーザUと対話する際の対話装置100自身の処理負荷を軽くしている。
上述した第1実施形態では、対話装置100は、サーバ装置200との通信が切断している間にユーザが発話した内容全体の中で最も多く使われている特定ワード等(1つの特徴単語)に対応する応答文で応答する。特徴単語はユーザの印象に残りやすいので、このような応答でもあまり問題は生じないと考えられるが、場合によってはユーザが発話中に話題が変化し、時間の経過とともに複数の特徴単語が同じ位多く使われることもあり得る。このような場合は、話題毎にそれぞれ最も多く使われている特徴単語を抽出して、抽出された複数の特徴単語それぞれに対応する応答文により複数回応答した方が望ましい場合もあると考えられる。そこで、このような複数の応答文により応答可能な第2実施形態について説明する。
対話装置が自己の位置を取得できるようにすると、応答文に位置に関する情報を含めることができるようになり、ユーザの発話内容をどこで聞いていたかということも示すことができるようになる。このような第3実施形態について説明する。
上述の各実施形態は任意に組み合わせることができる。例えば第2実施形態と第3実施形態とを組み合わせることにより、複数の話題に対応した応答文を、各話題を発話した場所についての前置きとともに発話させることができるようになる。これにより、例えば、「そういえば、さっき、第一公園にいたときに、暑いって言ってたけど、暑い暑い言ってると余計暑くなるよ。」、「そういえば、映画って言ってましたけど、映画って良いよね。私も映画大好き。」、「そういえば、さっき、第三食堂にいたときに、かわいいって言ってたけど、かわいいって私のこと?嬉しい。」のような発話を対話装置にさせることができる。これにより、対話装置がサーバ装置と通信できない状態のときのユーザの発話内容の話題の変化や各話題がどの場所で発話されたかに対して、あたかも対話装置がきちんと聞いていたかのように受け答えすることができる。したがって、この対話装置の変形例は、通信状況が悪い場合の受け答え技術をさらに改善することができる。
ユーザが発話した音声に対する応答文を外部のサーバ装置と通信しながら作成する対話装置であって、
ユーザが発話した音声を音声データとして取得する音声取得部と、
前記音声取得部が取得した音声データに基づく音声情報を記録する音声記録部と、
前記サーバ装置と通信する通信部と、
前記通信部による前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録部が記録した音声情報を前記サーバ装置に送信し、前記音声情報に対する応答文情報を前記サーバ装置から取得する、応答文情報取得部と、
前記応答文情報取得部が取得した応答文情報に基づいて作成された応答文でユーザに応答する応答部と、
を備える対話装置。
前記通信部による前記サーバ装置との通信が切断している間ユーザに聞いている風に見せかける見せかけ部をさらに備える、
付記1に記載の対話装置。
前記見せかけ部は、前記音声取得部が取得した前記音声データに応じてうなずく、相づちを打つ、つぶやく、の少なくとも1つを実行する、
付記2に記載の対話装置。
前記見せかけ部は、釈明基準時間が経過すると、ユーザに対し適切な応答ができないことを釈明する、
付記2又は3に記載の対話装置。
前記応答文は、前記音声データを音声認識して取得したテキストデータに含まれる特徴単語に基づいて作成される、
付記1から4のいずれか1つに記載の対話装置。
前記特徴単語は、前記音声データを音声認識して取得したテキストデータに最も多く含まれる特定ワードである、
付記5に記載の対話装置。
前記特徴単語は、前記音声データを音声認識して取得したテキストデータに含まれる特定ワードのうち、強調修飾語に修飾された特定ワードである、
付記5に記載の対話装置。
前記応答文は、前記特徴単語に応答文作成ルールを適用することによって作成される、
付記5から7のいずれか1つに記載の対話装置。
前記応答文情報取得部は、通信切断中に前記音声記録部が記録した音声情報の話題毎の前記音声情報に対する応答文情報を前記サーバ装置から取得し、
前記応答部は、前記応答文情報取得部が取得した話題毎の応答文情報に基づいて作成した応答文でユーザに応答する、
付記1から8のいずれか1つに記載の対話装置。
前記応答部は、前記応答文情報取得部が取得した応答文情報に基づいて作成した応答文に前置きを追加した応答文で、ユーザに応答する、
付記1から9のいずれか1つに記載の対話装置。
自己の位置データを取得する位置取得部をさらに備え、
前記応答文情報取得部は、前記通信部による前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録部が記録した音声情報及び通信切断中に前記位置取得部が取得した位置データを前記サーバ装置に送信し、前記音声情報に対する応答文情報及び前記位置データに対応する場所名を前記サーバ装置から取得し、
前記応答部は、前記応答文情報取得部が取得した応答文情報に基づいて作成された応答文に、前記応答文情報取得部が取得した場所名を含む前置きを追加した応答文でユーザに応答する、
付記1から10のいずれか1つに記載の対話装置。
制御部が、ユーザが発話した音声に基づく音声情報を記録し、
外部のサーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に記録された前記音声情報に対応する応答文情報を前記サーバ装置に作成させ、
前記サーバ装置から受信した前記応答文情報に基づいた応答文でユーザに応答する対話方法。
ユーザが発話した音声に対する応答文をサーバ装置と通信しながら作成する対話装置と、前記サーバ装置と、を備える対話システムにおけるサーバ装置であって、
前記対話装置と通信する通信部と、
前記ユーザが発話した音声に基づく音声情報を前記対話装置から前記通信部を介して受信する受信部と、
前記受信部が受信した音声情報に含まれる音声データを音声認識してテキストデータを生成する音声認識部と、
前記音声認識部が生成したテキストデータから該テキストデータに含まれる特徴的な単語である特徴単語を抽出する特徴単語抽出部と、
前記特徴単語抽出部が抽出した特徴単語に基づき、応答文情報を作成する応答作成部と、
前記応答作成部が作成した応答文情報を前記通信部を介して送信する送信部と、
を備え、
前記通信部による前記対話装置との通信が一時的に切断した後に回復した状態において、通信切断中の音声情報を前記対話装置から受信し、前記受信した音声情報に対する応答文情報を作成して前記対話装置に送信する、
ことを特徴とするサーバ装置。
ユーザが発話した音声に対する応答文を外部のサーバ装置と通信しながら作成する対話装置のコンピュータに、
ユーザが発話した音声に基づく音声情報を記録する音声記録ステップ、
前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録ステップで記録した音声情報を前記サーバ装置に送信し、前記音声情報に対する応答文情報を前記サーバ装置から取得する、応答文情報取得ステップ、及び、
前記応答文情報取得ステップで取得した応答文情報に基づいて作成された応答文でユーザに応答する応答ステップ、
を実行させるためのプログラム。
Claims (6)
- ユーザが発話した音声に対する応答文を外部のサーバ装置と通信しながら作成する対話装置であって、
自己の位置データを取得する位置取得部と、
ユーザが発話した音声を音声データとして取得する音声取得部と、
前記音声取得部が取得した音声データに基づく音声情報を記録する音声記録部と、
前記サーバ装置と通信する通信部と、
前記通信部による前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録部が記録した音声情報及び通信切断中に前記位置取得部が取得した位置データを前記サーバ装置に送信し、前記音声情報に対する応答文情報及び前記位置データに対応する場所名を前記サーバ装置から取得する、応答文情報取得部と、
前記応答文情報取得部が取得した応答文情報を用いて所定の応答文作成ルールに従って作成された応答文に前記応答文情報取得部が取得した場所名を含む前置きを追加した応答文でユーザに応答する応答部と、
を備えることを特徴とする対話装置。 - 前記通信部による前記サーバ装置との通信が切断している間ユーザに聞いている風に見せかける見せかけ部をさらに備える、
ことを特徴とする請求項1に記載の対話装置。 - 前記見せかけ部は、前記音声取得部が取得した前記音声データに応じてうなずく、相づちを打つ、つぶやく、の少なくとも1つを実行する、
ことを特徴とする請求項2に記載の対話装置。 - 外部のサーバ装置との間で通信する通信部を有し、ユーザが発話した音声に対する応答文を前記通信部を介して前記サーバ装置と通信しながら作成する対話装置が実行する対話方法であって、
自己の位置データを取得する位置取得処理と、
ユーザが発話した音声に基づく音声情報を記録する音声記録処理と、
前記通信部を介した前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録処理で記録した音声情報及び通信切断中に前記位置取得処理で取得した位置データを前記サーバ装置に送信し、前記音声情報に対する応答文情報及び前記位置データに対応する場所名を前記サーバ装置から取得する、応答文情報取得処理と、
前記応答文情報取得処理で取得した応答文情報を用いて所定の応答文作成ルールに従って作成された応答文に前記応答文情報取得処理で取得した場所名を含む前置きを追加した応答文でユーザに応答する応答処理と、
を含むことを特徴とする対話方法。 - ユーザが発話した音声に対する応答文をサーバ装置と通信しながら作成する対話装置と、前記サーバ装置と、を備える対話システムにおけるサーバ装置であって、
前記対話装置と通信する通信部と、
前記ユーザが発話した音声に基づく音声情報を前記対話装置から前記通信部を介して受信する受信部と、
前記受信部が受信した音声情報に含まれる音声データを音声認識してテキストデータを生成する音声認識部と、
前記音声認識部が生成したテキストデータから該テキストデータに含まれる特徴的な単語である特徴単語を抽出する特徴単語抽出部と、
前記特徴単語抽出部が抽出した特徴単語と所定の応答文作成ルールとに基づき、応答文情報を作成する応答作成部と、
前記応答作成部が作成した応答文情報を前記通信部を介して送信する送信部と、
を備え、
前記通信部による前記対話装置との通信が一時的に切断した後に回復した状態において、通信切断中の音声情報及び通信切断中の前記対話装置の位置データを前記対話装置から受信し、前記受信した音声情報に対して作成した応答文情報及び前記受信した位置データに対応する場所名を前記対話装置に送信する、
ことを特徴とするサーバ装置。 - 外部のサーバ装置との間で通信する通信部を有し、ユーザが発話した音声に対する応答文を前記通信部を介して前記サーバ装置と通信しながら作成する対話装置のコンピュータに、
自己の位置データを取得する位置取得処理、
ユーザが発話した音声を音声データとして取得する音声取得処理、
前記音声取得処理で取得した音声データに基づく音声情報を記録する音声記録処理、
前記通信部を介した前記サーバ装置との通信が一時的に切断した後に回復した状態において、通信切断中に前記音声記録処理で記録した音声情報及び通信切断中に前記位置取得処理で取得した位置データを前記サーバ装置に送信し、前記音声情報に対する応答文情報及び前記位置データに対応する場所名を前記サーバ装置から取得する、応答文情報取得処理、及び、
前記応答文情報取得処理で取得した応答文情報を用いて所定の応答文作成ルールに従って作成された応答文に前記応答文情報取得処理で取得した場所名を含む前置きを追加した応答文でユーザに応答する応答処理、
を実行させるためのプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017186013A JP6962105B2 (ja) | 2017-09-27 | 2017-09-27 | 対話装置、サーバ装置、対話方法及びプログラム |
| CN201811122774.6A CN109568973B (zh) | 2017-09-27 | 2018-09-26 | 对话装置、对话方法、服务器装置及计算机可读存储介质 |
| US16/142,585 US20190096405A1 (en) | 2017-09-27 | 2018-09-26 | Interaction apparatus, interaction method, and server device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017186013A JP6962105B2 (ja) | 2017-09-27 | 2017-09-27 | 対話装置、サーバ装置、対話方法及びプログラム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2019061098A JP2019061098A (ja) | 2019-04-18 |
| JP2019061098A5 JP2019061098A5 (ja) | 2020-10-22 |
| JP6962105B2 true JP6962105B2 (ja) | 2021-11-05 |
Family
ID=65807771
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017186013A Active JP6962105B2 (ja) | 2017-09-27 | 2017-09-27 | 対話装置、サーバ装置、対話方法及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20190096405A1 (ja) |
| JP (1) | JP6962105B2 (ja) |
| CN (1) | CN109568973B (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102637339B1 (ko) * | 2018-08-31 | 2024-02-16 | 삼성전자주식회사 | 음성 인식 모델을 개인화하는 방법 및 장치 |
| US10516777B1 (en) * | 2018-09-11 | 2019-12-24 | Qualcomm Incorporated | Enhanced user experience for voice communication |
| US20200090648A1 (en) * | 2018-09-14 | 2020-03-19 | International Business Machines Corporation | Maintaining voice conversation continuity |
| CN113555010A (zh) * | 2021-07-16 | 2021-10-26 | 广州三星通信技术研究有限公司 | 语音处理方法和语音处理装置 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3925140B2 (ja) * | 2001-10-09 | 2007-06-06 | ソニー株式会社 | 情報提供方法及び情報提供装置、並びにコンピュータ・プログラム |
| JP3925326B2 (ja) * | 2002-06-26 | 2007-06-06 | 日本電気株式会社 | 端末通信システム、連携サーバ、音声対話サーバ、音声対話処理方法および音声対話処理プログラム |
| JP2008083100A (ja) * | 2006-09-25 | 2008-04-10 | Toshiba Corp | 音声対話装置及びその方法 |
| JP2009198871A (ja) * | 2008-02-22 | 2009-09-03 | Toyota Central R&D Labs Inc | 音声対話装置 |
| JP6052610B2 (ja) * | 2013-03-12 | 2016-12-27 | パナソニックIpマネジメント株式会社 | 情報通信端末、およびその対話方法 |
| JP6120708B2 (ja) * | 2013-07-09 | 2017-04-26 | 株式会社Nttドコモ | 端末装置およびプログラム |
| JP6054283B2 (ja) * | 2013-11-27 | 2016-12-27 | シャープ株式会社 | 音声認識端末、サーバ、サーバの制御方法、音声認識システム、音声認識端末の制御プログラム、サーバの制御プログラムおよび音声認識端末の制御方法 |
| JP2015184563A (ja) * | 2014-03-25 | 2015-10-22 | シャープ株式会社 | 対話型家電システム、サーバ装置、対話型家電機器、家電システムが対話を行なうための方法、当該方法をコンピュータに実現させるためのプログラム |
| JP2017049471A (ja) * | 2015-09-03 | 2017-03-09 | カシオ計算機株式会社 | 対話制御装置、対話制御方法及びプログラム |
| CN106057205B (zh) * | 2016-05-06 | 2020-01-14 | 北京云迹科技有限公司 | 一种智能机器人自动语音交互方法 |
-
2017
- 2017-09-27 JP JP2017186013A patent/JP6962105B2/ja active Active
-
2018
- 2018-09-26 CN CN201811122774.6A patent/CN109568973B/zh active Active
- 2018-09-26 US US16/142,585 patent/US20190096405A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| CN109568973A (zh) | 2019-04-05 |
| CN109568973B (zh) | 2021-02-12 |
| JP2019061098A (ja) | 2019-04-18 |
| US20190096405A1 (en) | 2019-03-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6962105B2 (ja) | 対話装置、サーバ装置、対話方法及びプログラム | |
| WO2017057170A1 (ja) | 対話装置及び対話方法 | |
| US11151997B2 (en) | Dialog system, dialog method, dialog apparatus and program | |
| JP6420769B2 (ja) | 二分岐音声認識 | |
| JP4595436B2 (ja) | ロボット、その制御方法及び制御用プログラム | |
| JP7038210B2 (ja) | 対話セッション管理用のシステム及び方法 | |
| JP4622384B2 (ja) | ロボット、ロボット制御装置、ロボットの制御方法およびロボットの制御用プログラム | |
| JP6497372B2 (ja) | 音声対話装置および音声対話方法 | |
| JP6376096B2 (ja) | 対話装置及び対話方法 | |
| US11222634B2 (en) | Dialogue method, dialogue system, dialogue apparatus and program | |
| JP6589514B2 (ja) | 対話装置及び対話制御方法 | |
| US11501768B2 (en) | Dialogue method, dialogue system, dialogue apparatus and program | |
| US11354517B2 (en) | Dialogue method, dialogue system, dialogue apparatus and program | |
| WO2018003196A1 (ja) | 情報処理システム、記憶媒体、および情報処理方法 | |
| TW201909166A (zh) | 主動聊天裝置 | |
| EP4336492A1 (en) | Localized voice recognition assistant | |
| WO2018107389A1 (zh) | 语音联合协助的实现方法、装置及机器人 | |
| JP2006243555A (ja) | 対応決定システム、ロボット、イベント出力サーバ、および対応決定方法 | |
| US20200082818A1 (en) | Voice interaction device, control method for voice interaction device, and non-transitory recording medium storing program | |
| KR20230133864A (ko) | 스피치 오디오 스트림 중단들을 처리하는 시스템들및 방법들 | |
| WO2021153101A1 (ja) | 情報処理装置、情報処理方法および情報処理プログラム | |
| JP2017068359A (ja) | 対話装置及び対話制御方法 | |
| CN112700783A (zh) | 通讯的变声方法、终端设备和存储介质 | |
| Nakadai et al. | Robot-audition-based human-machine interface for a car | |
| WO2020031367A1 (ja) | 情報処理装置、情報処理方法、およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200910 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200910 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20210617 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210810 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210830 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210914 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210927 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6962105 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |