JP6256594B2 - プログラム、管理方法およびコンピュータ - Google Patents
プログラム、管理方法およびコンピュータ Download PDFInfo
- Publication number
- JP6256594B2 JP6256594B2 JP2016509845A JP2016509845A JP6256594B2 JP 6256594 B2 JP6256594 B2 JP 6256594B2 JP 2016509845 A JP2016509845 A JP 2016509845A JP 2016509845 A JP2016509845 A JP 2016509845A JP 6256594 B2 JP6256594 B2 JP 6256594B2
- Authority
- JP
- Japan
- Prior art keywords
- server
- virtual server
- servers
- virtual
- hierarchy
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images

































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/20—Arrangements for monitoring or testing data switching networks the monitoring system or the monitored elements being virtualised, abstracted or software-defined entities, e.g. SDN or NFV
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5083—Techniques for rebalancing the load in a distributed system
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/06—Generation of reports
- H04L43/062—Generation of reports related to network traffic
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/08—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters
- H04L43/0805—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters by checking availability
- H04L43/0817—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters by checking availability by checking functioning
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1001—Protocols in which an application is distributed across nodes in the network for accessing one among a plurality of replicated servers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/0813—Configuration setting characterised by the conditions triggering a change of settings
- H04L41/0816—Configuration setting characterised by the conditions triggering a change of settings the condition being an adaptation, e.g. in response to network events
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/40—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks using virtualisation of network functions or resources, e.g. SDN or NFV entities
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Environmental & Geological Engineering (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer And Data Communications (AREA)
- Debugging And Monitoring (AREA)
Description
例えば、複数の異なるハードウェアおよびソフトウェア(すなわち、プラットフォーム)の異なる組合せを持つ複数の異なる装置を使用するネットワークの最適化システムが提案されている。このシステムは、このようなネットワークの性能を正確に評価し、調節し、最適化する。
本発明の上記および他の目的、特徴および利点は本発明の例として好ましい実施の形態を表す添付の図面と関連した以下の説明により明らかになるであろう。
[第1の実施の形態]
図1は、第1の実施の形態の情報処理システムを示す図である。第1の実施の形態の情報処理システムは、サーバ10,10a,10b,10cを有する。サーバ10,10a,10b,10cは仮想マシンでもよい。サーバ10,10a,10b,10cは、複数の処理を並行して実施する。サーバ10,10a,10b,10cは、負荷値の受け渡し関係が木構造で定義されている。サーバ10,10a,10b,10cは、それぞれ、木構造において1つ下に接続された1以上のサーバ10aから、木構造においてそのサーバ10a以下に接続されたサーバ群(サーバ10a,10b)の負荷値を受信する。そして、サーバ10,10a,10b,10cは、それぞれ、受信した負荷値に基づいて、オートスケールを行うか否かの判定を自律的に実行する。オートスケールは、システムの負荷に応じてスケールアウト・スケールインを自動的に行う機能である。スケールアウトは、システムを構成するサーバの数を増やすことである。スケールアウトは、例えばシステムの処理能力を向上させるために実行される。スケールインは、システムを構成するサーバの数を減らすことである。スケールインは、例えばシステム全体のリソースの効率的に使用するために実行される。オートスケールを行うか否かの判定のために、サーバ10,10a,10b,10cは、自己のサーバの負荷値を計測する機能を有する。負荷値とは、例えば、サーバが実行する所定時間あたりのトランザクション数やCPU(Central Processing Unit)使用率など自己のサーバにかかる負荷を示す値である。
次に、仮想化されたサーバを用いたオートスケールの実施例について説明する。仮想化とは、コンピュータの物理リソースを抽象化することである。例えば、サーバを仮想化すると、1台のサーバ装置を複数のサーバ装置に見せかけることができる。以下、仮想化されたサーバ装置を、仮想サーバと呼ぶ。仮想化において、仮想サーバのスケールアウトは、システムの構成に仮想サーバを増やすことである。仮想サーバのスケールインは、システムの構成から仮想サーバを減らすことである。
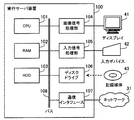
図3は、実行サーバ装置のハードウェア例を示すブロック図である。実行サーバ装置100は、CPU101、RAM102、HDD103、画像信号処理部104、入力信号処理部105、ディスクドライブ106および通信インタフェース107を有する。上記の各ユニットは、実行サーバ装置100が備えるバス108に接続されている。
図6は、実行サーバ装置と管理サーバの機能例を示すブロック図である。実行サーバ装置100は、ハイパーバイザ110および仮想サーバ#1を有する。ハイパーバイザ110は、仮想サーバ#1の仮想化を実現するため、仮想サーバ#1上のOSを制御するプログラムである。ハイパーバイザ110は、仮想サーバ#1へ実行サーバ装置100のリソース(例えば、CPU101、RAM102、HDD103など)を効率的に配分する。
管理情報記憶部120は、仮想サーバ#1がオートスケールを実現するために管理する情報を記憶する。管理情報記憶部120は、閾値情報テーブル121、負荷分析値テーブル122、サーバ数管理テーブル123および階層管理テーブル124を有する。閾値情報テーブル121は、平均トランザクション数の閾値等、仮想サーバ#1がスケールアウトまたはスケールインを判断するために用いる閾値の情報を格納する。閾値情報テーブル121に記憶されている情報は、例えば、システムの管理者により設定されたものでもよい。負荷分析値テーブル122は、仮想サーバ#1の階層以下の階層における各仮想サーバのトランザクション数を所定時間毎に集計・分析した値(平均トランザクション数など)を格納する。サーバ数管理テーブル123は、親、子および自己の仮想サーバの数を格納する。サーバ数管理テーブル123は、トランザクション数を分析するために用いられる。階層管理テーブル124は、仮想サーバ#1が親または子の仮想サーバを把握するための情報を格納する。
スケールアウト実行部210は、仮想サーバ#1からスケールアウトを要求されたとき、仮想サーバをスケールアウトする。次に、スケールアウト実行部210は、スケールアウトが完了した旨を仮想サーバ#1に応答する。
図12は、階層管理テーブルの例を示す図である。階層管理テーブル124は、階層およびホスト名の項目を有する。階層の項目には、自己の仮想サーバとの階層の関係を示す情報が設定される。階層=「親」の場合、自己の仮想サーバの1つ上の階層であることを示す。階層=「子」の場合、自己の仮想サーバの1つ下の階層であることを示す。階層=「自分」の場合、自己の仮想サーバであることを示す。ホスト名の項目には、階層の項目に対応する仮想サーバのホスト名が設定される。例えば、仮想サーバ#1が子の仮想サーバのホスト名=#1−1である仮想サーバを子の仮想サーバとして登録したとき、登録した情報は階層=「子」かつホスト名=#1−1となる。以下、仮想サーバのホスト名は、仮想サーバの符号であるものとする。
図14は、仮想サーバによるオートスケールの手順例を示すフローチャートである。
(ステップS12)負荷計測部130は、選択した仮想サーバについて、総トランザクション数など性能測定値を取得する。処理の詳細は後述する(図15参照)。
(ステップS16)オートスケール判定部150は、スケールアウトまたはスケールインの有無を判定する。そして、オートスケール実行部160は、判定に応じてスケールアウトまたはスケールインを実行する。処理の詳細は後述する(図17参照)。
(ステップS121)負荷計測部130は、所定時間を確認する。所定時間は、仮想サーバ#1がトランザクション数などの性能測定値を計測または分析する時間間隔である。所定時間は、例えば、本システムの管理者などにより設定された設定値を使用する。また、所定時間には、管理者が設定する前に予め初期値が設定されていてもよいし、管理者が設定を省略した場合に省略値が設定されるようにしてもよい。設定された所定時間は、例えば、仮想サーバ#1の有する記憶領域に記憶される。
(ステップS141)負荷分析部140は、ステップS121と同様の所定時間を確認する。
(ステップS143)負荷分析部140は、ステップS12で取得した子の仮想サーバ自身の数および子の仮想サーバの総仮想サーバ数を集計する。負荷分析部140は、集計した総仮想サーバ数で、サーバ数管理テーブル123における子の仮想サーバ数を更新する。
(ステップS145)負荷分析部140は、集計したトランザクション数および仮想サーバ数に基づき、自己の仮想サーバの平均トランザクション数を算出する。具体的には、トランザクション数の集計値÷(サーバ数管理テーブル123における子の仮想サーバ数+1(自己の仮想サーバの数))により算出する。
(ステップS148)負荷分析部140は、トランザクション変化量に0を設定する。
(ステップS161)オートスケール判定部150は、ステップS149で登録された平均トラン数が閾値以上であるか確認する。閾値は、閾値情報テーブル121の平均トラン数(上限)を参照する。平均トラン数が閾値以上の場合、処理をステップS162へ進める。平均トラン数が閾値未満の場合、処理をステップS163へ進める。
(ステップS163)オートスケール判定部150は、ステップS149で登録された平均トラン変化量が閾値以上であるか確認する。閾値は、閾値情報テーブル121の平均トラン変化量(上限)を参照する。平均トラン変化量が閾値以上の場合、処理をステップS164へ進める。平均トラン数が閾値未満の場合、処理をステップS165へ進める。
(ステップS165)オートスケール判定部150は、ステップS149で登録された平均トラン数が閾値未満であるか確認する。閾値は、閾値情報テーブル121の平均トラン数(下限)を参照する。平均トラン数が閾値未満の場合、処理をステップS166へ進める。平均トラン数が閾値以上の場合、処理をステップS172へ進める。
(ステップS168)オートスケール判定部150は、階層管理テーブル124を参照し、親の仮想サーバがなく、かつ、子の仮想サーバがあるか判定する。親の仮想サーバがなく、かつ、子の仮想サーバがある場合、処理をステップS169へ進める。親の仮想サーバがある、または、子の仮想サーバがない場合、処理をステップS170へ進める。
(ステップS170)オートスケール判定部150は、階層管理テーブル124を参照し、親の仮想サーバがあり、かつ、子の仮想サーバがあるか判定する。親の仮想サーバがあり、かつ、子の仮想サーバがある場合、処理をステップS171へ進める。親の仮想サーバがない、または、子の仮想サーバがない場合、処理をステップS172へ進める。
(ステップS172)オートスケール判定部150は、負荷分析値テーブル122の平均トラン変化量が閾値未満であるか確認する。閾値は、閾値情報テーブル121の平均トラン変化量(下限)を参照する。平均トラン変化量が閾値未満の場合、処理をステップS173へ進める。平均トラン変化量が閾値以上の場合、処理を終了する。
(ステップS175)オートスケール判定部150は、階層管理テーブル124を参照し、親の仮想サーバがなく、かつ、子の仮想サーバがあるか判定する。親の仮想サーバがなく、かつ、子の仮想サーバがある場合、処理をステップS176へ進める。親の仮想サーバがある、または、子の仮想サーバがない場合、処理をステップS177へ進める。
(ステップS177)オートスケール判定部150は、階層管理テーブル124を参照し、親の仮想サーバがあり、かつ、子の仮想サーバがあるか判定する。親の仮想サーバがあり、かつ、子の仮想サーバがある場合、処理をステップS178へ進める。親の仮想サーバがない、または、子の仮想サーバがない場合、処理を終了する。
次に、スケールアウトの処理について説明する。図18は、スケールアウトの手順例を示すフローチャートである。図18のフローチャートが示す処理は、ステップS162,S164において実行される。
(ステップS182)スケールアウト実行部210は、仮想サーバ#1の要求を受信し、スケールアウトを実施する。そして、スケールアウト実行部210は、仮想サーバ#1にスケールアウトした仮想サーバのホスト名(または、IPアドレス)を応答する。
(ステップS184)オートスケール実行部160は、階層=「子」かつホスト名=確認したホスト名のレコードを階層管理テーブル124に登録する。
まず、仮想サーバ#1−1は、仮想化管理サーバ装置200に仮想サーバのスケールアウトを要求する(ステップS181)。仮想化管理サーバ装置200は、仮想サーバ#1−1から要求を受信し、仮想サーバ#1−1−1のスケールアウトを実施する(ステップS182)。仮想サーバ#1−1は、スケールアウトされた仮想サーバ#1−1−1のホスト名=#1−1−1含む応答を仮想化管理サーバ装置200から受信する(ステップS183)。
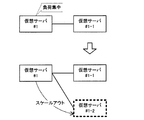
図20は、スケールアウト例を示す第1のブロック図である。図20において、仮想サーバ#1のみが存在する。仮想サーバ#1がスケールアウトを要求したとき、スケールアウトされた仮想サーバ#1−1は、仮想サーバ#1の子の仮想サーバとして構成される。
(ステップS192)オートスケール実行部160は、実行中のトランザクションの実行が全て完了後、トランザクションを実行するプロセスを停止する。
(ステップS199)スケールイン実行部220は、仮想サーバ#1から要求を受信し、仮想サーバ#1をスケールインする。そして、スケールイン実行部220は、スケールインを実施した旨を仮想サーバ#1に応答する。
図24は、第1のスケールインにおける装置間の応答例を示す図である。図24では、仮想サーバ#1−1−1が、スケールインを要求する場合について説明する。図24において、仮想サーバ#1−1と、仮想サーバ#1−1の子の仮想サーバ#1−1−1が存在する。仮想サーバ#1−1−1には、子の仮想サーバが存在しない。
仮想サーバ#1−1−1は、階層管理テーブル124kから階層=「自分」または「親」であるホスト名を検索する。仮想サーバ#1−1−1は、検索された階層=「自分」であるホスト名=#1−1−1を、階層管理テーブル124iから削除するよう仮想サーバ#1−1に要求する(ステップS195)。仮想サーバ#1−1は、階層=子かつホスト名=#1−1−1のレコードを、階層管理テーブル124iから削除する(ステップS196)。その結果、レコードの削除前の階層管理テーブル124iは、レコードの削除後の階層管理テーブル124jとなる。仮想サーバ#1−1は、削除の結果を仮想サーバ#1−1−1に応答する。仮想サーバ#1−1−1は、仮想サーバ#1−1から応答を受信する(ステップS197)。
(ステップS202)オートスケール実行部160は、実行中のトランザクションの実行が全て完了後、トランザクションを実行するプロセスを停止する。
(ステップS210)オートスケール実行部160は、選択した子の仮想サーバに、階層=「親」かつホスト名=ステップS203で検索されたホスト名であるレコードを階層管理テーブルから削除するよう要求する。
(ステップS218)スケールイン実行部220は、仮想サーバ#1から要求を受信し、仮想サーバ#1をスケールインする。そして、スケールイン実行部220は、スケールインを実施した旨を仮想サーバ#1に応答する。
図27は、第2のスケールインにおける装置間の応答例を示す図である。図27では、仮想サーバ#1が、スケールインを要求する場合について説明する。図27において、仮想サーバ#1、仮想サーバ#1の子の仮想サーバ#1−1,#1−2が存在する。仮想サーバ#1には、親の仮想サーバが存在しない。
仮想サーバ#1は、階層管理テーブル124lから階層=「自分」であるホスト名=#1を検索する。また、仮想サーバ#1は、階層管理テーブル124lから階層=「子」であるホスト名=#1−1,#1−2を検索する。そして、検索された階層=「子」のホスト名からホスト名=#1−1を選択する。
(ステップS222)オートスケール実行部160は、実行中のトランザクションの実行が全て完了することを待った上で、仮想サーバ#1におけるトランザクションを実行するプロセスを停止する。
(ステップS233)スケールイン実行部220は、仮想サーバ#1から要求を受信し、仮想サーバ#1をスケールインする。そして、スケールイン実行部220は、スケールインを実施した旨を仮想サーバ#1に応答する。
図30は、第3のスケールインにおける装置間の応答例を示す図である。図30では、仮想サーバ#1−1が、スケールインを要求する場合について説明する。図30において、仮想サーバ#1、仮想サーバ#1の子の仮想サーバ#1−1、および仮想サーバ#1−1の子の仮想サーバ#1−1−1が存在する。
仮想サーバ#1−1は、階層管理テーブル124qから階層=「自分」であるホスト名=#1−1を検索する。また、仮想サーバ#1−1は、階層管理テーブル124qから階層=「親」であるホスト名=#1を検索する。また、仮想サーバ#1−1は、階層管理テーブル124qから階層=「子」であるホスト名=#1−1−1を検索する。
11,11a,11b,11c 受信部
12,12a,12b,12c 判定部
Claims (12)
- コンピュータに、
前記コンピュータまたは前記コンピュータと同じシステムに属する他のコンピュータが、サーバソフトウェアを実行することで実現される複数のサーバが接続され、それぞれの接続が、負荷値の受け渡しに関する従属関係を構成しており、前記コンピュータで実現される第1のサーバに従属する1以上の第2のサーバから、前記1以上の第2のサーバ以下に従属する1以上のサーバ群に属するサーバの負荷値を受信し、
前記第1のサーバの負荷値と、前記1以上の第2のサーバから受信した負荷値に基づいて、前記システムを増強させるか否かを判定する、
処理を実行させることを特徴とするプログラム。 - 前記コンピュータに、さらに、
前記システムを増強させると判定した場合、前記第1のサーバに従属するサーバの追加要求を出力する、
ことを特徴とする請求項1記載のプログラム。 - 前記判定では、前記第1のサーバおよび前記1以上のサーバ群に属するサーバの負荷値の平均値が閾値以上の場合、前記システムを増強させると判定する、ことを特徴とする請求項1または2のいずれかに記載のプログラム。
- 前記判定では、さらに、
前記第1のサーバおよび前記1以上のサーバ群に属するサーバの負荷値の平均値が閾値未満の場合、前記システムを縮小させると判定する、
ことを特徴とする請求項1乃至3のいずれかに記載のプログラム。 - 前記コンピュータに、さらに、
前記システムを縮小させると判定した場合、前記第1のサーバの停止要求を出力する、
処理を実行させることを特徴とする請求項4記載のプログラム。 - 前記判定では、さらに、
前記第1のサーバおよび前記1以上のサーバ群に属するサーバの負荷値の平均値の変化量が閾値以上の場合、前記システムを増強させると判定する、ことを特徴とする請求項1記載のプログラム。 - 前記判定では、さらに、
前記第1のサーバおよび前記1以上のサーバ群に属するサーバの負荷値の平均値の変化量が閾値未満の場合、前記システムを縮小させると判定する、
ことを特徴とする請求項1記載のプログラム。 - 前記第1のサーバは、前記コンピュータによって構築された仮想マシンによって実現されており、前記受信と、前記判定とを、該仮想マシンに実行させる、
ことを特徴とする請求項1乃至7のいずれかに記載のプログラム。 - 前記コンピュータによって複数の仮想マシンが構築され、各仮想マシン上でサーバが実現されている場合、各仮想マシンに対し、該仮想マシン上で実現されているサーバを前記第1のサーバとして、前記受信と、前記判定とを実行させる、
ことを特徴とする請求項8記載のプログラム。 - 前記複数のサーバは、負荷の受け渡し関係が木構造となるように接続されていることを特徴とする請求項1乃至9のいずれかに記載のプログラム。
- コンピュータに、
前記コンピュータまたは前記コンピュータと同じシステムに属する他のコンピュータが、サーバソフトウェアを実行することで実現される複数のサーバが接続され、それぞれの接続が、負荷値の受け渡しに関する従属関係を構成しており、前記コンピュータで実現される第1のサーバに従属する1以上の第2のサーバから、前記1以上の第2のサーバ以下に従属する1以上のサーバ群に属するサーバの負荷値を受信し、
前記第1のサーバの負荷値と、1以上の第2のサーバそれぞれから受信した負荷値に基づいて、前記システムを増強させるか否かを判定する、
処理を実行させることを特徴とする管理方法。 - コンピュータまたは前記コンピュータと同じシステムに属する他のコンピュータが、サーバソフトウェアを実行することで実現される複数のサーバが接続され、それぞれの接続が、負荷値の受け渡しに関する従属関係を構成しており、前記コンピュータで実現される第1のサーバに従属する1以上の第2のサーバから、前記1以上の第2のサーバ以下に従属する1以上のサーバ群に属するサーバの負荷値を受信する受信部と、
前記第1のサーバの負荷値と、1以上の第2のサーバそれぞれから受信した負荷値に基づいて、前記システムを増強させるか否かを判定する判定部と、
を有することを特徴とするコンピュータ。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2014/059259 WO2015145753A1 (ja) | 2014-03-28 | 2014-03-28 | プログラム、管理方法およびコンピュータ |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2015145753A1 JPWO2015145753A1 (ja) | 2017-04-13 |
| JP6256594B2 true JP6256594B2 (ja) | 2018-01-10 |
Family
ID=54194339
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016509845A Expired - Fee Related JP6256594B2 (ja) | 2014-03-28 | 2014-03-28 | プログラム、管理方法およびコンピュータ |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20170019462A1 (ja) |
| JP (1) | JP6256594B2 (ja) |
| WO (1) | WO2015145753A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12077146B2 (en) | 2019-03-06 | 2024-09-03 | Denso Corporation | Process allocation control method, process allocation control system, process allocation control device, and server device |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10277524B1 (en) * | 2018-02-23 | 2019-04-30 | Capital One Services, Llc | Monitoring data streams and scaling computing resources based on the data streams |
| US11409568B2 (en) * | 2020-10-05 | 2022-08-09 | International Business Machines Corporation | Dynamically scaling out pods using a recursive way |
| US11025710B1 (en) * | 2020-10-26 | 2021-06-01 | Verizon Digital Media Services Inc. | Systems and methods for dynamic load balancing based on server utilization and content popularity |
| JP7669842B2 (ja) * | 2021-07-16 | 2025-04-30 | 富士通株式会社 | ジョブ運用プログラム、ジョブ運用システムおよびジョブ運用方法 |
| CN115225506B (zh) * | 2022-06-02 | 2025-07-15 | 圆壹智慧科技(宁波)有限公司 | 基于云平台的数据处理方法、系统、电子设备及存储介质 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7506011B2 (en) * | 2006-07-26 | 2009-03-17 | International Business Machines Corporation | System and apparatus for optimally trading off the replication overhead and consistency level in distributed applications |
| JP5446040B2 (ja) * | 2009-09-28 | 2014-03-19 | 日本電気株式会社 | コンピュータシステム、及び仮想マシンのマイグレーション方法 |
| US8631403B2 (en) * | 2010-01-04 | 2014-01-14 | Vmware, Inc. | Method and system for managing tasks by dynamically scaling centralized virtual center in virtual infrastructure |
| JP5843459B2 (ja) * | 2011-03-30 | 2016-01-13 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 情報処理システム、情報処理装置、スケーリング方法、プログラムおよび記録媒体 |
| TW201324357A (zh) * | 2011-12-01 | 2013-06-16 | Univ Tunghai | 虛擬機叢集之綠能管理方法 |
| JP2013186745A (ja) * | 2012-03-08 | 2013-09-19 | Fuji Xerox Co Ltd | 処理システム及びプログラム |
| JP5914245B2 (ja) * | 2012-08-10 | 2016-05-11 | 株式会社日立製作所 | 多階層の各ノードを考慮した負荷分散方法 |
| TW201409357A (zh) * | 2012-08-31 | 2014-03-01 | Hon Hai Prec Ind Co Ltd | 虛擬機資源負載平衡系統及方法 |
| US9208015B2 (en) * | 2013-06-18 | 2015-12-08 | Vmware, Inc. | Hypervisor remedial action for a virtual machine in response to an error message from the virtual machine |
-
2014
- 2014-03-28 WO PCT/JP2014/059259 patent/WO2015145753A1/ja not_active Ceased
- 2014-03-28 JP JP2016509845A patent/JP6256594B2/ja not_active Expired - Fee Related
-
2016
- 2016-09-27 US US15/277,308 patent/US20170019462A1/en not_active Abandoned
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12077146B2 (en) | 2019-03-06 | 2024-09-03 | Denso Corporation | Process allocation control method, process allocation control system, process allocation control device, and server device |
Also Published As
| Publication number | Publication date |
|---|---|
| US20170019462A1 (en) | 2017-01-19 |
| JPWO2015145753A1 (ja) | 2017-04-13 |
| WO2015145753A1 (ja) | 2015-10-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6256594B2 (ja) | プログラム、管理方法およびコンピュータ | |
| JP6248560B2 (ja) | 管理プログラム、管理方法、および管理装置 | |
| US9851911B1 (en) | Dynamic distribution of replicated data | |
| JP5218390B2 (ja) | 自律制御サーバ、仮想サーバの制御方法及びプログラム | |
| US9628404B1 (en) | Systems and methods for multi-tenancy management within a distributed database | |
| CN103036994B (zh) | 实现负载均衡的云存储系统 | |
| US9613037B2 (en) | Resource allocation for migration within a multi-tiered system | |
| US10192165B2 (en) | System and method for navigating multi-dimensional decision trees using acceptable alternate nodes | |
| CN110780819A (zh) | 一种分布式存储系统的数据读写方法 | |
| JP6269140B2 (ja) | アクセス制御プログラム、アクセス制御方法、およびアクセス制御装置 | |
| US20140282540A1 (en) | Performant host selection for virtualization centers | |
| WO2016174764A1 (ja) | 管理装置および管理方法 | |
| JP6807963B2 (ja) | 情報処理システム及び情報処理方法 | |
| CN112948279B (zh) | 管理存储系统中的访问请求的方法、设备和程序产品 | |
| CN103677993A (zh) | 虚拟机资源负载平衡系统及方法 | |
| JP2014229235A (ja) | ストレージ制御装置、ストレージ制御方法およびストレージ制御プログラム | |
| US12386808B2 (en) | Evolution of communities derived from access patterns | |
| WO2019091349A1 (zh) | 数据均衡方法、装置及计算机设备 | |
| JP6582721B2 (ja) | 制御装置、ストレージシステム、及び制御プログラム | |
| US20170228178A1 (en) | Effective utilization of storage arrays within and across datacenters | |
| US20140365681A1 (en) | Data management method, data management system, and data management apparatus | |
| JP6630442B2 (ja) | 適切なitリソース上にアプリケーションを配備するための管理コンピュータ及び非一時的なコンピュータ可読媒体 | |
| WO2017045545A1 (zh) | 多存储盘负载管理方法、装置、文件系统及存储网络系统 | |
| Huang et al. | Load balancing for hybrid NoSQL database management systems | |
| Ra et al. | Fighting with unknowns: Estimating the performance of scalable distributed storage systems with minimal measurement data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170711 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170911 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171107 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171120 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6256594 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |