JP6655331B2 - 電子機器及び方法 - Google Patents
電子機器及び方法 Download PDFInfo
- Publication number
- JP6655331B2 JP6655331B2 JP2015186801A JP2015186801A JP6655331B2 JP 6655331 B2 JP6655331 B2 JP 6655331B2 JP 2015186801 A JP2015186801 A JP 2015186801A JP 2015186801 A JP2015186801 A JP 2015186801A JP 6655331 B2 JP6655331 B2 JP 6655331B2
- Authority
- JP
- Japan
- Prior art keywords
- character
- character code
- code string
- data
- area
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/26—Techniques for post-processing, e.g. correcting the recognition result
- G06V30/262—Techniques for post-processing, e.g. correcting the recognition result using context analysis, e.g. lexical, syntactic or semantic context
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/263—Language identification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/28—Character recognition specially adapted to the type of the alphabet, e.g. Latin alphabet
- G06V30/287—Character recognition specially adapted to the type of the alphabet, e.g. Latin alphabet of Kanji, Hiragana or Katakana characters
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Character Discrimination (AREA)
- Document Processing Apparatus (AREA)
Description
タブレットコンピュータ10は、図2に示されるように、CPU101、システムコントローラ102、主メモリ103、グラフィクスコントローラ104、BIOS−ROM105、不揮発性メモリ106、無線通信デバイス107、エンベデッドコントローラ(EC)108、カメラ109、等を備える。
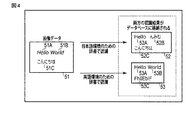
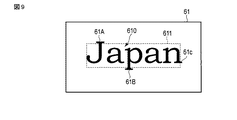
図9に示す例では、文字を装飾する要素61A,61B,61Cが文字の一部として認識されなかったために、それら要素61A,61B,61Cが、認識された文字列610を囲む領域611内に含まれていない。一方、図10に示す例では、文字を装飾する要素61A,61B,61Cが文字の一部として認識されたので、それら要素61A,61B,61Cが、認識された文字列610を囲む領域612内に含まれている。これは、例えば、図9に示した例で用いられた辞書データ41が、文字を装飾する要素を含まないフォント(例えば、ゴシック体)を考慮した文字特徴量を規定していたのに対して、図10に示した例で用いられた辞書データ41が、文字を装飾する要素を含むフォント(例えば、Times New Roman)を考慮した文字特徴量を規定していたことによるものである。
Claims (6)
- 第1言語の文字を認識するための辞書が記憶される第1辞書データと、
前記第1言語とは異なる第2言語の文字を認識するための辞書が記憶される第2辞書データと、
少なくとも前記第1言語の文字列および前記第2言語の文字列が描画される画像データを含む複数の画像データが格納されるデータベースと、
前記画像データに描画される前記複数の文字列を前記第1辞書データと前記第2辞書データを用いて文字認識すると共に、前記データベースの検索を実行するプロセッサと、を具備し、
前記プロセッサは、
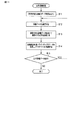
前記データベースから前記画像データを読み取り、前記第1辞書データを用いて、前記画像データに含まれる複数の文字列を認識して、その認識した前記複数の文字列に対応する第1文字コード列を生成し、
前記第2辞書データを用いて、前記画像データに含まれる前記複数の文字列を認識して、その認識した前記複数の文字列に対応する第2文字コード列を生成し、
前記第1文字コード列と前記複数の文字列とを対応付けた第1インデックスデータと、前記第2文字コード列と前記複数の文字列とを対応付けた第2インデックスデータとを含む検索用のインデックスデータを生成して前記データベースに記憶し、
キーワードの入力に対し前記検索用のインデックスデータを検索して、前記キーワードと前記第1文字コード列又は前記第2文字コード列が一致する場合は、前記第1文字コード列又は前記第2文字コード列に対応する画像データを前記データベースから読み出す
電子機器。 - 前記第1インデックスデータは、前記第1文字コード列と、前記第1文字コード列の位置に対応する前記画像データ内の第1領域の座標とを少なくとも含み、
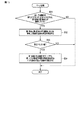
前記第2インデックスデータは、前記第2文字コード列と、前記第2文字コード列の位置に対応する前記画像データ内の第2領域の座標とを少なくとも含む請求項1記載の電子機器。 - 前記プロセッサは、
前記キーワードが前記第1文字コード列および第2文字コード列に含まれる場合、前記第1領域と前記第2領域が重複しているか否かを判定し、
重複している割合が閾値より大きいと判定した場合、前記第1領域と前記第2領域をマージすると共に、前記第1領域と前記第2領域をハイライトにした前記画像データを表示する請求項2記載の電子機器。 - 前記プロセッサは、前記第1領域と前記第2領域とをマージするために、前記第1領域と前記第2領域の中間の領域を算出するか、又は前記第1領域と前記第2領域を包含する領域を算出する請求項3記載の電子機器。
- 第1言語の文字列および前記第1言語とは異なる第2言語の文字列が少なくとも描画される画像データを含む複数の画像データが格納されるデータベースから前記画像データを読み取り、
前記第1言語の文字を認識するための辞書が記憶される第1辞書データを用いて、前記画像データに含まれる複数の文字列を認識して、その認識した前記複数の文字列に対応する第1文字コード列を生成し、
前記第2言語の文字を認識するための辞書が記憶される第2辞書データを用いて、前記画像データに含まれる前記複数の文字列を認識して、その認識した前記複数の文字列に対応する第2文字コード列を生成し、
前記第1文字コード列と前記複数の文字列とを対応付けた第1インデックスデータと、前記第2文字コード列と前記複数の文字列とを対応付けた第2インデックスデータとを含む検索用のインデックスデータを生成して前記データベースに記憶し、
キーワードの入力に対し前記検索用のインデックスデータを検索して、前記キーワードと前記第1文字コード列又は前記第2文字コード列が一致する場合は、前記第1文字コード列又は前記第2文字コード列に対応する画像データを前記データベースから読み出す方法。 - コンピュータにより実行されるプログラムであって、前記プログラムは、
第1言語の文字列および前記第1言語とは異なる第2言語の文字列が少なくとも描画される画像データを含む複数の画像データが格納されるデータベースから前記画像データを読み取る手順と、
前記第1言語の文字を認識するための辞書が記憶される第1辞書データを用いて、前記画像データに含まれる複数の文字列を認識する手順と、
その認識した前記複数の文字列に対応する第1文字コード列を生成する手順と、
前記第2言語の文字を認識するための辞書が記憶される第2辞書データを用いて、前記画像データに含まれる前記複数の文字列を認識する手順と、
その認識した前記複数の文字列に対応する第2文字コード列を生成する手順と、
前記第1文字コード列と前記複数の文字列とを対応付けた第1インデックスデータと、前記第2文字コード列と前記複数の文字列とを対応付けた第2インデックスデータとを含む検索用のインデックスデータを生成して前記データベースに記憶する手順と、
キーワードの入力に対し前記検索用のインデックスデータを検索して、前記キーワードと前記第1文字コード列又は前記第2文字コード列が一致する場合は、前記第1文字コード列又は前記第2文字コード列に対応する画像データを前記データベースから読み出す手順と、
を前記コンピュータに実行させるプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015186801A JP6655331B2 (ja) | 2015-09-24 | 2015-09-24 | 電子機器及び方法 |
| US15/270,772 US10127478B2 (en) | 2015-09-24 | 2016-09-20 | Electronic apparatus and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015186801A JP6655331B2 (ja) | 2015-09-24 | 2015-09-24 | 電子機器及び方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017062584A JP2017062584A (ja) | 2017-03-30 |
| JP2017062584A5 JP2017062584A5 (ja) | 2018-09-13 |
| JP6655331B2 true JP6655331B2 (ja) | 2020-02-26 |
Family
ID=58406533
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015186801A Active JP6655331B2 (ja) | 2015-09-24 | 2015-09-24 | 電子機器及び方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10127478B2 (ja) |
| JP (1) | JP6655331B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10810467B2 (en) * | 2017-11-17 | 2020-10-20 | Hong Kong Applied Science and Technology Research Institute Company Limited | Flexible integrating recognition and semantic processing |
| CN112801239B (zh) * | 2021-01-28 | 2023-11-21 | 科大讯飞股份有限公司 | 输入识别方法、装置、电子设备和存储介质 |
| JP2023141193A (ja) * | 2022-03-23 | 2023-10-05 | 富士フイルムビジネスイノベーション株式会社 | 情報処理装置およびプログラム |
Family Cites Families (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2166248C (en) | 1995-12-28 | 2000-01-04 | Abdel Naser Al-Karmi | Optical character recognition of handwritten or cursive text |
| JPH10124505A (ja) | 1996-10-25 | 1998-05-15 | Hitachi Ltd | 文字入力装置 |
| US6047251A (en) * | 1997-09-15 | 2000-04-04 | Caere Corporation | Automatic language identification system for multilingual optical character recognition |
| US6157905A (en) * | 1997-12-11 | 2000-12-05 | Microsoft Corporation | Identifying language and character set of data representing text |
| US6567547B1 (en) * | 1999-03-05 | 2003-05-20 | Hewlett-Packard Company | System and method for dynamically switching OCR packages |
| DE10126835B4 (de) * | 2001-06-01 | 2004-04-29 | Siemens Dematic Ag | Verfahren und Vorrichtung zum automatischen Lesen von Adressen in mehr als einer Sprache |
| RU2251737C2 (ru) * | 2002-10-18 | 2005-05-10 | Аби Софтвер Лтд. | Способ автоматического определения языка распознаваемого текста при многоязычном распознавании |
| JP3919617B2 (ja) * | 2002-07-09 | 2007-05-30 | キヤノン株式会社 | 文字認識装置および文字認識方法、プログラムおよび記憶媒体 |
| JP2005208687A (ja) * | 2004-01-19 | 2005-08-04 | Ricoh Co Ltd | 多言語文書処理装置及びプログラム |
| JP2006260115A (ja) * | 2005-03-16 | 2006-09-28 | Ricoh Co Ltd | 文書管理システム |
| US7546524B1 (en) * | 2005-03-30 | 2009-06-09 | Amazon Technologies, Inc. | Electronic input device, system, and method using human-comprehensible content to automatically correlate an annotation of a paper document with a digital version of the document |
| US9141607B1 (en) * | 2007-05-30 | 2015-09-22 | Google Inc. | Determining optical character recognition parameters |
| JP2010108087A (ja) | 2008-10-28 | 2010-05-13 | Sharp Corp | 文字認識装置、文字認識方法、および文字認識プログラム |
| JP5289032B2 (ja) * | 2008-12-22 | 2013-09-11 | 三菱電機株式会社 | 文書検索装置 |
| CN102053991B (zh) * | 2009-10-30 | 2014-07-02 | 国际商业机器公司 | 用于多语言文档检索的方法及系统 |
| US8385652B2 (en) * | 2010-03-31 | 2013-02-26 | Microsoft Corporation | Segmentation of textual lines in an image that include western characters and hieroglyphic characters |
| US9043349B1 (en) * | 2012-11-29 | 2015-05-26 | A9.Com, Inc. | Image-based character recognition |
| US9411801B2 (en) * | 2012-12-21 | 2016-08-09 | Abbyy Development Llc | General dictionary for all languages |
| JP2014197341A (ja) * | 2013-03-29 | 2014-10-16 | 富士フイルム株式会社 | 電子書籍制作装置、電子書籍システム、電子書籍制作方法及びプログラム |
| US20140363082A1 (en) * | 2013-06-09 | 2014-12-11 | Apple Inc. | Integrating stroke-distribution information into spatial feature extraction for automatic handwriting recognition |
| RU2613847C2 (ru) * | 2013-12-20 | 2017-03-21 | ООО "Аби Девелопмент" | Выявление китайской, японской и корейской письменности |
| US9798943B2 (en) * | 2014-06-09 | 2017-10-24 | I.R.I.S. | Optical character recognition method |
-
2015
- 2015-09-24 JP JP2015186801A patent/JP6655331B2/ja active Active
-
2016
- 2016-09-20 US US15/270,772 patent/US10127478B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US10127478B2 (en) | 2018-11-13 |
| US20170091596A1 (en) | 2017-03-30 |
| JP2017062584A (ja) | 2017-03-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20150169948A1 (en) | Electronic apparatus and method | |
| US9390341B2 (en) | Electronic device and method for manufacturing the same | |
| JP5270027B1 (ja) | 情報処理装置および手書き文書検索方法 | |
| JP6180888B2 (ja) | 電子機器、方法およびプログラム | |
| US9606981B2 (en) | Electronic apparatus and method | |
| US20140143721A1 (en) | Information processing device, information processing method, and computer program product | |
| US9274704B2 (en) | Electronic apparatus, method and storage medium | |
| US20130300675A1 (en) | Electronic device and handwritten document processing method | |
| US20160147436A1 (en) | Electronic apparatus and method | |
| US9378427B2 (en) | Displaying handwritten strokes on a device according to a determined stroke direction matching the present direction of inclination of the device | |
| JP6426417B2 (ja) | 電子機器、方法及びプログラム | |
| JPWO2014147712A1 (ja) | 情報処理装置、情報処理方法及びプログラム | |
| JP6655331B2 (ja) | 電子機器及び方法 | |
| US9183276B2 (en) | Electronic device and method for searching handwritten document | |
| US9940536B2 (en) | Electronic apparatus and method | |
| JP5735126B2 (ja) | システムおよび筆跡検索方法 | |
| JP6342194B2 (ja) | 電子機器、方法及びプログラム | |
| JP6223687B2 (ja) | 電子機器および手書き文書検索方法 | |
| US9697422B2 (en) | Electronic device, handwritten document search method and storage medium | |
| US9411885B2 (en) | Electronic apparatus and method for processing documents | |
| US20150128019A1 (en) | Electronic apparatus, method and storage medium | |
| JPWO2016031016A1 (ja) | 電子機器、方法及びプログラム | |
| US20150253878A1 (en) | Electronic device and method | |
| KR20160090938A (ko) | 촬영된 사진 내 텍스트를 이용한 검색 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180731 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180731 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20181206 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20181207 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20190604 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190723 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190912 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200107 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200203 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6655331 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |