JP6566076B2 - 音声合成方法およびプログラム - Google Patents
音声合成方法およびプログラム Download PDFInfo
- Publication number
- JP6566076B2 JP6566076B2 JP2018076522A JP2018076522A JP6566076B2 JP 6566076 B2 JP6566076 B2 JP 6566076B2 JP 2018076522 A JP2018076522 A JP 2018076522A JP 2018076522 A JP2018076522 A JP 2018076522A JP 6566076 B2 JP6566076 B2 JP 6566076B2
- Authority
- JP
- Japan
- Prior art keywords
- pitch
- answer
- question
- speech
- ending
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000001308 synthesis method Methods 0.000 title claims description 6
- 230000005236 sound signal Effects 0.000 claims description 7
- 239000011295 pitch Substances 0.000 description 260
- 230000015572 biosynthetic process Effects 0.000 description 23
- 238000003786 synthesis reaction Methods 0.000 description 23
- 238000000034 method Methods 0.000 description 17
- 238000012545 processing Methods 0.000 description 14
- 241001465754 Metazoa Species 0.000 description 13
- 238000010586 diagram Methods 0.000 description 10
- 230000008569 process Effects 0.000 description 10
- 230000004044 response Effects 0.000 description 9
- 230000008859 change Effects 0.000 description 6
- 230000002194 synthesizing effect Effects 0.000 description 5
- 238000001514 detection method Methods 0.000 description 4
- 238000012805 post-processing Methods 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000035876 healing Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 230000001755 vocal effect Effects 0.000 description 2
- 235000008314 Echinocereus dasyacanthus Nutrition 0.000 description 1
- 240000005595 Echinocereus dasyacanthus Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images











Description
本発明は、音声合成方法およびプログラムに関する。
近年、音声合成技術としては、次のようなものが提案されている。すなわち、利用者の話調や声質に対応した音声を合成出力することによって、より人間らしく発音する技術(例えば特許文献1参照)や、利用者の音声を分析して、当該利用者の心理状態や健康状態などを診断する技術(例えば特許文献2参照)が提案されている。
また、利用者が入力した音声を認識する一方で、シナリオで指定された内容を音声合成で出力して、利用者との音声対話を実現する音声対話システムも提案されている(例えば特許文献3参照)。
また、利用者が入力した音声を認識する一方で、シナリオで指定された内容を音声合成で出力して、利用者との音声対話を実現する音声対話システムも提案されている(例えば特許文献3参照)。
ところで、上述した音声合成技術と音声対話システムとを組み合わせて、利用者の音声による問いに対し、データを検索して音声合成により出力する対話システムを想定する。この場合、音声合成によって出力される音声が利用者に不自然な感じ、具体的には、いかにも機械が喋っている感じを与えるときがある、という問題が指摘されている。
本発明は、このような事情に鑑みてなされたものであり、その目的の一つは、利用者に自然な感じを与えるような、具体的には、利用者に対して好印象や悪印象などを与えることが可能な音声合成方法およびプログラムを提供することにある。
本発明は、このような事情に鑑みてなされたものであり、その目的の一つは、利用者に自然な感じを与えるような、具体的には、利用者に対して好印象や悪印象などを与えることが可能な音声合成方法およびプログラムを提供することにある。
本件発明者は、利用者による問いに対する回答を音声合成で出力(返答)するマン・マシンのシステムを検討するにあたって、まず、人同士では、どのような対話がなされるかについて、言語的情報以外の非言語情報(ノンバーバル情報)、とりわけ対話を特徴付ける音高(周波数)に着目して考察した。
ここでは、人同士の対話として、一方の人(aとする)による問い(問い掛け)に対し、他方の人(bとする)が返答する場合について検討する。この場合において、aが問いを発したとき、aだけなく、当該問いに対して回答しようとするbも、当該問いのうちの、ある区間における音高を強い印象で残していることが多い。bは、同意や、賛同、肯定などの意で回答するときには、印象に残っている問いの音高に対し、当該回答を特徴付ける部分、例えば語尾や語頭の音高が、所定の関係、具体的には協和音程の関係となるように発声する。当該回答を聞いたaは、自己の問いについて印象に残っている音高と当該問いに対する回答を特徴付ける部分の音高とが上記関係にあるので、bの回答に対して心地良く、安心するような好印象を抱くことになる、と、本件発明者は考えた。
また、言語の無い太古の昔より人同士はコミュニケーションをとってきたわけであるが、そのような環境での人同士のコミュニケーションにおいて、音量とともに音高が非常に重要な役割を担っていたものと推察している。言語の発達した現代においては、その音高コミュケーションが忘れ去られているが、太古の昔の「所定の音高関係」がDNAに刻まれて伝承されているために「なぜか心地良い」と感じるのだとも推察している。
また、言語の無い太古の昔より人同士はコミュニケーションをとってきたわけであるが、そのような環境での人同士のコミュニケーションにおいて、音量とともに音高が非常に重要な役割を担っていたものと推察している。言語の発達した現代においては、その音高コミュケーションが忘れ去られているが、太古の昔の「所定の音高関係」がDNAに刻まれて伝承されているために「なぜか心地良い」と感じるのだとも推察している。
人同士の対話について具体的な例を挙げて説明すると、例えば、aが「そうでしょ?」という問いを発したとき、aおよびbは、当該問いのうち、念押しや確認などの意が強く表れる語尾の「しょ」の音高を記憶に残した状態となる。この状態において、bが、当該問いに対して「あ、はい」と肯定的に回答しようとする場合に、印象に残っている「しょ」の音高に対して、回答を特徴付ける部分、例えば語尾の「い」の音高が上記関係になるように「あ、はい」と回答する。
図2は、このような実際の対話におけるフォルマントを示している。この図において、横軸が時間であり、縦軸が周波数であって、スペクトルは、白くなるにつれて強度が強い状態を示している。
図に示されるように、人の音声を周波数解析して得られるスペクトルは、時間的に移動する複数のピーク、すなわちフォルマントとして現れる。詳細には、「そうでしょ?」に相当するフォルマント、および、「あ、はい」に相当するフォルマントは、それぞれ3つのピーク帯(時間軸に沿って移動する白い帯状の部分)として現れている。
これらの3つのピーク帯のうち、周波数の最も低い第1フォルマントについて着目してみると、「そうでしょ?」の「しょ」に相当する符号A(の中心部分)の周波数はおおよそ400Hzである。一方、符号Bは、「あ、はい」の「い」に相当する符号Bの周波数はおおよそ260Hzである。このため、符号Aの周波数は、符号Bの周波数に対して、ほぼ3/2となっていることが判る。
図に示されるように、人の音声を周波数解析して得られるスペクトルは、時間的に移動する複数のピーク、すなわちフォルマントとして現れる。詳細には、「そうでしょ?」に相当するフォルマント、および、「あ、はい」に相当するフォルマントは、それぞれ3つのピーク帯(時間軸に沿って移動する白い帯状の部分)として現れている。
これらの3つのピーク帯のうち、周波数の最も低い第1フォルマントについて着目してみると、「そうでしょ?」の「しょ」に相当する符号A(の中心部分)の周波数はおおよそ400Hzである。一方、符号Bは、「あ、はい」の「い」に相当する符号Bの周波数はおおよそ260Hzである。このため、符号Aの周波数は、符号Bの周波数に対して、ほぼ3/2となっていることが判る。
周波数の比が3/2であるという関係は、音程でいえば、「ソ」に対して同じオクターブの「ド」や、「ミ」に対して1つ下のオクターブの「ラ」などをいい、後述するように、完全5度の関係にある。この周波数の比(音高同士における所定の関係)については、好適な一例であるが、後述するように様々な例が挙げられる。
なお、図3は、音名(階名)と人の声の周波数との関係について示す図である。この例では、第4オクターブの「ド」を基準にしたときの周波数比も併せて示しており、「ソ」は「ド」を基準にすると、上記のように3/2である。また、第3オクターブの「ラ」を基準にしたときの周波数比についても並列に例示している。
このように人同士の対話では、問いの音高と返答する回答の音高とは無関係ではなく、上記のような関係がある、と考察できる。そして、本件発明者は、多くの対話例を分析し、多くの人による評価を統計的に集計して、この考えがおおよそ正しいことを裏付けた。このような考察や裏付けを踏まえて、利用者による問いに対する回答を音声合成で出力(返答)する対話システムを検討したときに、当該音声合成について上記目的を達成するために、次のような構成とした。
すなわち、上記目的を達成するために、本発明の一態様に係る音声合成装置は、音声信号による問いを入力する音声入力部と、前記問いのうち、特定の第1区間の音高を解析する音高解析部と、前記問いに対する回答を取得する取得部と、取得された回答のうち、特定の第2区間の音高を、前記第1区間の音高に対して所定の関係にある音高となるように変更して出力する音声合成部と、を具備することを特徴とする。
この一態様によれば、入力された音声信号による問いに対して、音声合成される回答に、不自然な感じが伴わないようにすることができる。なお、回答には、問いに対する具体的な答えに限られず、「ええ」、「なるほど」、「そうですね」などの相槌(間投詞)も含まれる。また、回答には、人による声のほかにも、「ワン」(bowwow)、「ニャー」(meow)などの動物の鳴き声も含まれる。すなわち、ここでいう回答や音声とは、人が発する声のみならず、動物の鳴き声を含む概念である。
この一態様によれば、入力された音声信号による問いに対して、音声合成される回答に、不自然な感じが伴わないようにすることができる。なお、回答には、問いに対する具体的な答えに限られず、「ええ」、「なるほど」、「そうですね」などの相槌(間投詞)も含まれる。また、回答には、人による声のほかにも、「ワン」(bowwow)、「ニャー」(meow)などの動物の鳴き声も含まれる。すなわち、ここでいう回答や音声とは、人が発する声のみならず、動物の鳴き声を含む概念である。
上記態様において、前記第1区間は、前記問いの語尾であり、前記第2区間は、前記回答の語頭または語尾であることが好ましい。上述したように、問いの印象を特徴付ける区間は、当該問いの語尾であり、回答の印象を特徴付ける区間は、回答の語頭または語尾であることが多いからである。
また、前記所定の関係は、完全1度を除いた協和音程の関係であることが好ましい。ここで、協和とは、複数の楽音が同時に発生したときに、それらが互いに溶け合って良く調和する関係をいい、これらの音程関係を協和音程という。協和の程度は、2音間の周波数比(振動数比)が単純なものほど高い。周波数比が最も単純な1/1(完全1度)と、2/1(完全8度)とを、特に絶対協和音程といい、これに3/2(完全5度)と4/3(完全4度)とを加えて完全協和音程という。5/4(長3度)、6/5(短3度)、5/3(長6度)および8/5(短6度)を不完全協和音程といい、これ以外のすべての周波数比の関係(長・短の2度と7度、各種の増・減音程など)を不協和音程という。
なお、回答の語頭または語尾の音高を、問いの語尾の音高と同一となる場合には、対話として不自然な感じを伴うと考えられるので、問いの音高と回答の音高との関係において、完全1度が除かれている。
なお、回答の語頭または語尾の音高を、問いの語尾の音高と同一となる場合には、対話として不自然な感じを伴うと考えられるので、問いの音高と回答の音高との関係において、完全1度が除かれている。
上記態様において、問いの音高と回答の音高とにおける所定の関係としては、完全1度を除く協和音程だけでなく、次のような範囲内の音高関係としても良い。すなわち、前記音声合成部は、前記第2区間の音高を、前記第1区間の音高に対して、同一を除く、上下1オクターブの範囲内の音高関係となるように変更して出力する構成でも良い。問いの音高に対して、回答の音高が上下1オクターブ以上離れると、上記協和音程の関係が成立しないだけでなく、対話として不自然になる、という知見によるものである。なお、この構成においても、回答の音高と問いの音高とが同一である場合、上述したように対話として不自然になるので、上下1オクターブの範囲内の音高関係から除かれている。
上記態様において、前記音声合成部は、前記第2区間の音高を、前記第1区間の音高に対して、5度下の協和音程の関係にある音高となるように変更して出力する構成が好ましい。この構成によれば、問いを発した利用者に、当該問いに対して返答される回答について好印象を持たせることができる。
上記態様において、前記音声合成部は、前記第2区間の音高を、前記第1区間の音高に対して所定の関係にある音高となるように変更しようとする場合に、変更しようとする音高が所定の閾値音高よりも低ければ、変更しようとする音高をさらに1オクターブ上の音高にシフトする、または、変更しようとする音高が所定の閾値音高よりも高ければ、変更しようとする音高を1オクターブ下の音高にシフトする、構成としても良い。この構成によれば、回答における第2区間の音高を変更しようとする場合に、当該音高が所定の閾値音高よりも低ければ(高ければ)、1オクターブ上(下)の音高にシフトするので、例えば不自然な低音(高音)で回答が音声合成されてしまう事態を回避することができる。
上記態様において、前記音声合成部は、前記第2区間の音高を、前記第1区間の音高に対して所定の関係にある音高となるように変更しようとする場合に、所定の属性が定められていれば、所定の関係にある音高をさらに1オクターブ上または下の音高にシフトする構成としても良い。属性とは、例えば音声合成する声の属性であって、女性や子供(成人男性)の声で合成することが定められていれば、変更しようとする音高を、所定の関係にある音高よりも1オクターブ上(下)の音高にシフトすることによって、不自然な低音(高音)で合成されてしまう事態を回避することができる。
上記態様において、動作モードとして第1モードおよび第2モードがあり、前記音声合成部は、前記動作モードが前記第1モードであれば、前記第2区間の音高を、前記第1区間の音高に対して、完全1度を除いた協和音程の関係にある音高となるように変更して出力し、前記動作モードが前記第2モードであれば、前記第2区間の音高を、前記第1区間の音高に対して、不協和音程の関係にある音高となるように変更して出力する構成としても良い。この態様において、動作モードが第2モードであれば、不協和音程の関係にある回答が音声合成されるので、問いを発した利用者に違和感を与えることができる。逆にいえば、第2モードにすることによって、利用者に、注意喚起したり、意図的に嫌悪な感じを与えたりすることができる。
本発明の態様について、音声合成装置のみならず、コンピュータを当該音声合成装置として機能させるプログラムとして概念することも可能である。
なお、本発明では、問いの音高(周波数)を解析対象とし、回答の音高を制御対象としているが、ヒトの音声は、上述したフォルマントの例でも明らかなように、ある程度の周波数域を有するので、解析や制御についても、ある程度の周波数範囲を持ってしまうのは避けられない。また、解析や制御については、当然のことながら誤差が発生する。このため、本件において、音高の解析や制御については、音高(周波数)の数値が同一であることのみならず、ある程度の範囲を伴うことが許容される。
なお、本発明では、問いの音高(周波数)を解析対象とし、回答の音高を制御対象としているが、ヒトの音声は、上述したフォルマントの例でも明らかなように、ある程度の周波数域を有するので、解析や制御についても、ある程度の周波数範囲を持ってしまうのは避けられない。また、解析や制御については、当然のことながら誤差が発生する。このため、本件において、音高の解析や制御については、音高(周波数)の数値が同一であることのみならず、ある程度の範囲を伴うことが許容される。
以下、本発明の実施形態について図面を参照して説明する。
<第1実施形態>
まず、第1実施形態に係る音声合成装置について説明する。
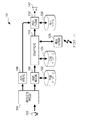
図1は、本発明の第1実施形態に係る音声合成装置10の構成を示す図である。
この図において、音声合成装置10は、CPU(Central Processing Unit)や、音声入力部102、スピーカ142を有する、例えば携帯電話機のような端末装置である。音声合成装置10においてCPUが、予めインストールされたアプリケーションプログラムを実行することによって、複数の機能ブロックが次のように構築される。
詳細には、音声合成装置10では、発話区間検出部104、音高解析部106、言語解析部108、回答作成部110、音声合成部112、言語データベース122、回答データベース124、情報取得部126および音声ライブラリ128が構築される。
なお、特に図示しないが、このほかにも音声合成装置10は、表示部や操作入力部なども有し、利用者が装置の状況を確認したり、装置に対して各種の操作を入力したりすることができるようになっている。また、音声合成装置10は、携帯電話機のような端末装置に限られず、ノート型やタブレット型のパーソナルコンピュータであっても良い。
まず、第1実施形態に係る音声合成装置について説明する。
図1は、本発明の第1実施形態に係る音声合成装置10の構成を示す図である。
この図において、音声合成装置10は、CPU(Central Processing Unit)や、音声入力部102、スピーカ142を有する、例えば携帯電話機のような端末装置である。音声合成装置10においてCPUが、予めインストールされたアプリケーションプログラムを実行することによって、複数の機能ブロックが次のように構築される。
詳細には、音声合成装置10では、発話区間検出部104、音高解析部106、言語解析部108、回答作成部110、音声合成部112、言語データベース122、回答データベース124、情報取得部126および音声ライブラリ128が構築される。
なお、特に図示しないが、このほかにも音声合成装置10は、表示部や操作入力部なども有し、利用者が装置の状況を確認したり、装置に対して各種の操作を入力したりすることができるようになっている。また、音声合成装置10は、携帯電話機のような端末装置に限られず、ノート型やタブレット型のパーソナルコンピュータであっても良い。
音声入力部102は、詳細については省略するが、音声を電気信号に変換するマイクロフォンと、変換された音声信号の高域成分をカットするLPF(ローパスフィルタ)と、高域成分をカットした音声信号をデジタル信号に変換するA/D変換器とで構成される。
発話区間検出部104は、デジタル信号に変換された音声信号を処理して発話(有音)区間を検出する。
発話区間検出部104は、デジタル信号に変換された音声信号を処理して発話(有音)区間を検出する。
音高解析部106は、発話区間として検出された音声信号を周波数解析するとともに、解析して得られた第1フォルマントのうち、特定の区間(第1区間)の音高を求めて、当該音高を示す音高データを出力する。なお、第1区間とは、例えば問いの語尾である。また、第1フォルマントとは、例えば音声を周波数解析したときに得られる複数のフォルマントのうち、周波数の最も低い成分をいい、図2の例でいえば、末端が符号Aとなっているピーク帯をいう。周波数解析については、FFT(Fast Fourier Transform)や、その他公知の方法を用いることができる。問いにおける語尾を特定するための具体的手法の一例については後述する。
言語解析部108は、発話区間として検出された音声信号がどの音素に近いのかを、言語データベース122に予め作成された音素モデルを参照することにより判定して、音声信号で規定される言葉の意味を解析(特定)する。なお、このような音素モデルには、例えば隠れマルコフモデルを用いることができる。
回答作成部110は、言語解析部108によって解析された言葉の意味に対応する回答を、回答データベース124および情報取得部126を参照して作成する。例えば「いまなんじ?(今、何時?)」という問いに対しては、音声合成装置10は、内蔵のリアルタイムクロック(図示省略)から時刻情報を取得するとともに、時刻情報以外の情報を回答データベース124から取得することで、「ただいま○○時○○分です」という回答を作成することが可能である。
一方で、音声合成装置10は、「あしたのてんきは?(明日の天気は?)」という問いに対しては、外部サーバにアクセスして天気情報を取得しないと、音声合成装置10の単体で回答を作成することができない。このように、回答データベース124のみでは回答が作成できない場合、情報取得部126が、インターネットを介し外部サーバにアクセスして、回答に必要な情報を取得する構成となっている。すなわち、回答作成部110は、問いに対する回答を、回答データベース124または外部サーバから取得する構成となっている。
なお、回答作成部110は、本実施形態では回答を、音素列であって、各音素に対応する音高や発音タイミングを規定した音声シーケンスにて出力する。音声合成部112が音高や発音タイミングが規定された音声シーケンスにしたがって音声合成すれば、当該回答の基本音声を出力することができる。ただし、本実施形態では、音声シーケンスで規定される基本音声を、音声合成部112が変更して出力する。
一方で、音声合成装置10は、「あしたのてんきは?(明日の天気は?)」という問いに対しては、外部サーバにアクセスして天気情報を取得しないと、音声合成装置10の単体で回答を作成することができない。このように、回答データベース124のみでは回答が作成できない場合、情報取得部126が、インターネットを介し外部サーバにアクセスして、回答に必要な情報を取得する構成となっている。すなわち、回答作成部110は、問いに対する回答を、回答データベース124または外部サーバから取得する構成となっている。
なお、回答作成部110は、本実施形態では回答を、音素列であって、各音素に対応する音高や発音タイミングを規定した音声シーケンスにて出力する。音声合成部112が音高や発音タイミングが規定された音声シーケンスにしたがって音声合成すれば、当該回答の基本音声を出力することができる。ただし、本実施形態では、音声シーケンスで規定される基本音声を、音声合成部112が変更して出力する。
音声合成部112は、回答作成部110で作成された音声シーケンスのうち、特定の区間(第2区間)の音高を、音高解析部106から供給される音高データに対して所定の関係にある音高に変更して音声合成し、音声信号として出力する。なお、本実施形態において第2区間を、回答の語尾とするが、後述するように語尾に限られない。また、本実施形態において、音高データに対して所定の関係にある音高を、5度の下の関係にある音高とするが、後述するように、5度下以外の関係にある音高としても良い。
また、音声合成部112は、音声を合成するにあたって、音声ライブラリ128に登録された音声素片データを用いる。音声ライブラリ128は、単一の音素や音素から音素への遷移部分など、音声の素材となる各種の音声素片の波形を定義した音声素片データを、予めデータベース化したものである。音声合成部112は、具体的には、音声シーケンスの一音一音(音素)の音声素片データを組み合わせて、繋ぎ部分が連続するように修正しつつ、上記のように回答の語尾の音高を変更して音声信号を生成する。
なお、音声合成された音声信号は、図示省略したD/A変換部によってアナログ信号に変換された後、スピーカ142によって音響変換されて出力される。
なお、音声合成された音声信号は、図示省略したD/A変換部によってアナログ信号に変換された後、スピーカ142によって音響変換されて出力される。
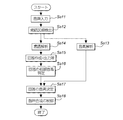
次に、音声合成装置10の動作について説明する。図4は、音声合成装置10における処理動作を示すフローチャートである。
はじめに、利用者が所定の操作をしたとき、例えば対話処理に対応したアイコンなどをメインメニュー画面(図示省略)において選択したとき、CPUが当該処理に対応したアプリケーションプログラムを起動する。このアプリケーションプログラムを実行することによって、CPUは、図1で示した機能ブロックを構築する。
はじめに、利用者が所定の操作をしたとき、例えば対話処理に対応したアイコンなどをメインメニュー画面(図示省略)において選択したとき、CPUが当該処理に対応したアプリケーションプログラムを起動する。このアプリケーションプログラムを実行することによって、CPUは、図1で示した機能ブロックを構築する。
まず、ステップSa11において利用者が音声入力部102に対して音声で問いを入力する。次に、ステップSa12において発話区間検出部104は、当該音声の大きさ、すなわち音量が閾値以下となる状態が所定期間以上連続する区間を無音区間とし、それ以外の区間を発話区間として検出して、当該発話区間の音声信号を音高解析部106および言語解析部108のそれぞれに供給する。
ステップSa13において音高解析部106は、検出された発話区間における問いの音声信号を解析し、当該問いにおける第1区間(語尾)の音高を特定して、当該音高を示す音高データを音声合成部112に供給する。ここで、音高解析部106における問いの語尾を特定する具体的手法の一例について説明する。
問いを発した人が、当該問い対する回答を欲するような対話を想定した場合、問いの語尾に相当する部分では、音量が他の部分として比較して一時的に大きくなる、と考えられる。そこで、音高解析部106による第1区間(語尾)の音高については、例えば次のようにして求めることできる。
第1に、音高解析部106は、発話区間として検出された問いの音声信号を、音量と音高(ピッチ)とに分けて波形化する。図5の(a)は、音声信号についての音量を縦軸で、経過時間を横軸で表した音量波形の一例であり、(b)は、同じ音声信号について周波数解析して得られる第1フォルマントの音高を縦軸で、経過時間を横軸で表した音高波形である。なお、(a)の音量波形と(b)の音高波形との時間軸は共通である。
第2に、音高解析部106は、(a)の音量波形のうち、時間的に最後の極大P1のタイミングを特定する。
第3に、音高解析部106は、特定した極大P1のタイミングを前後に含む所定の時間範囲(例えば100μ秒〜300μ秒)を語尾であると認定する。
第4に、音高解析部106は、(b)の音高波形のうち、認定した語尾に相当する区間Q1の平均音高を、音高データとして出力する。
このように、発話区間における音量波形について最後の極大P1を、問いの語尾に相当するタイミングとして特定することによって、会話としての問いの語尾の誤検出を少なくすることができる、と考えられる。
ここでは、(a)の音量波形のうち、時間的に最後の極大P1のタイミングを前後に含む所定の時間範囲を語尾であると認定したが、極大P1のタイミングを始期または終期とする所定の時間範囲を語尾と認定しても良い。また、認定した語尾に相当する区間Q1の平均音高ではなく、区間Q1の始期、終期や、極大P1のタイミングの音高を、音高データとして出力する構成としても良い。
第1に、音高解析部106は、発話区間として検出された問いの音声信号を、音量と音高(ピッチ)とに分けて波形化する。図5の(a)は、音声信号についての音量を縦軸で、経過時間を横軸で表した音量波形の一例であり、(b)は、同じ音声信号について周波数解析して得られる第1フォルマントの音高を縦軸で、経過時間を横軸で表した音高波形である。なお、(a)の音量波形と(b)の音高波形との時間軸は共通である。
第2に、音高解析部106は、(a)の音量波形のうち、時間的に最後の極大P1のタイミングを特定する。
第3に、音高解析部106は、特定した極大P1のタイミングを前後に含む所定の時間範囲(例えば100μ秒〜300μ秒)を語尾であると認定する。
第4に、音高解析部106は、(b)の音高波形のうち、認定した語尾に相当する区間Q1の平均音高を、音高データとして出力する。
このように、発話区間における音量波形について最後の極大P1を、問いの語尾に相当するタイミングとして特定することによって、会話としての問いの語尾の誤検出を少なくすることができる、と考えられる。
ここでは、(a)の音量波形のうち、時間的に最後の極大P1のタイミングを前後に含む所定の時間範囲を語尾であると認定したが、極大P1のタイミングを始期または終期とする所定の時間範囲を語尾と認定しても良い。また、認定した語尾に相当する区間Q1の平均音高ではなく、区間Q1の始期、終期や、極大P1のタイミングの音高を、音高データとして出力する構成としても良い。
一方、ステップSa14において言語解析部108は、音声信号における言葉の意味を解析して、その意味内容を示すデータを、回答作成部110に供給する。ステップSa15において、回答作成部110は、解析された言葉の意味に対応する回答を、回答データベース124を用いて作成したり、必要に応じて情報取得部126を介し外部サーバから取得したりして、当該回答に基づく音声シーケンスを作成し、音声合成部112に供給する。
図6の(a)は、例えば「あしたのてんきは?」という問いに対して作成された回答の音声(音声シーケンス)の一例である。この図の例では、回答である「はれです」の一音一音に音符を割り当てて、音声シーケンスによる基本音声の各語(音素)の音高や発音タイミングを示している。なお、この例では、説明簡略化のために、一音(音素)に音符を1つ割り当てているが、スラーやタイなどのように、一音に複数の音符を割り当てても良い。
次に、ステップSa16において音声合成部112は、回答作成部110から供給された音声シーケンスから、当該音声シーケンスにおける語尾の音高(初期音高)を特定する。
続いて、ステップSa17において、音声合成部112は、音声シーケンスで規定された語尾の初期音高が音高解析部106からの音高データで示される音高に対して5度下の関係となるように、当該音声シーケンスで規定された音高を変更する。
例えば図6の(b)で示されるように、「あしたのてんきは?」という問いのうち、符号Aで示される語尾の「は」の区間の音高が音高データによって「ソ」であると示される場合、音声合成部112は、「はれです」という回答のうち、符号Bで示される語尾の「す」の区間の音高が「ソ」に対して5度下の音高である「ド」になるように音声シーケンス全体の音高を変更する。
そして、ステップSa18において音声合成部112は、変更した音声シーケンスの音声を合成して出力する。なお、回答の音声を出力すると、特に図示しないが、CPUは、当該アプリケーションプログラムの実行を終了させて、メニュー画面に戻す。
続いて、ステップSa17において、音声合成部112は、音声シーケンスで規定された語尾の初期音高が音高解析部106からの音高データで示される音高に対して5度下の関係となるように、当該音声シーケンスで規定された音高を変更する。
例えば図6の(b)で示されるように、「あしたのてんきは?」という問いのうち、符号Aで示される語尾の「は」の区間の音高が音高データによって「ソ」であると示される場合、音声合成部112は、「はれです」という回答のうち、符号Bで示される語尾の「す」の区間の音高が「ソ」に対して5度下の音高である「ド」になるように音声シーケンス全体の音高を変更する。
そして、ステップSa18において音声合成部112は、変更した音声シーケンスの音声を合成して出力する。なお、回答の音声を出力すると、特に図示しないが、CPUは、当該アプリケーションプログラムの実行を終了させて、メニュー画面に戻す。
図7は、本実施形態に係る音声合成装置10が利用者に与える印象を説明するための図である。同図の(a)に示されるように、利用者Wが「あしたのてんきは?」という問いを端末装置である音声合成装置10に入力する。このときの問いの語尾に相当する「は」の音高が「ソ」であれば、実施形態では、同図の(b)で示されるように、「はれです」という音声シーケンスにおいて、語尾に相当する「す」の音高が「ド」になるように音高がシフトされて音声合成される。このため、利用者Wに不自然な感じを与えず、あたかも対話しているかのような好印象を与えることができる。
一方、同図の(c)で示されるように「はれです」という音声シーケンスの音高をシフトしないで音声合成した場合(図6(a)参照)、語尾に相当する「す」の音高が「ファ」で出力される。この場合において音高の「ファ」は、「あしたのてんきは?」という問いの語尾に相当する「は」の音高の「ソ」に対して不協和音程の関係にある。すなわち、図3を参照すれば、「ソ」の周波数(396.0Hz)は「ファ」の周波数(352.0Hz)に対して9/8の関係にある。このため、利用者Wに不自然な感じを与えるのではなく、むしろ嫌悪のような悪印象を与えてしまう。ただし、後述するように、音声合成装置10において、このような悪印象を利用者に積極的に与える構成もあり得る。
一方、同図の(c)で示されるように「はれです」という音声シーケンスの音高をシフトしないで音声合成した場合(図6(a)参照)、語尾に相当する「す」の音高が「ファ」で出力される。この場合において音高の「ファ」は、「あしたのてんきは?」という問いの語尾に相当する「は」の音高の「ソ」に対して不協和音程の関係にある。すなわち、図3を参照すれば、「ソ」の周波数(396.0Hz)は「ファ」の周波数(352.0Hz)に対して9/8の関係にある。このため、利用者Wに不自然な感じを与えるのではなく、むしろ嫌悪のような悪印象を与えてしまう。ただし、後述するように、音声合成装置10において、このような悪印象を利用者に積極的に与える構成もあり得る。
<第2実施形態>
次に、第2実施形態について説明する。
図8は、第2実施形態に係る音声合成装置10の構成を示すブロック図である。
第1実施形態では、回答作成部110が、問いに対する回答として、一音一音に音高が割り当てられた音声シーケンスを出力する構成としたが、第2実施形態では、回答音声出力部113が、問いに対する回答を取得して、当該回答の音声波形データを出力する。
なお、取得した回答には、回答音声出力部113が作成したものや、外部サーバから取得したもの、予め複数用意された回答のうち、選択されたものなどが含まれる。また、音声波形データは、例えばwav形式のようなデータであり、上述した音声シーケンスのように一音一音に音高が割り当てられない。したがって、このような音声波形データを単純に再生しただけでは、図9の(a)に示されるように、抑揚があるだけで、機械的な感じになる。
次に、第2実施形態について説明する。
図8は、第2実施形態に係る音声合成装置10の構成を示すブロック図である。
第1実施形態では、回答作成部110が、問いに対する回答として、一音一音に音高が割り当てられた音声シーケンスを出力する構成としたが、第2実施形態では、回答音声出力部113が、問いに対する回答を取得して、当該回答の音声波形データを出力する。
なお、取得した回答には、回答音声出力部113が作成したものや、外部サーバから取得したもの、予め複数用意された回答のうち、選択されたものなどが含まれる。また、音声波形データは、例えばwav形式のようなデータであり、上述した音声シーケンスのように一音一音に音高が割り当てられない。したがって、このような音声波形データを単純に再生しただけでは、図9の(a)に示されるように、抑揚があるだけで、機械的な感じになる。
さて、音声波形データを再生したときに、問いの語尾に対して回答の語尾が協和音程の関係となるように変更するのが、後処理部114である。詳細には、後処理部114は、音声波形データを単純に再生した場合における語尾の音高を解析するとともに、当該解析した音高が音高解析部106からの音高データで示される音高に対して例えば5度下の関係となるように、回答音声出力部113から出力される音声波形データを音高変換(ピッチ変換)する。すなわち、第2実施形態では、後処理部114が、取得された回答の語尾の音高を、問いの語尾の音高に対して協和音程の一例である5度下の音高となるように変更して出力する。
この変換の結果は、図9の(b)に示されるように、図6の(b)に示した音高シフトとほぼ同様である。この構成によれば、問いに対する回答が具体的であることが必要でない場合、例えば「はい」や「いいえ」のような単純な返事や「そうですね」のような相槌などのように回答する場合には、回答音声出力部113は、予め複数記憶させた音声波形データのち、当該問いに対して、いずれかの音声波形データを選択して出力する構成で済む。
<応用例・変形例>
本発明は、上述した第1実施形態や第2実施形態に限定されるものではなく、例えば次に述べるような各種の応用・変形が可能である。また、次に述べる応用・変形の態様は、任意に選択された一または複数を適宜に組み合わせることもできる。
本発明は、上述した第1実施形態や第2実施形態に限定されるものではなく、例えば次に述べるような各種の応用・変形が可能である。また、次に述べる応用・変形の態様は、任意に選択された一または複数を適宜に組み合わせることもできる。
<音声入力部>
実施形態では、音声入力部102は、利用者の音声(発言)をマイクロフォンで入力して音声信号に変換する構成としたが、この構成に限られず、他の処理部で処理された音声信号や、他の装置から供給(または転送された)音声信号を入力する構成としても良い。すなわち、音声入力部102は、音声信号による発言をなんらかの形で入力する構成であれば良い。
実施形態では、音声入力部102は、利用者の音声(発言)をマイクロフォンで入力して音声信号に変換する構成としたが、この構成に限られず、他の処理部で処理された音声信号や、他の装置から供給(または転送された)音声信号を入力する構成としても良い。すなわち、音声入力部102は、音声信号による発言をなんらかの形で入力する構成であれば良い。
<回答等の語尾、語頭>
第1実施形態や第2実施形態では、問いの語尾の音高に対応して回答の語尾の音高を制御する構成としたが、言語や、方言、言い回しなどによっては回答の語尾以外の部分、例えば語頭が特徴的となる場合もある。このような場合には、問いを発した人は、当該問いに対する回答があったときに、当該問いの語尾の音高と、当該回答の特徴的な語頭の音高とを無意識のうち比較して当該回答に対する印象を判断する。したがって、この場合には、問いの語尾の音高に対応して回答の語頭の音高を制御する構成とすれば良い。この構成によれば、回答の語頭が特徴的である場合、当該回答を受け取る利用者に対して心理的な印象を与えることが可能となる。
第1実施形態や第2実施形態では、問いの語尾の音高に対応して回答の語尾の音高を制御する構成としたが、言語や、方言、言い回しなどによっては回答の語尾以外の部分、例えば語頭が特徴的となる場合もある。このような場合には、問いを発した人は、当該問いに対する回答があったときに、当該問いの語尾の音高と、当該回答の特徴的な語頭の音高とを無意識のうち比較して当該回答に対する印象を判断する。したがって、この場合には、問いの語尾の音高に対応して回答の語頭の音高を制御する構成とすれば良い。この構成によれば、回答の語頭が特徴的である場合、当該回答を受け取る利用者に対して心理的な印象を与えることが可能となる。
問いについても同様であり、語尾に限られず、語頭で判断される場合も考えられる。また、問い、回答については、語頭、語尾に限られず、平均的な音高で判断される場合や、最も強く発音した部分の音高で判断される場合なども考えられる。このため、問いの第1区間および回答の第2区間は、必ずしも語頭や語尾に限られない、ということができる。
<音程の関係>
上述した実施形態では、問いの語尾等に対して回答の語尾等の音高が5度下となるように音声合成を制御する構成としたが、5度下以外の協和音程の関係に制御する構成であっても良い。例えば、上述したように完全8度、完全5度、完全4度、長・短3度、長・短6度であっても良い。
また、協和音程の関係でなくても、経験的に良い(または悪い)印象を与える音程の関係の存在が認められる場合もあるので、当該音程の関係に回答の音高を制御する構成としても良い。ただし、この場合においても、問いの語尾等の音高と回答の語尾等の音高との2音間の音程が離れ過ぎると、問いに対する回答が不自然になりやすいので、問いの音高と回答の音高とが上下1オクターブの範囲内にあることが望ましい。
上述した実施形態では、問いの語尾等に対して回答の語尾等の音高が5度下となるように音声合成を制御する構成としたが、5度下以外の協和音程の関係に制御する構成であっても良い。例えば、上述したように完全8度、完全5度、完全4度、長・短3度、長・短6度であっても良い。
また、協和音程の関係でなくても、経験的に良い(または悪い)印象を与える音程の関係の存在が認められる場合もあるので、当該音程の関係に回答の音高を制御する構成としても良い。ただし、この場合においても、問いの語尾等の音高と回答の語尾等の音高との2音間の音程が離れ過ぎると、問いに対する回答が不自然になりやすいので、問いの音高と回答の音高とが上下1オクターブの範囲内にあることが望ましい。
<回答の音高シフト>
ところで、音声シーケンスや音声波形データで規定される回答の語尾等の音高を、問いの語尾等の音高に対して所定の関係となるように制御する構成では、詳細には、実施形態のように例えば5度下となるように変更する構成では、5度下の音高が低すぎると、不自然な低音で回答が音声合成されてしまう場合がある。そこで次に、このような場合を回避するための応用例(その1、および、その2)について説明する。
ところで、音声シーケンスや音声波形データで規定される回答の語尾等の音高を、問いの語尾等の音高に対して所定の関係となるように制御する構成では、詳細には、実施形態のように例えば5度下となるように変更する構成では、5度下の音高が低すぎると、不自然な低音で回答が音声合成されてしまう場合がある。そこで次に、このような場合を回避するための応用例(その1、および、その2)について説明する。
図10は、このうちの応用例(その1)における処理の要部を示す図である。なお、ここでいう処理の要部とは、図4におけるステップSa17の「回答の音高決定」で実行される処理をいう。すなわち、応用例(その1)では、図4に示されるステップSa17において、図10で示される処理が実行される、という関係にあり、詳細については次の通りである。
まず、音声合成部112は、音高解析部106からの音高データで示される音高に対して、例えば5度下の関係にある音高を求めて仮決定する(ステップSb171)。
次に、音声合成部112は、仮決定した音高が予め定められた閾値音高よりも低いか否かを判別する(ステップSb172)。なお、閾値音高は、音声合成する際の下限周波数に相当する音高や、これより低ければ不自然な感じを与えるような音高などに設定される。
まず、音声合成部112は、音高解析部106からの音高データで示される音高に対して、例えば5度下の関係にある音高を求めて仮決定する(ステップSb171)。
次に、音声合成部112は、仮決定した音高が予め定められた閾値音高よりも低いか否かを判別する(ステップSb172)。なお、閾値音高は、音声合成する際の下限周波数に相当する音高や、これより低ければ不自然な感じを与えるような音高などに設定される。
仮決定した音高、すなわち問いにおける語尾の音高よりも5度下の音高が閾値音高よりも低ければ(ステップSb172の判別結果が「Yes」であれば)、音声合成部112は、仮決定した音高を1オクターブ上の音高にシフトする(ステップSb173)。
一方、求めた音高が閾値音高以上であれば(ステップSb172の判別結果が「No」であれば)、上記ステップSb173の処理がスキップされる。
そして、音声合成部112は、回答の音高をシフトする際に目標となる語尾の音高を、次のような音高に本決定する(ステップSb174)。すなわち、音声合成部112は、仮決定した音高が閾値音高よりも低ければ、仮決定した音高を1オクターブ上に変更した音高に、また、仮決定した音高が閾値音高以上であれば、当該仮決定した音高をそのまま、それぞれ目標となる音高を本決定する。
なお、処理手順は、ステップSb174の後においては、図4のステップSa18に戻る。このため、音声合成部112は、本決定の音高に変更した音声シーケンスの音声を合成して出力する。
一方、求めた音高が閾値音高以上であれば(ステップSb172の判別結果が「No」であれば)、上記ステップSb173の処理がスキップされる。
そして、音声合成部112は、回答の音高をシフトする際に目標となる語尾の音高を、次のような音高に本決定する(ステップSb174)。すなわち、音声合成部112は、仮決定した音高が閾値音高よりも低ければ、仮決定した音高を1オクターブ上に変更した音高に、また、仮決定した音高が閾値音高以上であれば、当該仮決定した音高をそのまま、それぞれ目標となる音高を本決定する。
なお、処理手順は、ステップSb174の後においては、図4のステップSa18に戻る。このため、音声合成部112は、本決定の音高に変更した音声シーケンスの音声を合成して出力する。
この応用例(その1)によれば、変更しようとする音高が閾値音高よりも低ければ、当該音高よりも1オクターブ上の音高となるようにシフトされるので、不自然な低音で回答が音声合成される、という点を回避することができる。
ここでは、回答の語尾等の音高を1オクターブ上の音高にシフトした例であったが、1オクターブ下の音高にシフトしても良い。詳細には、利用者が発した問いの語尾等の音高が高いために、当該音高に対して5度下の音高が高すぎると、不自然な高音で回答が音声合成されてしまう。これを回避するために、音高データで示される音高に対して5度下の関係にある音高(仮決定した音高)が閾値音高より高ければ、回答の語尾等の音高を、仮決定した音高よりも1オクターブ下の音高にシフトすれば良い。
ここでは、回答の語尾等の音高を1オクターブ上の音高にシフトした例であったが、1オクターブ下の音高にシフトしても良い。詳細には、利用者が発した問いの語尾等の音高が高いために、当該音高に対して5度下の音高が高すぎると、不自然な高音で回答が音声合成されてしまう。これを回避するために、音高データで示される音高に対して5度下の関係にある音高(仮決定した音高)が閾値音高より高ければ、回答の語尾等の音高を、仮決定した音高よりも1オクターブ下の音高にシフトすれば良い。
また、音声合成する際には、性別や年齢別(子供/大人の別)などが定められた仮想的なキャラクタの声で出力することができる場合がある。この場合のように女性や子供のキャラクタが指定されているとき、一律に問いの語尾に対して5度下の音高に下げてしまうと、当該キャラクタに不似合いの低音で回答が音声合成されてしまうので、同様に、1オクターブ上の音高となるようにシフトする構成としても良い。
図11は、このような応用例(その2)における処理の要部を示す図であり、図4におけるステップSa17の「回答の音高決定」で実行される処理を示している。図10と異なる点を中心に説明すると、ステップSb171において、音声合成部112は、音高解析部106からの音高データで示される音高に対して5度下の関係にある音高を求めて仮決定した後、当該キャラクタを規定する属性として女性や子供が指定されているか否かを判別する(ステップSc172)。
音声合成部112は、当該属性として女性や子供が指定されていれば(ステップSc172の判別結果が「Yes」であれば)、仮決定した音高を1オクターブ上の音高にシフトし(ステップSb173)、一方、当該属性として女性や子供が指定されていなければ、例えば男性や大人が指定されていれば(ステップSc172の判別結果が「No」であれば)、上記ステップSb173の処理がスキップされる。以降については応用例(その1)と同様である。
この応用例(その2)によれば、女性や子供の声で回答させるような設定がなされていれば、仮決定の音高よりも1オクターブ上の音高となるようにシフトされるので、不自然な低音で回答が音声合成されると、という点を回避することができる。
ここでは、属性として女性や子供が指定されていれば、1オクターブ上の音高にシフトした例であったが、例えば属性として成人男性が指定されていれば、当該属性に対応したキャラクタに不似合いの高音で回答が音声合成されてしまうのを回避するために、1オクターブ下の音高にシフトしても良い。
この応用例(その2)によれば、女性や子供の声で回答させるような設定がなされていれば、仮決定の音高よりも1オクターブ上の音高となるようにシフトされるので、不自然な低音で回答が音声合成されると、という点を回避することができる。
ここでは、属性として女性や子供が指定されていれば、1オクターブ上の音高にシフトした例であったが、例えば属性として成人男性が指定されていれば、当該属性に対応したキャラクタに不似合いの高音で回答が音声合成されてしまうのを回避するために、1オクターブ下の音高にシフトしても良い。
<不協和音程>
上述した実施形態では、問いの語尾等に対して、回答の語尾等の音高が協和音程の関係となるように音声合成を制御する構成としたが、不協和音程の関係になるように音声合成を制御しても良い。なお、回答を不協和音程の関係にある音高で合成すると、問いを発した利用者に、不自然な感じや、悪印象、険悪な感じなどを与えて、スムーズな対話が成立しなくなる、という懸念もあるが、このような感じが逆にストレス解消に良いという見解もある。
そこで、動作モードとして、好印象等の回答を望むモード(第1モード)、悪印象等の回答を望むモード(第2モード)を用意しておき、いずれかのモードに応じて音声合成を制御する構成としても良い。
上述した実施形態では、問いの語尾等に対して、回答の語尾等の音高が協和音程の関係となるように音声合成を制御する構成としたが、不協和音程の関係になるように音声合成を制御しても良い。なお、回答を不協和音程の関係にある音高で合成すると、問いを発した利用者に、不自然な感じや、悪印象、険悪な感じなどを与えて、スムーズな対話が成立しなくなる、という懸念もあるが、このような感じが逆にストレス解消に良いという見解もある。
そこで、動作モードとして、好印象等の回答を望むモード(第1モード)、悪印象等の回答を望むモード(第2モード)を用意しておき、いずれかのモードに応じて音声合成を制御する構成としても良い。
図12は、このような応用例(その3)における処理の要部を示す図であり、図4におけるステップSa17の「回答の音高決定」で実行される処理を示している。図10と異なる点を中心に説明すると、音声合成部112は、動作モードとして第1モードが設定されているか否かを判別する(ステップSd172)。
音声合成部112は、動作モードとして第1モードが設定されていれば(ステップSd172の判別結果が「Yes」であれば)、回答の例えば語尾の音高を、問いの例えば語尾の音高に対して協和音程の関係にある音高となるように決定する(ステップSd173A)。一方、音声合成部112は、動作モードとして第2モードが設定されていれば(ステップSd172の判別結果が「No」であれば)、回答の語尾の音高を、問いの語尾の音高に対して不協和音程の関係にある音高となるように決定する(ステップSd173B)。以降については応用例(その1)、応用例(その2)と同様である。
したがって、この応用例(その3)によれば、第1モードが設定されていれば、問いの音高に対して協和音程の関係にある音高で回答が音声合成される一方、第2モードが設定されていれば、問いの音高に対して不協和音程の関係にある音高で回答が音声合成されるので、利用者は、適宜動作モードを使い分けることができることになる。
したがって、この応用例(その3)によれば、第1モードが設定されていれば、問いの音高に対して協和音程の関係にある音高で回答が音声合成される一方、第2モードが設定されていれば、問いの音高に対して不協和音程の関係にある音高で回答が音声合成されるので、利用者は、適宜動作モードを使い分けることができることになる。
なお、応用例(その1)や、応用例(その2)、応用例(その3)は、第1実施形態のような音声シーケンスを用いる例で説明したが、第2実施形態のような音声波形データを用いる場合であっても良いのはもちろんである。
<音声・回答>
実施形態については、回答を、人の声で音声合成する構成としたが、人による声のほかにも、動物の鳴き声で音声合成しても良い。すなわち、ここでいう音声は、人の声に限られず、動物の鳴き声を含む概念である。そこで次に、回答を動物の鳴き声で音声合成する応用例(その4)について説明する。
実施形態については、回答を、人の声で音声合成する構成としたが、人による声のほかにも、動物の鳴き声で音声合成しても良い。すなわち、ここでいう音声は、人の声に限られず、動物の鳴き声を含む概念である。そこで次に、回答を動物の鳴き声で音声合成する応用例(その4)について説明する。
図13は、この応用例(その4)の動作概要を示す図である。回答を動物の鳴き声で音声合成する場合、問いの語尾の音高に対して、鳴き声の語尾が所定の音高とさせるだけの処理となる。このため、問いの意味を解析して、当該解析した意味に対応する情報を取得する、当該情報に基づいた回答を作成する、という処理等は不要となる。
同図の(a)に示されるように、利用者Wが「いいてんきだね」という問いを発して音声合成装置10に入力した場合、音声合成装置10は、問いの語尾に相当する「ね」の音高を解析し、当該音高が例えば「ソ」であれば、「ワン」という犬の鳴き声の音声波形データを後処理して、「ワン」の語尾に相当する「ン」の音高を、問いの語尾の音高に対して協和音程の一例である5度下の音高である「ド」となるように変更して出力する。
回答が動物の鳴き声で音声合成する場合、回答で利用者が望む情報を得ることはできない。つまり、利用者が問いとして「あすのてんきは?」と質問しても、当該利用者は明日の天気情報を得ることはできない。しかしながら、利用者がなんらかの問いを発したときに、当該問いの語尾の音高に対して、鳴き声の語尾が例えば5度下の関係となるように音声合成されると、当該鳴き声は心地良く、安心するような好印象を抱かせる点においては、回答を人の声で音声合成する場合と同じである。したがって、動物の鳴き声を音声合成する場合でも、利用者に対して、当該鳴き声を発する仮想的な動物とあたかも意志が通じているかのような、一種の癒しの効果を与えることが期待できるのである。
なお、音声合成装置10に表示部を設けて、同図の(b)に示されるように、仮想的な動物を表示させるとともに、当該動物について、音声合成に同期させて尻尾を振る、首を傾けるなどの動画で表示させる構成としても良い。このような構成によって、上記癒し効果をより高めることができる。
また、鳴き声を合成する動物を例えば犬とする場合、犬種(チワワ、ポメラニアン、ゴールデン・レトリバーなど)を選択することができる構成としても良い。
回答を動物の鳴き声で音声合成する音声合成装置10については、端末装置に限られず、当該動物を模したペットロボットや、縫いぐるみなどに適用しても良い。
また、鳴き声を合成する動物を例えば犬とする場合、犬種(チワワ、ポメラニアン、ゴールデン・レトリバーなど)を選択することができる構成としても良い。
回答を動物の鳴き声で音声合成する音声合成装置10については、端末装置に限られず、当該動物を模したペットロボットや、縫いぐるみなどに適用しても良い。
<その他>
実施形態にあっては、問いに対する回答を取得する構成である言語解析部108、言語データベース122および回答データベース124を音声合成装置10の側に設けたが、端末装置などでは、処理の負荷が重くなる点や、記憶容量に制限がある点などを考慮して、外部サーバの側に設ける構成としても良い。すなわち、音声合成装置10において回答作成部110(回答音声出力部113)は、問いに対する回答をなんらかの形で取得するとともに、当該回答の音声シーケンス(音声波形データ)を出力する構成であれば足り、その回答を、音声合成装置10の側で作成するのか、音声合成装置10以外の他の構成(例えば外部サーバ)の側で作成するのか、については問われない。
なお、音声合成装置10において、問いに対する回答について、外部サーバ等にアクセスしないで作成可能な用途であれば、情報取得部126は不要である。
実施形態にあっては、問いに対する回答を取得する構成である言語解析部108、言語データベース122および回答データベース124を音声合成装置10の側に設けたが、端末装置などでは、処理の負荷が重くなる点や、記憶容量に制限がある点などを考慮して、外部サーバの側に設ける構成としても良い。すなわち、音声合成装置10において回答作成部110(回答音声出力部113)は、問いに対する回答をなんらかの形で取得するとともに、当該回答の音声シーケンス(音声波形データ)を出力する構成であれば足り、その回答を、音声合成装置10の側で作成するのか、音声合成装置10以外の他の構成(例えば外部サーバ)の側で作成するのか、については問われない。
なお、音声合成装置10において、問いに対する回答について、外部サーバ等にアクセスしないで作成可能な用途であれば、情報取得部126は不要である。
102…音声入力部、104…発話区間検出部、106…音高解析部、108…言語解析部、110…回答作成部、112…音声合成部、126…情報取得部。
Claims (4)
- コンピュータが、
音声信号による問いを取得し、
前記問いに対する回答を取得し、
取得した回答のうち、特定の第2区間の音高を、前記問いのうち、特定の第1区間の音高に対して所定の関係にある音高となるように制御する
音声合成方法であって、
前記第1区間は、前記問いの語尾であり、
前記第2区間は、前記回答の語頭または語尾であり、
前記所定の関係は、不協和音程の関係である、
ことを特徴とする音声合成方法。 - 前記第2区間の音高を、前記第1区間の音高に対して、協和音程を除く音程の関係にある音高に制御する
請求項1に記載の音声合成方法。 - 動作モードとして第1モードおよび第2モードがあり、
前記動作モードが前記第1モードであれば、前記第2区間の音高を、前記第1区間の音高に対して、協和音程の関係にある音高となるように制御し、
前記動作モードが前記第2モードであれば、前記第2区間の音高を、前記第1区間の音高に対して、不協和音程の関係にある音高となるように制御する、
請求項1に記載の音声合成方法。 - コンピュータを、
音声信号による問いを取得する手段、
前記問いに対する回答を取得する手段、および、
取得した回答のうち、特定の第2区間の音高を、前記問いのうち、特定の第1区間の音高に対して所定の関係にある音高となるように制御する手段
として機能させ、
前記第1区間は、前記問いの語尾であり、
前記第2区間は、前記回答の語頭または語尾であり、
前記所定の関係は、不協和音程の関係である、
ことを特徴とするプログラム。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013115111 | 2013-05-31 | ||
| JP2013115111 | 2013-05-31 | ||
| JP2013198217 | 2013-09-25 | ||
| JP2013198217 | 2013-09-25 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016088798A Division JP6323491B2 (ja) | 2013-05-31 | 2016-04-27 | 音声合成装置および音声合成方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2018128690A JP2018128690A (ja) | 2018-08-16 |
| JP6566076B2 true JP6566076B2 (ja) | 2019-08-28 |
Family
ID=53050546
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014048636A Expired - Fee Related JP5954348B2 (ja) | 2013-05-31 | 2014-03-12 | 音声合成装置および音声合成方法 |
| JP2016088798A Expired - Fee Related JP6323491B2 (ja) | 2013-05-31 | 2016-04-27 | 音声合成装置および音声合成方法 |
| JP2018076522A Expired - Fee Related JP6566076B2 (ja) | 2013-05-31 | 2018-04-12 | 音声合成方法およびプログラム |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014048636A Expired - Fee Related JP5954348B2 (ja) | 2013-05-31 | 2014-03-12 | 音声合成装置および音声合成方法 |
| JP2016088798A Expired - Fee Related JP6323491B2 (ja) | 2013-05-31 | 2016-04-27 | 音声合成装置および音声合成方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (3) | JP5954348B2 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017021125A (ja) * | 2015-07-09 | 2017-01-26 | ヤマハ株式会社 | 音声対話装置 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS57122497A (en) * | 1980-12-30 | 1982-07-30 | Tokuko Ikegami | Voice input/output apparatus |
| JPS62115199A (ja) * | 1985-11-14 | 1987-05-26 | 日本電気株式会社 | 音声応答装置 |
| JP3350293B2 (ja) * | 1994-08-09 | 2002-11-25 | 株式会社東芝 | 対話処理装置及び対話処理方法 |
| JP3437064B2 (ja) * | 1997-08-25 | 2003-08-18 | シャープ株式会社 | 音声合成装置 |
| JPH11175082A (ja) * | 1997-12-10 | 1999-07-02 | Toshiba Corp | 音声対話装置及び音声対話用音声合成方法 |
| JP2001005487A (ja) * | 1999-06-18 | 2001-01-12 | Mitsubishi Electric Corp | 音声認識装置 |
| JP3578961B2 (ja) * | 2000-02-29 | 2004-10-20 | 日本電信電話株式会社 | 音声合成方法及び装置 |
| JP2003271194A (ja) * | 2002-03-14 | 2003-09-25 | Canon Inc | 音声対話装置及びその制御方法 |
| US8768701B2 (en) * | 2003-01-24 | 2014-07-01 | Nuance Communications, Inc. | Prosodic mimic method and apparatus |
| US7280968B2 (en) * | 2003-03-25 | 2007-10-09 | International Business Machines Corporation | Synthetically generated speech responses including prosodic characteristics of speech inputs |
| JP2005208162A (ja) * | 2004-01-20 | 2005-08-04 | Canon Inc | 音情報生成装置及びその音情報生成方法、音声合成装置及びその音声合成方法、並びに制御プログラム |
| JP5750839B2 (ja) * | 2010-06-14 | 2015-07-22 | 日産自動車株式会社 | 音声情報提示装置および音声情報提示方法 |
| US20120234158A1 (en) * | 2011-03-15 | 2012-09-20 | Agency For Science, Technology And Research | Auto-synchronous vocal harmonizer |
| WO2013187610A1 (en) * | 2012-06-15 | 2013-12-19 | Samsung Electronics Co., Ltd. | Terminal apparatus and control method thereof |
-
2014
- 2014-03-12 JP JP2014048636A patent/JP5954348B2/ja not_active Expired - Fee Related
-
2016
- 2016-04-27 JP JP2016088798A patent/JP6323491B2/ja not_active Expired - Fee Related
-
2018
- 2018-04-12 JP JP2018076522A patent/JP6566076B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2018128690A (ja) | 2018-08-16 |
| JP2016136284A (ja) | 2016-07-28 |
| JP6323491B2 (ja) | 2018-05-16 |
| JP2015087740A (ja) | 2015-05-07 |
| JP5954348B2 (ja) | 2016-07-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10490181B2 (en) | Technology for responding to remarks using speech synthesis | |
| US10789937B2 (en) | Speech synthesis device and method | |
| JP6648805B2 (ja) | 音声制御方法、音声制御装置およびプログラム | |
| WO2016088557A1 (ja) | 会話評価装置および方法 | |
| JP6343895B2 (ja) | 音声制御装置、音声制御方法およびプログラム | |
| JP6566076B2 (ja) | 音声合成方法およびプログラム | |
| JP6375605B2 (ja) | 音声制御装置、音声制御方法およびプログラム | |
| JP6375604B2 (ja) | 音声制御装置、音声制御方法およびプログラム | |
| JP6424419B2 (ja) | 音声制御装置、音声制御方法およびプログラム | |
| JP6648786B2 (ja) | 音声制御装置、音声制御方法およびプログラム | |
| JP6343896B2 (ja) | 音声制御装置、音声制御方法およびプログラム | |
| JP6232892B2 (ja) | 音声合成装置およびプログラム | |
| JP6536713B2 (ja) | 音声制御装置、音声制御方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180412 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20190702 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20190715 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 6566076 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| LAPS | Cancellation because of no payment of annual fees |