JP6556748B2 - コンピュータにおいて複数のスレッドをディスパッチするための方法、システム、およびコンピュータ・プログラム - Google Patents
コンピュータにおいて複数のスレッドをディスパッチするための方法、システム、およびコンピュータ・プログラム Download PDFInfo
- Publication number
- JP6556748B2 JP6556748B2 JP2016558045A JP2016558045A JP6556748B2 JP 6556748 B2 JP6556748 B2 JP 6556748B2 JP 2016558045 A JP2016558045 A JP 2016558045A JP 2016558045 A JP2016558045 A JP 2016558045A JP 6556748 B2 JP6556748 B2 JP 6556748B2
- Authority
- JP
- Japan
- Prior art keywords
- guest
- thread
- core
- threads
- state
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 37
- 238000004590 computer program Methods 0.000 title claims description 14
- 230000009471 action Effects 0.000 claims description 12
- 230000000977 initiatory effect Effects 0.000 claims description 2
- 238000005192 partition Methods 0.000 description 36
- 238000010586 diagram Methods 0.000 description 20
- 230000006870 function Effects 0.000 description 20
- 238000012545 processing Methods 0.000 description 17
- 230000008901 benefit Effects 0.000 description 8
- 230000008569 process Effects 0.000 description 6
- 230000005540 biological transmission Effects 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 230000014616 translation Effects 0.000 description 4
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 230000001902 propagating effect Effects 0.000 description 2
- MZZYGYNZAOVRTG-UHFFFAOYSA-N 2-hydroxy-n-(1h-1,2,4-triazol-5-yl)benzamide Chemical compound OC1=CC=CC=C1C(=O)NC1=NC=NN1 MZZYGYNZAOVRTG-UHFFFAOYSA-N 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 101000658622 Homo sapiens Testis-specific Y-encoded-like protein 2 Proteins 0.000 description 1
- 102000004137 Lysophosphatidic Acid Receptors Human genes 0.000 description 1
- 108090000642 Lysophosphatidic Acid Receptors Proteins 0.000 description 1
- 102100034917 Testis-specific Y-encoded-like protein 2 Human genes 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000008602 contraction Effects 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 238000010926 purge Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30076—Arrangements for executing specific machine instructions to perform miscellaneous control operations, e.g. NOP
- G06F9/3009—Thread control instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/3017—Runtime instruction translation, e.g. macros
- G06F9/30174—Runtime instruction translation, e.g. macros for non-native instruction set, e.g. Javabyte, legacy code
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
- G06F9/3851—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution from multiple instruction streams, e.g. multistreaming
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45545—Guest-host, i.e. hypervisor is an application program itself, e.g. VirtualBox
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5077—Logical partitioning of resources; Management or configuration of virtualized resources
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/45575—Starting, stopping, suspending or resuming virtual machine instances
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/5018—Thread allocation
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Executing Machine-Instructions (AREA)
- Advance Control (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Stored Programmes (AREA)
- Debugging And Monitoring (AREA)
Description
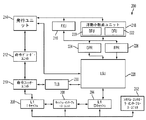
または複数のCPUを含むことができる単一のゲスト構成を指すために互換的に使用される。本明細書で使用される「論理コア」という用語は、MTが指定されるstart−VE命令の一部として一緒にディスパッチされるように定義された論理ゲスト・スレッドまたはCPUのグループを指す。ゲストVMは、単一の論理コア(STもしくはMTのいずれか)または複数の論理コア(同様にその各々がSTもしくはMTであり得る)から作成され得る。
Claims (11)
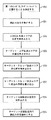
- シングルスレッド(ST)モードおよびマルチスレッディング(MT)モードで動作することが可能なコアを備える構成内で複数のスレッドをディスパッチするためのコンピュータ実装方法であって、前記コアが、複数の物理スレッドを含み、前記方法が、
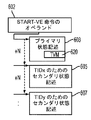
前記コア上で前記STモードで実行するホスト・プログラムによって、前記コア上で、ゲスト仮想マシン(VM)のすべてまたは一部を含むゲスト・エンティティをディスパッチするための仮想実行開始(start−VE)命令を発行することを備え、前記start−VE命令が、前記コアによって実行され、前記実行が、
前記start−VE命令によって指定された位置から、ゲスト状態を有する第1の状態記述を得ることと、
前記ゲスト状態に基づいて、前記ゲスト・エンティティが単一のゲスト・スレッドまたは複数のゲスト・スレッドのいずれを含むのかを決定することと、
前記ゲスト状態と、前記ゲスト・エンティティが複数のゲスト・スレッドを含むと決定することとに基づいて、前記MTモードで前記コア上で、互いに独立して実行される前記ゲスト・スレッドを開始することと、及び
前記ゲスト状態と、前記ゲスト・エンティティが単一のゲスト・スレッドを含むと決定することとに基づいて、前記STモードで前記コア上で前記ゲスト・スレッドを開始することと
を含む、方法。 - 前記コアが、前記コアが前記MTモードにある場合に、前記複数の物理スレッド間で共有されるリソースの使用を制御するためのコンピュータ命令を含む、請求項1に記載の方法。
- 前記ホスト・プログラムが、前記コアが前記MTモードにある場合に、単一の論理コアとして前記ゲスト・エンティティを管理するためのものである、請求項1に記載の方法。
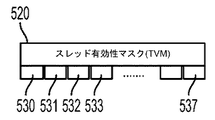
- スレッド有効性マスクが、前記ゲスト・エンティティ内の前記1以上のゲスト・スレッドの有効性を示すために前記ホスト・プログラムによって利用される、請求項1に記載の方法。
- 前記ホスト・プログラムに制御を返す前に、前記ゲスト・エンティティ内の前記1以上のゲスト・スレッドのすべてをエグジットすることをさらに含む、請求項1に記載の方法。
- 複数のゲスト・スレッドを含む前記ゲスト・エンティティに基づいて、1つのスレッドのための状態データが第1の状態記述に含まれ、1以上の追加のスレッドの各々のための状態データが追加の状態記述に含まれる、請求項1に記載の方法。
- 複数のゲスト・スレッドを含む前記ゲスト・エンティティに基づいて、すべての前記ゲスト・スレッドに共通の状態データの少なくとも一部が単一の場所に記憶される、請求項1に記載の方法。
- 前記第1の状態記述および前記追加の状態記述が、リングおよびリスト構造のうちの少なくとも1つに記憶される、請求項6に記載の方法。
- 非アクション・エグジットを実行することをさらに備え、前記非アクション・エグジットが、別のゲスト・スレッドからの要求に基づいてゲスト・スレッドをエグジットすることを含む、請求項1に記載の方法。
- 請求項1ないし9のいずれかに記載の方法のすべてのステップを実行するように適合された手段を備えるシステム。
- コンピュータ・プログラムがコンピュータ・システム上で実行されたとき、請求項1ないし9のいずれかに記載の方法のすべてのステップを実行するための命令を備えるコンピュータ・プログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/227,003 | 2014-03-27 | ||
| US14/227,003 US9223574B2 (en) | 2014-03-27 | 2014-03-27 | Start virtual execution instruction for dispatching multiple threads in a computer |
| PCT/EP2015/054731 WO2015144421A1 (en) | 2014-03-27 | 2015-03-06 | Start virtual execution instruction for dispatching multiple threads in a computer |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017515203A JP2017515203A (ja) | 2017-06-08 |
| JP6556748B2 true JP6556748B2 (ja) | 2019-08-07 |
Family
ID=52633273
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016558045A Active JP6556748B2 (ja) | 2014-03-27 | 2015-03-06 | コンピュータにおいて複数のスレッドをディスパッチするための方法、システム、およびコンピュータ・プログラム |
Country Status (14)
| Country | Link |
|---|---|
| US (1) | US9223574B2 (ja) |
| EP (1) | EP3123325A1 (ja) |
| JP (1) | JP6556748B2 (ja) |
| KR (1) | KR101807450B1 (ja) |
| CN (1) | CN106104465B (ja) |
| AU (1) | AU2015238706B2 (ja) |
| BR (1) | BR112016022436B1 (ja) |
| CA (1) | CA2940891C (ja) |
| IL (1) | IL247858B (ja) |
| MX (1) | MX2016012532A (ja) |
| RU (1) | RU2667791C2 (ja) |
| SG (1) | SG11201606092XA (ja) |
| TW (1) | TWI614680B (ja) |
| WO (1) | WO2015144421A1 (ja) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8789034B1 (en) * | 2011-12-31 | 2014-07-22 | Parallels IP Holdings GmbH | Method for updating operating system without memory reset |
| US9191435B2 (en) | 2012-08-23 | 2015-11-17 | TidalScale, Inc. | Selective data migration or remapping of virtual processors to provide required data accessibility to processor cores |
| US9213569B2 (en) * | 2014-03-27 | 2015-12-15 | International Business Machines Corporation | Exiting multiple threads in a computer |
| US9898348B2 (en) * | 2014-10-22 | 2018-02-20 | International Business Machines Corporation | Resource mapping in multi-threaded central processor units |
| CN105871917A (zh) * | 2016-06-08 | 2016-08-17 | 北京金山安全管理系统技术有限公司 | 传输控制协议tcp连接调度的方法及装置 |
| US10353736B2 (en) * | 2016-08-29 | 2019-07-16 | TidalScale, Inc. | Associating working sets and threads |
| US11023135B2 (en) | 2017-06-27 | 2021-06-01 | TidalScale, Inc. | Handling frequently accessed pages |
| US10817347B2 (en) | 2017-08-31 | 2020-10-27 | TidalScale, Inc. | Entanglement of pages and guest threads |
| CN109032792A (zh) * | 2018-07-10 | 2018-12-18 | 矩阵元技术(深圳)有限公司 | 外包计算方法及系统 |
| CN110032407B (zh) * | 2019-03-08 | 2020-12-22 | 创新先进技术有限公司 | 提升cpu并行性能的方法及装置和电子设备 |
| US11029991B2 (en) | 2019-03-08 | 2021-06-08 | International Business Machines Corporation | Dispatch of a secure virtual machine |
| CN111552574A (zh) * | 2019-09-25 | 2020-08-18 | 华为技术有限公司 | 一种多线程同步方法及电子设备 |
| US11676013B2 (en) * | 2019-12-30 | 2023-06-13 | International Business Machines Corporation | Job-launch time reduction by node pre-configuration |
| US12020059B2 (en) | 2021-08-30 | 2024-06-25 | International Business Machines Corporation | Inaccessible prefix pages during virtual machine execution |
Family Cites Families (69)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4456954A (en) * | 1981-06-15 | 1984-06-26 | International Business Machines Corporation | Virtual machine system with guest architecture emulation using hardware TLB's for plural level address translations |
| WO1985000453A1 (en) | 1983-07-11 | 1985-01-31 | Prime Computer, Inc. | Data processing system |
| US4779188A (en) | 1983-12-14 | 1988-10-18 | International Business Machines Corporation | Selective guest system purge control |
| CA1213986A (en) | 1983-12-14 | 1986-11-12 | Thomas O. Curlee, Iii | Selective guest system purge control |
| US4792895A (en) | 1984-07-30 | 1988-12-20 | International Business Machines Corp. | Instruction processing in higher level virtual machines by a real machine |
| JPH0658650B2 (ja) | 1986-03-14 | 1994-08-03 | 株式会社日立製作所 | 仮想計算機システム |
| US5317754A (en) | 1990-10-23 | 1994-05-31 | International Business Machines Corporation | Method and apparatus for enabling an interpretive execution subset |
| US5437033A (en) * | 1990-11-16 | 1995-07-25 | Hitachi, Ltd. | System for recovery from a virtual machine monitor failure with a continuous guest dispatched to a nonguest mode |
| AU3424293A (en) | 1992-01-02 | 1993-07-28 | Amdahl Corporation | Computer system with two levels of guests |
| US5485626A (en) | 1992-11-03 | 1996-01-16 | International Business Machines Corporation | Architectural enhancements for parallel computer systems utilizing encapsulation of queuing allowing small grain processing |
| US6453392B1 (en) | 1998-11-10 | 2002-09-17 | International Business Machines Corporation | Method of and apparatus for sharing dedicated devices between virtual machine guests |
| US6349365B1 (en) | 1999-10-08 | 2002-02-19 | Advanced Micro Devices, Inc. | User-prioritized cache replacement |
| US6854114B1 (en) | 1999-10-21 | 2005-02-08 | Oracle International Corp. | Using a virtual machine instance as the basic unit of user execution in a server environment |
| US6357016B1 (en) * | 1999-12-09 | 2002-03-12 | Intel Corporation | Method and apparatus for disabling a clock signal within a multithreaded processor |
| JP2004506262A (ja) | 2000-08-04 | 2004-02-26 | イントリンジック グラフィックス, インコーポレイテッド | グラフィックハードウェアおよびソフトウェアの開発 |
| EP1182567B1 (en) | 2000-08-21 | 2012-03-07 | Texas Instruments France | Software controlled cache configuration |
| US6971084B2 (en) | 2001-03-02 | 2005-11-29 | National Instruments Corporation | System and method for synchronizing execution of a batch of threads |
| US20040128448A1 (en) | 2002-12-31 | 2004-07-01 | Intel Corporation | Apparatus for memory communication during runahead execution |
| US7155600B2 (en) | 2003-04-24 | 2006-12-26 | International Business Machines Corporation | Method and logical apparatus for switching between single-threaded and multi-threaded execution states in a simultaneous multi-threaded (SMT) processor |
| US7530067B2 (en) | 2003-05-12 | 2009-05-05 | International Business Machines Corporation | Filtering processor requests based on identifiers |
| US7130949B2 (en) * | 2003-05-12 | 2006-10-31 | International Business Machines Corporation | Managing input/output interruptions in non-dedicated interruption hardware environments |
| US7610473B2 (en) | 2003-08-28 | 2009-10-27 | Mips Technologies, Inc. | Apparatus, method, and instruction for initiation of concurrent instruction streams in a multithreading microprocessor |
| US7849297B2 (en) | 2003-08-28 | 2010-12-07 | Mips Technologies, Inc. | Software emulation of directed exceptions in a multithreading processor |
| US7493621B2 (en) | 2003-12-18 | 2009-02-17 | International Business Machines Corporation | Context switch data prefetching in multithreaded computer |
| US7526515B2 (en) * | 2004-01-21 | 2009-04-28 | International Business Machines Corporation | Method and system for a grid-enabled virtual machine with movable objects |
| US7526421B2 (en) | 2004-02-27 | 2009-04-28 | International Business Machines Corporation | System and method for modeling LPAR behaviors in a simulation tool |
| US9189230B2 (en) * | 2004-03-31 | 2015-11-17 | Intel Corporation | Method and system to provide concurrent user-level, non-privileged shared resource thread creation and execution |
| US8271976B2 (en) | 2004-06-30 | 2012-09-18 | Microsoft Corporation | Systems and methods for initializing multiple virtual processors within a single virtual machine |
| US7873776B2 (en) | 2004-06-30 | 2011-01-18 | Oracle America, Inc. | Multiple-core processor with support for multiple virtual processors |
| US8356143B1 (en) | 2004-10-22 | 2013-01-15 | NVIDIA Corporatin | Prefetch mechanism for bus master memory access |
| US20060242389A1 (en) | 2005-04-21 | 2006-10-26 | International Business Machines Corporation | Job level control of simultaneous multi-threading functionality in a processor |
| US9785485B2 (en) * | 2005-07-27 | 2017-10-10 | Intel Corporation | Virtualization event processing in a layered virtualization architecture |
| US7814486B2 (en) * | 2006-06-20 | 2010-10-12 | Google Inc. | Multi-thread runtime system |
| US8607228B2 (en) * | 2006-08-08 | 2013-12-10 | Intel Corporation | Virtualizing performance counters |
| US7698540B2 (en) | 2006-10-31 | 2010-04-13 | Hewlett-Packard Development Company, L.P. | Dynamic hardware multithreading and partitioned hardware multithreading |
| US8621459B2 (en) * | 2006-12-22 | 2013-12-31 | Intel Corporation | Method and apparatus for multithreaded guest operating system execution through a multithreaded host virtual machine monitor |
| US8286170B2 (en) | 2007-01-31 | 2012-10-09 | International Business Machines Corporation | System and method for processor thread allocation using delay-costs |
| US7685409B2 (en) * | 2007-02-21 | 2010-03-23 | Qualcomm Incorporated | On-demand multi-thread multimedia processor |
| JP5595633B2 (ja) | 2007-02-26 | 2014-09-24 | スパンション エルエルシー | シミュレーション方法及びシミュレーション装置 |
| EP2159687B1 (en) * | 2007-06-20 | 2012-12-05 | Fujitsu Limited | Arithmetic unit |
| US9164784B2 (en) | 2007-10-12 | 2015-10-20 | International Business Machines Corporation | Signalizing an external event using a dedicated virtual central processing unit |
| US7739434B2 (en) | 2008-01-11 | 2010-06-15 | International Business Machines Corporation | Performing a configuration virtual topology change and instruction therefore |
| WO2009101563A1 (en) | 2008-02-11 | 2009-08-20 | Nxp B.V. | Multiprocessing implementing a plurality of virtual processors |
| US8086811B2 (en) | 2008-02-25 | 2011-12-27 | International Business Machines Corporation | Optimizations of a perform frame management function issued by pageable guests |
| US8676976B2 (en) * | 2009-02-25 | 2014-03-18 | International Business Machines Corporation | Microprocessor with software control over allocation of shared resources among multiple virtual servers |
| US9250973B2 (en) | 2009-03-12 | 2016-02-02 | Polycore Software, Inc. | Apparatus and associated methodology of generating a multi-core communications topology |
| US9535767B2 (en) * | 2009-03-26 | 2017-01-03 | Microsoft Technology Licensing, Llc | Instantiating a virtual machine with a virtual non-uniform memory architecture |
| FR2950714B1 (fr) | 2009-09-25 | 2011-11-18 | Bull Sas | Systeme et procede de gestion de l'execution entrelacee de fils d'instructions |
| US8650554B2 (en) | 2010-04-27 | 2014-02-11 | International Business Machines Corporation | Single thread performance in an in-order multi-threaded processor |
| US8595469B2 (en) * | 2010-06-24 | 2013-11-26 | International Business Machines Corporation | Diagnose instruction for serializing processing |
| US8589922B2 (en) | 2010-10-08 | 2013-11-19 | International Business Machines Corporation | Performance monitor design for counting events generated by thread groups |
| CN102193779A (zh) | 2011-05-16 | 2011-09-21 | 武汉科技大学 | 一种面向MPSoC的多线程调度方法 |
| US8856452B2 (en) | 2011-05-31 | 2014-10-07 | Illinois Institute Of Technology | Timing-aware data prefetching for microprocessors |
| US8990830B2 (en) | 2011-07-19 | 2015-03-24 | International Business Machines Corporation | Thread management in parallel processes |
| US8752036B2 (en) | 2011-10-31 | 2014-06-10 | Oracle International Corporation | Throughput-aware software pipelining for highly multi-threaded systems |
| US8850450B2 (en) | 2012-01-18 | 2014-09-30 | International Business Machines Corporation | Warning track interruption facility |
| US9110878B2 (en) | 2012-01-18 | 2015-08-18 | International Business Machines Corporation | Use of a warning track interruption facility by a program |
| US8930950B2 (en) | 2012-01-19 | 2015-01-06 | International Business Machines Corporation | Management of migrating threads within a computing environment to transform multiple threading mode processors to single thread mode processors |
| US9032191B2 (en) | 2012-01-23 | 2015-05-12 | International Business Machines Corporation | Virtualization support for branch prediction logic enable / disable at hypervisor and guest operating system levels |
| CN102866957B (zh) | 2012-07-31 | 2014-07-30 | 中国人民解放军国防科学技术大学 | 面向多核多线程微处理器的虚拟活跃页缓冲方法及装置 |
| JP6074955B2 (ja) | 2012-08-31 | 2017-02-08 | 富士通株式会社 | 情報処理装置および制御方法 |
| US10002031B2 (en) | 2013-05-08 | 2018-06-19 | Nvidia Corporation | Low overhead thread synchronization using hardware-accelerated bounded circular queues |
| US9195493B2 (en) * | 2014-03-27 | 2015-11-24 | International Business Machines Corporation | Dispatching multiple threads in a computer |
| US9772867B2 (en) * | 2014-03-27 | 2017-09-26 | International Business Machines Corporation | Control area for managing multiple threads in a computer |
| US9213569B2 (en) * | 2014-03-27 | 2015-12-15 | International Business Machines Corporation | Exiting multiple threads in a computer |
| US9804846B2 (en) * | 2014-03-27 | 2017-10-31 | International Business Machines Corporation | Thread context preservation in a multithreading computer system |
| US9921848B2 (en) * | 2014-03-27 | 2018-03-20 | International Business Machines Corporation | Address expansion and contraction in a multithreading computer system |
| US9218185B2 (en) * | 2014-03-27 | 2015-12-22 | International Business Machines Corporation | Multithreading capability information retrieval |
| US9594660B2 (en) * | 2014-03-27 | 2017-03-14 | International Business Machines Corporation | Multithreading computer system and program product for executing a query instruction for idle time accumulation among cores |
-
2014
- 2014-03-27 US US14/227,003 patent/US9223574B2/en active Active
-
2015
- 2015-03-06 AU AU2015238706A patent/AU2015238706B2/en active Active
- 2015-03-06 JP JP2016558045A patent/JP6556748B2/ja active Active
- 2015-03-06 WO PCT/EP2015/054731 patent/WO2015144421A1/en active Application Filing
- 2015-03-06 RU RU2016127443A patent/RU2667791C2/ru active
- 2015-03-06 SG SG11201606092XA patent/SG11201606092XA/en unknown
- 2015-03-06 CN CN201580015800.3A patent/CN106104465B/zh active Active
- 2015-03-06 BR BR112016022436-1A patent/BR112016022436B1/pt active IP Right Grant
- 2015-03-06 MX MX2016012532A patent/MX2016012532A/es unknown
- 2015-03-06 KR KR1020167020926A patent/KR101807450B1/ko active IP Right Grant
- 2015-03-06 CA CA2940891A patent/CA2940891C/en active Active
- 2015-03-06 EP EP15708810.5A patent/EP3123325A1/en not_active Withdrawn
- 2015-03-23 TW TW104109237A patent/TWI614680B/zh active
-
2016
- 2016-09-15 IL IL247858A patent/IL247858B/en active IP Right Grant
Also Published As
| Publication number | Publication date |
|---|---|
| CA2940891A1 (en) | 2015-10-01 |
| RU2016127443A (ru) | 2018-04-28 |
| CN106104465B (zh) | 2019-03-01 |
| MX2016012532A (es) | 2016-12-20 |
| WO2015144421A1 (en) | 2015-10-01 |
| AU2015238706B2 (en) | 2018-05-10 |
| US20150277908A1 (en) | 2015-10-01 |
| TWI614680B (zh) | 2018-02-11 |
| EP3123325A1 (en) | 2017-02-01 |
| TW201610838A (zh) | 2016-03-16 |
| BR112016022436A2 (ja) | 2017-08-15 |
| US9223574B2 (en) | 2015-12-29 |
| CN106104465A (zh) | 2016-11-09 |
| AU2015238706A1 (en) | 2016-08-04 |
| KR20160104060A (ko) | 2016-09-02 |
| RU2667791C2 (ru) | 2018-09-24 |
| JP2017515203A (ja) | 2017-06-08 |
| SG11201606092XA (en) | 2016-08-30 |
| CA2940891C (en) | 2023-09-26 |
| KR101807450B1 (ko) | 2018-01-18 |
| IL247858B (en) | 2019-03-31 |
| RU2016127443A3 (ja) | 2018-04-28 |
| BR112016022436B1 (pt) | 2023-10-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6556748B2 (ja) | コンピュータにおいて複数のスレッドをディスパッチするための方法、システム、およびコンピュータ・プログラム | |
| JP6509248B2 (ja) | コンピュータ内の複数のスレッドを管理する制御エリアを提供するためのシステム、方法、およびコンピュータ・プログラム製品 | |
| JP6501791B2 (ja) | マルチスレッド・ゲスト仮想マシン(vm)をディスパッチするためのシステム、方法およびコンピュータ・プログラム製品 | |
| JP6556747B2 (ja) | コンピュータ内の複数のスレッドをエグジットするための方法、システム、およびコンピュータ・プログラム | |
| US9389897B1 (en) | Exiting multiple threads of a simulation environment in a computer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20171116 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20180928 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20181016 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190110 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20190618 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20190710 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6556748 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |