以下、本実施の形態を図面を参照して説明する。
[第1の実施の形態]
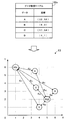
図1は、第1の実施の形態のデータ管理装置を示す図である。データ管理装置1は、種々のデータを記憶する。データ管理装置1は、ネットワークを介して接続された他の装置(図示を省略)からデータに対するアクセス要求を受け付ける。アクセス要求は、例えばデータの読み出しの要求である。データ管理装置1は、アクセス要求に応じたデータを要求元の装置に提供する。
データ管理装置1上で動作するソフトウェアがアクセス要求を生成することもある。その場合、データ管理装置1は、要求に応じてデータを当該ソフトウェアに提供する。データ管理装置1は、コンピュータでもよいし、データを記憶するストレージ装置でもよい。データ管理装置1は、記憶部1a,1bおよび演算部1cを有する。
記憶部1a,1bは、データを記憶する。記憶部1aは、記憶部1bよりもランダムアクセスを高速に行える。記憶部1aは、記憶部1bに記憶されたデータを一時的に保持するキャッシュとして用いられる。例えば、記憶部1aは、RAM(Random Access Memory)などの揮発性の記憶媒体でもよいし、SSD(Solid State Drive)などの不揮発性の記憶媒体でもよい。例えば、記憶部1bは不揮発性の記憶媒体である。例えば、記憶部1aをRAMとすれば、記憶部1bをHDD(Hard Disk Drive)、SSD、光ディスクまたは磁気テープなどとすることが考えられる。また、記憶部1aをSSDとすれば、記憶部1bをHDD、光ディスクまたは磁気テープなどとすることが考えられる。
演算部1cは、CPU(Central Processing Unit)、DSP(Digital Signal Processor)、ASIC(Application Specific Integrated Circuit)、FPGA(Field Programmable Gate Array)などを含み得る。演算部1cは、プログラムを実行するプロセッサであってもよい。ここでいう「プロセッサ」には、複数のプロセッサの集合(マルチプロセッサ)も含まれ得る。
演算部1cは、データに対するアクセス要求を受け付ける。演算部1cは、要求されたデータが記憶部1aに格納されている場合(キャッシュヒット)、記憶部1aにアクセスする。演算部1cは、要求されたデータが記憶部1aに格納されていない場合(キャッシュミス)、記憶部1bにアクセスする。キャッシュヒットの場合、キャッシュミスの場合よりも高速に、要求されたデータの読み出しを行える。よって、キャッシュヒット率を向上させれば、データに対するアクセスの高速化を図れる。
演算部1cは、記憶部1bに記憶された複数のデータを複数のグループに分けて管理する。関係性のあるデータ同士をグループ化し、グループ単位に先読みを行うことで、キャッシュヒット率の向上を図れるからである。データ間に「関係性がある」とは、あるデータがアクセスされたときに、他のデータが将来(例えば、未来の所定期間内に)アクセスされる可能性があることを示す。例えば、連続してアクセスされる可能性のあるデータ同士を関係性があるとしてもよい。
演算部1cは、データ間の関係性を、各データおよび各グループに付与された座標(例えば、2次元や3次元)を用いて管理する。座標を、所定次元における各データおよび各グループの位置を示す情報ということもできる。例えば、記憶部1bはデータX1,X2,Y1,Y2を記憶する。データX1,X2の組をグループG1とする。データY1,Y2の組をグループG2とする。ここで、グループ毎のデータ数を2としている(ただし、他のデータ数としてもよい)。図1ではx軸およびy軸が直交する2次元の座標系を例示している。領域R1は、このときのグループG1に所属するデータX1,X2を囲った領域である。領域R2はグループG2に所属するデータY1,Y2を囲った領域である。
記憶部1aは、データX1,X2,Y1,Y2それぞれに対応付けられた座標の情報を記憶する。記憶部1aはグループG1,G2それぞれに対応付けられた座標の情報を記憶する。グループG1,G2の座標の情報は記憶部1aに予め格納される。グループG1,G2の座標を所定の規則により与えてもよい。例えば、2次元座標上において、所定間隔の格子点として、Z-orderingなどの順序に従って、各グループに順番に座標を与えることが考えられる。データX1,X2,Y1,Y2の座標には所定の初期値が予め与えられる。各グループの座標は固定であるのに対し、各データの座標はデータへのアクセスに伴って更新され得る。
演算部1cは、グループG1に属するデータX1とグループG2に属するデータY1との間の関係性を検出する(ステップS1)。例えば、演算部1cは、データX1の次にデータY1に対するアクセス要求を受け付けたとき、データX1,Y1の間に、連続的にアクセスされるという関係性を検出することが考えられる。
すると、演算部1cは記憶部1aを参照し、グループG2の座標を用いてデータX1の座標を更新する。また、グループG1の座標を用いてデータY1の座標を更新する(ステップS2)。具体的には、データX1がグループG2の座標に近づくようにデータX1の座標を更新する。また、データY1がグループG1の座標に近づくようにデータY1の座標を更新する。
ここで、データの座標とグループの座標との距離は、データと当該グループに属する他のデータとの関係の強さを示していると考えられる。例えば、データX1の座標がグループG2の座標に近づくことは、データX1とグループG2に属するデータY1との関係が強まった(例えば、連続してアクセスされる可能性が高まった)ことを意味する。同様に、データY1の座標がグループG1の座標に近づくことは、データY1とグループG1に属するデータX1との関係が強まったことを意味する。すなわち、この場合、データX1,Y1の関係が相互に強まったことになる。
演算部1cは、グループG1,G2に属するデータX1,X2,Y1,Y2それぞれの座標と、グループG1,G2それぞれの座標とに基づいて、グループG1,G2それぞれに所属させるデータを決定する(ステップS3)。
例えば、演算部1cは、データX1,X2,Y1,Y2の座標とグループG1,G2の座標との座標間の距離を用いて、グループG1,G2それぞれに所属させるデータを決定する。ここで、距離d1はデータX1の座標とグループG1の座標との距離である。距離d2はデータX2の座標とグループG1の座標との距離である。距離d3はデータY1の座標とグループG1の座標との距離である。距離d4はデータY2の座標とグループG1の座標との距離である。距離d5はデータX1の座標とグループG2の座標との距離である。距離d6はデータX2の座標とグループG2の座標との距離である。距離d7はデータY1の座標とグループG2の座標との距離である。距離d8はデータY2の座標とグループG2の座標との距離である。
例えば、演算部1cは、グループG1に所属させる各データの座標とグループG1の座標との距離の和DS1と、グループG2に所属させる各データの座標とグループG2の座標との距離の和DS2との合計DS=DS1+DS2が最小になるようにグループ分けを行う。同一グループの座標に対する距離が小さいデータの組み合わせ程、関係が強い(例えば、連続してアクセスされる可能性が高い)と考えられるからである。
距離d1〜d8の例でいえば、合計DSの候補(グループ化の方法の候補)は6通りある。その中で、DS1=d1+d3、DS2=d6+d8のときが最小である。よって、演算部1cはデータX1,Y1をグループG1に所属させ、データX2,Y2をグループG2に所属させると決定する(ステップS4)。例えば、演算部1cは、グループG1,G2をラウンドロビンで選び、選択したグループの座標に最も距離が近いデータから当該グループに所属させると決定してもよい。領域R1aは、決定後のグループG1に所属するデータX1,Y1を囲った領域である。領域R2aは、決定後のグループG2に所属するデータX2,Y2を囲った領域である。
あるいは、演算部1cは、データX1,X2,Y1,Y2の座標で示される各ベクトル(位置ベクトル)とグループG1,G2の座標で示されるベクトルの内積を用いて、グループG1,G2それぞれに所属させるデータを決定してもよい。例えば、演算部1cはグループG1の座標からグループG2の座標へのベクトルと、データの座標で示されるベクトルとの内積をデータ毎に計算する。各内積を比較することで、各データの座標が相対的にどちらのグループの座標に近いかを簡便に把握できる。この場合、内積を昇順にソートして、相対的に内積の小さい2つのデータをグループG1に、相対的に内積の大きい2つのデータをグループG2に所属させる。このようにして、データX1,Y1をグループG1に所属させ、データX2,Y2をグループG2に所属させると決定することもできる。この場合、距離d1〜d8を直接用いて計算するよりも、演算コストを削減し得る。
以後、演算部1cは、更新後のグループG1,G2単位に記憶部1bから記憶部1aへの先読みを行える。例えば、その後、グループG1に属するデータX1に対するアクセスがあったとき、既にデータX1の記憶領域が記憶部1aから解放されていることもある。この場合、演算部1cは、記憶部1bからグループG1に属するデータX1,Y1を取得して、記憶部1aに配置する。例えば、連続してアクセスされたことを関係性として検出してグループG1の所属を決定したのであれば、次にデータY1がアクセスされる可能性が高く、次のアクセスに対するキャッシュヒット率を向上できる。
データ管理装置1によれば、演算部1cにより、グループG1に属するデータX1とグループG2に属するデータY1との間に関係性が検出される。演算部1cにより、グループG2の座標を用いてデータX1の座標が更新され、グループG1の座標を用いてデータY1の座標が更新される。演算部1cにより、グループG1,G2に属するデータX1,X2,Y1,Y2の座標と、グループG1,G2の座標とに基づいて、グループG1,G2それぞれに所属させるデータが決定される。
これにより、グループ化の精度を向上できる。ここで、例えば、グループ化を行うタイミングで、各データに対する過去のアクセス履歴を参照して、連続してアクセスされた頻度がより高いデータ同士を同一グループに割当てることも考えられる。この場合、グループ化に利用するアクセス履歴の情報量が多い程、統計的に高信頼のグループ化を行える。ところが、全てのアクセス履歴を保存していると、時間経過と共にアクセス履歴の情報量が増大し、メモリの使用量が増大するおそれがある。一方、メモリの使用量を節約するために、ある期間のみのアクセス履歴を保存することも考えられる。しかし、この場合、他の期間のアクセス履歴の情報が失われるので、グループ化の精度が低下し得る。
そこで、データ管理装置1は、データ間の関係性を、各データの座標を用いて管理する。そして、データ管理装置1は、データ間の関係性が検出されるたびに、関係性が検出された各データの座標を更新することで、当該データ間の相互の関係が強まったことを記録する。このため、データ管理装置1は、全てのデータについてのアクセス履歴を保持しておかなくてよい。ある時点におけるデータ毎の座標は、その時点よりも過去のアクセス履歴が反映された情報だからである。
この場合、データ管理装置1は、各データに対する座標を記録するためのメモリ領域を確保しておけばよい。よって、アクセス履歴を全て記憶しておくよりも、メモリ(例えば、記憶部1a)の使用量の増大を抑制できる。また、データ毎の座標に過去のアクセス履歴を全て反映させることができるので、ある期間のみのアクセス履歴を保存する場合に比べて、グループ化の精度を向上し得る。
また、データ間の関係性が検出されたタイミングで、当該データ間の関係を更新していくので、全てのアクセス履歴を解析する場合のように一度に大量の情報を処理せずに済む。このため、データ間の関係性を解析するためにデータ管理装置1の負荷が高まることを抑制できる。このように、各データの座標によりデータ間の関係性を管理することで、データ間の関係性を効率的に管理できる。
[第2の実施の形態]
図2は、第2の実施の形態の情報処理システムを示す図である。第2の実施の形態の情報処理システムは、サーバ100およびクライアント200を含む。サーバ100およびクライアント200は、ネットワーク10に接続されている。ネットワーク10は、LAN(Local Area Network)でもよいし、WAN(Wide Area Network)やインターネットなどの広域ネットワークでもよい。
サーバ100は、種々のデータを記憶するサーバコンピュータである。サーバ100は、クライアント200からデータに対するアクセス要求を受け付ける。アクセス要求は、データの読み出しの要求である。例えば、サーバ100は、要求されたデータをクライアント200に応答する。サーバ100は、サーバ100上で動作するソフトウェアからデータに対するアクセス要求を受け付けることもある。その場合、サーバ100は、要求されたデータを当該ソフトウェアへ応答することができる。
サーバ100は、連続してアクセスされる可能性の高いデータを、1つのグループにまとめて管理する。サーバ100は、あるデータに対するアクセス要求を受け付けたとき、当該データが属するグループ単位に(すなわち、当該グループに属する全てのデータを)、キャッシュに格納する。これにより、未だアクセス要求を受けていないデータに対するアクセス要求を受け付けたときのキャッシュヒット率の向上を図る。ここで、サーバ100は、第1の実施の形態のデータ管理装置1の一例である。
クライアント200は、ユーザによって利用されるクライアントコンピュータである。例えば、クライアント200は、自身が実行する処理に応じて、所定のデータに対するアクセス要求をサーバ100に送信する。また、ユーザは、クライアント200を操作して、データに対するアクセス要求をクライアント200からサーバ100へ送信させることもできる。ユーザは、サーバ100を直接操作して、データに対するアクセス要求をサーバ100に入力することもできる。
図3は、第2の実施の形態のサーバのハードウェア例を示す図である。サーバ100は、プロセッサ101、RAM102、HDD103、通信部104、画像信号処理部105、入力信号処理部106、ディスクドライブ107および機器接続部108を有する。各ユニットはサーバ100のバスに接続されている。なお、クライアント200も、サーバ100と同様のハードウェアを用いて実現できる。
プロセッサ101は、サーバ100の情報処理を制御する。プロセッサ101は、例えばCPU、DSP、ASICまたはFPGAなどである。プロセッサ101は、マルチプロセッサであってもよい。プロセッサ101は、CPU、DSP、ASIC、FPGAなどのうちの2以上の要素の組合せであってもよい。
RAM102は、サーバ100の主記憶装置である。RAM102は、プロセッサ101に実行させるOS(Operating System)のプログラムやアプリケーションプログラムの少なくとも一部を一時的に記憶する。また、RAM102は、プロセッサ101による処理に用いる各種データを記憶する。
HDD103は、サーバ100の補助記憶装置である。HDD103は、内蔵した磁気ディスクに対して、磁気的にデータの書き込みおよび読み出しを行う。HDD103には、OSのプログラム、アプリケーションプログラム、および各種データが格納される。サーバ100は、フラッシュメモリやSSDなどの他の種類の補助記憶装置を備えてもよく、複数の補助記憶装置を備えてもよい。
通信部104は、ネットワーク10を介して他のコンピュータと通信を行える通信インタフェースである。通信部104は、有線通信インタフェースでもよいし、無線通信インタフェースでもよい。
画像信号処理部105は、プロセッサ101からの命令に従って、サーバ100に接続されたディスプレイ11に画像を出力する。ディスプレイ11としては、CRT(Cathode Ray Tube)ディスプレイや液晶ディスプレイなどを用いることができる。
入力信号処理部106は、サーバ100に接続された入力デバイス12から入力信号を取得し、プロセッサ101に出力する。入力デバイス12としては、例えば、マウスやタッチパネルなどのポインティングデバイス、キーボードなどを用いることができる。
ディスクドライブ107は、レーザ光などを利用して、光ディスク13に記録されたプログラムやデータを読み取る駆動装置である。光ディスク13として、例えば、DVD(Digital Versatile Disc)、DVD−RAM、CD−ROM(Compact Disc Read Only Memory)、CD−R(Recordable)/RW(ReWritable)などを使用できる。ディスクドライブ107は、例えば、プロセッサ101からの命令に従って、光ディスク13から読み取ったプログラムやデータをRAM102またはHDD103に格納する。
機器接続部108は、サーバ100に周辺機器を接続するための通信インタフェースである。例えば、機器接続部108にはメモリ装置14やリーダライタ装置15を接続できる。メモリ装置14は、機器接続部108との通信機能を搭載した記録媒体である。リーダライタ装置15は、メモリカード16へのデータの書き込み、またはメモリカード16からのデータの読み出しを行う装置である。メモリカード16は、カード型の記録媒体である。機器接続部108は、例えば、プロセッサ101からの命令に従って、メモリ装置14またはメモリカード16から読み取ったプログラムやデータをRAM102またはHDD103に格納する。
図4は、第2の実施の形態のサーバの機能例を示す図である。サーバ100は、キャッシュ110、データ記憶部120、管理情報記憶部130、アクセス部140および制御部150を有する。アクセス部140および制御部150は、プロセッサ101によって実行されるプログラムのモジュールであってもよい。
キャッシュ110は、RAM102に確保された記憶領域を用いて実現できる。データ記憶部120は、HDD103に確保された記憶領域を用いて実現できる。管理情報記憶部130は、RAM102またはHDD103に確保された記憶領域を用いて実現できる。キャッシュ110は、第1の実施の形態の記憶部1aの一例である。データ記憶部120は、第1の実施の形態の記憶部1bの一例である。ただし、データ記憶部120は、サーバ100とネットワーク10を介して接続された記憶装置の記憶領域でもよい。データ記憶部120はサーバ100に外付けされた記憶装置の記憶領域でもよい。
キャッシュ110は、データ記憶部120よりも高速なランダムアクセスが可能である。キャッシュ110は、データ記憶部120に対するキャッシュとして用いられ、データ記憶部120から読み出されたデータを一時的に記憶する。
データ記憶部120は、サーバ100で管理される各種のデータを記憶する。データ記憶部120では、1つのグループを連続した記憶領域に格納する。1つのグループに対してシーケンシャルにアクセスできれば、グループ単位の読み出しを高速化できるからである。以下の説明では、データ記憶部120における、グループを格納するための連続した記憶領域をセグメントと呼ぶことがある。
管理情報記憶部130は、サーバ100で管理されるデータ毎の管理情報を記憶する。管理情報は、データ間の関係性や各データが何れのグループに属するかを示す情報を含む。ここで、データ間の関係性は、各データに付与された座標によって表される。第2の実施の形態では一例として2次元の座標系を想定する。ただし、1次元または3次元以上の座標系を用いることを妨げるものではない。
アクセス部140は、クライアント200やサーバ100上のソフトウェア(図示を省略)からデータへのアクセス要求を受け付ける。アクセス部140は、アクセス要求されたデータを、要求元(クライアント200やサーバ100上のソフトウェア)に応答する。このとき、アクセス部140は、連続してアクセスされたデータを制御部150に通知する。また、アクセス部140は未だアクセス要求されていないデータの先読みを行う。
例えば、アクセス部140は、あるデータに対するアクセス要求を受け付けたとき、当該データがキャッシュ110になければ(キャッシュミス)、当該データのグループに属する全てのデータをデータ記憶部120から取得して、キャッシュ110に格納する。更に、アクセス部140は要求されたデータを要求元に提供する。アクセス部140は、あるデータに対するアクセス要求を受け付けたとき、当該データがキャッシュ110にあれば(キャッシュヒット)、キャッシュ110から当該データを読み出して、要求元に提供する。アクセス部140は、管理情報記憶部130に記憶された管理情報を参照することで、データとグループとの対応関係を把握する。
制御部150は、アクセス部140から連続してアクセスされたデータの通知を受け付けると、当該通知に応じて、管理情報記憶部130に記憶された管理情報を更新する。具体的には、制御部150は連続してアクセスされたデータ間の関係を強めるように、各データの座標を更新する。制御部150は、更新後のデータの座標に基づいて、各グループに所属させるデータを決定する。アクセス部140が各データに対する連続アクセスを受け付けるたびに、制御部150は各データの座標を更新する。こうして、連続してアクセスされるデータが検出されるたびに、データ間の関係性が更新されていくことになる。
制御部150は、決定したグループに従って、データ記憶部120におけるセグメント内のデータ配置を変更する。具体的には、制御部150は、何れかのグループのキャッシュ110上の記憶領域(例えば、ページ)が解放されるタイミングで、当該グループに変更があれば、当該グループに対応するセグメント内のデータ配置を変更する。ただし、グループ内のデータの所属が変更されるたびにセグメント内のデータ配置を変更することを妨げるものではない。
図5は、第2の実施の形態のセグメントの例を示す図である。データ記憶部120は、データA,B,C,D,・・・を記憶する。また、データ記憶部120は、セグメントSG1,SG2,・・・を有する。第2の実施の形態では、セグメント当たりに格納できるデータの数(セグメントサイズ)を2とする。この場合、1つのグループに属するデータの個数も2である。ただし、セグメントサイズを3以上としてもよい(セグメントサイズとグループ当たりのデータ数とは一致する)。
データA,BはグループG11に属する。データA,B(グループG11)は、セグメントSG1に格納されている。データC,DはグループG12に属する。データC,D(グループG12)は、セグメントSG2に格納されている。
例えば、アクセス部140は、データAに対するアクセス要求を受け付ける。当該アクセス要求を受け付ける直前のタイミングにおいて、キャッシュ110にデータAが格納されていなければ、アクセス部140は、データ記憶部120に存在するセグメントSG1上のデータA,Bを複製して、キャッシュ110に格納する。また、アクセス部140は、データAを要求元に応答する。この場合、データAに対してデータBが先読みされたことになる。アクセス部140は、キャッシュ110の連続した記憶領域にデータA,Bを配置してもよい。キャッシュ110上でもデータA,Bに対してシーケンシャルにアクセスできれば、データA,Bと連続したアクセスを高速に行えるからである。
ここで、第2の実施の形態では、グループはセグメントと1対1に対応する。例えば、グループG11はセグメントSG1に対応付けられる(グループG11はセグメントSG1に配置される)。また、グループG12はセグメントSG2に対応付けられる(グループG12はセグメントSG2に配置される)。
図6は、第2の実施の形態のセグメント管理テーブルの例を示す図である。セグメント管理テーブル131は、各セグメントに対応付けられた座標を登録した情報である。セグメントとグループとは1対1に対応付けられるから、セグメントに対応付けられた座標を、グループに対応付けられた座標ということもできる。セグメント管理テーブル131には、管理情報記憶部130に格納される。セグメント管理テーブル131は、セグメント、座標およびデータ所属変更の項目を含む。
セグメントの項目には、セグメントの識別情報が登録される。座標の項目には、当該セグメント(あるいは、グループ)に対応付けられた座標が登録される。データ所属変更の項目には、セグメント内のデータの所属に変更があるか否かを示す情報が登録される。
例えば、セグメント管理テーブル131には、セグメントが“SG1”、座標が“(1,6)”、データ所属変更が“なし”という情報が登録される。これは、セグメントSG1(あるいは、グループG11)に対応付けられた2次元座標が“(1,6)”であることを示す。また、現時点において、セグメントSG1にデータの所属の変更がないことを示す(データの所属の変更がある場合は、データ所属変更の項目に“あり”が設定される)。また、セグメントSG2の座標は、“(5,2)”である。
各セグメントに対応する座標は、ユーザによりサーバ100に予め与えられる。例えば、2次元座標上に所定の規則で(例えば、2次元座標上において所定間隔の格子点として、Z-orderingの順序に従って)、各セグメントに対応する座標を付与してもよい。ここで、Z-orderingとは、座標上の格子点を“Z”の文字の書き順に沿って選択していく手法である。格子(各セグメントに対応する座標の頂点の並び)は矩形格子、斜方格子、正三角格子などの何れかとすることが考えられる。また、Z-ordering以外の順序で、各セグメントの座標を付与してもよい。あるいは、各セグメントに対応する座標を、2次元座標上にランダムに与えてもよい。
図7は、第2の実施の形態のデータ管理テーブルの例を示す図である。データ管理テーブル132は、各データに対応付けられた座標を登録した情報である。データ管理テーブル132は、管理情報記憶部130に格納される。データ管理テーブル132は、データおよび座標の項目を含む。
データの項目には、データの識別情報が登録される。座標の項目には、当該データに対応付けられた座標が登録される。例えば、データ管理テーブル132には、データが“A”、座標が“(3,6)”という情報が登録される。これは、データAに対応付けられた2次元座標が“(3,6)”であることを示す。
また、データBの座標は“(6,3)”である。データCの座標は“(4,3)”である。データDの座標は“(4,1)”である。
なお、データ管理テーブル132に登録される各データの座標の初期値は任意に与えることができる。例えば、データの座標の初期値を規則的に与えてもよいし、ランダムに与えてもよい。
図8は、第2の実施の形態の所属テーブルの例を示す図である。所属テーブル133は、データとセグメント(あるいは、グループ)との対応関係を登録した情報である。所属テーブル133は、管理情報記憶部130に格納される。所属テーブル133は、データおよびセグメントの項目を含む。
データの項目には、データの識別情報が登録される。セグメントの項目には、当該データが所属するセグメントが登録される。なお、前述のようにセグメントとグループとは1対1に対応付けられるから、当該セグメントは、当該データが所属するグループを示しているということができる。
例えば、所属テーブル133には、データが“A”、セグメントが“SG1”という情報が登録される。これは、データAがセグメントSG1に所属している(あるいは、グループG11に所属している)ことを示す。
図9は、第2の実施の形態のグループの例を示す図である。座標系F1は、直交するX軸およびY軸により2次元座標系を表している。座標系F1では、セグメントSG1,SG2およびデータA,B,C,Dを、セグメント管理テーブル131およびデータ管理テーブル132で例示した座標により表している。
領域R11は、セグメントSG1に属するデータA,Bを囲った領域である。領域R11を、グループG11に対応する領域ということもできる。領域R12は、セグメントSG2に属するデータC,Dを囲った領域である。領域R12を、グループG12に対応する領域ということもできる。
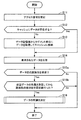
図10は、第2の実施の形態のアクセス処理の例を示すフローチャートである。以下、図10に示す処理をステップ番号に沿って説明する。
(S11)アクセス部140は、何れかのデータに対するアクセス要求をクライアント200から受け付ける。
(S12)アクセス部140は、要求されたデータがキャッシュ110に存在するか否かを判定する。存在する場合、アクセス部140は、要求されたデータをキャッシュ110から取得して、処理をステップS14に進める。存在しない場合、処理をステップS13に進める。なお、何れのデータがキャッシュ110の何れの記憶領域に存在するかは、キャッシュ110にデータが格納されるたびに、アクセス部140により記録される。例えば、アクセス部140は何れのデータがキャッシュ110に存在するかを記録した情報をキャッシュ110や管理情報記憶部130に格納する。アクセス部140は当該情報を参照することでステップS12の判定を行える。
(S13)アクセス部140は、所属テーブル133を参照して、要求されたデータが属するセグメントを特定する。アクセス部140は、データ記憶部120上の特定したセグメントを参照して、当該セグメントに含まれる各データを取得する。アクセス部140は、取得した各データを複製して、キャッシュ110に格納する。
(S14)アクセス部140は、要求されたデータをクライアント200に応答する。
(S15)アクセス部140は、データ間の関係性を検出したか否かを判定する。検出した場合、処理をステップS16に進める。検出していない場合、処理を終了する。具体的には、アクセス部140は、2つのデータが連続してアクセスされた場合、これらのデータについて、「連続してアクセスされた」という関係性を検出する。
(S16)アクセス部140は、「連続してアクセスされた」という関係性が検出された各データを制御部150に通知する。制御部150は、データ間の関係性を更新する。制御部150は、データ間の更新された関係性に基づいて、各セグメントに所属させるデータを決定する。制御部150は各セグメントに所属させるデータを決定するに留め、データ記憶部120上でセグメントを実際に更新することまでは行わない。
なお、ステップS15において、アクセス部140は、データ間の関係性を検出するための条件を追加してもよい。例えば、アクセス部140は、同一のクライアント200または同一のユーザにより2つのデータが連続してアクセスされた場合に、これらのデータについて関係性を検出してもよい。例えば、クライアント200は、クライアント200の識別情報やユーザの識別情報をアクセス要求に含める。そうすれば、アクセス部140は、アクセス要求に含まれる情報に基づいて、同一クライアントまたは同一ユーザによるものか否かを把握できる。
また、アクセス部140は、最初のアクセスと次のアクセスが所定時間内に行われた場合に連続アクセスと判断し、最初のアクセスと次のアクセスとの間の時間間隔が所定時間を経過している場合は連続アクセスでないと判断することも考えられる。
更に、クライアント200は前回アクセスしたデータをアクセス要求に含めてもよい。例えば、クライアント200は、前回データAにアクセスし、今回データCにアクセスする場合、今回のアクセス要求に前回アクセスしたデータAの識別情報を含めてもよい。その場合、ステップS14において、アクセス部140は、アクセス要求から連続してアクセスされた2つのデータを検出できる。
図11は、第2の実施の形態の関係性更新の例を示すフローチャートである。以下、図11に示す処理をステップ番号に沿って説明する。図11に示す処理は図10のステップS16に相当する。
(S21)制御部150は、関係性が検出された2つのデータの識別情報をアクセス部140から取得する。制御部150は、データ管理テーブル132を参照して、当該2つのデータの座標を取得する。また、制御部150は、セグメント管理テーブル131を参照して、当該2つのデータが所属するセグメント(解析対象セグメントということがある)の座標を取得する。ここで、一方のデータの座標で示されるベクトルをベクトルpi、そのデータが所属するセグメントの座標で示されるベクトルをベクトルqiとする。他方のデータの座標で示されるベクトルをベクトルpj、そのデータが所属するセグメントの座標で示されるベクトルをベクトルqjとする。ここで、添え字i,jは、データおよびセグメントを識別するための符号である。
(S22)制御部150は、式(1)、(2)を用いて、ベクトルpi,pjを更新する。
ここで、添え字m,nは0以上の整数であり、各ベクトルが更新された回数を示す。m=n=0の場合は初期値である(初期値は予め与えられる)。また、重み付け定数αは、0<α<1の実数である。重み付け定数αは、環境に応じて任意の値とすることができる。例えば、各データの既存の関係性を重視するならば、α=0.9程度が好ましい。制御部150は、更新結果をデータ管理テーブル132に登録する。
(S23)制御部150は、データ管理テーブル132および所属テーブル133を参照して、解析対象セグメントに属する全てのデータ(解析対象データということがある)の座標を取得する。
(S24)制御部150は、各解析対象データの座標と各解析対象セグメントの座標との距離に基づいて、各解析対象データのグループ分け(セグメントに対するデータの所属の決定)を行う。具体的には、制御部150は、距離の合計DS=DS1+DS2が最小になるようにセグメントに対するデータの所属を決定する。ここで、DS1は、一方のセグメントに所属させる各データの座標と当該一方のセグメントの座標との距離の和である。DS2は、他方のセグメントに所属させる各データの座標と当該他方のセグメントの座標との距離の和である。
(S25)制御部150は、ステップS24のグループ分けの結果に応じて、所属テーブル133を更新する。なお、ステップS23において、何れのセグメントについてもデータの所属に変更がなければ、制御部150はステップS25,S26をスキップする。
(S26)制御部150は、所属するデータが変更されたセグメントについて、セグメント管理テーブル131にデータ所属変更がある旨を登録する。
なお、ステップS21,S22では、2つのデータが異なるセグメントに属する場合を想定したが、2つのデータが同一のセグメントに属することもある。その場合、上記の式(1)、(2)に代えて、下記の式(3)、(4)を用いることで、各データの座標を更新することができる。
これにより、関係性の検出された2つのデータの座標と、2つのデータが所属する同一セグメントの座標とが近づくことになる。これは、当該同一セグメントに属する2つのデータの関係性が強まったことを意味する。なお、関係性が検出された2つのデータが同一のセグメントに属している場合、制御部150は、ステップS23〜S26をスキップする。次に、上記ステップS24の処理を具体的に説明する。
図12は、第2の実施の形態のデータとセグメントの距離の例を示す図である。図12では、データA,Cの関係性が検出され、ステップS22によりデータA,Cの座標が更新された後の状態を示している。データ管理テーブル132aは、データ管理テーブル132に対して、データA,Cの座標が更新された状態を示している。座標系F2は、データ管理テーブル132aで示される各データの座標を図示したものである。
座標系F2において、距離dA1は、データAの座標とセグメントSG1の座標との距離である。距離dA2は、データAの座標とセグメントSG2の座標との距離である。距離dB1は、データBの座標とセグメントSG1の座標との距離である。距離dB2は、データBの座標とセグメントSG2の座標との距離である。距離dC1は、データCの座標とセグメントSG1の座標との距離である。距離dC2は、データCの座標とセグメントSG2の座標との距離である。dD1は、データDの座標とセグメントSG1の座標との距離である。dD2は、データDの座標とセグメントSG2の座標との距離である。
ここで、各距離の値は、例えば次の通りである。dA1=2.23。dA2=4.02。dB1=5.83。dB2=1.41。dC1=3.74。dC2=1.91。dD1=5.83。dD2=1.41。
図13は、第2の実施の形態の距離の合計の計算例を示す図である。図12の例の場合、データA,B,C,Dのグループ分けの候補は次の6つである。テーブル134は、その候補を例示している。テーブル134は、制御部150による下記の計算のために管理情報記憶部130に格納されてもよい。
(1)セグメントSG1にデータA,Bを所属させ、セグメントSG2にデータC,Dを所属させる。この場合、DS1=dA1+dB1=8.06である。DS2=dC2+dD2=3.32である。よって、DS=DS1+DS2=11(有効数字を2桁とする。以下同様)である。
(2)セグメントSG1にデータA,Cを所属させ、セグメントSG2にデータB,Dを所属させる。この場合、DS1=dA1+dC1=5.97である。DS2=dB2+dD2=2.82である。よって、DS=DS1+DS2=8.8である。
(3)セグメントSG1にデータA,Dを所属させ、セグメントSG2にデータB,Cを所属させる。この場合、DS1=dA1+dD1=8.06である。DS2=dB2+dC2=3.32である。よって、DS=DS1+DS2=11である。
(4)セグメントSG1にデータB,Cを所属させ、セグメントSG2にデータA,Dを所属させる。この場合、DS1=dB1+dC1=9.57である。DS2=dA2+dD2=5.43である。よって、DS=DS1+DS2=15である。
(5)セグメントSG1にデータB,Dを所属させ、セグメントSG2にデータA,Cを所属させる。この場合、DS1=dB1+dD1=11.66である。DS2=dA2+dC2=5.93である。よって、DS=DS1+DS2=18である。
(6)セグメントSG1にデータC,Dを所属させ、セグメントSG2にデータA,Bを所属させる。この場合、DS1=dC1+dD1=9.57である。DS2=dA2+dB2=5.43である。よって、DS=DS1+DS2=15である。
制御部150は、これらの候補のうち、DSが最小になる候補を選択する。上記(1)〜(6)のうち、DSが最小になるのは(2)のパターンである。よって、制御部150は、セグメントSG1にデータA,Cを所属させ、セグメントSG2にデータB,Dを所属させると決定する。制御部150は、この結果により、所属テーブル133を更新する。所属テーブル133aは、更新後の登録内容を示している。
例えば、上記のようなグループ分けを簡便に行うために、制御部150は、セグメントSG1,SG2をラウンドロビンで選び、選択したセグメントの座標に最も距離が近いデータから当該セグメントに所属させると決定してもよい。例えば、セグメントSG1を選択した場合、セグメントSG1の座標に最も近いのはデータA,Cの座標である。したがって、制御部150は、データA,CをセグメントSG1に所属させると決定する。また、制御部150は、残りのデータB,DをセグメントSG2に所属させると決定する。
図14は、第2の実施の形態の更新後のグループの例を示す図である。座標系F3は、所属テーブル133aで示されるようにグループ分けした状態を示している。領域R11aは、セグメントSG1に所属させるデータA,Cを囲った領域である。領域R11aをグループG11に対応する領域ということもできる。領域R12aは、セグメントSG2に所属させるデータB,Dを囲った領域である。領域R12aをグループG12に対応する領域ということもできる。
ここで、キャッシュ110に配置されたデータは、頻繁にアクセスされる可能性が高く、キャッシュ110上に存在している限り、データ間の関係性が更新されていく可能性が高い。このため、各セグメントのデータの所属が決定されるたびに、データ記憶部120内のセグメントを更新しても、各セグメントのデータの所属が再決定される(変更される)可能性が高い。しかも、各セグメントのデータの所属が決定されるたびに、セグメントを更新していると、セグメントの更新が頻繁に発生することになり、当該更新によるサーバ100の負荷が高まる可能性もある。
そこで、制御部150は、あるセグメントに対応する記憶領域がキャッシュ110から解放されるタイミングで、データ記憶部120上の当該セグメントの更新を行う。具体的には次の手順である。
図15は、第2の実施の形態のセグメントの更新例を示すフローチャートである。以下、図15に示す処理をステップ番号に沿って説明する。
(S31)制御部150は、キャッシュ110から何れかの記憶領域を解放するか否かを判定する。何れかの記憶領域を解放する場合、処理をステップS32に進める。何れの記憶領域も解放しない場合、処理を終了する。例えば、制御部150は、キャッシュ110の容量が不足した場合に、最も過去にアクセスされた記憶領域を解放することで、当該記憶領域を再利用可能とする(LRU:Least Recently Used)。
(S32)制御部150は、セグメント管理テーブル131を参照して、解放対象の記憶領域に格納したセグメントについて、データ所属変更があるか否かを判定する。当該セグメントについてデータ所属変更がある場合、処理をステップS33に進める。当該セグメントについてデータ所属変更がない場合、処理をステップS34に進める。なお、キャッシュ110の各記憶領域に格納したセグメントの情報は、図10のステップS12で説明したように、アクセス部140により記録され、管理情報記憶部130に格納されている。
(S33)制御部150は、解放対象の記憶領域に格納したセグメントを、データの所属を変更した状態でデータ記憶部120上に再作成することで、当該セグメントを更新する。例えば、セグメントSG1内のデータ配置をデータA,BからデータA,Cとする場合、データ記憶部120上で、データA,Cを配置したセグメントを作成し、これをセグメントSG1とする。制御部150は、データ記憶部120上の元のセグメントSG1(データA,Bを配置した旧セグメント)の領域を解放し、上書き可能として管理する。更に、制御部150は、再作成したセグメントから追い出されたデータ(上記の例ではデータB)を所属させるセグメントもデータ記憶部120上に再作成する。例えば、データBをセグメントSG2に所属させるならセグメントSG2も再作成する。
(S34)制御部150は、解放対象の記憶領域をキャッシュ110から解放する。これにより、当該記憶領域は再利用可能となる。
このように、制御部150は、キャッシュ110から何れかの記憶領域がLRUで解放される際に、当該記憶領域に格納したセグメントに対するデータの所属変更を、データ記憶部120に反映する。キャッシュ110上で所定期間アクセスされなくなったグループに対して、データ記憶部120上でのセグメントの更新を行えば、データ記憶部120上でのセグメントの更新頻度を低減できる。よって、セグメントの更新に伴うサーバ100の負荷を軽減できる。
なお、1度アクセスされたデータは当分の間アクセスされない前提で、解放する記憶領域をMRU(Most Recently Used)により決定することも考えられる。その場合にも、上記と同様の手順を用いて、データ記憶部120上でのセグメントの更新を行える。
図16は、第2の実施の形態のデータとセグメントの距離の他の例を示す図である。図15までの例では、関係性が検出された各データが属するセグメント(解析対象セグメント)について、データの所属を決定するものとした。一方、解析対象セグメントの対象を拡張することも考えられる。例えば、セグメントSG1,SG2に所属するデータA,Cの関係性が検出された場合に、セグメントSG1またはセグメントSG2から最も近傍にあるセグメントSG3を解析対象セグメントに含めてもよい。その場合にも、図11におけるステップS23〜S26の手順を適用することで、各解析対象セグメントのデータの所属を決定できる。
具体的には、座標系F4には、セグメントSG1,SG2,SG3が図示されている。セグメントSG3にはデータE,Fが属している。この場合、図12で例示した距離に加え、距離dA3,dB3,dC3,dD3,dE1,dE2,dE3,dF1,dF2,dF3を考えることができる。距離dA3は、データAの座標とセグメントSG3の座標との距離である。距離dB3は、データBの座標とセグメントSG3の座標との距離である。距離dC3は、データCの座標とセグメントSG3の座標との距離である。距離dD3は、データDの座標とセグメントSG3の座標との距離である。
距離dE1は、データEの座標とセグメントSG1の座標との距離である。距離dE2は、データEの座標とセグメントSG2の座標との距離である。距離dE3は、データEの座標とセグメントSG3の座標との距離である。距離dF1は、データFの座標とセグメントSG1の座標との距離である。距離dF2は、データFの座標とセグメントSG2の座標との距離である。距離dF3は、データFの座標とセグメントSG3の座標との距離である。
図11のステップS24の考え方を適用すれば、上記の各距離(図12で例示した距離も含む)に基づいて、データA,B,C,D,E,Fのグループ分けを行う。具体的には、制御部150は、距離の合計DS=DS1+DS2+DS3が最小になるようにセグメントSG1,SG2,SG3に対するデータの所属を決定する。例えば、DS1は、セグメントSG1に所属させる各データの座標とセグメントSG1の座標との距離の和である。DS2は、セグメントSG2に所属させる各データの座標とセグメントSG2の座標との距離の和である。DS3は、セグメントSG3に所属させる各データの座標とセグメントSG3の座標との距離の和である。
このように、解析対象セグメントの数を3以上に拡張することができる。例えば、図16の例に加えて解析対象セグメントの数を更に1つ追加するなら、距離の合計DSをDS=DS1+DS2+DS3+DS4と表せる。解析対象セグメントの数がN個(Nは2以上の整数)なら、距離の合計DS=DS1+・・・+DSNとなる(DSNは、セグメントSGNに所属させる各データの座標とセグメントSGNの座標との距離の和である)。このように、関係性が検出された各データが属するセグメント以外のセグメントの座標も考慮して、各セグメントに所属させるデータを決定してもよい。
この場合にも、前述のように、制御部150は、セグメントSG1,・・・,SGNをラウンドロビンで選び、選択したセグメントの座標に最も距離が近いデータから当該セグメントに所属させると決定してもよい。
図17は、第2の実施の形態の座標系の他の例を示す図である。座標系F5は、X軸、Y軸、Z軸が直交する3次元の座標系である。このように、セグメントSG1,SG2の座標およびデータA,B,C,Dの座標を、3次元で与えてもよい。また、各データの座標と各セグメントの座標との間の距離(座標間を結ぶベクトルの絶対値)を考えることができれば、1次元でもよいし、4次元以上でもよい。
以上のようにして、サーバ100は、RAM102の使用量の増大を抑えながらグループ化の精度を向上できる。
ここで、例えば、グループ化を行う所定のタイミングで、各データに対する過去のアクセス履歴を参照して、連続してアクセスされた頻度がより高いデータ同士を同一グループに割当てることも考えられる。
この場合、グループ化に利用するアクセス履歴の情報量が多い程、統計的に高信頼のグループ化を行える。ところが、全てのアクセス履歴を保存していると、時間経過と共にアクセス履歴の情報量が増大し、RAM102の使用量が増大するおそれがある。一方、RAM102の使用量を節約するために、ある期間のみのアクセス履歴を保存することも考えられる。しかし、この場合、他の期間のアクセス履歴の情報が失われるので、グループ化の精度が低下し得る。具体的には次の通りである。
図18は、アクセス履歴の例を示す図である。アクセス履歴30は、比較的長期間のデータA,B,C,Dに対して受け付けたアクセス要求の履歴を例示している。また、アクセス履歴31は、アクセス履歴30のうちの一部の期間について、データA,B,C,Dに対して受け付けたアクセス要求の履歴を例示している。
図19は、アクセス履歴によるグループ化の例を示す図である。図19(A)は、アクセス履歴30に基づいてグループ化を行った場合の例である。図19(A)の例は、アクセス履歴31に基づいてグループ化を行う場合に対して、(時間的に)大局的なグループ化を行った場合といえる。
アクセス履歴30の例によれば、データA,BおよびデータB,Aの順にアクセスが行われた回数は4である。データA,CおよびデータC,Aの順にアクセスが行われた回数は5である。データA,DおよびデータD,Aの順にアクセスが行われた回数は0である。データB,CおよびデータC,Bの順にアクセスが行われた回数は0である。データB,DおよびデータD,Bの順にアクセスが行われた回数は7である。データC,DおよびデータD,Cの順にアクセスが行われた回数は3である。セグメントサイズを2とするなら、連続してアクセスされた頻度が相対的に高いデータA,Cを第1のグループ、データB,Dを第2のグループとグループ分けできる。
一方、図19(B)は、アクセス履歴31に基づいてグループ化を行った場合の例である。図19(B)の例は、アクセス履歴30に基づいてグループ化を行う場合に対して、(時間的に)局所的なグループ化を行った場合といえる。
アクセス履歴31の例によれば、データA,BおよびデータB,Aの順にアクセスが行われた回数は2である。データA,CおよびデータC,Aの順にアクセスが行われた回数は0である。データA,DおよびデータD,Aの順にアクセスが行われた回数は0である。データB,CおよびデータC,Bの順にアクセスが行われた回数は0である。データB,DおよびデータD,Bの順にアクセスが行われた回数は1である。データC,DおよびデータD,Cの順にアクセスが行われた回数は2である。セグメントサイズを2とするなら、連続してアクセスされた頻度が相対的に高いデータA,Bを第1のグループ、データC,Dを第2のグループとグループ分けできる。
このように、アクセス履歴30,31の何れを用いるかによって、グループ分けの結果が異なる可能性がある。アクセス履歴30を用いる場合、アクセス履歴31よりも多くの情報を利用できるから、グループ内のデータが連続してアクセスされる可能性が高いことに対し、統計的に信頼性の高いグループを作成できる。その反面、アクセス履歴30を全て保持するためにRAM102の容量を比較的多く使用する。その使用量は時間経過とともに増大する。
他方、アクセス履歴31に限定して記憶しておけば、アクセス履歴30よりもRAM102の使用量を低減できる。しかし、アクセス履歴31以外の期間のアクセス履歴の情報は失われる。このため、アクセス履歴30を用いる場合よりもグループ化の精度は低下する(グループ内のデータが連続してアクセスされる可能性が高いことに対する統計的な信頼性が低下する)。例えば、図19のように、大局的にはデータA,Cが連続してアクセスされた頻度が比較的高く、かつ、データB,Dが連続してアクセスされた頻度が比較的高いにも関わらず、データA,Bの組、および、データC,Dの組でグループ化されてしまうことがある。
そこで、サーバ100は、データ間の関係性を各データの座標を用いて管理する。そして、データ間の関係性が検出されるたびに、当該データ同士の座標を更新することで、当該データ間の相互の関係が強まったことを記録する。このため、サーバ100は、全てのデータについてのアクセス履歴を保持しておかなくてよい。ある時点におけるデータ毎の座標は、その時点よりも過去のアクセス履歴が反映された情報だからである。
この場合、サーバ100は、各データに対する座標を記録するための領域をRAM102上に確保しておけばよい。よって、アクセス履歴を全て記憶しておくよりも、RAM102の使用量の増大を抑制できる。また、データ毎の座標に過去のアクセス履歴(例えば、アクセス履歴30)を全て反映させることができるので、ある期間のみのアクセス履歴(例えば、アクセス履歴31)を保存する場合に比べて、グループ化の精度を向上し得る。
また、データ間の関係性が検出されたタイミングで、当該データ間の関係を更新していくので、全てのアクセス履歴を解析する場合のように一度に大量の情報を処理せずに済む。このため、データ間の関係性を解析するためにサーバ100の負荷が高まることを抑制できる。このように、各データの座標によりデータ間の関係性を管理することで、データ間の関係性を効率的に管理できる。
なお、セグメントサイズとして2を想定したが、3以上としてもよい。例えば、セグメントサイズをk(kは3以上の整数)個とし、2k個のデータをセグメントSG1,SG2に分ける場合を考える。この場合、DS1はk個のデータの座標とセグメントSG1の座標とによって求められるk個の距離の和になる。また、DS2も他のk個のデータの座標とセグメントSG2の座標とによって求められるk個の距離の和になる。その中で最小のDS=DS1+DS2を選択すればよい。このように、セグメントサイズが3以上の場合にも第2の実施の形態の方法を適用できる。
[第3の実施の形態]
次に、第3の実施の形態を説明する。前述の第2の実施の形態との相違する事項を主に説明し、共通する事項の説明を省略する。
第2の実施の形態では、各データと各セグメントとの距離を用いて、各セグメントに所属させるデータを決定する例を示した。一方、ベクトルの内積を利用して、各セグメントに所属させるデータを決定してもよい。第3の実施の形態では、その機能を提供する。
ここで、第3の実施の形態の情報処理システムは、図2で示した第2の実施の形態の情報処理システムと同様である。また、第3の実施の形態の情報処理システムに含まれる装置や機能は、図3,4で示した第2の実施の形態の装置や機能と同様である。そこで、第3の実施の形態では、第2の実施の形態と同じ符号、名称を用いる。
ここで、第3の実施の形態のアクセス処理の手順は、図10の手順と同様である。また、第3の実施の形態のセグメント更新の手順は、図15の手順と同様である。一方、第3の実施の形態では、関係性更新の手順が図11の手順と一部異なる。
図20は、第3の実施の形態の関係性更新の例を示すフローチャートである。以下、図20に示す処理をステップ番号に沿って説明する。第3の実施の形態では、図11のステップS24に代えて、ステップS24a,S24bを実行する点が異なる。そこで、ステップS24a,S24bを説明し、他のステップの説明を省略する。
(S24a)制御部150は、解析対象データの座標で示されるベクトル(解析対象データの位置ベクトル)と、解析対象セグメントの座標間を結ぶベクトルとの内積を、解析対象データ毎に計算する。位置ベクトルは原点に対する各データの座標位置を示すベクトルである。
(S24b)制御部150は、ステップS24aで求めた各内積をソートし、内積の大きさの順に各データをグループ化する。
図21は、第3の実施の形態の内積の例を示す図である。座標系F6では、ベクトルV,V1,V2,V3,V4を例示している。ベクトルVは、セグメントSG1の座標を始点、セグメントSG2の座標を終点とするベクトルである。
ベクトルV1は、データAの座標で示されるベクトル(データAの位置ベクトル)である。ベクトルV2は、データBの座標で示されるベクトル(データBの位置ベクトル)である。ベクトルV3は、データCの座標で示されるベクトル(データCの位置ベクトル)である。ベクトルV4は、データDの座標で示されるベクトル(データDの位置ベクトル)である。
例えば、ベクトルVとベクトルV1との内積は−9.6である。ベクトルVとベクトルV2との内積は12である。ベクトルVとベクトルV3との内積は1.2である。ベクトルVとベクトルV4との内積は12である。内積の大きさにより、データA,B,C,Dの座標が、セグメントSG1,SG2のどちらの座標に近いかを相対的に評価できる。
図22は、第3の実施の形態の内積のソート結果の例を示す図である。図22では、ベクトルVに対するベクトルV1,V2,V3,V4それぞれの内積および各内積に対応するデータを昇順に並べている(図22では、紙面の上から順に並べている)。具体的には、データA,C,B,Dの順となる(ただし、データB,Dの内積の値は同じなので、データB,Dの順序は入れ替わってもよい)。
ベクトルVは、セグメントSG1の座標を始点、セグメントSG2の座標を終点としたベクトルである。このため、ベクトルVとデータのベクトルとの内積が小さい程、データの座標はセグメントSG2の座標よりもセグメントSG1の座標に近い。したがって、この場合、制御部150は、データA,CをセグメントSG1に所属させると決定する。また、データB,DをセグメントSG2に所属させると決定する。その結果、制御部150は、所属テーブル133を所属テーブル133aのように更新する。
このように、各データのベクトルとセグメント間のベクトルとの内積を用いて、セグメントに所属させるデータを決定してもよい。この場合、図13のテーブル134で示したように、距離の合計DSの候補を全て求めるよりも、演算コストを軽減し得る。この内積を用いる方法は、2つのセグメント間でデータの所属を決定する際に特に有用である。
なお、セグメントサイズとして2を想定したが、3以上としてもよい。例えば、セグメントサイズをk(kは3以上の整数)個とし、2k個のデータをセグメントSG1,SG2に分ける場合を考える。
この場合、制御部150は、2k個のデータの座標で示される2k個のベクトルと、セグメントSG1の座標からセグメントSG2の座標へ向けたベクトルとの2k個の内積を求める。そして、相対的に内積の小さいk個のデータをセグメントSG1に所属させる。また、相対的に内積の大きいk個のデータをセグメントSG2に所属させる。このように、セグメントサイズが3以上の場合にも第3の実施の形態の方法を適用できる。
[第4の実施の形態]
次に、第4の実施の形態を説明する。前述の第2,3の実施の形態との相違する事項を主に説明し、共通する事項の説明を省略する。
第2,第3の実施の形態では、データ間に関係性が検出されるたびに関係性が検出された各データの座標を更新するものとした。一方、関係性の検出が複数回行われるたびに、関係性の検出された各データの座標を更新してもよい。第4の実施の形態では、この機能を提供する。
ここで、第4の実施の形態の情報処理システムは、図2で示した第2の実施の形態の情報処理システムと同様である。また、第4の実施の形態の情報処理システムに含まれる装置や機能は、図3,4で示した第2の実施の形態の装置や機能と同様である。そこで、第4の実施の形態では、第2の実施の形態と同じ符号、名称を用いる。ただし、第4の実施の形態では、データ管理テーブル132に代えて、データ管理テーブル132bを用いる点が、第2の実施の形態と異なる。
図23は、第4の実施の形態のデータ管理テーブルの例を示す図である。データ管理テーブル132bは、管理情報記憶部130に格納される。データ管理テーブル132bは、データ、座標および関係性の項目を含む。
データの項目には、データの識別情報が登録される。座標の項目には、当該データに対応付けられた座標が登録される。関係性の項目には、当該データに対して関係性が検出された他のデータの識別情報が登録される。
例えば、データ管理テーブル132bには、データが“A”、座標が“(3,6)”、関係性が“C”という情報が登録される。これは、データAに対応付けられた2次元座標が“(3,6)”であることを示す。また、データA,Cは連続してアクセスされたことを示す。
次に、第4の実施の形態の処理手順を説明する。第4の実施の形態では、アクセス処理の手順が図10の手順と一部異なる。
図24は、第4の実施の形態の関係性更新の例を示すフローチャートである。以下、図24に示す処理をステップ番号に沿って説明する。第4の実施の形態では、図10のステップS15に代えて、ステップS15a,S15bを実行する点が異なる。そこで、ステップS15a,S15bを説明し、他のステップの説明を省略する。
(S15a)アクセス部140は、データ間の関係性を検出したか否かを判定する。検出した場合、アクセス部140は、データ管理テーブル132bに検出したデータ間の関係性を記録し、処理をステップS15bに進める。検出していない場合、処理を終了する。ここで、ステップS15で説明したように、アクセス部140は、2つのデータが連続してアクセスされた場合に、これらのデータについて、「連続してアクセスされた」という関係性を検出する。例えば、データA,Cが連続してアクセスされたなら、データ管理テーブル132bのデータAのエントリ(関係性の項目)にデータCを記録し、データCのエントリ(関係性の項目)にデータAを記録する。
(S15b)アクセス部140は、前回データの所属を決定してから関係性の検出を所定回数(例えば、2回または5回など)行ったか否かを判定する。所定回数行った場合、処理をステップS16に進める。所定回数行っていない場合、処理を終了する。
このように、アクセス部140は、データ管理テーブル132bにデータ間の関係性を記録してもよい。この場合、ステップS16において(あるいは、図11の関係性更新の処理において)、制御部150はデータ管理テーブル132bを参照し、関係性の項目に他のデータが記録された全てのデータについて、検出された関係性に応じて座標を更新する。そして、更新後の座標に基づいてセグメントの所属を決定する。制御部150は、セグメントの所属を決定したデータについては、データ管理テーブル132bの関係性の項目をクリアする。
なお、ステップS15bでは、データ間の関係性を所定回数検出したか否かを判定するものとしたが、前回データの所属を決定してから所定時間が経過したか否かを判定してもよい。その場合、所定時間が経過していれば、処理をステップS16に進める。所定時間が経過していなければ、処理を終了する。
図25は、第4の実施の形態の更新直後の管理情報の例を示す図である。図25(A)はデータ管理テーブル132cを例示している。例えば、ステップS15bの所定回数を2回とし、データA,Cの関係性およびデータB,Dの関係性(2つの関係性)が検出されたタイミングで、制御部150は、これらの各データの座標を更新する。座標を更新する直前では、データA,BはセグメントSG1に属している。また、データC,DはセグメントSG2に属している。
したがって、制御部150は式(1)、(2)を用いて、データAの座標をセグメントSG2の座標を用いて更新する(データCがセグメントSG2に属するため)。また、データCの座標をセグメントSG1の座標を用いて更新する(データAがセグメントSG1に属するため)。
同様に、制御部150は式(1)、(2)を用いて、データBの座標をセグメントSG2の座標を用いて更新する(データDがセグメントSG2に属するため)。また、データDの座標をセグメントSG1の座標を用いて更新する(データBがセグメントSG1に属するため)。なお、データ管理テーブル132cでは、各データの関係性の項目の設定はクリアされている(ハイフン“−”と表記している)。
ここで、データ管理テーブル132cでは、α=0.9とした場合のデータA,B,C,Dの更新後の座標を図示している。その結果、制御部150は、データA,CをセグメントSG1に所属させ、データB,DをセグメントSG2に所属させると決定する。図25(B)は更新後の所属テーブル133bを示している。
図26は、第4の実施の形態の更新後のグループの例を示す図である。座標系F7では、図25で示したデータA,B,C,Dの座標更新を図示している。制御部150は、当該座標更新の結果、データ管理テーブル132cを得る。
座標系F8は、所属テーブル133bで示されるようにグループ分けした状態を示している。領域R11bは、セグメントSG1に所属させるデータA,Cを囲った領域である。領域R11bをグループG11に対応する領域ということもできる。領域R12bは、セグメントSG2に所属させるデータB,Dを囲った領域である。領域R12bをグループG12に対応する領域ということもできる。
このように、サーバ100は、データ間の関係性の検出内容を記録しておき、複数回の検出を行った後に、一括して、関係性の検出されたデータの座標を更新してもよい。この場合も第2の実施の形態と同様に、サーバ100はRAM102の使用量の増大を抑えながら、グループ化の精度を向上できる。
[第5の実施の形態]
次に、第5の実施の形態を説明する。第2〜第4の実施の形態と相違する事項を主に説明し、共通する事項の説明を省略する。
第2〜第4の実施の形態では、データを管理するノードとしてサーバ100を想定した。一方、複数のノードを設けて、各セグメントを複数のノードで分散して管理することも考えられる。各ノードのデータアクセスに伴う負荷を軽減でき、また、データアクセスの高速化を図れるからである。
図27は、第5の実施の形態の情報処理システムの例を示す図である。第5の実施の形態の情報処理システムでは、第2の実施の形態で説明したサーバ100に加えて、サーバ100a,100bを含む。サーバ100a,100bは、ネットワーク10に接続されている。サーバ100a,100bは、サーバ100と同様の機能を備えたサーバコンピュータである。
サーバ100,100a,100bは、複数のセグメントを分散管理する。例えば、セグメントSG1をサーバ100が担当し、セグメントSG2をサーバ100aが担当し、セグメントSG3をサーバ100bが担当する。何れかのセグメントのデータに対するアクセス要求を受け付けた場合は、当該セグメントを担当するサーバが当該アクセス要求に応答する。例えば、サーバ100bがセグメントSG1のデータに対するアクセス要求を受け付けた場合、サーバ100bはサーバ100に当該アクセス要求を転送する。サーバ100は、当該アクセス要求を受け付けると、要求されたデータを要求元に送信する。
ここで、サーバ100a,100bは、サーバ100と同様のハードウェアを用いて実現できる。また、サーバ100a,100bの機能は、図4で説明したサーバ100の機能と同様である。ただし、各サーバの制御部は相互に通信して、各サーバで保持されるデータ管理テーブルおよび所属テーブルを最新の状態に同期する。また、サーバ100,100a,100bは、セグメントと担当サーバとの対応関係を保持している。
図28は、第5の実施の形態のセグメント担当テーブルの例を示す図である。セグメント担当テーブル135は、管理情報記憶部130に格納される。サーバ100a,100bもセグメント担当テーブル135と同様のテーブルを保持する。セグメント担当テーブル135は、セグメントおよび担当サーバの項目を含む。
セグメントの項目には、セグメントの識別情報が登録される。担当サーバの項目には、当該セグメントを担当するサーバの識別情報が登録される。例えば、セグメント担当テーブル135には、セグメントが“SG1”、担当サーバが“サーバ100”という情報が登録される。これは、セグメントSG1をサーバ100が担当することを示している。
このように、各サーバは、何れのセグメントを何れのサーバが担当するかを把握している。このため、データの座標を変更することで、セグメントに対するデータの所属が変更になった場合にも、各サーバは、何れのサーバに当該データを送信すればよいかを把握できる。
ここで、第5の実施の形態でも第2〜第4の実施の形態と同様に、データ間の関係性の検出、各データの座標の更新およびセグメントに対するデータの所属の決定を行える。ただし、データ間の関係性を検出するために、各サーバは、今回何れのデータに対するアクセス要求に応答したかを互いに通知し合う。あるいは、アクセス要求に前回アクセスされたデータが含まれていれば、アクセス要求から連続してアクセスされたデータを把握できるので、サーバ相互で当該通知を行わなくてもよい。
また、関係性が検出された各データの座標の更新やセグメントに対するデータの所属の決定は、何れかのサーバで行われればよい。例えば、最後にアクセス要求に応答したサーバが、データ間の関係性の検出の有無に応じて、各データの座標の更新やセグメントに対するデータの所属の決定を行うことが考えられる。
そして、何れかのサーバで、データの所属が変更されたセグメントがメモリ落ちする(対応するキャッシュ領域が解放される)際に、各サーバは、セグメント担当テーブルに基づいて、サーバ間で配置転換するデータの送受信を行う。こうして、各サーバはセグメントの内容を更新する。第5の実施の形態の場合にも、アクセス履歴を全て保持しておかなくてもよいので、サーバ100,100a,100bはRAMの使用量の増大を抑えられる。また、各データの座標に過去のアクセス履歴を反映させることができるので、当該座標を用いることでグループ化の精度を向上できる。
なお、以上の説明では、主に、キャッシュ110としてRAM102を、データ記憶部120としてHDD103を想定したが、これら以外の組み合わせも考えられる。例えば、キャッシュ110としてRAM102を、データ記憶部120としてSSD、光ディスク13およびテープ媒体などを用いてもよい。また、キャッシュ110としてSSDを、データ記憶部120としてHDD103、光ディスク13およびテープ媒体などを用いてもよい。
また、第2〜第5の実施の形態では、主にサーバコンピュータを例示したが、データアクセスを制御するプロセッサ、ディスク装置およびキャッシュメモリを備えるストレージ装置に第2〜第5の実施の形態を適用することもできる。例えば、ストレージ装置にも、図4で例示したサーバ100と同様の機能を設けることができる。
また、第1の実施の形態の情報処理は、演算部1cにプログラムを実行させることで実現できる。また、第2〜第5の実施の形態の情報処理は、各サーバが備えるプロセッサにプログラムを実行させることで実現できる。プログラムは、コンピュータ読み取り可能な記録媒体(例えば、光ディスク13、メモリ装置14およびメモリカード16など)に記録できる。
例えば、プログラムを記録した記録媒体を配布することで、プログラムを流通させることができる。また、プログラムを他のコンピュータに格納しておき、ネットワーク経由でプログラムを配布してもよい。コンピュータは、例えば、記録媒体に記録されたプログラムまたは他のコンピュータから受信したプログラムを、RAM102やHDD103などの記憶装置に格納し(インストールし)、当該記憶装置からプログラムを読み込んで実行してもよい。