以下、図面を参照して、本発明の実施形態について説明する。
(第1の実施形態)
図1は、第1の実施形態におけるロボット100が備える機能構成の概略を示す図である。ロボット100は、会話支援システムの一例である。第1の実施形態におけるロボット100は、複数人の参加者と会話を行うロボットである。図1に示すように、ロボット100は、マイク101と、カメラ102と、センサ103と、音声入力部104と、映像入力部105と、センサ入力部106と、発話区間検出部107と、次話者確率推定部108と、制御部109と、音制御部110と、口部制御部111と、視線制御部112と、頭部制御部113と、胴部制御部114と、スピーカ115と、口部駆動部116と、眼部駆動部117と、頭部駆動部118と、胴部駆動部119とを備える。
マイク101は、会話する参加者の音声等を含むロボット100の周囲の音を集音して、音声信号を含む音信号(以下の説明では単に音声信号という)を出力する。マイク101が少なくとも参加者の音声を集音可能であれば、マイク101の設置位置と数は任意とすることができる。例えば、マイク101は、複数の各参加者それぞれに装着された複数のマイクで構成される。このようにマイク101を参加者の口元に近く、参加者個別に装着することで精度よく集音することができる。また、例えば、マイク101は、ロボット100に搭載されてもよく、参加者やロボット100以外の外界に設置されてもよい。ロボット100において、複数のマイク101と音声入力部104とは、有線又は無線で音声信号の送受信が可能に接続された構成である。
カメラ102は、会話する参加者の映像を撮影して、映像信号を出力する。カメラ102が参加者全員を撮影可能であれば、カメラ102の設置位置と台数は任意とすることができる。例えば、カメラ102は、参加者全員の姿が画角にはいるよう広角な画角を有する撮像装置である。また、例えば、カメラ102は、参加者全員の姿をそれぞれ撮影する参加者の人数分の複数のカメラであってもよい。この場合には、ロボット100において、映像入力部105と、複数のカメラとは、有線又は無線で映像信号を送受信可能に接続された構成となる。
センサ103は、ロボット100の位置に対する、会話する参加者の位置を計測する第1のセンサ、参加者の呼吸動作を計測する第2のセンサ、参加者の注視対象を検出する第3のセンサ及び参加者の頭部動作を検出する第4のセンサ等の複数のセンサを備え、それらの各センサからのセンサ信号をセンサ入力部106へ出力する。
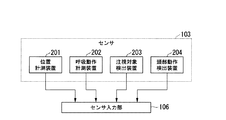
図2は、第1の実施形態におけるセンサ103の具体的な構成例を示す図である。
図2に示すように、センサ103は、ロボット100の位置に対する、会話する参加者の位置(特に顔位置)を計測する位置計測装置(第1のセンサ)201と、参加者の呼吸動作を計測する呼吸動作計測装置(第2のセンサ)202と、参加者の注視対象を検出する注視対象検出装置(第3のセンサ)203と、参加者の頭部動作を検出する頭部動作検出装置(第4のセンサ)204とを備える。位置計測装置201は、例えばロボット100内に設置される。呼吸動作計測装置202は、参加者の体幹等に装着され、注視対象検出装置203及び頭部動作検出装置204は、参加者の頭部等に装着される。位置計測装置201は、センサ入力部106と接続されている。呼吸動作計測装置202、注視対象検出装置203及び頭部動作検出装置204は、センサ入力部106と、有線又は無線でセンサ信号の送受信が可能に接続されている。
図1の音声入力部104は、マイク101からの音声信号を入力とし、発話区間検出部107、次話者確率推定部108及び音制御部110へ音声信号を出力する。音声入力部104は、マイク101からの音声信号を、ロボット100内で処理可能な信号形式の音声信号に変換する等の処理を行う。映像入力部105は、カメラ102からの映像信号を入力とし、次話者確率推定部108へ映像信号を出力する。映像入力部105は、カメラ102からの映像信号を、ロボット100内で処理可能な信号形式の映像信号に変換する等の処理を行う。センサ入力部106は、センサ103からのセンサ信号を入力とし、次話者確率推定部108へセンサ信号を出力する。センサ入力部106は、センサ103からのセンサ信号を、ロボット100内で処理可能な信号形式のセンサ信号に変換する等の処理を行う。
発話区間検出部107は、既存の任意の技術により、音声入力部104からの音声信号から得られる音声特徴量に基づいて、各参加者が発話を行った区間を検出する。例えば、発話区間検出部107は、音声入力部104からの音声信号に基づいて、任意の窓幅を設けてその区間内の音声信号のパワー、ゼロ交差数、周波数などを、音声の特徴を示す値である音声特徴量として算出する。発話区間検出部107は、算出した音声特徴量と所定の閾値を比較して発話区間を検出する。発話区間検出部107は、検出した発話区間に関する情報である発話区間情報を次話者確率推定部108、制御部109及び音制御部110へ出力する。発話区間情報には、発話の開始及び終了の時刻、及び、発話者の情報が含まれる。なお、マイク101から取得される音声信号において、音声の存在する区間(発話区間)と音声の存在しない区間(非発話区間)を自動的に検出するVAD(Voice Activity Detection)技術は、以下の参考文献1に示すように公知の技術である。発話区間検出部107は、公知のVAD技術を用いて発話区間を検出する。
参考文献1:澤田 宏、外4名、"多人数多マイクでの発話区間検出〜ピンマイクでの事例〜"、日本音響学会 春季研究発表会、pp.679−680、2007年3月
次話者確率推定部108は、音声入力部104からの音声信号と、映像入力部105からの映像信号と、センサ入力部106からのセンサ信号と、発話区間検出部107からの発話区間情報とを入力とし、各参加者が時刻tに次話者となる確率である次話者確率を出力する。次話者確率推定部108は、音声信号、映像信号、センサ信号及び発話区間情報に基づいて、発話区間情報で特定される発話区間の発話者を示す発話者情報を取得する。次話者確率推定部108は、音声信号、映像信号、センサ信号及び取得した発話者情報に基づいて、各参加者iが時刻tに次話者となる確率である次話者確率Pns i(t)を算出して、制御部109へ出力する。次話者確率推定部108は、参加者の非言語行動に基づいて次話者確率Pns i(t)を算出している。すなわち、次話者確率推定部108は、次話者確率Pns i(t)の算出に、参加者の発話内容を解析等して利用者の言語行動に関する情報を得る必要はない。次話者確率推定部108は、次話者確率Pns i(t)の他に、発話者情報及び参加者の位置情報を制御部109へ出力する。
なお、次話者確率推定部108は、参加者の位置情報を、例えば、センサ103の参加者の位置を計測したセンサ信号に基づいて取得してもよいし、映像信号に基づいて取得してもよいし、センサ103の参加者の位置を計測したセンサ信号及び映像信号に基づいて取得してもよい。
図3は、第1の実施形態における次話者確率推定部108が出力する次話者確率Pns i(t)の例を示す図である。図3においては、4名の参加者A〜Dについて参加者Aの発話の切れ目となる時刻tbue以降における次話者確率Pns i(t)の変化例を示している。符号31を付与した矩形は、参加者Aの発話区間を示している。発話区間31は、発話終了時刻tbueで終了している。次話者確率Pns A(t)32で示す点線は、発話終了時刻tbue以降の時刻tにおける参加者Aの次話者確率の変化を示している。次話者確率Pns B(t)33で示す点線は、発話終了時刻tbue以降の時刻tにおける参加者Bの次話者確率の変化を示している。次話者確率Pns C(t)34で示す点線は、発話終了時刻tbue以降の時刻tにおける参加者Cの次話者確率の変化を示している。次話者確率Pns D(t)35で示す点線は、発話終了時刻tbue以降の時刻tにおける参加者Dの次話者確率の変化を示している。このように、次話者確率推定部108は、参加者i(i∈{A,B,C,D})の発話終了時刻tbue以降の時刻tにおける次話者確率Pns i(t)の変化を算出する。なお、次話者確率推定部108における次話者の推定処理の詳細については後述する。
図1の制御部109は、次話者確率推定部108からの次話者確率を入力とし、入力した次話者確率に基づいて次に発話を行うと予測される参加者である予測次話者と、予測次話者が発話を開始するタイミング(発話開始タイミング)を推定する。制御部109は、動作パターン情報格納部1091を備える。動作パターン情報格納部1091は、ロボット100が発話を促す動作を示す動作パターン情報を格納している。
制御部109は、以下に示す第1〜第5の次話者選択方法のいずれかを用いて予測次話者を選択する。なお、以下の説明においては、参加者A、B、C、Dの4名とロボット100とが会話を行う場合について説明する。制御部109は、次話者確率推定部108からA〜Dの次話者確率Pns i(t),(i∈{A,B,C,D})を取得する。
(第1の次話者選択方法)
制御部109は、参加者A〜Dそれぞれの次話者確率Pns i(t),(i∈{A,B,C,D})を比較する。制御部109は、次話者確率Pns i(t)の最大値が最も高い参加者A〜Dのいずれかを予測次話者と判断する。制御部109は、予測次話者の次話者確率Pns i(t)が最大値を取るときの時刻tを予測次話者の発話開始タイミングとする。なお、制御部109は、参加者A〜Dのいずれの次話者確率Pns i(t)も第1の閾値を超えない場合、予測次話者がロボット100であると判断してもよい。
(第2の次話者選択方法)
制御部109は、参加者A〜Dのうち、次話者確率Pns i(t),(i∈{A,B,C,D})が最も早い時刻に第2の閾値以上の最大値をとる参加者を予測次話者と判断する。制御部109は、予測次話者の次話者確率Pns i(t)が最大値を取るときの時刻tを予測次話者の発話開始タイミングとする。なお、制御部109は、参加者A〜Dのいずれの次話者確率Pns i(t)も第2の閾値を超えない場合、予測次話者がロボット100であると判断してもよい。
(第3の次話者選択方法)
制御部109は、参加者A〜Dの次話者確率Pns i(t),(i∈{A,B,C,D})それぞれを、時刻tについて所定時間(例えば、発話終了時刻から3〜4秒以上の時間)積分して、積分値Pns iを取得する。なお、積分区間を発話終了時刻から無限時間としてもよく、全参加者A〜Dの次話者確率Pns i(t)が所定値未満となり有意な値ではなくなる時間までとしてもよい。制御部109は、この積分値Pns iが最も大きい参加者A〜Dのいずれかを予測次話者と判断する。制御部109は、予測次話者の次話者確率Pns i(t)が最大値を取るときの時刻tを予測次話者の発話開始タイミングとする。なお、制御部109は、全ての参加者A〜Dとも積分値Pns iが第3の閾値を超えないときには、予測次話者がロボット100であると判断してもよい。
(第4の次話者選択方法)
制御部109は、参加者A〜Dの次話者確率Pns i(t),(i∈{A,B,C,D})を加算した加算値(Pns A(t)+Pns B(t)+Pns C(t)+Pns D(t))を取得し、第4の閾値である任意の確率Pγと比較する。制御部109は、参加者A〜D全員の次話者確率の加算値が確率Pγ以上である((Pns A(t)+Pns B(t)+Pns C(t)+Pns D(t))≧Pγ)場合は、上記の第1〜第3のいずれかの次話者選択方法によって、予測次話者と発話開始タイミングを得る。ただし、第1〜第3の次話者選択方法において、第1〜第3の閾値との比較は行わなくてもよい。制御部109は、参加者A〜D全員の次話者確率の加算値が確率Pγ未満である((Pns A(t)+Pns B(t)+Pns C(t)+Pns D(t))<Pγ)場合は、予測次話者がロボット100であると判断する。
(第5の次話者選択方法)
制御部109は、参加者A〜Dの次話者確率Pns i(t),(i∈{A,B,C,D})のそれぞれを、時刻tについて所定時間(例えば、3〜4秒以上の時間)積分して、積分値Pns iを取得する。なお、積分区間を発話終了から無限時間としてもよく、全参加者の次話者確率Pns i(t)が所定値未満となる時間までとしてもよい。制御部109は、参加者A〜Dの全員の積分値Pns iを加算した加算値(Pns A+Pns B+Pns C+Pns D)を取得し、第5の閾値である任意の確率Pθと比較する。制御部109は、参加者A〜Dの積分値の加算値が確率Pθ以上である((Pns A+Pns B+Pns C+Pns D)≧Pθ)場合は、上記の第1〜第3のいずれかの次話者選択方法によって、予測次話者と発話開始タイミングを得る。ただし、第1〜第3の次話者選択方法において、第1〜第3の閾値との比較は行わなくてもよい。制御部109は、参加者A〜Dの全員の積分値の加算値が確率Pθ未満である((Pns A+Pns B+Pns C+Pns D)<Pθ)場合は、予測次話者がロボット100であると判断する。
次話者確率Pns i(t),(i∈{A,B,C,D})は、図3に示したように、発話終了から所定時間後にピークを有する場合が多い。そこで、制御部109は、第1〜第5の次話者選択方法において、次話者確率Pns i(t)を求める時刻tを含む窓幅を設けて、その窓幅の中における次話者確率の最大値を、時刻tにおける次話者確率Pns i(t)として用いるようにしてもよい。また、制御部109は、第1〜第5の次話者選択方法において、次話者確率Pns i(t)を求める時刻tを含む窓幅を設けて、その窓幅の中における次話者確率に複数のピークがある場合に、n番目(nは1以上の整数)のピークの次話者確率を、時刻tにおける次話者確率Pns i(t)として用いるようにしてもよい。
制御部109は、第1〜第5の次話者選択方法により予測次話者がロボット100であると判断した場合、音制御部110に対して発話を行うよう指示する発話制御信号を出力する。制御部109は、予測次話者が参加者A〜Dのいずれかであると判断した場合、音制御部110に対して発話を抑制するよう指示する発話制御信号を出力するとともに、推定された発話開始タイミングに予測次話者が発話を行ったか否かを判断する。制御部109は、推定された発話開始タイミングに予測次話者が発話を行わなかったことを検出すると、動作パターン情報格納部1091から動作パターン情報を読み出す。制御部109は、読み出した動作パターン情報が示す動作を行わせるよう指示する発話誘導動作制御信号を、音制御部110、口部制御部111、視線制御部112、頭部制御部113、及び、胴部制御部114のうち1以上に出力する。発話誘導動作制御信号は、発話誘導対象者に対して発話を促す動作を行うよう指示する信号である。動作パターン情報は、例えば、発話誘導対象者に対して発話を促す内容の発話の音声を出力する、視線を発話誘導対象者の方向に向ける、発話誘導対象者の方向に上肢を差し出す、などの動作を示す。発話誘導動作制御信号には、発話誘導対象者を特定する情報が含まれる。制御部109は、発話誘導対象者を、予測次話者又は予測次話者とは異なる参加者とする。視線制御部112、頭部制御部113、又は、胴部制御部114に出力する発話誘導動作制御信号には、発話誘導対象者の位置の情報がさらに含まれる。
制御部109は、発話誘導動作制御信号を出力したのち所定のタイミングまでに発話区間の開始を検出しなかった場合、新たな発話誘導対象者を選択する。制御部109は、新たな発話誘導対象者に対して発話を促す動作を行うよう指示する発話誘導動作制御信号を生成し、発話誘導動作制御信号を音制御部110、口部制御部111、視線制御部112、頭部制御部113、及び、胴部制御部114のうち一以上に出力する。
口部制御部111と、視線制御部112と、頭部制御部113と、胴部制御部114と、スピーカ115と、口部駆動部116と、眼部駆動部117と、頭部駆動部118と、胴部駆動部119とは、制御部109からの指示を受け、発話誘導対象者に発話を促す処理を行う発話誘導部として動作する。
音制御部110は、制御部109からの発話制御信号又は発話誘導動作制御信号に基づいて、スピーカ115に対して音信号を出力する。音制御部110は、発話制御信号に基づいて、ロボット100に発話を行わせるか否かを判断する。音制御部110は、発話制御信号に基づいて、ロボット100に発話を行わせると判断した場合には、ロボット100に発話させる会話内容(言葉)を含む会話情報を生成し、生成した会話情報に基づいた音信号を出力する。音制御部110は、例えば、音声信号及び発話区間情報に基づいて参加者の会話内容を解析し、解析結果に基づいて、ロボット100に発話させるための会話情報を生成する。また、音制御部110は、発話誘導動作制御信号を受信した場合、発話誘導動作制御信号に設定されている発話誘導対象者に発話を促す内容の会話情報を生成し、生成した会話情報に基づいた音信号を出力する。
ここで、第1の実施形態における音制御部110の構成の詳細について一例を示して説明する。
図4は、第1の実施形態における音制御部110の構成の詳細の具体例を示す図である。音制御部110は、音声解析部401と、会話情報生成部402と、会話情報DB(データベース)403と、発声情報生成部404と、音信号生成部405とを備える。
会話情報DB403は、ロボット100に会話させるための会話サンプル情報を格納する。会話サンプル情報とは、日常の会話でよく使われる名詞、「こんにちは」等の挨拶及び「ありがとうございます」、「大丈夫ですか」等の日常会話でよく利用するフレーズの音声信号を含む情報である。さらに、会話情報DB403は、各話者の名前の音声信号と、「〜さんは、どう思いますか」、「〜さんは、何かありますか」などの発話を促すフレーズの音声信号を記憶する。
音声解析部401は、音声入力部104からの音声信号と、発話区間検出部107からの発話区間情報とに基づいて、音声信号を解析して、その内容(言葉)を特定し、解析結果を出力する。
会話情報生成部402は、発話制御信号を受信した場合、音声解析部401の解析結果に基づいて、ロボット100の発話内容となる会話情報を生成する。会話情報生成部402は、音声解析部401の解析結果に基づいて、会話する内容に応じた会話サンプル情報を会話情報DB403から取得する。会話情報生成部402は、取得した会話サンプル情報に基づいて、会話情報を生成する。会話情報生成部402は、発声情報生成部404からの会話情報の要求に応じて、会話情報を生成し、発声情報生成部404へ出力する。
また、会話情報生成部402は、発話誘導動作制御信号を受信した場合、その発話誘導動作制御信号に設定されている発話誘導対象者の名前の音声信号と、発話を促すフレーズの音声信号とを会話情報DB403から取得する。会話情報生成部402は、これらの音声信号を続けて出力する会話情報を生成し、発声情報生成部404へ出力する。
発声情報生成部404は、会話情報生成部402からの会話情報と、制御部109からの発話制御信号又は発話誘導動作制御信号とを入力として、発話信号を出力する。発声情報生成部404は、制御部109からの発話制御信号又は発話誘導動作制御信号に基づいて、会話情報生成部402に対して会話情報を要求する。発声情報生成部404は、要求に応じて会話情報生成部402から取得した会話情報と、制御部109からの発話制御信号又は発話誘導動作制御信号とに基づいて、ロボット100が発声するための発話信号を生成する。発声情報生成部404は、生成した発話信号を音信号生成部405へ出力する。
音信号生成部405は、発声情報生成部404からの発話信号を入力とし、音信号を出力する。音信号生成部405は、発声情報生成部404からの発話信号に基づいてスピーカ115から発話させるための音信号を生成して、スピーカ115へ出力する。
図1に示す口部制御部111は、制御部109からの発話誘導動作制御信号に基づいて、口部駆動部116に対して口部駆動信号を出力する。視線制御部112は、制御部109からの発話誘導動作制御信号に基づいて、眼部駆動部117に対して眼部駆動信号を出力する。頭部制御部113は、制御部109からの発話誘導動作制御信号に基づいて、頭部駆動部118に対して頭部駆動信号を出力する。胴部制御部114は、制御部109からの発話誘導動作制御信号に基づいて、胴部駆動部119に対して胴部駆動信号を出力する。
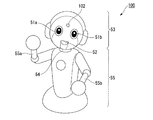
図5は、第1の実施形態におけるロボット100の外観及び構成の具体例を示す図である。第1の実施形態におけるロボット100は、例えば図5に示す外観を有し、図1に示す機能構成を有する。
図5に示すように、ロボット100は、例えば、人間の上半身をモデルとした形状のヒューマノイドロボット(人型ロボット)である。ロボット100は、発話を行う発話機能、人の音声を認識する音声認識機能、参加者を撮影するカメラ機能を少なくとも備える。ロボット100は、右目51a及び左目51bと、口部52とが配置された顔を有する頭部53を備える。
ロボット100は、頭部53を支持する頸部54と、頸部54を支える胴部55とを備える。胴部55は、上肢である右腕55aと左腕55bとが側面上部に設けられている。また、頭部53の右目51a、左目51bの間には、カメラ102が設置されている。以下の説明において、右目51a、左目51bをまとめて説明する場合は、眼部51と称する。
図1に示す構成の内、図5に示しているのは、カメラ102のみであるので、カメラ102以外の図1に示す構成の設置位置の一例について説明する。マイク101及びセンサ103は、ロボット100の胴部55内における任意の位置又は胴部55から離れた位置(例えば参加者の位置)に設置される。図1に示すマイク101、カメラ102及びセンサ103以外の構成は、ロボット100内部に設置されるものであり、例えば、スピーカ115は、図5に示した口部52の内部に設置されている。
ここで、ロボット100が備える口部駆動部116、眼部駆動部117、頭部駆動部118及び胴部駆動部119の配置と駆動する対象について説明する。頭部53は、右目51a及び左目51bの黒目(視線)を移動させる眼部駆動部117と、口部52の開閉を行う口部駆動部116とを備える。
頸部54は、頭部53に対して所定の動き(例えば、頷かせたり、顔の方向を変えたりする動き)を行わせる頭部駆動部118を備え、頭部53を支持する。胴部55は、呼吸をしているかのように、肩を動かしたり、胸の部分を膨らませたりする胴部駆動部119を備える。口部駆動部116は、口部制御部111からの口部駆動信号に基づいてロボット100の口部52の開閉を行う。眼部駆動部117は、視線制御部112からの眼部駆動信号に基づいてロボット100の眼部51における黒目の方向(=ロボット100の視線の方向)を制御する。
頭部駆動部118は、頭部制御部113からの頭部駆動信号に基づいてロボット100の頭部53の動きを制御する。胴部駆動部119は、胴部制御部114からの胴部駆動信号に基づいてロボット100の胴部55の形状を制御する。また、胴部駆動部119は、胴部制御部114からの胴部駆動信号に基づいてロボット100の右腕55aと左腕55bの動きも制御する。
次に、第1の実施形態におけるロボット100の動作について説明する。
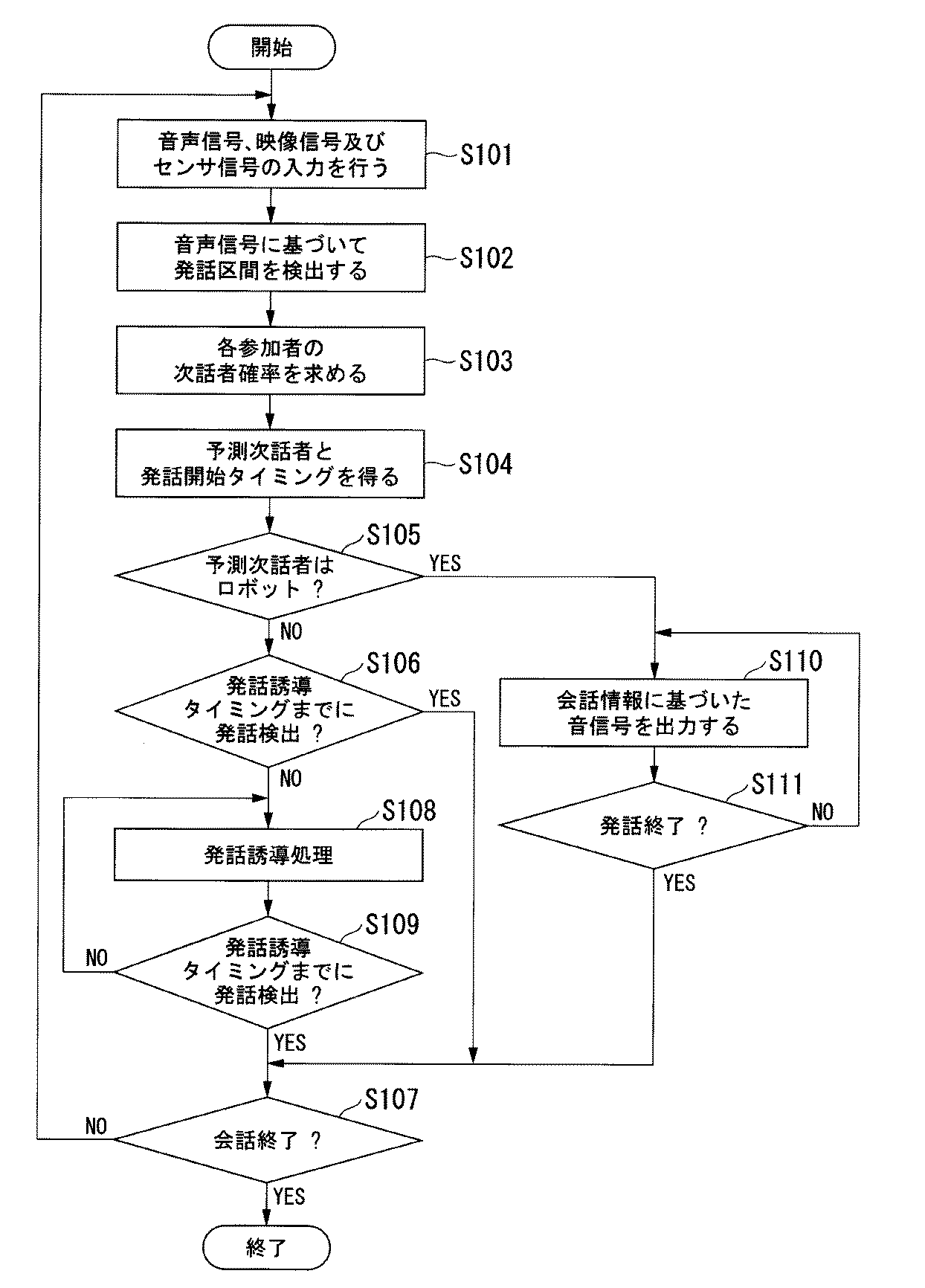
図6は、第1の実施形態におけるロボット100の動作を示すフロー図である。図6に示す処理は、ロボット100において、複数の参加者と会話を行う動作を開始した際に行う処理である。以下では、参加者A〜Dとロボット100が会話に参加している場合を例に説明する。
音声入力部104は、マイク101からの音声信号が入力され、映像入力部105は、カメラ102からの映像信号が入力され、センサ入力部106は、センサ103からのセンサ信号が入力される(ステップS101)。発話区間検出部107は、音声入力部104からの音声信号に基づいて、音声特徴量を算出し、算出した音声特徴量と所定の閾値を比較して発話区間を検出する(ステップS102)。
次話者確率推定部108は、音声信号、映像信号、センサ信号及び取得した発話者情報に基づいて、各参加者i(i∈{A,B,C,D})が時刻tに次話者となる確率である次話者確率Pns i(t)を算出する(ステップS103)。制御部109は、次話者確率推定部108が算出した各参加者の次話者確率に基づいて、上述した第1〜第5の次話者選択方法のいずれかを用いて、予測次話者と予測次話者の発話開始タイミングを得る(ステップS104)。
制御部109は、予測次話者が参加者A〜Dのいずれかであるかを判断する(ステップS105)。制御部109は、予測次話者が参加者A〜Dのいずれかであると判断した場合(ステップS105のNO)、音制御部110に、発話を行わないよう指示する発話制御信号を出力する。制御部109は、発話誘導タイミングが経過するまでの間に参加者A〜Dのいずれかが発話したか否かを判断する(ステップS106)。この発話誘導タイミングは、発話開始タイミング以降のタイミングであり、発話開始タイミングの直後であってもよく、会話中に沈黙が継続した場合に不自然と感じる時間に基づいて決められたタイミングであってもよい。後者のタイミングの場合、例えば、発話終了時刻から所定時間(例えば、2〜3秒)経過後としてもよく、推定された発話開始タイミングから所定時間経過後としてもよい。また、発話誘導タイミングは、予測次話者の次話者確率が所定値以下となる時刻であってもよい。
制御部109は、発話区間検出部107が発話誘導タイミングまでに発話区間の開始を検出した場合、参加者A〜Dのいずれかが発話したと判断し(ステップS106のYES)、ステップS107の処理を実行する。
一方、制御部109は、発話区間検出部107が発話誘導タイミングまでに発話区間の開始を検出しない場合(ステップS106のNO)、発話誘導処理を行う(ステップS108)。発話誘導処理において、制御部109は、発話誘導対象者を、予測次話者、又は、予測次話者の次に次話者確率が高い話者とする。発話誘導対象者を、予測次話者にするか、予測次話者の次に次話者確率が高い話者とするかは予め決められてもよく、動的に決定してもよい。動的に決定する場合、例えば、予測次話者である参加者x(xはA〜Dのいずれか)に対して過去に発話を促したときに参加者xが発話を行った確率Pxや、予測次話者の次に次話者確率が高い参加者y(y≠x、yはA〜Dのいずれか)に対して過去に発話を促したときに参加者yが発話を行った確率Pyに基づいて決定することができる。具体的には、Pxが所定の閾値以上である場合や、Px>Pyの場合に参加者xを予測次話者とし、Pxが所定の閾値よりも低い場合や、Px<Pyの場合に参加者yを予測次話者とする。
制御部109は、発話誘導対象者を特定する情報を設定した発話誘導動作制御信号を音制御部110、口部制御部111、視線制御部112、頭部制御部113、及び、胴部制御部114のうち1以上に出力する。制御部109は、視線制御部112、頭部制御部113、又は、胴部制御部114に出力する発話誘導動作制御信号に、発話誘導対象者の位置の情報をさらに設定する。これにより、ロボット100は、以下の(動作1)〜(動作5)いずれかまたは複数の動作を行い、発話誘導対象者への発話権の委譲を合図する。
(動作1)音制御部110は、発話誘導対象者に対して発話を促す内容の発話の音声をスピーカ115から出力する。例えば、発話誘導対象者に対して質問や要求を行う内容の発話を出力する。具体的には、「XXさんはどう思いますか?」(「XXさん」は、発話誘導対象者の名前)といった発話を行う。同時に、口部制御部111は、口部駆動信号を口部駆動部116に出力し、音声をスピーカ115から出力している間、口部52を開閉するよう制御する。
(動作2)視線制御部112は、眼部駆動信号を眼部駆動部117に出力し、眼部21における黒目の方向を、発話誘導対象者の方向となるように制御する。なお、視線を向けることは発話促進になることが知られている(参考文献2)。
参考文献2:石井 亮、外2名、“アバタ音声チャットシステムにおける会話促進のための注視制御”、ヒューマンインタフェース学会論文誌、Vol.10、No.1、p.87−94、2008年
(動作3)頭部制御部113は、頭部駆動信号を頭部駆動部118に出力し、頸部54を動かして頭部53を発話誘導対象者の方向に向けるように制御する。これにより、頭部53と視線を予測次話者の方向となるように制御する。
(動作4)胴部制御部114は、胴部駆動信号を胴部駆動部119に出力し、胴部55を発話誘導対象者の方向に回転させるように制御する。これにより、胴部、頭部、及び、視線を発話誘導対象者の方向となるように制御する。
(動作5)胴部制御部114は、胴部駆動信号を胴部駆動部119に出力し、右腕55aと左腕55bの一方又は両方を発話誘導対象者の方向に差し出すように制御する。
制御部109は、ステップS108において発話誘導処理を行った後、次の発話誘導タイミングが経過するまでの間に参加者A〜Dのいずれかが発話したか否かを判断する(ステップS109)。制御部109は、次の発話誘導タイミングが経過するまでの間に、発話区間検出部107が発話区間の開始を検出しない場合(ステップS109のNO)、再び、発話誘導処理を行う(ステップS108)。
制御部109は、ステップS109でNOと判断した後に発話誘導処理を行う場合、発話誘導対象者を、直前の発話誘導処理における発話誘導対象者としてもよく、直前の発話誘導処理において発話誘導対象者とした参加者の次に次話者確率が高い参加者としてもよい。例えば、制御部109は、同じ参加者がm回(mは1以上の整数)以上連続して発話誘導対象者となった場合に、その参加者の次に次話者確率が高い話者としてもよい。また、制御部109は、発話誘導対象者を、次話者確率が最大値となる時刻が直前の発話誘導処理における発話誘導対象者の次の参加者としてもよい。また、あるいは、制御部109は、予測次話者がまだ発話誘導対象者となっていない場合、発話誘導対象者を予測次話者としてもよい。
具体的には、第1又は第4の次話者選択方法において、参加者xの次話者確率Pns i(t)が最も高く、発話開始タイミングが時刻t1であったとき、時刻t1に参加者xが発話を開始しない条件下で、次話者確率Pns x(t)がある任意の確率oを下回る時刻をt2(Pns x(t2)<o)とする。時刻t2において次話者確率Pns x(t2)を上回る他の参加者yがいるとき(Pns x(t2)<Pns y(t2))、ロボット100は参加者yに時刻t2で発話を促す(t2≧t1)。
また、第3又は第5の次話者選択方法において、参加者xの積分値Pns iが最も高く、次話者確率Pns x(t)が最大となる時刻t1(発話開始タイミング)に参加者xが発話を開始しない条件下で、次話者確率Pns x(t)がある任意の確率oを下回る時刻をt2(Pns x(t2)<o)とする。時刻t2において次話者確率Pns x(t2)を上回る他の参加者yがいるとき(Pns x(t2)<Pns y(t2))、ロボット100は参加者yに時刻t2で発話を促す(t2≧t1)。
なお、第2の次話者選択方法において、参加者xの次話者確率Pns x(t)が最大となる時刻t1の次に、次話者確率が最大値をとる他の参加者yがいるとき、ロボット100は参加者yに時刻t2で発話を促す(t2≧t1)。
制御部109は、次の発話誘導タイミングが経過するまでの間に、発話区間検出部107が発話区間の開始を検出した場合(ステップS109のYES)、参加者A〜Dのいずれかが発話したと判断し、ステップS107の処理を実行する。
ステップS105において、制御部109は、予測次話者がロボット100であると判断した場合(ステップS105:YES)、ロボット100に発話を行わせるよう制御する発話制御信号を出力する。音制御部110は、制御部109からの発話制御信号に基づいて発話を行わせると判断し、ロボット100に発話させるための会話情報を生成し、生成した会話情報に基づいた音信号をスピーカ115へ出力する(ステップS110)。これにより、ロボット100は、音信号に応じた発話をスピーカ115から発音する。
音制御部110は、制御部109からの発話制御信号に基づいて、ロボット100の発話を終了するか否かを判断する(ステップS111)。ここで、ロボット100の発話を終了しない場合(ステップS111のNO)には、音制御部110は、ステップS110の処理に戻る。ロボット100の発話を終了する場合(ステップS111のYES)には、音制御部110は、会話情報の生成を停止することに応じて音信号の出力を停止する。
ステップS106、ステップS109、又はステップS111においてYESと判断された後、ロボット100は、複数の参加者と会話を行う会話動作を終了するか否かを判断する(ステップS107)。ここで、会話動作を終了しないと判断した場合(ステップS107のNO)には、ステップS101の処理に戻る。会話動作を終了すると判断した場合(ステップS107のYES)には、ロボット100は、会話動作を終了する。例えば、参加者が電源スイッチ(図示せず)を入れたタイミングや会話モードのスイッチ(図示せず)をオンにしたタイミングで、ロボット100は、会話動作を開始し、参加者が電源スイッチを切ったタイミングや会話モードのスイッチをオフにしたタイミングで、ロボット100は、会話動作を終了する。
以上に説明したとおり、第1の実施形態におけるロボット100は、複数の参加者と会話する際に、各参加者の次話者確率に基づいて次話者を推定し、推定された次話者が発話のタイミングを逸した場合、次話者に発話を促す。これにより、発話のタイミングを逸した参加者が発話しやすいように誘導することができる。また、推定された次話者が発話のタイミングを逸した場合、他の話者に発話を促すことも可能である。例えば、参加者は意図的に発話を控えていることもある。そこで、他の参加者に発話を促すことにより、会話中に沈黙が発生して、参加者が気まずさを感じたりすることが少なくなる。
なお、上記のステップS109において、次の発話誘導タイミングが経過するまでの間に、発話区間検出部107が発話区間の開始を検出しない場合、ロボット100は、ステップS103からの処理を行い、各参加者A〜Dの次話者確率を算出しなおしてもよい。
また、上記のステップS106において、制御部109は、いずれかの参加者の発話を検出したと判断した場合(ステップS106のYES)、さらに、発話者が予測次話者であるか否かを判断するようにしてもよい。制御部109は、発話者が予測次話者であると判断した場合、ステップS107の処理を実行する。一方、制御部109は、発話者が予測次話者ではないと判断した場合、予測次話者である参加者xが発話行う予定だったにもかかわらず、他の参加者yが割り込んで発話を行ったとみなし、参加者xに発話を促すようロボット100を制御する。促すタイミングは任意とすることができる。例えば、参加者yの発話の切れ目を検出し、この切れ目を検出した直後、又は、切れ目から所定時間後に、予測次話者を発話誘導対象者として発話誘導処理を行う。切れ目とは、例えば、「〜です。」といった語尾が発話された際や、無音区間がある任意の時間Dsを超えた時とすることができる。また、制御部109は、参加者yの発話を検出した直後、あるいは、参加者yの発話開始時刻から所定時間後に、参加者yの発話を制止する内容の音声を出力するよう指示する制御信号を音制御部110に出力してもよい。これにより、音制御部110は、「YYさん、ちょっと待ってください」といった内容の発話の音声をスピーカ115から出力する。その後、ロボット100は、予測次話者を発話誘導対象者として、ステップS108からの処理を実行してもよい。このように、参加者yの発話を制止する内容の音声によって、予測次話者の発話を促してもよい。
また、上記のステップS109において、制御部109は、いずれかの参加者の発話を検出したと判断した場合(ステップS109のYES)、発話者が発話誘導対象者であるか否かを判断するようにしてもよい。制御部109は、発話者が発話誘導対象者であると判断した場合、ステップS107の処理を実行する。一方、制御部109は、発話者が発話誘導対象者ではないと判断した場合、発話誘導対象者である参加者xが発話行う予定だったにもかかわらず、他の参加者yが割り込んで発話を行ったとみなし、参加者xに発話を促すようロボット100を制御する。例えば、上記と同様に、制御部109は、参加者yの発話の切れ目を検出した直後、又は、切れ目から所定時間後に、同じ発話誘導対象者について発話誘導処理を行う。あるいは、制御部109は、参加者yの発話を検出した直後、あるいは、参加者yの発話開始時刻から所定時間後に、参加者yの発話を制止する内容の音声を出力するよう指示する制御信号を音制御部110に出力する。
なお、本実施形態では、ロボット100が会話に参加する場合を例に記載したが、ロボット100は、会話に参加せず、参加者の発話を促す動作のみを行ってもよい。
(第2の実施形態)
第2の実施形態では、ロボット自身の動き(呼吸動作、視線動作、頭部動作)からロボット自身の次話者確率Pns R(t)を求める。ロボットは、求めた次話者確率Pns R(t)と他の参加者の次話者確率とに基づいて、予測次話者及び発話開始タイミングを推定する。そのため、ロボットは、会話に参加し、会話中に、会話中の人間同様の動きを行う。つまり、ロボットは、会話中に、呼吸音を発したり胸の膨らみを変化させたりする呼吸動作、視線を話者に向ける等の視線動作、会話に応じて頷いたりする頭部動作を行う。以下では、第1の実施形態との差分を中心に説明する。
図7は、第2の実施形態におけるロボット100Aが備える機能構成の概略を示す図である。図7に示す第2の実施形態におけるロボット100Aは、第1の実施形態におけるロボット100と同じ構成要素を含む。よって、ロボット100Aの説明においては、第1の実施形態におけるロボット100と同じ構成要素については、同じ符号を付与して説明を省略する。
図7に示すように、ロボット100Aは、マイク101と、カメラ102と、センサ103と、音声入力部104と、映像入力部105と、センサ入力部106と、発話区間検出部107と、次話者確率推定部108Aと、制御部109Aと、音制御部110と、口部制御部111と、視線制御部112と、頭部制御部113と、胴部制御部114と、スピーカ115と、口部駆動部116と、眼部駆動部117と、頭部駆動部118と、胴部駆動部119と、センサ信号変換部120とを備える。
次話者確率推定部108Aは、音声入力部104からの音声信号と、映像入力部105からの映像信号と、センサ入力部106からのセンサ信号と、発話区間検出部107からの発話区間情報と、制御部109Aからの疑似センサ信号とを入力とし、各参加者及びロボット100Aのそれぞれが時刻tに次話者となる確率である次話者確率を出力する。疑似センサ信号は、制御部109Aが生成する動作制御信号に基づいてロボット100を動作させ、かつ、そのロボット100Aの動作をセンサ103で検出したと仮定した場合に、センサ103が出力するセンサ信号である。
次話者確率推定部108Aは、音声信号、映像信号、センサ信号及び発話区間情報に基づいて、発話区間情報で特定される発話区間の発話者を示す発話者情報を取得する。次話者確率推定部108Aは、音声信号、映像信号、センサ信号、疑似センサ信号及び取得した発話者情報に基づいて、ロボット100Aが時刻tに次話者となる確率であるPns R(t)及び各参加者iが時刻tに次話者となる確率である次話者確率Pns i(t)を算出して、制御部109Aへ出力する。次話者確率推定部108Aは、次話者確率Pns R(t)及びPns i(t)の他に、発話者情報及び参加者の位置情報を制御部109Aへ出力する。
次話者確率推定部108Aは、参加者の位置情報を、例えば、センサ103の参加者の位置を計測したセンサ信号に基づいて取得してもよいし、映像信号に基づいて取得してもよいし、センサ103の参加者の位置を計測したセンサ信号及び映像信号に基づいて取得してもよい。
制御部109Aは、次話者確率推定部108Aからの次話者確率Pns i(t)、発話者情報及び参加者の位置情報を入力とし、発話制御信号又は発話誘導動作制御信号を出力する。制御部109Aは、各参加者及びロボット100Aの次話者確率Pns i(t)に基づいて予測次話者と発話開始タイミングを推定する。制御部109Aは、具体的には、以下に示す第6〜第10の次話者選択方法のいずれかを用いて次話者を選択する。なお、以下の説明においては、参加者A、B、C、Dの4名とロボット100Aとが会話を行う場合について説明する。制御部109Aは、次話者確率推定部108Aから次話者確率Pns i(t),(i∈{A,B,C,D,R})を取得する。
(第6の次話者選択方法)
制御部109Aは、参加者A〜D及びロボット100Aの次話者確率Pns i(t),(i∈{A,B,C,D,R})を比較する。制御部109Aは、Pns R(t)が最大であると判断した場合は、ロボット100Aを予測次話者とする。制御部109Aは、Pns R(t)が最大ではないと判断した場合は、次話者確率Pns i(t)の最大値が最も高い参加者A〜Dのいずれかを予測次話者と判断する。制御部109Aは、予測次話者の次話者確率Pns i(t)が最大値を取るときの時刻tを予測次話者の発話開始タイミングとする。
(第7の次話者選択方法)
制御部109Aは、次話者確率Pns i(t),(i∈{A,B,C,D,R})が最も早い時刻に最大値をとる参加者又はロボット100Aのいずれかを予測次話者と判断する。制御部109Aは、予測次話者の次話者確率Pns i(t)が最大値を取るときの時刻tを予測次話者の発話開始タイミングとする。
(第8の次話者選択方法)
制御部109Aは、参加者A〜D及びロボット100Aの次話者確率Pns i(t),(i∈{A,B,C,D,R})それぞれを、時刻tについて所定時間(例えば、発話終了から3〜4秒以上の時間)積分して、積分値Pns iを取得する。なお、積分区間を発話終了から無限時間としてもよく、全参加者の次話者確率Pns i(t)が所定値未満となり有意な値ではなくなる時間までとしてもよい。制御部109Aは、この積分値Pns iが最も大きい参加者A〜D又はロボット100Aのいずれかを予測次話者と判断する。制御部109Aは、予測次話者の次話者確率Pns i(t)が最大値を取るときの時刻tを予測次話者の発話開始タイミングとする。
(第9の次話者選択方法)
制御部109Aは、参加者A〜Dの次話者確率Pns i(t),(i∈{A,B,C,D})を加算した加算値(Pns A(t)+Pns B(t)+Pns C(t)+Pns D(t))を取得する。制御部109Aは、この加算値と、ロボット100Aの次話者確率Pns R(t)に定数ιを乗算したPns R(t)・ιと比較する(ιは正の値となる任意の定数)。制御部109Aは、加算値(Pns A(t)+Pns B(t)+Pns C(t)+Pns D(t))<Pns R(t)・ιと判断した場合は、ロボット100Aを予測次話者とする。制御部109Aは、加算値(Pns A(t)+Pns B(t)+Pns C(t)+Pns D(t))≧Pns R(t)・ιと判断した場合は、第1の実施形態の第1〜第3のいずれかの次話者選択方法によって、予測次話者と発話開始タイミングを得る。ただし、第1〜第3の次話者選択方法において、第1〜第3の閾値との比較は行わなくてもよい。このときの予測次話者は、参加者A〜Dのいずれかである。
(第10の次話者選択方法)
制御部109Aは、参加者A〜D及びロボット100Aの次話者確率Pns i(t),(i∈{A,B,C,D,R})それぞれを、時刻tについて所定時間(例えば、3〜4秒以上の時間)積分して、積分値Pns iを取得する。制御部109Aは、参加者A〜Dの全員の積分値Pns iを加算した加算値(Pns A+Pns B+Pns C+Pns D)と、ロボット100Aの積分値Pns Rに定数ζを乗算したPns R・ζと比較する(ζは正の値となる任意の定数)。制御部109Aは、(Pns A+Pns B+Pns C+Pns D)<Pns R・ζと判断した場合は、ロボット100Aを予測次話者とする。制御部109Aは、(Pns A+Pns B+Pns C+Pns D)≧Pns R・ζと判断した場合は、第1の実施形態の第1〜第3のいずれかの次話者選択方法によって、予測次話者と発話開始タイミングを得る。ただし、第1〜第3の次話者選択方法において、第1〜第3の閾値との比較は行わなくてもよい。このときの予測次話者は、参加者A〜Dのいずれかである。
次話者確率Pns i(t),(i∈{A,B,C,D,R})は、図3に示したように、発話終了から所定時間後にピークを有する場合が多い。そこで、制御部109Aは、第6〜第10の次話者選択方法において、次話者確率Pns i(t)を求める時刻tを含む窓幅を設けて、その窓幅の中における次話者確率の最大値を、時刻tにおける次話者確率Pns i(t)として用いるようにしてもよい。また、制御部109Aは、第6〜第10の次話者選択方法において、次話者確率Pns i(t)を求める時刻tを含む窓幅を設けて、その窓幅の中における次話者確率に複数のピークがある場合に、n番目(nは1以上の整数)のピークの次話者確率を、時刻tにおける次話者確率Pns i(t)として用いるようにしてもよい。
制御部109Aが備える動作パターン情報格納部1091Aは、第1の実施形態の動作パターン情報格納部1091が記憶する動作パターンに加え、ロボット100Aが会話中に行う動作の動作パターン情報を格納する。ロボット100Aが会話中に行う動作とは、例えば、発話を開始する前に、これから発話を行うことを周りの人に察知させるよう人が行っている動作と同様の動作である。例えば、複数人が会話している際に、非話者である人が次話者として発話する直前に行う行動を解析した結果、以下の(1)〜(3)の行動が「次は私が話を始めます」ということを周囲に示す行動であると考えられる。
(1)吸気音又はフィラーを発声する
(2)現話者に視線向ける
(3)現話者の会話に頷く
上述した解析結果を参考にして、制御部109Aは、ロボット100Aの発話前に、ロボット100Aに上述した(1)〜(3)の動作を行わせるよう制御することで、ロボット100Aがもうすぐ発話を開始することを参加者に予見させることができる。ロボット100Aが上述した(1)〜(3)の動作を行うと次話者確率推定部108Aが推定するロボット100Aの次話者確率Pns R(t)が上昇する。すなわち、発話を行うことを周りの人に察知させる動作とは、例えば、現話者に視線を移動させる動作、頭を頷かせる動作、吸気音とともに吸気する動作等を含む。
制御部109Aは、以下の公知文献に記載の技術を用いてロボット100Aに上述した(1)〜(3)の動作を行わせるよう制御してもよい。
(1)の吸気音を発声する動作をロボット100Aに行わせるための技術として以下の参考文献3に記載された公知技術がある。
参考文献3:吉田直人、外3名、“吐息と腹部運動を伴う呼吸表現に関する因子分析に基づいた生物的身体感情インタラクションの設計”、HAIシンポジウム2014、2014年
(2)の現話者に視線を向ける動作をロボット100Aに行わせるための技術として上記の参考文献2に記載された公知技術がある。
(3)の現話者の会話に頷く動作をロボット100Aに行わせるための技術として以下の参考文献4に記載された公知技術がある。
参考文献4:渡辺富夫、外3名、“InterActorを用いた発話音声に基づく身体的インタラクションシステム”、ヒューマンインタフェース学会論文誌、Vol.2、No.2、pp.21−29、2000年
制御部109Aは、予測次話者がいずれかの参加者である場合、第1の実施形態の制御部109と同様の動作を行う。制御部109Aは、予測次話者がロボット100Aの場合、ロボット100Aの発話の制御を行う発話制御信号を音制御部110に出力する。さらに、制御部109Aは、呼吸音やフィラーを発音するよう指示する発音指示信号を音制御部110へ出力する。ここで、フィラーとは、言い淀み時などに出現する場つなぎのための発声であり、例えば、「あのー」、「そのー」、「えっと」、等の音声である。また、制御部109Aは、次話者確率推定部108Aからの発話者情報及び参加者の位置情報に基づいて、動作パターン情報格納部1091Aから動作パターン情報を取得して動作制御信号を生成し、生成した動作制御信号を口部制御部111、視線制御部112、頭部制御部113及び胴部制御部114へ出力する。
センサ信号変換部120は、制御部109Aが生成した動作制御信号を疑似センサ信号に変換して次話者確率推定部108Aに出力する。
第2の実施形態におけるロボット100Aの外観は、図2に示したロボット100と同一である。
以上の構成により、ロボット100Aは、発話を行いたい場合に、発話前に、動作制御信号に基づいて視線を参加者に向けたり、呼吸音やフィラーを発音したりすることができる。参加者は、ロボット100Aが発話を開始する前に、ロボット100Aがまもなく発話することを予見することができる。この予見により、参加者とロボット100Aとの発話衝突を防ぎ、スムーズな会話を実現することができる。
次に、第2の実施形態におけるロボット100Aの動作について説明する。
図8は、第2の実施形態におけるロボット100Aの動作を示すフロー図である。図8に示す処理は、図6に示した処理と同様に、ロボット100Aにおいて、複数の参加者と会話を行う動作を開始した際に行う処理である。
音声入力部104は、マイク101からの音声信号が入力され、映像入力部105は、カメラ102からの映像信号が入力され、センサ入力部106は、センサ103からのセンサ信号が入力される。また、制御部109Aの制御によりロボット100Aの会話動作を行う(ステップS201)。ロボット100Aの会話動作には、上述した(1)〜(3)の動作が含まれる。このロボット100Aの会話動作に応じて、センサ信号変換部120は、疑似センサ信号を次話者確率推定部108Aに出力する。
発話区間検出部107は、音声入力部104からの音声信号に基づいて、音声特徴量を算出し、算出した音声特徴量と所定の閾値を比較して発話区間を検出する(ステップS202)。次話者確率推定部108Aは、音声信号、映像信号、センサ信号、疑似センサ信号及び発話者情報に基づいて、ロボット100A及び各参加者iが時刻tに次話者となる確率である次話者確率Pns i(t)を算出する(ステップS203)。
制御部109Aは、次話者確率推定部108Aからのロボット100A及び各参加者の次話者確率に基づいて、上述した第6〜第10の次話者選択方法のいずれかを用いて、予測次話者と予測次話者の発話開始タイミングを得る(ステップS204)。
ロボット100AのステップS205〜ステップS211の処理は、第1の実施形態のステップS105〜ステップS111の処理と同様である。ただし、ロボット100Aは、ステップS210の処理の前に、動作制御信号に基づいて視線を参加者に向けたり、発音指示信号に基づいて呼吸音やフィラーを発音したりする。
以上に説明したとおり、第2の実施形態におけるロボット100Aは、他の参加者と発話のタイミングが重なる発話衝突の発生を低減し、適切なタイミングで発話を行いながらも、参加者が発話のタイミングを逸した場合に、発話を促すことができる。
(第1、第2の実施形態に共通の次話者を推定する処理の具体例)
次に、上述したロボット100および第2の実施形態におけるロボット100Aに共通である次話者を推定する処理の具体例について説明する。ロボット100及びロボット100Aにおける次話者推定には、例えば、以下の参考文献5、6の技術などを適用することができるが、任意の既存の技術を利用してもよい。参考文献5、6記載の技術を利用した場合は、注視対象検出装置203が出力する注視対象情報に基づく発話者と非発話者の注視行動の遷移パターンを用いて、次話者確率推定部108又は次話者確率推定部108Aは、次話者および発話のタイミングを予測する。
参考文献5:特開2014−238525号公報
参考文献6:石井亮、外4名、“複数人対話における注視遷移パターンに基づく次話者と発話タイミングの予測”、人工知能学会研究会資料、SIG-SLUD-B301-06、pp.27-34、2013年
以下に、本実施形態に適用可能な参考文献5、6以外の次話者推定技術の例を示す。
会話の参加者の呼吸動作は次発話者と発話のタイミングに深い関連性がある。このことを利用して、会話の参加者の呼吸動作をリアルタイムに計測し、計測された呼吸動作から発話の開始直前に行われる特徴的な呼吸動作を検出し、この呼吸動作を基に次発話者とその発話タイミングを高精度に算出する。具体的には、発話開始直前におこなわれる呼吸動作の特徴として、発話を行っている発話者は、継続して発話する際(発話者継続時)には、発話終了直後にすぐに急激に息を吸い込む。逆に発話者が次に発話を行わない際(発話者交替時)には、発話者継続時に比べて、発話終了時から間を空けて、ゆっくりと息を吸い込む。また、発話者交替時に、次に発話をおこなう次発話者は、発話を行わない非発話者に比べて大きく息を吸い込む。このような発話の前におこなわれる呼吸は、発話開始に対しておおよそ決められたタイミングで行われる。このように、発話の直前に次発話者は特徴的な息の吸い込みを行うため、このような息の吸い込みの情報は、次発話者とその発話タイミングを予測するのに有用である。本次話者推定技術では、人物の息の吸い込みに着目し、息の吸い込み量や吸い込み区間の長さ、タイミングなどの情報を用いて、次発話者と発話タイミングを予測する。
以下では、A人の参加者P1,…,PAが対面コミュニケーションを行う状況を想定する。参加者Pa(ただし、a=1,…,A、A≧2)には呼吸動作計測装置202およびマイク101が装着される。呼吸動作計測装置202は、参加者Paの呼吸動作を計測し、各離散時刻tでの計測結果を表す呼吸情報Ba,tを得て、次話者確率推定部108又は次話者確率推定部108Aに出力する。呼吸動作計測装置202が、バンド式の呼吸装置を備える構成について説明する。バンド式の呼吸装置は、バンドの伸縮の強さによって呼吸の深さの度合いを示す値を出力する。息の吸い込みが大きいほどバンドの伸びが大きくなり、逆に息の吐き出しが大きいほどバンドの縮みが大きくなる(バンドの伸びが小さくなる)。以降、この値をRSP値と呼ぶ。なお、RSP値は、バンドの伸縮の強さに応じて参加者Paごとに異なる大きさを取る。そこで、これに起因するPaごとのRSP値の相違を排除するために、各参加者PaのRSP値の平均値μaと標準偏差値δaを用いて、μa+δaが1、μa−δaが−1になるように参加者PaごとにRSP値を正規化する。これによって、すべての参加者Paの呼吸動作データを同一に分析することが可能となる。各呼吸動作計測装置202は、正規化されたRSP値を呼吸情報Ba,tとして次話者確率推定部108又は次話者確率推定部108Aに送る。
さらに、マイク101は、参加者Paの音声を取得し、各離散時刻tでの参加者Paの音声を表す音声信号Va,tを得て、次話者確率推定部108又は次話者確率推定部108Aに出力する。次話者確率推定部108又は次話者確率推定部108Aは、入力された音声信号Va,t(ただし、a=1,…,A)から雑音を除去し、さらに発話区間Uk(ただし、kは発話区間Ukの識別子)とその発話者Pukとを抽出する。ただし、「Puk」の下付き添え字はuk=1,…,Aを表す。1つの発話区間UkをTd[ms]連続した無音区間で囲まれた区間と定義し、この発話区間Ukを発話の一つの単位と規定する。これにより、次話者確率推定部108又は次話者確率推定部108Aは、各発話区間Ukを表す発話区間情報、およびその発話者Pukを表す発話者情報(参加者P1,…,PAのうち何れが発話区間Ukでの発話者Pukであるかを表す発話者情報)を得る。
次話者確率推定部108又は次話者確率推定部108Aは、各参加者Paの呼吸情報Ba,tを用いて、各参加者Paの息の吸い込み区間Ia,kを抽出し、さらに息の吸い込みに関するパラメータλa,kを取得する。息の吸い込み区間とは、息を吐いている状態から、息を吸い込みだす開始位置と、息を吸い込み終わる終了位置との間の区間を示す。
図9は、息の吸い込み区間の例を示す図である。図9を用いて、息の吸い込み区間Ia,kの算出方法を例示する。ここで参加者Paの離散時刻tでのRSP値をRa,tと表記する。RSP値Ra,tは呼吸情報Ba,tに相当する。図9に例示するように、例えば、以下の(式1)が成り立つとき、
離散時刻t=ts(k)の前2フレームでRSP値Ra,tが連続して減少し、その後2フレームでRSP値Ra,tが連続して上昇しているから、離散時刻ts(k)を息の吸い込みの開始位置とする。さらに、以下の(式2)が成り立つとき、
離散時刻t=te(k)の前2フレームのRSP値Ra,tが連続して上昇し、その後2フレームのRSP値Ra,tが連続して減少しているから、離散時刻te(k)を息の吸い込みの終了位置とする。このとき、参加者Paの息の吸い込み区間Ia,kはts(k)からte(k)までの区間となり、息の吸い込み区間の長さはte(k)−ts(k)となる。
次話者確率推定部108又は次話者確率推定部108Aは、息の吸い込み区間Ia,kが抽出されると、息の吸い込み区間Ia,k、呼吸情報Ba,t、および発話区間Ukの少なくとも一部を用い、息の吸い込みに関するパラメータλ’a,kを抽出する。パラメータλ’a,kは、参加者Paの吸い込み区間Ia,kでの息の吸い込みの量、吸い込み区間Ia,kの長さ、吸い込み区間Ia,kでの息の吸い込み量の時間変化、および発話区間Ukと吸い込み区間Ia,kとの時間関係の少なくとも一部を表す。パラメータλ’a,kは、これらの一つのみを表してもよいし、これらのうち複数を表してもよいし、これらすべてを表してもよい。パラメータλ’a,kは、例えば以下のパラメータMINa,k,MAXa,k,AMPa,k,DURa,k,SLOa,k,INT1a,kの少なくとも一部を含む。パラメータλ’a,kは、これらの1つのみを含んでいてもよいし、これらのうち複数を含んでいてもよいし、これらのすべてを含んでいてもよい。
・MINa,k:参加者Paの息の吸い込み開始時のRSP値Ra,t、すなわち、息の吸い込み区間Ia,kのRSP値Ra,tの最小値。
・MAXa,k:参加者Paの息の吸い込み終了時のRSP値Ra,t、すなわち、息の吸い込み区間Ia,kのRSP値Ra,tの最大値。
・AMPa,k:参加者Paの息の吸い込み区間Ia,kのRSP値Ra,tの振幅、すなわち、MAXa,k−MINa,kで算出される値。吸い込み区間Ia,kでの息の吸い込み量を表す。
・DURa,k:参加者Paの息の吸い込み区間Ia,kの長さ、すなわち、息の吸い込み区間Ia,kの終了位置の離散時刻te(k)から開始位置の離散時刻ts(k)を減じて得られる値te(k)−ts(k)。
・SLOa,k:参加者Paの息の吸い込み区間Ia,kにおけるRSP値Ra,tの単位時間当たりの傾きの平均値、すなわち、AMPa,k/DURa,kで算出される値。吸い込み区間Ia,kでの息の吸い込み量の時間変化を表す。
・INT1a,k:手前の発話区間Ukの終了時刻tue(k)(発話区間末)から参加者Paの息の吸い込みが開始されるまでの間隔、すなわち、息の吸い込み区間Ia,kの開始位置の離散時刻ts(k)から発話区間Ukの終了時刻tue(k)を減じて得られる値ts(k)−tue(k)。発話区間Ukと吸い込み区間Ia,kとの時間関係を表す。
次話者確率推定部108又は次話者確率推定部108Aは、さらに以下のパラメータINT2a,kを生成してもよい。
・INT2a,k:参加者Paの息の吸い込み終了時から次発話者の発話区間Uk+1が開始されるまでの間隔、すなわち、次発話者の発話区間Uk+1の開始時刻tus(k+1)から息の吸い込み区間Ia,kの終了位置の離散時刻te(k)を減じて得られる値tus(k+1)−te(k)。発話区間Uk+1と吸い込み区間Ia,kとの時間関係を表す。パラメータλ’a,kにINT2a,kを加えたものをパラメータλa,kと表記する。
次話者確率推定部108又は次話者確率推定部108Aは、例えば発話区間Uk+1を表す情報が得られ、さらに、パラメータλa,kが得られた以降(発話区間Uk+1が開始された後)に、発話区間Ukおよびその発話者Puk、発話区間Uk+1およびその発話者Puk+1とその発話開始タイミングTuk+1を表す情報とともにデータベースに記録する。次発話者Puk+1の発話タイミングとは、発話区間Uk+1の何れかの時点またはそれに対応する時点であればよい。発話タイミングTuk+1は、発話区間Uk+1の開始時刻tus(k+1)であってもよいし、時刻tus(k+1)+γ(ただし、γは正または負の定数)であってもよいし、発話区間Uk+1の終了時刻tue(k+1)であってもよいし、時刻tue(k+1)+γであってもよいし、発話区間Uk+1の中心時刻tus(k+1)+(tue(k+1)−tus(k+1))/2であってもよい。λa,k,Uk,Puk,Puk+1,Tuk+1を表す情報の一部またはすべてがデータベースに保持され、次話者確率推定部108又は次話者確率推定部108Aが発話区間Uk+1よりも後の次発話者とその発話タイミングを予測するために使用される。
次話者確率推定部108又は次話者確率推定部108Aは、発話者情報Puk、発話区間Uk、参加者Paの吸い込み区間Ia,kでの息の吸い込み量、吸い込み区間Ia,kの長さ、吸い込み区間Ia,kでの息の吸い込み量の時間変化、および発話区間Ukと吸い込み区間Ia,kとの時間関係の少なくとも一部に基づき、参加者P1,…,PAのうち何れが次発話者Puk+1であるか、および次発話者Puk+1の発話タイミングの少なくとも一方を表す推定情報を得る。ただし、「Puk+1」の下付き添え字「uk+1」はuk+1を表す。発話区間Ukの発話者Pukが発話区間Uk+1でも発話を行う場合(発話継続する場合)、次発話者は発話区間Ukの発話者Pukと同一である。一方、発話区間Ukの発話者Puk以外の参加者が発話区間Uk+1でも発話を行う場合(すなわち発話交替する場合)、次発話者は発話区間Ukの発話者Puk以外の参加者である。
次話者確率推定部108又は次話者確率推定部108Aは、発話者情報Puk、発話区間Uk、参加者Paの吸い込み区間Ia,kでの息の吸い込み量、吸い込み区間Ia,kの長さ、吸い込み区間Ia,kでの息の吸い込み量の時間変化、および発話区間Ukと吸い込み区間Ia,kとの時間関係の少なくとも一部に対応する特徴量fa,kに対する推定情報を得るためのモデルを機械学習し、このモデルを用いて特徴量に対する推定情報を得る。特徴量fa,kは、発話者情報Puk、発話区間Uk、参加者Paの吸い込み区間Ia,kでの息の吸い込み量、吸い込み区間Ia,kの長さ、吸い込み区間Ia,kでの息の吸い込み量の時間変化、および発話区間Ukと吸い込み区間Ia,kとの時間関係の1つのみに対応してもよいし、これらのうち複数に対応してもよいし、すべてに対応してもよい。モデルの機械学習には、例えば、過去の吸い込み区間Ia,i(ただし、i<k)での息の吸い込み量、吸い込み区間Ia,iの長さ、吸い込み区間Ia,iでの息の吸い込み量の時間変化、および発話区間Uiと吸い込み区間Ia,iとの時間関係の少なくとも一部に対応する特徴量fa,k、ならびに発話区間Ui,Ui+1およびそれらの発話者Puk,Puk+1の情報が学習データとして用いられる。
次話者確率推定部108又は次話者確率推定部108Aによる次発話者/発話タイミング推定処理を例示する。この例では、次発話者Puk+1を推定するモデルである次発話者推定モデルと、次発話者Puk+1の発話タイミングを推定するモデルである発話タイミング推定モデルとが生成され、それぞれのモデルを用いて次発話者Puk+1とその発話タイミングが推定される。
次発話者推定モデルを学習する場合、次話者確率推定部108又は次話者確率推定部108Aは、学習データとして、データベースから過去のパラメータλa,i(ただし、a=1,…,Aであり、i<kである)の少なくとも一部、および発話区間Ui,Ui+1およびそれらの発話者Pui,Pui+1を表す情報を読み出す。次話者確率推定部108又は次話者確率推定部108Aは、パラメータλa,iの少なくとも一部に対応する特徴量F1a,iおよびUi,Ui+1,Pui,Pui+1を学習データとして、次発話者推定モデルを機械学習する。次発話者推定モデルには、例えば、SVM(Support Vector Machine)、GMM(Gaussian Mixture Model)、HMM(Hidden Markov Model)等を用いることができる。
次話者確率推定部108又は次話者確率推定部108Aは、パラメータλ’a,kの少なくとも一部に対応する特徴量F1a,kを次発話者推定モデルに適用し、それによって推定された次発話Puk+1を表す情報を「推定情報」の一部とする。なお、次発話Puk+1を表す情報は、何れかの参加者Paを確定的に表すものであってもよいし、確率的に表すものであってもよい。参加者Paが次話者になる確率を、P1aとする。
発話タイミング推定モデルを学習する場合、次話者確率推定部108又は次話者確率推定部108Aは、学習データとして、データベースから過去のパラメータλa,i(ただし、a=1,…,Aであり、i<kである)の少なくとも一部、発話区間Ui,Ui+1およびそれらの発話者Pui,Pui+1、および発話区間Ui+1の発話開始タイミングTui+1を表す情報を読み出す。次話者確率推定部108又は次話者確率推定部108Aは、パラメータλa,iの少なくとも一部に対応する特徴量F2a,iおよびUi,Ui+1,Pui,Pui+1,Tui+1を学習データとして、発話タイミング推定モデルを機械学習する。次発話者推定モデルには、例えば、SVM、GMM、HMM等を用いることができる。
次話者確率推定部108又は次話者確率推定部108Aは、発話者Puk、パラメータλ’a,kの少なくとも一部、および次発話者推定モデルにより推定された次発話者Puk+1が得られると、パラメータλ’a,kの少なくとも一部に対応する特徴量F2a,kを発話タイミング推定モデルに適用する。次話者確率推定部108又は次話者確率推定部108Aは、特徴量F2a,kを発話タイミング推定モデルに適用して推定された次の発話区間Uk+1の発話タイミングTuk+1(例えば、発話区間Uk+1の開始時刻)を表す情報を「推定情報」の一部として出力する。なお、発話タイミングを表す情報は、何れかの発話タイミングを確定的に表すものであってもよいし、確率的に表すものであってもよい。参加者Paが時刻tに発話を開始する確率(時刻tが参加者Paの発話タイミングである確率)を、P2a(t)とする。
上述した実施形態の次話者確率推定部108又は次話者確率推定部108Aが推定する参加者iの時刻tにおける次話者確率Pns i(t)は、参加者iが本次話者推定技術における参加者Paである場合、確率P1a×確率P2a(t)により算出される。
上述の次話者確率推定部108又は次話者確率推定部108Aは、呼吸動作の観測値に基づいて次に発話を開始する参加者およびタイミングを推定しているが、さらに、視線の観測値を用いてもよい。
視線行動をさらに利用する場合、各参加者Pa(ただし、a=1,…,A)には注視対象検出装置203がさらに装着される。注視対象検出装置203は、参加者Paが誰を注視しているか(注視対象)を検出し、参加者Paおよび各離散時刻tでの注視対象Ga,tを表す情報を次話者確率推定部108又は次話者確率推定部108Aに送る。次話者確率推定部108又は次話者確率推定部108Aは、注視対象情報G1,t,…,GA,t、発話区間Uk、および話者情報Pukを入力とし、発話区間終了前後における注視対象ラベル情報θv,k(ただし、v=1,…,V、Vは注視対象ラベルの総数)を生成する。注視対象ラベル情報は、発話区間Ukの終了時点Tseに対応する時間区間における参加者の注視対象を表す情報である。ここでは、終了時点Tseを含む有限の時間区間における参加者Paの注視対象をラベル付けした注視対象ラベル情報θv,kを例示する。この場合、例えば、発話区間Ukの終了時点Tseよりも前の時点Tse−Tbから終了時点Tseよりも後の時点Tse+Taまでの区間に出現した注視行動を扱う。Tb,Taは0以上の任意の値でよいが、目安として、Tbは0秒〜2.0秒、Taは0秒〜3.0秒程度にするのが適当である。
次話者確率推定部108又は次話者確率推定部108Aは、注視対象の参加者を以下のような種別に分類し、注視対象のラベリングを行う。なお、ラベルの記号に意味はなく、判別できればどのような表記でも構わない。
・ラベルS:話者(すなわち、話者である参加者Pukを表す)
・ラベルLξ:非話者(ただし、ξは互いに異なる非話者である参加者を識別し、ξ=1,…,A−1である。例えば、ある参加者が、非話者P2、非話者P3、の順に注視をしていたとき、非話者P2にL1というラベル、非話者P3にL2というラベルが割り当てられる。)
・ラベルX:誰も見ていない
ラベルがSまたはLξのときには、相互注視(視線交差)が起きたか否かという情報を付与する。本形態では、相互注視が起きた際には、SM,LξM(下付き添え字の「ξM」はξMを表す)のように、ラベルS,Lξの末尾にMラベルを付与する。
図10は、注視対象ラベルの具体例を示す図である。図10はA=4の例であり、発話区間Uk,Uk+1と各参加者の注視対象が時系列に示されている。図10の例では、参加者P1が発話した後、発話交替が起き、新たに参加者P2が発話をした際の様子を示している。ここでは、話者である参加者P1が参加者P4を注視した後、参加者P2を注視している。Tse−Tbの時点からTse+Taの時点までの区間では、参加者P1が参加者P2を見ていたとき、参加者P2は参加者P1を見ている。これは、参加者P1と参加者P2とで相互注視が起きていることを表す。この場合、参加者P1の注視対象情報G1,tから生成される注視対象ラベルはL1とL2Mの2つとなる。上述の区間では、参加者P2は参加者P4を注視した後、話者である参加者P1を注視している。この場合、参加者P2の注視対象ラベルはL1とSMの2つとなる。また、上述の区間では、参加者P3は話者である参加者P1を注視している。この場合、参加者P3の注視対象ラベルはSとなる。また、上述の区間では、参加者P4は誰も見ていない。この場合、参加者P4の注視対象ラベルはXとなる。したがって、図10の例では、V=6である。
次話者確率推定部108又は次話者確率推定部108Aは、注視対象ラベルごとの開始時刻、終了時刻も取得する。ここで、誰(R∈{S,L})のどの注視対象ラベル(GL∈{S,SM,L1,L1M,L2,L2M,…})であるかを示す記号としてRGL、その開始時刻をST_RGL、終了時刻をET_RGLと定義する。ただし、Rは参加者の発話状態(話者か非話者か)を表し、Sは話者、Lは非話者である。例えば、図10の例において、参加者P1の最初の注視対象ラベルはSL1であり、その開始時刻はST_SL1、終了時刻はET_SL1である。注視対象ラベル情報θv,kは注視対象ラベルRGL、開始時刻ST_RGL、および終了時刻ET_RGLを含む情報である。
次話者確率推定部108又は次話者確率推定部108Aは、注視対象ラベル情報θv,kを用いて、各参加者Paの注視対象遷移パターンEa,kを生成する。注視対象遷移パターンの生成は、注視対象ラベルRGLを構成要素として、時間的な順序を考慮した遷移n−gramを生成して行う。ここで、nは正の整数である。例えば、図10の例を考えると、参加者P1の注視対象ラベルから生成される注視対象遷移パターンE1,kはL1−L2Mである。同様にして、参加者P2の注視対象遷移パターンE2,kはL1−SM、参加者P3の注視対象遷移パターンE3,kはS、参加者P4の注視対象遷移パターンE4,kはXとなる。
注視対象遷移パターンEa,kは、例えば発話区間Uk+1が開始された後に、発話区間Ukおよびその発話者Puk、発話区間Uk+1に該当する発話を行う次発話者Puk+1および次発話開始タイミングTuk+1を表す情報とともにデータベースに送られる。データベースでは、注視対象遷移パターンEa,kが、パラメータλa,kと併合され、Ea,k,λa,k,Uk,Puk,Puk+1,Tuk+1を表す情報の一部またはすべてがデータベースに保持される。
次話者確率推定部108又は次話者確率推定部108Aは、注視対象ラベル情報θv,kを入力とし、注視対象ラベルごとの時間構造情報Θv,kを生成する。時間構造情報は参加者の視線行動の時間的な関係を表す情報であり、(1)注視対象ラベルの時間長、(2)注視対象ラベルと発話区間の開始時刻または終了時刻との間隔、(3)注視対象ラベルの開始時刻または終了時刻と他の注視対象ラベルの開始時刻または終了時刻との間隔、をパラメータとして持つ。
具体的な時間構造情報のパラメータを以下に示す。以下では、発話区間の開始時刻をST_U、発話区間の終了時刻をET_Uと定義する。
・INT1(=ET_RGL−ST_RGL):注視対象ラベルRGLの開始時刻ST_RGLと終了時刻ET_RGLの間隔
・INT2(=ST_U−ST_RGL):注視対象ラベルRGLの開始時刻ST_RGLが発話区間の開始時刻ST_Uよりもどれくらい前であったか
・INT3(=ET_U−ST_RGL):注視対象ラベルRGLの開始時刻ST_RGLが発話区間の終了時刻ET_Uよりもどれくらい前であったか
・INT4(=ET_RGL−ST_U):注視対象ラベルRGLの終了時刻ET_RGLが発話区間の開始時刻ST_Uよりもどれくらい後であったか
・INT5(=ET_U−ET_RGL):注視対象ラベルRGLの終了時刻ET_RGLが発話区間の終了時刻ET_Uよりもどれくらい前であったか
・INT6(=ST_RGL−ST_RGL’):注視対象ラベルRGLの開始時刻ST_RGLが他の注視対象ラベルRGL’の開始時刻ST_RGL’よりもどれくらい後であったか
・INT7(=ET_RGL’−ST_RGL):注視対象ラベルRGLの開始時刻ST_RGLが他の注視対象ラベルRGL’の終了時刻ET_RGL’よりもどれくらい前であったか
・INT8(=ET_RGL−ST_RGL’):注視対象ラベルRGLの終了時刻ET_RGLが注視対象ラベルRGL’の開始時刻ST_RGL’よりもどれくらい後であったか
・INT9(=ET_RGL−ET_RGL’):注視対象ラベルRGLの終了時刻ET_RGLが注視対象ラベルRGL’の終了時刻ET_RGL’よりもどれくらい後であったか
なお、INT6〜INT9については、すべての参加者の注視対象ラベルとの組み合わせに対して取得する。図10の例では、注視対象ラベル情報は全部で6つ(L1,L2M,L1,SM,S,X)あるため、INT6〜INT9は、それぞれ6×5=30個のデータが生成される。
時間構造情報Θv,kは注視対象ラベル情報θv,kについてのパラメータINT1〜INT9からなる情報である。時間構造情報Θv,kを構成する上記の各パラメータについて、図11を用いて具体的に示す。図11は、話者である参加者P1(R=S)の注視対象ラベルL1についての時間構造情報を示す図である。すなわち、RGL=SL1における時間構造情報である。なお、INT6〜INT9については、図示を簡略化するために、参加者P2の注視対象ラベルL1、すなわちRGL=LL1との関係のみを示す。図11の例では、INT1〜INT9は以下のように求められることがわかる。
・INT1=ET_SL1−ST_SL1
・INT2=ST_U−ST_SL1
・INT3=ET_U−ST_SL1
・INT4=ET_SL1−ST_U
・INT5=ET_U−ET_SL1
・INT6=ST_SL1−ST_LL1
・INT7=ET_LL1−ST_SL1
・INT8=ET_SL1−ST_LL1
・INT9=ET_SL1−ET_LL1
時間構造情報Θv,kは、例えば発話区間Uk+1が開始された後に、発話区間Ukおよびその発話者Puk、発話区間Uk+1に該当する発話を行う次発話者Puk+1および次発話開始タイミングTuk+1を表す情報とともにデータベースに送られる。データベースでは、時間構造情報Θv,kが、パラメータλa,kと併合され、Θv,k,λa,k,Uk,Puk,Uk+1,Puk+1,Tuk+1を表す情報の一部またはすべてがデータベースに保持される。
次話者確率推定部108又は次話者確率推定部108Aは、注視対象遷移パターンEa,k、時間構造情報Θv,k、発話者情報Puk、発話区間Uk、参加者Paの吸い込み区間Ia,kでの息の吸い込み量、吸い込み区間Ia,kの長さ、吸い込み区間Ia,kでの息の吸い込み量の時間変化、および発話区間Ukと吸い込み区間Ia,kとの時間関係の少なくとも一部に対応する特徴量fa,kに対する推定情報を得るためのモデルを機械学習し、モデルを用いて特徴量に対する推定情報である次話者確率Pns i(t)を得て出力する。
上述の次話者確率推定部108又は次話者確率推定部108Aは、呼吸動作の観測値および視線の観測値に基づいて次に発話を開始する参加者およびタイミングを推定しているが、さらに、参加者の頭部の動きに関する情報を用いてもよい。これは、人は発話の直前に大きく頷く傾向があることを利用するものである。次話者確率推定部108又は次話者確率推定部108Aは、映像入力部105からの各参加者の画像データを解析して、頭部が上下に動いたか否かにより参加者が頷いたか否かを判定する。次話者確率推定部108又は次話者確率推定部108Aは、参加者iが時刻tの数秒前に頷いたと判定した場合には、参加者iの時刻tにおける次話者確率Pns i(t)に所定値を加算する処理等を行う。また、次話者確率推定部108又は次話者確率推定部108Aは、呼吸動作の観測値、視線の観測値および、参加者の頭部の動きに関する情報の少なくとも一つに基づいて次話者確率Pns i(t)を算出してもよい。
また、次話者確率推定部108又は次話者確率推定部108Aが呼吸動作の観測値、視線の観測値および、参加者の頭部の動きに関する情報の少なくとも一つを用いている場合は、次話者確率推定部108又は次話者確率推定部108Aで用いる情報に応じて、センサ103は、位置計測装置201、呼吸動作計測装置202、注視対象検出装置203及び頭部動作検出装置204のいずれか一つ又は複数を備える構成でよい。
なお、上述した第1の実施形態におけるロボット100及び第2の実施形態におけるロボット100Aは、マイク101、カメラ102、センサ103、音声入力部104、映像入力部105、センサ入力部106、発話区間検出部107、次話者確率推定部108又は次話者確率推定部108A及び制御部109又は制御部109Aを内蔵する構成としたが、この構成に限られるものではない。マイク101、カメラ102、センサ103、音声入力部104、映像入力部105、センサ入力部106、発話区間検出部107、次話者確率推定部108(又は次話者確率推定部108A)及び制御部109(又は制御部109A)の少なくとも一部を備える会話支援装置をロボット100(又はロボット100A)と別装置で設ける構成としてもよい。会話支援装置は、ロボット100(又はロボット100A)と通信可能な構成であり、制御部109(又は制御部109A)からの制御信号をロボット100(又はロボット100A)へ送信することで、ロボット100(又はロボット100A)の発話を制御する。
ロボット100及びロボット100Aは、その体の一部をディスプレイ等の表示部に体の一部を表示する構成であってもよく、全身が仮想的な人物であるエージェントとして表示部に表示されるものであってもよい。ロボット100及びロボット100Aの体の一部を表示部で表現するとは、例えば、顔全体が表示部となっており、その表示部に顔の画像を表示する構成等が考えられる。表示部に表示した顔の画像を変化させていろいろな表現を行うことができる。なお、ロボット100及びロボット100Aは、複数のマイク101及びセンサ103を備えない構成であってもよく、例えば、ロボット100及びロボット100Aの外部に設置された複数のマイク101及びセンサ103と有線又は無線にて信号を送受信可能な構成であってもよい。
実施形態におけるロボット100及び第2の実施形態におけるロボット100Aにおいて、上述した発話制御処理の妨げにならない範囲であれば、図1及び図7に示した機能以外の通常のロボットが備えている機能等を備えてもよい。また、第1の実施形態におけるロボット100は、第2の実施形態におけるロボット100Aのような呼吸動作等の会話時の人間と同様の動作を行うことができる構成としてもよい。
以上説明した実施形態によれば、会話支援システムは、例えばロボットであり、会話中の各参加者の視線、呼吸、頭部の動きなどの非言語行動の計測結果に基づいて、参加者それぞれが任意の時刻に次発話となる確率である次話者確率を推定する。会話支援システムは、各参加者の次話者確率に基づいて、次に発話を行うべき参加者である予測次話者と、予測次話者が発話を開始するタイミングとを推定し、推定されたタイミングに予測次話者が発話を行わなかったことを検出した場合に、予測次話者又は予測次話者とは異なる参加者を対象者として発話を促す。会話支援システムは、発話を促すために、対象者に発話権の移譲を示す動作を行うよう、ロボット、又は、表示装置に表示される話者(全身が仮想的な人物であるエージェント)を制御する。例えば、ロボット、又は、表示装置に表示される話者は、対象者の発話を促す音声を出力したり、眼、頭部、胴部を動かして対象者に視線や顔を向ける、上肢を対象者に差し出すなどの非言語行動をとったりする。
上述した実施形態によれば、発話のタイミングを逸してしまった参加者に対して、ロボット、又は、表示装置に表示される話者が発話を促すことで、その参加者の発話を促すことができる。また、会話中の沈黙が長くなり、会話の雰囲気が悪くなってしまわないように、参加者へ発話を促すことができる。
上述した本実施形態におけるロボット100又はロボット100Aの備える各機能部は、例えば、コンピュータで実現することができる。その場合、この機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することによって実現してもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含んでもよい。また上記プログラムは、前述した機能の一部を実現するためのものであってもよく、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであってもよく、FPGA(Field Programmable Gate Array)等のプログラマブルロジックデバイスを用いて実現されるものであってもよい。
以上、この発明の実施形態について図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計等も含まれる。