JP6616608B2 - 半導体装置 - Google Patents
半導体装置 Download PDFInfo
- Publication number
- JP6616608B2 JP6616608B2 JP2015142265A JP2015142265A JP6616608B2 JP 6616608 B2 JP6616608 B2 JP 6616608B2 JP 2015142265 A JP2015142265 A JP 2015142265A JP 2015142265 A JP2015142265 A JP 2015142265A JP 6616608 B2 JP6616608 B2 JP 6616608B2
- Authority
- JP
- Japan
- Prior art keywords
- register
- vector
- instruction
- additional information
- general
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000004065 semiconductor Substances 0.000 title claims description 34
- 238000004364 calculation method Methods 0.000 claims description 9
- 230000008878 coupling Effects 0.000 claims 6
- 238000010168 coupling process Methods 0.000 claims 6
- 238000005859 coupling reaction Methods 0.000 claims 6
- 230000000052 comparative effect Effects 0.000 description 43
- 238000010586 diagram Methods 0.000 description 26
- 238000000034 method Methods 0.000 description 15
- 238000003780 insertion Methods 0.000 description 6
- 230000037431 insertion Effects 0.000 description 6
- 238000003491 array Methods 0.000 description 5
- 230000001174 ascending effect Effects 0.000 description 5
- 230000006870 function Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30021—Compare instructions, e.g. Greater-Than, Equal-To, MINMAX
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30032—Movement instructions, e.g. MOVE, SHIFT, ROTATE, SHUFFLE
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30094—Condition code generation, e.g. Carry, Zero flag
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30101—Special purpose registers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/3012—Organisation of register space, e.g. banked or distributed register file
- G06F9/3013—Organisation of register space, e.g. banked or distributed register file according to data content, e.g. floating-point registers, address registers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
Description
その他の課題と新規な特徴は、本明細書の記述および添付図面から明らかになるであろう。
すなわち、ベクトル命令は、演算結果と別に付加情報を生成し、付加情報をベクトルレジスタとは異なるレジスタに蓄積する。
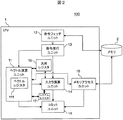
図1は実施形態に係るベクトル命令を説明するための図である。実施形態に係るベクトル命令はベクトルレジスタでの演算を行うベクトル命令で、ベクトル命令はN個分のデータを同時に演算する。このとき、ベクトル命令はN個の演算結果を生成すると共に、その演算結果に応じて、演算結果を補助するような情報(演算結果のフラグや比較結果などの付加情報)を生成する。
cmp1.N order,cond,wreg1,wreg2,wreg3
実施例に係るベクトル命令はベクトルレジスタ(wreg1)の内容とベクトルレジスタ(wreg2)の内容を比較して、その結果をベクトルレジスタ(wreg3)に格納するとともに、暗黙的に指定される汎用レジスタ(GR[1])114に付加情報を格納する。実施例に係るベクトル命令は、比較結果が不一致の場合は0を、比較結果が一致の場合はすべて1を、wreg3に格納する。wreg1、wreg2、wreg3は128ビット長であり、N(=1、2、4)個のデータに分割される。N=1の場合はベクトルレジスタの最下位ワードのw0を使用し、N=2の場合はベクトルレジスタの下位2ワードのw1、w0が使用され、N=4の場合はベクトルレジスタの全体のw3、w2、w1、w0が使用される。1ワードは32ビットであり、w3、w2、w1、w0はそれぞれ32ビットである。実施例に係るベクトル命令は、比較の結果、Nビットの付加情報(CC)を生成し、汎用レジスタ(GR[1])114に挿入する。ここでNビットの付加情報(CC)の挿入は、まず汎用レジスタ(GR[1])の値がNビット右または左にシフトされ、空いた部分に付加情報(CC)が格納されることにより行われる。このとき、「order」によって、汎用レジスタ(GR[1])に対して、付加情報(CC)を上位から挿入(右シフト)するか、下位から挿入(左シフト)するかが指定される。これによりアドレス上位からの検索とアドレス下位からの検索を可能とする。なお、図3では右にシフトする場合を示している。「cond」によって、付加情報のセット条件(=、>、<、≧、≦、≠等)が指定される。
レジスタの下位から挿入される場合(図4):
sysreg[L-1: 0] <= {sysreg[L-n: 0], FLAG[n-1: 0]}
レジスタの上位から挿入される場合(図5):
sysreg[L-1: 0] <= {FLAG[ 0:n-1], sysreg[L-n: 0]}
レジスタの下位からデータが挿入される場合、図4に示すように、Lビットのレジスタ(sysreg)の内容がnビット左にシフトされ、nビットの情報(FLAG)がsysregの下位に格納される。sysregの下位(L−n)ビットとnビットのFLAGとが連結され、sysregの上位nビットは破棄される。レジスタの上位からデータが挿入される場合、図5に示すように、Lビットのレジスタの内容がnビット右にシフトされ、nビットのFLAGがレジスタの上位に格納される。nビットのFLAG とsysregの上位(L−n)ビットとが連結され、sysregの下位nビットは破棄される。
次に、本願発明者が本開示に先立って検討した技術(以下、比較例という。)について説明する。図7は比較例に係るベクトル命令について説明するためのブロック図である。比較例に係るベクトル命令は、2つのベクトルレジスタを用いて演算を行い、その演算結果をベクトルレジスタに書き込むとともに、その演算結果に応じて、演算結果を補助するような情報(演算結果のフラグ、比較結果などの付加情報を処理してインデックス)を出力する命令であり、例えば以下に示すような命令である。
cmp3.N order,cond,wreg1,wreg2,wreg3
比較例に係るベクトル命令は、ベクトルレジスタ(wreg1)とベクトルレジスタ(wreg2)の中身を文字列として、wreg1とwreg2の各要素を比較し、その結果をベクトルレジスタ(wreg3)に格納するとともに、比較結果が成立した最上位/最下位ビットの位置(付加情報)を算出して汎用レジスタ(暗黙的に指定されるレジスタで例えばGR[1])に格納する命令である。つまり、比較例に係るベクトル命令は、比較が初めて成立したビットの位置(結果の位置情報)を汎用レジスタに格納する。
for (i = 0; i < M; i++) {
// array[]は探索する配列、borderは探索すべき境界
if (border > array[i]) return i;
}
図7に示すように、比較例に係るベクトル命令はベクトルレジスタ311の内容を文字列として捉え、ベクトル演算器312を用いて比較を実行し、その結果を専用回路313の連結回路3131によって集める。次に、専用回路313のインデックス生成回路3132は、比較結果の付加情報のビット列でビットが1となった最上位ビットの位置を算出し、インデックスを生成する。そして、その結果は汎用レジスタ(GR[1])314に格納される。また、比較が成立したベクトル要素が1つも存在しない場合、汎用レジスタ(GR[1])314には特別な数値が書き込まれる。比較対象とする文字がベクトルレジスタ311中に存在していたかどうかの確認は、比較例に係るベクトル命令を実行後、汎用レジスタ(GR[1])314を読み取り、汎用レジスタ(GR[1])314が、比較成立したベクトル要素が一つも存在しないことを示す特別な数値であるかをチェックすることにより行われる。この結果を元に次の文字列をベクトルレジスタ311に読み込み比較するかが決められる。これらの処理はスカラ命令を用いて行われる。
ステップ1:ANS=0とする。ANSは探索文字のインデックスを示す任意の汎用レジスタである。
ステップ2:比較例に係るベクトル命令を実行する。
ステップ3:GR[1]=4をチェックする。GR[1]=4ならば、ANS=ANS+GR[1]を実行後、ステップ4へ移動する。GR[1]≠4ならばステップ5へ移動する。GR[1]=4は特殊数値で、比較対象の値が存在しなかったことを示す。
ステップ4:次の文字列をベクトルレジスタにロードし、ステップ2へ移動する。
ステップ5:終了。ANS=ANS+GR[1]が探索文字のインデックスになる。
配列A=[0,4,5,10,12,8,16,27,9,1,5,8,1,0,1,1]と、
配列B=[1,3,7,9,15,9,20,13,11,0,3,1,9,0,0,0]と、
を比較例に係るベクトル命令を用いて比較する場合と、実施例に係るベクトル命令を用いて比較する場合について説明する。ベクトル命令の並列度は4とすると、それぞれの配列を4エレメント(要素)ずつロードしていき比較する。このとき、付加情報格納レジスタである汎用レジスタ(GR[1])は初期値0であるとし、A[i]<B[i]ならばフラグ(付加情報要素)は1、それ以外ならばフラグは0とする。
(1)最初の4要素である A=[0,4,5,10], B=[1,3,7,9] がベクトルレジスタにロードされ、比較が実行される。第1要素はベクトルレジスタの最下位ワードに第4要素は最上位ワードに格納される。したがって、wreg1=[10,5,4,0]、wreg2=[9,7,3,1]となり、最下位ワードは比較条件が成立するので、比較結果の付加情報(インデックス)=0となる。
(2)比較結果がベクトルレジスタに格納される。wreg3=[0x0000_0000, 0xffff_ffff, 0x0000_0000, 0xffff_ffff] となる。ここで、「0x」は16進数であることを示す。
(3)汎用レジスタ(GR[1])に付加情報(インデックス)の0が格納される。ここでは、GR[1]=0000_0000_0000_0000 となる。
(4)次の配列A、Bについて上記(1)〜(3)を繰り返す。
第3番目の4要素は、A=[9,1,5,8], B=[11,0,3,1,]であるので、wreg1=[8,5,1,9]、wreg2=[1,3,0,13]であり、最下位ワードは比較条件が成立するので、インデックス=0, GR[1]=0x0000となる。
第4番目の4要素は、A=[11,0,1,1],B=[9,0,0,0] であるので、wreg1=[1,1,0,11]、wreg2=[0,0,0,9]であり、いずれのワードも比較条件が成立しないので、インデックス=4, GR[1]=0x0004となる。
(1)最初の4要素である A=[0,4,5,10], B=[1,3,7,9] がベクトルレジスタにロードされ、比較が実行される。第1要素はベクトルレジスタの最下位ワードに第4要素は最上位ワードに格納される。したがって、wreg1=[10,5,4,0]、wreg2=[9,7,3,1]、比較結果の付加情報(フラグ)=[0,1,0,1] となる。
(2)比較結果がベクトルレジスタに格納される。wreg3=[0x0000_0000, 0xffff_ffff, 0x0000_0000, 0xffff_ffff] となる。ここで、「0x」は16進数であることを示す。
(3)付加情報格納レジスタ(GR[1])の内容が右にシフトされ、GR[1]にフラグの4ビット[0,1,0,1]が挿入される。ここでは、GR[1]の上位から付加情報が挿入されていき、GR[1]=0101_0000_0000_0000 となる。
(4)次の配列A、Bについて上記(1)〜(3)を繰り返す。
第3番目の4要素は、A=[9,1,5,8], B=[11,0,3,1,] であるので、wreg1=[8,5,1,9]、wreg2=[1,3,0,13]であり、フラグ=[0,0,0,1], GR[1]=0001_0111_0101_0000となる。
第4番目の4要素は、A=[11,0,1,1],B=[9,0,0,0] であるので、wreg1=[1,1,0,11]、wreg2=[0,0,0,9]であり、フラグ=[0,0,0,0], GR[1]=0000_0001_0111_0101となる。
cmp2.N order,cond,wreg1,wreg2,wreg3
実施例2に係るベクトル命令はベクトルレジスタ(wreg1)の内容とベクトルレジスタ(wreg2)の内容を比較して、その結果をベクトルレジスタ(wreg3)に格納するとともに、暗黙的に指定される専用レジスタ(SR)に付加情報を格納する。実施例2に係るベクトル命令は付加情報の格納先を除き、実施例1に係るベクトル命令と同様である。
// ベクトルレジスタvborderの全てのwayに、borderの値を格納する。
vborder = {border, border, …, border, border};
for (i = 0;i < M / N; i++) {
// arrayの中から値を取り出し、ベクトルレジスタに格納する
varray = {array[i*N+(N-1)], array[i*N+(N-2)],…, array[i*N+1], array[i*N+0]};
// 比較を実行
vresult = v_compare (vborder, array);
}
上記第2のアルゴリズムで、ベクトル命令を用いてNワードずつ値を比較することができるが、ベクトルレジスタ(vresult)から、比較結果の付加情報が変化した(配列の値がborderよりも大きくなった)場所を探索するためには、多くの命令が必要になる。通常は下記に示すような第3のアルゴリズムを取る。
// ベクトルレジスタvborderの全てのwayに、borderの値を格納する。
vborder = {border, border, …, border, border};
index = 0;
for (i = 0;i < M / N; i++) {
// arrayの中から値を取り出し、ベクトルレジスタに格納する
varray = {array[i*N+(N-1)], array[i*N+(N-2)],…, array[i*N+1], array[i*N+0]};
// 比較を実行
// vborderとvarrayの各要素を比較し、結果をvresultに格納する。
// flagには、各ベクトル要素のフラグが格納される(Nビット)
vresult = v_compare (vborder, varray, flag);
// ベクトル比較命令にてNワードの比較を実行後
if (全ての演算結果で比較結果不成立 (フラグなどを参照する)) {
//比較の結果、該当するベクトル要素が含まれている場合には脱出する
break;
} else {
index = index + N; // 比較したベクトル列の中にはヒットしなかった。
}
}
// 比較の結果、該当するベクトル要素が含まれている場合、どのベクトル要素から成立しているのかを1つずつ調べる。
for (i = 0; i < N; i++) {
if (flag[i] == 1) {
break;
} else {
index = index + 1;
}
}
例として、昇順の配列A=[0,1,2,4, 5,7,8,10, 12,15,16,20, 22,25,30,31]の中から、値15を越える配列のインデックスを探索する第3のアルゴリズムを比較例に係るベクトル命令を用いる場合について説明する。
if (GR[1]!=4) {
borderを越える値が見つかった
} else {
ANS = ANS + 4
}
(1)ベクトルレジスタ(wreg2)にborderの15が格納され、wreg2=[15,15,15,15]となる。
(2)ベクトルレジスタ(wreg1)に配列A[3-0] の値が格納とされ、wreg1=[4,2,1,0]となる。
(3)wreg1とwreg2とが比較され、インデックス=4、GR=0000_0000_0000_0100 となる。
if (GR[1]!=4) {
borderを越える値が見つかった
} else {
ANS = ANS + 4
}
(1)ベクトルレジスタ(wreg1)に配列A[7-4] の値が格納され、wreg1=[10,8,7,5] となる。
(2)wreg1とwreg2とが比較され、インデックス=4、GR=0000_0000_0000_0100 となる。
if (GR[1]!=4) {
borderを越える値が見つかった
ANS = ANS + GR[1] ⇒ ループ終了
}
ANS = ANS + GR[1];
}
(1)ベクトルレジスタ(wreg1)に配列A[11-8] の値が格納され、wreg1=[20,16,15,12]となる。
(2)wreg1とwreg2とが比較され、インデックス=2、GR=0000_0000_0000_0010 となる。
汎用レジスタの内容を比較する命令(比較命令)
比較命令の結果に基づいて分岐する分岐命令
が必要になり、ベクトル命令を効率的に活用できていることにはならない。
for (i = 0; i < M/K; i++) {
head_idx = i * K;
for (j = 0; j < K/N; j++) {
// arrayの中から値を取り出し、ベクトルレジスタに格納する
varray = {array[head_idx+(N-1)], array[head_idx+(N-2)], … aray[head_idx+0]};
// 比較を実行
vresult = v_compare (vborder, array);
head_idx = head_idx + N;
}
if (専用レジスタ != 0x00) {
goto finish;
}
}
finish:
// search_1_from_right は、1が立っているビットの場所をLSBから順に検索する
// この機能は多くのCPUでは命令として存在する。
one_index = search_1_from_right(専用レジスタ);
return head_idx + one_index;
例として、昇順の配列A=[0,1,2,4, 5,7,8,10, 12,15,16,20, 22,25,30,31]の中から、値15を越える配列のインデックスを探索する第4のアルゴリズムを実施例2に係るベクトル命令を用いる場合について説明する。ここで、M=16、K=16、N=4とする。なお、専用レジスタ(SR)214は32ビット幅であると説明したが、ここでは図面およびその説明を簡単にするために16ビット幅(K=16)としている。
(1)ベクトルレジスタ(wreg2)にborderの15が格納され、wreg2=[15,15,15,15]となる。
(2)ベクトルレジスタ(wreg1)に配列A[3-0] の値が格納され、wreg1=[4,2,1,0] となる。
(3)wreg1とwreg2とが比較され、フラグ=[0,0,0,0]、SR=0000_0000_0000_0000 となる。
(1)ベクトルレジスタ(wreg1)に配列A[7-4] の値が格納され、wreg1=[10,8,7,5]となる。
(2)wreg1とwreg2とが比較され、フラグ=[0,0,0,0]、SR=0000_0000_0000_0000 となる。
(1)ベクトルレジスタ(wreg1)に配列A[11-8] の値が格納され、wreg1=[20,16,15,12] となる。
(2)wreg1とwreg2とが比較され、フラグ=[1,1,0,0]、SR=1100_0000_0000_0000 となる。
(1)ベクトルレジスタ(wreg1)に配列A[15-12] の値が格納され、wreg1=[31,30,25,22] となる。
(2)wreg1とwreg2とが比較され、フラグ=[1,1,1,1]、SR=1111_1100_0000_0000 となる。
以下、実施態様について付記する。
(付記1)
ベクトル命令を実行可能なデータ処理装置を備える半導体装置であって、
前記データ処理装置は、前記ベクトル命令を実行した演算処理の結果から付加情報を生成し、
前記データ処理装置は付加情報格納レジスタを備え、
前記付加情報格納レジスタは、前記ベクトル命令に基づいて前記付加情報を表すビット数分だけシフトされて空いた部分に前記付加情報を表すビットを連結し格納する
半導体装置。
(付記1)に記載の半導体装置において、
前記付加情報格納レジスタは、複数回の前記データ処理装置の実行によって生成された前記付加情報を表すビットを格納する。
11・・・ベクトル演算ユニット
101・・・ベクトルレジスタ
102・・・演算器
103・・・専用回路
104・・・付加情報格納レジスタ
111・・・ベクトルレジスタ
112・・・演算器
113・・・専用回路
114・・・付加情報格納レジスタ(汎用レジスタ)
1131・・・連結回路
1132・・・シフタ
1133・・・連結回路
12・・・命令フェッチユニット
13・・・命令発行ユニット
14・・・スカラ演算ユニット
15・・・メモリアクセスユニット
16・・・汎用レジスタ
17・・・システムレジスタ
18・・・コミットユニット
2・・・記憶装置(メモリ)
11A・・・ベクトル演算ユニット
213・・・専用回路
214・・・付加情報格納レジスタ(専用レジスタ)
217・・・セレクタ
Claims (20)
- 半導体装置はベクトル命令およびスカラ命令を実行可能なデータ処理装置を備え、
前記データ処理装置は、第1および第2のベクトルレジスタと、汎用レジスタまたは専用レジスタと、を有し、
前記ベクトル命令は、前記第1のベクトルレジスタの内容と前記第2のベクトルレジスタの内容とを要素ごとに演算し、要素ごとの演算結果に基づく付加情報を連結し、前記汎用レジスタまたは前記専用レジスタの内容を右または左にシフトし、シフトによって空いた部分に連結した付加情報を挿入して、前記汎用レジスタまたは前記専用レジスタに前記付加情報を蓄積する命令であり、
前記データ処理装置は、1度目のベクトル命令の実行で、第1の連結した付加情報を前記汎用レジスタまたは前記専用レジスタに保存し、前記1度目の実行に連続する2度目の前記ベクトル命令の実行で、第2の連結した付加情報を前記汎用レジスタまたは前記専用レジスタにさらに保存し、前記第1の連結した付加情報および前記第2の連結した付加情報に基づいて前記スカラ命令を実行するよう構成される。 - 請求項1の半導体装置において、
前記第1および第2のベクトルレジスタはそれぞれN個の要素を格納可能であり、
前記データ処理装置は前記N個の要素の演算を並列に実行可能であり、N個の付加情報を生成するよう構成される。 - 請求項2の半導体装置において、
前記ベクトル命令は前記第1のベクトルレジスタの内容と前記第2のベクトルレジスタの内容を比較する命令であり、
前記付加情報は比較結果に基づくフラグであり、比較条件に合致する場合1または0になり、比較条件に合致しない場合は0または1になる。 - 請求項3の半導体装置において、
前記ベクトル命令は、前記右または左のシフトと、前記比較条件と、並列に演算する要素数と、を明示的に指定することが可能であり、前記汎用レジスタまたは前記専用レジスタは暗黙的に指定されるよう構成される。 - 請求項4の半導体装置において、
さらに、第3のベクトルレジスタを有し、
前記ベクトル命令は、前記演算結果を前記第3のベクトルレジスタに格納する命令である。 - 請求項5の半導体装置において、
Nは1から4であり、1要素は32ビットの幅であり、
前記第1、第2および第3のベクトルレジスタはそれぞれ128ビットの幅であり、
前記汎用レジスタおよび前記専用レジスタは32ビットの幅であり、
前記データ処理装置は、4個のベクトル命令を連続実行するごとに前記スカラ命令を実行するよう構成される。 - 請求項2の半導体装置において、
前記N個の付加情報はNビットの幅であり、
前記汎用レジスタおよび前記専用レジスタは、Mビット(N×2以上の自然数)の幅であり、
前記データ処理装置は、M÷N以下の数のベクトル命令を連続実行して、それぞれのベクトル命令の実行で生成された付加情報を、前記汎用レジスタまたは前記専用レジスタに順次格納することで全て保持し、前記汎用レジスタまたは前記専用レジスタに保持された前記付加情報に基づいて前記スカラ命令を実行するよう構成される。 - 請求項2の半導体装置において、さらに、
前記付加情報を連結する第1の連結回路と、
前記汎用レジスタまたは前記専用レジスタの内容を右または左にシフトするシフト回路と、
前記第1の連結回路の出力と前記シフト回路の出力とを連結する第2の連結回路と、
を備える。 - 請求項8の半導体装置において、
前記専用レジスタはデータの読む込みと書込みが並列して行うことが可能であるよう構成される。 - 請求項9の半導体装置において、
前記スカラ命令は前記専用レジスタの内容を前記汎用レジスタに転送する命令および前記汎用レジスタの下位ビットまたは上位ビットから最初に1または0がある場所を検出する命令を含む。 - 半導体装置は、
ベクトル命令およびスカラ命令を実行可能な中央処理装置と、
前記ベクトル命令および前記スカラ命令を格納可能な記憶装置と、
を備え、
前記中央処理装置は、
第1、第2および第3のベクトルレジスタと、
汎用レジスタと、
専用レジスタと、
を備え、
前記ベクトル命令は、第1のベクトルレジスタの内容と第2のベクトルレジスタの内容とを要素ごとに比較し、比較結果を前記第3のベクトルレジスタに格納し、要素ごとの比較結果に基づく付加情報を連結し、前記汎用レジスタまたは前記専用レジスタの内容を右または左にシフトし、シフトによって空いた部分に連結した付加情報を挿入して、前記汎用レジスタまたは前記専用レジスタに前記付加情報を蓄積する命令であり、
前記中央処理装置は、1度目のベクトル命令の実行で、第1の連結した付加情報を前記汎用レジスタまたは前記専用レジスタに保存し、前記1度目の実行に連続する2度目の前記ベクトル命令の実行で、第2の連結した付加情報を前記汎用レジスタまたは前記専用レジスタにさらに保存し、前記第1の連結した付加情報および前記第2の連結した付加情報に基づいて前記スカラ命令を実行するよう構成される。 - 請求項11の半導体装置において、
前記第1、第2および第3のベクトルレジスタはそれぞれN個の要素を格納可能であり、
前記中央処理装置は前記N個の要素の比較を並列に実行可能であり、N個の付加情報を生成するよう構成される。 - 請求項11の半導体装置において、
Nは1から4であり、1要素は32ビットの幅であり、
前記第1、第2および第3のベクトルレジスタはそれぞれ128ビットの幅であり、
前記汎用レジスタおよび前記専用レジスタは32ビットの幅であり、
前記中央処理装置は、4個のベクトル命令を連続実行するごとに前記スカラ命令を実行するよう構成される。 - 請求項12の半導体装置において、
前記N個の付加情報はNビットの幅であり、
前記汎用レジスタおよび前記専用レジスタは、Mビット(N×2以上の自然数)の幅であり、
前記中央処理装置は、M÷N以下の数のベクトル命令を連続実行して、それぞれのベクトル命令の実行で生成された付加情報を、前記汎用レジスタまたは前記専用レジスタに順次格納することで全て保持し、前記汎用レジスタまたは前記専用レジスタに保持された前記付加情報に基づいて前記スカラ命令を実行するよう構成される。 - 請求項12の半導体装置において、
前記付加情報は比較結果に基づくフラグであり、比較条件に合致する場合1または0になり、比較条件に合致しない場合は0または1になる。 - 請求項15の半導体装置において、
前記ベクトル命令は、前記右または左のシフトと、前記比較条件と、並列に演算する要素数と、を明示的に指定することが可能であり、前記汎用レジスタまたは前記専用レジスタは暗黙的に指定されるよう構成される。 - 請求項16の半導体装置において、さらに、
前記付加情報を連結する第1の連結回路と、
前記汎用レジスタまたは前記専用レジスタの内容を右または左にシフトするシフト回路と、
前記第1の連結回路の出力と前記シフト回路の出力とを連結する第2の連結回路と、
を備える。 - 請求項17の半導体装置において、
前記専用レジスタはデータの読む込みと書込みが並列して行うことが可能であるよう構成される。 - 請求項11の半導体装置において、
前記スカラ命令は前記専用レジスタの内容を前記汎用レジスタに転送する命令および前記汎用レジスタの下位ビットまたは上位ビットから最初に1または0がある場所を検出する命令を含む。 - 請求項19の半導体装置において、
前記中央処理装置は、
前記ベクトル命令を実行するベクトル演算ユニットと、
前記スカラ命令を実行するスカラ演算ユニットと、
を備える。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015142265A JP6616608B2 (ja) | 2015-07-16 | 2015-07-16 | 半導体装置 |
| US15/154,753 US20170017489A1 (en) | 2015-07-16 | 2016-05-13 | Semiconductor device |
| CN201610556654.1A CN106354477A (zh) | 2015-07-16 | 2016-07-14 | 半导体器件 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015142265A JP6616608B2 (ja) | 2015-07-16 | 2015-07-16 | 半導体装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017027149A JP2017027149A (ja) | 2017-02-02 |
| JP2017027149A5 JP2017027149A5 (ja) | 2018-07-05 |
| JP6616608B2 true JP6616608B2 (ja) | 2019-12-04 |
Family
ID=57775035
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015142265A Active JP6616608B2 (ja) | 2015-07-16 | 2015-07-16 | 半導体装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20170017489A1 (ja) |
| JP (1) | JP6616608B2 (ja) |
| CN (1) | CN106354477A (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11893393B2 (en) | 2017-07-24 | 2024-02-06 | Tesla, Inc. | Computational array microprocessor system with hardware arbiter managing memory requests |
| US11409692B2 (en) * | 2017-07-24 | 2022-08-09 | Tesla, Inc. | Vector computational unit |
| US10671349B2 (en) | 2017-07-24 | 2020-06-02 | Tesla, Inc. | Accelerated mathematical engine |
| US11157287B2 (en) | 2017-07-24 | 2021-10-26 | Tesla, Inc. | Computational array microprocessor system with variable latency memory access |
| US11157441B2 (en) | 2017-07-24 | 2021-10-26 | Tesla, Inc. | Computational array microprocessor system using non-consecutive data formatting |
| US11561791B2 (en) | 2018-02-01 | 2023-01-24 | Tesla, Inc. | Vector computational unit receiving data elements in parallel from a last row of a computational array |
| US10740098B2 (en) * | 2018-02-06 | 2020-08-11 | International Business Machines Corporation | Aligning most significant bits of different sized elements in comparison result vectors |
| JP6981329B2 (ja) * | 2018-03-23 | 2021-12-15 | 日本電信電話株式会社 | 分散深層学習システム |
| GB2601466A (en) * | 2020-02-10 | 2022-06-08 | Xmos Ltd | Rotating accumulator |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0616287B2 (ja) * | 1982-09-29 | 1994-03-02 | 株式会社日立製作所 | マスク付きベクトル演算処理装置 |
| JPS6327975A (ja) * | 1986-07-22 | 1988-02-05 | Hitachi Ltd | ベクトル演算制御方式 |
| JPH01271875A (ja) * | 1988-04-22 | 1989-10-30 | Nec Corp | ベクトル演算制御方式 |
| JPH04342067A (ja) * | 1991-05-20 | 1992-11-27 | Nec Software Ltd | ベクトル演算装置 |
| US5801975A (en) * | 1996-12-02 | 1998-09-01 | Compaq Computer Corporation And Advanced Micro Devices, Inc. | Computer modified to perform inverse discrete cosine transform operations on a one-dimensional matrix of numbers within a minimal number of instruction cycles |
| US6976049B2 (en) * | 2002-03-28 | 2005-12-13 | Intel Corporation | Method and apparatus for implementing single/dual packed multi-way addition instructions having accumulation options |
| US7293056B2 (en) * | 2002-12-18 | 2007-11-06 | Intel Corporation | Variable width, at least six-way addition/accumulation instructions |
| US7565514B2 (en) * | 2006-04-28 | 2009-07-21 | Freescale Semiconductor, Inc. | Parallel condition code generation for SIMD operations |
| US7676647B2 (en) * | 2006-08-18 | 2010-03-09 | Qualcomm Incorporated | System and method of processing data using scalar/vector instructions |
| JP4228241B2 (ja) * | 2006-12-13 | 2009-02-25 | ソニー株式会社 | 演算処理装置 |
| US9092213B2 (en) * | 2010-09-24 | 2015-07-28 | Intel Corporation | Functional unit for vector leading zeroes, vector trailing zeroes, vector operand 1s count and vector parity calculation |
-
2015
- 2015-07-16 JP JP2015142265A patent/JP6616608B2/ja active Active
-
2016
- 2016-05-13 US US15/154,753 patent/US20170017489A1/en not_active Abandoned
- 2016-07-14 CN CN201610556654.1A patent/CN106354477A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| CN106354477A (zh) | 2017-01-25 |
| JP2017027149A (ja) | 2017-02-02 |
| US20170017489A1 (en) | 2017-01-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6616608B2 (ja) | 半導体装置 | |
| US4860197A (en) | Branch cache system with instruction boundary determination independent of parcel boundary | |
| FI80532B (fi) | Centralenhet foer databehandlingssystem. | |
| CN104838357B (zh) | 向量化方法、系统及处理器 | |
| KR100956970B1 (ko) | 프로세서에서의 마스킹된 저장 동작들을 위한 시스템 및방법 | |
| US7177876B2 (en) | Speculative load of look up table entries based upon coarse index calculation in parallel with fine index calculation | |
| KR100346515B1 (ko) | 수퍼파이프라인된수퍼스칼라프로세서를위한임시파이프라인레지스터파일 | |
| KR20110055629A (ko) | 단일 명령 다중 데이터(simd)데이터 처리기에서 확장된 어드레싱 모드들의 제공 | |
| JPH11504458A (ja) | スーパースカラマイクロプロセッサにおける分岐予測正確度向上のための装置および方法 | |
| JP5834997B2 (ja) | ベクトルプロセッサ、ベクトルプロセッサの処理方法 | |
| KR101851439B1 (ko) | 충돌 검출을 수행하고, 레지스터의 콘텐츠를 다른 레지스터의 데이터 구성요소 위치들로 브로드캐스트하기 위한 시스템들, 장치들 및 방법들 | |
| JPH04245540A (ja) | 条件付き分岐を有するプログラムの効率的実行をするためのコンピュータシステム | |
| KR102379894B1 (ko) | 벡터 연산들 수행시의 어드레스 충돌 관리 장치 및 방법 | |
| US9965275B2 (en) | Element size increasing instruction | |
| KR20180066146A (ko) | 벡터 데이터 전송 명령어 | |
| US20050203928A1 (en) | Register move instruction for section select of source operand | |
| JPH063584B2 (ja) | 情報処理装置 | |
| TWI740851B (zh) | 用於向量負載指示之資料處理設備、方法及電腦程式 | |
| US20110302394A1 (en) | System and method for processing regular expressions using simd and parallel streams | |
| CN106610817A (zh) | 用于采取vliw处理器中的相同执行数据包中的常数扩展槽指定或扩展常数位数的方法 | |
| KR900010587A (ko) | 생산라인의 고성능 명령어 실행방법 및 장치 | |
| US7600102B2 (en) | Condition bits for controlling branch processing | |
| EP3340038A1 (en) | Processor instructions for determining two minimum and two maximum values | |
| US20040044885A1 (en) | Performing repeat string operations | |
| JPS6049340B2 (ja) | 分岐命令先取り方式 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160203 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180525 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180525 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20190219 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190319 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190515 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190806 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191003 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20191015 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20191108 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6616608 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |