JP6738579B2 - 命令フローを最適化するチェックを実行するための装置および方法 - Google Patents
命令フローを最適化するチェックを実行するための装置および方法 Download PDFInfo
- Publication number
- JP6738579B2 JP6738579B2 JP2017527720A JP2017527720A JP6738579B2 JP 6738579 B2 JP6738579 B2 JP 6738579B2 JP 2017527720 A JP2017527720 A JP 2017527720A JP 2017527720 A JP2017527720 A JP 2017527720A JP 6738579 B2 JP6738579 B2 JP 6738579B2
- Authority
- JP
- Japan
- Prior art keywords
- instruction
- operand
- sequence
- operations
- processor
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 26
- 230000015654 memory Effects 0.000 claims description 127
- 239000013598 vector Substances 0.000 claims description 93
- 238000004364 calculation method Methods 0.000 claims description 12
- 230000004044 response Effects 0.000 claims description 9
- 230000011664 signaling Effects 0.000 claims description 6
- 238000011156 evaluation Methods 0.000 claims 6
- 230000009191 jumping Effects 0.000 claims 3
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 77
- 238000006073 displacement reaction Methods 0.000 description 40
- 238000010586 diagram Methods 0.000 description 36
- 238000007667 floating Methods 0.000 description 19
- 230000006870 function Effects 0.000 description 12
- 238000012545 processing Methods 0.000 description 11
- 238000004422 calculation algorithm Methods 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 9
- 238000004891 communication Methods 0.000 description 9
- 239000000872 buffer Substances 0.000 description 7
- 230000008859 change Effects 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 7
- 230000000873 masking effect Effects 0.000 description 7
- 238000007620 mathematical function Methods 0.000 description 7
- 238000013519 translation Methods 0.000 description 6
- 230000006835 compression Effects 0.000 description 5
- 238000007906 compression Methods 0.000 description 5
- 238000013461 design Methods 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 230000003068 static effect Effects 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 4
- 238000013501 data transformation Methods 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 230000001052 transient effect Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 3
- 238000007792 addition Methods 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 206010000210 abortion Diseases 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 229910052754 neon Inorganic materials 0.000 description 1
- GKAOGPIIYCISHV-UHFFFAOYSA-N neon atom Chemical compound [Ne] GKAOGPIIYCISHV-UHFFFAOYSA-N 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 101150030355 scrB gene Proteins 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images





















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30076—Arrangements for executing specific machine instructions to perform miscellaneous control operations, e.g. NOP
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30181—Instruction operation extension or modification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3861—Recovery, e.g. branch miss-prediction, exception handling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45504—Abstract machines for programme code execution, e.g. Java virtual machine [JVM], interpreters, emulators
- G06F9/45516—Runtime code conversion or optimisation
- G06F9/4552—Involving translation to a different instruction set architecture, e.g. just-in-time translation in a JVM
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45504—Abstract machines for programme code execution, e.g. Java virtual machine [JVM], interpreters, emulators
- G06F9/45516—Runtime code conversion or optimisation
- G06F9/45525—Optimisation or modification within the same instruction set architecture, e.g. HP Dynamo
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Executing Machine-Instructions (AREA)
- Advance Control (AREA)
Description
命令セットは、1または複数の命令フォーマットを含む。所与の命令フォーマットは、とりわけ、実行されるオペレーション(オペコード)および当該オペレーションが実行されるオペランドを指定する様々なフィールド(ビットの数、ビットの位置)を定義する。いくつかの命令フォーマットは、命令テンプレート(またはサブフォーマット)の定義により更に分類される。例えば、所与の命令フォーマットの命令テンプレートは、異なるサブセットの命令フォーマットのフィールド(含まれるフィールドは、通常は同じ順序であるが、少なくともいくつかは、より少ないフィールドが含まれているので、異なるビット位置を有する)を有するものと定義され、および/または異なる解釈をされる所与のフィールドを有するものと定義され得る。従って、ISAの各命令は、所与の命令フォーマットを用いて(および定義される場合には、当該命令フォーマットの命令テンプレートのうちの所与の1つで)表され、オペレーションおよびオペランドを指定するためのフィールドを含む。例えば、例示的なADD命令は、特定のオペコード、ならびに当該オペコードを指定するオペコードフィールドおよびオペランド(ソース1/デスティネーション、およびソース2)を選択するオペランドフィールドを含む命令フォーマットを有する。命令ストリームにおけるこのADD命令が生じることにより、特定のオペランドを選択するオペランドフィールドに特定の内容を有する。Advanced Vector Extensions(AVX)(AVX1およびAVX2)と呼ばれ、ベクトル拡張(VEX)符号化スキームを用いるSIMD拡張のセットが、リリースおよび/または公開されている(例えば、Intel(登録商標)64 and IA−32 Architectures Software Developers Manual,October 2011およびIntel(登録商標)Advanced Vector Extensions Programming Reference,June 2011を参照されたい)。
本明細書に説明される命令の実施形態は、異なるフォーマットで実施され得る。更に、例示的なシステム、アーキテクチャ、およびパイプラインが以下に詳述される。命令の実施形態は、そのようなシステム、アーキテクチャ、およびパイプライン上で実行され得るが、詳述されるものに限定されない。
ベクトル向け命令フォーマットは、ベクトル命令に好適な命令フォーマットである。(例えば、ベクトルオペレーションに固有の一定のフィールドが存在する)。ベクトルおよびスカラオペレーションの両方がベクトル向け命令フォーマットによりサポートされる実施形態が説明されるが、代替的な実施形態は、ベクトル向け命令フォーマットによるベクトルオペレーションのみを用いる。
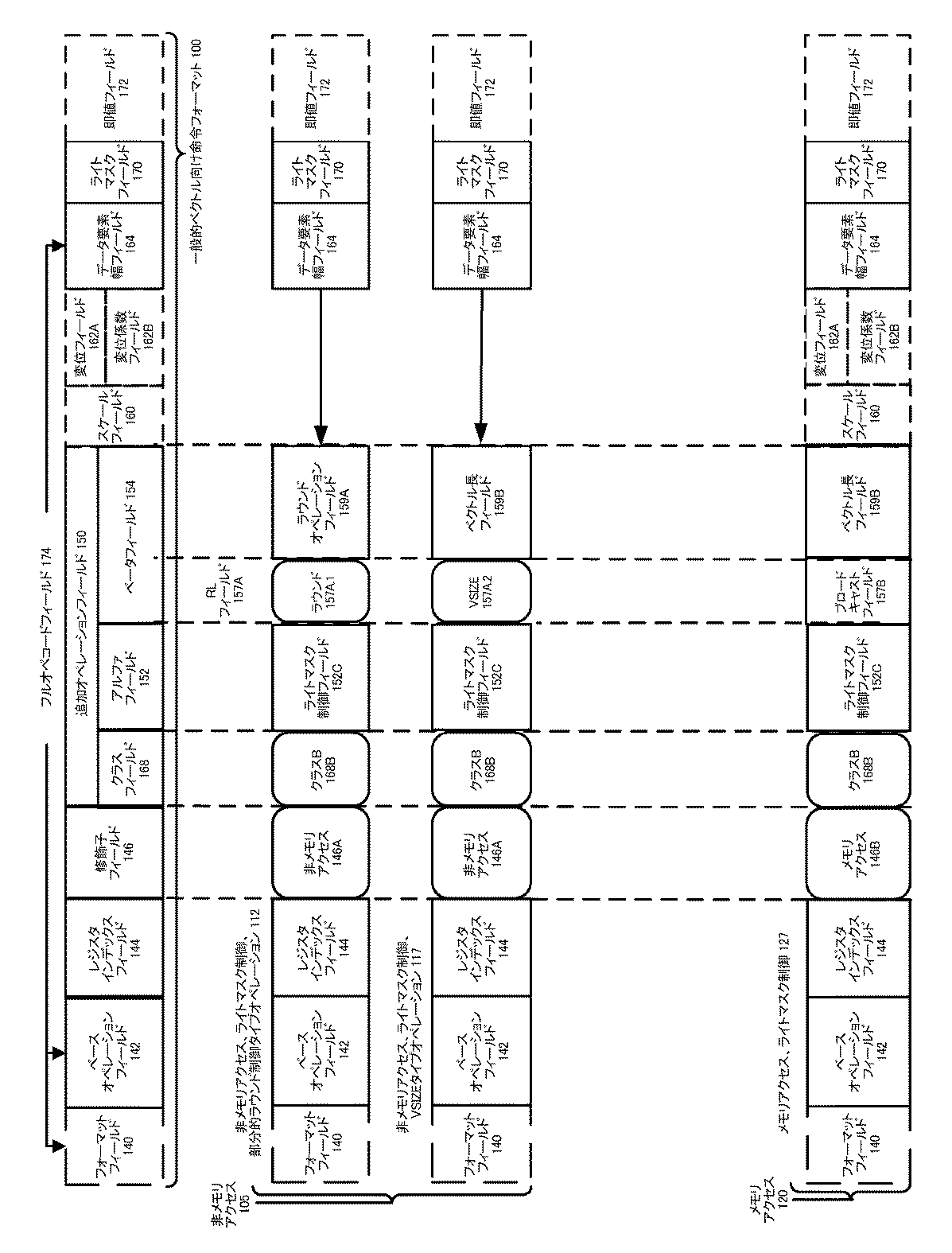
クラスAの非メモリアクセス105の命令テンプレートの場合に、アルファフィールド152は、RSフィールド152Aとして解釈され、その内容は、異なる追加オペレーションタイプのうちのどれが実行されるかを区別するが(例えば、ラウンド152A.1およびデータ変換152A.2は、各々、非メモリアクセス、ラウンドタイプオペレーション110、および非メモリアクセス、データ変換タイプオペレーション115の命令テンプレートに対して指定される)、ベータフィールド154は、指定されたタイプのオペレーションのうちいずれが実行されるかを区別する。非メモリアクセス105の命令テンプレートにおいて、スケールフィールド160、変位フィールド162A、および変位スケールフィールド162Bは、存在しない。
図2A〜図2Dは、本発明の実施形態による例示的な特定ベクトル向け命令フォーマットを示すブロック図である。図2A〜図2Dは、フィールドの位置、サイズ、解釈、および順序、ならびにそれらのフィールドのいくつかに対する値を指定するという意味で具体的な特定ベクトル向け命令フォーマット200を示す。特定ベクトル向け命令フォーマット200は、x86命令セットを拡張するために用いられ得、従ってフィールドのうちのいくつかは、既存のx86命令セットおよびその拡張(例えば、AVX)において用いられるものと類似するか、または同じである。このフォーマットは、拡張された既存のx86命令セットのプレフィックスエンコードフィールド、リアルオペコードバイトフィールド、MOD R/Mフィールド、SIBフィールド、変位フィールド、および即値フィールドとの整合性を保つ。図2A〜図2Dがフィールドにマッピングされる図1A〜図1Bのフィールドが示される。
図2Bは、本発明の一実施形態による、フルオペコードフィールド174を構成する特定ベクトル向け命令フォーマット200のフィールドを示すブロック図である。具体的には、フルオペコードフィールド174は、フォーマットフィールド140、ベースオペレーションフィールド142、およびデータ要素幅(W)フィールド164を含む。ベースオペレーションフィールド142は、プレフィックスエンコードフィールド225、オペコードマップフィールド215、およびリアルオペコードフィールド230を含む。
図2Cは、本発明の一実施形態による、レジスタインデックスフィールド144を構成する特定ベクトル向け命令フォーマット200のフィールドを示すブロック図である。具体的には、レジスタインデックスフィールド144は、REXフィールド205、REX'フィールド210、MODR/M.regフィールド244、MODR/M.r/mフィールド246、VVVVフィールド220、xxxフィールド254、およびbbbフィールド256を含む。
図2Dは、本発明の一実施形態による、追加オペレーションフィールド150を構成する特定ベクトル向け命令フォーマット200のフィールドを示すブロック図である。クラス(U)フィールド168が0を含む場合、EVEX.U0(クラスA168A)を意味する。1を含む場合、EVEX.U1(クラスB168B)を意味する。U=0、かつMODフィールド242が11を含む場合(非メモリアクセスオペレーションを意味する)、アルファフィールド152(EVEXバイト3、ビット[7]−EH)は、RSフィールド152Aとして解釈される。RSフィールド152Aが1(ラウンド152A.1)を含む場合、ベータフィールド154(EVEXバイト3、ビット[6:4]‐SSS)は、ラウンド制御フィールド154Aとして解釈される。ラウンド制御フィールド154Aは、1ビットのSAEフィールド156および2ビットのラウンドオペレーションフィールド158を含む。RSフィールド152Aが0(データ変換152A.2)を含む場合、ベータフィールド154(EVEXバイト3、ビット[6:4]‐SSS)は、3ビットのデータ変換フィールド154Bとして解釈される。U=0であり、かつMODフィールド242が00、01、または10を含む場合(メモリアクセスオペレーションを意味する)、アルファフィールド152(EVEXバイト3、ビット[7]‐EH)は、エビクションヒント(EH)フィールド152Bとして解釈され、ベータフィールド154(EVEXバイト3、ビット[6:4]‐SSS)は、3ビットのデータ操作フィールド154Cとして解釈される。
図3は、本発明の一実施形態による、レジスタアーキテクチャ300のブロック図である。示される実施形態において、512ビット幅の32個のベクトルレジスタ310が存在する。これらのレジスタは、zmm0〜zmm31として参照される。下位の16個のzmmレジスタの下位の256ビットは、レジスタymm0〜15上にオーバーレイされる。下位の16個のzmmレジスタの下位の128ビット(ymmレジスタの下位の128ビット)は、レジスタxmm0〜15上にオーバーレイされる。以下の表に示されるように、特定ベクトル向け命令フォーマット200は、これらのオーバーレイされたレジスタファイルで動作する。
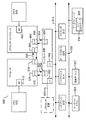
プロセッサコアは、異なる態様で異なる目的のために異なるプロセッサに実装され得る。例えば、そのようなコアの実装は、1)汎用演算用の汎用インオーダコア、2)汎用演算用の高性能汎用アウトオブオーダコア、3)主にグラフィックスおよび/またはサイエンティフィック(スループット)演算用の専用コアを含み得る。異なるプロセッサの実装は、1)汎用演算用の1もしくは複数の汎用インオーダコア、および/または汎用演算用の1もしくは複数の汎用アウトオブオーダコアを含むCPU、ならびに2)主にグラフィックスおよび/またはサイエンティフィック(スループット)用の1もしくは複数の専用コアを含むコプロセッサを含み得る。そのような異なるプロセッサは、異なるコンピュータシステムアーキテクチャをもたらし、異なるコンピュータシステムアーキテクチャは、1)CPUの別個のチップ上のコプロセッサ、2)CPUと同一のパッケージにおける別個のダイ上のコプロセッサ、3)CPUと同一のダイ上のコプロセッサ(この場合、そのようなコプロセッサは、場合によっては統合グラフィックスおよび/またはサイエンティフィック(スループット)ロジック等の専用ロジック、または専用コアとして言及される)、および4)同一のダイ上に、説明されたCPU(場合によっては、アプリケーションコアもしくはアプリケーションプロセッサとして言及される)、上記のコプロセッサ、および追加の機能性を含み得るシステムオンチップを含み得る。例示的なコアアーキテクチャが次に説明され、その次に例示的なプロセッサおよびコンピュータアーキテクチャの説明が続く。
除算および平方根のようなIEEEの正確な丸め関数は、2つの態様で実装され得る。すなわち、基数ベースのハードウェアディバイダを用いて機能をネイティブに提供するか、またはソフトウェア命令/マイクロコード(ucode)シーケンス、通常は、ニュートン・ファフソンアルゴリズムの形式/変形を実装し、最終的結果を得るべくシードに対してイテレートするかである。
Claims (18)
- 1または複数のソースオペランドを用いて複数の数学的命令を実行するための演算論理装置(ALU)と、
現在の数学的命令のための前記1または複数のソースオペランドを評価し、前記評価に基づいて、前記ALUによって前記現在の数学的命令を実行することを含むデフォルト演算シーケンスを実行するか否か、または特定のタイプのソースオペランドを有する前記数学的命令の結果を、前記デフォルト演算シーケンスより効率的に提供する代替的な演算シーケンスにジャンプするか否かを判断するための命令チェックロジックとを備え、
前記1または複数のソースオペランドの前記評価を実行すると、前記命令チェックロジックは、前記デフォルト演算シーケンスまたは前記代替的なシーケンスを実行するか否かを示すベクトル出力と、前記代替的なシーケンスで処理されるべき要素をシグナリングするマスク出力と、前記1または複数のソースオペランドに対する数学的オペレーションの実行から生じた1または複数の例外を示すべく出力された計算毎の例外フラグとを生成する
プロセッサ。 - 前記現在の数学的命令は、前記1または複数のソースオペランドにより指定された分子および分母を有する除算命令を含み、
前記命令チェックロジックは、非正規化オペランドであるか、無限大に等しいか、非数(NaN)オペランドであるか、およびゼロによる除算をもたらすかのうちの少なくとも1つである分子または分母のいずれかに応答して、前記代替的な演算シーケンスへのジャンプを生じさせる、請求項1に記載のプロセッサ。 - 前記命令チェックロジックは、ゼロ(ZE)による除算、無効な演算(IE)、および非正規化オペランド(DE)のうちの少なくとも1つを含む、1または複数の例外フラグを前記プロセッサ内で設定する、請求項2に記載のプロセッサ。
- 前記現在の命令は、平方根演算を実行するソースオペランド値を有する平方根命令を含み、
前記命令チェックロジックは、負の数であるか、非正規化オペランドであるか、無限大に等しいか、および非数(NaN)オペランドであるかのうちの少なくとも1つである前記ソースオペランドに応答して、前記代替的な演算シーケンスへのジャンプを生じさせる、請求項1〜3のいずれか1項に記載のプロセッサ。 - 前記現在の命令は、平方根演算を実行するソースオペランド値(x)を有する平方根命令を含み、
前記命令チェックロジックは、xを用いて実行される比較に応答して前記代替的な演算シーケンスへのジャンプを生じさせる、請求項1〜4のいずれか1項に記載のプロセッサ。 - 前記デフォルト演算シーケンスは、デフォルトシーケンスの命令またはマイクロオペレーションを含み、
前記代替的な演算シーケンスは、代替的なシーケンスの命令またはマイクロオペレーションを含む、請求項1〜5のいずれか1項に記載のプロセッサ。 - 現在の数学的命令のための1または複数のソースオペランドを取得する段階と、
前記現在の数学的命令のための前記1または複数のソースオペランドを評価する段階と、
前記評価に基づいて、前記現在の数学的命令を実行することを含むデフォルト演算シーケンスを実行するか否か、または特定のタイプのソースオペランドを有する前記数学的命令の結果を、前記デフォルト演算シーケンスより効率的に提供する代替的な演算シーケンスにジャンプするか否かを判断する段階と、
前記1または複数のソースオペランドの前記評価を実行すると、前記デフォルト演算シーケンスまたは前記代替的なシーケンスを実行するか否かを示すベクトル出力を生成する段階と、
前記代替的なシーケンスで処理されるべき要素をシグナリングするマスク出力を生成する段階と、
前記1または複数のソースオペランドに対する数学的オペレーションの実行から生じた1または複数の例外を示すべく出力された計算毎の例外フラグを生成する段階と、を備える、方法。 - 前記現在の数学的命令は、前記1または複数のソースオペランドにより指定された分子および分母を有する除算命令を含み、
前記方法は、非正規化オペランドであるか、無限大に等しいか、非数(NaN)オペランドであるか、およびゼロによる除算をもたらすかのうちの少なくとも1つである分子または分母のいずれかに応答して、前記代替的な演算シーケンスにジャンプする、請求項7に記載の方法。 - ゼロ(ZE)による除算、無効な演算(IE)、および非正規化オペランド(DE)のうちの少なくとも1つを含む、1または複数の例外フラグを前記方法において設定する段階を更に備える、請求項8に記載の方法。
- 前記現在の命令は、平方根演算を実行するソースオペランド値を有する平方根命令を含み、
前記方法は、負の数であるか、非正規化オペランドであるか、無限大に等しいか、および非数(NaN)オペランドであるかのうちの少なくとも1つである前記ソースオペランドに応答して、前記代替的な演算シーケンスにジャンプする段階を更に備える、請求項7〜9のいずれか1項に記載の方法。 - 前記現在の命令は、平方根演算を実行するソースオペランド値(x)を有する平方根命令を含み、
前記方法は、xを用いて実行される比較に応答して前記代替的な演算シーケンスにジャンプする段階を更に備える、請求項7〜10のいずれか1項に記載の方法。
- 前記デフォルト演算シーケンスは、デフォルトシーケンスの命令またはマイクロオペレーションを含み、
前記代替的な演算シーケンスは、代替的なシーケンスの命令またはマイクロオペレーションを含む、請求項7〜11のいずれか1項に記載の方法。 - 数学的命令およびグラフィックス命令を含む命令およびデータを格納するためのメモリと、
前記数学的命令を実行して前記データを処理するための複数のコアと、
前記グラフィックス命令に応答してグラフィックスオペレーションを実行するためのグラフィックスプロセッサユニットと、
ネットワークを介してデータを受信および送信するためのネットワークインタフェースと、
マウスまたはカーソル制御デバイスからユーザ入力を受信するためのインタフェースと、
1または複数のソースオペランドを用いて複数の数学的命令を実行するための演算論理装置(ALU)と、
現在の数学的命令のための前記1または複数のソースオペランドを評価し、前記評価に基づいて、前記ALUにより前記現在の数学的命令を実行することを含むデフォルト演算シーケンスを実行するか否か、または特定のタイプのソースオペランドを有する前記数学的命令についての結果を、前記デフォルト演算シーケンスより効率的に提供する代替的な演算シーケンスにジャンプするか否かを判断する命令チェックロジックとを備え、
前記1または複数のソースオペランドの前記評価を実行すると、前記命令チェックロジックは、前記デフォルト演算シーケンスまたは前記代替的なシーケンスを実行するか否かを示すベクトル出力と、前記代替的なシーケンスで処理されるべき要素をシグナリングするマスク出力と、前記1または複数のソースオペランドに対する数学的オペレーションの実行から生じた1または複数の例外を示すべく出力された計算毎の例外フラグとを生成する
システム。 - 前記現在の数学的命令は、前記1または複数のソースオペランドにより指定された分子および分母を有する除算命令を含み、
前記命令チェックロジックは、非正規化オペランドであるか、無限大に等しいか、非数(NaN)オペランドであるか、およびゼロによる除算をもたらすかのうちの少なくとも1つである分子または分母のいずれかに応答して、前記代替的な演算シーケンスへのジャンプを生じさせる、請求項13に記載のシステム。 - 前記命令チェックロジックは、ゼロ(ZE)による除算、無効な演算(IE)、および非正規化オペランド(DE)のうちの少なくとも1つを含む、1または複数の例外フラグをプロセッサ内で設定する、請求項14に記載のシステム。
- 前記現在の命令は、平方根演算を実行するソースオペランド値を有する平方根命令を含み、
前記命令チェックロジックは、負の数であるか、非正規化オペランドであるか、無限大に等しいか、および非数(NaN)オペランドであるかのうちの少なくとも1つである前記ソースオペランドに応答して、前記代替的な演算シーケンスへのジャンプを生じさせる、請求項13〜15のいずれか1項に記載のシステム。 - 前記現在の命令は、平方根演算を実行するソースオペランド値(x)を有する平方根命令を含み、
前記命令チェックロジックは、xを用いて実行される比較に応答して前記代替的な演算シーケンスへのジャンプを生じさせる、請求項13〜16のいずれか1項に記載のシステム。 - 前記命令チェックロジックは、マイクロオペレーションを実行するためのものである
請求項1〜6のいずれか1項に記載のプロセッサまたは請求項13〜17のいずれか1項に記載のシステム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/581,815 | 2014-12-23 | ||
| US14/581,815 US9696992B2 (en) | 2014-12-23 | 2014-12-23 | Apparatus and method for performing a check to optimize instruction flow |
| PCT/US2015/062056 WO2016105754A1 (en) | 2014-12-23 | 2015-11-23 | Apparatus and method for performing a check to optimize instruction flow |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2018507453A JP2018507453A (ja) | 2018-03-15 |
| JP6738579B2 true JP6738579B2 (ja) | 2020-08-12 |
Family
ID=56129459
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017527720A Active JP6738579B2 (ja) | 2014-12-23 | 2015-11-23 | 命令フローを最適化するチェックを実行するための装置および方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9696992B2 (ja) |
| EP (1) | EP3238066A4 (ja) |
| JP (1) | JP6738579B2 (ja) |
| KR (1) | KR102462283B1 (ja) |
| CN (1) | CN107003840B (ja) |
| TW (1) | TWI564796B (ja) |
| WO (1) | WO2016105754A1 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107729053B (zh) * | 2017-10-17 | 2020-11-27 | 安徽皖通邮电股份有限公司 | 一种实现高速缓存表的方法 |
| US10447983B2 (en) * | 2017-11-15 | 2019-10-15 | Nxp Usa, Inc. | Reciprocal approximation circuit |
| US11237827B2 (en) * | 2019-11-26 | 2022-02-01 | Advanced Micro Devices, Inc. | Arithemetic logic unit register sequencing |
| US20220206805A1 (en) * | 2020-12-26 | 2022-06-30 | Intel Corporation | Instructions to convert from fp16 to bf8 |
| WO2023000110A1 (en) * | 2021-07-23 | 2023-01-26 | Solid State Of Mind | Apparatus and method for energy-efficient and accelerated processing of an arithmetic operation |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5134693A (en) | 1989-01-18 | 1992-07-28 | Intel Corporation | System for handling occurrence of exceptions during execution of microinstructions while running floating point and non-floating point instructions in parallel |
| US7301541B2 (en) * | 1995-08-16 | 2007-11-27 | Microunity Systems Engineering, Inc. | Programmable processor and method with wide operations |
| CN1075646C (zh) * | 1996-01-19 | 2001-11-28 | 张胤微 | 一种高速乘法器 |
| US6108769A (en) * | 1996-05-17 | 2000-08-22 | Advanced Micro Devices, Inc. | Dependency table for reducing dependency checking hardware |
| US5844830A (en) | 1996-08-07 | 1998-12-01 | Sun Microsystems, Inc. | Executing computer instrucrions by circuits having different latencies |
| US6009511A (en) * | 1997-06-11 | 1999-12-28 | Advanced Micro Devices, Inc. | Apparatus and method for tagging floating point operands and results for rapid detection of special floating point numbers |
| AU2743600A (en) * | 1999-01-28 | 2000-08-18 | Ati International S.R.L. | Executing programs for a first computer architecture on a computer of a second architecture |
| US6338136B1 (en) * | 1999-05-18 | 2002-01-08 | Ip-First, Llc | Pairing of load-ALU-store with conditional branch |
| US6446197B1 (en) | 1999-10-01 | 2002-09-03 | Hitachi, Ltd. | Two modes for executing branch instructions of different lengths and use of branch control instruction and register set loaded with target instructions |
| US6732134B1 (en) * | 2000-09-11 | 2004-05-04 | Apple Computer, Inc. | Handler for floating-point denormalized numbers |
| AU2003210749A1 (en) * | 2002-01-31 | 2003-09-02 | Arc International | Configurable data processor with multi-length instruction set architecture |
| US20070061551A1 (en) * | 2005-09-13 | 2007-03-15 | Freescale Semiconductor, Inc. | Computer Processor Architecture Comprising Operand Stack and Addressable Registers |
| US7676653B2 (en) * | 2007-05-09 | 2010-03-09 | Xmos Limited | Compact instruction set encoding |
| GB2458487B (en) | 2008-03-19 | 2011-01-19 | Imagination Tech Ltd | Pipeline processors |
| US8458684B2 (en) | 2009-08-19 | 2013-06-04 | International Business Machines Corporation | Insertion of operation-and-indicate instructions for optimized SIMD code |
| CN102298352B (zh) * | 2010-06-25 | 2012-11-28 | 中国科学院沈阳自动化研究所 | 高性能可编程控制器专用处理器体系结构及其实现方法 |
| US10078515B2 (en) * | 2011-10-03 | 2018-09-18 | International Business Machines Corporation | Tracking operand liveness information in a computer system and performing function based on the liveness information |
| CN102566967B (zh) * | 2011-12-15 | 2015-08-19 | 中国科学院自动化研究所 | 一种采用多级流水线结构的高速浮点运算器 |
| US9158660B2 (en) | 2012-03-16 | 2015-10-13 | International Business Machines Corporation | Controlling operation of a run-time instrumentation facility |
| US9471315B2 (en) | 2012-03-16 | 2016-10-18 | International Business Machines Corporation | Run-time instrumentation reporting |
| US9411589B2 (en) | 2012-12-11 | 2016-08-09 | International Business Machines Corporation | Branch-free condition evaluation |
| FR3002341B1 (fr) | 2013-02-19 | 2015-04-03 | Commissariat Energie Atomique | Systeme de compilation dynamique d'au moins un flot d'instructions |
| US9268527B2 (en) * | 2013-03-15 | 2016-02-23 | Freescale Semiconductor, Inc. | Method and device for generating an exception |
-
2014
- 2014-12-23 US US14/581,815 patent/US9696992B2/en active Active
-
2015
- 2015-11-20 TW TW104138536A patent/TWI564796B/zh not_active IP Right Cessation
- 2015-11-23 KR KR1020177013594A patent/KR102462283B1/ko active IP Right Grant
- 2015-11-23 WO PCT/US2015/062056 patent/WO2016105754A1/en active Application Filing
- 2015-11-23 CN CN201580063586.9A patent/CN107003840B/zh active Active
- 2015-11-23 EP EP15873961.5A patent/EP3238066A4/en active Pending
- 2015-11-23 JP JP2017527720A patent/JP6738579B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| TWI564796B (zh) | 2017-01-01 |
| JP2018507453A (ja) | 2018-03-15 |
| EP3238066A1 (en) | 2017-11-01 |
| TW201640334A (zh) | 2016-11-16 |
| KR20170097617A (ko) | 2017-08-28 |
| KR102462283B1 (ko) | 2022-11-03 |
| CN107003840B (zh) | 2021-05-25 |
| US9696992B2 (en) | 2017-07-04 |
| CN107003840A (zh) | 2017-08-01 |
| WO2016105754A1 (en) | 2016-06-30 |
| EP3238066A4 (en) | 2018-08-08 |
| US20160179515A1 (en) | 2016-06-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6456867B2 (ja) | 密結合ヘテロジニアスコンピューティングのためのハードウェアプロセッサ及び方法 | |
| JP6711480B2 (ja) | ベクトルインデックスロードおよびストアのための方法および装置 | |
| KR102508075B1 (ko) | 인덱스 및 즉치로 벡터 치환을 수행하기 위한 방법 및 장치 | |
| KR20170097018A (ko) | 벡터 브로드캐스트 및 xorand 로직 명령어를 위한 장치 및 방법 | |
| JP6741006B2 (ja) | マスクレジスタとベクトルレジスタとの間で可変に拡張するための方法および装置 | |
| KR102462174B1 (ko) | 벡터 비트 셔플을 수행하기 위한 방법 및 장치 | |
| JP6635438B2 (ja) | ベクトルビット反転およびクロスを実行するための方法および装置 | |
| KR102460268B1 (ko) | 큰 정수 산술 연산을 수행하기 위한 방법 및 장치 | |
| KR20170099860A (ko) | 벡터 포화된 더블워드/쿼드워드 덧셈을 수행하기 위한 명령어 및 로직 | |
| JP6738579B2 (ja) | 命令フローを最適化するチェックを実行するための装置および方法 | |
| JP6835436B2 (ja) | マスクをマスク値のベクトルに拡張するための方法および装置 | |
| KR102528073B1 (ko) | 벡터 비트 수집을 수행하기 위한 방법 및 장치 | |
| JP2017534982A (ja) | 4d座標から4dのz曲線インデックスを計算するための機械レベル命令 | |
| TWI697836B (zh) | 處理包括高功率及標準指令之指令集的方法與處理器 | |
| KR20170099864A (ko) | 마스크 값을 압축하기 위한 방법 및 장치 | |
| KR20170097613A (ko) | 벡터 수평 로직 명령어를 위한 장치 및 방법 | |
| KR102321941B1 (ko) | 스핀-루프 점프를 수행하기 위한 장치 및 방법 | |
| CN113050994A (zh) | 用于512位操作的系统、装置和方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20181119 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20191203 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20191129 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200226 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200519 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20200617 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200713 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6738579 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |