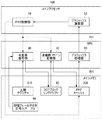
図1は、実施の形態に係るグラフィックス処理装置の構成図である。グラフィックス処理装置は、メインプロセッサ100、グラフィックスプロセッシングユニット(GPU)200、およびメインメモリ300を含む。
メインプロセッサ100は、単一のメインプロセッサであってもよく、複数のプロセッサを含むマルチプロセッサシステムであってもよく、あるいは、複数のプロセッサコアを1個のパッケージに集積したマルチコアプロセッサであってもよい。メインプロセッサ100はバスを介してメインメモリ300に対してデータを読み書きすることができる。
GPU200は、グラフィックプロセッサコアを搭載したグラフィックチップであり、バスを介してメインメモリ300に対してデータを読み書きすることができる。
メインプロセッサ100とGPU200は、バスで接続されており、メインプロセッサ100とGPU200は互いにバスを介してデータをやりとりすることができる。
同図は、グラフィックス処理の中で特にテクスチャ処理に関する構成を図示しており、それ以外の処理に関する構成は省略している。
メインメモリ300のメモリ領域はGPU200からアクセスできるようにGPU200が参照するアドレス空間にメモリマッピングされており、GPU200は、メインメモリ300からテクスチャデータを読み取ることができる。テクスチャデータは、PRT(Partially Resident Textures)と呼ばれる方法を用いて、部分的にメインメモリ300にキャッシュされる。
メインプロセッサ100は、グラフィックス演算部20およびPRT制御部10を含む。グラフィックス演算部20は、GPU200のグラフィックス処理部50からテクスチャの詳細度を示すLOD(level of detail)値を受け取り、PRT制御部10にLOD値を渡す。PRT制御部10は、グラフィックス処理部50から受け取ったLOD値にもとづいて、今後必要となるであろうミップマップテクスチャを算出し、テクスチャプールであるPRTキャッシュ320への展開を指示したり、使わなくなったページをはがしたりすることでPRTのマッピングを更新する。
図2(a)〜図2(c)は、ミップマップテクスチャを説明する図である。ミップマップテクスチャは、詳細度(LOD)に応じて解像度を異ならせた複数のテクスチャである。図2(a)のミップマップテクスチャ340は、高解像度のテクスチャである。図2(b)のミップマップテクスチャ342は、図2(a)の高解像度のミップマップテクスチャ340の縦、横のサイズをそれぞれ1/2にした、中解像度のテクスチャである。図2(c)のミップマップテクスチャ344は、図2(b)の中解像度のミップマップテクスチャ342の縦、横のサイズをそれぞれ1/2にした、低解像度のテクスチャである。
図1に戻り、PRT制御部10は、グラフィックス演算部20に指定された詳細度のミップマップテクスチャを読み出すようにGPU200に指示する。より具体的には、PRT制御部10は、GPU200の可変長復号部30および逆離散コサイン変換(IDCT)部40を制御し、また、メインメモリ300に格納されたPRTキャッシュ320のスワップイン、スワップアウトを制御する。
GPU200は、可変長復号部30、IDCT部40、およびグラフィックス処理部50を含む。
可変長復号部30は、PRT制御部10から指定された詳細度に対応する圧縮テクスチャ310をメインメモリ300から読み出し、即値フィールド付き符号化テーブル60(以下、略して「符号化テーブル60」と呼ぶこともある)を参照して圧縮テクスチャ310を可変長復号し、DCTブロックリングバッファ80に格納する。
IDCT部40は、DCTブロックリングバッファ80に格納された可変長復号後のテクスチャのDCTブロックを逆離散コサイン変換し、PRTキャッシュ320に格納する。
グラフィックス処理部50は、PRTキャッシュ320から必要なミップマップテクスチャを読み出す。PRTキャッシュ320は、テクスチャを部分的にキャッシュするテクスチャタイルプールであり、必要なテクスチャをスワップインし、不要なものはスワップアウトする。
図3は、本実施の形態のPRTの仕組みを説明する図である。
仮想メモリ上にはミップマップテクスチャ340、342、344の領域が配置される。テクスチャの領域を一定のサイズのチャンクに分け、ページテーブル330を用いて、必要なテクスチャ領域だけをテクスチャタイルプール360に格納する。ここで、テクスチャは圧縮テクスチャ310としてメインメモリ300に存在しているため、テクスチャタイルプール360にテクスチャ領域をキャッシュする際、圧縮テクスチャ310を伸張する処理が必要になる。PRT制御部10は、グラフィックス処理部50からの要求に従い、可変長復号部30およびIDCT部40を制御して、必要に応じて圧縮テクスチャ310を伸張させる。
同図の例では、高解像度のミップマップテクスチャ340のチャンク352、中解像度のミップマップテクスチャ342のチャンク358は、それぞれページテーブル330のページ332、338に対応づけられており、物理メモリがテクスチャタイルプール360からマップされている。
他方、高解像度のミップマップテクスチャ340のチャンク354、中解像度のミップマップテクスチャ342のチャンク356は、それぞれページテーブル330のページ334、336に対応づけられているが、いずれも物理メモリがまだテクスチャタイルプール360からマップされていない。この場合、前述のように、PRT制御部10は、グラフィックス処理部50から受け取ったLOD値にもとづいて必要なテクスチャがテクスチャタイルプール360にあるように制御し、テクスチャタイルプール360の物理メモリが割り当てられ、圧縮テクスチャ310から必要なテクスチャデータが伸張されてテクスチャタイルプール360に格納される。一方、グラフィックス処理部50は、メインプロセッサ100を介することなく、自分自身が計算したLOD値を使ってミップマップテクスチャをテクスチャタイルプール360から読み出す。このとき、もし計算したLOD値に対応するミップマップテクスチャがテクスチャタイルプール360に存在しない場合は、グラフィックス処理部50はフォールバックして、要求する詳細度を下げ、解像度の低いミップマップテクスチャをテクスチャタイルプール360から読み出し、描画する。
ここで、テクスチャのデータフォーマットについて説明する。圧縮される前の元のテクスチャデータは、たとえばRGB32ビットフォーマットで与えられる。GPU200が直接扱うことのできるテクスチャフォーマットとして、BC5またはBC7と呼ばれるテクスチャ圧縮方式により圧縮されたテクスチャがあり、これによれば、品質を比較的良好に保ったまま、元のテクスチャデータに比べておよそ1/4の圧縮率でデータ量を削減できる。品質が比較的低くなってもよいのであれば、BC1またはDXT1と呼ばれるテクスチャ圧縮方式により圧縮されたテクスチャを利用することもでき、この場合、元のテクスチャデータに比べておよそ1/8の圧縮率でデータ量を削減できる。
他方、GPU200が直接扱えなくなるが、JPEGにより圧縮されたテクスチャを利用すれば、元のテクスチャデータに比べておよそ1/20の圧縮率でデータ量を削減できる。この場合、GPU200のコンピュートシェーダではJPEG伸張のような複雑なアルゴリズムを実行することは非効率であり、JPEG伸張を行うことのできる専用ハードウェアがなければ、リアルタイムで圧縮テクスチャを伸張してグラフィックス処理に利用することは難しい。
本実施の形態では、DCTと即値フィールド付きの符号化テーブルを用いた可変長符号化を行うことで、およそ1/20の圧縮率でデータ量を削減できる。ここまで高圧縮されると、圧縮テクスチャ310はメインメモリ300に常駐させることが可能になる。GPU200は、メインメモリ300から圧縮テクスチャ310を読み出し、コンピュートシェーダによって、リアルタイムで即値フィールド付きの符号化テーブルを用いた可変長復号および逆離散コサイン変換(IDCT)を実行してテクスチャを復元することが可能である。
JPEG圧縮されたテクスチャは、GPU200が直接利用することができないため、JPEGデコーダによっていったん復号する必要がある。JPEGのコーデックが搭載されたグラフィックス装置であれば、JPEG圧縮されたテクスチャにも対応可能であるが、一般にはJPEGのコーデックを利用可能ではない。JPEG圧縮は、画像を離散コサイン変換し、量子化した後、ハフマン符号化を行うものである。ハフマン符号化は複雑な圧縮アルゴリズムであるから、仮にGPU200のコンピュートシェーダがJPEG圧縮されたテクスチャのハフマン復号を行ったとすると、計算量が膨大なものになってしまう。
それに対して、即値フィールド付き符号化テーブル60を用いた可変長符号化は、即値フィールドを用いたことで符号化テーブルを小さくすることができるため、通常のハフマン符号化とは違って、GPU200のコンピュートシェーダによって効率的に実行することができる。
通常のハフマン符号化では、連続する「0」の数を示す「ラン数(Run)」と「0」以外の値である「レベル値(Level)」の組み合わせに対して1個のハフマン符号を割り当てて符号化する。出現頻度の高いラン数とレベル値の組み合わせに対しては短い符号を、出現頻度の低いラン数とレベル値の組み合わせに対しては長い符号を割り当てることで、データの平均符号長を最小にすることができる。
これに対して、即値フィールド付き符号化テーブル60を用いた可変長符号化は、「ラン数」と「レベル値」のペアに、指数ゴロム的な「即値フィールド」を組み合わせて符号を作ることで、符号化テーブルの行数を小さくする。符号化テーブルの行数は高々12行程度であり、符号化テーブルの各行は、行毎に決められた「ラン数の範囲」と「レベル値の範囲」のペアを表しており、実際のラン数とレベル値は各行の即値フィールドに与えられる「即値」によって与えられる。ここで、「ラン数の範囲」と「レベル値の範囲」のペアについて、出願頻度の高いペアを短いビット長の符号で、出願頻度の低いペアを長いビット長の符号(コード)で表現する。
即値フィールド付き符号化テーブル60を用いた可変長復号時には、符号化テーブル60のいずれの行に当てはまるかをまずサーチし、当てはまった行から「ラン数の範囲」と「レベル値の範囲」のペアが特定され、その行の即値フィールドからラン数の即値とレベル値の即値を取得すればよい。通常のハフマン符号化のテーブルの場合、行数が多く、テーブルサーチが複雑でGPU200では実行することが難しいが、即値フィールド付き符号化テーブル60は行数が少ないため、条件分岐を少なくすることができ、GPU200で複数のスレッドを並列実行することで効率良く可変長復号することができる。
図4は、即値フィールド付き符号化テーブル60の一例を示す図である。この符号化テーブル60は4行であり、ラン数の範囲とレベル値の範囲のペアに対して異なるビット長の符号(コード)を割り当てる。ここでは、DCTブロックは16×16であり、12ビットのDCT係数の値を256個毎に区切って符号化するため、ラン数は0〜255の値を取り、レベル値は0〜4095の値を取る。
コード1「1RRsLL」は、ラン数の範囲0〜3(2ビット)、レベル値の範囲0〜3(2ビット)のペアに対応し、ビット長6である。先頭の「1」はコード1であることを識別する符号である。「RR」はラン数の即値であり、0〜3のいずれかの値を取る。「LL」はレベル値の即値であり、0〜3のいずれかの値を取る。「s」は符号(sign)ビットであり、レベル値の正負を示す(以下、同じ)。
コード2「01RRRRRsLLLLL」は、ラン数の範囲0〜31(5ビット)、レベル値の範囲0〜31(5ビット)のペアに対応し、ビット長13である。先頭の「01」はコード2であることを識別する符号である。「RRRRR」はラン数の即値であり、0〜31のいずれかの値を取る。「LLLLL」はレベル値の即値であり、0〜31のいずれかの値を取る。
コード3「001RRRRRRRRsLLLLLLLLLLLL」は、ラン数の範囲0〜255(8ビット)、レベル値の範囲0〜4095(12ビット)のペアに対応し、ビット長24である。先頭の「001」はコード3であることを識別する符号である。「RRRRRRRR」はラン数の即値であり、0〜255のいずれかの値を取る。「LLLLLLLLLLLL」はレベル値の即値であり、0〜4095のいずれかの値を取る。
コード4「0001」は、これ以降はすべて0であることを示す、ブロックの終わりを示す符号EOB(End of Block)に対応し、ビット長4である。「0001」はコード4であることを識別する符号である。
このように、即値フィールド付き符号化テーブル60の各行は、ラン数の範囲とレベル値の範囲のペアに対応するコード識別符号と、ラン数の即値、レベル値の即値、およびレベル値の正負を示す符号ビットを表現した即値フィールドとを含む。
本実施の形態のテクスチャ圧縮では、画像のブロックに対して離散コサイン変換(DCT)がなされた後、量子化され、可変長符号化される。自然画を離散コサイン変換すると、周波数成分のほとんどが低周波領域に集中し、高周波成分は無視できるほど小さくなる。特に量子化により、高周波成分のDCT係数はほとんどゼロになる。このことから、可変長符号化の入力データはゼロが多数連続することが多くなる。
あるテクスチャ画像の量子化DCT係数に対して図4の符号化テーブル60にもとづいて可変長符号化すると、各コードの出現個数は、コード1が7,200個、コード2が810個、コード3が62個、コード4が260個であった。出現個数に各コードのビット長を乗じて合計すると、圧縮テクスチャ全体の符号量は56,258ビットである。
図5は、即値フィールド付き符号化テーブル60の別の例を示す図である。図4の符号化テーブル60では、ラン数の範囲0〜3、レベル値の範囲0〜3のペアに対応するコード1の出現個数が非常に多かったことから、図5の符号化テーブル60では、図4の4行の符号化テーブル60に、ラン数の範囲0〜1、レベル値1のペアに対応する3ビットのコード1を追加することで5行のテーブルとした。
図5の符号化テーブル60では、コード1「10s」(3ビット)、コード2「01RRsLL」(7ビット)、コード3「001RRRRRsLLLLL」(14ビット)、コード4「0001RRRRRRRRsLLLLLLLLLLLL」(25ビット)、コード5「00001」(5ビット)で符号化される。
図4の符号化テーブル60では、コード1(6ビット)の出現個数は7,200個であり、コード1の合計ビット数は43,200ビットであったのに対して、図5の符号化テーブル60では、これが3,900個のコード1(3ビット)と3,300個のコード2(7ビット)に分かれ、コード1とコード2の合計ビット数は、11,700+23,100=34,800ビットに減少する。図5の符号化テーブル60を用いた場合、圧縮テクスチャ全体の符号量は48,990ビットであり、図4の符号化テーブル60を用いた場合よりも符号量を減らすことができる。
図6は、即値フィールド付き符号化テーブル60のさらに別の例を示す図である。図6の符号化テーブル60は、図5の符号化テーブル60に比べて、さらに行数、すなわち、ラン数の範囲とレベル値の範囲のペアの組み合わせの数を増やして10行、すなわち10コードのテーブルとした。
コード1「1Rs」は、ラン数の範囲0〜1(1ビット)、レベル値1のペアに対応し、ビット長3である。「R」は0または1の値を取り、ラン数の即値をそのまま表す。コード1は、(Run,Level)=(0,1)、(1,1)を符号化するコードである。
コード2「010RsL」は、ラン数の範囲0〜1(1ビット)、レベル値の範囲2〜3(1ビット)のペアに対応し、ビット長6である。「R」は0または1の値を取り、ラン数の即値をそのまま表す。「L」は0または1の値を取り、オフセット2を加算することで、レベル値の即値を表す。
コード3「011RRsLL」は、ラン数の範囲2〜5(2ビット)、レベル値の範囲1〜4(2ビット)のペアに対応し、ビット長8である。「RR」は0〜3のいずれかの値を取り、オフセット2を加算することで、ラン数の即値を表す。「LL」は0〜3のいずれかの値を取り、オフセット1を加算することで、レベル値の即値を表す。
コード4「0010RsLL」は、ラン数の範囲0〜1(1ビット)、レベル値の範囲4〜7(2ビット)のペアに対応し、ビット長8である。「R」は0または1の値を取り、ラン数の即値をそのまま表す。「LL」は0〜3のいずれかの値を取り、オフセット4を加算することで、レベル値の即値を表す。
コード5「0011RRsLL」は、ラン数の範囲6〜9(2ビット)、レベル値の範囲1〜4(2ビット)のペアに対応し、ビット長9である。「RR」は0〜3のいずれかの値を取り、オフセット6を加算することで、ラン数の即値を表す。「LL」は0〜3のいずれかの値を取り、オフセット1を加算することで、レベル値の即値を表す。
コード6「00010RRRRRRs」は、ラン数の範囲10〜73(6ビット)、レベル値1のペアに対応し、ビット長12である。「RRRRRR」は0〜63のいずれかの値を取り、オフセット10を加算することで、ラン数の即値を表す。
コード7「00011RRRRRsLLLLL」は、ラン数の範囲0〜31(5ビット)、レベル値の範囲0〜31(5ビット)のペアに対応し、ビット長16である。「RRRRR」は0〜31のいずれかの値を取り、ラン数の即値をそのまま表す。「LLLLL」は0〜31のいずれかの値を取り、レベル値の即値をそのまま表す。
コード8「00001sLLLLLLLLLLLL」は、ラン数0、レベル値の範囲0〜4095(12ビット)のペアに対応し、ビット長18である。「LLLLLLLLLLLL」は0〜4095のいずれかの値を取り、レベル値の即値をそのまま表す。
コード9「000001」は、これ以降はすべて0であることを示す、ブロックの終わりを示す符号EOB(End of Block)に対応し、ビット長6である。
コード10「0000001RRRRRRRRsLLLLLLLLLLLL」は、ラン数の範囲0〜255(8ビット)、レベル値の範囲0〜4095(12ビット)のペアに対応し、ビット長28である。「RRRRRRRR」は0〜255のいずれかの値を取り、ラン数の即値をそのまま表す。「LLLLLLLLLLLL」は0〜4095のいずれかの値を取り、レベル値の即値をそのまま表す。
コード1〜10のそれぞれの出現個数および合計ビット数は図示の通りである。図6の符号化テーブル60を用いた場合、ビット長の短いコードが増えたことで、各行の合計ビット数を小さく抑えることができ、その結果、圧縮テクスチャ全体の符号量は43,536ビットであり、図5の符号化テーブル60を用いた場合よりもさらに符号量を減らすことができる。
本実施の形態の即値フィールド付き符号化テーブル60はいずれも、異なるコード間でラン数の範囲とレベル値の範囲が重複することを許している。2以上のコードのラン数の範囲とレベル値の範囲に当てはまる場合は、より符号長の短いコードが優先的に用いられる。
図4の即値フィールド付き符号化テーブル60を参照して、即値フィールド付き符号化テーブル60を用いた可変長復号を説明する。符号化データが図4の符号化テーブル60のコード1〜4のいずれに当てはまるかをサーチするために、符号化データのビット列において最初に1が現れるのは何番目のビットであるかを調べる。
1番目のビットに最初に1が現れた場合(「分岐A」と呼ぶ)、コード1であり、残りの5ビットの即値フィールドからラン数の即値(2ビット)、符号ビット、レベル値の即値(2ビット)を順に読み出す。
2番目のビットに最初に1が現れた場合(「分岐B」と呼ぶ)、コード2であり、残りの11ビットの即値フィールドからラン数の即値(5ビット)、符号ビット、レベル値の即値(5ビット)を順に読み出す。
3番目のビットに最初に1が現れた場合(「分岐C」と呼ぶ)、コード3であり、残りの21ビットの即値フィールドからラン数の即値(8ビット)、符号ビット、レベル値の即値(12ビット)を順に読み出す。
4番目のビットに最初に1が現れた場合(「分岐D」と呼ぶ)、コード4であり、EOBである。
図4に示した各コードの出現個数の例から、図4の符号化テーブル60を用いて可変長符号化された圧縮テクスチャデータを可変長復号すると、分岐Aを通ることがきわめて多くなることがわかる。図4のような符号化テーブル60を用いた可変長符号化の性質によって、GPU200のコンピュートシェーダが効率良く可変長復号することができる。なぜなら、GPU200は、SIMD(Single Instruction Multiple Data)アーキテクチャであり、複数のスレッドが異なるデータに対して同じインストラクションを同時に実行するため、分岐条件に偏りがあれば、並列度が高まり、実行効率が上がる。
GPU200は、一つのプログラムカウンタ(PC)がインストラクションキャッシュに格納されたインストラクションを参照し、たとえば16個のALU(Arithmetic Logic Unit)が同時にPCが参照するインストラクションを実行する。if−then−else文のループやswitch−case文のループの分岐毎に異なる命令を16個のスレッドにセットして同時に実行することになる。16個のスレッドに対して、if−then−else文による条件分岐では、if条件が成立する場合(True)のピクセルを担当するスレッドを有効にして並列に実行し、else分岐では、else条件が成立する場合(False)のピクセルを担当するスレッドを有効にして並列に実行する。switch−case文による条件分岐では、条件が成立したcaseのピクセルを担当するスレッドを有効にして並列に実行する。
if−then−else文による条件分岐では、if条件が成立する場合とelse条件が成立する場合がほぼ同数である場合、Trueの場合とFalseの場合で有効化するスレッドの入れ替えを頻繁に行うことになるが、if条件成立が8割、else条件成立が2割のように偏っていれば、Trueの場合に有効化するスレッドの集合を繰り返し使えるため、実行効率が高まる。switch−case文による条件分岐では、各caseが成立する場合がほぼ同数である場合、case毎に有効化するスレッドの入れ替えを頻繁に行うことになるが、各caseの成立の頻度が偏っていれば、成立頻度の高いcaseで有効化するスレッドの集合を繰り返し使えるため、実行効率が高まる。図7および図8を参照してこの点をより詳しく説明する。
図7は、比較のため、分岐先に偏りがない場合のスレッドの実行過程を説明する図である。
GPU200は複数の計算ユニット(Computing Unit)を含む。GPU200の1つの計算ユニットで同時に実行されるスレッドの数は計算ユニット内の演算器の数によって決まるが、ここではこれを16個とする。1つの計算ユニットに同時に投入可能な最大16スレッドの集まりを「スレッドセット」と呼ぶ。スレッドセットに含まれる各スレッドは、同じシェーダプログラムを実行するが、処理するデータはそれぞれ異なり、プログラム内に分岐がある場合は、それぞれ別の分岐先をもつことがある。1つの計算ユニットはあるサイクルでは、1つのスレッドセット(ここでは最大16スレッド)を並列に実行する。
たとえば、各分岐先での必要な命令数が数個であっても、プラグラムカウンタが1個であり、計算ユニット内のすべての演算器は同一の命令を実行するSIMD構造であるため、スレッドマスクによって実行するスレッドを変えながら各分岐の一つ一つの命令を実行することになる。
一例として、図4の符号化テーブル60を用いて可変長復号する際の分岐Aは4命令、分岐Bは4命令、分岐Cは4命令、分岐Dは2命令で実行されるとする。図7の例では、スレッドセット450内の16個のスレッドの分岐先が順にA、A、B、A、A、A、B、C、B、A、B、A、B、A、B、Dである場合を説明している。
サイクル1において、分岐Aを実行するスレッドのみ(この場合、8個のスレッド)を有効にし、プログラムカウンタを1つずつ進めながら、分岐Aの4命令A−1、A−2、A−3、A−4を実行する。
サイクル5において、分岐Bを実行するスレッドのみ(この場合、6個のスレッド)を有効にし、プログラムカウンタを1つずつ進めながら、分岐Bの4命令B−1、B−2、B−3、B−4を実行する。
サイクル9において、分岐Cを実行するスレッドのみ(この場合、1個のスレッド)を有効にし、プログラムカウンタを1つずつ進めながら、分岐Cの4命令C−1、C−2、C−3、C−4を実行する。
サイクル13において、分岐Dを実行するスレッドのみ(この場合、1個のスレッド)を有効にし、プログラムカウンタを1つずつ進めながら、分岐Dの2命令D−1、D−2を実行する。
このように、図7の例では、スレッドセットに含まれる16個のスレッドが4つの分岐A〜Dのすべての命令を実行するために、14サイクルが必要となる。
図8は、分岐先に偏りがある場合のスレッドの実行過程を説明する図である。図8の例では、スレッドセット452内の16個のスレッドの分岐先が順にA、A、B、A、A、A、B、B、B、A、B、A、A、A、A、Aである場合を説明している。この例では、シェーダプログラム上は分岐先が4種類あるが、分岐条件が成立するピクセルが偏っており、分岐先が分岐Aと分岐Bの2種類しかない。スレッドセットに含まれる16個のスレッドはこの2種類の分岐だけを実行すればよい。
サイクル1において、分岐Aを実行するスレッドのみ(この場合、11個のスレッド)を有効にし、プログラムカウンタを1つずつ進めながら、分岐Aの4命令A−1、A−2、A−3、A−4を実行する。
サイクル5において、分岐Bを実行するスレッドのみ(この場合、5個のスレッド)を有効にし、プログラムカウンタを1つずつ進めながら、分岐Bの4命令B−1、B−2、B−3、B−4を実行する。
このように、図8の例では、スレッドセットに含まれる16個のスレッドが2つの分岐A、Bのすべての命令を実行すればよく、必要サイクル数は8サイクルに減る。
このように入力されるデータの性質によってプログラムの分岐先に偏りが生じる場合は、同じスレッドマスクをそのまま使って繰り返し命令を実行することができ、実行効率が向上する。分岐先にばらつきがあると、分岐毎にスレッドマスクを切り替えることになり、実行効率が低下する。
自然画由来のDCT係数の特性から、DCT係数行列の左上の低周波成分に0以外の値が集中し、DCT係数行列の右下の高周波成分に0が連続するようになる。したがって、離散コサイン変換後の画像ブロックをジグザグパターンにより1次元配列にすると、どのブロックのDCT係数も最初は非ゼロの値が続き、後半に0が連続するデータ列となる傾向がある。
このDCT係数の傾向を踏まえて、スレッドセットの各スレッドには、異なるDCTブロックのDCT係数を処理するように可変長符号化データを割り当て、各スレッドがDCTブロック内で相対的に同じ位置のDCT係数の可変長復号を行うようにスレッドセットを構成する。図4の符号化テーブル60の場合、分岐先が分岐A〜Dのいずれかになる。スレッドセットの構成から、DCTブロック内の相対的に同じ位置ではDCT係数の傾向が似るため、スレッドセット内の各スレッドの分岐先は同じものに偏るようになる。これにより、図7のように分岐先がばらつくのではなく、図8のように分岐先が偏るようになり、スレッドセットの効率的な実行状態を長く続けることができる。その結果、スレッドセットによって可変長復号は効率良く実行される。
図6の即値フィールド付き符号化テーブル60を用いた可変長復号の手順を詳しく説明する。図9は、符号化データが図6の符号化テーブル60のいずれの行に当てはまるかをサーチする際の分岐を説明する図である。符号化データのビット列において最初に1が現れるのが何番目のビットであるかを調べる。
1番目のビットに最初に1が現れた場合、case0であり、2番目のビットに最初に1が現れた場合、case1であり、3番目のビットに最初に1が現れた場合、case2であり、4番目のビットに最初に1が現れた場合、case3であり、5番目のビットに最初に1が現れた場合、case4であり、6番目のビットに最初に1が現れた場合、case5であり、7番目のビットに最初に1が現れた場合、case6である。
case0はコード1に対応し、case4はコード8に対応し、case5はコード9に対応し、case6はコード10に対応するから、残りの即値フィールドから適宜、ラン数の即値、レベル値の即値を読み出せばよい。
case1はコード2およびコード3に対応し、3ビット目が0であればコード2、3ビット目が1であればコード3であることが判明するから、その後は、残りの即値フィールドからラン数の即値、レベル値の即値を読み出せばよい。
同様に、case2はコード4およびコード5に対応し、4ビット目が0であればコード4、4ビット目が1であればコード5である。また、case3はコード6およびコード7に対応し、5ビット目が0であればコード6、4ビット目が1であればコード7である。いずれのコードであるかが特定されたなら、残りの即値フィールドから、適宜、ラン数の即値、レベル値の即値を読み出す。
図10は、図9で説明した分岐を有するプログラムソースコードを示す。clz=FirstSetBit_Hi_MSB(code)は、符号化データのビット列において最初に1が現れる列番号clzを求める演算式である。列番号は0からカウントしているから、プログラムコードのswitch文のcase 0〜case 6は図9のcase0〜case6に対応する。関数BITAT(code,n-1,m)は符号化データのビット列の第n列から前方にmビットのビット列を読み出す演算である。
switch文のcase 1のソースコードを説明すると、if(BITAT(code,2,1)==0)は、符号化データのビット列の3ビット目が0である場合であり、これは図9のコード2である。コード2では、4ビット目からラン数の即値を読み出せばよいから、run=BITAT(code,3,1)を実行する。次に6ビット目からレベル値の即値を読み出すが、オフセットとして2を加算する必要があるため、level=BITAT(code,5,1)+2を実行する。符号ビットは、5ビット目から読み出せばよいから、sign=BITAT(code,4,1)を実行する。
if(BITAT(code,2,1)==0)が成立しない場合、符号化データのビット列の3ビット目が1であるから、これは図9のコード3である。この場合、else文が実行される。コード3では、4ビット目と5ビット目からラン数の即値を読み出すが、オフセットとして2を加算する必要があるため、run=BITAT(code,4,2)+2を実行する。ここで、BITAT(code,4,2)は、5ビット目から前方へ2ビットのビット列を読み出す演算であるから、結果的に4ビット目と5ビット目が読み出されることに留意する。次に7ビット目と8ビット目からレベル値の即値を読み出すが、オフセットとして1を加算する必要があるため、level=BITAT(code,7,2)+1を実行する。符号ビットは、6ビット目から読み出せばよいから、sign=BITAT(code,5,1)を実行する。
switch文のcase 2〜case 6についても同様に各行で決められたラン数の範囲、レベル値の範囲に応じて即値フィールドからラン数の即値、レベル値の即値を読み出して、適宜オフセットを加算する演算を行えばよい。
図11は、即値フィールド付き符号化テーブル60の実施例を示す図である。図6の符号化テーブル60よりもさらに2行増やして、12種類のコードで符号化する。各行のコードのラン数の範囲、レベル値の範囲、ビット長、出現個数は図示した通りである。
図11の符号化テーブル60のコードの性質は次のようにまとめることができる。
(1)0〜73個の連続する0に続くレベル値1に対して3〜12ビットのコードを割り当てる。
(2)0〜9個の連続する0に続くレベル値2〜4に対して6〜9ビットのコードを割り当てる。
(3)1個以内の0に続くレベル値4〜7に対して8ビットのコードを割り当てる。
(4)0〜31個の連続する0に続くレベル値0〜31に対して16ビットのコードを割り当てる。
(5)32以上の連続するレベル値に対して18ビットのコードを割り当てる。
(6)その他の任意の連続する0に続く任意のレベル値に対して29ビットのコードを割り当てる。
ハフマン符号化では、与えられた画像に対して、出現頻度の高いラン数とレベル値の組み合わせに対して短い符号を、出現頻度の低いラン数とレベル値の組み合わせに対しては長い符号を割り当てた符号化テーブルが動的に生成される。それに対して、本実施の形態の即値フィールド付き符号化テーブル60を用いた可変長符号化では、即値フィールド付き符号化テーブル60は動的に生成されるのではなく、あらかじめ決められたものが用いられる。もっとも、複数の異なる即値フィールド付き符号化テーブル60を用意しておき、何らかの条件でいずれかのテーブルに切り替えて用いてもよく、複数の即値フィールド付き符号化テーブル60の中から、与えられた画像を実際に可変長符号化した場合の符号量が最も小さくなるテーブルを最適なテーブルとして選択してもよい。
本実施の形態のグラフィックス処理装置によれば、離散コサイン変換後に即値フィールド付き符号化テーブルを用いて可変長符号化されたテクスチャを用いるため、テクスチャ容量を大きく削減することができる。GPU200のコンピュートシェーダが圧縮テクスチャを即値フィールド付き符号化テーブルを用いて可変長復号し、逆離散コサイン変換するため、高速に圧縮テクスチャを伸張してグラフィックス処理に投入することができる。高圧縮されたテクスチャはメモリに常駐させることができるため、大容量のテクスチャをハードディスクなどの記憶装置から読み出す必要がなく、オンメモリでPRTを実行することが可能である。圧縮テクスチャがオンメモリ化されているため、必要に応じて圧縮テクスチャを読み出し、伸張してPRTキャッシュにスワップインする構成にしても、レイテンシは短く、リアルタイムでテクスチャ処理を実行することができる。
以上、本発明を実施の形態をもとに説明した。実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
上記の実施の形態では、圧縮テクスチャをメモリに格納したが、圧縮テクスチャをハードディスクや光ディスクなどの記録媒体に格納してもよい。テクスチャは高圧縮されているため、記憶容量を抑えることができ、また、オンメモリの場合のレイテンシにはかなわないが、記録媒体からの読み出しのレイテンシをある程度抑えることもできる。
上記の実施の形態では、画像の空間領域を空間周波数領域に変換する空間周波数変換の一例として、離散コサイン変換を用いたが、これ以外の空間周波数変換、たとえば離散フーリエ変換を用いてもよい。
上記の実施の形態では、GPU200が可変長復号部30とIDCT部40を含む構成において圧縮テクスチャを伸張する手順を説明したが、本実施の形態の即値フィールド付き符号化テーブル60を用いた可変長復号は、グラフィックス処理装置における圧縮テクスチャの伸張以外にも、一般的な画像処理装置において可変長符号化された画像を復号する場合にも利用することができる。