本実施の形態において1つの命令で複数のデータについて処理を行う命令をSIMD命令(またはマルチデータ命令)と称する。SIMD命令は,例えばSIMD幅の数のデータについてSIMD幅の数の演算器が並列に処理を行い,SIMD幅の数のレジスタを1つのレジスタ単位とするSIMDレジスタに処理結果を格納する。
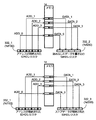
図1は,本実施の形態における演算処理装置が実現可能なインダイレクトメモリアクセス方式を説明する図である。図1は,SIMDレジスタ332_1に格納された複数の独立したデータをアドレスとして使用し,1つの命令でメモリ領域14の複数箇所にアクセスするインダイレクトメモリアクセス方式である。図1の例では,SIMD幅が4の例であり,このようなインダイレクトメモリアクセスを行う命令を,SIMDインダイレクトメモリアクセス命令と称する。
図1(A)は,SIMDインダイレクトロード命令(またはSIMD間接ロード命令)の例であり,SIMDレジスタ332_1に格納された4つの独立したデータをアドレスとして利用し,メモリ14の4つのアドレスADD_0-ADD_3のデータDATA_0-DATA_3を読み出し,別のSIMDレジスタ332_2に書込む。このSIMDインダイレクトロード命令は,例えば次のように記述される。
load %f100 %f200
ここで,%f100はアドレスが格納されたSIMDレジスタ332_1のレジスタ番号であり,%f200はデータを書込むSIMDレジスタ332_2のレジスタ番号である。
図1(B)は,SIMDインダイレクトストア命令(またはSIMD間接ストア命令)の例であり,SIMDレジスタ332_1に格納された4つの独立したデータをアドレスとして利用し,別のSIMDレジスタ332_3内のデータDATA_0-DATA_3をメモリ14の4つのアドレスADD_0-ADD_3の領域に書き込む。このSIMDインダイレクトストア命令は,例えば次のように記述される。
store %f100 %f300
ここで,%f100はアドレスが格納されたSIMDレジスタ332_1のレジスタ番号であり,%f300は書き込みデータが格納されたSIMDレジスタ332_3のレジスタ番号である。
上記の場合,SIMDレジスタ332_1に4つの独立したアドレスを書き込む処理は,例えば4回のロード命令を実行することで行われる。または,メモリの連続するアドレスに4つの独立したアドレスを書き込んでおき,メモリの先頭アドレスをソースアドレスとするSIMDロード命令を実行することで行われる。
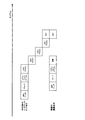
図2は,ブロックロード命令によるパイプライン処理の例を示す図である。ここでのブロックロード命令は,例えばメモリの連続領域のデータを複数の汎用レジスタに書き込む命令である。ブロックロード命令は,命令デコーダでデコードされると,命令デコーダが複数のメモリアクセス命令を生成し,その複数のメモリアクセス命令が,順次命令デコーダでデコードされ,メモリアクセス用リザベーションステーションにエントリされ,メモリアクセスされる。つまり,マルチフロー方式である。
したがって,4つのデータをメモリからロードする場合は,ブロックロード命令は4つのメモリアクセス命令に分割され,それぞれ命令デコードとリザベーションステーションへのエントリとメモリアクセスとが4回繰り返される。そのため,後続の演算命令は,4サイクルにわたりデコード待ち状態となる。
このようなブロックロード命令の手法を利用して上記のSIMDインダイレクトロード命令を実現しようとすると,同様に,命令デコードとリザベーションステーションへのエントリとインダイレクトロードの処理とを4回繰り返す必要があり,CPUコア内の資源を4サイクルにわたり占有し,後続の演算命令の命令デコードが可能になるのはマルチフローの最後の命令のデコードが完了した後になる。これでは,後続命令が依存関係のない命令の場合に利用可能なアウト・オブ・オーダの利点を生かすことができない。
[本実施の形態]
図3は,本実施の形態におけるSIMDインダイレクトメモリアクセス命令によるパイプライン処理を示す図である。本実施の形態のSIMDインダイレクトメモリアクセス命令では,1つのSIMDインダイレクトメモリアクセス命令を命令デコーダがデコードし,命令デコーダが1つの命令をSIMDリザベーションステーションにエントリし,4回のメモリアクセスを繰り返し実行する。したがって,命令デコーダは1サイクルで開放されるので,SIMDインダイレクトメモリアクセス命令と依存関係のない後続の演算命令を,次のサイクルで命令デコードすることができる。したがって,アウト・オブ・オーダのメリットを生かすことができる。さらに,図3には示されていないが,1つのSIMDインダイレクトメモリアクセス命令をSIMDリザベーションステーションにエントリするので,リザベーションステーションに複数のエントリを使用する必要はなく,コミットスタックエントリのエントリも1つしか使用しないので,CPUコア内の資源を効率的に使用する。
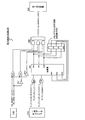
図4は,本実施の形態における演算処理装置を搭載した情報処理装置を示す図である。コンピュータなどの情報処理装置10は,CPU/メモリボード12と,大容量の記憶装置であるハードディスク11とを有する。CPU/メモリボード12は,CPUチップである演算処理装置20と,演算処理装置20と外部のハードディスク11などを接続するインタコネクト13と,DRAM等のメモリ14とを有する。
演算処理装置20は,例えば,4つのCPUコア(演算処理部)30A−30Dと,4つのCPUコアで共有される二次キャッシュ24と,入出力インタフェース26と,メインメモリ14へのアクセスを制御するメモリアクセスコントローラ28とを有する。
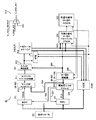
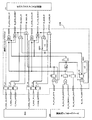
図5は,CPUコア30の全体構成を示す図である。CPUコア30は,分岐命令の予測を行う分岐予測部302と,プログラムカウンタPCと分岐予測部302の予測に基づいて命令フェッチアドレスを生成する命令フェッチアドレス生成器301と,一次命令キャッシュ303と,フェッチされた命令をデコードする命令デコーダ305と,レジスタリネーミング部306と,メモリアクセス用リザベーションステーションRSA(Reservation Station for Address generate)と,整数演算用リザベーションステーションRSE(Reservation Station for Execute)と,浮動小数点SIMDリザベーションステーションRSF(Reservation Station for Floating)と,分岐用リザベーションステーションRSBR(Reservation Station for Branch)と,コミットスタックエントリCSE(Commit Stack Entry)とを有する。
メモリアクセス用リザベーションステーションRSAのメモリアクセスパイプラインEAGAは,アドレス用インタフェース310と,オペランドアドレス生成器311と,アドレス選択回路313と,一次データキャッシュ312とを有する。整数演算用リザベーションステーションRSEの整数演算パイプラインEXAは,演算用インタフェース333と,固定小数点演算器320と,固定小数点リネーミングレジスタ321と,固定小数点レジスタ322とを有する。
また,浮動小数点SIMDリザベーションステーションRSFの浮動小数点SIMD演算パイプラインFLAは,演算用インタフェース333と,最大SIMD幅の数のSIMD演算器330と,浮動小数点SIMDリネーミングレジスタ331と,浮動小数点SIMDレジスタ332とを有する。さらに,CPUコア30は,2つのプログラムカウンタPC,NEXTPCを有する。また,CPUコア30は,演算器320,330が生成したデータを一時的に格納するストアバッファSTBを有する。
SIMD演算器330のSIMD幅は,例えば2もしくは4を命令で指定可能である。浮動小数点SIMDレジスタは最大SIMD幅の4つ要素で構成されている。これらのレジスタの要素をそれぞれ,要素0,要素1,要素2,要素3と呼ぶ。浮動小数点SIMD幅2の演算を行う場合,SIMDレジスタの要素0と要素1を使用する。浮動小数点SIMD幅4の演算を行う場合,SIMDレジスタのすべての要素を使用する。
メモリアクセスパイプラインEAGA,整数演算パイプラインEXA,浮動小数点SIMD演算パイプラインFLAは,それぞれ1つのパイプラインまたは2つ以上のパイプラインを有してもよく,それぞれ独立に命令を実行可能である。また,一次データキャッシュ312は,メモリアクセスパイプラインEAGAのパイプライン数が2の場合,それに合わせて,2つのポートを設け同時に最大2つのアドレスによりアクセスを行うことができるようにしてもよい。さらに,メモリアクセスパイプラインEAGAのパイプライン数を,最大SIMD幅と同じ4組にしてもよい。その場合は,一次データキャッシュ312も4つのポートを有して同時の最大4つのアドレスによりアクセスを行うことできるようにするのが望ましい。
命令フェッチアドレス生成器301は,分岐予測部302またはプログラムカウンタPCからの命令アドレスを選択し,一次命令キャッシュ303に対して命令フェッチリクエストを発行する。一次命令キャッシュ303は,命令フェッチリクエストに応じた命令を命令バッファ304に格納する。命令バッファ304から命令デコーダ305に対しては,プログラムにより指定された順番通りに,すなわちインオーダで命令が供給され,命令デコーダ305は,命令バッファから供給された命令をインオーダでデコードする。
命令デコーダ305は,デコードした命令の種類に応じて,各リザベーションステーションRSA,RSE,RSF及びRSBRのいずれかに,命令に対応する必要なエントリを作成する。これとともに命令デコーダ305はデコードされたすべての命令に対応するエントリをCSEに作成する。
レジスタリネーミング部306は,リザベーションステーションRSA,RSE,RSFのいずれかにエントリが作成された場合に,命令に応じた処理で使用されるレジスタのアドレスに,リネーミングレジスタ321,331のアドレスを割り当てる。
リザベーションステーションRSA,RSE,RSFは,保持されたエントリのうち,処理に必要な資源(データ,演算器,レジスタ等)が準備されたものから順次パイプラインに出力し,後段のパイプラインEAGA,EXA,FLAに出力したエントリに対応する処理を実行させる。これにより,命令がアウト・オブ・オーダで実行される。
浮動小数点演算用リザベーションステーションRSFには,例えば,SIMD演算命令に対応するエントリが格納される。1つのパイプラインFLAはSIMD幅の数のSIMD演算器330を有する。SIMD演算器330はRSFからのエントリに基づいて演算対象とするデータを選択し,SIMD幅の数のSIMD演算器で演算を並列に実行する。演算結果は浮動小数点・SIMDリネーミングレジスタ331に一時的に格納される。
メモリアクセス用リザベーションステーションRSAには,命令デコーダ305によりSIMDインダイレクトメモリアクセス命令以外のメモリアクセス命令に対応するエントリが生成され,格納される。そして,RSAは格納されている複数のエントリのいずれかを選択してパイプラインに出力する。メモリアクセス命令のエントリがパイプラインに出力されると,そのエントリに対応するメモリアクセス要求がパイプラインの各ステージを順番に転送する。オペランドアドレス生成回路311は,RSAのエントリのメモリアクセス要求に基づいて演算対象とするデータを選択し,アドレスを生成し,生成されたアドレスを用いてメモリアクセス要求を一次データキャッシュ312に入力する。一次データキャッシュ312は,メモリアクセス要求に対するメモリアクセスを実行する。
コミットスタックエントリCSEは,命令デコーダ305によりデコードされたすべての命令に対応するエントリを保持し,各エントリに対応する処理の実行状況を管理し,これらの命令をインオーダで完了させる。例えば,CSEは,次に完了させるべきエントリに対応する処理の結果が,固定小数点リネーミングレジスタ321および浮動小数点SIMDリネーミングレジスタ331に格納されたと判定すると,格納されたデータを固定小数点レジスタ322または浮動小数点SIMDレジスタ332に出力させる。これにより,各リザベーションステーションでアウト・オブ・オーダに実行された命令が,インオーダで完了する。
図5のCPUコア30では,固定小数点演算パイプラインEXAはSIMD構成になっていない。一方,浮動小数点演算パイプラインFLAはSIMD構成になっていて,最大SIMD幅の数のSIMD演算器330を有する。しかし,固定小数点演算パイプラインEXAもSIMD構成になっていてもよい。
本実施の形態のCPUコア30は,浮動小数点SIMD演算パイプラインFLAの演算用インタフェース333の出力信号をメモリアクセスパイプラインEAGAのアドレス用インタフェース310に供給してメモリアクセス命令を生成させるためのバス334と,SIMD演算器330が取得したアドレスをアドレス選択回路313に供給するためのバス335とを有する。アドレス用インタフェース310は,演算用インタフェース333の出力信号に基づいて生成したSIMD幅の数のメモリアクセス命令をメモリアクセスパイプラインEAGAに出力する。また,アドレス選択回路313は,オペランドアドレス生成器331からのバスに代えて浮動小数点SIMD演算器330からのバス335を選択し,SIMD演算器330が浮動小数点SIMDレジスタ332や浮動小数点SIMDリネーミングレジスタ331から取得したアドレスを,前述のSIMD幅のメモリアクセス命令と共に一次データキャッシュ312へ供給する。
[実施の形態のSIMDインダイレクトメモリアクセス命令を処理する構成と処理の概略]
図6は,本実施の形態のSIMDインダイレクトメモリアクセス(ロードまたはストア)命令を実行するCPUコアの構成を示す図である。図6には,後述するパイプラインの各サイクルが括弧付きで示されている。
図6のCPUコア30は,メモリアクセス用リザベーションステーションRSA(またはメモリアクセスエントリ部)がメモリアクセス命令のエントリを出力する1つのメモリアクセスパイプラインEAGAを有する。また,浮動小数点SIMDリザベーションステーションRSF(またはマルチデータ命令エントリ部)がSIMD命令のエントリを出力するSIMD演算パイプラインFLAも1つ有する。そして,SIMD演算パイプラインFLAは,最大SIMD幅4と同じ数の浮動小数点SIMD演算器330を有する。
本実施の形態のSIMDインダイレクトメモリアクセス命令の処理の概略は次のとおりである。命令デコーダ305は,SIMDインダイレクトメモリアクセス命令をデコードして,そのエントリを浮動小数点SIMDリザベーションステーションRSFに生成する。RSFは,SIMDインダイレクトメモリアクセス命令のエントリをSIMD演算パイプラインFLAに出力すると,それに応答してSIMD演算パイプラインFLAがバス334を介してSIMD幅に対応した数のメモリアクセス要求をメモリアクセスパイプラインEAGAに生成する。具体的には,演算用インタフェース333が投入されたエントリのフラグ信号群を,バス334を介してアドレス用インタフェース310に供給し,アドレス用インタフェース310がそのフラグ信号群に基づいてメモリアクセスパイプラインEAGAに複数のメモリアクセス命令のアクセス要求を順次生成する。または,演算用インタフェース333がそのフラグ信号に基づいて複数のメモリアクセス命令のアクセス要求を順次生成し,バス334を介してアドレス用インタフェース310に供給してパイプラインEAGAに生成してもよい。
また,SIMDインダイレクトメモリアクセス命令のエントリの投入または出力に応答して,SIMD幅の数のSIMD演算器330は,SIMD幅の数のアドレスを浮動小数点SIMDレジスタ332から並列に取得し,バス335を介してメモリアクセスパイプラインEAGAに供給する。具体的には,SIMD演算器330は,取得した複数のアドレスをバス335を経由して順次アドレス選択回路313に供給する。アドレス選択回路313は,バス335から供給される複数のアドレスを,先に生成された複数のメモリアクセス命令のアクセス要求のタイミングに合わせて選択し,一次データキャッシュ312に出力する。
具体的には,図6中の右上に示したとおり,アドレス選択回路313は,オペランドアドレス生成器311のアドレスフラグA_EAGA_ADDとバス335のいずれかを選択するセレクタL5を有する。そして,後述するようにSIMDインダイレクトメモリ命令のエントリがSIMD演算用パイプラインFLAに出力されたことに応答してアドレス用インタフェース310が生成するフラグ信号B1_EAGA_INDIRECTの「1」により,セレクタL5はバス335側を選択し,バス335を経由して供給されるアドレスを選択し,アドレスフラグA_EAGA_ADDとして一次データキャッシュ312に転送する。これにより,アドレス用インタフェース310がB1サイクルのステージで生成したメモリアクセス要求の転送タイミングに整合して,B1サイクルのステージより後のAサイクルのステージでバス335を介してアドレスが供給され,SIMDインダイレクトメモリアクセス命令のアドレスを加えたメモリアクセス要求が一次データキャッシュ312に転送される。
一次データキャッシュ312は,ロード命令の場合は一次キャッシュ312からまたはメモリ14から読み出した複数のデータを,浮動小数点SIMDリネーミングレジスタ331に格納する。そして,コミットスタックエントリからの指令に応じて,読み出した複数のデータを浮動小数点SIMDリネーミングレジスタ331から浮動小数点SIMDレジスタ332に転送する。これらのレジスタ331,332は,SIMD幅の数のレジスタが一括してレジスタ番号で特定される。また,ストア命令の場合は,浮動小数点SIMDレジスタ332に格納されている複数のデータを一次キャッシュ312またはメモリ14に順次書き込む。
SIMDインダイレクトメモリアクセス命令の処理の概略をより具体的に説明すると次の通りである。
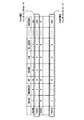
まず,命令デコーダ305はSIMDインダイレクトメモリアクセス命令をデコードし,RSF及びCSEにエントリを作成する。CSEのエントリ番号(エントリされた命令識別情報)をIIDと呼ぶ。演算やメモリアクセスの完了の際にCSEにこのIIDと完了信号を通知することにより,CSEは命令完了の判定を行う。エントリの作成と同時に,命令デコーダ305は,一次データキャッシュ312が管理する資源であるフェッチポートFPをSIMD幅と同数の連続した個数確保する。フェッチポートFPは,一次データキャッシュがメモリアクセスを行う際に必要なメモリアドレスを記憶しておく資源であり,通常のメモリアクセス命令では1つのFPが確保される。SIMDインダイレクトメモリアクセス命令ではSIMD幅と同数のアドレスによりアクセスを行うため,複数のプリフェッチポートFPを使用する。
図7は,浮動小数点演算リザベーションステーションRSFにエントリとして格納されるフラグ構成を示す図である。SIMDインダイレクトメモリアクセス命令を実行するため,インダイレクトフラグINDIRECTとフェッチポートフラグFPが追加されている。INDIRECTフラグはデコードした命令がSIMDインダイレクトメモリアクセス命令の場合に「1」となる。FPフラグはデコード時に確保した先頭のFP番号を示す。また,RSFには,これら以外にもSIMD演算器330に演算種の指示を行うOPCODE,命令のSIMD幅を識別する4SIMDフラグ(幅が2なら「0」,4なら「1」),演算に使用するオペランドを示すR1_ADRS,CSEのエントリ番号を示すIIDなどを格納する。
RSFは,SIMDインダイレクトメモリアクセス命令のエントリに必要な資源が準備され実行可能となると,浮動小数点SIMDパイプラインFLAの演算用インタフェース333にその命令のエントリを出力または投入する。
演算用インタフェース333は,RSFから出力された命令がSIMDインダイレクトメモリアクセス命令のエントリである場合,そのエントリのインダイレクト命令,SIMD幅,IID,FP,FLAの命令が有効か否かを示すバリッドのフラグ信号群を,バス334を介して,アドレス用インタフェース310に転送する。アドレス用インタフェース310はこのフラグ信号群に基づいて,メモリアクセスパイプラインEAGAに複数のメモリアクセス命令のメモリアクセス要求をシリアルに生成する。
上記の複数のメモリアクセス命令の生成と同時に,SIMD演算器330は,演算用インタフェース333からのフラグ信号に基づいて,SIMD幅の数のアドレスをSIMDレジスタ332から並列に読み出す。SIMDレジスタ332のレジスタ番号は,SIMDインダイレクトメモリアクセス命令のソースオペランドに示されている。SIMD演算器330は,SIMDレジスタ332からのアドレスの読み出しが完了すると,その複数のアドレスをアドレス選択回路313にバス335を介して転送する。そして,アドレス用インタフェース310が,アドレス用インタフェース310がパイプラインEAGAに順次生成した複数のメモリアクセス要求と,バス335を介して転送されてきた複数のアドレスとを,タイミングを整合させて,アドレス選択回路313に転送する。すなわち,アドレス選択回路313は,オペランドアドレス生成器331からのアドレスに代えて,SIMD演算器330から供給されてきたアドレスを選択し,複数のアドレスを一次データキャッシュ312にシリアルに転送する。一次データキャッシュ312は,複数のアドレスそれぞれについてデータの読み出しまたはSIMDレジスタ内のデータの書き込みを行う。
一次データキャッシュ312は,データの読み出しを完了すると読み出したデータを浮動小数点SIMDリネーミングレジスタに格納するとともに,CSEに読み出しが完了したエントリ識別情報IIDと完了通知を送る。データの書き込みの場合は,一次データキャッシュ312は,単にCSEに書き込みが完了したエントリ識別情報IIDと完了通知を送る。CSEはエントリ識別情報IIDと完了通知によりSIMD幅すべての要素の読み出しまたは書き込みが完了するのを待ち,SIMDインダイレクトメモリアクセス命令を完了させる。
次に,演算用インタフェース333は,SIMDインダイレクト命令のエントリに基づいて生成されるメモリアクセス要求が,後続のメモリアクセス命令のアクセス要求と衝突することを防止するために,RSAとRSFに命令のエントリの出力を抑止する抑止信号を生成する。すなわち,第1に,演算用インタフェース333は,SIMDインダイレクトメモリアクセス命令のエントリに応答して,抑止信号336をRSAに出力し,RSAに,そのSIMDインダイレクトメモリアクセス命令に基づいてアドレス用インタフェース310で生成されるメモリアクセス要求と衝突する後続のメモリアクセス命令のエントリの出力を抑止させる。第2に,演算用インタフェース333は,SIMDインダイレクトメモリアクセス命令のエントリに応答して,抑止信号337をRSFに出力し,RSFに,後続のSIMDインダイレクトメモリアクセス命令のエントリの出力を抑止させる。これにより,先行するSIMDインダイレクトメモリアクセス命令によりアドレス用インタフェース310に生成された複数サイクルにわたるメモリアクセス要求と,後続のSIMDインダイレクトメモリアクセス命令に基づいて生成されるメモリアクセス要求とが衝突することを防止する。
図8,図9は,SIMDインダイレクトロード命令と通常のロード命令の処理を示すフローチャートである。まず,命令フェッチ(S1),命令バッファに格納(S2),命令デコード(S3)が行われ,命令デコーダの結果,通常のロード命令の場合(S4のNO),工程S5以下の処理が行われ,SIMDインダイレクトメモリアクセス命令の場合(S4のYES),工程S21以下の処理が行われる。
通常のロード命令の場合(S4のNO),命令デコーダ305は,フェッチポートFPを1つ確保し,RSAへロード命令のエントリを作成する(S5)。RSAは,ロード命令のエントリを投入する準備が完了したことを確認し(S6のYES),先行するSIMDインダイレクトメモリアクセス命令に基づいて生成されるメモリアクセス命令と衝突していない場合(S7のNO),ロード命令のエントリをメモリアクセスパイプラインEAGAに出力または投入する。
メモリアクセスパイプラインEAGAでは,オペランドアドレス生成器311が固定小数点レジスタ322などからデータを読み出し(S8),オペランドアドレス生成器311がアドレスを生成し(S9),アドレス選択回路313がオペランドアドレス生成器からのアドレスを選択する(S10)。そして,一次データキャッシュ312がそのアドレスを使用してデータを読み出す処理を実行する(S11)。一次データキャッシュ312が読み出したデータを浮動小数点SIMDリネーミングレジスタに格納してその処理を完了すると(S12),通常のロード命令の場合は,CSEがフェッチポートFPを1個開放し,SIMDリネーミングレジスタ331からSIMDレジスタ332に読み出しデータを転送する(S19)。
以上のように,通常のロード命令は,RSAにロード命令のエントリが生成され,メモリアクセスパイプラインEAGAのオペランドアドレス生成器331がアドレスの取得と生成を行い,一次データキャッシュへ312にロード要求を行う。
なお,連続するメモリアドレスに対するSIMDロード命令のエントリがRSAに生成された場合は,オペランドアドレス生成器311がその先頭のアドレスを固定小数点レジスタ322などから読み出し,一次データキャッシュ312が連続する例えば2つのアドレスのデータを2つのSIMDリネーミングレジスタに格納する。ただし,この連続するメモリアドレスに対するSIMDロード命令は,本実施の形態における複数のSIMDレジスタ内の独立した複数のアドレスに対するSIMDインダイレクトメモリアクセス命令とは異なる命令である。
次に,SIMDインダイレクトメモリアクセス命令の場合(S4のYES),命令デコーダはフェッチポートFPをSIMD幅の個数確保し,RSFにSIMD命令のエントリを生成する(S21)。RSFは,エントリを投入する準備が完了したことを確認し(S22のYES),先行するSIMDインダイレクトメモリアクセス命令に基づいて生成されるメモリアクセス命令と衝突していない場合(S23のNO),SIMDインダイレクトメモリアクセス命令のエントリをSIMD演算パイプラインFLAに出力または投入する。
そして,SIMD演算パイプラインFLAのSIMD演算器330が,SIMD幅の数のアドレスをSIMDレジスタ332から並列に読み出す(S23)。この読み出しには後述するとおり2サイクルを要する。そして,この読み出しとともに,SIMD演算パイプラインFLAの演算用インタフェース333がバス334を介してアドレス用インタフェース310にフラグ信号群を転送し,メモリアクセスパイプラインEAGAにメモリアクセスのリクエスト0を生成させる(S24)。生成されたリクエストはメモリアクセスパイプラインEAGAを転送する。さらに,SIMD演算器330はSIMDレジスタ332から取得したSIMD幅の数のアドレスを,バス335を介してアドレス選択回路313に供給し(S35),アドレス選択回路313は,リクエスト0に基づきSIMD演算器からのアドレスを選択し(S26),リクエスト0にフェッチポートFPを割り当てる(S27)。
上記の工程S23-S27を2回繰り返す。2回目はメモリアクセスのリクエスト1が生成される。さらに,SIMD幅が4の場合(S28のYES),工程S23-S27と同じ処理工程S29-S32を2回繰り返す。これによりメモリアクセスのリクエスト2,3が生成される。
そして,一次データキャッシュ312は,フェッチポートFPのアドレスを利用してデータを読み出す処理を実行開始する(S11)。CSEは,SIMD幅が2の場合は2回の一次データキャッシュの処理完了通知(S12,S14)に応答して,SIMD幅が4の場合は4回の一次データキャッシュの処理完了通知(S12,S14,S16,S17)に応答して,SIMD処理の完了を検出し,フェッチポートFPをSIMD幅の個数開放し,SIMDリネーミングレジスタ331からSIMDレジスタ332に読み出しデータを転送する(S20)。
以上のように,SIMDインダイレクトロード命令の場合は,命令デコーダがSIMDインダイレクトロード命令を1回デコードし,命令デコーダがRSFにSIMDインダイレクトロード命令のエントリを1つ生成し,SIMD演算パイプラインFLAがメモリアクセスパイプラインEAGAにSIMD幅の数のメモリアクセスのリクエストを生成し,複数のSIMD演算器に複数のアドレスをSIMDレジスタから並列に取得させ,SIMD演算器が取得した複数のアドレスをメモリアクセスパイプラインEAGAに転送して複数のメモリアクセスのリクエストに合体させ,メモリアクセスパイプラインEAGAが一次データキャッシュへのロードリクエストを行う。SIMDインダイレクトストア命令の場合も,一次データキャッシュがメモリにストアすることを除いて上記のロード命令と同じ動作である。
次に,本実施の形態のSIMDインダイレクトメモリアクセス命令のパイプライン処理を説明する。まず,SIMDインダイレクトロード命令のパイプラインステージを以下に示す。図6に括弧付きで示したステージを参照することで以下のパイプラインステージが明らかになる。
D(Decode):命令デコーダが命令をデコードする。
DT(Decode Transfer):Dサイクルの命令を転送し,RSFに格納する。
P(Priority):RSFがSIMD演算器へ投入する命令のエントリを決定し出力(投入)する。
PT(Priority Transfer):Pサイクルのエントリのフラグ信号群を,演算用インタフェースを介して転送し,SIMD演算器330に投入する。
B1,B2(Buffer):SIMD演算器が演算に必要なデータをレジスタから入力する。例えば,データは浮動小数点SIMDレジスタ332やリネーミングレジスタ331から取得される。この例では取得に2サイクルを要する。
X(eXecution):SIMD演算器がメモリアクセスに必要なデータを読み出す。
A(Address):SIMD演算器がメモリにアクセスするアドレスをアドレス選択回路313に転送する。
T(Tag):一次データキャッシュがアドレスに基づいてタグにアクセスする。
M(Match):一次データキャッシュが読み出したキャッシュタグを比較する。
B(Buffer):一次データキャッシュから読み出したデータをバッファする。
R(Result):一次データキャッシュアクセスを完了する。
RT(Result):Rサイクルのデータを転送し,リネーミングレジスタへの書き込みを行い,CSEへ完了通知を行う。
C(Commit):すべての要素が完了したかどうかの命令完了の判定を行う。
W(Write):完了した命令による各種レジスタの更新やリソースの解放を行う。このとき,浮動小数点SIMDリネーミングレジスタ331からSIMDレジスタ332に読み出したデータを転送する。
SIMDインダイレクトロード命令以外の通常ロード命令のパイプラインステージを以下に示す。
D(Decode):命令をデコードする。
DT(Decode Transfer):Dサイクルの命令を転送し,RSAに命令のエントリを格納する。
P(Priority):リザベーションステーションRSAから実行ユニットへ投入する命令のエントリを決定し出力(投入)する。
B1,B2(Buffer):オペランドアドレス生成器がロードアドレス生成に必要なデータを決定しレジスタから入力する。
A(Address):オペランドアドレス生成器がメモリにアクセスするアドレスを計算する。
T(Tag):一次データキャッシュが計算したアドレスに基づいてタグにアクセスする。
M(Match):一次データキャッシュが読み出したキャッシュタグを比較する。
B(Buffer):一次データキャッシュから読み出したデータをバッファする。
R(Result):一次データキャッシュアクセスを完了する。
RT(Result):Rサイクルのデータを転送し,リネーミングレジスタへの書き込みを行い,CSEへ完了通知を行う。
C(Commit):命令完了の判定を行う。
W(Write):完了した命令による,各種レジスタの更新やリソースの解放を行う。このとき,リネーミングレジスタからレジスタに転送する。
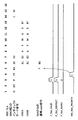
図10は,SIMDインダイレクトメモリアクセスの一つであるSIMDインダイレクトロード命令のパイプライン及びタイムチャートを示す図である。
RSFは,タイミング3のPサイクルでSIMDインダイレクトロード命令のエントリをSIMD演算パイプラインFLAに投入する。そして,タイミング5のB1サイクルで,演算用インタフェース333がSIMDインダイレクトロード命令のフラグ信号を出力する。
SIMD幅2のSIMDインダイレクトロード命令の場合は,SIMD演算パイプラインFLAが,タイミング6において,アドレス用インタフェース310内のパイプラインEAGAにメモリアクセス用のリクエスト0を生成し,次のタイミング7において,リクエスト1を生成する。生成されたメモリアクセスのリクエストは,メモリアクセスパイプラインEAGAにて,SIMDインダイレクトロード命令以外のロード命令におけるB1サイクルとなる。生成したメモリアクセスのエントリ識別情報IIDはSIMD演算パイプラインFLAから送られたものを使用し,フェッチポートFPはSIMD演算パイプラインFLAのFPの値とそれに1を加算した値を使用する。SIMD演算パイプラインFLAのSIMD演算器330が,タイミング7のX1サイクルでSIMDレジスタ(またはSIMDリネーミングレジスタ)から読み出した複数のデータのうち要素0を,タイミング8のX2サイクルでSIMDレジスタ(またはSIMDリネーミングレジスタ)から読み出した要素1をそれぞれシリアルにメモリアクセスパイプラインEAGAのアドレス選択回路313に転送する。タイミング8,9(Aサイクル)で,アドレス選択回路313は,SIMD演算パイプラインFLAから転送されてきた要素0と要素1のアドレスを選択し,一次データキャッシュ312に転送する。一次データキャッシュにアクセスしたデータすべてが存在した場合,一次データキャッシュ312は,タイミング13,14で読み出したデータをSIMDリネーミングレジスタ331に転送し,タイミング14ですべてのメモリアクセスの完了報告を行う。その結果,CSEは,命令完了の判定を行い,SIMDリネーミングレジスタ331のデータをSIMDレジスタ332に転送する。
また,SIMD幅4のSIMDインダイレクトロード命令の場合は,SIMD演算パイプラインFLAが,タイミング6,7,8,9において,アドレス用インタフェース内のパイプラインEAGAにメモリアクセス用のリクエスト0,1,2,3をシリアルに生成する。生成された4つのメモリアクセスのリクエストは,メモリアクセスパイプラインEAGAにて,SIMDインダイレクトロード命令以外のロード命令におけるB1サイクルとなる。生成したメモリアクセスのリクエストのエントリ識別情報IIDはSIMD演算パイプラインFLAから送られたものを使用し,フェッチポートFPはSIMD演算パイプラインFLAのFP値とそれに1,2,3を加算した値を使用する。SIMD演算パイプラインFLAのSIMD演算器330が,タイミング7,8,9,10のX1,X2,X3,X4サイクルでSIMDレジスタ(またはSIMDリネーミングレジスタ)から読み出したSIMDのデータのうち要素0と要素1と要素2と要素3をそれぞれ,シリアルにメモリアクセスパイプラインEAGAのアドレス選択回路313に転送する。タイミング8,9,10,11(Aサイクル)で,アドレス選択回路313は,SIMD演算パイプラインFLAから転送されてきたアドレスをそれぞれ選択し,一次データキャッシュ312に転送する。一次データキャッシュにアクセスしたデータすべてが存在した場合,一次データキャッシュ312は,タイミング13,14,15,16で読み出したデータをSIMDリネーミングレジスタ331に転送し,タイミング16ですべてのメモリアクセスの完了報告を行う。その結果,CSEは,命令完了の判定を行い,SIMDリネーミングレジスタ331のデータをSIMDレジスタ332に転送する。
以上,SIMDインダイレクトロード命令について説明したが,SIMDインダイレクトストア命令でも,SIMD演算パイプラインFLAがメモリアクセスパイプラインEAGAにSIMD幅の数のメモリアクセスのリクエストを生成することと,SIMD演算器がSIMD幅の数のアドレスをSIMDレジスタから並列に取得してメモリアクセスパイプラインEAGAにシリアルに転送することと,一次データキャッシュにSIMD幅の数のメモリストアのリクエストを投入することは同じである。SIMDインダイレクトストア命令の場合は,一次データキャッシュはSIMDレジスタに格納されているSIMD幅の数のデータを一次キャッシュメモリまたはメモリに書き込む。
[本実施の形態におけるSIMDインダイレクトメモリアクセスの詳細説明]
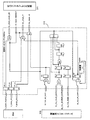
図11は,本実施の形態のSIMDインダイレクトメモリアクセス(ロードまたはストア)命令を実行するCPUコアの構成を示す図である。図11のCPUコアの構成におけるSIMDダイレクトメモリアクセスの詳細な説明を行う。
図11のCPUコア30は,図6と異なり,メモリアクセス用リザベーションステーションRSA(またはメモリアクセスエントリ部)が,メモリアクセス命令のエントリを出力するメモリアクセスパイプラインとして,2つのパイプラインEAGA,EAGBを有する。それに対応して,一次データキャッシュ312は,2つのメモリアクセス要求を並列に処理する構成を有する。また,浮動小数点SIMDリザベーションステーションRSF(またはマルチデータ命令エントリ部)が,SIMD命令のエントリを出力するSIMD演算パイプラインとして,2つのパイプラインFLA,FLBを有する。そして,SIMD演算パイプラインFLA,FLBは,最大SIMD幅4と同じ数の浮動小数点SIMD演算器330を,それぞれ有する。浮動小数点SIMDレジスタ332と浮動小数点SIMDリネーミングレジスタ331は,最大SIMD幅4と同じ数のレジスタが一括してレジスタ番号で指定可能である。それ以外の構成は,図6と同じである。
したがって,SIMD演算パイプラインFLAは,SIMDインダイレクトアクセスメモリ命令のエントリに応答して,2つのメモリアクセス要求を2つのメモリアクセスパイプラインEAGA,EAGBに同時に生成することができ,SIMD演算器330は,SIMDレジスタ332から取得した2つのアドレスを2つのメモリアクセスパイプラインEAGA,EAGBのアドレス選択回路313に並列に転送することができる。後述する図13に示す通りである。
SIMD幅が2の場合は,SIMD演算パイプラインFLAは,バス334を介して,1サイクルで2つのメモリアクセス要求を2つのパイプラインEAGA,EAGBに生成する。すなわち,演算用インタフェース333がフラグ信号群をバス334を介してアドレス用インタフェース310に転送し,アドレス用インタフェース310は,その転送されたフラグ信号群に基づいて,1サイクルで2つのメモリアクセス要求を2つのパイプラインEAGA,EAGBに生成する。そして,SIMD演算器330は,バス335を介して,1サイクルで2つのアドレスを2つのパイプラインEAGA,EAGBのアドレス選択回路313に転送する。アドレス選択回路313内のセレクタL5(図6参照)は,前述のとおり,インダイレクトフラグ信号B1_EAGA_INDIRECT,B1_WAGB_INDIRECTの「1」により,バス335側を選択し,SIMD演算器330から供給される2つのアドレスを2つのパイプラインEAGA,EAGBに出力する。これにより,アドレス用インタフェース310が生成した2つのメモリアクセス要求に,アドレス選択回路313のサイクルAのステージで,バス335から供給された2つのアドレスが加えられる。
また,SIMD幅が4の場合は,SIMD演算パイプラインFLAは,2サイクルで4つのメモリアクセス要求を2つのパイプラインEAGA,EAGBに生成し,2サイクルで4つのアドレスを転送する。図14に示すとおりである。
図8,図9のフローチャート図は,図11のCPUコアの構成にも適用できる。ただし,図1のCPUコアは,2つのメモリアクセスパイプラインEAGA,EAGBを有するので,図8の工程S24-S27,工程S29-S32をそれぞれ1回行えば良い。
[演算用インタフェース331とアドレス用インタフェース310によるインダイレクトメモリアクセス要求の生成]
図12は,演算用インタフェース331とアドレス用インタフェース310の構成を示す図である。演算用インタフェース331は,RSFから投入される演算命令のエントリから後段のSIMD演算器330などに対して制御信号を適切なタイミングで出力する。同様に,アドレス用インタフェース310は,RSAから投入されるメモリアクセス命令のエントリから後段のオペランドアドレス生成器311などに対して制御信号を適切なタイミングで出力する。
アドレス用インタフェース310は,RSAから2つのパイプラインEAGA,EAGBに投入された,SIMDインダイレクトメモリアクセス命令以外の通常メモリアクセス命令のエントリのフラグ信号を,ラッチ回路群F1_A,F1_Bでラッチし,後段のオペランドアドレス生成器311に転送する。一方,演算用インタフェース331は,RSFからSIMD演算パイプラインFLAに投入されたSIMDインダイレクトメモリアクセス命令のエントリのフラグ信号を,アドレス用インタフェース310にバス334を介して転送する。そして,アドレス用インタフェース310内のアンドゲートA1,A2,ラッチ回路群F2,F3,セレクタL1,L2,L3,L4,オアゲートアR1,R2,加算器ADD1,ADD2らの回路が,その転送されてきたフラグ信号に基づいて,2つのメモリアクセスパイプラインEAGA,EAGBに,それぞれメモリアクセスのリクエストを生成する。
図12では,アドレス用インタフェース310が破線で囲まれた回路を有するように示されている。しかし,破線で囲まれた回路の一部を演算用インタフェース333が有するようにしてもよい。したがって,演算用インタフェース333とアドレス用インタフェース310とバス334の構成により,SIMD演算パイプラインFLAが,2つのメモリアクセスパイプラインEAGA,EAGBに,それぞれメモリアクセスのリクエストを生成する。
図12の各信号について説明する。
パイプラインFLA側のエントリのフラグ信号については,次の通りである。入力信号(バリッド信号)B1_FLA_VALID_EAITFは,浮動小数点・SIMDパイプラインのB1サイクルでパイプラインFLAのSIMD演算器330に演算要求が出たときに1となる。
入力信号(インダイレクト信号)B1_FLA_INDIRECT_EAITFは,浮動小数点・SIMDパイプラインのB1サイクルで演算要求がSIMDインダイレクトメモリアクセス命令であった場合1となる。
入力信号(4SIMD信号)B1_FLA_4SIMD_EAITFは,浮動小数点・SIMDパイプラインのB1サイクルでSIMD幅が4であるときに1となる。
入力信号(IID信号)B1_FLA_IID_EAITFには,パイプラインFLAで実行される命令のエントリの識別情報IIDが転送される。
入力信号(FP信号)B1_FLA_FP_EAITFは,SIMDインダイレクトメモリアクセス命令において命令デコーダ305で確保したフェッチポートFPの先頭の番号を転送する。
パイプラインEAGA,EAGB側のエントリのフラグ信号については,次の通りである。入力信号(バリッド信号)P_EAGA_VALID,P_EAGB_VALIDは,RSAからオペランドアドレス生成器331及び一次データキャッシュ312へメモリアクセス要求が出力された時に1となる。
入力信号(FP信号)P_EAGA_FP,P_EAGB_FPには,RSAからオペランドアドレス生成器331にメモリアクセス要求が出たとき,一次キャッシュメモリ312で使用するフェッチポート番号FP番号が転送される。
入力信号(IID信号)P_EAGA_IID,P_EAGB_IIDには,RSAからオペランドアドレス生成器331にメモリアクセス要求が出たとき,それぞれの要求に対応するエントリ識別情報IIDが転送される。
アドレス用インタフェース回路310は,SIMDインダイレクトメモリアクセス命令のエントリがSIMD演算パイプラインFLAに投入された場合,演算用インタフェース333が出力するフラグ信号を用いて,メモリアクセスパイプラインEAGA,EAGBに2つもしくは4つのメモリアクセス要求を生成する。このメモリアクセス要求は,以下に説明する4つの出力信号B1_EAGA_***と,4つの出力信号B1_EAGB_***に対応する。また,アドレス用インタフェース回路310は,通常のメモリアクセス命令のエントリがメモリアクセスパイプラインEAGA,EAGBに投入された場合は,そのエントリのフラグ信号をそのままオペランドアドレス生成器311に転送する。
出力信号(バリッド信号)B1_EAGA_VALID_ORは,オアゲートR1により出力され,RSFが投入したSIMDインダイレクトメモリアクセス命令により生成されたメモリアクセス要求と,RSAからの通常のメモリアクセス命令に対するメモリアクセス要求の論理和である。このバリッド信号が1であるとき,メモリアクセスパイプラインEAGAのオペランドアドレス生成器311及び一次データキャッシュ312へのメモリアクセス要求が有効となる。
出力信号(バリッド信号)B1_EAGB_VALID_ORは,メモリアクセスパイプラインEAGB側のバリッド信号であり,上記と同様である。
出力信号(インダイレクト信号)B1_EAGA_INDIRECT,出力信号B1_EAGB_INDIRECTは,対応するバリッド信号B1_EAGA_VALID_OR,B1_EAGB_VALID_OR信号が1であるときに有効になる信号であり,メモリアクセス要求がSIMDインダイレクトメモリアクセス命令により生成されたことを示す。オアゲートR2が出力する。この信号は,後続のオペランドアドレス生成器311を経由してアドレス選択回路313に転送され,アドレス選択回路313においてSIMD演算器330からバス335を介して転送されるアドレスを選択するために使用される。
出力信号(IID信号)B1_EAGA_IID,出力信号(IID信号)B1_EAGB_IIDは,対応するバリッド信号B1_EAGA_VALID_OR,B1_EAGB_VALID_OR信号が1であるときに有効になる信号である。SIMDインダイレクトメモリアクセス命令である場合,セレクタL4が演算用インタフェース333から転送されてきた入力信号B1_FLA_IID_EAITFのエントリ識別情報IIDを選択する。もしそうでない場合,セレクタL4は,RSAからのIID信号P_EAGA_IID,P_EAGB_IIDを選択する。
出力信号(FP信号)B1_EAGA_FP,出力信号(FP信号)B1_EAGB_FPは,対応するバリッド信号B1_EAGA_VALID_OR,B1_EAGB_VALID_OR信号が1であるときに有効になる信号である。SIMDインダイレクトメモリアクセス命令の場合の場合で,SIMD幅が2である場合は,入力FP信号B1_FLA_FP_EAITFで転送されてきたFP値と,加算器ADD2で+1加算したFP値とが,セレクタL3で選択され出力される。一方,SIMD幅が4である場合は,次のクロックサイクルで,入力FP信号B1_FLA_FP_EAITFで転送されてきたFP値に加算器ADD1で+2されたFP値と,加算器ADD2で+1加算したFP値とが,セレクタL3で選択され出力される。例えば,SIMD幅4であり,SIMDインダイレクトメモリアクセス命令でありかつFP信号B1_FLA_FP_EAITFで転送された値が5であった場合,図14のタイミング6でパイプラインEAGAに生成されたリクエストのFP信号B1_EAGA_FPは5,パイプラインEAGBに生成されたリクエストのFP信号B1_EAGB_FPは6,タイミング7でパイプラインEAGAに生成されたリクエストのFP信号B1_EAGA_FPは7,パイプラインEAGBに生成されたリクエストのFP信号B1_EAGB_FPは8になる。SIMDインダイレクトメモリアクセス命令でない場合は,RSAからのFP信号P_EAGA_FP,P_EAGB_FPがそれぞれセレクタL3で選択される。
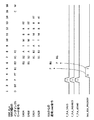
図13は,SIMD幅が2のSIMDインダイレクトメモリアクセス命令の場合のパイプラインとアドレス用インタフェース310の入出力信号変化を示す図である。SIMD演算パイプラインFLAの演算用インタフェース333が,タイミング5のサイクルB1で図12の入力信号(B1_FLA_***)を出力し,アドレス用インタフェース310が,それらの入力信号に基づいてタイミング6で図12の出力信号(B1_EAGA_***,B1_EAGB_***)によるメモリアクセス要求を生成する。
タイミング5の入力IID信号B1_FLA_IDD_EAITF(=2)がセレクタL1を介してラッチF2でラッチされ,タイミング6の出力IID信号B1_EAGA_IID,B1_EAGB_IIDが共に2になる。
タイミング5の入力バリッド信号B1_FLA_VALID_EAITF(=1)と入力インダイレクト信号B1_FLA_INDIRECT_EAITF(=1)の論理積がアンドゲートA1を介してラッチF2でラッチされ,オアゲートR1,R2を介して,タイミング6の出力バリッド信号B1_EAGA_VALID_OR,B1_EAGB_VALID_ORが共に1になり,出力インダイレクト信号B1_EAGA_INDIRECT,B1_EAGB_INDIRECTも共に1になる。
そして,タイミング5の入力FP信号B1_FLA_EAITF(=4)がセレクタL2を介してラッチF2_FPでラッチされ,セレクタL3を介して,タイミング6の出力FP信号B1_EAGA_FP(=4),B1_EAGB_FP(=5)になる。
上記の動作により,SIMD演算用パイプラインFLAは,演算用インタフェース333が出力するフラグ信号により,タイミング6で,アドレス用インタフェース310内の2つのメモリアクセスパイプラインEAGA,EAGBに,2つのメモリアクセス要求を生成する。
図14は,SIMD幅が4のSIMDインダイレクトメモリアクセス命令の場合のパイプラインとアドレス用インタフェース回路310の入出力信号変化を示す図である。SIMD演算パイプラインFLAの演算用インタフェース333が,タイミング5のサイクルB1で図12の入力信号(B1_FLA_***)を出力し,アドレス用インタフェース310が,それらの入力信号に基づいて,タイミング6,7で図12の出力信号(B1_EAGA_***,B1_EAGB_***)によるメモリアクセス要求を生成する。
タイミング5の演算用インタフェース333が出力する入力信号と,タイミング6でアドレス用インタフェース310内のメモリアクセスパイプラインEAGA,EAGBに生成される出力信号は,図13のSIMD幅2の場合と同じである。
ただし,SIMD幅4の場合は,タイミング6のラッチF2の入力IID信号をセレクタL1を介してラッチF2が再度ラッチし,タイミング6のアンドゲートA1の出力と入力4SIMD信号B1_FLA_4SIMD_EAITFのラッチ信号の論理積を,アンドゲートA2を介してラッチF3がラッチする。また,タイミング6の入力FP信号B1_FLA_FP_EAITFの値に加算器ADD1で+2した値を,セレクタL2を介してラッチF2_FPがラッチする。それに対応して,タイミング7では,タイミング6と同様にして,メモリアクセスパイプラインEAGA,EAGBの出力バリッド信号,出力インダイレクト信号が1を維持し,出力IID信号が2を維持し,出力FP信号が6,7になる。
上記の動作により,SIMD演算用パイプラインFLAは,演算用インタフェース333の出力する信号により,タイミング6で,アドレス用インタフェース310内の2つのメモリアクセスパイプラインEAGA,EAGBに,2つのメモリアクセス要求を生成し,さらに,タイミング7でメモリアクセスパイプラインEAGA,EAGBにさらに2つのメモリアクセス要求を生成する。
図15は,図6の1つのメモリアクセスパイプラインEAGAを有する場合の演算用インタフェース331とアドレス用インタフェース310の構成を示す図である。SIMDインダイレクトメモリアクセス命令の場合,図12と異なり次のような動作になる。図10も参照して説明する。
まず,タイミング5の入力バリッド信号B1_FLA_VALID_EAITFと入力インダイレクト信号B1_FLA_INDIRECT_EAITFの論理積が,アンドゲートA1を介して2つのラッチF2_1でラッチされ,そのラッチF2_1の出力がさらに次のタイミングでラッチF2_2でラッチされ,タイミング6,7で,出力バリッド信号B1_EAGA_VALID_ORと出力インダイレクト信号B1_EAGA_INDIRECTが2サイクルにわたり1を出力する。
SIMD幅が4の場合は,さらに,タイミング7のラッチF2_2の出力と入力4SIMD信号のラッチF2_2の出力の論理積が,アンドゲートA2を介してラッチF3_1でラッチされ,そのラッチF3_1の出力がさらに次のタイミングでラッチされ,タイミング8,9で,出力バリッド信号B1_EAGA_VALID_ORと出力インダイレクト信号B1_EAGA_INDIRECTが2サイクルにわたり1を出力する。
タイミング5の入力IID信号B1_FLA_IID_EAITFは,セレクタL1を介してラッチF2で4回ラッチされ,タイミング6,7,8,9でセレクタL4を介して出力IID信号B1_EAGA_IIDとして出力される。
タイミング5の入力FP信号B1_FLA_FP_EAITFは,セレクタL2を介してラッチF2_FPがラッチし,その後,3サイクルで加算器ADD1でそれぞれ+1したフェッチポートFPの値をラッチF2_FPがラッチする。そして,タイミング6,7,8,9で,出力FP信号B1_EAGA_FPが,入力FP値,それに+1,+2,+3されたFP値になる。
[衝突を回避するためのRSAとRAFによる新たなエントリ投入の抑止]
図16,図17は,SIMD幅2の場合と4の場合での後続するRSAから投入されるメモリアクセスとの衝突を示す図である。いずれも,図11の例で示している。
本実施の形態では,RAFがSIMDインダイレクトメモリアクセス命令のエントリをSIMD演算パイプラインFLAに投入すると,SIMD演算パイプラインFLAが,演算用インタフェース333が出力する信号を利用して,アドレス用インタフェース310内のメモリアクセスパイプラインEAGA,EAGBに複数のメモリアクセス要求を生成する。そのため,その生成されたメモリアクセス要求と後続のRSAから投入されるメモリアクセス要求とが衝突する場合がある。図11の例では,SIMD幅が2の場合は1回メモリアクセス要求が生成されるので1回衝突する場合があり,SIMD幅が4の場合は2回メモリアクセス要求が生成されるので2回衝突する場合がある。図6のメモリアクセスパイプラインEAGAが1つの例では,SIMD幅2では2回衝突し,SIMD幅4では4回衝突する場合がある。
図11の例で説明すると以下のとおりである。図16,17には衝突がB1への取消線で示されている。
(1)図16のSIMD幅2の場合は,タイミング3でRSFがパイプラインFLAにSIMD幅2のSIMDインダイレクトメモリアクセス命令のエントリを出力し,タイミング5でRSAがパイプラインEAGAもしくはEAGBにメモリアクセス命令のエントリを出力した場合,タイミング6で,SIMDインダイレクトメモリアクセス命令により生成されるメモリアクセス要求のサイクルB1の信号と,RSAから転送されるメモリアクセス要求のサイクルB1の信号が衝突する。
(2)図17のSIMD幅4の場合は,タイミング3でRSFがパイプラインFLAにSIMD幅4のインダイレクト命令のエントリを出力し,タイミング5もしくは6においてRSAがパイプラインEAGAもしくはEAGBにメモリアクセス命令のエントリを出力した場合,次の衝突が発生する。
すなわち,タイミング5でRSAがパイプラインEAGAもしくはEAGBにメモリアクセス命令のエントリを出力した場合,タイミング6でSIMDインダイレクトメモリアクセス命令により生成されるメモリアクセス要求のサイクルB1の信号と,RSAから転送されるメモリアクセス要求のサイクルB1の信号が衝突する。
また,タイミング6でRSAがパイプラインEAGAもしくはEAGBにメモリアクセス命令のエントリを出力した場合,タイミング7でSIMDインダイレクトメモリアクセス命令により生成されるメモリアクセス要求のサイクルB1の信号と,RSAから転送されるメモリアクセス要求のサイクルB1の信号とが衝突する。
図18は,SIMD幅4の場合での後続するSIMDインダイレクトメモリアクセス命令のエントリの投入により生成されるメモリアクセス要求との衝突を示す図である。いずれも,図11の2つのメモリアクセスパイプラインEAGA,EGABを有する例で示している。
本実施の形態では,SIMDインダイレクトメモリアクセス命令のエントリの投入に応答して,SIMD演算パイプラインFLAが,演算用インタフェース333が出力する信号を利用して,メモリアクセスパイプラインEAGA,EAGBにメモリアクセス要求を生成する。そのため,その生成されたメモリアクセス要求が,後続のSIMDインダイレクトメモリアクセス命令のエントリの投入に応答してメモリアクセスパイプラインEAGA,EAGBに生成されるメモリアクセス要求と衝突する場合がある。図11の例では,SIMD幅が4の場合に2回メモリアクセス要求が生成されるので,後続のSIMDインダイレクトメモリアクセス命令に対応するメモリアクセス要求と,1回衝突する場合がある。図6の例では,SIMD幅2では1回衝突し,SIMD幅4では3回衝突する場合がある。
図11の例で説明すると図18に示されるように以下のとおりである。図18には衝突がB1への取消線で示されている。
(3)タイミング3でRSFがSIMD幅4のSIMDインダイレクトメモリアクセス命令のエントリを出力し,タイミング4でRSFがSIMD幅2もしくは4のSIMDインダイレクトメモリアクセス命令のエントリを出力した場合,次のとおり衝突が発生する。すなわち,タイミング3でRSFから出力された4SIMDインダイレクトメモリアクセス命令により生成されたメモリアクセス要求のサイクルB1の信号と,次のタイミング4でRSFから出力された2または4SIMDインダイレクトメモリアクセス命令により生成されたメモリアクセス要求のサイクルB1の信号とが,タイミング7で衝突する。
図19は,インダイレクトメモリアクセス要求の衝突を回避する抑止信号を生成する演算用インタフェース333の構成を示す図である。演算用インタフェース333は,RSFが投入するSIMDインダイレクトメモリアクセス命令のエントリのPサイクルのフラグ信号を入力し,ラッチ群F10でラッチし,さらにラッチ群F11でラッチする。それにより,演算用インタフェース333は,Pサイクルから2サイクル後のB1サイクルの出力信号を,SIMD演算パイプラインFLAのSIMD演算器330と,メモリアクセスパイプラインEAGA,EAGBのアドレス用インタフェース310に転送する。演算用インタフェース333が2つのラッチ群F10,F11を有するのは,例えば,タイミングを調整するためである。
そして,演算用インタフェース333は,Pサイクルの3つのフラグ信号からRSFへの後続のSIMDインダイレクトメモリアクセス命令のエントリの投入を抑止する抑止信号INH_FLA_INDIRECT_OPと,PTサイクルの2つのフラグ信号からとともに,B1サイクルの3つのフラグ信号からも,RSAへの後続のメモリアクセス命令の投入を抑止する抑止信号INH_RSA_PRIORITYを生成する。
演算用インタフェース333の動作は次のとおりである。
入力信号(バリッド信号)P_FLA_VALIDは,浮動小数点・SIMDパイプラインのPサイクルでパイプラインFLAへのSIMD演算器に演算要求が出力されたときに1となる。
入力信号(インダイレクト信号)P_FLA_INDIRECTは,入力バリッド信号P_FLA_VALIDが1のときに有効となる信号であり,演算要求がSIMDインダイレクトメモリアクセス命令の場合に,浮動小数点・SIMDパイプラインのPサイクルで1となる。
入力信号(4SIMD信号)P_FLA_4SIMDは,入力バリッド信号P_FLA_VALIDが1のときに有効となる信号であり,SIMD演算器の演算幅が4であるときに浮動小数点・SIMDパイプラインのPサイクルで1となる。
入力信号(IDD信号)P_FLA_IIDは,入力バリッド信号P_FLA_VALIDが1のときに有効となる信号であり,パイプラインFLAで実行される演算のCSEのエントリ番号を示す。
入力信号(FP信号)P_FLA_FPは,入力バリッド信号P_FLA_VALIDが1かつ入力インダイレクト信号P_FLA_INDIRECTが1のときに有効となる信号であり,SIMDインダイレクトメモリアクセス命令において命令デコーダで確保された一次データキャッシュ内のフェッチポートFPの先頭番号を示す。
演算用インタフェース333は,5つの入力信号をラッチF10,F11でラッチして中継し,5つの出力信号B1_FLA_VALID_EAITF,B1_FLA_INDIRECT_EAITF,B1_FLA_4SIMD_EAITF,B1_FLA_IID_EAITF,B1_FLA_FP_EAITFを,アドレス用インタフェース310に転送し,メモリアクセスのリクエストを生成させる。
同様に,演算用インタフェース333は,4つの入力信号をラッチF10,F11でラッチして中継し,4つの出力信号B1_FLA_VALID,B1_FLA_INDIRECT,B1_FLA_4SIMD,B1_FLA_IIDを,SIMD演算器に転送する。
演算用インタフェース333では,アンドゲートA4がPサイクルの2つの入力信号P_FLA_VALID,P_FLA_INDIRECTの論理積を後続の通常メモリアクセス命令の抑止信号INH_RSA_PRIORITYとして生成し,RSAに転送する。これにより,RSAは,後続のメモリアクセス命令のエントリのメモリアクセスパイプラインEAGA,EAGBへの投入を抑止する。
図16に示されるとおり,タイミング3のPサイクルの2つの信号が全て1の場合に,タイミング4で抑止信号INH_RSA_PRIORITYが1になり,タイミング5においてRSAがメモリアクセス命令のエントリのパイプラインEAGA,EAGBへの投入を抑止する。これにより,タイミング6でB1サイクルの信号が発生せず,衝突が回避される。
さらに,演算用インタフェース333では,アンドゲートA5がPサイクルの3つの入力信号P_FLA_VALID,P_FLA_INDIRECT,P_FLA_4SIMDの論理積を後続の通常メモリアクセス命令の抑止信号INH_RSA_PRIORITYとして生成し,RSAに転送する。これにより,RSAは,後続のメモリアクセス命令のメモリアクセスパイプラインEAGA,EAGBへの投入を抑止する。
図17に示されるとおり,タイミング3のPサイクルの3つの信号が全て1の場合に,タイミング5で抑止信号INH_RSA_PRIORITYが1になり,タイミング6においてRSAがメモリアクセス命令のパイプラインEAGA,EAGBへの投入を抑止する。これにより,タイミング7でB1サイクルの信号が発生せず,衝突が回避される。図17では,図16と同様にして,タイミング4で抑止信号INH_RSA_PRIORITYが1になり,タイミング5におけるRSAでのメモリアクセス命令の投入が抑止されている。
そして,演算用インタフェース333では,アンドゲートA3がPサイクルの3つの入力信号P_FLA_VALID,P_FLA_INDIRECT,P_FLA_4SIMDの論理積を後続のSIMDインダイレクトメモリアクセス命令の抑止信号INH_FLA_INDIRECT_OPとして生成し,RSFに転送する。これにより,RSFは,後続のSIMDインダイレクトメモリアクセス命令のエントリのSIMD演算パイプラインFLAへの投入を抑止する。
図18に示されるとおり,タイミング3のPサイクルの3つの信号が全て1の場合に,抑止信号INH_FLA_INDIRECT_OPが1になり,次のタイミング4においてRSFがSIMDインダイレクトメモリアクセス命令のエントリのパイプラインFLAへの投入を抑止する。これにより,タイミング7で生成されたB1サイクルの信号が発生せず,衝突が回避される。
図20は,RSFとそのSIMDインダイレクトメモリアクセス命令のエントリの出力抑止回路を示す図である。RSFは,例えば20個のエントリ保持部337を有し,リザベーションステーションRSFに生成された命令のエントリに対応するフラグが格納されている。フラグの例は図7に示されている。
各エントリ保持部337に対応するRSFエントリ出力条件検出回路338は,これらのフラグを用い,RSF内のエントリそれぞれについてパイプラインへの出力可能条件が成立したことを検出する。このRSFエントリ出力条件検出回路338は,RSFそれぞれに格納された命令のエントリが処理可能となった場合に1を出力し,出力が可能でない場合は0を出力する。
抑止回路339は,演算用インタフェース333で生成された抑止信号INH_FLA_INDIRECT_OPと,RSFのエントリ保持部337に格納されているINDIRECTフラグが共に1の場合に,出力条件検出回路338の出力を強制的に0にする。これにより,対応するRSFエントリが出力可能であるか否かを示すREADY信号がラッチRSFxx_READYにラッチされる。xxは00−19である。
FLA出力選択回路340は,このREADY信号が1のRSFエントリから,次に出力するRSFエントリを選択し,演算用インタフェース333へ出力する。ただし,SIMDインダイレクトメモリアクセス命令の場合は,INDIRECTフラグが1になるので,抑止信号INH_FLA_INDIRECT_OPが1となったとき,そのエントリのREADY信号が0となるため,FLA出力選択回路340はそのSIMDインダイレクトメモリアクセス命令のエントリを選択することはない。SIMDインダイレクトメモリアクセス命令以外の命令の場合は,INDIRECTフラグが0になるので,エントリ出力条件検出回路338の出力がREADY信号として使用される。したがって,SIMDインダイレクトメモリアクセス命令以外の命令については,必要な資源が準備されたエントリがあればその命令のエントリが出力される。これによりRSFが,抑止信号INH_FLA_INDIRECT_OPに応じて,SIMDインダイレクトメモリアクセス命令のエントリの出力を抑止する。
図21は,RSAとその通常のメモリアクセス命令のエントリの出力抑止回路を示す図である。RSAは,例えば20個のエントリ保持部314を有する。各エントリ保持部314に対応するRSAエントリ出力条件検出回路315は,RSAエントリそれぞれについてパイプラインへの出力可能条件が成立したことを検出する。このRSAエントリ出力条件検出回路315は,RSAそれぞれに格納された命令が処理可能となった場合に1を出力し,出力が可能でない場合は0を出力する。
抑止回路316は,演算用インタフェース333で生成された抑止信号INH_RSA_PRIORITYが1の場合に,RSAエントリ出力条件検出回路315の出力を強制的に0にする。これにより,対応するRSAエントリが出力可能であるか否かを示すREADY信号がラッチRSAxx_READYにラッチされる。
EAGA/EAGB出力選択回路317は,READY信号が1のRSAエントリから出力するRSAエントリを選択し,メモリアクセスパイプラインEAGAまたはEAGBに出力し,アドレス用インタフェースへ転送する。抑止信号INH_RSA_PRIORITYが1のとき,RSAエントリ出力条件検出回路315から出力された値に関わらず,すべてのRSAのREADY信号が0になる。これによりEAGA/EAGB出力選択回路315は出力可能なエントリがないため,メモリリクエストをメモリアクセスパイプラインEAGA,EAGBにエントリを出力しない。これによりRSAが,抑止信号INH_RSA_PRIORITYに応じて,メモリアクセス命令のエントリの出力を抑止する。
図22は,CSE内の完了待ち合わせ回路を示す図である。図22には,CSEの1つのエントリに対する完了待ち合わせ回路が示されている。
まず,CSEのエントリにインダイレクトフラグCSE_INDIRECTが含まれている。CSEのエントリがSIMDインダイレクトメモリアクセス命令の場合,そのエントリのインダイレクトフラグCSE_INDIRECTが1になる。また,その命令が4SIMDの場合に4SIMD信号CSE_4SIMDが1になる。CSEにエントリされた命令がSIMDインダイレクトメモリアクセス命令であった場合,一次データキャッシュ312が同じCSEのエントリ番号IIDに対して2SIMDなら2回,4SIMDなら4回の完了報告をCSEに行う。
入力信号(インダイレクト信号)CSE_INDIRECT,入力信号(4SIMD信号)CSE_4SIMDは,命令デコーダ305によりCSEに登録されたエントリのフラグである。入力信号CSE_INDIRECTが1のときCSEのエントリがSIMDインダイレクトメモリアクセス命令であることを示す。入力信号CSE_4SIMDが1のとき,CSEのエントリのSIMD幅が4であることを示し,0のときSIMD幅が2であることを示す。
本実施の形態の一次データキャッシュ312は,2つの独立したメモリアクセスを同時に処理する。そのため,一次データキャッシュ312は,メモリアクセス完了信号を2つ独立して通知する。
入力信号RT_STV_0,RT_STV_1は一次データキャッシュから転送されるメモリアクセスの完了信号である。
入力信号RT_STV_0_CSE_SEL,RT_STV_1_CSE_SELは,一次データキャッシュにおいて処理中のエントリ番号IIDが,CSEのエントリ番号と一致したとき1となる。
RT_STV_0とRT_STV_0_CSE_SELが1となったとき,もしくはRT_STV_1とRT_STV_1_CSE_SELが1となったとき,アンドゲートA8またはA9の出力により,CSEへのメモリアクセス完了報告が有効となる。メモリアクセス完了報告が有効になると,加算器351が3ビットの入力信号に+1加算してメモリアクセス完了回数記憶素子353に出力する。
命令デコードがCSEにエントリを作成したときに,メモリアクセス完了回数記憶素子353を0にリセットする。その後,一次データキャッシュ312からの完了報告により,RT_STV_0とRT_STV_0_CSE_SEL両方が1になった場合,もしくはRT_STV_1とRT_STV_1_CSE_SEL両方が1となった場合,加算器351がメモリアクセス完了回数を+1加算する。
メモリアクセス命令の種類により,メモリアクセス完了回数が規定の値(1,2,4回)となったとき,出力信号(完了信号)CSE_MEM_COMPが1となる。アンドゲートA6により,SIMDインダイレクトメモリアクセス命令かつSIMD幅が4の場合,4回のメモリアクセス完了が通知されたとき,加算器351のビット2の出力が1になり,完了信号CSE_MEM_COMPが1となる。SIMDインダイレクトメモリアクセス命令かつSIMD幅が2の場合,2回のメモリアクセス完了が通知されたとき,加算器351のビット1の出力が1になり,完了信号が1となる。そして,SIMDインダイレクト命令でないメモリアクセス命令の場合は,1回メモリアクセス完了が通知されたとき,加算器351のビット0の出力が1になり,完了信号CSE_MEM_COMPが1となる。
完了判定回路354は,この完了信号CSE_MEM_COMPを入力し,命令が完了可能となったことを示す信号を生成する。完了判定回路354は,処理が完了した命令をプログラムの順番に完了したと判定し,例えばリネーミングレジスタからレジスタに処理結果を転送し,エントリを開放する。
以上の通り,本実施の形態によれば,SIMDインダイレクトメモリアクセス命令のエントリをRSFに生成し,そのエントリがSIMD演算用パイプラインFLAに出力されると,メモリアクセスパイプラインEAGA,EGABにSIMD幅に応じた数のメモリアクセスを生成し,SIMD演算器330が複数のSIMDレジスタ332に格納されている独立した複数のアドレスを取得てメモリアクセスパイプラインEAGA,EGABに転送し,一次データキャッシュ312がその複数のアドレスを使用して複数のSIMDレジスタ332に格納されている複数のデータについてメモリアクセスを行う。したがって,命令デコーダやCSE,RSA,RSFのエントリなどの資源を効率的に使用してSIMDインダイレクトメモリアクセス命令を実行する。
以上の実施の形態をまとめると,次の付記のとおりである。
(付記1)
命令をデコードする命令デコーダと,
前記命令デコーダによりメモリアクセス命令のエントリを生成されるメモリアクセスエントリ部と,
前記メモリアクセスエントリ部から出力された前記メモリアクセス命令のエントリをメモリに対して実行するメモリアクセスパイプラインと,
前記命令デコーダにより複数のデータを1つの命令で処理するマルチデータ命令のエントリを生成されるマルチデータ命令エントリ部と,
複数の演算器と複数のマルチデータ命令用レジスタとを有し,前記マルチデータ命令エントリ部から出力された前記マルチデータ命令のエントリの処理を前記複数の演算器により並列に処理し,前記複数のマルチデータ命令用レジスタに演算結果を格納する演算パイプラインとを有し,
前記演算パイプラインは,前記複数のマルチデータ命令用レジスタに格納されている複数のメモリアドレスについて前記メモリにメモリアクセスするマルチデータインダイレクトメモリアクセス命令のエントリの出力に応答して,前記メモリアクセスパイプラインに前記マルチデータインダイレクトメモリアクセス命令に対応する複数のメモリアクセス要求を生成し,前記複数の演算器が前記複数のマルチデータ命令用レジスタから取得した前記複数のメモリアドレスを前記メモリアクセスパイプラインに供給する演算処理装置。
(付記2)
前記演算パイプラインは,前記メモリアクセスパイプラインの第1サイクルのステージに前記複数のメモリアクセス要求を生成し,前記メモリアクセスパイプラインの前記第1サイクルより後の第2サイクルのステージに前記複数のメモリアドレスを供給する
付記1に記載された演算処理装置。
(付記3)
前記演算パイプラインは,前記メモリアクセスパイプラインに生成した複数のメモリアクセス要求のパイプライン転送タイミングにあわせて前記複数のメモリアドレスを供給する
付記2に記載された演算処理装置。
(付記4)
さらに,前記メモリアクセスパイプラインに接続されたキャッシュユニットを有し,
前記演算パイプラインは,前記メモリアクセスパイプラインに生成する前記複数のメモリアクセス要求に前記キャッシュユニット内のアクセス先メモリアドレスを格納する複数のフェッチポートの識別情報を含める
付記1に記載された演算処理装置。
(付記5)
前記演算パイプラインは,前記メモリアクセスパイプラインに,前記複数のメモリアクセス要求をシリアルに生成し,前記複数のメモリアドレスをシリアルに供給する
付記1,2,3のいずれかに記載された演算処理装置。
(付記6)
前記メモリアクセスパイプラインが複数設けられ,
前記演算パイプラインは,前記複数のメモリアクセスパイプラインに,前記複数のメモリアクセス要求の少なくとも一部のメモリアクセス要求を並列に生成し,前記複数のメモリアドレスの少なくとも一部のアドレスを並列に供給する
付記1,2,3のいずれかに記載された演算処理装置。
(付記7)
さらに,前記メモリアクセスパイプラインに接続されたキャッシュユニットを有し,
前記キャッシュユニットは,前記複数のメモリアクセス要求に応答して,前記複数のマルチデータ命令用レジスタとの間でデータ転送を行う
付記1に記載された演算処理装置。
(付記8)
前記演算パイプラインは,前記メモリアクセスエントリ部に抑止信号を出力して,前記メモリアクセスエントリ部に,前記メモリアクセスパイプラインに生成する前記複数のメモリアクセス要求と衝突するメモリアクセス命令のエントリの出力を抑止させる
付記1に記載された演算処理装置。
(付記9)
前記演算パイプラインは,前記マルチデータ命令エントリ部に抑止信号を出力して,前記マルチデータ命令エントリ部に,前記メモリアクセスパイプラインにシリアルに生成する前記メモリアクセス要求と衝突するマルチデータインダイレクトメモリアクセス命令のエントリの出力を抑止させる
付記5に記載された演算処理装置。
(付記10)
前記演算パイプラインに出力される前記マルチデータインダイレクトメモリアクセス命令のエントリは,マルチデータインダイレクトメモリアクセスを示すインダイレクトメモリアクセス信号と,前記複数のデータの数を示すマルチデータ幅情報信号とを有し,
前記演算パイプラインは,前記メモリアクセスパイプラインに,前記マルチデータ幅情報信号が示す数の前記メモリアクセス要求を生成し,前記マルチデータ幅情報信号が示す数の前記複数のメモリアドレスを供給する
付記1に記載された演算処理装置。
(付記11)
命令をデコードする命令デコーダと,
前記命令デコーダによりメモリアクセス命令のエントリを生成されるメモリアクセスエントリ部と,
前記メモリアクセスエントリ部から出力された前記メモリアクセス命令のエントリをメモリに対して実行するメモリアクセスパイプラインと,
前記命令デコーダにより複数のデータを1つの命令で処理するマルチデータ命令のエントリを生成されるマルチデータ命令エントリ部と,
複数の演算器と複数のマルチデータ命令用レジスタとを有し,前記マルチデータ命令エントリ部から出力された前記マルチデータ命令のエントリの処理を前記複数の演算器により並列に処理し,前記複数のマルチデータ命令用レジスタに演算結果を格納する演算パイプラインとを有する演算処理装置の制御方法において,
前記演算パイプラインが,前記複数のマルチデータ命令用レジスタに格納されている複数のメモリアドレスについて前記メモリにメモリアクセスするマルチデータインダイレクトメモリアクセス命令のエントリの投入に応答して,前記メモリアクセスパイプラインに前記マルチデータインダイレクトメモリアクセス命令に対応する複数のメモリアクセス要求を生成し,
前記演算パイプラインが,前記複数の演算器が前記複数のマルチデータ命令用レジスタから取得した前記複数のメモリアドレスを前記メモリアクセスパイプラインに供給する演算処理装置の制御方法。
(付記12)
前記演算パイプラインが,前記メモリアクセスパイプラインの第1サイクルのステージに前記複数のメモリアクセス要求を生成し,前記メモリアクセスパイプラインの前記第1サイクルより後の第2サイクルのステージに前記複数のメモリアドレスを供給する
付記11に記載された演算処理装置の制御方法。