JP6201417B2 - データ抽出プログラム、データ抽出方法およびデータ抽出装置 - Google Patents
データ抽出プログラム、データ抽出方法およびデータ抽出装置 Download PDFInfo
- Publication number
- JP6201417B2 JP6201417B2 JP2013105573A JP2013105573A JP6201417B2 JP 6201417 B2 JP6201417 B2 JP 6201417B2 JP 2013105573 A JP2013105573 A JP 2013105573A JP 2013105573 A JP2013105573 A JP 2013105573A JP 6201417 B2 JP6201417 B2 JP 6201417B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- information
- master
- extraction
- condition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2453—Query optimisation
- G06F16/24534—Query rewriting; Transformation
- G06F16/24539—Query rewriting; Transformation using cached or materialised query results
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2455—Query execution
- G06F16/24568—Data stream processing; Continuous queries
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Business, Economics & Management (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Economics (AREA)
- Strategic Management (AREA)
- Human Resources & Organizations (AREA)
- Development Economics (AREA)
- Entrepreneurship & Innovation (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Educational Administration (AREA)
- Finance (AREA)
- Game Theory and Decision Science (AREA)
- Accounting & Taxation (AREA)
- Operations Research (AREA)
- Quality & Reliability (AREA)
- Tourism & Hospitality (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
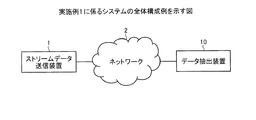
図1は、実施例1に係るシステムの全体構成例を示す図である。図1に示すように、このシステムは、ストリームデータ送信装置1とデータ抽出装置10とが、インターネットなどのネットワーク2を介して接続される。なお、ここでは、ストリームデータを例にして説明するが、これに限定されるものではなく、一般的なデータであっても同様に処理することができる。
図2は、実施例1に係るデータ抽出装置の機能構成を示す機能ブロック図である。図2に示すように、データ抽出装置10は、通信部11、第1記憶部12、第2記憶部13、制御部15を有する。
図8は、真偽判定表の生成例1を説明する図であり、図9は、真偽判定表の生成例2をを説明する図である。図8に示すように、条件判定部16は、マスタ情報DB12aのキーが「0001」のマスタデータについて、製品(PC)、スタイル(Desktop)、価格(60000)の各々が抽出条件を満たすか否かを判定する。そして、条件判定部16は、それぞれについて条件を満たすか否かを示す「True」か「False」を決定する。
図10は、実施例1に係るデータ抽出処理の流れを示すフローチャートである。図10に示すように、データ抽出装置10の条件判定部16は、処理が開始されると、すなわち、マスタ情報のメモリ展開が指示されると(S101:Yes)、抽出条件式DB12bから抽出条件式を読み出す(S102)。
図11は、実施例2に係るマスタ情報の削除例を説明する図である。図11では、マスタデータの更新によって真偽判定表13aの判定結果を更新する例を説明する。ここでは、一例としてマスタデータの削除を説明する。
図12は、実施例2に係る抽出条件の更新例を説明する図である。図12に示すように、データ抽出装置10は、抽出条件式「製品=PC AND (スタイル=ノート)or(価格=100000未満)」に基づいてデータ抽出判定を行った途中経過として、図5に示した中間データを記憶する。
図13と図14は、実施例3に係る真偽判定表更新時のストリームデータ処理例1を説明する図である。図13に示すように、データ抽出装置10は、ストリームデータを受信し、真偽判定表13aを用いてデータ抽出を行っている状況で、マスタ情報DB12aに記憶されるキーが「0004」のマスタデータを更新する(S201)。
図15と図16は、実施例3に係る真偽判定表更新時のストリームデータ処理例2を説明する図である。図15に示すように、データ抽出装置10は、真偽判定表13aを記憶するとともに、真偽判定表13aと同じデータで構成される真偽判定表13a´を記憶する。通常、データ抽出装置10は、真偽判定表13aを用いて、データ抽出判定処理を実行する。
例えば、データ抽出装置10は、複数の抽出条件式が抽出条件式DB12bに格納されている場合、条件式ごとに真偽判定表を生成することができる。図17は、真偽判定表の別例を説明する図である。
実施例1等では、データ抽出装置10が中間情報を生成する例を説明したが、これに限定されるものではなく、中間情報を生成することなく、マスタ情報から真偽判定表を生成することもできる。
実施例1等では、データ抽出装置10が、真偽判定表に、判定結果として「1(True)」、「0(False)」、「−1(NULL)」のいずれかを対応付ける例を説明したがこれに限定されるものではない。例えば、データ抽出装置10が、判定結果が「1(True)」であるデータだけを、真偽判定表に登録してもよい。こうすることで、データ抽出装置10は、データ抽出を高速化するとともに、メモリ容量の浪費を削減できる。
また、本実施例において説明した各処理のうち、自動的におこなわれるものとして説明した処理の全部または一部を手動的におこなうこともできる。あるいは、手動的におこなわれるものとして説明した処理の全部または一部を公知の方法で自動的におこなうこともできる。この他、上記文書中や図面中で示した処理手順、制御手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更することができる。
図18は、ハードウェア構成例を示す図である。図18に示すように、データ抽出装置10は、CPU(Central Processing Unit)101、メモリ102、HDD(Hard Disk Drive)103、通信インタフェース104、入力装置105、表示装置106を有する。また、図18に示した各部は、バス等で相互に接続される。
キー情報とデータ情報とを対応付けた各第1のデータにおける前記データ情報が、抽出条件を満たすか否かを判定し、
判定した前記データ情報に対応付けられる前記キー情報と判定結果とを対応付けた第2のデータを生成し、
受信データに含まれるキー情報を用いて、各第2のデータから前記判定結果を特定する
処理を実行させるデータ抽出プログラム。
前記抽出条件が更新された場合に、更新された前記条件に対応する各構成データが当該条件を満たすか否かを判定して前記第3のデータを更新し、
前記更新した前記第3のデータと前記抽出条件とに基づいて、前記第2のデータの判定結果を更新する処理をさらにコンピュータに実行させることを特徴とする付記1から3のいずれか一つに記載のデータ抽出プログラム。
キー情報とデータ情報とを対応付けた各第1のデータにおける前記データ情報が、抽出条件を満たすか否かを判定し、
判定した前記データ情報に対応付けられる前記キー情報と判定結果とを対応付けた第2のデータを生成し、
受信データに含まれるキー情報を用いて、各第2のデータから前記判定結果を特定する
処理を含むことを特徴とするデータ抽出方法。
前記判定部によって判定された前記データ情報に対応付けられる前記キー情報と判定結果とを対応付けた第2のデータを生成する生成部と、
受信データに含まれるキー情報を用いて、前記生成部によって生成された各第2のデータから前記判定結果を特定する特定部と
を有することを特徴とするデータ抽出装置。
前記メモリに接続されるプロセッサと、を有し、
前記プロセッサは、
キー情報とデータ情報とを対応付けた各第1のデータにおける前記データ情報が、抽出条件を満たすか否かを判定し、
判定した前記データ情報に対応付けられる前記キー情報と判定結果とを対応付けた第2のデータを生成し、
受信データに含まれるキー情報を用いて、各第2のデータから前記判定結果を特定する
処理を実行するデータ抽出装置。
判定した前記データ情報に対応付けられる前記キー情報と判定結果とを対応付けた第2のデータを生成し、
受信データに含まれるキー情報を用いて、各第2のデータから前記判定結果を特定する処理をコンピュータに実行させるデータ抽出プログラムを記憶する、コンピュータ読み取り可能な記憶媒体。
2 ネットワーク
10 データ抽出装置
11 通信部
12 第1記憶部
12a マスタ情報DB
12b 抽出条件式DB
12c 中間情報DB
13 第2記憶部
13a 真偽判定表
15 制御部
16 条件判定部
17 中間情報生成部
18 真偽判定表生成部
19 ストリームデータ処理部
Claims (6)
- コンピュータに、
複数のキー情報にそれぞれ対応づけられた複数のマスタデータを含むマスタ情報と、前記複数のマスタデータに含まれるデータ情報に関する抽出条件とに基づいて、前記複数のキー情報と前記抽出条件による判定結果とを対応づける判定条件情報を生成し、
ストリームデータの受信に応じ、前記ストリームデータに含まれるキー情報、および、前記判定条件情報に基づき、前記ストリームデータで特定される前記マスタ情報の抽出要否を判定する
処理を実行させるデータ抽出プログラム。 - 前記生成する処理は、前記キー情報と前記データ情報とを有する前記複数のマスタデータのうち前記データ情報が前記抽出条件を満たすと判定された前記マスタデータのキー情報を対応付けた前記判定条件情報を生成することを特徴とする請求項1に記載のデータ抽出プログラム。
- 前記生成する処理は、前記マスタデータのデータ情報が更新された場合に、更新された前記マスタデータのキー情報に対応する判定条件情報の判定結果を、更新後の前記データ情報に基づいた判定結果で更新し、前記マスタデータが削除された場合に、削除された前記マスタデータのキー情報に対応する判定結果を、削除されたことを示す削除情報で更新することを特徴とする請求項2に記載のデータ抽出プログラム。
- 前記データ情報が前記抽出条件を満たすか否かを判定するのに際して、前記データ情報を構成する各構成データについて、前記抽出条件を構成する各条件のうち当該構成データに対応する条件を満たすか否かを判定した中間データを生成し、
前記抽出条件が更新された場合に、更新された前記条件に対応する各構成データが当該条件を満たすか否かを判定して前記中間データを更新し、
前記更新した前記中間データと前記抽出条件とに基づいて、前記判定結果を更新する処理をさらにコンピュータに実行させることを特徴とする請求項2に記載のデータ抽出プログラム。 - コンピュータが、
複数のキー情報にそれぞれ対応づけられた複数のマスタデータを含むマスタ情報と、前記複数のマスタデータに含まれるデータ情報に関する抽出条件とに基づいて、前記複数のキー情報と前記抽出条件による判定結果とを対応づける判定条件情報を生成し、
ストリームデータの受信に応じ、前記ストリームデータに含まれるキー情報、および、前記判定条件情報に基づき、前記ストリームデータで特定される前記マスタ情報の抽出要否を判定する
処理を含むことを特徴とするデータ抽出方法。 - 複数のキー情報にそれぞれ対応づけられた複数のマスタデータを含むマスタ情報と、前記複数のマスタデータに含まれるデータ情報に関する抽出条件とに基づいて、前記複数のキー情報と前記抽出条件による判定結果とを対応づける判定条件情報を生成する生成部と、
ストリームデータの受信に応じ、前記ストリームデータに含まれるキー情報、および、前記判定条件情報に基づき、前記ストリームデータで特定される前記マスタ情報の抽出要否を判定する判定部と
を有することを特徴とするデータ抽出装置。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013105573A JP6201417B2 (ja) | 2013-05-17 | 2013-05-17 | データ抽出プログラム、データ抽出方法およびデータ抽出装置 |
| US14/262,197 US9619516B2 (en) | 2013-05-17 | 2014-04-25 | Computer-readable recording medium, data extraction method, and data extraction device |
| EP14166166.0A EP2804140A1 (en) | 2013-05-17 | 2014-04-28 | Data extraction program, data extraction method, and data extraction device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013105573A JP6201417B2 (ja) | 2013-05-17 | 2013-05-17 | データ抽出プログラム、データ抽出方法およびデータ抽出装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014228894A JP2014228894A (ja) | 2014-12-08 |
| JP6201417B2 true JP6201417B2 (ja) | 2017-09-27 |
Family
ID=50624463
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013105573A Expired - Fee Related JP6201417B2 (ja) | 2013-05-17 | 2013-05-17 | データ抽出プログラム、データ抽出方法およびデータ抽出装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US9619516B2 (ja) |
| EP (1) | EP2804140A1 (ja) |
| JP (1) | JP6201417B2 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5928577B2 (ja) * | 2012-03-29 | 2016-06-01 | 富士通株式会社 | 判定装置、判定システム、判定方法および判定プログラム |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04102172A (ja) | 1990-08-22 | 1992-04-03 | Nec Corp | 情報検索方式 |
| JPH0756652B2 (ja) | 1992-03-24 | 1995-06-14 | インターナショナル・ビジネス・マシーンズ・コーポレイション | 動画像のフレーム列の検索 |
| JPH05324731A (ja) * | 1992-05-26 | 1993-12-07 | Chubu Nippon Denki Software Kk | データの検索処理方式 |
| US5918225A (en) | 1993-04-16 | 1999-06-29 | Sybase, Inc. | SQL-based database system with improved indexing methodology |
| US5710915A (en) | 1995-12-21 | 1998-01-20 | Electronic Data Systems Corporation | Method for accelerating access to a database clustered partitioning |
| US6453321B1 (en) * | 1999-02-11 | 2002-09-17 | Ibm Corporation | Structured cache for persistent objects |
| US6792414B2 (en) | 2001-10-19 | 2004-09-14 | Microsoft Corporation | Generalized keyword matching for keyword based searching over relational databases |
| US20060047696A1 (en) * | 2004-08-24 | 2006-03-02 | Microsoft Corporation | Partially materialized views |
| JP2006171800A (ja) | 2004-12-10 | 2006-06-29 | Fujitsu Ltd | データ集計装置、その方法、及びプログラム |
| JP2006215998A (ja) * | 2005-02-07 | 2006-08-17 | Keyence Corp | データ収集システム |
| US7769736B2 (en) * | 2007-07-02 | 2010-08-03 | Novell, Inc. | System and method for efficient issuance of queries |
| JPWO2010095459A1 (ja) * | 2009-02-20 | 2012-08-23 | 日本電気株式会社 | 解析前処理システム、解析前処理方法および解析前処理プログラム |
| US8250325B2 (en) * | 2010-04-01 | 2012-08-21 | Oracle International Corporation | Data deduplication dictionary system |
| US8326821B2 (en) * | 2010-08-25 | 2012-12-04 | International Business Machines Corporation | Transforming relational queries into stream processing |
| US9213759B2 (en) | 2011-06-03 | 2015-12-15 | Hitachi, Ltd. | System, apparatus, and method for executing a query including boolean and conditional expressions |
| US9965520B2 (en) * | 2011-06-17 | 2018-05-08 | Microsoft Corporation | Efficient logical merging over physically divergent streams |
-
2013
- 2013-05-17 JP JP2013105573A patent/JP6201417B2/ja not_active Expired - Fee Related
-
2014
- 2014-04-25 US US14/262,197 patent/US9619516B2/en not_active Expired - Fee Related
- 2014-04-28 EP EP14166166.0A patent/EP2804140A1/en not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| US9619516B2 (en) | 2017-04-11 |
| JP2014228894A (ja) | 2014-12-08 |
| US20140344268A1 (en) | 2014-11-20 |
| EP2804140A1 (en) | 2014-11-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11281724B2 (en) | Method and system for providing recommendation query using search context | |
| US11086873B2 (en) | Query-time analytics on graph queries spanning subgraphs | |
| CN111767051B (zh) | 一种网络页面的渲染方法及设备 | |
| KR102349522B1 (ko) | 장기간 연관성 높은 문서 클러스터링을 위한 방법 및 시스템 | |
| CN109710088B (zh) | 一种信息搜索方法及装置 | |
| KR101054824B1 (ko) | 키워드 시맨틱 네트워크 구성을 통한 특허정보 시각화 시스템 및 그 방법 | |
| JP2008176782A (ja) | 関心事を反映して抽出した情報提供方法及びシステム | |
| KR20200086574A (ko) | 키워드 관계 구조를 이용한 신규 키워드 추출 방법 및 시스템 | |
| CN112559913A (zh) | 一种数据处理方法、装置、计算设备及可读存储介质 | |
| CN113312432A (zh) | 关联信息处理方法及装置、计算机存储介质、电子设备 | |
| US10372299B2 (en) | Preserve input focus in virtualized dataset | |
| JP6201417B2 (ja) | データ抽出プログラム、データ抽出方法およびデータ抽出装置 | |
| JP2011215723A (ja) | シソーラス構築システム、シソーラス構築方法およびシソーラス構築プログラム | |
| CN116127098A (zh) | 知识图谱的构建方法、装置 | |
| CN113625922B (zh) | 一种文件翻译方法、计算设备及可读存储介质 | |
| JP5880637B2 (ja) | 情報処理装置、その制御方法、及びプログラム、並びに情報処理システム、その制御方法、及びプログラム | |
| JP6617499B2 (ja) | 情報処理装置、電子ホワイトボードの検索方法、及びプログラム | |
| JP6075051B2 (ja) | サーバ装置、電子会議システム及びプログラム | |
| CN110929207B (zh) | 数据处理方法、装置和计算机可读存储介质 | |
| CN114996301A (zh) | 一种信息搜索方法、装置、存储介质及电子设备 | |
| JP5155351B2 (ja) | 地図データ処理装置及び方法 | |
| CN113377378A (zh) | 用于小程序的处理方法、装置、设备及存储介质 | |
| JP6623698B2 (ja) | 情報処理装置、情報処理方法、プログラム | |
| JP2013214165A (ja) | 情報処理装置、履歴制御方法および履歴制御プログラム | |
| KR20240108619A (ko) | 생일 정보를 이용하여 친구를 검색하는 방법, 컴퓨터 장치, 및 컴퓨터 프로그램 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160226 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161212 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170207 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170410 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170606 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170714 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170801 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170814 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6201417 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |