JP6097791B2 - Topic continuation desire determination device, method, and program - Google Patents
Topic continuation desire determination device, method, and program Download PDFInfo
- Publication number
- JP6097791B2 JP6097791B2 JP2015123890A JP2015123890A JP6097791B2 JP 6097791 B2 JP6097791 B2 JP 6097791B2 JP 2015123890 A JP2015123890 A JP 2015123890A JP 2015123890 A JP2015123890 A JP 2015123890A JP 6097791 B2 JP6097791 B2 JP 6097791B2
- Authority
- JP
- Japan
- Prior art keywords
- utterance
- feature
- flag
- user
- topic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Landscapes
- Machine Translation (AREA)
Description
本発明は、ユーザとの間で対話を行う対話システムにおいて、ユーザ発話の後、ユーザが該ユーザ発話の直前のシステム発話の話題を継続したがっているか否かを判定するための話題継続願望判定装置、方法、及びプログラムに関する。 The present invention relates to a topic continuation desire determination apparatus for determining whether or not a user wants to continue a topic of a system utterance immediately before the user utterance after a user utterance in an interactive system that performs a dialogue with the user, The present invention relates to a method and a program.
一般に対話における発話には、その内容の対象となっている事物を表す焦点が存在する。図5のシステム発話とユーザ発話のカラムは、対話を行っているシステムとユーザの発話列を示すもので、最初の行から順に各行において、システム発話・ユーザ発話の順で発話がされたことを示す。各行の焦点は、一つ前の行のユーザ発話までの発話列からシステムが抽出した焦点を表している。焦点抽出は、ルールベースないし機械学習の手法を用いて行う。システムは、この抽出した焦点について言及した文を、発話知識データから選択ないし生成して、該文を次発話として発する。当該行のシステム発話が、この次発話である。 In general, utterances in dialogue have a focal point that represents the object that is the subject of the content. The system utterance and user utterance columns in FIG. 5 indicate the utterance strings of the system and the user that are engaged in the conversation. In each row in order from the first row, the utterance in the order of system utterance / user utterance is shown. Show. The focus of each row represents the focus extracted by the system from the utterance sequence up to the user utterance in the previous row. Focus extraction is performed using a rule-based or machine learning technique. The system selects or generates a sentence referring to the extracted focus from the utterance knowledge data, and utters the sentence as the next utterance. The system utterance of the line is the next utterance.
以下の非特許文献1の手法は、上記に述べたようなやり方を取っている。
The technique of the following
上記で述べた、焦点に基づいて発されたシステム発話の話題が、ユーザにとって継続したい場合と、したくない場合がある。図5の1〜3行目のユーザ発話を見ると、ユーザは直前のシステム発話の話題を継続したがっている。しかし、4〜5行目のユーザ発話を見ると、ユーザは直前のシステム発話の話題を継続したがっていない。6行目のユーザ発話を見ると、ユーザは直前のシステム発話の話題に興味を持ち、継続したがっている。 There are cases where the topic of system utterances uttered based on the focus as described above may or may not be continued for the user. Looking at the user utterances in the first to third lines in FIG. 5, the user wants to continue the topic of the immediately preceding system utterance. However, when viewing the user utterances in the 4th to 5th lines, the user does not want to continue the topic of the immediately preceding system utterance. Looking at the user utterance on the sixth line, the user is interested in the topic of the last system utterance and wants to continue.
ユーザが直前のシステム発話の話題を継続したがっている場合は、システムは、同じ話題を継続するか、あるいは、適宜、話題を変更するのがよいと言える。一方、ユーザが直前のシステム発話の話題を継続したがっていない場合は、システムは、話題を必ず変更する必要がある。このように、システムが適切な発話を行うには、ユーザが直前のシステム発話の話題を継続したがっているか否かの情報が必要となる。 If the user wants to continue the topic of the last system utterance, it can be said that the system should continue the same topic or change the topic as appropriate. On the other hand, if the user does not want to continue the topic of the last system utterance, the system must change the topic without fail. Thus, in order for the system to properly speak, information on whether or not the user wants to continue the topic of the immediately preceding system utterance is required.
しかしながら現状の対話技術においては、ユーザが直前のシステム発話の話題を継続したがっているか否かを判定する機構がない。このため、ユーザが直前のシステム発話の話題を継続したがっていないにも関わらず、同じ話題を継続することがあり、対話に対するユーザの満足度が低いものとなる。これを解決するため、常に定期的に(例えば2、3システム発話ごとに)話題を変更する処置を取っても、今度は、ユーザが直前のシステム発話と同じ話題を継続したがっている場合でも、話題が変わってしまい、対話に対するユーザの満足度が低いものとなることは解決されない。このように、適切な発話戦略を取ることができないため、対話に対するユーザの満足度が低いという課題がある。 However, in the current interactive technology, there is no mechanism for determining whether or not the user wants to continue the topic of the immediately preceding system utterance. For this reason, although the user does not want to continue the topic of the immediately preceding system utterance, the same topic may be continued, and the user's satisfaction with the dialogue is low. To solve this problem, even if you take a procedure to change the topic regularly (for example, every second or third system utterance), even if the user wants to continue the same topic as the previous system utterance, It will not be resolved that the user will be less satisfied with the dialogue. Thus, since an appropriate speech strategy cannot be taken, there exists a subject that the user's satisfaction with respect to a dialogue is low.
本発明は、上記課題を解決するためのものであり、ユーザが直前のシステム発話の話題を継続したがっているか否かを判定することができる話題継続願望判定装置、方法、及びプログラムを提供することを目的としている。 This invention is for solving the said subject, and provides the topic continuation desire determination apparatus, method, and program which can determine whether the user wants to continue the topic of the last system utterance. It is aimed.
上記課題を解決するため、第1の発明に係る話題継続願望判定装置は、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する学習手段と、発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定する判定手段とを含むことを特徴とする。 In order to solve the above-described problem, a topic continuation desire determination device according to a first invention includes a sequence of utterances in a dialog between a system and a user, and the user utterances given in advance to each user utterance in the sequence After that, for each flag in each dialog information, the flag is set for each flag in the dialog information including a flag string indicating whether or not the user has a desire to continue the topic of the previous system utterance. The feature value for a predetermined feature is extracted from the utterance sequence up to the utterance corresponding to, and a feature vector that is a set of the feature and the feature value is generated, and a set of each flag and the corresponding feature vector Learning means for generating a classification model for determining a flag corresponding to an arbitrary feature vector from the set, and an utterance string as input, and a feature value for each feature used by the learning means from the utterance string Extracted and generates a feature vector is a set of a set of feature and its feature value, by referring to the classification model, characterized in that it comprises a determining means for determining flag corresponding to the plain of the vector.
また第2の発明に係る話題継続願望判定方法は、学習手段及び判定手段を含む話題継続願望判定装置における話題継続願望判定方法であって、前記学習手段が、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成するステップと、判定手段が、発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定するステップとを含むことを特徴とする。 A topic continuation desire determination method according to the second invention is a topic continuation desire determination method in a topic continuation desire determination apparatus including a learning means and a determination means, wherein the learning means is in a dialogue between the system and a user. A sequence of utterances and a column of flags that are given in advance to each user utterance in the sequence and indicate whether or not the user has a desire to continue the topic of the previous system utterance after the user utterance For each flag in each dialogue information, a feature value for a predetermined feature is extracted from each utterance sequence up to the utterance corresponding to the flag, and a set of the feature and its feature value is input. Generate a feature vector that is a set of, and generate a classification model to determine the flag corresponding to an arbitrary feature vector from the set of pairs of feature vectors corresponding to each flag The step and the determination means take the utterance string as input, extract a feature value for each feature used in the learning means from the utterance string, and generate a feature vector that is a set of the feature and the feature value; Referring to a classification model and determining a flag corresponding to the feature vector.
また、上記の前記学習手段と前記判定手段で用いる素性値は、発話中の単語や単語n-gramの頻度、または、発話中の単語の意味カテゴリの頻度、または、発話に対応する概念ベクトルの各要素値、または、発話中の文末表現の有無、または、発話中のポジティブ表現やネガティブ表現の頻度、または、発話中の文字数、または、発話中の文字種の字数、または、発話に対応する対話行為の有無、または、発話間の類似度、または、同一話題の連続出現回数、または、発話から抽出される他の任意の素性の値であることを特徴とする。 The feature value used in the learning unit and the determination unit is the frequency of the word or word n-gram being spoken, the frequency of the semantic category of the word being spoken, or the concept vector corresponding to the speech. Each element value, presence / absence of sentence ending during utterance, frequency of positive or negative expression during utterance, number of characters during utterance, number of characters of utterance, or dialogue corresponding to utterance It is characterized by the presence / absence of an action, the similarity between utterances, the number of consecutive appearances of the same topic, or any other feature value extracted from the utterance.
また、本発明のプログラムは、コンピュータを、上記の話題継続願望判定装置を構成する各手段として機能させるためのプログラムである。 Moreover, the program of this invention is a program for functioning a computer as each means which comprises said topic continuation desire determination apparatus.
本発明により、判定手段の入力となる発話列Aに対し、学習手段の入力となった学習データにおいて、傾向がAと類似した発話列に対応するフラグが判定結果となるので、適切な判定結果を得ることが可能となる。 According to the present invention, the flag corresponding to the utterance string whose tendency is similar to A in the learning data that is input to the learning means becomes the determination result for the utterance string A that is input to the determination means. Can be obtained.
本発明により、ユーザが直前のシステム発話の話題を継続したがっているか否かを判定することができ、次発話として相応しい発話をシステムが返すことにより、システムとユーザとのインタラクションが円滑になるという効果を奏する。 According to the present invention, it is possible to determine whether or not the user wants to continue the topic of the immediately preceding system utterance, and the system returns an utterance suitable as the next utterance, thereby facilitating smooth interaction between the system and the user. Play.
以下、図面とともに本発明の実施の形態を説明する。 Hereinafter, embodiments of the present invention will be described with reference to the drawings.
<本発明の実施の形態に係る話題継続願望判定装置の構成> <Configuration of topic continuation desire determination apparatus according to an embodiment of the present invention>
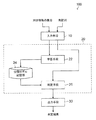
本発明の第1の実施の形態に係る話題継続願望判定装置の構成について説明する。図1は、本発明の話題継続願望判定装置の構成例である。図1に示すように、本発明の実施の形態に係る話題継続願望判定装置100は、CPUと、RAMと、後述する学習処理ルーチン及び判定処理ルーチンを実行するためのプログラムや各種データを記憶したROMと、を含むコンピュータで構成することが出来る。この話題継続願望判定装置100は、機能的には図1に示すように入力手段10と、演算手段20と、出力手段30とを備えている。
The configuration of the topic continuation desire determination apparatus according to the first embodiment of the present invention will be described. FIG. 1 is a configuration example of a topic continuation desire determination apparatus according to the present invention. As shown in FIG. 1, the topic continuation desire
入力手段10は、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として受け付ける。上記図5のシステム発話とユーザ発話とフラグのカラムが、そのような対話情報の一例である。フラグは、ユーザが直前のシステム発話の話題を継続する願望を持っている場合、1とし、持っていない場合、0とする。このフラグは、人が発話列の内容を見て付与するものである。フラグを、発話列中の一部のユーザ発話に対してのみ付与するというようにしてもよい。また、入力手段10は、最後がユーザ発話である発話列を受け付ける。 The input means 10 includes a sequence of utterances in the dialogue between the system and the user, and after the user utterance given in advance to each user utterance in the sequence, the user continues the topic of the previous system utterance. A set of dialogue information including a flag string indicating whether or not the applicant has a desire is accepted as an input. The system utterance, user utterance, and flag columns in FIG. 5 are examples of such dialogue information. The flag is set to 1 when the user has a desire to continue the topic of the immediately preceding system utterance, and is set to 0 when the user does not have it. This flag is given by a person looking at the contents of the utterance string. The flag may be given only to some user utterances in the utterance string. Further, the input means 10 accepts an utterance sequence whose last is a user utterance.
演算手段20は、学習手段22と、分類モデル記憶部24と、判定手段26とを含んで構成されている。
The
学習手段22では、入力手段10によって受け付けられた対話情報の集合の各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。
The
以下、素性とその素性値の種類の例を述べる。素性は、種類が異なれば、同じ素性文字列でも別物として扱う。 Hereinafter, examples of features and types of feature values will be described. As for the feature, the same feature character string is treated as different if the type is different.
例えば、素性として発話中の単語を、素性値としてその頻度を取ることができる。また、対象発話として、該フラグに対応するユーザ発話や、その直前のシステム発話等を取ることができ、異なる発話中の同一素性は別物とすることもできる。このことは、以降の説明で述べる他の素性についても同様である。 For example, a word being uttered as a feature can be taken as a feature value. In addition, as a target utterance, a user utterance corresponding to the flag, a system utterance immediately before the utterance, or the like can be taken, and the same feature in different utterances can be different. The same applies to other features described in the following description.
上記図5の1行目のユーザ発話を対象としたとき、(素性:素性値)として、(ラーメン:1)、(が:1)、(好き:1)、(です:1)が取れる。素性の個数は、学習手段22の入力となるデータ中のユーザ発話に出現する単語の異なりの総数であり、3行目のユーザ発話に出現する単語「思う」は一素性であるが、1行目のユーザ発話に対しては、この素性「思う」に対する(素性:素性値)は(思う:0)となる。以後の説明において、素性値が0の(素性:素性値)は、断りが無い限り、明示しないものとする。また、(ラーメン:1)、(好き:1)のように、内容語のみを素性として取ることもできる。 When the user utterance on the first line in FIG. 5 is targeted, (Ramen: Feature value) can be taken as (Ramen: 1), (Gas: 1), (Like: 1), (I: 1). The number of features is the total number of different words that appear in the user utterance in the data that is input to the learning means 22, and the word “think” that appears in the user utterance on the third row is one feature, but one row For the user's utterance of eyes, (feature: feature value) for this feature “I think” is (I think: 0). In the following description, a feature value of 0 (feature: feature value) is not specified unless otherwise specified. Moreover, only content words can be taken as features, such as (Ramen: 1) and (Like: 1).
素性として発話中の単語n-gramを、素性値としてその頻度を取ることができる。n=2としたとき、上記図5の1行目のユーザ発話から、(素性:素性値)として、(ラーメン/が:1)、(が/好き:1)、(好き/です:1)が取れる。 The word n-gram being uttered as a feature can be taken as a feature value. When n = 2, from the user utterance on the first line in FIG. 5, as (feature: feature value), (ramen / ga: 1 :), (ga / like: 1), (like / like: 1) Can be taken.
素性として発話中の単語の意味カテゴリを、素性値としてその頻度を取ることができる。ここで、意味カテゴリとは、類義する単語を一つのカテゴリとしてまとめ上げたものを意味している。例えば、「ラーメン」の意味カテゴリが「麺類」で、「好き」の意味カテゴリが「+評価」であったとき、上記図5の1行目のユーザ発話から、(素性:素性値)として、(麺類:1)、(+評価:1)が取れる。 The semantic category of the word being uttered as a feature can be taken as the feature value. Here, the semantic category means a group of similar words as one category. For example, when the meaning category of “ramen” is “noodles” and the meaning category of “like” is “+ evaluation”, from the user utterance on the first line in FIG. 5 (feature: feature value), (Noodles: 1), (+ Evaluation: 1) can be taken.
素性として発話に対応する概念ベクトルの各要素を、素性値としてその要素値を取ることができる。ここで概念ベクトルとは、例えば、非特許文献2の手法によって生成する単語概念ベクトルを用いて、対象発話中の単語の単語概念ベクトルを合成して得られるものである。 Each element of the concept vector corresponding to the utterance can be taken as a feature value as a feature value. Here, the concept vector is obtained by, for example, synthesizing the word concept vector of the word in the target utterance using the word concept vector generated by the method of Non-Patent Document 2.
[非特許文献2]別所克人, 内山俊郎, 内山匡, 片岡良治, 奥雅博,“単語・意味属性間共起に基づくコーパス概念ベースの生成方式,”情報処理学会論文誌, Dec. 2008, Vol.49, No.12, pp.3997-4006. [Non-patent literature 2] Katsuto Bessho, Toshiro Uchiyama, Kei Uchiyama, Ryoji Kataoka, Masahiro Oku, “Corpus concept-based generation method based on co-occurrence between words and semantic attributes,” Information Processing Society of Japan, Dec. 2008, Vol.49, No.12, pp.3997-4006.
素性として発話中の文末表現を、素性値としてその有無(有る場合:1、無い場合:0)を取ることができる。ここで、文末表現とは、文末部分の付属語等を連結して得られる文字列である。(素性:素性値)として、上記図5の1行目のユーザ発話から、(です:1)が取れ、2行目のユーザ発話から、(だよ:1)が取れる。 The end-of-sentence expression being uttered as a feature and the presence / absence (if present: 1; absent: 0) can be taken as a feature value. Here, the sentence end expression is a character string obtained by concatenating the attached words at the end of the sentence. As (feature: feature value), (I: 1) can be obtained from the user utterance on the first line in FIG. 5, and (Dayo: 1) can be obtained from the user utterance on the second line.
素性として発話中のポジティブ表現やネガティブ表現の文字列を、素性値としてその頻度を取ることができる。上記図5の1行目のユーザ発話からは、「好き」がポジティブ表現の文字列なので、(素性:素性値)として、(好き:1)が取れる。また、素性を「ポジティブ表現」と「ネガティブ表現」とし、素性値を、各表現に属する発話中文字列の頻度の和としてもよい。この場合、上記図5の1行目のユーザ発話からは、(素性:素性値)として、(ポジティブ表現:1)が取れる。 A character string of a positive expression or a negative expression being uttered as a feature can be used as a feature value. From the user utterance on the first line in FIG. 5 above, since “like” is a character string of positive expression, (like: feature value) can be taken as (like: 1). Also, the features may be “positive expression” and “negative expression”, and the feature value may be the sum of the frequencies of utterance character strings belonging to each expression. In this case, (positive expression: 1) can be taken as (feature: feature value) from the user utterance on the first line in FIG.
また、素性値として発話中の文字数を取ることができる。上記図5の1行目のユーザ発話からは、(素性:素性値)として、(文字数:9)が取れる。 Moreover, the number of characters in speech can be taken as the feature value. From the user utterance on the first line in FIG. 5, (character number: 9) can be taken as (feature: feature value).
素性として発話中の文字種を、素性値としてその文字種の字数を取ることができる。上記図5の1行目のユーザ発話からは、(素性:素性値)として、(ひらがな:4)、(カタカナ:4)、(漢字:1)が取れる。 It is possible to take the character type being uttered as a feature and the number of characters of that character type as a feature value. From the user utterance in the first line in FIG. 5, (Hiragana: 4), (Katakana: 4), and (Kanji: 1) can be taken as (Feature: Feature Value).
これまでに説明した素性の種類の中で、単語、単語n-gram、単語意味カテゴリ、ポジティブ・ネガティブ表現(及びその文字列)、発話中の文字種については、それぞれの素性の種類において、各素性の素性値として、該素性に対応する頻度を、全素性に対応する頻度の総和に占める割合としてもよい。例えば、発話中の文字種については、上記図5の1行目のユーザ発話からは、(素性:素性値)として、(ひらがな:4/9)、(カタカナ:4/9)、(漢字:1/9)が取れる。 Among the types of features described so far, words, word n-grams, word semantic categories, positive / negative expressions (and their character strings), and the type of character being uttered, for each type of feature, As the feature value, the frequency corresponding to the feature may be a ratio of the total frequency corresponding to all the features. For example, for the character type being uttered, (Hiragana: 4/9), (Katakana: 4/9), (Kanji: 1) as (feature: feature value) from the user utterance on the first line in FIG. / 9).
素性として発話に対応する対話行為を、素性値としてその有無(有る場合:1、無い場合:0)を取ることができる。ここで、発話の対話行為とは、その発話をした話者の発話意図であり、あらかじめ一定個数のものを定めておく。対象発話としては、該フラグに対応するユーザ発話までの一定個数の発話を取る。例えば、対象発話を、該フラグに対応するユーザ発話までの2個の発話(即ち該ユーザ発話とその直前のシステム発話)とする。各発話に対し、機械学習等の手法を用いて、対応する対話行為を導出する。(素性:素性値)として、上記図5の1行目のシステム発話から、(質問_評価:1)が取れ、1行目のユーザ発話から、(自己開示_評価+:1)が取れる。 As a feature, a dialogue action corresponding to an utterance can be taken as a feature value (1 if present, 0 if not present). Here, the dialogue action of the utterance is the utterance intention of the speaker who made the utterance, and a predetermined number of conversation actions are determined in advance. As the target utterance, a certain number of utterances up to the user utterance corresponding to the flag are taken. For example, the target utterances are two utterances up to the user utterance corresponding to the flag (that is, the user utterance and the system utterance immediately before the utterance). For each utterance, a corresponding dialogue action is derived using a method such as machine learning. As (feature: feature value), (question_evaluation: 1) can be obtained from the system utterance on the first line in FIG. 5, and (self-disclosure_evaluation +: 1) can be obtained from the user utterance on the first line.
素性値として、該フラグに対応するユーザ発話までの発話列中のある2発話(例えば、該ユーザ発話とその直前のシステム発話)の間の類似度を取ることができる。発話間の類似度は、各発話に対応するベクトルの間の余弦測度等を取ることができる。ここで、発話に対応するベクトルとして、これまでに説明した素性と素性値の組の集合である、単語頻度ベクトル、または、単語n-gram頻度ベクトル、または、単語意味カテゴリ頻度ベクトル、または、概念ベクトル等を取ることができる。あるいは発話間の類似度を、各発話から抽出された焦点集合の間に交わりが有る場合、1とし、無い場合、0とするというようにしてもよい。 As the feature value, the similarity between two utterances in the utterance string up to the user utterance corresponding to the flag (for example, the user utterance and the immediately preceding system utterance) can be taken. The similarity between utterances can be a cosine measure between vectors corresponding to each utterance. Here, as a vector corresponding to an utterance, a word frequency vector, a word n-gram frequency vector, a word meaning category frequency vector, or a concept, which is a set of the features and feature values described above. Can take vectors etc. Alternatively, the similarity between utterances may be set to 1 when there is an intersection between the focus sets extracted from each utterance, and may be set to 0 when there is no intersection.
素性値として、該フラグに対応するユーザ発話までの、システム発話あるいはユーザ発話において、直近の発話に至るまで、同一の話題が連続して出現した回数を取ることができる。話題としては、発話から抽出された焦点を取ることができる。システム発話に対してであれば、該システム発話を選定する基となった焦点(上記図5の焦点カラムの値)を取ることもできる。この場合、上記図5の6行目のフラグに対しては、直近のシステム発話に至るまで、同一焦点(「ラーメン」)が連続して出現した回数は5となる。同一の話題と認定する他のやり方として、各発話の概念ベクトル等の話題ベクトルと、直近の発話の話題ベクトルとの類似度が、ある閾値以上ならば、該発話群の話題は同一であるとするやり方も考えられる。 As the feature value, in the system utterance or user utterance up to the user utterance corresponding to the flag, the number of times that the same topic appears continuously until the latest utterance can be taken. As a topic, the focus extracted from the utterance can be taken. For system utterances, the focus (value in the focus column in FIG. 5) that is the basis for selecting the system utterances can also be taken. In this case, for the flag in the sixth line in FIG. 5, the number of times that the same focus (“ramen”) appears continuously until the most recent system utterance is five. As another method of certifying the same topic, if the similarity between the topic vector such as the concept vector of each utterance and the topic vector of the latest utterance is equal to or greater than a certain threshold, the topic of the utterance group is the same A way to do it is also possible.
その他、該フラグに対応するユーザ発話までの発話列から抽出される任意の素性とその素性値を、以降の処理に利用することができる。 In addition, an arbitrary feature extracted from the utterance string up to the user utterance corresponding to the flag and its feature value can be used for subsequent processing.
学習手段22は、上記に述べた素性の種類の中で、いくつかの種類の素性とその素性値の組の集合である素性ベクトルを、各フラグに対し生成する。図2は、各フラグと対応する素性ベクトルとの組の集合の例である。 The learning means 22 generates, for each flag, a feature vector that is a set of several types of features and their feature values among the types of features described above. FIG. 2 shows an example of a set of sets of flag and corresponding feature vector.
次に、学習手段22は、各フラグを分類カテゴリとみなし、各フラグと対応する素性ベクトルとの組の集合から、サポートベクタマシン等の分類アルゴリズムを用いて、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する。そして、学習手段22は、生成された分類モデルを分類モデル記憶部24に格納する。
Next, the learning means 22 regards each flag as a classification category, and uses a classification algorithm such as a support vector machine to set a flag corresponding to an arbitrary feature vector from a set of pairs of feature vectors corresponding to each flag. A classification model for determination is generated. Then, the
分類モデル記憶部24には、学習手段22によって生成された分類モデルが格納される。
The classification
判定手段26は、入力手段10によって受け付けられた、最後がユーザ発話である発話列を入力とし、該発話列から学習手段22で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。そして、分類モデル記憶部24に格納された前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定する。判定結果のフラグが1であれば、ユーザは直前のシステム発話の話題を継続したがっていると推定し、判定結果のフラグが0であれば、ユーザは直前のシステム発話の話題を継続したがっていないと推定する。
The
出力手段30は、判定手段26によって得られた判定結果を出力する。
The
<話題継続願望判定装置の作用>
図3は、話題継続願望判定装置100の学習処理フローの一例である。図3に沿って、話題継続願望判定装置100の学習処理の処理内容を説明する。
<Operation of topic continuation desire determination device>
FIG. 3 is an example of a learning process flow of the topic continuation
まず、ステップS100において、入力手段10は、対話情報の集合を受け付ける。 First, in step S100, the input means 10 receives a set of dialogue information.
ステップS102において、学習手段22は、上記ステップS100で受け付けた対話情報の集合の各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。 In step S102, the learning means 22 obtains a feature value for a predetermined feature from the utterance string up to the utterance corresponding to the flag for each flag in the dialogue information of the dialogue information set received in step S100. Extraction is performed to generate a feature vector which is a set of features and feature values.
ステップS104において、学習手段22は、各フラグを分類カテゴリとみなし、上記ステップS102で生成された、各フラグと対応する素性ベクトルとの組の集合から、サポートベクタマシン等の分類アルゴリズムを用いて、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する。
In step S104, the
ステップS106において、学習手段22は、上記ステップS104で生成された分類モデルを分類モデル記憶部24に格納し、学習処理ルーチンを終了する。
In step S106, the
図4は、話題継続願望判定装置100の判定処理フローの一例である。図4に沿って、話題継続願望判定装置100の判定処理の処理内容を説明する。
FIG. 4 is an example of a determination process flow of the topic continuation
ステップS200において、入力手段10は、最後がユーザ発話である発話列を受け付ける。
In step S <b> 200, the
ステップS202において、判定手段26は、上記ステップS200で受け付けた発話列から学習手段22で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。
In step S202, the
ステップS204において、判定手段26は、分類モデル記憶部24に格納された分類モデルを参照して、上記ステップS202で生成された素性ベクトルに対応するフラグを判定する。
In step S204, the
ステップS206において、出力手段30は、上記ステップS204で得られた判定結果を出力して、判定処理ルーチンを終了する。
In step S206, the
これまで述べた処理をプログラムとして構築し、当該プログラムを通信回線または記録媒体からインストールし、CPU等の手段で実施することが可能である。 It is possible to construct the processing described so far as a program, install the program from a communication line or a recording medium, and implement it by means such as a CPU.
なお、本発明は、上記の実施例に限定されることなく、特許請求の範囲内において、種々変更・応用が可能である。 The present invention is not limited to the above-described embodiments, and various modifications and applications are possible within the scope of the claims.
本発明は、システムとユーザとの円滑なインタラクションを実現する対話処理技術に適用可能である。 The present invention can be applied to a dialogue processing technique that realizes a smooth interaction between a system and a user.
10 入力手段
20 演算手段
22 学習手段
24 分類モデル記憶部
26 判定手段
30 出力手段
100 話題継続願望判定装置
DESCRIPTION OF
Claims (5)
発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定する判定手段と
を含むことを特徴とする話題継続願望判定装置。 The sequence of utterances in the dialogue between the system and the user, and whether the user has a desire to continue the topic of the immediately preceding system utterance after the user utterances given in advance to each user utterance in the sequence A set of dialogue information including a flag sequence indicating whether or not a flag is input, and for each flag in each dialogue information, a feature value for a predetermined feature is extracted from the utterance sequence up to the utterance corresponding to the flag. Then, a feature vector that is a set of features and feature values is generated, and a classification model for determining a flag corresponding to an arbitrary feature vector is generated from the set of feature vectors corresponding to each flag. Learning means to
Using an utterance string as an input, extracting a feature value for each feature used by the learning means from the utterance string, generating a feature vector that is a set of the feature and the feature value, and referring to the classification model, A topic continuation desire determination device comprising: determination means for determining a flag corresponding to the feature vector.
請求項1記載の話題継続願望判定装置。 The feature value used in the learning means and the determination means is the frequency of the word or word n-gram being uttered, the frequency of the semantic category of the word being uttered, or each element value of the concept vector corresponding to the utterance, Or, the presence or absence of sentence ending expressions during utterance, the frequency of positive or negative expressions during utterance, the number of characters being uttered, the number of characters in the utterance, or the presence or absence of interactive actions corresponding to the utterance, The topic continuation desire determination apparatus according to claim 1, wherein the topic continuation desire determination apparatus is a similarity between utterances, a continuous appearance count of the same topic, or any other feature value extracted from the utterance.
前記学習手段が、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成するステップと、
前記判定手段が、発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定するステップと
を含むことを特徴とする
話題継続願望判定方法。 A topic continuation desire determination method in a topic continuation desire determination apparatus including a learning means and a determination means,
The learning means includes a sequence of utterances in the dialogue between the system and the user, and after the user utterance given in advance to each user utterance in the sequence, the user continues the topic of the immediately preceding system utterance. A set of dialogue information including whether or not the applicant has a desire is input, and for each flag in each dialogue information, an utterance sequence up to the utterance corresponding to the flag is used for a predetermined feature. To extract a feature value, generate a feature vector that is a set of a feature and a set of feature values, and determine a flag corresponding to an arbitrary feature vector from a set of feature vectors corresponding to each flag Generating a classification model of
The determination unit receives an utterance string, extracts a feature value for each feature used by the learning unit from the utterance string, generates a feature vector that is a set of the feature and the feature value, and the classification model And a step of determining a flag corresponding to the feature vector.
請求項3記載の話題継続願望判定方法。 The feature value used in the learning means and the determination means is the frequency of the word or word n-gram being uttered, the frequency of the semantic category of the word being uttered, or each element value of the concept vector corresponding to the utterance, Or, the presence or absence of sentence ending expressions during utterance, the frequency of positive or negative expressions during utterance, the number of characters being uttered, the number of characters in the utterance, or the presence or absence of interactive actions corresponding to the utterance, The topic continuation desire determination method according to claim 3, wherein the method is a similarity between utterances, a continuous appearance count of the same topic, or another arbitrary feature value extracted from the utterance.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015123890A JP6097791B2 (en) | 2015-06-19 | 2015-06-19 | Topic continuation desire determination device, method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015123890A JP6097791B2 (en) | 2015-06-19 | 2015-06-19 | Topic continuation desire determination device, method, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017010207A JP2017010207A (en) | 2017-01-12 |
| JP6097791B2 true JP6097791B2 (en) | 2017-03-15 |
Family
ID=57761736
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015123890A Active JP6097791B2 (en) | 2015-06-19 | 2015-06-19 | Topic continuation desire determination device, method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6097791B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6998517B2 (en) | 2017-06-14 | 2022-01-18 | パナソニックIpマネジメント株式会社 | Utterance continuation judgment method, utterance continuation judgment device and program |
| WO2019155716A1 (en) * | 2018-02-08 | 2019-08-15 | ソニー株式会社 | Information processing device, information processing system, information processing method, and program |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006201870A (en) * | 2005-01-18 | 2006-08-03 | Toyota Central Res & Dev Lab Inc | Interactive processor |
| JP5300497B2 (en) * | 2009-01-07 | 2013-09-25 | 株式会社東芝 | Dialogue device, dialogue program, and dialogue method |
| JP6529761B2 (en) * | 2012-12-28 | 2019-06-12 | 株式会社ユニバーサルエンターテインメント | Topic providing system and conversation control terminal device |
-
2015
- 2015-06-19 JP JP2015123890A patent/JP6097791B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2017010207A (en) | 2017-01-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113962315B (en) | Model pre-training method, device, equipment, storage medium and program product | |
| CN110210029B (en) | Method, system, device and medium for correcting error of voice text based on vertical field | |
| US10949709B2 (en) | Method for determining sentence similarity | |
| US10811013B1 (en) | Intent-specific automatic speech recognition result generation | |
| CN112417102B (en) | Voice query method, device, server and readable storage medium | |
| JP6884947B2 (en) | Dialogue system and computer programs for it | |
| US9922650B1 (en) | Intent-specific automatic speech recognition result generation | |
| CN109215630B (en) | Real-time voice recognition method, device, equipment and storage medium | |
| Adel et al. | Features for factored language models for code-Switching speech. | |
| CN111191450A (en) | Corpus cleaning method, corpus entry device and computer-readable storage medium | |
| Dethlefs et al. | Conditional random fields for responsive surface realisation using global features | |
| CN110069611B (en) | Topic-enhanced chat robot reply generation method and device | |
| King et al. | Evaluating approaches to personalizing language models | |
| JP2017125921A (en) | Utterance selecting device, method and program | |
| CN107657949A (en) | The acquisition methods and device of game data | |
| JP2016001242A (en) | Question sentence creation method, device, and program | |
| CN111309893A (en) | Method and device for generating similar problems based on source problems | |
| JP6097791B2 (en) | Topic continuation desire determination device, method, and program | |
| CN107734123A (en) | A kind of contact sequencing method and device | |
| JP4992925B2 (en) | Spoken dialogue apparatus and program | |
| JP5136512B2 (en) | Response generating apparatus and program | |
| WO2020199590A1 (en) | Mood detection analysis method and related device | |
| CN111428487A (en) | Model training method, lyric generation method, device, electronic equipment and medium | |
| JP6126965B2 (en) | Utterance generation apparatus, method, and program | |
| JP5722375B2 (en) | End-of-sentence expression conversion apparatus, method, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170214 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170220 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6097791 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |